web development Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords

Website Developmemt Technologies: A Review
Abstract: Service Science is that the basis of knowledge system and net services that judge to the provider/client model. This paper developments a technique which will be utilized in the event of net services like websites, net applications and eCommerce. The goal is to development a technique that may add structure to a extremely unstructured drawback to help within the development and success of net services. The new methodology projected are going to be referred to as {the net|the online|the net} Development Life Cycle (WDLC) and tailored from existing methodologies and applied to the context of web development. This paper can define well the projected phases of the WDLC. Keywords: Web Development, Application Development, Technologies, eCommerce.
Analysis of Russian Segment of the Web Development Market Operating Online on Upwork
The Russian segment of the web services market in the online environment, on the platform of the Upwork freelance exchange, is considered, its key characteristics, the composition of participants, development trends are highlighted, and the market structure is identified. It is found that despite the low barriers to entry, the web development market is very stable, since the composition of entrenched firms that have been operating for more than six years remains. The pricing policy of most Russian companies indicates that they work in the middle price segment and have low budgets, which is due to the specifics of the foreign market and high competition.
Farming Assistant Web Services: Agricultor
Abstract: Our farming assistant web services provides assistance to new as well as establish farmers to get the solutions to dayto-day problems faced in the field. A farmer gets to connect with other farmers throughout India to get more information about a particular crop which is popular in other states. Keywords: Farmers, Assistance, Web Development
Tradução de ementas e histórico escolar para o inglês: contribuição para participação de discentes do curso técnico em informática para internet integrado ao ensino médio em programas de mobilidade acadêmica / Translation of summary and school records into english: contribution to the participation of high school with associate technical degree on web development students in academic mobility programs
Coded websites vs wordpress websites.
This document gives multiple instructions related to web developers using older as well as newer technology. Websites are being created using newer technologies like wordpress whereas on the other hand many people prefer making websites using the traditional way. This document will clear the doubt whether an individual should use wordpress websites or coded websites according to the users convenience. The Responsiveness of the websites, the use of CMS nowadays, more and more up gradation of technologies with SEO, themes, templates, etc. make things like web development much much easier. The aesthetics, the culture, the expressions, the features all together add up in order make the designing and development a lot more efficient and effective. Digital Marketing has a tremendous growth over the last two years and yet shows no signs of stopping, is closely related with the web development environment. Nowadays all businesses are going online due to which the impact of web development has become such that it has become an integral part of any online business.
Cognitive disabilities and web accessibility: a survey into the Brazilian web development community
Cognitive disabilities include a diversity of conditions related to cognitive functions, such as reading, understanding, learning, solving problems, memorization and speaking. They differ largely from each other, making them a heterogeneous complex set of disabilities. Although the awareness about cognitive disabilities has been increasing in the last few years, it is still less than necessary compared to other disabilities. The need for an investigation about this issue is part of the agenda of the Challenge 2 (Accessibility and Digital Inclusion) from GranDIHC-Br. This paper describes the results of an online exploratory survey conducted with 105 web development professionals from different sectors to understand their knowledge and barriers regarding accessibility for people with cognitive disabilities. The results evidenced three biases that potentially prevent those professionals from approaching cogni-tive disabilities: strong organizational barriers; difficulty to understand user needs related to cognitive disabilities; a knowledge gap about web accessibility principles and guidelines. Our results confirmed that web development professionals are unaware about cognitive disabilities mostly by a lack of knowledge about them, even if they understand web accessibility in a technical level. Therefore, we suggest that applied research studies focus on how to fill this knowledge gap before providing tools, artifacts or frameworks.
PERANCANGAN WEB RESPONSIVE UNTUK SISTEM INFORMASI OBAT-OBATAN
A good information system must not only be neat, effective, and resilient, but also must be user friendly and up to date. In a sense, it is able to be applied to various types of electronic devices, easily accessible at any whereand time (real time), and can be modified according to user needs in a relatively easy and simple way. Information systems are now needed by various parties, especially in the field of administration and sale of medicines for Cut Nyak Dhien Hospital. During this time, recording in books has been very ineffective and caused many problems, such as difficulty in accessing old data, asa well as the information obtained was not real time. To solve it, this research raises the theme of the appropriate information system design for the hospital concerned, by utilizing CSS Bootstrap framework and research methodology for web development, namely Web Development Life Cycle. This research resulted in a responsive system by providing easy access through desktop computers, tablets, and smartphones so that it would help the hospital in the data processing process in real time.
Web Development and performance comparison of Web Development Technologies in Node.js and Python
“tom had us all doing front-end web development”: a nostalgic (re)imagining of myspace, assessment of site classifications according to layout type in web development, export citation format, share document.
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
- We're Hiring!
- Help Center
Web Applications
- Most Cited Papers
- Most Downloaded Papers
- Newest Papers
- Save to Library
- Last »
- Inventory Management Follow Following
- Happy and Simple Person Follow Following
- Web Development Follow Following
- Web Technologies Follow Following
- Web Design Follow Following
- Computer Science Follow Following
- Web 2.0 Follow Following
- Semantic Web Follow Following
- Australia Follow Following
- Web Engineering Follow Following
Enter the email address you signed up with and we'll email you a reset link.
- Academia.edu Publishing
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Our approach
- Responsibility
- Infrastructure
- Try Meta AI
RECOMMENDED READS
- 5 Steps to Getting Started with Llama 2
- The Llama Ecosystem: Past, Present, and Future
- Introducing Code Llama, a state-of-the-art large language model for coding
- Meta and Microsoft Introduce the Next Generation of Llama
- Today, we’re introducing Meta Llama 3, the next generation of our state-of-the-art open source large language model.
- Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
- We’re dedicated to developing Llama 3 in a responsible way, and we’re offering various resources to help others use it responsibly as well. This includes introducing new trust and safety tools with Llama Guard 2, Code Shield, and CyberSec Eval 2.
- In the coming months, we expect to introduce new capabilities, longer context windows, additional model sizes, and enhanced performance, and we’ll share the Llama 3 research paper.
- Meta AI, built with Llama 3 technology, is now one of the world’s leading AI assistants that can boost your intelligence and lighten your load—helping you learn, get things done, create content, and connect to make the most out of every moment. You can try Meta AI here .
Today, we’re excited to share the first two models of the next generation of Llama, Meta Llama 3, available for broad use. This release features pretrained and instruction-fine-tuned language models with 8B and 70B parameters that can support a broad range of use cases. This next generation of Llama demonstrates state-of-the-art performance on a wide range of industry benchmarks and offers new capabilities, including improved reasoning. We believe these are the best open source models of their class, period. In support of our longstanding open approach, we’re putting Llama 3 in the hands of the community. We want to kickstart the next wave of innovation in AI across the stack—from applications to developer tools to evals to inference optimizations and more. We can’t wait to see what you build and look forward to your feedback.
Our goals for Llama 3
With Llama 3, we set out to build the best open models that are on par with the best proprietary models available today. We wanted to address developer feedback to increase the overall helpfulness of Llama 3 and are doing so while continuing to play a leading role on responsible use and deployment of LLMs. We are embracing the open source ethos of releasing early and often to enable the community to get access to these models while they are still in development. The text-based models we are releasing today are the first in the Llama 3 collection of models. Our goal in the near future is to make Llama 3 multilingual and multimodal, have longer context, and continue to improve overall performance across core LLM capabilities such as reasoning and coding.
State-of-the-art performance
Our new 8B and 70B parameter Llama 3 models are a major leap over Llama 2 and establish a new state-of-the-art for LLM models at those scales. Thanks to improvements in pretraining and post-training, our pretrained and instruction-fine-tuned models are the best models existing today at the 8B and 70B parameter scale. Improvements in our post-training procedures substantially reduced false refusal rates, improved alignment, and increased diversity in model responses. We also saw greatly improved capabilities like reasoning, code generation, and instruction following making Llama 3 more steerable.

*Please see evaluation details for setting and parameters with which these evaluations are calculated.
In the development of Llama 3, we looked at model performance on standard benchmarks and also sought to optimize for performance for real-world scenarios. To this end, we developed a new high-quality human evaluation set. This evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. To prevent accidental overfitting of our models on this evaluation set, even our own modeling teams do not have access to it. The chart below shows aggregated results of our human evaluations across of these categories and prompts against Claude Sonnet, Mistral Medium, and GPT-3.5.

Preference rankings by human annotators based on this evaluation set highlight the strong performance of our 70B instruction-following model compared to competing models of comparable size in real-world scenarios.
Our pretrained model also establishes a new state-of-the-art for LLM models at those scales.

To develop a great language model, we believe it’s important to innovate, scale, and optimize for simplicity. We adopted this design philosophy throughout the Llama 3 project with a focus on four key ingredients: the model architecture, the pretraining data, scaling up pretraining, and instruction fine-tuning.
Model architecture
In line with our design philosophy, we opted for a relatively standard decoder-only transformer architecture in Llama 3. Compared to Llama 2, we made several key improvements. Llama 3 uses a tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently, which leads to substantially improved model performance. To improve the inference efficiency of Llama 3 models, we’ve adopted grouped query attention (GQA) across both the 8B and 70B sizes. We trained the models on sequences of 8,192 tokens, using a mask to ensure self-attention does not cross document boundaries.
Training data
To train the best language model, the curation of a large, high-quality training dataset is paramount. In line with our design principles, we invested heavily in pretraining data. Llama 3 is pretrained on over 15T tokens that were all collected from publicly available sources. Our training dataset is seven times larger than that used for Llama 2, and it includes four times more code. To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages. However, we do not expect the same level of performance in these languages as in English.
To ensure Llama 3 is trained on data of the highest quality, we developed a series of data-filtering pipelines. These pipelines include using heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers to predict data quality. We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.
We also performed extensive experiments to evaluate the best ways of mixing data from different sources in our final pretraining dataset. These experiments enabled us to select a data mix that ensures that Llama 3 performs well across use cases including trivia questions, STEM, coding, historical knowledge, etc.
Scaling up pretraining
To effectively leverage our pretraining data in Llama 3 models, we put substantial effort into scaling up pretraining. Specifically, we have developed a series of detailed scaling laws for downstream benchmark evaluations. These scaling laws enable us to select an optimal data mix and to make informed decisions on how to best use our training compute. Importantly, scaling laws allow us to predict the performance of our largest models on key tasks (for example, code generation as evaluated on the HumanEval benchmark—see above) before we actually train the models. This helps us ensure strong performance of our final models across a variety of use cases and capabilities.
We made several new observations on scaling behavior during the development of Llama 3. For example, while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens. Larger models can match the performance of these smaller models with less training compute, but smaller models are generally preferred because they are much more efficient during inference.
To train our largest Llama 3 models, we combined three types of parallelization: data parallelization, model parallelization, and pipeline parallelization. Our most efficient implementation achieves a compute utilization of over 400 TFLOPS per GPU when trained on 16K GPUs simultaneously. We performed training runs on two custom-built 24K GPU clusters . To maximize GPU uptime, we developed an advanced new training stack that automates error detection, handling, and maintenance. We also greatly improved our hardware reliability and detection mechanisms for silent data corruption, and we developed new scalable storage systems that reduce overheads of checkpointing and rollback. Those improvements resulted in an overall effective training time of more than 95%. Combined, these improvements increased the efficiency of Llama 3 training by ~three times compared to Llama 2.
Instruction fine-tuning
To fully unlock the potential of our pretrained models in chat use cases, we innovated on our approach to instruction-tuning as well. Our approach to post-training is a combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO). The quality of the prompts that are used in SFT and the preference rankings that are used in PPO and DPO has an outsized influence on the performance of aligned models. Some of our biggest improvements in model quality came from carefully curating this data and performing multiple rounds of quality assurance on annotations provided by human annotators.
Learning from preference rankings via PPO and DPO also greatly improved the performance of Llama 3 on reasoning and coding tasks. We found that if you ask a model a reasoning question that it struggles to answer, the model will sometimes produce the right reasoning trace: The model knows how to produce the right answer, but it does not know how to select it. Training on preference rankings enables the model to learn how to select it.
Building with Llama 3
Our vision is to enable developers to customize Llama 3 to support relevant use cases and to make it easier to adopt best practices and improve the open ecosystem. With this release, we’re providing new trust and safety tools including updated components with both Llama Guard 2 and Cybersec Eval 2, and the introduction of Code Shield—an inference time guardrail for filtering insecure code produced by LLMs.
We’ve also co-developed Llama 3 with torchtune , the new PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. torchtune provides memory efficient and hackable training recipes written entirely in PyTorch. The library is integrated with popular platforms such as Hugging Face, Weights & Biases, and EleutherAI and even supports Executorch for enabling efficient inference to be run on a wide variety of mobile and edge devices. For everything from prompt engineering to using Llama 3 with LangChain we have a comprehensive getting started guide and takes you from downloading Llama 3 all the way to deployment at scale within your generative AI application.
A system-level approach to responsibility
We have designed Llama 3 models to be maximally helpful while ensuring an industry leading approach to responsibly deploying them. To achieve this, we have adopted a new, system-level approach to the responsible development and deployment of Llama. We envision Llama models as part of a broader system that puts the developer in the driver’s seat. Llama models will serve as a foundational piece of a system that developers design with their unique end goals in mind.

Instruction fine-tuning also plays a major role in ensuring the safety of our models. Our instruction-fine-tuned models have been red-teamed (tested) for safety through internal and external efforts. Our red teaming approach leverages human experts and automation methods to generate adversarial prompts that try to elicit problematic responses. For instance, we apply comprehensive testing to assess risks of misuse related to Chemical, Biological, Cyber Security, and other risk areas. All of these efforts are iterative and used to inform safety fine-tuning of the models being released. You can read more about our efforts in the model card .
Llama Guard models are meant to be a foundation for prompt and response safety and can easily be fine-tuned to create a new taxonomy depending on application needs. As a starting point, the new Llama Guard 2 uses the recently announced MLCommons taxonomy, in an effort to support the emergence of industry standards in this important area. Additionally, CyberSecEval 2 expands on its predecessor by adding measures of an LLM’s propensity to allow for abuse of its code interpreter, offensive cybersecurity capabilities, and susceptibility to prompt injection attacks (learn more in our technical paper ). Finally, we’re introducing Code Shield which adds support for inference-time filtering of insecure code produced by LLMs. This offers mitigation of risks around insecure code suggestions, code interpreter abuse prevention, and secure command execution.
With the speed at which the generative AI space is moving, we believe an open approach is an important way to bring the ecosystem together and mitigate these potential harms. As part of that, we’re updating our Responsible Use Guide (RUG) that provides a comprehensive guide to responsible development with LLMs. As we outlined in the RUG, we recommend that all inputs and outputs be checked and filtered in accordance with content guidelines appropriate to the application. Additionally, many cloud service providers offer content moderation APIs and other tools for responsible deployment, and we encourage developers to also consider using these options.
Deploying Llama 3 at scale
Llama 3 will soon be available on all major platforms including cloud providers, model API providers, and much more. Llama 3 will be everywhere .
Our benchmarks show the tokenizer offers improved token efficiency, yielding up to 15% fewer tokens compared to Llama 2. Also, Group Query Attention (GQA) now has been added to Llama 3 8B as well. As a result, we observed that despite the model having 1B more parameters compared to Llama 2 7B, the improved tokenizer efficiency and GQA contribute to maintaining the inference efficiency on par with Llama 2 7B.
For examples of how to leverage all of these capabilities, check out Llama Recipes which contains all of our open source code that can be leveraged for everything from fine-tuning to deployment to model evaluation.
What’s next for Llama 3?
The Llama 3 8B and 70B models mark the beginning of what we plan to release for Llama 3. And there’s a lot more to come.
Our largest models are over 400B parameters and, while these models are still training, our team is excited about how they’re trending. Over the coming months, we’ll release multiple models with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities. We will also publish a detailed research paper once we are done training Llama 3.
To give you a sneak preview for where these models are today as they continue training, we thought we could share some snapshots of how our largest LLM model is trending. Please note that this data is based on an early checkpoint of Llama 3 that is still training and these capabilities are not supported as part of the models released today.

We’re committed to the continued growth and development of an open AI ecosystem for releasing our models responsibly. We have long believed that openness leads to better, safer products, faster innovation, and a healthier overall market. This is good for Meta, and it is good for society. We’re taking a community-first approach with Llama 3, and starting today, these models are available on the leading cloud, hosting, and hardware platforms with many more to come.
Try Meta Llama 3 today
We’ve integrated our latest models into Meta AI, which we believe is the world’s leading AI assistant. It’s now built with Llama 3 technology and it’s available in more countries across our apps.
You can use Meta AI on Facebook, Instagram, WhatsApp, Messenger, and the web to get things done, learn, create, and connect with the things that matter to you. You can read more about the Meta AI experience here .
Visit the Llama 3 website to download the models and reference the Getting Started Guide for the latest list of all available platforms.
You’ll also soon be able to test multimodal Meta AI on our Ray-Ban Meta smart glasses.
As always, we look forward to seeing all the amazing products and experiences you will build with Meta Llama 3.
Our latest updates delivered to your inbox
Subscribe to our newsletter to keep up with Meta AI news, events, research breakthroughs, and more.
Join us in the pursuit of what’s possible with AI.

Product experiences
Foundational models
Latest news
Meta © 2024

Advances in Cryptology – EUROCRYPT 2024
43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zurich, Switzerland, May 26–30, 2024, Proceedings, Part I
- Conference proceedings
- © 2024
- Marc Joye ORCID: https://orcid.org/0000-0003-4433-2333 0 ,
- Gregor Leander ORCID: https://orcid.org/0000-0002-2579-8587 1
Zama, Paris, France
You can also search for this editor in PubMed Google Scholar
Ruhr University Bochum, Bochum, Germany
Part of the book series: Lecture Notes in Computer Science (LNCS, volume 14651)
Included in the following conference series:
- EUROCRYPT: Annual International Conference on the Theory and Applications of Cryptographic Techniques
Conference proceedings info: EUROCRYPT 2024.
This is a preview of subscription content, log in via an institution to check access.
Access this book
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Other ways to access
Licence this eBook for your library
Institutional subscriptions
Table of contents (16 papers)
Front matter, awarded papers, sqisignhd: new dimensions in cryptography.
- Pierrick Dartois, Antonin Leroux, Damien Robert, Benjamin Wesolowski
Tight Indistinguishability Bounds for the XOR of Independent Random Permutations by Fourier Analysis
Aprèssqi: extra fast verification for sqisign using extension-field signing.
- Maria Corte-Real Santos, Jonathan Komada Eriksen, Michael Meyer, Krijn Reijnders
Symmetric Cryptology
The exact multi-user security of (tweakable) key alternating ciphers with a single permutation.
- Yusuke Naito, Yu Sasaki, Takeshi Sugawara
Partial Sums Meet FFT: Improved Attack on 6-Round AES
- Orr Dunkelman, Shibam Ghosh, Nathan Keller, Gaëtan Leurent, Avichai Marmor, Victor Mollimard
New Records in Collision Attacks on SHA-2
- Yingxin Li, Fukang Liu, Gaoli Wang
Improving Linear Key Recovery Attacks Using Walsh Spectrum Puncturing
- Antonio Flórez-Gutiérrez, Yosuke Todo
A Generic Algorithm for Efficient Key Recovery in Differential Attacks – and its Associated Tool
- Christina Boura, Nicolas David, Patrick Derbez, Rachelle Heim Boissier, María Naya-Plasencia
Tight Security of TNT and Beyond
- Ashwin Jha, Mustafa Khairallah, Mridul Nandi, Abishanka Saha
Improved Differential Meet-in-the-Middle Cryptanalysis
- Zahra Ahmadian, Akram Khalesi, Dounia M’Foukh, Hossein Moghimi, María Naya-Plasencia
Post-quantum Security of Tweakable Even-Mansour, and Applications
- Gorjan Alagic, Chen Bai, Jonathan Katz, Christian Majenz, Patrick Struck
Probabilistic Extensions: A One-Step Framework for Finding Rectangle Attacks and Beyond
- Ling Song, Qianqian Yang, Yincen Chen, Lei Hu, Jian Weng
Massive Superpoly Recovery with a Meet-in-the-Middle Framework
- Jiahui He, Kai Hu, Hao Lei, Meiqin Wang
Diving Deep into the Preimage Security of AES-Like Hashing
- Shiyao Chen, Jian Guo, Eik List, Danping Shi, Tianyu Zhang
Public Key Primitives with Advanced Functionalities (I/II)
Twinkle: threshold signatures from ddh with full adaptive security.
- Renas Bacho, Julian Loss, Stefano Tessaro, Benedikt Wagner, Chenzhi Zhu
Toothpicks: More Efficient Fork-Free Two-Round Multi-signatures
- Jiaxin Pan, Benedikt Wagner
Other volumes
- cryptography
- computer security
- data privacy
- data security
- network protocols
- public key cryptography
- authentication
- zero-knowledge
- multi-party computation
- symmetric key
- cryptanalysis
- post-quantum
- information theory
- theory of computation
- computational complexity
- cryptographic protocols
- cryptographic implementation
About this book
The 7-volume set LNCS 14651 - 14657 conference volume constitutes the proceedings of the 43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques, EUROCRYPT 2024, held in in Zurich, Switzerland, in May 2024. The 105 papers included in these proceedings were carefully reviewed and selected from 500 submissions. They were organized in topical sections as follows: Part I: Awarded papers; symmetric cryptology; public key primitives with advanced functionalities; Part II: Public key primitives with advances functionalities; Part III: AI and blockchain; secure and efficient implementation, cryptographic engineering, and real-world cryptography; theoretical foundations; Part IV: Theoretical foundations; Part V: Multi-party computation and zero-knowledge; Part VI: Multi-party computation and zero-knowledge; classic public key cryptography, Part VII: Classic public key cryptography.
Editors and Affiliations
Gregor Leander
Bibliographic Information
Book Title : Advances in Cryptology – EUROCRYPT 2024
Book Subtitle : 43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zurich, Switzerland, May 26–30, 2024, Proceedings, Part I
Editors : Marc Joye, Gregor Leander
Series Title : Lecture Notes in Computer Science
DOI : https://doi.org/10.1007/978-3-031-58716-0
Publisher : Springer Cham
eBook Packages : Computer Science , Computer Science (R0)
Copyright Information : International Association for Cryptologic Research 2024
Softcover ISBN : 978-3-031-58715-3 Published: 29 April 2024
eBook ISBN : 978-3-031-58716-0 Published: 28 April 2024
Series ISSN : 0302-9743
Series E-ISSN : 1611-3349
Edition Number : 1
Number of Pages : XVIII, 492
Number of Illustrations : 15 b/w illustrations, 48 illustrations in colour
Topics : Cryptology , Security Services , Mobile and Network Security , Computer Communication Networks , Computer Applications
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Help | Advanced Search
Computer Science > Computation and Language
Title: phi-3 technical report: a highly capable language model locally on your phone.
Abstract: We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
- Open access
- Published: 18 April 2024
Research ethics and artificial intelligence for global health: perspectives from the global forum on bioethics in research
- James Shaw 1 , 13 ,
- Joseph Ali 2 , 3 ,
- Caesar A. Atuire 4 , 5 ,
- Phaik Yeong Cheah 6 ,
- Armando Guio Español 7 ,
- Judy Wawira Gichoya 8 ,
- Adrienne Hunt 9 ,
- Daudi Jjingo 10 ,
- Katherine Littler 9 ,
- Daniela Paolotti 11 &
- Effy Vayena 12
BMC Medical Ethics volume 25 , Article number: 46 ( 2024 ) Cite this article
973 Accesses
6 Altmetric
Metrics details
The ethical governance of Artificial Intelligence (AI) in health care and public health continues to be an urgent issue for attention in policy, research, and practice. In this paper we report on central themes related to challenges and strategies for promoting ethics in research involving AI in global health, arising from the Global Forum on Bioethics in Research (GFBR), held in Cape Town, South Africa in November 2022.
The GFBR is an annual meeting organized by the World Health Organization and supported by the Wellcome Trust, the US National Institutes of Health, the UK Medical Research Council (MRC) and the South African MRC. The forum aims to bring together ethicists, researchers, policymakers, research ethics committee members and other actors to engage with challenges and opportunities specifically related to research ethics. In 2022 the focus of the GFBR was “Ethics of AI in Global Health Research”. The forum consisted of 6 case study presentations, 16 governance presentations, and a series of small group and large group discussions. A total of 87 participants attended the forum from 31 countries around the world, representing disciplines of bioethics, AI, health policy, health professional practice, research funding, and bioinformatics. In this paper, we highlight central insights arising from GFBR 2022.
We describe the significance of four thematic insights arising from the forum: (1) Appropriateness of building AI, (2) Transferability of AI systems, (3) Accountability for AI decision-making and outcomes, and (4) Individual consent. We then describe eight recommendations for governance leaders to enhance the ethical governance of AI in global health research, addressing issues such as AI impact assessments, environmental values, and fair partnerships.
Conclusions
The 2022 Global Forum on Bioethics in Research illustrated several innovations in ethical governance of AI for global health research, as well as several areas in need of urgent attention internationally. This summary is intended to inform international and domestic efforts to strengthen research ethics and support the evolution of governance leadership to meet the demands of AI in global health research.
Peer Review reports
Introduction
The ethical governance of Artificial Intelligence (AI) in health care and public health continues to be an urgent issue for attention in policy, research, and practice [ 1 , 2 , 3 ]. Beyond the growing number of AI applications being implemented in health care, capabilities of AI models such as Large Language Models (LLMs) expand the potential reach and significance of AI technologies across health-related fields [ 4 , 5 ]. Discussion about effective, ethical governance of AI technologies has spanned a range of governance approaches, including government regulation, organizational decision-making, professional self-regulation, and research ethics review [ 6 , 7 , 8 ]. In this paper, we report on central themes related to challenges and strategies for promoting ethics in research involving AI in global health research, arising from the Global Forum on Bioethics in Research (GFBR), held in Cape Town, South Africa in November 2022. Although applications of AI for research, health care, and public health are diverse and advancing rapidly, the insights generated at the forum remain highly relevant from a global health perspective. After summarizing important context for work in this domain, we highlight categories of ethical issues emphasized at the forum for attention from a research ethics perspective internationally. We then outline strategies proposed for research, innovation, and governance to support more ethical AI for global health.
In this paper, we adopt the definition of AI systems provided by the Organization for Economic Cooperation and Development (OECD) as our starting point. Their definition states that an AI system is “a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. AI systems are designed to operate with varying levels of autonomy” [ 9 ]. The conceptualization of an algorithm as helping to constitute an AI system, along with hardware, other elements of software, and a particular context of use, illustrates the wide variety of ways in which AI can be applied. We have found it useful to differentiate applications of AI in research as those classified as “AI systems for discovery” and “AI systems for intervention”. An AI system for discovery is one that is intended to generate new knowledge, for example in drug discovery or public health research in which researchers are seeking potential targets for intervention, innovation, or further research. An AI system for intervention is one that directly contributes to enacting an intervention in a particular context, for example informing decision-making at the point of care or assisting with accuracy in a surgical procedure.
The mandate of the GFBR is to take a broad view of what constitutes research and its regulation in global health, with special attention to bioethics in Low- and Middle- Income Countries. AI as a group of technologies demands such a broad view. AI development for health occurs in a variety of environments, including universities and academic health sciences centers where research ethics review remains an important element of the governance of science and innovation internationally [ 10 , 11 ]. In these settings, research ethics committees (RECs; also known by different names such as Institutional Review Boards or IRBs) make decisions about the ethical appropriateness of projects proposed by researchers and other institutional members, ultimately determining whether a given project is allowed to proceed on ethical grounds [ 12 ].
However, research involving AI for health also takes place in large corporations and smaller scale start-ups, which in some jurisdictions fall outside the scope of research ethics regulation. In the domain of AI, the question of what constitutes research also becomes blurred. For example, is the development of an algorithm itself considered a part of the research process? Or only when that algorithm is tested under the formal constraints of a systematic research methodology? In this paper we take an inclusive view, in which AI development is included in the definition of research activity and within scope for our inquiry, regardless of the setting in which it takes place. This broad perspective characterizes the approach to “research ethics” we take in this paper, extending beyond the work of RECs to include the ethical analysis of the wide range of activities that constitute research as the generation of new knowledge and intervention in the world.
Ethical governance of AI in global health
The ethical governance of AI for global health has been widely discussed in recent years. The World Health Organization (WHO) released its guidelines on ethics and governance of AI for health in 2021, endorsing a set of six ethical principles and exploring the relevance of those principles through a variety of use cases. The WHO guidelines also provided an overview of AI governance, defining governance as covering “a range of steering and rule-making functions of governments and other decision-makers, including international health agencies, for the achievement of national health policy objectives conducive to universal health coverage.” (p. 81) The report usefully provided a series of recommendations related to governance of seven domains pertaining to AI for health: data, benefit sharing, the private sector, the public sector, regulation, policy observatories/model legislation, and global governance. The report acknowledges that much work is yet to be done to advance international cooperation on AI governance, especially related to prioritizing voices from Low- and Middle-Income Countries (LMICs) in global dialogue.
One important point emphasized in the WHO report that reinforces the broader literature on global governance of AI is the distribution of responsibility across a wide range of actors in the AI ecosystem. This is especially important to highlight when focused on research for global health, which is specifically about work that transcends national borders. Alami et al. (2020) discussed the unique risks raised by AI research in global health, ranging from the unavailability of data in many LMICs required to train locally relevant AI models to the capacity of health systems to absorb new AI technologies that demand the use of resources from elsewhere in the system. These observations illustrate the need to identify the unique issues posed by AI research for global health specifically, and the strategies that can be employed by all those implicated in AI governance to promote ethically responsible use of AI in global health research.
RECs and the regulation of research involving AI
RECs represent an important element of the governance of AI for global health research, and thus warrant further commentary as background to our paper. Despite the importance of RECs, foundational questions have been raised about their capabilities to accurately understand and address ethical issues raised by studies involving AI. Rahimzadeh et al. (2023) outlined how RECs in the United States are under-prepared to align with recent federal policy requiring that RECs review data sharing and management plans with attention to the unique ethical issues raised in AI research for health [ 13 ]. Similar research in South Africa identified variability in understanding of existing regulations and ethical issues associated with health-related big data sharing and management among research ethics committee members [ 14 , 15 ]. The effort to address harms accruing to groups or communities as opposed to individuals whose data are included in AI research has also been identified as a unique challenge for RECs [ 16 , 17 ]. Doerr and Meeder (2022) suggested that current regulatory frameworks for research ethics might actually prevent RECs from adequately addressing such issues, as they are deemed out of scope of REC review [ 16 ]. Furthermore, research in the United Kingdom and Canada has suggested that researchers using AI methods for health tend to distinguish between ethical issues and social impact of their research, adopting an overly narrow view of what constitutes ethical issues in their work [ 18 ].
The challenges for RECs in adequately addressing ethical issues in AI research for health care and public health exceed a straightforward survey of ethical considerations. As Ferretti et al. (2021) contend, some capabilities of RECs adequately cover certain issues in AI-based health research, such as the common occurrence of conflicts of interest where researchers who accept funds from commercial technology providers are implicitly incentivized to produce results that align with commercial interests [ 12 ]. However, some features of REC review require reform to adequately meet ethical needs. Ferretti et al. outlined weaknesses of RECs that are longstanding and those that are novel to AI-related projects, proposing a series of directions for development that are regulatory, procedural, and complementary to REC functionality. The work required on a global scale to update the REC function in response to the demands of research involving AI is substantial.
These issues take greater urgency in the context of global health [ 19 ]. Teixeira da Silva (2022) described the global practice of “ethics dumping”, where researchers from high income countries bring ethically contentious practices to RECs in low-income countries as a strategy to gain approval and move projects forward [ 20 ]. Although not yet systematically documented in AI research for health, risk of ethics dumping in AI research is high. Evidence is already emerging of practices of “health data colonialism”, in which AI researchers and developers from large organizations in high-income countries acquire data to build algorithms in LMICs to avoid stricter regulations [ 21 ]. This specific practice is part of a larger collection of practices that characterize health data colonialism, involving the broader exploitation of data and the populations they represent primarily for commercial gain [ 21 , 22 ]. As an additional complication, AI algorithms trained on data from high-income contexts are unlikely to apply in straightforward ways to LMIC settings [ 21 , 23 ]. In the context of global health, there is widespread acknowledgement about the need to not only enhance the knowledge base of REC members about AI-based methods internationally, but to acknowledge the broader shifts required to encourage their capabilities to more fully address these and other ethical issues associated with AI research for health [ 8 ].
Although RECs are an important part of the story of the ethical governance of AI for global health research, they are not the only part. The responsibilities of supra-national entities such as the World Health Organization, national governments, organizational leaders, commercial AI technology providers, health care professionals, and other groups continue to be worked out internationally. In this context of ongoing work, examining issues that demand attention and strategies to address them remains an urgent and valuable task.
The GFBR is an annual meeting organized by the World Health Organization and supported by the Wellcome Trust, the US National Institutes of Health, the UK Medical Research Council (MRC) and the South African MRC. The forum aims to bring together ethicists, researchers, policymakers, REC members and other actors to engage with challenges and opportunities specifically related to research ethics. Each year the GFBR meeting includes a series of case studies and keynotes presented in plenary format to an audience of approximately 100 people who have applied and been competitively selected to attend, along with small-group breakout discussions to advance thinking on related issues. The specific topic of the forum changes each year, with past topics including ethical issues in research with people living with mental health conditions (2021), genome editing (2019), and biobanking/data sharing (2018). The forum is intended to remain grounded in the practical challenges of engaging in research ethics, with special interest in low resource settings from a global health perspective. A post-meeting fellowship scheme is open to all LMIC participants, providing a unique opportunity to apply for funding to further explore and address the ethical challenges that are identified during the meeting.
In 2022, the focus of the GFBR was “Ethics of AI in Global Health Research”. The forum consisted of 6 case study presentations (both short and long form) reporting on specific initiatives related to research ethics and AI for health, and 16 governance presentations (both short and long form) reporting on actual approaches to governing AI in different country settings. A keynote presentation from Professor Effy Vayena addressed the topic of the broader context for AI ethics in a rapidly evolving field. A total of 87 participants attended the forum from 31 countries around the world, representing disciplines of bioethics, AI, health policy, health professional practice, research funding, and bioinformatics. The 2-day forum addressed a wide range of themes. The conference report provides a detailed overview of each of the specific topics addressed while a policy paper outlines the cross-cutting themes (both documents are available at the GFBR website: https://www.gfbr.global/past-meetings/16th-forum-cape-town-south-africa-29-30-november-2022/ ). As opposed to providing a detailed summary in this paper, we aim to briefly highlight central issues raised, solutions proposed, and the challenges facing the research ethics community in the years to come.
In this way, our primary aim in this paper is to present a synthesis of the challenges and opportunities raised at the GFBR meeting and in the planning process, followed by our reflections as a group of authors on their significance for governance leaders in the coming years. We acknowledge that the views represented at the meeting and in our results are a partial representation of the universe of views on this topic; however, the GFBR leadership invested a great deal of resources in convening a deeply diverse and thoughtful group of researchers and practitioners working on themes of bioethics related to AI for global health including those based in LMICs. We contend that it remains rare to convene such a strong group for an extended time and believe that many of the challenges and opportunities raised demand attention for more ethical futures of AI for health. Nonetheless, our results are primarily descriptive and are thus not explicitly grounded in a normative argument. We make effort in the Discussion section to contextualize our results by describing their significance and connecting them to broader efforts to reform global health research and practice.
Uniquely important ethical issues for AI in global health research
Presentations and group dialogue over the course of the forum raised several issues for consideration, and here we describe four overarching themes for the ethical governance of AI in global health research. Brief descriptions of each issue can be found in Table 1 . Reports referred to throughout the paper are available at the GFBR website provided above.
The first overarching thematic issue relates to the appropriateness of building AI technologies in response to health-related challenges in the first place. Case study presentations referred to initiatives where AI technologies were highly appropriate, such as in ear shape biometric identification to more accurately link electronic health care records to individual patients in Zambia (Alinani Simukanga). Although important ethical issues were raised with respect to privacy, trust, and community engagement in this initiative, the AI-based solution was appropriately matched to the challenge of accurately linking electronic records to specific patient identities. In contrast, forum participants raised questions about the appropriateness of an initiative using AI to improve the quality of handwashing practices in an acute care hospital in India (Niyoshi Shah), which led to gaming the algorithm. Overall, participants acknowledged the dangers of techno-solutionism, in which AI researchers and developers treat AI technologies as the most obvious solutions to problems that in actuality demand much more complex strategies to address [ 24 ]. However, forum participants agreed that RECs in different contexts have differing degrees of power to raise issues of the appropriateness of an AI-based intervention.
The second overarching thematic issue related to whether and how AI-based systems transfer from one national health context to another. One central issue raised by a number of case study presentations related to the challenges of validating an algorithm with data collected in a local environment. For example, one case study presentation described a project that would involve the collection of personally identifiable data for sensitive group identities, such as tribe, clan, or religion, in the jurisdictions involved (South Africa, Nigeria, Tanzania, Uganda and the US; Gakii Masunga). Doing so would enable the team to ensure that those groups were adequately represented in the dataset to ensure the resulting algorithm was not biased against specific community groups when deployed in that context. However, some members of these communities might desire to be represented in the dataset, whereas others might not, illustrating the need to balance autonomy and inclusivity. It was also widely recognized that collecting these data is an immense challenge, particularly when historically oppressive practices have led to a low-trust environment for international organizations and the technologies they produce. It is important to note that in some countries such as South Africa and Rwanda, it is illegal to collect information such as race and tribal identities, re-emphasizing the importance for cultural awareness and avoiding “one size fits all” solutions.
The third overarching thematic issue is related to understanding accountabilities for both the impacts of AI technologies and governance decision-making regarding their use. Where global health research involving AI leads to longer-term harms that might fall outside the usual scope of issues considered by a REC, who is to be held accountable, and how? This question was raised as one that requires much further attention, with law being mixed internationally regarding the mechanisms available to hold researchers, innovators, and their institutions accountable over the longer term. However, it was recognized in breakout group discussion that many jurisdictions are developing strong data protection regimes related specifically to international collaboration for research involving health data. For example, Kenya’s Data Protection Act requires that any internationally funded projects have a local principal investigator who will hold accountability for how data are shared and used [ 25 ]. The issue of research partnerships with commercial entities was raised by many participants in the context of accountability, pointing toward the urgent need for clear principles related to strategies for engagement with commercial technology companies in global health research.
The fourth and final overarching thematic issue raised here is that of consent. The issue of consent was framed by the widely shared recognition that models of individual, explicit consent might not produce a supportive environment for AI innovation that relies on the secondary uses of health-related datasets to build AI algorithms. Given this recognition, approaches such as community oversight of health data uses were suggested as a potential solution. However, the details of implementing such community oversight mechanisms require much further attention, particularly given the unique perspectives on health data in different country settings in global health research. Furthermore, some uses of health data do continue to require consent. One case study of South Africa, Nigeria, Kenya, Ethiopia and Uganda suggested that when health data are shared across borders, individual consent remains necessary when data is transferred from certain countries (Nezerith Cengiz). Broader clarity is necessary to support the ethical governance of health data uses for AI in global health research.
Recommendations for ethical governance of AI in global health research
Dialogue at the forum led to a range of suggestions for promoting ethical conduct of AI research for global health, related to the various roles of actors involved in the governance of AI research broadly defined. The strategies are written for actors we refer to as “governance leaders”, those people distributed throughout the AI for global health research ecosystem who are responsible for ensuring the ethical and socially responsible conduct of global health research involving AI (including researchers themselves). These include RECs, government regulators, health care leaders, health professionals, corporate social accountability officers, and others. Enacting these strategies would bolster the ethical governance of AI for global health more generally, enabling multiple actors to fulfill their roles related to governing research and development activities carried out across multiple organizations, including universities, academic health sciences centers, start-ups, and technology corporations. Specific suggestions are summarized in Table 2 .
First, forum participants suggested that governance leaders including RECs, should remain up to date on recent advances in the regulation of AI for health. Regulation of AI for health advances rapidly and takes on different forms in jurisdictions around the world. RECs play an important role in governance, but only a partial role; it was deemed important for RECs to acknowledge how they fit within a broader governance ecosystem in order to more effectively address the issues within their scope. Not only RECs but organizational leaders responsible for procurement, researchers, and commercial actors should all commit to efforts to remain up to date about the relevant approaches to regulating AI for health care and public health in jurisdictions internationally. In this way, governance can more adequately remain up to date with advances in regulation.
Second, forum participants suggested that governance leaders should focus on ethical governance of health data as a basis for ethical global health AI research. Health data are considered the foundation of AI development, being used to train AI algorithms for various uses [ 26 ]. By focusing on ethical governance of health data generation, sharing, and use, multiple actors will help to build an ethical foundation for AI development among global health researchers.
Third, forum participants believed that governance processes should incorporate AI impact assessments where appropriate. An AI impact assessment is the process of evaluating the potential effects, both positive and negative, of implementing an AI algorithm on individuals, society, and various stakeholders, generally over time frames specified in advance of implementation [ 27 ]. Although not all types of AI research in global health would warrant an AI impact assessment, this is especially relevant for those studies aiming to implement an AI system for intervention into health care or public health. Organizations such as RECs can use AI impact assessments to boost understanding of potential harms at the outset of a research project, encouraging researchers to more deeply consider potential harms in the development of their study.
Fourth, forum participants suggested that governance decisions should incorporate the use of environmental impact assessments, or at least the incorporation of environment values when assessing the potential impact of an AI system. An environmental impact assessment involves evaluating and anticipating the potential environmental effects of a proposed project to inform ethical decision-making that supports sustainability [ 28 ]. Although a relatively new consideration in research ethics conversations [ 29 ], the environmental impact of building technologies is a crucial consideration for the public health commitment to environmental sustainability. Governance leaders can use environmental impact assessments to boost understanding of potential environmental harms linked to AI research projects in global health over both the shorter and longer terms.
Fifth, forum participants suggested that governance leaders should require stronger transparency in the development of AI algorithms in global health research. Transparency was considered essential in the design and development of AI algorithms for global health to ensure ethical and accountable decision-making throughout the process. Furthermore, whether and how researchers have considered the unique contexts into which such algorithms may be deployed can be surfaced through stronger transparency, for example in describing what primary considerations were made at the outset of the project and which stakeholders were consulted along the way. Sharing information about data provenance and methods used in AI development will also enhance the trustworthiness of the AI-based research process.
Sixth, forum participants suggested that governance leaders can encourage or require community engagement at various points throughout an AI project. It was considered that engaging patients and communities is crucial in AI algorithm development to ensure that the technology aligns with community needs and values. However, participants acknowledged that this is not a straightforward process. Effective community engagement requires lengthy commitments to meeting with and hearing from diverse communities in a given setting, and demands a particular set of skills in communication and dialogue that are not possessed by all researchers. Encouraging AI researchers to begin this process early and build long-term partnerships with community members is a promising strategy to deepen community engagement in AI research for global health. One notable recommendation was that research funders have an opportunity to incentivize and enable community engagement with funds dedicated to these activities in AI research in global health.
Seventh, forum participants suggested that governance leaders can encourage researchers to build strong, fair partnerships between institutions and individuals across country settings. In a context of longstanding imbalances in geopolitical and economic power, fair partnerships in global health demand a priori commitments to share benefits related to advances in medical technologies, knowledge, and financial gains. Although enforcement of this point might be beyond the remit of RECs, commentary will encourage researchers to consider stronger, fairer partnerships in global health in the longer term.
Eighth, it became evident that it is necessary to explore new forms of regulatory experimentation given the complexity of regulating a technology of this nature. In addition, the health sector has a series of particularities that make it especially complicated to generate rules that have not been previously tested. Several participants highlighted the desire to promote spaces for experimentation such as regulatory sandboxes or innovation hubs in health. These spaces can have several benefits for addressing issues surrounding the regulation of AI in the health sector, such as: (i) increasing the capacities and knowledge of health authorities about this technology; (ii) identifying the major problems surrounding AI regulation in the health sector; (iii) establishing possibilities for exchange and learning with other authorities; (iv) promoting innovation and entrepreneurship in AI in health; and (vi) identifying the need to regulate AI in this sector and update other existing regulations.
Ninth and finally, forum participants believed that the capabilities of governance leaders need to evolve to better incorporate expertise related to AI in ways that make sense within a given jurisdiction. With respect to RECs, for example, it might not make sense for every REC to recruit a member with expertise in AI methods. Rather, it will make more sense in some jurisdictions to consult with members of the scientific community with expertise in AI when research protocols are submitted that demand such expertise. Furthermore, RECs and other approaches to research governance in jurisdictions around the world will need to evolve in order to adopt the suggestions outlined above, developing processes that apply specifically to the ethical governance of research using AI methods in global health.
Research involving the development and implementation of AI technologies continues to grow in global health, posing important challenges for ethical governance of AI in global health research around the world. In this paper we have summarized insights from the 2022 GFBR, focused specifically on issues in research ethics related to AI for global health research. We summarized four thematic challenges for governance related to AI in global health research and nine suggestions arising from presentations and dialogue at the forum. In this brief discussion section, we present an overarching observation about power imbalances that frames efforts to evolve the role of governance in global health research, and then outline two important opportunity areas as the field develops to meet the challenges of AI in global health research.
Dialogue about power is not unfamiliar in global health, especially given recent contributions exploring what it would mean to de-colonize global health research, funding, and practice [ 30 , 31 ]. Discussions of research ethics applied to AI research in global health contexts are deeply infused with power imbalances. The existing context of global health is one in which high-income countries primarily located in the “Global North” charitably invest in projects taking place primarily in the “Global South” while recouping knowledge, financial, and reputational benefits [ 32 ]. With respect to AI development in particular, recent examples of digital colonialism frame dialogue about global partnerships, raising attention to the role of large commercial entities and global financial capitalism in global health research [ 21 , 22 ]. Furthermore, the power of governance organizations such as RECs to intervene in the process of AI research in global health varies widely around the world, depending on the authorities assigned to them by domestic research governance policies. These observations frame the challenges outlined in our paper, highlighting the difficulties associated with making meaningful change in this field.
Despite these overarching challenges of the global health research context, there are clear strategies for progress in this domain. Firstly, AI innovation is rapidly evolving, which means approaches to the governance of AI for health are rapidly evolving too. Such rapid evolution presents an important opportunity for governance leaders to clarify their vision and influence over AI innovation in global health research, boosting the expertise, structure, and functionality required to meet the demands of research involving AI. Secondly, the research ethics community has strong international ties, linked to a global scholarly community that is committed to sharing insights and best practices around the world. This global community can be leveraged to coordinate efforts to produce advances in the capabilities and authorities of governance leaders to meaningfully govern AI research for global health given the challenges summarized in our paper.
Limitations
Our paper includes two specific limitations that we address explicitly here. First, it is still early in the lifetime of the development of applications of AI for use in global health, and as such, the global community has had limited opportunity to learn from experience. For example, there were many fewer case studies, which detail experiences with the actual implementation of an AI technology, submitted to GFBR 2022 for consideration than was expected. In contrast, there were many more governance reports submitted, which detail the processes and outputs of governance processes that anticipate the development and dissemination of AI technologies. This observation represents both a success and a challenge. It is a success that so many groups are engaging in anticipatory governance of AI technologies, exploring evidence of their likely impacts and governing technologies in novel and well-designed ways. It is a challenge that there is little experience to build upon of the successful implementation of AI technologies in ways that have limited harms while promoting innovation. Further experience with AI technologies in global health will contribute to revising and enhancing the challenges and recommendations we have outlined in our paper.
Second, global trends in the politics and economics of AI technologies are evolving rapidly. Although some nations are advancing detailed policy approaches to regulating AI more generally, including for uses in health care and public health, the impacts of corporate investments in AI and political responses related to governance remain to be seen. The excitement around large language models (LLMs) and large multimodal models (LMMs) has drawn deeper attention to the challenges of regulating AI in any general sense, opening dialogue about health sector-specific regulations. The direction of this global dialogue, strongly linked to high-profile corporate actors and multi-national governance institutions, will strongly influence the development of boundaries around what is possible for the ethical governance of AI for global health. We have written this paper at a point when these developments are proceeding rapidly, and as such, we acknowledge that our recommendations will need updating as the broader field evolves.
Ultimately, coordination and collaboration between many stakeholders in the research ethics ecosystem will be necessary to strengthen the ethical governance of AI in global health research. The 2022 GFBR illustrated several innovations in ethical governance of AI for global health research, as well as several areas in need of urgent attention internationally. This summary is intended to inform international and domestic efforts to strengthen research ethics and support the evolution of governance leadership to meet the demands of AI in global health research.
Data availability
All data and materials analyzed to produce this paper are available on the GFBR website: https://www.gfbr.global/past-meetings/16th-forum-cape-town-south-africa-29-30-november-2022/ .
Clark P, Kim J, Aphinyanaphongs Y, Marketing, Food US. Drug Administration Clearance of Artificial Intelligence and Machine Learning Enabled Software in and as Medical devices: a systematic review. JAMA Netw Open. 2023;6(7):e2321792–2321792.
Article Google Scholar
Potnis KC, Ross JS, Aneja S, Gross CP, Richman IB. Artificial intelligence in breast cancer screening: evaluation of FDA device regulation and future recommendations. JAMA Intern Med. 2022;182(12):1306–12.
Siala H, Wang Y. SHIFTing artificial intelligence to be responsible in healthcare: a systematic review. Soc Sci Med. 2022;296:114782.
Yang X, Chen A, PourNejatian N, Shin HC, Smith KE, Parisien C, et al. A large language model for electronic health records. NPJ Digit Med. 2022;5(1):194.
Meskó B, Topol EJ. The imperative for regulatory oversight of large language models (or generative AI) in healthcare. NPJ Digit Med. 2023;6(1):120.
Jobin A, Ienca M, Vayena E. The global landscape of AI ethics guidelines. Nat Mach Intell. 2019;1(9):389–99.
Minssen T, Vayena E, Cohen IG. The challenges for Regulating Medical Use of ChatGPT and other large Language models. JAMA. 2023.
Ho CWL, Malpani R. Scaling up the research ethics framework for healthcare machine learning as global health ethics and governance. Am J Bioeth. 2022;22(5):36–8.
Yeung K. Recommendation of the council on artificial intelligence (OECD). Int Leg Mater. 2020;59(1):27–34.
Maddox TM, Rumsfeld JS, Payne PR. Questions for artificial intelligence in health care. JAMA. 2019;321(1):31–2.
Dzau VJ, Balatbat CA, Ellaissi WF. Revisiting academic health sciences systems a decade later: discovery to health to population to society. Lancet. 2021;398(10318):2300–4.
Ferretti A, Ienca M, Sheehan M, Blasimme A, Dove ES, Farsides B, et al. Ethics review of big data research: what should stay and what should be reformed? BMC Med Ethics. 2021;22(1):1–13.
Rahimzadeh V, Serpico K, Gelinas L. Institutional review boards need new skills to review data sharing and management plans. Nat Med. 2023;1–3.
Kling S, Singh S, Burgess TL, Nair G. The role of an ethics advisory committee in data science research in sub-saharan Africa. South Afr J Sci. 2023;119(5–6):1–3.
Google Scholar
Cengiz N, Kabanda SM, Esterhuizen TM, Moodley K. Exploring perspectives of research ethics committee members on the governance of big data in sub-saharan Africa. South Afr J Sci. 2023;119(5–6):1–9.
Doerr M, Meeder S. Big health data research and group harm: the scope of IRB review. Ethics Hum Res. 2022;44(4):34–8.
Ballantyne A, Stewart C. Big data and public-private partnerships in healthcare and research: the application of an ethics framework for big data in health and research. Asian Bioeth Rev. 2019;11(3):315–26.
Samuel G, Chubb J, Derrick G. Boundaries between research ethics and ethical research use in artificial intelligence health research. J Empir Res Hum Res Ethics. 2021;16(3):325–37.
Murphy K, Di Ruggiero E, Upshur R, Willison DJ, Malhotra N, Cai JC, et al. Artificial intelligence for good health: a scoping review of the ethics literature. BMC Med Ethics. 2021;22(1):1–17.
Teixeira da Silva JA. Handling ethics dumping and neo-colonial research: from the laboratory to the academic literature. J Bioethical Inq. 2022;19(3):433–43.
Ferryman K. The dangers of data colonialism in precision public health. Glob Policy. 2021;12:90–2.
Couldry N, Mejias UA. Data colonialism: rethinking big data’s relation to the contemporary subject. Telev New Media. 2019;20(4):336–49.
Organization WH. Ethics and governance of artificial intelligence for health: WHO guidance. 2021.
Metcalf J, Moss E. Owning ethics: corporate logics, silicon valley, and the institutionalization of ethics. Soc Res Int Q. 2019;86(2):449–76.
Data Protection Act - OFFICE OF THE DATA PROTECTION COMMISSIONER KENYA [Internet]. 2021 [cited 2023 Sep 30]. https://www.odpc.go.ke/dpa-act/ .
Sharon T, Lucivero F. Introduction to the special theme: the expansion of the health data ecosystem–rethinking data ethics and governance. Big Data & Society. Volume 6. London, England: SAGE Publications Sage UK; 2019. p. 2053951719852969.
Reisman D, Schultz J, Crawford K, Whittaker M. Algorithmic impact assessments: a practical Framework for Public Agency. AI Now. 2018.
Morgan RK. Environmental impact assessment: the state of the art. Impact Assess Proj Apprais. 2012;30(1):5–14.
Samuel G, Richie C. Reimagining research ethics to include environmental sustainability: a principled approach, including a case study of data-driven health research. J Med Ethics. 2023;49(6):428–33.
Kwete X, Tang K, Chen L, Ren R, Chen Q, Wu Z, et al. Decolonizing global health: what should be the target of this movement and where does it lead us? Glob Health Res Policy. 2022;7(1):3.
Abimbola S, Asthana S, Montenegro C, Guinto RR, Jumbam DT, Louskieter L, et al. Addressing power asymmetries in global health: imperatives in the wake of the COVID-19 pandemic. PLoS Med. 2021;18(4):e1003604.
Benatar S. Politics, power, poverty and global health: systems and frames. Int J Health Policy Manag. 2016;5(10):599.
Download references
Acknowledgements
We would like to acknowledge the outstanding contributions of the attendees of GFBR 2022 in Cape Town, South Africa. This paper is authored by members of the GFBR 2022 Planning Committee. We would like to acknowledge additional members Tamra Lysaght, National University of Singapore, and Niresh Bhagwandin, South African Medical Research Council, for their input during the planning stages and as reviewers of the applications to attend the Forum.
This work was supported by Wellcome [222525/Z/21/Z], the US National Institutes of Health, the UK Medical Research Council (part of UK Research and Innovation), and the South African Medical Research Council through funding to the Global Forum on Bioethics in Research.
Author information
Authors and affiliations.
Department of Physical Therapy, Temerty Faculty of Medicine, University of Toronto, Toronto, Canada
Berman Institute of Bioethics, Johns Hopkins University, Baltimore, MD, USA
Bloomberg School of Public Health, Johns Hopkins University, Baltimore, MD, USA
Department of Philosophy and Classics, University of Ghana, Legon-Accra, Ghana
Caesar A. Atuire
Centre for Tropical Medicine and Global Health, Nuffield Department of Medicine, University of Oxford, Oxford, UK
Mahidol Oxford Tropical Medicine Research Unit, Faculty of Tropical Medicine, Mahidol University, Bangkok, Thailand
Phaik Yeong Cheah
Berkman Klein Center, Harvard University, Bogotá, Colombia
Armando Guio Español
Department of Radiology and Informatics, Emory University School of Medicine, Atlanta, GA, USA
Judy Wawira Gichoya
Health Ethics & Governance Unit, Research for Health Department, Science Division, World Health Organization, Geneva, Switzerland
Adrienne Hunt & Katherine Littler
African Center of Excellence in Bioinformatics and Data Intensive Science, Infectious Diseases Institute, Makerere University, Kampala, Uganda
Daudi Jjingo
ISI Foundation, Turin, Italy
Daniela Paolotti
Department of Health Sciences and Technology, ETH Zurich, Zürich, Switzerland
Effy Vayena
Joint Centre for Bioethics, Dalla Lana School of Public Health, University of Toronto, Toronto, Canada
You can also search for this author in PubMed Google Scholar
Contributions
JS led the writing, contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. JA contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. CA contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. PYC contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. AE contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. JWG contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. AH contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. DJ contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. KL contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. DP contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper. EV contributed to conceptualization and analysis, critically reviewed and provided feedback on drafts of this paper, and provided final approval of the paper.
Corresponding author
Correspondence to James Shaw .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Shaw, J., Ali, J., Atuire, C.A. et al. Research ethics and artificial intelligence for global health: perspectives from the global forum on bioethics in research. BMC Med Ethics 25 , 46 (2024). https://doi.org/10.1186/s12910-024-01044-w
Download citation
Received : 31 October 2023
Accepted : 01 April 2024
Published : 18 April 2024
DOI : https://doi.org/10.1186/s12910-024-01044-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Artificial intelligence
- Machine learning
- Research ethics
- Global health
BMC Medical Ethics
ISSN: 1472-6939
- General enquiries: [email protected]
Mechanism Reform: An Application to Child Welfare
In many market-design applications, a new mechanism is introduced to reform an existing institution. Compared to the design of a mechanism in isolation, the presence of a status-quo system introduces both challenges and opportunities for the designer. We study this problem in the context of reforming the mechanism used to assign Child Protective Services (CPS) investigators to reported cases of child maltreatment in the U.S. CPS investigators make the consequential decision of whether to place a child in foster care when their safety at home is in question. We develop a design framework built on two sets of results: (i) an identification strategy that leverages the status-quo random assignment of investigators—along with administrative data on previous assignments and outcomes—to estimate investigator performance; and (ii) mechanism-design results allowing us to elicit investigators’ preferences and efficiently allocate cases. This alternative mechanism can be implemented by setting personalized non-linear rates at which each investigator can exchange various types of cases. In a policy simulation, we show that this mechanism reduces the number of investigators’ false positives (children placed in foster care who would have been safe in their homes) by 10% while also decreasing false negatives (children left at home who are subsequently maltreated) and overall foster care placements. Importantly, the mechanism is designed so that no investigator is made worse-off relative to the status quo. We show that a naive approach which ignores investigator preference heterogeneity would generate substantial welfare losses for investigators, with potential adverse effects on investigator recruitment and turnover.
We thank Peter Arcidiacono, Pat Bayer, Sylvain Chassang, Michael Dinerstein, Laura Doval, Joseph Doyle, Federico Echenique, Natalia Emanuel, Maria Fitzpatrick, Ezra Goldstein, Peter Hull, Chris Mills, Matt Pecenco, Katherine Rittenhouse, Alex Teytelboym and seminar participants at the 2024 ASSA Annual Meeting, SAET 2024, UC Berkeley, and Duke University for helpful comments and suggestions. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research.
MARC RIS BibTeΧ
Download Citation Data
Working Groups
More from nber.
In addition to working papers , the NBER disseminates affiliates’ latest findings through a range of free periodicals — the NBER Reporter , the NBER Digest , the Bulletin on Retirement and Disability , the Bulletin on Health , and the Bulletin on Entrepreneurship — as well as online conference reports , video lectures , and interviews .

Microsoft Research Blog
Microsoft at asplos 2024: advancing hardware and software for high-scale, secure, and efficient modern applications.
Published April 29, 2024
By Rodrigo Fonseca , Sr Principal Research Manager Madan Musuvathi , Partner Research Manager
Share this page
- Share on Facebook
- Share on Twitter
- Share on LinkedIn
- Share on Reddit
- Subscribe to our RSS feed

Modern computer systems and applications, with unprecedented scale, complexity, and security needs, require careful co-design and co-evolution of hardware and software. The ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) (opens in new tab) , is the main forum where researchers bridge the gap between architecture, programming languages, and operating systems to advance the state of the art.
ASPLOS 2024 is taking place in San Diego between April 27 and May 1, and Microsoft researchers and collaborators have a strong presence, with members of our team taking on key roles in organizing the event. This includes participation in the program and external review committees and leadership as the program co-chair.
We are pleased to share that eight papers from Microsoft researchers and their collaborators have been accepted to the conference, spanning a broad spectrum of topics. In the field of AI and deep learning, subjects include power and frequency management for GPUs and LLMs, the use of Process-in-Memory for deep learning, and instrumentation frameworks. Regarding infrastructure, topics include memory safety with CHERI, I/O prefetching in modern storage, and smart oversubscription of burstable virtual machines. This post highlights some of this work.
Microsoft Research Podcast

Collaborators: Holoportation™ communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
Paper highlights
Characterizing power management opportunities for llms in the cloud.
The rising popularity of LLMs and generative AI has led to an unprecedented demand for GPUs. However, the availability of power is a key limiting factor in expanding a GPU fleet. This paper characterizes the power usage in LLM clusters, examines the power consumption patterns across multiple LLMs, and identifies the differences between inference and training power consumption patterns. This investigation reveals that the average and peak power consumption in inference clusters is not very high, and that there is substantial headroom for power oversubscription. Consequently, the authors propose POLCA: a framework for power oversubscription that is robust, reliable, and readily deployable for GPU clusters. It can deploy 30% more servers in the same GPU clusters for inference tasks, with minimal performance degradation.
PIM-DL: Expanding the Applicability of Commodity DRAM-PIMs for Deep Learning via Algorithm-System Co-Optimization
PIM-DL is the first deep learning framework specifically designed for off-the-shelf processing-in-memory (PIM) systems, capable of offloading most computations in neural networks. Its goal is to surmount the computational limitations of PIM hardware by replacing traditional compute-heavy matrix multiplication operations with Lookup Tables (LUTs). PIM-DL first enables neural networks to operate efficiently on PIM architectures, significantly reducing the need for complex arithmetic operations. PIM-DL demonstrates significant speed improvements, achieving up to ~37x faster performance than traditional GEMM-based systems and showing competitive speedups against CPUs and GPUs.
Cornucopia Reloaded: Load Barriers for CHERI Heap Temporal Safety
Memory safety bugs have persistently plagued software for over 50 years and underpin some 70% of common vulnerabilities and exposures (CVEs) every year. The CHERI capability architecture (opens in new tab) is an emerging technology (opens in new tab) (especially through Arm’s Morello (opens in new tab) and Microsoft’s CHERIoT (opens in new tab) platforms) for spatial memory safety and software compartmentalization. In this paper, the authors demonstrate the viability of object-granularity heap temporal safety built atop CHERI with considerably lower overheads than prior work.
AUDIBLE: A Convolution-Based Resource Allocator for Oversubscribing Burstable Virtual Machines
Burstable virtual machines (BVMs) are a type of virtual machine in the cloud that allows temporary increases in resource allocation. This paper shows how to oversubscribe BVMs. It first studies the characteristics of BVMs on Microsoft Azure and explains why traditional approaches based on using a fixed oversubscription ratio or based on the Central Limit Theorem do not work well for BVMs: they lead to either low utilization or high server capacity violation rates. Based on the lessons learned from the workload study, the authors developed a new approach, called AUDIBLE, using a nonparametric statistical model. This makes the approach lightweight and workload independent. This study shows that AUDIBLE achieves high system utilization while enforcing stringent requirements on server capacity violations.
Complete list of accepted publications by Microsoft researchers
Amanda: Unified Instrumentation Framework for Deep Neural Networks Yue Guan, Yuxian Qiu, and Jingwen Leng; Fan Yang , Microsoft Research; Shuo Yu, Shanghai Jiao Tong University; Yunxin Liu, Tsinghua University; Yu Feng and Yuhao Zhu, University of Rochester; Lidong Zhou , Microsoft Research; Yun Liang, Peking University; Chen Zhang, Chao Li, and Minyi Guo, Shanghai Jiao Tong University
AUDIBLE: A Convolution-Based Resource Allocator for Oversubscribing Burstable Virtual Machines Seyedali Jokar Jandaghi and Kaveh Mahdaviani, University of Toronto; Amirhossein Mirhosseini, University of Michigan; Sameh Elnikety , Microsoft Research; Cristiana Amza and Bianca Schroeder, University of Toronto, Cristiana Amza and Bianca Schroeder, University of Toronto
Characterizing Power Management Opportunities for LLMs in the Cloud (opens in new tab) Pratyush Patel, Microsoft Azure and University of Washington; Esha Choukse (opens in new tab) , Chaojie Zhang (opens in new tab) , and Íñigo Goiri (opens in new tab) , Azure Research; Brijesh Warrier (opens in new tab) , Nithish Mahalingam, Ricardo Bianchini (opens in new tab) , Microsoft AzureResearch
Cornucopia Reloaded: Load Barriers for CHERI Heap Temporal Safety Nathaniel Wesley Filardo , University of Cambridge and Microsoft Research; Brett F. Gutstein, Jonathan Woodruff, Jessica Clarke, and Peter Rugg, University of Cambridge; Brooks Davis, SRI International; Mark Johnston, University of Cambridge; Robert Norton , Microsoft Research; David Chisnall, SCI Semiconductor; Simon W. Moore, University of Cambridge; Peter G. Neumann, SRI International; Robert N. M. Watson, University of Cambridge
CrossPrefetch: Accelerating I/O Prefetching for Modern Storage Shaleen Garg and Jian Zhang, Rutgers University; Rekha Pitchumani, Samsung; Manish Parashar, University of Utah; Bing Xie , Microsoft; Sudarsun Kannan, Rutgers University
Kimbap: A Node-Property Map System for Distributed Graph Analytics Hochan Lee, University of Texas at Austin; Roshan Dathathri, Microsoft Research; Keshav Pingali, University of Texas at Austin
PIM-DL: Expanding the Applicability of Commodity DRAM-PIMs for Deep Learning via Algorithm-System Co-Optimization Cong Li and Zhe Zhou, Peking University; Yang Wang , Microsoft Research; Fan Yang, Nankai University; Ting Cao and Mao Yang , Microsoft Research; Yun Liang and Guangyu Sun, Peking University
Predict; Don’t React for Enabling Efficient Fine-Grain DVFS in GPUs Srikant Bharadwaj , Microsoft Research; Shomit Das, Qualcomm; Kaushik Mazumdar and Bradford M. Beckmann, AMD; Stephen Kosonocky, Uhnder
Conference organizers from Microsoft
Program co-chair, madan musuvathi, submission chairs.
Jubi Taneja Olli Saarikivi
Program Committee
Abhinav Jangda (opens in new tab) Aditya Kanade (opens in new tab) Ashish Panwar (opens in new tab) Jacob Nelson (opens in new tab) Jay Lorch (opens in new tab) Jilong Xue (opens in new tab) Paolo Costa (opens in new tab) Rodrigo Fonseca (opens in new tab) Shan Lu (opens in new tab) Suman Nath (opens in new tab) Tim Harris (opens in new tab)
External Review Committee
Career opportunities.
Microsoft welcomes talented individuals across various roles at Microsoft Research, Azure Research, and other departments. We are always pushing the boundaries of computer systems to improve the scale, efficiency, and security of all our offerings. You can review our open research-related positions here .
Related publications
Crossprefetch: accelerating i/o prefetching for modern storage, kimbap: a node-property map system for distributed graph analytics, predict; don’t react for enabling efficient fine-grain dvfs in gpus, amanda: unified instrumentation framework for deep neural networks, meet the authors.

Rodrigo Fonseca
Sr Principal Research Manager

Partner Research Manager
Continue reading

Research Focus: Week of April 15, 2024

Research at Microsoft 2023: A year of groundbreaking AI advances and discoveries

PwR: Using representations for AI-powered software development

Research Focus: Week of November 22, 2023
Research areas.
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
Share this page:
Web 3.0 Decentralized Application Using Blockchain Technology
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.

AI + Machine Learning , Announcements , Azure AI , Azure AI Studio
Introducing Phi-3: Redefining what’s possible with SLMs
By Misha Bilenko Corporate Vice President, Microsoft GenAI
Posted on April 23, 2024 4 min read
- Tag: Copilot
- Tag: Generative AI
We are excited to introduce Phi-3, a family of open AI models developed by Microsoft. Phi-3 models are the most capable and cost-effective small language models (SLMs) available, outperforming models of the same size and next size up across a variety of language, reasoning, coding, and math benchmarks. This release expands the selection of high-quality models for customers, offering more practical choices as they compose and build generative AI applications.
Starting today, Phi-3-mini , a 3.8B language model is available on Microsoft Azure AI Studio , Hugging Face , and Ollama .
- Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
- It is instruction-tuned, meaning that it’s trained to follow different types of instructions reflecting how people normally communicate. This ensures the model is ready to use out-of-the-box.
- It is available on Azure AI to take advantage of the deploy-eval-finetune toolchain, and is available on Ollama for developers to run locally on their laptops.
- It has been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across graphics processing unit (GPU), CPU, and even mobile hardware.
- It is also available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere. And has been optimized for NVIDIA GPUs .
In the coming weeks, additional models will be added to Phi-3 family to offer customers even more flexibility across the quality-cost curve. Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog and other model gardens shortly.
Microsoft continues to offer the best models across the quality-cost curve and today’s Phi-3 release expands the selection of models with state-of-the-art small models.

Azure AI Studio
Phi-3-mini is now available
Groundbreaking performance at a small size
Phi-3 models significantly outperform language models of the same and larger sizes on key benchmarks (see benchmark numbers below, higher is better). Phi-3-mini does better than models twice its size, and Phi-3-small and Phi-3-medium outperform much larger models, including GPT-3.5T.
All reported numbers are produced with the same pipeline to ensure that the numbers are comparable. As a result, these numbers may differ from other published numbers due to slight differences in the evaluation methodology. More details on benchmarks are provided in our technical paper .
Note: Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts.
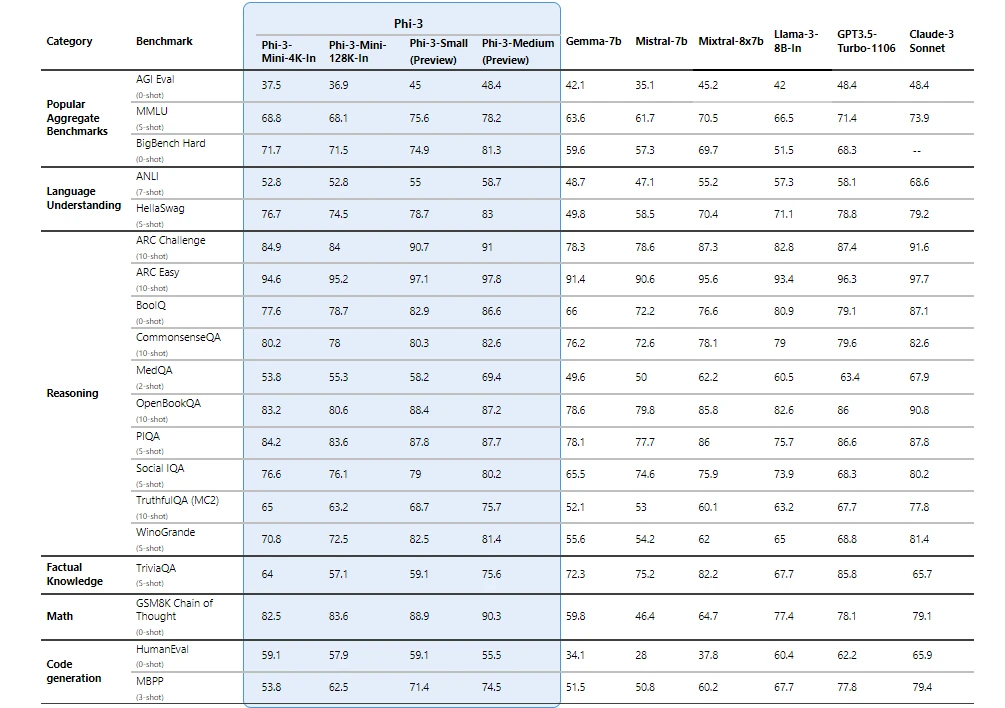
Safety-first model design
Responsible ai principles
Phi-3 models were developed in accordance with the Microsoft Responsible AI Standard , which is a company-wide set of requirements based on the following six principles: accountability, transparency, fairness, reliability and safety, privacy and security, and inclusiveness. Phi-3 models underwent rigorous safety measurement and evaluation, red-teaming, sensitive use review, and adherence to security guidance to help ensure that these models are responsibly developed, tested, and deployed in alignment with Microsoft’s standards and best practices.
Building on our prior work with Phi models (“ Textbooks Are All You Need ”), Phi-3 models are also trained using high-quality data. They were further improved with extensive safety post-training, including reinforcement learning from human feedback (RLHF), automated testing and evaluations across dozens of harm categories, and manual red-teaming. Our approach to safety training and evaluations are detailed in our technical paper , and we outline recommended uses and limitations in the model cards. See the model card collection .
Unlocking new capabilities
Microsoft’s experience shipping copilots and enabling customers to transform their businesses with generative AI using Azure AI has highlighted the growing need for different-size models across the quality-cost curve for different tasks. Small language models, like Phi-3, are especially great for:
- Resource constrained environments including on-device and offline inference scenarios.
- Latency bound scenarios where fast response times are critical.
- Cost constrained use cases, particularly those with simpler tasks.
For more on small language models, see our Microsoft Source Blog .
Thanks to their smaller size, Phi-3 models can be used in compute-limited inference environments. Phi-3-mini, in particular, can be used on-device, especially when further optimized with ONNX Runtime for cross-platform availability. The smaller size of Phi-3 models also makes fine-tuning or customization easier and more affordable. In addition, their lower computational needs make them a lower cost option with much better latency. The longer context window enables taking in and reasoning over large text content—documents, web pages, code, and more. Phi-3-mini demonstrates strong reasoning and logic capabilities, making it a good candidate for analytical tasks.
Customers are already building solutions with Phi-3. One example where Phi-3 is already demonstrating value is in agriculture, where internet might not be readily accessible. Powerful small models like Phi-3 along with Microsoft copilot templates are available to farmers at the point of need and provide the additional benefit of running at reduced cost, making AI technologies even more accessible.
ITC, a leading business conglomerate based in India, is leveraging Phi-3 as part of their continued collaboration with Microsoft on the copilot for Krishi Mitra, a farmer-facing app that reaches over a million farmers.
“ Our goal with the Krishi Mitra copilot is to improve efficiency while maintaining the accuracy of a large language model. We are excited to partner with Microsoft on using fine-tuned versions of Phi-3 to meet both our goals—efficiency and accuracy! ” Saif Naik, Head of Technology, ITCMAARS
Originating in Microsoft Research, Phi models have been broadly used, with Phi-2 downloaded over 2 million times. The Phi series of models have achieved remarkable performance with strategic data curation and innovative scaling. Starting with Phi-1, a model used for Python coding, to Phi-1.5, enhancing reasoning and understanding, and then to Phi-2, a 2.7 billion-parameter model outperforming those up to 25 times its size in language comprehension. 1 Each iteration has leveraged high-quality training data and knowledge transfer techniques to challenge conventional scaling laws.
Get started today
To experience Phi-3 for yourself, start with playing with the model on Azure AI Playground . You can also find the model on the Hugging Chat playground . Start building with and customizing Phi-3 for your scenarios using the Azure AI Studio . Join us to learn more about Phi-3 during a special live stream of the AI Show.
1 Microsoft Research Blog, Phi-2: The surprising power of small language models, December 12, 2023 .
Let us know what you think of Azure and what you would like to see in the future.
Provide feedback
Build your cloud computing and Azure skills with free courses by Microsoft Learn.
Explore Azure learning
Related posts
AI + Machine Learning , Azure AI , Azure AI Content Safety , Azure Cognitive Search , Azure Kubernetes Service (AKS) , Azure OpenAI Service , Customer stories
AI-powered dialogues: Global telecommunications with Azure OpenAI Service chevron_right
AI + Machine Learning , Azure AI , Azure AI Content Safety , Azure OpenAI Service , Customer stories
Generative AI and the path to personalized medicine with Microsoft Azure chevron_right
AI + Machine Learning , Azure AI , Azure AI Services , Azure AI Studio , Azure OpenAI Service , Best practices
AI study guide: The no-cost tools from Microsoft to jump start your generative AI journey chevron_right
AI + Machine Learning , Azure AI , Azure VMware Solution , Events , Microsoft Copilot for Azure , Microsoft Defender for Cloud
Get ready for AI at the Migrate to Innovate digital event chevron_right
IMAGES
VIDEO
COMMENTS
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on WEB APPLICATIONS. Find methods information, sources, references or conduct a literature review on WEB ...
Mohammed Charaf Eddine Meftah. Okba Kazar. This paper proposes a formal approach for development of safe web applications. This approach involves the generation of a web application on both sides ...
Our literature search for related studies retrieved 193 papers in the area of web application testing, which have appeared between 2000 and 2013. Objective. ... of the web application testing (WAT) research domain. In a recent work, we conducted a systematic mapping (SM) study (Garousi et al., 2013) in which we reviewed 79 papers in the WAT ...
Web3, the next generation web, promises a decentralized and democratized internet that puts users in control of their data and online identities. ... To address these challenges, this review paper provides a comprehensive analysis of Web3, including its key advancements and implications, as well as an overview of its major applications in ...
This paper. provides an overview o f the generic web appl ications, and then extends the discussion t hrough a. contemporary perspective, proposing the umbrella. term "web-based application" t ...
The research carried out by other authors and included in this study, serves as a fundamental approach for the comparison between the tools used by the development methodologies detailed in Table 9. Table 9. Comparison between web application development methodologies. Empty Cell.
The recommendations presented in this paper offer a practical guide, enabling individuals and security personnel across various industries and organizations to implement tested and proven security measures for web applications. Furthermore, it serves as a roadmap for security developers, aiding them in creating more accurate and quantifiable ...
The Online Examination Portal is a web application for taking an online test productively along with face recognition capabilities to perform live proctoring, and there is no time wasted for checking the paper. This report will incorporate all highlights and procedures which are required to develop this portal.
Jordan to investigate current web application development and measurement practices in small software firms. This paper presents findings of the pilot study. 2. Methodology The research was conducted in three stages: data coding, variable clustering and acceptance degree identification. Fig 1 shows the flow of the research. Data coding
Website Developmemt Technologies: A Review. Abstract: Service Science is that the basis of knowledge system and net services that judge to the provider/client model. This paper developments a technique which will be utilized in the event of net services like websites, net applications and eCommerce. The goal is to development a technique that ...
This thesis systematically analyzes the field of functional, system level web application testing tools and generates a feature model of the domain that can be used to identify trends and problems, extraordinary features, help decision making of tool purchase or guide scientists how to focus research. Expand. 1. 1 Excerpt.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications. ... Cui-hong, H. Research on Web 3. ...
OWASP (Open Web Application Security Project) is a non-profit organization which gives the severity, impact and prevention methods about Top 10 vulnerabilities in web applications. This research deals with the implementation of bestsecurity practices for Node.js web applications in detail. This research paper proposes the security mechanisms ...
This paper presents benchmarks regarding a web application that aims at displaying and visualizing a dataset for air quality monitoring, experimenting using two different programming languages. Specifically, an application is developed via the use of PHP and Python frameworks in order to study the impact of the CPU, the hard disk architecture ...
This web application is supposed to feature a wide domain and global applications. From the world of technology to the vast remains of history and the travelogues all around the world sewed at one place. It will also support multi-lingual features and sections. A separate section for current discount coupons and offers from various websites ...
This paper combines the theory and the actual research, analyzes the HTTP protocol, introduces the attack of the mainstream Web application and its bypass method. For the defects of the HTTP protocol and the shortcomings of the pattern matching, the feature matching is implemented by using the block retrieval technology.
The application was designed according to the paradigms of patient-centered care and user-centered design (UCD). It considers the patient as the main empowered and motivating factor in the management of his or her well-being. Implementation was informed through a family needs and technology perception assessment.
The world is exceedingly reliant on the Internet. Nowadays, web security is biggest challenge in the corporate world. It is considered as the principle framework for the worldwide data society. Web applications are prone to security attacks. Web security is securing a web application layer from attacks by unauthorized users. A lot of the issues that occur over a web application is mainly due ...
Focusing on the web application security testing, we were able to find three review papers (secondary) (Bhargav and Kumar, 2010, Mohanty et al., 2019, Seng et al., 2018) which have been reported and we list these papers in Table 1.For each paper, its type, its publication year, number of papers reviewed and focus area were extracted.
A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications. Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the ...
Developing Web Applicati ons. Sabah Al-Fedaghi. Computer Engineering Department - Kuwait University. [email protected]. Abstract. One approach to developing service-oriented Web applications is ...
Llama Guard models are meant to be a foundation for prompt and response safety and can easily be fine-tuned to create a new taxonomy depending on application needs. As a starting point, the new Llama Guard 2 uses the recently announced MLCommons taxonomy, in an effort to support the emergence of industry standards in this important area.
The 7-volume set LNCS 14651 - 14657 conference volume constitutes the proceedings of the 43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques, EUROCRYPT 2024, held in in Zurich, Switzerland, in May 2024. The 105 papers included in these proceedings were carefully reviewed and selected from 500 submissions.
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our ...
The ethical governance of Artificial Intelligence (AI) in health care and public health continues to be an urgent issue for attention in policy, research, and practice [1,2,3].Beyond the growing number of AI applications being implemented in health care, capabilities of AI models such as Large Language Models (LLMs) expand the potential reach and significance of AI technologies across health ...
In many market-design applications, a new mechanism is introduced to reform an existing institution. Compared to the design of a mechanism in isolation, the presence of a status-quo system introduces both challenges and opportunities for the designer. We study this problem in the context of ...
Modern computer systems and applications, with unprecedented scale, complexity, and security needs, require careful co-design and co-evolution of hardware and software. The ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) (opens in new ...
The use of blockchain technology is growing every day, as are its applications. It is a cutting-edge technology that enables users to interact without the use of a reliable intermediary. This research paper explores the development of a decentralized application (Dapp) and the design considerations involved in building a secure, scalable, and userfriendly application on a blockchain or ...
This SLR is intended to improve research work in the domain of DL-based web attacks detection, as it covers a significant number of research papers and identifies the key points that need to be ...
A cloud-native web application firewall (WAF) service that provides powerful protection for web apps ... Our approach to safety training and evaluations are detailed in our technical paper, and we outline recommended uses and limitations in the model cards. ... Originating in Microsoft Research, Phi models have been broadly used, with Phi-2 ...