- Contact Tracing
- Pandemic Data Initiative
- Events & News
- Tracking Home
- Data in Motion
- Tracking FAQ

JHU has stopped collecting data as of
After three years of around-the-clock tracking of COVID-19 data from...
Follow global cases and trends. Updated daily.
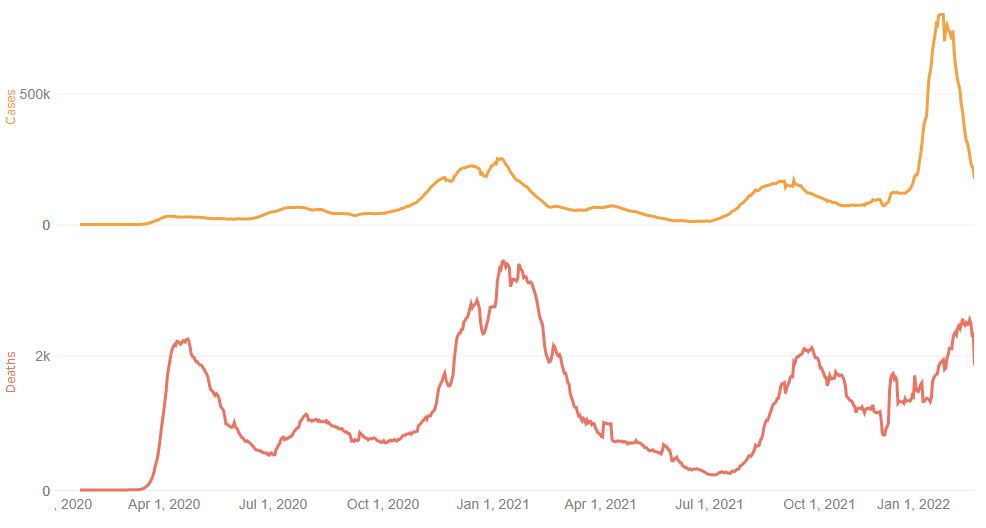
U.S. Trends
Trace U.S. Pandemic Timelines
Compare cases, deaths and more since 2020 and for last 90 days.
International Vaccines
View Worldwide Vaccinations
See where over 4 billion vaccinated people are located.
Tracking Covid
Explore critical data
Examine the pandemic through a variety of demographic lenses: age, race, ethnicity, and gender.
U.S. State Data Availability
Which states have released breakdowns of Covid-19 data by race?
Visual representations of released state data.
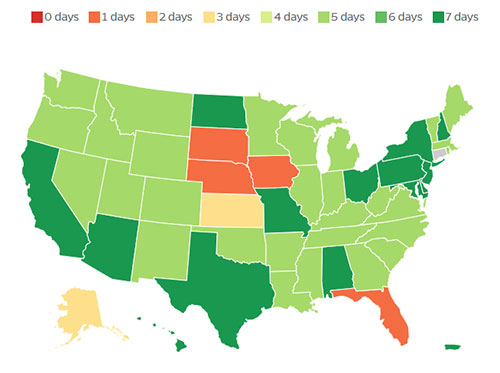
Reporting Frequencies
State Reporting Frequencies
Compare the various frequencies U.S. states employ for reporting on pandemic data. States are shifting their reporting to different cadences, which impacts the ability to spot timely trends.
The Search For Covid-19 Variants
Sequencing the genome of SARS-CoV-2 allows scientists to identify emerging variants
Variant surveillance helps determine if emerging mutations are rendering the virus more contagious or resistant to existing vaccines and medicines.
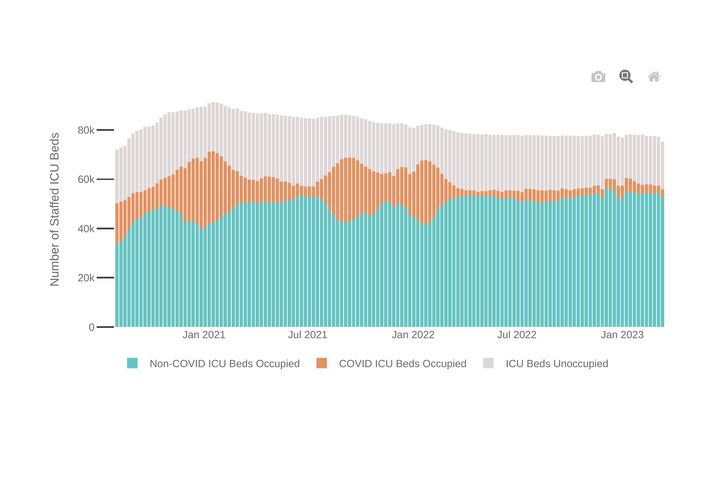
Hospitalized Patients
Examine U.S. Hospital Capacity
Review 7-day trends in hospitalizations of COVID patients.
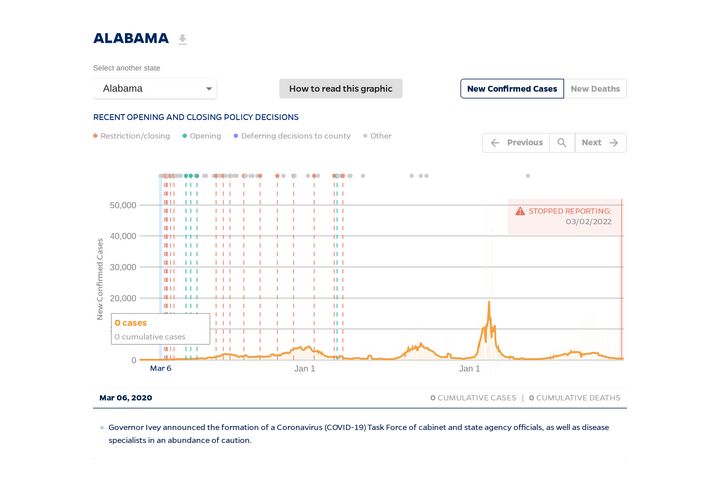
State Timeline
Timeline of COVID-19 policies, cases, and deaths in your state
A look at how social distancing measures may have influenced trends in COVID-19 cases and deaths
New Cases of COVID-19 in US States
Track COVID-19 Trends Across the U.S.
See if new cases are rising or declining as states reopen.
Explore Global Case Trends
Track daily reported infections in hardest hit nations.
Hubei Timeline
How did events unfold in Hubei, China?
Major events and actions taken in Hubei Province at the start of the outbreak.
Animated Maps
Where are COVID-19 cases increasing?
Animations depicting daily confirmed new cases and cumulative cases.
Cumulative Cases
How is the outbreak growing?
Cumulative confirmed cases and deaths for the 20 most affected countries over time.
COVID Deaths
Compare Mortality Rates
Examine how fatalities differ by country.
Testing Trends: Map
Chart New Confirmed Cases
View state-by-state changes in infections per 100,000 people.
View Weekly Case Trends
Examine how infections fluctuate state-by-state.
Latest News & Resources
news | May 24, 2022
ABC News: Pandemic-weary Americans plan for summer despite COVID surge
A COVID-19 surge is underway that is starting to cause disruptions as the school year wraps up and Americans prepare for summer vacations.
news | May 18, 2022
MarketWatch: U.S. officially surpasses 1 million COVID-19 deaths
The U.S. has officially surpassed 1 million deaths from COVID-19, according to data Tuesday from John Hopkins University.
news | April 12, 2022
The New York Times: The world surpasses half a billion known coronavirus cases, amid concerns about testing.
The coronavirus is continuing to stalk the world at an astonishing clip, racing past a grim succession of pandemic milestones in 2022.
news | February 22, 2022
CNBC: COVID infections plummet 90% from U.S. pandemic high, states lift mask mandates
U.S. health officials are optimistic, albeit cautiously, the country has turned the corner on the unprecedented wave of infection caused by the Omicron COVID variant as new cases plummet 90% from a pandemic record set just five weeks ago.
news | February 8, 2022
The Washington Post: COVID deaths highest in a year as Omicron targets the unvaccinated and elderly
Though considered milder than other coronavirus variants, Omicron has infected so many people that it has driven the number of daily deaths beyond where it was last spring, before vaccines were widely available.
news | February 7, 2022
CNET: How the Omicron variant differs from Delta
While the average daily rate of COVID-19 cases is falling in the US, deaths are not.
experts | February 4, 2022
NPR: The U.S. has reached 900,000 deaths from COVID-19
The U.S. has hit more than 900,000 deaths from COVID-19 — yet another once-unimaginable new toll.
experts | February 2, 2022
PBS Newshour: Why the COVID death rate in the U.S. is so much higher than other wealthy nations
More than two years into this pandemic, the United States death toll is the highest in the world.
news | February 1, 2022
CNBC: U.S. COVID fatalities reach highest level in a year as Omicron cases subside
The U.S. death toll from COVID rose to an average of more than 2,400 fatalities per day over the previous seven days.
news | January 27, 2022
U.S. News & World Report: Endemic, ‘new normal’ chatter intensifies as U.S. coronavirus cases start to decline
With increased levels of immunity due to vaccines and the massive number of infections caused by Omicron, talks of whether the U.S. is approaching a “new normal” are intensifying.
news | January 20, 2022
CNBC: Omicron might be the worst COVID gets when it comes to transmissibility, experts predict
Some experts say that when it comes to contagiousness, Omicron could be the “most transmissible the virus can get.”
Advisory Board: Has Omicron peaked? Yes – and no.
New data suggests the Omicron surge has peaked nationwide and cases are now starting to decline.
- Research article
- Open access
- Published: 04 June 2021
Coronavirus disease (COVID-19) pandemic: an overview of systematic reviews
- Israel Júnior Borges do Nascimento 1 , 2 ,
- Dónal P. O’Mathúna 3 , 4 ,
- Thilo Caspar von Groote 5 ,
- Hebatullah Mohamed Abdulazeem 6 ,
- Ishanka Weerasekara 7 , 8 ,
- Ana Marusic 9 ,
- Livia Puljak ORCID: orcid.org/0000-0002-8467-6061 10 ,
- Vinicius Tassoni Civile 11 ,
- Irena Zakarija-Grkovic 9 ,
- Tina Poklepovic Pericic 9 ,
- Alvaro Nagib Atallah 11 ,
- Santino Filoso 12 ,
- Nicola Luigi Bragazzi 13 &
- Milena Soriano Marcolino 1
On behalf of the International Network of Coronavirus Disease 2019 (InterNetCOVID-19)
BMC Infectious Diseases volume 21 , Article number: 525 ( 2021 ) Cite this article
16k Accesses
28 Citations
13 Altmetric
Metrics details
Navigating the rapidly growing body of scientific literature on the SARS-CoV-2 pandemic is challenging, and ongoing critical appraisal of this output is essential. We aimed to summarize and critically appraise systematic reviews of coronavirus disease (COVID-19) in humans that were available at the beginning of the pandemic.
Nine databases (Medline, EMBASE, Cochrane Library, CINAHL, Web of Sciences, PDQ-Evidence, WHO’s Global Research, LILACS, and Epistemonikos) were searched from December 1, 2019, to March 24, 2020. Systematic reviews analyzing primary studies of COVID-19 were included. Two authors independently undertook screening, selection, extraction (data on clinical symptoms, prevalence, pharmacological and non-pharmacological interventions, diagnostic test assessment, laboratory, and radiological findings), and quality assessment (AMSTAR 2). A meta-analysis was performed of the prevalence of clinical outcomes.
Eighteen systematic reviews were included; one was empty (did not identify any relevant study). Using AMSTAR 2, confidence in the results of all 18 reviews was rated as “critically low”. Identified symptoms of COVID-19 were (range values of point estimates): fever (82–95%), cough with or without sputum (58–72%), dyspnea (26–59%), myalgia or muscle fatigue (29–51%), sore throat (10–13%), headache (8–12%) and gastrointestinal complaints (5–9%). Severe symptoms were more common in men. Elevated C-reactive protein and lactate dehydrogenase, and slightly elevated aspartate and alanine aminotransferase, were commonly described. Thrombocytopenia and elevated levels of procalcitonin and cardiac troponin I were associated with severe disease. A frequent finding on chest imaging was uni- or bilateral multilobar ground-glass opacity. A single review investigated the impact of medication (chloroquine) but found no verifiable clinical data. All-cause mortality ranged from 0.3 to 13.9%.
Conclusions
In this overview of systematic reviews, we analyzed evidence from the first 18 systematic reviews that were published after the emergence of COVID-19. However, confidence in the results of all reviews was “critically low”. Thus, systematic reviews that were published early on in the pandemic were of questionable usefulness. Even during public health emergencies, studies and systematic reviews should adhere to established methodological standards.
Peer Review reports
The spread of the “Severe Acute Respiratory Coronavirus 2” (SARS-CoV-2), the causal agent of COVID-19, was characterized as a pandemic by the World Health Organization (WHO) in March 2020 and has triggered an international public health emergency [ 1 ]. The numbers of confirmed cases and deaths due to COVID-19 are rapidly escalating, counting in millions [ 2 ], causing massive economic strain, and escalating healthcare and public health expenses [ 3 , 4 ].
The research community has responded by publishing an impressive number of scientific reports related to COVID-19. The world was alerted to the new disease at the beginning of 2020 [ 1 ], and by mid-March 2020, more than 2000 articles had been published on COVID-19 in scholarly journals, with 25% of them containing original data [ 5 ]. The living map of COVID-19 evidence, curated by the Evidence for Policy and Practice Information and Co-ordinating Centre (EPPI-Centre), contained more than 40,000 records by February 2021 [ 6 ]. More than 100,000 records on PubMed were labeled as “SARS-CoV-2 literature, sequence, and clinical content” by February 2021 [ 7 ].
Due to publication speed, the research community has voiced concerns regarding the quality and reproducibility of evidence produced during the COVID-19 pandemic, warning of the potential damaging approach of “publish first, retract later” [ 8 ]. It appears that these concerns are not unfounded, as it has been reported that COVID-19 articles were overrepresented in the pool of retracted articles in 2020 [ 9 ]. These concerns about inadequate evidence are of major importance because they can lead to poor clinical practice and inappropriate policies [ 10 ].
Systematic reviews are a cornerstone of today’s evidence-informed decision-making. By synthesizing all relevant evidence regarding a particular topic, systematic reviews reflect the current scientific knowledge. Systematic reviews are considered to be at the highest level in the hierarchy of evidence and should be used to make informed decisions. However, with high numbers of systematic reviews of different scope and methodological quality being published, overviews of multiple systematic reviews that assess their methodological quality are essential [ 11 , 12 , 13 ]. An overview of systematic reviews helps identify and organize the literature and highlights areas of priority in decision-making.
In this overview of systematic reviews, we aimed to summarize and critically appraise systematic reviews of coronavirus disease (COVID-19) in humans that were available at the beginning of the pandemic.
Methodology
Research question.
This overview’s primary objective was to summarize and critically appraise systematic reviews that assessed any type of primary clinical data from patients infected with SARS-CoV-2. Our research question was purposefully broad because we wanted to analyze as many systematic reviews as possible that were available early following the COVID-19 outbreak.
Study design
We conducted an overview of systematic reviews. The idea for this overview originated in a protocol for a systematic review submitted to PROSPERO (CRD42020170623), which indicated a plan to conduct an overview.
Overviews of systematic reviews use explicit and systematic methods for searching and identifying multiple systematic reviews addressing related research questions in the same field to extract and analyze evidence across important outcomes. Overviews of systematic reviews are in principle similar to systematic reviews of interventions, but the unit of analysis is a systematic review [ 14 , 15 , 16 ].
We used the overview methodology instead of other evidence synthesis methods to allow us to collate and appraise multiple systematic reviews on this topic, and to extract and analyze their results across relevant topics [ 17 ]. The overview and meta-analysis of systematic reviews allowed us to investigate the methodological quality of included studies, summarize results, and identify specific areas of available or limited evidence, thereby strengthening the current understanding of this novel disease and guiding future research [ 13 ].
A reporting guideline for overviews of reviews is currently under development, i.e., Preferred Reporting Items for Overviews of Reviews (PRIOR) [ 18 ]. As the PRIOR checklist is still not published, this study was reported following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2009 statement [ 19 ]. The methodology used in this review was adapted from the Cochrane Handbook for Systematic Reviews of Interventions and also followed established methodological considerations for analyzing existing systematic reviews [ 14 ].
Approval of a research ethics committee was not necessary as the study analyzed only publicly available articles.
Eligibility criteria
Systematic reviews were included if they analyzed primary data from patients infected with SARS-CoV-2 as confirmed by RT-PCR or another pre-specified diagnostic technique. Eligible reviews covered all topics related to COVID-19 including, but not limited to, those that reported clinical symptoms, diagnostic methods, therapeutic interventions, laboratory findings, or radiological results. Both full manuscripts and abbreviated versions, such as letters, were eligible.
No restrictions were imposed on the design of the primary studies included within the systematic reviews, the last search date, whether the review included meta-analyses or language. Reviews related to SARS-CoV-2 and other coronaviruses were eligible, but from those reviews, we analyzed only data related to SARS-CoV-2.
No consensus definition exists for a systematic review [ 20 ], and debates continue about the defining characteristics of a systematic review [ 21 ]. Cochrane’s guidance for overviews of reviews recommends setting pre-established criteria for making decisions around inclusion [ 14 ]. That is supported by a recent scoping review about guidance for overviews of systematic reviews [ 22 ].
Thus, for this study, we defined a systematic review as a research report which searched for primary research studies on a specific topic using an explicit search strategy, had a detailed description of the methods with explicit inclusion criteria provided, and provided a summary of the included studies either in narrative or quantitative format (such as a meta-analysis). Cochrane and non-Cochrane systematic reviews were considered eligible for inclusion, with or without meta-analysis, and regardless of the study design, language restriction and methodology of the included primary studies. To be eligible for inclusion, reviews had to be clearly analyzing data related to SARS-CoV-2 (associated or not with other viruses). We excluded narrative reviews without those characteristics as these are less likely to be replicable and are more prone to bias.
Scoping reviews and rapid reviews were eligible for inclusion in this overview if they met our pre-defined inclusion criteria noted above. We included reviews that addressed SARS-CoV-2 and other coronaviruses if they reported separate data regarding SARS-CoV-2.
Information sources
Nine databases were searched for eligible records published between December 1, 2019, and March 24, 2020: Cochrane Database of Systematic Reviews via Cochrane Library, PubMed, EMBASE, CINAHL (Cumulative Index to Nursing and Allied Health Literature), Web of Sciences, LILACS (Latin American and Caribbean Health Sciences Literature), PDQ-Evidence, WHO’s Global Research on Coronavirus Disease (COVID-19), and Epistemonikos.
The comprehensive search strategy for each database is provided in Additional file 1 and was designed and conducted in collaboration with an information specialist. All retrieved records were primarily processed in EndNote, where duplicates were removed, and records were then imported into the Covidence platform [ 23 ]. In addition to database searches, we screened reference lists of reviews included after screening records retrieved via databases.
Study selection
All searches, screening of titles and abstracts, and record selection, were performed independently by two investigators using the Covidence platform [ 23 ]. Articles deemed potentially eligible were retrieved for full-text screening carried out independently by two investigators. Discrepancies at all stages were resolved by consensus. During the screening, records published in languages other than English were translated by a native/fluent speaker.
Data collection process
We custom designed a data extraction table for this study, which was piloted by two authors independently. Data extraction was performed independently by two authors. Conflicts were resolved by consensus or by consulting a third researcher.
We extracted the following data: article identification data (authors’ name and journal of publication), search period, number of databases searched, population or settings considered, main results and outcomes observed, and number of participants. From Web of Science (Clarivate Analytics, Philadelphia, PA, USA), we extracted journal rank (quartile) and Journal Impact Factor (JIF).
We categorized the following as primary outcomes: all-cause mortality, need for and length of mechanical ventilation, length of hospitalization (in days), admission to intensive care unit (yes/no), and length of stay in the intensive care unit.
The following outcomes were categorized as exploratory: diagnostic methods used for detection of the virus, male to female ratio, clinical symptoms, pharmacological and non-pharmacological interventions, laboratory findings (full blood count, liver enzymes, C-reactive protein, d-dimer, albumin, lipid profile, serum electrolytes, blood vitamin levels, glucose levels, and any other important biomarkers), and radiological findings (using radiography, computed tomography, magnetic resonance imaging or ultrasound).
We also collected data on reporting guidelines and requirements for the publication of systematic reviews and meta-analyses from journal websites where included reviews were published.
Quality assessment in individual reviews
Two researchers independently assessed the reviews’ quality using the “A MeaSurement Tool to Assess Systematic Reviews 2 (AMSTAR 2)”. We acknowledge that the AMSTAR 2 was created as “a critical appraisal tool for systematic reviews that include randomized or non-randomized studies of healthcare interventions, or both” [ 24 ]. However, since AMSTAR 2 was designed for systematic reviews of intervention trials, and we included additional types of systematic reviews, we adjusted some AMSTAR 2 ratings and reported these in Additional file 2 .
Adherence to each item was rated as follows: yes, partial yes, no, or not applicable (such as when a meta-analysis was not conducted). The overall confidence in the results of the review is rated as “critically low”, “low”, “moderate” or “high”, according to the AMSTAR 2 guidance based on seven critical domains, which are items 2, 4, 7, 9, 11, 13, 15 as defined by AMSTAR 2 authors [ 24 ]. We reported our adherence ratings for transparency of our decision with accompanying explanations, for each item, in each included review.
One of the included systematic reviews was conducted by some members of this author team [ 25 ]. This review was initially assessed independently by two authors who were not co-authors of that review to prevent the risk of bias in assessing this study.
Synthesis of results
For data synthesis, we prepared a table summarizing each systematic review. Graphs illustrating the mortality rate and clinical symptoms were created. We then prepared a narrative summary of the methods, findings, study strengths, and limitations.
For analysis of the prevalence of clinical outcomes, we extracted data on the number of events and the total number of patients to perform proportional meta-analysis using RStudio© software, with the “meta” package (version 4.9–6), using the “metaprop” function for reviews that did not perform a meta-analysis, excluding case studies because of the absence of variance. For reviews that did not perform a meta-analysis, we presented pooled results of proportions with their respective confidence intervals (95%) by the inverse variance method with a random-effects model, using the DerSimonian-Laird estimator for τ 2 . We adjusted data using Freeman-Tukey double arcosen transformation. Confidence intervals were calculated using the Clopper-Pearson method for individual studies. We created forest plots using the RStudio© software, with the “metafor” package (version 2.1–0) and “forest” function.
Managing overlapping systematic reviews
Some of the included systematic reviews that address the same or similar research questions may include the same primary studies in overviews. Including such overlapping reviews may introduce bias when outcome data from the same primary study are included in the analyses of an overview multiple times. Thus, in summaries of evidence, multiple-counting of the same outcome data will give data from some primary studies too much influence [ 14 ]. In this overview, we did not exclude overlapping systematic reviews because, according to Cochrane’s guidance, it may be appropriate to include all relevant reviews’ results if the purpose of the overview is to present and describe the current body of evidence on a topic [ 14 ]. To avoid any bias in summary estimates associated with overlapping reviews, we generated forest plots showing data from individual systematic reviews, but the results were not pooled because some primary studies were included in multiple reviews.
Our search retrieved 1063 publications, of which 175 were duplicates. Most publications were excluded after the title and abstract analysis ( n = 860). Among the 28 studies selected for full-text screening, 10 were excluded for the reasons described in Additional file 3 , and 18 were included in the final analysis (Fig. 1 ) [ 25 , 26 , 27 , 28 , 29 , 30 , 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 39 , 40 , 41 , 42 ]. Reference list screening did not retrieve any additional systematic reviews.

PRISMA flow diagram
Characteristics of included reviews
Summary features of 18 systematic reviews are presented in Table 1 . They were published in 14 different journals. Only four of these journals had specific requirements for systematic reviews (with or without meta-analysis): European Journal of Internal Medicine, Journal of Clinical Medicine, Ultrasound in Obstetrics and Gynecology, and Clinical Research in Cardiology . Two journals reported that they published only invited reviews ( Journal of Medical Virology and Clinica Chimica Acta ). Three systematic reviews in our study were published as letters; one was labeled as a scoping review and another as a rapid review (Table 2 ).
All reviews were published in English, in first quartile (Q1) journals, with JIF ranging from 1.692 to 6.062. One review was empty, meaning that its search did not identify any relevant studies; i.e., no primary studies were included [ 36 ]. The remaining 17 reviews included 269 unique studies; the majority ( N = 211; 78%) were included in only a single review included in our study (range: 1 to 12). Primary studies included in the reviews were published between December 2019 and March 18, 2020, and comprised case reports, case series, cohorts, and other observational studies. We found only one review that included randomized clinical trials [ 38 ]. In the included reviews, systematic literature searches were performed from 2019 (entire year) up to March 9, 2020. Ten systematic reviews included meta-analyses. The list of primary studies found in the included systematic reviews is shown in Additional file 4 , as well as the number of reviews in which each primary study was included.
Population and study designs
Most of the reviews analyzed data from patients with COVID-19 who developed pneumonia, acute respiratory distress syndrome (ARDS), or any other correlated complication. One review aimed to evaluate the effectiveness of using surgical masks on preventing transmission of the virus [ 36 ], one review was focused on pediatric patients [ 34 ], and one review investigated COVID-19 in pregnant women [ 37 ]. Most reviews assessed clinical symptoms, laboratory findings, or radiological results.
Systematic review findings
The summary of findings from individual reviews is shown in Table 2 . Overall, all-cause mortality ranged from 0.3 to 13.9% (Fig. 2 ).

A meta-analysis of the prevalence of mortality
Clinical symptoms
Seven reviews described the main clinical manifestations of COVID-19 [ 26 , 28 , 29 , 34 , 35 , 39 , 41 ]. Three of them provided only a narrative discussion of symptoms [ 26 , 34 , 35 ]. In the reviews that performed a statistical analysis of the incidence of different clinical symptoms, symptoms in patients with COVID-19 were (range values of point estimates): fever (82–95%), cough with or without sputum (58–72%), dyspnea (26–59%), myalgia or muscle fatigue (29–51%), sore throat (10–13%), headache (8–12%), gastrointestinal disorders, such as diarrhea, nausea or vomiting (5.0–9.0%), and others (including, in one study only: dizziness 12.1%) (Figs. 3 , 4 , 5 , 6 , 7 , 8 and 9 ). Three reviews assessed cough with and without sputum together; only one review assessed sputum production itself (28.5%).

A meta-analysis of the prevalence of fever

A meta-analysis of the prevalence of cough

A meta-analysis of the prevalence of dyspnea

A meta-analysis of the prevalence of fatigue or myalgia

A meta-analysis of the prevalence of headache

A meta-analysis of the prevalence of gastrointestinal disorders

A meta-analysis of the prevalence of sore throat
Diagnostic aspects
Three reviews described methodologies, protocols, and tools used for establishing the diagnosis of COVID-19 [ 26 , 34 , 38 ]. The use of respiratory swabs (nasal or pharyngeal) or blood specimens to assess the presence of SARS-CoV-2 nucleic acid using RT-PCR assays was the most commonly used diagnostic method mentioned in the included studies. These diagnostic tests have been widely used, but their precise sensitivity and specificity remain unknown. One review included a Chinese study with clinical diagnosis with no confirmation of SARS-CoV-2 infection (patients were diagnosed with COVID-19 if they presented with at least two symptoms suggestive of COVID-19, together with laboratory and chest radiography abnormalities) [ 34 ].
Therapeutic possibilities
Pharmacological and non-pharmacological interventions (supportive therapies) used in treating patients with COVID-19 were reported in five reviews [ 25 , 27 , 34 , 35 , 38 ]. Antivirals used empirically for COVID-19 treatment were reported in seven reviews [ 25 , 27 , 34 , 35 , 37 , 38 , 41 ]; most commonly used were protease inhibitors (lopinavir, ritonavir, darunavir), nucleoside reverse transcriptase inhibitor (tenofovir), nucleotide analogs (remdesivir, galidesivir, ganciclovir), and neuraminidase inhibitors (oseltamivir). Umifenovir, a membrane fusion inhibitor, was investigated in two studies [ 25 , 35 ]. Possible supportive interventions analyzed were different types of oxygen supplementation and breathing support (invasive or non-invasive ventilation) [ 25 ]. The use of antibiotics, both empirically and to treat secondary pneumonia, was reported in six studies [ 25 , 26 , 27 , 34 , 35 , 38 ]. One review specifically assessed evidence on the efficacy and safety of the anti-malaria drug chloroquine [ 27 ]. It identified 23 ongoing trials investigating the potential of chloroquine as a therapeutic option for COVID-19, but no verifiable clinical outcomes data. The use of mesenchymal stem cells, antifungals, and glucocorticoids were described in four reviews [ 25 , 34 , 35 , 38 ].
Laboratory and radiological findings
Of the 18 reviews included in this overview, eight analyzed laboratory parameters in patients with COVID-19 [ 25 , 29 , 30 , 32 , 33 , 34 , 35 , 39 ]; elevated C-reactive protein levels, associated with lymphocytopenia, elevated lactate dehydrogenase, as well as slightly elevated aspartate and alanine aminotransferase (AST, ALT) were commonly described in those eight reviews. Lippi et al. assessed cardiac troponin I (cTnI) [ 25 ], procalcitonin [ 32 ], and platelet count [ 33 ] in COVID-19 patients. Elevated levels of procalcitonin [ 32 ] and cTnI [ 30 ] were more likely to be associated with a severe disease course (requiring intensive care unit admission and intubation). Furthermore, thrombocytopenia was frequently observed in patients with complicated COVID-19 infections [ 33 ].
Chest imaging (chest radiography and/or computed tomography) features were assessed in six reviews, all of which described a frequent pattern of local or bilateral multilobar ground-glass opacity [ 25 , 34 , 35 , 39 , 40 , 41 ]. Those six reviews showed that septal thickening, bronchiectasis, pleural and cardiac effusions, halo signs, and pneumothorax were observed in patients suffering from COVID-19.
Quality of evidence in individual systematic reviews
Table 3 shows the detailed results of the quality assessment of 18 systematic reviews, including the assessment of individual items and summary assessment. A detailed explanation for each decision in each review is available in Additional file 5 .
Using AMSTAR 2 criteria, confidence in the results of all 18 reviews was rated as “critically low” (Table 3 ). Common methodological drawbacks were: omission of prospective protocol submission or publication; use of inappropriate search strategy: lack of independent and dual literature screening and data-extraction (or methodology unclear); absence of an explanation for heterogeneity among the studies included; lack of reasons for study exclusion (or rationale unclear).
Risk of bias assessment, based on a reported methodological tool, and quality of evidence appraisal, in line with the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) method, were reported only in one review [ 25 ]. Five reviews presented a table summarizing bias, using various risk of bias tools [ 25 , 29 , 39 , 40 , 41 ]. One review analyzed “study quality” [ 37 ]. One review mentioned the risk of bias assessment in the methodology but did not provide any related analysis [ 28 ].
This overview of systematic reviews analyzed the first 18 systematic reviews published after the onset of the COVID-19 pandemic, up to March 24, 2020, with primary studies involving more than 60,000 patients. Using AMSTAR-2, we judged that our confidence in all those reviews was “critically low”. Ten reviews included meta-analyses. The reviews presented data on clinical manifestations, laboratory and radiological findings, and interventions. We found no systematic reviews on the utility of diagnostic tests.
Symptoms were reported in seven reviews; most of the patients had a fever, cough, dyspnea, myalgia or muscle fatigue, and gastrointestinal disorders such as diarrhea, nausea, or vomiting. Olfactory dysfunction (anosmia or dysosmia) has been described in patients infected with COVID-19 [ 43 ]; however, this was not reported in any of the reviews included in this overview. During the SARS outbreak in 2002, there were reports of impairment of the sense of smell associated with the disease [ 44 , 45 ].
The reported mortality rates ranged from 0.3 to 14% in the included reviews. Mortality estimates are influenced by the transmissibility rate (basic reproduction number), availability of diagnostic tools, notification policies, asymptomatic presentations of the disease, resources for disease prevention and control, and treatment facilities; variability in the mortality rate fits the pattern of emerging infectious diseases [ 46 ]. Furthermore, the reported cases did not consider asymptomatic cases, mild cases where individuals have not sought medical treatment, and the fact that many countries had limited access to diagnostic tests or have implemented testing policies later than the others. Considering the lack of reviews assessing diagnostic testing (sensitivity, specificity, and predictive values of RT-PCT or immunoglobulin tests), and the preponderance of studies that assessed only symptomatic individuals, considerable imprecision around the calculated mortality rates existed in the early stage of the COVID-19 pandemic.
Few reviews included treatment data. Those reviews described studies considered to be at a very low level of evidence: usually small, retrospective studies with very heterogeneous populations. Seven reviews analyzed laboratory parameters; those reviews could have been useful for clinicians who attend patients suspected of COVID-19 in emergency services worldwide, such as assessing which patients need to be reassessed more frequently.
All systematic reviews scored poorly on the AMSTAR 2 critical appraisal tool for systematic reviews. Most of the original studies included in the reviews were case series and case reports, impacting the quality of evidence. Such evidence has major implications for clinical practice and the use of these reviews in evidence-based practice and policy. Clinicians, patients, and policymakers can only have the highest confidence in systematic review findings if high-quality systematic review methodologies are employed. The urgent need for information during a pandemic does not justify poor quality reporting.
We acknowledge that there are numerous challenges associated with analyzing COVID-19 data during a pandemic [ 47 ]. High-quality evidence syntheses are needed for decision-making, but each type of evidence syntheses is associated with its inherent challenges.
The creation of classic systematic reviews requires considerable time and effort; with massive research output, they quickly become outdated, and preparing updated versions also requires considerable time. A recent study showed that updates of non-Cochrane systematic reviews are published a median of 5 years after the publication of the previous version [ 48 ].
Authors may register a review and then abandon it [ 49 ], but the existence of a public record that is not updated may lead other authors to believe that the review is still ongoing. A quarter of Cochrane review protocols remains unpublished as completed systematic reviews 8 years after protocol publication [ 50 ].
Rapid reviews can be used to summarize the evidence, but they involve methodological sacrifices and simplifications to produce information promptly, with inconsistent methodological approaches [ 51 ]. However, rapid reviews are justified in times of public health emergencies, and even Cochrane has resorted to publishing rapid reviews in response to the COVID-19 crisis [ 52 ]. Rapid reviews were eligible for inclusion in this overview, but only one of the 18 reviews included in this study was labeled as a rapid review.
Ideally, COVID-19 evidence would be continually summarized in a series of high-quality living systematic reviews, types of evidence synthesis defined as “ a systematic review which is continually updated, incorporating relevant new evidence as it becomes available ” [ 53 ]. However, conducting living systematic reviews requires considerable resources, calling into question the sustainability of such evidence synthesis over long periods [ 54 ].
Research reports about COVID-19 will contribute to research waste if they are poorly designed, poorly reported, or simply not necessary. In principle, systematic reviews should help reduce research waste as they usually provide recommendations for further research that is needed or may advise that sufficient evidence exists on a particular topic [ 55 ]. However, systematic reviews can also contribute to growing research waste when they are not needed, or poorly conducted and reported. Our present study clearly shows that most of the systematic reviews that were published early on in the COVID-19 pandemic could be categorized as research waste, as our confidence in their results is critically low.
Our study has some limitations. One is that for AMSTAR 2 assessment we relied on information available in publications; we did not attempt to contact study authors for clarifications or additional data. In three reviews, the methodological quality appraisal was challenging because they were published as letters, or labeled as rapid communications. As a result, various details about their review process were not included, leading to AMSTAR 2 questions being answered as “not reported”, resulting in low confidence scores. Full manuscripts might have provided additional information that could have led to higher confidence in the results. In other words, low scores could reflect incomplete reporting, not necessarily low-quality review methods. To make their review available more rapidly and more concisely, the authors may have omitted methodological details. A general issue during a crisis is that speed and completeness must be balanced. However, maintaining high standards requires proper resourcing and commitment to ensure that the users of systematic reviews can have high confidence in the results.
Furthermore, we used adjusted AMSTAR 2 scoring, as the tool was designed for critical appraisal of reviews of interventions. Some reviews may have received lower scores than actually warranted in spite of these adjustments.
Another limitation of our study may be the inclusion of multiple overlapping reviews, as some included reviews included the same primary studies. According to the Cochrane Handbook, including overlapping reviews may be appropriate when the review’s aim is “ to present and describe the current body of systematic review evidence on a topic ” [ 12 ], which was our aim. To avoid bias with summarizing evidence from overlapping reviews, we presented the forest plots without summary estimates. The forest plots serve to inform readers about the effect sizes for outcomes that were reported in each review.
Several authors from this study have contributed to one of the reviews identified [ 25 ]. To reduce the risk of any bias, two authors who did not co-author the review in question initially assessed its quality and limitations.
Finally, we note that the systematic reviews included in our overview may have had issues that our analysis did not identify because we did not analyze their primary studies to verify the accuracy of the data and information they presented. We give two examples to substantiate this possibility. Lovato et al. wrote a commentary on the review of Sun et al. [ 41 ], in which they criticized the authors’ conclusion that sore throat is rare in COVID-19 patients [ 56 ]. Lovato et al. highlighted that multiple studies included in Sun et al. did not accurately describe participants’ clinical presentations, warning that only three studies clearly reported data on sore throat [ 56 ].
In another example, Leung [ 57 ] warned about the review of Li, L.Q. et al. [ 29 ]: “ it is possible that this statistic was computed using overlapped samples, therefore some patients were double counted ”. Li et al. responded to Leung that it is uncertain whether the data overlapped, as they used data from published articles and did not have access to the original data; they also reported that they requested original data and that they plan to re-do their analyses once they receive them; they also urged readers to treat the data with caution [ 58 ]. This points to the evolving nature of evidence during a crisis.
Our study’s strength is that this overview adds to the current knowledge by providing a comprehensive summary of all the evidence synthesis about COVID-19 available early after the onset of the pandemic. This overview followed strict methodological criteria, including a comprehensive and sensitive search strategy and a standard tool for methodological appraisal of systematic reviews.
In conclusion, in this overview of systematic reviews, we analyzed evidence from the first 18 systematic reviews that were published after the emergence of COVID-19. However, confidence in the results of all the reviews was “critically low”. Thus, systematic reviews that were published early on in the pandemic could be categorized as research waste. Even during public health emergencies, studies and systematic reviews should adhere to established methodological standards to provide patients, clinicians, and decision-makers trustworthy evidence.
Availability of data and materials
All data collected and analyzed within this study are available from the corresponding author on reasonable request.
World Health Organization. Timeline - COVID-19: Available at: https://www.who.int/news/item/29-06-2020-covidtimeline . Accessed 1 June 2021.
COVID-19 Dashboard by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU). Available at: https://coronavirus.jhu.edu/map.html . Accessed 1 June 2021.
Anzai A, Kobayashi T, Linton NM, Kinoshita R, Hayashi K, Suzuki A, et al. Assessing the Impact of Reduced Travel on Exportation Dynamics of Novel Coronavirus Infection (COVID-19). J Clin Med. 2020;9(2):601.
Chinazzi M, Davis JT, Ajelli M, Gioannini C, Litvinova M, Merler S, et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science. 2020;368(6489):395–400. https://doi.org/10.1126/science.aba9757 .
Article CAS PubMed PubMed Central Google Scholar
Fidahic M, Nujic D, Runjic R, Civljak M, Markotic F, Lovric Makaric Z, et al. Research methodology and characteristics of journal articles with original data, preprint articles and registered clinical trial protocols about COVID-19. BMC Med Res Methodol. 2020;20(1):161. https://doi.org/10.1186/s12874-020-01047-2 .
EPPI Centre . COVID-19: a living systematic map of the evidence. Available at: http://eppi.ioe.ac.uk/cms/Projects/DepartmentofHealthandSocialCare/Publishedreviews/COVID-19Livingsystematicmapoftheevidence/tabid/3765/Default.aspx . Accessed 1 June 2021.
NCBI SARS-CoV-2 Resources. Available at: https://www.ncbi.nlm.nih.gov/sars-cov-2/ . Accessed 1 June 2021.
Gustot T. Quality and reproducibility during the COVID-19 pandemic. JHEP Rep. 2020;2(4):100141. https://doi.org/10.1016/j.jhepr.2020.100141 .
Article PubMed PubMed Central Google Scholar
Kodvanj, I., et al., Publishing of COVID-19 Preprints in Peer-reviewed Journals, Preprinting Trends, Public Discussion and Quality Issues. Preprint article. bioRxiv 2020.11.23.394577; doi: https://doi.org/10.1101/2020.11.23.394577 .
Dobler CC. Poor quality research and clinical practice during COVID-19. Breathe (Sheff). 2020;16(2):200112. https://doi.org/10.1183/20734735.0112-2020 .
Article Google Scholar
Bastian H, Glasziou P, Chalmers I. Seventy-five trials and eleven systematic reviews a day: how will we ever keep up? PLoS Med. 2010;7(9):e1000326. https://doi.org/10.1371/journal.pmed.1000326 .
Lunny C, Brennan SE, McDonald S, McKenzie JE. Toward a comprehensive evidence map of overview of systematic review methods: paper 1-purpose, eligibility, search and data extraction. Syst Rev. 2017;6(1):231. https://doi.org/10.1186/s13643-017-0617-1 .
Pollock M, Fernandes RM, Becker LA, Pieper D, Hartling L. Chapter V: Overviews of Reviews. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.1 (updated September 2020). Cochrane. 2020. Available from www.training.cochrane.org/handbook .
Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, et al. Cochrane handbook for systematic reviews of interventions version 6.1 (updated September 2020). Cochrane. 2020; Available from www.training.cochrane.org/handbook .
Pollock M, Fernandes RM, Newton AS, Scott SD, Hartling L. The impact of different inclusion decisions on the comprehensiveness and complexity of overviews of reviews of healthcare interventions. Syst Rev. 2019;8(1):18. https://doi.org/10.1186/s13643-018-0914-3 .
Pollock M, Fernandes RM, Newton AS, Scott SD, Hartling L. A decision tool to help researchers make decisions about including systematic reviews in overviews of reviews of healthcare interventions. Syst Rev. 2019;8(1):29. https://doi.org/10.1186/s13643-018-0768-8 .
Hunt H, Pollock A, Campbell P, Estcourt L, Brunton G. An introduction to overviews of reviews: planning a relevant research question and objective for an overview. Syst Rev. 2018;7(1):39. https://doi.org/10.1186/s13643-018-0695-8 .
Pollock M, Fernandes RM, Pieper D, Tricco AC, Gates M, Gates A, et al. Preferred reporting items for overviews of reviews (PRIOR): a protocol for development of a reporting guideline for overviews of reviews of healthcare interventions. Syst Rev. 2019;8(1):335. https://doi.org/10.1186/s13643-019-1252-9 .
Moher D, Liberati A, Tetzlaff J, Altman DG, PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Open Med. 2009;3(3):e123–30.
Krnic Martinic M, Pieper D, Glatt A, Puljak L. Definition of a systematic review used in overviews of systematic reviews, meta-epidemiological studies and textbooks. BMC Med Res Methodol. 2019;19(1):203. https://doi.org/10.1186/s12874-019-0855-0 .
Puljak L. If there is only one author or only one database was searched, a study should not be called a systematic review. J Clin Epidemiol. 2017;91:4–5. https://doi.org/10.1016/j.jclinepi.2017.08.002 .
Article PubMed Google Scholar
Gates M, Gates A, Guitard S, Pollock M, Hartling L. Guidance for overviews of reviews continues to accumulate, but important challenges remain: a scoping review. Syst Rev. 2020;9(1):254. https://doi.org/10.1186/s13643-020-01509-0 .
Covidence - systematic review software. Available at: https://www.covidence.org/ . Accessed 1 June 2021.
Shea BJ, Reeves BC, Wells G, Thuku M, Hamel C, Moran J, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ. 2017;358:j4008.
Borges do Nascimento IJ, et al. Novel Coronavirus Infection (COVID-19) in Humans: A Scoping Review and Meta-Analysis. J Clin Med. 2020;9(4):941.
Article PubMed Central Google Scholar
Adhikari SP, Meng S, Wu YJ, Mao YP, Ye RX, Wang QZ, et al. Epidemiology, causes, clinical manifestation and diagnosis, prevention and control of coronavirus disease (COVID-19) during the early outbreak period: a scoping review. Infect Dis Poverty. 2020;9(1):29. https://doi.org/10.1186/s40249-020-00646-x .
Cortegiani A, Ingoglia G, Ippolito M, Giarratano A, Einav S. A systematic review on the efficacy and safety of chloroquine for the treatment of COVID-19. J Crit Care. 2020;57:279–83. https://doi.org/10.1016/j.jcrc.2020.03.005 .
Li B, Yang J, Zhao F, Zhi L, Wang X, Liu L, et al. Prevalence and impact of cardiovascular metabolic diseases on COVID-19 in China. Clin Res Cardiol. 2020;109(5):531–8. https://doi.org/10.1007/s00392-020-01626-9 .
Article CAS PubMed Google Scholar
Li LQ, Huang T, Wang YQ, Wang ZP, Liang Y, Huang TB, et al. COVID-19 patients’ clinical characteristics, discharge rate, and fatality rate of meta-analysis. J Med Virol. 2020;92(6):577–83. https://doi.org/10.1002/jmv.25757 .
Lippi G, Lavie CJ, Sanchis-Gomar F. Cardiac troponin I in patients with coronavirus disease 2019 (COVID-19): evidence from a meta-analysis. Prog Cardiovasc Dis. 2020;63(3):390–1. https://doi.org/10.1016/j.pcad.2020.03.001 .
Lippi G, Henry BM. Active smoking is not associated with severity of coronavirus disease 2019 (COVID-19). Eur J Intern Med. 2020;75:107–8. https://doi.org/10.1016/j.ejim.2020.03.014 .
Lippi G, Plebani M. Procalcitonin in patients with severe coronavirus disease 2019 (COVID-19): a meta-analysis. Clin Chim Acta. 2020;505:190–1. https://doi.org/10.1016/j.cca.2020.03.004 .
Lippi G, Plebani M, Henry BM. Thrombocytopenia is associated with severe coronavirus disease 2019 (COVID-19) infections: a meta-analysis. Clin Chim Acta. 2020;506:145–8. https://doi.org/10.1016/j.cca.2020.03.022 .
Ludvigsson JF. Systematic review of COVID-19 in children shows milder cases and a better prognosis than adults. Acta Paediatr. 2020;109(6):1088–95. https://doi.org/10.1111/apa.15270 .
Lupia T, Scabini S, Mornese Pinna S, di Perri G, de Rosa FG, Corcione S. 2019 novel coronavirus (2019-nCoV) outbreak: a new challenge. J Glob Antimicrob Resist. 2020;21:22–7. https://doi.org/10.1016/j.jgar.2020.02.021 .
Marasinghe, K.M., A systematic review investigating the effectiveness of face mask use in limiting the spread of COVID-19 among medically not diagnosed individuals: shedding light on current recommendations provided to individuals not medically diagnosed with COVID-19. Research Square. Preprint article. doi : https://doi.org/10.21203/rs.3.rs-16701/v1 . 2020 .
Mullins E, Evans D, Viner RM, O’Brien P, Morris E. Coronavirus in pregnancy and delivery: rapid review. Ultrasound Obstet Gynecol. 2020;55(5):586–92. https://doi.org/10.1002/uog.22014 .
Pang J, Wang MX, Ang IYH, Tan SHX, Lewis RF, Chen JIP, et al. Potential Rapid Diagnostics, Vaccine and Therapeutics for 2019 Novel coronavirus (2019-nCoV): a systematic review. J Clin Med. 2020;9(3):623.
Rodriguez-Morales AJ, Cardona-Ospina JA, Gutiérrez-Ocampo E, Villamizar-Peña R, Holguin-Rivera Y, Escalera-Antezana JP, et al. Clinical, laboratory and imaging features of COVID-19: a systematic review and meta-analysis. Travel Med Infect Dis. 2020;34:101623. https://doi.org/10.1016/j.tmaid.2020.101623 .
Salehi S, Abedi A, Balakrishnan S, Gholamrezanezhad A. Coronavirus disease 2019 (COVID-19): a systematic review of imaging findings in 919 patients. AJR Am J Roentgenol. 2020;215(1):87–93. https://doi.org/10.2214/AJR.20.23034 .
Sun P, Qie S, Liu Z, Ren J, Li K, Xi J. Clinical characteristics of hospitalized patients with SARS-CoV-2 infection: a single arm meta-analysis. J Med Virol. 2020;92(6):612–7. https://doi.org/10.1002/jmv.25735 .
Yang J, Zheng Y, Gou X, Pu K, Chen Z, Guo Q, et al. Prevalence of comorbidities and its effects in patients infected with SARS-CoV-2: a systematic review and meta-analysis. Int J Infect Dis. 2020;94:91–5. https://doi.org/10.1016/j.ijid.2020.03.017 .
Bassetti M, Vena A, Giacobbe DR. The novel Chinese coronavirus (2019-nCoV) infections: challenges for fighting the storm. Eur J Clin Investig. 2020;50(3):e13209. https://doi.org/10.1111/eci.13209 .
Article CAS Google Scholar
Hwang CS. Olfactory neuropathy in severe acute respiratory syndrome: report of a case. Acta Neurol Taiwanica. 2006;15(1):26–8.
Google Scholar
Suzuki M, Saito K, Min WP, Vladau C, Toida K, Itoh H, et al. Identification of viruses in patients with postviral olfactory dysfunction. Laryngoscope. 2007;117(2):272–7. https://doi.org/10.1097/01.mlg.0000249922.37381.1e .
Rajgor DD, Lee MH, Archuleta S, Bagdasarian N, Quek SC. The many estimates of the COVID-19 case fatality rate. Lancet Infect Dis. 2020;20(7):776–7. https://doi.org/10.1016/S1473-3099(20)30244-9 .
Wolkewitz M, Puljak L. Methodological challenges of analysing COVID-19 data during the pandemic. BMC Med Res Methodol. 2020;20(1):81. https://doi.org/10.1186/s12874-020-00972-6 .
Rombey T, Lochner V, Puljak L, Könsgen N, Mathes T, Pieper D. Epidemiology and reporting characteristics of non-Cochrane updates of systematic reviews: a cross-sectional study. Res Synth Methods. 2020;11(3):471–83. https://doi.org/10.1002/jrsm.1409 .
Runjic E, Rombey T, Pieper D, Puljak L. Half of systematic reviews about pain registered in PROSPERO were not published and the majority had inaccurate status. J Clin Epidemiol. 2019;116:114–21. https://doi.org/10.1016/j.jclinepi.2019.08.010 .
Runjic E, Behmen D, Pieper D, Mathes T, Tricco AC, Moher D, et al. Following Cochrane review protocols to completion 10 years later: a retrospective cohort study and author survey. J Clin Epidemiol. 2019;111:41–8. https://doi.org/10.1016/j.jclinepi.2019.03.006 .
Tricco AC, Antony J, Zarin W, Strifler L, Ghassemi M, Ivory J, et al. A scoping review of rapid review methods. BMC Med. 2015;13(1):224. https://doi.org/10.1186/s12916-015-0465-6 .
COVID-19 Rapid Reviews: Cochrane’s response so far. Available at: https://training.cochrane.org/resource/covid-19-rapid-reviews-cochrane-response-so-far . Accessed 1 June 2021.
Cochrane. Living systematic reviews. Available at: https://community.cochrane.org/review-production/production-resources/living-systematic-reviews . Accessed 1 June 2021.
Millard T, Synnot A, Elliott J, Green S, McDonald S, Turner T. Feasibility and acceptability of living systematic reviews: results from a mixed-methods evaluation. Syst Rev. 2019;8(1):325. https://doi.org/10.1186/s13643-019-1248-5 .
Babic A, Poklepovic Pericic T, Pieper D, Puljak L. How to decide whether a systematic review is stable and not in need of updating: analysis of Cochrane reviews. Res Synth Methods. 2020;11(6):884–90. https://doi.org/10.1002/jrsm.1451 .
Lovato A, Rossettini G, de Filippis C. Sore throat in COVID-19: comment on “clinical characteristics of hospitalized patients with SARS-CoV-2 infection: a single arm meta-analysis”. J Med Virol. 2020;92(7):714–5. https://doi.org/10.1002/jmv.25815 .
Leung C. Comment on Li et al: COVID-19 patients’ clinical characteristics, discharge rate, and fatality rate of meta-analysis. J Med Virol. 2020;92(9):1431–2. https://doi.org/10.1002/jmv.25912 .
Li LQ, Huang T, Wang YQ, Wang ZP, Liang Y, Huang TB, et al. Response to Char’s comment: comment on Li et al: COVID-19 patients’ clinical characteristics, discharge rate, and fatality rate of meta-analysis. J Med Virol. 2020;92(9):1433. https://doi.org/10.1002/jmv.25924 .
Download references
Acknowledgments
We thank Catherine Henderson DPhil from Swanscoe Communications for pro bono medical writing and editing support. We acknowledge support from the Covidence Team, specifically Anneliese Arno. We thank the whole International Network of Coronavirus Disease 2019 (InterNetCOVID-19) for their commitment and involvement. Members of the InterNetCOVID-19 are listed in Additional file 6 . We thank Pavel Cerny and Roger Crosthwaite for guiding the team supervisor (IJBN) on human resources management.
This research received no external funding.
Author information
Authors and affiliations.
University Hospital and School of Medicine, Universidade Federal de Minas Gerais, Belo Horizonte, Minas Gerais, Brazil
Israel Júnior Borges do Nascimento & Milena Soriano Marcolino
Medical College of Wisconsin, Milwaukee, WI, USA
Israel Júnior Borges do Nascimento
Helene Fuld Health Trust National Institute for Evidence-based Practice in Nursing and Healthcare, College of Nursing, The Ohio State University, Columbus, OH, USA
Dónal P. O’Mathúna
School of Nursing, Psychotherapy and Community Health, Dublin City University, Dublin, Ireland
Department of Anesthesiology, Intensive Care and Pain Medicine, University of Münster, Münster, Germany
Thilo Caspar von Groote
Department of Sport and Health Science, Technische Universität München, Munich, Germany
Hebatullah Mohamed Abdulazeem
School of Health Sciences, Faculty of Health and Medicine, The University of Newcastle, Callaghan, Australia
Ishanka Weerasekara
Department of Physiotherapy, Faculty of Allied Health Sciences, University of Peradeniya, Peradeniya, Sri Lanka
Cochrane Croatia, University of Split, School of Medicine, Split, Croatia
Ana Marusic, Irena Zakarija-Grkovic & Tina Poklepovic Pericic
Center for Evidence-Based Medicine and Health Care, Catholic University of Croatia, Ilica 242, 10000, Zagreb, Croatia
Livia Puljak
Cochrane Brazil, Evidence-Based Health Program, Universidade Federal de São Paulo, São Paulo, Brazil
Vinicius Tassoni Civile & Alvaro Nagib Atallah
Yorkville University, Fredericton, New Brunswick, Canada
Santino Filoso
Laboratory for Industrial and Applied Mathematics (LIAM), Department of Mathematics and Statistics, York University, Toronto, Ontario, Canada
Nicola Luigi Bragazzi
You can also search for this author in PubMed Google Scholar
Contributions
IJBN conceived the research idea and worked as a project coordinator. DPOM, TCVG, HMA, IW, AM, LP, VTC, IZG, TPP, ANA, SF, NLB and MSM were involved in data curation, formal analysis, investigation, methodology, and initial draft writing. All authors revised the manuscript critically for the content. The author(s) read and approved the final manuscript.
Corresponding author
Correspondence to Livia Puljak .
Ethics declarations
Ethics approval and consent to participate.
Not required as data was based on published studies.
Consent for publication
Not applicable.
Competing interests
The authors declare no conflict of interest.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: appendix 1..
Search strategies used in the study.
Additional file 2: Appendix 2.
Adjusted scoring of AMSTAR 2 used in this study for systematic reviews of studies that did not analyze interventions.
Additional file 3: Appendix 3.
List of excluded studies, with reasons.
Additional file 4: Appendix 4.
Table of overlapping studies, containing the list of primary studies included, their visual overlap in individual systematic reviews, and the number in how many reviews each primary study was included.
Additional file 5: Appendix 5.
A detailed explanation of AMSTAR scoring for each item in each review.
Additional file 6: Appendix 6.
List of members and affiliates of International Network of Coronavirus Disease 2019 (InterNetCOVID-19).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Borges do Nascimento, I.J., O’Mathúna, D.P., von Groote, T.C. et al. Coronavirus disease (COVID-19) pandemic: an overview of systematic reviews. BMC Infect Dis 21 , 525 (2021). https://doi.org/10.1186/s12879-021-06214-4
Download citation
Received : 12 April 2020
Accepted : 19 May 2021
Published : 04 June 2021
DOI : https://doi.org/10.1186/s12879-021-06214-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Coronavirus
- Evidence-based medicine
- Infectious diseases
BMC Infectious Diseases
ISSN: 1471-2334
- Submission enquiries: [email protected]
- General enquiries: [email protected]

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Springer Nature - PMC COVID-19 Collection
On the role of data, statistics and decisions in a pandemic
1 Institute of Public Health, Medical Decision Making and Health Technology Assessment, Department of Public Health, Health Services Research and Health Technology Assessment, UMIT – University for Health Sciences, Medical Informatics and Technology, Hall i.T., Austria
Sarah Friedrich
2 Department of Medical Statistics, University Medical Center Göttingen, Göttingen, Germany
Joachim Behnke
3 Zeppelin University Friedrichshafen, Friedrichshafen, Germany
Joachim Engel
4 Pädagogische Hochschule Ludwigsburg, Ludwigsburg, Germany
Ursula Garczarek
5 Cytel Inc, 675, Massachusetts Avenue, Cambridge, MA 02139 USA
Ralf Münnich
6 Economic and Social Statistics, Trier University, Trier, Germany
Markus Pauly
7 Department of Statistics, TU Dortmund University, Dortmund, Germany
Adalbert Wilhelm
8 Psychology and Methods, Jacobs University Bremen, Bremen, Germany
Olaf Wolkenhauer
9 Department of Systems Biology and Bioinformatics, University of Rostock, Rostock, Germany
10 Leibniz-Institute for Food Systems Biology, Technical University of Munich, Munich, Germany
Markus Zwick
11 Division of Economic Policy and Quantitative Methods, Goethe University Frankfurt, Frankfurt, Germany
Uwe Siebert
12 Institute for Technology Assessment and Department of Radiology, Massachusetts General Hospital, Harvard Medical School, Boston, MA USA
13 Center for Health Decision Science and Departments of Epidemiology and Health Policy and Management, Harvard T.H. Chan School of Public Health, Boston, MA USA
Associated Data
An essential basis for research and for evidence-based policy is high quality data. The mere presence of data is not enough, as the process of data definition, collection and processing determines the quality of the data in reflecting the phenomena on which to provide evidence. Poor definition of data concepts and variables as well as bad choices in their collection and processing can lead to misleading data, that is data with severe bias, or to an unacceptably large remaining level of uncertainty about the phenomena of interest, so that any results generated with that data form an inadequate basis for decision making. Below, we describe which quality characteristics have to be considered when planning a data collection or when assessing the quality of already existing data for a task at hand. The underlying concepts are general and well-known. Despite this, they are regretfully often neglected, and thus, we summarize them as eight characteristics in the context of policy making.
- Suitability for a target: Data in itself are neither good nor bad, but only more or less suitable for achieving a certain goal. In order to assess data, it is first necessary to understand, agree on, and describe the goal that the data are supposed to support.
- Relevance: Data must provide relevant information to achieve the goal. To do this, the data must measure the characteristics needed (e.g., how to measure population immunity?) on the right individuals (e.g., representative sample for generalization, or high-resolution data for local action?).
- Transparency: The data collection process must be transparent in terms of origin, time of data collection and nature of the data. Transparency is a requirement for peer-review processes to ensure correctness of results and for an adequate modeling of uncertainties.
- Quality standards: Data are well suited for policy making requiring general overviews and spatio-temporal trends if local data collection follows a clear and uniform definition of what is recorded and how it has been recorded. Standardization includes, for example, the harmonization of data processes, adequate training of the persons involved in the collection, and monitoring of the processes.
- Trustworthiness: To place trust in the data, these must be collected and processed independently, impartially and objectively. In particular, conflicts of interest should be avoided in order not to jeopardize their credibility.
- Sources of error: Most data contain errors, such as measurement errors, input errors, transmission errors or errors that occur due to non-response. With a good description of data collection and data processing (see ‘Transparency’ above), possible sources of error can be assessed and incorporated into the modeling for the quantification of uncertainty and the interpretation of results.
- Timeliness and accuracy: Ideally, data used for policy-making should meet all quality criteria. However, information derived from data must additionally be up-to-date, and some decisions (e.g., contact restrictions) cannot be postponed to wait until standardized processes have been defined and implemented, and optimal data have been collected. The greater uncertainty in the data associated with this must be met with transparency and with great care in its interpretation.
- Access to data for science: In order to achieve the overall goal of evidence-based policy making, it is important to make good data available as a resource to a wide scientific public. This allows for the data to be analyzed in different contexts and with different methods and enables the data to be interpreted from the perspective of different social groups and scientific disciplines.
These eight aspects are included in the European Statistics Code of Practice (European Statistics Code of Practice 2017 ). This Code of Practice, however, goes beyond the above mentioned points by covering further aspects of statistical processes and statistical outputs as well as an additional section on the institutional environment. The aim is to provide a common quality framework of the European Statistical System.
The items presented above mainly refer to a primary data generating process, that is, when the data are directly generated to provide information on a pre-defined target. Especially in the context of COVID-19, information from available sources often has to be considered, where the data generation does not necessarily coincide with the aim of the study. One prominent example is the number of infections, which are gathered by the local health authorities, but are used for comparing regional incidences which are the basis of several policy decisions. Particular attention in this case has to be paid to selection bias. One way to assess (and thus address) selection bias would come from accompanying information on asymptomatically infected persons gained through representative studies. Other information to mitigate selection bias comes from the number of tests and the reasons for testing, but these are not appropriately reported in Germany. Both problems yield biased regional incidences. Hence, modeling based on these data may cause misleading results and has to be considered carefully. Additionally, the data generating process may be subject to informative sampling (Pfeffermann and Sverchkov 2009 ).
The above aspects always have to be seen in light of the research question. Incidences and infection patterns need highly different data. Available data are often inappropriate, or must be accompanied by additional data sources. Due to the highly volatile character of COVID-19 infections, data gathering—especially via additional samples—must be very carefully planned to foster the necessary quality to provide the foundation for policy actions (Rendtel et al. 2021 ).
Representativity implies drawing adequate conclusions from the sample on the population or parameters of the population. To achieve this, known inclusion probabilities on a complete list of elements must be given in order to allow statistical inference. Nowadays, the term representativity is generalized to cover regional smaller granularity, as well as in accordance with the time scale. Further details, especially for subgroup representativity, can be drawn from Gabler and Quatember ( 2013 ). In household or business surveys, the term representativity has to be seen in the context of non-response and its compensation (Schnell 2019 ). In practice, the term representativity is often recognized as a sufficiently high quality sample. This is entirely misleading. Indeed, statistical properties, and especially accuracy, have to be additionally considered (Münnich 2020 ). Finally, it has to be pointed out that these aspects have to be separately considered for each variable or target of interest.
A pandemic poses particular challenges to decision-making because of the need to continuously adapt decisions to rapidly changing evidence and available data. For example, which countermeasures are appropriate at a particular stage of the pandemic? How can the severity of the pandemic be measured? What is the effect of vaccination in the population and which groups should be vaccinated first? The process of decision-making starts with data collection and modeling and continues to the dissemination of results and the subsequent decisions taken. The goal of this paper is to give an overview of this process and to provide recommendations for the different steps from a statistical perspective. In particular, we discuss a range of modeling techniques including mathematical, statistical and decision-analytic models along with their applications in the COVID-19 context. With this overview, we aim to foster the understanding of the goals of these modeling approaches and the specific data requirements that are essential for the interpretation of results and for successful interdisciplinary collaborations. A special focus is on the role played by data in these different models, and we incorporate into the discussion the importance of statistical literacy and of effective dissemination and communication of findings.
Introduction
In December 2019, the first cases of coronavirus disease 2019 (COVID-19) were reported in Wuhan, China (Zhou et al. 2020 ; Wu et al. 2020 ) and the outbreak of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) was declared a pandemic in March 2020 by the World Health Organization. In order to control the spread of the virus and limit the negative consequences of the pandemic, important decisions had and still have to be made. These concern the spread of the disease, its impact on health, the utilization of health care resources or potential effects of counter measures and vaccination strategies, to name some examples. Statistical modeling plays an important role in different fields of COVID-19 research. This starts with the collection of adequate data and the preprocessing of this data, a complex sequence of steps, where input is required from the data users, taking into account their questions and information needs. After this preprocessing, examples of statistical models range from characterizing the disease (Küchenhoff et al. 2021 ; Roy et al. 2021 ; Luo et al. 2021 ), investigating comorbidities (Gross et al. 2021 ; Hadzibegovic et al. 2021 ; Evangelou et al. 2021 ), evaluating new treatments and vaccines with respect to efficacy and safety (Horby et al. 2020 ; RECOVERY Collaborative Group 2020 ; Shinde et al. 2021 ; Flaxman et al. 2020 ) as well as planning corresponding trials (Mütze and Friede 2020 ; Stallard et al. 2020 ; Beyersmann et al. 2021 ), assessing the spread of the disease in potential scenarios—such as comparing lockdown or vaccination strategies (Nussbaumer-Streit et al. 2020 ; Van Pelt et al. 2021 ; Jahn et al. 2021 )—and evaluating the impact of the pandemic on clinical trials (Kunz et al. 2020 ; Anker et al. 2020 ). One important aspect in the special situation of a pandemic with a novel pathogen is the incorporation of sequential inference, that is, continuously updating the research as new data become available.
In the course of the pandemic, the availability and quality of data, the varying interpretations of modeling results, as well as apparently contradicting statements by scientists, have caused confusion and fostered intense debate. The role, use and misuse of modeling for infectious disease policy making have been critically discussed (James et al. 2021 ; Holmdahl and Buckee 2020 ). Furthermore, the CODAG reports (COVID-19 Data Analysis Group 2021 ) clarify why models can lead to conflicting conclusions and discuss the purposes of modeling and the validity of the results. For instance, policies to contain the pandemic were—in the beginning—mainly guided by 7-day incidence. Measures such as curfews, limited numbers of guests at events and restricted opening hours of stores were driven by this figure. However, considering the 7-day incidence alone does not provide a meaningful view of the overall picture as discussed by Küchenhoff et al. ( 2021 ). As mentioned in the series “Unstatistik” (RWI – Leibniz-Institut für Wirtschaftsforschung 2020 ), a value of 50 cases per 100,000 inhabitants in October 2020 in Germany had an entirely different meaning than six months earlier due to changes in testing strategies and improved treatments among other factors. Concerning the expected number of intensive care patients and deaths, a value of approximately 50 in October 2020 is likely to correspond to a value of 15 to 20 in April 2020, possibly even less (RWI – Leibniz-Institut für Wirtschaftsforschung 2020 ). Recently, the hospitalization and ICU incidences have been considered as additional measures. While this provides a more reliable picture of the severity of the situation and is less affected by differing testing strategies, it is not without shortcomings. For example, under-reporting and time-lags lead to large differences between reported and actual numbers. Moreover, as the severity of COVID infections dropped with the Omicron variant and prevalence increased, a new discussion of hospitalization “with” or “because of” COVID-19 emerged. These examples highlight the need to use statistical methods such as nowcasting (Günther et al. 2021 ; Schneble et al. 2021 ; Salas 2021 ; Altmejd et al. 2020 ) for more precise estimations.
As known from the field of evidence-based medicine and health data and decision science, decisions should be underpinned by the best available evidence. For evidence-based decision making, three components are important: a) data, b) statistical, mathematical and decision-analytic models (which reduce the amount and the complexity of the data to meaningful indices, visualizations and/or predictions), and c) a set of available decisions, interventions or strategies with their consequences described through a utility or loss function (decision-making framework) and the related tradeoffs. General international guidance on these assessments and decision analysis is implemented in a country-specific manner, mainly by Health Technology Assessment (HTA) organisations (Drummond et al. 2008 ; Gandjour 2020 ). COVID-19 examples include the evaluation of vaccination strategies (Kohli et al. 2021 ; Debrabant et al. 2021 ; Reddy et al. 2021 ) or treatment (Sheinson et al. 2021 ). Scientists of the German Network for Evidence-based Medicine raised the question on “COVID-19: Where is the evidence?” (EbM-Netzwerk 2020 ) which motivated a discussion about the need of randomized controlled trials to investigate the effectiveness of preventive measures, feasibility of such studies and longitudinal, representative data generation.
In the pandemic, a multitude of models has been used but the systematic comparison across different classes of models is lacking. The goal of this paper is to provide an overview of the process from data collection (primary and secondary) and modeling, up to communication and decision making and to provide recommendations related to these areas. We discuss a range of modeling techniques including mathematical, statistical and decision-analytic models along with their application in the COVID-19 context. With this overview, we aim to foster the understanding of the goals of these modeling approaches, and the specific data requirements that are essential for the interpretation of results and a successful interdisciplinary collaboration. Model types less known to statisticians, such as decision-analytic models, still require statistical thinking. In particular, functional relationships and input parameters for these models are often provided by statisticians and epidemiologists. Our target audience, therefore, is broad. It includes data scientists—such as statisticians—mathematicians, physicists, epidemiologists, economists, social and computer scientists and decision scientists.
The paper is organized as follows. In Sect. 2 , we give a short overview of modeling purposes and approaches with a special focus on differences between disciplines. In Sect. 3 , we discuss requirements of data quality and why this is fundamental for the entire process. We then move on to modeling, with Sect. 4 dealing with the different purposes of modeling. In Sect. 5 , we explain how decisions can be informed based on these models. We discuss aspects of the reporting and communication of results in Sect. 6 , provide recommendations in Sect. 7 and a discussion in Sect. 8 .
Overview of modeling approaches and their purposes
As a statistician, the process of gaining knowledge starts with a research question and continues with the acquisition of data, which then enters into the statistical model—see Figure 1 in Friedrich et al. ( 2021 ) for an illustration. Data acquisition here might refer either to the design of an adequate experiment or observation, or to the use of so-called secondary data, which has been collected for a different purpose. Statistical principles of design are relevant, even when using secondary data (Rubin 2008 ). In Bayesian statistics, other information can be incorporated as a priori information (e.g., O’Hagan 2004 ). This might stem from previous studies or might be based on expert opinions. The prior information combined with the data (likelihood) then results in a posterior distribution. In modeling contexts outside statistics, data and/or information is used in different ways. Simulation models use prior information (again based either on data or on other sources such as expert opinion or beliefs) to determine the parameters of interest and are usually validated on a data set. The formal representation of the mathematical or decision-analytic model makes assumptions about the system that generates the data (Roberts et al. 2012 ), and the (mis)match between data and model then provides insights that can be used as basis for decisions. In contrast to statistical models, the order of data and modeling is thus reversed. An illustration is depicted in Fig. Fig.1. 1 . For the purpose of illustration, Fig. Fig.1 1 depicts the process as a sequence of steps. As the pandemic progresses, however, some steps such as data capturing and modeling might be iterated.

For evidence-based decision making, a complex process is often necessary. In both statistical and mathematical/decision-analytic modeling, the path starts with a research question and ends in guidance for decision making. In statistics (upper path), using data as the basis for modeling is common. In mathematical and decision-analytic modeling (lower path), models are based on subject matter knowledge and validated or calibrated using data sets. For the purpose of illustration, the process is depicted as a sequence of steps here. In reality, however, these are more likely to be cyclic, iterating steps such as data capturing and modeling and informing new questions based on previous results
From a mathematical perspective, a statistic f is a quantity or function defined on the sampling space. Note that the term statistic is used both for the function f as well as for the value f ( x ) of the function on a given data set x (DeGroot and Schervish 2014 ; Licker 2003 ). Choices of f include very simple preprocessing steps, e.g., taking the mean where f ( x 1 , ⋯ , x n ) = 1 n ∑ i = 1 n x i , as well as estimates obtained from complex statistical models, such as hierarchical Bayesian models used for nowcasting (Günther et al. 2021 ) or sophisticated regression models for prediction (Iwendi et al. 2020 ). Thus, the input to a statistical model might either be ‘raw data’ or might have undergone some previous steps, like scaling or transformation applied to variables before entering them in a regression model. These previous steps are often referred to as preprocessing (especially in the context of machine learning) and examples include descriptive statistics and exploratory data analysis, see also Friedrich et al. ( 2021 ) and the references cited therein. It should be noted, however, that data can often not be analyzed directly, but is the product of a complex sequence of processing steps. In particular, Desrosières ( 2010 ) separates three aspects of statistics, namely “(1) that of quantification properly speaking, the making of numbers, (2) that of the uses of numbers as variables, and finally, (3) the prospective inscription of variables in more complex constructions, models”. Throughout this paper, we refer to the model input parameters as ‘data’ irrespective of whether some preprocessing took place or not. Official statistics, for instance, usually refer to crude observations when talking about ‘data’, while the information obtained by (pre-)processing this data is called statistics. For this paper, however, we adapt a slightly different view on the same aspect and do not distinguish between crude and preprocessed data. In this sense, the measures of quality and trustworthiness discussed in Sect. 3 similarly extend to preprocessing, descriptive statistics and exploratory data analysis (Friedrich et al. 2021 ).
As mentioned above, modeling is an integral part of evidence-based decision making. Here, we distinguish three purposes of modeling, which are summarized in Table 1 . The first category contains models which aim to explain patterns and trends in the data. The second category aims to predict the present (so-called now-casting) or the future (forecasting). Finally, decision-analytic models aim to inform decision makers by simulating the consequences of interventions and their related tradeoffs (e.g., benefit-harm tradeoff, cost-effectiveness tradeoff).
Overview of modeling purposes and approaches
For each different group of models (columns), we describe goals, approaches and challenges. ABM Agent-based model, DES discrete event simulation, SD system dynamics, ICU intensive-care unit, MSM microsimulation modeling
In medical decision making and health economics, this leads to a formal decision framework, which relates to statistical decision theory (Siebert 2003 , 2005 ). In this framework, (Parmigiani and Inoue 2009 ) the decision maker has to choose among a set of different actions. The consequences of these actions depend on an unknown “state of the world”. The basis for decision making depends on the quantitative assessment of these uncertain consequences. To this end, a loss or utility function must be defined which allows the quantification of benefits, risk, cost or other consequences of different actions. Minimizing the loss function (or maximizing the utility function) then leads to optimal decisions.
Data availability and quality
From data to insights: the purposes of modeling.
Data and decisions are often linked using statistical models or simulations. As noted in Sect. 2 , we refer to data as the input to statistical models irrespective of any preprocessing steps. As such, data preparation, descriptive statistics and preprocessing are not the focus of this paper and are thus not discussed in detail. Nonetheless, they are an essential step in any statistical analysis and especially in a situation such as the COVID-19 pandemic, where data are, in particular in the early stages of a pandemic, sparse and often disorganized. Exploratory data analysis is an important step to check data quality and discover potential anomalies in the data. An important aspect, however, is to keep in mind that data are a product of a complex sequence of steps. Here, transparency concerning the origin of the data and the whole process of data preparation is important and should be included as meta-data. As outlined in the Sect. 2 , modeling can serve three purposes. Each of them can be approached from either a statistical or a mathematical modeling perspective. In these models, data can play different roles: while statistical models use data as the basis for the model itself, simulations are based on parameters according to prior information and predictions based on the simulation can be checked against real data to assess the precision and validity of the constructed model.
An important aspect is handling and communicating uncertainty. In statistical models, different types of uncertainty occur: sampling variation, model uncertainty, incomplete data, applicability of information and confounding are common examples (e.g., Altman and Bland 2014 ; Abadie et al. 2020 ; Chatfield 1995 ). In mathematical and decision-analytic models, there are usually alternative approaches to determine the values for key parameters used in simulations. For decision-making purposes, therefore, it is important to compare different methods for determining the indicators. Consequently, in most cases, not a single number but an interval or distribution has to be considered. In the following, we will consider the three purposes of modeling in more detail. For each of them, we provide some mathematical background, explain the difference between statistical models and mathematical or decision-analytic models and give some examples of how these approaches were applied in the COVID-19 pandemic.
Modeling for explanation
The main goal of these models is to explain patterns, trends or interactions. Statistical models for this purpose include, for example, regression models (Fahrmeir et al. 2007 ) as well as factor, cluster or contingency analyses (e.g., Fabrigar and Wegener 2011 ; Duran and Odell 2013 ). In this context, associations are often misinterpreted as causal relationships. The discovery of correlations and associations, however, cannot be equated to establishing causal claims. In statistics and clinical epidemiology, for example, the Bradford Hill criteria (Hill 1965 ) can be used to define a causal effect.
From a statistical perspective, there are two possibilities to tackle this issue. The gold standard is to design a randomized experiment, which enables causal conclusions. In the context of the SARS-CoV-2 pandemic, randomized controlled trials were used for assessment of COVID-19 treatments including the RECOVERY platform trial leading to publications such as Horby et al. ( 2020 ); Abani et al. ( 2021 ); RECOVERY Collaborative Group ( 2020 ). In the development of vaccines, too, randomized controlled trials (RCT) played a vital role (e.g., Baden et al. 2021 ; Shinde et al. 2021 ). However, randomized experiments are not always feasible due to ethical considerations, cost constraints and other reasons. Moreover, RCTs have been criticised for a number of problems including their lack of external validity (Rothwell 2005 ) or the Hawthorne effect (Mayo 2004 ).
Where randomized experiments are not possible and observational data is used instead, causal conclusions are harder to draw. In order to get valid estimates in this situation, a common approach is the counterfactual framework by Rubin ( 1974 ). For simplicity, assume that we are interested in the effect of a binary “treatment” A ∈ { 0 , 1 } (this could be an “ immediate lockdown” vs. “no immediate lockdown”, for example) on some outcome Y (e.g., number of infections with COVID-19). Then we denote Y a = 1 as the outcome that would have been observed under treatment a = 1 , and Y a = 0 the outcome that would have been observed under no treatment ( a = 0 ). A causal effect of A on Y is now present, if Y a = 1 ≠ Y a = 0 for an individual. In practice, however, only one outcome can be observed for each individual. Thus, it is only possible to estimate an average causal effect, i.e., E ( Y a = 1 ) - E ( Y a = 0 ) (Hernán and Robins 2020 ). Different possibilities for estimating a causal effect have been proposed, for example, propensity score methods (Cochran and Rubin 1973 ), the parametric g-formula (Robins et al. 2004 ), marginal structural models (Robins et al. 2000 ), structural nested models (Robins 1998 ) and graphical models (Didelez 2007 ). Recent works have shown that these methods have difficulties when it comes to small sample studies as in the context of COVID-19 (Friedrich and Friede 2020 ). Note that the methods explained here can also be applied to more complex situations such as non-binary treatments. In the pandemic, for example, it might be relevant to compare different time points for starting the lockdown, i.e., to include a time dimension in the considerations above. Furthermore, the methods can also be extended to more complicated outcome variables, e.g., time-to-event data.
Mathematical models and simulations can also be used to understand and explain dynamic patterns. Examples are simulation studies for public health interventions such as lockdown and exit strategies, where general consequences of different measures can be compared. Seemingly simple simulation models have played an important role in communicating the dynamics during a pandemic. In these models, assumptions about the system that generates the data and (causal) relationships are made. The (mis)match between data and model then provides insights that can be used as basis for decisions. However, this procedure does not establish causal relationships in the statistical sense described above.
The main challenge in modeling for explanation is good communication, irrespective of whether the model is based on statistical or mathematical approaches. Therefore, we consider standards for good communication in detail in Sect. 6 . Anticipating the human bias for interpreting results causally, clear statements need to be made to which extent (from “not at all” to “plausible”) specific detected associations allow some causal interpretation and why. The two extreme interpretations—on the one hand, the simple disclaimer that “correlation is not causation”, on the other, blanket and unqualified causal interpretations—do a disservice to the complexity of the problem as outlined by the methods above.
Modeling for prediction
In statistical prediction models, the modeler can choose from large toolboxes in (spatio)-time-series analysis as well as statistics and machine learning (ML). Examples cover simple but interpretable ARIMA models (Benvenuto et al. 2020 ; Roy et al. 2021 ), support vector machines (Rustam et al. 2020 ), joint hierarchical Bayes approaches (Flaxman et al. 2020 ) or state-of-the art ML methods, such as long short-term memory (LSTM) or extreme gradient boosting (XGBoost) (Luo et al. 2021 ). A comprehensive overview is also given by Kristjanpoller et al. ( 2021 ).
For predictions based on such models, one can distinguish different aims: now-casting and forecasting. For now-casting , information up to the current date and state are used to estimate or predict key figures, like the R value, for example, which estimates during a pandemic how many people an infected person infects on average. In forecasting , spatio-temporal predictions or simulations are used to look ahead in time, as in a weather forecast, or to estimate the required number of ICU beds. An important aspect in this situation is that the behavior of people influences the process that is being modeled. To be concrete, policy decisions are based on the predictions of a statistical or mathematical model and by introducing certain counter-measures, the original predictions of the model never come true. Thus, these models are not prediction models in a classical sense but more like projections, i.e., scenarios of what would happen if no intervention was taken. A thorough discussion of this topic can be found in Hellewell ( 2021 ). In forecasting models, a causal relationship between the predictors and the outcome may be required, while now-casting can also be achieved with predictive variables that do not necessarily have a causal effect on the outcome. Several statistical models have been proposed for now-casting, for example hierarchical Bayesian models (Günther et al. 2021 ) or trend regression models (Küchenhoff et al. 2021 ). Related approaches are discussed in Altmejd et al. ( 2020 ), Schneble et al. ( 2021 ), Salas ( 2021 ).
Dynamic Models/Time-variant Dynamics A unique feature of pandemic assessment is the dynamic nature of the event. By this, we not only refer to the explosive (exponential) growth that may occur but the fact that the properties of the processes that describe spatio-temporal changes are a function of time themselves. This is due to the fact that the behavior of the people continuously changes the properties of the system that we are trying to understand and make predictions for. This contrasts with other natural systems, like the current weather, and most systems in the engineering and physical sciences.
Simple infectious disease compartmental models can be described by the stock of susceptible S , infected I , and removed population R (either by death or recovery), the contact rate κ , the infection probability β , the recovery rate γ , the death rate μ and the birth rate Λ (Kermack and McKendrick 1927 ; Hethcote 2000 ; Andersson and Britton 2012 ; Grassly and Fraser 2008 ). Here,
where t denotes the time point, and N is the total number of individuals in the population, i.e., N = I + S + R .
Assuming that the susceptible individual first goes through a latent period after infection before becoming infectious E , adapted models such as SEI, SEIR or SEIRS, depending on whether the acquired immunity is permanent or not can be applied (Jit and Brisson 2011 ). Modeling the COVID-19 pandemic, applications include further approaches such as SIR-X accounting for the removal (quarantine) of symptomatic infected individuals and various other extensions and applications (Dehning et al. 2020 ; Dings et al. 2021 ) including prediction of the impact of vaccination (Bubar et al. 2021 ).
In this deterministic compartment model, predictions are determined entirely by their initial conditions, the set of underlying equations, and the input parameter values. Deterministic compartmental models have the advantage of being conceptually simple and easy to implement, but they lack for example stochasticity inherent in infectious disease transmission. In stochastic compartment models, the occurrence of events like transmission of infection or recovery is determined by probability distributions. Therefore, the chain of events (like an outbreak) is not exactly predictable. However, there are many possible types of stochastic epidemic models (Britton 2010 ; Kretzschmar et al. 2020 ).
Agent-based models (ABM) Agent-based modeling as an alternative approach uses individual-level simulation (Karnon et al. 2012 ). ABMs have been used to model biological processes, ecological systems, traffic management, customer flow management or stock markets, and in recent years increasingly for decision analysis as discussed later (Marshall et al. 2015 ; Bonabeau 2002 ; Macal and North 2008 ). ABMs represent complex systems in which individual ‘agents’ act autonomously and are capable of interactions (Miksch et al. 2019 ). These agents can represent the heterogeneity of individuals, and the behavior of individuals can be described by simple rules. Such rules include how agents interact, move between geographical zones, form households or consume resources (Chhatwal and He 2015 ; Bruch and Atwell 2015 ; Hunter et al. 2017 ). ABMs are often applied to study “emergent behavior” as a result of these predefined rules. In infectious disease modeling, agent behaviors combined with transmission patterns and disease progression lead to population-wide dynamics, such as disease outbreaks (Macal and North 2010 ). In agent-based models, either all affected individuals are simulated individually, or specific networks of individuals are integrated into the simulation.
Discrete Event Simulation (DES) Discrete event simulation is an individual-level simulation (Pidd 2004 ; Karnon et al. 2012 ; Jun et al. 1999 ; Zhang 2018 ). The core concepts of DES are entities (e.g., patients), attributes (e.g., patient characteristics), events, resources (i.e., physical resources such as medical staff and medical equipment), queues and time (Pidd 2004 ; Banks et al. 2005 ; Jahn et al. 2010 ). In addition to health outcomes, performance measures such as resource use or waiting times can be calculated, as physical resources (e.g., hospital beds) can be explicitly modeled (Jahn et al. 2010 ). The term discrete refers to the fact that DES moves forward in time at discrete intervals (i.e., the model jumps from the time of one event to the time of the next) and that events are discrete (mutually exclusive) (Karnon et al. 2012 ).
Microsimulation Microsimulation methods, introduced by Orcutt ( 1957 ), are used to simulate policy actions on real populations. Li and O’Donoghue ( 2013 ) describe microsimulations as “a tool to generate synthetic micro-unit-based data, which can then be used to answer many “what-if” questions that, otherwise, cannot be answered”. The main difficulty for microsimulation is considered to be the choice of an appropriate data source on which these simulations can be conducted. Often, survey data are used. Nowadays, the first step in microsimulation is the realistic generation of data in the necessary geographic depth (e.g., Li and O’Donoghue 2013 ). A full-population approach is described in Münnich et al. ( 2021 ). Thereafter, the scenario-based microsimulation analysis yields the necessary information for building conclusions for policy support. In microsimulation methods, we distinguish between static and dynamic models. The latter can be divided into time-continuous and time-discrete models. An overview of microsimulation methods is given in Li and O’Donoghue ( 2013 ) and the references therein. For modeling COVID-19, dynamic models have to be considered. Bock et al. ( 2020 ) presents a continuous time SIR microsimulation approach as an example for a dynamic transmission model. In contrast to ABM, other microsimulations are often based on survey data, or on realistic but synthetically extended survey data. The above-mentioned cohort simulations are usually deterministic simulations, in which an initial cohort of interest is followed over different paths over time, and thus leading to a distribution of outcomes after the analytic-time horizon. Recently, the dividing line between these methods and the related terminology has become blurred, Which method is ultimately used often depends on the background of the research team.
A key objective of forecasting in this context is to obtain numerically precise predictions, for variables such as the number of ICU beds. With this goal in mind, the reliability or accuracy of the predictions highly depends on the availability and quality of the data used to estimate the values of the parameters in the underlying mathematical or statistical models.
It should be noted that these models are highly sensitive to context in the following sense: changes in the underlying system in variables that are not part of the model can lead to changes in the relationship between the selected predictors and the predictions, rendering the predictions and their assumed uncertainty meaningless.
While it is widely appreciated that, for example, weather forecasts are only reliable for a couple of days, forecasting during a pandemic is even more complicated since the behavior of people influences the process that is being modeled. Forecasting during pandemics is, therefore, itself a continuous process with time-varying parameters. For this reason, such modeling effort is a complex undertaking requiring a range of data and expertise. Such activities should, therefore, be realized and coordinated through cross-disciplinary teams. To account for regional differences, one would expect a collective of modeling groups that support decision making for different parts of a country.
Decision-analytic modeling
Depending on the research question, different modeling approaches are used for decision-analytic modeling and development of computer simulations (IQWiG 2020 ; Roberts et al. 2012 ; Stiko 2016 ). These include decision tree models, state-transition models, discrete event simulation models, agent-based models and dynamic transmission models. Some of them have been introduced already since they are also commonly used for prediction. Models introduced in this section are predominantly used for decision analysis but could potentially be used for other purposes as well (Table (Table1 1 ).
The selection of the model type depends on the decision problem and the disease. In general, decision trees are applied for simple problems, without time-dependent parameters and with a fixed and comparatively short time horizon. If the decision problem requires the evaluation over a longer time period and if parameters are time or age dependent, a state-transition cohort (Markov) models (STM) could be applied. STMs allow for the modeling of different health states and transitions between these states and thus also for repeated events. They are applied when time to event is important. If the decision problem can be represented in an STM “with a manageable number of health states that incorporate all characteristics relevant to the decision problem, including the relevant history, a cohort simulation should be chosen because of its transparency, efficiency, ease of debugging and ability to conduct specific value of information analyses.” (Siebert et al. 2012 ). If the representation of the decision problem would lead to an unmanageable number of states, then an individual-level state-transition model is recommended (Siebert et al. 2012 ). Especially in situations where interactions of individuals among each other or the health-care system need to be considered, that is, when we are confronted with scarce physical resources, queuing problems and waiting lines (e.g., limited testing capacities), discrete event simulation (DES) would be an appropriate modeling technique. DES allows the modeler to incorporate time-to-event data (e.g., time to progression), and physical resources are explicitly defined (Karnon et al. 2012 ). Modeling types such as differential equation systems, agent-based models and system dynamics account for the specific features of infectious diseases such as the transmissibility from infected to susceptible individuals and the uncertainties arising from complex natural history and epidemiology (Pitman et al. 2012 ; Grassly and Fraser 2008 ; Jit and Brisson 2011 ).
Decision tree models In a decision-tree model, the consequences of alternative interventions or health technologies are described by possible paths. Decision trees start with decision nodes, followed by alternative choices (interventions, technologies, etc.) of the decision maker. For each alternative, the patients’ paths, which are determined by chance and that are outside the decision maker’s control, are then described by chance nodes. At the end of the paths, the respective consequences of each path are shown. Consequences or outcomes may include symptoms, survival, quality of life, number of deaths or costs. Finally, the expected outcomes of each alternative choice are calculated by taking a weighted average over all pathways (Hunink et al. 2001 ; Rochau et al. 2015 ), such as in the evaluation of COVID-19 testing strategies for university campuses in a decision-tree analysis (Van Pelt et al. 2021 ).
State-transition models A state-transition model is conceptualized in terms of a set of (health) states and transitions between these states. Time is represented in time intervals. Transition probabilities, time cycle length, state values (“rewards”) and termination criteria are defined in advance. During the simulations, individuals can only be in one state in each cycle. Paths of individuals determined by events during a cycle are modeled with a Markov cycle tree that uses a set of random nodes. The average number of cycles in which individuals are in each state can be used in conjunction with the rewards (e.g., life years, health-related quality of life or costs) to estimate the consequences in terms of life expectancy, quality-adjusted life expectancy, and the expected costs of alternative interventions or health technologies. There are two common types of analyses of state-transition models: Cohort models (“Markov”) (Beck and Pauker 1983 ; Sonnenberg and Beck 1993 ) and individual-level models (“first order Monte Carlo” models) (Spielauer 2007 ; Groot Koerkamp et al. 2010 ; Weinstein 2006 ). Simple cohort models are defined in mathematical literature as discrete-time Markov chains. A discrete-time Markov chain is a sequence of random variables X 0 , X 1 , X 2 , … representing health states with the Markov property, namely that the probability of moving to the next health state depends only on the present state and not on the previous states:
Generalized models such as continuous time Markov chains with finite or infinite state space are not commonly applied in health decision science. Applications of state-transition models in the pandemic include evaluation of treatments (Sheinson et al. 2021 ) and vaccination strategies (Kohli et al. 2021 ). We also find hybrid models including the combination of decision trees and STMs (see Fig. Fig.2 2 ).

Example: a cost-effectiveness framework for COVID-19 treatments for hospitalized patients in the United States, (Sheinson et al. 2021 )
Discrete Event Simulation (DES) Similar to decision trees and state-transition models, health outcomes and costs of alternative health technologies can be assessed. In addition to these outcomes, as mentioned earlier, performance measures can be calculated as additional information for decision makers, and the impact of scarce resources on costs and health outcomes can be evaluated (Jahn et al. 2010 ). The increased use of DES to support decision making under uncertainty is shown in the review of Zhang ( 2018 ). Model applications in COVID-19 include optimizations of processes with scarce resources such as bed capacities (Melman et al. 2021 ) or testing stations (Saidani et al. 2021 ) and laboratory processes (Gralla 2020 ).
Dynamic Models/Time-variant Dynamics The dynamic SIR type models explained in Sect. 4.2 can also be used in the context of decision-analytic modeling (e.g., vaccination allocation, ECDC 2020a ; Sandmann et al. 2021 ) . This model type can be extended by further compartments such as Death (D) and other states (X), reflecting, for example, quarantine or other states relevant to the research question. Such SIRDX models have been used frequently to model non-pharmaceutical intervention effects during the COVID-19 pandemics (Nussbaumer-Streit et al. 2020 ). As in Markov state-transition models, a deterministic cohort simulation approach is used to model the distribution of compartments over time. Deterministic compartment models are useful for modeling the average behavior of disease epidemics in larger populations. When stochastic effects (e.g., the extinction of disease in smaller populations), more complex interactions between disease and individual behavior or distinctly nonrandom mixing patterns (e.g., the spread of the disease in different networks) are relevant, stochastic agent-based approaches can be used (see next section).
Agent-based models (ABM) Agent-based models as introduced earlier, have been used for decision analysis, for example for cost-effectiveness analyses in health care in the recent years (Marshall et al. 2015 ; Chhatwal and He 2015 ). ABMs are also used in public health studies to model noncommunicable diseases (Nianogo and Arah 2015 ). A comparison of ABM, DES and system dynamics can be found in Marshall et al. ( 2015 ), Marshall et al. ( 2015 ) and Pitman et al. ( 2012 ). ABMs are increasingly applied for COVID-19 evaluations including decision support for vaccination allocation accounting explicitly for network structure and contact behavior (Bicher et al. 2021 ; Jahn et al. 2021 ).
Microsimulation Microsimulation as a modeling approach based on survey data and combining characteristics of above mentioned modeling approaches is used for prediction and decision analysis in various fields, especially for policy support using scenarios. Recently, MSM are also used for modeling diseases (Hennessy et al. 2015 ) including infectious diseases.
Table Table2 2 provides a short comparative overview of these commonly applied modeling approaches with example applications for COVID-19 research, in addition to our general comparison at the beginning of the section. Further guidance on model selection for a given problem at hand exists (IQWiG 2020 ; Roberts et al. 2012 ; Siebert et al. 2012 ; Marshall et al. 2015 ).
Overview of differences and similarities of simulation models commonly used as the basis for health decision sciences
Decision analysis
The models described in Sect. 4 are built to inform decision making. Therefore, the so-called decision analysis framework is used. Decision analysis aims to support decisions under uncertainty by means of systematic, explicit and quantitative methods. In particular, computer simulations and prediction models as described above are used to calculate the short-term and long-term benefits and harms (as well as the costs) of alternative interventions, technologies or measures in health care (Schöffski and Schulenburg 2011 ; Richardson and Spiegelhalter 2021 ). The decision-analytic framework includes, among other things, the relevant health states and events considered to describe possible disease trajectories, the type of analysis (e.g., benefit-harm, cost-benefit, budget-impact analyses (Drummond et al. 2005 )) and the simulation method (cohort- or individual-based). In addition to base-case analysis (using the most likely parameters), scenario and sensitivity analyses (Briggs et al. 2012 ) should be performed to show the robustness or uncertainty of the results. Value of information analysis can be applied to assess the value of future research to reduce uncertainty (Fenwick et al. 2020 ; Siebert et al. 2013 ).
Decision tradeoffs
A central idea in decision analysis is that tradeoffs in outcomes of alternative choices are formalized and, if possible, quantified. In addition, the tradeoff between such outcomes is explicitly expressed, usually in the form of an incremental tradeoff ratio. In the context of a benefit-harm analysis, for example, this relates to quantifying the benefits of COVID-19 vaccination in terms of (incremental) deaths avoided and the harms of vaccination in terms of (incremental) potential side effects.Alternatively, the tradeoff of different school closure strategies in a pandemic (e.g., according to incidence level) weighting benefits in terms of (incremental) deaths or hospitalisations avoided and lost education time should be considered. In general, two or more interventions can be compared in a stepwise incremental fashion (Keeney and Raiffa 1976 ). Benefit-harm analyses are often applied in screening evaluations (Mandelblatt et al. 2016 ; Sroczynski et al. 2020 ). To detect efficient strategies, so-called strongly dominated strategies are first excluded. These are strategies that result in higher harms (e.g., due to testing or invasive diagnostic work-up) and lower benefits (e.g., cancer-cases avoided, life-years gained) than other strategies. Second, weakly dominated strategies are excluded, that is strategies that result in higher harms per additional benefit compared with the next most harmful strategy, or in other words, strategies that are strongly dominated by a linear combination of any two other strategies. Third, the incremental harm-benefit ratios (IHBRs) are calculated for the non-dominated strategies.
There is no general benchmark for how much additional harm individuals are willing to accept per unit of additional benefit. Strategies are explored as a function of willingness-to-accept thresholds, and they are displayed as harm-benefit acceptability curves on the efficiency frontier (Neumann et al. 2016 ).
In this context, the choice of measures that are presented and discussed also influences decision behavior (Ariely and Jones 2008 ). The same applies to changes in decision-making due to alternatives that are presented. Regarding optimization of vaccination interventions, temporal aspects of availability and effectiveness of vaccinations can be considered. Alternative strategies can be evaluated, like in the comparison of immediate vaccination with lower vaccine protection, against later vaccination with expected higher effectiveness but risk of intermediate infection. Further non-pharmaceutical measures like school-closure strategies can be evaluated depending on incidence level but also accounting for additional measures to reduce the spread of the disease.
Statistical decision theory
As a more general framework, statistical decision theory can help to make decisions on a formal basis. In this framework, the decision maker has to choose among a set of different actions a by quantitatively assessing the consequences of these actions. To this end, we consider a loss function L ( θ , a ) , where the unknown parameter θ refers to the “state of the world”. The interesting question for the statistician is how to use the data in order to make optimal decisions. Assume we observe an experimental outcome x with possible values in a set X , which depends on the unknown parameter θ . Furthermore, let f ( x | θ ) be the corresponding likelihood function. Then, we define a decision function δ ( x ) which turns data into actions (Parmigiani and Inoue 2009 ). To choose between decision functions, we measure their performance by a risk function
These can be approached from either a frequentist perspective (e.g., the minimax decision rule) or a Bayesian perspective, where the risk is associated with a prior distribution π ( θ ) . For a more thorough treatment of these concepts, we refer to Parmigiani and Inoue ( 2009 ).
Examples for loss functions in the context of COVID-19 include the number of avoided deaths (Bubar et al. 2021 ), negative reward functions in Markovian decision models (Eftekhari et al. 2020 ) or the social loss function as proposed in a recent discussion paper of the European Commission (Buelens et al. 2021 ).
Reporting and communication
For data analysis and modeling to have an impact as a component of decision making, appropriate reporting and communication is key. There are numerous standards and guidelines for study planning and statistical reporting in the numerous application areas, such as the ESS standard for quality reporting, the CONSORT, PRISMA, CHEERs guidelines and others (see https://equator-network.org ). These standards are based on commonly accepted core quality principles and values such as accuracy, relevance, timeliness, clarity, coherence and reproducibility. For measures to restrain and overcome an epidemic effectively, communication among experts that follows highest professional and ethical standards is not sufficient. In a democratic society, policy measures can only be implemented if they are accepted by the wider population. This puts high demand on skills associated with communicating statistical evidence on the side of scientists, governments and media, and a citizenry able to understand statistical messages.
In recent decades, there have been numerous publications, initiatives, and ideas to improve the communication of quantitative and statistical information, see Hoffrage et al. ( 2000 ), Tufte ( 2001 ), Rosling and Zhang ( 2011 ), Otava and Mylona ( 2020 ), to name only a few. Data journalism has recently taken off as an innovative component of news publishing, and COVID-19 provides numerous excellent examples, often using an interactive visual format on the Internet, such as dashboards. A fundamental problem in assessing probabilities, for example, lies in the intuitive conflation of subjective risks (“how likely am I to become infected”) and general risks (“how likely is it that some person will become infected”). Another issue is that of equating sensitivity of a diagnostic test and the positive predictive value (Eddy 1982 ; Gigerenzer et al. 2007 ; McDowell et al. 2019 ; Binder et al. 2020 ). In particular, the prevalence (or base rate) is often neglected leading to this confusion. Fact boxes combined with icon arrays are recommended for the presentation of test results. Both representations are based on natural frequencies (Gigerenzer 2011 ; Krauss et al. 2020 ) and present case numbers as simply and concretely as possible. Many scientific studies show that icon arrays help people understand numbers and risks more easily (e.g., McDowell et al. 2019 ). The Harding Center for Risk Literacy shows many other examples of transparent communication of risks, including COVID-19 1 and a collection of misleading or wrong communication of statistics, such as for vaccination effects (“Unstatistik”).
When communicating the results of an analysis to policy makers or the general public, the following aspects must also be kept in mind. While human thinking tends towards pattern simplification and political communication also prefers a simple cause-effect relationship, real phenomena are often multivariate. Thus, when studying COVID-19 and predicting its spread, it is important to consider its symptomatology, the incidence and geographic distribution of diseases, population behavior patterns, government policies and impacts on the economy, on schools, on people in nursing homes and on social life as a whole. However, it is also crucial to integrate these into data analyses and to communicate results clearly and transparently; for example, it might be important to state that associations observed in the data could be caused by other, omitted variables (confounders). In addition, much of the data comes from observational studies, which usually makes a robust causal attribution problematic. As many of these phenomena cannot be studied other than by observation (for ethical and feasibility reasons), causal attribution might be achieved as a scientific consensus opinion among scientists from the relevant disciplines that understand the complexity of the models and the subject matter studied. Visual representations take a central position in public communication and aim to represent the corresponding dynamics and contents in a quickly understandable way. Usually either time-dependent parameters or data with a spatial reference are visualized. For spatially distributed data, choropleth maps are predominantly used, in which administrative regions defined by the responsible health authorities are colored according to the distribution density of the infection figures or variables derived from them (see Fig. 3 ). Their visual perception problems—such as the visual dominance of the area of administrative regulatory frameworks that have no direct relation to infection events—are well known but the effects of such problems are still widespread. In addition, the use of ordinance thresholds as the basis for color scaling is often at odds with color schemes that emphasize real spatial distributional differences.

Choropleth map of the incidence figures on 2021-02-12 for Germany by district. Source: Robert-Koch-Institute https://app.23degrees.io/export/oCRP768wQ3mCswE7-choro-corona-faelle-pro-100-000/image
For time-dependent parameters, different variants of time series diagrams are used, predominantly line and column diagrams. The use of logarithmic scales in time series diagrams should be evaluated with caution (Romano et al. 2020 ). On the one hand, they tempt superficial readers to underestimate dynamic growth processes; on the other hand, they increase the demands on the mathematical and statistical literacy of the readership without corresponding advantages of visual representation. Figure 4 shows the time course of the 7-day incidence per 100,000 people between 24 January and 4 February 2021 for some selected countries. While the differences appear relatively small on the logarithmic scale, the linear scale shows considerable differences.

The 7-day incidence for different countries over time. On the logarithmic scale (top graphic), differences appear small. The linear scale (bottom graphic), however, shows considerable differences. Source: Our World in Data, https://ourworldindata.org/covid-cases?country=INDUSAGBRCANDEUFRA , accessed 2022-02-22
Recommendations
Reaching a decision based on data requires several steps, which we have illustrated in this paper: Data provide the basis for different kinds of models, which can be used for prediction, explanation and decision making. This forms the basis for making decisions within a formal framework. The results of these models must be communicated to non-scientists in order to gain acceptance of and adherence to policy decisions. Each of these steps comes with its own caveats and requires sound statistical knowledge.
Data: Lessons learned from the current pandemic about data, variables and information that should be obtained are critically discussed for specific countries (Grossmann et al. 2022 ; The Royal Statistical Society 2021 ; Rendtel et al. 2021 ) and on a European and international level (Kucharski et al. 2021 ; ECDC 2020b ), (Dean 2022 ; Mathieu 2022 ). Examples include establishing new vaccination registries, extending coronavirus registries with further socio-demographic parameters and data sharing. We recommend the implementation of standards (European Statistics Code of Practice 2017 ) and processes for data collection on a national and international level, especially within Europe. These standards need to be refined, meeting the requirements of relevance, transparency, truthfulness, timeliness and accuracy to improve the handling of epidemics and pandemics in the coming years. National and international strategies and systematic collection and sharing of data allowing researchers to access the information that is important to build comparable statistical and decision-analytic models.
Modeling Methods: Depending on the modeling approach, the model can be fit to one data set (e.g., regression model) or data from different sources with different levels of evidence can be used to populate the model (e.g., decision-analytic models). In addition, several modeling approaches may be applicable for one research question (e.g., differential equation model or ABM for the prognosis of COVID-19 spread and consequences). We recommend clear communication about 1) the purpose of the model, 2) how the model uses data, 3) the database or additional assumptions and their evidence basis, and 4) risks and uncertainties. If applicable, several modeling approaches should be applied. As a result, the model best fitting the data would be selected or different modeling approaches could provide insights into uncertainty, like in national forecasting consortia (e.g., as in the Austrian COVID Prognosis Consortium (CPK 2021 )) and nowcast/forecast ensembles. The infrastructure of comprehensive population or microsimulation models—including population, disease and flexible intervention or policy modules—needs to be established and maintained beyond the current crisis.
Data Aquisition: Models require data from various sources, and different modeling approaches allow data transformation and synthesis from different sources. Data aquisition for scientific evaluations requires a further improved infrastructure to speed up model development and to parameterize models with high level evidence including vaccine effectiveness in real time. We recommend the creation of a central national DataLab, collecting data in a unified way and linking data from different sources as well as enabling accessibility for experienced users. With regard to data sharing, it is important that this is manageable from a practical point of view in terms of the time frame and resources needed.
Transparency: In the wake of the COVID-19 pandemic, reporting of infection numbers and derived epidemiological indicators boomed, demonstrating with dramatic clarity the knowledge gap between experts, policymakers and the public. To increase the acceptance of decisions and associated measures, all steps in the decision-making process must be disclosed. We recommend a transparent decision-making process and communication of this process starting with the data, continuing with the choice of models, relevant perspectives, outcomes or metrics for several outcomes and an explicit discussion of considered tradeoffs (see, e.g., Gigerenzer et al. 2007 ; Gigerenzer and Edwards 2003 ; Richardson and Spiegelhalter 2021 ). In this context, the media also play a crucial role.
Interdisciplinary cooperation: A pandemic poses particular challenges to society as a whole. In order to tackle these as efficiently as possible, interdisciplinary cooperation, such as that fostered by the DAGStat, is essential. We recommend that experts act as a specialist group rather than as individuals, broadly positioned and media-sensitive. These interdisciplinary collaborations should consist of data scientists including statisticians, epidemiologists, experts in public health, social sciences and ethics, as well as decision and communication scientists. The DAGStat as an umbrella organization of various professional societies, the Competence Network Public Health COVID-19 or the Society for Medical Decision Making (SMDM) are examples for existing networks that can be built upon.
Statistical Literacy / Data Literacy: The COVID-19 crisis brought into the general public’s awareness that our social interaction and political decisions are essentially based on data, modeling, the weighing of risks and benefits, and thus on probability estimates, expected values and incremental harm-benefit ratios. Clearly, we need additional efforts to promote statistical or data literacy at all levels of society. The ability to critically evaluate and interpret data and to critically reflect on model outcomes serves to promote maturity in a modern digitized world. We recommend promotion of statistical literacy to be intensified at all levels of education (school/vocational education/training) following the Data Literacy Charta (Schüller et al. 2021 ) and including risk competency (Ball et al. 2020 ; Loss et al. 2021 ). Therefore, collaboration between statisticians and all stakeholders involved in statistical literacy is necessary.
In our paper, we discussed all steps starting from data capturing to statistics, modeling, decision making and communication which are important aspects in the context of evidence-based decision making. The current pandemic has shown that, in particular in Germany, we are still far from such an evidence-based decision-making process. Aims of this process include the following: First, it should result in the best possible decision given the available evidence, and it is necessary to explicitly consider the tradeoffs involved with certain interventions. Second, gaining the public’s acceptance of the decisions is fundamental. In order to achieve these goals, we need reliable data, careful interpretation of the results and a clear communication, especially concerning uncertainty, see, for instance, WHO ( 2020 ).
It is important to note that the considerations described in our paper not only apply to the current pandemic, but also extend to future pandemics 2 and other (public or political) challenges such as the climate change debate (Ritchie 2021 ).
Our paper has several limitations. First, we refer to data as the input to the statistical models irrespective of possible preprocessing steps. An upcoming publication on data and data infrastructure in Germany will include more details on data preparation, building upon the DAGStat white paper (Deutsche Arbeitsgemeinschaft Statistik 2021 ). Second, our overview of modeling techniques does not provide a detailed discussion of all modeling approaches and their advantages and limitations but it should foster interdisciplinary collaboration among data scientists. References on guidance papers provide valuable further readings. Third, the decision-making process involves a variety of stakeholders, including politicians, government agencies and health authorities, health care providers, citizens, patients and their relatives, scientists, and they all take different perspectives. We have not discussed this aspect in detail in our paper, but the original white paper included a paragraph on political decision making (Deutsche Arbeitsgemeinschaft Statistik 2021 ).
The German Consortium in Statistics (DAGStat), a network of 13 statistical associations and the German Federal Office of Statistics 3 and the Society for Medical Decision Making (SMDM), initiated a collaboration of scientists with backgrounds in all areas of statistics as well as epidemiology, decision analysis and political sciences to critically discuss the role of data and statistics as a basis for decision-making motivated by the COVID-19 pandemic. We found that similar concepts are often considered in different areas, but different notation and wording can hinder transferability. In this sense, this paper also aims to bridge the gaps between disciplines and to broaden the research focus of statistical disciplines to prepare for future pandemics.
Acknowledgements
We thank Lyndon James (Harvard T.H. Chan School of Public Health) for proofreading and language editing.
Open Access funding enabled and organized by Projekt DEAL. Tim Friede and Markus Pauly are grateful for support by the Volkswagen Foundation (“Bayesian and Nonparametric Statistics—Teaming up two opposing theories for the benefit of prognostic studies in Covid-19”). Research by Beate Jahn and Uwe Siebert was also funded in part by the Austrian Federal Ministry for Digital and Economic Affairs BMDW and handled by the Austrian Research Promotion Agency (FFG) within the Emergency Call for research into COVID-19 in response to the SARS-CoV-2 outbreak (CIDS-Concurrent Infectious Disease Simulation) (881665) and by the Gordon and Betty Moore Foundation through Grant (GBMF9634) to Johns Hopkins University to support the work of the Society for Medical Decision Making COVID-19 Decision Modeling Initiative.
Declarations
The authors declare that they have no conflict of interest.
1 https://www.hardingcenter.de/de/ .
2 https://www.statnews.com/2021/05/18/luck-is-not-a-strategy-the-world-needs-to-start-preparing-now-for-the-next-pandemic/ .
3 https://www.dagstat.de/en/about-us/cooperating-societies .
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Beate Jahn and Sarah Friedrich: Shared first authorship.
- Abadie A, Athey S, Imbens GW, Wooldridge JM. Sampling-based versus design-based uncertainty in regression analysis. Econometrica. 2020; 88 (1):265–296. [ Google Scholar ]
- Abani O, Abbas A, Abbas F, Abbas M, Abbasi S, Abbass H, Abbott A, Abdallah N, Abdelaziz A, Abdelfattah M, et al. Convalescent plasma in patients admitted to hospital with COVID-19 (RECOVERY): a randomised controlled, open-label, platform trial. The Lancet. 2021; 397 (10289):2049–2059. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Altman DG, Bland JM. Uncertainty beyond sampling error. BMJ. 2014; 349 :g7065. [ PubMed ] [ Google Scholar ]
- Altmejd, A., Rocklöv, J., Wallin, J.: Nowcasting Covid-19 statistics reported with delay: a case-study of Sweden. (2020). arXiv:2006.06840
- Andersson H, Britton T. Stochastic Epidemic Models and Their Statistical Analysis. Berlin: Springer; 2012. [ Google Scholar ]
- Anker SD, Butler J, Khan MS, Abraham WT, Bauersachs J, Bocchi E, Bozkurt B, Braunwald E, Chopra VK, Cleland JG, Ezekowitz J, Filippatos G, Friede T, Hernandez AF, Lam CSP, Lindenfeld J, McMurray JJV, Mehra M, Metra M, Packer M, Pieske B, Pocock SJ, Ponikowski P, Rosano GMC, Teerlink JR, Tsutsui H, Van Veldhuisen DJ, Verma S, Voors AA, Wittes J, Zannad F, Zhang J, Seferovic P, Coats AJS. Conducting clinical trials in heart failure during (and after) the COVID-19 pandemic: an Expert Consensus Position Paper from the Heart Failure Association (HFA) of the European Society of Cardiology (ESC) Eur. Heart J. 2020; 41 (22):2109–2117. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Ariely D, Jones S. Predictably Irrational. New York: Harper Audio; 2008. [ Google Scholar ]
- Baden LR, El Sahly HM, Essink B, Kotloff K, Frey S, Novak R, Diemert D, Spector SA, Rouphael N, Creech CB, McGettigan J, Khetan S, Segall N, Solis J, Brosz A, Fierro C, Schwartz H, Neuzil K, Corey L, Gilbert P, Janes H, Follmann D, Marovich M, Mascola J, Polakowski L, Ledgerwood J, Graham BS, Bennett H, Pajon R, Knightly C, Leav B, Deng W, Zhou H, Han S, Ivarsson M, Miller J, Zaks T. Efficacy and safety of the mRNA-1273 SARS-CoV-2 Vaccine. N. Engl. J. Med. 2021; 384 (5):403–416. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Ball, D., Humpherson, E., Johnson, B., McDowell, M., Ng, R., Radaelli, C., Renn, O., Seedhouse, D., Spiegelhalter, D., Uhl, A., Watt, J.: Improving Society’s Management of Risks—a statement of principles. Collaboration to explore new avenues to improve public understanding and management of risk (CAPUR). Atomium, EISMD (2020)
- Banks J, Carson JS, Nelson BL, Nicol DM. Discrete Event System Simulation. New Delhi: Pearson Education India; 2005. [ Google Scholar ]
- Beck JR, Pauker SG. The Markov process in medical prognosis. Med. Decis. Mak. 1983; 3 (4):419–458. [ PubMed ] [ Google Scholar ]
- Benvenuto D, Giovanetti M, Vassallo L, Angeletti S, Ciccozzi M. Application of the ARIMA model on the COVID-2019 epidemic dataset. Data Brief. 2020; 29 :105340. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Beyersmann, J., Friede, T., Schmoor, C.: Design aspects of COVID-19 treatment trials: improving probability and time of favorable events. Biometr. J. (2021) [ PMC free article ] [ PubMed ]
- Bicher, M., Rippinger, C., Urach, C., Brunmeir, D., Siebert, U., Popper, N.: Evaluation of Contact-Tracing Policies against the Spread of SARS-CoV-2 in Austria: An Agent-Based Simulation. Medical decision making : an international Journal of the Society for Medical Decision Making pp. 1–16 (2021) [ PubMed ]
- Binder K, Krauss S, Wiesner P. A new visualization for probabilistic situations containing two binary events: the frequency net. Front. Psychol. 2020; 11 :750. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Bock, W., Adamik, B., Bawiec, M., Bezborodov, V., Bodych, M., Burgard, J.P., Goetz, T., Krueger, T., Migalska, A., Pabjan, B., et al.: Mitigation and herd immunity strategy for COVID-19 is likely to fail. medRxiv (2020)
- Bonabeau E. Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. 2002; 99 (suppl 3):7280–7287. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Briggs AH, Weinstein MC, Fenwick EAL, Karnon J, Sculpher MJ, Paltiel AD. Model Parameter Estimation and Uncertainty Analysis: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force Working Group-6. Med. Decis. Making. 2012; 32 (5):722–732. [ PubMed ] [ Google Scholar ]
- Britton T. Stochastic epidemic models: A survey. Math. Biosci. 2010; 225 (1):24–35. [ PubMed ] [ Google Scholar ]
- Bruch E, Atwell J. Agent-based models in empirical social research. Sociological Methods & Research. 2015; 44 (2):186–221. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Bubar, K.M., Reinholt, K., Kissler, S.M., Lipsitch, M., Cobey, S., Grad, Y.H., Larremore, D.B.: Model-informed COVID-19 vaccine prioritization strategies by age and serostatus. Science 371 (6532), 916–921 (2021). 10.1126/science.abe6959, https://www.science.org/doi/abs/10.1126/science.abe6959 [ PMC free article ] [ PubMed ]
- Buelens C, et al. (2021) Lockdown policy choices, outcomes and the value of preparation time - a stylised model. Tech. rep., Directorate General Economic and Financial Affairs (DG ECFIN), European Commission
- Chatfield C. Model uncertainty, data mining and statistical inference. J. R. Stat. Soc. A. Stat. Soc. 1995; 158 (3):419–444. [ Google Scholar ]
- Chhatwal J, He T. Economic evaluations with agent-based modelling: an introduction. Pharmacoeconomics. 2015; 33 (5):423–433. [ PubMed ] [ Google Scholar ]
- Cochran, W.G., Rubin, D.B.: Controlling bias in observational studies: A review. Sankhyā: The Indian Journal of Statistics, Series A pp. 417–446 (1973)
- COVID-19 Data Analysis Group: CODAG Berichte. (2021). https://www.covid19.statistik.uni-muenchen.de/newsletter/index.html
- CPK: Covid-prognose-konsortium. (2021). https://www.sozialministerium.at/Informationen-zum-Coronavirus/Neuartiges-Coronavirus-(2019-nCov)/COVID-Prognose-Konsortium.html
- Dean N. Tracking COVID-19 infections: time for change. Nature. 2022; 602 (7896):185. doi: 10.1038/d41586-022-00336-8. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Debrabant K, Grønbæk L, Kronborg C. The cost-effectiveness of a covid-19 vaccine in a danish context. Clin. Drug Investig. 2021; 41 :975–988. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- DeGroot MH, Schervish MJ. Probability and Statistics. New Delhi: Pearson Education Limited; 2014. [ Google Scholar ]
- Dehning, J., Zierenberg, J., Spitzner, F.P., Wibral, M., Neto, J.P., Wilczek, M., Priesemann, V.: Inferring change points in the spread of COVID-19 reveals the effectiveness of interventions. Science 369 (6500), (2020) [ PMC free article ] [ PubMed ]
- Desrosières, A.: A politics of knowledge-tools: The case of statistics. Between Enlightenment and Disaster: Dimensions of the Political Use of Knowledge, Brussels: Peter Lang pp 111–129 (2010)
- Deutsche Arbeitsgemeinschaft Statistik: Stellungnahme der DAGStat. Daten und Statistik als Grundlage für Entscheidungen: Eine Diskussion am Beispiel der Corona-Pandemie. (2021). https://www.dagstat.de/fileadmin/dagstat/documents/DAGStat_Covid_Stellungnahme.pdf
- Didelez V. Graphical models for composable finite Markov processes. Scand. J. Stat. 2007; 34 (1):169–185. [ Google Scholar ]
- Dings, C., Götz, K., Och, K., Sihinevich, I., Selzer, D., Werthner, Q., Kovar, L., Marok, F., Schräpel, C., Fuhr, L., Türk, D., Britz, H., Smola, S., Volk, T., Kreuer, S., Rissland, J., Lehr, T.: COVID-19 Simulator. (2021). https://covid-simulator.com/en
- Drummond, M., Sculpher, M., Torrance, G., O’Brien, B., Stoddart, G.: Methods for the economic evaluation of health care programmes, 3rd edn, Oxford University Press, New York, USA, chap Chapter 2: Basic types of economic evaluation, pp. 6–33 (2005)
- Drummond MF, Schwartz JS, Jönsson B, Luce BR, Neumann PJ, Siebert U, Sullivan SD. Key principles for the improved conduct of health technology assessments for resource allocation decisions. Int. J. Technol. Assess. Health Care. 2008; 24 :244–258. [ PubMed ] [ Google Scholar ]
- Duran BS, Odell PL. Cluster analysis: a survey. Berlin: Springer; 2013. [ Google Scholar ]
- EbM-Netzwerk: COVID-19: Wo ist die Evidenz? (2020). https://www.ebm-netzwerk.de/de/veroeffentlichungen/stellungnahmen-pressemitteilungen
- ECDC: Covid-19 vaccination and prioritisation strategies in theeu/eea. (2020a). https://www.ecdc.europa.eu/sites/default/files/documents/COVID-19-vaccination-and-prioritisation-strategies.pdf
- ECDC: Strategic andperformance analysisof ecdc response tothe covid-19 pandemic. (2020b). https://www.ecdc.europa.eu/sites/default/files/documents/ECDC_report_on_response_Covid-19.pdf
- Eddy DM. Probabilistic reasoning in clinical medicine: Problems and opportunities. In: Kahneman D, Slovic P, Tversky A, editors. Judgment under Uncertainty: Heuristics and Biases. Cambridge: Cambridge University Press; 1982. pp. 249–267. [ Google Scholar ]
- Eftekhari, H., Mukherjee, D., Banerjee, M., Ritov, Y.: Markovian And Non-Markovian Processes with Active Decision Making Strategies For Addressing The COVID-19 Pandemic. (2020). arXiv preprint arXiv:200800375
- European Statistics Code of Practice (2017). URL europa.eu
- Evangelou, N,. Garjani, A., dasNair, R., Hunter, R., Tuite-Dalton, K.A., Craig, E.M., Rodgers, W.J., Coles, A., Dobson, R., Duddy, M., Ford, D.V., Hughes, S., Pearson, O., Middleton, L.A., Rog, D., Tallantyre, E.C., Friede, T., Middleton, R.M., Nicholas, R.: Self-diagnosed covid-19 in people with multiple sclerosis: a community-based cohort of the uk ms register. Journal of Neurology, Neurosurgery & Psychiatry 92 (1),107–109 (2021). https://jnnp.bmj.com/content/92/1/107 [ PMC free article ] [ PubMed ]
- Fabrigar LR, Wegener DT. Exploratory factor analysis. Oxfordd: Oxford University Press; 2011. [ Google Scholar ]
- Fahrmeir L, Kneib T, Lang S, Marx B. Regression. Berlin: Springer; 2007. [ Google Scholar ]
- Fenwick E, Steuten L, Knies S, Ghabri S, Basu A, Murray JF, Koffijberg HE, Strong M, Sanders Schmidler GD, Rothery C. Value of Information Analysis for Research Decisions-An Introduction: Report 1 of the ISPOR Value of Information Analysis Emerging Good Practices Task Force. Value in health : the Journal of the International Society for Pharmacoeconomics and Outcomes Research. 2020; 23 :139–150. [ PubMed ] [ Google Scholar ]
- Flaxman S, Mishra S, Gandy A, Unwin HJT, Mellan TA, Coupland H, Whittaker C, Zhu H, Berah T, Eaton JW, et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature. 2020; 584 (7820):257–261. [ PubMed ] [ Google Scholar ]
- Friedrich S, Friede T. Causal inference methods for small non-randomized studies: Methods and an application in COVID-19. Contemp. Clin. Trials. 2020; 99 :106213. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Friedrich, S., Antes, G., Behr, S., Binder, H., Brannath, W., Dumpert, F., Ickstadt, K., Kestler, H.A., Lederer, J., Leitgöb, H., Pauly, M., Steland, A., Wilhelm, A., Friede, T.: Is there a role for statistics in artificial intelligence? Advances in Data Analysis and Classification pp. 1–24 (2021)
- Gabler S, Quatember A. Repräsentativität von Subgruppen bei geschichteten Zufallsstichproben. AStA Wirtschafts-und Sozialstatistisches Archiv. 2013; 7 (3–4):105–119. [ Google Scholar ]
- Gandjour, A.: Willingness to pay for new medicines: a step towards narrowing the gap between NICE and IQWiG. BMC Health Services Research 20 , (2020) [ PMC free article ] [ PubMed ]
- Gigerenzer G. What are natural frequencies? BMJ. 2011; 343 :d6386. [ PubMed ] [ Google Scholar ]
- Gigerenzer G, Edwards A. Simple tools for understanding risks: from innumeracy to insight. BMJ. 2003; 327 (7417):741–744. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Gigerenzer G, Gaissmaier W, Kurz-Milcke E, Schwartz LM, Woloshin S. Helping doctors and patients make sense of health statistics. Psychological Science in the Public Interest. 2007; 8 (2):53–96. [ PubMed ] [ Google Scholar ]
- Gralla, E.: Discrete Event Simulation for COVID-19 Testing: Identifying Bottlenecks and Supporting Scale-Up. In: 42nd Annual Meeting of the Society for Medical Decision Making, SMDM (2020)
- Grassly NC, Fraser C. Mathematical models of infectious disease transmission. Nat. Rev. Microbiol. 2008; 6 :477–487. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Groot Koerkamp B, Weinstein MC, Stijnen T, Heijenbrok-Kal MH, Hunink MM. Uncertainty and patient heterogeneity in medical decision models. Med. Decis. Making. 2010; 30 (2):194–205. [ PubMed ] [ Google Scholar ]
- Gross, O., Moerer, O., Rauen, T., Böckhaus, J., Hoxha, E., Jörres, A., Kamm, M., Elfanish, A., Windisch, W., Dreher, M., Floege, J., Kluge, S., Schmidt-Lauber, C., Turner, J.E., Huber, S., Addo, M.M., Scheithauer, S., Friede, T., Braun, G.S., Huber, T.B., Blaschke, S.: Validation of a Prospective Urinalysis-Based Prediction Model for ICU Resources and Outcome of COVID-19 Disease: A Multicenter Cohort Study. Journal of Clinical Medicine 10 (14), (2021) [ PMC free article ] [ PubMed ]
- Grossmann, W., Hackl, P., Richter, J.: Corona: Concepts for an improved statistical database. Austrian Journal of Statistics 51 (3), 1–26 (2022). https://ajs.or.at/index.php/ajs/article/view/1350
- Günther F, Bender A, Katz K, Küchenhoff H, Höhle M. Nowcasting the COVID-19 pandemic in Bavaria. Biom. J. 2021; 63 (3):490–502. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Hadzibegovic S, Lena A, Churchill TW, Ho JE, Potthoff S, Denecke C, Rösnick L, Heim KM, Kleinschmidt M, Sander LE, Witzenrath M, Suttorp N, Krannich A, Porthun J, Friede T, Butler J, Wilkenshoff U, Pieske B, Landmesser U, Anker SD, Lewis GD, Tschöpe C, Anker MS. Heart failure with preserved ejection fraction according to the HFA-PEFF score in COVID-19 patients: clinical correlates and echocardiographic findings. Eur. J. Heart Fail. 2021; 23 (11):1891–1902. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Hellewell, J.: Is COVID-19 forecasting bad, or are you just projecting? (2021). https://jhellewell14.github.io/2021/11/16/forecasting-projecting.html
- Hennessy DA, Flanagan WM, Tanuseputro P, Bennett C, Tuna M, Kopec J, Wolfson MC, Manuel DG. The population health model (pohem): an overview of rationale, methods and applications. Popul. Health Metrics. 2015; 13 :24. doi: 10.1186/s12963-015-0057-x. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hernán MA, Robins JM. Causal Inference: What If. Boca Raton: Chapman & Hall/ CRC; 2020. [ Google Scholar ]
- Hethcote HW. The mathematics of infectious diseases. SIAM Rev. 2000; 42 (4):599–653. [ Google Scholar ]
- Hill AB. The environment and disease: association or causation? Proc. R. Soc. Med. 1965; 58 (5):295–300. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Hoffrage U, Lindsey S, Hertwig R, Gigerenzer G. Communicating statistical information. Science. 2000; 290 (5500):2261–2262. [ PubMed ] [ Google Scholar ]
- Holmdahl I, Buckee C. Wrong but useful - what Covid-19 epidemiologic models can and cannot tell us. N. Engl. J. Med. 2020; 383 (4):303–305. [ PubMed ] [ Google Scholar ]
- Horby PW, Mafham M, Bell JL, Linsell L, Staplin N, Emberson J, Palfreeman A, Raw J, Elmahi E, Prudon B, et al. Lopinavir-ritonavir in patients admitted to hospital with COVID-19 (RECOVERY): a randomised, controlled, open-label, platform trial. The Lancet. 2020; 396 (10259):1345–1352. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Hunink, M., Glasziou, P., Siegel, J., Weeks, J., Pliskin, J., Elstein, A., Weinstein, M.: Managing uncertainty. Decision Making in Health and Medicine: Integrating Evidence and Values. Cambridge University Press, New York, USA, (2001). https://ebm.bmj.com/content/10/1/30
- Hunter, E., Mac Namee, B., Kelleher, J.D.: A taxonomy for agent-based models in human infectious disease epidemiology. Journal of Artificial Societies and Social Simulation 20 (3), (2017)
- IQWiG: IQWiG: Allgemeine Methoden. Version 6.0 vom 05.11.2020. Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (2020), https://www.iqwig.de/methoden/allgemeine-methoden_version-6-0.pdf?rev=180500
- Iwendi C, Bashir AK, Peshkar A, Sujatha R, Chatterjee JM, Pasupuleti S, Mishra R, Pillai S, Jo O. COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health. 2020; 8 :357. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Jahn B, Pfeiffer KP, Theurl E, Tarride JE, Goeree R. Capacity Constraints and Cost-Effectiveness: A Discrete Event Simulation for Drug-Eluting Stents. Med. Decis. Making. 2010; 30 (1):16–28. [ PubMed ] [ Google Scholar ]
- Jahn B, Theurl E, Siebert U, Pfeiffer KP. Tutorial in medical decision modeling incorporating waiting lines and queues using discrete event simulation. Value in Health. 2010; 13 (4):501–506. [ PubMed ] [ Google Scholar ]
- Jahn B, Sroczynski G, Bicher M, Rippinger C, Mühlberger N, Santamaria J, Urach C, Schomaker M, Stojkov I, Schmid D, Weiss G, Wiedermann U, Redlberger-Fritz M, Druml C, Kretzschmar M, Paulke-Korinek M, Ostermann H, Czasch C, Endel G, Bock W, Popper N, Siebert U. Targeted COVID-19 Vaccination (TAV-COVID) Considering Limited Vaccination Capacities-An Agent-Based Modeling Evaluation. Vaccines. 2021; 9 (5):434. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- James LP, Salomon JA, Buckee CO, Menzies NA. The use and misuse of mathematical modeling for infectious disease Policymaking: lessons for the COVID-19 pandemic. Med. Decis. Making. 2021; 41 (4):379–385. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Jit M, Brisson M. Modelling the epidemiology of infectious diseases for decision analysis. Pharmacoeconomics. 2011; 29 (5):371–386. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Jun JB, Jacobson SH, Swisher JR. Application of discrete-event simulation in health care clinics: A survey. Journal of the Operational Research Society. 1999; 50 (2):109–123. [ Google Scholar ]
- Karnon J, Stahl J, Brennan A, Caro JJ, Mar J, Möller J. Modeling Using Discrete Event Simulation: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force–4. Med. Decis. Making. 2012; 32 (5):701–711. [ PubMed ] [ Google Scholar ]
- Keeney RL, Raiffa H. Decision analysis with multiple conflicting objectives. New York: Wiley & Sons; 1976. [ Google Scholar ]
- Kermack WO, McKendrick AG. A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London Series A, Containing papers of a mathematical and physical character. 1927; 115 (772):700–721. [ Google Scholar ]
- Kohli M, Maschio M, Becker D, Weinstein MC. The potential public health and economic value of a hypothetical COVID-19 vaccine in the United States: Use of cost-effectiveness modeling to inform vaccination prioritization. Vaccine. 2021; 39 :1157–1164. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Krauss S, Weber P, Binder K, Bruckmaier G. Natürliche Häufigkeiten als numerische Darstellungsart von Anteilen und Unsicherheit-Forschungsdesiderate und einige Antworten. J. Math.-Didakt. 2020; 41 (2):485–521. [ Google Scholar ]
- Kretzschmar ME, Rozhnova G, Bootsma MCJ, van Boven M, van de Wijgert JHHM, Bonten MJM. Impact of delays on effectiveness of contact tracing strategies for COVID-19: a modelling study. The Lancet Public health. 2020; 5 :e452–e459. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Kristjanpoller W, Michell K, Minutolo MC. A causal framework to determine the effectiveness of dynamic quarantine policy to mitigate COVID-19. Appl. Soft Comput. 2021; 104 :107241. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Kucharski, A.J., Hodcroft, E.B., Kraemer, M.U.G.: Sharing, synthesis and sustainability of data analysis for epidemic preparedness in europe. The Lancet Regional Health - Europe, 9 ,100215 (2021), https://www.sciencedirect.com/science/article/pii/S2666776221001927 [ PMC free article ] [ PubMed ]
- Küchenhoff, H., Günther, F., Höhle, M., Bender, A.: Analysis of the early COVID-19 epidemic curve in Germany by regression models with change points. Epidemiology & Infection, 149 , (2021) [ PMC free article ] [ PubMed ]
- Kunz CU, Jörgens S, Bretz F, Stallard N, Lancker KV, Xi D, Zohar S, Gerlinger C, Friede T. Clinical Trials Impacted by the COVID-19 Pandemic: Adaptive Designs to the Rescue? Statistics in Biopharmaceutical Research. 2020; 12 (4):461–477. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Küchenhoff, H., Antes, G., Berger, U., Hoyer, A., Brinks, R., Kauermann, G.: CODAG Bericht Nr. 18. Informationen zur Pandemiesteuerung: Welche Daten benötigen wir? (2021). https://www.covid19.statistik.uni-muenchen.de/newsletter/index.html
- Li J, O’Donoghue C. A survey of dynamic microsimulation models: uses, model structure and methodology. International Journal of Microsimulation. 2013; 6 (2):3–55. [ Google Scholar ]
- Licker, M.D. (ed): McGraw-Hill dictionary of mathematics. McGraw-Hill Companies, Inc (2003)
- Loss J, Boklage E, Jordan S, Jenny MA, Weishaar H, El Bcheraoui C. Risikokommunikation bei der Eindämmung der COVID-19-Pandemie: Herausforderungen und Erfolg versprechende Ansätze. Bundesgesundheitsblatt - Gesundheitsforschung - Gesundheitsschutz. 2021; 64 (3):294–303. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Luo, J., Zhang, Z., Fu, Y., Rao, F.: Time series prediction of COVID-19 transmission in America using LSTM and XGBoost algorithms. Results in Physics p 104462 (2021) [ PMC free article ] [ PubMed ]
- Macal, C.M., North, M.J.: Agent-based modeling and simulation: ABMS examples. In: 2008 Winter Simulation Conference, IEEE, pp. 101–112 (2008)
- Macal CM, North MJ. Tutorial on agent-based modelling and simulation. Journal of Simulation. 2010; 4 (3):151–162. [ Google Scholar ]
- Mandelblatt JS, Stout NK, Schechter CB, van den Broek JJ, Miglioretti DL, Krapcho M, Trentham-Dietz A, Munoz D, Lee SJ, Berry DA, van Ravesteyn NT, Alagoz O, Kerlikowske K, Tosteson ANA, Near AM, Hoeffken A, Chang Y, Heijnsdijk EA, Chisholm G, Huang X, Huang H, Ergun MA, Gangnon R, Sprague BL, Plevritis S, Feuer E, de Koning HJ, Cronin KA. Collaborative Modeling of the Benefits and Harms Associated With Different U.S. Breast Cancer Screening Strategies. Ann. Intern. Med. 2016; 164 :215–225. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Marshall DA, Burgos-Liz L, IJzerman MJ, Crown W, Padula WV, Wong PK, Pasupathy KS, Higashi MK, Osgood ND. Selecting a dynamic simulation modeling method for health care delivery research-Part 2: Report of the ISPOR Dynamic Simulation Modeling Emerging Good Practices Task Force. Value in Health. 2015; 18 (2):147–160. [ PubMed ] [ Google Scholar ]
- Marshall, D.A., Burgos-Liz, L., IJzerman MJ, Osgood ND, Padula WV, Higashi MK, Wong PK, Pasupathy KS, Crown W,: Applying dynamic simulation modeling methods in health care delivery research-the SIMULATE checklist: report of the ISPOR simulation modeling emerging good practices task force. Value in Health 18 (1), 5–16 (2015) [ PubMed ]
- Mathieu E. Commit to transparent COVID data until the WHO declares the pandemic is over. Nature. 2022; 602 (7898):549–549. doi: 10.1038/d41586-022-00424-9. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Mayo E. The human problems of an industrial civilization. Abingdon: Routledge; 2004. [ Google Scholar ]
- McDowell M, Gigerenzer G, Wegwarth O, Rebitschek FG. Effect of tabular and icon fact box formats on comprehension of benefits and harms of prostate cancer screening: a randomized trial. Med. Decis. Making. 2019; 39 (1):41–56. [ PubMed ] [ Google Scholar ]
- Melman, G., Parlikad, A., Cameron, E.: Balancing scarce hospital resources during the COVID-19 pandemic using discrete-event simulation. Health Care Management Science pp. 1–19 (2021) [ PMC free article ] [ PubMed ]
- Miksch F, Jahn B, Espinosa KJ, Chhatwal J, Siebert U, Popper N. Why should we apply ABM for decision analysis for infectious diseases?-An example for dengue interventions. PLoS ONE. 2019; 14 (8):e0221564. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Münnich, R.: Qualität der regionalen Armutsmessung–vom Design zum Modell. In: Qualität bei zusammengeführten Daten, Springer, pp. 7–25 (2020)
- Münnich, R., Schnell, R., Brenzel, H., Dieckmann, H., Dräger, S., Emmenegger, J., Höcker, P., Kopp, J., Merkle, H., Neufang, K., Obersneider, M., Reinhold, J., Schaller, J., Schmaus, S., Stein, P.: A Population Based Regional Dynamic Microsimulation of Germany: The MikroSim Model. Methods, Data, Analyses, 15 (2), 241–264 (2021), https://mda.gesis.org/index.php/mda/article/view/2021.03
- Mütze T, Friede T. Data monitoring committees for clinical trials evaluating treatments of COVID-19. Contemp. Clin. Trials. 2020; 98 :106154. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Neumann PJ, Sanders GD, Russell LB, Siegel JE, Ganiats TG. Cost-Effectiveness in Health and Medicine. Oxford: Oxford University Press; 2016. [ Google Scholar ]
- Nianogo RA, Arah OA. Agent-based modeling of noncommunicable diseases: a systematic review. Am. J. Public Health. 2015; 105 (3):e20–e31. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Nussbaumer-Streit B, Mayr V, Dobrescu AI, Chapman A, Persad E, Klerings I, Wagner G, Siebert U, Ledinger D, Zachariah C, et al. Quarantine alone or in combination with other public health measures to control covid-19: a rapid review. Cochrane Database Syst. Rev. 2020; 4 (4):CD013574. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Orcutt GH. A new type of socio-economic system. Rev. Econ. Stat. 1957; 39 (2):116–123. [ Google Scholar ]
- Otava M, Mylona K. Communicating statistical conclusions of experiments to scientists. Qual. Reliab. Eng. Int. 2020; 36 (8):2688–2698. [ Google Scholar ]
- O’Hagan, A.: Bayesian statistics: principles and benefits. Frontis pp. 31–45 (2004)
- Parmigiani G, Inoue L. Decision theory: Principles and approaches. Hoboken: Wiley; 2009. [ Google Scholar ]
- Pfeffermann, D., Sverchkov, M.: Inference under informative sampling. In: Handbook of Statistics, vol 29, Elsevier, pp. 455–487 (2009)
- Pidd M. Computer simulation in management science. 5. Hoboken: Wiley; 2004. [ Google Scholar ]
- Pitman R, Fisman D, Zaric GS, Postma M, Kretzschmar M, Edmunds J, Brisson M. Dynamic transmission modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force Working Group-5. Med. Decis. Making. 2012; 32 (5):712–721. [ PubMed ] [ Google Scholar ]
- RECOVERY Collaborative Group: Effect of hydroxychloroquine in hospitalized patients with Covid-19. New England Journal of Medicine 383 (21), 2030–2040 (2020) [ PMC free article ] [ PubMed ]
- Reddy KP, Fitzmaurice KP, Scott JA, Harling G, Lessells RJ, Panella C, Shebl FM, Freedberg KA, Siedner MJ. Clinical outcomes and cost-effectiveness of covid-19 vaccination in south africa. Nat. Commun. 2021; 12 :6238. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Rendtel, U., Liebig, S., Meister, R., Wagner, G.G., Zinn, S.: Die erforschung der dynamik der corona-pandemie in deutschland: Survey-konzepte und eine exemplarische umsetzung mit dem sozio-oekonomischen panel (soep). AStA Wirtschafts-und Sozialstatistisches Archiv pp. 1–42 (2021)
- Richardson, S., Spiegelhalter, D.: How ideas from decision theory can help guide our actions. (2021). https://rss.org.uk/news-publication/news-publications/2021/general-news/how-ideas-from-decision-theory-can-help-guide-our/
- Ritchie H. COVID’s lessons for climate, sustainability and more from our world in data. Nature. 2021; 598 (7879):9–9. doi: 10.1038/d41586-021-02691-4. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Roberts M, Russell LB, Paltiel AD, Chambers M, McEwan P, Krahn M, Force I. Conceptualizing a model: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force-2. Medical decision making : an international Journal of the Society for Medical Decision Making. 2012; 32 :678–689. [ PubMed ] [ Google Scholar ]
- Robins JM. Structural nested failure time models. Encyclopedia of Biostatistics. 1998; 6 :4372–4389. [ Google Scholar ]
- Robins JM, Hernán MA, Brumback B. Marginal structural models and causal inference in epidemiology. Epidemiology. 2000; 11 (5):550–560. [ PubMed ] [ Google Scholar ]
- Robins JM, Hernán MA, Siebert U. Estimations of the effects of multiple interventions. In: Ezzati M, Lopez A, Rodgers A, Murray C, editors. Comparative Quantification of Health Risks: Global and Regional Burden of Disease Attributable to Selected Major Risk Factors. Geneva: World Health Organization; 2004. pp. 2191–2230. [ Google Scholar ]
- Rochau U, Jahn B, Qerimi V, Burger EA, Kurzthaler C, Kluibenschaedl M, Willenbacher E, Gastl G, Willenbacher W, Siebert U. Decision-analytic modeling studies: An overview for clinicians using multiple myeloma as an example. Crit. Rev. Oncol. Hematol. 2015; 94 (2):164–178. [ PubMed ] [ Google Scholar ]
- Romano A, Sotis C, Dominioni G, Guidi S. The scale of covid-19 graphs affects understanding, attitudes, and policy preferences. Health Econ. 2020; 29 (11):1482–1494. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Rosling H, Zhang Z. Health advocacy with gapminder animated statistics. Journal of Epidemiology and Global Health. 2011; 1 :11–14. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Rothwell PM. External validity of randomised controlled trials:“to whom do the results of this trial apply?” The Lancet. 2005; 365 (9453):82–93. [ PubMed ] [ Google Scholar ]
- Roy S, Bhunia GS, Shit PK. Spatial prediction of COVID-19 epidemic using ARIMA techniques in India. Modeling Earth Systems and Environment. 2021; 7 (2):1385–1391. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Rubin DB. Estimating causal effects of treatments in randomized and nonrandomized studies. J. Educ. Psychol. 1974; 66 (5):688. [ Google Scholar ]
- Rubin DB. For objective causal inference, design trumps analysis. The Annals of Applied Statistics. 2008; 2 (3):808–840. [ Google Scholar ]
- Rustam F, Reshi AA, Mehmood A, Ullah S, On BW, Aslam W, Choi GS. COVID-19 future forecasting using supervised machine learning models. IEEE access. 2020; 8 :101489–101499. [ Google Scholar ]
- RWI – Leibniz-Institut für Wirtschaftsforschung: Anti-corona measures - don’t just look at new infections. (2020). https://www.rwi-essen.de/unstatistik/108/
- Saidani M, Kim H, Kim J. Designing optimal COVID-19 testing stations locally: A discrete event simulation model applied on a university campus. PLoS ONE. 2021; 16 (6):e0253869. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Salas, J.: Improving the estimation of the COVID-19 effective reproduction number using nowcasting. Statistical Methods in Medical Research p 09622802211008939 (2021) [ PubMed ]
- Sandmann, F.G., Davies, N.G., Vassall, A., Edmunds, W.J., Jit, M., for the Mathematical Modelling of Infectious Diseases COVID-19 working group C,: The potential health and economic value of sars-cov-2 vaccination alongside physical distancing in the uk: a transmission model-based future scenario analysis and economic evaluation. The Lancet Infectious diseases 21 , 962–974 (2021). 10.1016/S1473-3099(21)00079-7 [ PMC free article ] [ PubMed ]
- Schneble M, De Nicola G, Kauermann G, Berger U. Nowcasting fatal COVID-19 infections on a regional level in Germany. Biom. J. 2021; 63 (3):471–489. [ PubMed ] [ Google Scholar ]
- Schnell R. Survey-Interviews: Methoden standardisierter Befragungen. 2. Berlin: Springer VS; 2019. [ Google Scholar ]
- Schöffski O, Schulenburg JMG. Gesundheitsökonomische Evaluationen. Berlin Heidelberg: Springer; 2011. [ Google Scholar ]
- Schüller, K., Koch, H., Rampelt, F.: Data Literacy Charta. (2021). https://www.stifterverband.org/data-literacy-charter , accessed Dec 21, 2021
- Sheinson D, Dang J, Shah A, Meng Y, Elsea D, Kowal S. A Cost-Effectiveness Framework for COVID-19 Treatments for Hospitalized Patients in the United States. Adv. Ther. 2021; 38 :1811–1831. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Shinde V, Bhikha S, Hoosain Z, Archary M, Bhorat Q, Fairlie L, Lalloo U, Masilela MS, Moodley D, Hanley S, Fouche L, Louw C, Tameris M, Singh N, Goga A, Dheda K, Grobbelaar C, Kruger G, Carrim-Ganey N, Baillie V, de Oliveira T, Lombard Koen A, Lombaard JJ, Mngqibisa R, Bhorat AE, Benadé G, Lalloo N, Pitsi A, Vollgraaff PL, Luabeya A, Esmail A, Petrick FG, Oommen-Jose A, Foulkes S, Ahmed K, Thombrayil A, Fries L, Cloney-Clark S, Zhu M, Bennett C, Albert G, Faust E, Plested JS, Robertson A, Neal S, Cho I, Glenn GM, Dubovsky F, Madhi SA. Efficacy of NVX-CoV2373 Covid-19 Vaccine against the B.1.351 Variant. N. Engl. J. Med. 2021; 384 (20):1899–1909. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Siebert U. When should decision-analytic modeling be used in the economic evaluation of health care? Eur. J. Health Econ. 2003; 4 :143–150. [ Google Scholar ]
- Siebert U. Using decision-analytic modelling to transfer international evidence from health technology assessment to the context of the german health care system. GMS Health Technol Assess. 2005; 1 (Doc03):1. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Siebert U, Alagoz O, Bayoumi AM, Jahn B, Owens DK, Cohen DJ, Kuntz KM. State-transition modeling: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force-3. Medical decision making : an international journal of the Society for Medical Decision Making. 2012; 32 :690–700. [ PubMed ] [ Google Scholar ]
- Siebert U, Rochau U, Claxton K. When is enough evidence enough?-Using systematic decision analysis and value-of-information analysis to determine the need for further evidence. Z. Evid. Fortbild. Qual. Gesundhwes. 2013; 107 (9–10):575–584. [ PubMed ] [ Google Scholar ]
- Sonnenberg FA, Beck JR. Markov models in medical decision making: a practical guide. Med. Decis. Making. 1993; 13 (4):322–338. [ PubMed ] [ Google Scholar ]
- Spielauer M. Dynamic microsimulation of health care demand, health care finance and the economic impact of health behaviours: survey and review. International Journal of Microsimulation. 2007; 1 (1):35–53. [ Google Scholar ]
- Sroczynski G, Esteban E, Widschwendter A, Oberaigner W, Borena W, von Laer D, Hackl M, Endel G, Siebert U. Reducing overtreatment associated with overdiagnosis in cervical cancer screening–a model-based benefit-harm analysis for austria. Int. J. Cancer. 2020; 147 (4):1131–1142. doi: 10.1002/ijc.32849. [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Stallard N, Hampson L, Benda N, Brannath W, Burnett T, Friede T, Kimani PK, Koenig F, Krisam J, Mozgunov P, Posch M, Wason J, Wassmer G, Whitehead J, Williamson SF, Zohar S, Jaki T. Efficient Adaptive Designs for Clinical Trials of Interventions for COVID-19. Statistics in Biopharmaceutical Research. 2020; 12 (4):483–497. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- STIKO: Stiko (2016) methoden zur durchführung und berücksichtigung von modellierungen zur vorhersage epidemiologischer und gesundheitsökonomischer effekte von impfungen für die ständige impfkommission, version 1.0 (stand: 16.03.2016), berlin. (2016). https://www.rki.de/DE/Content/Kommissionen/STIKO/Aufgaben_Methoden/Methoden_Modellierung.pdf?__blob=publicationFile
- The Royal Statistical Society: Statistics, Data and Covid - “Ten statistical lessons the government can learn from the past year. (2021). https://rss.org.uk/policy-campaigns/policy/covid-19-task-force/statistics,-data-and-covid/
- Tufte ER. The Visual Display of Quantitative Information. 2. Cheshire, CT: Graphics Press; 2001. [ Google Scholar ]
- Van Pelt A, Glick HA, Yang W, Rubin D, Feldman M, Kimmel SE. Evaluation of COVID-19 testing strategies for repopulating college and university campuses: a decision tree analysis. J. Adolesc. Health. 2021; 68 (1):28–34. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Weinstein MC. Recent developments in decision-analytic modelling for economic evaluation. Pharmacoeconomics. 2006; 24 (11):1043–1053. [ PubMed ] [ Google Scholar ]
- WHO: Communicating and Managing Uncertainty in the COVID-19 Pandemic: A quick guide. (2020). https://cdn.who.int/media/docs/default-source/searo/whe/coronavirus19/managing-uncertainty-in-covid-19-a-quick-guide.pdf
- Wu F, Zhao S, Yu B, Chen YM, Wang W, Song ZG, Hu Y, Tao ZW, Tian JH, Pei YY, et al. A new coronavirus associated with human respiratory disease in China. Nature. 2020; 579 (7798):265–269. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Zhang X. Application of discrete event simulation in health care: a systematic review. BMC Health Serv. Res. 2018; 18 (1):1–11. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Zhou P, Yang XL, Wang XG, Hu B, Zhang L, Zhang W, Si HR, Zhu Y, Li B, Huang CL, et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature. 2020; 579 (7798):270–273. [ PMC free article ] [ PubMed ] [ Google Scholar ]
Click through the PLOS taxonomy to find articles in your field.
For more information about PLOS Subject Areas, click here .
Loading metrics
Open Access
Peer-reviewed
Research Article
A statistical analysis of the novel coronavirus (COVID-19) in Italy and Spain
Roles Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Validation, Visualization, Writing – original draft, Writing – review & editing
* E-mail: [email protected]
Affiliation School of Statistics, Renmin University of China, Beijing, China
- Jeffrey Chu
- Published: March 25, 2021
- https://doi.org/10.1371/journal.pone.0249037
- Reader Comments
The novel coronavirus (COVID-19) that was first reported at the end of 2019 has impacted almost every aspect of life as we know it. This paper focuses on the incidence of the disease in Italy and Spain—two of the first and most affected European countries. Using two simple mathematical epidemiological models—the Susceptible-Infectious-Recovered model and the log-linear regression model, we model the daily and cumulative incidence of COVID-19 in the two countries during the early stage of the outbreak, and compute estimates for basic measures of the infectiousness of the disease including the basic reproduction number, growth rate, and doubling time. Estimates of the basic reproduction number were found to be larger than 1 in both countries, with values being between 2 and 3 for Italy, and 2.5 and 4 for Spain. Estimates were also computed for the more dynamic effective reproduction number, which showed that since the first cases were confirmed in the respective countries the severity has generally been decreasing. The predictive ability of the log-linear regression model was found to give a better fit and simple estimates of the daily incidence for both countries were computed.
Citation: Chu J (2021) A statistical analysis of the novel coronavirus (COVID-19) in Italy and Spain. PLoS ONE 16(3): e0249037. https://doi.org/10.1371/journal.pone.0249037
Editor: Abdallah M. Samy, Faculty of Science, Ain Shams University (ASU), EGYPT
Received: July 14, 2020; Accepted: March 9, 2021; Published: March 25, 2021
Copyright: © 2021 Jeffrey Chu. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: The raw data files for the incidence of COVID-19 in Italy and Spain are available from the following links: https://github.com/pcm-dpc/COVID-19 https://github.com/datadista/datasets/tree/master/COVID%2019 .
Funding: The author(s) received no specific funding for this work.
Competing interests: The authors have declared that no competing interests exist.
Introduction
The novel coronavirus (COVID-19) was widely reported to have first been detected in Wuhan (Hebei province, China) in December 2019. After the initial outbreak, COVID-19 continued to spread to all provinces in China and very quickly spread to other countries within and outside of Asia. At present, over 45 million cases of infected individuals have been confirmed in over 180 countries with in excess of 1 million deaths [ 1 ]. Although the foundations of this disease are very similar to the severe acute respiratory syndrome (SARS) virus that took hold of Asia in 2003, it is shown to spread much more easily and there currently exists no vaccine.
Since the first confirmed cases were reported in China, much of the literature has focused on the outbreak in China including the transmission of the disease, the risk factors of infection, and the biological properties of the virus—see for example key literature such as [ 2 – 6 ]. However, more recent literature has started to cover an increasing number of regions outside of China.
For example, studies covering the wider Asia region include: investigations into the outbreak on board the Diamond Princess cruise ship in Japan, using a Bayesian framework with a Hamiltonian Monte Carlo algorithm [ 7 ]; estimation of the ascertainment rate in Japan using a Poisson process [ 8 ]; modelling the evolution of the basic and effective reproduction numbers in South Korea using Susceptible-Infected-Susceptible models [ 9 ] and generalised growth models with varying growth rates [ 10 ]; modelling the basic reproduction number in India with a classical Susceptible-Exposed-Infectious-Recovered-type compartmental model [ 11 ]; forecasting numbers of cases in Indian states using deep learning-based models [ 12 ].
Analyses on North and South America have also used similar classical methods, for example [ 13 ] model the progression of the outbreak in the United States until the end of 2021 with the simple Susceptible-Infected-Recovered model, and [ 14 ] predict epidemic trends in Brazil and Peru using a logistic growth model and machine learning techniques. However, other studies include: analysis of the spatial variability of the incidence in the United States using spatial lag and error models, and geographically weighted regression [ 15 ]; estimation of the number of deaths in the United States using a modified logistic fault-dependent detection model [ 16 ]; estimating prevalence and infection rates across different states in the United States using a sample selection model [ 17 ]; investigating the relationship between social media communication and the incidence in Colombia using non-linear regression models.
Focusing on Africa, [ 18 ] simulate and predict the spread of the disease in South Africa, Egypt, Algeria, Nigeria, Senegal, and Kenya, using a modified Susceptible-Exposed-Infectious-Recovered model; [ 19 ] apply a six-compartmental model to model the transmission in South Africa; [ 20 ] predict the spread of the disease in West Africa using a deterministic Susceptible-Exposed-Infectious-Recovered model; [ 21 ] implement Autoregressive Integrated Moving Average models to forecast the prevalence of COVID-19 in East Africa; [ 22 ] predict the spread of the disease using travel history and personal contact in Nigeria through ordinary least squares regression; [ 23 ] use logistic growth and Susceptible-Infected-Recovered models to generate real-time forecasts of daily confirmed cases in Saudi Arabia.
Aside from many of the classical models mentioned above, recent developments in the econometrics and statistics literature have led to a number of new models that could potentially be applied in the modelling of infectious diseases. These include (but are not limited to) mixed frequency analysis, model selection and combination, and dynamic time warping. Mixed frequency analysis is an iterative approach proposed for dealing with the joint dynamics of time series data which are sampled at different frequencies [ 24 ]. In the economic literature, the common example is quarterly gross domestic product (GDP) and monthly inflation. [ 25 ] notes that studying the co-movements between mixed frequency data usually involves analysing the joint process sampled at a common low frequency, however, this can mis-specify the relationship. [ 24 , 25 ] propose vector autoregressive models for mixed frequency analysis that operate at the highest sampling frequency of all the time series in the model. These models allow for the modelling of the joint dynamics of the dependent and independent variables using time disaggregation, where the low frequency variables are interpolated and time-aggregated into a higher frequency. In the context of infectious diseases, such models could be beneficial for modelling the relationship between higher frequency data such as the number of daily cases or deaths and lower frequency data relating to, say, weekly cases or deaths, news and information about health prevention measures, etc. [ 26 , 27 ] propose the use of Bayesian Predictive Synthesis (BPS) for model selection and combination. They note that there are many scenarios that generate multiple, interrelated time series, where the dependence has a significant impact on decisions, policies, and their outcomes. In addition, methods need to learn and integrate information about forecasters and models, bias, etc. and how they change over time, to improve their accuracy [ 26 ]. Decision and policy makers often use multiple sources, models, and forecasters to generate forecasts, in particular, probabilistic density forecasts. However, although complex estimation methods may have useful properties for policy makers, large standard deviations may be a result of the complexity of the data, model, etc., and it may be difficult to know the source. The aim is to use the dependencies between time series to improve forecasts over multiple horizons for policy decisions [ 27 ]. For example, in the economic literature, setting interest rates based on utility or loss that account for inflation, real economy measures, employment, etc. BPS relates to a decision maker that accounts for multiple models as providers of “forecast data” to be used for prior-posterior updating. The decision maker learns over time about relationships between agents, forecasts, and dependencies, which are incorporated into the model, and dynamically calibrate, learn, and update weights for ranges of forecasts from dynamic models, with multiple lags and predictors [ 26 ]. In epidemiology, BPS could potentially be used in a similar context to analyse the dependency between various interrelated time series such as daily cases and deaths, hospital capacity, number vaccinations, etc. Different models and sources of data could then be combined and characterised in one single model improving the accuracy of forecasts. Dynamic time warping as noted by [ 28 , 29 ] is a technique that has not been widely used outside of speech and gesture recognition. It can be used to identify the relation structure between two time series by describing their non-linear alignment with warping paths [ 28 ]. The procedure involves a local cost measure characterising the sum of the differences between pairs of realisations of data at each time point, where an optimal warping path gives the lowest total cost. The optimal path is found under a variable lead-lag structure, where the most suitable lag can then be found [ 28 ]. This then reveals and identifies the lead-lag effects between the time series data. Indeed, dynamic time warping has recently been used in the modelling of COVID-19 by [ 30 ]. [ 30 ] use the method to determine the lead-lag relation between the cumulative number of daily cases of COVID-19 in various countries, in addition to forecasting the future incidence in selected countries. This allows for the classification of countries as being in the early, middle, and late stages of an outbreak.
Controlling an infectious disease such as COVID-19 is an important, time-critical but difficult issue. The health of the global population is, perhaps, the most important factor as research is directed towards vaccines and governments scramble to implement public health measures to reduce the spread of the disease. In most countries around the world, these measures have come in the form of local or national lockdowns where individuals are advised or required to remain at home unless they have good reason not to—e.g. for educational or medical purposes, or if they are unable to work from home. However, the implications of trying to control COVID-19 are being felt not only by the health sector, but also in areas such as the economy, environment, and society.
As the number of cases of infected individuals has risen rapidly, there has been an increase in pressure on medical services as healthcare providers seek to test and diagnose infected individuals, in addition to the normal load of medical services that are offered in general. In many cases, trying to control COVID-19 has led to a backlog for and deprivation of other medical procedures [ 31 ], with healthcare providers needing to find a balance between the two. [ 32 ] note that this conflict may change the nature of healthcare with public and private health sectors working together more often. The implementation of restrictions on the movement of individuals has also led to many suggesting that anxiety and distress may lead to increased psychiatric disorders. These may be related to suicidal behaviour and morbidity and may have a long-term negative impact on the mental health of individuals [ 33 , 34 ].
In addition to restrictions on the movement of individuals, governments have required most non-essential businesses to close. This has negatively impacted national economies with many businesses permanently closing leading to a significant increase in unemployment. Limits on travel have severely affected the tourism and travel industries, and countries and economies that are dependent on these for income. Whilst many of the implications of controlling COVID-19 on the economy are negative, there have been some positive changes as businesses adapt to the ‘new normal’. For example, the banking industry is dealing with increased credit risks, while the insurance industry is developing more digital products and pandemic-focused solutions [ 32 ]. The automotive industry is expected to see profits reduced by approximately $100 billion, which may be offset by the development of software subscription services of modern vehicles [ 32 ]. Some traditional office-based businesses have been able to reduce costs by shifting to remote working, while the restaurant industry has shifted towards takeaway and delivery services [ 32 ].
In terms of the environment, the limitations on businesses that have been able to continue operating throughout the epidemic has led to possible improvements in the environment—mainly from the reduction in pollution [ 35 ]. However, societal issues have been exacerbated. [ 32 ] note that the reduction in the labour force that has resulted from controlling for COVID-19 has affected ethnic minorities and women most significantly. Furthermore, in many countries health services employ more women than men creating a dilemma for working mothers—either leave the labour force and provide childcare for their families or remain in employment and pay extra costs for childcare.
In Europe, Italy and Spain were two of the first European countries to be significantly affected by COVID-19. However, the majority of the literature covering the two countries focuses on the clinical aspects of the disease, [ 36 – 40 ], with only a limited number exploring the prevalence of the disease, [ 41 – 43 ].
As as a result of this on going pandemic, new results and reports are being produced and published daily. Thus, our motivation stems from wanting to contribute to the statistical analysis of the incidence of COVID-19 in Italy and Spain, where the literature is limited. The main contributions of this paper are: i) to model the incidence of COVID-19 in Italy and Spain using simple mathematical models in epidemiology; ii) to provide estimates of basic measures of the infectiousness and severity of COVID-19 in Italy and Spain; iii) to investigate the predictive ability of simple mathematical models and provide simple forecasts for the future incidence of COVID-19 in Italy and Spain.
The contents of this paper are organised as follows. In the data section, we describe the incidence data used in the main analysis and provide a brief summary analysis. The method section outlines the Susceptible-Infectious-Recovered model and the log-linear model used to model the incidence of COVID-19, and introduces the basic reproduction number and effective reproduction number as measures of the infectiousness of diseases. In the results section, we present the main results for the fitted models and estimates of the measures of infectiousness, in addition to simple predictions for the future incidence of COVID-19. Some concluding remarks are given in the conclusion.
The data used in this analysis consists of the daily and cumulative incidence (confirmed cases) of COVID-19 for Italy and Spain (nationally), and their respective regions or autonomous provinces. For Italy, this data covers 21 regions for 37 days from 21st February 2020 to 28th March 2020, inclusive; for Spain, this data covers 19 regions for 34 days from 27th February to 31st March 2020, inclusive. The data for Italy was obtained from [ 44 ] where the raw data was sourced from the Italian Department of Civil Protection; the data for Spain was obtained from [ 45 ] where the raw data was sourced from the Spanish Ministry of Health. The starting dates for both sets of data indicate the dates on which the first cases were confirmed in each country, however, it should be noted that in some regions cases were not confirmed until after these dates. These particular time periods were chosen as they cover over one month since the initial outbreaks in both countries and were the most up to date data available at the time of writing. In the remainder of this section, we provide a simple exploratory analysis of the incidence data.
Fig 1 plots the daily cumulative incidence for Italy and its 21 regions over the whole sample period. All cumulative incidence appears to show an exponential trend, increasing slowly for the first 14 days after the first cases are confirmed before growing rapidly. Checking the same plot on a log-linear scale, shown in Fig 2 , we find that the logarithm of cumulative incidence in some regions exhibits an approximate linear trend suggesting that cumulative incidence is growing exponentially. However, in the majority of regions (and nationally) this trend is not exactly linear, suggesting a slightly sub-exponential growth in cumulative incidence.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
https://doi.org/10.1371/journal.pone.0249037.g001
https://doi.org/10.1371/journal.pone.0249037.g002
Of all the regions in Italy, the northern region of Lombardy is one of the worst affected and Fig 3 plots the daily incremental incidence for both Lombardy and Italy, respectively. In terms of the number of new cases confirmed each day, the trends are very similar and, again, possibly exponential until peaking around 21st March 2020 before levelling off. Comparing the trends for the other regions in Fig 4 , it can be seen that other significantly affected northern regions such as Piedmont and Emilia-Romagna exhibit similarities to Lombardy—growing, peaking, and levelling around the same times. However, many other regions show some slight differences such as peaking at earlier or later dates, and even exhibiting an erratic trend.
https://doi.org/10.1371/journal.pone.0249037.g003
https://doi.org/10.1371/journal.pone.0249037.g004
In Fig 5 , things are put in perspective when the cumulative incidence of all Italian regions are plotted on the same scale. It is clear that Lombardy is the most affected region contributing to the largest share of national cumulative incidence, and indeed it is the epicentre of the outbreak in Italy.
https://doi.org/10.1371/journal.pone.0249037.g005
In the case of Spain, Fig 6 plots the daily cumulative incidence nationally and for all 19 Spanish regions over the whole sample period. The trend appears to be exponential and is similar between regions, but is also similar to that of the daily cumulative incidence in Italy. On a log-linear scale, in Fig 7 , the growth of the daily cumulative incidence appears to be closer to an exponential trend compared with Italy, due to the plots arguably exhibiting a more linear trend. It can be seen that there is a slight difference with Italy in that it appears as though most Spanish regions were affected at approximately the same time—when the country’s first cases were confirmed. This is reflected by the majority of plots starting from the very left of the x-axis, with the exception of the plots for a few regions such as Ceuta and Melilla. In Italy only a small number of regions were affected when the country’s first cases were confirmed, with the growth in cumulative incidence for the majority of the other regions coming later on.
https://doi.org/10.1371/journal.pone.0249037.g006
https://doi.org/10.1371/journal.pone.0249037.g007
The worst affected regions in Spain are Madrid and Catalonia, and Fig 8 plots the daily incremental incidence for both regions and the national trend. The growth in daily incidence, in all three cases, could be classed as being approximately exponential, however, daily incidence appears to peak on 26th March 2020 before falling and peaking again on 31st March 2020. It is confirmed that the true peak daily incidence does indeed occur on 31st March 2020 and we return to this point later on in the analysis. In comparison to other Spanish regions, it seems that Madrid and Catalonia are the exceptions as the majority of regions exhibit an exponential rise in daily incidence and peak around 26th and 27th March 2020 before falling.
https://doi.org/10.1371/journal.pone.0249037.g008
Plotting the daily incidence of all regions on the same scale in Fig 9 , it is clear that Madrid and Catalonia are the most affected regions contributing the largest share of the national cumulative incidence. Whilst Madrid and Catalonia are the main epicentres of the outbreak in Spain, many coastal regions also show significant numbers of confirmed cases, although not quite on the same scale.
https://doi.org/10.1371/journal.pone.0249037.g009
The SIR (Susceptible-Infectious-Recovered) model
In the mathematical modelling of infectious diseases, there exist many compartmental models that can be used to describe the spread of a disease within a population. One of the simplest models is the SIR (Susceptible-Infectious-Recovered) model proposed by [ 46 ], in which the population is split into three groups or compartments: those who are susceptible ( S ) but not yet infected with the disease; those who are infectious ( I ); those who have recovered ( R ) and are immune to the disease or who have deceased.
The SIR model has been extensively researched and applied in practice, thus it would not be practical to mention and cover all of the literature. However, some of the most prominent literature covers areas such as the stability and optimality of the simple SIR model ([ 47 – 51 ]); pulse vaccination strategy in the SIR model ([ 52 – 55 ]); applications of the SIR in the modelling of infectious diseases ([ 56 – 64 ]).
With regards to COVID-19, many have applied the basic SIR model (or slightly modified versions) to model the outbreak. Some particular examples include (but are not limited to): [ 2 ] who estimate the overall symptomatic case fatality risk of COVID-19 in Wuhan and use the SIR model to generate simulations of the COVID-19 outbreak in Wuhan; [ 65 ] who apply a modified SIR model to identify contagion, recovery, and death rates of COVID-19 in Italy; [ 66 ] who combine the SIR model with probabilistic and statistical methods to estimate the true number of infected individuals in France; [ 67 ] who use a number of methods including the SIR model to estimate the basic and controlled reproduction numbers for the COVID-19 outbreak in Wuhan, China; [ 68 ] who show that the basic SIR model performs better than extended versions in modelling confirmed cases of COVID-19 and present predictions for cases after the lockdown of Wuhan, China; [ 69 ] who model the temporal dynamics of COVID-19 in China, Italy, and France, and find that although the rate of recovery appears to be similar in the three countries, infection and death rates are more variable; [ 70 ] who simulate the outbreak in Wuhan, China, using an extended SIR model and investigate the age distribution of cases; [ 71 ] who study the number of infections and deaths from COVID-19 in Sweden using the SIR model; [ 72 ] who use the SIR model, with an additional parameter for social distancing, to model and forecast the early stages of the COVID-19 outbreak in Brazil.
In reference to the SIR model, [ 74 ] note that it “examines only the temporal dynamics of the infection cycle and should thus be appropriate for the description of a well-localised epidemic outburst”, therefore, it would appear to be reasonable for use in analysis at city, province, or country level. In the form above, the dynamics of the model are controlled by the parameters β and γ , representing the rates of transition from S to I (susceptibility to infection), and I to R (infection to recovery or death), respectively.
To fit the model and find the optimal parameter values of β and γ , we use the optim function in R [ 75 ] to solve the minimisation problem. The system of differential equations, Eqs ( 1 ) to ( 3 ), are set up as a single function. The model is then initialised with starting values for S , I , and R , with parameters β and γ unknown. We obtain the daily cumulative incidence for the sample period, total population ( N ), and the susceptible population ( S ) as the total population minus the number of currently infected individuals. This is defined as the cumulative number of infected individuals minus the number of recovered or dead, however, these exact values are difficult to obtain. Thus, the cumulative number of infected individuals at the start date of the sample period is used as a proxy—since at the start date of the disease, this is likely to be close to the true value, as the number of recovered or dead should be very small (if not zero).
The residual sum of squares is then defined and set up as a function of β and γ . The optim package is used for general purpose optimisation problems, and in this case it is used to minimise the function RSS with respect to the sample of cumulative incidence. More specifically, we use the limited memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS-B) algorithm for the minimisation, which allows us to specify box constraints (lower and upper bounds) for the unknown parameters β and γ . The lower and upper bounds of zero and one, respectively, were selected for both parameters. The optim function then searches for the β and γ that minimise the RSS function, given starting values of 0.5 for both parameters. The optimal solution is found via the gradient method by repeatedly improving the estimates of RSS to try and find a solution with a lower value. The function makes small changes to the parameters in the direction of where RSS changes the fastest, where in this direction the lowest value of RSS is. This is repeated until no further improvement can be made or the improvement is below a threshold.
We consider convergence as the main criteria for finding an optimal solution in the minimisation of RSS —when the lowest RSS has been found, and no further improvement can be found or the improvement is below a threshold. In the case where convergence is not achieved, or there is some related error, then we use the parscale function in the optimisation. As the true values of β and γ are unknown, in the default case, the parameters are adjusted by a fixed step starting from their initial values. Most common issues were addressed using the parscale function to rescale—alter the sensitivity/magnitude of the parameters on the objective function. In other words, it allows the algorithm to compute the gradient at a finer scale (similar to the ndeps parameter—used to adjust step sizes for the finite-difference approximation to the gradient). In most cases, issues were solved by using a step size of 10 −4 . Of course, smaller step sizes could be used, but there is a risk that selecting too small a step size will lead to the optimal values of β and γ being found at their starting values. However, the results should be interpreted with caution. It is possible that estimates will vary with different population sizes N and the starting values specified for β and γ , which may also cause the optimisation process to be unstable.
It should be noted that the application of the basic SIR model to COVID-19 simplifies the analysis and makes the strong assumption that individuals who become infected but recover are immune to COVID-19. This is assumed purely for the simplification of modelling and we do not claim this to be true in reality. At present, it remains unclear whether those who recover from infection are immune [ 76 ]. Indeed, there have been studies and unconfirmed reports of individuals who have possibly recovered but then subsequently tested positive for the virus again, see for example [ 77 – 79 ].
The basic reproduction number R 0
Whilst the fitted model and optimal parameters allow us to make a simple prediction about how the trajectory of the number of susceptible, infectious, and recovered individuals evolves over time, a more useful statistic or parameter that can be computed from the fitted model is the basic reproduction number R 0 . Originally developed for the study of demographics in the early 20th century, it was adapted for use in the study of infectious diseases in the 1950’s [ 80 ]. It is defined as the “expected number of secondary infections arising from a single individual during his or her entire infectious period, in a population of susceptibles” [ 80 ], and is widely considered to be a fundamental concept in the study of epidemiology. In other words, it is the estimated number of people that an individual will go on to infect after becoming infected.
The R 0 value can provide an indication of the severity of the outbreak of an infectious disease: if R 0 < 1, each infected individual will go on to infect less than one individual (on average) and the disease will die out; if R 0 = 1, each infected individual will go on to infect one individual (on average) and the disease will continue to spread but will be stable; if R 0 > 1, each infected individual will go on to infect more than one individual (on average) and the disease will continue to spread and grow, with the possibility of becoming a pandemic ([ 80 , 81 ]).
Log-linear model
https://doi.org/10.1371/journal.pone.0249037.g010
To fit the log-linear model, we use the incidence package [ 82 ] in R [ 75 ] to obtain the optimal values of the parameters. Using the estimated parameters, the fitted model can be used to predict the trajectory of the incidence up until the peak incidence in the growth phase. However, although the log-linear model allows for the modelling and prediction of the incidence, compared with the SIR model it does not provide any indication about the number of susceptible or recovered individuals.
We are able to use the epitrix R package [ 84 ] to implement the method by [ 83 ] for empirical distributions to estimate R 0 from the growth rate r . However, [ 83 ] note that an “epidemic model implicitly specifies a generation interval distribution” (also known as the serial interval distribution), which is defined as “the time between the onset of symptoms in a primary case and the onset of symptoms in secondary cases” [ 85 ]. As we do not have access to more detailed COVID-19 patient data, we are not able to compute the parameters of the serial interval distribution directly. However, a number of existing analyses of COVID-19 patient data report some preliminary estimates of the best fitting serial interval distributions and their corresponding model parameters. These are: i) gamma distribution with mean μ = 7.5 and standard deviation σ = 3.4 [ 81 ]; ii) gamma distribution with mean μ = 7 and standard deviation σ = 4.5 [ 2 ]; iii) gamma distribution with mean μ = 6.3 and standard deviation σ = 4.2 [ 86 ]. By using these three serial intervals in conjunction with the above method, we are able to obtain estimates of R 0 from estimates of the growth rate r . It should be noted that serial interval distributions are not only restricted to the gamma distribution—other common distributions used include the Weibull and log-normal distributions, and that the parameters are dependent on a number of factors including the time to isolation [ 86 ].
The effective reproduction number R e
As mentioned above, the estimation of the R 0 value is not always ideal, due to it being a single fixed value reflecting a specific period of growth (in the log-linear model) or requiring assumptions that only hold true in specific time periods (in the basic SIR model). In other words, it is “time and situation specific” [ 85 ]. In reality, the reproduction number will vary over time but it will also be influenced by governments and health authorities implementing measures in order to reduce the impact of the disease. Therefore, a more useful approach for measuring the severity of an infectious disease is to track the reproduction number over time. The effective reproduction number R e is one way to achieve this, and thus allows us to see how the reproduction number changes over time in response to the development of the disease itself but also effectiveness of interventions. Although there are numerous methods that can be used to analyse the severity of a disease over time, the majority are not straightforward to implement (especially in software) [ 85 ].
One popular method for estimating R e is that proposed by [ 85 ]. The basic premise of this method is that “once infected, individuals have an infectivity profile given by a probability distribution w s , dependent on time since infection of the case, s , but independent of calendar time, t . For example, an individual will be most infectious at time s when w s is the largest. The distribution w s typically depends on individual biological factors such as pathogen shedding or symptom severity” [ 85 ].
The function models the transmissibility of a disease with a Poisson process, such that an individual infected at time t − s will generate new infections at time t at a rate of R t w s , where R t is the instantaneous (effective) reproduction number at time t . Thus, the incidence at time t is defined to be Poisson distributed with mean equal to the average daily incidence (number of new cases) at time t . This value is just for a single time period t , however, estimates for a single time period can be highly variable meaning that it is not easy to interpret, especially for making policy decisions. Therefore, we consider longer time periods of one week (seven days)—assuming that within a rolling window the instantaneous reproduction number remains constant. Note that there is a potential trade off, as using longer rolling windows gives more precise estimates of R t but this means fewer estimates can be computed (requires more incidence values to start with) and a more delayed trend reducing the ability to detect changes in transmissibility. Whereas shorter rolling windows lead to more rapid detection in changes but with more noise. Using this method, it is recommended that a minimum cumulative daily incidence of 12 cases have been observed before attempting to estimate R e . For the data sets used, this does not pose a problem as a cumulative total of 16 and 17 cases, respectively, exist on the first day of the sample at the country level, and by the seventh day the totals are around 200 and 650 for Spain and Italy, respectively.
From the posterior distribution, the posterior mean R t , τ can be computed at time t for the rolling window of [ t − τ , t ] by the ratio of the gamma distribution parameters. We refer the readers to the supplementary information of [ 85 ] for further details regarding the Bayesian framework. As noted by [ 85 ], this method works best when times of infection are known and the infectivity profile or distribution can be estimated from patient level data. However, as mentioned above, we do not have access to this level of data, and instead utilise three different serial intervals from the literature that have been estimated from real data.
In practice, the transmission of a disease will vary over time especially when health prevention measures are implemented. However, this method is the only reproduction number that can be easily computed in real-time, and in comparison to similar methods, it captures the effect of control measures since it will cause sudden decreases in estimates compared with other methods.
In this analysis, we use the most basic version of this method and estimate the effective reproduction number over a rolling window of seven days. This appears to be sufficient and in line with our results, as we do not suffer from the problem of small sample sizes as the samples are sufficiently large and we start computing the effective reproduction number after one mean serial interval. It should be noted that estimates of this reproduction number are dependent on the distribution of the infectiousness profile w s . In addition, it is known that this distribution may not always be well documented, especially in the early parts of an epidemic. However, here we assume that the serial interval is defined for our sample period and the use of the three serial intervals from the literature appears to give satisfactory results.
If problems did arise, or to account for uncertainty in the serial interval distribution, an alternative method is to implement a modified procedure by [ 85 ], which allows for uncertainty in the serial interval distribution. This modified method assumes that the serial interval is gamma distributed but the mean and standard deviation are allowed to vary according to a standard normal distribution. Some N * pairs of means and standard deviations are simulated—mean first and standard deviation second, with the constraint that the mean is less than the standard deviation to ensure that for each pair the probability density function of the serial interval distribution is null at time t = 0. Then, for each rolling window 1000 realisations are sampled of the instantaneous reproduction number using the posterior distribution conditional on the pair of parameters.
The SIR model and R 0
For both Italy and Spain, we set up and solve the minimisation problem for the SIR model described in Section for region-level and national-level COVID-19 incidence for the first 14 days after the first cases were confirmed in each respective country and region. The first 14 days after the first cases are detected can be considered to be the early stage of an outbreak, and it is reasonable to assume that there are few, if no, infected or immune individuals prior to this. However, it is a rather strong assumption as it is possible that individuals may be infected but do not display any symptoms. Tables 1 and 2 show the output corresponding to each region/country including the date that the first cases were confirmed, the population size (obtained from [ 88 ]), the cumulative number of cases at the 14th day after the first cases were confirmed, the fitted estimates for the parameters β and γ , and estimates for R 0 .
https://doi.org/10.1371/journal.pone.0249037.t001
https://doi.org/10.1371/journal.pone.0249037.t002
From Tables 1 and 2 , we observe that many of the first regions to be affected in both countries are those with the largest population sizes, however, the cumulative number of cases (after the first 14 days) in these regions are not always the highest among all regions. The estimates of the parameters β and γ also do not show any particular trends and this is reflected in the estimated R 0 values. It can be seen that for all regions in both Italy and Spain, the estimated R 0 values fall between one and three. This suggests that, according to the thresholds described above, the disease is spreading and growing in all Italian and Spanish regions during the 14 days after the first localised cases were confirmed. At a national level, the estimated values of R 0 are greater than two for both countries, again, suggesting a spreading and growing disease. This is perhaps not surprising since this time period reflects the early stages of the spread of the disease, thus we would expect it to be growing and spreading quickly before any preventative action is taken.
We note that in Tables 1 and 2 , there are some cases where the estimated value of β is very close to or at the upper limit of 1.000—e.g. Lombardy (Italy) and Madrid (Spain). This leads to the consequence that the parameter estimates appear to be bound by the upper limit. However, all parameter estimates are dependent on the starting values defined for β and γ , and the upper and lower bounds specified. For all cases of estimating the parameters in Tables 1 and 2 , we used the same optimisation procedure and criteria for determining a satisfactory estimate that is the convergence in the minimisation of the RSS ( Eq (4) ). In all cases, convergence was achieved but this is still slightly problematic. For cases where the estimated value of β is 1.000, although convergence was achieved, this indicates only that it generates the lowest RSS within the upper and lower limits defined. Therefore, there may or may not exist values of the parameter outside of this range that may be more optimal. Indeed, the results may vary depending on the upper and lower bounds, and the starting values that are selected. Thus, there is also the question of how to change the starting values and bounds appropriately (instead of, say, simply increasing them). Furthermore, as the R 0 value in the SIR model is computed as β / γ , another consequence of the estimated value of β being 1.000 is that the true value of β may actually be larger than this, and so the true value of R 0 may be larger than the estimated value.
Using the estimated parameters for the best fitted models, the predicted trajectories of the numbers in each of the compartments of the model can be generated. For brevity, in the remainder of the analysis, we show only the results for Italy, Spain, and their worst affected regions. Fig 11 plots the observed and predicted cumulative incidence for the 14 days immediately following the first confirmed cases in Lombardy and Italy, respectively. It can be seen that the model appears to under predict the true total number of cases in both cases during the early part of the outbreak before over estimating towards the end of the 14 days. In Fig 12 the SIR model trajectories are plotted along with the observed cumulative incidence on a logarithmic scale for Lombardy and Italy. The under prediction of the cumulative incidence in the first 14 days (to the left of the vertical dashed black line) is indicated by the solid red line (predicted cumulative incidence) lying below the black points (observed cumulative incidence) however, after the initial 14 days and after the implementation of a nationwide lock down (vertical dashed red line), the observed cumulative incidence grows at a slower rate than predicted by the fitted model. Indeed, this reflects the fact that the model is based only on the initial 14 days and does not account for any interventions.
https://doi.org/10.1371/journal.pone.0249037.g011
https://doi.org/10.1371/journal.pone.0249037.g012
In Fig 13 , the observed and predicted cumulative incidence for the 14 days immediately following the first confirmed cases in Catalonia, Madrid, and Italy, respectively, are shown. In contrast to the results for Italy, the fitted model for all three appears to predict the true total number of cases across the whole of the first 14 days reasonably well. Fig 14 plots the SIR model trajectories and the observed cumulative incidence on a logarithmic scale for Catalonia, Madrid, and Spain. Here, the more accurate predictions of the cumulative incidence are reflected in the area to the left of the vertical dashed black line. However, it can be seen that at the time when the nationwide lock down came into force (vertical dashed red line) the growth of the true total number of cases slowed down. It is likely that this is coincidental, since it is known that the effect on the incidence of infectious diseases from health interventions is not immediate, but instead lags behind.
https://doi.org/10.1371/journal.pone.0249037.g013
https://doi.org/10.1371/journal.pone.0249037.g014
Log-linear model and R 0
Following the SIR model, we implemented the log-linear model as described above for region-level and national-level COVID-19 daily incidence for the entire growth phase (from the time of the first confirmed cases until the time at which daily incidence peaks). The estimated parameters of the fitted log-linear models for the daily incidence of Lombardy and Italy, respectively, are shown in Table 3 . It can be seen that the peak daily incidence in both Lombardy and at country level occurred on the same day (21st March 2020), however, the growth rate (doubling time) is found to be slightly greater (shorter) at country level (0.18 and 3.88) compared with the Lombardy region (0.16 and 4.34). In comparison to the SIR model and modelling the cumulative incidence, the log-linear model modelling the daily incidence in the growth phase (as shown in Fig 15 ) appears to be slightly more accurate.
Upper and lower limits of the 95% confidence intervals are indicated by the dashed red lines.
https://doi.org/10.1371/journal.pone.0249037.g015
https://doi.org/10.1371/journal.pone.0249037.t003
In Table 4 , the estimated parameters of the fitted log-linear models for the daily incidence of Madrid, Catalonia, and Spain, respectively, are given. Similarly, the peak daily incidence occurs on the same day (31st March 2020) for Madrid, Catalonia, and Spain, although this is later than that for Italy. Interestingly, the growth rate (doubling time) is greatest (shortest) for Catalonia (0.24 and 3.85), whilst Madrid and Spain share similar growth rates and doubling times (0.21/0.22 and 3.24/3.21). It should be noted that there appears to be a slight difference in the observed daily incidence compared with the case of Italy and its regions. In Fig 16 , it can be seen that the observed daily incidence appears to initially peak in the last few days of March in all cases before falling, but then increases to a higher peak at the end of the growth phase. This seems to throw off the fitted log-linear model, as after the initial (approximate) 14 days the fitted model under predicts and then over predicts the daily incidence.
https://doi.org/10.1371/journal.pone.0249037.g016
https://doi.org/10.1371/journal.pone.0249037.t004
As with the SIR model, we are also able to use the fitted log-linear models in conjunction with the three serial intervals mentioned above to compute estimates of the R 0 value. Table 5 shows the mean estimates of the R 0 value for Italy, Spain, and their most affected regions, computed from the fitted log-linear models and the three serial intervals. In each case, the mean estimates are computed from 10,000 samples of R 0 values generated from the log-linear regression of the incidence data in the growth phase, and the distributions of these samples are plotted in S1 Fig . Compared with the estimates from the SIR model, we find that in all but the case of Italy, the estimates of R 0 from the log-linear model are greater than that from the SIR model—in these cases, the lowest estimates of R 0 from the log-linear models are larger by between 0.5 to 1. In the case of Italy, we find that the estimate of R 0 computed from the SIR model is approximately the same as that computed from the log-linear model using a serial interval using a gamma distribution with mean μ = 7 and standard deviation σ = 4.5 [ 2 ]. Using the log-linear models, the largest R 0 values computed are for Catalonia, whereas the smallest values are for Lombardy. It can also be seen that serial distributions with a lower mean appear to correspond with lower R 0 values. A possible explanation for the difference between the estimated R 0 values computed from the SIR models and the log-linear models is that the only incidence data from the first 14 days was used in the former, whereas incidence data from the whole growth phase was used in the latter—almost double the data. Therefore, it is arguable that the R 0 estimates from the log-linear models could be considered to be more accurate.
https://doi.org/10.1371/journal.pone.0249037.t005
Effective reproductive number R e .
Turning towards the more dynamic measure of the infectiousness of diseases, Figs 17 and 18 plot the estimated reproductive numbers computed for Lombardy, Italy, Madrid, Catalonia, and Spain, over the entire sample period. Using the method proposed by [ 85 ], in each case estimates were computed using rolling windows of the daily incidence over the previous 7 days and the same three serial distributions as for the log-linear models. As a result, no estimates are computed for the first 7 days of each respective sample period. In all cases, we analyse and compute the R e values over the whole sample period available allowing us to see how the infectiousness of COVID-19 varies during the initial outbreak stages and the effect of any interventions implemented by the respective governments. In Fig 17 , we observe that for both Lombardy and Italy, R e is generally decreasing over the time (under any of the three serial distributions), and although it is initially larger for Italy, after approximately the first 7 days the R e values are similar. However, the trend of R e both to the left and right (before and after) of the nationwide lockdown (indicated by the dotted line) shows some differences. Prior to the nationwide lockdown, R e decreases rapidly towards a value of between three and four, which could be attributed to the fact that northern Italy (including Lombardy) was the most affected area in the early stages of the outbreak and lockdowns local to the area were already being enforced from 21st February 2020. Thus, this is likely to have contributed (in part) to the initial reduction in the R e value. After the nationwide lockdown came into force on 9th March 2020, R e continues to decrease but at a slower pace and appears to level off approximately 14 days later—this coincides with the peak in daily incidence on 21st March 2020. After this point, it is likely that the effects of the nationwide lockdown are starting to appear with R e appearing to decrease again more rapidly towards the critical value of one (solid horizontal line)—suggesting that the disease is still spreading but stabilising.
Upper and lower limits of the 95% confidence intervals for the mean are indicated by the red dashed lines, and the grey dotted line indicates the date at which the national lock down becomes effective.
https://doi.org/10.1371/journal.pone.0249037.g017
https://doi.org/10.1371/journal.pone.0249037.g018
In Fig 18 , we observe a different trend in the R e value for Madrid, Catalonia, and Spain, compared with Lombardy and Italy. Whilst R e exhibits a decrease over the sample time period (under any of the three serial distributions), the initial values are actually larger for Madrid and Catalonia, however, the values for all three are similar after the initial 7 days. The trend in the estimated R e values before and after the nationwide lockdown again show some differences, but also differ to those for the cases of Lombardy and Italy. Prior to the nationwide lockdown (indicated by the dotted line), the trend of the estimated R e values is very erratic: decreasing, increasing, and then decreasing again. This could be due to the daily incidence for Madrid, Catalonia, and Spain, showing greater variation compared with that for Italy before the respective lockdowns. It is found that in the period before the lockdowns, Spanish daily incidence appears to show more alternation between increases and decreases compared with the previous day’s incidence, whilst Italian daily incidence shows much less. After the nationwide lockdown on 14th March 2020, for all three cases the estimated R e decreases significantly towards a value of two. More specifically, in mid-March 2020 daily incidence for Madrid, Catalonia, and Spain, levels off corresponding to the reduction in R e , but in the run up to 23rd March 2020 daily incidence again becomes more variable and alternates between significantly larger and smaller daily incidence, with R e levelling off. After 23rd March 2020, this levelling off is more sustained for Madrid and Spain compared with Catalonia. This may be attributed to the daily incidence initially peaking and then decreasing much more significantly for Catalonia, leading to a more significant decrease in R e at the latter end of the sample period. In general, the estimated R e values are larger for Spain than Italy, since Spain is lagging behind in terms of the start of the outbreak, however, it is found that the estimated R e is larger for Italy than Spain, but larger for Madrid and Catalonia than Lombardy.
Predictive ability of models.
Whilst the results regarding the estimated reproduction values ( R 0 and R e ) provide useful indicators about the infectiousness of COVID-19 and the variability over time, the predictive ability of models is also key—especially in the decay phase of an outbreak after the daily incidence has peaked and is in decline. Predictions about the daily incidence in the decay phase can contribute to determining whether health interventions are working, but can additionally provide time frames for when daily incidence may reach certain thresholds—e.g. below which the disease may be considered under control. To compare the predictive ability of the SIR and log-linear models, we use the projections package [ 89 ] in R [ 75 ]. As this section acts to provide only a brief analysis of the predictive ability of the models, we refer the readers to [ 89 ] for in-depth documentation regarding the finer details of the computations. The initial step is to consider which of the two models provides the best predictive ability in the growth phase of the COVID-19 outbreak and for simplicity, we analyse only Italy and Spain at country level. Using the estimated R 0 values for Italy and Spain from the SIR and log-linear models above, we combine these with the three serial distributions mentioned earlier. We then use the projections package [ 89 ] to forecast and predict the daily incidence for Italy and Spain from the 14th day (since the first cases in each location) until the day of peak incidence.
Plots of the true daily incidence in Italy and Spain during their respective growth phases and the predicted values using the SIR and log-linear models are shown in Figs 19 and 20 . In each figure, the first row plots the predictions using the SIR model; the second row plots the predictions using the log-linear model. For the case of Italy, the plots in Fig 19 appear to show that the predictions using the R 0 value estimated from the SIR model and the serial interval of a gamma distribution with mean μ = 7.5 and standard deviation σ = 3.4 [ 81 ] provide the most accurate general predictions. However, although using the R 0 value estimated from the log-linear model generates predictions which are accurate up until the last 7 days of the growth phase (where all three cases show over prediction), these results are more consistent compared with those using the SIR model. For the case of Spain, the plots in Fig 20 show that the predictions using the R 0 value estimated from the SIR model are consistent but significantly under predicting the observed daily incidence. In contrast, predictions using the R 0 value estimated from the log-linear model are consistent and accurate up until the initial peak in daily incidence a few days before the true peak at the end of the growth phase. Based on these results for the growth phase of the outbreak, we propose to use the log-linear model to compute basic predictions for the decay phase.
95% confidence intervals for the predicted incidence are indicated by the shaded light purple regions.
https://doi.org/10.1371/journal.pone.0249037.g019
https://doi.org/10.1371/journal.pone.0249037.g020
At the time of conducting this part of the analysis, approximately one month of daily incidence data was available for the decay phase (following peak daily incidence) of both Italy and Spain. Similarly, we follow the methodology for fitting the log-linear model but now apply it to the decay phase daily incidence. The model is fitted to the decay phase daily incidence in the same way, and model parameters can be computed. Note that for the decay phase, the values and interpretation of the estimated parameters change—the growth rate takes a negative value and the doubling time becomes the halving time (both reflecting the decay and decrease in daily incidence). The fitted log-linear regressions for Italy and Spain are shown in the left hand plots of Figs 21 and 22 , respectively. The fitted models appear to provide reasonable fits to the observed decay phase daily incidence much like the case for the growth phase.
Plots of the observed (dot-dashed black line) and projected daily incidence for the next 180 days using the log-linear model and serial interval distributions SI 1 (green line), SI 2 (blue line), and SI 3 (red line) (right).
https://doi.org/10.1371/journal.pone.0249037.g021
https://doi.org/10.1371/journal.pone.0249037.g022
Also, as in the growth phase, the R 0 value can still be computed for the log-linear model during the decay phase, and for consistency we obtain mean estimates of R 0 from 10,000 samples of R 0 generated from the log-linear regressions of the daily incidence during the decay phase in conjunction with the three serial distributions. Distributions of these estimates are plotted in S2 Fig and it can be seen that (in contrast to the growth phase) the mean estimates of R 0 for Italy and Spain, individually, are very similar (under the three serial distributions)—between 0.85 and 0.87 for Italy, and 0.77 and 0.83 for Spain. Using the mean estimated R 0 values and the three serial distributions, we computed projections of the daily incidence for the 180 days immediately following the end of the decay phase sample period on 22nd April 2020. The paths of these projections for Italy and Spain are shown in the right hand plots of Figs 21 and 22 , respectively.
A simple comparison of the projected daily incidence for both countries is given in Table 6 , at one and two months following the end of the decay phase sample period. Observed daily incidence for the remainder of the decay phase was obtained from [ 44 , 90 , 91 ]. In general, it appears that the predictions for future daily incidence (under all three serial distributions) in both Italy and Spain are significantly greater than the observed daily incidence. At the one month time point (21st May 2020) projections of daily incidence for Italy are approximately twice as large as the true incidence; projections of daily incidence for Spain are approximately two to three times as large as the true incidence. Moving forward to the two month time point (21st June 2020) projections of the daily incidence for Italy are approximately two to three times as large as the true incidence; projections of the daily incidence for Spain are up to twice as large as the true incidence. However, the projection of Spanish daily incidence using the serial interval of a gamma distribution with mean μ = 6.3 and standard deviation σ = 4.2 [ 86 ] is almost identical to the true incidence.
https://doi.org/10.1371/journal.pone.0249037.t006
Whilst the results of the projections generally show significant over estimation of future daily incidence in both Italy and Spain, they do provide some additional information to the reproduction values regarding the trends of daily incidence. However, such forecasts should be not be taken directly at face value as there are a number of pitfalls that will influence the predictions. Limited decay phase incidence data was available at the time of the original analysis, which is likely to have led to less accurate estimates of R 0 and thus predictions. On a related note, the predictions are conditional on the data up until the end of the sample decay phase data and thus do not account for any health policies or interventions implemented after this, likely leading to the over estimation.
In this paper, we have provided a simple statistical analysis of the novel Coronavirus (COVID-19) outbreak in Italy and Spain—two of the worst affected countries in Europe. Using data of the daily and cumulative incidence in both countries over approximately the first month after the first cases were confirmed in each respective country, we have analysed the trends and modelled the incidence and estimated the basic reproduction value using two common approaches in epidemiology—the SIR model and a log-linear model.
Results from the SIR model showed an adequate fit to the cumulative incidence of Spain and its most affected regions in the early stages of the outbreak, however, it showed significant under estimation in the case of Italy and its most affected regions. Estimates of the basic reproduction number in the early stage of the outbreak from the model were found to be greater than one in all cases, suggesting a growing infectiousness of COVID-19—in line with expectations. Applying the log-linear regression model to the daily incidence, results for the growth phase of the outbreak in Italy and Spain revealed a greater growth rate for Spain compared with Italy (and their most affected regions)—approximately between 0.21 to 0.24 for the former and 0.15 to 0.18 for the latter. The time for the daily incidence to double for Spain was also found to be shorter than Italy (approximately three days compared to four days).
With the lack of detailed clinical COVID-19 data for the two countries, we utilised existing results regarding the serial interval distribution of COVID-19 from the literature to estimate the basic reproduction number via the log-linear model. Estimates of this value were found to be between 2.1 and 3 for Italy and its most affected region Lombardy, and between 2.5 and approximately 4 for Spain and its most affected regions of Madrid and Catalonia. Further analysis of the effective reproduction number (based on the incidence over the previous seven days) indicated that in both countries the infectious of COVID-19 was decreasing and reflecting the positive impact of health interventions such as nationwide lock downs.
Basic predictions of future daily incidence in Italy and Spain were estimated using the log-linear regression model for the decay phase of the outbreak. Estimates of the projected daily incidence at various time points in the future were generally found to be between two to three times larger than the true levels of daily incidence. These results highlight the fact that the estimates may only give reasonable indications in the short term, since they are based on past data which may or may not account for factors which change in the short term—e.g. new health interventions, public policy, etc.
Despite the simplicity of our results, we believe that they provide an interesting insight into the statistics of the COVID-19 outbreak in two of the worst affected countries in Europe. Our results appear to indicate that the log-linear model may be more suitable in modelling the incidence of COVID-19 and other infectious diseases in both the growth and decay phases, and for short term predictions of the growth (or decay) of the number of new cases when no intervention measures have recently been implemented. In addition, the results could be useful in contributing to health policy decisions or government interventions—especially in the case of a significant second wave of COVID-19. However, these results should be used in conjunction with the results from other more complex mathematical and epidemiological models.
Supporting information
S1 fig. plots of the distributions of samples of r 0 values computed from the fitted log-linear regressions of growth phase incidence..
i) Lombardy (top left); ii) Italy (top right); iii) Madrid (middle left); iv) Catalonia (middle right); v) Spain (bottom). a) SI 1 (blue); b) SI 2 (red) c) SI 3 (green).
https://doi.org/10.1371/journal.pone.0249037.s001
S2 Fig. Plots of the distributions of samples of R 0 values computed from the fitted log-linear regressions of decay phase incidence.
i) Italy (left); ii) Spain (right). a) SI 1 (green); b) SI 2 (red) c) SI 3 (blue).
https://doi.org/10.1371/journal.pone.0249037.s002
- 1. Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU), 2020. Coronavirus COVID-19 (2019-nCoV). Available at: https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6 .
- View Article
- Google Scholar
- PubMed/NCBI
- 13. Atkeson, A., 2020. What Will Be the Economic Impact of COVID-19 in the US? Rough Estimates of Disease Scenarios. National Bureau of Economic Research, Working Paper 26867.
- 17. Benatia, D., Godefroy, R. and Lewis, J., 2020. Estimating COVID-19 Prevalence in the United States: A Sample Selection Model Approach. Available at: https://ssrn.com/abstract=3578760 .
- 32. McKinsey & Company, 2020. COVID-19: Implications for business. Available at: https://www.mckinsey.com/business-functions/risk/our-insights/covid-19-implications-for-business .
- 44. GitHub, 2020a. pcm-dpc/COVID-19: COVID-19 Italia—Monitoraggio situazione. Available at: https://github.com/pcm-dpc/COVID-19 .
- 45. GitHub, 2020b. datasets/COVID 19 at master ⋅ datadista/datasets. Available at: https://github.com/datadista/datasets/tree/master/COVID%2019 .
- 64. Correia A.M., Mena F.C., Soares A.J., 2011. An Application of the SIR Model to the Evolution of Epidemics in Portugal. In: M. Peixoto, A. Pinto and D. Rand eds. Dynamics, Games and Science II. Springer Proceedings in Mathematics, vol 2. Berlin: Springer. pp. 247-250.
- 65. Calafiore, G.C., Novara, C. and Possieri, C., 2020. A Modified SIR Model for the COVID-19 Contagion in Italy. arXiv:2003.14391v1.
- 66. Roques, L., Klein, E., Papax, J., Sar, A. and Soubeyrand, S., 2020. Using early data to estimate the actual infection fatality ratio from COVID-19 in France (Running title: Infection fatality ratio from COVID-19). arXiv:2003.10720v3.
- 67. You, C., Deng, Y., Hu, Y., Sun, J., Lin, Q., Zhou, F., et al. Estimation of the Time-Varying Reproduction Number of COVID-19 Outbreak in China. Available at SSRN: https://ssrn.com/abstract=3539694 .
- 71. Qi, C., Karlsson, D., Sallmen, K. and Wyss, R., 2020. Model studies on the COVID-19 pandemic in Sweden. arXiv:2004.01575v1.
- 72. Bastos, S.B. and Cajuero, D.O., 2020. Modeling and forecasting the early evolution of the Covid-19 pandemic in Brazil. arXiv:2003.14288v2.
- 75. R Development Core Team, 2020. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2020).
- 76. World Health Organization, 2020. “‘Immunity passports” in the context of COVID-19’. Available at: https://www.who.int/news-room/commentaries/detail/immunity-passports-in-the-context-of-covid-19 .
- 79. Reuters, 2020. “Explainer: Coronavirus reappears in discharged patients, raising questions in containment fight”. Available at: https://uk.reuters.com/article/us-china-health-reinfection-explainer/explainer-coronavirus-reappears-in-discharged-patients-raising-questions-in-containment-fight-idUKKCN20M124 .
- 82. Jombart, T., Kamvar, Z.N., FitzJohn, R., Cai, J., Bhatia, S., Schumacher, J, et al. 2020. incidence: Compute, Handle, Plot and Model Incidence of Dated Events. R package version 1.7.1. https://CRAN.R-project.org/package=incidence .
- 84. Jombart, T., Cori, A., Kamvar, Z.N. and Schumacher, D., 2019. epitrix: Small Helpers and Tricks for Epidemics Analysis. R package version 0.2.2. https://CRAN.R-project.org/package=epitrix .
- 87. Cori, A., Cauchemez, S., Ferguson, N.M., Fraser, C., Dahlqwist, E., Demarsh, P.A., et al. 2019. EpiEstim: Estimate Time Varying Reproduction Numbers from Epidemic Curves. R package version 2.2-1 https://cran.r-project.org/package=EpiEstim .
- 88. Eurostat, 2019. Population: demography, population projections, census, asylum & migration—Overview. Available at: https://ec.europa.eu/eurostat/web/population/overview .
- 89. Jombart, T., Nouvellat, P., Bhatia, S. and Kamvar, Z.N., 2018. projections: Project Future Case Incidence. R package version 0.3.1. https://CRAN.R-project.org/package=projections .
- 90. Worldometer, 2020. Worldometer—real time world statistics. Available at: https://www.worldometers.info/ .
- 91. Ministerio de Sanidad, Consumo y Bienestar Social. Enfermedad por nuevo coronavirus, COVID-19. Available at: https://www.mscbs.gob.es/profesionales/saludPublica/ccayes/alertasActual/nCov-China/ .
Coronavirus (COVID-19) Cases
Research and data: Edouard Mathieu, Hannah Ritchie, Lucas Rodés-Guirao, Cameron Appel, Daniel Gavrilov, Charlie Giattino, Joe Hasell, Bobbie Macdonald, Saloni Dattani, Diana Beltekian, Esteban Ortiz-Ospina, and Max Roser
We are grateful to everyone whose editorial review and expert feedback on this work helps us to continuously improve our work on the pandemic. Thank you. Here you find the acknowledgements.
- Coronavirus
- Data explorer
- Hospitalizations
- Vaccinations
- Mortality risk
- Excess mortality
- Policy responses
Our work belongs to everyone
- All our code is open-source
- All our research and visualizations are free for everyone to use for all purposes
Explore the global data on confirmed COVID-19 cases
Select countries to show in all charts.
This page has a large number of charts on the pandemic. In the box below you can select any country you are interested in – or several, if you want to compare countries.
All charts on this page will then show data for the countries that you selected .
Confirmed cases
What is the daily number of confirmed cases, daily confirmed cases per million people, what is the cumulative number of confirmed cases, cumulative confirmed cases per million people, weekly and biweekly cases : where are confirmed cases increasing or falling, related charts:.
Which world regions have the most daily confirmed cases?
This chart shows the number of confirmed COVID-19 cases per day.
What is important to note about these case figures?
- The reported case figures on a given date do not necessarily show the number of new cases on that day – this is due to delays in reporting.
- The actual number of cases is likely to be much higher than the number of confirmed cases – this is due to limited testing. In a separate post we discuss how models of COVID-19 help us estimate the actual number of cases .
→ We provide more detail on these points in the section ‘ Cases of COVID-19: background ‘.
Five quick reminders on how to interact with this chart
- By clicking on Edit countries and regions you can show and compare the data for any country in the world you are interested in.
- If you click on the title of the chart, the chart will open in a new tab. You can then copy-paste the URL and share it.
- You can switch the chart to a logarithmic axis by clicking on ‘LOG’.
- If you move both ends of the time-slider to a single point you will see a bar chart for that point in time.
- Map view: switch to a global map of confirmed cases using the ‘MAP’ tab at the bottom of the chart.
Differences in the population size between different countries are often large – it is insightful to compare the number of confirmed cases per million people.
Keep in mind that in countries that do very little testing the actual number of cases can be much higher than the number of confirmed cases shown here.
Three tips on how to interact with this map
- By clicking on any country on the map you see the change over time in this country.
- By moving the time slider (below the map) you can see how the global situation has changed over time.
- You can focus on a particular world region using the dropdown menu to the top-right of the map.

Which world regions have the most cumulative confirmed cases?
How do the number of tests compare to the number of confirmed COVID-19 cases? See them plotted against each other.
The previous charts looked at the number of confirmed cases per day – this chart shows the cumulative number of confirmed cases since the beginning of the COVID-19 pandemic.
This chart shows the cumulative number of confirmed cases per million people.
Why is it useful to look at weekly or biweekly changes in confirmed cases?
For all global data sources on the pandemic, daily data does not necessarily refer to the number of new confirmed cases on that day – but to the cases reported on that day.
Since reporting can vary significantly from day to day – irrespectively of any actual variation of cases – it is helpful to look at changes from week to week. This provides a slightly clearer picture of where the pandemic is accelerating, slowing, or in fact reducing.
The maps shown here provide figures on weekly and biweekly confirmed cases: one set shows the number of confirmed cases per million people in the previous seven (or fourteen) days (the weekly or biweekly cumulative total); the other set shows the percentage change (growth rate) over these periods.
Coronavirus sequences by variant
About this data.
Our data on SARS-CoV-2 sequencing and variants is sourced from GISAID , a global science initiative that provides open-access to genomic data of SARS-CoV-2. We recognize the work of the authors and laboratories responsible for producing this data and sharing it via the GISAID initiative.
Khare, S., et al (2021) GISAID’s Role in Pandemic Response. China CDC Weekly, 3(49): 1049-1051. doi: 10.46234/ccdcw2021.255 PMCID: 8668406 Elbe, S. and Buckland-Merrett, G. (2017) Data, disease and diplomacy: GISAID’s innovative contribution to global health. Global Challenges, 1:33-46. doi:10.1002/gch2.1018 PMCID: 31565258 Shu, Y. and McCauley, J. (2017) GISAID: from vision to reality. EuroSurveillance, 22(13) doi:10.2807/1560-7917.ES.2017.22.13.30494 PMCID: PMC5388101
We download aggregate-level data via CoVariants.org .
All countries report data on the results from sequenced samples every 14 days, although some of them may share partial data in advance. We obtain the share of each variant by dividing the number of sequences labelled for that variant by the total number of sequences. Since only a fraction of all cases are sequenced, this share may not reflect the complete breakdown of cases. In addition, recently-discovered or actively-monitored variants may be overrepresented, as suspected cases of these variants are likely to be sequenced preferentially or faster than other cases.
Confirmed deaths and cases: our data source
Our world in data relies on data from the world health organization.
In this document, the many linked charts, our COVID-19 Data Explorer , and the Complete COVID-19 dataset, we report and visualize the data on confirmed cases and deaths from the World Health Organization (WHO). We make the data in our charts and tables downloadable as complete and structured CSV, XLSX, and JSON files on GitHub .
The WHO has published updates on confirmed cases and deaths on its dashboard for all countries since 31 December 2019. From 31 December 2019 to 21 March 2020, this data was sourced through official communications under the International Health Regulations (IHR, 2005), complemented by publications on official ministries of health websites and social media accounts. Since 22 March 2020, the data has been compiled through WHO region-specific dashboards or direct reporting to WHO.
The WHO updates its data once per week.
Cases of COVID-19: background
How is a covid-19 case defined.
In epidemiology, individuals who meet the case definition of a disease are often categorized on three different levels.
These definitions are often specific to the particular disease, but generally have some clear and overlapping criteria.
Cases of COVID-19 – as with other diseases – are broadly defined under a three-level system: suspected , probable and confirmed cases.
- Suspected case A suspected case is someone who shows clinical signs and symptoms of having COVID-19, but has not been laboratory-tested.
- Probable case A suspected case with an epidemiological link to a confirmed case. This means someone who is showing symptoms of COVID-19 and has either been in close contact with a positive case, or is in a particularly COVID-affected area. 1
- Confirmed case A confirmed case is “a person with laboratory confirmation of COVID-19 infection” as the World Health Organization (WHO) explains. 2
Typically, for a case to be confirmed, a person must have a positive result from laboratory tests. This is true regardless of whether they have shown symptoms of COVID-19 or not.
This means that the number of confirmed cases is lower than the number of probable cases, which is in turn lower than the number of suspected cases. The gap between these figures is partially explained by limited testing for the disease.
How are cases reported?
We have three levels of case definition: suspected, probable and confirmed cases. What is measured and reported by governments and international organizations?
International organizations – namely the WHO and European CDC – report case figures submitted by national governments. Wherever possible they aim to report confirmed cases , for two key reasons:
1. They have a higher degree of certainty because they have laboratory confirmation;
2. They help to provide standardised comparisons between countries.
However, international bodies can only provide figures as submitted by national governments and reporting institutions. Countries can define slightly different criteria for how cases are defined and reported. 3 Some countries have, over the course of the outbreak, changed their reporting methodologies to also include probable cases.
One example of this is the United States. Until 14 th April 2020 the US CDC provided daily reports on the number of confirmed cases. However, as of 14 th April, it now provides a single figure of cases: the sum of confirmed and probable cases.
Suspected case figures are usually not reported. The European CDC notes that suspected cases should not be reported at the European level (although countries may record this information for national records) but are used to understand who should be tested for the disease.
Reported new cases on a particular day do not necessarily represent new cases on that day
The number of confirmed cases reported by any institution – including the WHO, the ECDC, Johns Hopkins and others – on a given day does not represent the actual number of new cases on that date. This is because of the long reporting chain that exists between a new case and its inclusion in national or international statistics.
The steps in this chain are different across countries, but for many countries the reporting chain includes most of the following steps:
- Doctor or laboratory diagnoses a COVID-19 case based on testing or combination of symptoms and epidemiological probability (such as a close family member testing positive).
- Doctor or laboratory submits a report to the health department of the city or local district.
- Health department receives the report and records each individual case in the reporting system, including patient information.
- The ministry or another governmental organization brings this data together and publishes the latest figures.
- International data bodies such as the WHO or the ECDC can then collate statistics from hundreds of such national accounts.
This reporting chain can take several days. This is why the figures reported on any given date do not necessarily reflect the number of new cases on that specific date.
The number of actual cases is higher than the number of confirmed cases
To understand the scale of the COVID-19 outbreak, and respond appropriately, we would want to know how many people are infected by COVID-19. We would want to know the actual number of cases.
However, the actual number of COVID-19 cases is not known. When media outlets claim to report the ‘number of cases’ they are not being precise and omit to say that it is the number of confirmed cases they speak about.
The actual number of cases is not known, not by us at Our World in Data, nor by any other research, governmental or reporting institution.
The number of confirmed cases is lower than the number of actual cases because not everyone is tested. Not all cases have a “laboratory confirmation”; testing is what makes the difference between the number of confirmed and actual cases.
All countries have been struggling to test a large number of cases, which means that not every person that should have been tested has been tested.
Since an understanding of testing for COVID-19 is crucial for an interpretation of the reported numbers of confirmed cases we have looked into the testing for COVID-19 in more detail.
You find our work on testing here . In a separate post we discuss how models of COVID-19 help us estimate the actual number of cases .
Acknowledgements
We would like to acknowledge and thank a number of people in the development of this work: Carl Bergstrom , Bernadeta Dadonaite , Natalie Dean , Joel Hellewell, Jason Hendry , Adam Kucharski , Moritz Kraemer and Eric Topol for their very helpful and detailed comments and suggestions on earlier versions of this work. We thank Tom Chivers for his editorial review and feedback.
And we would like to thank the many hundreds of readers who give us feedback on this work. Your feedback is what allows us to continuously clarify and improve it. We very much appreciate you taking the time to write. We cannot respond to every message we receive, but we do read all feedback and aim to take the many helpful ideas into account.
Our World in Data is free and accessible for everyone.
Help us do this work by making a donation.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 16 June 2020
COVID-19 impact on research, lessons learned from COVID-19 research, implications for pediatric research
- Debra L. Weiner 1 , 2 ,
- Vivek Balasubramaniam 3 ,
- Shetal I. Shah 4 &
- Joyce R. Javier 5 , 6
on behalf of the Pediatric Policy Council
Pediatric Research volume 88 , pages 148–150 ( 2020 ) Cite this article
146k Accesses
81 Citations
19 Altmetric
Metrics details
The COVID-19 pandemic has resulted in unprecedented research worldwide. The impact on research in progress at the time of the pandemic, the importance and challenges of real-time pandemic research, and the importance of a pediatrician-scientist workforce are all highlighted by this epic pandemic. As we navigate through and beyond this pandemic, which will have a long-lasting impact on our world, including research and the biomedical research enterprise, it is important to recognize and address opportunities and strategies for, and challenges of research and strengthening the pediatrician-scientist workforce.
The first cases of what is now recognized as SARS-CoV-2 infection, termed COVID-19, were reported in Wuhan, China in December 2019 as cases of fatal pneumonia. By February 26, 2020, COVID-19 had been reported on all continents except Antarctica. As of May 4, 2020, 3.53 million cases and 248,169 deaths have been reported from 210 countries. 1
Impact of COVID-19 on ongoing research
The impact on research in progress prior to COVID-19 was rapid, dramatic, and no doubt will be long term. The pandemic curtailed most academic, industry, and government basic science and clinical research, or redirected research to COVID-19. Most clinical trials, except those testing life-saving therapies, have been paused, and most continuing trials are now closed to new enrollment. Ongoing clinical trials have been modified to enable home administration of treatment and virtual monitoring to minimize participant risk of COVID-19 infection, and to avoid diverting healthcare resources from pandemic response. In addition to short- and long-term patient impact, these research disruptions threaten the careers of physician-scientists, many of whom have had to shift efforts from research to patient care. To protect research in progress, as well as physician-scientist careers and the research workforce, ongoing support is critical. NIH ( https://grants.nih.gov/policy/natural-disasters/corona-virus.htm ), PCORI ( https://www.pcori.org/funding-opportunities/applicant-and-awardee-faqs-related-covid-19 ), and other funders acted swiftly to provide guidance on proposal submission and award management, and implement allowances that enable grant personnel to be paid and time lines to be relaxed. Research institutions have also implemented strategies to mitigate the long-term impact of research disruptions. Support throughout and beyond the pandemic to retain currently well-trained research personnel and research support teams, and to accommodate loss of research assets, including laboratory supplies and study participants, will be required to complete disrupted research and ultimately enable new research.
In the long term, it is likely that the pandemic will force reallocation of research dollars at the expense of research areas funded prior to the pandemic. It will be more important than ever for the pediatric research community to engage in discussion and decisions regarding prioritization of funding goals for dedicated pediatric research and meaningful inclusion of children in studies. The recently released 2020 National Institute of Child Health and Development (NICHD) strategic plan that engaged stakeholders, including scientists and patients, to shape the goals of the Institute, will require modification to best chart a path toward restoring normalcy within pediatric science.
COVID-19 research
This global pandemic once again highlights the importance of research, stable research infrastructure, and funding for public health emergency (PHE)/disaster preparedness, response, and resiliency. The stakes in this worldwide pandemic have never been higher as lives are lost, economies falter, and life has radically changed. Ultimate COVID-19 mitigation and crisis resolution is dependent on high-quality research aligned with top priority societal goals that yields trustworthy data and actionable information. While the highest priority goals are treatment and prevention, biomedical research also provides data critical to manage and restore economic and social welfare.
Scientific and technological knowledge and resources have never been greater and have been leveraged globally to perform COVID-19 research at warp speed. The number of studies related to COVID-19 increases daily, the scope and magnitude of engagement is stunning, and the extent of global collaboration unprecedented. On January 5, 2020, just weeks after the first cases of illness were reported, the genetic sequence, which identified the pathogen as a novel coronavirus, SARS-CoV-2, was released, providing information essential for identifying and developing treatments, vaccines, and diagnostics. As of May 3, 2020 1133 COVID-19 studies, including 148 related to hydroxychloroquine, 13 to remdesivir, 50 to vaccines, and 100 to diagnostic testing, were registered on ClinicalTrials.gov, and 980 different studies on the World Health Organization’s International Clinical Trials Registry Platform (WHO ICTRP), made possible, at least in part, by use of data libraries to inform development of antivirals, immunomodulators, antibody-based biologics, and vaccines. On April 7, 2020, the FDA launched the Coronavirus Treatment Acceleration Program (CTAP) ( https://www.fda.gov/drugs/coronavirus-covid-19-drugs/coronavirus-treatment-acceleration-program-ctap ). On April 17, 2020, NIH announced a partnership with industry to expedite vaccine development ( https://www.nih.gov/news-events/news-releases/nih-launch-public-private-partnership-speed-covid-19-vaccine-treatment-options ). As of May 1, 2020, remdesivir (Gilead), granted FDA emergency use authorization, is the only approved therapeutic for COVID-19. 2
The pandemic has intensified research challenges. In a rush for data already thousands of manuscripts, news reports, and blogs have been published, but to date, there is limited scientifically robust data. Some studies do not meet published clinical trial standards, which now include FDA’s COVID-19-specific standards, 3 , 4 , 5 and/or are published without peer review. Misinformation from studies diverts resources from development and testing of more promising therapeutic candidates and has endangered lives. Ibuprofen, initially reported as unsafe for patients with COVID-19, resulted in a shortage of acetaminophen, endangering individuals for whom ibuprofen is contraindicated. Hydroxychloroquine initially reported as potentially effective for treatment of COVID-19 resulted in shortages for patients with autoimmune diseases. Remdesivir, in rigorous trials, showed decrease in duration of COVID-19, with greater effect given early. 6 Given the limited availability and safety data, the use outside clinical trials is currently approved only for severe disease. Vaccines typically take 10–15 years to develop. As of May 3, 2020, of nearly 100 vaccines in development, 8 are in trial. Several vaccines are projected to have emergency approval within 12–18 months, possibly as early as the end of the year, 7 still an eternity for this pandemic, yet too soon for long-term effectiveness and safety data. Antibody testing, necessary for diagnosis, therapeutics, and vaccine testing, has presented some of the greatest research challenges, including validation, timing, availability and prioritization of testing, interpretation of test results, and appropriate patient and societal actions based on results. 8 Relaxing physical distancing without data regarding test validity, duration, and strength of immunity to different strains of COVID-19 could have catastrophic results. Understanding population differences and disparities, which have been further exposed during this pandemic, is critical for response and long-term pandemic recovery. The “Equitable Data Collection and Disclosure on COVID-19 Act” calls for the CDC (Centers for Disease Control and Prevention) and other HHS (United States Department of Health & Human Services) agencies to publicly release racial and demographic information ( https://bass.house.gov/sites/bass.house.gov/files/Equitable%20Data%20Collection%20and%20Dislosure%20on%20COVID19%20Act_FINAL.pdf )
Trusted sources of up-to-date, easily accessible information must be identified (e.g., WHO https://www.who.int/emergencies/diseases/novel-coronavirus-2019/global-research-on-novel-coronavirus-2019-ncov , CDC https://www.cdc.gov/coronavirus/2019-nCoV/hcp/index.html , and for children AAP (American Academy of Pediatrics) https://www.aappublications.org/cc/covid-19 ) and should comment on quality of data and provide strategies and crisis standards to guide clinical practice.
Long-term, lessons learned from research during this pandemic could benefit the research enterprise worldwide beyond the pandemic and during other PHE/disasters with strategies for balancing multiple novel approaches and high-quality, time-efficient, cost-effective research. This challenge, at least in part, can be met by appropriate study design, collaboration, patient registries, automated data collection, artificial intelligence, data sharing, and ongoing consideration of appropriate regulatory approval processes. In addition, research to develop and evaluate innovative strategies and technologies to improve access to care, management of health and disease, and quality, safety, and cost effectiveness of care could revolutionize healthcare and healthcare systems. During PHE/disasters, crisis standards for research should be considered along with ongoing and just-in-time PHE/disaster training for researchers willing to share information that could be leveraged at time of crisis. A dedicated funded core workforce of PHE/disaster researchers and funded infrastructure should be considered, potentially as a consortium of networks, that includes physician-scientists, basic scientists, social scientists, mental health providers, global health experts, epidemiologists, public health experts, engineers, information technology experts, economists and educators to strategize, consult, review, monitor, interpret studies, guide appropriate clinical use of data, and inform decisions regarding effective use of resources for PHE/disaster research.
Differences between adult and pediatric COVID-19, the need for pediatric research
As reported by the CDC, from February 12 to April 2, 2020, of 149,760 cases of confirmed COVID-19 in the United States, 2572 (1.7%) were children aged <18 years, similar to published rates in China. 9 Severe illness has been rare. Of 749 children for whom hospitalization data is available, 147 (20%) required hospitalization (5.7% of total children), and 15 of 147 required ICU care (2.0%, 0.58% of total). Of the 95 children aged <1 year, 59 (62%) were hospitalized, and 5 (5.3%) required ICU admission. Among children there were three deaths. Despite children being relatively spared by COVID-19, spread of disease by children, and consequences for their health and pediatric healthcare are potentially profound with immediate and long-term impact on all of society.
We have long been aware of the importance and value of pediatric research on children, and society. COVID-19 is no exception and highlights the imperative need for a pediatrician-scientist workforce. Understanding differences in epidemiology, susceptibility, manifestations, and treatment of COVID-19 in children can provide insights into this pathogen, pathogen–host interactions, pathophysiology, and host response for the entire population. Pediatric clinical registries of COVID-infected, COVID-exposed children can provide data and specimens for immediate and long-term research. Of the 1133 COVID-19 studies on ClinicalTrials.gov, 202 include children aged ≤17 years. Sixty-one of the 681 interventional trials include children. With less diagnostic testing and less pediatric research, we not only endanger children, but also adults by not identifying infected children and limiting spread by children.
Pediatric considerations and challenges related to treatment and vaccine research for COVID-19 include appropriate dosing, pediatric formulation, and pediatric specific short- and long-term effectiveness and safety. Typically, initial clinical trials exclude children until safety has been established in adults. But with time of the essence, deferring pediatric research risks the health of children, particularly those with special needs. Considerations specific to pregnant women, fetuses, and neonates must also be addressed. Childhood mental health in this demographic, already struggling with a mental health pandemic prior to COVID-19, is now further challenged by social disruption, food and housing insecurity, loss of loved ones, isolation from friends and family, and exposure to an infodemic of pandemic-related information. Interestingly, at present mental health visits along with all visits to pediatric emergency departments across the United States are dramatically decreased. Understanding factors that mitigate and worsen psychiatric symptoms should be a focus of research, and ideally will result in strategies for prevention and management in the long term, including beyond this pandemic. Social well-being of children must also be studied. Experts note that the pandemic is a perfect storm for child maltreatment given that vulnerable families are now socially isolated, facing unemployment, and stressed, and that children are not under the watch of mandated reporters in schools, daycare, and primary care. 10 Many states have observed a decrease in child abuse reports and an increase in severity of emergency department abuse cases. In the short term and long term, it will be important to study the impact of access to care, missed care, and disrupted education during COVID-19 on physical and cognitive development.
Training and supporting pediatrician-scientists, such as through NIH physician-scientist research training and career development programs ( https://researchtraining.nih.gov/infographics/physician-scientist ) at all stages of career, as well as fostering research for fellows, residents, and medical students willing to dedicate their research career to, or at least understand implications of their research for, PHE/disasters is important for having an ongoing, as well as a just-in-time surge pediatric-focused PHE/disaster workforce. In addition to including pediatric experts in collaborations and consortiums with broader population focus, consideration should be given to pediatric-focused multi-institutional, academic, industry, and/or government consortiums with infrastructure and ongoing funding for virtual training programs, research teams, and multidisciplinary oversight.
The impact of the COVID-19 pandemic on research and research in response to the pandemic once again highlights the importance of research, challenges of research particularly during PHE/disasters, and opportunities and resources for making research more efficient and cost effective. New paradigms and models for research will hopefully emerge from this pandemic. The importance of building sustained PHE/disaster research infrastructure and a research workforce that includes training and funding for pediatrician-scientists and integrates the pediatrician research workforce into high-quality research across demographics, supports the pediatrician-scientist workforce and pipeline, and benefits society.
Johns Hopkins Coronavirus Resource Center. Covid-19 Case Tracker. Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU). https://coronavirus.jhu.edu/map.html (2020).
US Food and Drug Administration. Coronavirus (COVID-19) update: FDA issues emergency use authorization for potential COVID-19 treatment. FDA News Release . https://www.fda.gov/news-events/press-announcements/coronavirus-covid-19-update-fda-issues-emergency-use-authorization-potential-covid-19-treatment (2020).
Evans, S. R. Fundamentals of clinical trial design. J. Exp. Stroke Transl. Med. 3 , 19–27 (2010).
Article Google Scholar
Antman, E. M. & Bierer, B. E. Standards for clinical research: keeping pace with the technology of the future. Circulation 133 , 823–825 (2016).
Food and Drug Administration. FDA guidance on conduct of clinical trials of medical products during COVID-19 public health emergency. Guidance for Industry, Investigators and Institutional Review Boards . https://www.fda.gov/regulatory-information/search-fda-guidance-documents/fda-guidance-conduct-clinical-trials-medical-products-during-covid-19-public-health-emergency (2020).
National Institutes of Health. NIH clinical trials shows remdesivir accelerates recovery from advanced COVID-19. NIH New Releases . https://www.nih.gov/news-events/news-releases/nih-clinical-trial-shows-remdesivir-accelerates-recovery-advanced-covid-19#.XrIX75ZmQeQ.email (2020).
Radcliffe, S. Here’s exactly where we are with vaccines and treatments for COVID-19. Health News . https://www.healthline.com/health-news/heres-exactly-where-were-at-with-vaccines-and-treatments-for-covid-19 (2020).
Abbasi, J. The promise and peril of antibody testing for COVID-19. JAMA . https://doi.org/10.1001/jama.2020.6170 (2020).
CDC COVID-19 Response Team. Coronavirus disease 2019 in children—United States, February 12–April 2, 2020. Morb. Mortal Wkly Rep . 69 , 422–426 (2020).
Agarwal, N. Opinion: the coronavirus could cause a child abuse epidemic. The New York Times . https://www.nytimes.com/2020/04/07/opinion/coronavirus-child-abuse.html (2020).
Download references
Author information
Authors and affiliations.
Department of Pediatrics, Division of Emergency Medicine, Boston Children’s Hospital, Boston, MA, USA
Debra L. Weiner
Harvard Medical School, Boston, MA, USA
Department of Pediatrics, University of Wisconsin School of Medicine and Public Health, Madison, WI, USA
Vivek Balasubramaniam
Department of Pediatrics and Division of Neonatology, Maria Fareri Children’s Hospital at Westchester Medical Center, New York Medical College, Valhalla, NY, USA
Shetal I. Shah
Division of General Pediatrics, Children’s Hospital Los Angeles, Los Angeles, CA, USA
Joyce R. Javier
Keck School of Medicine, University of Southern California, Los Angeles, CA, USA
You can also search for this author in PubMed Google Scholar
Contributions
All authors made substantial contributions to conception and design, data acquisition and interpretation, drafting the manuscript, and providing critical revisions. All authors approve this final version of the manuscript.
Pediatric Policy Council
Scott C. Denne, MD, Chair, Pediatric Policy Council; Mona Patel, MD, Representative to the PPC from the Academic Pediatric Association; Jean L. Raphael, MD, MPH, Representative to the PPC from the Academic Pediatric Association; Jonathan Davis, MD, Representative to the PPC from the American Pediatric Society; DeWayne Pursley, MD, MPH, Representative to the PPC from the American Pediatric Society; Tina Cheng, MD, MPH, Representative to the PPC from the Association of Medical School Pediatric Department Chairs; Michael Artman, MD, Representative to the PPC from the Association of Medical School Pediatric Department Chairs; Shetal Shah, MD, Representative to the PPC from the Society for Pediatric Research; Joyce Javier, MD, MPH, MS, Representative to the PPC from the Society for Pediatric Research.
Corresponding author
Correspondence to Debra L. Weiner .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Members of the Pediatric Policy Council are listed below Author contributions.
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Weiner, D.L., Balasubramaniam, V., Shah, S.I. et al. COVID-19 impact on research, lessons learned from COVID-19 research, implications for pediatric research. Pediatr Res 88 , 148–150 (2020). https://doi.org/10.1038/s41390-020-1006-3
Download citation
Received : 07 May 2020
Accepted : 21 May 2020
Published : 16 June 2020
Issue Date : August 2020
DOI : https://doi.org/10.1038/s41390-020-1006-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Catalysing global surgery: a meta-research study on factors affecting surgical research collaborations with africa.
- Thomas O. Kirengo
- Hussein Dossajee
- Nchafatso G. Obonyo
Systematic Reviews (2024)
Lessons learnt while designing and conducting a longitudinal study from the first Italian COVID-19 pandemic wave up to 3 years
- Alvisa Palese
- Stefania Chiappinotto
- Carlo Tascini
Health Research Policy and Systems (2023)
Pediatric Research and COVID-19: the changed landscape
- E. J. Molloy
- C. B. Bearer
Pediatric Research (2022)
Cancer gene therapy 2020: highlights from a challenging year
- Georgios Giamas
- Teresa Gagliano
Cancer Gene Therapy (2022)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

The impacts of COVID-19 around the world, as told by statistics

An empty wharf in the Port of Los Angeles in April is a reminder of the collapse in global trade. Image: REUTERS/Lucy Nicholson - RC216G9GU4BQ
.chakra .wef-1c7l3mo{-webkit-transition:all 0.15s ease-out;transition:all 0.15s ease-out;cursor:pointer;-webkit-text-decoration:none;text-decoration:none;outline:none;color:inherit;}.chakra .wef-1c7l3mo:hover,.chakra .wef-1c7l3mo[data-hover]{-webkit-text-decoration:underline;text-decoration:underline;}.chakra .wef-1c7l3mo:focus,.chakra .wef-1c7l3mo[data-focus]{box-shadow:0 0 0 3px rgba(168,203,251,0.5);} Steve MacFeely
.chakra .wef-9dduvl{margin-top:16px;margin-bottom:16px;line-height:1.388;font-size:1.25rem;}@media screen and (min-width:56.5rem){.chakra .wef-9dduvl{font-size:1.125rem;}} Explore and monitor how .chakra .wef-15eoq1r{margin-top:16px;margin-bottom:16px;line-height:1.388;font-size:1.25rem;color:#F7DB5E;}@media screen and (min-width:56.5rem){.chakra .wef-15eoq1r{font-size:1.125rem;}} COVID-19 is affecting economies, industries and global issues

.chakra .wef-1nk5u5d{margin-top:16px;margin-bottom:16px;line-height:1.388;color:#2846F8;font-size:1.25rem;}@media screen and (min-width:56.5rem){.chakra .wef-1nk5u5d{font-size:1.125rem;}} Get involved with our crowdsourced digital platform to deliver impact at scale
Stay up to date:.
- A new report offers statistical insights into the changes COVID-19 has wrought on the world.
- The pandemic poses its own problems for statisticians, however.
- A global effort is needed to support statisticians - especially those in low-income countries, who may be struggling.
We are living through unprecedented times. The impact of the novel coronavirus and the disease it causes, COVID-19, has reverberated through every corner of the globe — taking lives, destroying livelihoods, and changing everything about how we interact with each other and the world.
At a time of crisis, governments more than ever must rely on timely, reliable data to make decisions to mitigate harm and support their citizens. What’s more, given the grave impacts of the coronavirus pandemic on our interconnected world, decisions made today will have consequences that will last far into the future, affecting people in every region and community.
Have you read?
A data visualization expert answers 5 key questions on coronavirus graphics, how policymakers should use the wealth of covid-19 data, lessons from covid-19 modeling: the interplay of data, models and behaviour.
That’s why the Committee for the Coordination of Statistical Activities (CCSA), a partnership of international and supranational organizations, has just released its new report: How COVID-19 is changing the world: a statistical perspective . The report aims to share information on the impacts of the novel coronavirus across a range of areas, including its economic, social and statistical impacts on regions and countries.
The trends seen over the past few months would have been unimaginable in 2019. New statistical records are being set on an almost weekly basis. On the economic side, for example, the aviation industry is facing its deepest-ever crisis, with 90% of the global fleet grounded . Meanwhile, global commodity prices have seen their largest fall on record, dropping 20.4% in the month to March 2020 . Global trade for the second quarter of 2020 is now forecasted to drop by a precipitous 27% compared with the same quarter last year. Tourism is forecasted to fall this year by between 58% to 78%.

In terms of social costs, the education of 1.6 billion learners has been disrupted; that is 9 out of every 10 students in the world. Unsurprisingly, urban areas - which account for more than 90% of COVID-19 cases - are bearing the brunt of the pandemic. The Lockdown measures have reduced violence in countries with a relatively low homicide rate, such as Italy, but has had little or no impact on violence in countries with high levels of organized crime and gang violence driven homicide.
Meanwhile, efforts to eliminate extreme poverty are being set back immensely, with global poverty expected to increase for the first time since the 1998 Asian Financial Crisis. Nowcasts shows that 40 to 60 million people are expected to be pushed into extreme poverty in 2020—that is, living on less than $1.90 a day—as a result of the coronavirus pandemic. At the same time, the threat to children who are already impoverished is expected to be catastrophic, given the expected long-term impacts tied to lack of access to life-saving vaccinations, increased risk of violence, and interruptions to education.

The reason that the international organisations can share this snapshot into the impacts of COVID-19 is because of the existing investments that have been made by the international community in the field of statistics.
Unfortunately, the pandemic poses a significant challenge to this vital information stream. Statistical capacity is being squeezed around the globe, particularly in low-income countries that have limited resources to invest into their public goods. Furthermore, the 2020 round of censuses which were scheduled to take place in more than 120 countries are at grave risk of falling behind or being cancelled, limiting our collective ability to ensure representative data to guide policies.

The collaborative effort involved in putting together this new statistical report—bringing together 36 international organizations to provide high-quality statistics on COVID-19 and its impacts is as an example of the kind of collaboration that will be critically needed going forward.
The Chief Executives Board of the United Nations has reinforced this point. At their virtual meeting of May 14, board members "welcomed How Covid-19 is Changing the World: a Statistical Perspective , published by the CCSA, as a strong example of what the international statistical community can achieve when confronted with a dire global challenge".
It is essential that the international statistical community continue to work closely together, particularly to support struggling statistical offices in low-income countries. In the troubled times that lie ahead, timely and accurate statistics are our best bet to ensure that no one is left behind.
Don't miss any update on this topic
Create a free account and access your personalized content collection with our latest publications and analyses.
License and Republishing
World Economic Forum articles may be republished in accordance with the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International Public License, and in accordance with our Terms of Use.
The views expressed in this article are those of the author alone and not the World Economic Forum.
Related topics:
The agenda .chakra .wef-n7bacu{margin-top:16px;margin-bottom:16px;line-height:1.388;font-weight:400;} weekly.
A weekly update of the most important issues driving the global agenda
.chakra .wef-1dtnjt5{display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;} More on Health and Healthcare Systems .chakra .wef-17xejub{-webkit-flex:1;-ms-flex:1;flex:1;justify-self:stretch;-webkit-align-self:stretch;-ms-flex-item-align:stretch;align-self:stretch;} .chakra .wef-nr1rr4{display:-webkit-inline-box;display:-webkit-inline-flex;display:-ms-inline-flexbox;display:inline-flex;white-space:normal;vertical-align:middle;text-transform:uppercase;font-size:0.75rem;border-radius:0.25rem;font-weight:700;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;line-height:1.2;-webkit-letter-spacing:1.25px;-moz-letter-spacing:1.25px;-ms-letter-spacing:1.25px;letter-spacing:1.25px;background:none;padding:0px;color:#B3B3B3;-webkit-box-decoration-break:clone;box-decoration-break:clone;-webkit-box-decoration-break:clone;}@media screen and (min-width:37.5rem){.chakra .wef-nr1rr4{font-size:0.875rem;}}@media screen and (min-width:56.5rem){.chakra .wef-nr1rr4{font-size:1rem;}} See all

Market failures cause antibiotic resistance. Here's how to address them
Katherine Klemperer and Anthony McDonnell
April 25, 2024

Equitable healthcare is the industry's north star. Here's how AI can get us there
Vincenzo Ventricelli

Bird flu spread a ‘great concern’, plus other top health stories
Shyam Bishen
April 24, 2024

This Earth Day we consider the impact of climate change on human health
Shyam Bishen and Annika Green
April 22, 2024

Scientists have invented a method to break down 'forever chemicals' in our drinking water. Here’s how
Johnny Wood
April 17, 2024

Young people are becoming unhappier, a new report finds
Correlations and Timeliness of COVID-19 Surveillance Data Sources and Indicators ― United States, October 1, 2020–March 22, 2023
Weekly / May 12, 2023 / 72(19);529–535
On May 5, 2023, this report was posted online as an MMWR Early Release.
Heather M. Scobie, PhD 1, *; Mark Panaggio, PhD 2, *; Alison M. Binder, MS 3 ; Molly E. Gallagher, PhD 2 ; William M. Duck, MPH 1 ,4 ; Philip Graff, PhD 2 ; Benjamin J. Silk, PhD 1 ( View author affiliations )
What is already known about this topic?
COVID-19 monitoring will remain a public health priority after the U.S. public health emergency declaration expires on May 11, 2023.
What is added by this report?
Assessment of available surveillance indicators found that COVID-19 hospital admission levels were concordant with COVID-19 Community Levels. COVID-19–associated hospital admission rates lagged 1 day behind case rates and 4 days behind percentages of COVID-19 emergency department visits and positive SARS-CoV-2 test results. National Vital Statistics System trends in the percentage of COVID-19 deaths strongly correlated with, and were 13 days timelier, than aggregate death count data.
What are the implications for public health practice?
Rates of COVID-19–associated hospital admission and the percentages of positive test results, COVID-19 emergency department visits, and COVID-19 deaths are suitable and timely indicators of trends in COVID-19 activity and severity.
Views: Views equals page views plus PDF downloads
- Article PDF
- Full Issue PDF
When the U.S. COVID-19 public health emergency declaration expires on May 11, 2023, national reporting of certain categories of COVID-19 public health surveillance data will be transitioned to other data sources or will be discontinued; COVID-19 hospitalization data will be the only data source available at the county level ( 1 ). In anticipation of the transition, national COVID-19 surveillance data sources and indicators were evaluated for purposes of ongoing monitoring. The timeliness and correlations among surveillance indicators were analyzed to assess the usefulness of COVID-19–associated hospital admission rates as a primary indicator for monitoring COVID-19 trends, as well as the suitability of other replacement data sources. During April 2022–March 2023, COVID-19 hospital admission rates from the National Healthcare Safety Network (NHSN) † lagged 1 day behind case rates and 4 days behind percentages of positive test results and COVID-19 emergency department (ED) visits from the National Syndromic Surveillance Program (NSSP). In the same analysis, National Vital Statistics System (NVSS) trends in the percentage of deaths that were COVID-19–associated, which is tracked by date of death rather than by report date, were observable 13 days earlier than those from aggregate death count data, which will be discontinued ( 1 ). During October 2020–March 2023, strong correlations were observed between NVSS and aggregate death data (0.78) and between the percentage of positive SARS-CoV-2 test results from the National Respiratory and Enteric Viruses Surveillance System (NREVSS) and COVID-19 electronic laboratory reporting (CELR) (0.79), which will also be discontinued ( 1 ). Weekly COVID-19 Community Levels (CCLs) will be replaced with levels of COVID-19 hospital admission rates (low, medium, or high) which demonstrated >99% concordance by county during February 2022–March 2023. COVID-19–associated hospital admission levels are a suitable primary metric for monitoring COVID-19 trends, the percentage of COVID-19 deaths is a timely disease severity indicator, and the percentages of positive SARS-CoV-2 test results from NREVSS and ED visits serve as early indicators for COVID-19 monitoring. Collectively, these surveillance data sources and indicators can support monitoring of the impact of COVID-19 and related prevention and control strategies as ongoing public health priorities.
Authorizations to collect certain categories of public health data will expire on May 11, 2023 ( 1 ), including national data on the percentage of positive SARS-CoV-2 test results from CELR ( 2 ); national reporting of aggregate case and death counts, which CDC compiles from official public health jurisdiction sources, will also be discontinued ( 3 ). CDC will transition to using provisional mortality data from NVSS as the primary data source on COVID-19 deaths ( 4 ) and to using SARS-CoV-2 test positivity data from NREVSS, an established sentinel network of more than 450 clinical, public health, and commercial laboratories ( 5 ). Finally, county COVID-19 hospital admission levels based on admission rates per 100,000 population will replace CCLs § as a primary metric for COVID-19 monitoring. CCLs were first designed to assist communities and members of the public in making prevention decisions based on local context and unique needs ( 6 ).
Statistical measures were used to compare trends in moving 7-day averages for COVID-19 surveillance indicators during October 1, 2020–March 22, 2023, including cross-correlation, autocorrelation, pairwise correlations, and a geographic consistency metric at the state level. Daily averages were available for most data sources; weekly data were available for NVSS, ¶ NREVSS, and aggregate case and death counts after a shift to weekly cadence in October 2022, with some jurisdictions continuing to report daily totals. Cross-correlation was used to estimate the lag (offset in days) in indicators relative to COVID-19–associated hospital admission rates** during April 1, 2022–March 22, 2023, by calculating Spearman’s correlation coefficients by state with reporting lags from −35 days to 35 days over a moving 12-week window; the lag that produced the highest mean correlation was selected. Lags were adjusted to obtain temporal alignment of indicators in subsequent analyses. Pairwise Spearman’s correlations were used to evaluate associations between indicators, and mean correlations were calculated and ranked. Spearman’s autocorrelations were used to assess the signal-to-noise ratio for each indicator (compared with itself, offset by 7 days). Geographic consistency was evaluated using a metric calculated by computing daily z-scores for each indicator, averaging these scores by U.S. state, and computing the standard deviation over all states. Surveillance indicators with lower values for the geographic consistency metric were less likely to have jurisdictions consistently reporting higher or lower than average indicator values.
A linear regression model †† was fit for each surveillance indicator during October 1, 2020–March 31, 2022, and April 1, 2022–March 22, 2023, to estimate ratios (slopes) relative to the COVID-19–associated hospital admission rates. To categorize indicators for data visualized on maps, the calculated ratios were used to identify thresholds for each indicator that were anchored to hospital admission rates used in the CCLs (10 and 20 admissions per 100,000 population), but the lower two categories were divided to increase resolution during periods of lower incidence (five, 10, 15, and 20 admissions per 100,000 population). Percent agreement for weekly CCLs and COVID-19 hospital admission levels (<10.0, 10.0–19.9, and ≥20.0 per 100,000 population) was calculated among the 3,220 U.S. counties (and county-equivalent areas) during February 24, 2022–March 23, 2023 (i.e., since the CCLs were launched). The analysis was carried out using Python (version 3.8.6; Python Software Foundation) with packages Pandas (version 1.5.2) and NumPy (version 1.21.6) for all correlations. Linear regression was carried out using scikit-learn (version 1.1.1). This activity was reviewed by CDC and conducted consistent with applicable federal law and CDC policy. §§
Normalized trends in surveillance indicators largely aligned over time; differences were observed in lag and proportionality relative to hospital admission rates for both early indicators of COVID-19 activity and disease severity indicators ( Figure ). Analysis of cross-correlations between surveillance indicators showed that trends in hospital admission rates lagged 1 day behind case rates and 4 days behind the percentages of COVID-19 ED visits and positive test results (either from CELR or NREVSS [i.e., early indicators]) ( Table 1 ). Severity indicators that lagged behind hospital admission rates included inpatient and intensive care unit (ICU) bed occupancy (3–4 days) and deaths (8 days for NVSS and 21 days for aggregate death counts).
Rates of COVID-19–associated hospital admissions and percentages of inpatient beds occupied by COVID-19 patients, deaths that were COVID-19–associated, and ED visits with a diagnosis of COVID-19 had the highest mean correlations for capturing trends across all indicators ( Table 2 ). Hospital admission rates exhibited both a high signal-to-noise ratio and a low geographic consistency, suggesting that this indicator might provide more easily interpretable and reliable information than others. Since October 2020, correlation was strong ( 7 ) between death rates from NVSS and aggregate death counts (0.79) and between NREVSS and CELR positive test results (0.79); correlation since April 2022 was lower for deaths (0.41) and slightly lower for positive test results (0.70).
Estimated ratios for percentage of positive test results relative to hospital admission rates from both CELR and NREVSS have increased since April 2022 related to decreased testing volumes, although CELR was more affected, possibly related to differential reporting of negative results (Table 1) (Figure). ¶¶ The ratios for percentage of ICU beds occupied by COVID-19 patients, percentage of deaths that are COVID-19–associated, and rates of COVID-19 deaths have decreased relative to hospital admissions since April 2022, likely due to decreased severity of recent infections as a consequence of high population levels of vaccine- and infection-induced immunity, improvements in medical treatment, and changes in variants over time.
A comparison of CCL and COVID-19 hospital admission level designations (low, medium, or high) by week during February 2022–March 2023 demonstrated >99% concordance among 3,220 counties (Supplementary Figure, https://stacks.cdc.gov/view/cdc/127731 ). Most discordant levels were reported during periods of high COVID-19 incidence during February and March 2022. When the levels were discordant, CCLs exceeded the hospital admission levels.
This evaluation of national COVID-19 surveillance data sources and indicators was performed in anticipation of the transition from the COVID-19 pandemic response to routine public health activities that require sustainable sources of surveillance data and reliable indicators after the end of the public health emergency declaration on May 11, 2023. The evaluation determined that hospital admission rates are a suitable and timely primary indicator for monitoring COVID-19 trends. Using COVID-19 mortality data from NVSS improves timeliness for monitoring disease severity by up to 13 days. Leading indicators such as the percentage of ED visits with a COVID-19 diagnosis and percentage of positive SARS-CoV-2 test results can capture changes in trends approximately 4 days earlier than hospital admission rates and provide complementary monitoring information, albeit with more limited geographic coverage.
COVID-19–associated hospital admission rates are available down to the level of the health service area, which is mapped to counties ( 1 ). The high concordance with CCLs is not surprising, because COVID-19 hospital admissions are the primary driver of CCLs and apply identical threshold levels, ensuring continuity beyond the public health emergency. One limitation of the existing level thresholds is insufficient granularity to detect changes during periods of low incidence; further monitoring and analysis would be needed before adjusting thresholds.
Early in the pandemic, aggregate death reporting provided more up-to-date death counts than did NVSS, but timeliness for the two systems has become more similar over time because of improvements in NVSS death certificate data processing ( 8 ). Analysis of the NVSS data by date of death makes the impact of reporting delays on recent deaths more apparent than aggregate death data by date of report (i.e., backfill death counts are assigned to recent report dates rather than the dates when the deaths occurred). However, NVSS data elements are more complete (e.g., for race and ethnicity), and the percentage of COVID-19 deaths from NVSS is not biased by incomplete reporting in recent weeks because death certificate data from COVID-19 and all causes have similar timeliness ( 4 ).
Over the course of the pandemic, the NSSP network has expanded considerably with ED visit data available for most jurisdictions ( 1 ). The data source for percentage of positive SARS-CoV-2 test results will change from CELR to NREVSS after the public health emergency declaration expires and will be reported at the regional level because of limited numbers of reporting laboratories in some states ( 1 ). Voluntary reporting to NREVSS has been used for many years to track the percentage of positive test results for numerous respiratory viruses including influenza and respiratory syncytial virus ( 5 ).
The findings in this report are subject to at least three limitations. First, it was not possible to distinguish between lags related to time to event (e.g., time from infection until death) and reporting delays. Further, retrospective findings do not account for reporting lags affecting recent data or potential future changes to reporting cadence (e.g., change from daily to weekly reporting), including for hospitalization data ( 1 ). As such, the lags presented serve as lower bounds on the effective lag when using these data for real-time monitoring, especially for recent weeks with incomplete reporting. Second, data availability is changing with the end of public health emergency declaration on May 11, 2023, and data availability and quality will likely continue to change over time, potentially affecting their utility for COVID-19 monitoring. The current analysis focused on available data sources moving forward. Finally, this national evaluation used states and territories as a geographic unit of analysis, but findings might vary by jurisdiction based on geographic heterogeneity. This report can serve as a model for similar evaluations that could be undertaken at state levels.
COVID-19 hospital admission rates from NHSN are a timely and suitable primary indicator for monitoring trends in COVID-19 activity. Using the percentage of COVID-19 deaths from NVSS will allow more timely monitoring of COVID-19 severity and mortality trends. The percentage of COVID-19 ED visits and percentage of positive test results can serve as early indicators for COVID-19 trend monitoring. Collectively, these surveillance data sources and indicators can support monitoring of the impact of COVID-19 and related prevention and control strategies as ongoing public health priorities.
Acknowledgments
Amanda R. Galante, Mohammed A. Kemal, Kaitlin Rainwater-Lovett, Rachel O. Sholder, Applied Physics Laboratory, Johns Hopkins University; Andrea Cool, Booz Allen Hamilton; Farida B. Ahmad, Robert N. Anderson, Jodi A. Cisewski, Stephanie Dietz, Aron Hall, Kathleen Hartnett, Diba Khan, Seth Kroop, Aaron Kite-Powell, Barbara E. Mahon, Meredith McMorrow, Tess Palmer, Matthew D. Ritchey, Michael Sheppard, Karl Soetebier, Paul Sutton, Akili P. Weakland, Amber Winn, Caryn M. Womack, CDC; Kim Del Guercio, Deloitte Consulting, LLP.
Corresponding author: Heather M. Scobie, [email protected] .
1 Coronavirus and Other Respiratory Viruses Division, National Center for Immunization and Respiratory Diseases, CDC; 2 Applied Physics Laboratory, Johns Hopkins University, Laurel, Maryland; 3 Division of Healthcare Quality Promotion, National Center for Emerging and Zoonotic Infectious Diseases, CDC; 4 Office of Public Health Data, Surveillance, and Technology, CDC.
All authors have completed and submitted the International Committee of Medical Journal Editors form for disclosure of potential conflicts of interest. No potential conflicts of interest were disclosed.
* These authors contributed equally to this report.
† As of December 15, 2022, COVID-19 hospital data are required to be reported to CDC’s NHSN, which monitors national and local trends in health care system stress, capacity, and community disease levels for approximately 6,000 hospitals in the United States. Data reported by hospitals to NHSN represent aggregated counts and include metrics capturing information specific to hospital capacity, occupancy, hospitalizations, and admissions. Before December 15, 2022, hospitals reported data directly to the U.S. Department of Health and Human Services (HHS) or via a state submission for collection in the HHS Unified Hospital Data Surveillance System.
§ CCLs are a composite metric using COVID-19 hospital admissions per 100,000 population, the percentage of inpatient beds occupied by COVID-19 patients from NHSN, and COVID-19 cases per 100,000 population from aggregate case reporting at the county or county-equivalent level. Because of the choice of thresholds for each of these data elements, the hospital admissions rate is the primary determinant of the CCL for any county, and CCLs for each county will be as high as or higher than the corresponding COVID-19 hospital admission level (i.e., categorized using identical rate thresholds).
¶ NVSS data also contained suppressed values for areas and weeks with counts between 1 and 9. Suppressed counts were treated as 1 when calculating percentage of deaths and deaths per 100,000 population. A sensitivity analysis that replaced suppressed counts with 9 obtained similar results.
** Negative lags correspond to indicators that precede hospital admissions, and positive lags correspond to indicators that follow admissions. Null values were omitted during these calculations.
†† This model took the form y = mx + b where x represents the hospital admission rate, y represents the indicator of interest, the slope m represents the ratio between indicators, and the intercept b was fixed at zero. In this formulation, the ratio can be interpreted as the increase in the indicator of interest ( y ) corresponding to a one-unit increase in admissions per 100,000 population ( x ).
§§ 45 C.F.R. part 46.102(l)(2), 21 C.F.R. part 56; 42 U.S.C. Sect. 241(d); 5 U.S.C.0 Sect. 552a; 44 U.S.C. Sect. 3501 et seq.
¶¶ The CELR data have become more variable in quality or altogether unavailable in many jurisdictions over time.
- Silk BJ, Scobie HM, Duck WM, et al. COVID-19 surveillance after expiration of the public health emergency declaration—United States, May 11, 2023. MMWR Morb Mortal Wkly Rep 2023;72. https://www.cdc.gov/mmwr/volumes/72/wr/mm7219e1.htm?s_cid=mm7219e1_w
- HHS. Fact sheet: COVID-19 public health emergency transition roadmap. Washington, DC: US Department of Health and Human Services; 2023. https://www.hhs.gov/about/news/2023/02/09/fact-sheet-covid-19-public-health-emergency-transition-roadmap.html
- Khan D, Park M, Burkholder J, et al. Tracking COVID-19 in the United States with surveillance of aggregate cases and deaths. Public Health Rep . Epub March 24, 2023. https://doi.org/10.1177/00333549231163531 PMID:36960828
- CDC. National Center for Health Statistics. Technical notes: provisional death counts for coronavirus disease (COVID-19). Atlanta, GA: US Department of Health and Human Services, CDC; 2023. Accessed April 18, 2023. https://www.cdc.gov/nchs/nvss/vsrr/covid19/tech_notes.htm
- CDC. The National Respiratory and Enteric Virus Surveillance System (NREVSS). Atlanta, GA: US Department of Health and Human Services, CDC; 2023. Accessed April 19, 2023. https://www.cdc.gov/surveillance/nrevss/index.html
- CDC. COVID-19. Science brief: indicators for monitoring COVID-19 community levels and making public health recommendations. Atlanta, GA: US Department of Health and Human Services, CDC; 2022. Accessed April 18, 2023. https://www.cdc.gov/coronavirus/2019-ncov/science/science-briefs/indicators-monitoring-community-levels.html
- Schober P, Boer C, Schwarte LA. Correlation coefficients: appropriate use and interpretation. Anesthesia & Analgesia 2018;126(5):1763–8 https://doi.org/10.1213/ane.0000000000002864 PMID:29481436
- Ahmad FB, Anderson RN, Knight K, Rossen LM, Sutton PD. Advancements in the National Vital Statistics System to meet the real-time data needs of a pandemic. Am J Public Health 2021;111:2133–40. https://doi.org/10.2105/AJPH.2021.306519 PMID:34878853
FIGURE . Trends in normalized values* of leading (A) and lagging (B) † COVID-19 surveillance indicators — United States, October 1, 2020–March 22, 2023
Abbreviations: ACDC = aggregate cases and death counts; CELR = COVID-19 electronic laboratory reporting; ED = emergency department; ICU = intensive care unit; NHSN = National Healthcare Safety Network; NREVSS = National Respiratory and Enteric Viruses Surveillance System; NVSS = National Vital Statistics System.
* Normalized values were obtained by dividing each indicator by its maximum over the displayed time frame, which fixes the peak for each curve at 1.
† Leading or lagging indicators were defined relative to hospital admission rates, which are shown in each panel.
Abbreviations: ACDC = aggregate cases and death counts; Auto = automatic assignment of six categories based on dynamic natural breaks; CCL = COVID-19 Community Level; CELR = COVID-19 electronic laboratory reporting; ED = emergency department; HHS = U.S. Department of Health and Human Services; ICU = intensive care unit; NA = not applicable after May 11, 2023; NAAT = nucleic acid amplification test; NHSN = National Healthcare Safety Network; NREVSS = National Respiratory and Enteric Viruses Surveillance System; NSSP = National Syndromic Surveillance Program; NVSS = National Vital Statistics System. * Moving 7-day averages were used for all indicators. These averages were available daily for all data sources except NVSS and NREVSS, which were available weekly. † Cross-correlation was used to calculate the lag (number of days) in indicators relative to hospital admissions as follows: Spearman’s correlations between indicators compared with hospital admission rates per 100,000 population were computed over a moving 12-week window. The offset (ranging from −35 days to 35 days) in indicators that produced the highest mean correlation across all windows and states is displayed. Negative lags correspond to indicators that lead admissions and positive lags correspond to indicators that lag admissions. § A linear regression model y = mx + b was fit where x represents the hospital admission rate, y represents the indicator of interest, m represents the ratio between indicators, and the intercept b was fixed at zero, such that for a one-unit rise in admissions per 100,000 population ( x ), the indicator of interest ( y ) will increase by the ratio value. ¶ To categorize indicators for data visualized in maps on COVID Data Tracker, the calculated ratios were used to identify thresholds for each indicator that were anchored to hospital admission rates used in the CCLs (10 and 20 admissions per 100,000 population), but the lower two categories were divided to increase resolution during periods of lower incidence (five, 10, 15, and 20 admissions per 100,000 population). ** As of December 15, 2022, COVID-19 hospital data are required to be reported to CDC’s NHSN, which monitors national and local trends in health care system stress, capacity, and community disease levels for approximately 6,000 hospitals in the United States. Data reported by hospitals to NHSN represent aggregated counts and include metrics capturing information specific to hospital capacity, occupancy, hospitalizations, and admissions. Before December 15, 2022, hospitals reported data directly to HHS or via a state submission for collection in the HHS Unified Hospital Data Surveillance System. Full guidance on hospital reporting and a list of data elements and definitions can be found online. https://www.hhs.gov/sites/default/files/covid-19-faqs-hospitals-hospital-laboratory-acute-care-facility-data-reporting.pdf †† National weekly COVID-19 ACDC data are compiled by CDC using automated data extraction from official jurisdictional data sources (e.g., through application programming interfaces) and direct submissions from jurisdictions. ACDC data shifted from daily to weekly cadence in October 2022, with some jurisdictions continuing to report daily totals and others reporting only weekly totals. §§ NSSP is a collaboration among CDC, local and state health departments, and academic and private partners to collect and analyze electronic health care data, including data from ED visits. NSSP has expanded substantially during the COVID-19 pandemic, with data from 6,300 facilities in all 50 U.S. states, the District of Columbia, and Guam. NSSP includes 75% of all ED visits in the United States. Data are not shown on COVID Data Tracker for states where ED facility participation is low (currently Minnesota and Oklahoma) or diagnosis information is incomplete (currently Missouri). https://www.cdc.gov/nssp/index.html ¶¶ NVSS collects and reports mortality statistics using U.S. death certificate data. These data are provided through contracts between CDC’s National Center for Health Statistics and vital registration systems operating in the various jurisdictions legally responsible for the registration of vital events. NVSS data from U.S. territories, other than Puerto Rico, are not included in provisional mortality reporting. https://www.cdc.gov/nchs/nvss/index.htm *** CELR has become more variable in quality or altogether unavailable in many jurisdictions over time. With the expiration of the COVID-19 public health emergency, HHS can no longer require reporting of negative SARS-CoV-2 laboratory testing results via CELR. https://www.cdc.gov/coronavirus/2019-ncov/lab/reporting-lab-data.html ††† NREVSS collects weekly aggregate SARS-CoV-2 NAAT results from a sentinel network of reporting laboratories in the United States including clinical, public health and commercial laboratories. These data exclude a small proportion of antigen test results and do not include antibody and at-home test results. NREVSS percent positivity data will be added to COVID Data Tracker after May 11, 2023. https://www.cdc.gov/surveillance/nrevss/index.html
Abbreviations: ACDC = aggregate cases and death counts; CCL = COVID-19 Community Level; CELR = COVID-19 electronic laboratory reporting; ED = emergency department; HHS = U.S. Department of Health and Human Services; ICU = intensive care unit; NA = not applicable after May 11, 2023; NAAT = nucleic acid amplification test; NHSN = National Healthcare Safety Network; NREVSS = National Respiratory and Enteric Viruses Surveillance System; NSSP = National Syndromic Surveillance Program; NVSS = National Vital Statistics System. * Pairwise Spearman’s correlations were used to evaluate associations between indicators after adjusting for lag, and mean correlations were calculated and ranked. † Autocorrelations (Spearman’s) were used to assess the signal-to-noise ratio for each indicator (compared with itself but offset by 7 days); indicators were ranked based on autocorrelation. § Geographic consistency was evaluated using a metric calculated by computing daily z-scores for each indicator, averaging these scores by state, and computing the standard deviation over all states. Surveillance indicators with lower values for the geographic consistency metric are less likely to have jurisdictions consistently reporting indicator values higher or lower than the average. Indicators were ranked based on their geographic consistency metric. ¶ As of December 15, 2022, COVID-19 hospital data are required to be reported to CDC’s NHSN, which monitors national and local trends in health care system stress, capacity, and community disease levels for approximately 6,000 hospitals in the United States. Data reported by hospitals to NHSN represent aggregated counts and include metrics capturing information specific to hospital capacity, occupancy, hospitalizations, and admissions. Before December 15, 2022, hospitals reported data directly to HHS or via a state submission for collection in the HHS Unified Hospital Data Surveillance System. Full guidance on hospital reporting and a list of data elements and definitions can be found online. https://www.hhs.gov/sites/default/files/covid-19-faqs-hospitals-hospital-laboratory-acute-care-facility-data-reporting.pdf ** NVSS collects and reports mortality statistics using U.S. death certificate data. These data are provided through contracts between CDC’s National Center for Health Statistics and vital registration systems operating in the various jurisdictions legally responsible for the registration of vital events. NVSS data from U.S. territories, other than Puerto Rico, are not included in provisional mortality reporting. https://www.cdc.gov/nchs/nvss/index.htm †† NSSP is a collaboration among CDC, local and state health departments, and academic and private partners to collect and analyze electronic health care data, including data from emergency department visits. NSSP has expanded substantially during the COVID-19 pandemic, with data from 6,300 facilities in all 50 U.S. states, the District of Columbia, and Guam. NSSP includes 75% of all emergency department visits in the United States. Data are not shown on COVID Data Tracker for states where ED facility participation is low (currently Minnesota and Oklahoma) or diagnosis information is incomplete (currently Missouri). https://www.cdc.gov/nssp/index.html §§ National weekly COVID-19 ACDC data are compiled by CDC using automated data extraction from official jurisdictional data sources (e.g., through application programming interfaces) and direct submissions from jurisdictions. ACDC data shifted from daily to weekly cadence in October 2022, with some jurisdictions continuing to report daily totals and others reporting only weekly totals. ¶¶ Percent positivity from CELR have become more variable in quality or altogether unavailable in many jurisdictions over time. With the expiration of the COVID-19 public health emergency, HHS can no longer require reporting of negative SARS-CoV-2 laboratory testing results via CELR. https://www.cdc.gov/coronavirus/2019-ncov/lab/reporting-lab-data.html *** NREVSS collects weekly aggregate SARS-CoV-2 NAAT results from a sentinel network of reporting laboratories in the United States including clinical, public health and commercial laboratories. These data exclude a small proportion of antigen test results and do not include antibody and at-home test results. NREVSS percent positivity data will be added to COVID Data Tracker after May 11, 2023. https://www.cdc.gov/surveillance/nrevss/index.html
Suggested citation for this article: Scobie HM, Panaggio M, Binder AM, et al. Correlations and Timeliness of COVID-19 Surveillance Data Sources and Indicators ― United States, October 1, 2020–March 22, 2023. MMWR Morb Mortal Wkly Rep 2023;72:529–535. DOI: http://dx.doi.org/10.15585/mmwr.mm7219e2 .
MMWR and Morbidity and Mortality Weekly Report are service marks of the U.S. Department of Health and Human Services. Use of trade names and commercial sources is for identification only and does not imply endorsement by the U.S. Department of Health and Human Services. References to non-CDC sites on the Internet are provided as a service to MMWR readers and do not constitute or imply endorsement of these organizations or their programs by CDC or the U.S. Department of Health and Human Services. CDC is not responsible for the content of pages found at these sites. URL addresses listed in MMWR were current as of the date of publication.
All HTML versions of MMWR articles are generated from final proofs through an automated process. This conversion might result in character translation or format errors in the HTML version. Users are referred to the electronic PDF version ( https://www.cdc.gov/mmwr ) and/or the original MMWR paper copy for printable versions of official text, figures, and tables.
Exit Notification / Disclaimer Policy
- The Centers for Disease Control and Prevention (CDC) cannot attest to the accuracy of a non-federal website.
- Linking to a non-federal website does not constitute an endorsement by CDC or any of its employees of the sponsors or the information and products presented on the website.
- You will be subject to the destination website's privacy policy when you follow the link.
- CDC is not responsible for Section 508 compliance (accessibility) on other federal or private website.
- Introduction
- Article Information
eReferences
Data Sharing Statement
See More About
Sign up for emails based on your interests, select your interests.
Customize your JAMA Network experience by selecting one or more topics from the list below.
- Academic Medicine
- Acid Base, Electrolytes, Fluids
- Allergy and Clinical Immunology
- American Indian or Alaska Natives
- Anesthesiology
- Anticoagulation
- Art and Images in Psychiatry
- Artificial Intelligence
- Assisted Reproduction
- Bleeding and Transfusion
- Caring for the Critically Ill Patient
- Challenges in Clinical Electrocardiography
- Climate and Health
- Climate Change
- Clinical Challenge
- Clinical Decision Support
- Clinical Implications of Basic Neuroscience
- Clinical Pharmacy and Pharmacology
- Complementary and Alternative Medicine
- Consensus Statements
- Coronavirus (COVID-19)
- Critical Care Medicine
- Cultural Competency
- Dental Medicine
- Dermatology
- Diabetes and Endocrinology
- Diagnostic Test Interpretation
- Drug Development
- Electronic Health Records
- Emergency Medicine
- End of Life, Hospice, Palliative Care
- Environmental Health
- Equity, Diversity, and Inclusion
- Facial Plastic Surgery
- Gastroenterology and Hepatology
- Genetics and Genomics
- Genomics and Precision Health
- Global Health
- Guide to Statistics and Methods
- Hair Disorders
- Health Care Delivery Models
- Health Care Economics, Insurance, Payment
- Health Care Quality
- Health Care Reform
- Health Care Safety
- Health Care Workforce
- Health Disparities
- Health Inequities
- Health Policy
- Health Systems Science
- History of Medicine
- Hypertension
- Images in Neurology
- Implementation Science
- Infectious Diseases
- Innovations in Health Care Delivery
- JAMA Infographic
- Law and Medicine
- Leading Change
- Less is More
- LGBTQIA Medicine
- Lifestyle Behaviors
- Medical Coding
- Medical Devices and Equipment
- Medical Education
- Medical Education and Training
- Medical Journals and Publishing
- Mobile Health and Telemedicine
- Narrative Medicine
- Neuroscience and Psychiatry
- Notable Notes
- Nutrition, Obesity, Exercise
- Obstetrics and Gynecology
- Occupational Health
- Ophthalmology
- Orthopedics
- Otolaryngology
- Pain Medicine
- Palliative Care
- Pathology and Laboratory Medicine
- Patient Care
- Patient Information
- Performance Improvement
- Performance Measures
- Perioperative Care and Consultation
- Pharmacoeconomics
- Pharmacoepidemiology
- Pharmacogenetics
- Pharmacy and Clinical Pharmacology
- Physical Medicine and Rehabilitation
- Physical Therapy
- Physician Leadership
- Population Health
- Primary Care
- Professional Well-being
- Professionalism
- Psychiatry and Behavioral Health
- Public Health
- Pulmonary Medicine
- Regulatory Agencies
- Reproductive Health
- Research, Methods, Statistics
- Resuscitation
- Rheumatology
- Risk Management
- Scientific Discovery and the Future of Medicine
- Shared Decision Making and Communication
- Sleep Medicine
- Sports Medicine
- Stem Cell Transplantation
- Substance Use and Addiction Medicine
- Surgical Innovation
- Surgical Pearls
- Teachable Moment
- Technology and Finance
- The Art of JAMA
- The Arts and Medicine
- The Rational Clinical Examination
- Tobacco and e-Cigarettes
- Translational Medicine
- Trauma and Injury
- Treatment Adherence
- Ultrasonography
- Users' Guide to the Medical Literature
- Vaccination
- Venous Thromboembolism
- Veterans Health
- Women's Health
- Workflow and Process
- Wound Care, Infection, Healing
Get the latest research based on your areas of interest.
Others also liked.
- Download PDF
- X Facebook More LinkedIn
Torres JR , Taira BR , Bi A, et al. COVID-19 Vaccine Uptake in Undocumented Latinx Patients Presenting to the Emergency Department. JAMA Netw Open. 2024;7(4):e248578. doi:10.1001/jamanetworkopen.2024.8578
Manage citations:
© 2024
- Permissions
COVID-19 Vaccine Uptake in Undocumented Latinx Patients Presenting to the Emergency Department
- 1 David Geffen School of Medicine, University of California, Los Angeles
- 2 Olive View-UCLA Medical Center, Los Angeles, California
- 3 School of Medicine, University of California, San Francisco
COVID-19 has disproportionately affected the US Latinx population, with significantly higher rates of infections, hospitalizations, and mortality. 1 , 2 Although the undocumented Latinx population in the US is growing, 3 there are limited data regarding their COVID-19 infection status, vaccination uptake, and perceptions about the COVID-19 vaccine.
We conducted this prospective, cross-sectional survey study from September 2, 2021, through March 31, 2022, at Olive View-UCLA Medical Center and San Francisco General Hospital, which serve large Latinx immigrant populations. After verbal consent, as approved by the institutional review boards of both facilities, a convenience sample of adult (aged ≥18 years) emergency department (ED) patients participated in structured interviews in English or Spanish. The study followed the STROBE reporting guideline.
We excluded patients who were critically ill, on psychiatric holds, or incarcerated or who had altered mentation. Participants were enrolled in 3 approximately equal groups based on self-reported race and ethnicity (non-Latinx [including Asian, Black, Native Hawaiian or other Pacific Islander, Middle Eastern, White, and other], legal Latinx resident or citizen, and undocumented Latinx).
Descriptive statistics were used to summarize participant responses, and comparisons were performed using bivariate hypothesis testing. Data were analyzed using Stata, version 16.1 (StataCorp LLC). Additional details on methodology and the survey instrument are provided in the eMethods in Supplement 1 .
This study included 306 participants (median [IQR] age, 51 [40-60] years; 146 female [48%], 157 male [51%], and 3 with missing sex data [1%]); 209 identified as Latinx (68%) and 34 as non-Latinx Black (11%), 43 as non-Latinx White (14%), and 20 as other race or ethnicity (7%). Among the undocumented Latinx group, 26 (25%) were uninsured, 99 (95%) reported Spanish as their primary language, and 31 (30%) used the ED as their usual source of health care ( Table 1 ).
Compared with the non-Latinx group, a prior COVID-19 infection was more likely reported by undocumented Latinx participants (odds ratio [OR], 3.42; 95% CI, 1.66-7.23) and legal Latinx residents (OR, 2.73; 95% CI, 1.32-5.83). Of all participants, 265 (87%) reported having received at least 1 COVID-19 vaccine and 41 (13%) reporting a decline in vaccination, with similar distributions for all 3 groups. The most common reason for declining vaccines was concern about potential side effects (15 participants [37%]). Compared with the undocumented Latinx group, the non-Latinx group was less likely to believe that undocumented immigrants could receive the COVID-19 vaccine in the US (OR, 0.09; 95% CI, 0.01-0.39), and 41 (13%) reported knowing undocumented people who did not obtain the vaccine because of fear of discovery and deportation ( Table 2 ). Among those who previously declined a COVID-19 vaccine, 9 (22%) expressed interest in receiving the vaccine while in the ED.
Among the population studied, a prior COVID-19 infection was most commonly reported by Latinx participants. Despite the health care access barriers undocumented Latinx individuals face, 4 we found no differences in the proportion who had received COVID-19 vaccines. Additionally, there were minimal perceptions of exclusion from eligibility for vaccination among this group. However, 13% of all participants knew people who were reluctant to get vaccinated due to concerns about their immigration status.
Limitations of our work include group differences in age, sex, and insurance status, factors that may have influenced their responses to key questions. Additionally, citizenship status and prior COVID-19 infection were self-reported, and we only sampled patients who sought care in the ED; thus, individuals who were most fearful of discovery of their immigration status may have been undercounted. Our study was also restricted to 2 EDs affiliated with teaching hospitals in California; therefore, generalizability may be limited. Overall, our findings highlight the utility of EDs for greater inclusion of the undocumented immigrant population in public health surveillance research.
Accepted for Publication: February 28, 2024.
Published: April 26, 2024. doi:10.1001/jamanetworkopen.2024.8578
Open Access: This is an open access article distributed under the terms of the CC-BY License . © 2024 Torres JR et al. JAMA Network Open .
Corresponding Author: Jesus R. Torres, MD, MPH, MSc, David Geffen School of Medicine, University of California, Los Angeles, 1100 Glendon Ave, Ste 1200, Los Angeles, CA 90024 ( [email protected] ).
Author Contributions: Drs Torres and Rodriguez had full access to all of the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis.
Concept and design: Torres, Taira, Rodriguez.
Acquisition, analysis, or interpretation of data: Torres, Taira, Bi, Gomez, Delgado, Vera, Rodriguez.
Drafting of the manuscript: Torres, Rodriguez.
Critical review of the manuscript for important intellectual content: Torres, Taira, Bi, Gomez, Delgado, Vera, Rodriguez.
Statistical analysis: Torres.
Administrative, technical, or material support: All authors.
Supervision: Torres, Taira, Rodriguez.
Conflict of Interest Disclosures: None reported.
Data Sharing Statement: See Supplement 2 .
Additional Contributions: The authors thank Jennifer M. Diaz, BA; Aura M. Elias, BS; and Rose Diaz, MD, MPH, from the UCLA David Geffen School of Medicine for their contributions to data collection. They did not receive compensation.
- Register for email alerts with links to free full-text articles
- Access PDFs of free articles
- Manage your interests
- Save searches and receive search alerts
- Election Integrity
- Immigration
Political Thought
- American History
- Conservatism
- Progressivism
International
- Global Politics
- Middle East
Government Spending
- Budget and Spending
Energy & Environment
- Environment
Legal and Judicial
- Crime and Justice
- Second Amendment
- The Constitution
National Security
- Cybersecurity
Domestic Policy
- Government Regulation
- Health Care Reform
- Marriage and Family
- Religious Liberty
- International Economies
- Markets and Finance
COVID-19: A Statistical Analysis of Data from Throughout the Pandemic and Recommendations for Moving On
Authors: Kevin Dayaratna and Doug Badger
Key Takeaways
New Heritage analysis finds COVID-19 hospitalization statistics have been both inflated and highly misleading. This is not a "pandemic of the unvaccinated."
The data also clearly show that natural immunity, vaccines, and newly developed anti-virals can make a positive impact in reducing hospitalizations due to COVID-19.
It is time for policymakers to realize that "zero-COVID" is unrealistic, abandon unwise policies, learn to live with the virus, and move on from the pandemic.
Select a Section 1 /0
Alex Azar, then-Secretary of Health and Human Services (HHS), declared a national public health emergency in response to COVID-19 on January 31, 2020. REF The declaration soon triggered a frenzy of government interventions in the social and economic lives of 330 million Americans. Those interventions aimed to mitigate or eradicate the SARS-CoV-2 virus.
More than two years into the pandemic, “zero-COVID” now appears to be an unrealistic goal. The last major virus to be truly eradicated was smallpox over 40 years ago—almost 200 years after the development of its vaccine in 1796. REF
This Special Report statistically examines how the pandemic, and our understanding of it, has evolved over time. Using data from a variety of sources—both foreign and domestic—we examine the efficacy of natural and vaccine-acquired immunity in reducing the risk of COVID-19-related hospitalizations and mortality. We also look at whether the data support the assertion that the United States is suffering a “pandemic of the unvaccinated.” Lastly, we assess how new data, along with the advent of innovative treatments, should reshape public policy toward COVID-19.
We conclude that policymakers should adapt their approach to ever-changing facts on the ground, including the increasing likelihood that the SARS-CoV-2 virus will remain in circulation indefinitely. In fact, the director of the Centers of Disease Control and Prevention (CDC), Rochelle Walenksy, noted that COVID-19 “is likely to become an endemic disease here in the United States and really around the world.” REF We will thus need to learn to live with the virus as we already do with many other problems such as heart disease, cancer, hepatitis, influenza, and HIV. Coexistence should replace eradication as the lodestar of pandemic policy.
More specifically, we suggest that policymakers eschew restrictions and mandates and instead restore pre-pandemic social and economic arrangements, understanding the usefulness of vaccinations, natural immunity, and anti-virals at being able to control the virus. Or, to put it more simply, it is time to return to our pre-pandemic understanding of “normal.”
What We Have Learned About the Pandemic
COVID-19 Cases and Hospitalizations Reached New Heights in January 2022 Despite Aggressive Pharmaceutical and Nonpharmaceutical Interventions. Newly confirmed cases of COVID-19, generally defined as the number of people who return positive tests, have continued to rise and fall throughout the first two years of the pandemic.
As Chart 1 illustrates, after the first confirmed COVID-19 case was reported in Washington State in January 2020, infections and deaths fluctuated over the coming months, subsequently reaching a peak in December 2020 and January 2021. REF After the wave of new infections crested, the United States experienced a steep decline. The Food and Drug Administration (FDA) granted emergency use authorizations (EUAs) to two mRNA vaccines in December 2020. REF The ebbing of cases and deaths occurred as tens of millions of people were being vaccinated, feeding the hope that immunizations would end the pandemic.
But during the summer of 2021, the Delta variant became dominant in the United States, leading to an increase in cases and hospitalizations, which subsided in September.
The Omicron variant, which became the dominant strain in December 2021, caused the biggest spike in cases since the pandemic’s onset. The new variant also caused a rise in deaths with COVID-19, although the peak number of daily deaths has remained far below the levels seen before widespread immunizations.
Hospitalizations, presented in Chart 1, traced an arc similar to the rise and fall in cases. Hospitalizations achieved three primary peaks: the winter of 2020–2021, the summer of 2021 during the Delta variant phase, and now most recently during the winter of 2021–2022 with the Omicron variant. Public health experts have cited disease proliferation as a primary justification for restrictive measures such as travel bans, mask mandates, and vaccine mandates. REF
It Is Not a Pandemic of the Unvaccinated. Since mass immunizations were believed to augur the pandemic’s end, some public officials attributed the surges in cases and hospitalizations during the summer of 2021 and the subsequent winter to the unvaccinated. This allegation took on highly political tones in the United States, where vaccine resistance was more common in red states than in blue ones. President Biden, for example, attributed a recent increase in hospitalizations to a “pandemic of the unvaccinated.” REF
“The unvaccinated are taking up hospital beds and crowding emergency rooms and intensive care units,” he said on January 4, 2022. “That’s a place that other people will need access to those hospitals.” REF
It is impossible to verify these claims using HHS data. These data do not identify whether a patient hospitalized with COVID-19 was admitted because of COVID-19, nor do they differentiate between vaccinated and unvaccinated patients. REF
Data sources compiled by states as well as the United Kingdom, however, suggest the President’s assertions are untrue. For example, Chart 2 presents data from New York State, which distinguish between patients admitted because of COVID-19 and those admitted for other reasons but who also tested positive for COVID-19.
As Chart 2 demonstrates, New York has consistently had between 4,000 and 13,000 patients testing positive for COVID-19. However, roughly 40 percent of these patients entered the hospital for reasons other than a COVID-19 diagnosis. They were hospitalized with the infection, not because of it. U.S. government data that count beds that are “in use” by patients with COVID-19 without making these distinctions thus overstate the impact of the disease itself on hospital resources. REF
It is also difficult to find comprehensive data that sort hospitalized COVID-19 patients by vaccination status. Although the CDC does provide some data via its COVID-net system, these data are based on a self-selected sample of hospitals and are thus not comprehensive. There are, however, some data on the issue from the Commonwealth of Massachusetts and the United Kingdom on the vaccination status of patients admitted with COVID-19.
The Commonwealth of Massachusetts. Massachusetts provides breakdowns of raw hospitalization numbers across all counties by vaccination status, presented in Chart 3. REF As is apparent in Chart 3, the number of fully vaccinated patients hospitalized with COVID-19 is indeed non-trivial and has picked up significantly during the Omicron surge. Chart 3 presents the percentage of patients hospitalized for COVID-19 who are fully vaccinated.
As of mid-January, nearly half the patients hospitalized with COVID-19 in Massachusetts were fully vaccinated or boosted. REF Like New York State, Massachusetts also reports data that differentiate between hospitalizations with COVID-19 from hospitalizations caused by COVID-19. These data are presented in Chart 4.
As Chart 4 illustrates, since January 13, 2022, there has been a roughly 50/50 split amongst hospitalizations for and with COVID-19. In mid-January 2022, around 52 percent of inpatients who tested positive for COVID-19 were admitted for that reason or to treat complications of the disease. This percentage declined throughout the month of January, with incidental hospitalizations with COVID-19 surpassing hospitalizations for the virus in February.
The United Kingdom. Data from other countries can also shed light on the effect of vaccines on hospitalization and death, especially since the CDC fails to compile sufficiently comprehensive data on the issue. The U.K. government keeps data on the vaccination status of patients admitted due to COVID-19 after having presented themselves for emergency care. REF Table 1 shows the U.K. data for the four weeks between January 16 and February 6, 2022, during which Omicron was the dominant variant. REF
Of the 11,197 patients who visited emergency rooms in the U.K. and were subsequently admitted for COVID-19 over this period, 739 either had an unknown vaccine status or had received only their first dose. Unvaccinated patients accounted for 3,261 admissions (29 percent of the total number of COVID-19 admissions), while fully vaccinated or boosted patients accounted for 7,197 admissions (64 percent of COVID-19 patients).
In every adult age cohort, the number of vaccinated patients hospitalized for COVID-19 exceeded the number of hospitalized unvaccinated patients. In older patients—those ages 60 and above—the number of boosted COVID-19 patients outnumbered unvaccinated COVID-19 patients.
The President’s assertion that the unvaccinated are overcrowding hospitals and denying care to other seriously ill patients is thus unsupported by the data we have examined. The Massachusetts and U.K. data suggest that among hospital patients admitted for COVID-19, there is indeed a substantial number (nearly 50 percent to over 60 percent) that are vaccinated.
Vaccines Reduce the Risk of Hospitalization and Death from COVID-19. Although many, if not most, patients hospitalized with COVID-19 are vaccinated, that does not mean vaccines do not work. The reason: a smaller percentage of vaccinated people than of unvaccinated people enter hospitals. The risk that a vaccinated person enters a hospital due to COVID-19 is thus lower than the risk to an unvaccinated person, even if the number of vaccinated hospitalizations exceeds the number of unvaccinated hospitalizations. Analysis from both Massachusetts and the U.K. document this interesting finding that is perhaps counterintuitive to some.
Massachusetts Data. Chart 5 shows the percentage of vaccinated and unvaccinated Massachusetts residents who entered hospitals with COVID-19 between August 16, 2021, and February 9, 2022.
As Chart 5 illustrates, both groups have incurred increases in hospitalizations for COVID-19 over the past few months despite also having relatively low percentages (less than 0.15 percent) of their respective cohorts hospitalized for COVID-19. Nevertheless, Chart 5 demonstrates that the fully vaccinated comprise a significantly lower percentage than their unvaccinated counterparts, suggesting that they are, as a group, less likely to be hospitalized for COVID-19.
There are two limitations to this inference. First, Massachusetts does not group patients by age. Second, the data do not match vaccinated and unvaccinated patients for comorbidities. Those same limitations, of course, also apply to the raw counts of hospitalizations. Without such data it is difficult to comprehensively ascertain the effect of vaccinations at preventing hospitalization, which is worthy of future research. Nevertheless, based on our analysis using data that are available, it does appear that the overall hospitalization rate in Massachusetts is indeed lower among the vaccinated than the unvaccinated.
U.K. Data. Unlike the data from Massachusetts, data from the U.K. do indeed group patients hospitalized with COVID-19 by age as well as vaccination status. Table 1 above showed that roughly twice as many vaccinated patients as unvaccinated patients were hospitalized for COVID-19 between January 16 and February 6, 2022.
Chart 6 shows that, for most age brackets, the percentage of vaccinated people hospitalized for COVID-19 was smaller than that of unvaccinated people hospitalized for the disease.
For all ages, approximately 0.06 percent of unvaccinated people entered hospitals because of COVID-19. This percentage is more than three times that of people who have received one, two, or three doses (0.02 percent). Across all ages, the percentage of people hospitalized is lower for those who received three doses than for the unvaccinated, suggesting that those boosted against COVID-19 have the lowest risk of hospitalization.
All age groups under 80 have lower percentages of hospitalizations among those with one, two, or three shots than their unvaccinated counterparts. Hospitalization rates for those in their 80s and older are higher among people who have had one or two doses than among the unvaccinated, but those in that age group who have been boosted have the lowest rates of all. Regardless, all percentages are under 1 percent of each cohort’s population.
The U.K. data on COVID-19-related mortality exhibit a similar pattern. Chart 7 shows the number of deaths during the four weeks between January 16 and February 6, 2022, by age and vaccination status.
As expected, deaths are most numerous at the oldest age groups, rare among those under 30, and low among those ages 30–50. What is striking is the large number of deaths among the vaccinated and boosted compared with the unvaccinated. Those who have completed their vaccination courses account for the largest number of deaths, followed by those who have been boosted. Together, more than twice as many deaths occurred among these two groups as among unvaccinated people.
These numbers do not establish that vaccinated and boosted people are more likely to die from COVID-19 than are the unvaccinated. Chart 7 shows the percentage of COVID-19 deaths with 60 days of admission by age and vaccination status.
Chart 7 shows that the overall risk of dying from COVID-19 is minuscule for people younger than 50, regardless of vaccination status (<0.01 percent for all such groups having any level of vaccination and 0.01 percent for the 40–49 unvaccinated age group). For those in their 50s and 60s, the risk is most significant for the unvaccinated. That changes for those ages 70 and older. In the two oldest age brackets, the mortality risk is highest for those who have gotten two vaccine doses and lowest for those with three doses. While assessing the value of boosters is beyond the scope of this paper, this analysis appears to suggest that among the cohorts at greatest risk of COVID-19 mortality, boosters may offer the greatest level of protection. REF
This assessment is subject to limitations since, as with raw counts of the number of deaths by vaccination status, unvaccinated and vaccinated people were not matched by gender, comorbidities, natural immunity acquired from prior infection, and other potentially relevant factors. Adjusting for these factors would be a more comprehensive way to assess the efficacy of vaccines. Acquiring and analyzing such data are areas worthy of future research.
Altogether, however, our analysis of data from Massachusetts and the U.K. demonstrates that a significant number of people hospitalized because of COVID-19 are vaccinated and that most COVID-19 deaths that have occurred during the Omicron wave in the U.K. occurred among people who have been vaccinated or boosted. However, our analysis based on percentage computations across age groups also suggests that risk of hospitalization and death is lower for the vaccinated than for the unvaccinated for most age groupings.
Natural Immunity Reduces the Risk of Infection and Hospitalization. Since the pandemic began, research has suggested that natural immunity can be quite robust at preventing subsequent infection. REF The CDC, however, did not release meaningful data on natural immunity until January 2022. REF The study examines the impact of vaccination and prior COVID-19 infection against subsequent infections and hospitalizations between May and November 2021 across California and New York, which, the authors note, account for 18 percent of the U.S. population. It considered four cohorts of adults (over 18):
- Those who were unvaccinated with no prior laboratory-confirmed COVID-19 diagnosis;
- Those vaccinated (14 days after completion of a primary COVID-19 vaccination series) with no prior COVID-19 diagnosis;
- Those unvaccinated with a prior COVID-19 diagnosis; and
- Those vaccinated and with a prior COVID-19 diagnosis.
The authors compared these four groups in terms of incidence of confirmed COVID-19 cases and hospitalizations for California while only providing case incidence comparisons for New York (citing unavailable hospitalization data). Their results for California are presented in Chart 8.
As Chart 8 shows, the CDC study suggests that natural immunity is even more effective at preventing case incidence and hospitalization than vaccine-induced immunity is. Those who have both recovered from infection and been vaccinated appear slightly more protected. According to the study, there does not appear to be any meaningful positive effect of natural immunity coupled with vaccine-induced immunity on the incidence of hospitalization.
As the CDC study does not examine mortality, it is not possible to determine whether the same pattern holds for deaths as for infections and hospitalizations. Regardless, the CDC data indicate that natural immunity indeed provides robust protection against subsequent infection and hospitalization. REF
Recent research published in the Journal of the American Medical Association found that breakthrough infections of the Delta variant created a robust immune reaction in response to the Delta variant. Although little work has yet been done on the Omicron variant, the authors suggest that the immune response may very well be highly efficacious against other variants as well, suggesting—though not establishing—that the Omicron variant could induce super-immunity against the virus. REF
While hospitalization and per capita death rates of COVID-19 were the primary reasons for initial government nonpharmaceutical interventions, statistics now indicate that natural and vaccine-induced immunity provides overwhelming protection against COVID-19.
COVID-Related Mortality Is Highly Age-Stratified Regardless of Vaccination Status. COVID-19 has impacted various age groups in society in different ways. As Chart 9 illustrates, more than 85 percent of confirmed cases are among people under 65, while more than 75 percent of COVID-19-related deaths are among people aged 65 and older.
Chart 9 lays out the probability of surviving a confirmed case of COVID-19 by age group. As Chart 9 demonstrates, the overall probability of surviving COVID-19 is over 98 percent. Those under 50 have better than a 99.5 percent chance of recovery. These probabilities drop quickly for older age groups, but still, those between the ages of 65 and 74 have a 95.4 percent survival rate, and those ages 85 and older have a 77.3 percent survival rate.
It is helpful to put the mortality of COVID-19 in perspective with other causes of death. We do so for COVID-19 in 2020 and 2021 and other causes of the first year before the pandemic in 2019, by presenting crude death rates in Chart 10.
Across all age groups, heart disease was the leading cause of death in the country in 2019, followed by cancer. COVID-19 was the next leading cause of death in 2020 and 2021 (115.9 and 135.6 per capita, respectively). The fully vaccinated, however, had a significantly lower per capita death rate (35.6), similar to other causes of death, including diabetes (26.7), influenza (15.1), nephritis (15.7), and suicide (14.5).
We also present a number of similar calculations in Appendix Chart 1, broken down by age. These statistics suggest that, for all groups under 65, the fully vaccinated are protected against COVID-19 as the virus carries a significantly lower per capita death rate than most if not all other causes of death across the respective age groups. Given the analysis presented in the prior section, this finding may also be true for the naturally immune.
The group 65 and above, not surprisingly, has the highest per capita death rates for a variety of illnesses, with cancer, heart disease, chronic lower respiratory diseases, and cerebrovascular illnesses leading the list prior to the pandemic. The per capita death rates for COVID-19 in both 2020 and 2021 (573.4 and 572.4, respectively), however, exceed a number of leading causes prior to the pandemic, demonstrating that COVID-19 has been a particularly dangerous potential cause of death for people above the age of 65. In fact, for the unvaccinated, the estimated per capita death rate (1612.3) exceeds all other causes of mortality. Fortunately, for the vaccinated this rate is significantly lower (115.2), below Alzheimer’s and diabetes mellitus. Thankfully, as Appendix Chart 1 illustrates, those in this age cohort who contract COVID-19 have between a 77 percent and 95 percent chance of survival depending on their age. Additionally, although the per capita death rate for the fully vaccinated (115.2 per capita) is indeed higher for the above-65 age group than their younger counterparts, on a percentage basis, this rate translates to 0.12 percent of the age cohort’s population.
Unvaccinated People Are Unlikely to Change Their Minds. Our analysis indicates that although natural immunity from COVID-19 does seem to provide strong protection, there are benefits of vaccination at averting serious illness from COVID-19. And while the chances of surviving infection are high for most age groups, vaccinated people have a much lower COVID-19-related mortality rate than do the unvaccinated.
Chart 11 represents the evolution of the number of people fully vaccinated against COVID-19 over time. After the FDA granted EUAs for two vaccines in December 2020 and the pace of production, distribution, and administration quickened, the rate of daily new vaccinations grew rapidly, peaking in the spring of 2021.
Afterward, uptake gradually declined, despite ample supply, with slight upticks before the fall and winter 2021 seasons. The American Academy of Family Medicine noted that primary reasons for vaccine hesitancy included a preference for natural immunity, concerns about safety and efficacy, distrust of government and health organizations, and desire for autonomy and personal freedom. REF As of February 22, 2022, 65 percent of the American population has been fully vaccinated against COVID-19. "> REF
After vaccination rates slowed during the summer of 2021, even as the number of confirmed cases spiked, President Biden reversed his opposition to federal vaccine mandates. REF His executive orders directed various federal agencies to impose COVID-19 vaccine mandates on federal workers and contractors, hospitals and other health care facilities, and private firms with at least 100 employees. REF
These mandates faced court challenges. The U.S. Supreme Court struck down an emergency temporary standard issued by the Occupational Safety and Health Administration that placed a mandate on private companies, but it upheld an interim final rule by the Centers for Medicare and Medicaid Services mandating that health facilities require their workers to be immunized. REF
Many companies continue to impose vaccine mandates on their workers. Some states prohibit such mandates by private employers. Others permit them but require employers to grant exemptions. REF Some states require public workers to be vaccinated, while others prohibit counties and cities from establishing and enforcing such mandates on their employees. REF
This patchwork of mandate policies had an uncertain effect on vaccination rates, which in January 2022 fell to the lowest levels since January 2021, when vaccines were still in short supply. REF
All of this suggests that attitudes among the unvaccinated have hardened. In September 2021, the Cato Institute commissioned YouGov to survey attitudes toward the vaccine and if specific incentives could change the minds of the vaccine-hesitant. REF We present some of the results in the study in Chart 12.
As this chart demonstrates, although most Americans have been vaccinated, and others say they are willing to take the vaccine, a high percentage (17.5 percent) is completely unwilling to do so. As presented in Chart 12, resistance varies by race but is nevertheless non-trivial across all races. Vaccine resistance remains strongest among young adults. Through February 22, 2022, over 23 percent of adults ages 18–24 and over 21 percent of those ages 25–39 had not received a single dose of the vaccine. REF
As the data compiled in Chart 12 illustrate, many unimmunized adults will not change their minds about the vaccine. The public health effects of their resistance to vaccines are mitigated to some extent by the fact that many unvaccinated people likely have natural immunity.
Promising New Treatments Can Vastly Reduce the Risk of Hospitalization and Death Among Those with COVID-19. In December 2020, the FDA granted EUAs for two vaccine products, both of which have reduced the risks of severe illness and death from COVID-19. In December 2021, the FDA granted EUAs for two anti-viral products: Molnupiravir (produced by Merck) and Paxlovid (made by Pfizer). REF Both are oral medications.
Randomized controlled trials for Molnupiravir found the drug to prevent 30 percent of symptomatic cases from progressing to severe disease. REF Paxlovid was 89 percent effective in preventing hospitalization, with no deaths reported in clinical trials. REF Both drugs were so effective that trials were interrupted because it would have been unethical to deny the medication to the placebo arms. REF
The Biden Administration has ordered 10 million courses of Paxlovid, making it widely available to prevent hospitalizations. REF One of the reasons some have continued to advocate for government protection measures for COVID-19 is because hospitalizations of COVID-19 still exceed those of common respiratory infections including influenza and respiratory syncytial virus (RSV). This comparison is discussed in a recent paper published in the Journal of the American Medical Association co-authored by former Obama White House adviser Ezekiel Emanuel, who now serves as a vice provost at the University of Pennsylvania Medical School: REF
The appropriate threshold should reflect peak weekly deaths, hospitalizations, and community prevalence of viral respiratory illnesses during high-severity years, such as 2017–2018. That year had approximately 41 million symptomatic cases of influenza, 710000 hospitalizations and 52000 deaths. In addition, the CDC estimates that each year RSV leads to more than 235000 hospitalizations and 15000 deaths in the US. This would translate into a risk threshold of approximately 35000 hospitalizations and 3000 deaths (<1 death/100 000 population) in the worst week.
Whether the stated metrics are indeed the proper thresholds to be using is up for debate. For example, a recent paper published in the European Heart Journal noted that sepsis and heart failure appeared to be the leading cause of hospitalizations in the United States in 2018. REF The authors note, however, that they do not have data to compare these rates against COVID-19 and that doing so is a valuable avenue of future research. Regardless, earlier in this paper in Chart 2 we did observe that over 40 percent of COVID-19 hospitalizations in New York State are not even due to COVID-19 itself, and thus the CDC almost surely overstates the impact of COVID-19 on the American hospital system.
Nevertheless, if Paxlovid indeed fulfills the promise of its clinical trials, then the drug could dramatically reduce the severity of illness and burdens on hospitals imposed by COVID-19 to considerably lower levels. As a result, we developed a model to estimate what monthly hospitalizations would look like under various assumptions of uptake of Paxlovid. We estimated that, from December 21, 2021, to January 21, 2022, the hospitalization rate of COVID-19 was approximately 3.5 percent of confirmed cases. REF Assuming 3.5 percent, 5 percent, and 7 percent hospitalization rates from new cases and that 60 percent of COVID-19 hospitalizations are indeed for COVID-19 (and not with COVID-19, as indicated by Chart 2), Chart 13 provides estimates of what the weekly hospitalization rate will be under a variety of scenarios of daily caseloads and people testing positive for COVID-19 taking Paxlovid.
Note that under all such assumptions, weekly hospitalizations are below the stated threshold from 2017 to 2018 stated in Emanuel et al., even if COVID-19 were to mutate to a more dangerous form and current hospitalization rates of 3.5 percent were to double to 7 percent. REF
Although Paxlovid is not recommended for patients with specific conditions such as kidney or liver problems, REF our analysis in Chart 13 does not assume 100 percent uptake, and if other people testing positive for COVID-19 take other treatments such as Molnupiravir, these hospitalization numbers would decline further.
Altogether, as Chart 12 illustrates, many of the vaccine-hesitant are unlikely to change their minds. However, as Chart 13 shows, although the fully vaccinated are unlikely to get hospitalized for COVID-19, antivirals such as Paxlovid do offer alternatives—especially for the vaccine-hesitant—for avoiding unnecessary hospitalizations and getting the country well below influenza and RSV levels.
Policy Implications
Zero COVID Is an Unrealistic Aim. The public policy response to the pandemic in the United States and throughout the highly developed world has focused on nonpharmaceutical interventions and vaccines. Both policies appear to have reached the limits of their utility.
Federal public health authorities urged lockdowns, mask mandates, school closures, and related policies in hopes of slowing the spread of the contagion until a vaccine became available. When massive immunizations began during the winter of 2021, there was great optimism that they would end the pandemic. Cases, hospitalizations, and deaths were declining from what were then their highest peaks, just as tens of millions of Americans were getting immunized.
By early July, President Biden, who had campaigned promising to “shut down” the virus, REF proclaimed that the United States was “closer than ever to declaring our independence from a deadly virus.” REF But independence proved elusive, as cases reached a new high during the summer and vaccination rates stalled.
The Omicron variant produced the steepest spike in cases to date, prompting Dr. Anthony Fauci, chief medical adviser to the President, to acknowledge that, despite the vaccines, COVID-19 “will ultimately find just about everybody.” REF While vaccines continue to protect against severe illness, there is little hope they will eradicate the virus.
Public Policy Should Be Transparent, Open, and Broadly Acceptable to the Public. Policymakers should plainly and emphatically communicate that it is highly unlikely that the pathogen will be extinguished. It is far more likely that the virus will continue to circulate and that new variants will emerge, as has been the case with other respiratory diseases.
They should also shift from crisis communication mode, which depicts the risks of the virus in dire terms and without context. As Appendix Chart 1 shows, unintentional injuries, homicides, and suicides are more likely causes of death than COVID-19 among the fully vaccinated in many age groups. Additionally, data from New York State and Massachusetts on hospitalizations for and with COVID-19 suggest that hospitalization statistics presented by the agency may very well be inflated above actual levels.
The CDC should juxtapose hospitalization and mortality statistics for COVID-19 with analogous statistics for other common illnesses and causes of death and emphasize that risks are highly age-stratified. Statistics of this nature will enable the public to put COVID-19 in perspective with other public health problems we have faced as a nation, including obesity, HIV, and influenza, among others. Just as the CDC has a responsibility to inform Americans of public health dangers, the agency should also tell people when they are safe from severe illness and death from COVID-19.
End Nonpharmaceutical Interventions, Mandates, and Vax Shaming. Lockdowns, mask mandates, suspensions of in-person learning, and other nonpharmaceutical interventions were of dubious value. A meta-analysis of peer-reviewed studies of the value of lockdowns published by Johns Hopkins University concluded that while “lockdowns have had little to no public health effects, they have imposed enormous economic and social costs where they have been adopted.” REF A meta-analysis of the value of cloth masks published by the Cato Institute found “weak evidence” for facemask efficacy, adding that “ethical principles require that the strength of the evidence and the best estimates of amount of benefit be truthfully communicated to the public.” REF A study of the efficacy of extended school closures published by the British Royal Society concluded that “the lower susceptibility of school children substantially limited the effectiveness of school closure in reducing COVID-19 transmissibility.” REF A United Nations study noted that the costs of school closures “stand to be tremendous in terms of learning losses, health and well-being and drop-out.” REF
Nonpharmaceutical interventions, where aggressively pursued, thus had a questionable effect on public health and inflicted undeniable economic, social, and cognitive harm. Similarly, seeking to ostracize those who have refused immunizations—falsely proclaiming a “pandemic of the unvaccinated” and alleging without evidence that those who have declined vaccines are overcrowding hospitals—has not changed many minds. Nor has resorting to vaccine mandates, some of which were unlawful, driven up immunization rates.
Public officials should retreat from these policies and instead provide accurate information to support informed decision-making by private citizens.
Promote Effective Treatments. Anti-viral medications such as Paxlovid and Molnupiravir show considerable promise in preventing the progression of COVID-19 and averting hospitalizations and deaths. The Biden Administration’s decision to purchase 10 million courses of Paxlovid seems a sound one. Effective new treatments allow public officials to pivot away from apocalyptic pandemic narratives and instead urge people who suspect they have COVID-19 to seek testing and treatment. These treatments are a good alternative that the vaccine-hesitant could discuss with their doctors should they need them.
Recognize That We Will Need to Learn to Live with COVID-19 and Return to Normal. Public officials have bombarded Americans with negative information and false hopes for nearly two years. They have suggested that restrictions on businesses, churches, schools, and citizens would hold the contagion at bay until vaccines extinguished it. The gap between their rhetoric and reality has eroded public trust and deepened political and social divisions.
Policymakers can rebuild this trust by adapting their message to the evolving facts on the ground. The data we have presented suggest that the combination of vaccines, natural immunity, and new treatments have helped pave the way for a more measured and balanced policy response to the pandemic.
Leading U.S. figures and some foreign governments have begun to move in this direction, removing or relaxing mandates and restrictions and advocating policies based on coexisting with the pathogen rather than imagining its eradication.
As Ezekiel Emanuel notes in his Journal of the American Medical Association paper referenced earlier: REF
COVID-19 is here to stay. As the U.S. moves from crisis to control, this national strategy needs to be updated. Policymakers need to specify the goals and strategies for the “new normal” of life with COVID-19 and communicate them clearly to the public.
The authors agree with us acknowledging that eliminating COVID-19 is impractical:
The goal for the “new normal” with COVID-19 does not include eradication or elimination, e.g., the “zero COVID” strategy. Neither COVID-19 vaccination nor infection appear to confer lifelong immunity.
They instead call for learning to live with the virus. That includes understanding the SARS-CoV-2 virus as one of several respiratory viruses in circulation, including influenza and RSV.
On February 1, Denmark became the first European Union country to lift virtually all COVID-19 restrictions. REF The government rescinded mask mandates, no longer requires the use of vaccine passports, has allowed nightclubs to reopen, lifted limits on indoor gatherings, and ended social distancing. The announcement came after daily confirmed cases rose to 7,900 per million on January 29, more than triple the U.S. peak of 2,411 infections per million on January 15. REF The government cited high vaccination rates for its decision.
The United States has a lower vaccination rate but also has a lower case rate, millions of treatment courses on order, and an overwhelming majority of citizens favoring the course the Danish government has set. A Monmouth College poll released in January 2022 found that 70 percent of Americans agree that “it’s time we accept that COVID is here to stay and we just need to get on with our lives.” REF
That sentiment is shared by Americans who have experienced the pandemic in vastly different ways, including 78 percent of those who say they have had COVID-19 and 65 percent of those who say they have not. Men (73 percent) and women (68 percent) agreed with the statement, as did college graduates (63 percent) and those with no degree (74 percent), voters in red states (71 percent) and blue (70 percent), white non-Hispanics (71 percent) and racial minorities (69 percent), young adults (69 percent), the middle-aged (68 percent), and those ages 55 and older (73 percent). There is a partisan divide, with 89 percent of Republicans and 71 percent of independents but only 47 percent of Democrats agreeing with the statement.
A sea change in pandemic policy, in addition to being consistent with our evolving understanding of the contagion, would likely be well received by the public.
The national public health emergency is now in its third year. The pandemic has been the obsessive focus of public policy throughout that time. Perpetuating the national emergency mindset is futile, misguided, and infeasible, especially given what the data indicate as well as massive shifts in public opinion.
Public officials should communicate clearly that COVID-19 is one of many public health problems and diseases in circulation, that vaccines and natural immunity reduce the risk of severe illness and death, and that new medicines make COVID-19 a treatable disease. People at greatest risk of illness should still take precautions, but government mandates and restrictions are no longer appropriate.
It is time for policymakers to restore normality and move on from COVID-19.
Kevin Dayaratna is Principal Statistician, Data Scientist, and Research Fellow in the Center for Data Analysis, of the Institute for Economic Freedom, at The Heritage Foundation. Doug Badger is Senior Fellow in Domestic Policy Studies, of the Institute for Family, Community, and Opportunity, at The Heritage Foundation.

Chief Statistician, Data Scientist, Senior Research Fellow

Former Senior Research Fellow
Public Health
Public health promotes and protects the health of people and the communities where they live, learn, work and play.
Heritage COVID-19 Resources: An Interactive Toolkit
COVID-19 Vaccine Tracker: What's Going on in the States?
COMMENTARY 3 min read
COMMENTARY 4 min read
Subscribe to email updates
© 2024, The Heritage Foundation
- Open supplemental data
- Reference Manager
- Simple TEXT file
People also looked at
Brief research report article, representativeness of a national, probability-based panel survey of covid-19 isolation practices—united states, 2020–2022.

- 1 Mathematica, Cambridge, MA, United States
- 2 U.S. Centers for Disease Control and Prevention, COVID-19 Response Team, Atlanta, GA, United States
The U.S. Centers for Disease Control and Prevention (CDC) received surveillance data on how many people tested positive for SARS-CoV-2, but there was little information about what individuals did to mitigate transmission. To fill the information gap, we conducted an online, probability-based survey among a nationally representative panel of adults living in the United States to better understand the behaviors of individuals following a positive SARS-CoV-2 test result. Given the low response rates commonly associated with panel surveys, we assessed how well the survey data aligned with CDC surveillance data from March, 2020 to March, 2022. We used CDC surveillance data to calculate monthly aggregated COVID-19 case counts and compared these to monthly COVID-19 case counts captured by our survey during the same period. We found high correlation between our overall survey data estimates and monthly case counts reported to the CDC during the analytic period ( r : +0.94; p < 0.05). When stratified according to demographic characteristics, correlations remained high. These correlations strengthened our confidence that the panel survey participants were reflective of the cases reported to CDC and demonstrated the potential value of panel surveys to inform decision making.
Local and state health departments report limited public health data to the U.S. Centers for Disease Control and Prevention (CDC) to monitor the number of people who tested positive for SARS-CoV-2 ( 1 – 3 ). Although routine case-based surveillance can enumerate the people notified by public health programs, as a nation, we knew much less about the actions of individuals who tested positive or received an exposure notification. To fill the information gap, we conducted an online, probability-based survey among a nationally representative panel of adults living in the United States to better understand the experiences and behaviors of individuals following a positive SARS-CoV-2 test result. This survey was designed to provide information and fill a gap in public health knowledge that could not be achieved through routine programmatic and surveillance data. Although the potential contributions of the survey were many, there were concerns about the panel survey design. These included the representativeness of survey participants relative to the population of the United States, given low response rates are often associated with population-based panel surveys, and the potential for recall bias that results from reflecting on life experiences more than a year past. The within-panel completion rate for the survey was strong (70%). The overall response rate was 4% and was computed in accordance with American Association of Public Opinion Research standards ( 4 ). 1 Low response rates and non-response bias do not always directly correlate ( 5 , 6 ), but low rates may raise concerns about the representativeness of the findings. We were concerned that potential sample bias and recall error could threaten the value of our findings. Herein we examine how well the panel responses ( 7 ) aligned with public health data reported to CDC ( 1 ). To assess sample bias, it is ideal, though usually not possible, to compare the characteristics of the survey respondents with a gold standard, in the same period, and on the same measures of interest. For this analysis, we had a unique opportunity to correlate and validate our survey data against the gold standard for COVID-19 programmatic and surveillance data collected and maintained by CDC.
In January 2020, CDC began collecting COVID-19 case reports from public health jurisdictions to track trends of positive case counts and fatalities ( 8 ) by state, and by local jurisdictions such as county ( 2 , 9 – 11 ). COVID-19 case-based reporting includes individual demographic characteristics such as age, sex, and race/ethnicity ( 1 ). CDC released weekly aggregated case-based COVID-19 surveillance and mortality data beginning in March 2020 ( 12 ). We used a probability-based panel survey of a nationally representative sample to understand the actions of people who self-reported positive SARS-CoV-2 test results ( 7 ). Detailed survey, sampling, and weighting methodology is available in the supplemental material. Briefly, we drew the sample from the Ipsos KnowledgePanel®, a probability-based, web-based panel that provides a representative sampling frame for all noninstitutionalized adults who resided in the United States ( 13 ). An address-based recruitment method based on the US Postal Service's Delivery Sequence File, stratified random sampling, and a priori weighting ensured that the geodemographic composition was comparable with the US adult population ( 7 ). We sought to compare monthly COVID-19 case counts based on our survey data with CDC's case-based, line-level surveillance data to answer the following questions:
1. How well did the case-based survey data align with CDC data of the number of reports of all adults (aged 18 years or older) who tested positive for SARS-CoV-2?
2. How well did the case-based survey data align with CDC data of the number of reports of all adults who tested positive for SARS-CoV-2 by select demographic characteristics?
We obtained aggregated, publicly available data from CDC ( 14 ). We calculated monthly aggregated case counts from March 2020, the first month for which the aggregated data are available, through March 2022 by summing weekly counts of all adults reported to provide comparability to the survey responses of adults who participated. We also subtracted monthly aggregated case-fatality counts from the surveillance data because the survey results excluded fatalities. We generated epidemiologic curves of both the survey data and CDC surveillance data to visualize the distribution of COVID-19 cases over time estimated by each data source and stratified by age, sex, and race/ethnicity. We then calculated Pearson's correlation coefficients ( r ) and associated p -values, comparing the surveillance data and weighted survey case counts. We calculated these correlation coefficients for each age, sex, and race/ethnicity group and for all adults age 18 and older.
Here, we provide results from the analysis that compared the survey and surveillance data by research question.
How well did the case-based survey data align with CDC data of the number of reports of all adults who tested positive for SARS-CoV-2?
Figure 1 presents a comparison of survey-based monthly case counts, both weighted and unweighted, and surveillance-based monthly case counts reported to CDC from January 2020 to March 2022.

Figure 1 . Monthly COVID-19 case counts of adults aged 18 years or older in the United States by data source (surveillance, weighted survey, and unweighted survey), excluding fatalities, January 2020–March 2022.
The weighted survey case counts mirror the temporal trends of the epidemiologic curve, as represented by the surveillance data. There was a strong correlation coefficient between the weighted survey and surveillance data ( r : +0.94; p < 0.05). Although they are on a different scale, the unweighted survey cases also follow the epidemiologic curve. We compared the weighted survey data against the surveillance data with and without fatality counts included. From March 2020 to March 2022, fatality counts comprised 1.4% of the overall case counts in the surveillance data. The results for including and excluding fatality counts were the same at two decimal places and strongly correlated ( r : +0.94; p < 0.05).
How well did the case-based survey data align with CDC data of the number of reports of all adults who tested positive for SARS-CoV-2 by select demographic characteristics? We recreated the epidemiologic curve with both data sets across five age groups (18–29, 30–39, 40–49, 50–64, 65 years and older). We found high correlation by age group between the survey and surveillance data for each group ( Figure 2 ). For each age group, we note that the peaks for the survey and surveillance cases happen within 1 month of each other. The age group with the lowest correlation coefficient between the survey and surveillance data is the 65 years and older age group ( r : +0.90; p < 0.05). The age group with the highest correlation coefficient was the 30–39 age group ( r : +0.96; p < 0.05).

Figure 2 . Monthly COVID-19 case counts in the United States by age group and data source (surveillance and weighted survey), excluding fatalities, January 2020–March 2022.
Finally, we assessed how well the survey data estimated the epidemiologic curve by sex and racial and ethnic groups. Findings from this analysis are available in Supplementary Material Figures S1 and S2 . For sex ( Supplementary Material Figure S1 ), we saw high levels of correlation, mirroring the findings shown for the population overall. For race and ethnicity ( Supplementary Material Figure S2 ), it was not feasible to conduct a one-to-one comparison across the two data sources. Some of race/ethnicity classifications in the two datasets were not comparable and there was a high degree of missingness (35.4%) for the race/ethnicity variable in the CDC case-reports. Nonetheless, we found that the surveillance and survey data had statistically significant correlation coefficients for the following race/ethnicity groups: Hispanic; Black, non-Hispanic; White, non-Hispanic; and Asian or Pacific Islander, non-Hispanic. However, due to lower survey counts of people who identified as American Indian or Alaskan Native, non-Hispanic, we cannot draw conclusions on the relationship between the surveillance and survey data for people in this group. Although we found high correlation coefficients for most of the race/ethnicity groups, these results are complicated by the aggregated surveillance data not reporting a category for two or more races, an option that is available in the survey data.
This panel survey represented an opportunity to collect meaningful information to guide pandemic response, by capturing common behaviors in response to a COVID-19 diagnosis. However, panel survey results are sometimes devalued on the basis of low response rates. This study suggests that despite low overall response rates, the information gained from the survey may be meaningfully representative. Few surveys have the opportunity to compare their findings against surveillance records for the same population, in the same period, and on the same measures of interest. This survey presented a unique opportunity to assess the validity of survey data by comparing against a gold standard—case-based data reported to CDC during the analytic period. This comparison served as a validation that the survey data collected mirrored the U.S. adult population of COVID-19 cases overall and by age group. We observed a strong correlation between COVID-19 case counts generated by the survey and those reported by the CDC. This correlation strengthens confidence that self-reported SARS-COV-2 test results in our survey are reflective of the cases reported to the CDC during that same time period. Thus, the estimates generated by this survey may fill information gaps to better understand the experiences and behaviors of cases and contacts across the pandemic ( 7 ). The survey data might be particularly valuable for creating population estimates and facilitating analysis of these data by different demographic characteristics, such as age or race, which are subject to high rates of missingness in surveillance data.
This analysis has some limitations. Each data set might not reflect the entirety of the population of interest. For example, the panel survey does not include some segments of the U.S. population, people with language or literacy barriers that preclude participation in English or Spanish, those residing in congregate settings that were hit hard by COVID-19 (e.g., nursing homes, assisted living centers, and correctional facilities), and those experiencing homelessness. Conversely, CDC case-based data does not include people whose positive test results were not reported to public health officials, such as those who used at-home tests. In addition, although the completion rate among sampled panel members was high, the response rate for this survey was low, as is common with most panel surveys ( 15 ).
Despite these potential limitations, the panel survey provided a valuable approach and method to quickly estimate the proportion of people who isolated or quarantined for COVID-19, which did not previously exist ( 7 ). For example, although reporting confirmed cases was mandatory during the earlier days of the pandemic, maintaining this requirement was difficult when home-testing kits became available. Recent estimates suggest as many as 12 million adults had results exclusively from home-based tests during the analytic period ( 16 ). These results suggested that during the later days of the pandemic, up to 18% of people who reported being a case tested themselves and would not have been counted in the CDC case-based, line-listed surveillance data. These findings also provide important insight on the value and potential quality of probability-based panel surveys. This may be especially valuable when the new data can help inform planning ( 17 ), such as in public health emergencies like the COVID-19 pandemic, when researchers require more complete demographic data than surveillance sources might provide. It is important to note that a low response rate alone does not mean the data quality is poor ( 18 , 19 ). The results from our analysis provide supporting evidence that probability-based panel surveys, when created with scientific rigor and deployed successfully, can provide a valid mechanism to collect data from the U.S. adult population that serve to generate national estimates on topics of interest with a high degree of accuracy.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Centers for Disease Control and Prevention. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
HM: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Project administration, Writing – original draft, Writing – review & editing, Resources. DV: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Visualization, Writing – review & editing, Project administration. W-CC: Writing – review & editing, Data curation, Formal Analysis, Visualization. JO: Conceptualization, Funding acquisition, Methodology, Project administration, Resources, Supervision, Writing – review & editing, Investigation. PM: Conceptualization, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Writing – review & editing. MT: Conceptualization, Funding acquisition, Methodology, Project administration, Resources, Supervision, Writing – review & editing. CC: Writing – review & editing, Data curation. AW: Conceptualization, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article.
This work was supported by funding from the Centers for Disease Control and Prevention (no. RFA-DR-21-087.2).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fepid.2024.1379256/full#supplementary-material
1 The response rate computation is based on the following: a random sample of 22,514 panel members was drawn from Ipsos’ KnowledgePanel®. A total of 15,923 participants (excluding breakoffs) responded to the invitation, and 9,269 qualified for the survey, yielding a final stage completion rate of 70.7% and a qualification rate of 58.2%. The recruitment rate for this study, as reported by ( 13 ) was 9.9%, and the profile rate was 56.8%, for a cumulative response rate of 4.0% ( 4 ).
1. Centers for Disease Control and Prevention. COVID-19 Case Surveillance Public Use Data with Geography. (2023). Available online at: https://data.cdc.gov/Case-Surveillance/COVID-19-Case-Surveillance-Pulic-Use-Data-with-Ge/n8mc-4w4 (accessed August 11, 2023).
Google Scholar
2. Lash RR, Donovan CV, Fleischauer AT, Moore ZS, Harris G, Hayes S, et al. COVID-19 contact tracing in two counties—North Carolina, June–July 2020. MMWR Morb Mortal Wkly Rep . (2020) 69(38):1360–3. doi: 10.15585/mmwr.mm6938e3
PubMed Abstract | Crossref Full Text | Google Scholar
3. Spencer KD, Chung CL, Stargel A, Shultz A, Thorpe PG, Carter MW, et al. COVID-19 Case investigation and contact tracing efforts from health departments—united States, June 25-July 24, 2020. Morb Mortal Wkly Rep . (2021) 70:83–7. doi: 10.15585/mmwr.mm7003a3
Crossref Full Text | Google Scholar
4. American Association for Public Opinion Research. Standard Definitions. Final Dispositions of Case Codes and Outcome Rates for Surveys. (2023). Available online at: https://aapor.org/standards-and-ethics/standard-definitions/ (Accessed April 10, 2024).
5. Groves RM. Nonresponse rates and nonresponse bias in household survey. Public Opin Q . (2006) 70:646–75. doi: 10.1093/poq/nfl033
6. Groves RM, Peytcheva E. The impact of nonresponse rates on nonresponse bias: a meta-analysis. Public Opin Q . (2008) 72:167–89. doi: 10.1093/poq/nfn011
7. Oeltmann JE, Vohra D, Matulewicz HH, DeLuca N, Smith JP, Couzens C, et al. Isolation and quarantine for coronavirus disease 2019 in the United States, 2020–2022. Clin Infect Dis . (2023) 77(2):212–9. doi: 10.1093/cid/ciad163
8. Council of State and Territorial Epidemiologists. Update to the Standardized Surveillance Case Definition and National Notification for Sars-Cov-2 Infection (the Virus that Causes Covid-19). (2021). Available online at: https: https://cdn.ymaws.com/www.cste.org/resource/resmgr/ps/ps2022/22-ID-01_COVID19.pdf (accessed September 20, 2023).
9. Bonacci RA, Manahan LM, Miller JS, Moonan PK, Lipparelli MB, DiFedele LM, et al. COVID-19 contact tracing outcomes in Washington state, August and October 2020. Front Public Health . (2021) 9:782296. doi: 10.3389/fpubh.2021.782296
10. Borah BF, Pringle J, Flaherty M, Oeltmann JE, Moonan PK, Kelso P. High community transmission of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) associated with decreased contact tracing effectiveness for identifying persons at elevated risk of infection-Vermont. Clin Infect Dis . (2022) 75(Suppl 2):S334–7. doi: 10.1093/cid/ciac518
11. Lash RR, Moonan PK, Byers BL, Bonacci RA, Bonner KE, Donahue M, et al. COVID-19 case investigation and contact tracing in the US, 2020. JAMA Netw Open . (2021) 4(6):e2115850. doi: 10.1001/jamanetworkopen.2021.15850
12. Khan D, Park M, Burkholder J, et al. Tracking COVID-19 in the United States with surveillance of aggregate cases and deaths. Public Health Rep . (2023) 138(3):428–37. doi: 10.1177/00333549231163531
13. Ipsos. Public Affairs KnowledgePanel. Available online at: https://www.ipsos.com/en-us/solutions/pulic-affairs/knowledgepanel (accessed May 5, 2023).
14. Centers for Disease Control and Prevention. COVID-19 Weekly Cases and Deaths by Age, Race/Ethnicity, and Sex. (2023). Available online at: https://data.cdc.gov/Pulic-Health-Surveillance/COVID-19-Weekly-Cases-and-Deaths-y-Age-Race-Ethni/hrdz-jaxc (accessed August 11, 2023).
15. Hays RD, Liu H, Kapteyn A. Use of internet panels to conduct surveys. Behav Res Methods . (2015) 47:685–90. doi: 10.3758/s13428-015-0617-9
16. Moonan PK, Smith JP, Borah BF, Vohra D, Matulewicz HH, DeLuca N, et al. Home-based testing and COVID-19 isolation recommendations, United States. Emerg Infect Dis . (2023) 29(9):1921–4. doi: 10.3201/eid2909.230494
17. Jeon S, Watson-Lewis L, Rainisch G, et al. Adapting COVID-19 contact tracing protocols to accommodate resource constraints, Philadelphia, Pennsylvania, USA, 2021. Emerg Infect Dis . (2024) 30(2):333–6. doi: 10.3201/eid3002.230988
18. Keeter S, Hatley N, Kennedy C, Lau A. What Low Response Rates Mean for Telephone Surveys. (2017). Available online at: https://www.pewresearch.org/methods/2017/05/15/what-low-response-rates-mean-for-telephone-surveys/ (accessed June 9, 2023).
19. Keeter S, Hatley N, Lau A, Kennedy C. What 2020’s Election Poll Errors Tell Us About the Accuracy of Issue Polling. (2021). Available online at: https://www.pewresearch.org/methods/2021/03/02/what-2020s-election-poll-errors-tell-us-aout-the-accuracy-of-issue-polling/ (accessed August 20, 2023).
Keywords: representativeness, panel survey, validity, isolation, COVID-19, SARS-CoV-2
Citation: Matulewicz HH, Vohra D, Crawford-Crudell W, Oeltmann JE, Moonan PK, Taylor MM, Couzens C and Weiss A (2024) Representativeness of a national, probability-based panel survey of COVID-19 isolation practices—United States, 2020–2022. Front. Epidemiol. 4:1379256. doi: 10.3389/fepid.2024.1379256
Received: 30 January 2024; Accepted: 9 April 2024; Published: 26 April 2024.
Reviewed by:
© 2024 Matulewicz, Vohra, Crawford-Crudell, Oeltmann, Moonan, Taylor, Couzens and Weiss. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Holly H. Matulewicz [email protected]
Numbers, Facts and Trends Shaping Your World
Read our research on:
Full Topic List
Regions & Countries
- Publications
- Our Methods
- Short Reads
- Tools & Resources
Read Our Research On:
Discrimination Experiences Shape Most Asian Americans’ Lives
4. asian americans and discrimination during the covid-19 pandemic, table of contents.
- Key findings from the survey
- Most Asian Americans have been treated as foreigners in some way, no matter where they were born
- Most Asian Americans have been subjected to ‘model minority’ stereotypes, but many haven’t heard of the term
- Experiences with other daily and race-based discrimination incidents
- In their own words: Key findings from qualitative research on Asian Americans and discrimination experiences
- Discrimination in interpersonal encounters with strangers
- Racial discrimination at security checkpoints
- Encounters with police because of race or ethnicity
- Racial discrimination in the workplace
- Quality of service in restaurants and stores
- Discrimination in neighborhoods
- Experiences with name mispronunciation
- Discrimination experiences of being treated as foreigners
- In their own words: How Asian Americans would react if their friend was told to ‘go back to their home country’
- Awareness of the term ‘model minority’
- Views of the term ‘model minority’
- How knowledge of Asian American history impacts awareness and views of the ‘model minority’ label
- Most Asian Americans have experienced ‘model minority’ stereotypes
- In their own words: Asian Americans’ experiences with the ‘model minority’ stereotype
- Asian adults who personally know an Asian person who has been threatened or attacked since COVID-19
- In their own words: Asian Americans’ experiences with discrimination during the COVID-19 pandemic
- Experiences with talking about racial discrimination while growing up
- Is enough attention being paid to anti-Asian racism in the U.S.?
- Acknowledgments
- Sample design
- Data collection
- Weighting and variance estimation
- Methodology: 2021 focus groups of Asian Americans
- Appendix: Supplemental tables
Following the coronavirus outbreak, reports of discrimination and violence toward Asian Americans increased. A previous Pew Research Center survey of English-speaking Asian adults showed that as of 2021, one-third said they feared someone might threaten or physically attack them. English-speaking Asian adults in 2022 were also more likely than other racial or ethnic groups to say they had changed their daily routines due to concerns they might be threatened or attacked. 19
In this new 2022-23 survey, Asian adults were asked if they personally know another Asian person in the U.S. who had been attacked since the pandemic began.

About one-third of Asian adults (32%) say they personally know an Asian person in the U.S. who has been threatened or attacked because of their race or ethnicity since the COVID-19 pandemic began in 2020.
Whether Asian adults know someone with this experience varies across Asian ethnic origin groups:
- About four-in-ten Chinese adults (39%) say they personally know another Asian person who has been threatened or attacked since the coronavirus outbreak. Similar shares of Korean adults (35%) and those who belong to less populous Asian origin groups (39%) – those categorized as “other” in this report – say the same.
- About three-in-ten Vietnamese (31%), Japanese (28%) and Filipino (28%) Americans and about two-in-ten Indian adults (21%) say they know another Asian person in the U.S. who has been the victim of a racially motivated threat or attack.
Additionally, there are some differences by regional origin groups:
- Overall, similar shares of East and Southeast Asian adults say they know another Asian person who’s been threatened or attacked because of their race or ethnicity (36% and 33%, respectively).
- A somewhat smaller share of South Asian adults say the same (24%).

There are also differences across nativity and immigrant generations:
- U.S.-born Asian adults are more likely than Asian immigrants to say they know another Asian person who has been threatened or attacked during the COVID-19 pandemic (40% vs. 28%, respectively).
- Among immigrants, those who are 1.5 generation – those who came to the U.S. as children – are more likely than the first generation – those who immigrated as adults – to say they know someone with this experience (37% vs. 25%).
- And among U.S.-born Asian Americans, 44% of second-generation adults say this, compared with 28% of third- or higher-generation Asian adults.
Whether Asian Americans personally know another Asian person who was threatened or attacked because of their race or ethnicity since the beginning of the pandemic also varies across other demographic groups:
- Age: 44% of Asian adults under 30 years old say they know someone who has been threatened or attacked during the pandemic, compared with 18% of those 65 and older.
- Gender: Asian women are somewhat more likely than men to say they know an Asian person in the U.S. who has been threatened or attacked during the COVID-19 pandemic (35% vs. 28%, respectively).
- Party: 36% of Asian Democrats and Democratic leaners say they know another Asian person who has been threatened or attacked because of their race or ethnicity, higher than the share among Republicans and Republican leaners (25%).
Heightened anti-Asian discrimination during the COVID-19 pandemic
These survey findings follow a spike in reports of discrimination against Asian Americans during the COVID-19 pandemic. The number of federally recognized hate crime incidents of anti-Asian bias increased from 158 in 2019 to 279 in 2020 and 746 in 2021, according to hate crime statistics published by the FBI . In 2022, the number of anti-Asian hate crimes decreased for the first time since the coronavirus outbreak, to 499 incidents. Between March 2020 and May 2023, the organization Stop AAPI Hate received more than 11,000 self-reported incidents of anti-Asian bias, the vast majority of which involved harassment, bullying, shunning and other discrimination incidents.
Additionally, previous research found that calling COVID-19 the “Chinese Virus,” “Asian Virus” or other names that attach location or ethnicity to the disease was associated with anti-Asian sentiment in online discourse. Use of these phrases by politicians or other prominent public officials, such as by former President Donald Trump , coincided with greater use among the general public and more frequent instances of bias against Asian Americans.
In the 2021 Pew Research Center focus groups of Asian Americans, participants discussed their experiences of being discriminated against because of their race or ethnicity during the COVID-19 pandemic.
Participants talked about being shamed in both public and private spaces. Some Asian immigrant participants talked about being afraid to speak out because of how it might impact their immigration status:
“I was walking in [the city where I live], and a White old woman was poking me in the face saying, ‘You are disgusting,’ and she was trying to hit me. I ran away crying. … At the time, I was with my boyfriend, but he also just came to the U.S., so we ran away together thinking that if we cause trouble, we could be deported.”
–Immigrant woman of Korean origin in late 20s (translated from Korean)
“[A very close friend of mine] lived at [a] school dormitory, and when the pandemic just happened … his room was directly pasted with the adhesive tape saying things like ‘Chinese virus quarantine.’”
–Immigrant man of Chinese origin in early 30s (translated from Mandarin)
Many participants talked about being targeted because others perceive them as Chinese , regardless of their ethnicity:
“I think the crimes [that happened] against other Asian people can happen to me while going through COVID-19. When I see a White person, I don’t know if their ancestors are Scottish or German, so they will look at me and think the same. It seems that they can’t distinguish between Korean and Chinese and think that we are from Asia and the onset of COVID-19 is our fault. This is something that can happen to all of us. So I think Asian Americans should come together and let people know that we are also human and we have rights. I came to think about Asian Americans that they shouldn’t stay still even if they’re trampled on.”
–Immigrant woman of Korean origin in early 50s (translated from Korean)
“Even when I was just getting on the bus, [people acted] as if I was carrying the virus. People would not sit with me, they would sit a bit far. It was because I look Chinese.”
–Immigrant woman of Bhutanese origin in early 30s (translated from Dzongkha)
Amid these incidents, some participants talked about feeling in community and kinship with other Asian people:
“[When I hear stories about Asian people in the news,] I feel like automatically you just have a sense of connection to someone that’s Asian. … [I]t makes me and my family and everyone else that I know that is Asian super mad and upset that this is happening. [For example,] the subway attacks where there was a mother who got dragged down the stairs for absolutely no reason. It just kind of makes you scared because you are Asian, and I would tell my mom, ‘You’re not going anywhere without me.’ We got pepper spray and all of that. But there is definitely a difference because you just feel a connection with them no matter if you don’t know them.”
–U.S.-born woman of Taiwanese origin in early 20s
“[A]s a result of the pandemic, I think we saw an increase in Asian hate in the media. I think that was one time where I realized as an Asian person, I felt a lot of pain. I felt a lot of fear, I felt a lot of anger and frustration for my community. … I think it was just at that specific moment when I saw the Asian hate, Asian hate crimes, and I realized, ‘Oh, they’re targeting my people.’ I don’t know how to explain it exactly. I never really referred to myself just plainly as an Asian American, but when I saw it in that media and I saw people who looked like me or people who I related with getting hurt and mistreated, I felt anger for that community, for my community.””
–U.S.-born woman of Korean origin in late teens
Some connected discrimination during the pandemic to other times of heightened anti-Asian discrimination . For example, one woman connected anti-Asian discrimination during COVID-19 to the period after Sept. 11:
“[T]he hate crimes I’m reading about now are towards Chinese [people] because of COVID, but I remember after 9/11, that was – I remember the looks that people would give me on the subway but also reading the violent acts committed towards Indians of all types, just the confusion – I mean, I say confusion but I mean really they wanted to attack Muslims, but they didn’t care, they were just looking for a brown person to attack. So there’s always something that happens that then suddenly falls on one community or another.”
–U.S.-born man of Indian origin in late 40s
- Pew Research Center’s American Trends Panel surveys of Asian adults were conducted only in English and are representative of the English-speaking Asian adult population. In 2021, 70% of Asian adults spoke only English or said they speak English “very well,” according to a Pew Research Center analysis of the 2021 American Community Survey. By contrast, the Center’s 2022-23 survey of Asian Americans was conducted in six languages, including Chinese (Simplified and Traditional), English, Hindi, Korean, Tagalog and Vietnamese. ↩
Sign up for our weekly newsletter
Fresh data delivery Saturday mornings
Sign up for The Briefing
Weekly updates on the world of news & information
- Asian Americans
- Discrimination & Prejudice
- Immigration Issues
- Race Relations
- Racial Bias & Discrimination
Key facts about Asian Americans living in poverty
Methodology: 2023 focus groups of asian americans, 1 in 10: redefining the asian american dream (short film), the hardships and dreams of asian americans living in poverty, key facts about asian american eligible voters in 2024, most popular, report materials.
1615 L St. NW, Suite 800 Washington, DC 20036 USA (+1) 202-419-4300 | Main (+1) 202-857-8562 | Fax (+1) 202-419-4372 | Media Inquiries
Research Topics
- Age & Generations
- Coronavirus (COVID-19)
- Economy & Work
- Family & Relationships
- Gender & LGBTQ
- Immigration & Migration
- International Affairs
- Internet & Technology
- Methodological Research
- News Habits & Media
- Non-U.S. Governments
- Other Topics
- Politics & Policy
- Race & Ethnicity
- Email Newsletters
ABOUT PEW RESEARCH CENTER Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
Copyright 2024 Pew Research Center
Terms & Conditions
Privacy Policy
Cookie Settings
Reprints, Permissions & Use Policy
National Statistical
News and insight from the office for national statistics, exploring findings from the winter covid-19 infection study.
- James Tucker
- April 25, 2024

In November 2023 ONS and UK Health Security Agency (UKHSA) launched the Winter COVID-19 Infection Study (Winter CIS) to gather vital data on levels of the virus in the colder months. James Tucker explores some of the findings and takes a deeper look at what they can tell us about ongoing symptoms and risk factors.
The Winter CIS ran between November 2023 and March 2024 in England and Scotland and around 125,500 participants took part. Each participant was sent a questionnaire and asked to take a Lateral Flow Device test every four weeks for the detection of COVID-19. If participants tested positive, they were asked to test every other day and report their results and symptoms until they tested negative.
Over the course of the study, ONS published data on test positivity and symptoms . The data collected has been used by the UKHSA to understand changes in the infection hospitalisation rate, enabling them to assess potential increased demand on health services.
Our findings from November 2023 to March 2024 showed a peak in Covid rates in a two-week period from mid-December. Alongside this, we also know from the prevalence data published by UKHSA that the virus was less prevalent in the oldest age groups (those age 65 and above).
Shining a light on long C ovid
We know that understanding of long Covid is still developing, which is why data from those impacted is so valuable.
Our results showed an estimated 2 million people were experiencing self-reported long Covid during the study period, with nearly a third experiencing symptoms for at least three years. The most common symptoms reported were weakness or tiredness, shortness of breath and difficulty concentrating.
Self-reported long Covid was most common in people aged 45 to 64 years and among women. We also saw higher levels of long Covid in those who were not working and not looking for work. In line with previous work, this study highlights the impact long Covid can have on someone’s life. Nearly 75% of those with self-reported long Covid said their symptoms adversely impacted their day-to-day activities, and a further fifth told us their ability to undertake day-to-day activities has been “limited a lot”.
What else did we learn about Covid infections ?
By drawing together finding from across the study we can identify characteristics of those who test positive and those who don’t.
We can see that people who have had a vaccine since September 2023 were less likely to test positive in the early waves of the study, but by later waves of the study the difference was no longer noticeable.
The oldest age groups (65-74, 75+) and youngest age groups (3-17) were less likely to test positive for Covid than 45-54 year olds.
People living in Scotland were typically less likely to test positive than people living in the South East of England. For participants of working age (18-64) , t hose working in teaching and education were typically more likely to test positive compared to those who were unemployed or economically inactive . F or those employed in other work sectors there was no clear or consistent difference in the likelihood of testing positive .
What are the most common symptoms?
For participants who tested positive for Covid, the most reported symptom, for both males and females and all ages, was a runny nose, followed by a cough. Other common symptoms were t iredness, a sore throat and a headache. These findings are similar to the results seen in the Coronavirus Infection Survey. Interestingly though, we saw that the percentage of people with Covid who reported each symptom was higher among participants in the winter study. It’s not possible to say whether this is down to a change in the nature of the virus. It could also reflect differences in the survey or how people answered questions.
A partnership
The Winter CIS has built on our experience of running the gold standard Coronavirus Infection Survey, which we delivered in partnership with Oxford University and UKHSA. We are proud to have delivered Winter CIS in partnership with UKHSA. There were around 125,500 other partners; the study participants, to whom we’re very grateful. Those taking part represented a wide range of ages and communities and their input allowed us to analyse around 32,000 lateral flow tests a week. This provided timely understanding of potential health pressures over the winter period.
We had some great feedback from participants who told us how easy the survey was to complete and how they valued being part of this important work.
“Excellent survey very clear questions. Quick and easy to complete.”
“I am happy to take part, hope the information I give is useful in planning for any future outbreak.”
Going forward, our learning from the study and feedback received will help with development of programmes to capture data on other respiratory viruses and infections if needed.
For more information about the Winter CIS visit our study pages.

Dr James Tucker, Deputy Director, Winter CIS
Share this post
Can Neosporin Protect You From Getting COVID-19?

F or years, researchers have been working on vaccines that aim to prevent viral infections by strengthening immune defenses at viruses’ doorway to the body: the nose.
A small study recently published in PNAS presents a similar, if lower-tech, idea. Coating the inside of the nose with the over-the-counter antibiotic ointment Neosporin seems to trigger an immune response that may help the body repel respiratory viruses like those that cause COVID-19 and the flu, the study suggests.
The research raises the idea that Neosporin could serve as an “extra layer” of protection against respiratory illnesses, on top of existing tools like vaccines and masks, says study co-author Akiko Iwasaki, an immunobiologist at the Yale School of Medicine and one of the U.S.’ leading nasal vaccine researchers .
The study builds upon some of Iwasaki’s prior research —which has shown that similar antibiotics can trigger potentially protective immune changes in the body—but it’s still preliminary, she cautions. For the new study, her team had 12 people apply Neosporin inside their nostrils twice a day for a week, while another seven people used Vaseline for comparison. At several points during the study, the researchers swabbed the participants’ noses and ran PCR tests to see what was going on inside.
Read More : What to Do About Your Bunions
They found that Neosporin—and specifically one of its active ingredients, the antibiotic neomycin sulfate—seems to stimulate receptors in the nose that “are fooled into thinking there’s a viral infection” and in turn create “a barrier that’s put up against any virus,” Iwasaki explains. In theory, she says, that means it could protect against a range of different infections.
Right now, though, that’s just a theory. For this study, Iwasaki’s team didn’t take the next step of testing whether that immune response actually prevents people from getting infected when they’re exposed to viruses—in part because it’s ethically questionable to intentionally expose people to pathogens for research. (They did, however, demonstrate that rodents whose noses were coated with neomycin were protected from the virus that causes COVID-19.)
On its website, the maker of Neosporin says that the product has not "been tested or formulated to prevent against COVID-19 or any other virus," and also note that they do not advise putting the product inside the eyes, nose, or mouth.
Dr. James Crowe, who directs the Vanderbilt Vaccine Center and was not involved in the research, says the study is “intriguing,” but he’d need to see more human data before he gets excited. “I’m skeptical it would be strongly effective in people,” Crowe says. “If you have a modest effect on the virus, is that enough to really benefit you clinically?”
It is somewhat counterintuitive to think that an antibiotic, which kills bacteria, could do anything to protect people from viruses. It’s not that the antibiotic has a direct effect against viruses, Iwasaki explains. Instead, it seems that neomycin, when applied topically, provoke changes in the body that help it fight off viruses—essentially, triggering a natural antiviral effect.
So should you smear Neosporin in your nose next time a COVID-19 wave hits ? Not so fast, says Dr. Benjamin Bleier, who specializes in nasal disorders at Massachusetts Eye and Ear and has studied nasal immunity .
Read More : COVID-Cautious Americans Feel Abandoned
Bleier, who was not involved in the new study, calls the research “very well done,” but says there are questions that need to be answered before it hits “clinical prime time.” First, could the body develop tolerance or resistance to neomycin if the antibiotic were regularly used in this way? (Antibiotic resistance is a growing concern, and overusing or inappropriately prescribing antibiotics is a contributor to the problem.) Second, could the average person apply neomycin deeply and thoroughly enough for meaningful protection? And finally, could this approach damage the delicate inner nose or have other side effects over time? (Even in the small study, one of the people who used intranasal Neosporin dropped out due to minor side effects, apparently related to a drug allergy.)
“It’s great science, but there’s still a long way to go before we should put it in our noses,” agrees Dr. Sean Liu, an infectious disease physician at New York’s Mount Sinai health system who was also not involved in the study.
Iwasaki agrees that more research is necessary. She says the next step is testing higher doses of neomycin, since Neosporin contains a fairly small amount that may not be enough to provide robust protection for humans. To gather more data, she says, researchers could track people going about their normal lives—except that some apply neomycin to their noses and some apply Vaseline—and see if one group gets sick less often than the other, though that would require a lot of time and people.
Despite the difficulties, Liu says there’s good reason for further study. Finding new uses for affordable, widely accessible medications is good for public health, and any progress toward neutralizing viruses is welcome. If the approach is proven to work, it could also be useful to have a tool that's effective against a broad range of viruses and could potentially be paired with other drugs to strengthen its efficacy, Crowe adds.
Plus, Iwasaki says, additional disease-prevention tools could help people who are especially vulnerable to respiratory diseases—such as those who are immunocompromised —and need additional protection to feel safe. If further research proves promising, Iwasaki says, she could imagine neomycin serving as an additional disease-fighting tool when people are in particularly germy places, like a crowded party or an airport.
More Must-Reads From TIME
- The 100 Most Influential People of 2024
- Coco Gauff Is Playing for Herself Now
- Scenes From Pro-Palestinian Encampments Across U.S. Universities
- 6 Compliments That Land Every Time
- If You're Dating Right Now , You're Brave: Column
- The AI That Could Heal a Divided Internet
- Fallout Is a Brilliant Model for the Future of Video Game Adaptations
- Want Weekly Recs on What to Watch, Read, and More? Sign Up for Worth Your Time
Write to Jamie Ducharme at [email protected]

Examining Coping Skills, Anxiety, and Depression Dynamics Amidst the COVID-19 Pandemic
Article sidebar.

Main Article Content
This cross-sectional study, conducted amid the COVID-19 pandemic, delves into the intricate connections between coping strategies and levels of anxiety and depression, presenting vital implications for medical, clinical, and broader societal contexts. As crises like the pandemic highlight the importance of adaptive coping, this investigation underscores the imperative to comprehend and address maladaptive coping strategies. The study utilized a diverse sample of 386 participants during the pandemic's peak, employing online platforms for recruitment and ensuring broad demographic representation. Data were collected through self-report measures, including the Patient Health Questionnaire-4 (PHQ-4) for depression and anxiety symptoms and the Brief Coping Orientation to Problems Experienced (COPE) inventory to assess coping skills across various domains. The coping skills assessment measured strategies such as Self-Distraction, Active Coping, Denial, Substance Use, Emotional and Instrumental Support, Behavioral Disengagement, Venting, Positive Reframing, Planning, Humor, Acceptance, Religion, and Self-Blame. The Colorado Multiple Institutional Review Board prioritized and approved ethical considerations, and participants provided informed consent. Data analysis involved rigorous cleaning, recoding, and quantitative analysis using SPSS. Descriptive statistics, regression analyses, and correlation analyses were employed to uncover nuanced relationships between coping strategies and mental health outcomes, contributing to understanding the phenomena under investigation within the context of the pandemic. The findings highlight the pivotal role of individualized approaches and the potential of humor as an essential coping mechanism, emphasizing the need for tailored interventions during crises.
Article Details

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License .
IMAGES
VIDEO
COMMENTS
NCHS collects, analyzes, and disseminates information on the health of the nation. In response to the COVID-19 pandemic, NCHS is providing the most recent data available on deaths, mental health, and access to health care, loss of work due to illness, and telemedicine from the vital statistics system, the NCHS Research and Development Survey, and through a partnership with the U.S. Census Bureau.
2.1. Basic statistics. COVID‐19 has currently spread to 181 countries and most national authorities have failed to keep its rapid spread contained. 13 WHO reports that it began in Wuhan city, located in Hubei province of China, first reported on 21st January. 14 COVID‐19 categorizes in three distinctions concerning it is infected host's severity of disease. 15, 16 To date, the statistics ...
Coronavirus Pandemic (COVID-19) Research and data: Edouard Mathieu, Hannah Ritchie, Lucas Rodés-Guirao, Cameron Appel, Daniel Gavrilov, Charlie Giattino, Joe Hasell, Bobbie Macdonald, Saloni Dattani, Diana Beltekian, Esteban Ortiz-Ospina, and Max Roser. The data on the coronavirus pandemic is updated daily.
New data suggests the Omicron surge has peaked nationwide and cases are now starting to decline. Johns Hopkins experts in global public health, infectious disease, and emergency preparedness have been at the forefront of the international response to COVID-19. This website is a resource to help advance the understanding of the virus, inform the ...
To explore the utility of the described statistical procedures for analyzing trends in COVID-19 data, daily rates of cases per 100,000 individuals were collected for the U.S. as well as several individual states. The states were selected based upon their COVID-19 incidence history or recent reports of "surges" in cases.
COVID-19 can involve persistence, sequelae, and other medical complications that last weeks to months after initial recovery. ... Statistical analysis. ... More evidence and research from multi ...
Our statistical approach to estimating SARS-CoV-2 infection allows estimates to be updated and disseminated rapidly on the basis of newly available data, which has and will be crucially important for timely COVID-19 research, science, and policy responses. Funding. Bill & Melinda Gates Foundation, J Stanton, T Gillespie, and J and E Nordstrom. ...
The spread of the "Severe Acute Respiratory Coronavirus 2" (SARS-CoV-2), the causal agent of COVID-19, was characterized as a pandemic by the World Health Organization (WHO) in March 2020 and has triggered an international public health emergency [].The numbers of confirmed cases and deaths due to COVID-19 are rapidly escalating, counting in millions [], causing massive economic strain ...
The WHO Covid-19 Research Database was maintained by the WHO Library & Digital Information Networks and was funded by COVID-19 emergency funds. The database was built by BIREME, the Specialized Center of PAHO/AMRO. Its content spanned the time period March 2020 to June 2023. It has now been archived, and no longer searchable since January 2024.
The COVID-19 model digraph can be expressed as a graph G = (N, L), ... Future research on identifying key critical elements might extend the explanations of the new COVID-19 more widely. It will be important that future research investigates more suggested transmissions between the model groups. For example, the model will further improve by ...
Find COVID-19 datasets, data tools, and publications to use in research. EXPLORE COVID-19 DATA. Learn how NIH is supporting research in COVID-19 testing, treatments, and vaccines.
Statistical modeling plays an important role in different fields of COVID-19 research. This starts with the collection of adequate data and the preprocessing of this data, a complex sequence of steps, where input is required from the data users, taking into account their questions and information needs.
Just 20% of the public views the coronavirus as a major threat to the health of the U.S. population and only 10% are very concerned about getting a serious case themselves. In addition, a relatively small share of U.S. adults (28%) say they've received an updated COVID-19 vaccine since last fall. report | Mar 28, 2023.
The novel coronavirus (COVID-19) that was first reported at the end of 2019 has impacted almost every aspect of life as we know it. This paper focuses on the incidence of the disease in Italy and Spain—two of the first and most affected European countries. Using two simple mathematical epidemiological models—the Susceptible-Infectious-Recovered model and the log-linear regression model, we ...
Cases of COVID-19 - as with other diseases - are broadly defined under a three-level system: suspected, probable and confirmed cases. Suspected case. A suspected case is someone who shows clinical signs and symptoms of having COVID-19, but has not been laboratory-tested. Probable case.
It is contagious in humans and is the cause of the coronavirus disease 2019 (COVID-19). Latest Research and Reviews Mucosal prime-boost immunization with live murine pneumonia virus-vectored SARS ...
Here the authors show that, in convalescent COVID-19 patients, memory T cell responses are detectable up to 317 days post-symptom onset, in which the presence of stem cell-like memory T cells ...
The impact on research in progress prior to COVID-19 was rapid, dramatic, and no doubt will be long term. The pandemic curtailed most academic, industry, and government basic science and clinical ...
The latest data on how COVID-19 has affected global tradeImage: Committee for the Coordination of Statistical Activities. International tourism has taken a huge hitImage: CCSA/UNWTO. In terms of social costs, the education of 1.6 billion learners has been disrupted; that is 9 out of every 10 students in the world.
A research team from Johns Hopkins Medicine and The Johns Hopkins University has created and preliminarily tested a machine-learning statistical model that — using data from electronic health records — may soon be able to predict who is naturally resistant to infection by SARS-CoV-2 (seen as yellow particles in the photograph), the virus that causes COVID-19.
When the U.S. COVID-19 public health emergency declaration expires on May 11, 2023, national reporting of certain categories of COVID-19 public health surveillance data will be transitioned to other data sources or will be discontinued; COVID-19 hospitalization data will be the only data source available at the county level (1).In anticipation of the transition, national COVID-19 surveillance ...
It seeks to identify how people recuperate from COVID-19 and who is at risk for developing post-acute sequelae of SARS-CoV-2 (PASC). Researchers are also working with patients, clinicians, and communities across the United States to identify strategies to prevent and treat the long-term effects of COVID, including long COVID.
COVID-19 has disproportionately affected the US Latinx population, with significantly higher rates of infections, hospitalizations, and mortality. 1,2 Although the undocumented Latinx population in the US is growing, 3 there are limited data regarding their COVID-19 infection status, vaccination uptake, and perceptions about the COVID-19 vaccine.
The per capita death rates for COVID-19 in both 2020 and 2021 (573.4 and 572.4, respectively), however, exceed a number of leading causes prior to the pandemic, demonstrating that COVID-19 has ...
The U.S. Centers for Disease Control and Prevention (CDC) received surveillance data on how many people tested positive for SARS-CoV-2, but there was little information about what individuals did to mitigate transmission. To fill the information gap, we conducted an online, probability-based survey among a nationally representative panel of adults living in the United States to better ...
Following the coronavirus outbreak, reports of discrimination and violence toward Asian Americans increased. A previous Pew Research Center survey of English-speaking Asian adults showed that as of 2021, one-third said they feared someone might threaten or physically attack them. English-speaking Asian adults in 2022 were also more likely than other racial or ethnic groups to say they had ...
In November 2023 ONS and UK Health Security Agency (UKHSA) launched the Winter COVID-19 Infection Study (Winter CIS) to gather vital data on levels of the virus in the colder months. James Tucker explores some of the findings and takes a deeper look at what they can tell us about ongoing symptoms and risk factors. The Winter CIS ran between November 2023 and March 2024 in England and Scotland ...
COVID-19 once again demonstrated the importance of the relationship between health and the ... Further research into the statistical relationship between air quality parameters and factors affecting air quality in the future will provide more understanding about the behavior of air pollutants which will be useful for direct and immediate ...
A new study finds that putting Neosporin in the nose provokes an immune response that may protect against viral infections like COVID-19. More research is needed, but a small new study has ...
Descriptive statistics, regression analyses, and correlation analyses were employed to uncover nuanced relationships between coping strategies and mental health outcomes, contributing to understanding the phenomena under investigation within the context of the pandemic. ... research during the COVID-19 pandemic and its aftermath. The British ...