Pytest With Eric

How to Use Hypothesis and Pytest for Robust Property-Based Testing in Python
There will always be cases you didn’t consider, making this an ongoing maintenance job. Unit testing solves only some of these issues.
Example-Based Testing vs Property-Based Testing
Project set up, getting started, prerequisites, simple example, source code, simple example — unit tests, example-based testing, running the unit test, property-based testing, complex example, source code, complex example — unit tests, discover bugs with hypothesis, define your own hypothesis strategies, model-based testing in hypothesis, additional reading.
Table of Contents
Testing your python code with hypothesis, installing & using hypothesis, a quick example, understanding hypothesis, using hypothesis strategies, filtering and mapping strategies, composing strategies, constraints & satisfiability, writing reusable strategies with functions.
- @composite: Declarative Strategies
- @example: Explicitly Testing Certain Values
Hypothesis Example: Roman Numeral Converter
I can think of a several Python packages that greatly improved the quality of the software I write. Two of them are pytest and hypothesis . The former adds an ergonomic framework for writing tests and fixtures and a feature-rich test runner. The latter adds property-based testing that can ferret out all but the most stubborn bugs using clever algorithms, and that’s the package we’ll explore in this course.
In an ordinary test you interface with the code you want to test by generating one or more inputs to test against, and then you validate that it returns the right answer. But that, then, raises a tantalizing question: what about all the inputs you didn’t test? Your code coverage tool may well report 100% test coverage, but that does not, ipso facto , mean the code is bug-free.
One of the defining features of Hypothesis is its ability to generate test cases automatically in a manner that is:
Repeated invocations of your tests result in reproducible outcomes, even though Hypothesis does use randomness to generate the data.
You are given a detailed answer that explains how your test failed and why it failed. Hypothesis makes it clear how you, the human, can reproduce the invariant that caused your test to fail.
You can refine its strategies and tell it where or what it should or should not search for. At no point are you compelled to modify your code to suit the whims of Hypothesis if it generates nonsensical data.
So let’s look at how Hypothesis can help you discover errors in your code.
You can install hypothesis by typing pip install hypothesis . It has few dependencies of its own, and should install and run everywhere.
Hypothesis plugs into pytest and unittest by default, so you don’t have to do anything to make it work with it. In addition, Hypothesis comes with a CLI tool you can invoke with hypothesis . But more on that in a bit.
I will use pytest throughout to demonstrate Hypothesis, but it works equally well with the builtin unittest module.
Before I delve into the details of Hypothesis, let’s start with a simple example: a naive CSV writer and reader. A topic that seems simple enough: how hard is it to separate fields of data with a comma and then read it back in later?
But of course CSV is frighteningly hard to get right. The US and UK use '.' as a decimal separator, but in large parts of the world they use ',' which of course results in immediate failure. So then you start quoting things, and now you need a state machine that can distinguish quoted from unquoted; and what about nested quotes, etc.
The naive CSV reader and writer is an excellent stand-in for any number of complex projects where the requirements outwardly seem simple but there lurks a large number of edge cases that you must take into account.
Here the writer simply string quotes each field before joining them together with ',' . The reader does the opposite: it assumes each field is quoted after it is split by the comma.
A naive roundtrip pytest proves the code “works”:
And evidently so:
And for a lot of code that’s where the testing would begin and end. A couple of lines of code to test a couple of functions that outwardly behave in a manner that anybody can read and understand. Now let’s look at what a Hypothesis test would look like, and what happens when we run it:
At first blush there’s nothing here that you couldn’t divine the intent of, even if you don’t know Hypothesis. I’m asking for the argument fields to have a list ranging from one element of generated text up to ten. Aside from that, the test operates in exactly the same manner as before.
Now watch what happens when I run the test:
Hypothesis quickly found an example that broke our code. As it turns out, a list of [','] breaks our code. We get two fields back after round-tripping the code through our CSV writer and reader — uncovering our first bug.
In a nutshell, this is what Hypothesis does. But let’s look at it in detail.
Simply put, Hypothesis generates data using a number of configurable strategies . Strategies range from simple to complex. A simple strategy may generate bools; another integers. You can combine strategies to make larger ones, such as lists or dicts that match certain patterns or structures you want to test. You can clamp their outputs based on certain constraints, like only positive integers or strings of a certain length. You can also write your own strategies if you have particularly complex requirements.
Strategies are the gateway to property-based testing and are a fundamental part of how Hypothesis works. You can find a detailed list of all the strategies in the Strategies reference of their documentation or in the hypothesis.strategies module.
The best way to get a feel for what each strategy does in practice is to import them from the hypothesis.strategies module and call the example() method on an instance:
You may have noticed that the floats example included inf in the list. By default, all strategies will – where feasible – attempt to test all legal (but possibly obscure) forms of values you can generate of that type. That is particularly important as corner cases like inf or NaN are legal floating-point values but, I imagine, not something you’d ordinarily test against yourself.
And that’s one pillar of how Hypothesis tries to find bugs in your code: by testing edge cases that you would likely miss yourself. If you ask it for a text() strategy you’re as likely to be given Western characters as you are a mishmash of unicode and escape-encoded garbage. Understanding why Hypothesis generates the examples it does is a useful way to think about how your code may interact data it has no control over.
Now if it were simply generating text or numbers from an inexhaustible source of numbers or strings, it wouldn’t catch as many errors as it actually does . The reason for that is that each test you write is subjected to a battery of examples drawn from the strategies you’ve designed. If a test case fails, it’s put aside and tested again but with a reduced subset of inputs, if possible. In Hypothesis it’s known as shrinking the search space to try and find the smallest possible result that will cause your code to fail. So instead of a 10,000-length string, if it can find one that’s only 3 or 4, it will try to show that to you instead.
You can tell Hypothesis to filter or map the examples it draws to further reduce them if the strategy does not meet your requirements:
Here I ask for integers where the number is greater than 0 and is evenly divisible by 8. Hypothesis will then attempt to generate examples that meets the constraints you have imposed on it.
You can also map , which works in much the same way as filter. Here I’m asking for lowercase ASCII and then uppercasing them:
Having said that, using either when you don’t have to (I could have asked for uppercase ASCII characters to begin with) is likely to result in slower strategies.
A third option, flatmap , lets you build strategies from strategies; but that deserves closer scrutiny, so I’ll talk about it later.
You can tell Hypothesis to pick one of a number of strategies by composing strategies with | or st.one_of() :
An essential feature when you have to draw from multiple sources of examples for a single data point.
When you ask Hypothesis to draw an example it takes into account the constraints you may have imposed on it: only positive integers; only lists of numbers that add up to exactly 100; any filter() calls you may have applied; and so on. Those are constraints. You’re taking something that was once unbounded (with respect to the strategy you’re drawing an example from, that is) and introducing additional limitations that constrain the possible range of values it can give you.
But consider what happens if I pass filters that will yield nothing at all:
At some point Hypothesis will give up and declare it cannot find anything that satisfies that strategy and its constraints.
Hypothesis gives up after a while if it’s not able to draw an example. Usually that indicates an invariant in the constraints you’ve placed that makes it hard or impossible to draw examples from. In the example above, I asked for numbers that are simultaneously below zero and greater than zero, which is an impossible request.
As you can see, the strategies are simple functions, and they behave as such. You can therefore refactor each strategy into reusable patterns:
The benefit of this approach is that if you discover edge cases that Hypothesis does not account for, you can update the pattern in one place and observe its effects on your code. It’s functional and composable.
One caveat of this approach is that you cannot draw examples and expect Hypothesis to behave correctly. So I don’t recommend you call example() on a strategy only to pass it into another strategy.
For that, you want the @composite decorator.
@composite : Declarative Strategies
If the previous approach is unabashedly functional in nature, this approach is imperative.
The @composite decorator lets you write imperative Python code instead. If you cannot easily structure your strategy with the built-in ones, or if you require more granular control over the values it emits, you should consider the @composite strategy.
Instead of returning a compound strategy object like you would above, you instead draw examples using a special function you’re given access to in the decorated function.
This example draws two randomized names and returns them as a tuple:
Note that the @composite decorator passes in a special draw callable that you must use to draw samples from. You cannot – well, you can , but you shouldn’t – use the example() method on the strategy object you get back. Doing so will break Hypothesis’s ability to synthesize test cases properly.
Because the code is imperative you’re free to modify the drawn examples to your liking. But what if you’re given an example you don’t like or one that breaks a known invariant you don’t wish to test for? For that you can use the assume() function to state the assumptions that Hypothesis must meet if you try to draw an example from generate_full_name .
Let’s say that first_name and last_name must not be equal:
Like the assert statement in Python, the assume() function teaches Hypothesis what is, and is not, a valid example. You use this to great effect to generate complex compound strategies.
I recommend you observe the following rules of thumb if you write imperative strategies with @composite :
If you want to draw a succession of examples to initialize, say, a list or a custom object with values that meet certain criteria you should use filter , where possible, and assume to teach Hypothesis why the value(s) you drew and subsequently discarded weren’t any good.
The example above uses assume() to teach Hypothesis that first_name and last_name must not be equal.
If you can put your functional strategies in separate functions, you should. It encourages code re-use and if your strategies are failing (or not generating the sort of examples you’d expect) you can inspect each strategy in turn. Large nested strategies are harder to untangle and harder still to reason about.
If you can express your requirements with filter and map or the builtin constraints (like min_size or max_size ), you should. Imperative strategies that use assume may take more time to converge on a valid example.
@example : Explicitly Testing Certain Values
Occasionally you’ll come across a handful of cases that either fails or used to fail, and you want to ensure that Hypothesis does not forget to test them, or to indicate to yourself or your fellow developers that certain values are known to cause issues and should be tested explicitly.
The @example decorator does just that:
You can add as many as you like.
Let’s say I wanted to write a simple converter to and from Roman numerals.
Here I’m collecting Roman numerals into numerals , one at a time, by looping over SYMBOLS of valid numerals, subtracting the value of the symbol from number , until the while loop’s condition ( number >= 1 ) is False .
The test is also simple and serves as a smoke test. I generate a random integer and convert it to Roman numerals with to_roman . When it’s all said and done I turn the string of numerals into a set and check that all members of the set are legal Roman numerals.
Now if I run pytest on it seems to hang . But thanks to Hypothesis’s debug mode I can inspect why:
Ah. Instead of testing with tiny numbers like a human would ordinarily do, it used a fantastically large one… which is altogether slow.
OK, so there’s at least one gotcha; it’s not really a bug , but it’s something to think about: limiting the maximum value. I’m only going to limit the test, but it would be reasonable to limit it in the code also.
Changing the max_value to something sensible, like st.integers(max_value=5000) and the test now fails with another error:
It seems our code’s not able to handle the number 0! Which… is correct. The Romans didn’t really use the number zero as we would today; that invention came later, so they had a bunch of workarounds to deal with the absence of something. But that’s neither here nor there in our example. Let’s instead set min_value=1 also, as there is no support for negative numbers either:
OK… not bad. We’ve proven that given a random assortment of numbers between our defined range of values that, indeed, we get something resembling Roman numerals.
One of the hardest things about Hypothesis is framing questions to your testable code in a way that tests its properties but without you, the developer, knowing the answer (necessarily) beforehand. So one simple way to test that there’s at least something semi-coherent coming out of our to_roman function is to check that it can generate the very numerals we defined in SYMBOLS from before:
Here I’m sampling from a tuple of the SYMBOLS from earlier. The sampling algorithm’ll decide what values it wants to give us, all we care about is that we are given examples like ("I", 1) or ("V", 5) to compare against.
So let’s run pytest again:
Oops. The Roman numeral V is equal to 5 and yet we get five IIIII ? A closer examination reveals that, indeed, the code only yields sequences of I equal to the number we pass it. There’s a logic error in our code.
In the example above I loop over the elements in the SYMBOLS dictionary but as it’s ordered the first element is always I . And as the smallest representable value is 1, we end up with just that answer. It’s technically correct as you can count with just I but it’s not very useful.
Fixing it is easy though:
Rerunning the test yields a pass. Now we know that, at the very least, our to_roman function is capable of mapping numbers that are equal to any symbol in SYMBOLS .
Now the litmus test is taking the numeral we’re given and making sense of it. So let’s write a function that converts a Roman numeral back into decimal:
Like to_roman we walk through each character, get the numeral’s numeric value, and add it to the running total. The test is a simple roundtrip test as to_roman has an inverse function from_roman (and vice versa) such that :
Invertible functions are easier to test because you can compare the output of one against the input of another and check if it yields the original value. But not every function has an inverse, though.
Running the test yields a pass:
So now we’re in a pretty good place. But there’s a slight oversight in our Roman numeral converters, though: they don’t respect the subtraction rule for some of the numerals. For instance VI is 6; but IV is 4. The value XI is 11; and IX is 9. Only some (sigh) numerals exhibit this property.
So let’s write another test. This time it’ll fail as we’ve yet to write the modified code. Luckily we know the subtractive numerals we must accommodate:
Pretty simple test. Check that certain numerals yield the value, and that the values yield the right numeral.
With an extensive test suite we should feel fairly confident making changes to the code. If we break something, one of our preexisting tests will fail.
The rules around which numerals are subtractive is rather subjective. The SUBTRACTIVE_SYMBOLS dictionary holds the most common ones. So all we need to do is read ahead of the numerals list to see if there exists a two-digit numeral that has a prescribed value and then we use that instead of the usual value.
The to_roman change is simple. A union of the two numeral symbol dictionaries is all it takes . The code already understands how to turn numbers into numerals — we just added a few more.
This method requires Python 3.9 or later. Read how to merge dictionaries
If done right, running the tests should yield a pass:
And that’s it. We now have useful tests and a functional Roman numeral converter that converts to and from with ease. But one thing we didn’t do is create a strategy that generates Roman numerals using st.text() . A custom composite strategy to generate both valid and invalid Roman numerals to test the ruggedness of our converter is left as an exercise to you.
In the next part of this course we’ll look at more advanced testing strategies.
Unlike a tool like faker that generates realistic-looking test data for fixtures or demos, Hypothesis is a property-based tester . It uses heuristics and clever algorithms to find inputs that break your code.
Testing a function that does not have an inverse to compare the result against – like our Roman numeral converter that works both ways – you often have to approach your code as though it were a black box where you relinquish control of the inputs and outputs. That is harder, but makes for less brittle code.
It’s perfectly fine to mix and match tests. Hypothesis is useful for flushing out invariants you would never think of. Combine it with known inputs and outputs to jump start your testing for the first 80%, and augment it with Hypothesis to catch the remaining 20%.
Be Inspired Sign up and we’ll tell you about new articles and courses
Absolutely no spam. We promise!
Liked the Article?
Why not follow us …, be inspired get python tips sent to your inbox.
We'll tell you about the latest courses and articles.

Visual Design.
Upgrade to get unlimited access ($10 one off payment).
7 Tips for Beginner to Future-Proof your Machine Learning Project

LLM Prompt Engineering Techniques for Knowledge Graph Integration

Develop a Data Analytics Web App in 3 Steps

What Does ChatGPT Say About Machine Learning Trend and How Can We Prepare For It?

- Apr 14, 2022
An Interactive Guide to Hypothesis Testing in Python
Updated: Jun 12, 2022

upgrade and grab the cheatsheet from our infographics gallery
What is hypothesis testing.
Hypothesis testing is an essential part in inferential statistics where we use observed data in a sample to draw conclusions about unobserved data - often the population.
Implication of hypothesis testing:
clinical research: widely used in psychology, biology and healthcare research to examine the effectiveness of clinical trials
A/B testing: can be applied in business context to improve conversions through testing different versions of campaign incentives, website designs ...
feature selection in machine learning: filter-based feature selection methods use different statistical tests to determine the feature importance
college or university: well, if you major in statistics or data science, it is likely to appear in your exams
For a brief video walkthrough along with the blog, check out my YouTube channel.
4 Steps in Hypothesis testing
Step 1. define null and alternative hypothesis.
Null hypothesis (H0) can be stated differently depends on the statistical tests, but generalize to the claim that no difference, no relationship or no dependency exists between two or more variables.
Alternative hypothesis (H1) is contradictory to the null hypothesis and it claims that relationships exist. It is the hypothesis that we would like to prove right. However, a more conservational approach is favored in statistics where we always assume null hypothesis is true and try to find evidence to reject the null hypothesis.
Step 2. Choose the appropriate test
Common Types of Statistical Testing including t-tests, z-tests, anova test and chi-square test

T-test: compare two groups/categories of numeric variables with small sample size
Z-test: compare two groups/categories of numeric variables with large sample size
ANOVA test: compare the difference between two or more groups/categories of numeric variables
Chi-Squared test: examine the relationship between two categorical variables
Correlation test: examine the relationship between two numeric variables
Step 3. Calculate the p-value
How p value is calculated primarily depends on the statistical testing selected. Firstly, based on the mean and standard deviation of the observed sample data, we are able to derive the test statistics value (e.g. t-statistics, f-statistics). Then calculate the probability of getting this test statistics given the distribution of the null hypothesis, we will find out the p-value. We will use some examples to demonstrate this in more detail.
Step 4. Determine the statistical significance
p value is then compared against the significance level (also noted as alpha value) to determine whether there is sufficient evidence to reject the null hypothesis. The significance level is a predetermined probability threshold - commonly 0.05. If p value is larger than the threshold, it means that the value is likely to occur in the distribution when the null hypothesis is true. On the other hand, if lower than significance level, it means it is very unlikely to occur in the null hypothesis distribution - hence reject the null hypothesis.
Hypothesis Testing with Examples
Kaggle dataset “ Customer Personality Analysis” is used in this case study to demonstrate different types of statistical test. T-test, ANOVA and Chi-Square test are sensitive to large sample size, and almost certainly will generate very small p-value when sample size is large . Therefore, I took a random sample (size of 100) from the original data:
T-test is used when we want to test the relationship between a numeric variable and a categorical variable.There are three main types of t-test.
one sample t-test: test the mean of one group against a constant value
two sample t-test: test the difference of means between two groups
paired sample t-test: test the difference of means between two measurements of the same subject
For example, if I would like to test whether “Recency” (the number of days since customer’s last purchase - numeric value) contributes to the prediction of “Response” (whether the customer accepted the offer in the last campaign - categorical value), I can use a two sample t-test.
The first sample would be the “Recency” of customers who accepted the offer:
The second sample would be the “Recency” of customers who rejected the offer:
To compare the “Recency” of these two groups intuitively, we can use histogram (or distplot) to show the distributions.

It appears that positive response have lower Recency compared to negative response. To quantify the difference and make it more scientific, let’s follow the steps in hypothesis testing and carry out a t-test.
Step1. define null and alternative hypothesis
null: there is no difference in Recency between the customers who accepted the offer in the last campaign and who did not accept the offer
alternative: customers who accepted the offer has lower Recency compared to customers who did not accept the offer
Step 2. choose the appropriate test
To test the difference between two independent samples, two-sample t-test is the most appropriate statistical test which follows student t-distribution. The shape of student-t distribution is determined by the degree of freedom, calculated as the sum of two sample size minus 2.
In python, simply import the library scipy.stats and create the t-distribution as below.
Step 3. calculate the p-value
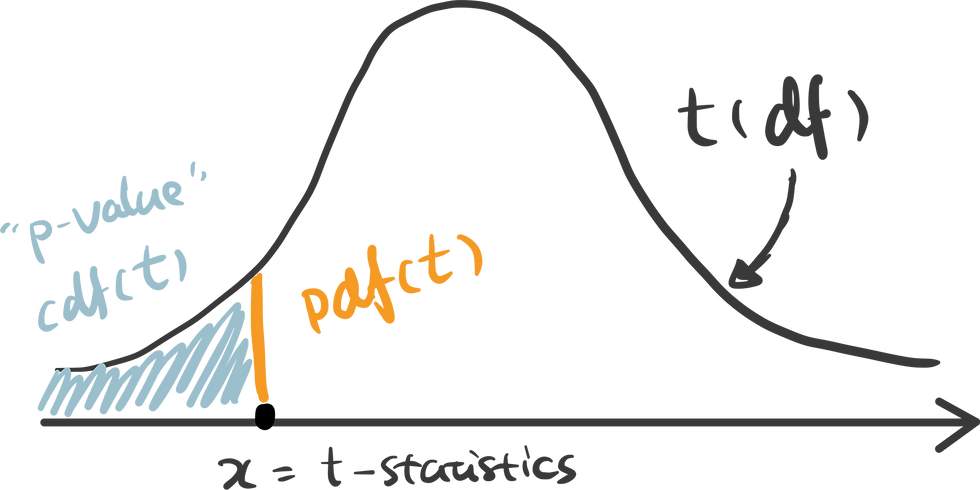
There are some handy functions in Python calculate the probability in a distribution. For any x covered in the range of the distribution, pdf(x) is the probability density function of x — which can be represented as the orange line below, and cdf(x) is the cumulative density function of x — which can be seen as the cumulative area. In this example, we are testing the alternative hypothesis that — Recency of positive response minus the Recency of negative response is less than 0. Therefore we should use a one-tail test and compare the t-statistics we get against the lowest value in this distribution — therefore p-value can be calculated as cdf(t_statistics) in this case.
ttest_ind() is a handy function for independent t-test in python that has done all of these for us automatically. Pass two samples rececency_P and recency_N as the parameters, and we get the t-statistics and p-value.

Here I use plotly to visualize the p-value in t-distribution. Hover over the line and see how point probability and p-value changes as the x shifts. The area with filled color highlights the p-value we get for this specific test.
Check out the code in our Code Snippet section, if you want to build this yourself.
An interactive visualization of t-distribution with t-statistics vs. significance level.
Step 4. determine the statistical significance
The commonly used significance level threshold is 0.05. Since p-value here (0.024) is smaller than 0.05, we can say that it is statistically significant based on the collected sample. A lower Recency of customer who accepted the offer is likely not occur by chance. This indicates the feature “Response” may be a strong predictor of the target variable “Recency”. And if we would perform feature selection for a model predicting the "Recency" value, "Response" is likely to have high importance.
Now that we know t-test is used to compare the mean of one or two sample groups. What if we want to test more than two samples? Use ANOVA test.
ANOVA examines the difference among groups by calculating the ratio of variance across different groups vs variance within a group . Larger ratio indicates that the difference across groups is a result of the group difference rather than just random chance.
As an example, I use the feature “Kidhome” for the prediction of “NumWebPurchases”. There are three values of “Kidhome” - 0, 1, 2 which naturally forms three groups.
Firstly, visualize the data. I found box plot to be the most aligned visual representation of ANOVA test.

It appears there are distinct differences among three groups. So let’s carry out ANOVA test to prove if that’s the case.
1. define hypothesis:
null hypothesis: there is no difference among three groups
alternative hypothesis: there is difference between at least two groups
2. choose the appropriate test: ANOVA test for examining the relationships of numeric values against a categorical value with more than two groups. Similar to t-test, the null hypothesis of ANOVA test also follows a distribution defined by degrees of freedom. The degrees of freedom in ANOVA is determined by number of total samples (n) and the number of groups (k).
dfn = n - 1
dfd = n - k
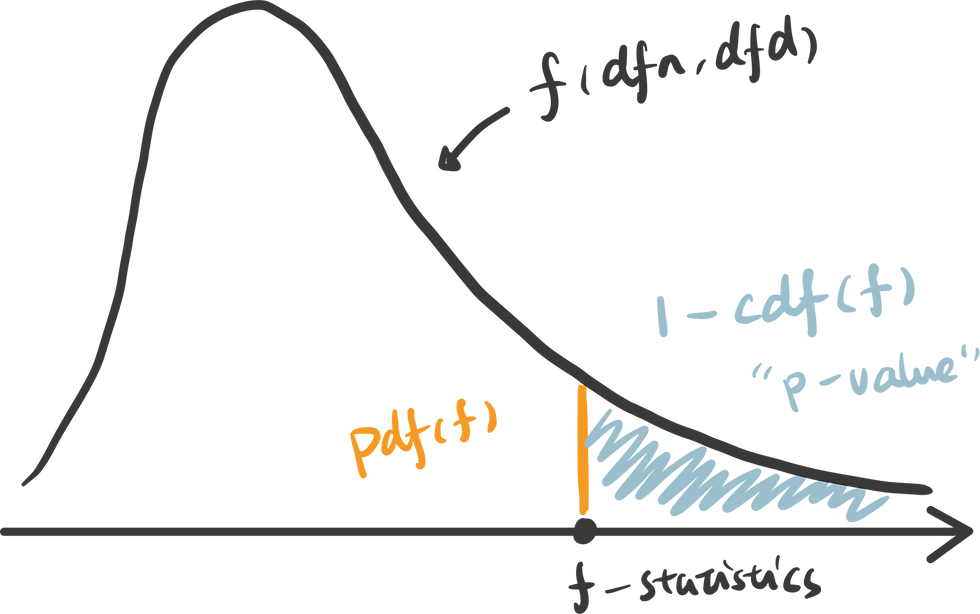
3. calculate the p-value: To calculate the p-value of the f-statistics, we use the right tail cumulative area of the f-distribution, which is 1 - rv.cdf(x).
To easily get the f-statistics and p-value using Python, we can use the function stats.f_oneway() which returns p-value: 0.00040.
An interactive visualization of f-distribution with f-statistics vs. significance level. (Check out the code in our Code Snippet section, if you want to build this yourself. )
4. determine the statistical significance : Compare the p-value against the significance level 0.05, we can infer that there is strong evidence against the null hypothesis and very likely that there is difference in “NumWebPurchases” between at least two groups.
Chi-Squared Test
Chi-Squared test is for testing the relationship between two categorical variables. The underlying principle is that if two categorical variables are independent, then one categorical variable should have similar composition when the other categorical variable change. Let’s look at the example of whether “Education” and “Response” are independent.
First, use stacked bar chart and contingency table to summary the count of each category.
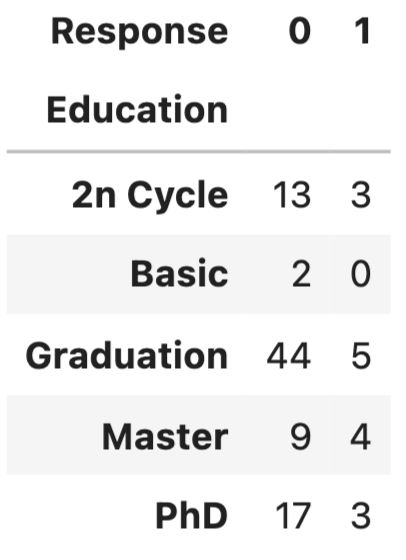
If these two variables are completely independent to each other (null hypothesis is true), then the proportion of positive Response and negative Response should be the same across all Education groups. It seems like composition are slightly different, but is it significant enough to say there is dependency - let’s run a Chi-Squared test.
null hypothesis: “Education” and “Response” are independent to each other.
alternative hypothesis: “Education” and “Response” are dependent to each other.
2. choose the appropriate test: Chi-Squared test is chosen and you probably found a pattern here, that Chi-distribution is also determined by the degree of freedom which is (row - 1) x (column - 1).
3. calculate the p-value: p value is calculated as the right tail cumulative area: 1 - rv.cdf(x).
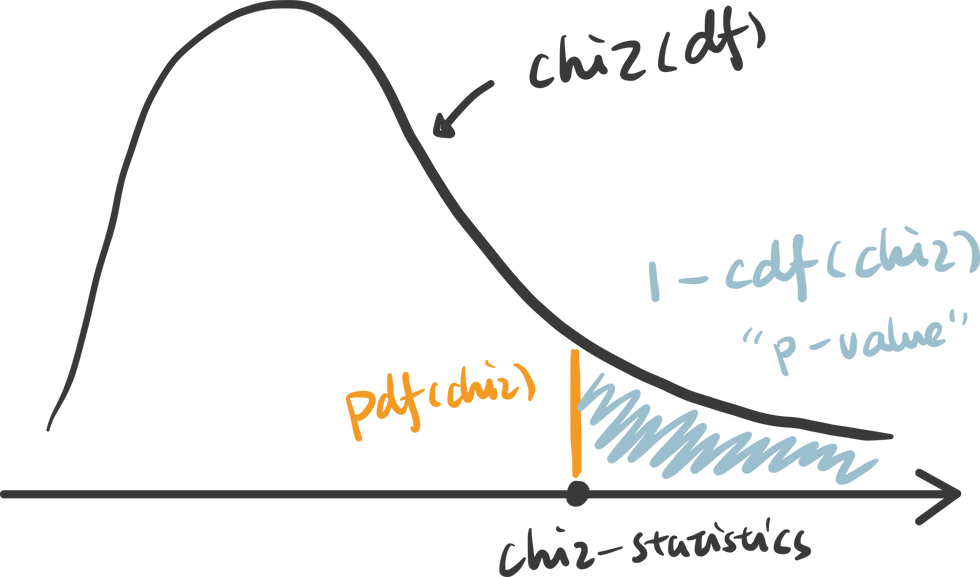
Python also provides a useful function to get the chi statistics and p-value given the contingency table.
An interactive visualization of chi-distribution with chi-statistics vs. significance level. (Check out the code in our Code Snippet section, if you want to build this yourself. )
4. determine the statistical significanc e: the p-value here is 0.41, suggesting that it is not statistical significant. Therefore, we cannot reject the null hypothesis that these two categorical variables are independent. This further indicates that “Education” may not be a strong predictor of “Response”.
Thanks for reaching so far, we have covered a lot of contents in this article but still have two important hypothesis tests that are worth discussing separately in upcoming posts.
z-test: test the difference between two categories of numeric variables - when sample size is LARGE
correlation: test the relationship between two numeric variables
Hope you found this article helpful. If you’d like to support my work and see more articles like this, treat me a coffee ☕️ by signing up Premium Membership with $10 one-off purchase.
Take home message.
In this article, we interactively explore and visualize the difference between three common statistical tests: t-test, ANOVA test and Chi-Squared test. We also use examples to walk through essential steps in hypothesis testing:
1. define the null and alternative hypothesis
2. choose the appropriate test
3. calculate the p-value
4. determine the statistical significance
- Data Science
Recent Posts
How to Self Learn Data Science in 2022
No More Seat Costs: Semaphore Plans Just Got Better!
- Talk to a developer
- Start building for free
- System Status
- Semaphore On-Premise
- Semaphore Hybrid
- Premium support
- Docker & Kubernetes
- vs GitHub Actions
- vs Travis CI
- vs Bitbucket
- Write with us
- Get started
Getting Started With Property-Based Testing in Python With Hypothesis and Pytest

This tutorial will be your gentle guide to property-based testing. Property-based testing is a testing philosophy; a way of approaching testing, much like unit testing is a testing philosophy in which we write tests that verify individual components of your code.
By going through this tutorial, you will:
- learn what property-based testing is;
- understand the key benefits of using property-based testing;
- see how to create property-based tests with Hypothesis;
- attempt a small challenge to understand how to write good property-based tests; and
- Explore several situations in which you can use property-based testing with zero overhead.
What is Property-Based Testing?
In the most common types of testing, you write a test by running your code and then checking if the result you got matches the reference result you expected. This is in contrast with property-based testing , where you write tests that check that the results satisfy certain properties . This shift in perspective makes property-based testing (with Hypothesis) a great tool for a variety of scenarios, like fuzzing or testing roundtripping.
In this tutorial, we will be learning about the concepts behind property-based testing, and then we will put those concepts to practice. In order to do that, we will use three tools: Python, pytest, and Hypothesis.
- Python will be the programming language in which we will write both our functions that need testing and our tests.
- pytest will be the testing framework.
- Hypothesis will be the framework that will enable property-based testing.
Both Python and pytest are simple enough that, even if you are not a Python programmer or a pytest user, you should be able to follow along and get benefits from learning about property-based testing.
Setting up your environment to follow along
If you want to follow along with this tutorial and run the snippets of code and the tests yourself – which is highly recommendable – here is how you set up your environment.
Installing Python and pip
Start by making sure you have a recent version of Python installed. Head to the Python downloads page and grab the most recent version for yourself. Then, make sure your Python installation also has pip installed. [ pip ] is the package installer for Python and you can check if you have it on your machine by running the following command:
(This assumes python is the command to run Python on your machine.) If pip is not installed, follow their installation instructions .
Installing pytest and Hypothesis
pytest, the Python testing framework, and Hypothesis, the property-based testing framework, are easy to install after you have pip. All you have to do is run this command:
This tells pip to install pytest and Hypothesis and additionally it tells pip to update to newer versions if any of the packages are already installed.
To make sure pytest has been properly installed, you can run the following command:
The output on your machine may show a different version, depending on the exact version of pytest you have installed.
To ensure Hypothesis has been installed correctly, you have to open your Python REPL by running the following:
and then, within the REPL, type import hypothesis . If Hypothesis was properly installed, it should look like nothing happened. Immediately after, you can check for the version you have installed with hypothesis.__version__ . Thus, your REPL session would look something like this:
Your first property-based test
In this section, we will write our very first property-based test for a small function. This will show how to write basic tests with Hypothesis.
The function to test
Suppose we implemented a function gcd(n, m) that computes the greatest common divisor of two integers. (The greatest common divisor of n and m is the largest integer d that divides evenly into n and m .) What’s more, suppose that our implementation handles positive and negative integers. Here is what this implementation could look like:
If you save that into a file, say gcd.py , and then run it with:
you will enter an interactive REPL with your function already defined. This allows you to play with it a bit:
Now that the function is running and looks about right, we will test it with Hypothesis.
The property test
A property-based test isn’t wildly different from a standard (pytest) test, but there are some key differences. For example, instead of writing inputs to the function gcd , we let Hypothesis generate arbitrary inputs. Then, instead of hardcoding the expected outputs, we write assertions that ensure that the solution satisfies the properties that it should satisfy.
Thus, to write a property-based test, you need to determine the properties that your answer should satisfy.
Thankfully for us, we already know the properties that the result of gcd must satisfy:
“[…] the greatest common divisor (GCD) of two or more integers […] is the largest positive integer that divides each of the integers.”
So, from that Wikipedia quote, we know that if d is the result of gcd(n, m) , then:
- d is positive;
- d divides n ;
- d divides m ; and
- no other number larger than d divides both n and m .
To turn these properties into a test, we start by writing the signature of a test_ function that accepts the same inputs as the function gcd :
(The prefix test_ is not significant for Hypothesis. We are using Hypothesis with pytest and pytest looks for functions that start with test_ , so that is why our function is called test_gcd .)
The arguments n and m , which are also the arguments of gcd , will be filled in by Hypothesis. For now, we will just assume that they are available.
If n and m are arguments that are available and for which we want to test the function gcd , we have to start by calling gcd with n and m and then saving the result. It is after calling gcd with the supplied arguments and getting the answer that we get to test the answer against the four properties listed above.
Taking the four properties into account, our test function could look like this:
Go ahead and put this test function next to the function gcd in the file gcd.py . Typically, tests live in a different file from the code being tested but this is such a small example that we can have everything in the same file.
Plugging in Hypothesis
We have written the test function but we still haven’t used Hypothesis to power the test. Let’s go ahead and use Hypothesis’ magic to generate a bunch of arguments n and m for our function gcd. In order to do that, we need to figure out what are all the legal inputs that our function gcd should handle.
For our function gcd , the valid inputs are all integers, so we need to tell Hypothesis to generate integers and feed them into test_gcd . To do that, we need to import a couple of things:
given is what we will use to tell Hypothesis that a test function needs to be given data. The submodule strategies is the module that contains lots of tools that know how to generate data.
With these two imports, we can annotate our test:
You can read the decorator @given(st.integers(), st.integers()) as “the test function needs to be given one integer, and then another integer”. To run the test, you can just use pytest :
(Note: depending on your operating system and the way you have things configured, pytest may not end up in your path, and the command pytest gcd.py may not work. If that is the case for you, you can use the command python -m pytest gcd.py instead.)
As soon as you do so, Hypothesis will scream an error message at you, saying that you got a ZeroDivisionError . Let us try to understand what Hypothesis is telling us by looking at the bottom of the output of running the tests:
This shows that the tests failed with a ZeroDivisionError , and the line that reads “Falsifying example: …” contains information about the test case that blew our test up. In our case, this was n = 0 and m = 0 . So, Hypothesis is telling us that when the arguments are both zero, our function fails because it raises a ZeroDivisionError .
The problem lies in the usage of the modulo operator % , which does not accept a right argument of zero. The right argument of % is zero if n is zero, in which case the result should be m . Adding an if statement is a possible fix for this:
However, Hypothesis still won’t be happy. If you run your test again, with pytest gcd.py , you get this output:
This time, the issue is with the very first property that should be satisfied. We can know this because Hypothesis tells us which assertion failed while also telling us which arguments led to that failure. In fact, if we look further up the output, this is what we see:
This time, the issue isn’t really our fault. The greatest common divisor is not defined when both arguments are zero, so it is ok for our function to not know how to handle this case. Thankfully, Hypothesis lets us customise the strategies used to generate arguments. In particular, we can say that we only want to generate integers between a minimum and a maximum value.
The code below changes the test so that it only runs with integers between 1 and 100 for the first argument ( n ) and between -500 and 500 for the second argument ( m ):
That is it! This was your very first property-based test.
Why bother with Property-Based Testing?
To write good property-based tests you need to analyse your problem carefully to be able to write down all the properties that are relevant. This may look quite cumbersome. However, using a tool like Hypothesis has very practical benefits:
- Hypothesis can generate dozens or hundreds of tests for you, while you would typically only write a couple of them;
- tests you write by hand will typically only cover the edge cases you have already thought of, whereas Hypothesis will not have that bias; and
- thinking about your solution to figure out its properties can give you deeper insights into the problem, leading to even better solutions.
These are just some of the advantages of using property-based testing.
Using Hypothesis for free
There are some scenarios in which you can use property-based testing essentially for free (that is, without needing to spend your precious brain power), because you don’t even need to think about properties. Let’s look at two such scenarios.
Testing Roundtripping
Hypothesis is a great tool to test roundtripping. For example, the built-in functions int and str in Python should roundtrip. That is, if x is an integer, then int(str(x)) should still be x . In other words, converting x to a string and then to an integer again should not change its value.
We can write a simple property-based test for this, leveraging the fact that Hypothesis generates dozens of tests for us. Save this in a Python file:
Now, run this file with pytest. Your test should pass!
Did you notice that, in our gcd example above, the very first time we ran Hypothesis we got a ZeroDivisionError ? The test failed, not because of an assert, but simply because our function crashed.
Hypothesis can be used for tests like this. You do not need to write a single property because you are just using Hypothesis to see if your function can deal with different inputs. Of course, even a buggy function can pass a fuzzing test like this, but this helps catch some types of bugs in your code.
Comparing against a gold standard
Sometimes, you want to test a function f that computes something that could be computed by some other function f_alternative . You know this other function is correct (that is why you call it a “gold standard”), but you cannot use it in production because it is very slow, or it consumes a lot of resources, or for some other combination of reasons.
Provided it is ok to use the function f_alternative in a testing environment, a suitable test would be something like the following:
When possible, this type of test is very powerful because it directly tests if your solution is correct for a series of different arguments.
For example, if you refactored an old piece of code, perhaps to simplify its logic or to make it more performant, Hypothesis will give you confidence that your new function will work as it should.
The importance of property completeness
In this section you will learn about the importance of being thorough when listing the properties that are relevant. To illustrate the point, we will reason about property-based tests for a function called my_sort , which is your implementation of a sorting function that accepts lists of integers.
The results are sorted
When thinking about the properties that the result of my_sort satisfies, you come up with the obvious thing: the result of my_sort must be sorted.
So, you set out to assert this property is satisfied:
Now, the only thing missing is the appropriate strategy to generate lists of integers. Thankfully, Hypothesis knows a strategy to generate lists, which is called lists . All you need to do is give it a strategy that generates the elements of the list.
Now that the test has been written, here is a challenge. Copy this code into a file called my_sort.py . Between the import and the test, define a function my_sort that is wrong (that is, write a function that does not sort lists of integers) and yet passes the test if you run it with pytest my_sort.py . (Keep reading when you are ready for spoilers.)
Notice that the only property that we are testing is “all elements of the result are sorted”, so we can return whatever result we want , as long as it is sorted. Here is my fake implementation of my_sort :
This passes our property test and yet is clearly wrong because we always return an empty list. So, are we missing a property? Perhaps.
The lengths are the same
We can try to add another obvious property, which is that the input and the output should have the same length, obviously. This means that our test becomes:
Now that the test has been improved, here is a challenge. Write a new version of my_sort that passes this test and is still wrong. (Keep reading when you are ready for spoilers.)
Notice that we are only testing for the length of the result and whether or not its elements are sorted, but we don’t test which elements are contained in the result. Thus, this fake implementation of my_sort would work:
Use the right numbers
To fix this, we can add the obvious property that the result should only contain numbers from the original list. With sets, this is easy to test:
Now that our test has been improved, I have yet another challenge. Can you write a fake version of my_sort that passes this test? (Keep reading when you are ready for spoilers).
Here is a fake version of my_sort that passes the test above:
The issue here is that we were not precise enough with our new property. In fact, set(result) <= set(int_list) ensures that we only use numbers that were available in the original list, but it doesn’t ensure that we use all of them. What is more, we can’t fix it by simply replacing the <= with == . Can you see why?I will give you a hint. If you just replace the <= with a == , so that the test becomes:
then you can write this passing version of my_sort that is still wrong:
This version is wrong because it reuses the largest element of the original list without respecting the number of times each integer should be used. For example, for the input list [1, 1, 2, 2, 3, 3] the result should be unchanged, whereas this version of my_sort returns [1, 2, 3, 3, 3, 3] .
The final test
A test that is correct and complete would have to take into account how many times each number appears in the original list, which is something the built-in set is not prepared to do. Instead, one could use the collections.Counter from the standard library:
So, at this point, your test function test_my_sort is complete. At this point, it is no longer possible to fool the test! That is, the only way the test will pass is if my_sort is a real sorting function.
Use properties and specific examples
This section showed that the properties that you test should be well thought-through and you should strive to come up with a set of properties that are as specific as possible. When in doubt, it is better to have properties that may look redundant over having too few.
Another strategy that you can follow to help mitigate the danger of having come up with an insufficient set of properties is to mix property-based testing with other forms of testing, which is perfectly reasonable.
For example, on top of having the property-based test test_my_sort , you could add the following test:
This article covered two examples of functions to which we added property-based tests. We only covered the basics of using Hypothesis to run property-based tests but, more importantly, we covered the fundamental concepts that enable a developer to reason about and write complete property-based tests.
Property-based testing isn’t a one-size-fits-all solution that means you will never have to write any other type of test, but it does have characteristics that you should take advantage of whenever possible. In particular, we saw that property-based testing with Hypothesis was beneficial in that:
This article also went over a couple of common gotchas when writing property-based tests and listed scenarios in which property-based testing can be used with no overhead.
If you are interested in learning more about Hypothesis and property-based testing, we recommend you take a look at the Hypothesis docs and, in particular, to the page “What you can generate and how” .
Learn CI/CD
Level up your developer skills to use CI/CD at its max.
5 thoughts on “ Getting Started With Property-Based Testing in Python With Hypothesis and Pytest ”
Awesome intro to property based testing for Python. Thank you, Dan and Rodrigo!
Greeting! Unfortunately, I don’t understand due to translation difficulties. PyCharm writes error messages and does not run the codes. The installation was done fine, check ok. I created a virtual environment. I would like a single good, usable, complete code, an example of what to write in gcd.py and what in test_gcd.py, which the development environment runs without errors. Thanks!
Thanks for article!
“it is better to have properties that may look redundant over having too few” Isn’t it the case with: assert len(result) == len(int_list) and: assert Counter(result) == Counter(int_list) ? I mean: is it possible to satisfy the second condition without satisfying the first ?
Yes. One case could be if result = [0,1], int_list = [0,1,1], and the implementation of Counter returns unique count.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Test faster, fix more
How do I use pytest fixtures with Hypothesis?
pytest is a great test runner, and is the one Hypothesis itself uses for testing (though Hypothesis works fine with other test runners too).
It has a fairly elaborate fixture system , and people are often unsure how that interacts with Hypothesis. In this article we’ll go over the details of how to use the two together.
Mostly, Hypothesis and py.test fixtures don’t interact: Each just ignores the other’s presence.
When using a @given decorator, any arguments that are not provided in the @given will be left visible in the final function:
This then outputs the following:
We’ve hidden the arguments ‘a’ and ‘c’, but the unspecified arguments ‘b’ and ‘d’ are still left to be passed in. In particular, they can be provided as py.test fixtures:
This also works if we want to use @given with positional arguments:
The positional argument fills in from the right, replacing the ‘a’ argument and leaving us with ‘stuff’ to be provided by the fixture.
Personally I don’t usually do this because I find it gets a bit confusing - if I’m going to use fixtures then I always use the named variant of given. There’s no reason you can’t do it this way if you prefer though.
@given also works fine in combination with parametrized tests:
This will run 3 tests, one for each value for ‘stuff’.
There is one unfortunate feature of how this interaction works though: In pytest you can declare fixtures which do set up and tear down per function. These will “work” with Hypothesis, but they will run once for the entire test function rather than once for each time given calls your test function. So the following will fail:
The counter will not get reset at the beginning of each call to the test function, so it will be incremented each time and the test will start failing after the first call.
There currently aren’t any great ways around this unfortunately. The best you can really do is do manual setup and teardown yourself in your tests using Hypothesis (e.g. by implementing a version of your fixture as a context manager).
Long-term, I’d like to resolve this by providing a mechanism for allowing fixtures to be run for each example (it’s probably not correct to have every function scoped fixture run for each example), but for now it’s stalled because it requires changes on the py.test side as well as the Hypothesis side and we haven’t quite managed to find the time and place to collaborate on figuring out how to fix this yet.

Statistics Made Easy
How to Perform Hypothesis Testing in Python (With Examples)
A hypothesis test is a formal statistical test we use to reject or fail to reject some statistical hypothesis.
This tutorial explains how to perform the following hypothesis tests in Python:
- One sample t-test
- Two sample t-test
- Paired samples t-test
Let’s jump in!
Example 1: One Sample t-test in Python
A one sample t-test is used to test whether or not the mean of a population is equal to some value.
For example, suppose we want to know whether or not the mean weight of a certain species of some turtle is equal to 310 pounds.
To test this, we go out and collect a simple random sample of turtles with the following weights:
Weights : 300, 315, 320, 311, 314, 309, 300, 308, 305, 303, 305, 301, 303
The following code shows how to use the ttest_1samp() function from the scipy.stats library to perform a one sample t-test:
The t test statistic is -1.5848 and the corresponding two-sided p-value is 0.1389 .
The two hypotheses for this particular one sample t-test are as follows:
- H 0 : µ = 310 (the mean weight for this species of turtle is 310 pounds)
- H A : µ ≠310 (the mean weight is not 310 pounds)
Because the p-value of our test (0.1389) is greater than alpha = 0.05, we fail to reject the null hypothesis of the test.
We do not have sufficient evidence to say that the mean weight for this particular species of turtle is different from 310 pounds.
Example 2: Two Sample t-test in Python
A two sample t-test is used to test whether or not the means of two populations are equal.
For example, suppose we want to know whether or not the mean weight between two different species of turtles is equal.
To test this, we collect a simple random sample of turtles from each species with the following weights:
Sample 1 : 300, 315, 320, 311, 314, 309, 300, 308, 305, 303, 305, 301, 303
Sample 2 : 335, 329, 322, 321, 324, 319, 304, 308, 305, 311, 307, 300, 305
The following code shows how to use the ttest_ind() function from the scipy.stats library to perform this two sample t-test:
The t test statistic is – 2.1009 and the corresponding two-sided p-value is 0.0463 .
The two hypotheses for this particular two sample t-test are as follows:
- H 0 : µ 1 = µ 2 (the mean weight between the two species is equal)
- H A : µ 1 ≠ µ 2 (the mean weight between the two species is not equal)
Since the p-value of the test (0.0463) is less than .05, we reject the null hypothesis.
This means we have sufficient evidence to say that the mean weight between the two species is not equal.
Example 3: Paired Samples t-test in Python
A paired samples t-test is used to compare the means of two samples when each observation in one sample can be paired with an observation in the other sample.
For example, suppose we want to know whether or not a certain training program is able to increase the max vertical jump (in inches) of basketball players.
To test this, we may recruit a simple random sample of 12 college basketball players and measure each of their max vertical jumps. Then, we may have each player use the training program for one month and then measure their max vertical jump again at the end of the month.
The following data shows the max jump height (in inches) before and after using the training program for each player:
Before : 22, 24, 20, 19, 19, 20, 22, 25, 24, 23, 22, 21
After : 23, 25, 20, 24, 18, 22, 23, 28, 24, 25, 24, 20
The following code shows how to use the ttest_rel() function from the scipy.stats library to perform this paired samples t-test:
The t test statistic is – 2.5289 and the corresponding two-sided p-value is 0.0280 .
The two hypotheses for this particular paired samples t-test are as follows:
- H 0 : µ 1 = µ 2 (the mean jump height before and after using the program is equal)
- H A : µ 1 ≠ µ 2 (the mean jump height before and after using the program is not equal)
Since the p-value of the test (0.0280) is less than .05, we reject the null hypothesis.
This means we have sufficient evidence to say that the mean jump height before and after using the training program is not equal.
Additional Resources
You can use the following online calculators to automatically perform various t-tests:
One Sample t-test Calculator Two Sample t-test Calculator Paired Samples t-test Calculator

Published by Zach
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
IMAGES
VIDEO
COMMENTS
For example, everything_except(int) returns a strategy that can generate anything that from_type() can ever generate, except for instances of int, and excluding instances of types added via register_type_strategy(). This is useful when writing tests which check that invalid input is rejected in a certain way. hypothesis.strategies. frozensets (elements, *, min_size = 0, max_size = None ...
The typing module changes between different Python releases, including at minor versions. These are all supported on a best-effort basis, but you may encounter problems. ... Projects that provide Hypothesis strategies and use type hints may wish to annotate their strategies too. This is a supported use-case, again on a best-effort provisional ...
0. If Python hypothesis strategies are too deeply nested, using draw will not create an actual example, but a LazyStrategy. This can be quite problematic at times because the resulting object behaves very differently from an actual example. Is there a way to enforce eager evaluations of strategies, such that calling draw always returns an ...
import hypothesis.strategies as st NodeStrategy = st. builds (Node, st. integers (), st. lists (st. booleans (), max_size = 10)) We want to generate short lists of values so that there's a decent chance of one being a prefix of the other (this is also why the choice of bool as the elements). We then define a strategy which builds a node out ...
To use Hypothesis in this example, we import the given, strategies and assume in-built methods.. The @given decorator is placed just before each test followed by a strategy.. A strategy is specified using the strategy.X method which can be st.list(), st.integers(), st.text() and so on.. Here's a comprehensive list of strategies.. Strategies are used to generate test data and can be heavily ...
It tests the null hypothesis that the population variances are equal (called homogeneity of variance or homoscedasticity). Suppose the resulting p-value of Levene's test is less than the significance level (typically 0.05).In that case, the obtained differences in sample variances are unlikely to have occurred based on random sampling from a population with equal variances.
Using Hypothesis Strategies. Simply put, Hypothesis generates data using a number of configurable strategies. Strategies range from simple to complex. A simple strategy may generate bools; another integers. You can combine strategies to make larger ones, such as lists or dicts that match certain patterns or structures you want to test.
4. Unit testing is key to developing quality code. There's a host of libraries and services available that you can use to perfect testing of your Python code. However, "traditional" unit testing is time intensive and is unlikely to cover the full spectrum of cases that your code is supposed to be able to handle.
The classic coin-flipping exercise is to test the fairness off a coin. If a coin is fair, it'll land on heads 50% of the time (and tails 50% of the time). Let's translate into hypothesis testing language: Null Hypothesis: Probability of landing on Heads = 0.5. Alt Hypothesis: Probability of landing on Heads != 0.5.
In this article, we interactively explore and visualize the difference between three common statistical tests: t-test, ANOVA test and Chi-Squared test. We also use examples to walk through essential steps in hypothesis testing: 1. define the null and alternative hypothesis. 2. choose the appropriate test.
Welcome to Hypothesis! Hypothesis is a Python library for creating unit tests which are simpler to write and more powerful when run, finding edge cases in your code you wouldn't have thought to look for. It is stable, powerful and easy to add to any existing test suite. It works by letting you write tests that assert that something should be ...
We can write a simple property-based test for this, leveraging the fact that Hypothesis generates dozens of tests for us. Save this in a Python file: from hypothesis import given, strategies as st. @given(st.integers()) def test_int_str_roundtripping(x): assert x == int(str(x)) Now, run this file with pytest.
We've hidden the arguments 'a' and 'c', but the unspecified arguments 'b' and 'd' are still left to be passed in. In particular, they can be provided as py.test fixtures: from hypothesis import given, strategies as st from pytest import fixture @fixture def stuff(): return "kittens" @given(a=st.none()) def test_stuff(a, stuff ...
Hypothesis for the scientific stack¶ numpy¶. Hypothesis offers a number of strategies for NumPy testing, available in the hypothesis[numpy] extra.It lives in the hypothesis.extra.numpy package.. The centerpiece is the arrays() strategy, which generates arrays with any dtype, shape, and contents you can specify or give a strategy for. To make this as useful as possible, strategies are ...
A null hypothesis (𝐻0) is put forward which states that nothing has changed and an alternative hypothesis (𝐻1 or 𝐻𝐴) is proposed indicating that something of interest has changed. If the alternative hypothesis is looking for a new state that is either greater than or less than the old state this is called a "one tailed test".
A detail: This works because Hypothesis ignores any arguments it hasn't been told to provide (positional arguments start from the right), so the self argument to the test is simply ignored and works as normal. This also means that Hypothesis will play nicely with other ways of parameterizing tests. e.g it works fine if you use pytest fixtures ...
Example 1: One Sample t-test in Python. A one sample t-test is used to test whether or not the mean of a population is equal to some value. For example, suppose we want to know whether or not the mean weight of a certain species of some turtle is equal to 310 pounds. To test this, we go out and collect a simple random sample of turtles with the ...
let b = a + 1 + abs diff. Assert.Equal (abs (b - a), -(a - b)) Here, (somewhat redundantly) we set a = seed and then b = a + 1 + abs diff according to the above description. (I only included the redundant seed function parameter to illustrate the general idea. Sometimes, you need one or more values calculated from a seed, but not the seed itself.
Working with the python testing framework hypothesis, I would like to achieve a rather complex composition of testing strategies: 1.I would like to test against create strings s which consist of a unique character set. 2. Each of these examples I want to run through a function func(s: str, n: int) -> Tuple[str, int] which takes a string s and an integer n as a parameters.