
Analytics Insight

Top 10 Must-Read Data Science Research Papers in 2022

Are you a data science enthusiast? If yes, then this Data Science Research Paper listing is for you
- 1 0 DATA SCIENTISTS THAT TECH ENTHUSIASTS CAN FOLLOW ON LINKEDIN
- ARE YOU A JOB SEEKER? KNOW THE IMPACT OF AI AND DATA SCIENCE
- TOP 10 PYTHON + DATA SCIENCE COURSES YOU SHOULD TAKE UP IN 2022
The Research Papers Includes
Documentation matters: human-centered ai system to assist data science code documentation in computational notebooks, assessing the effects of fuel energy consumption, foreign direct investment and gdp on co2 emission: new data science evidence from europe & central asia, impact on stock market across covid-19 outbreak, exploring the political pulse of a country using data science tools, situating data science, veridicalflow: a python package for building trustworthy data science pipelines with pcs, from ai ethics principles to data science practice: a reflection and a gap analysis based on recent frameworks and practical experience, building an effective data science practice, detection of road traffic anomalies based on computational data science, data science data governance [ai ethics].

Disclaimer: Any financial and crypto market information given on Analytics Insight are sponsored articles, written for informational purpose only and is not an investment advice. The readers are further advised that Crypto products and NFTs are unregulated and can be highly risky. There may be no regulatory recourse for any loss from such transactions. Conduct your own research by contacting financial experts before making any investment decisions. The decision to read hereinafter is purely a matter of choice and shall be construed as an express undertaking/guarantee in favour of Analytics Insight of being absolved from any/ all potential legal action, or enforceable claims. We do not represent nor own any cryptocurrency, any complaints, abuse or concerns with regards to the information provided shall be immediately informed here .
You May Also Like

Is Scorpion Casino Token The Next 100x Crypto After Shiba Inu and Pepe Coin?

10 Project Ideas Based on Generative Adversarial Networks (GAN)

Reviewing the Behaviour of Neanderthals using AI Applications

10 Tips for Online Casino Promotion in 2023-2024
Analytics Insight® is an influential platform dedicated to insights, trends, and opinion from the world of data-driven technologies. It monitors developments, recognition, and achievements made by Artificial Intelligence, Big Data and Analytics companies across the globe.

- Select Language:
- Privacy Policy
- Content Licensing
- Terms & Conditions
- Submit an Interview
Special Editions
- Dec – Crypto Weekly Vol-1
- 40 Under 40 Innovators
- Women In Technology
- Market Reports
- AI Glossary
- Infographics
Latest Issue

Disclaimer: Any financial and crypto market information given on Analytics Insight is written for informational purpose only and is not an investment advice. Conduct your own research by contacting financial experts before making any investment decisions, more information here .
Second Menu

Subscribe to the PwC Newsletter
Join the community, search results, data interpreter: an llm agent for data science.
1 code implementation • 28 Feb 2024
Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness.

Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science
3 code implementations • 20 Mar 2016
As the field of data science continues to grow, there will be an ever-increasing demand for tools that make machine learning accessible to non-experts.
Automating biomedical data science through tree-based pipeline optimization
1 code implementation • 28 Jan 2016
Over the past decade, data science and machine learning has grown from a mysterious art form to a staple tool across a variety of fields in academia, business, and government.

Identifying and Harnessing the Building Blocks of Machine Learning Pipelines for Sensible Initialization of a Data Science Automation Tool
1 code implementation • 29 Jul 2016
In this chapter, we present a genetic programming-based AutoML system called TPOT that optimizes a series of feature preprocessors and machine learning models with the goal of maximizing classification accuracy on a supervised classification problem.
Lux: Always-on Visualization Recommendations for Exploratory Dataframe Workflows
1 code implementation • 30 Apr 2021
Exploratory data science largely happens in computational notebooks with dataframe APIs, such as pandas, that support flexible means to transform, clean, and analyze data.
Databases Human-Computer Interaction
Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence
2 code implementations • 12 Feb 2020
Smarter applications are making better use of the insights gleaned from data, having an impact on every industry and research discipline.
Xorbits: Automating Operator Tiling for Distributed Data Science
1 code implementation • 29 Dec 2023
However, existing systems often struggle with processing large datasets due to Out-of-Memory (OOM) problems caused by poor data partitioning.
Distributed, Parallel, and Cluster Computing
Machine Learning in Asset Management—Part 2: Portfolio Construction—Weight Optimization. The Journal of Financial Data Science
1 code implementation • Journal of Financial Data Science 2020
This is the second in a series of articles dealing with machine learning in asset management.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
1 code implementation • 26 Apr 2021
We present Syft 0. 5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems.
A generic framework for privacy preserving deep learning
4 code implementations • 9 Nov 2018
We detail a new framework for privacy preserving deep learning and discuss its assets.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Int J Environ Res Public Health
Data Science in Healthcare: COVID-19 and Beyond
Data science is an interdisciplinary field that applies numerous techniques, such as machine learning (ML), neural networks (NN) and artificial intelligence (AI), to create value, based on extracting knowledge and insights from available ‘big’ data [ 1 ]. The recent advances in data science and AI have had a major impact on healthcare already, as can be seen in the recent biomedical literature [ 2 ]. Improved sharing and analysis of medical data results in earlier and better diagnoses, and more patient-tailored treatments. This increased data sharing, in combination with advances in health data management, works hand-in-hand with trends such as increased patient-centricity (with shared decision making), self-care (e.g., using wearables), and integrated healthcare delivery. Using data science and AI, researchers can deliver new approaches to merge, analyze, and process complex data and gain more actionable insights, understanding, and knowledge at the individual and population level [ 3 ]. AI can be applied in all three major areas of early detection and diagnosis, treatment, as well as outcome prediction and prognosis evaluation [ 4 ]. ML algorithms can make predictions on how a disease will develop or respond to treatment, deep learning algorithms can find malignant tumors in magnetic resonance (MR) images and digital pathology images, and natural language-processing (NLP) algorithms can analyze unstructured documents with high speed and accuracy. These are just a few examples of what data science can do. This Special Issue focuses on how data science and AI are used in healthcare, and on related topics such as data sharing and data management. Since this Special Issue contains papers from 2020 to 2022, naturally there are a few papers about the COVID-19 pandemic: one on the determination of potential risk factors for the case fatality rate, one on the analysis of Arabic Twitter data to detect government pandemic measures and public concerns, and one on an enhanced sentinel surveillance system for outbreak prediction. There are also papers about data-sharing initiatives, depression treatment, the relationship between depression and metabolic status, cardiac thoracic pain, hand-foot-and-mouth disease infection, arteriovenous fistula (AVF) failure, chronic kidney disease (CKD) and breast cancer diagnosis.
“Coronavirus Disease 2019 (COVID-19): A Modeling Study of Factors Driving Variation in Case Fatality Rate by Country” by Pan et al. [ 5 ], “COVID-19: Detecting Government Pandemic Measures and Public Concerns from Twitter Arabic Data using Distributed Machine Learning” by Alomari et al. [ 6 ] and “Enhanced Sentinel Surveillance System for COVID-19 Outbreak Prediction in a Large European Dialysis Clinics Network” by Bellocchio et al. [ 7 ] all present research around the COVID-19 pandemic. Pan et al. [ 5 ] identified 24 potential risk factors driving variation in SARS-CoV-2 case fatality rate (CFR). Their model predicted an increased CFR for countries that waited over 14 days to implement social distancing interventions after the 100th reported case. Smoking prevalence and the percentage population over the age of 70 years were also associated with higher CFR. Hospital beds per 1000 and CT scanners per million were identified as possible protective factors associated with decreased CFR. Alomari et al. [ 6 ] proposes a software tool comprising a collection of unsupervised Latent Dirichlet Allocation (LDA) ML and other methods for the analysis of Twitter data in Arabic with the aim to detect government pandemic measures and public concerns during the COVID-19 pandemic. Using the tool, they collected a dataset comprising 14 million tweets from the Kingdom of Saudi Arabia (KSA) for the period 1 February to 1 June 2020. They detected 15 government pandemic measures and public concerns, and six macro-concerns (economic sustainability, social sustainability, etc.), and formulated their information-structural, temporal, and spatio-temporal relationships. Bellocchio et al. [ 7 ] present a sentinel surveillance system supported by an ML prediction model, whereby the occurrence of COVID-19 cases in a clinic propagates distance-weighted risk estimates to adjacent dialysis units. The system allows for a prompt risk assessment and a timely response to the challenges posed by the COVID-19 epidemic throughout Fresenius Medical Care (FMC) European dialysis clinics.
“Sharing Is Caring-Data Sharing Initiatives in Healthcare” by Hulsen [ 8 ] shows an analysis of the current literature around data sharing, and discusses five aspects of data sharing in the medical domain, namely publisher requirements, data ownership, growing support for data sharing, data sharing initiatives and how the use of federated data might be a solution. With federated data, there is no need for a centralized source database (with all its privacy issues), because the algorithm is brought to the data instead of the other way around. The author also discusses some potential future developments around data sharing, such as medical crowdsourcing and data generalists.
“Digital Training for Non-Specialist Health Workers to Deliver a Brief Psychological Treatment for Depression in Primary Care in India: Findings From a Randomized Pilot Study” by Muke et al. [ 9 ] evaluates the feasibility and acceptability of a digital program for training non-specialist health workers to deliver a brief psychological treatment for depression. This study, performed in Sehore (a rural district in Madhya Pradesh, India) adds to mounting efforts aimed at leveraging digital technology to increase the availability of evidence-based mental health services in low-resource primary care settings in.
“Association of Metabolically Healthy Obesity and Future Depression; Using National Health Insurance System Data in Korea from 2009–2017” by Seo et al. [ 10 ] investigates if depression and metabolic status are relevant by classifying them into the following four categories by their metabolic status and body mass index: (1) metabolically healthy non-obese (MHN); (2) metabolically healthy obese (MHO); (3) metabolically unhealthy non-obese (MUN); and (4) metabolically unhealthy obese (MUO). Their results show that the MHN ratio in women is higher than in men. In both men and women, depression incidence was the highest among MUO participants. In female participants, MHO is also related to a higher risk of depressive symptoms. This indicates that MHO is not an entirely benign condition in relation to depression in women. Therefore, reducing the number of metabolic syndrome and obesity patients in Korea will likely reduce the incidence of depression.
“Assessment of Thoracic Pain Using Machine Learning: A Case Study from Baja California, Mexico” by Rojas-Mendizabal et al. [ 11 ] aims to determine the correlated variables with thoracic pain of cardiac origin. Their analysis of 258 geriatric patients from Medical Norte Hospital in Tijuana (Baja California, Mexico) uses two ML techniques, i.e., tree classification and cross-validation. Their results suggest that among the main factors related to cardiac thoracic pain are dyslipidemia, chronic kidney failure, hypertension, diabetes, smoking habits, and troponin levels at the time of admission.
“Optimized Neural Network Based on Genetic Algorithm to Construct Hand-Foot-and-Mouth Disease Prediction and Early-Warning Model” by Lin et al. [ 12 ] discusses the high number of recent infections of hand-foot-and-mouth disease (HFMD). Previous research on the prevalence of HFMD mainly predicts the number of future cases based on the number of historical cases in various places, and the influence of many related factors that affect the prevalence of this disease is ignored. Existing early-warning research of HFMD mainly uses direct case report, which uses statistical methods in time and space to provide early-warnings of outbreaks separately. It leads to a high error rate and low confidence in the early-warning results. This paper uses ML methods to establish an HFMD epidemic prediction model with a high accuracy. Both incidence data and environmental (mostly weather) data are used.
“Development and Validation of a Machine Learning Model Predicting Arteriovenous Fistula Failure in a Large Network of Dialysis Clinics” by Ricardo et al. [ 13 ] derived and validated an arteriovenous fistula failure model (AVF-FM) based on ML. The model was trained in the derivation set (70% of initial cohort) by exploiting the information routinely collected in the Nephrocare European Clinical Database (EuCliD; 13,369 patients). Model performance was tested by concordance statistic and calibration charts in the remaining 30% of records. Feature importance was computed using the SHapley Additive exPlanations (SHAP) method. The model achieved good discrimination and calibration properties by combining routinely collected clinical and sensor data, requiring no additional effort by healthcare staff. Therefore, it can potentially facilitate risk-based personalization of AVF surveillance strategies.
In “Validation of a Novel Predictive Algorithm for Kidney Failure in Patients Suffering from Chronic Kidney Disease: The Prognostic Reasoning System for Chronic Kidney Disease (PROGRES-CKD)” by Ricardo et al. [ 14 ] a novel algorithm predicting end-stage kidney disease (ESKD) is described, named PROGRES-CKD. This Naïve-Bayes classifier accurately predicts kidney failure onset among chronic kidney disease (CKD) patients. Contrary to equation-based scores, PROGRES-CKD extends to patients with incomplete data and allows for the explicit assessment of prediction robustness in case of missing values. The algorithm may efficiently assist physicians’ prognostic reasoning in real-life applications.
Finally, Rasool et al. [ 15 ] discuss in “Improved Machine Learning-based Predictive Models for Breast Cancer Diagnosis” four different predictive models to improve breast-cancer diagnostic accuracy, as well as data exploratory techniques (DET) such as feature distribution, correlation, elimination and hyperparameter optimization. The Wisconsin Diagnostic Breast Cancer (WDBC) and Breast Cancer Coimbra Dataset (BCCD) datasets were used as input. They report a significant improvement in the models’ diagnostic capability with their DET. Therefore, the techniques can help to improve breast cancer diagnosis.
The manuscripts in this Special Issue give us only a brief overview of the wide use of data science in healthcare, and offer a glimpse into the future, where even faster computers and more advanced AI algorithms will make many more applications possible. For example, whereas many AI algorithms only use data from specific data types, this can be expanded to a combination of a wide range of patient-related (structured or unstructured) data, including clinical data, imaging data, digital pathology data, genomics data, data from wearables, and much more, to optimize the result for the patient. AI systems will not replace clinicians on a large scale, but rather will support their care for patients [ 16 ]. For example, AI can also be used to optimize the workflow in the hospital, or to create intelligent chatbots to help patients while reducing the workload for the clinicians. Furthermore, AI algorithms created in these times of COVID-19 might be of good use when managing similar pandemics in the future. It is probably safe to say that in ten years from now, there will not be a ‘Data Science in Healthcare’ Special Issue, because by that time almost everything in healthcare will be influenced by data science.
This research received no external funding.
Conflicts of Interest
The author declares no conflict of interest.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts

Two decades of fumigation data from the Soybean Free Air Concentration Enrichment facility
- Elise Kole Aspray
- Timothy A. Mies
- Elizabeth A. Ainsworth
Announcements

Collection open for submissions
Scientific Data is open to submissions for this special collection: Meteorology and hydroclimate observations and models

Scientific Data is open to submissions for this special collection: Genomics data for plant ecology, conservation and agriculture

Scientific Data is open to submissions for this special collection: Medical imaging data for digital diagnostics
Find out more about Scientific Data
Find the right repository for your data
Advertisement
Latest Research articles

Multi-year time series of daily solute and isotope measurements from three Swiss pre-Alpine catchments
- Julia L. A. Knapp
- Tracy Napitupulu
- James W. Kirchner
Towards Gender Harmony Dataset: Gender Beliefs and Gender Stereotypes in 62 Countries
- Natasza Kosakowska-Berezecka
- Tomasz Besta
- Magdalena Żadkowska

High spatial resolution elevation change dataset derived from ICESat-2 crossover points on the Tibetan Plateau
- Tengfei Chen

Total irrigation by crop in the Continental United States from 2008 to 2020
- P. J. Ruess
- Megan Konar
- Marc F. P. Bierkens

Spatiotemporal atmospheric in-situ carbon dioxide data over the Indian sites-data perspective
- Mahesh Pathakoti
- Mahalakshmi D.V.
- Vinay Kumar Dadhwal

High-quality chromosome-level genome assembly of Nicotiana benthamiana
- Sanghee Lee
- Ah-Young Shin
News & Comment

AI and the democratization of knowledge
The solution of the longstanding “protein folding problem” in 2021 showcased the transformative capabilities of AI in advancing the biomedical sciences. AI was characterized as successfully learning from protein structure data , which then spurred a more general call for AI-ready datasets to drive forward medical research. Here, we argue that it is the broad availability of knowledge , not just data, that is required to fuel further advances in AI in the scientific domain. This represents a quantum leap in a trend toward knowledge democratization that had already been developing in the biomedical sciences: knowledge is no longer primarily applied by specialists in a sub-field of biomedicine, but rather multidisciplinary teams, diverse biomedical research programs, and now machine learning. The development and application of explicit knowledge representations underpinning democratization is becoming a core scientific activity, and more investment in this activity is required if we are to achieve the promise of AI.
- Christophe Dessimoz
- Paul D. Thomas

A Framework for the Interoperability of Cloud Platforms: Towards FAIR Data in SAFE Environments
As the number of cloud platforms supporting scientific research grows, there is an increasing need to support interoperability between two or more cloud platforms. A well accepted core concept is to make data in cloud platforms Findable, Accessible, Interoperable and Reusable (FAIR). We introduce a companion concept that applies to cloud-based computing environments that we call a S ecure and A uthorized F AIR E nvironment (SAFE). SAFE environments require data and platform governance structures and are designed to support the interoperability of sensitive or controlled access data, such as biomedical data. A SAFE environment is a cloud platform that has been approved through a defined data and platform governance process as authorized to hold data from another cloud platform and exposes appropriate APIs for the two platforms to interoperate.
- Robert L. Grossman
- Rebecca R. Boyles
Who owns (or controls) health data?
The ongoing debate on secondary use of health data for research has been renewed by the passage of comprehensive data privacy laws that shift control from institutions back to the individuals on whom the data was collected. Rights-based data privacy laws, while lauded by individuals, are viewed as problematic for the researcher due to the distributed nature of data control. Efforts such as the European Health Data Space initiative seek to build a new mechanism for secondary use that erodes individual control in favor of broader secondary use for beneficial health research. Health information sharing platforms do exist that embrace rights-based data privacy while simultaneously providing a rich research environment for secondary data use. The benefits of embracing rights-based data privacy to promote transparency of data use along with control of one’s participation builds the trust necessary for more inclusive/diverse/representative clinical research.
- Scott D. Kahn
- Sharon F. Terry

A General Primer for Data Harmonization
Data harmonization is an important method for combining or transforming data. To date however, articles about data harmonization are field-specific and highly technical, making it difficult for researchers to derive general principles for how to engage in and contextualize data harmonization efforts. This commentary provides a primer on the tradeoffs inherent in data harmonization for researchers who are considering undertaking such efforts or seek to evaluate the quality of existing ones. We derive this guidance from the extant literature and our own experience in harmonizing data for the emergent and important new field of COVID-19 public health and safety measures (PHSM).
- Cindy Cheng
- Luca Messerschmidt
- Joan Barceló

Enhancing radiomics and Deep Learning systems through the standardization of medical imaging workflows
Recent advances in computer-aided diagnosis, treatment response and prognosis in radiomics and deep learning challenge radiology with requirements for world-wide methodological standards for labeling, preprocessing and image acquisition protocols. The adoption of these standards in the clinical workflows is a necessary step towards generalization and interoperability of radiomics and artificial intelligence algorithms in medical imaging.
- Miriam Cobo
- Pablo Menéndez Fernández-Miranda
- Lara Lloret Iglesias
Journal Production Guidance for Software and Data Citations
Software and data citation are emerging best practices in scholarly communication. This article provides structured guidance to the academic publishing community on how to implement software and data citation in publishing workflows. These best practices support the verifiability and reproducibility of academic and scientific results, sharing and reuse of valuable data and software tools, and attribution to the creators of the software and data. While data citation is increasingly well-established, software citation is rapidly maturing. Software is now recognized as a key research result and resource, requiring the same level of transparency, accessibility, and disclosure as data. Software and data that support academic or scientific results should be preserved and shared in scientific repositories that support these digital object types for discovery, transparency, and use by other researchers. These goals can be supported by citing these products in the Reference Section of articles and effectively associating them to the software and data preserved in scientific repositories. Publishers need to markup these references in a specific way to enable downstream processes.
- Shelley Stall
- Geoffrey Bilder
- Timothy Clark
Trending - Altmetric
Curation of a list of chemicals in biosolids from EPA National Sewage Sludge Surveys & Biennial Review Reports
A large normative connectome for exploring the tractographic correlates of focal brain interventions
Physiological data for affective computing in HRI with anthropomorphic service robots: the AFFECT-HRI data set
This journal is a member of and subscribes to the principles of the Committee on Publication Ethics.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

data analysis Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Introduce a Survival Model with Spatial Skew Gaussian Random Effects and its Application in Covid-19 Data Analysis
Futuristic prediction of missing value imputation methods using extended ann.
Missing data is universal complexity for most part of the research fields which introduces the part of uncertainty into data analysis. We can take place due to many types of motives such as samples mishandling, unable to collect an observation, measurement errors, aberrant value deleted, or merely be short of study. The nourishment area is not an exemption to the difficulty of data missing. Most frequently, this difficulty is determined by manipulative means or medians from the existing datasets which need improvements. The paper proposed hybrid schemes of MICE and ANN known as extended ANN to search and analyze the missing values and perform imputations in the given dataset. The proposed mechanism is efficiently able to analyze the blank entries and fill them with proper examining their neighboring records in order to improve the accuracy of the dataset. In order to validate the proposed scheme, the extended ANN is further compared against various recent algorithms or mechanisms to analyze the efficiency as well as the accuracy of the results.
Applications of multivariate data analysis in shelf life studies of edible vegetal oils – A review of the few past years
Hypothesis formalization: empirical findings, software limitations, and design implications.
Data analysis requires translating higher level questions and hypotheses into computable statistical models. We present a mixed-methods study aimed at identifying the steps, considerations, and challenges involved in operationalizing hypotheses into statistical models, a process we refer to as hypothesis formalization . In a formative content analysis of 50 research papers, we find that researchers highlight decomposing a hypothesis into sub-hypotheses, selecting proxy variables, and formulating statistical models based on data collection design as key steps. In a lab study, we find that analysts fixated on implementation and shaped their analyses to fit familiar approaches, even if sub-optimal. In an analysis of software tools, we find that tools provide inconsistent, low-level abstractions that may limit the statistical models analysts use to formalize hypotheses. Based on these observations, we characterize hypothesis formalization as a dual-search process balancing conceptual and statistical considerations constrained by data and computation and discuss implications for future tools.
The Complexity and Expressive Power of Limit Datalog
Motivated by applications in declarative data analysis, in this article, we study Datalog Z —an extension of Datalog with stratified negation and arithmetic functions over integers. This language is known to be undecidable, so we present the fragment of limit Datalog Z programs, which is powerful enough to naturally capture many important data analysis tasks. In limit Datalog Z , all intensional predicates with a numeric argument are limit predicates that keep maximal or minimal bounds on numeric values. We show that reasoning in limit Datalog Z is decidable if a linearity condition restricting the use of multiplication is satisfied. In particular, limit-linear Datalog Z is complete for Δ 2 EXP and captures Δ 2 P over ordered datasets in the sense of descriptive complexity. We also provide a comprehensive study of several fragments of limit-linear Datalog Z . We show that semi-positive limit-linear programs (i.e., programs where negation is allowed only in front of extensional atoms) capture coNP over ordered datasets; furthermore, reasoning becomes coNEXP-complete in combined and coNP-complete in data complexity, where the lower bounds hold already for negation-free programs. In order to satisfy the requirements of data-intensive applications, we also propose an additional stability requirement, which causes the complexity of reasoning to drop to EXP in combined and to P in data complexity, thus obtaining the same bounds as for usual Datalog. Finally, we compare our formalisms with the languages underpinning existing Datalog-based approaches for data analysis and show that core fragments of these languages can be encoded as limit programs; this allows us to transfer decidability and complexity upper bounds from limit programs to other formalisms. Therefore, our article provides a unified logical framework for declarative data analysis which can be used as a basis for understanding the impact on expressive power and computational complexity of the key constructs available in existing languages.
An empirical study on Cross-Border E-commerce Talent Cultivation-—Based on Skill Gap Theory and big data analysis
To solve the dilemma between the increasing demand for cross-border e-commerce talents and incompatible students’ skill level, Industry-University-Research cooperation, as an essential pillar for inter-disciplinary talent cultivation model adopted by colleges and universities, brings out the synergy from relevant parties and builds the bridge between the knowledge and practice. Nevertheless, industry-university-research cooperation developed lately in the cross-border e-commerce field with several problems such as unstable collaboration relationships and vague training plans.
The Effects of Cross-border e-Commerce Platforms on Transnational Digital Entrepreneurship
This research examines the important concept of transnational digital entrepreneurship (TDE). The paper integrates the host and home country entrepreneurial ecosystems with the digital ecosystem to the framework of the transnational digital entrepreneurial ecosystem. The authors argue that cross-border e-commerce platforms provide critical foundations in the digital entrepreneurial ecosystem. Entrepreneurs who count on this ecosystem are defined as transnational digital entrepreneurs. Interview data were dissected for the purpose of case studies to make understanding from twelve Chinese immigrant entrepreneurs living in Australia and New Zealand. The results of the data analysis reveal that cross-border entrepreneurs are in actual fact relying on the significant framework of the transnational digital ecosystem. Cross-border e-commerce platforms not only play a bridging role between home and host country ecosystems but provide entrepreneurial capitals as digital ecosystem promised.
Subsampling and Jackknifing: A Practically Convenient Solution for Large Data Analysis With Limited Computational Resources
The effects of cross-border e-commerce platforms on transnational digital entrepreneurship, a trajectory evaluator by sub-tracks for detecting vot-based anomalous trajectory.
With the popularization of visual object tracking (VOT), more and more trajectory data are obtained and have begun to gain widespread attention in the fields of mobile robots, intelligent video surveillance, and the like. How to clean the anomalous trajectories hidden in the massive data has become one of the research hotspots. Anomalous trajectories should be detected and cleaned before the trajectory data can be effectively used. In this article, a Trajectory Evaluator by Sub-tracks (TES) for detecting VOT-based anomalous trajectory is proposed. Feature of Anomalousness is defined and described as the Eigenvector of classifier to filter Track Lets anomalous trajectory and IDentity Switch anomalous trajectory, which includes Feature of Anomalous Pose and Feature of Anomalous Sub-tracks (FAS). In the comparative experiments, TES achieves better results on different scenes than state-of-the-art methods. Moreover, FAS makes better performance than point flow, least square method fitting and Chebyshev Polynomial Fitting. It is verified that TES is more accurate and effective and is conducive to the sub-tracks trajectory data analysis.
Export Citation Format
Share document.
Data Science and Artificial Intelligence
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Data Science
Methods, infrastructure, and applications, latest issue, back volumes, issn online, aims & scope, editorial board, author guidelines, abstracted/indexed in, peer review.
Data Science is an interdisciplinary journal that addresses the development that data has become a crucial factor for a large number and variety of scientific fields. This journal covers aspects around scientific data over the whole range from data creation, mining, discovery, curation, modeling, processing, and management to analysis, prediction, visualization, user interaction, communication, sharing, and re-use. We are interested in general methods and concepts, as well as specific tools, infrastructures, and applications. The ultimate goal is to unleash the power of scientific data to deepen our understanding of physical, biological, and digital systems, gain insight into human social and economic behavior, and design new solutions for the future. The rising importance of scientific data, both big and small, brings with it a wealth of challenges to combine structured, but often siloed data with messy, incomplete, and unstructured data from text, audio, visual content such as sensor and weblog data. New methods to extract, transport, pool, refine, store, analyze, and visualize data are needed to unleash their power while simultaneously making tools and workflows easier to use by the public at large. The journal invites contributions ranging from theoretical and foundational research, platforms, methods, applications, and tools in all areas. We welcome papers which add a social, geographical, and temporal dimension to data science research, as well as application-oriented papers that prepare and use data in discovery research.
Core Topics
This journal focuses on methods, infrastructure, and applications around the following core topics:
- scientific data mining, machine learning, and Big Data analytics
- scientific data management, network analysis, and knowledge discovery
- scholarly communication and (semantic) publishing
- research data publication, indexing, quality, and discovery
- data wrangling, integration, and provenance of scientific data
- trend analysis, prediction, and visualization of research topics
- crowdsourcing and collaboration in science
- corroboration, validation, trust, and reproducibility of scientific results
- scalable computing, analysis, and learning for data science
- scientific web services and executable workflows
- scientific analytics, intelligence, and real time decision making
- socio-technical systems
- social impacts of data science
Open Access The journal is open access and articles are published under the CC-BY license.
Speedy Reviewing Data Science is committed to avoid wasting time during the reviewing period. Authors will receive the first decision within weeks rather than months. To achieve that, the journal asks reviewers to complete their reviews within 10 days.
Open and Attributed Reviews Reviews are non-anonymous by default (but reviewers can request to stay anonymous). All reviews are made openly available under CC-BY licenses after a decision has been made for the submission (independent of whether the decision was accept or reject). In addition to solicited reviews, everybody is welcome to submit additional reviews and comments for papers that are under review. Editors and non-anonymous reviewers will be mentioned in the published articles.
Pre-Prints All submitted papers are made available as pre-prints before the reviewing starts, so reviewers and everybody else are free to not only read but also share submitted papers. Pre-prints will remain available after reviewing, independent of whether the paper was accepted or rejected for publication.
Data Standards Data Science wishes to promote an environment where annotated data is produced and shared with the wider research community. The journal therefore requires authors to ensure that any data used or produced in their study are represented with community-based data formats and metadata standards. These data should furthermore be made openly available and freely reusable, unless privacy concerns apply.
Semantic Publishing Data Science encourages authors to provide (meta)data with formal semantics, as a step towards the vision of semantic publishing to integrate, combine, organize, and reuse scientific knowledge. Data Science plans to experiment with different such approaches, and we will announce more details soon.
HTML The journal encourages authors to submit their papers in HTML (but accepts Word and LaTeX submissions too).
ORCID Data Science is working with ORCID to collect iDs for all authors, co-authors, editorial board members, and reviewers and connect them to the information about your research activities stored in our systems.
Editors-in-Chief
Michel Dumontier Maastricht University The Netherlands
Tobias Kuhn VU University Amsterdam The Netherlands
Editorial Assistant
Cristina Bucur VU University Amsterdam The Netherlands
Victor de Boer VU University Amsterdam The Netherlands
Philip E. Bourne University of Virginia USA
Alison Callahan Stanford University USA
Thomas Chadefaux Trinity College Dublin Ireland
Christine Chichester Nestle Institute of Health Sciences Switzerland
Tim Clark University of Virginia USA
Oscar Corcho Universidad Politécnica de Madrid Spain
Gargi Datta SomaLogic USA
Brian Davis NUI Galway Ireland
Manisha Desai Stanford University USA
Emilio Ferrara University of Southern California USA
Pascale Gaudet SIB Swiss Institute of Bioinformatics Switzerland
Olivier Gevaert Stanford University USA
Yolanda Gil University of Southern California USA
Frank van Harmelen VU University Amsterdam The Netherlands
Rinke Hoekstra VU University Amsterdam The Netherlands
Robert Hoehndorf KAUST Saudi Arabia
Lawrence Hunter University of Colorado Denver USA
Toshiaki Katayama Database Center for Life Science Japan
Michael Krauthammer Yale University USA
Thomas Maillart UC Berkeley USA
Richard Mann Leeds University United Kingdom
Michael Mäs University of Groningen The Netherlands
Jamie McCusker RPI USA
Pablo Mendes IBM USA
Izabela Moise ETH Zurich Switzerland
Matjaz Perc University of Maribor Slovenia
Silvio Peroni University of Bologna Italy
Steve Pettifer Manchester United Kingdom
Evangelos Pournaras ETH Zurich Switzerland
Núria Queralt Rosinach The Scripps Research Institute USA
Jodi Schneider University of Illinois at Urbana-Champaign USA
Manik Sharma DAV University Jalandhar India
Ruben Verborgh Ghent University Belgium
Karin Verspoor University of Melbourne Australia
Mark Wilkinson UPM Madrid Spain
Olivia Woolley Meza ETH Zurich Switzerland
Submissions
By submitting my article to this journal, I agree to the Author Copyright Agreement , the IOS Press Ethics Policy , and the IOS Press Privacy Policy .
Open Access
Data Science is an open acces journal with articles published under the Creative Commons Attribution License (CC BY 4.0). The article publication charges (APCs) are waived for papers submitted before December 31, 2023. Please visit datasciencehub.net for details.
Guidelines for Authors
Authors should closely follow the guidelines below before submitting a manuscript.
All papers have to be written in English.
Paper Types
Data Science is open for submissions of the following types:
- Research Papers : We accept as main category research papers that report on original research. Results previously published at conferences or workshops may be submitted as extended versions.
- Position Papers : We accept position papers presenting discussions and viewpoints around data science topics. These papers do not need an evaluation, but need to present relevant and novel discussion points in a thorough manner.
- Survey Papers : We also publish survey papers of the state of the art of topics central to the journal’s scope. Survey articles should be comprehensive and balanced, and should have the potential to become well-known introductory and overview texts.
- Resource Papers : Resource papers introduce and describe a resource of value for further research, including but not limited to datasets, benchmarks, software tools/frameworks/services, methodologies, and protocols.
By submitting your manuscript you agree that it will be made available on the journal website as a preprint, and it will remain available after acceptance or rejection together with the reviews. Removal of a manuscript during or after review is not possible.
Paper Length
The following length limits apply for the different paper types:
- Research papers: 12,000 words
- Position papers: 8,000 words
- Survey papers: 16,000 words
- Reports: 5,000 words
Note that these word counts are not targets but maximum values. Papers may be significantly shorter. Exceptions for longer papers are possible if well justified (contact the editors-in-chief before submitting papers that exceed the stated word limits).
These word counts include the abstract, tables, and figure and table captions. Author lists and references, however, are not counted. Each figure counts for an additional 300 words.
Author contributions
Any author included in the author list should have contributed significantly to the paper, and no person who has made a significant contribution should be omitted from the list of authors. Please read the IOS Press authorship policy for further information.
Papers in HTML
We encourage authors to submit their papers in HTML. There are various tools and templates for that, such as RASH , dokieli , and Authorea .
The Research Articles in Simplified HTML (RASH) ( doc, paper ) is a markup language that restricts the use of HTML elements to only 32 elements for writing academic research articles. It is possible to includes also RDFa annotations within any element of the language and other RDF statements in Turtle, JSON-LD and RDF/XML format by using the appropriate tag script. Authors can start from this generic template , which can be also found in the convenient ZIP archive ZIP archive containing the whole RASH package. Alternatively, these guidelines for OpenOffice and Word explain how to write a scholarly paper by using the basic features available in OpenOffice Writer and Microsoft Word, in a way that it can be converted into RASH by means of the RASH Online Conversion Service ( ROCS ) ( src, paper ).
As a second alternative, dokieli is a client-side editor for decentralized article publishing in HTML+RDFa, annotations and social interactions, compliant with the Linked Research initiative. There are a variety of examples in the wild , including the LNCS and ACM author guidelines as templates.
Papers in Word or LaTeX
We prefer HTML, but we also accept submissions in Word or LaTeX. In that case, please use the official templates by IOS Press .
Semantic Publishing
This is optional, but we would like to encourage you to provide semantic (meta-)data with your scientific papers, but unfortunately no accepted standards, best practices, or nice tools exist for that yet. We are working to fix this. In the meantime, and if you are a bit experienced with RDF, we are very happy to receive your RDFa-enriched paper or a submission with separate RDF statements. We are also happy to help you with that, if you are not experienced with RDF.
We hope to be able to provide more general and more user-friendly guidelines for semantic publishing in the near future.
All relevant data that were used or produced for conducting the work presented in a paper must be made FAIR and compliant with the PLOS data availability guidelines prior to submission. See in particular the list of recommended data repositories . (We might provide our own data availability guidelines in the future, but we borrow the excellent PLOS guidelines for now.) In a nutshell, data have to be made openly accessible and freely reusable via established institutions and standards, unless privacy concerns forbid such a publication. In any case, metadata have to be made publicly accessible and visible.
Evaluation Criteria
See the reviewing guidelines below for the specific criteria according to which submitted papers are evaluated.
Copyright of your article Authors submitting a manuscript do so on the understanding that they have read and agreed to the terms of the IOS Press Author Copyright Agreement .
Article sharing Authors of journal articles are permitted to self-archive and share their work through institutional repositories, personal websites, and preprint servers. Authors have the right to use excerpts of their article in other works written by the authors themselves, provided that the original work is properly cited. The consent for sharing an article, in whole or in part, depends on the version of the article that is shared, where it is shared, and the copyright license under which the article is published. Please refer to the IOS Press Article Sharing Policy for further information.
Quoting from other publications Authors, when quoting from someone else's work or when considering reproducing figures or tables from a book or journal article, should make sure that they are not infringing a copyright. Although in general authors may quote from other published works, permission should be obtained from the holder of the copyright if there will be substantial extracts or reproduction of tables, plates, or other figures. If the copyright holder is not the author of the quoted or reproduced material, it is recommended that the permission of the author should also be sought. Material in unpublished letters and manuscripts is also protected and must not be published unless permission has been obtained. Submission of a paper will be interpreted as a statement that the author has obtained all the necessary permission. A suitable acknowledgement of any borrowed material must always be made.
Please visit the IOS Press Authors page for further information.
Guidelines for reviewers.
In order to facilitate a speedy reviewing process, reviewers are requested to submit their assessment within 10 days. Reviews consist of the parts described below.
Overall recommendation
The review of a paper should suggest one of the following overall recommendations:
- Accept. The article is accepted as is, or only minor problems must be addressed by the authors that do not require another round of reviewing but can be verified by the editorial and publication team.
- Undecided. Authors must revise their manuscript to address specific concerns before a final decision is reached. A revised manuscript will be subject to second round of peer review in which the decision will be either Accept or Reject and no further review will be performed.
- Reject. The work cannot be published based on the lack of interest, lack of novelty, insufficient conceptual advance or major technical and/or interpretational problems.
The review should evaluate the paper with respect to the following criteria.
Significance:
- Does the work address an important problem within the research fields covered by the journal?
Background:
- Is the work appropriately based on and connected to the relevant related work?
- For research papers: Does the work provide new insights or new methods of a substantial kind?
- For position papers: Does the work provide a novel and potentially disruptive view on the given topic?
- For survey papers: Does the work provide an overview that is unique in its scope or structure for the given topic?
Technical quality:
- For research papers: Are the methods adequate for the addressed problem, are they correctly and thoroughly applied, and are their results interpreted in a sound manner?
- For position papers: Is the advocated position supported by sound and thorough arguments?
- For survey papers: Is the topic covered in a comprehensive and well balanced manner, are the covered approaches accurately described and compared, and are they placed in a convincing common framework?
Presentation:
- Are the text, figures, and tables of the work accessible, pleasant to read, clearly structured, and free of major errors in grammar or style?
- Is the length of the manuscript appropriate for what it presents?
Data availability:
- Are all used and produced data are openly available in established data repositories, as mandated by FAIR and the data availability guidelines ?
Summary and Comments
- Summary of paper in a few sentences
- Reasons to accept
- Reasons to reject
- Further comments (optional)
IOS Pre-press This journal publishes all its articles in the IOS Press Pre-Press module. By publishing articles ahead of print the latest research can be accessed much quicker. The pre-press articles are the corrected proof versions of the article and are published online shortly after the proof is created and author corrections implemented. Pre-press articles are fully citable by using the DOI number. As soon as the pre-press article is assigned to an issue, the final bibliographic information will be added. The pre-press version will then be replaced by the updated, final version.
Archiving Data Science deposits all published articles in trusted digital archiving services. These include CLOCKSS and the e-depot of the National Library of the Netherlands. This ensures that articles are preserved and always remain available and openly accessible to everyone.
ACM Guide to Computing Literature DBLP DOAJ Google Scholar Scopus
Data Science Peer Review Policy
Data Science relies on an open and transparent peer review process. Papers submitted to the journal are quickly pre-screened by the Editors-in-Chief and if deemed suitable for formal review they are immediately published as pre-prints on the journal’s website . Please visit our reviewer guidelines for further information about how to conduct a review.
Reasons to reject a paper in the pre-screening process could be because the work does not fall within the aims and scope, the writing is of poor quality, the instructions to authors were not followed or the presented work is not novel.
Papers that are suitable for review are posted on the journal's website and are publicly available. In addition to solicited reviews by members of the editorial board, public reviews and comments are welcome by any researcher and can be uploaded using the journal website. All reviews and responses from the authors are posted on the website as well. All involved reviewers and editors will be acknowledged in the final published version.
Reviewers are by default identified by name although all reviewers do have the option to remain anonymous. All review reports are made openly available under CC-BY licenses after a decision has been made for the submission (independent of whether the decision was accept or reject). In addition to solicited reviews, any researcher is welcome to submit additional reviews and comments for papers that are under review. Editors and non-anonymous reviewers will be mentioned in the published articles.
Each paper that undergoes peer review is assigned a handling editor who will be responsible for inviting reviewers to comment on the paper.
The reviewer of a paper is asked to submit one of the following overall recommendations:
- Accept . The article is accepted as is, or only minor problems must be addressed by the authors that do not require another round of reviewing but can be verified by the editorial and publication team.
- Undecided . Authors must revise their manuscript to address specific concerns before a final decision is reached. A revised manuscript will be subject to second round of peer review in which the decision will be either Accept or Reject and no further review will be performed.
- Reject . The work cannot be published based on the lack of interest, lack of novelty, insufficient conceptual advance or major technical and/or interpretational problems.
Reviewers are requested to evaluate a paper with respect to the following criteria:
- Significance . Does the work address an important problem within the research fields covered by the journal?
- Background . Is the work appropriately based on and connected to the relevant related work?
- Novelty . For research papers: Does the work provide new insights or new methods of a substantial kind? For position papers: Does the work provide a novel and potentially disruptive view on the given topic? For survey papers: Does the work provide an overview that is unique in its scope or structure for the given topic? For resource papers: Does the presented resource have significant unique features that can enable novel scientific work?
- Technical quality . For research papers: Are the methods adequate for the addressed problem, are they correctly and thoroughly applied, and are their results interpreted in a sound manner? For position papers: Is the advocated position supported by sound and thorough arguments? For survey papers: Is the topic covered in a comprehensive and well balanced manner, are the covered approaches accurately described and compared, and are they placed in a convincing common framework? For resource papers: Is the presented resource carefully designed and implemented following the relevant best practices, and does it provide sound evidence of its (potential for) reuse?
- Presentation . Are the text, figures, and tables of the work accessible, pleasant to read, clearly structured, and free of major errors in grammar or style?
- Length . Is the length of the manuscript appropriate for what it presents?
- Data availability . Are all used and produced data are openly available in established data repositories, as mandated by FAIR and the data availability guidelines ?
Finally, reviewers are asked to answer the following points:
Accept or reject decisions are made by the Editors-in-Chief, whose decision is final.
APCs Waived : Article processing charges (APCs) are waived for papers submitted to the open access Data Science (DS) journal before Dec 31, 2022.
Newsletter : You can view a sample newsletter here . Be sure to sign up to the DS newsletter to receive alerts of new issues and other journal news. Sign up via this link: tiny.cc/DSsignup .
Latest Articles
Discover the contents of the latest journal issue:.
Towards time-evolving analytics: Online learning for time-dependent evolving data streams Alessio Bernardo, Giacomo Ziffer, Emanuele Della Valle, Vitor Cerqueira, Albert Bifet
DWAEF: a deep weighted average ensemble framework harnessing novel indicators for sarcasm detection1 Simrat Deol, Richa Sharma, Udit Kaushish, Prakher Pandey, Vishal Maurya
Sustainable Development Goals
The content of this journal relates to sdg:.

Visit the SDG page for more information.
Supporting diversity and inclusion, this journal supports ios press' actions relating to the sustainable development goals (sdgs) and commits to the diversity and inclusion statement ..

More information will be available in due course. Check the SDGs page for updates.
Related News
Sage grows research portfolio by acquiring ios press.
Los Angeles, USA – Global independent academic publisher Sage has acquired IOS Press, an independent publisher founded in Amsterdam in 1987 that specializes in...
Towards FAIR Principles for Research Software
The most viewed article in Data Science in the first half of 2020 focuses on FAIR principles in relation to research software. The position paper analyzes where...
IOS Press Publishes Inaugural Issue of Open Access journal Data Science
Amsterdam, NL – IOS Press is proud to announce the publication of the first issue of Data Science , a new interdisciplinary peer-reviewed open access journal...
Related Publications
International symposium on world ecological design, publication date, electronic engineering and informatics, artificial intelligence and human-computer interaction.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: ferret-ui: grounded mobile ui understanding with multimodal llms.
Abstract: Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Read our research on: Gun Policy | International Conflict | Election 2024
Regions & Countries
Political typology quiz.
Notice: Beginning April 18th community groups will be temporarily unavailable for extended maintenance. Thank you for your understanding and cooperation.
Where do you fit in the political typology?
Are you a faith and flag conservative progressive left or somewhere in between.

Take our quiz to find out which one of our nine political typology groups is your best match, compared with a nationally representative survey of more than 10,000 U.S. adults by Pew Research Center. You may find some of these questions are difficult to answer. That’s OK. In those cases, pick the answer that comes closest to your view, even if it isn’t exactly right.
About Pew Research Center Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
- MyU : For Students, Faculty, and Staff
Fall 2024 CSCI Special Topics Courses
Cloud computing.
Meeting Time: 09:45 AM‑11:00 AM TTh Instructor: Ali Anwar Course Description: Cloud computing serves many large-scale applications ranging from search engines like Google to social networking websites like Facebook to online stores like Amazon. More recently, cloud computing has emerged as an essential technology to enable emerging fields such as Artificial Intelligence (AI), the Internet of Things (IoT), and Machine Learning. The exponential growth of data availability and demands for security and speed has made the cloud computing paradigm necessary for reliable, financially economical, and scalable computation. The dynamicity and flexibility of Cloud computing have opened up many new forms of deploying applications on infrastructure that cloud service providers offer, such as renting of computation resources and serverless computing. This course will cover the fundamentals of cloud services management and cloud software development, including but not limited to design patterns, application programming interfaces, and underlying middleware technologies. More specifically, we will cover the topics of cloud computing service models, data centers resource management, task scheduling, resource virtualization, SLAs, cloud security, software defined networks and storage, cloud storage, and programming models. We will also discuss data center design and management strategies, which enable the economic and technological benefits of cloud computing. Lastly, we will study cloud storage concepts like data distribution, durability, consistency, and redundancy. Registration Prerequisites: CS upper div, CompE upper div., EE upper div., EE grad, ITI upper div., Univ. honors student, or dept. permission; no cr for grads in CSci. Complete the following Google form to request a permission number from the instructor ( https://forms.gle/6BvbUwEkBK41tPJ17 ).
CSCI 5980/8980
Machine learning for healthcare: concepts and applications.
Meeting Time: 11:15 AM‑12:30 PM TTh Instructor: Yogatheesan Varatharajah Course Description: Machine Learning is transforming healthcare. This course will introduce students to a range of healthcare problems that can be tackled using machine learning, different health data modalities, relevant machine learning paradigms, and the unique challenges presented by healthcare applications. Applications we will cover include risk stratification, disease progression modeling, precision medicine, diagnosis, prognosis, subtype discovery, and improving clinical workflows. We will also cover research topics such as explainability, causality, trust, robustness, and fairness.
Registration Prerequisites: CSCI 5521 or equivalent. Complete the following Google form to request a permission number from the instructor ( https://forms.gle/z8X9pVZfCWMpQQ6o6 ).
Visualization with AI
Meeting Time: 04:00 PM‑05:15 PM TTh Instructor: Qianwen Wang Course Description: This course aims to investigate how visualization techniques and AI technologies work together to enhance understanding, insights, or outcomes.
This is a seminar style course consisting of lectures, paper presentation, and interactive discussion of the selected papers. Students will also work on a group project where they propose a research idea, survey related studies, and present initial results.
This course will cover the application of visualization to better understand AI models and data, and the use of AI to improve visualization processes. Readings for the course cover papers from the top venues of AI, Visualization, and HCI, topics including AI explainability, reliability, and Human-AI collaboration. This course is designed for PhD students, Masters students, and advanced undergraduates who want to dig into research.
Registration Prerequisites: Complete the following Google form to request a permission number from the instructor ( https://forms.gle/YTF5EZFUbQRJhHBYA ). Although the class is primarily intended for PhD students, motivated juniors/seniors and MS students who are interested in this topic are welcome to apply, ensuring they detail their qualifications for the course.
Visualizations for Intelligent AR Systems
Meeting Time: 04:00 PM‑05:15 PM MW Instructor: Zhu-Tian Chen Course Description: This course aims to explore the role of Data Visualization as a pivotal interface for enhancing human-data and human-AI interactions within Augmented Reality (AR) systems, thereby transforming a broad spectrum of activities in both professional and daily contexts. Structured as a seminar, the course consists of two main components: the theoretical and conceptual foundations delivered through lectures, paper readings, and discussions; and the hands-on experience gained through small assignments and group projects. This class is designed to be highly interactive, and AR devices will be provided to facilitate hands-on learning. Participants will have the opportunity to experience AR systems, develop cutting-edge AR interfaces, explore AI integration, and apply human-centric design principles. The course is designed to advance students' technical skills in AR and AI, as well as their understanding of how these technologies can be leveraged to enrich human experiences across various domains. Students will be encouraged to create innovative projects with the potential for submission to research conferences.
Registration Prerequisites: Complete the following Google form to request a permission number from the instructor ( https://forms.gle/Y81FGaJivoqMQYtq5 ). Students are expected to have a solid foundation in either data visualization, computer graphics, computer vision, or HCI. Having expertise in all would be perfect! However, a robust interest and eagerness to delve into these subjects can be equally valuable, even though it means you need to learn some basic concepts independently.
Sustainable Computing: A Systems View
Meeting Time: 09:45 AM‑11:00 AM Instructor: Abhishek Chandra Course Description: In recent years, there has been a dramatic increase in the pervasiveness, scale, and distribution of computing infrastructure: ranging from cloud, HPC systems, and data centers to edge computing and pervasive computing in the form of micro-data centers, mobile phones, sensors, and IoT devices embedded in the environment around us. The growing amount of computing, storage, and networking demand leads to increased energy usage, carbon emissions, and natural resource consumption. To reduce their environmental impact, there is a growing need to make computing systems sustainable. In this course, we will examine sustainable computing from a systems perspective. We will examine a number of questions: • How can we design and build sustainable computing systems? • How can we manage resources efficiently? • What system software and algorithms can reduce computational needs? Topics of interest would include: • Sustainable system design and architectures • Sustainability-aware systems software and management • Sustainability in large-scale distributed computing (clouds, data centers, HPC) • Sustainability in dispersed computing (edge, mobile computing, sensors/IoT)
Registration Prerequisites: This course is targeted towards students with a strong interest in computer systems (Operating Systems, Distributed Systems, Networking, Databases, etc.). Background in Operating Systems (Equivalent of CSCI 5103) and basic understanding of Computer Networking (Equivalent of CSCI 4211) is required.
- Future undergraduate students
- Future transfer students
- Future graduate students
- Future international students
- Diversity and Inclusion Opportunities
- Learn abroad
- Living Learning Communities
- Mentor programs
- Programs for women
- Student groups
- Visit, Apply & Next Steps
- Information for current students
- Departments and majors overview
- Departments
- Undergraduate majors
- Graduate programs
- Integrated Degree Programs
- Additional degree-granting programs
- Online learning
- Academic Advising overview
- Academic Advising FAQ
- Academic Advising Blog
- Appointments and drop-ins
- Academic support
- Commencement
- Four-year plans
- Honors advising
- Policies, procedures, and forms
- Career Services overview
- Resumes and cover letters
- Jobs and internships
- Interviews and job offers
- CSE Career Fair
- Major and career exploration
- Graduate school
- Collegiate Life overview
- Scholarships
- Diversity & Inclusivity Alliance
- Anderson Student Innovation Labs
- Information for alumni
- Get engaged with CSE
- Upcoming events
- CSE Alumni Society Board
- Alumni volunteer interest form
- Golden Medallion Society Reunion
- 50-Year Reunion
- Alumni honors and awards
- Outstanding Achievement
- Alumni Service
- Distinguished Leadership
- Honorary Doctorate Degrees
- Nobel Laureates
- Alumni resources
- Alumni career resources
- Alumni news outlets
- CSE branded clothing
- International alumni resources
- Inventing Tomorrow magazine
- Update your info
- CSE giving overview
- Why give to CSE?
- College priorities
- Give online now
- External relations
- Giving priorities
- Donor stories
- Impact of giving
- Ways to give to CSE
- Matching gifts
- CSE directories
- Invest in your company and the future
- Recruit our students
- Connect with researchers
- K-12 initiatives
- Diversity initiatives
- Research news
- Give to CSE
- CSE priorities
- Corporate relations
- Information for faculty and staff
- Administrative offices overview
- Office of the Dean
- Academic affairs
- Finance and Operations
- Communications
- Human resources
- Undergraduate programs and student services
- CSE Committees
- CSE policies overview
- Academic policies
- Faculty hiring and tenure policies
- Finance policies and information
- Graduate education policies
- Human resources policies
- Research policies
- Research overview
- Research centers and facilities
- Research proposal submission process
- Research safety
- Award-winning CSE faculty
- National academies
- University awards
- Honorary professorships
- Collegiate awards
- Other CSE honors and awards
- Staff awards
- Performance Management Process
- Work. With Flexibility in CSE
- K-12 outreach overview
- Summer camps
- Outreach events
- Enrichment programs
- Field trips and tours
- CSE K-12 Virtual Classroom Resources
- Educator development
- Sponsor an event
Towards synergy: network facility development, whole process carbon reduction and pollution reduction, and regional disparities
- Research Article
- Published: 17 April 2024
Cite this article
- Xuefeng Zhang 1 , 2 ,
- Hui Sun 1 , 2 ,
- Xuechao Xia 1 , 2 ,
- Zedong Yang 1 , 2 &
- Shusen Zhu 1 , 2
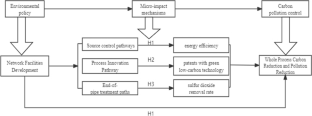
The in-depth implementation of the “Broadband China Strategy” is of great significance in promoting the synergistic governance of urban carbon reduction and pollution reduction. In this paper, based on the “Broadband China” pilot program implemented in China in 2014 as a quasi-natural experiment, the coupled synergy model is used to measure the carbon and pollution reduction synergy index based on the balanced panel data of 277 prefectural-level cities and above in China from 2006 to 2020, and the staggered and synthetic DID methods are applied to investigate the impact of the Broadband China strategy on carbon and pollution reduction synergy and its mechanism. strategy on carbon and pollution reduction synergy and its mechanism. The conclusions of the study show that (1) the Broadband China strategy significantly improves the synergistic governance of carbon reduction and pollution reduction. (2) The mechanism results show that Broadband China mainly realizes carbon and pollution synergistic governance by promoting source control and process innovation but does not have an effective mediating role in end-of-pipe treatment. (3) The results of heterogeneity analysis show that Broadband China weakens the traditional geographic advantage, narrows the carbon pollution synergistic governance gap at the national and regional levels, and significantly improves the regional carbon reduction and pollution reduction governance level. This paper examines the micro-mechanism of the Broadband China strategy on carbon pollution synergistic governance from the whole process of production activities, which provides a new perspective for the study of carbon pollution synergistic governance, and provides an empirical basis for carbon pollution synergistic governance in China.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Data availability
Not applicable.
Aldakhil AM, Zaheer A, Younas S (2019) Efficiently managing green information and communication technologies, high-technology exports, and research and development expenditures: a case study. J Clean Prod 240:118164
Article Google Scholar
Arkhangelsky D, Athey S, Hirshberg D, Imbens G, Wager S (2021) Synthetic difference in differences. American Economic Review 111(12):4088–4118
Ayres RU, Walter J (1991) The greenhouse effect: damages, costs and abatement. Environ Resource Econ 1(3):237–270
Bhui B, Vairakannu P (2019) Prospects and issues of integration of co-combustion of solid fuels (coal and biomass) in chemical loo** technology. J Environ Manage 231:1241–1256
Article CAS Google Scholar
Burtraw D, Krupnick A, Palmer K et al (2003) Ancillary benefits of reduced air pollution in the US from moderate greenhouse gas mitigation policies in the electricity sector. J Environ Econ Manag 45(3):650–673
Cengiz D, Dube A, Lindner A, Zipperer B (2019) The effect of minimum wages on low-wage jobs. Q J Econ 134(3):1405–1454
Chen Y, Lee C (2020) Does technological innovation reduce CO2 emissions? Cross-country evidence. J Clean Prod 263:121550
Cohen M, Tubb A (2017) The impact of environmental regulation on firm and country competitiveness: a meta-analysis of the Porter hypothesis. J Assoc Environ Resour Econ 5:371–399
Google Scholar
Dai Z, Viswanathan H, Middleton R, Pan F, Ampomah W, Yang C, Jia W, Xiao T, Lee S, McPherson B, Balch R, Grigg R, White M (2016) CO2 Accounting and risk analysis for CO2 sequestration at enhanced oil recovery sites. Environ Sci Technol 50(14):7546–7554
De Chaisemartin C, D’Haultfoeuille X (2020) Two-way fixed effects estimators with heterogeneous treatment effects. Am Econ Rev 110(9):2964–2996
Dong H, Dai H, Dong L, Fujita T, Geng Y, Klimont Z, Inoue T, Bunya S, Fujii M, Masui T (2015) Pursuing air pollutant co-benefits of CO 2 mitigation in China: a provincial leveled analysis. Appl Energy 144:165–174
Dong L, Fujita T, Dai M, Geng Y, Ren J, Fujii M, Wang Y, Ohnishi S (2016) Towards preventative eco-industrial development: an industrial and urban symbiosis case in one typical industrial city in China. J Clean Prod 114:387–400
Du LJ ,Liu Y, Diao XW (2019) Assessing regional differences in green innovation efficiency of industrial enterprises in China[J]. Int J Environ Res Public Health 16(6):940
Freyaldenhoven S, Hansen C, Pérez JP, Shapiro JM (2021) Visualization, identification, and estimation in the linear panel event-study design (No. w29170). Natl Bureau Econ Res
Gao XW, Liu N, Hua YJ (2022) Environmental protection tax law on the synergy of pollution reduction and carbon reduction in China: evidence from a panel data of 107 cities. Sustain Prod Consum 33:425–437
Gong DC, Kao CW, Peters BA (2019) Sustainability investments and production planning decisions based on environmental management. J Clean Prod 225:196–208
Goodman-Bacon A (2021) Difference-in-differences with variation in treatment timing. J Econom 225(2):254–277
Griffith R, Redding S, Van Reenen J (2004) Mapping the two faces of R&D: productivity growth in a panel of OECD industries. Rev Econ Rev Econ Stats 86(4):883–895
Gu B, Chen F, Zhang K (2021) The policy effect of green finance in promoting industrial transformation and upgrading efficiency in China: analysis from the perspective of government regulation and public environmental demands. Environ Sci Pollut Res 28(34):47474–47491
Guo J-X (2019) Cleaner technology choice in the synergistic control process for greenhouse gases and air pollutions. J Clean Prod 117885
Halkos GE, Gkampoura EC (2021) Examining the linkages among carbon dioxide emissions, electricity production and economic growth in different income levels. Energies 14(6):1682
Harris I, Naim M, Palmer A, Potter A, Mumford C (2011) Assessing the impact of cost optimization based on infrastructure modelling on CO2 emissions. Int J Prod Econ 131:313–321
Hossain M (2015) Broadband internet through home electric power cable and network of electronic equipments. Int J Adv Sci Technol 85:9–16
Hung L, Goggins J, Meier P, Monahan E, Foley M (2020) An investigation of a passive opened top-end pipe as an alternative solution for passive soil depressurisation systems for indoor radon mitigation. Sci Total Environ 748:141167
IPCC, 2021, Climate Change (2021) The physical science basis contribution of working group I to the sixth assessment report of the intergovernmental panel on climate change
Jakob M, Steckel J, Klasen S, Lay J, Grunewald N, Martínez-Zarzoso I, Renner S, Edenhofer O (2014) Feasible mitigation actions in developing countries. Nat Clim Chang 4:961–968
Jaramillo P, Muller N (2016) Air pollution emissions and damages from energy production in the U.S: 2002–2011. Energy Policy 90:202–211
Jiao JD, Huang Y, Liao CP (2020) Co-benefits of reducing CO2 and air pollutant emissions in the urban transport sector: a case of Guangzhou. Energy Sustain Dev 59:131–143
Kowarsch M (2016) An evaluation of the IPCC WG III assessments. 249–272. https://doi.org/10.1007/978-3-319-43281-6_10
Li Z, Zheng C, Liu A et al (2022) Environmental taxes, green subsidies, and cleaner production willingness: evidence from China’s publicly traded companies. Technol Forecast Soc Chang 183:121906
Liu L, Wang Y, Xu Y (2022) A practical guide to counterfactual estimators for causal inference with time‐series cross‐sectional data[J]. Am J Political Sci 68(1):160–176
Liu B, Li Y, Tian X, Sun L, Xiu P (2023) Can digital economy development contribute to the low-carbon transition? Evidence from the city level in China[J]. Int J Environ Res Public Health 20(3):2733
Lorente DB, Joof F, Samour A (2023) Renewable energy, economic complexity and biodiversity risk: new insights from China. Environ Sustain Indic 18:100244
Marsden G, Rye T (2010) The governance of transport and climate change. J Transp Geogr 18:669–678
Nam KM, Waugh CJ, Paltsev S (2013) Carbon co-benefits of tighter SO2 and NO, regulations in China. Glob Environ Chang 6:1648–1661
Palencia J, Furubayashi T, Nakata T (2013) Analysis of CO2 emissions reduction potential in secondary production and semi-fabrication of non-ferrous metals. Energy Policy 52:328–341
Renna P (2013) Decision model to support the SMEs’ decision to participate or leave a collaborative network. Int J Prod Res 51:1973–1983
Roodman D, Nielsen M, MacKinnon JG, Webb MD (2019) Fast and wild: bootstrap inference in Stata. Stata J 19(1):4–60
Salahuddin M, Alam K, Ozturk I (2016) The effects of internet usage and economic growth on CO2 emissions in OECD countries: a panel investigation. Renew Sustain Energy Rev 62:1226–1235
Shao X, Zhong Y, Liu W, Li R (2021) Modeling the effect of green technology innovation and renewable energy on carbon neutrality in N-11 countries? Evidence from advance panel estimations. J Environ Manage 296:113189
Sun Y, Bi K, Yin S (2020) Measuring and integrating risk management into green innovation practices for green manufacturing under the global value chain. Sustainability 12(2):545
Surugiu MR (2007) Alternative sources of energy-alternative sources of pollution? Romanian J Econ 24.1(33):93–120
Swart R, Amann M, Raes F (2004) A good climate for clean air: linkages between climate change and air pollution. an editorial essay. Clim Change 66:263–269
Taleb M (2023) Modelling environmental energy efficiency in the presence of carbon emissions: Modified oriented efficiency measures under polluting technology of data envelopment analysis[J]. J Clean Prod, p 414
Tao CQ, Yi MY, Wang CS (2023) Coupling coordination analysis and spatiotemporal heterogeneity between data elements and green development in China. Econ Anal Policy 77:1–15
Wang H, Cui H, Zhao Q (2021a) Effect of green technology innovation on green total factor productivity in China: evidence from spatial Durbin model analysis. Production 288:125624
Wang L, Chen Y, Ramsey T, Hewings G (2021b) Will researching digital technology really empower green development? Technol Soc, p 66
Wang J, Zhao J, Dong K, Dong X (2022) How does the internet economy affect CO2 emissions? Evidence from China. Appl Econ 55:447–466
Wang J, Lv W (2023) Research on the impact of green innovation network embeddedness on corporate environmental responsibility[J]. Int J Environ Res Public Health 20(4):3433
Wanlu W, Cheng Y, Xiqiao L, Yao X (2019) How does the implementation of the policy of electricity Substitution influence green economic growth in China? Energy Policy 131:251–261
Williams ML (2007) UK air quality in 2050: synergies with climate change policies. Environ Sci Policy 10(2):169–175
Wu H, Guo H, Zhang B (2017) Westward movement of new polluting firms in China: pollution reduction mandates and location choice. J Comp Econ 45(1):119–138
Xie H, Tan X, Li J, Qu S, Yang C (2023) Does information infrastructure promote low-carbon development? Evidence from the “Broadband China” pilot policy[J]. Int J Environ Res Public Health 20(2):962
Xu L, Fan M, Yang L, Shao S (2021) Heterogeneous green innovations and carbon emission performance: evidence at China’s city level. Energy Econ
Xu B, Lin B (2016) Reducing carbon dioxide emissions in China’s manufacturing industry: a dynamic vector autoregression approach. J Clean Prod 131:594–606
Yan Z, Zhou Z, Du K (2023) How does environmental regulatory stringency affect energy consumption? Evidence from Chinese firms[J]. Energy Econ, p 118
Yi W, Zou L, Guo J, Wang K, Wei Y (2011) How can China reach its CO2 intensity reduction targets by 2020? A regional allocation based on equity and development. Energy Policy 39:2407–2415
Yu X, Wang P (2021) Economic effects analysis of environmental regulation policy in the process of industrial structure upgrading: evidence from Chinese. Sci Total Environ 753:142004
Yu Y, Zhang N (2021) Low-carbon city pilot and carbon emission efficiency: quasi-experimental evidence from China. Energy Econ 96:105125
Zeng L, Chen M, Zhang F (2020) Urban cost performance and industrial agglomeration: city-level evidence from China. Emerg Mark Financ Trade 56:1615–1629
Zeng H, Li X, Zhou Q (2022) Local government environmental regulatory pressures and corporate environmental strategies: Evidence from natural resource accountability audits in China. Bus Strateg Environ 31(7):3060–3082
Zhang Y, Ma S, Yang H, Lv J, Liu Y (2018) A big data driven analytical framework for energy-intensive manufacturing industries. J Clean Prod 197:57–72
Zhong X, Liu G, Chen P (2022) The impact of internet development on urban eco-efficiency-a quasi-natural experiment of “Broadband China” pilot policy. Int J Environ Res Public Health 19(3):1363
Download references
This research was supported by the National Natural Science Foundation of China (71963030), Xinjiang Social Science Foundation of China (21BJY050), and Major Projects of Science and Technology Ministry of China (SQ2021xjkk01800).
Author information
Authors and affiliations.
Xinjiang Innovation Management Research Center, Xinjiang University, Urumqi, 830046, Xinjiang, China
Xuefeng Zhang, Hui Sun, Xuechao Xia, Zedong Yang & Shusen Zhu
School of Economics and Management, Xinjiang University, Urumqi, 830046, Xinjiang, China
You can also search for this author in PubMed Google Scholar
Contributions
Xuefeng Zhang: conceptualization, formal analysis, methodology, writing—original draft, software. Hui Sun: funding acquisition. Xuechao Xia: supervision, project administration, review and editing. Zedong Yang: supervision, project administration, review and editing, Shusen Zhu: data curation, validation.
Corresponding author
Correspondence to Hui Sun .
Ethics declarations
Ethics approval, consent to participate, consent for publication, conflict of interest.
The authors declared that they have no conflicts of interest to this work.
Additional information
Responsible Editor: Ilhan Ozturk
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Zhang, X., Sun, H., Xia, X. et al. Towards synergy: network facility development, whole process carbon reduction and pollution reduction, and regional disparities. Environ Sci Pollut Res (2024). https://doi.org/10.1007/s11356-024-33271-4
Download citation
Received : 19 December 2023
Accepted : 06 April 2024
Published : 17 April 2024
DOI : https://doi.org/10.1007/s11356-024-33271-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Network facility construction
- Carbon reduction and pollution reduction synergy
- Heterogeneous treatment effect
- Regional disparity
- Find a journal
- Publish with us
- Track your research
Facility for Rare Isotope Beams
At michigan state university, frib researchers lead team to merge nuclear physics experiments and astronomical observations to advance equation-of-state research, world-class particle-accelerator facilities and recent advances in neutron-star observation give physicists a new toolkit for describing nuclear interactions at a wide range of densities..
For most stars, neutron stars and black holes are their final resting places. When a supergiant star runs out of fuel, it expands and then rapidly collapses on itself. This act creates a neutron star—an object denser than our sun crammed into a space 13 to 18 miles wide. In such a heavily condensed stellar environment, most electrons combine with protons to make neutrons, resulting in a dense ball of matter consisting mainly of neutrons. Researchers try to understand the forces that control this process by creating dense matter in the laboratory through colliding neutron-rich nuclei and taking detailed measurements.
A research team—led by William Lynch and Betty Tsang at FRIB—is focused on learning about neutrons in dense environments. Lynch, Tsang, and their collaborators used 20 years of experimental data from accelerator facilities and neutron-star observations to understand how particles interact in nuclear matter under a wide range of densities and pressures. The team wanted to determine how the ratio of neutrons to protons influences nuclear forces in a system. The team recently published its findings in Nature Astronomy .
“In nuclear physics, we are often confined to studying small systems, but we know exactly what particles are in our nuclear systems. Stars provide us an unbelievable opportunity, because they are large systems where nuclear physics plays a vital role, but we do not know for sure what particles are in their interiors,” said Lynch, professor of nuclear physics at FRIB and in the Michigan State University (MSU) Department of Physics and Astronomy. “They are interesting because the density varies greatly within such large systems. Nuclear forces play a dominant role within them, yet we know comparatively little about that role.”
When a star with a mass that is 20-30 times that of the sun exhausts its fuel, it cools, collapses, and explodes in a supernova. After this explosion, only the matter in the deepest part of the star’s interior coalesces to form a neutron star. This neutron star has no fuel to burn and over time, it radiates its remaining heat into the surrounding space. Scientists expect that matter in the outer core of a cold neutron star is roughly similar to the matter in atomic nuclei but with three differences: neutron stars are much larger, they are denser in their interiors, and a larger fraction of their nucleons are neutrons. Deep within the inner core of a neutron star, the composition of neutron star matter remains a mystery.
“If experiments could provide more guidance about the forces that act in their interiors, we could make better predictions of their interior composition and of phase transitions within them. Neutron stars present a great research opportunity to combine these disciplines,” said Lynch.
Accelerator facilities like FRIB help physicists study how subatomic particles interact under exotic conditions that are more common in neutron stars. When researchers compare these experiments to neutron-star observations, they can calculate the equation of state (EOS) of particles interacting in low-temperature, dense environments. The EOS describes matter in specific conditions, and how its properties change with density. Solving EOS for a wide range of settings helps researchers understand the strong nuclear force’s effects within dense objects, like neutron stars, in the cosmos. It also helps us learn more about neutron stars as they cool.
“This is the first time that we pulled together such a wealth of experimental data to explain the equation of state under these conditions, and this is important,” said Tsang, professor of nuclear science at FRIB. “Previous efforts have used theory to explain the low-density and low-energy end of nuclear matter. We wanted to use all the data we had available to us from our previous experiences with accelerators to obtain a comprehensive equation of state.”
Researchers seeking the EOS often calculate it at higher temperatures or lower densities. They then draw conclusions for the system across a wider range of conditions. However, physicists have come to understand in recent years that an EOS obtained from an experiment is only relevant for a specific range of densities. As a result, the team needed to pull together data from a variety of accelerator experiments that used different measurements of colliding nuclei to replace those assumptions with data. “In this work, we asked two questions,” said Lynch. “For a given measurement, what density does that measurement probe? After that, we asked what that measurement tells us about the equation of state at that density.”
In its recent paper, the team combined its own experiments from accelerator facilities in the United States and Japan. It pulled together data from 12 different experimental constraints and three neutron-star observations. The researchers focused on determining the EOS for nuclear matter ranging from half to three times a nuclei’s saturation density—the density found at the core of all stable nuclei. By producing this comprehensive EOS, the team provided new benchmarks for the larger nuclear physics and astrophysics communities to more accurately model interactions of nuclear matter.
The team improved its measurements at intermediate densities that neutron star observations do not provide through experiments at the GSI Helmholtz Centre for Heavy Ion Research in Germany, the RIKEN Nishina Center for Accelerator-Based Science in Japan, and the National Superconducting Cyclotron Laboratory (FRIB’s predecessor). To enable key measurements discussed in this article, their experiments helped fund technical advances in data acquisition for active targets and time projection chambers that are being employed in many other experiments world-wide.
In running these experiments at FRIB, Tsang and Lynch can continue to interact with MSU students who help advance the research with their own input and innovation. MSU operates FRIB as a scientific user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. FRIB is the only accelerator-based user facility on a university campus as one of 28 DOE-SC user facilities . Chun Yen Tsang, the first author on the Nature Astronomy paper, was a graduate student under Betty Tsang during this research and is now a researcher working jointly at Brookhaven National Laboratory and Kent State University.
“Projects like this one are essential for attracting the brightest students, which ultimately makes these discoveries possible, and provides a steady pipeline to the U.S. workforce in nuclear science,” Tsang said.
The proposed FRIB energy upgrade ( FRIB400 ), supported by the scientific user community in the 2023 Nuclear Science Advisory Committee Long Range Plan , will allow the team to probe at even higher densities in the years to come. FRIB400 will double the reach of FRIB along the neutron dripline into a region relevant for neutron-star crusts and to allow study of extreme, neutron-rich nuclei such as calcium-68.
Eric Gedenk is a freelance science writer.
Michigan State University operates the Facility for Rare Isotope Beams (FRIB) as a user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. Hosting what is designed to be the most powerful heavy-ion accelerator, FRIB enables scientists to make discoveries about the properties of rare isotopes in order to better understand the physics of nuclei, nuclear astrophysics, fundamental interactions, and applications for society, including in medicine, homeland security, and industry.
The U.S. Department of Energy Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of today’s most pressing challenges. For more information, visit energy.gov/science.
IMAGES
VIDEO
COMMENTS
Assessing the effects of fuel energy consumption, foreign direct investment and GDP on CO2 emission: New data science evidence from Europe & Central Asia. Fuel . 10.1016/j.fuel.2021.123098 . 2022 . Vol 314 . pp. 123098. Author (s): Muhammad Mohsin . Sobia Naseem .
Assessing the effects of fuel energy consumption, foreign direct investment and GDP on CO2 emission: New data science evidence from Europe & Central Asia. The research paper is written by- Muhammad Mohsin, SobiaNaseem, Muddassar Sarfraz Tamoor, Azam This research paper deals with how bad the effects of fuel consumption are and how data science ...
As an open access platform of the Harvard Data Science Initiative, Harvard Data Science Review (HDSR) features foundational thinking, research milestones, educational innovations, and major applications, with a primary emphasis on reproducibility, replicability, and readability.We aim to publish content that help define and shape data science as a scientifically rigorous and globally impactful ...
This paper shows data science's potential for disruptive innovation in science, industry, policy, and people's lives. We present how data science impacts science and society at large in the coming years, including ethical problems in managing human behavior data and considering the quantitative expectations of data science economic impact. We introduce concepts such as open science and e ...
This paper, released in early 2021 by OpenAI, is probably one of the greatest revolutions in zero-shot classification algorithms, presenting a novel model known as Contrastive Language-Image Pre-Training, or CLIP for short. CLIP was trained over a massive dataset of 400 million pairs of images and their corresponding captions, and has learnt to ...
This research contributes to the creation of a research vector on the role of data science in central banking. In , the authors provide an overview and tutorial on the data-driven design of intelligent wireless networks. The authors in provide a thorough understanding of computational optimal transport with application to data science.
Overview. The International Journal of Data Science and Analytics is a pioneering journal in data science and analytics, publishing original and applied research outcomes. Focuses on fundamental and applied research outcomes in data and analytics theories, technologies and applications. Promotes new scientific and technological approaches for ...
1,000. Paper. Code. Machine Learning in Asset Management—Part 2: Portfolio Construction—Weight Optimization. The Journal of Financial Data Science. 1 code implementation • Journal of Financial Data Science 2020. This is the second in a series of articles dealing with machine learning in asset management. Asset Management BIG-bench Machine ...
Data Science in Science is founded as an open access international journal that publishes original research, letters, and reviews at the intersection of Science and Data Science. Its aim is to advance: Development of additional shared Principles for interpretable, transparent, explainable, and ethical Data Science.
1. Introduction. The use of data science methodologies in medicine and public health has been enabled by the wide availability of big data of human mobility, contact tracing, medical imaging, virology, drug screening, bioinformatics, electronic health records and scientific literature along with the ever-growing computing power [1-4].With these advances, the huge passion of researchers and ...
Data Science in Science is an open access, international journal publishing original research and reviews at the intersection of Science and Data Science. new practices for scientific reproducibility and replicability enabled through Data Science. It promotes the intrinsically multidisciplinary nature of the field of Data Science and seeks ...
Machine learning-based detection of acute psychosocial stress from body posture and movements. Robert Richer. Veronika Koch. Nicolas Rohleder. Open Access. All Research & Reviews.
Data science is an interdisciplinary field that applies numerous techniques, such as machine learning (ML), neural networks (NN) and artificial intelligence (AI), to create value, based on extracting knowledge and insights from available 'big' data [ 1 ]. The recent advances in data science and AI have had a major impact on healthcare ...
data science research activities, along the implications of dif-ferent methods for executing industry and business projects. At present, data science is a young field and conveys the impres-Preprint submitted to Big Data Research - Elsevier January 6, 2020 arXiv:2106.07287v2 [cs.LG] 14 Jan 2022
Scientific Data is an open access journal dedicated to data, publishing descriptions of research datasets and articles on research data sharing from all areas ...
Groq, and the Hardware of AI — Intuitively and Exhaustively Explained. An analysis of the major pieces…. Read more…. 369. 4 responses. Read the latest stories published by Towards Data Science. Your home for data science. A Medium publication sharing concepts, ideas and codes.
About the journal. Data Science and Management (DSM) is a peer-reviewed open access journal for original research articles, review articles and technical reports related to all aspects of data science and its application in the field of business, economics, finance, operations, engineering, healthcare, …. View full aims & scope.
Data science combines the power of computer science and applications, modeling, statistics, engineering, economy and analytics. Whereas a... | Explore the latest full-text research PDFs, articles ...
Joint Representation Learning with Generative Adversarial Imputation Network for Improved Classification of Longitudinal Data. Sharon Torao Pingi. Duoyi Zhang. Richi Nayak. Research Paper Open access 17 October 2023 Pages: 5 - 25. Part of 1 collection: The Innovative Use of Data Science to Transform How We Work and Live.
The Given. Missing data is universal complexity for most part of the research fields which introduces the part of uncertainty into data analysis. We can take place due to many types of motives such as samples mishandling, unable to collect an observation, measurement errors, aberrant value deleted, or merely be short of study.
Read the latest articles of Journal of Computational Mathematics and Data Science at ScienceDirect.com, Elsevier's leading platform of peer-reviewed scholarly literature ... Journal of Computational Mathematics and Data Science welcomes two types of papers: A) Full research papers B) Microarticles: short papers, no more than 6 pages. They may ...
The articles in this special section are dedicated to the application of artificial intelligence AI), machine learning (ML), and data analytics to address different problems of communication systems, presenting new trends, approaches, methods, frameworks, systems for efficiently managing and optimizing networks related operations. Even though AI/ML is considered a key technology for next ...
The journal invites contributions ranging from theoretical and foundational research, platforms, methods, applications, and tools in all areas. We welcome papers which add a social, geographical, and temporal dimension to data science research, as well as application-oriented papers that prepare and use data in discovery research. Core Topics
In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any ...
Take our quiz to find out which one of our nine political typology groups is your best match, compared with a nationally representative survey of more than 10,000 U.S. adults by Pew Research Center. You may find some of these questions are difficult to answer. That's OK. In those cases, pick the answer that comes closest to your view, even if ...
Meeting Time: 04:00 PM‑05:15 PM MW. Instructor: Zhu-Tian Chen. Course Description: This course aims to explore the role of Data Visualization as a pivotal interface for enhancing human-data and human-AI interactions within Augmented Reality (AR) systems, thereby transforming a broad spectrum of activities in both professional and daily contexts.
Based on panel data from 277 prefectural-level cities and above in China from 2006 to 2020, this paper takes the pilot events of China's Broadband China regime in 2014, 2015, and 2016 as the research object and validates the effect of the policy implementation using a multi-temporal double-difference model.
FRIB is the only accelerator-based user facility on a university campus as one of 28 DOE-SC user facilities. Chun Yen Tsang, the first author on the Nature Astronomy paper, was a graduate student under Betty Tsang during this research and is now a researcher working jointly at Brookhaven National Laboratory and Kent State University.