Conveniently hear PDF files read aloud.

The option to have a PDF file read aloud offers numerous advantages. It’s also an easy feature to master.
Perhaps you need your documents read aloud to you because reading print text is too difficult. Or maybe you’ve just downloaded a PDF file of a book to listen to, but you really want to savor the story and language slowly. Adobe Reader enables you to have your files read aloud and even customize the experience by setting the narrator’s voice and choosing the pace of the reading to best suit your needs.

How to have a PDF read aloud.
Having a PDF read aloud can increase accessibility if you are visually impaired or have difficulty reading the text. Listening to a PDF can also help you multitask. Use Adobe’s free Acrobat Reader app to have the text in your PDF read aloud to you.
Simply follow these steps to have Acrobat Reader read PDF aloud:
- Open Reader and navigate to the document page you want to have read aloud.
- From the top-left menu, click View, then Read Out Loud.
- You can choose to have the whole document read aloud or just the page you’re on.
- Select either Read to End of Document or Read This Page Only, respectively.
The reading will start at the page you’re currently on, even if you select Read to End of Document. To start at the beginning, navigate to the first page.
At any point, you can also choose from several options to customize the experience of having your PDFs read out loud:
- To pause or stop the read-out-loud function, go back to the Read Out Loud selection from the View dropdown menu and select either option.
- To choose your preferred reader voice, go to the top-right menu and click Edit, then Preferences. Choose Reading. Remove the checkmark on Use Default Voice, and finally choose the narration voice you like from the dropdown list.
- To adjust the pace of the reading, either increase the Words Per Minute count or lower it, depending on your needs.
Now you can have your PDF read aloud with your unique preference selections.
Benefits of text to speech for PDFs.
Text to speech can be a useful tool for a variety of people. People with vision loss can access a PDF with text to speech. Anyone who prefers to listen to text, whether it’s in an effort to avoid eyestrain or improve workflow, can use Acrobat Reader’s simple PDF text to speech feature. Text to speech can also help you multitask.
To make sure that a PDF is accessible to someone with vision loss, ensure that the text is not in an image but is recognized as text by Acrobat Reader. You can also tag headings, tables, and lists to increase accessibility.
Listen to PDF documents on the go.
Fortunately, Acrobat Reader can read PDF aloud on any device, so you can listen to the content of a PDF from anywhere. For example, if you have a long commute and you’re trying to ramp up productivity, you can use the PDF reader voice to listen to notes, documents, books, or other important information while you drive. If you need a refresher on your notes before a meeting, listen to your PDF while you travel to your meeting. You can use text to speech to enjoy all the features of Acrobat Reader and work with PDFs from anywhere.
Do more with your PDF.
The PDF is one of the most widely used formats in professional settings and is an industry standard for people in many fields, from business to education to law. Its printable format shows up the same across all devices, so it’s easy to share and view on the go. Adobe’s powerful PDF tools can help you use the PDF to its fullest, from creating forms to redacting or encrypting.
See what else you can do with PDFs with Acrobat , from converting files like Word to PDF to splitting files , merging PDFs , rotating pages , and more.
Read and Listen to PDF Documents Online
Easily hear your PDF documents as audio books and experience the joy of hands-free reading. Start listening to your favorite PDF documents online today with ReadLoudly.
Select a PDF file
Max file size 100MB.
How to listen to your PDF documents
Listening to your PDF documents hands-free is simple with ReadLoudly. Here's how to get started:
Select the PDF document you want to listen to. Our website allows you to easily upload and select the PDF document you want to listen to.
Once the PDF is loaded, navigate to the page you want to listen to. Our intuitive interface allows you to quickly and easily navigate to any page in your PDF document.
Click the play button to start listening. Our advanced text-to-speech technology will read your document out loud, allowing you to sit back, relax, and enjoy your PDF hands-free.
With ReadLoudly, you can enjoy your favorite PDF documents without having to read them yourself. Start listening today and experience the joy of hands-free reading.
Read and Listen Anywhere
With ReadLoudly.com, you can easily upload any PDF document and read it as a flipbook from anywhere, at any time. Plus, with the integrated text-to-speech feature, you can listen to your documents on any device.
Safe and Secure
We take your privacy seriously, which is why we never store any documents on our server or share them without your permission. Rest assured that your data is safe and secure with ReadLoudly.com.
Customizable Reading Experience
With ReadLoudly.com, you can customize your reading experience with adjustable font sizes, colors, and backgrounds. Plus, you can easily navigate between pages and sections with our user-friendly interface.
Share with Ease
Once you're done reading or listening to a document, you can easily share the flipbook with anyone via email or social media. Spread awareness and enjoyment in no time!
Customizable Text-to-Speech
Choose from a range of voices, customize the speed and pitch to your liking, and let ReadLoudly.com read your PDF document to you. Personalize your reading experience with our customizable text-to-speech feature.
No Downloads Required
You don't need to download any software or plugins to use ReadLoudly.com. It's a hassle-free way to read and listen to PDF documents online.
Listening to your eBooks hands-free is simple with ReadLoudly. Here's how to get started:
Frequently Asked Questions
What is Readloudly?
Readloudly is a versatile online platform designed for reading and listening to a wide range of content, including PDFs, flipbooks, ebooks, and text-to-speech materials. Users can access the platform as guests or by logging in with their email, where they can enjoy a personalized experience tailored to their preferences.
How do I access my account on Readloudly?
Users can access their accounts on Readloudly either as guests or by logging in with their email, including Gmail login. Once logged in, users can access their personalized dashboard, where they can store books, manage preferences, and access exclusive features.
Can I share books with friends on Readloudly?
Yes, users can easily share books with friends via email by utilizing the built-in sharing feature on Readloudly. Simply enter the recipient's email address, and they will receive access to the shared book.
Can I customize my reading and listening experience on Readloudly?
Absolutely! Readloudly offers a plethora of customization options, including changing the language while listening, selecting from over 50 different voices, adjusting playback speed, enabling dark mode, zooming in and out while reading, and setting preferences for text highlight colors and dark mode.
How can I interact with PDFs on Readloudly?
With Readloudly, users can interact with PDFs in various ways, including highlighting and bookmarking specific lines, playing, repeating, and jumping to any page using the sidebar's page view option. Additionally, users can toggle between text and page view modes for a more streamlined reading experience.
Is customer support available on Readloudly?
Yes, Readloudly offers 24/7 customer support to address any inquiries or issues users may encounter while using the platform. Users can contact the support team through the help button on the website or dashboard and can expect prompt assistance.
What exclusive features are available on the user dashboard?
The user dashboard on Readloudly provides access to four exclusive options: "Books You Have Listened," "Add New Book," "Lines You Have Bookmarked," and "Preferences." Users can manage their listened books, add new ones, access bookmarked lines, and customize preferences such as text highlight and dark mode settings.
How do I access my highlighted lines and bookmarks on Readloudly?
Users can easily access their highlighted lines and bookmarks by navigating to the "Bookmark" tab on their dashboard. Here, they can view and manage all their bookmarked content for easy reference.
Can I provide feedback or report issues on Readloudly?
Yes, Readloudly welcomes user feedback and encourages users to report any issues they encounter while using the platform. Users can provide feedback or report issues through the help button, and the support team will promptly address them.
Is Readloudly accessible on mobile devices?
Yes, Readloudly is accessible on various devices, including smartphones and tablets, through the website or the mobile app. Users can enjoy their favorite books and stories on the go, ensuring a seamless reading and listening experience across different devices.
Site News and Updates
March 3rd, 2024.
Exciting news! We've enhanced our OCR capabilities, providing more accurate text recognition. Now, with OCR, we offer support for over a hundred languages, making your reading experience truly global. Explore a world of literature in your preferred language!
Say goodbye to language barriers! With our new language change option, navigating through diverse literary landscapes is now hassle-free. Choose your preferred language and immerse yourself in a seamless reading experience.
Discover a refined reading experience with our latest design changes on the most viewed viewer page. Enjoy a smoother user experience, cleaner reading interface, and cool icons that enhance your interaction with the content. Immerse yourself in the world of literature with style and simplicity!
January 24th, 2024
Embark on a seamless reading journey with our new Text Viewer—an immersive experience designed to focus solely on the textual content of PDFs. Enjoy features such as highlighting, bookmarking, and effortless reading, all tailored to enhance your interaction with the written word.
For the PDF Viewer, take control with precision using zoom in and zoom out buttons. In the Text Viewer, elevate your reading experience by customizing font sizes with easy-to-use buttons. Your preferences shape your unique reading adventure!
Explore the power of Text-to-Speech with our new caption section! Enable captions to view the current sentence you're reading or listening to. Dive into the immersive experience where each spoken word is highlighted with a distinct color. Experience reading in a whole new way!
December 12th, 2023
Tired of straining your eyes during late-night reading sessions? We've got you covered! Introducing our new Dark Mode feature—because your comfort matters. Enjoy a soothing, eye-friendly interface while delving into your favorite documents.
Exciting news! Now, you can share the joy of reading seamlessly. Whether it's a captivating PDF, an engaging eBook, or a valuable textbook, sharing is caring! Head to your dashboard's book section, hit the share option, enter your friend's email, and voilà—spread the reading love!
But wait, there's more! Our Share Option isn't just about sharing; it's your personal storage haven. Safeguard your cherished documents while creating a vibrant reading community. Update your experience now and let the reading revolution begin! 🚀
Nov 22th,2023
A new version for added flexibility. Store and access multiple books effortlessly, eliminating the need to upload the same book repeatedly. Enjoy reading or listening whenever you want!
- Login : Experience a streamlined and secure login process, ensuring easy access to your personalized features and content.
- Personal Dashboard : Your customized hub for an organized and efficient user experience, providing quick access to all your account settings and activities.
- Book Storage : Store and manage multiple books effortlessly, eliminating the need to re-upload, and enjoy a clutter-free reading environment.
- Highlight and Bookmark : Enhance your reading experience by highlighting and bookmarking specific sections, making it easy to revisit and engage with key content.
- Preference : Personalize your reading experience with color customization for highlights and bookmarks, allowing you to tailor the visual aspects to your preferences.
Sep 27th,2023
We're thrilled to introduce a game-changing update to the ReadLoudly PDF viewer that promises an even smoother reading experience. 📚
- Each page is now processed on our powerful servers, significantly reducing the load on your browser.
- Enjoy lightning-fast page loading and navigation, no matter the size of your PDF document.
- Say goodbye to slow rendering and hello to a seamless reading experience.
Sep 19th,2023
Enhance your reading experience with our new Text-to-Speech page. Now, you can easily convert written text or upload a TXT file and listen to it being read aloud. Whether it's articles, notes, or your own writings, our text-to-speech technology brings content to life, making it accessible and engaging.
Introducing our convenient Page Selection option! We've made it even easier to read books and documents. You can now select the specific pages you want to read, resulting in faster load times for larger books. Customize your reading experience and access content more efficiently.
Sep 13th,2023
We've added a handy option to Repeat a Single Sentence. Now, you can easily replay a specific sentence or passage while listening, ensuring you never miss a word of your favorite content.
Our team has been hard at work, addressing issues to improve your audio playback experience. Say goodbye to audio player glitches and enjoy smoother, uninterrupted listening.
Sep 6th,2023
We're excited to unveil our fresh, new logo! It represents our commitment to providing you with innovative and user-friendly reading and listening experiences.
Introducing the eBook Reader Page, where you can now listen to your eBooks directly. Immerse yourself in your favorite eBooks with our text-to-speech technology.
Transform your eBooks into interactive flipbooks effortlessly. Visit our eBook to Flipbook Page to view your eBook files in an engaging flipbook format.
Sep 1st,2023
We've upgraded to a more powerful server! This means your books will be ready for reading even faster than before. Enjoy quicker access to your content.
Your security is our priority. We've implemented enhancements to ensure your data and reading experience are more secure than ever.
PDF Text to Speech
Read PDF aloud with 700 realistic AI text to speech voices supporting 90 languages. Try our PDF audio reader free online now. Convert PDF to speech, online PDF read out loud.
Get Started
Read PDF Aloud
Listen to PDF documents using Narakeet, providing a great alternative way to consume content for multitaskers or those on the go. Use our “PDF Read” feature to read out loud PDF documents.

Read PDF Out Loud
In just a few minutes, you will get an audio version of your PDF. Download the audio, and play it in any audio player to listen to a pdf document.
Get started
Important PDF to speech converter limitations
At the moment, Narakeet can only read PDF documents out loud if they have text embedded into the document, and not just vectors for printing. PDF creation apps can turn the document into vector shapes and optimize it for printing, without keeping the embedded text. Documents like that require optical character recognition (OCR) for reading - effectively scanning images back into text. Although we plan to support reading pdf out loud using OCR in the future, this is not directly possible with Narakeet.
To read out loud PDF using Narakeet, make sure it still contains text, and not just vector shapes.
If you would like to be notified when it becomes possible to use text to speech for PDF documents containing only vector shapes (with OCR), get in touch with [email protected] .
PDF to Speech Free
You can use Narakeet as a PDF to speech app, and read a pdf out loud without even registering. Narakeet allows you convert 20 files into audio for free. After that, you can sign up for one of our paid plans and continue using our text to speech PDF reader.
Text to Speech PDF
Read the text from a PDF document aloud, and turn PDF documents into podcasts or audiobooks easily. Our PDF text to speech reader has many usages, from reading essays and papers while running, to making it possible for people with visual impairments or dyslexia to consume the content from PDF articles.
PDF to speech converter
Narakeet is an app that reads PDF out loud, as well as many other types of documents (Word, RTF, EPUB and many others). You can use our pdf to speech converter easily online. Our PDF text to speech reader is perfect for people who are slow readers, or have difficulty reading, as it provides an accessible way to consume information from written files. In addition, it can be a helpful tool for those who want to multitask and listen to their documents while doing other activities.
How to read out loud a PDF file?
Narakeet TTS text to speech makes it easy to read out loud PDF documents. You can upload a PDF document to our text to voice converter by clicking on the “Upload Document” button. Make sure to check the content of the PDF - especially to remove any page headers or footers, then click “Create Audio” to convert the PDF to MP3 or WAV file.
You can convert PDF to MP3 for small files, or create uncompressed WAV files for professional use such as broadcasting or audiobooks.
How to listen to a PDF document?
Listen to a PDF document easily by using Narakeet. Our life-like speech synthesizers can read out loud PDF in 90 using 700. Just upload your document to our text to audio tool , and experience a convenient, hands-free way to consume content. Our cutting-edge technology ensures that the generated speech maintains proper intonation, pacing, and clarity, providing you with an enjoyable and immersive listening experience.
With Narakeet, you can customize the narration style to suit your preferences or match the document’s context, giving you a personalized listening experience. You can use multiple voices when reading the document , adjust the reading speed to match your focus, and add pauses to make the content easier to consume. Mnd modify many other properties of the PDF audio reader, including voice pitch and volume .
Narakeet helps you create text to speech voiceovers , turn Powerpoint presentations and Markdown scripts into engaging videos. It is under active development, so things change frequently. Keep up to date: RSS , Slack , Twitter , YouTube , Facebook , Instagram , TikTok
9 Best PDF Voice Reader for Windows
Reading is fun and there’s no doubt about it. But there are times when you would rather like to hear it out. For instance, boring reports and other articles that you receive in your email in PDF format aren’t fun to read. They are boring and monotonous.
So, why not use a PDF voice reader app that makes your life a whole lot easier. They will translate the text into voice and read it out to you. So you can also multi-task and work on something else. A real time saver.
Native Option
1. microsoft edge.
The easiest way to convert PDF to voice is via the in-built Microsoft Edge browser. All you have to do is right-click on the PDF file and select “Microsoft Edge”. Once you have the PDF opened in Microsoft Edge, you will have a “Read Aloud” option on the top toolbar.

Additionally, Microsoft Edge also provides you the option to read aloud a select part of a PDF. To do that, just select a portion of the PDF, right-click and click on the “Read aloud selection” option. Moreover, you can also change the language of the reader, the voice of the reader, the reading speed, etc.

Third-party Apps
2. adobe acrobat reader.
Adobe Acrobat Reader is a popular PDF reader app. Most people use it and chances are that you already have Adobe Reader installed on your PC. If not, then you can download the latest version using the link below. Uncheck unnecessary add-ons accordingly. I don’t like McAfee much.

Once you are done, open any PDF file that you want to be read to you. By default, it should open within Adobe Acrobat Reader. If not, right-click and choose the “Open With” option.
Once the PDF is open, click on View and select the “ Read Out Loud” option at the bottom of the list. Now, the Read aloud mode is activated. Once the feature is activated, you can click on a paragraph and it’ll be read out to you. When Adobe is reading to you, ideally, you should see a progress bar somewhere in the middle.

While it gets the job done, the trouble is, I have to click on paragraphs once the machine is done reading it to me. To counter this problem, what you can do is go back to Settings. This time, you will see new options. You can have Adobe read the current page or the entire document.

On a side note, it’s better to memorize the shortcuts so you don’t have to mess around with the options anymore.
Download Adobe Reader (Free)
3. Natural Reader
Natural Reader takes things to the next level. Foremost, it works with PDF as well as Word, TXT, ePub files. Additionally, it can not only convert text to audio, but it can also create audio files from PDF files. This means you can transfer these audio files on your mobile and play it while you go for your morning jog. Moreover, you can control the speed and speaker settings.
Natural Reader also has an online version that you can use to quickly read blogs and news stories. There are apps available for both Android and iOS platforms.

Also Read: Best Free Open Source PDF Editors for Windows and Mac
My favorite feature is the pronunciation editor that lets you tweak the pronunciation of individual words. This makes Natural Reader sound more human. Natural Reader also offers a Commercial version of the product for a one-time payment of $129.50 and an Ultimate version for $199.50. The premium version offers a few additional features like an OCR feature that helps you to convert printed text to digital text, batch conversion, voice presets, etc.
Download Natural Reader (Freemium)
4. Read Aloud
Read Aloud lands somewhere in between Adobe Reader which is fairly basic and Natural Reader which is a powerful tool. This free software comes from the den of Microsoft.
Similar to Natural Reader, Read Aloud can read not only PDF files on your PC but it can also handle web pages, and a number of different formats like Word, Epub, TXT, DOCX, and more. If you are using Windows 10 and Edge browser, you can share files directly with the app.

You also get all the usual voice settings like volume control, speed rate, pitch rate, fonts, color scheme, etc. There is a pronunciation editor as well that you can use to change the way a word sounds. This gives you more control over the way Read Aloud looks, feels, and functions.
Download Read-Aloud (Free)
5. Power Text to Speech Reader
Now, Read Aloud doesn’t provide an option to convert PDF to audio files. This is where Power Text to Speech Reader steps in. It lets you convert PDF to audio files and save it for later listening. So now I can carry the audio file in a PD or upload it to Drive. Another striking feature is that also there is also support for email format (EML) and RTF along with HTML and Doc. This matters because if I receive a long email, I can use it to listen to the whole thing instead of just reading the attachment.
Power Text to Speech Reader also works with Windows 7/8 machines. Moreover, there is a handy plugin available that will allow you to make it work with IE. Edge, as you know, is only available on Windows 10 onwards. As far as voice support is concerned, there are more than a dozen voices to choose from which brings it on par with Natural Reader.
Download Power Text to Speech Reader (Free)

Also Read: Best Apps to Convert PDF to Word Document
6. Balabolka
Another free Text-To-Speech (TTS) program that will help you listen to your PDF files while you are working on other things. Balabolka can convert and save PDF files into audio formats like MP3, MP4, OGG, and WMA. Balabolka supports the maximum number of file formats I have seen in any TTS software list so far. It supports AZW, XLS, XLSX, CHM, DjVu, DOC, DOCX, EML, EPUB, FB2, HTML, etc.

There is also a portable version of the software that you can carry on a flash drive. It’s good for people like me who are constantly traveling and use different computers. There is support for different languages and voices (8 using SAPI 4 by Microsoft). There is a skin pack available to change the way UI looks, plus you can change fonts and colors. You can change pitch and rate too.
Download Balabolka (Free)
Chrome Extension
7. read aloud.
No, this was not developed by Microsoft as the software that I shared above. This is a 3rd party extension for Chrome that will allow you to listen to PDF files on the web without having to download them to your PC.

Install the extension like any other. When you click on the icon, you will see something like in the above screenshot. Choose your language and voice, desired speed and pitch as well as volume.
Now, when you click on the icon again while you are on a page, it will begin translating text to voice and you will see the following screen instead.

You can pause or stop whenever you want. Really simple.
This is not to say that it won’t work for local PDF files. To play the PDF file form your hard drive, simply drag and drop them to the chrome browser and click on the extension, and that’s it. The extension is light-weight and would help you when you receive PDF files in your Gmail or Outlook. This is a bare-bones tool with little to no additional features. It does offer a number of voices to choose from which will make the experience more human.
Install Read Aloud (Free)
Online Tool
8. ttsreader.
Like the previous one, TTSReader is not a Windows tool, instead, it’s an online website. The only reason it made it into the list is because of the ease of use and simplicity. All you have to do is copy-paste the PDF file into the textbox or just drag-and-drop your PDF file into it. It will convert text to voice in no time.
Visit TTSReader (Free)

Wrapping Up: PDF Voice Reader for Windows
Microsoft Edge and TTSReader is a great option if you don’t want to install any third-party app. For basic use cases, Adobe Reader is the ideal option. For more power users, I would recommend Balabolka which offers a lot for free. If you can afford a paid software and want good support, or maybe need a commercial version, Natural Reader will serve you well.
For more issues or queries, let me know in the comments below.
Also Read: 10 Best Text-to-Speech Apps for Android

Gaurav Bidasaria
Gaurav is an editor here at TechWiser but also contributes as a writer. He has more than 10 years of experience as a writer and has written how-to guides, comparisons, listicles, and in-depth explainers on Windows, Android, web, and cloud apps, and the Apple ecosystem. He loves tinkering with new gadgets and learning about new happenings in the tech world. He has previously worked on Guiding Tech, Make Tech Easier, and other prominent tech blogs and has over 1000+ articles that have been read over 50 million times.
You may also like
9 fixes for poor print quality on an..., is copy and paste not working on windows..., 6 fixes for windows computer restarts instead of..., you need to try these fixes when whatsapp..., 7 fixes for sd card not showing up..., how to enable snipping tool to show recent..., 6 fixes for bluetooth device connected but no..., 10 fixes for snipping tool not working on..., 7 fixes for itunes not opening on windows, 11 fixes for spotify not working on windows..., leave a comment cancel reply.
You must be logged in to post a comment.
TurboScribe
Unlimited audio & video transcription, convert audio and video to accurate text in seconds..
Sign up with email address
Upload audio & video files
Powered by whisper.
#1 in speech to text accuracy
Welcome To Unlimited
Unlimited transcriptions, 10 hour uploads, audio & video support, download transcripts.
"...the simple , high-powered transcription service I've been waiting for."
#1 in Speech to Text Accuracy
98+ languages, built-in translation, speaker recognition, private & secure.
"I am very impressed with the speed and accuracy. Great product and love using it."
TurboScribe Free
Turboscribe unlimited, $10 / month.

I rarely leave testimonials, but this app 100% deserved one in my books. TurboScribe has been such a game-changer for me. I used to pick and choose what to transcribe due to time it took to upload BUT mostly due to cost. I'm transcribing all sorts of business interactions—meetings, calls, videos, you name it.
Since switching to TurboScribe - I transcribe everything without thinking . Large numbers of small files or several HUGE files it handles it. It saved me money, enabled me to offer more services and a TON of time. My once a year review is done, but I feel Turboscribe deserves is hands down.

I formerly had students transcribe audios (8 hrs. work for 1 hr. audio). Your program is literally saving me thousands of hours . The accuracy is actually better than when I had human help doing it. Yours is an incredibly useful piece of software.
We're using to transcribe medical reports with rare terms. Very impressed by the speed and quality.
I used this for one of my university assessments today and it's absolutely killer . Hope your business grows because it's excellent . We even had three different accents in our group and your service straight up nailed it.

Yesterday I stumbled upon ingenious tool: https://turboscribe.ai
Subtitles for videos in over 130 languages in super quality. So all my future videos will have at least English subtitles. And also some older videos.
For example, my #ChatGPT course is getting an upgrade where I'm adding English subtitles to all videos.

I've been searching for what seems like centuries, for a piece of transcription software that delivers with accuracy! TurboScribe IS THAT SOFTWARE.
Not only does it transcribe with amazing accuracy , it also filters out a ton of the unnecessary noise associated with pauses in audio. On top of that, it performs to perfection with the built in ChatGPT prompts (this was another area I was previously struggling with).
I used to farm out transcripts to be completed manually since I was unable to find an AI solution that met my needs. Less than 1 month into my subscription and I've done away with farming out transcriptions completely; it's much more cost effective and efficient to do them in house with TurboScribe. Keep up the great work!
Easily the best AI transcription service I've used. Intuitive, quick, and super helpful features for anyone with a high volume workload.

What is TurboScribe?
TurboScribe is an AI transcription service that provides unlimited audio and video transcription. TurboScribe converts audio and video files to text in 98+ languages with extremely high accuracy.
How much does it cost?
TurboScribe Unlimited costs $10/month (billed yearly) or $20/month (billed monthly).
Is TurboScribe really unlimited?
Yes! TurboScribe really is unlimited. There are no caps on overall usage. The only "rule" is you can't share your login/account with others.
Can I upload large files?
Yes! TurboScribe is built to handle massive uploads. Each uploaded file can be up to 10 hours long and 5GB in size. Unlimited members can upload up to 50 files at a time.
Is TurboScribe secure?
Yes. Your transcripts, uploaded files, and account information are encrypted and only you can access them. You can delete them at any time. We use Stripe to securely process payments and we don't store your credit card number.
For more information about security and privacy, check out our Security & Privacy FAQ .
Which audio / video formats do you support?
TurboScribe supports the vast majority of common audio and video formats, including MP3, M4A, MP4, MOV, AAC, WAV, OGG, OPUS, MPEG, WMA, WMV, AVI, FLAC, AIFF, ALAC, 3GP, MKV, WEBM, VOB, RMVB, MTS, TS, QuickTime, and DivX.
Can I export my transcript?
Yes! Transcripts can be downloaded in the following formats: PDF, DOCX, captions & subtitles (SRT/VTT), CSV, and TXT.
You can also export multiple files at the same time with Bulk Actions .
Which languages do you support?
TurboScribe converts speech to text in over 98 languages using the highest accuracy AI transcription technology.
Languages like English are the most accurate, typically with human levels of performance and strong recognition of specialized, domain-specific vocabulary. Voice to text accuracy varies by language. You'll get the best results in the following languages: English, Spanish, French, German, Italian, Portuguese, Dutch, Chinese, Japanese, Russian, Arabic, Hindi, Swedish, Norwegian, Danish, Polish, Turkish, Hebrew, Greek, Czech, Vietnamese, and Korean. You are encouraged to use the free tier to experiment.
What about accents, background noise, and poor audio quality?
While clean and clear audio produces the best results, TurboScribe generally does well with accents, background noise, and lower audio quality.
If you're transcribing files with very poor audio quality, TurboScribe has a built-in audio restoration tool. It can be enabled via the "Restore Audio" option (under "More Settings") when uploading files. This uses AI to remove background noise and enhance human speech. Audio restoration takes an extra 2-3 minutes per hour of audio/video.
Is speaker recognition free?
Yes! Speaker recognition is free! It can be enabled via the "Speaker Recognition" checkbox (under "More Settings") when uploading files. It will take an extra minute or two (per hour of audio) to create a transcript labeled with speakers.
Can I translate transcripts and subtitles to other languages?
Yes! You can translate transcripts or subtitles to 134+ languages. Click the "Translate" button when viewing any transcript to open the Translation Tool. Then select your desired language and file format to download a translated transcript or subtitles.
You can also transcribe audio or video files (in any language) directly to English by selecting "Transcribe to English" under "More Settings" when uploading files.
How much can I transcribe?
We don't have caps on overall usage and our systems are designed to enable you to convert at least 720 hours of audio or video to text per month.
That means you could use TurboScribe to transcribe your entire life (24 hours per day x 30 days per month = 720 hours, or 43,200 minutes)! As one customer said, "I transcribe everything without thinking."
If you're transcribing very high volumes (> 720 hours per month, or top 0.1% of usage), we wrote up a helpful guide to help you get the most out of TurboScribe.
How do I cancel my subscription?
You can cancel your subscription at any time by navigating to "Account Settings" and clicking "Manage Subscription". You'll have full access to TurboScribe through the end of the current billing period.
Who is behind TurboScribe?
I have more questions..
Email me at [email protected] with any questions and I will get back to you ASAP. I want to hear from you!
" Scarily good . I transcribed hundreds of audio and video files in only a few minutes."
From The Blog

Getting Started with TurboScribe
A guide to transcribing your first file with TurboScribe, including features like language selection, speaker recognition, and downloading transcri...

Export Transcripts and Manage Files in Bulk
Export transcripts and manage multiple files at the same time. Learn more about TurboScribe's bulk management tools.

Security and Privacy: Frequently Asked Questions
Learn more about data privacy and security with TurboScribe.
"...wow, completely different game and great results. This is a solution I was waiting for."
Ready to start transcribing?
Get full access to...
2021 © Aspose
Convert PDF to speech online
Read a scanned pdf aloud with this free online application..
Powered by Aspose.com and Aspose.cloud
or drag it in this box *
Automatically adjust image contrast to make text clearer
Automatically straighten a skewed or rotated image
Upscale a low-resolution image to increase details
We try to recognize image type if it’s a document or just an image with text.
If your image is small or contains only lines of text without other content or noise.
Use document structure recognition model to extract structure of the document.
Use a text detection algorithm that works well with sparse text, tables, IDs, invoices, complex layouts, small images.
Combination of DSR and Text Detector algorithm if you had a document-like structure and want to detect all text.
Choose the optimal recognition mode
Do not read dim or blurry areas
Try to read all areas of an image
Downloading started...
Other OCR apps
We have already processed 2631030 files with a total size of 2529263 MB
Aspose.OCR PDF to speech
Aspose.OCR can go beyond extracting text from scanned PDFs and converting them into editable and searchable documents. With it, you can read aloud any PDF document in a fluid, natural-sounding human voice that can be played in the background or downloaded. Read aloud books, articles, contracts, and other documents that only contain scanned images without written text or a special accessibility layer.
This free online application allows you to explore our PDF-to-speech capabilities without installing any applications and writing a single line of code. It supports all modern browsers on desktops and smartphones. Just paste a text, sit back and listen to the information you need.
This free app provided by Aspose OCR
How to convert PDF to speech
Provide an pdf.
Upload a PDF file, or simply enter the document's web address.
Start recognition
Click "Recognize" button to start analyzing the document.
Wait a few seconds
Wait until the text is extracted from the PDF.
Read text aloud
Click "Play" button to read the PDF aloud or download an audio file.
Does this app support my language?
At the moment, the application can only read English. Support for other languages may be added in the future.
I don’t like the result. What can I do to improve it?
Try enabling automatic image corrections under Options: enhance contrast, straighten and upscale image.
Do I need an editable PDF?
The application can read PDF documents that consist only of scanned images without text or accessibility layers.
Can I use the app from mobile devices?
Yes, the application works in all popular web browsers on all devices and platforms, including smartphones. No additional software is required.
Can I save and share results?
You can play the synthesized speech, save and listen to it later, send it via your favorite messenger or email, and share it in the cloud storage.
Is this app free?
Yes, the application provides full capabilities of Aspose.OCR for free, for as long as you need.
The features you will like
Sit back and listen
Listen to the content of a scanned PDF while staying focused on the task at hand: while driving, cooking, working out, and more.
Export speech to audio files
Save the PDF content as an audio file to listen to it later, send it via your favorite messenger or email, and share it in the cloud storage.
Recognize documents from the Internet
There is no need to upload PDFs to your system. Just paste the web address of the document and read aloud the text.
Top recognition quality
Years of development resulted in a state-of-art optical character recognition engine with superior speed and accuracy. Aspose products are used by most Fortune 100 companies across 114 countries.
Flexible recognition settings
Built-in pre-processing filters can straighten rotated and skewed pages, automatically enhance contrast, or attempt to restore additional detail in low-resolution images. You can turn them on at any time to further improve recognition accuracy.
Zero system load
Recognition is carried out by high-performance Aspose Cloud. The application has minimum hardware or operating system requirements - you can use it even on entry-level systems and mobile devices without loss of accuracy and performance.
- Free Support
- Free Consulting
- Paid Consulting
© Aspose Pty Ltd 2001-2023. All Rights Reserved.
Something went wrong!
Enjoying this app.
Tell us about your experience
Audio to Text
Transcribe audio to text automatically, using AI. Over +120 languages supported

Accurate audio transcriptions with AI
Effortlessly convert spoken words into written text with unmatched accuracy using VEED’s AI audio-to-text technology. Get instant transcriptions for your podcasts, interviews, lectures, meetings, and all types of business communications. Say goodbye to manually transcribing your audio and embrace efficiency. Our advanced algorithms use machine learning to ensure contextually relevant transcripts, even for complex recordings.
With customizable options and quick turnaround, you have full control over the transcription process. Join countless professionals who rely on VEED to streamline their work, making every spoken word accessible and searchable. Our text converter also features a built-in video and audio editor to help you achieve a crisp, studio-quality sound for your recordings. Increase your productivity to new heights!
How to transcribe audio to text:

Upload or record
Upload your audio or video to VEED or record one using our online audio recorder .

Auto-transcribe and translate
Auto-transcribe your video from the Subtitles menu. You can also translate your transcript to over 120 languages. Select a language and translate the transcript instantly.

Review and export
Review and edit the transcription if necessary. Just click on a line of text and start typing. Download your transcript in VTT, SRT, or TXT format.
Learn more about our audio-to-text tool in this video:

Instant transcription downloads for better documentation
VEED uses cutting-edge technology to transcribe your audio to text at lightning-fast speed. Download your transcript in one click and keep track of your records better—without paying for expensive transcription services. Get a written copy of your recordings instantly and one proofread for 100% accuracy. Downloading transcriptions is available to premium subscribers. Check our pricing page for more info.

Transcribe videos to bump your content in search results
Our audio-to-text tool is part of a robust and powerful video editing software that also lets you edit and transcribe your video content. Transcribe your video and add captions to help your content rank higher in search engine results. Drive traffic to your website, increase engagement in your social media pages, and grow your channel. Animate your captions and captivate viewers in just a few clicks!
Convert audio to text and create globally accessible content
VEED can help your brand create content that caters to a diverse audience. With automatic transcriptions and instant translations , you can publish globally accessible and inclusive content. Translate your audio and video transcriptions to over 100 languages. Reach untapped markets and help your business grow with instant, reliable, and affordable transcriptions.

Frequently Asked Questions
VEED lets you automatically transcribe your audio to text at lightning-fast speed! Upload your audio file to VEED and click on the Subtitles tool on the left menu. Upload your audio file to VEED and auto-transcribe from the Subtitles menu. Download your transcript in VTT, TXT, or SRT format!
Yes, you can! Upload your video file to VEED and our software will transcribe the original audio that was recorded in your video with the help of AI.
Absolutely! When you’re done downloading the TXT, VTT, or SRT file, click on ‘Export’ to download the video with the subtitles on it. Your video will be exported as an MP4 file.
Depending on how the speech or recording is spaced out through the video, VEED will separate the transcriptions into different boxes. Just click on each box and start typing or editing the text.
Yes—but only the subtitles appearing on the video and not the TXT file. You can choose from a wide range of fonts and styles. Change its size, color, and opacity.
VEED features a 98.5% accuracy in automatic transcriptions and translations with the help of AI. Transcribe your audio to text and translate them to over 100 languages instantly without sacrificing quality.
Discover more:
- Assamese Speech to Text
- Audio Transcription
- Bengali Speech to Text
- Cantonese Speech to Text
- Chinese Speech to Text
- Dictation Transcription
- German Speech to Text
- Japanese Speech to Text
- Kannada Speech to Text
- Korean Speech to Text
- M4A to Text
- MP3 to Text
- Music Transcription
- Sinhala Speech to Text
- Speech to Text Arabic
- Speech to Text Bulgarian
- Speech to Text Danish
- Speech to Text Dutch
- Speech to Text Finnish
- Speech to Text in Marathi
- Speech to Text Italian
- Speech to Text Portuguese
- Speech to Text Russian
- Speech to Text Serbian
- Speech to Text Slovak
- Speech to Text Swedish
- Speech to Text Thai
- Speech to Text Turkish
- Speech to Text Vietnamese
- Tamil Audio to Text
- Telugu Audio to Text Converter
- Transcribe Recordings to Text
- Verbatim Transcription
- Voice Memo Transcription
- Voice Message to Text
- WAV to Text
What they say about VEED
Veed is a great piece of browser software with the best team I've ever seen. Veed allows for subtitling, editing, effect/text encoding, and many more advanced features that other editors just can't compete with. The free version is wonderful, but the Pro version is beyond perfect. Keep in mind that this a browser editor we're talking about and the level of quality that Veed allows is stunning and a complete game changer at worst.
I love using VEED as the speech to subtitles transcription is the most accurate I've seen on the market. It has enabled me to edit my videos in just a few minutes and bring my video content to the next level
Laura Haleydt - Brand Marketing Manager, Carlsberg Importers
The Best & Most Easy to Use Simple Video Editing Software! I had tried tons of other online editors on the market and been disappointed. With VEED I haven't experienced any issues with the videos I create on there. It has everything I need in one place such as the progress bar for my 1-minute clips, auto transcriptions for all my video content, and custom fonts for consistency in my visual branding.
Diana B - Social Media Strategist, Self Employed
More from VEED

How to Get the Transcript of a YouTube Video [Fast & Easy]
The easiest way to get the transcript of a YouTube video without jumping through a million hoops. Here's how.
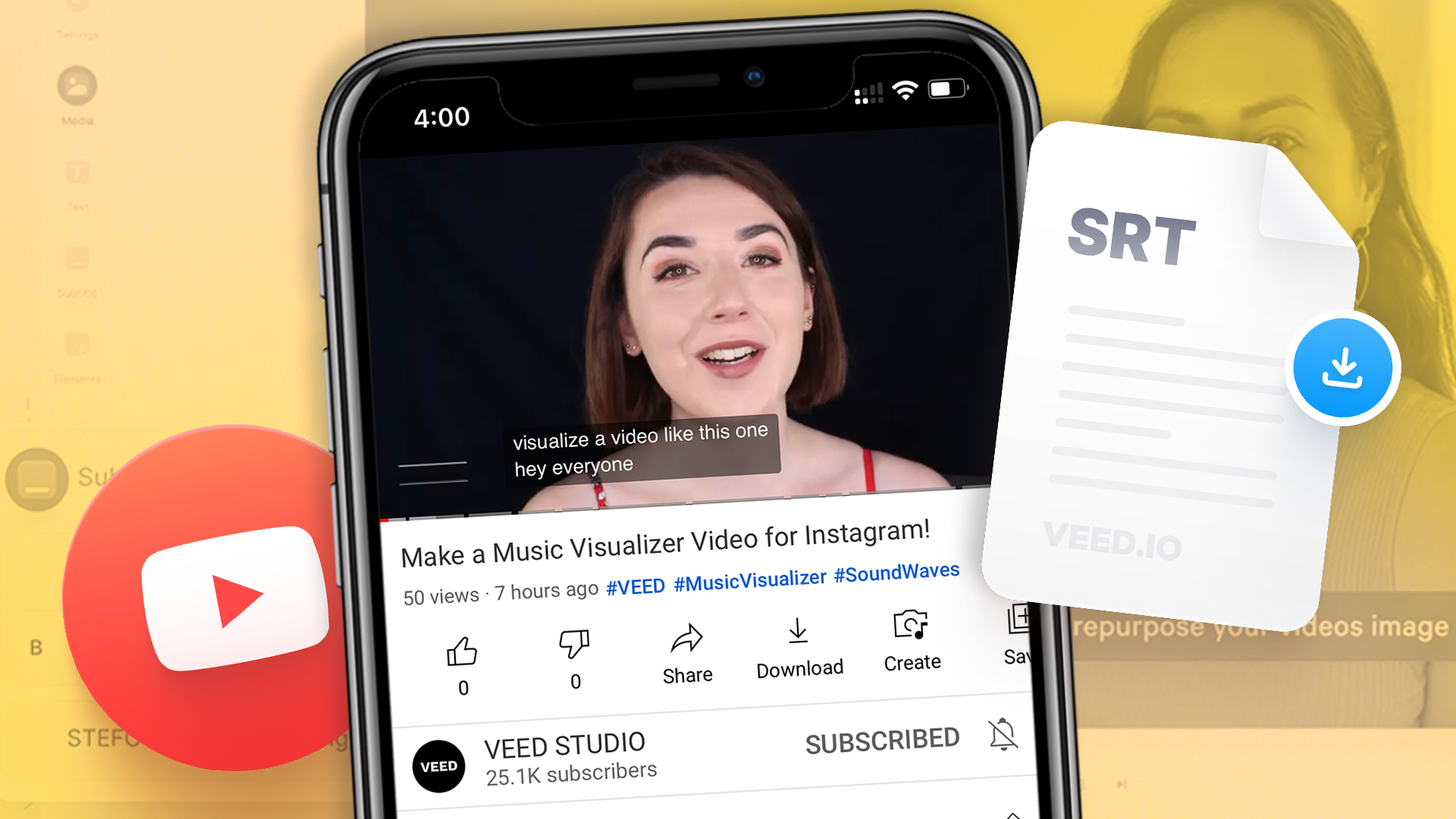
How to Download SRT Subtitle Files Online (Quick and Easy)
Want to bump up your engagement, improve video SEO, and make your content more inclusive? Here's how to download and upload SRT files for your next video!

11 Easy Ways to Add Music to Video [Step-By-Step Guide]
Not sure where to find music for video whether free or paid? Want to learn how to find it, pick the right song, and then add it to your video content? Then dig in!
Convert audio to text, translate to multiple languages, and more!
VEED is a comprehensive and incredibly easy-to-use video editing software that allows you to do so much more than just transcribe audio to text. Apart from transcribing an audio file, you can transcribe the original recording of a video. Add subtitles to your videos to make them more accessible for everyone. It also has all the video editing tools you need. All tools are accessible online so you don’t need to install any software. Try VEED today and start creating professional-quality, globally accessible content!

Speech to Text - Voice Typing & Transcription
Take notes with your voice for free, or automatically transcribe audio & video recordings. secure, accurate & blazing fast..
~ Proudly serving millions of users since 2015 ~
I need to >
Dictate Notes
Start taking notes, on our online voice-enabled notepad right away, for free.
Transcribe Recordings
Automatically transcribe (and optionally translate) audios & videos - upload files from your device or link to an online resource (Drive, YouTube, TikTok or other). Export to text, docx, video subtitles and more.
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export options, Speechnotes provides an efficient and user-friendly dictation and transcription experience. Proudly serving millions of users since 2015, Speechnotes is the go-to tool for anyone who needs fast, accurate & private transcription. Our Portfolio of Complementary Speech-To-Text Tools Includes:
Voice typing - Chrome extension
Dictate instead of typing on any form & text-box across the web. Including on Gmail, and more.
Transcription API & webhooks
Speechnotes' API enables you to send us files via standard POST requests, and get the transcription results sent directly to your server.
Zapier integration
Combine the power of automatic transcriptions with Zapier's automatic processes. Serverless & codeless automation! Connect with your CRM, phone calls, Docs, email & more.
Android Speechnotes app
Speechnotes' notepad for Android, for notes taking on your mobile, battle tested with more than 5Million downloads. Rated 4.3+ ⭐
iOS TextHear app
TextHear for iOS, works great on iPhones, iPads & Macs. Designed specifically to help people with hearing impairment participate in conversations. Please note, this is a sister app - so it has its own pricing plan.
Audio & video converting tools
Tools developed for fast - batch conversions of audio files from one type to another and extracting audio only from videos for minimizing uploads.
Our Sister Apps for Text-To-Speech & Live Captioning
Complementary to Speechnotes
Reads out loud texts, files & web pages
Reads out loud texts, PDFs, e-books & websites for free
Speechlogger
Live Captioning & Translation
Live captions & translations for online meetings, webinars, and conferences.
Need Human Transcription? We Can Offer a 10% Discount Coupon
We do not provide human transcription services ourselves, but, we partnered with a UK company that does. Learn more on human transcription and the 10% discount .
Dictation Notepad
Start taking notes with your voice for free
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing.
Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts. We strive to provide the best online dictation tool by engaging cutting-edge speech-recognition technology for the most accurate results technology can achieve today, together with incorporating built-in tools (automatic or manual) to increase users' efficiency, productivity and comfort. Works entirely online in your Chrome browser. No download, no install and even no registration needed, so you can start working right away.
Speechnotes is especially designed to provide you a distraction-free environment. Every note, starts with a new clear white paper, so to stimulate your mind with a clean fresh start. All other elements but the text itself are out of sight by fading out, so you can concentrate on the most important part - your own creativity. In addition to that, speaking instead of typing, enables you to think and speak it out fluently, uninterrupted, which again encourages creative, clear thinking. Fonts and colors all over the app were designed to be sharp and have excellent legibility characteristics.
Example use cases
- Voice typing
- Writing notes, thoughts
- Medical forms - dictate
- Transcribers (listen and dictate)
Transcription Service
Start transcribing
Fast turnaround - results within minutes. Includes timestamps, auto punctuation and subtitles at unbeatable price. Protects your privacy: no human in the loop, and (unlike many other vendors) we do NOT keep your audio. Pay per use, no recurring payments. Upload your files or transcribe directly from Google Drive, YouTube or any other online source. Simple. No download or install. Just send us the file and get the results in minutes.
- Transcribe interviews
- Captions for Youtubes & movies
- Auto-transcribe phone calls or voice messages
- Students - transcribe lectures
- Podcasters - enlarge your audience by turning your podcasts into textual content
- Text-index entire audio archives
Key Advantages
Speechnotes is powered by the leading most accurate speech recognition AI engines by Google & Microsoft. We always check - and make sure we still use the best. Accuracy in English is very good and can easily reach 95% accuracy for good quality dictation or recording.
Lightweight & fast
Both Speechnotes dictation & transcription are lightweight-online no install, work out of the box anywhere you are. Dictation works in real time. Transcription will get you results in a matter of minutes.
Super Private & Secure!
Super private - no human handles, sees or listens to your recordings! In addition, we take great measures to protect your privacy. For example, for transcribing your recordings - we pay Google's speech to text engines extra - just so they do not keep your audio for their own research purposes.
Health advantages
Typing may result in different types of Computer Related Repetitive Strain Injuries (RSI). Voice typing is one of the main recommended ways to minimize these risks, as it enables you to sit back comfortably, freeing your arms, hands, shoulders and back altogether.
Saves you time
Need to transcribe a recording? If it's an hour long, transcribing it yourself will take you about 6! hours of work. If you send it to a transcriber - you will get it back in days! Upload it to Speechnotes - it will take you less than a minute, and you will get the results in about 20 minutes to your email.
Saves you money
Speechnotes dictation notepad is completely free - with ads - or a small fee to get it ad-free. Speechnotes transcription is only $0.1/minute, which is X10 times cheaper than a human transcriber! We offer the best deal on the market - whether it's the free dictation notepad ot the pay-as-you-go transcription service.
Dictation - Free
- Online dictation notepad
- Voice typing Chrome extension
Dictation - Premium
- Premium online dictation notepad
- Premium voice typing Chrome extension
- Support from the development team
Transcription
$0.1 /minute.
- Pay as you go - no subscription
- Audio & video recordings
- Speaker diarization in English
- Generate captions .srt files
- REST API, webhooks & Zapier integration
Compare plans
Privacy policy.
We at Speechnotes, Speechlogger, TextHear, Speechkeys value your privacy, and that's why we do not store anything you say or type or in fact any other data about you - unless it is solely needed for the purpose of your operation. We don't share it with 3rd parties, other than Google / Microsoft for the speech-to-text engine.
Privacy - how are the recordings and results handled?
- transcription service.
Our transcription service is probably the most private and secure transcription service available.
- HIPAA compliant.
- No human in the loop. No passing your recording between PCs, emails, employees, etc.
- Secure encrypted communications (https) with and between our servers.
- Recordings are automatically deleted from our servers as soon as the transcription is done.
- Our contract with Google / Microsoft (our speech engines providers) prohibits them from keeping any audio or results.
- Transcription results are securely kept on our secure database. Only you have access to them - only if you sign in (or provide your secret credentials through the API)
- You may choose to delete the transcription results - once you do - no copy remains on our servers.
- Dictation notepad & extension
For dictation, the recording & recognition - is delegated to and done by the browser (Chrome / Edge) or operating system (Android). So, we never even have access to the recorded audio, and Edge's / Chrome's / Android's (depending the one you use) privacy policy apply here.
The results of the dictation are saved locally on your machine - via the browser's / app's local storage. It never gets to our servers. So, as long as your device is private - your notes are private.
Payments method privacy
The whole payments process is delegated to PayPal / Stripe / Google Pay / Play Store / App Store and secured by these providers. We never receive any of your credit card information.
More generic notes regarding our site, cookies, analytics, ads, etc.
- We may use Google Analytics on our site - which is a generic tool to track usage statistics.
- We use cookies - which means we save data on your browser to send to our servers when needed. This is used for instance to sign you in, and then keep you signed in.
- For the dictation tool - we use your browser's local storage to store your notes, so you can access them later.
- Non premium dictation tool serves ads by Google. Users may opt out of personalized advertising by visiting Ads Settings . Alternatively, users can opt out of a third-party vendor's use of cookies for personalized advertising by visiting https://youradchoices.com/
- In case you would like to upload files to Google Drive directly from Speechnotes - we'll ask for your permission to do so. We will use that permission for that purpose only - syncing your speech-notes to your Google Drive, per your request.
Text to Speech PDF: Revolutionizing How We Interact with Documents
Table of contents.
In our fast-paced digital world, the ability to convert written text into spoken words is a significant leap in technology. “Text to speech PDF” represents this transformative journey, offering a bridge between traditional reading and auditory processing. This article delves into the realm of text to speech (TTS) technology, specifically focusing on its application in reading aloud PDF files, enhancing accessibility, and streamlining learning.
Understanding Text to Speech (TTS)
Text to speech technology converts written text into spoken words. This tool has evolved significantly, offering natural-sounding voices that can read out loud documents, web pages, and PDF files. With TTS , users can listen to the content instead of reading it, aiding in multitasking and accessibility for individuals with disabilities.
Key Players and Platforms
- NaturalReader and Speechify : Popular TTS tools that offer high-quality voiceovers.
- Platforms : TTS technology is available across various platforms including Windows, Android, iOS, and Mac.
PDF Files and TTS Integration
PDF documents are a standard format for digital documentation. TTS integration allows these documents to be read aloud, transforming them into audio files that can be consumed on the go. This feature is particularly useful for users with dyslexia or visual impairments.
Compatibility with Popular PDF Readers
Adobe Acrobat and Adobe Reader : Leading PDF readers that support TTS functionality.
AI Voice and Customization : Modern PDF readers offer AI-generated natural-sounding voices with customization options for reading speed and voice types.
Expanding TTS Use Cases
- Educational Tools : For students, especially those with dyslexia, TTS helps in reading and comprehending complex texts.
- Workplace Efficiency : Professionals can convert lengthy docs and reports into audio for multitasking.
- Accessibility for Impairments : Individuals with visual impairments can access information in PDFs easily.
- Multilingual Support : TTS helps non-native English speakers understand content in PDFs by reading it out in their preferred language.
Platforms and Devices
- Mobile Devices : TTS apps are available on iPhone, Android, iPad, and other tablets.
- Desktop : Windows and Mac computers offer built-in TTS capabilities.
- Browsers : Extensions like Google Chrome’s TTS add-ons enhance online PDF reading.
Innovative Features in TTS for PDFs
- AI Text to Speech : Leveraging AI for more natural and context-aware voice modulation.
- Customization : Adjusting speech voices, speed, and language settings.
- Accessibility Features : Making content accessible for people with various disabilities.
Integrating TTS in Daily Life
- Epub and Audiobooks : Convert epub files and other formats into audiobooks.
- Podcasts and Voiceovers : Creating voiceovers for digital content.
- Education and Learning : Assisting in reading and comprehension for students.
Step-by-Step Guides and Tutorials
- Adobe Acrobat and Microsoft Edge : Guides on activating TTS features in popular PDF readers and browsers.
- Mobile Apps : Tutorials for using TTS apps available on the App Store and Google Play.
The Future of TTS in PDF Reading
Looking ahead, TTS technology will continue to evolve, offering more natural-sounding voices, enhanced customization, and greater accessibility options. As AI advances, the integration of TTS in our daily digital interactions, especially in reading PDF documents, is set to become more seamless and intuitive.
Try Speechify PDF Reader
Cost : Free to try
Speechify’s PDF reader brings the transformative power of text-to-speech technology directly to the realm of PDF documents. This tool allows users to listen to their PDFs rather than read them, ensuring that dense, text-heavy documents are more accessible and digestible. Among its top features are:
- High-Quality Voices : Converting PDF text into clear and lifelike audio, Speechify offers a range of natural-sounding voices for a genuine listening experience.
- Text Highlighting : As Speechify reads out the content, it highlights the corresponding text in the PDF, enabling users to follow along visually and reinforcing comprehension.
- Speed Control : Catering to individual preferences, listeners can adjust the reading speed, whether they need a quick overview or a deep understanding.
- Navigation Tools : Speechify’s PDF reader allows users to effortlessly navigate through pages, jump to specific sections, and bookmark crucial parts for easy reference later on.
- Offline Access : Users can download and save PDFs within the app, facilitating offline listening and ensuring uninterrupted access to their documents, regardless of internet connectivity.
- AI Cha t: Interact with Speechify’s AI bot in your PDF reader to ask important questions about your PDF.
Overall, the Speechify PDF reader offers an innovative solution for those looking to transform the way they engage with PDF content.
Frequently Asked Questions
What is the free text to speech app for pdf.
There are several free text to speech (TTS) apps available for reading PDF files. For instance, NaturalReader offers a free version that can read PDF documents aloud on various platforms including Windows, Mac, iOS, and Android. Another option is Speechify, which also has a free text to speech reader available on the App Store and Google Play. These apps typically offer features like natural-sounding voices and the ability to adjust reading speed.
What are the best text to speech PDFs?
The best text to speech PDF tools are those that offer high-quality voiceovers, customization options, and compatibility with various file formats. NaturalReader and Speechify are popular choices for their natural-sounding voices and ease of use. Adobe Reader and Microsoft Edge also provide built-in read aloud features for PDF files. For users who prioritize multitasking, these tools offer the ability to convert pdf text into audio files, enabling users to listen to documents like audiobooks.
How do I read a PDF using text to speech?
To read a PDF using text to speech:
- Choose a TTS Application : Install a text to speech app like NaturalReader or Speechify on your device.
- Open Your PDF : Use the app to open the PDF file you wish to read.
- Activate TTS Features : In the app, find the ‘read aloud’ or ‘voice reader’ option to start the TTS.
- Customization : Adjust settings like voice type, reading speed, and language as needed.
- Listen : The app will read the PDF text out loud, allowing you to listen to the content.
Why can’t I hear the text to speech on PDFs?
If you can’t hear text to speech on PDFs, consider these factors:
- Volume Settings : Ensure your device’s volume is turned up and not muted.
- TTS App Settings : Check if the TTS app’s settings are correctly configured, including the voice selection and audio output.
- File Compatibility : Verify if the PDF file format is compatible with your TTS app.
- App Updates : Ensure your text to speech app is updated to the latest version.
- Device Compatibility : Some apps may have specific requirements for iOS, Android, Windows, or Mac, so make sure your device is compatible.
- Audio Output Device : Check if your headphones or speakers are properly connected and functioning.
- Previous Text to Speech Online Free Download: Revolutionizing Communication
- Next Text to Speech Online Free Unlimited: Revolutionizing Digital Communication

Cliff Weitzman
Cliff Weitzman is a dyslexia advocate and the CEO and founder of Speechify, the #1 text-to-speech app in the world, totaling over 100,000 5-star reviews and ranking first place in the App Store for the News & Magazines category. In 2017, Weitzman was named to the Forbes 30 under 30 list for his work making the internet more accessible to people with learning disabilities. Cliff Weitzman has been featured in EdSurge, Inc., PC Mag, Entrepreneur, Mashable, among other leading outlets.
Recent Blogs

Is Text to Speech HSA Eligible?

Can You Use an HSA for Speech Therapy?

Surprising HSA-Eligible Items

Ultimate guide to ElevenLabs
Voice changer for Discord

How to download YouTube audio

Speechify 3.0 is the Best Text to Speech App Yet.

Voice API: Everything You Need to Know

Best text to speech generator apps
The best AI tools other than ChatGPT

Top voice over marketplaces reviewed
Speechify Studio vs. Descript

Everything to Know About Google Cloud Text to Speech API
Source of Joe Biden deepfake revealed after election interference
How to listen to scientific papers
How to add music to CapCut
What is CapCut?
VEED vs. InVideo

Speechify Studio vs. Kapwing
Voices.com vs. Voice123

Voices.com vs. Fiverr Voice Over
Fiverr voice overs vs. Speechify Voice Over Studio
Voices.com vs. Speechify Voice Over Studio
Voice123 vs. Speechify Voice Over Studio
Voice123 vs. Fiverr voice overs

HeyGen vs. Synthesia
Hour One vs. Synthesia
HeyGen vs. Hour One
Speechify makes Google’s Favorite Chrome Extensions of 2023 list

How to Add a Voice Over to Vimeo Video: A Comprehensive Guide
Speechify text to speech helps you save time
Popular blogs, the best celebrity voice generators in 2024.
YouTube Text to Speech: Elevating Your Video Content with Speechify
The 7 best alternatives to Synthesia.io
Everything you need to know about text to speech on TikTok
The 10 best text-to-speech apps for android.
How to convert a PDF to speech
The top girl voice changers.
How to use Siri text to speech
Obama text to speech, robot voice generators: the futuristic frontier of audio creation, pdf read aloud: free & paid options, alternatives to fakeyou text to speech.
All About Deepfake Voices
TikTok voice generator
Text to speech goanimate, the best celebrity text to speech voice generators, pdf audio reader, how to get text to speech indian voices, elevating your anime experience with anime voice generators.
Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.
- Export Audio
Free Text To Speech Reader
Instantly reads out loud text & pdf with natural sounding voices online - works out of the box. drop the text and click play..
Drag text or pdf files to the text-box, or directly type/paste in text. Select language and click Play. Remembers text and caret position between sessions. Works on Chrome and Safari, desktop and mobile. Enjoy listening :)
Best Text to Speech Online
- Online speech synthesizer, single click to read out loud any text
- Listen instead of reading
- Multiple languages and voices
- Reads PDF files too
TTSReader-X
- Chrome extension
- Listen to ANY website without leaving the page
- Adds a 'play' functionality to Chrome
- Clean page for readability and / or print
Try it Now for FREE
TTSReader / Android
- Podcast any written content
- Save data - works offline too
Get it on the Play store
Fun, Online, Free. Listen to great content
Drag, drop & play (or directly copy text & play). That’s it. No downloads. No logins. No passwords. No fuss. Simply fun to use and listen to great content. Great for listening in the background. Great for proof-reading. Great for kids and more. Learn more, including a YouTube we made, here .
Multilingual, Natural Voices
We facilitate high-quality natural-sounding voices from different sources. There are male & female voices, in different accents and different languages. Choose the voice you like, insert text, click play to generate the synthesized speech and enjoy listening.
Exit, Come Back & Play from Where You Stopped
TTSReader remembers the article and last position when paused, even if you close the browser. This way, you can come back to listening right where you previously left. Works on Chrome & Safari on mobile too. Ideal for listening to articles.
Better than Podcasts
In many aspects, synthesized speech has advantages over recorded podcasts. Here are some: First of all - you have unlimited - free - content. That includes high-quality articles and books, that are not available on podcasts. Second - it’s free. Third - it uses almost no data - so it’s available offline too, and you save money. If you like listening on the go, as while driving or walking - get our free Android Text Reader App .
Read PDF Files, Texts & Websites
TTSReader extracts the text from pdf files, and reads it out loud. Also useful for simply copying text from pdf to anywhere. In addition, it highlights the text currently being read - so you can follow with your eyes. If you specifically want to listen to websites - such as blogs, news, wiki - you should get our free extension for Chrome
Commercial-Ready
Use our apps for commercial purposes. Generated audio can be used for YouTubes, games, telephony and more. To export the generated speech into high-quality audio files, you can either use our Android app , or record them, as explained here . Read more for ttsreader’s commercial terms. Read more
We love to hear your feedback. Here’s what users said about us:
The new male voice is great. It is quite melodic and natural, much more so then other sites I have tried to use. This is a GREAT tool, well done thanks!
ttsreader.com
This product works amazingly well. I use it to edit my books, pasting in a chapter, having it read back to me while I edit the original. Cuts down my book edit time by over 50% !
Multiple voices from different nationalities. Easy to use interface. Paste text and it will speak. Can create mp3 files.
ttsreader for Android
Great app. Can handle long texts, something other apps can’t. Highly recommended!
What a great App! exactly what i needed, a reader to provide me content efficiently.
ttsreader-x for Chrome
Recent Posts
Read about our different products, get the news & tips from our developers.
Amazon's Kindle Fire - Can Now Read Websites
on June 6, 2017
Amazon’s Kindle Fire - Can Now Read Websites As TTSReader is Now Available on Amazon’s App Store Get it now for FREE Exciting news! Kindle lovers now got upgraded with some new great features. TTSReader on the Kindle can read out loud any text, pdf and website. It uses the latest algorithms to extract only the relevant text out of the usually-cluttered websites. Great for listening to Wiki articles for instance, blogs and more.
Continue reading
Android Gets the Best In Class Websites Reader
Android Gets Best In Class Websites Reader - With Latest Update to TTSReader Pro Start listening now for FREE Exciting news, as Android’s TTSReader Pro app, has been updated to use TTSReaderX’s algorithms to extract only the relevant text out of websites. This is super important for a text-to-speech website reader, as otherwise the reader would start reading out loud all the ads, menus, sharing buttons and more clutter.
Commercial Licensing & Terms
on May 10, 2017
When is a Commercial License Necessary Using ttsreader.com within your institution If you are a company, or organization, using ttsreader.com, please use our paypal donate link. If you are a personal user, or an educational institute - ttsreader.com is free, no need to even donate - you are welcome, of course :). Using the generated speech for commercial purposes Recording and using the audio generated by TTSReader in a commercial application (ie publishing)
Export Speech to Audio Files
How to Record Audio Played on PC (Speakers) for Free Need to record audio from TTSReader, YouTube or other? Here’s how in a few simple steps (includes screenshots). No need to record the speakers - you can record the audio from within the pc itself. It will be of higher audio quality - as it’s the original digital signal, clear and without ambient noise. Also, no need to purchase a software for that.
See All Posts
Want to see more?
Visit our company's page, to see more of our speech to text (dictation) and text to speech apps for desktops and mobile. For news and tips from our developers visit our blog.
More from WellSource
PRIVACY: We don't store any of your text, in fact, it doesn't even leave your computer. We do use cookies and your local storage to enhance your experience. Copyright (c) 2015 - 2017, WellSource Ltd. ; all rights reserved. Template by Bootstrapious . Ported to Hugo by DevCows
English Deutsch español Français italiano 日本の 中國
Bring Text-To-Speech into ANY website. Add our new TTSReader Extension for free.
- Files & More
- More: MP3 TO PDF MP3 TO PDF M4A TO WORD M4A TO PDF M4A TO DOC M4A TO DOCX VOICE TO TEXT SPEECH TO TEXT SPEECH TO TXT VOICE TO TXT More Converters
SPEECH to PDF
- Step 1: Submit the SPEECH audio you want to convert to PDF to the upload box at the left.
- Step 2: Wait a moment until the conversion from SPEECH to PDF is complete. The process starts automatically.
- Step 3: Click on the download button and get your converted file for free!
Supported intput formats: WAV, MP3, FLAC, AAC, OGG and M4A. For other formats use the search in the page header.


- User Manual
- Global Team
ReaderIt - Your Personal Text-to-Speech Companion

United Kingdom

United States

Listen on the Go: The Power of Text-to-Speech Advantages
We are here for you.

Experience the Magic of Text-to-Speech on iOS, Android, Chrome and Mac: Share the Fun with Friends, Anytime, Anywhere
Chrome extension.
Discover the Joy of Listening

Find Your Perfect Match for the Ultimate Audio Experience
Immerse yourself in a world of diverse voices

Get the Most out of Your Time
Maximize Efficiency and Productivity with Every Moment

The Power of Social Productivity
Maximize Your Time, Connect, and Thrive Together!
Enjoy your new reading superpowers
Listen at any speed
Listen on desktop or mobile devices.
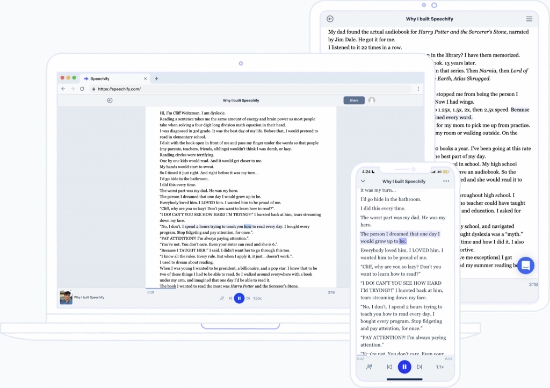
Natural-sounding human voices
Listen to any page.

Frequently asked questions
ReaderIt is a powerful text-to-speech AI product that converts written text into high-quality, natural-sounding speech
ReaderIt is available as a Chrome extension, iOS app, Android app, and Web-to-Voice feature accessible through the website.
You can easily share the audio by generating a link or using social sharing options provided within the app.
Yes, premium users enjoy access to a wider range of voices, allowing for more personalized and engaging audio experiences.
Yes, ReaderIt supports PDF to voice conversion, making it easy to listen to the content of PDF documents.
In addition to the core text-to-speech functionality, ReaderIt offers features like text highlighting, speed control, language selection, and the ability to save and organize favorite articles or documents.
ReaderIt can integrate seamlessly with various applications and websites through its API, allowing for a customizable and versatile user experience.
ReaderIt utilizes advanced AI technology to deliver high-quality and natural-sounding speech. While it strives for accuracy, minor variations may occur depending on the text and chosen voice.
Yes, ReaderIt supports multiple languages, providing users with the flexibility to listen to content in their preferred language.
For any support or feedback regarding ReaderIt, you can reach out to our dedicated support team through the app or website. We value your input and are committed to improving the user experience.
ReaderIt ensures excellent sound quality with its advanced speech synthesis technology. The generated speech is clear, natural-sounding, and highly intelligible.
- Accessibility: ReaderIt makes written content accessible to individuals with visual impairments or reading difficulties.
- Multitasking: Listen to text while performing other tasks, enhancing productivity and efficiency.
- Language Learning: Improve pronunciation and language skills by hearing accurate spoken text.
- Content Sharing: Easily share audio versions of articles or documents through links or social media.
- Premium Features: Unlock additional voices and enjoy a more personalized experience.
- PDF Conversion: Convert PDF files into audio for convenient listening.
- Versatile Platforms: Use ReaderIt on Chrome, iOS, Android, or through the web, ensuring access across devices.
Must Read Content
Exploring the enchanting world of purple garden: a haven for spiritual guidance and personal growth.
In the midst of the fast-paced digital era, finding moments of serenity and self-discovery can be elusive. However, there exists a virtual sanctuary beckoning individuals

Unlocking a World of Voices: Multilingual and Premium Features with Readerit
Readerit doesn’t just offer a one-size-fits-all solution; it’s a platform that adapts to your individual needs. With a wide selection of voices spanning various languages,
Seamless Onboarding: Your Guide to Getting Started with Readerit Registration
Embarking on your journey with Readerit opens the door to a world of effortless text-to-speech conversion. To begin this transformative experience, you’ll need to go
Featured Blogs

Unlock the Power of Text-to-Speech with Readerit: Your Ultimate TTS Online Software
Welcome to Readerit, the leading text-to-speech (TTS) online software that empowers you to transform written content into captivating audio. Whether you’re looking to listen to

Empower Your Experience with Speech Synthesis: Discover the Advantages of Our TTS Online Software
In a world where information is abundant but time is scarce, imagine having the ability to convert text into lifelike speech effortlessly. Introducing our Speech

Transform Text into Audio with ReaderIt: The Ultimate TTS Online Tool
In a fast-paced digital era, finding efficient ways to consume written content is crucial. Imagine being able to convert text into high-quality audio with just

Explore the Evolution of Online Voice Generators: Unleash the Power of Cutting-Edge Technology
Online voice generators have come a long way, revolutionizing the way we interact with digital content. From the past to the present, these remarkable tools

Enhance Your Listening Experience with Readerit: The Leading Online Audio Reader
In today’s fast-paced world, where time is limited and multitasking is the norm, audio content has gained tremendous popularity. Whether you’re a busy professional, a

Unlock the Power of Reading Aloud Online with Readerit: Your Ultimate Companion
Reading aloud is a powerful practice that enhances comprehension, improves pronunciation, and adds a touch of engagement to written content. In today’s digital age, where

Sign up to Newsletter
Follow us on:.
- Privacy Policy
- Terms Of Use
Copyright © 2023 TECHIDO. All Rights Reserved
Transcribe speech to text ゜ 4+
Audio transcription, sarun wongpatcharapakorn.
- 3.8 • 4 Ratings
- Offers In-App Purchases
Screenshots
Description.
Offline Transcription provides a fast and privacy-safe way to transcribe audio, video, and podcast files. If you are looking for an app to transcribe - Minutes of meetings. - Classroom audio recording. - Create subtitles for YouTube videos. - Transcribe podcasts into text. - etc. ◼ Features: - No data leaves your Mac. Transcription happens locally without the internet. - Easy to use interface. Drag and drop + one click are all you need to do. - Supported formats: - Audio: mp3, wav, m4a, ogg, aac, and caf - Video: mov and mp4 - Exported formats: text, srt, vtt, and csv. - Transcribes multiple files at once. ◼ Supported 100 different languages The app can transcribe audio in 100 different languages: Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Azerbaijani, Bangla, Bashkir, Basque, Belarusian, Bosnian, Breton, Bulgarian, Burmese, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Lao, Latin, Latvian, Lingala, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Māori, Marathi, Mongolian, Nepali, Norwegian, Norwegian Nynorsk, Occitan, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Sanskrit, Serbian, Shona, Sindhi, Sinhala, Slovak, Slovenian, Somali, Spanish, Sundanese, Swahili, Swedish, Tagalog, Tajik, Tamil, Tatar, Telugu, Thai, Tibetan, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, Yiddish, Yoruba Terms of Use: https://offlinetranscription.com/terms/ Privacy Policy: https://offlinetranscription.com/privacy/
Version 1.0.5
Minor bug fixes and improvements.
Ratings and Reviews
Anything remotely long doesn't work.
I had it do something two hours long and it just repeated the same phrase over and over again, like it had just stopped working
App Privacy
The developer, Sarun Wongpatcharapakorn , indicated that the app’s privacy practices may include handling of data as described below. For more information, see the developer’s privacy policy .
Data Not Linked to You
The following data may be collected but it is not linked to your identity:
Privacy practices may vary, for example, based on the features you use or your age. Learn More
Information
- Flexible Plan $2.99
- Lifetime $12.99
- All-Year Plan $7.99
- Developer Website
- App Support
- Privacy Policy
More By This Developer
Thai Showtimes
Last Time Tracker
PanTalk Lite for Pantip
Grammar Check & Corrector
You Might Also Like
SumCast: Podcasts To Text
Transcribe: Voice to Text+
Whisper AI transcriber - V2T
Transcribe Voice to text :Waya
VoicePen: AI Speech to Text
HiText - Transcript Tool
- Share full article
Advertisement
Supported by
Africa’s Youngest President Takes Office, Promising ‘Systemic Change’
Senegal’s new president, Bassirou Diomaye Faye, took the oath of office in Tuesday’s ceremony. Close behind him sat the popular opposition leader who had clinched the win.

By Ruth Maclean
Reporting from Diamniadio, Senegal.
Still reeling from a whirlwind campaign, young people in Senegal threw jackets over their worn election T-shirts on Tuesday to attend the inauguration of an opposition politician who went from political prisoner to president in less than three weeks.
Their new leader, Bassirou Diomaye Faye — at 44, Africa’s youngest elected president — took the oath of office promising “systemic change,” and paying homage to the many people killed, injured, and imprisoned in the yearslong lead-up to the West African country’s election.
“I will always keep in mind the heavy sacrifices made so as to never disappoint you,” Mr. Faye said, addressing a vast auditorium in which African heads of state and dignitaries sat at the front. From the back, hundreds of supporters of Mr. Faye and his powerful backer, the opposition leader Ousmane Sonko, shouted for joy.
Hours later, Mr. Faye appointed Mr. Sonko prime minister in the new government, according to a post on the president’s official account on X.
It was the culmination of months of drama, after the former president, Macky Sall, canceled the election with just weeks to go, citing irregularities at the constitutional council — and then, under intense domestic and international pressure, agreed to hold it after all.
Mr. Sall’s handpicked candidate was resoundingly beaten by Mr. Faye, a tax inspector and political rookie who got more than 54 percent of the vote, despite having only 10 days of freedom in which to campaign . He had been jailed on charges of defamation and contempt of court, and was awaiting trial when Mr. Sall announced the adoption of an amnesty law and was released.
“You’re Senegal’s uncontested and dazzling choice,” said the president of the constitutional council, Mamadou Badio Camara, presiding over the inauguration.
But Mr. Faye was not the only politician that Senegal had effectively endorsed. Mr. Sonko, the man whose support helped get Mr. Faye elected, was sitting in the second row.
“Thank you, Sonko, thank you,” yelled his supporters at key moments in Tuesday’s ceremony.
Mr. Sonko, until now Senegal’s foremost opposition leader, was also in jail until three weeks ago, barred from running for president himself after convictions on charges of defamation and “corruption of youth” in relation to accusations brought by a young massage parlor employee .
When he was released, he immediately went on the campaign trail with Mr. Faye, telling his supporters that a vote for Mr. Faye was a vote for him.
Mr. Faye made no mention in his speech of Mr. Sonko, who cut a low profile in a black hat and tunic. But Mr. Sonko was a constant presence. He hobnobbed with the African presidents who waited for the ceremony to begin in an antechamber of a conference center in Diamniadio, a new city still under construction and a pet project of Mr. Sall.
Then, in the hangar-like room where Mr. Faye would take his oath, Mr. Sonko took his place in the second row, just behind the two first ladies — wives of the polygamous new president. And Mr. Sonko got the biggest cheers of the day, every time his face appeared on the large screens at the front of the auditorium.
Much cheering also rang out for the military president of Guinea, and the representatives of Mali and Burkina Faso, three West African countries whose governments were overthrown in coups in recent years and are now ruled by juntas. The rhetoric of those juntas — focused on sovereignty from France, the former colonial power perceived by many West Africans as continuing to meddle in their affairs — mirrors that of Mr. Sonko and Mr. Faye.
“The youth of Senegal is connecting with the youth of those countries, over these issues of sovereignty,” the president’s uncle, also named Diomaye Faye, said in an interview on Tuesday.
Mr. Faye and Mr. Sonko have pledged to drop or change the terms of the CFA, the regional currency backed by France, and renegotiate Senegal’s contracts with foreign-owned companies to extract newly discovered oil and gas.
In his speech, Mr. Faye stressed that Senegal would remain open to relations with other countries that are “respectful of our sovereignty, consistent with our people’s aspirations, and in a mutually winning partnership.”
After the swearing-in, a motorcade carried him to the presidential palace. Last week, Mr. Sall had welcomed him and Mr. Sonko, his former archrivals, in a stiff but determinedly friendly meeting — official photographs of which were later given to the media.
On Tuesday, Mr. Sall, a two-term president who had served for 12 years, welcomed Mr. Faye once more, who arrived this time with a presidential guard.
After sitting chatting for a while and handing over the important documents, Mr. Sall climbed into a Toyota, pulling out of the palace gates and leaving for good.
Ruth Maclean is the West Africa bureau chief for The Times, covering 25 countries including Nigeria, Congo, the countries in the Sahel region as well as Central Africa. More about Ruth Maclean
- Skip to main content
- Keyboard shortcuts for audio player
The Arizona Supreme Court allows a near-total abortion ban to take effect soon
Katherine Davis-Young

After the Arizona Supreme Court allowed for near-total abortion ban, a group of abortion-rights protesters gathered outside the Arizona state Capitol in Phoenix on April 9, 2024. Katherine Davis-Young/KJZZ hide caption
After the Arizona Supreme Court allowed for near-total abortion ban, a group of abortion-rights protesters gathered outside the Arizona state Capitol in Phoenix on April 9, 2024.
PHOENIX - Abortions will soon be outlawed in Arizona except in cases where a pregnant person's life is at risk. The state Supreme Court has ruled Arizona should follow a restrictive abortion law dating back to the 1860s.
Since Dec. 2022, Arizona doctors have been allowed to provide abortions up to 15 weeks into a pregnancy, based on a lower court's interpretation of state laws. But the state Supreme Court now says Arizona should follow a law banning abortions in almost all cases . It makes no exceptions for rape or incest and makes performing an abortion punishable by two to five years in prison.

Florida's abortion fight is headed to voters after court allows for a 6-week ban
In the ruling, justices wrote that they will stay enforcement for 14 days , possibly longer, allowing abortions to continue during that time. Planned Parenthood Arizona, the state's largest abortion provider, says it plans to continue providing abortions as long as allowed.
An effort is already underway to put a measure on 2024 ballots that would enshrine abortion rights in the state constitution.
Democratic President Joe Biden criticized Arizona's ban in a statement, calling on Congress to pass federal abortion protections.
"Millions of Arizonans will soon live under an even more extreme and dangerous abortion ban, which fails to protect women even when their health is at risk or in tragic cases of rape or incest," he said. "This ruling is a result of the extreme agenda of Republican elected officials who are committed to ripping away women's freedom."
Vice President Kamala Harris is scheduled to travel to Tucson on Friday for an event focusing on "reproductive freedom." It's Harris' second trip to Arizona this year to push for expanding abortion access.
Abortion across the country
The decision comes a little more than a week after the Florida Supreme Court decided to allow that state's week's 6-week ban to take effect May 1, and a day following former President Donald Trump's announcement that abortion should be left up to the states , angering some of his supporters ahead of 2024 election.

Trump declines to back nationwide abortion ban, says it should be left to the states
The U.S. Supreme Court reversed Roe v. Wade nearly two years ago and handed abortion decisions back to states resulting in a patchwork of laws across the country.
Fourteen states ban abortion with very limited exceptions , according to the Guttmacher Institute, a group that supports abortion rights. Another 15 states protect abortion rights in various ways, according to Guttmacher.
This November, there are efforts in about a dozen states, including the one in Arizona, to add a question to voters' ballots supporting abortion rights.
Correction April 9, 2024
An earlier version of this story said that Arizona would not be able to enforce the state Supreme Court decision for 45 days. In fact, enforcement is stayed for 14 days, possibly longer.
ORIGINAL RESEARCH article
Linguistic changes in neurodegenerative diseases relate to clinical symptoms.

- 1 Winterlight Labs, Toronto, ON, Canada
- 2 Department of Psychology, University of Toronto, Toronto, ON, Canada
- 3 Hurvitz Brain Sciences Program, Sunnybrook Research Institute, Toronto, ON, Canada
- 4 School of Public Health Sciences, University of Waterloo, Waterloo, ON, Canada
- 5 Ontario Brain Institute, Toronto, ON, Canada
- 6 Department of Medicine (Neurology), University of Toronto, Toronto, ON, Canada
Background: The detection and characterization of speech changes may help in the identification and monitoring of neurodegenerative diseases. However, there is limited research validating the relationship between speech changes and clinical symptoms across a wide range of neurodegenerative diseases.
Method: We analyzed speech recordings from 109 patients who were diagnosed with various neurodegenerative diseases, including Alzheimer’s disease, Frontotemporal Dementia, and Vascular Cognitive Impairment, in a cognitive neurology memory clinic. Speech recordings of an open-ended picture description task were processed using the Winterlight speech analysis platform which generates >500 speech features, including the acoustics of speech and linguistic properties of spoken language. We investigated the relationship between the speech features and clinical assessments including the Mini Mental State Examination (MMSE), Mattis Dementia Rating Scale (DRS), Western Aphasia Battery (WAB), and Boston Naming Task (BNT) in a heterogeneous patient population.
Result: Linguistic features including lexical and syntactic features were significantly correlated with clinical assessments in patients, across diagnoses. Lower MMSE and DRS scores were associated with the use of shorter words and fewer prepositional phrases. Increased impairment on WAB and BNT was correlated with the use of fewer nouns but more pronouns. Patients also differed from healthy adults as their speech duration was significantly shorter with more pauses.
Conclusion: Linguistic changes such as the use of simpler vocabularies and syntax were detectable in patients with different neurodegenerative diseases and correlated with cognitive decline. Speech has the potential to be a sensitive measure for detecting cognitive impairments across various neurodegenerative diseases.
1 Introduction
Speech and language impairments are a prominent symptom in many neurodegenerative diseases including Alzheimer’s Disease (AD), Frontotemporal Dementia (FTD) and Vascular Dementia (VD) ( 1 – 5 ). These changes emerge along with the primary set of symptoms such as memory deficits and unusual behaviors associated with each neurodegenerative disease. There have been efforts in differentiating various dementias from healthy older populations based on speech and language assessments ( 1 , 4 , 6 – 10 ). However, many patients with dementia diagnoses exhibit comorbid conditions. The manifestation of symptoms could differ dramatically from one to another patient despite having received the same diagnosis, making characterization of disease incredibly complicated. Nevertheless, beyond the diagnosis of the patient, each neurodegenerative disease presents multiple symptoms that progress differently in each individual. Thus, understanding how speech and language changes manifest themselves in neurodegenerative diseases and how they relate to clinical symptoms can help add to the clinical picture and improve characterization of neurodegenerative disease. Here, we investigate this question by leveraging a rich, heterogeneous dataset that includes a wide range of neurodegenerative disease diagnoses.
Speech and language changes are an integral part of symptom progression in neurodegenerative diseases such as in AD. Although symptoms of typical AD concern deficits in episodic memory, executive function or reasoning, patients might also experience language impairments, specifically, in semantic abilities, verbal fluency or language comprehension ( 1 , 8 , 11 , 12 ). These language deficits manifest themselves as impairments in verbal naming, speech pauses and word finding ability ( 13 – 15 ). Atypical AD, specifically the logopenic variant of primary progressive aphasia (PPA), is associated with impaired lexical access, naming difficulty, dysfluencies ( 16 – 19 ). Recent efforts identified a set of language changes, specifically in lexical retrieval and fluency, that differed between the logopenic variant of PPA and the typical AD although these were not related to clinical outcomes ( 20 ). Nevertheless, typical AD and the logopenic variant of PPA share certain language deficits such as production of more adverbs, fewer prepositions and nouns ( 20 ). In fact, many neurodegenerative diseases show overlapping speech and language changes, emphasizing the importance of understanding their relation to cognitive decline.
Frontotemporal Dementia (FTD) encompasses distinct cognitive, social and behavioral symptoms that differ from AD, yet speech changes have also been reported across subtypes. Clinically, FTD could present itself as the behavioral variant or PPA, which could be further subdivided into fluent (semantic) and non-fluent variants ( 21 ). Patients with the non-fluent variant exhibit deficits in prosody, articulation and local coherence of speech ( 22 – 24 ). Thus, the symptoms include effortful speech, morphological or syntactic deficits, and word finding difficulty that result in simplified language ( 1 ). Semantic dementia (fluent variant), on the other hand, is characterized by decline of conceptual knowledge (i.e., semantic memory), primarily involving word comprehension ( 25 ). These patients lose the meaning of the words, mostly, nouns, but speech fluency and phonology stays relatively intact ( 26 ). As a result, patients with semantic dementia tend to produce fewer but more familiar nouns, and more adverbs than healthy adults ( 9 ). Lastly, patients with the logopenic variant of PPA, who tend to show AD pathology at autopsy, exhibit word finding difficulty, phonemic errors, and increased number of pronouns ( 16 , 19 , 22 ). In contrast to fluent and non-fluent variants of FTD, semantic memory, grammar, syntax and production of speech remain relatively unaffected in these patients ( 16 , 19 , 22 ). Lastly, speech and language change in naming, single word or discourse comprehension, and prosody in the behavioral variant of FTD although, historically, this variant was not considered to present such symptoms ( 27 – 30 ). The heterogeneity across different variants of FTD complicates the characterization of distinct speech and language differences for each disease.
Overlapping speech and language deficits across neurodegenerative diseases blur the diagnostic boundaries. Flow of speech as known as fluency could depend on the stage of the disease, in other words, the degree of cognitive decline ( 31 ). Fluency changes are common in AD although it remains unclear whether these reflect deficits in semantic knowledge, accessing or retrieving information while producing speech ( 32 , 33 ). Early onset of AD often exhibits similar speech and language deficits as mild cognitive impairment, primarily in lexico-semantic domain such as access to semantic knowledge or lexical decisions ( 12 , 34 , 35 ). Language changes including difficulty with name generation and single word comprehension in AD are also common in semantic dementia (i.e., fluent FTD). Although single word comprehension is spared in logopenic progressive aphasia, speech rate tends to be slow due to slow word retrieval and frequency pauses to find the right words ( 17 ). In fact, logopenic variant aphasia can exhibit AD pathology or progress into dementia caused by AD in later stages ( 36 , 37 ). Thus, similar speech and language changes may occur across different neurodegenerative diseases depending on the disease stage, social factors, and co-morbid condition.
Heterogeneity in and across neurogenerative diseases necessitates the development of digital speech and language biomarkers that can capture the cognitive decline and clinical symptoms, extending beyond the diagnostic categories. Literature reveals overlapping clinical symptoms and speech changes across neurogenerative diseases. For example, semantic dementia or progressive non-fluent aphasia could present different clinical symptoms, but both patient groups use significantly shorter words than healthy controls ( 9 ). However, the word length does not differ between the patients group ( 9 ). Similarly, both AD and semantic dementia (i.e., fluent FTD) may exhibit difficulty with name generation or word comprehension ( 12 , 25 , 38 ). Distinct diagnoses may share similar speech and language symptoms although the underlying pathology or affected cognitive domains may differ. Thus, understanding how speech and language changes are linked to cognitive impairment and clinical symptoms beyond the diagnosis labels is as crucial as distinguishing patients from healthy controls. As speech and language changes occur across a variety of neurodegenerative diseases, speech assessments might not be as powerful for differentiating diagnoses, but relate more to cognition, function, and clinical outcomes across diseases. This would mean that speech might be more useful for a cross-diagnosis cognitive assessment, rather than a sole diagnostic tool.
Speech and language features have the potential to be used as a screening or symptom-monitoring tool for neurodegenerative diseases. There is an added benefit of the feasibility of collecting speech samples remotely and with high frequency. We recently demonstrated the importance of high frequency speech assessments in understanding the individual symptom fluctuations relating to depression and cognitive impairment ( 30 , 39 , 40 ). In neurodegenerative diseases, there are no standardized speech and language assessments to be utilized. Thus, short, automated speech assessments which can be administered remotely and with high frequency can be powerful tools in understanding disease progressions. Machine learning and natural language processing models could be used to classify patients with dementia using speech features or differentiate them from healthy controls. Yet, the challenge is to interpret the speech and language changes in terms of the clinical symptoms. Here, our aim is to determine how speech and language changes relate to clinical outcomes in neurodegenerative diseases, beyond the diagnostic categories. Thus, we leveraged a rich, heterogenous patient sample with many neurodegenerative diseases and comorbid diagnoses and investigated the link between clinical outcomes and hundreds of speech features derived through natural language processing. Understanding how potential speech and language biomarkers relate to clinical symptoms will enable early detection or monitoring of cognitive decline at the individual level, as a way of addressing heterogeneity in neurodegenerative diseases.
2.1 Participants
The part of this study related to the patient cohort was approved by the Sunnybrook Research Ethics Board. Patients were recruited from the memory clinics at Sunnybrook Health Sciences Center in Toronto, Ontario, Canada. An informed consent discussion was conducted with all research candidates; all of these candidates agreed to participate, provided a written consent, and were successfully enrolled in the study. For our additional analyses, we also included a healthy older adult sample to compare timing related speech features to patients. The healthy control arm of this study was approved by the Advarra Research Ethics Board. Healthy controls were recruited from the community. Informed consent was collected from all participants. To be eligible for the study, participants needed to be between the ages of 50–95 and fluent English speakers (i.e., either English as their first language or they can speak with conversational proficiency). The exclusion criteria included the following: residing outside of Canada or the United States and having diagnosis of dementia, memory impairment, recent concussion or traumatic brain injury, or uncorrected hearing or visual impairment.
2.2 Clinical assessments
Patients completed a series of cognitive assessments including the Mini Mental State Examination (MMSE) ( 41 ), Dementia Rating Scale (DRS) ( 42 ), Western Aphasia Battery (WAB) ( 43 ), and Boston Naming Test (BNT) ( 44 ). MMSE and DRS have been administered to assess cognitive impairment in patients while WAB and BNT have been used to assess speech and language related changes. WAB is helpful in characterizing many different aspects of speech and language including fluency, comprehension, naming, reading and writing. BNT is mostly used to assess retrieval of lexical information while naming an object. WAB and BNT were used to validate our speech features and determine how they relate to specific speech changes. On the other hand, MMSE and DRS were used to assess the cognitive decline and its relationship to speech and language changes detected with our extensive features.
2.3 Acoustic and linguistic speech features
Patients’ speech recordings were collected in the clinic while they were performing a picture description task as part of WAB. The picture that participants described was a line drawing of a picnic scene. Healthy controls completed the picture description task as well, but using an app-based interface and a picture of a family in the kitchen scene. The recordings from healthy controls were collected with the Winterlight Speech App. Because of the significant differences between the 2 stimuli, we only analyzed the timing related speech features for the comparison between the patients and healthy controls since linguistic differences of spoken language could relate to the different picture content.
The patients’ speech recordings were transferred to the Ontario Brain Institute’s “Brain-CODE” informatics platform 1 for processing and analysis. “Brain-CODE” was designed to support the collection, integration, sharing, and analysis of patient-level data, while abiding by ethical principles and government legislation ( 45 ).
First, a trained transcriptionist transcribed and labeled the speech samples, ensuring the quality of audio content and flagged any recordings with significant issues for removal, such as no audible speech or poor audio quality. Although speech recordings were transcribed for quality purposes, the analyses are based on the recorded spoken speech. To make the distinction between speech and language, here acoustics refer to the auditory features of speech while the linguistics relates to the spoken language. Speech samples were then passed through the Winterlight Lab processing pipeline, which relies on python-based language processing libraries and proprietary custom code. Open source packages include SpaCy for parts-of-speech tagging and morphological features ( 46 ), the Stanford NLP parser for syntactic features ( 47 ), Praat and Parselmouth for acoustic features ( 48 , 49 ), and GloVe and FastText models for semantic features ( 50 , 51 ). The pipeline also uses custom code to compute additional features based on the transcript and audio file, using lexical norms from previous publications ( 52 – 55 ) or previously published models and features ( 56 ).
The Winterlight Lab processing pipeline enables us to extract 707 speech features from the audio files and transcripts. These features reflect various aspects of speech: acoustics (e.g., properties of the sound wave, speech rate, number of pauses), lexical content (e.g., rates and types of words used, and their characteristics such as frequency and imageability, which reflect how commonly words are used and how easy they are to picture, respectively), semantics (relating to the meaning of the words, e.g., semantic relatedness of subsequent utterances, semantic relatedness of utterances to the items in the picture) and syntactic (relating to the grammar of the sentences, e.g., syntactic complexity, use of different syntactic constructions) properties of the recordings. While it is not possible to review each feature in detail, we provide more detailed definitions for some of the features of interest in this paper. For instance, average word length and noun or pronoun count fall under the lexical category. Average word length represents the mean number of letters in each word used to describe the picture. Noun and pronoun count are calculated based on the number of nouns or pronouns in a transcript divided by the number of words, respectively. Lexical features also include noun familiarity and frequency, which represent the mean familiarity or frequency of the nouns in the transcript, based on familiarity or frequency norms, respectively ( 52 , 54 ). In other words, familiarity is a subjective rating of how common the word is, and frequency is how often it appears in a standard corpus of speech. Prepositional phrase count, as an example of syntactic features, is the number of times the phrase occurs in a transcript. Timing related features include mean speech or pause duration. Speech duration is the total number of seconds that participants take to describe the picture while pause duration is calculated by dividing the duration of unvoiced segments of speech by the total number of unvoiced segments. An overview of the feature categories, definitions, numbers, and examples is provided in Table 1 .

Table 1 . Speech feature overview, definitions, numbers, and examples.
2.4 Statistical analyses
All analyses were completed on R statistical software, version 4.1.2 ( 57 ). We eliminated the speech features that had empty values for at least 20% of participants. 80% of the features eliminated fell under morphological or syntactic speech categories. Specifically, a total of 146 morphological and 94 syntactic speech features had empty values, because of a combination of adverb and prepositional phrases that did not occur in all transcripts, and thus were eliminated from the analyses. Some of the remaining 62 speech features eliminated were related to tags for specific words, for instance, the words with a hyphen (e.g., t-shirt) in them. Most of the remaining speech categories in Table 1 were not affected from this cleaning process, yielding 405 features in total.
We fit separate linear mixed effects models to each speech feature to investigate their unique relationship with the clinical assessments, with covariates of age, sex, and years of education. These analyses were done separately for each of the cognitive assessments; MMSE, DRS, BNT and WAB. Statistical significance was set to an alpha level equal to 0.0001 taking multiple comparisons into consideration through Bonferroni correction (0.05/405 features). Using a series of analysis of variances (ANOVAs), we have compared different diagnoses in terms of the speech feature that we identified in the above analyses. However, these analyses did not yield significant results due to small sample size in each diagnosis.
Lastly, we included a healthy control dataset to be able to compare the speech changes in patients. We only included the timing related features for this comparison. As mentioned above, acoustic and linguistic features might not be appropriate for the comparison because the healthy older adults described a different picture, and recordings were obtained using different devices (digital vs. analog) and recording conditions. We used a Principal Component Analysis (PCA) to reduce the dimensionality of the feature set and distinguish the patients from healthy controls based on the resulting composite variables. This was used as an exploratory cluster analysis. We focused on the first few principal components, that, when combined, were able to explain at least 80% variance. Although there is no straight forward way to determine the number of principal components to retain, the first few components are expected to explain at least 75% of variance or even less in some situations ( 58 – 60 ).
3.1 Demographics
This study included 109 patients (52 females, 57 males) with an age range of 51–91 (M = 72.63 ± 8.61). Patient diagnoses included AD, FTD and Vascular dementia. The largest subset of patients was those diagnosed with AD and familial AD, consisting of 34 patients ( Supplementary Table S1 ). All patients completed MMSE, DRS, WAB and BNT as well as the picture description task as part of WAB ( Table 2 ). We also included 74 healthy controls (39 females) with mean age 61.31 ± 7.29. Healthy controls only completed the picture description task, but no additional clinical assessments reported here.

Table 2 . Patient demographics.
3.2 MMSE and DRS relate to linguistic features
We investigated the relationship of clinical scores on MMSE and DRS to acoustic and linguistic speech features. We conducted separate linear mixed effects models for each speech feature and repeated the analyses for MMSE and DRS separately. We observed that of all the features, average word length was significantly associated with MMSE, R 2 = 0.14, F (4, 103) = 5.46, β = 0.01, p = 0.001, 95% CI [0.005, 0.02], and DRS total scores, R 2 = 0.20, F (4, 100) = 7.35, β = 0.005, p = 5.82E-05, 95% CI [0.003, 0.008] ( Figures 1A , B ). Similarly, prepositional phrase count was also significantly correlated with MMSE, R 2 = 0.14, F (4, 103) = 5.53, β = 0.002, p = 0.0001, 95% CI [0.001, 0.003], and DRS total scores, R 2 = 0.13, F (4, 100) = 5.03, β = 0.0007, p = 0.0002, 95% CI [0.0003, 0.001] ( Figures 1C , D ). All of these results remained significant following Bonferroni correction.

Figure 1 . Clinical impairment measured with MMSE and DRS is correlated with average word length and prepositional phrase usage. (A) Lower MMSE and (B) DRS scores are associated with shorter word length. (C) Lower MMSE and (D) DRS are also correlated with use of fewer prepositional phrases.
Additional results included that the use of familiar nouns was inversely associated with MMSE, R 2 = 0.14, F (4, 103) = 5.20, β = −1.60, p = 0.0001, 95% CI [−2.40, −0.80], and DRS total scores, R 2 = 0.14, F (4, 100) = 5.42, β = −0.51, p = 0.0001, 95% CI [−0.76, −0.26]. Similarly, using frequent nouns were negatively correlated with MMSE, R 2 = 0.14, F(4, 103) = 5.29, β = −0.02, p = 0.00005, 95% CI [−0.03, −0.01], and DRS total scores, R 2 = 0.12, F (4, 100) = 4.21, β = −0.006, p = 0.0005, 95% CI [−0.01, −0.003].
3.3 WAB and BNT relate to linguistic features
We investigated the relationship of language deficits reported on WAB and BNT to acoustic and linguistic speech features. We conducted separate linear mixed effects models for each speech feature and repeated the analyses for WAB and BNT separately. We observed that noun count was significantly associated with WAB, R 2 = 0.16, F (4, 104) = 6.13, β = 0.001, p = 0.0002, 95% CI [0.0007, 0.002], and BNT total scores, R 2 = 0.24, F (4, 98) = 8.95, β = 0.005, p = 1.25E-06, 95% CI [0.002, 0.005] ( Figures 2A , B ). On the contrary, pronoun count was negatively correlated with WAB, R 2 = 0.09, F (4, 104) = 3.63, β = −0.001, p = 0.002, 95% CI [−0.002, −0.0005], and BNT total scores, R 2 = 0.11, F (4, 98) = 4.25, β = −0.003, p = 0.0003, 95% CI [−0.004, −0.001] ( Figures 2C , D ).

Figure 2 . Impairment in language (WAB) and semantic processing (BNT) is associated with the amount of noun and pronoun usage. (A) Lower WAB total and (B) BNT scores are correlated with reduced noun usage. Conversely, (C) lower WAB total and (D) BNT scores relate to higher pronoun usage.
3.4 Timing features distinguish patients from healthy older adults
Principal component analysis based on timing related features, including duration of speech and pauses, differentiated patients from healthy older adults ( Figure 3A ). The first two principal components explained more than 80% of the variance within the data ( Figure 3A ). Mean pause and total speech duration had two of the highest loadings and were used to show the differences between the patients and healthy controls. According to the student t-test, patients (M = 0.59, SD = 0.16) produced significantly shorter speech than the healthy controls (M = 0.79, SD = 0.12), t (180.41) = −9.63, p = 2.2E-16 ( Figure 3B ). On the other hand, patients (M = 0.95, SD = 0.49) paused significantly more than the healthy controls (M = 0.75, SD = 0.37), t (182.05) = −3.36, p = 0.001 ( Figure 3C ).

Figure 3 . Timing related speech features distinguish patients with neurodegenerative diseases from healthy older adults. (A) First 2 principal components based on timing features distinguish patients from healthy controls. Patients produced significantly (B) shorter speech durations but (C) longer pauses than healthy controls.
4 Discussion
This study reports that clinical symptoms in a wide range of neurodegenerative diseases are linked to digital linguistic speech features. Many of the speech and language changes that distinguish patients from the healthy older adults might be overlapping between different neurodegenerative diseases ( 1 ). We leveraged a rich and heterogeneous patient sample with many diagnostic labels to investigate how digital speech measures relate to cognitive impairment as well as the linguistic deficits measured with traditional assessments. We show that patients with neurodegenerative diseases tend to use simpler vocabulary and syntax; shorter words and fewer prepositional phrases, reflecting cognitive impairment. They utilize fewer nouns and mostly those that are familiar or frequently used in everyday life. In fact, there appears to be a tradeoff between reduced nouns and increased pronouns, which could result in less specific language. While a healthy older adult might describe a picnic scene as “A lady is sitting on the grass and pouring a beverage next to a gentleman by the lake,” a patient with dementia might only say “She is sitting and pouring something. There is a man.” Building on our previous work looking at longitudinal linguistic changes in AD and FTD ( 30 , 40 ), the link between linguistic changes and cognition across diagnoses highlights the importance of these language properties beyond the neurodegenerative disease categories.
Our results revealed that the cognitive impairment measured with MMSE and DRS was correlated with use of shorter words on average. Shorter word length is reported in many neurodegenerative diseases including AD, semantic dementia, progressive non-fluent aphasia, behavioral variant of FTD ( 9 , 40 , 61 , 62 ). Those with semantic dementia and progressive nonfluent aphasia, for example, may differ from healthy controls in terms of word length, yet the 2 patient groups were not previously found to differ from each other ( 9 ). Thus, it is necessary to understand how word length is linked to cognitive impairment in addition to distinguishing patients from healthy controls. Our analyses on a heterogenous patient sample revealed a link between word length and cognitive impairment, suggesting the relationship is beyond the diagnostic labels. This is in line with recent findings that shorter word usage in typical AD and the logopenic variant of PPA is correlated with MMSE and BNT ( 20 ). Patients with different neurodegenerative diseases may exhibit common linguistic changes, possibly emerging from different underlying deficits. Change in word length might arise from top-down lexical and semantic processing. Unavailability of long, sophisticated words might also result in word finding difficulty, which is commonly reported across diseases ( 1 , 19 , 22 ).
Since the earlier work, naming difficulty has been linked to word frequency and familiarity in dementia ( 63 , 64 ). Noun frequency and familiarity are two related linguistic features reflecting vocabulary complexity, and have been previously shown to be impacted in semantic dementia and, more generally, in FTD ( 30 , 65 ). These features could even distinguish semantic dementia from healthy controls and patients with progressive non-fluent aphasia ( 9 ). Besides FTD, we report the involvement of noun frequency and familiarity across many neurodegenerative diseases. These linguistic features are also closely linked to cognitive impairment on MMSE and DRS. Similarly, noun frequency in conversation was recently reported to be implicated in AD ( 66 ). However, the frequency was reported to decrease with age, suggesting increased use of more rare or complex words with increased age ( 66 ). It was speculated that the frequency measure could vary with education ( 66 , 67 ). Thus, the varying sensitivity of linguistic features also adds to the heterogeneity in dementia. This emphasizes the importance of understanding the link between linguistic changes and cognitive impairment, not specifically at the diagnostic level, but at the individual level.
Syntactic properties might be less sensitive to dementia than lexical features such as word length or noun frequency ( 68 ). We report that patients use fewer prepositional phrases – a syntactic feature - as cognitive impairment increases. Overall, prepositional phrases are relatively less studied, but they could be contributing to fragmented sentences in neurodegenerative diseases ( 68 , 69 ) or a reduced ability to form connections between concepts. Typical AD and the logopenic variant of PPA produce fewer prepositions than healthy controls ( 20 ). Similarly, patients with FTD use fewer and fewer prepositional phrases over time ( 30 ). Prepositional phrases in AD were associated with performance on BNT, relating to the difficulty in efficiently retrieving semantic information ( 20 ). Interestingly, while prepositional phrase count was related to MMSE and DRS scores in our study, we identified distinct linguistic features relating to traditional language assessments such as BNT and WAB.
With increased deficits on WAB and BNT, we observed decreased use of nouns but increased number of pronouns in patients with neurodegenerative diseases. Linguistic impairments measured with WAB were associated with the severity of dementia across diagnoses such as behavioral variant of FTD, primary progressive aphasia and AD ( 70 ). Patients with typical AD or the logopenic variant of PPA produce fewer nouns ( 20 ), and the use of nouns in AD and FTD decreases over time ( 30 , 40 ). Semantic dementia also presents with decreased noun use, specifically in connected speech ( 9 ). Supporting these findings, we showed that decreased noun use along with increased pronouns across neurodegenerative diseases was associated with language deficits measured with WAB and BNT. This might indicate semantic deficits ( 65 ), which might extend to other neurodegenerative diseases beyond semantic dementia as our results suggest. Indeed, BNT relies heavily on semantic memory ( 71 ) and is thus more correlated with category fluency such as knowledge of words rather than the rhyming of words or verbal fluency ( 32 , 33 ). This could be why BNT performance is linked to nouns and pronouns across diseases in the current study as these features are capturing more of the semantic processing.
Characteristics of speech production such as rate and timing are also affected in neurodegenerative diseases. Our results show that patients produced significantly shorter speech and more pauses in speech than the healthy older adults. This might indirectly be an indication of lexico-semantic deficits in these patients and relate to our findings discussed above. Patients with dementia produced shorter speech recordings than healthy controls ( 20 , 72 ). Similarly, those with logopenic variants of PPA or AD pause more or longer ( 14 , 17 , 20 , 73 ). Increased pauses are observable in MCI and early AD as well ( 74 ). Between-utterance pauses were also shown to differ between AD and MCI, and was related to episodic memory performance, suggesting its importance in early detection of symptoms ( 14 ). Supporting this, we provided evidence that timing features distinguished healthy controls from the heterogenous patient sample that included more than 10 different diagnoses and various comorbid conditions. Yet, we did not observe any associations between number of pauses and MMSE or DRS. This might suggest that timing of speech could be involved in specific cognitive domains rather than overall cognitive decline. This emphasizes the importance of understanding how each speech and language change is linked to a particular clinical outcome beyond the clinical diagnoses, which could be the key in unpacking the heterogeneity and comorbidity seen in neurodegenerative diseases.
We were not able to distinguish the linguistic differences between the diagnostic groups due to small sample size in each group. Although many neurodegenerative diseases show a great overlap in terms of speech changes, future research should investigate the relationship between linguistic speech changes and various clinical outcomes in each disease population separately. These identified language features here can be the first step in understanding how linguistic changes manifest themselves as cognitive impairment progresses in each disease. In addition to linguistic changes, acoustic aspects of speech have recently been part of the efforts in capturing speech changes in neurodegenerative diseases. We generated a wide range of acoustic features including but not limited to the power spectrum of speech signals, speech intensity, and jitter. Yet, acoustic features were not significantly correlated with clinical scores. The speech recordings were collected during clinical interviews on relatively older devices and on a platform other than the Winterlight App. Future research should investigate the acoustic features in high quality speech samples collected with more up-to-date devices.
This study identified several linguistic features that are linked to cognitive impairment in neurodegenerative diseases. It suggested that certain linguistic features may relate to cognition more generally, others to language abilities while timing related features were best suited for broadly distinguishing patients and healthy controls. In particular, it could be that word length and prepositions relate more to cognitive abilities in general, nouns and pronouns relate more specifically to language abilities and speech duration/pausing distinguishes controls from patients. Although these results alone are not enough to make a strong argument, future research should explore this idea that perhaps we could use one assessment to derive different features to inform on different aspects of cognition/language. Gold standard assessments for cognitive impairment can be laborious to conduct as they require expertise and time. Speech assessments, on the other hand, are automated, fast and could be administered in addition to the existing clinical assessments. Nevertheless, many neurodegenerative diseases including various variants of AD and FTD present overlapping speech and language changes ( 1 ). There have been efforts in understanding disease specific changes, yet individual differences make this investigation complicated. Each patients’ medical history, severity level, lifestyle, and cognitive resource might be contributing to their phenotype in different ways. A recent review suggests that neurodegenerative diseases should be considered as a multi-faceted condition that involves biology, psychology and social levels to explain the resulting digital phenotypes ( 75 ). We can get one step closer to a more objective understanding of cognitive decline in neurodegenerative diseases through development of digital linguistic biomarkers that link to specific cognitive deficits.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by 1. Sunnybrook Research Ethics Board or 2. Advarra Research Ethics Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
MG: Formal analysis, Visualization, Writing – original draft, Writing – review & editing. MK: Data curation, Writing – review & editing. CMS: Resources, Writing – review & editing. AB: Project administration, Writing – review & editing. JR: Supervision, Writing – review & editing. SEB: Conceptualization, Supervision, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This study was conducted with the support of the Ontario Brain Institute, an independent non-profit corporation, funded partially by the Ontario government. This study was also supported by Canadian Institutes of Health Research (CIHR) Grants (MOP13129 and FDN159910) awarded to SEB.
Acknowledgments
We would like to thank the Ontario Brain Institute for providing access to Brain-CODE, a secure neuroinformatics platform, which was used for the data storage, data sharing and analysis workspace.
Conflict of interest
MG and JR were employed by Winterlight Labs that is part of Cambridge Cognition.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fneur.2024.1373341/full#supplementary-material
1. ^ www.braincode.ca
1. Boschi, V, Catricalà, E, Consonni, M, Chesi, C, Moro, A, and Cappa, SF. Connected speech in neurodegenerative language disorders: a review. Front Psychol . (2017) 8:269. doi: 10.3389/fpsyg.2017.00269
PubMed Abstract | Crossref Full Text | Google Scholar
2. Cuetos, F, Arango-Lasprilla, JC, Uribe, C, Valencia, C, and Lopera, F. Linguistic changes in verbal expression: a preclinical marker of Alzheimer’s disease. J Int Neuropsychol Soc . (2007) 13:433–9. doi: 10.1017/S1355617707070609
Crossref Full Text | Google Scholar
3. Geraudie, A, Battista, P, García, AM, Allen, IE, Miller, ZA, Gorno-Tempini, ML, et al. Speech and language impairments in behavioral variant frontotemporal dementia: a systematic review. Neurosci Biobehav Rev . (2021) 131:1076–95. doi: 10.1016/j.neubiorev.2021.10.015
4. Martínez-Nicolás, I, Llorente, TE, Martínez-Sánchez, F, and Meilán, JJG. Ten years of research on automatic voice and speech analysis of people with Alzheimer’s disease and mild cognitive impairment: a systematic review article. Front Psychol . (2021) 12:620251. doi: 10.3389/fpsyg.2021.620251
5. Martínez-Nicolás, I, Llorente, TE, Martínez-Sánchez, F, and Meilán, JJG. Speech biomarkers of risk factors for vascular dementia in people with mild cognitive impairment. Front Hum Neurosci . (2022) 16:1057578. doi: 10.3389/fnhum.2022.1057578
6. Bertola, L, Mota, NB, Copelli, M, Rivero, T, Diniz, BS, Romano-Silva, MA, et al. Graph analysis of verbal fluency test discriminate between patients with Alzheimer’s disease, mild cognitive impairment and normal elderly controls. Front Aging Neurosci . (2014) 6:185. doi: 10.3389/fnagi.2014.00185
7. Cho, S, Nevler, N, Ash, S, Shellikeri, S, Irwin, DJ, Massimo, L, et al. Automated analysis of lexical features in frontotemporal degeneration. Cortex . (2021) 137:215–31. doi: 10.1016/j.cortex.2021.01.012
8. Forbes-McKay, KE, and Venneri, A. Detecting subtle spontaneous language decline in early Alzheimer’s disease with a picture description task. Neurol Sci . (2005) 26:243–54. doi: 10.1007/s10072-005-0467-9
9. Fraser, KC, Meltzer, JA, Graham, NL, Leonard, C, Hirst, G, Black, SE, et al. Automated classification of primary progressive aphasia subtypes from narrative speech transcripts. Cortex . (2014) 55:43–60. doi: 10.1016/j.cortex.2012.12.006
10. Petti, U, Baker, S, and Korhonen, A. A systematic literature review of automatic Alzheimer’s disease detection from speech and language. J Am Med Inform Assoc . (2020) 27:1784–97. doi: 10.1093/jamia/ocaa174
11. Catricalà, E, Della Rosa, PA, Plebani, V, Perani, D, Garrard, P, and Cappa, SF. Semantic feature degradation and naming performance. Evidence from neurodegenerative disorders. Brain Lang . (2015) 147:58–65. doi: 10.1016/j.bandl.2015.05.007
12. Taler, V, and Phillips, NA. Language performance in Alzheimer’s disease and mild cognitive impairment: a comparative review. J Clin Exp Neuropsychol . (2008) 30:501–56. doi: 10.1080/13803390701550128
13. Fox, NC, Warrington, EK, Seiffer, AL, Agnew, SK, and Rossor, MN. Presymptomatic cognitive deficits in individuals at risk of familial Alzheimer’s disease. A longitudinal prospective study. Brain . (1998) 121:1631–9. doi: 10.1093/brain/121.9.1631
14. Pistono, A, Jucla, M, Barbeau, EJ, Saint-Aubert, L, Lemesle, B, Calvet, B, et al. Pauses during autobiographical discourse reflect episodic memory processes in early Alzheimer’s disease. J Alzheimers Dis . (2016) 50:687–98. doi: 10.3233/JAD-150408
15. Silagi, ML, Bertolucci, PHF, and Ortiz, KZ. Naming ability in patients with mild to moderate Alzheimer’s disease: what changes occur with the evolution of the disease? Clinics (São Paulo) . (2015) 70:423–8. doi: 10.6061/clinics/2015(06)07
16. Ash, S, Evans, E, O’Shea, J, Powers, J, Boller, A, Weinberg, D, et al. Differentiating primary progressive aphasias in a brief sample of connected speech. Neurology . (2013) 81:329–36. doi: 10.1212/WNL.0b013e31829c5d0e
17. Gorno-Tempini, ML, Brambati, SM, Ginex, V, Ogar, J, Dronkers, NF, Marcone, A, et al. The logopenic/phonological variant of primary progressive aphasia. Neurology . (2008) 71:1227–34. doi: 10.1212/01.wnl.0000320506.79811.da
18. Gorno-Tempini, ML, Dronkers, NF, Rankin, KP, Ogar, JM, Phengrasamy, L, Rosen, HJ, et al. Cognition and anatomy in three variants of primary progressive aphasia. Ann Neurol . (2004) 55:335–46. doi: 10.1002/ana.10825
19. Wilson, SM, Henry, ML, Besbris, M, Ogar, JM, Dronkers, NF, Jarrold, W, et al. Connected speech production in three variants of primary progressive aphasia. Brain . (2010) 133:2069–88. doi: 10.1093/brain/awq129
20. Cho, S, Cousins, KAQ, Shellikeri, S, Ash, S, Irwin, DJ, Liberman, MY, et al. Lexical and acoustic speech features relating to Alzheimer disease pathology. Neurology . (2022) 99:e313–22. doi: 10.1212/WNL.0000000000200581
21. Boxer, AL, and Miller, BL. Clinical features of frontotemporal dementia. Alzheimer Dis Assoc Disord . (2005) 19:S3–6. doi: 10.1097/01.wad.0000183086.99691.91
22. Ash, S, and Grossman, M. Why study connected speech production? In: RM Willems, editor. Cognitive neuroscience of natural language use . Cambridge: Cambridge University Press (2015). 29–58.
Google Scholar
23. Ash, S, Moore, P, Antani, S, McCawley, G, Work, M, and Grossman, M. Trying to tell a tale: discourse impairments in progressive aphasia and frontotemporal dementia. Neurology . (2006) 66:1405–13. doi: 10.1212/01.wnl.0000210435.72614.38
24. Graham, NL, Patterson, K, and Hodges, JR. When more yields less: speaking and writing deficits in nonfluent progressive aphasia. Neurocase . (2004) 10:141–55. doi: 10.1080/13554790409609945
25. Snowden, J, Goulding, PJ, and David, N. Semantic dementia: a form of circumscribed cerebral atrophy. Behav Neurol . (1989) 2:167–82. doi: 10.1155/1989/124043
26. Hodges, JR, Patterson, K, Oxbury, S, and Funnell, E. Semantic dementia. Progressive fluent aphasia with temporal lobe atrophy. Brain . (1992) 115:1783–806. doi: 10.1093/brain/115.6.1783
27. Hardy, CJD, Buckley, AH, Downey, LE, Lehmann, M, Zimmerer, VC, Varley, RA, et al. The language profile of behavioral variant frontotemporal dementia. J Alzheimers Dis . (2016) 50:359–71. doi: 10.3233/JAD-150806
28. Luzzi, S, Baldinelli, S, Ranaldi, V, Fiori, C, Plutino, A, Fringuelli, FM, et al. The neural bases of discourse semantic and pragmatic deficits in patients with frontotemporal dementia and Alzheimer’s disease. Cortex . (2020) 128:174–91. doi: 10.1016/j.cortex.2020.03.012
29. Nevler, N, Ash, S, Jester, C, Irwin, DJ, Liberman, M, and Grossman, M. Automatic measurement of prosody in behavioral variant FTD. Neurology . (2017) 89:650–6. doi: 10.1212/WNL.0000000000004236
30. Robin, J, Xu, M, Kaufman, LD, Simpson, W, McCaughey, S, Tatton, N, et al. Development of a speech-based composite score for remotely quantifying language changes in frontotemporal dementia. Cogn Behav Neurol . (2023) 36:237–48. doi: 10.1097/WNN.0000000000000356
31. Kertesz, A, Davidson, W, McCabe, P, Takagi, K, and Munoz, D. Primary progressive aphasia: diagnosis, varieties, evolution. J Int Neuropsychol Soc . (2003) 9:710–9. doi: 10.1017/S1355617703950041
32. Henry, JD, Crawford, JR, and Phillips, LH. Verbal fluency performance in dementia of the Alzheimer’s type: a meta-analysis. Neuropsychologia . (2004) 42:1212–22. doi: 10.1016/j.neuropsychologia.2004.02.001
33. Weakley, A, and Schmitter-Edgecombe, M. Analysis of verbal fluency ability in Alzheimer’s disease: the role of clustering, switching and semantic proximities. Arch Clin Neuropsychol . (2014) 29:256–68. doi: 10.1093/arclin/acu010
34. Duong, A, Whitehead, V, Hanratty, K, and Chertkow, H. The nature of lexico-semantic processing deficits in mild cognitive impairment. Neuropsychologia . (2006) 44:1928–35. doi: 10.1016/j.neuropsychologia.2006.01.034
35. Tsantali, E, Economidis, D, and Tsolaki, M. Could language deficits really differentiate mild cognitive impairment (MCI) from mild Alzheimer’s disease? Arch Gerontol Geriatr . (2013) 57:263–70. doi: 10.1016/j.archger.2013.03.011
36. Appell, J, Kertesz, A, and Fisman, M. A study of language functioning in Alzheimer patients. Brain Lang . (1982) 17:73–91. doi: 10.1016/0093-934X(82)90006-2
37. Oh, MJ, Kim, S, Park, YH, Suh, J, and Yi, S. Early onset Alzheimer’s disease presenting as Logopenic primary progressive aphasia. Dement Neurocogn Disord . (2018) 17:66–70. doi: 10.12779/dnd.2018.17.2.66
38. Macoir, J, and Turgeon, Y. Dementia and language In: K Brown, editor. Encyclopedia of Language & Linguistics . Oxford: Elsevier (2006). 423–30.
39. Gumus, M, DeSouza, DD, Xu, M, Fidalgo, C, Simpson, W, and Robin, J. Evaluating the utility of daily speech assessments for monitoring depression symptoms. Digital Health . (2023) 9:20552076231180523. doi: 10.1177/20552076231180523
40. Robin, J, Xu, M, Balagopalan, A, Novikova, J, Kahn, L, Oday, A, et al. Automated detection of progressive speech changes in early Alzheimer’s disease. Alz Dem Diag Ass Dis Mo . (2023) 15:e12445. doi: 10.1002/dad2.12445
41. Folstein, MF, Folstein, SE, and McHugh, PR. Mini-mental state. J Psychiatr Res . (1975) 12:189–98. doi: 10.1016/0022-3956(75)90026-6
42. Mattis, S. Dementia rating scale: Professional manual . Lutz, FL: Psychological Assessment Resources, Incorporated (1988).
43. Risser, AH, and Spreen, O. The Western aphasia battery. J Clin Exp Neuropsychol . (1985) 7:463–70. doi: 10.1080/01688638508401277
44. Kaplan, E, Goodglass, H, and Weintraub, S. Boston Naming. TEST . (1983). doi: 10.1037/t27208-000
45. Vaccarino, AL, Dharsee, M, Strother, S, Aldridge, D, Arnott, SR, Behan, B, et al. Brain-CODE: a secure Neuroinformatics platform for management, federation, sharing and analysis of multi-dimensional neuroscience data. Front Neuroinform . (2018) 12:28. doi: 10.3389/fninf.2018.00028
46. Honnibal, M., and Montani, I. (2017). spaCy 2: natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing. Available at: https://sentometrics-research.com/publication/72/
47. Chen, D., and Manning, C. (2014). A fast and accurate dependency parser using neural networks. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (Doha, Qatar: Association for Computational Linguistics).
48. Boersma, P., and Weenink, D. (2010). Praat: Doing phonetics by computer. Available at: http://www.praat.org/
49. Jadoul, Y, Thompson, B, and de Boer, B. Introducing Parselmouth: a Python interface to Praat. J Phon . (2018) 71:1–15. doi: 10.1016/j.wocn.2018.07.001
50. Bojanowski, P, Grave, E, Joulin, A, and Mikolov, T. Enriching word vectors with subword information. Comput Language . (2017). doi: 10.48550/arXiv.1607.04606
51. Pennington, J., Socher, R., and Manning, C. (2014). GloVe: global vectors for word representation. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (Doha, Qatar: Association for Computational Linguistics).
52. Brysbaert, M, and New, B. Moving beyond Kučera and Francis: a critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behav Res Methods . (2009) 41:977–90. doi: 10.3758/BRM.41.4.977
53. Kuperman, V, Stadthagen-Gonzalez, H, and Brysbaert, M. Age-of-acquisition ratings for 30,000 English words. Behav Res . (2012) 44:978–90. doi: 10.3758/s13428-012-0210-4
54. Stadthagen-Gonzalez, H, and Davis, CJ. The Bristol norms for age of acquisition, imageability, and familiarity. Behav Res Methods . (2006) 38:598–605. doi: 10.3758/BF03193891
55. Warriner, AB, Kuperman, V, and Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav Res . (2013) 45:1191–207. doi: 10.3758/s13428-012-0314-x
56. Mota, NB, Vasconcelos, NAP, Lemos, N, Pieretti, AC, Kinouchi, O, Cecchi, GA, et al. Speech graphs provide a quantitative measure of thought disorder in psychosis. PLoS One . (2012) 7:e34928. doi: 10.1371/journal.pone.0034928
57. R Core Team (2021). R: A Language and Environment for Statistical Computing. Available at: https://www.R-project.org/
58. Habeck, C, Foster, NL, Perneczky, R, Kurz, A, Alexopoulos, P, Koeppe, RA, et al. Multivariate and univariate neuroimaging biomarkers of Alzheimer’s disease. NeuroImage . (2008) 40:1503–15. doi: 10.1016/j.neuroimage.2008.01.056
59. Jolliffe, IT. Principal component analysis . New York, NY: Springer (1986).
60. Stühler, E, Merhof, D, Stühler, E, and Merhof, D. Principal component analysis applied to SPECT and PET data of dementia patients – a review In: P Sanguansat, editor. Principal component analysis-multidisciplinary applications (IntechOpen) . England: InTech (2012)
61. Cumming, TB, Patterson, K, Verfaellie, M, and Graham, KS. One bird with two stones: abnormal word length effects in pure alexia and semantic dementia. Cogn Neuropsychol . (2006) 23:1130–61. doi: 10.1080/02643290600674143
62. Ferrante, FJ, Migeot, J, Birba, A, Amoruso, L, Pérez, G, Hesse, E, et al. Multivariate word properties in fluency tasks reveal markers of Alzheimer’s dementia. Alzheimers Dement . (2023) 20:925–40. doi: 10.1002/alz.13472
63. Ralph, MAL, Graham, KS, Ellis, AW, and Hodges, JR. Naming in semantic dementia—what matters? Neuropsychologia . (1998) 36:775–84. doi: 10.1016/S0028-3932(97)00169-3
64. Taylor, R. Effects of age of acquisition, word frequency, and familiarity on object recognition and naming in dementia. Percept Mot Skills . (1998) 87:573–4. doi: 10.2466/pms.1998.87.2.573
65. Bird, H, Ralph, MAL, Patterson, K, and Hodges, JR. The rise and fall of frequency and imageability: noun and verb production in semantic dementia. Brain Lang . (2000) 73:17–49. doi: 10.1006/brln.2000.2293
66. Williams, E, Theys, C, and McAuliffe, M. Lexical-semantic properties of verbs and nouns used in conversation by people with Alzheimer’s disease. PLoS One . (2023) 18:e0288556. doi: 10.1371/journal.pone.0288556
67. Tainturier, MJ, Tremblay, M, and Lecours, AR. Educational level and the word frequency effect: a lexical decision investigation. Brain Lang . (1992) 43:460–74. doi: 10.1016/0093-934x(92)90112-r
68. Hier, DB, Hagenlocker, K, and Shindler, AG. Language disintegration in dementia: effects of etiology and severity. Brain Lang . (1985) 25:117–33. doi: 10.1016/0093-934x(85)90124-5
69. Banovic, S, Zunic, LJ, and Sinanovic, O. Communication difficulties as a result of dementia. Mater Sociomed . (2018) 30:221–4. doi: 10.5455/msm.2018.30.221-224
70. Blair, M, Marczinski, CA, Davis-Faroque, N, and Kertesz, A. A longitudinal study of language decline in Alzheimer’s disease and frontotemporal dementia. J Inter Neuropsych Soc . (2007) 13:237–45. doi: 10.1017/S1355617707070269
71. Ivnik, RJ, Malec, JF, Smith, GE, Tangalos, EG, and Petersen, RC. Neuropsychological tests’ norms above age 55: COWAT, BNT, MAE token, WRAT-R Reading, AMNART, STROOP, TMT, and JLO. Clin Neuropsychol . (1996) 10:262–78. doi: 10.1080/13854049608406689
72. Sluis, RA, Angus, D, Wiles, J, Back, A, Gibson, T, Liddle, J, et al. An automated approach to examining pausing in the speech of people with dementia. Am J Alzheimers Dis Other Dement . (2020) 35:1533317520939773. doi: 10.1177/1533317520939773
73. Davis, BH, and Maclagan, M. Examining pauses in Alzheimer’s discourse. Am J Alzheimers Dis Other Dement . (2009) 24:141–54. doi: 10.1177/1533317508328138
74. Robin, J, Xu, M, Kaufman, LD, and Simpson, W. Using digital speech assessments to detect early signs of cognitive impairment. Front Digit Health . (2021) 3:749758. doi: 10.3389/fdgth.2021.749758
75. Alfalahi, H, Dias, SB, Khandoker, AH, Chaudhuri, KR, and Hadjileontiadis, LJ. A scoping review of neurodegenerative manifestations in explainable digital phenotyping. NPJ Parkinsons Dis . (2023) 9:49. doi: 10.1038/s41531-023-00494-0
Keywords: speech, linguistic, neurodegenerative diseases, digital health, clinical symptoms
Citation: Gumus M, Koo M, Studzinski CM, Bhan A, Robin J and Black SE (2024) Linguistic changes in neurodegenerative diseases relate to clinical symptoms. Front. Neurol . 15:1373341. doi: 10.3389/fneur.2024.1373341
Received: 19 January 2024; Accepted: 07 March 2024; Published: 25 March 2024.
Reviewed by:
Copyright © 2024 Gumus, Koo, Studzinski, Bhan, Robin and Black. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Melisa Gumus, [email protected]
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
IMAGES
VIDEO
COMMENTS
Benefits of text to speech for PDFs. Text to speech can be a useful tool for a variety of people. People with vision loss can access a PDF with text to speech. Anyone who prefers to listen to text, whether it's in an effort to avoid eyestrain or improve workflow, can use Acrobat Reader's simple PDF text to speech feature. Text to speech can ...
Text-to-Speech Page. Enhance your reading experience with our new Text-to-Speech page. Now, you can easily convert written text or upload a TXT file and listen to it being read aloud. Whether it's articles, notes, or your own writings, our text-to-speech technology brings content to life, making it accessible and engaging. Page Selection Option
NaturalReader converts text, PDF, and 20+ formats into spoken audio so you can listen to your documents, ebooks, and school materials anytime, anywhere ... Users can use text-to-speech technology to create voiceover by typing a written script and having an AI voice read aloud the script, just as a human would. ...
Read PDF Out Loud. 1 Upload your PDF document to our text to voice converter. 2 Select the language of your document from 90 languages and dialects, and choose one of our 700 text to speech voices. 3 Click "Create Audio" and let Narakeet do its magic. In just a few minutes, you will get an audio version of your PDF.
Download Power Text to Speech Reader (Free) Also Read: Best Apps to Convert PDF to Word Document. 6. Balabolka. Another free Text-To-Speech (TTS) program that will help you listen to your PDF files while you are working on other things. Balabolka can convert and save PDF files into audio formats like MP3, MP4, OGG, and WMA.
Start Transcribing for Free — Convert unlimited audio and video files to accurate text. 99.8% accuracy. 98+ languages. Transcribes in seconds. 3 Free Transcripts Every Day. Download as docx, pdf, txt, and subtitles. Import audio and video files. Export accurate text and subtitles. TurboScribe is fastest, most accurate AI transcriber on Earth.
This free online application allows you to explore our PDF-to-speech capabilities without installing any applications and writing a single line of code. It supports all modern browsers on desktops and smartphones. Just paste a text, sit back and listen to the information you need. This free app provided by Aspose OCR.
Dragon Professional. $699.00 at Nuance. See It. Dragon is one of the most sophisticated speech-to-text tools. You use it not only to type using your voice but also to operate your computer with ...
Here's how: Click on the ' Speechify ' plugin at the top right in your browser. 2. Click on Upload PDF. 3. This will take you to a screen where you can drag and drop any PDF file from your computer. 4. Once, it has been added to your library, you can click on the file you wish to read and it will automatically play the file.
NaturalReader converts text, PDF, and 20+ formats into spoken audio so you can listen to your documents, ebooks, and school materials anytime, anywhere. Get Started For Free.
Accurate audio transcriptions with AI. Effortlessly convert spoken words into written text with unmatched accuracy using VEED's AI audio-to-text technology. Get instant transcriptions for your podcasts, interviews, lectures, meetings, and all types of business communications. Say goodbye to manually transcribing your audio and embrace efficiency.
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing. Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts.
How to convert a PDF to speech. If you are looking for a way to use text-to-speech (or TTS) to turn web pages or PDF Files into audio files, there are several options available. Regardless of whether you have a Windows device, an Android phone, an iPhone with iOS, or a Mac with macOS, there are several apps that can help you save time and read out loud through a PDF reader.
#1 Text To Speech. Type or upload any text, file, website & book for listening online, proofreading, reading-along or generating professional mp3 voice-overs. ... TTSReader extracts the text from pdf files, and reads it out loud. Also useful for simply copying text from pdf to anywhere. In addition, it highlights the text currently being read ...
To read a PDF using text to speech: Choose a TTS Application: Install a text to speech app like NaturalReader or Speechify on your device. Open Your PDF: Use the app to open the PDF file you wish to read. Activate TTS Features: In the app, find the 'read aloud' or 'voice reader' option to start the TTS. Customization: Adjust settings ...
4. Beside the PDF document click on the 3 vertical dots > Open > Open in Browser 5. Click on the PDF icon to open it in OrbitNote 6. Use the reading tools and T Typewriter tools to write on the PDF. There is Speech to Text and Word prediction options on the T Toolbar.
Free. Text To Speech Reader. Instantly reads out loud text & PDF with natural sounding voices. Online - works out of the box. Drop the text and click play. Drag text or pdf files to the text-box, or directly type/paste in text. Select language and click Play. Remembers text and caret position between sessions.
Text to speech (TTS) is a technology that converts text into spoken audio. It can read aloud PDFs, websites, and books using natural AI voices. Text-to-speech (TTS) technology can be helpful for anyone who needs to access written content in an auditory format, and it can provide a more inclusive and accessible way of communication for many ...
The speech is converted to the corresponding text and produces summarized text. This has various applications like lecture notes creation, summarizing catalogues for lengthy documents and so on.
SPEECH to PDF. Step 1: Submit the SPEECH audio you want to convert to PDF to the upload box at the left. Step 2: Wait a moment until the conversion from SPEECH to PDF is complete. The process starts automatically. Step 3: Click on the download button and get your converted file for free! Supported intput formats: WAV, MP3, FLAC, AAC, OGG and M4A.
Language Learning: Improve pronunciation and language skills by hearing accurate spoken text. Content Sharing: Easily share audio versions of articles or documents through links or social media. Premium Features: Unlock additional voices and enjoy a more personalized experience. PDF Conversion: Convert PDF files into audio for convenient listening.
- Transcribe podcasts into text. - etc. Features: - No data leaves your Mac. Transcription happens locally without the internet. - Easy to use interface. Drag and drop + one click are all you need to do. - Supported formats: - Audio: mp3, wav, m4a, ogg, aac, and caf - Video: mov and mp4 - Exported formats: text, srt, vtt, and csv.
Don Bosco University, Assam, India. *For correspondence. ([email protected]) Abstract: VOICE RECOGNITION SYSTEM:SPEECH-TO-TEXT is a software that lets the user control. computer functions and ...
Senegal's new president, Bassirou Diomaye Faye, took the oath of office in Tuesday's ceremony. Close behind him sat the popular opposition leader who had clinched the win.
After the Arizona Supreme Court allowed for near-total abortion ban, a group of abortion-rights protesters gathered outside the Arizona state Capitol in Phoenix on April 9, 2024.
1 Introduction. Speech and language impairments are a prominent symptom in many neurodegenerative diseases including Alzheimer's Disease (AD), Frontotemporal Dementia (FTD) and Vascular Dementia (VD) (1-5).These changes emerge along with the primary set of symptoms such as memory deficits and unusual behaviors associated with each neurodegenerative disease.