Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 3. Psychological Science

3.2 Psychologists Use Descriptive, Correlational, and Experimental Research Designs to Understand Behaviour
Learning objectives.
- Differentiate the goals of descriptive, correlational, and experimental research designs and explain the advantages and disadvantages of each.
- Explain the goals of descriptive research and the statistical techniques used to interpret it.
- Summarize the uses of correlational research and describe why correlational research cannot be used to infer causality.
- Review the procedures of experimental research and explain how it can be used to draw causal inferences.
Psychologists agree that if their ideas and theories about human behaviour are to be taken seriously, they must be backed up by data. However, the research of different psychologists is designed with different goals in mind, and the different goals require different approaches. These varying approaches, summarized in Table 3.2, are known as research designs . A research design is the specific method a researcher uses to collect, analyze, and interpret data . Psychologists use three major types of research designs in their research, and each provides an essential avenue for scientific investigation. Descriptive research is research designed to provide a snapshot of the current state of affairs . Correlational research is research designed to discover relationships among variables and to allow the prediction of future events from present knowledge . Experimental research is research in which initial equivalence among research participants in more than one group is created, followed by a manipulation of a given experience for these groups and a measurement of the influence of the manipulation . Each of the three research designs varies according to its strengths and limitations, and it is important to understand how each differs.
Descriptive Research: Assessing the Current State of Affairs
Descriptive research is designed to create a snapshot of the current thoughts, feelings, or behaviour of individuals. This section reviews three types of descriptive research : case studies , surveys , and naturalistic observation (Figure 3.4).
Sometimes the data in a descriptive research project are based on only a small set of individuals, often only one person or a single small group. These research designs are known as case studies — descriptive records of one or more individual’s experiences and behaviour . Sometimes case studies involve ordinary individuals, as when developmental psychologist Jean Piaget used his observation of his own children to develop his stage theory of cognitive development. More frequently, case studies are conducted on individuals who have unusual or abnormal experiences or characteristics or who find themselves in particularly difficult or stressful situations. The assumption is that by carefully studying individuals who are socially marginal, who are experiencing unusual situations, or who are going through a difficult phase in their lives, we can learn something about human nature.
Sigmund Freud was a master of using the psychological difficulties of individuals to draw conclusions about basic psychological processes. Freud wrote case studies of some of his most interesting patients and used these careful examinations to develop his important theories of personality. One classic example is Freud’s description of “Little Hans,” a child whose fear of horses the psychoanalyst interpreted in terms of repressed sexual impulses and the Oedipus complex (Freud, 1909/1964).
Another well-known case study is Phineas Gage, a man whose thoughts and emotions were extensively studied by cognitive psychologists after a railroad spike was blasted through his skull in an accident. Although there are questions about the interpretation of this case study (Kotowicz, 2007), it did provide early evidence that the brain’s frontal lobe is involved in emotion and morality (Damasio et al., 2005). An interesting example of a case study in clinical psychology is described by Rokeach (1964), who investigated in detail the beliefs of and interactions among three patients with schizophrenia, all of whom were convinced they were Jesus Christ.
In other cases the data from descriptive research projects come in the form of a survey — a measure administered through either an interview or a written questionnaire to get a picture of the beliefs or behaviours of a sample of people of interest . The people chosen to participate in the research (known as the sample) are selected to be representative of all the people that the researcher wishes to know about (the population). In election polls, for instance, a sample is taken from the population of all “likely voters” in the upcoming elections.
The results of surveys may sometimes be rather mundane, such as “Nine out of 10 doctors prefer Tymenocin” or “The median income in the city of Hamilton is $46,712.” Yet other times (particularly in discussions of social behaviour), the results can be shocking: “More than 40,000 people are killed by gunfire in the United States every year” or “More than 60% of women between the ages of 50 and 60 suffer from depression.” Descriptive research is frequently used by psychologists to get an estimate of the prevalence (or incidence ) of psychological disorders.
A final type of descriptive research — known as naturalistic observation — is research based on the observation of everyday events . For instance, a developmental psychologist who watches children on a playground and describes what they say to each other while they play is conducting descriptive research, as is a biopsychologist who observes animals in their natural habitats. One example of observational research involves a systematic procedure known as the strange situation , used to get a picture of how adults and young children interact. The data that are collected in the strange situation are systematically coded in a coding sheet such as that shown in Table 3.3.
The results of descriptive research projects are analyzed using descriptive statistics — numbers that summarize the distribution of scores on a measured variable . Most variables have distributions similar to that shown in Figure 3.5 where most of the scores are located near the centre of the distribution, and the distribution is symmetrical and bell-shaped. A data distribution that is shaped like a bell is known as a normal distribution .
A distribution can be described in terms of its central tendency — that is, the point in the distribution around which the data are centred — and its dispersion, or spread . The arithmetic average, or arithmetic mean , symbolized by the letter M , is the most commonly used measure of central tendency . It is computed by calculating the sum of all the scores of the variable and dividing this sum by the number of participants in the distribution (denoted by the letter N ). In the data presented in Figure 3.5 the mean height of the students is 67.12 inches (170.5 cm). The sample mean is usually indicated by the letter M .
In some cases, however, the data distribution is not symmetrical. This occurs when there are one or more extreme scores (known as outliers ) at one end of the distribution. Consider, for instance, the variable of family income (see Figure 3.6), which includes an outlier (a value of $3,800,000). In this case the mean is not a good measure of central tendency. Although it appears from Figure 3.6 that the central tendency of the family income variable should be around $70,000, the mean family income is actually $223,960. The single very extreme income has a disproportionate impact on the mean, resulting in a value that does not well represent the central tendency.
The median is used as an alternative measure of central tendency when distributions are not symmetrical. The median is the score in the center of the distribution, meaning that 50% of the scores are greater than the median and 50% of the scores are less than the median . In our case, the median household income ($73,000) is a much better indication of central tendency than is the mean household income ($223,960).
A final measure of central tendency, known as the mode , represents the value that occurs most frequently in the distribution . You can see from Figure 3.6 that the mode for the family income variable is $93,000 (it occurs four times).
In addition to summarizing the central tendency of a distribution, descriptive statistics convey information about how the scores of the variable are spread around the central tendency. Dispersion refers to the extent to which the scores are all tightly clustered around the central tendency , as seen in Figure 3.7.
Or they may be more spread out away from it, as seen in Figure 3.8.
One simple measure of dispersion is to find the largest (the maximum ) and the smallest (the minimum ) observed values of the variable and to compute the range of the variable as the maximum observed score minus the minimum observed score. You can check that the range of the height variable in Figure 3.5 is 72 – 62 = 10. The standard deviation , symbolized as s , is the most commonly used measure of dispersion . Distributions with a larger standard deviation have more spread. The standard deviation of the height variable is s = 2.74, and the standard deviation of the family income variable is s = $745,337.
An advantage of descriptive research is that it attempts to capture the complexity of everyday behaviour. Case studies provide detailed information about a single person or a small group of people, surveys capture the thoughts or reported behaviours of a large population of people, and naturalistic observation objectively records the behaviour of people or animals as it occurs naturally. Thus descriptive research is used to provide a relatively complete understanding of what is currently happening.
Despite these advantages, descriptive research has a distinct disadvantage in that, although it allows us to get an idea of what is currently happening, it is usually limited to static pictures. Although descriptions of particular experiences may be interesting, they are not always transferable to other individuals in other situations, nor do they tell us exactly why specific behaviours or events occurred. For instance, descriptions of individuals who have suffered a stressful event, such as a war or an earthquake, can be used to understand the individuals’ reactions to the event but cannot tell us anything about the long-term effects of the stress. And because there is no comparison group that did not experience the stressful situation, we cannot know what these individuals would be like if they hadn’t had the stressful experience.
Correlational Research: Seeking Relationships among Variables
In contrast to descriptive research, which is designed primarily to provide static pictures, correlational research involves the measurement of two or more relevant variables and an assessment of the relationship between or among those variables. For instance, the variables of height and weight are systematically related (correlated) because taller people generally weigh more than shorter people. In the same way, study time and memory errors are also related, because the more time a person is given to study a list of words, the fewer errors he or she will make. When there are two variables in the research design, one of them is called the predictor variable and the other the outcome variable . The research design can be visualized as shown in Figure 3.9, where the curved arrow represents the expected correlation between these two variables.
One way of organizing the data from a correlational study with two variables is to graph the values of each of the measured variables using a scatter plot . As you can see in Figure 3.10 a scatter plot is a visual image of the relationship between two variables . A point is plotted for each individual at the intersection of his or her scores for the two variables. When the association between the variables on the scatter plot can be easily approximated with a straight line , as in parts (a) and (b) of Figure 3.10 the variables are said to have a linear relationship .
When the straight line indicates that individuals who have above-average values for one variable also tend to have above-average values for the other variable , as in part (a), the relationship is said to be positive linear . Examples of positive linear relationships include those between height and weight, between education and income, and between age and mathematical abilities in children. In each case, people who score higher on one of the variables also tend to score higher on the other variable. Negative linear relationships , in contrast, as shown in part (b), occur when above-average values for one variable tend to be associated with below-average values for the other variable. Examples of negative linear relationships include those between the age of a child and the number of diapers the child uses, and between practice on and errors made on a learning task. In these cases, people who score higher on one of the variables tend to score lower on the other variable.
Relationships between variables that cannot be described with a straight line are known as nonlinear relationships . Part (c) of Figure 3.10 shows a common pattern in which the distribution of the points is essentially random. In this case there is no relationship at all between the two variables, and they are said to be independent . Parts (d) and (e) of Figure 3.10 show patterns of association in which, although there is an association, the points are not well described by a single straight line. For instance, part (d) shows the type of relationship that frequently occurs between anxiety and performance. Increases in anxiety from low to moderate levels are associated with performance increases, whereas increases in anxiety from moderate to high levels are associated with decreases in performance. Relationships that change in direction and thus are not described by a single straight line are called curvilinear relationships .
The most common statistical measure of the strength of linear relationships among variables is the Pearson correlation coefficient , which is symbolized by the letter r . The value of the correlation coefficient ranges from r = –1.00 to r = +1.00. The direction of the linear relationship is indicated by the sign of the correlation coefficient. Positive values of r (such as r = .54 or r = .67) indicate that the relationship is positive linear (i.e., the pattern of the dots on the scatter plot runs from the lower left to the upper right), whereas negative values of r (such as r = –.30 or r = –.72) indicate negative linear relationships (i.e., the dots run from the upper left to the lower right). The strength of the linear relationship is indexed by the distance of the correlation coefficient from zero (its absolute value). For instance, r = –.54 is a stronger relationship than r = .30, and r = .72 is a stronger relationship than r = –.57. Because the Pearson correlation coefficient only measures linear relationships, variables that have curvilinear relationships are not well described by r , and the observed correlation will be close to zero.
It is also possible to study relationships among more than two measures at the same time. A research design in which more than one predictor variable is used to predict a single outcome variable is analyzed through multiple regression (Aiken & West, 1991). Multiple regression is a statistical technique, based on correlation coefficients among variables, that allows predicting a single outcome variable from more than one predictor variable . For instance, Figure 3.11 shows a multiple regression analysis in which three predictor variables (Salary, job satisfaction, and years employed) are used to predict a single outcome (job performance). The use of multiple regression analysis shows an important advantage of correlational research designs — they can be used to make predictions about a person’s likely score on an outcome variable (e.g., job performance) based on knowledge of other variables.
An important limitation of correlational research designs is that they cannot be used to draw conclusions about the causal relationships among the measured variables. Consider, for instance, a researcher who has hypothesized that viewing violent behaviour will cause increased aggressive play in children. He has collected, from a sample of Grade 4 children, a measure of how many violent television shows each child views during the week, as well as a measure of how aggressively each child plays on the school playground. From his collected data, the researcher discovers a positive correlation between the two measured variables.
Although this positive correlation appears to support the researcher’s hypothesis, it cannot be taken to indicate that viewing violent television causes aggressive behaviour. Although the researcher is tempted to assume that viewing violent television causes aggressive play, there are other possibilities. One alternative possibility is that the causal direction is exactly opposite from what has been hypothesized. Perhaps children who have behaved aggressively at school develop residual excitement that leads them to want to watch violent television shows at home (Figure 3.13):
Although this possibility may seem less likely, there is no way to rule out the possibility of such reverse causation on the basis of this observed correlation. It is also possible that both causal directions are operating and that the two variables cause each other (Figure 3.14).
Still another possible explanation for the observed correlation is that it has been produced by the presence of a common-causal variable (also known as a third variable ). A common-causal variable is a variable that is not part of the research hypothesis but that causes both the predictor and the outcome variable and thus produces the observed correlation between them . In our example, a potential common-causal variable is the discipline style of the children’s parents. Parents who use a harsh and punitive discipline style may produce children who like to watch violent television and who also behave aggressively in comparison to children whose parents use less harsh discipline (Figure 3.15)
In this case, television viewing and aggressive play would be positively correlated (as indicated by the curved arrow between them), even though neither one caused the other but they were both caused by the discipline style of the parents (the straight arrows). When the predictor and outcome variables are both caused by a common-causal variable, the observed relationship between them is said to be spurious . A spurious relationship is a relationship between two variables in which a common-causal variable produces and “explains away” the relationship . If effects of the common-causal variable were taken away, or controlled for, the relationship between the predictor and outcome variables would disappear. In the example, the relationship between aggression and television viewing might be spurious because by controlling for the effect of the parents’ disciplining style, the relationship between television viewing and aggressive behaviour might go away.
Common-causal variables in correlational research designs can be thought of as mystery variables because, as they have not been measured, their presence and identity are usually unknown to the researcher. Since it is not possible to measure every variable that could cause both the predictor and outcome variables, the existence of an unknown common-causal variable is always a possibility. For this reason, we are left with the basic limitation of correlational research: correlation does not demonstrate causation. It is important that when you read about correlational research projects, you keep in mind the possibility of spurious relationships, and be sure to interpret the findings appropriately. Although correlational research is sometimes reported as demonstrating causality without any mention being made of the possibility of reverse causation or common-causal variables, informed consumers of research, like you, are aware of these interpretational problems.
In sum, correlational research designs have both strengths and limitations. One strength is that they can be used when experimental research is not possible because the predictor variables cannot be manipulated. Correlational designs also have the advantage of allowing the researcher to study behaviour as it occurs in everyday life. And we can also use correlational designs to make predictions — for instance, to predict from the scores on their battery of tests the success of job trainees during a training session. But we cannot use such correlational information to determine whether the training caused better job performance. For that, researchers rely on experiments.
Experimental Research: Understanding the Causes of Behaviour
The goal of experimental research design is to provide more definitive conclusions about the causal relationships among the variables in the research hypothesis than is available from correlational designs. In an experimental research design, the variables of interest are called the independent variable (or variables ) and the dependent variable . The independent variable in an experiment is the causing variable that is created (manipulated) by the experimenter . The dependent variable in an experiment is a measured variable that is expected to be influenced by the experimental manipulation . The research hypothesis suggests that the manipulated independent variable or variables will cause changes in the measured dependent variables. We can diagram the research hypothesis by using an arrow that points in one direction. This demonstrates the expected direction of causality (Figure 3.16):
Research Focus: Video Games and Aggression
Consider an experiment conducted by Anderson and Dill (2000). The study was designed to test the hypothesis that viewing violent video games would increase aggressive behaviour. In this research, male and female undergraduates from Iowa State University were given a chance to play with either a violent video game (Wolfenstein 3D) or a nonviolent video game (Myst). During the experimental session, the participants played their assigned video games for 15 minutes. Then, after the play, each participant played a competitive game with an opponent in which the participant could deliver blasts of white noise through the earphones of the opponent. The operational definition of the dependent variable (aggressive behaviour) was the level and duration of noise delivered to the opponent. The design of the experiment is shown in Figure 3.17
Two advantages of the experimental research design are (a) the assurance that the independent variable (also known as the experimental manipulation ) occurs prior to the measured dependent variable, and (b) the creation of initial equivalence between the conditions of the experiment (in this case by using random assignment to conditions).
Experimental designs have two very nice features. For one, they guarantee that the independent variable occurs prior to the measurement of the dependent variable. This eliminates the possibility of reverse causation. Second, the influence of common-causal variables is controlled, and thus eliminated, by creating initial equivalence among the participants in each of the experimental conditions before the manipulation occurs.
The most common method of creating equivalence among the experimental conditions is through random assignment to conditions, a procedure in which the condition that each participant is assigned to is determined through a random process, such as drawing numbers out of an envelope or using a random number table . Anderson and Dill first randomly assigned about 100 participants to each of their two groups (Group A and Group B). Because they used random assignment to conditions, they could be confident that, before the experimental manipulation occurred, the students in Group A were, on average, equivalent to the students in Group B on every possible variable, including variables that are likely to be related to aggression, such as parental discipline style, peer relationships, hormone levels, diet — and in fact everything else.
Then, after they had created initial equivalence, Anderson and Dill created the experimental manipulation — they had the participants in Group A play the violent game and the participants in Group B play the nonviolent game. Then they compared the dependent variable (the white noise blasts) between the two groups, finding that the students who had viewed the violent video game gave significantly longer noise blasts than did the students who had played the nonviolent game.
Anderson and Dill had from the outset created initial equivalence between the groups. This initial equivalence allowed them to observe differences in the white noise levels between the two groups after the experimental manipulation, leading to the conclusion that it was the independent variable (and not some other variable) that caused these differences. The idea is that the only thing that was different between the students in the two groups was the video game they had played.
Despite the advantage of determining causation, experiments do have limitations. One is that they are often conducted in laboratory situations rather than in the everyday lives of people. Therefore, we do not know whether results that we find in a laboratory setting will necessarily hold up in everyday life. Second, and more important, is that some of the most interesting and key social variables cannot be experimentally manipulated. If we want to study the influence of the size of a mob on the destructiveness of its behaviour, or to compare the personality characteristics of people who join suicide cults with those of people who do not join such cults, these relationships must be assessed using correlational designs, because it is simply not possible to experimentally manipulate these variables.
Key Takeaways
- Descriptive, correlational, and experimental research designs are used to collect and analyze data.
- Descriptive designs include case studies, surveys, and naturalistic observation. The goal of these designs is to get a picture of the current thoughts, feelings, or behaviours in a given group of people. Descriptive research is summarized using descriptive statistics.
- Correlational research designs measure two or more relevant variables and assess a relationship between or among them. The variables may be presented on a scatter plot to visually show the relationships. The Pearson Correlation Coefficient ( r ) is a measure of the strength of linear relationship between two variables.
- Common-causal variables may cause both the predictor and outcome variable in a correlational design, producing a spurious relationship. The possibility of common-causal variables makes it impossible to draw causal conclusions from correlational research designs.
- Experimental research involves the manipulation of an independent variable and the measurement of a dependent variable. Random assignment to conditions is normally used to create initial equivalence between the groups, allowing researchers to draw causal conclusions.
Exercises and Critical Thinking
- There is a negative correlation between the row that a student sits in in a large class (when the rows are numbered from front to back) and his or her final grade in the class. Do you think this represents a causal relationship or a spurious relationship, and why?
- Think of two variables (other than those mentioned in this book) that are likely to be correlated, but in which the correlation is probably spurious. What is the likely common-causal variable that is producing the relationship?
- Imagine a researcher wants to test the hypothesis that participating in psychotherapy will cause a decrease in reported anxiety. Describe the type of research design the investigator might use to draw this conclusion. What would be the independent and dependent variables in the research?
Image Attributions
Figure 3.4: “ Reading newspaper ” by Alaskan Dude (http://commons.wikimedia.org/wiki/File:Reading_newspaper.jpg) is licensed under CC BY 2.0
Aiken, L., & West, S. (1991). Multiple regression: Testing and interpreting interactions . Newbury Park, CA: Sage.
Ainsworth, M. S., Blehar, M. C., Waters, E., & Wall, S. (1978). Patterns of attachment: A psychological study of the strange situation . Hillsdale, NJ: Lawrence Erlbaum Associates.
Anderson, C. A., & Dill, K. E. (2000). Video games and aggressive thoughts, feelings, and behavior in the laboratory and in life. Journal of Personality and Social Psychology, 78 (4), 772–790.
Damasio, H., Grabowski, T., Frank, R., Galaburda, A. M., Damasio, A. R., Cacioppo, J. T., & Berntson, G. G. (2005). The return of Phineas Gage: Clues about the brain from the skull of a famous patient. In Social neuroscience: Key readings. (pp. 21–28). New York, NY: Psychology Press.
Freud, S. (1909/1964). Analysis of phobia in a five-year-old boy. In E. A. Southwell & M. Merbaum (Eds.), Personality: Readings in theory and research (pp. 3–32). Belmont, CA: Wadsworth. (Original work published 1909).
Kotowicz, Z. (2007). The strange case of Phineas Gage. History of the Human Sciences, 20 (1), 115–131.
Rokeach, M. (1964). The three Christs of Ypsilanti: A psychological study . New York, NY: Knopf.
Stangor, C. (2011). Research methods for the behavioural sciences (4th ed.). Mountain View, CA: Cengage.
Long Descriptions
Figure 3.6 long description: There are 25 families. 24 families have an income between $44,000 and $111,000 and one family has an income of $3,800,000. The mean income is $223,960 while the median income is $73,000. [Return to Figure 3.6]
Figure 3.10 long description: Types of scatter plots.
- Positive linear, r=positive .82. The plots on the graph form a rough line that runs from lower left to upper right.
- Negative linear, r=negative .70. The plots on the graph form a rough line that runs from upper left to lower right.
- Independent, r=0.00. The plots on the graph are spread out around the centre.
- Curvilinear, r=0.00. The plots of the graph form a rough line that goes up and then down like a hill.
- Curvilinear, r=0.00. The plots on the graph for a rough line that goes down and then up like a ditch.
[Return to Figure 3.10]
Introduction to Psychology - 1st Canadian Edition Copyright © 2014 by Jennifer Walinga and Charles Stangor is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Chapter 2: Psychological Research
Descriptive research.
Psychologists use descriptive, experimental, and correlational methods to conduct research. Descriptive, or qualitative, methods include the case study, naturalistic observation, surveys, archival research, longitudinal research, and cross-sectional research.
https://assessments.lumenlearning.com/assessments/2706
There are many research methods available to psychologists in their efforts to understand, describe, and explain behavior and the cognitive and biological processes that underlie it. Some methods rely on observational techniques. Other approaches involve interactions between the researcher and the individuals who are being studied—ranging from a series of simple questions to extensive, in-depth interviews—to well-controlled experiments.
The three main categories of psychological research are descriptive, correlational, and experimental research. Research studies that do not test specific relationships between variables are called descriptive, or qualitative, studies . These studies are used to describe general or specific behaviors and attributes that are observed and measured. In the early stages of research it might be difficult to form a hypothesis, especially when there is not any existing literature in the area. In these situations designing an experiment would be premature, as the question of interest is not yet clearly defined as a hypothesis. Often a researcher will begin with a non-experimental approach, such as a descriptive study, to gather more information about the topic before designing an experiment or correlational study to address a specific hypothesis.
Video 1. Descriptive Research Design provides explanation and examples for quantitative descriptive research. A closed-captioned version of this video is available here .
Descriptive research is distinct from correlational research , in which psychologists formally test whether a relationship exists between two or more variables. Experimental research goes a step further beyond descriptive and correlational research and randomly assigns people to different conditions, using hypothesis testing to make inferences about how these conditions affect behavior. It aims to determine if one variable directly impacts and causes another. Correlational and experimental research both typically use hypothesis testing, whereas descriptive research does not.
Each of these research methods has unique strengths and weaknesses, and each method may only be appropriate for certain types of research questions. For example, studies that rely primarily on observation produce incredible amounts of information, but the ability to apply this information to the larger population is somewhat limited because of small sample sizes. Survey research, on the other hand, allows researchers to easily collect data from relatively large samples. While this allows for results to be generalized to the larger population more easily, the information that can be collected on any given survey is somewhat limited and subject to problems associated with any type of self-reported data. Some researchers conduct archival research by using existing records. While this can be a fairly inexpensive way to collect data that can provide insight into a number of research questions, researchers using this approach have no control on how or what kind of data was collected.
Correlational research can find a relationship between two variables, but the only way a researcher can claim that the relationship between the variables is cause and effect is to perform an experiment. In experimental research, which will be discussed later in the text, there is a tremendous amount of control over variables of interest. While this is a powerful approach, experiments are often conducted in very artificial settings. This calls into question the validity of experimental findings with regard to how they would apply in real-world settings. In addition, many of the questions that psychologists would like to answer cannot be pursued through experimental research because of ethical concerns.
Data Collection
Regardless of the method of research, data collection will be necessary. The method of data collection selected will primarily depend on the type of information the researcher needs for their study; however, other factors, such as time, resources, and even ethical considerations can influence the selection of a data collection method. All of these factors need to be considered when selecting a data collection method because each method has unique strengths and weaknesses. We will discuss the uses and assessment of the most common data collection methods: observation, surveys, archival data, and tests.
Observation
If you want to understand how behavior occurs, one of the best ways to gain information is to simply observe the behavior in its natural context. However, people might change their behavior in unexpected ways if they know they are being observed. How do researchers obtain accurate information when people tend to hide their natural behavior? As an example, imagine that your professor asks everyone in your class to raise their hand if they always wash their hands after using the restroom. Chances are that almost everyone in the classroom will raise their hand, but do you think hand washing after every trip to the restroom is really that universal?
This is very similar to the phenomenon mentioned earlier in this module: many individuals do not feel comfortable answering a question honestly. But if we are committed to finding out the facts about handwashing, we have other options available to us.
Suppose we send a classmate into the restroom to actually watch whether everyone washes their hands after using the restroom. Will our observer blend into the restroom environment by wearing a white lab coat, sitting with a clipboard, and staring at the sinks? We want our researcher to be inconspicuous—perhaps standing at one of the sinks pretending to put in contact lenses while secretly recording the relevant information. This type of observational study is called naturalistic observation : observing behavior in its natural setting. To better understand peer exclusion, Suzanne Fanger collaborated with colleagues at the University of Texas to observe the behavior of preschool children on a playground. How did the observers remain inconspicuous over the duration of the study? They equipped a few of the children with wireless microphones (which the children quickly forgot about) and observed while taking notes from a distance. Also, the children in that particular preschool (a “laboratory preschool”) were accustomed to having observers on the playground (Fanger, Frankel, & Hazen, 2012).

Figure 1 . Seeing a police car behind you would probably affect your driving behavior. (credit: Michael Gil)
It is critical that the observer be as unobtrusive and as inconspicuous as possible: when people know they are being watched, they are less likely to behave naturally. If you have any doubt about this, ask yourself how your driving behavior might differ in two situations: In the first situation, you are driving down a deserted highway during the middle of the day; in the second situation, you are being followed by a police car down the same deserted highway (Figure 1).
It should be pointed out that naturalistic observation is not limited to research involving humans. Indeed, some of the best-known examples of naturalistic observation involve researchers going into the field to observe various kinds of animals in their own environments. As with human studies, the researchers maintain their distance and avoid interfering with the animal subjects so as not to influence their natural behaviors. Scientists have used this technique to study social hierarchies and interactions among animals ranging from ground squirrels to gorillas. The information provided by these studies is invaluable in understanding how those animals organize socially and communicate with one another. The anthropologist Jane Goodall, for example, spent nearly five decades observing the behavior of chimpanzees in Africa (Figure 2). As an illustration of the types of concerns that a researcher might encounter in naturalistic observation, some scientists criticized Goodall for giving the chimps names instead of referring to them by numbers—using names was thought to undermine the emotional detachment required for the objectivity of the study (McKie, 2010).

Figure 2 . (a) Jane Goodall made a career of conducting naturalistic observations of (b) chimpanzee behavior. (credit “Jane Goodall”: modification of work by Erik Hersman; “chimpanzee”: modification of work by “Afrika Force”/Flickr.com)
The greatest benefit of naturalistic observation is the validity, or accuracy, of information collected unobtrusively in a natural setting. Having individuals behave as they normally would in a given situation means that we have a higher degree of ecological validity, or realism, than we might achieve with other research approaches. Therefore, our ability to generalize the findings of the research to real-world situations is enhanced. If done correctly, we need not worry about people or animals modifying their behavior simply because they are being observed. Sometimes, people may assume that reality programs give us a glimpse into authentic human behavior. However, the principle of inconspicuous observation is violated as reality stars are followed by camera crews and are interviewed on camera for personal confessionals. Given that environment, we must doubt how natural and realistic their behaviors are.
The major downside of naturalistic observation is that they are often difficult to set up and control. In our restroom study, what if you stood in the restroom all day prepared to record people’s handwashing behavior and no one came in? Or, what if you have been closely observing a troop of gorillas for weeks only to find that they migrated to a new place while you were sleeping in your tent? The benefit of realistic data comes at a cost. As a researcher, you have no control of when (or if) you have behavior to observe. In addition, this type of observational research often requires significant investments of time, money, and a good dose of luck.
Sometimes studies involve structured observation. In these cases, people are observed while engaging in set, specific tasks. An excellent example of structured observation comes from Strange Situation by Mary Ainsworth (you will read more about this in the module on lifespan development). The Strange Situation is a procedure used to evaluate attachment styles that exist between an infant and caregiver. In this scenario, caregivers bring their infants into a room filled with toys. The Strange Situation involves a number of phases, including a stranger coming into the room, the caregiver leaving the room, and the caregiver’s return to the room. The infant’s behavior is closely monitored at each phase, but it is the behavior of the infant upon being reunited with the caregiver that is most telling in terms of characterizing the infant’s attachment style with the caregiver.
Another potential problem in observational research is observer bias . Generally, people who act as observers are closely involved in the research project and may unconsciously skew their observations to fit their research goals or expectations. To protect against this type of bias, researchers should have clear criteria established for the types of behaviors recorded and how those behaviors should be classified. In addition, researchers often compare observations of the same event by multiple observers, in order to test inter-rater reliability : a measure of reliability that assesses the consistency of observations by different observers.
Often, psychologists develop surveys as a means of gathering data. Surveys are lists of questions to be answered by research participants, and can be delivered as paper-and-pencil questionnaires, administered electronically, or conducted verbally (Figure 3). Generally, the survey itself can be completed in a short time, and the ease of administering a survey makes it easy to collect data from a large number of people.
Surveys allow researchers to gather data from larger samples than may be afforded by other research methods . A sample is a subset of individuals selected from a population , which is the overall group of individuals that the researchers are interested in. Researchers study the sample and seek to generalize their findings to the population.

Figure 3 . Surveys can be administered in a number of ways, including electronically administered research, like the survey shown here. (credit: Robert Nyman)
There is both strength and weakness of the survey in comparison to case studies. By using surveys, we can collect information from a larger sample of people. A larger sample is better able to reflect the actual diversity of the population, thus allowing better generalizability. Therefore, if our sample is sufficiently large and diverse, we can assume that the data we collect from the survey can be generalized to the larger population with more certainty than the information collected through a case study. However, given the greater number of people involved, we are not able to collect the same depth of information on each person that would be collected in a case study.
Another potential weakness of surveys is something we touched on earlier in this module: people don’t always give accurate responses. They may lie, misremember, or answer questions in a way that they think makes them look good. For example, people may report drinking less alcohol than is actually the case.
Any number of research questions can be answered through the use of surveys. One real-world example is the research conducted by Jenkins, Ruppel, Kizer, Yehl, and Griffin (2012) about the backlash against the US Arab-American community following the terrorist attacks of September 11, 2001. Jenkins and colleagues wanted to determine to what extent these negative attitudes toward Arab-Americans still existed nearly a decade after the attacks occurred. In one study, 140 research participants filled out a survey with 10 questions, including questions asking directly about the participant’s overt prejudicial attitudes toward people of various ethnicities. The survey also asked indirect questions about how likely the participant would be to interact with a person of a given ethnicity in a variety of settings (such as, “How likely do you think it is that you would introduce yourself to a person of Arab-American descent?”). The results of the research suggested that participants were unwilling to report prejudicial attitudes toward any ethnic group. However, there were significant differences between their pattern of responses to questions about social interaction with Arab-Americans compared to other ethnic groups: they indicated less willingness for social interaction with Arab-Americans compared to the other ethnic groups. This suggested that the participants harbored subtle forms of prejudice against Arab-Americans, despite their assertions that this was not the case (Jenkins et al., 2012).
Archival Data and Case Studies
Some researchers gain access to large amounts of data without interacting with a single research participant. Instead, they use existing records to answer various research questions. This type of research approach is known as archival research. Archival research relies on looking at past records or data sets to look for interesting patterns or relationships.
For example, a researcher might access the academic records of all individuals who enrolled in college within the past ten years and calculate how long it took them to complete their degrees, as well as course loads, grades, and extracurricular involvement. Archival research could provide important information about who is most likely to complete their education, and it could help identify important risk factors for struggling students (Figure 4).

Figure 4 . A researcher doing archival research examines records, whether archived as a (a) hardcopy or (b) electronically. (credit “paper files”: modification of work by “Newtown graffiti”/Flickr; “computer”: modification of work by INPIVIC Family/Flickr)
In comparing archival research to other research methods, there are several important distinctions. For one, the researcher employing archival research never directly interacts with research participants. Therefore, the investment of time and money to collect data is considerably less with archival research. Additionally, researchers have no control over what information was originally collected. Therefore, research questions have to be tailored so they can be answered within the structure of the existing data sets. There is also no guarantee of consistency between the records from one source to another, which might make comparing and contrasting different data sets problematic.
https://assessments.lumenlearning.com/assessments/2712
A good test will aid researchers in assessing a particular psychological construct. What is a good test? Researchers want a test that is standardized, reliable, and valid. A standardized test is one that is administered, scored, and analyzed in the same way for each participant. This minimizes differences in test scores due to confounding factors, such as variability in the testing environment or scoring process, and assures that scores are comparable. Reliability refers to the consistency of a measure. Researchers consider three types of consistency: over time (test-retest reliability), across items (internal consistency), and across different researchers (interrater reliability). Validity is the extent to which the scores from a measure represent the variable they are intended to. When a measure has good test-retest reliability and internal consistency, researchers should be more confident that the scores represent what they are supposed to.
There are various types of tests used in psychological research. Self-report measures are those in which participants report on their own thoughts, feelings, and actions, such as the Rosenberg Self-Esteem Scale or the Big Five Personality Test. Some tests measure performance, ability, aptitude, or skill, like the Stanford-Binet Intelligence Scale or the SATs.There are also tests that measure physiological states, including electrical activity or blood flow in the brain.
Video 2. Methods of Data Collection explains various means for gathering data for quantitative and qualitative research. A closed-captioned version of this video is available here .
Studying Changes over Time
Sometimes, especially in developmental research, the researcher is interested in examining changes over time and will need to consider a research design that will capture these changes. Remember, research methods are tools that are used to collect information, while r esearch design is the strategy or blueprint for deciding how to collect and analyze information. Research design dictates which methods are used and how. There are three types of developmental research designs: cross-sectional, longitudinal, and sequential.
Video 3. Developmental Research Designs
Cross-Sectional Design
The majority of developmental studies use cross-sectional designs because they are less time-consuming and less expensive than other developmental designs. Cross-sectional research designs are used to examine behavior in participants of different ages who are tested at the same point in time. Let’s suppose that researchers are interested in the relationship between intelligence and aging. They might have a hypothesis that intelligence declines as people get older. The researchers might choose to give a particular intelligence test to individuals who are 20 years old, individuals who are 50 years old, and individuals who are 80 years old at the same time and compare the data from each age group. This research is cross-sectional in design because the researchers plan to examine the intelligence scores of individuals of different ages within the same study at the same time; they are taking a “cross-section” of people at one point in time. Let’s say that the comparisons find that the 80-year-old adults score lower on the intelligence test than the 50-year-old adults, and the 50-year-old adults score lower on the intelligence test than the 20-year-old adults. Based on these data, the researchers might conclude that individuals become less intelligent as they get older. Would that be a valid (accurate) interpretation of the results?

Figure 5. Example of cross-sectional research design
No, that would not be a valid conclusion because the researchers did not follow individuals as they aged from 20 to 50 to 80 years old. One of the primary limitations of cross-sectional research is that the results yield information about age differences not necessarily changes over time. That is, although the study described above can show that the 80-year-olds scored lower on the intelligence test than the 50-year-olds, and the 50-year-olds scored lower than the 20-year-olds, the data used for this conclusion were collected from different individuals (or groups). It could be, for instance, that when these 20-year-olds get older, they will still score just as high on the intelligence test as they did at age 20. Similarly, maybe the 80-year-olds would have scored relatively low on the intelligence test when they were young; the researchers don’t know for certain because they did not follow the same individuals as they got older.
With each cohort being members of a different generation, it is also possible that the differences found between the groups are not due to age, per se, but due to cohort effects. Differences between these cohorts’ IQ results could be due to differences in life experiences specific to their generation, such as differences in education, economic conditions, advances in technology, or changes in health and nutrition standards, and not due to age-related changes.
Another disadvantage of cross-sectional research is that it is limited to one time of measurement. Data are collected at one point in time, and it’s possible that something could have happened in that year in history that affected all of the participants, although possibly each cohort may have been affected differently.
Longitudinal Research Design

Longitudinal research designs are used to examine behavior in the same individuals over time. For instance, with our example of studying intelligence and aging, a researcher might conduct a longitudinal study to examine whether 20-year-olds become less intelligent with age over time. To this end, a researcher might give an intelligence test to individuals when they are 20 years old, again when they are 50 years old, and then again when they are 80 years old. This study is longitudinal in nature because the researcher plans to study the same individuals as they age. Based on these data, the pattern of intelligence and age might look different than from the cross-sectional research; it might be found that participants’ intelligence scores are higher at age 50 than at age 20 and then remain stable or decline a little by age 80. How can that be when cross-sectional research revealed declines in intelligence with age?

Figure 6. Example of a longitudinal research design
Since longitudinal research happens over a period of time (which could be short term, as in months, but is often longer, as in years), there is a risk of attrition. Attrition occurs when participants fail to complete all portions of a study. Participants may move, change their phone numbers, die, or simply become disinterested in participating over time. Researchers should account for the possibility of attrition by enrolling a larger sample into their study initially, as some participants will likely drop out over time. There is also something known as selective attrition— this means that certain groups of individuals may tend to drop out. It is often the least healthy, least educated, and lower socioeconomic participants who tend to drop out over time. That means that the remaining participants may no longer be representative of the whole population, as they are, in general, healthier, better educated, and have more money. This could be a factor in why our hypothetical research found a more optimistic picture of intelligence and aging as the years went by. What can researchers do about selective attrition? At each time of testing, they could randomly recruit more participants from the same cohort as the original members to replace those who have dropped out.
The results from longitudinal studies may also be impacted by repeated assessments. Consider how well you would do on a math test if you were given the exact same exam every day for a week. Your performance would likely improve over time, not necessarily because you developed better math abilities, but because you were continuously practicing the same math problems. This phenomenon is known as a practice effect. Practice effects occur when participants become better at a task over time because they have done it again and again (not due to natural psychological development). So our participants may have become familiar with the intelligence test each time (and with the computerized testing administration).
Another limitation of longitudinal research is that the data are limited to only one cohort. As an example, think about how comfortable the participants in the 2010 cohort of 20-year-olds are with computers. Since only one cohort is being studied, there is no way to know if findings would be different from other cohorts. In addition, changes that are found as individuals age over time could be due to age or to time of measurement effects. That is, the participants are tested at different periods in history, so the variables of age and time of measurement could be confounded (mixed up). For example, what if there is a major shift in workplace training and education between 2020 and 2040, and many of the participants experience a lot more formal education in adulthood, which positively impacts their intelligence scores in 2040? Researchers wouldn’t know if the intelligence scores increased due to growing older or due to a more educated workforce over time between measurements.
Sequential Research Design
Sequential research designs include elements of both longitudinal and cross-sectional research designs. Similar to longitudinal designs, sequential research features participants who are followed over time; similar to cross-sectional designs, sequential research includes participants of different ages. This research design is also distinct from those that have been discussed previously in that individuals of different ages are enrolled into a study at various points in time to examine age-related changes, development within the same individuals as they age, and to account for the possibility of cohort and/or time of measurement effects
Consider, once again, our example of intelligence and aging. In a study with a sequential design, a researcher might recruit three separate groups of participants (Groups A, B, and C). Group A would be recruited when they are 20 years old in 2010 and would be tested again when they are 50 and 80 years old in 2040 and 2070, respectively (similar in design to the longitudinal study described previously). Group B would be recruited when they are 20 years old in 2040 and would be tested again when they are 50 years old in 2070. Group C would be recruited when they are 20 years old in 2070, and so on.
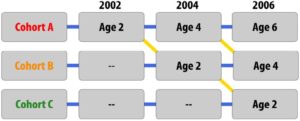
Figure 7. Example of sequential research design
Studies with sequential designs are powerful because they allow for both longitudinal and cross-sectional comparisons—changes and/or stability with age over time can be measured and compared with differences between age and cohort groups. This research design also allows for the examination of cohort and time of measurement effects. For example, the researcher could examine the intelligence scores of 20-year-olds at different times in history and different cohorts (follow the yellow diagonal lines in figure 3). This might be examined by researchers who are interested in sociocultural and historical changes (because we know that lifespan development is multidisciplinary). One way of looking at the usefulness of the various developmental research designs was described by Schaie and Baltes (1975): cross-sectional and longitudinal designs might reveal change patterns while sequential designs might identify developmental origins for the observed change patterns.
Since they include elements of longitudinal and cross-sectional designs, sequential research has many of the same strengths and limitations as these other approaches. For example, sequential work may require less time and effort than longitudinal research (if data are collected more frequently than over the 30-year spans in our example) but more time and effort than cross-sectional research. Although practice effects may be an issue if participants are asked to complete the same tasks or assessments over time, attrition may be less problematic than what is commonly experienced in longitudinal research since participants may not have to remain involved in the study for such a long period of time.
Comparing Developmental Research Designs
When considering the best research design to use in their research, scientists think about their main research question and the best way to come up with an answer. A table of advantages and disadvantages for each of the described research designs is provided here to help you as you consider what sorts of studies would be best conducted using each of these different approaches.
Table 1. Advantages and disadvantages of different research designs
Candela Citations
- Introductory content. Provided by : Lumen Learning. License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Modification, adaptation, and original content. Provided by : Lumen Learning. License : CC BY-SA: Attribution-ShareAlike
- Paragraph on correlation. Authored by : Christie Napa Scollon. Provided by : Singapore Management University. Located at : http://nobaproject.com/modules/research-designs?r=MTc0ODYsMjMzNjQ%3D . Project : The Noba Project. License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Psychology, Approaches to Research. Authored by : OpenStax College. Located at : http://cnx.org/contents/[email protected]:mfArybye@7/Analyzing-Findings . License : CC BY: Attribution . License Terms : Download for free at http://cnx.org/contents/[email protected]
- Lec 2 | MIT 9.00SC Introduction to Psychology, Spring 2011. Authored by : John Gabrieli. Provided by : MIT OpenCourseWare. Located at : https://www.youtube.com/watch?v=syXplPKQb_o . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Descriptive Research. Provided by : Boundless. Located at : https://courses.lumenlearning.com/boundless-psychology/ . License : CC BY-SA: Attribution-ShareAlike
- Researchers review documents. Authored by : National Cancer Institute. Provided by : Wikimedia. Located at : https://commons.wikimedia.org/wiki/File:Researchers_review_documents.jpg . License : Public Domain: No Known Copyright

Privacy Policy