What is Correlational Research? (+ Design, Examples)
Appinio Research · 04.03.2024 · 30min read

Ever wondered how researchers explore connections between different factors without manipulating them? Correlational research offers a window into understanding the relationships between variables in the world around us. From examining the link between exercise habits and mental well-being to exploring patterns in consumer behavior, correlational studies help us uncover insights that shape our understanding of human behavior, inform decision-making, and drive innovation. In this guide, we'll dive into the fundamentals of correlational research, exploring its definition, importance, ethical considerations, and practical applications across various fields. Whether you're a student delving into research methods or a seasoned researcher seeking to expand your methodological toolkit, this guide will equip you with the knowledge and skills to conduct and interpret correlational studies effectively.

What is Correlational Research?
Correlational research is a methodological approach used in scientific inquiry to examine the relationship between two or more variables. Unlike experimental research, which seeks to establish cause-and-effect relationships through manipulation and control of variables, correlational research focuses on identifying and quantifying the degree to which variables are related to one another. This method allows researchers to investigate associations, patterns, and trends in naturalistic settings without imposing experimental manipulations.
Importance of Correlational Research
Correlational research plays a crucial role in advancing scientific knowledge across various disciplines. Its importance stems from several key factors:
- Exploratory Analysis : Correlational studies provide a starting point for exploring potential relationships between variables. By identifying correlations, researchers can generate hypotheses and guide further investigation into causal mechanisms and underlying processes.
- Predictive Modeling: Correlation coefficients can be used to predict the behavior or outcomes of one variable based on the values of another variable. This predictive ability has practical applications in fields such as economics, psychology, and epidemiology, where forecasting future trends or outcomes is essential.
- Diagnostic Purposes: Correlational analyses can help identify patterns or associations that may indicate the presence of underlying conditions or risk factors. For example, correlations between certain biomarkers and disease outcomes can inform diagnostic criteria and screening protocols in healthcare.
- Theory Development: Correlational research contributes to theory development by providing empirical evidence for proposed relationships between variables. Researchers can refine and validate theoretical models in their respective fields by systematically examining correlations across different contexts and populations.
- Ethical Considerations: In situations where experimental manipulation is not feasible or ethical, correlational research offers an alternative approach to studying naturally occurring phenomena. This allows researchers to address research questions that may otherwise be inaccessible or impractical to investigate.
Correlational vs. Causation in Research
It's important to distinguish between correlation and causation in research. While correlational studies can identify relationships between variables, they cannot establish causal relationships on their own. Several factors contribute to this distinction:
- Directionality: Correlation does not imply the direction of causation. A correlation between two variables does not indicate which variable is causing the other; it merely suggests that they are related in some way. Additional evidence, such as experimental manipulation or longitudinal studies, is needed to establish causality.
- Third Variables: Correlations may be influenced by third variables, also known as confounding variables, that are not directly measured or controlled in the study. These third variables can create spurious correlations or obscure true causal relationships between the variables of interest.
- Temporal Sequence: Causation requires a temporal sequence, with the cause preceding the effect in time. Correlational studies alone cannot establish the temporal order of events, making it difficult to determine whether one variable causes changes in another or vice versa.
Understanding the distinction between correlation and causation is critical for interpreting research findings accurately and drawing valid conclusions about the relationships between variables. While correlational research provides valuable insights into associations and patterns, establishing causation typically requires additional evidence from experimental studies or other research designs.
Key Concepts in Correlation
Understanding key concepts in correlation is essential for conducting meaningful research and interpreting results accurately.
Correlation Coefficient
The correlation coefficient is a statistical measure that quantifies the strength and direction of the relationship between two variables. It's denoted by the symbol r and ranges from -1 to +1.
- A correlation coefficient of -1 indicates a perfect negative correlation, meaning that as one variable increases, the other decreases in a perfectly predictable manner.
- A coefficient of +1 signifies a perfect positive correlation, where both variables increase or decrease together in perfect sync.
- A coefficient of 0 implies no correlation, indicating no systematic relationship between the variables.
Strength and Direction of Correlation
The strength of correlation refers to how closely the data points cluster around a straight line on the scatterplot. A correlation coefficient close to -1 or +1 indicates a strong relationship between the variables, while a coefficient close to 0 suggests a weak relationship.
- Strong correlation: When the correlation coefficient approaches -1 or +1, it indicates a strong relationship between the variables. For example, a correlation coefficient of -0.9 suggests a strong negative relationship, while a coefficient of +0.8 indicates a strong positive relationship.
- Weak correlation: A correlation coefficient close to 0 indicates a weak or negligible relationship between the variables. For instance, a coefficient of -0.1 or +0.1 suggests a weak correlation where the variables are minimally related.
The direction of correlation determines how the variables change relative to each other.
- Positive correlation: When one variable increases, the other variable also tends to increase. Conversely, when one variable decreases, the other variable tends to decrease. This is represented by a positive correlation coefficient.
- Negative correlation: In a negative correlation, as one variable increases, the other variable tends to decrease. Similarly, when one variable decreases, the other variable tends to increase. This relationship is indicated by a negative correlation coefficient.
Scatterplots
A scatterplot is a graphical representation of the relationship between two variables. Each data point on the plot represents the values of both variables for a single observation. By plotting the data points on a Cartesian plane, you can visualize patterns and trends in the relationship between the variables.
- Interpretation: When examining a scatterplot, observe the pattern of data points. If the points cluster around a straight line, it indicates a strong correlation. However, if the points are scattered randomly, it suggests a weak or no correlation.
- Outliers: Identify any outliers or data points that deviate significantly from the overall pattern. Outliers can influence the correlation coefficient and may warrant further investigation to determine their impact on the relationship between variables.
- Line of Best Fit: In some cases, you may draw a line of best fit through the data points to visually represent the overall trend in the relationship. This line can help illustrate the direction and strength of the correlation between the variables.
Understanding these key concepts will enable you to interpret correlation coefficients accurately and draw meaningful conclusions from your data.
How to Design a Correlational Study?
When embarking on a correlational study, careful planning and consideration are crucial to ensure the validity and reliability of your research findings.
Research Question Formulation
Formulating clear and focused research questions is the cornerstone of any successful correlational study. Your research questions should articulate the variables you intend to investigate and the nature of the relationship you seek to explore. When formulating your research questions:
- Be Specific: Clearly define the variables you are interested in studying and the population to which your findings will apply.
- Be Testable: Ensure that your research questions are empirically testable using correlational methods. Avoid vague or overly broad questions that are difficult to operationalize.
- Consider Prior Research: Review existing literature to identify gaps or unanswered questions in your area of interest. Your research questions should build upon prior knowledge and contribute to advancing the field.
For example, if you're interested in examining the relationship between sleep duration and academic performance among college students, your research question might be: "Is there a significant correlation between the number of hours of sleep per night and GPA among undergraduate students?"
Participant Selection
Selecting an appropriate sample of participants is critical to ensuring the generalizability and validity of your findings. Consider the following factors when selecting participants for your correlational study:
- Population Characteristics: Identify the population of interest for your study and ensure that your sample reflects the demographics and characteristics of this population.
- Sampling Method: Choose a sampling method that is appropriate for your research question and accessible, given your resources and constraints. Standard sampling methods include random sampling, stratified sampling, and convenience sampling.
- Sample Size: Determine the appropriate sample size based on factors such as the effect size you expect to detect, the desired level of statistical power, and practical considerations such as time and budget constraints.
For example, suppose you're studying the relationship between exercise habits and mental health outcomes in adults aged 18-65. In that case, you might use stratified random sampling to ensure representation from different age groups within the population.
Variables Identification
Identifying and operationalizing the variables of interest is essential for conducting a rigorous correlational study. When identifying variables for your research:
- Independent and Dependent Variables: Clearly distinguish between independent variables (factors that are hypothesized to influence the outcome) and dependent variables (the outcomes or behaviors of interest).
- Control Variables: Identify any potential confounding variables or extraneous factors that may influence the relationship between your independent and dependent variables. These variables should be controlled for in your analysis.
- Measurement Scales: Determine the appropriate measurement scales for your variables (e.g., nominal, ordinal, interval, or ratio) and select valid and reliable measures for assessing each construct.
For instance, if you're investigating the relationship between socioeconomic status (SES) and academic achievement, SES would be your independent variable, while academic achievement would be your dependent variable. You might measure SES using a composite index based on factors such as income, education level, and occupation.
Data Collection Methods
Selecting appropriate data collection methods is essential for obtaining reliable and valid data for your correlational study. When choosing data collection methods:
- Quantitative vs. Qualitative : Determine whether quantitative or qualitative methods are best suited to your research question and objectives. Correlational studies typically involve quantitative data collection methods like surveys, questionnaires, or archival data analysis.
- Instrument Selection: Choose measurement instruments that are valid, reliable, and appropriate for your variables of interest. Pilot test your instruments to ensure clarity and comprehension among your target population.
- Data Collection Procedures : Develop clear and standardized procedures for data collection to minimize bias and ensure consistency across participants and time points.
For example, if you're examining the relationship between smartphone use and sleep quality among adolescents, you might administer a self-report questionnaire assessing smartphone usage patterns and sleep quality indicators such as sleep duration and sleep disturbances.
Crafting a well-designed correlational study is essential for yielding meaningful insights into the relationships between variables. By meticulously formulating research questions , selecting appropriate participants, identifying relevant variables, and employing effective data collection methods, researchers can ensure the validity and reliability of their findings.
With Appinio , conducting correlational research becomes even more seamless and efficient. Our intuitive platform empowers researchers to gather real-time consumer insights in minutes, enabling them to make informed decisions with confidence.
Experience the power of Appinio and unlock valuable insights for your research endeavors. Schedule a demo today and revolutionize the way you conduct correlational studies!
Book a Demo
How to Analyze Correlational Data?
Once you have collected your data in a correlational study, the next crucial step is to analyze it effectively to draw meaningful conclusions about the relationship between variables.
How to Calculate Correlation Coefficients?
The correlation coefficient is a numerical measure that quantifies the strength and direction of the relationship between two variables. There are different types of correlation coefficients, including Pearson's correlation coefficient (for linear relationships), Spearman's rank correlation coefficient (for ordinal data ), and Kendall's tau (for non-parametric data). Here, we'll focus on calculating Pearson's correlation coefficient (r), which is commonly used for interval or ratio-level data.
To calculate Pearson's correlation coefficient (r), you can use statistical software such as SPSS, R, or Excel. However, if you prefer to calculate it manually, you can use the following formula:
r = Σ((X - X̄)(Y - Ȳ)) / ((n - 1) * (s_X * s_Y))
- X and Y are the scores of the two variables,
- X̄ and Ȳ are the means of X and Y, respectively,
- n is the number of data points,
- s_X and s_Y are the standard deviations of X and Y, respectively.
Interpreting Correlation Results
Once you have calculated the correlation coefficient (r), it's essential to interpret the results correctly. When interpreting correlation results:
- Magnitude: The absolute value of the correlation coefficient (r) indicates the strength of the relationship between the variables. A coefficient close to 1 or -1 suggests a strong correlation, while a coefficient close to 0 indicates a weak or no correlation.
- Direction: The sign of the correlation coefficient (positive or negative) indicates the direction of the relationship between the variables. A positive correlation coefficient indicates a positive relationship (as one variable increases, the other tends to increase), while a negative correlation coefficient indicates a negative relationship (as one variable increases, the other tends to decrease).
- Statistical Significance : Assess the statistical significance of the correlation coefficient to determine whether the observed relationship is likely to be due to chance. This is typically done using hypothesis testing, where you compare the calculated correlation coefficient to a critical value based on the sample size and desired level of significance (e.g., α =0.05).
Statistical Significance
Determining the statistical significance of the correlation coefficient involves conducting hypothesis testing to assess whether the observed correlation is likely to occur by chance. The most common approach is to use a significance level (alpha, α ) of 0.05, which corresponds to a 5% chance of obtaining the observed correlation coefficient if there is no true relationship between the variables.
To test the null hypothesis that the correlation coefficient is zero (i.e., no correlation), you can use inferential statistics such as the t-test or z-test. If the calculated p-value is less than the chosen significance level (e.g., p <0.05), you can reject the null hypothesis and conclude that the correlation coefficient is statistically significant.
Remember that statistical significance does not necessarily imply practical significance or the strength of the relationship. Even a statistically significant correlation with a small effect size may not be meaningful in practical terms.
By understanding how to calculate correlation coefficients, interpret correlation results, and assess statistical significance, you can effectively analyze correlational data and draw accurate conclusions about the relationships between variables in your study.
Correlational Research Limitations
As with any research methodology, correlational studies have inherent considerations and limitations that researchers must acknowledge and address to ensure the validity and reliability of their findings.
Third Variables
One of the primary considerations in correlational research is the presence of third variables, also known as confounding variables. These are extraneous factors that may influence or confound the observed relationship between the variables under study. Failing to account for third variables can lead to spurious correlations or erroneous conclusions about causality.
For example, consider a correlational study examining the relationship between ice cream consumption and drowning incidents. While these variables may exhibit a positive correlation during the summer months, the true causal factor is likely to be a third variable—such as hot weather—that influences both ice cream consumption and swimming activities, thereby increasing the risk of drowning.
To address the influence of third variables, researchers can employ various strategies, such as statistical control techniques, experimental designs (when feasible), and careful operationalization of variables.
Causal Inferences
Correlation does not imply causation—a fundamental principle in correlational research. While correlational studies can identify relationships between variables, they cannot determine causality. This is because correlation merely describes the degree to which two variables co-vary; it does not establish a cause-and-effect relationship between them.
For example, consider a correlational study that finds a positive relationship between the frequency of exercise and self-reported happiness. While it may be tempting to conclude that exercise causes happiness, it's equally plausible that happier individuals are more likely to exercise regularly. Without experimental manipulation and control over potential confounding variables, causal inferences cannot be made.
To strengthen causal inferences in correlational research, researchers can employ longitudinal designs, experimental methods (when ethical and feasible), and theoretical frameworks to guide their interpretations.
Sample Size and Representativeness
The size and representativeness of the sample are critical considerations in correlational research. A small or non-representative sample may limit the generalizability of findings and increase the risk of sampling bias .
For example, if a correlational study examines the relationship between socioeconomic status (SES) and educational attainment using a sample composed primarily of high-income individuals, the findings may not accurately reflect the broader population's experiences. Similarly, an undersized sample may lack the statistical power to detect meaningful correlations or relationships.
To mitigate these issues, researchers should aim for adequate sample sizes based on power analyses, employ random or stratified sampling techniques to enhance representativeness and consider the demographic characteristics of the target population when interpreting findings.
Ensure your survey delivers accurate insights by using our Sample Size Calculator . With customizable options for margin of error, confidence level, and standard deviation, you can determine the optimal sample size to ensure representative results. Make confident decisions backed by robust data.
Reliability and Validity
Ensuring the reliability and validity of measures is paramount in correlational research. Reliability refers to the consistency and stability of measurement over time, whereas validity pertains to the accuracy and appropriateness of measurement in capturing the intended constructs.
For example, suppose a correlational study utilizes self-report measures of depression and anxiety. In that case, it's essential to assess the measures' reliability (e.g., internal consistency, test-retest reliability) and validity (e.g., content validity, criterion validity) to ensure that they accurately reflect participants' mental health status.
To enhance reliability and validity in correlational research, researchers can employ established measurement scales, pilot-test instruments, use multiple measures of the same construct, and assess convergent and discriminant validity.
By addressing these considerations and limitations, researchers can enhance the robustness and credibility of their correlational studies and make more informed interpretations of their findings.
Correlational Research Examples and Applications
Correlational research is widely used across various disciplines to explore relationships between variables and gain insights into complex phenomena. We'll examine examples and applications of correlational studies, highlighting their practical significance and impact on understanding human behavior and societal trends across various industries and use cases.
Psychological Correlational Studies
In psychology, correlational studies play a crucial role in understanding various aspects of human behavior, cognition, and mental health. Researchers use correlational methods to investigate relationships between psychological variables and identify factors that may contribute to or predict specific outcomes.
For example, a psychological correlational study might examine the relationship between self-esteem and depression symptoms among adolescents. By administering self-report measures of self-esteem and depression to a sample of teenagers and calculating the correlation coefficient between the two variables, researchers can assess whether lower self-esteem is associated with higher levels of depression symptoms.
Other examples of psychological correlational studies include investigating the relationship between:
- Parenting styles and academic achievement in children
- Personality traits and job performance in the workplace
- Stress levels and coping strategies among college students
These studies provide valuable insights into the factors influencing human behavior and mental well-being, informing interventions and treatment approaches in clinical and counseling settings.
Business Correlational Studies
Correlational research is also widely utilized in the business and management fields to explore relationships between organizational variables and outcomes. By examining correlations between different factors within an organization, researchers can identify patterns and trends that may impact performance, productivity, and profitability.
For example, a business correlational study might investigate the relationship between employee satisfaction and customer loyalty in a retail setting. By surveying employees to assess their job satisfaction levels and analyzing customer feedback and purchase behavior, researchers can determine whether higher employee satisfaction is correlated with increased customer loyalty and retention.
Other examples of business correlational studies include examining the relationship between:
- Leadership styles and employee motivation
- Organizational culture and innovation
- Marketing strategies and brand perception
These studies provide valuable insights for organizations seeking to optimize their operations, improve employee engagement, and enhance customer satisfaction.
Marketing Correlational Studies
In marketing, correlational studies are instrumental in understanding consumer behavior, identifying market trends, and optimizing marketing strategies. By examining correlations between various marketing variables, researchers can uncover insights that drive effective advertising campaigns, product development, and brand management.
For example, a marketing correlational study might explore the relationship between social media engagement and brand loyalty among millennials. By collecting data on millennials' social media usage, brand interactions, and purchase behaviors, researchers can analyze whether higher levels of social media engagement correlate with increased brand loyalty and advocacy.
Another example of a marketing correlational study could focus on investigating the relationship between pricing strategies and customer satisfaction in the retail sector. By analyzing data on pricing fluctuations, customer feedback , and sales performance, researchers can assess whether pricing strategies such as discounts or promotions impact customer satisfaction and repeat purchase behavior.
Other potential areas of inquiry in marketing correlational studies include examining the relationship between:
- Product features and consumer preferences
- Advertising expenditures and brand awareness
- Online reviews and purchase intent
These studies provide valuable insights for marketers seeking to optimize their strategies, allocate resources effectively, and build strong relationships with consumers in an increasingly competitive marketplace. By leveraging correlational methods, marketers can make data-driven decisions that drive business growth and enhance customer satisfaction.
Correlational Research Ethical Considerations
Ethical considerations are paramount in all stages of the research process, including correlational studies. Researchers must adhere to ethical guidelines to ensure the rights, well-being, and privacy of participants are protected. Key ethical considerations to keep in mind include:
- Informed Consent: Obtain informed consent from participants before collecting any data. Clearly explain the purpose of the study, the procedures involved, and any potential risks or benefits. Participants should have the right to withdraw from the study at any time without consequence.
- Confidentiality: Safeguard the confidentiality of participants' data. Ensure that any personal or sensitive information collected during the study is kept confidential and is only accessible to authorized individuals. Use anonymization techniques when reporting findings to protect participants' privacy.
- Voluntary Participation: Ensure that participation in the study is voluntary and not coerced. Participants should not feel pressured to take part in the study or feel that they will suffer negative consequences for declining to participate.
- Avoiding Harm: Take measures to minimize any potential physical, psychological, or emotional harm to participants. This includes avoiding deceptive practices, providing appropriate debriefing procedures (if necessary), and offering access to support services if participants experience distress.
- Deception: If deception is necessary for the study, it must be justified and minimized. Deception should be disclosed to participants as soon as possible after data collection, and any potential risks associated with the deception should be mitigated.
- Researcher Integrity: Maintain integrity and honesty throughout the research process. Avoid falsifying data, manipulating results, or engaging in any other unethical practices that could compromise the integrity of the study.
- Respect for Diversity: Respect participants' cultural, social, and individual differences. Ensure that research protocols are culturally sensitive and inclusive, and that participants from diverse backgrounds are represented and treated with respect.
- Institutional Review: Obtain ethical approval from institutional review boards or ethics committees before commencing the study. Adhere to the guidelines and regulations set forth by the relevant governing bodies and professional organizations.
Adhering to these ethical considerations ensures that correlational research is conducted responsibly and ethically, promoting trust and integrity in the scientific community.
Correlational Research Best Practices and Tips
Conducting a successful correlational study requires careful planning, attention to detail, and adherence to best practices in research methodology. Here are some tips and best practices to help you conduct your correlational research effectively:
- Clearly Define Variables: Clearly define the variables you are studying and operationalize them into measurable constructs. Ensure that your variables are accurately and consistently measured to avoid ambiguity and ensure reliability.
- Use Valid and Reliable Measures: Select measurement instruments that are valid and reliable for assessing your variables of interest. Pilot test your measures to ensure clarity, comprehension, and appropriateness for your target population.
- Consider Potential Confounding Variables: Identify and control for potential confounding variables that could influence the relationship between your variables of interest. Consider including control variables in your analysis to isolate the effects of interest.
- Ensure Adequate Sample Size: Determine the appropriate sample size based on power analyses and considerations of statistical power. Larger sample sizes increase the reliability and generalizability of your findings.
- Random Sampling: Whenever possible, use random sampling techniques to ensure that your sample is representative of the population you are studying. If random sampling is not feasible, carefully consider the characteristics of your sample and the extent to which findings can be generalized.
- Statistical Analysis : Choose appropriate statistical techniques for analyzing your data, taking into account the nature of your variables and research questions. Consult with a statistician if necessary to ensure the validity and accuracy of your analyses.
- Transparent Reporting: Transparently report your methods, procedures, and findings in accordance with best practices in research reporting. Clearly articulate your research questions, methods, results, and interpretations to facilitate reproducibility and transparency.
- Peer Review: Seek feedback from colleagues, mentors, or peer reviewers throughout the research process. Peer review helps identify potential flaws or biases in your study design, analysis, and interpretation, improving your research's overall quality and credibility.
By following these best practices and tips, you can conduct your correlational research with rigor, integrity, and confidence, leading to valuable insights and contributions to your field.
Conclusion for Correlational Research
Correlational research serves as a powerful tool for uncovering connections between variables in the world around us. By examining the relationships between different factors, researchers can gain valuable insights into human behavior, health outcomes, market trends, and more. While correlational studies cannot establish causation on their own, they provide a crucial foundation for generating hypotheses, predicting outcomes, and informing decision-making in various fields. Understanding the principles and practices of correlational research empowers researchers to explore complex phenomena, advance scientific knowledge, and address real-world challenges. Moreover, embracing ethical considerations and best practices in correlational research ensures the integrity, validity, and reliability of study findings. By prioritizing informed consent, confidentiality, and participant well-being, researchers can conduct studies that uphold ethical standards and contribute meaningfully to the body of knowledge. Incorporating transparent reporting, peer review, and continuous learning further enhances the quality and credibility of correlational research. Ultimately, by leveraging correlational methods responsibly and ethically, researchers can unlock new insights, drive innovation, and make a positive impact on society.
How to Collect Data for Correlational Research in Minutes?
Discover the revolutionary power of Appinio , the real-time market research platform. With Appinio, conducting your own correlational research has never been easier or more exciting. Gain access to real-time consumer insights, empowering you to make data-driven decisions in minutes. Here's why Appinio stands out:
- From questions to insights in minutes: Say goodbye to lengthy research processes. With Appinio, you can gather valuable insights swiftly, allowing you to act on them immediately.
- Intuitive platform for everyone: No need for a PhD in research. Appinio's user-friendly interface makes it accessible to anyone, empowering you to conduct professional-grade research effortlessly.
- Extensive reach, global impact: Define your target group from over 1200 characteristics and survey consumers in over 90 countries. With Appinio, the world is your research playground.

Get free access to the platform!
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

17.04.2024 | 25min read
Quota Sampling: Definition, Types, Methods, Examples

15.04.2024 | 34min read
What is Market Share? Definition, Formula, Examples

11.04.2024 | 34min read
What is Data Analysis? Definition, Tools, Examples
- Privacy Policy
Buy Me a Coffee
Home » Correlational Research – Methods, Types and Examples
Correlational Research – Methods, Types and Examples
Table of Contents

Correlational Research
Correlational Research is a type of research that examines the statistical relationship between two or more variables without manipulating them. It is a non-experimental research design that seeks to establish the degree of association or correlation between two or more variables.
Types of Correlational Research
There are three types of correlational research:
Positive Correlation
A positive correlation occurs when two variables increase or decrease together. This means that as one variable increases, the other variable also tends to increase. Similarly, as one variable decreases, the other variable also tends to decrease. For example, there is a positive correlation between the amount of time spent studying and academic performance. The more time a student spends studying, the higher their academic performance is likely to be. Similarly, there is a positive correlation between a person’s age and their income level. As a person gets older, they tend to earn more money.
Negative Correlation
A negative correlation occurs when one variable increases while the other decreases. This means that as one variable increases, the other variable tends to decrease. Similarly, as one variable decreases, the other variable tends to increase. For example, there is a negative correlation between the number of hours spent watching TV and physical activity level. The more time a person spends watching TV, the less physically active they are likely to be. Similarly, there is a negative correlation between the amount of stress a person experiences and their overall happiness. As stress levels increase, happiness levels tend to decrease.
Zero Correlation
A zero correlation occurs when there is no relationship between two variables. This means that the variables are unrelated and do not affect each other. For example, there is zero correlation between a person’s shoe size and their IQ score. The size of a person’s feet has no relationship to their level of intelligence. Similarly, there is zero correlation between a person’s height and their favorite color. The two variables are unrelated to each other.
Correlational Research Methods
Correlational research can be conducted using different methods, including:
Surveys are a common method used in correlational research. Researchers collect data by asking participants to complete questionnaires or surveys that measure different variables of interest. Surveys are useful for exploring the relationships between variables such as personality traits, attitudes, and behaviors.
Observational Studies
Observational studies involve observing and recording the behavior of participants in natural settings. Researchers can use observational studies to examine the relationships between variables such as social interactions, group dynamics, and communication patterns.
Archival Data
Archival data involves using existing data sources such as historical records, census data, or medical records to explore the relationships between variables. Archival data is useful for investigating the relationships between variables that cannot be manipulated or controlled.
Experimental Design
While correlational research does not involve manipulating variables, researchers can use experimental design to establish cause-and-effect relationships between variables. Experimental design involves manipulating one variable while holding other variables constant to determine the effect on the dependent variable.
Meta-Analysis
Meta-analysis involves combining and analyzing the results of multiple studies to explore the relationships between variables across different contexts and populations. Meta-analysis is useful for identifying patterns and inconsistencies in the literature and can provide insights into the strength and direction of relationships between variables.
Data Analysis Methods
Correlational research data analysis methods depend on the type of data collected and the research questions being investigated. Here are some common data analysis methods used in correlational research:
Correlation Coefficient
A correlation coefficient is a statistical measure that quantifies the strength and direction of the relationship between two variables. The correlation coefficient ranges from -1 to +1, with -1 indicating a perfect negative correlation, +1 indicating a perfect positive correlation, and 0 indicating no correlation. Researchers use correlation coefficients to determine the degree to which two variables are related.
Scatterplots
A scatterplot is a graphical representation of the relationship between two variables. Each data point on the plot represents a single observation. The x-axis represents one variable, and the y-axis represents the other variable. The pattern of data points on the plot can provide insights into the strength and direction of the relationship between the two variables.
Regression Analysis
Regression analysis is a statistical method used to model the relationship between two or more variables. Researchers use regression analysis to predict the value of one variable based on the value of another variable. Regression analysis can help identify the strength and direction of the relationship between variables, as well as the degree to which one variable can be used to predict the other.
Factor Analysis
Factor analysis is a statistical method used to identify patterns among variables. Researchers use factor analysis to group variables into factors that are related to each other. Factor analysis can help identify underlying factors that influence the relationship between two variables.
Path Analysis
Path analysis is a statistical method used to model the relationship between multiple variables. Researchers use path analysis to test causal models and identify direct and indirect effects between variables.
Applications of Correlational Research
Correlational research has many practical applications in various fields, including:
- Psychology : Correlational research is commonly used in psychology to explore the relationships between variables such as personality traits, behaviors, and mental health outcomes. For example, researchers may use correlational research to examine the relationship between anxiety and depression, or the relationship between self-esteem and academic achievement.
- Education : Correlational research is useful in educational research to explore the relationships between variables such as teaching methods, student motivation, and academic performance. For example, researchers may use correlational research to examine the relationship between student engagement and academic success, or the relationship between teacher feedback and student learning outcomes.
- Business : Correlational research can be used in business to explore the relationships between variables such as consumer behavior, marketing strategies, and sales outcomes. For example, marketers may use correlational research to examine the relationship between advertising spending and sales revenue, or the relationship between customer satisfaction and brand loyalty.
- Medicine : Correlational research is useful in medical research to explore the relationships between variables such as risk factors, disease outcomes, and treatment effectiveness. For example, researchers may use correlational research to examine the relationship between smoking and lung cancer, or the relationship between exercise and heart health.
- Social Science : Correlational research is commonly used in social science research to explore the relationships between variables such as socioeconomic status, cultural factors, and social behavior. For example, researchers may use correlational research to examine the relationship between income and voting behavior, or the relationship between cultural values and attitudes towards immigration.
Examples of Correlational Research
- Psychology : Researchers might be interested in exploring the relationship between two variables, such as parental attachment and anxiety levels in young adults. The study could involve measuring levels of attachment and anxiety using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying potential risk factors for anxiety in young adults, and in developing interventions that could help improve attachment and reduce anxiety.
- Education : In a correlational study in education, researchers might investigate the relationship between two variables, such as teacher engagement and student motivation in a classroom setting. The study could involve measuring levels of teacher engagement and student motivation using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying strategies that teachers could use to improve student motivation and engagement in the classroom.
- Business : Researchers might explore the relationship between two variables, such as employee satisfaction and productivity levels in a company. The study could involve measuring levels of employee satisfaction and productivity using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying factors that could help increase productivity and improve job satisfaction among employees.
- Medicine : Researchers might examine the relationship between two variables, such as smoking and the risk of developing lung cancer. The study could involve collecting data on smoking habits and lung cancer diagnoses, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying risk factors for lung cancer and in developing interventions that could help reduce smoking rates.
- Sociology : Researchers might investigate the relationship between two variables, such as income levels and political attitudes. The study could involve measuring income levels and political attitudes using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in understanding how socioeconomic factors can influence political beliefs and attitudes.
How to Conduct Correlational Research
Here are the general steps to conduct correlational research:
- Identify the Research Question : Start by identifying the research question that you want to explore. It should involve two or more variables that you want to investigate for a correlation.
- Choose the research method: Decide on the research method that will be most appropriate for your research question. The most common methods for correlational research are surveys, archival research, and naturalistic observation.
- Choose the Sample: Select the participants or data sources that you will use in your study. Your sample should be representative of the population you want to generalize the results to.
- Measure the variables: Choose the measures that will be used to assess the variables of interest. Ensure that the measures are reliable and valid.
- Collect the Data: Collect the data from your sample using the chosen research method. Be sure to maintain ethical standards and obtain informed consent from your participants.
- Analyze the data: Use statistical software to analyze the data and compute the correlation coefficient. This will help you determine the strength and direction of the correlation between the variables.
- Interpret the results: Interpret the results and draw conclusions based on the findings. Consider any limitations or alternative explanations for the results.
- Report the findings: Report the findings of your study in a research report or manuscript. Be sure to include the research question, methods, results, and conclusions.
Purpose of Correlational Research
The purpose of correlational research is to examine the relationship between two or more variables. Correlational research allows researchers to identify whether there is a relationship between variables, and if so, the strength and direction of that relationship. This information can be useful for predicting and explaining behavior, and for identifying potential risk factors or areas for intervention.
Correlational research can be used in a variety of fields, including psychology, education, medicine, business, and sociology. For example, in psychology, correlational research can be used to explore the relationship between personality traits and behavior, or between early life experiences and later mental health outcomes. In education, correlational research can be used to examine the relationship between teaching practices and student achievement. In medicine, correlational research can be used to investigate the relationship between lifestyle factors and disease outcomes.
Overall, the purpose of correlational research is to provide insight into the relationship between variables, which can be used to inform further research, interventions, or policy decisions.
When to use Correlational Research
Here are some situations when correlational research can be particularly useful:
- When experimental research is not possible or ethical: In some situations, it may not be possible or ethical to manipulate variables in an experimental design. In these cases, correlational research can be used to explore the relationship between variables without manipulating them.
- When exploring new areas of research: Correlational research can be useful when exploring new areas of research or when researchers are unsure of the direction of the relationship between variables. Correlational research can help identify potential areas for further investigation.
- When testing theories: Correlational research can be useful for testing theories about the relationship between variables. Researchers can use correlational research to examine the relationship between variables predicted by a theory, and to determine whether the theory is supported by the data.
- When making predictions: Correlational research can be used to make predictions about future behavior or outcomes. For example, if there is a strong positive correlation between education level and income, one could predict that individuals with higher levels of education will have higher incomes.
- When identifying risk factors: Correlational research can be useful for identifying potential risk factors for negative outcomes. For example, a study might find a positive correlation between drug use and depression, indicating that drug use could be a risk factor for depression.
Characteristics of Correlational Research
Here are some common characteristics of correlational research:
- Examines the relationship between two or more variables: Correlational research is designed to examine the relationship between two or more variables. It seeks to determine if there is a relationship between the variables, and if so, the strength and direction of that relationship.
- Non-experimental design: Correlational research is typically non-experimental in design, meaning that the researcher does not manipulate any variables. Instead, the researcher observes and measures the variables as they naturally occur.
- Cannot establish causation : Correlational research cannot establish causation, meaning that it cannot determine whether one variable causes changes in another variable. Instead, it only provides information about the relationship between the variables.
- Uses statistical analysis: Correlational research relies on statistical analysis to determine the strength and direction of the relationship between variables. This may include calculating correlation coefficients, regression analysis, or other statistical tests.
- Observes real-world phenomena : Correlational research is often used to observe real-world phenomena, such as the relationship between education and income or the relationship between stress and physical health.
- Can be conducted in a variety of fields : Correlational research can be conducted in a variety of fields, including psychology, sociology, education, and medicine.
- Can be conducted using different methods: Correlational research can be conducted using a variety of methods, including surveys, observational studies, and archival studies.
Advantages of Correlational Research
There are several advantages of using correlational research in a study:
- Allows for the exploration of relationships: Correlational research allows researchers to explore the relationships between variables in a natural setting without manipulating any variables. This can help identify possible relationships between variables that may not have been previously considered.
- Useful for predicting behavior: Correlational research can be useful for predicting future behavior. If a strong correlation is found between two variables, researchers can use this information to predict how changes in one variable may affect the other.
- Can be conducted in real-world settings: Correlational research can be conducted in real-world settings, which allows for the collection of data that is representative of real-world phenomena.
- Can be less expensive and time-consuming than experimental research: Correlational research is often less expensive and time-consuming than experimental research, as it does not involve manipulating variables or creating controlled conditions.
- Useful in identifying risk factors: Correlational research can be used to identify potential risk factors for negative outcomes. By identifying variables that are correlated with negative outcomes, researchers can develop interventions or policies to reduce the risk of negative outcomes.
- Useful in exploring new areas of research: Correlational research can be useful in exploring new areas of research, particularly when researchers are unsure of the direction of the relationship between variables. By conducting correlational research, researchers can identify potential areas for further investigation.
Limitation of Correlational Research
Correlational research also has several limitations that should be taken into account:
- Cannot establish causation: Correlational research cannot establish causation, meaning that it cannot determine whether one variable causes changes in another variable. This is because it is not possible to control all possible confounding variables that could affect the relationship between the variables being studied.
- Directionality problem: The directionality problem refers to the difficulty of determining which variable is influencing the other. For example, a correlation may exist between happiness and social support, but it is not clear whether social support causes happiness, or whether happy people are more likely to have social support.
- Third variable problem: The third variable problem refers to the possibility that a third variable, not included in the study, is responsible for the observed relationship between the two variables being studied.
- Limited generalizability: Correlational research is often limited in terms of its generalizability to other populations or settings. This is because the sample studied may not be representative of the larger population, or because the variables studied may behave differently in different contexts.
- Relies on self-reported data: Correlational research often relies on self-reported data, which can be subject to social desirability bias or other forms of response bias.
- Limited in explaining complex behaviors: Correlational research is limited in explaining complex behaviors that are influenced by multiple factors, such as personality traits, situational factors, and social context.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Quantitative Research – Methods, Types and...

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide
- Correlational Research Designs: Types, Examples & Methods

A human mind is a powerful tool that allows you to sift through seemingly unrelated variables and establish a connection with regards to a specific subject at hand. This skill is what comes to play when we talk about correlational research.
Correlational research is something that we do every day; think about how you establish a connection between the doorbell ringing at a particular time and the milkman’s arrival. As such, it is expedient to understand the different types of correlational research that are available and more importantly, how to go about it.
What is Correlational Research?
Correlational research is a type of research method that involves observing two variables in order to establish a statistically corresponding relationship between them. The aim of correlational research is to identify variables that have some sort of relationship do the extent that a change in one creates some change in the other.
This type of research is descriptive, unlike experimental research that relies entirely on scientific methodology and hypothesis. For example, correlational research may reveal the statistical relationship between high-income earners and relocation; that is, the more people earn, the more likely they are to relocate or not.
What are the Types of Correlational Research?
Essentially, there are 3 types of correlational research which are positive correlational research, negative correlational research, and no correlational research. Each of these types is defined by peculiar characteristics.
- Positive Correlational Research
Positive correlational research is a research method involving 2 variables that are statistically corresponding where an increase or decrease in 1 variable creates a like change in the other. An example is when an increase in workers’ remuneration results in an increase in the prices of goods and services and vice versa.
- Negative Correlational Research
Negative correlational research is a research method involving 2 variables that are statistically opposite where an increase in one of the variables creates an alternate effect or decrease in the other variable. An example of a negative correlation is if the rise in goods and services causes a decrease in demand and vice versa.
- Zero Correlational Research
Zero correlational research is a type of correlational research that involves 2 variables that are not necessarily statistically connected. In this case, a change in one of the variables may not trigger a corresponding or alternate change in the other variable.
Zero correlational research caters for variables with vague statistical relationships. For example, wealth and patience can be variables under zero correlational research because they are statistically independent.
Sporadic change patterns that occur in variables with zero correlational are usually by chance and not as a result of corresponding or alternate mutual inclusiveness.
Correlational research can also be classified based on data collection methods. Based on these, there are 3 types of correlational research: Naturalistic observation research, survey research and archival research.
What are the Data Collection Methods in Correlational research?
Data collection methods in correlational research are the research methodologies adopted by persons carrying out correlational research in order to determine the linear statistical relationship between 2 variables. These data collection methods are used to gather information in correlational research.
The 3 methods of data collection in correlational research are naturalistic observation method, archival data method, and the survey method. All of these would be clearly explained in the subsequent paragraphs.
- Naturalistic Observation
Naturalistic observation is a correlational research methodology that involves observing people’s behaviors as shown in the natural environment where they exist, over a period of time. It is a type of research-field method that involves the researcher paying closing attention to natural behavior patterns of the subjects under consideration.
This method is extremely demanding as the researcher must take extra care to ensure that the subjects do not suspect that they are being observed else they deviate from their natural behavior patterns. It is best for all subjects under observation to remain anonymous in order to avoid a breach of privacy.
The major advantages of the naturalistic observation method are that it allows the researcher to fully observe the subjects (variables) in their natural state. However, it is a very expensive and time-consuming process plus the subjects can become aware of this act at any time and may act contrary.
- Archival Data
Archival data is a type of correlational research method that involves making use of already gathered information about the variables in correlational research. Since this method involves using data that is already gathered and analyzed, it is usually straight to the point.
For this method of correlational research, the research makes use of earlier studies conducted by other researchers or the historical records of the variables being analyzed. This method helps a researcher to track already determined statistical patterns of the variables or subjects.
This method is less expensive, saves time and provides the researcher with more disposable data to work with. However, it has the problem of data accuracy as important information may be missing from previous research since the researcher has no control over the data collection process.
- Survey Method
The survey method is the most common method of correlational research; especially in fields like psychology. It involves random sampling of the variables or the subjects in the research in which the participants fill a questionnaire centered on the subjects of interest.
This method is very flexible as researchers can gather large amounts of data in very little time. However, it is subject to survey response bias and can also be affected by biased survey questions or under-representation of survey respondents or participants.
These would be properly explained under data collection methods in correlational research.
Examples of Correlational Research
Correlational research examples are numerous and highlight several instances where a correlational study may be carried out in order to determine the statistical behavioral trend with regards to the variables under consideration. Here are 3 case examples of correlational research.
- You want to know if wealthy people are less likely to be patient. From your experience, you believe that wealthy people are impatient. However, you want to establish a statistical pattern that proves or disproves your belief. In this case, you can carry out correlational research to identify a trend that links both variables.
- You want to know if there’s a correlation between how much people earn and the number of children that they have. You do not believe that people with more spending power have more children than people with less spending power.
You think that how much people earn hardly determines the number of children that they have. Yet, carrying out correlational research on both variables could reveal any correlational relationship that exists between them.
- You believe that domestic violence causes a brain hemorrhage. You cannot carry out an experiment as it would be unethical to deliberately subject people to domestic violence.
However, you can carry out correlational research to find out if victims of domestic violence suffer brain hemorrhage more than non-victims.
What are the Characteristics of Correlational Research?
- Correlational Research is non-experimental
Correlational research is non-experimental as it does not involve manipulating variables using a scientific methodology in order to agree or disagree with a hypothesis. In correlational research, the researcher simply observes and measures the natural relationship between 2 variables; without subjecting either of the variables to external conditioning.
- Correlational Research is Backward-looking
Correlational research doesn’t take the future into consideration as it only observes and measures the recent historical relationship that exists between 2 variables. In this sense, the statistical pattern resulting from correlational research is backward-looking and can seize to exist at any point, going forward.
Correlational research observes and measures historical patterns between 2 variables such as the relationship between high-income earners and tax payment. Correlational research may reveal a positive relationship between the aforementioned variables but this may change at any point in the future.
- Correlational Research is Dynamic
Statistical patterns between 2 variables that result from correlational research are ever-changing. The correlation between 2 variables changes on a daily basis and such, it cannot be used as a fixed data for further research.
For example, the 2 variables can have a negative correlational relationship for a period of time, maybe 5 years. After this time, the correlational relationship between them can become positive; as observed in the relationship between bonds and stocks.
- Data resulting from correlational research are not constant and cannot be used as a standard variable for further research.
What is the Correlation Coefficient?
A correlation coefficient is an important value in correlational research that indicates whether the inter-relationship between 2 variables is positive, negative or non-existent. It is usually represented with the sign [r] and is part of a range of possible correlation coefficients from -1.0 to +1.0.
The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson’s r) . A positive correlation is indicated by a value of 1.0, a perfect negative correlation is indicated by a value of -1.0 while zero correlation is indicated by a value of 0.0.
It is important to note that a correlation coefficient only reflects the linear relationship between 2 variables; it does not capture non-linear relationships and cannot separate dependent and independent variables. The correlation coefficient helps you to determine the degree of statistical relationship that exists between variables.
What are the Advantages of Correlational Research?
- In cases where carrying out experimental research is unethical, correlational research can be used to determine the relationship between 2 variables. For example, when studying humans, carrying out an experiment can be seen as unsafe or unethical; hence, choosing correlational research would be the best option.
- Through correlational research, you can easily determine the statistical relationship between 2 variables.
- Carrying out correlational research is less time-consuming and less expensive than experimental research. This becomes a strong advantage when working with a minimum of researchers and funding or when keeping the number of variables in a study very low.
- Correlational research allows the researcher to carry out shallow data gathering using different methods such as a short survey. A short survey does not require the researcher to personally administer it so this allows the researcher to work with a few people.
What are the Disadvantages of Correlational Research?
- Correlational research is limiting in nature as it can only be used to determine the statistical relationship between 2 variables. It cannot be used to establish a relationship between more than 2 variables.
- It does not account for cause and effect between 2 variables as it doesn’t highlight which of the 2 variables is responsible for the statistical pattern that is observed. For example, finding that education correlates positively with vegetarianism doesn’t explain whether being educated leads to becoming a vegetarian or whether vegetarianism leads to more education.
- Reasons for either can be assumed, but until more research is done, causation can’t be determined. Also, a third, unknown variable might be causing both. For instance, living in the state of Detroit can lead to both education and vegetarianism.
- Correlational research depends on past statistical patterns to determine the relationship between variables. As such, its data cannot be fully depended on for further research.
- In correlational research, the researcher has no control over the variables. Unlike experimental research, correlational research only allows the researcher to observe the variables for connecting statistical patterns without introducing a catalyst.
- The information received from correlational research is limited. Correlational research only shows the relationship between variables and does not equate to causation.
What are the Differences between Correlational and Experimental Research?
- Methodology
The major difference between correlational research and experimental research is methodology. In correlational research, the researcher looks for a statistical pattern linking 2 naturally-occurring variables while in experimental research, the researcher introduces a catalyst and monitors its effects on the variables.
- Observation
In correlational research, the researcher passively observes the phenomena and measures whatever relationship that occurs between them. However, in experimental research, the researcher actively observes phenomena after triggering a change in the behavior of the variables.
In experimental research, the researcher introduces a catalyst and monitors its effects on the variables, that is, cause and effect. In correlational research, the researcher is not interested in cause and effect as it applies; rather, he or she identifies recurring statistical patterns connecting the variables in research.
- Number of Variables
research caters to an unlimited number of variables. Correlational research, on the other hand, caters to only 2 variables.
- Experimental research is causative while correlational research is relational.
- Correlational research is preliminary and almost always precedes experimental research.
- Unlike correlational research, experimental research allows the researcher to control the variables.
How to Use Online Forms for Correlational Research
One of the most popular methods of conducting correlational research is by carrying out a survey which can be made easier with the use of an online form. Surveys for correlational research involve generating different questions that revolve around the variables under observation and, allowing respondents to provide answers to these questions.
Using an online form for your correlational research survey would help the researcher to gather more data in minimum time. In addition, the researcher would be able to reach out to more survey respondents than is plausible with printed correlational research survey forms .
In addition, the researcher would be able to swiftly process and analyze all responses in order to objectively establish the statistical pattern that links the variables in the research. Using an online form for correlational research also helps the researcher to minimize the cost incurred during the research period.
To use an online form for a correlational research survey, you would need to sign up on a data-gathering platform like Formplus . Formplus allows you to create custom forms for correlational research surveys using the Formplus builder.
You can customize your correlational research survey form by adding background images, new color themes or your company logo to make it appear even more professional. In addition, Formplus also has a survey form template that you can edit for a correlational research study.
You can create different types of survey questions including open-ended questions , rating questions, close-ended questions and multiple answers questions in your survey in the Formplus builder. After creating your correlational research survey, you can share the personalized link with respondents via email or social media.
Formplus also enables you to collect offline responses in your form.
Conclusion
Correlational research enables researchers to establish the statistical pattern between 2 seemingly interconnected variables; as such, it is the starting point of any type of research. It allows you to link 2 variables by observing their behaviors in the most natural state.
Unlike experimental research, correlational research does not emphasize the causative factor affecting 2 variables and this makes the data that results from correlational research subject to constant change. However, it is quicker, easier, less expensive and more convenient than experimental research.
It is important to always keep the aim of your research at the back of your mind when choosing the best type of research to adopt. If you simply need to observe how the variables react to change then, experimental research is the best type to subscribe for.
It is best to conduct correlational research using an online correlational research survey form as this makes the data-gathering process, more convenient. Formplus is a great online data-gathering platform that you can use to create custom survey forms for correlational research.
Connect to Formplus, Get Started Now - It's Free!
- characteristics of correlational research
- types of correlational research
- what is correlational research
- busayo.longe
You may also like:
What is Pure or Basic Research? + [Examples & Method]
Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education and psychology
Recall Bias: Definition, Types, Examples & Mitigation
This article will discuss the impact of recall bias in studies and the best ways to avoid them during research.
Exploratory Research: What are its Method & Examples?
Overview on exploratory research, examples and methodology. Shows guides on how to conduct exploratory research with online surveys
Extrapolation in Statistical Research: Definition, Examples, Types, Applications
In this article we’ll look at the different types and characteristics of extrapolation, plus how it contrasts to interpolation.
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
7.2 Correlational Research
Learning objectives.
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of nonexperimental research.
What Is Correlational Research?
Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variable do not apply to this kind of research.
The other reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, Allen Kanner and his colleagues thought that the number of “daily hassles” (e.g., rude salespeople, heavy traffic) that people experience affects the number of physical and psychological symptoms they have (Kanner, Coyne, Schaefer, & Lazarus, 1981). But because they could not manipulate the number of daily hassles their participants experienced, they had to settle for measuring the number of daily hassles—along with the number of symptoms—using self-report questionnaires. Although the strong positive relationship they found between these two variables is consistent with their idea that hassles cause symptoms, it is also consistent with the idea that symptoms cause hassles or that some third variable (e.g., neuroticism) causes both.
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure 7.2 “Results of a Hypothetical Study on Whether People Who Make Daily To-Do Lists Experience Less Stress Than People Who Do Not Make Such Lists” shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. It is how the study is conducted.
Figure 7.2 Results of a Hypothetical Study on Whether People Who Make Daily To-Do Lists Experience Less Stress Than People Who Do Not Make Such Lists

Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated. However, because some approaches to data collection are strongly associated with correlational research, it makes sense to discuss them here. The two we will focus on are naturalistic observation and archival data. A third, survey research, is discussed in its own chapter.
Naturalistic Observation
Naturalistic observation is an approach to data collection that involves observing people’s behavior in the environment in which it typically occurs. Thus naturalistic observation is a type of field research (as opposed to a type of laboratory research). It could involve observing shoppers in a grocery store, children on a school playground, or psychiatric inpatients in their wards. Researchers engaged in naturalistic observation usually make their observations as unobtrusively as possible so that participants are often not aware that they are being studied. Ethically, this is considered to be acceptable if the participants remain anonymous and the behavior occurs in a public setting where people would not normally have an expectation of privacy. Grocery shoppers putting items into their shopping carts, for example, are engaged in public behavior that is easily observable by store employees and other shoppers. For this reason, most researchers would consider it ethically acceptable to observe them for a study. On the other hand, one of the arguments against the ethicality of the naturalistic observation of “bathroom behavior” discussed earlier in the book is that people have a reasonable expectation of privacy even in a public restroom and that this expectation was violated.
Researchers Robert Levine and Ara Norenzayan used naturalistic observation to study differences in the “pace of life” across countries (Levine & Norenzayan, 1999). One of their measures involved observing pedestrians in a large city to see how long it took them to walk 60 feet. They found that people in some countries walked reliably faster than people in other countries. For example, people in the United States and Japan covered 60 feet in about 12 seconds on average, while people in Brazil and Romania took close to 17 seconds.
Because naturalistic observation takes place in the complex and even chaotic “real world,” there are two closely related issues that researchers must deal with before collecting data. The first is sampling. When, where, and under what conditions will the observations be made, and who exactly will be observed? Levine and Norenzayan described their sampling process as follows:
Male and female walking speed over a distance of 60 feet was measured in at least two locations in main downtown areas in each city. Measurements were taken during main business hours on clear summer days. All locations were flat, unobstructed, had broad sidewalks, and were sufficiently uncrowded to allow pedestrians to move at potentially maximum speeds. To control for the effects of socializing, only pedestrians walking alone were used. Children, individuals with obvious physical handicaps, and window-shoppers were not timed. Thirty-five men and 35 women were timed in most cities. (p. 186)
Precise specification of the sampling process in this way makes data collection manageable for the observers, and it also provides some control over important extraneous variables. For example, by making their observations on clear summer days in all countries, Levine and Norenzayan controlled for effects of the weather on people’s walking speeds.
The second issue is measurement. What specific behaviors will be observed? In Levine and Norenzayan’s study, measurement was relatively straightforward. They simply measured out a 60-foot distance along a city sidewalk and then used a stopwatch to time participants as they walked over that distance. Often, however, the behaviors of interest are not so obvious or objective. For example, researchers Robert Kraut and Robert Johnston wanted to study bowlers’ reactions to their shots, both when they were facing the pins and then when they turned toward their companions (Kraut & Johnston, 1979). But what “reactions” should they observe? Based on previous research and their own pilot testing, Kraut and Johnston created a list of reactions that included “closed smile,” “open smile,” “laugh,” “neutral face,” “look down,” “look away,” and “face cover” (covering one’s face with one’s hands). The observers committed this list to memory and then practiced by coding the reactions of bowlers who had been videotaped. During the actual study, the observers spoke into an audio recorder, describing the reactions they observed. Among the most interesting results of this study was that bowlers rarely smiled while they still faced the pins. They were much more likely to smile after they turned toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.

Naturalistic observation has revealed that bowlers tend to smile when they turn away from the pins and toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.
sieneke toering – bowling big lebowski style – CC BY-NC-ND 2.0.
When the observations require a judgment on the part of the observers—as in Kraut and Johnston’s study—this process is often described as coding . Coding generally requires clearly defining a set of target behaviors. The observers then categorize participants individually in terms of which behavior they have engaged in and the number of times they engaged in each behavior. The observers might even record the duration of each behavior. The target behaviors must be defined in such a way that different observers code them in the same way. This is the issue of interrater reliability. Researchers are expected to demonstrate the interrater reliability of their coding procedure by having multiple raters code the same behaviors independently and then showing that the different observers are in close agreement. Kraut and Johnston, for example, video recorded a subset of their participants’ reactions and had two observers independently code them. The two observers showed that they agreed on the reactions that were exhibited 97% of the time, indicating good interrater reliability.
Archival Data
Another approach to correlational research is the use of archival data , which are data that have already been collected for some other purpose. An example is a study by Brett Pelham and his colleagues on “implicit egotism”—the tendency for people to prefer people, places, and things that are similar to themselves (Pelham, Carvallo, & Jones, 2005). In one study, they examined Social Security records to show that women with the names Virginia, Georgia, Louise, and Florence were especially likely to have moved to the states of Virginia, Georgia, Louisiana, and Florida, respectively.
As with naturalistic observation, measurement can be more or less straightforward when working with archival data. For example, counting the number of people named Virginia who live in various states based on Social Security records is relatively straightforward. But consider a study by Christopher Peterson and his colleagues on the relationship between optimism and health using data that had been collected many years before for a study on adult development (Peterson, Seligman, & Vaillant, 1988). In the 1940s, healthy male college students had completed an open-ended questionnaire about difficult wartime experiences. In the late 1980s, Peterson and his colleagues reviewed the men’s questionnaire responses to obtain a measure of explanatory style—their habitual ways of explaining bad events that happen to them. More pessimistic people tend to blame themselves and expect long-term negative consequences that affect many aspects of their lives, while more optimistic people tend to blame outside forces and expect limited negative consequences. To obtain a measure of explanatory style for each participant, the researchers used a procedure in which all negative events mentioned in the questionnaire responses, and any causal explanations for them, were identified and written on index cards. These were given to a separate group of raters who rated each explanation in terms of three separate dimensions of optimism-pessimism. These ratings were then averaged to produce an explanatory style score for each participant. The researchers then assessed the statistical relationship between the men’s explanatory style as college students and archival measures of their health at approximately 60 years of age. The primary result was that the more optimistic the men were as college students, the healthier they were as older men. Pearson’s r was +.25.
This is an example of content analysis —a family of systematic approaches to measurement using complex archival data. Just as naturalistic observation requires specifying the behaviors of interest and then noting them as they occur, content analysis requires specifying keywords, phrases, or ideas and then finding all occurrences of them in the data. These occurrences can then be counted, timed (e.g., the amount of time devoted to entertainment topics on the nightly news show), or analyzed in a variety of other ways.
Key Takeaways
- Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
- Correlational research is not defined by where or how the data are collected. However, some approaches to data collection are strongly associated with correlational research. These include naturalistic observation (in which researchers observe people’s behavior in the context in which it normally occurs) and the use of archival data that were already collected for some other purpose.
Discussion: For each of the following, decide whether it is most likely that the study described is experimental or correlational and explain why.
- An educational researcher compares the academic performance of students from the “rich” side of town with that of students from the “poor” side of town.
- A cognitive psychologist compares the ability of people to recall words that they were instructed to “read” with their ability to recall words that they were instructed to “imagine.”
- A manager studies the correlation between new employees’ college grade point averages and their first-year performance reports.
- An automotive engineer installs different stick shifts in a new car prototype, each time asking several people to rate how comfortable the stick shift feels.
- A food scientist studies the relationship between the temperature inside people’s refrigerators and the amount of bacteria on their food.
- A social psychologist tells some research participants that they need to hurry over to the next building to complete a study. She tells others that they can take their time. Then she observes whether they stop to help a research assistant who is pretending to be hurt.
Kanner, A. D., Coyne, J. C., Schaefer, C., & Lazarus, R. S. (1981). Comparison of two modes of stress measurement: Daily hassles and uplifts versus major life events. Journal of Behavioral Medicine, 4 , 1–39.
Kraut, R. E., & Johnston, R. E. (1979). Social and emotional messages of smiling: An ethological approach. Journal of Personality and Social Psychology, 37 , 1539–1553.
Levine, R. V., & Norenzayan, A. (1999). The pace of life in 31 countries. Journal of Cross-Cultural Psychology, 30 , 178–205.
Pelham, B. W., Carvallo, M., & Jones, J. T. (2005). Implicit egotism. Current Directions in Psychological Science, 14 , 106–110.
Peterson, C., Seligman, M. E. P., & Vaillant, G. E. (1988). Pessimistic explanatory style is a risk factor for physical illness: A thirty-five year longitudinal study. Journal of Personality and Social Psychology, 55 , 23–27.
Research Methods in Psychology Copyright © 2016 by University of Minnesota is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
6.2 Correlational Research
Learning objectives.
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while I might be interested in the relationship between the frequency people use cannabis and their memory abilities I cannot ethically manipulate the frequency that people use cannabis. As such, I must rely on the correlational research strategy; I must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis use is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity. In contrast, correlational studies typically have low internal validity because nothing is manipulated or control but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] . These converging results provide strong evidence that there is a real relationship (indeed a causal relationship) between watching violent television and aggressive behavior.
Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
Correlations Between Quantitative Variables
Correlations between quantitative variables are often presented using scatterplots . Figure 6.3 shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure 6.3 represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

Figure 6.3 Scatterplot Showing a Hypothetical Positive Relationship Between Stress and Number of Physical Symptoms. The circled point represents a person whose stress score was 10 and who had three physical symptoms. Pearson’s r for these data is +.51.
The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson’s r ) . As Figure 6.4 shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

Figure 6.4 Range of Pearson’s r, From −1.00 (Strongest Possible Negative Relationship), Through 0 (No Relationship), to +1.00 (Strongest Possible Positive Relationship)
There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure 6.5, for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure 6.5 shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

Figure 6.5 Hypothetical Nonlinear Relationship Between Sleep and Depression
The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure 6.6. Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure 6.6—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Figure 6.6 Hypothetical Data Showing How a Strong Overall Correlation Can Appear to Be Weak When One Variable Has a Restricted Range.The overall correlation here is −.77, but the correlation for the 18- to 24-year-olds (in the blue box) is 0.
Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations.
Some excellent and funny examples of spurious correlations can be found at http://www.tylervigen.com (Figure 6.7 provides one such example).

“Lots of Candy Could Lead to Violence”
Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who determined how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in (because, again, it was the researcher who determined how much they exercised). Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
Key Takeaways
- Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
- Correlation does not imply causation. A statistical relationship between two variables, X and Y , does not necessarily mean that X causes Y . It is also possible that Y causes X , or that a third variable, Z , causes both X and Y .
- While correlational research cannot be used to establish causal relationships between variables, correlational research does allow researchers to achieve many other important objectives (establishing reliability and validity, providing converging evidence, describing relationships and making predictions)
- Correlation coefficients can range from -1 to +1. The sign indicates the direction of the relationship between the variables and the numerical value indicates the strength of the relationship.
- A cognitive psychologist compares the ability of people to recall words that they were instructed to “read” with their ability to recall words that they were instructed to “imagine.”
- A manager studies the correlation between new employees’ college grade point averages and their first-year performance reports.
- An automotive engineer installs different stick shifts in a new car prototype, each time asking several people to rate how comfortable the stick shift feels.
- A food scientist studies the relationship between the temperature inside people’s refrigerators and the amount of bacteria on their food.
- A social psychologist tells some research participants that they need to hurry over to the next building to complete a study. She tells others that they can take their time. Then she observes whether they stop to help a research assistant who is pretending to be hurt.
2. Practice: For each of the following statistical relationships, decide whether the directionality problem is present and think of at least one plausible third variable.
- People who eat more lobster tend to live longer.
- People who exercise more tend to weigh less.
- College students who drink more alcohol tend to have poorer grades.
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵

Share This Book
- Increase Font Size
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
Correlation Studies in Psychology Research
Determining the relationship between two or more variables.
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "example of conclusion in correlational research")
Emily is a board-certified science editor who has worked with top digital publishing brands like Voices for Biodiversity, Study.com, GoodTherapy, Vox, and Verywell.
:max_bytes(150000):strip_icc():format(webp)/Emily-Swaim-1000-0f3197de18f74329aeffb690a177160c.jpg "example of conclusion in correlational research")
Verywell / Brianna Gilmartin
- Characteristics
Potential Pitfalls
Frequently asked questions.
A correlational study is a type of research design that looks at the relationships between two or more variables. Correlational studies are non-experimental, which means that the experimenter does not manipulate or control any of the variables.
A correlation refers to a relationship between two variables. Correlations can be strong or weak and positive or negative. Sometimes, there is no correlation.
There are three possible outcomes of a correlation study: a positive correlation, a negative correlation, or no correlation. Researchers can present the results using a numerical value called the correlation coefficient, a measure of the correlation strength. It can range from –1.00 (negative) to +1.00 (positive). A correlation coefficient of 0 indicates no correlation.
- Positive correlations : Both variables increase or decrease at the same time. A correlation coefficient close to +1.00 indicates a strong positive correlation.
- Negative correlations : As the amount of one variable increases, the other decreases (and vice versa). A correlation coefficient close to -1.00 indicates a strong negative correlation.
- No correlation : There is no relationship between the two variables. A correlation coefficient of 0 indicates no correlation.
Characteristics of a Correlational Study
Correlational studies are often used in psychology, as well as other fields like medicine. Correlational research is a preliminary way to gather information about a topic. The method is also useful if researchers are unable to perform an experiment.
Researchers use correlations to see if a relationship between two or more variables exists, but the variables themselves are not under the control of the researchers.
While correlational research can demonstrate a relationship between variables, it cannot prove that changing one variable will change another. In other words, correlational studies cannot prove cause-and-effect relationships.
When you encounter research that refers to a "link" or an "association" between two things, they are most likely talking about a correlational study.
Types of Correlational Research
There are three types of correlational research: naturalistic observation, the survey method, and archival research. Each type has its own purpose, as well as its pros and cons.
Naturalistic Observation
The naturalistic observation method involves observing and recording variables of interest in a natural setting without interference or manipulation.
Can inspire ideas for further research
Option if lab experiment not available
Variables are viewed in natural setting
Can be time-consuming and expensive
Extraneous variables can't be controlled
No scientific control of variables
Subjects might behave differently if aware of being observed
This method is well-suited to studies where researchers want to see how variables behave in their natural setting or state. Inspiration can then be drawn from the observations to inform future avenues of research.
In some cases, it might be the only method available to researchers; for example, if lab experimentation would be precluded by access, resources, or ethics. It might be preferable to not being able to conduct research at all, but the method can be costly and usually takes a lot of time.
Naturalistic observation presents several challenges for researchers. For one, it does not allow them to control or influence the variables in any way nor can they change any possible external variables.
However, this does not mean that researchers will get reliable data from watching the variables, or that the information they gather will be free from bias.
For example, study subjects might act differently if they know that they are being watched. The researchers might not be aware that the behavior that they are observing is not necessarily the subject's natural state (i.e., how they would act if they did not know they were being watched).
Researchers also need to be aware of their biases, which can affect the observation and interpretation of a subject's behavior.
Surveys and questionnaires are some of the most common methods used for psychological research. The survey method involves having a random sample of participants complete a survey, test, or questionnaire related to the variables of interest. Random sampling is vital to the generalizability of a survey's results.
Cheap, easy, and fast
Can collect large amounts of data in a short amount of time
Results can be affected by poor survey questions
Results can be affected by unrepresentative sample
Outcomes can be affected by participants
If researchers need to gather a large amount of data in a short period of time, a survey is likely to be the fastest, easiest, and cheapest option.
It's also a flexible method because it lets researchers create data-gathering tools that will help ensure they get the information they need (survey responses) from all the sources they want to use (a random sample of participants taking the survey).
Survey data might be cost-efficient and easy to get, but it has its downsides. For one, the data is not always reliable—particularly if the survey questions are poorly written or the overall design or delivery is weak. Data is also affected by specific faults, such as unrepresented or underrepresented samples .
The use of surveys relies on participants to provide useful data. Researchers need to be aware of the specific factors related to the people taking the survey that will affect its outcome.
For example, some people might struggle to understand the questions. A person might answer a particular way to try to please the researchers or to try to control how the researchers perceive them (such as trying to make themselves "look better").
Sometimes, respondents might not even realize that their answers are incorrect or misleading because of mistaken memories .
Archival Research
Many areas of psychological research benefit from analyzing studies that were conducted long ago by other researchers, as well as reviewing historical records and case studies.
For example, in an experiment known as "The Irritable Heart ," researchers used digitalized records containing information on American Civil War veterans to learn more about post-traumatic stress disorder (PTSD).
Large amount of data
Can be less expensive
Researchers cannot change participant behavior
Can be unreliable
Information might be missing
No control over data collection methods
Using records, databases, and libraries that are publicly accessible or accessible through their institution can help researchers who might not have a lot of money to support their research efforts.
Free and low-cost resources are available to researchers at all levels through academic institutions, museums, and data repositories around the world.
Another potential benefit is that these sources often provide an enormous amount of data that was collected over a very long period of time, which can give researchers a way to view trends, relationships, and outcomes related to their research.
While the inability to change variables can be a disadvantage of some methods, it can be a benefit of archival research. That said, using historical records or information that was collected a long time ago also presents challenges. For one, important information might be missing or incomplete and some aspects of older studies might not be useful to researchers in a modern context.
A primary issue with archival research is reliability. When reviewing old research, little information might be available about who conducted the research, how a study was designed, who participated in the research, as well as how data was collected and interpreted.
Researchers can also be presented with ethical quandaries—for example, should modern researchers use data from studies that were conducted unethically or with questionable ethics?
You've probably heard the phrase, "correlation does not equal causation." This means that while correlational research can suggest that there is a relationship between two variables, it cannot prove that one variable will change another.
For example, researchers might perform a correlational study that suggests there is a relationship between academic success and a person's self-esteem. However, the study cannot show that academic success changes a person's self-esteem.
To determine why the relationship exists, researchers would need to consider and experiment with other variables, such as the subject's social relationships, cognitive abilities, personality, and socioeconomic status.
The difference between a correlational study and an experimental study involves the manipulation of variables. Researchers do not manipulate variables in a correlational study, but they do control and systematically vary the independent variables in an experimental study. Correlational studies allow researchers to detect the presence and strength of a relationship between variables, while experimental studies allow researchers to look for cause and effect relationships.
If the study involves the systematic manipulation of the levels of a variable, it is an experimental study. If researchers are measuring what is already present without actually changing the variables, then is a correlational study.
The variables in a correlational study are what the researcher measures. Once measured, researchers can then use statistical analysis to determine the existence, strength, and direction of the relationship. However, while correlational studies can say that variable X and variable Y have a relationship, it does not mean that X causes Y.
The goal of correlational research is often to look for relationships, describe these relationships, and then make predictions. Such research can also often serve as a jumping off point for future experimental research.
Heath W. Psychology Research Methods . Cambridge University Press; 2018:134-156.
Schneider FW. Applied Social Psychology . 2nd ed. SAGE; 2012:50-53.
Curtis EA, Comiskey C, Dempsey O. Importance and use of correlational research . Nurse Researcher . 2016;23(6):20-25. doi:10.7748/nr.2016.e1382
Carpenter S. Visualizing Psychology . 3rd ed. John Wiley & Sons; 2012:14-30.
Pizarro J, Silver RC, Prause J. Physical and mental health costs of traumatic war experiences among civil war veterans . Arch Gen Psychiatry . 2006;63(2):193. doi:10.1001/archpsyc.63.2.193
Post SG. The echo of Nuremberg: Nazi data and ethics . J Med Ethics . 1991;17(1):42-44. doi:10.1136/jme.17.1.42
Lau F. Chapter 12 Methods for Correlational Studies . In: Lau F, Kuziemsky C, eds. Handbook of eHealth Evaluation: An Evidence-based Approach . University of Victoria.
Akoglu H. User's guide to correlation coefficients . Turk J Emerg Med . 2018;18(3):91-93. doi:10.1016/j.tjem.2018.08.001
Price PC. Research Methods in Psychology . California State University.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Correlational Research: What it is with Examples

Our minds can do some brilliant things. For example, it can memorize the jingle of a pizza truck. The louder the jingle, the closer the pizza truck is to us. Who taught us that? Nobody! We relied on our understanding and came to a conclusion. We don’t stop there, do we? If there are multiple pizza trucks in the area and each one has a different jingle, we would memorize it all and relate the jingle to its pizza truck.
This is what correlational research precisely is, establishing a relationship between two variables, “jingle” and “distance of the truck” in this particular example. The correlational study looks for variables that seem to interact with each other. When you see one variable changing, you have a fair idea of how the other variable will change.
What is Correlational research?
Correlational research is a type of non-experimental research method in which a researcher measures two variables and understands and assesses the statistical relationship between them with no influence from any extraneous variable. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities.
Correlational Research Example
The correlation coefficient shows the correlation between two variables (A correlation coefficient is a statistical measure that calculates the strength of the relationship between two variables), a value measured between -1 and +1. When the correlation coefficient is close to +1, there is a positive correlation between the two variables. If the value is relative to -1, there is a negative correlation between the two variables. When the value is close to zero, then there is no relationship between the two variables.
Let us take an example to understand correlational research.
Consider hypothetically, a researcher is studying a correlation between cancer and marriage. In this study, there are two variables: disease and marriage. Let us say marriage has a negative association with cancer. This means that married people are less likely to develop cancer.
However, this doesn’t necessarily mean that marriage directly avoids cancer. In correlational research, it is not possible to establish the fact, what causes what. It is a misconception that a correlational study involves two quantitative variables. However, the reality is two variables are measured, but neither is changed. This is true independent of whether the variables are quantitative or categorical.
Types of correlational research
Mainly three types of correlational research have been identified:
1. Positive correlation: A positive relationship between two variables is when an increase in one variable leads to a rise in the other variable. A decrease in one variable will see a reduction in the other variable. For example, the amount of money a person has might positively correlate with the number of cars the person owns.
2. Negative correlation: A negative correlation is quite literally the opposite of a positive relationship. If there is an increase in one variable, the second variable will show a decrease, and vice versa.
For example, being educated might negatively correlate with the crime rate when an increase in one variable leads to a decrease in another and vice versa. If a country’s education level is improved, it can lower crime rates. Please note that this doesn’t mean that lack of education leads to crimes. It only means that a lack of education and crime is believed to have a common reason – poverty.
3. No correlation: There is no correlation between the two variables in this third type . A change in one variable may not necessarily see a difference in the other variable. For example, being a millionaire and happiness are not correlated. An increase in money doesn’t lead to happiness.
Characteristics of correlational research
Correlational research has three main characteristics. They are:
- Non-experimental : The correlational study is non-experimental. It means that researchers need not manipulate variables with a scientific methodology to either agree or disagree with a hypothesis. The researcher only measures and observes the relationship between the variables without altering them or subjecting them to external conditioning.
- Backward-looking : Correlational research only looks back at historical data and observes events in the past. Researchers use it to measure and spot historical patterns between two variables. A correlational study may show a positive relationship between two variables, but this can change in the future.
- Dynamic : The patterns between two variables from correlational research are never constant and are always changing. Two variables having negative correlation research in the past can have a positive correlation relationship in the future due to various factors.
Data collection
The distinctive feature of correlational research is that the researcher can’t manipulate either of the variables involved. It doesn’t matter how or where the variables are measured. A researcher could observe participants in a closed environment or a public setting.

Researchers use two data collection methods to collect information in correlational research.
01. Naturalistic observation
Naturalistic observation is a way of data collection in which people’s behavioral targeting is observed in their natural environment, in which they typically exist. This method is a type of field research. It could mean a researcher might be observing people in a grocery store, at the cinema, playground, or in similar places.
Researchers who are usually involved in this type of data collection make observations as unobtrusively as possible so that the participants involved in the study are not aware that they are being observed else they might deviate from being their natural self.
Ethically this method is acceptable if the participants remain anonymous, and if the study is conducted in a public setting, a place where people would not normally expect complete privacy. As mentioned previously, taking an example of the grocery store where people can be observed while collecting an item from the aisle and putting in the shopping bags. This is ethically acceptable, which is why most researchers choose public settings for recording their observations. This data collection method could be both qualitative and quantitative . If you need to know more about qualitative data, you can explore our newly published blog, “ Examples of Qualitative Data in Education .”
02. Archival data
Another approach to correlational data is the use of archival data. Archival information is the data that has been previously collected by doing similar kinds of research . Archival data is usually made available through primary research .
In contrast to naturalistic observation, the information collected through archived data can be pretty straightforward. For example, counting the number of people named Richard in the various states of America based on social security records is relatively short.
Use the correlational research method to conduct a correlational study and measure the statistical relationship between two variables. Uncover the insights that matter the most. Use QuestionPro’s research platform to uncover complex insights that can propel your business to the forefront of your industry.
Research to make better decisions. Start a free trial today. No credit card required.
LEARN MORE FREE TRIAL
MORE LIKE THIS

21 Best Customer Advocacy Software for Customers in 2024
Apr 19, 2024

10 Quantitative Data Analysis Software for Every Data Scientist
Apr 18, 2024

11 Best Enterprise Feedback Management Software in 2024

17 Best Online Reputation Management Software in 2024
Apr 17, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Correlational Research in Psychology: Definition and How It Works
Categories Research Methods

Sharing is caring!
Correlational research is a type of scientific investigation in which a researcher looks at the relationships between variables but does not vary, manipulate, or control them. It can be a useful research method for evaluating the direction and strength of the relationship between two or more different variables.
When examining how variables are related to one another, researchers may find that the relationship is positive or negative. Or they may also find that there is no relationship at all.
Table of Contents
How Does Correlational Research Work?
In correlational research, the researcher measures the values of the variables of interest and calculates a correlation coefficient, which quantifies the strength and direction of the relationship between the variables.
The correlation coefficient ranges from -1.0 to +1.0, where -1.0 represents a perfect negative correlation, 0 represents no correlation, and +1.0 represents a perfect positive correlation.
A negative correlation indicates that as the value of one variable increases, the value of the other variable decreases, while a positive correlation indicates that as the value of one variable increases, the value of the other variable also increases. A zero correlation indicates that there is no relationship between the variables.
Correlational Research vs. Experimental Research
Correlational research differs from experimental research in that it does not involve manipulating variables. Instead, it focuses on analyzing the relationship between two or more variables.
In other words, correlational research seeks to determine whether there is a relationship between two variables and, if so, the nature of that relationship.
Experimental research, on the other hand, involves manipulating one or more variables to determine the effect on another variable. Because of this manipulation and control of variables, experimental research allows for causal conclusions to be drawn, while correlational research does not.
Both types of research are important in understanding the world around us, but they serve different purposes and are used in different situations.
Types of Correlational Research
There are three main types of correlational studies:
Cohort Correlational Study
This type of study involves following a cohort of participants over a period of time. This type of research can be useful for understanding how certain events might influence outcomes.
For example, researchers might study how exposure to a traumatic natural disaster influences the mental health of a group of people over time.
By examining the data collected from these individuals, researchers can determine whether there is a correlation between the two variables under investigation. This information can be used to develop strategies for preventing or treating certain conditions or illnesses.
Cross-Sectional Correlational Study
A cross-sectional design is a research method that examines a group of individuals at a single time. This type of study collects information from a diverse group of people, usually from different backgrounds and age groups, to gain insight into a particular phenomenon or issue.
The data collected from this type of study is used to analyze relationships between variables and identify patterns and trends within the group.
Cross-sectional studies can help identify potential risk factors for certain conditions or illnesses, and can also be used to evaluate the prevalence of certain behaviors, attitudes, or beliefs within a population.
Case-Control Correlational Study
A case-control correlational study is a type of research design that investigates the relationship between exposure and health outcomes. In this study, researchers identify a group of individuals with the health outcome of interest (cases) and another group of individuals without the health outcome (controls).
The researchers then compare the exposure history of the cases and controls to determine whether the exposure and health outcome correlate.
This type of study design is often used in epidemiology and can provide valuable information about potential risk factors for a particular disease or condition.
When to Use Correlational Research
There are a number of situations where researchers might opt to use a correlational study instead of some other research design.
Correlational research can be used to investigate a wide range of psychological phenomena, including the relationship between personality traits and academic performance, the association between sleep duration and mental health, and the correlation between parental involvement and child outcomes.
To Generate Hypotheses
Correlational research can also be used to generate hypotheses for further research by identifying variables that are associated with each other.
To Investigate Variables Without Manipulating Them
Researchers should use correlational research when they want to investigate the relationship between two variables without manipulating them. This type of research is useful when the researcher cannot or should not manipulate one of the variables or when it is impossible to conduct an experiment due to ethical or practical concerns.
To Identify Patterns
Correlational research allows researchers to identify patterns and relationships between variables, which can inform future research and help to develop theories. However, it is important to note that correlational research does not prove that one variable causes changes in the other.
While correlational research has its limitations, it is still a valuable tool for researchers in many fields, including psychology, sociology, and education.
How to Collect Data in Correlational Research
Researchers can collect data for correlational research in a few different ways. To conduct correlational research, data can be collected using the following:
- Surveys : One method is through surveys, where participants are asked to self-report their behaviors or attitudes. This approach allows researchers to gather large amounts of data quickly and affordably.
- Naturalistic observation : Another method is through observation, where researchers observe and record behaviors in a natural or controlled setting. This method allows researchers to learn more about the behavior in question and better generalize the results to real-world settings.
- Archival, retrospective data : Additionally, researchers can collect data from archival sources, such as medical, school records, official records, or past polls.
The key is to collect data from a large and representative sample to measure the relationship between two variables accurately.
Pros and Cons of Correlational Research
There are some advantages of using correlational research, but there are also some downsides to consider.
- One of the strengths of correlational research is its ability to identify patterns and relationships between variables that may be difficult or unethical to manipulate in an experimental study.
- Correlational research can also be used to examine variables that are not under the control of the researcher , such as age, gender, or socioeconomic status.
- Correlational research can be used to make predictions about future behavior or outcomes, which can be valuable in a variety of fields.
- Correlational research can be conducted quickly and inexpensively , making it a practical option for researchers with limited resources.
- Correlational research is limited by its inability to establish causality between variables. Correlation does not imply causation, and it is possible that a third variable may be influencing both variables of interest, creating a spurious correlation. Therefore, it is important for researchers to use multiple methods of data collection and to be cautious when interpreting correlational findings.
- Correlational research relies heavily on self-reported data , which can be biased or inaccurate.
- Correlational research is limited in its ability to generalize findings to larger populations, as it only measures the relationship between two variables in a specific sample.
Frequently Asked Questions About Correlational Research
What are the main problems with correlational research.
Some of the main problems that can occur in correlational research include selection bias, confounding variables. and misclassification.
- Selecting participants based on their exposure to an event means that the sample might be biased since the selection was not randomized.
- Correlational studies may also be impacted by extraneous factors that researchers cannot control.
- Finally, there may be problems with how accurately data is recorded and classified, which can be particularly problematic in retrospective studies.
What are the variables in a correlational study?
In a correlational study, variables refer to any measurable factors being examined for their potential relationship or association with each other. These variables can be continuous (meaning they can take on a range of values) or categorical (meaning they fall into distinct categories or groups).
For example, in a study examining the correlation between exercise and mental health, the independent variable would be exercise frequency (measured in times per week), while the dependent variable would be mental health (measured using a standardized questionnaire).
What is the goal of correlational research?
The goal of correlational research is to examine the relationship between two or more variables. It involves analyzing data to determine if there is a statistically significant connection between the variables being studied.
Correlational research is useful for identifying patterns and making predictions but cannot establish causation. Instead, it helps researchers to better understand the nature of the relationship between variables and to generate hypotheses for further investigation.
How do you identify correlational research?
To identify correlational research, look for studies that measure two or more variables and analyze their relationship using statistical techniques. The results of correlational studies are typically presented in the form of correlation coefficients or scatterplots, which visually represent the degree of association between the variables being studied.
Correlational research can be useful for identifying potential causal relationships between variables but cannot establish causation on its own.
Curtis EA, Comiskey C, Dempsey O. Importance and use of correlational research . Nurse Researcher . 2016;23(6):20-25. doi10.7748/nr.2016.e1382
Lau F. Chapter 12 Methods for Correlational Studies . University of Victoria; 2017.
Mitchell TR. An evaluation of the validity of correlational research conducted in organizations . The Academy of Management Review . 1985;10(2):192. doi:10.5465/amr.1985.4277939
Seeram E. An overview of correlational research . Radiol Technol . 2019;91(2):176-179.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 3. Psychological Science
3.2 Psychologists Use Descriptive, Correlational, and Experimental Research Designs to Understand Behaviour
Learning objectives.
- Differentiate the goals of descriptive, correlational, and experimental research designs and explain the advantages and disadvantages of each.
- Explain the goals of descriptive research and the statistical techniques used to interpret it.
- Summarize the uses of correlational research and describe why correlational research cannot be used to infer causality.
- Review the procedures of experimental research and explain how it can be used to draw causal inferences.
Psychologists agree that if their ideas and theories about human behaviour are to be taken seriously, they must be backed up by data. However, the research of different psychologists is designed with different goals in mind, and the different goals require different approaches. These varying approaches, summarized in Table 3.2, are known as research designs . A research design is the specific method a researcher uses to collect, analyze, and interpret data . Psychologists use three major types of research designs in their research, and each provides an essential avenue for scientific investigation. Descriptive research is research designed to provide a snapshot of the current state of affairs . Correlational research is research designed to discover relationships among variables and to allow the prediction of future events from present knowledge . Experimental research is research in which initial equivalence among research participants in more than one group is created, followed by a manipulation of a given experience for these groups and a measurement of the influence of the manipulation . Each of the three research designs varies according to its strengths and limitations, and it is important to understand how each differs.
Descriptive Research: Assessing the Current State of Affairs
Descriptive research is designed to create a snapshot of the current thoughts, feelings, or behaviour of individuals. This section reviews three types of descriptive research : case studies , surveys , and naturalistic observation (Figure 3.4).
Sometimes the data in a descriptive research project are based on only a small set of individuals, often only one person or a single small group. These research designs are known as case studies — descriptive records of one or more individual’s experiences and behaviour . Sometimes case studies involve ordinary individuals, as when developmental psychologist Jean Piaget used his observation of his own children to develop his stage theory of cognitive development. More frequently, case studies are conducted on individuals who have unusual or abnormal experiences or characteristics or who find themselves in particularly difficult or stressful situations. The assumption is that by carefully studying individuals who are socially marginal, who are experiencing unusual situations, or who are going through a difficult phase in their lives, we can learn something about human nature.
Sigmund Freud was a master of using the psychological difficulties of individuals to draw conclusions about basic psychological processes. Freud wrote case studies of some of his most interesting patients and used these careful examinations to develop his important theories of personality. One classic example is Freud’s description of “Little Hans,” a child whose fear of horses the psychoanalyst interpreted in terms of repressed sexual impulses and the Oedipus complex (Freud, 1909/1964).
Another well-known case study is Phineas Gage, a man whose thoughts and emotions were extensively studied by cognitive psychologists after a railroad spike was blasted through his skull in an accident. Although there are questions about the interpretation of this case study (Kotowicz, 2007), it did provide early evidence that the brain’s frontal lobe is involved in emotion and morality (Damasio et al., 2005). An interesting example of a case study in clinical psychology is described by Rokeach (1964), who investigated in detail the beliefs of and interactions among three patients with schizophrenia, all of whom were convinced they were Jesus Christ.
In other cases the data from descriptive research projects come in the form of a survey — a measure administered through either an interview or a written questionnaire to get a picture of the beliefs or behaviours of a sample of people of interest . The people chosen to participate in the research (known as the sample) are selected to be representative of all the people that the researcher wishes to know about (the population). In election polls, for instance, a sample is taken from the population of all “likely voters” in the upcoming elections.
The results of surveys may sometimes be rather mundane, such as “Nine out of 10 doctors prefer Tymenocin” or “The median income in the city of Hamilton is $46,712.” Yet other times (particularly in discussions of social behaviour), the results can be shocking: “More than 40,000 people are killed by gunfire in the United States every year” or “More than 60% of women between the ages of 50 and 60 suffer from depression.” Descriptive research is frequently used by psychologists to get an estimate of the prevalence (or incidence ) of psychological disorders.
A final type of descriptive research — known as naturalistic observation — is research based on the observation of everyday events . For instance, a developmental psychologist who watches children on a playground and describes what they say to each other while they play is conducting descriptive research, as is a biopsychologist who observes animals in their natural habitats. One example of observational research involves a systematic procedure known as the strange situation , used to get a picture of how adults and young children interact. The data that are collected in the strange situation are systematically coded in a coding sheet such as that shown in Table 3.3.
The results of descriptive research projects are analyzed using descriptive statistics — numbers that summarize the distribution of scores on a measured variable . Most variables have distributions similar to that shown in Figure 3.5 where most of the scores are located near the centre of the distribution, and the distribution is symmetrical and bell-shaped. A data distribution that is shaped like a bell is known as a normal distribution .
A distribution can be described in terms of its central tendency — that is, the point in the distribution around which the data are centred — and its dispersion, or spread . The arithmetic average, or arithmetic mean , symbolized by the letter M , is the most commonly used measure of central tendency . It is computed by calculating the sum of all the scores of the variable and dividing this sum by the number of participants in the distribution (denoted by the letter N ). In the data presented in Figure 3.5 the mean height of the students is 67.12 inches (170.5 cm). The sample mean is usually indicated by the letter M .
In some cases, however, the data distribution is not symmetrical. This occurs when there are one or more extreme scores (known as outliers ) at one end of the distribution. Consider, for instance, the variable of family income (see Figure 3.6), which includes an outlier (a value of $3,800,000). In this case the mean is not a good measure of central tendency. Although it appears from Figure 3.6 that the central tendency of the family income variable should be around $70,000, the mean family income is actually $223,960. The single very extreme income has a disproportionate impact on the mean, resulting in a value that does not well represent the central tendency.
The median is used as an alternative measure of central tendency when distributions are not symmetrical. The median is the score in the center of the distribution, meaning that 50% of the scores are greater than the median and 50% of the scores are less than the median . In our case, the median household income ($73,000) is a much better indication of central tendency than is the mean household income ($223,960).
A final measure of central tendency, known as the mode , represents the value that occurs most frequently in the distribution . You can see from Figure 3.6 that the mode for the family income variable is $93,000 (it occurs four times).
In addition to summarizing the central tendency of a distribution, descriptive statistics convey information about how the scores of the variable are spread around the central tendency. Dispersion refers to the extent to which the scores are all tightly clustered around the central tendency , as seen in Figure 3.7.
Or they may be more spread out away from it, as seen in Figure 3.8.
One simple measure of dispersion is to find the largest (the maximum ) and the smallest (the minimum ) observed values of the variable and to compute the range of the variable as the maximum observed score minus the minimum observed score. You can check that the range of the height variable in Figure 3.5 is 72 – 62 = 10. The standard deviation , symbolized as s , is the most commonly used measure of dispersion . Distributions with a larger standard deviation have more spread. The standard deviation of the height variable is s = 2.74, and the standard deviation of the family income variable is s = $745,337.
An advantage of descriptive research is that it attempts to capture the complexity of everyday behaviour. Case studies provide detailed information about a single person or a small group of people, surveys capture the thoughts or reported behaviours of a large population of people, and naturalistic observation objectively records the behaviour of people or animals as it occurs naturally. Thus descriptive research is used to provide a relatively complete understanding of what is currently happening.
Despite these advantages, descriptive research has a distinct disadvantage in that, although it allows us to get an idea of what is currently happening, it is usually limited to static pictures. Although descriptions of particular experiences may be interesting, they are not always transferable to other individuals in other situations, nor do they tell us exactly why specific behaviours or events occurred. For instance, descriptions of individuals who have suffered a stressful event, such as a war or an earthquake, can be used to understand the individuals’ reactions to the event but cannot tell us anything about the long-term effects of the stress. And because there is no comparison group that did not experience the stressful situation, we cannot know what these individuals would be like if they hadn’t had the stressful experience.
Correlational Research: Seeking Relationships among Variables
In contrast to descriptive research, which is designed primarily to provide static pictures, correlational research involves the measurement of two or more relevant variables and an assessment of the relationship between or among those variables. For instance, the variables of height and weight are systematically related (correlated) because taller people generally weigh more than shorter people. In the same way, study time and memory errors are also related, because the more time a person is given to study a list of words, the fewer errors he or she will make. When there are two variables in the research design, one of them is called the predictor variable and the other the outcome variable . The research design can be visualized as shown in Figure 3.9, where the curved arrow represents the expected correlation between these two variables.
One way of organizing the data from a correlational study with two variables is to graph the values of each of the measured variables using a scatter plot . As you can see in Figure 3.10 a scatter plot is a visual image of the relationship between two variables . A point is plotted for each individual at the intersection of his or her scores for the two variables. When the association between the variables on the scatter plot can be easily approximated with a straight line , as in parts (a) and (b) of Figure 3.10 the variables are said to have a linear relationship .
When the straight line indicates that individuals who have above-average values for one variable also tend to have above-average values for the other variable , as in part (a), the relationship is said to be positive linear . Examples of positive linear relationships include those between height and weight, between education and income, and between age and mathematical abilities in children. In each case, people who score higher on one of the variables also tend to score higher on the other variable. Negative linear relationships , in contrast, as shown in part (b), occur when above-average values for one variable tend to be associated with below-average values for the other variable. Examples of negative linear relationships include those between the age of a child and the number of diapers the child uses, and between practice on and errors made on a learning task. In these cases, people who score higher on one of the variables tend to score lower on the other variable.
Relationships between variables that cannot be described with a straight line are known as nonlinear relationships . Part (c) of Figure 3.10 shows a common pattern in which the distribution of the points is essentially random. In this case there is no relationship at all between the two variables, and they are said to be independent . Parts (d) and (e) of Figure 3.10 show patterns of association in which, although there is an association, the points are not well described by a single straight line. For instance, part (d) shows the type of relationship that frequently occurs between anxiety and performance. Increases in anxiety from low to moderate levels are associated with performance increases, whereas increases in anxiety from moderate to high levels are associated with decreases in performance. Relationships that change in direction and thus are not described by a single straight line are called curvilinear relationships .
The most common statistical measure of the strength of linear relationships among variables is the Pearson correlation coefficient , which is symbolized by the letter r . The value of the correlation coefficient ranges from r = –1.00 to r = +1.00. The direction of the linear relationship is indicated by the sign of the correlation coefficient. Positive values of r (such as r = .54 or r = .67) indicate that the relationship is positive linear (i.e., the pattern of the dots on the scatter plot runs from the lower left to the upper right), whereas negative values of r (such as r = –.30 or r = –.72) indicate negative linear relationships (i.e., the dots run from the upper left to the lower right). The strength of the linear relationship is indexed by the distance of the correlation coefficient from zero (its absolute value). For instance, r = –.54 is a stronger relationship than r = .30, and r = .72 is a stronger relationship than r = –.57. Because the Pearson correlation coefficient only measures linear relationships, variables that have curvilinear relationships are not well described by r , and the observed correlation will be close to zero.
It is also possible to study relationships among more than two measures at the same time. A research design in which more than one predictor variable is used to predict a single outcome variable is analyzed through multiple regression (Aiken & West, 1991). Multiple regression is a statistical technique, based on correlation coefficients among variables, that allows predicting a single outcome variable from more than one predictor variable . For instance, Figure 3.11 shows a multiple regression analysis in which three predictor variables (Salary, job satisfaction, and years employed) are used to predict a single outcome (job performance). The use of multiple regression analysis shows an important advantage of correlational research designs — they can be used to make predictions about a person’s likely score on an outcome variable (e.g., job performance) based on knowledge of other variables.
An important limitation of correlational research designs is that they cannot be used to draw conclusions about the causal relationships among the measured variables. Consider, for instance, a researcher who has hypothesized that viewing violent behaviour will cause increased aggressive play in children. He has collected, from a sample of Grade 4 children, a measure of how many violent television shows each child views during the week, as well as a measure of how aggressively each child plays on the school playground. From his collected data, the researcher discovers a positive correlation between the two measured variables.
Although this positive correlation appears to support the researcher’s hypothesis, it cannot be taken to indicate that viewing violent television causes aggressive behaviour. Although the researcher is tempted to assume that viewing violent television causes aggressive play, there are other possibilities. One alternative possibility is that the causal direction is exactly opposite from what has been hypothesized. Perhaps children who have behaved aggressively at school develop residual excitement that leads them to want to watch violent television shows at home (Figure 3.13):
Although this possibility may seem less likely, there is no way to rule out the possibility of such reverse causation on the basis of this observed correlation. It is also possible that both causal directions are operating and that the two variables cause each other (Figure 3.14).
Still another possible explanation for the observed correlation is that it has been produced by the presence of a common-causal variable (also known as a third variable ). A common-causal variable is a variable that is not part of the research hypothesis but that causes both the predictor and the outcome variable and thus produces the observed correlation between them . In our example, a potential common-causal variable is the discipline style of the children’s parents. Parents who use a harsh and punitive discipline style may produce children who like to watch violent television and who also behave aggressively in comparison to children whose parents use less harsh discipline (Figure 3.15)
In this case, television viewing and aggressive play would be positively correlated (as indicated by the curved arrow between them), even though neither one caused the other but they were both caused by the discipline style of the parents (the straight arrows). When the predictor and outcome variables are both caused by a common-causal variable, the observed relationship between them is said to be spurious . A spurious relationship is a relationship between two variables in which a common-causal variable produces and “explains away” the relationship . If effects of the common-causal variable were taken away, or controlled for, the relationship between the predictor and outcome variables would disappear. In the example, the relationship between aggression and television viewing might be spurious because by controlling for the effect of the parents’ disciplining style, the relationship between television viewing and aggressive behaviour might go away.
Common-causal variables in correlational research designs can be thought of as mystery variables because, as they have not been measured, their presence and identity are usually unknown to the researcher. Since it is not possible to measure every variable that could cause both the predictor and outcome variables, the existence of an unknown common-causal variable is always a possibility. For this reason, we are left with the basic limitation of correlational research: correlation does not demonstrate causation. It is important that when you read about correlational research projects, you keep in mind the possibility of spurious relationships, and be sure to interpret the findings appropriately. Although correlational research is sometimes reported as demonstrating causality without any mention being made of the possibility of reverse causation or common-causal variables, informed consumers of research, like you, are aware of these interpretational problems.
In sum, correlational research designs have both strengths and limitations. One strength is that they can be used when experimental research is not possible because the predictor variables cannot be manipulated. Correlational designs also have the advantage of allowing the researcher to study behaviour as it occurs in everyday life. And we can also use correlational designs to make predictions — for instance, to predict from the scores on their battery of tests the success of job trainees during a training session. But we cannot use such correlational information to determine whether the training caused better job performance. For that, researchers rely on experiments.
Experimental Research: Understanding the Causes of Behaviour
The goal of experimental research design is to provide more definitive conclusions about the causal relationships among the variables in the research hypothesis than is available from correlational designs. In an experimental research design, the variables of interest are called the independent variable (or variables ) and the dependent variable . The independent variable in an experiment is the causing variable that is created (manipulated) by the experimenter . The dependent variable in an experiment is a measured variable that is expected to be influenced by the experimental manipulation . The research hypothesis suggests that the manipulated independent variable or variables will cause changes in the measured dependent variables. We can diagram the research hypothesis by using an arrow that points in one direction. This demonstrates the expected direction of causality (Figure 3.16):
Research Focus: Video Games and Aggression
Consider an experiment conducted by Anderson and Dill (2000). The study was designed to test the hypothesis that viewing violent video games would increase aggressive behaviour. In this research, male and female undergraduates from Iowa State University were given a chance to play with either a violent video game (Wolfenstein 3D) or a nonviolent video game (Myst). During the experimental session, the participants played their assigned video games for 15 minutes. Then, after the play, each participant played a competitive game with an opponent in which the participant could deliver blasts of white noise through the earphones of the opponent. The operational definition of the dependent variable (aggressive behaviour) was the level and duration of noise delivered to the opponent. The design of the experiment is shown in Figure 3.17
Two advantages of the experimental research design are (a) the assurance that the independent variable (also known as the experimental manipulation ) occurs prior to the measured dependent variable, and (b) the creation of initial equivalence between the conditions of the experiment (in this case by using random assignment to conditions).
Experimental designs have two very nice features. For one, they guarantee that the independent variable occurs prior to the measurement of the dependent variable. This eliminates the possibility of reverse causation. Second, the influence of common-causal variables is controlled, and thus eliminated, by creating initial equivalence among the participants in each of the experimental conditions before the manipulation occurs.
The most common method of creating equivalence among the experimental conditions is through random assignment to conditions, a procedure in which the condition that each participant is assigned to is determined through a random process, such as drawing numbers out of an envelope or using a random number table . Anderson and Dill first randomly assigned about 100 participants to each of their two groups (Group A and Group B). Because they used random assignment to conditions, they could be confident that, before the experimental manipulation occurred, the students in Group A were, on average, equivalent to the students in Group B on every possible variable, including variables that are likely to be related to aggression, such as parental discipline style, peer relationships, hormone levels, diet — and in fact everything else.
Then, after they had created initial equivalence, Anderson and Dill created the experimental manipulation — they had the participants in Group A play the violent game and the participants in Group B play the nonviolent game. Then they compared the dependent variable (the white noise blasts) between the two groups, finding that the students who had viewed the violent video game gave significantly longer noise blasts than did the students who had played the nonviolent game.
Anderson and Dill had from the outset created initial equivalence between the groups. This initial equivalence allowed them to observe differences in the white noise levels between the two groups after the experimental manipulation, leading to the conclusion that it was the independent variable (and not some other variable) that caused these differences. The idea is that the only thing that was different between the students in the two groups was the video game they had played.
Despite the advantage of determining causation, experiments do have limitations. One is that they are often conducted in laboratory situations rather than in the everyday lives of people. Therefore, we do not know whether results that we find in a laboratory setting will necessarily hold up in everyday life. Second, and more important, is that some of the most interesting and key social variables cannot be experimentally manipulated. If we want to study the influence of the size of a mob on the destructiveness of its behaviour, or to compare the personality characteristics of people who join suicide cults with those of people who do not join such cults, these relationships must be assessed using correlational designs, because it is simply not possible to experimentally manipulate these variables.
Key Takeaways
- Descriptive, correlational, and experimental research designs are used to collect and analyze data.
- Descriptive designs include case studies, surveys, and naturalistic observation. The goal of these designs is to get a picture of the current thoughts, feelings, or behaviours in a given group of people. Descriptive research is summarized using descriptive statistics.
- Correlational research designs measure two or more relevant variables and assess a relationship between or among them. The variables may be presented on a scatter plot to visually show the relationships. The Pearson Correlation Coefficient ( r ) is a measure of the strength of linear relationship between two variables.
- Common-causal variables may cause both the predictor and outcome variable in a correlational design, producing a spurious relationship. The possibility of common-causal variables makes it impossible to draw causal conclusions from correlational research designs.
- Experimental research involves the manipulation of an independent variable and the measurement of a dependent variable. Random assignment to conditions is normally used to create initial equivalence between the groups, allowing researchers to draw causal conclusions.
Exercises and Critical Thinking
- There is a negative correlation between the row that a student sits in in a large class (when the rows are numbered from front to back) and his or her final grade in the class. Do you think this represents a causal relationship or a spurious relationship, and why?
- Think of two variables (other than those mentioned in this book) that are likely to be correlated, but in which the correlation is probably spurious. What is the likely common-causal variable that is producing the relationship?
- Imagine a researcher wants to test the hypothesis that participating in psychotherapy will cause a decrease in reported anxiety. Describe the type of research design the investigator might use to draw this conclusion. What would be the independent and dependent variables in the research?
Image Attributions
Figure 3.4: “ Reading newspaper ” by Alaskan Dude (http://commons.wikimedia.org/wiki/File:Reading_newspaper.jpg) is licensed under CC BY 2.0
Aiken, L., & West, S. (1991). Multiple regression: Testing and interpreting interactions . Newbury Park, CA: Sage.
Ainsworth, M. S., Blehar, M. C., Waters, E., & Wall, S. (1978). Patterns of attachment: A psychological study of the strange situation . Hillsdale, NJ: Lawrence Erlbaum Associates.
Anderson, C. A., & Dill, K. E. (2000). Video games and aggressive thoughts, feelings, and behavior in the laboratory and in life. Journal of Personality and Social Psychology, 78 (4), 772–790.
Damasio, H., Grabowski, T., Frank, R., Galaburda, A. M., Damasio, A. R., Cacioppo, J. T., & Berntson, G. G. (2005). The return of Phineas Gage: Clues about the brain from the skull of a famous patient. In Social neuroscience: Key readings. (pp. 21–28). New York, NY: Psychology Press.
Freud, S. (1909/1964). Analysis of phobia in a five-year-old boy. In E. A. Southwell & M. Merbaum (Eds.), Personality: Readings in theory and research (pp. 3–32). Belmont, CA: Wadsworth. (Original work published 1909).
Kotowicz, Z. (2007). The strange case of Phineas Gage. History of the Human Sciences, 20 (1), 115–131.
Rokeach, M. (1964). The three Christs of Ypsilanti: A psychological study . New York, NY: Knopf.
Stangor, C. (2011). Research methods for the behavioural sciences (4th ed.). Mountain View, CA: Cengage.
Long Descriptions
Figure 3.6 long description: There are 25 families. 24 families have an income between $44,000 and $111,000 and one family has an income of $3,800,000. The mean income is $223,960 while the median income is $73,000. [Return to Figure 3.6]
Figure 3.10 long description: Types of scatter plots.
- Positive linear, r=positive .82. The plots on the graph form a rough line that runs from lower left to upper right.
- Negative linear, r=negative .70. The plots on the graph form a rough line that runs from upper left to lower right.
- Independent, r=0.00. The plots on the graph are spread out around the centre.
- Curvilinear, r=0.00. The plots of the graph form a rough line that goes up and then down like a hill.
- Curvilinear, r=0.00. The plots on the graph for a rough line that goes down and then up like a ditch.
[Return to Figure 3.10]
Introduction to Psychology - 1st Canadian Edition Copyright © 2014 by Jennifer Walinga and Charles Stangor is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
Interpretation of correlations in clinical research
1 University of Utah Department of Orthopaedic Surgery Operations, Salt Lake City, Utah, USA
Jerry Bounsanga
Maren wright voss, background:.
Critically analyzing research is a key skill in evidence-based practice and requires knowledge of research methods, results interpretation, and applications, all of which rely on a foundation based in statistics. Evidence-based practice makes high demands on trained medical professionals to interpret an ever-expanding array of research evidence.
As clinical training emphasizes medical care rather than statistics, it is useful to review the basics of statistical methods and what they mean for interpreting clinical studies.
We reviewed the basic concepts of correlational associations, violations of normality, unobserved variable bias, sample size, and alpha inflation. The foundations of causal inference were discussed and sound statistical analyses were examined. We discuss four ways in which correlational analysis is misused, including causal inference overreach, over-reliance on significance, alpha inflation, and sample size bias.
Recent published studies in the medical field provide evidence of causal assertion overreach drawn from correlational findings. The findings present a primer on the assumptions and nature of correlational methods of analysis and urge clinicians to exercise appropriate caution as they critically analyze the evidence before them and evaluate evidence that supports practice.
Conclusion:
Critically analyzing new evidence requires statistical knowledge in addition to clinical knowledge. Studies can overstate relationships, expressing causal assertions when only correlational evidence is available. Failure to account for the effect of sample size in the analyses tends to overstate the importance of predictive variables. It is important not to overemphasize the statistical significance without consideration of effect size and whether differences could be considered clinically meaningful.
Introduction
It is common for physicians to underestimate the relevance and importance of their training in statistics and probability, at least until its relevance becomes clear in later clinical practice. 1 Evidence based practice is the standard of care, yet evaluating the quality of evidence can be a difficult process. The British Medical Journal established clear statistical guidelines for contributions to medical journals in the 1980’s. 2 A survey of medical residents showed near perfect agreement (95%) that understanding statistics they encounter in medical journals is important, but 75% said they lacked knowledge. 3 The average score on the basic biostatistics exam for the residents surveyed was 41% correct, showing both the objective and subjective need for a stronger statistical training foundation. An international survey of practicing doctors similarly found that doctors averaged scores of 40% when tested on the basics of statistical methods and epidemiology. 4
The efforts to improve the methods behind clinical science are ongoing. Consolidated Standards of Reporting Trials (CONSORT) have been established, 5 along with multiple other research and statistical method guidelines in recent years. 6 These guidelines are updated periodically 7 and endorsed or extended by specific clinical medical groups, 8 , 9 or medical journals. 10 – 13 Key to many of these guidelines are attempts to ensure that bias and error are minimized in research, ensuring interpretations are meaningful and accurate. It would not be practical to detail an exhaustive list of guidance and recommendations. However, with new information and research approaches constantly coming forward, physicians must have the ability to critically evaluate the quality of evidence presented. Critically analyzing research is a key skill in evidence based practice and requires knowledge of methods, results interpretation, and applicability—all three of which require an understanding of basic statistics. 14
The intention of this article is to serve as a basic primer regarding critical statistical concepts that appear in medical literature with a focus on the concept of correlation and how it is best utilized in clinical interpretation for understanding the relationships between health factors. At its foundation, correlational analysis quantifies the direction and strength of relationships between two variables. Understanding correlations can form the basis for interpreting applications of clinical research.
1. What Does Correlation Tell Us?
Correlation is concerned with association; it can look at any two measured concepts and compare their relationships. These measured concepts are often referred to as variables and are assigned letter labels (X, Y). Thus, the correlation is the measure of the relationship between X and Y, and it ranges from −1 to 1. Its value (or coefficient) is scaled within this range to assist in interpretation, with 0 indicating no relationship between variables X and Y, and −1 or 1 indicating the ability to perfectly predict X from Y or Y from X (see Figure 1 ). A correlation coefficient provides two pieces of information. First, it predicts where X (the measured value of interest) falls on a line given a known value of Y. Second, it expresses a reduction in variability associated with knowing Y, telling us something about the expected range of the X value. 15 Correlation takes into account the full range of scores, but as a statistical tool it is not very sensitive to scores on the very high or very low ends of our X value. The common Pearson correlation is best used to describe linear relationships. If the pattern of association between the two variables is, for example, a “U” shaped curve, the correlation results might be low, even though a defined relationship exists. 16

1) Perfect negative correlation between two variables; 2) No patterned relationship between 2 variables; 3) Perfect positive correlation between two variables
Correlation is not easily impacted by skewed or off-center data results. The nature of the data can be described by its parameters, like measures of central tendency, which inform us about the distribution of the data. Parametric tests make assumptions, such as the data are normally distributed, while non-parametric tests are called distribution-free tests because they make no assumptions about the distribution of the data. Yet even if the pattern of scores are not in a normal bell shaped curve or they don’t create a direct linear relationship, correlations can still be reliable. A number of correlation measures have been developed to handle different types of data (non-parametric tests like the kendall rank, spearman rank correlation, phi correlation, biserial correlation, point-biserial correlation and gamma correlation). Yet even the simple Pearson correlation handles extreme violations of normality (no bell shape to the pattern of scores) and scale. The Pearson correlation was tested by randomly drawing 5,000 small samples (n=5 to n=15) from a population of 10,000 to calculate the distribution of r values yielded (small samples might challenge parametric assumptions), and was still found to be a reliable indicator of the relationship between variables. 17 It is also possible to use transformations to normalize the distribution of data. Correlation can be a robust measure, in part from its ability to tolerate these violations of normally distributed data while staying sensitive to the individual case. The properties of correlation make the technique useful in interpreting the meaning derived from clinical data.
2. Use of Correlation
There are many concerns with the statistical techniques that are commonly utilized in the literature. Some concerns arise from a misunderstanding of the statistical measure and others from its misapplication. We discuss four ways in which correlational analysis is misused, including causal inference overreach, over-reliance on significance, alpha inflation, and sample size bias. Importantly, correlation is a measure of association, which is insufficient to infer causation. Correlation can only measure whether a relationship exists between two variables, but it does not indicate causal relationship. There must be a convincing body of evidence to take the next step on the path to inferring that one variable causes the other. Randomized controlled trials or more advanced statistical methods such as path analysis and structural equation modeling, coupled with proper research design, are needed in order to take the next step of inference in the causal chain, testing a causal hypothesis. While correlational analyses are by definition from non-experimental research, research without carefully controlled experimental conditions, it is nevertheless relevant to evidence-based practice. 18 Observational methods of study can be conducted using either a cross-sectional design (a snap-shot of prevalence at one time-point), a retrospective design (looking back to compare current with past attributes) or prospective design (documenting current occurrences and following up at a future time-point to make comparisons). Correlations drawn from cross-sectional studies cannot establish the temporal relationship that links cause with effect, yet adding a retrospective or prospective observational design provides additional strength to the association and helps support hypothesis generation to then later test the causal assertions with a different research design. 19
When non-experimental methods are used, it means the relationship seen between the two variables is vulnerable to bias from anything that was not measured (unobserved variables). Whether studying pain or function or treatment response, there are a host of possible factors that might be important to the observed correlational relationship between X and Y. Any given study has only measured and reported on a fraction of the potential variables of impact. These unobserved variables could potentially explain the observed relationship, so it would be premature to assume a treatment effect based on correlational data. The unobserved variables might be affecting the study variables, changing the relationship in a way that might alter the interpretation of the data. Thus interpretation of correlational findings must be quite cautious until further research is completed.
Another concern is the use (or abuse) of the term ‘statistically significant’ in correlational analysis. This concern is not new. The abuse of significance testing was noted in a 1987 review published in the New England Journal of Medicine. That article found that a number of components in clinical trials, such as having several measures of the outcome (i.e., multiple tests of function, health, or pain), repeated measures over time, including subgroup analyses, or multiple treatments in the same trial, can lead to a bias in reporting which exaggerates the size or importance of observed differences. 20 It is natural for researchers to want to thoroughly evaluate the potential difference between treatments conditions. This has been sometimes referred to as the kitchen sink approach and it presents a problem for using significance tests. Significance as a statistical procedure addresses the question of the probability of the hypothesized occurrence. If the probability ( p ) is less than say 5% or 1%, the researcher might feel comfortable making the assumption that the observed event was not due to chance. The 0.05 significance value was original proposed by Sir Ronald Fisher in 1925, but the 0.05 value was never intended as a hard and fast rule. 21 If researchers use a cut-off of p=0.05 to determine whether the effect they see in their research has occurred randomly by chance, running multiple tests can quickly move the needle from a rare to an expected event. Every analysis run with a p =0.05 alpha criteria yields a 5% chance that the “significant” finding is actually a chance occurrence, called a Type 1 error.
So we can see the difficulty that occurs when running 20 different analyses on the same data. This would produce a 64% chance that a significant p -value will show up erroneously, when there is no systematic relationship, and it is really just a chance occurrence (see Figure 2 ). This over analysis of the data can possibly create an interpretation that a test or treatment should be used when there was no actual treatment effect. This is the problem of alpha-inflation and it needs to be carefully considered both in conducting and interpreting correlational research. It can be corrected by planning ahead for the analyses that will be run and keeping them limited to key theoretical questions. 20 Additionally, alpha can be adjusted in the statistical calculation, for example with the Bonferroni correction, a procedure used to reduce alpha and statistically correct for the inflation created by multiple comparisons. It is performed by simply dividing the alpha value (α) by the number of hypotheses or measures ( m ) tested. If the study wanted to evaluate 5 different surgical placements, using the Bonferroni correction would adjust an original α=0.05 by applying the formula, α/ m or 0.05/5, yielding α=0.01, a stricter standard before a study finding would be considered significant. A Bonferroni correction is a conservative correction for multiple comparisons that reduces the Type 1 error, 22 though less conservative alternatives exist like the Tukey or the Holm-Sidak corrections. The main idea is that clinicians acknowledge the problem of multiple comparisons made in a single study and address the concern so that spurious relationships are not erroneously reported as significant. A lack of awareness about this issue can lead to naïve interpretations of study findings.

As the number of comparisons increases, the alpha error rate increases; running 20 comparisons with no correction factor and a significance level set at 0.05 will result in 64% chance of a relationship appearing to be significant (better than 50/50 odds).
Exaggeration of significance testing leads to a third point - are the findings clinically meaningful? A significant finding does not infer a meaningful finding. This is because factors other than variance in scores influence the p -value or significance in a correlational analysis. Sample size is an important element in whether a non-random effect will be found. Small sample sizes might produce unstable, but significant, correlation estimates, so sample sizes greater than 150 to 200 have been recommended. 23 Yet, it is not uncommon for published papers to report significant effects through correlational analysis of sample sizes of less than 150 patients. 24 – 26 While reporting and publishing both the significant and non-significant results are important, given the instability that comes from a small sample size, there should be caution taken with interpretation until replication studies can verify the findings.
Likewise, large samples can also be problematic. A large sample might reveal a statistically significant difference between groups, but its effect might be minimal. In a classic example, a sample of 22,000 subjects showed a highly significant ( p <.00001) reduction in myocardial infarctions that prompted a general recommendation to take aspirin for myocardial infarction prevention. 27 The effect size, however, was less than a 1% reduction in risk, such that the risk of taking aspirin exceeded the benefit. Effect size is the standardized mean difference between groups and is a measure of the magnitude of between group differences. A significant p -value indicates only that a difference exists with no indication of size of the effect. Additionally, a confidence interval (CI) can be constructed for the effect size. CIs present a lower and upper range where the true population value is most likely to lie. 28 If a zero value is not included within the CI of the effect size, we have added assurance that the effect exists, with the size of the CI helpful in estimating the size of the effect. 29 It has been recommended that effect sizes or confidence intervals be included in all reported medical research so that the clinical significance of findings can be assessed. 20 , 28 , 30
3. Proper Interpretation of Correlation
Correlational analyses have been reported as one of the most common analytic techniques in research at the beginning of the 21 st century, particularly in health and epidemiological research. 15 Thus effective and proper interpretation is critical to understanding the literature. Cautious interpretation is particularly important, not only due to the interpretive concerns just detailed (causal inference overreach, over-reliance on significance, alpha inflation, and sample size bias), but also given the publication bias of journals to accept and publish studies with positive findings. 31 If clinicians are less likely to be exposed to under-published contradictory reports, based on null findings that treatments actually had no effect, the interpretation of the positive results must necessarily be cautious until confirmed through strong evidence.
One recent clinical example of correlational findings is an inference that because Cobb angle and sagittal balance are related to symptom severity in back pain, treatments should be aimed to improve sagittal balance. Studies used to draw these conclusions were making an important first step in identifying potentially relationships, but were not conclusive as they did not establish causal relationships, did not report effect sizes, and did not include control groups in the analyses. 32 – 34 The Pearson correlation or the Spearman correlation are tools that predict X from Y or Y from X. The nature of the correlation is symmetric, so that if the variables are inferred from a reversed direction (pain predicting spine function rather than spine function predicting pain), the same prediction holds true. 15 If one is looking for cause and effect, the correlational statistics cannot help. The mathematics of correlation tells us that Y is just as likely to precede X as to come after, because the prediction is the same regardless of which variable is inputted first. Effects cannot be determined directly through correlational analysis and perhaps the reverse relationship is the true relationship.
Because of the possibility of a bidirectional relationship, causal inference will be premature if relying purely on correlational statistics, no matter how many studies report the correlational finding. Correlation can be interpreted as the association between two variables. It cannot be used to indicate causal relationship. In fact, statistical tests cannot prove causal relationships but can only be used to test causal hypotheses. Misinterpretation of correlation is generally related to a lack of understanding of what a statistical test can or cannot do, as well as lacking knowledge in proper research design. Rather than jumping to an assumption of causality, the correlations should prompt the next stage of clinical research through randomly controlled clinical trials or the application of more complex statistical methods such as causal and path analysis. Perhaps a part of the tendency to jump too quickly to causal assertion arises from the nature of the questions asked in clinical research and the desire to quickly move to enhance patient care. New frameworks are emerging in the health sciences that challenge the appeal to a single cause by considering potential outcomes in a more complex ways. 35 Until then, understanding the nature of correlational analysis allows clinicians to be more cautious in interpreting study results.
Advances in research have led to many significant findings that are shaping how we diagnose and treat patients. As these findings might guide surgeons and clinicians into new treatment directions, it is important to consider the strength and nature of the research. Critically analyzing new evidence requires understanding of research methods and relevant statistical applications, all of which require an understanding of the analytic methodologies that lie behind the study findings.14 Evidence based practice is demanding new skills of trained medical professionals as they are presented with an ever-expanding array of research evidence. This short primer on theassumptions and nature of correlational methods of analysis can assist emerging physicians in understanding and exercising the appropriate caution as they critically analyze the evidence before them.
Acknowledgments
This investigation was supported by the University of Utah Department of Orthopaedics Quality Outcomes Research and Assessment, Study Design and Biostatistics Center, with funding in part from the National Center for Research Resources and the National Center for Advancing Translational Sciences, National Institutes of Health, through Grant 5UL1TR001067–02.
Declaration of Interests
The authors have no relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript. This includes employment, consultancies, honoraria, stock ownership or options, expert testimony, grants or patents received or pending, or royalties.
- Basics of Research Process
- Methodology
Correlational Study: Design, Methods and Examples
- Speech Topics
- Basics of Essay Writing
- Essay Topics
- Other Essays
- Main Academic Essays
- Research Paper Topics
- Basics of Research Paper Writing
- Miscellaneous
- Chicago/ Turabian
- Data & Statistics
- Admission Writing Tips
- Admission Advice
- Other Guides
- Student Life
- Studying Tips
- Understanding Plagiarism
- Academic Writing Tips
- Basics of Dissertation & Thesis Writing
- Essay Guides
- Research Paper Guides
- Formatting Guides
- Admission Guides
- Dissertation & Thesis Guides

Table of contents
Use our free Readability checker
Correlational research is a type of research design used to examine the relationship between two or more variables. In correlational research, researchers measure the extent to which two or more variables are related, without manipulating or controlling any of the variables.
Whether you are a beginner or an experienced researcher, chances are you’ve heard something about correlational research. It’s time that you learn more about this type of study more in-depth, since you will be using it a lot.
- What is correlation?
- When to use it?
- How is it different from experimental studies?
- What data collection method will work?
Grab your pen and get ready to jot down some notes as our paper writing service is going to cover all questions you may have about this type of study. Let’s get down to business!
What Is Correlational Research: Definition
A correlational research is a preliminary type of study used to explore the connection between two variables. In this type of research, you won’t interfere with the variables. Instead of manipulating or adjusting them, researchers focus more on observation. Correlational study is a perfect option if you want to figure out if there is any link between variables. You will conduct it in 2 cases:
- When you want to test a theory about non-causal connection. For example, you may want to know whether drinking hot water boosts the immune system. In this case, you expect that vitamins, healthy lifestyle and regular exercise are those factors that have a real positive impact. However, this doesn’t mean that drinking hot water isn’t associated with the immune system. So measuring this relationship will be really useful.
- When you want to investigate a causal link. You want to study whether using aerosol products leads to ozone depletion. You don’t have enough expenses for conducting complex research. Besides, you can’t control how often people use aerosols. In this case, you will opt for a correlational study.
Correlational Study: Purpose
Correlational research is most useful for purposes of observation and prediction. Researcher's goal is to observe and measure variables to determine if any relationship exists. In case there is some association, researchers assess how strong it is. As an initial type of research, this method allows you to test and write the hypotheses. Correlational study doesn’t require much time and is rather cheap.
Correlational Research Design
Correlational research designs are often used in psychology, epidemiology , medicine and nursing. They show the strength of correlation that exists between the variables within a population. For this reason, these studies are also known as ecological studies. Correlational research design methods are characterized by such traits:
- Non-experimental method. No manipulation or exposure to extra conditions takes place. Researchers only examine how variables act in their natural environment without any interference.
- Fluctuating patterns. Association is never the same and can change due to various factors.
- Quantitative research. These studies require quantitative research methods . Researchers mostly run a statistical analysis and work with numbers to get results.
- Association-oriented study. Correlational study is aimed at finding an association between 2 or more phenomena or events. This has nothing to do with causal relationships between dependent and independent variables .
Correlational Research Questions
Correlational research questions usually focus on how one variable related to another one. If there is some connection, you will observe how strong it is. Let’s look at several examples.
Correlational Research Types
Depending on the direction and strength of association, there are 3 types of correlational research:
- Positive correlation If one variable increases, the other one will grow accordingly. If there is any reduction, both variables will decrease.

- Negative correlation All changes happen in the reverse direction. If one variable increases, the other one should decrease and vice versa.

- Zero correlation No association between 2 factors or events can be found.

Correlational Research: Data Collection Methods
There are 3 main methods applied to collect data in correlational research:
- Surveys and polls
- Naturalistic observation
- Secondary or archival data.
It’s essential that you select the right study method. Otherwise, it won’t be possible to achieve accurate results and answer the research question correctly. Let’s have a closer look at each of these methods to make sure that you make the right choice.
Surveys in Correlational Study
Survey is an easy way to collect data about a population in a correlational study. Depending on the nature of the question, you can choose different survey variations. Questionnaires, polls and interviews are the three most popular formats used in a survey research study. To conduct an effective study, you should first identify the population and choose whether you want to run a survey online, via email or in person.
Naturalistic Observation: Correlational Research
Naturalistic observation is another data collection approach in correlational research methodology. This method allows us to observe behavioral patterns in a natural setting. Scientists often document, describe or categorize data to get a clear picture about a group of people. During naturalistic observations, you may work with both qualitative and quantitative research information. Nevertheless, to measure the strength of association, you should analyze numeric data. Members of a population shouldn’t know that they are being studied. Thus, you should blend in a target group as naturally as possible. Otherwise, participants may behave in a different way which may cause a statistical error.
Correlational Study: Archival Data
Sometimes, you may access ready-made data that suits your study. Archival data is a quick correlational research method that allows to obtain necessary details from the similar studies that have already been conducted. You won’t deal with data collection techniques , since most of numbers will be served on a silver platter. All you will be left to do is analyze them and draw a conclusion. Unfortunately, not all records are accurate, so you should rely only on credible sources.
Pros and Cons of Correlational Research
Choosing what study to run can be difficult. But in this article, we are going to take an in-depth look at advantages and disadvantages of correlational research. This should help you decide whether this type of study is the best fit for you. Without any ado, let’s dive deep right in.
Advantages of Correlational Research
Obviously, one of the many advantages of correlational research is that it can be conducted when an experiment can’t be the case. Sometimes, it may be unethical to run an experimental study or you may have limited resources. This is exactly when ecological study can come in handy. This type of study also has several benefits that have an irreplaceable value:
- Works well as a preliminary study
- Allows examining complex connection between multiple variables
- Helps you study natural behavior
- Can be generalized to other settings.
If you decide to run an archival study or conduct a survey, you will be able to save much time and expenses.
Disadvantages of Correlational Research
There are several limitations of correlational research you should keep in mind while deciding on the main methodology. Here are the advantages one should consider:
- No causal relationships can be identified
- No chance to manipulate extraneous variables
- Biased results caused by unnatural behavior
- Naturalistic studies require quite a lot of time.
As you can see, these types of studies aren’t end-all, be-all. They may indicate a direction for further research. Still, correlational studies don’t show a cause-and-effect relationship which is probably the biggest disadvantage.
Difference Between Correlational and Experimental Research
Now that you’ve come this far, let’s discuss correlational vs experimental research design . Both studies involve quantitative data. But the main difference lies in the aim of research. Correlational studies are used to identify an association which is measured with a coefficient, while an experiment is aimed at determining a causal relationship. Due to a different purpose, the studies also have different approaches to control over variables. In the first case, scientists can’t control or otherwise manipulate the variables in question. Meanwhile, experiments allow you to control variables without limit. There is a causation vs correlation blog on our website. Find out their differences as it will be useful for your research.
Example of Correlational Research
Above, we have offered several correlational research examples. Let’s have a closer look at how things work using a more detailed example.
Example You want to determine if there is any connection between the time employees work in one company and their performance. An experiment will be rather time-consuming. For this reason, you can offer a questionnaire to collect data and assess an association. After running a survey, you will be able to confirm or disprove your hypothesis.
Correlational Study: Final Thoughts
That’s pretty much everything you should know about correlational study. The key takeaway is that this type of study is used to measure the connection between 2 or more variables. It’s a good choice if you have no chance to run an experiment. However, in this case you won’t be able to control for extraneous variables . So you should consider your options carefully before conducting your own research.

We’ve got your back! Entrust your assignment to our skilled paper writers and they will complete a custom research paper with top quality in mind!
Frequently Asked Questions About Correlational Study
1. what is a correlation.
Correlation is a connection that shows to which extent two or more variables are associated. It doesn’t show a causal link and only helps to identify a direction (positive, negative or zero) or the strength of association.
2. How many variables are in a correlation?
There can be many different variables in a correlation which makes this type of study very useful for exploring complex relationships. However, most scientists use this research to measure the association between only 2 variables.
3. What is a correlation coefficient?
Correlation coefficient (ρ) is a statistical measure that indicates the extent to which two variables are related. Association can be strong, moderate or weak. There are different types of p coefficients: positive, negative and zero.
4. What is a correlational study?
Correlational study is a type of statistical research that involves examining two variables in order to determine association between them. It’s a non-experimental type of study, meaning that researchers can’t change independent variables or control extraneous variables.

Joe Eckel is an expert on Dissertations writing. He makes sure that each student gets precious insights on composing A-grade academic writing.
You may also like

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 2: Psychological Research
Correlational Research
Correlation means that there is a relationship between two or more variables (such as ice cream consumption and crime), but this relationship does not necessarily imply cause and effect. When two variables are correlated, it simply means that as one variable changes, so does the other. We can measure correlation by calculating a statistic known as a correlation coefficient. A correlation coefficient is a number from -1 to +1 that indicates the strength and direction of the relationship between variables. The correlation coefficient is usually represented by the letter r .
The number portion of the correlation coefficient indicates the strength of the relationship. The closer the number is to 1 (be it negative or positive), the more strongly related the variables are, and the more predictable changes in one variable will be as the other variable changes. The closer the number is to zero, the weaker the relationship and the less predictable the relationship between the variables becomes. For instance, a correlation coefficient of 0.9 indicates a far stronger relationship than a correlation coefficient of 0.3. If the variables are not related to one another at all, the correlation coefficient is 0. The example above about ice cream and crime is an example of two variables that we might expect to have no relationship to each other.
The sign—positive or negative—of the correlation coefficient indicates the direction of the relationship (Figure 2.9). A positive correlation means that the variables move in the same direction. Put another way, it means that as one variable increases so does the other, and conversely, when one variable decreases so does the other. A negative correlation means that the variables move in opposite directions. If two variables are negatively correlated, a decrease in one variable is associated with an increase in the other and vice versa.
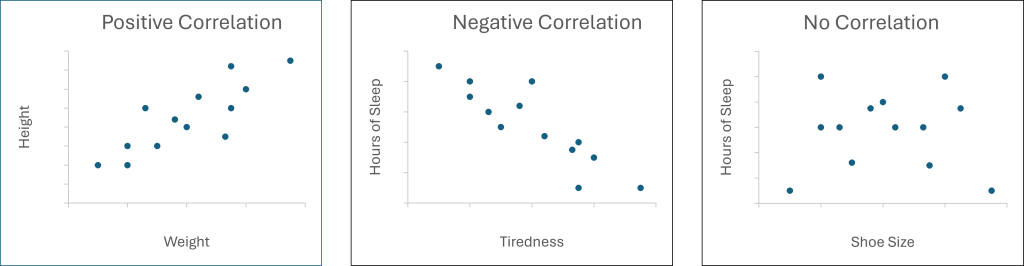
Figure 2.9 Scatterplots are a graphical view of the strength and direction of correlations. The stronger the correlation, the closer the data points are to a straight line. In these examples, we see that there is (a) a positive correlation between weight and height, (b) a negative correlation between tiredness and hours of sleep, and (c) no correlation between shoe size and hours of sleep.
The example of ice cream and crime rates is a positive correlation because both variables increase when temperatures are warmer. Other examples of positive correlations are the relationship between an individual’s height and weight or the relationship between a person’s age and number of wrinkles. One might expect a negative correlation to exist between someone’s tiredness during the day and the number of hours they slept the previous night: the amount of sleep decreases as the feelings of tiredness increase. In a real-world example of negative correlation, student researchers at the University of Minnesota found a weak negative correlation ( r = -0.29) between the average number of days per week that students got fewer than 5 hours of sleep and their GPA (Lowry, Dean, & Manders, 2010). Keep in mind that a negative correlation is not the same as no correlation. For example, we would probably find no correlation between hours of sleep and shoe size.
Video 2.8 Correlational Research Design provides explanation and examples for correlational research. A closed-captioned version of this video is available here .
Manipulate this interactive scatterplot to practice your understanding of positive and negative correlations.
As mentioned earlier, correlations have predictive value. Imagine that you are on the admissions committee of a major university. You are faced with a massive number of applications, but you are able to accommodate only a small percentage of the applicant pool. How might you decide who should be admitted? You might try to correlate your current students’ college GPA with their scores on standardized tests like the SAT or ACT. By observing which correlations were strongest for your current students, you could use this information to predict the relative success of those students who have applied for admission into the university.
Correlation Does Not Indicate Causation
Correlational research is useful because it allows us to discover the strength and direction of relationships that exist between two variables. However, correlation is limited because establishing the existence of a relationship tells us little about cause and effect. While variables are sometimes correlated because one does cause the other, it could also be that some other factor, a confounding variable , is actually causing the systematic movement in our variables of interest. In the ice cream/crime rate example mentioned earlier, temperature is a confounding variable that could account for the relationship between the two variables.
Even when we cannot point to clear confounding variables, we should not assume that a correlation between two variables implies that one variable causes changes in another. This can be frustrating when a cause-and-effect relationship seems clear and intuitive. Think back to our discussion of the research done by the American Cancer Society and how their research projects were some of the first demonstrations of the link between smoking and cancer. It seems reasonable to assume that smoking causes cancer, but if we were limited to correlational research, we would be overstepping our bounds by making this assumption.
Unfortunately, people mistakenly make claims of causation as a function of correlations all the time. Such claims are especially common in advertisements and news stories. For example, recent research found that people who eat cereal on a regular basis achieve healthier weights than those who rarely eat cereal (Frantzen, Treviño, Echon, Garcia-Dominic, & DiMarco, 2013; Barton et al., 2005). Guess how the cereal companies report this finding. Does eating cereal really cause an individual to maintain a healthy weight, or are there other possible explanations, such as, someone at a healthy weight is more likely to regularly eat a healthy breakfast than someone who is obese or someone who avoids meals in an attempt to diet? While correlational research is invaluable in identifying relationships among variables, a significant limitation is the inability to establish causality. Psychologists want to make statements about cause and effect, but the only way to do that is to conduct an experiment to answer a research question. The next section describes how scientific experiments incorporate methods that eliminate or control for alternative explanations, which allow researchers to explore how changes in one variable cause changes in another variable.
Video 2.9 Correlation and Causality provides an explanation for why correlation does not imply causality.
Illusory Correlations
The temptation to make erroneous cause-and-effect statements based on correlational research is not the only way we tend to misinterpret data. We also tend to make the mistake of illusory correlations, especially with unsystematic observations. Illusory correlations , or false correlations, occur when people believe that relationships exist between two things when no such relationship exists. One well-known illusory correlation is the supposed effect that the moon’s phases have on human behavior. Many people passionately assert that human behavior is affected by the phase of the moon, and specifically, that people act strangely when the moon is full (Figure 2.10).

There is no denying that the moon exerts a powerful influence on our planet. The ebb and flow of the ocean’s tides are tightly tied to the gravitational forces of the moon. Many people believe, therefore, that it is logical that we are affected by the moon as well. After all, our bodies are largely made up of water. A meta-analysis of nearly 40 studies consistently demonstrated, however, that the relationship between the moon and our behavior does not exist (Rotton & Kelly, 1985). While we may pay more attention to odd behavior during the full phase of the moon, the rates of odd behavior remain constant throughout the lunar cycle. Why are we so apt to believe in illusory correlations like this? Often we read or hear about them and simply accept the information as valid. Or, we have a hunch about how something works and then look for evidence to support that hunch, ignoring evidence that would tell us our hunch is false; this is known as confirmation bias . Other times, we find illusory correlations based on the information that comes most easily to mind, even if that information is severely limited. And while we may feel confident that we can use these relationships to better understand and predict the world around us, illusory correlations can have significant drawbacks. For example, research suggests that illusory correlations—in which certain behaviors are inaccurately attributed to certain groups—are involved in the formation of prejudicial attitudes that can ultimately lead to discriminatory behavior (Fiedler, 2004).
a relationship between two or more variables
a number from -1 to +1 that indicates the strength and direction of the relationship between variables
as one variable increases so does the other
a decrease in one variable is associated with an increase in the other and vice versa
a factor not being studied that may actually be causing the systematic movement in the variables of interest
false correlations that occur when people believe that relationships exist between two things when no such relationship exists
look for evidence to support that hunch, ignoring evidence that would tell us our hunch is false
Child and Adolescent Development Copyright © 2023 by Krisztina Jakobsen and Paige Fischer is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
5.3: Correlational Research
- Last updated
- Save as PDF
- Page ID 20165

- Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton
- Kwantlen Polytechnic U., Washington State U., & Texas A&M U.—Texarkana
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression, which is discussed further in the section on Complex Correlation in this chapter).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while a researcher might be interested in the relationship between the frequency people use cannabis and their memory abilities they cannot ethically manipulate the frequency that people use cannabis. As such, they must rely on the correlational research strategy; they must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity as artificial conditions are introduced that do not exist in reality. In contrast, correlational studies typically have low internal validity because nothing is manipulated or controlled but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] .
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of daily hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure \(\PageIndex{1}\) shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. What defines a study is how the study is conducted.

Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
scatterplots. Figure \(\PageIndex{2}\) shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure \(\PageIndex{2}\) represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. In other words, they move in the same direction, either both up or both down. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. In other words, they move in opposite directions. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson's r ) . As Figure \(\PageIndex{3}\) shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure \(\PageIndex{4}\), for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure \(\PageIndex{4}\) shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure \(\PageIndex{5}\). Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure \(\PageIndex{5}\)—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations.
Some excellent and amusing examples of spurious correlations can be found at http://www.tylervigen.com (Figure \(\PageIndex{6}\) provides one such example).

Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who used random assignment to determine how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in. Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵
- Open access
- Published: 17 April 2024
Deciphering the influence: academic stress and its role in shaping learning approaches among nursing students: a cross-sectional study
- Rawhia Salah Dogham 1 ,
- Heba Fakieh Mansy Ali 1 ,
- Asmaa Saber Ghaly 3 ,
- Nermine M. Elcokany 2 ,
- Mohamed Mahmoud Seweid 4 &
- Ayman Mohamed El-Ashry ORCID: orcid.org/0000-0001-7718-4942 5
BMC Nursing volume 23 , Article number: 249 ( 2024 ) Cite this article
172 Accesses
Metrics details
Nursing education presents unique challenges, including high levels of academic stress and varied learning approaches among students. Understanding the relationship between academic stress and learning approaches is crucial for enhancing nursing education effectiveness and student well-being.
This study aimed to investigate the prevalence of academic stress and its correlation with learning approaches among nursing students.
Design and Method
A cross-sectional descriptive correlation research design was employed. A convenient sample of 1010 nursing students participated, completing socio-demographic data, the Perceived Stress Scale (PSS), and the Revised Study Process Questionnaire (R-SPQ-2 F).
Most nursing students experienced moderate academic stress (56.3%) and exhibited moderate levels of deep learning approaches (55.0%). Stress from a lack of professional knowledge and skills negatively correlates with deep learning approaches (r = -0.392) and positively correlates with surface learning approaches (r = 0.365). Female students showed higher deep learning approach scores, while male students exhibited higher surface learning approach scores. Age, gender, educational level, and academic stress significantly influenced learning approaches.
Academic stress significantly impacts learning approaches among nursing students. Strategies addressing stressors and promoting healthy learning approaches are essential for enhancing nursing education and student well-being.
Nursing implication
Understanding academic stress’s impact on nursing students’ learning approaches enables tailored interventions. Recognizing stressors informs strategies for promoting adaptive coping, fostering deep learning, and creating supportive environments. Integrating stress management, mentorship, and counseling enhances student well-being and nursing education quality.
Peer Review reports
Introduction
Nursing education is a demanding field that requires students to acquire extensive knowledge and skills to provide competent and compassionate care. Nursing education curriculum involves high-stress environments that can significantly impact students’ learning approaches and academic performance [ 1 , 2 ]. Numerous studies have investigated learning approaches in nursing education, highlighting the importance of identifying individual students’ preferred approaches. The most studied learning approaches include deep, surface, and strategic approaches. Deep learning approaches involve students actively seeking meaning, making connections, and critically analyzing information. Surface learning approaches focus on memorization and reproducing information without a more profound understanding. Strategic learning approaches aim to achieve high grades by adopting specific strategies, such as memorization techniques or time management skills [ 3 , 4 , 5 ].
Nursing education stands out due to its focus on practical training, where the blend of academic and clinical coursework becomes a significant stressor for students, despite academic stress being shared among all university students [ 6 , 7 , 8 ]. Consequently, nursing students are recognized as prone to high-stress levels. Stress is the physiological and psychological response that occurs when a biological control system identifies a deviation between the desired (target) state and the actual state of a fitness-critical variable, whether that discrepancy arises internally or externally to the human [ 9 ]. Stress levels can vary from objective threats to subjective appraisals, making it a highly personalized response to circumstances. Failure to manage these demands leads to stress imbalance [ 10 ].
Nursing students face three primary stressors during their education: academic, clinical, and personal/social stress. Academic stress is caused by the fear of failure in exams, assessments, and training, as well as workload concerns [ 11 ]. Clinical stress, on the other hand, arises from work-related difficulties such as coping with death, fear of failure, and interpersonal dynamics within the organization. Personal and social stressors are caused by an imbalance between home and school, financial hardships, and other factors. Throughout their education, nursing students have to deal with heavy workloads, time constraints, clinical placements, and high academic expectations. Multiple studies have shown that nursing students experience higher stress levels compared to students in other fields [ 12 , 13 , 14 ].
Research has examined the relationship between academic stress and coping strategies among nursing students, but no studies focus specifically on the learning approach and academic stress. However, existing literature suggests that students interested in nursing tend to experience lower levels of academic stress [ 7 ]. Therefore, interest in nursing can lead to deep learning approaches, which promote a comprehensive understanding of the subject matter, allowing students to feel more confident and less overwhelmed by coursework and exams. Conversely, students employing surface learning approaches may experience higher stress levels due to the reliance on memorization [ 3 ].
Understanding the interplay between academic stress and learning approaches among nursing students is essential for designing effective educational interventions. Nursing educators can foster deep learning approaches by incorporating active learning strategies, critical thinking exercises, and reflection activities into the curriculum [ 15 ]. Creating supportive learning environments encouraging collaboration, self-care, and stress management techniques can help alleviate academic stress. Additionally, providing mentorship and counselling services tailored to nursing students’ unique challenges can contribute to their overall well-being and academic success [ 16 , 17 , 18 ].
Despite the scarcity of research focusing on the link between academic stress and learning methods in nursing students, it’s crucial to identify the unique stressors they encounter. The intensity of these stressors can be connected to the learning strategies employed by these students. Academic stress and learning approach are intertwined aspects of the student experience. While academic stress can influence learning approaches, the choice of learning approach can also impact the level of academic stress experienced. By understanding this relationship and implementing strategies to promote healthy learning approaches and manage academic stress, educators and institutions can foster an environment conducive to deep learning and student well-being.
Hence, this study aims to investigate the correlation between academic stress and learning approaches experienced by nursing students.
Study objectives
Assess the levels of academic stress among nursing students.
Assess the learning approaches among nursing students.
Identify the relationship between academic stress and learning approach among nursing students.
Identify the effect of academic stress and related factors on learning approach and among nursing students.
Materials and methods
Research design.
A cross-sectional descriptive correlation research design adhering to the STROBE guidelines was used for this study.
A research project was conducted at Alexandria Nursing College, situated in Egypt. The college adheres to the national standards for nursing education and functions under the jurisdiction of the Egyptian Ministry of Higher Education. Alexandria Nursing College comprises nine specialized nursing departments that offer various nursing specializations. These departments include Nursing Administration, Community Health Nursing, Gerontological Nursing, Medical-Surgical Nursing, Critical Care Nursing, Pediatric Nursing, Obstetric and Gynecological Nursing, Nursing Education, and Psychiatric Nursing and Mental Health. The credit hour system is the fundamental basis of both undergraduate and graduate programs. This framework guarantees a thorough evaluation of academic outcomes by providing an organized structure for tracking academic progress and conducting analyses.
Participants and sample size calculation
The researchers used the Epi Info 7 program to calculate the sample size. The calculations were based on specific parameters such as a population size of 9886 students for the academic year 2022–2023, an expected frequency of 50%, a maximum margin of error of 5%, and a confidence coefficient of 99.9%. Based on these parameters, the program indicated that a minimum sample size of 976 students was required. As a result, the researchers recruited a convenient sample of 1010 nursing students from different academic levels during the 2022–2023 academic year [ 19 ]. This sample size was larger than the minimum required, which could help to increase the accuracy and reliability of the study results. Participation in the study required enrollment in a nursing program and voluntary agreement to take part. The exclusion criteria included individuals with mental illnesses based on their response and those who failed to complete the questionnaires.
socio-demographic data that include students’ age, sex, educational level, hours of sleep at night, hours spent studying, and GPA from the previous semester.
Tool two: the perceived stress scale (PSS)
It was initially created by Sheu et al. (1997) to gauge the level and nature of stress perceived by nursing students attending Taiwanese universities [ 20 ]. It comprises 29 items rated on a 5-point Likert scale, where (0 = never, 1 = rarely, 2 = sometimes, 3 = reasonably often, and 4 = very often), with a total score ranging from 0 to 116. The cut-off points of levels of perceived stress scale according to score percentage were low < 33.33%, moderate 33.33–66.66%, and high more than 66.66%. Higher scores indicate higher stress levels. The items are categorized into six subscales reflecting different sources of stress. The first subscale assesses “stress stemming from lack of professional knowledge and skills” and includes 3 items. The second subscale evaluates “stress from caring for patients” with 8 items. The third subscale measures “stress from assignments and workload” with 5 items. The fourth subscale focuses on “stress from interactions with teachers and nursing staff” with 6 items. The fifth subscale gauges “stress from the clinical environment” with 3 items. The sixth subscale addresses “stress from peers and daily life” with 4 items. El-Ashry et al. (2022) reported an excellent internal consistency reliability of 0.83 [ 21 ]. Two bilingual translators translated the English version of the scale into Arabic and then back-translated it into English by two other independent translators to verify its accuracy. The suitability of the translated version was confirmed through a confirmatory factor analysis (CFA), which yielded goodness-of-fit indices such as a comparative fit index (CFI) of 0.712, a Tucker-Lewis index (TLI) of 0.812, and a root mean square error of approximation (RMSEA) of 0.100.
Tool three: revised study process questionnaire (R-SPQ-2 F)
It was developed by Biggs et al. (2001). It examines deep and surface learning approaches using only 20 questions; each subscale contains 10 questions [ 22 ]. On a 5-point Likert scale ranging from 0 (never or only rarely true of me) to 4 (always or almost always accurate of me). The total score ranged from 0 to 80, with a higher score reflecting more deep or surface learning approaches. The cut-off points of levels of revised study process questionnaire according to score percentage were low < 33%, moderate 33–66%, and high more than 66%. Biggs et al. (2001) found that Cronbach alpha value was 0.73 for deep learning approach and 0.64 for the surface learning approach, which was considered acceptable. Two translators fluent in English and Arabic initially translated a scale from English to Arabic. To ensure the accuracy of the translation, they translated it back into English. The translated version’s appropriateness was evaluated using a confirmatory factor analysis (CFA). The CFA produced several goodness-of-fit indices, including a Comparative Fit Index (CFI) of 0.790, a Tucker-Lewis Index (TLI) of 0.912, and a Root Mean Square Error of Approximation (RMSEA) of 0.100. Comparative Fit Index (CFI) of 0.790, a Tucker-Lewis Index (TLI) of 0.912, and a Root Mean Square Error of Approximation (RMSEA) of 0.100.
Ethical considerations
The Alexandria University College of Nursing’s Research Ethics Committee provided ethical permission before the study’s implementation. Furthermore, pertinent authorities acquired ethical approval at participating nursing institutions. The vice deans of the participating institutions provided written informed consent attesting to institutional support and authority. By giving written informed consent, participants confirmed they were taking part voluntarily. Strict protocols were followed to protect participants’ privacy during the whole investigation. The obtained personal data was kept private and available only to the study team. Ensuring participants’ privacy and anonymity was of utmost importance.
Tools validity
The researchers created tool one after reviewing pertinent literature. Two bilingual translators independently translated the English version into Arabic to evaluate the applicability of the academic stress and learning approach tools for Arabic-speaking populations. To assure accuracy, two additional impartial translators back-translated the translation into English. They were also assessed by a five-person jury of professionals from the education and psychiatric nursing departments. The scales were found to have sufficiently evaluated the intended structures by the jury.
Pilot study
A preliminary investigation involved 100 nursing student applicants, distinct from the final sample, to gauge the efficacy, clarity, and potential obstacles in utilizing the research instruments. The pilot findings indicated that the instruments were accurate, comprehensible, and suitable for the target demographic. Additionally, Cronbach’s Alpha was utilized to further assess the instruments’ reliability, demonstrating internal solid consistency for both the learning approaches and academic stress tools, with values of 0.91 and 0.85, respectively.
Data collection
The researchers convened with each qualified student in a relaxed, unoccupied classroom in their respective college settings. Following a briefing on the study’s objectives, the students filled out the datasheet. The interviews typically lasted 15 to 20 min.
Data analysis
The data collected were analyzed using IBM SPSS software version 26.0. Following data entry, a thorough examination and verification were undertaken to ensure accuracy. The normality of quantitative data distributions was assessed using Kolmogorov-Smirnov tests. Cronbach’s Alpha was employed to evaluate the reliability and internal consistency of the study instruments. Descriptive statistics, including means (M), standard deviations (SD), and frequencies/percentages, were computed to summarize academic stress and learning approaches for categorical data. Student’s t-tests compared scores between two groups for normally distributed variables, while One-way ANOVA compared scores across more than two categories of a categorical variable. Pearson’s correlation coefficient determined the strength and direction of associations between customarily distributed quantitative variables. Hierarchical regression analysis identified the primary independent factors influencing learning approaches. Statistical significance was determined at the 5% (p < 0.05).
Table 1 presents socio-demographic data for a group of 1010 nursing students. The age distribution shows that 38.8% of the students were between 18 and 21 years old, 32.9% were between 21 and 24 years old, and 28.3% were between 24 and 28 years old, with an average age of approximately 22.79. Regarding gender, most of the students were female (77%), while 23% were male. The students were distributed across different educational years, a majority of 34.4% in the second year, followed by 29.4% in the fourth year. The students’ hours spent studying were found to be approximately two-thirds (67%) of the students who studied between 3 and 6 h. Similarly, sleep patterns differ among the students; more than three-quarters (77.3%) of students sleep between 5- to more than 7 h, and only 2.4% sleep less than 2 h per night. Finally, the student’s Grade Point Average (GPA) from the previous semester was also provided. 21% of the students had a GPA between 2 and 2.5, 40.9% had a GPA between 2.5 and 3, and 38.1% had a GPA between 3 and 3.5.
Figure 1 provides the learning approach level among nursing students. In terms of learning approach, most students (55.0%) exhibited a moderate level of deep learning approach, followed by 25.9% with a high level and 19.1% with a low level. The surface learning approach was more prevalent, with 47.8% of students showing a moderate level, 41.7% showing a low level, and only 10.5% exhibiting a high level.

Nursing students? levels of learning approach (N=1010)
Figure 2 provides the types of academic stress levels among nursing students. Among nursing students, various stressors significantly impact their academic experiences. Foremost among these stressors are the pressure and demands associated with academic assignments and workload, with 30.8% of students attributing their high stress levels to these factors. Challenges within the clinical environment are closely behind, contributing significantly to high stress levels among 25.7% of nursing students. Interactions with peers and daily life stressors also weigh heavily on students, ranking third among sources of high stress, with 21.5% of students citing this as a significant factor. Similarly, interaction with teachers and nursing staff closely follow, contributing to high-stress levels for 20.3% of nursing students. While still significant, stress from taking care of patients ranks slightly lower, with 16.7% of students reporting it as a significant factor contributing to their academic stress. At the lowest end of the ranking, but still notable, is stress from a perceived lack of professional knowledge and skills, with 15.9% of students experiencing high stress in this area.

Nursing students? levels of academic stress subtypes (N=1010)
Figure 3 provides the total levels of academic stress among nursing students. The majority of students experienced moderate academic stress (56.3%), followed by those experiencing low academic stress (29.9%), and a minority experienced high academic stress (13.8%).

Nursing students? levels of total academic stress (N=1010)
Table 2 displays the correlation between academic stress subscales and deep and surface learning approaches among 1010 nursing students. All stress subscales exhibited a negative correlation regarding the deep learning approach, indicating that the inclination toward deep learning decreases with increasing stress levels. The most significant negative correlation was observed with stress stemming from the lack of professional knowledge and skills (r=-0.392, p < 0.001), followed by stress from the clinical environment (r=-0.109, p = 0.001), stress from assignments and workload (r=-0.103, p = 0.001), stress from peers and daily life (r=-0.095, p = 0.002), and stress from patient care responsibilities (r=-0.093, p = 0.003). The weakest negative correlation was found with stress from interactions with teachers and nursing staff (r=-0.083, p = 0.009). Conversely, concerning the surface learning approach, all stress subscales displayed a positive correlation, indicating that heightened stress levels corresponded with an increased tendency toward superficial learning. The most substantial positive correlation was observed with stress related to the lack of professional knowledge and skills (r = 0.365, p < 0.001), followed by stress from patient care responsibilities (r = 0.334, p < 0.001), overall stress (r = 0.355, p < 0.001), stress from interactions with teachers and nursing staff (r = 0.262, p < 0.001), stress from assignments and workload (r = 0.262, p < 0.001), and stress from the clinical environment (r = 0.254, p < 0.001). The weakest positive correlation was noted with stress stemming from peers and daily life (r = 0.186, p < 0.001).
Table 3 outlines the association between the socio-demographic characteristics of nursing students and their deep and surface learning approaches. Concerning age, statistically significant differences were observed in deep and surface learning approaches (F = 3.661, p = 0.003 and F = 7.983, p < 0.001, respectively). Gender also demonstrated significant differences in deep and surface learning approaches (t = 3.290, p = 0.001 and t = 8.638, p < 0.001, respectively). Female students exhibited higher scores in the deep learning approach (31.59 ± 8.28) compared to male students (29.59 ± 7.73), while male students had higher scores in the surface learning approach (29.97 ± 7.36) compared to female students (24.90 ± 7.97). Educational level exhibited statistically significant differences in deep and surface learning approaches (F = 5.599, p = 0.001 and F = 17.284, p < 0.001, respectively). Both deep and surface learning approach scores increased with higher educational levels. The duration of study hours demonstrated significant differences only in the surface learning approach (F = 3.550, p = 0.014), with scores increasing as study hours increased. However, no significant difference was observed in the deep learning approach (F = 0.861, p = 0.461). Hours of sleep per night and GPA from the previous semester did not exhibit statistically significant differences in deep or surface learning approaches.
Table 4 presents a multivariate linear regression analysis examining the factors influencing the learning approach among 1110 nursing students. The deep learning approach was positively influenced by age, gender (being female), educational year level, and stress from teachers and nursing staff, as indicated by their positive coefficients and significant p-values (p < 0.05). However, it was negatively influenced by stress from a lack of professional knowledge and skills. The other factors do not significantly influence the deep learning approach. On the other hand, the surface learning approach was positively influenced by gender (being female), educational year level, stress from lack of professional knowledge and skills, stress from assignments and workload, and stress from taking care of patients, as indicated by their positive coefficients and significant p-values (p < 0.05). However, it was negatively influenced by gender (being male). The other factors do not significantly influence the surface learning approach. The adjusted R-squared values indicated that the variables in the model explain 17.8% of the variance in the deep learning approach and 25.5% in the surface learning approach. Both models were statistically significant (p < 0.001).
Nursing students’ academic stress and learning approaches are essential to planning for effective and efficient learning. Nursing education also aims to develop knowledgeable and competent students with problem-solving and critical-thinking skills.
The study’s findings highlight the significant presence of stress among nursing students, with a majority experiencing moderate to severe levels of academic stress. This aligns with previous research indicating that academic stress is prevalent among nursing students. For instance, Zheng et al. (2022) observed moderated stress levels in nursing students during clinical placements [ 23 ], while El-Ashry et al. (2022) found that nearly all first-year nursing students in Egypt experienced severe academic stress [ 21 ]. Conversely, Ali and El-Sherbini (2018) reported that over three-quarters of nursing students faced high academic stress. The complexity of the nursing program likely contributes to these stress levels [ 24 ].
The current study revealed that nursing students identified the highest sources of academic stress as workload from assignments and the stress of caring for patients. This aligns with Banu et al.‘s (2015) findings, where academic demands, assignments, examinations, high workload, and combining clinical work with patient interaction were cited as everyday stressors [ 25 ]. Additionally, Anaman-Torgbor et al. (2021) identified lectures, assignments, and examinations as predictors of academic stress through logistic regression analysis. These stressors may stem from nursing programs emphasizing the development of highly qualified graduates who acquire knowledge, values, and skills through classroom and clinical experiences [ 26 ].
The results regarding learning approaches indicate that most nursing students predominantly employed the deep learning approach. Despite acknowledging a surface learning approach among the participants in the present study, the prevalence of deep learning was higher. This inclination toward the deep learning approach is anticipated in nursing students due to their engagement with advanced courses, requiring retention, integration, and transfer of information at elevated levels. The deep learning approach correlates with a gratifying learning experience and contributes to higher academic achievements [ 3 ]. Moreover, the nursing program’s emphasis on active learning strategies fosters critical thinking, problem-solving, and decision-making skills. These findings align with Mahmoud et al.‘s (2019) study, reporting a significant presence (83.31%) of the deep learning approach among undergraduate nursing students at King Khalid University’s Faculty of Nursing [ 27 ]. Additionally, Mohamed &Morsi (2019) found that most nursing students at Benha University’s Faculty of Nursing embraced the deep learning approach (65.4%) compared to the surface learning approach [ 28 ].
The study observed a negative correlation between the deep learning approach and the overall mean stress score, contrasting with a positive correlation between surface learning approaches and overall stress levels. Elevated academic stress levels may diminish motivation and engagement in the learning process, potentially leading students to feel overwhelmed, disinterested, or burned out, prompting a shift toward a surface learning approach. This finding resonates with previous research indicating that nursing students who actively seek positive academic support strategies during academic stress have better prospects for success than those who do not [ 29 ]. Nebhinani et al. (2020) identified interface concerns and academic workload as significant stress-related factors. Notably, only an interest in nursing demonstrated a significant association with stress levels, with participants interested in nursing primarily employing adaptive coping strategies compared to non-interested students.
The current research reveals a statistically significant inverse relationship between different dimensions of academic stress and adopting the deep learning approach. The most substantial negative correlation was observed with stress arising from a lack of professional knowledge and skills, succeeded by stress associated with the clinical environment, assignments, and workload. Nursing students encounter diverse stressors, including delivering patient care, handling assignments and workloads, navigating challenging interactions with staff and faculty, perceived inadequacies in clinical proficiency, and facing examinations [ 30 ].
In the current study, the multivariate linear regression analysis reveals that various factors positively influence the deep learning approach, including age, female gender, educational year level, and stress from teachers and nursing staff. In contrast, stress from a lack of professional knowledge and skills exert a negative influence. Conversely, the surface learning approach is positively influenced by female gender, educational year level, stress from lack of professional knowledge and skills, stress from assignments and workload, and stress from taking care of patients, but negatively affected by male gender. The models explain 17.8% and 25.5% of the variance in the deep and surface learning approaches, respectively, and both are statistically significant. These findings underscore the intricate interplay of demographic and stress-related factors in shaping nursing students’ learning approaches. High workloads and patient care responsibilities may compel students to prioritize completing tasks over deep comprehension. This pressure could lead to a surface learning approach as students focus on meeting immediate demands rather than engaging deeply with course material. This observation aligns with the findings of Alsayed et al. (2021), who identified age, gender, and study year as significant factors influencing students’ learning approaches.
Deep learners often demonstrate better self-regulation skills, such as effective time management, goal setting, and seeking support when needed. These skills can help manage academic stress and maintain a balanced learning approach. These are supported by studies that studied the effect of coping strategies on stress levels [ 6 , 31 , 32 ]. On the contrary, Pacheco-Castillo et al. study (2021) found a strong significant relationship between academic stressors and students’ level of performance. That study also proved that the more academic stress a student faces, the lower their academic achievement.
Strengths and limitations of the study
This study has lots of advantages. It provides insightful information about the educational experiences of Egyptian nursing students, a demographic that has yet to receive much research. The study’s limited generalizability to other people or nations stems from its concentration on this particular group. This might be addressed in future studies by using a more varied sample. Another drawback is the dependence on self-reported metrics, which may contain biases and mistakes. Although the cross-sectional design offers a moment-in-time view of the problem, it cannot determine causation or evaluate changes over time. To address this, longitudinal research may be carried out.
Notwithstanding these drawbacks, the study substantially contributes to the expanding knowledge of academic stress and nursing students’ learning styles. Additional research is needed to determine teaching strategies that improve deep-learning approaches among nursing students. A qualitative study is required to analyze learning approaches and factors that may influence nursing students’ selection of learning approaches.
According to the present study’s findings, nursing students encounter considerable academic stress, primarily stemming from heavy assignments and workload, as well as interactions with teachers and nursing staff. Additionally, it was observed that students who experience lower levels of academic stress typically adopt a deep learning approach, whereas those facing higher stress levels tend to resort to a surface learning approach. Demographic factors such as age, gender, and educational level influence nursing students’ choice of learning approach. Specifically, female students are more inclined towards deep learning, whereas male students prefer surface learning. Moreover, deep and surface learning approach scores show an upward trend with increasing educational levels and study hours. Academic stress emerges as a significant determinant shaping the adoption of learning approaches among nursing students.
Implications in nursing practice
Nursing programs should consider integrating stress management techniques into their curriculum. Providing students with resources and skills to cope with academic stress can improve their well-being and academic performance. Educators can incorporate teaching strategies that promote deep learning approaches, such as problem-based learning, critical thinking exercises, and active learning methods. These approaches help students engage more deeply with course material and reduce reliance on surface learning techniques. Recognizing the gender differences in learning approaches, nursing programs can offer gender-specific support services and resources. For example, providing targeted workshops or counseling services that address male and female nursing students’ unique stressors and learning needs. Implementing mentorship programs and peer support groups can create a supportive environment where students can share experiences, seek advice, and receive encouragement from their peers and faculty members. Encouraging students to reflect on their learning processes and identify effective study strategies can help them develop metacognitive skills and become more self-directed learners. Faculty members can facilitate this process by incorporating reflective exercises into the curriculum. Nursing faculty and staff should receive training on recognizing signs of academic stress among students and providing appropriate support and resources. Additionally, professional development opportunities can help educators stay updated on evidence-based teaching strategies and practical interventions for addressing student stress.
Data availability
The datasets generated and/or analysed during the current study are not publicly available due to restrictions imposed by the institutional review board to protect participant confidentiality, but are available from the corresponding author on reasonable request.
Liu J, Yang Y, Chen J, Zhang Y, Zeng Y, Li J. Stress and coping styles among nursing students during the initial period of the clinical practicum: A cross-section study. Int J Nurs Sci. 2022a;9(2). https://doi.org/10.1016/j.ijnss.2022.02.004 .
Saifan A, Devadas B, Daradkeh F, Abdel-Fattah H, Aljabery M, Michael LM. Solutions to bridge the theory-practice gap in nursing education in the UAE: a qualitative study. BMC Med Educ. 2021;21(1). https://doi.org/10.1186/s12909-021-02919-x .
Alsayed S, Alshammari F, Pasay-an E, Dator WL. Investigating the learning approaches of students in nursing education. J Taibah Univ Med Sci. 2021;16(1). https://doi.org/10.1016/j.jtumed.2020.10.008 .
Salah Dogham R, Elcokany NM, Saber Ghaly A, Dawood TMA, Aldakheel FM, Llaguno MBB, Mohsen DM. Self-directed learning readiness and online learning self-efficacy among undergraduate nursing students. Int J Afr Nurs Sci. 2022;17. https://doi.org/10.1016/j.ijans.2022.100490 .
Zhao Y, Kuan HK, Chung JOK, Chan CKY, Li WHC. Students’ approaches to learning in a clinical practicum: a psychometric evaluation based on item response theory. Nurse Educ Today. 2018;66. https://doi.org/10.1016/j.nedt.2018.04.015 .
Huang HM, Fang YW. Stress and coping strategies of online nursing practicum courses for Taiwanese nursing students during the COVID-19 pandemic: a qualitative study. Healthcare. 2023;11(14). https://doi.org/10.3390/healthcare11142053 .
Nebhinani M, Kumar A, Parihar A, Rani R. Stress and coping strategies among undergraduate nursing students: a descriptive assessment from Western Rajasthan. Indian J Community Med. 2020;45(2). https://doi.org/10.4103/ijcm.IJCM_231_19 .
Olvera Alvarez HA, Provencio-Vasquez E, Slavich GM, Laurent JGC, Browning M, McKee-Lopez G, Robbins L, Spengler JD. Stress and health in nursing students: the Nurse Engagement and Wellness Study. Nurs Res. 2019;68(6). https://doi.org/10.1097/NNR.0000000000000383 .
Del Giudice M, Buck CL, Chaby LE, Gormally BM, Taff CC, Thawley CJ, Vitousek MN, Wada H. What is stress? A systems perspective. Integr Comp Biol. 2018;58(6):1019–32. https://doi.org/10.1093/icb/icy114 .
Article PubMed Google Scholar
Bhui K, Dinos S, Galant-Miecznikowska M, de Jongh B, Stansfeld S. Perceptions of work stress causes and effective interventions in employees working in public, private and non-governmental organisations: a qualitative study. BJPsych Bull. 2016;40(6). https://doi.org/10.1192/pb.bp.115.050823 .
Lavoie-Tremblay M, Sanzone L, Aubé T, Paquet M. Sources of stress and coping strategies among undergraduate nursing students across all years. Can J Nurs Res. 2021. https://doi.org/10.1177/08445621211028076 .
Article PubMed PubMed Central Google Scholar
Ahmed WAM, Abdulla YHA, Alkhadher MA, Alshameri FA. Perceived stress and coping strategies among nursing students during the COVID-19 pandemic: a systematic review. Saudi J Health Syst Res. 2022;2(3). https://doi.org/10.1159/000526061 .
Pacheco-Castillo J, Casuso-Holgado MJ, Labajos-Manzanares MT, Moreno-Morales N. Academic stress among nursing students in a Private University at Puerto Rico, and its Association with their academic performance. Open J Nurs. 2021;11(09). https://doi.org/10.4236/ojn.2021.119063 .
Tran TTT, Nguyen NB, Luong MA, Bui THA, Phan TD, Tran VO, Ngo TH, Minas H, Nguyen TQ. Stress, anxiety and depression in clinical nurses in Vietnam: a cross-sectional survey and cluster analysis. Int J Ment Health Syst. 2019;13(1). https://doi.org/10.1186/s13033-018-0257-4 .
Magnavita N, Chiorri C. Academic stress and active learning of nursing students: a cross-sectional study. Nurse Educ Today. 2018;68. https://doi.org/10.1016/j.nedt.2018.06.003 .
Folkvord SE, Risa CF. Factors that enhance midwifery students’ learning and development of self-efficacy in clinical placement: a systematic qualitative review. Nurse Educ Pract. 2023;66. https://doi.org/10.1016/j.nepr.2022.103510 .
Myers SB, Sweeney AC, Popick V, Wesley K, Bordfeld A, Fingerhut R. Self-care practices and perceived stress levels among psychology graduate students. Train Educ Prof Psychol. 2012;6(1). https://doi.org/10.1037/a0026534 .
Zeb H, Arif I, Younas A. Nurse educators’ experiences of fostering undergraduate students’ ability to manage stress and demanding situations: a phenomenological inquiry. Nurse Educ Pract. 2022;65. https://doi.org/10.1016/j.nepr.2022.103501 .
Centers for Disease Control and Prevention. User Guide| Support| Epi Info™ [Internet]. Atlanta: CDC; [cited 2024 Jan 31]. Available from: CDC website.
Sheu S, Lin HS, Hwang SL, Yu PJ, Hu WY, Lou MF. The development and testing of a perceived stress scale for nursing students in clinical practice. J Nurs Res. 1997;5:41–52. Available from: http://ntur.lib.ntu.edu.tw/handle/246246/165917 .
El-Ashry AM, Harby SS, Ali AAG. Clinical stressors as perceived by first-year nursing students of their experience at Alexandria main university hospital during the COVID-19 pandemic. Arch Psychiatr Nurs. 2022;41:214–20. https://doi.org/10.1016/j.apnu.2022.08.007 .
Biggs J, Kember D, Leung DYP. The revised two-factor study process questionnaire: R-SPQ-2F. Br J Educ Psychol. 2001;71(1):133–49. https://doi.org/10.1348/000709901158433 .
Article CAS PubMed Google Scholar
Zheng YX, Jiao JR, Hao WN. Stress levels of nursing students: a systematic review and meta-analysis. Med (United States). 2022;101(36). https://doi.org/10.1097/MD.0000000000030547 .
Ali AM, El-Sherbini HH. Academic stress and its contributing factors among faculty nursing students in Alexandria. Alexandria Scientific Nursing Journal. 2018; 20(1):163–181. Available from: https://asalexu.journals.ekb.eg/article_207756_b62caf4d7e1e7a3b292bbb3c6632a0ab.pdf .
Banu P, Deb S, Vardhan V, Rao T. Perceived academic stress of university students across gender, academic streams, semesters, and academic performance. Indian J Health Wellbeing. 2015;6(3):231–235. Available from: http://www.iahrw.com/index.php/home/journal_detail/19#list .
Anaman-Torgbor JA, Tarkang E, Adedia D, Attah OM, Evans A, Sabina N. Academic-related stress among Ghanaian nursing students. Florence Nightingale J Nurs. 2021;29(3):263. https://doi.org/10.5152/FNJN.2021.21030 .
Mahmoud HG, Ahmed KE, Ibrahim EA. Learning Styles and Learning Approaches of Bachelor Nursing Students and its Relation to Their Achievement. Int J Nurs Didact. 2019;9(03):11–20. Available from: http://www.nursingdidactics.com/index.php/ijnd/article/view/2465 .
Mohamed NAAA, Morsi MES, Learning Styles L, Approaches. Academic achievement factors, and self efficacy among nursing students. Int J Novel Res Healthc Nurs. 2019;6(1):818–30. Available from: www.noveltyjournals.com.
Google Scholar
Onieva-Zafra MD, Fernández-Muñoz JJ, Fernández-Martínez E, García-Sánchez FJ, Abreu-Sánchez A, Parra-Fernández ML. Anxiety, perceived stress and coping strategies in nursing students: a cross-sectional, correlational, descriptive study. BMC Med Educ. 2020;20:1–9. https://doi.org/10.1186/s12909-020-02294-z .
Article Google Scholar
Aljohani W, Banakhar M, Sharif L, Alsaggaf F, Felemban O, Wright R. Sources of stress among Saudi Arabian nursing students: a cross-sectional study. Int J Environ Res Public Health. 2021;18(22). https://doi.org/10.3390/ijerph182211958 .
Liu Y, Wang L, Shao H, Han P, Jiang J, Duan X. Nursing students’ experience during their practicum in an intensive care unit: a qualitative meta-synthesis. Front Public Health. 2022;10. https://doi.org/10.3389/fpubh.2022.974244 .
Majrashi A, Khalil A, Nagshabandi E, Al MA. Stressors and coping strategies among nursing students during the COVID-19 pandemic: scoping review. Nurs Rep. 2021;11(2):444–59. https://doi.org/10.3390/nursrep11020042 .
Download references
Acknowledgements
Our sincere thanks go to all the nursing students in the study. We also want to thank Dr/ Rasha Badry for their statistical analysis help and contribution to this study.
The research was not funded by public, commercial, or non-profit organizations.
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and affiliations.
Nursing Education, Faculty of Nursing, Alexandria University, Alexandria, Egypt
Rawhia Salah Dogham & Heba Fakieh Mansy Ali
Critical Care & Emergency Nursing, Faculty of Nursing, Alexandria University, Alexandria, Egypt
Nermine M. Elcokany
Obstetrics and Gynecology Nursing, Faculty of Nursing, Alexandria University, Alexandria, Egypt
Asmaa Saber Ghaly
Faculty of Nursing, Beni-Suef University, Beni-Suef, Egypt
Mohamed Mahmoud Seweid
Psychiatric and Mental Health Nursing, Faculty of Nursing, Alexandria University, Alexandria, Egypt
Ayman Mohamed El-Ashry
You can also search for this author in PubMed Google Scholar
Contributions
Ayman M. El-Ashry & Rawhia S. Dogham: conceptualization, preparation, and data collection; methodology; investigation; formal analysis; data analysis; writing-original draft; writing-manuscript; and editing. Heba F. Mansy Ali & Asmaa S. Ghaly: conceptualization, preparation, methodology, investigation, writing-original draft, writing-review, and editing. Nermine M. Elcokany & Mohamed M. Seweid: Methodology, investigation, formal analysis, data collection, writing-manuscript & editing. All authors reviewed the manuscript and accept for publication.
Corresponding author
Correspondence to Ayman Mohamed El-Ashry .
Ethics declarations
Ethics approval and consent to participate.
The research adhered to the guidelines and regulations outlined in the Declaration of Helsinki (DoH-Oct2008). The Faculty of Nursing’s Research Ethical Committee (REC) at Alexandria University approved data collection in this study (IRB00013620/95/9/2022). Participants were required to sign an informed written consent form, which included an explanation of the research and an assessment of their understanding.
Consent for publication
Not applicable.
Competing interests
The authors declare that there is no conflict of interest.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Dogham, R.S., Ali, H.F.M., Ghaly, A.S. et al. Deciphering the influence: academic stress and its role in shaping learning approaches among nursing students: a cross-sectional study. BMC Nurs 23 , 249 (2024). https://doi.org/10.1186/s12912-024-01885-1
Download citation
Received : 31 January 2024
Accepted : 21 March 2024
Published : 17 April 2024
DOI : https://doi.org/10.1186/s12912-024-01885-1
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Academic stress
- Learning approaches
- Nursing students
BMC Nursing
ISSN: 1472-6955
- General enquiries: [email protected]
- Open access
- Published: 19 April 2024
Asparagine reduces the risk of schizophrenia: a bidirectional two-sample mendelian randomization study of aspartate, asparagine and schizophrenia
- Huang-Hui Liu 1 , 2 na1 ,
- Yao Gao 1 , 2 na1 ,
- Dan Xu 1 , 2 ,
- Xin-Zhe Du 1 , 2 ,
- Si-Meng Wei 1 , 2 ,
- Jian-Zhen Hu 1 , 2 ,
- Yong Xu 1 , 2 &
- Liu Sha 1 , 2
BMC Psychiatry volume 24 , Article number: 299 ( 2024 ) Cite this article
54 Accesses
Metrics details
Despite ongoing research, the underlying causes of schizophrenia remain unclear. Aspartate and asparagine, essential amino acids, have been linked to schizophrenia in recent studies, but their causal relationship is still unclear. This study used a bidirectional two-sample Mendelian randomization (MR) method to explore the causal relationship between aspartate and asparagine with schizophrenia.
This study employed summary data from genome-wide association studies (GWAS) conducted on European populations to examine the correlation between aspartate and asparagine with schizophrenia. In order to investigate the causal effects of aspartate and asparagine on schizophrenia, this study conducted a two-sample bidirectional MR analysis using genetic factors as instrumental variables.
No causal relationship was found between aspartate and schizophrenia, with an odds ratio (OR) of 1.221 (95%CI: 0.483–3.088, P -value = 0.674). Reverse MR analysis also indicated that no causal effects were found between schizophrenia and aspartate, with an OR of 0.999 (95%CI: 0.987–1.010, P -value = 0.841). There is a negative causal relationship between asparagine and schizophrenia, with an OR of 0.485 (95%CI: 0.262-0.900, P -value = 0.020). Reverse MR analysis indicates that there is no causal effect between schizophrenia and asparagine, with an OR of 1.005(95%CI: 0.999–1.011, P -value = 0.132).
This study suggests that there may be a potential risk reduction for schizophrenia with increased levels of asparagine, while also indicating the absence of a causal link between elevated or diminished levels of asparagine in individuals diagnosed with schizophrenia. There is no potential causal relationship between aspartate and schizophrenia, whether prospective or reverse MR. However, it is important to note that these associations necessitate additional research for further validation.
Peer Review reports
Introduction
Schizophrenia is a serious psychiatric illness that affects 0.5 -1% of the global population [ 1 ]. The burden of mental illness was estimated to account for 7% of all diseases worldwide in 2016, and nearly 20% of all years lived with disability [ 2 ]. The characteristics of schizophrenia are positive symptoms, negative symptoms, and cognitive symptoms, which are often severe functional impairments and significant social maladaptations for patients suffering from schizophrenia [ 3 ]. It is still unclear what causes schizophrenia and what the pathogenesis is. There are a number of hypotheses based on neurochemical mechanisms, including dopaminergic and glutamatergic systems [ 4 ]. Although schizophrenia research has made significant advances in the past, further insight into its mechanisms and causes is still needed.
Association genetics research and genome-wide association studies have successfully identified more than 24 candidate genes that serve as molecular biomarkers for the susceptibility to treatment- refractory schizophrenia (TRS). It is worth noting that some proteins in these genes are related to glutamate transfer, especially the N-methyl-D-aspartate receptor (NMDAR) [ 5 ]. It is thought that NMDARs are important for neural plasticity, which is the ability of the brain itself to adapt to new environments. With age, NMDAR function usually declines, which may lead to decreased plasticity, leading to learning and memory problems. Consequently, the manifestation of cognitive deficits observed in diverse pathologies, including Alzheimer’s disease, amyotrophic lateral sclerosis, Huntington’s disease, Parkinson’s disease, schizophrenia, and major depression, can be attributed to the dysfunction of NMDAR [ 4 ]. There are two enantiomers of aspartate (Asp): L and D [ 6 ]. In the brain, D-aspartate (D-Asp) stimulates glutamate receptors and dopaminergic neurons through its direct NMDAR agonist action [ 7 ]. According to the glutamate theory of Sch, glutamate NMDAR dysfunction is a primary contributor to the development of this psychiatric disorder and TRS [ 8 ]. It has been shown in two autopsy studies that D-Asp of prefrontal cortex neurons in patients with schizophrenia are significantly reduced, which is related to an increased expression of D-Asp oxidase [ 9 ] or an increased activity of D-Asp oxidase [ 10 ]. Several studies in animal models and humans have shown that D-amino acids, particularly D-Ser and D-Asp [ 11 ], are able to modulate several NMDAR-dependent processes, including synaptic plasticity, brain development, cognition and brain ageing [ 12 ]. In addition, D-Asp is synthesized in hippocampal and prefrontal cortex neurons, which play an important role in the development of schizophrenia [ 13 ]. It has been reported that the precursor substance of asparagine (Asn), aspartate, activates the N-methyl-D-aspartate receptor [ 14 ]. Asparagine is essential for the survival of all cells [ 15 ], and it was decreased in schizophrenia patients [ 16 ]. Asparagine can cause metabolic disorders of alanine, aspartate, and glutamic acid, leading to dysfunction of the glutamine-glutamate cycle and further affecting it Gamma-Aminobutyric Acid(GABA) level [ 17 ].It is widely understood that the imbalance of GABA levels and NMDAR plays a crucial role in the pathogenesis of schizophrenia, causing neurotoxic effects, synaptic dysfunction, and cognitive impairments [ 18 ].Schizophrenic patients exhibited significantly higher levels of serum aspartate, glutamate, isoleucine, histidine and tyrosine and significantly lower concentrations of serum asparagine, tryptophan and serine [ 19 ]. Other studies have also shown that schizophrenics have higher levels of asparagine, phenylalanine, and cystine, and lower ratios of tyrosine, tryptophan, and tryptophan to competing amino acids, compared to healthy individuals [ 20 ]. Aspartate and asparagine’s association with schizophrenia is not fully understood, and their causal relationship remains unclear.
The MR method is a method that uses Mendelian independence principle to infer causality, which uses genetic variation to study the impact of exposure on outcomes. By using this approach, confounding factors in general research are overcome, and causal reasoning is provided on a reasonable temporal basis [ 21 ]. The instrumental variables for genetic variation that are chosen must adhere to three primary hypotheses: the correlation hypothesis, which posits a robust correlation between single nucleotide polymorphisms (SNPs) and exposure factors; the independence hypothesis, which asserts that SNPs are not affected by various confounding factors; the exclusivity hypothesis, which maintains that SNPs solely influence outcomes through on exposure factors. In a recent study, Mendelian randomization was used to reveal a causal connection between thyroid function and schizophrenia [ 22 ]. According to another Mendelian randomization study, physical activity is causally related to schizophrenia [ 23 ]. Therefore, this study used Mendelian randomization method to explore the causal effects of aspartate on schizophrenia and asparagine on schizophrenia.
To elucidate the causal effects of aspartate and asparagine on schizophrenia. This study used bidirectional MR analysis. In the prospective analysis of MR, the exposure factors under consideration were aspartate and asparagine, while the outcome of interest was the risk of schizophrenia. On the contrary, in the reverse MR analysis, schizophrenia was utilized as the exposure factor, with aspartate and asparagine being chosen as the outcomes.
Materials and methods
Obtaining data sources, select genetic tools closely related to aspartate or asparagine.
In this research, publicly accessible GWAS summary statistical datasets from the MR basic platform were utilized. These datasets consisted of 7721 individuals of European ancestry [ 24 ] for the exposure phenotype instrumental variable of aspartate, and 7761 individuals of European ancestry [ 24 ] for the exposure phenotype instrumental variable of asparagine.
Select genetic tools closely related to schizophrenia
Data from the MR basic platform was used in this study for GWAS summary statistics, which included 77,096 individuals of European ancestry [ 5 ], as instrumental variables related to schizophrenia exposure phenotype.
Obtaining result data
The publicly accessible GWAS summary statistical dataset for schizophrenia was utilized on the MR basic platform, with a sample size of 77096. Additionally, the summary level data for aspartate and asparagine were obtained from the publicly available GWAS summary dataset on the MR basic platform, with sample sizes of 7721 and 7761, respectively, serving as outcome variables.
Instrumental variable filtering
Eliminating linkage disequilibrium.
The selection criteria for identifying exposure related SNPs from the aggregated data of GWAS include: (1) Reaching a significance level that meets the threshold for whole genome research, expressed as P -value < 5 * 10 − 6 [ 25 ]; (2) Ensure the independence of the selected SNPs and eliminate linkage disequilibrium SNPs ( r 2 < 0.001, window size of 10000KB) [ 26 ]; (3) There are corresponding data related to the research results in the GWAS summary data.
Eliminating weak instruments
To evaluate whether the instrumental variables selected for this MR study have weak values, we calculated the F-statistic. If the F-value is greater than 10, it indicates that there are no weak instruments in this study, indicating the reliability of the study. Using the formula F =[(N-K-1)/K] × [R 2 /(1-R 2 )], where N denotes the sample size pertaining to the exposure factor, K signifies the count of instrumental variables, and R 2 denotes the proportion of variations in the exposure factor that can be elucidated by the instrumental variables.
The final instrumental variable obtained
As a result of removing linkage disequilibrium and weak instrumental variables, finally, 3 SNPs related to aspartate and 24 SNPs related to asparagine were selected for MR analysis.
Bidirectional MR analysis
Research design.
Figure 1 presents a comprehensive depiction of the overarching design employed in the MR analysis undertaken in this study. We ascertained SNPs exhibiting robust correlation with the target exposure through analysis of publicly available published data, subsequently investigating the existence of a causal association between these SNPs and the corresponding outcomes. This study conducted two bidirectional MR analyses, one prospective and reverse MR on the causal relationship between aspartate and schizophrenia, and the other prospective and reverse MR on the causal relationship between asparagine and schizophrenia.

A MR analysis of aspartate and schizophrenia (located in the upper left corner). B MR analysis of schizophrenia and aspartate (located in the upper right corner). C MR analysis of asparagine and schizophrenia (located in the lower left corner). D MR analysis of schizophrenia and asparagine (located in the lower right corner)
Statistical analysis
Weighted median, weighted mode, MR Egger, and inverse variance weighting (IVW) were used to conduct a MR study. The primary research findings were derived from the results obtained through IVW, the results of sensitivity analysis using other methods to estimate causal effects are considered. Statistical significance was determined if the P -value was less than 0.05. To enhance the interpretation of the findings, this study converted the beta values obtained in to OR, accompanied by the calculation of a 95% confidence interval (CI).
Test for directional horizontal pleiotropy
This study used MR Egger intercept to test horizontal pleiotropy. If the P -value is greater than 0.05, it indicates that there is no horizontal pleiotropy in this study, meaning that instrumental variables can only regulate outcome variables through exposure factors.
Results of bidirectional MR analysis of aspartate and schizophrenia
Analysis results of aspartate and schizophrenia.
In prospective MR analysis, this study set aspartate as the exposure factor and schizophrenia as the outcome. We used 3 SNPs significantly associated with aspartate screened across the entire genome. The instrumental variables exhibited F-values exceeding 10, signifying the absence of weak instruments and thereby affirming the robustness of our findings. Through MR analysis (Fig. 2 A), we assessed the individual influence of each SNP locus on schizophrenia. The results of the IVW method indicate that no causal effect was found between aspartate and schizophrenia, with an OR of 1.221 (95%CI: 0.483–3.088, P -value = 0.674).
In addition, the analyses conducted using the weighted mode and weighted median methods yielded similar results, indicating the absence of a causal association between aspartate and schizophrenia. Furthermore, the MR Egger analysis demonstrated no statistically significant disparity in effectiveness between aspartate and schizophrenia, as evidenced by a P -value greater than 0.05 (Table 1 ; Fig. 2 B).
In order to test the reliability of the research results, this study used MR Egger intercept analysis to examine horizontal pleiotropy, and the result was P -value = 0.579 > 0.05, indicating the absence of level pleiotropy. Furthermore, a leave-one-out test was conducted to demonstrate that no single SNP had a substantial impact on the stability of the results, indicating that this study has considerable stability (Fig. 2 C). Accordingly, the MR analysis results demonstrate the conclusion that aspartate and schizophrenia do not exhibit a causal relationship.
Analysis results of schizophrenia and aspartate
Different from prospective MR studies, in reverse MR studies, schizophrenia was set as an exposure factor and aspartate was set as the outcome. Through MR analysis (Fig. 2 D), we assessed the individual influence of each SNP locus on aspartate .The results of the IVW method indicate that there is no causal effect between schizophrenia and aspartate, with an OR of 0.999(95%CI: 0.987–1.010, P -value = 0.841). Similarly, the weighted mode, weighted median methods also failed to demonstrate a causal link between schizophrenia and aspartate. Additionally, the MR Egger analysis did not reveal any statistically significant difference in effectiveness between schizophrenia and aspartate ( P -value > 0.05) (Table 1 and Fig . 2 E).
The MR Egger intercept was used to test horizontal pleiotropy, and the result was P -value = 0.226 > 0.05, proving that this study is not affected by horizontal pleiotropy. Furthermore, a leave-one-out test revealed that no individual SNP significantly influenced the robustness of the findings (Fig. 2 F).

Depicts the causal association between aspartate and schizophrenia through diverse statistical analyses, as well as the causal association between schizophrenia and aspartate through diverse statistical analyses. A The forest plot of aspartate related SNPs and schizophrenia analysis results, with the red line showing the MR Egger test and IVW method. B Scatter plot of the analysis results of aspartate and schizophrenia, with the slope indicating the strength of the causal relationship. C Leave-one-out test of research results on aspartate and schizophrenia. D The forest plot of schizophrenia related SNPs and aspartate analysis results, with the red line showing the MR Egger test and IVW method. E Scatter plot of the analysis results of schizophrenia and aspartate, with the slope indicating the strength of the causal relationship. F Leave-one-out test of research results on schizophrenia and aspartate
Results of bidirectional MR analysis of asparagine and schizophrenia
Analysis results of asparagine and schizophrenia.
In prospective MR studies, we used asparagine as an exposure factor and schizophrenia as a result to investigate the potential causal relationship between them. Through a rigorous screening process, we identified 24 genome-wide significant SNPs associated with asparagine. In addition, the instrumental variable F values all exceeded 10, indicating that this study was not affected by weak instruments, thus proving the stability of the results. This study conducted MR analysis to evaluate the impact of all SNP loci on schizophrenia. (Fig. 3 A). According to the results of IVW, a causal relationship was found between asparagine and schizophrenia, and the relationship is negatively correlated, with an OR of 0.485 (95%CI: 0.262-0.900, P -value = 0.020).
The weighted median results also showed a causal relationship between asparagine and schizophrenia, and it was negatively correlated. In the weighted mode method, asparagine and schizophrenia did not have a causal relationship, while in the MR Egger method, there was no statistically significant difference in efficacy between them ( P -value > 0.05) (Table 1 ; Fig. 3 B).
In order to examine the horizontal pleiotropy, the MR Egger intercept was applied, and P -value = 0.768 > 0.05 result proves that this study is not affected by horizontal pleiotropy Furthermore, a leave-one-out test was conducted to demonstrate that no individual SNP had a substantial impact on the stability of the results, indicating that this study has good stability. (Fig. 3 C). Therefore, MR analysis shows that asparagine is inversely proportional to schizophrenia.
Analysis results of schizophrenia and asparagine
In reverse MR analysis, schizophrenia is considered an exposure factor, and asparagine is considered the result, studying the causal effects of schizophrenia and asparagine. Through MR analysis (Fig. 3 D), we assessed the individual influence of each SNP locus on s asparagine. The IVW method results indicated no potential causal relationship between schizophrenia and asparagine, with an OR of 1.005(95%CI: 0.999–1.011, P -value = 0.132). The research results of weighted mode method and weighted median method did not find a causal effects of schizophrenia and asparagine. Additionally, the MR Egger analysis did not reveal any statistically significant difference in effectiveness between schizophrenia and asparagine ( P -value > 0.05) (Table 1 ; Fig. 3 E).
In order to examine the horizontal pleiotropy, the MR Egger intercept was applied, and the result was P -value = 0.474 > 0.05, proving that this study is not affected by horizontal pleiotropy. Furthermore, a leave-one-out test was conducted to demonstrate that no individual SNP had a substantial impact on the stability of the results, indicating that this study has good stability (Fig. 3 F).

Depicts the causal association between asparagine and schizophrenia through diverse statistical analyses, as well as the causal association between schizophrenia and asparagine through diverse statistical analyses. A The forest plot of asparagine related SNPs and schizophrenia analysis results, with the red line showing the MR Egger test and IVW method. B Scatter plot of the analysis results of asparagine and schizophrenia, with the slope indicating the strength of the causal relationship. C Leave-one-out test of research results on asparagine and schizophrenia. D The forest plot of schizophrenia related SNPs and asparagine analysis results, with the red line showing the MR Egger test and IVW method. E Scatter plot of the analysis results of schizophrenia and asparagine, with the slope indicating the strength of the causal relationship. F Leave-one-out test of research results on schizophrenia and asparagine
In this study, the MR analysis results after sensitivity analysis suggested a causal relationship between asparagine and schizophrenia, which was negatively correlated. However, the reverse MR analysis did not reveal any potential relationship between schizophrenia and asparagine, no potential causal relationship between aspartate and schizophrenia was found in both prospective and reverse MR analyses (Fig. 4 ).

Summary of results from bidirectional two-sample MR study
The levels of asparagine in schizophrenia patients decrease, according to studies [ 16 ]. Based on the findings of the Madis Parksepp research team, a continuous five-year administration of antipsychotic drugs (AP) has been observed to induce significant metabolic changes in individuals diagnosed with schizophrenia. Significantly, the concentrations of asparagine, glutamine (Gln), methionine, ornithine, and taurine have experienced a substantial rise, whereas aspartate, glutamate (Glu), and alpha-aminoadipic acid(α-AAA) levels have demonstrated a notable decline. Olanzapine (OLZ) treatment resulted in significantly lower levels of Asn compared to control mice [ 27 ]. Asn and Asp play significant roles in various biological processes within the human body, such as participating in glycoprotein synthesis and contributing to brain functionality. It is worth noting that the ammonia produced in brain tissue needs to have a rapid excretion pathway in the brain. Asn plays a crucial role in regulating cellular function within neural tissues through metabolic control. This amino acid is synthesized by the combination of Asp and ammonia, facilitated by the enzyme asparagine synthase. Additionally, the brain effectively manages ammonia elimination by producing glutamine Gln and Asn. This may be an explanation for the significant increase in Asn and Gln levels (as well as a decrease in Asp and Glu levels) during 5 years of illness and after receiving AP treatment [ 28 ]. The study by Marie Luise Rao’s team compared unmedicated schizophrenic patients, healthy individuals and patients receiving antipsychotic treatment. Unmedicated schizophrenics had higher levels of asparagine, citrulline, phenylalanine, and cysteine, while the ratios of tyrosine, tryptophan, and tryptophan to competing amino acids were significantly lower than in healthy individuals [ 29 ].
The findings of our study demonstrate an inverse association between asparagine levels and the susceptibility to schizophrenia, suggesting that asparagine may serve as a protective factor against the development of this psychiatric disorder. However, we did not find a causal relationship between schizophrenia and asparagine. Consequently, additional investigation and scholarly discourse are warranted to gain a comprehensive understanding of this complex association.
Two different autopsy studies measured D-ASP levels in two different brain samples from patients with schizophrenia and a control group [ 14 ]. The first study, which utilized a limited sample size (7–10 subjects per diagnosis), demonstrated a reduction in D-ASP levels within the prefrontal cortex (PFC) postmortem among individuals diagnosed with schizophrenia, amounting to approximately 101%. This decrease was found to be correlated with a notable elevation in D-aspartate oxidase (DDO) mRNA levels within the same cerebral region [ 30 ]. In addition, the second study was conducted on a large sample size (20 subjects/diagnosis/brain regions). The findings of this study indicated a noteworthy decrease of approximately 30% in D-ASP selectivity within the dorsal lateral PFC (DLPFC) of individuals diagnosed with schizophrenia, when compared to corresponding brain regions of individuals without schizophrenia. However, no significant reduction in D-ASP was observed in the hippocampus of patients with schizophrenia. The decrease in D-Asp content was associated with a significant increase (about 25%) in DDO enzyme activity in the DLPFC of schizophrenia patients. This observation highlights the existence of a dysfunctional metabolic process in DDO activity levels in the brains of schizophrenia patients [ 31 ].
Numerous preclinical investigations have demonstrated the influence of D-Asp on various phenotypes reliant on NMDAR, which are linked to schizophrenia. After administering D-Asp to D-Asp oxidase gene knockout mice, the abnormal neuronal pre-pulse inhibition induced by psychoactive drugs such as MK-801 and amphetamine was significantly reduced by the sustained increase in D-Asp [ 32 ]. According to a review, free amino acids, specifically D-Asp and D-Ser (D-serine), have been identified as highly effective and safe nutrients for promoting mental well-being. These amino acids not only serve as integral components of the central nervous system’s structural proteins, but also play a vital role in maintaining optimal functioning of the central nervous system. This is due to their essential role in regulating neurotransmitter levels, including dopamine, norepinephrine, serotonin, and others. For many patients with schizophrenia, a most persistent and effective improvement therapy may be supplementing amino acids, which can improve the expected therapeutic effect of AP and alleviate positive and negative symptoms of schizophrenia [ 33 ].
Numerous studies have demonstrated a plausible correlation between aspartate and schizophrenia; however, our prospective and reverse MR investigations have failed to establish a causal link between aspartate and schizophrenia. This discrepancy may be attributed to the indirect influence of aspartate on the central nervous system through the stimulation of NMDAR, necessitating further investigation to elucidate the direct relationship between aspartate and schizophrenia.
This study used a bidirectional two-sample MR analysis method to explore the causal relationship between aspartate and asparagine with schizophrenia, as well as its inverse relationship [ 34 ]. The utilization of MR analysis presents numerous benefits in the determination of causality [ 35 ]. Notably, the random allocation of alleles to gametes within this method permits the assumption of no correlation between instrumental variables and confounding factors. Consequently, this approach effectively alleviates bias stemming from confounding factors during the inference of causality. Furthermore, the study’s utilization of a substantial sample size in the GWAS summary data engenders a heightened level of confidence in the obtained results [ 36 ]. Consequently, this investigation not only advances the existing body of research on the relationship between aspartate and asparagine with schizophrenia, but also contributed to clinical treatment decisions for patients with schizophrenia.
Nevertheless, this study possesses certain limitations, as it solely relies on populations of European ancestry for both exposure and results. Consequently, it remains uncertain whether these findings can be replicated among non-European races, necessitating further investigation. In addition, in this study, whether the effects of aspartate and asparagine on schizophrenia vary by gender or age cannot be evaluated, and stratified MR analysis should be performed. Additional experimental research is imperative for a comprehensive understanding of the underlying biological mechanisms connecting aspartate and asparagine with schizophrenia.
In summary, our MR analysis found a negative correlation between asparagine and schizophrenia, indicating that asparagine reduces the risk of schizophrenia. However, there is no potential causal relationship between schizophrenia and asparagine. This study provides new ideas for the early detection of schizophrenia in the clinical setting and offers new insights into the etiology and pathogenesis of schizophrenia. Nonetheless, additional research is required to elucidate the potential mechanisms that underlie the association between aspartate and asparagine with schizophrenia.
Availability of data and materials
The datasets generated and analysed during the current study are available in the GWAS repository. https://gwas.mrcieu.ac.uk/datasets/met-a-388/ , https://gwas.mrcieu.ac.uk/datasets/met-a-638/ , https://gwas.mrcieu.ac.uk/datasets/ieu-b-42/ .
Charlson FJ, Ferrari AJ, Santomauro DF, Diminic S, Stockings E, Scott JG, McGrath JJ, Whiteford HA. Global epidemiology and burden of schizophrenia: findings from the global burden of disease study 2016. Schizophr Bull. 2018;44(6):1195–203.
Article PubMed PubMed Central Google Scholar
Rehm J, Shield KD. Global burden of disease and the impact of mental and addictive disorders. Curr Psychiatry Rep. 2019;21(2):10.
Article PubMed Google Scholar
Vita A, Minelli A, Barlati S, Deste G, Giacopuzzi E, Valsecchi P, Turrina C, Gennarelli M. Treatment-resistant Schizophrenia: genetic and neuroimaging correlates. Front Pharmacol. 2019;10:402.
Article CAS PubMed PubMed Central Google Scholar
Adell A. Brain NMDA receptors in schizophrenia and depression. Biomolecules. 2020;10(6):947.
Biological insights from 108 schizophrenia-associated genetic loci. Nature. 2014;511(7510):421–7.
Abdulbagi M, Wang L, Siddig O, Di B, Li B. D-Amino acids and D-amino acid-containing peptides: potential disease biomarkers and therapeutic targets? Biomolecules. 2021;11(11):1716.
Krashia P, Ledonne A, Nobili A, Cordella A, Errico F, Usiello A, D’Amelio M, Mercuri NB, Guatteo E, Carunchio I. Persistent elevation of D-Aspartate enhances NMDA receptor-mediated responses in mouse substantia Nigra pars compacta dopamine neurons. Neuropharmacology. 2016;103:69–78.
Article CAS PubMed Google Scholar
Kantrowitz JT, Epstein ML, Lee M, Lehrfeld N, Nolan KA, Shope C, Petkova E, Silipo G, Javitt DC. Improvement in mismatch negativity generation during d-serine treatment in schizophrenia: correlation with symptoms. Schizophr Res. 2018;191:70–9.
Elkis H, Buckley PF. Treatment-resistant Schizophrenia. Psychiatr Clin North Am. 2016;39(2):239–65.
Dunlop DS, Neidle A, McHale D, Dunlop DM, Lajtha A. The presence of free D-aspartic acid in rodents and man. Biochem Biophys Res Commun. 1986;141(1):27–32.
de Bartolomeis A, Vellucci L, Austin MC, De Simone G, Barone A. Rational and translational implications of D-Amino acids for treatment-resistant Schizophrenia: from neurobiology to the clinics. Biomolecules. 2022;12(7):909.
Taniguchi K, Sawamura H, Ikeda Y, Tsuji A, Kitagishi Y, Matsuda S. D-amino acids as a biomarker in schizophrenia. Diseases. 2022;10(1):9.
Singh SP, Singh V. Meta-analysis of the efficacy of adjunctive NMDA receptor modulators in chronic schizophrenia. CNS Drugs. 2011;25(10):859–85.
Errico F, Napolitano F, Squillace M, Vitucci D, Blasi G, de Bartolomeis A, Bertolino A, D’Aniello A, Usiello A. Decreased levels of D-aspartate and NMDA in the prefrontal cortex and striatum of patients with schizophrenia. J Psychiatr Res. 2013;47(10):1432–7.
Rousseau J, Gagné V, Labuda M, Beaubois C, Sinnett D, Laverdière C, Moghrabi A, Sallan SE, Silverman LB, Neuberg D, et al. ATF5 polymorphisms influence ATF function and response to treatment in children with childhood acute lymphoblastic leukemia. Blood. 2011;118(22):5883–90.
Liu L, Zhao J, Chen Y, Feng R. Metabolomics strategy assisted by transcriptomics analysis to identify biomarkers associated with schizophrenia. Anal Chim Acta. 2020;1140:18–29.
Cao B, Wang D, Brietzke E, McIntyre RS, Pan Z, Cha D, Rosenblat JD, Zuckerman H, Liu Y, Xie Q, et al. Characterizing amino-acid biosignatures amongst individuals with schizophrenia: a case-control study. Amino Acids. 2018;50(8):1013–23.
Olthof BMJ, Gartside SE, Rees A. Puncta of neuronal nitric oxide synthase (nNOS) mediate NMDA receptor signaling in the Auditory Midbrain. J Neuroscience: Official J Soc Neurosci. 2019;39(5):876–87.
Article CAS Google Scholar
Tortorella A, Monteleone P, Fabrazzo M, Viggiano A, De Luca L, Maj M. Plasma concentrations of amino acids in chronic schizophrenics treated with clozapine. Neuropsychobiology. 2001;44(4):167–71.
Rao ML, Strebel B, Gross G, Huber G. Serum amino acid profiles and dopamine in schizophrenic patients and healthy subjects: window to the brain? Amino Acids. 1992;2(1–2):111–8.
Davey Smith G, Ebrahim S. What can mendelian randomisation tell us about modifiable behavioural and environmental exposures? BMJ (Clinical Res ed). 2005;330(7499):1076–9.
Article Google Scholar
Freuer D, Meisinger C. Causal link between thyroid function and schizophrenia: a two-sample mendelian randomization study. Eur J Epidemiol. 2023;38(10):1081–8.
Papiol S, Schmitt A, Maurus I, Rossner MJ, Schulze TG, Falkai P. Association between Physical Activity and Schizophrenia: results of a 2-Sample mendelian randomization analysis. JAMA Psychiat. 2021;78(4):441–4.
Shin SY, Fauman EB, Petersen AK, Krumsiek J, Santos R, Huang J, Arnold M, Erte I, Forgetta V, Yang TP, et al. An atlas of genetic influences on human blood metabolites. Nat Genet. 2014;46(6):543–50.
Zhao JV, Kwok MK, Schooling CM. Effect of glutamate and aspartate on ischemic heart disease, blood pressure, and diabetes: a mendelian randomization study. Am J Clin Nutr. 2019;109(4):1197–206.
Zhou K, Zhu L, Chen N, Huang G, Feng G, Wu Q, Wei X, Gou X. Causal associations between schizophrenia and cancers risk: a mendelian randomization study. Front Oncol. 2023;13:1258015.
Zapata RC, Rosenthal SB, Fisch K, Dao K, Jain M, Osborn O. Metabolomic profiles associated with a mouse model of antipsychotic-induced food intake and weight gain. Sci Rep. 2020;10(1):18581.
Parksepp M, Leppik L, Koch K, Uppin K, Kangro R, Haring L, Vasar E, Zilmer M. Metabolomics approach revealed robust changes in amino acid and biogenic amine signatures in patients with schizophrenia in the early course of the disease. Sci Rep. 2020;10(1):13983.
Rao ML, Gross G, Strebel B, Bräunig P, Huber G, Klosterkötter J. Serum amino acids, central monoamines, and hormones in drug-naive, drug-free, and neuroleptic-treated schizophrenic patients and healthy subjects. Psychiatry Res. 1990;34(3):243–57.
Errico F, D’Argenio V, Sforazzini F, Iasevoli F, Squillace M, Guerri G, Napolitano F, Angrisano T, Di Maio A, Keller S, et al. A role for D-aspartate oxidase in schizophrenia and in schizophrenia-related symptoms induced by phencyclidine in mice. Transl Psychiatry. 2015;5(2):e512.
Nuzzo T, Sacchi S, Errico F, Keller S, Palumbo O, Florio E, Punzo D, Napolitano F, Copetti M, Carella M, et al. Decreased free d-aspartate levels are linked to enhanced d-aspartate oxidase activity in the dorsolateral prefrontal cortex of schizophrenia patients. NPJ Schizophr. 2017;3:16.
Errico F, Rossi S, Napolitano F, Catuogno V, Topo E, Fisone G, D’Aniello A, Centonze D, Usiello A. D-aspartate prevents corticostriatal long-term depression and attenuates schizophrenia-like symptoms induced by amphetamine and MK-801. J Neurosci. 2008;28(41):10404–14.
Nasyrova RF, Khasanova AK, Altynbekov KS, Asadullin AR, Markina EA, Gayduk AJ, Shipulin GA, Petrova MM, Shnayder NA. The role of D-Serine and D-aspartate in the pathogenesis and therapy of treatment-resistant schizophrenia. Nutrients. 2022;14(23):5142.
Hao D, Liu C. Deepening insights into food and medicine continuum within the context of pharmacophylogeny. Chin Herb Med. 2023;15(1):1–2.
PubMed Google Scholar
Zhang Y. Awareness and ability of paradigm shift are needed for research on dominant diseases of TCM. Chin Herb Med. 2023;15(4):475.
CAS PubMed PubMed Central Google Scholar
Chen J. Essential role of medicine and food homology in health and wellness. Chin Herb Med. 2023;15(3):347–8.
PubMed PubMed Central Google Scholar
Download references
This work was supported by the National Natural Science Foundation of China (82271546, 82301725, 81971601); National Key Research and Development Program of China (2023YFC2506201); Key Project of Science and Technology Innovation 2030 of China (2021ZD0201800, 2021ZD0201805); China Postdoctoral Science Foundation (2023M732155); Fundamental Research Program of Shanxi Province (202203021211018, 202203021212028, 202203021212038). Research Project Supported by Shanxi Scholarship Council of China (2022 − 190); Scientific Research Plan of Shanxi Health Commission (2020081, 2020SYS03,2021RC24); Shanxi Provincial Administration of Traditional Chinese Medicine (2023ZYYC2034), Scientific and Technological Innovation Programs of Higher Education Institutions in Shanxi (2022L132); Shanxi Medical University School-level Doctoral Initiation Fund Project (XD2102); Youth Project of First Hospital of Shanxi Medical University (YQ2203); Doctor Fund Project of Shanxi Medical University in Shanxi Province (SD2216); Shanxi Science and Technology Innovation Talent Team (202304051001049); 136 Medical Rejuvenation Project of Shanxi Province, China; STI2030-Major Projects-2021ZD0200700. Key laboratory of Health Commission of Shanxi Province (2020SYS03);
Author information
Huang-Hui Liu and Yao Gao contributed equally to this work.
Authors and Affiliations
Department of Psychiatry, First Hospital/First Clinical Medical College of Shanxi Medical University, NO.85 Jiefang Nan Road, Taiyuan, China
Huang-Hui Liu, Yao Gao, Dan Xu, Xin-Zhe Du, Si-Meng Wei, Jian-Zhen Hu, Yong Xu & Liu Sha
Shanxi Key Laboratory of Artificial Intelligence Assisted Diagnosis and Treatment for Mental Disorder, First Hospital of Shanxi Medical University, Taiyuan, China
You can also search for this author in PubMed Google Scholar
Contributions
Huang-Hui Liu and Yao Gao provided the concept and designed the study. Huang-Hui Liu and Yao Gao conducted the analyses and wrote the manuscript. Dan Xu, Huang-Hui Liu and Yao Gao participated in data collection. Xin-Zhe Du, Si-Meng Wei and Jian-Zhen Hu participated in the analysis of the data. Liu Sha, Yong Xu and Yao Gao revised and proof-read the manuscript. All authors contributed to the article and approved the submitted version.
Corresponding authors
Correspondence to Yong Xu or Liu Sha .
Ethics declarations
Ethics approval and consent to participate.
Not applicable’ for that section.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Liu, HH., Gao, Y., Xu, D. et al. Asparagine reduces the risk of schizophrenia: a bidirectional two-sample mendelian randomization study of aspartate, asparagine and schizophrenia. BMC Psychiatry 24 , 299 (2024). https://doi.org/10.1186/s12888-024-05765-5
Download citation
Received : 20 February 2024
Accepted : 15 April 2024
Published : 19 April 2024
DOI : https://doi.org/10.1186/s12888-024-05765-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Schizophrenia
- Mendelian randomization
BMC Psychiatry
ISSN: 1471-244X
- Submission enquiries: [email protected]
- General enquiries: [email protected]
A behind-the-scenes blog about research methods at Pew Research Center
For our latest findings, visit pewresearch.org .
How we created a representative sample of adult Twitter users in the U.S.

Over the past few years, Pew Research Center has published several reports examining the characteristics, attitudes and behaviors of U.S. adults who use Twitter.
To produce these reports, we created a representative sample of U.S. adult Twitter users. We did this by asking members of our nationally representative online survey panel, the American Trends Panel , if they use Twitter and if so, whether they would share their Twitter handles with us for research purposes. Having this sample allows us to filter out bots, minors, institutional accounts and international users, and lets us focus on real-life American adults who use the platform. It also allows us to link our respondents’ personal characteristics and attitudes — such as their attitudes toward privacy or their broader news consumption habits — with their actual behaviors on Twitter.
So who are the people who are willing to share their Twitter data for research purposes? Do they differ from Twitter users who aren’t willing to share their handles? Are they representative of all adult Twitter users on our survey panel?
In this post, we’ll discuss how we assembled our collection of U.S. adults’ Twitter handles, the characteristics of those who gave us their usernames, and how well our weighted estimates for these Twitter users compare with our estimates for Twitter users as a whole.
Data collection
Here’s a somewhat simplified version of how we collected Twitter handles in our most recent effort:
At the end of a larger survey conducted in March 2021, we asked our panelists whether they use Twitter. If they said yes, we asked them to provide their Twitter handles for research purposes. (See this companion post for more about the language we used to ask for people’s handles and how that language has changed over time.) We then conducted another survey in May 2021 that was fielded only to the members of our panel who said they use Twitter. This second survey asked about a wide range of Twitter-specific attitudes and behaviors.
Once both surveys were complete, we went back to the initial poll and manually examined the handles of every respondent who volunteered one. We did this to confirm that each handle likely belonged to the panelist who provided it. We removed any handles that were not actually handles (responses such as “no” or “none”), that were inaccessible or did not exist, or that belonged to an institution, company or organization. We also removed a small number of handles that were extremely unlikely to belong to the person who submitted them based on the nature, language or physical location of the account and the personal characteristics of that respondent. Around 6% of our handles, or 63 in total, were deemed invalid and removed for one or more of these reasons.
Overall, 41% of our panel members who use Twitter and took the second survey provided us with a valid, usable handle. The chart below shows the (unweighted) share of Twitter users in different demographic groups who provided a valid handle:

As the chart indicates, certain groups of Twitter users were more likely to provide a valid handle than others. For instance, larger shares of Democrats and Democratic-leaning independents gave handles than Republicans and Republican leaners, as did college graduates relative to those who have not attended college. Larger shares of White and Hispanic respondents gave handles compared with Black and Asian respondents. Consent rates were also relatively low among the oldest (ages 65+) and youngest (18–29) users.
To account for differential consent rates across groups, we weighted the “handle giver” population back to our broader sample of adult Twitter users from the March 2021 survey. Specifically, we weighted our final sample of 1,039 U.S. adult Twitter users with valid handles so it matched the broader sample along the following dimensions: gender, age, race, place of birth, years lived in the United States, education, region, party identification, volunteerism, voter registration, metropolitan area and frequency of internet use. (See more information about our weighting process more generally.) This weighting process ensured that our subset of Twitter users with valid handles largely mirrored the broader U.S. adult Twitter user population in terms of its demographics and other basic characteristics that were part of the weighting process itself.
We hoped that our weighted estimates for subgroups would also mirror the broader population of adult Twitter users on factors we did not weight on, such as how often they report using the platform or their described experiences on it. As it turned out, that was largely true: The weighted estimates for our handle givers generally looked similar to those of the total sample of U.S. adult Twitter users. For instance, comparable shares in each group said they have experienced harassing or abusive behavior on the site; use the site too many times to count on a typical day; mostly use Twitter to see what others are saying, rather than express their own views; mostly follow people with similar political beliefs to their own; and get news on the platform.
On other questions, however, there were some differences between those who gave us valid Twitter handles and the broader population of adult Twitter users. The following table compares the weighted shares of those with valid Twitter handles and the total Twitter user sample on some key questions. For reference, it also includes the share of those who did not give us valid Twitter handles:

Even after weighting, we can see some differences on questions that might serve as a proxy for trust in Twitter itself, such as whether Twitter is bad for democracy or whether it is a problem for Twitter to ban users from its platform (as it has done recently for a number of major conservative political figures).
Out of all the questions on the survey, the most notable difference emerged on a question about whether respondents have their Twitter profile set to public or private. Our handle givers indicated quite a bit more often than the overall sample that their profile is set to public so anyone can see it — 64% said this, compared with 53% of all U.S. adult Twitter users and just 48% of those who did not give us a handle. (These figures only reflect the shares who say their handle is set to public, even if that is not actually the case. We have previously found that many users who think their account is private actually have it set to public .)
It’s hard to know exactly why this difference exists, but it may reflect some variation in respondents’ concerns about digital privacy. Past Pew Research Center surveys have documented that Americans have long felt “ concerned, confused and lacking control ” over their personal information. Digital privacy may simply be an issue that question wording and statistical weighting techniques could not completely address.
When asking respondents for permission to use their Twitter data, it’s important to note that we do try to make clear what information we can and can’t access. If an account is set to private, we are only able to access the very basic metadata that anyone visiting an account can see.
To answer the question we posed at the outset of this post, survey respondents who are willing to provide their Twitter handles do differ somewhat from those who are not willing to share this information. But despite the presence of a group of potentially privacy-conscious users, standard weighting techniques do a fairly good job of aligning the characteristics and attitudes of those who provided their Twitter handles with the larger sample of U.S. adult Twitter users.
More from Decoded
More from decoded.
- Survey Methods
To browse all of Pew Research Center findings and data by topic, visit pewresearch.org
About Decoded
This is a blog about research methods and behind-the-scenes technical matters at Pew Research Center. To get our latest findings, visit pewresearch.org .
Copyright 2024 Pew Research Center
IMAGES
VIDEO
COMMENTS
Correlational research is a type of study that explores how variables are related to each other. It can help you identify patterns, trends, and predictions in your data. In this guide, you will learn when and how to use correlational research, and what its advantages and limitations are. You will also find examples of correlational research questions and designs. If you want to know the ...
For example, a correlation coefficient of -0.9 suggests a strong negative relationship, while a coefficient of +0.8 indicates a strong positive relationship. ... Conclusion for Correlational Research. Correlational research serves as a powerful tool for uncovering connections between variables in the world around us. By examining the ...
A correlational study is an experimental design that evaluates only the correlation between variables. The researchers record measurements but do not control or manipulate the variables. Correlational research is a form of observational study. A correlation indicates that as the value of one variable increases, the other tends to change in a ...
Correlational research design is a type of nonexperimental research that is used to examine the relationship between two or more variables. ... Examples of Correlational Research. ... of your study in a research report or manuscript. Be sure to include the research question, methods, results, and conclusions. Purpose of Correlational Research.
Revised on 5 December 2022. A correlational research design investigates relationships between variables without the researcher controlling or manipulating any of them. A correlation reflects the strength and/or direction of the relationship between two (or more) variables. The direction of a correlation can be either positive or negative.
Here are 3 case examples of correlational research. ... Conclusion Correlational research enables researchers to establish the statistical pattern between 2 seemingly interconnected variables; as such, it is the starting point of any type of research. It allows you to link 2 variables by observing their behaviors in the most natural state.
Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between ...
The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson's Correlation Coefficient (or Pearson's r). As Figure 6.2.2 6.2. 2 shows, Pearson's r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship).
The other common situations in which the value of Pearson's r can be misleading is when one or both of the variables have a limited range in the sample relative to the population.This problem is referred to as restriction of range.Assume, for example, that there is a strong negative correlation between people's age and their enjoyment of hip hop music as shown by the scatterplot in Figure 6.6.
A correlational study is a type of research design that looks at the relationships between two or more variables. Correlational studies are non-experimental, which means that the experimenter does not manipulate or control any of the variables. A correlation refers to a relationship between two variables. Correlations can be strong or weak and ...
Mainly three types of correlational research have been identified: 1. Positive correlation:A positive relationship between two variables is when an increase in one variable leads to a rise in the other variable. A decrease in one variable will see a reduction in the other variable. For example, the amount of money a person has might positively ...
Correlational research is a type of research that looks at the strength and direction of relationships between variables. Learn more about how and when it is used. ... experimental research allows for causal conclusions to be drawn, while correlational research does not. ... For example, in a study examining the correlation between exercise and ...
An important limitation of correlational research designs is that they cannot be used to draw conclusions about the causal relationships among the measured variables. Consider, for instance, a researcher who has hypothesized that viewing violent behaviour will cause increased aggressive play in children.
One recent clinical example of correlational findings is an inference that because Cobb angle and sagittal balance are related to symptom severity in back pain, treatments should be aimed to improve sagittal balance. ... Conclusion. Advances in research have led to many significant findings that are shaping how we diagnose and treat patients ...
Correlational research designs are often used in psychology, epidemiology, medicine and nursing. They show the strength of correlation that exists between the variables within a population. For this reason, these studies are also known as ecological studies. Correlational research design methods are characterized by such traits:
Correlational Research. Correlation means that there is a relationship between two or more variables (such as ice cream consumption and crime), but this relationship does not necessarily imply cause and effect. When two variables are correlated, it simply means that as one variable changes, so does the other.
questions can help them distinguish between causal and correlational research. Students could have been explicitly taught about the types of conclusions researchers can make after correlational and experimental research. Instructions 1. Teacher provides sample psychological studies from recent research (see sample below). 2.
The conclusions are as stated below: i. Students' use of language in the oral sessions depicted their beliefs and values. based on their intentions. The oral sessions prompted the students to be ...
If correlation is +/- 0.8 and above, high degree of correlation or the association between the dependent variables are strong. correlation between +/- 0.5 to+/_0.8, sufficient degree of ...
Correlational research is a type of non-experimental research in which ... As a concrete example, correlational studies establishing that there is a relationship between watching violent ... Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships. ...
It was proven by coefficient correlational between students' reading interest and their reading comprehension was r (0.983), it means those variables were significantly correlated.
A cross-sectional descriptive correlation research design was employed. A convenient sample of 1010 nursing students participated, completing socio-demographic data, the Perceived Stress Scale (PSS), and the Revised Study Process Questionnaire (R-SPQ-2 F). ... Conclusion. According to the present study's findings, nursing students encounter ...
Despite ongoing research, the underlying causes of schizophrenia remain unclear. Aspartate and asparagine, essential amino acids, have been linked to schizophrenia in recent studies, but their causal relationship is still unclear. This study used a bidirectional two-sample Mendelian randomization (MR) method to explore the causal relationship between aspartate and asparagine with schizophrenia.
Over the past few years, Pew Research Center has published several reports examining the characteristics, attitudes and behaviors of U.S. adults who use Twitter. To produce these reports, we created a representative sample of U.S. adult Twitter users. We did this by asking members of our nationally representative online survey panel, the ...