
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Oral Maxillofac Pathol
- v.23(2); May-Aug 2019

Hypothesis-driven Research
Umadevi krishnamohan rao.
1 Department of Oral and Maxillofacial Pathology, Ragas Dental College and Hospital, Chennai, Tamil Nadu, India E-mail: moc.liamg@kvuamu

As Oral Pathologists, we have the responsibility to upgrade our quality of service with an open mind attitude and gratitude for the contributions made by our professional colleagues. Teaching the students is the priority of the faculty, and with equal priority, oral pathologists have the responsibility to contribute to the literature too as a researcher.
Research is a scientific method of answering a question. This can be achieved when the work done in a representative sample of the population, i.e., the outcome of the result, can be applied to the rest of the population, from which the sample is drawn. In this context, frequently done research is a hypothesis-driven research which is based on scientific theories. Specific aims are listed in this type of research, and the objectives are stated. The scope of a well-designed methodology in a hypothesis-driven research equips the researcher to establish an opportunity to state the outcome of the study.
A provisional statement in which the relationship between two variables is described is known as hypothesis. It is very specific and offers the freedom of evaluating a prediction between the variables stated. It facilitates the researcher to envision and gauge as to what changes can occur in the listed specific outcome variables (dependent) when changes are made in a specific predictor (independent) variable. Thus, any given hypothesis should include both these variables, and the primary aim of the study should be focused on demonstrating the association between the variables, by maintaining the highest ethical standards.
The other requisites for a hypothesis-based study are we should state the level of statistical significance and should specify the power, which is defined as the probability that a statistical test will indicate a significant difference when it truly exists.[ 1 ] In a hypothesis-driven research, specifications of methodology help the grant reviewers to differentiate good science from bad science, and thus, hypothesis-driven research is the most funded research.[ 2 ]
“Hypotheses aren’t simply useful tools in some potentially outmoded vision of science; they are the whole point.” This was stated by Sean Carroll, from the California Institute of Technology, in response to Editor-In-Chief of “ Wired ” Chris Anderson, who argued that “biology is too complex for hypotheses and models, and he favored working on enormous data by correlative analysis.”[ 3 ]
Research does not stop by stating the hypotheses but must ensure that it is clear, testable and falsifiable and should serve as the fundamental basis for constructing a methodology that will allow either its acceptance (study favoring a null hypothesis) or rejection (study rejecting the null hypothesis in favor of the alternative hypothesis).
It is very worrying to observe that many research projects, which require a hypothesis, are being done without stating one. This is the fundamental backbone of the question to be asked and tested, and later, the findings need to be extrapolated in an analytical study, addressing a research question.
A good dissertation or thesis which is submitted for fulfillment of a curriculum or a submitted manuscript is comprised of a thoughtful study, addressing an interesting concept, and has to be scientifically designed. Nowadays, evolving academicians are in a competition to prove their point and be academically visible, which is very vital in their career graph. In any circumstance, unscientific research or short-cut methodology should never be conducted or encouraged to produce a research finding or publish the same as a manuscript.
The other type of research is exploratory research, which is based on a journey for discovery, which is not backed by previously established theories and is driven by hope and chance of breakthrough. The advantage of using these data is that statistics can be applied to establish predictions without the consideration of the principles of designing a study, which is the fundamental requirement of a conventional hypothesis. There is a need to set standards of statistical evidence with a much higher cutoff value for acceptance when we consider doing a study without a hypothesis.
In the past few years, there is an emergence of nonhypothesis-driven research, which does receive encouragement from funding agencies such as innovative molecular analysis technologies. The point to be taken here is that funding of nonhypothesis-driven research does not implicate decrease in support to hypothesis-driven research, but the objective is to encourage multidisciplinary research which is dependent on coordinated and cooperative execution of many branches of science and institutions. Thus, translational research is challenging and does carry a risk associated with the lack of preliminary data to establish a hypothesis.[ 4 ]
The merit of hypothesis testing is that it takes the next stride in scientific theory, having already stood the rigors of examination. Hypothesis testing is in practice for more than five decades and is considered to be a standard requirement when proposals are being submitted for evaluation. Stating a hypothesis is mandatory when we intend to make the study results applicable. Young professionals must be appraised of the merits of hypothesis-based research and must be trained to understand the scope of exploratory research.
Loading metrics
Open Access
Perspective
Perspective: Dimensions of the scientific method
* E-mail: [email protected]
Affiliation Department of Biomedical Engineering, Georgia Institute of Technology and Emory University, Atlanta, Georgia, United States of America
- Eberhard O. Voit
Published: September 12, 2019
- https://doi.org/10.1371/journal.pcbi.1007279
- Reader Comments
The scientific method has been guiding biological research for a long time. It not only prescribes the order and types of activities that give a scientific study validity and a stamp of approval but also has substantially shaped how we collectively think about the endeavor of investigating nature. The advent of high-throughput data generation, data mining, and advanced computational modeling has thrown the formerly undisputed, monolithic status of the scientific method into turmoil. On the one hand, the new approaches are clearly successful and expect the same acceptance as the traditional methods, but on the other hand, they replace much of the hypothesis-driven reasoning with inductive argumentation, which philosophers of science consider problematic. Intrigued by the enormous wealth of data and the power of machine learning, some scientists have even argued that significant correlations within datasets could make the entire quest for causation obsolete. Many of these issues have been passionately debated during the past two decades, often with scant agreement. It is proffered here that hypothesis-driven, data-mining–inspired, and “allochthonous” knowledge acquisition, based on mathematical and computational models, are vectors spanning a 3D space of an expanded scientific method. The combination of methods within this space will most certainly shape our thinking about nature, with implications for experimental design, peer review and funding, sharing of result, education, medical diagnostics, and even questions of litigation.
Citation: Voit EO (2019) Perspective: Dimensions of the scientific method. PLoS Comput Biol 15(9): e1007279. https://doi.org/10.1371/journal.pcbi.1007279
Editor: Jason A. Papin, University of Virginia, UNITED STATES
Copyright: © 2019 Eberhard O. Voit. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Funding: This work was supported in part by grants from the National Science Foundation ( https://www.nsf.gov/div/index.jsp?div=MCB ) grant NSF-MCB-1517588 (PI: EOV), NSF-MCB-1615373 (PI: Diana Downs) and the National Institute of Environmental Health Sciences ( https://www.niehs.nih.gov/ ) grant NIH-2P30ES019776-05 (PI: Carmen Marsit). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing interests: The author has declared that no competing interests exist.
The traditional scientific method: Hypothesis-driven deduction
Research is the undisputed core activity defining science. Without research, the advancement of scientific knowledge would come to a screeching halt. While it is evident that researchers look for new information or insights, the term “research” is somewhat puzzling. Never mind the prefix “re,” which simply means “coming back and doing it again and again,” the word “search” seems to suggest that the research process is somewhat haphazard, that not much of a strategy is involved in the process. One might argue that research a few hundred years ago had the character of hoping for enough luck to find something new. The alchemists come to mind in their quest to turn mercury or lead into gold, or to discover an elixir for eternal youth, through methods we nowadays consider laughable.
Today’s sciences, in stark contrast, are clearly different. Yes, we still try to find something new—and may need a good dose of luck—but the process is anything but unstructured. In fact, it is prescribed in such rigor that it has been given the widely known moniker “scientific method.” This scientific method has deep roots going back to Aristotle and Herophilus (approximately 300 BC), Avicenna and Alhazen (approximately 1,000 AD), Grosseteste and Robert Bacon (approximately 1,250 AD), and many others, but solidified and crystallized into the gold standard of quality research during the 17th and 18th centuries [ 1 – 7 ]. In particular, Sir Francis Bacon (1561–1626) and René Descartes (1596–1650) are often considered the founders of the scientific method, because they insisted on careful, systematic observations of high quality, rather than metaphysical speculations that were en vogue among the scholars of the time [ 1 , 8 ]. In contrast to their peers, they strove for objectivity and insisted that observations, rather than an investigator’s preconceived ideas or superstitions, should be the basis for formulating a research idea [ 7 , 9 ].
Bacon and his 19th century follower John Stuart Mill explicitly proposed gaining knowledge through inductive reasoning: Based on carefully recorded observations, or from data obtained in a well-planned experiment, generalized assertions were to be made about similar yet (so far) unobserved phenomena [ 7 ]. Expressed differently, inductive reasoning attempts to derive general principles or laws directly from empirical evidence [ 10 ]. An example is the 19th century epigram of the physician Rudolf Virchow, Omnis cellula e cellula . There is no proof that indeed “every cell derives from a cell,” but like Virchow, we have made the observation time and again and never encountered anything suggesting otherwise.
In contrast to induction, the widely accepted, traditional scientific method is based on formulating and testing hypotheses. From the results of these tests, a deduction is made whether the hypothesis is presumably true or false. This type of hypotheticodeductive reasoning goes back to William Whewell, William Stanley Jevons, and Charles Peirce in the 19th century [ 1 ]. By the 20th century, the deductive, hypothesis-based scientific method had become deeply ingrained in the scientific psyche, and it is now taught as early as middle school in order to teach students valid means of discovery [ 8 , 11 , 12 ]. The scientific method has not only guided most research studies but also fundamentally influenced how we think about the process of scientific discovery.
Alas, because biology has almost no general laws, deduction in the strictest sense is difficult. It may therefore be preferable to use the term abduction, which refers to the logical inference toward the most plausible explanation, given a set of observations, although this explanation cannot be proven and is not necessarily true.
Over the decades, the hypothesis-based scientific method did experience variations here and there, but its conceptual scaffold remained essentially unchanged ( Fig 1 ). Its key is a process that begins with the formulation of a hypothesis that is to be rigorously tested, either in the wet lab or computationally; nonadherence to this principle is seen as lacking rigor and can lead to irreproducible results [ 1 , 13 – 15 ].
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
The central concept of the traditional scientific method is a falsifiable hypothesis regarding some phenomenon of interest. This hypothesis is to be tested experimentally or computationally. The test results support or refute the hypothesis, triggering a new round of hypothesis formulation and testing.
https://doi.org/10.1371/journal.pcbi.1007279.g001
Going further, the prominent philosopher of science Sir Karl Popper argued that a scientific hypothesis can never be verified but that it can be disproved by a single counterexample. He therefore demanded that scientific hypotheses had to be falsifiable, because otherwise, testing would be moot [ 16 , 17 ] (see also [ 18 ]). As Gillies put it, “successful theories are those that survive elimination through falsification” [ 19 ]. Kelley and Scott agreed to some degree but warned that complete insistence on falsifiability is too restrictive as it would mark many computational techniques, statistical hypothesis testing, and even Darwin’s theory of evolution as nonscientific [ 20 ].
While the hypothesis-based scientific method has been very successful, its exclusive reliance on deductive reasoning is dangerous because according to the so-called Duhem–Quine thesis, hypothesis testing always involves an unknown number of explicit or implicit assumptions, some of which may steer the researcher away from hypotheses that seem implausible, although they are, in fact, true [ 21 ]. According to Kuhn, this bias can obstruct the recognition of paradigm shifts [ 22 ], which require the rethinking of previously accepted “truths” and the development of radically new ideas [ 23 , 24 ]. The testing of simultaneous alternative hypotheses [ 25 – 27 ] ameliorates this problem to some degree but not entirely.
The traditional scientific method is often presented in discrete steps, but it should really be seen as a form of critical thinking, subject to review and independent validation [ 8 ]. It has proven very influential, not only by prescribing valid experimentation, but also for affecting the way we attempt to understand nature [ 18 ], for teaching [ 8 , 12 ], reporting, publishing, and otherwise sharing information [ 28 ], for peer review and the awarding of funds by research-supporting agencies [ 29 , 30 ], for medical diagnostics [ 7 ], and even in litigation [ 31 ].
A second dimension of the scientific method: Data-mining–inspired induction
A major shift in biological experimentation occurred with the–omics revolution of the early 21st century. All of a sudden, it became feasible to perform high-throughput experiments that generated thousands of measurements, typically characterizing the expression or abundances of very many—if not all—genes, proteins, metabolites, or other biological quantities in a sample.
The strategy of measuring large numbers of items in a nontargeted fashion is fundamentally different from the traditional scientific method and constitutes a new, second dimension of the scientific method. Instead of hypothesizing and testing whether gene X is up-regulated under some altered condition, the leading question becomes which of the thousands of genes in a sample are up- or down-regulated. This shift in focus elevates the data to the supreme role of revealing novel insights by themselves ( Fig 2 ). As an important, generic advantage over the traditional strategy, this second dimension is free of a researcher’s preconceived notions regarding the molecular mechanisms governing the phenomenon of interest, which are otherwise the key to formulating a hypothesis. The prominent biologists Patrick Brown and David Botstein commented that “the patterns of expression will often suffice to begin de novo discovery of potential gene functions” [ 32 ].
Data-driven research begins with an untargeted exploration, in which the data speak for themselves. Machine learning extracts patterns from the data, which suggest hypotheses that are to be tested in the lab or computationally.
https://doi.org/10.1371/journal.pcbi.1007279.g002
This data-driven, discovery-generating approach is at once appealing and challenging. On the one hand, very many data are explored simultaneously and essentially without bias. On the other hand, the large datasets supporting this approach create a genuine challenge to understanding and interpreting the experimental results because the thousands of data points, often superimposed with a fair amount of noise, make it difficult to detect meaningful differences between sample and control. This situation can only be addressed with computational methods that first “clean” the data, for instance, through the statistically valid removal of outliers, and then use machine learning to identify statistically significant, distinguishing molecular profiles or signatures. In favorable cases, such signatures point to specific biological pathways, whereas other signatures defy direct explanation but may become the launch pad for follow-up investigations [ 33 ].
Today’s scientists are very familiar with this discovery-driven exploration of “what’s out there” and might consider it a quaint quirk of history that this strategy was at first widely chastised and ridiculed as a “fishing expedition” [ 30 , 34 ]. Strict traditionalists were outraged that rigor was leaving science with the new approach and that sufficient guidelines were unavailable to assure the validity and reproducibility of results [ 10 , 35 , 36 ].
From the view point of philosophy of science, this second dimension of the scientific method uses inductive reasoning and reflects Bacon’s idea that observations can and should dictate the research question to be investigated [ 1 , 7 ]. Allen [ 36 ] forcefully rejected this type of reasoning, stating “the thinking goes, we can now expect computer programs to derive significance, relevance and meaning from chunks of information, be they nucleotide sequences or gene expression profiles… In contrast with this view, many are convinced that no purely logical process can turn observation into understanding.” His conviction goes back to the 18th century philosopher David Hume and again to Popper, who identified as the overriding problem with inductive reasoning that it can never truly reveal causality, even if a phenomenon is observed time and again [ 16 , 17 , 37 , 38 ]. No number of observations, even if they always have the same result, can guard against an exception that would violate the generality of a law inferred from these observations [ 1 , 35 ]. Worse, Popper argued, through inference by induction, we cannot even know the probability of something being true [ 10 , 17 , 36 ].
Others argued that data-driven and hypothesis-driven research actually do not differ all that much in principle, as long as there is cycling between developing new ideas and testing them with care [ 27 ]. In fact, Kell and Oliver [ 34 ] maintained that the exclusive acceptance of hypothesis-driven programs misrepresents the complexities of biological knowledge generation. Similarly refuting the prominent rule of deduction, Platt [ 26 ] and Beard and Kushmerick [ 27 ] argued that repeated inductive reasoning, called strong inference, corresponds to a logically sound decision tree of disproving or refining hypotheses that can rapidly yield firm conclusions; nonetheless, Platt had to admit that inductive inference is not as certain as deduction, because it projects into the unknown. Lander compared the task of obtaining causality by induction to the problem of inferring the design of a microprocessor from input-output readings, which in a strict sense is impossible, because the microprocessor could be arbitrarily complicated; even so, inference often leads to novel insights and therefore is valuable [ 39 ].
An interesting special case of almost pure inductive reasoning is epidemiology, where hypothesis-driven reasoning is rare and instead, the fundamental question is whether data-based evidence is sufficient to associate health risks with specific causes [ 31 , 34 ].
Recent advances in machine learning and “big-data” mining have driven the use of inductive reasoning to unprecedented heights. As an example, machine learning can greatly assist in the discovery of patterns, for instance, in biological sequences [ 40 ]. Going a step further, a pithy article by Andersen [ 41 ] proffered that we may not need to look for causality or mechanistic explanations anymore if we just have enough correlation: “With enough data, the numbers speak for themselves, correlation replaces causation, and science can advance even without coherent models or unified theories.”
Of course, the proposal to abandon the quest for causality caused pushback on philosophical as well as mathematical grounds. Allen [ 10 , 35 ] considered the idea “absurd” that data analysis could enhance understanding in the absence of a hypothesis. He felt confident “that even the formidable combination of computing power with ease of access to data cannot produce a qualitative shift in the way that we do science: the making of hypotheses remains an indispensable component in the growth of knowledge” [ 36 ]. Succi and Coveney [ 42 ] refuted the “most extravagant claims” of big-data proponents very differently, namely by analyzing the theories on which machine learning is founded. They contrasted the assumptions underlying these theories, such as the law of large numbers, with the mathematical reality of complex biological systems. Specifically, they carefully identified genuine features of these systems, such as nonlinearities, nonlocality of effects, fractal aspects, and high dimensionality, and argued that they fundamentally violate some of the statistical assumptions implicitly underlying big-data analysis, like independence of events. They concluded that these discrepancies “may lead to false expectations and, at their nadir, even to dangerous social, economical and political manipulation.” To ameliorate the situation, the field of big-data analysis would need new strong theorems characterizing the validity of its methods and the numbers of data required for obtaining reliable insights. Succi and Coveney go as far as stating that too many data are just as bad as insufficient data [ 42 ].
While philosophical doubts regarding inductive methods will always persist, one cannot deny that -omics-based, high-throughput studies, combined with machine learning and big-data analysis, have been very successful [ 43 ]. Yes, induction cannot truly reveal general laws, no matter how large the datasets, but they do provide insights that are very different from what science had offered before and may at least suggest novel patterns, trends, or principles. As a case in point, if many transcriptomic studies indicate that a particular gene set is involved in certain classes of phenomena, there is probably some truth to the observation, even though it is not mathematically provable. Kepler’s laws of astronomy were arguably derived solely from inductive reasoning [ 34 ].
Notwithstanding the opposing views on inductive methods, successful strategies shape how we think about science. Thus, to take advantage of all experimental options while ensuring quality of research, we must not allow that “anything goes” but instead identify and characterize standard operating procedures and controls that render this emerging scientific method valid and reproducible. A laudable step in this direction was the wide acceptance of “minimum information about a microarray experiment” (MIAME) standards for microarray experiments [ 44 ].
A third dimension of the scientific method: Allochthonous reasoning
Parallel to the blossoming of molecular biology and the rapid rise in the power and availability of computing in the late 20th century, the use of mathematical and computational models became increasingly recognized as relevant and beneficial for understanding biological phenomena. Indeed, mathematical models eventually achieved cornerstone status in the new field of computational systems biology.
Mathematical modeling has been used as a tool of biological analysis for a long time [ 27 , 45 – 48 ]. Interesting for the discussion here is that the use of mathematical and computational modeling in biology follows a scientific approach that is distinctly different from the traditional and the data-driven methods, because it is distributed over two entirely separate domains of knowledge. One consists of the biological reality of DNA, elephants, and roses, whereas the other is the world of mathematics, which is governed by numbers, symbols, theorems, and abstract work protocols. Because the ways of thinking—and even the languages—are different in these two realms, I suggest calling this type of knowledge acquisition “allochthonous” (literally Greek: in or from a “piece of land different from where one is at home”; one could perhaps translate it into modern lingo as “outside one’s comfort zone”). De facto, most allochthonous reasoning in biology presently refers to mathematics and computing, but one might also consider, for instance, the application of methods from linguistics in the analysis of DNA sequences or proteins [ 49 ].
One could argue that biologists have employed “models” for a long time, for instance, in the form of “model organisms,” cell lines, or in vitro experiments, which more or less faithfully reflect features of the organisms of true interest but are easier to manipulate. However, this type of biological model use is rather different from allochthonous reasoning, as it does not leave the realm of biology and uses the same language and often similar methodologies.
A brief discussion of three experiences from our lab may illustrate the benefits of allochthonous reasoning. (1) In a case study of renal cell carcinoma, a dynamic model was able to explain an observed yet nonintuitive metabolic profile in terms of the enzymatic reaction steps that had been altered during the disease [ 50 ]. (2) A transcriptome analysis had identified several genes as displaying significantly different expression patterns during malaria infection in comparison to the state of health. Considered by themselves and focusing solely on genes coding for specific enzymes of purine metabolism, the findings showed patterns that did not make sense. However, integrating the changes in a dynamic model revealed that purine metabolism globally shifted, in response to malaria, from guanine compounds to adenine, inosine, and hypoxanthine [ 51 ]. (3) Data capturing the dynamics of malaria parasites suggested growth rates that were biologically impossible. Speculation regarding possible explanations led to the hypothesis that many parasite-harboring red blood cells might “hide” from circulation and therewith from detection in the blood stream. While experimental testing of the feasibility of the hypothesis would have been expensive, a dynamic model confirmed that such a concealment mechanism could indeed quantitatively explain the apparently very high growth rates [ 52 ]. In all three cases, the insights gained inductively from computational modeling would have been difficult to obtain purely with experimental laboratory methods. Purely deductive allochthonous reasoning is the ultimate goal of the search for design and operating principles [ 53 – 55 ], which strives to explain why certain structures or functions are employed by nature time and again. An example is a linear metabolic pathway, in which feedback inhibition is essentially always exerted on the first step [ 56 , 57 ]. This generality allows the deduction that a so far unstudied linear pathway is most likely (or even certain to be) inhibited at the first step. Not strictly deductive—but rather abductive—was a study in our lab in which we analyzed time series data with a mathematical model that allowed us to infer the most likely regulatory structure of a metabolic pathway [ 58 , 59 ].
A typical allochthonous investigation begins in the realm of biology with the formulation of a hypothesis ( Fig 3 ). Instead of testing this hypothesis with laboratory experiments, the system encompassing the hypothesis is moved into the realm of mathematics. This move requires two sets of ingredients. One set consists of the simplification and abstraction of the biological system: Any distracting details that seem unrelated to the hypothesis and its context are omitted or represented collectively with other details. This simplification step carries the greatest risk of the entire modeling approach, as omission of seemingly negligible but, in truth, important details can easily lead to wrong results. The second set of ingredients consists of correspondence rules that translate every biological component or process into the language of mathematics [ 60 , 61 ].
This mathematical and computational approach is distributed over two realms, which are connected by correspondence rules.
https://doi.org/10.1371/journal.pcbi.1007279.g003
Once the system is translated, it has become an entirely mathematical construct that can be analyzed purely with mathematical and computational means. The results of this analysis are also strictly mathematical. They typically consist of values of variables, magnitudes of processes, sensitivity patterns, signs of eigenvalues, or qualitative features like the onset of oscillations or the potential for limit cycles. Correspondence rules are used again to move these results back into the realm of biology. As an example, the mathematical result that “two eigenvalues have positive real parts” does not make much sense to many biologists, whereas the interpretation that “the system is not stable at the steady state in question” is readily explained. New biological insights may lead to new hypotheses, which are tested either by experiments or by returning once more to the realm of mathematics. The model design, diagnosis, refinements, and validation consist of several phases, which have been discussed widely in the biomathematical literature. Importantly, each iteration of a typical modeling analysis consists of a move from the biological to the mathematical realm and back.
The reasoning within the realm of mathematics is often deductive, in the form of an Aristotelian syllogism, such as the well-known “All men are mortal; Socrates is a man; therefore, Socrates is mortal.” However, the reasoning may also be inductive, as it is the case with large-scale Monte-Carlo simulations that generate arbitrarily many “observations,” although they cannot reveal universal principles or theorems. An example is a simulation randomly drawing numbers in an attempt to show that every real number has an inverse. The simulation will always attest to this hypothesis but fail to discover the truth because it will never randomly draw 0. Generically, computational models may be considered sets of hypotheses, formulated as equations or as algorithms that reflect our perception of a complex system [ 27 ].
Impact of the multidimensional scientific method on learning
Almost all we know in biology has come from observation, experimentation, and interpretation. The traditional scientific method not only offered clear guidance for this knowledge gathering, but it also fundamentally shaped the way we think about the exploration of nature. When presented with a new research question, scientists were trained to think immediately in terms of hypotheses and alternatives, pondering the best feasible ways of testing them, and designing in their minds strong controls that would limit the effects of known or unknown confounders. Shaped by the rigidity of this ever-repeating process, our thinking became trained to move forward one well-planned step at a time. This modus operandi was rigid and exact. It also minimized the erroneous pursuit of long speculative lines of thought, because every step required testing before a new hypothesis was formed. While effective, the process was also very slow and driven by ingenuity—as well as bias—on the scientist’s part. This bias was sometimes a hindrance to necessary paradigm shifts [ 22 ].
High-throughput data generation, big-data analysis, and mathematical-computational modeling changed all that within a few decades. In particular, the acceptance of inductive principles and of the allochthonous use of nonbiological strategies to answer biological questions created an unprecedented mix of successes and chaos. To the horror of traditionalists, the importance of hypotheses became minimized, and the suggestion spread that the data would speak for themselves [ 36 ]. Importantly, within this fog of “anything goes,” the fundamental question arose how to determine whether an experiment was valid.
Because agreed-upon operating procedures affect research progress and interpretation, thinking, teaching, and sharing of results, this question requires a deconvolution of scientific strategies. Here I proffer that the single scientific method of the past should be expanded toward a vector space of scientific methods, with spanning vectors that correspond to different dimensions of the scientific method ( Fig 4 ).
The traditional hypothesis-based deductive scientific method is expanded into a 3D space that allows for synergistic blends of methods that include data-mining–inspired, inductive knowledge acquisition, and mathematical model-based, allochthonous reasoning.
https://doi.org/10.1371/journal.pcbi.1007279.g004
Obviously, all three dimensions have their advantages and drawbacks. The traditional, hypothesis-driven deductive method is philosophically “clean,” except that it is confounded by preconceptions and assumptions. The data-mining–inspired inductive method cannot offer universal truths but helps us explore very large spaces of factors that contribute to a phenomenon. Allochthonous, model-based reasoning can be performed mentally, with paper and pencil, through rigorous analysis, or with a host of computational methods that are precise and disprovable [ 27 ]. At the same time, they are incomparable faster, cheaper, and much more comprehensive than experiments in molecular biology. This reduction in cost and time, and the increase in coverage, may eventually have far-reaching consequences, as we can already fathom from much of modern physics.
Due to its long history, the traditional dimension of the scientific method is supported by clear and very strong standard operating procedures. Similarly, strong procedures need to be developed for the other two dimensions. The MIAME rules for microarray analysis provide an excellent example [ 44 ]. On the mathematical modeling front, no such rules are generally accepted yet, but trends toward them seem to emerge at the horizon. For instance, it seems to be becoming common practice to include sensitivity analyses in typical modeling studies and to assess the identifiability or sloppiness of ensembles of parameter combinations that fit a given dataset well [ 62 , 63 ].
From a philosophical point of view, it seems unlikely that objections against inductive reasoning will disappear. However, instead of pitting hypothesis-based deductive reasoning against inductivism, it seems more beneficial to determine how the different methods can be synergistically blended ( cf . [ 18 , 27 , 34 , 42 ]) as linear combinations of the three vectors of knowledge acquisition ( Fig 4 ). It is at this point unclear to what degree the identified three dimensions are truly independent of each other, whether additional dimensions should be added [ 24 ], or whether the different versions could be amalgamated into a single scientific method [ 18 ], especially if it is loosely defined as a form of critical thinking [ 8 ]. Nobel Laureate Percy Bridgman even concluded that “science is what scientists do, and there are as many scientific methods as there are individual scientists” [ 8 , 64 ].
Combinations of the three spanning vectors of the scientific method have been emerging for some time. Many biologists already use inductive high-throughput methods to develop specific hypotheses that are subsequently tested with deductive or further inductive methods [ 34 , 65 ]. In terms of including mathematical modeling, physics and geology have been leading the way for a long time, often by beginning an investigation in theory, before any actual experiment is performed. It will benefit biology to look into this strategy and to develop best practices of allochthonous reasoning.
The blending of methods may take quite different shapes. Early on, Ideker and colleagues [ 65 ] proposed an integrated experimental approach for pathway analysis that offered a glimpse of new experimental strategies within the space of scientific methods. In a similar vein, Covert and colleagues [ 66 ] included computational methods into such an integrated approach. Additional examples of blended analyses in systems biology can be seen in other works, such as [ 43 , 67 – 73 ]. Generically, it is often beneficial to start with big data, determine patterns in associations and correlations, then switch to the mathematical realm in order to filter out spurious correlations in a high-throughput fashion. If this procedure is executed in an iterative manner, the “surviving” associations have an increased level of confidence and are good candidates for further experimental or computational testing (personal communication from S. Chandrasekaran).
If each component of a blended scientific method follows strict, commonly agreed guidelines, “linear combinations” within the 3D space can also be checked objectively, per deconvolution. In addition, guidelines for synergistic blends of component procedures should be developed. If we carefully monitor such blends, time will presumably indicate which method is best for which task and how the different approaches optimally inform each other. For instance, it will be interesting to study whether there is an optimal sequence of experiments along the three axes for a particular class of tasks. Big-data analysis together with inductive reasoning might be optimal for creating initial hypotheses and possibly refuting wrong speculations (“we had thought this gene would be involved, but apparently it isn’t”). If the logic of an emerging hypotheses can be tested with mathematical and computational tools, it will almost certainly be faster and cheaper than an immediate launch into wet-lab experimentation. It is also likely that mathematical reasoning will be able to refute some apparently feasible hypothesis and suggest amendments. Ultimately, the “surviving” hypotheses must still be tested for validity through conventional experiments. Deconvolving current practices and optimizing the combination of methods within the 3D or higher-dimensional space of scientific methods will likely result in better planning of experiments and in synergistic blends of approaches that have the potential capacity of addressing some of the grand challenges in biology.
Acknowledgments
The author is very grateful to Dr. Sriram Chandrasekaran and Ms. Carla Kumbale for superb suggestions and invaluable feedback.
- View Article
- Google Scholar
- 2. Gauch HGJ. Scientific Method in Brief. Cambridge, UK.: Cambridge University Press; 2012.
- 3. Gimbel S (Ed). Exploring the Scientific Method: Cases and Questions. Chicago, IL: The University of Chicago Press; 2011.
- PubMed/NCBI
- 8. McLelland CV. The nature of science and the scientific method. Boulder, CO: The Geological Society of America; 2006.
- 9. Ladyman J. Understanding Philosophy of Science. Abington, Oxon: Routledge; 2002.
- 16. Popper KR. Conjectures and Refutations: The Growth of Scientific Knowledge. Abingdon, Oxon: Routledge and Kegan Paul; 1963.
- 17. Popper KR. The Logic of Scientific Discovery. Abingdon, Oxon: Routledge; 2002.
- 21. Harding SE. Can theories be refuted?: Essays on the Duhem-Quine thesis. Dordrecht-Holland / Boston, MA: D. Reidel Publ. Co; 1976.
- 22. Kuhn TS. The Structure of Scientific Revolutions. Chicago, IL: University of Chicago Press; 1962.
- 37. Hume D. An enquiry concerning human understanding. Oxford, U.K.: Oxford University Press; 1748/1999.
- 38. Popper KR. Objective knowledge. An evolutionary approach. Oxford, U.K.: Oxford University Press; 1972.
- 47. von Bertalanffy L. General System Theory: Foundations, Development, Applications. New York: George Braziller; 1968.
- 48. May RM. Stability and Complexity in Model Ecosystems: Princeton University Press; 1973.
- 57. Savageau MA. Biochemical Systems Analysis: A Study of Function and Design in Molecular Biology. Reading, Mass: Addison-Wesley Pub. Co. Advanced Book Program (reprinted 2009); 1976.
- 60. Reither F. Über das Denken mit Analogien und Modellen. In: Schaefer G, Trommer G, editors. Denken in Modellen. Braunschweig, Germany: Georg Westermann Verlag; 1977.
- 61. Voit EO. A First Course in Systems Biology, 2nd Ed. New York, NY: Garland Science; 2018.
- 64. Bridgman PW. Reflections of a Physicist. New York, NY: reprinted by Kessinger Legacy Reprints, 2010; 1955.
What Is A Research (Scientific) Hypothesis? A plain-language explainer + examples
By: Derek Jansen (MBA) | Reviewed By: Dr Eunice Rautenbach | June 2020
If you’re new to the world of research, or it’s your first time writing a dissertation or thesis, you’re probably noticing that the words “research hypothesis” and “scientific hypothesis” are used quite a bit, and you’re wondering what they mean in a research context .
“Hypothesis” is one of those words that people use loosely, thinking they understand what it means. However, it has a very specific meaning within academic research. So, it’s important to understand the exact meaning before you start hypothesizing.
Research Hypothesis 101
- What is a hypothesis ?
- What is a research hypothesis (scientific hypothesis)?
- Requirements for a research hypothesis
- Definition of a research hypothesis
- The null hypothesis
What is a hypothesis?
Let’s start with the general definition of a hypothesis (not a research hypothesis or scientific hypothesis), according to the Cambridge Dictionary:
Hypothesis: an idea or explanation for something that is based on known facts but has not yet been proved.
In other words, it’s a statement that provides an explanation for why or how something works, based on facts (or some reasonable assumptions), but that has not yet been specifically tested . For example, a hypothesis might look something like this:
Hypothesis: sleep impacts academic performance.
This statement predicts that academic performance will be influenced by the amount and/or quality of sleep a student engages in – sounds reasonable, right? It’s based on reasonable assumptions , underpinned by what we currently know about sleep and health (from the existing literature). So, loosely speaking, we could call it a hypothesis, at least by the dictionary definition.
But that’s not good enough…
Unfortunately, that’s not quite sophisticated enough to describe a research hypothesis (also sometimes called a scientific hypothesis), and it wouldn’t be acceptable in a dissertation, thesis or research paper . In the world of academic research, a statement needs a few more criteria to constitute a true research hypothesis .
What is a research hypothesis?
A research hypothesis (also called a scientific hypothesis) is a statement about the expected outcome of a study (for example, a dissertation or thesis). To constitute a quality hypothesis, the statement needs to have three attributes – specificity , clarity and testability .
Let’s take a look at these more closely.
Need a helping hand?
Hypothesis Essential #1: Specificity & Clarity
A good research hypothesis needs to be extremely clear and articulate about both what’ s being assessed (who or what variables are involved ) and the expected outcome (for example, a difference between groups, a relationship between variables, etc.).
Let’s stick with our sleepy students example and look at how this statement could be more specific and clear.
Hypothesis: Students who sleep at least 8 hours per night will, on average, achieve higher grades in standardised tests than students who sleep less than 8 hours a night.
As you can see, the statement is very specific as it identifies the variables involved (sleep hours and test grades), the parties involved (two groups of students), as well as the predicted relationship type (a positive relationship). There’s no ambiguity or uncertainty about who or what is involved in the statement, and the expected outcome is clear.
Contrast that to the original hypothesis we looked at – “Sleep impacts academic performance” – and you can see the difference. “Sleep” and “academic performance” are both comparatively vague , and there’s no indication of what the expected relationship direction is (more sleep or less sleep). As you can see, specificity and clarity are key.

Hypothesis Essential #2: Testability (Provability)
A statement must be testable to qualify as a research hypothesis. In other words, there needs to be a way to prove (or disprove) the statement. If it’s not testable, it’s not a hypothesis – simple as that.
For example, consider the hypothesis we mentioned earlier:
Hypothesis: Students who sleep at least 8 hours per night will, on average, achieve higher grades in standardised tests than students who sleep less than 8 hours a night.
We could test this statement by undertaking a quantitative study involving two groups of students, one that gets 8 or more hours of sleep per night for a fixed period, and one that gets less. We could then compare the standardised test results for both groups to see if there’s a statistically significant difference.
Again, if you compare this to the original hypothesis we looked at – “Sleep impacts academic performance” – you can see that it would be quite difficult to test that statement, primarily because it isn’t specific enough. How much sleep? By who? What type of academic performance?
So, remember the mantra – if you can’t test it, it’s not a hypothesis 🙂

Defining A Research Hypothesis
You’re still with us? Great! Let’s recap and pin down a clear definition of a hypothesis.
A research hypothesis (or scientific hypothesis) is a statement about an expected relationship between variables, or explanation of an occurrence, that is clear, specific and testable.
So, when you write up hypotheses for your dissertation or thesis, make sure that they meet all these criteria. If you do, you’ll not only have rock-solid hypotheses but you’ll also ensure a clear focus for your entire research project.
What about the null hypothesis?
You may have also heard the terms null hypothesis , alternative hypothesis, or H-zero thrown around. At a simple level, the null hypothesis is the counter-proposal to the original hypothesis.
For example, if the hypothesis predicts that there is a relationship between two variables (for example, sleep and academic performance), the null hypothesis would predict that there is no relationship between those variables.
At a more technical level, the null hypothesis proposes that no statistical significance exists in a set of given observations and that any differences are due to chance alone.
And there you have it – hypotheses in a nutshell.
If you have any questions, be sure to leave a comment below and we’ll do our best to help you. If you need hands-on help developing and testing your hypotheses, consider our private coaching service , where we hold your hand through the research journey.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:

16 Comments

Very useful information. I benefit more from getting more information in this regard.

Very great insight,educative and informative. Please give meet deep critics on many research data of public international Law like human rights, environment, natural resources, law of the sea etc

In a book I read a distinction is made between null, research, and alternative hypothesis. As far as I understand, alternative and research hypotheses are the same. Can you please elaborate? Best Afshin

This is a self explanatory, easy going site. I will recommend this to my friends and colleagues.

Very good definition. How can I cite your definition in my thesis? Thank you. Is nul hypothesis compulsory in a research?

It’s a counter-proposal to be proven as a rejection

Please what is the difference between alternate hypothesis and research hypothesis?

It is a very good explanation. However, it limits hypotheses to statistically tasteable ideas. What about for qualitative researches or other researches that involve quantitative data that don’t need statistical tests?

In qualitative research, one typically uses propositions, not hypotheses.

could you please elaborate it more

I’ve benefited greatly from these notes, thank you.

This is very helpful

well articulated ideas are presented here, thank you for being reliable sources of information

Excellent. Thanks for being clear and sound about the research methodology and hypothesis (quantitative research)
I have only a simple question regarding the null hypothesis. – Is the null hypothesis (Ho) known as the reversible hypothesis of the alternative hypothesis (H1? – How to test it in academic research?

this is very important note help me much more
Trackbacks/Pingbacks
- What Is Research Methodology? Simple Definition (With Examples) - Grad Coach - […] Contrasted to this, a quantitative methodology is typically used when the research aims and objectives are confirmatory in nature. For example,…
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

How to Implement Hypothesis-Driven Development
Remember back to the time when we were in high school science class. Our teachers had a framework for helping us learn – an experimental approach based on the best available evidence at hand. We were asked to make observations about the world around us, then attempt to form an explanation or hypothesis to explain what we had observed. We then tested this hypothesis by predicting an outcome based on our theory that would be achieved in a controlled experiment – if the outcome was achieved, we had proven our theory to be correct.
We could then apply this learning to inform and test other hypotheses by constructing more sophisticated experiments, and tuning, evolving or abandoning any hypothesis as we made further observations from the results we achieved.
Experimentation is the foundation of the scientific method, which is a systematic means of exploring the world around us. Although some experiments take place in laboratories, it is possible to perform an experiment anywhere, at any time, even in software development.
Practicing Hypothesis-Driven Development is thinking about the development of new ideas, products and services – even organizational change – as a series of experiments to determine whether an expected outcome will be achieved. The process is iterated upon until a desirable outcome is obtained or the idea is determined to be not viable.
We need to change our mindset to view our proposed solution to a problem statement as a hypothesis, especially in new product or service development – the market we are targeting, how a business model will work, how code will execute and even how the customer will use it.
We do not do projects anymore, only experiments. Customer discovery and Lean Startup strategies are designed to test assumptions about customers. Quality Assurance is testing system behavior against defined specifications. The experimental principle also applies in Test-Driven Development – we write the test first, then use the test to validate that our code is correct, and succeed if the code passes the test. Ultimately, product or service development is a process to test a hypothesis about system behaviour in the environment or market it is developed for.
The key outcome of an experimental approach is measurable evidence and learning.
Learning is the information we have gained from conducting the experiment. Did what we expect to occur actually happen? If not, what did and how does that inform what we should do next?
In order to learn we need use the scientific method for investigating phenomena, acquiring new knowledge, and correcting and integrating previous knowledge back into our thinking.
As the software development industry continues to mature, we now have an opportunity to leverage improved capabilities such as Continuous Design and Delivery to maximize our potential to learn quickly what works and what does not. By taking an experimental approach to information discovery, we can more rapidly test our solutions against the problems we have identified in the products or services we are attempting to build. With the goal to optimize our effectiveness of solving the right problems, over simply becoming a feature factory by continually building solutions.
The steps of the scientific method are to:
- Make observations
- Formulate a hypothesis
- Design an experiment to test the hypothesis
- State the indicators to evaluate if the experiment has succeeded
- Conduct the experiment
- Evaluate the results of the experiment
- Accept or reject the hypothesis
- If necessary, make and test a new hypothesis
Using an experimentation approach to software development
We need to challenge the concept of having fixed requirements for a product or service. Requirements are valuable when teams execute a well known or understood phase of an initiative, and can leverage well understood practices to achieve the outcome. However, when you are in an exploratory, complex and uncertain phase you need hypotheses.
Handing teams a set of business requirements reinforces an order-taking approach and mindset that is flawed.
Business does the thinking and ‘knows’ what is right. The purpose of the development team is to implement what they are told. But when operating in an area of uncertainty and complexity, all the members of the development team should be encouraged to think and share insights on the problem and potential solutions. A team simply taking orders from a business owner is not utilizing the full potential, experience and competency that a cross-functional multi-disciplined team offers.
Framing hypotheses
The traditional user story framework is focused on capturing requirements for what we want to build and for whom, to enable the user to receive a specific benefit from the system.
As A…. <role>
I Want… <goal/desire>
So That… <receive benefit>
Behaviour Driven Development (BDD) and Feature Injection aims to improve the original framework by supporting communication and collaboration between developers, tester and non-technical participants in a software project.
In Order To… <receive benefit>
As A… <role>
When viewing work as an experiment, the traditional story framework is insufficient. As in our high school science experiment, we need to define the steps we will take to achieve the desired outcome. We then need to state the specific indicators (or signals) we expect to observe that provide evidence that our hypothesis is valid. These need to be stated before conducting the test to reduce biased interpretations of the results.
If we observe signals that indicate our hypothesis is correct, we can be more confident that we are on the right path and can alter the user story framework to reflect this.
Therefore, a user story structure to support Hypothesis-Driven Development would be;

We believe < this capability >
What functionality we will develop to test our hypothesis? By defining a ‘test’ capability of the product or service that we are attempting to build, we identify the functionality and hypothesis we want to test.
Will result in < this outcome >
What is the expected outcome of our experiment? What is the specific result we expect to achieve by building the ‘test’ capability?
We will know we have succeeded when < we see a measurable signal >
What signals will indicate that the capability we have built is effective? What key metrics (qualitative or quantitative) we will measure to provide evidence that our experiment has succeeded and give us enough confidence to move to the next stage.
The threshold you use for statistically significance will depend on your understanding of the business and context you are operating within. Not every company has the user sample size of Amazon or Google to run statistically significant experiments in a short period of time. Limits and controls need to be defined by your organization to determine acceptable evidence thresholds that will allow the team to advance to the next step.
For example if you are building a rocket ship you may want your experiments to have a high threshold for statistical significance. If you are deciding between two different flows intended to help increase user sign up you may be happy to tolerate a lower significance threshold.
The final step is to clearly and visibly state any assumptions made about our hypothesis, to create a feedback loop for the team to provide further input, debate and understanding of the circumstance under which we are performing the test. Are they valid and make sense from a technical and business perspective?
Hypotheses when aligned to your MVP can provide a testing mechanism for your product or service vision. They can test the most uncertain areas of your product or service, in order to gain information and improve confidence.
Examples of Hypothesis-Driven Development user stories are;
Business story
We Believe That increasing the size of hotel images on the booking page
Will Result In improved customer engagement and conversion
We Will Know We Have Succeeded When we see a 5% increase in customers who review hotel images who then proceed to book in 48 hours.
It is imperative to have effective monitoring and evaluation tools in place when using an experimental approach to software development in order to measure the impact of our efforts and provide a feedback loop to the team. Otherwise we are essentially blind to the outcomes of our efforts.
In agile software development we define working software as the primary measure of progress.
By combining Continuous Delivery and Hypothesis-Driven Development we can now define working software and validated learning as the primary measures of progress.
Ideally we should not say we are done until we have measured the value of what is being delivered – in other words, gathered data to validate our hypothesis.
Examples of how to gather data is performing A/B Testing to test a hypothesis and measure to change in customer behaviour. Alternative testings options can be customer surveys, paper prototypes, user and/or guerrilla testing.
One example of a company we have worked with that uses Hypothesis-Driven Development is lastminute.com . The team formulated a hypothesis that customers are only willing to pay a max price for a hotel based on the time of day they book. Tom Klein, CEO and President of Sabre Holdings shared the story of how they improved conversion by 400% within a week.
Combining practices such as Hypothesis-Driven Development and Continuous Delivery accelerates experimentation and amplifies validated learning. This gives us the opportunity to accelerate the rate at which we innovate while relentlessly reducing cost, leaving our competitors in the dust. Ideally we can achieve the ideal of one piece flow: atomic changes that enable us to identify causal relationships between the changes we make to our products and services, and their impact on key metrics.
As Kent Beck said, “Test-Driven Development is a great excuse to think about the problem before you think about the solution”. Hypothesis-Driven Development is a great opportunity to test what you think the problem is, before you work on the solution.
How can you achieve faster growth?
Type of Research projects Part 2: Hypothesis-driven versus hypothesis-generating research (1 August 2018)

Deductive Approach (Deductive Reasoning)
A deductive approach is concerned with “developing a hypothesis (or hypotheses) based on existing theory, and then designing a research strategy to test the hypothesis” [1]
It has been stated that “deductive means reasoning from the particular to the general. If a causal relationship or link seems to be implied by a particular theory or case example, it might be true in many cases. A deductive design might test to see if this relationship or link did obtain on more general circumstances” [2] .
Deductive approach can be explained by the means of hypotheses, which can be derived from the propositions of the theory. In other words, deductive approach is concerned with deducting conclusions from premises or propositions.
Deduction begins with an expected pattern “that is tested against observations, whereas induction begins with observations and seeks to find a pattern within them” [3] .
Advantages of Deductive Approach
Deductive approach offers the following advantages:
- Possibility to explain causal relationships between concepts and variables
- Possibility to measure concepts quantitatively
- Possibility to generalize research findings to a certain extent
Alternative to deductive approach is inductive approach. The table below guides the choice of specific approach depending on circumstances:
Choice between deductive and inductive approaches
Deductive research approach explores a known theory or phenomenon and tests if that theory is valid in given circumstances. It has been noted that “the deductive approach follows the path of logic most closely. The reasoning starts with a theory and leads to a new hypothesis. This hypothesis is put to the test by confronting it with observations that either lead to a confirmation or a rejection of the hypothesis” [4] .
Moreover, deductive reasoning can be explained as “reasoning from the general to the particular” [5] , whereas inductive reasoning is the opposite. In other words, deductive approach involves formulation of hypotheses and their subjection to testing during the research process, while inductive studies do not deal with hypotheses in any ways.
Application of Deductive Approach (Deductive Reasoning) in Business Research
In studies with deductive approach, the researcher formulates a set of hypotheses at the start of the research. Then, relevant research methods are chosen and applied to test the hypotheses to prove them right or wrong.

Generally, studies using deductive approach follow the following stages:
- Deducing hypothesis from theory.
- Formulating hypothesis in operational terms and proposing relationships between two specific variables
- Testing hypothesis with the application of relevant method(s). These are quantitative methods such as regression and correlation analysis, mean, mode and median and others.
- Examining the outcome of the test, and thus confirming or rejecting the theory. When analysing the outcome of tests, it is important to compare research findings with the literature review findings.
- Modifying theory in instances when hypothesis is not confirmed.
My e-book, The Ultimate Guide to Writing a Dissertation in Business Studies: a step by step assistance contains discussions of theory and application of research approaches. The e-book also explains all stages of the research process starting from the selection of the research area to writing personal reflection. Important elements of dissertations such as research philosophy , research design , methods of data collection , data analysis and sampling are explained in this e-book in simple words.
John Dudovskiy

[1] Wilson, J. (2010) “Essentials of Business Research: A Guide to Doing Your Research Project” SAGE Publications, p.7
[2] Gulati, PM, 2009, Research Management: Fundamental and Applied Research, Global India Publications, p.42
[3] Babbie, E. R. (2010) “The Practice of Social Research” Cengage Learning, p.52
[4] Snieder, R. & Larner, K. (2009) “The Art of Being a Scientist: A Guide for Graduate Students and their Mentors”, Cambridge University Press, p.16
[5] Pelissier, R. (2008) “Business Research Made Easy” Juta & Co., p.3
The conundrum of porter hypothesis, pollution haven hypothesis, and pollution halo hypothesis: evidence from the Indian manufacturing sector
- Original Paper
- Published: 16 May 2024
Cite this article

- Prantik Bagchi ORCID: orcid.org/0000-0002-9056-5835 1 &
- Santosh Kumar Sahu ORCID: orcid.org/0000-0003-3480-6507 2 , 3
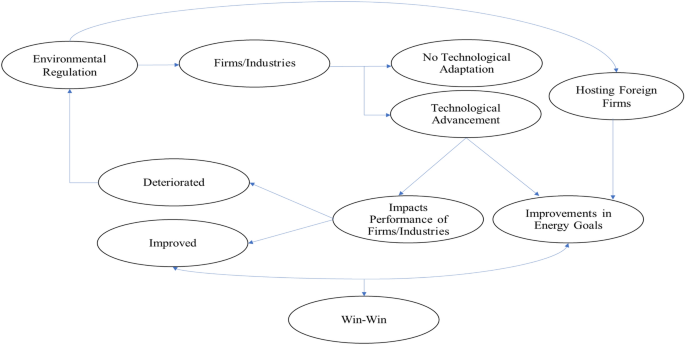
In the globalized world, factors, such as environmental regulations and outcomes, are interlinked with foreign direct investment and technological innovation. However, firm-level theories mostly treat them independently. We have filled the gap by carrying out empirical research with an integrated approach at the firm level. The theoretical framework is based on Porter’s hypothesis and the pollution haven hypothesis/pollution halo hypothesis. We collect the data from the center for monitoring Indian Economy Prowess IQ and the Ministry of Environment, Forest, and Climate Change. Using the modified Krugman specialization index, we find that Indian manufacturing firms are neither converging nor specialized in terms of technical progress. Estimating a z -score for environmental stringency, we interact that with the pollution loads of the firms. Our findings suggest that environmental regulation does not ensure a “win–win” situation for the producers, refuting Porter’s hypothesis. Rather, factors such as profit margin and R&D produce robust results across different models to induce the productivity of the firm. One of the concerning facts is older firms using vintage capital are detrimental to productivity enhancement, and there is evidence of layoff at the cost of increasing profits to improve the firm performance. Also, more dependence for export-intensive firms on material increases the cost and, thereby, reduces productivity. In addition, we apply a panel threshold regression model and conclude that there is evidence of a single threshold, and irrespective of the choice of technology foreign firms induces the energy intensity, confirming a pollution Haven hypothesis.
Graphical abstract
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
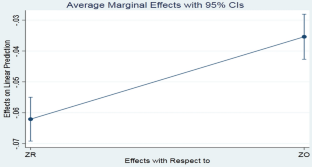
Data availability
Enquiries about data availability should be directed to the authors.
Environment is considered to be a factor of production.
One of the threat perceptions is that the resource-rich countries are vulnerable to PHH, known as the resource curse hypothesis, although the evidence is mixed (Liang et al. 2023 ).
India imports a large volume of non-renewable resources despite a large volume of production, and this has been increasing over the years (Energy Statistics 2023). A substantial part of it is exported as it does not meet the environmental standard. As there is an excess demand for the same, they import it from the developed countries. A part of this import might be the surplus that does not meet environmental standards in those countries, and the laxity of regulations may induce the threat of both PH and PHH/PHaH.
To the best of our knowledge, this is the first empirical paper to integrate PH and PHH for Indian manufacturing firms.
Since PH incentivizes the firms with a “win–win” situation, the decision of the firm will be taken based on the possibility of the improvement of their outcome. Often this is measured in terms of total factor productivity (TFP).
In this paper, we are not interested in focusing on the narrow version because: i. The interest of the paper does not lie in validating this; and ii. there is an acute shortage of the data.
The list of the indicators will be discussed later. Input intensities refer to labor intensity, capital intensity, material intensity, and energy intensity.
Z = (X it -X t )/σ it.
Intensities are not considered separately to omit the problem of correlation and multicollinearity problems as these variables are used while calculating the TFP.
We have not reported the green firms as it will be considered as base in the regression models.
There is a possibility of the existence of a nonlinearity; specifically, it may have an exponential effect. This may lead to the probabilistic measures to cross their bounds.
As a rule of thumb, we have tested for multicollinearity, stationarity, and cointegration. Since the independent variables have VIFs less than 10, they are found to be non-colinear. Besides, they are stationary in the first difference, and they are found to exhibit a long-term relationship due to the significant cointegration.
We have calculated the mean spending on R&D by domestic and foreign firms. It is seen that foreign firms are spending four to five times more on R&D than domestic firms.
We have tested the correlation of the dependent variable and the covariates. It exhibits that tax and profit are highly correlated (0.49), and hence, we keep both of them in separate regression and compare them. This was carried out for the unbalanced panel as well, but in that case, the correlation was less than 0.3.
Abid N, Ahmad F, Aftab J, Razzaq A (2023) A blessing or a burden? Assessing the impact of climate change mitigation efforts in Europe using quantile regression models. Energy Policy 178:113589
Article Google Scholar
Al-Mulali U, Tang CF (2013) Investigating the validity of pollution haven hypothesis in the gulf cooperation council (GCC) countries. Energy Policy 60:813–819
Ambec S, Cohen MA, Elgie S, Lanoie P (2013) The Porter hypothesis at 20: Can environmental regulation enhance innovation and competitiveness? Rev Environ Econ Policy 7(1):2–22. https://doi.org/10.1093/reep/res016
Ashford, N. A. (1993). Understanding technological responses of industrial firms to environmental problems: Implications for government policy (chapter).
Bagchi P, Sahu SK (2020) Energy intensity, productivity and pollution loads:empirical evidence from manufacturing sector of India. Stud Microecon 8(2):194–211
Bagchi P, Sahu SK, Kumar A, Tan KH (2022) Analysis of carbon productivity for firms in the manufacturing sector of India. Technol Forecast Soc Chang 178:121606
Bradford DF, Fender RA, Shore SH, Wagner M (2005) The environmental Kuznets curve: exploring a fresh specification. Contrib Econ Anal Policy 4(1):1–28
Bramber T, Clark WR, Golder M (2006) Understanding interaction models: improving empirical analysis. Polit Anal 14(3):63–82
Brunnermeier SB, Cohen MA (2003) Determinants of environmental innovation in US manufacturing industries. J Environ Econ Manag 45(2):278–293
Bu M, Qiao Z, Liu B (2020) Voluntary environmental regulation and firm innovation in China. Econ Model 89:10–18
Chandrika R, Mahesh R, Tripathy N (2022) Is India a pollution haven? Evidence from cross-border mergers and acquisitions. J Clean Prod 376:134355
Cole MA (2004) Trade, the pollution haven hypothesis and the environmental Kuznets curve: examining the linkages. Ecol Econ 48(1):71–81
D’Agostino LM (2015) How MNEs respond to environmental regulation: integrating the Porter hypothesis and the pollution haven hypothesis. Economia Politica 32:245–269
Falkowska A (2020) The impact of environmental policy on location patterns in the waste management industry. Economia Politica 37(1):167–195
Ghosh A, Kayal P, Bagchi P (2024) Climate change and tourism: Assessing the nexus and climate-related disasters in diverse economies. J Clean Prod 443:141097. https://doi.org/10.1016/j.jclepro.2024.141097
M Greenstone, J A List, C Syverson. (2012). The effects of environmental regulation on the competitiveness of US manufacturing (No. w18392). National Bureau of Economic Research
Grossman GM, Krueger AB (1991) Environmental impacts of a North American free trade agreement. NBER Working Paper No. 3914. National Bureau of Economic Research.
Hansen BE (1996) Inference when a nuisance parameter is not identified under the null hypothesis. Econometrica 64(2):413. https://doi.org/10.2307/2171789
Hansen BE (1999) Threshold effects in non-dynamic panels: Estimation, testing, and inference. J Econ 93(2):345–368
Jaffe AB, Palmer K (1997) Environmental regulation and innovation: a panel data study. Rev Econ Stat 79(4):610–619
Kearsley A, Riddel M (2010) A further inquiry into the pollution Haven hypothesis and the environmental Kuznets curve. Ecol Econ 69(4):905–919
Kheder SB, Zugravu N (2012) Environmental regulation and French firms location abroad: an economic geography model in an international comparative study. Ecol Econ 77:48–61
Liang H, Shi C, Abid N, Yu Y (2023) Are digitalization and human development discarding the resource curse in emerging economies? Resour Policy 85:103844
Liu J, Qu J, Zhao K (2019) Is China’s development conforms to the environmental Kuznets curve hypothesis and the pollution haven hypothesis? J Clean Prod 234:787–796
Ma R, Abid N, Yang S, Ahmad F (2023) From crisis to resilience: strengthening climate action in OECD countries through environmental policy and energy transition. Environ Sci Pollut Res 30(54):115480–115495
Markusen JR, Venables AJ (1999) Foreign direct investment as a catalyst for industrial development. Eur Econ Rev 43(2):335–356
Pethig R (1976) Pollution, welfare, and environmental policy in the theory of comparative advantage. J Environ Econ Manag 2(3):160–169
Porter ME, Linde CVD (1995) Toward a new conception of the environment-competitiveness relationship. J Econ Perspect 9(4):97–118
Rubashkina Y, Galeotti M, Verdolini E (2015) Environmental regulation and competitiveness: empirical evidence on the Porter hypothesis from European manufacturing sectors. Energy Policy 83:288–300
Sahu SK, Bagchi P (2023) Waste from production: an analysis at the firm level. Qual Quant 57(3):2641–2656
Sahu SK, Bagchi P, Kumar A, Tan KH (2022) Technology, price instruments and energy intensity: a study of firms in the manufacturing sector of the Indian economy. Ann Oper Res 313(1):319–339
Shen F, Liu B, Luo F, Wu C, Chen H, Wei W (2021) The effect of economic growth target constraints on green technology innovation. J Environ Manage 292:112765
Wang X, Luo Y (2020) Has technological innovation capability addressed environmental pollution from the dual perspective of FDI quantity and quality? Evidence from China. J Clean Prod 258:120941. https://doi.org/10.1016/j.jclepro.2020.120941
Wei D, Ahmad F, Abid N, Khan I (2023) The impact of digital inclusive finance on the growth of the renewable energy industry: theoretical and logical Chinese experience. J Clean Prod 428:139357
Yuan B, Zhang K (2017) Can environmental regulation promote industrial innovation and productivity? Based on the strong and weak Porter hypothesis. Chinese J Popul Resou Environ 15(4):322–336
Google Scholar
Zhang N, Deng J, Ahmad F, Draz MU, Abid N (2023a) The dynamic association between public environmental demands, government environmental governance, and green technology innovation in China: evidence from panel VAR model. Environ Dev Sustain 25(9):9851–9875
Zhang Y, Zeng S, Wu Q, Fu J, Li T (2023b) A study on the impact of the carbon emissions trading policy on the mining industry based on Porter hypothesis. Resour Policy 87:104349
Download references
Acknowledgement
The paper is presented in the SHADG 2024 Conference, CoE-SEA, IIT Kharagpur. The authors are highly benefitted with the valueable comments and suggestions received by the reviewers and the editor of the paper.
The authors have not disclosed any funding.
Author information
Authors and affiliations.
Department of Humanities and Social Sciences, Indian Institute of Technology Kharagpur, Kharagpur, West Bengal, 721302, India
Prantik Bagchi
Department of Humanities and Social Sciences, Indian Institute of Technology Madras, Chennai, Tamil Nadu, 600036, India
Santosh Kumar Sahu
School of Sustainability, Indian Institute of Technology Madras, Chennai, Tamil Nadu, 600036, India
You can also search for this author in PubMed Google Scholar
Contributions
The first author conceptualizes the paper, estimates, and writes the paper. The second author conceptualizes the paper, downloads and cleans the data, and edits the manuscript.
Corresponding author
Correspondence to Prantik Bagchi .
Ethics declarations
Conflict of interest.
The authors did not receive any funding from anywhere. Also, there is no direct or indirect financial or non-financial interest to disclose. There is no other conflict of interest.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Bagchi, P., Sahu, S.K. The conundrum of porter hypothesis, pollution haven hypothesis, and pollution halo hypothesis: evidence from the Indian manufacturing sector. Clean Techn Environ Policy (2024). https://doi.org/10.1007/s10098-024-02886-z
Download citation
Received : 14 January 2024
Accepted : 06 May 2024
Published : 16 May 2024
DOI : https://doi.org/10.1007/s10098-024-02886-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Productivity
- Pollution haven hypothesis
- Pollution halo hypothesis
- Energy transition
- Indian manufacturing
- Find a journal
- Publish with us
- Track your research
A business journal from the Wharton School of the University of Pennsylvania
Four Pillars of Decision-driven Analytics
May 14, 2024 • 5 min read.
In an excerpt from their new book, Wharton’s Stefano Puntoni and co-author Bart De Langhe argue that the power of data can only be realized by leveraging human intelligence.

In a new book titled Decision-Driven Analytics: Leveraging Human Intelligence to Unlock the Power of Data , professors and behavioral scientists Bart De Langhe and Stefano Puntoni challenge the idea that our decisions should be driven by data. Rather, they argue that the power of data can only be realized by putting data in the background.
In this excerpt from their book, De Langhe and Puntoni draw from their own research and teaching to offer four pillars of decision-driven analytics.
In the mid-1850s, astronomers figured that the orbit of the planet Uranus was not like it should be according to the laws of physics. A French astronomer, Alexis Bouvard, thought that perhaps that was because we didn’t know about a planet further out in the solar system that exerted an influence on Uranus’s orbit. People started searching the sky for it. Soon enough, Urbain Le Verrier, another Frenchman, found the missing planet. It was named Neptune.
This was a great victory for the power of observation. Investing in data collection saved the day. It taught astronomers that the key to unraveling the mysteries of the cosmos was more and better data.
The rationale for making decisions with input from analytics rests on similar principles. Without data we navigate blind, while with data we can make decisions rooted in evidence. The implication is that good thinking means thinking with data.
The story doesn’t end here, though. An anomaly was soon observed also in the orbit of another planet: Mercury. The same Urbain Le Verrier who had found Neptune now hypothesized the existence of a missing planet lying between Mercury and the Sun. He called this missing planet Vulcan. Again, people started looking for it, only this time nobody could find it. Astronomers kept looking for Vulcan in the subsequent decades but the missing planet remained missing, and the mystery of Mercury unsolved.
The anomaly in the orbit of Mercury could be explained only half a century later. The explanation had to wait for Albert Einstein’s publication of a new theory of gravitation, called the theory of general relativity. This theory revolutionized our understanding of the universe by placing space and time in a four-dimensional continuum.
Although nobody knew that before Einstein entered the scene, all planetary orbits were in fact not conforming to Isaac Newton’s laws. Nobody knew that because the difference between the predictions of the two theories are smaller and smaller as you move away from the Sun. Only in the case of Mercury, which is the planet closest to the Sun, the curvature in space-time caused by the mass of the Sun was large enough for the divergence between the predictions based on Newton’s and Einstein’s theories to be detected by the telescopes of the time.
The mystery of Mercury was solved in a very different way from the mystery of Uranus. While the latter could be solved with better observations, the former could only be solved with better theory, by thinking without data.
Managers are like astronomers, looking to solve problems and find solutions in a complex world, where data is abundant but often hard to make sense of. The message is clear: Data and algorithms are crucial to making good decisions. But human judgment and intelligence are crucial, too.
The Four Pillars of Decision-driven Analytics
Many companies are witnessing an expanding gap between data and decisions, even with the goal of being a “data-driven organization.” The increasing complexity of data and algorithms can make it harder for decision-makers to collaborate with data analysts. For a business to thrive, it’s essential for both groups to understand and value each other’s expertise.
Many businesses find themselves overwhelmed by the sheer volume of data at their disposal. Putting decisions firmly at the center of the analytics process can be transformative. Starting with decisions and working back to the data will improve the quality of decision-making, improve the collaboration between managers and data analysts, and ultimately foster an organizational culture that is action oriented and that prizes the quality of decisions over ego or politics.
Here are the four core principles of decision-driven analytics:
- Decisions. Identify controllable, relevant decision alternatives. Consider diverse perspectives and a wide array of solutions. Prioritize feasible and impactful alternatives to achieve important business outcomes.
- Questions. Formulate precise questions that will help rank the identified decision alternatives. Ambiguous questions can lead to miscommunication and poor decisions.
- Data. Evaluate the data-generating mechanism. While Big Data can be tempting, the emphasis should be on collecting relevant data.
- Answers. When the earlier steps are done right, determining the best action becomes straightforward. Remember, acknowledging uncertainty and sidestepping overconfidence are key for informed decisions.
Decision-driven analytics is about making informed choices, not just processing data or flooding presentations with graphs. It emphasizes gleaning actionable insights from pertinent data. Embracing this approach means letting go of the notion that every data point is vital and not being distracted by the newest tools.
Data is just a means to an end. What matters is the decisions we make.
Excerpted and adapted from Decision-Driven Analytics: Leveraging Human Intelligence to Unlock the Power of Data, by Bart De Langhe and Stefano Puntoni, copyright 2024. Reprinted by permission of Wharton School Press.
More From Knowledge at Wharton

NBA Motion Tracking Data
Nba playing time statistics, 2024 kentucky derby with jeff seder, looking for more insights.
Sign up to stay informed about our latest article releases.
Hypothesis: Research Journal for Health Information Professionals

Announcements
Editorial board application closed, save the date(s) for the hypothesis open forae, expand your professional skills: apply for our editorial board positions, new submission category: consider writing and submitting a brief report, seeking research process and research experience submissions, meet nina exner, hypothesis editor, submit your research to mla hypothesis open access journal, volunteers and ideas request, current issue, the pre-submission checklist for hypothesis authors, brief report, development of an empowering language assessment tool for type 1 diabetes, an introduction to statistics for librarians (part three): an introduction to statistical tests, public health research in the news: an exploratory study of topics, coverage, and open access status, the research mentor, incentives that drive the editorial peer review process, voices of experience, case-based ebm instruction for osteopathic medical students: a case report, make a submission, developed by, information.
- For Readers
- For Authors
- For Librarians
- Español (España)
Hypothesis ISSN: 1093-5665 eISSN: 2688-1268

- Reference Manager
- Simple TEXT file
People also looked at
Original research article, research on the impact of green insurance on regional environmental quality: evidence from china.

- 1 Jiangsu Maritime Institute, Nanjing, China
- 2 School of International Economics and Trade, Nanjing University of Finance and Economics, Nanjing, China
- 3 School of Management Science and Engineering, Nanjing University of Information Science and Technology, Nanjing, China
Green insurance ( GI ), as an innovative product integrating environmental protection and the financial sector, not only contributes to improving regional environmental quality ( EQ ) but also enhances corporate environmental risk management and awareness, driving the flourishing development of green finance and the environmental protection industry. Therefore, understanding the relationship between GI and EQ is crucial. This article delves into the mechanisms through which GI influences EQ , proposing a hypothesis that suggests an inverted “U” shape impact. Subsequently, based on panel data from 30 provinces in China spanning from 2000 to 2021, nonlinear regression models and threshold regression models were constructed to test the hypothesis. The research findings indicate: (1) Results from the fixed-effects regression model demonstrate that the impact of GI on China’s EQ follows an inverted “U” shape. (2) Results from the threshold regression model also reveal an inverted “U” shape impact of GI on China’s EQ , with a threshold value of 2.196. (3) Economic level and industrial structure exhibit significant inhibitory effects on EQ improvement. Technological level and environmental regulations demonstrate notable promotional effects. Population size shows no significant impact on EQ improvement. The study identifies a nonlinear effect of GI on EQ improvement, surpassing existing linear effect research, deepening the understanding of its impact on EQ , and contributing to the enhancement of regional EQ .
1 Introduction
In recent years, environmental pollution has emerged as one of the most pressing global challenges. Taking air pollution as an example, the 2023 Global Air Quality Report released by the International Energy Agency revealed that only seven countries worldwide met the World Health Organization’s PM2.5 guideline standards in 2023. A staggering 92.5% of countries and regions fell short of these standards ( Dimitroulopoulou et al., 2023 ). Green insurance ( GI ), as an innovative product merging environmental protection with the financial sector, offers a novel avenue for enhancing environmental quality ( EQ ) ( Hu et al., 2023 ). Therefore, this study aims to illuminate the impact of GI on regional EQ , unraveling its underlying mechanisms in environmental governance. It seeks to provide insights and inspiration for the development of regional green finance and the enhancement of EQ .
In recent years, China has experienced rapid economic growth, marked by swift strides in marketization, industrialization, and internationalization. However, escalating environmental pollution has emerged as a bottleneck hindering China’s sustainable development. Furthermore, China’s enormous population, rapid industrialization and urbanization, and export-oriented economy have propelled it to become one of the world’s largest carbon emitters. Nevertheless, the Chinese government has actively promoted ecological civilization construction in recent years, implementing a series of environmental protection policies and measures. Lastly, China stands as a significant testing ground for the development of green finance. In 2023, China’s GI revenue reached 229.7 billion yuan, with payouts totaling 121.5 billion yuan, spanning various sectors including transportation infrastructure, clean energy, and wastewater treatment ( Wen et al., 2024 ). In summary, China’s environmental governance practices and the advancement of green finance wield significant influence and serve as exemplary models for global environmental protection endeavors.
To thoroughly investigate the impact of GI on regional EQ , this paper first constructs an EQ evaluation index system to conduct an in-depth assessment of the current EQ in China. Furthermore, through an in-depth research of the impact mechanisms of GI on EQ , the hypothesis is proposed that the impact of GI on China’s EQ follows an inverted “U” shape. Subsequently, this paper uses panel data from 30 provinces in China from 2000 to 2021 to construct nonlinear panel regression models and threshold regression models to validate the proposed hypotheses. Finally, based on the research findings, recommendations for strategies to promote the improvement of China’s EQ are put forward. Studying the impact of GI on regional EQ can provide a new theoretical perspective for the field of environmental economics. Deepen the understanding of the coordinated relationship between environmental protection and economic development. To provide support for building more effective environmental governance theories. On the other hand, this article intends to examine the inverted U-shaped nonlinear relationship between GI and EQ , which goes beyond the scope of traditional linear analysis. Deepening its understanding of the impact on EQ can provide scientific basis for government environmental governance. Promote the transformation of the economy towards a green and sustainable direction.
The significance of this study lies in the ambiguity surrounding the operational mechanisms of GI as an emerging tool for environmental protection. A comprehensive investigation into the impact of GI on EQ holds paramount importance. Moreover, empirical analysis of the relationship between GI and EQ can furnish governmental bodies with scientific grounds for formulating more precise environmental policies. Finally, by delving into the inverted U -shaped relationship between GI and EQ , this study aids in unveiling the latent mechanisms of GI in environmental governance, thereby offering valuable insights and inspiration for the development of green finance.
Compared to previous studies, the primary contribution of this research lies in its systematic exploration of the impact of GI on the EQ of Chinese provinces through the introduction of a threshold regression model. Furthermore, it substantiates the existence of an inverted U -shaped relationship. Additionally, this study accounts for the heterogeneity among Chinese provinces, robustly examining the validity of its findings, thus enhancing the credibility and persuasiveness of the research outcomes.
2 Literature review
With the continuous severity of global environmental issues, enhancing EQ has become a focal point of widespread attention in academic and policy domains. Regional EQ is influenced by various factors. Some studies have found that the production processes of heavy industry often generate large amounts of industrial solid waste, wastewater, and exhaust gases ( Wang et al., 2023a ). The production and use of fossil fuels also result in significant greenhouse gas emissions ( Gillingham and Stock, 2018 ). Therefore, the industry structure dominated by heavy industry and the energy structure dominated by fossil fuels are important factors affecting regional EQ . On the other hand, advanced technological levels contribute to the improvement of clean technologies and resource utilization efficiency ( Wang et al., 2024 ). Environmental protection policies enacted and enforced by the government directly impact the behavior of businesses and individuals ( Wang et al., 2023b ). Therefore, technological levels and environmental protection policies are crucial factors in enhancing regional EQ . In addition, some scholars have found that the increase in the level of urbanization is often accompanied by the rapid development of industrialization and extensive infrastructure construction, leading to increased emissions of pollutants and a decrease in regional EQ ( Liang et al., 2019 ). However, other scholars have different findings, suggesting that urbanization improves the utilization of production factors, reduces resource waste, and lowers pollutant emissions ( Li et al., 2022 ). Finally, a minority of scholars have delved into the impact of factors such as foreign direct investment (FDI) ( Wang et al., 2023c ), population mobility ( Dhondt et al., 2012 ), and motor vehicles ( Montag, 2015 ) on regional EQ .
GI, as an emerging insurance model, aims to enhance EQ through financial means ( Mills, 2009 ). In recent years, numerous scholars have extensively researched the development and application of GI . Through theoretical analysis, many scholars have found that GI plays a positive role not only in strengthening enterprise environmental risk management ( Yang and Zhang, 2022 ) but also in accelerating the layout of green industries ( Mills, 2003 ) and promoting innovation in green technologies ( Hu et al., 2023 ). It can continuously enhance public and societal environmental awareness ( Brogi et al., 2022 ), guide the direction of social funds ( Desalegn, 2023 ), and promote the improvement of regional EQ . On the other hand, a minority of scholars, through empirical research, have delved into the impact of GI on EQ . The research by Ning and other scholars indicates that GI , through flexible premium designs, incentivizes enterprises to adopt more environmentally friendly production methods, encouraging the reduction of pollution emissions ( Ning et al., 2023 ). Studies by Hou and others indicate that enterprises purchasing GI allocate more funds to environmental protection projects ( Hou and Wang, 2022 ). A limited number of scholars have delved into an empirical analysis to further investigate the impact of GI on environmental pollution. Scholars such as Ning have uncovered that the differentiated premium design of GI serves as an incentive for enterprises to adopt more environmentally friendly production methods, thereby exerting a promoting effect on the enhancement of regional EQ ( Ning et al., 2023 ). The research conducted by Hou and others reveals that enterprises purchasing GI allocate more funds to environmental construction, leading to a reduction in pollution emissions ( Hou and Wang, 2022 ). However, divergent conclusions have been drawn by some scholars who argue that GI may impede the improvement of EQ . Lu and collaborators found that an excessive reliance on GI could diminish the proactive innovation in green technologies by enterprises, ultimately hindering long-term benefits for the enhancement of regional EQ as companies merely satisfy minimum environmental standards ( Lu et al., 2022 ). In their study focused on China’s environmental protection industry, Yang and team discovered a relatively modest impetus of GI on the environmental protection industry and a limited impact on the improvement of EQ ( Hou and Wang, 2022 ).
In conclusion, the study of the impact of GI on EQ is still in its infancy as an emerging field. Existing research outcomes suggest a linear relationship between GI and EQ , yet discrepancies and contradictions persist among these findings. Some studies assert the positive effects of GI , while others hold opposing views. This paper aims to employ threshold regression and nonlinear models to examine the inverted U -shaped relationship, thereby elucidating the aforementioned contradictions. By transcending traditional linear analyses, this research deepens our comprehension of how GI influences EQ . It provides a more nuanced and profound perspective for the study of GI and EQ , ultimately empowering governments to tailor and adjust GI policies with greater precision. This strategic approach maximizes the positive impact on the environment, fostering sustainable regional development.
3 Influencing mechanism and hypothesis
GI plays a crucial role in improving regional EQ , and its impact on EQ varies at different stages, as shown in Figure 1 .

Figure 1 . Analysis chart of impact mechanism.
First is the initiation stage of the promotion effect. In the early introduction of GI , regional society and government have a low level of attention to EQ issues. The development of the green industry is weak, and businesses have a limited understanding of GI . This leads to a small market share for GI and a lower promotion effect on EQ ( Zhu et al., 2023 ).
Second is the expansion stage of the promotion effect. As EQ issues receive widespread attention from society and government, the GI market gradually expands, and the EQ promotion effect of GI significantly increases. This includes the improvement of enterprise environmental risk management systems, risk monitoring, economic incentives and penalties, technological upgrades and applications, environmental responsibility tracking, risk sharing, support for green industries, etc., effectively promoting a rapid improvement in regional EQ . Moreover, with the increase in corporate information transparency and the emphasis on corporate environmental responsibility by society, companies begin to take voluntary environmental measures, accelerating the improvement of EQ ( Rahmatiar, 2018 ).
Third is the slowing stage of the effect. As the GI market continues to expand, certain factors contribute to the gradual slowdown of the EQ promotion effect of GI ( Lee and Fung, 2023 ). First, enterprise environmental risk management systems are becoming increasingly perfected, and pollution reduction measures that are relatively easy to implement have become widely adopted. Second, environmental standards are gradually increasing, environmental incentive mechanisms are insufficient, and green technologies face bottlenecks, leading to rising environmental costs and a slowdown in the promotion effect. Third, the growth of the green industry is slowing, with the primary factor affecting green industry development no longer being a lack of funds but rather technological breakthroughs. Fourth, with the expansion of the GI market, market supervision may lag behind market changes, leading to regulatory loopholes in the GI market.
Fourth is the suppression effect stage. When the market share of GI reaches saturation, the promotional effect of GI transforms into a suppression effect. On one hand, as competition intensifies in the GI market and related regulations become stricter, insurance companies are compelled to raise environmental standards and reduce support for highly polluting enterprises ( Wang et al., 2021 ). On the other hand, with the comprehensive expansion of the GI market, excessive reliance by the government, industry, and enterprises on the EQ promotion effect of GI leads to the government lowering environmental standards, the green industry lacking market competitiveness, and enterprises merely meeting the minimum environmental standards, resulting in a decline in EQ ( Wang et al., 2014 ).
In summary, this paper proposes a research hypothesis: In China, the impact of GI on EQ follows an inverted “U” shape. There is a positive relationship up to a certain extent, but with the influence of various factors, this relationship may reverse.
4 Methodology and data
4.1 environmental quality evaluation, 4.1.1 evaluation index system of environmental quality.
Since the 21st century, global environmental pollution issues have become more prominent. Different regions choose various environmental indicators for EQ assessments based on their specific circumstances. For example, air quality index, carbon emission index, noise pollution index, etc. Some scholars integrate multiple environmental dimensions such as atmosphere, water, soil, ecology, and noise to establish a comprehensive evaluation index, thereby conducting a comprehensive assessment of regional EQ . According to the analysis of the impact paths of GI on regional EQ , it can be observed that currently, GI in China primarily focuses on industrial pollutant emissions, with minimal impact on residential pollution ( Shi et al., 2023 ). In light of the mentioned characteristics, this paper draws extensively upon the contributions of scholars such as Miao in the research field ( Miao et al., 2016 ). Ultimately, nine specific indicators were selected to establish a comprehensive EQ evaluation index from the critical dimensions of regional environmental carrying capacity and environmental governance level. The detailed interpretation of these indicators is presented in Table 1 .

Table 1 . Chinese EQ evaluation indicators.
4.1.2 Evaluation method for environmental quality
Evaluating regional EQ requires not only the establishment of an EQ evaluation index system but also the determination of weights for each indicator. In the academic realm, methods for determining indicator weights can be categorized into subjective and objective approaches. Subjective methods rely on personal judgment, such as expert scoring and the analytic hierarchy process (AHP). Objective methods, on the other hand, use data and mathematical models to determine weights, including the entropy method and principal component analysis. Objective weighting methods, relying on mathematical models and data analysis, are more scientific and objective, less susceptible to personal subjective views, and more flexible in dealing with complex issues and multi-criteria decision-making. Drawing on the research of scholars like Cheng, this paper applies the entropy method to further evaluate regional EQ ( Cheng et al., 2023 ).
The entropy method is a mathematical approach used for multi-criteria decision analysis. It is primarily employed to determine the weights of each decision factor for a better understanding and evaluation of various alternative solutions. The steps in applying the entropy method include:
Step 1, data standardization processing. Standardize the data of each indicator in the EQ evaluation index. Ensure that the data for each indicator is within the same dimension and range of variation. The standardized processing formulas for positive and negative indicator data are shown in formula (1) and formula (2) , respectively.
Step 2, calculate the entropy value. Calculate the entropy value of each indicator in the evaluation index system using the formula (3) . Among them, p_ij is the proportion of the j th data under indicator i, and N is the number of samples in the dataset. The entropy value reflects the uncertainty and information content of the indicator, and the larger the value, the higher the information uncertainty.
Step 3, calculate the weights. Calculate the weight of the entropy value for each indicator, as shown in formula (4) . Among them, k is the number of indicators.
Step 4, normalize weights. Normalize the calculated weights to ensure that the sum of weights for each indicator is 1.
4.2 Regression models construction
To test the hypothesis that the impact of GI on EQ in China follows an inverted “U” shape, this paper first introduces the quadratic term of the core explanatory variable to construct a nonlinear regression model. Secondly, borrowing from Hansen’s method, a threshold regression model based on GI for EQ is constructed ( Yi and Xiao, 2018 ).
4.2.1 Variable selection and data interpretation
Through a comprehensive review of existing research results on factors influencing EQ , we found a diverse range of factors affecting regional EQ , including economic, population, industrial, technological, energy, and policy factors. Combining the commonalities in the development of EQ across Chinese provinces, we systematically selected six key influencing factors, as shown in Table 2 .

Table 2 . Variable descriptions.
Interpreted variable: The EQ of various provinces in China is calculated based on the EQ evaluation index system constructed in the previous sections.
Core explanatory variable: The GI of various provinces in China is expressed by the proportion of environmental pollution liability insurance revenue to the total insurance revenue.
Control variables: (1) Selecting per capita GDP to reflect the regional economic development level. Regions with higher economic development levels may have more industrial activities and transportation, leading to increased emissions of pollutants such as exhaust gases and wastewater. Therefore, this indicator may decrease regional EQ ( Lu et al., 2017 ). (2) Selecting total population to reflect the regional population level. Regions with large population concentrations may lead to higher levels of industrialization and urbanization, thereby increasing pollutant emissions. At the same time, the demand from a large population also drives more traffic and production activities, increasing pollutant emissions. Therefore, this indicator may decrease regional EQ ( Li et al., 2019 ). (3) Selecting the proportion of the secondary industry to reflect regional industrial structure characteristics. The secondary industry, compared to the primary and tertiary industries, requires more production materials and may emit more pollutants. Therefore, this indicator may decrease regional EQ ( Chen et al., 2021 ). (4) Selecting unit GDP energy consumption to reflect regional technological level. Advanced technological levels imply more efficient resource utilization, which can reduce fossil fuel consumption and even use clean energy. Therefore, this indicator may increase regional EQ ( Mughal et al., 2022 ). (5) Selecting the proportion of investment in industrial pollution control to industrial value-added to reflect the level of environmental regulation. Reasonable environmental regulations can promote the upgrading of pollution control facilities by enterprises, reduce pollution emissions, and achieve improvement in regional EQ ( Yang et al., 2018 ).
Considering the availability and completeness of the data, this paper selects relevant data from 30 provinces in China for the period 2000-2021 to investigate the relationship between GI and EQ . The dataset does not include data from the regions of Hong Kong, Macao, Taiwan, and Tibet. GI data is obtained from the annual “China Insurance Yearbook,” while other data is collected from the annual “China Statistical Yearbook,” “China Environmental Statistical Yearbook,” and provincial statistical yearbooks. It is important to note that, to prevent the influence of non-stationarity of macro data on empirical results, all variables have been log-transformed. For missing data, we used either the mean imputation method or the nearest neighbor interpolation method for supplementation.
4.2.2 Nonlinear regression model (NRM)
This article uses a quadratic regression model to test the hypothesis that the impact of GI on China’s EQ is an inverted “U” shape. The coefficients of the quadratic regression model bear an intuitive interpretation. The coefficient of the linear term variable signifies the slope of the linear relationship within the model, while the coefficient of the quadratic term variable reflects the concavity or convexity of the nonlinear relationship. This imparts a heightened level of intuitiveness and operability to the explication of the model outcomes. The underlying principle of the model unfolds as follows: when the coefficient of the quadratic term variable takes a negative value, the model manifests a inverted U -shaped form after the variable reaches a certain level. This configuration aligns with our conceptualization of an inverted U -shaped relationship, wherein the optimal EQ is attained when the GI level is moderate. Conversely, under excessively high or low GI levels, the EQ might experience a decline. A notably negative coefficient of the quadratic term variable indicates the presence of an inverted U-shaped relationship between GI and EQ .
To test the hypothesis that the impact of GI on EQ in China follows an inverted “U” shape, this paper introduces the quadratic term of GI ( Haans et al., 2016 ). And introduce other variables that affect EQ , such as PGDP , TP , IS , TL , and ER . The complete nonlinear regression model for studying EQ is shown in Formula (5) . In the Formula (5) , i represents the i th province among the 30 provinces in China, and t represents the t th year from 2000 to 2021. For example, E Q i t represents the environmental quality level of province i in year t , and G I i t represents the green insurance level of province i in year t . Similarly, P G D P i t , T P i t , I S i t , T L i t respectively represent the per capita GDP, total population, industrial structure, technological level, and environmental regulation level of province i in year t .
4.2.3 Threshold regression model (TRM)
To further test the hypothesis that the impact of GI on EQ in China follows an inverted “U” shape, this paper employs Hansen’s proposed threshold panel model to analyze the influence of GI on EQ at different development stages. This paper constructs a regional environmental quality threshold regression model using GI as a threshold variable. The final model is shown in Formulas (6) and (7) ( Lv and Xu, 2023 ). The meanings of each character in formulas (6) and (7) are consistent with those in formula (1) . In addition, η represents the threshold value.
The threshold regression model consists of two components: one capturing the linear relationship below the threshold and the other above the threshold. Such a model structure enhances the flexibility to depict the nonlinear impact of GI on EQ . It allows for modeling variations in EQ near the threshold. The pivotal aspect of the threshold regression model lies in the examination of the threshold. Through hypothesis testing on the threshold, it can be determined whether there exists a threshold for the impact of GI on EQ . This aids in comprehending at what level of GI the impact on EQ is optimized. The threshold regression model furnishes explanations for both stages below and above the threshold, enabling researchers to gain a clearer understanding of the mechanism through which GI affects EQ . Such interpretability holds practical guidance for policy formulation and operational practices.
5 Results and discussions
5.1 descriptive statistical analysis.
The results of the descriptive statistical analysis are shown in Table 3 . The extreme values of the seven variables are relatively small, mostly within two digits, and each variable has a small skewness and a large kurtosis. This indicates that the sample data distribution is relatively symmetrical, but with heavier tails. In addition, the p -values of the JB statistics are all less than 0.05, rejecting the null hypothesis. There is sufficient evidence to conclude that the seven variables do not follow a normal distribution.

Table 3 . Descriptive statistical analysis results.
5.2 Unit root test
Unit root testing is a crucial step in time series analysis and is used to detect whether time series data exhibits non-stationarity. Non-stationary time series data can lead to potential issues in many statistical methods and models, making unit root testing essential for the accuracy and reliability of subsequent analyses. This paper employs LLC test, ADF test, and IPS test to conduct unit root tests on the selected variables, as shown in Table 4 . The test statistics of the three unit root testing methods are significantly larger than the critical values, leading to the acceptance of the alternative hypothesis that the sequence is stationary.

Table 4 . Unit root test results.
5.3 Results and discussion of the nonlinear panel regression model
5.3.1 results.
In testing the hypothesis that the impact relationship between green insurance and environmental quality is an inverted “U” shape using a nonlinear panel regression model, it is necessary to determine whether to use a fixed effects model or a random effects model. These two models handle heterogeneity among individuals in panel data differently. Therefore, this paper employs the Hausman test method to test the fixed effects model against the random effects model. The results are shown in Table 5 . The test results indicate a chi-square value of 57.98, with a corresponding probability value of 0.0000. Consequently, this research rejects the random effects regression model and tends to choose the fixed effects regression model.

Table 5 . Hausman test results.
The results of the fixed effects regression model are shown in Table 6 , with an R-squared equal to 0.893, indicating that the explanatory variables included in the model can effectively explain the variation in the dependent variable. The p -values corresponding to l n G I , l n G I 2 , l n P G D P , l n I S , l n T L , and l n E R are all less than 0.05, significantly affecting China’s EQ . However, at a significance level of 10%, TP did not have a significant impact on EQ .

Table 6 . Fixed effects regression results.
5.3.2 Discussion
The coefficient of l n G I on l n E Q is positive, with a value of 0.305, indicating that as the level of GI increases, the level of EQ also rises. The coefficient of l n G I 2 on l n E Q is −0.071, indicating that the impact of GI on EQ follows an inverted “U” shape. In the early stage of GI development, it can enhance the enterprise’s environmental risk management system and establish a scientific environmental protection strategy. It can promote increased environmental investment by implementing economic incentives and penalties. Through risk monitoring mechanisms and responsibility tracking mechanisms, it encourages companies to actively fulfill their environmental responsibilities. It can share the risk of technological innovation, promote the upgrade and application of green technologies. Financial support can guide investment direction and support the stable and rapid development of the green industry. Therefore, GI can reduce pollution emissions and promote the improvement of regional EQ . On the other hand, as the level of GI development continues to rise, when the market share of GI reaches saturation, the promotional effect of GI transforms into an inhibitory effect. The main reasons are that with the continuous development of the GI level, market competition intensifies, and related regulations become more stringent, forcing insurance companies to raise environmental standards and reduce insurance support for highly polluting enterprises. Additionally, as the GI market fully unfolds, excessive reliance on the EQ promotion effect of GI by the government, industry, and enterprises leads to a lowering of environmental standards by the government, a lack of market competitiveness in the green industry, and companies merely meeting the minimum environmental standards. This results in a decline in EQ . Existing research findings on the impact of GI on EQ have yielded contradictory results. Some studies posit a positive effect of GI on EQ , while others hold a contrary perspective. For instance, Rizwanullah et al., based on linear regression analysis, found a positive impact of GI on the EQ of BRICS ( Rizwanullah et al., 2022 ). Conversely, Ahmed et al., utilizing linear regression analysis as well, discovered a negative impact of GI on the EQ of the United States ( Ahmed et al., 2022 ). Through the revelation of an inverted U-shaped relationship in this study, not only can these conflicting results be elucidated, but it also expands the research perspective on the enhancement effects of GI on EQ . The discovery of such a nonlinear relationship provides a more profound and comprehensive understanding of GI research, offering insights into its nuanced impact on EQ .
Further calculations reveal that when the value of GI equals 8.567, the relationship between GI and EQ begins to show a turning point. That is, when GI is greater than 8.567, EQ decreases with the increase of GI . Spatial-temporal difference analysis of 30 provinces in China conducted in this study found that in 2016, the level of GI in Jiangsu Province first exceeded 8.567, followed by Beijing, Shanghai, Zhejiang, and Yunnan provinces. Combining with the development history of GI in China, we found that since the implementation of GI policies, the level of GI in China has continuously increased, growing from 4.42 in 2000 to 9.08 in 2021. In the initial stage, the introduction of GI effectively reduced pollutant emissions, leading to an improvement in regional EQ . However, the blind promotion of GI development has also brought a series of environmental pollution issues, inhibiting the improvement of EQ . Taking Jiangsu as an example. The GI and EQ of Jiangsu Province in 2000 were 4.41 and 0.466, respectively. With the continuous development of GI , EQ continued to rise, reaching the highest value of 0.768 by 2016. Then, Jiangsu Province’s EQ declined continuously with the growth of GI . By 2021, Jiangsu Province’s GI had grown to 9.13, and EQ had reduced to 0.658.
Analyze the impact of each control variable on EQ in detail. (1) The impact coefficient of PGDP on EQ is −0.212, indicating a significant inhibitory effect of PGDP on EQ. Currently, China’s rapid economic growth relies predominantly on high-energy-consuming and pollution-intensive heavy industries and manufacturing. The development of these traditional industries often accompanies substantial energy consumption and environmental pollution emissions, leading to deteriorating EQ . Hence, the improvement of EQ in China exhibits a suppressing effect due to PGDP. Existing research outcomes on the influence of PGDP on Chinese EQ have yielded conflicting results. Some studies suggest a positive effect of PGDP on EQ, while others hold the opposite view. Song et al. found that, influenced by high-energy-consuming and high-emission industries, Chinese EQ declines with the growth of PGDP, consistent with the findings of this study ( Song et al., 2020 ). However, Awan et al. focused on Shanghai and discovered that with economic development, an increase in per capita GDP leads people to be more inclined towards investing in environmental protection and improvement measures, thereby enhancing EQ ( Awan and Azam, 2022 ). (2) The significant negative impact coefficient of IS indicates that for every increase of 1 unit in IS, EQ decreases by 0.17 units, demonstrating a notable inhibitory effect of IS on EQ. China’s secondary industry primarily comprises industries such as manufacturing and heavy manufacturing, which often exhibit high energy consumption and pollution characteristics. With the increasing proportion of the secondary industry, the development of industries such as manufacturing may lead to significant energy consumption and emissions of environmental pollutants, thereby exerting adverse effects on EQ . Yin and Song conducted an empirical analysis on the impact of industrial structure on regional EQ in China. The results consistently indicate a decline in regional EQ with the increase in the proportion of the secondary industry, aligning with the conclusions of this study ( Song et al., 2022 ; Yin et al., 2024 ). (3) The significant positive impact coefficient of TL indicates that for every increase of 1 unit in TL, EQ increases by 0.121 units, demonstrating a noteworthy promoting effect of TL on EQ. In recent years, China has witnessed rapid development and widespread adoption of renewable and clean energy technologies, reducing reliance on traditional fossil fuels, and consequently lowering carbon emissions and other pollutants, thereby benefiting EQ . Furthermore, China’s advancements in production technology have continuously elevated resource utilization efficiency, reducing wastage and consumption of resources effectively. This has also led to a reduction in pollutant emissions during the production process, thereby alleviating environmental pressures. Villanthenkodath and Chishti respectively studied India and the BRICS economies, empirically analyzing the impact of technological levels on regional EQ . The results consistently demonstrate an improvement in regional EQ with the enhancement of technological levels, aligning with the conclusions of this study ( Chishti and Sinha, 2022 ; Villanthenkodath and Mahalik, 2022 ). (4) The impact factor of ER is significantly positive. For every one-unit increase in ER, EQ increases by 0.263 units, indicating a significant promoting effect of ER on EQ. Environmental regulations in China enforce emission standards and restrictions on enterprises, compelling them to take measures to reduce pollutant emissions. This fosters enhanced clean production and technological innovation within enterprises and can also elevate public and corporate awareness of environmental protection, thereby driving improvements in EQ . Tang and Feng respectively focus on China and the Yangtze River Economic Belt as their study subjects, empirically analyzing the influence of environmental regulations on regional EQ . The results consistently demonstrate that regional EQ improves with the enhancement of environmental regulations, corroborating the findings of this study ( Tang et al., 2020 ; Feng et al., 2023 ).
5.4 Results and discussion of the threshold regression model
5.4.1 results.
To further verify the inverted “U” relationship between Chinese GI and EQ , this paper examines the threshold variable l n G I under three different threshold conditions. Specifically, we investigated the cases where l n G I has no threshold, has one threshold, and has two thresholds. The F-statistics and p -values for each threshold test are presented in Table 7 . The threshold variable l n G I only passed the single threshold test at a significance level of 1%, not passing the double and triple threshold tests. The estimated single threshold value and its 95% confidence interval for the threshold variable l n G I are shown in Table 8 . The estimated value for the single threshold is 2.196. Therefore, GI has a significant impact on EQ, and there is a single threshold effect. The results of the threshold regression model are shown in Table 9 .

Table 7 . Threshold test (bootstrap = 10,000 10,000 10,000).

Table 8 . Threshold estimation results (level = 95).

Table 9 . Single threshold regression results.
5.4.2 Discussion
The results indicate that the threshold variable l n G I passes the statistical test at a 1% significance level, whether it is less than 2.196 or greater than 2.196. When l n G I is less than 2.196, the impact coefficient is 0.685, indicating a significant promoting effect of GI on EQ . With the increase of GI , EQ also improves. When l n G I is greater than 2.169, the impact coefficient is −0.227, indicating a significant inhibitory effect of GI on EQ . With the increase of GI , EQ decreases. The conclusion of the threshold regression model is consistent with the fixed-effects regression model, both indicating an inverted “U”-shaped impact of GI on EQ .
5.5 Regional comparative analysis
The preceding analysis examined the impact of GI on China’s EQ at the aggregate sample level. However, there exist disparities among China’s 30 provinces in terms of EQ , levels of GI , and geographical location. For different types of provinces, the influence of GI on their EQ may vary. Hence, this study conducts a comparative analysis of Chinese provinces from three major perspectives: EQ level, GI level, and geographical location. The present study categorizes the 30 sample provinces of China based on their geographical locations into four regions: Eastern, Central, Western, and Northeastern regions. Additionally, provinces are divided into high and low GI levels and further categorized into high-pollution and low-pollution provinces based on their EQ levels. Empirical analyses are then conducted for each category, with the respective results presented in Tables 10 , 11 , and 12 .

Table 10 . Compare the regression results by sample based on geographical location.

Table 11 . Compare the regression results by sample based on levels of GI .

Table 12 . Compare the regression results by sample based on levels of EQ .
Regression results for the comparison of samples based on geographical locations are shown in Table 10 . GI exhibits significant impacts on the EQ of China’s Eastern, Northeastern, Central, and Western regions. Specifically, there is an inverted U-shaped relationship between GI and EQ in the Eastern and Central regions. Meanwhile, there exists a certain promoting effect on the EQ of the Northeastern and Western regions, with the promoting effect being more pronounced in the Northeastern region. The Eastern and Central regions of China boast developed economies and possess well-established financial systems and insurance markets, laying a solid foundation for the development of GI . Moreover, the rapid economic growth in these regions has brought about prominent environmental issues, compelling both the government and enterprises to prioritize environmental protection and consequently increasing the demand for GI . The market share of GI has undergone stages from initial development to saturation and then to oversupply. Therefore, there exists an inverted U -shaped relationship between GI and the improvement of EQ in the Eastern and Central regions of China. Conversely, the Northeastern and Western regions exhibit relatively weaker economic development, resulting in slow progress in regional GI development, which has yet to reach saturation. Consequently, the roles of GI , such as economic incentives and penalties, environmental responsibility tracking, and risk sharing, are more pronounced, thereby fostering improvements in regional EQ . The Northeastern region, in particular, has undergone industrial transformations, facing severe pollution issues from legacy industrialization. The significant demand from the government to enhance EQ in this region amplifies the promoting effect of GI , making it more pronounced in the Northeastern region.
The regression results for the comparison of samples based on levels of GI are presented in Table 11 . GI exhibits an inverted U -shaped relationship with the improvement of EQ in provinces with high levels of GI , while it shows a promoting effect in provinces with low levels of GI . In provinces with high levels of GI , the market share of GI has undergone stages from initial development to saturation and then to oversupply, resulting in an inverted U -shaped impact on EQ improvement. Conversely, in provinces with low levels of GI , where the market share of GI has not yet reached saturation, the positive effects of GI , including economic incentives and penalties, technological upgrades, environmental responsibility tracking, and risk sharing, are significant.
The regression results for the comparison of samples based on EQ levels are depicted in Table 12 . GI exhibits only a promoting effect on the improvement of EQ in both high-pollution and low-pollution provinces, without displaying an inverted U -shaped relationship. This can be attributed to several factors. Firstly, although high-pollution provinces demonstrate a strong demand for EQ improvement, some provinces with lower levels of economic development hinder the rapid growth of the GI industry. Consequently, the impact of GI on EQ improvement remains in the promoting stage. Secondly, low-pollution provinces, benefiting from relatively better EQ , do not urgently require the development of the GI industry. This results in sluggish regional development of the GI industry, maintaining its impact on EQ in the promoting stage.
5.6 Robustness test
Robustness tests ensure that model results remain reliable and effective when facing various potential anomalies, thereby enhancing the credibility and interpretability of the research. A review of relevant literature reveals that common methods for conducting robustness tests include: altering sample periods, substituting the dependent variable, introducing additional control variables, and changing the measurement methods of variables ( Ferreira et al., 2017 ).
This study conducts robustness tests by changing the expression indicators of explanatory variables and the calculation methods of the dependent variable. The test results are presented in Table 13 . Due to space limitations, the details of control variables are not elaborated in Table 13 . A comparison between Table 6 and Table 13 reveals the following: (1) The study measures the level of GI development in various provinces of China using the proportion of regional environmental pollution liability insurance income to total premium income. The regional environmental pollution liability insurance income is used as the dependent variable during validation. After changing the expression indicators of explanatory variables, the coefficients of explanatory variables in Table 13 are largely consistent with those in Table 6 . (2) EQ was initially measured using entropy methods in the previous sections, while principal component analysis is employed in this study. Despite this change in the measurement method of EQ , the robustness test results still indicate a quadratic relationship (inverted U-shaped) between GI and EQ . In summary, the robustness test results further confirm the strong reliability of the estimated results of the nonlinear panel regression model constructed in this study.

Table 13 . Robustness test results.
6 Conclusions and suggestions
6.1 conclusions.
As an innovative product integrating environmental protection and the financial sector, GI provides a new avenue for enhancing EQ . Existing research outcomes predominantly focus on the linear relationship between GI and EQ or simplistic notions of positive and negative impacts. However, this study, through the identification of an inverted U-shaped relationship, broadens the research perspective on the influence of GI . The unveiling of such a nonlinear relationship offers a more profound and comprehensive understanding of GI research, enriching the discourse on the nuanced dynamics of its impact. This paper focuses on China and empirically analyzes the impact of GI on EQ . The results indicate: (1) The fixed-effects regression model demonstrates that the impact of GI on China’s EQ follows an inverted “U”-shaped pattern. (2) The results of the threshold regression model also support the inverted “U”-shaped relationship, with a threshold value of 2.196. (3) Economic level and industrial structure exert a significantly inhibitory effect on improving EQ , while technological level and environmental regulation have a significant promoting effect. Population size does not show a significant impact on improving EQ .
6.2 Policy implications
At present, the government promotes the development of GI through measures such as tax incentives, government procurement, and reward mechanisms, with a singular focus on maximizing the GI market. However, this study reveals that an excessively high level of the GI market exerts a suppressive effect on environmental improvement. Therefore, differentiated policies tailored to the characteristics of different stages of GI development are essential. In the initial stages, the government should prioritize incentivizing, guiding, and supporting the establishment of the market. Various multidimensional measures should be implemented to provide impetus and a foundation for the development of GI institutions, promoting their stable growth in the early market.
Firstly, the government can encourage and guide GI institutions to enter the market by offering economic incentives, tax benefits, special funds, and other incentivizing policies. Secondly, through regular discussions and seminars, the government can actively guide deep cooperation between GI institutions and the environmental protection industry, inspiring these institutions to better adapt to the needs of the environmental protection industry.
In the later stages of GI development, the government should focus on upgrading GI products, fostering collaborations, and managing market risks to ensure a more significant role for GI in the field of environmental protection and achieve a win-win situation between environmental protection and the economy. Firstly , the government should encourage continuous improvement in the technical content and adaptability of GI products. This can be achieved through reward mechanisms for technological innovation, support for intellectual property protection, and the provision of favorable conditions for the research and development of GI products. The government can establish dedicated technology innovation bases or laboratories, providing resources and collaboration platforms for institutions to drive continuous innovation in GI products, environmental monitoring technologies, and assessment methods, enhancing the quality and effectiveness of GI products. Secondly , the government should actively guide GI institutions to collaborate and co-build with environmental organizations, research institutions, and enterprises. Regular discussions and seminars can be employed to strengthen the exchange of professional knowledge. Environmental organizations and research institutions often possess the latest environmental technologies and scientific research results, while enterprises understand actual operational conditions. By leveraging resources from various parties, a forward-looking and innovative project can be created, constructing a closed-loop industry chain from environmental technology research and development to practical application in enterprises, and further to the design and promotion of GI . This comprehensive approach ensures all-encompassing environmental management from the source to the end. Finally , the government needs to strengthen market risk management for GI to ensure its healthy operation. This involves comprehensive monitoring of market monopolies, unfair competition, and the financial conditions of GI institutions. The government can enact and implement relevant regulations, establish regulatory bodies, or enhance the functions of existing regulatory bodies to effectively address potential risks and uncertainties. This is crucial for maintaining the overall safety of the GI market.
On the other hand, this study reveals significant inhibitory effects of economic level and industrial structure on the improvement of EQ in China, while technological level and environmental regulations demonstrate significant promoting effects. Consequently, we propose policy recommendations to promote the enhancement of EQ in China from four dimensions: economic level, industrial structure, technological level, and environmental regulations. (1) Economic Development: Establishing a green product certification system to certify products that meet environmental standards and assign them corresponding green labels would help consumers identify and choose green products, enhancing their confidence in purchasing them. Conducting extensive environmental propaganda and education campaigns through various channels such as media, the internet, and communities would raise awareness among residents about the importance and benefits of green consumption, thereby increasing public understanding and consciousness of green consumption. (2) Industrial Development: The government should formulate and implement targeted industrial policies to clarify development directions and key areas. Measures such as tax incentives, fiscal subsidies, and land policies should be adopted to encourage and support the upgrading of industrial structure. Encouraging the construction of green industrial clusters and parks and increasing investment in infrastructure construction in green industrial parks would facilitate the entry of upstream and downstream enterprises in the industrial chain, thereby forming a complete green industrial chain and value chain. (3) Technological Advancement: The government should establish a green technology innovation fund to increase investment in scientific and technological innovation, supporting R&D and innovation in green industries to enhance technological levels and product quality. Additionally, establishing and supporting green technology incubation platforms to provide services such as technology transfer, professional consultation, and market promotion would assist research institutions and enterprises in translating technological achievements into practical productivity. (4) Environmental Regulations: Enhancing the legal system for environmental laws and regulations and enacting stricter environmental protection laws and regulations are essential to ensure the legal guarantees for the development of green industries and create a fair competitive market environment. Establishing an environmental information disclosure system to promptly release environmental monitoring data and emission information of green industry enterprises to the public would increase public attention and participation in environmental issues.
6.3 Limitations
This study finds that the impact of GI on China’s EQ follows an inverted “U” shape. The control variables in the econometric model constructed in this study are determined based on existing research findings. Control variables were not directly determined without analyzing the factors influencing EQ . Additionally, our team’s research reveals that the impact of GI on EQ varies across countries with different EQ levels. Particularly for developed countries, GI ’s impact on EQ may exhibit a dual-threshold effect. That is, GI might initially have a promoting effect on EQ , then transition to a suppressive effect, before ultimately reverting to a promoting effect.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.stats.gov.cn/sj/ndsj/ .
Author contributions
XY: Conceptualization, Methodology, Writing–original draft. JW: Data curation, Formal Analysis, Methodology, Writing–review and editing. ZL: Investigation, Software, Validation, Writing–review and editing.
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahmed, N., Hamid, Z., Mahboob, F., Rehman, K. U., Ali, M. S. e., Senkus, P., et al. (2022). Causal linkage among agricultural insurance, air pollution, and agricultural green total factor productivity in United States: pairwise granger causality approach. Agriculture 12 (9), 1320. doi:10.3390/agriculture12091320
CrossRef Full Text | Google Scholar
Awan, A. M., and Azam, M. (2022). Evaluating the impact of GDP per capita on environmental degradation for G-20 economies: does N-shaped environmental Kuznets curve exist? Environ. Dev. Sustain. 24 (9), 11103–11126. doi:10.1007/s10668-021-01899-8
Brogi, M., Cappiello, A., Lagasio, V., and Santoboni, F. (2022). Determinants of insurance companies' environmental, social, and governance awareness. Corp. Soc. Responsib. Environ. Manag. 29 (5), 1357–1369. doi:10.1002/csr.2274
Chen, L., Li, K., Chen, S., Wang, X., and Tang, L. (2021). Industrial activity, energy structure, and environmental pollution in China. Energy Econ. 104, 105633. doi:10.1016/j.eneco.2021.105633
Cheng, X., Zhang, M., Xu, J., and Tang, D. (2023). Research on the impact of sustainable urbanization on urban rural income disparity in China. Sustainability 15 (6), 5274. doi:10.3390/su15065274
Chishti, M. Z., and Sinha, A. (2022). Do the shocks in technological and financial innovation influence the environmental quality? Evidence from BRICS economies. Technol. Soc. 68, 101828. doi:10.1016/j.techsoc.2021.101828
Desalegn, G. (2023). Insuring a greener future: how green insurance drives investment in sustainable projects in developing countries? Green Finance 5 (2), 195–210. doi:10.3934/GF.2023008
Dhondt, S., Beckx, C., Degraeuwe, B., Lefebvre, W., Kochan, B., Bellemans, T., et al. (2012). Integration of population mobility in the evaluation of air quality measures on local and regional scales. Atmos. Environ. 59, 67–74. doi:10.1016/j.atmosenv.2012.04.055
Dimitroulopoulou, S., Dudzińska, M. R., Gunnarsen, L., Hägerhed, L., Maula, H., Singh, R., et al. (2023). Indoor air quality guidelines from across the world: an appraisal considering energy saving, health, productivity, and comfort. Environ. Int. 178, 108127. doi:10.1016/j.envint.2023.108127
PubMed Abstract | CrossRef Full Text | Google Scholar
Feng, Q., Teo, T. S. H., and Sun, T. (2023). Effects of official and unofficial environmental regulations on environmental quality: evidence from the Yangtze River Economic Belt, China. Environ. Res. 226, 115667. doi:10.1016/j.envres.2023.115667
Ferreira, S. L. C., Caires, A. O., Borges, T. S., Lima, A. M., Silva, L. O., and dos Santos, W. N. (2017). Robustness evaluation in analytical methods optimized using experimental designs. Microchem. J. 131, 163–169. doi:10.1016/j.microc.2016.12.004
Gillingham, K., and Stock, J. H. (2018). The cost of reducing greenhouse gas emissions. J. Econ. Perspect. 32 (4), 53–72. doi:10.1257/jep.32.4.53
Haans, R. F. J., Pieters, C., and He, Z. L. (2016). Thinking about U: theorizing and testing U-and inverted U-shaped relationships in strategy research. Strategic Manag. J. 37 (7), 1177–1195. doi:10.1002/smj.2399
Hou, D., and Wang, X. (2022). Inhibition or promotion? the effect of agricultural insurance on agricultural green development. Front. Public Health 10, 910534. doi:10.3389/fpubh.2022.910534
Hu, Y., Du, S., Wang, Y., and Yang, X. (2023). How does green insurance affect green innovation? Evidence from China. Sustainability 15 (16), 12194. doi:10.3390/su151612194
Lee, W. Y., and Fung, D. W. H. (2023). Current deficiencies and reinforcement of institutional pillars for reform in the green insurance market: a systematic review. Eur. J. Sustain. Dev. Res. 7 (4), em0235. doi:10.29333/ejosdr/13634
Li, J., Li, F., and Li, J. (2022). Does new-type urbanization help reduce haze pollution damage? Evidence from China’s county-level panel data. Environ. Sci. Pollut. Res. 29 (31), 47123–47136. doi:10.1007/s11356-022-19272-1
Li, K., Fang, L., and He, L. (2019). How population and energy price affect China's environmental pollution? Energy policy 129, 386–396. doi:10.1016/j.enpol.2019.02.020
Liang, L., Wang, Z., and Li, J. (2019). The effect of urbanization on environmental pollution in rapidly developing urban agglomerations. J. Clean. Prod. 237, 117649. doi:10.1016/j.jclepro.2019.117649
Lu, N., Wu, J., and Liu, Z. (2022). How does green finance reform affect enterprise green technology innovation? Evidence from China. Sustainability 14 (16), 9865. doi:10.3390/su14169865
Lu, Z. N., Chen, H., Hao, Y., Wang, J., Song, X., and Mok, T. M. (2017). The dynamic relationship between environmental pollution, economic development and public health: evidence from China. J. Clean. Prod. 166, 134–147. doi:10.1016/j.jclepro.2017.08.010
Lv, Z., and Xu, T. (2023). Tourism and environmental performance: new evidence using a threshold regression analysis. Tour. Econ. 29 (1), 194–209. doi:10.1177/13548166211042450
Miao, C., Sun, L., and Yang, L. (2016). The studies of ecological environmental quality assessment in Anhui Province based on ecological footprint. Ecol. Indic. 60, 879–883. doi:10.1016/j.ecolind.2015.08.040
Mills, E. (2003). The insurance and risk management industries: new players in the delivery of energy-efficient and renewable energy products and services. Energy policy 31 (12), 1257–1272. doi:10.1016/S0301-4215(02)00186-6
Mills, E. (2009). A global review of insurance industry responses to climate change. Geneva Pap. Risk Insurance-Issues Pract. 34, 323–359. doi:10.1057/gpp.2009.14
Montag, J. (2015). The simple economics of motor vehicle pollution: a case for fuel tax. Energy Policy 85, 138–149. doi:10.1016/j.enpol.2015.05.020
Mughal, N., Arif, A., Jain, V., Chupradit, S., Shabbir, M. S., Ramos-Meza, C. S., et al. (2022). The role of technological innovation in environmental pollution, energy consumption and sustainable economic growth: evidence from South Asian economies. Energy Strategy Rev. 39, 100745. doi:10.1016/j.esr.2021.100745
Ning, J., Yuan, Z., Shi, F., et al. (2023). Environmental pollution liability insurance and green innovation of enterprises: incentive tools or self-interest means? Front. Environ. Sci. 11, 1077128. doi:10.3389/fenvs.2023.1077128
Rahmatiar, Y. (2018). The role of environmental insurance as the prevention effort of environmental pollution. J. Arts Humanit. 7 (5), 46–53. doi:10.18533/journal.v7i5.1392
Rizwanullah, M., Nasrullah, M., and Liang, L. (2022). On the asymmetric effects of insurance sector development on environmental quality: challenges and policy options for BRICS economies. Environ. Sci. Pollut. Res. 29, 10802–10811. doi:10.1007/s11356-021-16364-2
Shi, B., Jiang, L., Bao, R., Zhang, Z., and Kang, Y. (2023). The impact of insurance on pollution emissions: evidence from China's environmental pollution liability insurance. Econ. Model. 121, 106229. doi:10.1016/j.econmod.2023.106229
Song, M., Tao, W., and Shen, Z. (2022). Improving high-quality development with environmental regulation and industrial structure in China. J. Clean. Prod. 366, 132997. doi:10.1016/j.jclepro.2022.132997
Song, W., Wang, C., Chen, W., Zhang, X., Li, H., and Li, J. (2020). Unlocking the spatial heterogeneous relationship between per capita GDP and nearby air quality using bivariate local indicator of spatial association. Resour. Conservation Recycl. 160, 104880. doi:10.1016/j.resconrec.2020.104880
Tang, L., Li, K., and Jia, P. (2020). Impact of environmental regulations on environmental quality and public health in China: empirical analysis with panel data approach. Sustainability 12 (2), 623. doi:10.3390/su12020623
Villanthenkodath, M. A., and Mahalik, M. K. (2022). Technological innovation and environmental quality nexus in India: does inward remittance matter? J. Public Aff. 22 (1), e2291. doi:10.1002/pa.2291
Wang, J., Guo, Q., Wang, F., Aviso, K. B., Tan, R. R., and Jia, X. (2021). System dynamics simulation for park-wide environmental pollution liability insurance. Resour. Conservation Recycl. 170, 105578. doi:10.1016/j.resconrec.2021.105578
Wang, P., Xing, L. N., and Li, F. (2014). Exploration of the governmental responsibility in environmental pollution liability insurance. Adv. Mater. Res. 962, 2040–2045.
Wang, Q., Ge, Y., and Li, R. (2023a). Does improving economic efficiency reduce ecological footprint? The role of financial development, renewable energy, and industrialization. Energy and Environ. , 0958305X231183914. doi:10.1177/0958305X231183914
Wang, Q., Ren, F., and Li, R. Exploring the impact of geopolitics on the environmental Kuznets curve research. Sustain. Dev. , 2023b. doi:10.1002/sd.2743
Wang, Q., Sun, T., and Li, R. (2024). Does artificial intelligence promote green innovation? An assessment based on direct, indirect, spillover, and heterogeneity effects. Energy and Environ. , 0958305X231220520. doi:10.1177/0958305X231220520
Wang, Q., Wang, L., and Li, R. (2023c). Trade openness helps move towards carbon neutrality—insight from 114 countries. Sustain. Dev . doi:10.1002/sd.2720
Wen, H., Cui, T., Wu, X., and Nie, P. y. (2024). Environmental insurance and green productivity: a firm-level evidence from China. J. Clean. Prod. 435, 140482. doi:10.1016/j.jclepro.2023.140482
Yang, J., Guo, H., Liu, B., Shi, R., Zhang, B., and Ye, W. (2018). Environmental regulation and the pollution haven hypothesis: do environmental regulation measures matter? J. Clean. Prod. 202, 993–1000. doi:10.1016/j.jclepro.2018.08.144
Yang, R., and Zhang, R. (2022). Environmental pollution liability insurance and corporate performance: evidence from China in the perspective of green development. Int. J. Environ. Res. Public Health 19 (19), 12089. doi:10.3390/ijerph191912089
Yi, S., and Xiao, A. (2018). Application of threshold regression analysis to study the impact of regional technological innovation level on sustainable development. Renew. Sustain. Energy Rev. 89, 27–32. doi:10.1016/j.rser.2018.03.005
Yin, K., Miao, Y., and Huang, C. (2024). Environmental regulation, technological innovation, and industrial structure upgrading. Energy and Environ. 35 (1), 207–227. doi:10.1177/0958305X221125645
Zhu, D., Chen, K., Sun, C., and Lyu, C. (2023). Does environmental pollution liability insurance promote environmental performance? Firm-level evidence from quasi-natural experiment in China. Energy Econ. 118, 106493. doi:10.1016/j.eneco.2022.106493
Keywords: green insurance (GI), environmental quality (EQ), an inverted “U” shape, threshold regression model, China
Citation: You X, Wu J and Li Z (2024) Research on the impact of green insurance on regional environmental quality: evidence from China. Front. Environ. Sci. 12:1364288. doi: 10.3389/fenvs.2024.1364288
Received: 02 January 2024; Accepted: 25 April 2024; Published: 13 May 2024.
Reviewed by:
Copyright © 2024 You, Wu and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiaxin Wu, [email protected]
This article is part of the Research Topic
Green Finance & Carbon Neutrality: Strategies and Policies for a Sustainable Future
IMAGES
VIDEO
COMMENTS
In a hypothesis-driven research, specifications of methodology help the grant reviewers to differentiate good science from bad science, and thus, hypothesis-driven research is the most funded research. "Hypotheses aren't simply useful tools in some potentially outmoded vision of science; they are the whole point."
Hypothesis-driven study is a fundamental, useful skill; applicable to many other things Be aware of applying hypothesis-driven research Limitation of hypothesis-driven research Design your research before doing it: Require a lot of thinking, get input from others Integrate hypothesis-driven and discovery-driven research Summary
Some research is not hypothesis-driven. Terms used to describe non-hypothesis-driven research are 'descriptive research,' in which information is collected without a particular question in mind, and 'discovery science,' where large volumes of experimental data are analyzed with the goal of finding new patterns or correlations.
The traditional scientific method: Hypothesis-driven deduction. Research is the undisputed core activity defining science. Without research, the advancement of scientific knowledge would come to a screeching halt. While it is evident that researchers look for new information or insights, the term "research" is somewhat puzzling.
3. Simple hypothesis. A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, "Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking. 4.
Traditionalists argue that in purely data-driven methods, one may not know where to look for those interesting findings if no hypotheses were formed beforehand. Big data advocates, on the other hand, argue that with no prior beliefs, one is not constrained by established ways of thinking or doing, opening the possibilities of breakthrough ...
This paper has had two goals. The first has been to propose revisions to the framework of Ratti ( 2015) for the study of the role of hypothesis-driven research in large-scale contemporary biological studies, in light of studies such as GWAS and its associated missing heritability problem.
5. Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable. If a first-year student starts attending more lectures, then their exam scores will improve.
A research hypothesis (also called a scientific hypothesis) is a statement about the expected outcome of a study (for example, a dissertation or thesis). To constitute a quality hypothesis, the statement needs to have three attributes - specificity, clarity and testability. Let's take a look at these more closely.
It represented a shift away from the traditional paradigm of hypothesis-driven research but kept the individual investigator-initiated focus that NIH has historically and traditionally supported. It brought together individuals from multiple and historically disparate communities, institutions, and organizations in order to focus their ...
In research, there are different, overlapping ways in which the plan of analysis may be described. This article explains planned (prespecified) vs post hoc, primary vs secondary, hypothesis-driven vs exploratory, and subgroup and sensitivity analyses; intent-to-treat vs per-protocol vs completer analysis was explained in an earlier article in this column.
Practicing Hypothesis-Driven Development is thinking about the development of new ideas, products and services - even organizational change - as a series of experiments to determine whether an expected outcome will be achieved. The process is iterated upon until a desirable outcome is obtained or the idea is determined to be not viable.
The research hypothesis summarizes the elements of the study: the sample, the sample size, the design, the predictor and the outcome variables. The primary necessity of stating the. hypothesis is ...
paper argues that hypothesis-driven and data-driven research work together to inform the research process. At the core of these approaches are theoretical underpinnings that drive progress in the field. Here, we present several exemplars of research on the gut-brain axis that outline the innate values and challenges of these approaches. As nurses are trained to integrate multiple body systems ...
Wiki Definition. A hypothesis is a proposed explanation for a phenomenon. For a hypothesis to be put forward in science or engineering, the scientific method requires that one can test it. Scientists/engineers generally base hypotheses on previous observations that cannot satisfactorily be explained with the available scientific theories.
In hypothesis-driven research, we basically come up with a hypothesis that might explain a certain phenomenon. The hypothesis is usually based on doing prior research (published research or work in your own laboratory) and requires that you read, analyze and come up with a new idea. Or your supervisor may have done this for you.
A deductive approach is concerned with "developing a hypothesis (or hypotheses) based on existing theory, and then designing a research strategy to test the hypothesis" [1] It has been stated that "deductive means reasoning from the particular to the general. If a causal relationship or link seems to be implied by a particular theory or ...
McKinsey consultants follow three steps in this cycle: Form a hypothesis about the problem and determine the data needed to test the hypothesis. Gather and analyze the necessary data, comparing ...
A current research on linguistic analysis of startups in the context of the air transport industry and an author will develop a methodology for analysis of values based on a model of automatic identification of values in the text of a startup's landing page in the air transportation industry.
1 Hypothesis Alignment. To ensure that your research design aligns with your hypotheses, start by clearly articulating each hypothesis. This means specifying the expected relationships or ...
Porter hypothesis. The view of mainstream economics suggests that pollution leads to cost inefficiency and loss of global competitiveness. This view has been challenged by a few economists since the 1980s (Ashford 1993).Porter and Linde challenged this idea by framing a theory.Based on some case studies, he suggested the possibility of a "win-win" situation for firms and the environment.
Here are the four core principles of decision-driven analytics: Decisions. Identify controllable, relevant decision alternatives. Consider diverse perspectives and a wide array of solutions ...
The interpretation of cryo-EM maps often includes the docking of known or predicted structures of the components, which is particularly useful when the map resolution is worse than 4 Angstrom. Although it can be effective to search the entire map to find the best placement of a component, the process can be slow when the maps are large. However, frequently there is a well-founded hypothesis ...
Hypothesis is the official journal of the Research Caucus of the Medical Library Association. ... Open Menu Hypothesis: Research Journal for Health Information Professionals Current Issue Announcements Submissions Overview ... Case-based EBM instruction for Osteopathic Medical Students: A Case Report Laura Lipke
Subsequently, based on panel data from 30 provinces in China spanning from 2000 to 2021, nonlinear regression models and threshold regression models were constructed to test the hypothesis. The research findings indicate: (1) Results from the fixed-effects regression model demonstrate that the impact of GI on China's EQ follows an inverted ...
This research contributes to the overarching objectives of achieving carbon neutrality and enhancing environmental governance by examining the role of artificial intelligence-enhanced multi-energy optimization in rural energy planning within the broader context of a sustainable energy economy. By proposing an innovative planning framework that accounts for geographical and economic disparities ...