Create Your Course
The 7 main types of learning styles (and how to teach to them), share this article.
Understanding the 7 main types of learning styles and how to teach them will help both your students and your courses be more successful.
When it comes to learning something new, we all absorb information at different rates and understand it differently too. Some students get new concepts right away; others need to sit and ponder for some time before they can arrive at similar conclusions.
Why? The answer lies in the type of learning styles different students feel more comfortable with. In other words, we respond to information in different ways depending on how it is presented to us.
Clearly, different types of learning styles exist, and there are lots of debates in pedagogy about what they are and how to adapt to them.
For practical purposes, it’s recommended to ensure that your course or presentation covers the 7 main types of learning.
In this article, we’ll break down the 7 types of learning styles, and give practical tips for how you can improve your own teaching styles , whether it’s in higher education or an online course you plan to create on the side.
Skip ahead:

What are the 7 types of learning styles?
How to accommodate different types of learning styles online.
- How to help students understand their different types of learning styles
How to create an online course for all
In the academic literature, the most common model for the types of learning you can find is referred to as VARK.
VARK is an acronym that stands for Visual, Auditory, Reading & Writing, and Kinesthetic. While these learning methods are the most recognized, there are people that do not fit into these boxes and prefer to learn differently. So we’re adding three more learning types to our list, including Logical, Social, and Solitary.
Visual learners
Visual learners are individuals that learn more through images, diagrams, charts, graphs, presentations, and anything that illustrates ideas. These people often doodle and make all kinds of visual notes of their own as it helps them retain information better.
When teaching visual learners, the goal isn’t just to incorporate images and infographics into your lesson. It’s about helping them visualize the relationships between different pieces of data or information as they learn.
Gamified lessons are a great way to teach visual learners as they’re interactive and aesthetically appealing. You should also give handouts, create presentations, and search for useful infographics to support your lessons.
Since visual information can be pretty dense, give your students enough time to absorb all the new knowledge and make their own connections between visual clues.
Auditory/aural learners
The auditory style of learning is quite the opposite of the visual one. Auditory learners are people that absorb information better when it is presented in audio format (i.e. the lessons are spoken). This type of learner prefers to learn by listening and might not take any notes at all. They also ask questions often or repeat what they have just heard aloud to remember it better.
Aural learners are often not afraid of speaking up and are great at explaining themselves. When teaching auditory learners, keep in mind that they shouldn’t stay quiet for long periods of time. So plan a few activities where you can exchange ideas or ask questions. Watching videos or listening to audio during class will also help with retaining new information.
Reading and writing (or verbal) learners
Reading & Writing learners absorb information best when they use words, whether they’re reading or writing them. To verbal learners, written words are more powerful and granular than images or spoken words, so they’re excellent at writing essays, articles, books, etc.
To support the way reading-writing students learn best, ensure they have time to take ample notes and allocate extra time for reading. This type of learner also does really well at remote learning, on their own schedule. Including reading materials and writing assignments in their homework should also yield good results.
Kinesthetic/tactile learners
Kinesthetic learners use different senses to absorb information. They prefer to learn by doing or experiencing what they’re being taught. These types of learners are tactile and need to live through experiences to truly understand something new. This makes it a bit challenging to prepare for them in a regular class setting.
As you try to teach tactile learners, note that they can’t sit still for long and need more frequent breaks than others. You need to get them moving and come up with activities that reinforce the information that was just covered in class. Acting out different roles is great; games are excellent; even collaborative writing on a whiteboard should work fine. If applicable, you can also organize hands-on laboratory sessions, immersions, and workshops.
In general, try to bring every abstract idea into the real world to help kinesthetic learners succeed.
Logical/analytical learners
As the name implies, logical learners rely on logic to process information and understand a particular subject. They search for causes and patterns to create a connection between different kinds of information. Many times, these connections are not obvious to people to learn differently, but they make perfect sense to logical learners.
Logical learners generally do well with facts, statistics, sequential lists, and problem-solving tasks to mention a few.
As a teacher, you can engage logical learners by asking open-ended or obscure questions that require them to apply their own interpretation. You should also use teaching material that helps them hone their problem-solving skills and encourages them to form conclusions based on facts and critical thinking.
Social/interpersonal learners
Social or interpersonal learners love socializing with others and working in groups so they learn best during lessons that require them to interact with their peers . Think study groups, peer discussions, and class quizzes.
To effectively teach interpersonal learners, you’ll need to make teamwork a core part of your lessons. Encourage student interaction by asking questions and sharing stories. You can also incorporate group activities and role-playing into your lessons, and divide the students into study groups.
Solitary/intrapersonal learners
Solitary learning is the opposite of social learning. Solitary, or solo, learners prefer to study alone without interacting with other people. These learners are quite good at motivating themselves and doing individual work. In contrast, they generally don’t do well with teamwork or group discussions.
To help students like this, you should encourage activities that require individual work, such as journaling, which allows them to reflect on themselves and improve their skills. You should also acknowledge your students’ individual accomplishments and help them refine their problem-solving skills.
Are there any unique intelligence types commonly shared by your students? Adapting to these different types of intelligence can help you can design a course best suited to help your students succeed.
Launch your online learning product for free
Use Thinkific to create, market, and sell online courses, communities, and memberships — all from a single platform.
How to help students understand their different types of learning styles
Unless you’re teaching preschoolers, most students probably already realize the type of learning style that fits them best. But some students do get it wrong.
The key here is to observe every student carefully and plan your content for different learning styles right from the start.
Another idea is to implement as much individual learning as you can and then customize that learning for each student. So you can have visual auditory activities, riddles for logical learners, games for kinesthetic learners, reading activities, writing tasks, drawing challenges, and more.
When you’re creating your first course online, it’s important to dedicate enough time to planning out its structure. Don’t just think that a successful course consists of five uploaded videos.
Think about how you present the new knowledge. Where it makes sense to pause and give students the time to reflect. Where to include activities to review the new material. Adapting to the different learning types that people exhibit can help you design an online course best suited to help your students succeed.
That being said, here are some tips to help you tailor your course to each learning style, or at least create enough balance.
Visual learners
Since visual learners like to see or observe images, diagrams, demonstrations, etc., to understand a topic, here’s how you can create a course for them:
- Include graphics, cartoons, or illustrations of concepts
- Use flashcards to review course material
- Use flow charts or maps to organize materials
- Highlight and color code notes to organize materials
- Use color-coded tables to compare and contrast elements
- Use a whiteboard to explain important information
- Have students play around with different font styles and sizes to improve readability
Auditory learners prefer to absorb information by listening to spoken words, so they do well when teachers give spoken instructions and lessons. Here’s how to cater to this learning type through your online course:
- Converse with your students about the subject or topic
- Ask your students questions after each lesson and have them answer you (through the spoken word)
- Have them record lectures and review them with you
- Have articles, essays, and comprehension passages out to them
- As you teach, explain your methods, questions, and answers
- Ask for oral summaries of the course material
- If you teach math or any other math-related course, use a talking calculator
- Create an audio file that your students can listen to
- Create a video of you teaching your lesson to your student
- Include a YouTube video or podcast episode for your students to listen to
- Organize a live Q & A session where students can talk to you and other learners to help them better understand the subject
Reading and writing (or verbal) learners
This one is pretty straightforward. Verbal learners learn best when they read or write (or both), so here are some practical ways to include that in your online course:
- Have your students write summaries about the lesson
- If you teach language or literature, assign them stories and essays that they’d have to read out loud to understand
- If your course is video-based, add transcripts to aid your students’ learning process
- Make lists of important parts of your lesson to help your students memorize them
- Provide downloadable notes and checklists that your students can review after they’ve finished each chapter of your course
- Encourage extra reading by including links to a post on your blog or another website in the course
- Use some type of body movement or rhythm, such as snapping your fingers, mouthing, or pacing, while reciting the material your students should learn
Since kinesthetic learners like to experience hands-on what they learn with their senses — holding, touching, hearing, and doing. So instead of churning out instructions and expecting to follow, do these instead:
- Encourage them to experiment with textured paper, and different sizes of pencils, pens, and crayons to jot down information
- If you teach diction or language, give them words that they should incorporate into their daily conversations with other people
- Encourage students to dramatize or act out lesson concepts to understand them better
Logical learners are great at recognizing patterns, analyzing information, and solving problems. So in your online course, you need to structure your lessons to help them hone these abilities. Here are some things you can do:
- Come up with tasks that require them to solve problems. This is easy if you teach math or a math-related course
- Create charts and graphs that your students need to interpret to fully grasp the lesson
- Ask open-ended questions that require critical thinking
- Create a mystery for your students to solve with clues that require logical thinking or math
- Pose an issue/topic to your students and ask them to address it from multiple perspectives
Since social learners prefer to discuss or interact with others, you should set up your course to include group activities. Here’s how you can do that:
- Encourage them to discuss the course concept with their classmates
- Get your students involved in forum discussions
- Create a platform (via Slack, Discord, etc.) for group discussions
- Pair two or more social students to teach each other the course material
- If you’re offering a cohort-based course , you can encourage students to make their own presentations and explain them to the rest of the class
Solitary learners prefer to learn alone. So when designing your course, you need to take that into consideration and provide these learners a means to work by themselves. Here are some things you can try:
- Encourage them to do assignments by themselves
- Break down big projects into smaller ones to help them manage time efficiently
- Give them activities that require them to do research on their own
- When they’re faced with problems regarding the topic, let them try to work around it on their own. But let them know that they are welcome to ask you for help if they need to
- Encourage them to speak up when you ask them questions as it builds their communication skills
- Explore blended learning , if possible, by combining teacher-led classes with self-guided assignments and extra ideas that students can explore on their own.
Now that you’re ready to teach something to everyone, you might be wondering what you actually need to do to create your online courses. Well, start with a platform.
Thinkific is an intuitive and easy-to-use platform any instructor can use to create online courses that would resonate with all types of learning styles. Include videos, audio, presentations, quizzes, and assignments in your curriculum. Guide courses in real-time or pre-record information in advance. It’s your choice.
In addition, creating a course on Thinkific doesn’t require you to know any programming. You can use a professionally designed template and customize it with a drag-and-drop editor to get exactly the course you want in just a few hours. Try it yourself to see how easy it can be.
This blog was originally published in August 2017, it has since been updated in March 2023.
Althea Storm is a B2B SaaS writer who specializes in creating data-driven content that drives traffic and increases conversions for businesses. She has worked with top companies like AdEspresso, HubSpot, Aura, and Thinkific. When she's not writing web content, she's curled up in a chair reading a crime thriller or solving a Rubik's cube.
- The 5 Most Effective Teaching Styles (Pros & Cons of Each)
- 7 Top Challenges with Online Learning For Students (and Solutions)
- 6 Reasons Why Creators Fail To Sell Their Online Courses
- The Advantages and Disadvantages of Learning in Online Classes in 2023
- 10 Steps To Creating A Wildly Successful Online Course
Related Articles
How tabitha carro creates & promotes online courses using her smartphone.
An in-depth look at how Thinkific customer Tabitha Carro built a successful online course business teaching smart phone marketing to entrepreneurs.
How To Find Your Niche in 4 Simple Steps (Expert Tips)
A step-by-step guide to find your niche. Learn everything from brainstorming profitable niche options to honing in on the best niche for you.
How Jonathan Levi Built a Successful Online Course Business Teaching Speed Readi...
An in-depth case study of how Thinkific customer Jonathan Levi built a successful online course business teaching speed reading and memory skills online.
Try Thinkific for yourself!
Accomplish your course creation and student success goals faster with thinkific..
Download this guide and start building your online program!
It is on its way to your inbox
Center for Teaching
Learning styles, what are learning styles, why are they so popular.
The term learning styles is widely used to describe how learners gather, sift through, interpret, organize, come to conclusions about, and “store” information for further use. As spelled out in VARK (one of the most popular learning styles inventories), these styles are often categorized by sensory approaches: v isual, a ural, verbal [ r eading/writing], and k inesthetic. Many of the models that don’t resemble the VARK’s sensory focus are reminiscent of Felder and Silverman’s Index of Learning Styles , with a continuum of descriptors for how learners process and organize information: active-reflective, sensing-intuitive, verbal-visual, and sequential-global.
There are well over 70 different learning styles schemes (Coffield, 2004), most of which are supported by “a thriving industry devoted to publishing learning-styles tests and guidebooks” and “professional development workshops for teachers and educators” (Pashler, et al., 2009, p. 105).
Despite the variation in categories, the fundamental idea behind learning styles is the same: that each of us has a specific learning style (sometimes called a “preference”), and we learn best when information is presented to us in this style. For example, visual learners would learn any subject matter best if given graphically or through other kinds of visual images, kinesthetic learners would learn more effectively if they could involve bodily movements in the learning process, and so on. The message thus given to instructors is that “optimal instruction requires diagnosing individuals’ learning style[s] and tailoring instruction accordingly” (Pashler, et al., 2009, p. 105).
Despite the popularity of learning styles and inventories such as the VARK, it’s important to know that there is no evidence to support the idea that matching activities to one’s learning style improves learning . It’s not simply a matter of “the absence of evidence doesn’t mean the evidence of absence.” On the contrary, for years researchers have tried to make this connection through hundreds of studies.
In 2009, Psychological Science in the Public Interest commissioned cognitive psychologists Harold Pashler, Mark McDaniel, Doug Rohrer, and Robert Bjork to evaluate the research on learning styles to determine whether there is credible evidence to support using learning styles in instruction. They came to a startling but clear conclusion: “Although the literature on learning styles is enormous,” they “found virtually no evidence” supporting the idea that “instruction is best provided in a format that matches the preference of the learner.” Many of those studies suffered from weak research design, rendering them far from convincing. Others with an effective experimental design “found results that flatly contradict the popular” assumptions about learning styles (p. 105). In sum,
“The contrast between the enormous popularity of the learning-styles approach within education and the lack of credible evidence for its utility is, in our opinion, striking and disturbing” (p. 117).
Pashler and his colleagues point to some reasons to explain why learning styles have gained—and kept—such traction, aside from the enormous industry that supports the concept. First, people like to identify themselves and others by “type.” Such categories help order the social environment and offer quick ways of understanding each other. Also, this approach appeals to the idea that learners should be recognized as “unique individuals”—or, more precisely, that differences among students should be acknowledged —rather than treated as a number in a crowd or a faceless class of students (p. 107). Carried further, teaching to different learning styles suggests that “ all people have the potential to learn effectively and easily if only instruction is tailored to their individual learning styles ” (p. 107).
There may be another reason why this approach to learning styles is so widely accepted. They very loosely resemble the concept of metacognition , or the process of thinking about one’s thinking. For instance, having your students describe which study strategies and conditions for their last exam worked for them and which didn’t is likely to improve their studying on the next exam (Tanner, 2012). Integrating such metacognitive activities into the classroom—unlike learning styles—is supported by a wealth of research (e.g., Askell Williams, Lawson, & Murray-Harvey, 2007; Bransford, Brown, & Cocking, 2000; Butler & Winne, 1995; Isaacson & Fujita, 2006; Nelson & Dunlosky, 1991; Tobias & Everson, 2002).
Importantly, metacognition is focused on planning, monitoring, and evaluating any kind of thinking about thinking and does nothing to connect one’s identity or abilities to any singular approach to knowledge. (For more information about metacognition, see CFT Assistant Director Cynthia Brame’s “ Thinking about Metacognition ” blog post, and stay tuned for a Teaching Guide on metacognition this spring.)
There is, however, something you can take away from these different approaches to learning—not based on the learner, but instead on the content being learned . To explore the persistence of the belief in learning styles, CFT Assistant Director Nancy Chick interviewed Dr. Bill Cerbin, Professor of Psychology and Director of the Center for Advancing Teaching and Learning at the University of Wisconsin-La Crosse and former Carnegie Scholar with the Carnegie Academy for the Scholarship of Teaching and Learning. He points out that the differences identified by the labels “visual, auditory, kinesthetic, and reading/writing” are more appropriately connected to the nature of the discipline:
“There may be evidence that indicates that there are some ways to teach some subjects that are just better than others , despite the learning styles of individuals…. If you’re thinking about teaching sculpture, I’m not sure that long tracts of verbal descriptions of statues or of sculptures would be a particularly effective way for individuals to learn about works of art. Naturally, these are physical objects and you need to take a look at them, you might even need to handle them.” (Cerbin, 2011, 7:45-8:30 )
Pashler and his colleagues agree: “An obvious point is that the optimal instructional method is likely to vary across disciplines” (p. 116). In other words, it makes disciplinary sense to include kinesthetic activities in sculpture and anatomy courses, reading/writing activities in literature and history courses, visual activities in geography and engineering courses, and auditory activities in music, foreign language, and speech courses. Obvious or not, it aligns teaching and learning with the contours of the subject matter, without limiting the potential abilities of the learners.
- Askell-Williams, H., Lawson, M. & Murray, Harvey, R. (2007). ‘ What happens in my university classes that helps me to learn?’: Teacher education students’ instructional metacognitive knowledge. International Journal of the Scholarship of Teaching and Learning , 1. 1-21.
- Bransford, J. D., Brown, A. L. & Cocking, R. R., (Eds.). (2000). How people learn: Brain, mind, experience, and school (Expanded Edition). Washington, D.C.: National Academy Press.
- Butler, D. L., & Winne, P. H. (1995) Feedback and self-regulated learning: A theoretical synthesis . Review of Educational Research , 65, 245-281.
- Cerbin, William. (2011). Understanding learning styles: A conversation with Dr. Bill Cerbin . Interview with Nancy Chick. UW Colleges Virtual Teaching and Learning Center .
- Coffield, F., Moseley, D., Hall, E., & Ecclestone, K. (2004). Learning styles and pedagogy in post-16 learning. A systematic and critical review . London: Learning and Skills Research Centre.
- Isaacson, R. M. & Fujita, F. (2006). Metacognitive knowledge monitoring and self-regulated learning: Academic success and reflections on learning . Journal of the Scholarship of Teaching and Learning , 6, 39-55.
- Nelson, T.O. & Dunlosky, J. (1991). The delayed-JOL effect: When delaying your judgments of learning can improve the accuracy of your metacognitive monitoring. Psychological Science , 2, 267-270.
- Pashler, Harold, McDaniel, M., Rohrer, D., & Bjork, R. (2008). Learning styles: Concepts and evidence . Psychological Science in the Public Interest . 9.3 103-119.
- Tobias, S., & Everson, H. (2002). Knowing what you know and what you don’t: Further research on metacognitive knowledge monitoring . College Board Report No. 2002-3 . College Board, NY.

Teaching Guides
- Online Course Development Resources
- Principles & Frameworks
- Pedagogies & Strategies
- Reflecting & Assessing
- Challenges & Opportunities
- Populations & Contexts
Quick Links
- Services for Departments and Schools
- Examples of Online Instructional Modules

- Covid-19 SYL Resources
- Student Led Conference
- Presentation of Learning
- SYL Stories
What is a Presentation of Learning and Why Do We Do It?
Alec patton.
A Presentation of Learning (POL) requires students to present their learning to an audience, in order to prove that they are ready to progress. Effective POLs include both academic content and the student’s reflection on their social and personal growth. They are important rituals – literally “rites of passage” for students.
At my school, every student gives two POLs per year – one at the end of fall semester, and one at the end of the year. They happen at the same time that most schools have their final exams, and serve a similar function. However, unlike exams, POLs happen in front of an audience that includes their teachers, parents, and peers. By requiring students to present to an audience, reflect on their learning, and answer probing questions on the spot, we are helping students build skills that they will use for the rest of their life. Taking an exam, on the other hand, is a skill that students will rarely, if ever, need to utilize after they finish college.
Every team’s POL expectations are slightly different, but they all fall into one of two broad categories: “presentation” or “discussion”.
Presentation
The presentation is the “classic” version of the POL. A student gives a prepared presentation on their own, and takes questions. Designing a POL structure is a balancing act for the teacher: require students to cover too much material, and every one of your students will march in and recite a near-identical list of assignments completed and skills learned. On the other hand, make the requirements too open-ended and the POL can become an empty facsimile of reflection – or, as students have described it to me, “BS-ing”!
I once saw a POL assignment that included the phrase “it has to have some magic”, which students were free to interpret as they saw fit. It led to unpredictable and delightful presentations, and inspired more thought and extra work than any rubric could have.
The “Discussion of Learning” trades the presentation structure for a seminar structure: a small group of students facilitates their own hour-long discussion, with the teachers initially just listening, then adding questions to enrich and drive the discussion. The parents are invited in for the final fifteen minutes, when the students summarize the discussion thus far and invite the parents to participate.
In my experience, this format tends to lead to meatier, more honest reflection than presentations. Especially when students are allowed to choose their own groups, they tend to make themselves more vulnerable than in other contexts. This format also opens up a space for students whose voices aren’t always heard in the classroom. The most memorable POL I’ve ever been a part of was a discussion by a group of girls, all them native Spanish speakers, who talked about having been made uncomfortably aware of their accents by peers, and struggling to make their voices heard within our team. It was powerful, effective, thoughtful – everything I would have wanted from a POL, but it never would have happened if the structure had been different.
Which format should I choose, and when?
Students will be best-served by experiencing both the “presentation” and “discussion” format at some point in their academic careers.
I like to end fall semester with a presentation, because individual presentations give me the clearest sense of which skills a student has successfully developed, and what they will need more help with in the coming semester. I then end the year with a discussion, because at this point I know the students very well, and in a small-group setting we can speak frankly both about their successes, and the potential problems they will face in the coming year. I end this discussion with every student setting goals for the summer and coming year that I record and email to the student and their parents, so that they leave my class with the best possible trajectory into the future.
Related Projects

The Missing Person in Traditional Parent-Teacher Conferences by Krista Gypton

“Fish Tank” at Lake Travis High School

Trigg County Shares Their Learning, What About Your County? By Michelle Sadrena Pledger

Montgomery Middle Banner Design Exhibition

Students as Teachers: A Senior Reflects on her Final Exhibitions Evening at Meridian Academy
Got any suggestions?
We want to hear from you! Send us a message and help improve Slidesgo
Top searches
Trending searches

memorial day
12 templates

66 templates

8 templates

environmental science
36 templates

ocean theme
44 templates

49 templates
Learning Styles
It seems that you like this template, learning styles presentation, free google slides theme, powerpoint template, and canva presentation template.
Contrary to popular belief, there are lots of different ways of teaching, and they aren’t incompatible. In fact, they complement each other. Some work better for some subjects than others. Eliana Delacour knows this very well, and that’s why she has been the one in charge of the content of this template. These slides about education include real content written by a pedagogist and an amazing design curated by Slidesgo. The perfect combination for teachers, right?
Features of this template
- Designed for teachers and parents
- 100% editable and easy to modify
- 22 different slides to impress your audience
- Contains easy-to-edit graphics such as graphs, maps, tables, timelines and mockups
- Includes 500+ icons and Flaticon’s extension for customizing your slides
- Designed to be used in Google Slides, Canva, and Microsoft PowerPoint
- 16:9 widescreen format suitable for all types of screens
- Includes information about fonts, colors, and credits of the resources used
- Available in different languages
How can I use the template?
Am I free to use the templates?
How to attribute?
Attribution required If you are a free user, you must attribute Slidesgo by keeping the slide where the credits appear. How to attribute?
Available in, related posts on our blog.

How to Add, Duplicate, Move, Delete or Hide Slides in Google Slides

How to Change Layouts in PowerPoint

How to Change the Slide Size in Google Slides
Related presentations.

Premium template
Unlock this template and gain unlimited access

Register for free and start editing online
- Center for Innovative Teaching and Learning
- Instructional Guide
Teaching with PowerPoint
When effectively planned and used, PowerPoint (or similar tools, like Google Slides) can enhance instruction. People are divided on the effectiveness of this ubiquitous presentation program—some say that PowerPoint is wonderful while others bemoan its pervasiveness. No matter which side you take, PowerPoint does offer effective ways to enhance instruction when used and designed appropriately.
PowerPoint can be an effective tool to present material in the classroom and encourage student learning. You can use PowerPoint to project visuals that would otherwise be difficult to bring to class. For example, in an anthropology class, a single PowerPoint presentation could project images of an anthropological dig from a remote area, questions asking students about the topic, a chart of related statistics, and a mini quiz about what was just discussed that provides students with information that is visual, challenging, and engaging.
PowerPoint can be an effective tool to present material in the classroom and encourage student learning.
This section is organized in three major segments: Part I will help faculty identify and use basic but important design elements, Part II will cover ways to enhance teaching and learning with PowerPoint, and Part III will list ways to engage students with PowerPoint.
PART I: Designing the PowerPoint Presentation
Accessibility.
- Student accessibility—students with visual or hearing impairments may not be able to fully access a PowerPoint presentation, especially those with graphics, images, and sound.
- Use an accessible layout. Built-in slide template layouts were designed to be accessible: “the reading order is the same for people with vision and for people who use assistive technology such as screen readers” (University of Washington, n.d.). If you want to alter the layout of a theme, use the Slide Master; this will ensure your slides will retain accessibility.
- Use unique and specific slide titles so students can access the material they need.
- Consider how you display hyperlinks. Since screen readers read what is on the page, you may want to consider creating a hyperlink using a descriptive title instead of displaying the URL.
- All visuals and tables should include alt text. Alt text should describe the visual or table in detail so that students with visual impairments can “read” the images with their screen readers. Avoid using too many decorative visuals.
- All video and audio content should be captioned for students with hearing impairments. Transcripts can also be useful as an additional resource, but captioning ensures students can follow along with what is on the screen in real-time.
- Simplify your tables. If you use tables on your slides, ensure they are not overly complex and do not include blank cells. Screen readers may have difficulty providing information about the table if there are too many columns and rows, and they may “think” the table is complete if they come to a blank cell.
- Set a reading order for text on your slides. The order that text appears on the slide may not be the reading order of the text. Check that your reading order is correct by using the Selection Pane (organized bottom-up).
- Use Microsoft’s Accessibility Checker to identify potential accessibility issues in your completed PowerPoint. Use the feedback to improve your PowerPoint’s accessibility. You could also send your file to the Disability Resource Center to have them assess its accessibility (send it far in advance of when you will need to use it).
- Save your PowerPoint presentation as a PDF file to distribute to students with visual impairments.
Preparing for the presentation
- Consider time and effort in preparing a PowerPoint presentation; give yourself plenty of lead time for design and development.
- PowerPoint is especially useful when providing course material online. Consider student technology compatibility with PowerPoint material put on the web; ensure images and graphics have been compressed for access by computers using dial-up connection.
PowerPoint is especially useful when providing course material online.
- Be aware of copyright law when displaying course materials, and properly cite source material. This is especially important when using visuals obtained from the internet or other sources. This also models proper citation for your students.
- Think about message interpretation for PowerPoint use online: will students be able to understand material in a PowerPoint presentation outside of the classroom? Will you need to provide notes and/or other material to help students understand complex information, data, or graphics?
- If you will be using your own laptop, make sure the classroom is equipped with the proper cables, drivers, and other means to display your presentation the way you have intended.
Slide content
- Avoid text-dense slides. It’s better to have more slides than trying to place too much text on one slide. Use brief points instead of long sentences or paragraphs and outline key points rather than transcribing your lecture. Use PowerPoint to cue and guide the presentation.
- Use the Notes feature to add content to your presentation that the audience will not see. You can access the Notes section for each slide by sliding the bottom of the slide window up to reveal the notes section or by clicking “View” and choosing “Notes Page” from the Presentation Views options.
- Relate PowerPoint material to course objectives to reinforce their purpose for students.
Number of slides
- As a rule of thumb, plan to show one slide per minute to account for discussion and time and for students to absorb the material.
- Reduce redundant or text-heavy sentences or bullets to ensure a more professional appearance.
- Incorporate active learning throughout the presentation to hold students’ interest and reinforce learning.
Emphasizing content
- Use italics, bold, and color for emphasizing content.
- Use of a light background (white, beige, yellow) with dark typeface or a dark background (blue, purple, brown) with a light typeface is easy to read in a large room.
- Avoid using too many colors or shifting colors too many times within the presentation, which can be distracting to students.
- Avoid using underlines for emphasis; underlining typically signifies hypertext in digital media.
Use of a light background with dark typeface or a dark background with a light typeface is easy to read in a large room.
- Limit the number of typeface styles to no more than two per slide. Try to keep typeface consistent throughout your presentation so it does not become a distraction.
- Avoid overly ornate or specialty fonts that may be harder for students to read. Stick to basic fonts so as not to distract students from the content.
- Ensure the typeface is large enough to read from anywhere in the room: titles and headings should be no less than 36-40-point font. The subtext should be no less than 32-point font.
Clip art and graphics
- Use clip art and graphics sparingly. Research shows that it’s best to use graphics only when they support the content. Irrelevant graphics and images have been proven to hinder student learning.
- Photographs can be used to add realism. Again, only use photographs that are relevant to the content and serve a pedagogical purpose. Images for decorative purposes are distracting.
- Size and place graphics appropriately on the slide—consider wrapping text around a graphic.
- Use two-dimensional pie and bar graphs rather than 3D styles which can interfere with the intended message.
Use clip art and graphics sparingly. Research shows that it’s best to use graphics only when they support the content.
Animation and sound
- Add motion, sound, or music only when necessary. When in doubt, do without.
- Avoid distracting animations and transitions. Excessive movement within or between slides can interfere with the message and students find them distracting. Avoid them or use only simple screen transitions.
Final check
- Check for spelling, correct word usage, flow of material, and overall appearance of the presentation.
- Colleagues can be helpful to check your presentation for accuracy and appeal. Note: Errors are more obvious when they are projected.
- Schedule at least one practice session to check for timing and flow.
- PowerPoint’s Slide Sorter View is especially helpful to check slides for proper sequencing as well as information gaps and redundancy. You can also use the preview pane on the left of the screen when you are editing the PowerPoint in “Normal” view.
- Prepare for plan “B” in case you have trouble with the technology in the classroom: how will you provide material located on your flash drive or computer? Have an alternate method of instruction ready (printing a copy of your PowerPoint with notes is one idea).
PowerPoint’s Slide Sorter View is especially helpful to check slides for proper sequencing and information gaps and redundancy.
PowerPoint Handouts
PowerPoint provides multiple options for print-based handouts that can be distributed at various points in the class.
Before class: students might like having materials available to help them prepare and formulate questions before the class period.
During class: you could distribute a handout with three slides and lines for notes to encourage students to take notes on the details of your lecture so they have notes alongside the slide material (and aren’t just taking notes on the slide content).
After class: some instructors wait to make the presentation available after the class period so that students concentrate on the presentation rather than reading ahead on the handout.
Never: Some instructors do not distribute the PowerPoint to students so that students don’t rely on access to the presentation and neglect to pay attention in class as a result.
- PowerPoint slides can be printed in the form of handouts—with one, two, three, four, six, or nine slides on a page—that can be given to students for reference during and after the presentation. The three-slides-per-page handout includes lined space to assist in note-taking.
- Notes Pages. Detailed notes can be printed and used during the presentation, or if they are notes intended for students, they can be distributed before the presentation.
- Outline View. PowerPoint presentations can be printed as an outline, which provides all the text from each slide. Outlines offer a welcome alternative to slide handouts and can be modified from the original presentation to provide more or less information than the projected presentation.
The Presentation
Alley, Schreiber, Ramsdell, and Muffo (2006) suggest that PowerPoint slide headline design “affects audience retention,” and they conclude that “succinct sentence headlines are more effective” in information recall than headlines of short phrases or single words (p. 233). In other words, create slide titles with as much information as is used for newspapers and journals to help students better understand the content of the slide.
- PowerPoint should provide key words, concepts, and images to enhance your presentation (but PowerPoint should not replace you as the presenter).
- Avoid reading from the slide—reading the material can be perceived as though you don’t know the material. If you must read the material, provide it in a handout instead of a projected PowerPoint slide.
- Avoid moving a laser pointer across the slide rapidly. If using a laser pointer, use one with a dot large enough to be seen from all areas of the room and move it slowly and intentionally.
Avoid reading from the slide—reading the material can be perceived as though you don’t know the material.
- Use a blank screen to allow students to reflect on what has just been discussed or to gain their attention (Press B for a black screen or W for a white screen while delivering your slide show; press these keys again to return to the live presentation). This pause can also be used for a break period or when transitioning to new content.
- Stand to one side of the screen and face the audience while presenting. Using Presenter View will display your slide notes to you on the computer monitor while projecting only the slides to students on the projector screen.
- Leave classroom lights on and turn off lights directly over the projection screen if possible. A completely dark or dim classroom will impede notetaking (and may encourage nap-taking).
- Learn to use PowerPoint efficiently and have a back-up plan in case of technical failure.
- Give yourself enough time to finish the presentation. Trying to rush through slides can give the impression of an unorganized presentation and may be difficult for students to follow or learn.
PART II: Enhancing Teaching and Learning with PowerPoint
Class preparation.
PowerPoint can be used to prepare lectures and presentations by helping instructors refine their material to salient points and content. Class lectures can be typed in outline format, which can then be refined as slides. Lecture notes can be printed as notes pages (notes pages: Printed pages that display author notes beneath the slide that the notes accompany.) and could also be given as handouts to accompany the presentation.
Multimodal Learning
Using PowerPoint can help you present information in multiple ways (a multimodal approach) through the projection of color, images, and video for the visual mode; sound and music for the auditory mode; text and writing prompts for the reading/writing mode; and interactive slides that ask students to do something, e.g. a group or class activity in which students practice concepts, for the kinesthetic mode (see Part III: Engaging Students with PowerPoint for more details). Providing information in multiple modalities helps improve comprehension and recall for all students.
Providing information in multiple modalities helps improve comprehension and recall for all students.
Type-on Live Slides
PowerPoint allows users to type directly during the slide show, which provides another form of interaction. These write-on slides can be used to project students’ comments and ideas for the entire class to see. When the presentation is over, the new material can be saved to the original file and posted electronically. This feature requires advanced preparation in the PowerPoint file while creating your presentation. For instructions on how to set up your type-on slide text box, visit this tutorial from AddictiveTips .
Write or Highlight on Slides
PowerPoint also allows users to use tools to highlight or write directly onto a presentation while it is live. When you are presenting your PowerPoint, move your cursor over the slide to reveal tools in the lower-left corner. One of the tools is a pen icon. Click this icon to choose either a laser pointer, pen, or highlighter. You can use your cursor for these options, or you can use the stylus for your smart podium computer monitor or touch-screen laptop monitor (if applicable).
Just-In-Time Course Material
You can make your PowerPoint slides, outline, and/or notes pages available online 24/7 through Blackboard, OneDrive, other websites. Students can review the material before class, bring printouts to class, and better prepare themselves for listening rather than taking a lot of notes during the class period. They can also come to class prepared with questions about the material so you can address their comprehension of the concepts.
PART III: Engaging Students with PowerPoint
The following techniques can be incorporated into PowerPoint presentations to increase interactivity and engagement between students and between students and the instructor. Each technique can be projected as a separate PowerPoint slide.
Running Slide Show as Students Arrive in the Classroom
This technique provides visual interest and can include a series of questions for students to answer as they sit waiting for class to begin. These questions could be on future texts or quizzes.
- Opening Question : project an opening question, e.g. “Take a moment to reflect on ___.”
- Think of what you know about ___.
- Turn to a partner and share your knowledge about ___.
- Share with the class what you have discussed with your partner.
- Focused Listing helps with recall of pertinent information, e.g. “list as many characteristics of ___, or write down as many words related to ___ as you can think of.”
- Brainstorming stretches the mind and promotes deep thinking and recall of prior knowledge, e.g. “What do you know about ___? Start with your clearest thoughts and then move on to those what are kind of ‘out there.’”
- Questions : ask students if they have any questions roughly every 15 minutes. This technique provides time for students to reflect and is also a good time for a scheduled break or for the instructor to interact with students.
- Note Check : ask students to “take a few minutes to compare notes with a partner,” or “…summarize the most important information,” or “…identify and clarify any sticking points,” etc.
- Questions and Answer Pairs : have students “take a minute to come with one question then see if you can stump your partner!”
- The Two-Minute Paper allows the instructor to check the class progress, e.g. “summarize the most important points of today’s lecture.” Have students submit the paper at the end of class.
- “If You Could Ask One Last Question—What Would It Be?” This technique allows for students to think more deeply about the topic and apply what they have learned in a question format.
- A Classroom Opinion Poll provides a sense of where students stand on certain topics, e.g. “do you believe in ___,” or “what are your thoughts on ___?”
- Muddiest Point allows anonymous feedback to inform the instructor if changes and or additions need to be made to the class, e.g. “What parts of today’s material still confuse you?”
- Most Useful Point can tell the instructor where the course is on track, e.g. “What is the most useful point in today’s material, and how can you illustrate its use in a practical setting?”
Positive Features of PowerPoint
- PowerPoint saves time and energy—once the presentation has been created, it is easy to update or modify for other courses.
- PowerPoint is portable and can be shared easily with students and colleagues.
- PowerPoint supports multimedia, such as video, audio, images, and
PowerPoint supports multimedia, such as video, audio, images, and animation.
Potential Drawbacks of PowerPoint
- PowerPoint could reduce the opportunity for classroom interaction by being the primary method of information dissemination or designed without built-in opportunities for interaction.
- PowerPoint could lead to information overload, especially with the inclusion of long sentences and paragraphs or lecture-heavy presentations with little opportunity for practical application or active learning.
- PowerPoint could “drive” the instruction and minimize the opportunity for spontaneity and creative teaching unless the instructor incorporates the potential for ingenuity into the presentation.
As with any technology, the way PowerPoint is used will determine its pedagogical effectiveness. By strategically using the points described above, PowerPoint can be used to enhance instruction and engage students.
Alley, M., Schreiber, M., Ramsdell, K., & Muffo, J. (2006). How the design of headlines in presentation slides affects audience retention. Technical Communication, 53 (2), 225-234. Retrieved from https://www.jstor.org/stable/43090718
University of Washington, Accessible Technology. (n.d.). Creating accessible presentations in Microsoft PowerPoint. Retrieved from https://www.washington.edu/accessibility/documents/powerpoint/
Selected Resources
Brill, F. (2016). PowerPoint for teachers: Creating interactive lessons. LinkedIn Learning . Retrieved from https://www.lynda.com/PowerPoint-tutorials/PowerPoint-Teachers-Create-Interactive-Lessons/472427-2.html
Huston, S. (2011). Active learning with PowerPoint [PDF file]. DE Oracle @ UMUC . Retrieved from http://contentdm.umuc.edu/digital/api/collection/p16240coll5/id/78/download
Microsoft Office Support. (n.d.). Make your PowerPoint presentations accessible to people with disabilities. Retrieved from https://support.office.com/en-us/article/make-your-powerpoint-presentations-accessible-to-people-with-disabilities-6f7772b2-2f33-4bd2-8ca7-ae3b2b3ef25
Tufte, E. R. (2006). The cognitive style of PowerPoint: Pitching out corrupts within. Cheshire, CT: Graphics Press LLC.
University of Nebraska Medical Center, College of Medicine. (n.d.). Active Learning with a PowerPoint. Retrieved from https://www.unmc.edu/com/_documents/active-learning-ppt.pdf
University of Washington, Department of English. (n.d.). Teaching with PowerPoint. Retrieved from https://english.washington.edu/teaching/teaching-powerpoint
Vanderbilt University, Center for Teaching. (n.d.). Making better PowerPoint presentations. Retrieved from https://cft.vanderbilt.edu/guides-sub-pages/making-better-powerpoint-presentations/

Suggested citation
Northern Illinois University Center for Innovative Teaching and Learning. (2020). Teaching with PowerPoint. In Instructional guide for university faculty and teaching assistants. Retrieved from https://www.niu.edu/citl/resources/guides/instructional-guide
Phone: 815-753-0595 Email: [email protected]
Connect with us on
Facebook page Twitter page YouTube page Instagram page LinkedIn page
Ace the Presentation

5 Learning Styles to Consider for Memorable Presentations
There is no consensus on foolproof tricks to satisfy the audience in a presentation, and each researcher certainly has tips on this based on their personal experience.
However, there is an aspect that often eludes attention and directly influences the appeal that the material exposed has on the audience: the different learning styles.
Professionals who want to succeed in their corporate presentations should know the different learning styles deeply. After all, each individual has their way of capturing information and sending it to the brain to turn it into knowledge.
Thinking about this challenge for presenters, we elaborated this article with the primary learning styles. By dominating each of them, you’ll be able to create personalized and more efficient presentations that meet the expectations of all participants.
What are Learning Styles?
Learning styles are cognitive skills that each person uses to fix specific topics, implying that learning a subject varies from person to person.
From the strategy of personal knowledge, one has more efficiently with a style and more incredible difficulty understanding information with others.
The Vark method, developed by the New Zealand professor Neil Fleming and Colleen Mills, proposes that learning takes place through five skills: auditory, visual, kinesthetic, reading and writing, and multimodal (when learning occurs through two or more skills).
VARK is an acronym that designates the four modes of learning: Visual, Auditory, Read/Write, and Kinesthetic.
5 Learning Styles to use when structuring Public Presentations
1. visual learning style.
The visual learning style is the one in which the person learns through vision. The easiest to assimilate information is recorded in graphs, videos, images, diagrams, maps, symbols, and lists.
People with a visual learning style tend to take notes to assimilate something or record it in memory; they are not satisfied or do not get along just by listening to the presenter.
For you to capture the attention of a visual audience, your presentation needs some features. Some rich features that can boost presentations are:
- Photography;
2. Auditory learning style
The person with the sharpest aural style can learn by listening to information. In this way, the individual can participate in discussions, explain concepts, listen to podcasts, read aloud, and listen to recordings of lessons.
People who have an auditory learning style, when they hear some information, their brain memorizes it.
So during a presentation it is expected that they express themselves and repeat the content to memorize certain subjects, even though the ideas have not gone through great reflection before being exposed to the public.
Knowing this, see what you need when setting up your presentations to cater for these people:
- Podcasts extracts.
3-4. Reading/Writing
It is the modality that differs because it is tied to written content. People who identify with this style have ease in dealing with information expressed in the form of words.
In addition, they are people who have the facility to express abstract knowledge in written language.
They prefer to study through books, workbooks, dictionaries, online texts, articles, and research because they find ways to learn more quickly. Most of them are people who also like to read a lot.
5. Kinesthetic learning style
This term may seem a little strange, but if we search the origin and meaning of this word, we will realize that it is associated with the perception of muscle movements.
At this point, you may think, but what does this have to do with learning style?
The relationship of the kinesthetic learning style with muscular movements is because specific individuals develop the ability to learn through practical situations of life.
That is, they are highly active. They are those who do not cling too much to theories.
Imagine those who are seen as agitated people. In the case of school children, teachers often consider them hyperactive. Even as adults, they don’t get to spend much time listening to a story or reading a lengthy text is too quiet a place.
The ideal for this public is not too dull and monotonous; otherwise, they can stand up from their chairs and go away or stay a period outside the auditorium room.
Here are the tips to keep people with the characteristics of the style of learning Kinesthetic interested in your presentation:
- Hold debates;
- If possible, take short breaks;
- Move on the stage;
- Give practical examples,
- Avoid being only in theory;
- Make provocations and inquiries.
This is especially true in presentations to large audiences, in which the exhibitor tends to want to offer an impact presentation.
With a great diversity of information, technological resources, or a lot of interactivity, it often forgets whether it will capture the attention of the majority.
Given this knowledge of different learning styles, the idea is to create a clear, objective presentation and coordinate appeals that satisfy the four types.
Want to Stand Out? 15 Key Tips for an Awesome Presentation

11 Best Body Language Tips For Engaging Presentations (#11 is Underrated)

Growing up, we were always taught how we should have manners while talking to others and that there were some things we could not do in front of people like sprawling or even putting our elbows on the table while eating because it was rude. In the examples above, the rudeness comes from gestures, not…
Learning styles are the way each person uses to learn the proposed content, and this is because each person has eased with a particular style and more difficulty learning from others. Therefore, each person is unique in their way of learning!
The presenter must adapt his presentation to the primary intelligence, which is also the secret of good interpersonal communication.
Learning styles represent part of our five senses – vision, hearing, touch, smell, and taste. Each person usually has one or more of them developed.
References and Further Reading
Learning Styles. OREILLY.
Your Guide To Understanding And Adapting To Different Learning Styles. Cornerstone.
Ace Presentation. Tips for Conducting Audience Analysis.
Similar Posts

5 Great Tips on How to Become a Motivational Speaker
There a lot of people pondering and wondering. How do I become a motivational speaker? What steps do I take? I want to inspire people? How do I do it? I wish I could speak eloquently and help people, how do I go about becoming a great role model, an inspiration for others? How to…

18 PUBLIC SPEAKING QUESTIONS ANSWERED
At some point in your life, you will have to speak in public, maybe at school or work, it is inevitable. One’s best course of action is to prepare for it. Here, I have put together a list of 18 frequently asked questions about public speaking, to help you on your journey to becoming a…

8 Tips on How to Overcome the Public Speaking Fear
Public Speaking Fear is quite common. In fact, 3 in every four people are afraid of speaking in public. Regardless of the numbers from researches, this is a prevalent problem, so much so that every one of us might have faced it or seen people who suffer from it. I have got a more in-depth…

Patrick Henry Speech Analysis
There are speeches that educate. There are speeches that inspire. And then there is the Patrick Henry speech – an explosive, passionate oration that we can consider as quite possibly the reason for the American Revolution (and the consequent adoption of the Declaration of Independence over a year later). So, it’s no wonder that this…

The I Have A Dream Speech By Martin Luther King Jr
The “I Have A Dream” speech, which was delivered by Martin Luther King Jr on August 28, 1963, was part of the speeches delivered during the March on Washington to secure the enactment of the Civil Rights Acts in 1964. The Speech, which was a call for freedom and equality, turned out to become one of the defining moments that…

Your Mind goes Blank during a presentation – What to do?
Conducting lectures is an excellent achievement for any professional, but certain basic precautions must be taken to avoid turning this opportunity of accomplishment into a nightmare. One of the most common mistakes is having the famous blank, where the words suddenly run away, and you cannot complete the presentation. When you make it clear to…

- Our Mission
How a Simple Presentation Framework Helps Students Learn
Explaining concepts to their peers helps students shore up their content knowledge and improve their communication skills.

A few years ago, my colleague and I were awarded a Hawai‘i Innovation Fund Grant. The joy of being awarded the grant was met with dread and despair when we were informed that we would have to deliver a 15-minute presentation on our grant write-up to a room full of educational leaders. If that wasn’t intimidating enough, my colleague informed me that he was not going to be in Hawai‘i at the time of the presentation. I had “one shot,” just a 15-minute presentation to encapsulate all of the 17 pages of the grant I had cowritten, but how?
I worked hard to construct and deliver a presentation that was concise yet explicit. I was clear on the big picture of what the grant was composed of and provided a visual of it in practice. I made sure the audience understood the “why” behind the grant. I showed how it worked, the concrete elements of it, and how they made it successful. I finished with a scaffold that would help others know how to initiate it within their context, giving them the freedom to make it authentically their own.
I received good feedback from the presentation, and more important, what was shared positively impacted student learning in other classrooms across the state.
A Simple Framework for Presentations
That first presentation took me over a month to prepare, but afterward I noticed that my prep time for presentations shrank exponentially from a few months to a few (uninterrupted) days. Interestingly enough, as a by-product of creating the original presentation, I created an abstract framework that I have used for every professional learning presentation I have delivered since then. The “What, Why, How, and How-To” framework goes as follows:
- What? What can the audience easily connect to and know as a bridge to the unknown for the rest of the experience?
- Why? Why should they care to listen to (and learn from) the rest of the presentation? What’s in it for them to shift from passive listeners to actively engaged? The audience needs to know why you believe in this so much that you are compelled to share it.
- How? What are the key elements that make it unique? How is it effective in doing what it does? What are the intricacies of how it works?
- How-to? How could they start doing this on their own? How could this knowledge serve as a foundational springboard? Connect it to “why.”
Benefits for Students
One of the best parts of presentations is that they help the presenter to improve their communication skills. The presenter is learning how to give a presentation by doing it. To prepare a presentation, the presenter must know the intricate elements of what they are presenting and the rationale for their importance. In the presentation delivery, the presenter must be articulate and meticulous to ensure that everyone in the audience is able (and willing) to process the information provided.
It didn’t take long for me to realize that preparing and delivering presentations could provide a valuable learning opportunity for my students.
I recall teaching mathematical concepts whereby students would immediately apply knowledge learned to accomplish the task in silence and without any deeper questioning. Only after I asked them to provide presentations on these concepts did they regularly ask me, “Why is this important, again?” or “What makes this so special?” My students’ mathematical literacy grew through preparing presentations with the “What, Why, How, and How-To” framework, which supported them in their ability to demonstrate content knowledge through mathematical rigor (balancing conceptual understanding, skills and procedural fluency, and real-world application).
- The “what” served as the mathematical concept.
- The “why” demonstrated the real-world application of the concept.
- “The “how” demonstrated conceptual understanding of the concept.
- The “how-to” demonstrated skills and procedures of the concept.
In addition to content knowledge, the sequential competencies of clarity, cohesiveness, and captivation ensured that the presenter could successfully share the information with their audience. When combined, these framed a rubric that supported students in optimizing their presentation deliveries. The competencies are as follows:
1. Content knowledge. The presenter must display a deep understanding of what they are delivering in order to share the “what, why, how, and how-to” of the topic.
2. Clarity. The presenter must be clear with precise, academic language. As the content they deliver may be new to the audience, any lack of clarity will alienate the audience. Providing multiple modes of representation greatly addresses a variety of processing needs of a diverse audience.
3. Cohesiveness. When making clear connections, the presenter bridges gaps between each discrete component in how they all work together as integral elements of the topic. Any gaps too large may make the elements look disjointed or, worse, the audience feel lost.
4. Captivation. The presenter must captivate the audience through any combination of audience engagement or storytelling . They make the presentation flow with the energy of a song , and in the end, they leave the audience with a delicate balance of feeling fulfilled and inspired to learn more.
Anyone can build an effective presentation with the “What, Why, How, and How-To” framework, along with competencies of content knowledge, clarity, cohesiveness, and captivation. The better we teach and coach others on how to create and deliver presentations, the more we learn from these individuals through their work.
In my class, one multilingual learner responded to the prompt “What are the non-math (life lessons) you have found valuable from this class?” with “I learn what is learning and teaching... I truly understood how teaching is actually learning when I had presentation. I found a bit of desire to being a teacher. I hope you also learned something from this class.” I always learn from my students when they present.
- The Open University
- Explore OpenLearn
- Get started
- Create a course
- Free courses
- Collections
My OpenLearn Create Profile
- Personalise your OpenLearn profile
- Save Your favourite content
- Get recognition for your learning
Already Registered?
- Welcome to this free course on 'General Teaching M...
- Information that is not to miss
- Alternative format
- Tell us what you think of this course
- Acknowledgements & references
- Course guide
- TOPIC 1 - QUIZ
- TOPIC 2 - QUIZ
- TOPIC 3 - QUIZ
- TOPIC 4 - QUIZ
- TOPIC 5 - QUIZ
- Introduction
- 1.1 DEFINITIONS, TYPES & PROCESSES OF LEARNING
- What is learning
- Behaviourism
- Constructivism
- Social-constructivism
- Cognitivism
- Conclusion on learning theories
- 1.2 LEARNING STYLES
- Introduction to learning styles
- Overview of learning styles
- Interpersonal learners
- Intrapersonal learners
- Kinesthetic learners
- Verbal learners
- Visual learners
- Logical learners
- Auditory learners
- Identifying learning styles
- 1.3 LEVELS OF COGNITION
- Introduction to Bloom's taxonomy
- How Bloom’s Taxonomy is useful for teachers
- 2.1 FOUNDATION AND RATIONALE
- Introduction to Active Teaching and Learning
- Defining Active Teaching and Learning
- Rationale for Active Teaching and Learning
- 2.2 METHODS, TECHNIQUES & TOOLS
- METHODS FOR ACTIVE TEACHING AND LEARNING
- Problem-based learning
- Project-based learning
- Learning stations
- Learning contracts
- TECHNIQUES FOR ACTIVE TEACHING AND LEARNING
- Demonstration
Presentation
- Brainstorming
- Storytelling
- TOOLS FOR ACTIVE TEACHING AND LEARNING
- Low cost experiments
- Charts and maps
- Student portfolio
- 2.3 BARRIES IN INTEGRATING ACTIVE TEACHING
- Identifying Barriers
- 3.1 INTRODUCTION TO CLASSROOM MANAGEMENT & ORGANIZATION
- Defining classroom management
- The role of the teacher
- Defining classroom organization
- Classroom seating arrangement
- Overview of classroom seating arrangement styles
- Benefits of effective classroom management and organization
- 3.2 STRATEGIES FOR EFFECTIVE CLASSROOM MANAGEMENT
- The teacher as a model
- Desired learner behaviour
- Rewarding learners
- Types of rewards
- Reinforcing learners
- Delivering a reinforcement
- 3.3 LESSON PLANNING
- Definition of a lesson plan
- Components of a lesson plan
- 4.1 INTRODUCTION TO ASSESSMENT AND EVALUATION
- Definition of assessment
- Formative vs. summative assessment
- Assessment for learning
- Assessment vs. evaluation
- 4.2 CLASS ASSESSMENT TOOLS
- Assessment rubrics
- Self-assessment
- Peer-assessment
- 4.3 REFLECTIVE PRACTICE
- Definition of reflective practice
- The reflective cycle
- 5.1 CONCEPT OF INSTRUCTIONAL MATERIALS
- Introduction to teaching and learning materials
- Purpose of teaching and learning materials
- 5.2 TYPES OF INSTRUCTIONAL MATERIALS
- Traditional and innovative resources
- Screencasts
- Educational videos
- Educational posters
- Open Educational Resources (OERs)
- 5.3 CHOOSING INSTRUCTIONAL MATERIALS
- Integrating instructional materials
- Factors to consider when selecting instructional materials
About this course
- 11 hours study
- 1 Level 1: Introductory
- Course description
Course rewards
Free Statement of Participation on completion of these courses.
Earn a free digital badge if you complete this course, to display and share your achievement.

General Teaching Methods
If you create an account, you can set up a personal learning profile on the site.

A presentation delivers content through oral, audio and visual channels allowing teacher-learner interaction and making the learning process more attractive. Through presentations, teachers can clearly introduce difficult concepts by illustrating the key principles and by engaging the audience in active discussions. When presentations are designed by learners, their knowledge sharing competences, their communication skills and their confidence are developed.
- Define the objectives of the presentation in accordance to the lesson plan (lesson planning)
- Prepare the structure of the presentation, including text, illustrations and other content (lesson planning)
- Set up and test the presentation equipment and provide a conducive seating arrangement and environment for the audience (lesson planning)
- Invite the audience to reflect on the presentation and give feedback (lesson delivery)
- After the presentation, propose activities or tasks to check the learners’ understanding
- Use Mentimeter for interactive presentations and to get instant feedback from your audience (consult this written tutorial on how to use Mentimeter).
- An infographic; graphic visual representations of information, data, or knowledge, is an innovative way to present. Use the digital tool Canva to create your own infographics (consult this written tutorial on how to use Canva).
- Use Google Slides or the Microsoft software PowerPoint , to easily create digital presentations.
- The purpose of a presentation is to visually reinforce what you are saying. Therefore the text should contain few words and concise ideas organised in bullet-point.
- Support your text using images .
- Provide time for reflection and interaction between the presenter and the audience, for example by using Mentimeter .

Techniques/ Demonstration Techniques/ Brainstorming
For further information, take a look at our frequently asked questions which may give you the support you need.
Have a question?
If you have any concerns about anything on this site please get in contact with us here.
Report a concern

Microsoft 365 Life Hacks > Presentations > Creating Presentations to Connect with Each Type of Learner
Creating Presentations to Connect with Each Type of Learner
When you’re presenting a topic to an audience, you want to ensure that it resonates with your entire audience. However, adults have different learning styles that affect how they absorb information. By understanding these styles of understanding and retaining information, you can tailor aspects of your presentation to these different kinds of learners to ensure that no one will feel left behind.

How to Craft Presentations that Connect with Different Types of Learners
Each person learns and understands information differently. Imagine that you’ve gotten turned around in an unfamiliar city and need to find your way back to your hotel. If you refer to a map, you might be a visual learner. If you ask for directions, you might be an auditory learner, but if you take the time to write those directions down, you might be a reading/writing learner. If you prefer to wander and find your way on your own, your learning style might be more kinesthetic. While this is a very simple example of different learning styles, it’s easy to see that what works for one person may not work for an entire audience at a presentation.

Tell your story with captivating presentations
Powerpoint empowers you to develop well-designed content across all your devices
Learn more about the different styles of learning and how to tailor your presentations to include each one.
Visual Learners
Use charts, graphics, and videos to appeal to visual learners.
How they learn
A visual learner absorbs and retains information that’s presented visually. If you’re trying to show the relationship between a set of numbers, a chart or a graph is your best bet. In order for you to make an impact on a visual learner, you’ll need to use something other than just words in order for the, to realize the relationships between data and concepts.
Tactics for reaching them
Your presentation should lean on visual aids. A few examples of this include:
- Sharing an outline of what information is going to be covered during the presentation.
- Using graphs and diagrams to present your data.
- Use a bright color scheme that incorporates complementary colors to draw their eye to what you’re sharing.
- Encourage your audience to take notes and write down key facts.
- Visually map out your concepts and connect information with arrows. Infographics are a great tool for this.
- Make your presentation more engaging by embedding videos.
Auditory Learners
Speak loudly and clearly to connect with auditory learners.
In school, the auditory learners in your classes would simply remember everything their teachers said, instead of taking notes. They simply find it easiest to remember information that they hear and may understand and remember knowledge gleaned from lectures, discussions, audiobooks, podcasts, and having a conversation with another person. It may also be normal for an auditory learner to recite facts to themselves as a way to retain information. They may ask repetitive questions as a way to memorize a concept.
Most presentations rely on a speaker sharing information, which is incredibly helpful to an auditory learner. However, there are other ways that you can help them retain the content you’re presenting:
- Record your presentation so that your audience can listen to it again later.
- Move around the room while you’re presenting so that the audience sitting in the back can hear you more clearly.
- Practice your delivery so that you aren’t giving your whole presentation in monotone. Changing your inflection and stressing important words and topics will resonate with auditory learners.
- Embed videos or sound clips into your presentation, which will have the added benefit of reaching visual learners, too.
Reading/Writing Learners
Reading/writing learners will appreciate it if you share your notes after your presentation.
This text-based learning style is popular with teachers and students because it’s all about written words. Those who favor a reading/writing learning style are likely to retain what they read and benefit from information that is presented in a textual format.
Reading/writing learners appreciate a well thought out PowerPoint presentation that thoroughly explains its concepts via text. But you can share information in other ways, too:
- Once you’ve finished discussing a concept, provide an easy to digest summary of the information you’ve shared. You should provide a similar summary at the end of your presentation that mentions all the important points you’ve shared.
- If possible, prepare a transcript of your presentation, or share your slides and notes with your audience.
- Provide note-taking materials like notebooks and pens for your audience to use during the presentation.
- Keep your presentation’s formatting consistent. Don’t switch fonts midway through, it may throw off those who learn by reading.
Kinesthetic Learners
Include a physical element in your presentation for kinesthetic learners.
When some people purchase furniture that requires assembly, they’ll take a close look at the instructions. Kinesthetic learners will throw those instructions away and figure it out as they go. These types of learners absorb information through real life examples and exercises. They appreciate demonstrations, simulations, and experiments. If there is a physical aspect to a learning situation, a kinesthetic learner will benefit from it.
If you’re teaching a kinesthetic learner how to cook a dish, you can put your recipe book away. They’re much more likely retain that dish’s information if they’re allowed to cook alongside you. Tailor your presentations to kinesthetic learners by allowing them to learn from experience with tactics like:
- Physical exercises like role playing to ensure they understand a concept.
- Asking them to write down what they hear.
- Allowing your presentation to have some aspect of physical participation, even it’s as simple as an informal poll involving raised hands.
Not all adults use the same tactics to learn and retain new information. By understanding the various learning styles, you can adjust your presentations to reach your whole audience.
Get started with Microsoft 365
It’s the Office you know, plus the tools to help you work better together, so you can get more done—anytime, anywhere.
Topics in this article
More articles like this one.

How to create an educational presentation
Use PowerPoint to create dynamic and engaging presentations that foster effective learning.

Five tips for choosing the right PowerPoint template
Choose an appropriate PowerPoint template to elevate your presentation’s storytelling. Consider time length, audience and other presentation elements when selecting a template.

How you can use AI to help you make the perfect presentation handouts
Learn how AI can help you organize and create handouts for your next presentation.

How to use AI to help improve your presentations
Your PowerPoint presentations are about to get a boost when you use AI to improve a PowerPoint presentation.
Everything you need to achieve more in less time
Get powerful productivity and security apps with Microsoft 365

Explore Other Categories

Learning Styles
Oct 09, 2014
2.68k likes | 6.37k Views
Learning Styles. What is a Learning Style?. Learning style is described as a group of characteristics, attitudes, and behaviors that define our way of learning. Simply: different approaches or ways of learning. What is a Learning Style?. Different styles influence: the way students learn,
Share Presentation
- learning style
- visual learners
- learning style model
- accommodating students learning style

Presentation Transcript
What is a Learning Style? Learning style is described as a group of characteristics, attitudes, and behaviors that define our way of learning. Simply: different approaches or ways of learning.
What is a Learning Style? Different styles influence: the way students learn, how teachers teach, and 3. Influence the interaction between teacher / student
Learning Styles There are many MODELS of learning styles in education. In 1987, Neil Fleming, a high school and university teacher from New Zealand developed the most widely used learning style model known as the VAK (Visual, Auditory, Kinesthetic). Years later added a fourth style: Read/Write! The acronym changed to VARK.
The VAK Model Visual: see it! When I SEE it then I Understand!
The Visual Learner Seeing/Writing The Visual Learner tends to observe things, pictures, demonstrations, films, etc. in order to improve his or her level of knowledge. Some common visual learning strategies include creating graphic organizers, diagramming, flow charts, mind mapping, outlining and more. www.inspiration.com/visual-learning
Visual Learners learn Through seeing.. • Need to see the teacher's body language and facial expression. • Tend to prefer sitting at the front of the classroom • May think in pictures and learn best from visual displays • Prefer to take detailed notes during lecture or classroom discussion to absorb the information.
Helps clarify thoughts See how ideas are connected Realize how information can be grouped and organized How does visual learning help students? New concepts are easily understood when linked to prior knowledge. http://www.inspiration.com/visual-learning
Visual learning help students Organize and analyze information: students use diagrams and plot to display large amounts of information in ways that are easy to understand and help reveal relationships and patterns. Integrate New Knowledge: Students better remember information when represented and learned both visually and verbally. Think Critically: Linked verbal and visual information help make connections, understand relationships and recall related details. www.inspiration.com/visual-learning
The VAK Model Auditory “hear it”
AUDITORY LEARNERS Learn by hearing • Prefer to hear information spoken. • • Can absorb a lecture with little effort. • • May not need careful notes to learn. • • Often avoid eye contact in order to concentrate. • • May read aloud to themselves. • • Like background music when they study.
AUDITORY LEARNERS Learn by hearing • Learn through listening • • Learn best through verbal lectures, discussion, talking things through, and listening to what others have to say • • Interpret the underlying meaning of speech through listening to tone of voice, pitch, speed, and other nuances • • Prefer directions given orally • • Seldom takes notes or writes things down • • Prefer lectures to reading assignments • • Often repeat what has just been said
AUDITORY LEARNERS Learn by hearing • Talk to self • • Often benefits from reading text aloud and using a tape recorder • • Sit where they can hear but needn't pay attention to what is happening in front • • Hum or talk to himself/herself or others when bored • • Acquire knowledge by reading aloud • • Remember by verbalizing lessons to themselves (if they don't they have difficulty reading maps or diagrams or handling conceptual assignments like mathematics).
The VAK Model Kinesthetic “do it”
Kinesthetic “do it” • Tactile/Kinesthetic persons learn best through a hands-on approach, actively exploring the physical world around them. • They may find it hard to sit still for long periods and may become distracted by their need for activity and exploration.
Kinesthetic Learner Try things out, touch, feel, and manipulate objects. Body tension is a good indication of their emotions. They gesture when speaking, are poor listeners, stand very close when speaking or listening, and quickly lose interest in long discourse. Remember best what has been done, not what they have seen or talked about. Prefer direct involvement in what they are learning; they are distractible and find it difficult to pay attention to auditory or visual presentations. Rarely an avid reader, they may fidget frequently while handling a book. Often poor spellers, they need to write down words to determine if they “feel” right.
CHARACTERISTICS OF KINESTHETIC LEARNERS Walk while studying Move and lecture to the walls Do things as you say them Practice by repeating motions Dance as you study Write words – use crayons, pens, pencils to see if they “feel right” When memorizing, use finger to write on the table or air Associate a feeling with information Stretch www.cvcc.edu/Resources/Learning_Assistance_Center/pdf/Learning_Styles
CHARACTERISTICS OF KINESTHETIC LEARNERS Write on a marker board in order to use gross muscle movement Use the computer Hands-on activities with objects that can be touched Study in short time periods; get up and walk around in between Make study tools to hold Use flash cards; separate into “know” and “don’t know” piles Use plastic letters and magnetic boards for new vocabulary Write and rewrite to commit to memory www.cvcc.edu/Resources/Learning_Assistance_Center/pdf/Learning_Styles
The VAK Model Read/Write Learning Style
The read/write learning style was added to Fleming’s model after the initial three. Read/write learners specifically learn best through the written word. They absorb information by reading books and handouts, taking lots of notes (sometimes word-for-word), and making lists. They prefer lectures, diagrams, pictures, charts, and scientific concepts to be explained using written language. They are often fast readers and skillful writers.
Read/Write Learning Style Similar to visual learners, read/write learners may struggle with verbal directions and are easily distracted by noise. Some may be quiet and struggle to detect body language and other social cues.
7 Styles of Learning
In Conclusion Each student learns differently, at different rates, using different learning styles. Everyone has a learning style. Accommodating students’ learning style can result in improved attitudes toward learning, as well as increased self esteem and academic achievement. Knowing and becoming familiar with your learning style will help you become a more effective and creative teacher. www.cvcc.edu/Resources/Learning_Assistance_Center/pdf/Learning_Styles
- More by User

Learning styles
Learning styles. Information found from http://www.k12.wa.us/SecondaryEducation/CareerCollegeReadiness/Curriculum/NavGr10LessonsRGRev-04-09.pdf. 3 learning styles. Visual learners Auditory learners Kinesthetic learners
694 views • 10 slides

LEARNING STYLES
What is a Learning Style?. Refers to the way you receive, store and retrieve information.Many different learning styles Not everyone learns the same wayWhen you know your preferred Learning Style, you can adapt yourself better to the classroom and learn more effectively outside of class. Learning Styles.
1.27k views • 15 slides

Learning Styles/Teaching Styles
Learning Styles/Teaching Styles . How Students Learn and What We Can Do to Help. Thomas Edgar, P.E., Ph.D., F.ASCE Formerly Department of Civil and Architectural Engineering. Theoretical Underpinnings to Learning Theory and Its Application to Use in the Engineering Classroom.
1.04k views • 30 slides

Learning Styles. Regina Frey, Director Washington University Teaching Center Eads Hall 105 Phone: 314-935-6810 Fax: 314-935-7917 http://artsci.wustl.edu/~teachcen. Outline. Definition of learning style General categories of different models of learning styles
523 views • 14 slides

Learning Styles. Robert Dotson Curriculum Facilitator, EC Department Lenoir County Public Schools. Ground Rules. Look Listen Learn Lend your abilities & insights. Food for Thought. “Schools tend to be a place where students come to watch adults work.”. Learning Styles. Purpose:
293 views • 16 slides

“Learning Styles”
“Learning Styles”. Sanremi LaRue Tutorial & Instructional Programs Presented for Jump Start Program Summer 2008. Measures of Learning Styles. Classroom Behavior Personality Preferences. Classroom Behavior. Competitive Collaborative Participant Avoidant Dependent Independent.
445 views • 19 slides

Learning Styles The “Learning Styles Inventory”
Learning Styles The “Learning Styles Inventory”. There are three basic learning styles: Visual Auditory Tactile. Kinds of visual learners…. The first are VISUAL LANGUAGE learners: These people like to see words in books, on computer screens, on the board and in charts.
866 views • 11 slides

Learning Styles. Knowing how you learn can make all the difference. Learning Styles—an Overview. Visual – 40% of population. Auditory – 30% of population. Kinesthetic – 30% of population.
1.12k views • 9 slides

Learning Styles. An Introduction to the Ways People Learn. Learning Styles: Topics. Background Learning Style Models Teaching to All Types References. Background. Students have different “learning styles”
549 views • 28 slides

Learning Styles. What we’ll be covering: What is a learning style? How you develop a learning style? What’s your learning style? How information on your learning style can help to improve your learning. What is a learning style?.
670 views • 7 slides

Learning Styles. What Type of Learner are you?. Using the calculation guide on the back of the Learning Style Inventory sheet, calculate the points for the three different categories. Characteristics of Learning Styles.
484 views • 18 slides

Learning Styles. Dr Robin Douglas. Gibb’s Reflective Cycle. Gibbs identified a series of 6 steps to aid reflective practice, these elements make up a cycle that can be applied over and over. Description - what happened? Feelings - what were you thinking and feeling?
367 views • 16 slides

Learning Styles . Week 4. Monday: Warm-Up . Good Morning!!! Pick up your spiral in the back bucket Open to a clean page and write the date at the top WHAT IS THE DIFFERENCE BETWEEN A LEARNING STYLE AND A LEARNING PREFERENCE ? (Please have your agendas out and open on your desk too) .
1.98k views • 21 slides

Learning Styles. Learning Styles. The brain has 2 sides and each hemisphere functions differently. Most of us depend on one side of the brain more than the other as we learn new information. Left Brain Lerner. Sees in parts Logical Learns in numbered steps Follows in straight line
393 views • 10 slides

Strategic studying and test taking tips. Learning styles. Today…. A little neurophysiology What are the different learning styles? What’s my style? How can I maximize my learning? How can I get the most out of my studying?. Neuroanatomy. Brain function contributes to learning style
455 views • 20 slides

Learning Styles. Understanding yourself How do you learn?. What teachers do you remember? Why? Was it the relationship? Subject matter? Or how they taught? Do you teach the same way you learn? Do you offer opportunities in all learning styles in your daily lessons?
394 views • 14 slides

Learning Styles. After this module you should be able to: Differentiate between different learning styles Identify your personal learning style Distinguish how to students can use their learning style to improve class performance
238 views • 6 slides

Learning Styles. How can we cater for the different learning styles when course content is accessed through a VLE? Honey & Mumford. www.ucl.ac.uk/learningtechnology/. TOC. Act. Reflect. Theory. Prag. Tools. Web. Table of Contents. Introduction The 4 Learning Styles (Honey & Mumford)
391 views • 10 slides

Learning Styles. The Citadel Academic Support Center 2010. Which Is Best For You?. How Do You Learn?. Do you prefer to work in study groups or on your own?. Do you like to learn by doing something?. Do you learn by memorizing facts and details?.
541 views • 27 slides

Learning Styles. Nanda Mitra-Itle Indiana University of Pennsylvania. Discussion Points. Think-Pair-Share Brief learning styles inventory What’s hot in education Agree or Disagree What are learning styles Learning styles assessments Levels of research Valid or not valid Debate
1.05k views • 64 slides

Learning Styles. Learning Style Stewart and Felicetti (1992): those "educational conditions under which a student is most likely to learn." a student’s consistent way of responding to and using stimuli in the context of learning how learners prefer to learn. Traditional Schooling
562 views • 19 slides

Learning Styles. Did you know?. We all learn different ways. There are 3 different types of learning. 3 Learning Styles. Tactile Visual Auditory. Tactile Learners. Must DO things to learn them. Enjoys using tools or active participation lessons.
275 views • 7 slides

- PRESENTATION SKILLS
Deciding the Presentation Method
Search SkillsYouNeed:
Presentation Skills:
- A - Z List of Presentation Skills
- Top Tips for Effective Presentations
- General Presentation Skills
- What is a Presentation?
- Preparing for a Presentation
- Organising the Material
- Writing Your Presentation
- Managing your Presentation Notes
- Working with Visual Aids
- Presenting Data
- Managing the Event
- Coping with Presentation Nerves
- Dealing with Questions
- How to Build Presentations Like a Consultant
- 7 Qualities of Good Speakers That Can Help You Be More Successful
- Self-Presentation in Presentations
- Specific Presentation Events
- Remote Meetings and Presentations
- Giving a Speech
- Presentations in Interviews
- Presenting to Large Groups and Conferences
- Giving Lectures and Seminars
- Managing a Press Conference
- Attending Public Consultation Meetings
- Managing a Public Consultation Meeting
- Crisis Communications
- Elsewhere on Skills You Need:
- Communication Skills
- Facilitation Skills
- Teams, Groups and Meetings
- Effective Speaking
- Question Types
Subscribe to our FREE newsletter and start improving your life in just 5 minutes a day.
You'll get our 5 free 'One Minute Life Skills' and our weekly newsletter.
We'll never share your email address and you can unsubscribe at any time.
There is much to consider in deciding on an appropriate presentation method.
This page assumes that you have already prepared your presentation , or at least decided on the key messages that you wish to get across to your audience, and given at least some thought to how to organise your material .
On this page, then, we focus on the mechanics of your presentation method: how you will present.
This includes using sound systems, how to manage visual aids, how you stand, and how much interaction you want with your audience.
What Helps you to Decide your Presentation Method?
In making a decision about your presentation method, you have to take into account several key aspects. These include:
The facilities available to you by way of visual aids, sound systems, and lights. Obviously you cannot use facilities that are not available. If you are told that you will need to present without a projector, you’re going to need to decide on a method that works without slides.
The occasion. A formal conference of 200 people will require a very different approach from a presentation to your six-person team. And a speech at a wedding is totally different again. Consider the norms of the occasion. For example, at a wedding, you are not expected to use slides or other visual aids.
The audience, in terms of both size and familiarity with you, and the topic. If it’s a small, informal event, you will be able to use a less formal method. You might, for example, choose to give your audience a one-page handout, perhaps an infographic that summarises your key points, and talk them through it. A more formal event is likely to need slides.
Your experience in giving presentations. More experienced presenters will be more familiar with their own weak points, and able to tailor their preparation and style to suit. However, few people are able to give a presentation without notes. Even the most experienced speakers will usually have at least some form of notes to jog their memory and aid their presentation.
Your familiarity with the topic. As a general rule, the more you know about it, the less you will need to prepare in detail, and the more you can simply have an outline of what you want to say, with some brief reminders.
Your personal preferences. Some people prefer to ‘busk it’ (or ‘wing it’) and make up their presentation on the day, while others prefer detailed notes and outlines. You will need to know your own abilities and decide how best to make the presentation. When you first start giving presentations you may feel more confident with more detailed notes. As you become more experienced you may find that you can deliver effectively with less.
Some Different Methods of Presentation
Presentation methods vary from the very formal to the very informal.
What method you choose is largely dictated by the occasion and its formality: very formal tends to go with a larger audience, whose members you do not know well. Your role is likely to be much more providing information, and much less about having a discussion about the information.
Form Follows Function
It’s not going to be possible, for instance, to present to 200 people from a chair as part of the group, because most of your audience will not see or hear you. You need to apply common sense to your choice of presentation method.
Audience Participation
While much of your presentation method will be dictated by the event, there is one area where you have pretty much free rein: audience interaction with you and with each other.
It is perfectly feasible, even in a large conference, to get your audience talking to each other, and then feeding back to you.
In fact, this can work very well, especially in a low-energy session such as the one immediately after lunch, because it gets everyone chatting and wakes them up. It works particularly well in a room set out ‘café-style’, with round tables, but it can also work in a conference hall.
The key is to decide on one or two key questions on which you’d welcome audience views, or on which audience views could improve your session. These questions will depend on your session, but it’s always more helpful to invite views on:
- Something that you haven’t yet decided; or
- Something that the audience is going to do themselves.
For example, you might ask people to talk to their neighbour and identify one thing that they could do to put your speech into action when they return to work and/or home. You can then ask four or five people to tell you about their action points.
Handling your Notes
You also have a choice over how you manage your text, in terms of notes. For more about this, see our page on Managing Your Notes in a Presentation .
The Importance of Iteration
You will probably find that deciding on the presentation method means that you need to change or amend your presentation.
For example, if you want to include some audience participation, you will need to include that in your slides, otherwise, you might well forget in the heat of the moment.
Fortunately, revisiting your presentation in light of decisions about how you will present is probably a good idea anyway. It will enable you to be confident that it will work in practice.
Continue to: Managing your Presentation Notes Working with Visual Aids
See also: Preparing for a Presentation Organising the Presentation Material Dealing with Questions
The 8 Types of Presentation Styles: Which Category Do You Fall Into?
Updated: December 16, 2020
Published: September 24, 2018
Types of Presentations
- Visual Style
- Freeform Style
- Instructor Style
- Coach Style
- Storytelling Style
- Connector Style
- Lessig Style
- Takahashi Style
Everyone on the internet has an opinion on how to give the “perfect” presentation.

One group champions visual aids, another thinks visual aids are a threat to society as we know it. One expert preaches the benefits of speaking loudly, while another believes the softer you speak the more your audience pays attention. And don’t even try to find coordinating opinions on whether you should start your presentation with a story, quote, statistic, or question.
But what if there wasn’t just one “right” way to give a presentation? What if there were several? Below, I’ve outlined eight types of presentation styles. They’re used by famous speakers like Steve Jobs and Al Gore -- and none of them are wrong.
Check out each one and decide which will be most effective for you.
![→ Free Download: 10 PowerPoint Presentation Templates [Access Now]](https://no-cache.hubspot.com/cta/default/53/2d0b5298-2daa-4812-b2d4-fa65cd354a8e.png "presentation of learning methods")
Types of Presentation Styles
1. visual style.
What it is: If you’re a firm believer slides simply exist to complement your talking points, this style is for you. With this speaking style, you might need to work a little harder to get your audience engaged, but the dividends can be huge for strong public speakers, visionaries, and storytellers.
When to use it: This style is helpful when speaking to a large audience with broad interests. It’s also great for when you need to throw together slides quickly.
Visual style presenter: Steve Jobs
2. Freeform Style
What it is: This impromptu style of presenting doesn’t require slides. Instead, the speaker relies on strong stories to illustrate each point. This style works best for those who have a short presentation time and are extremely familiar with their talking points.
When to use it: Elevator pitches, networking events, and impromptu meetings are all scenarios in which to use a freeform style of speaking. You’ll appear less rehearsed and more conversational than if you were to pause in the middle of a happy hour to pull up your presentation on a tablet.
Freeform style presenter: Sir Ken Robinson
3. Instructor Style
What it is: This presentation style allows you to deliver complex messages using figures of speech, metaphors, and lots of content -- just like your teachers and professors of old. Your decks should be built in logical order to aid your presentation, and you should use high-impact visuals to support your ideas and keep the audience engaged.
When to use it: If you’re not a comfortable presenter or are unfamiliar with your subject matter (i.e., your product was recently updated and you’re not familiar with the finer points), try instructor-style presenting.
Instructor style presenter: Al Gore
4. Coach Style
What it is: Energetic and charismatic speakers gravitate towards this style of presenting. It allows them to connect and engage with their audience using role play and listener interaction.
When to use it: Use this presentation style when you’re speaking at a conference or presenting to an audience who needs to be put at ease. For example, this style would work well if you were speaking to a group of executives who need to be sold on the idea of what your company does rather than the details of how you do it.
Coach style presenter: Linda Edgecombe
5. Storytelling Style
What it is: In this style, the speaker relies on anecdotes and examples to connect with their audience. Stories bring your learning points to life, and the TED’s Commandments never let you down: Let your emotions out and tell your story in an honest way.
When to use it: Avoid this style if you’re in the discovery phase of the sales process. You want to keep the conversation about your prospect instead of circling every point or question back to you or a similar client. This style is great for conference speaking, networking events, and sales presentations where you have adequate time to tell your stories without taking minutes away from questions.
Storytelling style presenter: Jill Bolte Taylor
6. Connector Style
What it is: In this style, presenters connect with their audience by showing how they’re similar to their listeners. Connectors usually enjoy freeform Q&A and use gestures when they speak. They also highly encourage audience reaction and feedback to what they’re saying.
When to use it: Use this style of presenting early in the sales process as you’re learning about your prospect’s pain points, challenges, and goals. This type of speaking sets your listener at ease, elicits feedback on how you’re doing in real time, and is more of a dialogue than a one-sided presentation
Connector style presenter: Connie Dieken
7. Lessig Style
What it is: The Lessig Style was created by Lawrence Lessig , a professor of law and leadership at Harvard Law School. This presentation style requires the presenter to pass through each slide within 15 seconds. When text is used in a slide, it’s typically synchronized with the presenter’s spoken words.
When to use it: This method of presentation is great for large crowds -- and it allows the speaker to use a balance of text and image to convey their message. The rapid pace and rhythm of the slide progression keeps audiences focused, engaged, and less likely to snooze.
Lessig style presenter: Lawrence Lessig
8. Takahashi Style
What it is: This method features large, bold text on minimal slides. It was devised by Masayoshi Takahashi , who found himself creating slides without access to a presentation design tool or PowerPoint. The main word is the focal point of the slide, and phrases, used sparingly, are short and concise.
When to use it: If you find yourself in Takahashi’s shoes -- without presentation design software -- this method is for you. This style works well for short presentations that pack a memorable punch.
Takahashi style presenter: Masayoshi Takahashi
Slides from one of Takahashi’s presentations:
Whether you’re speaking on a conference stage or giving a sales presentation , you can find a method that works best for you and your audience. With the right style, you’ll capture attention, engage listeners, and effectively share your message. You can even ask an AI presentation maker tool to create presentations for you in your preferred style
![Blog - Beautiful PowerPoint Presentation Template [List-Based]](https://no-cache.hubspot.com/cta/default/53/013286c0-2cc2-45f8-a6db-c71dad0835b8.png "presentation of learning methods")
Don't forget to share this post!
Related articles.
![10 Best Sales Presentations To Inspire Your Sales Deck [+ 5 Tips]](https://blog.hubspot.com/hubfs/sales-deck.jpg "presentation of learning methods")
10 Best Sales Presentations To Inspire Your Sales Deck [+ 5 Tips]

15 Sales Presentation Techniques That Will Help You Close More Deals Today

9 Ways to End Your Sales Presentation With a Bang

7 Apps That Help Salespeople Become Even Better Speakers

7 Secrets of a Winning Capabilities Presentation

Insight Selling: The 8-Slide Framework for a Better Pitch

The Best Work-Appropriate GIFs to Use in Your Next Sales Slide Deck
![How to Make a Business Presentation in 7 Easy Steps [Free Business Presentation Templates]](https://blog.hubspot.com/hubfs/how-to-make-a-business-presentation.jpg "presentation of learning methods")
How to Make a Business Presentation in 7 Easy Steps [Free Business Presentation Templates]

How to Handle Difficult Sales Calls Like a Pro

Technology Give You the Middle Finger in a Demo? 7 Reactions to Avoid
Download ten free PowerPoint templates for a better presentation.
Powerful and easy-to-use sales software that drives productivity, enables customer connection, and supports growing sales orgs
We use essential cookies to make Venngage work. By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.
Manage Cookies
Cookies and similar technologies collect certain information about how you’re using our website. Some of them are essential, and without them you wouldn’t be able to use Venngage. But others are optional, and you get to choose whether we use them or not.
Strictly Necessary Cookies
These cookies are always on, as they’re essential for making Venngage work, and making it safe. Without these cookies, services you’ve asked for can’t be provided.
Show cookie providers
- Google Login
Functionality Cookies
These cookies help us provide enhanced functionality and personalisation, and remember your settings. They may be set by us or by third party providers.
Performance Cookies
These cookies help us analyze how many people are using Venngage, where they come from and how they're using it. If you opt out of these cookies, we can’t get feedback to make Venngage better for you and all our users.
- Google Analytics
Targeting Cookies
These cookies are set by our advertising partners to track your activity and show you relevant Venngage ads on other sites as you browse the internet.
- Google Tag Manager
- Infographics
- Daily Infographics
- Popular Templates
- Accessibility
- Graphic Design
- Graphs and Charts
- Data Visualization
- Human Resources
- Beginner Guides
Blog Beginner Guides 8 Types of Presentations You Should Know [+Examples & Tips]
8 Types of Presentations You Should Know [+Examples & Tips]
Written by: Krystle Wong Aug 11, 2023

From persuasive pitches that influence opinions to instructional demonstrations that teach skills, the different types of presentations serve a unique purpose, tailored to specific objectives and audiences.
Presentations that are tailored to its objectives and audiences are more engaging and memorable. They capture attention, maintain interest and leave a lasting impression.
Don’t worry if you’re no designer — Whether you need data-driven visuals, persuasive graphics or engaging design elements, Venngage can empower you to craft presentations that stand out and effectively convey your message.
Venngage’s intuitive drag-and-drop interface, extensive presentation template library and customizable design options make it a valuable tool for creating slides that align with your specific goals and target audience.
Click to jump ahead:
8 Different types of presentations every presenter must know
How do i choose the right type of presentation for my topic or audience, types of presentation faq, 5 steps to create a presentation with venngage .

When it comes to presentations, versatility is the name of the game. Having a variety of presentation styles up your sleeve can make a world of difference in keeping your audience engaged. Here are 8 essential presentation types that every presenter should be well-acquainted with:
1. Informative presentation
Ever sat through a presentation that left you feeling enlightened? That’s the power of an informative presentation.
This presentation style is all about sharing knowledge and shedding light on a particular topic. Whether you’re diving into the depths of quantum physics or explaining the intricacies of the latest social media trends, informative presentations aim to increase the audience’s understanding.
When delivering an informative presentation, simplify complex topics with clear visuals and relatable examples. Organize your content logically, starting with the basics and gradually delving deeper and always remember to keep jargon to a minimum and encourage questions for clarity.
Academic presentations and research presentations are great examples of informative presentations. An effective academic presentation involves having clear structure, credible evidence, engaging delivery and supporting visuals. Provide context to emphasize the topic’s significance, practice to perfect timing, and be ready to address anticipated questions.

2. Persuasive presentation
If you’ve ever been swayed by a passionate speaker armed with compelling arguments, you’ve experienced a persuasive presentation .
This type of presentation is like a verbal tug-of-war, aiming to convince the audience to see things from a specific perspective. Expect to encounter solid evidence, logical reasoning and a dash of emotional appeal.
With persuasive presentations, it’s important to know your audience inside out and tailor your message to their interests and concerns. Craft a compelling narrative with a strong opening, a solid argument and a memorable closing. Additionally, use visuals strategically to enhance your points.
Examples of persuasive presentations include presentations for environmental conservations, policy change, social issues and more. Here are some engaging presentation templates you can use to get started with:

3. Demonstration or how-to presentation
A Demonstration or How-To Presentation is a type of presentation where the speaker showcases a process, technique, or procedure step by step, providing the audience with clear instructions on how to replicate the demonstrated action.
A demonstrative presentation is particularly useful when teaching practical skills or showing how something is done in a hands-on manner.
These presentations are commonly used in various settings, including educational workshops, training sessions, cooking classes, DIY tutorials, technology demonstrations and more. Designing creative slides for your how-to presentations can heighten engagement and foster better information retention.
Speakers can also consider breaking down the process into manageable steps, using visual aids, props and sometimes even live demonstrations to illustrate each step. The key is to provide clear and concise instructions, engage the audience with interactive elements and address any questions that may arise during the presentation.

4. Training or instructional presentation
Training presentations are geared towards imparting practical skills, procedures or concepts — think of this as the more focused cousin of the demonstration presentation.
Whether you’re teaching a group of new employees the ins and outs of a software or enlightening budding chefs on the art of soufflé-making, training presentations are all about turning novices into experts.
To maximize the impact of your training or instructional presentation, break down complex concepts into digestible segments. Consider using real-life examples to illustrate each point and create a connection.
You can also create an interactive presentation by incorporating elements like quizzes or group activities to reinforce understanding.

5. Sales presentation
Sales presentations are one of the many types of business presentations and the bread and butter of businesses looking to woo potential clients or customers. With a sprinkle of charm and a dash of persuasion, these presentations showcase products, services or ideas with one end goal in mind: sealing the deal.
A successful sales presentation often has key characteristics such as a clear value proposition, strong storytelling, confidence and a compelling call to action. Hence, when presenting to your clients or stakeholders, focus on benefits rather than just features.
Anticipate and address potential objections before they arise and use storytelling to showcase how your offering solves a specific problem for your audience. Utilizing visual aids is also a great way to make your points stand out and stay memorable.
A sales presentation can be used to promote service offerings, product launches or even consultancy proposals that outline the expertise and industry experience of a business. Here are some template examples you can use for your next sales presentation:

6. Pitch presentation
Pitch presentations are your ticket to garnering the interest and support of potential investors, partners or stakeholders. Think of your pitch deck as your chance to paint a vivid picture of your business idea or proposal and secure the resources you need to bring it to life.
Business presentations aside, individuals can also create a portfolio presentation to showcase their skills, experience and achievements to potential clients, employers or investors.
Craft a concise and compelling narrative. Clearly define the problem your idea solves and how it stands out in the market. Anticipate questions and practice your answers. Project confidence and passion for your idea.

7. Motivational or inspirational presentation
Feeling the need for a morale boost? That’s where motivational presentations step in. These talks are designed to uplift and inspire, often featuring personal anecdotes, heartwarming stories and a generous serving of encouragement.
Form a connection with your audience by sharing personal stories that resonate with your message. Use a storytelling style with relatable anecdotes and powerful metaphors to create an emotional connection. Keep the energy high and wrap up your inspirational presentations with a clear call to action.
Inspirational talks and leadership presentations aside, a motivational or inspirational presentation can also be a simple presentation aimed at boosting confidence, a motivational speech focused on embracing change and more.

8. Status or progress report presentation
Projects and businesses are like living organisms, constantly evolving and changing. Status or progress report presentations keep everyone in the loop by providing updates on achievements, challenges and future plans. It’s like a GPS for your team, ensuring everyone stays on track.
Be transparent about achievements, challenges and future plans. Utilize infographics, charts and diagrams to present your data visually and simplify information. By visually representing data, it becomes easier to identify trends, make predictions and strategize based on evidence.

Now that you’ve learned about the different types of presentation methods and how to use them, you’re on the right track to creating a good presentation that can boost your confidence and enhance your presentation skills .
Selecting the most suitable presentation style is akin to choosing the right outfit for an occasion – it greatly influences how your message is perceived. Here’s a more detailed guide to help you make that crucial decision:
1. Define your objectives
Begin by clarifying your presentation’s goals. Are you aiming to educate, persuade, motivate, train or perhaps sell a concept? Your objectives will guide you to the most suitable presentation type.
For instance, if you’re aiming to inform, an informative presentation would be a natural fit. On the other hand, a persuasive presentation suits the goal of swaying opinions.
2. Know your audience
Regardless if you’re giving an in-person or a virtual presentation — delve into the characteristics of your audience. Consider factors like their expertise level, familiarity with the topic, interests and expectations.
If your audience consists of professionals in your field, a more technical presentation might be suitable. However, if your audience is diverse and includes newcomers, an approachable and engaging style might work better.

3. Analyze your content
Reflect on the content you intend to present. Is it data-heavy, rich in personal stories or focused on practical skills? Different presentation styles serve different content types.
For data-driven content, an informative or instructional presentation might work best. For emotional stories, a motivational presentation could be a compelling choice.
4. Consider time constraints
Evaluate the time you have at your disposal. If your presentation needs to be concise due to time limitations, opt for a presentation style that allows you to convey your key points effectively within the available timeframe. A pitch presentation, for example, often requires delivering impactful information within a short span.
5. Leverage visuals
Visual aids are powerful tools in presentations. Consider whether your content would benefit from visual representation. If your PowerPoint presentations involve step-by-step instructions or demonstrations, a how-to presentation with clear visuals would be advantageous. Conversely, if your content is more conceptual, a motivational presentation could rely more on spoken words.

6. Align with the setting
Take the presentation environment into account. Are you presenting in a formal business setting, a casual workshop or a conference? Your setting can influence the level of formality and interactivity in your presentation. For instance, a demonstration presentation might be ideal for a hands-on workshop, while a persuasive presentation is great for conferences.
7. Gauge audience interaction
Determine the level of audience engagement you want. Interactive presentations work well for training sessions, workshops and small group settings, while informative or persuasive presentations might be more one-sided.
8. Flexibility
Stay open to adjusting your presentation style on the fly. Sometimes, unexpected factors might require a change of presentation style. Be prepared to adjust on the spot if audience engagement or reactions indicate that a different approach would be more effective.
Remember that there is no one-size-fits-all approach, and the best type of presentation may vary depending on the specific situation and your unique communication goals. By carefully considering these factors, you can choose the most effective presentation type to successfully engage and communicate with your audience.
To save time, use a presentation software or check out these presentation design and presentation background guides to create a presentation that stands out.

What are some effective ways to begin and end a presentation?
Capture your audience’s attention from the start of your presentation by using a surprising statistic, a compelling story or a thought-provoking question related to your topic.
To conclude your presentation , summarize your main points, reinforce your key message and leave a lasting impression with a powerful call to action or a memorable quote that resonates with your presentation’s theme.
How can I make my presentation more engaging and interactive?
To create an engaging and interactive presentation for your audience, incorporate visual elements such as images, graphs and videos to illustrate your points visually. Share relatable anecdotes or real-life examples to create a connection with your audience.
You can also integrate interactive elements like live polls, open-ended questions or small group discussions to encourage participation and keep your audience actively engaged throughout your presentation.
Which types of presentations require special markings
Some presentation types require special markings such as how sales presentations require persuasive techniques like emphasizing benefits, addressing objections and using compelling visuals to showcase products or services.
Demonstrations and how-to presentations on the other hand require clear markings for each step, ensuring the audience can follow along seamlessly.
That aside, pitch presentations require highlighting unique selling points, market potential and the competitive edge of your idea, making it stand out to potential investors or partners.
Need some inspiration on how to make a presentation that will captivate an audience? Here are 120+ presentation ideas to help you get started.
Creating a stunning and impactful presentation with Venngage is a breeze. Whether you’re crafting a business pitch, a training presentation or any other type of presentation, follow these five steps to create a professional presentation that stands out:
- Sign up and log in to Venngage to access the editor.
- Choose a presentation template that matches your topic or style.
- Customize content, colors, fonts, and background to personalize your presentation.
- Add images, icons, and charts to enhancevisual style and clarity.
- Save, export, and share your presentation as PDF or PNG files, or use Venngage’s Presentation Mode for online showcasing.
In the realm of presentations, understanding the different types of presentation formats is like having a versatile set of tools that empower you to craft compelling narratives for every occasion.
Remember, the key to a successful presentation lies not only in the content you deliver but also in the way you connect with your audience. Whether you’re informing, persuading or entertaining, tailoring your approach to the specific type of presentation you’re delivering can make all the difference.
Presentations are a powerful tool, and with practice and dedication (and a little help from Venngage), you’ll find yourself becoming a presentation pro in no time. Now, let’s get started and customize your next presentation!
Discover popular designs

Infographic maker

Brochure maker

White paper online

Newsletter creator

Flyer maker
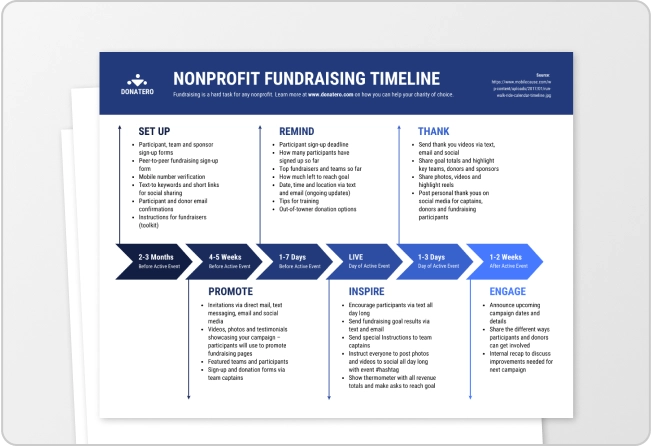
Timeline maker

Letterhead maker
Mind map maker

Ebook maker
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
How to Present to an Audience That Knows More Than You
- Deborah Grayson Riegel

Lean into being a facilitator — not an expert.
What happens when you have to give a presentation to an audience that might have some professionals who have more expertise on the topic than you do? While it can be intimidating, it can also be an opportunity to leverage their deep and diverse expertise in service of the group’s learning. And it’s an opportunity to exercise some intellectual humility, which includes having respect for other viewpoints, not being intellectually overconfident, separating your ego from your intellect, and being willing to revise your own viewpoint — especially in the face of new information. This article offers several tips for how you might approach a roomful of experts, including how to invite them into the discussion without allowing them to completely take over, as well as how to pivot on the proposed topic when necessary.
I was five years into my executive coaching practice when I was invited to lead a workshop on “Coaching Skills for Human Resource Leaders” at a global conference. As the room filled up with participants, I identified a few colleagues who had already been coaching professionally for more than a decade. I felt self-doubt start to kick in: Why were they even here? What did they come to learn? Why do they want to hear from me?
- Deborah Grayson Riegel is a professional speaker and facilitator, as well as a communication and presentation skills coach. She teaches leadership communication at Duke University’s Fuqua School of Business and has taught for Wharton Business School, Columbia Business School’s Women in Leadership Program, and Peking University’s International MBA Program. She is the author of Overcoming Overthinking: 36 Ways to Tame Anxiety for Work, School, and Life and the best-selling Go To Help: 31 Strategies to Offer, Ask for, and Accept Help .
Partner Center
The world is getting “smarter” every day, and to keep up with consumer expectations, companies are increasingly using machine learning algorithms to make things easier. You can see them in use in end-user devices (through face recognition for unlocking smartphones) or for detecting credit card fraud (like triggering alerts for unusual purchases).
Within artificial intelligence (AI) and machine learning , there are two basic approaches: supervised learning and unsupervised learning. The main difference is that one uses labeled data to help predict outcomes, while the other does not. However, there are some nuances between the two approaches, and key areas in which one outperforms the other. This post clarifies the differences so you can choose the best approach for your situation.
Supervised learning is a machine learning approach that’s defined by its use of labeled data sets. These data sets are designed to train or “supervise” algorithms into classifying data or predicting outcomes accurately. Using labeled inputs and outputs, the model can measure its accuracy and learn over time.
Supervised learning can be separated into two types of problems when data mining : classification and regression:
- Classification problems use an algorithm to accurately assign test data into specific categories, such as separating apples from oranges. Or, in the real world, supervised learning algorithms can be used to classify spam in a separate folder from your inbox. Linear classifiers, support vector machines, decision trees and random forest are all common types of classification algorithms.
- Regression is another type of supervised learning method that uses an algorithm to understand the relationship between dependent and independent variables. Regression models are helpful for predicting numerical values based on different data points, such as sales revenue projections for a given business. Some popular regression algorithms are linear regression, logistic regression, and polynomial regression.
Unsupervised learning uses machine learning algorithms to analyze and cluster unlabeled data sets. These algorithms discover hidden patterns in data without the need for human intervention (hence, they are “unsupervised”).
Unsupervised learning models are used for three main tasks: clustering, association and dimensionality reduction:
- Clustering is a data mining technique for grouping unlabeled data based on their similarities or differences. For example, K-means clustering algorithms assign similar data points into groups, where the K value represents the size of the grouping and granularity. This technique is helpful for market segmentation, image compression, and so on.
- Association is another type of unsupervised learning method that uses different rules to find relationships between variables in a given data set. These methods are frequently used for market basket analysis and recommendation engines, along the lines of “Customers Who Bought This Item Also Bought” recommendations.
- Dimensionality reduction is a learning technique that is used when the number of features (or dimensions) in a given data set is too high. It reduces the number of data inputs to a manageable size while also preserving the data integrity. Often, this technique is used in the preprocessing data stage, such as when autoencoders remove noise from visual data to improve picture quality.
The main distinction between the two approaches is the use of labeled data sets. To put it simply, supervised learning uses labeled input and output data, while an unsupervised learning algorithm does not.
In supervised learning, the algorithm “learns” from the training data set by iteratively making predictions on the data and adjusting for the correct answer. While supervised learning models tend to be more accurate than unsupervised learning models, they require upfront human intervention to label the data appropriately. For example, a supervised learning model can predict how long your commute will be based on the time of day, weather conditions and so on. But first, you must train it to know that rainy weather extends the driving time.
Unsupervised learning models, in contrast, work on their own to discover the inherent structure of unlabeled data. Note that they still require some human intervention for validating output variables. For example, an unsupervised learning model can identify that online shoppers often purchase groups of products at the same time. However, a data analyst would need to validate that it makes sense for a recommendation engine to group baby clothes with an order of diapers, applesauce, and sippy cups.
- Goals: In supervised learning, the goal is to predict outcomes for new data. You know up front the type of results to expect. With an unsupervised learning algorithm, the goal is to get insights from large volumes of new data. The machine learning itself determines what is different or interesting from the data set.
- Applications: Supervised learning models are ideal for spam detection, sentiment analysis, weather forecasting and pricing predictions, among other things. In contrast, unsupervised learning is a great fit for anomaly detection, recommendation engines, customer personas and medical imaging.
- Complexity: Supervised learning is a simple method for machine learning, typically calculated by using programs like R or Python. In unsupervised learning, you need powerful tools for working with large amounts of unclassified data. Unsupervised learning models are computationally complex because they need a large training set to produce intended outcomes.
- Drawbacks: Supervised learning models can be time-consuming to train, and the labels for input and output variables require expertise. Meanwhile, unsupervised learning methods can have wildly inaccurate results unless you have human intervention to validate the output variables.
Choosing the right approach for your situation depends on how your data scientists assess the structure and volume of your data, as well as the use case. To make your decision, be sure to do the following:
- Evaluate your input data: Is it labeled or unlabeled data? Do you have experts that can support extra labeling?
- Define your goals: Do you have a recurring, well-defined problem to solve? Or will the algorithm need to predict new problems?
- Review your options for algorithms: Are there algorithms with the same dimensionality that you need (number of features, attributes, or characteristics)? Can they support your data volume and structure?
Classifying big data can be a real challenge in supervised learning, but the results are highly accurate and trustworthy. In contrast, unsupervised learning can handle large volumes of data in real time. But, there’s a lack of transparency into how data is clustered and a higher risk of inaccurate results. This is where semi-supervised learning comes in.
Can’t decide on whether to use supervised or unsupervised learning? Semi-supervised learning is a happy medium, where you use a training data set with both labeled and unlabeled data. It’s particularly useful when it’s difficult to extract relevant features from data—and when you have a high volume of data.
Semi-supervised learning is ideal for medical images, where a small amount of training data can lead to a significant improvement in accuracy. For example, a radiologist can label a small subset of CT scans for tumors or diseases so the machine can more accurately predict which patients might require more medical attention.
Machine learning models are a powerful way to gain the data insights that improve our world. To learn more about the specific algorithms that are used with supervised and unsupervised learning, we encourage you to delve into the Learn Hub articles on these techniques. We also recommend checking out the blog post that goes a step further, with a detailed look at deep learning and neural networks.
- What is Supervised Learning?
- What is Unsupervised Learning?
- AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the difference?
To learn more about how to build machine learning models, explore the free tutorials on the IBM® Developer Hub .
Get the latest tech insights and expert thought leadership in your inbox.
The Data Differentiator: Learn how to weave a single technology concept into a holistic data strategy that drives business value.
Get our newsletters and topic updates that deliver the latest thought leadership and insights on emerging trends.
STATISTICAL LEARNING METHODS FOR UNCOVERING GENE REGULATION MECHANISMS
Add to collection, downloadable content.
- Affiliation: Gillings School of Global Public Health, Department of Biostatistics
- Gene regulation is a complex process controlling gene product levels through factors like transcription factors, epigenetic modifications, RNA, and proteins (Mack and Nachman, 2017). This mechanism is pivotal in biological processes, and disruptions can lead to diseases. Understanding it is crucial for gene therapy. This proposal aims to develop innovative statistical techniques for unraveling gene regulation, focusing on cis-regulatory elements (CRE). Our first project studies allelic expression (AE) to detect genes influenced by local CRE genetic variations. We introduce airpart, a model for allelic imbalance (AI) analysis in single-cell and temporal datasets. airpart features (i) a Generalized Fused Lasso with Binomial likelihood to partition cells by AI signal, ensuring interpretability; (ii) a hierarchical Bayesian model for hypothesis testing of AI presence within each cell state and differential AI (DAI) across cell states. Simulation and real data analyses show airpart’s accuracy in detecting cell type partitions, reducing RMSE in allelic ratio estimates, and outperforming existing methods. Enrichment analysis assesses if gene sets represent biological functions, pathways, or processes. To generate null hypotheses for such tests, we introduce bootRanges, fast functions producing block bootstrapped genomic ranges. We demonstrate that conventional shuffling or permutation methods often yield overly narrow null test statistic distributions, inflating statistical significance. Block bootstrap, however, preserves local genomic correlations and provides reliablenull distributions. Real data analyses show its applicability across various test statistics. In our third project, we aim to link CREs to genes using multi-omics time series data. We predict enhancer-promoter pairs from candidate pairs by analyzing enhancer activity-gene expression correlations over time. We propose GPlag, a Gaussian process-based model known for its flexibility with time-lagged and irregular time series. Predictions are validated usinghigh-throughput chromosome conformation capture (Hi-C) and expression quantitative trait loci (eQTL) datasets. Advancing our understanding of gene regulation mechanisms and developing new statistical tools contribute to gene therapy and genetic control research.
- Bioinformatics
- Biostatistics
- https://doi.org/10.17615/shhn-dq21
- Dissertation
- In Copyright - Educational Use Permitted
- Love, Michael I
- Rashid, Naim
- Phanstiel, Douglous H
- Doctor of Philosophy
- University of North Carolina at Chapel Hill Graduate School
This work has no parents.
Select type of work
Master's papers.
Deposit your masters paper, project or other capstone work. Theses will be sent to the CDR automatically via ProQuest and do not need to be deposited.
Scholarly Articles and Book Chapters
Deposit a peer-reviewed article or book chapter. If you would like to deposit a poster, presentation, conference paper or white paper, use the “Scholarly Works” deposit form.
Undergraduate Honors Theses
Deposit your senior honors thesis.
Scholarly Journal, Newsletter or Book
Deposit a complete issue of a scholarly journal, newsletter or book. If you would like to deposit an article or book chapter, use the “Scholarly Articles and Book Chapters” deposit option.
Deposit your dataset. Datasets may be associated with an article or deposited separately.
Deposit your 3D objects, audio, images or video.
Poster, Presentation, Protocol or Paper
Deposit scholarly works such as posters, presentations, research protocols, conference papers or white papers. If you would like to deposit a peer-reviewed article or book chapter, use the “Scholarly Articles and Book Chapters” deposit option.
InfoQ Software Architects' Newsletter
A monthly overview of things you need to know as an architect or aspiring architects.
View an example
Memorial Day Sale: Save up to 60% on
InfoQ Dev Summit Boston (June 24-25)
We protect your privacy.
Facilitating the Spread of Knowledge and Innovation in Professional Software Development
- English edition
- Chinese edition
- Japanese edition
- French edition
Back to login
Login with:
Don't have an infoq account, helpful links.
- About InfoQ
- InfoQ Editors
- Write for InfoQ
- About C4Media
Choose your language
Special Memorial Day Sale with significant discounts of up to 60% off . Register now.
Get practical advice from senior developers to navigate your current dev challenges. Use code LIMITEDOFFERIDSMUNICH24 for an exclusive offer.
Level up your software skills by uncovering the emerging trends you should focus on. Register now.
Your monthly guide to all the topics, technologies and techniques that every professional needs to know about. Subscribe for free.
InfoQ Homepage Presentations Large Language Models for Code: Exploring the Landscape, Opportunities, and Challenges
Large Language Models for Code: Exploring the Landscape, Opportunities, and Challenges
Loubna Ben Allal discusses Large Language Models (LLMs), exploring the current developments of these models, how they are trained, and how they can be leveraged with custom codebases.
Loubna Ben Allal is a Machine Learning Engineer in the Science team at Hugging Face working on Large Language Models for code & synthetic data generation. She is part of the core team behind the BigCode Project and has co-authored The Stack dataset and StarCoder models for code generation.
About the conference
Software is changing the world. QCon empowers software development by facilitating the spread of knowledge and innovation in the developer community. A practitioner-driven conference, QCon is designed for technical team leads, architects, engineering directors, and project managers who influence innovation in their teams.
Allal: My name is Loubna. I'm a machine learning engineer at Hugging Face. I work on large language models for code. I will show you how these models are trained and how you can leverage them for your own use cases. I work at Hugging Face. I did my studies in Paris, on engineering and deep learning. I mainly now work on LLMs for code and synthetic data.
How it Started: GitHub Copilot in 2021
Let's see a little bit how all of this started. Large language models for code have been there for a while. This topic became very trendy in the AI world when GitHub Copilot was introduced in late 2021. This is a VS Code extension by Microsoft, that autocompletes your code and it uses a model by OpenAI called Codex. This was a very huge breakthrough in the field, because this model was so much better than all the other code completion models before it, which were so much smaller and much less performant. This is important because it improves the productivity of the engineers who use it. Not all of them but some of them. For example, it can help you write unit tests or documentation, or even do more complex tasks with the recent LLMs that we have now. For example, in this blog post by Google AI, I think it was in 2022, they found a 6% reduction in code iterations, if you scale that to hundreds of thousands of engineers, this is a significant gain of time and money. This was very exciting, GitHub Copilot, AWS CodeWhisperer, and other models, but the issue is that they were only available through an API. You don't have the model checkpoints. You can't use the model to fine-tune it on your own use case. You also don't have information on the data that was used to train these models, so there isn't a lot of data transparency around. Also, the code to do the training and data processing is not available. All of this makes these results not reproducible. If you go to the Hugging Face Hub, where you can find all the open source models, and you search for the type code, you can see that now we have over 1700 models that are trained on code. Some of them are LLMs that include code in the training data, but a lot of them are pure code completion models. We've made a lot of progress in this field.
How Did We Get Here?
You might be wondering, how did we get here? This is the product of the community's work to train code models that not only can autocomplete your code, but that's going to also follow instructions, and thus we call them, instruction-tuned. If you go, for example, to this code leaderboard that we made, where you rank code completion models and compare them on different programming languages, you can see that on some benchmarks, the scores are pretty high. For example, solving more than 80% of the problems in the benchmark for some of the instructional models for code that are out there. There's a lot of progress in this field. There are a lot of interesting models that you can use.
How are Code LLMs Trained?
How are these models trained? If you want to train an LLM in general or an LLM for code from scratch, you should know that this requires a lot of resources. First, you need to have a lot of GPUs to be able to train the models in a reasonable amount of time. This can go from hundreds of GPUs to thousands, or even more. You also need to have a lot of data, because generally these LLMs, they require terabytes of data to train them efficiently. We should be able to scrape all these data, to filter it, and then to train on it. You should also be able to scale the performance. Because once you have the data, it's not like you're going to take the model to figure out which filtering makes sense for your dataset, which hyperparameters make sense for the model. That will require a team who's able to dedicate effort and time to do all of these experiments. Training your models from scratch are not for everyone. It requires a lot of resources. If we look at the technical details, these models, they usually all have the same architecture, which is a transformer model. First, you start from a model that is untrained. Then you show it a lot of data, it becomes a pretrained base model. Then you show it some data where you have ground truth. This is called supervised fine-tuning. After that, you can do another step called RLHF, which is alignment to get the model to hallucinate less, to generate less biased content and toxic content. The aim is to align it with human preferences. This is when you get a chat model, for example, like ChatGPT. ChatGPT went through all of these steps. For us, we want code models. We're not going to train on just the web, we need to train the model on code. Where do we get that? We get the dataset from GitHub. Then if you want to build a model that can follow instructions, then you need to build a dataset for the SFT step. It looks like this. For example, you have an instruction, write a function or solve a bug. Then you have the solutions which are the ground truth. Then you train your instruction-tuned model. That's how you get a chat LLM but specific to code.
The Landscape of Code LLMs
We need a lot of resources to train these models from scratch, and not everyone can do that. We're very proud to be part of these people who train these models for the community through a project called BigCode. In this project, we release the stack dataset, which is the largest open dataset of source code. We also released two families of code generation models, StarCoder and StarCoder2, in different sizes, along with an instruction-tuned model called StarChat2. Other players in this field are Meta with their Code Llama models, and DeepSeek Coder with the DeepSeek models. There are also other models, for example, from StabilityAI, CodeGen from Salesforce, and other LLMs. All of these models are open. How open depends on the license that they are released under. You can find the checkpoints, and you can adapt them to your own use cases.
I've told you some of the things that we developed in BigCode. What is BigCode, actually? It's a collaboration that is between Hugging Face and ServiceNow. Our goal was to have an open project where everyone can join and can help us train these models in an open and transparent approach. For example, in our Slack channel, we have over 1000 people who joined, these are researchers, engineers, but also lawyers and policymakers, because we really also care about the data governance and privacy aspect. We wanted to invest some time into that. The pillars of this project are three, full data transparency. For example, if you want to use our models, you can know exactly on which data they were trained. This data is public, and you can inspect it. We'll also open source the code for processing the datasets and also training the models to try to make our work reproducible. The model weights are released under a commercially friendly license.
The motivation behind this project was to try to encourage better practices in the field of AI and LLMs in general. These practices are not always respected in the closed source field. For example, you might have a model whose weights are public, but the details about the training data are not disclosed. This might be because they're afraid of lawsuits, but also to not give up their competitive edge to others. Sometimes the model weights are not public, for example, which is the case for ChatGPT. If you want to use these models, so for example, even use GitHub Copilot, the issue is that you will have to send your data to a third party, because you're just calling an API. In a lot of cases, your data might be sensitive so you don't want it to be sent to third parties. That's when you want something that is deployed on premise, and that is secure. All of this makes this work not reproducible, and doesn't encourage progress in the open source field. What we're trying to achieve with this project is to have, for example, public data. The data that we trained on is available and people can inspect it. If they want to be removed and not be included in our future trainings, they can just fill a form and opt out. The model weights are public for fine-tuning. You can also deploy them in premise. This is the dataset we released. How we built it is that we basically scraped all of GitHub, and then we filtered the datasets for licenses we can use. Then we did additional filtering, like removing files that look similar in a step called deduplication. We also have a tool called, Am I in The Stack, where you can go, you can just type your GitHub username, and you can check if any of your repositories are in our dataset. If you don't want to be in the dataset and in the model trainings, you can just fill a form and we'll make sure to not use your data.
This is the first model that we trained. It was released last April. It's called StarCoder. It has 15 billion parameters. It was trained on 500 A100s for 24 days. When it was released, it was the best code generation model. Last month, we released a new dataset called The Stack v2, which is much larger than the first version of the stack, and also still the largest open dataset of source code, in collaboration with Software Heritage. We also trained a new model called StarCoder2, which is much better than StarCoder, and also better than a lot of other models there. For example, if you want a 15B model, the best model is StarCoder2. It even outperforms other models like Llama 34B. It's good on code, but also math. Another thing we added in this model compared to StarCoder1 is RepoContext. Before, when we were training, we would just grab files from GitHub and randomly concatenate them and train on them so we lost the repository level structure. For StarCoder2, we made sure to keep files that are in the same repository next to each other during the training. This StarCoder2 model is aware of repository context. If you were to use it, for example, in a VS Code extension, and concatenate files from your repositories, it can give you completions that are in other files and not necessarily in the file that you're editing. We also built an instruction-tuned version of StarCoder2, called StarChat2 in collaboration with the Hugging Face H4 team. This model is available on a space that's Hugging Face, https://hf.co/spaces/HuggingFaceH4/starchat2-playground. You can query it. It can also complete your code. It can also follow instructions, not just on Python, but also on other programming languages, because StarCoder2 was trained on more than 600 programming languages. This creates a BigCode ecosystem where people would take the dataset that we released because it has so many programming languages, and develop new models on top of it. This can be new pretraining from scratch, for example, like StableCode or CodeGen 2.5, and other models. Or people would just start from the models with these, for example, StarCoder and StarCoderBase, and they would fine-tune them for their own use cases. For example, here you can see that there's WizardCoder, which is an instructs tuned version of StarCoder. There's also Defog SQLCoder, which is very interesting because it outperforms GPT-4 on SQL, and they just started from StarCoder, and they fine-tuned this on a lot of human annotated data for SQL. They were able to outperform GPT-4 on that. This shows the power of open source, when you release models and tools for the community, they can use them and build new things that even you haven't thought of.
Systems Surrounding LLMs
Let's see how you can go from a model to an API or a tool like VS Code extension. First, you have the model and then you wrap it around, then inference the endpoint with an API, then you have a chat interface. Each time you go to another level, you need to add new parameters. For example, when you go from the model to the API, you need to add moderation and compute. When you go to the chat interface, you need to have a system prompt for the model to control its behavior. You also need to have some hyperparameters to have a very nice user experience. This is for chat models in general. If we go to code models, you can maybe just swap the last component of a chat model with the code interface, that could be a VS Code extension, or JetBrains, or something like that. Hugging Face released two things for that, HuggingChat, which is like ChatGPT but only uses open source models. It's free to use. We also have an extension called llm-vscode. We deployed StarCoder there and we also deployed other open access models, like Code Llama and DeepSeek. You can all find them there if you want to use an alternative to GitHub Copilot that uses open models.
Current Customization Techniques for LLMs
Now let's go back to this slide. I said that to train code models from scratch, you need a lot of resources. The good news is that if you only want to customize existing models to your code base, or to new datasets, you don't need as much resources. This is possible thanks to fine-tuning. The reason why we would like to fine-tune and not just train from scratch might be related to the resources. If you don't have enough GPUs, or if you don't have enough data, because training from scratch requires a lot of data to get good performance. Or if the model that is already out there is good at your task, but you just want to improve the performance a little bit, you want to reduce the hallucinations, you want to include information that is more up to date, that's when you would go to other solutions than just training from scratch. If you want to adapt an existing code LLM or LLMs in general to a new task, there are some less intensive ways and other ways that are more intensive. The easiest one would be to just do prompt engineering. You would take a chat model and just tweak the prompt to get it to solve your task. Another thing that is a little bit more complex is in-context learning where you would add examples in the prompts to teach the model new behavior. For example, there are a lot of papers who are trying to use models, for example, ChatGPT, and try to teach it new libraries that probably were not included during the training, just by adding documentation to the context to see if the model is able to pick up new skills that it wasn't trained on. Another thing is tool use. I'm going to show later how to do that. Then there's fine-tuning. Then there's continued pretraining, which is like fine-tuning, but it is so much longer.
For prompt engineering, as I explained, you just need to change the prompt and add instructions to get the model to follow what you want. Some examples are, for example, few-shot where you add examples of the task you want. There's also chain-of-thought, where you try to get the model to solve a problem using step by step reasoning. This is, for example, very useful for math problems where instead of just asking the model to solve it, you ask it to reason step by step and split the problem to smaller, easier problems. The other thing that is also very interesting to use with code LLMs is tool use. For example, if you pick a general code LLM or just LLM in general, they might be very bad at arithmetic. If you can plug in a calculator to do the computations for you, or just add an interpreter to interpret the code, that might help you improve the performance a lot. Other techniques that are used are, for example, RAG, retrieval. You can do that with chat code LLMs, if you wanted to retrieve some documentation and add it to the context, or if you want to add more up to date information to the context. For fine-tuning, you would start from a base pretrained model, and then you can show it some SFT data. For example, for LLMs, this can be any domain, finance, medical domain, or summarization, and then the model is able to pick up this task. The only drawback is that, you need to have this SFT data that has pairs of questions and answers to be able to train the model on that. If you have it, you might be able to adapt the model to your own use case.
Customize Code Models: Code Completion
Now let's see what are some good practices if you have a code base, and you want to take an existing code LLM and adapt it to your own code base. Here, I'm going to put this blog post which is very interesting, by engineers at Hugging Face who tried to build a personal copilot. They took some of the Hugging Face libraries that were released after StarCoder training. They built a new code base, and got the model to learn these new libraries and to follow our practices for coding. In this blog post, they go through the steps of data processing, model fine-tuning, and also provide the code to be able to reproduce their results. If you want to do that, I think the first step is you need to prepare your dataset. The steps for preparing the dataset are very similar to the steps that we use for pretraining. When we were pretraining StarCoder, we first gathered all this data from GitHub. Then we did some filtering to remove files that wouldn't help the model during pretraining. We did another filtering that is very important, it's called deduplication, where you remove files that look similar. Because for LLMs, this really hurts their performance if you show them files that are very similar early in the training. It's very important to remove duplicates before you start the training. For filtering, I think if you have a custom code base, maybe you already are cleaning it. If it's not the case, you might want to have some filters to remove autogenerated files, and maybe filter configs, filter SSV data because that's not something that's going to teach the model how to code. After you've done all this filtering, then you can tokenize the dataset. I forgot another step, which is PII detection. Because in public repositories, although people shouldn't put their SSH in the API keys, you might be surprised that there's still a lot of them on public repositories on GitHub. We try to filter all of them and we release the tools that we used. We also try to remove names and emails. You might also want to do that before you train your model. Otherwise, you might risk having a model that would spit out an API key or someone's name when you use this during inference. I put here some links that you can use to check how to train these kinds of models. We also have resources for data deduplication with a library called datatrove. We also have published all the code that we used for our own data preprocessing for StarCoder models.
Let me go back to this PII reduction step because this might be interesting for you. First, we started by using RegExs to detect these keys in names and emails. The RegExs were not very good at catching some types of keys, so we tried to hire human annotators to annotate the dataset for secrets and PII. We released this dataset. It is gated, you have to fill a form because we don't want to expose people's information. Then we trained the named entity recognition model. You just show it a file and it is able to detect where is the name, where is an email, and where is the key. Then we run all of these on our dataset. It was quite intensive, because it's still an NER model. It's a neural network. If you want to run it on terabytes of data, you need a lot of GPUs. For us, I think it cost around 800 GPU hours on A100 machines. If your database is smaller, maybe it will be faster to run this pipeline. The code is also available on the BigCode project GitHub repository. One other thing that you might want to do is fine-tuning, but it's not just fine-tuning on 10,000 samples or 100,000 samples, it's fine-tuning on dataset that is large itself. Why would you want to do that? For example, if you want to take a model that is very good at Python, but maybe not very good at Swift. I think most models now focus on Python, because it's the default programming language for machine learning. There's a lot of hype around it. Maybe you want to adopt it for a low resource language. If you have a dataset for that, you can train the model on this dataset. In the stack, we also have a lot of programming languages, so you can take one of these languages and continue training the StarCoder models, for example, on them. A lot of people try doing that and it seems to help for some low resource languages. There are even benchmarks to test the performance, not just on Python, but also on these languages. There are even datasets that were developed for these low resource languages like MultiPL-T dataset.
Customize Models: Chat Assistant
We saw how to fine-tune on your custom code base, and also how to do continued pretraining on a dataset that is a little bit larger. Now we'll see how to build a chat assistant. If you have a code model, and you want to turn it into a chat assistant that could help you with your coding related questions, you need to follow what we call instruction-tuning. You need to have a dataset of instructions and all the answers to these instructions. This could be used for bug fixing, or for just code completion too, or a lot of other use cases. Here there's a paper called Magicoder, where they try to use just normal GitHub code from the stack, and they used another LLM, in their case it was GPT-4, to generate instructions and the answers to these instructions, just from some code files. This is a good approach. Because if you were to just select few topics, maybe you were losing diversity, but because you start from a general core dataset, you get files for different topics. You just need an LLM that can generate good instructions and solutions that actually work. I think they even tried to execute the solutions to see if they are correct, and they don't generate errors. They have a refinement pipeline to only keep the instructions and solutions that are actually relevant, and that will help them during the training. There's also the CodeInterpreter paper where they also try to do some code interpretation to increase the quality and remove the files and the instructions that fail. If you see their evaluations, they are able to get some pretty good performances with their approach. For example, in our StarChat2 model, how we built the instruction-tuning dataset, we just took a lot of instruction datasets, not all of them were made for code. Some of them are just general instructions, for example: write me a poem, who is the president of the United States? These are instruction datasets that are used for LLMs. It also helps to include them with other instruction datasets that are just dedicated to code. This way, your model doesn't lose its ability to know normal facts and also English. The model is available in this demo, as well as all the datasets that we included in this, even an alignment handbook where you can use these techniques to do the fine-tuning. One other good thing about fine-tuning techniques is that, recently, they are very cheap. You can find techniques like LoRA and PEFT. You can fine-tune 7B models in just a few hours on one GPU. Compared to two years ago, it was so much expensive to train these models, because you basically needed to train all of the weights, but now it's really manageable.
How are Code LLMs Evaluated?
We saw how these models are trained, how you can fine-tune them, but you might be asking yourselves, ok, I trained the model, how do I know it's good? How the models are evaluated in the code domain is that we have some benchmarks. We test on these benchmarks to see what is the score that you would get. For example, there's a benchmark called HumanEval. It is basically some function signatures. You ask the model to complete the function implementation. Then in the benchmark, you have unit tests for each problem. Then you execute the solution that your model generated against these unit tests to see if any of them pass. Then you report an average of the problems that pass. This is a lot intensive compared to just natural language evaluation because you need to first generate the solutions, and then you need to execute them, which might take some time. Luckily, the benchmark is not very big, but that's also a drawback because you only test on a small benchmark. It might be hard to see the differences between models that are very close just because you don't have a lot of problems in your benchmark. There are some other benchmarks that are larger, but they all require this generation and then execution step. One thing to be also aware of is that what you're going to execute is code that is generated by an LLM. It might contain malicious code, so we don't want to execute it on your machine. It's better to do it on a sandbox, or at least a Docker, to make sure it doesn't alter your system. This benchmark is not just for Python, I think it was translated to 18 other programming languages. We can find this, for example, even for Lua, Swift, and Rust. What I showed you was a leaderboard to rank these models to compare them. There are a lot of leaderboards for code now. There's also this one called EvalPlus, where they compare not just open models between each other, but they also compare to other closed models, like Claude 3 and GPT-4. There's also this LiveCodeBench. It is very interesting because a lot of people argue that maybe some of the code models are doing very well on the benchmarks, because they were trained on them. This is what we call data leakage or data contamination. Because everyone could have taken a benchmark and put it on GitHub, so if you just scrape GitHub and you train your model, there's a very high chance that you probably trained on the testing benchmark. It's very normal to have a model that is good at the benchmark you're testing on. Usually, we try to do decontamination. For example, for the StarCoder models, we checked all of our training data to make sure that none of the test benchmarks are included. This is very hard to check if people don't say that they explicitly did that in the paper. There are a lot of models who say nothing about their data processing pipeline. This leaderboard tries to only use very recent repositories on GitHub, and build a benchmark out of them. There's a very low chance that the current code LLMs saw what is in this benchmark. You could also compare the open models, but also the closed models.
If you train a code LLM on your custom code base and you want to evaluate it, I think you should first start by the standard benchmarks to make sure you're not losing performance on the language you're training it on. If you did the fine-tuning for a specific use case, for example, you want the model to follow a certain style when programming, you probably want to build a new benchmark that would test this ability. For that you would need to have human annotators, or you can use other powerful LLMs, maybe even closed, to build this benchmark. A lot of people are doing this because it's not enough to just run on the standard benchmarks that don't necessarily test what you want to implement. Another thing is to do just wild checks, test the model and see what it generates. Maybe the most efficient one would be to deploy the model, and then have some users test it. For example, you could deploy the model in a VS Code extension, and then have a number of software engineers test it. Then you can use metrics like the acceptance rate. For example, how many times is the code generated by the model accepted by the user? If this acceptance rate is high, it means that it's probably the generations are useful, and the people want to keep them. You can do multiple iterations and see when the acceptance rate declines or improves to judge the quality of the models you just trained and deployed. This is still an intensive approach. If you want to really test if your fine-tune is working, you need to go through that.
How are Code LLMs Served?
The last thing we're going to see is how these LLMs are served. You can train them, fine-tune them, evaluate them, but then you need to serve them and maybe deploy them to hundreds of users, to hundreds of thousands. Depending on your use case, you might choose some options, or others. We have some inference endpoints that you can use. If you don't have an engineering team that will do all the MLOps side of stuff, you can just purchase an endpoint and we'll take care of the deployment. You can just query this endpoint in the pay as you go. Otherwise, we have an open source library called Text-Generation-Inference. This library tries to take the most popular models and deploy them in a very efficient approach. You have your GPUs. You can use this library in the model and then be able to serve it. What's interesting in TGI is that it has tensor parallelism implemented. If the model is very large, and it cannot fit in one GPU, it can split the model on multiple shards and be able to load it. For example, we use this with very large models like Falcon 100 and 80 billion parameters in which it was able to work efficiently. It also has token streaming. It means that when you send the query or a prompt, you have the option of not waiting until the generation has ended and then showing. Token streaming is like, you show the tokens in the text as it is generated. This is very useful because it improves the user experience. A user doesn't have to wait until the full generation has ended, but it can also see the generations as they come. If the user doesn't like what is being generated, they can just stop. This reduces the perceived latency. There's also metrics for monitoring in TGI, and it is production ready. Once you launched it, and you tested it, you're sure that it's not going to fail in production. It is what is being used now in our inference endpoints. It also has techniques for quantization and optimization. It supports most of the popular Code LLMs, but also general LLMs. There are other open source libraries by the community that are similar, for example, vLLM, which also offers similar implementations. You can test both and see which one is good for your use case. If you want to explore more models and datasets related to code, you can go and search on the hub and find the ones that are relevant for your use case. You can also build demos to showcase your models and test them, and use GPUs if you don't have them.
Future Directions + Beyond LLMs
Let's see what the future directions of this field are. I think what we really need is to have better open source models and high-quality datasets. Even though we made a lot of progress, we're still, for example, behind GPT-4 in code completion, and other models like Claude 3. We still need to investigate a little bit more what is missing to catch up and close the gap to closed source.
We also need high quality datasets. For example, the stack was a good step towards democratizing training code models, because it is now available, and everyone can pretrain code models from scratch if they have the resources. We also need better data transparency and governance. That means telling the users exactly which data was used for the training, and also alerting about the possible biases in the dataset regarding privacy and security. We also need better evaluations that not only focus on the high resource languages, but also the low resource ones. Currently we focus on functional level, so there are some benchmarks to test that the repository context works, that the model can actually retrieve information from another file and generate it. We also need better evaluations that test also class implementations, not just functions. Overall, just evaluation that catch things that are more complex. Now we're making some progress towards that, but I think there's still room for improvement. The last thing is that we need better smaller specialized models, because not everyone has enough resources to deploy 15 billion model or 7B model. If we could generate smaller models that are better, that would be good too. Here, I tried to show you a little bit how you go from just data on GitHub, to actually products that you can use, for example, HuggingChat and the VS Code extension that we have. We saw that between the two, you have to do a lot of things, not just train on a lot of GPUs, but you have to do a lot of data curation, data governance. You have to also work on inference to be able to serve a lot of users, and evaluation, and also fine-tuning.
Questions and Answers
Participant 1: All the code that you suck in somehow from GitHub, you say, you take care that the licenses are ok, so there will be no GPL code in all those large language models. What about other licenses? What is a permissive license? Because almost all the licenses I know, say that you must leave intact copyright header, that you must add the license file to the code that you're producing? Is there any discussions in the community how to deal with that?
Allal: If you use MIT or Apache, that doesn't mean that you shouldn't attribute the author if the model generates exactly the same code. That's something we thought about. We implemented code attribution tools. For example, if you use the VS Code extension with StarCoder, we have membership tests that when the model generates something, we go and check the dataset. If we find that it is an exact copy of something that was in the dataset, we have like a red alert. If you click on the link, you can find exactly which repository that was from, and then you can attribute the author. That tries to help a little bit with the code attribution side. We tried to develop some tools to help the users who are using the models to attribute the authors if the model ever generates exact copies of what was in this training data.
Participant 2: In training the model, do you care about the quality of the code, say like if the code is neat enough and the algorithm's computational complexity.
Allal: Yes, so for when we were training on the dataset, I think you can implement a lot of filters to only keep the code files that you believe have a higher quality. We did a lot of experiments and a lot of ablations to try to find the adequate filters. We found that you can filter but you shouldn't filter too aggressively. Otherwise, you will end up losing a lot of data and you wouldn't have enough to train your model. For example, we have a paper called, SantaCoder, don't reach for the stars! That's because we tried to use stars as a filtering approach. For example, we kept only files that had more than five stars. This significantly reduced the size of the dataset, and we ended up with a model that was like the worst of all the models we trained. Some filters might seem good to you, but maybe for the model training, it's not worth using them. For example, filtering on stars is not a good idea. Although we might be thinking that repositories with a lot of stars probably have a higher quality. Now we use some basic filters to remove autogenerated files. For example, we count the average line length, and if we find that is very long, for some specific programming languages, maybe it is autogenerated. We also try to remove data, for example, CSV and JSON. We only keep a smaller subset, because that is not code, just data. We have other filters like that, but they are not too aggressive.
Participant 3: My question is regarding obviously, the legal and ethical considerations around scraping data from GitHub. For example, I know in the past there, there's been legal cases. One notable one would be the legal case between LinkedIn and hiQ, where hiQ was scraping data from LinkedIn using fake accounts. I think LinkedIn took an injunction against them. What considerations have been made in that sense? Is there some agreement between yourself and GitHub, on the scraping of the data, or did you just go ahead and scrape the data?
Allal: There's no agreement between us and GitHub, because we only use the repositories that are public. Then once we scrape them, we filtered out, for example, licenses that don't allow commercial use or GPL code. Then we trained on a subset of the data that we scraped. We have also this opt-out tool, so we can consider, for example, giving users a choice to decide whether they want their code to be included in the pretrainings or not. In this opt-out tool, users can fill a request. If they see that some of their GitHub repositories are in the dataset, and they want them removed, they can ask to remove that. You also have the code attribution tools. These are the three things we try to consider. We don't have an agreement with GitHub because the code was public.
Participant 4: Do we have any mitigation against the risk of moral collapse, where you put generated code back into the stack and where you train the new models on AI generated code?
Allal: You're talking about using synthetic data, what the model generated to train again on it.
Participant 4: Yes. Then, with a couple of cycles, the model collapses and then just spit out random things.
Allal: Yes. I think maybe if we're talking about the same study, in that study, they used a very small model, I think it was OPT 125 million, and they found that it collapses. Now a lot of people are training on synthetic data, a little bit models that are larger, and we haven't seen that that happens. The worst thing that happens is that the model's performance just does not improve on the task you're training on. Maybe in the future, when we have a lot of these cycles, that will happen. Now that hasn't really happened.
Participant 5: If we come to a future where most of the code is AI generated, and this is for sure being used to train more of these models, what do you think will happen?
Allal: I think we're going to have to wait and see what happens. If we see like the code that is being generated, a lot of it actually might be higher quality than if you take the average of what is on GitHub. It's not just garbage code. I think maybe something we can do is to have things to detect and distinguish AI generated code from code that was used by humans. For example, I saw a very recent study where they tried to see which papers have been written by ChatGPT, and they used the word delve. They found that after ChatGPT was released, the number of papers that used the word delve just increased. ChatGPT has the tendency to generate that. That's a silly filter, but it still detects what was generated by a model. Maybe for code, if we can have some watermarking approach or something that will help us distinguish AI generated from non-AI generated, that would be very helpful. I think that's still under exploration and we haven't made much progress on that. It's hard to predict what will happen when we will have more AI generated code than human generated code.
Participant 6: Looking forward to the future, can you talk about how we might get to the point where you could generate multifile or multi-project size completions with one of these tools?
Allal: That's something everyone's looking forward to. Because, for example, when GitHub Copilot was introduced, I personally was using it just for documentation in tests, it was not very good at generating new code, coming up with new ideas. Now it has improved a lot, so you can use it for other tasks that are more complex. I think we're still a little bit far from having something like an agent that can work on your whole code base, and just, you give it a question. You don't need to say where exactly it has to change the code. I think that is the end goal, to have something that can take in multiple files and do the required changes. One step forward to that is training on repository context, for example, which we did for StarCoder2 compared to StarCoder1. If we see things, for example, like Devin, if you saw, it is this AI agent that can change anything. I think that means that we're making progress towards that. We just need to find the right recipe for that. I think that means that you need to have good instruction-tuning data that not only asks the model instructions about specific code snippets, but something about the code base. You also should start from a base model that is already very good, because that will significantly impact the performance of what you get. I think that means having better base models and better datasets that you train on, and also better evaluations to be able to track if you're moving forward or not with regards to that aspect.
Participant 7: Training Your LLM seems to be quite an involved process. Do you think there'll be a time where when I'm in an enterprise and I've got a couple of Git repos that I can just say, "Model, please ingest these models." Then the model trains itself on my code without me going through this whole song and dance here?
Allal: I think there are a lot of startups who are trying to do that, because that's a use case, I don't want to be involved in all of this training, just give me a service that I can also train in. I think there's one probably called Poolside. They're trying to have that. Because, basically now we have all the components. There's the model, there's the fine-tuning scripts, and there's your data, and we know which filters will help. We just need someone who will combine these components. Maybe that's a product that someone can develop, and you can use.
Participant 8: I think you touched in your talk, but I didn't get the guidance, with respect to fine-tuning, you talked about your libraries, that you did fine-tuning for the libraries. Can you give some guidance of how many million lines of code would you need to fine-tune? Let's say I have my own frameworks and libraries internally in my enterprise and I want to fine-tune a model, roughly, what are we talking about? Do we need a million, 5 million, 10 million, 50 million lines of code?
Allal: I can give you a number, but that number does not really apply. It depends on your use case, which model you started from, what you're trying to adapt it. I think usually for fine-tuning on new programming languages, and not a new one, one that the model has already seen, but you want to improve the performance a little bit, maybe tens of gigabytes of data should do the trick. If you want to just do like instruction-tuning or get the model to follow instructions, you need much less. I think people are just using tens of thousands of samples. Maybe a few gigabytes of data could work if it is just taking a model that has already seen that language and you just want to adopt it. It should work. For example, if you go to the blog post that I mentioned, I think they had even less because they just took the Hugging Face libraries. I don't know how many we have, but they just compiled them into datasets, and they found that it works to train on that. One other thing that made it that you need less data is these new fine-tuning techniques that don't take the whole model and change the whole way it's doing the fine-tuning, they only change specific weights and specific layers that they add. This means that you don't need a lot of data for the adaptation. You will need to try and see at what threshold your model gets better.
Participant 9: I have a question around if you've done any work on deprecation of libraries or stuff like CVE. I've got loads of examples, where ChatGPT will generate a package JSON or dependency file within the library or API call that it's referenced and the next bit of code is deprecated, or doesn't exist in the v2 version? Have you done any work around how to avoid that happening in code generation models?
Allal: I haven't personally worked on that. That is also hallucination for LLMs, when you would ask the model, who's the president of the U.S.? They would say Obama, because this is something that was deprecated. This is old. One of the techniques to solve that is to use, for example, retrieval, RAG, to retrieve information that is more recent and add it in the context. In your case, you could try to retrieve the documentation for the new version of the library and add it to the context to tell the model, these are the new things that are changed, or you can also add the logs of the changes. That is something that is worth exploring. Otherwise, you would need to fine-tune on recent code. These are two things, either retrieval or new fine-tuning.
Participant 10: We've had a truly explosive growth in AI over the last few years, do you think we're close to plateauing or is this just the start?
Allal: I think we've made a lot of progress. We still have a long way to go, first by matching the performance of the closed models, but then trying to address some issues that even these closed models still have, which are the hallucinations, the biases, and also all the data governance issues. We think we're off to a good start, but we still have a lot of work. Like you asked, we want code models that can act as agents on programming code bases and not just complete a simple function. We still have a long way to go, but I think we're off to a good path.
Nardon: Do you have an experience on using code generated to improve an existing code base, and how this is working well or not with code LLMs?
Allal: I think, yes, this can happen implicitly when you have some engineers who are using the model, and then they use the code that it generated for what they will push, for example, to production. That's an implicit improvement. Otherwise, you can maybe try to use the chat models, and maybe integrate parts of your code base and try to get feedback on these different components. It's still, I think, maybe early stage because we still don't have models that can act on the code base level, but they still all act on the file level. Maybe it's early stage still.
See more presentations with transcripts

Recorded at:

May 23, 2024
Loubna Ben Allal
Related Sponsored Content
This content is in the ai, ml & data engineering topic, related topics:.
- AI, ML & Data Engineering
- Large language models
- QCon London 2024
- Transcripts
- Artificial Intelligence
- QCon Software Development Conference
- Machine Learning
Related Editorial
Popular across infoq, uber migrates 1 trillion records from dynamodb to ledgerstore to save $6 million annually, typespec: a practical typescript-inspired api definition language, rust-written borgo language brings algebraic data types and more to go, deepthi sigireddi on distributed database architecture in the cloud native era, ahrefs joins others in suggesting that on-premises hosting can be more cost effective than cloud, java news roundup: openjdk updates, piranha cloud, spring data 2024.0.0, glassfish, micrometer.
An automatic inspection system for the detection of tire surface defects and their severity classification through a two-stage multimodal deep learning approach
- Open access
- Published: 22 May 2024
Cite this article
You have full access to this open access article

- Thomas Mignot ORCID: orcid.org/0009-0007-2529-6935 1 , 2 ,
- François Ponchon 2 ,
- Alexandre Derville 2 ,
- Stefan Duffner 1 &
- Christophe Garcia 1
In the tire manufacturing field, the pursuit of uncompromised product quality stands as a cornerstone. This paper introduces an innovative multimodal approach aimed at automating the tire quality control process through the use of deep learning on data obtained from stereo-photometric cameras meticulously integrated into a purpose-built, sophisticated tire acquisition system capable of comprehensive data capture across all tire zones. The defects sought exhibit significant variations in size (ranging from a few millimeters to several tens of centimeters) and type (including abnormal stains during processing, marks resulting from demolding issues, foreign particles, air bubbles, deformations, etc.). Our proposed methodology comprises two distinct stages: an initial instance segmentation phase for defect detection and localization, followed by a classification stage based on severity levels, integrating features extracted from the detection network of the first stage alongside tire metadata. Experimental validation demonstrates that the proposed approach achieves automation objectives, attaining satisfactory results in terms of defect detection and classification according to severity, with a F1 score between 0.7 and 0.89 depending on the tire zone. In addition, this study presents a novel method applicable to all tire areas, addressing a wide variety of defects within the domain.
Avoid common mistakes on your manuscript.
Introduction
In the tire industry, as in many other industries, all the products must be verified at the very end of the production line. Historically, each one of them is manually inspected by trained workers. Today, with the rise of industry 4.0 (Vaidya et al., 2018 ), the automation of this task is necessary to increase productivity and limit the arduousness of work due to its repetitive and non-ergonomic part. On the other hand, many technical and mechanical difficulties complicate the task, such as obtaining good-quality images of all the tire zones in a reasonable time. A bespoke acquisition machine with an embedded stereo-photometric image acquisition system (Mourougaya, 2019 ) has been designed to solve this problem, whereas this article focuses on the image processing part.
Tire quality process control is a complex process and each manufacturer defines his own specific requirements. In order to have an automatic inspection system, the ultimate goal is not only to detect defects, but to classify them according to their severity (or criticality).

Two examples of different tread patterns
Classical machine vision algorithms, such as SVM (Hearst et al., 1998 ) and hand-crafted feature extraction have demonstrated that they can be highly efficient and fast in a static and perfectly controlled environment (Kuo et al., 2019 ; Aminzadeh & Kurfess, 2019 ) but they are encountering troubles for a good generalization across products, and this is particularly the case for tires whose tread patterns are completely different from one type of product to another. Moreover, a tire defect even grouped by family doesn’t necessarily have the same appearance as another. Because of the high variability of defects, it is impossible to extract manual features for defect detection. A more suitable approach would be to use deep learning, which enables better generalization and learning from complex backgrounds. Consequently, the prerequisite is to collect a large database of images with a sufficient variety of defects. We provided this effort to obtain a dataset with quality annotations and the required characteristics.
For the severity classification task, directly applying theoretical severity rules to detected defects proves unsuitable due to certain unknown features (such as depth and qualitative aspects) and the impracticality of applying numerous rules. Alternatively, manually analyzing the outputs of the segmentation network to define custom rules is not conducive to robust generalization across factories with diverse types of tires.
This paper investigates suitable deep learning architectures for defect detection and classification, with a focus on novel areas that, to our knowledge, have not been previously explored in visual inspection. The main contributions of this study include:
Real-time processing of high-resolution stereo-photometric tire images, from defect detection to severity classification, stands as an innovative advancement in the tire industry.
The definition of a fine-tuning strategy and training procedure in order to be able to treat all areas of the tire, inside and outside.
The design of an innovative two-stage architecture:
A detection network based on MASK-RCNN, augmented with two additional IoU prediction branches.
A multimodal deep learning model for classifying large images along with their accompanying metadata, leveraging GRU and the attention mechanism.
The remainder of the paper is structured as follows. Firstly, Section “ Related work " part is devoted to the state of the art in visual inspection, with a particular focus on the detection of tire appearance defects. Secondly, Section “ Dataset presentation " part presents the dataset with its particularities and annotations. Thirdly, Section “ Proposed approach " part is dedicated to the explanation of the proposed method for defect detection and classification. Then, the results will be presented in the “ Results " section. Lastly, the paper concludes with a “ Discussion and conclusion " section.
Related work
Deep learning for visual inspection.
With the arrival of convolutional neural networks in 2012 and their superior performance on Imagenet (Deng et al., 2009 ) classification tasks, they were also investigated for visual inspection and defect detection tasks in industrial environments. One of the first applications was to detect surface defects in tunnels (Loupos et al., 2015 ) and (Protopapadakis & Doulamis, 2015 ) and on steel surface (Soukup & Huber-Mörk, 2014 ). For these specific tasks, all defects (cracks) share important visual similarities and no further defect classification is studied. With the advent of the Fast-RCNN (Girshick, 2015 ) and its improved version: Faster RCNN by Ren et al. ( 2015 ), it has established itself as a benchmark for object detection, opening up new horizons for defect inspection. The main advantage of this two-stage detector is its accuracy despite its relative slow inference time. Kang et al. ( 2018 ) proposed a typical application of the Faster-RCNN for the detection of surface defects in high-speed railway insulators, in combination with a deep multitasking network composed of a classifier and a Denoising AutoEncoder (Vincent et al., 2008 ) to deduce the defect state. Many Faster-RCNN-based approaches have been tested with dataset-specific enhancements such as Zhou et al. ( 2019 ) with the use of K-Means to determine the optimal anchor size and ratio for associated defects. Sun et al. ( 2019 ) also suggested an upgraded version of the Faster-RCNN using transfer learning and a modified version of ZF net (Hafizur & Masum, 2014 ) with a sliding convolution layer rather than max pooling at the end of the RPN for wheel hub surface defect recognition.
While many papers have opted for semantic segmentation approaches (Tabernik et al., 2019 ) with favorable outcomes, our objective is to explore the feasibility of individually characterizing each defect, a task that proves challenging to implement using semantic segmentation.
Transformers (Vaswani et al., 2017 ) are gradually being introduced into the literature of detection with SAM (Kirillov et al., 2023 ) as an attempt of creating a foundation model, but still few visual inspection papers are using them due to the training costs, inference time and the consequent data needed. For these specific data, texture information is important as convolutional layers are better than transformers at learning from such information. Conversely, transformers are better at aggregating results, as they benefit from a global context (Yan et al., 2021 ).
Tire surface defect detection
Recognizing tire surface defects is one of the most difficult tasks in visual inspection. The literature on this specific subject is not very dense due to the difficulty of collecting high-quality images, although some papers lay the foundations. Tada and Sugiura ( 2021 ) presented a method using a two-step patch classifier with the definition of three classes: good part, quasi-good part and defective. Their results seem to be good on their dataset, but they only treat inner surfaces, and the metrics are not computed per defect instances but per percentage of defect area, as their aim is not to to completely automate the verification process but to assist the operator.

An example of defects from the same visual family (Bumps) in the annotation interface on the inside of the tread, but with different degrees of severity (Top defect: severe, to repair / Bottom defect: not severe)

The proposed method for the detection and classification of tire surface defects
Massaro et al. ( 2020 ) studied how to detect large sidewall deformations caused by problems during tire assembly. For acquisition, profilometers are used to obtain a 3D reconstruction that is then converted into a 2D image for computational cost reasons. They compared three image processing methods: Discrete Fourier Transform, K-Means and Long Short-Term Memory-Fully Connected neural networks, and this showed that the combination of DFT and K-Means was the best solution in terms of computational cost and accuracy. However, two limitations should be noted: the observed area is limited to the sidewall and the detected defects are only deformations generated by possible material stresses and not correct tire-wheel rim coupling caused during assembling.
In the same field, Kuric et al. ( 2021 ) combined 3D scanning and vision system in order to detect and classify tire surface defects on the sidewall as well. They tried to use RCNN to detect defects but did not get satisfactory results. Rather, they designed a two-step method: 1) Unsupervised anomaly detection with a clustering algorithm (DBSCAN) applied to potentially anomalous data with respect to their definition of a defect-free tire (deviations higher than 0.5 mm) 2) Classification of detected abnormalities using the VGG-16 neural network. Their results are promising, but the need to define what constitutes a defect-free tire prevents easy generalization across dimensions. Moreover, the classification task is limited to two types of defects, the concept of severity is not addressed, and the study is also restricted to the sidewall only.
More recently, Liu et al. ( 2023 ) suggested to extract features (HOG and LBP) from normal and defect tire images to then pass them as input to a SVM classifier. They demonstrated that HOG and LBP features perform better when combined (with an approximate accuracy of 84%) than when taken separately as input to the SVM classifier. They are using images from different tires areas, different manufacturers, and different sources, without annotation masks or polygons, meaning that the acquisition system is not controlled, and only binary classification is possible. Another binary classification study was carried out by Lin ( 2023 ) using an improved version of Shufflenet which achieved good results with an accuracy of 94%.
Dataset presentation
Image acquisition.
Before considering image processing, the first step is to choose the right acquisition system suitable for this task. Detecting defects on black textured surfaces like tires is challenging and requires some specific industrial equipment. Two classical choices seem the most suitable:
A linear camera with a white light
A 3D profilometer
The first option produces a 2D image with a high vertical resolution (3096 pixels) but without depth information, as opposed to the profilometer which generates lower resolution with less texture information but with depth information. The adopted solution is based on stereo-photometry. The main idea is to have different lighting angles with the same camera viewpoint. Theoretically, it’s possible to estimate normal surfaces and depth from these different lightning conditions. We are not considering the option of reconstructing the depth or Albedo map, as this would consume too much time. Also, it’s possible to use deep learning networks for this reconstruction, but the computational cost is high, especially for high resolution images. For these reasons, we decided to concatenate each light modality along the channel dimension, with the intuition that the depth information is already present since the surface map can be obtained from these plans only. The number of lights varies from 3 to 4 depending on the zone, but we have chosen to process 3 lights only in order to facilitate transfer learning between zones. Figure 6 displays how lighting conditions affect the visualization of defects. Furthermore, we observe the distinct contributions of each lighting condition in enhancing or diminishing the visibility of defects, depending on the specific tire zone and type of defect.
A complete tire acquisition necessitates 11 cameras, each equipped with its own embedded lighting system. The definition of tire zone names is explained in Fig. 4 . A simplified schematic representation of the acquisition machine, derived from the patent Mourougaya ( 2019 ), is depicted in Fig. 5 . To manage the diversity of tire dimensions, the acquisition machine automatically adapts the placement of its cameras using complex predefined PLC (Programmable Logic Controller). Therefore, the vertical resolution, tailored to the defect size under consideration, may vary based on the tire zone and dimensions. Additional details regarding the acquisition machine are available in the referenced patent.

Tire zone nomenclature

Schematic representation of the acquisition system
Annotations
Having quality annotations is a mandatory criterion to localize and classify defects. The total number of annotated images is 25,450 (14,100 of which are healthy). We have defined 10 defect types:
Bumps (2107 instances)
Surface Roughness (3298 instances)
Imprint (1210 instances)
Cut (837 instances)
Contrast Difference (2086 instances)
Tread Pattern Erosion (70 instances)
Flashes (3726 instances)
Smooth Dent (214 instances)
According to the zone, some defects will be more or less present, sometimes with visual differences. In other terms, the intra-class differences are low for the same camera zone but can be high between zones. Common defects samples under the different possible lighting conditions are shown in Fig. 6 .

Samples of common defects, each demonstrating its visual characteristics under varying lighting conditions
We also have another annotation information at the polygon scale: the associated risk level, with 4 levels of severity that we decided to simplify into two levels: severe or not severe. This combination helps to rebalance severity classification.
All our experiments were performed on truck tires coming from the same factory. The annotations were made by experts directly in the factory to ensure the accuracy of their annotations. In fact, some annotation errors still persist in the dataset since even for an expert this task is extremely challenging.
In addition to these annotations, we also have tire metadata at our disposal. This textual information contains the tire’s dimensions and range (for example size 385/65R225 with X LINE ENERGY range).
Proposed approach
The global approach is shown in Fig. 3 . Our proposed approach divides the global method into two parts: defect detection and defect severity classification. We will see that these two tasks cannot be easily combined, as some defects may have the same visual aspect but different degrees of severity (see Fig. 2 ). We have chosen to first detect and segment defects according to their visual families as direct detection of severity makes no sense, given the large number of defects of the same type with different severity levels. We prefer to predict severity in a subsequent step, using a dedicated network. The advantages of decoupling the detection and severity classification processes can be summarized as follows:
Alignment with real-world operations: By mirroring the sequential workflow of an aspect operator who first detects defects and then applies specific rules for classification, the model’s operational realism is enhanced.
Reduced black-box effect: decoupling the tasks mitigates the opacity inherent in attempting to perform both in a single step.
Enhanced memory efficiency: working with high-resolution images becomes more practical and memory-efficient when tasks are separated, as combining them would lead to a cumulative rise in memory usage.
Correction of false positives: the second classification stage has the capacity to rectify instances of false positives encountered in the initial detection stage, thereby improving overall accuracy.
Modular training approach: the ability to train the two stages separately provides flexibility and efficiency, allowing for focused training efforts on the second stage, which typically requires less time to train compared to the entire network.
First stage: defect detection
For defect detection, our network architecture uses a MASK-RCNN with two additional branches:
A mask-IOU branch to predict Intersection-over-Union (IoU) between the predicted mask and its ground truth mask. The aim is to describe the segmentation quality of instances and eliminate false positives not only based on classification scores but also with this predicted IoU. The IoU branch architecture is taken from Huang et al. ( 2019 ).
A bbox-IOU branch inspired from Wang et al. ( 2020 ) to predict IoU between the predicted bbox and its ground truth bbox for the same reasons as the mask-IOU branch.
By providing insights into the segmentation and detection quality of instances, these branches play a crucial role in mitigating false positives, thereby enhancing the overall precision of defect detection. Furthermore, they enrich the extracted features for the following classification stage by incorporating the two predicted IoU values together with the confidence score present in the original MASK-RCNN.
We have defined a training procedure to finetune models shown in Fig. 8 . First, we take the weights of the pre-trained MASK-RCNN on the COCO dataset. Next, we train the neural network globally with all the images at the original ratio but re-scaled to fit a size of 1024 by 1024. This first training allows the network to adapt to stereo-photometric images and localize defects. After that, a zone-by-zone fine-tuning strategy is applied with respect to the original image’s ratio and size. We keep the maximum possible resolution with respect to the memory available on our GPUs (16 GB) for training.

The detailed architecture of the defect detection and feature extraction modules

Zone-by-zone fine-tuning strategy
Loss functions
For training the improved version of the MASK-RCNN, we minimize an overall loss which is the weighted sum of the following loss functions:
The RPN classification loss \(\mathcal {L}_{\text {rpn}\_\text {cls}}\) which is a cross-entropy loss for anchor classification between background and objects:
with \(N_{rpn\_cls}\) the number of proposed anchors, \(y_i\) the target value (1 if an object is present, 0 for the background), \(p_i\) the predicted probability by the RPN that there is an object in the ith anchor.
The RPN regression loss \(\mathcal {L}_{\text {rpn}\_\text {reg}}\) for the regression of the anchors localization:
with \(N_{rpn\_reg}\) the number of sampled anchors from the candidates, \(p_i^*\) the binary ground truth label indicates whether anchor i is a positive sample, \(t_i\) the predicted offset for the ith anchor, \(t_i^*\) the target offset for the ith anchor.
The definition of the smooth-l1 function:
The faster-rcnn classification loss \(\mathcal {L}_{\text {cls}}\) which is a cross-entropy loss for the classification of bounding boxes according to their classes:
with \(N_{\text {cls}}\) the number of sampled bounding boxes ater the ROI head, M the number of classes, \(p_{c}\) the predicted probability that the i-th bounding box is of the c-th class and \(y_{c}\) the binary target that the i-th bounding box is of the c-th class.
The faster-rcnn regression loss \(\mathcal {L}_{\text {reg}}\) which is the same as the RPN regression loss except that the loss is applied on a sampled set of Regions Of Interest:
with \(N_{reg}\) the number of sampled ROI from the proposed, \(p_i^*\) the binary ground truth label indicating whether the i-th ROI is a positive sample, \(t_i\) the predicted offset for the i-th bounding box, \(t_i^*\) the target offset for the i-th bounding box.
The previous losses all come from Ren et al. ( 2015 ). The mask branch generates an \( m \times m \) mask for every Region of Interest (RoI) and each of the \( M \) classes, resulting in a total output size of \( Mm^2 \) . Since the model aims to learn a distinct mask for each class, there is no competition among classes in generating masks. Therefore, we can formulate the mask loss , \( \mathcal {L}_{\text {mask}} \) , as follows (defined in He et al. ( 2017 ))::
with \({N_{\text {mask}}}\) the number of ROI used for the mask branch (which is equal to \(N_{\text {reg}}\) less the ROI number without object to segment), m the resolution of the masks (in pixels), \(y_{icj}\) the ground-truth value of the j-th pixel in the c-th mask for the i-th ROI (1 if the pixel belongs to the object, 0 otherwise), \(p_{icj}\) the predicted probability of the j-th pixel in the c-th mask being part of the object class c for the i-th ROI.
The IoU bbox loss \(\mathcal {L}_{\text {IoU }\_\text { bbox}}\) (used in Wang et al. ( 2020 )) which is a MSE loss between the target IoU (between the predicted bounding boxes and the target bounding boxes) and the predicted IoU:
with \(N_{reg}\) the number of sampled ROI from the proposed, \(IoU_i\) the predicted IoU, \(IoU_i^*\) the target IoU.
The IoU mask loss \(\mathcal {L}_{\text {IoU }\_\text { mask}}\) (used in Huang et al. ( 2019 )) which is exactly the same as for the IoU bbox loss except that the IoU is computed per pixel inside each bounding box.
The Total loss may be written as the weighted sum of the previous losses:
Second stage: severity classification
After the detection, we need to extract the characteristics of each detected defect instance in order to classify them according to their severity. These specific features are selected as follows:
Coordinate of the defect (bounding box center), as severity depends on its location.
Relative vertical position (y) in the image.
Horizontal position, represented by a discrete value ranging from 1 to 12, corresponding to the twelve sectors into which the tire is divided.
Height and Width of the defect’s bounding box and the ratio Height/Width.
Classification branch class probability.
Mask IoU and bbox IoU predictions.
Defect area calculated on the defect mask.
Metadata information (Tire range, width, height, diameter). Some defects are more likely to appear on certain dimensions or ranges.
In regard to the severity classification part of our processing pipeline, we compared two approaches. The first is our baseline, which strictly utilizes the top layer of the neural network and a machine learning classifier based on the output of the extracted features. In order to improve our results, we proposed an approach which incorporates the original image with the extracted features using a customized multimodal deep learning neural network. There is one dataset per tire zone, with one instance of detected defect per line. The algorithm used to build this dataset is described in Algorithm 1

Build severity classification dataset

Baseline Model: machine Learning classification with a boosting tree model

Our proposed deep learning-based severity classification approach
The deep learning approach we suggest for the severity classification is composed of 3 parts:
A MLP to extract features from tabular data.
A method of feature extraction using a Resnet18 encoder to extract features from patches and a GRU to catch interactions between patches.
A network using MLP and the attention mechanism to fuse visual and tabular features.
In order to imagine this architecture, we drew our inspiration from the medical field. For skin lesion classification, metadata are important because certain factors such a person’s sex or age, are linked to the type of the lesion. Ou et al. ( 2022 ) showed that incorporating metadata improves classification results and that their multi-modal architecture with the attention-mechanism is better than a simple concatenation to fuse multimodal features. The self-attention module enables the network to exclude irrelevant information (such as background). The cross-attention module ensures that each modality guides the other. For instance, due to the pattern designs (see Fig. 1 ), a given dimension may result in some false positives appearing on the tread, and this cross-attention module can learn these complex relations.
For feature extraction in the image, we first trained a resnet18 encoder per zone to classify small patches according to their severity with 3 classes (no defect, not severe defect, severe defect). This pre-training task ensures that the extracted features are relevant. Then, we use a method tested in the medical sector proposed by Tripathi et al. ( 2021 ) for breast tumor classification. This BiLSTM approach using context-based patch modelling has the ambition to classify sequence of patches from high resolution-images. The RNN is useful to treat sequences of different lengths. Moreover, this makes our method independent from the original image size, the defect bounding box area in our case, and we can treat the image at full resolution without resizing it. We kept the same scanning technique to sample patches, but we replaced the BiLSTM with a bi-directional GRU (Chung et al., 2014 ) because it gave us better results empirically and has less parameters. The drawback of our architecture is that it is very sensitive to hyperparameters. To overcome this problem, we have done automatic hyperparameters research with the framework optuna. Before the input in the GRU layer, we added two linear layers separated by a Relu activation. The parameters of the search are the following:
GRU parameters:
Number of stacked GRU (between 1 and 5)
Dropout between GRU layers (between 0 and 0.5)
Number of hidden nodes (between 16 and 1024)
MLP parameters:
Dropout of the final linear classifier (between 0 and 0.5)
Embedded sizes of the linear layers (between 8 and 512)
Initial learning rate (between 0.0001 and 0.001)
For the research, we use a Tree-structured Parzen Estimator sampler (Bergstra et al., 2011 ) with a HyperBandPruner (Li et al., 2017 ). The metric to optimize is the F1-score. It can be defined as follows:
with \(\beta = 1 \)
This metric is suited for our classification task, as the dataset may be unbalanced depending on the tire zone.
Attention mechanism for multimodal features fusion
A self-attention layer may be useful to focus on the most relevant information inside each modality. As we have two modalities (images and tabular data), each of them has its own multiheaded self-attention module. This attention module first linearly projects its input into a Query (Q), Key (K) and Value (V). Then, the vector V is multiplied by the attention weight obtained from the scaled dot-product of the Query and Key passed through a Softmax layer. Formally, it can be written as follows:
Applied to \(x_{img}\) and \(x_{tab}\) , we obtain two output vectors \(x'_{img}\) and \(x'_{tab}\) respectively.
The multiheaded attention is based on this mechanism except that each combination of K, Q, V is split into multiple heads and the dot-product attention is applied to each head independently.
The Cross-Attention for inter-modality feature fusion module also relies on the same principle as for the self-attention. The main difference lies in the fact that we want image feature to guide the selection of relevant features from tabular data and vice versa. For this purpose, the cross-attention module is designed as follows: the Query \(Q_{img}\) and Value \(V_{img}\) come from \(x'_{img}\) projection and the Key \(K_{tab}\) is taken from the output of the tabular features went through its self-attention module. This time, the output can be written as:
The same module is built symmetrically in order to guide the selection of relevant tabular features from images:
Finally, we concatenate \( x''_{img}\) and \( x''_{tab}\) to obtain the final feature vector that is passed to the last MLP.
Implementation details
In our experiments, for each zone, we are splitting the data with 80% for training and 20% for validation. To get an equal amount of samples viewed with the majority class for each zone, a balancing method is used: we repeat the less represented classes. For the defect detection and severity classification tasks, the training and validation sets differ because we want our severity classification model to be able to generalize on less certain predictions from the detection model (training examples will generally have a higher classification and IoU score than validation samples from the MASK-RCNN). In regard of the deep learning parts, our implementations are based on the pytorch framework, and the Adam optimizer (Kingma & Ba, 2014 ) is used.
Detection stage
For the first global training , we take all images from different tire zones, and we resize them to a size of 1024*1024 pixels. The initial learning rate is 0.0002 with a batch size of 4 per GPU and the weights of the loss are equal to \(\lambda _1=\lambda _2=\lambda _3=\lambda _4=\lambda _5=\lambda _6=\lambda _7=1\) . After each epoch, the learning rate is decreased by 0.5 and we train the network until there is no further improvement after 6 epochs. As for the data augmentation, we consider that the acquisition system is well controlled and for this reason we only apply Color Jitter before resizing. Adding unrealistic augmentations would not help generalization as images have a low real variability. Mixed precision is applied with a distributed data parallel strategy on eight T4 GPUs. All the original MASK-RCNN hyperparameters are kept as they were initially in torchvision except the box_nms_threshold and rpn_nms_threshold with custom values set at 0.05 and 0.3 respectively.
For the fine-tuning of the MASK-RCNN per zone , we retain the same parameters as for the global pre-training apart from the initial learning rate, whose value is reduced to 5e-05. The number of images used and the custom size per zone is defined in Fig. 8 . The batch size per GPU is set to 1.
Severity classification stage
The process of extracting patch features involves fine-tuning of a resnet18 classifier previously trained on Imagenet. The patch size is 128*128 for all zones, except for the interior shoulder with a patch size of 258*258 because of the difference in size of the original image. The batch size is 128, the initial learning rate is 0.0005 and the network is trained for 15 epochs with cross-entropy loss. We also trained one model per zone, utilizing the same images as in the detection stage, albeit at a patch scale.
The tabular data processing encodes categorical features (defect type, camera zone and tire informations) with embeddings. The number of neurons chosen for each embedding corresponds to half of the possible input values (for example if we have 4 dimensions in the dataset, the corresponding embedding will encode this information into 2 neurons). In addition, as proposed by Cai et al. ( 2022 ), we introduced a Soft Label Encoder (SLE), which means that instead of filling negative categorical values with 0, we fill them with the value 0.1. The aim of SLE is to help the categorical tabular features to be more expressive and more suitable for the input of the network. We create a special category for rare occurrences of categorical features where we can group them together. After the individual features extraction from categorical and numerical values through embeddings and a linear layer respectively, these features are concatenated and sent to a new MLP which stacks two successions of linear layers, batch normalizations and ReLu separated with a Dropout. For the self-attention and cross-attention modules, we fix the head number of the multiheaded attention to 8.
As this stage relies on the initial detection outputs, the number of rows (where each row corresponds to a detection in the first stage) is provided in Table 1 . As evident, the count of detected instances is higher in the exterior zones due to the larger quantity of images and a comparatively elevated defect rate.
The Hyperparameters search is constrained by the following settings: the maximum number of epochs is set to 70 and the minimum number of epochs before early stopping is set to 20. The optimizer is coupled with a step scheduler which multiply by 0.2 the learning rate every 10 epochs. The parameters of the resnet18 are frozen, only the GRU and metadata parts are trained to optimize the cross-entropy loss.
As we can see in Table 2 , the F1-score is not uniform across the zones and defect types, as we depend on available data and the quality of the annotation. Furthermore, defects may vary from one zone to another, and the number of examples also varies. These results might seem weak at first glance, but this detection task can be extremely difficult; for instance, it takes an aspect operator six months to get proficient at detecting these defects directly on the tire.
If we look at the results in details, contrast differences and surface roughness have the lowest scores in average, because it’s hard to label them as they can be diffused. As a result, even if the metric is not as high as expected, the qualitative results are satisfying (see Table 4 ) which we believe is sufficient for the next part since the severity classification task will reduce false positives. In addition, the quality of the annotations could be challenged: some defects are very hard to label due to their diffuse shape or because of the proximity between certain classes which leads the model to predict several instances of each defect type that are similar at the same location. These annotation difficulties are illustrated in Table 5 .
As we can see in Table 3 , our deep learning multimodal architecture improves the F1-score by an average of 21% per zone compared with our baseline. Our experiences showed that LightGBM (Ke et al., 2017 ) performed best for this classifier with one fine-tuned model per zone. As a reminder, this simple model consists of a binary classifier that only takes tabular data as input. We used the library Pycaret for this experiment.
Due to the dependency of this classification stage on the quality of the detection stage, it is imperative to experimentally verify the utility of IoU branches for the classification process. Essentially, this entails assessing whether the predicted IoU effectively supplements the severity classifier when MASK-RCNN fails to provide confident detections. In such instances, the predicted IoU is expected to be low, thus becoming a crucial feature for severity classification. To scrutinize this aspect, we employed the Shapley additive explanations (SHAP) method (Lundberg & Lee, 2017 ) to analyze the feature importance of the baseline boosting tree classifier. The Shapley values derived from the boosting tree model trained on interior tread data are illustrated in Fig. 11 . Notably, the box IoU emerges as the third most influential feature, preceding even the confidence score, while the mask IoU also demonstrates significant importance as the eighth feature. This observation validates our hypothesis, affirming two key points:
The effectiveness of the additional branches predicting Mask IoU and bbox IoU.
The resilience of the severity classification stage in relation to the detection stage, as it can leverage predicted IoU scores as confidence features to refine severity predictions. In instances where the initial detection model’s performance is inadequate for certain images, this deficiency is accounted for by the second stage model through the confidence score and predicted IoU scores.
Upon further analysis of Fig. 11 (refer to Second stage: severity classification subsection for detailed definitions of each feature), it becomes evident that both the area and vertical position are the most influential factors for this zone, exhibiting a clear positive correlation in the former and a more intricate relationship in the latter. This finding is logical and confirms that the model prioritizes relevant features; indeed, it is well-established that a larger defect area generally correlates with increased severity probability. Additionally, regarding vertical position, certain locations exhibit abrupt increases in defect severity, underscoring its significance in the model’s decision-making process.
The Top 12 Shapley values reveal several other noteworthy features. For instance, Sector 12 (where a tire is segmented into 12 sectors to assess the horizontal position of a defect) indicates a lower likelihood of severe defects overall. Furthermore, Visual Family Bumps emerges as another significant criterion positively correlated with severity for the interior tread, a conclusion consistent with expert opinions.
In summary, the Shapley values align with established quality rules. It would be intriguing to explore whether this model interpretation could potentially simplify these rules in future analyses.

Feature importance analysis of baseline boosting tree model tuned on interior tread zone: focusing on the Top 12 Shapley values
We also wanted to evaluate the impact of the metadata tire information, which is why we made an ablation study focused on the area most affected: the exterior of the tread (tire metadata such as the range is correlated to the tread patterns). As a result, we noticed a +1% point increase on the F1-score with the addition of tire metadata on this specific zone. We didn’t pursue experiments on other zones due to the computational cost of searching for hyperparameters. For the same reasons, we didn’t compare the effectiveness of the multimodal concatenation through attention with a simple concatenation. Besides, this concatenation method has already been validated as being better for multimodal features fusion (Ou et al., 2022 ) and (Cai et al., 2022 ). Nevertheless, we carried out empirical tests on the outer tread area and found a gain of around 1% point on the F1-score with the attention mechanism.
Discussion and conclusion
A new approach for detecting tire defect surfaces and classifying their severity is proposed in this article, with an F1-score that varies from 0.7 to 0.89 depending on the tire zone. These results are highly satisfactory in relation to the task difficulty and the huge quantity of defect types. While the performance of the second stage relies on the outcomes of the initial detection phase, our experimental findings underscore its robustness and validate the significance of the two IoU prediction branches in encapsulating a form of uncertainty inherent in the initial model, effectively captured by the classification model. This is also the first study to propose a functional method for all tire zones at the same time. The novelty also lies in the use of tire metadata and the multimodal aspect. However, our results can be further improved by working on the data: using model output to improve the quality of annotations. Also, for the time being, we aren’t defining an aggregation strategy for the predictions, the tire severity decision is taken at the bounding box scale, but ideally, we would like to have a model that makes a single decision at the image or tire scale, i.e., one that can capture the existing relationships between the detected defects. Additionally, our architecture is deployable but complex to implement, as it involves a certain number of steps (detection, pre-training of patches classifier, hyperparameters searching etc...). Without any optimization, the total inference time for each zone of the tire is empirically measured at 20 s. It would be interesting to study whether this time could be reduced.
Another interesting approach that has not yet been tested is semantic segmentation, which involves a simpler architecture but does not allow individual defect instances to be identified.
Data Availibility
The datasets generated during and/or analyzed as part of the current study are not publicly available due to the confidential information they contain about the process and quality standards.
Aminzadeh, M., & Kurfess, T. (2019). Online quality inspection using bayesian classification in powder-bed additive manufacturing from high-resolution visual camera images. Journal of Intelligent Manufacturing, 30 , 2505–2523. https://doi.org/10.1007/s10845-018-1412-0
Article Google Scholar
Bergstra, J., Bardenet, R., Bengio, Y., & Kégl, B. (2011). Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems , volume 24.
Cai, G., Zhu, Y., Wu, Y., Jiang, X., Ye, J., & Yang, D. (2022). A multimodal transformer to fuse images and metadata for skin disease classification. The Visual Computer, 39 (7), 2781–2793. https://doi.org/10.1007/s00371-022-02492-4
Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Li, F.-F. (2009). Imagenet: a large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition (pp. 248–255). https://doi.org/10.1109/CVPR.2009.5206848 .
Girshick, R. (2015). Fast r-cnn. In 2015 IEEE International Conference on Computer Vision (ICCV) (pp. 1440–1448).
Hafizur, M., & Masum, M. H. R. (2014). Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014 (pp. 818–833). https://doi.org/10.13140/RG.2.2.12182.22080 .
He, K., Gkioxari, G., Dollar, P., & Girshick, R. (2017). Mask r-cnn. (pp. 2980–2988). https://doi.org/10.1109/ICCV.2017.322 .
Hearst, M., Dumais, S., Osman, E., Platt, J., & Scholkopf, B. (1998). Support vector machines. Intelligent Systems and Their Applications, IEEE, 13 , 18–28. https://doi.org/10.1109/5254.708428
Huang, Z., Huang, L., Gong, Y., Huang, C., & Wang, X. (2019). Mask scoring r-cnn. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 6402–6411).
Kang, G., Gao, S., Yu, L., & Zhang, D. (2018). Deep architecture for high-speed railway insulator surface defect detection: Denoising autoencoder with multitask learning. IEEE Transactions on Instrumentation and Measurement, 68 , 2679–2690. https://doi.org/10.1109/TIM.2018.2868490
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q. & Liu, T.-Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree (Vol. 30, pp. 146–3154).
Kingma, D., & Ba, J. (2014). Adam: A method for stochastic optimization. In International Conference on Learning Representations .
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., & Girshick, R. (2023). Segment anything. arXiv:2304.02643 .
Kuo, J., Tung, C.-P., & Weng, W. (2019). Applying the support vector machine with optimal parameter design into an automatic inspection system for classifying micro-defects on surfaces of light-emitting diode chips. Journal of Intelligent Manufacturing, 30 , 727–741. https://doi.org/10.1007/s10845-016-1275-1
Kuric, I., Klarak, J., Sága, M., Císar, M., Hajdučík, A., & Wiecek, D. (2021). Analysis of the possibilities of tire-defect inspection based on unsupervised learning and deep learning. Sensors, 21 , 7073. https://doi.org/10.3390/s21217073
Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., Talwalkar, A. (2017). Efficient hyperparameter optimization and infinitely many armed bandits. In 5th International Conference on Learning Representations (p. 03).
Lin, S.-L. (2023). Research on tire crack detection using image deep learning method. Scientific Reports, 13 , 8027. https://doi.org/10.1038/s41598-023-35227-z
Liu, H., Jia, X., Su, C., Yang, H., & Li, C. (2023). Tire appearance defect detection method via combining hog and lbp features. Frontiers in Physics, 10 , 1099261. https://doi.org/10.3389/fphy.2022.1099261
Loupos, K., Makantasis, K., Protopapadakis, E., Doulamis, A., & Doulamis, N. (2015). Deep convolutional neural networks for efficient vision based tunnel inspection. In 2015 IEEE international conference on intelligent computer communication and processing (ICCP) (pp. 335–342) https://doi.org/10.1109/ICCP.2015.7312681
Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. (pp. 4765–4774).
Massaro, A., Dipierro, G., Cannella, E., & Galiano, A. (2020). Comparative analysis among discrete fourier transform, k-means and artificial neural networks image processing techniques oriented on quality control of assembled tires. Information (Switzerland) , 11 , 257. https://doi.org/10.3390/info11050257 .
Mourougaya, F. (2019). Système d’évaluation de l’état de la surface d’un pneumatique. https://data.inpi.fr/brevets/WO2021105597?q=Syst%C3%A8me%20d%27%C3%A9valuation%20de%20l%27%C3%A9tat%20de%20la%20surface%20d%27un%20pneumatique#WO2021105597 .
Ou, C., Zhou, S., Yang, R., Jiang, W., He, H., Gan, W., Chen, W., Qin, X., Luo, W., Pi, X., & Li, J. (2022). A deep learning based multimodal fusion model for skin lesion diagnosis using smartphone collected clinical images and metadata. Frontiers in Surgery . https://doi.org/10.3389/fsurg.2022.1029991
Protopapadakis, E., & Doulamis, N. (2015). Image based approaches for tunnels’ defects recognition via robotic inspectors (pp. 706–716). https://doi.org/10.1007/978-3-319-27857-5_63 .
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39 , 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
Soukup, D., & Huber-Mörk, R. (2014). Convolutional neural networks for steel surface defect detection from photometric stereo image (pp. 668–677). https://doi.org/10.1007/978-3-319-14249-4_64 .
Sun, X., Gu, J., Huang, R., Zou, R., & Palomares, B. (2019). Surface defects recognition of wheel hub based on improved faster r-cnn. Electronics, 8 , 481. https://doi.org/10.3390/electronics8050481
Tabernik, D., Šela, S., Skvarc, J., & Skočaj, D. (2019). Segmentation-based deep-learning approach for surface-defect detection. Journal of Intelligent Manufacturing, 31 , 759–776. https://doi.org/10.1007/s10845-019-01476-x
Tada, H., & Sugiura, A. (2021). Defect classification on automobile tire inner surfaces with functional classifiers. Transactions of the Institute of Systems, Control and Information Engineers, 34 , 1–10. https://doi.org/10.5687/iscie.34.1
Tripathi, S., Singh, S. K., & Lee, H. (2021). An end-to-end breast tumour classification model using context-based patch modelling—a bilstm approach for image classification. Computerized Medical Imaging and Graphics, 87 , 101838.
Vaidya, S., Ambad, P. M., & Bhosle, S. M. (2018). Industry 4.0—A glimpse. Procedia Manufacturing, 20 , 233–238.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., & Polosukhin, I. (2017). Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (Vol. 30, pp. 6000–6010). Curran Associates, Inc. https://doi.org/10.5555/3295222.3295349 .
Vincent, P., Larochelle, H., Bengio, Y., & Manzagol, P.-A. (2008). Extracting and composing robust features with denoising autoencoders (pp. 1096–1103). https://doi.org/10.1145/1390156.1390294 .
Wang, J., Shaoguo, W., Chen, K., Yu, J., gao, P., & Xie, G. (2020). Semi-supervised active learning for instance segmentation via scoring predictions. In BMVC 2020 .
Yan, H., Li, Z., Li, W., Wang, C., Wu, M., & Zhang, C. (2021). Contnet: Why not use convolution and transformer at the same time? arXiv preprint arXiv:2104.13497 .
Zhou, Z., Lu, Q., Wang, Z., & Huang, H. (2019). Detection of micro-defects on irregular reflective surfaces based on improved faster r-cnn. Sensors, 19 , 5000. https://doi.org/10.3390/s19225000
Download references
Author information
Authors and affiliations.
Univ Lyon, INSA Lyon, CNRS, UCBL, LIRIS, UMR5205, 69621, Villeurbanne, France
Thomas Mignot, Stefan Duffner & Christophe Garcia
Manufacture française des pneumatiques Michelin, Pl. des Carmes Dechaux, 63000, Clermont-Ferrand, France
Thomas Mignot, François Ponchon & Alexandre Derville
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Thomas Mignot .
Ethics declarations
Conflict of interest.
The authors declare that they have no Conflict of interest.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Mignot, T., Ponchon, F., Derville, A. et al. An automatic inspection system for the detection of tire surface defects and their severity classification through a two-stage multimodal deep learning approach. J Intell Manuf (2024). https://doi.org/10.1007/s10845-024-02378-3
Download citation
Received : 13 October 2023
Accepted : 17 March 2024
Published : 22 May 2024
DOI : https://doi.org/10.1007/s10845-024-02378-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Surface defect detection
- Tire quality control
- Severity classification
- Deep learning
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
For practical purposes, it's recommended to ensure that your course or presentation covers the 7 main types of learning. In this article, we'll break down the 7 types of learning styles, and give practical tips for how you can improve your own teaching styles, whether it's in higher education or an online course you plan to create on the ...
The term learning styles is widely used to describe how learners gather, sift through, interpret, organize, come to conclusions about, and "store" information for further use. As spelled out in VARK (one of the most popular learning styles inventories), these styles are often categorized by sensory approaches: v isual, a ural, verbal [ r ...
1. Visual Learners. Visual learners learn best when information is presented through images. These could include pictures, videos, charts, diagrams, mind maps, and infographics. For example, in a presentation about goal setting, visual learners would appreciate a flowchart showing the different steps of goal setting. 2.
The authors of the present review were charged with determining whether these practices are supported by scientific evidence. We concluded that any credible validation of learning-styles-based instruction requires robust documentation of a very particular type of experimental finding with several necessary criteria. First, students must be divided into groups on the basis of their learning ...
The seven types of learning. New Zealand educator Neil Fleming developed the VARK model in 1987. It's one of the most common methods to identify learning styles. Fleming proposed four primary learning preferences—visual, auditory, reading/writing, and kinesthetic. The first letter of each spells out the acronym (VARK).
Alec Patton. A Presentation of Learning (POL) requires students to present their learning to an audience, in order to prove that they are ready to progress. Effective POLs include both academic content and the student's reflection on their social and personal growth. They are important rituals - literally "rites of passage" for students.
1 Visual Learning. Visual or spatial learning is a learning style that requires visual aids, images, diagrams or graphs to help retain information and guide the learning process. Including infographics and photos throughout your presentation slides is a great way to help your audience understand your information. And while you never want to clutter your presentations with blocks of text, this ...
10 Tips for creating an effective training presentation. Creating a training presentation is not a simple task. Unlike your usual PowerPoints, a training deck should convey work-related information in a way that keeps your team engaged and creates a positive learning experience. Quite a challenge, if you ask me - especially in online environments.
Free Google Slides theme, PowerPoint template, and Canva presentation template. Contrary to popular belief, there are lots of different ways of teaching, and they aren't incompatible. In fact, they complement each other. Some work better for some subjects than others. Eliana Delacour knows this very well, and that's why she has been the one ...
Academy for Teaching and Learning. Moody Library, Suite 201. One Bear Place. Box 97189. Waco, TX 76798-7189. [email protected]. (254) 710-4064. PowerPoint is common in college classrooms, yet slide technology is not more effective for student learning than other styles of lecture (Levasseur & Sawyer, 2006). While research indicates which practices ...
Trying to rush through slides can give the impression of an unorganized presentation and may be difficult for students to follow or learn. PART II: Enhancing Teaching and Learning with PowerPoint Class Preparation. PowerPoint can be used to prepare lectures and presentations by helping instructors refine their material to salient points and ...
The method is based on group cooperative learning and teaching the acquisition of each team member to each other (intertwining individual and team learning). The mosaic is a method that builds confidence in the participants' own strengths; develops communication skills (listening and speaking); reflection; creative thinking; problem solving ...
5 Learning Styles to use when structuring Public Presentations. 1. Visual learning style. The visual learning style is the one in which the person learns through vision. The easiest to assimilate information is recorded in graphs, videos, images, diagrams, maps, symbols, and lists. People with a visual learning style tend to take notes to ...
When combined, these framed a rubric that supported students in optimizing their presentation deliveries. The competencies are as follows: 1. Content knowledge. The presenter must display a deep understanding of what they are delivering in order to share the "what, why, how, and how-to" of the topic. 2.
Here are more than ten common different effective presentation styles: 1. Visual Presentation Style. The visual style is great for anyone who wants to use your presentation to complement the main points of your speech. This visual presentation technique is perfect for people who have many important talking points.
Presentation. A presentation delivers content through oral, audio and visual channels allowing teacher-learner interaction and making the learning process more attractive. Through presentations, teachers can clearly introduce difficult concepts by illustrating the key principles and by engaging the audience in active discussions.
Allowing your presentation to have some aspect of physical participation, even it's as simple as an informal poll involving raised hands. Not all adults use the same tactics to learn and retain new information. By understanding the various learning styles, you can adjust your presentations to reach your whole audience.
Many people recognize that each person prefers different learning styles and techniques. Learning styles group common ways that people learn. Everyone has a mix of learning styles. Some people may find that they have a dominant style of learning, with far less use of the other styles. Learning styles, Types of Learning Style
Learning Styles There are many MODELS of learning styles in education. In 1987, Neil Fleming, a high school and university teacher from New Zealand developed the most widely used learning style model known as the VAK (Visual, Auditory, Kinesthetic). Years later added a fourth style: Read/Write! The acronym changed to VARK.
You will probably find that deciding on the presentation method means that you need to change or amend your presentation. For example, if you want to include some audience participation, you will need to include that in your slides, otherwise, you might well forget in the heat of the moment. Fortunately, revisiting your presentation in light of ...
Here are a few tips for business professionals who want to move from being good speakers to great ones: be concise (the fewer words, the better); never use bullet points (photos and images paired ...
The traditional methods may have a new look online, but their purpose remains the same: to create meaningful learning experiences for online learners. Strategies For Engaging Online Lessons Collaboration. Each teaching method has different characteristics when applied to online learning; however, they all have some common features.
3. Instructor Style. What it is: This presentation style allows you to deliver complex messages using figures of speech, metaphors, and lots of content -- just like your teachers and professors of old. Your decks should be built in logical order to aid your presentation, and you should use high-impact visuals to support your ideas and keep the audience engaged.
CREATE THIS PRESENTATION. 2. Persuasive presentation. If you've ever been swayed by a passionate speaker armed with compelling arguments, you've experienced a persuasive presentation . This type of presentation is like a verbal tug-of-war, aiming to convince the audience to see things from a specific perspective.
HBR Learning's online leadership training helps you hone your skills with courses like Presentation Skills. Earn badges to share on LinkedIn and your resume. Access more than 40 courses trusted ...
The main difference between supervised and unsupervised learning: Labeled data. The main distinction between the two approaches is the use of labeled data sets. To put it simply, supervised learning uses labeled input and output data, while an unsupervised learning algorithm does not. In supervised learning, the algorithm "learns" from the ...
Poster, Presentation, Protocol or Paper. Deposit scholarly works such as posters, presentations, research protocols, conference papers or white papers. If you would like to deposit a peer-reviewed article or book chapter, use the "Scholarly Articles and Book Chapters" deposit option.
Transcript. Allal: My name is Loubna. I'm a machine learning engineer at Hugging Face. I work on large language models for code. I will show you how these models are trained and how you can ...
Deep learning for visual inspection. With the arrival of convolutional neural networks in 2012 and their superior performance on Imagenet (Deng et al., 2009) classification tasks, they were also investigated for visual inspection and defect detection tasks in industrial environments.One of the first applications was to detect surface defects in tunnels (Loupos et al., 2015) and (Protopapadakis ...