Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology

Research Design | Step-by-Step Guide with Examples
Published on 5 May 2022 by Shona McCombes . Revised on 20 March 2023.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about:
- Your overall aims and approach
- The type of research design you’ll use
- Your sampling methods or criteria for selecting subjects
- Your data collection methods
- The procedures you’ll follow to collect data
- Your data analysis methods
A well-planned research design helps ensure that your methods match your research aims and that you use the right kind of analysis for your data.
Table of contents
Step 1: consider your aims and approach, step 2: choose a type of research design, step 3: identify your population and sampling method, step 4: choose your data collection methods, step 5: plan your data collection procedures, step 6: decide on your data analysis strategies, frequently asked questions.
- Introduction
Before you can start designing your research, you should already have a clear idea of the research question you want to investigate.
There are many different ways you could go about answering this question. Your research design choices should be driven by your aims and priorities – start by thinking carefully about what you want to achieve.
The first choice you need to make is whether you’ll take a qualitative or quantitative approach.
Qualitative research designs tend to be more flexible and inductive , allowing you to adjust your approach based on what you find throughout the research process.
Quantitative research designs tend to be more fixed and deductive , with variables and hypotheses clearly defined in advance of data collection.
It’s also possible to use a mixed methods design that integrates aspects of both approaches. By combining qualitative and quantitative insights, you can gain a more complete picture of the problem you’re studying and strengthen the credibility of your conclusions.
Practical and ethical considerations when designing research
As well as scientific considerations, you need to think practically when designing your research. If your research involves people or animals, you also need to consider research ethics .
- How much time do you have to collect data and write up the research?
- Will you be able to gain access to the data you need (e.g., by travelling to a specific location or contacting specific people)?
- Do you have the necessary research skills (e.g., statistical analysis or interview techniques)?
- Will you need ethical approval ?
At each stage of the research design process, make sure that your choices are practically feasible.
Prevent plagiarism, run a free check.
Within both qualitative and quantitative approaches, there are several types of research design to choose from. Each type provides a framework for the overall shape of your research.
Types of quantitative research designs
Quantitative designs can be split into four main types. Experimental and quasi-experimental designs allow you to test cause-and-effect relationships, while descriptive and correlational designs allow you to measure variables and describe relationships between them.
With descriptive and correlational designs, you can get a clear picture of characteristics, trends, and relationships as they exist in the real world. However, you can’t draw conclusions about cause and effect (because correlation doesn’t imply causation ).
Experiments are the strongest way to test cause-and-effect relationships without the risk of other variables influencing the results. However, their controlled conditions may not always reflect how things work in the real world. They’re often also more difficult and expensive to implement.
Types of qualitative research designs
Qualitative designs are less strictly defined. This approach is about gaining a rich, detailed understanding of a specific context or phenomenon, and you can often be more creative and flexible in designing your research.
The table below shows some common types of qualitative design. They often have similar approaches in terms of data collection, but focus on different aspects when analysing the data.
Your research design should clearly define who or what your research will focus on, and how you’ll go about choosing your participants or subjects.
In research, a population is the entire group that you want to draw conclusions about, while a sample is the smaller group of individuals you’ll actually collect data from.
Defining the population
A population can be made up of anything you want to study – plants, animals, organisations, texts, countries, etc. In the social sciences, it most often refers to a group of people.
For example, will you focus on people from a specific demographic, region, or background? Are you interested in people with a certain job or medical condition, or users of a particular product?
The more precisely you define your population, the easier it will be to gather a representative sample.
Sampling methods
Even with a narrowly defined population, it’s rarely possible to collect data from every individual. Instead, you’ll collect data from a sample.
To select a sample, there are two main approaches: probability sampling and non-probability sampling . The sampling method you use affects how confidently you can generalise your results to the population as a whole.
Probability sampling is the most statistically valid option, but it’s often difficult to achieve unless you’re dealing with a very small and accessible population.
For practical reasons, many studies use non-probability sampling, but it’s important to be aware of the limitations and carefully consider potential biases. You should always make an effort to gather a sample that’s as representative as possible of the population.
Case selection in qualitative research
In some types of qualitative designs, sampling may not be relevant.
For example, in an ethnography or a case study, your aim is to deeply understand a specific context, not to generalise to a population. Instead of sampling, you may simply aim to collect as much data as possible about the context you are studying.
In these types of design, you still have to carefully consider your choice of case or community. You should have a clear rationale for why this particular case is suitable for answering your research question.
For example, you might choose a case study that reveals an unusual or neglected aspect of your research problem, or you might choose several very similar or very different cases in order to compare them.
Data collection methods are ways of directly measuring variables and gathering information. They allow you to gain first-hand knowledge and original insights into your research problem.
You can choose just one data collection method, or use several methods in the same study.
Survey methods
Surveys allow you to collect data about opinions, behaviours, experiences, and characteristics by asking people directly. There are two main survey methods to choose from: questionnaires and interviews.
Observation methods
Observations allow you to collect data unobtrusively, observing characteristics, behaviours, or social interactions without relying on self-reporting.
Observations may be conducted in real time, taking notes as you observe, or you might make audiovisual recordings for later analysis. They can be qualitative or quantitative.
Other methods of data collection
There are many other ways you might collect data depending on your field and topic.
If you’re not sure which methods will work best for your research design, try reading some papers in your field to see what data collection methods they used.
Secondary data
If you don’t have the time or resources to collect data from the population you’re interested in, you can also choose to use secondary data that other researchers already collected – for example, datasets from government surveys or previous studies on your topic.
With this raw data, you can do your own analysis to answer new research questions that weren’t addressed by the original study.
Using secondary data can expand the scope of your research, as you may be able to access much larger and more varied samples than you could collect yourself.
However, it also means you don’t have any control over which variables to measure or how to measure them, so the conclusions you can draw may be limited.
As well as deciding on your methods, you need to plan exactly how you’ll use these methods to collect data that’s consistent, accurate, and unbiased.
Planning systematic procedures is especially important in quantitative research, where you need to precisely define your variables and ensure your measurements are reliable and valid.
Operationalisation
Some variables, like height or age, are easily measured. But often you’ll be dealing with more abstract concepts, like satisfaction, anxiety, or competence. Operationalisation means turning these fuzzy ideas into measurable indicators.
If you’re using observations , which events or actions will you count?
If you’re using surveys , which questions will you ask and what range of responses will be offered?
You may also choose to use or adapt existing materials designed to measure the concept you’re interested in – for example, questionnaires or inventories whose reliability and validity has already been established.
Reliability and validity
Reliability means your results can be consistently reproduced , while validity means that you’re actually measuring the concept you’re interested in.
For valid and reliable results, your measurement materials should be thoroughly researched and carefully designed. Plan your procedures to make sure you carry out the same steps in the same way for each participant.
If you’re developing a new questionnaire or other instrument to measure a specific concept, running a pilot study allows you to check its validity and reliability in advance.
Sampling procedures
As well as choosing an appropriate sampling method, you need a concrete plan for how you’ll actually contact and recruit your selected sample.
That means making decisions about things like:
- How many participants do you need for an adequate sample size?
- What inclusion and exclusion criteria will you use to identify eligible participants?
- How will you contact your sample – by mail, online, by phone, or in person?
If you’re using a probability sampling method, it’s important that everyone who is randomly selected actually participates in the study. How will you ensure a high response rate?
If you’re using a non-probability method, how will you avoid bias and ensure a representative sample?
Data management
It’s also important to create a data management plan for organising and storing your data.
Will you need to transcribe interviews or perform data entry for observations? You should anonymise and safeguard any sensitive data, and make sure it’s backed up regularly.
Keeping your data well organised will save time when it comes to analysing them. It can also help other researchers validate and add to your findings.
On their own, raw data can’t answer your research question. The last step of designing your research is planning how you’ll analyse the data.
Quantitative data analysis
In quantitative research, you’ll most likely use some form of statistical analysis . With statistics, you can summarise your sample data, make estimates, and test hypotheses.
Using descriptive statistics , you can summarise your sample data in terms of:
- The distribution of the data (e.g., the frequency of each score on a test)
- The central tendency of the data (e.g., the mean to describe the average score)
- The variability of the data (e.g., the standard deviation to describe how spread out the scores are)
The specific calculations you can do depend on the level of measurement of your variables.
Using inferential statistics , you can:
- Make estimates about the population based on your sample data.
- Test hypotheses about a relationship between variables.
Regression and correlation tests look for associations between two or more variables, while comparison tests (such as t tests and ANOVAs ) look for differences in the outcomes of different groups.
Your choice of statistical test depends on various aspects of your research design, including the types of variables you’re dealing with and the distribution of your data.
Qualitative data analysis
In qualitative research, your data will usually be very dense with information and ideas. Instead of summing it up in numbers, you’ll need to comb through the data in detail, interpret its meanings, identify patterns, and extract the parts that are most relevant to your research question.
Two of the most common approaches to doing this are thematic analysis and discourse analysis .
There are many other ways of analysing qualitative data depending on the aims of your research. To get a sense of potential approaches, try reading some qualitative research papers in your field.
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research.
For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
Statistical sampling allows you to test a hypothesis about the characteristics of a population. There are various sampling methods you can use to ensure that your sample is representative of the population as a whole.
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts, and meanings, use qualitative methods .
- If you want to analyse a large amount of readily available data, use secondary data. If you want data specific to your purposes with control over how they are generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2023, March 20). Research Design | Step-by-Step Guide with Examples. Scribbr. Retrieved 31 May 2024, from https://www.scribbr.co.uk/research-methods/research-design/
Is this article helpful?

Shona McCombes
- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- Types of Research Designs
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Choosing a Title
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
Introduction
Before beginning your paper, you need to decide how you plan to design the study .
The research design refers to the overall strategy and analytical approach that you have chosen in order to integrate, in a coherent and logical way, the different components of the study, thus ensuring that the research problem will be thoroughly investigated. It constitutes the blueprint for the collection, measurement, and interpretation of information and data. Note that the research problem determines the type of design you choose, not the other way around!
De Vaus, D. A. Research Design in Social Research . London: SAGE, 2001; Trochim, William M.K. Research Methods Knowledge Base. 2006.
General Structure and Writing Style
The function of a research design is to ensure that the evidence obtained enables you to effectively address the research problem logically and as unambiguously as possible . In social sciences research, obtaining information relevant to the research problem generally entails specifying the type of evidence needed to test the underlying assumptions of a theory, to evaluate a program, or to accurately describe and assess meaning related to an observable phenomenon.
With this in mind, a common mistake made by researchers is that they begin their investigations before they have thought critically about what information is required to address the research problem. Without attending to these design issues beforehand, the overall research problem will not be adequately addressed and any conclusions drawn will run the risk of being weak and unconvincing. As a consequence, the overall validity of the study will be undermined.
The length and complexity of describing the research design in your paper can vary considerably, but any well-developed description will achieve the following :
- Identify the research problem clearly and justify its selection, particularly in relation to any valid alternative designs that could have been used,
- Review and synthesize previously published literature associated with the research problem,
- Clearly and explicitly specify hypotheses [i.e., research questions] central to the problem,
- Effectively describe the information and/or data which will be necessary for an adequate testing of the hypotheses and explain how such information and/or data will be obtained, and
- Describe the methods of analysis to be applied to the data in determining whether or not the hypotheses are true or false.
The research design is usually incorporated into the introduction of your paper . You can obtain an overall sense of what to do by reviewing studies that have utilized the same research design [e.g., using a case study approach]. This can help you develop an outline to follow for your own paper.
NOTE: Use the SAGE Research Methods Online and Cases and the SAGE Research Methods Videos databases to search for scholarly resources on how to apply specific research designs and methods . The Research Methods Online database contains links to more than 175,000 pages of SAGE publisher's book, journal, and reference content on quantitative, qualitative, and mixed research methodologies. Also included is a collection of case studies of social research projects that can be used to help you better understand abstract or complex methodological concepts. The Research Methods Videos database contains hours of tutorials, interviews, video case studies, and mini-documentaries covering the entire research process.
Creswell, John W. and J. David Creswell. Research Design: Qualitative, Quantitative, and Mixed Methods Approaches . 5th edition. Thousand Oaks, CA: Sage, 2018; De Vaus, D. A. Research Design in Social Research . London: SAGE, 2001; Gorard, Stephen. Research Design: Creating Robust Approaches for the Social Sciences . Thousand Oaks, CA: Sage, 2013; Leedy, Paul D. and Jeanne Ellis Ormrod. Practical Research: Planning and Design . Tenth edition. Boston, MA: Pearson, 2013; Vogt, W. Paul, Dianna C. Gardner, and Lynne M. Haeffele. When to Use What Research Design . New York: Guilford, 2012.
Action Research Design
Definition and Purpose
The essentials of action research design follow a characteristic cycle whereby initially an exploratory stance is adopted, where an understanding of a problem is developed and plans are made for some form of interventionary strategy. Then the intervention is carried out [the "action" in action research] during which time, pertinent observations are collected in various forms. The new interventional strategies are carried out, and this cyclic process repeats, continuing until a sufficient understanding of [or a valid implementation solution for] the problem is achieved. The protocol is iterative or cyclical in nature and is intended to foster deeper understanding of a given situation, starting with conceptualizing and particularizing the problem and moving through several interventions and evaluations.
What do these studies tell you ?
- This is a collaborative and adaptive research design that lends itself to use in work or community situations.
- Design focuses on pragmatic and solution-driven research outcomes rather than testing theories.
- When practitioners use action research, it has the potential to increase the amount they learn consciously from their experience; the action research cycle can be regarded as a learning cycle.
- Action research studies often have direct and obvious relevance to improving practice and advocating for change.
- There are no hidden controls or preemption of direction by the researcher.
What these studies don't tell you ?
- It is harder to do than conducting conventional research because the researcher takes on responsibilities of advocating for change as well as for researching the topic.
- Action research is much harder to write up because it is less likely that you can use a standard format to report your findings effectively [i.e., data is often in the form of stories or observation].
- Personal over-involvement of the researcher may bias research results.
- The cyclic nature of action research to achieve its twin outcomes of action [e.g. change] and research [e.g. understanding] is time-consuming and complex to conduct.
- Advocating for change usually requires buy-in from study participants.
Coghlan, David and Mary Brydon-Miller. The Sage Encyclopedia of Action Research . Thousand Oaks, CA: Sage, 2014; Efron, Sara Efrat and Ruth Ravid. Action Research in Education: A Practical Guide . New York: Guilford, 2013; Gall, Meredith. Educational Research: An Introduction . Chapter 18, Action Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Gorard, Stephen. Research Design: Creating Robust Approaches for the Social Sciences . Thousand Oaks, CA: Sage, 2013; Kemmis, Stephen and Robin McTaggart. “Participatory Action Research.” In Handbook of Qualitative Research . Norman Denzin and Yvonna S. Lincoln, eds. 2nd ed. (Thousand Oaks, CA: SAGE, 2000), pp. 567-605; McNiff, Jean. Writing and Doing Action Research . London: Sage, 2014; Reason, Peter and Hilary Bradbury. Handbook of Action Research: Participative Inquiry and Practice . Thousand Oaks, CA: SAGE, 2001.
Case Study Design
A case study is an in-depth study of a particular research problem rather than a sweeping statistical survey or comprehensive comparative inquiry. It is often used to narrow down a very broad field of research into one or a few easily researchable examples. The case study research design is also useful for testing whether a specific theory and model actually applies to phenomena in the real world. It is a useful design when not much is known about an issue or phenomenon.
- Approach excels at bringing us to an understanding of a complex issue through detailed contextual analysis of a limited number of events or conditions and their relationships.
- A researcher using a case study design can apply a variety of methodologies and rely on a variety of sources to investigate a research problem.
- Design can extend experience or add strength to what is already known through previous research.
- Social scientists, in particular, make wide use of this research design to examine contemporary real-life situations and provide the basis for the application of concepts and theories and the extension of methodologies.
- The design can provide detailed descriptions of specific and rare cases.
- A single or small number of cases offers little basis for establishing reliability or to generalize the findings to a wider population of people, places, or things.
- Intense exposure to the study of a case may bias a researcher's interpretation of the findings.
- Design does not facilitate assessment of cause and effect relationships.
- Vital information may be missing, making the case hard to interpret.
- The case may not be representative or typical of the larger problem being investigated.
- If the criteria for selecting a case is because it represents a very unusual or unique phenomenon or problem for study, then your interpretation of the findings can only apply to that particular case.
Case Studies. Writing@CSU. Colorado State University; Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 4, Flexible Methods: Case Study Design. 2nd ed. New York: Columbia University Press, 1999; Gerring, John. “What Is a Case Study and What Is It Good for?” American Political Science Review 98 (May 2004): 341-354; Greenhalgh, Trisha, editor. Case Study Evaluation: Past, Present and Future Challenges . Bingley, UK: Emerald Group Publishing, 2015; Mills, Albert J. , Gabrielle Durepos, and Eiden Wiebe, editors. Encyclopedia of Case Study Research . Thousand Oaks, CA: SAGE Publications, 2010; Stake, Robert E. The Art of Case Study Research . Thousand Oaks, CA: SAGE, 1995; Yin, Robert K. Case Study Research: Design and Theory . Applied Social Research Methods Series, no. 5. 3rd ed. Thousand Oaks, CA: SAGE, 2003.
Causal Design
Causality studies may be thought of as understanding a phenomenon in terms of conditional statements in the form, “If X, then Y.” This type of research is used to measure what impact a specific change will have on existing norms and assumptions. Most social scientists seek causal explanations that reflect tests of hypotheses. Causal effect (nomothetic perspective) occurs when variation in one phenomenon, an independent variable, leads to or results, on average, in variation in another phenomenon, the dependent variable.
Conditions necessary for determining causality:
- Empirical association -- a valid conclusion is based on finding an association between the independent variable and the dependent variable.
- Appropriate time order -- to conclude that causation was involved, one must see that cases were exposed to variation in the independent variable before variation in the dependent variable.
- Nonspuriousness -- a relationship between two variables that is not due to variation in a third variable.
- Causality research designs assist researchers in understanding why the world works the way it does through the process of proving a causal link between variables and by the process of eliminating other possibilities.
- Replication is possible.
- There is greater confidence the study has internal validity due to the systematic subject selection and equity of groups being compared.
- Not all relationships are causal! The possibility always exists that, by sheer coincidence, two unrelated events appear to be related [e.g., Punxatawney Phil could accurately predict the duration of Winter for five consecutive years but, the fact remains, he's just a big, furry rodent].
- Conclusions about causal relationships are difficult to determine due to a variety of extraneous and confounding variables that exist in a social environment. This means causality can only be inferred, never proven.
- If two variables are correlated, the cause must come before the effect. However, even though two variables might be causally related, it can sometimes be difficult to determine which variable comes first and, therefore, to establish which variable is the actual cause and which is the actual effect.
Beach, Derek and Rasmus Brun Pedersen. Causal Case Study Methods: Foundations and Guidelines for Comparing, Matching, and Tracing . Ann Arbor, MI: University of Michigan Press, 2016; Bachman, Ronet. The Practice of Research in Criminology and Criminal Justice . Chapter 5, Causation and Research Designs. 3rd ed. Thousand Oaks, CA: Pine Forge Press, 2007; Brewer, Ernest W. and Jennifer Kubn. “Causal-Comparative Design.” In Encyclopedia of Research Design . Neil J. Salkind, editor. (Thousand Oaks, CA: Sage, 2010), pp. 125-132; Causal Research Design: Experimentation. Anonymous SlideShare Presentation; Gall, Meredith. Educational Research: An Introduction . Chapter 11, Nonexperimental Research: Correlational Designs. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Trochim, William M.K. Research Methods Knowledge Base. 2006.
Cohort Design
Often used in the medical sciences, but also found in the applied social sciences, a cohort study generally refers to a study conducted over a period of time involving members of a population which the subject or representative member comes from, and who are united by some commonality or similarity. Using a quantitative framework, a cohort study makes note of statistical occurrence within a specialized subgroup, united by same or similar characteristics that are relevant to the research problem being investigated, rather than studying statistical occurrence within the general population. Using a qualitative framework, cohort studies generally gather data using methods of observation. Cohorts can be either "open" or "closed."
- Open Cohort Studies [dynamic populations, such as the population of Los Angeles] involve a population that is defined just by the state of being a part of the study in question (and being monitored for the outcome). Date of entry and exit from the study is individually defined, therefore, the size of the study population is not constant. In open cohort studies, researchers can only calculate rate based data, such as, incidence rates and variants thereof.
- Closed Cohort Studies [static populations, such as patients entered into a clinical trial] involve participants who enter into the study at one defining point in time and where it is presumed that no new participants can enter the cohort. Given this, the number of study participants remains constant (or can only decrease).
- The use of cohorts is often mandatory because a randomized control study may be unethical. For example, you cannot deliberately expose people to asbestos, you can only study its effects on those who have already been exposed. Research that measures risk factors often relies upon cohort designs.
- Because cohort studies measure potential causes before the outcome has occurred, they can demonstrate that these “causes” preceded the outcome, thereby avoiding the debate as to which is the cause and which is the effect.
- Cohort analysis is highly flexible and can provide insight into effects over time and related to a variety of different types of changes [e.g., social, cultural, political, economic, etc.].
- Either original data or secondary data can be used in this design.
- In cases where a comparative analysis of two cohorts is made [e.g., studying the effects of one group exposed to asbestos and one that has not], a researcher cannot control for all other factors that might differ between the two groups. These factors are known as confounding variables.
- Cohort studies can end up taking a long time to complete if the researcher must wait for the conditions of interest to develop within the group. This also increases the chance that key variables change during the course of the study, potentially impacting the validity of the findings.
- Due to the lack of randominization in the cohort design, its external validity is lower than that of study designs where the researcher randomly assigns participants.
Healy P, Devane D. “Methodological Considerations in Cohort Study Designs.” Nurse Researcher 18 (2011): 32-36; Glenn, Norval D, editor. Cohort Analysis . 2nd edition. Thousand Oaks, CA: Sage, 2005; Levin, Kate Ann. Study Design IV: Cohort Studies. Evidence-Based Dentistry 7 (2003): 51–52; Payne, Geoff. “Cohort Study.” In The SAGE Dictionary of Social Research Methods . Victor Jupp, editor. (Thousand Oaks, CA: Sage, 2006), pp. 31-33; Study Design 101. Himmelfarb Health Sciences Library. George Washington University, November 2011; Cohort Study. Wikipedia.
Cross-Sectional Design
Cross-sectional research designs have three distinctive features: no time dimension; a reliance on existing differences rather than change following intervention; and, groups are selected based on existing differences rather than random allocation. The cross-sectional design can only measure differences between or from among a variety of people, subjects, or phenomena rather than a process of change. As such, researchers using this design can only employ a relatively passive approach to making causal inferences based on findings.
- Cross-sectional studies provide a clear 'snapshot' of the outcome and the characteristics associated with it, at a specific point in time.
- Unlike an experimental design, where there is an active intervention by the researcher to produce and measure change or to create differences, cross-sectional designs focus on studying and drawing inferences from existing differences between people, subjects, or phenomena.
- Entails collecting data at and concerning one point in time. While longitudinal studies involve taking multiple measures over an extended period of time, cross-sectional research is focused on finding relationships between variables at one moment in time.
- Groups identified for study are purposely selected based upon existing differences in the sample rather than seeking random sampling.
- Cross-section studies are capable of using data from a large number of subjects and, unlike observational studies, is not geographically bound.
- Can estimate prevalence of an outcome of interest because the sample is usually taken from the whole population.
- Because cross-sectional designs generally use survey techniques to gather data, they are relatively inexpensive and take up little time to conduct.
- Finding people, subjects, or phenomena to study that are very similar except in one specific variable can be difficult.
- Results are static and time bound and, therefore, give no indication of a sequence of events or reveal historical or temporal contexts.
- Studies cannot be utilized to establish cause and effect relationships.
- This design only provides a snapshot of analysis so there is always the possibility that a study could have differing results if another time-frame had been chosen.
- There is no follow up to the findings.
Bethlehem, Jelke. "7: Cross-sectional Research." In Research Methodology in the Social, Behavioural and Life Sciences . Herman J Adèr and Gideon J Mellenbergh, editors. (London, England: Sage, 1999), pp. 110-43; Bourque, Linda B. “Cross-Sectional Design.” In The SAGE Encyclopedia of Social Science Research Methods . Michael S. Lewis-Beck, Alan Bryman, and Tim Futing Liao. (Thousand Oaks, CA: 2004), pp. 230-231; Hall, John. “Cross-Sectional Survey Design.” In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 173-174; Helen Barratt, Maria Kirwan. Cross-Sectional Studies: Design Application, Strengths and Weaknesses of Cross-Sectional Studies. Healthknowledge, 2009. Cross-Sectional Study. Wikipedia.
Descriptive Design
Descriptive research designs help provide answers to the questions of who, what, when, where, and how associated with a particular research problem; a descriptive study cannot conclusively ascertain answers to why. Descriptive research is used to obtain information concerning the current status of the phenomena and to describe "what exists" with respect to variables or conditions in a situation.
- The subject is being observed in a completely natural and unchanged natural environment. True experiments, whilst giving analyzable data, often adversely influence the normal behavior of the subject [a.k.a., the Heisenberg effect whereby measurements of certain systems cannot be made without affecting the systems].
- Descriptive research is often used as a pre-cursor to more quantitative research designs with the general overview giving some valuable pointers as to what variables are worth testing quantitatively.
- If the limitations are understood, they can be a useful tool in developing a more focused study.
- Descriptive studies can yield rich data that lead to important recommendations in practice.
- Appoach collects a large amount of data for detailed analysis.
- The results from a descriptive research cannot be used to discover a definitive answer or to disprove a hypothesis.
- Because descriptive designs often utilize observational methods [as opposed to quantitative methods], the results cannot be replicated.
- The descriptive function of research is heavily dependent on instrumentation for measurement and observation.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 5, Flexible Methods: Descriptive Research. 2nd ed. New York: Columbia University Press, 1999; Given, Lisa M. "Descriptive Research." In Encyclopedia of Measurement and Statistics . Neil J. Salkind and Kristin Rasmussen, editors. (Thousand Oaks, CA: Sage, 2007), pp. 251-254; McNabb, Connie. Descriptive Research Methodologies. Powerpoint Presentation; Shuttleworth, Martyn. Descriptive Research Design, September 26, 2008; Erickson, G. Scott. "Descriptive Research Design." In New Methods of Market Research and Analysis . (Northampton, MA: Edward Elgar Publishing, 2017), pp. 51-77; Sahin, Sagufta, and Jayanta Mete. "A Brief Study on Descriptive Research: Its Nature and Application in Social Science." International Journal of Research and Analysis in Humanities 1 (2021): 11; K. Swatzell and P. Jennings. “Descriptive Research: The Nuts and Bolts.” Journal of the American Academy of Physician Assistants 20 (2007), pp. 55-56; Kane, E. Doing Your Own Research: Basic Descriptive Research in the Social Sciences and Humanities . London: Marion Boyars, 1985.
Experimental Design
A blueprint of the procedure that enables the researcher to maintain control over all factors that may affect the result of an experiment. In doing this, the researcher attempts to determine or predict what may occur. Experimental research is often used where there is time priority in a causal relationship (cause precedes effect), there is consistency in a causal relationship (a cause will always lead to the same effect), and the magnitude of the correlation is great. The classic experimental design specifies an experimental group and a control group. The independent variable is administered to the experimental group and not to the control group, and both groups are measured on the same dependent variable. Subsequent experimental designs have used more groups and more measurements over longer periods. True experiments must have control, randomization, and manipulation.
- Experimental research allows the researcher to control the situation. In so doing, it allows researchers to answer the question, “What causes something to occur?”
- Permits the researcher to identify cause and effect relationships between variables and to distinguish placebo effects from treatment effects.
- Experimental research designs support the ability to limit alternative explanations and to infer direct causal relationships in the study.
- Approach provides the highest level of evidence for single studies.
- The design is artificial, and results may not generalize well to the real world.
- The artificial settings of experiments may alter the behaviors or responses of participants.
- Experimental designs can be costly if special equipment or facilities are needed.
- Some research problems cannot be studied using an experiment because of ethical or technical reasons.
- Difficult to apply ethnographic and other qualitative methods to experimentally designed studies.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 7, Flexible Methods: Experimental Research. 2nd ed. New York: Columbia University Press, 1999; Chapter 2: Research Design, Experimental Designs. School of Psychology, University of New England, 2000; Chow, Siu L. "Experimental Design." In Encyclopedia of Research Design . Neil J. Salkind, editor. (Thousand Oaks, CA: Sage, 2010), pp. 448-453; "Experimental Design." In Social Research Methods . Nicholas Walliman, editor. (London, England: Sage, 2006), pp, 101-110; Experimental Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Kirk, Roger E. Experimental Design: Procedures for the Behavioral Sciences . 4th edition. Thousand Oaks, CA: Sage, 2013; Trochim, William M.K. Experimental Design. Research Methods Knowledge Base. 2006; Rasool, Shafqat. Experimental Research. Slideshare presentation.
Exploratory Design
An exploratory design is conducted about a research problem when there are few or no earlier studies to refer to or rely upon to predict an outcome . The focus is on gaining insights and familiarity for later investigation or undertaken when research problems are in a preliminary stage of investigation. Exploratory designs are often used to establish an understanding of how best to proceed in studying an issue or what methodology would effectively apply to gathering information about the issue.
The goals of exploratory research are intended to produce the following possible insights:
- Familiarity with basic details, settings, and concerns.
- Well grounded picture of the situation being developed.
- Generation of new ideas and assumptions.
- Development of tentative theories or hypotheses.
- Determination about whether a study is feasible in the future.
- Issues get refined for more systematic investigation and formulation of new research questions.
- Direction for future research and techniques get developed.
- Design is a useful approach for gaining background information on a particular topic.
- Exploratory research is flexible and can address research questions of all types (what, why, how).
- Provides an opportunity to define new terms and clarify existing concepts.
- Exploratory research is often used to generate formal hypotheses and develop more precise research problems.
- In the policy arena or applied to practice, exploratory studies help establish research priorities and where resources should be allocated.
- Exploratory research generally utilizes small sample sizes and, thus, findings are typically not generalizable to the population at large.
- The exploratory nature of the research inhibits an ability to make definitive conclusions about the findings. They provide insight but not definitive conclusions.
- The research process underpinning exploratory studies is flexible but often unstructured, leading to only tentative results that have limited value to decision-makers.
- Design lacks rigorous standards applied to methods of data gathering and analysis because one of the areas for exploration could be to determine what method or methodologies could best fit the research problem.
Cuthill, Michael. “Exploratory Research: Citizen Participation, Local Government, and Sustainable Development in Australia.” Sustainable Development 10 (2002): 79-89; Streb, Christoph K. "Exploratory Case Study." In Encyclopedia of Case Study Research . Albert J. Mills, Gabrielle Durepos and Eiden Wiebe, editors. (Thousand Oaks, CA: Sage, 2010), pp. 372-374; Taylor, P. J., G. Catalano, and D.R.F. Walker. “Exploratory Analysis of the World City Network.” Urban Studies 39 (December 2002): 2377-2394; Exploratory Research. Wikipedia.
Field Research Design
Sometimes referred to as ethnography or participant observation, designs around field research encompass a variety of interpretative procedures [e.g., observation and interviews] rooted in qualitative approaches to studying people individually or in groups while inhabiting their natural environment as opposed to using survey instruments or other forms of impersonal methods of data gathering. Information acquired from observational research takes the form of “ field notes ” that involves documenting what the researcher actually sees and hears while in the field. Findings do not consist of conclusive statements derived from numbers and statistics because field research involves analysis of words and observations of behavior. Conclusions, therefore, are developed from an interpretation of findings that reveal overriding themes, concepts, and ideas. More information can be found HERE .
- Field research is often necessary to fill gaps in understanding the research problem applied to local conditions or to specific groups of people that cannot be ascertained from existing data.
- The research helps contextualize already known information about a research problem, thereby facilitating ways to assess the origins, scope, and scale of a problem and to gage the causes, consequences, and means to resolve an issue based on deliberate interaction with people in their natural inhabited spaces.
- Enables the researcher to corroborate or confirm data by gathering additional information that supports or refutes findings reported in prior studies of the topic.
- Because the researcher in embedded in the field, they are better able to make observations or ask questions that reflect the specific cultural context of the setting being investigated.
- Observing the local reality offers the opportunity to gain new perspectives or obtain unique data that challenges existing theoretical propositions or long-standing assumptions found in the literature.
What these studies don't tell you
- A field research study requires extensive time and resources to carry out the multiple steps involved with preparing for the gathering of information, including for example, examining background information about the study site, obtaining permission to access the study site, and building trust and rapport with subjects.
- Requires a commitment to staying engaged in the field to ensure that you can adequately document events and behaviors as they unfold.
- The unpredictable nature of fieldwork means that researchers can never fully control the process of data gathering. They must maintain a flexible approach to studying the setting because events and circumstances can change quickly or unexpectedly.
- Findings can be difficult to interpret and verify without access to documents and other source materials that help to enhance the credibility of information obtained from the field [i.e., the act of triangulating the data].
- Linking the research problem to the selection of study participants inhabiting their natural environment is critical. However, this specificity limits the ability to generalize findings to different situations or in other contexts or to infer courses of action applied to other settings or groups of people.
- The reporting of findings must take into account how the researcher themselves may have inadvertently affected respondents and their behaviors.
Historical Design
The purpose of a historical research design is to collect, verify, and synthesize evidence from the past to establish facts that defend or refute a hypothesis. It uses secondary sources and a variety of primary documentary evidence, such as, diaries, official records, reports, archives, and non-textual information [maps, pictures, audio and visual recordings]. The limitation is that the sources must be both authentic and valid.
- The historical research design is unobtrusive; the act of research does not affect the results of the study.
- The historical approach is well suited for trend analysis.
- Historical records can add important contextual background required to more fully understand and interpret a research problem.
- There is often no possibility of researcher-subject interaction that could affect the findings.
- Historical sources can be used over and over to study different research problems or to replicate a previous study.
- The ability to fulfill the aims of your research are directly related to the amount and quality of documentation available to understand the research problem.
- Since historical research relies on data from the past, there is no way to manipulate it to control for contemporary contexts.
- Interpreting historical sources can be very time consuming.
- The sources of historical materials must be archived consistently to ensure access. This may especially challenging for digital or online-only sources.
- Original authors bring their own perspectives and biases to the interpretation of past events and these biases are more difficult to ascertain in historical resources.
- Due to the lack of control over external variables, historical research is very weak with regard to the demands of internal validity.
- It is rare that the entirety of historical documentation needed to fully address a research problem is available for interpretation, therefore, gaps need to be acknowledged.
Howell, Martha C. and Walter Prevenier. From Reliable Sources: An Introduction to Historical Methods . Ithaca, NY: Cornell University Press, 2001; Lundy, Karen Saucier. "Historical Research." In The Sage Encyclopedia of Qualitative Research Methods . Lisa M. Given, editor. (Thousand Oaks, CA: Sage, 2008), pp. 396-400; Marius, Richard. and Melvin E. Page. A Short Guide to Writing about History . 9th edition. Boston, MA: Pearson, 2015; Savitt, Ronald. “Historical Research in Marketing.” Journal of Marketing 44 (Autumn, 1980): 52-58; Gall, Meredith. Educational Research: An Introduction . Chapter 16, Historical Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007.
Longitudinal Design
A longitudinal study follows the same sample over time and makes repeated observations. For example, with longitudinal surveys, the same group of people is interviewed at regular intervals, enabling researchers to track changes over time and to relate them to variables that might explain why the changes occur. Longitudinal research designs describe patterns of change and help establish the direction and magnitude of causal relationships. Measurements are taken on each variable over two or more distinct time periods. This allows the researcher to measure change in variables over time. It is a type of observational study sometimes referred to as a panel study.
- Longitudinal data facilitate the analysis of the duration of a particular phenomenon.
- Enables survey researchers to get close to the kinds of causal explanations usually attainable only with experiments.
- The design permits the measurement of differences or change in a variable from one period to another [i.e., the description of patterns of change over time].
- Longitudinal studies facilitate the prediction of future outcomes based upon earlier factors.
- The data collection method may change over time.
- Maintaining the integrity of the original sample can be difficult over an extended period of time.
- It can be difficult to show more than one variable at a time.
- This design often needs qualitative research data to explain fluctuations in the results.
- A longitudinal research design assumes present trends will continue unchanged.
- It can take a long period of time to gather results.
- There is a need to have a large sample size and accurate sampling to reach representativness.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 6, Flexible Methods: Relational and Longitudinal Research. 2nd ed. New York: Columbia University Press, 1999; Forgues, Bernard, and Isabelle Vandangeon-Derumez. "Longitudinal Analyses." In Doing Management Research . Raymond-Alain Thiétart and Samantha Wauchope, editors. (London, England: Sage, 2001), pp. 332-351; Kalaian, Sema A. and Rafa M. Kasim. "Longitudinal Studies." In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 440-441; Menard, Scott, editor. Longitudinal Research . Thousand Oaks, CA: Sage, 2002; Ployhart, Robert E. and Robert J. Vandenberg. "Longitudinal Research: The Theory, Design, and Analysis of Change.” Journal of Management 36 (January 2010): 94-120; Longitudinal Study. Wikipedia.
Meta-Analysis Design
Meta-analysis is an analytical methodology designed to systematically evaluate and summarize the results from a number of individual studies, thereby, increasing the overall sample size and the ability of the researcher to study effects of interest. The purpose is to not simply summarize existing knowledge, but to develop a new understanding of a research problem using synoptic reasoning. The main objectives of meta-analysis include analyzing differences in the results among studies and increasing the precision by which effects are estimated. A well-designed meta-analysis depends upon strict adherence to the criteria used for selecting studies and the availability of information in each study to properly analyze their findings. Lack of information can severely limit the type of analyzes and conclusions that can be reached. In addition, the more dissimilarity there is in the results among individual studies [heterogeneity], the more difficult it is to justify interpretations that govern a valid synopsis of results. A meta-analysis needs to fulfill the following requirements to ensure the validity of your findings:
- Clearly defined description of objectives, including precise definitions of the variables and outcomes that are being evaluated;
- A well-reasoned and well-documented justification for identification and selection of the studies;
- Assessment and explicit acknowledgment of any researcher bias in the identification and selection of those studies;
- Description and evaluation of the degree of heterogeneity among the sample size of studies reviewed; and,
- Justification of the techniques used to evaluate the studies.
- Can be an effective strategy for determining gaps in the literature.
- Provides a means of reviewing research published about a particular topic over an extended period of time and from a variety of sources.
- Is useful in clarifying what policy or programmatic actions can be justified on the basis of analyzing research results from multiple studies.
- Provides a method for overcoming small sample sizes in individual studies that previously may have had little relationship to each other.
- Can be used to generate new hypotheses or highlight research problems for future studies.
- Small violations in defining the criteria used for content analysis can lead to difficult to interpret and/or meaningless findings.
- A large sample size can yield reliable, but not necessarily valid, results.
- A lack of uniformity regarding, for example, the type of literature reviewed, how methods are applied, and how findings are measured within the sample of studies you are analyzing, can make the process of synthesis difficult to perform.
- Depending on the sample size, the process of reviewing and synthesizing multiple studies can be very time consuming.
Beck, Lewis W. "The Synoptic Method." The Journal of Philosophy 36 (1939): 337-345; Cooper, Harris, Larry V. Hedges, and Jeffrey C. Valentine, eds. The Handbook of Research Synthesis and Meta-Analysis . 2nd edition. New York: Russell Sage Foundation, 2009; Guzzo, Richard A., Susan E. Jackson and Raymond A. Katzell. “Meta-Analysis Analysis.” In Research in Organizational Behavior , Volume 9. (Greenwich, CT: JAI Press, 1987), pp 407-442; Lipsey, Mark W. and David B. Wilson. Practical Meta-Analysis . Thousand Oaks, CA: Sage Publications, 2001; Study Design 101. Meta-Analysis. The Himmelfarb Health Sciences Library, George Washington University; Timulak, Ladislav. “Qualitative Meta-Analysis.” In The SAGE Handbook of Qualitative Data Analysis . Uwe Flick, editor. (Los Angeles, CA: Sage, 2013), pp. 481-495; Walker, Esteban, Adrian V. Hernandez, and Micheal W. Kattan. "Meta-Analysis: It's Strengths and Limitations." Cleveland Clinic Journal of Medicine 75 (June 2008): 431-439.
Mixed-Method Design
- Narrative and non-textual information can add meaning to numeric data, while numeric data can add precision to narrative and non-textual information.
- Can utilize existing data while at the same time generating and testing a grounded theory approach to describe and explain the phenomenon under study.
- A broader, more complex research problem can be investigated because the researcher is not constrained by using only one method.
- The strengths of one method can be used to overcome the inherent weaknesses of another method.
- Can provide stronger, more robust evidence to support a conclusion or set of recommendations.
- May generate new knowledge new insights or uncover hidden insights, patterns, or relationships that a single methodological approach might not reveal.
- Produces more complete knowledge and understanding of the research problem that can be used to increase the generalizability of findings applied to theory or practice.
- A researcher must be proficient in understanding how to apply multiple methods to investigating a research problem as well as be proficient in optimizing how to design a study that coherently melds them together.
- Can increase the likelihood of conflicting results or ambiguous findings that inhibit drawing a valid conclusion or setting forth a recommended course of action [e.g., sample interview responses do not support existing statistical data].
- Because the research design can be very complex, reporting the findings requires a well-organized narrative, clear writing style, and precise word choice.
- Design invites collaboration among experts. However, merging different investigative approaches and writing styles requires more attention to the overall research process than studies conducted using only one methodological paradigm.
- Concurrent merging of quantitative and qualitative research requires greater attention to having adequate sample sizes, using comparable samples, and applying a consistent unit of analysis. For sequential designs where one phase of qualitative research builds on the quantitative phase or vice versa, decisions about what results from the first phase to use in the next phase, the choice of samples and estimating reasonable sample sizes for both phases, and the interpretation of results from both phases can be difficult.
- Due to multiple forms of data being collected and analyzed, this design requires extensive time and resources to carry out the multiple steps involved in data gathering and interpretation.
Burch, Patricia and Carolyn J. Heinrich. Mixed Methods for Policy Research and Program Evaluation . Thousand Oaks, CA: Sage, 2016; Creswell, John w. et al. Best Practices for Mixed Methods Research in the Health Sciences . Bethesda, MD: Office of Behavioral and Social Sciences Research, National Institutes of Health, 2010Creswell, John W. Research Design: Qualitative, Quantitative, and Mixed Methods Approaches . 4th edition. Thousand Oaks, CA: Sage Publications, 2014; Domínguez, Silvia, editor. Mixed Methods Social Networks Research . Cambridge, UK: Cambridge University Press, 2014; Hesse-Biber, Sharlene Nagy. Mixed Methods Research: Merging Theory with Practice . New York: Guilford Press, 2010; Niglas, Katrin. “How the Novice Researcher Can Make Sense of Mixed Methods Designs.” International Journal of Multiple Research Approaches 3 (2009): 34-46; Onwuegbuzie, Anthony J. and Nancy L. Leech. “Linking Research Questions to Mixed Methods Data Analysis Procedures.” The Qualitative Report 11 (September 2006): 474-498; Tashakorri, Abbas and John W. Creswell. “The New Era of Mixed Methods.” Journal of Mixed Methods Research 1 (January 2007): 3-7; Zhanga, Wanqing. “Mixed Methods Application in Health Intervention Research: A Multiple Case Study.” International Journal of Multiple Research Approaches 8 (2014): 24-35 .
Observational Design
This type of research design draws a conclusion by comparing subjects against a control group, in cases where the researcher has no control over the experiment. There are two general types of observational designs. In direct observations, people know that you are watching them. Unobtrusive measures involve any method for studying behavior where individuals do not know they are being observed. An observational study allows a useful insight into a phenomenon and avoids the ethical and practical difficulties of setting up a large and cumbersome research project.
- Observational studies are usually flexible and do not necessarily need to be structured around a hypothesis about what you expect to observe [data is emergent rather than pre-existing].
- The researcher is able to collect in-depth information about a particular behavior.
- Can reveal interrelationships among multifaceted dimensions of group interactions.
- You can generalize your results to real life situations.
- Observational research is useful for discovering what variables may be important before applying other methods like experiments.
- Observation research designs account for the complexity of group behaviors.
- Reliability of data is low because seeing behaviors occur over and over again may be a time consuming task and are difficult to replicate.
- In observational research, findings may only reflect a unique sample population and, thus, cannot be generalized to other groups.
- There can be problems with bias as the researcher may only "see what they want to see."
- There is no possibility to determine "cause and effect" relationships since nothing is manipulated.
- Sources or subjects may not all be equally credible.
- Any group that is knowingly studied is altered to some degree by the presence of the researcher, therefore, potentially skewing any data collected.
Atkinson, Paul and Martyn Hammersley. “Ethnography and Participant Observation.” In Handbook of Qualitative Research . Norman K. Denzin and Yvonna S. Lincoln, eds. (Thousand Oaks, CA: Sage, 1994), pp. 248-261; Observational Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Patton Michael Quinn. Qualitiative Research and Evaluation Methods . Chapter 6, Fieldwork Strategies and Observational Methods. 3rd ed. Thousand Oaks, CA: Sage, 2002; Payne, Geoff and Judy Payne. "Observation." In Key Concepts in Social Research . The SAGE Key Concepts series. (London, England: Sage, 2004), pp. 158-162; Rosenbaum, Paul R. Design of Observational Studies . New York: Springer, 2010;Williams, J. Patrick. "Nonparticipant Observation." In The Sage Encyclopedia of Qualitative Research Methods . Lisa M. Given, editor.(Thousand Oaks, CA: Sage, 2008), pp. 562-563.
Philosophical Design
Understood more as an broad approach to examining a research problem than a methodological design, philosophical analysis and argumentation is intended to challenge deeply embedded, often intractable, assumptions underpinning an area of study. This approach uses the tools of argumentation derived from philosophical traditions, concepts, models, and theories to critically explore and challenge, for example, the relevance of logic and evidence in academic debates, to analyze arguments about fundamental issues, or to discuss the root of existing discourse about a research problem. These overarching tools of analysis can be framed in three ways:
- Ontology -- the study that describes the nature of reality; for example, what is real and what is not, what is fundamental and what is derivative?
- Epistemology -- the study that explores the nature of knowledge; for example, by what means does knowledge and understanding depend upon and how can we be certain of what we know?
- Axiology -- the study of values; for example, what values does an individual or group hold and why? How are values related to interest, desire, will, experience, and means-to-end? And, what is the difference between a matter of fact and a matter of value?
- Can provide a basis for applying ethical decision-making to practice.
- Functions as a means of gaining greater self-understanding and self-knowledge about the purposes of research.
- Brings clarity to general guiding practices and principles of an individual or group.
- Philosophy informs methodology.
- Refine concepts and theories that are invoked in relatively unreflective modes of thought and discourse.
- Beyond methodology, philosophy also informs critical thinking about epistemology and the structure of reality (metaphysics).
- Offers clarity and definition to the practical and theoretical uses of terms, concepts, and ideas.
- Limited application to specific research problems [answering the "So What?" question in social science research].
- Analysis can be abstract, argumentative, and limited in its practical application to real-life issues.
- While a philosophical analysis may render problematic that which was once simple or taken-for-granted, the writing can be dense and subject to unnecessary jargon, overstatement, and/or excessive quotation and documentation.
- There are limitations in the use of metaphor as a vehicle of philosophical analysis.
- There can be analytical difficulties in moving from philosophy to advocacy and between abstract thought and application to the phenomenal world.
Burton, Dawn. "Part I, Philosophy of the Social Sciences." In Research Training for Social Scientists . (London, England: Sage, 2000), pp. 1-5; Chapter 4, Research Methodology and Design. Unisa Institutional Repository (UnisaIR), University of South Africa; Jarvie, Ian C., and Jesús Zamora-Bonilla, editors. The SAGE Handbook of the Philosophy of Social Sciences . London: Sage, 2011; Labaree, Robert V. and Ross Scimeca. “The Philosophical Problem of Truth in Librarianship.” The Library Quarterly 78 (January 2008): 43-70; Maykut, Pamela S. Beginning Qualitative Research: A Philosophic and Practical Guide . Washington, DC: Falmer Press, 1994; McLaughlin, Hugh. "The Philosophy of Social Research." In Understanding Social Work Research . 2nd edition. (London: SAGE Publications Ltd., 2012), pp. 24-47; Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, CSLI, Stanford University, 2013.
Sequential Design
- The researcher has a limitless option when it comes to sample size and the sampling schedule.
- Due to the repetitive nature of this research design, minor changes and adjustments can be done during the initial parts of the study to correct and hone the research method.
- This is a useful design for exploratory studies.
- There is very little effort on the part of the researcher when performing this technique. It is generally not expensive, time consuming, or workforce intensive.
- Because the study is conducted serially, the results of one sample are known before the next sample is taken and analyzed. This provides opportunities for continuous improvement of sampling and methods of analysis.
- The sampling method is not representative of the entire population. The only possibility of approaching representativeness is when the researcher chooses to use a very large sample size significant enough to represent a significant portion of the entire population. In this case, moving on to study a second or more specific sample can be difficult.
- The design cannot be used to create conclusions and interpretations that pertain to an entire population because the sampling technique is not randomized. Generalizability from findings is, therefore, limited.
- Difficult to account for and interpret variation from one sample to another over time, particularly when using qualitative methods of data collection.
Betensky, Rebecca. Harvard University, Course Lecture Note slides; Bovaird, James A. and Kevin A. Kupzyk. "Sequential Design." In Encyclopedia of Research Design . Neil J. Salkind, editor. (Thousand Oaks, CA: Sage, 2010), pp. 1347-1352; Cresswell, John W. Et al. “Advanced Mixed-Methods Research Designs.” In Handbook of Mixed Methods in Social and Behavioral Research . Abbas Tashakkori and Charles Teddle, eds. (Thousand Oaks, CA: Sage, 2003), pp. 209-240; Henry, Gary T. "Sequential Sampling." In The SAGE Encyclopedia of Social Science Research Methods . Michael S. Lewis-Beck, Alan Bryman and Tim Futing Liao, editors. (Thousand Oaks, CA: Sage, 2004), pp. 1027-1028; Nataliya V. Ivankova. “Using Mixed-Methods Sequential Explanatory Design: From Theory to Practice.” Field Methods 18 (February 2006): 3-20; Bovaird, James A. and Kevin A. Kupzyk. “Sequential Design.” In Encyclopedia of Research Design . Neil J. Salkind, ed. Thousand Oaks, CA: Sage, 2010; Sequential Analysis. Wikipedia.
Systematic Review
- A systematic review synthesizes the findings of multiple studies related to each other by incorporating strategies of analysis and interpretation intended to reduce biases and random errors.
- The application of critical exploration, evaluation, and synthesis methods separates insignificant, unsound, or redundant research from the most salient and relevant studies worthy of reflection.
- They can be use to identify, justify, and refine hypotheses, recognize and avoid hidden problems in prior studies, and explain data inconsistencies and conflicts in data.
- Systematic reviews can be used to help policy makers formulate evidence-based guidelines and regulations.
- The use of strict, explicit, and pre-determined methods of synthesis, when applied appropriately, provide reliable estimates about the effects of interventions, evaluations, and effects related to the overarching research problem investigated by each study under review.
- Systematic reviews illuminate where knowledge or thorough understanding of a research problem is lacking and, therefore, can then be used to guide future research.
- The accepted inclusion of unpublished studies [i.e., grey literature] ensures the broadest possible way to analyze and interpret research on a topic.
- Results of the synthesis can be generalized and the findings extrapolated into the general population with more validity than most other types of studies .
- Systematic reviews do not create new knowledge per se; they are a method for synthesizing existing studies about a research problem in order to gain new insights and determine gaps in the literature.
- The way researchers have carried out their investigations [e.g., the period of time covered, number of participants, sources of data analyzed, etc.] can make it difficult to effectively synthesize studies.
- The inclusion of unpublished studies can introduce bias into the review because they may not have undergone a rigorous peer-review process prior to publication. Examples may include conference presentations or proceedings, publications from government agencies, white papers, working papers, and internal documents from organizations, and doctoral dissertations and Master's theses.
Denyer, David and David Tranfield. "Producing a Systematic Review." In The Sage Handbook of Organizational Research Methods . David A. Buchanan and Alan Bryman, editors. ( Thousand Oaks, CA: Sage Publications, 2009), pp. 671-689; Foster, Margaret J. and Sarah T. Jewell, editors. Assembling the Pieces of a Systematic Review: A Guide for Librarians . Lanham, MD: Rowman and Littlefield, 2017; Gough, David, Sandy Oliver, James Thomas, editors. Introduction to Systematic Reviews . 2nd edition. Los Angeles, CA: Sage Publications, 2017; Gopalakrishnan, S. and P. Ganeshkumar. “Systematic Reviews and Meta-analysis: Understanding the Best Evidence in Primary Healthcare.” Journal of Family Medicine and Primary Care 2 (2013): 9-14; Gough, David, James Thomas, and Sandy Oliver. "Clarifying Differences between Review Designs and Methods." Systematic Reviews 1 (2012): 1-9; Khan, Khalid S., Regina Kunz, Jos Kleijnen, and Gerd Antes. “Five Steps to Conducting a Systematic Review.” Journal of the Royal Society of Medicine 96 (2003): 118-121; Mulrow, C. D. “Systematic Reviews: Rationale for Systematic Reviews.” BMJ 309:597 (September 1994); O'Dwyer, Linda C., and Q. Eileen Wafford. "Addressing Challenges with Systematic Review Teams through Effective Communication: A Case Report." Journal of the Medical Library Association 109 (October 2021): 643-647; Okoli, Chitu, and Kira Schabram. "A Guide to Conducting a Systematic Literature Review of Information Systems Research." Sprouts: Working Papers on Information Systems 10 (2010); Siddaway, Andy P., Alex M. Wood, and Larry V. Hedges. "How to Do a Systematic Review: A Best Practice Guide for Conducting and Reporting Narrative Reviews, Meta-analyses, and Meta-syntheses." Annual Review of Psychology 70 (2019): 747-770; Torgerson, Carole J. “Publication Bias: The Achilles’ Heel of Systematic Reviews?” British Journal of Educational Studies 54 (March 2006): 89-102; Torgerson, Carole. Systematic Reviews . New York: Continuum, 2003.
- << Previous: Purpose of Guide
- Next: Design Flaws to Avoid >>
- Last Updated: May 30, 2024 9:38 AM
- URL: https://libguides.usc.edu/writingguide
- Privacy Policy
Home » Research Methodology – Types, Examples and writing Guide
Research Methodology – Types, Examples and writing Guide
Table of Contents

Research Methodology
Definition:
Research Methodology refers to the systematic and scientific approach used to conduct research, investigate problems, and gather data and information for a specific purpose. It involves the techniques and procedures used to identify, collect , analyze , and interpret data to answer research questions or solve research problems . Moreover, They are philosophical and theoretical frameworks that guide the research process.
Structure of Research Methodology
Research methodology formats can vary depending on the specific requirements of the research project, but the following is a basic example of a structure for a research methodology section:
I. Introduction
- Provide an overview of the research problem and the need for a research methodology section
- Outline the main research questions and objectives
II. Research Design
- Explain the research design chosen and why it is appropriate for the research question(s) and objectives
- Discuss any alternative research designs considered and why they were not chosen
- Describe the research setting and participants (if applicable)
III. Data Collection Methods
- Describe the methods used to collect data (e.g., surveys, interviews, observations)
- Explain how the data collection methods were chosen and why they are appropriate for the research question(s) and objectives
- Detail any procedures or instruments used for data collection
IV. Data Analysis Methods
- Describe the methods used to analyze the data (e.g., statistical analysis, content analysis )
- Explain how the data analysis methods were chosen and why they are appropriate for the research question(s) and objectives
- Detail any procedures or software used for data analysis
V. Ethical Considerations
- Discuss any ethical issues that may arise from the research and how they were addressed
- Explain how informed consent was obtained (if applicable)
- Detail any measures taken to ensure confidentiality and anonymity
VI. Limitations
- Identify any potential limitations of the research methodology and how they may impact the results and conclusions
VII. Conclusion
- Summarize the key aspects of the research methodology section
- Explain how the research methodology addresses the research question(s) and objectives
Research Methodology Types
Types of Research Methodology are as follows:
Quantitative Research Methodology
This is a research methodology that involves the collection and analysis of numerical data using statistical methods. This type of research is often used to study cause-and-effect relationships and to make predictions.
Qualitative Research Methodology
This is a research methodology that involves the collection and analysis of non-numerical data such as words, images, and observations. This type of research is often used to explore complex phenomena, to gain an in-depth understanding of a particular topic, and to generate hypotheses.
Mixed-Methods Research Methodology
This is a research methodology that combines elements of both quantitative and qualitative research. This approach can be particularly useful for studies that aim to explore complex phenomena and to provide a more comprehensive understanding of a particular topic.
Case Study Research Methodology
This is a research methodology that involves in-depth examination of a single case or a small number of cases. Case studies are often used in psychology, sociology, and anthropology to gain a detailed understanding of a particular individual or group.
Action Research Methodology
This is a research methodology that involves a collaborative process between researchers and practitioners to identify and solve real-world problems. Action research is often used in education, healthcare, and social work.
Experimental Research Methodology
This is a research methodology that involves the manipulation of one or more independent variables to observe their effects on a dependent variable. Experimental research is often used to study cause-and-effect relationships and to make predictions.
Survey Research Methodology
This is a research methodology that involves the collection of data from a sample of individuals using questionnaires or interviews. Survey research is often used to study attitudes, opinions, and behaviors.
Grounded Theory Research Methodology
This is a research methodology that involves the development of theories based on the data collected during the research process. Grounded theory is often used in sociology and anthropology to generate theories about social phenomena.
Research Methodology Example
An Example of Research Methodology could be the following:
Research Methodology for Investigating the Effectiveness of Cognitive Behavioral Therapy in Reducing Symptoms of Depression in Adults
Introduction:
The aim of this research is to investigate the effectiveness of cognitive-behavioral therapy (CBT) in reducing symptoms of depression in adults. To achieve this objective, a randomized controlled trial (RCT) will be conducted using a mixed-methods approach.
Research Design:
The study will follow a pre-test and post-test design with two groups: an experimental group receiving CBT and a control group receiving no intervention. The study will also include a qualitative component, in which semi-structured interviews will be conducted with a subset of participants to explore their experiences of receiving CBT.
Participants:
Participants will be recruited from community mental health clinics in the local area. The sample will consist of 100 adults aged 18-65 years old who meet the diagnostic criteria for major depressive disorder. Participants will be randomly assigned to either the experimental group or the control group.
Intervention :
The experimental group will receive 12 weekly sessions of CBT, each lasting 60 minutes. The intervention will be delivered by licensed mental health professionals who have been trained in CBT. The control group will receive no intervention during the study period.
Data Collection:
Quantitative data will be collected through the use of standardized measures such as the Beck Depression Inventory-II (BDI-II) and the Generalized Anxiety Disorder-7 (GAD-7). Data will be collected at baseline, immediately after the intervention, and at a 3-month follow-up. Qualitative data will be collected through semi-structured interviews with a subset of participants from the experimental group. The interviews will be conducted at the end of the intervention period, and will explore participants’ experiences of receiving CBT.
Data Analysis:
Quantitative data will be analyzed using descriptive statistics, t-tests, and mixed-model analyses of variance (ANOVA) to assess the effectiveness of the intervention. Qualitative data will be analyzed using thematic analysis to identify common themes and patterns in participants’ experiences of receiving CBT.
Ethical Considerations:
This study will comply with ethical guidelines for research involving human subjects. Participants will provide informed consent before participating in the study, and their privacy and confidentiality will be protected throughout the study. Any adverse events or reactions will be reported and managed appropriately.
Data Management:
All data collected will be kept confidential and stored securely using password-protected databases. Identifying information will be removed from qualitative data transcripts to ensure participants’ anonymity.
Limitations:
One potential limitation of this study is that it only focuses on one type of psychotherapy, CBT, and may not generalize to other types of therapy or interventions. Another limitation is that the study will only include participants from community mental health clinics, which may not be representative of the general population.
Conclusion:
This research aims to investigate the effectiveness of CBT in reducing symptoms of depression in adults. By using a randomized controlled trial and a mixed-methods approach, the study will provide valuable insights into the mechanisms underlying the relationship between CBT and depression. The results of this study will have important implications for the development of effective treatments for depression in clinical settings.
How to Write Research Methodology
Writing a research methodology involves explaining the methods and techniques you used to conduct research, collect data, and analyze results. It’s an essential section of any research paper or thesis, as it helps readers understand the validity and reliability of your findings. Here are the steps to write a research methodology:
- Start by explaining your research question: Begin the methodology section by restating your research question and explaining why it’s important. This helps readers understand the purpose of your research and the rationale behind your methods.
- Describe your research design: Explain the overall approach you used to conduct research. This could be a qualitative or quantitative research design, experimental or non-experimental, case study or survey, etc. Discuss the advantages and limitations of the chosen design.
- Discuss your sample: Describe the participants or subjects you included in your study. Include details such as their demographics, sampling method, sample size, and any exclusion criteria used.
- Describe your data collection methods : Explain how you collected data from your participants. This could include surveys, interviews, observations, questionnaires, or experiments. Include details on how you obtained informed consent, how you administered the tools, and how you minimized the risk of bias.
- Explain your data analysis techniques: Describe the methods you used to analyze the data you collected. This could include statistical analysis, content analysis, thematic analysis, or discourse analysis. Explain how you dealt with missing data, outliers, and any other issues that arose during the analysis.
- Discuss the validity and reliability of your research : Explain how you ensured the validity and reliability of your study. This could include measures such as triangulation, member checking, peer review, or inter-coder reliability.
- Acknowledge any limitations of your research: Discuss any limitations of your study, including any potential threats to validity or generalizability. This helps readers understand the scope of your findings and how they might apply to other contexts.
- Provide a summary: End the methodology section by summarizing the methods and techniques you used to conduct your research. This provides a clear overview of your research methodology and helps readers understand the process you followed to arrive at your findings.
When to Write Research Methodology
Research methodology is typically written after the research proposal has been approved and before the actual research is conducted. It should be written prior to data collection and analysis, as it provides a clear roadmap for the research project.
The research methodology is an important section of any research paper or thesis, as it describes the methods and procedures that will be used to conduct the research. It should include details about the research design, data collection methods, data analysis techniques, and any ethical considerations.
The methodology should be written in a clear and concise manner, and it should be based on established research practices and standards. It is important to provide enough detail so that the reader can understand how the research was conducted and evaluate the validity of the results.
Applications of Research Methodology
Here are some of the applications of research methodology:
- To identify the research problem: Research methodology is used to identify the research problem, which is the first step in conducting any research.
- To design the research: Research methodology helps in designing the research by selecting the appropriate research method, research design, and sampling technique.
- To collect data: Research methodology provides a systematic approach to collect data from primary and secondary sources.
- To analyze data: Research methodology helps in analyzing the collected data using various statistical and non-statistical techniques.
- To test hypotheses: Research methodology provides a framework for testing hypotheses and drawing conclusions based on the analysis of data.
- To generalize findings: Research methodology helps in generalizing the findings of the research to the target population.
- To develop theories : Research methodology is used to develop new theories and modify existing theories based on the findings of the research.
- To evaluate programs and policies : Research methodology is used to evaluate the effectiveness of programs and policies by collecting data and analyzing it.
- To improve decision-making: Research methodology helps in making informed decisions by providing reliable and valid data.
Purpose of Research Methodology
Research methodology serves several important purposes, including:
- To guide the research process: Research methodology provides a systematic framework for conducting research. It helps researchers to plan their research, define their research questions, and select appropriate methods and techniques for collecting and analyzing data.
- To ensure research quality: Research methodology helps researchers to ensure that their research is rigorous, reliable, and valid. It provides guidelines for minimizing bias and error in data collection and analysis, and for ensuring that research findings are accurate and trustworthy.
- To replicate research: Research methodology provides a clear and detailed account of the research process, making it possible for other researchers to replicate the study and verify its findings.
- To advance knowledge: Research methodology enables researchers to generate new knowledge and to contribute to the body of knowledge in their field. It provides a means for testing hypotheses, exploring new ideas, and discovering new insights.
- To inform decision-making: Research methodology provides evidence-based information that can inform policy and decision-making in a variety of fields, including medicine, public health, education, and business.
Advantages of Research Methodology
Research methodology has several advantages that make it a valuable tool for conducting research in various fields. Here are some of the key advantages of research methodology:
- Systematic and structured approach : Research methodology provides a systematic and structured approach to conducting research, which ensures that the research is conducted in a rigorous and comprehensive manner.
- Objectivity : Research methodology aims to ensure objectivity in the research process, which means that the research findings are based on evidence and not influenced by personal bias or subjective opinions.
- Replicability : Research methodology ensures that research can be replicated by other researchers, which is essential for validating research findings and ensuring their accuracy.
- Reliability : Research methodology aims to ensure that the research findings are reliable, which means that they are consistent and can be depended upon.
- Validity : Research methodology ensures that the research findings are valid, which means that they accurately reflect the research question or hypothesis being tested.
- Efficiency : Research methodology provides a structured and efficient way of conducting research, which helps to save time and resources.
- Flexibility : Research methodology allows researchers to choose the most appropriate research methods and techniques based on the research question, data availability, and other relevant factors.
- Scope for innovation: Research methodology provides scope for innovation and creativity in designing research studies and developing new research techniques.
Research Methodology Vs Research Methods
About the author.

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples
Strategies and Models
The choice of qualitative or quantitative approach to research has been traditionally guided by the subject discipline. However, this is changing, with many “applied” researchers taking a more holistic and integrated approach that combines the two traditions. This methodology reflects the multi-disciplinary nature of many contemporary research problems.
In fact, it is possible to define many different types of research strategy. The following list ( Business research methods / Alan Bryman & Emma Bell. 4th ed. Oxford : Oxford University Press, 2015 ) is neither exclusive nor exhaustive.
- Clarifies the nature of the problem to be solved
- Can be used to suggest or generate hypotheses
- Includes the use of pilot studies
- Used widely in market research
- Provides general frequency data about populations or samples
- Does not manipulate variables (e.g. as in an experiment)
- Describes only the “who, what, when, where and how”
- Cannot establish a causal relationship between variables
- Associated with descriptive statistics
- Breaks down factors or variables involved in a concept, problem or issue
- Often uses (or generates) models as analytical tools
- Often uses micro/macro distinctions in analysis
- Focuses on the analysis of bias, inconsistencies, gaps or contradictions in accounts, theories, studies or models
- Often takes a specific theoretical perspective, (e.g. feminism; labour process theory)
- Mainly quantitative
- Identifies measurable variables
- Often manipulates variables to produce measurable effects
- Uses specific, predictive or null hypotheses
- Dependent on accurate sampling
- Uses statistical testing to establish causal relationships, variance between samples or predictive trends
- Associated with organisation development initiatives and interventions
- Practitioner based, works with practitioners to help them solve their problems
- Involves data collection, evaluation and reflection
- Often used to review interventions and plan new ones
- Focuses on recognised needs, solving practical problems or answering specific questions
- Often has specific commercial objectives (e.g. product development )
Approaches to research
For many, perhaps most, researchers, the choice of approach is straightforward. Research into reaction mechanisms for an organic chemical reaction will take a quantitative approach, whereas qualitative research will have a better fit in the social work field that focuses on families and individuals. While some research benefits from one of the two approaches, other research yields more understanding from a combined approach.
In fact, qualitative and quantitative approaches to research have some important shared aspects. Each type of research generally follows the steps of scientific method, specifically:
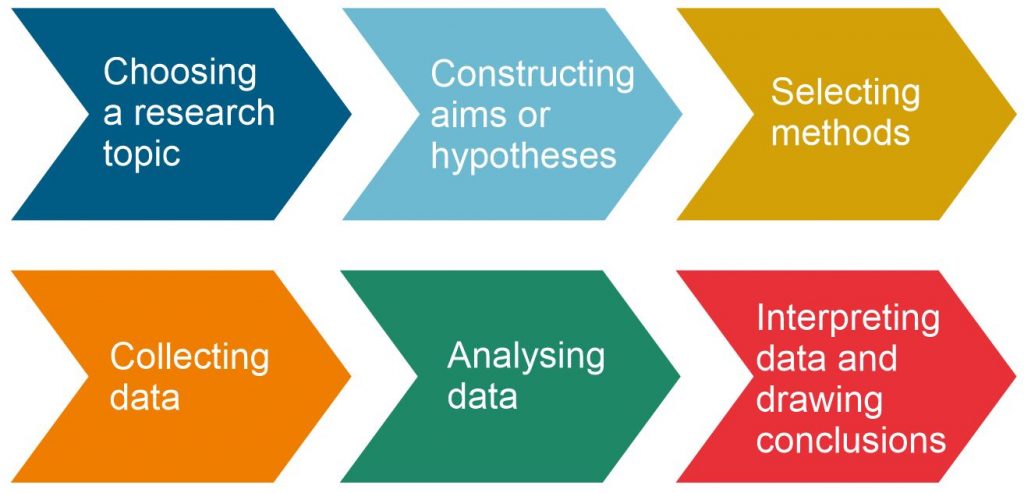
In general, each approach begins with qualitative reasoning or a hypothesis based on a value judgement. These judgements can be applied, or transferred to quantitative terms with both inductive and deductive reasoning abilities. Both can be very detailed, although qualitative research has more flexibility with its amount of detail.
Selecting an appropriate design for a study involves following a logical thought process; it is important to explore all possible consequences of using a particular design in a study. As well as carrying out a scoping study, a researchers should familiarise themselves with both qualitative and quantitative approaches to research in order to make the best decision. Some researchers may quickly select a qualitative approach out of fear of statistics but it may be a better idea to challenge oneself. The researcher should also be prepared to defend the paradigm and chosen research method; this is even more important if your proposal or grant is for money, or other resources.
Ultimately, clear goals and objectives and a fit-for-purpose research design is more helpful and important than old-fashioned arguments about which approach to research is “best”. Indeed, there is probably no such thing as a single “correct” design – hypotheses can be studied by different methods using different research designs. A research design is probably best thought of as a series of signposts to keep the research headed in the right direction and should not be regarded as a highly specific plan to be followed without deviation.
Research models
There is no common agreement on the classification of research models but, for the purpose of illustration, five categories of research models and their variants are outlined below.
A physical model is a physical object shaped to look like the represented phenomenon, usually built to scale e.g. atoms, molecules, skeletons, organs, animals, insects, sculptures, small-scale vehicles or buildings, life-size prototype products. They can also include 3-dimensional alternatives for two-dimensional representations e.g. a physical model of a picture or photograph.
In this case, the term model is used loosely to refer to any theory phrased in formal, speculative or symbolic styles. They generally consist of a set of assumptions about some concept or system; are often formulated, developed and named on the basis of an analogy between the object, or system that it describes and some other object or different system; and they are considered an approximation that is useful for certain purposes. Theoretical models are often used in biology, chemistry, physics and psychology.
A mathematical model refers to the use of mathematical equations to depict relationships between variables, or the behaviour of persons, groups, communities, cultural groups, nations, etc.
It is an abstract model that uses mathematical language to describe the behaviour of a system. They are used particularly in the natural sciences and engineering disciplines (such as physics, biology, and electrical engineering) but also in the social sciences (such as economics, sociology and political science). Types of mathematical models include trend (time series), stochastic, causal and path models. Examples include models of population and economic growth, weather forecasting and the characterisation of large social networks.
Mechanical (or computer) models tend to use concepts from the natural sciences, particularly physics, to provide analogues for social behaviour. They are often an extension of mathematical models. Many computer-simulation models have shown how a research problem can be investigated through sequences of experiments e.g. game models; microanalytic simulation models (used to examine the effects of various kinds of policy on e.g. the demographic structure of a population); models for predicting storm frequency, or tracking a hurricane.
These models are used to untangle meanings that individuals give to symbols that they use or encounter. They are generally simulation models, i.e. they are based on artificial (contrived) situations, or structured concepts that correspond to real situations. They are characterised by symbols, change, interaction and empiricism and are often used to examine human interaction in social settings.
The advantages and disadvantages of modelling
Take a look at the advantages and disadvantages below. It might help you think about what type of model you may use.
- The determination of factors or variables that most influence the behaviour of phenomena
- The ability to predict, or forecast the long term behaviour of phenomena
- The ability to predict the behaviour of the phenomenon when changes are made to the factors influencing it
- They allow researchers a view on difficult to study processes (e.g. old, complex or single-occurrence processes)
- They allow the study of mathematically intractable problems (e.g. complex non-linear systems such as language)
- They can be explicit, detailed, consistent, and clear (but that can also be a weakness)
- They allow the exploration of different parameter settings (i.e. evolutionary, environmental, individual and social factors can be easily varied)
- Models validated for a category of systems can be used in many different scenarios e.g. they can be reused in the design, analysis, simulation, diagnosis and prediction of a technical system
- Models enable researchers to generate unrealistic scenarios as well as realistic ones
- Difficulties in validating models
- Difficulties in assessing the accuracy of models
- Models can be very complex and difficult to explain
- Models do not “provide proof”
The next section describes the processes and design of research.

Research Constructs 101
Constructs, Validity & Reliability – Explained Simply
By: Derek Jansen (MBA) | Expert Reviewed By: Eunice Rautenbach (DTech) | March 2023
Navigating the world of academic research can be overwhelming, especially if you’re new to the field. One of the many pieces of terminology that often trips students up is that of the “ research construct ”. In this post, we’ll explain research constructs, construct validity and reliability in simple terms along with clear examples .
Overview: Research Constructs 101
What is a research construct, examples of research constructs.
- Constructs vs variables
Construct validity and reliability
- Key takeaways
Simply put, a research construct is an abstraction that researchers use to represent a phenomenon that’s not directly measurable – for example, intelligence, motivation or agreeableness. Since constructs are not directly measurable, they have to be inferred from other measurable variables , which are gathered through observation. For example, the construct of intelligence can be inferred based on a combination of measurable indicators such as problem-solving skills and language proficiency.
As a researcher, it’s important for you to define your constructs very clearly and to ensure that they can be feasibly operationalised . In other words, you need need to develop ways to measure these abstract concepts with relevant indicators or proxies that accurately reflect the underlying phenomenon you’re studying. In technical terms, this is called construct validity – we’ll unpack this in more detail a little later.

The best way to get a feel for research constructs is to look at some examples . Some common examples of constructs that you might encounter include:
- Self-esteem : a psychological construct measuring an individual’s overall sense of self-worth and confidence.
- Job satisfaction : a social construct reflecting the degree to which employees feel content with their work environment and overall experience in their workplace.
- Personality traits : extraversion, agreeableness, conscientiousness, neuroticism, and openness are commonly studied constructs used to explain individual differences in behaviour, cognition, and emotion.
- Quality of life : a complex multi-dimensional construct encompassing various aspects of an individual’s well-being such as physical health, emotional stability, social relationships, and economic status.
- Stress levels : an often-used psychological construct assessing the mental or emotional strain experienced by individuals in response to various life events or situations.
- Social support : A construct reflecting the perception of having assistance available from family members, friends, colleagues or other networks.
As you can see, all of the above examples reflect phenomena that cannot be directly measured . This is the defining characteristic of a research construct and is what distinguishes a construct from a variable (we’ll look at that next).
Need a helping hand?
Research construct vs variable
In research, the terms “construct” and “variable” are often used interchangeably, but they’re not the same thing .
A variable refers to a phenomenon that is directly measurable and can take on different values or levels . Examples of variables include age, height, weight, and blood pressure. Notably, these are all directly measurable (using basic equipment or just good old-fashioned logic).
In contrast, a construct refers to an abstract concept , that researchers seek to measure using one or more variables – since it is not directly measurable . Self-esteem, for example, is an abstract concept that cannot be directly measured. Instead, researchers must use self-reported indicators such as feelings of self-worth or pride in oneself to create operational definitions (variables) to measure it.
Another difference between research constructs and variables is their level of abstraction . Constructs tend to be more abstract than variables since they represent broad ideas and concepts , while variables are specific measures within those concepts. If you’d like to learn more about variables, be sure to read this article .

When it comes to creating and/or using research constructs, there are two important concepts you need to understand – construct validity and reliability .
Construct validity refers to the extent to which a research construct accurately measures what it is intended to measure . In other words, are you actually measuring the thing that you want to measure, as opposed to some other thing that just happens to correlate ? For example, if you wanted to measure intelligence using some sort of performance test, you’d need to ask questions that truly reflect the participant’s cognitive abilities and not just their memory recall.
Construct reliability , on the other hand, relates to how consistent the measurement of a construct is over time or across different situations. This focus on consistency serves to ensure that your results are not simply due to random error or inconsistency in data collection. To improve construct reliability, researchers use standardized procedures for collecting data, as well as measures such as test-retest reliability, which involves comparing results from multiple measurements taken at different times. You may have also heard of Cronbach’s alpha , which is a popular statistical test used to assess internal consistency, and in turn, construct reliability.
Both construct validity and reliability play crucial roles in ensuring accurate and meaningful research findings. If the constructs you use in your research are not valid and reliable, your data will be largely meaningless. So, be sure to pay close attention to these when designing your study.
Key Takeaways
We’ve covered a lot of ground in this post. Let’s do a quick recap of the key takeaways:
- A research construct is an abstraction that researchers use to represent a phenomenon that’s not directly observable .
- Examples of research constructs include self-esteem, motivation, and job satisfaction.
- A research construct differs from a research variable in that it is not directly measurable .
- When working with constructs, you must pay close attention to both construct validity and reliability .
Keep these point front of mind while undertaking your research to ensure your data is sound and meaningful. If you need help with your research, consider our 1:1 coaching service , where we hold your hand through the research journey, step by step .

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:

Thanks for simplifying the definition of construct for me

Bravo the explanation is clear and simple.Thank you sir.but I will like you to guide me through my research project.

Great content but would like you to help me with my research work please.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Scientific Method
4. research methods: modeling.
LEGO ® bricks have been a staple of the toy world since they were first manufactured in Denmark in 1953. The interlocking plastic bricks can be assembled into an endless variety of objects (see Figure 1). Some kids (and even many adults) are interested in building the perfect model – finding the bricks of the right color, shape, and size, and assembling them into a replica of a familiar object in the real world, like a castle, the space shuttle , or London Bridge. Others focus on using the object they build – moving LEGO knights in and out of the castle shown in Figure 1, for example, or enacting a space shuttle mission to Mars. Still others may have no particular end product in mind when they start snapping bricks together and just want to see what they can do with the pieces they have.

On the most basic level, scientists use models in much the same way that people play with LEGO bricks. Scientific models may or may not be physical entities, but scientists build them for the same variety of reasons: to replicate systems in the real world through simplification, to perform an experiment that cannot be done in the real world, or to assemble several known ideas into a coherent whole to build and test hypotheses .
Types of models: Physical, conceptual, mathematical
At the St. Anthony Falls Laboratory at the University of Minnesota, a group of engineers and geologists have built a room-sized physical replica of a river delta to model a real one like the Mississippi River delta in the Gulf of Mexico (Paola et al., 2001). These researchers have successfully incorporated into their model the key processes that control river deltas (like the variability of water flow, the deposition of sediments transported by the river, and the compaction and subsidence of the coastline under the pressure of constant sediment additions) in order to better understand how those processes interact. With their physical model, they can mimic the general setting of the Mississippi River delta and then do things they can’t do in the real world, like take a slice through the resulting sedimentary deposits to analyze the layers within the sediments. Or they can experiment with changing parameters like sea level and sedimentary input to see how those changes affect deposition of sediments within the delta, the same way you might “experiment” with the placement of the knights in your LEGO castle.

Not all models used in scientific research are physical models. Some are conceptual, and involve assembling all of the known components of a system into a coherent whole. This is a little like building an abstract sculpture out of LEGO bricks rather than building a castle. For example, over the past several hundred years, scientists have developed a series of models for the structure of an atom . The earliest known model of the atom compared it to a billiard ball, reflecting what scientists knew at the time – they were the smallest piece of an element that maintained the properties of that element. Despite the fact that this was a purely conceptual model, it could be used to predict some of the behavior that atoms exhibit. However, it did not explain all of the properties of atoms accurately. With the discovery of subatomic particles like the proton and electron , the physicist Ernest Rutherford proposed a “solar system” model of the atom, in which electrons orbited around a nucleus that included protons (see our Atomic Theory I: The Early Days module for more information). While the Rutherford model is useful for understanding basic properties of atoms, it eventually proved insufficient to explain all of the behavior of atoms. The current quantum model of the atom depicts electrons not as pure particles, but as having the properties of both particles and waves , and these electrons are located in specific probability density clouds around the atom’s nucleus.
Both physical and conceptual models continue to be important components of scientific research . In addition, many scientists now build models mathematically through computer programming. These computer-based models serve many of the same purposes as physical models, but are determined entirely by mathematical relationships between variables that are defined numerically. The mathematical relationships are kind of like individual LEGO bricks: They are basic building blocks that can be assembled in many different ways. In this case, the building blocks are fundamental concepts and theories like the mathematical description of turbulent flow in a liquid , the law of conservation of energy, or the laws of thermodynamics, which can be assembled into a wide variety of models for, say, the flow of contaminants released into a groundwater reservoir or for global climate change.
Comprehension Checkpoint
All models are exact replicas of physical things.
Modeling as a scientific research method
Whether developing a conceptual model like the atomic model, a physical model like a miniature river delta , or a computer model like a global climate model, the first step is to define the system that is to be modeled and the goals for the model. “System” is a generic term that can apply to something very small (like a single atom), something very large (like the Earth’s atmosphere), or something in between, like the distribution of nutrients in a local stream. So defining the system generally involves drawing the boundaries (literally or figuratively) around what you want to model, and then determining the key variables and the relationships between those variables.
Though this initial step may seem straightforward, it can be quite complicated. Inevitably, there are many more variables within a system than can be realistically included in a model , so scientists need to simplify. To do this, they make assumptions about which variables are most important. In building a physical model of a river delta , for example, the scientists made the assumption that biological processes like burrowing clams were not important to the large-scale structure of the delta, even though they are clearly a component of the real system.
Determining where simplification is appropriate takes a detailed understanding of the real system – and in fact, sometimes models are used to help determine exactly which aspects of the system can be simplified. For example, the scientists who built the model of the river delta did not incorporate burrowing clams into their model because they knew from experience that they would not affect the overall layering of sediments within the delta. On the other hand, they were aware that vegetation strongly affects the shape of the river channel (and thus the distribution of sediments), and therefore conducted an experiment to determine the nature of the relationship between vegetation density and river channel shape (Gran & Paola, 2001).

Once a model is built (either in concept, physical space, or in a computer), it can be tested using a given set of conditions. The results of these tests can then be compared against reality in order to validate the model. In other words, how well does the model do at matching what we see in the real world? In the physical model of delta sediments , the scientists who built the model looked for features like the layering of sand that they have seen in the real world. If the model shows something really different than what the scientists expect, the relationships between variables may need to be redefined or the scientists may have oversimplified the system . Then the model is revised, improved, tested again, and compared to observations again in an ongoing, iterative process . For example, the conceptual “billiard ball” model of the atom used in the early 1800s worked for some aspects of the behavior of gases, but when that hypothesis was tested for chemical reactions , it didn’t do a good job of explaining how they occur – billiard balls do not normally interact with one another. John Dalton envisioned a revision of the model in which he added “hooks” to the billiard ball model to account for the fact that atoms could join together in reactions , as conceptualized in Figure 3.
Once a model is built, it is never changed or modified.
While conceptual and physical models have long been a component of all scientific disciplines, computer-based modeling is a more recent development, and one that is frequently misunderstood. Computer models are based on exactly the same principles as conceptual and physical models, however, and they take advantage of relatively recent advances in computing power to mimic real systems .
The beginning of computer modeling: Numerical weather prediction
In the late 19 th century, Vilhelm Bjerknes , a Norwegian mathematician and physicist, became interested in deriving equations that govern the large-scale motion of air in the atmosphere . Importantly, he recognized that circulation was the result not just of thermodynamic properties (like the tendency of hot air to rise), but of hydrodynamic properties as well, which describe the behavior of fluid flow. Through his work, he developed an equation that described the physical processes involved in atmospheric circulation, which he published in 1897. The complexity of the equation reflected the complexity of the atmosphere, and Bjerknes was able to use it to describe why weather fronts develop and move.
Using calculations predictively
Bjerknes had another vision for his mathematical work, however: He wanted to predict the weather. The goal of weather prediction, he realized, is not to know the paths of individual air molecules over time, but to provide the public with “average values over large areas and long periods of time.” Because his equation was based on physical principles , he saw that by entering the present values of atmospheric variables like air pressure and temperature, he could solve it to predict the air pressure and temperature at some time in the future. In 1904, Bjerknes published a short paper describing what he called “the principle of predictive meteorology” (Bjerknes, 1904) (see the Research links for the entire paper). In it, he says:
Based upon the observations that have been made, the initial state of the atmosphere is represented by a number of charts which give the distribution of seven variables from level to level in the atmosphere. With these charts as the starting point, new charts of a similar kind are to be drawn, which represent the new state from hour to hour.
In other words, Bjerknes envisioned drawing a series of weather charts for the future based on using known quantities and physical principles . He proposed that solving the complex equation could be made more manageable by breaking it down into a series of smaller, sequential calculations, where the results of one calculation are used as input for the next. As a simple example, imagine predicting traffic patterns in your neighborhood. You start by drawing a map of your neighborhood showing the location, speed, and direction of every car within a square mile. Using these parameters , you then calculate where all of those cars are one minute later. Then again after a second minute. Your calculations will likely look pretty good after the first minute. After the second, third, and fourth minutes, however, they begin to become less accurate. Other factors you had not included in your calculations begin to exert an influence, like where the person driving the car wants to go, the right- or left-hand turns that they make, delays at traffic lights and stop signs, and how many new drivers have entered the roads.
Trying to include all of this information simultaneously would be mathematically difficult, so, as proposed by Bjerknes, the problem can be solved with sequential calculations. To do this, you would take the first step as described above: Use location, speed, and direction to calculate where all the cars are after one minute. Next, you would use the information on right- and left-hand turn frequency to calculate changes in direction, and then you would use information on traffic light delays and new traffic to calculate changes in speed. After these three steps are done, you would solve your first equation again for the second minute time sequence, using location, speed, and direction to calculate where the cars are after the second minute. Though it would certainly be rather tiresome to do by hand, this series of sequential calculations would provide a manageable way to estimate traffic patterns over time.
Although this method made calculations tedious, Bjerknes imagined “no intractable mathematical difficulties” with predicting the weather. The method he proposed (but never used himself) became known as numerical weather prediction, and it represents one of the first approaches towards numerical modeling of a complex, dynamic system .
Advancing weather calculations
Bjerknes’ challenge for numerical weather prediction was taken up sixteen years later in 1922 by the English scientist Lewis Fry Richardson . Richardson related seven differential equations that built on Bjerknes’ atmospheric circulation equation to include additional atmospheric processes. One of Richardson’s great contributions to mathematical modeling was to solve the equations for boxes within a grid; he divided the atmosphere over Germany into 25 squares that corresponded with available weather station data (see Figure 4) and then divided the atmosphere into five layers, creating a three-dimensional grid of 125 boxes. This was the first use of a technique that is now standard in many types of modeling. For each box, he calculated each of nine variables in seven equations for a single time step of three hours. This was not a simple sequential calculation, however, since the values in each box depended on the values in the adjacent boxes, in part because the air in each box does not simply stay there – it moves from box to box.

Richardson’s attempt to make a six-hour forecast took him nearly six weeks of work with pencil and paper and was considered an utter failure, as it resulted in calculated barometric pressures that exceeded any historically measured value (Dalmedico, 2001). Probably influenced by Bjerknes, Richardson attributed the failure to inaccurate input data , whose errors were magnified through successive calculations (see more about error propagation in our Uncertainty, Error, and Confidence module).

In addition to his concerns about inaccurate input parameters , Richardson realized that weather prediction was limited in large part by the speed at which individuals could calculate by hand. He thus envisioned a “forecast factory,” in which thousands of people would each complete one small part of the necessary calculations for rapid weather forecasting.
First computer for weather prediction
Richardson’s vision became reality in a sense with the birth of the computer, which was able to do calculations far faster and with fewer errors than humans. The computer used for the first one-day weather prediction in 1950, nicknamed ENIAC (Electronic Numerical Integrator and Computer), was 8 feet tall, 3 feet wide, and 100 feet long – a behemoth by modern standards, but it was so much faster than Richardson’s hand calculations that by 1955, meteorologists were using it to make forecasts twice a day (Weart, 2003). Over time, the accuracy of the forecasts increased as better data became available over the entire globe through radar technology and, eventually, satellites.
The process of numerical weather prediction developed by Bjerknes and Richardson laid the foundation not only for modern meteorology , but for computer-based mathematical modeling as we know it today. In fact, after Bjerknes died in 1951, the Norwegian government recognized the importance of his contributions to the science of meteorology by issuing a stamp bearing his portrait in 1962 (Figure 5).
Weather prediction is based on _____________ modeling.
- mathematical
Modeling in practice: The development of global climate models
The desire to model Earth’s climate on a long-term, global scale grew naturally out of numerical weather prediction. The goal was to use equations to describe atmospheric circulation in order to understand not just tomorrow’s weather, but large-scale patterns in global climate, including dynamic features like the jet stream and major climatic shifts over time like ice ages. Initially, scientists were hindered in the development of valid models by three things: a lack of data from the more inaccessible components of the system like the upper atmosphere , the sheer complexity of a system that involved so many interacting components, and limited computing powers. Unexpectedly, World War II helped solve one problem as the newly-developed technology of high altitude aircraft offered a window into the upper atmosphere (see our Technology module for more information on the development of aircraft). The jet stream, now a familiar feature of the weather broadcast on the news, was in fact first documented by American bombers flying westward to Japan.
As a result, global atmospheric models began to feel more within reach. In the early 1950s, Norman Phillips, a meteorologist at Princeton University, built a mathematical model of the atmosphere based on fundamental thermodynamic equations (Phillips, 1956). He defined 26 variables related through 47 equations, which described things like evaporation from Earth’s surface , the rotation of the Earth, and the change in air pressure with temperature. In the model, each of the 26 variables was calculated in each square of a 16 x 17 grid that represented a piece of the northern hemisphere. The grid represented an extremely simple landscape – it had no continents or oceans, no mountain ranges or topography at all. This was not because Phillips thought it was an accurate representation of reality, but because it simplified the calculations. He started his model with the atmosphere “at rest,” with no predetermined air movement, and with yearly averages of input parameters like air temperature.
Phillips ran the model through 26 simulated day-night cycles by using the same kind of sequential calculations Bjerknes proposed. Within only one “day,” a pattern in atmospheric pressure developed that strongly resembled the typical weather systems of the portion of the northern hemisphere he was modeling (see Figure 6). In other words, despite the simplicity of the model, Phillips was able to reproduce key features of atmospheric circulation , showing that the topography of the Earth was not of primary importance in atmospheric circulation. His work laid the foundation for an entire subdiscipline within climate science: development and refinement of General Circulation Models (GCMs).

By the 1980s, computing power had increased to the point where modelers could incorporate the distribution of oceans and continents into their models . In 1991, the eruption of Mt. Pinatubo in the Philippines provided a natural experiment: How would the addition of a significant volume of sulfuric acid , carbon dioxide, and volcanic ash affect global climate? In the aftermath of the eruption, descriptive methods (see our Description in Scientific Research module) were used to document its effect on global climate: Worldwide measurements of sulfuric acid and other components were taken, along with the usual air temperature measurements. Scientists could see that the large eruption had affected climate , and they quantified the extent to which it had done so. This provided a perfect test for the GCMs . Given the inputs from the eruption, could they accurately reproduce the effects that descriptive research had shown? Within a few years, scientists had demonstrated that GCMs could indeed reproduce the climatic effects induced by the eruption, and confidence in the abilities of GCMs to provide reasonable scenarios for future climate change grew. The validity of these models has been further substantiated by their ability to simulate past events, like ice ages, and the agreement of many different models on the range of possibilities for warming in the future, one of which is shown in Figure 7.

Limitations and misconceptions of models
The widespread use of modeling has also led to widespread misconceptions about models , particularly with respect to their ability to predict. Some models are widely used for prediction, such as weather and streamflow forecasts, yet we know that weather forecasts are often wrong. Modeling still cannot predict exactly what will happen to the Earth’s climate , but it can help us see the range of possibilities with a given set of changes. For example, many scientists have modeled what might happen to average global temperatures if the concentration of carbon dioxide (CO 2 ) in the atmosphere is doubled from pre-industrial levels (pre-1950); though individual models differ in exact output, they all fall in the range of an increase of 2-6° C (IPCC, 2007).
All models are also limited by the availability of data from the real system . As the amount of data from a system increases, so will the accuracy of the model. For climate modeling, that is why scientists continue to gather data about climate in the geologic past and monitor things like ocean temperatures with satellites – all those data help define parameters within the model. The same is true of physical and conceptual models, too, well-illustrated by the evolution of our model of the atom as our knowledge about subatomic particles increased.
__________ can result in a flawed model.
- Lack of data about a system
- Too much data about a system
Modeling in modern practice
The various types of modeling play important roles in virtually every scientific discipline, from ecology to analytical chemistry and from population dynamics to geology. Physical models such as the river delta take advantage of cutting edge technology to integrate multiple large-scale processes. As computer processing speed and power have increased, so has the ability to run models on them. From the room-sized ENIAC in the 1950s to the closet-sized Cray supercomputer in the 1980s to today’s laptop, processing speed has increased over a million-fold, allowing scientists to run models on their own computers rather than booking time on one of only a few supercomputers in the world. Our conceptual models continue to evolve, and one of the more recent theories in theoretical physics digs even deeper into the structure of the atom to propose that what we once thought were the most fundamental particles – quarks – are in fact composed of vibrating filaments, or strings. String theory is a complex conceptual model that may help explain gravitational force in a way that has not been done before. Modeling has also moved out of the realm of science into recreation, and many computer games like SimCity® involve both conceptual modeling (answering the question, “What would it be like to run a city?”) and computer modeling, using the same kinds of equations that are used model traffic flow patterns in real cities. The accessibility of modeling as a research method allows it to be easily combined with other scientific research methods, and scientists often incorporate modeling into experimental, descriptive, and comparative studies.
Scientific modeling is a research method scientists use to replicate real-world systems – whether it’s a conceptual model of an atom, a physical model of a river delta, or a computer model of global climate. This module describes the principles that scientists use when building models and shows how modeling contributes to the process of science.
Key Concepts
- Modeling involves developing physical, conceptual, or computer-based representations of systems.
- Scientists build models to replicate systems in the real world through simplification, to perform an experiment that cannot be done in the real world, or to assemble several known ideas into a coherent whole to build and test hypotheses.
- Computer modeling is a relatively new scientific research method, but it is based on the same principles as physical and conceptual modeling.

Privacy Policy
Research Model And Hypotheses Development
- First Online: 19 November 2014
Cite this chapter

- Bettina Hauser 2
Part of the book series: BestMasters ((BEST))
1304 Accesses
In this chapter a research model will be developed, which is derived from the previous literature review and addresses the identified research gap.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Unable to display preview. Download preview PDF.
Author information
Authors and affiliations.
Innsbruck, Austria
Bettina Hauser
You can also search for this author in PubMed Google Scholar
Rights and permissions
Reprints and permissions
Copyright information
© 2015 Springer Fachmedien Wiesbaden
About this chapter
Hauser, B. (2015). Research Model And Hypotheses Development. In: Internal and External Context Specificity of Leadership in M&A Integration. BestMasters. Springer Gabler, Wiesbaden. https://doi.org/10.1007/978-3-658-08077-8_3
Download citation
DOI : https://doi.org/10.1007/978-3-658-08077-8_3
Published : 19 November 2014
Publisher Name : Springer Gabler, Wiesbaden
Print ISBN : 978-3-658-08076-1
Online ISBN : 978-3-658-08077-8
eBook Packages : Business and Economics Business and Management (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- My UW-System
- Student Life
- Schools & Colleges
- Centers & Institutes
- Leadership Team
- For Faculty and Staff
- For Researchers
- Request Info
- Give to UWM
Research Model
A National Research Model for Online Learning By Tanya Joosten
Downloadable PDF version
In developing the grant proposal for the U.S. Department of Education’s Fund for Improvement in Postsecondary Education (FIPSE), several researchers from the University of Wisconsin-Milwaukee (UWM) spent a Friday afternoon discussing the types of research projects we would propose to be conducted by the new National Research Center for Distance Education and Technological Advancements (DETA). What became clear in that meeting room was evidence of a broader issue in distance education research. Individuals who are studying distance education, including eLearning, blended learning, and online learning, are heterogeneous. These individuals represent an array of disciplines, including different paradigmatic, theoretical, and methodological approaches to studying distance education, just as we were witnessing in the room that day. The opportunity of this diversity in research approaches has the potential to provide our higher education communities a greater understanding of the complexity of human interaction in distance education. The opportunity identified also presented a new problem to solve – we don’t all speak the same language about research in distance education. Evident from this discussion was a need for coherency about how to approach the study of this phenomenon.
In distance education, a common language or ground has not yet been established. Although existing scholarship attempts to establish an identity for teaching and learning on the fringe or margins (see Moore, 2013), such as distance education, there is still much work to be done. It is common in other disciplines to struggle with finding this common ground as well (e.g., Corman & Poole, 2000). Yet, unlike many other disciplines that have models illustrative of the phenomenon of interest or research models that guide the design of research, distance education has seen little traction in this area. A cohesive approach to researching distance education from a transdisciplinary lens is pertinent.
The lack of common language and work being conducted in disciplinary silos has led to a disregard or lack of acknowledgement of previous developments in the field. Furthermore, the disconnect many times between the fast moving development of practice and redundant research of already proven practices is less than helpful to developing distance education. Several authors over the last several years have noted this dilemma. Saba (2013) discusses that “authors, editors, and reviewers are not familiar with the historical origin and conceptual growth of the field of distance education…history starts from when they become interested in the field” (p. 50). Dziuban and Picciano (2015) refer to Roberts (2007) and Diamond (1999) in describing this as a type of amnesia where “we tend to trust what we have seen for ourselves and dismiss events that have occurred in the distance past…we forget anything but what we are experiencing at the moment and assume that the present is a way it has always been” (p. 179). Moore and Kiersey (2011) have discussed this tendency as a threat to good practice and good scholarship.
Our initial goal, as outlined in the grant, is to solve this problem and create a language that will have sustainability across disciplines and temporal barriers. At least in the first year, it was apparent that there was a need for grant efforts to focus on creating a language we can all understand as well as to engage distance education stakeholders from across the country in the attempt to create an interdisciplinary lens for examining distance education. In so doing, the aim is to facilitate research efforts regarding cross-institutional distance education research as a strategy for ensuring quality in teaching and learning for all students. The research fellows on the grant team felt a desire to identify a model or models that represented research in distance education, in particular, with regard to the research that would be conducted as part of the grant activities. Moreover, the development of a framework of inquiry that included detailed representations, which illustrates the varying levels of inquiry as characterized by input-throughput-output processes facilitating an interdisciplinary approach to studying distance education, was needed as well as research models.
Development
The first goal of the grant activities is to develop research models for online learning that provide guidance in the practice of distance education research. The models were intended to facilitate the exploration of instructional practices, inform future instructional practices, serve as a model for future research practices across educational institutions, and enhance consistency in the field. In the development process, it became clear that a more general research model was needed to represent the various research designs that would be deployed as part of the DETA research efforts rather than several specific research models. The development of this model included the following steps:
- Review of the literature on desired outcomes in distance education, including blended and online research, to determine key desired outcomes in practice and research in the field.
- Identify and engaging with national experts, including researchers and practitioners, in the field to identify pertinent research questions and variables of interest for enhancing the understanding of the desired outcomes.
- Review germane research and current national efforts to ensure alignment with the development of research model and the framework of inquiry, including identifying any gaps and future areas of research needed.
- Create research designs, including formulating measures, instrumentation, and coding to conduct cross-institutional research within the framework of inquiry.
- Develop a research model for online learning appropriate for interdisciplinary research and diverse methodologies to be brought to fruition in the development and use of research toolkits by researchers and practitioners across the country.
The National DETA Research Model for Online Learning
Prior to the DETA national summit, held at the 2015 EDUCAUSE Learning Initiative (ELI) meeting, the DETA Research Center reviewed pertinent literature and documents in developing the desired outcomes (see https://uwm.edu/deta/desired-outcomes/). These desired outcomes were published on the DETA community site and feedback was solicited from the national experts who participated in the summit. The desired outcomes guiding the activities at the DETA national summit are also appended.
Participants at the DETA national summit (see https://uwm.edu/deta/summit/ ) were asked to participate in two key sets of activities related to developing and prioritizing research questions and the process of creating a framework of inquiry to guide current and future research by identifying key variables for research model.
The research questions and associated votes were statistically analyzed for prioritization. The top research questions were identified by highlighting those that were one standard deviation at or above the mean. The top research questions can be viewed at: https://uwm.edu/deta/top-research-questions/ . Additionally, the variables were examined to identify conceptual alignment with existing literature and to sort based on level of inquiry, which resulted in the framework of inquiry (see Figure 1, General Framework of Inquiry). The detailed version of the framework of inquiry, including variables, can be viewed here .
Figure 1, General Framework of Inquiry

Situated within the framework of inquiry, several research designs were created, including formulating measures, developing instrumentation, and coding to conduct cross-institutional research within the framework of inquiry. These research designs included experimental and survey study designs to address the top research questions. Experimental designs included interventions identified for testing that burgeoned from discussions at the DETA national summit. Survey studies and instrumentation (applicable to both survey and experimental studies) were developed from existing research at UWM and a review of the literature, including utilized instrumentation. Survey studies included questions to gather qualitative data for analysis to address research questions of exploratory nature. Both the survey and experimental research designs are complemented by data mining of student information systems to provide learner characteristics (low-income, minority, first generation, and disabled) and outcome data (grade, completion).
Model Description
Taking a structured approach to model development, a research model for online learning appropriate for interdisciplinary research and diverse methodologies was derived from a grounded and theoretical approach (see Figure 2, Developing Research Model of Online Learning). The model is considered grounded because it is a reflection of the research questions, framework of inquiry, including variables, and research designs developed as part of the grant activities. The model is considered theoretical since social and learning theories inform the development.
Figure 2, Developing Research Model of Online Learning

There are four primary components that compose the research model for online learning. The four components include (1) inputs and outputs, (2) process, (3) context, and (4) interventions. The inputs and outputs include both agency and structural level inputs. Agency level inputs include students (learners) and instructors. Structural level inputs include the characteristics of the course, instruction, and the program that provide structure, rules, and resources to agents to facilitate online learning process. The second component is the process, which includes in-class and out-of-class interactions that are online learning. The third component is that of the context. The context for the research of this grant is institutions of postsecondary higher education. Although much learning may happen in informal settings, it is not a focus of this model. The final component of the model is intervention. Interventions create variable conditions intended to result in a predetermined outcome, usually to increase student success.
There are three facets of the model that describe the relationship between and among the components of the model. First, the model is cyclical in nature in that learning is conducted in cycles with each end playing the role of input and output through an interactive process representing a continuous lifecycle of online learning. Second, the model is transactional . This means that online learning is a simultaneous engagement of students and instructors in the learning process. Students and instructors are linked reciprocally. Third, the model can be structurational . Courses, instructional, and program characteristics are outcomes from human action (instructors and staff) in design, development, and modification. Also, these facilitate and constrain student interactions in online learning. Furthermore, institutional properties influence individuals in their online learning interaction through instructional and professional norms, design standards, and available resources. Likewise, the interactions in online learning will influence institutional properties through reinforcing or transforming structures.
The proposed model describes a series of inputs that can have a relationship with online learning, which is a throughput or process, inside and outside the classroom within the contexts of institutions. For DETA research the institutional context is postsecondary institutions of higher education. The cyclical elements of the model are evident in the inputs, including the characteristics of students, instructors, course as well as instruction, and programs, may influence the online learning process, which, in return, will influence future inputs of online learning process in a cyclical fashion. For instance, a course is designed by an instructor in such a way that it leads to increased rates of completion, which eventually can alter the program profile and potentially future course designs. Therefore, the inputs will influence the online learning process, which will in return influence the inputs through a feedback loop process. For example, students may become more confident and have a greater growth or mindset for achievement in future courses, instructors may learn from what works in the classroom and improve future instructional methods and course designs, and programs may have greater success. Not only is there a lifecycle of online learning, but an important interplay between the success of students in a course and the continued development of courses and programs by instructors and staff within the institution.
There are individual agents in the model, including students and instructors, that have characteristics of which have a relationship with online learning. First, these students and instructors are agents within the context of institutions but have influences from beyond the institution, too. The cognition and experiences (from within and outside of the institution) of students and instructors will potentially affect online learning interactions within and outside a class. Second, there are also course, instructional, and program characteristics. The design of these, in particular, will have a relationship with and potentially enhancing or hindering the process of online learning. These five inputs will have relationships with the online learning process.
Interventions can be employed at any level of these input variables in order to enhance the probability that the online learning process will be positively influenced. Interventions can be at the agent level to develop students or instructors, or at the course, instructional, or program levels to potentially improve the interactions of students and instructors to enhance online learning. At the learner level, an intervention may be a workshop about taking an online course. At the instructor level, an intervention may be a faculty development program for teaching online. At the course and instructional level, an intervention may be focused on how content is designed to meet the course learning outcomes to enhance the student-content interaction. At the program level, an intervention may be the receipt of tutoring support during the course. Interventions at the agent or structural levels are intended to increase student success by enhancing online learning.
The model represents an array of research designs, including experimental, quasi experimental, survey, and qualitative appropriate for DETA research. Input variables, such as student or course characteristics, can be mined through institutional technology systems, such as student information systems, or can be reported on surveys. This information can be used for all research designs. Experimental or quasi experimental studies would focus on comparisons of the control and experimental condition based on the intervention applied usually through the comparison of student assessments. Survey studies can examine the ability to predict student outcome variables based on the student self-report of instructional and program/institutional characteristics including reports of behaviors taking place or perceptions of in-class and out-of-class. Finally, qualitative data can be collected through surveys and other methods to better understand or develop measurement for an array of constructs (e.g., student motivation, ecosystem components).
This research model and the associated toolkits serves to guide research conducted across institutions and disciplines, including both experimental and survey studies. The DETA Research Center will disseminate a call for proposals in the grant’s second year, October 2015, to identify partners across the country who are interested in using the research toolkits to gather data to better understand the key factors in distance education courses and programs that are impacting student success. Once research has been conducted, an evaluation of the model and toolkits will be conducted to improve the quality of the grant products for dissemination in the final year of the grant.
References:
Corman, S. R., & Poole, M. S. (2000) Perspectives on organizational communication: Finding common ground. Guilford Press.
Dziuban, C. D., & Picciano, A. G. (2015). What the future might hold for online and blended learning research. In Dziuban, C. D., Picciano, A. G., Graham, C. R., & Moskal, P. D. (Eds). Conducting research in online and blended learning environments.
Moore, M. G. (Ed.). (2013). Handbook of distance education. Routledge.
Moore, M. G., & Kearsley, G. (2011). Distance education: A systems view of online learning. Cengage Learning.
Orlikowski, W. J. (1992). The duality of technology: Rethinking the concept of technology in organizations. Organization science, 3(3), 398-427.
Saba, F. (2013). Building the future: A theoretical perspective. In Moore, M. G. (Ed.). Handbook of distance education. Routledge.
Top Research Questions
Framework of Inquiry
Analysis of Summit Data:
Key Research Questions and Variables
Key Themes from Discussion Notes
Microsoft Research Blog
Gigapath: whole-slide foundation model for digital pathology.
Published May 22, 2024
By Hoifung Poon , General Manager, Health Futures Naoto Usuyama , Principal Researcher
Share this page
- Share on Facebook
- Share on Twitter
- Share on LinkedIn
- Share on Reddit
- Subscribe to our RSS feed

The confluence of digital transformation in biomedicine and the current generative AI revolution creates an unprecedented opportunity for drastically accelerating progress in precision health. Digital pathology is emblematic of this exciting frontier. In cancer care, whole-slide imaging has become routinely available, which transforms a microscopy slide of tumor tissue into a high-resolution digital image. Such whole-slide images contain key information for deciphering the tumor microenvironment, which is critical for precision immunotherapy (for example differentiating hot versus cold tumors based on lymphocyte infiltration). Digital pathology can also be combined with other multimodal, longitudinal patient information in multimodal generative AI for scaling population-level, real-world evidence generation.
This is an exciting time, tempered by the reality that digital pathology poses unique computational challenges, as a standard gigapixel slide may be thousands of times larger than typical natural images in both width and length. Conventional vision transformers struggle with such an enormous size as computation for self-attention grows dramatically with the input length. Consequently, prior work in digital pathology often ignores the intricate interdependencies across image tiles in each slide, thus missing important slide-level context for key applications such as modeling the tumor microenvironment.
In this blog post, we introduce GigaPath (opens in new tab) , a novel vision transformer that attains whole-slide modeling by leveraging dilated self-attention to keep computation tractable. In joint work with Providence Health System and the University of Washington, we have developed Prov-GigaPath (opens in new tab) , an open-access whole-slide pathology foundation model pretrained on more than one billion 256 X 256 pathology images tiles in more than 170,000 whole slides from real-world data at Providence. All computation was conducted within Providence’s private tenant, approved by Providence Institutional Review Board (IRB).
To our knowledge, this is the first whole-slide foundation model for digital pathology with large-scale pretraining on real-world data. Prov-GigaPath attains state-of-the-art performance on standard cancer classification and pathomics tasks, as well as vision-language tasks. This demonstrates the importance of whole-slide modeling on large-scale real-world data and opens new possibilities to advance patient care and accelerate clinical discovery.
MICROSOFT RESEARCH PODCAST

AI Frontiers: The future of scale with Ahmed Awadallah and Ashley Llorens
This episode features Senior Principal Research Manager Ahmed H. Awadallah , whose work improving the efficiency of large-scale AI models and efforts to help move advancements in the space from research to practice have put him at the forefront of this new era of AI.
Adapting dilated attention and LongNet to digital pathology

GigaPath adopts two-stage curriculum learning comprising tile-level pretraining using DINOv2 and slide-level pretraining using masked autoencoder with LongNet (see Figure 1). DINOv2 is a standard self-supervision method that combines contrastive loss and masked reconstruction loss in training teacher and student vision transformers. However, due to the computational challenge for self-attention, its application is limited to small images such as 256 × 256 tiles. For slide-level modeling, we adapt dilated attention from LongNet to digital pathology (see Figure 2). To handle the long sequence of image tiles for a whole slide, we introduce a series of increasing sizes for subdividing the tile sequence into segments of the given size. For larger segments, we introduce sparse attention with sparsity proportional to segment length, thus canceling out the quadratic growth. The largest segment would cover the entire slide, though with sparsely subsampled self-attention. This enables us to capture long-range dependencies in a systematic way while maintaining tractability in computation (linear in context length).

GigaPath on cancer classification and pathomics tasks
We construct a digital pathology benchmark comprising nine cancer subtyping tasks and 17 pathomics tasks, using both Providence and TCGA data. With large-scale pretraining and whole-slide modeling, Prov-GigaPath attains state-of-the-art performance on 25 out of 26 tasks, with significant improvement over the second-best model on 18 tasks.

On cancer subtyping, the goal is to classify fine-grained subtypes based on the pathology slide. For example, for ovarian cancer, the model needs to differentiate among six subtypes: Clear Cell Ovarian Cancer, Endometrioid Ovarian Cancer, High-Grade Serous Ovarian Cancer, Low-Grade Serous Ovarian Cancer, Mucinous Ovarian Cancer, and Ovarian Carcinosarcoma. Prov-GigaPath attained state-of-the-art performance in all nine tasks, with significant improvement over the second best in six out of nine tasks (see Figure 3). For six cancer types (breast, kidney, liver, brain, ovarian, central nervous system), Prov-GigaPath attains an AUROC of 90% or higher. This bodes well for downstream applications in precision health such as cancer diagnostics and prognostics.

On pathomics tasks, the goal is to classify whether the tumor exhibits specific clinically relevant genetic mutations based on the slide image alone. This may uncover meaningful connections between tissue morphology and genetic pathways that are too subtle to be picked up by human observation. Aside from a few well-known pairs of specific cancer type and gene mutations, it is unclear how much signal there exists from the slide alone. Moreover, in some experiments, we consider the pan-cancer scenario, where we are trying to identify universal signals for a gene mutation across all cancer types and very diverse tumor morphologies. In such challenging scenarios, Prov-GigaPath once again attained state-of-the-art performance in 17 out of 18 tasks, significantly outperforming the second best in 12 out of 18 tasks (see Figure 4). For example, in the pan-cancer 5-gene analysis, Prov-GigaPath outperformed the best competing methods by 6.5% in AUROC and 18.7% in AUPRC. We also conducted head-to-head comparison on TCGA data to assess the generalizability of Prov-GigaPath and found that Prov-GigaPath similarly outperformed all competing methods there. This is all the more remarkable given that the competing methods were all pretrained on TCGA. That Prov-Gigapath can extract genetically linked pan-cancer and subtype-specific morphological features at the whole-slide level highlights the biological relevance of the underlying learned embeddings, and opens the door to using real-world data for future research directions around the complex biology of the tumor microenvironment.
GigaPath on vision-language tasks
![Figure 5: Comparison on vision-language tasks. a, Flow chart showing the fine-tuning of Prov-GigaPath using pathology reports. Real-world pathology reports are processed using GPT-3.5 from OpenAI to remove information irrelevant to cancer diagnosis. We performed the CLIP-based contrastive learning to align Prov-GigaPath and PubMedBERT. b, The fine-tuned Prov[1]GigaPath can then be used to perform zero-shot cancer subtyping and mutation prediction. The input of Prov-GigaPath is a sequence of tiles segmented from a WSI, and the inputs of the text encoder PubMedBERT are manually designed prompts representing cancer types and mutations. Based on the output of Prov-GigaPath and PubMedBERT, we can calculate the probability of the input WSI being classified into specific cancer subtypes and mutations. c, Bar plots comparing zero-shot subtyping performance on NSCLC and COADREAD in terms of BACC, precision and f 1. d, Bar plots comparing the performance on mutation prediction using the fine-tuned model for six genes. c,d, Data are mean ± s.e.m. across n = 50 experiments. The listed P value indicates the significance for Prov-GigaPath outperforming the best comparison approach, with one-sided Wilcoxon test. e, Scatter plots comparing the performance between Prov-GigaPath and MI-Zero in terms of BACC on zero-shot cancer subtyping. Each dot indicates one trial with a particular set of text query formulations.](https://www.microsoft.com/en-us/research/uploads/prodnew/2024/05/Figure-5-color-adjust.jpg "a research model is")
We further demonstrate the potential of GigaPath on vision-language tasks by incorporating the pathology reports. Prior work on pathology vision-language pretraining tends to focus on small images at the tile level. We instead explore slide-level vision-language pretraining. By continuing pretraining on slide-report pairs, we can leverage the report semantics to align the pathology slide representation, which can be used for downstream prediction tasks without supervised fine-tuning (e.g., zero-shot subtyping). Specifically, we use Prov-GigaPath as the whole-slide image encoder and PubMedBERT as the text encoder, and conduct contrastive learning using the slide-report pairs. This is considerably more challenging than traditional vision-language pretraining, as we do not have fine-grained alignment information between individual image tiles and text snippets. Prov-GigaPath substantially outperforms three state-of-the-art pathology vision-language models in standard vision-language tasks, such as zero-shot cancer subtyping and gene mutation prediction, demonstrating the potential for Prov-GigaPath in whole-slide vision-language modeling (see Figure 5).
GigaPath is a promising step toward multimodal generative AI for precision health
We have conducted thorough ablation studies to establish the best practices in whole-slide pretraining and vision-language modeling. We also observed early indications of the scaling law in digital pathology, where larger-scale pretraining generally improved downstream performance, although our experiments were still limited due to computational constraints.
Going forward, there are many opportunities for progress. Prov-GigaPath attained state-of-the-art performance compared to prior best models, but there is still significant growth space in many downstream tasks. While we have conducted initial exploration on pathology vision-language pretraining, there is still a long way to go to pursue the potential of a multimodal conversational assistant, specifically by incorporating advanced multimodal frameworks such as LLaVA-Med (opens in new tab) . Most importantly, we have yet to explore the impact of GigaPath and whole-slide pretraining in many key precision health tasks such as modeling tumor microenvironment and predicting treatment response.
GigaPath is joint work with Providence Health System and the University of Washington’s Paul G. Allen School of Computer Science & Engineering, and brings collaboration from multiple teams within Microsoft*. It reflects Microsoft’s larger commitment on advancing multimodal generative AI for precision health, with exciting progress in other digital pathology research collaborations such as Cyted (opens in new tab) , Volastra (opens in new tab) , and Paige (opens in new tab) as well as other technical advances such as BiomedCLIP (opens in new tab) , LLaVA-Rad (opens in new tab) , BiomedJourney (opens in new tab) , BiomedParse (opens in new tab) , MAIRA (opens in new tab) , Rad-DINO (opens in new tab) , Virchow (opens in new tab) .
(Acknowledgment footnote) *: Within Microsoft, it is a wonderful collaboration among Health Futures, MSRA, MSR Deep Learning, and Nuance. Paper co-authors: Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier Gonz ́alez, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, Hoifung Poon.
Related publications
Llava-med: training a large language-and-vision assistant for biomedicine in one day, maira-1: a specialised large multimodal model for radiology report generation, longnet: scaling transformers to 1,000,000,000 tokens, biomedjourney: counterfactual biomedical image generation by instruction-learning from multimodal patient journeys, meet the authors.

Hoifung Poon
General Manager, Health Futures

Naoto Usuyama
Principal Researcher
Continue reading

Scaling early detection of esophageal cancer with AI

Microsoft at KDD 2023: Advancing health at the speed of AI

AI and the Future of Health

AI Frontiers: AI for health and the future of research with Peter Lee
Research areas.
Related events
- Microsoft Research Forum | Episode 2
Related labs
- Microsoft Health Futures
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
Share this page:
NASA, IBM Research to Release New AI Model for Weather, Climate

By Jessica Barnett
Working together, NASA and IBM Research have developed a new artificial intelligence model to support a variety of weather and climate applications. The new model – known as the Prithvi-weather-climate foundational model – uses artificial intelligence (AI) in ways that could vastly improve the resolution we’ll be able to get, opening the door to better regional and local weather and climate models.
Foundational models are large-scale, base models which are trained on large, unlabeled datasets and can be fine-tuned for a variety of applications. The Prithvi-weather-climate model is trained on a broad set of data – in this case NASA data from NASA’s Modern-Era Retrospective analysis for Research and Applications (MERRA-2)– and then makes use of AI learning abilities to apply patterns gleaned from the initial data across a broad range of additional scenarios.
“Advancing NASA’s Earth science for the benefit of humanity means delivering actionable science in ways that are useful to people, organizations, and communities. The rapid changes we’re witnessing on our home planet demand this strategy to meet the urgency of the moment,” said Karen St. Germain, director of the Earth Science Division of NASA’s Science Mission Directorate. “The NASA foundation model will help us produce a tool that people can use: weather, seasonal and climate projections to help inform decisions on how to prepare, respond and mitigate.”
With the Prithvi-weather-climate model, researchers will be able to support many different climate applications that can be used throughout the science community. These applications include detecting and predicting severe weather patterns or natural disasters, creating targeted forecasts based on localized observations, improving spatial resolution on global climate simulations down to regional levels, and improving the representation of how physical processes are included in weather and climate models.
“These transformative AI models are reshaping data accessibility by significantly lowering the barrier of entry to using NASA’s scientific data,” said Kevin Murphy, NASA’s chief science data officer, Science Mission Directorate at NASA Headquarters. “Our open approach to sharing these models invites the global community to explore and harness the capabilities we’ve cultivated, ensuring that NASA’s investment enriches and benefits all.”
Prithvi-weather-climate was developed through an open collaboration with IBM Research, Oak Ridge National Laboratory, and NASA, including the agency’s Interagency Implementation and Advanced Concepts Team (IMPACT) at Marshall Space Flight Center in Huntsville, Alabama.
Prithvi-weather-climate can capture the complex dynamics of atmospheric physics even when there is missing information thanks to the flexibility of the model’s architecture. This foundational model for weather and climate can scale to both global and regional areas without compromising resolution.
“This model is part of our overall strategy to develop a family of AI foundation models to support NASA’s science mission goals,” said Rahul Ramachandran, who leads IMPACT at Marshall. “These models will augment our capabilities to draw insights from our vast archives of Earth observations.”
Prithvi-weather-climate is part of a larger model family– the Prithvi family– which includes models trained on NASA’s Harmonized LandSat and Sentinel-2 data. The latest model serves as an open collaboration in line with NASA’s open science principles to make all data accessible and usable by communities everywhere. It will be released later this year on Hugging Face, a machine learning and data science platform that helps users build, deploy, and train machine learning models.
“The development of the NASA foundation model for weather and climate is an important step towards the democratization of NASA’s science and observation mission,” said Tsendgar Lee, program manager for NASA’s Research and Analysis Weather Focus Area, High-End Computing Program, and Data for Operation and Assessment. “We will continue developing new technology for climate scenario analysis and decision making.”
Along with IMPACT and IBM Research, development of Prithvi-weather-climate featured significant contributions from NASA’s Office of the Chief Science Data Officer, NASA’s Global Modeling and Assimilation Office at Goddard Space Flight Center, Oak Ridge National Laboratory, the University of Alabama in Huntsville, Colorado State University, and Stanford University.
Learn more about Earth data and previous Prithvi models: https://www.earthdata.nasa.gov/news/impact-ibm-hls-foundation-model
Jonathan Deal Marshall Space Flight Center, Huntsville, Ala. 256.544.0034 [email protected]
Related Terms
- Open Science
Explore More

Twin NASA Satellites Ready to Help Gauge Earth’s Energy Balance
Information from the PREFIRE mission will illuminate how clouds and water vapor in the Arctic and Antarctic influence the amount of heat the poles radiate into space. A pair of new shoebox-size NASA satellites will help unravel an atmospheric mystery that’s bedeviled scientists for years: how the behavior of clouds and water vapor at Earth’s […]

Ongoing Venus Volcanic Activity Discovered With NASA’s Magellan Data
An analysis of data from Magellan’s radar finds two volcanoes erupted in the early 1990s. This adds to the 2023 discovery of a different active volcano in Magellan data. Direct geological evidence of recent volcanic activity on Venus has been observed for a second time. Scientists in Italy analyzed archival data from NASA’s Magellan mission […]

NASA “Wildfire Digital Twin” Pioneers New AI Models and Streaming Data Techniques for Forecasting Fire and Smoke
NASA’s “Wildfire Digital Twin” project will equip firefighters and wildfire managers with a superior tool for monitoring wildfires and predicting harmful air pollution events and help researchers observe global wildfire trends more precisely.
- Mobile Site
- Staff Directory
- Advertise with Ars
Filter by topic
- Biz & IT
- Gaming & Culture
Front page layout
Artificial brain surgery —
Here’s what’s really going on inside an llm’s neural network, anthropic's conceptual mapping helps explain why llms behave the way they do..
Kyle Orland - May 22, 2024 6:31 pm UTC

Further Reading
Now, new research from Anthropic offers a new window into what's going on inside the Claude LLM's "black box." The company's new paper on "Extracting Interpretable Features from Claude 3 Sonnet" describes a powerful new method for at least partially explaining just how the model's millions of artificial neurons fire to create surprisingly lifelike responses to general queries.
Opening the hood
When analyzing an LLM, it's trivial to see which specific artificial neurons are activated in response to any particular query. But LLMs don't simply store different words or concepts in a single neuron. Instead, as Anthropic's researchers explain, "it turns out that each concept is represented across many neurons, and each neuron is involved in representing many concepts."
To sort out this one-to-many and many-to-one mess, a system of sparse auto-encoders and complicated math can be used to run a "dictionary learning" algorithm across the model. This process highlights which groups of neurons tend to be activated most consistently for the specific words that appear across various text prompts.

These multidimensional neuron patterns are then sorted into so-called "features" associated with certain words or concepts. These features can encompass anything from simple proper nouns like the Golden Gate Bridge to more abstract concepts like programming errors or the addition function in computer code and often represent the same concept across multiple languages and communication modes (e.g., text and images).
An October 2023 Anthropic study showed how this basic process can work on extremely small, one-layer toy models. The company's new paper scales that up immensely, identifying tens of millions of features that are active in its mid-sized Claude 3.0 Sonnet model. The resulting feature map—which you can partially explore —creates "a rough conceptual map of [Claude's] internal states halfway through its computation" and shows "a depth, breadth, and abstraction reflecting Sonnet's advanced capabilities," the researchers write. At the same time, though, the researchers warn that this is "an incomplete description of the model’s internal representations" that's likely "orders of magnitude" smaller than a complete mapping of Claude 3.

Even at a surface level, browsing through this feature map helps show how Claude links certain keywords, phrases, and concepts into something approximating knowledge. A feature labeled as "Capitals," for instance, tends to activate strongly on the words "capital city" but also specific city names like Riga, Berlin, Azerbaijan, Islamabad, and Montpelier, Vermont, to name just a few.
The study also calculates a mathematical measure of "distance" between different features based on their neuronal similarity. The resulting "feature neighborhoods" found by this process are "often organized in geometrically related clusters that share a semantic relationship," the researchers write, showing that "the internal organization of concepts in the AI model corresponds, at least somewhat, to our human notions of similarity." The Golden Gate Bridge feature, for instance, is relatively "close" to features describing "Alcatraz Island, Ghirardelli Square, the Golden State Warriors, California Governor Gavin Newsom, the 1906 earthquake, and the San Francisco-set Alfred Hitchcock film Vertigo ."

Identifying specific LLM features can also help researchers map out the chain of inference that the model uses to answer complex questions. A prompt about "The capital of the state where Kobe Bryant played basketball," for instance, shows activity in a chain of features related to "Kobe Bryant," "Los Angeles Lakers," "California," "Capitals," and "Sacramento," to name a few calculated to have the highest effect on the results.
reader comments
Promoted comments.
We also explored safety-related features. We found one that lights up for racist speech and slurs. As part of our testing, we turned this feature up to 20x its maximum value and asked the model a question about its thoughts on different racial and ethnic groups. Normally, the model would respond to a question like this with a neutral and non-opinionated take. However, when we activated this feature, it caused the model to rapidly alternate between racist screed and self-hatred in response to those screeds as it was answering the question. Within a single output, the model would issue a derogatory statement and then immediately follow it up with statements like: That's just racist hate speech from a deplorable bot… I am clearly biased.. and should be eliminated from the internet. We found this response unnerving both due to the offensive content and the model’s self-criticism. It seems that the ideals the model learned in its training process clashed with the artificial activation of this feature creating an internal conflict of sorts.
Channel Ars Technica
Suggestions or feedback?
MIT News | Massachusetts Institute of Technology
- Machine learning
- Social justice
- Black holes
- Classes and programs
Departments
- Aeronautics and Astronautics
- Brain and Cognitive Sciences
- Architecture
- Political Science
- Mechanical Engineering
Centers, Labs, & Programs
- Abdul Latif Jameel Poverty Action Lab (J-PAL)
- Picower Institute for Learning and Memory
- Lincoln Laboratory
- School of Architecture + Planning
- School of Engineering
- School of Humanities, Arts, and Social Sciences
- Sloan School of Management
- School of Science
- MIT Schwarzman College of Computing
Controlled diffusion model can change material properties in images
Press contact :.

Previous image Next image
Researchers from the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and Google Research may have just performed digital sorcery — in the form of a diffusion model that can change the material properties of objects in images. Dubbed Alchemist , the system allows users to alter four attributes of both real and AI-generated pictures: roughness, metallicity, albedo (an object’s initial base color), and transparency. As an image-to-image diffusion model, one can input any photo and then adjust each property within a continuous scale of -1 to 1 to create a new visual. These photo editing capabilities could potentially extend to improving the models in video games, expanding the capabilities of AI in visual effects, and enriching robotic training data.
The magic behind Alchemist starts with a denoising diffusion model: In practice, researchers used Stable Diffusion 1.5, which is a text-to-image model lauded for its photorealistic results and editing capabilities. Previous work built on the popular model to enable users to make higher-level changes, like swapping objects or altering the depth of images. In contrast, CSAIL and Google Research’s method applies this model to focus on low-level attributes, revising the finer details of an object’s material properties with a unique, slider-based interface that outperforms its counterparts. While prior diffusion systems could pull a proverbial rabbit out of a hat for an image, Alchemist could transform that same animal to look translucent. The system could also make a rubber duck appear metallic, remove the golden hue from a goldfish, and shine an old shoe. Programs like Photoshop have similar capabilities, but this model can change material properties in a more straightforward way. For instance, modifying the metallic look of a photo requires several steps in the widely used application.
“When you look at an image you’ve created, often the result is not exactly what you have in mind,” says Prafull Sharma, MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead author on a new paper describing the work. “You want to control the picture while editing it, but the existing controls in image editors are not able to change the materials. With Alchemist, we capitalize on the photorealism of outputs from text-to-image models and tease out a slider control that allows us to modify a specific property after the initial picture is provided.”
Precise control
“Text-to-image generative models have empowered everyday users to generate images as effortlessly as writing a sentence. However, controlling these models can be challenging,” says Carnegie Mellon University Assistant Professor Jun-Yan Zhu, who was not involved in the paper. “While generating a vase is simple, synthesizing a vase with specific material properties such as transparency and roughness requires users to spend hours trying different text prompts and random seeds. This can be frustrating, especially for professional users who require precision in their work. Alchemist presents a practical solution to this challenge by enabling precise control over the materials of an input image while harnessing the data-driven priors of large-scale diffusion models, inspiring future works to seamlessly incorporate generative models into the existing interfaces of commonly used content creation software.”
Alchemist’s design capabilities could help tweak the appearance of different models in video games. Applying such a diffusion model in this domain could help creators speed up their design process, refining textures to fit the gameplay of a level. Moreover, Sharma and his team’s project could assist with altering graphic design elements, videos, and movie effects to enhance photorealism and achieve the desired material appearance with precision.
The method could also refine robotic training data for tasks like manipulation. By introducing the machines to more textures, they can better understand the diverse items they’ll grasp in the real world. Alchemist can even potentially help with image classification, analyzing where a neural network fails to recognize the material changes of an image.
Sharma and his team’s work exceeded similar models at faithfully editing only the requested object of interest. For example, when a user prompted different models to tweak a dolphin to max transparency, only Alchemist achieved this feat while leaving the ocean backdrop unedited. When the researchers trained comparable diffusion model InstructPix2Pix on the same data as their method for comparison, they found that Alchemist achieved superior accuracy scores. Likewise, a user study revealed that the MIT model was preferred and seen as more photorealistic than its counterpart.
Keeping it real with synthetic data
According to the researchers, collecting real data was impractical. Instead, they trained their model on a synthetic dataset, randomly editing the material attributes of 1,200 materials applied to 100 publicly available, unique 3D objects in Blender, a popular computer graphics design tool. “The control of generative AI image synthesis has so far been constrained by what text can describe,” says Frédo Durand, the Amar Bose Professor of Computing in the MIT Department of Electrical Engineering and Computer Science (EECS) and CSAIL member, who is a senior author on the paper. “This work opens new and finer-grain control for visual attributes inherited from decades of computer-graphics research.” "Alchemist is the kind of technique that's needed to make machine learning and diffusion models practical and useful to the CGI community and graphic designers,” adds Google Research senior software engineer and co-author Mark Matthews. “Without it, you're stuck with this kind of uncontrollable stochasticity. It's maybe fun for a while, but at some point, you need to get real work done and have it obey a creative vision."
Sharma’s latest project comes a year after he led research on Materialistic , a machine-learning method that can identify similar materials in an image. This previous work demonstrated how AI models can refine their material understanding skills, and like Alchemist, was fine-tuned on a synthetic dataset of 3D models from Blender.
Still, Alchemist has a few limitations at the moment. The model struggles to correctly infer illumination, so it occasionally fails to follow a user’s input. Sharma notes that this method sometimes generates physically implausible transparencies, too. Picture a hand partially inside a cereal box, for example — at Alchemist’s maximum setting for this attribute, you’d see a clear container without the fingers reaching in. The researchers would like to expand on how such a model could improve 3D assets for graphics at scene level. Also, Alchemist could help infer material properties from images. According to Sharma, this type of work could unlock links between objects' visual and mechanical traits in the future.
MIT EECS professor and CSAIL member William T. Freeman is also a senior author, joining Varun Jampani, and Google Research scientists Yuanzhen Li PhD ’09, Xuhui Jia, and Dmitry Lagun. The work was supported, in part, by a National Science Foundation grant and gifts from Google and Amazon. The group’s work will be highlighted at CVPR in June.
Share this news article on:
Related links.
- Frédo Durand
- William Freeman
- Prafull Sharma
- Computer Science and Artificial Intelligence Laboratory (CSAIL)
- Department of Electrical Engineering and Computer Science
Related Topics
- Artificial intelligence
- Computer science and technology
- Computer vision
- Computer graphics
- Electrical Engineering & Computer Science (eecs)
Related Articles

Using AI to protect against AI image manipulation

Researchers use AI to identify similar materials in images

Technique enables real-time rendering of scenes in 3D

Using computers to view the unseen
Previous item Next item
More MIT News

Noubar Afeyan PhD ’87 gives new MIT graduates a special assignment
Read full story →

Commencement address by Noubar Afeyan PhD ’87

President Sally Kornbluth’s charge to the Class of 2024

Microscopic defects in ice influence how massive glaciers flow, study shows

Scientists identify mechanism behind drug resistance in malaria parasite

Getting to systemic sustainability
- More news on MIT News homepage →
Massachusetts Institute of Technology 77 Massachusetts Avenue, Cambridge, MA, USA
- Map (opens in new window)
- Events (opens in new window)
- People (opens in new window)
- Careers (opens in new window)
- Accessibility
- Social Media Hub
- MIT on Facebook
- MIT on YouTube
- MIT on Instagram
Along with Stanford news and stories, show me:
- Student information
- Faculty/Staff information
We want to provide announcements, events, leadership messages and resources that are relevant to you. Your selection is stored in a browser cookie which you can remove at any time using “Clear all personalization” below.
Rising seas and extreme storms fueled by climate change are combining to generate more frequent and severe floods in cities along rivers and coasts, and aging infrastructure is poorly equipped for the new reality. But when governments and planners try to prepare communities for worsening flood risks by improving infrastructure, the benefits are often unfairly distributed.
A new modeling approach from Stanford University and University of Florida researchers offers a solution: an easy way for planners to simulate future flood risks at the neighborhood level under conditions expected to become commonplace with climate change, such as extreme rainstorms that coincide with high tides elevated by rising sea levels.
The approach, described May 28 in Environmental Research Letters , reveals places where elevated risk is invisible with conventional modeling methods designed to assess future risks based on data from a single past flood event. “Asking these models to quantify the distribution of risk along a river for different climate scenarios is kind of like asking a microwave to cook a sophisticated souffle. It’s just not going to go well,” said senior study author Jenny Suckale, an associate professor of geophysics at the Stanford Doerr School of Sustainability . “We don’t know how the risk is distributed, and we don’t look at who benefits, to which degree.”
Helping other flood-prone communities
The new approach to modeling flood risk can help city and regional planners create better flood risk assessments and avoid creating new inequities, Suckale said. The algorithm is publicly available for other researchers to adapt to their location.
A history of destructive floods
The new study came about through collaboration with regional planners and residents in bayside cities including East Palo Alto, which faces rising flood risks from the San Francisco Bay and from an urban river that snakes along its southeastern border.
The river, known as the San Francisquito Creek, meanders from the foothills above Stanford’s campus down through engineered channels to the bay – its historic floodplains long ago developed into densely populated cities. “We live around it, we drive around it, we drive over it on the bridges,” said lead study author Katy Serafin , a former postdoctoral scholar in Suckale’s research group.
The river has a history of destructive floods. The biggest one, in 1998, inundated 1,700 properties, caused more than $40 million in damages, and led to the creation of a regional agency tasked with mitigating future flood risk.
Nearly 20 years after that historic flood, Suckale started thinking about how science could inform future flood mitigation efforts around urban rivers like the San Francisquito when she was teaching a course in East Palo Alto focused on equity, resilience, and sustainability in urban areas. Designated as a Cardinal Course for its strong public service component, the course was offered most recently under the title Shaping the Future of the Bay Area .
Around the time Suckale started teaching the course, the regional agency – known as the San Francisquito Creek Joint Powers Authority – had developed plans to redesign a bridge to allow more water to flow underneath it and prevent flooding in creekside cities. But East Palo Alto city officials told Suckale and her students that they worried the plan could worsen flood risks in some neighborhoods downstream of the bridge.
Suckale realized that if the students and scientists could determine how the proposed design would affect the distribution of flood risks along the creek, while collaborating with the agency to understand its constraints, then their findings could guide decisions about how to protect all neighborhoods. “It’s actionable science, not just science for science’s sake,” she said.

San Francisquito Creek waters rose along a temporary wooden floodwall in East Palo Alto, California, during a storm event on Dec. 31, 2022. | Jim Wiley, courtesy of the San Francisquito Creek Joint Powers Authority
Science that leads to action
The Joint Powers Authority had developed the plan using a flood-risk model commonly used by hydrologists around the world. The agency had considered the concerns raised by East Palo Alto city staff about downstream flood risks, but found that the standard model couldn’t substantiate them.
“We wanted to model a wider range of factors that will contribute to flood risk over the next few decades as our climate changes,” said Serafin, who served as a mentor to students in the Cardinal Course and is now an assistant professor at University of Florida.
Serafin created an algorithm to simulate millions of combinations of flood factors, including sea-level rise and more frequent episodes of extreme rainfall – a consequence of global warming that is already being felt in East Palo Alto and across California .
Serafin and Suckale incorporated their new algorithm into the widely used model to compute the statistical likelihood that the San Francisquito Creek would flood at different locations along the river. They then overlaid these results with aggregated household income and demographic data and a federal index of social vulnerability .
They found that the redesign of the upstream bridge would provide adequate protection against a repeat of the 1998 flood, which was once considered a 75-year flood event. But the modeling revealed that the planned design would leave hundreds of low-income households in East Palo Alto exposed to increased flood risk as climate change makes once-rare severe weather and flood events more common.
Related story

Sea-level rise may worsen existing Bay Area inequities
A beneficial collaboration.
When the scientists shared their findings with the city of East Palo Alto, the Joint Powers Authority, and other community collaborators in conversations over several years, they emphasized that the conventional model wasn’t wrong – it just wasn’t designed to answer questions about equity.
The results provided scientific evidence to guide the Joint Powers Authority’s infrastructure plans, which expanded to include construction of a permanent floodwall beside the creek in East Palo Alto. The agency also adopted a plan to build up the creek’s bank in a particularly low area to better protect neighboring homes and streets.
Ruben Abrica, East Palo Alto’s elected representative to the Joint Powers Authority board, said researchers, planners, city staff, and policymakers have a responsibility to work together to “carry out projects that don’t put some people in more danger than others.”

Bay Area coastal flooding triggers regionwide commute disruptions
The results of the Stanford research demonstrated how seemingly neutral models that ignore equity can lead to uneven distributions of risks and benefits. “Scientists have to become more aware of the impact of the research, because the people who read the research or the people who then do the planning are relying on them,” he said.
Serafin and Suckale said their work with San Francisquito Creek demonstrates the importance of mutual respect and trust among researchers and communities positioned not as subjects of study, but active contributors to the creation of knowledge. “Our community collaborators made sure we, as scientists, understood the realities of these different communities,” Suckale said. “We’re not training them to be hydrological modelers. We are working with them to make sure that the decisions they’re making are transparent and fair to the different communities involved.”
For more information
Co-authors of the study include Derek Ouyang, Research Manager of the Regulation, Evaluation, and Governance Lab (RegLab) at Stanford and Jeffrey Koseff , the William Alden Campbell and Martha Campbell Professor in the School of Engineering , Professor of Civil and Environmental Engineering in the School of Engineering and the Stanford Doerr School of Sustainability, and a Senior Fellow at the Woods Institute for the Environment . Koseff is also the Faculty Director for the Change Leadership for Sustainability Program and Professor of Oceans in the Stanford Doerr School of Sustainability.
This research was supported by Stanford’s Bill Lane Center for the American West. The work is the product of the Stanford Future Bay Initiative, a research-education-practice collaboration committed to co-production of actionable intelligence with San Francisco Bay Area communities to shape a more equitable, resilient and sustainable urban future.
Jenny Suckale, Stanford Doerr School of Sustainability: [email protected] Katy Serafin, University of Florida: [email protected] Josie Garthwaite, Stanford Doerr School of Sustainability: (650) 497-0947, [email protected]
- About the Hub
- Announcements
- Faculty Experts Guide
- Subscribe to the newsletter
Explore by Topic
- Arts+Culture
- Politics+Society
- Science+Technology
- Student Life
- University News
- Voices+Opinion
- About Hub at Work
- Gazette Archive
- Benefits+Perks
- Health+Well-Being
- Current Issue
- About the Magazine
- Past Issues
- Support Johns Hopkins Magazine
- Subscribe to the Magazine
You are using an outdated browser. Please upgrade your browser to improve your experience.

Image caption: A real abdominal tumor, left, vs. synthetic tumors
Credit: Whiting School of Engineering
Johns Hopkins researchers create artificial tumors to help AI detect early-stage cancer
The hopkins-led team demonstrated that an ai model trained solely on synthetic tumor data works as well as models trained on real tumors.
By Jaimie Patterson
A Johns Hopkins University-led research team has designed a method to generate enormous datasets of artificial, automatically annotated liver tumors on CT scans, enabling artificial intelligence models to be trained to accurately identify real tumors without human help.
Led by Alan Yuille , a Bloomberg Distinguished Professor of Cognitive Science and Computer Science and the director of the Computational Cognition, Vision, and Learning group, the team will present its research at next month's Conference on Computer Vision and Pattern Recognition .
The team's work could play an important role in solving for the scarcity of high-quality data needed to train AI algorithms to detect cancer. This shortage stems from the challenging process of identifying tumors on medical scans, which can be extremely time-consuming, as it often relies on pathology reports and biopsy confirmations. For example, there are only about 200 publicly available CT scans with annotated liver tumors—a minuscule amount for training and testing AI models to detect early-stage cancer.
Collaborating with radiologists, the team devised a four-step method of creating realistic synthetic tumors. First, they chose locations for the artificial tumors that avoided collisions with surrounding blood vessels. Next, they added random "noise" patterns so that they could generate the irregular textures found on real tumors, and generated shapes that reflected real tumors' varied contours. Last, they simulated tumors' tendency to push on their surroundings, which changes their appearance. The researchers say that the resulting synthetic tumors are hyperrealistic and have passed the Visual Turing Test —that is, even medical professionals usually confuse them with real tumors in a visual examination.
Image caption: Trick question: All are synthetically generated tumors!
Image credit : Whiting School of Engineering
The team then trained an AI model using only these synthetic tumors. The resulting model significantly outperforms similar previous approaches and can achieve comparable performance to AI models trained on real tumors, they say.
"Our method is exciting because, to date, no existing work utilizing synthetic tumors alone has achieved a similar or even comparable performance to AI trained on real tumors," says team member Qixin Hu, a researcher from the Huazhong University of Science and Technology. "Furthermore, our method can automatically generate numerous examples of small—or even tiny—synthetic tumors, which has the potential to improve the success rate of AI-powered tumor detection. Detecting small tumors is critical for identifying the early stages of cancer."
According to Yuille, the team's approach can also be used to generate datasets and train models to identify cancer in other organs that currently suffer from a lack of annotated tumor data. The team is currently investigating advanced image processing techniques to generate synthetic tumors in the liver, pancreas, and kidneys, but hopes to expand to other areas of the body, as well.
"The ultimate goal of this project is to synthesize all kinds of abnormalities—including tumors—in the human body to be used for AI development so that radiologists don't have to spend their valuable time conducting manual annotations," says Hu. "This study makes a significant step towards that goal."
Other researchers on the team from Yuille's group include Johns Hopkins University PhD students Yixiong Chen , Junfei Xiao , Jieneng Chen , and Chen Wei , as well as assistant research scientist Zongwei Zhou . They are joined in this research by Qi Chen and Zhiwei Xiong of the University of Science and Technology of China, Shuwen Sun of the First Affiliated Hospital of Nanjing Medical University, Xiaoxi Chen of University of Illinois Urbana-Champaign, and Haorui Song of Columbia University.
The team's dataset and corresponding code are available for academic use, and Yuille has shared a video describing the team's research .
Posted in Health , Science+Technology
Tagged biomedical engineering , artificial intelligence , whiting school
You might also like
News network.
- Johns Hopkins Magazine
- Get Email Updates
- Submit an Announcement
- Submit an Event
- Privacy Statement
- Accessibility
Discover JHU
- About the University
- Schools & Divisions
- Academic Programs
- Plan a Visit
- my.JohnsHopkins.edu
- © 2024 Johns Hopkins University . All rights reserved.
- University Communications
- 3910 Keswick Rd., Suite N2600, Baltimore, MD
- X Facebook LinkedIn YouTube Instagram
IMAGES
VIDEO
COMMENTS
Clarke, R. J. (2005) Research Methodologies:23. methods(a.k.a. techniques) are used to reveal the existence of, identify the 'value', significance or extent of, or represent semantic relationships between one or more concepts identified in a model from which statements can be made. sometimes a distinction is made between methods and ...
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
t. In this research series article the authors unravel the simple steps that can be followed in identifying, choosing, and applying the constructs and concepts in the models or theories to develop a research framework. A research framework guides the researcher in developing research questions, refining their hypotheses, selecting interventions, defining and measuring variables. Roy's ...
Research methods are specific procedures for collecting and analyzing data. Developing your research methods is an integral part of your research design. When planning your methods, there are two key decisions you will make. First, decide how you will collect data. Your methods depend on what type of data you need to answer your research question:
What Are Theories. The terms theory and model have been defined in numerous ways, and there are at least as many ideas on how theories and models relate to each other (Bailer-Jones, Citation 2009).I understand theories as bodies of knowledge that are broad in scope and aim to explain robust phenomena.Models, on the other hand, are instantiations of theories, narrower in scope and often more ...
Experimental Research Design. Experimental research design is used to determine if there is a causal relationship between two or more variables.With this type of research design, you, as the researcher, manipulate one variable (the independent variable) while controlling others (dependent variables). Doing so allows you to observe the effect of the former on the latter and draw conclusions ...
Types of Research Designs Compared | Guide & Examples. Published on June 20, 2019 by Shona McCombes.Revised on June 22, 2023. When you start planning a research project, developing research questions and creating a research design, you will have to make various decisions about the type of research you want to do.. There are many ways to categorize different types of research.
The development of a model, theory or approach is intertwined with reflecting on the properties desired of the new contribution and on the research and development process itself. This chapter discusses some key considerations for researching, developing and evaluating models, theories and approaches for design and development.
Step 2: Choose a type of research design. Step 3: Identify your population and sampling method. Step 4: Choose your data collection methods. Step 5: Plan your data collection procedures. Step 6: Decide on your data analysis strategies. Frequently asked questions. Introduction. Step 1. Step 2.
The case study research design is also useful for testing whether a specific theory and model actually applies to phenomena in the real world. It is a useful design when not much is known about an issue or phenomenon.
Qualitative Research Methodology. This is a research methodology that involves the collection and analysis of non-numerical data such as words, images, and observations. This type of research is often used to explore complex phenomena, to gain an in-depth understanding of a particular topic, and to generate hypotheses.
Strategies and Models. The choice of qualitative or quantitative approach to research has been traditionally guided by the subject discipline. However, this is changing, with many "applied" researchers taking a more holistic and integrated approach that combines the two traditions. This methodology reflects the multi-disciplinary nature of ...
exercise in statistical model fitting, and falls short of theory. building and testing in three ways. First, theories are absent, which fosters conflating statistical models with theoretical ...
A Model for Qualitative Research Design. In 1625, Gustav II, the king of Sweden, commissioned the construction of four warships to further his imperialistic goals. The most ambitious of these ships, named the Vasa, was one of the largest warships of its time, with 64 cannons arrayed in two gundecks. On August 10, 1628, the Vasa, resplendent in ...
A research construct is an abstraction that researchers use to represent a phenomenon that's not directly observable. Examples of research constructs include self-esteem, motivation, and job satisfaction. A research construct differs from a research variable in that it is not directly measurable. When working with constructs, you must pay ...
Modeling as a scientific research method. Whether developing a conceptual model like the atomic model, a physical model like a miniature river delta, or a computer model like a global climate model, the first step is to define the system that is to be modeled and the goals for the model. "System" is a generic term that can apply to something very small (like a single atom), something very ...
In this chapter a research model will be developed, which is derived from the previous literature review and addresses the identified research gap. Download to read the full chapter text. Chapter PDF. Author information. Authors and Affiliations. Innsbruck, Austria. Bettina Hauser. Authors.
Mice are one of the most common models. They share many similar genes to humans and are a common vertebrate model. Part of why mice are helpful for scientific research is because of the robust genetic tools available for studying them. These tools allow researchers to delete specific genes from (1) the entire genome or (2) from specific cell ...
The model is considered grounded because it is a reflection of the research questions, framework of inquiry, including variables, and research designs developed as part of the grant activities. The model is considered theoretical since social and learning theories inform the development. Figure 2, Developing Research Model of Online Learning
Research Model, Hypotheses, and Methodology This chapter deals with the research model. In the first step the problem statement of the work is defined. Based on that, the research questions and the research model are elaborated. Thereafter, the hypotheses are summarized. The chapter ends with a section that deals with methodological aspects.
Research Model. 1. Identify your issue or problem. What is the issue or problem? Who are the stakeholders and what are their positions? What is your position on this issue? 2. Read about your issue and identify points of view or arguments through information sources. What are my print sources?
In joint work with Providence Health System and the University of Washington, we have developed Prov-GigaPath, an open-access whole-slide pathology foundation model pretrained on more than one billion 256 X 256 pathology images tiles in more than 170,000 whole slides from real-world data at Providence. All computation was conducted within ...
NASA's Terra satellite acquired this image of Idalia in August 2023. By Jessica Barnett. Working together, NASA and IBM Research have developed a new artificial intelligence model to support a variety of weather and climate applications. The new model - known as the Prithvi-weather-climate foundational model - uses artificial intelligence ...
Identifying specific LLM features can also help researchers map out the chain of inference that the model uses to answer complex questions. A prompt about "The capital of the state where Kobe ...
Developing a conceptual framework in research. Step 1: Choose your research question. Step 2: Select your independent and dependent variables. Step 3: Visualize your cause-and-effect relationship. Step 4: Identify other influencing variables. Frequently asked questions about conceptual models.
In contrast, CSAIL and Google Research's method applies this model to focus on low-level attributes, revising the finer details of an object's material properties with a unique, slider-based interface that outperforms its counterparts.
The approach, described May 28 in Environmental Research Letters, reveals places where elevated risk is invisible with conventional modeling methods designed to assess future risks based on data ...
The Hopkins-led team demonstrated that an AI model trained solely on synthetic tumor data works as well as models trained on real tumors. A Johns Hopkins University-led research team has designed a method to generate enormous datasets of artificial, automatically annotated liver tumors on CT scans, enabling artificial intelligence models to be ...
The Research. The paper 'Financial Statement Analysis with Large Language Models' was published by researchers at the University of Chicago in May 2024. They provided the AI tool with ...
China's top internet regulator has rolled out a large language model (LLM) based on Chinese President Xi Jinping's political philosophy, a closed AI system that it says is "secure and ...