Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base

Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
Prevent plagiarism. Run a free check.
The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved April 3, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
6a.2 - steps for hypothesis tests, the logic of hypothesis testing section .
A hypothesis, in statistics, is a statement about a population parameter, where this statement typically is represented by some specific numerical value. In testing a hypothesis, we use a method where we gather data in an effort to gather evidence about the hypothesis.
How do we decide whether to reject the null hypothesis?
- If the sample data are consistent with the null hypothesis, then we do not reject it.
- If the sample data are inconsistent with the null hypothesis, but consistent with the alternative, then we reject the null hypothesis and conclude that the alternative hypothesis is true.
Six Steps for Hypothesis Tests Section
In hypothesis testing, there are certain steps one must follow. Below these are summarized into six such steps to conducting a test of a hypothesis.
- Set up the hypotheses and check conditions : Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as \(H_0 \), which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is evidence to suggest otherwise. The second hypothesis is called the alternative, or research hypothesis, notated as \(H_a \). The alternative hypothesis is a statement of a range of alternative values in which the parameter may fall. One must also check that any conditions (assumptions) needed to run the test have been satisfied e.g. normality of data, independence, and number of success and failure outcomes.
- Decide on the significance level, \(\alpha \): This value is used as a probability cutoff for making decisions about the null hypothesis. This alpha value represents the probability we are willing to place on our test for making an incorrect decision in regards to rejecting the null hypothesis. The most common \(\alpha \) value is 0.05 or 5%. Other popular choices are 0.01 (1%) and 0.1 (10%).
- Calculate the test statistic: Gather sample data and calculate a test statistic where the sample statistic is compared to the parameter value. The test statistic is calculated under the assumption the null hypothesis is true and incorporates a measure of standard error and assumptions (conditions) related to the sampling distribution.
- Calculate probability value (p-value), or find the rejection region: A p-value is found by using the test statistic to calculate the probability of the sample data producing such a test statistic or one more extreme. The rejection region is found by using alpha to find a critical value; the rejection region is the area that is more extreme than the critical value. We discuss the p-value and rejection region in more detail in the next section.
- Make a decision about the null hypothesis: In this step, we decide to either reject the null hypothesis or decide to fail to reject the null hypothesis. Notice we do not make a decision where we will accept the null hypothesis.
- State an overall conclusion : Once we have found the p-value or rejection region, and made a statistical decision about the null hypothesis (i.e. we will reject the null or fail to reject the null), we then want to summarize our results into an overall conclusion for our test.
We will follow these six steps for the remainder of this Lesson. In the future Lessons, the steps will be followed but may not be explained explicitly.
Step 1 is a very important step to set up correctly. If your hypotheses are incorrect, your conclusion will be incorrect. In this next section, we practice with Step 1 for the one sample situations.
Hypothesis Testing
Hypothesis testing is a tool for making statistical inferences about the population data. It is an analysis tool that tests assumptions and determines how likely something is within a given standard of accuracy. Hypothesis testing provides a way to verify whether the results of an experiment are valid.
A null hypothesis and an alternative hypothesis are set up before performing the hypothesis testing. This helps to arrive at a conclusion regarding the sample obtained from the population. In this article, we will learn more about hypothesis testing, its types, steps to perform the testing, and associated examples.
What is Hypothesis Testing in Statistics?
Hypothesis testing uses sample data from the population to draw useful conclusions regarding the population probability distribution . It tests an assumption made about the data using different types of hypothesis testing methodologies. The hypothesis testing results in either rejecting or not rejecting the null hypothesis.
Hypothesis Testing Definition
Hypothesis testing can be defined as a statistical tool that is used to identify if the results of an experiment are meaningful or not. It involves setting up a null hypothesis and an alternative hypothesis. These two hypotheses will always be mutually exclusive. This means that if the null hypothesis is true then the alternative hypothesis is false and vice versa. An example of hypothesis testing is setting up a test to check if a new medicine works on a disease in a more efficient manner.
Null Hypothesis
The null hypothesis is a concise mathematical statement that is used to indicate that there is no difference between two possibilities. In other words, there is no difference between certain characteristics of data. This hypothesis assumes that the outcomes of an experiment are based on chance alone. It is denoted as \(H_{0}\). Hypothesis testing is used to conclude if the null hypothesis can be rejected or not. Suppose an experiment is conducted to check if girls are shorter than boys at the age of 5. The null hypothesis will say that they are the same height.
Alternative Hypothesis
The alternative hypothesis is an alternative to the null hypothesis. It is used to show that the observations of an experiment are due to some real effect. It indicates that there is a statistical significance between two possible outcomes and can be denoted as \(H_{1}\) or \(H_{a}\). For the above-mentioned example, the alternative hypothesis would be that girls are shorter than boys at the age of 5.
Hypothesis Testing P Value
In hypothesis testing, the p value is used to indicate whether the results obtained after conducting a test are statistically significant or not. It also indicates the probability of making an error in rejecting or not rejecting the null hypothesis.This value is always a number between 0 and 1. The p value is compared to an alpha level, \(\alpha\) or significance level. The alpha level can be defined as the acceptable risk of incorrectly rejecting the null hypothesis. The alpha level is usually chosen between 1% to 5%.
Hypothesis Testing Critical region
All sets of values that lead to rejecting the null hypothesis lie in the critical region. Furthermore, the value that separates the critical region from the non-critical region is known as the critical value.
Hypothesis Testing Formula
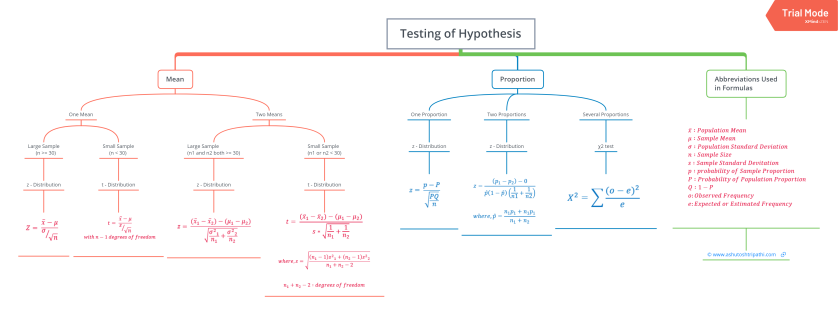
Depending upon the type of data available and the size, different types of hypothesis testing are used to determine whether the null hypothesis can be rejected or not. The hypothesis testing formula for some important test statistics are given below:
- z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\). \(\overline{x}\) is the sample mean, \(\mu\) is the population mean, \(\sigma\) is the population standard deviation and n is the size of the sample.
- t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\). s is the sample standard deviation.
- \(\chi ^{2} = \sum \frac{(O_{i}-E_{i})^{2}}{E_{i}}\). \(O_{i}\) is the observed value and \(E_{i}\) is the expected value.
We will learn more about these test statistics in the upcoming section.
Types of Hypothesis Testing
Selecting the correct test for performing hypothesis testing can be confusing. These tests are used to determine a test statistic on the basis of which the null hypothesis can either be rejected or not rejected. Some of the important tests used for hypothesis testing are given below.
Hypothesis Testing Z Test
A z test is a way of hypothesis testing that is used for a large sample size (n ≥ 30). It is used to determine whether there is a difference between the population mean and the sample mean when the population standard deviation is known. It can also be used to compare the mean of two samples. It is used to compute the z test statistic. The formulas are given as follows:
- One sample: z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
- Two samples: z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing t Test
The t test is another method of hypothesis testing that is used for a small sample size (n < 30). It is also used to compare the sample mean and population mean. However, the population standard deviation is not known. Instead, the sample standard deviation is known. The mean of two samples can also be compared using the t test.
- One sample: t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\).
- Two samples: t = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{s_{1}^{2}}{n_{1}}+\frac{s_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing Chi Square
The Chi square test is a hypothesis testing method that is used to check whether the variables in a population are independent or not. It is used when the test statistic is chi-squared distributed.
One Tailed Hypothesis Testing
One tailed hypothesis testing is done when the rejection region is only in one direction. It can also be known as directional hypothesis testing because the effects can be tested in one direction only. This type of testing is further classified into the right tailed test and left tailed test.
Right Tailed Hypothesis Testing
The right tail test is also known as the upper tail test. This test is used to check whether the population parameter is greater than some value. The null and alternative hypotheses for this test are given as follows:
\(H_{0}\): The population parameter is ≤ some value
\(H_{1}\): The population parameter is > some value.
If the test statistic has a greater value than the critical value then the null hypothesis is rejected

Left Tailed Hypothesis Testing
The left tail test is also known as the lower tail test. It is used to check whether the population parameter is less than some value. The hypotheses for this hypothesis testing can be written as follows:
\(H_{0}\): The population parameter is ≥ some value
\(H_{1}\): The population parameter is < some value.
The null hypothesis is rejected if the test statistic has a value lesser than the critical value.

Two Tailed Hypothesis Testing
In this hypothesis testing method, the critical region lies on both sides of the sampling distribution. It is also known as a non - directional hypothesis testing method. The two-tailed test is used when it needs to be determined if the population parameter is assumed to be different than some value. The hypotheses can be set up as follows:
\(H_{0}\): the population parameter = some value
\(H_{1}\): the population parameter ≠ some value
The null hypothesis is rejected if the test statistic has a value that is not equal to the critical value.

Hypothesis Testing Steps
Hypothesis testing can be easily performed in five simple steps. The most important step is to correctly set up the hypotheses and identify the right method for hypothesis testing. The basic steps to perform hypothesis testing are as follows:
- Step 1: Set up the null hypothesis by correctly identifying whether it is the left-tailed, right-tailed, or two-tailed hypothesis testing.
- Step 2: Set up the alternative hypothesis.
- Step 3: Choose the correct significance level, \(\alpha\), and find the critical value.
- Step 4: Calculate the correct test statistic (z, t or \(\chi\)) and p-value.
- Step 5: Compare the test statistic with the critical value or compare the p-value with \(\alpha\) to arrive at a conclusion. In other words, decide if the null hypothesis is to be rejected or not.
Hypothesis Testing Example
The best way to solve a problem on hypothesis testing is by applying the 5 steps mentioned in the previous section. Suppose a researcher claims that the mean average weight of men is greater than 100kgs with a standard deviation of 15kgs. 30 men are chosen with an average weight of 112.5 Kgs. Using hypothesis testing, check if there is enough evidence to support the researcher's claim. The confidence interval is given as 95%.
Step 1: This is an example of a right-tailed test. Set up the null hypothesis as \(H_{0}\): \(\mu\) = 100.
Step 2: The alternative hypothesis is given by \(H_{1}\): \(\mu\) > 100.
Step 3: As this is a one-tailed test, \(\alpha\) = 100% - 95% = 5%. This can be used to determine the critical value.
1 - \(\alpha\) = 1 - 0.05 = 0.95
0.95 gives the required area under the curve. Now using a normal distribution table, the area 0.95 is at z = 1.645. A similar process can be followed for a t-test. The only additional requirement is to calculate the degrees of freedom given by n - 1.
Step 4: Calculate the z test statistic. This is because the sample size is 30. Furthermore, the sample and population means are known along with the standard deviation.
z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
\(\mu\) = 100, \(\overline{x}\) = 112.5, n = 30, \(\sigma\) = 15
z = \(\frac{112.5-100}{\frac{15}{\sqrt{30}}}\) = 4.56
Step 5: Conclusion. As 4.56 > 1.645 thus, the null hypothesis can be rejected.
Hypothesis Testing and Confidence Intervals
Confidence intervals form an important part of hypothesis testing. This is because the alpha level can be determined from a given confidence interval. Suppose a confidence interval is given as 95%. Subtract the confidence interval from 100%. This gives 100 - 95 = 5% or 0.05. This is the alpha value of a one-tailed hypothesis testing. To obtain the alpha value for a two-tailed hypothesis testing, divide this value by 2. This gives 0.05 / 2 = 0.025.
Related Articles:
- Probability and Statistics
- Data Handling
Important Notes on Hypothesis Testing
- Hypothesis testing is a technique that is used to verify whether the results of an experiment are statistically significant.
- It involves the setting up of a null hypothesis and an alternate hypothesis.
- There are three types of tests that can be conducted under hypothesis testing - z test, t test, and chi square test.
- Hypothesis testing can be classified as right tail, left tail, and two tail tests.
Examples on Hypothesis Testing
- Example 1: The average weight of a dumbbell in a gym is 90lbs. However, a physical trainer believes that the average weight might be higher. A random sample of 5 dumbbells with an average weight of 110lbs and a standard deviation of 18lbs. Using hypothesis testing check if the physical trainer's claim can be supported for a 95% confidence level. Solution: As the sample size is lesser than 30, the t-test is used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) > 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 5, s = 18. \(\alpha\) = 0.05 Using the t-distribution table, the critical value is 2.132 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = 2.484 As 2.484 > 2.132, the null hypothesis is rejected. Answer: The average weight of the dumbbells may be greater than 90lbs
- Example 2: The average score on a test is 80 with a standard deviation of 10. With a new teaching curriculum introduced it is believed that this score will change. On random testing, the score of 38 students, the mean was found to be 88. With a 0.05 significance level, is there any evidence to support this claim? Solution: This is an example of two-tail hypothesis testing. The z test will be used. \(H_{0}\): \(\mu\) = 80, \(H_{1}\): \(\mu\) ≠ 80 \(\overline{x}\) = 88, \(\mu\) = 80, n = 36, \(\sigma\) = 10. \(\alpha\) = 0.05 / 2 = 0.025 The critical value using the normal distribution table is 1.96 z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) z = \(\frac{88-80}{\frac{10}{\sqrt{36}}}\) = 4.8 As 4.8 > 1.96, the null hypothesis is rejected. Answer: There is a difference in the scores after the new curriculum was introduced.
- Example 3: The average score of a class is 90. However, a teacher believes that the average score might be lower. The scores of 6 students were randomly measured. The mean was 82 with a standard deviation of 18. With a 0.05 significance level use hypothesis testing to check if this claim is true. Solution: The t test will be used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) < 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 6, s = 18 The critical value from the t table is -2.015 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = \(\frac{82-90}{\frac{18}{\sqrt{6}}}\) t = -1.088 As -1.088 > -2.015, we fail to reject the null hypothesis. Answer: There is not enough evidence to support the claim.
go to slide go to slide go to slide

Book a Free Trial Class
FAQs on Hypothesis Testing
What is hypothesis testing.
Hypothesis testing in statistics is a tool that is used to make inferences about the population data. It is also used to check if the results of an experiment are valid.
What is the z Test in Hypothesis Testing?
The z test in hypothesis testing is used to find the z test statistic for normally distributed data . The z test is used when the standard deviation of the population is known and the sample size is greater than or equal to 30.
What is the t Test in Hypothesis Testing?
The t test in hypothesis testing is used when the data follows a student t distribution . It is used when the sample size is less than 30 and standard deviation of the population is not known.
What is the formula for z test in Hypothesis Testing?
The formula for a one sample z test in hypothesis testing is z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) and for two samples is z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
What is the p Value in Hypothesis Testing?
The p value helps to determine if the test results are statistically significant or not. In hypothesis testing, the null hypothesis can either be rejected or not rejected based on the comparison between the p value and the alpha level.
What is One Tail Hypothesis Testing?
When the rejection region is only on one side of the distribution curve then it is known as one tail hypothesis testing. The right tail test and the left tail test are two types of directional hypothesis testing.
What is the Alpha Level in Two Tail Hypothesis Testing?
To get the alpha level in a two tail hypothesis testing divide \(\alpha\) by 2. This is done as there are two rejection regions in the curve.
- Business Essentials
- Leadership & Management
- Credential of Leadership, Impact, and Management in Business (CLIMB)
- Entrepreneurship & Innovation
- *New* Digital Transformation
- Finance & Accounting
- Business in Society
- For Organizations
- Support Portal
- Media Coverage
- Founding Donors
- Leadership Team

- Harvard Business School →
- HBS Online →
- Business Insights →
Business Insights
Harvard Business School Online's Business Insights Blog provides the career insights you need to achieve your goals and gain confidence in your business skills.
- Career Development
- Communication
- Decision-Making
- Earning Your MBA
- Negotiation
- News & Events
- Productivity
- Staff Spotlight
- Student Profiles
- Work-Life Balance
- Alternative Investments
- Business Analytics
- Business Strategy
- Business and Climate Change
- Design Thinking and Innovation
- Digital Marketing Strategy
- Disruptive Strategy
- Economics for Managers
- Entrepreneurship Essentials
- Financial Accounting
- Global Business
- Launching Tech Ventures
- Leadership Principles
- Leadership, Ethics, and Corporate Accountability
- Leading with Finance
- Management Essentials
- Negotiation Mastery
- Organizational Leadership
- Power and Influence for Positive Impact
- Strategy Execution
- Sustainable Business Strategy
- Sustainable Investing
- Winning with Digital Platforms
A Beginner’s Guide to Hypothesis Testing in Business

- 30 Mar 2021
Becoming a more data-driven decision-maker can bring several benefits to your organization, enabling you to identify new opportunities to pursue and threats to abate. Rather than allowing subjective thinking to guide your business strategy, backing your decisions with data can empower your company to become more innovative and, ultimately, profitable.
If you’re new to data-driven decision-making, you might be wondering how data translates into business strategy. The answer lies in generating a hypothesis and verifying or rejecting it based on what various forms of data tell you.
Below is a look at hypothesis testing and the role it plays in helping businesses become more data-driven.
Access your free e-book today.
What Is Hypothesis Testing?
To understand what hypothesis testing is, it’s important first to understand what a hypothesis is.
A hypothesis or hypothesis statement seeks to explain why something has happened, or what might happen, under certain conditions. It can also be used to understand how different variables relate to each other. Hypotheses are often written as if-then statements; for example, “If this happens, then this will happen.”
Hypothesis testing , then, is a statistical means of testing an assumption stated in a hypothesis. While the specific methodology leveraged depends on the nature of the hypothesis and data available, hypothesis testing typically uses sample data to extrapolate insights about a larger population.
Hypothesis Testing in Business
When it comes to data-driven decision-making, there’s a certain amount of risk that can mislead a professional. This could be due to flawed thinking or observations, incomplete or inaccurate data , or the presence of unknown variables. The danger in this is that, if major strategic decisions are made based on flawed insights, it can lead to wasted resources, missed opportunities, and catastrophic outcomes.
The real value of hypothesis testing in business is that it allows professionals to test their theories and assumptions before putting them into action. This essentially allows an organization to verify its analysis is correct before committing resources to implement a broader strategy.
As one example, consider a company that wishes to launch a new marketing campaign to revitalize sales during a slow period. Doing so could be an incredibly expensive endeavor, depending on the campaign’s size and complexity. The company, therefore, may wish to test the campaign on a smaller scale to understand how it will perform.
In this example, the hypothesis that’s being tested would fall along the lines of: “If the company launches a new marketing campaign, then it will translate into an increase in sales.” It may even be possible to quantify how much of a lift in sales the company expects to see from the effort. Pending the results of the pilot campaign, the business would then know whether it makes sense to roll it out more broadly.
Related: 9 Fundamental Data Science Skills for Business Professionals
Key Considerations for Hypothesis Testing
1. alternative hypothesis and null hypothesis.
In hypothesis testing, the hypothesis that’s being tested is known as the alternative hypothesis . Often, it’s expressed as a correlation or statistical relationship between variables. The null hypothesis , on the other hand, is a statement that’s meant to show there’s no statistical relationship between the variables being tested. It’s typically the exact opposite of whatever is stated in the alternative hypothesis.
For example, consider a company’s leadership team that historically and reliably sees $12 million in monthly revenue. They want to understand if reducing the price of their services will attract more customers and, in turn, increase revenue.
In this case, the alternative hypothesis may take the form of a statement such as: “If we reduce the price of our flagship service by five percent, then we’ll see an increase in sales and realize revenues greater than $12 million in the next month.”
The null hypothesis, on the other hand, would indicate that revenues wouldn’t increase from the base of $12 million, or might even decrease.
Check out the video below about the difference between an alternative and a null hypothesis, and subscribe to our YouTube channel for more explainer content.
2. Significance Level and P-Value
Statistically speaking, if you were to run the same scenario 100 times, you’d likely receive somewhat different results each time. If you were to plot these results in a distribution plot, you’d see the most likely outcome is at the tallest point in the graph, with less likely outcomes falling to the right and left of that point.

With this in mind, imagine you’ve completed your hypothesis test and have your results, which indicate there may be a correlation between the variables you were testing. To understand your results' significance, you’ll need to identify a p-value for the test, which helps note how confident you are in the test results.
In statistics, the p-value depicts the probability that, assuming the null hypothesis is correct, you might still observe results that are at least as extreme as the results of your hypothesis test. The smaller the p-value, the more likely the alternative hypothesis is correct, and the greater the significance of your results.
3. One-Sided vs. Two-Sided Testing
When it’s time to test your hypothesis, it’s important to leverage the correct testing method. The two most common hypothesis testing methods are one-sided and two-sided tests , or one-tailed and two-tailed tests, respectively.
Typically, you’d leverage a one-sided test when you have a strong conviction about the direction of change you expect to see due to your hypothesis test. You’d leverage a two-sided test when you’re less confident in the direction of change.

4. Sampling
To perform hypothesis testing in the first place, you need to collect a sample of data to be analyzed. Depending on the question you’re seeking to answer or investigate, you might collect samples through surveys, observational studies, or experiments.
A survey involves asking a series of questions to a random population sample and recording self-reported responses.
Observational studies involve a researcher observing a sample population and collecting data as it occurs naturally, without intervention.
Finally, an experiment involves dividing a sample into multiple groups, one of which acts as the control group. For each non-control group, the variable being studied is manipulated to determine how the data collected differs from that of the control group.

Learn How to Perform Hypothesis Testing
Hypothesis testing is a complex process involving different moving pieces that can allow an organization to effectively leverage its data and inform strategic decisions.
If you’re interested in better understanding hypothesis testing and the role it can play within your organization, one option is to complete a course that focuses on the process. Doing so can lay the statistical and analytical foundation you need to succeed.
Do you want to learn more about hypothesis testing? Explore Business Analytics —one of our online business essentials courses —and download our Beginner’s Guide to Data & Analytics .

About the Author

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
9. Hypothesis Testing
9.1 Hypothesis Testing Problem Solving Steps

- Interpretation : Summarize results in a sentence and/or present a graphic or table.
A generic test statistic may be defined by :
![\[\mbox{test value} = \frac{\mbox{(observed value)} - \mbox{(expected }H_{0} \mbox{ value)}}{\mbox{standard error}}.\]](https://openpress.usask.ca/app/uploads/quicklatex/quicklatex.com-4a09ca07d9b70473d898640a85e0c19c_l3.png "Rendered by QuickLaTeX.com")
Introduction to Applied Statistics for Psychology Students Copyright © 2022 by Gordon E. Sarty is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Forgot password? New user? Sign up
Existing user? Log in
Hypothesis Testing
Already have an account? Log in here.
A hypothesis test is a statistical inference method used to test the significance of a proposed (hypothesized) relation between population statistics (parameters) and their corresponding sample estimators . In other words, hypothesis tests are used to determine if there is enough evidence in a sample to prove a hypothesis true for the entire population.
The test considers two hypotheses: the null hypothesis , which is a statement meant to be tested, usually something like "there is no effect" with the intention of proving this false, and the alternate hypothesis , which is the statement meant to stand after the test is performed. The two hypotheses must be mutually exclusive ; moreover, in most applications, the two are complementary (one being the negation of the other). The test works by comparing the \(p\)-value to the level of significance (a chosen target). If the \(p\)-value is less than or equal to the level of significance, then the null hypothesis is rejected.
When analyzing data, only samples of a certain size might be manageable as efficient computations. In some situations the error terms follow a continuous or infinite distribution, hence the use of samples to suggest accuracy of the chosen test statistics. The method of hypothesis testing gives an advantage over guessing what distribution or which parameters the data follows.
Definitions and Methodology
Hypothesis test and confidence intervals.
In statistical inference, properties (parameters) of a population are analyzed by sampling data sets. Given assumptions on the distribution, i.e. a statistical model of the data, certain hypotheses can be deduced from the known behavior of the model. These hypotheses must be tested against sampled data from the population.
The null hypothesis \((\)denoted \(H_0)\) is a statement that is assumed to be true. If the null hypothesis is rejected, then there is enough evidence (statistical significance) to accept the alternate hypothesis \((\)denoted \(H_1).\) Before doing any test for significance, both hypotheses must be clearly stated and non-conflictive, i.e. mutually exclusive, statements. Rejecting the null hypothesis, given that it is true, is called a type I error and it is denoted \(\alpha\), which is also its probability of occurrence. Failing to reject the null hypothesis, given that it is false, is called a type II error and it is denoted \(\beta\), which is also its probability of occurrence. Also, \(\alpha\) is known as the significance level , and \(1-\beta\) is known as the power of the test. \(H_0\) \(\textbf{is true}\)\(\hspace{15mm}\) \(H_0\) \(\textbf{is false}\) \(\textbf{Reject}\) \(H_0\)\(\hspace{10mm}\) Type I error Correct Decision \(\textbf{Reject}\) \(H_1\) Correct Decision Type II error The test statistic is the standardized value following the sampled data under the assumption that the null hypothesis is true, and a chosen particular test. These tests depend on the statistic to be studied and the assumed distribution it follows, e.g. the population mean following a normal distribution. The \(p\)-value is the probability of observing an extreme test statistic in the direction of the alternate hypothesis, given that the null hypothesis is true. The critical value is the value of the assumed distribution of the test statistic such that the probability of making a type I error is small.
Methodologies: Given an estimator \(\hat \theta\) of a population statistic \(\theta\), following a probability distribution \(P(T)\), computed from a sample \(\mathcal{S},\) and given a significance level \(\alpha\) and test statistic \(t^*,\) define \(H_0\) and \(H_1;\) compute the test statistic \(t^*.\) \(p\)-value Approach (most prevalent): Find the \(p\)-value using \(t^*\) (right-tailed). If the \(p\)-value is at most \(\alpha,\) reject \(H_0\). Otherwise, reject \(H_1\). Critical Value Approach: Find the critical value solving the equation \(P(T\geq t_\alpha)=\alpha\) (right-tailed). If \(t^*>t_\alpha\), reject \(H_0\). Otherwise, reject \(H_1\). Note: Failing to reject \(H_0\) only means inability to accept \(H_1\), and it does not mean to accept \(H_0\).
Assume a normally distributed population has recorded cholesterol levels with various statistics computed. From a sample of 100 subjects in the population, the sample mean was 214.12 mg/dL (milligrams per deciliter), with a sample standard deviation of 45.71 mg/dL. Perform a hypothesis test, with significance level 0.05, to test if there is enough evidence to conclude that the population mean is larger than 200 mg/dL. Hypothesis Test We will perform a hypothesis test using the \(p\)-value approach with significance level \(\alpha=0.05:\) Define \(H_0\): \(\mu=200\). Define \(H_1\): \(\mu>200\). Since our values are normally distributed, the test statistic is \(z^*=\frac{\bar X - \mu_0}{\frac{s}{\sqrt{n}}}=\frac{214.12 - 200}{\frac{45.71}{\sqrt{100}}}\approx 3.09\). Using a standard normal distribution, we find that our \(p\)-value is approximately \(0.001\). Since the \(p\)-value is at most \(\alpha=0.05,\) we reject \(H_0\). Therefore, we can conclude that the test shows sufficient evidence to support the claim that \(\mu\) is larger than \(200\) mg/dL.
If the sample size was smaller, the normal and \(t\)-distributions behave differently. Also, the question itself must be managed by a double-tail test instead.
Assume a population's cholesterol levels are recorded and various statistics are computed. From a sample of 25 subjects, the sample mean was 214.12 mg/dL (milligrams per deciliter), with a sample standard deviation of 45.71 mg/dL. Perform a hypothesis test, with significance level 0.05, to test if there is enough evidence to conclude that the population mean is not equal to 200 mg/dL. Hypothesis Test We will perform a hypothesis test using the \(p\)-value approach with significance level \(\alpha=0.05\) and the \(t\)-distribution with 24 degrees of freedom: Define \(H_0\): \(\mu=200\). Define \(H_1\): \(\mu\neq 200\). Using the \(t\)-distribution, the test statistic is \(t^*=\frac{\bar X - \mu_0}{\frac{s}{\sqrt{n}}}=\frac{214.12 - 200}{\frac{45.71}{\sqrt{25}}}\approx 1.54\). Using a \(t\)-distribution with 24 degrees of freedom, we find that our \(p\)-value is approximately \(2(0.068)=0.136\). We have multiplied by two since this is a two-tailed argument, i.e. the mean can be smaller than or larger than. Since the \(p\)-value is larger than \(\alpha=0.05,\) we fail to reject \(H_0\). Therefore, the test does not show sufficient evidence to support the claim that \(\mu\) is not equal to \(200\) mg/dL.
The complement of the rejection on a two-tailed hypothesis test (with significance level \(\alpha\)) for a population parameter \(\theta\) is equivalent to finding a confidence interval \((\)with confidence level \(1-\alpha)\) for the population parameter \(\theta\). If the assumption on the parameter \(\theta\) falls inside the confidence interval, then the test has failed to reject the null hypothesis \((\)with \(p\)-value greater than \(\alpha).\) Otherwise, if \(\theta\) does not fall in the confidence interval, then the null hypothesis is rejected in favor of the alternate \((\)with \(p\)-value at most \(\alpha).\)
- Statistics (Estimation)
- Normal Distribution
- Correlation
- Confidence Intervals
Problem Loading...
Note Loading...
Set Loading...
The Genius Blog
Hypothesis Testing Solved Examples(Questions and Solutions)
Here is a list hypothesis testing exercises and solutions. Try to solve a question by yourself first before you look at the solution.
Question 1 In the population, the average IQ is 100 with a standard deviation of 15. A team of scientists want to test a new medication to see if it has either a positive or negative effect on intelligence, or not effect at all. A sample of 30 participants who have taken the medication has a mean of 140. Did the medication affect intelligence? View Solution to Question 1
A professor wants to know if her introductory statistics class has a good grasp of basic math. Six students are chosen at random from the class and given a math proficiency test. The professor wants the class to be able to score above 70 on the test. The six students get the following scores:62, 92, 75, 68, 83, 95. Can the professor have 90% confidence that the mean score for the class on the test would be above 70. Solution to Question 2
Question 3 In a packaging plant, a machine packs cartons with jars. It is supposed that a new machine would pack faster on the average than the machine currently used. To test the hypothesis, the time it takes each machine to pack ten cartons are recorded. The result in seconds is as follows.
Do the data provide sufficient evidence to conclude that, on the average, the new machine packs faster? Perform the required hypothesis test at the 5% level of significance. Solution to Question 3
Question 4 We want to compare the heights in inches of two groups of individuals. Here are the measurements: X: 175, 168, 168, 190, 156, 181, 182, 175, 174, 179 Y: 120, 180, 125, 188, 130, 190, 110, 185, 112, 188 Solution to Question 4
Question 5 A clinic provides a program to help their clients lose weight and asks a consumer agency to investigate the effectiveness of the program. The agency takes a sample of 15 people, weighing each person in the sample before the program begins and 3 months later. The results a tabulated below
Determine is the program is effective. Solution to Question 5
Question 6 A sample of 20 students were selected and given a diagnostic module prior to studying for a test. And then they were given the test again after completing the module. . The result of the students scores in the test before and after the test is tabulated below.
We want to see if there is significant improvement in the student’s performance due to this teaching method Solution to Question 6
Question 7 A study was performed to test wether cars get better mileage on premium gas than on regular gas. Each of 10 cars was first filled with regular or premium gas, decided by a coin toss, and the mileage for the tank was recorded. The mileage was recorded again for the same cars using other kind of gasoline. Determine wether cars get significantly better mileage with premium gas.
Mileage with regular gas: 16,20,21,22,23,22,27,25,27,28 Mileage with premium gas: 19, 22,24,24,25,25,26,26,28,32 Solution to Question 7
Question 8 An automatic cutter machine must cut steel strips of 1200 mm length. From a preliminary data, we checked that the lengths of the pieces produced by the machine can be considered as normal random variables with a 3mm standard deviation. We want to make sure that the machine is set correctly. Therefore 16 pieces of the products are randomly selected and weight. The figures were in mm: 1193,1196,1198,1195,1198,1199,1204,1193,1203,1201,1196,1200,1191,1196,1198,1191 Examine wether there is any significant deviation from the required size Solution to Question 8
Question 9 Blood pressure reading of ten patients before and after medication for reducing the blood pressure are as follows
Patient: 1,2,3,4,5,6,7,8,9,10 Before treatment: 86,84,78,90,92,77,89,90,90,86 After treatment: 80,80,92,79,92,82,88,89,92,83
Test the null hypothesis of no effect agains the alternate hypothesis that medication is effective. Execute it with Wilcoxon test Solution to Question 9
Question on ANOVA Sussan Sound predicts that students will learn most effectively with a constant background sound, as opposed to an unpredictable sound or no sound at all. She randomly divides 24 students into three groups of 8 each. All students study a passage of text for 30 minutes. Those in group 1 study with background sound at a constant volume in the background. Those in group 2 study with nose that changes volume periodically. Those in group 3 study with no sound at all. After studying, all students take a 10 point multiple choice test over the material. Their scores are tabulated below.
Group1: Constant sound: 7,4,6,8,6,6,2,9 Group 2: Random sound: 5,5,3,4,4,7,2,2 Group 3: No sound at all: 2,4,7,1,2,1,5,5 Solution to Question 10
Question 11 Using the following three groups of data, perform a one-way analysis of variance using α = 0.05.
Solution to Question 11
Question 12 In a packaging plant, a machine packs cartons with jars. It is supposed that a new machine would pack faster on the average than the machine currently used. To test the hypothesis, the time it takes each machine to pack ten cartons are recorded. The result in seconds is as follows.
New Machine: 42,41,41.3,41.8,42.4,42.8,43.2,42.3,41.8,42.7 Old Machine: 42.7,43.6,43.8,43.3,42.5,43.5,43.1,41.7,44,44.1
Perform an F-test to determine if the null hypothesis should be accepted. Solution to Question 12
Question 13 A random sample 500 U.S adults are questioned about their political affiliation and opinion on a tax reform bill. We need to test if the political affiliation and their opinon on a tax reform bill are dependent, at 5% level of significance. The observed contingency table is given below.
Solution to Question 13
Question 14 Can a dice be considered regular which is showing the following frequency distribution during 1000 throws?
Solution to Question 14
Solution to Question 15
Question 16 A newly developed muesli contains five types of seeds (A, B, C, D and E). The percentage of which is 35%, 25%, 20%, 10% and 10% according to the product information. In a randomly selected muesli, the following volume distribution was found.
Lets us decide about the null hypothesis whether the composition of the sample corresponds to the distribution indicated on the packaging at alpha = 0.1 significance level. Solution to Question 16
Question 17 A research team investigated whether there was any significant correlation between the severity of a certain disease runoff and the age of the patients. During the study, data for n = 200 patients were collected and grouped according to the severity of the disease and the age of the patient. The table below shows the result
Let us decided about the correlation between the age of the patients and the severity of disease progression. Solution to Question 17
Question 18 A publisher is interested in determine which of three book cover is most attractive. He interviews 400 people in each of the three states (California, Illinois and New York), and asks each person which of the cover he or she prefers. The number of preference for each cover is as follows:
Do these data indicate that there are regional differences in people’s preferences concerning these covers? Use the 0.05 level of significance. Solution to Question 18
Question 19 Trees planted along the road were checked for which ones are healthy(H) or diseased (D) and the following arrangement of the trees were obtained:
H H H H D D D H H H H H H H D D H H D D D
Test at the = 0.05 significance wether this arrangement may be regarded as random
Solution to Question 19
Question 20 Suppose we flip a coin n = 15 times and come up with the following arrangements
H T T T H H T T T T H H T H H
(H = head, T = tail)
Test at the alpha = 0.05 significance level whether this arrangement may be regarded as random.
Solution to Question 20
kindsonthegenius
You might also like, hypothesis testing question 20 – run test( suppose we flip a coin…), what is run test in statistics – a simple explanation with step by step examples, hypothesis testing question 21 – wald-wolfowitz run test for large sample (step by step procedure).
I am really impressed with your writing abilities as well as with the structure to your weblog. Is this a paid subject matter or did you modify it yourself?
Either way stay up the excellent high quality writing, it’s uncommon to look a great blog like this one these days..
Below are given the gain in weights (in lbs.) of pigs fed on two diet A and B Dieta 25 32 30 34 24 14 32 24 30 31 35 25 – – DietB 44 34 22 10 47 31 40 30 32 35 18 21 35 29
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
Statistics and probability
Course: statistics and probability > unit 12, simple hypothesis testing.
- Idea behind hypothesis testing
- Examples of null and alternative hypotheses
- Writing null and alternative hypotheses
- P-values and significance tests
- Comparing P-values to different significance levels
- Estimating a P-value from a simulation
- Estimating P-values from simulations
- Using P-values to make conclusions
- Your answer should be
- an integer, like 6
- an exact decimal, like 0.75
- a simplified proper fraction, like 3 / 5
- a simplified improper fraction, like 7 / 4
- a mixed number, like 1 3 / 4
- a percent, like 12.34 %
- (Choice A) We cannot reject the hypothesis. A We cannot reject the hypothesis.
- (Choice B) We should reject the hypothesis. B We should reject the hypothesis.
Data Science Duniya
Learn Data Science, Machine Learning and Artificial Intelligence
Practice Problems on Hypothesis Testing
In this post I have put together the practice problems (from my academics study notes) to explain how in practical Hypothesis Testing works. This post is written mostly for the learners who want to deep dive into the statistics for data science. Focus will be on problem solving. For concepts please refer my previous posts on testing of hypothesis.
Prerequisite to understand Hypothesis testing examples:
- Understanding of hypothesis testing concepts
- How to use z-table, t-table and chi square table.
Formula list:
Critical Regions
In hypothesis testing, critical region is represented by set of values, where null hypothesis is rejected. So it is also know as region of rejection. It takes different boundary values for different level of significance. Below info graphics shows the region of rejection that is critical region and region of acceptance with respect to the level of significance 1%.

A Telecom service provider claims that individual customers pay on an average 400 rs. per month with standard deviation of 25 rs. A random sample of 50 customers bills during a given month is taken with a mean of 250 and standard deviation of 15. What to say with respect to the claim made by the service provider?

From the data available, it is observed that 400 out of 850 customers purchased the groceries online. Can we say that most of the customers are moving towards online shopping even for groceries?

It is found that 250 errors in the randomly selected 1000 lines of code from Team A and 300 errors in 800 lines of code from Team B. Can we assume that team B’s performance is superior to that of A.

Following is the record of number of accidents took place during the various days of the week.
Can we conclude that accident s are independent of the day of week?

Analyze the below data and tell whether you can conclude that smoking causes cancer or not?

It is claimed that the mean of the population is 67 at 5% level of significance. Mean obtained from a random sample of size 100 is 64 with SD 3. Validate the claim.

There is an assumption that there is no significant difference between boys and girls with respect to intelligence. Tests are conducted on two groups and the following are the observations
Validate the claim with 5% LoS (Level of Significance)

An automobile tyre manufacturer claims that the average life of a particular grade of tyre is more than 20,000 km. A random sample of 16 tyres is having mean 22,000 km with a standard deviation of 5000 km.
Validate the claim of the manufacturer at 5% LoS.

That is all for now. Please share your thoughts using the comment section below.
Type your email…
Share this:
- Click to share on Twitter (Opens in new window)
- Click to share on Facebook (Opens in new window)
- Click to print (Opens in new window)
- Click to email a link to a friend (Opens in new window)
- Click to share on LinkedIn (Opens in new window)
- Click to share on Reddit (Opens in new window)
- Click to share on WhatsApp (Opens in new window)
- Click to share on Tumblr (Opens in new window)
- Click to share on Pinterest (Opens in new window)
- Click to share on Pocket (Opens in new window)
- Click to share on Telegram (Opens in new window)
I think smoking problem is wrongly concluded. There the H0 is assumed of dependency(smoking and cancer are dependent) while for chi square test, the null hypothesis is always for independence. So the H0 should be “Smoking and Cancer are independent”.
Please how can I download this page?
In the last sum the alternate hypothesis is less than 22,000 and the null hypothesis is more than 20,000. If the value turns out to be 21,000 then which hypothesis will you accept? I guess there’s an error, the alternate hypothesis should be less than equal to 20,000 and not 22,000. Correct me if I’m wrong.
Thanks for presenting above test cases, it really really helps to understand the tail concept. I am reading z-test and refer your hypothesis page as an example. I go through z-test example and in example no.8 last one it is “One tail – Left tailed test” but in the diag below it shows the right tailed. Not sure am I interpret wrong or diag error ? pls . correct me. Thanks.
The alternate hypothesis is the opposite of null hypothesis so it’s less less than or left tailed. Since the null hypothesis was accepted the graph is Right Tailed had the null hypothesis been rejected or the alternate hypothesis been accepted the graph would have been left tailed. I hope I cleared your doubt
Leave a Reply Cancel reply
This site uses Akismet to reduce spam. Learn how your comment data is processed .

- Already have a WordPress.com account? Log in now.
- Subscribe Subscribed
- Copy shortlink
- Report this content
- View post in Reader
- Manage subscriptions
- Collapse this bar
with Answer, Solution | Statistical Inference - Hypothesis Testing: Solved Example Problems | 12th Business Maths and Statistics : Chapter 8 : Sampling Techniques and Statistical Inference
Chapter: 12th business maths and statistics : chapter 8 : sampling techniques and statistical inference, hypothesis testing: solved example problems.
Example 8.14
An auto company decided to introduce a new six cylinder car whose mean petrol consumption is claimed to be lower than that of the existing auto engine. It was found that the mean petrol consumption for the 50 cars was 10 km per litre with a standard deviation of 3.5 km per litre. Test at 5% level of significance, whether the claim of the new car petrol consumption is 9.5 km per litre on the average is acceptable.
Population mean μ = 9.5 km
Since population SD is unknown we consider σ = s
The sample is a large sample and so we apply Z-test
Null Hypothesis: There is no significant difference between the sample average and the company’s claim, i.e., H 0 : μ = 9.5
Alternative Hypothesis: There is significant difference between the sample average and the company’s claim, i.e., H 1 : μ ≠ 9.5 (two tailed test)
The level of significance α = 5% = 0.05
Applying the test statistic

Thus the calculated value 1.01 and the significant value or table value Z α /2 = 1.96
Comparing the calculated and table value ,Here Z < Z α /2 i.e., 1.01<1.96.
Inference:Since the calculated value is less than table value i.e., Z < Z α /2 at 5% level of sinificance, the null hypothesis H 0 is accepted. Hence we conclude that the company’s claim that the new car petrol consumption is 9.5 km per litre is acceptable.
Example 8.15
A manufacturer of ball pens claims that a certain pen he manufactures has a mean writing life of 400 pages with a standard deviation of 20 pages. A purchasing agent selects a sample of 100 pens and puts them for test. The mean writing life for the sample was 390 pages. Should the purchasing agent reject the manufactures claim at 1% level?
Population SD σ = 20 pages
The sample is a large sample and so we apply Z -test
Null Hypothesis: There is no significant difference between the sample mean and the population mean of writing life of pen he manufactures, i.e., H 0 : μ = 400
Alternative Hypothesis: There is significant difference between the sample mean and the population mean of writing life of pen he manufactures, i.e., H 1 : μ ≠ 400 (two tailed test)
The level of significance a = 1% = 0.01

Thus the calculated value |Z| = 5 and the significant value or table value Z α /2 = 2.58
Comparing the calculated and table values, we found Z > Z α /2 i.e., 5 > 2.58
Inference: Since the calculated value is greater than table value i.e., Z > Z α /2 at 1% level of significance, the null hypothesis is rejected and Therefore we concluded that μ ≠ 400 and the manufacturer’s claim is rejected at 1% level of significance.
Example 8.16
(i) A sample of 900 members has a mean 3.4 cm and SD 2.61 cm. Is the sample taken from a large population with mean 3.25 cm. and SD 2.62 cm?
(ii) If the population is normal and its mean is unknown, find the 95% and 98% confidence limits of true mean.
Population mean μ= 3.25 cm, Population SD σ = 2.61 cm
Null Hypothesis H 0 : μ = 3.25 cm (the sample has been drawn from the population mean
μ = 3.25 cm and SD σ = 2.61 cm)
Alternative Hypothesis H 1 : μ ≠ 3.25 cm (two tail) i.e., the sample has not been drawn from the population mean μ = 3.25 cm and SD σ = 2.61 cm.
Teststatistic:

∴ Z = 1.724
Thus the calculated and the significant value or table value Z α /2 = 1.96
Comparing the calculated and table values, Z < Z α /2 i.e., 1.724 < 1.96
Inference:Since the calculated value is less than table value i.e., Z > Z α /2 at 5% level of significance, the null hypothesis is accepted. Hence we conclude that the2 data doesn’t provide us any evidence against the null hypothesis. Therefore, the sample has been drawn from the population mean μ = 3.25 cm and SD, σ = 2.61 cm.
(ii) Confidence limits
95% confidential limits for the population mean μ are :
3.4− (1.96× 0.087)≤ μ ≤ 3.4+ (1.96× 0.087)
3.229≤ μ ≤ 3.571
98% confidential limits for the population mean are :
3.4− (2.33× 0.087)≤ μ ≤ 3.4+ (2.33× 0.087)
3.197 ≤ μ≤ 3.603
Therefore,95% confidential limits is (3.229,3.571) and 98% confidential limits is (3.197,3.603).
Example 8.17
The mean weekly sales of soap bars in departmental stores were 146.3 bars per store. After an advertising campaign the mean weekly sales in 400 stores for a typical week increased to 153.7 and showed a standard deviation of 17.2. Was the advertising campaign successful?
Sample size n = 400 stores
Sample SD s = 17.2 bars
Population mean μ = 146.3 bars
Since population SD is unknown we can consider the sample SD s = σ
Null Hypothesis. The advertising campaign is not successful i.e, H 0 : μ = 146.3 (There is no significant difference between the mean weekly sales of soap bars in department stores before and after advertising campaign)
Alternative Hypothesis H 1 : μ > 143.3 (Right tail test). The advertising campaign was successful
Level of significance a = 0.05
Test statistic

∴ Z = 8.605
Comparing the calculated value Z = 8.605 and the significant value or table value Z α = 1.645 . we get 8.605 > 1.645
Inference: Since, the calculated value is much greater than table value i.e., Z > Z α , it is highly significant at 5% level of significance. Hence we reject the null hypothesis H0 and conclude that the advertising campaign was definitely successful in promoting sales.
Example 8.18
The wages of the factory workers are assumed to be normally distributed with mean and variance 25. A random sample of 50 workers gives the total wages equal to ₹ 2,550. Test the hypothesis μ = 52, against the alternative hypothesis μ = 49 at 1% level of significance.
Sample size n = 50 workers

Since alternative hypothesis is of two tailed test we can take | Z | = 1.4142
Critical value at 1% level of significance is Z α /2 = 2.58
Inference: Since the calculated value is less than table value i.e., Z < Za at 1% level of significance, the null hypothesis H 0 is accepted. Therefore, we conclude 2that there is no significant difference between the sample mean and population mean μ= 52 and SD σ = 5.
Example 8.19
An ambulance service claims that it takes on the average 8.9 minutes to reach its destination in emergency calls. To check on this claim, the agency which licenses ambulance services has them timed on 50 emergency calls, getting a mean of 9.3 minutes with a standard deviation of 1.6 minutes. What can they conclude at the level of significance.

Calculated value Z = 1.7676
Critical value at 5% level of significance is Z α /2 = 1.96
Inference: Since the calculated value is less than table value i.e., Z < Z α /2 at 5% level of significance, the null hypothesis is accepted. Therefore we conclude that an ambulance service claims on the average 8.9 minutes to reach its destination in emergency calls.
Related Topics
Privacy Policy , Terms and Conditions , DMCA Policy and Compliant
Copyright © 2018-2024 BrainKart.com; All Rights Reserved. Developed by Therithal info, Chennai.
How to Solve Hypothesis Testing Problems
One common type of problem you will find in Basic Statistics homework is the type of problem that involves using sample data to test a hypothesis .
A hypothesis is a statement about a population parameter. This is, it is a claim that we make about a certain population parameter, such as the population mean, or the population standard deviation.
For example, an engineer from a car manufacturer may claim that the population mean gas mileage of a new car model is 25 mpg. That would be an hypothesis. Or for example, a political polls researcher may claim that the voting share of certain candidate is 53%. That would be another hypothesis, about the true proportion of voters who support that certain candidate.
Consider the following example : A psychologist claims that the mean IQ scores of statistics instructors is greater than 100. She collects sample data from 15 statistics instructors and she finds that \(\bar{X}=118\) and s = 11. The sample data appear to come from a normally distributed population with unknown \(\mu\) and \(\sigma\).
Let us solve this problem:
Notice that we want to test the following null and alternative hypotheses
\[\begin{align}{{H}_{0}}:\mu {\le} {100}\, \\ {{H}_{A}}:\mu {>} {100} \\ \end{align}\]
Considering that the population standard deviation \(\sigma\) is not provided, we have to use a t-test with the following formula:
\[t =\frac{\bar{X}-\mu }{s / \sqrt{n}}\]
This corresponds to a right-tailed t-test. The t-statistics is given by the following formula:
\[t=\frac{\bar{X}-\mu }{s /\sqrt{n}}=\frac{{118}-100}{11/\sqrt{15}}={6.3376}\]
The critical value for \(\alpha = 0.05\) and for \(df = n- 1 = 15 -1 = 14\) degrees of freedom for this right-tailed test is \(t_{c} = 1.761\). The rejection region is given by
\[R = \left\{ t:\,\,\,t>{ 1.761 } \right\}\]
Since \(t = 6.3376 {>} t_c = 1.761\), then we reject the null hypothesis H 0 .
Alternatively, we can use the p-value approach. The right-tailed p-value for this test is calculated as
\[p=\Pr \left( {{t}_{14}}>6.3376 \right)=0.000\]
Considering that the p-value is such that \(p = 0.000 {<} 0.05\), we reject the null hypothesis H 0 .
Hence, we have enough evidence to support the claim that the mean IQ scores of statistics instructors is greater than 100.
log in to your account
Reset password.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
8.4: Hypothesis Test Examples for Proportions
- Last updated
- Save as PDF
- Page ID 11533

- In a hypothesis test problem, you may see words such as "the level of significance is 1%." The "1%" is the preconceived or preset \(\alpha\).
- The statistician setting up the hypothesis test selects the value of α to use before collecting the sample data.
- If no level of significance is given, a common standard to use is \(\alpha = 0.05\).
- When you calculate the \(p\)-value and draw the picture, the \(p\)-value is the area in the left tail, the right tail, or split evenly between the two tails. For this reason, we call the hypothesis test left, right, or two tailed.
- The alternative hypothesis, \(H_{a}\), tells you if the test is left, right, or two-tailed. It is the key to conducting the appropriate test.
- \(H_{a}\) never has a symbol that contains an equal sign.
- Thinking about the meaning of the \(p\)-value: A data analyst (and anyone else) should have more confidence that he made the correct decision to reject the null hypothesis with a smaller \(p\)-value (for example, 0.001 as opposed to 0.04) even if using the 0.05 level for alpha. Similarly, for a large p -value such as 0.4, as opposed to a \(p\)-value of 0.056 (\(\alpha = 0.05\) is less than either number), a data analyst should have more confidence that she made the correct decision in not rejecting the null hypothesis. This makes the data analyst use judgment rather than mindlessly applying rules.
Full Hypothesis Test Examples
Example \(\PageIndex{7}\)
Joon believes that 50% of first-time brides in the United States are younger than their grooms. She performs a hypothesis test to determine if the percentage is the same or different from 50% . Joon samples 100 first-time brides and 53 reply that they are younger than their grooms. For the hypothesis test, she uses a 1% level of significance.
Set up the hypothesis test:
The 1% level of significance means that α = 0.01. This is a test of a single population proportion .
\(H_{0}: p = 0.50\) \(H_{a}: p \neq 0.50\)
The words "is the same or different from" tell you this is a two-tailed test.
Calculate the distribution needed:
Random variable: \(P′ =\) the percent of of first-time brides who are younger than their grooms.
Distribution for the test: The problem contains no mention of a mean. The information is given in terms of percentages. Use the distribution for P′ , the estimated proportion.
\[P' - N\left(p, \sqrt{\frac{p-q}{n}}\right)\nonumber \]
\[P' - N\left(0.5, \sqrt{\frac{0.5-0.5}{100}}\right)\nonumber \]
where \(p = 0.50, q = 1−p = 0.50\), and \(n = 100\)
Calculate the p -value using the normal distribution for proportions:
\[p\text{-value} = P(p′ < 0.47 or p′ > 0.53) = 0.5485\nonumber \]
where \[x = 53, p' = \frac{x}{n} = \frac{53}{100} = 0.53\nonumber \].
Interpretation of the \(p\text{-value})\: If the null hypothesis is true, there is 0.5485 probability (54.85%) that the sample (estimated) proportion \(p'\) is 0.53 or more OR 0.47 or less (see the graph in Figure).

\(\mu = p = 0.50\) comes from \(H_{0}\), the null hypothesis.
\(p′ = 0.53\). Since the curve is symmetrical and the test is two-tailed, the \(p′\) for the left tail is equal to \(0.50 – 0.03 = 0.47\) where \(\mu = p = 0.50\). (0.03 is the difference between 0.53 and 0.50.)
Compare \(\alpha\) and the \(p\text{-value}\):
Since \(\alpha = 0.01\) and \(p\text{-value} = 0.5485\). \(\alpha < p\text{-value}\).
Make a decision: Since \(\alpha < p\text{-value}\), you cannot reject \(H_{0}\).
Conclusion: At the 1% level of significance, the sample data do not show sufficient evidence that the percentage of first-time brides who are younger than their grooms is different from 50%.
The \(p\text{-value}\) can easily be calculated.
Press STAT and arrow over to TESTS . Press 5:1-PropZTest . Enter .5 for \(p_{0}\), 53 for \(x\) and 100 for \(n\). Arrow down to Prop and arrow to not equals \(p_{0}\). Press ENTER . Arrow down to Calculate and press ENTER . The calculator calculates the \(p\text{-value}\) (\(p = 0.5485\)) and the test statistic (\(z\)-score). Prop not equals .5 is the alternate hypothesis. Do this set of instructions again except arrow to Draw (instead of Calculate ). Press ENTER . A shaded graph appears with \(\(z\) = 0.6\) (test statistic) and \(p = 0.5485\) (\(p\text{-value}\)). Make sure when you use Draw that no other equations are highlighted in \(Y =\) and the plots are turned off.
The Type I and Type II errors are as follows:
The Type I error is to conclude that the proportion of first-time brides who are younger than their grooms is different from 50% when, in fact, the proportion is actually 50%. (Reject the null hypothesis when the null hypothesis is true).
The Type II error is there is not enough evidence to conclude that the proportion of first time brides who are younger than their grooms differs from 50% when, in fact, the proportion does differ from 50%. (Do not reject the null hypothesis when the null hypothesis is false.)
Exercise \(\PageIndex{7}\)
A teacher believes that 85% of students in the class will want to go on a field trip to the local zoo. She performs a hypothesis test to determine if the percentage is the same or different from 85%. The teacher samples 50 students and 39 reply that they would want to go to the zoo. For the hypothesis test, use a 1% level of significance.
First, determine what type of test this is, set up the hypothesis test, find the \(p\text{-value}\), sketch the graph, and state your conclusion.
Since the problem is about percentages, this is a test of single population proportions.
- \(H_{0} : p = 0.85\)
- \(H_{a}: p \neq 0.85\)
- \(p = 0.7554\)

Because \(p > \alpha\), we fail to reject the null hypothesis. There is not sufficient evidence to suggest that the proportion of students that want to go to the zoo is not 85%.
Example \(\PageIndex{8}\)
Suppose a consumer group suspects that the proportion of households that have three cell phones is 30%. A cell phone company has reason to believe that the proportion is not 30%. Before they start a big advertising campaign, they conduct a hypothesis test. Their marketing people survey 150 households with the result that 43 of the households have three cell phones.
Set up the Hypothesis Test:
\(H_{0}: p = 0.30, H_{a}: p \neq 0.30\)
Determine the distribution needed:
The random variable is \(P′ =\) proportion of households that have three cell phones.
The distribution for the hypothesis test is \(P' - N\left(0.30, \sqrt{\frac{(0.30 \cdot 0.70)}{150}}\right)\)
Exercise 9.6.8.2
a. The value that helps determine the \(p\text{-value}\) is \(p′\). Calculate \(p′\).
a. \(p' = \frac{x}{n}\) where \(x\) is the number of successes and \(n\) is the total number in the sample.
\(x = 43, n = 150\)
\(p′ = 43150\)
Exercise 9.6.8.3
b. What is a success for this problem?
b. A success is having three cell phones in a household.
Exercise 9.6.8.4
c. What is the level of significance?
c. The level of significance is the preset \(\alpha\). Since \(\alpha\) is not given, assume that \(\alpha = 0.05\).
Exercise 9.6.8.5
d. Draw the graph for this problem. Draw the horizontal axis. Label and shade appropriately.
Calculate the \(p\text{-value}\).
d. \(p\text{-value} = 0.7216\)
Exercise 9.6.8.6
e. Make a decision. _____________(Reject/Do not reject) \(H_{0}\) because____________.
e. Assuming that \(\alpha = 0.05, \alpha < p\text{-value}\). The decision is do not reject \(H_{0}\) because there is not sufficient evidence to conclude that the proportion of households that have three cell phones is not 30%.
Exercise \(\PageIndex{8}\)
Marketers believe that 92% of adults in the United States own a cell phone. A cell phone manufacturer believes that number is actually lower. 200 American adults are surveyed, of which, 174 report having cell phones. Use a 5% level of significance. State the null and alternative hypothesis, find the p -value, state your conclusion, and identify the Type I and Type II errors.
- \(H_{0}: p = 0.92\)
- \(H_{a}: p < 0.92\)
- \(p\text{-value} = 0.0046\)
Because \(p < 0.05\), we reject the null hypothesis. There is sufficient evidence to conclude that fewer than 92% of American adults own cell phones.
- Type I Error: To conclude that fewer than 92% of American adults own cell phones when, in fact, 92% of American adults do own cell phones (reject the null hypothesis when the null hypothesis is true).
- Type II Error: To conclude that 92% of American adults own cell phones when, in fact, fewer than 92% of American adults own cell phones (do not reject the null hypothesis when the null hypothesis is false).
The next example is a poem written by a statistics student named Nicole Hart. The solution to the problem follows the poem. Notice that the hypothesis test is for a single population proportion. This means that the null and alternate hypotheses use the parameter \(p\). The distribution for the test is normal. The estimated proportion \(p′\) is the proportion of fleas killed to the total fleas found on Fido. This is sample information. The problem gives a preconceived \(\alpha = 0.01\), for comparison, and a 95% confidence interval computation. The poem is clever and humorous, so please enjoy it!
Example \(\PageIndex{9}\)
My dog has so many fleas,
They do not come off with ease. As for shampoo, I have tried many types Even one called Bubble Hype, Which only killed 25% of the fleas, Unfortunately I was not pleased.
I've used all kinds of soap, Until I had given up hope Until one day I saw An ad that put me in awe.
A shampoo used for dogs Called GOOD ENOUGH to Clean a Hog Guaranteed to kill more fleas.
I gave Fido a bath And after doing the math His number of fleas Started dropping by 3's! Before his shampoo I counted 42.
At the end of his bath, I redid the math And the new shampoo had killed 17 fleas. So now I was pleased.
Now it is time for you to have some fun With the level of significance being .01, You must help me figure out
Use the new shampoo or go without?
\(H_{0}: p \leq 0.25\) \(H_{a}: p > 0.25\)
In words, CLEARLY state what your random variable \(\bar{X}\) or \(P′\) represents.
\(P′ =\) The proportion of fleas that are killed by the new shampoo
State the distribution to use for the test.
\[N\left(0.25, \sqrt{\frac{(0.25){1-0.25}}{42}}\right)\nonumber \]
Test Statistic: \(z = 2.3163\)
Calculate the \(p\text{-value}\) using the normal distribution for proportions:
\[p\text{-value} = 0.0103\nonumber \]
In one to two complete sentences, explain what the p -value means for this problem.
If the null hypothesis is true (the proportion is 0.25), then there is a 0.0103 probability that the sample (estimated) proportion is 0.4048 \(\left(\frac{17}{42}\right)\) or more.
Use the previous information to sketch a picture of this situation. CLEARLY, label and scale the horizontal axis and shade the region(s) corresponding to the \(p\text{-value}\).

Indicate the correct decision (“reject” or “do not reject” the null hypothesis), the reason for it, and write an appropriate conclusion, using complete sentences.
Conclusion: At the 1% level of significance, the sample data do not show sufficient evidence that the percentage of fleas that are killed by the new shampoo is more than 25%.
Construct a 95% confidence interval for the true mean or proportion. Include a sketch of the graph of the situation. Label the point estimate and the lower and upper bounds of the confidence interval.

Confidence Interval: (0.26,0.55) We are 95% confident that the true population proportion p of fleas that are killed by the new shampoo is between 26% and 55%.
This test result is not very definitive since the \(p\text{-value}\) is very close to alpha. In reality, one would probably do more tests by giving the dog another bath after the fleas have had a chance to return.
Example \(\PageIndex{11}\)
In a study of 420,019 cell phone users, 172 of the subjects developed brain cancer. Test the claim that cell phone users developed brain cancer at a greater rate than that for non-cell phone users (the rate of brain cancer for non-cell phone users is 0.0340%). Since this is a critical issue, use a 0.005 significance level. Explain why the significance level should be so low in terms of a Type I error.
We will follow the four-step process.
- \(H_{0}: p \leq 0.00034\)
- \(H_{a}: p > 0.00034\)
If we commit a Type I error, we are essentially accepting a false claim. Since the claim describes cancer-causing environments, we want to minimize the chances of incorrectly identifying causes of cancer.
- We will be testing a sample proportion with \(x = 172\) and \(n = 420,019\). The sample is sufficiently large because we have \(np = 420,019(0.00034) = 142.8\), \(nq = 420,019(0.99966) = 419,876.2\), two independent outcomes, and a fixed probability of success \(p = 0.00034\). Thus we will be able to generalize our results to the population.
Figure 9.6.11.
Figure 9.6.12.
- Since the \(p\text{-value} = 0.0073\) is greater than our alpha value \(= 0.005\), we cannot reject the null. Therefore, we conclude that there is not enough evidence to support the claim of higher brain cancer rates for the cell phone users.
Example \(\PageIndex{12}\)
According to the US Census there are approximately 268,608,618 residents aged 12 and older. Statistics from the Rape, Abuse, and Incest National Network indicate that, on average, 207,754 rapes occur each year (male and female) for persons aged 12 and older. This translates into a percentage of sexual assaults of 0.078%. In Daviess County, KY, there were reported 11 rapes for a population of 37,937. Conduct an appropriate hypothesis test to determine if there is a statistically significant difference between the local sexual assault percentage and the national sexual assault percentage. Use a significance level of 0.01.
We will follow the four-step plan.
- We need to test whether the proportion of sexual assaults in Daviess County, KY is significantly different from the national average.
- \(H_{0}: p = 0.00078\)
- \(H_{a}: p \neq 0.00078\)
Figure 9.6.13.
Figure 9.6.14.
- Since the \(p\text{-value}\), \(p = 0.00063\), is less than the alpha level of 0.01, the sample data indicates that we should reject the null hypothesis. In conclusion, the sample data support the claim that the proportion of sexual assaults in Daviess County, Kentucky is different from the national average proportion.
The hypothesis test itself has an established process. This can be summarized as follows:
- Determine \(H_{0}\) and \(H_{a}\). Remember, they are contradictory.
- Determine the random variable.
- Determine the distribution for the test.
- Draw a graph, calculate the test statistic, and use the test statistic to calculate the \(p\text{-value}\). (A z -score and a t -score are examples of test statistics.)
- Compare the preconceived α with the p -value, make a decision (reject or do not reject H 0 ), and write a clear conclusion using English sentences.
Notice that in performing the hypothesis test, you use \(\alpha\) and not \(\beta\). \(\beta\) is needed to help determine the sample size of the data that is used in calculating the \(p\text{-value}\). Remember that the quantity \(1 – \beta\) is called the Power of the Test . A high power is desirable. If the power is too low, statisticians typically increase the sample size while keeping α the same.If the power is low, the null hypothesis might not be rejected when it should be.
- Data from Amit Schitai. Director of Instructional Technology and Distance Learning. LBCC.
- Data from Bloomberg Businessweek . Available online at http://www.businessweek.com/news/2011- 09-15/nyc-smoking-rate-falls-to-record-low-of-14-bloomberg-says.html.
- Data from energy.gov. Available online at http://energy.gov (accessed June 27. 2013).
- Data from Gallup®. Available online at www.gallup.com (accessed June 27, 2013).
- Data from Growing by Degrees by Allen and Seaman.
- Data from La Leche League International. Available online at www.lalecheleague.org/Law/BAFeb01.html.
- Data from the American Automobile Association. Available online at www.aaa.com (accessed June 27, 2013).
- Data from the American Library Association. Available online at www.ala.org (accessed June 27, 2013).
- Data from the Bureau of Labor Statistics. Available online at http://www.bls.gov/oes/current/oes291111.htm .
- Data from the Centers for Disease Control and Prevention. Available online at www.cdc.gov (accessed June 27, 2013)
- Data from the U.S. Census Bureau, available online at quickfacts.census.gov/qfd/states/00000.html (accessed June 27, 2013).
- Data from the United States Census Bureau. Available online at www.census.gov/hhes/socdemo/language/.
- Data from Toastmasters International. Available online at http://toastmasters.org/artisan/deta...eID=429&Page=1 .
- Data from Weather Underground. Available online at www.wunderground.com (accessed June 27, 2013).
- Federal Bureau of Investigations. “Uniform Crime Reports and Index of Crime in Daviess in the State of Kentucky enforced by Daviess County from 1985 to 2005.” Available online at http://www.disastercenter.com/kentucky/crime/3868.htm (accessed June 27, 2013).
- “Foothill-De Anza Community College District.” De Anza College, Winter 2006. Available online at research.fhda.edu/factbook/DA...t_da_2006w.pdf.
- Johansen, C., J. Boice, Jr., J. McLaughlin, J. Olsen. “Cellular Telephones and Cancer—a Nationwide Cohort Study in Denmark.” Institute of Cancer Epidemiology and the Danish Cancer Society, 93(3):203-7. Available online at http://www.ncbi.nlm.nih.gov/pubmed/11158188 (accessed June 27, 2013).
- Rape, Abuse & Incest National Network. “How often does sexual assault occur?” RAINN, 2009. Available online at www.rainn.org/get-information...sexual-assault (accessed June 27, 2013).
Contributors and Attributions
Barbara Illowsky and Susan Dean (De Anza College) with many other contributing authors. Content produced by OpenStax College is licensed under a Creative Commons Attribution License 4.0 license. Download for free at http://cnx.org/contents/[email protected] .
IMAGES
VIDEO
COMMENTS
There are 5 main steps in hypothesis testing: State your research hypothesis as a null hypothesis and alternate hypothesis (H o) and (H a or H 1 ). Collect data in a way designed to test the hypothesis. Perform an appropriate statistical test. Decide whether to reject or fail to reject your null hypothesis. Present the findings in your results ...
Step 7: Based on steps 5 and 6, draw a conclusion about H0. If the F\calculated F \calculated from the data is larger than the Fα F α, then you are in the rejection region and you can reject the null hypothesis with (1 − α) ( 1 − α) level of confidence. Note that modern statistical software condenses steps 6 and 7 by providing a p p -value.
9.6: Additional Information and Full Hypothesis Test Examples. For each of the word problems, use a solution sheet to do the hypothesis test. The solution sheet is found in . Please feel free to make copies of the solution sheets. ... Solve this problem and have some fun. Q 9.6.17
Below these are summarized into six such steps to conducting a test of a hypothesis. Set up the hypotheses and check conditions: Each hypothesis test includes two hypotheses about the population. One is the null hypothesis, notated as H 0, which is a statement of a particular parameter value. This hypothesis is assumed to be true until there is ...
In binary hypothesis testing problems, we'll often be presented with two choices which we call hypotheses, and we'll have to decide whether to pick one or the other. The hypotheses are represented by H₀ and H₁ and are called null and alternate hypotheses respectively. In hypothesis testing, we either reject or accept the null hypothesis.
The best way to solve a problem on hypothesis testing is by applying the 5 steps mentioned in the previous section. Suppose a researcher claims that the mean average weight of men is greater than 100kgs with a standard deviation of 15kgs. 30 men are chosen with an average weight of 112.5 Kgs. Using hypothesis testing, check if there is enough ...
3. One-Sided vs. Two-Sided Testing. When it's time to test your hypothesis, it's important to leverage the correct testing method. The two most common hypothesis testing methods are one-sided and two-sided tests, or one-tailed and two-tailed tests, respectively. Typically, you'd leverage a one-sided test when you have a strong conviction ...
Hypothesis testing is based directly on sampling theory and the probabilities P(test statistic ∣ H0) P ( test statistic ∣ H 0) that the sampling theory gives. Here are the steps we will follow : Hypotheses : Formulate H0 H 0 and H1 H 1. State which is the claim. Critical statistic : Find the critical values and regions.
9.1 Hypothesis Testing Problem Solving Steps Now that we have some background on setting up hypotheses and finding critical regions, we introduce the steps needed for every hypothesis testing procedure. Hypothesis testing is based directly on sampling theory and the probabilities that the sampling theory gives. Here are the steps we will follow :
A hypothesis test is a statistical inference method used to test the significance of a proposed (hypothesized) relation between population statistics (parameters) and their corresponding sample estimators. In other words, hypothesis tests are used to determine if there is enough evidence in a sample to prove a hypothesis true for the entire population. The test considers two hypotheses: the ...
View Solution to Question 1. Question 2. A professor wants to know if her introductory statistics class has a good grasp of basic math. Six students are chosen at random from the class and given a math proficiency test. The professor wants the class to be able to score above 70 on the test. The six students get the following scores:62, 92, 75 ...
This statistics video tutorial explains how to solve hypothesis testing problems with proportions. It explains how to calculate the sample proportion and th...
A statistical Hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientists to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is to examine the whole population.
Hypothesis Testing. Hypothesis Tests, or Statistical Hypothesis Testing, is a technique used to compare two datasets, or a sample from a dataset. ... HMMs are probabilistic models used to solve real life problems ranging from weather forecasting to finding the next word in a sentence.
Simple hypothesis testing. Niels has a Magic 8 -Ball, which is a toy used for fortune-telling or seeking advice. To consult the ball, you ask the ball a question and shake it. One of 5 different possible answers then appears at random in the ball. Niels sensed that the ball answers " Ask again later " too frequently.
Focus will be on problem solving. For concepts please refer my previous posts on testing of hypothesis. ... In hypothesis testing, critical region is represented by set of values, where null hypothesis is rejected. So it is also know as region of rejection. It takes different boundary values for different level of significance. Below info ...
p-value = P(x¯ > 67) = 0.0396 p -value = P ( x ¯ > 67) = 0.0396 where the sample mean and sample standard deviation are calculated as 67 and 3.1972 from the data. Interpretation of the p-value: If the null hypothesis is true, then there is a 0.0396 probability (3.96%) that the sample mean is 65 or more. Figure 8.3.11 8.3. 11.
This statistics video tutorial provides practice problems on hypothesis testing. It explains how to tell if you should Reject the Null Hypothesis or Fail to...
This statistics video tutorial provides practice problems on hypothesis testing. It explains how to tell if you should accept or reject the null hypothesis....
Statistical Inference : Hypothesis Testing: Solved Example Problems. Example 8.14. An auto company decided to introduce a new six cylinder car whose mean petrol consumption is claimed to be lower than that of the existing auto engine. It was found that the mean petrol consumption for the 50 cars was 10 km per litre with a standard deviation of ...
One common type of problem you will find in Basic Statistics homework is the type of problem that involves using sample data to test a hypothesis. A hypothesis is a statement about a population parameter. This is, it is a claim that we make about a certain population parameter, such as the population mean, or...
Example 8.4.7. Joon believes that 50% of first-time brides in the United States are younger than their grooms. She performs a hypothesis test to determine if the percentage is the same or different from 50%. Joon samples 100 first-time brides and 53 reply that they are younger than their grooms.
There is a repeating cycle of forming and testing hypotheses. McKinsey consultants follow three steps in this cycle: Form a hypothesis about the problem and determine the data needed to test the ...
To test the hypothesis that the one-dimensional distribution and the correlation length of the optical density of the medium have a large effect on radiation transfer, additional computations are performed for a random Poisson "field of air balls" in water. The grid approximation is generalized to anisotropic random fields.