- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research

Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

Cannabis Industry Business Intelligence: Impact on Research
May 28, 2024

Top 10 Dynata Alternatives & Competitors
May 27, 2024
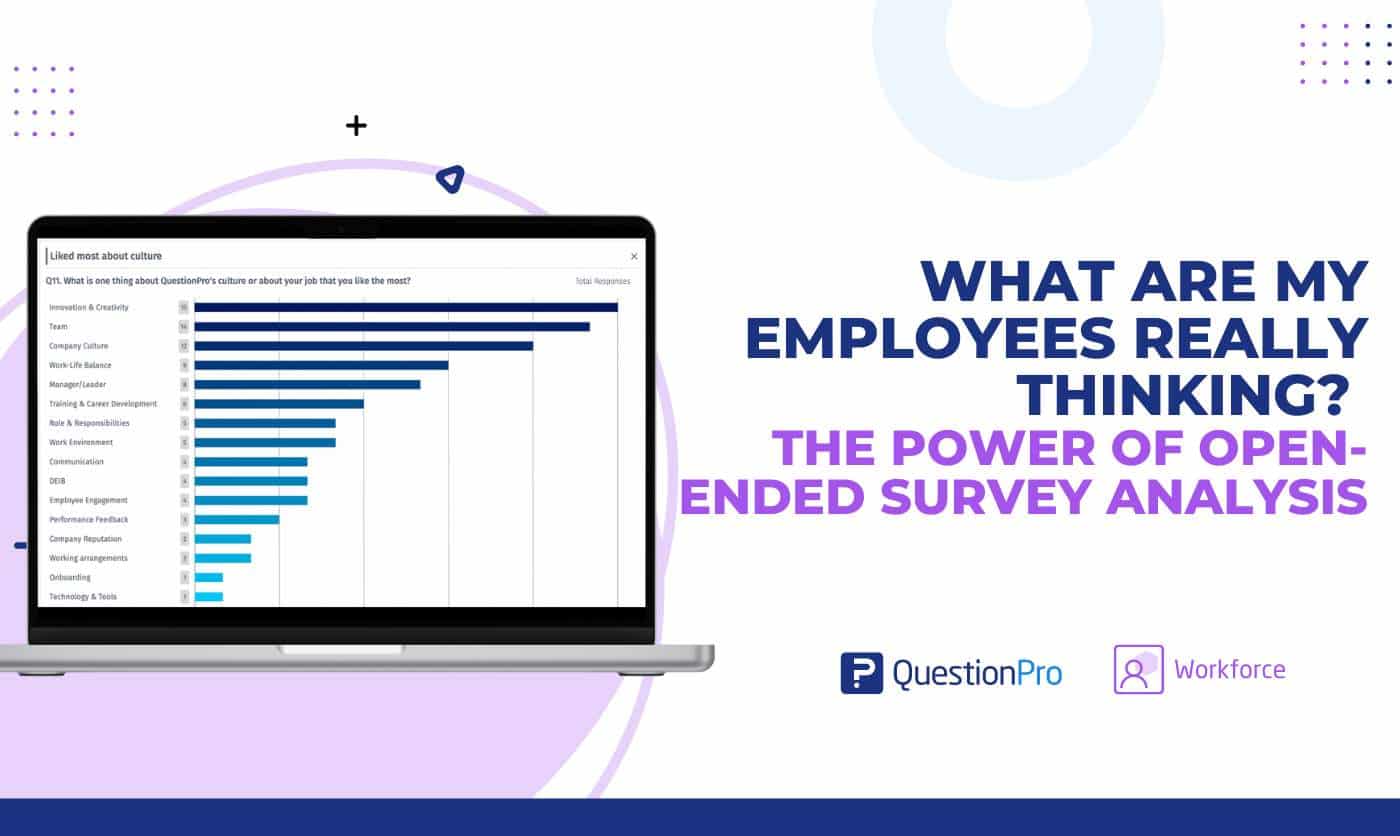
What Are My Employees Really Thinking? The Power of Open-ended Survey Analysis
May 24, 2024

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence

Data Analysis Techniques in Research – Methods, Tools & Examples

Varun Saharawat is a seasoned professional in the fields of SEO and content writing. With a profound knowledge of the intricate aspects of these disciplines, Varun has established himself as a valuable asset in the world of digital marketing and online content creation.

Data analysis techniques in research are essential because they allow researchers to derive meaningful insights from data sets to support their hypotheses or research objectives.
Data Analysis Techniques in Research : While various groups, institutions, and professionals may have diverse approaches to data analysis, a universal definition captures its essence. Data analysis involves refining, transforming, and interpreting raw data to derive actionable insights that guide informed decision-making for businesses.

A straightforward illustration of data analysis emerges when we make everyday decisions, basing our choices on past experiences or predictions of potential outcomes.
If you want to learn more about this topic and acquire valuable skills that will set you apart in today’s data-driven world, we highly recommend enrolling in the Data Analytics Course by Physics Wallah . And as a special offer for our readers, use the coupon code “READER” to get a discount on this course.
Table of Contents
What is Data Analysis?
Data analysis is the systematic process of inspecting, cleaning, transforming, and interpreting data with the objective of discovering valuable insights and drawing meaningful conclusions. This process involves several steps:
- Inspecting : Initial examination of data to understand its structure, quality, and completeness.
- Cleaning : Removing errors, inconsistencies, or irrelevant information to ensure accurate analysis.
- Transforming : Converting data into a format suitable for analysis, such as normalization or aggregation.
- Interpreting : Analyzing the transformed data to identify patterns, trends, and relationships.
Types of Data Analysis Techniques in Research
Data analysis techniques in research are categorized into qualitative and quantitative methods, each with its specific approaches and tools. These techniques are instrumental in extracting meaningful insights, patterns, and relationships from data to support informed decision-making, validate hypotheses, and derive actionable recommendations. Below is an in-depth exploration of the various types of data analysis techniques commonly employed in research:
1) Qualitative Analysis:
Definition: Qualitative analysis focuses on understanding non-numerical data, such as opinions, concepts, or experiences, to derive insights into human behavior, attitudes, and perceptions.
- Content Analysis: Examines textual data, such as interview transcripts, articles, or open-ended survey responses, to identify themes, patterns, or trends.
- Narrative Analysis: Analyzes personal stories or narratives to understand individuals’ experiences, emotions, or perspectives.
- Ethnographic Studies: Involves observing and analyzing cultural practices, behaviors, and norms within specific communities or settings.
2) Quantitative Analysis:
Quantitative analysis emphasizes numerical data and employs statistical methods to explore relationships, patterns, and trends. It encompasses several approaches:
Descriptive Analysis:
- Frequency Distribution: Represents the number of occurrences of distinct values within a dataset.
- Central Tendency: Measures such as mean, median, and mode provide insights into the central values of a dataset.
- Dispersion: Techniques like variance and standard deviation indicate the spread or variability of data.
Diagnostic Analysis:
- Regression Analysis: Assesses the relationship between dependent and independent variables, enabling prediction or understanding causality.
- ANOVA (Analysis of Variance): Examines differences between groups to identify significant variations or effects.
Predictive Analysis:
- Time Series Forecasting: Uses historical data points to predict future trends or outcomes.
- Machine Learning Algorithms: Techniques like decision trees, random forests, and neural networks predict outcomes based on patterns in data.
Prescriptive Analysis:
- Optimization Models: Utilizes linear programming, integer programming, or other optimization techniques to identify the best solutions or strategies.
- Simulation: Mimics real-world scenarios to evaluate various strategies or decisions and determine optimal outcomes.
Specific Techniques:
- Monte Carlo Simulation: Models probabilistic outcomes to assess risk and uncertainty.
- Factor Analysis: Reduces the dimensionality of data by identifying underlying factors or components.
- Cohort Analysis: Studies specific groups or cohorts over time to understand trends, behaviors, or patterns within these groups.
- Cluster Analysis: Classifies objects or individuals into homogeneous groups or clusters based on similarities or attributes.
- Sentiment Analysis: Uses natural language processing and machine learning techniques to determine sentiment, emotions, or opinions from textual data.
Also Read: AI and Predictive Analytics: Examples, Tools, Uses, Ai Vs Predictive Analytics
Data Analysis Techniques in Research Examples
To provide a clearer understanding of how data analysis techniques are applied in research, let’s consider a hypothetical research study focused on evaluating the impact of online learning platforms on students’ academic performance.
Research Objective:
Determine if students using online learning platforms achieve higher academic performance compared to those relying solely on traditional classroom instruction.
Data Collection:
- Quantitative Data: Academic scores (grades) of students using online platforms and those using traditional classroom methods.
- Qualitative Data: Feedback from students regarding their learning experiences, challenges faced, and preferences.
Data Analysis Techniques Applied:
1) Descriptive Analysis:
- Calculate the mean, median, and mode of academic scores for both groups.
- Create frequency distributions to represent the distribution of grades in each group.
2) Diagnostic Analysis:
- Conduct an Analysis of Variance (ANOVA) to determine if there’s a statistically significant difference in academic scores between the two groups.
- Perform Regression Analysis to assess the relationship between the time spent on online platforms and academic performance.
3) Predictive Analysis:
- Utilize Time Series Forecasting to predict future academic performance trends based on historical data.
- Implement Machine Learning algorithms to develop a predictive model that identifies factors contributing to academic success on online platforms.
4) Prescriptive Analysis:
- Apply Optimization Models to identify the optimal combination of online learning resources (e.g., video lectures, interactive quizzes) that maximize academic performance.
- Use Simulation Techniques to evaluate different scenarios, such as varying student engagement levels with online resources, to determine the most effective strategies for improving learning outcomes.
5) Specific Techniques:
- Conduct Factor Analysis on qualitative feedback to identify common themes or factors influencing students’ perceptions and experiences with online learning.
- Perform Cluster Analysis to segment students based on their engagement levels, preferences, or academic outcomes, enabling targeted interventions or personalized learning strategies.
- Apply Sentiment Analysis on textual feedback to categorize students’ sentiments as positive, negative, or neutral regarding online learning experiences.
By applying a combination of qualitative and quantitative data analysis techniques, this research example aims to provide comprehensive insights into the effectiveness of online learning platforms.
Also Read: Learning Path to Become a Data Analyst in 2024
Data Analysis Techniques in Quantitative Research
Quantitative research involves collecting numerical data to examine relationships, test hypotheses, and make predictions. Various data analysis techniques are employed to interpret and draw conclusions from quantitative data. Here are some key data analysis techniques commonly used in quantitative research:
1) Descriptive Statistics:
- Description: Descriptive statistics are used to summarize and describe the main aspects of a dataset, such as central tendency (mean, median, mode), variability (range, variance, standard deviation), and distribution (skewness, kurtosis).
- Applications: Summarizing data, identifying patterns, and providing initial insights into the dataset.
2) Inferential Statistics:
- Description: Inferential statistics involve making predictions or inferences about a population based on a sample of data. This technique includes hypothesis testing, confidence intervals, t-tests, chi-square tests, analysis of variance (ANOVA), regression analysis, and correlation analysis.
- Applications: Testing hypotheses, making predictions, and generalizing findings from a sample to a larger population.
3) Regression Analysis:
- Description: Regression analysis is a statistical technique used to model and examine the relationship between a dependent variable and one or more independent variables. Linear regression, multiple regression, logistic regression, and nonlinear regression are common types of regression analysis .
- Applications: Predicting outcomes, identifying relationships between variables, and understanding the impact of independent variables on the dependent variable.
4) Correlation Analysis:
- Description: Correlation analysis is used to measure and assess the strength and direction of the relationship between two or more variables. The Pearson correlation coefficient, Spearman rank correlation coefficient, and Kendall’s tau are commonly used measures of correlation.
- Applications: Identifying associations between variables and assessing the degree and nature of the relationship.
5) Factor Analysis:
- Description: Factor analysis is a multivariate statistical technique used to identify and analyze underlying relationships or factors among a set of observed variables. It helps in reducing the dimensionality of data and identifying latent variables or constructs.
- Applications: Identifying underlying factors or constructs, simplifying data structures, and understanding the underlying relationships among variables.
6) Time Series Analysis:
- Description: Time series analysis involves analyzing data collected or recorded over a specific period at regular intervals to identify patterns, trends, and seasonality. Techniques such as moving averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Fourier analysis are used.
- Applications: Forecasting future trends, analyzing seasonal patterns, and understanding time-dependent relationships in data.
7) ANOVA (Analysis of Variance):
- Description: Analysis of variance (ANOVA) is a statistical technique used to analyze and compare the means of two or more groups or treatments to determine if they are statistically different from each other. One-way ANOVA, two-way ANOVA, and MANOVA (Multivariate Analysis of Variance) are common types of ANOVA.
- Applications: Comparing group means, testing hypotheses, and determining the effects of categorical independent variables on a continuous dependent variable.
8) Chi-Square Tests:
- Description: Chi-square tests are non-parametric statistical tests used to assess the association between categorical variables in a contingency table. The Chi-square test of independence, goodness-of-fit test, and test of homogeneity are common chi-square tests.
- Applications: Testing relationships between categorical variables, assessing goodness-of-fit, and evaluating independence.
These quantitative data analysis techniques provide researchers with valuable tools and methods to analyze, interpret, and derive meaningful insights from numerical data. The selection of a specific technique often depends on the research objectives, the nature of the data, and the underlying assumptions of the statistical methods being used.
Also Read: Analysis vs. Analytics: How Are They Different?
Data Analysis Methods
Data analysis methods refer to the techniques and procedures used to analyze, interpret, and draw conclusions from data. These methods are essential for transforming raw data into meaningful insights, facilitating decision-making processes, and driving strategies across various fields. Here are some common data analysis methods:
- Description: Descriptive statistics summarize and organize data to provide a clear and concise overview of the dataset. Measures such as mean, median, mode, range, variance, and standard deviation are commonly used.
- Description: Inferential statistics involve making predictions or inferences about a population based on a sample of data. Techniques such as hypothesis testing, confidence intervals, and regression analysis are used.
3) Exploratory Data Analysis (EDA):
- Description: EDA techniques involve visually exploring and analyzing data to discover patterns, relationships, anomalies, and insights. Methods such as scatter plots, histograms, box plots, and correlation matrices are utilized.
- Applications: Identifying trends, patterns, outliers, and relationships within the dataset.
4) Predictive Analytics:
- Description: Predictive analytics use statistical algorithms and machine learning techniques to analyze historical data and make predictions about future events or outcomes. Techniques such as regression analysis, time series forecasting, and machine learning algorithms (e.g., decision trees, random forests, neural networks) are employed.
- Applications: Forecasting future trends, predicting outcomes, and identifying potential risks or opportunities.
5) Prescriptive Analytics:
- Description: Prescriptive analytics involve analyzing data to recommend actions or strategies that optimize specific objectives or outcomes. Optimization techniques, simulation models, and decision-making algorithms are utilized.
- Applications: Recommending optimal strategies, decision-making support, and resource allocation.
6) Qualitative Data Analysis:
- Description: Qualitative data analysis involves analyzing non-numerical data, such as text, images, videos, or audio, to identify themes, patterns, and insights. Methods such as content analysis, thematic analysis, and narrative analysis are used.
- Applications: Understanding human behavior, attitudes, perceptions, and experiences.
7) Big Data Analytics:
- Description: Big data analytics methods are designed to analyze large volumes of structured and unstructured data to extract valuable insights. Technologies such as Hadoop, Spark, and NoSQL databases are used to process and analyze big data.
- Applications: Analyzing large datasets, identifying trends, patterns, and insights from big data sources.
8) Text Analytics:
- Description: Text analytics methods involve analyzing textual data, such as customer reviews, social media posts, emails, and documents, to extract meaningful information and insights. Techniques such as sentiment analysis, text mining, and natural language processing (NLP) are used.
- Applications: Analyzing customer feedback, monitoring brand reputation, and extracting insights from textual data sources.
These data analysis methods are instrumental in transforming data into actionable insights, informing decision-making processes, and driving organizational success across various sectors, including business, healthcare, finance, marketing, and research. The selection of a specific method often depends on the nature of the data, the research objectives, and the analytical requirements of the project or organization.
Also Read: Quantitative Data Analysis: Types, Analysis & Examples
Data Analysis Tools
Data analysis tools are essential instruments that facilitate the process of examining, cleaning, transforming, and modeling data to uncover useful information, make informed decisions, and drive strategies. Here are some prominent data analysis tools widely used across various industries:
1) Microsoft Excel:
- Description: A spreadsheet software that offers basic to advanced data analysis features, including pivot tables, data visualization tools, and statistical functions.
- Applications: Data cleaning, basic statistical analysis, visualization, and reporting.
2) R Programming Language:
- Description: An open-source programming language specifically designed for statistical computing and data visualization.
- Applications: Advanced statistical analysis, data manipulation, visualization, and machine learning.
3) Python (with Libraries like Pandas, NumPy, Matplotlib, and Seaborn):
- Description: A versatile programming language with libraries that support data manipulation, analysis, and visualization.
- Applications: Data cleaning, statistical analysis, machine learning, and data visualization.
4) SPSS (Statistical Package for the Social Sciences):
- Description: A comprehensive statistical software suite used for data analysis, data mining, and predictive analytics.
- Applications: Descriptive statistics, hypothesis testing, regression analysis, and advanced analytics.
5) SAS (Statistical Analysis System):
- Description: A software suite used for advanced analytics, multivariate analysis, and predictive modeling.
- Applications: Data management, statistical analysis, predictive modeling, and business intelligence.
6) Tableau:
- Description: A data visualization tool that allows users to create interactive and shareable dashboards and reports.
- Applications: Data visualization , business intelligence , and interactive dashboard creation.
7) Power BI:
- Description: A business analytics tool developed by Microsoft that provides interactive visualizations and business intelligence capabilities.
- Applications: Data visualization, business intelligence, reporting, and dashboard creation.
8) SQL (Structured Query Language) Databases (e.g., MySQL, PostgreSQL, Microsoft SQL Server):
- Description: Database management systems that support data storage, retrieval, and manipulation using SQL queries.
- Applications: Data retrieval, data cleaning, data transformation, and database management.
9) Apache Spark:
- Description: A fast and general-purpose distributed computing system designed for big data processing and analytics.
- Applications: Big data processing, machine learning, data streaming, and real-time analytics.
10) IBM SPSS Modeler:
- Description: A data mining software application used for building predictive models and conducting advanced analytics.
- Applications: Predictive modeling, data mining, statistical analysis, and decision optimization.
These tools serve various purposes and cater to different data analysis needs, from basic statistical analysis and data visualization to advanced analytics, machine learning, and big data processing. The choice of a specific tool often depends on the nature of the data, the complexity of the analysis, and the specific requirements of the project or organization.
Also Read: How to Analyze Survey Data: Methods & Examples
Importance of Data Analysis in Research
The importance of data analysis in research cannot be overstated; it serves as the backbone of any scientific investigation or study. Here are several key reasons why data analysis is crucial in the research process:
- Data analysis helps ensure that the results obtained are valid and reliable. By systematically examining the data, researchers can identify any inconsistencies or anomalies that may affect the credibility of the findings.
- Effective data analysis provides researchers with the necessary information to make informed decisions. By interpreting the collected data, researchers can draw conclusions, make predictions, or formulate recommendations based on evidence rather than intuition or guesswork.
- Data analysis allows researchers to identify patterns, trends, and relationships within the data. This can lead to a deeper understanding of the research topic, enabling researchers to uncover insights that may not be immediately apparent.
- In empirical research, data analysis plays a critical role in testing hypotheses. Researchers collect data to either support or refute their hypotheses, and data analysis provides the tools and techniques to evaluate these hypotheses rigorously.
- Transparent and well-executed data analysis enhances the credibility of research findings. By clearly documenting the data analysis methods and procedures, researchers allow others to replicate the study, thereby contributing to the reproducibility of research findings.
- In fields such as business or healthcare, data analysis helps organizations allocate resources more efficiently. By analyzing data on consumer behavior, market trends, or patient outcomes, organizations can make strategic decisions about resource allocation, budgeting, and planning.
- In public policy and social sciences, data analysis is instrumental in developing and evaluating policies and interventions. By analyzing data on social, economic, or environmental factors, policymakers can assess the effectiveness of existing policies and inform the development of new ones.
- Data analysis allows for continuous improvement in research methods and practices. By analyzing past research projects, identifying areas for improvement, and implementing changes based on data-driven insights, researchers can refine their approaches and enhance the quality of future research endeavors.
However, it is important to remember that mastering these techniques requires practice and continuous learning. That’s why we highly recommend the Data Analytics Course by Physics Wallah . Not only does it cover all the fundamentals of data analysis, but it also provides hands-on experience with various tools such as Excel, Python, and Tableau. Plus, if you use the “ READER ” coupon code at checkout, you can get a special discount on the course.
For Latest Tech Related Information, Join Our Official Free Telegram Group : PW Skills Telegram Group
Data Analysis Techniques in Research FAQs
What are the 5 techniques for data analysis.
The five techniques for data analysis include: Descriptive Analysis Diagnostic Analysis Predictive Analysis Prescriptive Analysis Qualitative Analysis
What are techniques of data analysis in research?
Techniques of data analysis in research encompass both qualitative and quantitative methods. These techniques involve processes like summarizing raw data, investigating causes of events, forecasting future outcomes, offering recommendations based on predictions, and examining non-numerical data to understand concepts or experiences.
What are the 3 methods of data analysis?
The three primary methods of data analysis are: Qualitative Analysis Quantitative Analysis Mixed-Methods Analysis
What are the four types of data analysis techniques?
The four types of data analysis techniques are: Descriptive Analysis Diagnostic Analysis Predictive Analysis Prescriptive Analysis
Top 10 Data Analytics Trends to Watch Out for in 2024

Unlock the future of data by getting an overview of the top 10 data analytics trends for 2024 discover how…
What Is Big Data Analytics? Definition, Benefits, and More

Big data analytics is the process of identifying trends, patterns, and correlations in vast amounts of raw data in order to…
How to Analysis of Survey Data: Methods & Examples

Analysis of Survey Data transforms raw data into meaningful insights. By adhering to best practices, you can leverage survey findings…

Qualitative Data Analysis Methods 101:
The “big 6” methods + examples.
By: Kerryn Warren (PhD) | Reviewed By: Eunice Rautenbach (D.Tech) | May 2020 (Updated April 2023)
Qualitative data analysis methods. Wow, that’s a mouthful.
If you’re new to the world of research, qualitative data analysis can look rather intimidating. So much bulky terminology and so many abstract, fluffy concepts. It certainly can be a minefield!
Don’t worry – in this post, we’ll unpack the most popular analysis methods , one at a time, so that you can approach your analysis with confidence and competence – whether that’s for a dissertation, thesis or really any kind of research project.

What (exactly) is qualitative data analysis?
To understand qualitative data analysis, we need to first understand qualitative data – so let’s step back and ask the question, “what exactly is qualitative data?”.
Qualitative data refers to pretty much any data that’s “not numbers” . In other words, it’s not the stuff you measure using a fixed scale or complex equipment, nor do you analyse it using complex statistics or mathematics.
So, if it’s not numbers, what is it?
Words, you guessed? Well… sometimes , yes. Qualitative data can, and often does, take the form of interview transcripts, documents and open-ended survey responses – but it can also involve the interpretation of images and videos. In other words, qualitative isn’t just limited to text-based data.
So, how’s that different from quantitative data, you ask?
Simply put, qualitative research focuses on words, descriptions, concepts or ideas – while quantitative research focuses on numbers and statistics . Qualitative research investigates the “softer side” of things to explore and describe , while quantitative research focuses on the “hard numbers”, to measure differences between variables and the relationships between them. If you’re keen to learn more about the differences between qual and quant, we’ve got a detailed post over here .

So, qualitative analysis is easier than quantitative, right?
Not quite. In many ways, qualitative data can be challenging and time-consuming to analyse and interpret. At the end of your data collection phase (which itself takes a lot of time), you’ll likely have many pages of text-based data or hours upon hours of audio to work through. You might also have subtle nuances of interactions or discussions that have danced around in your mind, or that you scribbled down in messy field notes. All of this needs to work its way into your analysis.
Making sense of all of this is no small task and you shouldn’t underestimate it. Long story short – qualitative analysis can be a lot of work! Of course, quantitative analysis is no piece of cake either, but it’s important to recognise that qualitative analysis still requires a significant investment in terms of time and effort.
Need a helping hand?
In this post, we’ll explore qualitative data analysis by looking at some of the most common analysis methods we encounter. We’re not going to cover every possible qualitative method and we’re not going to go into heavy detail – we’re just going to give you the big picture. That said, we will of course includes links to loads of extra resources so that you can learn more about whichever analysis method interests you.
Without further delay, let’s get into it.
The “Big 6” Qualitative Analysis Methods
There are many different types of qualitative data analysis, all of which serve different purposes and have unique strengths and weaknesses . We’ll start by outlining the analysis methods and then we’ll dive into the details for each.
The 6 most popular methods (or at least the ones we see at Grad Coach) are:
- Content analysis
- Narrative analysis
- Discourse analysis
- Thematic analysis
- Grounded theory (GT)
- Interpretive phenomenological analysis (IPA)
Let’s take a look at each of them…
QDA Method #1: Qualitative Content Analysis
Content analysis is possibly the most common and straightforward QDA method. At the simplest level, content analysis is used to evaluate patterns within a piece of content (for example, words, phrases or images) or across multiple pieces of content or sources of communication. For example, a collection of newspaper articles or political speeches.
With content analysis, you could, for instance, identify the frequency with which an idea is shared or spoken about – like the number of times a Kardashian is mentioned on Twitter. Or you could identify patterns of deeper underlying interpretations – for instance, by identifying phrases or words in tourist pamphlets that highlight India as an ancient country.
Because content analysis can be used in such a wide variety of ways, it’s important to go into your analysis with a very specific question and goal, or you’ll get lost in the fog. With content analysis, you’ll group large amounts of text into codes , summarise these into categories, and possibly even tabulate the data to calculate the frequency of certain concepts or variables. Because of this, content analysis provides a small splash of quantitative thinking within a qualitative method.
Naturally, while content analysis is widely useful, it’s not without its drawbacks . One of the main issues with content analysis is that it can be very time-consuming , as it requires lots of reading and re-reading of the texts. Also, because of its multidimensional focus on both qualitative and quantitative aspects, it is sometimes accused of losing important nuances in communication.
Content analysis also tends to concentrate on a very specific timeline and doesn’t take into account what happened before or after that timeline. This isn’t necessarily a bad thing though – just something to be aware of. So, keep these factors in mind if you’re considering content analysis. Every analysis method has its limitations , so don’t be put off by these – just be aware of them ! If you’re interested in learning more about content analysis, the video below provides a good starting point.
QDA Method #2: Narrative Analysis
As the name suggests, narrative analysis is all about listening to people telling stories and analysing what that means . Since stories serve a functional purpose of helping us make sense of the world, we can gain insights into the ways that people deal with and make sense of reality by analysing their stories and the ways they’re told.
You could, for example, use narrative analysis to explore whether how something is being said is important. For instance, the narrative of a prisoner trying to justify their crime could provide insight into their view of the world and the justice system. Similarly, analysing the ways entrepreneurs talk about the struggles in their careers or cancer patients telling stories of hope could provide powerful insights into their mindsets and perspectives . Simply put, narrative analysis is about paying attention to the stories that people tell – and more importantly, the way they tell them.
Of course, the narrative approach has its weaknesses , too. Sample sizes are generally quite small due to the time-consuming process of capturing narratives. Because of this, along with the multitude of social and lifestyle factors which can influence a subject, narrative analysis can be quite difficult to reproduce in subsequent research. This means that it’s difficult to test the findings of some of this research.
Similarly, researcher bias can have a strong influence on the results here, so you need to be particularly careful about the potential biases you can bring into your analysis when using this method. Nevertheless, narrative analysis is still a very useful qualitative analysis method – just keep these limitations in mind and be careful not to draw broad conclusions . If you’re keen to learn more about narrative analysis, the video below provides a great introduction to this qualitative analysis method.
QDA Method #3: Discourse Analysis
Discourse is simply a fancy word for written or spoken language or debate . So, discourse analysis is all about analysing language within its social context. In other words, analysing language – such as a conversation, a speech, etc – within the culture and society it takes place. For example, you could analyse how a janitor speaks to a CEO, or how politicians speak about terrorism.
To truly understand these conversations or speeches, the culture and history of those involved in the communication are important factors to consider. For example, a janitor might speak more casually with a CEO in a company that emphasises equality among workers. Similarly, a politician might speak more about terrorism if there was a recent terrorist incident in the country.
So, as you can see, by using discourse analysis, you can identify how culture , history or power dynamics (to name a few) have an effect on the way concepts are spoken about. So, if your research aims and objectives involve understanding culture or power dynamics, discourse analysis can be a powerful method.
Because there are many social influences in terms of how we speak to each other, the potential use of discourse analysis is vast . Of course, this also means it’s important to have a very specific research question (or questions) in mind when analysing your data and looking for patterns and themes, or you might land up going down a winding rabbit hole.
Discourse analysis can also be very time-consuming as you need to sample the data to the point of saturation – in other words, until no new information and insights emerge. But this is, of course, part of what makes discourse analysis such a powerful technique. So, keep these factors in mind when considering this QDA method. Again, if you’re keen to learn more, the video below presents a good starting point.
QDA Method #4: Thematic Analysis
Thematic analysis looks at patterns of meaning in a data set – for example, a set of interviews or focus group transcripts. But what exactly does that… mean? Well, a thematic analysis takes bodies of data (which are often quite large) and groups them according to similarities – in other words, themes . These themes help us make sense of the content and derive meaning from it.
Let’s take a look at an example.
With thematic analysis, you could analyse 100 online reviews of a popular sushi restaurant to find out what patrons think about the place. By reviewing the data, you would then identify the themes that crop up repeatedly within the data – for example, “fresh ingredients” or “friendly wait staff”.
So, as you can see, thematic analysis can be pretty useful for finding out about people’s experiences , views, and opinions . Therefore, if your research aims and objectives involve understanding people’s experience or view of something, thematic analysis can be a great choice.
Since thematic analysis is a bit of an exploratory process, it’s not unusual for your research questions to develop , or even change as you progress through the analysis. While this is somewhat natural in exploratory research, it can also be seen as a disadvantage as it means that data needs to be re-reviewed each time a research question is adjusted. In other words, thematic analysis can be quite time-consuming – but for a good reason. So, keep this in mind if you choose to use thematic analysis for your project and budget extra time for unexpected adjustments.
")
QDA Method #5: Grounded theory (GT)
Grounded theory is a powerful qualitative analysis method where the intention is to create a new theory (or theories) using the data at hand, through a series of “ tests ” and “ revisions ”. Strictly speaking, GT is more a research design type than an analysis method, but we’ve included it here as it’s often referred to as a method.
What’s most important with grounded theory is that you go into the analysis with an open mind and let the data speak for itself – rather than dragging existing hypotheses or theories into your analysis. In other words, your analysis must develop from the ground up (hence the name).
Let’s look at an example of GT in action.
Assume you’re interested in developing a theory about what factors influence students to watch a YouTube video about qualitative analysis. Using Grounded theory , you’d start with this general overarching question about the given population (i.e., graduate students). First, you’d approach a small sample – for example, five graduate students in a department at a university. Ideally, this sample would be reasonably representative of the broader population. You’d interview these students to identify what factors lead them to watch the video.
After analysing the interview data, a general pattern could emerge. For example, you might notice that graduate students are more likely to read a post about qualitative methods if they are just starting on their dissertation journey, or if they have an upcoming test about research methods.
From here, you’ll look for another small sample – for example, five more graduate students in a different department – and see whether this pattern holds true for them. If not, you’ll look for commonalities and adapt your theory accordingly. As this process continues, the theory would develop . As we mentioned earlier, what’s important with grounded theory is that the theory develops from the data – not from some preconceived idea.
So, what are the drawbacks of grounded theory? Well, some argue that there’s a tricky circularity to grounded theory. For it to work, in principle, you should know as little as possible regarding the research question and population, so that you reduce the bias in your interpretation. However, in many circumstances, it’s also thought to be unwise to approach a research question without knowledge of the current literature . In other words, it’s a bit of a “chicken or the egg” situation.
Regardless, grounded theory remains a popular (and powerful) option. Naturally, it’s a very useful method when you’re researching a topic that is completely new or has very little existing research about it, as it allows you to start from scratch and work your way from the ground up .
")
QDA Method #6: Interpretive Phenomenological Analysis (IPA)
Interpretive. Phenomenological. Analysis. IPA . Try saying that three times fast…
Let’s just stick with IPA, okay?
IPA is designed to help you understand the personal experiences of a subject (for example, a person or group of people) concerning a major life event, an experience or a situation . This event or experience is the “phenomenon” that makes up the “P” in IPA. Such phenomena may range from relatively common events – such as motherhood, or being involved in a car accident – to those which are extremely rare – for example, someone’s personal experience in a refugee camp. So, IPA is a great choice if your research involves analysing people’s personal experiences of something that happened to them.
It’s important to remember that IPA is subject – centred . In other words, it’s focused on the experiencer . This means that, while you’ll likely use a coding system to identify commonalities, it’s important not to lose the depth of experience or meaning by trying to reduce everything to codes. Also, keep in mind that since your sample size will generally be very small with IPA, you often won’t be able to draw broad conclusions about the generalisability of your findings. But that’s okay as long as it aligns with your research aims and objectives.
Another thing to be aware of with IPA is personal bias . While researcher bias can creep into all forms of research, self-awareness is critically important with IPA, as it can have a major impact on the results. For example, a researcher who was a victim of a crime himself could insert his own feelings of frustration and anger into the way he interprets the experience of someone who was kidnapped. So, if you’re going to undertake IPA, you need to be very self-aware or you could muddy the analysis.

How to choose the right analysis method
In light of all of the qualitative analysis methods we’ve covered so far, you’re probably asking yourself the question, “ How do I choose the right one? ”
Much like all the other methodological decisions you’ll need to make, selecting the right qualitative analysis method largely depends on your research aims, objectives and questions . In other words, the best tool for the job depends on what you’re trying to build. For example:
- Perhaps your research aims to analyse the use of words and what they reveal about the intention of the storyteller and the cultural context of the time.
- Perhaps your research aims to develop an understanding of the unique personal experiences of people that have experienced a certain event, or
- Perhaps your research aims to develop insight regarding the influence of a certain culture on its members.
As you can probably see, each of these research aims are distinctly different , and therefore different analysis methods would be suitable for each one. For example, narrative analysis would likely be a good option for the first aim, while grounded theory wouldn’t be as relevant.
It’s also important to remember that each method has its own set of strengths, weaknesses and general limitations. No single analysis method is perfect . So, depending on the nature of your research, it may make sense to adopt more than one method (this is called triangulation ). Keep in mind though that this will of course be quite time-consuming.
As we’ve seen, all of the qualitative analysis methods we’ve discussed make use of coding and theme-generating techniques, but the intent and approach of each analysis method differ quite substantially. So, it’s very important to come into your research with a clear intention before you decide which analysis method (or methods) to use.
Start by reviewing your research aims , objectives and research questions to assess what exactly you’re trying to find out – then select a qualitative analysis method that fits. Never pick a method just because you like it or have experience using it – your analysis method (or methods) must align with your broader research aims and objectives.

Let’s recap on QDA methods…
In this post, we looked at six popular qualitative data analysis methods:
- First, we looked at content analysis , a straightforward method that blends a little bit of quant into a primarily qualitative analysis.
- Then we looked at narrative analysis , which is about analysing how stories are told.
- Next up was discourse analysis – which is about analysing conversations and interactions.
- Then we moved on to thematic analysis – which is about identifying themes and patterns.
- From there, we went south with grounded theory – which is about starting from scratch with a specific question and using the data alone to build a theory in response to that question.
- And finally, we looked at IPA – which is about understanding people’s unique experiences of a phenomenon.
Of course, these aren’t the only options when it comes to qualitative data analysis, but they’re a great starting point if you’re dipping your toes into qualitative research for the first time.
If you’re still feeling a bit confused, consider our private coaching service , where we hold your hand through the research process to help you develop your best work.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:

84 Comments

This has been very helpful. Thank you.

Thank you madam,

Thank you so much for this information

I wonder it so clear for understand and good for me. can I ask additional query?

Very insightful and useful

Good work done with clear explanations. Thank you.

Thanks so much for the write-up, it’s really good.

Thanks madam . It is very important .

thank you very good

This has been very well explained in simple language . It is useful even for a new researcher.

Great to hear that. Good luck with your qualitative data analysis, Pramod!

This is very useful information. And it was very a clear language structured presentation. Thanks a lot.

Thank you so much.

very informative sequential presentation

Precise explanation of method.

Hi, may we use 2 data analysis methods in our qualitative research?
Thanks for your comment. Most commonly, one would use one type of analysis method, but it depends on your research aims and objectives.

You explained it in very simple language, everyone can understand it. Thanks so much.

Thank you very much, this is very helpful. It has been explained in a very simple manner that even a layman understands

Thank nicely explained can I ask is Qualitative content analysis the same as thematic analysis?
Thanks for your comment. No, QCA and thematic are two different types of analysis. This article might help clarify – https://onlinelibrary.wiley.com/doi/10.1111/nhs.12048

This is my first time to come across a well explained data analysis. so helpful.

I have thoroughly enjoyed your explanation of the six qualitative analysis methods. This is very helpful. Thank you!

Thank you very much, this is well explained and useful

i need a citation of your book.

Thanks a lot , remarkable indeed, enlighting to the best

Hi Derek, What other theories/methods would you recommend when the data is a whole speech?

Keep writing useful artikel.

It is important concept about QDA and also the way to express is easily understandable, so thanks for all.

Thank you, this is well explained and very useful.

Very helpful .Thanks.

Hi there! Very well explained. Simple but very useful style of writing. Please provide the citation of the text. warm regards

The session was very helpful and insightful. Thank you
This was very helpful and insightful. Easy to read and understand

As a professional academic writer, this has been so informative and educative. Keep up the good work Grad Coach you are unmatched with quality content for sure.
Keep up the good work Grad Coach you are unmatched with quality content for sure.

Its Great and help me the most. A Million Thanks you Dr.

It is a very nice work

Very insightful. Please, which of this approach could be used for a research that one is trying to elicit students’ misconceptions in a particular concept ?

This is Amazing and well explained, thanks

great overview

What do we call a research data analysis method that one use to advise or determining the best accounting tool or techniques that should be adopted in a company.

Informative video, explained in a clear and simple way. Kudos

Waoo! I have chosen method wrong for my data analysis. But I can revise my work according to this guide. Thank you so much for this helpful lecture.

This has been very helpful. It gave me a good view of my research objectives and how to choose the best method. Thematic analysis it is.

Very helpful indeed. Thanku so much for the insight.

This was incredibly helpful.

Very helpful.

very educative

Nicely written especially for novice academic researchers like me! Thank you.

choosing a right method for a paper is always a hard job for a student, this is a useful information, but it would be more useful personally for me, if the author provide me with a little bit more information about the data analysis techniques in type of explanatory research. Can we use qualitative content analysis technique for explanatory research ? or what is the suitable data analysis method for explanatory research in social studies?

that was very helpful for me. because these details are so important to my research. thank you very much

I learnt a lot. Thank you

Relevant and Informative, thanks !

Well-planned and organized, thanks much! 🙂

I have reviewed qualitative data analysis in a simplest way possible. The content will highly be useful for developing my book on qualitative data analysis methods. Cheers!

Clear explanation on qualitative and how about Case study

This was helpful. Thank you

This was really of great assistance, it was just the right information needed. Explanation very clear and follow.
Wow, Thanks for making my life easy

This was helpful thanks .

Very helpful…. clear and written in an easily understandable manner. Thank you.

This was so helpful as it was easy to understand. I’m a new to research thank you so much.

so educative…. but Ijust want to know which method is coding of the qualitative or tallying done?

Thank you for the great content, I have learnt a lot. So helpful

precise and clear presentation with simple language and thank you for that.

very informative content, thank you.

You guys are amazing on YouTube on this platform. Your teachings are great, educative, and informative. kudos!

Brilliant Delivery. You made a complex subject seem so easy. Well done.

Beautifully explained.
Thanks a lot

Is there a video the captures the practical process of coding using automated applications?
Thanks for the comment. We don’t recommend using automated applications for coding, as they are not sufficiently accurate in our experience.

content analysis can be qualitative research?

THANK YOU VERY MUCH.

Thank you very much for such a wonderful content

do you have any material on Data collection

What a powerful explanation of the QDA methods. Thank you.

Great explanation both written and Video. i have been using of it on a day to day working of my thesis project in accounting and finance. Thank you very much for your support.

very helpful, thank you so much
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
- Top Courses
- Online Degrees
- Find your New Career
- Join for Free
What Is Data Analysis? (With Examples)
Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions.
![[Featured image] A female data analyst takes notes on her laptop at a standing desk in a modern office space](https://d3njjcbhbojbot.cloudfront.net/api/utilities/v1/imageproxy/https://images.ctfassets.net/wp1lcwdav1p1/2CUbULaq9mEfSSIq6lsCUu/b8ec58abf5106bf9bf75b17da09c39c0/What_is_data_analysis.png?w=1500&h=680&q=60&fit=fill&f=faces&fm=jpg&fl=progressive&auto=format%2Ccompress&dpr=1&w=1000 "data analysis example for research paper")
"It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock Holme's proclaims in Sir Arthur Conan Doyle's A Scandal in Bohemia.
This idea lies at the root of data analysis. When we can extract meaning from data, it empowers us to make better decisions. And we’re living in a time when we have more data than ever at our fingertips.
Companies are wisening up to the benefits of leveraging data. Data analysis can help a bank to personalize customer interactions, a health care system to predict future health needs, or an entertainment company to create the next big streaming hit.
The World Economic Forum Future of Jobs Report 2023 listed data analysts and scientists as one of the most in-demand jobs, alongside AI and machine learning specialists and big data specialists [ 1 ]. In this article, you'll learn more about the data analysis process, different types of data analysis, and recommended courses to help you get started in this exciting field.
Read more: How to Become a Data Analyst (with or Without a Degree)
Beginner-friendly data analysis courses
Interested in building your knowledge of data analysis today? Consider enrolling in one of these popular courses on Coursera:
In Google's Foundations: Data, Data, Everywhere course, you'll explore key data analysis concepts, tools, and jobs.
In Duke University's Data Analysis and Visualization course, you'll learn how to identify key components for data analytics projects, explore data visualization, and find out how to create a compelling data story.
Data analysis process
As the data available to companies continues to grow both in amount and complexity, so too does the need for an effective and efficient process by which to harness the value of that data. The data analysis process typically moves through several iterative phases. Let’s take a closer look at each.
Identify the business question you’d like to answer. What problem is the company trying to solve? What do you need to measure, and how will you measure it?
Collect the raw data sets you’ll need to help you answer the identified question. Data collection might come from internal sources, like a company’s client relationship management (CRM) software, or from secondary sources, like government records or social media application programming interfaces (APIs).
Clean the data to prepare it for analysis. This often involves purging duplicate and anomalous data, reconciling inconsistencies, standardizing data structure and format, and dealing with white spaces and other syntax errors.
Analyze the data. By manipulating the data using various data analysis techniques and tools, you can begin to find trends, correlations, outliers, and variations that tell a story. During this stage, you might use data mining to discover patterns within databases or data visualization software to help transform data into an easy-to-understand graphical format.
Interpret the results of your analysis to see how well the data answered your original question. What recommendations can you make based on the data? What are the limitations to your conclusions?
You can complete hands-on projects for your portfolio while practicing statistical analysis, data management, and programming with Meta's beginner-friendly Data Analyst Professional Certificate . Designed to prepare you for an entry-level role, this self-paced program can be completed in just 5 months.
Or, L earn more about data analysis in this lecture by Kevin, Director of Data Analytics at Google, from Google's Data Analytics Professional Certificate :
Read more: What Does a Data Analyst Do? A Career Guide
Types of data analysis (with examples)
Data can be used to answer questions and support decisions in many different ways. To identify the best way to analyze your date, it can help to familiarize yourself with the four types of data analysis commonly used in the field.
In this section, we’ll take a look at each of these data analysis methods, along with an example of how each might be applied in the real world.
Descriptive analysis
Descriptive analysis tells us what happened. This type of analysis helps describe or summarize quantitative data by presenting statistics. For example, descriptive statistical analysis could show the distribution of sales across a group of employees and the average sales figure per employee.
Descriptive analysis answers the question, “what happened?”
Diagnostic analysis
If the descriptive analysis determines the “what,” diagnostic analysis determines the “why.” Let’s say a descriptive analysis shows an unusual influx of patients in a hospital. Drilling into the data further might reveal that many of these patients shared symptoms of a particular virus. This diagnostic analysis can help you determine that an infectious agent—the “why”—led to the influx of patients.
Diagnostic analysis answers the question, “why did it happen?”
Predictive analysis
So far, we’ve looked at types of analysis that examine and draw conclusions about the past. Predictive analytics uses data to form projections about the future. Using predictive analysis, you might notice that a given product has had its best sales during the months of September and October each year, leading you to predict a similar high point during the upcoming year.
Predictive analysis answers the question, “what might happen in the future?”
Prescriptive analysis
Prescriptive analysis takes all the insights gathered from the first three types of analysis and uses them to form recommendations for how a company should act. Using our previous example, this type of analysis might suggest a market plan to build on the success of the high sales months and harness new growth opportunities in the slower months.
Prescriptive analysis answers the question, “what should we do about it?”
This last type is where the concept of data-driven decision-making comes into play.
Read more : Advanced Analytics: Definition, Benefits, and Use Cases
What is data-driven decision-making (DDDM)?
Data-driven decision-making, sometimes abbreviated to DDDM), can be defined as the process of making strategic business decisions based on facts, data, and metrics instead of intuition, emotion, or observation.
This might sound obvious, but in practice, not all organizations are as data-driven as they could be. According to global management consulting firm McKinsey Global Institute, data-driven companies are better at acquiring new customers, maintaining customer loyalty, and achieving above-average profitability [ 2 ].
Get started with Coursera
If you’re interested in a career in the high-growth field of data analytics, consider these top-rated courses on Coursera:
Begin building job-ready skills with the Google Data Analytics Professional Certificate . Prepare for an entry-level job as you learn from Google employees—no experience or degree required.
Practice working with data with Macquarie University's Excel Skills for Business Specialization . Learn how to use Microsoft Excel to analyze data and make data-informed business decisions.
Deepen your skill set with Google's Advanced Data Analytics Professional Certificate . In this advanced program, you'll continue exploring the concepts introduced in the beginner-level courses, plus learn Python, statistics, and Machine Learning concepts.
Frequently asked questions (FAQ)
Where is data analytics used .
Just about any business or organization can use data analytics to help inform their decisions and boost their performance. Some of the most successful companies across a range of industries — from Amazon and Netflix to Starbucks and General Electric — integrate data into their business plans to improve their overall business performance.
What are the top skills for a data analyst?
Data analysis makes use of a range of analysis tools and technologies. Some of the top skills for data analysts include SQL, data visualization, statistical programming languages (like R and Python), machine learning, and spreadsheets.
Read : 7 In-Demand Data Analyst Skills to Get Hired in 2022
What is a data analyst job salary?
Data from Glassdoor indicates that the average base salary for a data analyst in the United States is $75,349 as of March 2024 [ 3 ]. How much you make will depend on factors like your qualifications, experience, and location.
Do data analysts need to be good at math?
Data analytics tends to be less math-intensive than data science. While you probably won’t need to master any advanced mathematics, a foundation in basic math and statistical analysis can help set you up for success.
Learn more: Data Analyst vs. Data Scientist: What’s the Difference?
Article sources
World Economic Forum. " The Future of Jobs Report 2023 , https://www3.weforum.org/docs/WEF_Future_of_Jobs_2023.pdf." Accessed March 19, 2024.
McKinsey & Company. " Five facts: How customer analytics boosts corporate performance , https://www.mckinsey.com/business-functions/marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance." Accessed March 19, 2024.
Glassdoor. " Data Analyst Salaries , https://www.glassdoor.com/Salaries/data-analyst-salary-SRCH_KO0,12.htm" Accessed March 19, 2024.
Keep reading
Coursera staff.
Editorial Team
Coursera’s editorial team is comprised of highly experienced professional editors, writers, and fact...
This content has been made available for informational purposes only. Learners are advised to conduct additional research to ensure that courses and other credentials pursued meet their personal, professional, and financial goals.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Can J Hosp Pharm
- v.68(4); Jul-Aug 2015
Creating a Data Analysis Plan: What to Consider When Choosing Statistics for a Study
There are three kinds of lies: lies, damned lies, and statistics. – Mark Twain 1
INTRODUCTION
Statistics represent an essential part of a study because, regardless of the study design, investigators need to summarize the collected information for interpretation and presentation to others. It is therefore important for us to heed Mr Twain’s concern when creating the data analysis plan. In fact, even before data collection begins, we need to have a clear analysis plan that will guide us from the initial stages of summarizing and describing the data through to testing our hypotheses.
The purpose of this article is to help you create a data analysis plan for a quantitative study. For those interested in conducting qualitative research, previous articles in this Research Primer series have provided information on the design and analysis of such studies. 2 , 3 Information in the current article is divided into 3 main sections: an overview of terms and concepts used in data analysis, a review of common methods used to summarize study data, and a process to help identify relevant statistical tests. My intention here is to introduce the main elements of data analysis and provide a place for you to start when planning this part of your study. Biostatistical experts, textbooks, statistical software packages, and other resources can certainly add more breadth and depth to this topic when you need additional information and advice.
TERMS AND CONCEPTS USED IN DATA ANALYSIS
When analyzing information from a quantitative study, we are often dealing with numbers; therefore, it is important to begin with an understanding of the source of the numbers. Let us start with the term variable , which defines a specific item of information collected in a study. Examples of variables include age, sex or gender, ethnicity, exercise frequency, weight, treatment group, and blood glucose. Each variable will have a group of categories, which are referred to as values , to help describe the characteristic of an individual study participant. For example, the variable “sex” would have values of “male” and “female”.
Although variables can be defined or grouped in various ways, I will focus on 2 methods at this introductory stage. First, variables can be defined according to the level of measurement. The categories in a nominal variable are names, for example, male and female for the variable “sex”; white, Aboriginal, black, Latin American, South Asian, and East Asian for the variable “ethnicity”; and intervention and control for the variable “treatment group”. Nominal variables with only 2 categories are also referred to as dichotomous variables because the study group can be divided into 2 subgroups based on information in the variable. For example, a study sample can be split into 2 groups (patients receiving the intervention and controls) using the dichotomous variable “treatment group”. An ordinal variable implies that the categories can be placed in a meaningful order, as would be the case for exercise frequency (never, sometimes, often, or always). Nominal-level and ordinal-level variables are also referred to as categorical variables, because each category in the variable can be completely separated from the others. The categories for an interval variable can be placed in a meaningful order, with the interval between consecutive categories also having meaning. Age, weight, and blood glucose can be considered as interval variables, but also as ratio variables, because the ratio between values has meaning (e.g., a 15-year-old is half the age of a 30-year-old). Interval-level and ratio-level variables are also referred to as continuous variables because of the underlying continuity among categories.
As we progress through the levels of measurement from nominal to ratio variables, we gather more information about the study participant. The amount of information that a variable provides will become important in the analysis stage, because we lose information when variables are reduced or aggregated—a common practice that is not recommended. 4 For example, if age is reduced from a ratio-level variable (measured in years) to an ordinal variable (categories of < 65 and ≥ 65 years) we lose the ability to make comparisons across the entire age range and introduce error into the data analysis. 4
A second method of defining variables is to consider them as either dependent or independent. As the terms imply, the value of a dependent variable depends on the value of other variables, whereas the value of an independent variable does not rely on other variables. In addition, an investigator can influence the value of an independent variable, such as treatment-group assignment. Independent variables are also referred to as predictors because we can use information from these variables to predict the value of a dependent variable. Building on the group of variables listed in the first paragraph of this section, blood glucose could be considered a dependent variable, because its value may depend on values of the independent variables age, sex, ethnicity, exercise frequency, weight, and treatment group.
Statistics are mathematical formulae that are used to organize and interpret the information that is collected through variables. There are 2 general categories of statistics, descriptive and inferential. Descriptive statistics are used to describe the collected information, such as the range of values, their average, and the most common category. Knowledge gained from descriptive statistics helps investigators learn more about the study sample. Inferential statistics are used to make comparisons and draw conclusions from the study data. Knowledge gained from inferential statistics allows investigators to make inferences and generalize beyond their study sample to other groups.
Before we move on to specific descriptive and inferential statistics, there are 2 more definitions to review. Parametric statistics are generally used when values in an interval-level or ratio-level variable are normally distributed (i.e., the entire group of values has a bell-shaped curve when plotted by frequency). These statistics are used because we can define parameters of the data, such as the centre and width of the normally distributed curve. In contrast, interval-level and ratio-level variables with values that are not normally distributed, as well as nominal-level and ordinal-level variables, are generally analyzed using nonparametric statistics.
METHODS FOR SUMMARIZING STUDY DATA: DESCRIPTIVE STATISTICS
The first step in a data analysis plan is to describe the data collected in the study. This can be done using figures to give a visual presentation of the data and statistics to generate numeric descriptions of the data.
Selection of an appropriate figure to represent a particular set of data depends on the measurement level of the variable. Data for nominal-level and ordinal-level variables may be interpreted using a pie graph or bar graph . Both options allow us to examine the relative number of participants within each category (by reporting the percentages within each category), whereas a bar graph can also be used to examine absolute numbers. For example, we could create a pie graph to illustrate the proportions of men and women in a study sample and a bar graph to illustrate the number of people who report exercising at each level of frequency (never, sometimes, often, or always).
Interval-level and ratio-level variables may also be interpreted using a pie graph or bar graph; however, these types of variables often have too many categories for such graphs to provide meaningful information. Instead, these variables may be better interpreted using a histogram . Unlike a bar graph, which displays the frequency for each distinct category, a histogram displays the frequency within a range of continuous categories. Information from this type of figure allows us to determine whether the data are normally distributed. In addition to pie graphs, bar graphs, and histograms, many other types of figures are available for the visual representation of data. Interested readers can find additional types of figures in the books recommended in the “Further Readings” section.
Figures are also useful for visualizing comparisons between variables or between subgroups within a variable (for example, the distribution of blood glucose according to sex). Box plots are useful for summarizing information for a variable that does not follow a normal distribution. The lower and upper limits of the box identify the interquartile range (or 25th and 75th percentiles), while the midline indicates the median value (or 50th percentile). Scatter plots provide information on how the categories for one continuous variable relate to categories in a second variable; they are often helpful in the analysis of correlations.
In addition to using figures to present a visual description of the data, investigators can use statistics to provide a numeric description. Regardless of the measurement level, we can find the mode by identifying the most frequent category within a variable. When summarizing nominal-level and ordinal-level variables, the simplest method is to report the proportion of participants within each category.
The choice of the most appropriate descriptive statistic for interval-level and ratio-level variables will depend on how the values are distributed. If the values are normally distributed, we can summarize the information using the parametric statistics of mean and standard deviation. The mean is the arithmetic average of all values within the variable, and the standard deviation tells us how widely the values are dispersed around the mean. When values of interval-level and ratio-level variables are not normally distributed, or we are summarizing information from an ordinal-level variable, it may be more appropriate to use the nonparametric statistics of median and range. The first step in identifying these descriptive statistics is to arrange study participants according to the variable categories from lowest value to highest value. The range is used to report the lowest and highest values. The median or 50th percentile is located by dividing the number of participants into 2 groups, such that half (50%) of the participants have values above the median and the other half (50%) have values below the median. Similarly, the 25th percentile is the value with 25% of the participants having values below and 75% of the participants having values above, and the 75th percentile is the value with 75% of participants having values below and 25% of participants having values above. Together, the 25th and 75th percentiles define the interquartile range .
PROCESS TO IDENTIFY RELEVANT STATISTICAL TESTS: INFERENTIAL STATISTICS
One caveat about the information provided in this section: selecting the most appropriate inferential statistic for a specific study should be a combination of following these suggestions, seeking advice from experts, and discussing with your co-investigators. My intention here is to give you a place to start a conversation with your colleagues about the options available as you develop your data analysis plan.
There are 3 key questions to consider when selecting an appropriate inferential statistic for a study: What is the research question? What is the study design? and What is the level of measurement? It is important for investigators to carefully consider these questions when developing the study protocol and creating the analysis plan. The figures that accompany these questions show decision trees that will help you to narrow down the list of inferential statistics that would be relevant to a particular study. Appendix 1 provides brief definitions of the inferential statistics named in these figures. Additional information, such as the formulae for various inferential statistics, can be obtained from textbooks, statistical software packages, and biostatisticians.
What Is the Research Question?
The first step in identifying relevant inferential statistics for a study is to consider the type of research question being asked. You can find more details about the different types of research questions in a previous article in this Research Primer series that covered questions and hypotheses. 5 A relational question seeks information about the relationship among variables; in this situation, investigators will be interested in determining whether there is an association ( Figure 1 ). A causal question seeks information about the effect of an intervention on an outcome; in this situation, the investigator will be interested in determining whether there is a difference ( Figure 2 ).

Decision tree to identify inferential statistics for an association.

Decision tree to identify inferential statistics for measuring a difference.
What Is the Study Design?
When considering a question of association, investigators will be interested in measuring the relationship between variables ( Figure 1 ). A study designed to determine whether there is consensus among different raters will be measuring agreement. For example, an investigator may be interested in determining whether 2 raters, using the same assessment tool, arrive at the same score. Correlation analyses examine the strength of a relationship or connection between 2 variables, like age and blood glucose. Regression analyses also examine the strength of a relationship or connection; however, in this type of analysis, one variable is considered an outcome (or dependent variable) and the other variable is considered a predictor (or independent variable). Regression analyses often consider the influence of multiple predictors on an outcome at the same time. For example, an investigator may be interested in examining the association between a treatment and blood glucose, while also considering other factors, like age, sex, ethnicity, exercise frequency, and weight.
When considering a question of difference, investigators must first determine how many groups they will be comparing. In some cases, investigators may be interested in comparing the characteristic of one group with that of an external reference group. For example, is the mean age of study participants similar to the mean age of all people in the target group? If more than one group is involved, then investigators must also determine whether there is an underlying connection between the sets of values (or samples ) to be compared. Samples are considered independent or unpaired when the information is taken from different groups. For example, we could use an unpaired t test to compare the mean age between 2 independent samples, such as the intervention and control groups in a study. Samples are considered related or paired if the information is taken from the same group of people, for example, measurement of blood glucose at the beginning and end of a study. Because blood glucose is measured in the same people at both time points, we could use a paired t test to determine whether there has been a significant change in blood glucose.
What Is the Level of Measurement?
As described in the first section of this article, variables can be grouped according to the level of measurement (nominal, ordinal, or interval). In most cases, the independent variable in an inferential statistic will be nominal; therefore, investigators need to know the level of measurement for the dependent variable before they can select the relevant inferential statistic. Two exceptions to this consideration are correlation analyses and regression analyses ( Figure 1 ). Because a correlation analysis measures the strength of association between 2 variables, we need to consider the level of measurement for both variables. Regression analyses can consider multiple independent variables, often with a variety of measurement levels. However, for these analyses, investigators still need to consider the level of measurement for the dependent variable.
Selection of inferential statistics to test interval-level variables must include consideration of how the data are distributed. An underlying assumption for parametric tests is that the data approximate a normal distribution. When the data are not normally distributed, information derived from a parametric test may be wrong. 6 When the assumption of normality is violated (for example, when the data are skewed), then investigators should use a nonparametric test. If the data are normally distributed, then investigators can use a parametric test.
ADDITIONAL CONSIDERATIONS
What is the level of significance.
An inferential statistic is used to calculate a p value, the probability of obtaining the observed data by chance. Investigators can then compare this p value against a prespecified level of significance, which is often chosen to be 0.05. This level of significance represents a 1 in 20 chance that the observation is wrong, which is considered an acceptable level of error.
What Are the Most Commonly Used Statistics?
In 1983, Emerson and Colditz 7 reported the first review of statistics used in original research articles published in the New England Journal of Medicine . This review of statistics used in the journal was updated in 1989 and 2005, 8 and this type of analysis has been replicated in many other journals. 9 – 13 Collectively, these reviews have identified 2 important observations. First, the overall sophistication of statistical methodology used and reported in studies has grown over time, with survival analyses and multivariable regression analyses becoming much more common. The second observation is that, despite this trend, 1 in 4 articles describe no statistical methods or report only simple descriptive statistics. When inferential statistics are used, the most common are t tests, contingency table tests (for example, χ 2 test and Fisher exact test), and simple correlation and regression analyses. This information is important for educators, investigators, reviewers, and readers because it suggests that a good foundational knowledge of descriptive statistics and common inferential statistics will enable us to correctly evaluate the majority of research articles. 11 – 13 However, to fully take advantage of all research published in high-impact journals, we need to become acquainted with some of the more complex methods, such as multivariable regression analyses. 8 , 13
What Are Some Additional Resources?
As an investigator and Associate Editor with CJHP , I have often relied on the advice of colleagues to help create my own analysis plans and review the plans of others. Biostatisticians have a wealth of knowledge in the field of statistical analysis and can provide advice on the correct selection, application, and interpretation of these methods. Colleagues who have “been there and done that” with their own data analysis plans are also valuable sources of information. Identify these individuals and consult with them early and often as you develop your analysis plan.
Another important resource to consider when creating your analysis plan is textbooks. Numerous statistical textbooks are available, differing in levels of complexity and scope. The titles listed in the “Further Reading” section are just a few suggestions. I encourage interested readers to look through these and other books to find resources that best fit their needs. However, one crucial book that I highly recommend to anyone wanting to be an investigator or peer reviewer is Lang and Secic’s How to Report Statistics in Medicine (see “Further Reading”). As the title implies, this book covers a wide range of statistics used in medical research and provides numerous examples of how to correctly report the results.
CONCLUSIONS
When it comes to creating an analysis plan for your project, I recommend following the sage advice of Douglas Adams in The Hitchhiker’s Guide to the Galaxy : Don’t panic! 14 Begin with simple methods to summarize and visualize your data, then use the key questions and decision trees provided in this article to identify relevant statistical tests. Information in this article will give you and your co-investigators a place to start discussing the elements necessary for developing an analysis plan. But do not stop there! Use advice from biostatisticians and more experienced colleagues, as well as information in textbooks, to help create your analysis plan and choose the most appropriate statistics for your study. Making careful, informed decisions about the statistics to use in your study should reduce the risk of confirming Mr Twain’s concern.
Appendix 1. Glossary of statistical terms * (part 1 of 2)
- 1-way ANOVA: Uses 1 variable to define the groups for comparing means. This is similar to the Student t test when comparing the means of 2 groups.
- Kruskall–Wallis 1-way ANOVA: Nonparametric alternative for the 1-way ANOVA. Used to determine the difference in medians between 3 or more groups.
- n -way ANOVA: Uses 2 or more variables to define groups when comparing means. Also called a “between-subjects factorial ANOVA”.
- Repeated-measures ANOVA: A method for analyzing whether the means of 3 or more measures from the same group of participants are different.
- Freidman ANOVA: Nonparametric alternative for the repeated-measures ANOVA. It is often used to compare rankings and preferences that are measured 3 or more times.
- Fisher exact: Variation of chi-square that accounts for cell counts < 5.
- McNemar: Variation of chi-square that tests statistical significance of changes in 2 paired measurements of dichotomous variables.
- Cochran Q: An extension of the McNemar test that provides a method for testing for differences between 3 or more matched sets of frequencies or proportions. Often used as a measure of heterogeneity in meta-analyses.
- 1-sample: Used to determine whether the mean of a sample is significantly different from a known or hypothesized value.
- Independent-samples t test (also referred to as the Student t test): Used when the independent variable is a nominal-level variable that identifies 2 groups and the dependent variable is an interval-level variable.
- Paired: Used to compare 2 pairs of scores between 2 groups (e.g., baseline and follow-up blood pressure in the intervention and control groups).
Lang TA, Secic M. How to report statistics in medicine: annotated guidelines for authors, editors, and reviewers. 2nd ed. Philadelphia (PA): American College of Physicians; 2006.
Norman GR, Streiner DL. PDQ statistics. 3rd ed. Hamilton (ON): B.C. Decker; 2003.
Plichta SB, Kelvin E. Munro’s statistical methods for health care research . 6th ed. Philadelphia (PA): Wolters Kluwer Health/ Lippincott, Williams & Wilkins; 2013.
This article is the 12th in the CJHP Research Primer Series, an initiative of the CJHP Editorial Board and the CSHP Research Committee. The planned 2-year series is intended to appeal to relatively inexperienced researchers, with the goal of building research capacity among practising pharmacists. The articles, presenting simple but rigorous guidance to encourage and support novice researchers, are being solicited from authors with appropriate expertise.
Previous articles in this series:
- Bond CM. The research jigsaw: how to get started. Can J Hosp Pharm . 2014;67(1):28–30.
- Tully MP. Research: articulating questions, generating hypotheses, and choosing study designs. Can J Hosp Pharm . 2014;67(1):31–4.
- Loewen P. Ethical issues in pharmacy practice research: an introductory guide. Can J Hosp Pharm. 2014;67(2):133–7.
- Tsuyuki RT. Designing pharmacy practice research trials. Can J Hosp Pharm . 2014;67(3):226–9.
- Bresee LC. An introduction to developing surveys for pharmacy practice research. Can J Hosp Pharm . 2014;67(4):286–91.
- Gamble JM. An introduction to the fundamentals of cohort and case–control studies. Can J Hosp Pharm . 2014;67(5):366–72.
- Austin Z, Sutton J. Qualitative research: getting started. C an J Hosp Pharm . 2014;67(6):436–40.
- Houle S. An introduction to the fundamentals of randomized controlled trials in pharmacy research. Can J Hosp Pharm . 2014; 68(1):28–32.
- Charrois TL. Systematic reviews: What do you need to know to get started? Can J Hosp Pharm . 2014;68(2):144–8.
- Sutton J, Austin Z. Qualitative research: data collection, analysis, and management. Can J Hosp Pharm . 2014;68(3):226–31.
- Cadarette SM, Wong L. An introduction to health care administrative data. Can J Hosp Pharm. 2014;68(3):232–7.
Competing interests: None declared.
Further Reading
- Devor J, Peck R. Statistics: the exploration and analysis of data. 7th ed. Boston (MA): Brooks/Cole Cengage Learning; 2012. [ Google Scholar ]
- Lang TA, Secic M. How to report statistics in medicine: annotated guidelines for authors, editors, and reviewers. 2nd ed. Philadelphia (PA): American College of Physicians; 2006. [ Google Scholar ]
- Mendenhall W, Beaver RJ, Beaver BM. Introduction to probability and statistics. 13th ed. Belmont (CA): Brooks/Cole Cengage Learning; 2009. [ Google Scholar ]
- Norman GR, Streiner DL. PDQ statistics. 3rd ed. Hamilton (ON): B.C. Decker; 2003. [ Google Scholar ]
- Plichta SB, Kelvin E. Munro’s statistical methods for health care research. 6th ed. Philadelphia (PA): Wolters Kluwer Health/Lippincott, Williams & Wilkins; 2013. [ Google Scholar ]
Log in using your username and password
- Search More Search for this keyword Advanced search
- Latest content
- Current issue
- Write for Us
- BMJ Journals More You are viewing from: Google Indexer
You are here
- Volume 17, Issue 1
- Qualitative data analysis: a practical example
- Article Text
- Article info
- Citation Tools
- Rapid Responses
- Article metrics
- Helen Noble 1 ,
- Joanna Smith 2
- 1 School of Nursing and Midwifery, Queens's University Belfast , Belfast , UK
- 2 Department of Health Sciences , University of Huddersfield , Huddersfield , UK
- Correspondence to : Dr Helen Noble School of Nursing and Midwifery, Queen's University Belfast, Medical Biology Centre, 97 Lisburn Road, Belfast BT9 7BL, UK; helen.noble{at}qub.ac.uk
https://doi.org/10.1136/eb-2013-101603
Statistics from Altmetric.com
Request permissions.
If you wish to reuse any or all of this article please use the link below which will take you to the Copyright Clearance Center’s RightsLink service. You will be able to get a quick price and instant permission to reuse the content in many different ways.
The aim of this paper is to equip readers with an understanding of the principles of qualitative data analysis and offer a practical example of how analysis might be undertaken in an interview-based study.
What is qualitative data analysis?
What are the approaches in undertaking qualitative data analysis.
Although qualitative data analysis is inductive and focuses on meaning, approaches in analysing data are diverse with different purposes and ontological (concerned with the nature of being) and epistemological (knowledge and understanding) underpinnings. 2 Identifying an appropriate approach in analysing qualitative data analysis to meet the aim of a study can be challenging. One way to understand qualitative data analysis is to consider the processes involved. 3 Approaches can be divided into four broad groups: quasistatistical approaches such as content analysis; the use of frameworks or matrices such as a framework approach and thematic analysis; interpretative approaches that include interpretative phenomenological analysis and grounded theory; and sociolinguistic approaches such as discourse analysis and conversation analysis. However, there are commonalities across approaches. Data analysis is an interactive process, where data are systematically searched and analysed in order to provide an illuminating description of phenomena; for example, the experience of carers supporting dying patients with renal disease 4 or student nurses’ experiences following assignment referral. 5 Data analysis is an iterative or recurring process, essential to the creativity of the analysis, development of ideas, clarifying meaning and the reworking of concepts as new insights ‘emerge’ or are identified in the data.
Do you need data software packages when analysing qualitative data?
Qualitative data software packages are not a prerequisite for undertaking qualitative analysis but a range of programmes are available that can assist the qualitative researcher. Software programmes vary in design and application but can be divided into text retrievers, code and retrieve packages and theory builders. 6 NVivo and NUD*IST are widely used because they have sophisticated code and retrieve functions and modelling capabilities, which speed up the process of managing large data sets and data retrieval. Repetitions within data can be quantified and memos and hyperlinks attached to data. Analytical processes can be mapped and tracked and linkages across data visualised leading to theory development. 6 Disadvantages of using qualitative data software packages include the complexity of the software and some programmes are not compatible with standard text format. Extensive coding and categorising can result in data becoming unmanageable and researchers may find visualising data on screen inhibits conceptualisation of the data.
How do you begin analysing qualitative data?
Despite the diversity of qualitative methods, the subsequent analysis is based on a common set of principles and for interview data includes: transcribing the interviews; immersing oneself within the data to gain detailed insights into the phenomena being explored; developing a data coding system; and linking codes or units of data to form overarching themes/concepts, which may lead to the development of theory. 2 Identifying recurring and significant themes, whereby data are methodically searched to identify patterns in order to provide an illuminating description of a phenomenon, is a central skill in undertaking qualitative data analysis. Table 1 contains an extract of data taken from a research study which included interviews with carers of people with end-stage renal disease managed without dialysis. The extract is taken from a carer who is trying to understand why her mother was not offered dialysis. The first stage of data analysis involves the process of initial coding, whereby each line of the data is considered to identify keywords or phrases; these are sometimes known as in vivo codes (highlighted) because they retain participants’ words.
- View inline
Data extract containing units of data and line-by-line coding
When transcripts have been broken down into manageable sections, the researcher sorts and sifts them, searching for types, classes, sequences, processes, patterns or wholes. The next stage of data analysis involves bringing similar categories together into broader themes. Table 2 provides an example of the early development of codes and categories and how these link to form broad initial themes.
Development of initial themes from descriptive codes
Table 3 presents an example of further category development leading to final themes which link to an overarching concept.
Development of final themes and overarching concept
How do qualitative researchers ensure data analysis procedures are transparent and robust?
In congruence with quantitative researchers, ensuring qualitative studies are methodologically robust is essential. Qualitative researchers need to be explicit in describing how and why they undertook the research. However, qualitative research is criticised for lacking transparency in relation to the analytical processes employed, which hinders the ability of the reader to critically appraise study findings. 7 In the three tables presented the progress from units of data to coding to theme development is illustrated. ‘Not involved in treatment decisions’ appears in each table and informs one of the final themes. Documenting the movement from units of data to final themes allows for transparency of data analysis. Although other researchers may interpret the data differently, appreciating and understanding how the themes were developed is an essential part of demonstrating the robustness of the findings. Qualitative researchers must demonstrate rigour, associated with openness, relevance to practice and congruence of the methodological approch. 2 In summary qualitative research is complex in that it produces large amounts of data and analysis is time consuming and complex. High-quality data analysis requires a researcher with expertise, vision and veracity.
- Cheater F ,
- Robshaw M ,
- McLafferty E ,
- Maggs-Rapport F
Competing interests None.
Read the full text or download the PDF:
Business growth
Business tips
What is data analysis? Examples and how to get started

Even with years of professional experience working with data, the term "data analysis" still sets off a panic button in my soul. And yes, when it comes to serious data analysis for your business, you'll eventually want data scientists on your side. But if you're just getting started, no panic attacks are required.
Table of contents:
Quick review: What is data analysis?
Data analysis is the process of examining, filtering, adapting, and modeling data to help solve problems. Data analysis helps determine what is and isn't working, so you can make the changes needed to achieve your business goals.
Keep in mind that data analysis includes analyzing both quantitative data (e.g., profits and sales) and qualitative data (e.g., surveys and case studies) to paint the whole picture. Here are two simple examples (of a nuanced topic) to show you what I mean.
An example of quantitative data analysis is an online jewelry store owner using inventory data to forecast and improve reordering accuracy. The owner looks at their sales from the past six months and sees that, on average, they sold 210 gold pieces and 105 silver pieces per month, but they only had 100 gold pieces and 100 silver pieces in stock. By collecting and analyzing inventory data on these SKUs, they're forecasting to improve reordering accuracy. The next time they order inventory, they order twice as many gold pieces as silver to meet customer demand.
An example of qualitative data analysis is a fitness studio owner collecting customer feedback to improve class offerings. The studio owner sends out an open-ended survey asking customers what types of exercises they enjoy the most. The owner then performs qualitative content analysis to identify the most frequently suggested exercises and incorporates these into future workout classes.
Why is data analysis important?
Here's why it's worth implementing data analysis for your business:
Understand your target audience: You might think you know how to best target your audience, but are your assumptions backed by data? Data analysis can help answer questions like, "What demographics define my target audience?" or "What is my audience motivated by?"
Inform decisions: You don't need to toss and turn over a decision when the data points clearly to the answer. For instance, a restaurant could analyze which dishes on the menu are selling the most, helping them decide which ones to keep and which ones to change.
Adjust budgets: Similarly, data analysis can highlight areas in your business that are performing well and are worth investing more in, as well as areas that aren't generating enough revenue and should be cut. For example, a B2B software company might discover their product for enterprises is thriving while their small business solution lags behind. This discovery could prompt them to allocate more budget toward the enterprise product, resulting in better resource utilization.
Identify and solve problems: Let's say a cell phone manufacturer notices data showing a lot of customers returning a certain model. When they investigate, they find that model also happens to have the highest number of crashes. Once they identify and solve the technical issue, they can reduce the number of returns.
Types of data analysis (with examples)
There are five main types of data analysis—with increasingly scary-sounding names. Each one serves a different purpose, so take a look to see which makes the most sense for your situation. It's ok if you can't pronounce the one you choose.

Text analysis: What is happening?
Here are a few methods used to perform text analysis, to give you a sense of how it's different from a human reading through the text:
Word frequency identifies the most frequently used words. For example, a restaurant monitors social media mentions and measures the frequency of positive and negative keywords like "delicious" or "expensive" to determine how customers feel about their experience.
Language detection indicates the language of text. For example, a global software company may use language detection on support tickets to connect customers with the appropriate agent.
Keyword extraction automatically identifies the most used terms. For example, instead of sifting through thousands of reviews, a popular brand uses a keyword extractor to summarize the words or phrases that are most relevant.
Statistical analysis: What happened?
Statistical analysis pulls past data to identify meaningful trends. Two primary categories of statistical analysis exist: descriptive and inferential.
Descriptive analysis
Here are a few methods used to perform descriptive analysis:
Measures of frequency identify how frequently an event occurs. For example, a popular coffee chain sends out a survey asking customers what their favorite holiday drink is and uses measures of frequency to determine how often a particular drink is selected.
Measures of central tendency use mean, median, and mode to identify results. For example, a dating app company might use measures of central tendency to determine the average age of its users.
Measures of dispersion measure how data is distributed across a range. For example, HR may use measures of dispersion to determine what salary to offer in a given field.
Inferential analysis
Inferential analysis uses a sample of data to draw conclusions about a much larger population. This type of analysis is used when the population you're interested in analyzing is very large.
Here are a few methods used when performing inferential analysis:
Hypothesis testing identifies which variables impact a particular topic. For example, a business uses hypothesis testing to determine if increased sales were the result of a specific marketing campaign.
Regression analysis shows the effect of independent variables on a dependent variable. For example, a rental car company may use regression analysis to determine the relationship between wait times and number of bad reviews.
Diagnostic analysis: Why did it happen?
Diagnostic analysis, also referred to as root cause analysis, uncovers the causes of certain events or results.
Here are a few methods used to perform diagnostic analysis:
Time-series analysis analyzes data collected over a period of time. A retail store may use time-series analysis to determine that sales increase between October and December every year.
Correlation analysis determines the strength of the relationship between variables. For example, a local ice cream shop may determine that as the temperature in the area rises, so do ice cream sales.
Predictive analysis: What is likely to happen?
Predictive analysis aims to anticipate future developments and events. By analyzing past data, companies can predict future scenarios and make strategic decisions.
Here are a few methods used to perform predictive analysis:
Decision trees map out possible courses of action and outcomes. For example, a business may use a decision tree when deciding whether to downsize or expand.
Prescriptive analysis: What action should we take?
The highest level of analysis, prescriptive analysis, aims to find the best action plan. Typically, AI tools model different outcomes to predict the best approach. While these tools serve to provide insight, they don't replace human consideration, so always use your human brain before going with the conclusion of your prescriptive analysis. Otherwise, your GPS might drive you into a lake.
Here are a few methods used to perform prescriptive analysis:
Algorithms are used in technology to perform specific tasks. For example, banks use prescriptive algorithms to monitor customers' spending and recommend that they deactivate their credit card if fraud is suspected.
Data analysis process: How to get started
The actual analysis is just one step in a much bigger process of using data to move your business forward. Here's a quick look at all the steps you need to take to make sure you're making informed decisions.

Data decision
As with almost any project, the first step is to determine what problem you're trying to solve through data analysis.
Make sure you get specific here. For example, a food delivery service may want to understand why customers are canceling their subscriptions. But to enable the most effective data analysis, they should pose a more targeted question, such as "How can we reduce customer churn without raising costs?"
Data collection
Next, collect the required data from both internal and external sources.
Internal data comes from within your business (think CRM software, internal reports, and archives), and helps you understand your business and processes.
External data originates from outside of the company (surveys, questionnaires, public data) and helps you understand your industry and your customers.
Data cleaning
Data can be seriously misleading if it's not clean. So before you analyze, make sure you review the data you collected. Depending on the type of data you have, cleanup will look different, but it might include:
Removing unnecessary information
Addressing structural errors like misspellings
Deleting duplicates
Trimming whitespace
Human checking for accuracy
Data analysis
Now that you've compiled and cleaned the data, use one or more of the above types of data analysis to find relationships, patterns, and trends.
Data analysis tools can speed up the data analysis process and remove the risk of inevitable human error. Here are some examples.
Spreadsheets sort, filter, analyze, and visualize data.
Structured query language (SQL) tools manage and extract data in relational databases.
Data interpretation
After you analyze the data, you'll need to go back to the original question you posed and draw conclusions from your findings. Here are some common pitfalls to avoid:
Correlation vs. causation: Just because two variables are associated doesn't mean they're necessarily related or dependent on one another.
Confirmation bias: This occurs when you interpret data in a way that confirms your own preconceived notions. To avoid this, have multiple people interpret the data.
Small sample size: If your sample size is too small or doesn't represent the demographics of your customers, you may get misleading results. If you run into this, consider widening your sample size to give you a more accurate representation.
Data visualization
Automate your data collection, frequently asked questions.
Need a quick summary or still have a few nagging data analysis questions? I'm here for you.
What are the five types of data analysis?
The five types of data analysis are text analysis, statistical analysis, diagnostic analysis, predictive analysis, and prescriptive analysis. Each type offers a unique lens for understanding data: text analysis provides insights into text-based content, statistical analysis focuses on numerical trends, diagnostic analysis looks into problem causes, predictive analysis deals with what may happen in the future, and prescriptive analysis gives actionable recommendations.
What is the data analysis process?
The data analysis process involves data decision, collection, cleaning, analysis, interpretation, and visualization. Every stage comes together to transform raw data into meaningful insights. Decision determines what data to collect, collection gathers the relevant information, cleaning ensures accuracy, analysis uncovers patterns, interpretation assigns meaning, and visualization presents the insights.
What is the main purpose of data analysis?
In business, the main purpose of data analysis is to uncover patterns, trends, and anomalies, and then use that information to make decisions, solve problems, and reach your business goals.
Related reading:
This article was originally published in October 2022 and has since been updated with contributions from Cecilia Gillen. The most recent update was in September 2023.
Get productivity tips delivered straight to your inbox
We’ll email you 1-3 times per week—and never share your information.

Shea Stevens
Shea is a content writer currently living in Charlotte, North Carolina. After graduating with a degree in Marketing from East Carolina University, she joined the digital marketing industry focusing on content and social media. In her free time, you can find Shea visiting her local farmers market, attending a country music concert, or planning her next adventure.
- Data & analytics
- Small business

Data extraction is the process of taking actionable information from larger, less structured sources to be further refined or analyzed. Here's how to do it.
Related articles

How to start a successful side hustle

11 management styles, plus tips for applying each type
11 management styles, plus tips for applying...

Keep your company adaptable with automation

How to enrich lead data for personalized outreach
How to enrich lead data for personalized...
Improve your productivity automatically. Use Zapier to get your apps working together.

Generalized fused Lasso for grouped data in generalized linear models
- Original Paper
- Open access
- Published: 25 May 2024
- Volume 34 , article number 124 , ( 2024 )
Cite this article
You have full access to this open access article

- Mineaki Ohishi 1
1 Altmetric
Generalized fused Lasso (GFL) is a powerful method based on adjacent relationships or the network structure of data. It is used in a number of research areas, including clustering, discrete smoothing, and spatio-temporal analysis. When applying GFL, the specific optimization method used is an important issue. In generalized linear models, efficient algorithms based on the coordinate descent method have been developed for trend filtering under the binomial and Poisson distributions. However, to apply GFL to other distributions, such as the negative binomial distribution, which is used to deal with overdispersion in the Poisson distribution, or the gamma and inverse Gaussian distributions, which are used for positive continuous data, an algorithm for each individual distribution must be developed. To unify GFL for distributions in the exponential family, this paper proposes a coordinate descent algorithm for generalized linear models. To illustrate the method, a real data example of spatio-temporal analysis is provided.
Similar content being viewed by others

Coordinate descent algorithm of generalized fused Lasso logistic regression for multivariate trend filtering

Spatio-temporal clustering analysis using generalized lasso with an application to reveal the spread of Covid-19 cases in Japan

Assessing Spatial Stationarity and Segmenting Spatial Processes into Stationary Components
Avoid common mistakes on your manuscript.
1 Introduction
Assume we have grouped data such that \(y_{j 1}, \ldots , y_{j n_j}\) are observations of the j th group ( \(j \in \{ 1, \ldots , m \}\) ) for m groups. Further, assume the following generalized linear models (GLMs; Nelder and Wedderburn 1972 ) with canonical parameter \(\theta _{ji}\ (i \in \{ 1, \ldots , n_j \})\) and dispersion parameter \(\phi > 0\) :
where \(y_{j i}\) is independent with respect to j and i , \(a_{ji}\) is a constant defined by
\(a (\cdot ) > 0\) , \(b (\cdot )\) , and \(c (\cdot )\) are known functions, and \(b (\cdot )\) is differentiable.
The \(\theta _{ji}\) has the following structure:
where \(h (\cdot )\) is a known differentiable function, \(\beta _j\) is an unknown parameter, and \(q_{ji}\) is a known term called the offset, which is zero in many cases. Although \(\theta _{ji}\) depends not only on the group but also on the individual, the j th group is characterized by a common parameter \(\beta _j\) . We are thus interested in describing the relationship among the m groups. Here, the expectation of \(y_{ji}\) is given by
where \(\mu (\cdot )\) is a known function and \(\dot{b} (\cdot )\) is a derivative of \(b (\cdot )\) , i.e., \(\dot{b} (\theta ) = d b (\theta ) / d \theta \) . Furthermore, \(\mu ^{-1} (\cdot )\) is a link function, and \(h (\cdot )\) is an identify function, i.e., \(h (\eta ) = \eta \) , when \(\mu ^{-1} (\cdot )\) is a canonical link. Tables 1 , 2 , and 3 summarize the relationships between model ( 1 ) and each individual distribution. In this paper, we consider clustering for m groups or discrete smoothing via generalized fused Lasso (GFL; e.g., Höfling et al. 2010 ; Ohishi et al. 2021 ).
GFL is an extension of fused Lasso (Tibshirani et al. 2005 ) which can incorporate relationships among multiple variables, such as adjacent relationships and network structure, into parameter estimation. For example, Xin et al. ( 2014 ) applied GFL to the diagnosis of Alzheimer’s disease by expressing the structure of structural magnetic resonance images of human brains as a 3D grid graph; Ohishi et al. ( 2021 ) applied GFL to model spatial data based on geographical adjacency. Although the GFL in these particular instances is based on one factor (brain structure or a geographical relationship), it can deal with relationships based on multiple factors. For example, we can define an adjacent relationship for spatio-temporal cases based on two factors by combining geographical adjacency and the order of time. Yamamura et al. ( 2021 ), Ohishi et al. ( 2022 ), and Yamamura et al. ( 2023 ) dealt with multivariate trend filtering (e.g., Tibshirani 2014 ) based on multiple factors via GFL and applied it to the estimation of spatio-temporal trends. Yamamura et al. ( 2021 ) and Ohishi et al. ( 2022 ) used a logistic regression model, which coincides with model ( 1 ) when \(n_j = 1, q_{j i} = 0\ (\forall j \in \{ 1, \ldots , m \}; \forall i \in \{ 1, \ldots , n_j \})\) under a binomial distribution. Since this relationship holds by the reproductive property of the binomial distribution, their methods can also be applied to grouped data. Yamamura et al. ( 2023 ) used a Poisson regression model, which coincides with model ( 1 ) when \(n_j = 1\ (\forall j \in \{ 1, \ldots , m \})\) under a Poisson distribution. As is the case for Yamamura et al. ( 2021 ) and Ohishi et al. ( 2022 ), the method of Yamamura et al. ( 2023 ) can also be applied to grouped data from the reproductive property of the Poisson distribution. Yamamura et al. ( 2021 ), Ohishi et al. ( 2022 ) and Yamamura et al. ( 2023 ) proposed coordinate descent algorithms to obtain the GFL estimator. Although optimization problems for GLMs, such as logistic and Poisson regression models, are generally solved by linear approximation, Ohishi et al. ( 2022 ) and Yamamura et al. ( 2023 ) directly minimize coordinate-wise objective functions and derive update equations of a solution in closed form. Although Yamamura et al. ( 2021 ) minimized the coordinate-wise objective functions using linear approximation, Ohishi et al. ( 2022 ) showed numerically that direct minimization can provide the solution faster and more accurately than minimization using a linear approximation. Ohishi et al. ( 2021 ) also derived an explicit update equation for the coordinate descent algorithm, which corresponds to model ( 1 ) under the Gaussian distribution. As described, coordinate descent algorithms have been developed to produce GFL estimators for three specific distributions; however, none have been proposed for other distributions. For example, we have an option of using the negative binomial distribution to deal with overdispersion in the Poisson distribution (e.g., Gardner et al. 1995 ; Ver Hoef and Boveng 2007 ), or the gamma or inverse Gaussian distribution for positive continuous data. To apply GFL to these distributions, it is necessary to derive update equations for each distribution individually.
In this paper, we propose a coordinate descent algorithm to obtain GFL estimators for model ( 1 ) in order to unify the GFL approach for distributions in the exponential family. The negative log-likelihood function for model ( 1 ) is given by
We estimate parameter vector \({\varvec{\beta }}= (\beta _1, \ldots , \beta _m)'\) by minimizing the following function defined by removing terms that do not depend on \({\varvec{\beta }}\) from the above equation and by adding a GFL penalty:
where \(\lambda \) is a non-negative tuning parameter, \(D_j \subseteq \{ 1, \ldots , m \} \backslash \{ j \}\) is an index set expressing adjacent relationship among groups and satisfying \(\ell \in D_j \Leftrightarrow j \in D_\ell \) , and \(w_{j \ell }\) is a positive weight satisfying \(w_{j \ell } = w_{\ell j}\) . The GFL penalty shrinks the difference between two adjacent groups \(|\beta _j - \beta _\ell |\) and often gives a solution satisfying \(|\beta _j - \beta _\ell | = 0\ (\Leftrightarrow \beta _j = \beta _\ell )\) . That is, GFL can estimate some parameters to be exactly equal, thus enabling the clustering of m groups or the accomplishment of discrete smoothing. To obtain the GFL estimator for \({\varvec{\beta }}\) , we minimize the objective function ( 3 ) via a coordinate descent algorithm. As Ohishi et al. ( 2022 ) and Yamamura et al. ( 2023 ), we directly minimize coordinate-wise objective functions without the use of approximations. For ordinary situations, where a canonical link ( \(h (\eta ) = \eta \) ) is used and there is no offset ( \(q_{j i} = 0\) ), and for several other situations, the update equation of a solution can be derived in closed form.
Table 4 summarizes relationships between an individual distribution and an update equation. Here, \(\bigcirc \) indicates that the update equation can be obtained in closed form, and \(\times \) indicates that it cannot. Even when the update equation cannot be obtained in closed form, the proposed method can specify an interval that includes the solution, which means we can easily obtain the solution by a simple numerical search. Note that the proposed method is provided via R package GFLglm (Ohishi 2024 ). The dataset used in a real data example is available via GFLglm .
As a related work, Tang and Song ( 2016 ) proposed a regression coefficients clustering via fused Lasso approach, namely FLARCC. In this study, regression coefficients are estimated by minimizing a negative log-likelihood function with fused Lasso type penalty. However, our GFL approach in ( 3 ) shrinks and estimates parameters based on adjacent relationship, while FLARCC restricts pairs of two parameters used in the penalty based on the order of initial parameter values. Hence, FLARCC cannot be applied to minimize ( 3 ) and differs from our purpose. However, when using the complete graph structure as an adjacent relationship in ( 3 ), although the two objective functions of FLARCC and our method are different, their purposes are equivalent in terms of clustering without any constraint. Devriendt et al. ( 2021 ) proposed an algorithm based on a proximal gradient method for multi-type penalized sparse regression, namely SMuRF algorithm, which can be applied to minimize ( 3 ). As demonstrated in Ohishi et al. ( 2022 ), since the proximal gradient method involves an approximation of an objective function, its minimization procedure may be inefficient. That is, we can expect that our algorithm, which minimizes the objective function directly, can provide the solution faster and more accurately than SMuRF algorithm. Furthermore, Choi and Lee ( 2019 ) showed a serious phenomenon in fused Lasso approach for binomial distribution: a fusion phenomenon among parameters does not occur. It is possible for such a phenomenon to occur for modeling of a discrete response, such as logistic regression and Poisson regression. However, although our framework includes the situation that the phenomenon occurs as a special case, there is no practical concern.
The remainder of the paper is organized as follows: In Sect. 2 , we give an overview of coordinate descent algorithm and derive the objective functions for each step. In Sect. 3 , we discuss coordinate-wise minimization of the coordinate descent algorithm and derive update equations in closed form in many cases. In Sect. 4 , we evaluate the performance of the proposed method via numerical simulation. In Sect. 5 , we provide a real data example. Section 6 concludes the paper. Technical details are given in the Appendix.
2 Preliminaries
As in Ohishi et al. ( 2022 ) and Yamamura et al. ( 2023 ), we minimize the objective function ( 3 ) using a coordinate descent algorithm. Algorithm 1 gives an overview of the algorithm.

Overview of the coordinate descent algorithm
The descent cycle updates the parameters separately, and several parameters are often updated to be exactly equal. If several parameters are exactly equal, their updates can become stuck. To avoid this, the fusion cycle simultaneously updates equal parameters (see Friedman et al. 2007 ). In each cycle of the coordinate descent, the following function is essentially minimized:
where \(a_i\) and \(w_\ell \) are positive constants and \(z_\ell \ (\ell = 1, \ldots , r)\) are constants satisfying \(z_1< \cdots < z_{r}\) . The minimization of f ( x ) is described in Sect. 3 , and the following subsections show that an objective function in each cycle is essentially equal to f ( x ).
2.1 Descent cycle
The descent cycle repeats coordinate-wise minimizations of the objective function \(L ({\varvec{\beta }})\) in ( 3 ). To obtain a coordinate-wise objective function, we extract terms that depend on \(\beta _j\ (j \in \{ 1, \ldots , m \})\) from \(L ({\varvec{\beta }})\) . As described in Ohishi et al. ( 2021 ), the penalty term can be decomposed as
Then, only the first term depends on \(\beta _j\) . By regarding terms that do not depend on \(\beta _j\) as constants and removing them from \(L ({\varvec{\beta }})\) , the coordinate-wise objective function is obtained as
where \(\hat{\beta }_\ell \) indicates \(\beta _\ell \) is given. By sorting elements of \(D_j\) in increasing order of \(\hat{\beta }_\ell \ (\forall \ell \in D_j)\) , we can see that \(L_j (\beta )\) essentially equals f ( x ) in ( 4 ). If there exist \(\ell _1, \ell _2 \in D_j\ (\ell _1 \ne \ell _2)\) such that \(\hat{\beta }_{\ell _1} = \hat{\beta }_{\ell _2}\) , we can temporarily redefine \(D_j\) and \(w_{j \ell }\) as
Since GFL estimates several parameters as being equal, this redefinition is required in most updates.
2.2 Fusion cycle
In the fusion cycle, equal parameters are replaced by a common parameter and \(L ({\varvec{\beta }})\) is minimized with respect to the common parameter. Let \(\hat{\beta }_1, \ldots , \hat{\beta }_m\) be current solutions for \(\beta _1, \ldots , \beta _m\) , and \(\hat{\xi }_1, \ldots , \hat{\xi }_t\ (t < m)\) be their distinct values. The relationship among the current solutions and their distinct values is specified as
That is, the following statements are true:
Then, the \(\beta _j\ (\forall j \in E_k)\) are replaced by a common parameter \(\xi _k\) and \(L ({\varvec{\beta }})\) is minimized with respect to \(\xi _k\) . Hence, to obtain a coordinate-wise objective function, we extract terms that depend on \(\xi _k\ (k = 1, \ldots , t)\) from \(L ({\varvec{\beta }})\) .
We can decompose the first term of \(L ({\varvec{\beta }})\) as
Furthermore, as Ohishi et al. ( 2021 ), the penalty term of \(L ({\varvec{\beta }})\) can be decomposed as
By regarding terms that do not depend on \(\xi _k\) as constants and removing them from \(L ({\varvec{\beta }})\) , the coordinate-wise objective function is obtained as
As in the descent cycle, we can see that \(L_k^*(\xi )\) essentially equals f ( x ) in ( 4 ).
3 Main results
In this section, to obtain update equations for the descent and fusion cycles of the coordinate descent algorithm, we describe the minimization of f ( x ) in ( 4 ). Following Ohishi et al. ( 2022 ) and Yamamura et al. ( 2023 ), we directly minimize f ( x ). One of the difficulties of the minimization of f ( x ) is that f ( x ) has multiple non-differentiable points \(z_1, \ldots , z_r\) . We cope with this difficulty by using a subdifferential. The subdifferential of f ( x ) at \(\tilde{x} \in \mathbb {R}\) is given by
where \(g_- (x)\) and \(g_+ (x)\) are left and right derivatives defined by
Then, \(\tilde{x}\) is a stationary point of f ( x ) if \(0 \in \partial f (\tilde{x})\) . For details of a subdifferential, see, e.g., Rockafellar ( 1970 ), Parts V and VI. In the following subsections, we separately describe the minimization of f ( x ) in cases where a canonical link and a general link are used.
3.1 Canonical link
We first describe the minimization of f ( x ) in ( 4 ) with a canonical link, i.e., \(h (\eta ) = \eta \) . That is, the update equation of the coordinate descent algorithm is given by minimizing the following function:
Notice that f ( x ) in ( 7 ) is strictly convex. Hence, \(\tilde{x}\) is the minimizer of f ( x ) if and only if \(0 \in \partial f (\tilde{x})\) . First, based on this relationship, we derive the condition that f ( x ) attains the minimum at a non-differentiable point \(z_\ell \) .
The subdifferential of f ( x ) at \(z_\ell \) is given by
Hence, if there exists \(\ell _\star \in \{ 1, \ldots , r \}\) such that \(0 \in \partial f (z_{\ell _\star })\) , f ( x ) attains the minimum at \(x = z_{\ell _\star }\) and \(\ell _\star \) uniquely exists because of the strict convexity of f ( x ).
On the other hand, when \(\ell _\star \) does not exist, we can specify an interval that includes the minimizer by checking the signs of the left and right derivatives at each non-differentiable point. Let \(s (x) = (\textrm{sign}(g_- (x)), \textrm{sign}(g_+ (x)))\) . From \(z_1< \cdots < z_r\) and the strict convexity of f ( x ), we have
Then, the minimizer of f ( x ) exists in the following interval:
Hence, it is sufficient to search for the minimizer in \(R_*\) . For all \(x \in R_*\) , the following equation holds:
This result allows us to rewrite the penalty term in f ( x ) as
Hence, f ( x ) is rewritten in non-absolute form as
The f ( x ) is differentiable when \(x \in R_*\) and its derivative is given by
Then, the solution \(x_*\) of \(d f (x) / d x = 0\) is the minimizer of f ( x ). Hence, we have the following theorem.
Let \(\hat{x}\) be the minimizer of f ( x ) in ( 7 ). Then, \(\hat{x}\) is given by
where \(\ell _*\) exists if and only if \(\ell _\star \) does not exist.
We can execute Algorithm 1 by applying Theorem 1 to ( 5 ) and ( 6 ) in the descent and fusion cycles, respectively. Thus, a detailed implementation of Algorithm 1 when using a canonical link is provided in Algorithm 2.

The coordinate descent algorithm for a canonical link
To apply Theorem 1 , we need to obtain \(x_*\) . In many cases, \(x_*\) can be obtained in closed form according to the following proposition.
Proposition 2
Let \(x_*\) be the solution of \(d f (x) / d x = 0\) and \(q_0\) be a value such that \(q_1 = \cdots = q_d = q_0\) . Then, \(x_*\) is given as follows:
When \(q_0\) exists, \(x_*\) is given in a general form as
Even when \(q_0\) does not exist, \(x_*\) for the Gaussian distribution is given by
and \(x_*\) for the Poisson distribution is given by
For example, \(q_0\) exists and \(q_0 = 0\) holds for GLMs without an offset. When \(q_0\) does not exist, \(x_*\) can be obtained for each distribution. For the Gaussian and Poisson distributions, since \(\mu (x + q)\) can be divided with respect to x and q , \(x_*\) can be obtained in closed form. Note that \(x_*\) for a Gaussian distribution when \(q_0\) exists and equals 0 coincides with the result in Ohishi et al. ( 2021 ). For distributions for which such a decomposition is impossible, such as the binomial distribution, a numerical search is required to obtain \(x_*\) . However, we can easily obtain \(x_*\) by a simple algorithm, such as a line search, because f ( x ) is strictly convex and has its minimizer in the interval \(R_*\) . Moreover, when \(x_*\) can be obtained in closed form as in Proposition 2 , the minimization of f ( x ) requires the computational complexity of \(O (r (d + r))\) .
3.2 General link
Here, we consider the minimization of f ( x ) in ( 4 ) with a general link, i.e., \(h (\cdot )\) is a generally differentiable function. Then, although strict convexity of f ( x ) is not guaranteed, its continuity is maintained. This means the uniqueness of the minimizer of f ( x ) is not guaranteed, but we can obtain minimizer candidates by using the same procedure as in the previous subsection.
where \(\dot{h} (x) = d h (x) / d x\) . Since \(z_\ell \) satisfying \(0 \in \partial f (z_\ell )\) is a stationary point of f ( x ), such points are minimizer candidates of f ( x ). Next, we define intervals as \(R_\ell = (z_\ell , z_{\ell +1})\ (\ell = 0, 1, \ldots , r)\) . For \(x \in R_\ell \) , f ( x ) can be written in non-absolute form as
We can then search for minimizer candidates of f ( x ) by piecewise minimization. That is, \(x \in R_\ell \) minimizing \(f_\ell (x)\) is a minimizer candidate. Hence, we have the following theorem.
Let \(\hat{x}\) be the minimizer of f ( x ) in ( 4 ) and define a set \(\mathcal {S}\) by

Now, suppose that
where \(\dot{f}_\ell (x) = d f_\ell (x) / dx\) . Then, \(\mathcal {S}\) is the set of minimizer candidates of f ( x ) and \(\hat{x}\) is given by
The assumption ( 8 ) excludes the case in which f ( x ) attains the minimum at \(x = \pm \infty \) . Moreover, we have the following corollary (the proof is given in Appendix A).
Corollary 4
Suppose that for all \(\ell \in \{ 0, 1, \ldots , r \}\) ,
is true, and that ( 8 ) holds. Then, f ( x ) is strictly convex and \(\# (\mathcal {S}) = 1\) , where \(\mathcal {S}\) is given in Theorem 3 . Moreover, the unique element of \(\mathcal {S}\) is the minimizer of f ( x ) and is given as in Theorem 1 .
To execute Algorithm 1 for GLMs with a general link, we can replace Theorem 1 with Theorem 3 or Corollary 4 in Algorithm 2. The next subsection gives specific examples of using a general link.
3.2.1 Examples
This subsection focuses on the negative binomial, gamma, and inverse Gaussian distributions with a log-link as examples of using a general link. In the framework of regression, the negative binomial distribution is often used to deal with overdispersion in Poisson regression, making it natural to use a log-link. Note that NB-C and NB2 indicate negative binomial regression with canonical and log-links, respectively (for details, see, e.g., Hilbe 2011 ). The gamma and inverse Gaussian distributions are used to model positive continuous data. Their expectations must be positive. However, their canonical links do not guarantee that their expectations will, in fact, be positive. Hence, a log-link rather than a canonical link is often used for these distributions (e.g., Algamal 2018 ; Dunn and Smyth 2018 , Chap. 11). Here, we consider coordinate-wise minimizations for the three distributions with a log-link.
For \(x \in R_\ell \) , f ( x ) in ( 4 ) and its first- and second-order derivatives are given by
Inverse Gaussian:

We can see that \(\ddot{f}_\ell (x) > 0\) holds for all \(\ell \in \{ 0, 1, \ldots , r \}\) , for NB2 and the gamma distribution. Hence, the minimizers of f ( x ) can be uniquely obtained from Corollary 4 . On the other hand, the uniqueness of the minimizer for the inverse Gaussian distribution is not guaranteed; however, we have \(v_0 < 0\) , \(v_r > 0\) , and
This implies \(x< \min \{\log (u_1 / u_2), z_1 \} \Rightarrow \dot{f}_0 (x) < 0\) and \(x> \max \{ \log (u_1 / u_2), z_r \} \Rightarrow \dot{f}_r (x) > 0\) . Hence, the minimizer for the inverse Gaussian distribution can be obtained by Theorem 3 .
We now give specific solutions. From above, we have the following proposition.
Proposition 5
Let \(\tilde{x}_\ell \) be a stationary point of \(f_\ell (x)\) . If \(\tilde{x}_\ell \) exists, it is given by
NB2 only when \(\exists q_0\ s.t.\ q_1 = \cdots = q_d = q_0\) :
Moreover, a relationship between \(\tilde{x}_\ell \) and the minimizer of f ( x ) is given by
NB2 and Gamma:
3.3 Some comments regarding implementation
3.3.1 dispersion parameter estimation.
In the previous subsections, we discussed the estimation of \(\beta _j\) which corresponds to the estimation of the canonical parameter \(\theta _{ji}\) . The GLMs in ( 1 ) also have dispersion parameter \(\phi \) . Although \(\phi \) is fixed at one for the binomial and Poisson distributions, it is unknown for other distributions, and, hence, we need to estimate the value of \(\phi \) . The Pearson estimator is often used as a suitable estimator (e.g., Dunn and Smyth 2018 , Chap. 6). Let \(\hat{\beta }_1, \ldots , \hat{\beta }_m\) be estimators of \(\beta _1, \ldots , \beta _m\) , t be the number of distinct values of them, and \(\hat{\zeta }_{ji} = \mu (\hat{\beta }_j + q_{ji})\) . Then, the Pearson estimator of \(\phi \) is given by
where \(V (\cdot )\) is a variance function (see Table 2 ). For distributions other than the negative binomial distribution, the estimator of \(\phi \) can be obtained after \({\varvec{\beta }}\) is estimated since the estimation of \({\varvec{\beta }}\) does not depend on \(\phi \) . For the negative binomial distribution, the estimation of \({\varvec{\beta }}\) depends on \(\phi \) because \(\mu (\cdot )\) and \(b (\cdot )\) depend on \(\phi \) . Hence, we need to add a step updating \(\phi \) and repeat updates of \({\varvec{\beta }}\) and \(\phi \) alternately. Moreover, this Pearson estimator is used for the diagnosis of overdispersion in the binomial and Poisson distributions. If \(\hat{\phi } > 1\) , it is doubtful that the model is appropriate.
3.3.2 Penalty weights
The objective function \(L ({\varvec{\beta }})\) in ( 3 ) includes penalty weights, and the GFL estimation proceeds with the given weights. Although setting \(w_{j \ell } = 1\) is usual, this may cause a problem of over-shrinkage because all pairs of parameters are shrunk uniformly by the common \(\lambda \) . As one option to avoid this problem, we can use the following weight based on adaptive-Lasso (Zou 2006 ):
where \(\tilde{\beta }_j\) is an estimator of \(\beta _j\) and the maximum likelihood estimator (MLE) may be a reasonable choice for it. If there exists \(q_{j 0}\) such that \(q_{j1} = \cdots = q_{j n_j} = q_{j 0}\) , the MLE is given in the following closed form:
For other cases, see Appendix B.
3.3.3 Tuning parameter selection
It is important for a penalized estimation, such as GFL estimation, to select a tuning parameter, which, in this paper, is represented as \(\lambda \) in ( 3 ). Because \(\lambda \) adjusts the strength of the penalty against a model fitting, we need to select a good value of \(\lambda \) in order to obtain a good estimator. The optimal value of \(\lambda \) is commonly selected from candidates based on the minimization of, e.g., cross-validation and a model selection criterion. For a given \(\lambda _{\max }\) , candidates for \(\lambda \) are selected from the interval \([0, \lambda _{\max }]\) . Following Ohishi et al. ( 2021 ), \(\lambda _{\max }\) is defined by a value such that all \(\beta _j\ (j \in \{ 1, \ldots , m \})\) are updated as \(\hat{\beta }_{\max }\) when a current solution of \({\varvec{\beta }}\) is \(\hat{{\varvec{\beta }}}_{\max } = \hat{\beta }_{\max } {\varvec{1}}_m\) , where \(\hat{{\varvec{\beta }}}_{\max }\) is the MLE under \({\varvec{\beta }}= \beta {\varvec{1}}_m\) (see Appendix B) and \({\varvec{1}}_m\) is the m -dimensional vector of ones. When a current solution of \({\varvec{\beta }}\) is \(\hat{{\varvec{\beta }}}_{\max }\) , the discussion in Sect. 3.2 gives the condition that \(\beta _j\) is updated as \(\hat{\beta }_{\max }\) as
Hence, \(\lambda _{\max }\) is given by
3.3.4 Extension
In this paper, we proposed the algorithm for the model ( 1 ) with the structure ( 2 ), which means the model does not have any explanatory variables. However, the proposed method can also be applied to the model with explanatory variables by simple modifications.
Let \({\varvec{x}}_{ji}\) and \({\varvec{\beta }}_j\) be p -dimensional vectors of explanatory variables and regression coefficients, respectively. We rewrite \(\eta _{ji}\) in ( 2 ) as
Focusing on the k th ( \(k \in \{ 1, \ldots , p \}\) ) explanatory variable, we have
where \(x_{jil}\) and \(\beta _{jl}\) are the l th elements of \({\varvec{x}}_{ji}\) and \({\varvec{\beta }}_j\) , respectively. The coordinate descent method updates each \(\beta _{jk}\) by regarding \(\tilde{q}_{jik}\) as a constant. Thus, in each cycle of the coordinate descent for GFL problem with explanatory variables, the following function is essentially minimized:
where \(z_{0i}\) is a constant. Hence, we can search \(z_\ell \ (\ell \in \{ 1, \ldots , r \})\) satisfying \(0 \in \partial f (z_\ell )\) by the similarly procedure. On the other hand, we can obtain the explicit minimizer of \(f_\ell (x)\ (x \in R_\ell )\) for only Gaussian distribution and cannot obtain it for other distributions because \(\mu (\cdot )\) is not separable with respect to the product. However, the minimizer can also be easily searched here.
4 Simulation
In this section, we focus on modeling using count data and establish whether our proposed method can select the true cluster from the clustering of groups through simulation. For count data, Poisson regression and NB2 are often used. Hence, we compare the performance of the two approaches for various settings of the dispersion parameter. Note that GFL for Poisson regression has already been proposed by Yamamura et al. ( 2023 ) and that our contribution is to apply GFL to NB2. Note, too, that simulation studies were not conducted in Yamamura et al. ( 2023 ). Moreover, both of R packages metafuse and smurf (e.g., Tang et al. 2016 ; Reynkens et al. 2023 ), which implement FLARCC and SMuRF algorithm, respectively, can deal with Poisson regression but cannot deal with NB2.
Let \(m^*\) be the number of true clusters and \(E_k^*\subset \{ 1, \ldots , m \}\ (k \in \{ 1, \ldots , m^*\})\) be an index set specifying groups in the k th true cluster. Then, we generate simulation data from
We consider four cases of m and \(m^*\) as \((m, m^*) = (10, 3), (10, 6), (20, 6), (20, 12)\) , and use the same settings as Ohishi et al. ( 2021 ) for adjacent relationships of m groups and true clusters (see Figs. 1 and 2 ).

Adjacent relationship and true clusters when \(m = 10\)

Adjacent relationship and true clusters when \(m = 20\)
The sample sizes for each group are common, i.e., \(n_1 = \cdots = n_m = n_0\) . Furthermore, the estimation of \(\phi \) , the definition of the penalty weights, and the candidates for \(\lambda \) follow Sect. 3.3 , and the optimal value of \(\lambda \) is selected based on the minimization of BIC (Schwarz 1978 ) from 100 candidates. Here, the simulation studies are conducted based on Monte Carlo simulation with 1,000 iterations.
4.1 Comparison with existing methods
Before comparing the performances of Poisson regression and NB2, we compare our proposed method with the two existing methods: FLARCC and SMuRF algorithm, for Poisson regression (i.e., \(\phi = 0\) ). As described in Sect. 1 , although FLARCC differs from our purpose, they are equivalent when using the complete graph structure as adjacent relationship. Hence, we use the complete graph structure at the comparison with FLARCC. On the other hand, SMuRF algorithm can be applied to minimize ( 3 ). Thus, we compare the minimum value of the objective function and runtime under given \(\lambda \) .
Table 5 summarizes the results of the comparison with FLARCC, in which SP is the selection probability (%) of the true cluster, and time is runtime (in seconds). We can see that the SP values for both methods approach 100% as \(n_0\) increases. Moreover, FLARCC is always better than the proposed method in terms of SP. We can consider that this result is reasonable. In the proposed method, there are many choices of clustering patterns and each group has \(m-1\) choices. On the other hand, each group has only two choices at most in FLARCC because of the restriction. It would be natural to consider that a wrong fusion is hard to occur if choices get fewer. To support this suggestion, the MLE has an important role. In FLARCC, the MLE is used to restrict fusion patterns. On the other hand, in the proposed method, the MLE is used for penalty weights and the penalty weights contribute to identify whether two parameters are equal. If the restriction in FLARCC is correct, penalty weights in the proposed method would also perform well. In such a situation, we can consider that FLARCC which has fewer choices performs better. If the restriction in FLARCC is wrong, penalty weights in the proposed method would not also perform well. In such a situation, we can consider that the proposed method which has more choices is easier to make a wrong fusion. Since the MLE becomes stable as n increases, the difference between the two methods becomes small as \(n_0\) increases. Hence, if the purpose is clustering without any adjacency, using FLARCC is better. However, recall that the proposed method is proposed to minimize the objective function ( 3 ). FLARCC cannot be applied to minimize the objective function. Moreover, FLARCC requires a reparameterization for its estimation process and hence, it also requires to transform the estimation results to obtain the estimation results for the original form. This may be the reason why FLARCC is slower than the proposed method.
Table 6 summarizes the results of the comparison with SMuRF algorithm, in which difR, win, and time are defined by
respectively, and \(\lambda _j = \tau _j \lambda _{\max }\) , where \(\tau _1 = 1/100\) , \(\tau _2 = 1/10\) , \(\tau _3 = 1/2\) , and \(L_1^\star \) and \(L_2^\star \) are the minimum values of the objective function ( 3 ) by the proposed method and SMuRF algorithm, respectively. We can see that the difR value is always positive, the win value is 100% in most cases and even the minimum value is around 70%. This means that the proposed method better minimized the objective function than SMuRF algorithm. Notice that the actual difR value is very small since the displayed value is multiplied by 1,000. That is, the difference between the two minimum values is not large very well. The difR value also tell us that the difference becomes larger as \(\lambda \) increases and becomes smaller as n increases. Moreover, the time value shows that the proposed method was faster than SMuRF algorithm in most cases. Hence, we found that the proposed method can minimize the objective function faster and more accurately than SMuRF algorithm.
4.2 Poisson vs. NB2
In this subsection, we show the comparison of Poisson regression and NB2. Tables 7 and 8 summarize the results for \(m = 10, 20\) , respectively, in which SP is the selection probability (%) of the true cluster, \(\hat{\phi }\) is the Pearson estimator of \(\phi \) , and time is runtime (in seconds). Table 9 summarizes standard errors of \(\hat{\phi }\) . First, focusing on \(\phi =0\) , i.e., the true model according to the Poisson distribution, the value of SP using Poisson regression approaches 100% as \(n_0\) increases. Furthermore, we can say that Poisson regression provides good estimation since \(\hat{\phi }\) is approximately 1. On the other hand, NB2 is unable to select the true cluster. The reason for this may be that the dispersion parameter in the negative binomial distribution is positive. Moreover, standard error values tell us that the estimation of Poisson regression is more stable than that of NB2. Next, we focus on \(\phi > 0\) . Here, Poisson regression produced overdispersion since \(\hat{\phi }\) is larger than 1, and, hence, it is unable to select the true cluster. On the other hand, the SP value for NB2 approaches 100% as \(n_0\) increases. Furthermore, \(\hat{\phi }\) is roughly the true value, indicating that NB2 can provide good estimation. Standard error values are also evidence for the goodness of NB2. Finally, it is apparent that Poisson regression is always faster than NB2. The reason for this may be that Poisson regression requires only the estimation of \({\varvec{\beta }}\) , whereas NB2 requires repeatedly estimating \({\varvec{\beta }}\) and \(\phi \) alternately. We can conclude from this simulation that Poisson regression is better when the true model is according to a Poisson distribution and that NB2 can effectively deal with overdispersion in Poisson regression.
5 Real data example
In this section, we apply our method to the estimation of spatio-temporal trend using real crime data. The data consist of the number of recognized crimes committed in the Tokyo area as collected by the Metropolitan Police Department, available at TOKYO OPEN DATA ( https://portal.data.metro.tokyo.lg.jp/ ). Footnote 1 Although these data were aggregated for each chou-chou (level 4), the finest regional division, we integrate the data for each chou-oaza (level 3) and apply our method by regarding level 3 as individuals and the city (level 2) as the group (see Fig. 3 ).

Divisions of Tokyo
There are 53 groups as a division of space, and spatial adjacency is defined by the regional relationships of level 2. We use six years of data, from 2017 to 2022. The sample size is \(n = 9{,}570\) . Temporal adjacency is defined using a chain graph for the six time points. According to Yamamura et al. ( 2021 ), we can define adjacent spatio-temporal relationships for \(m = 318\ (= 53 \times 6)\) groups by combining spatial and temporal adjacencies. Furthermore, following Yamamura et al. ( 2023 ), we use population as a variable for the offset. The population data were obtained from the results of the population census, as provided in e-Stat ( https://www.e-stat.go.jp/en ). Since the population census is conducted every five years, we use the population in 2015 for the crimes in 2017 to 2019 and the population in 2020 for the crimes in 2020 to 2022.
In this analysis, we apply our method to the above crime data, with \(n = 9{,}570\) individuals aggregated into \(m = 318\) groups, and estimate the spatio-temporal trends in the data. Specifically, \(y_{ji}\) , the number of crimes in the i th region of the j th group, is modeled based on the Poisson and negative binomial distributions, respectively, as
where \(q_{j i}\) is a logarithm transformation of the population and canonical and log-links are used, respectively. Estimation of the dispersion parameter, the setting of penalty weights, and the candidates for the tuning parameter follow Sect. 3.3 . The optimal tuning parameter is selected from 100 candidates based on the minimization of BIC. Table 10 summarizes the estimation results.
The \(\hat{\phi }\) indicates the Pearson estimator of the dispersion parameter. Since the value of \(\hat{\phi }\) in the Poisson regression is far larger than 1, there is overdispersion, and we can say that using Poisson regression is inappropriate. To cope with this overdispersion, we adopted NB2. The cluster value in the table indicates the number of clusters using GFL. Poisson regression and NB2 clustered the \(m = 318\) groups into 160 and 109 groups, respectively. Figure 4 is a yearly choropleth map of the GFL estimates of \({\varvec{\beta }}\) using NB2. The map shows that the larger the value, the easier it is for crime to occur, and that the smaller the value, the harder it is. As in this figure, we can visualize the variation of trend with respect to time and space.

GFL estimates of \({\varvec{\beta }}\) by NB2
6 Conclusion
To unify models based on a variety of distributions, we proposed a coordinate descent algorithm to obtain GFL estimators for GLMs. Although Yamamura et al. ( 2021 ), Ohishi et al. ( 2022 ), and Yamamura et al. ( 2023 ) dealt with GFL for the binomial and Poisson distributions, our method is more general, covering both these distributions and others. The proposed method repeats the partial update of parameters and directly solves sub-problems without any approximations of the objective function. In many cases, the solution can be updated in closed form. Indeed, in the ordinary situation where a canonical link is used and there is no offset, we can always update the solution in closed form. Moreover, even when an explicit update is impossible, we can easily update the solution using a simple numerical search since the interval containing the solution can be specified. Hence, our algorithm can efficiently search the solution. In simulation studies, it was demonstrated by a computational time that the proposed method is efficient.
Data availibility
Data are available at https://portal.data.metro.tokyo.lg.jp/ and https://www.e-stat.go.jp/en .
We arranged and used the following production: Tokyo Metropolitan Government & Metropolitan Police Department. The number of recognized cases by region, crime type, and method (yearly total; in Japanese), https://creativecommons.org/licenses/by/4.0/deed.en .
Algamal, Z.Y.: Developing a ridge estimator for the gamma regression model. J. Chemom. 32 , 3054 (2018). https://doi.org/10.1002/cem.3054
Article Google Scholar
Choi, H., Lee, S.: Convex clustering for binary data. Adv. Data Anal. Classif. 13 , 991–1018 (2019). https://doi.org/10.1007/s11634-018-0350-1
Article MathSciNet Google Scholar
Devriendt, S., Antonio, K., Reynkens, T., Verbelen, R.: Sparse regression with multi-type regularized feature modeling. Insur. Math. Econ. 96 , 248–261 (2021). https://doi.org/10.1016/j.insmatheco.2020.11.010
Dunn, P.K., Smyth, G.K.: Generalized Linear Models With Examples in R. Springer, New York (2018)
Book Google Scholar
Friedman, J., Hastie, T., Höfling, H., Tibshirani, R.: Pathwise coordinate optimization. Ann. Appl. Stat. 1 , 302–332 (2007). https://doi.org/10.1214/07-AOAS131
Gardner, W., Mulvey, E.P., Shaw, E.C.: Regression analyses of counts and rates: Poisson, overdispersed Poisson, and negative binomial models. Psychol. Bull. 118 , 392–404 (1995). https://doi.org/10.1037/0033-2909.118.3.392
Hilbe, J.M.: Negative Binomial Regression, 2nd edn. Cambridge University Press, Cambridge (2011)
Höfling, H., Binder, H., Schumacher, M.: A coordinate-wise optimization algorithm for the fused Lasso. arXiv:1011.6409v1 (2010)
Nelder, J.A., Wedderburn, R.W.M.: Generalized linear models. J. R. Stat. Soc. Ser. A 135 , 370–384 (1972). https://doi.org/10.2307/2344614
Ohishi, M.: GFLglm: Generalized Fused Lasso for Grouped Data in Generalized Linear Models (2024). R package version 0.1.0. https://github.com/ohishim/GFLglm
Ohishi, M., Fukui, K., Okamura, K., Itoh, Y., Yanagihara, H.: Coordinate optimization for generalized fused Lasso. Comm. Stat. Theory Methods 50 , 5955–5973 (2021). https://doi.org/10.1080/03610926.2021.1931888
Ohishi, M., Yamamura, M., Yanagihara, H.: Coordinate descent algorithm of generalized fused Lasso logistic regression for multivariate trend filtering. Jpn. J. Stat. Data Sci. 5 , 535–551 (2022). https://doi.org/10.1007/s42081-022-00162-2
Reynkens, T., Devriendt, S., Antonio, K.: Smurf: Sparse Multi-Type Regularized Feature Modeling (2023). R package version 1.1.5. https://CRAN.R-project.org/package=smurf
Rockafellar, R.T.: Convex Analysis. Princeton University Press, New Jersey (1970)
Schwarz, G.: Estimating the dimension of a model. Ann. Stat. 6 , 461–464 (1978). https://doi.org/10.1214/aos/1176344136
Tang, L., Song, P.X.K.: Fused Lasso approach in regression coefficients clustering—learning parameter heterogeneity in data integration. J. Mach. Learn. Res. 17 , 1–23 (2016)
Tang, L., Zhou, L., Song, P.X.K.: Metafuse: Fused Lasso Approach in Regression Coefficient Clustering (2016). R package version 2.0-1. https://CRAN.R-project.org/package=metafuse
Tibshirani, R.J.: Adaptive piecewise polynomial estimation via trend filtering. Ann. Stat. 42 , 285–323 (2014). https://doi.org/10.1214/13-AOS1189
Tibshirani, R., Saunders, M., Rosset, S., Zhu, J., Knight, K.: Sparsity and smoothness via the fused Lasso. J. R. Stat. Soc. Ser. B. Stat. Methodol. 67 , 91–108 (2005). https://doi.org/10.1111/j.1467-9868.2005.00490.x
Ver Hoef, J.M., Boveng, P.L.: Quasi-Poisson vs. negative binomial regression: How should we model overdispersed count data? Ecology 88 , 2766–2772 (2007). https://doi.org/10.1890/07-0043.1
Xin, B., Kawahara, Y., Wang, Y., Gao, W.: Efficient generalized fused Lasso and its application to the diagnosis of Alzheimer’s disease. In: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, pp. 2163–2169. AAAI Press, California (2014)
Yamamura, M., Ohishi, M., Yanagihara, H.: Spatio-temporal adaptive fused Lasso for proportion data. In: Czarnowski, I., Howlett, R.J., Jain, L.C. (eds.) Intelligent Decision Technologies, pp. 479–489. Springer, Singapore (2021). https://doi.org/10.1007/978-981-16-2765-1_40
Chapter Google Scholar
Yamamura, M., Ohishi, M., Yanagihara, H.: Spatio-temporal analysis of rates derived from count data using generalized fused Lasso. In: Czarnowski, I., Howlett, R.J., Jain, L.C. (eds.) Intelligent Decision Technologies, pp. 225–234. Springer, Singapore (2023). https://doi.org/10.1007/978-981-99-2969-6_20
Zou, H.: The adaptive Lasso and its oracle properties. J. Am. Stat. Assoc. 101 , 1418–1429 (2006). https://doi.org/10.1198/016214506000000735
Download references
Acknowledgements
The author thanks Prof. Hirokazu Yanagihara of Hiroshima University for his many helpful comments and FORTE Science Communications ( https://www.forte-science.co.jp/ ) for English language editing of the first draft. Moreover, the author also thanks the associate editor and the two reviewers for their valuable comments. Furthermore, this work was partially supported by JSPS KAKENHI Grant Number JP20H04151, JP21K13834, JSPS Bilateral Program Grant Number JPJSBP120219927, and ISM Cooperative Research Program (2023-ISMCRP-4105).
Author information
Authors and affiliations.
Center for Data-Driven Science and Artificial Intelligence, Tohoku University, Kawauchi 41, Aoba-ku, Sendai, Miyagi, 980-8576, Japan
Mineaki Ohishi
You can also search for this author in PubMed Google Scholar
Contributions
M.O. contributed the whole paper.
Corresponding author
Correspondence to Mineaki Ohishi .
Ethics declarations
Conflict of interest.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Proof of Corollary 4
Suppose that for all \(\ell \in \{ 0, 1, \ldots , r \}\) , the statement
is true and that ( 8 ) holds. Then, \(\dot{f}_\ell (x)\) is strictly increasing on \(R_\ell \) and hence, \(f_\ell (x)\) is strictly convex. Moreover, for all \(\ell \in \{ 1, \ldots , r \}\) , there is the following relationship among a derivative and one-sided derivatives:
This fact and ( 8 ) imply the strict convexity of f ( x ) on \(\mathbb {R}\) and hence, the minimizer uniquely exists.
Appendix B: Derivation of MLEs
We first describe the derivation of the MLE of \(\beta _j\) . For distributions with a convex likelihood function, the MLE is obtained by solving
In Tables 2 and 3 , all distributions, with the exception of the inverse Gaussian distribution with log-link, have convexity. The MLE of \(\beta _j\) is given in closed form in the following cases:
\(q_{j1} = \cdots = q_{j n_j} = q_{j0}\) :
Poisson or Gamma with log-link:
Other distributions, including the inverse Gaussian distribution with log-link, require a numerical search. Furthermore, the negative binomial distribution requires the repeated updating of \({\varvec{\beta }}\) and \(\phi \) alternately.
Next, we describe the derivation of \(\beta _{\max }\) . The \(\beta _{\max }\) is the MLE of \(\beta \) under \({\varvec{\beta }}= \beta {\varvec{1}}_m\) , and for distributions with a convex likelihood function, its value is obtained by solving
Notice that this is essentially equal to the derivation of the MLE of \(\beta _j\) . Hence, \(\beta _{\max }\) is given in closed form in the following cases:
\(q_{j i} = q_0\ (\forall j, i)\) :
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Ohishi, M. Generalized fused Lasso for grouped data in generalized linear models. Stat Comput 34 , 124 (2024). https://doi.org/10.1007/s11222-024-10433-5
Download citation
Received : 12 February 2024
Accepted : 21 April 2024
Published : 25 May 2024
DOI : https://doi.org/10.1007/s11222-024-10433-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Grouped data
- Coordinate descent algorithm
- Generalized fused Lasso
- Generalized linear models
- Multivariate trend filtering
- Find a journal
- Publish with us
- Track your research
- Skip to content
- Skip to search
- Skip to footer
Products, Solutions, and Services
Want some help finding the Cisco products that fit your needs? You're in the right place. If you want troubleshooting help, documentation, other support, or downloads, visit our technical support area .
Contact Cisco
- Get a call from Sales
Call Sales:
- 1-800-553-6387
- US/CAN | 5am-5pm PT
- Product / Technical Support
- Training & Certification
Products by technology

- Software-defined networking
- Cisco Silicon One
- Cloud and network management
- Interfaces and modules
- Optical networking
- See all Networking

Wireless and Mobility
- Access points
- Outdoor and industrial access points
- Controllers
- See all Wireless and Mobility

- Secure Firewall
- Secure Endpoint
- Secure Email
- Secure Access
- Multicloud Defense
- See all Security

Collaboration
- Collaboration endpoints
- Conferencing
- Cisco Contact Center
- Unified communications
- Experience Management
- See all Collaboration

Data Center
- Servers: Cisco Unified Computing System
- Cloud Networking
- Hyperconverged infrastructure
- Storage networking
- See all Data Center

- Nexus Dashboard Insights
- Network analytics
- Cisco Secure Network Analytics (Stealthwatch)

- Video endpoints
- Cisco Vision
- See all Video

Internet of Things (IoT)
- Industrial Networking
- Industrial Routers and Gateways
- Industrial Security
- Industrial Switching
- Industrial Wireless
- Industrial Connectivity Management
- Extended Enterprise
- Data Management
- See all industrial IoT

- Cisco+ (as-a-service)
- Cisco buying programs
- Cisco Nexus Dashboard
- Cisco Networking Software
- Cisco DNA Software for Wireless
- Cisco DNA Software for Switching
- Cisco DNA Software for SD-WAN and Routing
- Cisco Intersight for Compute and Cloud
- Cisco ONE for Data Center Compute and Cloud
- See all Software
- Product index
Products by business type

Service providers

Small business

Midsize business
Cisco can provide your organization with solutions for everything from networking and data center to collaboration and security. Find the options best suited to your business needs.
- By technology
- By industry
- See all solutions
CX Services
Cisco and our partners can help you transform with less risk and effort while making sure your technology delivers tangible business value.
- See all services
Design Zone: Cisco design guides by category
Data center
- See all Cisco design guides
End-of-sale and end-of-life
- End-of-sale and end-of-life products
- End-of-Life Policy
- Cisco Commerce Build & Price
- Cisco Software Central
- Cisco Feature Navigator
- See all product tools
- Cisco Mobile Apps
- Design Zone: Cisco design guides
- Cisco DevNet
- Marketplace Solutions Catalog
- Product approvals
- Product identification standard
- Product warranties
- Cisco Security Advisories
- Security Vulnerability Policy
- Visio stencils
- Local Resellers
- Technical Support
Earth Sciences Research Journal
Analytic hierarchy process-fuzzy comprehensive evaluation method-based depletion assessment study of xinshan iron ore mine, evaluación del agotamiento de mena en la mina de hierro de xinshan con base al proceso de análisis jerárquico y la evaluación integral difusa.
- Chentao Sun School of Land and Resource Engineering, Kunming University of Science and Technology.
- Kepeng Hou School of Land and Resource Engineering, Kunming University of Science and Technology
- Shining Wang School of Nursing, Kunming Medical University, China
- Shanguang Qian School of Land and Resource Engineering, Kunming University of Science and Technology
How to Cite
- Abstract (en)
- Abstract (es)
Taking the Xinshan iron ore mine as an example, this paper, based on collecting and analyzing the actual production data and similar simulation test data of this iron ore mine, analyses various factors affecting ore depletion by bottomless column segmental chipping method by using hierarchical analysis method (AHP) and fuzzy comprehensive evaluation method (FCE), and establishes an evaluation system for comprehensively assessing the depletion of the ores. The results show that structural parameters, blasting parameters, loading parameters, and geological conditions are the main factors affecting ore depletion. The structural parameters are the most important factors, accounting for 35%. With the increase of the released amount, the released grade gradually decreases, the depletion rate gradually increases, and the comprehensive evaluation value gradually decreases. The released body is an approximate ellipsoidal block with a wide upper and narrower lower part. The end wall plays an obstructive role in the flow of the bulk body, which makes the end of the released grade higher and the middle of the released body higher. At the same time, due to the influence of blasting and shovel loading, the particles in the release body show some sorting phenomena. This paper provides a scientific basis and reference for predicting and controlling ore depletion in the bottomless column segmental chipping method.
Con la mina de hierro de Xinshan como un ejemplo y con el fin de recolectar y analizar la producción de información y los datos de prueba de simulaciones similares en esta mina, este trabajo analiza varios factores que afectan el agotamiento de la mena a través del método de astillado segmentario de pilar sin base por el Proceso de Análisis Jerárquico (del ingles AHP, Analytic Hierarchy Process) y por la Evaluación Integral Difusa (del inglés FCE, Fuzzy Evaluation Method, y establece un sistema de evaluación para medir ampliamente el agotamiento del recurso. Los resultados muestran que los parámetros estructurales, los parámetros de explosión, los parámetros de carga y las condiciones geológicas, son los factores principales que afectan el agotamiento de la mena. Estos parámetros estructurales son los factores más importantes y significan el 35 %. Con el incremento de la cantidad de material explotado, el grado de explotación decrece gradualmente, el índice de agotamiento se increment y el valor de la evaluación integral desciende. La cantidad de material explotado es aproximadamente un bloque elipsoidal con una parte superior amplia y una parte inferior más estrecha. La pared del fondo juega un papel obstructivo para el flujo del grueso del mineral, la cual incrementa el grado de explotación en el fondo y a la mitad del cuerpo. Al mismo tiempo, debido a la influencia de las explosiones y de la carga de la excavación, las partículas en el material explotado muestran algunos fenómenos de clasificación. Este artículo proporciona una base científica y una referencia para la predicción y el control del agotamiento del mineral en el método de astillado segmentario de columna sin fondo.
Brady, S. R. (2015). Utilizing and Adapting the Delphi Method for Use in Qualitative Research. International Journal of Qualitative Methods. https://doi.org/10.1177/1609406915621381
Chen, L. (2006). Research on physical modelling test technique and its application in geotechnical engineering (in Chinese). [Dissertation School of Academy of Sciences (Wuhan Institute of Geotechnics)].
Chen, W. W. (2019). Exploring the evaluation method of high-value medical consumables management software selection based on AHP and FCE (in Chinese). Medical and Health Equipment, 40(10), 85-89.
Chen, C., Zhang, X., Chen, J., Chen, F., Li, J., Chen, Y., Hou, H., & Shi, F. (2020). Assessment of site contaminated soil remediation based on an input output life cycle assessment. Journal of Cleaner Production, 263, 121422. https://doi.org/10.1016/j.jclepro.2020.121422
Dai, L. L., & Li, J. (2016). Study on the quality of private university education based on analytic hierarchy process and fuzzy comprehensive evaluation method. Journal of Intelligent & Fuzzy Systems, 31(4), 2241-2247. DOI: 10.3233/JIFS-169064
Dai, H. L. (2019). Research on the performance appraisal system of college administrators based on AHP and FCE (in Chinese). Journal of Ningbo Engineering College, 31(3), 87-93.
Feng, Q., & Sun, T. (2020). Comprehensive evaluation of benefits from environmental investment: take China as an example. Environmental Science and Pollution Research International, 27(13), 15292-15304. https://doi.org/10.1007/s11356-020-08033-7
Guo, J., Zhang, Z., & Sun, Q. (2008). Research and application of hierarchical analysis (in Chinese). Chinese Journal of Safety Science, 18(5), 148-153.
Han, L., Mei, Q., & Lu, Y. (2004). Analysis and research of AHP-fuzzy comprehensive evaluation method (in Chinese). Chinese Journal of Safety Science, 14(7), 86-89.
Jin, A., Sun, H., Meng, X., Gao, Y., Wu, Q., & Zhang, G. (2017). Study on the chipping step distance under different ore release methods of bottomless column segmental chipping method (in Chinese). Journal of Central South University (Natural Science Edition), 48(11), 3037-3043.
Luan, L., Qi, Z., & Kou, Y. (2020). Optimisation of tailing sand dewatering scheme based on AHP-FCE[J] (in Chinese). Mining Research and Development, 40(3), 150-154.
Peykani, P., Mohammadi, E., Saen, R. F., Sadjadi, S. J., & Rostamy-Malkhalifeh, M. (2020). Data envelopment analysis and robust optimization: A review. Expert Systems, 37(4), e12534. https://doi.org/10.1111/exsy.12534
Sun, W., Wang, J. L., Feng, C. M., Cao, P., & Han, W. (2013). Weighting of Performance Index by Analytic Hierarchy Process for Water Supply Enterprises. Applied Mechanics and Materials, 409-410, 1004-1007. https://doi.org/10.4028/www.scientific.net/AMM.409-410.1004
Wang, J., Guo, J., & Lian, X. (2005). A comparative study of two improved grey correlation analysis methods (in Chinese). Journal of North China Electric Power University, 32(6), 72-76.
Wang, Q., Ren, F. Y., & Gu, X. W. (1988). Mining science (in Chinese). Beijing: Metallurgical Industry Press, 1-18.
Wu, A., Wu W. C., Liu, X., Sun, X., Zhou, Y., Yin, S. (2012). Research on structural parameters of bottomless column segmental collapse method (in Chinese). Journal of Central South University (Natural Science Edition), 43(5), 1845-1850.
Xiong, D., & Xian, X. (2003). Improvement of fuzzy comprehensive evaluation method (in Chinese). Journal of Chongqing University (Natural Science Edition), 26(6), 93-95. DOI: 10.11835/j.issn.1000-582X.2003.06.026
Yang, G., Chen, Y., & Wang, X. (2017). Optimisation study of structural parameters of bottomless pillar segmental avalanche method in Maanshan 2~# ore body (in Chinese). Mining and Metallurgical Engineering, 37(02), 24-27.
Yang, J. X, & Wang, R. S. (1998). Review and Prospect of Life Cycle Assessment (in Chinese). Advances in Environmental Science, 6(2), 21-28.
Yu, H., & Zhang, K. (2014). The application of grey relational analysis model in the performance evaluation of agricultural product logistics companies. Applied Mechanics and Materials, 687-691, 5165-5168. https://doi.org/10.4028/www.scientific.net/AMM.687-691.5165
Yu, H., Chen, Y., Wu, Q., Zhang, L., Zhang, Z., Zhang, J., Miljković, M., & Oeser, M. (2020). Decision support for selecting optimal method of recycling waste tire rubber into wax-based warm mix asphalt based on fuzzy comprehensive evaluation. Journal of Cleaner Production, 265, 121781. https://doi.org/10.1016/j.jclepro.2020.121781
Zeng, W. (2020). Research on the theory of end release of bottomless column segmental chipping method and its application (in Chinese). [Dissertation Wuhan University of Science and Technology].
Zhang, D., Liu, H., & Xia, X. (2016). Evaluation of rural tourism service quality based on AHP-FCE model: taking Wuhan Dayuwan as an example (in Chinese). Anhui Agricultural Science, 44(27), 179-183.
Zhang, Y., & Fan, Q. (2020). The Application of the Fuzzy Analytic Hierarchy Process in the Assessment and Improvement of the Human Settlement Environment. Sustainability, 12(4), 1563. https://doi.org/10.3390/su12041563
Zhang, R. F. (2023). An investigation on the application of fuzzy mathematics in the evaluation of soil heavy metal pollution (in Chinese). Environmental Engineering, 41(04), 237.
Zhou, J., Chen, C., Wang, M., & Khandelwal, M. (2021). Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. International Journal of Mining Science and Technology, 31(5), 799-812. https://doi.org/10.1016/j.ijmst.2021.07.011
Download Citation
- Endnote/Zotero/Mendeley (RIS)
CrossRef Cited-by
Article abstract page views

This work is licensed under a Creative Commons Attribution 4.0 International License .
Earth Sciences Research Journal holds a Creative Commons Attribution license.
You are free to:
Share — copy and redistribute the material in any medium or format Adapt — remix, transform, and build upon the material for any purpose, even commercially. The licensor cannot revoke these freedoms as long as you follow the license terms.

Scimago Journal & Country Rank (SJR)
Indexed and registered.
Earth Sciences Research Journal - Universidad Nacional de Colombia (Sede Bogotá). Facultad de Ciencias. Departamento de Geociencias
Editor: Alexander Caneva Correo electrónico: [email protected]
ISSN impreso: 1794-6190 ISSN línea: 2339-3459 DOI: 10.15446/esrj

Indexada en:

IMAGES
VIDEO
COMMENTS
This article is a practical introduction to statistical analysis for students and researchers. We'll walk you through the steps using two research examples. The first investigates a potential cause-and-effect relationship, while the second investigates a potential correlation between variables. Example: Causal research question.
This article is a practical guide to conducting data analysis in general literature reviews. The general literature review is a synthesis and analysis of published research on a relevant clinical issue, and is a common format for academic theses at the bachelor's and master's levels in nursing, physiotherapy, occupational therapy, public health and other related fields.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
It is important to know w hat kind of data you are planning to collect or analyse as this w ill. affect your analysis method. A 12 step approach to quantitative data analysis. Step 1: Start with ...
For many researchers unfamiliar with qualitative research, determining how to conduct qualitative analyses is often quite challenging. Part of this challenge is due to the seemingly limitless approaches that a qualitative researcher might leverage, as well as simply learning to think like a qualitative researcher when analyzing data. From framework analysis (Ritchie & Spencer, 1994) to content ...
Data analysis techniques in research are essential because they allow researchers to derive meaningful insights from data sets to support their hypotheses or research objectives.. Data Analysis Techniques in Research: While various groups, institutions, and professionals may have diverse approaches to data analysis, a universal definition captures its essence.
18 2 Practical Data Analysis: An Example. Fig. 2.1 A histogram for the distribution of the value of attribute age using 8 bins. Fig. 2.2 A histogram for the distribution of the value of attribute ...
QDA Method #3: Discourse Analysis. Discourse is simply a fancy word for written or spoken language or debate. So, discourse analysis is all about analysing language within its social context. In other words, analysing language - such as a conversation, a speech, etc - within the culture and society it takes place.
Examples of distractions include: - Extra sentences, overly formal or flowery prose, or at the oth er extreme overly casual or overly ... The data analysis report isn't quite like a research paper or term paper in a class, nor like aresearch article in a journal. It is meant, primarily, to start an organized conversation between you and ...
Abstract. Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility.
Written by Coursera Staff • Updated on Apr 19, 2024. Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock ...
Discover data analysis techniques, methods, and approaches, and study examples of data analysis in research papers. Updated: 11/21/2023 Table of Contents
Abstract. Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise ...
For those interested in conducting qualitative research, previous articles in this Research Primer series have provided information on the design and analysis of such studies. 2, 3 Information in the current article is divided into 3 main sections: an overview of terms and concepts used in data analysis, a review of common methods used to ...
Data analysis is simply the process of converting the gathered data to meanin gf ul information. Different techniques such as modeling to reach trends, relatio nships, and therefore conclusions to ...
The aim of this paper is to equip readers with an understanding of the principles of qualitative data analysis and offer a practical example of how analysis might be undertaken in an interview-based study. Qualitative research is a generic term that refers to a group of methods, and ways of collecting and analysing data that are interpretative or explanatory in nature and focus on meaning.
Step 2: Obtain data from a representative sample. Once you have used an appropriate sampling procedure when conducting statistical analysis, you can extend your conclusions beyond your sample. Probability sampling involves selecting participants at random from the population to conduct a study. In non-probability sampling, some members of a ...
Data analysis is the process of examining, filtering, adapting, and modeling data to help solve problems. Data analysis helps determine what is and isn't working, so you can make the changes needed to achieve your business goals. Keep in mind that data analysis includes analyzing both quantitative data (e.g., profits and sales) and qualitative ...
To complete this study properly, it is necessary to analyse the data collected in order to test the hypothesis and answer the research questions. As already indicated in the preceding chapter, data is interpreted in a descriptive form. This chapter comprises the analysis, presentation and interpretation of the findings resulting from this study.
Generalized fused Lasso (GFL) is a powerful method based on adjacent relationships or the network structure of data. It is used in a number of research areas, including clustering, discrete smoothing, and spatio-temporal analysis. When applying GFL, the specific optimization method used is an important issue. In generalized linear models, efficient algorithms based on the coordinate descent ...
The final section contains sample papers generated by undergraduates illustrating three major forms of quantitative research - primary data collection, secondary data analysis, and content analysis.
Cisco+ (as-a-service) Cisco buying programs. Cisco Nexus Dashboard. Cisco Networking Software. Cisco DNA Software for Wireless. Cisco DNA Software for Switching. Cisco DNA Software for SD-WAN and Routing. Cisco Intersight for Compute and Cloud. Cisco ONE for Data Center Compute and Cloud.
Taking the Xinshan iron ore mine as an example, this paper, based on collecting and analyzing the actual production data and similar simulation test data of this iron ore mine, analyses various factors affecting ore depletion by bottomless column segmental chipping method by using hierarchical analysis method (AHP) and fuzzy comprehensive evaluation method (FCE), and establishes an evaluation ...
In October each year, the Mid-Year Trends report is released to provide updated figures and analysis for the initial six months of the current year (from 1 January to 30 June). These figures are preliminary, and the final data is included in the subsequent Global Trends report released in June of the following year.