- Machine Learning
- Español – América Latina
- Português – Brasil
- Tiếng Việt
- Foundational courses
- Crash Course

Generalization
Generalization refers to your model's ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model.
The Big Picture
- Goal: predict well on new data drawn from (hidden) true distribution.
- Problem: we don't see the truth.
- We only get to sample from it.
- If model h fits our current sample well, how can we trust it will predict well on other new samples?
How Do We Know If Our Model Is Good?
- Theoretically:
- Interesting field: generalization theory
- Based on ideas of measuring model simplicity / complexity
- Intuition: formalization of Ockham's Razor principle
- The less complex a model is, the more likely that a good empirical result is not just due to the peculiarities of our sample
- Asking: will our model do well on a new sample of data?
- Evaluate: get a new sample of data-call it the test set
- Good performance on the test set is a useful indicator of good performance on the new data in general:
- If the test set is large enough
- If we don't cheat by using the test set over and over
The ML Fine Print
Three basic assumptions in all of the above:
- We draw examples independently and identically (i.i.d.) at random from the distribution
- The distribution is stationary : It doesn't change over time
- We always pull from the same distribution : Including training, validation, and test sets
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2022-07-18 UTC.
Evaluating Hypotheses: Estimating hypotheses Accuracy
For estimating hypothesis accuracy, statistical methods are applied. In this blog, we’ll have a look at evaluating hypotheses and estimating it’s accuracy.
Evaluating hypotheses:
Whenever you form a hypothesis for a given training data set, for example, you came up with a hypothesis for the EnjoySport example where the attributes of the instances decide if a person will be able to enjoy their favorite sport or not.
Now to test or evaluate how accurate the considered hypothesis is we use different statistical measures. Evaluating hypotheses is an important step in training the model.
To evaluate the hypotheses precisely focus on these points:
When statistical methods are applied to estimate hypotheses,
- First, how well does this estimate the accuracy of a hypothesis across additional examples, given the observed accuracy of a hypothesis over a limited sample of data?
- Second, how likely is it that if one theory outperforms another across a set of data, it is more accurate in general?
- Third, what is the best strategy to use limited data to both learn and measure the accuracy of a hypothesis?
Motivation:
There are instances where the accuracy of the entire model plays a huge role in the model is adopted or not. For example, consider using a training model for Medical treatment. We need to have a high accuracy so as to depend on the information the model provides.
When we need to learn a hypothesis and estimate its future accuracy based on a small collection of data, we face two major challenges:
Bias in the estimation
There is a bias in the estimation. Initially, the observed accuracy of the learned hypothesis over training instances is a poor predictor of its accuracy over future cases.
Because the learned hypothesis was generated from previous instances, future examples will likely yield a skewed estimate of hypothesis correctness.
Estimation variability.
Second, depending on the nature of the particular set of test examples, even if the hypothesis accuracy is tested over an unbiased set of test instances independent of the training examples, the measurement accuracy can still differ from the true accuracy.
The anticipated variance increases as the number of test examples decreases.
When evaluating a taught hypothesis, we want to know how accurate it will be at classifying future instances.
Also, to be aware of the likely mistake in the accuracy estimate. There is an X-dimensional space of conceivable scenarios. We presume that different instances of X will be met at different times.
Assume there is some unknown probability distribution D that describes the likelihood of encountering each instance in X. This is a convenient method to model this.
A trainer draws each instance separately, according to the distribution D, and then passes the instance x together with its correct target value f (x) to the learner as training examples of the target function f.
The following two questions are of particular relevance to us in this context,
- What is the best estimate of the accuracy of h over future instances taken from the same distribution, given a hypothesis h and a data sample containing n examples picked at random according to the distribution D?
- What is the margin of error in this estimate of accuracy?
True Error and Sample Error:
We must distinguish between two concepts of accuracy or, to put it another way, error. One is the hypothesis’s error rate based on the available data sample.
The hypothesis’ error rate over the complete unknown distribution D of examples is the other. These will be referred to as the sampling error and real error, respectively.
The fraction of S that a hypothesis misclassifies is the sampling error of a hypothesis with respect to some sample S of examples selected from X.
Sample Error:
It is denoted by error s (h) of hypothesis h with respect to target function f and data sample S is
Where n is the number of examples in S, and the quantity is 1 if f(x) != h(x), and 0 otherwise.
True Error:
It is denoted by error D (h) of hypothesis h with respect to target function f and distribution D, which is the probability that h will misclassify an instance drawn at random according to D.
Confidence Intervals for Discrete-Valued Hypotheses:
“How accurate are error s (h) estimates of error D (h)?” – in the case of a discrete-valued hypothesis (h).
To estimate the true error for a discrete-valued hypothesis h based on its observed sample error over a sample S, where
- According to the probability distribution D, the sample S contains n samples drawn independently of one another and of h.
- Over these n occurrences, hypothesis h commits r mistakes error s (h) = r/n
Under these circumstances, statistical theory permits us to state the following:
- If no additional information is available, the most likely value of error D (h) is error s (h).
- The genuine error error D (h) lies in the interval with approximately 95% probability.
A more precise rule of thumb is that the approximation described above works well when
- School Guide
- Mathematics
- Number System and Arithmetic
- Trigonometry
- Probability
- Mensuration
- Maths Formulas
- Class 8 Maths Notes
- Class 9 Maths Notes
- Class 10 Maths Notes
- Class 11 Maths Notes
- Class 12 Maths Notes
- CM to Inches (cm to in) Converter
- Inches to Centimeters Converter - Inches to Cm
- Feet to Centimeters (feet to cm) Converter
- Table of 2 - Multiplication Table Chart and 2 Times Table
- Asymmetric Relation on a Set
- Anti-Symmetric Relation on a Set
- Symmetric Relation on a Set
- Irreflexive Relation on a Set
- Reflexive Relation on Set
- Difference between Simpson 's 1/3 rule and 3/8 rule
- Write the smallest and the largest six digit numbers in the Number System
- Determining Limits using Algebraic Manipulation
- Representation of a Set
- Figures on the Same Base and between the Same Parallels
- Division Algorithm for Polynomials
- Algebra of Continuous Functions - Continuity and Differentiability | Class 12 Maths
- Operations on Sets
- Algebraic Solutions of Linear Inequalities in One Variable and their Graphical Representation - Linear Inequalities | Class 11 Maths
Real Life Application of Maths in Machine Learning and Artificial Intelligence
Mathematics is the main subject, taking part in several AI and ML applications. For instance, AI makes use of statistical models, including optimization algorithms and mathematical concepts, to develop intelligent learning systems capable of deciding things on their own based on exposure to new information.
In this article, we will go through the applications of math in machine learning and AI.
What is Machine Learning (ML)?
Machine Learning (ML) is a branch of artificial intelligence (AI) that focuses on creating algorithms and systems that can learn from and make predictions or decisions based on data.
Instead of explicitly programmed instructions, ML algorithms are designed to improve their performance over time as they are exposed to more data. ML encompasses various techniques such as supervised learning, unsupervised learning, and reinforcement learning
What is Artificial Intelligence (AI)?
Artificial Intelligence (AI) is a broader concept that refers to the development of computer systems capable of performing tasks that typically require human intelligence. This includes problem-solving, natural language understanding, perception, learning, and decision-making.
AI can be categorized into two types: narrow AI, which is designed to perform specific tasks, and general AI, which would have the ability to understand, learn, and apply knowledge across various domains similar to human intelligence.
Applications of Maths in ML and AI
The application of mathematics in ML and AI encompasses a wide range of areas, including:
Statistical Modeling
Probability theory, linear algebra, and calculus are mainly utilized for the development of statistical models that represent the facts and relations among data, which leads to the generation of predictive analytics and takes the decision-making process to other level.
Optimization Algorithms
The process of training and optimizing machine learning models with mathematical optimizations techniques such as gradient descent, genetic algorithms, and convex optimizations is one of the most important components of machine learning models.
Machine Learning Algorithms
ML algorithms using regression, classification, clustering, and deep learning conduct operations using matrixes, derivatives and probability distributions to develop learning data and predictions.
Natural Language Processing (NLP)
Some of the most common NLP tasks such as sentiment analysis, language modeling, and machine translation are facilitated by mathematics which utilizes vector space models, Markov chains, and Bayesian inference.
Computer Vision
Calculus, linear algebra, and geometry, which form the basis of mathematical knowledge, are tools used in computer vision tasks like image classification, object detection, and image segmentation in order to extract useful results from visual data.
Real Life Application of Maths in ML and AI
Mathematics serves as the backbone of both Machine Learning (ML) and Artificial Intelligence (AI), providing the essential framework for understanding, modeling, and optimizing algorithms that power real-world applications.
Credit Scoring in Finance
- Mathematical Concepts Used: Credit scoring in finance utilizes mathematical concepts such as probability theory and logistic regression.
- Application: Banks and financial institutions employ machine learning algorithms to assess credit risk and determine credit scores for individuals based on their financial history, income, and various other factors.
Example: The bank performs statistical analysis of the information, which includes a customer’s credit behavior history, employment status and payment history as well as credit scores, rates, and other data, to generate a default prediction. Hence, this can help determine a borrower’s creditworthiness and, consequently, to make the right decisions on loan approvals and interest rates.
Healthcare Diagnosis and Prognosis
- Mathematical Concepts Used: They leverage mathematical concepts like parameter estimation and Bayesian estimation.
- Application: ML models of analyzing healthcare data such as medical records, lab outcomes, and imaging scans are allowing the doctors to reach diagnosis, predict better treatment outcomes, and personalize the care for patients.
Example: healthcare systems utilize ML algorithms to detect abnormalities in X-rays or MRIs, aiding radiologists in making precise diagnoses by identifying conditions such as fractures or tumors during examinations.
Predictive Maintenance in Manufacturing
- Mathematical Concepts Used: Predictive maintenance in manufacturing employs mathematical concepts like time series analysis and regression.
- Application: Manufacturers utilize ML models that anticipate machine breakdowns and trigger needed maintenance routinely in advance reducing unscheduled maintenance and time consequently improving the efficiency of the operations.
Example: An aircraft maintenance team utilizes ML models in order to analyze the sensor data obtained from engines, and an anticipating failure forecast is made that in consequence reduces a chance of in-flight failures and allows on time maintenance operations.
Recommendation Systems in E-Commerce
- Mathematical Concepts Used: Two complex algorithms are involved in this process: matrix factorization, collaborative filtering.
- Application: Online platforms utilize recommendation algorithms to suggest videos, music, or items which mirrors the users’ preferences, history and persona.
Example: The e-commerce portal performs collaborative filtering which predicts products to match the users’ expectations based on the user’s previous purchases, ratings, and people who have similar preferences, consequently generating profits for heightened users’ experience.
Autonomous Vehicles and Robotics
- Mathematical Concepts Used: Autonomous vehicles and robotics rely on mathematical concepts such as control methods, kinematic problem-solving, and path planning.
- Application: Self-driving cars and robots simulate mathematic models for accurate interaction with the surroundings thus to avoid crashing into obstacles and making decisions at the stipulated time for safety and efficiency.
Example: The program carrying the self-driving car runs around the roads considering the road conditions through the control algorithms and the sensor data. It scans the roadways of pedestrians, makes sense of traffic signals and performs the task of transporting without any involvement of humans in the process.
Mathematics serves as the cornerstone for these cutting-edge technologies, from creating data processing algorithms to optimizing neural networks. Researchers and engineers are breaking new ground in industries such as healthcare, finance, and autonomous systems by combining mathematical notions with computational power. As we dive deeper into the fields of machine learning and artificial intelligence, a thorough understanding and enthusiasm for mathematics will remain critical for driving innovation and addressing challenging real-world challenges.
Related Articles-
What is Artificial Intelligence? What is Machine Learning? Real Life Application of Maths in Computer Science
FAQs on Real Life Application of Maths in ML and AI
What’s the significance of mathematics in machine learning and artificial intelligence.
Mathematics provides the foundation for understanding and optimizing algorithms in Machine Learning (ML) and Artificial Intelligence (AI). It’s crucial for developing, analyzing, and improving complex models.
What are the essential mathematical concepts in Machine Learning?
Machine Learning relies on several core mathematical concepts, including linear algebra, calculus, probability theory, and statistics.
How does linear algebra contribute to Machine Learning?
Linear algebra is fundamental in ML for tasks like data representation, transformation, and optimization.
What role does calculus play in optimizing Machine Learning models?
Calculus is crucial for optimizing ML models through gradient-based techniques.
How does probability theory contribute to Machine Learning?
Probability theory is central in ML for reasoning under uncertainty and making probabilistic predictions.
Please Login to comment...
Similar reads.
- Real Life Application

Improve your Coding Skills with Practice
What kind of Experience do you want to share?

Concept Learning and General to Specific Ordering-Part(1)
Introduction, if we really wanted to simplify the whole story behind “learning” in machine learning, we could say that a machine learning algorithm strives to learn a general function out of a given limited training examples . in general, we can think of concept learning as a search problem. the learner searches through a space of hypotheses (we will explain what they are), to find the best one. which one would be the best one the answer is the one that fits the training examples the best. and while searching and trying different hypotheses, we would hope for the learner to eventually converge to the correct hypothesis. this convergence is the same idea as learning now, let’s go deeper…, what does a concept mean after all, a concept means the spirit of something, the category of something. for example, as human beings we have learned the concept of ship . we know what it is, and no matter how many new, high-tech and fancy ships we are shown, we can still classify them as ships, even though we might not have seen those specific models before we can do this because we have learned the general concept of ship that encompasses infinite number of different kinds of ships that were, are, or will ever be built what other concepts can you think of, stressful situation (that is right a concept doesn’t have to be a physical object), cold/hot/humid, and so on and so forth. now please note that, on a more technical level we can think of a concept as a boolean function as we know, every function has a domain (i.e., the inputs) and a range (i.e., the outputs) so can you think of the domain and range of a boolean function that represents a concept such as the concept of bird , hint: remember that this function is true for birds and false for anything else (tigers, ants, …).
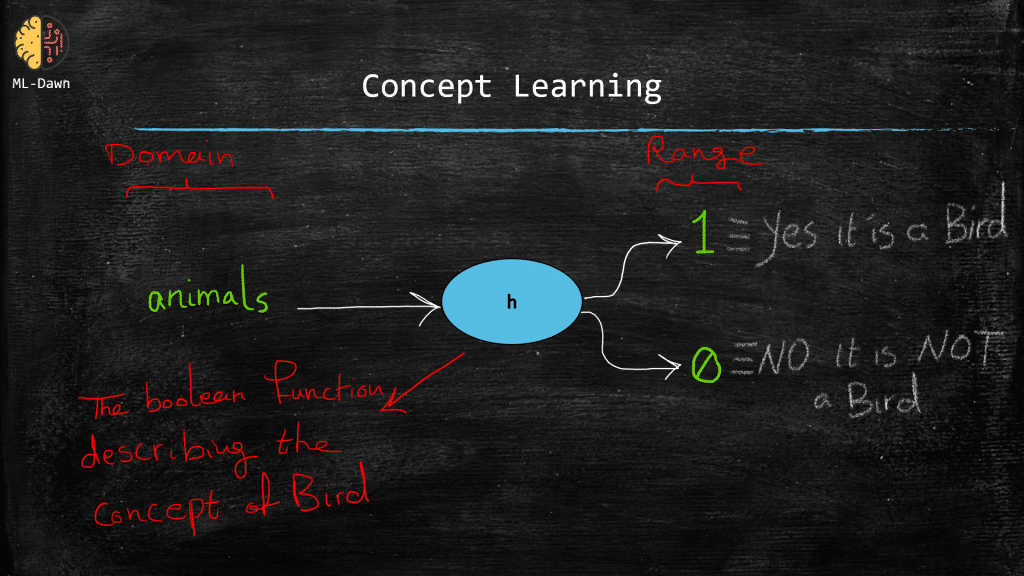
So this explanation makes machine learning more tangible, doesn’t it?
“A machine learning algorithm tries to infer the general definition of some concept, through some training examples that are labeled as members or non-members of that particular concept”
So this is called concept learning and the whole idea is to estimate the true underlying boolean function (i.e., concept), which can successfully fit the training examples perfectly and spit out the right output. This means that if the label for a training example is positive (i.e., a member of the concept) or negative, we would like for our learned function to correctly determine all these cases.
Note: The idea of labels in the training examples implies supervised learning . Please note that we don’t always have labels for our data. In these cases, unsupervised learning , we need to resort to other techniques to understand the training data and extract the concept out of them. Again we are learning a boolean function, but this time, the range of this function is NOT the labels associated with the training examples. You can think of the Auto-Encoders, which are ideal for unsupervised learning, and specifically for one-class classification:(aka. Anomaly Detection) . For those of you who are interested, in a standard Auto-encoder, we try to reconstruct the input examples! This might seem crazy but actually if we are able to reconstruct the training examples, then we have learned the behavior/distribution of the training data, but we are not going to go there in this post.
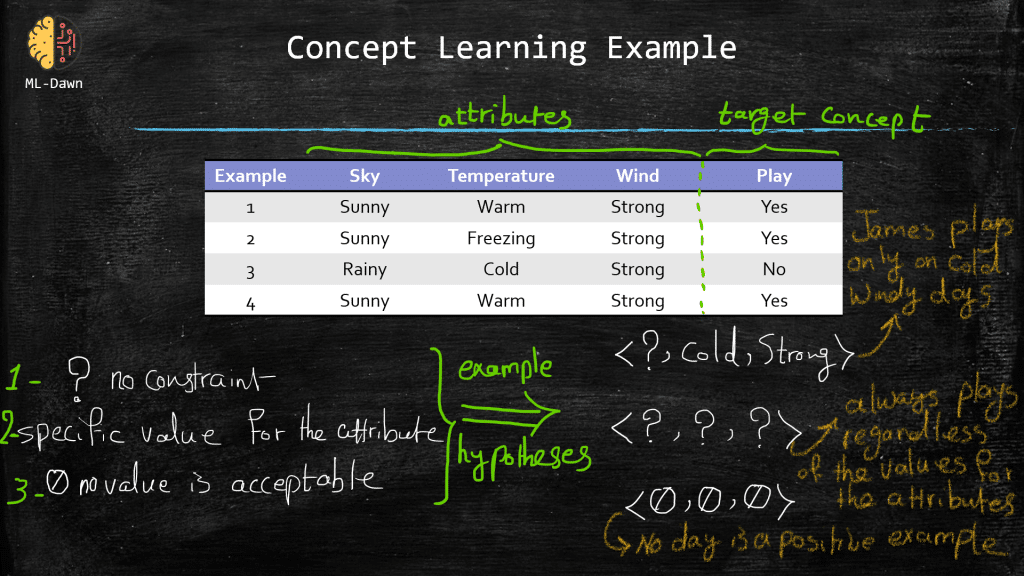
An Example for Concept Learning
Let’s say the task is to learn the following target concept :
Days on which James will play golf
Down below, in the slide entitled “ concept learning example “, you can see a set of example days, where each example consists of a set of attributes . Now, please note that the very last attribute, play, also known as the label or the ground-truth, shows whether James plays golf on that specific day.
We mentioned that the machine searches in the hypothesis space, to find the best hypothesis fitting the training examples. The big questions are:
What is a hypothesis?
How do we represent a hypothesis to a machine learning algorithm?
We can simply define a hypothesis as a vector of some constraints on the attributes. In our example below, a hypothesis consists of 3 constraints. Now, a constraint for a given attribute could have different shapes and forms:
Totally free of constraint (denoted with a question mark) : This means that we really don’t put any constraint on a particular attribute as that attribute doesn’t play an important role in learning the concept of play in this hypothesis . ( Please note that a hypothesis could consists of terrible constraints that will constantly fail to describe the concept. This is why the learner will search in the hypothesis space with the hopes of finding the best hypothesis )
Strong constraint on the value of the attribute : specified by the exact required value for that particular attribute
Strong constraint regardless of the value of the attribute : no value is acceptable for the attribute. Meaning that no day is a positive example (i.e., play=yes). Now, obviously we have examples in our table with “ play = yes “, so you can immediately see why a hypothesis with no value acceptable for any of its attributes, is a bad hypothesis in this example!
It is important to remind ourselves that if a given training example x (or a test example for that matter), could satisfy all the constraints in a given hypothesis h, (i.e., h(x) = 1), then we can say that hypothesis h classifies x as a positive example (i.e., play = yes). Otherwise, if x fails to satisfy even one constraint in h , the h(x) = 0, and this means that hypothesis h classifies input x as a negative example (i.e., play = No).
Now while a machine learning algorithm searches in the hypothesis space and tries to fit each one to the training examples, we hope that after the search is done, the learner will have found the true underlying hypothesis C! Basically, you can think of C as what we would like to estimate by trying different hypotheses. C is what we hope to converge to by trying different hypotheses!
So, for a positive training example x, C(x)=1 and for a negative training example C(x) = 0! Remember that we don’t know C but are trying to estimate it! So we can basically describe a training example x and its corresponding label as an ordered pair <x, C(x)>. We can say that the main job of the learner is to hypothesize and find a hypothesis h such that for every training example x in the training set: h(x) = C(x) !
The inductive learning hypothesis.
Yes, we look for the best-fit hypothesis that is identical to the true hypothesis C over the whole set of training instances! But of all the instances, we only have access to the available training examples at hand. As a result, ideally, the learned hypothesis will fit C perfectly, but JUST over the training examples! It is because the only knowledge we have about C is its output for the training examples that we have at hand. There will be unseen data for sure and that is where we hope that the learned hypothesis h that has done great on the training examples will do great on the unseen data (i.e., generalizing well)! This seems like an aggressive generalization but that is what happens out there in the machine learning world! The assumption is that during training, the best hypothesis for the future unseen data, is the one that best fits the available training examples where h(x) = C(x) for every x in our training set. This is the fundamental assumption of the inductive learning hypothesis.
Leave a Comment Cancel Reply
Your email address will not be published.
IMAGES
VIDEO
COMMENTS
A hypothesis is a function that best describes the target in supervised machine learning. The hypothesis that an algorithm would come up depends upon the data and also depends upon the restrictions and bias that we have imposed on the data. The Hypothesis can be calculated as: Where, y = range. m = slope of the lines. x = domain.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
The find-S algorithm is a basic concept learning algorithm in machine learning. The find-S algorithm finds the most specific hypothesis that fits all the positive examples. We have to note here that the algorithm considers only those positive training example. The find-S algorithm starts with the most specific hypothesis and generalizes this ...
This machine learning tutorial helps you gain a solid introduction to the fundamentals of machine learning and explore a wide range of techniques, including supervised, unsupervised, and reinforcement learning. Machine learning (ML) is a subdomain of artificial intelligence (AI) that focuses on developing systems that learn—or improve ...
Bayes' theorem is a fundamental concept in probability theory that plays a crucial role in various machine learning algorithms, especially in the fields of Bayesian statistics and probabilistic modelling. It provides a way to update probabilities based on new evidence or information. In the context of machine learning, Bayes' theorem is ...
A hypothesis is an explanation for something. It is a provisional idea, an educated guess that requires some evaluation. A good hypothesis is testable; it can be either true or false. In science, a hypothesis must be falsifiable, meaning that there exists a test whose outcome could mean that the hypothesis is not true.
Machine Learning is a branch of Artificial intelligence that focuses on the development of algorithms and statistical models that can learn from and make predictions on data. Linear regression is also a type of machine-learning algorithm more specifically a supervised machine-learning algorithm that learns from the labelled datasets and maps the data points to the most optimized linear ...
Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention. Do you get automatic recommendations on Netflix and Amazon Prime about the movies you should ...
The null hypothesis represented as H₀ is the initial claim that is based on the prevailing belief about the population. The alternate hypothesis represented as H₁ is the challenge to the null hypothesis. It is the claim which we would like to prove as True. One of the main points which we should consider while formulating the null and alternative hypothesis is that the null hypothesis ...
In this post, you will discover a cheat sheet for the most popular statistical hypothesis tests for a machine learning project with examples using the Python API. Each statistical test is presented in a consistent way, including: The name of the test. What the test is checking. The key assumptions of the test. How the test result is interpreted.
The hypothesis is one of the commonly used concepts of statistics in Machine Learning. It is specifically used in Supervised Machine learning, where an ML model learns a function that best maps the input to corresponding outputs with the help of an available dataset. In supervised learning techniques, the main aim is to determine the possible ...
This course will teach you everything about data science, from gathering various sorts of data to storing, preprocessing, analyzing, model building, and deploying them using the most recent data science methodologies. It consists of self-paced learning modules and live guidance sessions. VIEW DETAILED SYLLABUS.
Computational learning theory, or statistical learning theory, refers to mathematical frameworks for quantifying learning tasks and algorithms. These are sub-fields of machine learning that a machine learning practitioner does not need to know in great depth in order to achieve good results on a wide range of problems. Nevertheless, it is a sub-field where having a high-level understanding of ...
Learning Bound for Finite H - Consistent Case. Theorem: let H be a finite set of functions from X to 1} and L an algorithm that for any target concept c H and sample S returns a consistent hypothesis hS : . Then, for any 0 , with probability at least. (hS ) = 0 >.
Generalization. Generalization refers to your model's ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model. Estimated Time: 5 minutes. Learning Objectives. Develop intuition about overfitting. Determine whether a model is good or not. Divide a data set into a training set ...
We use a collection of training samples to train a machine learning algorithm to learn classification or regression patterns. Usually, we calculate various metrics to estimate its performance. Usually, we calculate various metrics to estimate its performance.
Just a small note on your answer: the size of the hypothesis space is indeed 65,536, but the a more easily explained expression for it would be 2(24) 2 ( 2 4), since, there are 24 2 4 possible unique samples, and thus 2(24) 2 ( 2 4) possible label assignments for the entire input space. - engelen. Jan 10, 2018 at 9:52.
Machine Learning- Issues in Machine Learning and How to solve them; Machine Learning- A concept Learning Task and Inductive Learning Hypothesis; Machine Learning- General-To-Specific Ordering of Hypothesis; Machine Learning- Finding a Maximally Specific Hypothesis: Find-S
In the last post, we said that all concept learning problems share 1 thing in common regarding their structure, and it is the fact that we can order the hypotheses from the most specific one to the most general one.This will enable the machine learning algorithm to explore the hypothesis space exhaustively, without having to enumerate through each and every hypothesis in this space, which is ...
Credit Scoring in Finance. Mathematical Concepts Used: Credit scoring in finance utilizes mathematical concepts such as probability theory and logistic regression. Application: Banks and financial institutions employ machine learning algorithms to assess credit risk and determine credit scores for individuals based on their financial history, income, and various other factors.
Introduction. If we really wanted to simplify the whole story behind "Learning" in machine learning, we could say that a machine learning algorithm strives to learn a general function out of a given limited training examples. In general, we can think of concept learning as a search problem. The learner searches through a space of hypotheses ...
In machine learning, a biased learner is a learning algorithm that consistently makes predictions that are systematically incorrect in some way. This means that the predictions made by a biased learner will be systematically different from the true values of the target variable, and this difference will not be random or arbitrary.
An important benefit of the maximize likelihood estimator in machine learning is that as the size of the dataset increases, the quality of the estimator continues to improve. Further Reading. This section provides more resources on the topic if you are looking to go deeper. Books. Chapter 5 Machine Learning Basics, Deep Learning, 2016.