

Document Analysis - How to Analyze Text Data for Research

Introduction
What is document analysis, where is document analysis used, how to perform document analysis, what is text analysis, atlas.ti as text analysis software.
In qualitative research , you can collect primary data through surveys , observations , or interviews , to name a few examples. In addition, you can rely on document analysis when the data already exists in secondary sources like books, public reports, or other archival records that are relevant to your research inquiry.
In this article, we will look at the role of document analysis, the relationship between document analysis and text analysis, and how text analysis software like ATLAS.ti can help you conduct qualitative research.

Document analysis is a systematic procedure used in qualitative research to review and interpret the information embedded in written materials. These materials, often referred to as “documents,” can encompass a wide range of physical and digital sources, such as newspapers, diaries, letters, policy documents, contracts, reports, transcripts, and many others.
At its core, document analysis involves critically examining these sources to gather insightful data and understand the context in which they were created. Research can perform sentiment analysis , text mining, and text categorization, to name a few methods. The goal is not just to derive facts from the documents, but also to understand the underlying nuances, motivations, and perspectives that they represent. For instance, a historical researcher may examine old letters not just to get a chronological account of events, but also to understand the emotions, beliefs, and values of people during that era.
Benefits of document analysis
There are several advantages to using document analysis in research:
- Authenticity : Since documents are typically created for purposes other than research, they can offer an unobtrusive and genuine insight into the topic at hand, without the potential biases introduced by direct observation or interviews.
- Availability : Documents, especially those in the public domain, are widely accessible, making it easier for researchers to source information.
- Cost-effectiveness : As these documents already exist, researchers can save time and resources compared to other data collection methods.
However, document analysis is not without challenges. One must ensure the documents are authentic and reliable. Furthermore, the researcher must be adept at discerning between objective facts and subjective interpretations present in the document.
Document analysis is a versatile method in qualitative research that offers a lens into the intricate layers of meaning, context, and perspective found within textual materials. Through careful and systematic examination, it unveils the richness and depth of the information housed in documents, providing a unique dimension to research findings.

Document analysis is employed in a myriad of sectors, serving various purposes to generate actionable insights. Whether it's understanding customer sentiments or gleaning insights from historical records, this method offers valuable information. Here are some examples of how document analysis is applied.
Analyzing surveys and their responses
A common use of document analysis in the business world revolves around customer surveys . These surveys are designed to collect data on the customer experience, seeking to understand how products or services meet or fall short of customer expectations.
By analyzing customer survey responses , companies can identify areas of improvement, gauge satisfaction levels, and make informed decisions to enhance the customer experience. Even if customer service teams designed a survey for a specific purpose, text analytics of the responses can focus on different angles to gather insights for new research questions.
Examining customer feedback through social media posts
In today's digital age, social media is a goldmine of customer feedback. Customers frequently share their experiences, both positive and negative, on platforms like Twitter, Facebook, and Instagram.
Through document analysis of social media posts, companies can get a real-time pulse of their customer sentiments. This not only helps in immediate issue resolution but also in shaping product or service strategies to align with customer preferences.
Interpreting customer support tickets
Another rich source of data is customer support tickets. These tickets often contain detailed descriptions of issues faced by customers, their frustrations, or sometimes their appreciation for assistance received.
By employing document analysis on these tickets, businesses can detect patterns, identify recurring issues, and work towards streamlining their support processes. This ensures a smoother and more satisfying customer experience.
Historical research and social studies
Beyond the world of business, document analysis plays a pivotal role in historical and social research. Scholars analyze old manuscripts, letters, and other archival materials to construct a narrative of past events, cultures, and civilizations.
As a result, document analysis is an ideal method for historical research since generating new data is less feasible than turning to existing sources for analysis. Researchers can not only examine historical narratives but also how those narratives were constructed in their own time.

Turn to ATLAS.ti for your data analysis needs
Try out our powerful data analysis tools with a free trial to make the most out of your data today.
Performing document analysis is a structured process that ensures researchers can derive meaningful, qualitative insights by organizing source material into structured data . Here's a brief outline of the process:
- Define the research question
- Choose relevant documents
- Prepare and organize the documents
- Begin initial review and coding
- Analyze and interpret the data
- Present findings and draw conclusions
The process in detail
Before diving into the documents, it's crucial to have a clear research question or objective. This serves as the foundation for the entire analysis and guides the selection and review of documents. A well-defined question will focus the research, ensuring that the document analysis is targeted and relevant.
The next step is to identify and select documents that align with the research question. It's vital to ensure that these documents are credible, reliable, and pertinent to the research inquiry. The chosen materials can vary from official reports, personal diaries, to digital resources like social media data , depending on the nature of the research.
Once the documents are selected, they need to be organized in a manner that facilitates smooth analysis. This could mean categorizing documents by themes, chronology, or source types. Digital tools and data analysis software , such as ATLAS.ti, can assist in this phase, making the organization more efficient and helping researchers locate specific data when needed.

With everything in place, the researcher starts an initial review of the documents. During this phase, the emphasis is on identifying patterns, themes, or specific information relevant to the research question.
Coding involves assigning labels or tags to sections of the text to categorize the information. This step is iterative, and codes can be refined as the researcher delves deeper.
After coding, interesting patterns across codes can be analyzed. Here, researchers seek to draw meaningful connections between codes, identify overarching themes, and interpret the data in the context of the research question .
This is where the hidden insights and deeper understanding emerge, as researchers juxtapose various pieces of information and infer meaning from them.
Finally, after the intensive process of document analysis, the researcher consolidates their findings, crafting a narrative or report that presents the results. This might also involve visual representations like charts or graphs, especially when demonstrating patterns or trends.
Drawing conclusions involves synthesizing the insights gained from the analysis and offering answers or perspectives in relation to the original research question.
Ultimately, document analysis is a meticulous and iterative procedure. But with a clear plan and systematic approach, it becomes a potent tool in the researcher's arsenal, allowing them to uncover profound insights from textual data.

Text analysis, often referenced alongside document analysis, is a method that focuses on extracting meaningful information from textual data. While document analysis revolves around reviewing and interpreting data from various sources, text analysis hones in on the intricate details within these documents, enabling a deeper understanding. Both these methods are vital in fields such as linguistics, literature, social sciences, and business analytics.
In the context of document analysis, text analysis emerges as a nuanced exploration of the textual content. After documents have been sourced, be it from books, articles, social networks, or any other medium, they undergo a preprocessing phase. Here, irrelevant information is eliminated, errors are rectified, and the text may be translated or converted to ensure uniformity.
This cleaned text is then tokenized into smaller units like words or phrases, facilitating a granular review. Techniques specific to text analysis, such as topic modeling to determine discussed subjects or pattern recognition to identify trends, are applied.
The derived insights can be visualized using tools like graphs or charts, offering a clearer understanding of the content's depth. Interpretation follows, allowing researchers to draw actionable insights or theoretical conclusions based on both the broader document context and the specific text analysis.
Merging text analysis with document analysis presents unique challenges. With the proliferation of digital content, managing vast data sets becomes a significant hurdle. The inherent variability of language, laden with cultural nuances, idioms, and sometimes sarcasm, can make precise interpretation elusive.
Many text analysis tools exist that can facilitate the analytical process. ATLAS.ti offers a well-rounded, useful solution as a text analytics software . In this section, we'll highlight some of the tools that can help you conduct document analysis.
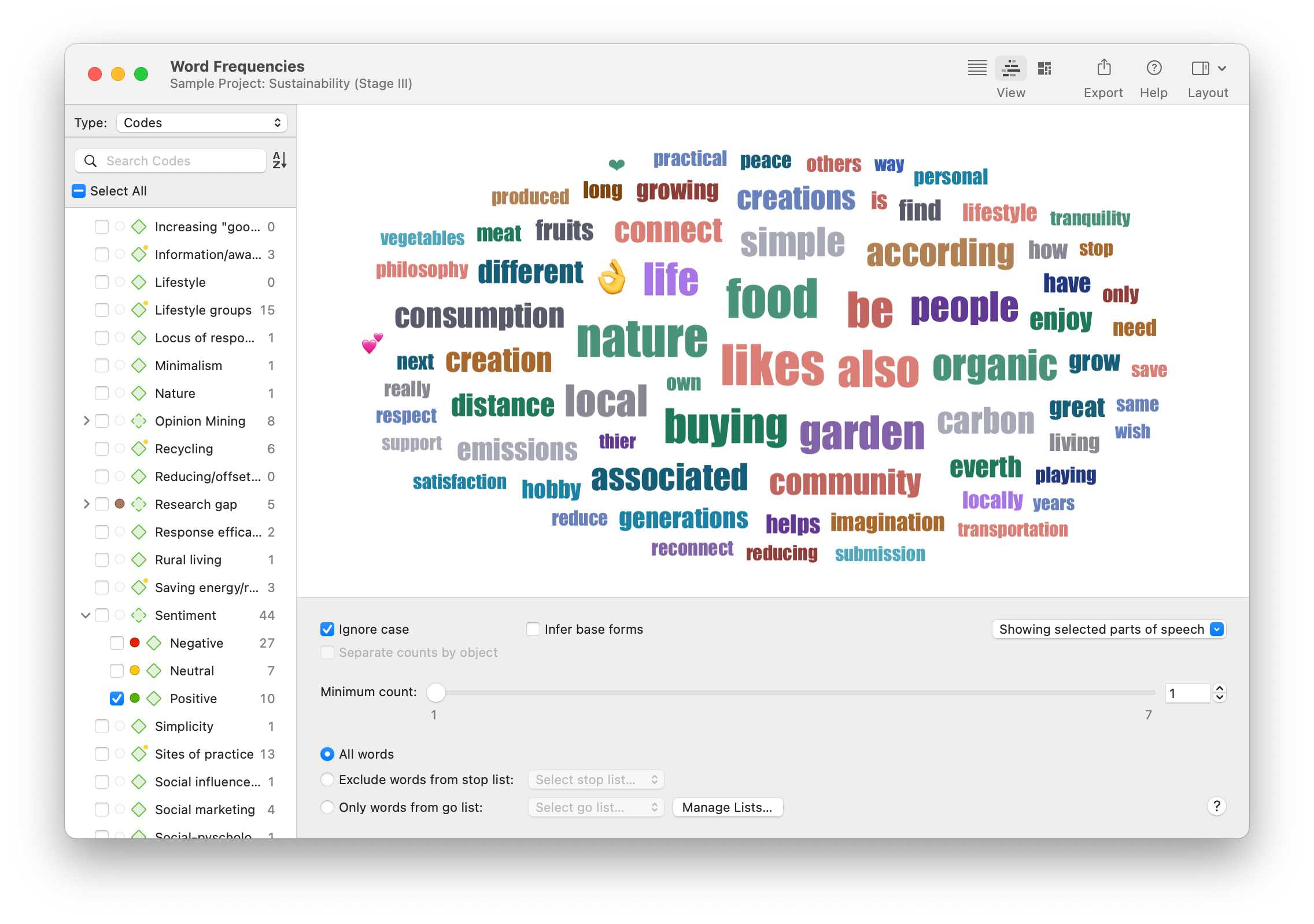
Word Frequencies
A word cloud can be a powerful text analytics tool to understand the nature of human language as it pertains to a particular context. Researchers can perform text mining on their unstructured text data to get a sense of what is being discussed. The Word Frequencies tool can also parse out specific parts of speech, facilitating more granular text extraction.
Sentiment Analysis
The Sentiment Analysis tool employs natural language processing (NLP) and machine learning to analyze text based on sentiment and facilitate natural language understanding. This is important for tasks such as, for example, analyzing customer reviews and assessing customer satisfaction, because you can quickly categorize large numbers of customer data records by their positive or negative sentiment.
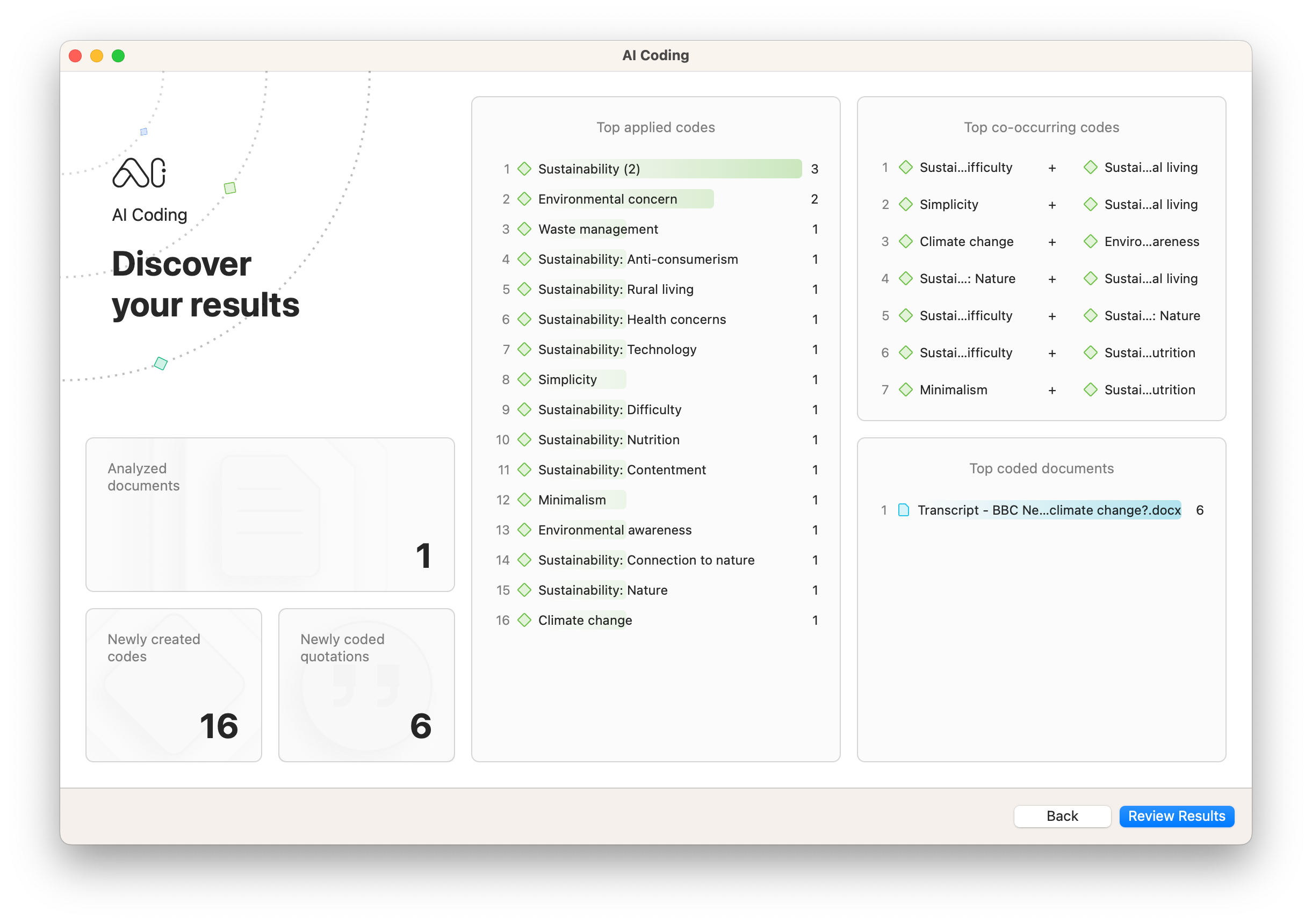
AI Coding relies on massive amounts of training data to interpret text and automatically code large amounts of qualitative data. Rather than read each and every document line by line, you can turn to AI Coding to process your data and devote time to the more essential tasks of analysis such as critical reflection and interpretation.
These text analytics tools can be a powerful complement to research. When you're conducting document analysis to understand the meaning of text, AI Coding can help with providing a code structure or organization of data that helps to identify deeper insights.
AI Summaries
Dealing with large numbers of discrete documents can be a daunting task if done manually, especially if each document in your data set is lengthy and complicated. Simplifying the meaning of documents down to their essential insights can help researchers identify patterns in the data.
AI Summaries fills this role by using natural language processing algorithms to simplify data to its salient points. Text generated by AI Summaries are stored in memos attached to documents to illustrate pathways to coding and analysis or to highlight how the data conveys meaning.
Take advantage of ATLAS.ti's analysis tools with a free trial
Let our powerful data analysis interface make the most out of your data. Download a free trial today.

- Privacy Policy
Home » Documentary Analysis – Methods, Applications and Examples
Documentary Analysis – Methods, Applications and Examples
Table of Contents

Documentary Analysis
Definition:
Documentary analysis, also referred to as document analysis , is a systematic procedure for reviewing or evaluating documents. This method involves a detailed review of the documents to extract themes or patterns relevant to the research topic .
Documents used in this type of analysis can include a wide variety of materials such as text (words) and images that have been recorded without a researcher’s intervention. The domain of document analysis, therefore, includes all kinds of texts – books, newspapers, letters, study reports, diaries, and more, as well as images like maps, photographs, and films.
Documentary analysis provides valuable insight and a unique perspective on the past, contextualizing the present and providing a baseline for future studies. It is also an essential tool in case studies and when direct observation or participant observation is not possible.
The process usually involves several steps:
- Sourcing : This involves identifying the document or source, its origin, and the context in which it was created.
- Contextualizing : This involves understanding the social, economic, political, and cultural circumstances during the time the document was created.
- Interrogating : This involves asking a series of questions to help understand the document better. For example, who is the author? What is the purpose of the document? Who is the intended audience?
- Making inferences : This involves understanding what the document says (either directly or indirectly) about the topic under study.
- Checking for reliability and validity : Just like other research methods, documentary analysis also involves checking for the validity and reliability of the documents being analyzed.
Documentary Analysis Methods
Documentary analysis as a qualitative research method involves a systematic process. Here are the main steps you would generally follow:
Defining the Research Question
Before you start any research , you need a clear and focused research question . This will guide your decision on what documents you need to analyze and what you’re looking for within them.
Selecting the Documents
Once you know what you’re looking for, you can start to select the relevant documents. These can be a wide range of materials – books, newspapers, letters, official reports, diaries, transcripts of speeches, archival materials, websites, social media posts, and more. They can be primary sources (directly from the time/place/person you are studying) or secondary sources (analyses created by others).
Reading and Interpreting the Documents
You need to closely read the selected documents to identify the themes and patterns that relate to your research question. This might involve content analysis (looking at what is explicitly stated) and discourse analysis (looking at what is implicitly stated or implied). You need to understand the context in which the document was created, the author’s purpose, and the audience’s perspective.
Coding and Categorizing the Data
After the initial reading, the data (text) can be broken down into smaller parts or “codes.” These codes can then be categorized based on their similarities and differences. This process of coding helps in organizing the data and identifying patterns or themes.
Analyzing the Data
Once the data is organized, it can be analyzed to make sense of it. This can involve comparing the data with existing theories, examining relationships between categories, or explaining the data in relation to the research question.
Validating the Findings
The researcher needs to ensure that the findings are accurate and credible. This might involve triangulating the data (comparing it with other sources or types of data), considering alternative explanations, or seeking feedback from others.
Reporting the Findings
The final step is to report the findings in a clear, structured way. This should include a description of the methods used, the findings, and the researcher’s interpretations and conclusions.
Applications of Documentary Analysis
Documentary analysis is widely used across a variety of fields and disciplines due to its flexible and comprehensive nature. Here are some specific applications:
Historical Research
Documentary analysis is a fundamental method in historical research. Historians use documents to reconstruct past events, understand historical contexts, and interpret the motivations and actions of historical figures. Documents analyzed may include personal letters, diaries, official records, newspaper articles, photographs, and more.
Social Science Research
Sociologists, anthropologists, and political scientists use documentary analysis to understand social phenomena, cultural practices, political events, and more. This might involve analyzing government policies, organizational records, media reports, social media posts, and other documents.
Legal Research
In law, documentary analysis is used in case analysis and statutory interpretation. Legal practitioners and scholars analyze court decisions, statutes, regulations, and other legal documents.
Business and Market Research
Companies often analyze documents to gather business intelligence, understand market trends, and make strategic decisions. This might involve analyzing competitor reports, industry news, market research studies, and more.
Media and Communication Studies
Scholars in these fields might analyze media content (e.g., news reports, advertisements, social media posts) to understand media narratives, public opinion, and communication practices.
Literary and Film Studies
In these fields, the “documents” might be novels, poems, films, or scripts. Scholars analyze these texts to interpret their meaning, understand their cultural context, and critique their form and content.
Educational Research
Educational researchers may analyze curricula, textbooks, lesson plans, and other educational documents to understand educational practices and policies.
Health Research
Health researchers may analyze medical records, health policies, clinical guidelines, and other documents to study health behaviors, healthcare delivery, and health outcomes.
Examples of Documentary Analysis
Some Examples of Documentary Analysis might be:
- Example 1 : A historian studying the causes of World War I might analyze diplomatic correspondence, government records, newspaper articles, and personal diaries from the period leading up to the war.
- Example 2 : A policy analyst trying to understand the impact of a new public health policy might analyze the policy document itself, as well as related government reports, statements from public health officials, and news media coverage of the policy.
- Example 3 : A market researcher studying consumer trends might analyze social media posts, customer reviews, industry reports, and news articles related to the market they’re studying.
- Example 4 : An education researcher might analyze curriculum documents, textbooks, and lesson plans to understand how a particular subject is being taught in schools. They might also analyze policy documents to understand the broader educational policy context.
- Example 5 : A criminologist studying hate crimes might analyze police reports, court records, news reports, and social media posts to understand patterns in hate crimes, as well as societal and institutional responses to them.
- Example 6 : A journalist writing a feature article on homelessness might analyze government reports on homelessness, policy documents related to housing and social services, news articles on homelessness, and social media posts from people experiencing homelessness.
- Example 7 : A literary critic studying a particular author might analyze their novels, letters, interviews, and reviews of their work to gain insight into their themes, writing style, influences, and reception.
When to use Documentary Analysis
Documentary analysis can be used in a variety of research contexts, including but not limited to:
- When direct access to research subjects is limited : If you are unable to conduct interviews or observations due to geographical, logistical, or ethical constraints, documentary analysis can provide an alternative source of data.
- When studying the past : Documents can provide a valuable window into historical events, cultures, and perspectives. This is particularly useful when the people involved in these events are no longer available for interviews or when physical evidence is lacking.
- When corroborating other sources of data : If you have collected data through interviews, surveys, or observations, analyzing documents can provide additional evidence to support or challenge your findings. This process of triangulation can enhance the validity of your research.
- When seeking to understand the context : Documents can provide background information that helps situate your research within a broader social, cultural, historical, or institutional context. This can be important for interpreting your other data and for making your research relevant to a wider audience.
- When the documents are the focus of the research : In some cases, the documents themselves might be the subject of your research. For example, you might be studying how a particular topic is represented in the media, how an author’s work has evolved over time, or how a government policy was developed.
- When resources are limited : Compared to methods like experiments or large-scale surveys, documentary analysis can often be conducted with relatively limited resources. It can be a particularly useful method for students, independent researchers, and others who are working with tight budgets.
- When providing an audit trail for future researchers : Documents provide a record of events, decisions, or conditions at specific points in time. They can serve as an audit trail for future researchers who want to understand the circumstances surrounding a particular event or period.
Purpose of Documentary Analysis
The purpose of documentary analysis in research can be multifold. Here are some key reasons why a researcher might choose to use this method:
- Understanding Context : Documents can provide rich contextual information about the period, environment, or culture under investigation. This can be especially useful for historical research, where the context is often key to understanding the events or trends being studied.
- Direct Source of Data : Documents can serve as primary sources of data. For instance, a letter from a historical figure can give unique insights into their thoughts, feelings, and motivations. A company’s annual report can offer firsthand information about its performance and strategy.
- Corroboration and Verification : Documentary analysis can be used to validate and cross-verify findings derived from other research methods. For example, if interviews suggest a particular outcome, relevant documents can be reviewed to confirm the accuracy of this finding.
- Substituting for Other Methods : When access to the field or subjects is not possible due to various constraints (geographical, logistical, or ethical), documentary analysis can serve as an alternative to methods like observation or interviews.
- Unobtrusive Method : Unlike some other research methods, documentary analysis doesn’t require interaction with subjects, and therefore doesn’t risk altering the behavior of those subjects.
- Longitudinal Analysis : Documents can be used to study change over time. For example, a researcher might analyze census data from multiple decades to study demographic changes.
- Providing Rich, Qualitative Data : Documents often provide qualitative data that can help researchers understand complex issues in depth. For example, a policy document might reveal not just the details of the policy, but also the underlying beliefs and attitudes that shaped it.
Advantages of Documentary Analysis
Documentary analysis offers several advantages as a research method:
- Unobtrusive : As a non-reactive method, documentary analysis does not require direct interaction with human subjects, which means that the research doesn’t affect or influence the subjects’ behavior.
- Rich Historical and Contextual Data : Documents can provide a wealth of historical and contextual information. They allow researchers to examine events and perspectives from the past, even from periods long before modern research methods were established.
- Efficiency and Accessibility : Many documents are readily accessible, especially with the proliferation of digital archives and databases. This accessibility can often make documentary analysis a more efficient method than others that require data collection from human subjects.
- Cost-Effective : Compared to other methods, documentary analysis can be relatively inexpensive. It generally requires fewer resources than conducting experiments, surveys, or fieldwork.
- Permanent Record : Documents provide a permanent record that can be reviewed multiple times. This allows for repeated analysis and verification of the data.
- Versatility : A wide variety of documents can be analyzed, from historical texts to contemporary digital content, providing flexibility and applicability to a broad range of research questions and fields.
- Ability to Cross-Verify (Triangulate) Data : Documentary analysis can be used alongside other methods as a means of triangulating data, thus adding validity and reliability to the research.
Limitations of Documentary Analysis
While documentary analysis offers several benefits as a research method, it also has its limitations. It’s important to keep these in mind when deciding to use documentary analysis and when interpreting your findings:
- Authenticity : Not all documents are genuine, and sometimes it can be challenging to verify the authenticity of a document, particularly for historical research.
- Bias and Subjectivity : All documents are products of their time and their authors. They may reflect personal, cultural, political, or institutional biases, and these biases can affect the information they contain and how it is presented.
- Incomplete or Missing Information : Documents may not provide all the information you need for your research. There may be gaps in the record, or crucial information may have been omitted, intentionally or unintentionally.
- Access and Availability : Not all documents are readily available for analysis. Some may be restricted due to privacy, confidentiality, or security considerations. Others may be difficult to locate or access, particularly historical documents that haven’t been digitized.
- Interpretation : Interpreting documents, particularly historical ones, can be challenging. You need to understand the context in which the document was created, including the social, cultural, political, and personal factors that might have influenced its content.
- Time-Consuming : While documentary analysis can be cost-effective, it can also be time-consuming, especially if you have a large number of documents to analyze or if the documents are lengthy or complex.
- Lack of Control Over Data : Unlike methods where the researcher collects the data themselves (e.g., through experiments or surveys), with documentary analysis, you have no control over what data is available. You are reliant on what others have chosen to record and preserve.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Narrative Analysis – Types, Methods and Examples

Multidimensional Scaling – Types, Formulas and...

Descriptive Statistics – Types, Methods and...

Discriminant Analysis – Methods, Types and...

Cluster Analysis – Types, Methods and Examples

Uniform Histogram – Purpose, Examples and Guide
To read this content please select one of the options below:
Please note you do not have access to teaching notes, document analysis as a qualitative research method.
Qualitative Research Journal
ISSN : 1443-9883
Article publication date: 3 August 2009
This article examines the function of documents as a data source in qualitative research and discusses document analysis procedure in the context of actual research experiences. Targeted to research novices, the article takes a nuts‐and‐bolts approach to document analysis. It describes the nature and forms of documents, outlines the advantages and limitations of document analysis, and offers specific examples of the use of documents in the research process. The application of document analysis to a grounded theory study is illustrated.
- Content analysis
- Grounded theory
- Thematic analysis
- Triangulation
Bowen, G.A. (2009), "Document Analysis as a Qualitative Research Method", Qualitative Research Journal , Vol. 9 No. 2, pp. 27-40. https://doi.org/10.3316/QRJ0902027
Emerald Group Publishing Limited
Copyright © 2009, Emerald Group Publishing Limited
Related articles
We’re listening — tell us what you think, something didn’t work….
Report bugs here
All feedback is valuable
Please share your general feedback
Join us on our journey
Platform update page.
Visit emeraldpublishing.com/platformupdate to discover the latest news and updates
Questions & More Information
Answers to the most commonly asked questions here
No products in the cart.
The Basics of Document Analysis

Document analysis is the process of reviewing or evaluating documents both printed and electronic in a methodical manner. The document analysis method, like many other qualitative research methods, involves examining and interpreting data to uncover meaning, gain understanding, and come to a conclusion.

What is Meant by Document Analysis?
Document analysis pertains to the process of interpreting documents for an assessment topic by the researcher as a means of giving voice and meaning. In Document Analysis as a Qualitative Research Method by Glenn A. Bowen , document analysis is described as, “... a systematic procedure for reviewing or evaluating documents—both printed and electronic (computer-based and Internet-transmitted) material. Like other analytical methods in qualitative research, document analysis requires that data be examined and interpreted in order to elicit meaning, gain understanding, and develop empirical knowledge.”
During the analysis of documents, the content is categorized into distinct themes, similar to the way transcripts from interviews or focus groups are analyzed. The documents may also be graded or scored using a rubric.
Document analysis is a social research method of great value, and it plays a crucial role in most triangulation methods, combining various methods to study a particular phenomenon.
>> View Webinar: How-To’s for Data Analysis
Documents fall into three main categories:
- Personal Documents: A personal account of an individual's beliefs, actions, and experiences. The following are examples: e-mails, calendars, scrapbooks, Facebook posts, incident reports, blogs, duty logs, newspapers, and reflections or journals.
- Public Records: Records of an organization's activities that are maintained continuously over time. These include mission statements, student transcripts, annual reports, student handbooks, policy manuals, syllabus, and strategic plans.
- Physical Evidence: Artifacts or items found within a study setting, also referred to as artifacts. Among these are posters, flyers, agendas, training materials, and handbooks.

The qualitative researcher generally makes use of two or more resources, each using a different data source and methodology, to achieve convergence and corroboration. An important purpose of triangulating evidence is to establish credibility through a convergence of evidence. Corroboration of findings across data sets reduces the possibility of bias, by examining data gathered in different ways.
It is important to note that document analysis differs from content analysis as content analysis refers to more than documents. As part of their definition for content analysis, Columbia Mailman School of Public Health states that, “Sources of data could be from interviews, open-ended questions, field research notes, conversations, or literally any occurrence of communicative language (such as books, essays, discussions, newspaper headlines, speeches, media, historical documents).
How Do You Do Document Analysis?
In order for a researcher to obtain reliable results from document analysis, a detailed planning process must be undertaken. The following is an outline of an eight-step planning process that should be employed in all textual analysis including document analysis techniques.
- Identify the texts you want to analyze such as samples, population, participants, and respondents.
- You should consider how texts will be accessed, paying attention to any cultural or linguistic barriers.
- Acknowledge and resolve biases.
- Acquire appropriate research skills.
- Strategize for ensuring credibility.
- Identify the data that is being sought.
- Take into account ethical issues.
- Keep a backup plan handy.

Researchers can use a wide variety of texts as part of their research, but the most common source is likely to be written material. Researchers often ask how many documents they should collect. There is an opinion that a wide selection of documents is preferable, but the issue should probably revolve more around the quality of the document than its quantity.
Why is Document Analysis Useful?
Different types of documents serve different purposes. They provide background information, indicate potential interview questions, serve as a mechanism for monitoring progress and tracking changes within a project, and allow for verification of any claims or progress made.
You can triangulate your claims about the phenomenon being studied using document analysis by using multiple sources and other research gathering methods.
Below are the advantages and disadvantages of document analysis
- Document analysis may assist researchers in determining what questions to ask your interviewees, as well as provide insight into what to watch out for during your participant observation.
- It is particularly useful to researchers who wish to focus on specific case studies
- It is inexpensive and quick in cases where data is easily obtainable.
- Documents provide specific and reliable data, unaffected by researchers' presence unlike with other research methods like participant observation.
Disadvantages
- It is likely that the documents researchers obtain are not complete or written objectively, requiring researchers to adopt a critical approach and not assume their contents are reliable or unbiased.
- There may be a risk of information overload due to the number of documents involved. Researchers often have difficulties determining what parts of each document are relevant to the topic being studied.
- It may be necessary to anonymize documents and compare them with other documents.
How NVivo Can Help with Document Analysis
Analyzing copious amounts of data and information can be a daunting and time-consuming prospect. Luckily, qualitative data analysis tools like NVivo can help!
NVivo’s AI-powered autocoding text analysis tool can help you efficiently analyze data and perform thematic analysis . By automatically detecting, grouping, and tagging noun phrases, you can quickly identify key themes throughout your documents – aiding in your evaluation.
Additionally, once you start coding part of your data, NVivo’s smart coding can take care of the rest for you by using machine learning to match your coding style. After your initial coding, you can run queries and create visualizations to expand on initial findings and gain deeper insights.
These features allow you to conduct data analysis on large amounts of documents – improving the efficiency of this qualitative research method. Learn more about these features in the webinar, NVivo 14: Thematic Analysis Using NVivo.
>> Watch Webinar NVivo 14: Thematic Analysis Using NVivo
Learn More About Document Analysis
Watch Twenty-Five Qualitative Researchers Share How-To's for Data Analysis

Recent Articles
Document analysis in health policy research: the READ approach
Affiliations.
- 1 Department of International Health, Johns Hopkins School of Public Health, 615 N. Wolfe St, Baltimore, MD 21205, USA.
- 2 Institute for Global Health, University College London, Institute for Global Health 3rd floor, 30 Guilford Street, London WC1N 1EH, UK.
- 3 School of Humanities and Social Sciences, Information Technology University, Arfa Software Technology Park, Ferozepur Road, Lahore 54000, Pakistan.
- 4 Heidelberg Institute of Global Health, Medical Faculty and University Hospital, University of Heidelberg, Im Neuenheimer Feld 130/3, 69120 Heidelberg, Germany.
- PMID: 33175972
- PMCID: PMC7886435
- DOI: 10.1093/heapol/czaa064
Document analysis is one of the most commonly used and powerful methods in health policy research. While existing qualitative research manuals offer direction for conducting document analysis, there has been little specific discussion about how to use this method to understand and analyse health policy. Drawing on guidance from other disciplines and our own research experience, we present a systematic approach for document analysis in health policy research called the READ approach: (1) ready your materials, (2) extract data, (3) analyse data and (4) distil your findings. We provide practical advice on each step, with consideration of epistemological and theoretical issues such as the socially constructed nature of documents and their role in modern bureaucracies. We provide examples of document analysis from two case studies from our work in Pakistan and Niger in which documents provided critical insight and advanced empirical and theoretical understanding of a health policy issue. Coding tools for each case study are included as Supplementary Files to inspire and guide future research. These case studies illustrate the value of rigorous document analysis to understand policy content and processes and discourse around policy, in ways that are either not possible using other methods, or greatly enrich other methods such as in-depth interviews and observation. Given the central nature of documents to health policy research and importance of reading them critically, the READ approach provides practical guidance on gaining the most out of documents and ensuring rigour in document analysis.
Keywords: Health policy; health systems research; interdisciplinary; methods; policy; policy analysis; policy research; qualitative; research methods; social sciences.
© The Author(s) 2020. Published by Oxford University Press in association with The London School of Hygiene and Tropical Medicine.
- Health Policy*
- Policy Making
- Qualitative Research
Monday, January 20, 2020
A QDA recipe? A ten-step approach for qualitative document analysis using MAXQDA

Guest post by Professional MAXQDA Trainer Dr. Daniel Rasch .
Introduction
Qualitative text or document analysis has evolved into one of the most used qualitative methods across several disciplines ( Kuckartz, 2014 & Mayring, 2010). Its straightforward structure and procedure enable the researcher to adapt the method to his or her special case – nearly to every need.

This article proposes a recipe of ten simple steps for conducting qualitative document analyses (QDA) using MAXQDA (see table 1 for an overview).
Table 1: Overview of the “QDA recipe”
The ten steps for conducting qualitative document analyses using MAXQDA
Step 1: the research question(s).
As always, research begins with the question(s). Three aspects should be covered when dealing with the research question(s):
- What do you want to find out exactly,
- what relevance does your research on this exact question have, and
- what contribution is your research going to make to your discipline?
Highlight these questions in your introduction and make your research stand out.
Step 2: Data collection and data sampling
After you have decided on the questions, you should think about how to answer them. What kind of qualitative data will best answer your question? Interviews – how many and with whom? Documents – which ones and where to collect them from?
At this point, you can already start thinking about validity: are you going to use a representative or a biased sample? Check the different options for sampling and its effects on validity ( Krippendorff, 2019 ).
Step 3: Select and prepare the data
For this step, MAXQDA 2020 is an excellent tool to help you prepare the selected data for any further steps . Whatever type of qualitative data you choose, you can import it into MAXQDA and then you can have MAXQDA assist in transcribing it. In the end, qualitative document analysis is all about written forms of communication (Kuckartz, 2014).

Figure 1: Import the data you have chosen or selected
Step 4: Codebook development
It takes time to develop a solid codebook. Working deductively, the process is a little easier with codes deriving from the theoretical considerations in the context of your research. Inductively, there are various steps you can use, ranging from creative coding to in-vivo-codes.
Content-wise, you can apply all sorts of codes, such as themes or evaluations, two of the most commonly used styles of content analysis (see thematic and evaluative content analysis in Kuckartz, 2014).

Figure 2: coding options in MAXQDA
- a brief definition,
- a long definition,
- criteria for when to use the code,
- criteria for when not to use the code, and
- an example.
Using MAXQDA’s code memos simplify the process of creating and maintaining a good codebook . First, you can always go back to the codes and view and review your codebook within your project, and second, you can simply export the codebook as an attachment or appendix for publication purposes (use: Reports > Codebook ).

Figure 3: Creating a new code with code memo
Step 5: Unitizing and coding instructions
Before the process of coding starts, it is necessary to decide on the units of, as well as the rules for, coding. It is especially important to decide on your unit of coding (sentences, paragraphs, quasi-sentences, etc.). Coding rules help to keep this choice consistent and support you to stick to your research question(s) because every passage you code and every memo you write should be done in order to answer your research question(s). Decision rules should be added: what are you going to do if a passage does not fit in your subcodes but should be coded because it is important for your research question?
Step 6: Trial, training, reliability
Trial runs are of major importance. Not only do they show you, which codes work and which do not, but they also help you to rethink your choices in terms of the unit of coding, the content of the codebook, and reliability. Since there are different options for the latter, stick to what works best for you: either a qualitative comparison of what you have coded or quantitative indicators like Krippendorff’s alpha if need be .
You can test yourself or a team you work with and there might even be some situations, where a reliability test is not helpful or needed. When testing the codebook, be sure to test the variability of your collected documents and be sure that the entire codebook is tested.
MAXQDA helps you compare different forms of agreement for more an unlimited number of texts, divided into two different document groups (one document group coded by coder 1, a second document group coded by coder 2 – be aware, that you can also test yourself and be coder 2 yourself).

Figure 4: Intercoder agreement
Step 7: Revision and modification
After checking, which codes work and which do not, you can revise the codebook and modify it. As Schreier puts it: “No coding frame (codebook – DR) is perfect” (Schreier, 2012: 147).
Step 8: Coding
There are many different coding strategies, but one thing is for sure: qualitative work needs time and reading, as well as working with the material over and over again.
One coding strategy might be to first make yourself comfortable with the documents and start coding after second or third reading only. Another strategy is to concentrate on some of your codes first and do a second round of coding with the other codes later.
Step 9: Analyze and compare
Analyze and compare – these two words are the essence of the qualitative analysis at this step. At the core of each qualitative document analysis is the description of the content and the comparison of these contents between the documents you analyze.
After everything has been coded, you can make use of different analysis strategies: paraphrase, write summaries, look for intersections of codes, patterns of likeliness between the documents using simple or complex queries.

Figure 5: different analysis strategies in MAXQDA
Step 10: Interpretation and presentation
Reporting and summarizing qualitative findings is difficult. Most often, we find simple descriptions of the content with the use of quotations, paraphrases or other references to the text. However, MAXQDA makes it fast and easier with many options to choose from . The easiest way is to generate a table to sum up your findings – if your data or the findings allow for this.
MAXQDA offers several options: either map relations of codes, documents or memos with the MAXMaps , create matrices between codes and documents ( Code Matrix Browser ) or codes and codes ( Code Relations Browser ) to display the distribution of codes inside your data or even using different colors to map the distribution of codes or single documents.

Figure 6: Visual Tools for presentation
The Code Matrix Browser also enables you to quantify the qualitative data using two clicks. You can export these numbers for further analysis with statistical packages, to run causal relation and effect calculations, such as regressions or correlations ( Rasch, 2018 ).
Summary and adoption
Qualitative document analysis is one of the most popular techniques and adaptable to nearly every field. MAXQDA is a software tool that offers many options to make your analysis and therefore your research easier .
The recipe works best for theory-driven, deductive coding. However, it can be also used for inductive, explorative work by switching some of these steps around: for example, your codebook development might be one step to do during or after the trial and testing, since codes are developed inductively during the coding process. Still, it is important to define these codes properly.
The above-mentioned recipe has been used as a basis for several publications by the author. Starting with simple comparison of qualitative and quantitative text analysis ( Boräng et al., 2014 ), to the usage of the qualitative data as a basis for regression models ( Eising et al., 2015 ; Eising et al., 2017 ) to a book using mixed methods and therefore both qualitative and quantitative data analysis ( Rasch, 2018 ).
About the author
Daniel Rasch is a post-doctoral researcher in political science at the German University of Administrative Sciences, Speyer. He received his Ph.D. with a mixed methods analysis of lobbyists‘ success in the European Union. He focuses on the quantification of qualitative data. He is an experienced MAXQDA lecturer and has been a Professional MAXQDA Trainer since 2012.
MAXQDA Newsletter
Our research and analysis tips, straight to your inbox.
Similar Articles
- #ResearchforChange Grants (46)
- Conferences & Events (32)
- Field Work Diary (39)
- Learning MAXQDA (110)
- Research Projects (132)
- Tip of the Month (57)
- Uncategorized (9)
- Updates (65)
- VERBI News (71)

- Search Menu
- Sign in through your institution
- Advance Articles
- Editor's Choice
- Supplements
- Open Access Articles
- Research Collections
- Review Collections
- Author Guidelines
- Submission Site
- Open Access Options
- Self-Archiving Policy
- About Health Policy and Planning
- About the London School of Hygiene and Tropical Medicine
- HPP at a glance
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Journals on Oxford Academic
- Books on Oxford Academic

Article Contents
Introduction, what is document analysis, the read approach, supplementary data, acknowledgements.
- < Previous
Document analysis in health policy research: the READ approach
- Article contents
- Figures & tables
Sarah L Dalglish, Hina Khalid, Shannon A McMahon, Document analysis in health policy research: the READ approach, Health Policy and Planning , Volume 35, Issue 10, December 2020, Pages 1424–1431, https://doi.org/10.1093/heapol/czaa064
- Permissions Icon Permissions
Document analysis is one of the most commonly used and powerful methods in health policy research. While existing qualitative research manuals offer direction for conducting document analysis, there has been little specific discussion about how to use this method to understand and analyse health policy. Drawing on guidance from other disciplines and our own research experience, we present a systematic approach for document analysis in health policy research called the READ approach: (1) ready your materials, (2) extract data, (3) analyse data and (4) distil your findings. We provide practical advice on each step, with consideration of epistemological and theoretical issues such as the socially constructed nature of documents and their role in modern bureaucracies. We provide examples of document analysis from two case studies from our work in Pakistan and Niger in which documents provided critical insight and advanced empirical and theoretical understanding of a health policy issue. Coding tools for each case study are included as Supplementary Files to inspire and guide future research. These case studies illustrate the value of rigorous document analysis to understand policy content and processes and discourse around policy, in ways that are either not possible using other methods, or greatly enrich other methods such as in-depth interviews and observation. Given the central nature of documents to health policy research and importance of reading them critically, the READ approach provides practical guidance on gaining the most out of documents and ensuring rigour in document analysis.
Rigour in qualitative research is judged partly by the use of deliberate, systematic procedures; however, little specific guidance is available for analysing documents, a nonetheless common method in health policy research.
Document analysis is useful for understanding policy content across time and geographies, documenting processes, triangulating with interviews and other sources of data, understanding how information and ideas are presented formally, and understanding issue framing, among other purposes.
The READ (Ready materials, Extract data, Analyse data, Distil) approach provides a step-by-step guide to conducting document analysis for qualitative policy research.
The READ approach can be adapted to different purposes and types of research, two examples of which are presented in this article, with sample tools in the Supplementary Materials .
Document analysis (also called document review) is one of the most commonly used methods in health policy research; it is nearly impossible to conduct policy research without it. Writing in early 20th century, Weber (2015) identified the importance of formal, written documents as a key characteristic of the bureaucracies by which modern societies function, including in public health. Accordingly, critical social research has a long tradition of documentary review: Marx analysed official reports, laws, statues, census reports and newspapers and periodicals over a nearly 50-year period to come to his world-altering conclusions ( Harvey, 1990 ). Yet in much of social science research, ‘documents are placed at the margins of consideration,’ with privilege given to the spoken word via methods such as interviews, possibly due to the fact that many qualitative methods were developed in the anthropological tradition to study mainly pre-literate societies ( Prior, 2003 ). To date, little specific guidance is available to help health policy researchers make the most of these wells of information.
The term ‘documents’ is defined here broadly, following Prior, as physical or virtual artefacts designed by creators, for users, to function within a particular setting ( Prior, 2003 ). Documents exist not as standalone objects of study but must be understood in the social web of meaning within which they are produced and consumed. For example, some analysts distinguish between public documents (produced in the context of public sector activities), private documents (from business and civil society) and personal documents (created by or for individuals, and generally not meant for public consumption) ( Mogalakwe, 2009 ). Documents can be used in a number of ways throughout the research process ( Bowen, 2009 ). In the planning or study design phase, they can be used to gather background information and help refine the research question. Documents can also be used to spark ideas for disseminating research once it is complete, by observing the ways those who will use the research speak to and communicate ideas with one another.
Documents can also be used during data collection and analysis to help answer research questions. Recent health policy research shows that this can be done in at least four ways. Frequently, policy documents are reviewed to describe the content or categorize the approaches to specific health problems in existing policies, as in reviews of the composition of drowning prevention resources in the United States or policy responses to foetal alcohol spectrum disorder in South Africa ( Katchmarchi et al. , 2018 ; Adebiyi et al. , 2019 ). In other cases, non-policy documents are used to examine the implementation of health policies in real-world settings, as in a review of web sources and newspapers analysing the functioning of community health councils in New Zealand ( Gurung et al. , 2020 ). Perhaps less frequently, document analysis is used to analyse policy processes, as in an assessment of multi-sectoral planning process for nutrition in Burkina Faso ( Ouedraogo et al. , 2020 ). Finally, and most broadly, document analysis can be used to inform new policies, as in one study that assessed cigarette sticks as communication and branding ‘documents,’ to suggest avenues for further regulation and tobacco control activities ( Smith et al. , 2017 ).
This practice paper provides an overarching method for conducting document analysis, which can be adapted to a multitude of research questions and topics. Document analysis is used in most or all policy studies; the aim of this article is to provide a systematized method that will enhance procedural rigour. We provide an overview of document analysis, drawing on guidance from disciplines adjacent to public health, introduce the ‘READ’ approach to document analysis and provide two short case studies demonstrating how document analysis can be applied.
Document analysis is a systematic procedure for reviewing or evaluating documents, which can be used to provide context, generate questions, supplement other types of research data, track change over time and corroborate other sources ( Bowen, 2009 ). In one commonly cited approach in social research, Bowen recommends first skimming the documents to get an overview, then reading to identify relevant categories of analysis for the overall set of documents and finally interpreting the body of documents ( Bowen, 2009 ). Document analysis can include both quantitative and qualitative components: the approach presented here can be used with either set of methods, but we emphasize qualitative ones, which are more adapted to the socially constructed meaning-making inherent to collaborative exercises such as policymaking.
The study of documents as a research method is common to a number of social science disciplines—yet in many of these fields, including sociology ( Mogalakwe, 2009 ), anthropology ( Prior, 2003 ) and political science ( Wesley, 2010 ), document-based research is described as ill-considered and underutilized. Unsurprisingly, textual analysis is perhaps most developed in fields such as media studies, cultural studies and literary theory, all disciplines that recognize documents as ‘social facts’ that are created, consumed, shared and utilized in socially organized ways ( Atkinson and Coffey, 1997 ). Documents exist within social ‘fields of action,’ a term used to designate the environments within which individuals and groups interact. Documents are therefore not mere records of social life, but integral parts of it—and indeed can become agents in their own right ( Prior, 2003 ). Powerful entities also manipulate the nature and content of knowledge; therefore, gaps in available information must be understood as reflecting and potentially reinforcing societal power relations ( Bryman and Burgess, 1994 ).
Document analysis, like any research method, can be subject to concerns regarding validity, reliability, authenticity, motivated authorship, lack of representativity and so on. However, these can be mitigated or avoided using standard techniques to enhance qualitative rigour, such as triangulation (within documents and across methods and theoretical perspectives), ensuring adequate sample size or ‘engagement’ with the documents, member checking, peer debriefing and so on ( Maxwell, 2005 ).
Document analysis can be used as a standalone method, e.g. to analyse the contents of specific types of policy as they evolve over time and differ across geographies, but document analysis can also be powerfully combined with other types of methods to cross-validate (i.e. triangulate) and deepen the value of concurrent methods. As one guide to public policy research puts it, ‘almost all likely sources of information, data, and ideas fall into two general types: documents and people’ ( Bardach and Patashnik, 2015 ). Thus, researchers can ask interviewees to address questions that arise from policy documents and point the way to useful new documents. Bardach and Patashnik suggest alternating between documents and interviews as sources as information, as one tends to lead to the other, such as by scanning interviewees’ bookshelves and papers for titles and author names ( Bardach and Patashnik, 2015 ). Depending on your research questions, document analysis can be used in combination with different types of interviews ( Berner-Rodoreda et al. , 2018 ), observation ( Harvey, 2018 ), and quantitative analyses, among other common methods in policy research.
The READ approach to document analysis is a systematic procedure for collecting documents and gaining information from them in the context of health policy studies at any level (global, national, local, etc.). The steps consist of: (1) ready your materials, (2) extract data, (3) analyse data and (4) distil your findings. We describe each of these steps in turn.
Step 1. Ready your materials
At the outset, researchers must set parameters in terms of the nature and number (approximately) of documents they plan to analyse, based on the research question. How much time will you allocate to the document analysis, and what is the scope of your research question? Depending on the answers to these questions, criteria should be established around (1) the topic (a particular policy, programme, or health issue, narrowly defined according to the research question); (2) dates of inclusion (whether taking the long view of several decades, or zooming in on a specific event or period in time); and (3) an indicative list of places to search for documents (possibilities include databases such as Ministry archives; LexisNexis or other databases; online searches; and particularly interview subjects). For difficult-to-obtain working documents or otherwise non-public items, bringing a flash drive to interviews is one of the best ways to gain access to valuable documents.
For research focusing on a single policy or programme, you may review only a handful of documents. However, if you are looking at multiple policies, health issues, or contexts, or reviewing shorter documents (such as newspaper articles), you may look at hundreds, or even thousands of documents. When considering the number of documents you will analyse, you should make notes on the type of information you plan to extract from documents—i.e. what it is you hope to learn, and how this will help answer your research question(s). The initial criteria—and the data you seek to extract from documents—will likely evolve over the course of the research, as it becomes clear whether they will yield too few documents and information (a rare outcome), far too many documents and too much information (a much more common outcome) or documents that fail to address the research question; however, it is important to have a starting point to guide the search. If you find that the documents you need are unavailable, you may need to reassess your research questions or consider other methods of inquiry. If you have too many documents, you can either analyse a subset of these ( Panel 1 ) or adopt more stringent inclusion criteria.
Exploring the framing of diseases in Pakistani media
In Table 1 , we present a non-exhaustive list of the types of documents that can be included in document analyses of health policy issues. In most cases, this will mean written sources (policies, reports, articles). The types of documents to be analysed will vary by study and according to the research question, although in many cases, it will be useful to consult a mix of formal documents (such as official policies, laws or strategies), ‘gray literature’ (organizational materials such as reports, evaluations and white papers produced outside formal publication channels) and, whenever possible, informal or working documents (such as meeting notes, PowerPoint presentations and memoranda). These latter in particular can provide rich veins of insight into how policy actors are thinking through the issues under study, particularly for the lucky researcher who obtains working documents with ‘Track Changes.’ How you prioritize documents will depend on your research question: you may prioritize official policy documents if you are studying policy content, or you may prioritize informal documents if you are studying policy process.
Types of documents that can be consulted in studies of health policy
During this initial preparatory phase, we also recommend devising a file-naming system for your documents (e.g. Author.Date.Topic.Institution.PDF), so that documents can be easily retrieved throughout the research process. After extracting data and processing your documents the first time around, you will likely have additional ‘questions’ to ask your documents and need to consult them again. For this reason, it is important to clearly name source files and link filenames to the data that you are extracting (see sample naming conventions in the Supplementary Materials ).
Step 2. Extract data
Data can be extracted in a number of ways, and the method you select for doing so will depend on your research question and the nature of your documents. One simple way is to use an Excel spreadsheet where each row is a document and each column is a category of information you are seeking to extract, from more basic data such as the document title, author and date, to theoretical or conceptual categories deriving from your research question, operating theory or analytical framework (Panel 2). Documents can also be imported into thematic coding software such as Atlas.ti or NVivo, and data extracted that way. Alternatively, if the research question focuses on process, documents can be used to compile a timeline of events, to trace processes across time. Ask yourself, how can I organize these data in the most coherent manner? What are my priority categories? We have included two different examples of data extraction tools in the Supplementary Materials to this article to spark ideas.
Case study Documents tell part of the story in Niger
Document analyses are first and foremost exercises in close reading: documents should be read thoroughly, from start to finish, including annexes, which may seem tedious but which sometimes produce golden nuggets of information. Read for overall meaning as you extract specific data related to your research question. As you go along, you will begin to have ideas or build working theories about what you are learning and observing in the data. We suggest capturing these emerging theories in extended notes or ‘memos,’ as used in Grounded Theory methodology ( Charmaz, 2006 ); these can be useful analytical units in themselves and can also provide a basis for later report and article writing.
As you read more documents, you may find that your data extraction tool needs to be modified to capture all the relevant information (or to avoid wasting time capturing irrelevant information). This may require you to go back and seek information in documents you have already read and processed, which will be greatly facilitated by a coherent file-naming system. It is also useful to keep notes on other documents that are mentioned that should be tracked down (sometimes you can write the author for help). As a general rule, we suggest being parsimonious when selecting initial categories to extract from data. Simply reading the documents takes significant time in and of itself—make sure you think about how, exactly, the specific data you are extracting will be used and how it goes towards answering your research questions.
Step 3. Analyse data
As in all types of qualitative research, data collection and analysis are iterative and characterized by emergent design, meaning that developing findings continually inform whether and how to obtain and interpret data ( Creswell, 2013 ). In practice, this means that during the data extraction phase, the researcher is already analysing data and forming initial theories—as well as potentially modifying document selection criteria. However, only when data extraction is complete can one see the full picture. For example, are there any documents that you would have expected to find, but did not? Why do you think they might be missing? Are there temporal trends (i.e. similarities, differences or evolutions that stand out when documents are ordered chronologically)? What else do you notice? We provide a list of overarching questions you should think about when viewing your body of document as a whole ( Table 2 ).
Questions to ask your overall body of documents

HIV and viral hepatitis articles by main frames (%). Note: The percentage of articles is calculated by dividing the number of articles appearing in each frame for viral hepatitis and HIV by the respectivenumber of sampled articles for each disease (N = 137 for HIV; N = 117 for hepatitis). Time frame: 1 January 2006 to 30 September 2016

Representations of progress toward Millennium Development Goal 4 in Nigerien policy documents. Sources: clockwise from upper left: ( WHO 2006 ); ( Institut National de la Statistique 2010 ); ( Ministè re de la Santé Publique 2010 ); ( Unicef 2010 )
In addition to the meaning-making processes you are already engaged in during the data extraction process, in most cases, it will be useful to apply specific analysis methodologies to the overall corpus of your documents, such as policy analysis ( Buse et al. , 2005 ). An array of analysis methodologies can be used, both quantitative and qualitative, including case study methodology, thematic content analysis, discourse analysis, framework analysis and process tracing, which may require differing levels of familiarity and skills to apply (we highlight a few of these in the case studies below). Analysis can also be structured according to theoretical approaches. When it comes to analysing policies, process tracing can be particularly useful to combine multiple sources of information, establish a chronicle of events and reveal political and social processes, so as to create a narrative of the policy cycle ( Yin, 1994 ; Shiffman et al. , 2004 ). Practically, you will also want to take a holistic view of the documents’ ‘answers’ to the questions or analysis categories you applied during the data extraction phase. Overall, what did the documents ‘say’ about these thematic categories? What variation did you find within and between documents, and along which axes? Answers to these questions are best recorded by developing notes or memos, which again will come in handy as you write up your results.
As with all qualitative research, you will want to consider your own positionality towards the documents (and their sources and authors); it may be helpful to keep a ‘reflexivity’ memo documenting how your personal characteristics or pre-standing views might influence your analysis ( Watt, 2007 ).
Step 4. Distil your findings
You will know when you have completed your document review when one of the three things happens: (1) completeness (you feel satisfied you have obtained every document fitting your criteria—this is rare), (2) out of time (this means you should have used more specific criteria), and (3) saturation (you fully or sufficiently understand the phenomenon you are studying). In all cases, you should strive to make the third situation the reason for ending your document review, though this will not always mean you will have read and analysed every document fitting your criteria—just enough documents to feel confident you have found good answers to your research questions.
Now it is time to refine your findings. During the extraction phase, you did the equivalent of walking along the beach, noticing the beautiful shells, driftwood and sea glass, and picking them up along the way. During the analysis phase, you started sorting these items into different buckets (your analysis categories) and building increasingly detailed collections. Now you have returned home from the beach, and it is time to clean your objects, rinse them of sand and preserve only the best specimens for presentation. To do this, you can return to your memos, refine them, illustrate them with graphics and quotes and fill in any incomplete areas. It can also be illuminating to look across different strands of work: e.g. how did the content, style, authorship, or tone of arguments evolve over time? Can you illustrate which words, concepts or phrases were used by authors or author groups?
Results will often first be grouped by theoretical or analytic category, or presented as a policy narrative, interweaving strands from other methods you may have used (interviews, observation, etc.). It can also be helpful to create conceptual charts and graphs, especially as this corresponds to your analytical framework (Panels 1 and 2). If you have been keeping a timeline of events, you can seek out any missing information from other sources. Finally, ask yourself how the validity of your findings checks against what you have learned using other methods. The final products of the distillation process will vary by research study, but they will invariably allow you to state your findings relative to your research questions and to draw policy-relevant conclusions.
Document analysis is an essential component of health policy research—it is also relatively convenient and can be low cost. Using an organized system of analysis enhances the document analysis’s procedural rigour, allows for a fuller understanding of policy process and content and enhances the effectiveness of other methods such as interviews and non-participant observation. We propose the READ approach as a systematic method for interrogating documents and extracting study-relevant data that is flexible enough to accommodate many types of research questions. We hope that this article encourages discussion about how to make best use of data from documents when researching health policy questions.
Supplementary data are available at Health Policy and Planning online.
The data extraction tool in the Supplementary Materials for the iCCM case study (Panel 2) was conceived of by the research team for the multi-country study ‘Policy Analysis of Community Case Management for Childhood and Newborn Illnesses’. The authors thank Sara Bennett and Daniela Rodriguez for granting permission to publish this tool. S.M. was supported by The Olympia-Morata-Programme of Heidelberg University. The funders had no role in the decision to publish, or preparation of the manuscript. The content is the responsibility of the authors and does not necessarily represent the views of any funder.
Conflict of interest statement . None declared.
Ethical approval. No ethical approval was required for this study.
Abdelmutti N , Hoffman-Goetz L. 2009 . Risk messages about HPV, cervical cancer, and the HPV vaccine Gardasil: a content analysis of Canadian and U.S. national newspaper articles . Women & Health 49 : 422 – 40 .
Google Scholar
Adebiyi BO , Mukumbang FC , Beytell A-M. 2019 . To what extent is fetal alcohol spectrum disorder considered in policy-related documents in South Africa? A document review . Health Research Policy and Systems 17 :
Atkinson PA , Coffey A. 1997 . Analysing documentary realities. In: Silverman D (ed). Qualitative Research: Theory, Method and Practice . London : SAGE .
Google Preview
Bardach E , Patashnik EM. 2015 . Practical Guide for Policy Analysis: The Eightfold Path to More Effective Problem Solving . Los Angeles : SAGE .
Bennett S , Dalglish SL , Juma PA , Rodríguez DC. 2015 . Altogether now… understanding the role of international organizations in iCCM policy transfer . Health Policy and Planning 30 : ii26 – 35 .
Berner-Rodoreda A , Bärnighausen T , Kennedy C et al. 2018 . From doxastic to epistemic: a typology and critique of qualitative interview styles . Qualitative Inquiry 26 : 291 – 305 . 1077800418810724.
Bowen GA. 2009 . Document analysis as a qualitative research method . Qualitative Research Journal 9 : 27 – 40 .
Bryman A. 1994 . Analyzing Qualitative Data .
Buse K , Mays N , Walt G. 2005 . Making Health Policy . New York : Open University Press .
Charmaz K. 2006 . Constructing Grounded Theory: A Practical Guide through Qualitative Analysis . London : SAGE .
Claassen L , Smid T , Woudenberg F , Timmermans DRM. 2012 . Media coverage on electromagnetic fields and health: content analysis of Dutch newspaper articles and websites . Health, Risk & Society 14 : 681 – 96 .
Creswell JW. 2013 . Qualitative Inquiry and Research Design . Thousand Oaks, CA : SAGE .
Dalglish SL , Rodríguez DC , Harouna A , Surkan PJ. 2017 . Knowledge and power in policy-making for child survival in Niger . Social Science & Medicine 177 : 150 – 7 .
Dalglish SL , Surkan PJ , Diarra A , Harouna A , Bennett S. 2015 . Power and pro-poor policies: the case of iCCM in Niger . Health Policy and Planning 30 : ii84 – 94 .
Entman RM. 1993 . Framing: toward clarification of a fractured paradigm . Journal of Communication 43 : 51 – 8 .
Fournier G , Djermakoye IA. 1975 . Village health teams in Niger (Maradi Department). In: Newell KW (ed). Health by the People . Geneva : WHO .
Gurung G , Derrett S , Gauld R. 2020 . The role and functions of community health councils in New Zealand’s health system: a document analysis . The New Zealand Medical Journal 133 : 70 – 82 .
Harvey L. 1990 . Critical Social Research . London : Unwin Hyman .
Harvey SA. 2018 . Observe before you leap: why observation provides critical insights for formative research and intervention design that you’ll never get from focus groups, interviews, or KAP surveys . Global Health: Science and Practice 6 : 299 – 316 .
Institut National de la Statistique. 2010. Rapport National sur les Progrès vers l'atteinte des Objectifs du Millénaire pour le Développement. Niamey, Niger: INS.
Kamarulzaman A. 2013 . Fighting the HIV epidemic in the Islamic world . Lancet 381 : 2058 – 60 .
Katchmarchi AB , Taliaferro AR , Kipfer HJ. 2018 . A document analysis of drowning prevention education resources in the United States . International Journal of Injury Control and Safety Promotion 25 : 78 – 84 .
Krippendorff K. 2004 . Content Analysis: An Introduction to Its Methodology . SAGE .
Marten R. 2019 . How states exerted power to create the Millennium Development Goals and how this shaped the global health agenda: lessons for the sustainable development goals and the future of global health . Global Public Health 14 : 584 – 99 .
Maxwell JA. 2005 . Qualitative Research Design: An Interactive Approach , 2 nd edn. Thousand Oaks, CA : Sage Publications .
Mayring P. 2004 . Qualitative Content Analysis . In: Flick U, von Kardorff E, Steinke I (eds). A Companion to Qualitative Research . SAGE .
Ministère de la Santé Publique. 2010. Enquête nationale sur la survie des enfants de 0 à 59 mois et la mortalité au Niger 2010. Niamey, Niger: MSP.
Mogalakwe M. 2009 . The documentary research method—using documentary sources in social research . Eastern Africa Social Science Research Review 25 : 43 – 58 .
Nelkin D. 1991 . AIDS and the news media . The Milbank Quarterly 69 : 293 – 307 .
Ouedraogo O , Doudou MH , Drabo KM et al. 2020 . Policy overview of the multisectoral nutrition planning process: the progress, challenges, and lessons learned from Burkina Faso . The International Journal of Health Planning and Management 35 : 120 – 39 .
Prior L. 2003 . Using Documents in Social Research . London: SAGE .
Shiffman J , Stanton C , Salazar AP. 2004 . The emergence of political priority for safe motherhood in Honduras . Health Policy and Planning 19 : 380 – 90 .
Smith KC , Washington C , Welding K et al. 2017 . Cigarette stick as valuable communicative real estate: a content analysis of cigarettes from 14 low-income and middle-income countries . Tobacco Control 26 : 604 – 7 .
Strömbäck J , Dimitrova DV. 2011 . Mediatization and media interventionism: a comparative analysis of Sweden and the United States . The International Journal of Press/Politics 16 : 30 – 49 .
UNICEF. 2010. Maternal, Newborn & Child Surival Profile. Niamey, Niger: UNICEF
Watt D. 2007 . On becoming a qualitative researcher: the value of reflexivity . Qualitative Report 12 : 82 – 101 .
Weber M. 2015 . Bureaucracy. In: Waters T , Waters D (eds). Rationalism and Modern Society: New Translations on Politics, Bureaucracy, and Social Stratification . London : Palgrave MacMillan .
Wesley JJ. 2010 . Qualitative Document Analysis in Political Science.
World Health Organization. 2006. Country Health System Fact Sheet 2006: Niger. Niamey, Niger: WHO.
Yin R. 1994 . Case Study Research: Design and Methods . Thousand Oaks, CA : Sage .
Supplementary data
Email alerts, citing articles via.
- Recommend to Your Librarian
Affiliations
- Online ISSN 1460-2237
- Copyright © 2024 The London School of Hygiene and Tropical Medicine and Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Research Methodology in Education
- Get Edit Link
- The Writing Space
- Welcome Desk

March 9, 2016
- An Introduction to Document Analysis
Introduction
Document analysis is a form of qualitative research in which documents are interpreted by the researcher to give voice and meaning around an assessment topic (Bowen, 2009). Analyzing documents incorporates coding content into themes similar to how focus group or interview transcripts are analyzed (Bowen,2009). A rubric can also be used to grade or score document. There are three primary types of documents (O’Leary, 2014):
- Public Records: The official, ongoing records of an organization’s activities. Examples include student transcripts, mission statements, annual reports, policy manuals, student handbooks, strategic plans, and syllabi.
- Personal Documents: First-person accounts of an individual’s actions, experiences, and beliefs. Examples include calendars, e-mails, scrapbooks, blogs, Facebook posts, duty logs, incident reports, reflections/journals, and newspapers.
- Physical Evidence: Physical objects found within the study setting (often called artifacts). Examples include flyers, posters, agendas, handbooks, and training materials.
Document analysis is a social research method and is an important research tool in its own right, and is an invaluable part of most schemes of triangulation, the combination of methodologies in the study of the same phenomenon (Bowen, 2009). In order to seek convergence and corroboration, qualitative researchers usually use at least two resources through using different data sources and methods. The purpose of triangulating is to provide a confluence of evidence that breeds credibility (Bowen, 2009). Corroborating findings across data sets can reduce the impact of potential bias by examining information collected through different methods. Also, combining qualitative and quantitative sometimes included in document analysis called mixed-methods studies.
Before actual document analysis takes place, the researcher must go through a detailed planning process in order to ensure reliable results. O’Leary outlines an 8-step planning process that should take place not just in document analysis, but all textual analysis (2014):
- Create a list of texts to explore (e.g., population, samples, respondents, participants).
- Consider how texts will be accessed with attention to linguistic or cultural barriers.
- Acknowledge and address biases.
- Develop appropriate skills for research.
- Consider strategies for ensuring credibility.
- Know the data one is searching for.
- Consider ethical issues (e.g., confidential documents).
- Have a backup plan.
A researcher can use a huge plethora of texts for research, although by far the most common is likely to be the use of written documents (O’Leary, 2014). There is the question of how many documents the researcher should gather. Bowen suggests that a wide array of documents is better, although the question should be more about quality of the document rather than quantity (Bowen, 2009). O’Leary also introduces two major issues to consider when beginning document analysis. The first is the issue of bias, both in the author or creator of the document, and the researcher as well (2014). The researcher must consider the subjectivity of the author and also the personal biases he or she may be bringing to the research. Bowen adds that the researcher must evaluate the original purpose of the document, such as the target audience (2009). He or she should also consider whether the author was a firsthand witness or used secondhand sources. Also important is determining whether the document was solicited, edited, and/or anonymous (Bowen, 2009). O’Leary’s second major issue is the “unwitting” evidence, or latent content, of the document. Latent content refers to the style, tone, agenda, facts or opinions that exist in the document. This is a key first step that the researcher must keep in mind (O’Leary, 2014). Bowen adds that documents should be assessed for their completeness; in other words, how selective or comprehensive their data is (2009). Also of paramount importance when evaluating documents is not to consider the data as “necessarily precise, accurate, or complete recordings of events that have occurred” (Bowen, 2009, p. 33). These issues are summed up in another eight-step process offered by O’Leary (2014):
- Gather relevant texts.
- Develop an organization and management scheme.
- Make copies of the originals for annotation.
- Asses authenticity of documents.
- Explore document’s agenda, biases.
- Explore background information (e.g., tone, style, purpose).
- Ask questions about document (e.g., Who produced it? Why? When? Type of data?).
- Explore content.
Step eight refers to the process of exploring the “witting” evidence, or the actual content of the documents, and O’Leary gives two major techniques for accomplishing this (2014). One is the interview technique. In this case, the researcher treats the document like a respondent or informant that provides the researcher with relevant information (O’Leary, 2014). The researcher “asks” questions then highlights the answer within the text. The other technique is noting occurrences, or content analysis, where the researcher quantifies the use of particular words, phrases and concepts (O’Leary, 2014). Essentially, the researcher determines what is being searched for, then documents and organizes the frequency and amount of occurrences within the document. The information is then organized into what is “related to central questions of the research” (Bowen, 2009, p. 32). Bowen notes that some experts object to this kind of analysis, saying that it obscures the interpretive process in the case of interview transcriptions (Bowen, 2009). However, Bowen reminds us that documents include a wide variety of types, and content analysis can be very useful for painting a broad, overall picture (2009). According to Bowen (2009), content analysis, then, is used as a “first-pass document review” (p. 32) that can provide the researcher a means of identifying meaningful and relevant passages.
In addition to content analysis, Bowen also notes thematic analysis, which can be considered a form of pattern recognition with the document’s data (2009). This analysis takes emerging themes and makes them into categories used for further analysis, making it a useful practice for grounded theory. It includes careful, focused reading and re-reading of data, as well as coding and category construction (Bowen, 2009). The emerging codes and themes may also serve to “integrate data gathered by different methods” (Bowen, 2009, p. 32). Bowen sums up the overall concept of document analysis as a process of “evaluating documents in such a way that empirical knowledge is produced and understanding is developed” (2009, p. 33). It is not just a process of lining up a collection of excerpts that convey whatever the researcher desires. The researcher must maintain a high level of objectivity and sensitivity in order for the document analysis results to be credible and valid (Bowen, 2009).
The Advantages of Document Analysis
There are many reasons why researchers choose to use document analysis. Firstly, document analysis is an efficient and effective way of gathering data because documents are manageable and practical resources. Documents are commonplace and come in a variety of forms, making documents a very accessible and reliable source of data. Obtaining and analysing documents is often far more cost efficient and time efficient than conducting your own research or experiments (Bowen, 2009). Also, documents are stable, “non-reactive” data sources, meaning that they can be read and reviewed multiple times and remain unchanged by the researcher’s influence or research process (Bowen, 2009, p. 31).
Document analysis is often used because of the many different ways it can support and strengthen research. Document analysis can be used in many different fields of research, as either a primary method of data collection or as a compliment to other methods. Documents can provide supplementary research data, making document analysis a useful and beneficial method for most research. Documents can provide background information and broad coverage of data, and are therefore helpful in contextualizing one’s research within its subject or field (Bowen, 2009). Documents can also contain data that no longer can be observed, provide details that informants have forgotten, and can track change and development. Document analysis can also point to questions that need to be asked or to situations that need to be observed, making the use of document analysis a way to ensure your research is critical and comprehensive (Bowen, 2009).
Concerns to Keep in Mind When Using Document Analysis
The disadvantages of using document analysis are not so much limitations as they are potential concerns to be aware of before choosing the method or when using it. An initial concern to consider is that documents are not created with data research agendas and therefore require some investigative skills. A document will not perfectly provide all of the necessary information required to answer your research questions. Some documents may only provide a small amount of useful data or sometimes none at all. Other documents may be incomplete, or their data may be inaccurate or inconsistent. Sometimes there are gaps or sparseness of documents, leading to more searching or reliance on additional documents then planned (Bowen, 2009). Also, some documents may not be available or easily accessible. For these reasons, it is important to evaluate the quality of your documents and to be prepared to encounter some challenges or gaps when employing document analysis.
Another concern to be aware of before beginning document analysis, and to keep in mind during, is the potential presence of biases, both in a document and from the researcher. Both Bowen and O’Leary state that it is important to thoroughly evaluate and investigate the subjectivity of documents and your understanding of their data in order to preserve the credibility of your research (2009; 2014).
The reason that the issues surrounding document analysis are concerns and not disadvantages is that they can be easily avoided by having a clear process that incorporates evaluative steps and measures, as previously mentioned above and exemplified by O’Leary’s two eight-step processes. As long as a researcher begins document analysis knowing what the method entails and has a clear process planned, the advantages of document analysis are likely to far outweigh the amount of issues that may arise.
References:
Bowen, G. A. (2009). Document analysis as a qualitative research method. Qualitative Research Journal, 9(2), 27-40. doi:10.3316/QRJ0902027 O’Leary, Z. (2014). The essential guide to doing your research project (2nd ed.). Thousand Oaks, CA: SAGE Publications, Inc.
And So It Was Written

Author: Triad 3
Published: March 9, 2016
Word Count: 1626

ORGANIZED BY
More to read, add yours →.

I found the document so interesting. Thank you

Dear Triad Your article was very insightful. I am currently researching about document analysis to make it my methodology strategy to analyze a web application. I would be glad if you had any more material regarding this subject to share.

Very helpful.

Thank you for this valuable information. I request for more such information in qualitative analysis.

I benefited from this article so much . thank you for taking your time to write and share it.

This is really helpful for understanding the basic concept of document analysis. Really impressive!

This is one of the good way to remove difficulties during writing the research

Hi, valuable information herein. My research is qualitative and I want to take a number of pictures which I will then use to formulate questions for the interview guide. My question is this, how do I formulate the document analysis checklist?
Regards, Nancy
Comments are closed.
Recently Written
- Observation: Not As Simple As You Thought (ADK)
- RESEARCH TOOLS: INTERVIEWS & QUESTIONNAIRES
- Grounded Theory: A Down-to-Earth Explanation
- Assignment (10)
View by Date Published
Search writings.
A TRU Writer powered SPLOT : Research Methodology in Education
Blame @cogdog — Up ↑
Retail Chatbots’ Main Themes and Research over Time: A Bibliometric and Content Analysis
- Conference paper
- First Online: 04 June 2024
- Cite this conference paper

- Joaquim Pratas ORCID: orcid.org/0000-0002-7432-9242 7 , 8 , 9 , 14 ,
- Carla Amorim 10 , 11 , 15 ,
- Zaila Oliveira 8 , 11 ,
- Vera Carlos 8 , 11 , 12 &
- José Luís Reis ORCID: orcid.org/0000-0002-0987-0980 8 , 11 , 13
Part of the book series: Smart Innovation, Systems and Technologies ((SIST,volume 386))
Included in the following conference series:
- International Conference on Marketing and Technologies
The purpose of this study is to analyze the most important themes and changes over time in retail chatbots’ research, using a bibliometric and content analysis of documents from Web of Science archive. The five identified themes are related with chatbots, e-retail applications, and online relationship marketing general and specific contexts’ characterization; shopper stimulus to use chatbots in retail and COVID-19 effects; barriers to consumer adoption of retail chatbots; user experience with chatbots in their consumer journey; and chatbots’ effectiveness and their relationship with customer satisfaction. This study contributes to the field by providing researchers the best practices and tendencies about retail chatbots. For practitioners, it offers guidance to create effective retail chatbots.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Zemčík, T.: A brief history of chatbots. DEStech Trans. Comput. Sci. Eng. (2019). https://doi.org/10.12783/dtcse/aicae2019/31439
Article Google Scholar
Rese, A., Ganster, L., Baier, D.: Chatbots in retailers’ customer communication: how to measure their acceptance? J. Retail. Consum. Serv. 56 , 102176 (2020). https://doi.org/10.1016/j.jretconser.2020.102176
Stefanowicz, B.: Retail chatbot: top use, case examples, benefits and tips (2023). Accessed 8 Sept 2023. https://www.tidio.com/blog/retail-chatbot/
Tran, A., Pallant, J., Johnson, L.: Exploring the impact of chatbots on consumer sentiment and expectations in retail. J. Retail. Consum. Serv. 63 , 102718 (2021). https://doi.org/10.1016/j.jretconser.2021.102718
Jenneboer, L., Herrando, C., Constantinides, E.: The impact of chatbots on customer loyalty: a systematic literature review. J. Theor. Appl. Electron. Commer. Res. 17 (1), 212–229 (2022). https://doi.org/10.3390/jtaer17010011
Lembics, A.: How a small company can use a chatbot to boost growth (2023). Accessed 8 Sept 2023. https://www.chatbot.com/blog/chatbot-for-small-business/
Kerly, A., Hall, P., Bull, S.: Bringing chatbots into education: towards natural language negotiation of open learner models. Knowl.-Based Syst. 20 (2), 177–185 (2007). https://doi.org/10.1016/j.knosys.2006.11.014
Dale, R.: The return of the chatbots. Nat. Lang. Eng. 22 , 811–817 (2016). https://doi.org/10.1017/S1351324916000243
Shawar, A., Atwell, E.: Chatbots: are they really useful? LDV-Forum 22 , 29–49 (2007)
Google Scholar
Ahmed, B.: Chatbots vs conversational AI—what’s the difference? (2023). Accessed 8 Sept 2023. https://yellow.ai/blog/chatbot-vs-conversational-ai/
O’Neill, S.: Chatbots vs conversational AI vs virtual assistants: what’s the difference? (2021). Accessed 8 Sept 2023. https://www.lxahub.com/stories/chatbots-vs-conversational-ai-vs-virtual-assistants-whats-the-difference
Cassell, J., Sullivan, J., Prevost, S., Churchill, F.: Embodied Conversational Agents. MIT Press (2000)
Chattaraman, V., Kwon, W., Gilbert, J.: Virtual agents in retail web sites: benefits of simulated social interaction for older users. Comput. Hum. Behav. 28 (6), 2055–2066 (2012). https://doi.org/10.1016/j.chb.2012.06.009
Silva, F., Barbosa, B.: Chatbot-based services: a study on users’ intention to reuse them. In: International Workshop in Marketing, 1, Porto, 2022. Sustainability and Resilience. Universidade Lusíada, Porto (2022)
Chung, M., Ko, E., Joung, H., Kim, S.: Chatbot e-service and customer satisfaction regarding luxury brands. J. Bus. Res. 117 , 587–595 (2020). https://doi.org/10.1016/j.jbusres.2018.10.004
Solis-Quispe, J., Quico-Cauti, K., Ugarte, W.: Chatbot to simplify customer interaction in e-commerce channels of retail companies. Inf. Technol. Syst. 1330 , 561–570 (2021). https://doi.org/10.1007/978-3-030-68285-9_52
Lajante, M., Del Prete, M.: Technology-infused organizational frontlines: when (not) to use chatbots in retailing to promote customer engagement. In: Pantano, E. (ed.) Retail Futures, pp. 71–84. Emerald Publishing Limited, Bingley (2020). https://doi.org/10.1108/978-1-83867-663-620201011
Luo, X., Tong, S., Fang, Z., Qu, Z.: Machines versus humans: the impact of AI chatbot disclosure on customer purchases. Mark. Sci. 38 (6), 937–947 (2019). https://doi.org/10.1287/mksc.2019.1192
Mozafari, N., Hammerschmidt, M., Weiger, W.: That’s so embarrassing! When not to design for social presence in human-chatbot interactions. In: Proceedings of the International Conference on Information Systems (2021)
Smith, M.: The impact of shopbots on electronic markets. J. Acad. Mark. Sci. 30 (4), 446–454 (2002)
Pantano, E., Pizzi, G.: Forecasting artificial intelligence on online customer assistance: evidence from chatbot patents analysis. J. Retail. Consum. Serv. 55 , 102096 (2020). https://doi.org/10.1016/j.jretconser.2020.102096
Nuruzzaman, M., Hussain, O.: A survey on chatbot implementation in customer service industry through deep neural networks. In: Proceedings of the 2018 IEEE 15th International Conference on e-Business Engineering (ICEBE), Xi’an, China, 12–14 Oct 2018, pp. 54–61
Ritcher, F.: ChatGPT is the most tried AI tool and users stick to it (2023). Accessed 8 Sept 2023. https://www.statista.com/chart/30003/usage-of-ai-tools-in-the-united-states/
Pratas, J., Amorim, C., Reis, J.L.: Subscription retailing research evolution analysis using bibliometric indicators and content analysis. In: Reis, J.L., Del Rio Araujo, M., Reis, L.P., dos Santos, J.P.M. (eds.) Marketing and Smart Technologies. ICMarkTech 2022. Smart Innovation, Systems and Technologies, vol. 344 (2024). Springer. https://doi.org/10.1007/978-981-99-0333-7_10
Pratas, J., Oliveira, Z.: QR codes research in marketing: a bibliometric and content analysis. In: Reis, J.L., Peter, M.K., González, J., Bogdanovic, Z. (eds.) Marketing and Smart Technologies. ICMarkTech 2022. Smart Innovation, Systems and Technologies. Springer (2023)
Tahai, A., Meyer, M.: A revealed preference study of management journals’ direct influences. Strateg. Manag. J. 20 (3), 279–296 (1999). https://doi.org/10.1002/(SICI)1097-0266(199903)20:3<279::AID-SMJ33>3.0.CO;2-2
Egghe, L., Rousseau, R.: Co-citation, bibliographic coupling and a characterization of lattice citation networks. Scientometrics 55 , 349–361 (2002). https://doi.org/10.1023/A:1020458612014
Steinhoff, L., Arli, D., Weaven, S., Kozlenkova, I.: Online relationship marketing. J. Acad. Mark. Sci. 47 , 369–393 (2019). https://doi.org/10.1007/s11747-018-0621-6
McBreen, H., Jack, M.: Evaluating humanoid synthetic agents in e-retail applications. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 31 (5), 394–405 (2001). https://doi.org/10.1109/3468.952714
Keeling, K., McGoldrick, P., Beatty, S.: Virtual onscreen assistants: a viable strategy to support online customer relationship building? Adv. Consum. Res. 34 (6), 138–144 (2007)
De Cicco, R., Silva, S., Alparone, F.: Millennials’ attitude toward chatbots: an experimental study in a social relationship perspective. Int. J. Retail Distrib. Manag. 48 (11) (2020)
Ramadan, Z.: Alexafying shoppers: the examination of Amazon’s captive relationship strategy. J. Retail. Consum. Serv. 62 , 102610 (2021). https://doi.org/10.1016/j.jretconser.2021.102610
Schanke, S., Burtch, G., Ray, G.: Estimating the impact of humanizing customer service chatbots. Inf. Syst. Res. 32 (3) (2021). https://doi.org/10.1287/isre.2021.1015
Xing, X., Song, M., Duan, Y., Mou, J.: Effects of different service failure types and recovery strategies on the consumer response mechanism of chatbots. Technol. Soc. 70 , 102049 (2022). https://doi.org/10.1016/j.techsoc.2022.102049
Chopra, K.: Indian shopper stimulus to use artificial intelligence: generating Vroom’s expectancy theory of stimulus using grounded theory approach. Int. J. Retail Distrib. Manag. 47 (3), 331–347 (2019). https://doi.org/10.1108/IJRDM-11-2018-0251
Moriuchi, E., Landers, V., Colton, D., Hair, N.: Engagement with chatbots versus augmented reality interactive technology in e-commerce. J. Strateg. Mark. 29 (5), 375–389 (2021). https://doi.org/10.1080/0965254X.2020.1740766
Wu, J., Song, S., Whang, C.: Personalizing 3D virtual fashion stores: exploring modularity with a typology of atmospherics based on user input. Inf. Manag. 58 (4), 103461 (2021). https://doi.org/10.1016/j.im.2021.103461
Sreejesh, S., Sarkar, J., Sarkar, A.: Digital healthcare retail: role of presence in creating patients’ experience. Int. J. Retail Distrib. Manag. 50 (1), 36–54 (2022). https://doi.org/10.1108/IJRDM-12-2020-0514
Agarwal, P., Swami, S., Malhotra, S.: Artificial intelligence adoption in the post COVID-19 new-normal and role of smart technologies in transforming business: a review. J. Sci. Technol. Policy Manag. (2022). https://doi.org/10.1108/JSTPM-08-2021-0122
Billewar, S., Jadhav, K., Sriram, V., Arun, A., Abdul, S., Gulati, K., Bhasin, D.: The rise of 3D E-commerce: the online shopping gets real with virtual reality and augmented reality during COVID-19. World J. Eng. 19 (2), 244–253 (2022). https://doi.org/10.1108/WJE-06-2021-0338
Hussain, A., Abid, M., Shamim, A., Ting, D., Abu Toha, M.: Videogames-as-a-service: how does in-game value co-creation enhance premium gaming co-creation experience for players? J. Retail. Consum. Serv. 70 , 103128 (2023). https://doi.org/10.1016/j.jretconser.2022.103128
De Bellis, E., Johar, G.: Autonomous shopping systems: identifying and overcoming barriers to consumer adoption. J. Retail. 96 (1), 74–87 (2020). https://doi.org/10.1016/j.jretai.2019.12.004
Schmitt, B.: Speciesism: an obstacle to AI and robot adoption. Mark. Lett. 31 , 3–6 (2020). https://doi.org/10.1007/s11002-019-09499-3
Soderlund, M., Oikarinen, E., Tan, T.: The hard-working virtual agent in the service encounter boosts customer satisfaction. Int. Rev. Retail Distrib. Consum. Res. 32 (4) (2022). https://doi.org/10.1080/09593969.2022.2042715
Kamoonpuri, S., Sengar, A.: Hi, may AI help you? An analysis of the barriers impeding the implementation and use of artificial intelligence-enabled virtual assistants in retail. J. Retail. Consum. Serv. 72 , 103258 (2023). https://doi.org/10.1016/j.jretconser.2023.103258
Kautish, P., Khare, A.: Investigating the moderating role of AI-enabled services on flow and awe experience. Int. J. Inf. Manage. 66 , 102519 (2022). https://doi.org/10.1016/j.ijinfomgt.2022.102519
Rana, J., Gaur, L., Singh, G., Awan, U., Rasheed, M.: Reinforcing customer journey through artificial intelligence: a review and research agenda. Int. J. Emerg. Mark. 17 (7), 1738–1758 (2022). https://doi.org/10.1108/IJOEM-08-2021-1214
De Keyser, A., Kunz, W.: Living and working with service robots: a TCCM analysis and considerations for future research. J. Serv. Manag. 33 (2), 165–196 (2022). https://doi.org/10.1108/JOSM-12-2021-0488
Chen, J., Le, T., Florence, D.: Usability and responsiveness of artificial intelligence chatbot on online customer experience in e-retailing. Int. J. Retail Distrib. Manag. 49 (11), 1512–1531 (2021). https://doi.org/10.1108/IJRDM-08-2020-0312
Morotti, E., Donatiello, L., Marfia, G.: Fostering fashion retail experiences through virtual reality and voice assistants. In: 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Atlanta, GA, pp. 338–342 (2020). https://doi.org/10.1109/VRW50115.2020.00074
Roy, R., Naidoo, V.: Enhancing chatbot effectiveness: the role of anthropomorphic conversational styles and time orientation. J. Bus. Res. 126 , 23–34 (2021). https://doi.org/10.1016/j.jbusres.2020.12.051
Jiang, K., Qin, M., Li, S.: Chatbots in retail: how do they affect the continued use and purchase intentions of Chinese consumers? J. Consum. Behav. 21 (4), 756–772 (2022). https://doi.org/10.1002/cb.2034
Xu, Y., Zhang, J., Deng, G.: Enhancing customer satisfaction with chatbots: the influence of communication styles and consumer attachment anxiety. Front. Psychol. 13 , 902782 (2023). https://doi.org/10.3389/fpsyg.2022.902782
Download references
Author information
Authors and affiliations.
Instituto Superior de Contabilidade e Administração do Porto—Instituto Politécnico do Porto (ISCAP—IPP), Matosinhos, Portugal
Joaquim Pratas
Research Unit UNICES, Universidade da Maia, Maia, Portugal
Joaquim Pratas, Zaila Oliveira, Vera Carlos & José Luís Reis
Research Unit GOVCOPP, Universidade de Aveiro, Aveiro, Portugal
Research Unit N2i, Instituto Politécnico da Maia—IPMAIA, Maia, Portugal
Carla Amorim
Universidade da Maia—ISMAI, Maia, Portugal
Carla Amorim, Zaila Oliveira, Vera Carlos & José Luís Reis
Research Unit NECE, Universidade da Beira Interior, Covilhã, Portugal
Vera Carlos
Research Unit LIACC, FEUP, University of Porto, Porto, Portugal
José Luís Reis
Centro de Estudos Organizacionais e Sociais do Politécnico do Porto, CEOS.PP, Matosinhos, Portugal
Instituto Politécnico da Maia, IPMAIA, Maia, Portugal
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Joaquim Pratas .
Editor information
Editors and affiliations.
University of Maia—UMAIA, Maia, Portugal
University College Prague, Praha, Czech Republic
Jiří Zelený
Technical University of Košice, Košice, Slovakia
Beáta Gavurová
José Paulo Marques dos Santos
Rights and permissions
Reprints and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper
Cite this paper.
Pratas, J., Amorim, C., Oliveira, Z., Carlos, V., Reis, J.L. (2024). Retail Chatbots’ Main Themes and Research over Time: A Bibliometric and Content Analysis. In: Reis, J.L., Zelený, J., Gavurová, B., Santos, J.P.M.d. (eds) Marketing and Smart Technologies. ICMarkTech 2023. Smart Innovation, Systems and Technologies, vol 386. Springer, Singapore. https://doi.org/10.1007/978-981-97-1552-7_7
Download citation
DOI : https://doi.org/10.1007/978-981-97-1552-7_7
Published : 04 June 2024
Publisher Name : Springer, Singapore
Print ISBN : 978-981-97-1551-0
Online ISBN : 978-981-97-1552-7
eBook Packages : Engineering Engineering (R0)
Share this paper
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Glob Qual Nurs Res
- v.9; Jan-Dec 2022
Developing a Feasible and Credible Method for Analyzing Healthcare Documents as Written Data
Tanja moilanen.
1 University of Turku, Finland
Mari Sivonen
2 Karelia University of Applied Sciences, Joensuu, Finland
3 Häme University of Applied Sciences, Finland
Hanna Kallio
Oili papinaho.
4 Oulu University Hospital, Finland
Minna Stolt
Riitta turjamaa.
5 Savonia University of Applied Sciences, Kuopio, Finland
Arja Häggman-Laitila
6 University of Eastern Finland, Kuopio, Finland
7 Department of Social Services and Health Care, Helsinki, Finland
Mari Kangasniemi
Healthcare provides a rich, and constantly increasing, number of written documents, which are underutilized in research data for health and nursing sciences, but previous literature has only provided limited guidance on the process of document analysis. The aim of this paper is to provide a methodological framework for analyzing health care documents as written data, based on a systematic methodological review and the research team’s experience of the method. Based on the results, the methods consist of seven phases: (i) identify the purpose, (ii) determine the document selection strategy, (iii) select or design an extraction matrix, (iv) carry out pilot testing, (v) collect and analyze the data, (vi) consider the credibility, and (vii) ethics of the study. The framework that has been developed can be used to carry out document analysis studies that are both feasible and credible.
Introduction
Document analysis is a topical method used in health and nursing sciences. Written, audio, and visual healthcare documents are constantly being produced ( Bowen, 2009 ; Coffey, 2014 ; Gibson & Brown, 2011 ) and the number of documents is increasing ( Olivares Bøgeskov & Grimshaw-Aagaard, 2019 ), because of wider healthcare regulations and the need to evaluate the effectiveness of care and services. Most of these healthcare documents are publicly available. The strength is that researchers have had no influence on their production, but the limitation is that data in healthcare documents have not been produced for research purposes ( Bowen, 2009 ; Gross, 2018 ; Miller & Alvarado, 2005 ; Olson, 2012 ) However, healthcare documents can provide knowledge that cannot be obtained by other methods. Document analysis is also a topical research method, because of the increased production of digital healthcare documents and the use of artificial intelligence to carry out data mining in health sciences ( Mehta & Pandit, 2018 ; Sundermann et al., 2019 ). Despite the topicality of the document analysis method, previous methodological literature have only proposed fragmented guidance on this research method ( Bowen, 2009 ; Miller & Alvarado, 2005 ).
Document analysis refers to a systematic process of reviewing and analyzing documents ( Kaae & Traulsen, 2015 ; Mercieca et al., 2019 ). It has been used as an independent method and has also been combined with other research methods ( Bowen, 2009 ; Olson, 2012 ; Siegner et al., 2018 ). The advantage of document analysis is that it can produce new and trustworthy knowledge ( Bowen, 2009 ; Gibson & Brown, 2011 ; Siegner et al., 2018 ) on study topics that cannot be empirically studied ( Bowen, 2009 ; Siegner et al., 2018 ), but the disadvantage is that usually the documents requires pre-working and multiple research skills ( Bowen, 2009 ).
This review regards healthcare documents as written data that have been produced, or used, to steer, organize, and implement care and services. For example, international and national steering documents aim to regulate and ensure the quality and availability of services ( Ritter et al., 2018 ) and to support the management and organization of healthcare. On an organizational level, healthcare documents have been used to regulate and guide the implementation of practices that aim to ensure conformity and quality of services. When it comes to implementation, documents have been used to plan, record, and evaluate care ( Olivares Bøgeskov & Grimshaw-Aagaard, 2019 ; Walker et al., 2018 ).
Healthcare documents can be official or unofficial ( Coffey, 2014 ; Gibson & Brown, 2011 ). Most healthcare documents are official responses to legislative requirements or stakeholders’ rights. They can comprise patient records, national and organizational health plans, and annual reports, but also include complaints from clients and patients. One example of unofficial documents is instructions for care practices. In addition, the security level of healthcare documents varies. For example, public health plans and national care guidelines are publicly available, complaints or disciplinary decisions related how healthcare staff are managed are classified. Also, the structure of the document data may provide heterogeneity within, and between, the documents. For example, client complaints can be structured, but also include free, manual text.
The aim of this paper is to provide a methodological framework for analyzing health care documents as written data, based on a systematic methodological review and the research team’s experience of the method. The ultimate aim was to identify the different phases of the document analysis method and the feasibility and credibility of this research process.
We used systematic methodological review design by applying the theory review method ( Campbell et al., 2014 ) with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses checklist ( Martín-Rodero et al., 2018 ; Moher et al., 2009 ) to identify previous methodological literature on document analysis. In addition, we used our experience of carrying out 14 studies using document analysis to examine the feasibility and credibility of the method. These document analyses employed qualitative and quantitative methods and used documents such as patient records or plans ( Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 , 2019 , 2020 ; Hipp et al., 2020 , 2021 ; Puustinen et al., 2021 ; Toivonen et al., 2020 ; Turjamaa et al., 2015 ), healthcare steering documents ( Kallio et al., 2018 , 2020 ), clients’ complaints ( Kangasniemi et al., 2022 ), and administrative healthcare decisions ( Papinaho et al., 2021 , 2022 ).
Search Methods
The literature searches were conducted ( Campbell et al., 2014 ) using the CINAHL, PsycInfo, PubMed, Scopus, SocInde, and Web of Science databases ( Figure 1 ). We determined the search terms by carrying out preliminary searches and consulting an information specialist and used the same search terms in the all databases. We limited the searches to scientific papers and book chapters that were published in the electronic databases from inception to May 2021 and had an abstract available. To make sure that our searches were comprehensive, we used general search terms as document analys * OR documentary analys * which were identified based on our preliminary searches. In addition, we also carried out manual searches of the reference lists of the selected papers. The electronic searches and the screening of reference lists were both limited to scientific papers and book chapters.

Flow chart of the literature searches and selection.
The database searches identified 17,021 publications. According to the inclusion and exclusion criteria, we selected 53 papers based on their title and abstract and 10 on their full text ( Figure 1 ). A further 10 papers were identified by the manual searches of the reference lists, and this meant that the final analysis comprised 20 publications. The selection of the publications was independently conducted by three authors (TM, MS, and MK), who then worked together to finalize the list.
The publications were selected based on predetermined inclusion and exclusion criteria ( Campbell et al., 2014 ). The inclusion criteria were that document analysis or corresponding methods were mentioned in the title and that abstract focused on document analysis. The inclusion criteria for the full texts were that document analysis was the target of the paper. Papers were excluded if they had used document analysis as a research method, but the study focused on an empirical subject. We did not limit what disciplines were covered by the publications.
Search Outcomes
The 20 publications that we selected were published between 1981 and 2018 and comprised 12 scientific papers and 8 book chapters. As a concept, 11 used document analysis, 3 documentary analysis and documentary research, 2 the analysis of documentary realities or sources, and 1 documentary method. There were 18 literature-based discussions, 1 review, and 1 commentary. About 6 of the 11 papers came from the United Kingdom, 3 from the USA, and 2 from Australia and Canada. Seven of the eight book chapters did not include any information on the country or origin and the one that did come from the United Kingdom. About 5 of the 11 papers covered health science, 5 social science, and 1 marketing. Nine papers did not specify the discipline ( Table 1 ).
Description of the Selected Publications.
Note . ns = not stated.
Data Analysis and Synthesis
The selected publications were read several times to gain an overall understanding of them. The titles, aims, methods, and main results were then tabulated ( Campbell et al., 2014 ). The content of the publications were analyzed using the constant comparison method ( Boeije, 2002 ; Olson, 2012). First, all the expressions about the document analysis method were extracted from the data and these were a couple of words, sentences, or paragraphs. After that, we grouped expressions about the different phases of document analysis, and questions on rigor and ethics, based on their similarities and differences. During this phase, we incorporated our methodological experiences and findings based on the 14 scientific, peer-reviewed papers published by our team and used them to illustrate and elaborate different phases of the document analysis. We synthesized the data by naming the phases inductively. Because the wording and terminology used in expressions varied, we constantly compared the original text in the publications to preserve the original meaning of the expressions. After the process of document analysis was formulated, we illustrated the phases based our previous experiences of using the document analysis method.
Our results indicated that the rigorous document analysis process consists of seven interlinked phases ( Figure 2 ). Although the phases are presented separately, they can simultaneously overlap with each other and two phases were integrated with the other five.

Phases of document analysis.
First Phase: Determining the Purpose, Data, and Study Design
The first phase of document analysis is to determine the purpose of the study and the data sources to be used by the study ( Figure 2 ). The aim of this phase is to indicate any gaps in current knowledge and identify documents that can be used for research purposes. Document analysis aims to identify or clarify knowledge ( Bowen, 2009 ; Gross, 2018 ; Olson, 2012 ; Siegner et al., 2018 ) by analyzing, synthetizing, or interpreting the study topic. In addition, the aim can be to describe or explain the meanings, patterns ( Kaae & Traulsen, 2015 ), classifications, or processes of the study topic. Document analysis produces retrospective knowledge ( Gibson & Brown, 2011 ; Gross, 2018 ; Olson, 2012 ), which enables us to track and understand changes and developments ( Bowen, 2009 ; Gross, 2018 ; O’Connor, 2011 ) in current or future healthcare needs ( Atkinson & Coffey, 2010 ; Bowen, 2009 ) and in healthcare organizations or social settings ( Coffey, 2014 ; Mercieca et al., 2019 ).
The research questions in document analysis can be either pre-determined or exploratory , depending on the information that is available. Pre-determined research questions are appropriate if there is previous scientific knowledge and sufficient information on the data that the contents of documents can provide ( Kallio et al., 2018 , 2020 ; Puustinen et al., 2021 ). Information or access may be unavailable before the data collection if highly confidential or sensitive data are involved. This means that the research questions are exploratory during this phase and can only be specified after an overview of the entire data has been obtained ( Häggman-Laitila et al., 2019 , 2020 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ). Determining the research questions and data can be based on previous studies and by consulting responsible authorities ( Appleton & Cowley, 1997 ) who hold relevant data or experts and practitioners engaged in the study topic. In addition, an empirical field study can be carried out to acquire sufficient knowledge to determine the research question.
It is important to identify the most relevant characteristics of the data provided by the documents used in any analysis. This includes evaluating whether the type ( Atkinson & Coffey, 2010 ; Gorichanaz & Latham, 2016 ) or form ( Appleton & Cowley, 1997 ; Kaae & Traulsen, 2015 ; Platt, 1981 ) of document is suitable for the study and the document’s author and/or audience. This phase includes providing reasons to justify the use of selected documents in the analysis, by identifying available and potentially suitable documents and any bias they may have (see phase 6). Justifying the use of documents is also crucial when using highly protected or sensitive data, such as complaints from clients and patients or official investigations ( Bowen, 2009 ; Häggman-Laitila et al., 2019 , 2020 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ).
The study design in the document analysis can be cross-sectional, longitudinal, or a case report, depending the purpose of the study and the documents that are available. In addition, document analysis can be conducted with different methodological approaches ( Bowen, 2009 ; Gross, 2018 ; Kaae & Traulsen, 2015 ; O’Connor, 2011 ). Qualitative methods are applicable when the purpose is to understand and describe emerging patterns, categories, or themes on the study topic ( Coffey, 2014 ; Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 ; Kaae & Traulsen, 2015 ; Miller & Alvarado, 2005 ). Quantitative methods can be used to describe statistics or interpret phenomenon ( Häggman-Laitila et al., 2019 , 2020 ; Hipp et al., 2020 , 2021 ; Olson, 2012 ; Toivonen et al., 2020 ).
Document analysis can have different focuses , depending on the study purpose ( Atkinson & Coffey, 2010 ; Coffey, 2014 ; Finnegan, 2011 ; Gorichanaz & Latham, 2016 ). First, it can be used to understand documents and their content in a specific context, such as an analysis of healthcare steering documents ( Papinaho et al., 2021 , 2022 ). For example, the analysis can focus on how the documents relate to real-life practical healthcare ( Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 , 2019 , 2020 ; Toivonen et al., 2020 ). This can include examining the philosophical aspects of documents, such as the role they play in cultural settings ( Coffey, 2014 ; Finnegan, 2011 ; Gorichanaz & Latham, 2016 ) and what emotions they generate ( Gorichanaz & Latham, 2016 ). Second, document analysis can focus on the intra- or intertextuality of the documents ( Atkinson & Coffey, 2010 ; Gorichanaz & Latham, 2016 ), by highlighting the similarities and differences ( Atkinson & Coffey, 2010 ; Finnegan, 2011 ) of the document in relation to others. Third, the analysis can focus on the social aspects of the documents, such as how they are produced, stored, and used ( Atkinson & Coffey, 2010 ; Finnegan, 2011 ; Gorichanaz & Latham, 2016 ).
Second Phase: Determining the Selection Strategy
The second phase of the document analysis process is to determine the document selection strategy, based on the research purpose ( Gross, 2018 ; O’Connor, 2011 ). The aim of this phase is to set limits on what is analyzed so that representative and unbiased data can be produced ( Figure 2 ).
The time limitations for the selection need to be set and decisions need to be made about the sampling strategy and whether this should be total, random, or purposeful ( Miller & Alvarado, 2005 ). If purposeful sampling is used, then researchers have to decided how, and when, the data saturation will be identified ( Finnegan, 2011 ; Miller & Alvarado, 2005 ; Scott, 2011 ; Siegner et al., 2018 ). The third decision is to make decisions about the entity of document , because a document can comprise several parts or attachments ( Gorichanaz & Latham, 2016 ). For example, the entity of a steering document produced by a ministry can be only be one document ( Kallio et al., 2018 ) but patients records ( Häggman-Laitila et al., 2019 , 2020 ; Hipp et al., 2020 , 2021 ; Toivonen et al., 2020 ) or clients’ complaints may comprise several sheets ( Kangasniemi et al., 2022 ). These sheets, or the parts of a document, can have an equal or hierarchical relation to each other. For example, when possible disciplinary cases are investigated, the file usually contains an administrative decision as well as the investigative material used to reach that decision ( Papinaho et al., 2021 , 2022 ). The fourth decision is to determine the inclusion and exclusion criteria for the content of the document ( Bowen, 2009 ; O’Connor, 2011 ), to ensure credible responses to the research questions. The criteria can relate to the scope, form, or expressions of information in the documents.
Third Phase: Selecting or Developing the Extraction Matrix
The aim of the third phase is to select, or develop, the extraction matrix so that this provides a credible tool for systematically recording and extracting document data ( Bowen, 2009 ; Gibson & Brown, 2011 ; Hall & Rist, 1999 ; Kaae & Traulsen, 2015 ; Figure 2 ). The content and structure of the extraction matrix depends on the purpose of the study, previous knowledge on the topic, and the content and form of the documents that are used. The extraction matrix can include structured, semi-structured, or open-ended items that can be used to extract data for the qualitative and/or quantitative analysis of the documents. The extraction matrix can be an existing , previously published structure for data extraction, such as existing care classifications ( Puustinen et al., 2021 ). In addition, the structure of certain existing documents, such as patient records, can be used as an extraction matrix.
Deductive or inductive development strategies can be used if an existing extraction matrix is not available or suitable. A deductive development strategy can be used to develop an extraction matrix that is based on previous knowledge, using either a systematic review method or systematic literature searches. If previous knowledge is limited, or unavailable, experts in the field can be consulted as part of the development process ( Häggman-Laitila et al., 2019 , 2020 ; Hipp et al., 2020 , 2021 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ). For example, we consulted relevant authorities when we developed an extraction matrix to study administrative decisions related to unprofessional conduct. During this phase there may be several questions about the extraction matrix and it can be used as a preliminary method of data extraction. The number of items can then be reduced during the pilot phase of the data collection ( Hipp et al., 2020 , 2021 ; Papinaho et al., 2021 , 2022 ).
An inductive development strategy can be used for the extraction matrix if previous literature is not available, the purpose of study is to provide a new point of view or if the structure of the documents are the same or not known. The first step in developing an inductive extraction matrix is to understand the entire data, then develop the items using a thematic or category-based strategy ( Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 ). For example, we used an inductive development strategy for a study on clients’ complaints, because of the heterogeneity of the structure of the documents and the content of the complaints. This method can be combined with a deductive-inductive strategy ( Kangasniemi et al., 2022 ).
Fourth Phase: Pilot Testing the Selection Strategy and Extraction Matrix With Sub-Data
The fourth phase is to pilot test the selection strategy and extraction matrix, to ensure rigor and consistent data extraction. The time limitations, sampling strategy, and decisions about the entirety of the document and the inclusion and exclusion criteria can be elaborated at this stage and the extraction matrix can be modified. This includes removing potential overlapping or repetitive items ( Kangasniemi et al., 2022 ). In addition, the deductive extraction matrix and item pool can be reduced, according to the document data. Pilot testing with a sub-sample of the documents has been suggested ( Gross, 2018 ) and we have found that approximately 10% of the data is needed to confirm the feasibility of the extraction matrix. After the inclusion and exclusion criteria and the extraction matrix have been elaborated and modified they can be used for the entire data ( Hipp et al., 2020 , 2021 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ).
Fifth Phase: Collecting and Analyzing the Data
Data collection is the fifth phase of document analysis ( Figure 2 ) and the aim of the analysis depends on the research question and chosen approach.
Qualitative document analysis
If qualitative methods are going to be used for document analysis, the first step is to read the entire data to get an overall understanding of it ( Appleton & Cowley, 1997 ; Bowen, 2009 ). Then the analysis units, and their focus and form, can be determined. These can be a word, sentence, or entire passage of text ( Bowen, 2009 ). The qualitative, inductive analysis of documents is an iterative process that combines elements from qualitative content analysis and thematic analysis. This analysis may require some level of interpretation ( Atkinson & Coffey, 2010 ; Bowen, 2009 ; Caulley, 1983 ; Finnegan, 2011 ; Gross, 2018 ; Kaae & Traulsen, 2015 ; Miller & Alvarado, 2005 ), if the words or terms are inconsistent in the documents ( Gross, 2018 ). The analysis aims to organize information into categories based on patterns and themes emerging from the data ( Bowen, 2009 ; Caulley, 1983 ; Gross, 2018 ; Miller & Alvarado, 2005 ; Murray & Sixsmith, 2002 ; O’Connor, 2011 ; Rasmussen et al., 2012 ). This requires focused re-reading and reviewing of the selected documents ( Bowen, 2009 ) with constant comparison ( Bowen, 2009 ; Gross, 2018 ; Olson, 2012 ) to organize it so that similar themes are clustered together ( Bowen, 2009 ). The analysis is completed, when the evidence from the documents create a consistent picture of themes. However, other qualitative methods can also be used for analyzing the data, such as grounded theory ( Bowen, 2009 ; Gross, 2018 ; Murray & Sixsmith, 2002 ) or discourse analysis ( Coffey, 2014 ; Gross, 2018 ; Murray & Sixsmith, 2002 ; O’Connor, 2011 ; Siegner et al., 2018 ).
When using an extraction matrix in qualitative analysis , the analysis units will be collected according to the matrix. After the entire data has been extracted, the items in the matrix can be reorganized, or combined in the categories and again in the categories as long as the condensation is needed ( Kallio et al., 2018 , 2020 ).
Quantitative document analysis
When using extraction matrix for quantitative analysis, the data can be collected ( Bowen, 2009 ; Caulley, 1983 ) to enable systematic analysis. The numerical data need to be collected according to the structured items in the extraction matrix and analyzed using statistical methods ( Hipp et al., 2020 , 2021 ; Papinaho et al., 2021 , 2022 ).
If the matrix includes structured, semi-structured, and open-ended items for verbal text collection, the expressions in the text are extracted to the matrix. After the entire data has been extracted, the text in the items need to be reduced, and condensed to variables. In addition, the items can be coded in numerical form, so that a statistical analysis can be conducted ( O’Connor, 2011 ; Siegner et al., 2018 ).
Sixth (Integrated) Phase: Ensuring Rigor of the Study
The sixth phase is the ensuring rigor of the document analysis ( Figure 2 ). It is an integrated phase that should be carried out and reflected throughout the document analysis process. The aim is to decrease potential bias during the document selection and analysis phases.
Rigor of the type of the documents
Purpose bias needs to be assessed because healthcare documents have been produced for specific, defined purposes ( Bowen, 2009 ; Gross, 2018 ; Murray & Sixsmith, 2002 ; Platt, 1981 ), and audiences ( Atkinson & Coffey, 2010 ; Bowen, 2009 ; Coffey, 2014 ; Finnegan, 2011 ; Gibson & Brown, 2011 ; O’Connor, 2011 ). Bias can relate to the document’s position on an issue, whether it relates to regulations and how formal it is. In addition, the purpose of the document can influence the content, structure, and the terminology that is used. For example, healthcare documents can be based on legal requirements, but their purposes can vary because of the different roles of the organizations that produce them. They can include health plans, statements, or organizational programs that aim to steer regional, national, or international health policies ( Kallio et al., 2018 ), patient records or plans that record whether patients’ rights have been exercised ( Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 , 2019 , 2020 ; Puustinen et al., 2021 ; Toivonen et al., 2020 ; Turjamaa et al., 2015 ), and client or patient complaints about their rights or dissatisfaction with their care ( Kangasniemi et al., 2022 ). In addition, care orders for children ( Häggman-Laitila et al., 2010 , 2019 , 2020 ; Toivonen et al., 2020 ) and disciplinary decisions by national regulatory authorities that restrict how healthcare professionals can practice ( Papinaho et al., 2021 , 2022 ) are based on legal requirements. The strength of legislation-based documents is that they provide structured content, within and among documents, but the purpose of the document may restrict or reduce descriptions of the content. Also, the aim of documents can be to demonstrate their activities or developmental work to funders or organizations ( Kallio et al., 2018 , 2020 ) or describe desired practices as a result of care guidelines. The purpose and consequences of documents need to be considered during the selection, analysis, and reporting phases of document analysis.
Author bias also needs to be considered. Healthcare documents can be written by an individual person, a team of authors, or organizations who may place a particular emphasis on certain aspects of an issue ( Atkinson & Coffey, 2010 ; Bowen, 2009 ; Gibson & Brown, 2011 ; Gross, 2018 ; Murray & Sixsmith, 2002 ; Scott, 2011 ). The documents can reflect the consensus reached by authors or organizations or include contributions by a number of professionals, such as in patients’ records ( Häggman-Laitila, 2003 ; Häggman-Laitila et al., 2010 , 2019 , 2020 ; Hipp et al., 2020 , 2021 ; Puustinen et al., 2021 ; Toivonen et al., 2020 ; Turjamaa et al., 2015 ) or in different parts of a document’s entity ( Papinaho et al., 2021 , 2022 ). The author or authors can reflect official authority or professional viewpoints, as in steering documents, patient records, or annual reports. Alternatively, they can reflect the views of private individuals, such as clients or patients complaining about care or healthcare professionals responding to regulatory authorities during official investigations into their conduct. Official state documents have been regarded as more credible than private documents ( Hall & Rist, 1999 ; Scott, 2011 ), because they have produced by organizations where individuals’ opinions have been minimized ( Scott, 2011 ). Author bias must also take account of the competencies or awareness ( Caulley, 1983 ; Miller & Alvarado, 2005 ; O’Connor, 2011 ) of individual authors and how they can vary within or between documents. For example, patient records are usually written by different healthcare professionals with varying education and sometimes the authors of documents can be difficult to establish ( Atkinson & Coffey, 2010 ; Scott, 2011 ). Author bias can also result from using second-hand reports on documents instead of the original texts ( Murray & Sixsmith, 2002 ).
Conflict of interest bias needs to be considered and this can relate to who funded a healthcare documents and what influence they may have had on the process ( Gibson & Brown, 2011 ).
Rigor of document selection and analysis
Selection bias can be linked to the databases that were used to create a document or to selections made by researchers. The way that electronic or manual databases or document storage are described, catalogued, or indexed can affect the accuracy of searches ( Caulley, 1983 ; Gross, 2018 ; Miller & Alvarado, 2005 ). Selection bias can also exist because of the limited availability of documents ( Appleton & Cowley, 1997 ; Bowen, 2009 ; Gross, 2018 ; Miller & Alvarado, 2005 ; Olson, 2012 ; Platt, 1981 ; Scott, 2011 ), as some are archived, but others are not retained ( Appleton & Cowley, 1997 ; Bowen, 2009 ; Murray & Sixsmith, 2002 ; Scott, 2011 ; Sixsmith & Murray, 2001 ). Researchers can cause selection bias if the inclusion or exclusion criteria for cataloguing documents in archives or databases are unclear or inconsistent ( Caulley, 1983 ; Gross, 2018 ; Miller & Alvarado, 2005 ). In addition, selection bias can occur if researchers only select or pinpoint data that support their own models and theories ( Gross, 2018 ; Murray & Sixsmith, 2002 ). Researchers need to consider whether the selected data meets the study purpose and is sufficient to provide answers to the research questions. In addition, selection bias can be reduced by consistent selection throughout the data collection process. For example, the pre-defined inclusion and exclusion criteria can be pilot tested ( Hipp et al., 2020 , 2021 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ) and two or more researchers can work together to double-check the data that are selected ( Häggman-Laitila et al., 2019 , 2020 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ).
Data bias can result from document characteristics, as they can vary in structure, length, and content and provide varying amounts, and quality of, data for the analysis. Documents can also include inaccuracies, such as faults, deceptions, or translation errors ( Appleton & Cowley, 1997 ; Caulley, 1983 ; Gibson & Brown, 2011 ; Hipp et al., 2021 ; Kallio et al., 2018 , 2020 ; Murray & Sixsmith, 2002 ; Scott, 2011 ). This means that the data in documents can be unbalanced, and provided at different levels, which can complicate the analysis. Documents can include edited or unedited text ( Bowen, 2009 ; Gibson & Brown, 2011 ; Olson, 2012 ) or form part of a larger text series ( Gibson & Brown, 2011 ; O’Connor, 2011 ). Text can also be based on underlying assumptions or hidden agendas ( Appleton & Cowley, 1997 ; O’Connor, 2011 ).
Interpretation bias can occur if documents are studied without considering their context ( Appleton & Cowley, 1997 ) or treated as an accurate and complete record ( Bowen, 2009 ; Coffey, 2014 ). Interpretation bias can also occur if the researchers are not familiar with the expressions in the text ( Caulley, 1983 ; Hall & Rist, 1999 ; Murray & Sixsmith, 2002 ; Platt, 1981 ), concepts vary or there are different political views within or between documents. Double-checking the data coding phase can decrease interpretation bias.
Reporting bias can result from inconsistent descriptions of the document analysis process, including determination ( Siegner et al., 2018 ) and justification of the use of the document analysis method ( O’Connor, 2011 ; Siegner et al., 2018 ). In addition, it can occur because of the way the research data are selected and described, the analysis and interpretation of the documents, and any potential biases and measures taken to address them.
Seventh (Integrated) Phase: Method Specific Research Ethics
The seventh, integrated, phase of the document analysis process is to reflect on the method specific research ethics of the study process ( Figure 2 ; Kaae & Traulsen, 2015 ). It is noteworthy that ethical consideration is an integrated phase throughout the document analysis process, starting from the planning of the study.
Research permission or organizational approval are often needed for the document analysis method ( Caulley, 1983 ; Murray & Sixsmith, 2002 ; Sixsmith & Murray, 2001 ) and this has to be evaluated in relation to how public the data is, who owns the data, and how the results will be presented. For example, research permission is not usually needed for data that are published on organizations’ web pages or in public documents ( Kallio et al., 2020 ). However, researchers need to consider whether an organization should be informed if the data in their publicly available documents will be used or presented as a case study. Research permission and ethical reviews are needed when using secure or classified documents as research data ( Häggman-Laitila et al., 2019 , 2020 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ). The organization or the holder of the protected data, such as patient records, may specify that each individual patient needs to give their informed consent for their data to be used ( Hipp et al., 2020 , 2021 ). In addition, it can be challenging when permission is restricted to certain unseen documents that do not contain the data that are required.
Commitments to non-disclosure agreements are important when highly secured or classified documents are used for research data. The holder of the data may require researchers to agree to non-disclosure statements that guarantee confidentiality. In addition, special arrangements for data collection can include the use of secured computers or the requirement to collect the data on the organization’s premises under supervision ( Häggman-Laitila et al., 2019 , 2020 ; Kangasniemi et al., 2022 ; Papinaho et al., 2021 , 2022 ; Toivonen et al., 2020 ). Thus, the ethical discussion of document analysis includes reports of potential non-disclosure agreements and how they have been implemented.
Protecting anonymity and privacy must also be considered during document analysis ( Murray & Sixsmith, 2002 ; Sixsmith & Murray, 2001 ). These can relate to individual data and data sources, but may also relate to document producers, target audiences, organizations, and health districts and emphasize the anonymity of minority groups, such as by gender, sexual orientation, or ethnicity. Special attention needs to be paid to confidential data, which may require extra steps to protect anonymity, for example by changing identifying information. In addition, researchers also need to consider whether it is necessary to anonymize publicly available data ( Kallio et al., 2018 , 2020 ).
Our theory review of previous methodological literature indicated that there was no systematic description of the document analysis method for healthcare documents as written data. The seven phases of the document analysis method presented in this paper follow methodological tradition, from determining the purpose of a study to reflecting on the research ethics ( Gray et al., 2016 ). It is noteworthy that there was very little information on the formulation of research questions, the development of extraction matrixes, and the systematic consideration of bias and ethical questions during the document analysis research process. However, these phases are crucial in relation to the credibility of the study. In addition, a rigorous extraction matrix is crucial to demonstrate how the knowledge is produced. In addition, the precisely reported development of extraction matrixes will enable them to be used in other studies. This will make it much easier to examine longitudinal or comparative findings on the same research topics.
The document analysis method also has its limitations. Healthcare documents are often produced for a specific context and influenced by national health policy and legislation ( Flaumenhaft, & Ben-Assuli, 2018 ). They also depend on authorities or professionals having the required competencies and resources to prepare documents ( Alonso et al., 2020 ; De Groot et al., 2019 ). The purpose, content, or storage of documents can also be regulated, which can hinder the rigor of document analysis ( Bowen, 2009 ). In addition, documents are usually structured, prioritized, and interpreted at least once and they provide indirect descriptions of empirical reality. However, the transparent and systematic reporting of data and selection biases strengthen the rigor and use of the results produced by the document analysis method.
Health science researchers need to pay more attention to the document analysis method in the future. Healthcare documents increasingly provide rich data that focus on multiple target audiences and perspectives and this can deepen our understanding of different aspects of health and healthcare. This enables researchers to study topics that would be otherwise out of reach and makes longitudinal study designs easily available. However, current and future healthcare documents need to be critically analyzed to identify whether they are credible for research data. For example, developing categories that assess the reliability of documents in relation to their availability, legal status, formality, and the dependability of their authors, would help researchers to make informed selections about document data. The synthesized categorization of documents would support digital data pools in healthcare and enable comparative research to be carried out on national and international levels. In future, multi-professional collaboration with healthcare providers is needed during the planning phases of healthcare documents. This would help to identify all potential healthcare documents that could also be used for research. It would also identify how future documents could provide content that increased the information needed to evaluate the quality and effectiveness of healthcare.
In addition, using existing data from documents also supports the social and environmental sustainability of research, by minimizing disturbing healthcare professionals and patients, and decreasing the environmental burdens of data collection ( Patel et al., 2020 ). The increasing number of documents being produced, their characteristics and the development of new research methods is rapidly changing the research context of document analysis. We expect that, in the future, artificial intelligence and data mining will be able to provide knowledge that is unreachable by traditional methods ( Mehta & Pandit, 2018 ; Sundermann et al., 2019 ). In addition, increasing use and availability of big data will provide a data source for document analysis method but also challenge methodological development of document analysis in the future. However, methodological starting points needs to be rigorous and repeatable ( Caulley, 1983 ), regardless of the data collection and analysis methods ( Bowen, 2009 ; Siegner et al., 2018 ). Our rigorous process for document analysis provides a basis for studies that use documents as research data.
Limitations
There are some strengths and limitations to consider when interpreting the study findings. The theory review method was used ( Campbell et al., 2014 ), because there was no review method available for theoretical and methodological papers. To strengthen the reliability of this study, we have reported the search strategy, including the combination of search words and the inclusion and exclusion criteria. In addition, the search query parameters were formulated in collaboration with an information specialist, to decrease the search bias. However, as we only limited our searches to publications in English, this may have caused language bias ( Martín-Rodero et al., 2018 ). We conducted both electronic and manual searches to decrease publication bias. We included book chapters that were available on the electronic databases or identified based on the reference lists of the selected papers. Thus, there is a risk that other suitable chapters may not have been identified. The papers were selected by three independent researchers to strengthen the quality and trustworthiness of the study but the use of screening software would have decreased the human error of selection. We also used the Preferred Reporting Items for Systematic Reviews and Meta-Analyses checklist to verify the comprehensiveness of our review ( Martín-Rodero et al., 2018 ; Moher et al., 2009 ). However, the quality of the reviewed publications was not evaluated, due to the lack of specific criteria for methodological papers and book chapters.
The increasing number of healthcare documents provides an important source of scientific knowledge, but the scientific use of multiple documents requires systematic and transparent methods. Previous methodological literature, have not provided a systematic description of the document analysis process and little attention has been paid to formulating research questions, developing extraction matrixes, and the systematic consideration of bias and ethics. The seven-phrase document analysis method developed by this study can be used to carry out, and evaluate, document analysis studies and it contributes to the feasibility and credibility of the method. A rigorous process for document analysis method is needed to strengthen the potential, and use, of knowledge on what healthcare documents can provide in the future.
Author Biographies
Tanja Moilanen , RN, PhD is a Postdoctoral researcher at the University of Turku, Faculty of Medicine, Department of Nursing Science, Turku, Finland.
Mari Sivonen , RN, MNSc, is a lecturer at the Karelia University of Applied Sciences, Joensuu, Finland.
Kirsi Hipp , RN, PhD is a principal research scientist at the Häme University of Applied Sciences, Hämeenlinna, Finland.
Hanna Kallio , PN, PhD, is a postdoctoral researcher at the University of Turku, Faculty of Medicine, Department of Nursing Science, Turku, Finland.
Oili Papinaho , RN, PhD candidate is a PhD researcher at the at the University of Turku, Faculty of Medicine, Department of Nursing Science, Turku, Finland and education coordinator at the Oulu University Hospital, Oulu, Finland.
Minna Stolt , Podiatrist, PhD, Docent is a university lecturer at the University of Turku, Faculty of Medicine, Department of Nursing Science, Turku, Finland.
Riitta Turjamaa , RN, PhD is a senior lecturer in nursing at the Savonia University of Applied Sciences, Kuopio, Finland.
Arja Häggman-Laitila RN, PhD is a professor at the University of Eastern Finland, Faculty of Health Sciences, Department of Nursing Science, Kuopio, Finland and chief nursing officer at the Department of Social Services and Health Care, City of Helsinki, Helsinki, Finland.
Mari Kangasniemi , RN, PhD is a professor at the University of Turku, Faculty of Medicine, Department of Nursing Science, Turku, Finland and the Satakunta Hospital District, Pori, Finland.
Declaration of Conflicting Interests: The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding: The authors received no financial support for the research, authorship, and/or publication of this article.

- Alonso V., Santos J. V., Pinto M., Ferreira J., Lema I., Lopes F., Freitas A. (2020). Health records as the basis of clinical coding: Is the quality adequate? A qualitative study of medical coders’ perceptions . Health Information Management Journal , 49 ( 1 ), 28–37. 10.1177/1833358319826351 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Appleton J. V., Cowley S. (1997). Analysing clinical practice guidelines. A method of documentary analysis . Journal of Advanced Nursing , 25 ( 5 ), 1008–1017. https://doi:10.1046/j.1365-2648.1997.19970251008.x [ PubMed ] [ Google Scholar ]
- Atkinson P., Coffey A. (2010). Analysing documentary realities . In Silverman D. (Ed.), Qualitative research (pp. 56–76). SAGE. [ Google Scholar ]
- Boeije H. (2002). A purposeful approach to the constant comparative method . Quality & Quantity , 36 ( 4 ), 391–409. https://doi:10.1023/A:1020909529486 [ Google Scholar ]
- Bowen G. A. (2009). Document analysis as a qualitative research method . Qualitative Research Journal , 9 ( 2 ), 27–40. https://doi:10.3316/QRJ0902027 [ Google Scholar ]
- Campbell M., Egan M., Lorenc T., Bond L., Popham F., Fenton C., Benzeval M. (2014). Considering methodological options for reviews of theory: Illustrated by a review of theories linking income and health . Systematic Reviews , 3 ( 1 ), 1–11. https://doi:10.1186/2046-4053-3-114 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Caulley D. (1983). Document analysis in program evaluation . Evaluation and Program Planning , 6 ( 1 ), 19–29. https://doi:10.1016/0149-7189(83)90041-1 [ Google Scholar ]
- Coffey A. (2014). Analysing documents . In Flick U. (Ed.), The SAGE handbook of qualitative data analysis (pp. 367–379). SAGE. https://doi:10.4135/9781446282243.n25 [ Google Scholar ]
- De Groot K., Triemstra M., Paans W., Francke A. L. (2019). Quality criteria, instruments, and requirements for nursing documentation: A systematic review of systematic reviews . Journal of Advanced Nursing , 75 ( 7 ), 1379–1393. 10.1111/jan.13919 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Finnegan R. (2011). Using documents . In Sapsford R., Jupp V. (Eds.), Data collection and analysis (pp. 138–152). SAGE. 10.1007/978-1-4842-4492-0_1 [ CrossRef ] [ Google Scholar ]
- Flaumenhaft Y., Ben-Assuli O. (2018). Personal health records, global policy and regulation review . Health Policy , 122 ( 8 ), 815–826. 10.1016/j.healthpol.2018.05.002 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Gibson W., Brown A. (2011). Using documents in research in: Working with qualitative data . In Gibson W., Brown A. (Eds.), Working with qualitative data (pp. 65–83). SAGE. [ Google Scholar ]
- Gorichanaz T., Latham K. F. (2016). Document phenomenology: A framework for holistic analysis . Journal of Documentation , 72 ( 69 ), 1114–1133. https://doi:10.1108/JD-01-2016-0007 [ Google Scholar ]
- Gray J., Grove S., Sutherland S. (2016). Nursing research (8th ed.). Elsevier Saunders. [ Google Scholar ]
- Gross J. (2018). Document analysis . In Frey B. (Ed.), The SAGE Encyclopedia of educational research, measurement and evaluation (pp. 545–548). SAGE. https://doi:10.1002/9781118901731.iecrm0071 [ Google Scholar ]
- Häggman-Laitila A. (2003). Early support needs of Finnish families with small children . Journal of Advanced Nursing , 41 ( 6 ), 1–12. 10.1046/j.1365-2648.2003.02571.x [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Häggman-Laitila A., Salokekkilä P., Satka M., Toivonen K., Kekolahti P., Ryynänen O-P. (2019). The coping of young Finnish adults after out-of-home care and aftercare services: A document-based analysis . Children and Youth Services Review , 120 , 150–157. 10.1016/j.childyouth.2019.05.009 [ CrossRef ] [ Google Scholar ]
- Häggman-Laitila A., Tanninen H. -M., Pietilä A.-M. (2010). Effectiveness of resource-enhancing family-oriented intervention . Journal of Clinical Nursing , 19 ( 17–18 ), 2500–2510. 10.1111/j.1365-2702.2010.03288.x [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Häggman-Laitila A., Toivonen K., Puustelli A., Salokekkilä P. (2020). Do aftercare services take young people’s health behavior into consideration? A retrospective document analysis from Finland . Journal of Pediatric Nursing , 55 , 134–140. 10.1016/j.pedn.2020.08.005 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hall A., Rist R. (1999). Integrating multiple qualitative research methods (or avoiding the precariousness of a one-legged stool) . Psychology & Marketing , 16 ( 4 ), 291–304. https://doi:10.1002/(SICI)1520-6793(199907) [ Google Scholar ]
- Hipp K., Tiihonen E., Kuosmanen L., Kangasniemi M. (2020). As needed medication events in a forensic psychiatric hospital: A document analysis of the prevalence and reasons . Journal of Forensic Mental Health , 19 ( 4 ), 329–340. 10.1080/14999013.2020.1774686 [ CrossRef ] [ Google Scholar ]
- Hipp K., Tiihonen E., Kuosmanen L., Katajisto J., Kangasniemi M. (2021). Patient participation in pro re nata medication in forensic psychiatric care: A nursing document analysis . Journal of Psychiatric and Mental Health Nursing , 28 ( 4 ), 611–621. 10.1111/jpm.12706 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kaae S., Traulsen J. M. (2015). Qualitative methods in pharmacy practice research . In Babar Z.-U.-D. (Ed.), Pharmacy practice research methods (pp. 49–68). Springer International Publishing. 10.1007/978-3-319-14672-0 [ CrossRef ] [ Google Scholar ]
- Kallio H., Pietilä A.-M., Johnson M., Kangasniemi M. (2018). Environmental responsibility in university hospitals. A qualitative study of environmental programs and the views of environmental managers . Journal of Hospital Administration , 7 ( 5 ), 56–69. 10.5430/jha.v7n5p56. [ CrossRef ] [ Google Scholar ]
- Kallio H., Voutilainen A., Viinamäki L., Kangasniemi M. (2020). In-service training to enhance the competence of health and social care professionals: A document analysis of web-based training reports . Nurse Education Today , 92 , 104493. 10.1016/j.nedt.2020.104493 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kangasniemi M., Papinaho O., Moilanen T., Leino-Kilpi H., Siipi H., Suominen S., Suhonen R. (2022). Neglecting the care of older people in residential care settings: A national document analysis of complaints reported to the Finnish supervisory authority . Health and Social Care in Community , 30 , e1313–e1324. 10.1111/hsc.13538 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Martín-Rodero H., Sanz-Valero J., Galindo-Villardon P. (2018). The methodological quality of systematic reviews indexed in the MEDLINE database. A multivariate approach . Electronic Library , 36 ( 1 ), 146–158. 10.1108/EL-01-2017-0002 [ CrossRef ] [ Google Scholar ]
- Mehta N., Pandit A. (2018). Concurrence of big data analytics and healthcare: A systematic review . International Journal of Medical Informatics , 114 , 57–65. 10.1016/j.ijmedinf.2018.03.013 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Mercieca S., Belderbos J. S. A., van Baardwijk A., Delorme S., van Herk M. (2019). The impact of training and professional collaboration on the interobserver variation of lung cancer delineations: A multi-institutional study . Acta Oncologica , 58 ( 2 ), 200–208. 10.1080/0284186X.2018.1529422 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Miller F., Alvarado K. (2005). Incorporating documents into qualitative nursing research . Journal of Nursing Scholarship , 37 ( 4 ), 348–353. https://doi:10.1111/j.1547-5069.2005.00060.x [ PubMed ] [ Google Scholar ]
- Moher D., Liberati A., Tetzlaff J., Altman D. G. (2009). Preferred reporting items for systematic reviews and meta-analyses: The PRISMA meta-analyses . British Medical Journal , 339 ( 12 ), b2535. 10.1136/bmj.b2535 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Murray C. D., Sixsmith J. (2002). Qualitative health research via the Internet: Practical and methodological issues . Health Informatics Journal , 8 ( 1 ), 47–53. https://doi:10.1177/146045820200800109 [ Google Scholar ]
- O’Connor M. (2011). Documentary analysis and policy . In Addington-Hall J., Bruera E., Higginson I., Payne S. (Eds.), Research methods in palliative care (pp. 229–245). Oxford University Press. [ Google Scholar ]
- Olivares Bøgeskov B., Grimshaw-Aagaard S. L. S. (2019). Essential task or meaningless burden? Nurses’ perceptions of the value of documentation . Nordic Journal of Nursing Research , 39 ( 1 ), 9–19. 10.1177/2057158518773906 [ CrossRef ] [ Google Scholar ]
- Olson M. (2012). Document analysis . In Mills A., Durepos G., Wiebe E. (Eds.), The Encyclopedia of case study research (pp. 319–320). SAGE. 10.4135/9781473914230 [ CrossRef ] [ Google Scholar ]
- Papinaho O., Häggman-Laitila A., Kangasniemi M. (2021). Unprofessional conduct by registered nurses: A document analysis of disciplinary decisions in Finland . Nursing Ethics , 19 ( 1 ), 131–144. 10.1177/09697330211015289 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Papinaho O., Häggman-Laitila A., Pasanen M., Kangasniemi M. (2022). Disciplinary processes for nurses, from organizational supervision to outcomes: A document analysis of a regulatory authority’s decisions . Journal of Nursing Management . Advance online publication. 10.1111/jonm.13679 [ PMC free article ] [ PubMed ] [ CrossRef ]
- Patel S. P., Webster R. K., Greenberg N., Weston D., Brooks S. K. (2020). Research fatigue in COVID-19 pandemic and post-disaster research: Causes, consequences and recommendations . Disaster Prevention Management , 29 ( 4 ), 445–455. https://doi:10.1108/DPM-05-2020-0164 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Platt J. (1981). Evidence and proof in documentary research: Some shared problems of documentary research . Sociological Review , 29 ( 1 ), 53–67. https://doi:10.1111/j.1467-954X.1981.tb03021.x [ Google Scholar ]
- Puustinen J., Kangasniemi M., Turjamaa R. (2021). Are comprehensive and individually designed care and service plans for older people’s home care a vision or a reality in Finland? Health and Social Care in the Community , 29 ( 5 ), e144–e152. 10.1111/hsc.13255 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rasmussen P., Muir-Cochrane E., Henderson A. (2012). Document analysis using an aggregative and iterative process . International Journal of Evidence-Based Healthcare , 10 ( 2 ), 142–145. https://doi:10.1111/j.1744-1609.2012.00262.x [ PubMed ] [ Google Scholar ]
- Ritter A. Z., Bowles K. H., O’Sullivan A. L., Carthon M. B., Fairman J. A. (2018). A policy analysis of legally required supervision of nurse practitioners and other health professionals . Nursing Outlook , 66 ( 6 ), 551–559. https://doi:10.1016/j.outlook.2018.05.004 [ PubMed ] [ Google Scholar ]
- Scott B. J. (2011). Documents, types of . In Lewis-Beck M., Bryman A., Liao T. (Eds.), The SAGE Encyclopedia of social science research methods (pp. 282–284). SAGE. [ Google Scholar ]
- Siegner M., Hagerman S., Kozak R. (2018). Going deeper with documents: A systematic review of the application of extant texts in social research on forests . Forest Policy and Economics , 92 , 128–135. https://doi:10.1016/j.forpol.2018.05.001 [ Google Scholar ]
- Sixsmith J., Murray C. D. (2001). Ethical issues in the documentary data analysis of Internet posts and archives . Analysis of Internet Posts and Archives , 11 ( 3 ), 423–432. https://doi:10.1177/104973201129119109 [ PubMed ] [ Google Scholar ]
- Sundermann A., Miller J., Marsh J., Saul M., Shutt K., Pacey M., Mustapha M., Ayres A., Pasculle W., Chen J., Snyder G., Dubrawski A., Harrison L. (2019). Corrigendum: Automated data mining of the electronic health record for investigation of healthcare-associated outbreaks . Infection Control and Hospital Epidemiology , 40 ( 5 ), 314–319. 10.1017/ice.2019.84 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Toivonen K., Salokekkilä P., Puustelli A., Häggman-Laitila A. (2020). Somatic and mental symptoms, medical treatments and service use in aftercare: Document analysis of Finnish care leavers . Children and Youth Services Review , 114 , 105079. 10.1016/j.childyouth.2020.105079 [ CrossRef ] [ Google Scholar ]
- Turjamaa R., Hartikainen S., Kangasniemi M., Pietilä A.-M. (2015). Is it time for a comprehensive approach in older home care clients’ care planning in Finland? Scandinavian Journal of Caring Sciences , 29 ( 2 ), 317–324. 10.1111/scs.12165 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Walker E., McMahan R., Barnes D., Katen M., Lamas D., Sudore R. (2018). Advance care planning documentation practices and accessibility in the electronic health record: Implications for patient safety . Journal of Pain and Symptom Management , 55 ( 2 ), 256–264. 10.1016/j.jpainsymman.2017.09.018 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
NTRS - NASA Technical Reports Server
Available downloads, related records.
- Systematic Review
- Open access
- Published: 24 May 2024
Turnover intention and its associated factors among nurses in Ethiopia: a systematic review and meta-analysis
- Eshetu Elfios 1 ,
- Israel Asale 1 ,
- Merid Merkine 1 ,
- Temesgen Geta 1 ,
- Kidist Ashager 1 ,
- Getachew Nigussie 1 ,
- Ayele Agena 1 ,
- Bizuayehu Atinafu 1 ,
- Eskindir Israel 2 &
- Teketel Tesfaye 3
BMC Health Services Research volume 24 , Article number: 662 ( 2024 ) Cite this article
339 Accesses
Metrics details
Nurses turnover intention, representing the extent to which nurses express a desire to leave their current positions, is a critical global public health challenge. This issue significantly affects the healthcare workforce, contributing to disruptions in healthcare delivery and organizational stability. In Ethiopia, a country facing its own unique set of healthcare challenges, understanding and mitigating nursing turnover are of paramount importance. Hence, the objectives of this systematic review and meta-analysis were to determine the pooled proportion ofturnover intention among nurses and to identify factors associated to it in Ethiopia.
A comprehensive search carried out for studies with full document and written in English language through an electronic web-based search strategy from databases including PubMed, CINAHL, Cochrane Library, Embase, Google Scholar and Ethiopian University Repository online. Checklist from the Joanna Briggs Institute (JBI) was used to assess the studies’ quality. STATA version 17 software was used for statistical analyses. Meta-analysis was done using a random-effects method. Heterogeneity between the primary studies was assessed by Cochran Q and I-square tests. Subgroup and sensitivity analyses were carried out to clarify the source of heterogeneity.
This systematic review and meta-analysis incorporated 8 articles, involving 3033 nurses in the analysis. The pooled proportion of turnover intention among nurses in Ethiopia was 53.35% (95% CI (41.64, 65.05%)), with significant heterogeneity between studies (I 2 = 97.9, P = 0.001). Significant association of turnover intention among nurses was found with autonomous decision-making (OR: 0.28, CI: 0.14, 0.70) and promotion/development (OR: 0.67, C.I: 0.46, 0.89).
Conclusion and recommendation
Our meta-analysis on turnover intention among Ethiopian nurses highlights a significant challenge, with a pooled proportion of 53.35%. Regional variations, such as the highest turnover in Addis Ababa and the lowest in Sidama, underscore the need for tailored interventions. The findings reveal a strong link between turnover intention and factors like autonomous decision-making and promotion/development. Recommendations for stakeholders and concerned bodies involve formulating targeted retention strategies, addressing regional variations, collaborating for nurse welfare advocacy, prioritizing career advancement, reviewing policies for nurse retention improvement.
Peer Review reports
Turnover intention pertaining to employment, often referred to as the intention to leave, is characterized by an employee’s contemplation of voluntarily transitioning to a different job or company [ 1 ]. Nurse turnover intention, representing the extent to which nurses express a desire to leave their current positions, is a critical global public health challenge. This issue significantly affects the healthcare workforce, contributing to disruptions in healthcare delivery and organizational stability [ 2 ].
The global shortage of healthcare professionals, including nurses, is an ongoing challenge that significantly impacts the capacity of healthcare systems to provide quality services [ 3 ]. Nurses, as frontline healthcare providers, play a central role in patient care, making their retention crucial for maintaining the functionality and effectiveness of healthcare delivery. However, the phenomenon of turnover intention, reflecting a nurse’s contemplation of leaving their profession, poses a serious threat to workforce stability [ 4 ].
Studies conducted globally shows that high turnover rates among nurses in several regions, with notable figures reported in Alexandria (68%), China (63.88%), and Jordan (60.9%) [ 5 , 6 , 7 ]. In contrast, Israel has a remarkably low turnover rate of9% [ 8 ], while Brazil reports 21.1% [ 9 ], and Saudi hospitals26% [ 10 ]. These diverse turnover rates highlight the global nature of the nurse turnover phenomenon, indicating varying degrees of workforce mobility in different regions.
The magnitude and severity of turnover intention among nurses worldwide underscore the urgency of addressing this issue. High turnover rates not only disrupt healthcare services but also result in a loss of valuable skills and expertise within the nursing workforce. This, in turn, compromises the continuity and quality of patient care, with potential implications for patient outcomes and overall health service delivery [ 11 ]. Extensive research conducted worldwide has identified a range of factors contributing to turnover intention among nurses [ 11 , 12 , 13 , 14 , 15 , 16 , 17 ]. These factors encompass both individual and organizational aspects, such as high workload, inadequate support, limited career advancement opportunities, job satisfaction, conflict, payment or reward, burnout sense of belongingness to their work environment. The complex interplay of these factors makes addressing turnover intention a multifaceted challenge that requires targeted interventions.
In Ethiopia, a country facing its own unique set of healthcare challenges, understanding and mitigating nursing turnover are of paramount importance. The healthcare system in Ethiopia grapples with issues like resource constraints, infrastructural limitations, and disparities in healthcare access [ 18 ]. Consequently, the factors influencing nursing turnover in Ethiopia may differ from those in other regions. Previous studies conducted in the Ethiopian context have started to unravel some of these factors, emphasizing the need for a more comprehensive examination [ 18 , 19 ].
Although many cross-sectional studies have been conducted on turnover intention among nurses in Ethiopia, the results exhibit variations. The reported turnover intention rates range from a minimum of 30.6% to a maximum of 80.6%. In light of these disparities, this systematic review and meta-analysis was undertaken to ascertain the aggregated prevalence of turnover intention among nurses in Ethiopia. By systematically analyzing findings from various studies, we aimed to provide a nuanced understanding of the factors influencing turnover intention specific to the Ethiopian healthcare context. Therefore, this systematic review and meta-analysis aimed to answer the following research questions.
What is the pooled prevalence of turnover intention among nurses in Ethiopia?
What are the factors associated with turnover intention among nurses in Ethiopia?
The primary objective of this review was to assess the pooled proportion of turnover intention among nurses in Ethiopia. The secondary objective was identifying the factors associated to turnover intention among nurses in Ethiopia.
Study design and search strategy
A comprehensive systematic review and meta-analysis was conducted, examining observational studies on turnover intention among nurses in Ethiopia. The procedure for this systematic review and meta-analysis was developed in accordance with the Preferred Reporting Items for Systematic review and Meta-analysis Protocols (PRISMA-P) statement [ 20 ]. PRISMA-2015 statement was used to report the findings [ 21 , 22 ]. This systematic review and meta-analysis were registered on PROSPERO with the registration number of CRD42024499119.
We conducted systematic and an extensive search across multiple databases, including PubMed, CINAHL, Cochrane Library, Embase, Google Scholar and Ethiopian University Repository online to identify studies reporting turnover intention among nurses in Ethiopia. We reviewed the database available at http://www.library.ucsf.edu and the Cochrane Library to ensure that the intended task had not been previously undertaken, preventing any duplication. Furthermore, we screened the reference lists to retrieve relevant articles. The process involved utilizing EndNote (version X8) software for downloading, organizing, reviewing, and citing articles. Additionally, a manual search for cross-references was performed to discover any relevant studies not captured through the initial database search. The search employed a comprehensive set of the following search terms:“prevalence”, “turnover intention”, “intention to leave”, “attrition”, “employee attrition”, “nursing staff turnover”, “Ethiopian nurses”, “nurses”, and “Ethiopia”. These terms were combined using Boolean operators (AND, OR) to conduct a thorough and systematic search across the specified databases.
Eligibility criteria
Inclusion criteria.
The established inclusion criteria for this meta-analysis and systematic review are as follows to guide the selection of articles for inclusion in this review.
Population: Nurses working in Ethiopia.
Study period: studies conducted or published until 23November 2023.
Study design: All observational study designs, such as cross-sectional, longitudinal, and cohort studies, were considered.
Setting: Only studies conducted in Ethiopia were included.
Outcome; turnover intention.
Study: All studies, whether published or unpublished, in the form of journal articles, master’s theses, and dissertations, were included up to the final date of data analysis.
Language: This study exclusively considered studies in the English language.
Exclusion criteria
Excluded were studies lacking full text or Studies with a Newcastle–Ottawa Quality Assessment Scale (NOS) score of 6 or less. Studies failing to provide information on turnover intention among nurses or studies for which necessary details could not be obtained were excluded. Three authors (E.E., T.G., K.A) independently assessed the eligibility of retrieved studies, other two authors (E.I & M.M) input sought for consensus on potential in- or exclusion.
Quality assessment and data extraction
Two authors (E.E, A.A, G.N) independently conducted a critical appraisal of the included studies. Joanna Briggs Institute (JBI) checklists of prevalence study was used to assess the quality of the studies. Studies with a Newcastle–Ottawa Quality Assessment Scale (NOS) score of seven or more were considered acceptable [ 23 ]. The tool has nine parameters, which have yes, no, unclear, and not applicable options [ 24 ]. Two reviewers (I.A, B.A) were involved when necessary, during the critical appraisal process. Accordingly, all studies were included in our review. ( Table 1 ) Questions to evaluate the methodological quality of studies on turnover intention among nurses and its associated factors in Ethiopia are the followings:
Q1 = was the sample frame appropriate to address the target population?
Q2. Were study participants sampled appropriately.
Q3. Was the sample size adequate?
Q4. Were the study subjects and the setting described in detail?
Q5. Was the data analysis conducted with sufficient coverage of the identified sample?
Q6. Were the valid methods used for the identification of the condition?
Q7. Was the condition measured in a standard, reliable way for all participants?
Q8. Was there appropriate statistical analysis?
Q9. Was the response rate adequate, and if not, was the low response rate.
managed appropriately?
Data was extracted and recorded in a Microsoft Excel as guided by the Joanna Briggs Institute (JBI) data extraction form for observational studies. Three authors (E.E, M.G, T.T) independently conducted data extraction. Recorded data included the first author’s last name, publication year, study setting or country, region, study design, study period, sample size, response rate, population, type of management, proportion of turnover intention, and associated factors. Discrepancies in data extraction were resolved through discussion between extractors.
Data processing and analysis
Data analysis procedures involved importing the extracted data into STATA 14 statistical software for conducting a pooled proportion of turnover intention among nurses. To evaluate potential publication bias and small study effects, both funnel plots and Egger’s test were employed [ 25 , 26 ]. We used statistical tests such as the I statistic to quantify heterogeneity and explore potential sources of variability. Additionally, subgroup analyses were conducted to investigate the impact of specific study characteristics on the overall results. I 2 values of 0%, 25%, 50%, and 75% were interpreted as indicating no, low, medium, and high heterogeneity, respectively [ 27 ].
To assess publication bias, we employed several methods, including funnel plots and Egger’s test. These techniques allowed us to visually inspect asymmetry in the distribution of study results and statistically evaluate the presence of publication bias. Furthermore, we conducted sensitivity analyses to assess the robustness of our findings to potential publication bias and other sources of bias.
Utilizing a random-effects method, a meta-analysis was performed to assess turnover intention among nurses, employing this method to account for observed variability [ 28 ]. Subgroup analyses were conducted to compare the pooled magnitude of turnover intention among nurses and associated factors across different regions. The results of the pooled prevalence were visually presented in a forest plot format with a 95% confidence interval.
Study selection
After conducting the initial comprehensive search concerning turnover intention among nurses through Medline, Cochran Library, Web of Science, Embase, Ajol, Google Scholar, and other sources, a total of 1343 articles were retrieved. Of which 575 were removed due to duplication. Five hundred ninety-three articles were removed from the remaining 768 articles by title and abstract. Following theses, 44 articles which cannot be retrieved were removed. Finally, from the remaining 131 articles, 8 articles with a total 3033 nurses were included in the systematic review and meta-analysis (Fig. 1 ).

PRISMA flow diagram of the selection process of studies on turnover intention among nurses in Ethiopia, 2024
Study characteristics
All included 8 studies had a cross-sectional design and of which, 2 were from Tigray region, 2 were from Addis Ababa(Capital), 1 from south region, 1 from Amhara region, 1 from Sidama region, and 1 was multiregional and Nationwide. The prevalence of turnover intention among nurses ‘ranges from 30.6 to 80.6%. Table 2 .
Pooled prevalence of turnover intention among nurses in Ethiopia
Our comprehensive meta-analysis revealed a notable turnover intention rate of 53.35% (95% CI: 41.64, 65.05%) among Ethiopian nurses, accompanied by substantial heterogeneity between studies (I 2 = 97.9, P = 0.000) as depicted in Fig. 2 . Given the observed variability, we employed a random-effects model to analyze the data, ensuring a robust adjustment for the significant heterogeneity across the included studies.

Forest plot showing the pooled proportion of turnover intention among nurses in Ethiopia, 2024
Subgroup analysis of turnover intention among nurses in Ethiopia
To address the observed heterogeneity, we conducted a subgroup analysis based on regions. The results of the subgroup analysis highlighted considerable variations, with the highest level of turnover intention identified in Addis Ababa at 69.10% (95% CI: 46.47, 91.74%) and substantial heterogeneity (I 2 = 98.1%). Conversely, the Sidama region exhibited the lowest level of turnover intention among nurses at 30.6% (95% CI: 25.18, 36.02%), accompanied by considerable heterogeneity (I 2 = 100.0%) ( Fig. 3 ).

Subgroup analysis of systematic review and meta-analysis by region of turnover intention among nurses in Ethiopia, 2024
Publication bias of turnover intention among nurses in Ethiopia
The Egger’s test result ( p = 0.64) is not statistically significant, indicating no evidence of publication bias in the meta-analysis (Table 3 ). Additionally, the symmetrical distribution of included studies in the funnel plot (Fig. 4 ) confirms the absence of publication bias across studies.

Funnel plot of systematic review and meta-analysis on turnover intention among nurses in Ethiopia, 2024
Sensitivity analysis
The leave-out-one sensitivity analysis served as a meticulous evaluation of the influence of individual studies on the comprehensive pooled prevalence of turnover intention within the context of Ethiopian nurses. In this systematic process, each study was methodically excluded from the analysis one at a time. The outcomes of this meticulous examination indicated that the exclusion of any particular study did not lead to a noteworthy or statistically significant alteration in the overall pooled estimate of turnover intention among nurses in Ethiopia. The findings are visually represented in Fig. 5 , illustrating the stability and robustness of the overall pooled estimate even with the removal of specific studies from the analysis.

Sensitivity analysis of pooled prevalence for each study being removed at a time for systematic review and meta-analysis of turnover intention among nurses in Ethiopia
Factors associated with turnover intention among nurses in Ethiopia
In our meta-analysis, we comprehensively reviewed and conducted a meta-analysis on the determinants of turnover intention among nurses in Ethiopia by examining eight relevant studies [ 6 , 29 , 30 , 31 , 32 , 33 , 34 , 35 ]. We identified a significant association between turnover intention with autonomous decision-making (OR: 0.28, CI: 0.14, 0.70) (Fig. 6 ) and promotion/development (OR: 0.67, CI: 0.46, 0.89) (Fig. 7 ). In both instances, the odds ratios suggest a negative association, signifying that increased levels of autonomous decision-making and promotion/development were linked to reduced odds of turnover intention.

Forest plot of the association between autonomous decision making with turnover intention among nurses in Ethiopia2024

Forest plot of the association between promotion/developpment with turnover intention among nurses in Ethiopia, 2024
In our comprehensive meta-analysis exploring turnover intention among nurses in Ethiopia, our findings revealed a pooled proportion of turnover intention at 53.35%. This significant proportion warrants a comparative analysis with turnover rates reported in other global regions. Distinct variations emerge when compared with turnover rates in Alexandria (68%), China (63.88%), and Jordan (60.9%) [ 5 , 6 , 7 ]. This comparison highlights that the multifaceted nature of turnover intention, influenced by diverse contextual, cultural, and organizational factors. Conversely, Ethiopia’s turnover rate among nurses contrasts with substantially lower figures reported in Israel (9%) [ 8 ], Brazil (21.1%) [ 9 ], and Saudi hospitals (26%) [ 10 ]. Challenges such as work overload, economic constraints, limited promotional opportunities, lack of recognition, and low job rewards are more prevalent among nurses in Ethiopia, contributing to higher turnover intention compared to their counterparts [ 7 , 29 , 36 ].
The highest turnover intention was observed in Addis Ababa, while Sidama region displayed the lowest turnover intention among nurses, These differences highlight the complexity of turnover intention among Ethiopian nurses, showing the importance of specific interventions in each region to address unique factors and improve nurses’ retention.
Our systematic review and meta-analysis in the Ethiopian nursing context revealed a significant inverse association between turnover intention and autonomous decision-making. The odd of turnover intention is approximately reduced by 72% in employees with autonomous decision-making compared to those without autonomous decision-making. This finding was supported by other similar studies conducted in South Africa, Tanzania, Kenya, and Turkey [ 37 , 38 , 39 , 40 ].
The significant association of turnover intention with promotion/development in our study underscores the crucial role of career advancement opportunities in alleviating turnover intention among nurses. Specifically, our analysis revealed that individuals with promotion/development had approximately 33% lower odds of turnover intention compared to those without such opportunities. These results emphasize the pivotal influence of organizational support in shaping the professional environment for nurses, providing substantive insights for the formulation of evidence-based strategies targeted at enhancing workforce retention. This finding is in line with former researches conducted in Taiwan, Philippines and Italy [ 41 , 42 , 43 ].
Our meta-analysis on turnover intention among Ethiopian nurses reveals a considerable challenge, with a pooled proportion of 53.35%. Regional variations highlight the necessity for region-specific strategies, with Addis Ababa displaying the highest turnover intention and Sidama region the lowest. A significant inverse association was found between turnover intention with autonomous decision-making and promotion/development. These insights support the formulation of evidence-based strategies and policies to enhance nurse retention, contributing to the overall stability of the Ethiopian healthcare system.
Recommendations
Federal ministry of health (fmoh).
The FMoH should consider the regional variations in turnover intention and formulate targeted retention strategies. Investment in professional development opportunities and initiatives to enhance autonomy can be integral components of these strategies.
Ethiopian nurses association (ENA)
ENA plays a pivotal role in advocating for the welfare of nurses. The association is encouraged to collaborate with healthcare institutions to promote autonomy, create mentorship programs, and advocate for improved working conditions to mitigate turnover intention.
Healthcare institutions
Hospitals and healthcare facilities should prioritize the provision of career advancement opportunities and recognize the value of professional autonomy in retaining nursing staff. Tailored interventions based on regional variations should be considered.
Policy makers
Policymakers should review existing healthcare policies to identify areas for improvement in nurse retention. Policy changes that address challenges such as work overload, limited promotional opportunities, and economic constraints can positively impact turnover rates.
Future research initiatives
Further research exploring the specific factors contributing to turnover intention in different regions of Ethiopia is recommended. Understanding the nuanced challenges faced by nurses in various settings will inform the development of more targeted interventions.
Strength and limitations
Our systematic review and meta-analysis on nurse turnover intention in Ethiopia present several strengths. The comprehensive inclusion of diverse studies provides a holistic view of the issue, enhancing the generalizability of our findings. The use of a random-effects model accounts for potential heterogeneity, ensuring a more robust and reliable synthesis of data.
However, limitations should be acknowledged. The heterogeneity observed across studies, despite the use of a random-effects model, may impact the precision of the pooled estimate. These considerations should be taken into account when interpreting and applying the results of our analysis.
Data availability
Data set used on this analysis will available from corresponding author upon reasonable request.
Abbreviations
Ethiopian Nurses Association
Federal Ministry of Health
Joanna Briggs Institute
Preferred Reporting Items for Systematic review and Meta-analysis Protocols
Kanchana L, Jayathilaka R. Factors impacting employee turnover intentions among professionals in Sri Lankan startups. PLoS ONE. 2023;18(2):e0281729.
Article CAS PubMed PubMed Central Google Scholar
Boateng AB, et al. Factors influencing turnover intention among nurses and midwives in Ghana. Nurs Res Pract. 2022;2022:4299702.
PubMed PubMed Central Google Scholar
Organization WH. WHO Guideline on Health Workforce Development Attraction, Recruitment and Retention in Rural and Remote Areas, 2021, pp. 1-104.
Hayes LJ, et al. Nurse turnover: a literature review. Int J Nurs Stud. 2006;43(2):237–63.
Article PubMed Google Scholar
Yang H, et al. Validation of work pressure and associated factors influencing hospital nurse turnover: a cross-sectional investigation in Shaanxi Province, China. BMC Health Serv Res. 2017;17:1–11.
Article Google Scholar
Ayalew E et al. Nurses’ intention to leave their job in sub-Saharan Africa: A systematic review and meta-analysis. Heliyon, 2021. 7(6).
Al Momani M. Factors influencing public hospital nurses’ intentions to leave their current employment in Jordan. Int J Community Med Public Health. 2017;4(6):1847–53.
DeKeyser Ganz F, Toren O. Israeli nurse practice environment characteristics, retention, and job satisfaction. Isr J Health Policy Res. 2014;3(1):1–8.
de Oliveira DR, et al. Intention to leave profession, psychosocial environment and self-rated health among registered nurses from large hospitals in Brazil: a cross-sectional study. BMC Health Serv Res. 2017;17(1):21.
Article PubMed PubMed Central Google Scholar
Dall’Ora C, et al. Association of 12 h shifts and nurses’ job satisfaction, burnout and intention to leave: findings from a cross-sectional study of 12 European countries. BMJ Open. 2015;5(9):e008331.
Lu H, Zhao Y, While A. Job satisfaction among hospital nurses: a literature review. Int J Nurs Stud. 2019;94:21–31.
Ramoo V, Abdullah KL, Piaw CY. The relationship between job satisfaction and intention to leave current employment among registered nurses in a teaching hospital. J Clin Nurs. 2013;22(21–22):3141–52.
Al Sabei SD, et al. Nursing work environment, turnover intention, Job Burnout, and Quality of Care: the moderating role of job satisfaction. J Nurs Scholarsh. 2020;52(1):95–104.
Wang H, Chen H, Chen J. Correlation study on payment satisfaction, psychological reward satisfaction and turnover intention of nurses. Chin Hosp Manag. 2018;38(03):64–6.
Google Scholar
Loes CN, Tobin MB. Interpersonal conflict and organizational commitment among licensed practical nurses. Health Care Manag (Frederick). 2018;37(2):175–82.
Wei H, et al. The state of the science of nurse work environments in the United States: a systematic review. Int J Nurs Sci. 2018;5(3):287–300.
Nantsupawat A, et al. Effects of nurse work environment on job dissatisfaction, burnout, intention to leave. Int Nurs Rev. 2017;64(1):91–8.
Article CAS PubMed Google Scholar
Ayalew F, et al. Factors affecting turnover intention among nurses in Ethiopia. World Health Popul. 2015;16(2):62–74.
Debie A, Khatri RB, Assefa Y. Contributions and challenges of healthcare financing towards universal health coverage in Ethiopia: a narrative evidence synthesis. BMC Health Serv Res. 2022;22(1):866.
Moher D, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst Reviews. 2015;4(1):1–9.
Moher D, et al. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Ann Intern Med. 2009;151(4):264–9.
Moher D et al. Group, P.-P.(2015) Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement.
Institute JB. Checklist for Prevalence Studies. Checkl prevalance Stud [Internet]. 2016;7.
Sakonidou S, et al. Interventions to improve quantitative measures of parent satisfaction in neonatal care: a systematic review. BMJ Paediatr Open. 2020;4(1):e000613.
Egger M, Smith GD. Meta-analysis: potentials and promise. BMJ. 1997;315(7119):1371.
Tura G, Fantahun M, Worku A. The effect of health facility delivery on neonatal mortality: systematic review and meta-analysis. BMC Pregnancy Childbirth. 2013;13:18.
Lin L. Comparison of four heterogeneity measures for meta-analysis. J Eval Clin Pract. 2020;26(1):376–84.
McFarland LV. Meta-analysis of probiotics for the prevention of antibiotic associated diarrhea and the treatment of Clostridium difficile disease. Am J Gastroenterol. 2006;101(4):812–22.
Asegid A, Belachew T, Yimam E. Factors influencing job satisfaction and anticipated turnover among nurses in Sidama zone public health facilities, South Ethiopia Nursing research and practice, 2014. 2014.
Wubetie A, Taye B, Girma B. Magnitude of turnover intention and associated factors among nurses working in emergency departments of governmental hospitals in Addis Ababa, Ethiopia: a cross-sectional institutional based study. BMC Nurs. 2020;19:97.
Getie GA, Betre ET, Hareri HA. Assessment of factors affecting turnover intention among nurses working at governmental health care institutions in east Gojjam, Amhara region, Ethiopia, 2013. Am J Nurs Sci. 2015;4(3):107–12.
Gebregziabher D, et al. The relationship between job satisfaction and turnover intention among nurses in Axum comprehensive and specialized hospital Tigray, Ethiopia. BMC Nurs. 2020;19(1):79.
Negarandeh R et al. Magnitude of nurses’ intention to leave their jobs and its associated factors of nurses working in tigray regional state, north ethiopia: cross sectional study 2020.
Nigussie Bolado G, et al. The magnitude of turnover intention and Associated factors among nurses working at Governmental Hospitals in Southern Ethiopia: a mixed-method study. Nursing: Research and Reviews; 2023. pp. 13–29.
Woldekiros AN, Getye E, Abdo ZA. Magnitude of job satisfaction and intention to leave their present job among nurses in selected federal hospitals in Addis Ababa, Ethiopia. PLoS ONE. 2022;17(6):e0269540.
Rhoades L, Eisenberger R. Perceived organizational support: a review of the literature. J Appl Psychol. 2002;87(4):698.
Lewis M. Causal factors that influence turnover intent in a manufacturing organisation. University of Pretoria (South Africa); 2008.
Kuria S, Alice O, Wanderi PM. Assessment of causes of labour turnover in three and five star-rated hotels in Kenya International journal of business and social science, 2012. 3(15).
Blaauw D, et al. Comparing the job satisfaction and intention to leave of different categories of health workers in Tanzania, Malawi, and South Africa. Global Health Action. 2013;6(1):19287.
Masum AKM, et al. Job satisfaction and intention to quit: an empirical analysis of nurses in Turkey. PeerJ. 2016;4:e1896.
Song L. A study of factors influencing turnover intention of King Power Group at Downtown Area in Bangkok, Thailand. Volume 2. International Review of Research in Emerging Markets & the Global Economy; 2016. 3.
Karanikola MN, et al. Moral distress, autonomy and nurse-physician collaboration among intensive care unit nurses in Italy. J Nurs Manag. 2014;22(4):472–84.
Labrague LJ, McEnroe-Petitte DM, Tsaras K. Predictors and outcomes of nurse professional autonomy: a cross-sectional study. Int J Nurs Pract. 2019;25(1):e12711.
Download references
No funding was received.
Author information
Authors and affiliations.
School of Nursing, College of Health Science and Medicine, Wolaita Sodo University, Wolaita Sodo, Ethiopia
Eshetu Elfios, Israel Asale, Merid Merkine, Temesgen Geta, Kidist Ashager, Getachew Nigussie, Ayele Agena & Bizuayehu Atinafu
Department of Midwifery, College of Health Science and Medicine, Wolaita Sodo University, Wolaita Sodo, Ethiopia
Eskindir Israel
Department of Midwifery, College of Health Science and Medicine, Wachamo University, Hossana, Ethiopia
Teketel Tesfaye
You can also search for this author in PubMed Google Scholar
Contributions
E.E. conceptualized the study, designed the research, performed statistical analysis, and led the manuscript writing. I.A, T.G, M.M contributed to the study design and provided critical revisions. K.A., G.N, B.A., E.I., and T.T. participated in data extraction and quality assessment. M.M. and T.G. K.A. and G.N. contributed to the literature review. I.A, A.A. and B.A. assisted in data interpretation. E.I. and T.T. provided critical revisions to the manuscript. All authors read and approved the final version.
Corresponding author
Correspondence to Eshetu Elfios .
Ethics declarations
Ethical approval.
Ethical approval and informed consent are not required, as this study is a systematic review and meta-analysis that only involved the use of previously published data.
Ethical guidelines
Not applicable.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Elfios, E., Asale, I., Merkine, M. et al. Turnover intention and its associated factors among nurses in Ethiopia: a systematic review and meta-analysis. BMC Health Serv Res 24 , 662 (2024). https://doi.org/10.1186/s12913-024-11122-9
Download citation
Received : 20 January 2024
Accepted : 20 May 2024
Published : 24 May 2024
DOI : https://doi.org/10.1186/s12913-024-11122-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Turnover intention
- Systematic review
- Meta-analysis
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]

Is AI-Generated Content Actually Detectable?
Umd artificial intelligence experts soheil feizi and furong huang share their latest research on large language models like chatgpt, the possible implications of their use and what’s coming next..

In recent years, artificial intelligence (AI) has made tremendous strides thanks to advances in machine learning and growing pools of data to learn from. Large language models (LLMs) and their derivatives, such as OpenAI’s ChatGPT and Google’s BERT, can now generate material that is increasingly similar to content created by humans. As a result, LLMs have become popular tools for creating high-quality, relevant and coherent text for a range of purposes, from composing social media posts to drafting academic papers.
Despite the wide variety of potential applications, LLMs face increasing scrutiny. Critics, especially educators and original content creators, view LLMs as a means for plagiarism, cheating, deception and manipulative social engineering.
In response to these concerns, researchers have developed novel methods to help distinguish between human-made content and machine-generated texts. The hope is that the ability to identify automated content will limit LLM abuse and its consequences.
But University of Maryland computer scientists are working to answer an important question: can these detectors accurately identify AI-generated content?
The short answer: No—at least, not now
“Current detectors of AI aren’t reliable in practical scenarios,” said Soheil Feizi , an assistant professor of computer science at UMD. “There are a lot of shortcomings that limit how effective they are at detecting. For example, we can use a paraphraser and the accuracy of even the best detector we have drops from 100% to the randomness of a coin flip. If we simply paraphrase something that was generated by an LLM, we can often outwit a range of detecting techniques.”

In a recent paper , Feizi described two types of errors that impact an AI text detector’s reliability: type I (when human text is detected as AI-generated) and type II (when AI-generated text is simply not detected).
“Using a paraphraser, which is now a fairly common tool available online, can cause the second type of error,” explained Feizi, who also holds a joint appointment in the University of Maryland Institute for Advanced Computer Studies . “There was also a recent example of the first type of error that went viral. Someone used AI detection software on the U.S. Constitution and it was flagged as AI-generated, which is obviously very wrong.”
According to Feizi, such mistakes made by AI detectors can be extremely damaging and often impossible to dispute when authorities like educators and publishers accuse students and other content creators of using AI. When and if such accusations are proven false, the companies and individuals responsible for developing the faulty AI detectors could also suffer reputational loss. In addition, even LLMs protected by watermarking schemes remain vulnerable against spoofing attacks where adversarial humans can infer hidden watermarks and add them to non-AI text so that it’s detected to be AI-generated. Reputations and intellectual property may be irreversibly tainted after faulty results—a major reason why Feizi calls for caution when it comes to relying solely on AI detectors to authenticate human-created content.
“Let’s say you’re given a random sentence,” Feizi said. “Theoretically, you can never reliably say that this sentence was written by a human or some kind of AI because the distribution between the two types of content is so close to each other. It’s especially true when you think about how sophisticated LLMs and LLM-attackers like paraphrasers or spoofing are becoming.”
“The line between what’s considered human and artificial becomes even thinner because of all these variables,” he added. “There is an upper bound on our detectors that fundamentally limits them, so it’s very unlikely that we’ll be able to develop detectors that will reliably identify AI-generated content.”
Another view: more data could lead to better detection
UMD Assistant Professor of Computer Science Furong Huang has a more optimistic outlook on the future of AI detection.

Although she agrees with her colleague Feizi that current detectors are imperfect, Huang believes that it is possible to point out artificially generated content—as long as there are enough examples of what constitutes human-created content available. In other words, when it comes to AI analysis, more is better.
“LLMs are trained on massive amounts of text. The more information we feed to them, the better and more human-like their outputs,” explained Huang, who also holds a joint appointment in the University of Maryland Institute for Advanced Computer Studies . “If we do the same with detectors—that is, provide them more samples to learn from—then the detectors will also grow more sophisticated. They’ll be better at spotting AI-generated text.”
Huang’s recent paper on this topic examined the possibility of designing superior AI detectors, as well as determining how much data would be required to improve its detection capabilities.
“Mathematically speaking, we’ll always be able to collect more data and samples for detectors to learn from,” said UMD computer science Ph.D. student Souradip Chakraborty , who is a co-author of the paper. “For example, there are numerous bots on social media platforms like Twitter. If we collect more bots and the data they have, we’ll be better at discerning what’s spam and what’s human text on the platform.”
Huang’s team suggests that detectors should take a more holistic approach and look at bigger samples to try to identify this AI-generated “spam.”
“Instead of focusing on a single phrase or sentence for detection, we suggest using entire paragraphs or documents,” added Amrit Singh Bedi , a research scientist at the Maryland Robotics Center who is also a co-author of Huang’s paper. “Multiple sentence analysis would increase accuracy in AI detection because there is more for the system to learn from than just an individual sentence.”
Huang’s group also believes that the innate diversity within the human population makes it difficult for LLMs to create content that mimics human-produced text. Distinctly human characteristics such as certain grammatical patterns and word choices could help identify text that was written by a person rather than a machine.
“It’ll be like a constant arms race between generative AI and detectors,” Huang said. “But we hope that this dynamic relationship actually improves how we approach creating both the generative LLMs and their detectors in the first place.”
What’s next for AI and AI detection
Although Feizi and Huang have differing opinions on the future of LLM detection, they do share several important conclusions that they hope the public will consider moving forward.
“One thing’s for sure—banning LLMs and apps like ChatGPT is not the answer,” Feizi said. “We have to accept that these tools now exist and that they’re here to stay. There’s so much potential in them for fields like education, for example, and we should properly integrate these tools into systems where they can do good.”
Feizi suggests in his research that security methods used to counter generative LLMs, including detectors, don’t need to be 100% foolproof—they just need to be more difficult for attackers to break, starting with closing the loopholes that researchers already know about. Huang agrees.
“We can’t just give up if the detector makes one mistake in one instance,” Huang said. “There has to be an active effort to protect the public from the consequences of LLM abuse, particularly members of our society who identify as minorities and are already encountering social biases in their lives.”
Both researchers also believe that multimodality (the use of text in conjunction with images, videos and other forms of media) will also be key to improved AI detection in the future. Feizi cites the use of secondary verification tools already in practice, such as authenticating phone numbers linked to social media accounts or observing behavioral patterns in content submissions, as additional safeguards to prevent false AI detection and bias.
“We want to encourage open and honest discussion about ethical and trustworthy applications of generative LLMs,” Feizi said. “There are so many ways we can use these AI tools to improve our society, especially for student learning or preventing the spread of misinformation.”
As AI-generated texts become more pervasive, researchers like Feizi and Huang recognize that it’s important to develop more proactive stances in how the public approaches LLMs and similar forms of AI.
“We have to start from the top,” Huang said. “Stakeholders need to start having a discussion about these LLMs and talk to policymakers about setting ground rules through regulation. There needs to be oversight on how LLMs progress while researchers like us develop better detectors, watermarks or other approaches to handling AI abuse.”
The paper “ Can AI-Generated Text be Reliably Detected ?” was published online as an electronic pre-print in in arXiv on March 17, 2023.
Other than Feizi, additional UMD researchers who co-authored this paper include computer science master’s student Sriram Balasubramanian and computer science Ph.D. students Vinu Sankar Sadasivan, Aounon Kumar and Wenxiao Wang.
The paper “ On the Possibilities of AI-Generated Text Detection ” was published online as an electronic preprint in arXiv on April 10, 2023.
Other than Huang, Chakraborty and Bedi, additional UMD researchers who co-authored this paper include Distinguished University Professor of Computer Science Dinesh Manocha and computer science Ph.D. students Sicheng Zhu and Bang An.
This research was supported by the National Science Foundation (Award Nos. 1942230 and CCF2212458 and the Division of Information and Intelligence Program on Fairness in Artificial Intelligence), the National Institute of Standards and Technology (Award No. 60NANB20D134), Meta (Award No. 23010098), the Office of Naval Research, the Air Force Office of Scientific Research, the Defense Advanced Research Projects Agency, Capital One, Adobe, and JPMorgan Chase & Co. This story does not necessarily reflect the views of these organizations.
About the College of Computer, Mathematical, and Natural Sciences
The College of Computer, Mathematical, and Natural Sciences at the University of Maryland educates more than 8,000 future scientific leaders in its undergraduate and graduate programs each year. The college's 10 departments and nine interdisciplinary research centers foster scientific discovery with annual sponsored research funding exceeding $250 million.
Media Relations Contact
Georgia jiang, related news.

- Soheil Feizi
- Furong Huang
- Dinesh Manocha
- Distinguished University Professor
- Artificial Intelligence
- Take on Humanity's Grand Challenges
- Partner to Advance the Public Good
IMAGES
VIDEO
COMMENTS
Document analysis is a versatile method in qualitative research that offers a lens into the intricate layers of meaning, context, and perspective found within textual materials. Through careful and systematic examination, it unveils the richness and depth of the information housed in documents, providing a unique dimension to research findings.
The origins of document analysis as a social science research method can be traced back to Goode and Hatt (), who recommended that scholars screen, count, and code documents content and use it as appropriate evidence.Later, Glaser and Strauss argued that documents should be considered in social investigation similar to "anthropologist's informant or a sociologist's interviewee" (p. 163).
Documentary Analysis. Definition: Documentary analysis, also referred to as document analysis, is a systematic procedure for reviewing or evaluating documents.This method involves a detailed review of the documents to extract themes or patterns relevant to the research topic.. Documents used in this type of analysis can include a wide variety of materials such as text (words) and images that ...
Abstract and Figures. This article examines the function of documents as a data source in qualitative research and discusses document analysis procedure in the context of actual research ...
Document analysis is a qualitative research technique used by researchers. The process involves evaluating electronic and physical documents to interpret them, gain an understanding of their meaning and develop upon the information they provide. Researchers use three main types of documents in their research:
What is document analysis? Document analysis is a systematic procedure for reviewing or evaluating documents, which can be used to provide context, generate questions, supplement other types of research data, track change over time and corroborate other sources (Bowen, 2009).In one commonly cited approach in social research, Bowen recommends first skimming the documents to get an overview ...
material can be a source for qualitative analysis (Flick, 2018). Since document analysis is a valuable research method, one would expect to find a wide variety of literature on this topic. Unfortunately, the literature on documentary research is scant (Tight, 2019). In this paper, I offer information designed to close the gap in the literature ...
Abstract. This article examines the function of documents as a data source in qualitative research and discusses document analysis procedure in the context of actual research experiences. Targeted to research novices, the article takes a nuts‐and‐bolts approach to document analysis. It describes the nature and forms of documents, outlines ...
Morgan (2022) states that document analysis is a research method for analyzing written documents such as books, newspapers, journals, and visual documents such as photos, videos, and films. In ...
Published: Dec. 12, 2023. Document analysis is the process of reviewing or evaluating documents both printed and electronic in a methodical manner. The document analysis method, like many other qualitative research methods, involves examining and interpreting data to uncover meaning, gain understanding, and come to a conclusion.
In relation to other qualitative research methods, document analysis has both advantages and limitations. Let us look first at the advantages. Efficient method: Document analysis is less time-consuming and therefore more efficient than other research methods. It requires data selection, instead of data collection.
Document analysis is one of the most commonly used and powerful methods in health policy research. While existing qualitative research manuals offer direction for conducting document analysis, there has been little specific discussion about how to use this method to understand and analyse health pol …
Qualitative document analysis is one of the most popular techniques and adaptable to nearly every field. MAXQDA is a software tool that offers many options to make your analysis and therefore your research easier. The recipe works best for theory-driven, deductive coding.
specific examples of the use of documents in the research process. The application of document analysis to a grounded theory study is illustrated. Keywords: Content analysis, documents, grounded ...
Document analysis is a topical method used in health and nursing sciences. Written, audio, and visual healthcare documents are constantly being produced (Bowen, 2009; Coffey, 2014; Gibson & Brown, 2011) and the number of documents is increasing (Olivares Bøgeskov & Grimshaw-Aagaard, 2019), because of wider healthcare regulations and the need to evaluate the effectiveness of care and services.
The nature and forms of documents are described, the advantages and limitations of document analysis are outlined, and specific examples of the use of documents in the research process are offered. This article examines the function of documents as a data source in qualitative research and discusses document analysis procedure in the context of actual research experiences. Targeted to research ...
Milestone 6. Margaret Zeegers, Deirdre Barron, in Milestone Moments in Getting your PhD in Qualitative Research, 2015. Document analysis. Document analysis may also be taken as discourse analysis, taking the documents under analysis as discourses which construct and constitute their own social reality. The American Declaration of Independence, for example, famously enshrined humanity's, not ...
Since document analysis is a valuable research method, one would expect to find a wide variety of literature on this topic. Unfortunately, the literature on documentary research is scant. This paper is designed to close the gap in the literature on conducting a qualitative document analysis by focusing on the advantages and limitations of using ...
Document analysis (also called document review) is one of the most commonly used methods in health policy research; it is nearly impossible to conduct policy research without it. Writing in early 20th century, Weber (2015) identified the importance of formal, written documents as a key characteristic of the bureaucracies by which modern ...
Since document analysis is a valuable research method, one would expect to find a wide variety of literature on this topic. Unfortunately, the literature on documentary research is scant. This paper is designed to close the gap in the literature on conducting a qualitative document analysis by focusing on the advantages and limitations of using ...
Triad 3. Introduction. Document analysis is a form of qualitative research in which documents are interpreted by the researcher to give voice and meaning around an assessment topic (Bowen, 2009). Analyzing documents incorporates coding content into themes similar to how focus group or interview transcripts are analyzed (Bowen,2009).
Policy document analysis: A practical educational leadership tool and a qualitative re-search method. Kuram ve Uygulamada Eğitim Yönetimi, 24(4), 623-640. doi: 10.14527/kuey.2018.016. 624. ... As a research tool, policy document analysis is a method for investigating the nature of a policy document in order to look at both what lies behind it and
To address the first research question, a citation analysis was conducted, identifying the most influential scientific documents by their frequency of citations. The technique of citation analysis measures each document's significance within its field, as assessed by its citation counts [ 26 ].
Background. Document analysis refers to a systematic process of reviewing and analyzing documents (Kaae & Traulsen, 2015; Mercieca et al., 2019).It has been used as an independent method and has also been combined with other research methods (Bowen, 2009; Olson, 2012; Siegner et al., 2018).The advantage of document analysis is that it can produce new and trustworthy knowledge (Bowen, 2009 ...
The structural response of two composite tow-steered shells with small cutouts in end compression is assessed using analyses and experimental measurements. The cylindrical shells were manufactured without cutouts using an automated fiber placement system, where the shells' fiber orientation angles vary continuously around the shell circumference from ±10 degrees on the axially stiff crown ...
The analysis also suggests that in males, motivation and ability demonstrate significant positive effects on research scholars' behavior to use LLM in their research, with B of 0.480 and 0.535, respectively (Table 6). The result suggests that higher levels of motivation and ability are associated with increased behavior values.
The software architecture of a system represents the design decisions related to overall system structure and behavior. Architecture helps stakeholders understand and analyze how the system will achieve essential qualities such as modifiability, availability, and security. Software architecture supports analysis of system qualities when teams ...
QM-E009-0503-0506-2500-COM333. Lab 2 Configure Cisco Routers for Syslog NTP and SSH Operations (1) Xid-487813291. P06 (a) - SMB Enumerations II v2. 31 MayDriving Conversion with Facebook CPAS & Google Ads. Information-systems document from Philippine Normal University, 5 pages, Competitors' Analysis BUSINESS NAME WEBSITE FACEBOOK INSTAGRAM FFL ...
Nurses turnover intention, representing the extent to which nurses express a desire to leave their current positions, is a critical global public health challenge. This issue significantly affects the healthcare workforce, contributing to disruptions in healthcare delivery and organizational stability. In Ethiopia, a country facing its own unique set of healthcare challenges, understanding and ...
"Instead of focusing on a single phrase or sentence for detection, we suggest using entire paragraphs or documents," added Amrit Singh Bedi, a research scientist at the Maryland Robotics Center who is also a co-author of Huang's paper. "Multiple sentence analysis would increase accuracy in AI detection because there is more for the ...