

Building a Data Lake on AWS: A Comprehensive Guide
by Brad Winett | Jun 8, 2023 | White Papers

Introduction
Definition and components of a data lake, key features and advantages of aws data lakes, common use cases for data lakes on aws, defining objectives and goals, identifying data sources and types, architectural considerations and design patterns, evaluating and selecting aws services for the data lake, creating an aws account and configuring security settings, setting up amazon s3 for data storage , configuring aws glue for data cataloging and etl, integrating amazon athena for serverless querying, optional: adding amazon emr for big data processing , data ingestion methods and best practices , extracting, transforming, and loading (etl) data with aws glue , managing data catalog and metadata with aws glue data catalog , data governance and access control best practices .
- Querying Data with Amazon Athena
Leveraging Amazon QuickSight for Data Visualization
Advanced analytics and machine learning on aws, data lake monitoring best practices .
- Data Lake Performance Optimization Techniques
Backup and Disaster Recovery Strategies
Security and compliance considerations , data lake integration with other aws services , real-time streaming and iot data in the data lake .
- Conclusion
About TrackIt
A data lake is a centralized repository that allows users to store and analyze vast amounts of structured, semi-structured, and unstructured data in its raw form. Unlike traditional data warehouses, data lakes retain data in its original format until it’s required for analysis. This flexibility enables businesses to perform advanced analytics, gain actionable insights, and drive data-driven decision-making.
AWS (Amazon Web Services) provides a comprehensive suite of services that assist in building robust and scalable data lakes on the cloud. This range of services includes storage, data processing, cataloging, analytics, and visualization, making it an ideal platform for building and managing data lakes. Below is a detailed guide that covers various aspects of building a data lake on AWS, from architecture and planning to setting up, ingesting, and managing data. The guide aims to provide readers with a thorough understanding of how to leverage AWS services to build and maintain a reliable data lake.
Understanding Data Lakes
Data lakes consist of three key components: data storage, data catalog, and data analysis. The data storage component typically consists of using Amazon Simple Storage Service (S3) for storing data in its raw format. The data catalog component is usually powered by AWS Glue , a data integration service that helps catalog and prepare data for analysis. The data analysis component often includes services like Amazon Athena and Amazon Elastic MapReduce (EMR) used for efficient querying, analytics, and processing of data.
AWS provides several key features that make it an ideal platform for data lake implementations. These features include scalability, durability, cost-effectiveness, flexibility, security, and seamless integration with other AWS services. Building data lakes on AWS allows companies to handle large volumes of data, ensure data durability through redundancy, and optimize costs by taking advantage of AWS’s pay-as-you-go pricing model.
Common use cases for data lakes include data analytics, business intelligence, machine learning, IoT data analysis, log analysis, fraud detection, and customer behavior analysis. Data lakes provide valuable business insights and drive innovation by ingesting, processing, and analyzing diverse data types from multiple sources.
Planning Your Data Lake on AWS
It is essential to clearly define objectives and goals before building a data lake on AWS. These can include improving data accessibility, enabling self-service analytics, accelerating time-to-insights performance, facilitating data-driven decision-making, and fostering innovation within the organization. Defining clear goals assists in making informed decisions during the planning and implementation phases.
Proper identification of data sources and data types to be ingested into the data lake is crucial. Data sources can include transactional databases, log files, streaming data, social media feeds, sensor data, and more. Understanding the different data types and formats such as structured, semi-structured, or unstructured, helps in the selection of appropriate AWS services for ingestion, processing, and analysis.
Architectural considerations play a vital role in the success of a data lake implementation. The following factors need to be taken into account:
- Data ingestion patterns
- Data transformation requirements
- Data access patterns
- Security and compliance requirements
- Integration with existing systems
AWS provides architectural design patterns and principles that can guide companies in designing a robust and scalable data lake architecture.
AWS offers a diverse array of services that can be leveraged to build a data lake. The selection of services is often reliant on the specific requirements of the implementation. Services such as Amazon S3 for data storage, AWS Glue for data cataloging and ETL, Amazon Athena for serverless querying, and AWS EMR for big data processing are commonly used in data lake implementations. Evaluating and selecting the right combination of services is essential for a successful data lake deployment.
Setting Up Your AWS Data Lake
To begin setting up the AWS data lake, an AWS account is required. During the account setup, it is crucial to configure appropriate security settings, including IAM (Identity and Access Management) policies, security groups, encryption options, and network settings. Security best practices should be followed to ensure data protection and compliance with industry standards.
Amazon S3 serves as the primary data storage layer for the data lake. Essential steps in the setup process include:
- Creating an S3 bucket
- Defining the appropriate access controls
- Encryption settings
- Versioning options
Amazon S3 provides high scalability, durability, and availability, making it an ideal choice for storing large volumes of data.
AWS Glue is a fully-managed extract, transform, and load (ETL) service that simplifies the process of cataloging and preparing data for analysis. Setting up AWS Glue involves four steps:
- Step 1: Creating a data catalog
- Step 2: Defining crawler configurations to automatically discover and catalog data
- Step 3: Creating and running ETL jobs
- Step 4: Managing metadata
AWS Glue enables the transformation of raw data into a queryable and analyzable format.
Amazon Athena is a serverless query service that helps analyze data stored in S3 using standard SQL queries. Setting up Amazon Athena requires three steps:
- Step 1: Defining the database and table schemas (not required if a crawler was run as specified in the previous section)
- Step 2: Configuring query result locations
- Step 3: Granting appropriate permissions for accessing data
Amazon Athena provides a convenient way to interactively query data stored in the data lake without the need for infrastructure provisioning or management.
For scenarios requiring complex data processing, Amazon EMR (Elastic MapReduce) can be integrated into the data lake architecture. Amazon EMR provides a managed big data processing framework that supports popular processing engines such as Apache Spark and Apache Hadoop. Setting up Amazon EMR requires three steps:
- Step 1: Defining cluster configurations
- Step 2: Launching and managing clusters
- Step 3: Executing data processing jobs at scale
Ingesting and Managing Data in the Data Lake
Ingesting data into the data lake can be achieved through several methods, including batch ingestion, streaming ingestion, and direct data integration. AWS provides services such as AWS Data Pipeline , AWS Glue , Amazon AppFlow , and AWS Kinesis to facilitate data ingestion. Best practices for data ingestion include data validation, data compression, error handling, and monitoring.
AWS Glue simplifies the ETL process by automating the extraction, transformation, and loading of data from multiple sources. Glue jobs can be created to do the following:
- Transform raw data into a desired format
- Apply data cleansing and enrichment
- Load transformed data into the data lake.
AWS Glue also provides visual tools and pre-built transformations that simplify the process of building scalable and efficient ETL workflows.
The AWS Glue Data Catalog acts as a centralized metadata repository for the data lake. It stores metadata information such as table definitions, schema details, and data partitions. Managing the data catalog requires two steps:
- Step 1: Configuring metadata databases, tables, and partitions
- Step 2: Ensuring data catalog integrity and consistency
The data catalog enables users to easily discover, explore, and analyze data within the data lake.
Data governance and access control are critical to data lake management. AWS provides several mechanisms for implementing data governance including:
- IAM policies
- S3 bucket policies
- AWS Glue security configurations
Additionally, AWS Lake Formation can play a pivotal role in managing resources and permissions associated with the data lake. Lake Formation simplifies data lake management by providing comprehensive control and oversight. The service helps establish and enforce data access policies, define fine-grained permissions, and manage resource-level permissions efficiently.
One powerful feature offered by AWS Lake Formation is the ability to assign LF (Lake Formation) tags to specific columns or tables. These tags enable partial access control, allowing companies to grant or restrict access based on user requirements. For example, User A can access all tables except the columns labeled with the “sensitive” LF tag. This granular access control provides enhanced data security.
In addition to data governance and access control, implementing encryption mechanisms can also be prioritized to ensure adherence to data privacy regulations.
Analyzing and Visualizing Data in the Data Lake
Querying data with amazon athena .
Amazon Athena enables the querying of data stored in Amazon S3 using standard SQL queries. Users can create tables, define data schemas, and run ad hoc queries against the data lake. Amazon Athena supports multiple data formats, including CSV, JSON, Parquet, and Apache Avro. Query results can be exported to various formats or integrated with other AWS services for further analysis.
Amazon QuickSight is a business intelligence and data visualization service that integrates seamlessly with data lakes on AWS. It allows users to create interactive dashboards, visualizations, and reports using data from the data lake. Setting up Amazon QuickSight requires connecting to the data lake as a data source, defining data transformations, and creating visualizations using a drag-and-drop interface.
AWS provides a range of advanced analytics and machine learning services that can be integrated with the data lake for more sophisticated analysis. The following services can be leveraged:
- Amazon Redshift : Data warehouse used to efficiently store and organize large volumes of data. Redshift can be used to perform complex queries and analyses of data.
- Amazon SageMaker : Cloud machine-learning platform used to build, train, and deploy machine-learning models using the data in the data lake. The trained models help extract valuable insights, make predictions, and automate decision-making processes.
- Amazon Forecast : Time-series forecasting service used to generate accurate forecasts and predictions from historical data stored in the data lake. These forecasts can help businesses optimize inventory management, demand planning, and resource allocation.
Data Lake Maintenance and Monitoring
Monitoring the health and performance of a data lake is crucial to ensuring uninterrupted service. AWS provides services like Amazon CloudWatch , AWS CloudTrail , and AWS Glue DataBrew for monitoring various aspects of the data lake, including resource utilization, data quality, job executions, and data lineage. Implementing proactive monitoring practices helps in detecting issues and optimizing the data lake’s performance.
Data Lake Performance Optimization Techniques
To achieve optimal performance, companies can employ established techniques such as partitioning data, optimizing query performance, and using appropriate compression formats. AWS Glue DataBrew can be used to profile and optimize data quality and structure. Properly configuring and tuning the data lake components and leveraging AWS best practices can significantly enhance overall performance. Files can also be converted into columnar formats such as Parquet or Avro to reduce the number of files to be scanned for analysis and enable cost optimization.
Backup and disaster recovery strategies protect the data lake from data loss and ensure business continuity. AWS provides services and features such as AWS Backup and AWS S3 versioning to create automated backup schedules, define retention policies, and restore data in case of disasters or accidental deletions.
Ensuring data lake security and compliance is critical for any organization running business-critical workloads in the cloud. The following AWS security best practices can be followed to ensure security:
- Implementing encryption mechanisms for data at rest and in transit
- Enabling audit logging
- Regularly updating security configurations.
Compliance requirements such as GDPR or HIPAA should also be considered and addressed to ensure data privacy and regulatory compliance within the data lake.
Additional Data Lake Concepts and Strategies
AWS provides a vast ecosystem of services that can be integrated with the data lake to extend its capabilities. Integration with services like AWS Lambda for serverless computing and AWS Step Functions for workflow orchestration helps build more sophisticated data processing workflows and enhance data lake functionality.
Note: As of June 2023, AWS Step Functions are not well-integrated with AWS Glue. It is currently recommended to use Glue workflows for workflow orchestration.
Integrating real-time streaming data and IoT data into the data lake opens up new possibilities for real-time analytics and insights. AWS services such as Amazon Kinesis and AWS IoT Core facilitate the ingestion and processing of streaming and IoT data. Combining batch and streaming data helps derive valuable real-time insights from the data lake.
Conclusion
Building a data lake on AWS helps unlock the value of data, gain actionable insights, and drive innovation. However, the process of building a data lake on AWS requires thorough planning, architectural considerations, and choosing the right combination of AWS services. Following the comprehensive guide outlined in this article allows companies to take the first steps toward building a robust and scalable data lake on AWS.
Implementing a data lake on AWS can be a complex endeavor that requires expertise in data analytics workflows, architectural design, and AWS services. To ensure a smooth and successful implementation, it is advisable for companies to partner with an AWS Partner like TrackIt that has deep expertise in building data lakes and implementing data analytics solutions.
TrackIt can provide guidance throughout the entire process, from planning and architecture design to implementation and ongoing maintenance. TrackIt’s experience and knowledge in working with AWS services and data analytics workflows can significantly accelerate the development of a robust and efficient data lake.
TrackIt is an Amazon Web Services Advanced Tier Services Partner specializing in cloud management, consulting, and software development solutions based in Marina del Rey, CA.
TrackIt specializes in Modern Software Development, DevOps, Infrastructure-As-Code, Serverless, CI/CD, and Containerization with specialized expertise in Media & Entertainment workflows, High-Performance Computing environments, and data storage.
In addition to providing cloud management, consulting, and modern software development services, TrackIt also provides an open-source AWS cost management tool that allows users to optimize their costs and resources on AWS.
- All Categories Blogs Case Studies Press Releases White Papers
- All Tags ad marker insertion ad markers ai ai video reviewer AI/ML aiml amazon bedrock amazon eks amazon ivs amazon opensearch amazon q amazon rekognition apache airflow archive archiving artificial intelligence athena aurora autodesk aws aws elemental aws glue aws map aws migration aws migration acceleration program aws nuke aws optimization aws security aws shield aws thinkbox deadline aws waf azure azure media services broadcast Case study CI/CD cloud computing cloud migration cloud optimization cloud security cloudformation CMS containerization containers content moderation content monetization cost optimization d2c data data accuracy data analytics data lake data quality data quality assurance data relevance data science data warehouse database ddos attacks ddos cost protection ddos protection deadline deadline. rfdk deepscan Devops digital rights management disaster recovery drm ec2 Ecommerce ecs EKS eks as a product eks blueprints Elasticsearch etl fargate fashion clothing recognition fashion image recognition fsx genai generative ai gke glacier glue HLS offline hpc iac iis website image recongition image upscaling incident management instance optimization instance size key-value kubernetes lambda large language models live remote production live streaming live video LLMs m&e machine learning map assess Media media asset management mediatailor metadata metadata extraction metadata generation migrate to aws migration movie summary generation mysql nimble studio nosql nosql database ods opensearch optimization ott pixelogic real time 3d video redshift reinvent Rekognition resource optimization retail sandbox Serverless sfmt shield advanced shield standard shot detection api sic sinclair software development sony ci sql sql query sre step functions streaming studio in the cloud tagging teradici terraform trackflix unreal engne vector engines video on demand video upscaling vmix vod VOD Pipeline web application firewall well architected windows container windows containers
Implementing a Large AWS Data Lake for Analysis of Heterogeneous Data
C4ADS users were finding it increasingly difficult to sift through the company’s massive database collection.
ClearScale implemented a data lake with an Amazon Virtual Private Cloud (VPC), designed a web-based user interface, and used AWS Lambda and API Gateway to ingest data.
C4ADS’ new solution can scale as needed without compromising security and is able to meet user demands more effectively.
AWS Services
Amazon Virtual Private Cloud (VPC), AWS S3, AWS Lambda, Amazon API Gateway, Amazon CloudWatch, AWS CloudTrail, Amazon DynamoDB
Executive Summary
C4ADS (Center for Advanced Defense Studies) is a nonprofit organization based in Washington DC that is dedicated to providing data-driven analysis and evidence-based reporting on global conflict and transnational security issues. In this pursuit, C4ADS focuses on a variety of issues, including threat finance, transnational organized crime, and proliferation networks.
The Challenge
The world is a complex ecosystem of people, economies, competing interests, and political ambiguity. Being able to track many different events to determine if there are patterns that would warrant a more critical look and analysis is a difficult task, even under the best conditions. With new regional or political developments each day, sometimes even hour by hour, combing through enormous sets of data is challenging; especially when that data is from different sources and in various formats.
C4ADS is tasked with just this sort of activity. Their clients require evidence-based and data-driven analysis concerning global conflict and transnational security issues. With a focus on identifying the drivers and enablers of such conflict, this organization has to be absolutely confident in the analysis and assessments they provide. However, the first step to performing any sort of review requires analysts to comb through extensive records from different sources and formats to compile a list of potential hits.
As C4ADS increased the number of datasets it ingested, new challenges arose, specifically the ability to make use of all the data at its disposal. As more and more data has become available, their analysts were finding it difficult to sift through all of the incoming information in a quick and expedient way. The company approached ClearScale, an AWS Premier Consulting Partner, and wanted to see if there was a way that they could leverage what they did currently by using AWS to assist in making the data more user-friendly.
The ClearScale Solution
The challenge put forth by C4ADS was that a solution had to be implemented quickly, provide the ability to scale as needed, and be extremely secure given the nature of the information they were reviewing. With these three criteria in mind, ClearScale reviewed various designs and approaches that they could develop and implement on AWS.
Data Storage with Data Lake Approach
The biggest challenge was finding a way to aggregate multiple different file formats (such as PDFs, emails, Microsoft Word and Excel files, logs, XML and JSON files) while still allowing C4ADS to perform easy searches within a large data repository. It rapidly became clear that to accomplish the requirements laid out by the client, ClearScale would have to implement a Data Lake approach within an AWS Virtual Private Cloud (VPC). Unlike traditional data warehouse methodologies that require data to conform to a specific set of schema, a data lake allows for any number of data types to be stored and referenced, so long as those data types have a consistent approach to querying and retrieving data.
It was immediately clear that trying to collapse or conform all the various file types that were available into a normalized format would be too resource-intensive. To overcome this, ClearScale chose instead to implement a solution that would tag all uploaded file content with consistent metadata tagging which, in turn, would allow for greater visibility and speedier search results. This automated metadata tagging for each file that was uploaded either manually or via bulk upload would mimic the client’s existing folder structure and schema that they had adopted internally. This approach would ensure that the new solution would be easily understood by analysts that were already familiar with the current operational processes.
Data Flow Model

System Architecture Diagram

Web-Based User Interface (Web UI)
To access and search these records, ClearScale designed and implemented a web-based user interface. This UI was designed to allow for complete management of the data sources — including data upload — beyond simply searching the Data Lake. From a data repository perspective, ClearScale needed to build and deploy a solution that was scalable and reactive to increased demand but also highly secure. To accomplish this, a combination of AWS S3 was used for the storage of the data uploaded, and DynamoDB for the storage of the file metadata; ElasticSearch was used for the robust search querying that was required.
In order to get the data uploaded, ClearScale leveraged AWS Lambda and API Gateway services to properly ingest the data and automate the creation of the file metadata. Both CloudWatch and CloudTrail were also put in place to monitor resource usage and serve as triggering mechanisms to scale the environment as required.
The entire solution was encased in AWS VPC for robust security and Cognito for SAML based authentication. This approach guarantees that the information was behind a robust security layer with additional work done for data to be encrypted both at rest and in transit. It also insured that administrators could grant access to specific document types based on group roles, both for internal and external role types.
UI Welcome Screen

Bulk Indexing — Add and Index an existed S3 Bucket or Folder

Bulk Indexing — Monitoring of Long Time Backend Tasks

Bulk Indexing — Login and Automatic Errors Handling

Multi-tenancy — Agile Access Setup

Metadata — Governance

Cart — Storing and Exploring Results in Personal Cart

The Benefits
The turnaround time from design to delivery to C4ADS was a mere two months, including deployment of the solution in both a Staging and Production environment as well as training for C4ADS staff on how to use the new solution. The first release provided everything that C4ADS originally asked for: it had to be deployed quickly, it had to have the ability to scale as needed, and it had to be highly secure. Launched in October 2017, the solution has already optimized the analysts’ job activities by giving them the tools necessary to do wide-ranging search profiles and aggregate disparate heterogeneous data types.
Later releases will introduce more robust security measures that will allow C4ADS to extend the service out to their partner organizations. It will also provide multi-lingual support and optical character recognition (OCR) technology to aid in identification of important data markers in the data that is uploaded.
There are plenty of challenges in the business and technology landscape. Finding ways to overcome these challenges is what ClearScale does best. By bringing our own development resources to bear on these complex problems, we can design, build, test, and implement a solution in partnership with your organization, thus allowing you to focus on more pressing matters in running your day-to-day operations.
Headquarters
50 California Street Suite 1500 San Francisco, CA 94111
O: 800-591-0442
5450 Thornwood Dr. Suite #L San Jose, CA 95123
O: 1-800-591-0442
7887 East Belleview Avenue Suite 1100 Denver, CO 80111
O: 1-303-209-9966
2942 N 24th St. Suite 114 Phoenix, AZ 85016
O: 1-602-560-1198
165 Broadway 23rd Floor New York, NY 10006
O: 1-646-759-3656
11757 Katy Fwy Suite 1300 Houston, TX 77079
O: 1-281-854-2088
100 King St. West Suite 5600 Toronto, Ontario M5X 1C9
O: 1-416-479-5447
Kraków, Poland
Kącik 4 30-549 Kraków Poland
Why Aptus Data Labs
Aptus Data Labs provides customized data science solutions, an experienced team, and cutting-edge technology to turn data into actionable insights, improve business outcomes and achieve measurable results. We offer ongoing support and maintain the highest security standards to unlock the full potential of your data.
Our Team Of Experts
Our AI/ML Product And Solution Expertise, Combined With Process Automation And Other IT Solutions, Provides Innovative Services Tailored To Your Needs. Optimize Your Business With Our Wide Range Of Services.

Our mission is to help businesses harness the power of data to drive growth and innovation. We provide cutting-edge data and AI solutions that deliver actionable insights and measurable results.

What happens when data-driven practice and advanced analytics competency with AI lead to stronger business outcomes? Organizations get ahead and stay ahead of the curve. That’s exactly how Aptus Data Labs helps the clients by implementing the business solutions here are the case studies for your reference.
- Case Study Data, Cloud, Analytics and AI case studies
Transform Your Business with Our Comprehensive Data Services. Our data science services help businesses extract insights from their data using advanced statistical analysis, machine learning, and data visualization techniques.

- Advisory Services
- Data Engineering & Value Management
- Cloud Solutions
- Artificial Intelligence & Analytics
- Generative AI
- Analytical Modernization & Migrations
- Operationalize data & AI platform
- Production Support
- Hyper Automation
- Robotics Automation
Digital Transformation
Embrace cloud-based infrastructure to enable flexible and scalable data storage, processing, and analysis.
- Data & AI Accelerators
- Industry & Business Focus
Our analytics partners can help you unlock insights from your data and make informed decisions.

- Amazon Web Services
- Google Cloud Platform
- Microsoft Azure
Unlock the power of data science and analytics - explore our blog, case studies, and partner insights.
- White Papers
- Case Studies
Quick contact

Novel Tech Park, #46/4, GB Palya, Near Kudlu Gate, Hosur Main Road, Bengaluru, India, Pin – 560068

+91 8861769911 +91 8861799911

[email protected]

Working Hours
Monday to Friday : 9:30am - 6pm Saturday & Sunday : Closed
Get Direction here

Do you have any query ?
We are a mission-focused team of analytics professionals, solving complex business problems through a data-driven culture and analytical competency with Data Science technologies.
Implemented a distributed data lake architecture and advanced analytics on the AWS cloud platform to reduce IT costs and improve productivity
Revolutionizing Pharma Analytics with AWS Data Lake

About the Client
The client is a multinational pharmaceutical company based in India. Moreover, the client deals in manufacturing and selling active pharmaceutical ingredients and pharmaceutical formulations in India and the US. Considered as one of the most reputed brands in India, the client has expanded with joint ventures and acquisitions in the last two decades.
The Business Challenge
The client wanted to improve and accelerate analytics-driven decisions and reduce the time for data analysis, data analytics, and data reporting on both structured and unstructured data. Furthermore, the client wanted to improve the deviation tracking of mitigation tasks and reduce the system stack cost by enabling an open-source, industrial-grade platform. In addition, the client also wanted to prepare ground and infra for AI/ML and advanced analytics.
Our Solution
We built enterprise data lake architecture and implemented analytics on the AWS platform. Specifically, this solution included AWS data lake architecture for scalable warehouse and AWS data lake architecture for IoT and unstructured data.
The Impact Aptus Data Labs Made
The enterprise data lake architecture on the AWS platform enabled the client to process, analyze, and report both structured and unstructured data quickly with better analytics-driven decisions. Additionally, this solution helped the client to reduce IT costs and improve business performance.
The Business and Technology Approach
Aptus Data Labs used the following process to build enterprise data lake architecture for scalable warehouse and for IoT and unstructured data to resolve the business challenge. The solution was in three stages.
- Carried out a detailed requirement and due diligence study
- Understood the client’s technology stack, infrastructure availability & business operation landscape
- Recommended AWS infrastructure/instance, and AWS services considering scalability, performance, and cost
- Created strategies for data migrations and AI/ML business use
- Installed, configured, and tested the instances & services
- Tested the deliverables platform and automated the process
- Followed the PMBOK project management process and CRISP-DM process for the data analytics solution
The Reference Architecture We Built
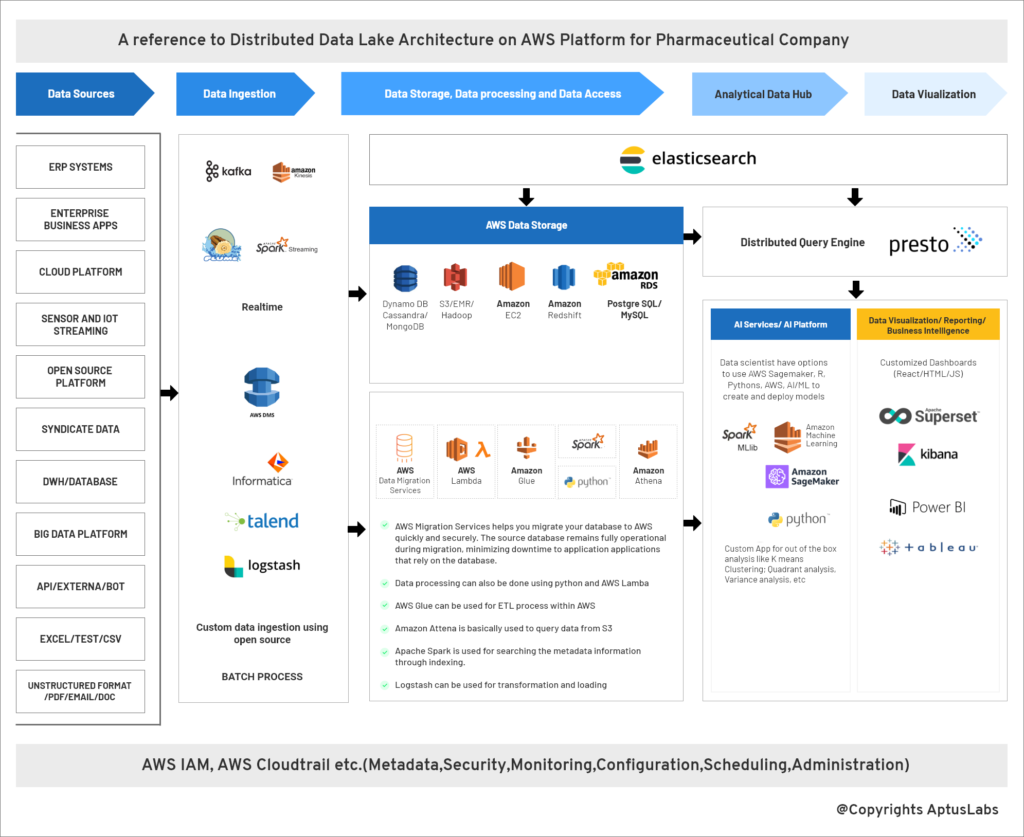
- AWS Glacier
- AWS Glue, ETL, and Data Catalog
- AWS CloudWatch
- AWS CloudTrail
- AWS DynamoDB
- AWS Quick sight
- Amazon Kinesis
- DbVis Software
The Outcome
The new data architecture based on AWS Cloud benefited the client in multiple ways and helped to resolve the business challenge. The benefits in all the three phases were:
- Advanced analytical capabilities-driven on both structured and unstructured data with Enterprise search enabled for any data
- Machine Learning used to drive improvements and productivity
- Demonstrated connectivity to various databases from Presto
- Backed up email and uploaded data to the cloud
- Uploaded IoT data to the cloud
- Established connectivity from R/Python to Cloud Database/S3 using Libraries
- Enabled Presto/AWS Athena for data search or ad-hoc queries
- Migrated Tableau dashboard to Superset or AWS Quicksights or D3.J3
Related Case Studies

Achieving low-latency API-based queries with Mongo DB

Boosting Performance with Apache Spark Migration
Unlock the potential of data science with aptus data labs.
Don't wait to harness the power of data science - contact Aptus Data Labs today and start seeing results.
If you’re looking to take your business to the next level with data science, we invite you to contact us today to schedule a consultation. Our team will work with you to assess your current data landscape and develop a customized solution that will help you gain valuable insights and drive growth.

Our team of experts helps businesses make informed decisions and drive growth through customized solutions. Contact us to learn more about how our services can help your business achieve its goals.
- AptFinTracker
- Saaransh.ai
- Scheduling & Optimization
- Our Services
- Data Engineering & Value Management
- Artificial Intelligence & Analytics
- Analytical Modernization & Migrations
- Operationalize data & AI Platform
- Request a Demo
©2022-23. Aptus Data Labs. All Rights Reserved.
- Privacy Policy
- Terms & Conditions
Case Study: Enterprise data lake on cloud
1CloudHub helped India’s leading television entertainment network bring its scattered big data into a single source of truth, to make advanced analytics affordable.
Cloud Advisory Services
Dc, servers & data, project scope, — data lake architecture design — data transformation and storage in data lake — customized reports in powerbi, about the client.
The client is a leading media production and broadcasting company, subsidiary of a global media conglomerate. They have over 30 television channels, a digital business and a movie production business, reaching over 700 million viewers in India.
Business challenge
As part of their digital strategy, our client wanted to optimise user experience across channels — iOS and Android apps, Fire TV, web, and so on — based on user behaviour and preferences. This required a deeper understanding of customer behavioural patterns across platforms.
Presently, they were using Segment as the tool to collect around 6.5 billion records (20TB of raw data) of behavioural data from their 30 million online viewers every month from across sources.
In order to deliver a user-focussed digital viewing experience, the client needed
- Reliable storage, with protection against data corruption and other types of data losses
- Security against un-authorized data access
- Ease of finding a single record in billions (by efficiently indexing data)
- An advanced analytics engine that can help them derive and visualise meaningful insights from the client’s high volume and variety of data.
- All of this forming their single source of truth.
We, at 1CloudHub, enabled an enterprise data lake for all of the client’s data to reside in one place — preserving accuracy and timeliness of the data.
Leveraging our client’s existing mechanism to collect and feed data into the data lake, we created a pipeline with EMR (Elastic MapReduce) for data crunching or ETL (Extract, Transform, Load) and Power BI for self-service visualisation.
Our approach

Completion and reporting
01. understand.
- In collaboration with the client’s development team, we outlined the volume, velocity, veracity and variety of data.
- We worked with the client’s business teams and domain experts to define reports in Power BI for the 18 use cases the client had identified.
- We mapped data to corresponding reports and planned data transformation.
- Based on these, we designed and architected the data lake and pipeline necessary for Power BI.
- With the client’s sign-off, we deployed the solution on AWS cloud.
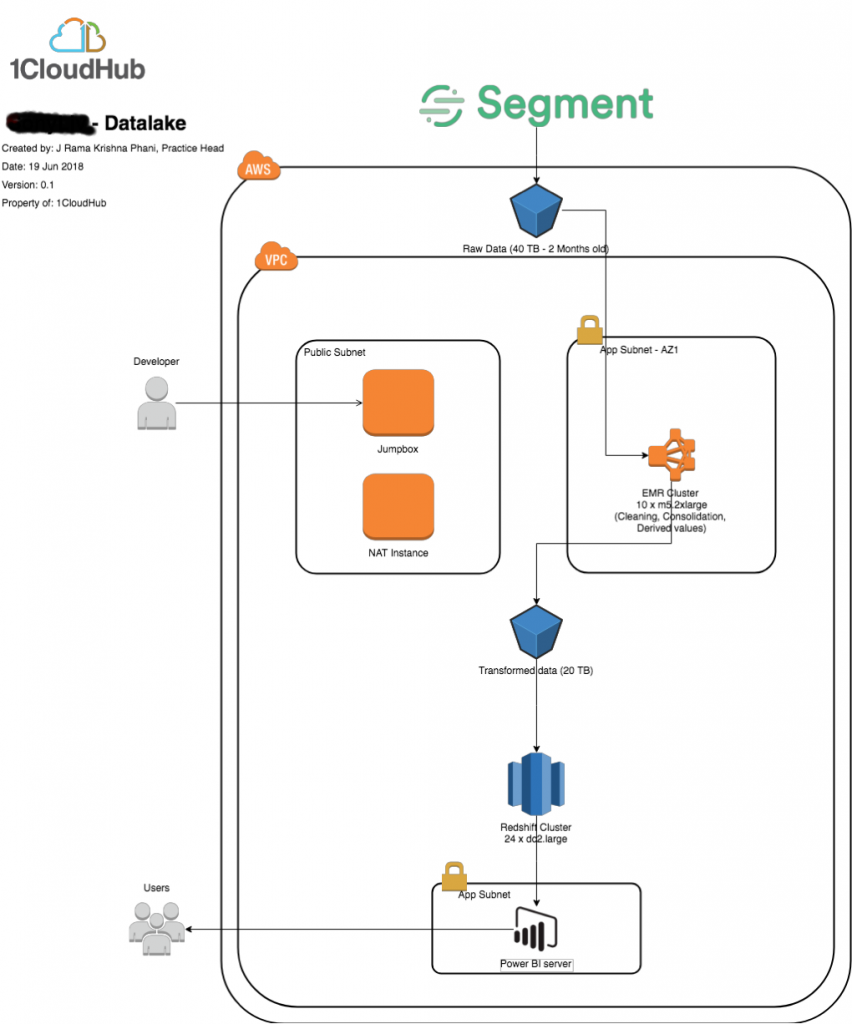
04. Transform
- Once the infrastructure was in place, our data engineering team performed the necessary ETL steps such as cleaning and consolidation to derive value from the raw data.
- We stored this in an S3 bucket as parquet formatted files.
- We imported transformed data as data-marts into AWS Redshift, to be used for Power BI reports.
05. Completion and reporting
- We delivered a summary of findings and recommendations for production deployment to bring the PoC to a meaningful closure.
We enabled advanced analytics for data from up to a year — compared to the 3 months data as per agreement — to deliver the meaningful insights the business teams sought.
We crunched over 12 million records in under an hour, running more than 100 VMs concurrently in a cluster.
We delivered each report at a cost of $70. At this cost, we delivered an excellent price-to-performance ratio, driven by the spot fleet instances we used and our on-demand or pay-as-you-use cloud model.
A similar setup on-premise in a data centre would have cost the client 12,000 times more.
Looking forward
We are delighted to have helped the client create a centralized, analytics-ready repository for their Big Data and look forward to helping them meet their strategic goals using our cloud capabilities.
Latest case studies

Modernization of Document Management System
Industry Financial ServicesOffering Cloud-Driven ModernizationCloud AWSPublished OnDecember 30, 2023 About the client Chola Financial Services, a leading financial institution with a widespread network of branches across India, embarked on a transformative journey to modernize its Document Management System (DMS), GENEX. Teaming up with 1CloudHub, the aim was to migrate GENEX to Amazon Web Services (AWS),[...]

Containerization and Migration of EC2 Applications to Amazon EKS
Industry Financial ServicesOffering EKS MigrationCloud AWSPublished OnDecember 30, 2023 About the client Validus, a leading Singaporean Fintech company, offers a one-stop SME business finance platform specializing in secure local and overseas money transfers. Requirements Validus recognized the benefits of containerization and chose Elastic Kubernetes Service (EKS) for a modernized architecture. The project with 1CloudHub aimed[...]

Elevating Financial Operations with AWS Migration
Industry Financial ServicesOffering MigrationCloud AWSPublished OnDecember 30, 2023 About the client Five Star Business Finance is exploring options on AWS cloud as part of the data centre exit strategy. They currently have challenges of scale and availability. This is due to lack of app environment segregation (Non-Prod and Prod), and co-hosting of multiple applications on[...]

Banking Infrastructure Migration to AWS: Achieving Scalability, Security, and Efficiency with 1CloudHub
Industry Financial ServicesOffering Cloud MigrationCloud AWSPublished OnDecember 30, 2023 About the client Orange Retail Finance India Pvt Ltd, a leading non-banking finance company certified by the Reserve Bank of India, sought to modernize its operations by migrating its on-premise infrastructure to the cloud. Requirements Orange Retail Finance needed to migrate critical banking applications to AWS,[...]

Enhancing E-Commerce Platforms with Image Processing Capabilities
Explore a successful e-commerce transformation with AWS and 1CloudHub. Learn how AWS Lambda-powered image processing optimizes scalability, reduces costs, and accelerates time-to-market.

Migrate and Modernize the MSSQL on RDS to PostgreSQL on Aurora (Babelfish) Using DMS
We helped to Migrate and Modernize the MSSQL on RDS to PostgreSQL on Aurora (Babelfish) Using DMS

Migrate from DB on Amazon EC2 to Amazon RDS for MySQL with HA using AWS DMS for Nalli E-Commerce Platform
We helped our top E-commerce platform customer to Migrate from DB on Amazon EC2 to Amazon RDS for MySQL with HA using AWS DMS

Migrate from MySQL on Amazon EC2 to Amazon RDS for MySQL
We helped our top customer in migrating from MySQL on Amazon EC2 to Amazon RDS for MySQL

DB Modernization MS SQL on RDS > PostgreSQL on Aurora
We helped our top customer in DB Modernization MS SQL on RDS > PostgreSQL on Aurora

AWS Well-Architected Review For A Retail NBFC
1CloudHub helped a top Retail NBFC by conducting Well-Architected Review For Their Applications

Cost effective, Scalable Cloud Solution for connected vehicle telematics
1CloudHub helped the automotive manufacturer with a Cost-effective, Scalable Cloud Solution for Connected vehicle telematics

Migrating LOB workloads for NBFC
1CloudHub helped a leading Investment and Finance Company in Migration.

E-Commerce Platform Migration to AWS Cloud
1CloudHub helped an Indian wardrobe store and silk saree emporium in migration

Application Modernization and Migration of Enterprise Workloads
1CloudHub helped a leading global shipping giant to organize shadow IT systems and bring in centralized governance.

Financial Services – Application Modernization to enhance agility & scalability
1CloudHub helped a Investment and Finance Company Limited in India in DevOps Implementation.

Winning the DevOps Way
1CloudHub helped a leading assessment and learning product firm in DevOps Implementation.

Application and Database Modernization along with CI/CD
1CloudHub helped the third largest Shipping and transportation company in DevOps Implementation.

Using DevOps To Keep An Edge
1CloudHub helped an Indian wardrobe store and silk saree emporium in DevOps Implementation.

Migration of large Windows landscape from On-prem Data center to AWS
Windows Workload Migration from On-Prem to AWS with Zero Down Time

Migration of e-Commerce portal from On-prem Data Center to AWS
1CloudHub helped the online shopping store in migrating from on-premises to AWS, reducing downtime and ensuring end-user security.

DevOps Implementation- Automated Deployment Process
Migrated the entire IT infrastructure – ERP & Financial systems – from OnPrem to Cloud without impacting the business which needs the systems to be running 24 x 7

Data Lake on AWS For Seats and Revenue Analytics
Data lake was successfully created by ingesting data from various sources which enabled the customer to perform seat and revenue analysis

IaC Automation & Data Generation
We at 1CloudHub successfully containerized an identified application, optimizing the cloud resources used by the application, for continuous delivery.

Migration of IT Infrastructure from OnPrem to Google Cloud

Leveraging AI/ML(Personalization) to Increase Checkout Ratio & Rationalize Discount Coupons for a leading B2C E-Ticketing Platform
Increase in Checkout Ratio by 2 basis points Decrease in cost to business by categorizing into 6 categories

App Cloud Maturity Enhancement (Using Containers)

Pro-Active 24×7 Managed Services
1CloudHub manages IT assets for India’s largest and no. 1 stem banking company to support their business continuity

CI/CD Application Deployment Process using Serverless Technology
1CloudHub helped building CI/CD pipelines for 20+ active and critical applications.

Knowledge Portal on AWS for a Leading Corporate Compliance in India
We helped one of the largest Corporate Compliance in India to create knowledge portal on AWS, cost effectively.

Migration of E-commerce Portal from OnPrem to AWS Cloud
Seamlessly migrated 10+ VMs to AWS with zero downtime. 5% savings on Infra spend by Right sizing and cost optimization

Migration of DNB platform for SMEs from an existing hyper cloud platform to Azure
Seamlessly migrated the DNB platform from an existing hyper cloud platform to Azure to support a transaction of INR 75 Cr every day

Personalize fitment to determine AI/ML driven Solution Roadmap for a leading B2C E-Ticketing Platform
1CloudHub helped one of India’s largest online e-ticketing company in Data Acquisition, Data Validation, Fitment to Personalize services and Roadmap with future insights.

SIFT Customer Engagement Platform on Cloud
We envisioned, designed and implemented cloud transformation strategy for APAC’s largest Customer Engagement Product company in a span of 4 weeks. We look forward to working with the client again on more cloud transformation projects that will help them achieve their business goals.

Digital Asset Management Platform
We helped one of the pre-school in India to build a Digital Asset Management platform which enable the organization to manage video files by tagging the assets based on their metadata for efficient search and retrieval.

DataLake and Analytics for Digital Exam Platform on AWS
We were able to unify multi source(including on-premise) data sets, created future proof analytical platform for delivering a hierarchical student performance reports.

SAP S/4 HANA Functional Enhancement & Implementation
We are glad to have played a key enabling role in helping customer to build a pricing functionality within SAP S/4 to move away from excel/manual pricing process for accurate and real-time business reporting

Case Study : Migration of popular news sites to Cloud with Zero Downtime
We at 1CloudHub successfully migrated one of India’s established news site to cloud seamlessly while optimizing the infra for cost and performance.

Case Study : Hospital Information System (HIS) set-up on Cloud
We helped one of India’s largest Health care provider, to set up their HIS application in a short period of 3 weeks

Case Study: SAP ECC Migration on Azure Cloud for a Health Care Manufacturer
Fast tracked On-Premise SAP ECC Dev, QA & Prod Landscapes to Azure while ensuring a smooth cutover within an hour.

Case Study : SAP S/4 HANA Greenfield Infra Implementation
We helped one of the largest security service company in Singapore to adopt their first cloud application (SAP S/4 HANA) in Azure cloud

Case Study: Big Data on Cloud
1CloudHub helped one of the world’s largest manufacturers of commercial vehicles deploy a cost-effective, scalable cloud solution for their Big Data.

Case Study: DR for geographically diverse SAP
We helped one of the world’s largest paper, pulp, and packaging companies, a first-time cloud adaptor, to establish a unified DR site.

Case Study: RPA on cloud
We helped a global shipping leader achieve on-demand scaling through a multi-geography accessible RPA solution.

Case Study: Multi-cloud strategy
We helped India’s leading integrated healthcare delivery service provider design and implement their HIS on cloud.

Case Study: Enterprise app migration
We helped a global leader in supply chain services efficiently and effectively host their applications on the cloud during a period of business transformation.

Case Study: DC backup and DR
We helped India’s leading television entertainment network architect, deploy, and manage their data backup system.

Case Study: SAP on cloud
We helped one of the world’s largest shipping companies increase the future load-capacity of their mission-critical SAP CRM, at significantly lower costs.

Case Study: DC and app migration
We envisioned, designed and implemented an end-to-end cloud transformation strategy for a leading gaming company in Malaysia.
Sharing is caring!


HyperAccel Case Study
HyperAccel Taps AMD Accelerator Card and FPGAs for New AI Inference Server
AMD Alveo™ U55C Accelerator Card and AMD Virtex™ UltraScale+™ FPGAs Help HyperAccel’s Orion Servers Accelerate Transformer-Based Large Language Models

Get in touch with a business expert and find out what AMD can do for you.
Related case studies.

PQR Offers Next-Gen IT Services with AMD Pensando™ DPUs
April 29, 2024

CDW StudioCloud quadruples core density with AMD EPYC™ CPUs
March 01, 2024

AMD Market Intelligence Expands Data Analytics Capabilities
July 19, 2023

Gaining Exceptional Data Center Efficiency with AMD EPYC™
July 18, 2023
IMAGES
VIDEO
COMMENTS
"However, having data in different systems or traditional data warehouses made it very complex," says Valderrama. Coca-Cola Andina's challenge was to collect all relevant information on the company, customers, logistics, coverage, and assets together within a single accurate source. This led the company to decide to build a data lake.
Amazon S3 hosts more than 10,000 data lakes and we wanted to showcase some recent case studies featuring customers of various industries and use cases that have built a data lake on Amazon S3 to gain value from their data. Siemens Handles 60,000 Cyber Threats per Second Using AWS Machine Learning. Siemens Cyber Defense Center (CDC) uses Amazon ...
BMW Group Uses AWS-Based Data Lake to Unlock the Power of Data. BMW Group uses AWS to process 10 TB of data daily from 1.2 million vehicles, create a voice-activated personal in-vehicle assistant, and derive real-time insights from vehicle and customer telemetry data. The organization, based in Germany, is a leading manufacturer of premium ...
Featured data lake Partners AWS case study: FINRA ... When you host your data lake on AWS, you gain access to a highly secure cloud infrastructure and a deep suite of security offerings like Amazon Macie, a security service that uses machine learning to automatically discover, classify, and protect sensitive data. ...
Data Ingestion: The first step in building a data lake is ingesting data from various sources. AWS offers multiple options for data ingestion, such as AWS Glue, AWS Data Pipeline, AWS Database ...
The data lake reference architecture in this guide leverages the different features and capabilities provided by AWS Lake Formation. The guide is intended for teams that are responsible for designing data lakes on the AWS Cloud, including enterprise data architects, data platform architects, designers, or data domain leads.
• What is a data lake? • Truly connected Upstream operations • Rivers of insight at every stage of Downstream • The AWS vision for maintaining stability in uncertain times • Building a data lake on AWS • Featured data lake partners • Case study: Royal Dutch Shell • Case study: Woodside • Getting started
S3 for storage. For example, a manufacturing site's data collection use case could require historical data to be ingested for machine history data as XML files, event data as JSON files, and purchase data from a relational database. This use case could also require that all three data sources must be joined.
AWS Glue is a fully-managed extract, transform, and load (ETL) service that simplifies the process of cataloging and preparing data for analysis. Setting up AWS Glue involves four steps: Step 1: Creating a data catalog. Step 2: Defining crawler configurations to automatically discover and catalog data.
AWS delivers the breadth and depth of services to build a secure, scalable, comprehensive, and cost-effective data lake solution. You can use the AWS services to ingest, store, find, process, and analyze data from a wide variety of sources. This whitepaper provides architectural best practices to technology roles, such as chief technology ...
This UI was designed to allow for complete management of the data sources — including data upload — beyond simply searching the Data Lake. From a data repository perspective, ClearScale needed to build and deploy a solution that was scalable and reactive to increased demand but also highly secure. To accomplish this, a combination of AWS S3 ...
With AWS' portfolio of data lakes and analytics services, it has never been easier and more cost effective for customers to collect, store, analyze and share insights to meet their business needs. AWS provides the most secure, scalable, comprehensive, and cost-effective portfolio of services that enable customers to build their data lake in the cloud, analyze all their data, including data ...
The impact. Visualize and transform data into insights and tangible actions. Access and security control to improve data transparency. Connect cross-function data assets. Enable data-driven decision-making process. Robust platform to support data and analytics requirements. Re-imagine your connection with customers.
Data Lake. The first part of this case study is the Data Lake. A Data Lake is a repository where data from multiple sources is stored. It allows for working with structured and unstructured data. In this case study, the Data Lake is used as a staging area allowing for centralizing all different data sources.
The Impact Aptus Data Labs Made. The enterprise data lake architecture on the AWS platform enabled the client to process, analyze, and report both structured and unstructured data quickly with better analytics-driven decisions. Additionally, this solution helped the client to reduce IT costs and improve business performance.
Start here with this package of real-world use cases you can tackle right away and line-by-line detail in example notebooks. This starter kit contains 3 resources: Demo: Databricks on AWS Cloud Integrations: Learn how to connect to EC2, S3, Glue and IAM, ingest Kinesis streams in Delta Lake and integrate Redshift and QuickSight.
Call us at 619.780.6100. Email us at [email protected]. Fill out our contact form. Read our customer case studies. See how SMBs leverage AWS data lakes for advanced analytics. Explore use cases, storage solutions, and data-driven decision-making. Contact us today!
Cost factors. Depending on the services you choose, the primary cost factors are: Storage - These are the costs you pay for storing your raw data as it arrives. Data transfer - These are the costs you pay for moving the data. Costs can be either bandwidth charges, leased line, or offline transfer.
Organizations of all sizes across all industries are transforming their businesses and delivering on their missions every day using AWS. Contact our experts and start your own AWS journey today. Contact Sales. Learn how organizations of all sizes use AWS to increase agility, lower costs, and accelerate innovation in the cloud.
Solution. We, at 1CloudHub, enabled an enterprise data lake for all of the client's data to reside in one place — preserving accuracy and timeliness of the data. Leveraging our client's existing mechanism to collect and feed data into the data lake, we created a pipeline with EMR (Elastic MapReduce) for data crunching or ETL (Extract ...
Real-World Case Studies. To gain a deeper understanding of how AWS Data Lakes and Data Warehouses are employed in practice, let's examine two real-world case studies showcasing their application in different industries and use cases. Case 1: AWS Data Lake for Customer Behavior Analysis
Your data lake customers need to be agile. They want their projects to either quickly succeed or fail fast and cheaply. The data lake solution on AWS has been designed to solve these problems by managing metadata alongside the data. You can use this to provide a rich description of the data you are storing.
HyperAccel Case Study. HyperAccel Taps AMD Accelerator Card and FPGAs for New AI Inference Server. AMD Alveo™ U55C Accelerator Card and AMD Virtex™ UltraScale+™ FPGAs Help HyperAccel's Orion Servers Accelerate Transformer-Based Large Language Models
Data movement. Data lakes allow you to import any amount of data that can come in real-time. Data is collected from multiple sources, and moved into the data lake in its original format. This process allows you to scale to data of any size, while saving time of defining data structures, schema, and transformations.
The impact of lake water level reduction was assessed by categorizing data into periods of normal lake conditions (1986-1995) and water level reduction (1996-2017). ... Carla S.S. Ferreira, and Zahra Kalantari. 2024. "Investigating the Impact of Large Lakes on Local Precipitation: Case Study of Lake Urmia, Iran" Water 16, no. 9: 1250. https ...
Amazon Security Lake automatically centralizes security data from Amazon Web Services (AWS) environments, software-as-a-service (SaaS) providers, and both on-premises and cloud sources into a purpose-built data lake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire ...