Guide to Computer Vision: Why It Matters and How It Helps Solve Problems

This post was written to enable the beginner developer community, especially those new to computer vision and computer science. NVIDIA recognizes that solving and benefiting the world’s visual computing challenges through computer vision and artificial intelligence requires all of us. NVIDIA is excited to partner and dedicate this post to the Black Women in Artificial Intelligence .
Computer vision’s real world use and reach is growing and its applications in turn are challenging and changing its meaning. Computer vision, which has been in some form of its present existence for decades, is becoming an increasingly common phrase littered in conversation, across the world and across industries: computer vision systems, computer vision software, computer vision hardware, computer vision development, computer vision pipelines, computer vision technology.

What is computer vision?
There is more to the term and field of computer vision than meets the eye, both literally and figuratively. Computer vision is also referred to as vision AI and traditional image processing in specific non-AI instances, and machine vision in manufacturing and industrial use cases.
Simply put, computer vision enables devices, including laptops, smartphones, self-driving cars, robots, drones, satellites, and x-ray machines to perceive, process, analyze, and interpret data in digital images and video.
In other words, computer vision fundamentally intakes image data or image datasets as inputs, including both still images and moving frames of a video, either recorded or from a live camera feed. Computer vision enables devices to have and use human-like vision capabilities just like our human vision system. In human vision, your eyes perceive the physical world around you as different reflections of light in real-time.
Similarly, computer vision devices perceive pixels of images and videos, detecting patterns and interpreting image inputs that can be used for further analysis or decision making. In this sense, computer vision “sees” just like human vision and uses intelligence and compute power to process input visual data to output meaningful insights, like a robot detecting and avoiding an obstacle in its path.
Different computer vision tasks mimic the human vision system, performing, automating, and enhancing functions similar to the human vision system.
How does computer vision relate to other forms of AI?
Computer vision is helping to teach and master seeing, just like conversational AI is helping teach and master the sense of sound through speech, in applications of recognizing, translating, and verbalizing text: the words we use to define and describe the physical world around us.
Similarly, computer vision helps teach and master the sense of sight through digital image and video. More broadly, the term computer vision can also be used to describe how device sensors, typically cameras, perceive and work as vision systems in applications of detecting, tracking and recognizing objects or patterns in images.
Multimodal conversational AI combines the capabilities of conversational AI with computer vision in multimedia conferencing applications, such as NVIDIA Maxine .
Computer vision can also be used broadly to describe how other types of sensors like light detection and ranging (LiDAR) and radio detection and ranging (RADAR) perceive the physical world. In self-driving cars, computer vision is used to describe how LiDAR and RADAR sensors work, often together and in-tandem with cameras to recognize and classify people, objects, and debris.
What are some common tasks?
While computer vision tasks cover a wide breadth of perception capabilities and the list continues to grow, the latest techniques support and help solve use cases involving detection, classification, segmentation, and image synthesis.
Detection tasks locate, and sometimes track, where an object exists in an image. For example, in healthcare for digital pathology, detection could involve identifying cancer cells through medical imaging. In robotics, software developers are using object detection to avoid obstacles on the factory floor.
Classification techniques determine what object exists within the visual data. For example, in manufacturing, an object recognition system classifies different types of bottles to package. In agriculture, farmers are using classification to identify weeds among their crops.
Segmentation tasks classify pixels belonging to a certain category, either individually by pixel (semantic image segmentation) or by assigning multiple object types of the same class as individual instances (instance image segmentation). For example, a self-driving car segments parts of a road scene as drivable and non-drivable space.
Image synthesis techniques create synthetic data by morphing existing digital images to contain desired content. Generative adversarial networks (GANs), such as EditGAN , enable generating synthetic visual information from text descriptions and existing images of landscapes and people. Using synthetic data to compliment and simulate real data is an emerging computer vision use case in logistics using vision AI for applications like smart inventory control.
What are the different types of computer vision?
To understand the different domains within computer vision, it is important to understand the techniques on which computer vision tasks are based. Most computer vision techniques begin with a model, or mathematical algorithm, that performs a specific elementary operation, task, or combination. While we classify traditional image processing and AI-based computer vision algorithms separately, most computer vision systems rely on a combination depending on the use case, complexity, and performance required.
Traditional computer vision
Traditional, non-deep learning-based computer vision can refer to both computer vision and image processing techniques.
In traditional computer vision, a specific set of instructions perform a specific task, like detecting corners or edges in an image to identify windows in an image of a building.
On the other hand, image processing performs a specific manipulation of an image that can be then used for further processing with a vision algorithm. For instance, you may want to smooth or compress an image’s pixels for display or reduce its overall size. This can be likened to bending the light that enters the eye to adjust focus or viewing field. Other examples of image processing include adjusting, converting, rescaling, and warping an input image.
AI-based computer vision
AI-based computer vision or vision AI relies on algorithms that have been trained on visual data to accomplish a specific task, as opposed to programmed, hard-coded instructions like that of image processing.
The detection, classification, segmentation, and synthesis tasks mentioned earlier typically are AI-based computer vision algorithms because of the accuracy and robustness that can be achieved. In many instances, AI-based computer vision algorithms can outperform traditional algorithms in terms of these two performance metrics.
AI-based computer vision algorithms mimic the human vision system more closely by learning from and adapting to visual data inputs, making them the computer vision models of choice in most cases. That being said, AI-based computer vision algorithms require large amounts of data and the quality of that data directly drives the quality of the model’s output. But, the performance outweighs the cost.
AI-based neural networks teach themselves, depending on the data the algorithm was trained on. AI-based computer vision is like learning from experience and making predictions based on context apart from explicit direction. The learning process is akin to when your eye sees an unfamiliar object and the brain tries to learn what it is and stores it for future predictions.
Machine learning compared to deep learning in AI-based computer vision
Machine learning computer vision is a type of AI-based computer vision. AI-based computer vision based on machine learning has artificial neural networks or layers, similar to that seen in the human brain, to connect and transmit signals about the visual data ingested. In machine learning, computer vision neural networks have separate and distinct layers, explicitly-defined connections between the layers, and predefined directions for visual data transmission.
Deep learning-based computer vision models are a subset of machine learning-based computer vision. The “deep” in deep learning derives its name from the depth or number of the layers in the neural network. Typically, a neural network with three or more layers is considered deep.
AI-based computer vision based on deep learning is trained on volumes of data. It is not uncommon to see hundreds of thousands and millions of digital images used to train and develop deep neural network models. For more information, see What’s the difference Between Artificial Intelligence, Machine Learning, and Deep Learning? .
Get started developing computer vision
Now that we have covered the fundamentals of computer vision, we encourage you to get started developing computer vision. We recommend that beginners get started with the Vision Programming Interface (VPI) Computer Vision and Image Processing Library for non-AI algorithms or one of the TAO Toolkit fully-operational, ready-to-use, pretrained AI models .
To see how NVIDIA enables the end-to-end computer vision workflow, see the Computer Vision Solutions page. NVIDIA provides models plus computer vision and image-processing tools. We also provide AI-based software application frameworks for training visual data, testing and evaluation of image datasets, deployment and execution, and scaling.
To help enable emerging computer vision developers everywhere, NVIDIA is curating a series of paths to mastery to chart and nurture next-generation leaders. Stay tuned for the upcoming release of the computer vision path to mastery to self-pace your learning journey and showcase your #NVCV progress on social media.
Related resources
- DLI course: Deep Learning for Industrial Inspection
- GTC session: The Visionaries: A Cross-Industry Exploration of Computer Vision
- GTC session: Vision AI Demystified
- GTC session: Boost your Vision AI Application with Vision Transformer
- NGC Containers: MATLAB
- Webinar: Transforming Warehouse Operation Management Using Computer Vision and Digital Twins
About the Authors

Related posts

Explainer: What Is Computer Vision?

The Future of Computer Vision

AI Startup Aims To Redefine How People Interact with Technology

AI Reinvents the Filmmaking Process

CSIRO Powers Bionic Vision Research with New GPU-Accelerated Supercomputer
Revolutionizing Graph Analytics: Next-Gen Architecture with NVIDIA cuGraph Acceleration

Efficient CUDA Debugging: Memory Initialization and Thread Synchronization with NVIDIA Compute Sanitizer

Analyzing the Security of Machine Learning Research Code

Comparing Solutions for Boosting Data Center Redundancy
Validating nvidia drive sim radar models.
- Skip to primary navigation
- Skip to main content
Open Computer Vision Library
A Comprehensive Guide to Computer Vision Research in 2024
bharat January 17, 2024 Leave a Comment AI Careers Tags: ai computer vision computer vision research computer vision research groups deep learning OpenCV

Introduction
In our earlier blogs , we discussed the best institutes across the world for computer vision research. In this fun read, we’ll look at the different stages of Computer Vision research and how you can go about publishing your research work. Let us delve into them now. Looking to become a Computer Vision Engineer? Check out our Comprehensive Guide !
Table of Contents
- Introduction
- Different Stages of Computer Vision
Research Publications
Different stages of computer vision research.
Computer Vision Research can be put into various stages, one building to the next. Let us look at them in detail.
Identification of Problem Statement
Computer Vision research starts with identifying the problem statement. It is a crucial step in defining the scope and goals of a research project. It involves clearly understanding the specific challenge or task the researchers aim to address using computer vision techniques. Here are the steps involved in identifying the problem statement in computer vision research:
- Problem Statement Analysis: The first step is to pinpoint the specific application domain within computer vision. This could be related to object recognition in autonomous vehicles or medical image analysis for disease detection.
- Defining the problem: Next, we define the precise problem we want to solve within that domain, like classifying images of animals or diagnosing diseases from X-rays.
- Understanding the objectives: We need to understand the research objectives and outline what we intend to achieve through this project. For instance, improving classification accuracy or reducing false positives in a medical imaging system.
- Data availability: Next, we need to analyze the availability of data for our project. Check if existing datasets are suitable for our task or if we need to gather our own data, like collecting images of specific objects or medical cases.
- Review: Conduct a thorough review of existing research and the latest methodologies in the field. This will help you gain insights into the current state-of-the-art techniques and the challenges others have faced in similar projects.
- Question formulation: Once we review the work, we can formulate research questions to guide our experiments. These questions could address specific aspects of our computer vision problem and help better structure our research.
- Metrics: Next, we define the evaluation metrics that we’ll use to measure the performance of our vision system. Some common metrics include accuracy, precision, recall, and F1-score.
- Highlighting: Highlight how solving the problem will have an effect in the real world. For instance, improving road safety through better object recognition or enhanced medical diagnoses for early treatment.
- Research Outline: Finally, outline the research plan, and detail the methodology employed for data collection, model development, and evaluation. A structured outline will ensure we are on the right track throughout our research project.

Let us move to the next step, data collection and creation.
Dataset Collection and Creation
Creating and gathering datasets is one of the key building blocks in computer vision research. These datasets facilitate the algorithms and models used in vision systems. Let us see how this is done.
- Firstly we need to know what we are trying to solve. For instance, are we training models to recognize dogs in photos or identify anomalies in medical images?
- Now, we’ll need images or videos. Depending on the research needs, we can find them on public datasets or collect our own.
- Next, we mark up the data. For instance, if you’re teaching a computer to spot dogs in pictures, you’ll draw boxes around the cars and say, “These are dogs!”
- Raw data can be a mess. We may need to resize images, adjust colors, or add more examples to ensure our dataset is neat and complete.
- 1-part for training your model
- 1-part for fine-tuning
- 1-part for testing how well your model works
- Next, ensure the dataset fairly represents the real world and doesn’t favor one group or category too much.
One can also share their dataset and research with others for inputs and improvements. Dataset collection and creation are vital in computer vision research.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) briefly analyzes a dataset to answer preliminary questions and guide the modeling process. For instance, this could be looking for patterns across different classes. This is not only used by Computer Vision Engineers but also Data Scientists to ensure that the data they provide are aligned with different business goals or outcomes. This step involves understanding the specifics of image datasets. For instance, EDA is used to spot anomalies, understand data distribution, or gain insights to further model training. Let us look at the role of EDA in model development.
- With EDA, one can develop data preprocessing pipelines and choose data augmentation strategies.
- We can analyze how the findings from EDA can affect the choice of model architecture. For instance, the need for some convolutional layers or input images.
- EDA is also crucial for advanced Computer Vision tasks like object detection, segmentation, and image generation backed by studies.

Now let us dive into the specifics of EDA methods and preparing image datasets for model development.
Visualization
- Sample Image Visualization involves displaying a random set of images from the dataset. This is a fundamental step where we get an idea of the data like lighting conditions or variations in image quality. From this, one can infer the visual diversity and any challenges in the dataset.
- Analyzing the pixel distribution intensities offers insights into the brightness and contrast variations across the dataset if there is any need for image enhancement techniques.
- Next, creating histograms for different color channels gives us a better understanding of the color distribution of the dataset. This is a crucial step for tasks such as image classification.
Image Property Analysis
- Another crucial part is understanding the resolution and the aspect ratio of images in the dataset. It helps make decisions like resizing the image or normalizing the aspect ratio, which is crucial in maintaining consistency in input data for neural networks.
- Analyzing the size and distribution of annotated objects can be insightful in datasets with annotations. This influences the design layers in the neural network and understanding the scale of objects.
Correlation Analysis
- With some advanced EDA processes like high dimensional image data, analyzing the relation between different features is helpful. This would aid with dimensionality reduction or feature selection.
- Next, it is crucial to understand the spatial correlations within images, like the relationship between different regions in an image. It helps in the development of spatial hierarchies in neural networks.
Class Distribution Analysis
- EDAs are important in understanding the imbalances in class distribution. This is key in classification tasks where imbalanced data can lead to biased models.
- Once the imbalances are identified, we can adopt techniques like undersampling majority classes or oversampling minority classes during model training.
Geometric Analysis
- Understanding geometric properties like edges, shapes, and textures in images offers insights into the features important for the problem at hand. We can make informed decisions on selecting specific filters or layers in the network architecture.
- It’s important to understand how different morphological transformations affect images for segmentation and object detection tasks.
Sequential Analysis
The sequential analysis applies to video data.
- For instance, analyzing changes between frames can offer information like motion, temporal consistency, or the need for temporal modeling in video datasets or video sequences.
- Identifying temporal variations and scene changes gives us insights into the dynamics within the video data that are crucial for tasks like event detection or action recognition.
Now that we’ve discussed Exploratory Data Analysis and some of its techniques let us move to the next stage in Computer Vision research, defining the model architecture.
Defining Model Architecture
Defining a model architecture is a critical component of research in computer vision, as it lays the foundation for how a machine learning model will perceive, process, and interpret visual data. We analyze a model that impacts the ability of the model to learn from visual data and perform tasks like object detection or semantic segmentation.
Model architecture in computer vision refers to the structural design of an artificial neural network. The architecture defines how the model processes input images, extracts features, and makes predictions and classifications.
What are the components of a model architecture? Let’s explore them.

Input Layer
This is where the model receives the image data, mostly in the form of a multi-dimensional array. For colored images, this could be a 3D array where color channels show RGB values. Preprocessing steps like normalization are applied here.
Convolutional Layers
These layers apply a set of filters to the input. Every filter convolves across the width and height of the input volume, computing the dot product between the entries of the filter and the input, producing a 2D activation map for each filter. Preserving the relationship between pixels captures spatial hierarchies in the image.
Activation Functions
Activation functions facilitate networks to learn more complex representations by introducing them to non-linear properties. For instance, the ReLU (Rectified Linear Unit) function applies a non-linear transformation (f(x) = max(0,x)) that retains only positive values and sets all negative values to zero. Other functions include sigmoid and tanh.
Pooling Layers
These layers are used to perform a down-sampling operation along the spatial dimensions (width, height), reducing the number of parameters and computations in the network. For instance, Max pooling, a common approach, takes the maximum value from a set of values in the filter area, is a common approach. This operation offers spatial variance, making the recognition of features in the input invariant to scale and orientation changes.
Fully Connected Layers
Here, the layers connect every neuron in one layer to every neuron in the next layer. In a CNN, the high-level reasoning in the neural network is performed via these dense layers. Typically, they are positioned near the end of the network and are used to flatten the output of convolutional and pooling layers to form a single vector of features used for final classification or regression tasks.
Dropout Layers
Dropout is a regularization technique where randomly selected neurons are ignored during training. This means that the contribution of these neurons to activate the downstream neurons is removed temporally on the forward pass and any weight updates are not applied to the neuron on the backward pass. This helps in preventing overfitting.
Batch Normalization
In batch normalization, the output from a previous activation layer is normalized by subtracting the batch mean and then dividing it by the standard deviation of the batch. This technique helps stabilize the learning process and significantly reduces the number of training epochs required for deep network training.
Loss Function
The difference between the expected outcomes and the predictions made by the model is quantified by the loss function. Cross-entropy for classification tasks and mean squared error for regression tasks are some of the common loss functions in computer vision.
The optimizer is an algorithm used to minimize the loss function. It updates the network’s weights based on the loss gradient. Some common optimizers include Stochastic Gradient Descent (SGD), Adam, and RMSprop. They use backpropagation to determine the direction in which each weight should be adjusted to minimize the loss.
Output Layer
This is the final layer, where the model’s output is produced. The output layer typically includes a softmax function for classification tasks that converts the outputs to probability values for each class. For regression tasks, the output layer may have a single neuron.
Frameworks like TensorFlow, PyTorch, and Keras are widely used for designing and implementing model architectures. They offer pre-built layers, training routines, and easy integration with hardware accelerators.
Defining a model architecture requires a good grasp of both the theoretical aspects of neural networks and the practical aspects of the specific task.
Training and Validation
Training and validation are crucial in developing a model. They help evaluate a model’s performance, especially when dealing with object detection or image classification tasks.
In this phase, the model is represented as a neural network that learns to recognize image patterns and features by altering its internal parameters iteratively. These parameters are weights and biases related to the network’s layers. Training is key for extracting meaningful features from raw visual data. Let us see how one can go about training a model.
- Acquiring a dataset is the first step. It could be in the form of images or videos for model learning purposes. For robustness, they cover various environmental conditions, variations, and object classes.
- Resizing is where all the input data has the same dimensions for batch processing.
- In Normalization, pixels are standardized to zero mean and unit variance, aiding convergence.
- Augmentation applies random transformations to increase the size of the dataset artificially, thereby improving the model’s ability to generalize.
- Once data preprocessing is done, we must choose the appropriate neural network architecture catering to the specific vision task. For instance, CNNs are widely used for image-related tasks.
- Next, we initialize the model parameters, usually weights, and biases, using random values or pre-trained weights from a model trained on a simple dataset. Transfer learning can significantly improve performance, especially when data is limited.
- Then we can optimize the algorithm to adjust its parameters iteratively with stochastic gradient descent (SGD) or RMSprop. Gradients in relation to the model’s parameters are computed through backpropagation which are used to update the parameters.
- Once the algorithm is optimized, the data is trained in mini-batches through the network, computing the loss for each mini-batch and performing gradient updates. This happens until the loss falls below a predefined threshold.
- Next, we must optimize the training performance and convergence speed by fine-tuning the hyperparameters. This could done by optimizing learning rates, batch sizes, weight regulation terms, or network architectures.
- We need to assess the model’s performance using validation or test datasets and eventually deploy the model in real-world applications through software integrations or embedded devices.
Now let us move to the next step- Validation.
Validation is fundamental for the quantitative assessment of performance and generalization capabilities of algorithms. It ensures the reliability and effectiveness of the models when applied to real-world data. Validation evaluates the ability of a model to make accurate predictions of previously unseen data hence being able to gauge its ability for generalization.
Now let us explore some of the key techniques involved in validation.
Cross-Validation Techniques
- K-Fold Cross-Validation is the method where the dataset is partitioned into K non-overlapping subsets. The model is trained and evaluated K times, with each fold taking turns as the validation set while the rest serve as the training set. The results are averaged to obtain a robust performance estimate.
- Leave-One-Out Cross-Validation or LOOCV is an extreme form of cross-validation where each data point is used as the validation set while the remaining data points constitute the training set.LOOCV offers an exhaustive evaluation of model performance.
Stratified Sampling
In some imbalanced datasets where a few classes have significantly fewer instances than others, stratified sampling ensures the balance between training and validation sets for the distribution of classes.
Performance Metrics
To assess the model’s performance, a range of performance metrics specified for computer vision tasks are deployed. They are not limited to the following.
- Accuracy is the ratio of the correctly predicted instances to the total number of instances.
- Precision is the proportion of true positive predictions among all positive predictions.
- Recall is the proportion of true positive predictions among all positive instances.
- F1-Score is the harmonic mean of precision and recall.
- Mean Average Precision (mAP)is commonly used in object detection and image retrieval tasks to evaluate the quality of ranked lists of results.
Hyperparameter Tuning
Validation is closely integrated with hyperparameter tuning, where the model’s hyperparameters are systematically adjusted and evaluated using the validation set. Techniques such as grid search, random search, or Bayesian optimization help identify the optimal hyperparameter configuration for the model.
Data Augmentation
Data augmentation techniques are applied to test the model’s robustness and the ability to handle different conditions or transformations during validation to simulate variations in the input data.
Training is where the model learns from labeled data, and Validation is where the model’s learning and generalization capabilities are assessed. They ensure that the final model is robust, accurate, and capable of performing well on unseen data, which is critical for computer vision research.
Hyperparameter tuning refers to systematically optimizing hyperparameters in deep learning models for tasks like image processing and segmentation. They control the learning algorithm’s performance but did not learn from the training data. Fine-tuning hyperparameters are crucial if we wish to achieve accurate results.

It is the number of training examples used in every forward and backward pass. Large batch sizes offer smoother convergence but need more memory. On the contrary, small batch sizes need less memory and can help escape local minima.
Number of Epochs
The Number of epochs defines how often the entire training dataset is processed during training. Too few epochs can lead to underfitting, and too many can lead to overfitting.
Learning Rate
This determines the step size during gradient-based optimization. If the learning rate is too high, it can lead to overshooting, causing the loss function to diverge, and if the learning rate is too short, it can cause slow convergence.
Weight Initialization
The training stability is affected by the initialization of weights. Techniques such as Glorot initialization are designed to address the vanishing gradient problems.
Regularization Techniques
Some techniques like dropout and weight decay aid in preventing overfitting. The model generalization is enhanced through random rotations using data augmentation.
Choice of Optimizer
The updates during training for model weights are determined by the optimizer. They have their parameters like momentum, decay rates and epsilon.
Hyperparameter tuning is usually approached as an optimization problem. Few techniques like Bayesian optimization efficiently explore the hyperparameter space balancing computational costs and do not slack on the performance. A well-defined hyperparameter tuning includes not just adjusting individual hyperparameters but also also considers their interactions.
Performance Evaluation on Unseen Data
In the earlier section, we discussed how one must go about doing the training and validation of a model. Now we’ll discuss how to evaluate the performance of a dataset on unseen data.

Training and validation dataset split is paramount when developing and evaluating models. This is not to be confused with the training and validation we discussed earlier for a model. Splitting the dataset for training and validation aids in understanding the model’s performance on unseen data. This ensures that the model generalizes well to new data. Let us look at them.
- A training dataset is a collection of labeled data points for training the model, adjusting parameters, and inferring patterns and features.
- A separate dataset is used for evaluating the model during development for hyperparameter tuning and model selection. This is the Validation dataset.
- Then there is the test dataset , an independent dataset used for assessing the final performance and generalization ability on unseen data.
Splitting datasets is needed to prevent the model from training on the same data. This would hinder the model’s performance. Some commonly used split ratios for the dataset are 70:30, 80:20, or 90:10. The larger portion is used for training, while the smaller portion is used for validation.
You have put so much effort into your research paper. But how do we publish it? Where do we publish it? How do I find the right computer vision research groups? That is what this section covers, so let’s get to it.
Conferences
There are some top-tier computer vision conferences happening across the globe. They are among the best places to showcase research work, look for future collaborations, and build networks.
Conference on Computer Vision and Pattern Recognition (CVPR)
Also called the CVPR , it is one of the most prestigious conferences in the world of Computer Vision. It is organized by the IEEE Computer Society and is an annual event. It has an amazing history of showcasing cutting-edge research papers in image analysis, object detection, deep learning techniques, and much more. CVPR has set the bar high, placing a strong emphasis on the technical aspects of the submissions. They must meet the following criteria.
Papers must possess an innovative contribution to the field. This could be the development of new algorithms, techniques, or methodologies that can bring advancements in computer vision.
If applicable, the submissions must have mathematical formulations of their methods, like equations and theorem proofs. This offers a solid theoretical foundation for the paper’s approach.
Next, the paper should include comprehensive experimental results involving many datasets and benchmarking against existing models. These are key to demonstrating the effectiveness of your proposed approach.
Clarity – this is a no-brainer; the writing and presentation must be clear and concise. The writers are expected to explain the algorithms, models, and results in a technically sound manner.

CVPR is an amazing platform for networking and engaging with the community. It’s a great place to meet academics, researchers, and industry experts to collaborate and exchange ideas. The acceptance rate for papers is only 25.8% hence the recognition within the vision community is impressive. It often leads to citations, greater visibility, and potential collaborations with renowned researchers and professionals.
International Conference on Computer Vision (ICCV)
The ICCV is another premier conference held annually once, offering an amazing platform for cutting-edge computer vision research. Much like the CVPR, the ICCV is also organized by the IEEE Computer Society, attracting worldwide visionaries, researchers, and professionals. Topics range from object detection and recognition all the way to computational photography. ICCV invites original papers offering a significant contribution to the field. The criteria for submissions are very similar to the CVPR. They must possess mathematical formulations, algorithms, experimental methodology, and results. ICCV adopts peer review to add a layer of technical rigor and quality to the accepted papers. Submissions usually undergo multiple stages of review, giving detailed feedback on the technical aspects of the research paper. The acceptance rates at ICCV are typically low at 26.2%.
Besides the main conference, the ICCV hosts workshops and tutorials that offer in-depth discussions and presentations in emerging research areas. It also offers challenges and competitions associated with computer vision tasks like image segmentation and object detection.
Like the CVPR, it offers excellent opportunities for future collaborations, networking with peers, and exchanging ideas. The papers accepted at the ICCV are typically published in the IEEE Computer Society and made available to the vision community. This offers significant visibility and recognition to researchers for papers that are accepted.
European Conference on Computer Vision (ECCV)
The European Conference on Computer Vision, or ECCV , is another comprehensive conference if you are looking for the top computer vision conferences globally. The ECCV lays a lot of emphasis on the scientific and technical quality of the paper. Like the above two conferences we discussed, it emphasizes how the researcher incorporates the mathematical foundations, algorithms, and detailed derivations and proofs with extensive experimental evaluations.
According to the ECCV formatting guidelines, the research paper ideally ranges from 10 to 14 pages. It adopts a double-blind peer review, where the researchers must make their submissions anonymous to curb any discrepancies.

ECCV also offers huge opportunities for collaborations and establishing connections. With an acceptance rate of 31.8%, a researcher can benefit from academic recognition, high visibility, and citations.
Winter Conference on Applications of Computer Vision (WACV)
WACV is a top international computer vision event with the main conference and a few workshops and tutorials. Much like the other conferences, it is held annually. With an acceptance rate below 30%, it attracts leading researchers and industry professionals. The conference usually takes place in the first week of January.

As a computer vision researcher, one must publish one’s works in journals to show your findings and give more insights into the field. Let us look at a few of the computer vision journals.
Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Also called the TPAMI , this journal focuses on the various aspects of machine intelligence, pattern recognition, and computer vision. It offers a hybrid publication permitting traditional or author-paid open-access manuscript submissions.
With open-access manuscripts, the paper has unrestricted access to it through the IEEE Xplore and Computer Society Digital Library.
Regarding traditional manuscript submissions, the IEEE Computer Society has various award-winning journals for publication. One can browse through the different topics that fit their research. They often publish special sections on emerging topics. Some factors you need to consider are submission to publications time, bibliometric scores like impact factor, and publishing fees.
International Journal of Computer Vision (IJCV)
The IJCV offers a platform for new research results. With 15 issues a year, the International Journal of Computer Vision offers high-quality, original contributions to the field of computer vision. The length of the articles ranges from 10-page regular articles to up to 30 pages for survey papers that offer state-of-the-art presentations and results. The research must cover mathematical, physics, and computational aspects of computer vision, like image formation, processing, interpretation, machine learning techniques, and statistical approaches. Researchers are not charged to publish on IJCV . It is not only a journal that opens doors for researchers to showcase their papers but also a goldmine of information in deep learning, artificial intelligence, and robotics.
Journal of Machine Learning Research (JMLR)
Established in 2000, JMLR is a forum for electronic and paper publications of comprehensive research papers. This platform covers topics like machine learning algorithms and techniques, deep learning, neural networks, robotics, and computer vision. JMLR is freely available to the public. It is run by volunteers, and the papers undergo rigorous reviews, which serve as a valuable resource for the latest updates in the field.
You’ve invested weeks and months into this paper. Why not get the recognition and credibility your work deserves? The above Journals and Conferences offer the ultimate gateway for a researcher to showcase their works and open up a plethora of opportunities for academic and industry collaborations.
In conclusion, our journey through the intricate world of computer vision research has been a fun one. From the initial stages of understanding the problem statements to the final steps of publication in computer vision research groups, we’ve comprehensively delved into each of them.
There is no research, big or small; each offers its own contributions to the ever-evolving field of the Computer Vision domain.
We’ve more detailed posts coming your way. Stay tuned! See you guys in the next one!!
Related Blog Posts
- How to Become a Computer Vision Engineer in 2024?
- Top Computer Vision Research Institutes in the USA
- Exploring OpenCV Applications in 2023
- Computer Vision and Image Processing: Understanding the Distinction and Connection
Related Posts

August 16, 2023 Leave a Comment

August 23, 2023 Leave a Comment

August 30, 2023 Leave a Comment
Become a Member
Stay up to date on OpenCV and Computer Vision news
Free Courses
- TensorFlow & Keras Bootcamp
- OpenCV Bootcamp
- Python for Beginners
- Mastering OpenCV with Python
- Fundamentals of CV & IP
- Deep Learning with PyTorch
- Deep Learning with TensorFlow & Keras
- Computer Vision & Deep Learning Applications
- Mastering Generative AI for Art
Partnership
- Intel, OpenCV’s Platinum Member
- Gold Membership
- Development Partnership
General Link
Subscribe and Start Your Free Crash Course
Stay up to date on OpenCV and Computer Vision news and our new course offerings
- We hate SPAM and promise to keep your email address safe.
Join the waitlist to receive a 20% discount
Courses are (a little) oversubscribed and we apologize for your enrollment delay. As an apology, you will receive a 20% discount on all waitlist course purchases. Current wait time will be sent to you in the confirmation email. Thank you!
Suggestions or feedback?
MIT News | Massachusetts Institute of Technology
- Machine learning
- Social justice
- Black holes
- Classes and programs
Departments
- Aeronautics and Astronautics
- Brain and Cognitive Sciences
- Architecture
- Political Science
- Mechanical Engineering
Centers, Labs, & Programs
- Abdul Latif Jameel Poverty Action Lab (J-PAL)
- Picower Institute for Learning and Memory
- Lincoln Laboratory
- School of Architecture + Planning
- School of Engineering
- School of Humanities, Arts, and Social Sciences
- Sloan School of Management
- School of Science
- MIT Schwarzman College of Computing
When computer vision works more like a brain, it sees more like people do
Press contact :.

Previous image Next image
From cameras to self-driving cars, many of today’s technologies depend on artificial intelligence to extract meaning from visual information. Today’s AI technology has artificial neural networks at its core, and most of the time we can trust these AI computer vision systems to see things the way we do — but sometimes they falter. According to MIT and IBM research scientists, one way to improve computer vision is to instruct the artificial neural networks that they rely on to deliberately mimic the way the brain’s biological neural network processes visual images.
Researchers led by MIT Professor James DiCarlo , the director of MIT’s Quest for Intelligence and member of the MIT-IBM Watson AI Lab, have made a computer vision model more robust by training it to work like a part of the brain that humans and other primates rely on for object recognition. This May, at the International Conference on Learning Representations, the team reported that when they trained an artificial neural network using neural activity patterns in the brain’s inferior temporal (IT) cortex, the artificial neural network was more robustly able to identify objects in images than a model that lacked that neural training. And the model’s interpretations of images more closely matched what humans saw, even when images included minor distortions that made the task more difficult.
Comparing neural circuits
Many of the artificial neural networks used for computer vision already resemble the multilayered brain circuits that process visual information in humans and other primates. Like the brain, they use neuron-like units that work together to process information. As they are trained for a particular task, these layered components collectively and progressively process the visual information to complete the task — determining, for example, that an image depicts a bear or a car or a tree.
DiCarlo and others previously found that when such deep-learning computer vision systems establish efficient ways to solve visual problems, they end up with artificial circuits that work similarly to the neural circuits that process visual information in our own brains. That is, they turn out to be surprisingly good scientific models of the neural mechanisms underlying primate and human vision.
That resemblance is helping neuroscientists deepen their understanding of the brain. By demonstrating ways visual information can be processed to make sense of images, computational models suggest hypotheses about how the brain might accomplish the same task. As developers continue to refine computer vision models, neuroscientists have found new ideas to explore in their own work.
“As vision systems get better at performing in the real world, some of them turn out to be more human-like in their internal processing. That’s useful from an understanding-biology point of view,” says DiCarlo, who is also a professor of brain and cognitive sciences and an investigator at the McGovern Institute for Brain Research.
Engineering a more brain-like AI
While their potential is promising, computer vision systems are not yet perfect models of human vision. DiCarlo suspected one way to improve computer vision may be to incorporate specific brain-like features into these models.
To test this idea, he and his collaborators built a computer vision model using neural data previously collected from vision-processing neurons in the monkey IT cortex — a key part of the primate ventral visual pathway involved in the recognition of objects — while the animals viewed various images. More specifically, Joel Dapello, a Harvard University graduate student and former MIT-IBM Watson AI Lab intern; and Kohitij Kar, assistant professor and Canada Research Chair (Visual Neuroscience) at York University and visiting scientist at MIT; in collaboration with David Cox, IBM Research’s vice president for AI models and IBM director of the MIT-IBM Watson AI Lab; and other researchers at IBM Research and MIT asked an artificial neural network to emulate the behavior of these primate vision-processing neurons while the network learned to identify objects in a standard computer vision task.
“In effect, we said to the network, ‘please solve this standard computer vision task, but please also make the function of one of your inside simulated “neural” layers be as similar as possible to the function of the corresponding biological neural layer,’” DiCarlo explains. “We asked it to do both of those things as best it could.” This forced the artificial neural circuits to find a different way to process visual information than the standard, computer vision approach, he says.
After training the artificial model with biological data, DiCarlo’s team compared its activity to a similarly-sized neural network model trained without neural data, using the standard approach for computer vision. They found that the new, biologically informed model IT layer was — as instructed — a better match for IT neural data. That is, for every image tested, the population of artificial IT neurons in the model responded more similarly to the corresponding population of biological IT neurons.
The researchers also found that the model IT was also a better match to IT neural data collected from another monkey, even though the model had never seen data from that animal, and even when that comparison was evaluated on that monkey’s IT responses to new images. This indicated that the team’s new, “neurally aligned” computer model may be an improved model of the neurobiological function of the primate IT cortex — an interesting finding, given that it was previously unknown whether the amount of neural data that can be currently collected from the primate visual system is capable of directly guiding model development.
With their new computer model in hand, the team asked whether the “IT neural alignment” procedure also leads to any changes in the overall behavioral performance of the model. Indeed, they found that the neurally-aligned model was more human-like in its behavior — it tended to succeed in correctly categorizing objects in images for which humans also succeed, and it tended to fail when humans also fail.
Adversarial attacks
The team also found that the neurally aligned model was more resistant to “adversarial attacks” that developers use to test computer vision and AI systems. In computer vision, adversarial attacks introduce small distortions into images that are meant to mislead an artificial neural network.
“Say that you have an image that the model identifies as a cat. Because you have the knowledge of the internal workings of the model, you can then design very small changes in the image so that the model suddenly thinks it’s no longer a cat,” DiCarlo explains.
These minor distortions don’t typically fool humans, but computer vision models struggle with these alterations. A person who looks at the subtly distorted cat still reliably and robustly reports that it’s a cat. But standard computer vision models are more likely to mistake the cat for a dog, or even a tree.
“There must be some internal differences in the way our brains process images that lead to our vision being more resistant to those kinds of attacks,” DiCarlo says. And indeed, the team found that when they made their model more neurally aligned, it became more robust, correctly identifying more images in the face of adversarial attacks. The model could still be fooled by stronger “attacks,” but so can people, DiCarlo says. His team is now exploring the limits of adversarial robustness in humans.
A few years ago, DiCarlo’s team found they could also improve a model’s resistance to adversarial attacks by designing the first layer of the artificial network to emulate the early visual processing layer in the brain. One key next step is to combine such approaches — making new models that are simultaneously neurally aligned at multiple visual processing layers.
The new work is further evidence that an exchange of ideas between neuroscience and computer science can drive progress in both fields. “Everybody gets something out of the exciting virtuous cycle between natural/biological intelligence and artificial intelligence,” DiCarlo says. “In this case, computer vision and AI researchers get new ways to achieve robustness, and neuroscientists and cognitive scientists get more accurate mechanistic models of human vision.”
This work was supported by the MIT-IBM Watson AI Lab, Semiconductor Research Corporation, the U.S. Defense Research Projects Agency, the MIT Shoemaker Fellowship, U.S. Office of Naval Research, the Simons Foundation, and Canada Research Chair Program.
Share this news article on:
Related links.
- Jim DiCarlo
- McGovern Institute for Brain Research
- MIT-IBM Watson AI Lab
- MIT Quest for Intelligence
- Department of Brain and Cognitive Sciences
Related Topics
- Brain and cognitive sciences
- McGovern Institute
- Artificial intelligence
- Computer vision
- Neuroscience
- Computer modeling
- Quest for Intelligence
Related Articles

Neuroscientists find a way to make object-recognition models perform better

Putting vision models to the test

How the brain distinguishes between objects
Previous item Next item
More MIT News
The power of App Inventor: Democratizing possibilities for mobile applications
Read full story →

Using MRI, engineers have found a way to detect light deep in the brain

A better way to control shape-shifting soft robots

From steel engineering to ovarian tumor research

Professor Emeritus David Lanning, nuclear engineer and key contributor to the MIT Reactor, dies at 96

Discovering community and cultural connections
- More news on MIT News homepage →
Massachusetts Institute of Technology 77 Massachusetts Avenue, Cambridge, MA, USA
- Map (opens in new window)
- Events (opens in new window)
- People (opens in new window)
- Careers (opens in new window)
- Accessibility
- Social Media Hub
- MIT on Facebook
- MIT on YouTube
- MIT on Instagram
What Is Computer Vision?

Computer vision is a field of artificial intelligence (AI) that applies machine learning to images and videos to understand media and make decisions about them. With computer vision, we can, in a sense, give vision to software and technology.
How Does Computer Vision Work?
Computer vision programs use a combination of techniques to process raw images and turn them into usable data and insights.
The basis for much computer vision work is 2D images, as shown below. While images may seem like a complex input, we can decompose them into raw numbers. Images are really just a combination of individual pixels and each pixel can be represented by a number (grayscale) or combination of numbers such as (255, 0, 0— RGB ).

Once we’ve translated an image to a set of numbers, a computer vision algorithm applies processing. One way to do this is a classic technique called convolutional neural networks (CNNs) that uses layers to group together the pixels in order to create successively more meaningful representations of the data. A CNN may first translate pixels into lines, which are then combined to form features such as eyes and finally combined to create more complex items such as face shapes.
Why Is Computer Vision Important?
Computer vision has been around since as early as the 1950s and continues to be a popular field of research with many applications. According to the deep learning research group, BitRefine , we should expect the computer vision industry to grow to nearly 50 billion USD in 2022, with 75 percent of the revenue deriving from hardware .
The importance of computer vision comes from the increasing need for computers to be able to understand the human environment. To understand the environment, it helps if computers can see what we do, which means mimicking the sense of human vision. This is especially important as we develop more complex AI systems that are more human-like in their abilities.
On That Note. . . How Do Self-Driving Cars Work?
Computer Vision Examples
Computer vision is often used in everyday life and its applications range from simple to very complex.
Optical character recognition (OCR) was one of the most widespread applications of computer vision. The most well-known case of this today is Google’s Translate , which can take an image of anything — from menus to signboards — and convert it into text that the program then translates into the user’s native language. We can also apply OCR in other use cases such as automated tolling of cars on highways and translating hand-written documents into digital counterparts.
A more recent application, which is still under development and will play a big role in the future of transportation, is object recognition. In object recognition an algorithm takes an input image and searches for a set of objects within the image, drawing boundaries around the object and labelling it. This application is critical in self-driving cars which need to quickly identify its surroundings in order to decide on the best course of action.
Computer Vision Applications
- Facial recognition
- Self-driving cars
- Robotic automation
- Medical anomaly detection
- Sports performance analysis
- Manufacturing fault detection
- Agricultural monitoring
- Plant species classification
- Text parsing
What Are the Risks of Computer Vision?
As with all technology, computer vision is a tool, which means that it can have benefits, but also risks. Computer vision has many applications in everyday life that make it a useful part of modern society but recent concerns have been raised around privacy. The issue that we see most often in the media is around facial recognition. Facial recognition technology uses computer vision to identify specific people in photos and videos. In its lightest form it’s used by companies such as Meta or Google to suggest people to tag in photos, but it can also be used by law enforcement agencies to track suspicious individuals. Some people feel facial recognition violates privacy, especially when private companies may use it to track customers to learn their movements and buying patterns.
Built In’s expert contributor network publishes thoughtful, solutions-oriented stories written by innovative tech professionals. It is the tech industry’s definitive destination for sharing compelling, first-person accounts of problem-solving on the road to innovation.
Great Companies Need Great People. That's Where We Come In.
What Is Computer Vision and How It Works

We perceive and interpret visual information from the world around us automatically. So implementing computer vision might seem like a trivial task. But is it really that easy to artificially model a process that took millions of years to evolve?
Read this post if you want to learn more about what is behind computer vision technology and how ML engineers teach machines to see things.
- What is computer vision?
Computer vision is a field of artificial intelligence and machine learning that studies the technologies and tools that allow for training computers to perceive and interpret visual information from the real world.
‘Seeing’ the world is the easy part: for that, you just need a camera. However, simply connecting a camera to a computer is not enough. The challenging part is to classify and interpret the objects in images and videos, the relationship between them, and the context of what is going on. What we want computers to do is to be able to explain what is in an image, video footage, or real-time video stream.
That means that the computer must effectively solve these three tasks:
- Automatically understand what the objects in the image are and where they are located.
- Categorize these objects and understand the relationships between them.
- Understand the context of the scene.
In other words, a general goal of this field is to ensure that a machine understands an image just as well or better than a human. As you will see later on, this is quite challenging.
How does computer vision work?
In order to make the machine recognize visual objects, it must be trained on hundreds of thousands of examples. For example, you want someone to be able to distinguish between cars and bicycles. How would you describe this task to a human?
Normally, you would say that a bicycle has two wheels, and a machine has four. Or that a bicycle has pedals, and the machine doesn’t. In machine learning, this is called feature engineering .
.png "problem solving computer vision")
However, as you might already notice, this method is far from perfect. Some bicycles have three or four wheels, and some cars have only two. Also, motorcycles and mopeds exist that can be mistaken for bicycles. How will the algorithm classify those?
When you are building more and more complicated systems (for example, facial recognition software) cases of misclassification become more frequent. Simply stating the eye or hair color of every person won’t do: the ML engineer would have to conduct hundreds of measurements like the space between the eyes, space between the eye and the corners of the mouth, etc. to be able to describe a person’s face.
Moreover, the accuracy of such a model would leave much to be desired: change the lighting, face expression, or angle and you have to start the measurements all over again.
Here are several common obstacles to solving computer vision problems.
- Different lighting
For computer vision, it is very important to collect knowledge about the real world that represents objects in different kinds of lighting. A filter might make a ball look blue or yellow while in fact it is still white. A red object under a red lamp becomes almost invisible.
.png "problem solving computer vision")
If the image has a lot of noise, it is hard for computer vision to recognize objects. Noise in computer vision is when individual pixels in the image appear brighter or darker than they should be. For example, videocams that detect violations on the road are much less effective when it is raining or snowing outside.
- Unfamiliar angles
It’s important to have pictures of the object from several angles. Otherwise, a computer won’t be able to recognize it if the angle changes.

- Overlapping
When there is more than one object on the image, they can overlap. This way, some characteristics of the objects might remain hidden, which makes it even more difficult for the machine to recognize them.
- Different types of objects
Things that belong to the same category may look totally different. For example, there are many types of lamps, but the algorithm must successfully recognize both a nightstand lamp and a ceiling lamp.

- Fake similarity
Items from different categories can sometimes look similar. For example, you have probably met people that remind you of a celebrity on photos taken from a certain angle but in real life not so much. Cases of misrecognition are common in CV. For example, samoyed puppies can be easily mistaken for little polar bears in some pictures.
It’s almost impossible to think about all of these cases and prevent them via feature engineering. That is why today, computer vision is almost exclusively dominated by deep artificial neural networks.
Convolutional neural networks are very efficient at extracting features and allow engineers to save time on manual work. VGG-16 and VGG-19 are among the most prominent CNN architectures. It is true that deep learning demands a lot of examples but it is not a problem: approximately 657 billion photos are uploaded to the internet each year!
- Uses of computer vision

Interpreting digital images and videos comes in handy in many fields. Let us look at some of the use cases:
Medical diagnosis. Image classification and pattern detection are widely used to develop software systems that assist doctors with the diagnosis of dangerous diseases such as lung cancer. A group of researchers has trained an AI system to analyze CT scans of oncology patients. The algorithm showed 95% accuracy, while humans – only 65%.
Factory management. It is important to detect defects in the manufacture with maximum accuracy, but this is challenging because it often requires monitoring on a micro-scale. For example, when you need to check the threading of hundreds of thousands of screws. A computer vision system uses real-time data from cameras and applies ML algorithms to analyze the data streams. This way it is easy to find low-quality items.
Retail. Amazon was the first company to open a store that runs without any cashiers or cashier machines. Amazon Go is fitted with hundreds of computer vision cameras. These devices track the items customers put in their shopping carts. Cameras are also able to track if the customer returns the product to the shelf and removes it from the virtual shopping cart. Customers are charged through the Amazon Go app, eliminating any necessity to stay in the line. Cameras also prevent shoplifting and prevent being out of product.
Security systems. Facial recognition is used in enterprises, schools, factories, and, basically, anywhere where security is important. Schools in the United States apply facial recognition technology to identify sex offenders and other criminals and reduce potential threats. Such software can also recognize weapons to prevent acts of violence in schools. Meanwhile, some airlines use face recognition for passenger identification and check-in, saving time and reducing the cost of checking tickets.
Animal conservation. Ecologists benefit from the use of computer vision to get data about the wildlife, including tracking the movements of rare species, their patterns of behavior, etc., without troubling the animals. CV increases the efficiency and accuracy of image review for scientific discoveries.
Self-driving vehicles. By using sensors and cameras, cars have learned to recognize bumpers, trees, poles, and parked vehicles around them. Computer vision enables them to freely move in the environment without human supervision.
Main problems in computer vision

Computer vision aids humans across a variety of different fields. But its possibilities for development are endless. Here are some fields that are yet to be improved and developed.
- Scene understanding
CV is good at finding and identifying objects. However, it experiences difficulties with understanding the context of the scene, especially if it’s non-trivial. Look at this image , for example. What do you think they are doing (don’t look at the URL!)?
You will immediately understand that these are children wearing cardboard boxes on their heads. It is not some sort of postmodern art that tries to expose the meaninglessness of school education. These children are watching a solar eclipse . But if you don’t have this context, you might never understand what’s going on. Artificial intelligence still feels like that in a vast majority of cases. To improve the situation, we would need to invent general artificial intelligence (i.e. AI whose problem-solving capabilities possibilities are more or less equal to that of a human and can be applied universally), but we are very far from doing that .
- Privacy issues
Computer vision has much to do with privacy since the systems for face recognition are being adopted by governments of different countries to promote national security. AI-powered cameras installed in the Moscow metro help catch criminals . Meanwhile, Chinese authorities profile Uyghur individuals (a Muslim ethnic minority) and single them out for tracking and incarceration. When facial recognition is everywhere, everything you do can be subject to policies and shaming. AI ethicists are still to figure out the consequences of omnipresent CV for public wellbeing.
Computer vision is an innovative field that uses the latest machine learning technologies to build software systems that assist humans across different fields. From retail to wildlife conservation, smart algorithms solve the problems of image classification and pattern recognition, sometimes even better than humans.
Want to learn more about technologies? Continue reading our blog and follow us on Twitter , Medium , or DEV for other exciting content.

- Skip to primary navigation
- Skip to main content
- Skip to primary sidebar
- Skip to footer
PyImageSearch
You can master Computer Vision, Deep Learning, and OpenCV - PyImageSearch
Book Examples of Image Search Engines Image Search Engine Basics Tutorials
Announcing “Case Studies: Solving real world problems with computer vision”
by Adrian Rosebrock on June 26, 2014

I have some big news to announce today…
Besides writing a ton of blog posts about computer vision, image processing, and image search engines, I’ve been behind the scenes, working on a second book .
And you may be thinking, hey, didn’t you just finish up Practical Python and OpenCV ?
Yep. I did.
Now, don’t get me wrong. The feedback for Practical Python and OpenCV has been amazing. And it’s done exactly what I thought it would — teach developers, programmers, and students just like you the basics of computer vision in a single weekend .
But now that you know the fundamentals of computer vision and have a solid starting point, it’s time to move on to something more interesting…
Let’s take your knowledge of computer vision and solve some actual, real world problems .
What type of problems?
I’m happy you asked. Read on and I’ll show you.
What does this book cover?
This book covers five main topics related to computer vision in the real world. Check out each one below, along with a screenshot of each.
#1. Face detection in photos and video

By far, the most requested tutorial of all time on this blog has been “How do I find faces in images?” If you’re interested in face detection and finding faces in images and video, then this book is for you.
#2. Object tracking in video
Another common question I get asked is “How can I track objects in video?” In this chapter, I discuss how you can use the color of an object to track its trajectory as it moves in the video.
#3. Handwriting recognition with Histogram of Oriented Gradients (HOG)

This is probably my favorite chapter in the entire Case Studies book, simply because it is so practical and useful .
Imagine you’re at a bar or pub with a group of friends, when all of a sudden a beautiful stranger comes up to you and hands you their phone number written on a napkin.
Do you stuff the napkin in your pocket, hoping you don’t lose it? Do you take out your phone and manually create a new contact?
Well you could. Or. You could take a picture of the phone number and have it automatically recognized and stored safely.
In this chapter of my Case Studies book, you’ll learn how to use the Histogram of Oriented Gradients (HOG) descriptor and Linear Support Vector Machines to classify digits in an image.
#4. Plant classification using color histograms and machine learning

A common use of computer vision is to classify the contents of an image . In order to do this, you need to utilize machine learning. This chapter explores how to extract color histograms using OpenCV and then train a Random Forest Classifier using scikit-learn to classify the species of a flower.
#5. Building an Amazon.com book cover search

Three weeks ago, I went out to have a few beers with my friend Gregory, a hot shot entrepreneur in San Francisco who has been developing a piece of software to instantly recognize and identify book covers — using only an image. Using this piece of software, users could snap a photo of books they were interested in, and then have them automatically added to their cart and shipped to their doorstep — at a substantially cheaper price than your standard Barnes & Noble!
Anyway, I guess Gregory had one too many beers, because guess what?
He clued me in on his secrets.
Gregory begged me not to tell…but I couldn’t resist.
In this chapter you’ll learn how to utilize keypoint extraction and SIFT descriptors to perform keypoint matching.
The end result is a system that can recognize and identify the cover of a book in a snap…of your smartphone!
All of these examples are covered in detail, from front to back, with lots of code.
By the time you finish reading my Case Studies book, you’ll be a pro at solving real world computer vision problems.
So who is this book for?
This book is for people like yourself who have a solid foundation of computer vision and image processing. Ideally, you have already read through Practical Python and OpenCV and have a strong grasp on the basics (if you haven’t had a chance to read Practical Python and OpenCV , definitely pick up a copy ).
I consider my new Case Studies book to be the next logical step in your journey to learn computer vision.
You see, this book focuses on taking the fundamentals of computer vision, and then applying them to solve, actual real-world problems .
So if you’re interested in applying computer vision to solve real world problems, you’ll definitely want to pick up a copy.
Reserve your spot in line to receive early access
If you signup for my newsletter, I’ll be sending out previews of each chapter so you can get see first hand how you can use computer vision techniques to solve real world problems.
But if you simply can’t wait and want to lock-in your spot in line to receive early access to my new Case Studies eBook, just click here .
Sound good?
Sign-up now to receive an exclusive pre-release deal when the book launches.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

About the Author
Hi there, I’m Adrian Rosebrock, PhD. All too often I see developers, students, and researchers wasting their time, studying the wrong things, and generally struggling to get started with Computer Vision, Deep Learning, and OpenCV. I created this website to show you what I believe is the best possible way to get your start.
Previous Article:
Applying deep learning and a RBM to MNIST using Python
Next Article:
Super fast color transfer between images
Comment section.
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.
Similar articles
Saving key event video clips with opencv, opencv gamma correction, opencv eigenfaces for face recognition.

You can learn Computer Vision, Deep Learning, and OpenCV.
Get your FREE 17 page Computer Vision, OpenCV, and Deep Learning Resource Guide PDF. Inside you’ll find our hand-picked tutorials, books, courses, and libraries to help you master CV and DL.
- Deep Learning
- Dlib Library
- Embedded/IoT and Computer Vision
- Face Applications
- Image Processing
- OpenCV Install Guides
- Machine Learning and Computer Vision
- Medical Computer Vision
- Optical Character Recognition (OCR)
- Object Detection
- Object Tracking
- OpenCV Tutorials
- Raspberry Pi
Books & Courses
- PyImageSearch University
- FREE CV, DL, and OpenCV Crash Course
- Practical Python and OpenCV
- Deep Learning for Computer Vision with Python
- PyImageSearch Gurus Course
- Raspberry Pi for Computer Vision
- Get Started
- Privacy Policy
Access the code to this tutorial and all other 500+ tutorials on PyImageSearch
Enter your email address below to learn more about PyImageSearch University (including how you can download the source code to this post):
What's included in PyImageSearch University?
- Easy access to the code, datasets, and pre-trained models for all 500+ tutorials on the PyImageSearch blog
- High-quality, well documented source code with line-by-line explanations (ensuring you know exactly what the code is doing)
- Jupyter Notebooks that are pre-configured to run in Google Colab with a single click
- Run all code examples in your web browser — no dev environment configuration required!
- Support for all major operating systems (Windows, macOS, Linux, and Raspbian)
- Full access to PyImageSearch University courses
- Detailed video tutorials for every lesson
- Certificates of Completion for all courses
- New courses added every month! — stay on top of state-of-the-art trends in computer vision and deep learning
PyImageSearch University is really the best Computer Visions "Masters" Degree that I wish I had when starting out. Being able to access all of Adrian's tutorials in a single indexed page and being able to start playing around with the code without going through the nightmare of setting up everything is just amazing. 10/10 would recommend. Sanyam Bhutani Machine Learning Engineer and 2x Kaggle Master
This is where the search bar goes
Solving real-world business problems with computer vision
Applications of CNNs for real-time image classification in the enterprise.

The process of data integration has traditionally been done using structured and semistructured data in batch-oriented use cases. In the last few years, real-time data has become the new frontier for many enterprises, and real-time streaming of unstructured or binary data has been a particularly tough nut to crack. In fact, many enterprises have large volumes of binary data that are not used to their full potential because of the inherent complexity of ingesting and processing such data.
Here are a few examples of how one might work with binary data :

Learn faster. Dig deeper. See farther.
Join the O'Reilly online learning platform. Get a free trial today and find answers on the fly, or master something new and useful.
- Performing speech-to-text recognition of audio files, recognizing individual speakers, and automatically cataloging files with enriched metadata so that audio recorded in interactive voice response systems is indexed and searchable.
- Automatically classifying image files based on the actual content of the image, such as recognizing products, faces, or other objects in the scene.
Of course, there are many other use cases. The good news is that working with binary data does not have to be that complicated. In this post, we’ll show how companies are using advances in computer vision, integrated with modern data ingestion technologies, to solve real-world business problems.
Applications of computer vision and deep learning in enterprise
The enterprise’s interest in machine vision techniques has ramped up sharply in the last few years due to the increased accuracy in competitions such as ImageNet . Computer vision methods have been around for decades, but it takes a certain level of accuracy for some use cases to move beyond the lab into real-world production applications. The advances seen in the ImageNet competition showed the world what was possible, and also harkened the rise of convolutional neural networks as the method of choice in computer vision.
Convolutional neural networks have the ability to learn location invariant features automatically by leveraging a network architecture that learns image features, as opposed to having them hand-engineered (as in traditional engineering). This aspect highlights a key property of deep learning networks—the ability of data scientists to choose the right architecture for the input data type so the network can automatically learn features. All of this is also directly dependent on having enough quality data that is properly labeled and appropriate for the problem at hand.
We’re seeing applications of computer vision across the spectrum of the enterprise:
- Financial Services
- Health care
In insurance, we see companies such as Orbital Insights analyzing satellite imagery to count cars and oil tank levels automatically to predict such things as mall sales and oil production, respectively. We are also seeing insurance companies leveraging computer vision to analyze the damage on assets under policy to better decide whom should be offered coverage.
The automotive industry has embraced computer vision (and deep learning) aggressively in the past five years with applications such as scene analysis, automated lane detection, and automated road sign reading to set speed limits.
The media world is leveraging computer vision to recognize images on social media to identify brands so companies can better position their brands around relevant content. Ebay recently used computer vision to let users visually search for items with photos.
In health care, we see the classic application of detecting disease in MRI scans, where companies like Arterys are now FDA-cleared to use deep learning to model medical imagery data. We’re also seeing this with partnerships, such as the relationship between Google, Nvidia, and Massachusetts General Hospital to leverage deep learning on radiology tasks.
In retail, we see companies interested in analyzing the shopping carts of in-store shoppers to detect items and make recommendations in store about what else they might want to buy. Think of this as a recommendation engine for a brick-and-mortar situation. We also see retailers using even more complex cameras taking more complex pictures (hyper-spectral imagery ) that are modeled with convolutional neural networks.
These are but a few examples of computer vision ideas that are in development or already in production across the Global 2000 enterprise. It seems like this deep learning stuff may be around for awhile.
Beyond convolutional neural networks, the automotive industry has leveraged deep learning and long-short-term memory networks to analyze sensor data to automatically detect other cars and objects around the car. On newer cars, if you try and change lanes on the highway without setting your turn signal, the car will correct you, automatically directing you back into your lane. James Long shared with us this anecdote on how he sees integrated machine learning as a force multiplier, as opposed to job replacement:
My father had auto-steer on his tractor for years. It allowed him to cover more ground and do a better job at higher speed—so maybe 20% more productive. That’s how robots will permeate.
It’s small examples like this that show how latent integrated intelligence in vehicles is slowly making them “progressively automated”—as opposed to the idea that all cars will be self-driving tomorrow. Deep learning is quickly becoming the standard platform for integrating automation and intelligence into the environment around us. We probably won’t turn on a complete self-driving car tomorrow; it will likely be a slow transition, to the point where the system progressively autocorrects more and more aspects of driving, and we just naturally stop wanting to drive manually.
Challenges of production deep learning
Computer vision and deep learning present challenges when going into production. These challenges include:
- Getting enough data of good quality
- Managing executives’ expectations about model performance
- Being pragmatic about how bleeding-edge we really need our network to be
- Planning data ingest, storage, security, and overall infrastructure
- Understanding how machine learning differs from software engineering, to avoid misaligned expectations
Most organizations do not collect enough quality data to produce the model their line of business wants in terms of accuracy (e.g., “Our model has an F1 of .80, but the line of business says the F1 has to be .95 to be financially viable to them”). The computer vision practitioner needs to understand the dynamics of model evaluation and how F1 scores , precision, and recall work in practice. This knowledge will allow the practicing data scientist to better communicate realistic expectations about the model performance to management and not set the project up for failure out of the gate.
Building off the concept of model training, we want to further delineate the training phase of machine learning from the inference phase of machine learning. In training, we are performing a batch-class operation, where we typically make multiple passes over a data set to build up the weights (or “parameters”) on the connections in the neural network model. This operation tends to happen on a single machine (with CPU or GPU, depending on situation) or on a cluster of machines (e.g., Hadoop with Spark). The training process can take anywhere from a few minutes to days to complete, and sometimes we’ll build the model multiple times to get the most accurate model for our input data. Making predictions (“inference”) based on the model produced from the training phase is different in terms of how we manage its execution. Sending a new record to a saved model and getting a prediction (e.g., “classification” or “regression”) output is a transactional class operation. We call this phase out separately in the context of an article on real-time streaming applications, as we want to make sure the reader understands that models are rarely trained inside a streaming system. Most of the time, the model is produced offline based on saved training data and then set up later in a way that a streaming system can make predictions transactionally as data flows into the system.
Another challenge for the enterprise is getting machine learning teams trained correctly to understand how to leverage the latest methods in convolutional network tuning and application. Most education sources are too academic for enterprise practitioners and are meant for a college classroom. While that is a good way to teach grad school students, enterprise software training courses often approach teaching material from a practitioner’s point of view.
Another tip for enterprises is to focus on leveraging good, tried-and-true convolutional architectures from the past few years, as opposed to trying to implement the “hot new ICML paper of the week.” Twitter is great for discovering new papers as they come out, but it can also encourage folks to jump from one hot idea to the next before they can actually leverage real production value from new networks. A pragmatic computer vision approach focuses on using networks that have good results and that are implemented on well-known deep learning libraries, such as deeplearning4j, TensorFlow, Keras, and Theano. Once you have established a baseline convolutional model that performs decently, deploy it to users/applications and then, while they are working against that model, you can try out newer architectures in parallel.
Data ingestion has long been a challenge for the enterprise. While it may seem simple on the surface, getting image data from here to there consistently and stored correctly is more work than it seems. Hurdles include the structure of the data, the rate of data ingest, and the overall infrastructure needs relative to the incoming data. Some marketing literature even uses the term “unstructured data,” which is a misnomer. Image data, and all data, has structure. Data that has no structure is unparseable and therefore unusable in a processing system. Most of the time, what people mean when they say “unstructured data” is that “it doesn’t look like a CSV file or a RDBMS table.” Ingest systems can also involve real-time tagging of images as they are ingested, helping us to understand if we have certain images as soon as they are ingested or serving an image detection system. Beyond ingest, companies should also consider their storage options, parallelization, GPU strategy, model serving, workflow management, and security implications. These factors are largely infrastructure-based but have direct impacts on our ability to take a computer vision model to production, regardless of how accurate the model is.
So often we hear customers talk about a fear of failure of data science projects because there is a large element of “the unknown” involved. Data science and deep learning are exploratory in nature, and it is hard to predict just how accurate a model can be on the front end by the input data we have. Many folks tend to conflate the idea of software engineering being fairly (within reason) deterministic (e.g., “We built a house out of these materials”) and data science having a wider range of outcomes with the same labor (e.g., “We mined for gold as long as the other team, but only found half as much gold on our land”). A best practice is to invest in the best possible infrastructure that builds, secures, and deploys our model in a way that IT can consume, then let the data science team focus on building as many models as possible to find the best one for the task at hand.
In this post, we’ve discussed the concepts of streaming technology and enterprise applications of computer vision. To learn in more detail how to implement convolutional neural networks into enterprise applications, see our post “ Integrating convolutional neural networks into enterprise pplications .” And, to hear more about applied machine learning in the context of streaming data infrastructure, attend our session Real-time image classification: Using convolutional neural networks on real-time streaming data ” at the Strata Data Conference in New York City, Sept. 25-28, 2017 .
For more information on the technologies mentioned in this article, email Josh ( [email protected] ) or Kirit ( [email protected] ).
Get the O’Reilly Radar Trends to Watch newsletter
Tracking need-to-know trends at the intersection of business and technology.
Please read our privacy policy .
Thank you for subscribing.
Top 4 Computer Vision Challenges & Solutions in 2024
Computer vision (CV) technology is revolutionizing many industries, including healthcare , retail, automotive, etc. As more companies invest in computer vision solutions, the global market is projected to multiply 9 times by 2026 to $2.4 Billion.
However, implementing computer vision in your business can be a challenging and expensive process, and improper preparation can lead to CV and AI project failure . Therefore, business managers need to be careful before initiating computer vision projects.
This article explores 4 challenges that business managers can face while implementing computer vision in their business and how they can overcome them to safeguard their investments and ensure maximum ROI. We also provide some examples in the recommendation sections
1. Poor data quality
You can work with an image data collection service to help you obtain high-quality visual datasets for your computer vision project.
Poor Quality
High-quality labeled and annotated datasets are the foundation of a successful computer vision system. In industries such as healthcare , where computer vision technology is being abundantly used, it is crucial to have high-quality data annotation , and labeling since the repercussions of inaccurate computer vision systems can be significantly damaging. For example, Many tools built to catch Covid-19 failed due to poor data quality.
Recommendations: Working with medical data annotation specialists can help mitigate this issue.
You can check our list of medical data annotation tools to choose the option that best suits your healthcare computer vision project needs.
Lack of training data
Collecting relevant and sufficient data can have various challenges . These challenges can lead to a lack of training data for computer vision systems. For example, gathering medical data is a challenge for data annotators. This is mainly due to the sensitivity and privacy aspects of healthcare data. Most medical images are either of a sensitive nature or are strictly private and are not shared by healthcare professionals and hospitals. Additionally, it is possible that the developers do not have the resources to collect sufficient data.
Recommendations: To ensure that you have adequate data to train your computer vision system, leverage outsourcing or crowdsourcing. This way, the burden of collecting data and ensuring its quality will be transferred to a third-party specialist, and you can focus on developing the computer vision model. You can also work with a video data collection service to obtain high-quality visual datasets for your CV project.
2. Inadequate hardware
Computer vision technology is implemented with a combination of software and hardware. To ensure the system’s effectiveness, a business needs to install high-resolution cameras, sensors, and bots. This hardware can be costly and, if suboptimal or improperly installed, can lead to blind spots and ineffective CV systems.
IoT-enabled sensors are also required in some CV systems; for example, a study presents the use of IoT-enabled flood monitoring sensors.
Recommendations
The following factors can be considered for effective CV hardware installation:
- The cameras are high-definition and provide the required frames per second (FPS) rate
- Cameras and sensors cover all surveillance areas
- The positioning covers all the objects of interest. For example, in a retail store, the camera should cover all the products on the shelf.
- All the devices are properly configured to avoid blind spots.
One good example of improper hardware for CV is Walmart’s shelf-scanning robots. Walmart recalled its shelf-scanning robots and finished the contract with the provider. Even though the CV system in the bots was working fine, the company found that customers might find them strange due to their size, and they found other more efficient ways.

On the other hand, Walmart-owned retail brand Sam’s club mounted new CV-enabled inventory scanning systems, made by Brain Corp, on its already operating autonomous floor cleaning robots. Sam’s club finds them more effective and plans on increasing the investment.
Another example is Noisy student , which is a semi-supervised learning approach developed by Google, that relies on convolutional neural networks (CNN) and 480 million parameters. Processes like these require heavy computer processing power.
Two of the most significant costs to consider before starting your computer vision project are:
- The hardware requirements of the project
- The costs of cloud computing
3. Weak planning for model development
Another challenge can be weak planning for creating the ML model that is deployed for the computer vision system. During the planning stage, executives tend to set overly ambitious targets, which are hard to achieve for the data science team.
Due to this, the business model:
- Does not meet business objectives
- Demands unrealistic computing power
- Becomes too costly
- Delivers insufficient accuracy and performance
To overcome such issues, it is important for business leaders to focus on:
- Creating a strong project plan by analyzing the business’s technological maturity levels
- Create a clear scope of the project with set objectives
- The ability to gather relevant data, purchase labeled datasets or gather synthetic data
- Consider the model training and deployment costs
- Examining existing success stories similar to your business.
4. Time shortage
During the planning phase of a computer vision project, business managers tend to focus overly on the model development stage. They fail to consider the extra time needed for:
- Setup, configuration, and calibration of the hardware, including cameras and sensors
- Collecting, cleaning, and labeling data
- Training and testing of the model
Failure to consider these tasks can create challenges and project delays
A study on companies developing AI models found that a significant number of companies have significantly exceeded the expected time for successful deployment.
Another recent study identified that 99% of computer vision project teams faced significant delays due to a multitude of reasons:
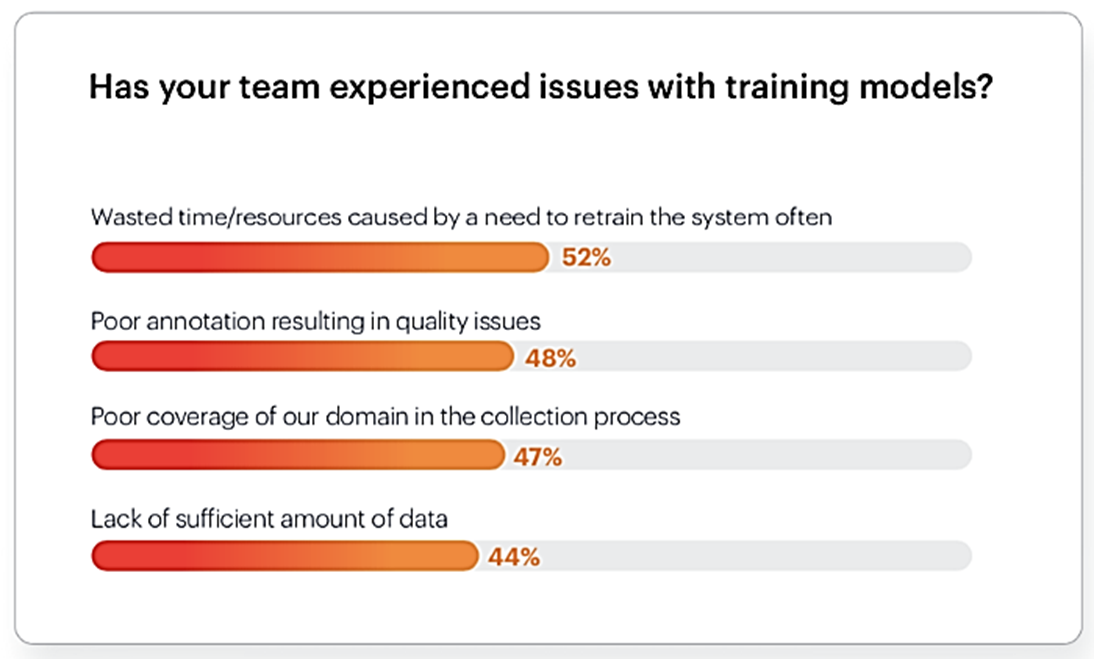
We recommend performing early calculations of each stage of the development process. If the project is time-constraint, then certain tasks, such as algorithm development or data collection, can be outsourced.
You can also check out our sortable and filterable lists of services, vendors, and tools to choose the option that best suits your business needs:
- Data Annotation / Labelling / Tagging / Classification Service
- Video Annotation Tools
- Medical Image Annotation Tools
Further reading
- Computer Vision In-Depth Guide
- Data Annotation: What it is & why does it matter?
- A Guide to Video Annotation Tools and Types
- Top 7 Computer Vision Use Cases in Healthcare
If you have any questions about challenges in computer vision, don’t hesitate to contact us:
Next to Read
Large vision models: examples, 7 use cases & challenges in 2024, computer vision in radiology in 2024: benefits & challenges, top 5 computer vision use cases in automotive in 2024.
Your email address will not be published. All fields are required.
Related research

Facial Recognition: Best Practices & Use Cases in 2024

Top 5 Use Cases of Computer Vision in Retail in 2024
Vision Tools: Using Computer and Machine Vision

According to IBM research, 77% of manufacturers say that computer vision and machine learning helps them meet their business goals. Indeed, computer vision and traditional machine vision play a crucial role in modern manufacturing processes.
Whether you want to read labels for quality assurance purposes, detect defects , detect the absence of products, or identify quality issues, computer vision can help solve your business problems. If an attribute is visible – for example, a defect, the presence or absence of an object – you can build a computer vision system to search for that attribute.
Enterprises around the world, across industries, depend on computer vision to solve problems. Car manufacturers use vision tools to identify defects, ensuring quality standards are met. Ice cream manufacturers use computer vision to detect when ice cream has melted on their assembly line, a costly problem.
For example, here is a machine vision model being used to identify metal defects:

You may be wondering: how can you incorporate vision tools into your manufacturing systems? That is the question we are going to answer in this guide.
In this guide, we will discuss what computer vision is, how it compares to machine vision, and the computer vision-powered tools you can implement to solve business problems. We will end with guidance on how to get started building a system that meets your needs.
Without further ado, let’s get started!
What is Computer Vision?
Computer vision is a set of technologies that use visual inputs to solve problems. Computer vision systems typically use artificial intelligence. State-of-the-art AI systems are more capable than ever at tasks like identifying objects, segmenting regions in an object, identifying key points, and more.

You can use computer vision for many purposes, including to:
- Identify the presence or absence of objects or defects.
- Verify the color of an object.
- Read barcodes, QR codes, ISBNs, and other identifiers.
- Read text on a package (i.e. a return label, a sell-by date).
- Verify the orientation of a product.
- Measure the dimensions of a product.
- Verify if an object is present in a particular region (i.e. if there are screws in all four corners of a product).
There are four main types of computer vision systems:
- Object detection: Detect the presence or absence of specific objects.
- Segmentation: Identify, to the pixel level, the location of an object in an image. Ideal for measuring objects.
- Classification: Assign one or more categories to an image.
- Keypoint detection: Identify key points on an image. Ideal for checking the orientation of a product.
To integrate a computer vision system into your manufacturing processes, you need a model that can identify objects of interest. This model can be tuned to identify specific objects and can be trained in an afternoon. By using your business data to train a model, you can build a system that attains greater accuracy than any pre-made system.
Once you have a model, you can integrate it directly into your manufacturing pipelines. Using an open source tool, like Roboflow Inference , you can run your model on camera feeds or RTSP streams in a factory. You can write custom logic that triggers an action when a particular condition is met. For example, if a defect is detected in a product, that product could be flagged in real-time and moved out of the assembly line.
Computer Vision vs. Machine Vision
Machine vision , also referred to as “rules-based” vision, has been solving problems in manufacturing for decades. Machine vision refers to rules-based algorithms that are written to solve specific problems like detecting edges or reading barcodes.

Machine vision systems can solve problems like:
- Detecting edges.
- Reading text.
- Bead inspection.
- Measuring edges.
- Pattern matching.
For these use cases, machine vision can be effective. With that said, computer vision opens many opportunities, allowing you to perform both basic and complex tasks, agnostic to hardware, and in a way that is adaptable to new environments and processes.
It’s possible to use a combination of both machine vision and computer vision in a facility. Installed machine vision systems, such as barcode readers, could be used alongside computer vision systems used to check that a product is free from specific defects or is oriented correctly.
Computer vision systems can be deployed on computers like NVIDIA Jetsons or Raspberry Pis, which are typically cheaper than purpose-built machine vision systems.
Integrating Computer Vision Tools Into an Assembly Line
Computer vision tools can help increase efficiency, reduce defect rates, ensure compliance, and more. Once a use case for computer vision is identified, the next step is to integrate computer vision systems into an assembly line or manufacturing process.
You can use a tool like Roboflow to build a system that meets your requirements. Roboflow offers the tools you need to create a vision system unique to your business. The following is a simplified overview of how to build such a system.
First, you need to collect data representative of your use case. For example, you might collect images of glass for a glass inspection system. You can then label objects of interest in your data – products, scratches, cracks, chips, or anything else. These labels can be used to train a purpose-built model for your use case.
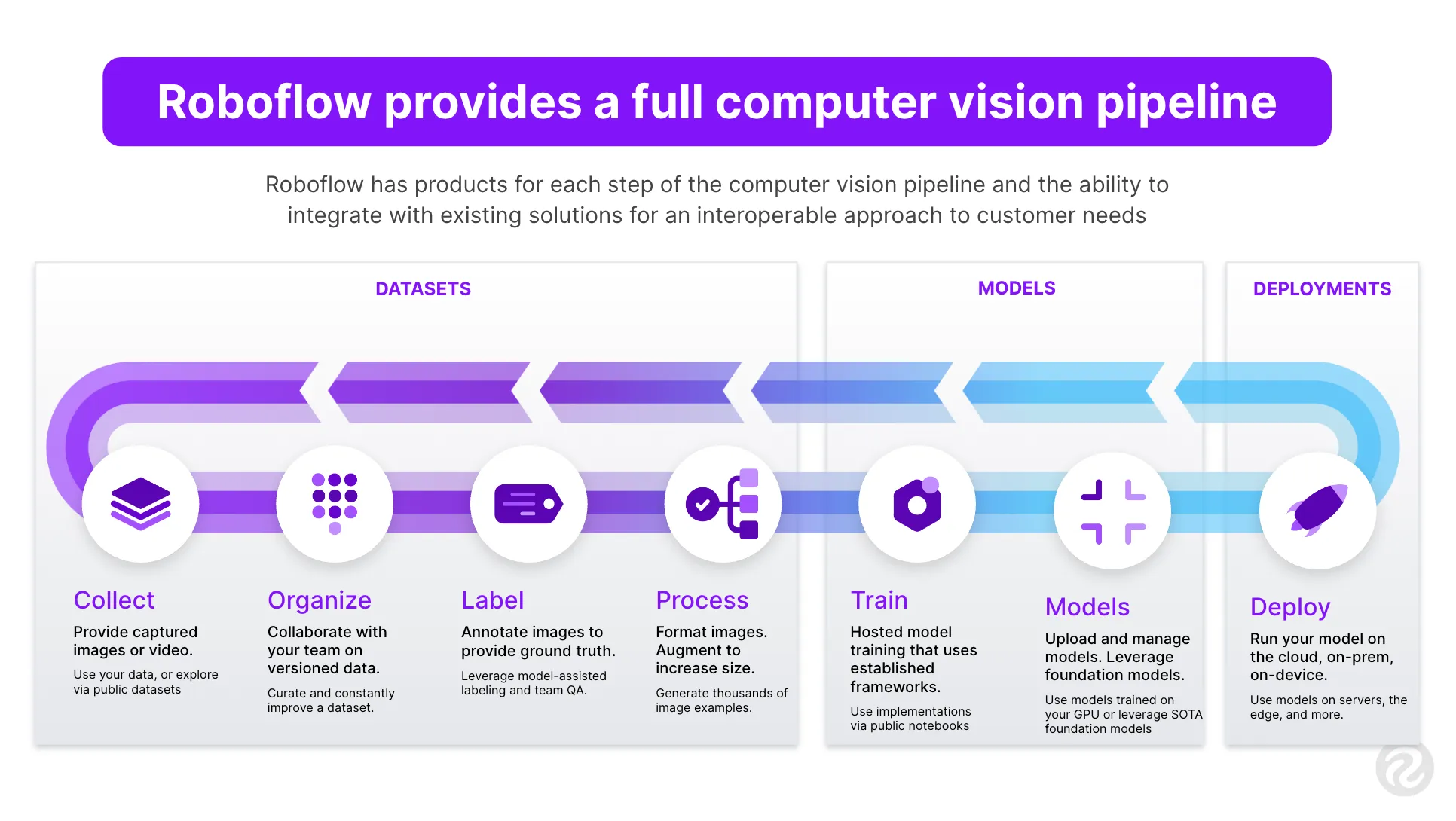
With a custom model, you can deploy it anywhere in your facility. This process involves identifying hardware on which you can run your models or using devices with internet connection.
The NVIDIA Jetson is a common choice for running models in manufacturing settings. Then, you will need a camera. Your camera does not need to have vision capabilities, but should offer an Ethernet or USB connection and support the image quality required to identify your objects of interest. You can combine your camera with your vision hardware to start running your model.
Once you have a model in production, you can work toward improving it. For example, your system might identify 95% of cracks in glass, but struggle with edge defects. You could collect more data in real time using active learning , a feature built into the Roboflow Inference deployment solution. This data can then be fed back in to train a new version of your model that is more accurate.
Vision tools – computer and machine vision – are a cornerstone of modern manufacturing processes.
You can combine machine vision systems with computer vision to build more powerful systems. For example, you can train a computer vision system to identify defects you notice in your assembly line; you can build a system that checks the orientation of a product.
Computer vision and machine vision allow you to reduce defect rates, ensure stability in your assembly line, and enforce robust quality checks for your products.
In this guide, we discussed what computer and machine vision are, the problems you can solve with each method, and how you can use computer vision to solve business problems.
If you think computer vision can solve your business problems, contact the Roboflow sales team . Our sales team are experts in developing custom computer vision solutions for use cases across industry, from logistics to manufacturing to analytics.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher . (Feb 6, 2024). Vision Tools: Using Computer and Machine Vision. Roboflow Blog: https://blog.roboflow.com/vision-tools/
Discuss this Post
If you have any questions about this blog post, start a discussion on the Roboflow Forum .
James Gallagher
James is a Technical Marketer at Roboflow, working toward democratizing access to computer vision.
Table of Contents
Manufacturing, counting rebar with computer vision, coffee bean inspection with computer vision, assess car damage with computer vision, build a juice box quality inspection system, how to broadcast computer vision predictions over mqtt, dimension measurement with computer vision.
This site uses cookies and by using the site you are consenting to this. We utilize cookies to optimize our brand’s web presence and website experience. To learn more about cookies, click here to read our privacy statement.
10 Ways Computer Vision Helps Solve Business Problems

Artificial intelligence (AI) and computer vision are all around us. A range of industries use AI and computer vision to accomplish things like automating tasks, improving the environment and saving lives.
Computer vision uses machine and deep learning techniques to allow computers to "see" not only what humans can see, but also beyond the visual spectrum of humans. In some cases, computers can see inside solid objects.
How far has the industry come using computer vision? From agriculture to medicine, from insurance to industrial applications, applying computer vision techniques can unlock capabilities never before possible. Let’s look at its short history and highlight some innovative ways computer vision and AI are solving problems today.
Computer vision is capable of great things . But with any advancing technology, there is also the capacity to do great harm. Using these technologies will always be a balance of augmenting human capability, while maintaining the privacy of individuals.
Where it all started

In the 60 years since, advancements in optics, computing power and powerful machine learning algorithms have made computer vision capable of real-time analysis of images and videos to detect objects, people, faces, poses, structural integrity issues, X-Rays/MRIs and temperature difference that the human eye is incapable of seeing. Computer vision, paired with audio augmentation, can even help the blind interact with the world around them like never before. The possibilities of how computer vision can transform lives and industries is limited—to use a cliché—only by our imaginations.
How computers "see"

A computer also does not know the difference between a car, a bus or a chair. Rather, the computer is trained on the differences of these objects – and sees these objects differently than humans do. A computer will only see a collection or matrix of numbers, that represents an image and within the image will be a number of objects.
To detect objects, a computer must be shown many examples of the objects we need the computer algorithm to recognize. This process is called ‘training’ a model where a model is an ordered collection of mathematical operations. The machine learning algorithms most commonly used to train computer vision systems are ‘convolutional neural networks’. These mathematical networks allow the computer to identify meaningful patterns for each object. After the model is trained, the computer will use the model to see if those meaningful patterns exist in the image.
Now, let’s spark your imagination . How might you use computer vision in your work ? Here’s some ways others are doing it.
1. Enforcing workplace safety

Computer vision can also be used to determine if workers are wearing the appropriate safety gear and protective equipment, like safety glasses and hard hats, before allowing entrance to the work site. Computer vision can be used to help inform and remind everyone in the workplace of the necessary safety measures.
2. Measuring immunity cells in cancer patients

Many articles have been written concerning how AI and computer vision can read X-rays and MRIs with near human accuracy rates. Today computer vision can ‘see’ anomalies in images that the human eye cannot. So while the accuracy rate might not exceed that of humans, the depth and breadth of what a computer and an algorithm can see is much greater. By using computer vision to augment the abilities of medical professionals, we can now see more than ever. The history of evolution is substantial. Suffice to say, each wave of technology modernization came about to solve a previous tech problem or need. Desktop applications were developed because everyone had a personal computer and wanted to “digitize” their processes. This led to massive data duplication, inconsistencies and security problems.
One area of interest is in measuring the number of immunity cells in cancer patients. Why is it that some patients succumb to cancer much quicker than other patients? One theory is that some patients have a much better immune response. Along with detecting cancerous cells, detecting the level of immune response is an indicator of patient prognosis.
Doctors can now apply coloring to cells to highlight the immune cells, an amazing feat in and of itself. But how does that doctor count and analyze the immune cells versus the cancerous cells? This is where computer vision plays an important role in this process. Computer vision systems can be trained to differentiate between cancerous and immune cells and apply coloring to provide information as to the ratio of immune cells to cancer cells. Without the augmentation of computer vision to this microscopic world, it would be difficult to measure this relationship.
In one study, researchers trained a system to determine that cancer cells in regions low in immune cells are more likely to trigger a relapse. Logically, this would make sense, but now doctors can actually see these areas and the extent to which the low immune cell regions exist.
3. Monitoring physical therapy progress
Pose recognition can be used to monitor a patient’s progress in a physical therapy program. It recognizes key body landmarks such as shoulders, elbows, wrists, knees, and facial features. This information can be used to determine a person’s pose in real time. Pose recognition can be used to measure posture during the activity, how long the patient has held the pose, and whether the patient achieved the desired outcomes. In the spirit of augmentation, this usage would not replace the physical therapist but augment the one-on-one instruction by a physical therapist to help monitor how a patient is progressing and if adjustments need to be made.
4. Analyzing X-rays for COVID-19 symptoms

Computer vision can be used to analyze chest X-rays and determine if the X-ray indicates COVID-19, or potentially pneumonia. Using computer vision, deep learning and thousands of training images, a model can be created to differentiate between pneumonia, heart failure, COVID or other illnesses. It takes a trained clinician to recognize the differences, which are subtle, and finding the differences in the X-ray patterns is exactly what deep learning is very good at doing. As Ramsey Wehbe, cardiologist, has said: “AI doesn’t confirm whether or not someone has the virus. But if we can flag a patient with this algorithm, we could speed up triage before the test results come back.” This is exactly where AI can augment the skills of a trained clinician for better patient outcomes.
5. Using drone imagery for insurance claims

Insurance companies are using computer vision and drones to collect high resolution pictures of a home’s roof and overall footprint. From this data, along with additional data about a home, insurance companies can provide quick quotes and settlements. Adjusters only need to be dispatched when an insurance claim cannot be settled by the computer vision application. This allows insurance companies to reduce the cost of claims adjustments on easy determinations and allow the adjuster to work on the more difficult claims.
6. Finding the lettuce core

The most talked about object detection is related to autonomous vehicles and the how the vehicle is detecting other vehicles, pedestrians, traffic control system, etc. One lesser known example is the ability to detect the location of the stem of a head of lettuce. Industrial machines designed to de-core heads of lettuce use computer vision and object detection to inform the machine where in the image the stem is located and how large the bounding box is so the machine can automatically de-core the lettuce.
7. Monitoring beer levels while bottling

Every step in the fast-paced bottling process is monitored and managed – particularly the final steps of filling the bottle. Making sure every bottle is filled to tolerance at the rate required is impossible for a human, and statistical sampling will be too slow to react to an issue. Computer vision can be used monitor liquid levels and flag the exact bottle that is out of tolerance, meaning no one will be left with a beer that leaves you wanting for a little more.
8. Finding defects in railroad tracks

There are more than 140,000 miles of railroad tracks. In 2018, the industry spent an average of $260,000 per mile for maintenance, funding and future needs. Identifying maintenance issues before there is a disruption to some of the 140,000 miles is paramount to efficiently running the railway system. How can all 140,000 miles of track be inspected and analyzed for potential defects? The answer is to mount cameras on railway cars, that are operating on the tracks already, to visually inspect every inch of the railroad track and the track bed. This allows for the continuous monitoring of the railroad infrastructure while using the tracks.Computer vision is used to capture high speed, high resolution pictures of the tracks and the track bed. These images are later analyzed and defects can be scored. A person can later go through and triage the most important projects.
9. Detecting parasites on salmon

Salmon ocean-farms are using AI and computer vision to detect parasites on salmon and directing low energy lasers to "zap" the parasites from the salmon. AI algorithms are developed to detect the parasites and instruct the laser where to focus to kill the parasite. Such systems help keep the ocean farms safe for the salmon and working around the clock in all weather.
10. Detect mites on bees

There are many risks to maintaining a healthy beehive, but mites that attack a hive can devastate the entire hive quickly. Beekeepers are creating an AI and computer vision system to detect when mites have attached themselves to bees and remove the mite in ways that won’t harm the bees.
Ready for what's next?
Computer vision with AI has revolutionized industries and will continue to do so. While computer vision technology has the potential to eliminate some jobs, it also has the potential to perform tasks that humans cannot. As with any disruptive technology – there will be disruption to the status quo.
Take a moment to consider how computer vision might be used in your industry. Is there an opportunity that needs to be explored? Together, we can help you identify opportunities where computer vision and AI could help you work more efficiently.
References: https://www.intenseye.com
https://link.springer.com/chapter/10.1007/978-3-319-10581-9_3
https://www.nature.com/articles/d41586-020-03157-9
https://heartbeat.fritz.ai/detecting-skin-cancer-on-ios-with-xcode-and-create-ml-4cb0f80cb3
https://medium.com/@_samkitjain/physio-pose-a-virtual-physiotherapy-assistant-7d1c17db3159
https://news.northwestern.edu/stories/2020/11/a-i-detects-covid-19-on-chest-x-rays-with-accuracy-and-speed/
https://agmanic.com/detect-bottle-fill-level-with-50-lines-of-python/
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3572179
https://www.globalrailwayreview.com/article/30202/computer-vision-based-solution-sign-detection/
https://www.stingray.no/delousing-with-laser/?lang=en
You're on a roll! Try these next:

Capabilities
Trending People
trending technology, trending entities.
- Systems & Design
- Low Power - High Performance
- Manufacturing, Packaging & Materials
- Test, Measurement & Analytics
- Auto, Security & Pervasive Computing
- Startup Corner
- Industry Research
- Special Reports
- Business & Startups
- Knowledge Center
- Architectures
- Automotive/ Aerospace
- Communication/Data Movement
- Design & Verification
- Lithography
- Manufacturing
- Optoelectronics / Photonics
- Power & Performance
- Test, Measurement & Analytics
- Transistors
- Z-End Applications
- Newsletters
- Low Power-High Performance
- Technical Papers
Fundamental Issues In Computer Vision Still Unresolved
Industry and academia are addressing next steps.

Given computer vision’s place as the cornerstone of an increasing number of applications from ADAS to medical diagnosis and robotics, it is critical that its weak points be mitigated, such as the ability to identify corner cases or if algorithms are trained on shallow datasets. While well-known bloopers are often the result of human decisions, there are also fundamental technical issues that require further research.
“Computer vision” and “machine vision” were once used nearly interchangeably, with machine vision most often referring to the hardware embodiment of vision, such as in robots. Computer vision (CV), which started as the academic amalgam of neuroscience and AI research, has now become the dominant idea and preferred term.
“In today’s world, even the robotics people now call it computer vision,” said Jay Pathak, senior director of research and development at Ansys . “The classical computer vision that used to happen outside of deep learning has been completely superseded. In terms of the success of AI, computer vision has a proven track record. Anytime self-driving is involved, any kind of robot that is doing work — its ability to perceive and take action — that’s all driven by deep learning.”
The original intent of CV was to replicate the power and versatility of human vision. Because vision is such a basic sense, the problem seemed like it would be far easier than higher-order cognitive challenges, like playing chess. Indeed, in the canonical anecdote about the field’s initial naïve optimism, Marvin Minsky, co-founder of the MIT AI Lab, having forgotten to include a visual system in a robot, assigned the task to undergraduates. But instead of being quick to solve, the problem consumed a generation of researchers.
Both academic and industry researchers work on problems that roughly can be split into three categories:
- Image capture: The realm of digital cameras and sensors. It may use AI for refinements or it may rely on established software and hardware.
- Image classification/detection: A subset of AI/ML that uses image datasets as training material to build models for visual recognition.
- Image generation: The most recent work, which uses tools like LLMs to create novel images, and with the breakthrough demonstration of OpenAI’s Sora, even photorealistic videos.
Each one alone has spawned dozens of PhD dissertations and industry patents . Image classification/detection, the primary focus of this article, underlies ADAS, as well as many inspection applications.
The change from lab projects to everyday uses came as researchers switched from rules-based systems that simulated visual processing as a series of if/then statements (if red and round, then apple) to neural networks (NNs), in which computers learned to derive salient features by training on image datasets. NNs are basically layered graphs. The earliest model, 1943’s Perceptron , was a one-layer simulation of a biological neuron, which is one element in a vast network of interconnecting brain cells. Neurons have inputs (dendrites) and outputs (axons), driven by electrical and chemical signaling. The Perceptron and its descendant neural networks emulated the form but skipped the chemistry, instead focusing on electrical signals with algorithms that weighted input values. Over the decades, researchers refined different forms of neural nets with vastly increased inputs and layers, eventually becoming the deep learning networks that underlie the current advances in AI.
The most recent forms of these network models are convolutional neural networks (CNNs) and transformers . In highly simplified terms, the primary difference between them is that CNNs are very good at distinguishing local features, while transformers perceive a more globalized picture.
Thus, transformers are a natural evolution from CNNs and recurrent neural networks , as well as long short-term memory approaches ( RNNs/LSTMs ), according to Gordon Cooper, product marketing manager for Synopsys’ embedded vision processor family.
“You get more accuracy at the expense of more computations and parameters. More data movement, therefore more power,” said Cooper. “But there are cases where accuracy is the most important metric for a computer vision application. Pedestrian detection comes to mind. While some vision designs still will be well served with CNNs, some of our customers have determined they are moving completely to transformers. Ten years ago, some embedded vision applications that used DSPs moved to NNs, but there remains a need for both NNs and DSPs in a vision system. Developers still need a good handle on both technologies and are better served to find a vendor that can provide a combined solution.”
The emergence of CNN-based neural networks began supplanting traditional CV techniques for object detection and recognition.
“While first implemented using hardwired CNN accelerator hardware blocks, many of those CNN techniques then quickly migrated to programmable solutions on software-driven NPUs and GPNPUs,” said Aman Sikka, chief architect at Quadric .
Two parallel trends continue to reshape CV systems. “The first is that transformer networks for object detection and recognition, with greater accuracy and usability than their convolution-based predecessors, are beginning to leave the theoretical labs and enter production service in devices,” Sikka explained. “The second is that CV experts are reinventing the classical ISP functions with NN and transformer-based models that offer superior results. Thus, we’ve seen waves of ISP functionality migrating first from pure hardwired to C++ algorithmic form, and now into advanced ML network formats, with a modern design today in 2024 consisting of numerous machine-learning models working together.”
CV for inspection While CV is well-known for its essential role in ADAS , another primary application is inspection. CV has helped detect everything from cancer tumors to manufacturing errors, or in the case of IBM’s productized research, critical flaws in the built environment. For example, a drone equipped with the IBM system could check if a bridge had cracks, a far safer and more precise way to perform visual inspection than having a human climb to dangerous heights.
By combining visual transformers with self-supervised learning, the annotation requirement is vastly reduced. In addition, the company has introduced a new process named “visual prompting,” where the AI can be taught to make the correct distinctions with limited supervision by using “in-context learning,” such as a scribble as a prompt. The optimal end result is that it should be able to respond to LLM-like prompts, such as “find all six-inch cracks.”
“Even if it makes mistakes and needs the help of human annotations, you’re doing far less labeling work than you would with traditional CNNs, where you’d have to do hundreds if not thousands of labels,” said Jayant Kalagnanam, director, AI applications at IBM Research.
Beware the humans Ideally, domain-specific datasets should increase the accuracy of identification. They are often created by expanding on foundation models already trained on general datasets, such as ImageNet . Both types of datasets are subject to human and technical biases. Google’s infamous racial identification gaffes resulted from both technical issues and subsequent human overcorrections.
Meanwhile, IBM was working on infrastructure identification, and the company’s experience of getting its model to correctly identify cracks, including the problem of having too many images of one kind of defect , suggests a potential solution to the bias problem, which is to allow the inclusion of contradictory annotations.
“Everybody who is not a civil engineer can easily say what a crack is,” said Cristiano Malossi, IBM principal research scientist. “Surprisingly, when we discuss which crack has to be repaired with domain experts, the amount of disagreement is very high because they’re taking different considerations into account and, as a result, they come to different conclusions. For a model, this means if there’s ambiguity in the annotations, it may be because the annotations have been done by multiple people, which may actually have the advantage of introducing less bias.”

Fig. 1: IBM’s Self-supervised learning model. Source: IBM
Corner cases and other challenges to accuracy The true image dataset is infinity, which in practical terms leaves most computer vision systems vulnerable to corner cases, potentially with fatal results, noted Alan Yuille, Bloomberg distinguished professor of cognitive science and computer science at Johns Hopkins University.
“So-called ‘corner cases’ are rare events that likely aren’t included in the dataset and may not even happen in everyday life,” said Yuille. “Unfortunately, all datasets have biases, and algorithms aren’t necessarily going to generalize to data that differs from the datasets they’re trained on. And one thing we have found with deep nets is if there is any bias in the dataset, the deep nets are wonderful at finding it and exploiting it.”
Thus, corner cases remain a problem to watch for. “A classic example is the idea of a baby in the road. If you’re training a car, you’re typically not going to have many examples of images with babies in the road, but you definitely want your car to stop if it sees a baby,” said Yuille. “If the companies are working in constrained domains, and they’re very careful about it, that’s not necessarily going to be a problem for them. But if the dataset is in any way biased, the algorithms may exploit the biases and corner cases, and may not be able to detect them, even if they may be of critical importance.”
This includes instances, such as real-world weather conditions, where an image may be partly occluded. “In academic cases, you could have algorithms that when evaluated on standard datasets like ImageNet are getting almost perfect results, but then you can give them an image which is occluded, for example, by a heavy rain,” he said. “In cases like that, the algorithms may fail to work, even if they work very well under normal weather conditions. A term for this is ‘out of domain.’ So you train in one domain and that may be cars in nice weather conditions, you test in out of domain, where there haven’t been many training images, and the algorithms would fail.”
The underlying reasons go back to the fundamental challenge of trying to replicate a human brain’s visual processing in a computer system.
“Objects are three-dimensional entities. Humans have this type of knowledge, and one reason for that is humans learn in a very different way than machine learning AI algorithms,” Yuille said. “Humans learn over a period of several years, where they don’t only see objects. They play with them, they touch them, they taste them, they throw them around.”
By contrast, current algorithms do not have that type of knowledge.
“They are trained as classifiers,” said Yuille. “They are trained to take images and output a class label — object one, object two, etc. They are not trained to estimate the 3D structure of objects. They have some sort of implicit knowledge of some aspects of 3D, but they don’t have it properly. That’s one reason why if you take some of those models, and you’ve contaminated the images in some way, the algorithms start degrading badly, because the vision community doesn’t have datasets of images with 3D ground truth. Only for humans, do we have datasets with 3D ground truth.”
Hardware implementation, challenges The hardware side is becoming a bottleneck, as academics and industry work to resolve corner cases and create ever-more comprehensive and precise results. “The complexity of the operation behind the transformer is quadratic,“ said Malossi. “As a result, they don’t scale linearly with the size of the problem or the size of the model.“
While the situation might be improved with a more scalable iteration of transformers, for now progress has been stalled as the industry looks for more powerful hardware or any suitable hardware. “We’re at a point right now where progress in AI is actually being limited by the supply of silicon, which is why there’s so much demand, and tremendous growth in hardware companies delivering AI,” said Tony Chan Carusone, CTO of Alphawave Semi . “In the next year or two, you’re going to see more supply of these chips come online, which will fuel rapid progress, because that’s the only thing holding it back. The massive investments being made by hyperscalers is evidence about the backlogs in delivering silicon. People wouldn’t be lining up to write big checks unless there were very specific projects they had ready to run as soon as they get the silicon.”
As more AI silicon is developed, designers should think holistically about CV, since visual fidelity depends not only on sophisticated algorithms, but image capture by a chain of co-optimized hardware and software, according to Pulin Desai, group director of product marketing and management for Tensilica vision, radar, lidar, and communication DSPs at Cadence . “When you capture an image, you have to look at the full optical path. You may start with a camera, but you’ll likely also have radar and lidar, as well as different sensors. You have to ask questions like, ‘Do I have a good lens that can focus on the proper distance and capture the light? Can my sensor perform the DAC correctly? Will the light levels be accurate? Do I have enough dynamic range? Will noise cause the levels to shift?’ You have to have the right equipment and do a lot of pre-processing before you send what’s been captured to the AI. Remember, as you design, don’t think of it as a point solution. It’s an end-to-end solution. Every different system requires a different level of full path, starting from the lens to the sensor to the processing to the AI.”
One of the more important automotive CV applications is passenger monitoring, which can help reduce the tragedies of parents forgetting children who are strapped into child seats. But such systems depend on sensors, which can be challenged by noise to the point of being ineffective.
“You have to build a sensor so small it goes into your rearview mirror,” said Jayson Bethurem, vice president of marketing and business development at Flex Logix . “Then the issue becomes the conditions of your car. The car can have the sun shining right in your face, saturating everything, to the complete opposite, where it’s completely dark and the only light in the car is emitting off your dashboard. For that sensor to have that much dynamic range and the level of detail that it needs to have, that’s where noise creeps in, because you can’t build a sensor of that much dynamic range to be perfect. On the edges, or when it’s really dark or oversaturated bright, it’s losing quality. And those are sometimes the most dangerous times.”
Breaking into the black box Finally, yet another serious concern for computer vision systems is the fact that they can’t be tested. Transformers, especially, are a notorious black box.
“We need to have algorithms that are more interpretable so that we can understand what’s going on inside them,” Yuille added. “AI will not be satisfactory till we move to a situation where we evaluate algorithms by being able to find the failure mode. In academia, and I hope companies are more careful, we test them on random samples. But if those random samples are biased in some way — and often they are — they may discount situations like the baby in the road, which don’t happen often. To find those issues, you’ve got to let your worst enemy test your algorithm and find the images that break it.”
Related Reading Dealing With AI/ML Uncertainty How neural network-based AI systems perform under the hood is currently unknown, but the industry is finding ways to live with a black box.
Karen Heyman
Leave a reply cancel reply.
Name * (Note: This name will be displayed publicly)
Email * (This will not be displayed publicly)
- Leveraging LLMs To Explain EDA Synthesis Errors And Help Train New Engineers May 8, 2024 by Technical Paper Link
- Materials And Technologies For High Temperature, Resilient Electronics May 7, 2024 by Technical Paper Link
- Synthesis Of Goldene Comprising Single-Atom Layer Gold (Linköping University) May 7, 2024 by Technical Paper Link
- Ultra Energy-Efficient HW Platform For Neuromorphic Computing Enabled By 2D-TMD Tunnel-FETs (UC Santa Barbara) May 7, 2024 by Technical Paper Link
- New Ways To Optimize GEMM-Based Applications Targeting Two Leading AI-Optimized FPGA Architectures May 7, 2024 by Technical Paper Link
Knowledge Centers Entities, people and technologies explored
Related articles, the rising price of power in chips, chiplet ip standards are just the beginning, electromigration concerns grow in advanced packages, silicon photonics manufacturing ramps up, backside power delivery gears up for 2nm devices, x-ray inspection in the semiconductor industry, sram scaling issues, and what comes next, what works best for chiplets, newsletter signup, popular tags, recent comments.
- Kevin Yao on 224G SerDes Trend and Solution
- David Scott on Is There Any Hope For Asynchronous Design?
- Ron Lavallee on Is There Any Hope For Asynchronous Design?
- Mahdoum on Multi-Die Design Pushes Complexity To The Max
- Cliff Cummings on Is There Any Hope For Asynchronous Design?
- Yaron k. on Is There Any Hope For Asynchronous Design?
- Shiv Sikand on Is There Any Hope For Asynchronous Design?
- Anne Meixner on Too Much Fab And Test Data, Low Utilization
- Mark Hahn on CXL: The Future Of Memory Interconnect?
- Dr. Richard Roy on Future-Proofing Automotive V2X
- Frank-Peter Ludwig on Enabling Advanced Devices With Atomic Layer Processes
- Piyush Kumar Mishra on Using AI/ML To Minimize IR Drop
- Rakesh on Timing Library LVF Validation For Production Design Flows
- Mike Cawthorn on What Will That Chip Cost?
- Liz Allan on Early STEM Education Key To Growing Future Chip Workforce
- Rob Pearson - RIT on Early STEM Education Key To Growing Future Chip Workforce
- Maury Wood on Examining The Impact Of Chip Power Reduction On Data Center Economics
- Erik Jan Marinissen on Chiplet IP Standards Are Just The Beginning
- Peter Bennet on Design Tool Think Tank Required
- Dr. Dev Gupta on Chiplet IP Standards Are Just The Beginning
- Jesse on Hunting For Open Defects In Advanced Packages
- Matt on Chip Ecosystem Apprenticeships Help Close The Talent Gap
- Leonard Schaper IEEE-LF on 2.5D Integration: Big Chip Or Small PCB?
- Apex on Nanoimprint Finally Finds Its Footing
- AKC on Gearing Up For Hybrid Bonding
- Allen Rasafar on Backside Power Delivery Gears Up For 2nm Devices
- Nathaniel on Intel, And Others, Inside
- Chris G on Intel, And Others, Inside
- Richard Collins on Too Much Fab And Test Data, Low Utilization
- Jerry Magera on Why Chiplets Are So Critical In Automotive
- Jenn Mullen on Shattered Silos: 2024’s Top Technology Trends
- Valerio Del Vecchio on Security Becoming Core Part Of Chip Design — Finally
- Lucas on Hybrid Bonding Basics: What Is Hybrid Bonding?
- Robin Grindley on Expand Your Semiconductor’s Market With Programmable Data Planes
- V.P.Sampath on RISC-V Micro-Architectural Verification
- Thermal Guy on Is UCIe Really Universal?
- Colt Wright on Shattered Silos: 2024’s Top Technology Trends
- Nicolas Dujarrier on The Future Of Memory
- Tony on Challenges Of Logic BiST In Automotive ICs
- Raymond Meixner's child on Visa Shakeup On Tap To Help Solve Worker Shortage
- Michael Alan Bruzzone on How Is The Chip Industry Really Doing?
- Art Scott on How Is The Chip Industry Really Doing?
- Liz Allan on Rethinking Engineering Education In The U.S.
- Telkom University on Rethinking Engineering Education In The U.S.
- Ramesh Babu Varadharajan on SRAM’s Role In Emerging Memories
- jake_leone on Visa Shakeup On Tap To Help Solve Worker Shortage
- d0x on How Secure Are FPGAs?
- Mike Bradley on RISC-V Micro-Architectural Verification
- Charles E. Bauer ,Ph.D. on Visa Shakeup On Tap To Help Solve Worker Shortage
- AMAN SINGH on Power Aware Intent And Structural Verification Of Low-Power Designs
- Ed Trevis on Visa Shakeup On Tap To Help Solve Worker Shortage
- AMAN SINGH on Get To Know The Gate-Level Power Aware Simulation
- Pitchumani Guruswamy on RISC-V Micro-Architectural Verification
- Manil Vasantha on AI Accelerator Architectures Poised For Big Changes
- Ramachandra on Packaging Demands For RF And Microwave Devices
- garry on New Insights Into IC Process Defectivity
- Brian Bailey on The Good Old Days Of EDA
- Ann Mutschler on AI Accelerator Architectures Poised For Big Changes
- John Derrick on AI Accelerator Architectures Poised For Big Changes
- allan cox on AI Accelerator Architectures Poised For Big Changes
- Madhusudhanan RAVISHANKAR on Curbing Automotive Cybersecurity Attacks
- Eric Cigan on The Good Old Days Of EDA
- Peter Flake on The Good Old Days Of EDA
- Mike Cummings on MEMS: New Materials, Markets And Packaging
- Bill Martin on The Good Old Days Of EDA
- Gretchen Patti on 3D-ICs May Be The Least-Cost Option
- Carlos on An Entangled Heterarchy
- Ann Mutschler on Flipping Processor Design On Its Head
- Gil Russell on Flipping Processor Design On Its Head
- Ed Sperling on China Unveils Memory Plans
- David on The Limits Of AI-Generated Models
- Bill on The Limits Of AI-Generated Models
- Dr. Dev Gupta on Gearing Up For Hybrid Bonding
- Faizan on China Unveils Memory Plans
- Jan Hoppe on Streamlining Failure Analysis Of Chips
- Riko R on Why Curvy Design Now? Manufacturing Is Possible And Scaling Needs It
- Derrick Meyer on Higher Automotive MCU Performance With Interface IP
- Kevin Cameron on Why Silent Data Errors Are So Hard To Find
- Rale on How Secure Are RISC-V Chips?
- Ed Sperling on Patterns And Issues In AI Chip Design
- Chip Greely on Building Better Bridges In Advanced Packaging
- Art Scott on Setting Standards For The Chip Industry
- Muhammet on Higher Creepage And Clearance Make For More Reliable Systems
- Andy Deng on Quantum Plus AI Widens Cyberattack Threat Concerns
- Dr. Rahul Razdan on The Threat Of Supply Chain Insecurity
- Roger on Patterns And Issues In AI Chip Design
- David Leary on Improving Reliability In Chips
- Ann Mutschler on The Threat Of Supply Chain Insecurity
- Cliff Greenberg on Setting Standards For The Chip Industry
- Kevin Parmenter on The Threat Of Supply Chain Insecurity
- Esther soria on Automotive Complexity, Supply Chain Strength Demands Tech Collaboration
- Kumar Venkatramani on Predicting The Future For Semiconductors
- Spike on Is UCIe Really Universal?
- David Sempek on Power Semis Usher In The Silicon Carbide Era
- Dp on Specialization Vs. Generalization In Processors
- Eric on Addressing The ABF Substrate Shortage With In-Line Monitoring
- Karl Stevens Logic Designer on Software-Hardware Co-Design Becomes Real
- Jim Handy on MRAM Getting More Attention At Smallest Nodes
- Nicolas Dujarrier on MRAM Getting More Attention At Smallest Nodes
- Lou Covey on Are In-Person Conferences Sustainable?
- Cas Wonsowicz on AI Transformer Models Enable Machine Vision Object Detection
- Nancy Zavada on Are In-Person Conferences Sustainable?
- Fred Chen on High-NA Lithography Starting To Take Shape
- Dave Taht on Wi-Fi 7 Moves Forward, Adding Yet Another Protocol
- Robert Boissy on Rethinking Engineering Education In The U.S.
- Allen Rasafar on High-NA Lithography Starting To Take Shape
- Mathias Tomandl on Multi-Beam Writers Are Driving EUV Mask Development
- K on High-NA Lithography Starting To Take Shape
- Adibhatla krishna Rao on How Do Robots Navigate?
- Doug L. on Getting Rid Of Heat In Chips
- Ken Rygler on DAC/Semicon West Wednesday
- Mark Camenzind on Why IC Industry Is Great Place To Work
- Peter Bennet on The True Cost Of Software Changes
- ALLEN RASAFAR on Balancing AI And Engineering Expertise In The Fab
- Ron Lavallee on The True Cost Of Software Changes
- Alex Peterson on Welcome To EDA 4.0 And The AI-Driven Revolution
- Allen Rasafar on Managing Yield With EUV Lithography And Stochastics
- Advertising on SemiEng
- Newsletter SignUp
- Low Power-High Perf
- Knowledge Centers
Connect With Us
- Twitter @semiEngineering
Privacy Overview
Data Collection
Building Blocks
Device Enrollment
Monitoring Dashboards
Video Annotation
Application Editor
Device Management
Remote Maintenance
Model Training
Application Library
Deployment Manager
Unified Security Center
AI Model Library
Configuration Manager
IoT Edge Gateway
Privacy-preserving AI
Ready to get started?

Transportation

Agriculture

Manufacturing
All Industries
Explore Use Cases
Custom Solutions
Evaluation Guide
Why Viso Suite?
The Viso Blog
Viso Suite Whitepaper
Industry Reports
Support Center
ROI Impact Study
Technology Guides
Security & Trust
Why Viso Suite
Viso Suite is the most advanced no-code computer vision platform to build, deploy and scale your applications. It is trusted by leading Fortune Global companies.
Develop Computer Vision with Visual Programming
Viso Suite is the most powerful no-code computer vision platform. Empowering businesses to build, deploy and monitor computer vision.
Object Detection and Counting
Face Detection and Facial Attributes
- Human Pose Estimation
Next-gen AI vision technology
Viso Suite offers full access to human-level AI technology without needing to be an AI expert. Use state of the art image recognition features including people or object detection, image segmentation, keypoint detection, pose estimation, face recognition and analysis. Start with customizable templates and build an AI product that you’ll be proud to show off to your prospects, customers, or investors.
Build scalable Computer Vision solutions
Powerful infrastructure for real-time, on-device Computer Vision and Visual Deep Learning applications. Explore more Computer Vision Use Cases .

Object Detection
Draw a square around the location of various recognized objects in an image.

Pose Estimation
Estimate the poses of people in an image by identifying various body joints.

Image Segmentation
Identify various objects in an image and their location on a pixel-by-pixel basis.
Detect, count and track objects or people in real-time
Object Detection is a computer vision technique to identify and locate objects in a video feed. Object Detection can be used to recognize and count objects and track their locations. Create Object Detection solutions with Viso Suite, based on a powerful AI vision platform.
- People Counting
- Vehicle detection
- Pedestrian detection
- Face detection
What users of Viso Suite say
Determine position, movement and orientation of a person.
Pose estimation refers to AI vision techniques that detect and track human poses. The AI jointly detects human body, hand, facial and foot key-points. With Viso Suite, you can create and power Pose Estimation applications .
- Movement Analysis
- Group Keypoint detection
- Gait analysis
Deep Learning Neural Networks for Image Classification
Image classification is a supervised learning problem where a computer can analyze an image and identify the ‘class’ the image falls under. A class is essentially a label, for example ‘car’, ‘animal’, ‘building’ and so on. You can use popular pre-trained models or your own custom trained models. Use Viso Suite to deliver Deep Learning applications , from building to scaling across multiple locations.
Visit the Viso Blog to see more examples, guides and insights about Deep Learning.
- Deep Neural Networks
- Pre-trained Models
- Custom Trained Models
Viso Suite unifies the best open source Computer Vision tools
We provide seamlessly integrated tools for Computer Vision and Deep Vision that work out-of-the-box so your teams don’t need to stitch together disparate systems or spend months integrating functionalities.
For innovation managers
Use state-of-the-art Open Source Computer Vision algorithms, ML frameworks and latest Edge Hardware. All without integration costs and overhead at scale.
For developers

Benefits of Viso Suite for your Computer Vision Projects
Viso Suite is the most powerful way to deliver next-gen, on-device deep learning vision technology.
Fast growing low-code platform
Everyone from a project manager to an IT professional can develop and deploy AI vision applications with little or no coding. Use intuitive visual builders, ready-to-use modules, application templates and built-in connectors to innovate fast.
End-to-end tools for on-device AI Vision
All the tools required to deliver an on-device AI Vision application: From application building to device management, deployment and data analytics dashboards. Use integrated tools to test new versions and scale your solutions.
Containerized software modules
Use fully integrated and read-to-use software as modules to create high-performing AI vision applications. We constantly add the latest, most powerful Open Source Software, Algorithms and Frameworks as modules to the Viso Suite platform.
Use Cross-platform hardware
Out-of-the box support for a wide range of Edge computing devices. Use GPU, CPU, VPU or TPU to process visuals. Migrate to different hardware platforms. We support cutting edge AI Hardware Accelerator Chips such as Intel NCS or Google Coral .
Get the software infrastructure you need to deliver computer vision - all in one platform
- One platform for all your computer vision use cases
- Build future-proof applications 10x faster
- Enterprise-grade scalability and security
- Deploy Apps
- Monitor Apps
- Manage Apps
- Help Center
Privacy Overview
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: power variable projection for initialization-free large-scale bundle adjustment.
Abstract: Initialization-free bundle adjustment (BA) remains largely uncharted. While Levenberg-Marquardt algorithm is the golden method to solve the BA problem, it generally relies on a good initialization. In contrast, the under-explored Variable Projection algorithm (VarPro) exhibits a wide convergence basin even without initialization. Coupled with object space error formulation, recent works have shown its ability to solve (small-scale) initialization-free bundle adjustment problem. We introduce Power Variable Projection (PoVar), extending a recent inverse expansion method based on power series. Importantly, we link the power series expansion to Riemannian manifold optimization. This projective framework is crucial to solve large-scale bundle adjustment problem without initialization. Using the real-world BAL dataset, we experimentally demonstrate that our solver achieves state-of-the-art results in terms of speed and accuracy. In particular, our work is the first, to our knowledge, that addresses the scalability of BA without initialization and opens new venues for initialization-free Structure-from-Motion.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Understanding and Preventing Computer Vision Syndrome
- BY Dr. Steven Liem
- May 02, 2024

Photo by XXSS IS BACK
In the digital age, our lives are often dominated by screens. Whether we’re working, studying, or relaxing, we’re likely looking at a digital display. This constant engagement with screens can lead to a condition known as Computer Vision Syndrome (CVS), also referred to as Digital Eye Strain.
What is Computer Vision Syndrome?
Computer Vision Syndrome is a group of eye and vision-related problems that result from prolonged computer, tablet, e-reader and mobile phone use. Symptoms of CVS might include headaches, blurred vision, neck pain, fatigue, eye strain, dry eyes, irritated eyes, double vision, vertigo/dizziness, polyopia, and difficulty refocusing the eyes. These symptoms can be further aggravated by poor lighting, glare on the digital screen, improper viewing distances, poor seating posture, and uncorrected vision problems.
How to Prevent Computer Vision Syndrome
Preventing Computer Vision Syndrome involves taking steps to reduce eye strain and increase comfort while using digital devices. Here are a few helpful tips:
- Follow the 20-20-20 rule: every 20 minutes, take a 20-second break and look at something 20 feet away. This can help reduce eye strain.
- Adjust your workstation: make sure your screen is at a comfortable viewing distance and angle. The top of the screen should be at eye level or below so you look slightly down at your work.
- Reduce glare: adjust the brightness of your screen and use window shades, desk lamps, or computer glasses to reduce glare.
- Remember to blink: Blinking moistens your eyes and prevents dryness and irritation.
Consider Computer Glasses
One effective way of preventing CVS is through the use of computer glasses . These glasses are specifically designed to reduce eye strain when you’re looking at digital screens. They often include features like blue light filters, magnification, and anti-reflective coating. Zenni Optical offers a variety of computer glasses that combine style with function, helping to protect your eyes while ensuring you look great.
Remember, if you’re experiencing CVS symptoms, it’s important to discuss this with your eye care professional. They can provide further guidance on how to relieve your symptoms and protect your eyes in the digital age.

Dr. Steven Liem
Dr. Steven Liem, O.D., F.A.A.O. is an optometrist based in Pasadena, California. After obtaining his doctorate from UC Berkeley’s School of Optometry, he completed his residency in Pediatrics, Vision Therapy & Rehabilitation and became a Fellow of the American Academy of Optometry. When he isn’t busy streaming or making Youtube videos about video games, Dr. Liem aims to broaden accessibility to vision health through his involvement in optometric industry and tech.
Related Posts

IMAGES
VIDEO
COMMENTS
While computer vision tasks cover a wide breadth of perception capabilities and the list continues to grow, the latest techniques support and help solve use cases involving detection, classification, segmentation, and image synthesis. Detection tasks locate, and sometimes track, where an object exists in an image.
Selecting an inadequate model architecture is another common computer vision problem that can be attributed to many factors. They affect the overall performance, efficiency, and applicability of the model for specific computational tasks. Let us discuss some of the common causes of poor model architecture selection.
Here are the steps involved in identifying the problem statement in computer vision research: Problem Statement Analysis: The first step is to pinpoint the specific application domain within computer vision. This could be related to object recognition in autonomous vehicles or medical image analysis for disease detection.
The field of computer vision is shifting from statistical methods to deep learning neural network methods. There are still many challenging problems to solve in computer vision. Nevertheless, deep learning methods are achieving state-of-the-art results on some specific problems. It is not just the performance of deep learning models on benchmark problems that is most interesting; it is the ...
DiCarlo and others previously found that when such deep-learning computer vision systems establish efficient ways to solve visual problems, they end up with artificial circuits that work similarly to the neural circuits that process visual information in our own brains. That is, they turn out to be surprisingly good scientific models of the ...
Machine learning provided a different approach to solving computer vision problems. With machine learning, developers no longer needed to manually code every single rule into their vision applications. Instead they programmed "features," smaller applications that could detect specific patterns in images. They then used a statistical ...
Computer vision is a field of artificial intelligence (AI) that applies machine learning to images and videos to understand media and make decisions about them. ... It is the tech industry's definitive destination for sharing compelling, first-person accounts of problem-solving on the road to innovation. Learn More. Great Companies Need Great ...
Here are several common obstacles to solving computer vision problems. Different lighting. For computer vision, it is very important to collect knowledge about the real world that represents objects in different kinds of lighting. A filter might make a ball look blue or yellow while in fact it is still white. A red object under a red lamp ...
A common use of computer vision is to classify the contents of an image. In order to do this, you need to utilize machine learning. This chapter explores how to extract color histograms using OpenCV and then train a Random Forest Classifier using scikit-learn to classify the species of a flower. #5.
A Gentle Introduction to Computer Vision. Computer Vision, often abbreviated as CV, is defined as a field of study that seeks to develop techniques to help computers "see" and understand the content of digital images such as photographs and videos. The problem of computer vision appears simple because it is trivially solved by people, even ...
Sep 13, 2017. 3. At least for about a decade now, there have been drastic improvements in the techniques used for solving problems in the domain of computer vision, some of the notable problems ...
Most of the problems we need to solve in vision are ill-posed,in Hadamard's sense that a well-posedproblem must have the following set of properties: ... In many respects, computer vision is an "AI-complete" problem: building general-purpose vision machines would entail, or require, solutions to most of the general goals of artificial ...
Definition. Computer vision is an interdisciplinary field that deals with how computers can be made to gain high-level understanding from digital images or videos.From the perspective of engineering, it seeks to automate tasks that the human visual system can do. "Computer vision is concerned with the automatic extraction, analysis, and understanding of useful information from a single image ...
Figure 1. Solving regularized inverse problems in vision typically requires using iterative solvers like conjugate gradients. We solve the same type of problems via filtering for a speed-up. In this work, we solve regularized optimization problems of the form. minimize ( ) = + (1) ‖ − ‖2 2 ∗.
The same is true for computer vision problems, except the steps look a little different. A seven-step process for solving computer vision problems. We'll walk through each of these steps, with the goal being that at the end of the process you know the steps needed to solve a computer vision problem as well as a good overview of computer vision ...
Viso Suite provides an extensive set of features to reduce the complexity of computer vision at every step of your development cycle. Here are 5 ways that Viso Suite will use to overcome the challenges: Visual Programming: Use a visual approach to build complex computer vision and deep learning solutions on the fly.
Computer vision and deep learning present challenges when going into production. These challenges include: Getting enough data of good quality. Managing executives' expectations about model performance. Being pragmatic about how bleeding-edge we really need our network to be.
It's the same problem with Computer Vision. To solve the problem, we need to use a lot of pictures of clothing, shoes, and handbags and tell the computer what's that picture is, and then have ...
Two of the most significant costs to consider before starting your computer vision project are: The hardware requirements of the project. The costs of cloud computing. 3. Weak planning for model development. Another challenge can be weak planning for creating the ML model that is deployed for the computer vision system.
Computer vision syndrome is a type of eye strain that happens when you spend a lot of time using computers, smartphones or other digital devices. Symptoms include dry, irritated eyes, blurry vision and headaches. Treatment focuses on lubricating your eyes, correcting vision errors and adjusting your posture when using digital devices.
Indeed, computer vision and traditional machine vision play a crucial role in modern manufacturing processes. Whether you want to read labels for quality assurance purposes, detect defects, detect the absence of products, or identify quality issues, computer vision can help solve your business problems. If an attribute is visible - for ...
These images are later analyzed and defects can be scored. A person can later go through and triage the most important projects. 9. Detecting parasites on salmon. Salmon ocean-farms are using AI and computer vision to detect parasites on salmon and directing low energy lasers to "zap" the parasites from the salmon.
Computer vision (CV), which started as the academic amalgam of neuroscience and AI research, has now become the dominant idea and preferred term. "In today's world, even the robotics people now call it computer vision," said Jay Pathak, senior director of research and development at Ansys. "The classical computer vision that used to ...
Detect, count and track objects or people in real-time. Object Detection is a computer vision technique to identify and locate objects in a video feed. Object Detection can be used to recognize and count objects and track their locations. Create Object Detection solutions with Viso Suite, based on a powerful AI vision platform.
Power Variable Projection for Initialization-Free Large-Scale Bundle Adjustment. Initialization-free bundle adjustment (BA) remains largely uncharted. While Levenberg-Marquardt algorithm is the golden method to solve the BA problem, it generally relies on a good initialization. In contrast, the under-explored Variable Projection algorithm ...
Computer Vision Syndrome is a group of eye and vision-related problems that result from prolonged computer, tablet, e-reader and mobile phone use. Symptoms of CVS might include headaches, blurred vision, neck pain, fatigue, eye strain, dry eyes, irritated eyes, double vision, vertigo/dizziness, polyopia, and difficulty refocusing the eyes.