Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.

Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
lead-scoring-case-study
Here are 14 public repositories matching this topic..., mukulsinghal001 / lead-scoring-model-python.
Lead Scoring is such a powerful metric when it comes to quantifying the lead & it is nowadays used by every CRM. In this repository, we are going to take a look at the UpGrad lead scoring case study and see how can we solve this problem through several supervised machine learning models.
- Updated Mar 17, 2021
- Jupyter Notebook
garima2811 / Lead_Scoring_Case_Study
In this repository, we are going to take a look at the UpGrad lead scoring case study and see how can we solve this problem through several supervised machine learning models.
- Updated Jul 3, 2021
amity024 / Lead_Score_Logistic_Regression
This case study involves helping X Education, an education company, improve its lead conversion rate by building a logistic regression model to assign lead scores. The aim is to identify potential leads with the highest chances of converting to paying customers and handling future problems to achieve a target conversion rate of 80%.
- Updated Feb 28, 2023
SumitSatam / Lead_Scoring_Case_Study
X Education has appointed you to help them select the most promising leads, i.e. the leads that are most likely to convert into paying customers.
- Updated Jan 20, 2021
abhiram-ds / lead_scoring_logistic_regression
Lead Scoring Case Study using Logistic Regression
- Updated Jan 28, 2021
shaiasi / Lead_Scoring_Logistic_Regression-Project
- Updated May 11, 2023
sahidul-shaikh / lead-scoring-for-education-company
Build a machine learning model for identifying the set of leads of X Education so that the lead conversion rate should go up and the sales team of the company focus more on communication with the potential leads rather than making calls to every customer.
- Updated Jan 16, 2021
sukhijapiyush / CodePro-mlops-using-airflow-mlflow
Airflow Pipeline for Lead Scoring to Maximize Profit with retraining pipeline and Development experimentation using mlflow
- Updated Jun 27, 2023
sailyshah / Lead-scoring-casestudy
Lead Score Case study solved using Logistic Regression Model
- Updated Feb 10, 2021
saptarshim7 / Lead_Scoring_Case_Study
This github repository contains a logistic regression model built for X Education to help the company prioritize potential leads based on their likelihood of conversion. It includes code for data preprocessing, feature selection, and model evaluation, as well as recommendations for utilizing the model effectively.
- Updated Mar 26, 2023
RishikeshRai / Lead-Scoring-Case-Study
An education company named X Education sells online courses to industry professionals. On any given day, many professionals who are interested in the courses land on their website and browse for courses. The company markets its courses on several websites and search engines like Google. Once these people land on the website, they might browse th…
- Updated Sep 30, 2020
VyasBhaumik / EdTech_Lead_Scoring_Analysis
An education company named X Education sells online courses to industry professionals. Now, although X Education gets a lot of leads, its lead conversion rate is very poor. The objective is to build a model to identify the hot/potential leads and achieve lead conversion rate to 80%.
- Updated Mar 7, 2022
GitarthaPal / Lead-scoring-case-study
Lead-Scoring-Case-Study
- Updated Nov 21, 2023
imumi17 / Lead-Scoring-Case-Study
- Updated Apr 29, 2023
Improve this page
Add a description, image, and links to the lead-scoring-case-study topic page so that developers can more easily learn about it.
Curate this topic
Add this topic to your repo
To associate your repository with the lead-scoring-case-study topic, visit your repo's landing page and select "manage topics."
- Why Displayr
- Product Features
- How It Works
- Displayr AI
- Integrations
CAPABILITIES
- Survey Analysis
- Data Visualization
- Dashboarding
- Automatic Updating
- PowerPoint Reporting
- Finding Data Stories
- Data Cleaning
- New Product Development
- Tracking Analysis
- Customer Feedback
- Segmentation
- Brand Analytics
- Pricing Research
- Advertising Research
- Statistical Testing
- Text Analysis
- Factor Analysis
- Driver Analysis
- Correspondence Analysis
- Cluster & Latent Class
- Success Stories
- Demo Videos
- Book a Demo
- Ebooks & Webinars
- Help Center
- Product Roadmap
LATEST WEBINAR
- Book a demo
- Choice Modeling/Conjoint Analysis
- Dimension Reduction
- Principal Component Analysis
- Machine Learning
- Linear Regression
- Cluster Analysis
- Latent Class Analysis
- Customer Feedback Surveys
- Dive Into Data
- Data Stories
- Data Stories Tutorials
- Account Administration
- Beginner's guides
- Dashboard Best Practices
- Getting Started
- Reporting/Exporting
- Troubleshooting Common Issues
- JavaScript How To...
- JavaScript in Displayr
- R How To...
- R in Displayr
- Visualizations
Selecting Data for Predictive Lead Scoring – a Case Study
This is the first of a series of posts where I step through a worked example of predictive lead scoring. The process will involve preparing the data, then building and comparing machine learning models. Along the way I will establish some general rules that apply to predictive lead scoring generally.
The data set that I will be using can be downloaded here . You can see and edit the Displayr document containing my analysis in this post here . Check out this post for a more general overview of what data you need for Predictive Lead Scoring .
Exploring the data
As my starting point, I assume that the data is a collation of all available and relevant information. The first stage of analyzing a new data set should always be to understand the "shape" of the data. Relevant questions and their answers are:
- How many cases (rows) are there? 9240
- How many variables (columns) are there? 122
- What is the target outcome variable that we want to predict and its type? "Lead Stage", a categorical variable with breakdown as follows:
- What does a sample of the data look like? See below for the first 5 rows (note that you need to scroll right to see all the columns)
What did we learn from these four simple questions?
- We have enough rows (at least a few hundred is a good start for building a model).
- Many models can handle 121 predictors but it is unlikely that all are useful. It generally provides more insight by starting with a simple model of fewer predictors and build back up.
- We are interested in the "Closed" category of the outcome. The distinction between some of the other categories does not seem to be relevant.
- There are many predictors with missing data. Actually looking at some data is an important and often overlooked step that allows us to identify problems early.
Feature selection
With the points above in mind, we will remove variables with a lot of missing data. There might be some useful information that is thrown away, but we could revisit that after building a solid model. Also removed are variables with no expected predictive power, such as "Prospect ID" and "Lead Number". These variables are unique to each lead, so provide no information that can be generalized to learn about other cases. Along the way I have also fixed the type of some variable by ensuring that dates and categories are recognized as such, and not as text.
This leaves us with a more manageable 19 predictor variables.
The next stage in feature selection is to check for redundant variables that are colinear. Essentially this means that the variables contain the same information. At a minimum that means the variables are unnecessary, but they can also cause problems with some models, particularly when describing how important each variables is for prediction. To do this, look at the correlation matrix below (excluding date variables),
Note that I have split each categorical variable into variables for each category (minus one "constant" reference). This means there are a lot of cells and the labels are a little difficult to read. However if you hover on the darkest blue cells there are very high correlations between "Last Notable Activity" and "Last Activity" and between "Lead Source" and "Lead Origin".
Taking a closer look at these variables confirms what their names imply, that that they contain very similar information. Thus, we'll remove "Last Notable Activity" , "Last Notable Activity Date" and "Lead Source" leaving us with 16 predictors for our models, as per the table below.
Note that I have included "Lead Score" and "Engagement Score" in our predictors. This makes an important point for predictive lead scoring - it can and should use traditional lead scoring as an input where possible. Although traditional lead scores may be flawed, they contain significant information. In that sense predictive scoring is an enhancement of, and not a replacement for, traditional scoring.
As a final check for this stage, we can see that only 1.5% of cases now have missing data. This is small enough that we can just remove those cases when building models.
Summary and next steps
The main points identified so far are:
- The first stage of analyzing a new data set should always be to understand the "shape" of the data.
- Remove variables with significant missing data, no predictive power and colinearity.
- Incorporate existing traditional lead scores where possible.
In the next post I will continue with the data preparation by transforming the variables to be more relevant.
Prepare to watch, play, learn, make, and discover!
Get access to all the premium content on displayr, last question, we promise, what type of survey data are you working with (select all that apply).
Market research Social research (commercial) Customer feedback Academic research Polling Employee research I don't have survey data
The state of lead scoring models and their impact on sales performance
- Published: 01 February 2023
- Volume 25 , pages 69–98, ( 2024 )
Cite this article
- Migao Wu ORCID: orcid.org/0000-0001-7286-8755 1 ,
- Pavel Andreev 2 &
- Morad Benyoucef 2
8343 Accesses
2 Citations
Explore all metrics
Although lead scoring is an essential component of lead management, there is a lack of a comprehensive literature review and a classification framework dedicated to it. Lead scoring is an effective and efficient way of measuring the quality of leads. In addition, as a critical Information Technology tool, a proper lead scoring model acts as an alleviator to weaken the conflicts between sales and marketing functions. Yet, little is known regarding lead scoring models and their impact on sales performance. Lead scoring models are commonly categorized into two classes: traditional and predictive. While the former primarily relies on the experience and knowledge of salespeople and marketers, the latter utilizes data mining models and machine learning algorithms to support the scoring process. This study aims to review and analyze the existing literature on lead scoring models and their impact on sales performance. A systematic literature review was conducted to examine lead scoring models. A total of 44 studies have met the criteria and were included for analysis. Fourteen metrics were identified to measure the impact of lead scoring models on sales performance. With the increased use of data mining and machine learning techniques in the fourth industrial revolution, predictive lead scoring models are expected to replace traditional lead scoring models as they positively impact sales performance. Despite the relative cost of implementing and maintaining predictive lead scoring models, it is still beneficial to supersede traditional lead scoring models, given the higher effectiveness and efficiency of predictive lead scoring models. This study reveals that classification is the most popular data mining model, while decision tree and logistic regression are the most applied algorithms among all the predictive lead scoring models. This study contributes by systematizing and recommending which machine learning method (i.e., supervised and/or unsupervised) shall be used to build predictive lead scoring models based on the integrity of different types of data sources. Additionally, this study offers both theoretical and practical research directions in the lead scoring field.
Similar content being viewed by others

Customer relationship management and its impact on entrepreneurial marketing: a literature review
Vicente Guerola-Navarro, Hermenegildo Gil-Gomez, … Pedro Soto-Acosta

Predictive big data analytics for supply chain demand forecasting: methods, applications, and research opportunities
Mahya Seyedan & Fereshteh Mafakheri

Applications of Artificial Intelligence in Inventory Management: A Systematic Review of the Literature
Özge Albayrak Ünal, Burak Erkayman & Bilal Usanmaz
Avoid common mistakes on your manuscript.
1 Introduction
1.1 inside sales and lead scoring modeling.
A lead is an essential raw material for sales organizations. Leads, being members of a target market segment, intentionally or unintentionally signal an interest in a company’s product(s)/service(s), regardless of whether that particular interest comes from a new prospect or an existing customer [ 14 , 44 ]. Companies invest significantly in advertisements, web campaigns, and marketing to generate new leads and allocate enormous resources to nurture and convert these leads into customers [ 56 , 59 ]. Conventional, outside sales (also called field sales) that are primarily based on in-person interactions with leads have been giving up the leading role to inside sales that mainly rely on remote sales conducted with the help of information and communication technologies (ICT) (e.g., phone, Internet) [ 49 , 50 , 51 ]. For some industries, inside sales became dominant and sometimes the only way to sell their products and services. The increasing cost of conventional sales, as well as advances in information technology (IT) tools and buyers’ higher demands and expectations, have contributed to the rapid growth of inside sales [ 55 , 62 ]. For the last two decades, we have observed a significant shift from conventional field sales to the dominating inside sales enabled by ICT. The current COVID-19 pandemic forced many organizations to reduce costs and eliminate unnecessary spending [ 75 ]. For this reason, it has become increasingly essential for organizations to maximize opportunities from new prospects and existing customers by taking advantage of inside sales.
Lead Management System (LMS), an integrated information system of inside sales, became the“driving force”for operations with leads. LMS uses various IT tools to streamline and automate complicated lead management processes [ 49 ], for example, lead generation, lead nurturing, lead distribution, and lead scoring [ 28 , 42 , 43 , 61 , 66 ]. However, not only the way of selling (i.e., traditional vs. ICT-enabled inside sales) has evolved during the last decades, but inside sales have further benefited by shifting from list-based (manually prioritizing and filtering of leads based on sales representatives’ knowledge and experience) to queue-based LMSs (an approach for prioritizing leads when the most promising leads are served first) [ 49 , 50 ]. The increased productivity, more efficient management control, and quicker response to leads have made queue-based LMSs the best solution for managing leads in inside sales [ 65 ].
Lead scoring has been widely acknowledged as the most effective and efficient way of qualifying the quality of a large number of leads for queue-based LMSs [ 11 , 17 , 20 , 37 , 39 , 44 ]. Lead scoring modeling is at the core of lead scoring, a qualification approach that assesses the leads’likelihood of making a purchase by ranking them against a scale to differentiate and prioritize them by generating a queue-based list for sales [ 7 , 20 , 48 ]. A high-quality lead scoring model with superior predictive power could convince salespeople to contact more market-qualified leads (MQLs) and convert those“ready-to-buy” leads to customers in a short time [ 25 , 56 ]. From a long-term perspective, having a high-quality lead-scoring model can also improve the internal collaboration between the marketing and sales functions [ 56 ].
1.2 Problem and motivation
Lead qualification and conversion to sales are the most critical success components of the inside sales process [ 54 ]. Without an appropriate inside sales lead management strategy, qualified leads that do not result in short-term sales often slip through and become lost revenue opportunities [ 42 , 43 ]. The average conversion rate of prospects to qualified leads is approximately 10%, and only 1-6% of leads ultimately become customers [ 16 , 17 , 21 ]. Such low conversion rates of leads to customers are mostly associated with the low quality of leads in queues that sales teams work with [ 39 , 48 ]. Sales teams spend valuable and limited time resources on low-quality leads that will never be converted [ 20 ]. The likelihood of conversion directly influences sales performance [ 51 ]. There is an overall challenge - to find a better way to increase sales performance and improve conversion rates in inside sales [ 20 , 39 ]. In addition, some determinants of sales success are stronger when selling remotely (i.e., when engaging in inside sales) [ 51 ].
Effective lead management in inside sales can reduce budgets and maximize revenue by focusing on the quality and not the number of leads [ 42 , 43 ]. Lead scoring has been widely acknowledged as a promising way to assist with the low conversion challenge [ 17 , 20 , 37 , 39 , 44 ]. Companies that employ lead scoring in their LMSs can potentially benefit from up to 70% increase in lead generation return on investment compared to companies that do not use lead scoring [ 39 ]. In addition, the conversion rate from prospects to qualified leads increases to 15-20% which means that eventually, more leads will convert to sales [ 17 , 20 ]. According to a 2018 report from GEM (Global Entrepreneurship Monitor), on average, three new companies are created every second [ 29 ]. This means that at least 0.8 million new companies are created over one night. A salesperson needs to contact approximately 800 leads per day, even if only 1% of the 0.8 million prospects are relevant to the company. Despite the number of leads, being able to differentiate between high-quality and low-quality leads in such a rapidly growing market is challenging.
Lead scoring models are emerging as a solution to that challenge but still little is known about how and what lead scoring models need to be employed for inside sales. Despite the importance of lead scoring models in inside sales and the call to find out how these models can address the challenge of inside sales performance, no study summarized the knowledge about existing lead scoring models and their impact on sales performance. Although a few studies have been dedicated to the subject [ 6 , 21 , 48 ], little is known regarding existing lead scoring models, their types, advantages and disadvantages; what algorithms have been used in building lead scoring models; which of them are more appropriate and efficient for specific conditions (i.e., data sources), and how lead scoring models influence sales performance. This paper aims to address this challenge. From a theoretical perspective, our motivation is to conduct a systematic literature review in the field of lead scoring models to identify research areas that require further investigation.
By knowing what lead scoring models exist and their corresponding suitability, we could choose which one to use, given the availability of data sources. As more efficient and effective machine learning (ML) algorithms are introduced, marketing teams can implement more sophisticated lead scoring models by integrating the more advanced algorithms to handle datasets with higher degrees of complexity. Because large datasets with higher degrees of complexity normally contain more hidden signals of good potential customers [ 15 , 29 ]. Therefore, it is imperative to grasp the knowledge of algorithms that have been applied to build lead scoring models. With more hidden signals extracted from datasets, more profitable leads could be identified, thus, sales performance could eventually increase.
1.3 Scope and contribution
To foster our understanding of how to improve inside sales performance, what role lead scoring models play in this improvement, and how different types of such models can influence sales performance, it is essential to summarize the existing knowledge on the domain. Because it is important to investigate the existing types of lead scoring models and their impact on sales performance, we argue that a framework is needed to classify existing lead scoring models. A systematic literature review (SLR) on lead scoring models should help fill the above-mentioned gaps. Hence this study proposed and addressed the following research questions (RQs):
RQ1. What are the advantages and disadvantages of the existing lead scoring models?
RQ2. What is the preferred model for which data source?
RQ3. How do lead scoring models influence sales performance?
The main contributions of this study to academic research and sales practice are:
This study identifies, evaluates, and analyzes various lead scoring models. In particular, it focuses on summarizing conventional methods, data mining (DM) models, and ML algorithms applied to lead scoring to uncover future research avenues.
Furthermore, this study proposes a classification framework and uses it to classify all the identified lead scoring models, summarize modeling processes, examine the models’impact on sales performance, and compare models’ impact to suggest lead scoring models. Additionally, this study suggests ways of improving sales performance in lead scoring models.
Moreover, since predictive lead scoring has become the trend, this study investigates the reason why the predictive approach is better than the traditional approach.
Most importantly, this study recommends which learning methods (i.e., supervised and/or unsupervised) should be used when building predictive lead scoring models, given the availability of data sources.
The rest of the paper is structured as follows. Section 2 describes the methodology employed in this study, followed by Sect. 3 , which discusses the proposed classification framework and shows the results of the literature review. Section 4 expatiates answers to the research questions and the limitations of this study. Finally, Sect. 5 presents the discussion, conclusions, and implications of this study.
2 Methodology
In this review, we followed Kitchenham’s SLR approach [ 34 ], which consists of three main steps, namely planning the review, conducting the review, and reporting on the review. We defined the review’s objectives (see Sect. 2.1 ) and developed a review protocol in the planning step. In the conducting review step (see Sect. 2.2 ), we executed search queries, selected studies, and assessed their quality. Finally, we extracted and synthesized the data in the reporting step (see Sect. 2.3 ). In addition, we validated, analyzed, and described the results and tabulated them in quantitative summaries. The entire process is detailed below.
2.1 Planning the review
Search strategy After defining research questions as shown in Sect. 1.3 , we identified the concepts in the two research questions involving two disciplines: (1) computer science and (2) business management. Therefore, an interdisciplinary literature search needed to be carried out for this SLR. Hence, we used synthetic databases such as Scopus and Web of Science to account for the interdisciplinary nature of the study. Furthermore, the technology and science-focused Institute of Electrical and Electronics Engineers (IEEE) Xplore library and business-focused databases such as Business Source Complete and ABI/INFORM Global were scanned for relevant studies. Moreover, since lead scoring systems have been employed in the industry, we searched grey literature to ensure complete coverage of industrial technical reports, research papers, project reports, and white papers. Typically, a grey literature scan is necessary to address publication bias in SLRs. For the grey literature search, we searched the OpenGrey database the same way we searched traditional literature databases.
To define the search queries, first, the research questions were decomposed into four concepts: (1) Lead Scoring, (2) Modeling, (3) Sales, and (4) Performance. Second, keywords were generated for each concept by using relevant background knowledge in the fields, the pearl growing technique [ 52 ], and brainstorming (see Table 1 ).
Third, we conducted a keyword search on the aforementioned databases. The final search queries were applied to the article title, abstract, and keywords fields. There was no need to include“full-text”in the search field since this would have led to many false positives at this search stage.
Inclusion/Exclusion criteria In the evaluation stage, the retrieved results were evaluated against the following inclusion criteria:
Peer-reviewed journal articles and conference proceeding papers that focus on lead scoring models, or applying DM models or ML algorithms to lead scoring;
Relevant papers on lead scoring models that are identified by the snowballing technique [ 12 ];
Grey literature: industrial technical reports, project reports, and white papers on lead scoring models.
Next, the included studies were evaluated against the following exclusion criteria:
Language: not in English;
Subject area: not in the business management domain;
Primary focus: not related to lead scoring;
Study form: studies in the form of abstracts or posters.
Quality criteria Each included study must meet all the following quality assessment criteria:
A study focuses on a lead scoring technique within the business scope;
A study addresses the impact of the proposed lead scoring model(s) on sales;
A study includes a performance evaluation scheme for evaluating the alleged lead scoring model(s);
Grey literature articles must address both traditional and predictive lead scoring for comparison purposes. Evaluation metrics can be left out in grey literature. Because it is an uncommon practice to include model performance evaluation schemes in grey literature.
2.2 Conducting the review
Identification After locating a few key papers by entering the preliminary search queries into the databases [ 7 , 17 , 20 , 48 , 60 ], a pearl growing technique (i.e., using keywords and index terms of key papers) [ 52 ] was executed to optimize search terms in the initial search queries. The subject headings and keywords of these key papers were used to optimize search terms and refine the preliminary search queries. Eventually, the final search queries were run in six databases. Additionally, a backward snowballing technique [ 3 , 12 ] was adopted to complement literature database searches. Table 2 shows the number of articles retrieved from each source.
Screening Then, we removed duplicates from a total of 1150 records. After excluding 345 duplicated records, we ended up with 805 papers. Figure 1 shows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) diagram for visualizing each stage’s selection process and results [ 36 ].

A total of 685 records were excluded, leaving 120 articles for full-text quality assessment (see Fig. 1 ). We used the inclusion/exclusion criteria (see Sect. 2.1 ), so articles fulfilling any of the exclusion criteria were disqualified. Specifically, we read each study’s title, abstract, and keywords.
Eligibility and inclusion After a full read of the 120 articles, a total of 44 studies were retained for qualitative synthesis using the quality criteria (see Sect. 2.1 ). The reasons for excluding articles during the full-text assessment phase were ineligible areas of focus, not addressing the impact on sales, retracted articles, and missing model evaluation scheme. For example, Hou and Yang [ 27 ] presented a classification model for potential customer identification and prioritization via the 80-20 principle. However, they omitted to address the evaluation metrics for assessing the proposed model. Thus, this study was not included in the final list of qualified studies. Xiaowen et al. [ 70 ] established a traditional lead scoring system of a three-layer value assessment structure via the analytic hierarchy process to locate potential government and corporate customers. However, this study lacked an evaluation of the proposed system and measurement of sales performance.
Some studies failed to meet the focused area criterion. For instance, Nguyen et al. [ 47 ] introduced a new model to identify the characteristics of customers using the rough set theory. However, their study mainly focused on distinguishing customers’characteristics while staying away from applying the lead scoring process. Therefore, this study was excluded from the final list. Furthermore, studies by Baecke and Van Den Poel [ 4 , 5 ] focused on incorporating spatial interdependence feature with auto-correlation and regression techniques to improve existing customer acquisition models instead of building a lead scoring model and analyzing its impact on sales. Hence these studies were excluded. Moreover, a qualitative case study by Jarvinen and Taiminen [ 28 ] demonstrated the use of marketing automation tools to generate high-quality sales leads through behavioral targeting and personalizing content without discussing lead scoring. Thus, this study was excluded.
2.3 Reporting on the review
All lead scoring models in the qualified studies were extracted and categorized to make the review unambiguous and comprehensive to address the research questions. Each study was thoroughly reviewed and classified according to the two lead scoring approaches and six classes of models (see Fig. 2 ). We validated the result and performance of each lead scoring model by assessing the proposed evaluation metrics and sales performance measurements. Additionally, we extracted all impact/influences of lead scoring models on sales performance. In the end, we analyzed how lead scoring models influence/impact sales performance.
The data extracted from the qualified studies (see Appendix 1 ) includes:
Title, authors, and year of the paper;
Suggested methods/models/algorithms;
Approach (traditional or predictive) of the proposed lead scoring models;
Evaluation metrics applied to the proposed lead scoring models;
Metrics used to measure sales performance;
A summary of lead scoring models’ impact on sales.
The results of the literature analysis are presented in the search results section (see Sect. 3 ).
3 Search results
We developed a classification framework for traditional and predictive lead scoring models to summarize the existing models (Fig. 2 ). This framework is based on a comprehensive review of the academic and grey literature on lead scoring models in LMSs. According to the studies conducted by Duncan and Elkan [ 20 ] and McDonnell [ 39 ], lead scoring can be split into two approaches: traditional and predictive. Additionally, Chorianopoulos [ 15 ] and Ahmed [ 2 ] described the major types of DM models in Customer Relationship Management (CRM), namely classification, clustering, and regression. Given the flexibility of this classification framework, it can be expanded as more traditional techniques or DM models are applied to lead scoring. In the following paragraphs, a short description of two lead scoring approaches, as well as traditional techniques and DM models are provided with some references for more details.

Classification framework
According to Duncan and Elkan [ 20 ] and McDonnell [ 39 ], lead scoring consists of two approaches, traditional and predictive. These two approaches have been studied by academics and practitioners. They share a common goal of scoring and prioritizing leads according to their likelihood of purchase. In traditional lead scoring, marketers attempt to quantify the quality of a lead to determine when it should be passed to salespeople [ 39 ].
In traditional lead scoring, marketers usually analyze explicit (e.g., industry type, job role, company size, and revenue) and implicit (e.g., website visits, email opens, clicks, form completions, and online behaviors) information on leads. They assign scores to leads based on criteria/rules and track them. Traditional lead scoring is usually supported by marketing automation software, such as Oracle Eloqua [ 37 ]. There are three main models in the traditional lead scoring segment, which are Lamb or Spam [ 11 ], rules/points-based [ 11 , 29 , 39 ], and scorecard [ 44 , 67 ]. The Lamb or Spam model filters out low-quality leads and surfaces relatively high-quality ones by assessing their attributes (e.g., email domain, company size) [ 11 ]. Rules-based or points-based lead scoring assigns points to leads’demographic and behavioral characteristics according to specific rules. These rules are stipulated based on human experience and intuition [ 29 ]. As a result, the lead score is the outcome of a weighted function of these attributes. The scorecard model is similar to the rules/points-based model, except for one major difference: the score is calculated by statistical and mathematical approaches based on the different factors’importance levels [ 67 ].
Predictive lead scoring uses advanced data-driven predictive analytics to discover insights within “cold”leads/prospects data, uncover hidden/non-linear relationships between various predictors and target/outcome events, and finally estimate a propensity score for each new prospect [ 11 , 15 , 39 , 48 ]. Within the context of predictive lead scoring, DM and ML techniques can be leveraged to identify various data patterns, filter out the most influential attributes, and generate predictive models based on historical data [ 15 ]. They can be leveraged to guide the decision-making process and predict decisions’effects [ 46 ]. Predictive lead scoring is supported by different DM models, including classification, clustering, and regression.
Classification is commonly used in DM [ 2 , 15 , 46 ]. Its goal is to build a model to predict the outcome of an event by classifying new records to the predefined classes [ 2 , 15 ]. The algorithms commonly used for classification are decision trees, logistic regression, and neural networks. Clustering segments a heterogeneous population into a few homogeneous clusters [ 2 , 46 ]. The major difference between clustering and classification is that the number of clusters is unknown in clustering. The commonly applied clustering algorithm is k-means. Regression is a frequently used statistical estimation technique for predicting the value of a continuous output based on the inputs [ 15 , 46 ]. Regression has been applied to test the significance of relationships between variables, fit curves, and predict continuous outcomes. Linear regression is the most common technique.
Table 3 shows the 44 qualified studies according to the proposed classification framework (see Fig. 2 ). The number of lead scoring studies has increased in the last few years. Figure 3 shows a trend against the timeline of the qualified lead scoring studies covered in this SLR.

Trend of studies on lead scoring models
Out of the 44 selected studies, 39 are journal or conference papers, while 5 are grey literature (see Table 4 ). From Table 4 , we can observe that the selected studies emphasize predictive lead scoring more than traditional lead scoring, showing the current trend in the research field.
We analyzed predictive lead scoring models in all the qualified predictive studies. The literature analysis reveals that there are 18 different predictive lead scoring models. Table 5 shows that the most popular models are decision tree classification and logistic regression.
Table 6 shows the number of traditional lead scoring models in the qualified studies. The most popular one is the rules/points-based model.
Table 7 shows various metrics used to measure sales performance after applying the proposed lead scoring model(s) in all the qualified studies. As Table 7 shows, the lead conversion rate is the most popular metric.
4 State of lead scoring models
As an IT tool in LMSs, a lead scoring model prioritizes sales and marketing efforts towards leads that are more likely to convert into customers [ 7 , 20 , 48 ]. Marketing and sales usually collaborate to build lead scoring models by defining what constitutes a good lead to pursue. There are two approaches to lead scoring: the traditional lead ranking method and the more advanced data-driven predictive approach [ 20 , 39 ]. Traditional lead scoring endeavors to quantify the quality of a lead [ 39 , 42 , 44 ]. Its goals are to prioritize leads to sales and develop scalable approaches if leads meet the minimum qualification requirements. Traditional lead scoring is based on salespeople’s experience and judgment, while the data-driven predictive approach promises to be more objective and efficient. Various DM models and ML algorithms have been applied to build predictive lead scoring models that assess the likelihood of converting leads to customers [ 11 , 15 , 39 , 48 ]. Recently, the sales industry has been leaning more towards predictive lead scoring approaches [ 11 , 29 ]. Moreover, with an increasing number of studies published on lead scoring models in the last few years, one can claim that this field has been gaining attention from academic research, especially predictive lead scoring. We first discuss lead scoring models in academic literature. As mentioned earlier, lead scoring can be divided into two categories, namely traditional and predictive.
4.1 Traditional lead scoring models
In traditional lead scoring, rules/points-based and scorecard models were frequently used a decade ago. Monat [ 44 ] proposed a practical qualitative modeling tool that predicts the probability of an industrial sales lead converting to a customer based on observable lead characteristics. The author claimed that this is the first lead characterization model that is theoretically based. A rules/points-based sales lead evaluation scorecard was provided to assess leads from eight determinants of sixteen manifest characteristics. In addition, details of points assignment, scoring procedure, and accuracy measures on a real company dataset were provided in this study. Furthermore, a couple of studies developed simple linear lead scoring models by combining points from several factors [ 24 , 26 ]. However, none of these studies have been field-validated.
Another conventional way to calculate a lead score is to use a scorecard model. An analytical hierarchy process-based (AHP-based) framework helps companies rank and prioritize prospective leads based on the different factors’ importance levels [ 67 ]. More specifically, input statistics are normalized on a relative scale for each criterion. On the first row of the scorecard are the weights of all criteria. The remaining rows are leads. The total score of a lead is the sum of all weighted factors in that row [ 67 ]. The lead scorecard model enables companies to assess the factors for acquiring potential leads. For instance, Lindahl [ 37 ] qualitatively examined traditional lead scoring in the Business-to-Business (B2B) marketing automation domain by exploring how lead scoring contributes to a more efficient and effective marketing process for a B2B service company. The results of this study indicated that the examined scorecard lead scoring model can be used in multiple ways in marketing automation. Indeed, Lindahl [ 37 ] presented a complete lead profile scorecard and an intact lead engagement scorecard with a lead score matrix that specifies lead score value thresholds. Additionally, this study recommended corresponding marketing actions for lead score values.
In traditional lead scoring systems, the decision to pursue a lead typically relies on personal experience, intuition, and cognitive capability [ 23 , 29 ]. These approaches can result in company resources being used inefficiently by dedicating them to the wrong leads [ 17 ]. Also, traditional lead scoring models could be error-prone due to the manual selection of values and human intervention [ 11 , 20 , 29 ]. Therefore, some of the results generated by traditional lead scoring could be inaccurate and biased. Moreover, traditional lead scoring models may fail to capture nonlinear effects and heavily rely on behavioral data [ 20 ].
4.2 Predictive lead scoring models
As various DM and ML techniques started to re-emerge, using advanced data-driven predictive analytics to discover insights within leads data and predicting lead scores have become the solution of choice in lead scoring [ 11 , 20 , 29 , 39 ]. These techniques can be leveraged to generate predictive models based on historical data to identify various data patterns, filter out the most influencing attributes of leads, and calculate lead scores [ 15 , 29 ]. As mentioned earlier, we adopted Chorianopoulos [ 15 ], Ahmed [ 2 ], and Ngai et al.’s [ 46 ] classification of DM models. DM models used to build predictive lead scoring models can be categorized into classification , clustering , and regression .
4.2.1 Classification
Under the classification category, we unidentified the following common algorithms used for lead scoring models: decision tree, random forest, neural network, and logistic regression.
Decision tree: aims to identify and classify the factors for turning potential customers into“real”customers [ 31 ]. Specifically, decision trees can deal with both continuous and discrete attributes for extracting valuable hidden knowledge from leads data. The decision tree consists of rules which can be automatically employed to predict the conversion of leads into customers [ 38 ]. Peng and Xu [ 53 ] proposed a predictive lead scoring model to identify potential and sustainable leads. This model adopts correlation analysis to detect relationships between variables and decision trees to find rules for identifying leads. As a supervised learning model [ 15 ], decision trees have been used to optimize and stabilize the predictive lead scoring model based on feedback information from the previous phase in the sales process [ 17 ]. With regards to the application of decision trees in the sales industry, the same success has been observed. GE Capital built a financing lead triggers system to automate the collection and aggregation of information on companies, which was then mined to identify actionable sales leads by using an embedded decision tree algorithm [ 1 ]. More specifically, a two-class decision tree was used to identify combinations of financial metrics and values over time that depict patterns common across the positive cases while not present in the negative cases. GE Capital announced that the productivity of salespeople had been improved by 30–50% in terms of phone calls and meetings after deploying the new system [ 1 ]. The salesforce’s increased productivity and effectiveness have led to a growth in the total volume of deals as approved by GE Capital.
As an ensemble method based on decision trees, bagged decision trees have been used in predicting potential customers during the acquisition process and have shown a decent prediction accuracy [ 18 ]. Moreover, as an improvement over the bagging technique, the gradient boosted trees algorithm has been used to prioritize leads based on the probability of conversion to sales opportunities [ 20 ]. Duncan and Elkan [ 20 ] used the three-class gradient boosted trees algorithm to classify leads with different characteristics into three classes in the lead qualification model. Gokhale and Joshi [ 23 ] showed that the two-class boosted decision tree has the best performance in an experiment of a set of ML models when modeling a lead identification and qualification process. A group of Microsoft researchers presented a generic automated lead ranking system based on a boosted decision tree with Bayesian optimization on hyperparameter tuning [ 30 ]. A dynamic CRM system integrates a special feature which enables human inputs into the loop for feature engineering and selection. Furthermore, a data mashup approach combining high-scale mobile consumer data with online food company data was introduced to acquire high-value potential customers [ 58 ]. A gradient boosted tree was used as a prediction classifier with an RFM (recency, frequency, and monetary value) model to label customers.
Random forest: is considered an all-sided classification algorithm built on the concept of decision trees. As an ensemble learning technique, random forest builds multiple decision trees on different bootstrap data samples [ 9 ]. It has been applied to perform classification on textual data. Meire et al. [ 41 ] used the random forest model to classify prospects with social media data as input. The random forest has also been used with explanation models for qualifying and classifying prospects based on a set of predefined features and historical data about existing customers [ 9 , 10 ]. The random forest is considered a“black-box”algorithm, making it challenging to interpret the generated results and their implications [ 9 ]. Despite the superior capability of analyzing large datasets with complicated relationships between variables,“black-box”algorithms cannot generally provide business practitioners with understandable insights that can help decision-making [ 17 ]. A couple of explanation methods, namely EXPLAIN and the Interactions-based Method for Explanation (IME) methods, were used to help comprehend how the output was achieved by a given input in “black-box”algorithms [ 10 ]. A social CRM analytics framework was introduced to improve customer acquisition, conversion, and retention [ 35 ]. In this framework, customer acquisition is an optimization task relying on a linear optimization model with random forest for lead classification, and a Latent Dirichlet Allocation (LDA) [ 8 ] to uncover the topics mentioned by customers on social media.
Neural network: another common problem in DM is the imbalanced number of outcomes in each target class. Imbalanced distribution of class labels in a dataset can have a negative impact on the prediction results of lead scoring models (i.e., the rate of false positives would be high since many minority labels would be classified as majority labels) [ 15 ]. Neural network algorithms can extract information about similar customers from related domains to handle the imbalance of minority class labels in a target domain [ 74 ]. Neural networks have been implemented not only to deal with the imbalanced class labels issue before building the lead scoring models, but also to reveal the typical buying patterns of customers in the dataset [ 32 ]. In a case study conducted in a telecommunications company, a lead qualification model based on ensemble neural networks was implemented to estimate the conversion probability of each lead [ 22 ]. The model integrates regression and principal component analysis to select significant variables before building the propensity model.
Logistic regression: was found to be a popular classification modeling algorithm for scoring and prioritizing leads. Logistic regression was used to predict the lead conversion probability after an initial list of features was extracted from a given customer dataset using a forward stepwise regression algorithm [ 60 ]. Moreover, Yan et al. [ 72 ] proposed a predictive lead scoring model to forecast the win propensity of sales leads over a period. They applied logistic regression to capture and estimate the impact of a salesperson’s daily activities and lead information on the sales outcomes (i.e., won or lost). Additionally, a logistic regression model was built based on the concepts extracted from existing customers’websites to predict the probabilities of new profitable leads [ 63 ]. Furthermore, a predictive lead scoring model was trained by using logistic regression to discover which concepts (i.e., words concurrently appearing across leads’websites are grouped into“concepts”) are more related to converted than unconverted leads [ 19 ]. The results of spherical clustering, latent semantic analysis, and expert knowledge are the input sources of the proposed model. As a common supervised learning algorithm, D’Haen and Van den Poel [ 17 ] used logistic regression to optimize a predictive lead scoring model by applying a step-wise selection to avoid possible model overfitting. In a case study on targeting potential customers of an energy service, a classification prediction model based on logistic regression was presented to accurately identify and prioritize target customers [ 68 ]. The features are selected from four dimensions by using a customer evaluation index system. In another case study on recruiting businesses for a building retrofit project, logistic regression was applied to find prospective leads, then screen and prioritize them for targeting [ 57 ].
In addition, companies can use the nearest neighbor algorithm to find similarities among prospects and construct a profiling model to group prospects of similar characteristics into the same group [ 17 ]. The nearest neighbor algorithm can be run when there is only available data on the current customer base and a list of prospects. The most significant advantage of the nearest neighbor algorithm is that it does not require prior knowledge of the distribution [ 17 ]. Benhaddou and Leray [ 7 ] applied the Bayesian network algorithm, a supervised learning that focuses on building probabilistic models to estimate the probabilities of leads belonging to target classes.
Furthermore, an empirical study was conducted to evaluate the feasibility and performance of four algorithms for automating lead scoring by using several assessment metrics [ 48 ]. The logistic regression model achieved the highest sensitivity but the lowest specificity. In other words, this model was more capable of identifying a positive class than a negative class. Overall, the random forest model was selected as the best-performing model. Nygård and Mezei [ 48 ] showed that automated lead scoring could improve the sales process by revealing insights into sales. A couple of studies [ 21 , 45 ] agreed on the performance of random forest by demonstrating its superior ability in predicting the probability of a lead conversion or a sales deal. Eitle and Buxmann [ 21 ] also extolled the predictive performance of CatBoost after comparing it with decision trees, support vector machine, and XGBoost. In a case study on bank customer acquisition, Başarslan and Argun [ 6 ] built multiple classifiers to estimate potential customers. Using k-fold cross-validation and holdout methods, they found that the best classifier to be random forest with an overall balanced performance among all evaluation metrics.
4.2.2 Clustering
With respect to the clustering DM model, k-means has been used to cluster potential customers into various groups for scoring purposes and to develop different marketing strategies accordingly [ 69 ]. Additionally, the application of the k-means clustering algorithm helps segment large amounts of customer data into groups and extracts hidden relationships from them [ 38 ]. The results of k-means clustering provide subjective segmentation, making the data more applicable and informative for further analysis. Self-organizing maps form another clustering approach identified by our review. They have been applied to customers’ data to determine the number of clusters prior to cluster analysis [ 69 ]. Each cluster contains potential customers with similar behavioral and demographic characteristics.
An Expectation-Maximization (EM) clustering algorithm was used to cluster potential prospects’ websites based on prevalent terminologies from the concepts that mainly occur on the websites of profitable business prospects and that seldom occur on the websites of non-profitable customers [ 63 ]. Consequently, the results of this clustering analysis can help companies identify profitable leads. D’Haen et al. [ 19 ] developed a lead qualification system that integrates expert knowledge and web crawling data to improve lead conversion rate. Specifically, the spherical clustering algorithm was applied to classify documents into a few groups based on a certain similarity measure and discover latent concepts in unstructured text documents. Prospects were clustered according to a spherical clustering. Since each document contains multiple concepts, assigning documents to a single cluster was problematic. Thus, a fuzzy clustering algorithm was also utilized to assist the clustering process [ 19 ]. For instance, Wei et al. [ 69 ] applied cluster analysis to identify the characteristics of loyal customers, which can be utilized with the RFM model for analyzing customers’values to determine potential customers with a higher profit.
4.2.3 Regression
Given the categorical/discrete outcomes of lead scoring (i.e., qualified or not qualified), applications of regression models have been scarce on this subject. Xu et al. [ 71 ] proposed a data-driven system by applying linear, exponential regression, and time series seasonal ARIMA model, as well as neural networks to forecast lead conversion rates and estimate sales revenue from opportunities. They claimed their proposed model is applicable to different sales patterns, products, and sales teams.
In summary of the current state of traditional and predictive lead scoring studies, we note that formal validation using statistical means is absent from the traditional lead scoring research stream [ 26 , 44 , 67 ]. Moreover, existing studies on predictive lead scoring only focus on conversion steps in the marketing-sales funnel [ 17 ] from the perspectives of selling organizations [ 7 , 17 , 20 , 48 ], hence neglecting insights in the buying decision-making process from the leads’perspectives.
4.3 Lead scoring models in grey literature
Regarding the reviewed grey literature, a report by the Aberdeen Group [ 42 ] identified the best practices in lead scoring and prioritization by analyzing the top-performing companies’ processes, models, capabilities, and performances. Lead scoring and prioritization is the path to higher conversion, ultimately increasing companies’annual revenue and sales figures while reducing the cost spent per lead [ 42 ]. Additionally, Jaskaran [ 29 ] compared the rules-based model to predictive lead scoring and explained why the rules-based approach is not popular. The conclusion was that the impact exerted by traditional rules-based models on sales was not significant. Furthermore, Lattice’guide, which considers the integration of predictive lead scoring, statistically showed that predictive lead scoring models enhance sales [ 39 ]. Also, Brown [ 13 ] proposed a traditional rules/points-based model to score and segment B2B sales leads and showed the benefits of lead scoring applications in the financial services industry. Finally, Boogar [ 11 ] discussed the three stages of lead scoring and concluded that lead scoring models evolve as marketing and sales departments grow. The positive impact imposed by traditional lead scoring on sales was not as significant as those exerted by predictive lead scoring.
4.4 The preferred model: supervised vs. unsupervised
Despite the broad choices offered by predictive lead scoring models, the literature is short of knowledge on the decision of which to use given different data sources (i.e., situations). This paper provides a way to classify these predictive lead scoring models and insights on when to use them. The classification and regression models are considered supervised learning models, while clustering is considered an unsupervised learning model. Supervised learning models can estimate the relationship between various prospects’attributes and the identified purchase behaviors (i.e., purchased, not purchased, and hesitation on purchase) [ 15 ]. Lead scoring models built using supervised learning models can score prospects based on the propensity to achieve the targeted purchase behaviors. On the other hand, unsupervised learning models can identify similar cases without target output; the pattern recognition is undirected [ 15 ]. Unsupervised learning models aim to uncover data patterns in a set of prospects’attributes.
Data identification is key in deciding which learning model to use for building a predictive lead scoring model. Data can be categorized into: commercial data and internet textual data [ 19 , 41 , 63 ]. Commercial data includes profile data (i.e., demographic information), account profile data (i.e., firmographic attributes), prospect intent data, and activity data.
When commercial data is available, supervised learning models shall be applied to build predictive lead scoring models. However, it can be challenging to establish commercial data integrity due to the normality of missing information [ 19 ]. Thus, internet textual data extracted from prospects’websites can be used to remedy the lack of satisfactory commercial data quality. Internet textual data includes website crawling data and social media data of prospects [ 19 , 41 , 63 ]. Given the nature of the unstructured and textual format of prospect data, directly applying any supervised classification modeling is unpractical. Instead, unsupervised learning models (i.e., clustering algorithms) with textual data transformation techniques shall be applied to find clusters consisting of similar textual information [ 15 , 19 ]. Then, latent semantic concepts extracted from each cluster along with expert knowledge (i.e., a set of binary variables about prospects) can be used as input for supervised learning models to estimate the likelihood of lead conversion and profitability of new potential customers [ 19 , 41 , 63 ].
In conclusion, if commercial data is available and mostly complete, then the direct application of supervised learning models is the recommended option to build predictive lead scoring models. However, when the quality of existing commercial data is low (i.e., too much missing data), then the recommended option is first to apply unsupervised learning models on internet textual data to identify key latent semantic concepts. The next step is to utilize supervised learning models with latent semantic concepts and incomplete commercial data as input to build predictive lead scoring models.
4.5 Impact of lead scoring models on sales performance
After investigating all lead scoring models found during the search, we examined the impact of lead scoring models on sales performance by studying each case further. We identified several metrics for assessing the impact of lead scoring models on sales performance. The most used performance metric is the lead conversion rate (see Table 7 ). It is calculated as the total number of conversions divided by the total number of leads [ 19 ].
In predictive lead scoring, D’Haen and Van den Poel [ 17 ] proposed a model consisting of three iterative phases, which produced a ranked list of high-quality prospects. After testing the proposed model on a telecom service company’s dataset, the model had a lead conversion rate (from prospects to qualified leads) of 15.73%, which was higher than the average conversion rate of 10% [ 17 ]. A higher conversion rate indicated a specific increase in sales. Also, the proposed sales force automation tool was designed to be implemented in a web application; users only need to pay a small membership fee to access the application instead of paying for the entire database of prospects. Thus, costs can be reduced. Three years later, D’Haen et al. [ 19 ] proposed a lead scoring system to integrate text mining on web data. The lead conversion rate (i.e., from prospect to customer) of the experiment was 6.4%, better than the previous result (i.e., 3.5%) [ 17 ] without text mining. We noticed a scarcity of studies regarding text mining in lead scoring models during our search. As text mining techniques become more mature in data science applications, more textual data sources become freely available, and because lead conversion rates can be improved, we call on future research to consider various text mining techniques when building lead scoring models.
Furthermore, the probabilistic lead scoring models suggested by Duncan and Elkan [ 20 ] increased the lead conversion rate from 8% to 17% in a three-month experimental period. The experimental results showed that the models in question have additional benefits, including the reduced average time needed to qualify leads, reduced number of calls placed to schedule a product demo, increased number of successful sales, as well as increased total revenue [ 20 ]. The prospective lead scoring models discovered high-quality leads at an early stage in the sales process because they focused on features that measure the fit of leads with the products being sold, in addition to leads’behaviors.
The customer acquisition process using a data mashup approach (i.e., high scale mobile consumer data and customers’online food ordering transactional data) improves business performance from two aspects [ 58 ]. First, the new customers are twice as likely to be high-impact potential customers than before. Second, the correctly predicted high-impact potential customers have 21.41% higher average revenue per user than the overall value. This reveals the importance of targeting the right group of consumers for acquisition over randomly picking them.
In traditional lead scoring, Lindahl’s study [ 37 ] showed that lead scoring could contribute to a more efficient marketing process by saving time for the sales and marketing departments, improving the lead conversion rate, reducing cost per lead, and enabling the automatization and personalization in digital markets. Monat [ 44 ] demonstrated that using a lead characterization model could significantly increase sales effectiveness and the accuracy of sales projections by increasing lead conversion rates and the total number of leads converted into sales. The research conducted by the Aberdeen Group revealed that companies that successfully implement effective lead scoring models deliver excellent performance in lead conversion rates (i.e., 26% average increase), annual revenue (i.e., 50% average increase), and cost per lead (i.e., 25% average decrease) [ 42 ]. These three metrics reflect the improvement in sales performance after deploying suitable lead scoring models. The improvements in sales performance indicate that lead scoring models can improve the effectiveness of lead management and sales and marketing efficiency. It is essential for companies to incorporate both implicit (i.e., behavioral information of leads) and explicit (i.e., manifest information of leads) attributes in the lead scoring model in order to influence sales performance significantly [ 42 , 43 ]. Thus, we propose that:
Proposition 1
The use of lead scoring models improves the lead conversion rate.
Cost reductions/monetary savings stand for money that can be saved per lead conversion. Kazemi et al. [ 31 ] proposed a predictive lead scoring model considering effective identification factors to increase sales and customer satisfaction by using a decision tree and a basket purchase technique to analyze which potential customers were the“real” ones. The suggested model was tested on data from a furniture producer. In the post-performance evaluation, administrative costs were reduced by 8%, and the profit was increased by 15% [ 31 ]. These results indicated that the proposed model positively affects sales in terms of cost reduction and profit growth. Additionally, Peng and Xu [ 53 ] integrated the rules generated from correlation analysis and decision trees to identify potential and sustainable customers for mobile communication companies. As results showed, marketing effectiveness has increased to 16.1%, compared to 2.1% without the model. Also, cost savings have been reached. Moreover, Meire et al. [ 41 ] showed the economic value of the advised customer acquisition decision support system by integrating social media data into the monetary savings and financial gains. They tested the system during a real-life field study at Coca-Cola Refreshments USA. The results showed that, on average, an increased lead response percentage of 4.75% can be achieved, which equaled 2376 extra leads that were likely to convert into customers without extra cost or an additional financial gain of 11 million dollars [ 41 ]. The above-mentioned studies showed that marketing and sales effectiveness could be enhanced if appropriate predictive lead scoring models were applied. Therefore, sales performance could be improved. For instance, Meire et al. [ 41 ] showed that using social media data in lead scoring within a B2B sales context can improve sales effectiveness. However, we did not find any literature in a Business-to-Customer (B2C) context in this regard. Thus, we call on further research to consider the application of predictive lead scoring models in a B2C context by using social media data and studying its impact on marketing and sales effectiveness.
Proposition 2
The use of lead scoring models reduces costs spent on converting leads.
Another metric to estimate sales performance is the customer value matrix. It was employed to analyze customer value by classifying potential customers and developing different marketing strategies accordingly [ 69 ]. This approach can enhance efficiency and effectiveness when prioritizing potential customers, and positively influencing sales. Furthermore, activity statistics (e.g., website visits, email click-throughs, form submits, etc.) were measured before and after implementing lead scoring models to measure leads’ purchase likelihood [ 48 ]. Outputs such as median activity amount per purchase probability group enabled sales to further understand trends and insights on customer groups. Moreover, a hybrid customer prediction system that combined forward step-wise and multiple logistic regression was proposed by Soroush et al. [ 60 ] to identify the top 20% of potential customers. This system was tested on an insurance company’s dataset. The results showed that the system selected 50% of the original features, reducing the computational cost and complexity [ 60 ]. Also, the number of insurance purchasers, the percentage of total purchases and predicted customers all increased, which proved that using the alleged system can improve prediction. They also demonstrated that as the prediction accuracy of the lead scoring models increases, sales performance improves. In other words, model prediction accuracy directly influences sales performance positively. This finding highlights the importance of checking the prediction accuracy of lead scoring models during the evaluation before model deployment.
In Luk et al.’s study [ 38 ], surveys were conducted to compare customer satisfaction before and after implementing an intelligent customer identification model (ICIM) for a company in the e-commerce logistics industry. Specifically, after adopting the ICIM, which integrated k-means clustering and decision tree classification, a 36.4% increase in overall satisfaction, a 50% increase in the number of customers who are willing to establish a close relationship, a 60% increase in the expected order frequency, and a 300% increase in the expected order spending amount have been observed [ 38 ]. With the potential customer classification rules produced by ICIM, the company can classify and prioritize potential customers with minimum time and resources. Because the model consisted of a historical view and analysis of all the existing customers, it can help companies prioritize leads based on the most valued attributes, maximizing profits and increasing sales. Thus, we propose that:
Proposition 3
The use of lead scoring models increases profits and revenue.
Thorleuchter et al. [ 63 ] proposed a content-based lead scoring model to support a mail-order company’s customer acquisition process. They compared the success rate of the traditional customer acquisition process and the suggested strategy to measure the improvement in sales performance. The results showed refinements in both profitable customer acquisition success rate and sales while reducing the cost of paying for brokers’provided list of potential customers. Also, the density of profitable customers (18%) in the prioritized list of potential customers generated by this approach outperformed the density in brokers’lists (5%) [ 63 ]. For a customer acquisition process in a queue-based LMS, marketing and sales teams collaborate to increase the density of profitable customers as one of the goals in lead scoring. Because an acquisition process is both time and cost-consuming and budgets are usually limited, identifying profitable customers in the top 20%-30% of a list is essential when assessing the excellence of a lead scoring model [ 60 , 63 ]. Being able to identify more profitable customers in a more significant portion of a list can increase sales performance. However, as an inevitable result, more company and human resources will be spent, increasing costs. Apparently, there is a trade-off. Maintaining the balance between the two while steadily enhancing sales performance is an intriguing future research topic.
In addition to the metrics mentioned above, Kim et al. [ 32 ] used the hit rate on the actual number of customers who purchased recreational vehicle insurance to scale the impact on sales performance. The results showed that the advised Evolutionary Local Selection Algorithm & Artificial Neural Networks (ELSA/ANN) model has the highest hit rate in training and testing datasets. Additionally, the small number of features provided by the ELSA/ANN model implied that companies could reduce data collection and storage costs considerably. In a case study, Bohanec et al. [ 9 ] applied post-results analysis using various visualization tools on their proposed predictive lead scoring model. The hit rate on the“won”deals was around 45% [ 9 ]. However, a year later, they integrated a more advanced explanation method (i.e., IME and EXPLAIN) with the same lead scoring model to better interpret and understand the results. After adjusting according to the what-if analysis and discovering more customers’ insights, they increased the hit rate up to 60% [ 10 ]. Thus, we argue for a better way to improve sales performance by applying explanation methods to analyze lead scoring results and modify attributes’weights in the model accordingly. Thus, we propose that:
Proposition 4
The use of lead scoring models increases the number of high-quality leads.
The four abovementioned propositions summarize the major sales performance metrics that are directly and positively influenced by the application of lead scoring models, and answer RQ3 (i.e., how do lead scoring models influence sales performance? ) Using lead scoring models when scoring, prioritizing, and managing leads is expected to enhance sales performance from various dimensionalities while reducing cost.
As another interesting sales performance measure in a real business case, the Gain curve/score [ 15 ] examined the distribution of won cases on the ranked prediction output list. Yan et al. [ 72 ] applied the Gain curve/score as the sales performance metric to compare the performance within a period. The results indicated that using data-driven predictive models is a promising way to drive better sales performance.
After analyzing sales performance in the selected studies, we can conclude that predictive lead scoring models impact sales performance positively in various ways. However, the impact posed by traditional lead scoring on sales performance may not be as significantly positive as predictive lead scoring. For example, the typical conversion rate from leads to customers is only 5% on average in traditional lead scoring systems, whereas the average conversion rate is 15% in predictive lead scoring systems [ 20 ]. Additionally, some results generated by traditional lead scoring can be inaccurate, which exerts a minimum positive impact on sales performance [ 39 , 42 ]. For instance, in traditional lead scoring systems, salespeople spend too much time dealing with a large volume of low-quality MQLs that will not become sales-qualified leads (SQLs) [ 20 , 39 ]. Instead of hiring more salespeople, which is expensive, prediction lead scoring models can produce a much-refined list of MQLs for sales to contact so that efforts can be focused on leads that are most likely to convert. Predictive lead scoring models are especially beneficial to small-medium-sized businesses (SMB). By concentrating the limited inside sales resources on leads with the highest conversion probability in SMBs, marketing could forward fewer MQLs to sales but yield higher lead conversion rates.
Another factor is the limited capability of processing a large amount of data [ 39 ]. A successful prediction of lead conversion relies on vast amounts of data for analysis. Traditional lead scoring does not have the ability to analyze vast amounts of lead data due to the lack of computational power. However, using predictive lead scoring is the right solution for forecasting the likelihood of leads converting to customers, given its high computational and analytical ability.
Meanwhile, traditional lead scoring models may fail to capture nonlinear effects between independent and dependent variables or complicated interactions between features [ 20 ]. These disadvantages mean spending resources on converting low-quality leads who are unlikely to convert at the end, which may degrade sales performance. However, predictive lead scoring can find various patterns and relationships between variables as well as identify trends and the most determinant features in the leads’data [ 15 ].
Finally, traditional lead scorecards are heavily reliant on behavioral data while negligent on demographic data, which may prevent the early discovery of high-quality leads [ 20 ]. A reliable predictive result of the likelihood that leads convert into customers should consider both the demographic and behavioral data of leads at different stages of the conversion process, not to mention that data on existing customers, old leads, and new leads should also be analyzed in calculating a lead score. In conclusion, predictive lead scoring is better than traditional lead scoring as it exerts more of a positive impact on sales performance.
4.6 Limitations
This study has limitations. The first one is the restricted year range of publications, as we only considered studies published between 2005 and 2022. In addition, the studies were extracted based on concepts and search keywords, as shown in Table 1 . Hence, publications investigating lead scoring models without a keyword index could have been missed during the search phase. Indeed, there might be a threat to the completeness and adequacy of the selected studies. As a second limitation, the search for papers was limited to six online databases. However, there might be more articles related to lead scoring models in other academic journals or grey literature databases. Finally, this review only included studies that were published in English. We believe that studies regarding lead scoring models might have been discussed and published in other languages as well.
5 Discussion and conclusions
Lead scoring is critical to a successful inside sales process, as it helps sales teams to prioritize their efforts and identify which prospects are most likely to convert [ 7 , 20 , 48 ]. However, implementing an effective lead scoring model into LMS can be challenging.
The first issue is that lead scoring models can be too time-consuming [ 20 , 39 ]. With so many leads to review and prioritize, it can be difficult for sales representatives to properly assess and score each lead in a timely manner. To address this issue, organizations should look for ways to automate the lead scoring process and consider artificial intelligence (AI)-based lead scoring models. By leveraging AI-based technologies, organizations can reduce the time it takes to score leads and ensure that each lead receives the attention it deserves [ 11 , 29 , 39 ]. Our study reviews all existing lead scoring models, summarizes benefits, and recommends what AI-driven models can be implemented and when.
The second issue with lead scoring models is that they can be ineffective since they are too simplistic [ 17 , 20 , 29 ]. Many organizations rely on basic metrics such as firmographics and demographics to prioritize leads [ 29 ]. While these metrics can be essential in providing a broad overview of a lead’s potential value, they can be limited and often fail to capture the nuances of an individual lead’s situation and preferences [ 20 ]. As a result, leads may be incorrectly scored and not given the attention they deserve. Additionally, existing studies on predictive lead scoring only focus on conversion steps in the marketing-sales funnel from the perspective of selling organizations [ 7 , 17 , 20 , 48 ], hence neglecting insights in the purchase decision-making process from the buyer’s perspective. To address this problem, our study recommends employing more sophisticated lead-scoring models that consider a wider range of factors including both the seller’s and buyer’s perspectives that will help understand what phase of purchasing journey buyers are in and what their preferences are.
The third issue with lead scoring models is companies can be too resistant to change. Many organizations rely on predetermined criteria to assign scores to leads, which can lead to leads being incorrectly scored or overlooked. To address this issue, we recommend creating scoring models that are dynamic/flexible and allow adjusting models on the fly taking into account new coming data and sales representatives’ inputs.
The last issue with lead scoring models is that they are mostly built based on low-quality data or insufficient, imbalanced datasets [ 22 , 32 , 74 ]. Organizations often build their scoring models based on historical data from previous sales cycles, which may not be reflective of the current market conditions. As a result, leads may be incorrectly scored or overlooked altogether. Our study recommends using industry and company-specific data up-to-date sources and provides recommendations when it is to deploying specific models considering data specifications.
There has been a growing body of literature on lead scoring models published in the past few years (see Fig. 3 ). There are many reasons for this phenomenon, such as the advancement of computational capabilities, the introduction of various LMSs that implement lead scoring models, and the availability of large sales datasets. In addition, trends in applications and development of DM, ML, and AI-based approaches for business in general and sales in particular, are other factors. Also, the COVID-19 pandemic accelerated the adoption of remote selling through LMSs. As a result, the importance and urgency of implementing suitable lead scoring models skyrocketed.
More studies appear to focus on building data-driven predictive lead scoring models to predict the probability of lead conversion to prioritize leads for further steps in the sales process. Indeed, predictive lead scoring models have attracted the attention of academics and practitioners. An array of DM and ML techniques have been used to discover trends, find insights, detect relationships between variables within data, and predict lead conversion outcomes. Eventually, these help decision-makers optimize business processes and enhance sales performance. This study conducted a comprehensive review of lead scoring models and their impact on sales performance. During our review of existing lead scoring models, we found few studies that examine the performance of a small number of supervised learning algorithms on estimating the purchase probabilities of leads [ 6 , 21 , 48 ]. In addition to the small number of supervised learning algorithms examined, these studies did not address the impact of lead scoring models on sales performance.
This review paper has identified 44 published studies between 2005 and 2022 relevant to lead scoring models in LMSs. Our goal is to provide a research summary on the lead scoring models, their impact on sales performance, and their applications in the CRM domain. The qualified studies in this review test different lead scoring models on various experimental and real datasets (i.e., company-provided datasets). The qualified studies use multiple metrics to measure the impact of the proposed models on sales performance. The results show that lead scoring models positively impact companies’sales performance in various ways. Notably, predictive lead scoring is more effective and efficient than traditional lead scoring in many aspects, which results in a more positive impact on sales performance.
The results of this study carry the following significant implications:
Based on increasing interest and past publication ratio in the area of lead scoring models, research in this area will increase significantly in the future, particularly, in the area of predictive lead scoring.
Most of the reviewed papers are in the predictive lead scoring domain (i.e., 85%, 39 articles). This number indicates the rising importance of predictive lead scoring models as tools in LMSs. In addition, these studies provide insights to decision-makers on the common DM and ML practices adopted in the process of customer acquisition.
Among all the DM models, classification is the most used model for predicting a lead’s propensity to make a purchase.
Among the 44 studies, it is surprising that neural network is not the most popular algorithm (i.e., seven studies). Neural networks can be applied to classification, regression, and clustering tasks given their flexibility and capability of studying complicated relationships [ 17 ]. Maybe this is due to the hardship of interpreting results generated by neural networks since they are“black-box”algorithms. However, the EXPLAIN and IME explanation methods can be applied to interpret complicated modeling processes in “black-box”algorithms and their generated results [ 10 ]. Thus, more research could be conducted on lead scoring models by using neural networks coupled with explanation methods.
Decision tree and logistic regression are tied as the most applied algorithms in lead scoring studies. The modeling processes of both algorithms are easier to understand than any “black-box”algorithms such as neural networks. In addition, the results of these two techniques can be interpreted easily. Hence, these two algorithms might be preferable to non-DM experts in the business field.
The most used metric to measure the impact of lead scoring models on sales performance is lead conversion rate. A growth in lead conversion rates shows that the application of lead scoring models indeed converts more leads into customers [ 56 ]. Furthermore, companies examined in this review (e.g., GE Capital and DocuSign Inc.) [ 1 , 39 ] indicated that the productivity and effectiveness of sales and marketing functions have improved after the deployment of lead scoring models. This underlines the role of lead scoring models in improving the internal collaboration between the marketing and sales functions [ 56 ].
There is not enough research discussing traditional lead scoring models. This implies that as DM models and ML algorithms become increasingly powerful in analyzing lead and customer data, the traditional way of scoring and prioritizing will probably be in decline.
From a theoretical perspective, the results of this review point to a few potential future work items:
Future research on lead scoring should be extended to study the methodology in each lead scoring model. An interesting research direction is to review methodologies in the lead scoring studies and their practical, real-life applications. Specifically, researchers should focus on analysis techniques in the lead scoring studies, research approaches and frameworks, and data collection steps. Discussion of the pros and cons of each methodology should be highlighted.
Additionally, various IT drivers can impact sales performance, such as automated lead generation, lead distribution, lead nurturing tools, and lead scoring models. Another possible research direction is exploring these IT drivers’impact on sales performance and their intra-relationships. To be specific, relevant survey questions could be sent out to participants. For data (i.e., survey question responses) analysis, statistical tools should be used to calculate and analyze correlation, T-Test, and regression.
Many factors influence the result of lead scoring, for example, customer characteristics, salesperson traits, organization types, and environmental attributes. A meta-analysis review could be carried out to examine the relationship between these factors and lead scoring outcomes. This could help identify the key determinants of lead scoring success in a B2B inside sales context. Another future research direction is use meta-analysis to validate the formulated propositions with regards to lead scoring models’impact on sales performance proposed in Sect. 4 .
As marketing has become increasingly customer-centric, another possible research avenue is to integrate insights from the buyers’perspective into building lead scoring models. This will likely bring more insights into the implementation of sophisticated lead scoring models.
From a practical perspective, the results of this review suggest the following future work items:
Deep learning methods have appeared and proved to be powerful enough when handling large data sets with a high degree of complexity. With the availability of larger data sets across industries, the application of deep learning models to improve sales performance seems feasible. Furthermore, with the help of explanation methods, the interpretation difficulty of predictions generated by “black-box”models, such as deep learning, should be reduced.
Moreover, another interesting research question could be measuring and comparing various lead scoring models under the same environment/setting to find the most effective DM model and ML algorithm. The evaluation and comparison could be executed in two phases, pre-campaign, and post-campaign. In the pre-campaign phase, researchers should focus on comparing confusion matrices and evaluation graphs (i.e., Gains, Response, Lift charts, ROC curves) to estimate models’performances. After deploying models on marketing campaign datasets, the actual performances are evaluated and compared by using measures such as lead conversion rate and revenue gained in the post-campaign phase.
Finally, as lead scoring models have been widely adopted across industries, future research should investigate the application of various lead scoring models to different types/sizes of companies, and how to adjust these models to adapt to different industries. Investigating how to improve the suitability and practicability of lead scoring models in an industry-wide context is another research direction.
Aggour KS, Hoogs B (2013) Financing lead triggers: empowering sales reps through knowledge discovery and fusion. Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining pp. 1141-1149
Ahmed SR (2004) Applications of data mining in retail business. Inform Technol: Coding and Comput 2:455–459
Google Scholar
Badampudi D, Wohlin C, Petersen K (2015) Experiences from using snowballing and database searches in systematic literature studies. Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering pp. 1-10
Baecke P, Van Den Poel D (2012) Including spatial interdependence in customer acquisition models: A cross-category comparison. Expert Syst Appl 39(15):12105–12113
Article Google Scholar
Baecke P, Van Den Poel D (2013) Improving customer acquisition models by incorporating spatial autocorrelation at different levels of granularity. J Intell Inform Syst 41(1):73–90
Başarslan MS, Argun İD (2020) Prediction of potential bank customers: application on Data Mining. Artificial Intelligence and Applied Mathematics in Engineering Problems pp. 96-106
Benhaddou Y, Leray P (2017) Customer relationship management and small data-application of bayesian network elicitation techniques for building a lead scoring model. 2017 IEEE/ACS 14th International Conference on Computational Science and Its Applications pp. 251-255
Blei DM (2012) Probabilistic topic models. Commun ACM 55(4):77–84
Bohanec M, Borštnar MK, Robnik-Šikonja M (2016) Integration of machine learning insights into organizational learning: a case of B2B sales forecasting. Lecture Notes in Information Systems and Organisation pp. 71-85
Bohanec M, Bortnar MK, Robnik-ikonja M (2017) Explaining machine learning models in sales predictions. Expert Syst Appl 71:416–428
Boogar L (2019) The three stages of lead scoring: Lambs, Ducks & Kudus. The MadKudu Blog post. https://blog.madkudu.com/three-stages-of-lead-scoring/. Accessed 28 June 2019
Brings J, Daun M, Kempe M, Weyer T (2018) On different search methods for systematic literature reviews and maps: experiences from a literature search on validation and verification of emergent behavior. Proceedings of the 22nd International Conference on Evaluation and Assessment in Software Engineering pp. 35-45
Brown G (2009) How real-time online sales lead scoring drives a competitive edge. Bloor Research White Paper No.1021. https://www.yumpu.com/en/document/read/18066356/real-time-lead-scoring-by-analyst-firm-bloor-research-ebureau/. Accessed 05 June 2021
Carroll B (2006) What ’s a Lead? Target Marketing, Philadelphia 29(11)
Chorianopoulos A (2016) Effective CRM using predictive analytics. John Wiley & Sons Ltd, United Kingdom
Coe JM (2004) The integration of direct marketing and field sales to form a new B2B sales coverage model. J Interact Mark 18(2):62–74
Article MathSciNet Google Scholar
D’Haen J, Van den Poel D (2013) Model-supported business-to-business prospect prediction based on an iterative customer acquisition framework. Ind Mark Manage 42(4):544–551
D’Haen J, Van den Poel D, Thorleuchter D (2013) Predicting customer profitability during acquisition: Finding the optimal combination of data source and data mining technique. Expert Syst Appl 40(6):2007–2012
D’Haen J, Van den Poel D, Thorleuchter D, Benoit DF (2016) Integrating expert knowledge and multilingual web crawling data in a lead qualification system. Decis Support Syst 82:69–78
Duncan B, Elkan C (2015) Probabilistic modeling of a sales funnel to prioritize leads. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 1751-1758
Eitle V, Buxmann P (2019) Business analytics for sales pipeline management in the software industry: a machine learning perspective. Proceedings of the 52nd Hawaii International Conference on System Sciences pp. 1013-1022
Espadinha-Cruz P, Fernandes A, Grilo A (2021) Lead management optimization using data mining: a case in the telecommunications sector. Computers and Industrial Engineering p. 154
Gokhale P, Joshi P (2018) A binary classification approach to lead identification and qualification. Communications in Computer and Information Science pp. 279-291
Grandy T (2005) What is a qualified sales lead. Reeves J: Plumbing, Heating, Cool 85(11):22–23
Hasselwander A (2006) B2B Pipeline Management. B2B Marketing Confidential. http://b2bmarketingconfidential.blogspot.com/2006/11/. Accessed 11 June 2021
Hornstein S (2005) Sizing up prospects. Sales & Market Manag 157:22
Hou JL, Yang ST (2006) A critical customer identification model for technology and service providers. Int J Services and Standards 2(4):417–436
Järvinen J, Taiminen H (2016) Harnessing marketing automation for B2B content marketing. Ind Mark Manage 54:164–175
Jaskaran (2018) Predictive Lead Scoring: Why, How & Where. Inbound Mantra. https://inboundmantra.com/blog/predictive-lead-scoring-why-how-where. Accessed 26 Nov 2019
Kasturi G, Ezzour AJ, Berezin H, Bhanavase S, Preizler R, Hauon E, Nir O, Ronen R (2021) Generic automated lead ranking in dynamics CRM. RecSys 2021 - 15th ACM Conference on Recommender Systems 757-759
Kazemi A, Babaei ME, Javad MOM (2015) A data mining approach for turning potential customers into real ones in basket purchase analysis. Int J Bus Inform Syst 19(2):139–158
Kim Y, Street WN, Russell GJ, Menczer F (2005) Customer targeting: a neural network approach guided by genetic algorithms. Manage Sci 51(2):264–276
Kulkarni T, Mokadam P, Bhat J, Devadkar K (2020) Potential customer classification in customer relationship management using Fuzzy Logic. Innovative Data Communication Technologies and Application 67-75
Kitchenham B (2004) Procedures for performing systematic reviews. Technical Report, Keele University and NICTA, Staffordshire, UK 33:1–26
Lamrhari S, Ghazi HE, Oubrich M, Faker AE (2022) A social CRM analytic framework for improving customer retention, acquisition, and conversion. Technological Forecasting and Social Change p. 174
Liberati A (2009) The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. Ann Intern Med 151(4):65–94
Lindahl E (2017) A qualitative examination of lead scoring in B2B marketing automation, with a recommendation for its practice. Research Project, KTH Vetenskap Och Konst
Luk CC, Choy KL, Lam HY (2019) Design of an intelligent customer identification model in e- commerce logistics industry. MATEC Web of Conf 255:04003
McDonnell D (2014) The Evolution From Traditional To Predictive Lead Scoring. Demand Gen Report. https://www.demandgenreport.com/industry-resources/ebooks/2892-the-evolution-from-traditional-to-predictive-lead-scoring. Accessed 23 Feb 2019
Megahed A, Yin P, Nezhad HR (2016) An optimization approach to services sales forecasting in a multi-staged sales pipeline. IEEE Int Conf Services Comput (SCC) 2016:713–719
Meire M, Ballings M, Van den Poel D (2017) The added value of social media data in B2B customer acquisition systems: a real-life experiment. Decis Support Syst 104:26–37
Michiels I (2008) Lead Prioritization and Scoring: The Path to Higher Conversion. Aberdeen Group. https://silo.tips/download/lead-prioritization-and-scoring. Accessed 25 May 2019
Michiels I (2009) Lead lifecycle management: building a pipeline that never leaks. Aberdeen Group, research report
Monat JP (2011) Industrial sales lead conversion modeling. Market Intell Plan 29(2):178–194
Mortensen S, Christison M, Li BC, Zhu AL, Venkatesan R (2019) Predicting and defining B2B sales success with machine learning. 2019 Systems and Information Engineering Design Symposium (SIEDS)
Ngai EWT, Xiu L, Chau DCK (2009) Application of data mining techniques in customer relationship management: a literature review and classification. Expert Syst Appl 36(2–2):2592–2602
Nguyen TT, Nguyen VLH, Nguyen PK (2012) Identifying customer characteristics by using rough set theory with a new algorithm and posterior probabilities. Fourth Int Conf Comput Inform Sci 2012:594–597
Nygård R, Mezei J (2020) Automating lead scoring with machine learning: an experiemntal study. In: Proceedings of the 53rd Hawaii International Conference on System Sciences pp. 1439-1448
Ohiomah A, Andreev P, Benyoucef M, Hood D (2019) The role of lead management systems in inside sales performance. J Bus Res 102:163–177
Ohiomah A, Benyoucef M, Andreev P (2016) Driving inside sales performance with lead management systems: a conceptual model. J Inform Syst Appl Res 9(1):4–15
Ohiomah A, Benyoucef M, Andreev P (2020) A multidimensional perspective of business-to-business sales success: a meta-analytic review. Ind Mark Manage 90:435–452
Papaioannou D, Sutton A, Carroll C, Booth A, Wong R (2010) Literature searching for social science systematic reviews: consideration of a range of search techniques: Literature searching for social science systematic reviews. Health Info Libr J 27(2):114–122
Article PubMed Google Scholar
Peng K, Xu D (2011) Modeling of potential customers identification based on correlation analysis and decision tree. Advances in Neural Networks - ISNN 2011 Lecture Notes in Computer Science 566-575
Pullins EB, Timonen H, Kaski T, Holopainen M (2017) An investigation of the theory practice gap in professional sales. J Market Theory Practice 25(1):17–38
Rutherford BN, Marshall GW, Park J (2014) The moderating effects of gender and inside versus outside sales role in multifaceted job satisfaction. J Bus Res 67(9):1850–1856
Sabnis G, Chatterjee SC, Grewal R, Lilien GL (2013) The sales lead black hole: on sales reps’follow-up of marketing leads. J Mark 77(1):52–67
Safari M, Asadi S (2020) A screening method for lowering customer acquisition cost in small commercial building energy efficiency projects. Energ Effi 13(8):1665–1676
Sangaralingam K, Verma N, Ravi A, Bae SW, Datta A (2019) High value customer acquisition retention modelling - A scalable data mashup approach. IEEE Int Conf Big Data 2019:1907–1916
Smith TM, Gopalakrishna S, Chatterjee R (2006) A three-stage model of integrated marketing communications at the marketing-sales interface. J Mark Res 43(4):564–579
Soroush A, Bahreininejad A, Van Den Berg J (2012) A hybrid customer prediction system based on multiple forward stepwise logistic regression mode. Intell Data Anal 16(2):265–278
Syam N, Sharma A (2018) Waiting for a sales renaissance in the fourth industrial revolution: Machine learning and artificial intelligence in sales research and practice. Ind Mark Manage 69:135–146
Thaichon P, Surachartkumtonkun J, Quach S, Weaven S, Palmatier RW (2018) Hybrid sales structures in the age of e-commerce. J Personal Sell Sales Manag 38(3):277–302
Thorleuchter D, Van Den Poel D, Prinzie A (2012) Analyzing existing customers’websites to improve the customer acquisition process as well as the profitability prediction in B-to-B marketing. Expert Syst Appl 39(3):2597–2605
Tu Y, Yang Z, Benslimane Y (2011) Towards an optimal classification model against imbalanced data for customer relationship management. 2011 7th International Conference on Natural Computation pp. 2401-2405
VanillaSoft (2014) 4 Ways queue-based lead management is shaping the inside sales industry. VanillaSoft.https://www.vanillasoft.com/resources/white-papers/queue-based-lead-management. Accessed 17 July 2021
Velocity (2013) Best lead distribution methods for optimal sales performance. Velocity. https://www.slideshare.net/Velocify/vel-best-leaddistromthdbookletfinal. Accessed 16 July 2021
Verma R, Koul S, Pai SS (2016) Identifying profitable clientele using the analytical hierarchy process. Int J Bus Syst Res 10(2–4):220–237
Wang M, Li Y, Li Q (2021) Target customer identification method of integrated energy service based on logistic regression. The 9th China International Conference on Electricity Distribution pp. 1025-1029
Wei JT, Lin SY, Yang YZ, Wu HH (2016) Applying data mining and rfm model to analyze Customers’Values of a veterinary hospital. Int Symp Comput Consum Control 2016:481–484
Xiaowen L, Lili T, Zuohao H (2014) Research on value assessment-based accurate identification of government and corporate customers of telecom operators. China Commun 11(11):168–173
Xu X, Tang L, Rangan V (2017) Hitting your number or not? A robust & intelligent sales forecast system. IEEE International Conference on Big Data (BIGDATA) 2017:3612–3622
Yan J, Gong M, Sun C, Huang J, Chu SM (2015) Sales pipeline win propensity prediction: A regression approach. 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM2015) 854-857
Ylijoki O (2018) Guidelines for assessing the value of a predictive algorithm: a case study. J Market Anal 6(1):19–26
Zhu B, Niu Y, Xiao J, Baesens B (2017) A new transferred feature selection algorithm for customer identification. Neural Comput Appl 28(9):2593–2603
Patma TS, Wardana LW, Wibowo A, Narmaditya BS, Akbarina F (2021) The impact of social media marketing for Indonesian smes sustainability: Lesson from covid-19 pandemic. Cogent Business & Management 8(1)
Download references
Acknowledgements
This study was funded by grants from Mitacs Canada (No. 310636).
Author information
Authors and affiliations.
Faculty of Engineering, University of Ottawa, Ottawa, ON, K1N 6N5, Canada
Telfer School of Management, University of Ottawa, Ottawa, ON, K1N 6N5, Canada
Pavel Andreev & Morad Benyoucef
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Migao Wu .
Ethics declarations
Conflict of interest.
The authors declare that they have no conflict of interest.
Research involving Human Participants and/or Animals
Not applicable
Code availability
Informed consent, additional information, publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix Table of extracted data
See Table 8
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Wu, M., Andreev, P. & Benyoucef, M. The state of lead scoring models and their impact on sales performance. Inf Technol Manag 25 , 69–98 (2024). https://doi.org/10.1007/s10799-023-00388-w
Download citation
Accepted : 07 January 2023
Published : 01 February 2023
Issue Date : March 2024
DOI : https://doi.org/10.1007/s10799-023-00388-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Lead scoring model
- Sales performance
- Data mining model
- Machine learning algorithm
- Systematic literature review
- Find a journal
- Publish with us
- Track your research
- Workflow Automation
A Complete Guide for Lead Scoring
Automate manual tasks and workflows using ai-driven workflow automation, introduction.
Lead scoring is an essential methodology in the realm of B2B sales and marketing. At its core, it involves assigning a numerical score to each lead, typically on a scale from 1 to 100, to gauge their likelihood of making a purchase.
This process is a strategic approach to understand the potential of every lead that comes into the sales funnel. It enables sales and marketing teams to prioritize leads, ensuring they focus their efforts on high scoring leads, which are those most likely to generate revenue.
Traditionally, lead scoring has been a manual process, relying on sales and marketing professionals' intuition and experience to rank leads. However, with advancements in AI and workflow automation, manual tasks associated with lead scoring can be automated completely. We shall discuss all this is detail in our blog.
Lead Scoring Metrics
Modern lead scoring methodologies now incorporate a mix of explicit and implicit scoring metrics, and can also incorporate predictive scoring to build a framework which arrives at accurate lead scores for your leads.
- Explicit scoring involves using concrete information such as job title, company size, or industry.
- Implicit scoring is based on behavioral data like website visits, email engagement, or content downloads.
- use AI on the data around your existing customers and your accepted & rejected leads, to give a lead score.
- use LLMs to replace the subjective decision making tasks in the lead scoring workflow.
Lead Scoring Methods
Let us now discuss popular frameworks used for lead scoring in detail. You can implement any of these frameworks and integrate them into your CRM and other apps using the Nanonets Workflow Builder, which will be covered after this section.
Explicit Lead Scoring Methods
Explicit methods focus on tangible, solid data to evaluate the potential of leads. These methods are grounded in specific, often demographic, information about a lead.
1. BANT (Budget, Authority, Need, Timeframe)
Description: BANT is a classic lead scoring method where leads are assessed based on four critical criteria: Budget, Authority, Need, and Timeframe.

- Budget: Determines if the lead has the financial resources to buy.
- Authority: Assesses if the contact person can make purchasing decisions.
- Need: Identifies if the lead's needs align with the product or service offered.
- Timeframe: Checks how soon the lead intends to make a purchase.
Workflow Example:
- A lead comes in through an online form.
- The form data is enriched using a tool like Clearbit to gather more detailed information about the lead’s company and role.
- In the CRM, a scoring rule is applied where points are assigned based on how well the lead matches each BANT criterion, based on pre-set rules on the enriched data.
- For instance, if the lead has a high authority level in their company and a pressing need for the product, they score higher.
- The CRM then updates the lead's score, prioritizing them for the sales team.
2. Firmographic Scoring
Description: This method scores leads based on firmographic data such as company size, sector, location, and revenue. It’s particularly useful in B2B scenarios where such factors significantly impact the likelihood of a sale.
- A lead is identified via LinkedIn.
- Company information is enriched using a tool like Clearbit to gather more detailed information about the lead’s company and role.
- The CRM scores the lead based on predefined firmographic criteria. For example, a large enterprise in a target sector may receive a higher score.
- This score helps in segmenting leads for tailored marketing strategies.
3. ANUM (Authority, Need, Urgency, Money)
Description: ANUM is another variant that prioritizes the authority and need of a lead, along with urgency and budget considerations.
- A potential lead interacts with a webinar hosted by the company.
- Post-webinar, their engagement and queries are analyzed for urgency and need based on the interaction.
- Their role and company are checked for authority and budget, typically done manually or via a lead enrichment tool.
- The CRM then assigns scores based on these criteria, fast-tracking leads with immediate needs and high purchasing power.
Automate lead enrichment, qualification and scoring workflows with our AI-driven workflow builder, designed by Nanonets for you and your teams.
Implicit Lead Scoring Methods
Implicit lead scoring focuses on the prospective customer's behavior and engagement to gauge their interest and potential to convert. These methods assess how leads interact with your brand, website, or content, offering insights that aren't always apparent through explicit data.
1. Engagement Scoring
Description: Engagement (or behavorial) scoring examines the actions leads take, like the type of content they consume, the duration of their website visits, and their responses to marketing campaigns.
- A lead regularly opens marketing emails and spends time on high-value pages like product demos or pricing.
- Each action (page visit, download, email opens) is tracked and points are assigned based on the level of engagement.
- The CRM, integrated with website analytics using workflow automation, updates the lead’s score automatically.
- High engagement leads are flagged for follow-up by the sales team.
2. Content Interaction Scoring
Description: Leads are scored based on the type and depth of content they interact with, such as blog articles, whitepapers, or videos. More in-depth interactions with technical or advanced content may indicate a higher level of interest.
- A lead spends time reading advanced technical blogs and viewing tutorial videos.
- Content management systems track these interactions, assigning higher scores for deeper engagement with complex content.
- This information is integrated into the CRM, raising the lead’s score.
- Leads engaging with advanced content are flagged as high-potential leads for the sales team.
Predictive Lead Scoring Methods
Predictive methods use AI with traditional methods to automate or increase accuracy.
1. LLM based Lead Scoring (Used with Explicit Lead Scoring)
This approach uses LLMs to gauge subjective parameters in explicit scoring such as Budget, Authority, Need, Timeframe in the BANT framework. This removes the manual task where a salesperson needs to fill the BANT form for a lead based on their personal interaction and available company information.
2. Machine Learning-Based Scoring (Used with Implicit Lead Scoring)
This approach uses machine learning algorithms to analyze past lead data, identifying patterns and characteristics of leads that successfully converted. The system then scores new leads based on how closely they match these success profiles.
We shall learn how this works in detail in the next section with the help of an example.
Automated Lead Scoring using Nanonets
Let's take the example of a BANT workflow and automate it using Nanonets Workflows. The existing manual workflow looks like this -
- Lead enters a form and provides email and a convenient time for a sales call.
- Salesperson creates a new record in Hubspot CRM.
- Salesperson creates the call event in Google Calendar based on the specified time indicated by the lead.
- Once the call is over, the salesperson uses his subjective memory of the call discussion and the sales call transcript fetched from Gong to fill the BANT form with Budget, Authority, Need, Timeframe fields.
- The lead score is thus calculated by the sales person using the filled BANT form and a pre-set formula with weights to each field.
- The lead score is updated manually in the corresponding Hubspot CRM record.
Now let us take a look at how we can automate this using Nanonets by creating an automated workflow that does all the tasks of the above workflow for us.
We feed the description of the workflow we wrote above as a prompt in the workflow generator, and an automated workflow spins up for us based on our description.
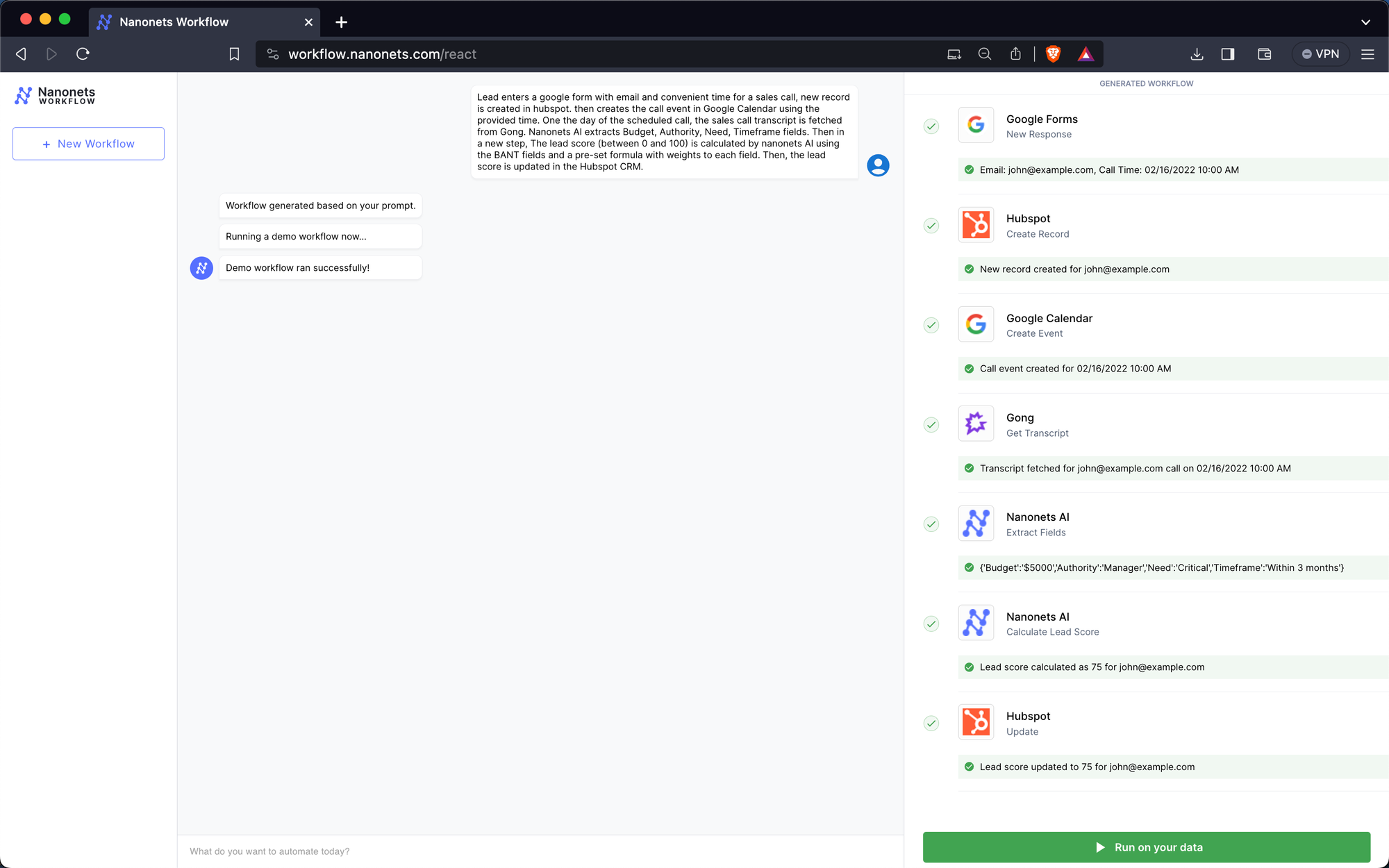
We move on and authenticate our Google, Hubspot and Gong accounts to provide the Nanonets workflow with access to the apps in order to facilitate the workflow to fetch data and perform actions directly within your apps.
The workflow runs as follows -
- Google Forms - Triggers a workflow run when the sales call Google Form is submitted.
- Hubspot - New Hubspot record is created with the email submitted by the lead.
- Google Calendar - New calendar event is created between the lead and the salesperson based on the time indicated.
- Gong - The workflow is delayed till the call happens. Once the call is done, the sales call transcript is fetched from Gong
- Nanonets AI - Nanonets AI reads the transcript and populates the BANT fields in a structured fashion.
- Nanonets AI - Nanonets AI uses self selected (default) weights for arriving at a lead score, from the BANT data extracted from the call transcript in the previous step. You can specify the lead score formula and the weights manually in the prompt as well.
- Hubspot - The Hubspot record created in the second step is populated with this lead score.
Here is a demo of the workflow in action.
Let's take a look at the results of automated lead scoring compared to manual lead scoring now.
Lead Scoring Case Study
Challenge: Sales teams often struggle with lead scoring, spending substantial time on manual processes that are prone to incomplete information and subjectivity. The BANT (Budget, Authority, Need, Timeline) framework, while effective, traditionally required time-consuming efforts and could result in biased lead scoring.
Solution: Created a Nanonets Workflow - integrating AI to transform the lead qualification process. This tool automates the extraction and analysis of BANT criteria from sales calls, offering a streamlined, efficient approach to lead scoring.
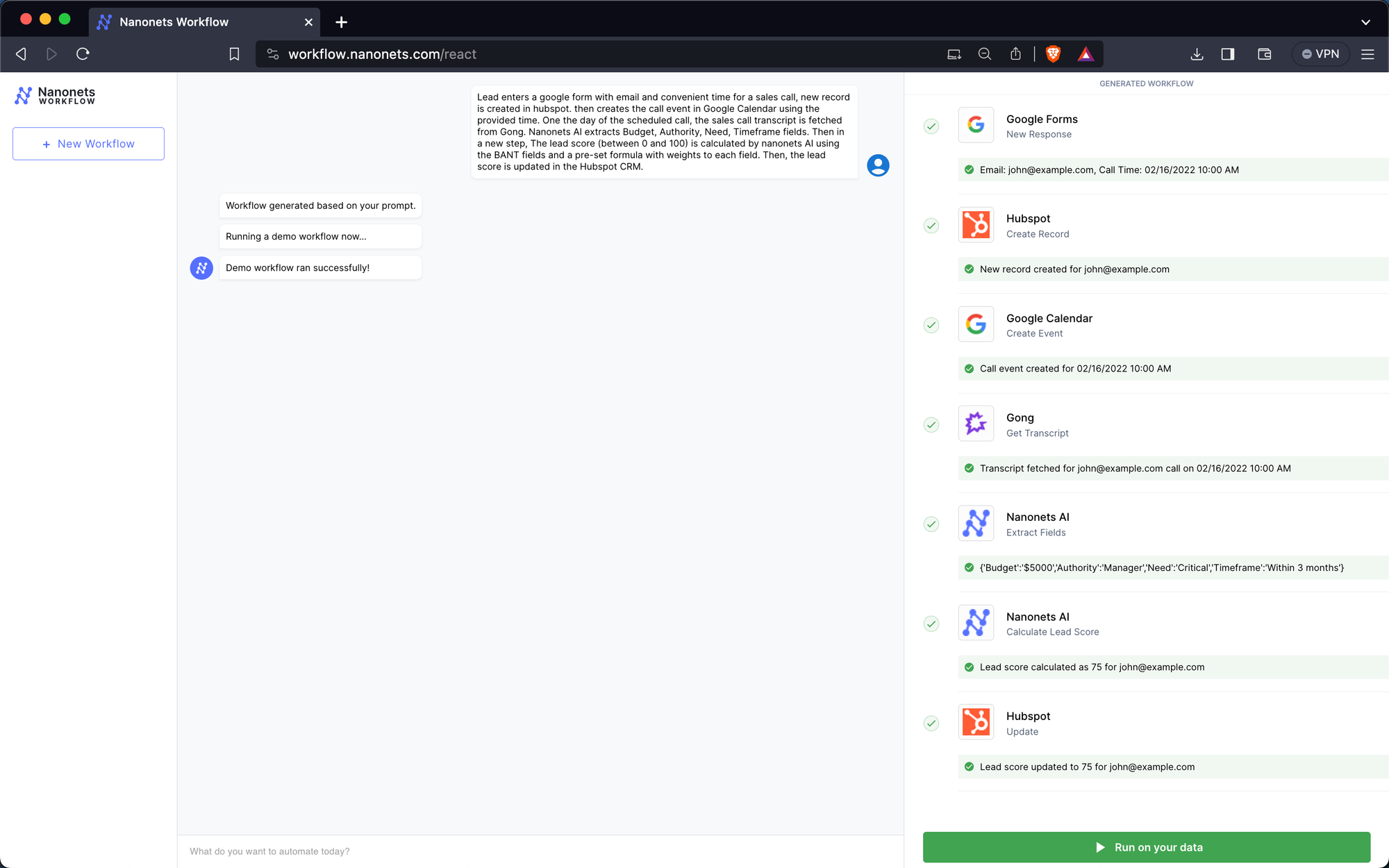
Results & Impact:
- Enhanced Precision: In a study comparing over 1500 sales calls, the workflow matched or outperformed AEs in identifying leads likely to close. Notably, its recall rate was 81%, significantly higher than the manual review's 41%, while the precision rate was similar.
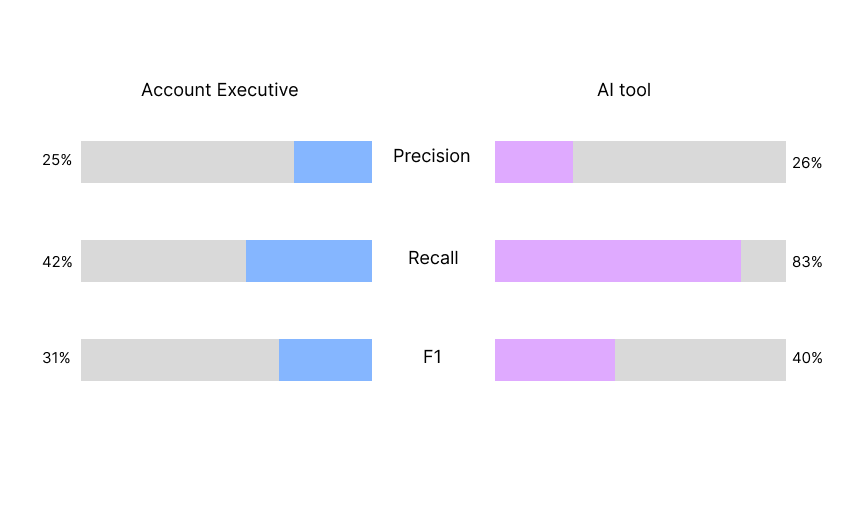
- Reduced Cycle Times: Leads scored 80+ by the AI tool showed 5-10% shorter closure cycle times, enhancing sales team efficiency.
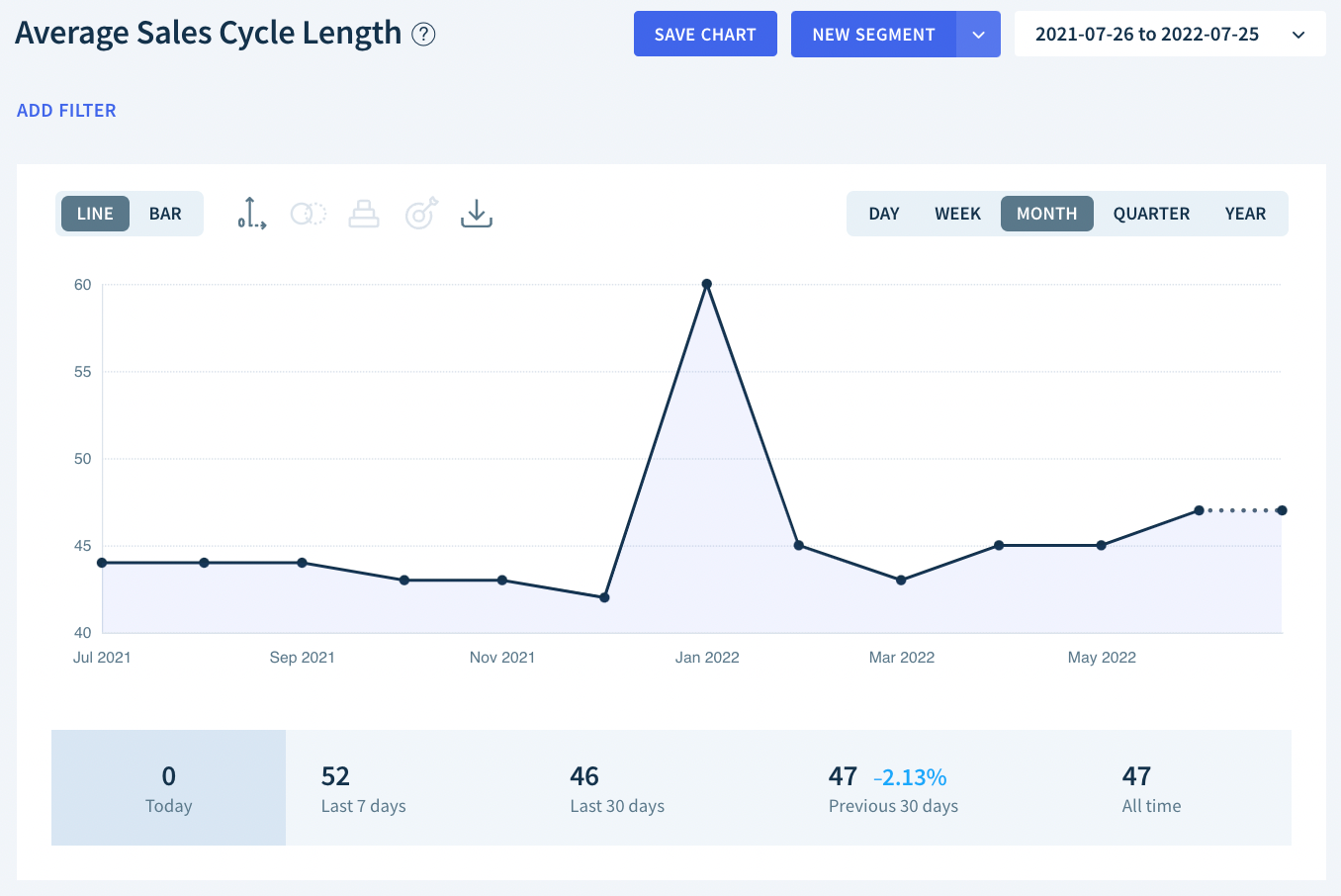
- Flexible Scoring: Unlike binary AE assessments, AI provides a nuanced 1-100 scoring scale, allowing more tailored sales approaches.
- Efficiency Gains: Sales teams reported faster BANT qualification, elimination of incomplete data issues, and more time for customer engagement and product development.
Conclusion: Workflow automation of lead scoring marked a significant leap in sales efficiency, combining human intuition with AI precision for more effective, customer-centric strategies.
Nanonets for Workflow Automation
In today's fast-paced business environment, workflow automation stands out as a crucial innovation, offering a competitive edge to companies of all sizes. The integration of automated workflows into daily business operations is not just a trend; it's a strategic necessity. In addition to this, the advent of LLMs has opened even more opportunities for automation of manual tasks and processes.
Welcome to Nanonets Workflow Automation, where AI-driven technology empowers you and your team to automate manual tasks and construct efficient workflows in minutes. Utilize natural language to effortlessly create and manage workflows that seamlessly integrate with all your documents, apps, and databases.
Our platform offers not only seamless app integrations for unified workflows but also the ability to build and utilize custom Large Language Models Apps for sophisticated text writing and response posting within your apps. All the while ensuring data security remains our top priority, with strict adherence to GDPR, SOC 2, and HIPAA compliance standards.
To better understand the practical applications of Nanonets workflow automation, let's delve into some real-world examples.
- Automated Customer Support and Engagement Process
- Ticket Creation – Zendesk : The workflow is triggered when a customer submits a new support ticket in Zendesk, indicating they need assistance with a product or service.
- Ticket Update – Zendesk : After the ticket is created, an automated update is immediately logged in Zendesk to indicate that the ticket has been received and is being processed, providing the customer with a ticket number for reference.
- Information Retrieval – Nanonets Browsing : Concurrently, the Nanonets Browsing feature searches through all the knowledge base pages to find relevant information and possible solutions related to the customer's issue.
- Customer History Access – HubSpot : Simultaneously, HubSpot is queried to retrieve the customer's previous interaction records, purchase history, and any past tickets to provide context to the support team.
- Ticket Processing – Nanonets AI : With the relevant information and customer history at hand, Nanonets AI processes the ticket, categorizing the issue and suggesting potential solutions based on similar past cases.
- Notification – Slack : Finally, the responsible support team or individual is notified through Slack with a message containing the ticket details, customer history, and suggested solutions, prompting a swift and informed response.
- Automated Issue Resolution Process
- Initial Trigger – Slack Message : The workflow begins when a customer service representative receives a new message in a dedicated channel on Slack, signaling a customer issue that needs to be addressed.
- Classification – Nanonets AI : Once the message is detected, Nanonets AI steps in to classify the message based on its content and past classification data (from Airtable records). Using LLMs, it classifies it as a bug along with determining urgency.
- Record Creation – Airtable : After classification, the workflow automatically creates a new record in Airtable, a cloud collaboration service. This record includes all relevant details from the customer's message, such as customer ID, issue category, and urgency level.
- Team Assignment – Airtable : With the record created, the Airtable system then assigns a team to handle the issue. Based on the classification done by Nanonets AI, the system selects the most appropriate team – tech support, billing, customer success, etc. – to take over the issue.
- Notification – Slack : Finally, the assigned team is notified through Slack. An automated message is sent to the team's channel, alerting them of the new issue, providing a direct link to the Airtable record, and prompting a timely response.
- Automated Meeting Scheduling Process
- Initial Contact – LinkedIn : The workflow is initiated when a professional connection sends a new message on LinkedIn expressing interest in scheduling a meeting. An LLM parses incoming messages and triggers the workflow if it deems the message as a request for a meeting from a potential job candidate.
- Document Retrieval – Google Drive : Following the initial contact, the workflow automation system retrieves a pre-prepared document from Google Drive that contains information about the meeting agenda, company overview, or any relevant briefing materials.
- Scheduling – Google Calendar : Next, the system interacts with Google Calendar to get available times for the meeting. It checks the calendar for open slots that align with business hours (based on the location parsed from LinkedIn profile) and previously set preferences for meetings.
- Confirmation Message as Reply – LinkedIn : Once a suitable time slot is found, the workflow automation system sends a message back through LinkedIn. This message includes the proposed time for the meeting, access to the document retrieved from Google Drive, and a request for confirmation or alternative suggestions.
- Invoice Processing in Accounts Payable
- Receipt of Invoice - Gmail : An invoice is received via email or uploaded to the system.
- Data Extraction - Nanonets OCR : The system automatically extracts relevant data (like vendor details, amounts, due dates).
- Data Verification - Quickbooks: The Nanonets workflow verifies the extracted data against purchase orders and receipts.
- Approval Routing - Slack : The invoice is routed to the appropriate manager for approval based on predefined thresholds and rules.
- Payment Processing - Brex : Once approved, the system schedules the payment according to the vendor's terms and updates the finance records.
- Archiving - Quickbooks : The completed transaction is archived for future reference and audit trails.
- Internal Knowledge Base Assistance
- Initial Inquiry – Slack : A team member, Smith, inquires in the #chat-with-data Slack channel about customers experiencing issues with QuickBooks integration.
- Ticket Lookup - Zendesk : The Zendesk app in Slack automatically provides a summary of today's tickets, indicating that there are issues with exporting invoice data to QuickBooks for some customers.
- Slack Search - Slack: Simultaneously, the Slack app notifies the channel that team members Patrick and Rachel are actively discussing the resolution of the QuickBooks export bug in another channel, with a fix scheduled to go live at 4 PM.
- Ticket Tracking – JIRA : The JIRA app updates the channel about a ticket created by Emily titled "QuickBooks export failing for QB Desktop integrations," which helps track the status and resolution progress of the issue.
- Reference Documentation – Google Drive : The Drive app mentions the existence of a runbook for fixing bugs related to QuickBooks integrations, which can be referenced to understand the steps for troubleshooting and resolution.
- Ongoing Communication and Resolution Confirmation – Slack : As the conversation progresses, the Slack channel serves as a real-time forum for discussing updates, sharing findings from the runbook, and confirming the deployment of the bug fix. Team members use the channel to collaborate, share insights, and ask follow-up questions to ensure a comprehensive understanding of the issue and its resolution.
- Resolution Documentation and Knowledge Sharing : After the fix is implemented, team members update the internal documentation in Google Drive with new findings and any additional steps taken to resolve the issue. A summary of the incident, resolution, and any lessons learned are already shared in the Slack channel. Thus, the team’s internal knowledge base is automatically enhanced for future use.
The Future of Business Efficiency
Nanonets Workflows is a secure, multi-purpose workflow automation platform that automates your manual tasks and workflows. It offers an easy-to-use user interface, making it accessible for both individuals and organizations.
To get started, you can schedule a call with one of our AI experts, who can provide a personalized demo and trial of Nanonets Workflows tailored to your specific use case.
Once set up, you can use natural language to design and execute complex applications and workflows powered by LLMs, integrating seamlessly with your apps and data.
Supercharge your teams with Nanonets Workflows allowing them to focus on what truly matters.
Related content

8 Ways to Use ChatGPT for Finance

Order entry automation simplified

What is the Role of AI in Lending and Loan Management?

Calendly Meeting Analytics
May we suggest a tag, may we suggest an author.
Powerpoint Templates
Icon Bundle
Kpi Dashboard
Professional
Business Plans
Swot Analysis
Gantt Chart
Business Proposal
Marketing Plan
Project Management
Business Case
Business Model
Cyber Security
Business PPT
Digital Marketing
Digital Transformation
Human Resources
Product Management
Artificial Intelligence
Company Profile
Acknowledgement PPT
PPT Presentation
Reports Brochures
One Page Pitch
Interview PPT
All Categories

Lead scoring case study ppt powerpoint presentation infographic template outfit cpb
Get everyone to come to an agreement with our Lead Scoring Case Study Ppt Powerpoint Presentation Infographic Template Outfit Cpb. It helps identify disputed aspects.

These PPT Slides are compatible with Google Slides
Compatible With Google Slides

- Google Slides is a new FREE Presentation software from Google.
- All our content is 100% compatible with Google Slides.
- Just download our designs, and upload them to Google Slides and they will work automatically.
- Amaze your audience with SlideTeam and Google Slides.

Want Changes to This PPT Slide? Check out our Presentation Design Services

Get Presentation Slides in WideScreen
Get This In WideScreen
- WideScreen Aspect ratio is becoming a very popular format. When you download this product, the downloaded ZIP will contain this product in both standard and widescreen format.

- Some older products that we have may only be in standard format, but they can easily be converted to widescreen.
- To do this, please open the SlideTeam product in Powerpoint, and go to
- Design ( On the top bar) -> Page Setup -> and select "On-screen Show (16:9)” in the drop down for "Slides Sized for".
- The slide or theme will change to widescreen, and all graphics will adjust automatically. You can similarly convert our content to any other desired screen aspect ratio.
- Add a user to your subscription for free
You must be logged in to download this presentation.
Do you want to remove this product from your favourites?
PowerPoint presentation slides
Presenting this set of slides with name Lead Scoring Case Study Ppt Powerpoint Presentation Infographic Template Outfit Cpb. This is an editable Powerpoint four stages graphic that deals with topics like Lead Scoring Case Study to help convey your message better graphically. This product is a premium product available for immediate download and is 100 percent editable in Powerpoint. Download this now and use it in your presentations to impress your audience.

People who downloaded this PowerPoint presentation also viewed the following :
- Diagrams , Business , Planning , Strategy , Icons , Business Slides , Flat Designs , Strategic Planning Analysis , Process Management
- Lead Scoring Case Study
Lead scoring case study ppt powerpoint presentation infographic template outfit cpb with all 2 slides:
Handle disputes carefully with our Lead Scoring Case Study Ppt Powerpoint Presentation Infographic Template Outfit Cpb. Give consideration to all the arguments.

Ratings and Reviews

Lead Scoring Case Study
Problem Statement : An education company named X Education sells online courses to industry professionals. On any given day, many professionals who are interested in the courses land on their website and browse for courses. The company markets its courses on several websites and search engines like Google. Once these people land on the website, they might browse the courses or fill up a form for the course or watch some videos. When these people fill up a form providing their email address or phone number, they are classified to be a lead. Moreover, the company also gets leads through past referrals. Once these leads are acquired, employees from the sales team start making calls, writing emails, etc. Through this process, some of the leads get converted while most do not. The typical lead conversion rate at X education is around 30%. There are a lot of leads generated in the initial stage (top) but only a few of them come out as paying customers from the bottom. In the middle stage, you need to nurture the potential leads well (i.e. educating the leads about the product, constantly communicating etc. ) in order to get a higher lead conversion. X Education has appointed you to help them select the most promising leads, i.e. the leads that are most likely to convert into paying customers. The company requires you to build a model wherein you need to assign a lead score to each of the leads such that the customers with higher lead score have a higher conversion chance and the customers with lower lead score have a lower conversion chance. The CEO, in particular, has given a ballpark of the target lead conversion rate to be around 80%.
Our Goals of the Case Study:
- To build a logistic regression model to assign a lead score between 0 and 100 to each of the leads which can be used by the company to target potential leads.
- To adjust to if the company's requirement changes in the future so you will need to handle these as well.
The steps are broadly:
- Read and understand the data
- Clean the data
- Prepare the data for Model Building
- Model Building
- Model Evaluation
- Making Predictions on the Test Set
Import modules
COMMENTS
To associate your repository with the lead-scoring-case-study topic, visit your repo's landing page and select "manage topics." GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Airbnb Case Study- UpGrad. Slide 1: Objective and Background. Slide 2: Data Preparation ... The objective of this presentation is to provide valuable insights and analysis to support the decision-making process for the Head of Acquisitions and Operations, NYC, and the Head of User Experience, NYC at Airbnb. ... Lead Scoring Analysis
The process will involve preparing the data, then building and comparing machine learning models. Along the way I will establish some general rules that apply to predictive lead scoring generally. The data set that I will be using can be downloaded here. You can see and edit the Displayr document containing my analysis in this post here.
Lead Score Case Study_presentation - Free download as PDF File (.pdf), Text File (.txt) or read online for free.
Although lead scoring is an essential component of lead management, there is a lack of a comprehensive literature review and a classification framework dedicated to it. Lead scoring is an effective and efficient way of measuring the quality of leads. In addition, as a critical Information Technology tool, a proper lead scoring model acts as an alleviator to weaken the conflicts between sales ...
This guide will help you understand why, how, and when to implement lead scoring. It will also help you improve execution with best practices and easy-to-use worksheets. Whether you're a lead scoring pro or just getting started, these scoring tactics, case studies, and measurement tips will transform your practices.
Introduction. Lead scoring is an essential methodology in the realm of B2B sales and marketing. At its core, it involves assigning a numerical score to each lead, typically on a scale from 1 to 100, to gauge their likelihood of making a purchase. This process is a strategic approach to understand the potential of every lead that comes into the ...
Presenting this set of slides with name Lead Scoring Case Study Ppt Powerpoint Presentation Infographic Template Outfit Cpb. This is an editable Powerpoint four stages graphic that deals with topics like Lead Scoring Case Study to help convey your message better graphically. This product is a premium product available for immediate download and ...
Lead Scoring Case Study_Summary - Free download as PDF File (.pdf), Text File (.txt) or read online for free. Lead Scoring Case Study Summary
Case Study: Lead Scoring less than 1 minute read Problem Statement. An education company named X Education sells online courses to industry professionals. The company markets its courses on several websites and search engines like Google. Once these people land on the website, they might browse the courses or fill up a form for the course or ...
If the issue persists, it's likely a problem on our side. Unexpected token < in JSON at position 4. keyboard_arrow_up. content_copy. SyntaxError: Unexpected token < in JSON at position 4. Refresh. Explore and run machine learning code with Kaggle Notebooks | Using data from Leads Dataset.
Lead Scoring Case Study Summary-Mamta Lohani and Garima Bansal - Free download as PDF File (.pdf), Text File (.txt) or read online for free. assignment
Goals of the Case Study. Build a logistic regression model to assign a lead score between 0 and 100 to each of the leads which can be used by the company to target potential leads. A higher score would mean that the lead is hot, i.e. is most likely to convert whereas a lower score would mean that the lead is cold and will mostly not get ...
Lead Scoring Case Study. Problem Statement : An education company named X Education sells online courses to industry professionals. On any given day, many professionals who are interested in the courses land on their website and browse for courses. The company markets its courses on several websites and search engines like Google.