
Open Science at NASA
NASA is making a long-term commitment to building an inclusive open science community over the next decade. Open-source science is a commitment to the open sharing of software, data, and knowledge (algorithms, papers, documents, ancillary information) as early as possible in the scientific process.
Open Principles
The principles of open-source science are to make publicly funded scientific research transparent, inclusive, accessible, and reproducible. Advances in technology, including collaborative tools and cloud computing, help enable open-source science, but technology alone is insufficient. Open-source science requires a culture shift to a more inclusive, transparent, and collaborative scientific process, which will increase the pace and quality of scientific progress.
Open science Facts
Open Transparent Science Scientific processes and results should be open such that they are reproducible by members of the community.
Open Inclusive Science Process and participants should welcome participation by and collaboration with diverse people and organizations.
Open Accessible Science Data, tools, software, documentation, and publications should be accessible to all (FAIR).
Open Reproducible Science Scientific process and results should be open such that they are reproducible by members of the community.
Why Do Open Science?
● Broadens participation and fosters greater collaboration in scientific investigations by lowering the barriers to entry into scientific exploration ● Generates greater impact and more citations to scientific results

Open Culture
To help build a culture of open science, NASA is championing a new initiative: the Open-Source Science Initiative (OSSI) . OSSI is a comprehensive program of activities to enable and support moving science towards openness, including policy adjustments, supporting open-source software, and enabling cyberinfrastructure. OSSI aims to implement NASA’s Strategy for Data Management and Computing for Groundbreaking Science 2019-2024 , which was developed through community input.

Open Science Features and Events

Unveiling the Sun: NASA’s Open Data Approach to Solar Eclipse Research
As the world anticipates the upcoming total solar eclipse on April 8, 2024, NASA is preparing for an extraordinary opportunity for scientific discovery, open collaboration, and public engagement.

Transform to Open Science (TOPS) 2024 Total Solar Eclipse Activities
Explore the data-driven domain of eclipses to help understand how open science principles facilitate the sharing and analysis of information among researchers, students, and enthusiasts.

NASA GeneLab Open Science Success Story: Henry Cope
Hear PhD candidate Henry Cope’s unique journey and how his experience with the Open Science datasets propelled his career in medical and space biology.

Software for the NASA Science Mission Directorate Workshop 2024
This workshop aims to explore the current opportunities and challenges for the various categories of software relevant for activities funded by the NASA Science Mission Directorate (SMD).
Explore Open Science at NASA

Transform to Open Science (TOPS)
Provides the visibility, advocacy, and community resources to support and enable the shift to open science.

Core Data and Computing
The Core Data and Computing Services Program (CDCSP) will provide a layered architecture on which SMD science can scale.

Data and Computing Architecture Study
The Data and Computing Architecture study will investigate the technology needed to support NASA's open science goals.

Artificial Intelligence and Machine Learning
Artificial Intelligence and Machine Learning will play an important role in advancing NASA science.

Open-Source Science Awards
NASA supports open science through call for new innovative programs, supplements to existing awards, and sustainability of software.

Scientific Information Policy
The information produced as part of NASA’s scientific research activities represents a significant public investment. Learn more about how and when it should be shared.

Science Mission Directorate Science Data
The Science Data Repository pages provides a comprehensive list of NASA Science Data Repositories.
Discover More Topics From NASA
James Webb Space Telescope

Perseverance Rover

Parker Solar Probe

Open Research Library

The Open Research Library (ORL) is planned to include all Open Access book content worldwide on one platform for user-friendly discovery, offering a seamless experience navigating more than 20,000 Open Access books.
- Search Search
- CN (Chinese)
- DE (German)
- ES (Spanish)
- FR (Français)
- JP (Japanese)
- Open research
- Booksellers
- Peer Reviewers
- Springer Nature Group ↗
- Fundamentals of open research
- Gold or Green routes to open research
- Benefits of open research
- Open research timeline
- Whitepapers
- About overview
- Journal pricing FAQs
- Publishing an OA book
- Journals & books overview
- Open access agreements
- OA article funding
- Article OA funding and policy guidance
- OA book funding
- Book OA funding and policy guidance
- Funding & support overview
- Springer Nature journal policies
- APC waivers and discounts
- Springer Nature book policies
- Publication policies overview
The fundamentals of open access and open research
What is open access and open research.
Open access (OA) refers to the free, immediate, online availability of research outputs such as journal articles or books, combined with the rights to use these outputs fully in the digital environment. OA content is open to all, with no access fees.
Open research goes beyond the boundaries of publications to consider all research outputs – from data to code and even open peer review. Making all outputs of research as open and accessible as possible means research can have a greater impact, and help to solve some of the world’s greatest challenges.
Learn more about gold open access
How can i publish my work open access.
As the author of a research article or book, you have the ability to ensure that your research can be accessed and used by the widest possible audience. Springer Nature supports immediate Gold OA as the most open, least restrictive form of OA: authors can choose to publish their research article in a fully OA journal, a hybrid or transformative journal, or as an OA book or OA chapter.
Alternatively, where articles, books or chapters are published via the subscription route, Springer Nature allows authors to archive the accepted version of their manuscript on their own personal website or their funder’s or institution’s repository, for public release after an embargo period (Green OA). Find out more.
Why should I publish OA?
What is cc by.
The CC BY licence is the most open licence available and considered the industry 'gold standard' for OA; it is also preferred by many funders. It lets others distribute, remix, tweak, and build upon your work, even commercially, as long as they credit you for the original creation. It offers maximum dissemination and use of licenced materials. All Springer Nature journals with OA options offer the CC BY licence, and this is now the default licence for the majority of Springer Nature fully OA journals. It is also the default license for OA books and chapters. Other Creative Commons licenses are available on request.
How do I pay for open access?
As costs are involved in every stage of the publication process, authors are asked to pay an open access fee in order for their article to be published open access under a creative commons license. Springer Nature offers a free open access support service to make it easier for our authors to discover and apply for funding to cover article processing charges (APCs) and/or book processing charges (BPCs). Find out more.
What is open data?
We believe that all research data, including research files and code, should be as open as possible and want to make it easier for researchers to share the data that support their publications, making them accessible and reusable. Find out more about our research data services and policies.
What is a preprint?
A preprint is a version of a scientific manuscript posted on a public server prior to formal peer review. Once posted, the preprint becomes a permanent part of the scientific record, citable with its own unique DOI . Early sharing is recommended as it offers an opportunity to receive feedback on your work, claim priority for a discovery, and help research move faster. In Review is one of the most innovative preprint services available, offering real time updates on your manuscript’s progress through peer review. Discover In Review and its benefits.
What is open peer review?
Open peer review refers to the process of making peer reviewer reports openly available. Many publishers and journals offer some form of open peer review, including BMC who were one of the first publishers to open up peer review in 1999. Find out more .
Blog posts on open access from "The Source"

Open Research
How to publish open access with fees covered
Could you publish open access with fees covered under a Springer Nature open access agreement?

Celebrating our 2000th open access book
We are proud to celebrate the publication of our 2000th open access book. Take a look at how we achieved this milestone.

open access
Why is Gold OA best for researchers?
Explore the advantages of Gold OA, by reading some of the highlights from our white paper "Going for Gold".

How researchers are using open data in 2022
How are researchers using open data in 2022? Read this year’s State of Open Data Report, providing insights into the attitudes, motivations and challenges of researchers towards open data.
Ready to publish?

A pioneer of open access publishing, BMC is committed to innovation and offers an evolving portfolio of some 300 journals.

Open research is at the heart of Nature Research. Our portfolio includes Nature Communications , Scientific Reports and many more.

Springer offers a variety of open access options for journal articles and books across a number of disciplines.

Palgrave Macmillan is committed to developing sustainable models of open access for the HSS disciplines.

Apress is dedicated to meeting the information needs of developers, IT professionals, and tech communities worldwide.
Discover more tools and resources along with our author services

Author services

Early Career Resource Center

Journal Suggester

Using Your ORCID ID

The Transfer Desk
Tutorials and educational resources.

How to Write a Manuscript

How to submit a journal article manuscript

Nature Masterclasses
Stay up to date.
Here to foster information exchange with the library community
Connect with us on LinkedIn and stay up to date with news and development.
- Tools & Services
- Account Development
- Sales and account contacts
- Professional
- Press office
- Locations & Contact
We are a world leading research, educational and professional publisher. Visit our main website for more information.
- © 2023 Springer Nature
- General terms and conditions
- Your US State Privacy Rights
- Your Privacy Choices / Manage Cookies
- Accessibility
- Legal notice
- Help us to improve this site, send feedback.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 01 February 2021
An open source machine learning framework for efficient and transparent systematic reviews
- Rens van de Schoot ORCID: orcid.org/0000-0001-7736-2091 1 ,
- Jonathan de Bruin ORCID: orcid.org/0000-0002-4297-0502 2 ,
- Raoul Schram 2 ,
- Parisa Zahedi ORCID: orcid.org/0000-0002-1610-3149 2 ,
- Jan de Boer ORCID: orcid.org/0000-0002-0531-3888 3 ,
- Felix Weijdema ORCID: orcid.org/0000-0001-5150-1102 3 ,
- Bianca Kramer ORCID: orcid.org/0000-0002-5965-6560 3 ,
- Martijn Huijts ORCID: orcid.org/0000-0002-8353-0853 4 ,
- Maarten Hoogerwerf ORCID: orcid.org/0000-0003-1498-2052 2 ,
- Gerbrich Ferdinands ORCID: orcid.org/0000-0002-4998-3293 1 ,
- Albert Harkema ORCID: orcid.org/0000-0002-7091-1147 1 ,
- Joukje Willemsen ORCID: orcid.org/0000-0002-7260-0828 1 ,
- Yongchao Ma ORCID: orcid.org/0000-0003-4100-5468 1 ,
- Qixiang Fang ORCID: orcid.org/0000-0003-2689-6653 1 ,
- Sybren Hindriks 1 ,
- Lars Tummers ORCID: orcid.org/0000-0001-9940-9874 5 &
- Daniel L. Oberski ORCID: orcid.org/0000-0001-7467-2297 1 , 6
Nature Machine Intelligence volume 3 , pages 125–133 ( 2021 ) Cite this article
70k Accesses
202 Citations
162 Altmetric
Metrics details
- Computational biology and bioinformatics
- Computer science
- Medical research
A preprint version of the article is available at arXiv.
To help researchers conduct a systematic review or meta-analysis as efficiently and transparently as possible, we designed a tool to accelerate the step of screening titles and abstracts. For many tasks—including but not limited to systematic reviews and meta-analyses—the scientific literature needs to be checked systematically. Scholars and practitioners currently screen thousands of studies by hand to determine which studies to include in their review or meta-analysis. This is error prone and inefficient because of extremely imbalanced data: only a fraction of the screened studies is relevant. The future of systematic reviewing will be an interaction with machine learning algorithms to deal with the enormous increase of available text. We therefore developed an open source machine learning-aided pipeline applying active learning: ASReview. We demonstrate by means of simulation studies that active learning can yield far more efficient reviewing than manual reviewing while providing high quality. Furthermore, we describe the options of the free and open source research software and present the results from user experience tests. We invite the community to contribute to open source projects such as our own that provide measurable and reproducible improvements over current practice.
Similar content being viewed by others

AI-assisted peer review
Alessandro Checco, Lorenzo Bracciale, … Giuseppe Bianchi

A typology for exploring the mitigation of shortcut behaviour
Felix Friedrich, Wolfgang Stammer, … Kristian Kersting

Distributed peer review enhanced with natural language processing and machine learning
Wolfgang E. Kerzendorf, Ferdinando Patat, … Tyler A. Pritchard
With the emergence of online publishing, the number of scientific manuscripts on many topics is skyrocketing 1 . All of these textual data present opportunities to scholars and practitioners while simultaneously confronting them with new challenges. Scholars often develop systematic reviews and meta-analyses to develop comprehensive overviews of the relevant topics 2 . The process entails several explicit and, ideally, reproducible steps, including identifying all likely relevant publications in a standardized way, extracting data from eligible studies and synthesizing the results. Systematic reviews differ from traditional literature reviews in that they are more replicable and transparent 3 , 4 . Such systematic overviews of literature on a specific topic are pivotal not only for scholars, but also for clinicians, policy-makers, journalists and, ultimately, the general public 5 , 6 , 7 .
Given that screening the entire research literature on a given topic is too labour intensive, scholars often develop quite narrow searches. Developing a search strategy for a systematic review is an iterative process aimed at balancing recall and precision 8 , 9 ; that is, including as many potentially relevant studies as possible while simultaneously limiting the total number of studies retrieved. The vast number of publications in the field of study often leads to a relatively precise search, with the risk of missing relevant studies. The process of systematic reviewing is error prone and extremely time intensive 10 . In fact, if the literature of a field is growing faster than the amount of time available for systematic reviews, adequate manual review of this field then becomes impossible 11 .
The rapidly evolving field of machine learning has aided researchers by allowing the development of software tools that assist in developing systematic reviews 11 , 12 , 13 , 14 . Machine learning offers approaches to overcome the manual and time-consuming screening of large numbers of studies by prioritizing relevant studies via active learning 15 . Active learning is a type of machine learning in which a model can choose the data points (for example, records obtained from a systematic search) it would like to learn from and thereby drastically reduce the total number of records that require manual screening 16 , 17 , 18 . In most so-called human-in-the-loop 19 machine-learning applications, the interaction between the machine-learning algorithm and the human is used to train a model with a minimum number of labelling tasks. Unique to systematic reviewing is that not only do all relevant records (that is, titles and abstracts) need to seen by a researcher, but an extremely diverse range of concepts also need to be learned, thereby requiring flexibility in the modelling approach as well as careful error evaluation 11 . In the case of systematic reviewing, the algorithm(s) are interactively optimized for finding the most relevant records, instead of finding the most accurate model. The term researcher-in-the-loop was introduced 20 as a special case of human-in-the-loop with three unique components: (1) the primary output of the process is a selection of the records, not a trained machine learning model; (2) all records in the relevant selection are seen by a human at the end of the process 21 ; (3) the use-case requires a reproducible workflow and complete transparency is required 22 .
Existing tools that implement such an active learning cycle for systematic reviewing are described in Table 1 ; see the Supplementary Information for an overview of all of the software that we considered (note that this list was based on a review of software tools 12 ). However, existing tools have two main drawbacks. First, many are closed source applications with black box algorithms, which is problematic as transparency and data ownership are essential in the era of open science 22 . Second, to our knowledge, existing tools lack the necessary flexibility to deal with the large range of possible concepts to be learned by a screening machine. For example, in systematic reviews, the optimal type of classifier will depend on variable parameters, such as the proportion of relevant publications in the initial search and the complexity of the inclusion criteria used by the researcher 23 . For this reason, any successful system must allow for a wide range of classifier types. Benchmark testing is crucial to understand the real-world performance of any machine learning-aided system, but such benchmark options are currently mostly lacking.
In this paper we present an open source machine learning-aided pipeline with active learning for systematic reviews called ASReview. The goal of ASReview is to help scholars and practitioners to get an overview of the most relevant records for their work as efficiently as possible while being transparent in the process. The open, free and ready-to-use software ASReview addresses all concerns mentioned above: it is open source, uses active learning, allows multiple machine learning models. It also has a benchmark mode, which is especially useful for comparing and designing algorithms. Furthermore, it is intended to be easily extensible, allowing third parties to add modules that enhance the pipeline. Although we focus this paper on systematic reviews, ASReview can handle any text source.
In what follows, we first present the pipeline for manual versus machine learning-aided systematic reviews. We then show how ASReview has been set up and how ASReview can be used in different workflows by presenting several real-world use cases. We subsequently demonstrate the results of simulations that benchmark performance and present the results of a series of user-experience tests. Finally, we discuss future directions.
Pipeline for manual and machine learning-aided systematic reviews
The pipeline of a systematic review without active learning traditionally starts with researchers doing a comprehensive search in multiple databases 24 , using free text words as well as controlled vocabulary to retrieve potentially relevant references. The researcher then typically verifies that the key papers they expect to find are indeed included in the search results. The researcher downloads a file with records containing the text to be screened. In the case of systematic reviewing it contains the titles and abstracts (and potentially other metadata such as the authors’s names, journal name, DOI) of potentially relevant references into a reference manager. Ideally, two or more researchers then screen the records’s titles and abstracts on the basis of the eligibility criteria established beforehand 4 . After all records have been screened, the full texts of the potentially relevant records are read to determine which of them will be ultimately included in the review. Most records are excluded in the title and abstract phase. Typically, only a small fraction of the records belong to the relevant class, making title and abstract screening an important bottleneck in systematic reviewing process 25 . For instance, a recent study analysed 10,115 records and excluded 9,847 after title and abstract screening, a drop of more than 95% 26 . ASReview therefore focuses on this labour-intensive step.
The research pipeline of ASReview is depicted in Fig. 1 . The researcher starts with a search exactly as described above and subsequently uploads a file containing the records (that is, metadata containing the text of the titles and abstracts) into the software. Prior knowledge is then selected, which is used for training of the first model and presenting the first record to the researcher. As screening is a binary classification problem, the reviewer must select at least one key record to include and exclude on the basis of background knowledge. More prior knowledge may result in improved efficiency of the active learning process.

The symbols indicate whether the action is taken by a human, a computer, or whether both options are available.
A machine learning classifier is trained to predict study relevance (labels) from a representation of the record-containing text (feature space) on the basis of prior knowledge. We have purposefully chosen not to include an author name or citation network representation in the feature space to prevent authority bias in the inclusions. In the active learning cycle, the software presents one new record to be screened and labelled by the user. The user’s binary label (1 for relevant versus 0 for irrelevant) is subsequently used to train a new model, after which a new record is presented to the user. This cycle continues up to a certain user-specified stopping criterion has been reached. The user now has a file with (1) records labelled as either relevant or irrelevant and (2) unlabelled records ordered from most to least probable to be relevant as predicted by the current model. This set-up helps to move through a large database much quicker than in the manual process, while the decision process simultaneously remains transparent.
Software implementation for ASReview
The source code 27 of ASReview is available open source under an Apache 2.0 license, including documentation 28 . Compiled and packaged versions of the software are available on the Python Package Index 29 or Docker Hub 30 . The free and ready-to-use software ASReview implements oracle, simulation and exploration modes. The oracle mode is used to perform a systematic review with interaction by the user, the simulation mode is used for simulation of the ASReview performance on existing datasets, and the exploration mode can be used for teaching purposes and includes several preloaded labelled datasets.
The oracle mode presents records to the researcher and the researcher classifies these. Multiple file formats are supported: (1) RIS files are used by digital libraries such as IEEE Xplore, Scopus and ScienceDirect; the citation managers Mendeley, RefWorks, Zotero and EndNote support the RIS format too. (2) Tabular datasets with the .csv, .xlsx and .xls file extensions. CSV files should be comma separated and UTF-8 encoded; the software for CSV files accepts a set of predetermined labels in line with the ones used in RIS files. Each record in the dataset should hold the metadata on, for example, a scientific publication. Mandatory metadata is text and can, for example, be titles or abstracts from scientific papers. If available, both are used to train the model, but at least one is needed. An advanced option is available that splits the title and abstracts in the feature-extraction step and weights the two feature matrices independently (for TF–IDF only). Other metadata such as author, date, DOI and keywords are optional but not used for training the models. When using ASReview in the simulation or exploration mode, an additional binary variable is required to indicate historical labelling decisions. This column, which is automatically detected, can also be used in the oracle mode as background knowledge for previous selection of relevant papers before entering the active learning cycle. If unavailable, the user has to select at least one relevant record that can be identified by searching the pool of records. At least one irrelevant record should also be identified; the software allows to search for specific records or presents random records that are most likely to be irrelevant due to the extremely imbalanced data.
The software has a simple yet extensible default model: a naive Bayes classifier, TF–IDF feature extraction, a dynamic resampling balance strategy 31 and certainty-based sampling 17 , 32 for the query strategy. These defaults were chosen on the basis of their consistently high performance in benchmark experiments across several datasets 31 . Moreover, the low computation time of these default settings makes them attractive in applications, given that the software should be able to run locally. Users can change the settings, shown in Table 2 , and technical details are described in our documentation 28 . Users can also add their own classifiers, feature extraction techniques, query strategies and balance strategies.
ASReview has a number of implemented features (see Table 2 ). First, there are several classifiers available: (1) naive Bayes; (2) support vector machines; (3) logistic regression; (4) neural networks; (5) random forests; (6) LSTM-base, which consists of an embedding layer, an LSTM layer with one output, a dense layer and a single sigmoid output node; and (7) LSTM-pool, which consists of an embedding layer, an LSTM layer with many outputs, a max pooling layer and a single sigmoid output node. The feature extraction techniques available are Doc2Vec 33 , embedding LSTM, embedding with IDF or TF–IDF 34 (the default is unigram, with the option to run n -grams while other parameters are set to the defaults of Scikit-learn 35 ) and sBERT 36 . The available query strategies for the active learning part are (1) random selection, ignoring model-assigned probabilities; (2) uncertainty-based sampling, which chooses the most uncertain record according to the model (that is, closest to 0.5 probability); (3) certainty-based sampling (max in ASReview), which chooses the record most likely to be included according to the model; and (4) mixed sampling, which uses a combination of random and certainty-based sampling.
There are several balance strategies that rebalance and reorder the training data. This is necessary, because the data is typically extremely imbalanced and therefore we have implemented the following balance strategies: (1) full sampling, which uses all of the labelled records; (2) undersampling the irrelevant records so that the included and excluded records are in some particular ratio (closer to one); and (3) dynamic resampling, a novel method similar to undersampling in that it decreases the imbalance of the training data 31 . However, in dynamic resampling, the number of irrelevant records is decreased, whereas the number of relevant records is increased by duplication such that the total number of records in the training data remains the same. The ratio between relevant and irrelevant records is not fixed over interactions, but dynamically updated depending on the number of labelled records, the total number of records and the ratio between relevant and irrelevant records. Details on all of the described algorithms can be found in the code and documentation referred to above.
By default, ASReview converts the records’s texts into a document-term matrix, terms are converted to lowercase and no stop words are removed by default (but this can be changed). As the document-term matrix is identical in each iteration of the active learning cycle, it is generated in advance of model training and stored in the (active learning) state file. Each row of the document-term matrix can easily be requested from the state-file. Records are internally identified by their row number in the input dataset. In oracle mode, the record that is selected to be classified is retrieved from the state file and the record text and other metadata (such as title and abstract) are retrieved from the original dataset (from the file or the computer’s memory). ASReview can run on your local computer, or on a (self-hosted) local or remote server. Data (all records and their labels) remain on the users’s computer. Data ownership and confidentiality are crucial and no data are processed or used in any way by third parties. This is unique by comparison with some of the existing systems, as shown in the last column of Table 1 .
Real-world use cases and high-level function descriptions
Below we highlight a number of real-world use cases and high-level function descriptions for using the pipeline of ASReview.
ASReview can be integrated in classic systematic reviews or meta-analyses. Such reviews or meta-analyses entail several explicit and reproducible steps, as outlined in the PRISMA guidelines 4 . Scholars identify all likely relevant publications in a standardized way, screen retrieved publications to select eligible studies on the basis of defined eligibility criteria, extract data from eligible studies and synthesize the results. ASReview fits into this process, particularly in the abstract screening phase. ASReview does not replace the initial step of collecting all potentially relevant studies. As such, results from ASReview depend on the quality of the initial search process, including selection of databases 24 and construction of comprehensive searches using keywords and controlled vocabulary. However, ASReview can be used to broaden the scope of the search (by keyword expansion or omitting limitation in the search query), resulting in a higher number of initial papers to limit the risk of missing relevant papers during the search part (that is, more focus on recall instead of precision).
Furthermore, many reviewers nowadays move towards meta-reviews when analysing very large literature streams, that is, systematic reviews of systematic reviews 37 . This can be problematic as the various reviews included could use different eligibility criteria and are therefore not always directly comparable. Due to the efficiency of ASReview, scholars using the tool could conduct the study by analysing the papers directly instead of using the systematic reviews. Furthermore, ASReview supports the rapid update of a systematic review. The included papers from the initial review are used to train the machine learning model before screening of the updated set of papers starts. This allows the researcher to quickly screen the updated set of papers on the basis of decisions made in the initial run.
As an example case, let us look at the current literature on COVID-19 and the coronavirus. An enormous number of papers are being published on COVID-19. It is very time consuming to manually find relevant papers (for example, to develop treatment guidelines). This is especially problematic as urgent overviews are required. Medical guidelines rely on comprehensive systematic reviews, but the medical literature is growing at breakneck pace and the quality of the research is not universally adequate for summarization into policy 38 . Such reviews must entail adequate protocols with explicit and reproducible steps, including identifying all potentially relevant papers, extracting data from eligible studies, assessing potential for bias and synthesizing the results into medical guidelines. Researchers need to screen (tens of) thousands of COVID-19-related studies by hand to find relevant papers to include in their overview. Using ASReview, this can be done far more efficiently by selecting key papers that match their (COVID-19) research question in the first step; this should start the active learning cycle and lead to the most relevant COVID-19 papers for their research question being presented next. A plug-in was therefore developed for ASReview 39 , which contained three databases that are updated automatically whenever a new version is released by the owners of the data: (1) the Cord19 database, developed by the Allen Institute for AI, with over all publications on COVID-19 and other coronavirus research (for example SARS, MERS and so on) from PubMed Central, the WHO COVID-19 database of publications, the preprint servers bioRxiv and medRxiv and papers contributed by specific publishers 40 . The CORD-19 dataset is updated daily by the Allen Institute for AI and updated also daily in the plugin. (2) In addition to the full dataset, we automatically construct a daily subset of the database with studies published after December 1st, 2019 to search for relevant papers published during the COVID-19 crisis. (3) A separate dataset of COVID-19 related preprints, containing metadata of preprints from over 15 preprints servers across disciplines, published since January 1st, 2020 41 . The preprint dataset is updated weekly by the maintainers and then automatically updated in ASReview as well. As this dataset is not readily available to researchers through regular search engines (for example, PubMed), its inclusion in ASReview provided added value to researchers interested in COVID-19 research, especially if they want a quick way to screen preprints specifically.
Simulation study
To evaluate the performance of ASReview on a labelled dataset, users can employ the simulation mode. As an example, we ran simulations based on four labelled datasets with version 0.7.2 of ASReview. All scripts to reproduce the results in this paper can be found on Zenodo ( https://doi.org/10.5281/zenodo.4024122 ) 42 , whereas the results are available at OSF ( https://doi.org/10.17605/OSF.IO/2JKD6 ) 43 .
First, we analysed the performance for a study systematically describing studies that performed viral metagenomic next-generation sequencing in common livestock such as cattle, small ruminants, poultry and pigs 44 . Studies were retrieved from Embase ( n = 1,806), Medline ( n = 1,384), Cochrane Central ( n = 1), Web of Science ( n = 977) and Google Scholar ( n = 200, the top relevant references). After deduplication this led to 2,481 studies obtained in the initial search, of which 120 were inclusions (4.84%).
A second simulation study was performed on the results for a systematic review of studies on fault prediction in software engineering 45 . Studies were obtained from ACM Digital Library, IEEExplore and the ISI Web of Science. Furthermore, a snowballing strategy and a manual search were conducted, accumulating to 8,911 publications of which 104 were included in the systematic review (1.2%).
A third simulation study was performed on a review of longitudinal studies that applied unsupervised machine learning techniques to longitudinal data of self-reported symptoms of the post-traumatic stress assessed after trauma exposure 46 , 47 ; 5,782 studies were obtained by searching Pubmed, Embase, PsychInfo and Scopus and through a snowballing strategy in which both the references and the citation of the included papers were screened. Thirty-eight studies were included in the review (0.66%).
A fourth simulation study was performed on the results for a systematic review on the efficacy of angiotensin-converting enzyme inhibitors, from a study collecting various systematic review datasets from the medical sciences 15 . The collection is a subset of 2,544 publications from the TREC 2004 Genomics Track document corpus 48 . This is a static subset from all MEDLINE records from 1994 through 2003, which allows for replicability of results. Forty-one publications were included in the review (1.6%).
Performance metrics
We evaluated the four datasets using three performance metrics. We first assess the work saved over sampling (WSS), which is the percentage reduction in the number of records needed to screen achieved by using active learning instead of screening records at random; WSS is measured at a given level of recall of relevant records, for example 95%, indicating the work reduction in screening effort at the cost of failing to detect 5% of the relevant records. For some researchers it is essential that all relevant literature on the topic is retrieved; this entails that the recall should be 100% (that is, WSS@100%). We also propose the amount of relevant references found after having screened the first 10% of the records (RRF10%). This is a useful metric for getting a quick overview of the relevant literature.
For every dataset, 15 runs were performed with one random inclusion and one random exclusion (see Fig. 2 ). The classical review performance with randomly found inclusions is shown by the dashed line. The average work saved over sampling at 95% recall for ASReview is 83% and ranges from 67% to 92%. Hence, 95% of the eligible studies will be found after screening between only 8% to 33% of the studies. Furthermore, the number of relevant abstracts found after reading 10% of the abstracts ranges from 70% to 100%. In short, our software would have saved many hours of work.

a – d , Results of the simulation study for the results for a study systematically review studies that performed viral metagenomic next-generation sequencing in common livestock ( a ), results for a systematic review of studies on fault prediction in software engineering ( b ), results for longitudinal studies that applied unsupervised machine learning techniques on longitudinal data of self-reported symptoms of posttraumatic stress assessed after trauma exposure ( c ), and results for a systematic review on the efficacy of angiotensin-converting enzyme inhibitors ( d ). Fiteen runs (shown with separate lines) were performed for every dataset, with only one random inclusion and one random exclusion. The classical review performances with randomly found inclusions are shown by the dashed lines.
Usability testing (user experience testing)
We conducted a series of user experience tests to learn from end users how they experience the software and implement it in their workflow. The study was approved by the Ethics Committee of the Faculty of Social and Behavioral Sciences of Utrecht University (ID 20-104).
Unstructured interviews
The first user experience (UX) test—carried out in December 2019—was conducted with an academic research team in a substantive research field (public administration and organizational science) that has conducted various systematic reviews and meta-analyses. It was composed of three university professors (ranging from assistant to full) and three PhD candidates. In one 3.5 h session, the participants used the software and provided feedback via unstructured interviews and group discussions. The goal was to provide feedback on installing the software and testing the performance on their own data. After these sessions we prioritized the feedback in a meeting with the ASReview team, which resulted in the release of v.0.4 and v.0.6. An overview of all releases can be found on GitHub 27 .
A second UX test was conducted with four experienced researchers developing medical guidelines based on classical systematic reviews, and two experienced reviewers working at a pharmaceutical non-profit organization who work on updating reviews with new data. In four sessions, held in February to March 2020, these users tested the software following our testing protocol. After each session we implemented the feedback provided by the experts and asked them to review the software again. The main feedback was about how to upload datasets and select prior papers. Their feedback resulted in the release of v.0.7 and v.0.9.
Systematic UX test
In May 2020 we conducted a systematic UX test. Two groups of users were distinguished: an unexperienced group and an experienced user who already used ASReview. Due to the COVID-19 lockdown the usability tests were conducted via video calling where one person gave instructions to the participant and one person observed, called human-moderated remote testing 49 . During the tests, one person (SH) asked the questions and helped the participant with the tasks, the other person observed and made notes, a user experience professional at the IT department of Utrecht University (MH).
To analyse the notes, thematic analysis was used, which is a method to analyse data by dividing the information in subjects that all have a different meaning 50 using the Nvivo 12 software 51 . When something went wrong the text was coded as showstopper, when something did not go smoothly the text was coded as doubtful, and when something went well the subject was coded as superb. The features the participants requested for future versions of the ASReview tool were discussed with the lead engineer of the ASReview team and were submitted to GitHub as issues or feature requests.
The answers to the quantitative questions can be found at the Open Science Framework 52 . The participants ( N = 11) rated the tool with a grade of 7.9 (s.d. = 0.9) on a scale from one to ten (Table 2 ). The unexperienced users on average rated the tool with an 8.0 (s.d. = 1.1, N = 6). The experienced user on average rated the tool with a 7.8 (s.d. = 0.9, N = 5). The participants described the usability test with words such as helpful, accessible, fun, clear and obvious.
The UX tests resulted in the new release v0.10, v0.10.1 and the major release v0.11, which is a major revision of the graphical user interface. The documentation has been upgraded to make installing and launching ASReview more straightforward. We made setting up the project, selecting a dataset and finding past knowledge is more intuitive and flexible. We also added a project dashboard with information on your progress and advanced settings.
Continuous input via the open source community
Finally, the ASReview development team receives continuous feedback from the open science community about, among other things, the user experience. In every new release we implement features listed by our users. Recurring UX tests are performed to keep up with the needs of users and improve the value of the tool.
We designed a system to accelerate the step of screening titles and abstracts to help researchers conduct a systematic review or meta-analysis as efficiently and transparently as possible. Our system uses active learning to train a machine learning model that predicts relevance from texts using a limited number of labelled examples. The classifier, feature extraction technique, balance strategy and active learning query strategy are flexible. We provide an open source software implementation, ASReview with state-of-the-art systems across a wide range of real-world systematic reviewing applications. Based on our experiments, ASReview provides defaults on its parameters, which exhibited good performance on average across the applications we examined. However, we stress that in practical applications, these defaults should be carefully examined; for this purpose, the software provides a simulation mode to users. We encourage users and developers to perform further evaluation of the proposed approach in their application, and to take advantage of the open source nature of the project by contributing further developments.
Drawbacks of machine learning-based screening systems, including our own, remain. First, although the active learning step greatly reduces the number of manuscripts that must be screened, it also prevents a straightforward evaluation of the system’s error rates without further onerous labelling. Providing users with an accurate estimate of the system’s error rate in the application at hand is therefore a pressing open problem. Second, although, as argued above, the use of such systems is not limited in principle to reviewing, no empirical benchmarks of actual performance in these other situations yet exist to our knowledge. Third, machine learning-based screening systems automate the screening step only; although the screening step is time-consuming and a good target for automation, it is just one part of a much larger process, including the initial search, data extraction, coding for risk of bias, summarizing results and so on. Although some other works, similar to our own, have looked at (semi-)automating some of these steps in isolation 53 , 54 , to our knowledge the field is still far removed from an integrated system that would truly automate the review process while guaranteeing the quality of the produced evidence synthesis. Integrating the various tools that are currently under development to aid the systematic reviewing pipeline is therefore a worthwhile topic for future development.
Possible future research could also focus on the performance of identifying full text articles with different document length and domain-specific terminologies or even other types of text, such as newspaper articles and court cases. When the selection of past knowledge is not possible based on expert knowledge, alternative methods could be explored. For example, unsupervised learning or pseudolabelling algorithms could be used to improve training 55 , 56 . In addition, as the NLP community pushes forward the state of the art in feature extraction methods, these are easily added to our system as well. In all cases, performance benefits should be carefully evaluated using benchmarks for the task at hand. To this end, common benchmark challenges should be constructed that allow for an even comparison of the various tools now available. To facilitate such a benchmark, we have constructed a repository of publicly available systematic reviewing datasets 57 .
The future of systematic reviewing will be an interaction with machine learning algorithms to deal with the enormous increase of available text. We invite the community to contribute to open source projects such as our own, as well as to common benchmark challenges, so that we can provide measurable and reproducible improvement over current practice.
Data availability
The results described in this paper are available at the Open Science Framework ( https://doi.org/10.17605/OSF.IO/2JKD6 ) 43 . The answers to the quantitative questions of the UX test can be found at the Open Science Framework (OSF.IO/7PQNM) 52 .
Code availability
All code to reproduce the results described in this paper can be found on Zenodo ( https://doi.org/10.5281/zenodo.4024122 ) 42 . All code for the software ASReview is available under an Apache 2.0 license ( https://doi.org/10.5281/zenodo.3345592 ) 27 , is maintained on GitHub 63 and includes documentation ( https://doi.org/10.5281/zenodo.4287120 ) 28 .
Bornmann, L. & Mutz, R. Growth rates of modern science: a bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 66 , 2215–2222 (2015).
Article Google Scholar
Gough, D., Oliver, S. & Thomas, J. An Introduction to Systematic Reviews (Sage, 2017).
Cooper, H. Research Synthesis and Meta-analysis: A Step-by-Step Approach (SAGE Publications, 2015).
Liberati, A. et al. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. J. Clin. Epidemiol. 62 , e1–e34 (2009).
Boaz, A. et al. Systematic Reviews: What have They Got to Offer Evidence Based Policy and Practice? (ESRC UK Centre for Evidence Based Policy and Practice London, 2002).
Oliver, S., Dickson, K. & Bangpan, M. Systematic Reviews: Making Them Policy Relevant. A Briefing for Policy Makers and Systematic Reviewers (UCL Institute of Education, 2015).
Petticrew, M. Systematic reviews from astronomy to zoology: myths and misconceptions. Brit. Med. J. 322 , 98–101 (2001).
Lefebvre, C., Manheimer, E. & Glanville, J. in Cochrane Handbook for Systematic Reviews of Interventions (eds. Higgins, J. P. & Green, S.) 95–150 (John Wiley & Sons, 2008); https://doi.org/10.1002/9780470712184.ch6 .
Sampson, M., Tetzlaff, J. & Urquhart, C. Precision of healthcare systematic review searches in a cross-sectional sample. Res. Synth. Methods 2 , 119–125 (2011).
Wang, Z., Nayfeh, T., Tetzlaff, J., O’Blenis, P. & Murad, M. H. Error rates of human reviewers during abstract screening in systematic reviews. PLoS ONE 15 , e0227742 (2020).
Marshall, I. J. & Wallace, B. C. Toward systematic review automation: a practical guide to using machine learning tools in research synthesis. Syst. Rev. 8 , 163 (2019).
Harrison, H., Griffin, S. J., Kuhn, I. & Usher-Smith, J. A. Software tools to support title and abstract screening for systematic reviews in healthcare: an evaluation. BMC Med. Res. Methodol. 20 , 7 (2020).
O’Mara-Eves, A., Thomas, J., McNaught, J., Miwa, M. & Ananiadou, S. Using text mining for study identification in systematic reviews: a systematic review of current approaches. Syst. Rev. 4 , 5 (2015).
Wallace, B. C., Trikalinos, T. A., Lau, J., Brodley, C. & Schmid, C. H. Semi-automated screening of biomedical citations for systematic reviews. BMC Bioinf. 11 , 55 (2010).
Cohen, A. M., Hersh, W. R., Peterson, K. & Yen, P.-Y. Reducing workload in systematic review preparation using automated citation classification. J. Am. Med. Inform. Assoc. 13 , 206–219 (2006).
Kremer, J., Steenstrup Pedersen, K. & Igel, C. Active learning with support vector machines. WIREs Data Min. Knowl. Discov. 4 , 313–326 (2014).
Miwa, M., Thomas, J., O’Mara-Eves, A. & Ananiadou, S. Reducing systematic review workload through certainty-based screening. J. Biomed. Inform. 51 , 242–253 (2014).
Settles, B. Active Learning Literature Survey (Minds@UW, 2009); https://minds.wisconsin.edu/handle/1793/60660
Holzinger, A. Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain Inform. 3 , 119–131 (2016).
Van de Schoot, R. & De Bruin, J. Researcher-in-the-loop for Systematic Reviewing of Text Databases (Zenodo, 2020); https://doi.org/10.5281/zenodo.4013207
Kim, D., Seo, D., Cho, S. & Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 477 , 15–29 (2019).
Nosek, B. A. et al. Promoting an open research culture. Science 348 , 1422–1425 (2015).
Kilicoglu, H., Demner-Fushman, D., Rindflesch, T. C., Wilczynski, N. L. & Haynes, R. B. Towards automatic recognition of scientifically rigorous clinical research evidence. J. Am. Med. Inform. Assoc. 16 , 25–31 (2009).
Gusenbauer, M. & Haddaway, N. R. Which academic search systems are suitable for systematic reviews or meta‐analyses? Evaluating retrieval qualities of Google Scholar, PubMed, and 26 other resources. Res. Synth. Methods 11 , 181–217 (2020).
Borah, R., Brown, A. W., Capers, P. L. & Kaiser, K. A. Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ Open 7 , e012545 (2017).
de Vries, H., Bekkers, V. & Tummers, L. Innovation in the Public Sector: a systematic review and future research agenda. Public Adm. 94 , 146–166 (2016).
Van de Schoot, R. et al. ASReview: Active Learning for Systematic Reviews (Zenodo, 2020); https://doi.org/10.5281/zenodo.3345592
De Bruin, J. et al. ASReview Software Documentation 0.14 (Zenodo, 2020); https://doi.org/10.5281/zenodo.4287120
ASReview PyPI Package (ASReview Core Development Team, 2020); https://pypi.org/project/asreview/
Docker container for ASReview (ASReview Core Development Team, 2020); https://hub.docker.com/r/asreview/asreview
Ferdinands, G. et al. Active Learning for Screening Prioritization in Systematic Reviews—A Simulation Study (OSF Preprints, 2020); https://doi.org/10.31219/osf.io/w6qbg
Fu, J. H. & Lee, S. L. Certainty-enhanced active learning for improving imbalanced data classification. In 2011 IEEE 11th International Conference on Data Mining Workshops 405–412 (IEEE, 2011).
Le, Q. V. & Mikolov, T. Distributed representations of sentences and documents. Preprint at https://arxiv.org/abs/1405.4053 (2014).
Ramos, J. Using TF–IDF to determine word relevance in document queries. In Proc. 1st Instructional Conference on Machine Learning Vol. 242, 133–142 (ICML, 2003).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12 , 2825–2830 (2011).
MathSciNet MATH Google Scholar
Reimers, N. & Gurevych, I. Sentence-BERT: sentence embeddings using siamese BERT-networks Preprint at https://arxiv.org/abs/1908.10084 (2019).
Smith, V., Devane, D., Begley, C. M. & Clarke, M. Methodology in conducting a systematic review of systematic reviews of healthcare interventions. BMC Med. Res. Methodol. 11 , 15 (2011).
Wynants, L. et al. Prediction models for diagnosis and prognosis of COVID-19: systematic review and critical appraisal. Brit. Med. J . 369 , 1328 (2020).
Van de Schoot, R. et al. Extension for COVID-19 Related Datasets in ASReview (Zenodo, 2020). https://doi.org/10.5281/zenodo.3891420 .
Lu Wang, L. et al. CORD-19: The COVID-19 open research dataset. Preprint at https://arxiv.org/abs/2004.10706 (2020).
Fraser, N. & Kramer, B. Covid19_preprints (FigShare, 2020); https://doi.org/10.6084/m9.figshare.12033672.v18
Ferdinands, G., Schram, R., Van de Schoot, R. & De Bruin, J. Scripts for ‘ASReview: Open Source Software for Efficient and Transparent Active Learning for Systematic Reviews’ (Zenodo, 2020); https://doi.org/10.5281/zenodo.4024122
Ferdinands, G., Schram, R., van de Schoot, R. & de Bruin, J. Results for ‘ASReview: Open Source Software for Efficient and Transparent Active Learning for Systematic Reviews’ (OSF, 2020); https://doi.org/10.17605/OSF.IO/2JKD6
Kwok, K. T. T., Nieuwenhuijse, D. F., Phan, M. V. T. & Koopmans, M. P. G. Virus metagenomics in farm animals: a systematic review. Viruses 12 , 107 (2020).
Hall, T., Beecham, S., Bowes, D., Gray, D. & Counsell, S. A systematic literature review on fault prediction performance in software engineering. IEEE Trans. Softw. Eng. 38 , 1276–1304 (2012).
van de Schoot, R., Sijbrandij, M., Winter, S. D., Depaoli, S. & Vermunt, J. K. The GRoLTS-Checklist: guidelines for reporting on latent trajectory studies. Struct. Equ. Model. Multidiscip. J. 24 , 451–467 (2017).
Article MathSciNet Google Scholar
van de Schoot, R. et al. Bayesian PTSD-trajectory analysis with informed priors based on a systematic literature search and expert elicitation. Multivar. Behav. Res. 53 , 267–291 (2018).
Cohen, A. M., Bhupatiraju, R. T. & Hersh, W. R. Feature generation, feature selection, classifiers, and conceptual drift for biomedical document triage. In Proc. 13th Text Retrieval Conference (TREC, 2004).
Vasalou, A., Ng, B. D., Wiemer-Hastings, P. & Oshlyansky, L. Human-moderated remote user testing: orotocols and applications. In 8th ERCIM Workshop, User Interfaces for All Vol. 19 (ERCIM, 2004).
Joffe, H. in Qualitative Research Methods in Mental Health and Psychotherapy: A Guide for Students and Practitioners (eds Harper, D. & Thompson, A. R.) Ch. 15 (Wiley, 2012).
NVivo v. 12 (QSR International Pty, 2019).
Hindriks, S., Huijts, M. & van de Schoot, R. Data for UX-test ASReview - June 2020. OSF https://doi.org/10.17605/OSF.IO/7PQNM (2020).
Marshall, I. J., Kuiper, J. & Wallace, B. C. RobotReviewer: evaluation of a system for automatically assessing bias in clinical trials. J. Am. Med. Inform. Assoc. 23 , 193–201 (2016).
Nallapati, R., Zhou, B., dos Santos, C. N., Gulcehre, Ç. & Xiang, B. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proc. 20th SIGNLL Conference on Computational Natural Language Learning 280–290 (Association for Computational Linguistics, 2016).
Xie, Q., Dai, Z., Hovy, E., Luong, M.-T. & Le, Q. V. Unsupervised data augmentation for consistency training. Preprint at https://arxiv.org/abs/1904.12848 (2019).
Ratner, A. et al. Snorkel: rapid training data creation with weak supervision. VLDB J. 29 , 709–730 (2020).
Systematic Review Datasets (ASReview Core Development Team, 2020); https://github.com/asreview/systematic-review-datasets
Wallace, B. C., Small, K., Brodley, C. E., Lau, J. & Trikalinos, T. A. Deploying an interactive machine learning system in an evidence-based practice center: Abstrackr. In Proc. 2nd ACM SIGHIT International Health Informatics Symposium 819–824 (Association for Computing Machinery, 2012).
Cheng, S. H. et al. Using machine learning to advance synthesis and use of conservation and environmental evidence. Conserv. Biol. 32 , 762–764 (2018).
Yu, Z., Kraft, N. & Menzies, T. Finding better active learners for faster literature reviews. Empir. Softw. Eng . 23 , 3161–3186 (2018).
Ouzzani, M., Hammady, H., Fedorowicz, Z. & Elmagarmid, A. Rayyan—a web and mobile app for systematic reviews. Syst. Rev. 5 , 210 (2016).
Przybyła, P. et al. Prioritising references for systematic reviews with RobotAnalyst: a user study. Res. Synth. Methods 9 , 470–488 (2018).
ASReview: Active learning for Systematic Reviews (ASReview Core Development Team, 2020); https://github.com/asreview/asreview
Download references
Acknowledgements
We would like to thank the Utrecht University Library, focus area Applied Data Science, and departments of Information and Technology Services, Test and Quality Services, and Methodology and Statistics, for their support. We also want to thank all researchers who shared data, participated in our user experience tests or who gave us feedback on ASReview in other ways. Furthermore, we would like to thank the editors and reviewers for providing constructive feedback. This project was funded by the Innovation Fund for IT in Research Projects, Utrecht University, the Netherlands.
Author information
Authors and affiliations.
Department of Methodology and Statistics, Faculty of Social and Behavioral Sciences, Utrecht University, Utrecht, the Netherlands
Rens van de Schoot, Gerbrich Ferdinands, Albert Harkema, Joukje Willemsen, Yongchao Ma, Qixiang Fang, Sybren Hindriks & Daniel L. Oberski
Department of Research and Data Management Services, Information Technology Services, Utrecht University, Utrecht, the Netherlands
Jonathan de Bruin, Raoul Schram, Parisa Zahedi & Maarten Hoogerwerf
Utrecht University Library, Utrecht University, Utrecht, the Netherlands
Jan de Boer, Felix Weijdema & Bianca Kramer
Department of Test and Quality Services, Information Technology Services, Utrecht University, Utrecht, the Netherlands
Martijn Huijts
School of Governance, Faculty of Law, Economics and Governance, Utrecht University, Utrecht, the Netherlands
Lars Tummers
Department of Biostatistics, Data management and Data Science, Julius Center, University Medical Center Utrecht, Utrecht, the Netherlands
Daniel L. Oberski
You can also search for this author in PubMed Google Scholar
Contributions
R.v.d.S. and D.O. originally designed the project, with later input from L.T. J.d.Br. is the lead engineer, software architect and supervises the code base on GitHub. R.S. coded the algorithms and simulation studies. P.Z. coded the very first version of the software. J.d.Bo., F.W. and B.K. developed the systematic review pipeline. M.Huijts is leading the UX tests and was supported by S.H. M.Hoogerwerf developed the architecture of the produced (meta)data. G.F. conducted the simulation study together with R.S. A.H. performed the literature search comparing the different tools together with G.F. J.W. designed all the artwork and helped with formatting the manuscript. Y.M. and Q.F. are responsible for the preprocessing of the metadata under the supervision of J.d.Br. R.v.d.S, D.O. and L.T. wrote the paper with input from all authors. Each co-author has written parts of the manuscript.
Corresponding author
Correspondence to Rens van de Schoot .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Peer review information Nature Machine Intelligence thanks Jian Wu and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information.
Overview of software tools supporting systematic reviews.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
van de Schoot, R., de Bruin, J., Schram, R. et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat Mach Intell 3 , 125–133 (2021). https://doi.org/10.1038/s42256-020-00287-7
Download citation
Received : 04 June 2020
Accepted : 17 December 2020
Published : 01 February 2021
Issue Date : February 2021
DOI : https://doi.org/10.1038/s42256-020-00287-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
A systematic review, meta-analysis, and meta-regression of the prevalence of self-reported disordered eating and associated factors among athletes worldwide.
- Hadeel A. Ghazzawi
- Lana S. Nimer
- Haitham Jahrami
Journal of Eating Disorders (2024)
Systematic review using a spiral approach with machine learning
- Amirhossein Saeidmehr
- Piers David Gareth Steel
- Faramarz F. Samavati
Systematic Reviews (2024)
The spatial patterning of emergency demand for police services: a scoping review
- Samuel Langton
- Stijn Ruiter
- Linda Schoonmade
Crime Science (2024)
The SAFE procedure: a practical stopping heuristic for active learning-based screening in systematic reviews and meta-analyses
- Josien Boetje
- Rens van de Schoot
Tunneling, cognitive load and time orientation and their relations with dietary behavior of people experiencing financial scarcity – an AI-assisted scoping review elaborating on scarcity theory
- Annemarieke van der Veer
- Tamara Madern
- Frank J. van Lenthe
International Journal of Behavioral Nutrition and Physical Activity (2024)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

- Investigations
- Justice & Accountability
Open source research has “come of age”, according to a recent article published by The Economist . What was once the niche realm of a relatively small number of individuals with free time and obsessive internet habits is now informing research and journalism in a wide range of fields and institutions. It’s hard to imagine a better time to roll up your sleeves and set off on the path of the open source researcher.
The promise of open source research is that anyone — not just journalists or researchers at select institutions — can contribute to investigations that uncover wrongdoing and hold perpetrators of crimes and atrocities to account.
When we say “anyone”, we mean anyone : if you’ve an internet connection, free time, and a stubborn commitment to getting the facts right, then you too, can be an open source researcher.
Getting started in open source research can be daunting, especially if the field is completely new to you. But there’s no reason to fear: this guide will cover concrete steps that you can take to develop skills, discover communities based on your interests, and eventually lend a helping hand to important research.
By following these steps, you’ll learn where to find open source researchers, how to observe and learn from their work, and how to practice the new skills that you’ll develop.
1. Take Stock of your Skills and Interests
Are you interested in a particular conflict? Or do you love solving puzzles, which could translate to geolocating images? Do you have a programming background, or knowledge of several languages? Or are you fascinated by military machinery and equipment?
Having an idea of what topics interest you and what you’re good at will help you find other researchers on social media whose work you might want to follow, and may eventually use to inform for your own.
If you’re not sure how your skills and interests might translate to this field, then don’t worry: that just means that you’ll have more to discover.
2. Get on Twitter
The importance of this step cannot be overstated.
Twitter is the primary medium for identifying, debating, and disseminating open source research. It’s full of practitioners who are eager to engage in discussions with others about best methods and practices, and to share their own work and that of others. Having a Twitter account will allow you to follow researchers so that you can learn from their work, as well as ask questions and engage in discussions with like-minded researchers.
If you’re security conscious or have any reason to want to be anonymous, you can easily set up a Twitter account that doesn’t contain your real name or other personal information. The open source research community welcomes anonymous accounts, and operating anonymously doesn’t have any negative connotations (though you may find that eventually you’ll have to reveal your identity if you get approached with publication offers or job opportunities).
If you’re still Twitter-averse, remember that you don’t have to post anything — ever. Twitter’s primary purpose can be to show you what other researchers are saying and publishing, so you don’t ever have to interact with anyone unless you want to.
3. Find Your People (and Put Them on a List)
Once you’re on Twitter, you’ll want to follow lots of open source researchers. This will allow you to see what topics the field is interested in, which organisations tend to focus on which issues, and which methods they employ in their research. More importantly, you’ll be able to learn directly from the experts about methods, tools, and best practices.
If you’ve just learned about the world of open source research, it might be a good idea to cast a wide net and follow researchers at established institutions like the New York Times Visual Investigations , Bellingcat , or the Washington Post Visual Forensics team.
One easy way to find open source researchers is to follow Twitter lists. Any user can create a list of accounts, and some — like Malachy Browne of the New York Times’ Visual Investigations Team — have made those lists available. His “OOSI List” contains more than 200 open source researchers whose work you can keep up with by following the list.
Some people use the term “online open source investigations” (OOSI), while others use “open source investigations” (OSI), but the term that’s been around the longest and is used most often on social media is “open source intelligence” (OSINT). These terms are usually used interchangeably, but there are some differences among them that you might want to consider.
The difference between OOSI and OSI is in the name: while OOSI refers to investigations that only use online sources, you would use OSI to describe an investigation that also used offline open sources.
Some who use OOSI or OSI instead of OSINT do so because they feel that the name “OSINT” has direct connotations to intelligence agencies. For these agencies, OSINT is part of an ecosystem of intelligence sources that includes HUMINT (human intelligence), SOCMINT (social media intelligence), IMINT (imagery intelligence), and others. While some independent researchers might be justifiably uncomfortable with that connotation, the term is still widely used and is probably the most recognised.
In any case, we’d recommend using all of these search terms in order to broaden the resources at your disposal.
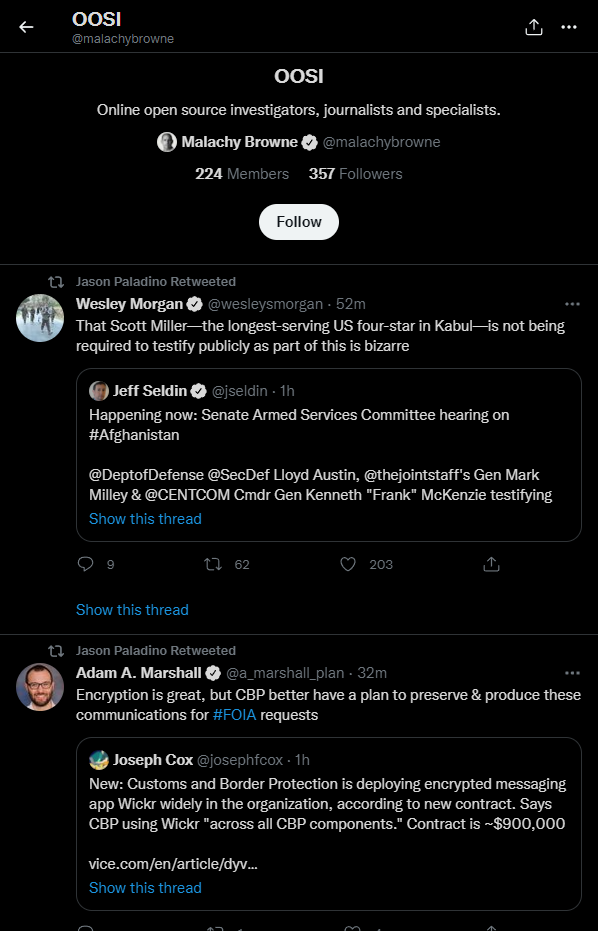
Malachy Browne’s OOSI Twitter List has over 200 researchers and organisations whose work you’re about to discover.
Other useful Twitter lists of researchers include:
- Gisela Pérez de Acha’s “OSINTers”
- Rawan Shaif’s “OSINT”
- Bianca Britton’s “Open Source”
- Julia Bayer’s “OSINT research verify”
As time goes by and you become more familiar with the field, you’ll start to notice how wide and varied it is. On some corners you’ll find researchers who focus exclusively on identifying weapons seen on videos from conflict zones; on some you’ll see people who dedicate their time to tracking aircraft or ships , while in others you’ll find expert geolocators . You might decide that you’ll want to create your own list of niche researchers, which you can do by following the instructions in this guide .
4. Find Community Branches
Open source researchers and enthusiasts tend to spend lots of time online, which means that they’re likely to be hanging out in digital spaces besides Twitter.
Discord is a popular messaging app on which several open source communities have chosen to set up base. These communities resemble the chatrooms of the early internet, and are called “servers” in Discord lingo.
Bellingcat’s Discord server is located here . Anyone can join and share tools, ask questions, and collaborate on research projects. The server is divided into topics where users are welcomed to post relevant content for discussion.
Other open source communities with Discord servers that you should check out are:
- The OSINT Curious Project: Community hub for OSINT Curious , a website dedicated to sharing news and educational information about open source research.
- Project OWL : At any given moment, you’re likely to find thousands of members online in this sprawling server dedicated to every imaginable facet of open source research.
- Bridaga Osint : This server is dedicated to sharing information and resources for the Spanish-speaking community.
There are many more open source-focused Discord servers out there, so never stop looking. Remember that open source research is a collaborative effort, so don’t be afraid to get out there and network.
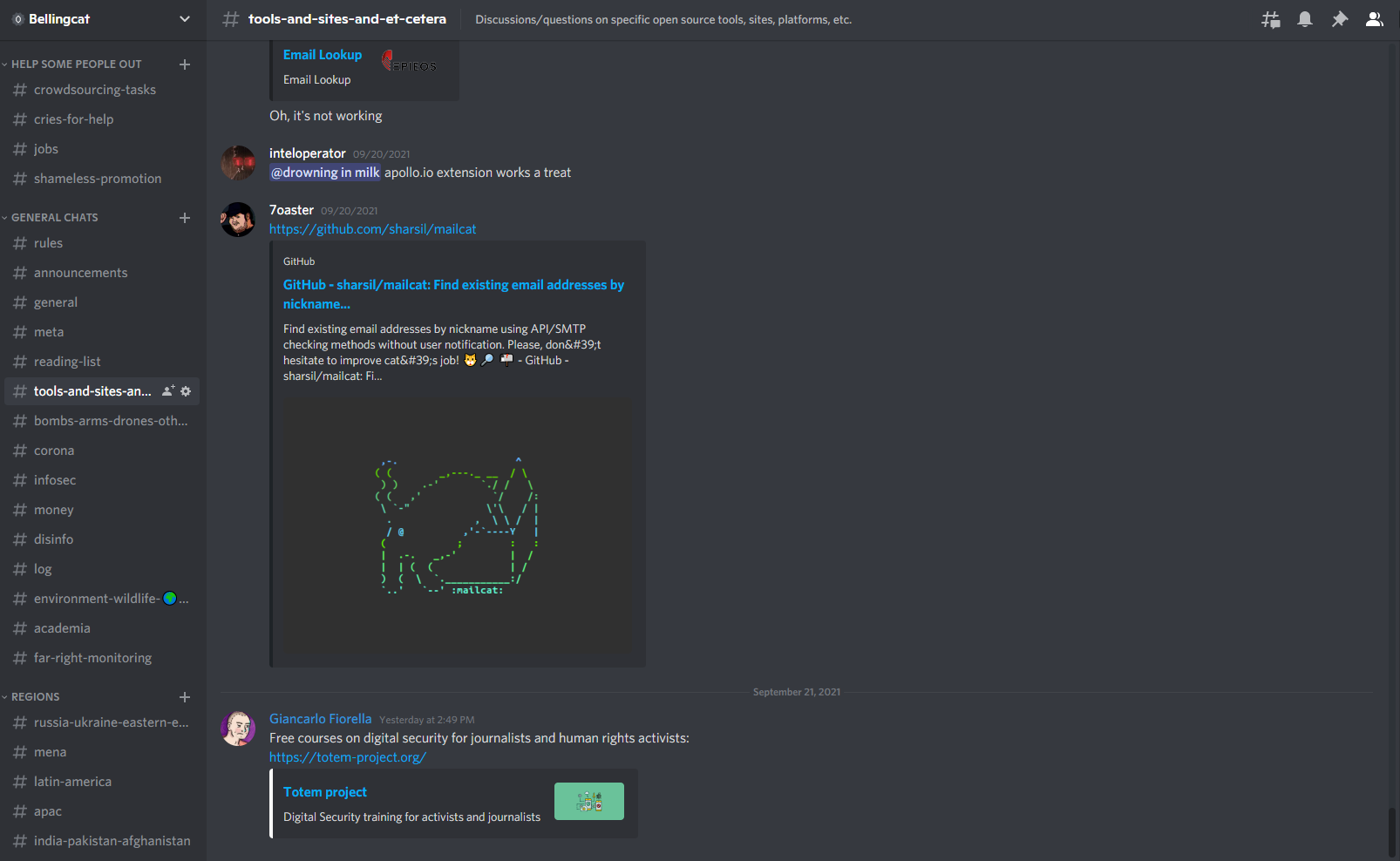
Discord channels are a great place to meet and chat with others interested in research. In the Bellingcat Discord server, there’s a channel dedicated to sharing research tools and resources.
Reddit also hosts open source research communities, including r/Bellingcat , a community-run subreddit. r/OSINT boasts over 26,000 members, making it an active hub of questions and answers on all things related to the field.
The r/TraceAnObject subreddit is dedicated to bringing together people who want to help EUROPOL with its #TraceAnObject campaign and the FBI’s Endangered Child Alert Program . The campaign allows law enforcement to request assistance from the public with identifying individuals, objects and locations seen in child sexual abuse images. Spending time in these subreddits will allow you not only to potentially assist in the rescue of a child, but in the process, to develop your open source research skills. Bellingcat’s own Carlos Gonzales got started in open source research by helping out with these two campaigns part-time.
Joining these kinds of spaces and interacting with fellow enthusiasts and researchers might result in opportunities for you to contribute to important projects, or even inspire you to launch your own.
5. Observe, Learn, and Practice
Now that you’ve got a sense for what the community looks like, where researchers hang out and who’s working on what, you can start to dedicate time to developing and practicing the new skills you’ll be picking up.
One excellent way to practice research skills is by trying out @Quiztime challenges on Twitter. This account posts daily images and challenges you to find out exactly where they were taken.
Sometimes the quizzes also build off an established geolocation for the image, asking you to determine what an object in the image is or when it was taken.

This Quiztime challenge asks you to determine where this bridge is located and when it was built. How would you go about doing that?
Geolocation is not the only skill that you could develop by doing Quiztime challenges.
With the example above in mind, how could you narrow down the number of search areas, from “anywhere on the planet” to a particular country or region? How might you determine what kind of bridge that was? Would a reverse image search work, or would you have to dig deeper into bridge design? Are there any bridge architecture databases or other resources that you could draw from? Google Maps would be the starting place for the geolocation, but many places in the world don’t have Google Street View. If that’s the case for the place where this bridge is located, how else might you find street-level imagery of this place?
These are just some of the questions that you might ask yourself if you were working to solve this challenge, and they’re the same kinds of questions that you might ask yourself if you were working on an open source project to verify images of atrocities in a conflict zone.
In a similar vein, Geoguessr is a geolocation game that is popular in the open source community (both Bellingcat and OSINT Curious , to name two examples, stream Geoguessr games on Twitch ). The game drops you into a Google Streetview image, and it’s your job to guess exactly where the picture was taken. After each guess, you’re given points. The closer your guess is to the actual spot, the more points you get.
You can play by different sets of rules, including no Googling for information or not moving from the spot where you land. These make the game well worth replaying and allow you to tweak its difficulty to your liking.
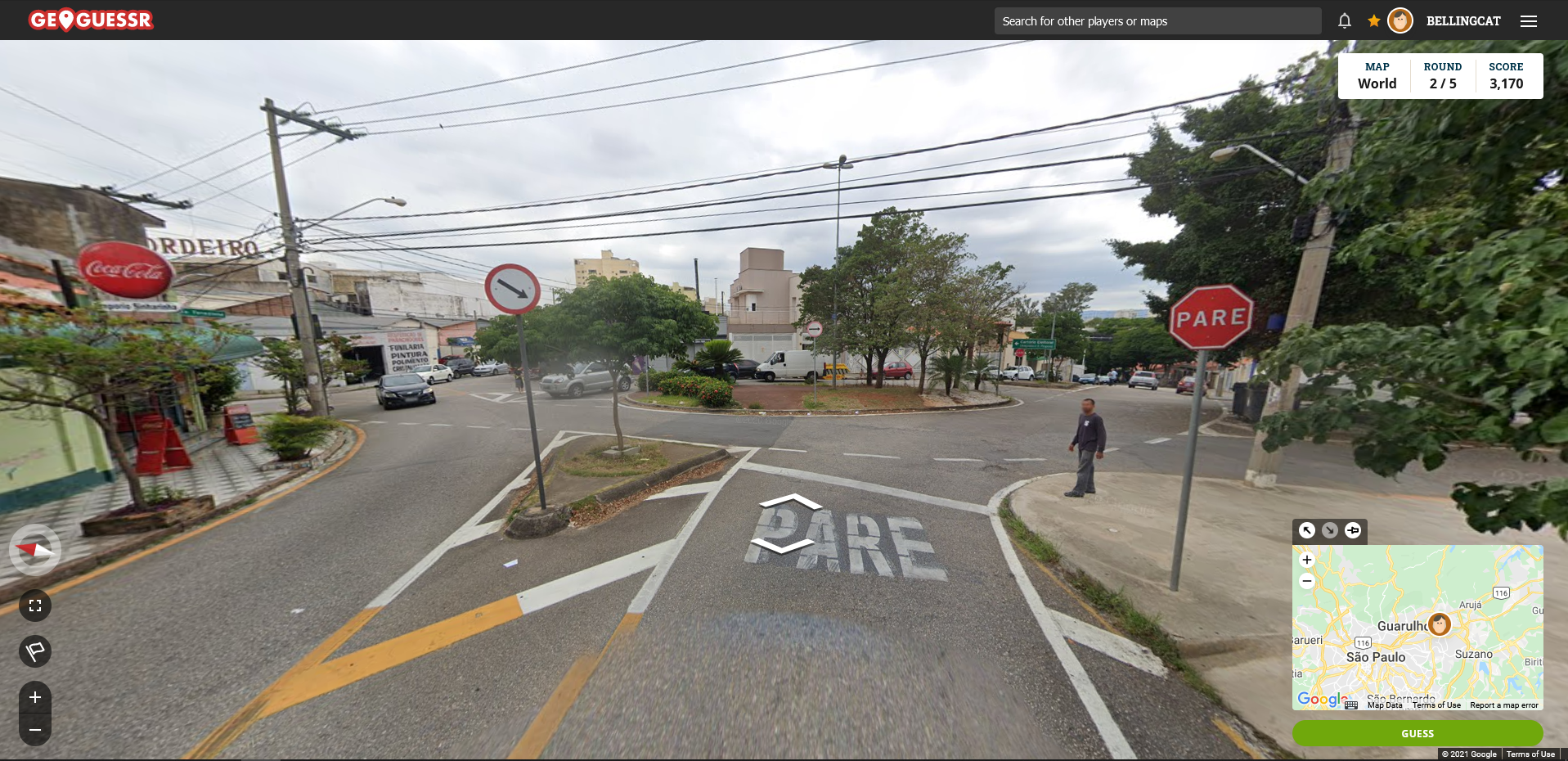
You could spend hours honing your geolocation skills on Geoguessr.
At this point, you can start putting some of these steps together. For example, you might decide that you want to collaborate on a Quiztime challenge with other Twitter users, or set up a Geoguessr Game Night with people you met in the Bellingcat Discord server.
You might also consider joining events like Trace Lab’s Search Party CTF , where four-person teams compete to find information about missing persons (you can read more about what exactly Trace Labs does and why in their “About” page). By participating in these events you’d not only be potentially helping find a missing person, but you’d also have the chance to work (and learn from) other OSI enthusiasts by putting your skills to practice in a team setting.
Now that you’re all set up, here are a few more ideas to get you on your way.
Bookmark Community Resources
One of the great characteristics of the open source research community is its willingness to share knowledge. This knowledge-sharing sometimes takes the form of newsletters and community resource pages that feature tools and research projects for you to explore.
Sector035 ’s Week in OSINT is a weekly newsletter that looks back over the previous seven days in the world of open source research. The newsletter covers everything from new tools that the community has discovered or developed, to new articles and other resources that have just been published. Week in OSINT delivers the best and newest in open source research to your inbox, making it a guaranteed way to learn the ropes of the field.
Bellingcat’s Guides and Resources section includes articles that focus on methodology. The purpose of the articles in this section is to show the reader a new tool or technique, and to provide an example of how it might be used in a research project. We also have a Digital Investigation Toolkit which is updated regularly with new tools.
Mentioned earlier for their Discord channel, OSINT Curious is a community of open source researchers who produce podcasts and live stream everything open source. They’re constantly putting out new content, so you’ll never be short on things to learn.
Individual researchers also take the initiative to collect resources and make them available to the public, like hatless1der’s Ultimate OSINT Collection , and the OSINT Hub . As you become familiar with the research landscape on Twitter, you’ll come to find individuals who, on their own initiative, share these kinds of useful resources with the community.
If you’re interested in learning about every single detail of how to put an open source research project together then make sure to bookmark the Berkeley Protocol on Digital Open Source Investigations. This document is a one-stop resource for all questions related to workflow, from ethical and legal considerations of research to security awareness and data collection and analysis. The Protocol was put together by an impressive team of some of the brightest minds in the field, and was spearheaded by the Human Rights Centre at the University of California, Berkeley .
Be Patient — and Have Fun
Chances are that you’re going to find out pretty quickly that geolocation, chronolocation, determining what objects are in images, or any of the other skills that you’ve chosen to develop are difficult to master. You might find that you’re not able to solve @Quiztime challenges, or that the conversations that people are having in your Discord server involve topics and techniques that you’ve never heard about.
Do not be discouraged. Be patient.
None of us who do this for a living had any of these skills on the first day, the first week, or even the first month (importantly, many or even most seasoned researchers don’t do this for a living at all). In fact, ask any open source researcher and they’ll tell you that they’re still learning new things every single day, and that there are some areas of the field in which they’re novices, too (for example, I barely know the first thing about Python).
Do not be discouraged if you feel like the pace at which you’re learning is slow. As long as you’re having fun learning, then you’re sure to make progress. If you stick with it, you’ll look back in a month or a year on your first day and realise how far you’ve come!
Remember to Take Care
As you set off on your journey as an open source researcher, it is important to be aware that you may be exposed to traumatic materials depending on the topics you follow and events you decide to investigate. This may come in the form of imagery from conflict zones, environmental destruction or human tragedy in the aftermath of natural disasters. Because we’re all different, we all have different triggers and thresholds for working with traumatic materials.
It’s important that you know that there are online resources to help you learn about trauma and how to build resilience. The Dart Centre for Journalism & Trauma is dedicated to providing journalists and researchers with resources related to working with trauma, including practical guides for working with traumatic imagery . Don’t wait until you’re in distress to check out these resources. Become familiar with them and implement their suggestions into your workflow to help ensure your mental health and well-being.
Don’t Just Take My Word for It
I’ve asked other open source researchers to share their own advice for people who are getting started in the field. Here’s what they had to say:
“Don’t worry about the OSINT tricks, or being very good at geolocating. You’ll get the hang of those. But be very, very, curious and creative. Be the person that keeps pulling that little thread until you know what’s on the other side.” — Annique Mossou (Investigator, Bellingcat)
“Enjoy yourself. And not in some wishy-washy general advice way: make sure you’re doing something you’re interested in.” — Nick Waters (Investigator, Bellingcat)
“Creativity, perseverance and determination rule above any toolkit available. Take your time to think about how to solve the problem. Follow your instinct, but record/archive what you are doing. Provide feedback to yourself to correct your track and avoid rabbit holes. Believe and enjoy what you are doing. Don’t hesitate to ask the open source community when you don’t know something. There are incredibly good people out there to help and guide you.” — Carlos Gonzales (Investigator, Bellingcat)
“Don’t try to become an expert in all types of OSINT at first: it can be too vast and overwhelming. Pick one type that interests you and develop it into a specialism. Tools are the flashier side of OSINT, but the real skill is methodology. So, look up successful examples of OSINT methodology to learn from, but also think about how you could have gone about investigating that particular case.” — Manisha Ganguly ( Journalist & OSINT documentary producer for BBC)
“OSINT is about curiosity, creativity, sharing and collaborating as well as constant learning. The beauty about the OSINT community is that everyone brings in a specific technical skill, a passion for something like bird watching, or a special knowledge on a topic like architecture. If you bring in this mindset then trust your gut-feeling and your skill set and get started at @Quiztime.” — Julia Bayer (Investigative journalist, DW News, and founder of Quiztime)
There’s a lot to be said for the insights that can be gleaned with OSINT to make a genuine difference to the world around you. A few principles: Don’t be afraid to ask questions of others or to make mistakes as you learn. Set specific targets for your projects if you can. Archive everything that you may need. Don’t take what others say as fact, check it yourself. Always seek context & don’t rush to be the first to post about a finding. — Calibre Obscura (Weapons and non-state armed groups analyst)
Get on Twitter, follow the OSI experts in the domains you’re interested in, and message them to understand their work and offer your help. That’s how most of us joined the community. — Aliaume Leroy (Open Source Investigator & Producer, BBC)
Gear Up to be a Bellingcat Volunteer
Now that you’ve got an idea of how to get started in open source research, how about setting a goal?
By following the steps in this guide, you can spend the next few months learning about open source research in preparation for the launch of our Volunteer Platform. Due to be launched in 2022, the platform will allow you to contribute to various open source research projects. You’ll be able to register on the platform, login, volunteer for tasks, and work on them together with other volunteers.
Keep your eyes on our Twitter account and on our website, where we’ll post instructions on how to get involved once the platform launches. We hope to see you there.
Related articles

- Social Media
Chronolocation: Determining When a Photo was Taken Using Facebook, Google Street View and Assorted Tiny Details

Using New Tech to Investigate Old Photographs

Using the Sun and the Shadows for Geolocation
Support bellingcat.
Your donation to Bellingcat is a direct contribution to our research. With your support, we will continue to publish groundbreaking investigations and uncover wrongdoing all around the world.
Join the Bellingcat Mailing List
Along with our published content, we will update our readers on events that our staff and contributors are involved with, such as noteworthy interviews and training workshops.
- Mission and history
- Platform features
- Library Advisory Group
- What’s in JSTOR
- For Librarians
- For Publishers
Open and free content on JSTOR and Artstor
Our partnerships with libraries and publishers help us make content discoverable and freely accessible worldwide
Search open content on JSTOR
Explore our growing collection of Open Access journals
Early Journal Content , articles published prior to the last 95 years in the United States, or prior to the last 143 years if initially published internationally, are freely available to all
Even more content is available when you register to read – millions of articles from nearly 2,000 journals
Thousands of Open Access ebooks are available from top scholarly publishers, including Brill, Cornell University Press, University College of London, and University of California Press – at no cost to libraries or users.
This includes Open Access titles in Spanish:
- Collaboration with El Colegio de México
- Partnership with the Latin American Council of Social Sciences
Images and media
JSTOR hosts a growing number of public collections , including Artstor’s Open Access collections , from museums, archives, libraries, and scholars worldwide.
Research reports
A curated set of more than 34,000 research reports from more than 140 policy institutes selected with faculty, librarian, and expert input.
Resources for librarians
Open content title lists:
- Open Access Journals (xlsx)
- Open Access Books (xlsx)
- JSTOR Early Journal Content (txt)
- Research Reports
Open Access ebook resources for librarians
Library-supported collections
Shared Collections : We have a growing corpus of digital special collections published on JSTOR by our institutional partners.
Reveal Digital : A collaboration with libraries to fund, source, digitize and publish open access primary source collections from under-represented voices.
JSTOR Daily
JSTOR Daily is an online publication that contextualizes current events with scholarship. All of our stories contain links to publicly accessible research on JSTOR. We’re proud to publish articles based in fact and grounded by careful research and to provide free access to that research for all of our readers.
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
Open Data is a strategy for incorporating research data into the permanent scientific record by releasing it under an Open Access license. Whether data is deposited in a purpose-built repository or published as Supporting Information alongside a research article, Open Data practices ensure that data remains accessible and discoverable. For verification, replication, reuse, and enhanced understanding of research.
Benefits of Open Data
Readers rely on raw scientific data to enhance their understanding of published research, for purposes of verification, replication and reanalysis, and to inform future investigations.
Ensure reproducibility Proactively sharing data ensures that your work remains reproducible over the long term.
Inspire trust Sharing data demonstrates rigor and signals to the community that the work has integrity.
Receive credit Making data public opens opportunities to get academic credit for collecting and curating data during the research process.
Make a contribution Access to data accelerates progress. According to the 2019 State of Open Data report, more than 70% of researchers use open datasets to inform their future research.
Preserve the scientific record Posting datasets in a repository or uploading them as Supporting Information prevents data loss.
Why do researchers choose to make their data public?
Watch the short video that explores the top benefits of data sharing, what types of research data you should share, and how you can get it ready to help ensure more impact for your research.
PLOS Open Data policy
Publishing in a PLOS journal carries with it a commitment to make the data underlying the conclusions in your research article publicly available upon publication.
Our data policy underscores the rigor of the research we publish, and gives readers a fuller understanding of each study.
Read more about Open Data
Data sharing has long been a hallmark of high-quality reproducible research. Now, Open Data is becoming...
For PLOS, increasing data-sharing rates—and especially increasing the amount of data shared in a repository—is a high priority.
Ensure that you’re publication-ready and ensure future reproducibility through good data management How you store your data matters. Even after…
Data repositories
All methods of data sharing data facilitate reproduction, improve trust in science, ensure appropriate credit, and prevent data loss. When you choose to deposit your data in a repository, those benefits are magnified and extended.
Data posted in a repository is…
…more discoverable.
Detailed metadata and bidirectional linking to and from related articles help to make data in public repositories easily findable.
…more reusable
Machine-readable data formatting allows research in a repository to be incorporated into future systematic reviews or meta analyses more easily.
…easier to cite
Repositories assign data its own unique DOI, distinct from that of related research articles, so datasets can accumulate citations in their own right, illustrating the importance and lasting relevance of the data itself.
…more likely to earn citations
A 2020 study of more than 500,000 published research articles found articles that link to data in a public repository were likely to have a 25% higher citation rate on average than articles where data is available on request or as Supporting Information.
Open Data is more discoverable and accessible than ever
Deposit your data in a repository and earn an accessible data icon.

You already know depositing research data in a repository yields benefits like improved reproducibility, discoverability, and more attention and citations for your research.
PLOS helps to magnify these benefits even further with our Accessible Data icon. When you link to select, popular data repositories, your article earns an eye-catching graphic with a link to the associated dataset, so it’s more visible to readers.
Participating data repositories include:
- Open Science Framework (OSF)
- Gene Expression Omnibus
- NCBI Bioproject
- NCBI Sequence Read Archive
- Demographic and Health Surveys
We aim to add more repositories to the list in future. Read more
The PLOS Open Science Toolbox
The future is open
The PLOS Open Science Toolbox is your source for sci-comm tips and best-practice. Learn practical strategies and hands-on tips to improve reproducibility, increase trust, and maximize the impact of your research through Open Science.
Sign up to have new issues delivered to your inbox every week.
Learn more about the benefits of Open Science. Open Science
- Advanced search
- Peer review

Discover relevant research today

Advance your research field in the open

Reach new audiences and maximize your readership
ScienceOpen puts your research in the context of
Publications
For Publishers
ScienceOpen offers content hosting, context building and marketing services for publishers. See our tailored offerings
- For academic publishers to promote journals and interdisciplinary collections
- For open access journals to host journal content in an interactive environment
- For university library publishing to develop new open access paradigms for their scholars
- For scholarly societies to promote content with interactive features
For Institutions
ScienceOpen offers state-of-the-art technology and a range of solutions and services
- For faculties and research groups to promote and share your work
- For research institutes to build up your own branding for OA publications
- For funders to develop new open access publishing paradigms
- For university libraries to create an independent OA publishing environment
For Researchers
Make an impact and build your research profile in the open with ScienceOpen
- Search and discover relevant research in over 93 million Open Access articles and article records
- Share your expertise and get credit by publicly reviewing any article
- Publish your poster or preprint and track usage and impact with article- and author-level metrics
- Create a topical Collection to advance your research field
Create a Journal powered by ScienceOpen
Launching a new open access journal or an open access press? ScienceOpen now provides full end-to-end open access publishing solutions – embedded within our smart interactive discovery environment. A modular approach allows open access publishers to pick and choose among a range of services and design the platform that fits their goals and budget.
Continue reading “Create a Journal powered by ScienceOpen”
What can a Researcher do on ScienceOpen?
ScienceOpen provides researchers with a wide range of tools to support their research – all for free. Here is a short checklist to make sure you are getting the most of the technological infrastructure and content that we have to offer. What can a researcher do on ScienceOpen? Continue reading “What can a Researcher do on ScienceOpen?”
ScienceOpen on the Road
Upcoming events.
- 20 – 22 February – ResearcherToReader Conferece
Past Events
- 09 November – Webinar for the Discoverability of African Research
- 26 – 27 October – Attending the Workshop on Open Citations and Open Scholarly Metadata
- 18 – 22 October – ScienceOpen at Frankfurt Book Fair.
- 27 – 29 September – Attending OA Tage, Berlin .
- 25 – 27 September – ScienceOpen at Open Science Fair
- 19 – 21 September – OASPA 2023 Annual Conference .
- 22 – 24 May – ScienceOpen sponsoring Pint of Science, Berlin.
- 16-17 May – ScienceOpen at 3rd AEUP Conference.
- 20 – 21 April – ScienceOpen attending Scaling Small: Community-Owned Futures for Open Access Books .
- 18 – 20 April – ScienceOpen at the London Book Fair .
What is ScienceOpen?
- Smart search and discovery within an interactive interface
- Researcher promotion and ORCID integration
- Open evaluation with article reviews and Collections
- Business model based on providing services to publishers
Live Twitter stream
Some of our partners:.


An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Springer Nature - PMC COVID-19 Collection
Open source intelligence and AI: a systematic review of the GELSI literature
Riccardo ghioni.
1 Department of Legal Studies, University of Bologna, Via Zamboni, 27, 40126 Bologna, IT Italy
Mariarosaria Taddeo
2 Oxford Internet Institute, University of Oxford, 1St Giles’, Oxford, OX1 3JS UK
3 The Alan Turing Institute, British Library, 96 Euston Rd, London, NW1 2DB UK
Luciano Floridi
Associated data.
The data that support the findings of this paper is available upon request.
Today, open source intelligence (OSINT), i.e., information derived from publicly available sources, makes up between 80 and 90 percent of all intelligence activities carried out by Law Enforcement Agencies (LEAs) and intelligence services in the West. Developments in data mining, machine learning, visual forensics and, most importantly, the growing computing power available for commercial use, have enabled OSINT practitioners to speed up, and sometimes even automate, intelligence collection and analysis, obtaining more accurate results more quickly. As the infosphere expands to accommodate ever-increasing online presence, so does the pool of actionable OSINT. These developments raise important concerns in terms of governance, ethical, legal, and social implications (GELSI). New and crucial oversight concerns emerge alongside standard privacy concerns, as some of the more advanced data analysis tools require little to no supervision. This article offers a systematic review of the relevant literature. It analyzes 571 publications to assess the current state of the literature on the use of AI-powered OSINT (and the development of OSINT software) as it relates to the GELSI framework, highlighting potential gaps and suggesting new research directions.
Introduction
Literature about intelligence studies claims that open source intelligence (OSINT), i.e., intelligence derived from publicly available sources, makes up between 70 and 90 percent of all contemporary intelligence material (Hulnick 2002 , 566; Unver 2018 , 5). This estimate is not surprising as open-source information increases and more efficient techniques from computer science, data science, and statistics are developed, streamlining collection and analysis. As capabilities grow with the development of artificial intelligent (AI) systems, performance becomes inextricably linked to the quality of the technical tools employed by OSINT analysts. As a result, important issues related to the governance of these developments arise in both academic and applied domains. Indeed, it has become crucial to devise appropriate legal, ethical and regulatory frameworks to tackle the challenges posed by the increasing complexity of AI systems as they interact with every stage of the OSINT cycle—direction, collection, processing, analysis, dissemination and integration, and feedback (Defense Technical Information Center (DTIC)—Department of Defense 2013 ). 1 Some earlier work, taking note of this trend, has provided an overview of the use of AI algorithms for OSINT analysis in the applied literature (Evangelista et al. 2021 ), while other authors have focused on the impact of the General Data Protection Regulation (GDPR) on the collection and analysis of OSINT (Shere 2020b ). So far, however, a thorough review of the Governance, Ethical, Legal and Social Implications (GELSI) 2 framework applied to OSINT is still lacking. This article sets out to fill this gap by providing a systematic review of the OSINT-GELSI literature as defined in Grant and Booth ( 2009 , 102), namely a systematic search and analysis of the relevant literature. This is achieved by collecting a bibliographic dataset of OSINT articles which is then vetted to identify articles dealing with the GELSI framework. Current research is then summarized according to its major underlying themes, and some novel research directions are suggested.
The article is structured as follows. Section two provides more detailed definitions of OSINT and presents a brief historical overview of its scope and applications over the years. We argue that, because of the digital revolution, OSINT capabilities have been greatly increased in terms of data availability and computational power. We also provide a working definition of the GELSI framework and how it relates to current research on AI auditing and regulation. Section three details the methodology used to retrieve the bibliographic dataset and presents the results of a bibliometric analysis conducted on the different strands of OSINT literature. It shows that, despite a vast increase in publications, papers dealing with the GELSI framework are still a small subset of the wider scholarship, with technical papers dealing with OSINT collection and analysis being the largest group. However, it also indicates that, once accounting for the low publication numbers, GELSI papers have become increasingly more influential over the years, both in terms of citation counts and ranking in search engines. Sections four to six provide a systematic review of the relevant literature in terms of GELSI, highlighting the main themes underpinning most of the reviewed material. Section seven then suggests future research directions concerning the role of AI-augmented OSINT systems. Finally, section eight summarizes the main findings and concludes the article.
Open source intelligence, AI, and the GELSI framework
A great deal of literature on OSINT has been devoted to finding a suitable definition for it. This is not easy because the concept of intelligence analysis is still contested in the relevant literature (Ish et al. 2021 ), with different authors and institutions providing different definitions, and because any definition of OSINT needs to accommodate advances in computer and data science and AI, which are constantly expanding the intelligence collection and analysis capabilities. One of the earliest definitions is found in the Intelligence Community Directive 301, a document aimed at increasing awareness of open-source information among intelligence agencies. Directive 301 borrowed its definition of OSINT from Public Law 109-163 (or the National Defense Authorization Act of 2006 ), stating that:
Open-source intelligence (OSINT) is intelligence that is produced from publicly available information and is collected, exploited, and disseminated in a timely manner to an appropriate audience for the purpose of addressing a specific intelligence requirement (Public Law 109-163 2006 , Division A, Title IX, Subtitle D, Sec. 931)
This definition is quite broad and does not detail the wide range of OSINT applications. Indeed, for most of its early history, OSINT has been limited to the physical retrieval and analysis of foreign media by offices such as the United States (US) Foreign Broadcast Information Service (FBIS), which was tasked with listening to, translating, and analyzing Axis broadcasts, to gain strategic information about the enemy’s intentions (Mercado 2001 ). This was the so-called first generation of OSINT, whose main tasks were document retrieval and translation and required little analytic work aside from some content analysis on the collected material (Williams and Blum 2018 , 40) .
The landscape changed dramatically at the turn of the century. The creation of the Open Source Center (OSC) in 2005, which replaced the FBIS in the US, marks the beginning of the second generation of OSINT, whose crucial innovations were made possible mainly by the digital revolution. As observed by Unver ( 2018 ), the shift from “classical” to “digital” OSINT unlocked powerful and previously unthinkable tools, which can be roughly divided into four major groups, namely linguistic and text-based, geospatial, network-based, and visual forensics.
Linguistic tools relate to the retrieval and analysis of textual data and constitute a clear bridge between the first and the second generations of OSINT. If the former had analysts sifting through documents to detect valuable information and produce executive summaries, the latter saw computer algorithms scanning digitized documents to extract keywords and identify their context. Natural Language Processing (NLP) is a discipline at the crossroads of linguistics and AI, dealing with the analysis of textual data in different domains. Many algorithms designed to solve a wide variety of problems in machine learning—such as topic discovery, entity recognition, and automatic text summarization (Unver 2018 , 8)—have been applied, together with information retrieval algorithms, to analyze open-source information gathered from online newspapers and social media. This has enabled researchers to sort rapidly through large pools of data and identify semantic patterns, translate and summarize long documents and detect behavioral changes through sentiment analysis (Chen 2011 ; Neri et al. 2012 ; Asghar et al. 2015 ).
Geospatial tools refer to any method through which open-source information directly or indirectly situates an actor or a group of actors in space. The emergence of commercial satellite imagery and other remote sensing tools has made geospatial OSINT very popular among analysts, who can now overlay locations mined from the web with satellite images, visualizing movements over time, and connections between locations (Unver 2018 , 11). Applications of geospatial OSINT include geolocation, geo-inference , i.e., retrieving users’ locations without explicit geotagging information, and georeferencing , namely uniquely identifying geographical objects (Williams and Blum 2018 , 33).
Network-based tools involve using measures borrowed from network science , a discipline studying pairwise relationships between entities. Social network data make for a great source of OSINT since relationships can be easily harvested and mapped, identifying the strength of relationships between actors (Unver 2018 , 12). Centrality measures can then be computed for the entities in a network, allowing analysts to quantify the relative importance of each unit in regulating the information flow through the group. These tools have found important applications in studying terrorist networks (Wiil 2011 ), and they are increasingly exploiting the enormous quantity of online social network data to obtain more accurate estimates.
Finally, visual forensics tools are techniques for extracting valuable information from image and video files (Unver 2018 , 13–14). For instance, metadata stored under the Exchangeable Image File Format (EXIF) in digital cameras and smartphones can yield crucial intelligence, such as the date, time, and location where the file was created. Moreover, tools for detecting doctored images and conducting photogrammetric analysis (the acquisition of measurements from photographs and videos) are also available to the OSINT analyst.
The increasing reliance on AI to automate most of the collection and analysis process foresees the emergence of a third-generation OSINT, more dependent on computer algorithms and automated reasoning than on the analyst’s supervision (Williams and Blum 2018 , 39–40).
The above historical excursus shows how difficult it has become to provide a unified definition of OSINT. Indeed, unlike other intelligence-gathering disciplines, OSINT is aided by developments in the digital world, and its domain expands with them. As new data sources become widely available, new, previously hidden patterns can be learned from them, further blurring the lines between different intelligence practices [see, for instance, the discussion on a possible expansion of OSINT to the augmented reality domain in Williams and Blum ( 2018 )].
Yet, despite these difficulties, the above presentation suffices to illustrate the far-reaching possibilities of OSINT and introduce our work. In the following pages, we shall review the literature dealing with the GELSI of second and third-generation OSINT. Although a formal definition of the GELSI framework is yet to be formulated, we take a broad approach (as the keyword specification in section three shows) and regard as GELSI-related literature any article tackling the meaningful changes or potential harms brought about by the use of AI-powered OSINT, together with the proposed solutions to such issues. The following section explains how we proceeded.
Methodology
To create our bibliographic dataset, we used Publish or Perish (PoP, Harzing 1997 ), a software that allows researchers to query multiple academic databases and export the resulting reference list to conduct analysis. We queried the two main scholarly databases, Google Scholar and Scopus. To include as much material as possible, we only required the phrase “Open Source Intelligence” or its acronym “OSINT” in the paper’s title. In a separate search, we specified the same criterion for the phrase “Open Source Information” and its acronym “OSINF”. We ran the same two queries on both databases, for a total of four queries. Table Table1 1 summarizes the results of this search, together with the number of results provided by PoP. After exporting the datasets, these were joined and scanned to remove both within and between-platform duplicates and works deemed irrelevant to the current analysis. These included documents, such as Master’s theses, conference talks, executive summaries and other papers that contained the search terms but in a different, unrelated context.
Summary of results from the PoP queries
As can be seen in the right columns, the number of entries that were eventually removed is high in both databases. Once eliminated, this left 571 papers or around 55% of the original dataset. As a final step in the data cleaning and collection process, we crawled the web for the papers’ abstracts. PoP provides an abstract entry in its bibliographic files, but abstracts are available only for entries taken from Google Scholar and are only previews downloaded from the search results page. Therefore, a parsing script was designed to retrieve the abstracts’ text based on each article’s Digital Object Identifier (DOI). Since the HTML structures of the DOIs’ landing pages is quite varied, the script only achieves a retrieval precision of 43.87%. Thus, when no abstract could be crawled, or the DOI was missing, the PoP abstract was kept instead.
After the initial data cleaning steps, we performed a keyword search routine to split the dataset into different literature strands. First, we iterated through each entry’s title, abstract, and journal name to identify those belonging to the Practitioner Literature , which we define as works dealing with the practical aspects of OSINT gathering, analysis and interpretation, with a specific focus on Digital OSINT. These documents cover a wide variety of topics, such as the development of efficient data mining techniques for OSINT gathering, the creation of OSINT platforms for social media intelligence, the optimisation of NLP algorithms for entity ranking and identification or the use of deep learning models for cyber threat classification from OSINT data. However, they have in common the applied nature of their research, focusing on algorithmic solutions for problems arising at each stage of the OSINT cycle.
Once the practitioner literature was removed from our dataset, we were left with what we define as the intelligence literature, namely those documents dealing with OSINT as a discipline. Once again, this is a broad categorization, including, among other topics, historical accounts of the emergence and evolution of the discipline, case studies on OSINT applications and theoretical examinations of the advantages and disadvantages of employing OSINT over standard intelligence. From this area of the OSINT literature, we sought to extract any articles related to the GELSI framework. To do this, we performed a second keyword search on the papers’ titles, abstracts, and journal names. The list of keywords used to identify each strand, together with their locations, is provided in Table Table2. 2 . Some of the keywords used are very specific (targeting specific papers identified before the keyword search). However, most are general and can be applied outside the OSINT corpus. This approach is not without issues. Indeed, some papers may lack any of the specified keywords in any of the fields, thus falling into the Intelligence category while belonging to one of the other two. Moreover, some entries may be of difficult classification, with their content not entirely fitting any of the above categories. However, a direct and careful inspection of the resulting dataset entries revealed that only a small fraction of papers was misclassified. This error was corrected. Most of the issues concerned only some minor overlap between the Practitioner and Intelligence strands, which are not the focus of the present review.
List of keywords used to classify the bibliographic dataset
Once the keywords were specified and the literature strands returned, we plotted their percentage distribution in Fig. 1 .

Distribution of literature areas
GELSI-themed papers only account for about 12% of the entire corpus, while the remaining papers are evenly split between the practitioner and intelligence areas. In Fig. 2 , we visualize the evolution of the OSINT literature over the last thirty years.

OSINT literature over the years (1992–2021)
The number of published articles has increased dramatically since the early 1990s and especially in the last ten years. While the practitioner literature has witnessed the highest increase, GELSI scholarship has also grown significantly in recent years. This testifies to the perceived importance of developing up-to-date practical tools to deal with the ever-increasing pool of OSINT data and the need for viable ethical and legal frameworks to deal with such tools. Looking at the above graphs, it seems that this need has only been partially addressed. Indeed, GELSI scholarship appears to be only a minor subfield of the wider OSINT literature in terms of sheer publication numbers. However, one might also be interested in checking how influential each publication is to the others. Figure 3 plots the number of citations per year received by each paper, obtained by dividing the number of citations by the number of years elapsed since publication. Aside from a few very influential outliers in the practitioner and intelligence literature, most papers cluster around the same citation performance each year, irrespective of the research area. A slight upward trend can be detected in the last couple of years, which is compatible with the overall increase in the number of publications.

Scatter plot of paper citations
Instead, if we consider each literature area as a separate corpus, i.e., we normalize citation rates by the number of publications in the same field each year, we obtain the average yearly citation rates, which we formally define as:
where T = {1992, …, 2022}, N t , f ∈ N is the number of papers from field f published in year t and c i ( t , f ) is the number of citations paper i ∈ { 1 , ⋯ , N ( t , f ) } from field f received in year t . Therefore, average yearly citation rates are functions of both year t and field f . These rates are plotted in Fig. 4 .

Average yearly citation rates by research area
This way, instead of the relative importance of specific papers, we obtain a rough estimate of the relative importance of each field and its evolution through the years. Although there is no clear trend detectable in the graph, we can see how GELSI papers suddenly stand out and appear to be highly influential, sometimes even more than papers in the remaining fields, despite being only 12% of the OSINT corpus.
Finally, another measure that is useful in quantifying each field’s relative influence is the Google Scholar rank, namely the position of each paper in the Google Scholar queries. Figure 5 shows the frequency distribution of Google Scholar ranks for each subfield. Note that these ranks are automatically recorded by PoP after each of the queries in Table Table1, 1 , and therefore they are not affected by any of the later keyword searches.

Frequency distribution of Google Scholar ranks
Indeed, while technical and intelligence articles have almost overlapping distributions of ranks, GELSI papers concentrate most of their values at the top, declining soon after. As it turns out, 72% of GELSI papers are found within the first 200 results, while the proportion drops to around 54% for the remaining literature fields. Computing the odds ratio, we discover that GELSI papers are twice more likely to be assigned a rank between 1 and 200 than papers belonging to any other field ( p < 0.01).
It has been shown that citation counts play a major role in Google Scholar ’s ranking algorithm (Beel and Gipp 2009 ). However, as the above plot and computations show, this is not the only metric considered when computing each paper’s rank. Indeed, other variables, such as the paper’s author and journal, also affect the ranking. The fact that a small subset of the OSINT corpus dealing with its ethical, legal, and social implications is more likely to be ranked higher than the remaining larger literature by one of the most prominent academic search engines testifies to the relevance of this area despite the low number of publications. Thus, it is paramount to investigate the OSINT-GELSI literature thoroughly and provide guidance on how researchers can further develop it.
Throughout the review, we also reference papers that do not belong to the bibliographic dataset described here either because they did not match any of the queries’ requirements or because they were found to help provide the necessary context to the topics discussed. Indeed, issues raised in other, maybe even loosely related fields could easily be applied to the OSINT landscape with much to gain in terms of a normative framework for modern OSINT applications. The following sections present the result of the analysis.
Review of the OSINT-GELSI literature
Following the analysis of the relevant literature, Fig. 6 provides a proposed taxonomy of the GELSI scholarship in the context of the more comprehensive OSINT corpus, together with some of the most prominent themes for each area. As it turns out, we can distinguish two main levels of analysis.

A proposed OSINT-GELSI taxonomy
The micro-level deals with the impact of OSINT on individuals and organizations, focusing on the legal and ethical challenges posed by the OSINT cycle, especially surrounding privacy issues emerging in the collection phase. We analyze papers addressing these aspects in Sect. 5 .
The macro-level is concerned with the impact of OSINT on society at large. These papers focus on the social, governance and even behavioral implications of open-source information, addressing issues, such as the emergence of citizen activism and the changes in users’ online habits triggered by the mainstreaming of OSINT data and techniques. We examine these themes and highlight the main arguments put forward in these papers in Sect. 6 .
Finally, in Sect. 7 , we consider how the OSINT-GELSI literature will likely evolve, given the ever-increasing reliance on AI algorithms by OSINT analysts. At the micro-level, these emerging trends include the auditing of AI algorithms at the processing and dissemination stages of the OSINT cycle, while at the macro-level, they revolve around issues of asymmetric technological advantage and institutional accountability. Moreover, following Glassman and Kang ( 2012 ), we also look at OSINT as a problem-solving strategy, changing how users approach information, and focus on how AI is likely to influence this process.
The GELSI of OSINT at the micro-level
The first, most prominent theme in the GELSI literature concerns the micro implications of second and third-generation OSINT. This scholarship mainly examines the legal and ethical aspects of open-source data gathering and analysis. Koops ( 2013 ) argues that the mere fact that some information is public does not mean privacy concerns should be discarded entirely. Moreover, modern OSINT techniques can aggregate several chunks of information and identify physical persons even when each element comes from anonymous sources (profiling). Therefore, the need for a framework to address the impact of OSINT on individual rights is quite evident in the literature (Rahman and Ivens 2020 ). So much so that several European projects dealing with the issue of privacy in OSINT investigations have been funded over the years. 3 These projects aimed at developing platform solutions for the retrieval, analysis, management and dissemination of OSINT across Law Enforcement Agencies (LEAs) in different policing contexts, keeping track of the evolving European data protection framework (Cuijpers 2013 ; Casanovas et al. 2014 ).
As a result, much literature has been produced in the practitioner (Dupont et al. 2011 ; Amardeilh et al. 2013 ; Ortiz-Arroyo 2015 ) and GELSI strands. Although the latter focuses mainly on the specific OSINT software tools developed as part of the European research projects, the main ethical and legal concerns are also laid out. The crucial issue is the impact of OSINT investigations on individuals’ privacy, and the go-to framework to address these concerns is Privacy by Design (PbD). A concept mainstreamed by Cavoukian and Borking in the 1990s (Hustinx 2010 , 253) and later adopted in data protection legislation (see, for instance, Art. 25, GDPR 2016 ), PbD is linked to the creation of Privacy Enhancing Technologies (PETs) that are aimed at safeguarding individual privacy during the design of data analysis software and platforms (Cuijpers 2013 ). Several principles have been suggested to achieve this behavior by default. Colesky et al. ( 2016 ) summarize them in eight tactics that should guide PbD strategies: minimize, hide, abstract, separate, inform, control, enforce, and demonstrate. These tactics cover both the data collection and use phases, and include essential tools, such as encryption, anonymization, data aggregation, informed consent, and auditing strategies.
Additionally, Koops et al. ( 2013 ) propose two ways of directly incorporating PbD principles into OSINT platforms: revocable privacy and enterprise privacy policies. The first one aims at enforcing the data minimisation strategy by allowing access to personal data “only if a predefined condition has been met” (Koops et al. 2013 , 681). This could be achieved either through spread responsibility, i.e., relying on a third party to verify whether the condition(s) has occurred and release the relevant data, or through a self-enforcing architecture, i.e., a set of hard-coded rules that would grant access to the relevant data automatically, if triggered by some precondition.
Enterprise privacy policies use technology itself to implement privacy rules. Specifically, they require a policy markup language to define the required data management and access rules (Koops et al. 2013 , 683). This way, more sophisticated legal compliance mechanisms can be embedded within machine code.
Another critical aspect, when considering the legal implications of OSINT platforms, is creating and maintaining specialized ontologies designed to automate parts of the analysis, such as document summarisation or entity extraction. These ontologies need to be specified correctly to be interoperable between agencies and need frequent updating to keep up with evolving regulatory frameworks. Ontologies are formally defined as “(meta)data schemas, providing a controlled vocabulary of concepts, each with an explicitly defined and machine processable semantics” (Maedche and Staab 2001 ). They play a crucial role in designing Semantic Web Regulatory Models (SWRM), which encode norms, rules and ethical principles into machine-readable regulation, which can then be applied across different organizations and countries (Casanovas 2015 ). However, ontology regulation is only partly addressed when it comes to OSINT. As Casanovas et al. ( 2014 ) put it, “[t]here are no neutral ontologies. They have a purpose and a particular shape, and need to be regularly updated”. Therefore, a practical framework for the definition (and maintenance) of ontologies for OSINT analysis is needed in the GELSI literature, especially considering the varied nature of OSINT sources and the potential deceitful use the opponent may make of it.
Other authors shift the focus from PETs to other legal devices to address the OSINT “privacy paradox” of information being freely available (not private) but also sometimes extremely sensitive and personal (therefore private). One hypothetical solution provided in the literature draws from Nissenbaum ( 2004 ). It considers privacy as contextual integrity, namely the idea that no area of life is exempt from privacy expectations and that every situation has contexts regulated by explicit or even implicit norms that, if violated, result in a breach of privacy. This idea, coupled with the extension of the concept of home to the digital realm, where each user can decide who has access to their “personal cyberspace”, would ensure that privacy is at least partly safeguarded against malicious use of personal data (Ten Hulsen 2020 ).
Indeed, at the moment, the availability of OSINT to inexperienced (or malicious) activists can lead to unethical and possibly even illegal behavior, such as the sharing of private information online or the misidentification of individuals involved in illegal activity (Belghith et al. 2022 ). This should be a source of concern for organizations and activist networks, as the infringement of the ethical code surrounding the OSINT community could have severe consequences regarding public safety and national security. Moreover, as Shere ( 2020a ) recently argued in a survey of OSINT analysts, the General Data Protection Regulation (GDPR) has failed to provide a significant change in OSINT gathering capabilities, with any meaningful change only being due to the updating of privacy settings by social media companies. These and other elements of concern for individuals and groups involved in OSINT investigations have been summarized by Hu ( 2016 ) in five major ethical concerns of OSINT practice. They include the origin and intent of sources, which should be carefully vetted, as they could bias the resulting analysis (more on this misinformation aspect in the following sections); the distribution of unclassified yet still sensitive information, which could harm the people involved; and the over-reliance on automated analysis, which could lead to mistakes if left unchecked. Moreover, the mosaic effect, whereby data subjects can be identified by integrating different data sources and the excessive publicity generated by successful OSINT investigations are also sources of concern for the analyst.
These aspects also find their way into the legal realm. Indeed, there is a difference between OSINT as intelligence and OSINT used as evidence in a criminal proceeding (Sampson 2016 ). While almost any information can be considered intelligence when it serves a specific purpose, in the latter case, the evidential material must answer further questions of admissibility and weight. Specifically, the evidence must be proven relevant to a fact in question, and its reliability must be established before it can be accepted. Looking at the general case of the signatories of the European Convention on Human Rights (ECHR), Sampson ( 2017 ) identifies some procedural issues in using OSINT as evidence, mainly concerning the fairness principles embodied in the ECHR. In general, aside from country-specific legislation, disclosure of evidence to defendants is expected in criminal trials. Moreover, the hearsay nature of many OSINT materials could lead to their rejection in court. According to the author, three main factors determine the admissibility of OSINT data as evidence in criminal trials. First, the provenance of the material requires that the data source be clearly identified, and that the collection procedure be lawful. In the specific case of digital OSINT, Lyle ( 2016 ) provides some examples of unlawful OSINT collection by law enforcement, such as impersonating someone on social media, which require specific legal authority and would compromise the admissibility of OSINT material in court. Second, data integrity concerns the reliability of the evidence itself. If the data could have been easily tampered with [see, for instance, the case of deep fakes in Koenig ( 2019 )], its admissibility and weight would be in question. The last aspect to be considered is the reliability of the author providing the evidence. If the material comes from an anonymous source or the author cannot corroborate the evidence, the data will likely be rejected during the trial (Sampson 2017 ).
While most of the scholarship at the micro-level is concerned with data subjects and how to safeguard their rights appropriately, there is yet another important line of research dealing with the potential harms occurring to OSINT practitioners conducting analyses. One of the main risks is known as vicarious trauma, namely the psychological trauma caused by handling materials portraying violence. While safety procedures and recommendations to reduce the impact of vicarious trauma, such as removing sound and reducing video resolution, have long been around in the OSINT community (Parry 2017 ), automated frameworks to identify and tag potentially sensitive digital content have also been proposed (Breton et al. 2021 ).
The GELSI of OSINT at the macro-level
At the macro-level of analysis, the focus shifts from individuals, software solutions, and organizations to broader debates about the social and political implications of OSINT. Here, we find papers dealing with OSINT in a more abstract sense, not limited to the intelligence studies domain, but encompassing the broader social science literature. This literature partly emerged as a reflection on the experience of the open-source hacking communities. Born and nurtured around a shared ethos of “transparency, truth and trust” (Steele 2012 ), such communities flourished in the early years of the Internet. They were responsible for developing several open-source projects, from operating systems to web servers. Through the trusted user system, a large community of programmers was able to update code and share information almost in real-time while working on a well-defined project, thus cementing the idea of the Internet as a “new ecology of interconnected ideas” (Glassman 2013 , 682).
As its software analog, Open Source Intelligence has been presented as a way of democratizing access to information and fostering citizen activism, removing any intermediary and allowing a collaborative search for the truth. Thanks to a shared moral code among OSINT practitioners, which “prioritizes transparency and accountability, frowns upon the use of subterfuge, and limits investigations to passive reconnaissance” (Belghith et al. 2022 , 2), some in the techno-libertarian fringe argue that OSINT will be able to increase oversight over secret government activity and therefore reduce the invasive reach of security agencies, eventually leading to an “Open Source Everything” society (Steele 2012 ).
Interestingly, this idea is tied to a long-standing debate about the nature and evolution of human cognition. Glassman and Kang ( 2012 ) interpret OSINT as a bridge between the two intelligence categories defined by Horn and Cattell ( 1967 ): fluid intelligence and crystallized intelligence. While the former represents a more intuitive approach to problem-solving based on abstraction and pattern detection, as seen in childhood, the latter defines intelligence as the ability to solve problems by applying methods and tools already learned through experience and is, therefore, more prominent in the later stages of human development. Thus, crystallized intelligence is typically applied to known problems and uses problem-solving strategies that are well-known and culturally shared, while fluid intelligence is relied upon when facing new problems requiring abstract thinking and mental flexibility. According to the authors, OSINT can bring insights and creativity from fluid intelligence into the realm of a more codified and community-based cultural intelligence. This process is enabled by the free access to the web and the horizontal nature of open-source information, allowing for novel approaches to investigative work that can be crowd-sourced across the (virtual) community. As the authors put it:
OSINT is controlled exploration that is open to new and different connections and possibilities combined with focused problem solving. OSINT promotes goal directed activity that is capable of transcending social and cultural boundaries (Glassman and Kang 2012 , 677, emphasis in text)
The ability to overcome cultural boundaries is ensured by the continuous flow of unfiltered information available to the citizen/analyst and constitutes a step forward in creating a Smart Nation , which, in the words of Robert David Steele:
educates and enables every citizen to be a collector, producer, and consumer of legal, ethical, open-source intelligence, and also to be a vibrant member of the authentic intelligence community of the whole—humanity connected as one, thinking as one, acting as one (Steele 2012 ).
A collection of smart nations would then build toward a global noosphere, a worldwide community based on “multinational information sharing and sense-making” (Steele 2012 ). Such a radical societal transformation finds significant parallels in the smart governance literature, where meaningful social change is reached through a dynamic dialog between state and non-state actors (Willke 2007 ). In this scenario, OSINT is seen as a critical tool in leveling the playing field and ensuring a degree of transparency conducive to this dialog.
While the above articles highlight how the nature of OSINT makes it a crucial tool for democratic oversight, this very nature can also be seen as a threat to citizens’ rights when authorities exploit it to increase social control (Wells 2016 ). Concerns about increased state surveillance and profiling have long been expressed in the literature (Eijkman and Weggemans 2012 ), together with the opacity in the analysis and OSINT-based decision-making by state authorities and private companies. Indeed, it has also been shown that the growing public awareness of state surveillance practices and fear of profiling can lead users to contemplate withholding or even falsifying personal information shared online (Bayerl and Akhgar 2015 ). Similarly, awareness of OSINT tools and capabilities has been linked to more robust security behavior in IT professionals (Daniels 2016 ). Consequently, efforts to educate users about the ramifications of their online activities have emerged, and are likely to reinforce this trend (Parry 2017 ; Young et al. 2018 ).
This, coupled with the blossoming of disinformation strategies in domestic and international affairs, contributes to the muddying of the OSINT waters and has obvious implications for the reliability of OSINT data collected during investigations (Miller 2018 ; Olaru and Ştefan 2018 ). “Open” does not equal “true”, also when it comes to OSINT, and in the absence of a shared standard to detect and filter out falsified information, each analyst has so far relied on their own sectorial experience to validate the intelligence collected. As McKeown et al. ( 2014 ) point out, this can lead to significant differences in reporting accuracy across analysts, as some may deem a source reliable while others may not. This could lead to a vicious cycle of distrust where OSINT sources get increasingly polluted with unreliable information that, if not promptly identified, could sway the decision-making process.
Future research directions: the GELSI of AI and OSINT
Listed at the bottom of Fig. 6 are a few suggestions for future research on the interplay between OSINT and AI at the micro and macro levels. These are developments we find most likely to occur in the upcoming OSINT literature, as AI algorithms become closely intertwined with everyday OSINT practice.
At the micro-level , the OSINT-GELSI scholarship has been concerned so far with the knowledge retrieval and management aspects of the OSINT pipeline. However, current legislation gives little importance to the phases of analysis and use of machine-gathered OSINT. Building on the work by Broeders et al. ( 2017 ) and others in the AI auditing literature, increased effort should be devoted to developing a theoretical framework to regulate those aspects in the data analysis phase which could impact algorithmic performance (i.e., variable selection, model weights, optimisation algorithms, etc.).
Moreover, more comprehensive scholarship on algorithmic opacity could inform future literature on OSINT and AI. Burrell ( 2016 ) identifies three main sources contributing to the overall lack of transparency in how AI algorithms are employed. The first one, corporate secrecy, relates to the intentional concealment of the inner workings of algorithms by companies to safeguard their products. Proposed solutions are mainly on the legislative side, and involve developing disclosure and auditing frameworks where trusted third parties would be tasked with reviewing code and ensuring that appropriate ethical standards are met (Pasquale 2015 ; Lu 2020 ). The second source of opacity, technical literacy, refers to the specialized nature of writing and reading computer code, which makes it difficult for end-users and regulators to understand fully the mechanics and results of AI algorithms. Increasing computer literacy and “computational thinking” (Lee et al. 2011 ) among critical sectors of civil society is seen as an essential step in countering this source of opacity. Finally, the black box structure of many machine learning models makes it difficult to interpret results correctly, even for practitioners. The reliance on multi-component systems only increases the complexity of the overall infrastructure, further increasing the time and effort required for auditing. Different solutions have been proposed to deal with this complexity. They are mainly focused on technical tools that can reduce the dimensionality of the data, create metrics that can evaluate the fairness of algorithms and provide graphical visualizations of relationships between key variables to aid the analysis (Dwork et al. 2012 ; Paudyal and William Wong 2018 ).
Transparency is even more crucial when it comes to OSINT data. Indeed, while many auditing strategies apply to all data types, open source data must satisfy more stringent validity requirements and should be specifically targeted as a priority when devising regulatory strategies. Moreover, since veracity assessment via machine learning algorithms has been growing in recent years (Manzoor and Singla 2019 ), it is also likely that the applied literature on misinformation detection will play an important role in designing strategies to filter out irrelevant data, thus preventing or at least reducing biased outcomes during analysis. There have already been some attempts at designing frameworks for automatic veracity assessments of open source information (see, for instance, Lozano et al. 2015 ). However, using AI to validate data also raises important ethical questions which have been largely left unanswered, as Lozano et al. ( 2020 ) point out. Some of these questions relate to the allocation of responsibilities when data is mislabelled, together with the optimal procedures to determine veracity in the first place.
Considering the original Open Source movement ethos, one could envisage oversight mechanisms that are themselves open source. For instance, publishing the source code of the algorithms employed during online investigations, together with the updated datasets and their respective veracity assessments. However, this would be not just extremely unlikely, given the secretive nature of most OSINT investigations. It could also become counterproductive, as data published by state authorities could be exploited as intelligence by actors interested in attacking the enemy’s infrastructure.
As for broader privacy concerns, AI algorithms could threaten the PbD tactics outlined in Sect. 5 and other solutions, such as contextual integrity approaches, specifically to the data retention and minimisation principles. As it turns out, analysts may be tempted to keep users’ information stored in their databases, especially since data that appear useless today may prove relevant in the future. This phenomenon, known as function creep in the literature (Koops 2021 ) has already been observed in OSINT investigations (Trottier 2015 ), and is likely to become more prominent as the growing computing power allows AI algorithms to process an enormous number of features.
Integrating AI tools into data acquisition and analysis routines also provides legal challenges when moving from intelligence collection to evidence presentation. It has already been observed how cognitive and technical biases influence digital OSINT collection by narrowing the search space based on the analyst query or the search engine’s ranking of results (McDermott et al. 2021 , 92–93). Thus, relying on automated collection and analysis could amplify these biases and raise questions of admissibility if intelligence is used as evidence in criminal trials.
At the macro-level, research about the GELSI of OSINT should address how AI-powered OSINT may invalidate the oversight potential of publicly available information (as claimed by the Open Source movement). Indeed, the availability of AI algorithms increases data processing capabilities (and, to a lesser extent, disinformation detection), and it does so asymmetrically. Standard OSINT gathering and analysis methods focus on selecting appropriate data sources and require only a limited grasp of technological solutions. However, automating collection and analysis involves a much deeper understanding of AI algorithms. This knowledge is unequally distributed among potential OSINT users and favors those with access to larger computing power and better expertise. Most commercial solutions available to the public (whether free or subscription-based) heavily use web crawlers that automate intelligence collection (Pastor-Galindo et al. 2020 ). However, currently available software does not provide AI algorithms in the analysis phase, which must be coded separately. Thus, in the future, actors with access to AI solutions for analyzing open source data will hold a comparative technological advantage over the rest, being able to process and classify a much larger quantity of data in considerably less time. This conflict could manifest between different state and non-state actors simultaneously, threatening the oversight role of OSINT data and exacerbating its surveillance and social control aspects. Moreover, the prevailing trend toward intelligence outsourcing to private companies could create even more friction between the public and private sectors, as already noted in Bean ( 2011 ), even more so when better algorithms yield better (intelligence) products.
Yet another essential issue that needs to be addressed in the OSINT-GELSI literature is whether AI will prevent OSINT from maintaining the equilibrium between fluid and crystallized intelligence. While it is true that OSINT can push analysts beyond traditional investigative routes that are determined by crystallized knowledge through its fluid intelligence properties, it is also true that current AI systems follow problem-solving strategies that are closely related to crystallized intelligence. Supervised machine learning is built to allow the computer algorithm to learn variable dependencies from a sanctioned body of knowledge (the labeled data ) to identify similar patterns in unseen data. Indeed, despite many attempts at developing new learning models for abstract reasoning, it has been argued that AI algorithms have only been able to achieve crystallized intelligence because they are designed to tackle only a given task (or a limited set of tasks), without being able to generalize their knowledge to previously unseen problems (Davidson and Walker 2019 ; van der Maas et al. 2021 , 5). Consider, for example, the case of digital media. While it would be possible to train an algorithm to detect enemy combatants from a digital open source, it is unlikely that the same algorithm will be able to infer other significant intelligence, such as geolocation data, if it has not been trained to recognize those data. At the same time, without specialized training, it would prove almost impossible to assess the context of the media data and determine, for instance, whether it was an excerpt from a movie or footage from an unrelated military exercise disseminated for disinformation purposes. Therefore, any OSINT analysis aided by AI algorithms heavily relies on a crystallized intelligence approach, and risks losing some of the abstract intuition of its fluid component every time a task requires “higher levels of behavioral flexibility and adaptivity” (Schilling et al. 2019 ). Furthermore, over-reliance on OSINT software like that mentioned in Sect. 5 will likely worsen this condition. Indeed, when OSINT data are automatically crawled and analyzed, only significant matches are returned through the analyst queries, and some crucial detail may go missing altogether. This problem has already emerged in the literature and will remain dominant (Odom 2008 , 325). Eldridge et al. ( 2018 ) argue that OSINT analysis should never get rid of its human component, and that “joint cognitive systems” (Eldridge et al. 2018 , 22) should be designed to strike the optimal balance between analysts and algorithms.
Conclusions
This article provides a systematic review of the GELSI literature on OSINT. The OSINT-GELSI scholarship can be broadly divided into two main categories, namely the micro and macro levels of analysis. At the micro-level, authors look at the impact of OSINT on individuals and organizations, tackling privacy issues and oversight mechanisms within the development of software for the exploitation of OSINT resources. At the macro-level, the main focus is on the social and political implications of the production and availability of OSINT data. Some articles analyze how increased awareness of OSINT tools and capabilities modifies online habits, with many users deciding to share less personal information or turn to anonymity to limit their online exposure. Meanwhile, other articles tie into the broader open-source movement literature, reflecting on the role of OSINT in the relationship between fluid and crystallized intelligence, leading to the growing democratization of intelligence and the creation of more transparent societies.
Research dealing with OSINT augmented by AI algorithms is emerging and will likely become predominant in future OSINT-GELSI scholarship. At the micro-level, greater emphasis should be placed on the AI-auditing literature. In particular, more research is needed to deal with regulatory strategies to oversee and direct the processes of information gathering and analysis carried out through data mining and machine learning techniques. This is increasingly pressing as more data are collected, processed, and labeled automatically for further use. Due to its many reliability issues, particular attention should be given to OSINT data. One key feature that should be targeted is using OSINT for deliberate disinformation, which could easily sway even the more sophisticated algorithms and pollute datasets used to train them. Efficient diagnostic techniques should be designed to tackle this issue and minimize errors, thus reducing the risk of incorporating bias into OSINT investigation results (Lozano et al. 2020 ).
At the macro-level, the OSINT-GELSI literature should look at the role of AI in shaping the relationship between OSINT and society. For instance, while it is believed that OSINT constitutes a bridge between crystallized and fluid intelligence, the very nature of machine learning algorithms places AI in the former group. This means that the increasing integration of AI in OSINT tools relying on automated rather than human-centered analysis could shift the balance toward a crystallized approach to OSINT problems. Another critical ramification to be considered at the macro-level is the changing nature of the owners of OSINT tools, which become exclusive providers of intelligence for public and private use.
As a general recommendation, the OSINT-GELSI scholarship should be more aware of the results of the OSINT practitioner literature to get a grasp of the emerging trends and be able to react promptly to potential ethical challenges raised by them. As we have argued in the previous sections, OSINT is not only improved by technology. Its scope is expanded as new sources of information become public. However, the more complex the data (and the larger the data pool), the more complex collection and analysis will become. As a result, state and non-state actors with access to enough computing power and the right expertise will have a comparative technological advantage over the others. Thus, a comprehensive GELSI analysis of OSINT tools and techniques cannot ignore the latest trends in the applied literature and should try to anticipate them by looking at other fields where the same issues have already become manifest. Increasing integration between the GELSI and applied domains is not just desirable but necessary to address current and future ethical issues.
This research was supported by Centre for Digital Ethics.
Data availability
Declarations.
The authors have no conflicts of interest to declare that are relevant to the content of this article.
1 Intelligence cycles are modeled in different ways by different intelligence organization, in this article we follow the model proposed in the US Joint Intelligence report (Defense Technical Information Center (DTIC)—Department of Defense 2013 ).
2 The acronym GELSI expands another acronym, ELSI (Ethical, Legal and Social Implications), which originated in the fields of biotechnology and genetics. This research field “addresses the relationship between the new and emerging techno-sciences and society” (Zwart and Nelis 2009 ) and involves predicting and possibly proposing solutions to new challenges posed by their interaction.
3 Projects like the Versatile InfoRmation Toolkit for end-Users oriented Open Sources explOitation (VIRTUOSO, 2010–2013), the Collaborative information, Acquisition, Processing, Exploitation and Reporting for the prevention of organized crime (CAPER, 2011–2014) and the Maritime Integrated Surveillance Awareness (MARISA, 2017–2020) are some of the most prominent examples.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
- Amardeilh F, Kraaij W, Spitters M, Versloot C and Yurtsever S (2013) Semi-automatic ontology maintenance in the virtuoso news monitoring system. In: 2013 European Intelligence and Security Informatics Conference, 135–138. IEEE
- Asghar MZ, Ahmad S, Marwat A and Kundi FM (2015) Sentiment analysis on Youtube: a brief survey. ArXiv Preprint http://arxiv.org/abs/1511.09142 .
- Bayerl PS, Akhgar B. Surveillance and falsification implications for open source intelligence investigations. Commun ACM. 2015; 58 (8):62–69. doi: 10.1145/2699410. [ CrossRef ] [ Google Scholar ]
- Bean H. Is open source intelligence an ethical issue? In government secrecy. Emerald Group Publishing Limited; 2011. [ Google Scholar ]
- Beel J and Gipp B (2009) Google scholar’s ranking algorithm: an introductory overview. In: Proceedings of the 12th International Conference on Scientometrics and Informetrics (ISSI’09), 1:230–241. Rio de Janeiro ( Brazil )
- Belghith Y, Venkatagiri S and Luther K (2022) Compete, collaborate, investigate: exploring the social structures of open source intelligence investigations. In: CHI Conference on Human Factors in Computing Systems, 1–18
- Breton M, Lavigne V, Djaffri M and Dionnea M (2021) Military dataset processing approaches or trauma risk mitigation in machine learning practitioners.
- Broeders D, Schrijvers E, van der Sloot B, Van Brakel R, de Hoog J, Ballin EH. Big data and security policies: towards a framework for regulating the phases of analytics and use of big data. Comput Law Secur Rev. 2017; 33 (3):309–323. doi: 10.1016/j.clsr.2017.03.002. [ CrossRef ] [ Google Scholar ]
- Burrell J. How the machine “thinks”: understanding opacity in machine learning algorithms. Big Data Soc. 2016; 3 (1):2053951715622512. doi: 10.1177/2053951715622512. [ CrossRef ] [ Google Scholar ]
- Casanovas P. Semantic web regulatory models: why ethics matter. Philosophy & Technology. 2015; 28 (1):33–55. doi: 10.1007/s13347-014-0170-y. [ CrossRef ] [ Google Scholar ]
- Casanovas P, Irujo JA, Melero F, González-Conejero J, Molcho G and Cuadros M (2014) Fighting organized crime through open source intelligence: regulatory strategies of the CAPER project. In: JURIX, 189–198
- Chen H. Dark web: exploring and data mining the dark side of the web. Springer Science & Business Media; 2011. [ Google Scholar ]
- Colesky, M, Hoepman J-H and Hillen C (2016) A critical analysis of privacy design strategies. In: 2016 IEEE Security and Privacy Workshops (SPW), 33–40. IEEE
- Cuijpers C. Legal aspects of open source intelligence—results of the VIRTUOSO project. Comput Law Secur Rev. 2013; 29 (6):642–653. doi: 10.1016/j.clsr.2013.09.002. [ CrossRef ] [ Google Scholar ]
- Daniels D (2016) Exploring the correlation between information security behavior and the awareness of open-source intelligence
- Davidson I, Walker PB. Towards fluid machine intelligence: Can we make a gifted AI? Proc AAAI Conf Artif Intell. 2019; 33 :9760–9764. [ Google Scholar ]
- Defense Technical Information Center (DTIC) - Department of Defense (2013) Joint publication 2–0—joint intelligence. https://web.archive.org/web/20160613010839/ ; http://www.dtic.mil/doctrine/new_pubs/jp2_0.pdf .
- Dupont GM, de Chalendar G, Khelif K, Voitsekhovitch D, Canet G and Brunessaux S (2011) Evaluation with the VIRTUOSO platform: an open source platform for information extraction and retrieval evaluation. In Proceedings of the 2011 workshop on data infrastructures for supporting information retrieval evaluation, 13–18
- Dwork C, Hardt M, Pitassi T, Reingold O and Zemel R (2012) Fairness through awareness. In: Proceedings of the 3rd innovations in theoretical computer science conference, 214–226
- Eijkman Q, Weggemans D. Open source intelligence and privacy dilemmas: is it time to reassess state accountability. Sec Hum Rts. 2012; 23 :285. [ Google Scholar ]
- Eldridge C, Hobbs C, Moran M. Fusing algorithms and analysts: open-source intelligence in the age of “Big Data” Intell Natl Secur. 2018; 33 (3):391–406. doi: 10.1080/02684527.2017.1406677. [ CrossRef ] [ Google Scholar ]
- Evangelista JR, Gonçalves RJ, Sassi MR, Napolitano D. Systematic literature review to investigate the application of open source intelligence (OSINT) with artificial intelligence. J Appl Secur Res. 2021; 16 (3):345–369. doi: 10.1080/19361610.2020.1761737. [ CrossRef ] [ Google Scholar ]
- GDPR (2016) Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/EC (General Data Protection Regulation). Official Journal L 119/1
- Glassman M. Open source theory. 01. Theory Psychol. 2013; 23 (5):675–692. doi: 10.1177/0959354313495471. [ CrossRef ] [ Google Scholar ]
- Glassman M, Kang MJ. Intelligence in the internet age: the emergence and evolution of open source intelligence (OSINT) Comput Hum Behav. 2012; 28 (2):673–682. doi: 10.1016/j.chb.2011.11.014. [ CrossRef ] [ Google Scholar ]
- Grant MJ, Booth A. A typology of reviews: an analysis of 14 review types and associated methodologies. Health Info Libr J. 2009; 26 (2):91–108. doi: 10.1111/j.1471-1842.2009.00848.x. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Harzing A-W. Publish or Perish. Tarma Software Research Pty Limited; 1997. [ Google Scholar ]
- Horn JL, Cattell RB. Age differences in fluid and crystallized intelligence. Acta Physiol (Oxf) 1967; 26 :107–129. [ PubMed ] [ Google Scholar ]
- Hu E (2016) Responsible data concerns with open source intelligence. Responsible Data (blog). 14 Nov 2016. https://responsibledata.io/2016/11/14/responsible-data-open-source-intelligence/
- Hulnick AS. The downside of open source intelligence. Int J Intell Counter Intell. 2002; 15 (4):565–579. [ Google Scholar ]
- Hustinx P. Privacy by design: delivering the promises. Identity Inf Soc. 2010; 3 (2):253–255. doi: 10.1007/s12394-010-0061-z. [ CrossRef ] [ Google Scholar ]
- Ish D, Ettinger J and Ferris C (2021) Evaluating the effectiveness of artificial intelligence systems in intelligence analysis. RAND Corporation. https://www.rand.org/pubs/research_reports/RRA464-1.html
- Koenig A. “Half the truth is often a great lie”: deep fakes, open source information, and international criminal law. Am J Int Law. 2019; 113 :250–255. [ Google Scholar ]
- Koops B-J. Police investigations in internet open sources: procedural-law issues. Comput Law Secur Rev. 2013; 29 (6):654–665. doi: 10.1016/j.clsr.2013.09.004. [ CrossRef ] [ Google Scholar ]
- Koops B-J. The concept of function creep. Law Innov Technol. 2021; 13 (1):29–56. doi: 10.1080/17579961.2021.1898299. [ CrossRef ] [ Google Scholar ]
- Koops B-J, Hoepman J-H, Leenes R. Open-source intelligence and privacy by design. Comput Law Secur Rev. 2013; 29 (6):676–688. doi: 10.1016/j.clsr.2013.09.005. [ CrossRef ] [ Google Scholar ]
- Lee I, Martin F, Denner J, Coulter B, Allan W, Erickson J, Malyn-Smith J, Werner L. Computational thinking for youth in practice. Acm Inroads. 2011; 2 (1):32–37. doi: 10.1145/1929887.1929902. [ CrossRef ] [ Google Scholar ]
- Lozano MG, Brynielsson J, Franke U, Rosell M, Tjörnhammar E, Varga S, Vlassov V. Veracity assessment of online data. Decis Support Syst. 2020; 129 :113132. doi: 10.1016/j.dss.2019.113132. [ CrossRef ] [ Google Scholar ]
- Lozano MG, Franke U, Rosell M and Vlassov V (2015) Towards automatic veracity assessment of open source information. In: 2015 IEEE International Congress on Big Data, 199–206. IEEE
- Lu S. Algorithmic opacity, private accountability, and corporate social disclosure in the age of artificial intelligence. Vand J Ent Tech l. 2020; 23 :99. [ Google Scholar ]
- Lyle A (2016) Legal considerations for using open source intelligence in the context of cybercrime and cyberterrorism. In: Open source intelligence investigation, 277–94. Springer
- Maas HLJ, Snoek L, Stevenson CE. How much intelligence is there in artificial intelligence? A 2020 update. Intelligence. 2021; 87 :101548. doi: 10.1016/j.intell.2021.101548. [ CrossRef ] [ Google Scholar ]
- Maedche A, Staab S. Ontology learning for the semantic web. IEEE Intell Syst. 2001; 16 (2):72–79. doi: 10.1109/5254.920602. [ CrossRef ] [ Google Scholar ]
- Manzoor SI and Singla J (2019) Fake news detection using machine learning approaches: a systematic review. In: 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), 230–34. IEEE
- McDermott Y, Koenig A, Murray D. Open source information’s blind spot: human and machine bias in international criminal investigations. J Int Crim Justice. 2021; 19 (1):85–105. doi: 10.1093/jicj/mqab006. [ CrossRef ] [ Google Scholar ]
- McKeown S, Maxwell D, Azzopardi L and Glisson WB (2014) Investigating people: a qualitative analysis of the search behaviours of open-source intelligence analysts. In: Proceedings of the 5th Information Interaction in Context Symposium, 175–184
- Mercado SC. Fbis against the axis, 1941–1945. Stud Intell. 2001; 11 :33–43. [ Google Scholar ]
- Miller BH. Open source intelligence (OSINT): an oxymoron? Int J Intell CounterIntell. 2018; 31 (4):702–719. doi: 10.1080/08850607.2018.1492826. [ CrossRef ] [ Google Scholar ]
- Neri F, Aliprandi C, Capeci F, Cuadros M and By T (2012) Sentiment analysis on social media. In: 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 919–926. IEEE
- Nissenbaum H. Privacy as contextual integrity. Wash l Rev. 2004; 79 :119. [ Google Scholar ]
- Odom WE. Intelligence analysis. Intell Natl Secur. 2008; 23 (3):316–332. doi: 10.1080/02684520802121216. [ CrossRef ] [ Google Scholar ]
- Olaru G and Ştefan T (2018) Fake news-a challenge for OSINT. In: International Conference RCIC
- Ortiz-Arroyo D (2015) Decision support in open source intelligence. In: Intelligent methods for cyber warfare, 115–27. Springer.
- Parry J (2017) Open source intelligence as critical pedagogy; or, the humanities classroom as digital human rights lab. Interdisciplinary Humanities.
- Pasquale F. The black box society: the secret algorithms that control money and information. Harvard University Press; 2015. [ Google Scholar ]
- Pastor-Galindo J, Nespoli P, Mármol FG, Pérez GM. The not yet exploited goldmine of OSINT: opportunities, open challenges and future trends. IEEE Access. 2020; 8 :10282–10304. doi: 10.1109/ACCESS.2020.2965257. [ CrossRef ] [ Google Scholar ]
- Paudyal P, and William Wong BL (2018) Algorithmic opacity: making algorithmic processes transparent through abstraction hierarchy. In: Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 62:192–196. SAGE Publications Sage CA: Los Angeles, CA
- Public Law 109–163 (2006) National defense authorization act
- Rahman Z and Ivens G (2020) Ethics in open source investigations. In: Digital witness: using open source information for human rights investigation, documentation, and accountability 249–270
- Sampson F (2016) Following the breadcrumbs: using open source intelligence as evidence in criminal proceedings. In: Open Source Intelligence Investigation, 295–304. Springer
- Sampson F. Intelligent evidence: using open source intelligence (OSINT) in criminal proceedings. The Police Journal. 2017; 90 (1):55–69. doi: 10.1177/0032258X16671031. [ CrossRef ] [ Google Scholar ]
- Schilling M, Ritter H and Ohl FW (2019) From crystallized adaptivity to fluid adaptivity in deep reinforcement learning—insights from biological systems on adaptive flexibility. In: 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), 1472–1478. IEEE
- Shere A. Now you [don’t] see me: how have new legislation and changing public awareness of the UK surveillance state impacted OSINT investigations? J Cyber Policy. 2020; 5 (3):429–448. doi: 10.1080/23738871.2020.1832129. [ CrossRef ] [ Google Scholar ]
- Shere A (2020b) Reading the investigators their rights: a review of literature on the general data protection regulation and open-source intelligence gathering and analysis. The New Collection 3
- Steele RD. The open-source everything manifesto: transparency, truth, and trust. North Atlantic Books; 2012. [ Google Scholar ]
- Ten Hulsen L. Open sourcing evidence from the internet-the protection of privacy in civilian criminal investigations using OSINT (open-source intelligence) Amsterdam LF. 2020; 12 :1. [ Google Scholar ]
- Trottier D. Open source intelligence, social media and law enforcement: visions, constraints and critiques. Eur J Cult Stud. 2015; 18 (4–5):530–547. doi: 10.1177/1367549415577396. [ CrossRef ] [ Google Scholar ]
- Unver A (2018) Digital open source intelligence and international security: a primer. EDAM Research Reports, Cyber Governance and Digital Democracy 8.
- Wells D (2016) Taking stock of subjective narratives surrounding modern OSINT. In: Open source intelligence investigation, 57–65. Springer
- Wiil UK. Counterterrorism and open source intelligence. Springer; 2011. [ Google Scholar ]
- Williams HJ and Blum I (2018) Defining second generation open source intelligence (OSINT) for the defense enterprise. RAND Corporation. https://www.rand.org/pubs/research_reports/RR1964.html
- Willke H. Smart governance: governing the global knowledge society. Campus Verlag; 2007. [ Google Scholar ]
- Young JA, Campbell KN, Fanti AN, Alicea A, Weiss MV, Burkhart JR and Braasch MR (2018) The development of an open source intelligence gathering exercise for teaching information security & privacy
- Zwart H, Nelis A. What is ELSA genomics? EMBO Rep. 2009; 10 (6):540–544. doi: 10.1038/embor.2009.115. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
You are using an outdated browser. Please upgrade your browser to improve your experience.
opensource.google.com
Google open source blog.
The latest news from Google on open source releases, major projects, events, and student outreach programs.
Showing Our Work: A Study In Understanding Open Source Contributors
Thursday, september 7, 2023.
In 2022, the research team within Google’s Open Source Programs Office launched an in-depth study to better understand open source developers, contributors, and maintainers. Since Alphabet is a large consumer of and contributor to open source, our primary goals were to investigate the evolving needs and motivations of open source contributors, and to learn how we can best support the communities we depend on. We also wanted to share our findings with the community in order to further research efforts and our collective understanding of open source work.
Key findings from this work suggest that community leaders should:
- Value your time together and apart: Lack of time was cited as the leading reason ‘not to contribute’ as well as motivation to ‘leave a community’. This should encourage community leaders to adopt practices that ensure that they are making the most of the time they have together. One example: some projects have planned breaks, no-meeting weeks, or official slowdowns during holidays or popular conference weeks.
- Invest in documentation: Contributors and maintainers expressed that task variety, delegation, and onboarding new maintainers could help to reduce burnout in open source. Documentation is one way to make individual knowledge accessible to the community. In addition to technical and procedural overviews, documentation can also be used to clarify roles, tasks, expectations, and a path to leadership.
- Always communicate with care: Contributors prefer projects that have welcoming communities, clear onboarding paths, and a code of conduct. Communication is the primary way for community leaders to promote welcoming and inclusive communities and set norms around language and behavior (as documented in a Code of Conduct). Communication is also how we build relationships, trust, and respect for each other.
- Create spaces for anonymous feedback: Variable answers between demographic subsets in our research suggest that while systematic approaches can be taken to reduce burnout, there is no one-size-fits-all approach. Feedback is a valuable tool for any project to adjust to the evolving needs of their contributor and user communities. When designed appropriately, surveys can serve as safe, anonymous, retaliation-free spaces for individuals to provide honest feedback.
How do contributors select projects?
Within Google’s Open Source Programs office, we are constantly looking for ways to improve support for contributors inside and outside of Google. Studies such as this one provide guidance to our programs and investments in the community. This work helps us to see we should continue to:
- Invest in documentation competency: Google Season of Docs provides support for open source projects to improve their documentation and gives professional technical writers an opportunity to gain experience in open source.
- Document roles and promote tactics that recognize work within communities: The ACROSS project continues to work with projects and communities to establish consistent language to define roles, responsibilities, and work done within open source projects.
- Exercise and discuss ‘better’ practices within the community: While we continually seek to improve our engagement practices within communities, we will also continue to share these experiences with the broader community in hopes that we can all learn from our successes and challenges. For example, we’ve published documentation around our release process, including resources for the creation and management of a code of conduct.
This research, along with other articles authored by the OSPO research team is now available on our site .
By Sophia Vargas – Researcher, Google Open Source Programs Office
Open-Data, Open-Source, Open-Knowledge: Towards Open-Access Research in Media Studies
- First Online: 05 November 2022
Cite this chapter

- Giulia Taurino 3
423 Accesses
Considering knowledge as a public resource (Hess and Ostrom in Understanding Knowledge as a Commons: From Theory to Practice, The MIT Press, Cambridge, MA, 2007), this article discusses a possible application of an open-access methodology for accessing, visualizing, and understanding large corpora in media studies. It does so by presenting a case study based on the extraction of a sample database of television series from Wikidata. The article outlines the process adopted to make open-access data not only freely available, but also understandable and readable with the support of open-source tools. Relying entirely on online resources, the project presented here helps us frame the distinct traits of an open-access work-flow, where each step in the research can be retraced online, thus guaranteeing transparency and participatory research practices. Similarly, the chapter evaluates the challenges and limitations of an open-access environment for the study of media.
- Open-access
- Media Studies
- Digital humanities
- Linked Open Data
- Data Visualization
- Knowledge Design
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Agt-Rickauer, Henning, Christian Hentschel, and Harald Sack. 2018. “Semantic Annotation and Automated Extraction of Audio-Visual Staging Patterns in Large-Scale Empirical Film Studies.” In Proceedings of the Posters and Demos Track of the 14th International Conference on Semantic Systems (SEMANTiCS 2018) , Vienna, Austria.
Google Scholar
Allison-Cassin, Stacy, and Dan Scott. 2018. “Wikidata: A Platform for Your Library’s Linked Open Data.” The Code4Lib Journal 40. https://journal.code4lib.org/articles/13424 .
Bhargava, Preeti, Nemanja Spasojevic, Sarah Ellinger, Adithya Rao, Abhinand Menon, Saul Fuhrmann, and Guoning Hu. 2019. “Learning to Map Wikidata Entities to Predefined Topics.” In Companion Proceedings of The 2019 World Wide Web Conference (WWW 2019). New York, NY: Association for Computing Machinery, 1194–202. https://doi.org/10.1145/3308560.3316749 .
Bizer, Christian, Tom Heath, and Tim Berners-Lee. 2009. “Linked Data—The Story So Far.” International Journal on Semantic Web and Information Systems 5 (3): 1–22. https://doi.org/10.4018/jswis.2009081901 .
Article Google Scholar
Brasileiro, Freddy, João Paulo A. Almeida, Victorio A. Carvalho, and Giancarlo Guizzardi. 2016. “Applying a Multi-Level Modeling Theory to Assess Taxonomic Hierarchies in Wikidata.” In Proceedings of the 25th International Conference Companion on World Wide Web : 975–80.
Bron, Marc, Jasmijn Van Gorp, and Maarten de Rijke. 2016. “Media Studies Research in the Data-Driven Age: How Research Questions Evolve.” Journal of the Association for Information Science and Technology 67 (7): 1535–54.
Brooks, John. 2018. “Researching Wikidata’s Added Value in Accommodating Audio-Visual Researchers’ Information Needs.” https://www.semanticscholar.org/paper/Researching-Wikidata%E2%80%99s-added-value-in-accommodating-Brooks/0aefdbc432c4a44b4c8af8603608237e8f8b6ae3 .
Crompton, Constance, Lori Antranikian, Ruth Truong, and Paige Maskell. 2020. “Familiar Wikidata: The Case for Building a Data Source We Can Trust.” Pop! Public. Open. Participatory 2. https://popjournal.ca/issue02/crompton .
de Boer, Victor, Tim de Bruyn, John Brooks, and Jesse de Vos. 2018. The Benefits of Linking Metadata for Internal and External Users of an Audiovisual Archive . Cham: Springer International Publishing.
Dooley, Paula, and Bojan Božić. 2019. “Towards Linked Data for Wikidata Revisions and Twitter Trending Hashtags.” In Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services (iiWAS2019) , 166–75. New York, NY: Association for Computing Machinery. https://doi.org/10.1145/3366030.3366048 .
Dutta, Nandita. 2020. “The Networked Fictional Narrative: Seriality and Adaptations in Popular Television and New Media . ” PhD dissertation, University of Western Ontario. Electronic Thesis and Dissertation Repository. https://ir.lib.uwo.ca/etd/7287 .
Erxleben, Fredo, Michael Günther, Markus Krötzsch, Julian Mendez, and Denny Vrandečić. 2014. “Introducing Wikidata to the Linked Data Web.” In Proceedings of International Semantic Web Conference , 50–65. Cham: Springer.
Färber, Michael, Basil Ell, Carsten Menne, and Achim Rettinger. 2015. “A Comparative Survey of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO.” Semantic Web Journal 1, 1–5.
Farda-Sarbas, Mariam, and Claudia Müller-Birn. 2019. “Wikidata from a Research Perspective—A Systematic Mapping Study of Wikidata.” ArXiv 1908 (11153).
Ferriter, Meghan. 2019. “Integrating Wikidata at the Library of Congress.” https://blogs.loc.gov/thesignal/2019/05/integrating-wikidata-at-the-library-of-congress/ .
Fukuda, Kazufumi. 2020. “Using Wikidata as Work Authority for Video Games.” International Conference on Dublin Core and Metadata Applications , 80–87. https://dcpapers.dublincore.org/pubs/article/view/4245 .
Harnad, Stevan, Tim Brody, François Vallières, Les Carr, Steve Hitchcock, Yves Gingras, Charles Oppenheim, Chawki Hajjem, and Eberhard R. Hilf. 2008. “The Access/Impact Problem and the Green and Gold Roads to Open Access: An Update.” Serials Review 34 (1): 36–40. https://doi.org/10.1080/00987913.2008.10765150 .
Heftberger, Adelheid. 2019. “Building Resources Together—Linked Open Data for Filmarchives.” Journal of Film Preservation 101: 65–73.
Heftberger, Adelheid, and Paul Duchesne. 2020. “Cataloguing Practices in the Age of Linked Open Data: Wikidata and Wikibase for Film Archives.” In International Federation of Film Archives, Brussels, Belgium. https://www.fiafnet.org/pages/E-Resources/Cataloguing-Practices-Linked-Open-Data.html .
Heftberger, Adelheid, Jakob Höper, Claudia Müller-Birn, and Niels-Oliver Walkowski. 2019. “Opening up Research Data in Film Studies by Using the Structured Knowledge Base Wikidata.” In Digital Cultural Heritage , edited by Horst Kremers . Cham: Springer. https://doi.org/10.1007/978-3-030-15200-0_27 .
Helmond, Anne. 2015. “The Platformization of the Web: Making Web Data Platform Ready.” Social Media + Society 1 (2). https://doi.org/10.1177/2056305115603080 .
Hess, Charlotte, and Elinor Ostrom. 2007. Understanding Knowledge as a Commons: From Theory to Practice. Cambridge, MA: The MIT Press.
Kanke, Timothy. 2018. “Exploring the Knowledge Curation Work of Wikidata.” In Proceedings of Joint Conference on Digital Libraries (JCDL 2018). New York, NY: Association for Computing Machinery.
Kapsalis, Effie. 2019. “Wikidata: Recruiting the Crowd to Power Access to Digital Archives.” Journal of Radio & Audio Media 26 (1): 134–42. https://doi.org/10.1080/19376529.2019.1559520 .
Khabsa, Madian, and C. Lee Giles. 2014. “The Number of Scholarly Documents on the Public Web.” PLoS ONE 9 (5): e93949.
Lemus-Rojas, Mairelys, and Jere D. Odell. 2018. “Creating Structured Linked Data to Generate Scholarly Profiles: A Pilot Project Using Wikidata and Scholia.” Journal of Librarianship and Scholarly Communication 6 (1). https://doi.org/10.7710/2162-3309.2272 .
Merrin, William. 2009. “Media Studies 2.0: Upgrading and Open-Sourcing the Discipline.” Interactions: Studies in Communication and Culture 1 (1): 17–34. https://doi.org/10.1386/iscc.1.1.17_1 .
Metilli, Daniele, Valentina Bartalesi, and Carlo Meghini. 2019. “A Wikidata-Based Tool for Building and Visualising Narratives.” International Journal of Digital on Digital Libraries 20: 417–32. https://doi.org/10.1007/s00799-019-00266-3 .
Mietchen, Daniel, Gregor Hagedorn, Egon Willighagen, Mariano Rico, Asunción Gómez-Pérez, Eduard Aibar, and Karima Rafes. 2015. “Enabling Open Science: Wikidata for Research (Wiki4R).” Research Ideas and Outcomes 1. https://doi.org/10.3897/rio.1.e7573
Mora-Cantallops, Marçal, Salvador Sánchez-Alonso, and Elena García-Barriocanal. 2019. “A Systematic Literature Review on Wikidata.” Data Technologies and Applications 53 (3): 250–68. https://doi.org/10.1108/DTA-12-2018-0110 .
Morell, Mayo Fuster. 2011. “The Unethics of Sharing: Wikiwashing.” The International Review of Information Ethics 15: 9–16. https://doi.org/10.29173/irie219 .
Nieborg, David B, and Thomas Poell. 2018. “The Platformization of Cultural Production: Theorizing the Contingent Cultural Commodity.” New Media & Society 20 (11): 4275–92. https://doi.org/10.1177/1461444818769694 .
Okoli, Chitu, Mohamad Mehdi, Mostafa Mesgari, Finn Årup Nielsen, and Arto Lanamäki. 2014. “Wikipedia in the Eyes of its Beholders: A Systematic Review of Scholarly Research on Wikipedia Readers and Readership.” Journal of the Association for Information Science and Technology . https://doi.org/10.2139/ssrn.2021326 .
Pellissier, Tanon, Thomas Denny Vrandecic, Sebastian Schaffert, Thomas Steiner, and Lydia Pintscher. 2016. “From Freebase to Wikidata: The Great Migration.” In Proceedings of the 25th International Conference on World Wide Web, (WWW 2016) , 1419–28. Montreal, Canada.
Pierce, Chris. 2020. “Unique Challenges Facing Linked Data Implementation for National Educational Television.” International Journal of Metadata, Semantics and Ontologies 14 (2). https://doi.org/10.1504/IJMSO.2020.108323 .
Piscopo, Alessandro, Christopher Phethean, and Elena Simperl. 2017a. “Wikidatians are Born: Paths to Full Participation in a Collaborative Structured Knowledge Base.” In 50th Hawaii International Conference on System Sciences, HICSS 2017a , Hilton Waikoloa Village, Hawaii, USA.
Piscopo, Alessandro, Pavlos Vougiouklis, Lucie-Aimée Kaffee, Christopher Phethean, Jonathon Hare, and Elena Simperl. 2017b. “What Do Wikidata and Wikipedia Have in Common? An Analysis of their Use of External References.” In Proceedings of the 13th International Symposium on Open Collaboration (OpenSym 2017b) , 1–10. New York: Association for Computing Machinery. https://doi.org/10.1145/3125433.3125445 .
Pooley, Jefferson. 2019. Open Media Scholarship: The Case for Open Access in Media Studies. MediArXiv. June 20. https://doi.org/10.33767/osf.io/te9as
Piscopo, Vougiouklis et al. 2017. What do Wikidata and Wikipedia have in common? An Analysis of their Use of External References. https://doi.org/10.1145/3125433.3125445
Rudnik, Charlotte, Thibault Ehrhart, Olivier Ferret, Denis Teyssou, Raphael Troncy, and Xavier Tannier. 2019. “Searching News Articles Using an Event Knowledge Graph Leveraged by Wikidata.” In Companion Proceedings of The 2019 World Wide Web Conference (WWW 2019) , 1232–39. New York: Association for Computing Machinery. https://doi.org/10.1145/3308560.3316761 .
Sample, Mark. 2012. “Notes Towards a Deformed Humanities.” @samplereality . http://www.samplereality.com/2012/05/02/notes-towards-a-deformedhumanities/ .
Samuels, Lisa, and Jerome McGann. 1999. “Deformance and Interpretation.” New Literary History 30 (1): 25–56. http://www.jstor.org/stable/20057521 .
Sanders, Elizabeth B.-N., and Stappers, Pieter Jan. 2014. “Probes, Toolkits and Prototypes: Three Approaches to Making in Codesigning.” CoDesign: International Journal of CoCreation in Design and the Arts 10 (1): 5–14.
Severin, Anna, Matthias Egger, Martin Paul Eve, and Daniel Hürlimann. 2020. “Discipline-Specific Open Access Publishing Practices and Barriers to Change: An Evidence-based Review.” F1000Research 7 (1925). https://doi.org/10.12688/f1000research.17328.2 .
Steiner, Thomas. 2014. “Bots vs. Wikipedians, Anons vs. Logged-Ins (Redux): A Global Study of Edit Activity on Wikipedia and Wikidata.” In Proceedings of The International Symposium on Open Collaboration (OpenSym 2014) , 27–29. Berlin, Germany.
Taurino, Giulia. 2019. “An Introduction to Network Visualization for Television Studies: Models and Practical Applications.” Series—International Journal of TV Serial Narratives 5 (1): 45–57. https://doi.org/10.6092/issn.2421-454X/8975 .
Taurino, Giulia, and Marta Boni. 2018. “Maps, Distant Reading and the Internet Movie Database: New Approaches for the Analysis of Large-Scale Datasets in Television Studies.” VIEW Journal of European Television History and Culture 7 (14): 24–37. https://doi.org/10.18146/2213-0969.2018.jethc151 .
Tennant, Jonathan P., François Waldner, Damien C. Jacques, Paola Masuzzo, Lauren B. Collister, and Chris. H. J. Hartgerink. 2016. “The Academic, Economic and Societal Impacts of Open Access: An Evidence-based Review.” F1000Research 5: 632. https://doi.org/10.12688/f1000research.8460.3 .
Thakkar, Harsh, Kemele M. Endris, Jose M. Gimenez-Garcia, Jeremy Debattista, Christoph Lange, and Sören Auer. 2016. “Are Linked Datasets Fit for Open-domain Question Answering? A Quality Assessment.” In Proceedings of the 6th International Conference on Web Intelligence, Mining and Semantics (WIMS ’16). New York: Association for Computing Machinery. https://doi.org/10.1145/2912845.2912857 .
Thornton, Katherine, Euan Cochrane, Thomas Ledoux, Bertrand Caron, and Carl Wilson. 2017. “Modeling the Domain of Digital Preservation in Wikidata.” iPRES . https://wikidp.org/about .
Vicente-Saez, Ruben, and Clara Martinez-Fuentes. 2018. “Open Science Now: A Systematic Literature Review for an Integrated Definition.” Journal of Business Research 88: 428–36. https://doi.org/10.1016/j.jbusres.2017.12.043 .
Vrandecic Denny, and Markus Krötzsch. 2014. “Wikidata: A Free Collaborative Knowledgebase.” Communications of the Association for Computing Machinery 57 (10): 78–85.
Wikidata. 2017. Wikidata:Sources—Wikidata, The Free Knowledge Base . https://www.wikidata.org/wiki/Help:Sources .
Wikidata. 2020. Wikidata:Statistics—Wikidata, The Free Knowledge Base . https://www.wikidata.org/wiki/Wikidata:Statistics .
Wilkinson, Mark D., Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg et al. 2016. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific Data 3. https://doi.org/10.1038/sdata.2016.18 .
Zangerle, Eva Wolfgang Gassler, Martin Pichl, Stefan Steinhauser, and Günther Specht. 2016. “An Empirical Evaluation of Property Recommender Systems for Wikidata and Collaborative Knowledge Bases.” In Proceedings of the 12th International Symposium on Open Collaboration (OpenSym ‘16) , 1–8. New York, NY: Association for Computing Machinery. https://doi.org/10.1145/2957792.2957804 .
Download references
Author information
Authors and affiliations.
Northeastern University, Boston, MA, USA
Giulia Taurino
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Giulia Taurino .
Editor information
Editors and affiliations.
School of Arts and Creative Industries, Edinburgh Napier University, Edinburgh, UK
Anne Schwan
Tara Thomson
Rights and permissions
Reprints and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Taurino, G. (2022). Open-Data, Open-Source, Open-Knowledge: Towards Open-Access Research in Media Studies. In: Schwan, A., Thomson, T. (eds) The Palgrave Handbook of Digital and Public Humanities. Palgrave Macmillan, Cham. https://doi.org/10.1007/978-3-031-11886-9_4
Download citation
DOI : https://doi.org/10.1007/978-3-031-11886-9_4
Published : 05 November 2022
Publisher Name : Palgrave Macmillan, Cham
Print ISBN : 978-3-031-11885-2
Online ISBN : 978-3-031-11886-9
eBook Packages : Literature, Cultural and Media Studies Literature, Cultural and Media Studies (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Skip to main content
- Skip to FDA Search
- Skip to in this section menu
- Skip to footer links

The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
U.S. Food and Drug Administration
- Search
- Menu
- Development & Approval Process | Drugs
- CDER Small Business & Industry Assistance (SBIA)
An Introduction to FDA MyStudies: An Open-Source, Digital Platform to Gather Real World Data for Clinical Trials and Research Studies – May 9, 2019
Follow us on LinkedIn
View Slides
Speakers and Recordings
About this event.
The FDA released code and technical documentation for the FDA MyStudies Platform on November 20, 2018. External organizations can now use these materials to configure and create branded apps for their own use in traditional clinical trials as well as real world evidence studies and registries.
This event will demonstrate the capabilities of the system as well as its associated web-based configuration portal and data storage environment. Developers will receive an orientation to the GitHub repository and will learn helpful tips for setting up and configuring the system for study managers and participants.
INTENDED AUDIENCE
- Professionals involved in Clinical Research, Post Market Studies, Regulatory Affairs, Medical Affairs, Real World Evidence, Health Economics and Outcomes Research, and Population Health Management
- Application developers and Secure Data Storage and Analytics Solutions developers working in the health care space
- Foreign regulators
Why attend?
- Hear directly from FDA subject matter experts on the use of digital tools such as the FDA MyStudies platform to gather real-world data for research and help inform regulatory decision-making.
- Understand the capabilities of the mobile apps built on iOS ResearchKit and Android ResearchStack frameworks, respectively.
- Learn how the code base of these apps is designed to make them ‘framework apps’ and can be replicated for any number of studies, with minimal coding effort, to set up new apps for new studies.
- Observe in real-time how study content can be created, published, and managed using the web-based Configuration Portal. See how those changes are reflected dynamically in the mobile apps and the Response Server.
- Take a deep dive into the capabilities and architecture of the Response Server to understand how responses are processed and stored. Learn about the many options provided for retrieving and analyzing these data, including linking responses to patient records.
- Identify features of the MyStudies platform intended to enhance usability and user experience.
- Understand the conceptual architecture of the MyStudies platform including use of iOS ResearchKit and Android ResearchStack in order to facilitate future private and public sector development.
- Take a guided virtual tour of the major components of the MyStudies GitHub repository and ask questions of subject matter experts from Boston Technology Corporation and LabKey who developed the platform applications.
- Learn how the MyStudies server components can be deployed in a FISMA- and HIPAA-compliant cloud hosting environment. Review key deployment decisions made and best practices used in hosting multiple studies using this system.
- FDA’s MyStudies Application (App)
- Framework for FDA's Real-World Evidence Program
- Guidance for Industry Part 11, Electronic Records; Electronic Signatures — Scope and Application
- Real World Evidence - FDA webpage
- Webinar: Framework for FDA’s Real-World Evidence Program – Mar 15, 2019
- FDA In Brief: FDA launches new digital tool to help capture real world data from patients to help inform regulatory decision-making
- GitHub FDA MyStudies Mobile Application System
- FDA GUIDANCE DOCUMENT - Use of Electronic Informed Consent in Clinical Investigations – Questions and Answers Guidance for Institutional Review Boards, Investigators, and Sponsors December 2016
- GUIDANCE DOCUMENT - Use of Electronic Records and Electronic Signatures in Clinical Investigations Under 21 CFR Part 11 – June 2017
- GUIDANCE DOCUMENT - Patient-Reported Outcome Measures: Use in Medical Product Development to Support Labeling Claims - Guidance for Industry - December 2009
- Real World Evidence
- GitHub Repository: Response Server Module
- Documentation and Support for Building & Deploying LabKey Server
Explore. Create. Collaborate.
Support a vibrant, educator-focused commons.
The tens of thousands of open resources on OER Commons are free - and they will be forever - but building communities to support them, developing new collections, and creating infrastructure to grow the open community isn’t. Grassroots donations from people like you can help us transform teaching and learning.
Make a Donation Today!
Introducing Open Author
Create OER with Open Author
Open Author helps you build and publish Open Educational Resources for you and for the benefit of educators and learners everywhere.
Build. Save. Collaborate.
Groups provides a flexible environment to organize, create, share, and discuss resources with others in your network. Collaborate with group members, tag and add resources to shared folders, create your own collections, all within a public or private group.
Extensive Library, Powerful Findability
Harness the power of the Commons
Dedicated to professional learning.
Our award-winning OER Professional Learning programs support instructors and curriculum specialists to gain the necessary skills required to find, adapt, and evaluate high quality open materials.
In-person and virtual OER workshops help focus instructors to develop a "commons" mindset, to experience the benefits of open processes using the platform's tools, collaborative features, and workflows. This can include using Open Author for creating, remixing, and publishing shared curriculum.
Become an OER Commons pro
How to Search OER Commons
How to Use Groups
How to Create a Profile
- Browse All Articles
- Newsletter Sign-Up
OpenSourceDistribution →
No results found in working knowledge.
- Were any results found in one of the other content buckets on the left?
- Try removing some search filters.
- Use different search filters.
- Search Menu
- Browse content in Arts and Humanities
- Browse content in Archaeology
- Anglo-Saxon and Medieval Archaeology
- Archaeological Methodology and Techniques
- Archaeology by Region
- Archaeology of Religion
- Archaeology of Trade and Exchange
- Biblical Archaeology
- Contemporary and Public Archaeology
- Environmental Archaeology
- Historical Archaeology
- History and Theory of Archaeology
- Industrial Archaeology
- Landscape Archaeology
- Mortuary Archaeology
- Prehistoric Archaeology
- Underwater Archaeology
- Urban Archaeology
- Zooarchaeology
- Browse content in Architecture
- Architectural Structure and Design
- History of Architecture
- Residential and Domestic Buildings
- Theory of Architecture
- Browse content in Art
- Art Subjects and Themes
- History of Art
- Industrial and Commercial Art
- Theory of Art
- Biographical Studies
- Byzantine Studies
- Browse content in Classical Studies
- Classical History
- Classical Philosophy
- Classical Mythology
- Classical Literature
- Classical Reception
- Classical Art and Architecture
- Classical Oratory and Rhetoric
- Greek and Roman Epigraphy
- Greek and Roman Law
- Greek and Roman Archaeology
- Greek and Roman Papyrology
- Late Antiquity
- Religion in the Ancient World
- Digital Humanities
- Browse content in History
- Colonialism and Imperialism
- Diplomatic History
- Environmental History
- Genealogy, Heraldry, Names, and Honours
- Genocide and Ethnic Cleansing
- Historical Geography
- History by Period
- History of Agriculture
- History of Education
- History of Emotions
- History of Gender and Sexuality
- Industrial History
- Intellectual History
- International History
- Labour History
- Legal and Constitutional History
- Local and Family History
- Maritime History
- Military History
- National Liberation and Post-Colonialism
- Oral History
- Political History
- Public History
- Regional and National History
- Revolutions and Rebellions
- Slavery and Abolition of Slavery
- Social and Cultural History
- Theory, Methods, and Historiography
- Urban History
- World History
- Browse content in Language Teaching and Learning
- Language Learning (Specific Skills)
- Language Teaching Theory and Methods
- Browse content in Linguistics
- Applied Linguistics
- Cognitive Linguistics
- Computational Linguistics
- Forensic Linguistics
- Grammar, Syntax and Morphology
- Historical and Diachronic Linguistics
- History of English
- Language Acquisition
- Language Variation
- Language Families
- Language Evolution
- Language Reference
- Lexicography
- Linguistic Theories
- Linguistic Typology
- Linguistic Anthropology
- Phonetics and Phonology
- Psycholinguistics
- Sociolinguistics
- Translation and Interpretation
- Writing Systems
- Browse content in Literature
- Bibliography
- Children's Literature Studies
- Literary Studies (Asian)
- Literary Studies (European)
- Literary Studies (Eco-criticism)
- Literary Studies (Modernism)
- Literary Studies (Romanticism)
- Literary Studies (American)
- Literary Studies - World
- Literary Studies (1500 to 1800)
- Literary Studies (19th Century)
- Literary Studies (20th Century onwards)
- Literary Studies (African American Literature)
- Literary Studies (British and Irish)
- Literary Studies (Early and Medieval)
- Literary Studies (Fiction, Novelists, and Prose Writers)
- Literary Studies (Gender Studies)
- Literary Studies (Graphic Novels)
- Literary Studies (History of the Book)
- Literary Studies (Plays and Playwrights)
- Literary Studies (Poetry and Poets)
- Literary Studies (Postcolonial Literature)
- Literary Studies (Queer Studies)
- Literary Studies (Science Fiction)
- Literary Studies (Travel Literature)
- Literary Studies (War Literature)
- Literary Studies (Women's Writing)
- Literary Theory and Cultural Studies
- Mythology and Folklore
- Shakespeare Studies and Criticism
- Browse content in Media Studies
- Browse content in Music
- Applied Music
- Dance and Music
- Ethics in Music
- Ethnomusicology
- Gender and Sexuality in Music
- Medicine and Music
- Music Cultures
- Music and Religion
- Music and Culture
- Music and Media
- Music Education and Pedagogy
- Music Theory and Analysis
- Musical Scores, Lyrics, and Libretti
- Musical Structures, Styles, and Techniques
- Musicology and Music History
- Performance Practice and Studies
- Race and Ethnicity in Music
- Sound Studies
- Browse content in Performing Arts
- Browse content in Philosophy
- Aesthetics and Philosophy of Art
- Epistemology
- Feminist Philosophy
- History of Western Philosophy
- Metaphysics
- Moral Philosophy
- Non-Western Philosophy
- Philosophy of Science
- Philosophy of Action
- Philosophy of Law
- Philosophy of Religion
- Philosophy of Language
- Philosophy of Mind
- Philosophy of Perception
- Philosophy of Mathematics and Logic
- Practical Ethics
- Social and Political Philosophy
- Browse content in Religion
- Biblical Studies
- Christianity
- East Asian Religions
- History of Religion
- Judaism and Jewish Studies
- Qumran Studies
- Religion and Education
- Religion and Health
- Religion and Politics
- Religion and Science
- Religion and Law
- Religion and Art, Literature, and Music
- Religious Studies
- Browse content in Society and Culture
- Cookery, Food, and Drink
- Cultural Studies
- Customs and Traditions
- Ethical Issues and Debates
- Hobbies, Games, Arts and Crafts
- Lifestyle, Home, and Garden
- Natural world, Country Life, and Pets
- Popular Beliefs and Controversial Knowledge
- Sports and Outdoor Recreation
- Technology and Society
- Travel and Holiday
- Visual Culture
- Browse content in Law
- Arbitration
- Browse content in Company and Commercial Law
- Commercial Law
- Company Law
- Browse content in Comparative Law
- Systems of Law
- Competition Law
- Browse content in Constitutional and Administrative Law
- Government Powers
- Judicial Review
- Local Government Law
- Military and Defence Law
- Parliamentary and Legislative Practice
- Construction Law
- Contract Law
- Browse content in Criminal Law
- Criminal Procedure
- Criminal Evidence Law
- Sentencing and Punishment
- Employment and Labour Law
- Environment and Energy Law
- Browse content in Financial Law
- Banking Law
- Insolvency Law
- History of Law
- Human Rights and Immigration
- Intellectual Property Law
- Browse content in International Law
- Private International Law and Conflict of Laws
- Public International Law
- IT and Communications Law
- Jurisprudence and Philosophy of Law
- Law and Politics
- Law and Society
- Browse content in Legal System and Practice
- Courts and Procedure
- Legal Skills and Practice
- Primary Sources of Law
- Regulation of Legal Profession
- Medical and Healthcare Law
- Browse content in Policing
- Criminal Investigation and Detection
- Police and Security Services
- Police Procedure and Law
- Police Regional Planning
- Browse content in Property Law
- Personal Property Law
- Study and Revision
- Terrorism and National Security Law
- Browse content in Trusts Law
- Wills and Probate or Succession
- Browse content in Medicine and Health
- Browse content in Allied Health Professions
- Arts Therapies
- Clinical Science
- Dietetics and Nutrition
- Occupational Therapy
- Operating Department Practice
- Physiotherapy
- Radiography
- Speech and Language Therapy
- Browse content in Anaesthetics
- General Anaesthesia
- Neuroanaesthesia
- Browse content in Clinical Medicine
- Acute Medicine
- Cardiovascular Medicine
- Clinical Genetics
- Clinical Pharmacology and Therapeutics
- Dermatology
- Endocrinology and Diabetes
- Gastroenterology
- Genito-urinary Medicine
- Geriatric Medicine
- Infectious Diseases
- Medical Oncology
- Medical Toxicology
- Pain Medicine
- Palliative Medicine
- Rehabilitation Medicine
- Respiratory Medicine and Pulmonology
- Rheumatology
- Sleep Medicine
- Sports and Exercise Medicine
- Clinical Neuroscience
- Community Medical Services
- Critical Care
- Emergency Medicine
- Forensic Medicine
- Haematology
- History of Medicine
- Browse content in Medical Dentistry
- Oral and Maxillofacial Surgery
- Paediatric Dentistry
- Restorative Dentistry and Orthodontics
- Surgical Dentistry
- Medical Ethics
- Browse content in Medical Skills
- Clinical Skills
- Communication Skills
- Nursing Skills
- Surgical Skills
- Medical Statistics and Methodology
- Browse content in Neurology
- Clinical Neurophysiology
- Neuropathology
- Nursing Studies
- Browse content in Obstetrics and Gynaecology
- Gynaecology
- Occupational Medicine
- Ophthalmology
- Otolaryngology (ENT)
- Browse content in Paediatrics
- Neonatology
- Browse content in Pathology
- Chemical Pathology
- Clinical Cytogenetics and Molecular Genetics
- Histopathology
- Medical Microbiology and Virology
- Patient Education and Information
- Browse content in Pharmacology
- Psychopharmacology
- Browse content in Popular Health
- Caring for Others
- Complementary and Alternative Medicine
- Self-help and Personal Development
- Browse content in Preclinical Medicine
- Cell Biology
- Molecular Biology and Genetics
- Reproduction, Growth and Development
- Primary Care
- Professional Development in Medicine
- Browse content in Psychiatry
- Addiction Medicine
- Child and Adolescent Psychiatry
- Forensic Psychiatry
- Learning Disabilities
- Old Age Psychiatry
- Psychotherapy
- Browse content in Public Health and Epidemiology
- Epidemiology
- Public Health
- Browse content in Radiology
- Clinical Radiology
- Interventional Radiology
- Nuclear Medicine
- Radiation Oncology
- Reproductive Medicine
- Browse content in Surgery
- Cardiothoracic Surgery
- Gastro-intestinal and Colorectal Surgery
- General Surgery
- Neurosurgery
- Paediatric Surgery
- Peri-operative Care
- Plastic and Reconstructive Surgery
- Surgical Oncology
- Transplant Surgery
- Trauma and Orthopaedic Surgery
- Vascular Surgery
- Browse content in Science and Mathematics
- Browse content in Biological Sciences
- Aquatic Biology
- Biochemistry
- Bioinformatics and Computational Biology
- Developmental Biology
- Ecology and Conservation
- Evolutionary Biology
- Genetics and Genomics
- Microbiology
- Molecular and Cell Biology
- Natural History
- Plant Sciences and Forestry
- Research Methods in Life Sciences
- Structural Biology
- Systems Biology
- Zoology and Animal Sciences
- Browse content in Chemistry
- Analytical Chemistry
- Computational Chemistry
- Crystallography
- Environmental Chemistry
- Industrial Chemistry
- Inorganic Chemistry
- Materials Chemistry
- Medicinal Chemistry
- Mineralogy and Gems
- Organic Chemistry
- Physical Chemistry
- Polymer Chemistry
- Study and Communication Skills in Chemistry
- Theoretical Chemistry
- Browse content in Computer Science
- Artificial Intelligence
- Computer Architecture and Logic Design
- Game Studies
- Human-Computer Interaction
- Mathematical Theory of Computation
- Programming Languages
- Software Engineering
- Systems Analysis and Design
- Virtual Reality
- Browse content in Computing
- Business Applications
- Computer Security
- Computer Games
- Computer Networking and Communications
- Digital Lifestyle
- Graphical and Digital Media Applications
- Operating Systems
- Browse content in Earth Sciences and Geography
- Atmospheric Sciences
- Environmental Geography
- Geology and the Lithosphere
- Maps and Map-making
- Meteorology and Climatology
- Oceanography and Hydrology
- Palaeontology
- Physical Geography and Topography
- Regional Geography
- Soil Science
- Urban Geography
- Browse content in Engineering and Technology
- Agriculture and Farming
- Biological Engineering
- Civil Engineering, Surveying, and Building
- Electronics and Communications Engineering
- Energy Technology
- Engineering (General)
- Environmental Science, Engineering, and Technology
- History of Engineering and Technology
- Mechanical Engineering and Materials
- Technology of Industrial Chemistry
- Transport Technology and Trades
- Browse content in Environmental Science
- Applied Ecology (Environmental Science)
- Conservation of the Environment (Environmental Science)
- Environmental Sustainability
- Environmentalist Thought and Ideology (Environmental Science)
- Management of Land and Natural Resources (Environmental Science)
- Natural Disasters (Environmental Science)
- Nuclear Issues (Environmental Science)
- Pollution and Threats to the Environment (Environmental Science)
- Social Impact of Environmental Issues (Environmental Science)
- History of Science and Technology
- Browse content in Materials Science
- Ceramics and Glasses
- Composite Materials
- Metals, Alloying, and Corrosion
- Nanotechnology
- Browse content in Mathematics
- Applied Mathematics
- Biomathematics and Statistics
- History of Mathematics
- Mathematical Education
- Mathematical Finance
- Mathematical Analysis
- Numerical and Computational Mathematics
- Probability and Statistics
- Pure Mathematics
- Browse content in Neuroscience
- Cognition and Behavioural Neuroscience
- Development of the Nervous System
- Disorders of the Nervous System
- History of Neuroscience
- Invertebrate Neurobiology
- Molecular and Cellular Systems
- Neuroendocrinology and Autonomic Nervous System
- Neuroscientific Techniques
- Sensory and Motor Systems
- Browse content in Physics
- Astronomy and Astrophysics
- Atomic, Molecular, and Optical Physics
- Biological and Medical Physics
- Classical Mechanics
- Computational Physics
- Condensed Matter Physics
- Electromagnetism, Optics, and Acoustics
- History of Physics
- Mathematical and Statistical Physics
- Measurement Science
- Nuclear Physics
- Particles and Fields
- Plasma Physics
- Quantum Physics
- Relativity and Gravitation
- Semiconductor and Mesoscopic Physics
- Browse content in Psychology
- Affective Sciences
- Clinical Psychology
- Cognitive Neuroscience
- Cognitive Psychology
- Criminal and Forensic Psychology
- Developmental Psychology
- Educational Psychology
- Evolutionary Psychology
- Health Psychology
- History and Systems in Psychology
- Music Psychology
- Neuropsychology
- Organizational Psychology
- Psychological Assessment and Testing
- Psychology of Human-Technology Interaction
- Psychology Professional Development and Training
- Research Methods in Psychology
- Social Psychology
- Browse content in Social Sciences
- Browse content in Anthropology
- Anthropology of Religion
- Human Evolution
- Medical Anthropology
- Physical Anthropology
- Regional Anthropology
- Social and Cultural Anthropology
- Theory and Practice of Anthropology
- Browse content in Business and Management
- Business Strategy
- Business History
- Business Ethics
- Business and Government
- Business and Technology
- Business and the Environment
- Comparative Management
- Corporate Governance
- Corporate Social Responsibility
- Entrepreneurship
- Health Management
- Human Resource Management
- Industrial and Employment Relations
- Industry Studies
- Information and Communication Technologies
- International Business
- Knowledge Management
- Management and Management Techniques
- Operations Management
- Organizational Theory and Behaviour
- Pensions and Pension Management
- Public and Nonprofit Management
- Strategic Management
- Supply Chain Management
- Browse content in Criminology and Criminal Justice
- Criminal Justice
- Criminology
- Forms of Crime
- International and Comparative Criminology
- Youth Violence and Juvenile Justice
- Development Studies
- Browse content in Economics
- Agricultural, Environmental, and Natural Resource Economics
- Asian Economics
- Behavioural Finance
- Behavioural Economics and Neuroeconomics
- Econometrics and Mathematical Economics
- Economic Systems
- Economic Methodology
- Economic History
- Economic Development and Growth
- Financial Markets
- Financial Institutions and Services
- General Economics and Teaching
- Health, Education, and Welfare
- History of Economic Thought
- International Economics
- Labour and Demographic Economics
- Law and Economics
- Macroeconomics and Monetary Economics
- Microeconomics
- Public Economics
- Urban, Rural, and Regional Economics
- Welfare Economics
- Browse content in Education
- Adult Education and Continuous Learning
- Care and Counselling of Students
- Early Childhood and Elementary Education
- Educational Equipment and Technology
- Educational Strategies and Policy
- Higher and Further Education
- Organization and Management of Education
- Philosophy and Theory of Education
- Schools Studies
- Secondary Education
- Teaching of a Specific Subject
- Teaching of Specific Groups and Special Educational Needs
- Teaching Skills and Techniques
- Browse content in Environment
- Applied Ecology (Social Science)
- Climate Change
- Conservation of the Environment (Social Science)
- Environmentalist Thought and Ideology (Social Science)
- Natural Disasters (Environment)
- Social Impact of Environmental Issues (Social Science)
- Browse content in Human Geography
- Cultural Geography
- Economic Geography
- Political Geography
- Browse content in Interdisciplinary Studies
- Communication Studies
- Museums, Libraries, and Information Sciences
- Browse content in Politics
- African Politics
- Asian Politics
- Chinese Politics
- Comparative Politics
- Conflict Politics
- Elections and Electoral Studies
- Environmental Politics
- European Union
- Foreign Policy
- Gender and Politics
- Human Rights and Politics
- Indian Politics
- International Relations
- International Organization (Politics)
- International Political Economy
- Irish Politics
- Latin American Politics
- Middle Eastern Politics
- Political Methodology
- Political Communication
- Political Philosophy
- Political Sociology
- Political Theory
- Political Behaviour
- Political Economy
- Political Institutions
- Politics and Law
- Public Administration
- Public Policy
- Quantitative Political Methodology
- Regional Political Studies
- Russian Politics
- Security Studies
- State and Local Government
- UK Politics
- US Politics
- Browse content in Regional and Area Studies
- African Studies
- Asian Studies
- East Asian Studies
- Japanese Studies
- Latin American Studies
- Middle Eastern Studies
- Native American Studies
- Scottish Studies
- Browse content in Research and Information
- Research Methods
- Browse content in Social Work
- Addictions and Substance Misuse
- Adoption and Fostering
- Care of the Elderly
- Child and Adolescent Social Work
- Couple and Family Social Work
- Developmental and Physical Disabilities Social Work
- Direct Practice and Clinical Social Work
- Emergency Services
- Human Behaviour and the Social Environment
- International and Global Issues in Social Work
- Mental and Behavioural Health
- Social Justice and Human Rights
- Social Policy and Advocacy
- Social Work and Crime and Justice
- Social Work Macro Practice
- Social Work Practice Settings
- Social Work Research and Evidence-based Practice
- Welfare and Benefit Systems
- Browse content in Sociology
- Childhood Studies
- Community Development
- Comparative and Historical Sociology
- Economic Sociology
- Gender and Sexuality
- Gerontology and Ageing
- Health, Illness, and Medicine
- Marriage and the Family
- Migration Studies
- Occupations, Professions, and Work
- Organizations
- Population and Demography
- Race and Ethnicity
- Social Theory
- Social Movements and Social Change
- Social Research and Statistics
- Social Stratification, Inequality, and Mobility
- Sociology of Religion
- Sociology of Education
- Sport and Leisure
- Urban and Rural Studies
- Browse content in Warfare and Defence
- Defence Strategy, Planning, and Research
- Land Forces and Warfare
- Military Administration
- Military Life and Institutions
- Naval Forces and Warfare
- Other Warfare and Defence Issues
- Peace Studies and Conflict Resolution
- Weapons and Equipment

- Open access
Our open access publishing is key to delivering on our mission
Open access (OA) is a key part of how Oxford University Press (OUP) supports our mission to achieve the widest possible dissemination of high-quality research. We publish rigorously peer-reviewed, world-leading, trusted open access research, upholding the highest standards of publication ethics and integrity.
We work closely with our publishing partners to ensure that we offer open access in a sustainable way, supporting publications for their communities and offering researchers publishing options for making their research available to all and compliant with funder mandates.
Our open access publishing in numbers
Our open access articles have the highest number of policy and patent document mentions, relative to volume of output, compared to other major academic publishers*
Our open access articles have the 2nd highest mean lifetime citation rate compared to other major academic publishers**
12 of our journals are diamond OA, meaning authors publish for free and readers access for free
We publish over 120 fully open access journals
More than 250 of the books we have published are open access
Over 400 of our journals have adopted a research data policy
Our Read & Publish agreements cover more than 900 institutions at which authors can use funds to publish their article open access in an OUP journal
More than 22,000 of the journal articles we published in 2022 are open access
Open access for Journals
OUP’s options for publishing open access in journals include:
Fully open access
Articles published in fully OA journals are available to all; no subscription is required. OUP’s fully OA journals use Creative Commons licenses and there is usually an Article Processing Charge (APC) for OA publication.
Hybrid open access
Hybrid journals include a mix of open access articles and articles available to those with a journal subscription.
Hybrid journals offer authors the option of gold open access publishing. With gold open access, authors usually pay an APC to make their research articles available immediately upon publication, under a Creative Commons licence with re-use rights for readers.
For articles published under a Creative Commons licence, readers can re-use the work under the terms of the applicable licence.
‘Read and Publish’ transformative agreements
OUP has agreements with many institutions to provide access to OUP journals for faculty and students and provide funding for open access publishing for affiliated researchers. Find out which institutions are participating, and how to take advantage of available funding for publishing in an OUP journal .
Green open access and self-archiving
OUP has self-archiving policies that permit authors to take advantage of green open access by depositing their accepted manuscript (i.e. the post-acceptance version, before copyediting) into a non-commercial repository. In non-commercial repositories, articles can become freely available after the proscribed embargo period. Find out more about OUP green OA for journals .
Inclusive publishing
OUP believes that the move to open access and open research needs to be equitable and inclusive for all. We want to ensure that authors can publish in their journal of choice. As part of our Developing Countries Initiative , corresponding authors based in qualifying countries publishing in any of OUP’s fully open access journals are eligible for a full waiver of their open access charge.
Open access for Books
OUP has supported OA for books since 2012 as part of our mission to publish high-quality academic and research publications and ensure they are accessible and discoverable.
Publishing your book on an OA basis makes your work freely available online, with no barriers to access. OUP applies the same peer review and editorial development processes to all books whether published open access or under a customer sales model.
If you are considering publishing a book on an OA basis with OUP, please discuss the idea with your Editor. In most instances, the open access fee for books is met by a research funder under their funding and open access policy. All prospective authors are encouraged to provide information on any funding which directly supports the research for a proposed book so that we can plan the publishing route accordingly. You can also consult our information on funders and funder policies.
When a book is published OA it is:
available to read on the Oxford Academic platform both in a browser and as a downloadable PDF
available on Google books as a full preview
indexed in, and available from, the OAPEN online library and the Directory of Open Access Books (DOAB) as a PDF
sold in print and as an eBook
Your editor will be able to provide a quote for open access based on your proposal. Our open access fee excludes any element for costs associated with print manufacture, stock, warehousing, and fulfilment. Our fee is based on the average costs associated with developing and producing a monograph adjusted in the case of longer works or works which involve additional features.
As well as publishing new books on an open access basis we are also able to convert backlist titles to OA and if you are the author of a published work and a funder has made funds available to help accelerate OA by converting existing published works, please contact your Editor.
Find out more about licences, charges and self-archiving for your open access book .
*Data source: Altmetric. Comparing number of policy and patent document mentions, relative to number of articles published, to Cambridge University Press, Elsevier, Frontiers, Hindawi, Institute of Physics Publishing, MDPI, PLOS, Sage, Springer Nature, Taylor & Francis, and Wiley.
**Data source: Dimensions. Comparing the mean lifetime citation rate of open access articles to those published by Cambridge University Press, Elsevier, Frontiers, Hindawi, Institute of Physics Publishing, MDPI, PLOS, Sage, Springer Nature, Taylor & Francis, and Wiley.
Related information
- Complying with funder policies on open access
- Charges, licences, and self-archiving
- Read and publish agreements
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Introduction
- Conclusions
- Article Information
Hazard ratio for obesity was modeled according to mean daily step counts and 25th, 50th, and 75th percentile PRS for body mass index. Shaded regions represent 95% CIs. Model is adjusted for age, sex, mean baseline step counts, cancer status, coronary artery disease status, systolic blood pressure, alcohol use, educational level, and a PRS × mean steps interaction term.
Mean daily steps and polygenic risk score (PRS) for higher body mass index are independently associated with hazard for obesity. Hazard ratios model the difference between the 75th and 25th percentiles for continuous variables. CAD indicate coronary artery disease; and SBP, systolic blood pressure.
Each point estimate is indexed to a hazard ratio for obesity of 1.00 (BMI [calculated as weight in kilograms divided by height in meters squared] ≥30). Error bars represent 95% CIs.
eTable. Cumulative Incidence Estimates of Obesity Based on Polygenic Risk Score for Body Mass Index and Mean Daily Steps at 1, 3, and 5 Years
eFigure 1. CONSORT Diagram
eFigure 2. Risk of Incident Obesity Modeled by Mean Daily Step Count and Polygenic Risk Scores Adjusted for Baseline Body Mass Index
Data Sharing Statement
See More About
Sign up for emails based on your interests, select your interests.
Customize your JAMA Network experience by selecting one or more topics from the list below.
- Academic Medicine
- Acid Base, Electrolytes, Fluids
- Allergy and Clinical Immunology
- American Indian or Alaska Natives
- Anesthesiology
- Anticoagulation
- Art and Images in Psychiatry
- Artificial Intelligence
- Assisted Reproduction
- Bleeding and Transfusion
- Caring for the Critically Ill Patient
- Challenges in Clinical Electrocardiography
- Climate and Health
- Climate Change
- Clinical Challenge
- Clinical Decision Support
- Clinical Implications of Basic Neuroscience
- Clinical Pharmacy and Pharmacology
- Complementary and Alternative Medicine
- Consensus Statements
- Coronavirus (COVID-19)
- Critical Care Medicine
- Cultural Competency
- Dental Medicine
- Dermatology
- Diabetes and Endocrinology
- Diagnostic Test Interpretation
- Drug Development
- Electronic Health Records
- Emergency Medicine
- End of Life, Hospice, Palliative Care
- Environmental Health
- Equity, Diversity, and Inclusion
- Facial Plastic Surgery
- Gastroenterology and Hepatology
- Genetics and Genomics
- Genomics and Precision Health
- Global Health
- Guide to Statistics and Methods
- Hair Disorders
- Health Care Delivery Models
- Health Care Economics, Insurance, Payment
- Health Care Quality
- Health Care Reform
- Health Care Safety
- Health Care Workforce
- Health Disparities
- Health Inequities
- Health Policy
- Health Systems Science
- History of Medicine
- Hypertension
- Images in Neurology
- Implementation Science
- Infectious Diseases
- Innovations in Health Care Delivery
- JAMA Infographic
- Law and Medicine
- Leading Change
- Less is More
- LGBTQIA Medicine
- Lifestyle Behaviors
- Medical Coding
- Medical Devices and Equipment
- Medical Education
- Medical Education and Training
- Medical Journals and Publishing
- Mobile Health and Telemedicine
- Narrative Medicine
- Neuroscience and Psychiatry
- Notable Notes
- Nutrition, Obesity, Exercise
- Obstetrics and Gynecology
- Occupational Health
- Ophthalmology
- Orthopedics
- Otolaryngology
- Pain Medicine
- Palliative Care
- Pathology and Laboratory Medicine
- Patient Care
- Patient Information
- Performance Improvement
- Performance Measures
- Perioperative Care and Consultation
- Pharmacoeconomics
- Pharmacoepidemiology
- Pharmacogenetics
- Pharmacy and Clinical Pharmacology
- Physical Medicine and Rehabilitation
- Physical Therapy
- Physician Leadership
- Population Health
- Primary Care
- Professional Well-being
- Professionalism
- Psychiatry and Behavioral Health
- Public Health
- Pulmonary Medicine
- Regulatory Agencies
- Reproductive Health
- Research, Methods, Statistics
- Resuscitation
- Rheumatology
- Risk Management
- Scientific Discovery and the Future of Medicine
- Shared Decision Making and Communication
- Sleep Medicine
- Sports Medicine
- Stem Cell Transplantation
- Substance Use and Addiction Medicine
- Surgical Innovation
- Surgical Pearls
- Teachable Moment
- Technology and Finance
- The Art of JAMA
- The Arts and Medicine
- The Rational Clinical Examination
- Tobacco and e-Cigarettes
- Translational Medicine
- Trauma and Injury
- Treatment Adherence
- Ultrasonography
- Users' Guide to the Medical Literature
- Vaccination
- Venous Thromboembolism
- Veterans Health
- Women's Health
- Workflow and Process
- Wound Care, Infection, Healing
Get the latest research based on your areas of interest.
Others also liked.
- Download PDF
- X Facebook More LinkedIn
Brittain EL , Han L , Annis J, et al. Physical Activity and Incident Obesity Across the Spectrum of Genetic Risk for Obesity. JAMA Netw Open. 2024;7(3):e243821. doi:10.1001/jamanetworkopen.2024.3821
Manage citations:
© 2024
- Permissions
Physical Activity and Incident Obesity Across the Spectrum of Genetic Risk for Obesity
- 1 Division of Cardiovascular Medicine, Vanderbilt University Medical Center, Nashville, Tennessee
- 2 Center for Digital Genomic Medicine, Department of Medicine, Vanderbilt University Medical Center, Nashville, Tennessee
- 3 Division of Genetic Medicine, Vanderbilt Genetics Institute, Vanderbilt University Medical Center, Nashville, Tennessee
- 4 Vanderbilt Institute of Clinical and Translational Research, Vanderbilt University Medical Center, Nashville, Tennessee
- 5 Department of Medicine, Vanderbilt University Medical Center, Nashville, Tennessee
- 6 Department of Pharmacology, Vanderbilt University Medical Center, Nashville, Tennessee
- 7 Department of Biomedical Informatics, Vanderbilt University Medical Center, Nashville, Tennessee
- 8 Department of Biomedical Engineering, Vanderbilt University Medical Center, Nashville, Tennessee
- 9 Department of Biostatistics, Vanderbilt University Medical Center, Nashville, Tennessee
- 10 Department of Psychiatry and Behavioral Sciences, Vanderbilt University Medical Center, Nashville, Tennessee
Question Does the degree of physical activity associated with incident obesity vary by genetic risk?
Findings In this cohort study of 3124 adults, individuals at high genetic risk of obesity needed higher daily step counts to reduce the risk of obesity than those at moderate or low genetic risk.
Meaning These findings suggest that individualized physical activity recommendations that incorporate genetic background may reduce obesity risk.
Importance Despite consistent public health recommendations, obesity rates in the US continue to increase. Physical activity recommendations do not account for individual genetic variability, increasing risk of obesity.
Objective To use activity, clinical, and genetic data from the All of Us Research Program (AoURP) to explore the association of genetic risk of higher body mass index (BMI) with the level of physical activity needed to reduce incident obesity.
Design, Setting, and Participants In this US population–based retrospective cohort study, participants were enrolled in the AoURP between May 1, 2018, and July 1, 2022. Enrollees in the AoURP who were of European ancestry, owned a personal activity tracking device, and did not have obesity up to 6 months into activity tracking were included in the analysis.
Exposure Physical activity expressed as daily step counts and a polygenic risk score (PRS) for BMI, calculated as weight in kilograms divided by height in meters squared.
Main Outcome and Measures Incident obesity (BMI ≥30).
Results A total of 3124 participants met inclusion criteria. Among 3051 participants with available data, 2216 (73%) were women, and the median age was 52.7 (IQR, 36.4-62.8) years. The total cohort of 3124 participants walked a median of 8326 (IQR, 6499-10 389) steps/d over a median of 5.4 (IQR, 3.4-7.0) years of personal activity tracking. The incidence of obesity over the study period increased from 13% (101 of 781) to 43% (335 of 781) in the lowest and highest PRS quartiles, respectively ( P = 1.0 × 10 −20 ). The BMI PRS demonstrated an 81% increase in obesity risk ( P = 3.57 × 10 −20 ) while mean step count demonstrated a 43% reduction ( P = 5.30 × 10 −12 ) when comparing the 75th and 25th percentiles, respectively. Individuals with a PRS in the 75th percentile would need to walk a mean of 2280 (95% CI, 1680-3310) more steps per day (11 020 total) than those at the 50th percentile to have a comparable risk of obesity. To have a comparable risk of obesity to individuals at the 25th percentile of PRS, those at the 75th percentile with a baseline BMI of 22 would need to walk an additional 3460 steps/d; with a baseline BMI of 24, an additional 4430 steps/d; with a baseline BMI of 26, an additional 5380 steps/d; and with a baseline BMI of 28, an additional 6350 steps/d.
Conclusions and Relevance In this cohort study, the association between daily step count and obesity risk across genetic background and baseline BMI were quantified. Population-based recommendations may underestimate physical activity needed to prevent obesity among those at high genetic risk.
In 2000, the World Health Organization declared obesity the greatest threat to the health of Westernized nations. 1 In the US, obesity accounts for over 400 000 deaths per year and affects nearly 40% of the adult population. Despite the modifiable nature of obesity through diet, exercise, and pharmacotherapy, rates have continued to increase.
Physical activity recommendations are a crucial component of public health guidelines for maintaining a healthy weight, with increased physical activity being associated with a reduced risk of obesity. 2 - 4 Fitness trackers and wearable devices have provided an objective means to capture physical activity, and their use may be associated with weight loss. 5 Prior work leveraging these devices has suggested that taking around 8000 steps/d substantially mitigates risk of obesity. 3 , 4 However, current recommendations around physical activity do not take into account other contributors such as caloric intake, energy expenditure, or genetic background, likely leading to less effective prevention of obesity for many people. 6
Obesity has a substantial genetic contribution, with heritability estimates ranging from 40% to 70%. 7 , 8 Prior studies 9 - 11 have shown an inverse association between genetic risk and physical activity with obesity, whereby increasing physical activity can help mitigate higher genetic risk for obesity. These results have implications for physical activity recommendations on an individual level. Most of the prior work 9 - 11 focused on a narrow set of obesity-associated variants or genes and relied on self-reported physical activity, and more recent work using wearable devices has been limited to 7 days of physical activity measurements. 12 Longer-term capture in large populations will be required to accurately estimate differences in physical activity needed to prevent incident obesity.
We used longitudinal activity monitoring and genome sequencing data from the All of Us Research Program (AoURP) to quantify the combined association of genetic risk for body mass index (BMI; calculated as weight in kilograms divided by height in meters squared) and physical activity with the risk of incident obesity. Activity monitoring was quantified as daily step counts obtained from fitness tracking devices. Genetic risk was quantified by using a polygenic risk score (PRS) from a large-scale genomewide association study (GWAS) of BMI. 13 We quantified the mean daily step count needed to overcome genetic risk for increased BMI. These findings represent an initial step toward personalized exercise recommendations that integrate genetic information.
Details on the design and execution of the AoURP have been published previously. 14 The present study used AoURP Controlled Tier dataset, version 7 (C2022Q4R9), with data from participants enrolled between May 1, 2018, and July 1, 2022. Participants who provided informed consent could share data from their own activity tracking devices from the time their accounts were first created, which may precede the enrollment date in AoURP. We followed the Strengthening the Reporting of Observational Studies in Epidemiology ( STROBE ) reporting guideline. In this study, only the authorized authors who completed All of Us Responsible Conduct of Research training accessed the deidentified data from the Researcher Workbench (a secured cloud-based platform). Since the authors were not directly involved with the participants, institutional review board review was exempted in compliance with AoURP policy.
Activity tracking data for this study came from the Bring Your Own Device program that allowed individuals who already owned a tracking device (Fitbit, Inc) to consent to link their activity data with other data in the AoURP. By registering their personal device on the AoURP patient portal, patients could share all activity data collected since the creation of their personal device account. For many participants, this allowed us to examine fitness activity data collected prior to enrollment in the AoURP. Activity data in AoURP are reported as daily step counts. We excluded days with fewer than 10 hours of wear time to enrich our cohort for individuals with consistently high wear time. The initial personal activity device cohort consisted of 12 766 individuals. Consistent with our prior data curation approach, days with less than 10 hours of wear time, less than 100 steps, or greater than 45 000 steps or for which the participant was younger than 18 years were removed. For time-varying analyses, mean daily steps were calculated on a monthly basis for each participant. Months with fewer than 15 valid days of monitoring were removed.
The analytic cohort included only individuals with a BMI of less than 30 at the time activity monitoring began. The primary outcome was incident obesity, defined as a BMI of 30 or greater documented in the medical record at least 6 months after initiation of activity monitoring. The latter stipulation reduced the likelihood that having obesity predated the beginning of monitoring but had not yet been clinically documented. We extracted BMI values and clinical characteristics from longitudinal electronic health records (EHRs) for the consenting participants who were associated with a health care provider organization funded by the AoURP. The EHR data have been standardized using the Observational Medical Outcomes Partnership Common Data Model. 15 In the AoURP, upon consent, participants are asked to complete the Basics survey, in which they may self-report demographic characteristics such as race, ethnicity, and sex at birth.
We filtered the data to include only biallelic, autosomal single-nucleotide variants (SNVs) that had passed AoURP initial quality control. 16 We then removed duplicate-position SNVs and kept only individual genotypes with a genotype quality greater than 20. We further filtered the SNVs based on their Hardy-Weinberg equilibrium P value (>1.0 × 10 −15 ) and missing rate (<5%) across all samples. Next, we divided the samples into 6 groups (Admixed American, African, East Asian, European, Middle Eastern, and South Asian) based on their estimated ancestral populations 16 , 17 and further filtered the SNVs within each population based on minor allele frequency (MAF) (>0.01), missing rate (<0.02), and Hardy-Weinberg equilibrium P value (>1.0 × 10 −6 ). The SNVs were mapped from Genome Reference Consortium Human Build 38 with coordinates to Build 37. Because the existing PRS models have limited transferability across ancestry groups and to ensure appropriate power of the subsequent PRS analysis, we limited our analysis to the populations who had a sample size of greater than 500, resulting in 5964 participants of European ancestry with 5 515 802 common SNVs for analysis.
To generate principal components, we excluded the regions with high linkage disequilibrium, including chr5:44-51.5 megabase (Mb), chr6:25-33.5 Mb, chr8:8-12 Mb, and chr11:45-57 Mb. We then pruned the remaining SNVs using PLINK, version 1.9 (Harvard University), pairwise independence function with 1-kilobase window shifted by 50 base pairs and requiring r 2 < 0.05 between any pair, resulting in 100 983 SNPs for further analysis. 18 Principal component analysis was run using PLINK, version 1.9. The European ancestry linkage disequilibrium reference panel from the 1000 Genomes Project phase 3 was downloaded, and nonambiguous SNPs with MAF greater than 0.01 were kept in the largest European ancestry GWAS summary statistics of BMI. 13 We manually harmonized the strand-flipping SNPs among the SNP information file, GWAS summary statistics files, and the European ancestry PLINK extended map files (.bim).
We used PRS–continuous shrinkage to infer posterior SNP effect sizes under continuous shrinkage priors with a scaling parameter set to 0.01, reflecting the polygenic architecture of BMI. GWAS summary statistics of BMI measured in 681 275 individuals of European ancestry was used to estimate the SNP weights. 19 The scoring command in PLINK, version 1.9, was used to produce the genomewide scores of the AoURP European individuals with their quality-controlled SNP genotype data and these derived SNP weights. 20 Finally, by using the genomewide scores as the dependent variable and the 10 principal components as the independent variable, we performed linear regression, and the obtained residuals were kept for the subsequent analysis. To check the performance of the PRS estimate, we first fit a generalized regression model with obesity status as the dependent variable and the PRS as the independent variable with age, sex, and the top 10 principal components of genetic ancestry as covariates. We then built a subset logistic regression model, which only uses the same set of covariates. By comparing the full model with the subset model, we measured the incremental Nagelkerke R 2 value to quantify how much variance in obesity status was explained by the PRS.
Differences in clinical characteristics across PRS quartiles were assessed using the Wilcoxon rank sum or Kruskal-Wallis test for continuous variables and the Pearson χ 2 test for categorical variables. Cox proportional hazards regression models were used to examine the association among daily step count (considered as a time-varying variable), PRS, and the time to event for obesity, adjusting for age, sex, mean baseline step counts, cancer status, coronary artery disease status, systolic blood pressure, alcohol use, educational level, and interaction term of PRS × mean steps. We presented these results stratified by baseline BMI and provided a model including baseline BMI in eFigure 2 in Supplement 1 as a secondary analysis due to collinearity between BMI and PRS.
Cox proportional hazards regression models were fit on a multiply imputed dataset. Multiple imputation was performed for baseline BMI, alcohol use, educational status, systolic blood pressure, and smoking status using bootstrap and predictive mean matching with the aregImpute function in the Hmisc package of R, version 4.2.2 (R Project for Statistical Computing). Continuous variables were modeled as restricted cubic splines with 3 knots, unless the nonlinear term was not significant, in which case it was modeled as a linear term. Fits and predictions of the Cox proportional hazards regression models were obtained using the rms package in R, version 4.2.2. The Cox proportional hazards regression assumptions were checked using the cox.zph function from the survival package in R, version 4.2.2.
To identify the combinations of PRS and mean daily step counts associated with a hazard ratio (HR) of 1.00, we used a 100-knot spline function to fit the Cox proportional hazards regression ratio model estimations across a range of mean daily step counts for each PRS percentile. We then computed the inverse of the fitted spline function to determine the mean daily step count where the HR equals 1.00 for each PRS percentile. We repeated this process for multiple PRS percentiles to generate a plot of mean daily step counts as a function of PRS percentiles where the HR was 1.00. To estimate the uncertainty around these estimations, we applied a similar spline function to the upper and lower estimated 95% CIs of the Cox proportional hazards regression model to find the 95% CIs for the estimated mean daily step counts at each PRS percentile. Two-sided P < .05 indicated statistical significance.
We identified 3124 participants of European ancestry without obesity at baseline who agreed to link their personal activity data and EHR data and had available genome sequencing. Among those with available data, 2216 of 3051 (73%) were women and 835 of 3051 (27%) were men, and the median age was 52.7 (IQR, 36.4-62.8) years. In terms of race and ethnicity, 2958 participants (95%) were White compared with 141 participants (5%) who were of other race or ethnicity (which may include Asian, Black or African American, Middle Eastern or North African, Native Hawaiian or Other Pacific Islander, multiple races or ethnicities, and unknown race or ethnicity) ( Table ). The analytic sample was restricted to individuals assigned European ancestry based on the All of Us Genomic Research Data Quality Report. 16 A study flowchart detailing the creation of the analytic dataset is provided in eFigure 1 in Supplement 1 . The BMI-based PRS explained 8.3% of the phenotypic variation in obesity (β = 1.76; P = 2 × 10 −16 ). The median follow-up time was 5.4 (IQR, 3.4-7.0) years and participants walked a median of 8326 (IQR, 6499-10 389) steps/d. The incidence of obesity over the study period was 13% (101 of 781 participants) in the lowest PRS quartile and 43% (335 of 781 participants) in the highest PRS quartile ( P = 1.0 × 10 −20 ). We observed a decrease in median daily steps when moving from lowest (8599 [IQR, 6751-10 768]) to highest (8115 [IQR, 6340-10 187]) PRS quartile ( P = .01).
We next modeled obesity risk stratified by PRS percentile with the 50th percentile indexed to an HR for obesity of 1.00 ( Figure 1 ). The association between PRS and incident obesity was direct ( P = .001) and linear (chunk test for nonlinearity was nonsignificant [ P = .07]). The PRS and mean daily step count were both independently associated with obesity risk ( Figure 2 ). The 75th percentile BMI PRS demonstrated an 81% increase in obesity risk (HR, 1.81 [95% CI, 1.59-2.05]; P = 3.57 × 10 −20 ) when compared with the 25th percentile BMI PRS, whereas the 75th percentile median step count demonstrated a 43% reduction in obesity risk (HR, 0.57 [95% CI, 0.49-0.67]; P = 5.30 × 10 −12 ) when compared with the 25th percentile step count. The PRS × mean steps interaction term was not significant (χ 2 = 1.98; P = .37).
Individuals with a PRS at the 75th percentile would need to walk a mean of 2280 (95% CI, 1680-3310) more steps per day (11 020 total) than those at the 50th percentile to reduce the HR for obesity to 1.00 ( Figure 1 ). Conversely, those in the 25th percentile PRS could reach an HR of 1.00 by walking a mean of 3660 (95% CI, 2180-8740) fewer steps than those at the 50th percentile PRS. When assuming a median daily step count of 8740 (cohort median), those in the 75th percentile PRS had an HR for obesity of 1.33 (95% CI, 1.25-1.41), whereas those at the 25th percentile PRS had an obesity HR of 0.74 (95% CI, 0.69-0.79).
The mean daily step count required to achieve an HR for obesity of 1.00 across the full PRS spectrum and stratified by baseline BMI is shown in Figure 3 . To reach an HR of 1.00 for obesity, when stratified by baseline BMI of 22, individuals at the 50th percentile PRS would need to achieve a mean daily step count of 3290 (additional 3460 steps/d); for a baseline BMI of 24, a mean daily step count of 7590 (additional 4430 steps/d); for a baseline BMI of 26, a mean daily step count of 11 890 (additional 5380 steps/d); and for a baseline BMI of 28, a mean daily step count of 16 190 (additional 6350 steps/d).
When adding baseline BMI to the full Cox proportional hazards regression model, daily step count and BMI PRS both remain associated with obesity risk. When comparing individuals at the 75th percentile with those at the 25th percentile, the BMI PRS is associated with a 61% increased risk of obesity (HR, 1.61 [95% CI, 1.45-1.78]). Similarly, when comparing the 75th with the 25th percentiles, daily step count was associated with a 38% lower risk of obesity (HR, 0.62 [95% CI, 0.53-0.72]) (eFigure 2 in Supplement 1 ).
The cumulative incidence of obesity increases over time and with fewer daily steps and higher PRS. The cumulative incidence of obesity would be 2.9% at the 25th percentile, 3.9% at the 50th percentile, and 5.2% at the 75th percentile for PRS in year 1; 10.5% at the 25th percentile, 14.0% at the 50th percentile, and 18.2% at the 75th percentile for PRS in year 3; and 18.5% at the 25th percentile, 24.3% at the 50th percentile, and 30.9% at the 75th percentile for PRS in year 5 ( Figure 4 ). The eTable in Supplement 1 models the expected cumulative incidence of obesity at 1, 3, and 5 years based on PRS and assumed mean daily steps of 7500, 10 000, and 12 500.
We examined the combined association of daily step counts and genetic risk for increased BMI with the incidence of obesity in a large national sample with genome sequencing and long-term activity monitoring data. Lower daily step counts and higher BMI PRS were both independently associated with increased risk of obesity. As the PRS increased, the number of daily steps associated with lower risk of obesity also increased. By combining these data sources, we derived an estimate of the daily step count needed to reduce the risk of obesity based on an individual’s genetic background. Importantly, our findings suggest that genetic risk for obesity is not deterministic but can be overcome by increasing physical activity.
Our findings align with those of prior literature 9 indicating that engaging in physical activity can mitigate genetic obesity risk and highlight the importance of genetic background for individual health and wellness. Using the data from a large population-based sample, Li et al 9 characterized obesity risk by genotyping 12 susceptibility loci and found that higher self-reported physical activity was associated with a 40% reduction in genetic predisposition to obesity. Our study extends these results in 2 important ways. First, we leveraged objectively measured longitudinal activity data from commercial devices to focus on physical activity prior to and leading up to a diagnosis of obesity. Second, we used a more comprehensive genomewide risk assessment in the form of a PRS. Our results indicate that daily step count recommendations to reduce obesity risk may be personalized based on an individual’s genetic background. For instance, individuals with higher genetic risk (ie, 75th percentile PRS) would need to walk a mean of 2280 more steps per day than those at the 50th percentile of genetic risk to have a comparable risk of obesity.
These results suggest that population-based recommendations that do not account for genetic background may not accurately represent the amount of physical activity needed to reduce the risk of obesity. Population-based exercise recommendations may overestimate or underestimate physical activity needs, depending on one’s genetic background. Underestimation of physical activity required to reduce obesity risk has the potential to be particularly detrimental to public health efforts to reduce weight-related morbidity. As such, integration of activity and genetic data could facilitate personalized activity recommendations that account for an individual’s genetic profile. The widespread use of wearable devices and the increasing demand for genetic information from both clinical and direct-to-consumer sources may soon permit testing the value of personalized activity recommendations. Efforts to integrate wearable devices and genomic data into the EHR further support the potential future clinical utility of merging these data sources to personalize lifestyle recommendations. Thus, our findings support the need for a prospective trial investigating the impact of tailoring step counts by genetic risk on chronic disease outcomes.
The most important limitation of this work is the lack of diversity and inclusion only of individuals with European ancestry. These findings will need validation in a more diverse population. Our cohort only included individuals who already owned a fitness tracking device and agreed to link their activity data to the AoURP dataset, which may not be generalizable to other populations. We cannot account for unmeasured confounding, and the potential for reverse causation still exists. We attempted to diminish the latter concern by excluding prevalent obesity and incident cases within the first 6 months of monitoring. Genetic risk was simplified to be specific to increased BMI; however, genetic risk for other cardiometabolic conditions could also inform obesity risk. Nongenetic factors that contribute to obesity risk such as dietary patterns were not available, reducing the explanatory power of the model. It is unlikely that the widespread use of drug classes targeting weight loss affects the generalizability of our results, because such drugs are rarely prescribed for obesity prevention, and our study focused on individuals who were not obese at baseline. Indeed, less than 0.5% of our cohort was exposed to a medication class targeting weight loss (phentermine, orlistat, or glucagonlike peptide-1 receptor agonists) prior to incident obesity or censoring. Finally, some fitness activity tracking devices may not capture nonambulatory activity as well as triaxial accelerometers.
This cohort study used longitudinal activity data from commercial wearable devices, genome sequencing, and clinical data to support the notion that higher daily step counts can mitigate genetic risk for obesity. These results have important clinical and public health implications and may offer a novel strategy for addressing the obesity epidemic by informing activity recommendations that incorporate genetic information.
Accepted for Publication: January 30, 2024.
Published: March 27, 2024. doi:10.1001/jamanetworkopen.2024.3821
Open Access: This is an open access article distributed under the terms of the CC-BY License . © 2024 Brittain EL et al. JAMA Network Open .
Corresponding Author: Evan L. Brittain, MD, MSc ( [email protected] ) and Douglas M. Ruderfer, PhD ( [email protected] ), Vanderbilt University Medical Center, 2525 West End Ave, Suite 300A, Nashville, TN 37203.
Author Contributions: Drs Brittain and Ruderfer had full access to all of the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis.
Concept and design: Brittain, Annis, Master, Roden, Ruderfer.
Acquisition, analysis, or interpretation of data: Brittain, Han, Annis, Master, Hughes, Harris, Ruderfer.
Drafting of the manuscript: Brittain, Han, Annis, Master, Ruderfer.
Critical review of the manuscript for important intellectual content: All authors.
Statistical analysis: Brittain, Han, Annis, Master.
Obtained funding: Brittain, Harris.
Administrative, technical, or material support: Brittain, Annis, Master, Roden.
Supervision: Brittain, Ruderfer.
Conflict of Interest Disclosures: Dr Brittain reported receiving a gift from Google LLC during the conduct of the study. Dr Ruderfer reported serving on the advisory board of Illumina Inc and Alkermes PLC and receiving grant funding from PTC Therapeutics outside the submitted work. No other disclosures were reported.
Funding/Support: The All of Us Research Program is supported by grants 1 OT2 OD026549, 1 OT2 OD026554, 1 OT2 OD026557, 1 OT2 OD026556, 1 OT2 OD026550, 1 OT2 OD 026552, 1 OT2 OD026553, 1 OT2 OD026548, 1 OT2 OD026551, 1 OT2 OD026555, IAA AOD21037, AOD22003, AOD16037, and AOD21041 (regional medical centers); grant HHSN 263201600085U (federally qualified health centers); grant U2C OD023196 (data and research center); 1 U24 OD023121 (Biobank); U24 OD023176 (participant center); U24 OD023163 (participant technology systems center); grants 3 OT2 OD023205 and 3 OT2 OD023206 (communications and engagement); and grants 1 OT2 OD025277, 3 OT2 OD025315, 1 OT2 OD025337, and 1 OT2 OD025276 (community partners) from the National Institutes of Health (NIH). This study is also supported by grants R01 HL146588 (Dr Brittain), R61 HL158941 (Dr Brittain), and R21 HL172038 (Drs Brittain and Ruderfer) from the NIH.
Role of the Funder/Sponsor: The NIH had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Data Sharing Statement: See Supplement 2 .
Additional Contributions: The All of Us Research Program would not be possible without the partnership of its participants.
- Register for email alerts with links to free full-text articles
- Access PDFs of free articles
- Manage your interests
- Save searches and receive search alerts
Research Roundup: Superbug-fighting drugs, affordable green energy and anti-aging

The The Daily’s academics desk gathers a weekly digest collecting some of the most impactful and interesting research publications and developments at Stanford. Read the latest in this week’s Research Roundup.
AI reveals new drugs to fight against antibiotic resistance
Stanford Medicine researchers have built a generative artificial intelligence (AI) program that identified six new potential drugs to combat antibiotic-resistant bacteria.
The model, SyntheMol, generates chemical “recipes” and instructions to construct drugs capable of killing bacteria that have grown to withstand the effects of traditional antibiotics (commonly called “superbugs”). Highlighted in a March 22 study published in the journal Nature Machine Intelligence, SyntheMol generated medication that could kill Acinetobacter baumannii, the most common example of drug-resistant bacteria.
Antibiotic resistance occurs when bacteria become able to survive rounds of antibiotics, becoming resistant to the effects of drugs. Every year, nearly five million people die globally due to resistant strains of bacteria, according to the World Health Organization (WHO).
“There’s a huge public health need to develop new antibiotics quickly,” said James Zou, a co-lead author and associate professor of biomedical data science.
The use of AI in the fields of chemistry and pharmaceutical medicine drastically reduces the computation time needed to create new drug compounds and optimizes the effectiveness of those medicines, the paper’s authors said.
The researchers valued their AI’s ability to explore molecules that do not occur in nature, which led to creative and effective new compounds. They plan to partner with other research groups in the field to expand SyntheMol’s applications, including in heart disease treatment.
A new way to supply clean energy to low-income communities
A Stanford-led study, published in Nature Energy on March 28, indicated that building solar panels atop commercial and non-residential buildings could prove effective in providing reliable renewable energy to low-income neighborhoods across the United States.
The authors of the paper, engineers at Stanford, described how businesses could be more receptive to government incentives for collecting solar energy using their buildings than residents may be. As these companies provide the renewable energy they have collected to the local electrical grids, the people in these neighborhoods can pay for the resource at a much lower cost than through installing their own solar panels.
Currently, low-income communities in the United States have a much lower rate of solar panel installation than wealthier areas (though this gap is decreasing). The solution proposed by the researchers could have a significant impact on increasing clean energy in the country and slowing the effects of climate change through a more widespread transition to renewable sources of energy.
“[The use of industrial spaces to host solar panels] would promote local clean and low-cost energy generation, which would also increase the resilience from outages and reduce the pollution caused by fossil fuel power plants – many of which are located in low-income areas,” Zhecheng Wang Ph.D. ’22, co-author and fellow at the Institute for Human-Centered AI (HAI), told Stanford News.
Reversing aging immune systems in mice
Researchers at Stanford Medicine successfully boosted the ability of the immune systems of aging mice to fight off viruses in a recent trial study. The paper, published on March 27 in Nature magazine, indicated the possibility of applying age-reversing technology to humans.
The authors treated a selection of mice in their study with an antibody that removed old immune cells. These mice displayed significantly younger and stronger immune systems compared to the untreated mice. In addition, the antibody decreased the amount of inflammation and related symptoms when the immune systems needed to fight off viruses.
“We were surprised that a single course of treatment had such a long-lasting effect. The difference between the treated and untreated animals remained dramatic even two months later,” said lead author and Stanford postdoctoral fellow Jason Ross ’06.
According to the study’s authors, the results of the study indicate a pathway toward implementing related techniques to help elderly people have greater resistance to viruses and infections.
Jack Quach ’27 is a beat reporter, covering research and awards, and staff writer for News. He is from San Francisco, CA, and in his free time loves cheering for his hometown sports teams, exploring the outdoors, learning new recipes and being the official™ S.F. expert/tour guide for his friends.
Login or create an account
Apply to the daily’s high school summer program, priority deadline is april 14.
- JOURNALISM WORKSHOP
- MULTIMEDIA & TECH BOOTCAMPS
- GUEST SPEAKERS
- FINANCIAL AID AVAILABLE
US and EU commit to links aimed at boosting AI safety and risk research

The European Union and United States put out a joint statement Friday affirming a desire to increase cooperation over artificial intelligence. The agreement covers AI safety and governance, but also, more broadly, an intent to collaborate across a number of other tech issues, such as developing digital identity standards and applying pressure on platforms to defend human rights.
As we reported Wednesday , this is the fruit of the sixth (and possibly last) meeting of the EU-U.S. Trade and Technology Council (TTC). The TTC has been meeting since 2021 in a bid to rebuild transatlantic relations battered by the Trump presidency.
Given the possibility of Donald Trump returning to the White House in the U.S. presidential elections taking place later this year, it’s not clear how much EU-U.S. cooperation on AI or any other strategic tech area will actually happen in the near future.
But, under the current political make-up across the Atlantic, the will to push for closer alignment across a range of tech issues has gained in strength. There is also a mutual desire to get this message heard — hence today’s joint statement — which is itself, perhaps, also a wider appeal aimed at each side’s voters to opt for a collaborative program, rather than a destructive opposite, come election time.
An AI dialogue
In a section of the joint statement focused on AI, filed under a heading of “Advancing Transatlantic Leadership on Critical and Emerging Technologies”, the pair write that they “reaffirm our commitment to a risk-based approach to artificial intelligence… and to advancing safe, secure, and trustworthy AI technologies.”
“We encourage advanced AI developers in the United States and Europe to further the application of the Hiroshima Process International Code of Conduct for Organisations Developing Advanced AI Systems which complements our respective governance and regulatory systems,” the statement also reads, referencing a set of risk-based recommendations that came out of G7 discussions on AI last year.
The main development out of the sixth TTC meeting appears to be a commitment from EU and U.S. AI oversight bodies, the European AI Office and the U.S. AI Safety Institute, to set up what’s couched as “a Dialogue.” The aim is a deeper collaboration between the AI institutions, with a particular focus on encouraging the sharing of scientific information among respective AI research ecosystems.
Topics highlighted here include benchmarks, potential risks and future technological trends.
“This cooperation will contribute to making progress with the implementation of the Joint Roadmap on Evaluation and Measurement Tools for Trustworthy AI and Risk Management , which is essential to minimise divergence as appropriate in our respective emerging AI governance and regulatory systems, and to cooperate on interoperable and international standards,” the two sides go on to suggest.
The statement also flags an updated version of a list of key AI terms, with “mutually accepted joint definitions” as another outcome from ongoing stakeholder talks flowing from the TTC.
Agreement on definitions will be a key piece of the puzzle to support work toward AI standardization.
A third element of what’s been agreed by the EU and U.S. on AI shoots for collaboration to drive research aimed at applying machine learning technologies for beneficial use cases, such as advancing healthcare outcomes, boosting agriculture and tackling climate change, with a particular focus on sustainable development. In a briefing with journalists earlier this week a senior commission official suggested this element of the joint working will focus on bringing AI advancements to developing countries and the global south.
“We are advancing on the promise of AI for sustainable development in our bilateral relationship through joint research cooperation as part of the Administrative Arrangement on Artificial Intelligence and computing to address global challenges for the public good,” the joint statement reads. “Working groups jointly staffed by United States science agencies and European Commission departments and agencies have achieved substantial progress by defining critical milestones for deliverables in the areas of extreme weather, energy, emergency response, and reconstruction . We are also making constructive progress in health and agriculture.”
In addition, an overview document on the collaboration around AI for the public good was published Friday. Per the document, multidisciplinary teams from the EU and U.S. have spent more than 100 hours in scientific meetings over the past half-year “discussing how to advance applications of AI in on-going projects and workstreams”.
“The collaboration is making positive strides in a number of areas in relation to challenges like energy optimisation, emergency response, urban reconstruction, and extreme weather and climate forecasting,” it continues, adding: “In the coming months, scientific experts and ecosystems in the EU and the United States intend to continue to advance their collaboration and present innovative research worldwide. This will unlock the power of AI to address global challenges.”
According to the joint statement, there is a desire to expand collaboration efforts in this area by adding more global partners.
“We will continue to explore opportunities with our partners in the United Kingdom, Canada, and Germany in the AI for Development Donor Partnership to accelerate and align our foreign assistance in Africa to support educators, entrepreneurs, and ordinary citizens to harness the promise of AI,” the EU and U.S. note.
On platforms, an area where the EU is enforcing recently passed, wide-ranging legislation — including laws like the Digital Services Act (DSA) and Digital Markets Act — the two sides are united in calling for Big Tech to take protecting “information integrity” seriously.
The joint statement refers to 2024 as “a Pivotal Year for Democratic Resilience”, on account of the number of elections being held around the world. It includes an explicit warning about threats posed by AI-generated information, saying the two sides “share the concern that malign use of AI applications, such as the creation of harmful ‘deepfakes,’ poses new risks, including to further the spread and targeting of foreign information manipulation and interference”.
It goes on to discuss a number of areas of ongoing EU-U.S. cooperation on platform governance and includes a joint call for platforms to do more to support researchers’ access to data — especially for the study of societal risks (something the EU’s DSA makes a legal requirement for larger platforms ).
On e-identity, the statement refers to ongoing collaboration on standards work, adding: “The next phase of this project will focus on identifying potential use cases for transatlantic interoperability and cooperation with a view toward enabling the cross-border use of digital identities and wallets.”
Other areas of cooperation the statement covers include clean energy, quantum and 6G.
EU and US set to announce joint working on AI safety, standards & R&D
We've detected unusual activity from your computer network
To continue, please click the box below to let us know you're not a robot.
Why did this happen?
Please make sure your browser supports JavaScript and cookies and that you are not blocking them from loading. For more information you can review our Terms of Service and Cookie Policy .
For inquiries related to this message please contact our support team and provide the reference ID below.
IMAGES
VIDEO
COMMENTS
OSSI is a comprehensive program of activities to enable and support moving science towards openness, including policy adjustments, supporting open-source software, and enabling cyberinfrastructure. OSSI aims to implement NASA's Strategy for Data Management and Computing for Groundbreaking Science 2019-2024, which was developed through ...
The Open Research Library (ORL) is planned to include all Open Access book content worldwide on one platform for user-friendly discovery, offering a seamless experience navigating more than 20,000 Open Access books.
Opening Science. PLOS is a nonprofit, Open Access publisher empowering researchers to accelerate progress in science and medicine by leading a transformation in research communication. Every country. Every career stage. Every area of science. Hundreds of thousands of researchers choose PLOS to share and discuss their work.
About the directory. DOAJ is a unique and extensive index of diverse open access journals from around the world, driven by a growing community, and is committed to ensuring quality content is freely available online for everyone. DOAJ is committed to keeping its services free of charge, including being indexed, and its data freely available.
Increased citation and usage: Studies have shown that open access articles are viewed and cited more often than articles behind a paywall.. Wider collaboration: Open access publications and data enable researchers to carry out collaborative research on a global scale.. Greater public engagement: Content is available to those who can't access subscription content.
OATD.org aims to be the best possible resource for finding open access graduate theses and dissertations published around the world. Metadata (information about the theses) comes from over 1100 colleges, universities, and research institutions. OATD currently indexes 7,426,620 theses and dissertations. About OATD (our FAQ). Visual OATD.org
It is a challenging task for any research field to screen the literature and determine what needs to be included in a systematic review in a transparent way. A new open source machine learning ...
Reddit also hosts open source research communities, including r/Bellingcat, a community-run subreddit. r/OSINT boasts over 26,000 members, making it an active hub of questions and answers on all things related to the field.. The r/TraceAnObject subreddit is dedicated to bringing together people who want to help EUROPOL with its #TraceAnObject campaign and the FBI's Endangered Child Alert ...
JSTOR hosts a growing number of public collections, including Artstor's Open Access collections, from museums, archives, libraries, and scholars worldwide. Research reports. A curated set of more than 34,000 research reports from more than 140 policy institutes selected with faculty, librarian, and expert input.
Introduction. Recognition and adoption of open research practices is growing, including new policies that increase public access to the academic literature (open access; Björk et al., 2014; Swan et al., 2015) and encourage sharing of data (open data; Heimstädt et al., 2014; Michener, 2015; Stodden et al., 2013), and code (open source; Stodden et al., 2013; Shamir et al., 2013).
The Open Source Intelligence Laboratory (OSI Lab) is an emerging national focal point for advanced research on open source research, methodologies, and tools. What We Do The OSI Lab conducts interdisciplinary and applied research on a wide variety of topics of interest to practitioners as well as scholars.
Open Data. Open Data is a strategy for incorporating research data into the permanent scientific record by releasing it under an Open Access license. Whether data is deposited in a purpose-built repository or published as Supporting Information alongside a research article, Open Data practices ensure that data remains accessible and discoverable.
As open source research is likely to comprise an important component of the human rights investigator's toolbox in the future, this article argues in favour of the institutional buy-in, resourcing, and methodological rigour that it deserves. ... Before presenting the key findings of this study, we define open source information and categorize ...
Make an impact and build your research profile in the open with ScienceOpen. Search and discover relevant research in over 93 million Open Access articles and article records; Share your expertise and get credit by publicly reviewing any article; Publish your poster or preprint and track usage and impact with article- and author-level metrics; Create a topical Collection to advance your ...
The Open Source Software (OSS) development model has emerged as an important competing paradigm to proprietary alternatives; however, insufficient research exists to understand the influence of ...
Introduction. Literature about intelligence studies claims that open source intelligence (OSINT), i.e., intelligence derived from publicly available sources, makes up between 70 and 90 percent of all contemporary intelligence material (Hulnick 2002, 566; Unver 2018, 5).This estimate is not surprising as open-source information increases and more efficient techniques from computer science, data ...
In 2022, the research team within Google's Open Source Programs Office launched an in-depth study to better understand open source developers, contributors, and maintainers. Since Alphabet is a large consumer of and contributor to open source, our primary goals were to investigate the evolving needs and motivations of open source contributors, and to learn how we can best support the ...
Moreover, open-source data visualization frameworks like RAW Graphs can be used to generate a variety of visual models and easily represent data extracted from Wikidata as well as other sources. ... Open-Source, Open-Knowledge: Towards Open-Access Research in Media Studies. In: Schwan, A., Thomson, T. (eds) The Palgrave Handbook of Digital and ...
An Introduction to FDA MyStudies: An Open-Source, Digital Platform to Gather Real World Data for Clinical Trials and Research Studies - May 9, 2019
Support a vibrant, educator-focused Commons. The tens of thousands of open resources on OER Commons are free - and they will be forever - but building communities to support them, developing new collections, and creating infrastructure to grow the open community isn't. Grassroots donations from people like you can help us transform teaching ...
New research on open source distribution from Harvard Business School faculty on issues including crowdsourcing, diaspora-based outsourcing, and the free and open distribution of products into a developer community for modification and redistribution. ... This study investigated the importance of Indian diaspora connections on the oDesk ...
Open access (OA) is a key part of how Oxford University Press (OUP) supports our mission to achieve the widest possible dissemination of high-quality research. We publish rigorously peer-reviewed, world-leading, trusted open access research, upholding the highest standards of publication ethics and integrity. We work closely with our publishing ...
Importance Despite consistent public health recommendations, obesity rates in the US continue to increase. Physical activity recommendations do not account for individual genetic variability, increasing risk of obesity. Objective To use activity, clinical, and genetic data from the All of Us Research Program (AoURP) to explore the association of genetic risk of higher body mass index (BMI ...
DBRX advances the state-of-the-art in efficiency among open models thanks to its fine-grained mixture-of-experts (MoE) architecture. Inference is up to 2x faster than LLaMA2-70B, and DBRX is about 40% of the size of Grok-1 in terms of both total and active parameter-counts. When hosted on Mosaic AI Model Serving, DBRX can generate text at up to ...
A History of the U.S. Army's Foreign Military Studies Office (FMSO) The Foreign Military Studies Office (FMSO), based at Ft. Leavenworth, KS, is part of the U.S. Army's Training and Doctrine Command (TRADOC)'s G-2 element. ... Open source research on foreign perspectives of defense and security issues, emphasizing those topics that are ...
Jack Quach '27 is a beat reporter, covering research and awards, and staff writer for News. He is from San Francisco, CA, and in his free time loves cheering for his hometown sports teams ...
The European Union and United States put out a Friday affirming a desire to increase cooperation over artificial intelligence — including in relation to AI safety and governance — as well as ...
Study suggests it's because their cells are aging faster. By Jonathan Wosen April 7, 2024. Reprints. Human colon cancer cells NIH/NCI Center for Cancer Research.
February 18, 2024 at 6:29 PM PST. Listen. 4:14. Vaccines that protect against severe illness, death and lingering long Covid symptoms from a coronavirus infection were linked to small increases in ...