Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What is Secondary Research? | Definition, Types, & Examples

What is Secondary Research? | Definition, Types, & Examples
Published on January 20, 2023 by Tegan George . Revised on January 12, 2024.
Secondary research is a research method that uses data that was collected by someone else. In other words, whenever you conduct research using data that already exists, you are conducting secondary research. On the other hand, any type of research that you undertake yourself is called primary research .
Secondary research can be qualitative or quantitative in nature. It often uses data gathered from published peer-reviewed papers, meta-analyses, or government or private sector databases and datasets.
Table of contents
When to use secondary research, types of secondary research, examples of secondary research, advantages and disadvantages of secondary research, other interesting articles, frequently asked questions.
Secondary research is a very common research method, used in lieu of collecting your own primary data. It is often used in research designs or as a way to start your research process if you plan to conduct primary research later on.
Since it is often inexpensive or free to access, secondary research is a low-stakes way to determine if further primary research is needed, as gaps in secondary research are a strong indication that primary research is necessary. For this reason, while secondary research can theoretically be exploratory or explanatory in nature, it is usually explanatory: aiming to explain the causes and consequences of a well-defined problem.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Secondary research can take many forms, but the most common types are:
Statistical analysis
Literature reviews, case studies, content analysis.
There is ample data available online from a variety of sources, often in the form of datasets. These datasets are often open-source or downloadable at a low cost, and are ideal for conducting statistical analyses such as hypothesis testing or regression analysis .
Credible sources for existing data include:
- The government
- Government agencies
- Non-governmental organizations
- Educational institutions
- Businesses or consultancies
- Libraries or archives
- Newspapers, academic journals, or magazines
A literature review is a survey of preexisting scholarly sources on your topic. It provides an overview of current knowledge, allowing you to identify relevant themes, debates, and gaps in the research you analyze. You can later apply these to your own work, or use them as a jumping-off point to conduct primary research of your own.
Structured much like a regular academic paper (with a clear introduction, body, and conclusion), a literature review is a great way to evaluate the current state of research and demonstrate your knowledge of the scholarly debates around your topic.
A case study is a detailed study of a specific subject. It is usually qualitative in nature and can focus on a person, group, place, event, organization, or phenomenon. A case study is a great way to utilize existing research to gain concrete, contextual, and in-depth knowledge about your real-world subject.
You can choose to focus on just one complex case, exploring a single subject in great detail, or examine multiple cases if you’d prefer to compare different aspects of your topic. Preexisting interviews , observational studies , or other sources of primary data make for great case studies.
Content analysis is a research method that studies patterns in recorded communication by utilizing existing texts. It can be either quantitative or qualitative in nature, depending on whether you choose to analyze countable or measurable patterns, or more interpretive ones. Content analysis is popular in communication studies, but it is also widely used in historical analysis, anthropology, and psychology to make more semantic qualitative inferences.

Secondary research is a broad research approach that can be pursued any way you’d like. Here are a few examples of different ways you can use secondary research to explore your research topic .
Secondary research is a very common research approach, but has distinct advantages and disadvantages.
Advantages of secondary research
Advantages include:
- Secondary data is very easy to source and readily available .
- It is also often free or accessible through your educational institution’s library or network, making it much cheaper to conduct than primary research .
- As you are relying on research that already exists, conducting secondary research is much less time consuming than primary research. Since your timeline is so much shorter, your research can be ready to publish sooner.
- Using data from others allows you to show reproducibility and replicability , bolstering prior research and situating your own work within your field.
Disadvantages of secondary research
Disadvantages include:
- Ease of access does not signify credibility . It’s important to be aware that secondary research is not always reliable , and can often be out of date. It’s critical to analyze any data you’re thinking of using prior to getting started, using a method like the CRAAP test .
- Secondary research often relies on primary research already conducted. If this original research is biased in any way, those research biases could creep into the secondary results.
Many researchers using the same secondary research to form similar conclusions can also take away from the uniqueness and reliability of your research. Many datasets become “kitchen-sink” models, where too many variables are added in an attempt to draw increasingly niche conclusions from overused data . Data cleansing may be necessary to test the quality of the research.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
Sources in this article
We strongly encourage students to use sources in their work. You can cite our article (APA Style) or take a deep dive into the articles below.
George, T. (2024, January 12). What is Secondary Research? | Definition, Types, & Examples. Scribbr. Retrieved April 8, 2024, from https://www.scribbr.com/methodology/secondary-research/
Largan, C., & Morris, T. M. (2019). Qualitative Secondary Research: A Step-By-Step Guide (1st ed.). SAGE Publications Ltd.
Peloquin, D., DiMaio, M., Bierer, B., & Barnes, M. (2020). Disruptive and avoidable: GDPR challenges to secondary research uses of data. European Journal of Human Genetics , 28 (6), 697–705. https://doi.org/10.1038/s41431-020-0596-x
Is this article helpful?

Tegan George
Other students also liked, primary research | definition, types, & examples, how to write a literature review | guide, examples, & templates, what is a case study | definition, examples & methods, unlimited academic ai-proofreading.
✔ Document error-free in 5minutes ✔ Unlimited document corrections ✔ Specialized in correcting academic texts

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Integrated Primary & Secondary Research
5 Types of Secondary Research Data

Secondary sources allow you to broaden your research by providing background information, analyses, and unique perspectives on various elements for a specific campaign. Bibliographies of these sources can lead to the discovery of further resources to enhance research for organizations.
There are two common types of secondary data: Internal data and External data. Internal data is the information that has been stored or organized by the organization itself. External data is the data organized or collected by someone else.
Internal Secondary Sources
Internal secondary sources include databases containing reports from individuals or prior research. This is often an overlooked resource—it’s amazing how much useful information collects dust on an organization’s shelves! Other individuals may have conducted research of their own or bought secondary research that could be useful to the task at hand. This prior research would still be considered secondary even if it were performed internally because it was conducted for a different purpose.
External Secondary Sources
A wide range of information can be obtained from secondary research. Reliable databases for secondary sources include Government Sources, Business Source Complete, ABI, IBISWorld, Statista, and CBCA Complete. This data is generated by others but can be considered useful when conducting research into a new scope of the study. It also means less work for a non-for-profit organization as they would not have to create their own data and instead can piggyback off the data of others.
Examples of Secondary Sources
Government sources.
A lot of secondary data is available from the government, often for free, because it has already been paid for by tax dollars. Government sources of data include the Census Bureau, the Bureau of Labor Statistics, and the National Centre for Health Statistics.
For example, through the Census Bureau, the Bureau of Labor Statistics regularly surveys individuals to gain information about them (Bls.gov, n.d). These surveys are conducted quarterly, through an interview survey and a diary survey, and they provide data on expenditures, income, and household information (families or single). Detailed tables of the Expenditures Reports include the age of the reference person, how long they have lived in their place of residence and which geographic region they live in.
Syndicated Sources
A syndicated survey is a large-scale instrument that collects information about a wide variety of people’s attitudes and capital expenditures. The Simmons Market Research Bureau conducts a National Consumer Survey by randomly selecting families throughout the country that agree to report in great detail what they eat, read, watch, drive, and so on. They also provide data about their media preferences.
Other Types of Sources
Gallup, which has a rich tradition as the world’s leading public opinion pollster, also provides in-depth reports based on its proprietary probability-based techniques (called the Gallup Panel), in which respondents are recruited through a random digit dial method so that results are more reliably generalizable. The Gallup organization operates one of the largest telephone research data-collection systems in the world, conducting more than twenty million interviews over the last five years and averaging ten thousand completed interviews per day across two hundred individual survey research questionnaires (GallupPanel, n.d).
Attribution
This page contains materials taken from:
Bls.gov. (n.d). U.S Bureau of Labor Statistics. Retrieved from https://www.bls.gov/
Define Quantitative and Qualitative Evidence. (2020). Retrieved July 23, 2020, from http://sgba-resource.ca/en/process/module-8-evidence/define-quantitative-and-qualitative-evidence/
GallupPanel. (n.d). Gallup Panel Research. Retrieved from http://www.galluppanel.com
Secondary Data. (2020). Retrieved July 23, 2020, from https://2012books.lardbucket.org/books/advertising-campaigns-start-to-finish/s08-03-secondary-data.html
An Open Guide to Integrated Marketing Communications (IMC) Copyright © by Andrea Niosi and KPU Marketing 4201 Class of Summer 2020 is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Secondary Research: Definition, Methods and Examples.

In the world of research, there are two main types of data sources: primary and secondary. While primary research involves collecting new data directly from individuals or sources, secondary research involves analyzing existing data already collected by someone else. Today we’ll discuss secondary research.
One common source of this research is published research reports and other documents. These materials can often be found in public libraries, on websites, or even as data extracted from previously conducted surveys. In addition, many government and non-government agencies maintain extensive data repositories that can be accessed for research purposes.
LEARN ABOUT: Research Process Steps
While secondary research may not offer the same level of control as primary research, it can be a highly valuable tool for gaining insights and identifying trends. Researchers can save time and resources by leveraging existing data sources while still uncovering important information.
What is Secondary Research: Definition
Secondary research is a research method that involves using already existing data. Existing data is summarized and collated to increase the overall effectiveness of the research.
One of the key advantages of secondary research is that it allows us to gain insights and draw conclusions without having to collect new data ourselves. This can save time and resources and also allow us to build upon existing knowledge and expertise.
When conducting secondary research, it’s important to be thorough and thoughtful in our approach. This means carefully selecting the sources and ensuring that the data we’re analyzing is reliable and relevant to the research question . It also means being critical and analytical in the analysis and recognizing any potential biases or limitations in the data.
LEARN ABOUT: Level of Analysis
Secondary research is much more cost-effective than primary research , as it uses already existing data, unlike primary research, where data is collected firsthand by organizations or businesses or they can employ a third party to collect data on their behalf.
LEARN ABOUT: Data Analytics Projects
Secondary Research Methods with Examples
Secondary research is cost-effective, one of the reasons it is a popular choice among many businesses and organizations. Not every organization is able to pay a huge sum of money to conduct research and gather data. So, rightly secondary research is also termed “ desk research ”, as data can be retrieved from sitting behind a desk.
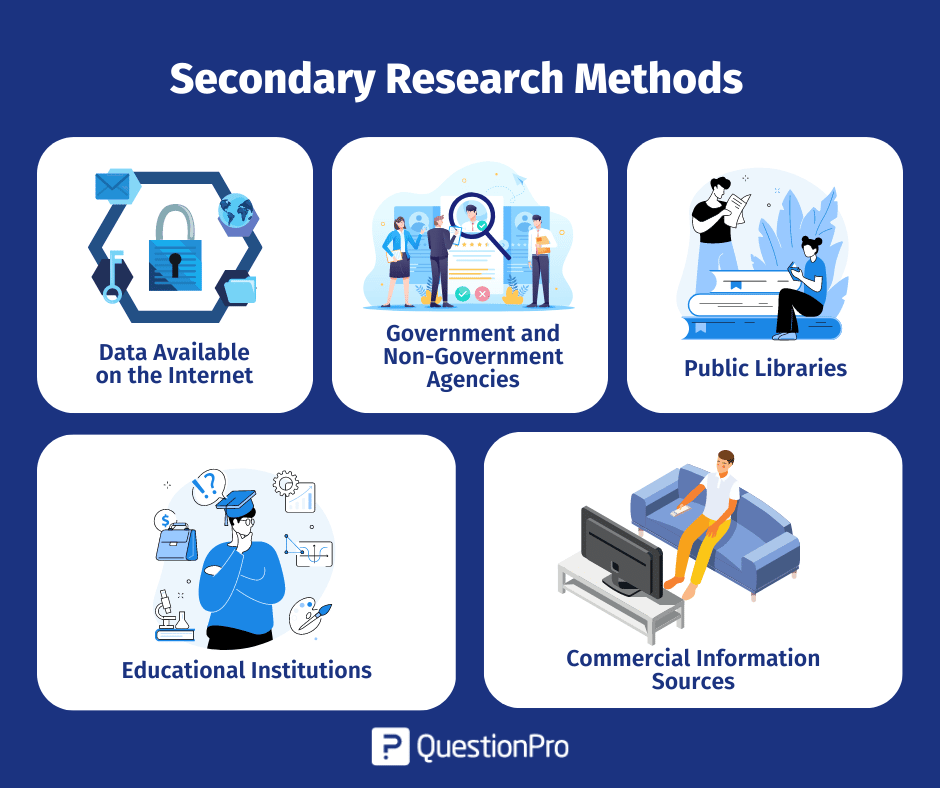
The following are popularly used secondary research methods and examples:
1. Data Available on The Internet
One of the most popular ways to collect secondary data is the internet. Data is readily available on the internet and can be downloaded at the click of a button.
This data is practically free of cost, or one may have to pay a negligible amount to download the already existing data. Websites have a lot of information that businesses or organizations can use to suit their research needs. However, organizations need to consider only authentic and trusted website to collect information.
2. Government and Non-Government Agencies
Data for secondary research can also be collected from some government and non-government agencies. For example, US Government Printing Office, US Census Bureau, and Small Business Development Centers have valuable and relevant data that businesses or organizations can use.
There is a certain cost applicable to download or use data available with these agencies. Data obtained from these agencies are authentic and trustworthy.
3. Public Libraries
Public libraries are another good source to search for data for this research. Public libraries have copies of important research that were conducted earlier. They are a storehouse of important information and documents from which information can be extracted.
The services provided in these public libraries vary from one library to another. More often, libraries have a huge collection of government publications with market statistics, large collection of business directories and newsletters.
4. Educational Institutions
Importance of collecting data from educational institutions for secondary research is often overlooked. However, more research is conducted in colleges and universities than any other business sector.
The data that is collected by universities is mainly for primary research. However, businesses or organizations can approach educational institutions and request for data from them.
5. Commercial Information Sources
Local newspapers, journals, magazines, radio and TV stations are a great source to obtain data for secondary research. These commercial information sources have first-hand information on economic developments, political agenda, market research, demographic segmentation and similar subjects.
Businesses or organizations can request to obtain data that is most relevant to their study. Businesses not only have the opportunity to identify their prospective clients but can also know about the avenues to promote their products or services through these sources as they have a wider reach.
Key Differences between Primary Research and Secondary Research
Understanding the distinction between primary research and secondary research is essential in determining which research method is best for your project. These are the two main types of research methods, each with advantages and disadvantages. In this section, we will explore the critical differences between the two and when it is appropriate to use them.
How to Conduct Secondary Research?
We have already learned about the differences between primary and secondary research. Now, let’s take a closer look at how to conduct it.
Secondary research is an important tool for gathering information already collected and analyzed by others. It can help us save time and money and allow us to gain insights into the subject we are researching. So, in this section, we will discuss some common methods and tips for conducting it effectively.
Here are the steps involved in conducting secondary research:
1. Identify the topic of research: Before beginning secondary research, identify the topic that needs research. Once that’s done, list down the research attributes and its purpose.
2. Identify research sources: Next, narrow down on the information sources that will provide most relevant data and information applicable to your research.
3. Collect existing data: Once the data collection sources are narrowed down, check for any previous data that is available which is closely related to the topic. Data related to research can be obtained from various sources like newspapers, public libraries, government and non-government agencies etc.
4. Combine and compare: Once data is collected, combine and compare the data for any duplication and assemble data into a usable format. Make sure to collect data from authentic sources. Incorrect data can hamper research severely.
4. Analyze data: Analyze collected data and identify if all questions are answered. If not, repeat the process if there is a need to dwell further into actionable insights.
Advantages of Secondary Research
Secondary research offers a number of advantages to researchers, including efficiency, the ability to build upon existing knowledge, and the ability to conduct research in situations where primary research may not be possible or ethical. By carefully selecting their sources and being thoughtful in their approach, researchers can leverage secondary research to drive impact and advance the field. Some key advantages are the following:
1. Most information in this research is readily available. There are many sources from which relevant data can be collected and used, unlike primary research, where data needs to collect from scratch.
2. This is a less expensive and less time-consuming process as data required is easily available and doesn’t cost much if extracted from authentic sources. A minimum expenditure is associated to obtain data.
3. The data that is collected through secondary research gives organizations or businesses an idea about the effectiveness of primary research. Hence, organizations or businesses can form a hypothesis and evaluate cost of conducting primary research.
4. Secondary research is quicker to conduct because of the availability of data. It can be completed within a few weeks depending on the objective of businesses or scale of data needed.
As we can see, this research is the process of analyzing data already collected by someone else, and it can offer a number of benefits to researchers.
Disadvantages of Secondary Research
On the other hand, we have some disadvantages that come with doing secondary research. Some of the most notorious are the following:
1. Although data is readily available, credibility evaluation must be performed to understand the authenticity of the information available.
2. Not all secondary data resources offer the latest reports and statistics. Even when the data is accurate, it may not be updated enough to accommodate recent timelines.
3. Secondary research derives its conclusion from collective primary research data. The success of your research will depend, to a greater extent, on the quality of research already conducted by primary research.
LEARN ABOUT: 12 Best Tools for Researchers
In conclusion, secondary research is an important tool for researchers exploring various topics. By leveraging existing data sources, researchers can save time and resources, build upon existing knowledge, and conduct research in situations where primary research may not be feasible.
There are a variety of methods and examples of secondary research, from analyzing public data sets to reviewing previously published research papers. As students and aspiring researchers, it’s important to understand the benefits and limitations of this research and to approach it thoughtfully and critically. By doing so, we can continue to advance our understanding of the world around us and contribute to meaningful research that positively impacts society.
QuestionPro can be a useful tool for conducting secondary research in a variety of ways. You can create online surveys that target a specific population, collecting data that can be analyzed to gain insights into consumer behavior, attitudes, and preferences; analyze existing data sets that you have obtained through other means or benchmark your organization against others in your industry or against industry standards. The software provides a range of benchmarking tools that can help you compare your performance on key metrics, such as customer satisfaction, with that of your peers.
Using QuestionPro thoughtfully and strategically allows you to gain valuable insights to inform decision-making and drive business success. Start today for free! No credit card is required.
LEARN MORE FREE TRIAL
MORE LIKE THIS

AI Question Generator: Create Easy + Accurate Tests and Surveys
Apr 6, 2024

Top 17 UX Research Software for UX Design in 2024
Apr 5, 2024

Healthcare Staff Burnout: What it Is + How To Manage It
Apr 4, 2024

Top 15 Employee Retention Software in 2024
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
What is Secondary Research? Types, Methods, Examples
Appinio Research · 20.09.2023 · 13min read

Have you ever wondered how researchers gather valuable insights without conducting new experiments or surveys? That's where secondary research steps in—a powerful approach that allows us to explore existing data and information others collect.
Whether you're a student, a professional, or someone seeking to make informed decisions, understanding the art of secondary research opens doors to a wealth of knowledge.
What is Secondary Research?
Secondary Research refers to the process of gathering and analyzing existing data, information, and knowledge that has been previously collected and compiled by others. This approach allows researchers to leverage available sources, such as articles, reports, and databases, to gain insights, validate hypotheses, and make informed decisions without collecting new data.
Benefits of Secondary Research
Secondary research offers a range of advantages that can significantly enhance your research process and the quality of your findings.
- Time and Cost Efficiency: Secondary research saves time and resources by utilizing existing data sources, eliminating the need for data collection from scratch.
- Wide Range of Data: Secondary research provides access to vast information from various sources, allowing for comprehensive analysis.
- Historical Perspective: Examining past research helps identify trends, changes, and long-term patterns that might not be immediately apparent.
- Reduced Bias: As data is collected by others, there's often less inherent bias than in conducting primary research, where biases might affect data collection.
- Support for Primary Research: Secondary research can lay the foundation for primary research by providing context and insights into gaps in existing knowledge.
- Comparative Analysis : By integrating data from multiple sources, you can conduct robust comparative analyses for more accurate conclusions.
- Benchmarking and Validation: Secondary research aids in benchmarking performance against industry standards and validating hypotheses.
Primary Research vs. Secondary Research
When it comes to research methodologies, primary and secondary research each have their distinct characteristics and advantages. Here's a brief comparison to help you understand the differences.

Primary Research
- Data Source: Involves collecting new data directly from original sources.
- Data Collection: Researchers design and conduct surveys, interviews, experiments, or observations.
- Time and Resources: Typically requires more time, effort, and resources due to data collection.
- Fresh Insights: Provides firsthand, up-to-date information tailored to specific research questions.
- Control: Researchers control the data collection process and can shape methodologies.
Secondary Research
- Data Source: Involves utilizing existing data and information collected by others.
- Data Collection: Researchers search, select, and analyze data from published sources, reports, and databases.
- Time and Resources: Generally more time-efficient and cost-effective as data is already available.
- Existing Knowledge: Utilizes data that has been previously compiled, often providing broader context.
- Less Control: Researchers have limited control over how data was collected originally, if any.
Choosing between primary and secondary research depends on your research objectives, available resources, and the depth of insights you require.
Types of Secondary Research
Secondary research encompasses various types of existing data sources that can provide valuable insights for your research endeavors. Understanding these types can help you choose the most relevant sources for your objectives.
Here are the primary types of secondary research:
Internal Sources
Internal sources consist of data generated within your organization or entity. These sources provide valuable insights into your own operations and performance.
- Company Records and Data: Internal reports, documents, and databases that house information about sales, operations, and customer interactions.
- Sales Reports and Customer Data: Analysis of past sales trends, customer demographics, and purchasing behavior.
- Financial Statements and Annual Reports: Financial data, such as balance sheets and income statements, offer insights into the organization's financial health.
External Sources
External sources encompass data collected and published by entities outside your organization.
These sources offer a broader perspective on various subjects.
- Published Literature and Journals: Scholarly articles, research papers, and academic studies available in journals or online databases.
- Market Research Reports: Reports from market research firms that provide insights into industry trends, consumer behavior, and market forecasts.
- Government and NGO Databases: Data collected and maintained by government agencies and non-governmental organizations, offering demographic, economic, and social information.
- Online Media and News Articles: News outlets and online publications that cover current events, trends, and societal developments.
Each type of secondary research source holds its value and relevance, depending on the nature of your research objectives. Combining these sources lets you understand the subject matter and make informed decisions.
How to Conduct Secondary Research?
Effective secondary research involves a thoughtful and systematic approach that enables you to extract valuable insights from existing data sources. Here's a step-by-step guide on how to navigate the process:
1. Define Your Research Objectives
Before delving into secondary research, clearly define what you aim to achieve. Identify the specific questions you want to answer, the insights you're seeking, and the scope of your research.
2. Identify Relevant Sources
Begin by identifying the most appropriate sources for your research. Consider the nature of your research objectives and the data type you require. Seek out sources such as academic journals, market research reports, official government databases, and reputable news outlets.
3. Evaluate Source Credibility
Ensuring the credibility of your sources is crucial. Evaluate the reliability of each source by assessing factors such as the author's expertise, the publication's reputation, and the objectivity of the information provided. Choose sources that align with your research goals and are free from bias.
4. Extract and Analyze Information
Once you've gathered your sources, carefully extract the relevant information. Take thorough notes, capturing key data points, insights, and any supporting evidence. As you accumulate information, start identifying patterns, trends, and connections across different sources.
5. Synthesize Findings
As you analyze the data, synthesize your findings to draw meaningful conclusions. Compare and contrast information from various sources to identify common themes and discrepancies. This synthesis process allows you to construct a coherent narrative that addresses your research objectives.
6. Address Limitations and Gaps
Acknowledge the limitations and potential gaps in your secondary research. Recognize that secondary data might have inherent biases or be outdated. Where necessary, address these limitations by cross-referencing information or finding additional sources to fill in gaps.
7. Contextualize Your Findings
Contextualization is crucial in deriving actionable insights from your secondary research. Consider the broader context within which the data was collected. How does the information relate to current trends, societal changes, or industry shifts? This contextual understanding enhances the relevance and applicability of your findings.
8. Cite Your Sources
Maintain academic integrity by properly citing the sources you've used for your secondary research. Accurate citations not only give credit to the original authors but also provide a clear trail for readers to access the information themselves.
9. Integrate Secondary and Primary Research (If Applicable)
In some cases, combining secondary and primary research can yield more robust insights. If you've also conducted primary research, consider integrating your secondary findings with your primary data to provide a well-rounded perspective on your research topic.
You can use a market research platform like Appinio to conduct primary research with real-time insights in minutes!
10. Communicate Your Findings
Finally, communicate your findings effectively. Whether it's in an academic paper, a business report, or any other format, present your insights clearly and concisely. Provide context for your conclusions and use visual aids like charts and graphs to enhance understanding.
Remember that conducting secondary research is not just about gathering information—it's about critically analyzing, interpreting, and deriving valuable insights from existing data. By following these steps, you'll navigate the process successfully and contribute to the body of knowledge in your field.
Secondary Research Examples
To better understand how secondary research is applied in various contexts, let's explore a few real-world examples that showcase its versatility and value.
Market Analysis and Trend Forecasting
Imagine you're a marketing strategist tasked with launching a new product in the smartphone industry. By conducting secondary research, you can:
- Access Market Reports: Utilize market research reports to understand consumer preferences, competitive landscape, and growth projections.
- Analyze Trends: Examine past sales data and industry reports to identify trends in smartphone features, design, and user preferences.
- Benchmark Competitors: Compare market share, customer satisfaction, and pricing strategies of key competitors to develop a strategic advantage.
- Forecast Demand: Use historical sales data and market growth predictions to estimate demand for your new product.
Academic Research and Literature Reviews
Suppose you're a student researching climate change's effects on marine ecosystems. Secondary research aids your academic endeavors by:
- Reviewing Existing Studies: Analyze peer-reviewed articles and scientific papers to understand the current state of knowledge on the topic.
- Identifying Knowledge Gaps: Identify areas where further research is needed based on what existing studies still need to cover.
- Comparing Methodologies: Compare research methodologies used by different studies to assess the strengths and limitations of their approaches.
- Synthesizing Insights: Synthesize findings from various studies to form a comprehensive overview of the topic's implications on marine life.
Competitive Landscape Assessment for Business Strategy
Consider you're a business owner looking to expand your restaurant chain to a new location. Secondary research aids your strategic decision-making by:
- Analyzing Demographics: Utilize demographic data from government databases to understand the local population's age, income, and preferences.
- Studying Local Trends: Examine restaurant industry reports to identify the types of cuisines and dining experiences currently popular in the area.
- Understanding Consumer Behavior: Analyze online reviews and social media discussions to gauge customer sentiment towards existing restaurants in the vicinity.
- Assessing Economic Conditions: Access economic reports to evaluate the local economy's stability and potential purchasing power.
These examples illustrate the practical applications of secondary research across various fields to provide a foundation for informed decision-making, deeper understanding, and innovation.
Secondary Research Limitations
While secondary research offers many benefits, it's essential to be aware of its limitations to ensure the validity and reliability of your findings.
- Data Quality and Validity: The accuracy and reliability of secondary data can vary, affecting the credibility of your research.
- Limited Contextual Information: Secondary sources might lack detailed contextual information, making it important to interpret findings within the appropriate context.
- Data Suitability: Existing data might not align perfectly with your research objectives, leading to compromises or incomplete insights.
- Outdated Information: Some sources might provide obsolete information that doesn't accurately reflect current trends or situations.
- Potential Bias: While secondary data is often less biased, biases might still exist in the original data sources, influencing your findings.
- Incompatibility of Data: Combining data from different sources might pose challenges due to variations in definitions, methodologies, or units of measurement.
- Lack of Control: Unlike primary research, you have no control over how data was collected or its quality, potentially affecting your analysis. Understanding these limitations will help you navigate secondary research effectively and make informed decisions based on a well-rounded understanding of its strengths and weaknesses.
Secondary research is a valuable tool that businesses can use to their advantage. By tapping into existing data and insights, companies can save time, resources, and effort that would otherwise be spent on primary research. This approach equips decision-makers with a broader understanding of market trends, consumer behaviors, and competitive landscapes. Additionally, benchmarking against industry standards and validating hypotheses empowers businesses to make informed choices that lead to growth and success.
As you navigate the world of secondary research, remember that it's not just about data retrieval—it's about strategic utilization. With a clear grasp of how to access, analyze, and interpret existing information, businesses can stay ahead of the curve, adapt to changing landscapes, and make decisions that are grounded in reliable knowledge.
How to Conduct Secondary Research in Minutes?
In the world of decision-making, having access to real-time consumer insights is no longer a luxury—it's a necessity. That's where Appinio comes in, revolutionizing how businesses gather valuable data for better decision-making. As a real-time market research platform, Appinio empowers companies to tap into the pulse of consumer opinions swiftly and seamlessly.
- Fast Insights: Say goodbye to lengthy research processes. With Appinio, you can transform questions into actionable insights in minutes.
- Data-Driven Decisions: Harness the power of real-time consumer insights to drive your business strategies, allowing you to make informed choices on the fly.
- Seamless Integration: Appinio handles the research and technical complexities, freeing you to focus on what truly matters: making rapid data-driven decisions that propel your business forward.
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

05.04.2024 | 27min read
What is Field Research? Definition, Types, Methods, Examples

03.04.2024 | 29min read
What is Cluster Sampling? Definition, Methods, Examples

01.04.2024 | 26min read
Cross-Tabulation Analysis: A Full Guide (+ Examples)
- Search Menu
- Browse content in Arts and Humanities
- Browse content in Archaeology
- Anglo-Saxon and Medieval Archaeology
- Archaeological Methodology and Techniques
- Archaeology by Region
- Archaeology of Religion
- Archaeology of Trade and Exchange
- Biblical Archaeology
- Contemporary and Public Archaeology
- Environmental Archaeology
- Historical Archaeology
- History and Theory of Archaeology
- Industrial Archaeology
- Landscape Archaeology
- Mortuary Archaeology
- Prehistoric Archaeology
- Underwater Archaeology
- Urban Archaeology
- Zooarchaeology
- Browse content in Architecture
- Architectural Structure and Design
- History of Architecture
- Residential and Domestic Buildings
- Theory of Architecture
- Browse content in Art
- Art Subjects and Themes
- History of Art
- Industrial and Commercial Art
- Theory of Art
- Biographical Studies
- Byzantine Studies
- Browse content in Classical Studies
- Classical History
- Classical Philosophy
- Classical Mythology
- Classical Literature
- Classical Reception
- Classical Art and Architecture
- Classical Oratory and Rhetoric
- Greek and Roman Papyrology
- Greek and Roman Epigraphy
- Greek and Roman Law
- Greek and Roman Archaeology
- Late Antiquity
- Religion in the Ancient World
- Digital Humanities
- Browse content in History
- Colonialism and Imperialism
- Diplomatic History
- Environmental History
- Genealogy, Heraldry, Names, and Honours
- Genocide and Ethnic Cleansing
- Historical Geography
- History by Period
- History of Emotions
- History of Agriculture
- History of Education
- History of Gender and Sexuality
- Industrial History
- Intellectual History
- International History
- Labour History
- Legal and Constitutional History
- Local and Family History
- Maritime History
- Military History
- National Liberation and Post-Colonialism
- Oral History
- Political History
- Public History
- Regional and National History
- Revolutions and Rebellions
- Slavery and Abolition of Slavery
- Social and Cultural History
- Theory, Methods, and Historiography
- Urban History
- World History
- Browse content in Language Teaching and Learning
- Language Learning (Specific Skills)
- Language Teaching Theory and Methods
- Browse content in Linguistics
- Applied Linguistics
- Cognitive Linguistics
- Computational Linguistics
- Forensic Linguistics
- Grammar, Syntax and Morphology
- Historical and Diachronic Linguistics
- History of English
- Language Evolution
- Language Reference
- Language Acquisition
- Language Variation
- Language Families
- Lexicography
- Linguistic Anthropology
- Linguistic Theories
- Linguistic Typology
- Phonetics and Phonology
- Psycholinguistics
- Sociolinguistics
- Translation and Interpretation
- Writing Systems
- Browse content in Literature
- Bibliography
- Children's Literature Studies
- Literary Studies (Romanticism)
- Literary Studies (American)
- Literary Studies (Asian)
- Literary Studies (European)
- Literary Studies (Eco-criticism)
- Literary Studies (Modernism)
- Literary Studies - World
- Literary Studies (1500 to 1800)
- Literary Studies (19th Century)
- Literary Studies (20th Century onwards)
- Literary Studies (African American Literature)
- Literary Studies (British and Irish)
- Literary Studies (Early and Medieval)
- Literary Studies (Fiction, Novelists, and Prose Writers)
- Literary Studies (Gender Studies)
- Literary Studies (Graphic Novels)
- Literary Studies (History of the Book)
- Literary Studies (Plays and Playwrights)
- Literary Studies (Poetry and Poets)
- Literary Studies (Postcolonial Literature)
- Literary Studies (Queer Studies)
- Literary Studies (Science Fiction)
- Literary Studies (Travel Literature)
- Literary Studies (War Literature)
- Literary Studies (Women's Writing)
- Literary Theory and Cultural Studies
- Mythology and Folklore
- Shakespeare Studies and Criticism
- Browse content in Media Studies
- Browse content in Music
- Applied Music
- Dance and Music
- Ethics in Music
- Ethnomusicology
- Gender and Sexuality in Music
- Medicine and Music
- Music Cultures
- Music and Media
- Music and Religion
- Music and Culture
- Music Education and Pedagogy
- Music Theory and Analysis
- Musical Scores, Lyrics, and Libretti
- Musical Structures, Styles, and Techniques
- Musicology and Music History
- Performance Practice and Studies
- Race and Ethnicity in Music
- Sound Studies
- Browse content in Performing Arts
- Browse content in Philosophy
- Aesthetics and Philosophy of Art
- Epistemology
- Feminist Philosophy
- History of Western Philosophy
- Metaphysics
- Moral Philosophy
- Non-Western Philosophy
- Philosophy of Language
- Philosophy of Mind
- Philosophy of Perception
- Philosophy of Science
- Philosophy of Action
- Philosophy of Law
- Philosophy of Religion
- Philosophy of Mathematics and Logic
- Practical Ethics
- Social and Political Philosophy
- Browse content in Religion
- Biblical Studies
- Christianity
- East Asian Religions
- History of Religion
- Judaism and Jewish Studies
- Qumran Studies
- Religion and Education
- Religion and Health
- Religion and Politics
- Religion and Science
- Religion and Law
- Religion and Art, Literature, and Music
- Religious Studies
- Browse content in Society and Culture
- Cookery, Food, and Drink
- Cultural Studies
- Customs and Traditions
- Ethical Issues and Debates
- Hobbies, Games, Arts and Crafts
- Lifestyle, Home, and Garden
- Natural world, Country Life, and Pets
- Popular Beliefs and Controversial Knowledge
- Sports and Outdoor Recreation
- Technology and Society
- Travel and Holiday
- Visual Culture
- Browse content in Law
- Arbitration
- Browse content in Company and Commercial Law
- Commercial Law
- Company Law
- Browse content in Comparative Law
- Systems of Law
- Competition Law
- Browse content in Constitutional and Administrative Law
- Government Powers
- Judicial Review
- Local Government Law
- Military and Defence Law
- Parliamentary and Legislative Practice
- Construction Law
- Contract Law
- Browse content in Criminal Law
- Criminal Procedure
- Criminal Evidence Law
- Sentencing and Punishment
- Employment and Labour Law
- Environment and Energy Law
- Browse content in Financial Law
- Banking Law
- Insolvency Law
- History of Law
- Human Rights and Immigration
- Intellectual Property Law
- Browse content in International Law
- Private International Law and Conflict of Laws
- Public International Law
- IT and Communications Law
- Jurisprudence and Philosophy of Law
- Law and Politics
- Law and Society
- Browse content in Legal System and Practice
- Courts and Procedure
- Legal Skills and Practice
- Primary Sources of Law
- Regulation of Legal Profession
- Medical and Healthcare Law
- Browse content in Policing
- Criminal Investigation and Detection
- Police and Security Services
- Police Procedure and Law
- Police Regional Planning
- Browse content in Property Law
- Personal Property Law
- Study and Revision
- Terrorism and National Security Law
- Browse content in Trusts Law
- Wills and Probate or Succession
- Browse content in Medicine and Health
- Browse content in Allied Health Professions
- Arts Therapies
- Clinical Science
- Dietetics and Nutrition
- Occupational Therapy
- Operating Department Practice
- Physiotherapy
- Radiography
- Speech and Language Therapy
- Browse content in Anaesthetics
- General Anaesthesia
- Neuroanaesthesia
- Clinical Neuroscience
- Browse content in Clinical Medicine
- Acute Medicine
- Cardiovascular Medicine
- Clinical Genetics
- Clinical Pharmacology and Therapeutics
- Dermatology
- Endocrinology and Diabetes
- Gastroenterology
- Genito-urinary Medicine
- Geriatric Medicine
- Infectious Diseases
- Medical Toxicology
- Medical Oncology
- Pain Medicine
- Palliative Medicine
- Rehabilitation Medicine
- Respiratory Medicine and Pulmonology
- Rheumatology
- Sleep Medicine
- Sports and Exercise Medicine
- Community Medical Services
- Critical Care
- Emergency Medicine
- Forensic Medicine
- Haematology
- History of Medicine
- Browse content in Medical Skills
- Clinical Skills
- Communication Skills
- Nursing Skills
- Surgical Skills
- Browse content in Medical Dentistry
- Oral and Maxillofacial Surgery
- Paediatric Dentistry
- Restorative Dentistry and Orthodontics
- Surgical Dentistry
- Medical Ethics
- Medical Statistics and Methodology
- Browse content in Neurology
- Clinical Neurophysiology
- Neuropathology
- Nursing Studies
- Browse content in Obstetrics and Gynaecology
- Gynaecology
- Occupational Medicine
- Ophthalmology
- Otolaryngology (ENT)
- Browse content in Paediatrics
- Neonatology
- Browse content in Pathology
- Chemical Pathology
- Clinical Cytogenetics and Molecular Genetics
- Histopathology
- Medical Microbiology and Virology
- Patient Education and Information
- Browse content in Pharmacology
- Psychopharmacology
- Browse content in Popular Health
- Caring for Others
- Complementary and Alternative Medicine
- Self-help and Personal Development
- Browse content in Preclinical Medicine
- Cell Biology
- Molecular Biology and Genetics
- Reproduction, Growth and Development
- Primary Care
- Professional Development in Medicine
- Browse content in Psychiatry
- Addiction Medicine
- Child and Adolescent Psychiatry
- Forensic Psychiatry
- Learning Disabilities
- Old Age Psychiatry
- Psychotherapy
- Browse content in Public Health and Epidemiology
- Epidemiology
- Public Health
- Browse content in Radiology
- Clinical Radiology
- Interventional Radiology
- Nuclear Medicine
- Radiation Oncology
- Reproductive Medicine
- Browse content in Surgery
- Cardiothoracic Surgery
- Gastro-intestinal and Colorectal Surgery
- General Surgery
- Neurosurgery
- Paediatric Surgery
- Peri-operative Care
- Plastic and Reconstructive Surgery
- Surgical Oncology
- Transplant Surgery
- Trauma and Orthopaedic Surgery
- Vascular Surgery
- Browse content in Science and Mathematics
- Browse content in Biological Sciences
- Aquatic Biology
- Biochemistry
- Bioinformatics and Computational Biology
- Developmental Biology
- Ecology and Conservation
- Evolutionary Biology
- Genetics and Genomics
- Microbiology
- Molecular and Cell Biology
- Natural History
- Plant Sciences and Forestry
- Research Methods in Life Sciences
- Structural Biology
- Systems Biology
- Zoology and Animal Sciences
- Browse content in Chemistry
- Analytical Chemistry
- Computational Chemistry
- Crystallography
- Environmental Chemistry
- Industrial Chemistry
- Inorganic Chemistry
- Materials Chemistry
- Medicinal Chemistry
- Mineralogy and Gems
- Organic Chemistry
- Physical Chemistry
- Polymer Chemistry
- Study and Communication Skills in Chemistry
- Theoretical Chemistry
- Browse content in Computer Science
- Artificial Intelligence
- Computer Architecture and Logic Design
- Game Studies
- Human-Computer Interaction
- Mathematical Theory of Computation
- Programming Languages
- Software Engineering
- Systems Analysis and Design
- Virtual Reality
- Browse content in Computing
- Business Applications
- Computer Security
- Computer Games
- Computer Networking and Communications
- Digital Lifestyle
- Graphical and Digital Media Applications
- Operating Systems
- Browse content in Earth Sciences and Geography
- Atmospheric Sciences
- Environmental Geography
- Geology and the Lithosphere
- Maps and Map-making
- Meteorology and Climatology
- Oceanography and Hydrology
- Palaeontology
- Physical Geography and Topography
- Regional Geography
- Soil Science
- Urban Geography
- Browse content in Engineering and Technology
- Agriculture and Farming
- Biological Engineering
- Civil Engineering, Surveying, and Building
- Electronics and Communications Engineering
- Energy Technology
- Engineering (General)
- Environmental Science, Engineering, and Technology
- History of Engineering and Technology
- Mechanical Engineering and Materials
- Technology of Industrial Chemistry
- Transport Technology and Trades
- Browse content in Environmental Science
- Applied Ecology (Environmental Science)
- Conservation of the Environment (Environmental Science)
- Environmental Sustainability
- Environmentalist Thought and Ideology (Environmental Science)
- Management of Land and Natural Resources (Environmental Science)
- Natural Disasters (Environmental Science)
- Nuclear Issues (Environmental Science)
- Pollution and Threats to the Environment (Environmental Science)
- Social Impact of Environmental Issues (Environmental Science)
- History of Science and Technology
- Browse content in Materials Science
- Ceramics and Glasses
- Composite Materials
- Metals, Alloying, and Corrosion
- Nanotechnology
- Browse content in Mathematics
- Applied Mathematics
- Biomathematics and Statistics
- History of Mathematics
- Mathematical Education
- Mathematical Finance
- Mathematical Analysis
- Numerical and Computational Mathematics
- Probability and Statistics
- Pure Mathematics
- Browse content in Neuroscience
- Cognition and Behavioural Neuroscience
- Development of the Nervous System
- Disorders of the Nervous System
- History of Neuroscience
- Invertebrate Neurobiology
- Molecular and Cellular Systems
- Neuroendocrinology and Autonomic Nervous System
- Neuroscientific Techniques
- Sensory and Motor Systems
- Browse content in Physics
- Astronomy and Astrophysics
- Atomic, Molecular, and Optical Physics
- Biological and Medical Physics
- Classical Mechanics
- Computational Physics
- Condensed Matter Physics
- Electromagnetism, Optics, and Acoustics
- History of Physics
- Mathematical and Statistical Physics
- Measurement Science
- Nuclear Physics
- Particles and Fields
- Plasma Physics
- Quantum Physics
- Relativity and Gravitation
- Semiconductor and Mesoscopic Physics
- Browse content in Psychology
- Affective Sciences
- Clinical Psychology
- Cognitive Psychology
- Cognitive Neuroscience
- Criminal and Forensic Psychology
- Developmental Psychology
- Educational Psychology
- Evolutionary Psychology
- Health Psychology
- History and Systems in Psychology
- Music Psychology
- Neuropsychology
- Organizational Psychology
- Psychological Assessment and Testing
- Psychology of Human-Technology Interaction
- Psychology Professional Development and Training
- Research Methods in Psychology
- Social Psychology
- Browse content in Social Sciences
- Browse content in Anthropology
- Anthropology of Religion
- Human Evolution
- Medical Anthropology
- Physical Anthropology
- Regional Anthropology
- Social and Cultural Anthropology
- Theory and Practice of Anthropology
- Browse content in Business and Management
- Business Ethics
- Business Strategy
- Business History
- Business and Technology
- Business and Government
- Business and the Environment
- Comparative Management
- Corporate Governance
- Corporate Social Responsibility
- Entrepreneurship
- Health Management
- Human Resource Management
- Industrial and Employment Relations
- Industry Studies
- Information and Communication Technologies
- International Business
- Knowledge Management
- Management and Management Techniques
- Operations Management
- Organizational Theory and Behaviour
- Pensions and Pension Management
- Public and Nonprofit Management
- Strategic Management
- Supply Chain Management
- Browse content in Criminology and Criminal Justice
- Criminal Justice
- Criminology
- Forms of Crime
- International and Comparative Criminology
- Youth Violence and Juvenile Justice
- Development Studies
- Browse content in Economics
- Agricultural, Environmental, and Natural Resource Economics
- Asian Economics
- Behavioural Finance
- Behavioural Economics and Neuroeconomics
- Econometrics and Mathematical Economics
- Economic History
- Economic Systems
- Economic Methodology
- Economic Development and Growth
- Financial Markets
- Financial Institutions and Services
- General Economics and Teaching
- Health, Education, and Welfare
- History of Economic Thought
- International Economics
- Labour and Demographic Economics
- Law and Economics
- Macroeconomics and Monetary Economics
- Microeconomics
- Public Economics
- Urban, Rural, and Regional Economics
- Welfare Economics
- Browse content in Education
- Adult Education and Continuous Learning
- Care and Counselling of Students
- Early Childhood and Elementary Education
- Educational Equipment and Technology
- Educational Strategies and Policy
- Higher and Further Education
- Organization and Management of Education
- Philosophy and Theory of Education
- Schools Studies
- Secondary Education
- Teaching of a Specific Subject
- Teaching of Specific Groups and Special Educational Needs
- Teaching Skills and Techniques
- Browse content in Environment
- Applied Ecology (Social Science)
- Climate Change
- Conservation of the Environment (Social Science)
- Environmentalist Thought and Ideology (Social Science)
- Natural Disasters (Environment)
- Social Impact of Environmental Issues (Social Science)
- Browse content in Human Geography
- Cultural Geography
- Economic Geography
- Political Geography
- Browse content in Interdisciplinary Studies
- Communication Studies
- Museums, Libraries, and Information Sciences
- Browse content in Politics
- African Politics
- Asian Politics
- Chinese Politics
- Comparative Politics
- Conflict Politics
- Elections and Electoral Studies
- Environmental Politics
- European Union
- Foreign Policy
- Gender and Politics
- Human Rights and Politics
- Indian Politics
- International Relations
- International Organization (Politics)
- International Political Economy
- Irish Politics
- Latin American Politics
- Middle Eastern Politics
- Political Behaviour
- Political Economy
- Political Institutions
- Political Methodology
- Political Communication
- Political Philosophy
- Political Sociology
- Political Theory
- Politics and Law
- Public Policy
- Public Administration
- Quantitative Political Methodology
- Regional Political Studies
- Russian Politics
- Security Studies
- State and Local Government
- UK Politics
- US Politics
- Browse content in Regional and Area Studies
- African Studies
- Asian Studies
- East Asian Studies
- Japanese Studies
- Latin American Studies
- Middle Eastern Studies
- Native American Studies
- Scottish Studies
- Browse content in Research and Information
- Research Methods
- Browse content in Social Work
- Addictions and Substance Misuse
- Adoption and Fostering
- Care of the Elderly
- Child and Adolescent Social Work
- Couple and Family Social Work
- Developmental and Physical Disabilities Social Work
- Direct Practice and Clinical Social Work
- Emergency Services
- Human Behaviour and the Social Environment
- International and Global Issues in Social Work
- Mental and Behavioural Health
- Social Justice and Human Rights
- Social Policy and Advocacy
- Social Work and Crime and Justice
- Social Work Macro Practice
- Social Work Practice Settings
- Social Work Research and Evidence-based Practice
- Welfare and Benefit Systems
- Browse content in Sociology
- Childhood Studies
- Community Development
- Comparative and Historical Sociology
- Economic Sociology
- Gender and Sexuality
- Gerontology and Ageing
- Health, Illness, and Medicine
- Marriage and the Family
- Migration Studies
- Occupations, Professions, and Work
- Organizations
- Population and Demography
- Race and Ethnicity
- Social Theory
- Social Movements and Social Change
- Social Research and Statistics
- Social Stratification, Inequality, and Mobility
- Sociology of Religion
- Sociology of Education
- Sport and Leisure
- Urban and Rural Studies
- Browse content in Warfare and Defence
- Defence Strategy, Planning, and Research
- Land Forces and Warfare
- Military Administration
- Military Life and Institutions
- Naval Forces and Warfare
- Other Warfare and Defence Issues
- Peace Studies and Conflict Resolution
- Weapons and Equipment

- < Previous chapter
- Next chapter >
28 Secondary Data Analysis
Department of Psychology, Michigan State University
Richard E. Lucas, Department of Psychology, Michigan State University, East Lansing, MI
- Published: 01 October 2013
- Cite Icon Cite
- Permissions Icon Permissions
Secondary data analysis refers to the analysis of existing data collected by others. Secondary analysis affords researchers the opportunity to investigate research questions using large-scale data sets that are often inclusive of under-represented groups, while saving time and resources. Despite the immense potential for secondary analysis as a tool for researchers in the social sciences, it is not widely used by psychologists and is sometimes met with sharp criticism among those who favor primary research. The goal of this chapter is to summarize the promises and pitfalls associated with secondary data analysis and to highlight the importance of archival resources for advancing psychological science. In addition to describing areas of convergence and divergence between primary and secondary data analysis, we outline basic steps for getting started and finding data sets. We also provide general guidance on issues related to measurement, handling missing data, and the use of survey weights.
The goal of research in the social science is to gain a better understanding of the world and how well theoretical predictions match empirical realities. Secondary data analysis contributes to these objectives through the application of “creative analytical techniques to data that have been amassed by others” ( Kiecolt & Nathan, 1985 , p. 10). Primary researchers design new studies to answer research questions, whereas the secondary data analyst uses existing resources. There is a deliberate coupling of research design and data analysis in primary research; however, the secondary data analyst rarely has had input into the design of the original studies in terms of the sampling strategy and measures selected for the investigation. For better or worse, the secondary data analyst simply has access to the final products of the data collection process in the form of a codebook or set of codebooks and a cleaned data set.
The analysis of existing data sets is routine in disciplines such as economics, political science, and sociology, but it is less well established in psychology ( but see Brooks-Gunn & Chase-Lansdale, 1991 ; Brooks-Gunn, Berlin, Leventhal, & Fuligini, 2000 ). Moreover, biases against secondary data analysis in favor of primary research may be present in psychology ( see McCall & Appelbaum, 1991 ). One possible explanation for this bias is that psychology has a rich and vibrant experimental tradition, and the training of many psychologists has likely emphasized this approach as the “gold standard” for addressing research questions and establishing causality ( see , e.g., Cronbach, 1957 ). As a result, the nonexperimental methods that are typically used in secondary analyses may be viewed by some as inferior. Psychological scientists trained in the experimental tradition may not fully appreciate the unique strengths that nonexperimental techniques have to offer and may underestimate the time, effort, and skills required for conducting secondary data analyses in a competent and professional manner. Finally, biases against secondary data analysis might stem from lingering concerns over the validity of the self-report methods that are typically used in secondary data analysis. These can include concerns about the possibility that placement of items in a survey can influence responses (e.g., differences in the average levels of reported marital and life satisfaction when questions occur back to back as opposed to having the questions separated in the survey; see Schwarz, 1999 ; Schwarz & Strack, 1999 ) and concerns with biased reporting of sensitive behaviors ( but see Akers, Massey, & Clarke, 1983 ).
Despite the initial reluctance to widely embrace secondary data analysis as a tool for psychological research, there are promising signs that the skepticism toward secondary analyses will diminish as psychology seeks to position itself as a hub science that plays a key role in interdisciplinary inquiry ( see Mroczek, Pitzer, Miller, Turiano, & Fingerman, 2011 ). Accordingly, there is a compelling argument for including secondary data analysis into the suite of methodological approaches used by psychologists ( see Trzesniewski, Donnellan, & Lucas, 2011 ).
The goal of this chapter is to summarize the promises and pitfalls associated with secondary data analysis and to highlight the importance of archival resources for advancing psychological science. We limit our discussion to analyses based on large-scale and often longitudinal national data sets such as the National Longitudinal Study of Adolescent Health (Add Health), the British Household Panel Study (BHPS), the German Socioeconomic Panel Study (GSOEP), and the National Institute of Child Health and Human Development (NICHD) Study of Early Child Care and Youth Development (SEC-CYD). However, much of our discussion applies to all secondary analyses. The perspective and specific recommendations found in this chapter draw on the edited volume by Trzesniewski et al. (2011 ). Following a general introduction to secondary data analysis, we will outline the necessary steps for getting started and finding data sets. Finally, we provide some general guidance on issues related to measurement, approaches to handling missing data, and survey weighting. Our treatment of these important topics is intended to draw attention to the relevant issues rather than to provide extensive coverage. Throughout, we take a practical approach to the issues and offer tips and guidance rooted in our experiences as data analysts and researchers with substantive interests in personality and life span developmental psychology.
Comparing Primary Research and Secondary Research
As noted in the opening section, it is possible that biases against secondary data analysis exist in the minds of some psychological scientists. To address these concerns, we have found it can be helpful to explicitly compare the processes of secondary analyses with primary research ( see also McCall & Appelbaum, 1991 ). An idealized and simplified list of steps is provided in Table 28.1 . As is evident from this table, both techniques start with a research question that is ideally rooted in existing theory and previous empirical results. The areas of biggest divergence between primary and secondary approaches occur after researchers have identified their questions (i.e., Steps 2 through 5 in Table 28.1 ). At this point, the primary researcher develops a set of procedures and then engages in pilot testing to refine procedures and methods, whereas the secondary analyst searches for data sets and evaluates codebooks. The primary researcher attempts to refine her or his procedures, whereas the secondary analyst determines whether a particular resource is appropriate for addressing the question at hand. In the next stages, the primary researcher collects new data, whereas the secondary data analyst constructs a working data set from a much larger data archive. At these stages, both types of researchers must grapple with the practical considerations imposed by real world constraints. There is no such thing as a perfect single study ( see Hunter & Schmidt, 2004 ), as all data sets are subject to limitations stemming from design and implementation. For example, the primary researcher may not have enough subjects to generate adequate levels of statistical power (because of a failure to take power calculations into account during the design phase, time or other resource constraints during the data collection phase, or because of problems with sample retention), whereas the secondary data analyst may have to cope with impoverished measurement of core constructs. Both sets of considerations will affect the ability of a given study to detect effects and provide unbiased estimates of effect sizes.
Table 28.1 also illustrates the fact that there are considerable areas of overlap between the two techniques. Researchers stemming from both traditions analyze data, interpret results, and write reports for dissemination to the wider scientific community. Both kinds of research require a significant investment of time and intellectual resources. Many skills required in conducting high-quality primary research are also required in conducting high-quality secondary data analysis including sound scientific judgment, attention to detail, and a firm grasp of statistical methodology.
Note: Steps modified and expanded from McCall and Appelbaum (1991 ).
We argue that both primary research and secondary data analysis have the potential to provide meaningful and scientifically valid research findings for psychology. Both approaches can generate new knowledge and are therefore reasonable ways of evaluating research questions. Blanket pronouncements that one approach is inherently superior to the other are usually difficult to justify. Many of the concerns about secondary data analysis are raised in the context of an unfair comparison—a contrast between the idealized conceptualization of primary research with the actual process of a secondary data analysis. Our point is that both approaches can be conducted in a thoughtful and rigorous manner, yet both approaches involve concessions to real-world constraints. Accordingly, we encourage all researchers and reviewers of papers to keep an open mind about the importance of both types of research.
Advantages and Disadvantages of Secondary Data Analysis
The foremost reason why psychologists should learn about secondary data analysis is that there are many existing data sets that can be used to answer interesting and important questions. Individuals who are unaware of these resources are likely to miss crucial opportunities to contribute new knowledge to the discipline and even risk reinventing the proverbial wheel by collecting new data. Regrettably, new data collection efforts may occur on a smaller scale than what is available in large national datasets. Researchers who are unaware of the potential treasure trove of variables in existing data sets risk unnecessarily duplicating considerable amounts of time and effort. At the very least, researchers may wish to familiarize themselves with publicly available data to truly address gaps in the literature when they undertake projects that involve new data collection.
The biggest advantage of secondary analyses is that the data have already been collected and are ready to be analyzed ( see Hofferth, 2005 ), thus conserving time and resources. Existing data sources are often of much larger and higher quality than could be feasibly collected by a single investigator. This advantage is especially pronounced when considering the investments of time and money necessary to collect longitudinal data. Some data sets were collected with scientific sampling plans (such as the GSOEP), which make it possible to generalize the findings to a specific population. Further, many publicly available data sets are quite large, and therefore provide adequate statistical power for conducting many analyses, including hypotheses about statistical interactions. Investigations of interactions often require a surprisingly high number of participants to achieve respectable levels of statistical power in the face of measurement error ( see Aiken & West, 1991 ). 1 Large-scale data sets are also well suited for subgroup analyses of populations that are often under-represented in smaller research studies.
Another advantage of secondary data analysis is that it forces researchers to adopt an open and transparent approach to their craft. Because data are publicly available, other investigators may attempt to replicate findings and specify alternative models for a given research question. This reality encourages transparency and detailed record keeping on the part of the researcher, including careful reporting of analysis and a reasoned justification for all analytic decisions. Freese (2007 ) has provided a useful discussion about policies for archiving material necessary for replicating results, and his treatment of the issues provides guidance to researchers interested in maintaining good records.
Despite the many advantages of secondary data analysis, it is not without its disadvantages. The most significant challenge is simply the flipside of the primary advantage—the data have already been collected by somebody else! Analysts must take advantage of what has been collected without input into design and measurement issues. In some cases, an existing data set may not be available to address the particular research questions of a given investigator without some limitations in terms of sampling, measurement, or other design feature. For example, data sets commonly used for secondary analysis often have a great deal of breadth in terms of the range of constructs assessed (e.g., finances, attitudes, personality, life satisfaction, physical health), but these constructs are often measured with a limited number of survey items. Issues of measurement reliability and validity are usually a major concern. Therefore, a strong grounding in basic and advanced psychometrics is extremely helpful for responding to criticisms and concerns about measurement issues that arise during the peer-review process.
A second consequence of the fact that the data have been collected by somebody else is that analysts may not have access to all of the information about data collection procedures and issues. The analyst simply receives a cleaned data set to use for subsequent analyses. Perhaps not obvious to the user is the amount of actual cleaning that occurred behind the scenes. Similarly, the complicated sampling procedures used in a given study may not be readily apparent to users, and this issue can prevent the appropriate use of survey weights ( Shrout & Napier, 2011 ).
Another significant disadvantage for secondary data analysis is the large amount of time and energy initially required to review data documentation. It can take hours and even weeks to become familiar with the codebooks and to discover which research questions have already been addressed by investigators using the existing data sets. It is very easy to underestimate how long it will take to move from an initial research idea to a competent final analysis. There is a risk that, unbeknownst to one another, researchers in different locations will pursue answers to the same research questions. On the other hand, once a researcher has become familiar with a data set and developed skills to work with the resource, they are able to pursue additional research questions resulting in multiple publications from the same data set. It is our experience that the process of learning about a data set can help generate new research ideas as it becomes clearer how the resource can be used to contribute to psychological science. Thus, the initial time and energy expended to learn about a resource can be viewed as initial investment that holds the potential to pay larger dividends over time.
Finally, a possible disadvantage concerns how secondary data analyses are viewed within particular subdisciplines of psychology and by referees during the peer-review process. Some journals and some academic departments may not value secondary data analyses as highly as primary research. Such preferences might break along Cronbach’s two disciplines or two streams of psychology—correlational versus experimental ( Cronbach, 1957 ; Tracy, Robins, & Sherman, 2009 ). The reality is that if original data collection is more highly valued in a given setting, then new investigators looking to build a strong case for getting hired or getting promoted might face obstacles if they base a career exclusively on secondary data analysis. Similarly, if experimental methods are highly valued and correlational methods are denigrated in a particular subfield, then results of secondary data analyses will face difficulties getting attention (and even getting published). The best advice is to be aware of local norms and to act accordingly.
Steps for Beginning a Secondary Data Analysis
Step 1: Find Existing Data Sets . After generating a substantive question, the first task is to find relevant data sets ( see Pienta, O’Rouke, & Franks, 2011 ). In some cases researchers will be aware of existing data sets through familiarity with the literature given that many well-cited papers have used such resources. For example, the GSOEP has now been widely used to address questions about correlates and developmental course of subjective well-being (e.g., Baird, Lucas, & Donnellan, 2010 ; Gerstorf, Ram, Estabrook, Schupp, Wagner, & Lindenberger, 2008 ; Gerstorf, Ram, Goebel, Schupp, Lindenberger, & Wagner, 2010 ; Lucas, 2005 ; 2007 ), and thus, researchers in this area know to turn to this resource if a new question arises. In other cases, however, researchers will attempt to find data sets using established archives such as the University of Michigan’s Interuniversity Consortium for Political and Social Research (ICPSR; http://www.icpsr.umich.edu/icpsrweb/ICPSR/ ). In addition to ICPSR, there are a number of other major archives ( see Pienta et al., 2011 ) that house potentially relevant data sets. Here are just a few starting points:
The Henry A. Murray Research Archive ( http://www.murray.harvard.edu/ )
The Howard W Odum Institute for Research in Social Science ( http://www.irss.unc.edu/odum/jsp/home2.jsp )
The National Opinion Research Center ( http://norc.org/homepage.htm )
The Roper Center of Public Opinion Research ( http://ropercenter.uconn.edu/ )
The United Kingdom Data Archive ( http://www.data-archive.ac.uk/ )
Individuals in charge of these archives and data depositories often catalog metadata, which is the technical term for information about the constituent data sets. Typical kinds of metadata include information about the original investigators, a description of the design and process of data collection, a list of the variables assessed, and notes about sampling weights and missing data. Searching through this information is an efficient way of gaining familiarity with data sets. In particular, the ICPSR has an impressive infrastructure for allowing researchers to search for data sets through a cataloguing of study metadata. The ICPSR is thus a useful starting point for finding the raw material for a secondary data analysis. The ICPSR also provides a new user tutorial for searching their holdings ( http://www.icpsr.umich.edu/icpsrweb/ICPSR/help/newuser.jsp ). We recommend that researchers search through their holdings to make a list of potential data sets. At that point, the next task is to obtain relevant codebooks to learn more about each resource.
Step 2: Read Codebooks . Researchers interesting in using an existing data set are strongly advised to thoroughly read the accompanying codebook ( Pienta et al., 2011 ). There are several reasons why a comprehensive understanding of the codebook is a critical first step when conducting a secondary data analysis. First, the codebook will detail the procedures and methods used to acquire the data and provide a list of all of the questions and assessments collected. A thorough reading of the codebook can provide insights into important covariates that can be included in subsequent models, and a careful reading will draw the analyst’s attention to key variables that will be missing because no such information was collected. Reading through a codebook can also help to generate new research questions.
Second, high-quality codebooks often report basic descriptive information for each variable such as raw frequency distributions and information about the extent of missing values. The descriptive information in the codebook can give investigators a baseline expectation for variables under consideration, including the expected distributions of the variables and the frequencies of under-represented groups (such as ethnic minority participants). Because it is important to verify that the descriptive statistics in the published codebook match those in the file analyzed by the secondary analyst, a familiarity with the codebook is essential. In addition to codebooks, many existing resources provide copies of the actual surveys completed by participants ( Pienta et al., 2011 ). However, the use of actual pencil-and-paper surveys is becoming less common with the advent of computer assisted interview techniques and Internet surveys. It is often the case that survey methods involve skip patterns (e.g., a participant is not asked about the consequences of her drinking if she responds that she doesn’t drink alcohol) that make it more difficult to assume the perspective of the “typical” respondent in a given study ( Pienta et al., 2011 ). Nonetheless, we recommend that analysts try to develop an understanding for the experiences of the participant in a given study. This perspective can help secondary analysts develop an intuitive understanding of certain patterns of missing data and anticipate concerns about question ordering effects ( see , e.g., Schwarz, 1999 ).
Step 3: Acquire Datasets and Construct a Working Datafile . Although there is a growing availability of Web-based resources for conducting basic analyses using selected data sets (e.g., the Survey Documentation Analysis software used by ICPSR), we are convinced that there is no substitute for the analysis of the raw data using the software packages of preference for a given investigator. This means that the analysts will need to acquire the data sets that they consider most relevant. This is typically a very straightforward process that involves acknowledging researcher responsibilities before downloading the entire data set from a website. In some cases, data are classified as restricted-use, and there are more extensive procedures for obtaining access that may involve submitting a detailed security plan and accompanying legal paperwork before becoming an authorized data user. When data involve children and other sensitive groups, Institutional Review Board approval is often required.
Each data set has different usage requirements, so it is difficult to provide blanket guidance. Researchers should be aware of the policies for using each data set and recognize their ethical responsibility for adhering to those regulations. A central issue is that the researcher must avoid deductive disclosure whereby otherwise anonymous participants are identified because of prior knowledge in conjunction with the personal characteristics coded in the dataset (e.g., gender, racial/ethnic group, geographic location, birth date). Such a practice violates the major ethical principles followed by responsible social scientists and has the potential to harm research participants.
Once the entire set of raw data is acquired, it is usually straightforward to import the files into the kinds of statistical packages used by researchers (e.g., R, SAS, SPSS, and STATA). At this point, it is likely that researchers will want to create smaller “working” file by pulling only relevant variables from the larger master files. It is often too cumbersome to work with a computer file that may have more than a thousand columns of information. The solution is to construct a working data file that has all of the needed variables tied to a particular research project. Researchers may also need to link multiple files by matching longitudinal data sets and linking to contextual variables such as information about schools or neighborhoods for data sets with a multilevel structure (e.g., individuals nested in schools or neighborhoods).
Explicit guidance about managing a working data file can be found in Willms (2011 ). Here, we simply highlight some particularly useful advice: (1) keep exquisite notes about what variables were selected and why; (2) keep detailed notes regarding changes to each variable and reasons why; and (3) keep track of sample sizes throughout this entire process. The guiding philosophy is to create documentation that is clear enough for an outside user to follow the logic and procedures used by the researcher. It is far too easy to overestimate the power of memory only to be disappointed when it comes time to revisit a particular analysis. Careful documentation can save time and prevent frustration. Willms (2011 ) noted that “keeping good notes is the sine qua non of the trade” (p. 33).
Step 4: Conduct Analyses . After assembling the working data file, the researcher will likely construct major study variables by creating scale composites (e.g., the mean of the responses to the items assessing the same construct) and conduct initial analyses. As previously noted, a comparison of the distributions and sample sizes with those in the study codebook is essential at this stage. Any deviations for the variables in the working data file and the codebook should be understood and documented. It is particularly useful to keep track of missing values to make sure that they have been properly coded. It should go without saying that an observed value of-9999 will typically require recoding to a missing value in the working file. Similarly, errors in reverse scoring items can be particularly common (and troubling) so researchers are well advised to conduct through item-level and scale analyses and check to make sure that reverse scoring was done correctly (e.g., examine the inter-item correlation matrix when calculating internal consistency estimates to screen for negative correlations). Willms (2011 ) provides some very savvy advice for the initial stages of actual data analysis: “Be wary of surprise findings” (p. 35). He noted that “too many times I have been excited by results only to find that I have made some mistake” (p. 35). Caution, skepticism, and a good sense of the underlying data set are essential for detecting mistakes.
An important comment about the nature of secondary data analysis is again worth emphasizing: These data sets are available to others in the scholarly community. This means that others should be able to replicate your results! It is also very useful to adopt a self-critical perspective because others will be able to subject findings to their own empirical scrutiny. Contemplate alternative explanations and attempt to conduct analyses to evaluate the plausibility of these explanations. Accordingly, we recommend that researchers strive to think of theoretically relevant control variables and include them in the analytic models when appropriate. Such an approach is useful both from the perspective of scientific progress (i.e., attempting to curb confirmation biases) and in terms of surviving the peer-review process.
Special Issue: Measurement Concerns in Existing Datasets
One issue with secondary data analyses that is likely to perplex psychologists are concerns regarding the measurement of core constructs. The reality is that many of the measures available in large-scale data sets consist of a subset of items derived from instruments commonly used by psychologists ( see Russell & Matthews, 2011 ). For example, the 10-item Rosenberg Self-Esteem scale ( Rosenberg, 1965 ) is the most commonly used measure of global self-esteem in the literature ( Donnellan, Trzesniewski, & Robins, 2011 ). Measures of self-esteem are available in many data sets like Monitoring the Future ( see Trzesniewski & Donnellan, 2010 ) but these measures are typically shorter than the original Rosenberg scale. Similarly, the GSOEP has a single-item rating of subjective well-being in the form of happiness, whereas psychologists might be more accustomed to measuring this construct with at least five items (e.g., Diener, Emmons, Larsen, & Griffin, 1985 ). Researchers using existing data sets will have to grapple with the consequences of having relatively short assessments in terms of the impact on reliability and validity.
For purposes of this chapter, we will make use of a conventional distinction between reliability and validity. Reliability will refer to the degree of measurement error present in a given set of scores (or alternatively the degree of consistency or precision in scores), whereas validity will refer to the degree to which measures capture the construct of interest and predict other variables in ways that are consistent with theory. More detailed but accessible discussions of reliability and validity can be found in Briggs and Cheek (1986 ), Clark and Watson (1995 ), John and Soto (2007 ), Messick (1995 ), Simms (2008 ), and Simms and Watson (2007 ). Widaman, Little, Preacher, and Sawalani (2011 ) have provided a discussion of these issues in the context of the shortened assessments available in existing data sets.
Short Measures and Reliability . Classical Test Theory (e.g., Lord & Novick, 1968 ) is the measurement perspective most commonly used among psychologists. According to this measurement philosophy, any observed score is a function of the underlying attribute (the so-called “true score”) and measurement error. Reliability is conceptualized as any deviation or inconsistency in observed scores for the same attribute across multiple assessments of that attribute. A thought experiment may help crystallize insights about reliability (e.g., Lord & Novick, 1968 ): Imagine a thousand identical clones each completing the same self-esteem instrument simultaneously. The underlying self-esteem attribute (i.e., the true scores) should be the same for each clone (by definition), whereas the observed scores may fluctuate across clones because of random measurement errors (e.g., a single clone misreading an item vs. another clone being frustrated by an extremely hot testing room). The extent of the observed fluctuations in reported scores across clones offers insight into how much measurement error is present in this instrument. If scores are tightly clustered around a single value, then measurement error is minimal; however, if scores are dramatically different across clones, then there is a clear indication of problems with reliability. The measure is imprecise because it yields inconsistent values across the same true scores.
These ideas about reliability can be applied to observed samples of scores such that the total observed variance is attributable to true score variance (i.e., true individual differences in underlying attributes) and variance stemming from random measurement errors. The assumption that measurement error is random means that it has an expected value of zero across observations. Using this framework, reliability can then be defined as the ratio of true score variance to the total observed variance. An assessment that is perfectly reliable (i.e., has no measurement error) will have a ratio of 1.0, whereas an assessment that is completely unreliable will yield a ratio of 0.0 ( see John & Soto, 2007 , for an expanded discussion). This perspective provides a formal definition of a reliability coefficient.
Psychologists have developed several tools to estimate the reliability of their measures, but the approach that is most commonly used is coefficient a ( Cronbach, 1951 ; see Schmitt, 1996 , for an accessible review). This approach considers reliability from the perspective of internal consistency. The basic idea is that fluctuations across items assessing the same construct reflect the presence of measurement error. The formula for the standardized α is a fairly simple function of the average inter-item correlation (a measure of inter-item homogeneity) and the total number of items in a scale. The α coefficient is typically judged acceptable if it is above 0.70, but the justification for this particular cutoff is somewhat arbitrary ( see Lance, Butts, & Michels, 2006 ). Researchers are therefore advised to take a more critical perspective on this statistic. A relevant concern is that α is negatively impacted when the measure is short.
Given concerns with scale length and α, many methodologically oriented researchers recommend evaluating and reporting the average inter-item correlation because it can be interpreted independently of length and thus represents a “more straightforward indicator of internal consistency” ( Clark & Watson, 1995 , p. 316). Consider that it is common to observe an average inter-item correlation for the 10-item Rosenberg Self-Esteem ( Rosenberg, 1965 ) scale around 0.40 (this is based on typically reported a coefficients; see Donnellan et al., 2011 ). This same level of internal homogeneity (i.e., an inter-item correlation of 0.40) yields an α of around 0.67 with a 3-item scale but an α of around 0.87 with 10 items. A measure of a broader construct like Extraversion may generate an average inter-item correlation of 0.20 ( Clark & Watson, 1995 , p. 316), which would translate to an α of 0.43 for a 3-item scale and 0.71 for a 10-item scale. The point is that α coefficients will fluctuate with scale length and the breadth of the construct. Because most scales in existing resources are short, the α coefficients might fall below the 0.70 convention despite having a respectable level of inter-item correlation.
Given these considerations, we recommend that researchers consider the average inter-item correlation more explicitly when working with secondary data sets. It is also important to consider the breadth of the underlying construct to generate expectations for reasonable levels of item homogeneity as indexed by the average inter-item correlation. Clark and Watson (1995 ; see also Briggs & Cheek, 1986 ) recommend values of around 0.40 to 0.50 for measures of fairly narrow constructs (e.g., self-esteem) and values of around 0.15 to 0.20 for measures of broader constructs (e.g., neuroticism). It is our experience that considerations about internal consistency often need to be made explicit in manuscripts so that reviewers will not take an unnecessarily harsh perspective on α’s that fall below their expectations. Finally, we want to emphasize that internal consistency is but one kind of reliability. In some cases, it might be that test—retest reliability is more informative and diagnostic of the quality of a measure ( McCrae, Kurtz, Yamagata, & Terracciano, 2011 ). Fortunately, many secondary data sets are longitudinal so it possible to get an estimate of longer term test-retest reliability from the existing data.
Beyond simply reporting estimates of reliability, it is worth considering why measurement reliability is such an important issue in the first place. One consequence of reliability for substantive research is that measurement imprecision tends to depress observed correlations with other variables. This notion of attenuation resulting from measurement error and a solution were discussed by Spearman as far back as 1904 ( see , e.g., pp. 88–94). Unreliable measures can affect the conclusions drawn from substantive research by imposing a downward bias on effect size estimation. This is perhaps why Widaman et al. (2011 ) advocate using latent variable structural modeling methods to combat this important consequence of measurement error. Their recommendation is well worth considering for those with experience with this technique ( see Kline, 2011 , for an introduction). Regardless of whether researchers use observed variables or latent variables for their analyses, it is important to recognize and appreciate the consequences of reliability.
Short Measures and Validity . Validity, for our purposes, reflects how well a measure captures the underlying conceptual attribute of interest. All discussions of validity are based, in part, on agreement in a field as to how to understand the construct in question. Validity, like reliability, is assessed as a matter of degree rather than a categorical distinction between valid or invalid measures. Cronbach and Meehl (1955 ) have provided a classic discussion of construct validity, perhaps the most overarching and fundamental form of validity considered in psychological research ( see also Smith, 2005 ). However, we restrict our discussion to content validity and criterion-related validity because these two types of validity are particularly relevant for secondary data analysis and they are more immediately addressable.
Content validity describes how well a measure captures the entire domain of the construct in question. Judgments regarding content validity are ideally made by panels of experts familiar with the focal construct. A measure is considered construct deficient if it fails to assess important elements of the construct. For example, if thoughts of suicide are an integral aspect of the concept depression and a given self-report measure is missing items that tap this content, then the measure would be deemed construct-deficient. A measure can also suffer from construct contamination if it includes extraneous items that are irrelevant to the focal construct. For example, if somatic symptoms like a rapid heartbeat are considered to reflect the construct of anxiety and not part of depression, then a depression inventory that has such an item would suffer from construct contamination. Given the reduced length of many assessments, concerns over construct deficiency are likely to be especially pressing. A short assessment may not include enough items to capture the full breadth of a broad construct. This limitation is not readily addressed and should be acknowledged ( see Widaman et al., 2011 ). In particular, researchers may need to clearly specify that their findings are based on a narrower content domain than is normally associated with the focal construct of interest.
A subtle but important point can arise when considering the content of measures with particularly narrow content. Internal consistency will increase when there is redundancy among items in the scale; however, the presence of similar items may decrease predictive power. This is known as the attenuation paradox in psycho metrics ( see Clark & Watson, 1995 ). When items are nearly identical, they contribute redundant information about a very specific aspect of the construct. However, the very specific attribute may not have predictive power. In essence, reliability can be maximized at the expense of creating a measure that is not very useful from the point of view of prediction (and likely explanation). Indeed, Clark and Watson (1995 ) have argued that the “goal of scale construction is to maximize validity rather than reliability” (p. 316). In short, an evaluation of content validity is also important when considering the predictive power of a given measure.
Whereas content validity is focused on the internal attributes of a measure, criterion-related validity is based on the empirical relations between measures and other variables. Using previous research and theory surrounding the focal construct, the researcher should develop an expectation regarding the magnitude and direction of observed associations (i.e., correlations) with other variables. A good supporting theory of a construct should stipulate a pattern of association, or nomological network, concerning those other variables that should be related and unrelated to the focal construct. This latter requirement is often more difficult to specify from existing theories, which tend to provide a more elaborate discussion of convergent associations rather than discriminant validity ( Widaman et al., 2011 ). For example, consider a very truncated nomological network for Agreeableness (dispositional kindness and empathy). Measures of this construct should be positively associated with romantic relationship quality, negatively related to crime (especially violent crime), and distinct from measures of cognitive ability such as tests of general intelligence.
Evaluations of criterion-related validity can be conducted within a data set as researchers document that a measure has an expected pattern of associations with existing criterion-related variables. Investigators using secondary data sets may want to conduct additional research to document the criterion-related validity of short measures with additional convenience samples (e.g., the ubiquitous college student samples used by many psychologists; Sears, 1986 ). For example, there are six items in the Add Health data set that appear to measure self-esteem (e.g., “I have a lot of good qualities” and “I like myself just the way I am”) ( see Russell, Crockett, Shen, &Lee, 2008 ). Although many of the items bear a strong resemblance to the items on the Rosenberg Self-Esteem scale ( Rosenberg, 1965 ), they are not exactly the same items. To obtain some additional data on the usefulness of this measure, we administered the Add Health items to a sample of 387 college students at our university along with the Rosenberg Self-Esteem scale and an omnibus measure of personality based on the Five-Factor model ( Goldberg, 1999 ). The six Add Health items were strongly correlated with the Rosenberg ( r = 0.79), and both self-esteem measures had a similar pattern of convergent and divergent associations with the facets of the Five-Factor model (the two profiles were very strongly associated: r > 0.95). This additional information can help bolster the case for the validity of the short Add Health self-esteem measure.
Special Issue: Missing Data in Existing Data Sets
Missing data is a fact of life in research— individuals may drop out of longitudinal studies or refuse to answer particular questions. These behaviors can affect the generalizability of findings because results may only apply to those individuals who choose to complete a study or a measure. Missing data can also diminish statistical power when common techniques like listwise deletion are used (e.g., only using cases with complete information, thereby reducing the sample size) and even lead to biased effect size estimates (e.g., McKnight & McKnight, 2011 ; McKnight, McKnight, Sidani, & Figuredo, 2007 ; Widaman, 2006 ). Thus, concerns about missing data are important for all aspects of research, including secondary data analysis. The development of specific techniques for appropriately handling missing data is an active area of research in quantitative methods ( Schafer & Graham, 2002 ).
Unfortunately, the literature surrounding missing data techniques is often technical and steeped in jargon, as noted by McKnight et al. (2007 ). The reality is that researchers attempting to understand issues of missing data need to pay careful attention to terminology. For example, a novice researcher may not immediately grasp the classification of missing data used in the literature ( see Schafer & Graham, 2002 , for a clear description). Consider the confusion that may stem from learning that data are missing at random (MAR) versus data are missing completely at random (MCAR). The term MAR does not mean that missing values only occurred because of chance factors. This is the case when data are missing completely at random (MCAR). Data that are MCAR are absent because of truly random factors. Data that are MAR refers to the situation in which the probability that the observations are missing depends only on other available information in the data set. Data that are MAR can be essentially “ignored” when the other factors are included in a statistical model. The last type of missing data, data missing not at random (MNAR), is likely to characterize the variables in many real-life data sets. As it stands, methods for handing data that are MAR and MCAR are better developed and more easily implemented than methods for handling data MNAR. Thus, many applied researchers will assume data are MAR for purposes of statistical modeling (and the ability to sleep comfortably at night). Fortunately, such an assumption might not create major problems for many analyses and may in fact represent the “practical state of the art” ( Schafer & Graham, 2002 , p. 173).
The literature on missing data techniques is growing, so we simply recommend that researchers keep current on developments in this area. McKnight et al. (2007 ) and Widaman (2006 ) both provide an accessible primer on missing data techniques. In keeping with the largely practical bent to the chapter, we suggest that researchers keep careful track of the amount of missing data present in their analyses and report such information clearly in research papers ( see McKnight & McKnight, 2011 ). Similarly, we recommend that researchers thoroughly screen their data sets for evidence that missing values depend on other measured variables (e.g., scores at Time 1 might be associated with Time 2 dropout). In general, we suggest that researchers avoid listwise and pairwise deletion methods because there is very little evidence that these are good practices ( see Jeličić, Phelps, & Lerner, 2009 ; Widaman, 2006 ). Rather, it might be easiest to use direct fitting methods such as the estimation procedures used in conventional structural equation modeling packages (e.g., Full Information Maximum Likelihood; see Allison, 2003 ). At the very least, it is usually instructive to compare results using listwise deletion with results obtained with direct model fitting in terms of the effect size estimates and basic conclusions regarding the statistical significance of focal coefficients.
Special Issue: Sample Weighting in Existing Data Sets
One of the advantages of many existing data sets is that they were collected using probabilistic sampling methods so that researchers can obtain unbiased population estimates. Such estimates, however, are only obtained when complex survey weights are formally incorporated into the statistical modeling procedures. Such weighting schemes can affect the correlations between variables, and therefore all users of secondary data sets should become familiar with sampling design when they begin working with a new data set. A considerable amount of time and effort is dedicated toward generating complex weighting schemes that account for the precise sampling strategies used in the given study, and users of secondary data sets should give careful consideration to using these weights appropriately.
In some cases, the addition of sampling weights will have little substantive implication on findings, so extensive concern over weighting might be overstated. On the other hand, any potential difference is ultimately an empirical question, so researchers are well advised to consider the importance of sampling weights ( Shrout & Napier, 2011 ). The problem is that many psychologists are not well versed in the use of sampling weights ( Shrout & Napier, 2011 ). Thus, psychologists may not be in a strong position to evaluate whether sample weighting concerns are relevant. In addition, it is sometimes necessary to use specialized software packages or add-ons to adjust analytic models appropriately for sampling weights. Programs such as STATA and SAS have such capabilities in the base package, whereas packages like SPSS sometimes require a complex survey model add-on that integrates with its existing capabilities. Whereas the graduate training of the modal sociologist or demographer is likely to emphasize survey research and thus presumably cover sampling, this is not the case with the methodological training of many psychologists ( Aiken, West, & Millsap, 2008 ). Psychologists who are unfamiliar with sample weighting procedures are well advised to seek the counsel of a survey methodologist before undertaking data analysis.
In terms of practical recommendations, it is important for the user of the secondary data set to develop a clear understanding of how the data were collected by reading documentation about the design and sampling procedure ( Shrout & Napier, 2011 ). This insight will provide a conceptual framework for understanding weighting schemes and for deciding how to appropriately weight the data. Once researchers have a clear idea of the sampling scheme and potential weights, actually incorporating available weights into analyses is not terribly difficult, provided researchers have the appropriate software ( Shrout & Napier, 2011 ). Weighting tutorials are often available for specific data sets. For example, the Add Health project has a document describing weighting ( http://www.cpc.unc.edu/projects/addhealth/faqs/aboutdata/weight1.pdf ) as does the Centers for Disease Control and Prevention for use with their Youth Risk Behavior Surveys ( http://www.cdc.gov/HealthyYouth/yrbs/pdf/YRBS_analysis_software.pdf ). These free documents may also provide useful and accessible background even for those who may not use the data from these projects.
Secondary data analysis refers to the analysis of existing data that may not have been explicitly collected to address a particular research question. Many of the quantitative techniques described in this volume can be applied using existing resources. To be sure, strong data analytic skills are important for fully realizing the potential benefits of secondary data sets, and such skills can help researchers recognize the limits of a data set for any given analysis.
In particular, measurement issues are likely to create the biggest hurdles for psychologists conducting secondary analyses in terms of the challenges associated with offering a reasonable interpretation of the results and in surviving the peer-review process. Accordingly, a familiarity with basic issues in psychometrics is very helpful. Beyond such skills, the effective use of these existing resources requires patience and strong attention to detail. Effective secondary data analysis also requires a fair bit of curiosity to seek out those resources that might be used to make important contribution to psychological science.
Ultimately, we hope that the field of psychology becomes more and more accepting of secondary data analysis. As psychologists use this approach with increasing frequency, it is likely that the organizers of major ongoing data collection efforts will be increasingly open to including measures of prime interest to psychologists. The individuals in charge of projects like the BHPS, the GSOEP, and the National Center for Education Statistics ( http://nces.ed.gov/ ) want their data to be used by the widest possible audiences and will respond to researcher demands. We believe that it is time that psychologists join their colleagues in economics, sociology, and political science in taking advantage of these existing resources. It is also time to move beyond divisive discussions surrounding the presumed superiority of primary data collection over secondary analysis. There is no reason to choose one over the other when the field of psychology can profit from both. We believe that the relevant topics of debate are not about the method of initial data collection but, rather, about the importance and intrinsic interest of the underlying research questions. If the question is important and the research design and measures are suitable, then there is little doubt in our minds that secondary data analysis can make a contribution to psychological science.
Author Note
M. Brent Donnellan, Department of Psychology, Michigan State University, East Lansing, MI 48824.
Richard E. Lucas, Department of Psychology, Michigan State University, East Lansing, MI 48824.
One consequence of large sample sizes, however, is that issues of effect size interpretation become paramount given that very small correlations or very small mean differences between groups are likely to be statistically significant using conventional null hypothesis significance tests (e.g., Trzesniewski & Donnellan, 2009 ). Researchers will therefore need to grapple with issues related to null hypothesis significance testing ( see Kline, 2004 ).
Aiken, L. S. , & West, S. G. ( 1991 ). Multiple regression: Testing and interpreting interactions . Newbury Park, CA: Sage.
Google Scholar
Google Preview
Aiken, L. S. , West, S. G. , & Millsap, R. E. ( 2008 ). Doctoral training in statistics, measurement, and methodology in psychology: Replication and extension of Aiken, West, Sechrest, and Reno’s (1990) survey of Ph.D. programs in North America. American Psychologist, 63, 32–50.
Akers, R. L. , Massey, J. , & Clarke, W ( 1983 ). Are self-reports of adolescent deviance valid? Biochemical measures, randomized response, and the bogus pipeline in smoking behavior. Social Forces, 62, 234–251.
Allison, P. D. ( 2003 ). Missing data techniques for structural equation modeling. Journal of Abnormal Psychology, 112, 545–557.
Baird, B. M. , Lucas, R. E. , & Donnellan, M. B. ( 2010 ). Life Satisfaction across the lifespan: Findings from two nationally representative panel studies. Social Indicators Research, 99, 183–203.
Briggs, S. R. , & Cheek, J. M. ( 1986 ). The role of factor analysis in the development and evaluation of personality scales. Journal of Personality 54, 106–148.
Brooks-Gunn, J. , Berlin, L. J. , Leventhal, T. , & Fuligini, A. S. ( 2000 ). Depending on the kindness of strangers: Current national data initiatives and developmental research. Child Development, 71, 257–268.
Brooks-Gunn, J. , & Chase-Lansdale, P. L. ( 1991 ) (Eds.). Secondary data analyses in developmental psychology [Special section]. Developmental Psychology, 27, 899–951.
Clark, L. A. , & Watson, D. ( 1995 ). Constructing validity: Basic issues in objective scale development. Psychological Assessment, 7, 309–319.
Cronbach, L. J. ( 1951 ). Coefficient alpha and the internal structure of tests. Psychometrika, 16, 297–234.
Cronbach, L. J. ( 1957 ). The two disciplines of scientific psychology. American Psychologist, 12, 671–684.
Cronbach, L. J. , & Meehl, P. ( 1955 ). Construct validity in psychological tests. Psychological Bulletin, 52, 281–302.
Diener, E. , Emmons, R. A. , Larsen, R. J. , & Griffin, S. ( 1985 ). The Satisfaction with Life Scale. Journal of Personality Assessment, 49, 71–75.
Donnellan, M. B. , Trzesniewski, K. H. , & Robins, R. W. ( 2011 ). Self-esteem: Enduring issues and controversies. In T Chamorro-Premuzic , S. von Stumm , and A. Furnham (Eds). The Wiley-Blackwell Handbook of Individual Differences (pp. 710–746). New York: Wiley-Blackwell.
Freese, J. ( 2007 ). Replication standards for quantitative social science: Why not sociology? Sociological Methods & Research, 36, 153–172.
Gerstorf, D. , Ram, N. , Estabrook, R. , Schupp, J. , Wagner, G. G. , & Lindenberger, U. ( 2008 ). Life satisfaction shows terminal decline in old age: Longitudinal evidence from the German Socio-Economic Panel Study (SOEP). Developmental Psychology, 44, 1148–1159.
Gerstorf, D. , Ram, N. , Goebel, J. , Schupp, J. , Lindenberger, U. , & Wagner, G. G. ( 2010 ). Where people live and die makes a difference: Individual and geographic disparities in well-being progression at the end of life. Psychology and Aging, 25, 661–676.
Goldberg, L. R. ( 1999 ). A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several five-factor models. In I Mervielde , I. Deary , F. De Fruyt , & F. Ostendorf (Eds.), Personality psychology in Europe (Vol. 7, pp. 7–28). Tilburg, The Netherlands: Tilburg University Press.
Hofferth, S. L. , ( 2005 ). Secondary data analysis in family research. Journal of Marriage and the Family, 67, 891–907.
Hunter, J. E. , & Schmidt, F. L. ( 2004 ). Methods of meta-analysis: Correcting error and bias in research findings (2nd ed.). Newbury Park, CA: Sage.
Jeličić, H. , Phelps, E. , & Lerner, R. M. ( 2009 ). Use of missing data methods in longitudinal studies: The persistence of bad practices in developmental psychology. Developmental Psychology, 45, 1195–1199.
John, O. P. , & Soto, C. J. ( 2007 ). The importance of being valid. In R. W Robins , R. C. Fraley , and R. F. Krueger (Eds). Handbook of Research Methods in Personality Psychology (pp. 461–494). New York: Guilford Press.
Kiecolt, K. J. & Nathan, L. E. ( 1985 ). Secondary analysis of survey data . Sage University Paper series on Quantitative Applications in the Social Sciences, No. 53). Newbury Park, CA: Sage.
Kline, R. B. ( 2004 ). Beyond significance testing: Reforming data analysis methods in behavioral research . Washington, DC: American Psychological Association.
Kline, R. B. ( 2011 ). Principles and practice of structural equation modeling (3rd ed.). New York: Guildford Press.
Lance, C. E. , Butts, M. M. , & Michels, L. C. ( 2006 ). The sources of four commonly reported cutoff criteria: What did they really say? Organizational Research Methods, 9, 202–220.
Lord, F. , & Novick, M. R. ( 1968 ). Statistical theories of mental test scores . Reading, MA: Addison-Wesley.
Lucas, R. E. ( 2005 ). Time does not heal all wounds. Psychological Science, 16, 945–950.
Lucas, R. E. ( 2007 ). Adaptation and the set-point model of subjective well-being: Does happiness change after major life events? Current Directions in Psychological Science, 16, 75–79.
McCall, R. B. , & Appelbaum, M. I. ( 1991 ). Some issues of conducting secondary analyses. Developmental Psychology, 27, 911–917.
McCrae, R. R. , Kurtz, J. E. , Yamagata, S. , & Terracciano, A. ( 2011 ). Internal consistency, retest reliability, and their implications for personality scale validity. Personality and Social Psychology Review, 15, 28–50.
Messick, S. ( 1995 ). Validity of psychological assessment: Validation of inferences from persons’ responses and performances as scientific inquiry into score meaning. American Psychologist, 50, 741–749.
McKnight, P. E. , & McKnight, K. M. ( 2011 ). Missing data in secondary data analysis. In K. H. Trzesniewski , M. B. Donnellan , & R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 83–101). Washington, DC: American Psychological Association.
McKnight, P. E. , McKnight, K. M. , Sidani, S. , & Figuredo, A. ( 2007 ). Missing data: A gentle introduction . New York: Guilford Press.
Mroczek, D. K. , Pitzer, L. , Miller, L. , Turiano, N. , & Fingerman, K. ( 2011 ). The use of secondary data in adult development and aging research. In K. H. Trzesniewski , M. B. Donnellan , and R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 121–132). Washington, DC: American Psychological Association.
Pienta, A. M. , O’Rourke, J. M. , & Franks, M. M. ( 2011 ). Getting started: Working with secondary data. In K. H. Trzesniewski , M. B. Donnellan , and R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 13–25). Washington, DC: American Psychological Association.
Rosenberg, M. ( 1965 ). Society and adolescent self image , Princeton, NJ: Princeton University.
Russell, S. T. , Crockett, L. J. , Shen, Y-L , & Lee, S-A. ( 2008 ). Cross-ethnic invariance of self-esteem and depression measures for Chinese, Filipino, and European American adolescents. Journal of Youth and Adolescence, 37, 50–61.
Russell, S. T. , & Matthews, E. ( 2011 ). Using secondary data to study adolescence and adolescent development. In K. H. Trzesniewski , M. B. Donnellan , & R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 163–176). Washington, DC: American Psychological Association.
Schafer, J. L. & Graham, J. W ( 2002 ). Missing data: Our view of the state of the art. Psychological Methods, 7, 147–177.
Schmitt, N. ( 1996 ). Uses and abuses of coefficient alpha. Psychological Assessment, 8, 350–353.
Schwarz, N. ( 1999 ). Self-reports: How the questions shape the answers. American Psychologist, 54, 93–105.
Schwarz, N. & Strack, F. ( 1999 ). Reports of subjective well-being: Judgmental processes and their methodological implications. In D. Kahneman , E. Diener , & N. Schwarz (Eds.). Well-being: The foundations of hedonic psychology (pp.61–84). New York: Russell Sage Foundation.
Sears, D. O. ( 1986 ). College sophomores in the lab: Influences of a narrow data base on social psychology’s view of human nature. Journal of Personality and Social Psychology, 51, 515–530.
Shrout, P. E. , & Napier, J. L. ( 2011 ). Analyzing survey data with complex sampling designs. In K. H. Trzesniewski , M. B. Donnellan , & R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 63–81). Washington, DC: American Psychological Association.
Simms, L. J. ( 2008 ). Classical and modern methods of psychological scale construction. Social and Personality Psychology Compass, 2/1, 414–433.
Simms, L. J. , & Watson, D. ( 2007 ). The construct validation approach to personality scale creation. In R. W Robins , R. C. Fraley , & R. F. Krueger (Eds). Handbook of Research Methods in Personality Psychology (pp. 240–258). New York: Guilford Press.
Smith, G. X ( 2005 ). On construct validity: Issues of method and measurement. Psychological Assessment, 17, 396–408.
Tracy, J. L. , Robins, R. W. , & Sherman, J. W. ( 2009 ). The practice of psychological science: Searching for Cronbach’s two streams in social-personality psychology. Journal of Personality and Social Psychology, 96, 1206–1225.
Trzesniewski, K.H. & Donnellan, M. B. ( 2009 ). Re-evaluating the evidence for increasing self-views among high school students: More evidence for consistency across generations (1976–2006). Psychological Science, 20, 920–922.
Trzesniewski, K. H. & Donnellan, M. B. ( 2010 ). Rethinking “Generation Me”: A study of cohort effects from 1976–2006. Perspectives in Psychological Science , 5, 58–75.
Trzesniewski, K. H. , Donnellan, M. B. , & Lucas, R. E. ( 2011 ) (Eds). Secondary data analysis: An introduction for psychologists . Washington, DC: American Psychological Association.
Widaman, K. F. ( 2006 ). Missing data: What to do with or without them. Monographs of the Society for Research in Child Development, 71, 42–64.
Widaman, K. F. , Little, T. D. , Preacher, K. K. , & Sawalani, G. M. ( 2011 ). On creating and using short forms of scales in secondary research. In K. H. Trzesniewski , M. B. Donnellan , & R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 39–61). Washington, DC: American Psychological Association.
Willms, J. D. ( 2011 ). Managing and using secondary data sets with multidisciplinary research teams. In K. H. Trzesniewski , M. B. Donnellan , & R. E. Lucas (Eds). Secondary data analysis: An introduction for psychologists (pp. 27–38). Washington, DC: American Psychological Association.
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Root out friction in every digital experience, super-charge conversion rates, and optimise digital self-service
Uncover insights from any interaction, deliver AI-powered agent coaching, and reduce cost to serve
Increase revenue and loyalty with real-time insights and recommendations delivered straight to teams on the ground
Know exactly how your people feel and empower managers to improve employee engagement, productivity, and retention
Take action in the moments that matter most along the employee journey and drive bottom line growth
Whatever they’re are saying, wherever they’re saying it, know exactly what’s going on with your people
Get faster, richer insights with qual and quant tools that make powerful market research available to everyone
Run concept tests, pricing studies, prototyping + more with fast, powerful studies designed by UX research experts
Track your brand performance 24/7 and act quickly to respond to opportunities and challenges in your market
Meet the operating system for experience management
- Free Account
- For Digital
- For Customer Care
- For Human Resources
- For Researchers
- Financial Services
- All Industries
Popular Use Cases
- Customer Experience
- Employee Experience
- Employee Exit Interviews
- Net Promoter Score
- Voice of Customer
- Customer Success Hub
- Product Documentation
- Training & Certification
- XM Institute
- Popular Resources
- Customer Stories
Market Research
- Artificial Intelligence
- Partnerships
- Marketplace
The annual gathering of the experience leaders at the world’s iconic brands building breakthrough business results.
- English/AU & NZ
- Español/Europa
- Español/América Latina
- Português Brasileiro
- REQUEST DEMO
- Experience Management
- Ultimate Guide to Market Research
- Secondary Research
Try Qualtrics for free
Secondary research: definition, methods, & examples.
18 min read This ultimate guide to secondary research helps you understand changes in market trends, customers buying patterns and your competition using existing data sources.
In situations where you’re not involved in the data gathering process ( primary research ), you have to rely on existing information and data to arrive at specific research conclusions or outcomes. This approach is known as secondary research.
In this article, we’re going to explain what secondary research is, how it works, and share some examples of it in practice.
What is secondary research?
Secondary research, also known as desk research, is a research method that involves compiling existing data sourced from a variety of channels . This includes internal sources (e.g.in-house research) or, more commonly, external sources (such as government statistics, organisational bodies, and the internet).
Secondary research comes in several formats, such as published datasets, reports, and survey responses , and can also be sourced from websites, libraries, and museums.
The information is usually free — or available at a limited access cost — and gathered using surveys , telephone interviews, observation, face-to-face interviews, and more.
When using secondary research, researchers collect, verify, analyse and incorporate it to help them confirm research goals for the research period.
As well as the above, it can be used to review previous research into an area of interest. Researchers can look for patterns across data spanning several years and identify trends — or use it to verify early hypothesis statements and establish whether it’s worth continuing research into a prospective area.
How to conduct secondary research
There are five key steps to conducting secondary research effectively and efficiently:
1. Identify and define the research topic
First, understand what you will be researching and define the topic by thinking about the research questions you want to be answered.
Ask yourself: What is the point of conducting this research? Then, ask: What do we want to achieve?
This may indicate an exploratory reason (why something happened) or confirm a hypothesis. The answers may indicate ideas that need primary or secondary research (or a combination) to investigate them.
2. Find research and existing data sources
If secondary research is needed, think about where you might find the information. This helps you narrow down your secondary sources to those that help you answer your questions. What keywords do you need to use?
Which organisations are closely working on this topic already? Are there any competitors that you need to be aware of?
Create a list of the data sources, information, and people that could help you with your work.
3. Begin searching and collecting the existing data
Now that you have the list of data sources, start accessing the data and collect the information into an organised system. This may mean you start setting up research journal accounts or making telephone calls to book meetings with third-party research teams to verify the details around data results.
As you search and access information, remember to check the data’s date, the credibility of the source, the relevance of the material to your research topic, and the methodology used by the third-party researchers. Start small and as you gain results, investigate further in the areas that help your research’s aims.
4. Combine the data and compare the results
When you have your data in one place, you need to understand, filter, order, and combine it intelligently. Data may come in different formats where some data could be unusable, while other information may need to be deleted.
After this, you can start to look at different data sets to see what they tell you. You may find that you need to compare the same datasets over different periods for changes over time or compare different datasets to notice overlaps or trends. Ask yourself: What does this data mean to my research? Does it help or hinder my research?
5. Analyse your data and explore further
In this last stage of the process, look at the information you have and ask yourself if this answers your original questions for your research. Are there any gaps? Do you understand the information you’ve found? If you feel there is more to cover, repeat the steps and delve deeper into the topic so that you can get all the information you need.
If secondary research can’t provide these answers, consider supplementing your results with data gained from primary research. As you explore further, add to your knowledge and update your findings. This will help you present clear, credible information.
eBook: The ultimate guide to conducting market research
Primary vs secondary research
Unlike secondary research, primary research involves creating data first-hand by directly working with interviewees, target users, or a target market. Primary research focuses on the method for carrying out research, asking questions, and collecting data using approaches such as:
- Interviews (panel, face-to-face or over the phone)
- Questionnaires or surveys
- Focus groups
Using these methods, researchers can get in-depth, targeted responses to questions, making results more accurate and specific to their research goals. However, it does take time to do and administer.
Unlike primary research, secondary research uses existing data, which also includes published results from primary research. Researchers summarise the existing research and use the results to support their research goals.
Both primary and secondary research have their places. Primary research can support the findings found through secondary research (and fill knowledge gaps), while secondary research can be a starting point for further primary research. Because of this, these research methods are often combined for optimal research results that are accurate at both the micro and macro level.
Sources of Secondary Research
There are two types of secondary research sources: internal and external. Internal data refers to in-house data that can be gathered from the researcher’s organisation. External data refers to data published outside of and not owned by the researcher’s organization.
Internal data
Internal data is a good first port of call for insights and knowledge, as you may already have relevant information stored in your systems. Because you own this information — and it won’t be available to other researchers — it can give you a competitive edge. Examples of internal data include:
- Database information on sales history and business goal conversions
- Information from website applications and mobile site data
- Customer-generated data on product and service efficiency and use
- Previous research results or supplemental research areas
- Previous campaign results
External data
External data is useful when you: 1) need information on a new topic, 2) want to fill in gaps in your knowledge, or 3) want data that breaks down a population or market for trend and pattern analysis. Examples of external data include:
- Government, non-government agencies, and trade body statistics
- Company reports and research
- Competitor research
- Public library collections
- Textbooks and research journals
- Media stories in newspapers
- Online journals and research sites
Three examples of secondary research methods in action
How and why might you conduct secondary research? Let’s look at a few examples:
1. Collecting factual information from the internet on a specific topic or market
There are plenty of sites that hold data for people to view and use in their research. For example, Google Scholar, ResearchGate, or Wiley Online Library all provide previous research on a particular topic. Researchers can create free accounts and use the search facilities to look into a topic by keyword, before following the instructions to download or export results for further analysis.
This can be useful for exploring a new market that your organisation wants to consider entering. For instance, by viewing the U.K census data for that area, you can see what the demographics of your target audience are , and create compelling marketing campaigns accordingly.
2. Finding out the views of your target audience on a particular topic
If you’re interested in seeing the historical views on a particular topic, for example, attitudes to women’s rights in the US, you can turn to secondary sources.
Textbooks, news articles, reviews, and journal entries can all provide qualitative reports and interviews covering how people discussed women’s rights. There may be multimedia elements like video or documented posters of propaganda showing biased language usage.
By gathering this information, synthesising it, and evaluating the language, who created it and when it was shared, you can create a timeline of how a topic was discussed over time.
3. When you want to know the latest thinking on a topic
Educational institutions, such as schools and colleges, create a lot of research-based reports on younger audiences or their academic specialisms. Dissertations from students also can be submitted to research journals, making these places useful places to see the latest insights from a new generation of academics.
Information can be requested — and sometimes academic institutions may want to collaborate and conduct research on your behalf. This can provide key primary data in areas that you want to research, as well as secondary data sources for your research.
Advantages of secondary research
There are several benefits of using secondary research, which we’ve outlined below:
- Easily and readily available data – There is an abundance of readily accessible data sources that have been pre-collected for use, in person at local libraries and online using the internet. This data is usually sorted by filters or can be exported into spreadsheet format, meaning that little technical expertise is needed to access and use the data.
- Faster research speeds – Since the data is already published and in the public arena, you don’t need to collect this information through primary research. This can make the research easier to do and faster, as you can get started with the data quickly.
- Low financial and time costs – Most secondary data sources can be accessed for free or at a small cost to the researcher, so the overall research costs are kept low. In addition, by saving on preliminary research, the time costs for the researcher are kept down as well.
- Secondary data can drive additional research actions – The insights gained can support future research activities (like conducting a follow-up survey or specifying future detailed research topics) or help add value to these activities.
- Secondary data can be useful pre-research insights – Secondary source data can provide pre-research insights and information on effects that can help resolve whether research should be conducted. It can also help highlight knowledge gaps, so subsequent research can consider this.
- Ability to scale up results – Secondary sources can include large datasets (like Census data results across several states) so research results can be scaled up quickly using large secondary data sources.
Disadvantages of secondary research
The disadvantages of secondary research are worth considering in advance of conducting research :
- Secondary research data can be out of date – Secondary sources can be updated regularly, but if you’re exploring the data between two updates, the data can be out of date. Researchers will need to consider whether the data available provides the right research coverage dates, so that insights are accurate and timely, or if the data needs to be updated. Also, fast-moving markets may find secondary data expires very quickly.
- Secondary research needs to be verified and interpreted – Where there’s a lot of data from one source, a researcher needs to review and analyse it. The data may need to be verified against other data sets or your hypotheses for accuracy and to ensure you’re using the right data for your research.
- The researcher has had no control over the secondary research – As the researcher has not been involved in the secondary research, invalid data can affect the results. It’s therefore vital that the methodology and controls are closely reviewed so that the data is collected in a systematic and error-free way.
- Secondary research data is not exclusive – As data sets are commonly available, there is no exclusivity and many researchers can use the same data. This can be problematic where researchers want to have exclusive rights over the research results and risk duplication of research in the future.
When do we conduct secondary research?
Now that you know the basics of secondary research, when do researchers normally conduct secondary research?
It’s often used at the beginning of research, when the researcher is trying to understand the current landscape. In addition, if the research area is new to the researcher, it can form crucial background context to help them understand what information exists already. This can plug knowledge gaps, supplement the researcher’s own learning or add to the research.
Secondary research can also be used in conjunction with primary research. Secondary research can become the formative research that helps pinpoint where further primary research is needed to find out specific information. It can also support or verify the findings from primary research.
You can use secondary research where high levels of control aren’t needed by the researcher, but a lot of knowledge on a topic is required from different angles.
Secondary research should not be used in place of primary research as both are very different and are used for various circumstances.
Questions to ask before conducting secondary research
Before you start your secondary research, ask yourself these questions:
Is there similar internal data that we have created for a similar area in the past?
If your organisation has past research, it’s best to review this work before starting a new project. The older work may provide you with the answers, and give you a starting dataset and context of how your organisation approached the research before. However, be mindful that the work is probably out of date and view it with that note in mind. Read through and look for where this helps your research goals or where more work is needed.
What am I trying to achieve with this research?
When you have clear goals, and understand what you need to achieve, you can look for the perfect type of secondary or primary research to support the aims. Different secondary research data will provide you with different information – for example, looking at news stories to tell you a breakdown of your market’s buying patterns won’t be as useful as internal or external data e-commerce and sales data sources.
How credible will my research be?
If you are looking for credibility, you want to consider how accurate the research results will need to be, and if you can sacrifice credibility for speed by using secondary sources to get you started. Bear in mind which sources you choose — low-credibility data sites, like political party websites that are highly biased to favor their own party, would skew your results.
What is the date of the secondary research?
When you’re looking to conduct research, you want the results to be as useful as possible, so using data that is 10 years old won’t be as accurate as using data that was created a year ago. Since a lot can change in a few years, note the date of your research and look for earlier data sets that can tell you a more recent picture of results. One caveat to this is using data collected over a long-term period for comparisons with earlier periods, which can tell you about the rate and direction of change.
Can the data sources be verified? Does the information you have check out?
If you can’t verify the data by looking at the research methodology, speaking to the original team or cross-checking the facts with other research, it could be hard to be sure that the data is accurate. Think about whether you can use another source, or if it’s worth doing some supplementary primary research to replicate and verify results to help with this issue.
We created a front-to-back guide on conducting market research, The ultimate guide to conducting market research , so you can understand the research journey with confidence.
In it, you’ll learn more about:
- What effective market research looks like
- The use cases for market research
- The most important steps to conducting market research
- And how to take action on your research findings
Download the free guide for a clearer view on secondary research and other key research types for your business.
Related resources
Market intelligence 9 min read, qualitative research questions 11 min read, ethnographic research 11 min read, business research methods 12 min read, qualitative research design 12 min read, business research 10 min read, qualitative research interviews 11 min read, request demo.
Ready to learn more about Qualtrics?

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Adv Pract Oncol
- v.10(4); May-Jun 2019
Secondary Analysis Research
In secondary data analysis (SDA) studies, investigators use data collected by other researchers to address different questions. Like primary data researchers, SDA investigators must be knowledgeable about their research area to identify datasets that are a good fit for an SDA. Several sources of datasets may be useful for SDA, and examples of some of these will be discussed. Advanced practice providers must be aware of possible advantages, such as economic savings, the ability to examine clinically significant research questions in large datasets that may have been collected over time (longitudinal data), generating new hypotheses or clarifying research questions, and avoiding overburdening sensitive populations or investigating sensitive areas. When reading an SDA report, the reader should be able to determine that the authors identified the limitation or disadvantages of their research. For example, a primary dataset cannot “fit” an SDA researcher’s study exactly, SDAs are inherently limited by the inability to definitively examine causality given their retrospective nature, and data may be too old to address current issues.
Secondary analysis of data collected by another researcher for a different purpose, or SDA, is increasing in the medical and social sciences. This is not surprising, given the immense body of health care–related research performed worldwide and the potential beneficial clinical implications of the timely expansion of primary research ( Johnston, 2014 ; Tripathy, 2013 ). Oncology advanced practitioners should understand why and how SDA studies are done, their potential advantages and disadvantages, as well as the importance of reading primary and secondary analysis research reports with the same discriminatory, evaluative eye for possible applicability to their practice setting.
To perform a primary research study, an investigator identifies a problem or question in a particular population that is amenable to the study, designs a research project to address that question, decides on a quantitative or qualitative methodology, determines an adequate sample size and recruits representative subjects, and systematically collects and analyzes data to address specific research questions. On the other hand, an SDA addresses new questions from that dataset previously gathered for a different primary study ( Castle, 2003 ). This might sound “easier,” but investigators who carry out SDA research must have a broad knowledge base and be up to date regarding the state of the science in their area of interest to identify important research questions, find appropriate datasets, and apply the same research principles as primary researchers.
Most SDAs use quantitative data, but some qualitative studies lend themselves to SDA. The researcher must have access to source data, as opposed to secondary source data (e.g., a medical record review). Original qualitative data sources could be videotaped or audiotaped interviews or transcripts, or other notes from a qualitative study ( Rew, Koniak-Griffin, Lewis, Miles, & O’Sullivan, 2000 ). Another possible source for qualitative analysis is open-ended survey questions that reflect greater meaning than forced-response items.
SECONDARY ANALYSIS PROCESS
An SDA researcher starts with a research question or hypothesis, then identifies an appropriate dataset or sets to address it; alternatively, they are familiar with a dataset and peruse it to identify other questions that might be answered by the available data ( Cheng & Phillips, 2014 ). In reality, SDA researchers probably move back and forth between these approaches. For example, an investigator who starts with a research question but does not find a dataset with all needed variables usually must modify the research question(s) based on the best available data.
Secondary data analysis researchers access primary data via formal (public or institutional archived primary research datasets) or informal data sharing sources (pooled datasets separately collected by two or more researchers, or other independent researchers in carrying out secondary analysis; Heaton, 2008 ). There are numerous sources of datasets for secondary analysis. For example, a graduate student might opt to perform a secondary analysis of an advisor’s research. University and government online sites may also be useful, such as the NYU Libraries Data Sources ( https://guides.nyu.edu/c.php?g=276966&p=1848686 ) or the National Cancer Institute, which has many subcategories of datasets ( https://www.cancer.gov/research/resources/search?from=0&toolTypes=datasets_databases ). The Google search engine is useful, and researchers can enter the search term “Archive sources of datasets (add key words related to oncology).”
In one secondary analysis method, researchers reuse their own data—either a single dataset or combined respective datasets to investigate new or additional questions for a new SDA.
Example of a Secondary Data Analysis
An example highlighting this method of reusing one’s own data is Winters-Stone and colleagues’ SDA of data from four previous primary studies they performed at one institution, published in the Journal of Clinical Oncology (JCO) in 2017. Their pooled sample was 512 breast cancer survivors (age 63 ± 6 years) who had been diagnosed and treated for nonmetastatic breast cancer 5.8 years (± 4.1 years) earlier. The investigators divided the cohort, which had no diagnosed neurologic conditions, into two groups: women who reported symptoms consistent with lower-extremity chemotherapy-induced peripheral neuropathy (CIPN; numbness, tingling, or discomfort in feet) vs. CIPN-negative women who did not have symptoms. The objectives of the study were to define patient-reported prevalence of CIPN symptoms in women who had received chemotherapy, compare objective and subjective measures of CIPN in these cancer survivors, and examine the relationship between CIPN symptom severity and outcomes. Objective and subjective measures were used to compare groups for manifestations influenced by CIPN (physical function, disability, and falls). Actual chemotherapy regimens administered had not been documented (a study limitation, but regimens likely included a taxane that is neurotoxic); therefore, investigators could only confirm that symptoms began during chemotherapy and how severely patients rated symptoms.
Up to 10 years after completing chemotherapy, 47% of women who had received chemotherapy were still having significant and potentially life-threatening sensory symptoms consistent with CIPN, did worse on physical function tests, reported poorer functioning, had greater disability, and had nearly twice the rate of falls compared with CIPN-negative women ( Winters-Stone et al., 2017 ). Furthermore, symptom severity was related to worse outcomes, while worsening cancer was not.
Stout (2017) recognized the importance of this secondary analysis in an accompanying editorial published in JCO, remarking that it was the first study that included both patient-reported subjective measures and objective measures of a clinically significant problem. Winter-Stone and others (2017) recognized that by analyzing what essentially became a large sample, they were able to achieve a more comprehensive understanding of the significance and impact of CIPN, and thus to challenge the notion that while CIPN may improve over time, it remains a major cancer survivorship issue. Thus, oncology advanced practitioners must systematically address CIPN at baseline and over time in vulnerable patients, and collaborate with others to implement potentially helpful interventions such as physical and occupational therapy ( Silver & Gilchrist, 2011 ). Other primary or secondary research projects might focus on the usefulness of such interventions.
ADVANTAGES OF SECONDARY DATA ANALYSIS
The advantages of doing SDA research that are cited most often are the economic savings—in time, money, and labor—and the convenience of using existing data rather than collecting primary data, which is usually the most time-consuming and expensive aspect of research ( Johnston, 2014 ; Rew et al., 2000 ; Tripathy, 2013 ). If there is a cost to access datasets, it is usually small (compared to performing the data collection oneself), and detailed information about data collection and statistician support may also be available ( Cheng & Phillips, 2014 ). Secondary data analysis may help a new investigator increase his/her clinical research expertise and avoid data collection challenges (e.g., recruiting study participants, obtaining large-enough sample sizes to yield convincing results, avoiding study dropout, and completing data collection within a reasonable time). Secondary data analyses may also allow for examining more variables than would be feasible in smaller studies, surveys of more diverse samples, and the ability to rethink data and use more advanced statistical techniques in analysis ( Rew et al., 2000 ).
Secondary Data Analysis to Answer Additional Research Questions
Another advantage is that an SDA of a large dataset, possibly combining data from more than one study or by using longitudinal data, can address high-impact, clinically important research questions that might be prohibitively expensive or time-consuming for primary study, and potentially generate new hypotheses ( Smith et al., 2011 ; Tripathy, 2013 ). Schadendorf and others (2015) did one such SDA: a pooled analysis of 12 phase II and phase III studies of ipilimumab (Yervoy) for patients with metastatic melanoma. The study goal was to more accurately estimate the long-term survival benefit of ipilimumab every 3 weeks for greater than or equal to 4 doses in 1,861 patients with advanced melanoma, two thirds of whom had been previously treated and one third who were treatment naive. Almost 89% of patients had received ipilimumab at 3 mg/kg (n = 965), 10 mg/kg (n = 706), or other doses, and about 54% had been followed for longer than 5 years. Across all studies, overall survival curves plateaued between 2 and 3 years, suggesting a durable survival benefit for some patients.
Irrespective of prior therapy, ipilimumab dose, or treatment regimen, median overall survival was 13.5 months in treatment naive patients and 10.7 months in previously treated patients ( Schadendorf et al., 2015 ). In addition, survival curves consistently plateaued at approximately year 3 and continued for up to 10 years (longest follow-up). This suggested that most of the 20% to 26% of patients who reached the plateau had a low risk of death from melanoma thereafter. The authors viewed these results as “encouraging,” given the historic median overall survival in patients with advanced melanoma of 8 to 10 months and 5-year survival of approximately 10%. They identified limitations of their SDA (discussed later in this article). Three-year survival was numerically (but not statistically significantly) greater for the patients who received ipilimumab at 10 mg/kg than at 3 mg/kg doses, which had been noted in one of the included studies.
The importance of this secondary analysis was clearly relevant to prescribers of anticancer therapies, and led to a subsequent phase III trial in the same population to answer the ipilimumab dose question. Ascierto and colleagues’ (2017) study confirmed ipilimumab at 10 mg/kg led to a significantly longer overall survival than at 3 mg/kg (15.7 months vs. 11.5 months) in a subgroup of patients not previously treated with a BRAF inhibitor or immune checkpoint inhibitor. However, this was attained at the cost of greater treatment-related adverse events and more frequent discontinuation secondary to severe ipilimumab-related adverse events. Both would be critical points for advanced practitioners to discuss with patients and to consider in relationship to the particular patient’s ability to tolerate a given regimen.
Secondary Data Analysis to Avoid Study Repetition and Over-Research
Secondary data analysis research also avoids study repetition and over-research of sensitive topics or populations ( Tripathy, 2013 ). For example, people treated for cancer in the United Kingdom are surveyed annually through the National Cancer Patient Experience Survey (NCPES), and questions regarding sexual orientation were first included in the 2013 NCPES. Hulbert-Williams and colleagues (2017) did a more rigorous SDA of this survey to gain an understanding of how lesbian, gay, or bisexual (LGB) patients’ experiences with cancer differed from heterosexual patients.
Sixty-four percent of those surveyed responded (n = 68,737) to the question regarding their “best description of sexual orientation.” 89.3% indicated “heterosexual/straight,” 425 (0.6%) indicated “lesbian or gay,” and 143 (0.2%) indicated “bisexual.” One insight gained from the study was that although the true population proportion of LGB was not known, the small number of self-identified LGB patients most likely did not reflect actual numbers and may have occurred because of ongoing unwillingness to disclose sexual orientation, along with the older mean age of the sample. Other cancer patients who selected “prefer not to answer” (3%), “other” (0.9%), or left the question blank (6%), were not included in the SDA to correctly avoid bias in assuming these responses were related to sexual orientation.
Bisexual respondents were significantly more likely to report that nurses or other health-care professionals informed them about their diagnosis, but that it was subsequently difficult to contact nurse specialists and get understandable answers from them; they were dissatisfied with their interaction with hospital nurses and the care and help provided by both health and social care services after leaving the hospital. Bisexual and lesbian/gay respondents wanted to be involved in treatment decision-making, but therapy choices were not discussed with them, and they were all less satisfied than heterosexuals with the information given to them at diagnosis and during treatment and aftercare—an important clinical implication for oncology advanced practitioners.
Hulbert-Williams and colleagues (2017) proposed that while health-care communication and information resources are not explicitly homophobic, we may perpetuate heterosexuality as “normal” by conversational cues and reliance on heterosexual imagery that implies a context exclusionary of LGB individuals. Sexual orientation equality is about matching care to individual needs for all patients regardless of sexual orientation rather than treating everyone the same way, which does not seem to have happened according to the surveyed respondents’ perceptions. In addition, although LGB respondents replied they did not have or chose to exclude significant others from their cancer experience, there was no survey question that clarified their primary relationship status. This is not a unique strategy for persons with cancer, as LGB individuals may do this to protect family and friends from the negative consequences of homophobia.
Hulbert-Williams and others (2017) identified that this dataset might be useful to identify care needs for patients who identify as LGBT or LGBTQ (queer or questioning; no universally used acronym) and be used to obtain more targeted information from subsequent surveys. There is a relatively small body of data for advanced practitioners and other providers that aid in the assessment and care (including supportive, palliative, and survivorship care) of LGBT individuals—a minority group with many subpopulations that may have unique needs. One such effort is the white paper action plan that came out of the first summit on cancer in the LGBT communities. In 2014, participants from the United States, the United Kingdom, and Canada met to identify LGBT communities’ concerns and needs for cancer research, clinical cancer care, health-care policy, and advocacy for cancer survivorship and LGBT health equity ( Burkhalter et al., 2016 ).
More specifically, Healthy People 2020 now includes two objectives regarding LGBT issues: (1) to increase the number of population-based data systems used to monitor Healthy People 2020 objectives, including a standardized set of questions that identify lesbian, gay, bisexual, and transgender populations; and (2) to increase the number of states and territories that include questions that identify sexual orientation and gender identity on state-level surveys or data systems ( Office of Disease Prevention and Health Promotion, 2019 ). We should help each patient to designate significant others’ (family or friends) degree of involvement in care, while recognizing that LGB patients may exclude their significant others if this process involves disclosing sexual orientation, as this may lead to continued social isolation of cancer patients. This SDA by Hulbert-Williams and colleagues (2017) produced findings in a relatively unexplored area of the overall care experiences of LGB patients.
DISADVANTAGES OF SECONDARY DATA ANALYSIS
Many drawbacks of SDA research center around the fact that a primary investigator collected data reflecting his/her unique perspectives and questions, which may not fit an SDA researcher’s questions ( Rew et al., 2000 ). Secondary data analysis researchers have no control over a desired study population, variables of interest, and study design, and probably did not have a role in collecting the primary data ( Castle, 2003 ; Johnston, 2014 ; Smith et al., 2011 ).
Furthermore, the primary data may not include particular demographic information (e.g., respondent zip codes, race, ethnicity, and specific ages) that were deleted to protect respondent confidentiality, or some other different variables that might be important in the SDA may not have been examined at all ( Cheng & Phillips, 2014 ; Johnston, 2014 ). Although primary data collection takes longer than SDA data collection, identifying and procuring suitable SDA data, analyzing the overall quality of the data, determining any limitations inherent in the original study, and determining whether there is an appropriate fit between the purpose of the original study and the purpose of the SDA can be very time consuming ( Castle, 2003 ; Cheng & Phillips, 2014 ; Rew et al., 2000 ).
Secondary data analysis research may be limited to descriptive, exploratory, and correlational designs and nonparametric statistical tests. By their nature, SDA studies are observational and retrospective, and the investigator cannot examine causal relationships (by a randomized, controlled design). An SDA investigator is challenged to decide whether archival data can be shaped to match new research questions; this means the researcher must have an in-depth understanding of the dataset and know how to alter research questions to match available data and recoded variables.
For example, in their pooled analysis of ipilimumab for advanced melanoma, Schadendorf and colleagues (2015) recognized study limitations that might also be disadvantages of other SDAs. These included the fact that they could not make definitive conclusions about the relationship of survival to ipilimumab dose because the study was not randomized, had no control group, and could not account for key baseline prognostic factors. Other limitations were differences in patient populations in several studies included in the SDA, studies that had been done over 10 years ago (although no other new therapies had improved overall survival during that time), and the fact that treatments received after ipilimumab could have affected overall survival.
READING SECONDARY ANALYSIS RESEARCH
Primary and secondary data investigators apply the same research principles, which should be evident in research reports ( Cheng & Phillips, 2014 ; Hulbert-Williams et al., 2017 ; Johnston, 2014 ; Rew et al., 2000 ; Smith et al., 2011 ; Tripathy, 2013 ).
- ● Did the investigator(s) make a logical and convincing case for the importance of their study?
- ● Is there a clear research question and/or study goals or objectives?
- ● Are there operational definitions for the variables of interest?
- ● Did the authors acknowledge the source of the original data and acquire ethical approval (as necessary)?
- ● Did the authors discuss the strengths and weaknesses of the dataset? For example, how old are the data? Is the dataset sufficiently large to have confidence in the results (adequately powered)?
- ● How well do the data seem to “fit” the SDA research question and design?
- ● Does the methods section allow you, the reader, to “see” how the study was done (e.g., how the sample was selected, the tools/instruments that were used, as well their validity and reliability to measure what was intended, the data collection process, and how the data was analyzed)?
- ● Do the findings, discussion, and conclusions—positive or negative—allow you to answer the “So what?” question, and does your evaluation match the investigator’s conclusion?
Answering these questions allows the advanced practice provider reader to assess the possible value of a secondary analysis (similarly to a primary research) report and its applicability to practice, and to identify further issues or areas for scientific inquiry.
The author has no conflicts of interest to disclose.
- Ascierto P. A., Del Vecchio M., Robert C., Mackiewicz A., Chiarion-Sileni V., Arance A.,…Maio M. (2017). Ipilimumab 10 mg/kg versus ipilimumab 3 mg/kg in patients with unresectable or metastatic melanoma: A randomised, double-blind, multicentre, phase 3 trial . Lancet Oncology , 18 ( 5 ), 611–622. 10.1016/S1470-2045(17)30231-0 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Burkhalter J. E., Margolies L., Sigurdsson H. O., Walland J., Radix A., Rice D.,…Maingi S. (2016). The National LGBT Cancer Action Plan: A white paper of the 2014 National Summit on Cancer in the LGBT Communities . LGBT Health , 3 ( 1 ), 19–31. 10.1089/lgbt.2015.0118 [ CrossRef ] [ Google Scholar ]
- Castle J. E. (2003). Maximizing research opportunities: Secondary data analysis . Journal of Neuroscience Nursing , 35 ( 5 ), 287–290. Retrieved from https://www.ncbi.nlm.nih.gov/pubmed/14593941 [ PubMed ] [ Google Scholar ]
- Cheng H. G., & Phillips M. R. (2014). Secondary analysis of existing data: Opportunities and implementation . Shanghai Archives of Psychiatry , 26 ( 6 ), 371–375. https://dx.doi.org/10.11919%2Fj.issn.1002-0829.214171 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Heaton J. (2008). Secondary analysis of qualitative data: An overview . Historical Social Research , 33 ( 3 ), 33–45. [ Google Scholar ]
- Hulbert-Williams N. J., Plumpton C. O., Flowers P., McHugh R., Neal R. D., Semlyen J., & Storey L. (2017). The cancer care experiences of gay, lesbian and bisexual patients: A secondary analysis of data from the UK Cancer Patient Experience Survey . European Journal of Cancer Care , 26 ( 4 ). 10.1111/ecc.12670 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Johnston M. P. (2014). Secondary data analysis: A method of which the time has come . Qualitative and Quantitative Methods in Libraries (QQML) , 3 , 619–626.r [ Google Scholar ]
- Office of Disease Prevention and Health Promotion. (2019). Lesbian, gay, bisexual, and transgender health . Retrieved from https://www.healthypeople.gov/2020/topics-objectives/topic/lesbian-gay-bisexual-and-transgender-health
- Rew L., Koniak-Griffin D., Lewis M. A., Miles M., & O’Sullivan A. (2000). Secondary data analysis: New perspective for adolescent research . Nursing Outlook , 48 ( 5 ), 223–239. 10.1067/mno.2000.104901 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Schadendorf D., Hodi F. S., Robert C., Weber J. S., Margolin K., Hamid O.,…Wolchok J. D. (2015). Pooled analysis of long-term survival data from phase II and phase III trials of ipilimumab in unresectable or metastatic melanoma . Journal of Clinical Oncology , 33 ( 17 ), 1889–1894. 10.1200/JCO.2014.56.2736 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Silver J. K., & Gilchrist L. S. (2011). Cancer rehabilitation with a focus on evidence-based outpatient physical and occupational therapy interventions . American Journal of Physical Medicine & Rehabilitation , 90 ( 5 Suppl 1 ), S5–S15. 10.1097/PHM.0b013e31820be4ae [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Smith A. K., Ayanian J. Z., Covinsky K. E., Landon B. E., McCarthy E. P., Wee C. C., & Steinman M. A. (2011). Conducting high-value secondary dataset analysis: An introductory guide and resources . Journal of General Internal Medicine , 26 ( 8 ), 920–929. 10.1007/s11606-010-1621-5 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Stout N. L. (2017). Expanding the perspective on chemotherapy-induced peripheral neuropathy management . Journal of Clinical Oncology , 35 ( 23 ), 2593–2594. 10.1200/JCO.2017.73.6207 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Tripathy J. P. (2013). Secondary data analysis: Ethical issues and challenges (letter) . Iranian Journal of Public Health , 42 ( 12 ), 1478–1479. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Winters-Stone K. M., Horak F., Jacobs P. G., Trubowitz P., Dieckmann N. F., Stoyles S., & Faithfull S. (2017). Falls, functioning, and disability among women with persistent symptoms of chemotherapy-induced peripheral neuropathy . Journal of Clinical Oncology , 35 ( 23 ) , 2604–2612. 10.1200/JCO.2016 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
A Guide To Secondary Data Analysis
What is secondary data analysis? How do you carry it out? Find out in this post.
Historically, the only way data analysts could obtain data was to collect it themselves. This type of data is often referred to as primary data and is still a vital resource for data analysts.
However, technological advances over the last few decades mean that much past data is now readily available online for data analysts and researchers to access and utilize. This type of data—known as secondary data—is driving a revolution in data analytics and data science.
Primary and secondary data share many characteristics. However, there are some fundamental differences in how you prepare and analyze secondary data. This post explores the unique aspects of secondary data analysis. We’ll briefly review what secondary data is before outlining how to source, collect and validate them. We’ll cover:
- What is secondary data analysis?
- How to carry out secondary data analysis (5 steps)
- Summary and further reading
Ready for a crash course in secondary data analysis? Let’s go!
1. What is secondary data analysis?
Secondary data analysis uses data collected by somebody else. This contrasts with primary data analysis, which involves a researcher collecting predefined data to answer a specific question. Secondary data analysis has numerous benefits, not least that it is a time and cost-effective way of obtaining data without doing the research yourself.
It’s worth noting here that secondary data may be primary data for the original researcher. It only becomes secondary data when it’s repurposed for a new task. As a result, a dataset can simultaneously be a primary data source for one researcher and a secondary data source for another. So don’t panic if you get confused! We explain exactly what secondary data is in this guide .
In reality, the statistical techniques used to carry out secondary data analysis are no different from those used to analyze other kinds of data. The main differences lie in collection and preparation. Once the data have been reviewed and prepared, the analytics process continues more or less as it usually does. For a recap on what the data analysis process involves, read this post .
In the following sections, we’ll focus specifically on the preparation of secondary data for analysis. Where appropriate, we’ll refer to primary data analysis for comparison.
2. How to carry out secondary data analysis
Step 1: define a research topic.
The first step in any data analytics project is defining your goal. This is true regardless of the data you’re working with, or the type of analysis you want to carry out. In data analytics lingo, this typically involves defining:
- A statement of purpose
- Research design
Defining a statement of purpose and a research approach are both fundamental building blocks for any project. However, for secondary data analysis, the process of defining these differs slightly. Let’s find out how.
Step 2: Establish your statement of purpose
Before beginning any data analytics project, you should always have a clearly defined intent. This is called a ‘statement of purpose.’ A healthcare analyst’s statement of purpose, for example, might be: ‘Reduce admissions for mental health issues relating to Covid-19′. The more specific the statement of purpose, the easier it is to determine which data to collect, analyze, and draw insights from.
A statement of purpose is helpful for both primary and secondary data analysis. It’s especially relevant for secondary data analysis, though. This is because there are vast amounts of secondary data available. Having a clear direction will keep you focused on the task at hand, saving you from becoming overwhelmed. Being selective with your data sources is key.
Step 3: Design your research process
After defining your statement of purpose, the next step is to design the research process. For primary data, this involves determining the types of data you want to collect (e.g. quantitative, qualitative, or both ) and a methodology for gathering them.
For secondary data analysis, however, your research process will more likely be a step-by-step guide outlining the types of data you require and a list of potential sources for gathering them. It may also include (realistic) expectations of the output of the final analysis. This should be based on a preliminary review of the data sources and their quality.
Once you have both your statement of purpose and research design, you’re in a far better position to narrow down potential sources of secondary data. You can then start with the next step of the process: data collection.
Step 4: Locate and collect your secondary data
Collecting primary data involves devising and executing a complex strategy that can be very time-consuming to manage. The data you collect, though, will be highly relevant to your research problem.
Secondary data collection, meanwhile, avoids the complexity of defining a research methodology. However, it comes with additional challenges. One of these is identifying where to find the data. This is no small task because there are a great many repositories of secondary data available. Your job, then, is to narrow down potential sources. As already mentioned, it’s necessary to be selective, or else you risk becoming overloaded.
Some popular sources of secondary data include:
- Government statistics , e.g. demographic data, censuses, or surveys, collected by government agencies/departments (like the US Bureau of Labor Statistics).
- Technical reports summarizing completed or ongoing research from educational or public institutions (colleges or government).
- Scientific journals that outline research methodologies and data analysis by experts in fields like the sciences, medicine, etc.
- Literature reviews of research articles, books, and reports, for a given area of study (once again, carried out by experts in the field).
- Trade/industry publications , e.g. articles and data shared in trade publications, covering topics relating to specific industry sectors, such as tech or manufacturing.
- Online resources: Repositories, databases, and other reference libraries with public or paid access to secondary data sources.
Once you’ve identified appropriate sources, you can go about collecting the necessary data. This may involve contacting other researchers, paying a fee to an organization in exchange for a dataset, or simply downloading a dataset for free online .
Step 5: Evaluate your secondary data
Secondary data is usually well-structured, so you might assume that once you have your hands on a dataset, you’re ready to dive in with a detailed analysis. Unfortunately, that’s not the case!
First, you must carry out a careful review of the data. Why? To ensure that they’re appropriate for your needs. This involves two main tasks:
Evaluating the secondary dataset’s relevance
- Assessing its broader credibility
Both these tasks require critical thinking skills. However, they aren’t heavily technical. This means anybody can learn to carry them out.
Let’s now take a look at each in a bit more detail.
The main point of evaluating a secondary dataset is to see if it is suitable for your needs. This involves asking some probing questions about the data, including:
What was the data’s original purpose?
Understanding why the data were originally collected will tell you a lot about their suitability for your current project. For instance, was the project carried out by a government agency or a private company for marketing purposes? The answer may provide useful information about the population sample, the data demographics, and even the wording of specific survey questions. All this can help you determine if the data are right for you, or if they are biased in any way.
When and where were the data collected?
Over time, populations and demographics change. Identifying when the data were first collected can provide invaluable insights. For instance, a dataset that initially seems suited to your needs may be out of date.
On the flip side, you might want past data so you can draw a comparison with a present dataset. In this case, you’ll need to ensure the data were collected during the appropriate time frame. It’s worth mentioning that secondary data are the sole source of past data. You cannot collect historical data using primary data collection techniques.
Similarly, you should ask where the data were collected. Do they represent the geographical region you require? Does geography even have an impact on the problem you are trying to solve?
What data were collected and how?
A final report for past data analytics is great for summarizing key characteristics or findings. However, if you’re planning to use those data for a new project, you’ll need the original documentation. At the very least, this should include access to the raw data and an outline of the methodology used to gather them. This can be helpful for many reasons. For instance, you may find raw data that wasn’t relevant to the original analysis, but which might benefit your current task.
What questions were participants asked?
We’ve already touched on this, but the wording of survey questions—especially for qualitative datasets—is significant. Questions may deliberately be phrased to preclude certain answers. A question’s context may also impact the findings in a way that’s not immediately obvious. Understanding these issues will shape how you perceive the data.
What is the form/shape/structure of the data?
Finally, to practical issues. Is the structure of the data suitable for your needs? Is it compatible with other sources or with your preferred analytics approach? This is purely a structural issue. For instance, if a dataset of people’s ages is saved as numerical rather than continuous variables, this could potentially impact your analysis. In general, reviewing a dataset’s structure helps better understand how they are categorized, allowing you to account for any discrepancies. You may also need to tidy the data to ensure they are consistent with any other sources you’re using.
This is just a sample of the types of questions you need to consider when reviewing a secondary data source. The answers will have a clear impact on whether the dataset—no matter how well presented or structured it seems—is suitable for your needs.
Assessing secondary data’s credibility
After identifying a potentially suitable dataset, you must double-check the credibility of the data. Namely, are the data accurate and unbiased? To figure this out, here are some key questions you might want to include:
What are the credentials of those who carried out the original research?
Do you have access to the details of the original researchers? What are their credentials? Where did they study? Are they an expert in the field or a newcomer? Data collection by an undergraduate student, for example, may not be as rigorous as that of a seasoned professor.
And did the original researcher work for a reputable organization? What other affiliations do they have? For instance, if a researcher who works for a tobacco company gathers data on the effects of vaping, this represents an obvious conflict of interest! Questions like this help determine how thorough or qualified the researchers are and if they have any potential biases.
Do you have access to the full methodology?
Does the dataset include a clear methodology, explaining in detail how the data were collected? This should be more than a simple overview; it must be a clear breakdown of the process, including justifications for the approach taken. This allows you to determine if the methodology was sound. If you find flaws (or no methodology at all) it throws the quality of the data into question.
How consistent are the data with other sources?
Do the secondary data match with any similar findings? If not, that doesn’t necessarily mean the data are wrong, but it does warrant closer inspection. Perhaps the collection methodology differed between sources, or maybe the data were analyzed using different statistical techniques. Or perhaps unaccounted-for outliers are skewing the analysis. Identifying all these potential problems is essential. A flawed or biased dataset can still be useful but only if you know where its shortcomings lie.
Have the data been published in any credible research journals?
Finally, have the data been used in well-known studies or published in any journals? If so, how reputable are the journals? In general, you can judge a dataset’s quality based on where it has been published. If in doubt, check out the publication in question on the Directory of Open Access Journals . The directory has a rigorous vetting process, only permitting journals of the highest quality. Meanwhile, if you found the data via a blurry image on social media without cited sources, then you can justifiably question its quality!
Again, these are just a few of the questions you might ask when determining the quality of a secondary dataset. Consider them as scaffolding for cultivating a critical thinking mindset; a necessary trait for any data analyst!
Presuming your secondary data holds up to scrutiny, you should be ready to carry out your detailed statistical analysis. As we explained at the beginning of this post, the analytical techniques used for secondary data analysis are no different than those for any other kind of data. Rather than go into detail here, check out the different types of data analysis in this post.
3. Secondary data analysis: Key takeaways
In this post, we’ve looked at the nuances of secondary data analysis, including how to source, collect and review secondary data. As discussed, much of the process is the same as it is for primary data analysis. The main difference lies in how secondary data are prepared.
Carrying out a meaningful secondary data analysis involves spending time and effort exploring, collecting, and reviewing the original data. This will help you determine whether the data are suitable for your needs and if they are of good quality.
Why not get to know more about what data analytics involves with this free, five-day introductory data analytics short course ? And, for more data insights, check out these posts:
- Discrete vs continuous data variables: What’s the difference?
- What are the four levels of measurement? Nominal, ordinal, interval, and ratio data explained
- What are the best tools for data mining?
- Privacy Policy
Buy Me a Coffee
Home » Research Data – Types Methods and Examples
Research Data – Types Methods and Examples
Table of Contents

Research Data
Research data refers to any information or evidence gathered through systematic investigation or experimentation to support or refute a hypothesis or answer a research question.
It includes both primary and secondary data, and can be in various formats such as numerical, textual, audiovisual, or visual. Research data plays a critical role in scientific inquiry and is often subject to rigorous analysis, interpretation, and dissemination to advance knowledge and inform decision-making.
Types of Research Data
There are generally four types of research data:
Quantitative Data
This type of data involves the collection and analysis of numerical data. It is often gathered through surveys, experiments, or other types of structured data collection methods. Quantitative data can be analyzed using statistical techniques to identify patterns or relationships in the data.
Qualitative Data
This type of data is non-numerical and often involves the collection and analysis of words, images, or sounds. It is often gathered through methods such as interviews, focus groups, or observation. Qualitative data can be analyzed using techniques such as content analysis, thematic analysis, or discourse analysis.
Primary Data
This type of data is collected by the researcher directly from the source. It can include data gathered through surveys, experiments, interviews, or observation. Primary data is often used to answer specific research questions or to test hypotheses.
Secondary Data
This type of data is collected by someone other than the researcher. It can include data from sources such as government reports, academic journals, or industry publications. Secondary data is often used to supplement or support primary data or to provide context for a research project.
Research Data Formates
There are several formats in which research data can be collected and stored. Some common formats include:
- Text : This format includes any type of written data, such as interview transcripts, survey responses, or open-ended questionnaire answers.
- Numeric : This format includes any data that can be expressed as numerical values, such as measurements or counts.
- Audio : This format includes any recorded data in an audio form, such as interviews or focus group discussions.
- Video : This format includes any recorded data in a video form, such as observations of behavior or experimental procedures.
- Images : This format includes any visual data, such as photographs, drawings, or scans of documents.
- Mixed media: This format includes any combination of the above formats, such as a survey response that includes both text and numeric data, or an observation study that includes both video and audio recordings.
- Sensor Data: This format includes data collected from various sensors or devices, such as GPS, accelerometers, or heart rate monitors.
- Social Media Data: This format includes data collected from social media platforms, such as tweets, posts, or comments.
- Geographic Information System (GIS) Data: This format includes data with a spatial component, such as maps or satellite imagery.
- Machine-Readable Data : This format includes data that can be read and processed by machines, such as data in XML or JSON format.
- Metadata: This format includes data that describes other data, such as information about the source, format, or content of a dataset.
Data Collection Methods
Some common research data collection methods include:
- Surveys : Surveys involve asking participants to answer a series of questions about a particular topic. Surveys can be conducted online, over the phone, or in person.
- Interviews : Interviews involve asking participants a series of open-ended questions in order to gather detailed information about their experiences or perspectives. Interviews can be conducted in person, over the phone, or via video conferencing.
- Focus groups: Focus groups involve bringing together a small group of participants to discuss a particular topic or issue in depth. The group is typically led by a moderator who asks questions and encourages discussion among the participants.
- Observations : Observations involve watching and recording behaviors or events as they naturally occur. Observations can be conducted in person or through the use of video or audio recordings.
- Experiments : Experiments involve manipulating one or more variables in order to measure the effect on an outcome of interest. Experiments can be conducted in a laboratory or in the field.
- Case studies: Case studies involve conducting an in-depth analysis of a particular individual, group, or organization. Case studies typically involve gathering data from multiple sources, including interviews, observations, and document analysis.
- Secondary data analysis: Secondary data analysis involves analyzing existing data that was collected for another purpose. Examples of secondary data sources include government records, academic research studies, and market research reports.
Analysis Methods
Some common research data analysis methods include:
- Descriptive statistics: Descriptive statistics involve summarizing and describing the main features of a dataset, such as the mean, median, and standard deviation. Descriptive statistics are often used to provide an initial overview of the data.
- Inferential statistics: Inferential statistics involve using statistical techniques to draw conclusions about a population based on a sample of data. Inferential statistics are often used to test hypotheses and determine the statistical significance of relationships between variables.
- Content analysis : Content analysis involves analyzing the content of text, audio, or video data to identify patterns, themes, or other meaningful features. Content analysis is often used in qualitative research to analyze open-ended survey responses, interviews, or other types of text data.
- Discourse analysis: Discourse analysis involves analyzing the language used in text, audio, or video data to understand how meaning is constructed and communicated. Discourse analysis is often used in qualitative research to analyze interviews, focus group discussions, or other types of text data.
- Grounded theory : Grounded theory involves developing a theory or model based on an analysis of qualitative data. Grounded theory is often used in exploratory research to generate new insights and hypotheses.
- Network analysis: Network analysis involves analyzing the relationships between entities, such as individuals or organizations, in a network. Network analysis is often used in social network analysis to understand the structure and dynamics of social networks.
- Structural equation modeling: Structural equation modeling involves using statistical techniques to test complex models that include multiple variables and relationships. Structural equation modeling is often used in social science research to test theories about the relationships between variables.
Purpose of Research Data
Research data serves several important purposes, including:
- Supporting scientific discoveries : Research data provides the basis for scientific discoveries and innovations. Researchers use data to test hypotheses, develop new theories, and advance scientific knowledge in their field.
- Validating research findings: Research data provides the evidence necessary to validate research findings. By analyzing and interpreting data, researchers can determine the statistical significance of relationships between variables and draw conclusions about the research question.
- Informing policy decisions: Research data can be used to inform policy decisions by providing evidence about the effectiveness of different policies or interventions. Policymakers can use data to make informed decisions about how to allocate resources and address social or economic challenges.
- Promoting transparency and accountability: Research data promotes transparency and accountability by allowing other researchers to verify and replicate research findings. Data sharing also promotes transparency by allowing others to examine the methods used to collect and analyze data.
- Supporting education and training: Research data can be used to support education and training by providing examples of research methods, data analysis techniques, and research findings. Students and researchers can use data to learn new research skills and to develop their own research projects.
Applications of Research Data
Research data has numerous applications across various fields, including social sciences, natural sciences, engineering, and health sciences. The applications of research data can be broadly classified into the following categories:
- Academic research: Research data is widely used in academic research to test hypotheses, develop new theories, and advance scientific knowledge. Researchers use data to explore complex relationships between variables, identify patterns, and make predictions.
- Business and industry: Research data is used in business and industry to make informed decisions about product development, marketing, and customer engagement. Data analysis techniques such as market research, customer analytics, and financial analysis are widely used to gain insights and inform strategic decision-making.
- Healthcare: Research data is used in healthcare to improve patient outcomes, develop new treatments, and identify health risks. Researchers use data to analyze health trends, track disease outbreaks, and develop evidence-based treatment protocols.
- Education : Research data is used in education to improve teaching and learning outcomes. Data analysis techniques such as assessments, surveys, and evaluations are used to measure student progress, evaluate program effectiveness, and inform policy decisions.
- Government and public policy: Research data is used in government and public policy to inform decision-making and policy development. Data analysis techniques such as demographic analysis, cost-benefit analysis, and impact evaluation are widely used to evaluate policy effectiveness, identify social or economic challenges, and develop evidence-based policy solutions.
- Environmental management: Research data is used in environmental management to monitor environmental conditions, track changes, and identify emerging threats. Data analysis techniques such as spatial analysis, remote sensing, and modeling are used to map environmental features, monitor ecosystem health, and inform policy decisions.
Advantages of Research Data
Research data has numerous advantages, including:
- Empirical evidence: Research data provides empirical evidence that can be used to support or refute theories, test hypotheses, and inform decision-making. This evidence-based approach helps to ensure that decisions are based on objective, measurable data rather than subjective opinions or assumptions.
- Accuracy and reliability : Research data is typically collected using rigorous scientific methods and protocols, which helps to ensure its accuracy and reliability. Data can be validated and verified using statistical methods, which further enhances its credibility.
- Replicability: Research data can be replicated and validated by other researchers, which helps to promote transparency and accountability in research. By making data available for others to analyze and interpret, researchers can ensure that their findings are robust and reliable.
- Insights and discoveries : Research data can provide insights into complex relationships between variables, identify patterns and trends, and reveal new discoveries. These insights can lead to the development of new theories, treatments, and interventions that can improve outcomes in various fields.
- Informed decision-making: Research data can inform decision-making in a range of fields, including healthcare, business, education, and public policy. Data analysis techniques can be used to identify trends, evaluate the effectiveness of interventions, and inform policy decisions.
- Efficiency and cost-effectiveness: Research data can help to improve efficiency and cost-effectiveness by identifying areas where resources can be directed most effectively. By using data to identify the most promising approaches or interventions, researchers can optimize the use of resources and improve outcomes.
Limitations of Research Data
Research data has several limitations that researchers should be aware of, including:
- Bias and subjectivity: Research data can be influenced by biases and subjectivity, which can affect the accuracy and reliability of the data. Researchers must take steps to minimize bias and subjectivity in data collection and analysis.
- Incomplete data : Research data can be incomplete or missing, which can affect the validity of the findings. Researchers must ensure that data is complete and representative to ensure that their findings are reliable.
- Limited scope: Research data may be limited in scope, which can limit the generalizability of the findings. Researchers must carefully consider the scope of their research and ensure that their findings are applicable to the broader population.
- Data quality: Research data can be affected by issues such as measurement error, data entry errors, and missing data, which can affect the quality of the data. Researchers must ensure that data is collected and analyzed using rigorous methods to minimize these issues.
- Ethical concerns: Research data can raise ethical concerns, particularly when it involves human subjects. Researchers must ensure that their research complies with ethical standards and protects the rights and privacy of human subjects.
- Data security: Research data must be protected to prevent unauthorized access or use. Researchers must ensure that data is stored and transmitted securely to protect the confidentiality and integrity of the data.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Primary Data – Types, Methods and Examples

Qualitative Data – Types, Methods and Examples

Quantitative Data – Types, Methods and Examples

Secondary Data – Types, Methods and Examples

Information in Research – Types and Examples
- What is Secondary Research? + [Methods & Examples]

In some situations, the researcher may not be directly involved in the data gathering process and instead, would rely on already existing data in order to arrive at research outcomes. This approach to systematic investigation is known as secondary research.
There are many reasons a researcher may want to make use of already existing data instead of collecting data samples, first-hand. In this article, we will share some of these reasons with you and show you how to conduct secondary research with Formplus.
What is Secondary Research?
Secondary research is a common approach to a systematic investigation in which the researcher depends solely on existing data in the course of the research process. This research design involves organizing, collating and analyzing these data samples for valid research conclusions.
Secondary research is also known as desk research since it involves synthesizing existing data that can be sourced from the internet, peer-reviewed journals , textbooks, government archives, and libraries. What the secondary researcher does is to study already established patterns in previous researches and apply this information to the specific research context.
Interestingly, secondary research often relies on data provided by primary research and this is why some researches combine both methods of investigation. In this sense, the researcher begins by evaluating and identifying gaps in existing knowledge before adopting primary research to gather new information that will serve his or her research.
What are Secondary Research Methods?
As already highlighted, secondary research involves data assimilation from different sources, that is, using available research materials instead of creating a new pool of data using primary research methods. Common secondary research methods include data collection through the internet, libraries, archives, schools and organizational reports.
- Online Data
Online data is data that is gathered via the internet. In recent times, this method has become popular because the internet provides a large pool of both free and paid research resources that can be easily accessed with the click of a button.
While this method simplifies the data gathering process , the researcher must take care to depend solely on authentic sites when collecting information. In some way, the internet is a virtual aggregation for all other sources of secondary research data.
- Data from Government and Non-government Archives
You can also gather useful research materials from government and non-government archives and these archives usually contain verifiable information that provides useful insights on varying research contexts. In many cases, you would need to pay a sum to gain access to these data.
The challenge, however, is that such data is not always readily available due to a number of factors. For instance, some of these materials are described as classified information as such, it would be difficult for researchers to have access to them.
- Data from Libraries
Research materials can also be accessed through public and private libraries. Think of a library as an information storehouse that contains an aggregation of important information that can serve as valid data in different research contexts.
Typically, researchers donate several copies of dissertations to public and private libraries; especially in cases of academic research. Also, business directories, newsletters, annual reports and other similar documents that can serve as research data, are gathered and stored in libraries, in both soft and hard copies.
- Data from Institutions of Learning
Educational facilities like schools, faculties, and colleges are also a great source of secondary data; especially in academic research. This is because a lot of research is carried out in educational institutions more than in other sectors.
It is relatively easier to obtain research data from educational institutions because these institutions are committed to solving problems and expanding the body of knowledge. You can easily request research materials from educational facilities for the purpose of a literature review.
Secondary research methods can also be categorized into qualitative and quantitative data collection methods . Quantitative data gathering methods include online questionnaires and surveys, reports about trends plus statistics about different areas of a business or industry.
Qualitative research methods include relying on previous interviews and data gathered through focus groups which helps an organization to understand the needs of its customers and plan to fulfill these needs. It also helps businesses to measure the level of employee satisfaction with organizational policies.
When Do We Conduct Secondary Research?
Typically, secondary research is the first step in any systematic investigation. This is because it helps the researcher to understand what research efforts have been made so far and to utilize this knowledge in mapping out a novel direction for his or her investigation.
For instance, you may want to carry out research into the nature of a respiratory condition with the aim of developing a vaccine. The best place to start is to gather existing research material about the condition which would help to point your research in the right direction.
When sifting through these pieces of information, you would gain insights into methods and findings from previous researches which would help you define your own research process. Secondary research also helps you to identify knowledge gaps that can serve as the name of your own research.
Questions to ask before conducting Secondary Research
Since secondary research relies on already existing data, the researcher must take extra care to ensure that he or she utilizes authentic data samples for the research. Falsified data can have a negative impact on the research outcomes; hence, it is important to always carry out resource evaluation by asking a number of questions as highlighted below:
- What is the purpose of the research? Again, it is important for every researcher to clearly define the purpose of the research before proceeding with it. Usually, the research purpose determines the approach that would be adopted.
- What is my research methodology? After identifying the purpose of the research, the next thing to do is outline the research methodology. This is the point where the researcher chooses to gather data using secondary research methods.
- What are my expected research outcomes?
- Who collected the data to be analyzed? Before going on to use secondary data for your research, it is necessary to ascertain the authenticity of the information. This usually affects the data reliability and determines if the researcher can trust the materials. For instance, data gathered from personal blogs and websites may not be as credible as information obtained from an organization’s website.
- When was the data collected? Data recency is another factor that must be considered since the recency of data can affect research outcomes. For instance, if you are carrying out research into the number of women who smoke in London, it would not be appropriate for you to make use of information that was gathered 5 years ago unless you plan to do some sort of data comparison.
- Is the data consistent with other data available from other sources? Always compare and contrast your data with other available research materials as this would help you to identify inconsistencies if any.
- What type of data was collected? Take care to determine if the secondary data aligns with your research goals and objectives.
- How was the data collected?
Advantages of Secondary Research
- Easily Accessible With secondary research, data can easily be accessed in no time; especially with the use of the internet. Apart from the internet, there are different data sources available in secondary research like public libraries and archives which are relatively easy to access too.
- Secondary research is cost-effective and it is not time-consuming. The researcher can cut down on costs because he or she is not directly involved in the data collection process which is also time-consuming.
- Secondary research helps researchers to identify knowledge gaps which can serve as the basis of further systematic investigation.
- It is useful for mapping out the scope of research thereby setting the stage for field investigations. When carrying out secondary research, the researchers may find that the exact information they were looking for is already available, thus eliminating the need and expense incurred in carrying out primary research in these areas.
Disadvantages of Secondary Research
- Questionable Data: With secondary research, it is hard to determine the authenticity of the data because the researcher is not directly involved in the research process. Invalid data can affect research outcomes negatively hence, it is important for the researcher to take extra care by evaluating the data before making use of it.
- Generalization: Secondary data is unspecific in nature and may not directly cater to the needs of the researcher. There may not be correlations between the existing data and the research process.
- Common Data: Research materials in secondary research are not exclusive to an individual or group. This means that everyone has access to the data and there is little or no “information advantage” gained by those who obtain the research.
- It has the risk of outdated research materials. Outdated information may offer little value especially for organizations competing in fast-changing markets.
How to Conduct Online Surveys with Formplus
Follow these 5 steps to create and administer online surveys for secondary research:
- Sign into Formplus
In the Formplus builder, you can easily create an online survey for secondary research by dragging and dropping preferred fields into your form. To access the Formplus builder, you will need to create an account on Formplus.
Once you do this, sign in to your account and click on “Create Form ” to begin.

- Edit Form Title

Click on the field provided to input your form title, for example, “Secondary Research Survey”.
- Click on the edit button to edit the form.

- Add Fields: Drag and drop preferred form fields into your form in the Formplus builder inputs column. There are several field input options for questionnaires in the Formplus builder.
- Edit fields
- Click on “Save”
- Preview form.
- Customize your Form

With the form customization options in the form builder, you can easily change the outlook of your form and make it more unique and personalized. Formplus allows you to change your form theme, add background images and even change the font according to your needs.
- Multiple Sharing Options

Formplus offers multiple form sharing options which enables you to easily share your questionnaire with respondents. You can use the direct social media sharing buttons to share your form link to your organization’s social media pages.
You can send out your survey form as email invitations to your research subjects too. If you wish, you can share your form’s QR code or embed it on your organization’s website for easy access.
Why Use Formplus as a Secondary Research Tool?
- Simple Form Builder Solution
The Formplus form builder is easy to use and does not require you to have any knowledge in computer programming, unlike other form builders. For instance, you can easily add form fields to your form by dragging and dropping them from the inputs section in the builder.
In the form builder, you can also modify your fields to be hidden or read-only and you can create smart forms with save and resume options, form lookup, and conditional logic. Formplus also allows you to customize your form by adding preferred background images and your organization’s logo.
- Over 25 Form Fields
With over 25 versatile form fields available in the form builder, you can easily collect data the way you like. You can receive payments directly in your form by adding payment fields and you can also add file upload fields to allow you receive files in your form too.
- Offline Form feature
With Formplus, you can collect data from respondents even without internet connectivity . Formplus automatically detects when there is no or poor internet access and allows forms to be filled out and submitted in offline mode.
Offline form responses are automatically synced with the servers when the internet connection is restored. This feature is extremely useful for field research that may involve sourcing for data in remote and rural areas plus it allows you to scale up on your audience reach.
- Team and Collaboration
You can add important collaborators and team members to your shared account so that you all can work on forms and responses together. With the multiple users options, you can assign different roles to team members and you can also grant and limit access to forms and folders.
This feature works with an audit trail that enables you to track changes and suggestions made to your form as the administrator of the shared account. You can set up permissions to limit access to the account while organizing and monitoring your form(s) effectively.
- Embeddable Form
Formplus allows you to easily add your form with respondents with the click of a button. For instance, you can directly embed your form in your organization’s web pages by adding Its unique shortcode to your site’s HTML.
You can also share your form to your social media pages using the social media direct sharing buttons available in the form builder. You can choose to embed the form as an iframe or web pop-up that is easy to fill.
With Formplus, you can share your form with numerous form respondents in no time. You can invite respondents to fill out your form via email invitation which allows you to also track responses and prevent multiple submissions in your form.
In addition, you can also share your form link as a QR code so that respondents only need to scan the code to access your form. Our forms have a unique QR code that you can add to your website or print in banners, business cards and the like.
While secondary research can be cost-effective and time-efficient, it requires the researcher to take extra care in ensuring that the data is authentic and valid. As highlighted earlier, data in secondary research can be sourced through the internet, archives, and libraries, amongst other methods.
Secondary research is usually the starting point of systematic investigation because it provides the researcher with a background of existing research efforts while identifying knowledge gaps to be filled. This type of research is typically used in science and education.
It is, however, important to note that secondary research relies on the outcomes of collective primary research data in carrying out its systematic investigation. Hence, the success of your research will depend, to a greater extent, on the quality of data provided by primary research in relation to the research context.
Connect to Formplus, Get Started Now - It's Free!
- primary secondary research differences
- primary secondary research method
- secondary data collection
- secondary research examples
- busayo.longe
You may also like:
Primary vs Secondary Research Methods: 15 Key Differences
Difference between primary and secondary research in definition, examples, data analysis, types, collection methods, advantages etc.
Exploratory Research: What are its Method & Examples?
Overview on exploratory research, examples and methodology. Shows guides on how to conduct exploratory research with online surveys
What is Pure or Basic Research? + [Examples & Method]
Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education and psychology
Recall Bias: Definition, Types, Examples & Mitigation
This article will discuss the impact of recall bias in studies and the best ways to avoid them during research.
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
- Login to Survey Tool Review Center
Secondary Research Advantages, Limitations, and Sources
Summary: secondary research should be a prerequisite to the collection of primary data, but it rarely provides all the answers you need. a thorough evaluation of the secondary data is needed to assess its relevance and accuracy..
5 minutes to read. By author Michaela Mora on January 25, 2022 Topics: Relevant Methods & Tips , Business Strategy , Market Research

Secondary research is based on data already collected for purposes other than the specific problem you have. Secondary research is usually part of exploratory market research designs.
The connection between the specific purpose that originates the research is what differentiates secondary research from primary research. Primary research is designed to address specific problems. However, analysis of available secondary data should be a prerequisite to the collection of primary data.
Advantages of Secondary Research
Secondary data can be faster and cheaper to obtain, depending on the sources you use.
Secondary research can help to:
- Answer certain research questions and test some hypotheses.
- Formulate an appropriate research design (e.g., identify key variables).
- Interpret data from primary research as it can provide some insights into general trends in an industry or product category.
- Understand the competitive landscape.
Limitations of Secondary Research
The usefulness of secondary research tends to be limited often for two main reasons:
Lack of relevance
Secondary research rarely provides all the answers you need. The objectives and methodology used to collect the secondary data may not be appropriate for the problem at hand.
Given that it was designed to find answers to a different problem than yours, you will likely find gaps in answers to your problem. Furthermore, the data collection methods used may not provide the data type needed to support the business decisions you have to make (e.g., qualitative research methods are not appropriate for go/no-go decisions).
Lack of Accuracy
Secondary data may be incomplete and lack accuracy depending on;
- The research design (exploratory, descriptive, causal, primary vs. repackaged secondary data, the analytical plan, etc.)
- Sampling design and sources (target audiences, recruitment methods)
- Data collection method (qualitative and quantitative techniques)
- Analysis point of view (focus and omissions)
- Reporting stages (preliminary, final, peer-reviewed)
- Rate of change in the studied topic (slowly vs. rapidly evolving phenomenon, e.g., adoption of specific technologies).
- Lack of agreement between data sources.
Criteria for Evaluating Secondary Research Data
Before taking the information at face value, you should conduct a thorough evaluation of the secondary data you find using the following criteria:
- Purpose : Understanding why the data was collected and what questions it was trying to answer will tell us how relevant and useful it is since it may or may not be appropriate for your objectives.
- Methodology used to collect the data : Important to understand sources of bias.
- Accuracy of data: Sources of errors may include research design, sampling, data collection, analysis, and reporting.
- When the data was collected : Secondary data may not be current or updated frequently enough for the purpose that you need.
- Content of the data : Understanding the key variables, units of measurement, categories used and analyzed relationships may reveal how useful and relevant it is for your purposes.
- Source reputation : In the era of purposeful misinformation on the Internet, it is important to check the expertise, credibility, reputation, and trustworthiness of the data source.
Secondary Research Data Sources
Compared to primary research, the collection of secondary data can be faster and cheaper to obtain, depending on the sources you use.
Secondary data can come from internal or external sources.
Internal sources of secondary data include ready-to-use data or data that requires further processing available in internal management support systems your company may be using (e.g., invoices, sales transactions, Google Analytics for your website, etc.).
Prior primary qualitative and quantitative research conducted by the company are also common sources of secondary data. They often generate more questions and help formulate new primary research needed.
However, if there are no internal data collection systems yet or prior research, you probably won’t have much usable secondary data at your disposal.
External sources of secondary data include:
- Published materials
- External databases
- Syndicated services.
Published Materials
Published materials can be classified as:
- General business sources: Guides, directories, indexes, and statistical data.
- Government sources: Census data and other government publications.
External Databases
In many industries across a variety of topics, there are private and public databases that can bed accessed online or by downloading data for free, a fixed fee, or a subscription.
These databases can include bibliographic, numeric, full-text, directory, and special-purpose databases. Some public institutions make data collected through various methods, including surveys, available for others to analyze.
Syndicated Services
These services are offered by companies that collect and sell pools of data that have a commercial value and meet shared needs by a number of clients, even if the data is not collected for specific purposes those clients may have.
Syndicated services can be classified based on specific units of measurements (e.g., consumers, households, organizations, etc.).
The data collection methods for these data may include:
- Surveys (Psychographic and Lifestyle, advertising evaluations, general topics)
- Household panels (Purchase and media use)
- Electronic scanner services (volume tracking data, scanner panels, scanner panels with Cable TV)
- Audits (retailers, wholesalers)
- Direct inquiries to institutions
- Clipping services tracking PR for institutions
- Corporate reports
You can spend hours doing research on Google in search of external sources, but this is likely to yield limited insights. Books, articles journals, reports, blogs posts, and videos you may find online are usually analyses and summaries of data from a particular perspective. They may be useful and give you an indication of the type of data used, but they are not the actual data. Whenever possible, you should look at the actual raw data used to draw your own conclusion on its value for your research objectives. You should check professionally gathered secondary research.
Here are some external secondary data sources often used in market research that you may find useful as starting points in your research. Some are free, while others require payment.
- Pew Research Center : Reports about the issues, attitudes, and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis, and other empirical social science research.
- Data.Census.gov : Data dissemination platform to access demographic and economic data from the U.S. Census Bureau.
- Data.gov : The US. government’s open data source with almost 200,00 datasets ranges in topics from health, agriculture, climate, ecosystems, public safety, finance, energy, manufacturing, education, and business.
- Google Scholar : A web search engine that indexes the full text or metadata of scholarly literature across an array of publishing formats and disciplines.
- Google Public Data Explorer : Makes large, public-interest datasets easy to explore, visualize and communicate.
- Google News Archive : Allows users to search historical newspapers and retrieve scanned images of their pages.
- Mckinsey & Company : Articles based on analyses of various industries.
- Statista : Business data platform with data across 170+ industries and 150+ countries.
- Claritas : Syndicated reports on various market segments.
- Mintel : Consumer reports combining exclusive consumer research with other market data and expert analysis.
- MarketResearch.com : Data aggregator with over 350 publishers covering every sector of the economy as well as emerging industries.
- Packaged Facts : Reports based on market research on consumer goods and services industries.
- Dun & Bradstreet : Company directory with business information.
Related Articles
- What Is Market Research?
- Step by Step Guide to the Market Research Process
- How to Leverage UX and Market Research To Understand Your Customers
- Why Your Business Needs Discovery Research
- Your Market Research Plan to Succeed As a Startup
- Top Reason Why Businesses Fail & What To Do About It
- What To Value In A Market Research Vendor
- Don’t Let The Budget Dictate Your Market Research Approach
- How To Use Research To Find High-Order Brand Benefits
- How To Prioritize What To Research
- Don’t Just Trust Your Gut — Do Research
- Understanding the Pros and Cons of Mixed-Mode Research
Subscribe to our newsletter to get notified about future articles
Subscribe and don’t miss anything!
Recent Articles
- Re: Design/Growth Podcast – Researching User Experiences for Business Growth
- Why You Need Positioning Concept Testing in New Product Development
- Why Conjoint Analysis Is Best for Price Research
- The Rise of UX
- Making the Case Against the Van Westendorp Price Sensitivity Meter
- How to Future-Proof Experience Management and Your Business
- When Using Focus Groups Makes Sense
- How to Make Segmentation Research Actionable
- How To Integrate Market Research and UX Research for Desired Business Outcomes
- How To Get Value Out of Your Research Budget
Popular Articles
- Which Rating Scales Should I Use?
- What To Consider in Survey Design
- 6 Decisions To Make When Designing Product Concept Tests
- Write Winning Product Concepts To Get Accurate Results In Concept Tests
- How to Use Qualitative and Quantitative Research in Product Development
- The Opportunity of UX Research Webinar
- Myths & Misunderstandings About UX – MR Realities Podcast
- 12 Research Techniques to Solve Choice Overload
- Concept Testing for UX Researchers
- UX Research Geeks Podcast – Using Market Research for Better Context in UX
- A Researcher’s Path – Data Stories Leaders At Work Podcast
- How To Improve Racial and Gender Inclusion in Survey Design
- Privacy Overview
- Strictly Necessary Cookies
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
Chapter 2: Sociological Research
Research methods: secondary data analysis, learning outcomes.
- Describe secondary data analysis
Secondary Data
While sociologists often engage in original research studies, they also contribute knowledge to the discipline through secondary data analysis . Secondary data do not result from firsthand research collected from primary sources, but are the already completed work of other researchers. Sociologists might study works written by historians, economists, teachers, or early sociologists. They might search through periodicals, newspapers, or magazines from any period in history.
Figure 1. This 1930 Chicago census record is an example of secondary data.
Using available information not only saves time and money but can also add depth to a study. Sociologists often interpret findings in a new way, a way that was not part of an author’s original purpose or intention. To study how women were encouraged to act and behave in the 1960s, for example, a researcher might watch movies, televisions shows, and situation comedies from that period. Or to research changes in behavior and attitudes due to the emergence of television in the late 1950s and early 1960s, a sociologist would rely on new interpretations of secondary data. Decades from now, researchers will most likely conduct similar studies on the advent of mobile phones, the Internet, or Facebook.
Content Analysis of Poor in Magazines
Martin Gilens (1996) wanted to find out why survey research shows that the American public substantially exaggerates the percentage of African Americans among the poor. He examined whether media representations influence public perceptions and did a content analysis of photographs of poor people in American news magazines. He coded and then systematically recorded incidences of three variables: (1) Race: white, black, indeterminate; (2) Employed: working, not working; and (3) Age.
Gilens discovered that not only were African Americans markedly over-represented in news magazine photographs of poverty, but that the photos also tended to under-represent “sympathetic” subgroups of the poor—the elderly and working poor—while over-representing less sympathetic groups—unemployed, working age adults. Gilens concluded that by providing a distorted representation of poverty, U.S. news magazines “reinforce negative stereotypes of blacks as mired in poverty and contribute to the belief that poverty is primarily a ‘black problem’” (1996).
Social scientists also learn by analyzing the research of a variety of agencies. Governmental departments and global groups, like the U.S. Bureau of Labor Statistics or the World Health Organization, publish studies with findings that are useful to sociologists. A public statistic like the foreclosure rate might be useful for studying the effects of the 2008 recession; a racial demographic profile might be compared with data on education funding to examine the resources accessible to different groups.
One of the advantages of secondary data is that they are nonreactive research (or unobtrusive research), meaning that they do not include direct contact with subjects and will not alter or influence people’s behaviors. Unlike studies requiring direct contact with people, using previously published data doesn’t require entering a population, with all the investment and potential risks inherent in that research process.
Using available data does have its challenges. Public records are not always easy to access. A researcher will need to do some legwork to track them down and gain access to records. To guide the search through a vast library of materials and avoid wasting time reading unrelated sources, sociologists employ content analysis , applying a systematic approach to record and value information gleaned from secondary data as they relate to the study at hand.
But, in some cases, there is no way to verify the accuracy of existing data. It is easy to count how many drunk drivers, for example, are pulled over by the police. But how many are not? While it is possible to discover the percentage of teenage students who drop out of high school, it might be more challenging to determine the number who return to school or get their GED later.
Another problem arises when data are unavailable in the exact form needed or do not include the precise angle the researcher seeks. For example, the average salaries paid to professors at a public school is a matter of public record. But the separate figures do not necessarily reveal how long it took each professor to reach the salary range, what their educational backgrounds are, or how long the have been teaching.
When conducting content analysis, it is important to consider the date of publication of an existing source and to take into account attitudes and common cultural ideals that may have influenced the research. For example, Robert S. Lynd and Helen Merrell Lynd gathered research for their book Middletown: A Study in Modern American Culture in the 1920s. Attitudes and cultural norms were vastly different then than they are now. Beliefs about gender roles, race, education, and work have changed significantly since then. At the time, the study’s purpose was to reveal the truth about small U.S. communities. Today, it is an illustration of attitudes and values of the 1920s.


- Teesside University Student & Library Services
- Learning Hub Group
Research Methods
Secondary research.
- Primary Research
What is Secondary Research?
Advantages and disadvantages of secondary research, secondary research in literature reviews, secondary research - going beyond literature reviews, main stages of secondary research, useful resources, using material on this page.
- Quantitative Research This link opens in a new window
- Qualitative Research This link opens in a new window
- Being Critical This link opens in a new window
- Subject LibGuides This link opens in a new window

Secondary research
Secondary research uses research and data that has already been carried out. It is sometimes referred to as desk research. It is a good starting point for any type of research as it enables you to analyse what research has already been undertaken and identify any gaps.
You may only need to carry out secondary research for your assessment or you may need to use secondary research as a starting point, before undertaking your own primary research .
Searching for both primary and secondary sources can help to ensure that you are up to date with what research has already been carried out in your area of interest and to identify the key researchers in the field.
"Secondary sources are the books, articles, papers and similar materials written or produced by others that help you to form your background understanding of the subject. You would use these to find out about experts’ findings, analyses or perspectives on the issue and decide whether to draw upon these explicitly in your research." (Cottrell, 2014, p. 123).
Examples of secondary research sources include:.
- journal articles
- official statistics, such as government reports or organisations which have collected and published data
Primary research involves gathering data which has not been collected before. Methods to collect it can include interviews, focus groups, controlled trials and case studies. Secondary research often comments on and analyses this primary research.
Gopalakrishnan and Ganeshkumar (2013, p. 10) explain the difference between primary and secondary research:
"Primary research is collecting data directly from patients or population, while secondary research is the analysis of data already collected through primary research. A review is an article that summarizes a number of primary studies and may draw conclusions on the topic of interest which can be traditional (unsystematic) or systematic".
Secondary Data
As secondary data has already been collected by someone else for their research purposes, it may not cover all of the areas of interest for your research topic. This research will need to be analysed alongside other research sources and data in the same subject area in order to confirm, dispute or discuss the findings in a wider context.
"Secondary source data, as the name infers, provides second-hand information. The data come ‘pre-packaged’, their form and content reflecting the fact that they have been produced by someone other than the researcher and will not have been produced specifically for the purpose of the research project. The data, none the less, will have some relevance for the research in terms of the information they contain, and the task for the researcher is to extract that information and re-use it in the context of his/her own research project." (Denscombe, 2021, p. 268)
In the video below Dr. Benedict Wheeler (Senior Research Fellow at the European Center for Environment and Human Health at the University of Exeter Medical School) discusses secondary data analysis. Secondary data was used for his research on how the environment affects health and well-being and utilising this secondary data gave access to a larger data set.
As with all research, an important part of the process is to critically evaluate any sources you use. There are tools to help with this in the Being Critical section of the guide.
Louise Corti, from the UK Data Archive, discusses using secondary data in the video below. T he importance of evaluating secondary research is discussed - this is to ensure the data is appropriate for your research and to investigate how the data was collected.
There are advantages and disadvantages to secondary research:
Advantages:
- Usually low cost
- Easily accessible
- Provides background information to clarify / refine research areas
- Increases breadth of knowledge
- Shows different examples of research methods
- Can highlight gaps in the research and potentially outline areas of difficulty
- Can incorporate a wide range of data
- Allows you to identify opposing views and supporting arguments for your research topic
- Highlights the key researchers and work which is being undertaken within the subject area
- Helps to put your research topic into perspective
Disadvantages
- Can be out of date
- Might be unreliable if it is not clear where or how the research has been collected - remember to think critically
- May not be applicable to your specific research question as the aims will have had a different focus
Literature reviews
Secondary research for your major project may take the form of a literature review . this is where you will outline the main research which has already been written on your topic. this might include theories and concepts connected with your topic and it should also look to see if there are any gaps in the research., as the criteria and guidance will differ for each school, it is important that you check the guidance which you have been given for your assessment. this may be in blackboard and you can also check with your supervisor..
The videos below include some insights from academics regarding the importance of literature reviews.
Secondary research which goes beyond literature reviews
For some dissertations/major projects there might only be a literature review (discussed above ). For others there could be a literature review followed by primary research and for others the literature review might be followed by further secondary research.
You may be asked to write a literature review which will form a background chapter to give context to your project and provide the necessary history for the research topic. However, you may then also be expected to produce the rest of your project using additional secondary research methods, which will need to produce results and findings which are distinct from the background chapter t o avoid repetition .
Remember, as the criteria and guidance will differ for each School, it is important that you check the guidance which you have been given for your assessment. This may be in Blackboard and you can also check with your supervisor.
Although this type of secondary research will go beyond a literature review, it will still rely on research which has already been undertaken. And, "just as in primary research, secondary research designs can be either quantitative, qualitative, or a mixture of both strategies of inquiry" (Manu and Akotia, 2021, p. 4) .
Your secondary research may use the literature review to focus on a specific theme, which is then discussed further in the main project. Or it may use an alternative approach. Some examples are included below. Remember to speak with your supervisor if you are struggling to define these areas.
Some approaches of how to conduct secondary research include:
- A systematic review is a structured literature review that involves identifying all of the relevant primary research using a rigorous search strategy to answer a focused research question.
- This involves comprehensive searching which is used to identify themes or concepts across a number of relevant studies.
- The review will assess the q uality of the research and provide a summary and synthesis of all relevant available research on the topic.
- The systematic review LibGuide goes into more detail about this process (The guide is aimed a PhD/Researcher students. However, students on other levels of study may find parts of the guide helpful too).
- Scoping reviews aim to identify and assess available research on a specific topic (which can include ongoing research).
- They are "particularly useful when a body of literature has not yet been comprehensively reviewed, or exhibits a complex or heterogeneous nature not amenable to a more precise systematic review of the evidence. While scoping reviews may be conducted to determine the value and probable scope of a full systematic review, they may also be undertaken as exercises in and of themselves to summarize and disseminate research findings, to identify research gaps, and to make recommendations for the future research." (Peters et al., 2015) .
- This is designed to summarise the current knowledge and provide priorities for future research.
- "A state-of-the-art review will often highlight new ideas or gaps in research with no official quality assessment." (Baguss, 2020) .
- "Bibliometric analysis is a popular and rigorous method for exploring and analyzing large volumes of scientific data." (Donthu et al., 2021)
- Quantitative methods and statistics are used to analyse the bibliographic data of published literature. This can be used to measure the impact of authors, publications, or topics within a subject area.
The bibliometric analysis often uses the data from a citation source such as Scopus or Web of Science .
- This is a technique used to combine the statistic results of prior quantitative studies in order to increase precision and validity.
- "It goes beyond the parameters of a literature review, which assesses existing literature, to actually perform calculations based on the results collated, thereby coming up with new results" (Curtis and Curtis, 2011, p. 220)
(Adapted from: Grant and Booth, 2009, cited in Sarhan and Manu, 2021, p. 72 )
- Grounded Theory is used to create explanatory theory from data which has been collected.
- "Grounded theory data analysis strategies can be used with different types of data, including secondary data." ( Whiteside, Mills and McCalman, 2012 )
- This allows you to use a specific theory or theories which can then be applied to your chosen topic/research area.
- You could focus on one case study which is analysed in depth, or you could examine more than one in order to compare and contrast the important aspects of your research question.
- "Good case studies often begin with a predicament that is poorly comprehended and is inadequately explained or traditionally rationalised by numerous conflicting accounts. Therefore, the aim is to comprehend an existent problem and to use the acquired understandings to develop new theoretical outlooks or explanations." ( Papachroni and Lochrie, 2015, p. 81 )
Main stages of secondary research for a dissertation/major project
In general, the main stages for conducting secondary research for your dissertation or major project will include:
Click on the image below to access the reading list which includes resources used in this guide as well as some additional useful resources.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License .
- << Previous: Primary Research
- Next: Quantitative Research >>
- Last Updated: Aug 11, 2022 3:41 PM
- URL: https://libguides.tees.ac.uk/researchmethods
Library Guides
Dissertations 4: methodology: methods.
- Introduction & Philosophy
- Methodology
Primary & Secondary Sources, Primary & Secondary Data
When describing your research methods, you can start by stating what kind of secondary and, if applicable, primary sources you used in your research. Explain why you chose such sources, how well they served your research, and identify possible issues encountered using these sources.
Definitions
There is some confusion on the use of the terms primary and secondary sources, and primary and secondary data. The confusion is also due to disciplinary differences (Lombard 2010). Whilst you are advised to consult the research methods literature in your field, we can generalise as follows:
Secondary sources
Secondary sources normally include the literature (books and articles) with the experts' findings, analysis and discussions on a certain topic (Cottrell, 2014, p123). Secondary sources often interpret primary sources.
Primary sources
Primary sources are "first-hand" information such as raw data, statistics, interviews, surveys, law statutes and law cases. Even literary texts, pictures and films can be primary sources if they are the object of research (rather than, for example, documentaries reporting on something else, in which case they would be secondary sources). The distinction between primary and secondary sources sometimes lies on the use you make of them (Cottrell, 2014, p123).
Primary data
Primary data are data (primary sources) you directly obtained through your empirical work (Saunders, Lewis and Thornhill 2015, p316).
Secondary data
Secondary data are data (primary sources) that were originally collected by someone else (Saunders, Lewis and Thornhill 2015, p316).
Comparison between primary and secondary data
Use
Virtually all research will use secondary sources, at least as background information.
Often, especially at the postgraduate level, it will also use primary sources - secondary and/or primary data. The engagement with primary sources is generally appreciated, as less reliant on others' interpretations, and closer to 'facts'.
The use of primary data, as opposed to secondary data, demonstrates the researcher's effort to do empirical work and find evidence to answer her specific research question and fulfill her specific research objectives. Thus, primary data contribute to the originality of the research.
Ultimately, you should state in this section of the methodology:
What sources and data you are using and why (how are they going to help you answer the research question and/or test the hypothesis.
If using primary data, why you employed certain strategies to collect them.
What the advantages and disadvantages of your strategies to collect the data (also refer to the research in you field and research methods literature).
Quantitative, Qualitative & Mixed Methods
The methodology chapter should reference your use of quantitative research, qualitative research and/or mixed methods. The following is a description of each along with their advantages and disadvantages.
Quantitative research
Quantitative research uses numerical data (quantities) deriving, for example, from experiments, closed questions in surveys, questionnaires, structured interviews or published data sets (Cottrell, 2014, p93). It normally processes and analyses this data using quantitative analysis techniques like tables, graphs and statistics to explore, present and examine relationships and trends within the data (Saunders, Lewis and Thornhill, 2015, p496).
Qualitative research
Qualitative research is generally undertaken to study human behaviour and psyche. It uses methods like in-depth case studies, open-ended survey questions, unstructured interviews, focus groups, or unstructured observations (Cottrell, 2014, p93). The nature of the data is subjective, and also the analysis of the researcher involves a degree of subjective interpretation. Subjectivity can be controlled for in the research design, or has to be acknowledged as a feature of the research. Subject-specific books on (qualitative) research methods offer guidance on such research designs.
Mixed methods
Mixed-method approaches combine both qualitative and quantitative methods, and therefore combine the strengths of both types of research. Mixed methods have gained popularity in recent years.
When undertaking mixed-methods research you can collect the qualitative and quantitative data either concurrently or sequentially. If sequentially, you can for example, start with a few semi-structured interviews, providing qualitative insights, and then design a questionnaire to obtain quantitative evidence that your qualitative findings can also apply to a wider population (Specht, 2019, p138).
Ultimately, your methodology chapter should state:
Whether you used quantitative research, qualitative research or mixed methods.
Why you chose such methods (and refer to research method sources).
Why you rejected other methods.
How well the method served your research.
The problems or limitations you encountered.
Doug Specht, Senior Lecturer at the Westminster School of Media and Communication, explains mixed methods research in the following video:
LinkedIn Learning Video on Academic Research Foundations: Quantitative
The video covers the characteristics of quantitative research, and explains how to approach different parts of the research process, such as creating a solid research question and developing a literature review. He goes over the elements of a study, explains how to collect and analyze data, and shows how to present your data in written and numeric form.

Link to quantitative research video
Some Types of Methods
There are several methods you can use to get primary data. To reiterate, the choice of the methods should depend on your research question/hypothesis.
Whatever methods you will use, you will need to consider:
why did you choose one technique over another? What were the advantages and disadvantages of the technique you chose?
what was the size of your sample? Who made up your sample? How did you select your sample population? Why did you choose that particular sampling strategy?)
ethical considerations (see also tab...)
safety considerations
validity
feasibility
recording
procedure of the research (see box procedural method...).
Check Stella Cottrell's book Dissertations and Project Reports: A Step by Step Guide for some succinct yet comprehensive information on most methods (the following account draws mostly on her work). Check a research methods book in your discipline for more specific guidance.
Experiments
Experiments are useful to investigate cause and effect, when the variables can be tightly controlled. They can test a theory or hypothesis in controlled conditions. Experiments do not prove or disprove an hypothesis, instead they support or not support an hypothesis. When using the empirical and inductive method it is not possible to achieve conclusive results. The results may only be valid until falsified by other experiments and observations.
For more information on Scientific Method, click here .
Observations
Observational methods are useful for in-depth analyses of behaviours in people, animals, organisations, events or phenomena. They can test a theory or products in real life or simulated settings. They generally a qualitative research method.
Questionnaires and surveys
Questionnaires and surveys are useful to gain opinions, attitudes, preferences, understandings on certain matters. They can provide quantitative data that can be collated systematically; qualitative data, if they include opportunities for open-ended responses; or both qualitative and quantitative elements.
Interviews
Interviews are useful to gain rich, qualitative information about individuals' experiences, attitudes or perspectives. With interviews you can follow up immediately on responses for clarification or further details. There are three main types of interviews: structured (following a strict pattern of questions, which expect short answers), semi-structured (following a list of questions, with the opportunity to follow up the answers with improvised questions), and unstructured (following a short list of broad questions, where the respondent can lead more the conversation) (Specht, 2019, p142).
This short video on qualitative interviews discusses best practices and covers qualitative interview design, preparation and data collection methods.
Focus groups
In this case, a group of people (normally, 4-12) is gathered for an interview where the interviewer asks questions to such group of participants. Group interactions and discussions can be highly productive, but the researcher has to beware of the group effect, whereby certain participants and views dominate the interview (Saunders, Lewis and Thornhill 2015, p419). The researcher can try to minimise this by encouraging involvement of all participants and promoting a multiplicity of views.
This video focuses on strategies for conducting research using focus groups.
Check out the guidance on online focus groups by Aliaksandr Herasimenka, which is attached at the bottom of this text box.
Case study
Case studies are often a convenient way to narrow the focus of your research by studying how a theory or literature fares with regard to a specific person, group, organisation, event or other type of entity or phenomenon you identify. Case studies can be researched using other methods, including those described in this section. Case studies give in-depth insights on the particular reality that has been examined, but may not be representative of what happens in general, they may not be generalisable, and may not be relevant to other contexts. These limitations have to be acknowledged by the researcher.
Content analysis
Content analysis consists in the study of words or images within a text. In its broad definition, texts include books, articles, essays, historical documents, speeches, conversations, advertising, interviews, social media posts, films, theatre, paintings or other visuals. Content analysis can be quantitative (e.g. word frequency) or qualitative (e.g. analysing intention and implications of the communication). It can detect propaganda, identify intentions of writers, and can see differences in types of communication (Specht, 2019, p146). Check this page on collecting, cleaning and visualising Twitter data.
Extra links and resources:
Research Methods
A clear and comprehensive overview of research methods by Emerald Publishing. It includes: crowdsourcing as a research tool; mixed methods research; case study; discourse analysis; ground theory; repertory grid; ethnographic method and participant observation; interviews; focus group; action research; analysis of qualitative data; survey design; questionnaires; statistics; experiments; empirical research; literature review; secondary data and archival materials; data collection.
Doing your dissertation during the COVID-19 pandemic
Resources providing guidance on doing dissertation research during the pandemic: Online research methods; Secondary data sources; Webinars, conferences and podcasts;
- Virtual Focus Groups Guidance on managing virtual focus groups
5 Minute Methods Videos
The following are a series of useful videos that introduce research methods in five minutes. These resources have been produced by lecturers and students with the University of Westminster's School of Media and Communication.

Case Study Research
Research Ethics
Quantitative Content Analysis
Sequential Analysis
Qualitative Content Analysis
Thematic Analysis
Social Media Research
Mixed Method Research
Procedural Method
In this part, provide an accurate, detailed account of the methods and procedures that were used in the study or the experiment (if applicable!).
Include specifics about participants, sample, materials, design and methods.
If the research involves human subjects, then include a detailed description of who and how many participated along with how the participants were selected.
Describe all materials used for the study, including equipment, written materials and testing instruments.
Identify the study's design and any variables or controls employed.
Write out the steps in the order that they were completed.
Indicate what participants were asked to do, how measurements were taken and any calculations made to raw data collected.
Specify statistical techniques applied to the data to reach your conclusions.
Provide evidence that you incorporated rigor into your research. This is the quality of being thorough and accurate and considers the logic behind your research design.
Highlight any drawbacks that may have limited your ability to conduct your research thoroughly.
You have to provide details to allow others to replicate the experiment and/or verify the data, to test the validity of the research.
Bibliography
Cottrell, S. (2014). Dissertations and project reports: a step by step guide. Hampshire, England: Palgrave Macmillan.
Lombard, E. (2010). Primary and secondary sources. The Journal of Academic Librarianship , 36(3), 250-253
Saunders, M.N.K., Lewis, P. and Thornhill, A. (2015). Research Methods for Business Students. New York: Pearson Education.
Specht, D. (2019). The Media And Communications Study Skills Student Guide . London: University of Westminster Press.
- << Previous: Introduction & Philosophy
- Next: Ethics >>
- Last Updated: Sep 14, 2022 12:58 PM
- URL: https://libguides.westminster.ac.uk/methodology-for-dissertations
CONNECT WITH US

- SMU Libraries
- Scholarship & Research
- Teaching & Learning
- Bridwell Library
- Business Library
- DeGolyer Library
- Fondren Library
- Hamon Arts Library
- Underwood Law Library
- Fort Burgwin Library
- Exhibits & Digital Collections
- SMU Scholar
- Special Collections & Archives
- Connect With Us
- Research Guides by Subject
- How Do I . . . ? Guides
- Find Your Librarian
- Writing Support
Types of Research Papers: Overview
A research paper is simply a piece of writing that uses outside sources. There are different types of research papers with varying purposes and expectations for sourcing.
While this guide explains those differences broadly, ask your professor about specific disciplinary conventions.
Need More Help?
Chat
Schedule Appointment
Related Guides
- Literature Reviews
- Annotated Bibliographies
- Starting Your Research
Research and Writing Lab
Need last minute help but didn't book an appointment? Every week we offer online drop-in labs.
Tuesdays 3:00pm - 4:30pm via Zoom @ https://smu.zoom.us/j/92637892352 and in-person, Fondren Red 1st floor (near elevators)
- Last Updated: Apr 8, 2024 10:13 AM
- URL: https://guides.smu.edu/c.php?g=1392924
IMAGES
VIDEO
COMMENTS
Secondary research is a research method that uses data that was collected by someone else. In other words, whenever you conduct research using data that already exists, you are conducting secondary research. On the other hand, any type of research that you undertake yourself is called primary research. Example: Secondary research.
Types of secondary data are as follows: Published data: Published data refers to data that has been published in books, magazines, newspapers, and other print media. Examples include statistical reports, market research reports, and scholarly articles. Government data: Government data refers to data collected by government agencies and departments.
Secondary research, also known as desk research, is a research method that involves compiling existing data sourced from a variety of channels. This includes internal sources (e.g.in-house research) or, more commonly, external sources (such as government statistics, organizational bodies, and the internet).
Bibliographies of these sources can lead to the discovery of further resources to enhance research for organizations. There are two common types of secondary data: Internal data and External data. Internal data is the information that has been stored or organized by the organization itself. External data is the data organized or collected by ...
Secondary analysis of qualitative data is a topic unto itself and is not discussed in this volume. The interested reader is referred to references such as James and Sorenson (2000) and Heaton (2004). The choice of primary or secondary data need not be an either/or ques-tion. Most researchers in epidemiology and public health will work with both ...
SDA involves investigations where data collected for a previous study is analyzed - either by the same researcher(s) or different researcher(s) - to explore new questions or use different analysis strategies that were not a part of the primary analysis (Szabo and Strang, 1997).For research involving quantitative data, SDA, and the process of sharing data for the purpose of SDA, has become ...
Secondary Research Methods with Examples. Secondary research is cost-effective, one of the reasons it is a popular choice among many businesses and organizations. Not every organization is able to pay a huge sum of money to conduct research and gather data. So, rightly secondary research is also termed "desk research", as data can be ...
Secondary Research. Data Source: Involves utilizing existing data and information collected by others. Data Collection: Researchers search, select, and analyze data from published sources, reports, and databases. Time and Resources: Generally more time-efficient and cost-effective as data is already available.
The analysis of existing data sets is routine in disciplines such as economics, political science, and sociology, but it is less well established in psychology (but see Brooks-Gunn & Chase-Lansdale, 1991; Brooks-Gunn, Berlin, Leventhal, & Fuligini, 2000).Moreover, biases against secondary data analysis in favor of primary research may be present in psychology (see McCall & Appelbaum, 1991).
Secondary research, also known as desk research, is a research method that involves compiling existing data sourced from a variety of channels. This includes internal sources (e.g.in-house research) or, more commonly, external sources (such as government statistics, organisational bodies, and the internet).
Secondary data analysis research may be limited to descriptive, exploratory, and correlational designs and nonparametric statistical tests. ... Secondary data analysis: A method of which the time has come. Qualitative and Quantitative Methods in Libraries (QQML), 3, 619-626.r [Google Scholar] Office of Disease Prevention and Health Promotion ...
The analysis is often done by another researcher not related to the primary study using different analysis methods (Szabo & Strang, 1997). Secondary analysis in the context of ... This article provides a guideline for a new secondary qualitative data research methodology that draws on a range of existing methods and adds a procedural structure ...
Evaluating secondary data: Once relevant data has been identified and collates, it will be evaluated to ensure it fulfils the criteria of the research topic. Then, it is analyzed either using the quantitative or qualitative method, depending on the type of data it is. You can learn more about secondary data analysis in this post. 5.
Step 3: Design your research process. After defining your statement of purpose, the next step is to design the research process. For primary data, this involves determining the types of data you want to collect (e.g. quantitative, qualitative, or both) and a methodology for gathering them. For secondary data analysis, however, your research ...
Secondary data is one of the two main types of data, where the second type is the primary data. These 2 data types are very useful in research and statistics, but for the sake of this article, we will be restricting our scope to secondary data. We will study secondary data, its examples, sources, and methods of analysis. What is Secondary Data?
Research data refers to any information or evidence gathered through systematic investigation or experimentation to support or refute a hypothesis or answer a research question. It includes both primary and secondary data, and can be in various formats such as numerical, textual, audiovisual, or visual. Research data plays a critical role in ...
Common secondary research methods include data collection through the internet, libraries, archives, schools and organizational reports. Online Data. Online data is data that is gathered via the internet. In recent times, this method has become popular because the internet provides a large pool of both free and paid research resources that can ...
Compared to primary research, the collection of secondary data can be faster and cheaper to obtain, depending on the sources you use. Secondary data can come from internal or external sources. Internal sources of secondary data include ready-to-use data or data that requires further processing available in internal management support systems ...
Secondary Data. While sociologists often engage in original research studies, they also contribute knowledge to the discipline through secondary data analysis. Secondary data do not result from firsthand research collected from primary sources, but are the already completed work of other researchers. Sociologists might study works written by ...
Secondary research. Secondary research uses research and data that has already been carried out. It is sometimes referred to as desk research. It is a good starting point for any type of research as it enables you to analyse what research has already been undertaken and identify any gaps. You may only need to carry out secondary research for ...
This research employs mixed qualitative and quantitative methods (Onwuegbuzie and Johnson, 2006), and it is strongly based on secondary data (Martins et al., 2018). In order to obtain data from ...
Secondary Data Research Methods The methods for conducting secondary data research typically involve finding and studying published research. There are several ways you can do this, including: Finding the data online: Many market research websites exist, as do blogs and other data analysis websites. Some are free, though some charge fees.
Mixed-method approaches combine both qualitative and quantitative methods, and therefore combine the strengths of both types of research. Mixed methods have gained popularity in recent years. When undertaking mixed-methods research you can collect the qualitative and quantitative data either concurrently or sequentially.
There are different types of research papers with varying purposes and expectations for sourcing. While this guide explains those differences broadly, ask your professor about specific disciplinary conventions. Type. Purpose. Research question. Use of sources. Academic argument essay. To argue for a single claim or thesis through evidence and ...
Data and Methods. This study used hospital-level data from 2017 to 2022. Data were obtained from the Medicare Hospital Cost Reports, the AHA Annual Survey, the Area Health Resource File, the Center for Disease Control and Prevention and the Kaiser Family Foundation. Data were merged using a unique hospital provider ID and a year identifier.
This paper addresses the increasing challenges of identifying novel psychoactive substances based on visual evaluation of spectra in gas chromatography-mass spectrometry; it lays out a summary of the research project, including major goals and objectives, research design, methods, and data analysis, outcomes, limitations, artifacts, references cited, and five appendices.