Get science-backed answers as you write with Paperpal's Research feature

How to Write a Research Paper Introduction (with Examples)

The research paper introduction section, along with the Title and Abstract, can be considered the face of any research paper. The following article is intended to guide you in organizing and writing the research paper introduction for a quality academic article or dissertation.
The research paper introduction aims to present the topic to the reader. A study will only be accepted for publishing if you can ascertain that the available literature cannot answer your research question. So it is important to ensure that you have read important studies on that particular topic, especially those within the last five to ten years, and that they are properly referenced in this section. 1 What should be included in the research paper introduction is decided by what you want to tell readers about the reason behind the research and how you plan to fill the knowledge gap. The best research paper introduction provides a systemic review of existing work and demonstrates additional work that needs to be done. It needs to be brief, captivating, and well-referenced; a well-drafted research paper introduction will help the researcher win half the battle.
The introduction for a research paper is where you set up your topic and approach for the reader. It has several key goals:
- Present your research topic
- Capture reader interest
- Summarize existing research
- Position your own approach
- Define your specific research problem and problem statement
- Highlight the novelty and contributions of the study
- Give an overview of the paper’s structure
The research paper introduction can vary in size and structure depending on whether your paper presents the results of original empirical research or is a review paper. Some research paper introduction examples are only half a page while others are a few pages long. In many cases, the introduction will be shorter than all of the other sections of your paper; its length depends on the size of your paper as a whole.
- Break through writer’s block. Write your research paper introduction with Paperpal Copilot
Table of Contents
What is the introduction for a research paper, why is the introduction important in a research paper, craft a compelling introduction section with paperpal. try now, 1. introduce the research topic:, 2. determine a research niche:, 3. place your research within the research niche:, craft accurate research paper introductions with paperpal. start writing now, frequently asked questions on research paper introduction, key points to remember.
The introduction in a research paper is placed at the beginning to guide the reader from a broad subject area to the specific topic that your research addresses. They present the following information to the reader
- Scope: The topic covered in the research paper
- Context: Background of your topic
- Importance: Why your research matters in that particular area of research and the industry problem that can be targeted
The research paper introduction conveys a lot of information and can be considered an essential roadmap for the rest of your paper. A good introduction for a research paper is important for the following reasons:
- It stimulates your reader’s interest: A good introduction section can make your readers want to read your paper by capturing their interest. It informs the reader what they are going to learn and helps determine if the topic is of interest to them.
- It helps the reader understand the research background: Without a clear introduction, your readers may feel confused and even struggle when reading your paper. A good research paper introduction will prepare them for the in-depth research to come. It provides you the opportunity to engage with the readers and demonstrate your knowledge and authority on the specific topic.
- It explains why your research paper is worth reading: Your introduction can convey a lot of information to your readers. It introduces the topic, why the topic is important, and how you plan to proceed with your research.
- It helps guide the reader through the rest of the paper: The research paper introduction gives the reader a sense of the nature of the information that will support your arguments and the general organization of the paragraphs that will follow. It offers an overview of what to expect when reading the main body of your paper.
What are the parts of introduction in the research?
A good research paper introduction section should comprise three main elements: 2
- What is known: This sets the stage for your research. It informs the readers of what is known on the subject.
- What is lacking: This is aimed at justifying the reason for carrying out your research. This could involve investigating a new concept or method or building upon previous research.
- What you aim to do: This part briefly states the objectives of your research and its major contributions. Your detailed hypothesis will also form a part of this section.
How to write a research paper introduction?
The first step in writing the research paper introduction is to inform the reader what your topic is and why it’s interesting or important. This is generally accomplished with a strong opening statement. The second step involves establishing the kinds of research that have been done and ending with limitations or gaps in the research that you intend to address. Finally, the research paper introduction clarifies how your own research fits in and what problem it addresses. If your research involved testing hypotheses, these should be stated along with your research question. The hypothesis should be presented in the past tense since it will have been tested by the time you are writing the research paper introduction.
The following key points, with examples, can guide you when writing the research paper introduction section:
- Highlight the importance of the research field or topic
- Describe the background of the topic
- Present an overview of current research on the topic
Example: The inclusion of experiential and competency-based learning has benefitted electronics engineering education. Industry partnerships provide an excellent alternative for students wanting to engage in solving real-world challenges. Industry-academia participation has grown in recent years due to the need for skilled engineers with practical training and specialized expertise. However, from the educational perspective, many activities are needed to incorporate sustainable development goals into the university curricula and consolidate learning innovation in universities.
- Reveal a gap in existing research or oppose an existing assumption
- Formulate the research question
Example: There have been plausible efforts to integrate educational activities in higher education electronics engineering programs. However, very few studies have considered using educational research methods for performance evaluation of competency-based higher engineering education, with a focus on technical and or transversal skills. To remedy the current need for evaluating competencies in STEM fields and providing sustainable development goals in engineering education, in this study, a comparison was drawn between study groups without and with industry partners.
- State the purpose of your study
- Highlight the key characteristics of your study
- Describe important results
- Highlight the novelty of the study.
- Offer a brief overview of the structure of the paper.
Example: The study evaluates the main competency needed in the applied electronics course, which is a fundamental core subject for many electronics engineering undergraduate programs. We compared two groups, without and with an industrial partner, that offered real-world projects to solve during the semester. This comparison can help determine significant differences in both groups in terms of developing subject competency and achieving sustainable development goals.
Write a Research Paper Introduction in Minutes with Paperpal
Paperpal Copilot is a generative AI-powered academic writing assistant. It’s trained on millions of published scholarly articles and over 20 years of STM experience. Paperpal Copilot helps authors write better and faster with:
- Real-time writing suggestions
- In-depth checks for language and grammar correction
- Paraphrasing to add variety, ensure academic tone, and trim text to meet journal limits
With Paperpal Copilot, create a research paper introduction effortlessly. In this step-by-step guide, we’ll walk you through how Paperpal transforms your initial ideas into a polished and publication-ready introduction.
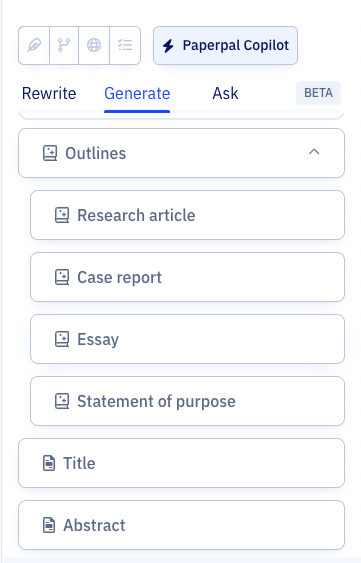
How to use Paperpal to write the Introduction section
Step 1: Sign up on Paperpal and click on the Copilot feature, under this choose Outlines > Research Article > Introduction
Step 2: Add your unstructured notes or initial draft, whether in English or another language, to Paperpal, which is to be used as the base for your content.
Step 3: Fill in the specifics, such as your field of study, brief description or details you want to include, which will help the AI generate the outline for your Introduction.
Step 4: Use this outline and sentence suggestions to develop your content, adding citations where needed and modifying it to align with your specific research focus.
Step 5: Turn to Paperpal’s granular language checks to refine your content, tailor it to reflect your personal writing style, and ensure it effectively conveys your message.
You can use the same process to develop each section of your article, and finally your research paper in half the time and without any of the stress.
The purpose of the research paper introduction is to introduce the reader to the problem definition, justify the need for the study, and describe the main theme of the study. The aim is to gain the reader’s attention by providing them with necessary background information and establishing the main purpose and direction of the research.
The length of the research paper introduction can vary across journals and disciplines. While there are no strict word limits for writing the research paper introduction, an ideal length would be one page, with a maximum of 400 words over 1-4 paragraphs. Generally, it is one of the shorter sections of the paper as the reader is assumed to have at least a reasonable knowledge about the topic. 2 For example, for a study evaluating the role of building design in ensuring fire safety, there is no need to discuss definitions and nature of fire in the introduction; you could start by commenting upon the existing practices for fire safety and how your study will add to the existing knowledge and practice.
When deciding what to include in the research paper introduction, the rest of the paper should also be considered. The aim is to introduce the reader smoothly to the topic and facilitate an easy read without much dependency on external sources. 3 Below is a list of elements you can include to prepare a research paper introduction outline and follow it when you are writing the research paper introduction. Topic introduction: This can include key definitions and a brief history of the topic. Research context and background: Offer the readers some general information and then narrow it down to specific aspects. Details of the research you conducted: A brief literature review can be included to support your arguments or line of thought. Rationale for the study: This establishes the relevance of your study and establishes its importance. Importance of your research: The main contributions are highlighted to help establish the novelty of your study Research hypothesis: Introduce your research question and propose an expected outcome. Organization of the paper: Include a short paragraph of 3-4 sentences that highlights your plan for the entire paper
Cite only works that are most relevant to your topic; as a general rule, you can include one to three. Note that readers want to see evidence of original thinking. So it is better to avoid using too many references as it does not leave much room for your personal standpoint to shine through. Citations in your research paper introduction support the key points, and the number of citations depend on the subject matter and the point discussed. If the research paper introduction is too long or overflowing with citations, it is better to cite a few review articles rather than the individual articles summarized in the review. A good point to remember when citing research papers in the introduction section is to include at least one-third of the references in the introduction.
The literature review plays a significant role in the research paper introduction section. A good literature review accomplishes the following: Introduces the topic – Establishes the study’s significance – Provides an overview of the relevant literature – Provides context for the study using literature – Identifies knowledge gaps However, remember to avoid making the following mistakes when writing a research paper introduction: Do not use studies from the literature review to aggressively support your research Avoid direct quoting Do not allow literature review to be the focus of this section. Instead, the literature review should only aid in setting a foundation for the manuscript.
Remember the following key points for writing a good research paper introduction: 4
- Avoid stuffing too much general information: Avoid including what an average reader would know and include only that information related to the problem being addressed in the research paper introduction. For example, when describing a comparative study of non-traditional methods for mechanical design optimization, information related to the traditional methods and differences between traditional and non-traditional methods would not be relevant. In this case, the introduction for the research paper should begin with the state-of-the-art non-traditional methods and methods to evaluate the efficiency of newly developed algorithms.
- Avoid packing too many references: Cite only the required works in your research paper introduction. The other works can be included in the discussion section to strengthen your findings.
- Avoid extensive criticism of previous studies: Avoid being overly critical of earlier studies while setting the rationale for your study. A better place for this would be the Discussion section, where you can highlight the advantages of your method.
- Avoid describing conclusions of the study: When writing a research paper introduction remember not to include the findings of your study. The aim is to let the readers know what question is being answered. The actual answer should only be given in the Results and Discussion section.
To summarize, the research paper introduction section should be brief yet informative. It should convince the reader the need to conduct the study and motivate him to read further. If you’re feeling stuck or unsure, choose trusted AI academic writing assistants like Paperpal to effortlessly craft your research paper introduction and other sections of your research article.
1. Jawaid, S. A., & Jawaid, M. (2019). How to write introduction and discussion. Saudi Journal of Anaesthesia, 13(Suppl 1), S18.
2. Dewan, P., & Gupta, P. (2016). Writing the title, abstract and introduction: Looks matter!. Indian pediatrics, 53, 235-241.
3. Cetin, S., & Hackam, D. J. (2005). An approach to the writing of a scientific Manuscript1. Journal of Surgical Research, 128(2), 165-167.
4. Bavdekar, S. B. (2015). Writing introduction: Laying the foundations of a research paper. Journal of the Association of Physicians of India, 63(7), 44-6.
Paperpal is a comprehensive AI writing toolkit that helps students and researchers achieve 2x the writing in half the time. It leverages 21+ years of STM experience and insights from millions of research articles to provide in-depth academic writing, language editing, and submission readiness support to help you write better, faster.
Get accurate academic translations, rewriting support, grammar checks, vocabulary suggestions, and generative AI assistance that delivers human precision at machine speed. Try for free or upgrade to Paperpal Prime starting at US$19 a month to access premium features, including consistency, plagiarism, and 30+ submission readiness checks to help you succeed.
Experience the future of academic writing – Sign up to Paperpal and start writing for free!
Related Reads:
- Scientific Writing Style Guides Explained
- 5 Reasons for Rejection After Peer Review
- Ethical Research Practices For Research with Human Subjects
- 8 Most Effective Ways to Increase Motivation for Thesis Writing
Practice vs. Practise: Learn the Difference
Academic paraphrasing: why paperpal’s rewrite should be your first choice , you may also like, how to write a high-quality conference paper, academic editing: how to self-edit academic text with..., measuring academic success: definition & strategies for excellence, phd qualifying exam: tips for success , ai in education: it’s time to change the..., is it ethical to use ai-generated abstracts without..., what are journal guidelines on using generative ai..., quillbot review: features, pricing, and free alternatives, what is an academic paper types and elements , should you use ai tools like chatgpt for....
- Privacy Policy
Home » Research Paper Introduction – Writing Guide and Examples
Research Paper Introduction – Writing Guide and Examples
Table of Contents

Research Paper Introduction
Research paper introduction is the first section of a research paper that provides an overview of the study, its purpose, and the research question (s) or hypothesis (es) being investigated. It typically includes background information about the topic, a review of previous research in the field, and a statement of the research objectives. The introduction is intended to provide the reader with a clear understanding of the research problem, why it is important, and how the study will contribute to existing knowledge in the field. It also sets the tone for the rest of the paper and helps to establish the author’s credibility and expertise on the subject.
How to Write Research Paper Introduction
Writing an introduction for a research paper can be challenging because it sets the tone for the entire paper. Here are some steps to follow to help you write an effective research paper introduction:
- Start with a hook : Begin your introduction with an attention-grabbing statement, a question, or a surprising fact that will make the reader interested in reading further.
- Provide background information: After the hook, provide background information on the topic. This information should give the reader a general idea of what the topic is about and why it is important.
- State the research problem: Clearly state the research problem or question that the paper addresses. This should be done in a concise and straightforward manner.
- State the research objectives: After stating the research problem, clearly state the research objectives. This will give the reader an idea of what the paper aims to achieve.
- Provide a brief overview of the paper: At the end of the introduction, provide a brief overview of the paper. This should include a summary of the main points that will be discussed in the paper.
- Revise and refine: Finally, revise and refine your introduction to ensure that it is clear, concise, and engaging.
Structure of Research Paper Introduction
The following is a typical structure for a research paper introduction:
- Background Information: This section provides an overview of the topic of the research paper, including relevant background information and any previous research that has been done on the topic. It helps to give the reader a sense of the context for the study.
- Problem Statement: This section identifies the specific problem or issue that the research paper is addressing. It should be clear and concise, and it should articulate the gap in knowledge that the study aims to fill.
- Research Question/Hypothesis : This section states the research question or hypothesis that the study aims to answer. It should be specific and focused, and it should clearly connect to the problem statement.
- Significance of the Study: This section explains why the research is important and what the potential implications of the study are. It should highlight the contribution that the research makes to the field.
- Methodology: This section describes the research methods that were used to conduct the study. It should be detailed enough to allow the reader to understand how the study was conducted and to evaluate the validity of the results.
- Organization of the Paper : This section provides a brief overview of the structure of the research paper. It should give the reader a sense of what to expect in each section of the paper.
Research Paper Introduction Examples
Research Paper Introduction Examples could be:
Example 1: In recent years, the use of artificial intelligence (AI) has become increasingly prevalent in various industries, including healthcare. AI algorithms are being developed to assist with medical diagnoses, treatment recommendations, and patient monitoring. However, as the use of AI in healthcare grows, ethical concerns regarding privacy, bias, and accountability have emerged. This paper aims to explore the ethical implications of AI in healthcare and propose recommendations for addressing these concerns.
Example 2: Climate change is one of the most pressing issues facing our planet today. The increasing concentration of greenhouse gases in the atmosphere has resulted in rising temperatures, changing weather patterns, and other environmental impacts. In this paper, we will review the scientific evidence on climate change, discuss the potential consequences of inaction, and propose solutions for mitigating its effects.
Example 3: The rise of social media has transformed the way we communicate and interact with each other. While social media platforms offer many benefits, including increased connectivity and access to information, they also present numerous challenges. In this paper, we will examine the impact of social media on mental health, privacy, and democracy, and propose solutions for addressing these issues.
Example 4: The use of renewable energy sources has become increasingly important in the face of climate change and environmental degradation. While renewable energy technologies offer many benefits, including reduced greenhouse gas emissions and energy independence, they also present numerous challenges. In this paper, we will assess the current state of renewable energy technology, discuss the economic and political barriers to its adoption, and propose solutions for promoting the widespread use of renewable energy.
Purpose of Research Paper Introduction
The introduction section of a research paper serves several important purposes, including:
- Providing context: The introduction should give readers a general understanding of the topic, including its background, significance, and relevance to the field.
- Presenting the research question or problem: The introduction should clearly state the research question or problem that the paper aims to address. This helps readers understand the purpose of the study and what the author hopes to accomplish.
- Reviewing the literature: The introduction should summarize the current state of knowledge on the topic, highlighting the gaps and limitations in existing research. This shows readers why the study is important and necessary.
- Outlining the scope and objectives of the study: The introduction should describe the scope and objectives of the study, including what aspects of the topic will be covered, what data will be collected, and what methods will be used.
- Previewing the main findings and conclusions : The introduction should provide a brief overview of the main findings and conclusions that the study will present. This helps readers anticipate what they can expect to learn from the paper.
When to Write Research Paper Introduction
The introduction of a research paper is typically written after the research has been conducted and the data has been analyzed. This is because the introduction should provide an overview of the research problem, the purpose of the study, and the research questions or hypotheses that will be investigated.
Once you have a clear understanding of the research problem and the questions that you want to explore, you can begin to write the introduction. It’s important to keep in mind that the introduction should be written in a way that engages the reader and provides a clear rationale for the study. It should also provide context for the research by reviewing relevant literature and explaining how the study fits into the larger field of research.
Advantages of Research Paper Introduction
The introduction of a research paper has several advantages, including:
- Establishing the purpose of the research: The introduction provides an overview of the research problem, question, or hypothesis, and the objectives of the study. This helps to clarify the purpose of the research and provide a roadmap for the reader to follow.
- Providing background information: The introduction also provides background information on the topic, including a review of relevant literature and research. This helps the reader understand the context of the study and how it fits into the broader field of research.
- Demonstrating the significance of the research: The introduction also explains why the research is important and relevant. This helps the reader understand the value of the study and why it is worth reading.
- Setting expectations: The introduction sets the tone for the rest of the paper and prepares the reader for what is to come. This helps the reader understand what to expect and how to approach the paper.
- Grabbing the reader’s attention: A well-written introduction can grab the reader’s attention and make them interested in reading further. This is important because it can help to keep the reader engaged and motivated to read the rest of the paper.
- Creating a strong first impression: The introduction is the first part of the research paper that the reader will see, and it can create a strong first impression. A well-written introduction can make the reader more likely to take the research seriously and view it as credible.
- Establishing the author’s credibility: The introduction can also establish the author’s credibility as a researcher. By providing a clear and thorough overview of the research problem and relevant literature, the author can demonstrate their expertise and knowledge in the field.
- Providing a structure for the paper: The introduction can also provide a structure for the rest of the paper. By outlining the main sections and sub-sections of the paper, the introduction can help the reader navigate the paper and find the information they are looking for.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Design – Types, Methods and Examples

Research Paper Title – Writing Guide and Example

Research Paper Conclusion – Writing Guide and...
- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- 4. The Introduction
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Choosing a Title
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
The introduction leads the reader from a general subject area to a particular topic of inquiry. It establishes the scope, context, and significance of the research being conducted by summarizing current understanding and background information about the topic, stating the purpose of the work in the form of the research problem supported by a hypothesis or a set of questions, explaining briefly the methodological approach used to examine the research problem, highlighting the potential outcomes your study can reveal, and outlining the remaining structure and organization of the paper.
Key Elements of the Research Proposal. Prepared under the direction of the Superintendent and by the 2010 Curriculum Design and Writing Team. Baltimore County Public Schools.
Importance of a Good Introduction
Think of the introduction as a mental road map that must answer for the reader these four questions:
- What was I studying?
- Why was this topic important to investigate?
- What did we know about this topic before I did this study?
- How will this study advance new knowledge or new ways of understanding?
According to Reyes, there are three overarching goals of a good introduction: 1) ensure that you summarize prior studies about the topic in a manner that lays a foundation for understanding the research problem; 2) explain how your study specifically addresses gaps in the literature, insufficient consideration of the topic, or other deficiency in the literature; and, 3) note the broader theoretical, empirical, and/or policy contributions and implications of your research.
A well-written introduction is important because, quite simply, you never get a second chance to make a good first impression. The opening paragraphs of your paper will provide your readers with their initial impressions about the logic of your argument, your writing style, the overall quality of your research, and, ultimately, the validity of your findings and conclusions. A vague, disorganized, or error-filled introduction will create a negative impression, whereas, a concise, engaging, and well-written introduction will lead your readers to think highly of your analytical skills, your writing style, and your research approach. All introductions should conclude with a brief paragraph that describes the organization of the rest of the paper.
Hirano, Eliana. “Research Article Introductions in English for Specific Purposes: A Comparison between Brazilian, Portuguese, and English.” English for Specific Purposes 28 (October 2009): 240-250; Samraj, B. “Introductions in Research Articles: Variations Across Disciplines.” English for Specific Purposes 21 (2002): 1–17; Introductions. The Writing Center. University of North Carolina; “Writing Introductions.” In Good Essay Writing: A Social Sciences Guide. Peter Redman. 4th edition. (London: Sage, 2011), pp. 63-70; Reyes, Victoria. Demystifying the Journal Article. Inside Higher Education.
Structure and Writing Style
I. Structure and Approach
The introduction is the broad beginning of the paper that answers three important questions for the reader:
- What is this?
- Why should I read it?
- What do you want me to think about / consider doing / react to?
Think of the structure of the introduction as an inverted triangle of information that lays a foundation for understanding the research problem. Organize the information so as to present the more general aspects of the topic early in the introduction, then narrow your analysis to more specific topical information that provides context, finally arriving at your research problem and the rationale for studying it [often written as a series of key questions to be addressed or framed as a hypothesis or set of assumptions to be tested] and, whenever possible, a description of the potential outcomes your study can reveal.
These are general phases associated with writing an introduction: 1. Establish an area to research by:
- Highlighting the importance of the topic, and/or
- Making general statements about the topic, and/or
- Presenting an overview on current research on the subject.
2. Identify a research niche by:
- Opposing an existing assumption, and/or
- Revealing a gap in existing research, and/or
- Formulating a research question or problem, and/or
- Continuing a disciplinary tradition.
3. Place your research within the research niche by:
- Stating the intent of your study,
- Outlining the key characteristics of your study,
- Describing important results, and
- Giving a brief overview of the structure of the paper.
NOTE: It is often useful to review the introduction late in the writing process. This is appropriate because outcomes are unknown until you've completed the study. After you complete writing the body of the paper, go back and review introductory descriptions of the structure of the paper, the method of data gathering, the reporting and analysis of results, and the conclusion. Reviewing and, if necessary, rewriting the introduction ensures that it correctly matches the overall structure of your final paper.
II. Delimitations of the Study
Delimitations refer to those characteristics that limit the scope and define the conceptual boundaries of your research . This is determined by the conscious exclusionary and inclusionary decisions you make about how to investigate the research problem. In other words, not only should you tell the reader what it is you are studying and why, but you must also acknowledge why you rejected alternative approaches that could have been used to examine the topic.
Obviously, the first limiting step was the choice of research problem itself. However, implicit are other, related problems that could have been chosen but were rejected. These should be noted in the conclusion of your introduction. For example, a delimitating statement could read, "Although many factors can be understood to impact the likelihood young people will vote, this study will focus on socioeconomic factors related to the need to work full-time while in school." The point is not to document every possible delimiting factor, but to highlight why previously researched issues related to the topic were not addressed.
Examples of delimitating choices would be:
- The key aims and objectives of your study,
- The research questions that you address,
- The variables of interest [i.e., the various factors and features of the phenomenon being studied],
- The method(s) of investigation,
- The time period your study covers, and
- Any relevant alternative theoretical frameworks that could have been adopted.
Review each of these decisions. Not only do you clearly establish what you intend to accomplish in your research, but you should also include a declaration of what the study does not intend to cover. In the latter case, your exclusionary decisions should be based upon criteria understood as, "not interesting"; "not directly relevant"; “too problematic because..."; "not feasible," and the like. Make this reasoning explicit!
NOTE: Delimitations refer to the initial choices made about the broader, overall design of your study and should not be confused with documenting the limitations of your study discovered after the research has been completed.
ANOTHER NOTE: Do not view delimitating statements as admitting to an inherent failing or shortcoming in your research. They are an accepted element of academic writing intended to keep the reader focused on the research problem by explicitly defining the conceptual boundaries and scope of your study. It addresses any critical questions in the reader's mind of, "Why the hell didn't the author examine this?"
III. The Narrative Flow
Issues to keep in mind that will help the narrative flow in your introduction :
- Your introduction should clearly identify the subject area of interest . A simple strategy to follow is to use key words from your title in the first few sentences of the introduction. This will help focus the introduction on the topic at the appropriate level and ensures that you get to the subject matter quickly without losing focus, or discussing information that is too general.
- Establish context by providing a brief and balanced review of the pertinent published literature that is available on the subject. The key is to summarize for the reader what is known about the specific research problem before you did your analysis. This part of your introduction should not represent a comprehensive literature review--that comes next. It consists of a general review of the important, foundational research literature [with citations] that establishes a foundation for understanding key elements of the research problem. See the drop-down menu under this tab for " Background Information " regarding types of contexts.
- Clearly state the hypothesis that you investigated . When you are first learning to write in this format it is okay, and actually preferable, to use a past statement like, "The purpose of this study was to...." or "We investigated three possible mechanisms to explain the...."
- Why did you choose this kind of research study or design? Provide a clear statement of the rationale for your approach to the problem studied. This will usually follow your statement of purpose in the last paragraph of the introduction.
IV. Engaging the Reader
A research problem in the social sciences can come across as dry and uninteresting to anyone unfamiliar with the topic . Therefore, one of the goals of your introduction is to make readers want to read your paper. Here are several strategies you can use to grab the reader's attention:
- Open with a compelling story . Almost all research problems in the social sciences, no matter how obscure or esoteric , are really about the lives of people. Telling a story that humanizes an issue can help illuminate the significance of the problem and help the reader empathize with those affected by the condition being studied.
- Include a strong quotation or a vivid, perhaps unexpected, anecdote . During your review of the literature, make note of any quotes or anecdotes that grab your attention because they can used in your introduction to highlight the research problem in a captivating way.
- Pose a provocative or thought-provoking question . Your research problem should be framed by a set of questions to be addressed or hypotheses to be tested. However, a provocative question can be presented in the beginning of your introduction that challenges an existing assumption or compels the reader to consider an alternative viewpoint that helps establish the significance of your study.
- Describe a puzzling scenario or incongruity . This involves highlighting an interesting quandary concerning the research problem or describing contradictory findings from prior studies about a topic. Posing what is essentially an unresolved intellectual riddle about the problem can engage the reader's interest in the study.
- Cite a stirring example or case study that illustrates why the research problem is important . Draw upon the findings of others to demonstrate the significance of the problem and to describe how your study builds upon or offers alternatives ways of investigating this prior research.
NOTE: It is important that you choose only one of the suggested strategies for engaging your readers. This avoids giving an impression that your paper is more flash than substance and does not distract from the substance of your study.
Freedman, Leora and Jerry Plotnick. Introductions and Conclusions. University College Writing Centre. University of Toronto; Introduction. The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Introductions. The Writing Center. University of North Carolina; Introductions. The Writer’s Handbook. Writing Center. University of Wisconsin, Madison; Introductions, Body Paragraphs, and Conclusions for an Argument Paper. The Writing Lab and The OWL. Purdue University; “Writing Introductions.” In Good Essay Writing: A Social Sciences Guide . Peter Redman. 4th edition. (London: Sage, 2011), pp. 63-70; Resources for Writers: Introduction Strategies. Program in Writing and Humanistic Studies. Massachusetts Institute of Technology; Sharpling, Gerald. Writing an Introduction. Centre for Applied Linguistics, University of Warwick; Samraj, B. “Introductions in Research Articles: Variations Across Disciplines.” English for Specific Purposes 21 (2002): 1–17; Swales, John and Christine B. Feak. Academic Writing for Graduate Students: Essential Skills and Tasks . 2nd edition. Ann Arbor, MI: University of Michigan Press, 2004 ; Writing Your Introduction. Department of English Writing Guide. George Mason University.
Writing Tip
Avoid the "Dictionary" Introduction
Giving the dictionary definition of words related to the research problem may appear appropriate because it is important to define specific terminology that readers may be unfamiliar with. However, anyone can look a word up in the dictionary and a general dictionary is not a particularly authoritative source because it doesn't take into account the context of your topic and doesn't offer particularly detailed information. Also, placed in the context of a particular discipline, a term or concept may have a different meaning than what is found in a general dictionary. If you feel that you must seek out an authoritative definition, use a subject specific dictionary or encyclopedia [e.g., if you are a sociology student, search for dictionaries of sociology]. A good database for obtaining definitive definitions of concepts or terms is Credo Reference .
Saba, Robert. The College Research Paper. Florida International University; Introductions. The Writing Center. University of North Carolina.
Another Writing Tip
When Do I Begin?
A common question asked at the start of any paper is, "Where should I begin?" An equally important question to ask yourself is, "When do I begin?" Research problems in the social sciences rarely rest in isolation from history. Therefore, it is important to lay a foundation for understanding the historical context underpinning the research problem. However, this information should be brief and succinct and begin at a point in time that illustrates the study's overall importance. For example, a study that investigates coffee cultivation and export in West Africa as a key stimulus for local economic growth needs to describe the beginning of exporting coffee in the region and establishing why economic growth is important. You do not need to give a long historical explanation about coffee exports in Africa. If a research problem requires a substantial exploration of the historical context, do this in the literature review section. In your introduction, make note of this as part of the "roadmap" [see below] that you use to describe the organization of your paper.
Introductions. The Writing Center. University of North Carolina; “Writing Introductions.” In Good Essay Writing: A Social Sciences Guide . Peter Redman. 4th edition. (London: Sage, 2011), pp. 63-70.
Yet Another Writing Tip
Always End with a Roadmap
The final paragraph or sentences of your introduction should forecast your main arguments and conclusions and provide a brief description of the rest of the paper [the "roadmap"] that let's the reader know where you are going and what to expect. A roadmap is important because it helps the reader place the research problem within the context of their own perspectives about the topic. In addition, concluding your introduction with an explicit roadmap tells the reader that you have a clear understanding of the structural purpose of your paper. In this way, the roadmap acts as a type of promise to yourself and to your readers that you will follow a consistent and coherent approach to addressing the topic of inquiry. Refer to it often to help keep your writing focused and organized.
Cassuto, Leonard. “On the Dissertation: How to Write the Introduction.” The Chronicle of Higher Education , May 28, 2018; Radich, Michael. A Student's Guide to Writing in East Asian Studies . (Cambridge, MA: Harvard University Writing n. d.), pp. 35-37.
- << Previous: Executive Summary
- Next: The C.A.R.S. Model >>
- Last Updated: May 25, 2024 4:09 PM
- URL: https://libguides.usc.edu/writingguide
How to Write the Introduction to a Scientific Paper?
- Open Access
- First Online: 24 October 2021
Cite this chapter
You have full access to this open access chapter

- Samiran Nundy 4 ,
- Atul Kakar 5 &
- Zulfiqar A. Bhutta 6
142 Altmetric
An Introduction to a scientific paper familiarizes the reader with the background of the issue at hand. It must reflect why the issue is topical and its current importance in the vast sea of research being done globally. It lays the foundation of biomedical writing and is the first portion of an article according to the IMRAD pattern ( I ntroduction, M ethodology, R esults, a nd D iscussion) [1].
I once had a professor tell a class that he sifted through our pile of essays, glancing at the titles and introductions, looking for something that grabbed his attention. Everything else went to the bottom of the pile to be read last, when he was tired and probably grumpy from all the marking. Don’t get put at the bottom of the pile, he said. Anonymous
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

The Introduction Section

Abstract and Keywords

Writing and publishing a scientific paper
1 what is the importance of an introduction.
An Introduction to a scientific paper familiarizes the reader with the background of the issue at hand. It must reflect why the issue is topical and its current importance in the vast sea of research being done globally. It lays the foundation of biomedical writing and is the first portion of an article according to the IMRAD pattern ( I ntroduction, M ethodology, R esults, a nd D iscussion) [ 1 ].
It provides the flavour of the article and many authors have used phrases to describe it for example—'like a gate of the city’ [ 2 ], ‘the beginning is half of the whole’ [ 3 ], ‘an introduction is not just wrestling with words to fit the facts, but it also strongly modulated by perception of the anticipated reactions of peer colleagues’, [ 4 ] and ‘an introduction is like the trailer to a movie’. A good introduction helps captivate the reader early.

2 What Are the Principles of Writing a Good Introduction?
A good introduction will ‘sell’ an article to a journal editor, reviewer, and finally to a reader [ 3 ]. It should contain the following information [ 5 , 6 ]:
The known—The background scientific data
The unknown—Gaps in the current knowledge
Research hypothesis or question
Methodologies used for the study
The known consist of citations from a review of the literature whereas the unknown is the new work to be undertaken. This part should address how your work is the required missing piece of the puzzle.
3 What Are the Models of Writing an Introduction?
The Problem-solving model
First described by Swales et al. in 1979, in this model the writer should identify the ‘problem’ in the research, address the ‘solution’ and also write about ‘the criteria for evaluating the problem’ [ 7 , 8 ].
The CARS model that stands for C reating A R esearch S pace [ 9 , 10 ].
The two important components of this model are:
Establishing a territory (situation)
Establishing a niche (problem)
Occupying a niche (the solution)
In this popular model, one can add a fourth point, i.e., a conclusion [ 10 ].
4 What Is Establishing a Territory?
This includes: [ 9 ]
Stating the general topic and providing some background about it.
Providing a brief and relevant review of the literature related to the topic.
Adding a paragraph on the scope of the topic including the need for your study.
5 What Is Establishing a Niche?
Establishing a niche includes:
Stating the importance of the problem.
Outlining the current situation regarding the problem citing both global and national data.
Evaluating the current situation (advantages/ disadvantages).
Identifying the gaps.
Emphasizing the importance of the proposed research and how the gaps will be addressed.
Stating the research problem/ questions.
Stating the hypotheses briefly.
Figure 17.1 depicts how the introduction needs to be written. A scientific paper should have an introduction in the form of an inverted pyramid. The writer should start with the general information about the topic and subsequently narrow it down to the specific topic-related introduction.

Flow of ideas from the general to the specific
6 What Does Occupying a Niche Mean?
This is the third portion of the introduction and defines the rationale of the research and states the research question. If this is missing the reviewers will not understand the logic for publication and is a common reason for rejection [ 11 , 12 ]. An example of this is given below:
Till date, no study has been done to see the effectiveness of a mesh alone or the effectiveness of double suturing along with a mesh in the closure of an umbilical hernia regarding the incidence of failure. So, the present study is aimed at comparing the effectiveness of a mesh alone versus the double suturing technique along with a mesh.
7 How Long Should the Introduction Be?
For a project protocol, the introduction should be about 1–2 pages long and for a thesis it should be 3–5 pages in a double-spaced typed setting. For a scientific paper it should be less than 10–15% of the total length of the manuscript [ 13 , 14 ].
8 How Many References Should an Introduction Have?
All sections in a scientific manuscript except the conclusion should contain references. It has been suggested that an introduction should have four or five or at the most one-third of the references in the whole paper [ 15 ].
9 What Are the Important Points Which Should be not Missed in an Introduction?
An introduction paves the way forward for the subsequent sections of the article. Frequently well-planned studies are rejected by journals during review because of the simple reason that the authors failed to clarify the data in this section to justify the study [ 16 , 17 ]. Thus, the existing gap in knowledge should be clearly brought out in this section (Fig. 17.2 ).

How should the abstract, introduction, and discussion look
The following points are important to consider:
The introduction should be written in simple sentences and in the present tense.
Many of the terms will be introduced in this section for the first time and these will require abbreviations to be used later.
The references in this section should be to papers published in quality journals (e.g., having a high impact factor).
The aims, problems, and hypotheses should be clearly mentioned.
Start with a generalization on the topic and go on to specific information relevant to your research.
10 Example of an Introduction

11 Conclusions
An Introduction is a brief account of what the study is about. It should be short, crisp, and complete.
It has to move from a general to a specific research topic and must include the need for the present study.
The Introduction should include data from a literature search, i.e., what is already known about this subject and progress to what we hope to add to this knowledge.
Moore A. What’s in a discussion section? Exploiting 2-dimensionality in the online world. Bioassays. 2016;38(12):1185.
Article Google Scholar
Annesley TM. The discussion section: your closing argument. Clin Chem. 2010;56(11):1671–4.
Article CAS Google Scholar
Bavdekar SB. Writing the discussion section: describing the significance of the study findings. J Assoc Physicians India. 2015;63(11):40–2.
PubMed Google Scholar
Foote M. The proof of the pudding: how to report results and write a good discussion. Chest. 2009;135(3):866–8.
Kearney MH. The discussion section tells us where we are. Res Nurs Health. 2017;40(4):289–91.
Ghasemi A, Bahadoran Z, Mirmiran P, Hosseinpanah F, Shiva N, Zadeh-Vakili A. The principles of biomedical scientific writing: discussion. Int J Endocrinol Metab. 2019;17(3):e95415.
Swales JM, Feak CB. Academic writing for graduate students: essential tasks and skills. Ann Arbor, MI: University of Michigan Press; 2004.
Google Scholar
Colombo M, Bucher L, Sprenger J. Determinants of judgments of explanatory power: credibility, generality, and statistical relevance. Front Psychol. 2017;8:1430.
Mozayan MR, Allami H, Fazilatfar AM. Metadiscourse features in medical research articles: subdisciplinary and paradigmatic influences in English and Persian. Res Appl Ling. 2018;9(1):83–104.
Hyland K. Metadiscourse: mapping interactions in academic writing. Nordic J English Stud. 2010;9(2):125.
Hill AB. The environment and disease: association or causation? Proc Royal Soc Med. 2016;58(5):295–300.
Alpert JS. Practicing medicine in Plato’s cave. Am J Med. 2006;119(6):455–6.
Walsh K. Discussing discursive discussions. Med Educ. 2016;50(12):1269–70.
Polit DF, Beck CT. Generalization in quantitative and qualitative research: myths and strategies. Int J Nurs Stud. 2010;47(11):1451–8.
Jawaid SA, Jawaid M. How to write introduction and discussion. Saudi J Anaesth. 2019;13(Suppl 1):S18–9.
Jawaid SA, Baig M. How to write an original article. In: Jawaid SA, Jawaid M, editors. Scientific writing: a guide to the art of medical writing and scientific publishing. Karachi: Published by Med-Print Services; 2018. p. 135–50.
Hall GM, editor. How to write a paper. London: BMJ Books, BMJ Publishing Group; 2003. Structure of a scientific paper. p. 1–5.
Download references
Author information
Authors and affiliations.
Department of Surgical Gastroenterology and Liver Transplantation, Sir Ganga Ram Hospital, New Delhi, India
Samiran Nundy
Department of Internal Medicine, Sir Ganga Ram Hospital, New Delhi, India
Institute for Global Health and Development, The Aga Khan University, South Central Asia, East Africa and United Kingdom, Karachi, Pakistan
Zulfiqar A. Bhutta
You can also search for this author in PubMed Google Scholar
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License ( http://creativecommons.org/licenses/by/4.0/ ), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Reprints and permissions
Copyright information
© 2022 The Author(s)
About this chapter
Nundy, S., Kakar, A., Bhutta, Z.A. (2022). How to Write the Introduction to a Scientific Paper?. In: How to Practice Academic Medicine and Publish from Developing Countries?. Springer, Singapore. https://doi.org/10.1007/978-981-16-5248-6_17
Download citation
DOI : https://doi.org/10.1007/978-981-16-5248-6_17
Published : 24 October 2021
Publisher Name : Springer, Singapore
Print ISBN : 978-981-16-5247-9
Online ISBN : 978-981-16-5248-6
eBook Packages : Medicine Medicine (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- PRO Courses Guides New Tech Help Pro Expert Videos About wikiHow Pro Upgrade Sign In
- EDIT Edit this Article
- EXPLORE Tech Help Pro About Us Random Article Quizzes Request a New Article Community Dashboard This Or That Game Popular Categories Arts and Entertainment Artwork Books Movies Computers and Electronics Computers Phone Skills Technology Hacks Health Men's Health Mental Health Women's Health Relationships Dating Love Relationship Issues Hobbies and Crafts Crafts Drawing Games Education & Communication Communication Skills Personal Development Studying Personal Care and Style Fashion Hair Care Personal Hygiene Youth Personal Care School Stuff Dating All Categories Arts and Entertainment Finance and Business Home and Garden Relationship Quizzes Cars & Other Vehicles Food and Entertaining Personal Care and Style Sports and Fitness Computers and Electronics Health Pets and Animals Travel Education & Communication Hobbies and Crafts Philosophy and Religion Work World Family Life Holidays and Traditions Relationships Youth
- Browse Articles
- Learn Something New
- Quizzes Hot
- This Or That Game
- Train Your Brain
- Explore More
- Support wikiHow
- About wikiHow
- Log in / Sign up
- Education and Communications
- College University and Postgraduate
- Academic Writing
- Research Papers
How to Write a Research Introduction
Last Updated: December 6, 2023 Fact Checked
This article was co-authored by Megan Morgan, PhD . Megan Morgan is a Graduate Program Academic Advisor in the School of Public & International Affairs at the University of Georgia. She earned her PhD in English from the University of Georgia in 2015. There are 7 references cited in this article, which can be found at the bottom of the page. This article has been fact-checked, ensuring the accuracy of any cited facts and confirming the authority of its sources. This article has been viewed 2,653,679 times.
The introduction to a research paper can be the most challenging part of the paper to write. The length of the introduction will vary depending on the type of research paper you are writing. An introduction should announce your topic, provide context and a rationale for your work, before stating your research questions and hypothesis. Well-written introductions set the tone for the paper, catch the reader's interest, and communicate the hypothesis or thesis statement.
Introducing the Topic of the Paper

- In scientific papers this is sometimes known as an "inverted triangle", where you start with the broadest material at the start, before zooming in on the specifics. [2] X Research source
- The sentence "Throughout the 20th century, our views of life on other planets have drastically changed" introduces a topic, but does so in broad terms.
- It provides the reader with an indication of the content of the essay and encourages them to read on.

- For example, if you were writing a paper about the behaviour of mice when exposed to a particular substance, you would include the word "mice", and the scientific name of the relevant compound in the first sentences.
- If you were writing a history paper about the impact of the First World War on gender relations in Britain, you should mention those key words in your first few lines.

- This is especially important if you are attempting to develop a new conceptualization that uses language and terminology your readers may be unfamiliar with.

- If you use an anecdote ensure that is short and highly relevant for your research. It has to function in the same way as an alternative opening, namely to announce the topic of your research paper to your reader.
- For example, if you were writing a sociology paper about re-offending rates among young offenders, you could include a brief story of one person whose story reflects and introduces your topic.
- This kind of approach is generally not appropriate for the introduction to a natural or physical sciences research paper where the writing conventions are different.
Establishing the Context for Your Paper

- It is important to be concise in the introduction, so provide an overview on recent developments in the primary research rather than a lengthy discussion.
- You can follow the "inverted triangle" principle to focus in from the broader themes to those to which you are making a direct contribution with your paper.
- A strong literature review presents important background information to your own research and indicates the importance of the field.

- By making clear reference to existing work you can demonstrate explicitly the specific contribution you are making to move the field forward.
- You can identify a gap in the existing scholarship and explain how you are addressing it and moving understanding forward.

- For example, if you are writing a scientific paper you could stress the merits of the experimental approach or models you have used.
- Stress what is novel in your research and the significance of your new approach, but don't give too much detail in the introduction.
- A stated rationale could be something like: "the study evaluates the previously unknown anti-inflammatory effects of a topical compound in order to evaluate its potential clinical uses".
Specifying Your Research Questions and Hypothesis

- The research question or questions generally come towards the end of the introduction, and should be concise and closely focused.
- The research question might recall some of the key words established in the first few sentences and the title of your paper.
- An example of a research question could be "what were the consequences of the North American Free Trade Agreement on the Mexican export economy?"
- This could be honed further to be specific by referring to a particular element of the Free Trade Agreement and the impact on a particular industry in Mexico, such as clothing manufacture.
- A good research question should shape a problem into a testable hypothesis.

- If possible try to avoid using the word "hypothesis" and rather make this implicit in your writing. This can make your writing appear less formulaic.
- In a scientific paper, giving a clear one-sentence overview of your results and their relation to your hypothesis makes the information clear and accessible. [10] X Trustworthy Source PubMed Central Journal archive from the U.S. National Institutes of Health Go to source
- An example of a hypothesis could be "mice deprived of food for the duration of the study were expected to become more lethargic than those fed normally".

- This is not always necessary and you should pay attention to the writing conventions in your discipline.
- In a natural sciences paper, for example, there is a fairly rigid structure which you will be following.
- A humanities or social science paper will most likely present more opportunities to deviate in how you structure your paper.
Research Introduction Help

Community Q&A
- Use your research papers' outline to help you decide what information to include when writing an introduction. Thanks Helpful 0 Not Helpful 1
- Consider drafting your introduction after you have already completed the rest of your research paper. Writing introductions last can help ensure that you don't leave out any major points. Thanks Helpful 0 Not Helpful 0

- Avoid emotional or sensational introductions; these can create distrust in the reader. Thanks Helpful 50 Not Helpful 12
- Generally avoid using personal pronouns in your introduction, such as "I," "me," "we," "us," "my," "mine," or "our." Thanks Helpful 31 Not Helpful 7
- Don't overwhelm the reader with an over-abundance of information. Keep the introduction as concise as possible by saving specific details for the body of your paper. Thanks Helpful 24 Not Helpful 14
You Might Also Like

- ↑ https://library.sacredheart.edu/c.php?g=29803&p=185916
- ↑ https://www.aresearchguide.com/inverted-pyramid-structure-in-writing.html
- ↑ https://libguides.usc.edu/writingguide/introduction
- ↑ https://writing.wisc.edu/Handbook/PlanResearchPaper.html
- ↑ https://dept.writing.wisc.edu/wac/writing-an-introduction-for-a-scientific-paper/
- ↑ https://writing.wisc.edu/handbook/assignments/planresearchpaper/
- ↑ http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3178846/
About This Article

To introduce your research paper, use the first 1-2 sentences to describe your general topic, such as “women in World War I.” Include and define keywords, such as “gender relations,” to show your reader where you’re going. Mention previous research into the topic with a phrase like, “Others have studied…”, then transition into what your contribution will be and why it’s necessary. Finally, state the questions that your paper will address and propose your “answer” to them as your thesis statement. For more information from our English Ph.D. co-author about how to craft a strong hypothesis and thesis, keep reading! Did this summary help you? Yes No
- Send fan mail to authors
Reader Success Stories
Abdulrahman Omar
Oct 5, 2018
Did this article help you?

May 9, 2021
Lavanya Gopakumar
Oct 1, 2016
Dengkai Zhang
May 14, 2018
Leslie Mae Cansana
Sep 22, 2016

Featured Articles

Trending Articles

Watch Articles

- Terms of Use
- Privacy Policy
- Do Not Sell or Share My Info
- Not Selling Info
Get all the best how-tos!
Sign up for wikiHow's weekly email newsletter
How to Write an Introduction for a Research Paper

How to write an introduction for a research paper? Eventually (and with practice) all writers will develop their own strategy for writing the perfect introduction for a research paper. Once you are comfortable with writing, you will probably find your own, but coming up with a good strategy can be tough for beginning writers.
The Purpose of an Introduction
Your opening paragraphs, phrases for introducing thesis statements, research paper introduction examples, using the introduction to map out your research paper.

Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% off with 24start discount code.
- First write your thesis.Your thesis should state the main idea in specific terms.
- After you have a working thesis, tackle the body of your paper before you write the rest of the introduction. Each paragraph in the body should explore one specific topic that proves, or summarizes your thesis. Writing is a thinking process. Once you have worked your way through that process by writing the body of the paper, you will have an intimate understanding of how you are supporting your thesis. After you have written the body paragraphs, go back and rewrite your thesis to make it more specific and to connect it to the topics you addressed in the body paragraph.
- Revise your introduction several times, saving each revision. Be sure your introduction previews the topics you are presenting in your paper. One way of doing this is to use keywords from the topic sentences in each paragraph to introduce, or preview, the topics in your introduction.This “preview” will give your reader a context for understanding how you will make your case.
- Experiment by taking different approaches to your thesis with every revision you make. Play with the language in the introduction. Strike a new tone. Go back and compare versions. Then pick the one that works most effectively with the body of your research paper.
- Do not try to pack everything you want to say into your introduction. Just as your introduction should not be too short, it should also not be too long. Your introduction should be about the same length as any other paragraph in your research paper. Let the content—what you have to say—dictate the length.
The first page of your research paper should draw the reader into the text. It is the paper’s most important page and, alas, often the worst written. There are two culprits here and effective ways to cope with both of them.
First, the writer is usually straining too hard to say something terribly BIG and IMPORTANT about the thesis topic. The goal is worthy, but the aim is unrealistically high. The result is often a muddle of vague platitudes rather than a crisp, compelling introduction to the thesis. Want a familiar example? Listen to most graduation speakers. Their goal couldn’t be loftier: to say what education means and to tell an entire football stadium how to live the rest of their lives. The results are usually an avalanche of clichés and sodden prose.
The second culprit is bad timing. The opening and concluding paragraphs are usually written late in the game, after the rest of the thesis is finished and polished. There’s nothing wrong with writing these sections last. It’s usually the right approach since you need to know exactly what you are saying in the substantive middle sections of the thesis before you can introduce them effectively or draw together your findings. But having waited to write the opening and closing sections, you need to review and edit them several times to catch up. Otherwise, you’ll putting the most jagged prose in the most tender spots. Edit and polish your opening paragraphs with extra care. They should draw readers into the paper.
After you’ve done some extra polishing, I suggest a simple test for the introductory section. As an experiment, chop off the first few paragraphs. Let the paper begin on, say, paragraph 2 or even page 2. If you don’t lose much, or actually gain in clarity and pace, then you’ve got a problem.
There are two solutions. One is to start at this new spot, further into the text. After all, that’s where you finally gain traction on your subject. That works best in some cases, and we occasionally suggest it. The alternative, of course, is to write a new opening that doesn’t flop around, saying nothing.
What makes a good opening? Actually, they come in several flavors. One is an intriguing story about your topic. Another is a brief, compelling quote. When you run across them during your reading, set them aside for later use. Don’t be deterred from using them because they “don’t seem academic enough.” They’re fine as long as the rest of the paper doesn’t sound like you did your research in People magazine. The third, and most common, way to begin is by stating your main questions, followed by a brief comment about why they matter.
Whichever opening you choose, it should engage your readers and coax them to continue. Having done that, you should give them a general overview of the project—the main issues you will cover, the material you will use, and your thesis statement (that is, your basic approach to the topic). Finally, at the end of the introductory section, give your readers a brief road map, showing how the paper will unfold. How you do that depends on your topic but here are some general suggestions for phrase choice that may help:
- This analysis will provide …
- This paper analyzes the relationship between …
- This paper presents an analysis of …
- This paper will argue that …
- This topic supports the argument that…
- Research supports the opinion that …
- This paper supports the opinion that …
- An interpretation of the facts indicates …
- The results of this experiment show …
- The results of this research show …
Comparisons/Contrasts
- A comparison will show that …
- By contrasting the results,we see that …
- This paper examines the advantages and disadvantages of …
Definitions/Classifications
- This paper will provide a guide for categorizing the following:…
- This paper provides a definition of …
- This paper explores the meaning of …
- This paper will discuss the implications of …
- A discussion of this topic reveals …
- The following discussion will focus on …
Description
- This report describes…
- This report will illustrate…
- This paper provides an illustration of …
Process/Experimentation
- This paper will identify the reasons behind…
- The results of the experiment show …
- The process revealed that …
- This paper theorizes…
- This paper presents the theory that …
- In theory, this indicates that …
Quotes, anecdotes, questions, examples, and broad statements—all of them can used successfully to write an introduction for a research paper. It’s instructive to see them in action, in the hands of skilled academic writers.
Let’s begin with David M. Kennedy’s superb history, Freedom from Fear: The American People in Depression and War, 1929–1945 . Kennedy begins each chapter with a quote, followed by his text. The quote above chapter 1 shows President Hoover speaking in 1928 about America’s golden future. The text below it begins with the stock market collapse of 1929. It is a riveting account of just how wrong Hoover was. The text about the Depression is stronger because it contrasts so starkly with the optimistic quotation.
“We in America today are nearer the final triumph over poverty than ever before in the history of any land.”—Herbert Hoover, August 11, 1928 Like an earthquake, the stock market crash of October 1929 cracked startlingly across the United States, the herald of a crisis that was to shake the American way of life to its foundations. The events of the ensuing decade opened a fissure across the landscape of American history no less gaping than that opened by the volley on Lexington Common in April 1775 or by the bombardment of Sumter on another April four score and six years later. The ratcheting ticker machines in the autumn of 1929 did not merely record avalanching stock prices. In time they came also to symbolize the end of an era. (David M. Kennedy, Freedom from Fear: The American People in Depression and War, 1929–1945 . New York: Oxford University Press, 1999, p. 10)
Kennedy has exciting, wrenching material to work with. John Mueller faces the exact opposite problem. In Retreat from Doomsday: The Obsolescence of Major War , he is trying to explain why Great Powers have suddenly stopped fighting each other. For centuries they made war on each other with devastating regularity, killing millions in the process. But now, Mueller thinks, they have not just paused; they have stopped permanently. He is literally trying to explain why “nothing is happening now.” That may be an exciting topic intellectually, it may have great practical significance, but “nothing happened” is not a very promising subject for an exciting opening paragraph. Mueller manages to make it exciting and, at the same time, shows why it matters so much. Here’s his opening, aptly entitled “History’s Greatest Nonevent”:
On May 15, 1984, the major countries of the developed world had managed to remain at peace with each other for the longest continuous stretch of time since the days of the Roman Empire. If a significant battle in a war had been fought on that day, the press would have bristled with it. As usual, however, a landmark crossing in the history of peace caused no stir: the most prominent story in the New York Times that day concerned the saga of a manicurist, a machinist, and a cleaning woman who had just won a big Lotto contest. This book seeks to develop an explanation for what is probably the greatest nonevent in human history. (John Mueller, Retreat from Doomsday: The Obsolescence of Major War . New York: Basic Books, 1989, p. 3)
In the space of a few sentences, Mueller sets up his puzzle and reveals its profound human significance. At the same time, he shows just how easy it is to miss this milestone in the buzz of daily events. Notice how concretely he does that. He doesn’t just say that the New York Times ignored this record setting peace. He offers telling details about what they covered instead: “a manicurist, a machinist, and a cleaning woman who had just won a big Lotto contest.” Likewise, David Kennedy immediately entangles us in concrete events: the stunning stock market crash of 1929. These are powerful openings that capture readers’ interests, establish puzzles, and launch narratives.
Sociologist James Coleman begins in a completely different way, by posing the basic questions he will study. His ambitious book, Foundations of Social Theory , develops a comprehensive theory of social life, so it is entirely appropriate for him to begin with some major questions. But he could just as easily have begun with a compelling story or anecdote. He includes many of them elsewhere in his book. His choice for the opening, though, is to state his major themes plainly and frame them as a paradox. Sociologists, he says, are interested in aggregate behavior—how people act in groups, organizations, or large numbers—yet they mostly examine individuals:
A central problem in social science is that of accounting for the function of some kind of social system. Yet in most social research, observations are not made on the system as a whole, but on some part of it. In fact, the natural unit of observation is the individual person… This has led to a widening gap between theory and research… (James S. Coleman, Foundations of Social Theory . Cambridge, MA: Harvard University Press, 1990, pp. 1–2)
After expanding on this point, Coleman explains that he will not try to remedy the problem by looking solely at groups or aggregate-level data. That’s a false solution, he says, because aggregates don’t act; individuals do. So the real problem is to show the links between individual actions and aggregate outcomes, between the micro and the macro.
The major problem for explanations of system behavior based on actions and orientations at a level below that of the system [in this case, on individual-level actions] is that of moving from the lower level to the system level. This has been called the micro-to-macro problem, and it is pervasive throughout the social sciences. (Coleman, Foundations of Social Theory , p. 6)
Explaining how to deal with this “micro-to-macro problem” is the central issue of Coleman’s book, and he announces it at the beginning.
Coleman’s theory-driven opening stands at the opposite end of the spectrum from engaging stories or anecdotes, which are designed to lure the reader into the narrative and ease the path to a more analytic treatment later in the text. Take, for example, the opening sentences of Robert L. Herbert’s sweeping study Impressionism: Art, Leisure, and Parisian Society : “When Henry Tuckerman came to Paris in 1867, one of the thousands of Americans attracted there by the huge international exposition, he was bowled over by the extraordinary changes since his previous visit twenty years before.” (Robert L. Herbert, Impressionism: Art, Leisure, and Parisian Society . New Haven, CT: Yale University Press, 1988, p. 1.) Herbert fills in the evocative details to set the stage for his analysis of the emerging Impressionist art movement and its connection to Parisian society and leisure in this period.
David Bromwich writes about Wordsworth, a poet so familiar to students of English literature that it is hard to see him afresh, before his great achievements, when he was just a young outsider starting to write. To draw us into Wordsworth’s early work, Bromwich wants us to set aside our entrenched images of the famous mature poet and see him as he was in the 1790s, as a beginning writer on the margins of society. He accomplishes this ambitious task in the opening sentences of Disowned by Memory: Wordsworth’s Poetry of the 1790s :
Wordsworth turned to poetry after the revolution to remind himself that he was still a human being. It was a curious solution, to a difficulty many would not have felt. The whole interest of his predicament is that he did feel it. Yet Wordsworth is now so established an eminence—his name so firmly fixed with readers as a moralist of self-trust emanating from complete self-security—that it may seem perverse to imagine him as a criminal seeking expiation. Still, that is a picture we get from The Borderers and, at a longer distance, from “Tintern Abbey.” (David Bromwich, Disowned by Memory: Wordsworth’s Poetry of the 1790s . Chicago: University of Chicago Press, 1998, p. 1)
That’s a wonderful opening! Look at how much Bromwich accomplishes in just a few words. He not only prepares the way for analyzing Wordsworth’s early poetry; he juxtaposes the anguished young man who wrote it to the self-confident, distinguished figure he became—the eminent man we can’t help remembering as we read his early poetry.
Let us highlight a couple of other points in this passage because they illustrate some intelligent writing choices. First, look at the odd comma in this sentence: “It was a curious solution, to a difficulty many would not have felt.” Any standard grammar book would say that comma is wrong and should be omitted. Why did Bromwich insert it? Because he’s a fine writer, thinking of his sentence rhythm and the point he wants to make. The comma does exactly what it should. It makes us pause, breaking the sentence into two parts, each with an interesting point. One is that Wordsworth felt a difficulty others would not have; the other is that he solved it in a distinctive way. It would be easy for readers to glide over this double message, so Bromwich has inserted a speed bump to slow us down. Most of the time, you should follow grammatical rules, like those about commas, but you should bend them when it serves a good purpose. That’s what the writer does here.
The second small point is the phrase “after the revolution” in the first sentence: “Wordsworth turned to poetry after the revolution to remind himself that he was still a human being.” Why doesn’t Bromwich say “after the French Revolution”? Because he has judged his book’s audience. He is writing for specialists who already know which revolution is reverberating through English life in the 1790s. It is the French Revolution, not the earlier loss of the American colonies. If Bromwich were writing for a much broader audience—say, the New York Times Book Review—he would probably insert the extra word to avoid confusion.
The message “Know your audience” applies to all writers. Don’t talk down to them by assuming they can’t get dressed in the morning. Don’t strut around showing off your book learnin’ by tossing in arcane facts and esoteric language for its own sake. Neither will win over readers.
Bromwich, Herbert, and Coleman open their works in different ways, but their choices work well for their different texts. Your task is to decide what kind of opening will work best for yours. Don’t let that happen by default, by grabbing the first idea you happen upon. Consider a couple of different ways of opening your thesis and then choose the one you prefer. Give yourself some options, think them over, then make an informed choice.
Whether you begin with a story, puzzle, or broad statement, the next part of the introduction should pose your main questions and establish your argument. This is your thesis statement—your viewpoint along with the supporting reasons and evidence. It should be articulated plainly so readers understand full well what your paper is about and what it will argue.
After that, give your readers a road map of what’s to come. That’s normally done at the end of the introductory section (or, in a book, at the end of the introductory chapter). Here’s John J. Mearsheimer presenting such a road map in The Tragedy of Great Power Politics . He not only tells us the order of upcoming chapters, he explains why he’s chosen that order and which chapters are most important:
The Plan of the Book The rest of the chapters in this book are concerned mainly with answering the six big questions about power which I identified earlier. Chapter 2, which is probably the most important chapter in the book, lays out my theory of why states compete for power and why they pursue hegemony. In Chapters 3 and 4, I define power and explain how to measure it. I do this in order to lay the groundwork for testing my theory… (John J. Mearsheimer, The Tragedy of Great Power Politics . New York: W. W. Norton, 2001, p. 27)
As this excerpt makes clear, Mearsheimer has already laid out his “six big questions” in the introduction. Now he’s showing us the path ahead, the path to answering those questions.
At the end of the introduction, give your readers a road map of what’s to come. Tell them what the upcoming sections will be and why they are arranged in this particular order.
After having written your introduction it’s time to move to the biggest part: body of a research paper.
Back to How To Write A Research Paper .
ORDER HIGH QUALITY CUSTOM PAPER

- If you are writing in a new discipline, you should always make sure to ask about conventions and expectations for introductions, just as you would for any other aspect of the essay. For example, while it may be acceptable to write a two-paragraph (or longer) introduction for your papers in some courses, instructors in other disciplines, such as those in some Government courses, may expect a shorter introduction that includes a preview of the argument that will follow.
- In some disciplines (Government, Economics, and others), it’s common to offer an overview in the introduction of what points you will make in your essay. In other disciplines, you will not be expected to provide this overview in your introduction.
- Avoid writing a very general opening sentence. While it may be true that “Since the dawn of time, people have been telling love stories,” it won’t help you explain what’s interesting about your topic.
- Avoid writing a “funnel” introduction in which you begin with a very broad statement about a topic and move to a narrow statement about that topic. Broad generalizations about a topic will not add to your readers’ understanding of your specific essay topic.
- Avoid beginning with a dictionary definition of a term or concept you will be writing about. If the concept is complicated or unfamiliar to your readers, you will need to define it in detail later in your essay. If it’s not complicated, you can assume your readers already know the definition.
- Avoid offering too much detail in your introduction that a reader could better understand later in the paper.
- picture_as_pdf Introductions
How to Write an Introduction For a Research Paper
Learn how to write a strong and efficient research paper introduction by following the suitable structure and avoiding typical errors.

An introduction to any type of paper is sometimes misunderstood as the beginning; yet, an introduction is actually intended to present your chosen subject to the audience in a way that makes it more appealing and leaves your readers thirsty for more information. After the title and abstract, your audience will read the introduction, thus it’s critical to get off to a solid start.
This article includes instructions on how to write an introduction for a research paper that engages the reader in your research. You can produce a strong opening for your research paper if you stick to the format and a few basic principles.
What is An Introduction To a Research Paper?
An introduction is the opening section of a research paper and the section that a reader is likely to read first, in which the objective and goals of the subsequent writing are stated.
The introduction serves numerous purposes. It provides context for your research, explains your topic and objectives, and provides an outline of the work. A solid introduction will establish the tone for the remainder of your paper, enticing readers to continue reading through the methodology, findings, and discussion.
Even though introductions are generally presented at the beginning of a document, we must distinguish an introduction from the beginning of your research. An introduction, as the name implies, is supposed to introduce your subject without extending it. All relevant information and facts should be placed in the body and conclusion, not the introduction.
Structure Of An Introduction
Before explaining how to write an introduction for a research paper , it’s necessary to comprehend a structure that will make your introduction stronger and more straightforward.
A Good Hook
A hook is one of the most effective research introduction openers. A hook’s objective is to stimulate the reader’s interest to read the research paper. There are various approaches you may take to generate a strong hook: startling facts, a question, a brief overview, or even a quotation.
Broad Overview
Following an excellent hook, you should present a wide overview of your major issue and some background information on your research. If you’re unsure about how to begin an essay introduction, the best approach is to offer a basic explanation of your topic before delving into specific issues. Simply said, you should begin with general information and then narrow it down to your relevant topics.
After offering some background information regarding your research’s main topic, go on to give readers a better understanding of what you’ll be covering throughout your research. In this section of your introduction, you should swiftly clarify your important topics in the sequence in which they will be addressed later, gradually introducing your thesis statement. You can use some The following are some critical questions to address in this section of your introduction: Who? What? Where? When? How? And why is that?
Thesis Statement
The thesis statement, which must be stated in the beginning clause of your research since your entire research revolves around it, is the most important component of your research.
A thesis statement presents your audience with a quick overview of the research’s main assertion. In the body section of your work, your key argument is what you will expose or debate about it. An excellent thesis statement is usually very succinct, accurate, explicit, clear, and focused. Typically, your thesis should be at the conclusion of your introductory paragraph/section.
Tips for Writing a Strong Introduction
Aside from the good structure, here are a few tips to make your introduction strong and accurate:
- Keep in mind the aim of your research and make sure your introduction supports it.
- Use an appealing and relevant hook that catches the reader’s attention right away.
- Make it obvious to your readers what your stance is.
- Demonstrate your knowledge of your subject.
- Provide your readers with a road map to help them understand what you will address throughout the research.
- Be succinct – it is advised that your opening introduction consists of around 8-9 percent of the overall amount of words in your article (for example, 160 words for a 2000 words essay).
- Make a strong and unambiguous thesis statement.
- Explain why the article is significant in 1-2 sentences.
- Remember to keep it interesting.
Mistakes to Avoid in Your Introduction
Check out what not to do and what to avoid now that you know the structure and how to write an introduction for a research paper .
- Lacking a feeling of direction or purpose.
- Giving out too much.
- Creating lengthy paragraphs.
- Excessive or insufficient background, literature, and theory.
- Including material that should be placed in the body and conclusion.
- Not writing enough or writing excessively.
- Using too many quotes.
Unleash the Power of Infographics with Mind the Graph
Do you believe your research is not efficient in communicating precisely or is not aesthetically appealing? Use the Mind The Graph tool to create great infographics and add more value to your research.

Subscribe to our newsletter
Exclusive high quality content about effective visual communication in science.
Unlock Your Creativity
Create infographics, presentations and other scientifically-accurate designs without hassle — absolutely free for 7 days!
About Jessica Abbadia
Jessica Abbadia is a lawyer that has been working in Digital Marketing since 2020, improving organic performance for apps and websites in various regions through ASO and SEO. Currently developing scientific and intellectual knowledge for the community's benefit. Jessica is an animal rights activist who enjoys reading and drinking strong coffee.
Content tags

Microsoft 365 Life Hacks > Writing > How to write an introduction for a research paper
How to write an introduction for a research paper
Beginnings are hard. Beginning a research paper is no exception. Many students—and pros—struggle with how to write an introduction for a research paper.
This short guide will describe the purpose of a research paper introduction and how to create a good one.

What is an introduction for a research paper?
Introductions to research papers do a lot of work.
It may seem obvious, but introductions are always placed at the beginning of a paper. They guide your reader from a general subject area to the narrow topic that your paper covers. They also explain your paper’s:
- Scope: The topic you’ll be covering
- Context: The background of your topic
- Importance: Why your research matters in the context of an industry or the world
Your introduction will cover a lot of ground. However, it will only be half of a page to a few pages long. The length depends on the size of your paper as a whole. In many cases, the introduction will be shorter than all of the other sections of your paper.

Write with Confidence using Editor
Elevate your writing with real-time, intelligent assistance
Why is an introduction vital to a research paper?
The introduction to your research paper isn’t just important. It’s critical.
Your readers don’t know what your research paper is about from the title. That’s where your introduction comes in. A good introduction will:
- Help your reader understand your topic’s background
- Explain why your research paper is worth reading
- Offer a guide for navigating the rest of the piece
- Pique your reader’s interest
Without a clear introduction, your readers will struggle. They may feel confused when they start reading your paper. They might even give up entirely. Your introduction will ground them and prepare them for the in-depth research to come.
What should you include in an introduction for a research paper?
Research paper introductions are always unique. After all, research is original by definition. However, they often contain six essential items. These are:
- An overview of the topic. Start with a general overview of your topic. Narrow the overview until you address your paper’s specific subject. Then, mention questions or concerns you had about the case. Note that you will address them in the publication.
- Prior research. Your introduction is the place to review other conclusions on your topic. Include both older scholars and modern scholars. This background information shows that you are aware of prior research. It also introduces past findings to those who might not have that expertise.
- A rationale for your paper. Explain why your topic needs to be addressed right now. If applicable, connect it to current issues. Additionally, you can show a problem with former theories or reveal a gap in current research. No matter how you do it, a good rationale will interest your readers and demonstrate why they must read the rest of your paper.
- Describe the methodology you used. Recount your processes to make your paper more credible. Lay out your goal and the questions you will address. Reveal how you conducted research and describe how you measured results. Moreover, explain why you made key choices.
- A thesis statement. Your main introduction should end with a thesis statement. This statement summarizes the ideas that will run through your entire research article. It should be straightforward and clear.
- An outline. Introductions often conclude with an outline. Your layout should quickly review what you intend to cover in the following sections. Think of it as a roadmap, guiding your reader to the end of your paper.
These six items are emphasized more or less, depending on your field. For example, a physics research paper might emphasize methodology. An English journal article might highlight the overview.
Three tips for writing your introduction
We don’t just want you to learn how to write an introduction for a research paper. We want you to learn how to make it shine.
There are three things you can do that will make it easier to write a great introduction. You can:
- Write your introduction last. An introduction summarizes all of the things you’ve learned from your research. While it can feel good to get your preface done quickly, you should write the rest of your paper first. Then, you’ll find it easy to create a clear overview.
- Include a strong quotation or story upfront. You want your paper to be full of substance. But that doesn’t mean it should feel boring or flat. Add a relevant quotation or surprising anecdote to the beginning of your introduction. This technique will pique the interest of your reader and leave them wanting more.
- Be concise. Research papers cover complex topics. To help your readers, try to write as clearly as possible. Use concise sentences. Check for confusing grammar or syntax . Read your introduction out loud to catch awkward phrases. Before you finish your paper, be sure to proofread, too. Mistakes can seem unprofessional.
Get started with Microsoft 365
It’s the Office you know, plus the tools to help you work better together, so you can get more done—anytime, anywhere.
Topics in this article
More articles like this one.

What is independent publishing?
Avoid the hassle of shopping your book around to publishing houses. Publish your book independently and understand the benefits it provides for your as an author.

What are literary tropes?
Engage your audience with literary tropes. Learn about different types of literary tropes, like metaphors and oxymorons, to elevate your writing.

What are genre tropes?
Your favorite genres are filled with unifying tropes that can define them or are meant to be subverted.

What is literary fiction?
Define literary fiction and learn what sets it apart from genre fiction.
Everything you need to achieve more in less time
Get powerful productivity and security apps with Microsoft 365

Explore Other Categories
Organizing Academic Research Papers: 4. The Introduction
- Purpose of Guide
- Design Flaws to Avoid
- Glossary of Research Terms
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Choosing a Title
- Making an Outline
- Paragraph Development
- Executive Summary
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tertiary Sources
- What Is Scholarly vs. Popular?
- Qualitative Methods
- Quantitative Methods
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Annotated Bibliography
- Dealing with Nervousness
- Using Visual Aids
- Grading Someone Else's Paper
- How to Manage Group Projects
- Multiple Book Review Essay
- Reviewing Collected Essays
- About Informed Consent
- Writing Field Notes
- Writing a Policy Memo
- Writing a Research Proposal
- Acknowledgements
The introduction serves the purpose of leading the reader from a general subject area to a particular field of research. It establishes the context of the research being conducted by summarizing current understanding and background information about the topic, stating the purpose of the work in the form of the hypothesis, question, or research problem, briefly explaining your rationale, methodological approach, highlighting the potential outcomes your study can reveal, and describing the remaining structure of the paper.
Key Elements of the Research Proposal. Prepared under the direction of the Superintendent and by the 2010 Curriculum Design and Writing Team. Baltimore County Public Schools.
Importance of a Good Introduction
Think of the introduction as a mental road map that must answer for the reader these four questions:
- What was I studying?
- Why was this topic important to investigate?
- What did we know about this topic before I did this study?
- How will this study advance our knowledge?
A well-written introduction is important because, quite simply, you never get a second chance to make a good first impression. The opening paragraph of your paper will provide your readers with their initial impressions about the logic of your argument, your writing style, the overall quality of your research, and, ultimately, the validity of your findings and conclusions. A vague, disorganized, or error-filled introduction will create a negative impression, whereas, a concise, engaging, and well-written introduction will start your readers off thinking highly of your analytical skills, your writing style, and your research approach.
Introductions . The Writing Center. University of North Carolina.
Structure and Writing Style
I. Structure and Approach
The introduction is the broad beginning of the paper that answers three important questions for the reader:
- What is this?
- Why am I reading it?
- What do you want me to think about / consider doing / react to?
Think of the structure of the introduction as an inverted triangle of information. Organize the information so as to present the more general aspects of the topic early in the introduction, then narrow toward the more specific topical information that provides context, finally arriving at your statement of purpose and rationale and, whenever possible, the potential outcomes your study can reveal.
These are general phases associated with writing an introduction:
- Highlighting the importance of the topic, and/or
- Making general statements about the topic, and/or
- Presenting an overview on current research on the subject.
- Opposing an existing assumption, and/or
- Revealing a gap in existing research, and/or
- Formulating a research question or problem, and/or
- Continuing a disciplinary tradition.
- Stating the intent of your study,
- Outlining the key characteristics of your study,
- Describing important results, and
- Giving a brief overview of the structure of the paper.
NOTE: Even though the introduction is the first main section of a research paper, it is often useful to finish the introduction very late in the writing process because the structure of the paper, the reporting and analysis of results, and the conclusion will have been completed and it ensures that your introduction matches the overall structure of your paper.
II. Delimitations of the Study
Delimitations refer to those characteristics that limit the scope and define the conceptual boundaries of your study . This is determined by the conscious exclusionary and inclusionary decisions you make about how to investigate the research problem. In other words, not only should you tell the reader what it is you are studying and why, but you must also acknowledge why you rejected alternative approaches that could have been used to examine the research problem.
Obviously, the first limiting step was the choice of research problem itself. However, implicit are other, related problems that could have been chosen but were rejected. These should be noted in the conclusion of your introduction.
Examples of delimitating choices would be:
- The key aims and objectives of your study,
- The research questions that you address,
- The variables of interest [i.e., the various factors and features of the phenomenon being studied],
- The method(s) of investigation, and
- Any relevant alternative theoretical frameworks that could have been adopted.
Review each of these decisions. You need to not only clearly establish what you intend to accomplish, but to also include a declaration of what the study does not intend to cover. In the latter case, your exclusionary decisions should be based upon criteria stated as, "not interesting"; "not directly relevant"; “too problematic because..."; "not feasible," and the like. Make this reasoning explicit!
NOTE: Delimitations refer to the initial choices made about the broader, overall design of your study and should not be confused with documenting the limitations of your study discovered after the research has been completed.
III. The Narrative Flow
Issues to keep in mind that will help the narrative flow in your introduction :
- Your introduction should clearly identify the subject area of interest . A simple strategy to follow is to use key words from your title in the first few sentences of the introduction. This will help focus the introduction on the topic at the appropriate level and ensures that you get to the primary subject matter quickly without losing focus, or discussing information that is too general.
- Establish context by providing a brief and balanced review of the pertinent published literature that is available on the subject. The key is to summarize for the reader what is known about the specific research problem before you did your analysis. This part of your introduction should not represent a comprehensive literature review but consists of a general review of the important, foundational research literature (with citations) that lays a foundation for understanding key elements of the research problem. See the drop-down tab for "Background Information" for types of contexts.
- Clearly state the hypothesis that you investigated . When you are first learning to write in this format it is okay, and actually preferable, to use a past statement like, "The purpose of this study was to...." or "We investigated three possible mechanisms to explain the...."
- Why did you choose this kind of research study or design? Provide a clear statement of the rationale for your approach to the problem studied. This will usually follow your statement of purpose in the last paragraph of the introduction.
IV. Engaging the Reader
The overarching goal of your introduction is to make your readers want to read your paper. The introduction should grab your reader's attention. Strategies for doing this can be to:
- Open with a compelling story,
- Include a strong quotation or a vivid, perhaps unexpected anecdote,
- Pose a provocative or thought-provoking question,
- Describe a puzzling scenario or incongruity, or
- Cite a stirring example or case study that illustrates why the research problem is important.
NOTE: Only choose one strategy for engaging your readers; avoid giving an impression that your paper is more flash than substance.
Freedman, Leora and Jerry Plotnick. Introductions and Conclusions . University College Writing Centre. University of Toronto; Introduction . The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Introductions . The Writing Center. University of North Carolina; Introductions . The Writer’s Handbook. Writing Center. University of Wisconsin, Madison; Introductions, Body Paragraphs, and Conclusions for an Argument Paper. The Writing Lab and The OWL. Purdue University; Resources for Writers: Introduction Strategies . Program in Writing and Humanistic Studies. Massachusetts Institute of Technology; Sharpling, Gerald. Writing an Introduction . Centre for Applied Linguistics, University of Warwick; Writing Your Introduction. Department of English Writing Guide. George Mason University.
Writing Tip
Avoid the "Dictionary" Introduction
Giving the dictionary definition of words related to the research problem may appear appropriate because it is important to define specific words or phrases with which readers may be unfamiliar. However, anyone can look a word up in the dictionary and a general dictionary is not a particularly authoritative source. It doesn't take into account the context of your topic and doesn't offer particularly detailed information. Also, placed in the context of a particular discipline, a term may have a different meaning than what is found in a general dictionary. If you feel that you must seek out an authoritative definition, try to find one that is from subject specific dictionaries or encyclopedias [e.g., if you are a sociology student, search for dictionaries of sociology].
Saba, Robert. The College Research Paper . Florida International University; Introductions . The Writing Center. University of North Carolina.
Another Writing Tip
When Do I Begin?
A common question asked at the start of any paper is, "where should I begin?" An equally important question to ask yourself is, "When do I begin?" Research problems in the social sciences rarely rest in isolation from the history of the issue being investigated. It is, therefore, important to lay a foundation for understanding the historical context underpinning the research problem. However, this information should be brief and succinct and begin at a point in time that best informs the reader of study's overall importance. For example, a study about coffee cultivation and export in West Africa as a key stimulus for local economic growth needs to describe the beginning of exporting coffee in the region and establishing why economic growth is important. You do not need to give a long historical explanation about coffee exportation in Africa. If a research problem demands a substantial exploration of historical context, do this in the literature review section; note in the introduction as part of your "roadmap" [see below] that you covering this in the literature review.
Yet Another Writing Tip
Always End with a Roadmap
The final paragraph or sentences of your introduction should forecast your main arguments and conclusions and provide a description of the rest of the paper [a "roadmap"] that let's the reader know where you are going and what to expect.
- << Previous: Executive Summary
- Next: Background Information >>
- Last Updated: Jul 18, 2023 11:58 AM
- URL: https://library.sacredheart.edu/c.php?g=29803
- QuickSearch
- Library Catalog
- Databases A-Z
- Publication Finder
- Course Reserves
- Citation Linker
- Digital Commons
- Our Website
Research Support
- Ask a Librarian
- Appointments
- Interlibrary Loan (ILL)
- Research Guides
- Databases by Subject
- Citation Help
Using the Library
- Reserve a Group Study Room
- Renew Books
- Honors Study Rooms
- Off-Campus Access
- Library Policies
- Library Technology
User Information
- Grad Students
- Online Students
- COVID-19 Updates
- Staff Directory
- News & Announcements
- Library Newsletter
My Accounts
- Interlibrary Loan
- Staff Site Login
FIND US ON

Module 1: Introduction: What is Research?

Learning Objectives
By the end of this module, you will be able to:
- Explain how the scientific method is used to develop new knowledge
- Describe why it is important to follow a research plan

The Scientific Method consists of observing the world around you and creating a hypothesis about relationships in the world. A hypothesis is an informed and educated prediction or explanation about something. Part of the research process involves testing the hypothesis , and then examining the results of these tests as they relate to both the hypothesis and the world around you. When a researcher forms a hypothesis, this acts like a map through the research study. It tells the researcher which factors are important to study and how they might be related to each other or caused by a manipulation that the researcher introduces (e.g. a program, treatment or change in the environment). With this map, the researcher can interpret the information he/she collects and can make sound conclusions about the results.
Research can be done with human beings, animals, plants, other organisms and inorganic matter. When research is done with human beings and animals, it must follow specific rules about the treatment of humans and animals that have been created by the U.S. Federal Government. This ensures that humans and animals are treated with dignity and respect, and that the research causes minimal harm.
No matter what topic is being studied, the value of the research depends on how well it is designed and done. Therefore, one of the most important considerations in doing good research is to follow the design or plan that is developed by an experienced researcher who is called the Principal Investigator (PI). The PI is in charge of all aspects of the research and creates what is called a protocol (the research plan) that all people doing the research must follow. By doing so, the PI and the public can be sure that the results of the research are real and useful to other scientists.
Module 1: Discussion Questions
- How is a hypothesis like a road map?
- Who is ultimately responsible for the design and conduct of a research study?
- How does following the research protocol contribute to informing public health practices?
Email Updates
More From Forbes
Enhancing environmental research: web scraping and sustainability.

- Share to Facebook
- Share to Twitter
- Share to Linkedin
Founder & CEO at Datamam .
Climate change, pollution, environmental degradation and resource depletion are just a few of the greatest challenges facing the world in the 21st century. Tackling these challenges means carrying out thorough research involving a huge pool of world data from sources such as satellite imagery, environmental monitoring stations and local field studies, providing an array of information on human interaction with nature.
But the real challenge comes in capturing massive amounts of real-time data so wise decisions can be made within the shortest time possible. To do this, we must better understand the role of modern data collection technologies in environmental research and how we can adapt our strategies to leverage these technologies more effectively.
Introduction To Environmental Research
Historical records show that concern for the environment goes back thousands of years. In fact, in 2700 BC, some of the first known laws were implemented to protect trees from continued deforestation in Ur, Mesopotamia. Centuries later, the establishment of Scotland's Coal Smoke Abatement Society in 1898 marked a significant community-driven response to environmental issues.
These movements have been fueled in the 21st century by advancements in technology—particularly in computing and data analysis—that have significantly impacted the research industry as a whole, beyond just the environmental sector. This then begs the question: With large-scale, global environmental data collection, how do we integrate and put such information to use to address environmental challenges?
The Birkenstock Memorial Day Sale Features Styles For Over 50% Off
The 82 best memorial day sales to shop now before they re gone, reacher season 3 set photo shows alan ritchson s hulking new nemesis, worldwide data collection for environmental insights.
Environmental monitoring is critical for evaluating vital factors such as air and water quality. Across the globe, various organizations and research groups deploy sophisticated data collection techniques to track environmental health.
For instance, the World Air Quality Index project collects data from over 12,000 stations in more than 1,000 cities worldwide. This project aggregates real-time data on air pollution levels, which is crucial for assessing health risks, informing the public and shaping policy decisions. Most of this data is publicly available, allowing analysts and researchers to utilize it for further studies and environmental assessments.
In the U.S., the National Weather Service gathers data from weather stations nationwide. This data, essential for generating accurate weather forecasts, plays a crucial role in emergency preparedness, particularly in areas susceptible to extreme weather events. This information is also generally accessible to the public, supporting a variety of applications from academic research to commercial use in weather-related industries.
Furthermore, conservation organizations like the World Wildlife Fund monitor deforestation, wildlife trafficking and illegal fishing activities. Public access to this data can vary, with some information available for open use to aid in raising awareness and promoting conservation efforts.
This transparency not only promotes accountability but also fosters a collaborative approach to tackling environmental challenges.
The Impact Of Web Scraping On Environmental Policy And Advocacy
In the context of environmental research and policymaking, the ability to access information without source limitations can be a significant advantage. Web scraping can be a useful tool in this scenario, enabling researchers, policymakers and advocates to gather and analyze data from virtually any online source, irrespective of geographical and linguistic boundaries. This capability is particularly helpful in environmental science, in which the global nature of challenges like climate change, pollution and biodiversity loss demands a comprehensive understanding that spans across nations.
Considerations When Using Web Scraping For Environmental Purposes
Ensure data integrity..
Credibility checking of sources is important to confirm the dependability of data collected using web scraping. If the data that web scraping provides is incorrect, it could lead to misguided decisions and policymaking; hence, data accuracy is the top-most priority. The data needs to be updated regularly to keep it relevant, and using as many sources as possible for cross-verification will add strength to your dataset.
Use data effectively.
Data can be used to track changes in the environment, monitor ecosystem health and inform policymakers. Actively participate in the collection and data analysis processes to ensure optimal environmental management.
Use high-level analytic tools.
Integrate advanced analytical tools and technologies to further enhance the value of the data collected through web scraping. Tools like AI and machine learning can help identify patterns and predictions that might not be evident through traditional analysis methods. Incorporating these technologies can provide deeper insights into environmental data, leading to more effective strategies and solutions.
Looking Ahead: The Evolving Role Of Data In Environmental Advocacy
Web scraping has emerged as one important tool in environmental research, offering a method to rapidly collect and analyze data from a multitude of sources. As technology advances, the capabilities of data collection technology will expand, offering even more sophisticated tools for data extraction and analysis. These advancements will not only enhance the accuracy and depth of environmental research but also open new avenues for public engagement and policy influence.
Forbes Technology Council is an invitation-only community for world-class CIOs, CTOs and technology executives. Do I qualify?

- Editorial Standards
- Reprints & Permissions

US State and Regional Energy Innovation Index

Vibrant regional energy innovation ecosystems are important for any national net-zero strategy. But to understand the potential contributions they can make to the price and performance of clean energy technologies, we must first benchmark the resources they bring to bear.
KEY TAKEAWAYS
Key takeaways.
Key Takeaways 1
Introduction . 2
Regional Innovation Ecosystems: Engines of the Energy Transition . 3
From TBED to CEBED: The Regional Moment in U.S. Energy and Climate Innovation Policy 5
Measuring State and Regional Energy Innovation Ecosystems 7
The Index 11
Conclusions and Recommendations 18
Appendix 1: Indicators and Weights 20
Appendix 2: Methodology and Sources 20
Appendix 3: Search Strategies 20
Endnotes 21
Introduction
The United States, along with the rest of the world, has embarked on a transition to clean energy. The transition’s ultimate endpoint is net-zero greenhouse gas (GHG) emissions to limit the impact of climate change. Energy security, human health, local environmental protection, and economic opportunity also motivate the global community to pursue this important objective. But the path to net zero is strewn with obstacles. Many of the technologies the world needs to stay on it are too expensive, perform too poorly, or are simply unavailable right now. Innovation should therefore be a major focus of any net-zero strategy. [1]
Regional energy innovation ecosystems have great potential to contribute to such strategies. Geographically concentrated networks of technology and service firms, research institutions, and nonprofit and public sector entities could drive price and performance improvements in a diverse array of clean energy sources and uses. This report assesses the potential of energy innovation ecosystems across the United States to contribute to this important mission, drawing on a wide range of data, such as federal and private funding, publications and patents, and state and regional policies and public opinion, covering nine categories of innovation system functions, to compile an index of this potential. Fourteen technology-specific indices, which draw on subsets of the main database, complement the main index and highlight regional diversity.
The index, while inevitably imperfect, provides a baseline against which to measure the future impact of recent federal legislation. Landmark bills passed by Congress in 2021 and 2022 support states and regions that seek to strengthen their energy innovation ecosystems. Quite a few states and regions had already begun to do so before the new federal programs were created, and many more are now responding to these opportunities. The report concludes by offering broad suggestions for sustaining this momentum and improving the odds that the new policies will succeed.
Explore the five accompanying data visualizations for detailed profiles of states , regions , metropolitan statistical areas , combined statistical areas , and metropolitan divisions , respectively:

Regional Innovation Ecosystems: Engines of the Energy Transition
Abundant, affordable, reliable energy is a fundamental requirement of a high standard of living. A small handful of individuals, following Thoreau, may choose a life of voluntary simplicity, but the vast majority of the world’s population seeks the comforts and opportunities that are widely available in high-income countries. While these need not be supplied as wastefully as they are now, especially in the United States, they intrinsically demand substantial energy inputs.
The Industrial Revolution, which brought for the first time a measure of comfort and opportunity to a large proportion of the population in the places it swept through, rested on energy from fossil fuels. That pattern continues today, with these same fuels providing about 80 percent of global primary energy. They remain abundant and reasonably affordable and reliable, but the social costs of burning them have mounted. Most notably, fossil fuel combustion accounts for about 75 percent of the GHG emissions that are driving catastrophic storms, wildfires, and other symptoms of global climate change. [2]
The challenge facing human civilization, then, is to enable all those who desire to live at a high standard to have the quantity and quality of energy they need to do so, while simultaneously and dramatically reducing the harm that would cause. As Gaster, Atkinson, and Righter argue, new and improved energy technologies that emit far fewer GHGs, while matching (or nearly so) the price and performance of the incumbents, lie at the core of any strategy with any chance of surmounting this monumental challenge. [3]
A diverse array of such innovations are needed. Some, such as solar panels and heat pumps, are well advanced, though still capable of significant improvement. Many others, such as green steel and carbon dioxide (CO 2 ) removal, are early in their development. Many of these new technologies are complex systems themselves, and nearly all must be further integrated with even more complex systems, such as the power grid. [4]
Energy innovation is a subject of discussion in international climate talks and figures into many national policies. Some national governments are making important contributions by funding clean energy research, development, and demonstration, fostering climate-tech venture investments, and the like. But the innovation rubber really hits the energy transition road at the regional level. That’s because innovation, especially innovation in complex systems, accelerates most quickly when dense networks of firms and supporting institutions, clustered in relatively compact geographic areas, pursue it. [5]
The concept of regional innovation ecosystems is an old one, dating back to the 19th century economist Alfred Marshall, who noted “something in the air” in places such as Sheffield, where Britain’s pioneering cutlery makers were concentrated. Modern research has revealed that “something” to have many elements: When working effectively, regional innovation ecosystems foster knowledge exchange, attract specialized labor, facilitate infrastructure investment, and encourage entrepreneurship, among other things. Regions diverge economically in large part because of these ecosystems. Some are home to innovative industries that serve growing markets beyond the regions in which they are located, while others rely on stagnant or shrinking sectors. Silicon Valley and Detroit epitomize these extremes in the public mind. [6]
Digitalization might have been expected to undermine these dynamics, but, as many analysts have noted, “the death of distance has been greatly exaggerated.” Van der Wouden and Youn, for instance, find that while the geographical distance between research collaborators grew substantially between 1975 and 2015, so had the “learning premium” associated with geographical proximity. Those who collaborated locally were far more likely to enter new fields and build their own capabilities than those who collaborated long distance. The effect was especially strong in STEM (science, technology, engineering, and math) disciplines, such as chemistry, materials science, and engineering, which are particularly important in energy innovation. [7]
The systemic nature of energy innovation heightens the importance of collaboration within regions. Innovative low-carbon power, transportation, and industrial systems typically involve diverse components that must be integrated carefully to optimize performance and minimize cost and emissions. These integration processes, in turn, often require learning-by-doing and learning-by-using across organizational and institutional boundaries. Geographic proximity is likely to ease them by facilitating hands-on and face-to-face interactions. [8]
The importance of regional energy innovation ecosystems in the coming decades will be heightened by the vulnerability to disruption of places dependent today on fossil-fuel-based industries. Wyoming’s coal mines, Houston’s petrochemical plants, and Detroit’s auto factories are among those at risk. Hanson, a co-author of 2016’s “The China Shock” paper (a belated recognition of that epochal impact by neoclassical economists) wrote that “the energy transition … is a shock foretold” for such regions. [9]
Whether such “brownfield” regions are willing and able to repurpose their existing assets or build new ones to seize the opportunities presented by the transition will go a long way toward determining their future economic dynamism in a low-carbon world. Wyoming’s effort to position itself as a leader in nuclear power and carbon capture, Houston’s push to become a hydrogen hub, and Detroit’s emerging shift to electric vehicles illustrate these dynamics. Of course, such retooling regions must frequently compete with “greenfield” locations elsewhere, domestically and globally. [10]
That competition has important consequences for the energy transition. If regional innovation ecosystems are able to lower the cost and improve the performance of emissions-reducing technologies, their uptake will expand, feeding ideas and resources back to the regions that make them. This virtuous cycle extending beyond the region will be enhanced and enabled by international agreements and national policies, but ultimately depends on positive feedbacks within the region among laboratories, factories, testbeds, and related facilities, organizations, and institutions.
From TBED to CEBED: The Regional Moment in U.S. Energy and Climate Innovation Policy
Some regional innovation ecosystems specializing in low-carbon technology have emerged relatively spontaneously. Wind energy innovation revitalized Denmark’s central Jutland region, for instance, repurposing older manufacturing assets beginning in the 1970s and later fending off higher-tech competitors elsewhere. Others have been built up more deliberately. The solar power manufacturing cluster in China’s Yangtze River Delta was created in the 2000s in large measure by targeted local, provincial, and national policies. [11]
The deliberate approach to building such ecosystems is likely to dominate going forward, as the need for energy innovation, and the extra-regional export opportunities created by the energy transition, are increasingly evident to policymakers worldwide. China’s success in solar manufacturing is part of a broader strategy to dominate emerging clean technologies. The European Union is pursuing a “smart specialization strategy” with an increasingly green tilt to diversify its regional economies and move them “up the ladder of higher knowledge complexity and value creation.” [12]
Some state and local governments in the United States adopted such strategies in the 2010s. New York has sought to establish its southern tier as a global center for energy storage manufacturing, while Colorado’s Front Range region has become a hub for cleantech start-ups. Until recently, however, the U.S. federal government has not kept pace with its global competitors in this regard. [13]
That changed with the passage of major legislation by the 117th Congress (2021–2022). New programs supported regional innovation ecosystems and technology-based economic development (TBED) across all industries, encouraging many states and regions to propose initiatives focusing on clean energy technologies. Five out of 21 regional coalitions that won the Build Back Better Regional Challenge, funded by the Department of Commerce (DOC) under the 2021 American Rescue Plan, focused on energy innovation. So did 7 of DOC’s 31 regional tech hubs designees and 7 of its 18 regional strategy development grantees, a program authorized by the 2022 CHIPS and Science Act. (See box 1 for a brief description of this program.) Six of the 10 winners of regional “engine” grants selected by the National Science Foundation (NSF) (also under CHIPS and Science) are seeking to drive sustainable energy or climate-related innovation as well. [14]
In addition, the Bipartisan Infrastructure Law and Inflation Reduction Act established programs and funding streams specifically to catalyze regional energy innovation. The new DOE Office of Clean Energy Demonstrations (OCED), for instance, is implementing an $8 billion program to create regional hubs for clean hydrogen production, distribution, and use. OCED has roughly $20 billion more for large-scale demonstration projects in other technology areas, including $6.3 billion for industrial decarbonization. DOE’s Office of Fossil Energy and Carbon Management has received an additional $3.5 billion to fund direct air capture hubs. More broadly, Congress has explicitly tasked DOE with responsibility for fostering regional competitiveness through clean energy innovation, and given preference to fossil-fuel-dependent communities in many of these programs. [15]
The response to these bills indicates that an increasing number of states and regions in the United States are seeking to enhance their competitive advantages in a world striving for net-zero emissions. (Box 2 briefly describes a regional strategy and box 3 a state strategy.) Their efforts fold into a broader discourse around TBED and “place-based” policies. Best practice in these domains rests on a grounded assessment of existing state and regional assets that allows identification of “adjacent possible” sectors. These are sectors with a realistic potential for future export growth rather than fantastic dreams of building the next Silicon Valley. [16]
This report advances the movement toward Clean Energy Based Economic Development (CEBED) by applying insights from the large corpus of analytical work that underpins TBED. We have compiled a wide range of indicators that measure how well a region’s energy innovation system is functioning today. We hope the findings will inform strategies to build a more prosperous and cleaner future.
Federal Regional Technology and Innovation Hub Program (Tech Hubs)
The Tech Hubs program, initially proposed by ITIF, was authorized by the 2022 CHIPS and Science Act. It seeks to enable regions (Metropolitan Statistical Areas (MSAs) or closely connected MSAs and nearby micropolitan statistical areas) to become globally competitive in “industries of the future.” Such industries lie within the ambit of 10 broad technology areas laid out in the act, including “advanced energy and industrial efficiency” as well as “disaster prevention or mitigation.” Congress authorized $10 billion for the program and appropriated $500 million through fiscal year 2023. [17]
Regional consortia seeking Tech Hubs grants from the Economic Development Administration (EDA), a unit of DOC, must include an institution of higher education; state, local, or tribal governments; industry; labor; and economic development organizations. These consortia must set forth a compelling narrative that describes a region’s potential to achieve world-class status, the barriers that impede its achievement, and projects that would address those barriers. Projects may advance innovation, strengthen the workforce, develop business and entrepreneurship opportunities, and build infrastructure. [18]
In October 2023, EDA designated 31 consortia as eligible for 5 to 10 grants of $50 million to $75 million. It also awarded 29 strategy development grants of roughly $500,000, 11 to consortia eligible now and 18 to consortia that may become eligible in future phases of the program. In addition to EDA funding, Tech Hubs will receive preferential treatment in a variety of other federal programs, such as those supporting foreign direct investment and providing export assistance. [19]
Seven of the eligible consortia fall within the categories of “Accelerating America’s Clean Energy Transition” and “Strengthening Our Critical Minerals Supply Chain”:
§ Louisiana: offshore wind and renewable energy
§ Idaho and Wyoming: small modular reactors (SMR) and advanced nuclear
§ South Carolina: exportable electricity technologies
§ Florida: sustainable and resilient infrastructure
§ New York: batteries
§ Nevada: lithium
§ Missouri: battery materials
Several others will contribute less directly to energy innovation, such as gallium nitride technology (Vermont), which underpins power system electronics. [20]
The governing statute for the program enumerates 13 considerations for selecting hubs, which EDA has distilled into 7 broad criteria: project quality and ability to execute, impact on economic and national security, investment and policy commitments, workforce, capital, equity and diversity, and governance. A consortium’s plan to leverage existing innovation assets is included in the first, fourth, and fifth criteria, while its forecast for the targeted technology’s impact and prospects for retaining manufacturing are incorporated into the second. [21]
Measuring State and Regional Energy Innovation Ecosystems
Energy innovation ecosystems are made up of complex networks of actors, institutions, and resources that contribute to the generation, development, diffusion, and use of innovative energy products and services. To be effective, such systems must perform a broad range of functions, including mobilizing resources, developing and diffusing new scientific and technical knowledge, facilitating experimentation by entrepreneurs, facilitating the formation of supply chains and new markets, legitimizing new technologies in society, guiding the search for new knowledge in certain directions, and guiding its spillover into other related industries. [22]
Our index is built from the following four subindices that seek to capture distinct groups of these functions:
▪ Knowledge development and diffusion
▪ Entrepreneurial experimentation
▪ Supply chain and market formation
▪ Social legitimation
In this section, we briefly review the categories and indicators included in each of the four subindices. Most indicators are available at the county level and are aggregated to the regional and state levels.
In addition to the main index, our work provides insights into regional technological specializations, which vary greatly across the United States. (See figure 1 for a comparison of Massachusetts and South Carolina.) Fourteen technology areas, each of which is covered by an index that draws on a subset of the main database and is constructed in the same fashion, are listed at the end of this section.
A very detailed account of sources and methods can be found in appendix 2.
Subindex: Knowledge Development and Diffusion
Knowledge development and diffusion activities comprise the first subindex. Unless new scientific and technical knowledge is developed and diffused, no new clean energy innovations will emerge, and there will be nothing to scale up. The subindex consists of three categories of indicators.
Category: Research and Development
Mobilization of resources to fund research and development (R&D) activities performed by companies, government laboratories, and academic institutions lies at the base of this subindex. The public sector plays a larger role in energy R&D than in many other sectors, in large part because the transition to clean energy is being driven by the environmental threat of climate change, and markets have not been responsive to it. The category focuses on federal low-carbon energy R&D spending, which far outpaces state and local investments, assessing the ability of states and regions to garner federal awards.
Category: Knowledge
R&D funding contributes to scientific discoveries. The quality of this new knowledge varies considerably. Most discoveries end up having little scientific or commercial value, while highly valued knowledge is ultimately recognized by and diffused through networks of academic and professional peers. We use data on publications as a proxy for new discoveries and data on publication citations to estimate their quality and extent of diffusion.
Category: Invention
R&D funding also to contributes to the development of technical know-how and the generation of new inventions. Like new knowledge, the quality and commercial viability of inventions varies considerably. We use data on patents as a proxy for new inventions and data on patent citations to estimate their quality and extent of diffusion.
Subindex: Entrepreneurial Experimentation
Entrepreneurial experimentation activities comprise the second subindex. These activities largely involve a different set of actors, institutions, and processes than those involved in knowledge development and diffusion, whose aim is to test and demonstrate the commercial viability of new technological innovations in niche markets.
Category: Demonstration
Technology demonstration projects seek to establish the market viability of new clean energy innovations. The public sector plays a larger role in energy demonstration projects than in many other sectors due to the high-risk nature and long development horizons of many emerging energy technologies. We use federal spending data to assess the ability of states and regions to garner federal awards for energy demonstration projects.
Category: Entrepreneurship
Entrepreneurs create new ventures that carry out the high-risk technological, business, and social experiments that must be performed before innovative energy products and services can join the mainstream. These new ventures may receive support from venture capitalists and federal grants and, when successful, scale up by exiting through acquisitions or initial public offerings (IPOs). We use data on federal seed investments, venture capital investments, and successful company exits to assess state and regional contributions to the entrepreneurship function.
Subindex: Supply Chain and Market Formation
Supply chain and market formation activities comprise the third subindex. Successful scale-up of innovations, whether carried out by a new or established business, depends on the availability of inputs at a competitive cost and on a growing array of buyers who find value in deploying these innovations. Some supply chains and markets may lie within the state or region where an innovation is made, although these functions frequently extend beyond these boundaries. Proximity to suppliers and customers can provide valuable feedback as innovations bridge from early adoption to mass markets.
Category: Industry
A central goal of CEBED is to create jobs and steady employment in clean energy industries. We use data on low-carbon energy employment to assess the ability of states and regions to create such jobs and strengthen state and regional supply chains.
Category: Technology Adoption
A long-term CEBED strategy ultimately depends on generating an abundant and reliable supply of low-carbon energy resources to power industrial activities and ensure sustainable economic development. We use data on the supply of low-carbon electricity generation and energy storage resources to assess the ability of states and regions to mobilize resources and facilitate market formation for building clean energy infrastructure.
Subindex: Social Legitimation
Social legitimation activities comprise the fourth subindex. Innovation is an intrinsically social process. Incumbent energy technologies are often buttressed by political, legal, and regulatory mechanisms and embedded in supportive state and regional cultures. The more innovations disrupt legacy systems, the more effort is required for them to break through to widespread adoption.
Category: Public Goals and Strategies
Social legitimation of innovations and CEBED depends on the goals and strategies of policymakers. We use data on published public policy and strategy documents to assess the degree to which states and regions have adopted CEBED strategies.
Category: Social Values
In a democracy, social legitimation and CEBED policies ultimately depend on the values of the general public. We use data on public opinion about clean energy R&D and climate action to assess the extent to which the citizens of states and regions value clean energy innovation and CEBED.
Technological Specialization
A function of energy innovation ecosystems that adds significant depth to the index is guidance on the direction of the search for new technologies, and ultimately, CEBED. The clean energy transition is a deliberate and purposeful attempt to guide the economy away from dependence on unabated fossil fuels and toward a sustainable path of low-carbon energy production and use. Within that overarching framework, energy innovation ecosystems may also be guided toward specific technology areas. The index seeks to capture these technological specializations at the state and regional level. These are measured by subindices covering fourteen technology areas:
1. Advanced energy materials
2. Bioenergy
3. Carbon capture, utilization, and storage (CCUS)
4. Clean energy manufacturing
5. Clean energy transportation
6. Energy efficiency
7. Energy storage
8. Geothermal energy
9. Grid technologies
10. Hydrogen and fuel cells
11. Nuclear energy
12. Solar energy
13. Water energy
14. Wind energy
Limitations
Our measures of state and regional energy innovation ecosystems are imperfect. For instance, private R&D spending is a very important input to these ecosystems, but it is not measured adequately enough to incorporate into the index. Data constraints also limit our visibility into clean energy employment and state and regional clean energy innovation policies in the third and fourth subindices. In the final section of this report, we recommend that federal agencies invest in improved measurement systems so that state and regional economic development strategists can become better informed.
New Energy New York
New York State’s Southern Tier, an eight-county region bordering Pennsylvania, was a thriving center of manufacturing in the first half of the 20th century. Major U.S. firms such as IBM and General Electric called the Southern Tier home. While the region’s strength in electronics manufacturing cushioned the blow, the Southern Tier suffered a long decline in the second half of the 20th century, which has worsened since then. [23]
New Energy New York (NENY) is a regional initiative led by Binghamton University that seeks to help revive the area by creating a globally competitive battery technology development and manufacturing hub. The NENY coalition includes state and local government agencies along with universities and a variety of community and nonprofit organizations. The initiative’s key elements include technology prototyping, supplier identification and certification, workforce development, and start-up incubation, with attention to equity across diverse populations throughout. [24]
The initiative emerged from a longer-term effort by both Binghamton to develop its innovation capacity in the wake of deindustrialization and by the state to target clean energy industries for economic development. A series of grants from federal and state sources, capped by a New York State Energy Research and Development Authority (NYSERDA)-funded clean energy incubator, put Binghamton in position to compete effectively in the new federal grant programs. M. Stanley Whittingham, a Binghamton University distinguished professor who won the Nobel Prize for his contributions to the invention of the lithium-ion battery, played a foundational role in establishing NENY’s credibility. A battery “gigafactory” being developed by iM3NY, on a site where IBM manufactured products from 1911 to 2002, is another anchor asset. [25]
With strong support from the state’s congressional delegation and significant state investments, NENY has run the table in federal grant competitions. It won $63.7 million In EDA’s Build Back Better Regional Challenge to construct a technology and manufacturing development center equipped with state-of-the-art manufacturing lines for the production of full-size battery cells. It was designated as an EDA Tech Hub, enabling it to compete for $50 million to $75 million in the next phase of the program and benefit from preferential treatment in other federal programs. In early 2024, it took home an NSF Regional Engine award worth $15 million over the next two years and up to $160 million in the next decade to carry out R&D, technology translation, and workforce development for the battery industry. NENY and its partners must now execute the challenging commitments they have made to secure these investments. [26]
This section reports illustrative results from the ITIF State and Regional Energy Innovation Index. The weighting scheme used to compile the index is set forth in appendix 1. The full results and the underlying database, which cover all 50 states and the District of Columbia and up to 935 regions (Core-Based Statistical Areas, as defined by the Office of Management and Budget), can be accessed through the ITIF Center for Clean Energy Innovation website. The website allows users to find scores for the overall index, four subindices, and nine functional categories for user-specified states or regions for the years 2016 to 2021. Users can also find the 14 technology-specific versions of these scores and generate charts displaying a location’s functional and technological strengths and weaknesses. The site also features national heat maps of this data.
Table 1 reports the top five and bottom five states in the 2021 Index and their strongest and weakest functional categories and technology areas. States with small populations take the top slots, perhaps because many index categories are scaled by the size of the state population or economy. Nonetheless, the index reveals important strengths and weaknesses. For example, while the Index’s top-ranked state, Vermont, ranks well across most categories, it is especially strong in start-ups (measured by federal Small Business Innovation Research (SBIR) grants, private venture capital investments, and successful company exits). The #2 state, South Dakota, by contrast, does well in technology adoption, thanks to the importance of wind power there, but does relatively poorly in generating and diffusing original research through scientific publications. Neighboring North Dakota, which ranks fifth overall, shows an even sharper contrast, capturing a disproportionate share of federal R&D spending for its size but coming in 48th in the social legitimation subindex due to very low public support for low-carbon energy research and climate action. The technology specializations reveal similar divergences. Hawaii, for instance, ranks last in grid technologies but sixth in solar energy.
Table 1: Top and bottom states and their strengths and weaknesses in the 2021 index
Table 2 reports the top 5 and bottom 5 out of 382 MSAs in the 2021 Index and their strongest and weakest functional categories and technology areas. Like the state index, the regional index reveals important strengths and weaknesses. The top region, which is in central Virginia, for instance, is at the top of the supply chain and market formation subindex, which includes clean energy employment, but only 123rd in the entrepreneurial experimentation subindex. The bottom region, Rome, Georgia, actually matches the top region in the entrepreneurship ranking, but is pulled down by extreme weakness in all the other subindices. Among larger, better-known metro regions, the San Francisco metropolitan region ranks 79th, Chicago 269th, Atlanta 293rd, and New York City 295th out of the 382 MSAs.
Table 2: Top and bottom regions and their strengths and weaknesses in the 2021 Index
Table 3 and table 4 report illustrative results for 5 of the 14 technology areas at the state and regional levels, respectively, for 2021. Vermont’s top ranking in the overall index is reflected in its high ranks in four of these five areas, while Rhode Island, which ranked 34th overall, leads in wind energy technological innovation. Similarly, among MSA regions, Bangor, Maine, ranks 1st in wind energy technological innovation (and 2nd in water technological innovation, which is not shown), but 25th overall and as low as 221st in hydrogen and 230th in nuclear energy.
Table 3: Top ten states across five technology areas in 2021
Table 4: Top ten regions across five technology areas in 2021
Finally, figure 1 and figure 2 compare two states in the middle of the rankings, Massachusetts (ranked 25th) and South Carolina (ranked 26th) to illustrate their functional and technological similarities and differences. Massachusetts outshines South Carolina in entrepreneurship and societal values, while South Carolina displays greater strength in clean energy employment (industry) and technology adoption. Across technological areas, Massachusetts ranks in the top 10 states across most, but in the bottom third in transportation and hydrogen. South Carolina’s top area is nuclear energy, where it ranks 4th, while its worst showing is in energy efficiency, where it ranks 28th.
Figure 1: Functional comparison of Massachusetts and South Carolina

Figure 2: Technological comparison of Massachusetts and South Carolina

South Carolina Nexus for Advanced Resilient Energy
The state of South Carolina entered the modern manufacturing economy in the early 1990s when German automaker BMW sited a new campus there. The auto plant and the industrial ecosystem that grew up around it took the place of a textile industry in decline. A decade later, Boeing began building parts of its 787 Dreamliner in the state, which is now the sole assembly site for the plane. A sprawling network of suppliers grew up around these anchor facilities. Manufacturing production and employment surged as the sector regained its role as a pillar of the state economy. [27]
When the federal Tech Hubs program was announced, the state’s economic development agency had completed a roadmapping exercise that identified further diversification of manufacturing as a key strategy. Burgeoning global markets in fields such as electric vehicles, nuclear power, and renewables beckoned. Tech Hub’s “advanced energy” key technology focus area aligned with this strategy. [28]
The state assembled a broad cross-sectoral coalition to support its Tech Hub proposal, including manufacturers such as Rolls Royce and Westinghouse, utilities, educational institutions, and DOE’s Savannah River National Laboratory, along with numerous state agencies. The South Carolina Nexus for Advanced Resilient Energy (SC Nexus) seeks to create a “globally leading hub driving innovation in core technologies that enable an end-to-end resilient, sustainable energy ecosystem across clean-electricity generation, distribution, and grid-scale storage.” [29] The proposal targets manufacturing of components for nuclear, offshore wind, hydrogen, and solar photovoltaic systems; the creation of a battery innovation and testing ecosystem; and power grid re-engineering. It includes a plan to establish an incubator to support the state’s advanced energy entrepreneurs. [30]
SC Nexus’s designation as a Tech Hub in October 2023 allows it to compete for a phase 2 award of $50 million to $75 million. Its phase 2 application, submitted in February 2024, focuses on manufacturing distributed energy resource systems and enabling their innovative use. It includes testbeds and simulation resources for improving grid operations and security, drawing on DOE and Department of Defense as well as academic capabilities, and a new enegy storage institute that aims to commercialize new technologies for grid-scale use. Whether or not the state wins this award, it plans to continue with the SC Nexus strategy. [31]
Conclusions and Recommendations
Regional innovation ecosystems have the potential to become vital engines of the global transition to low-carbon energy. The creation and strengthening of agile, geographically proximate learning networks of research institutions, suppliers, and producers, loosely coordinated by public and nonprofit regional organizations, offers a promising pathway to drive price and performance improvements in many specialized domains of clean-tech production and use.
The United States ought to be home to many of these ecosystems. As the world’s largest historic source of emissions, it has an obligation to contribute to climate solutions; as the world’s leader in science, technology, and innovation, it has tremendous potential to do so.
The ITIF State and Regional Energy Innovation Index provides a comprehensive map of that potential. This report summarizes indicators that seek to measure a wide range of energy innovation ecosystem functions including knowledge discovery and dissemination, entrepreneurial experimentation, supply chains and market formation, and social legitimation. These indicators are available at multiple geographical levels, including states and metropolitan regions, and cover 14 technological domains.
Economic development organizations in the United States are increasingly cognizant of the potential benefits of clean energy innovation. Recent federal legislation has amplified that awareness and provided resources to act on it. This index provides a baseline against which to measure the impacts of federal programs growing from that legislation in the coming years.
These prospective impacts would be enhanced by sustaining and improving key features of the new programs. We offer several recommendations to this end.
▪ The federal government should continue to support the development and implementation of innovation-based state and regional development strategies, including those relying on clean energy innovation. The economic development programs created by Congress over the last three years are fundamentally sound and long overdue. The CHIPS and Science Act provides the authority to expand several of them substantially. While fiscal conditions may not allow fully authorized levels to be reached for some time, moderate growth is necessary to sustain the institutional momentum that these programs have created at the state and regional levels. The strong bottom-up interest in clean energy innovation ensures that it will have a robust place in state and local strategies as long as federal resources continue to flow. [32]
▪ Federal programs supporting state and regional economic development strategies should continue to use evaluation criteria that enable clean energy innovation. The new programs generally mandate that federal grants address critical national challenges. The Tech Hubs program, for example, includes “advanced energy” as one of its key technology focus areas that may be tackled by applicants. Both the broad requirement to address national challenges and the specific inclusion of clean energy innovation within it are appropriate. Energy security, reliability, and affordability, and limiting the impact of climate change, are long-term, large-scale challenges to which clean energy innovation, rooted in regional industrial clusters, is an essential response. [33]
▪ Federal agencies should support data collection and related research that enable state and regional economic development strategists to make better-informed decisions about the growth potential and resource and asset requirements of industries drawing on clean energy innovation. A major difficulty in devising economic development strategies is that the industries of the future may not look like industries of the past. The infrastructure, skill requirements, supply chains, and technological foundations will evolve and may even transform. The difficulty is particularly acute for clean energy innovation because unabated fossil fuel combustion is so deeply embedded in the core technologies of many legacy sectors. Electric vehicles are very different from conventional cars, and green steelmaking processes look nothing like blast furnaces. While uncertainty about the future cannot be eliminated, a concerted national research program would help reduce it as well as help align expectations across regions about opportunities and threats posed by the energy transition. [34]
▪ Federal programs should continue to support state and regional capacity-building for clean energy innovation so that bottom-up strategies stand a better chance of success. States and regions vary in their sophistication about economic development and administrative capacity to execute strategies. Congress and federal implementing agencies impose uniform requirements that are challenging for a significant fraction of state and regional applicants to fulfill. For instance, the NSF Regional Engines program requires cross-sectoral partnerships that can translate new research into tangible economic outcomes, which many regions lack. The program recognizes that applicants do not start on a level playing field, and it prioritizes “regions … without well-established innovation ecosystems.” [35] For this approach to succeed, the agency will need to be patient, recognize potential as well as achievement in evaluating proposals, and cultivate that potential in the post-award period by encouraging awardees to build capacity.
▪ Federal programs supporting state and regional economic development strategies should strengthen coordination among themselves to reduce the administrative burdens on applicants to these programs and to ensure the programs are mutually complementary. A common theme in the discourse among participants in state and regional economic development policy is application fatigue. Applications for federal funds are lengthy and complex, and are not uniform across agencies. Congressional mandates bind federal agencies to some degree, but agencies have discretion to make the process easier without sacrificing either its legality or effectiveness. Federal program managers are aware of this challenge and have taken steps to address it. NSF and EDA have entered into a formal memorandum of understanding, for instance. They are collaborating to make their place-based grants with overlapping focus areas and regions of service “stackable” and exploring joint reporting, among other things. [36] DOE’s technology-specific programs seem to be less engaged in these interagency processes.
The U.S. economy’s ability to adapt to changing geopolitical, environmental, social, and technological circumstances has been an enduring strength throughout its history. The nation’s regional economies, individually and collectively, are a key element of this strength. This strength will be tested again by the energy transition and global climate change. Public policy at all levels of governance can and should foster regional clean energy innovation ecosystems to enable the nation to pass this latest test.
Appendix 1: Indicators and Weights
(See the PDF, pages 20–42 .)
Appendix 2: Methodology and Sources
(See the PDF, pages 43–59 .)
Appendix 3: Search Strategies
(See the PDF, pages 60–68 .)
Acknowledgments
The authors would like to thank Rob Atkinson, Robin Gaster, and Erica Schaffer of ITIF, Lachlan Carey and colleagues from RMI’s Accelerating Clean Regional Economies initiative, and numerous interviewees for sharing their ideas and experiences with us.
About the Authors
Chad A. Smith is a doctoral student in public policy at George Mason University’s Schar School of Policy and Government
David M. Hart is a professor at George Mason University’s Schar School of Policy and Government. He is a senior fellow at ITIF and the former director of ITIF’s Center for Clean Energy Innovation. Prof. Hart co-authored Energizing America (Columbia University Center for Global Energy Policy, 2020), Unlocking Energy Innovation (MIT Press, 2012), and numerous ITIF reports.
The Information Technology and Innovation Foundation (ITIF) is an independent 501(c)(3) nonprofit, nonpartisan research and educational institute that has been recognized repeatedly as the world’s leading think tank for science and technology policy. Its mission is to formulate, evaluate, and promote policy solutions that accelerate innovation and boost productivity to spur growth, opportunity, and progress. For more information, visit itif.org/about .
[1] . Robin Gaster, Robert D. Atkinson, and Ed Rightor, “Beyond Force: A Realist Pathway Through the Green Transition,” ITIF, July 10, 2023, https://itif.org/publications/2023/07/10/beyond-force-a-realist-pathway-through-the-green-transition/ .
[2] . International Energy Agency, World Energy Outlook 2023 (Paris: IEA, 2023), 101; United Nations, “Causes and Effects of Climate Change,” accessed January 11, 2024, https://www.un.org/en/climatechange/science/causes-effects-climate-change .
[3] . Gaster, Atkinson, and Rightor, “Beyond Force.”
[4] . International Energy Agency, “ETP Clean Energy Technology Guide,” accessed April 5, 2024, https://www.iea.org/data-and-statistics/data-tools/etp-clean-energy-technology-guide .
[5] . Chad Smith and David M. Hart, “The 2021 Global Energy Innovation Index: National Contributions to the Global Clean Energy Innovation System,” ITIF, October 18, 2021, https://itif.org/publications/2021/10/18/2021-global-energy-innovation-index-national-contributions-global-clean/ ; Bjorn T. Asheim, Arne Isaksen, and Michaela Trippl, “The role of the regional innovation system approach in contemporary regional policy: Is it still relevant in a globalised world?” in Asheim and Manuel Gonzalez-Lopez, eds., Regions and Innovation Policies in Europe (Springer 2020).
[6] . Mercedes Delgado, Michael E. Porter, and Scott Stern, “Clusters, Convergence, and Economic Performance,” Research Policy 43:1785-1799 (2014), https://doi.org/10.1016/j.respol.2014.05.007 ; Robert D. Atkinson, Mark Muro, and Jacob Whiton, “The Case for Growth Centers: How to Spread Tech Innovation Across America,” ITIF, December 9, 2019, https://itif.org/publications/2019/12/09/case-growth-centers-how-spread-tech-innovation-across-america/ .
[7] . Frank van der Wouden and Hyejin Youn, “The Impact of Geographical Distance on Learning Through Collaboration,” Research Policy 52(2):104698 (March 2023), https://doi.org/10.1016/j.respol.2022.104698 .
[8] . Philip Cooke, “Transition Regions: Regional-National Eco-Innovation Systems and Strategies,” Progress in Planning 76(3): 105–146 (October 2011), https://doi.org/10.1016/j.progress.2011.08.002 .
[9] . Gordon H. Hanson, “Local Labor Market Impacts of the Energy Transition: Prospects and Policies,” Harvard Kennedy School RWP23-005, January 2023, https://www.hks.harvard.edu/publications/local-labor-market-impacts-energy-transition-prospects-and-policies .
[10] . Michaela Trippl et al., “Unravelling Green Regional Industrial Path Development: Regional Preconditions, Asset Modification and Agency,” Geoforum 111:189–197 (2020), https://doi.org/10.1016/j.geoforum.2020.02.016 ; Laura Corb, et al., “Climate Tech Competitiveness: Can the US Raise Its Game?” McKinsey and Company, October 3, 2022, https://www.mckinsey.com/industries/public-sector/our-insights/climate-tech-competitiveness-can-the-united-states-raise-its-game .
[11] . Raghu Garud, Joel Gehman, and Peter Karnoe, “Winds of Change: A Neo-Design Approach to the Regeneration of Regions,” Organization and Environment 34:634–643 (2019), DOI: 10.1177/1086026619880342; Jeffrey Ball et al., “The New Solar System: China’s Evolving Solar Industry and Its Implications for Competitive Solar in the United States and the World,” Stanford Steyer-Taylor Center for Energy Policy and Finance, March 2017, https://law.stanford.edu/publications/the-new-solar-system/ .
[12] . Shinwei Ng, Nick Mabey, and Jonathan Gaventa, “Pulling Ahead on Clean Technology: China’s 13th Five Year Plan Challenges Europe’s Low Carbon Competitiveness,” E3G, March 2016, https://www.e3g.org/wp-content/uploads/E3G_Report_on_Chinas_13th_5_Year_Plan.pdf ; Asheim, Isaksen, and Trippl, op. cit., 17.
[13] . David M. Hart, “Clean Energy Based Regional Economic Development: Multiple Tracks for State and Local Policies in a Federal System” (ITIF, February 25, 2019), https://itif.org/publications/2019/02/25/clean-energy-based-economic-development-parallel-tracks-state-and-local/ ; Kavita Surana et al., “Regional Clean Energy Innovation,” Global Sustainability Initiative, University of Maryland, February 2020, https://cgs.umd.edu/sites/default/files/2020-02/Final_Regional%20Innovation%20Report_2.20.20.pdf .
[14] . Economic Development Administration, “$1B Build Back Better Regional Challenge,” accessed April 5, 2024, https://www.eda.gov/funding/programs/american-rescue-plan/build-back-better ; White House, “Biden-Harris Administration Announces 31 Regional Tech Hubs,” October 23, 2023, https://www.whitehouse.gov/briefing-room/statements-releases/2023/10/23/fact-sheet-biden-harris-administration-announces-31-regional-tech-hubs-to-spur-american-innovation-strengthen-manufacturing-and-create-good-paying-jobs-in-every-region-of-the-country/ ; Economic Development Administration, “EDA Tech Hubs Phase 1 Fact Sheet,” October 2023, https://www.eda.gov/sites/default/files/2023-10/EDA_TECH_HUBS_Phase_1_Fact_Sheet.pdf ; White House, “Biden-Harris Administration Announces Regional Innovation Engine Awards,“ January 29, 2024, https://www.whitehouse.gov/briefing-room/statements-releases/2024/01/29/fact-sheet-biden-harris-administration-announces-innovation-engines-awards-catalyzing-more-than-530-million-to-boost-economic-growth-and-innovation-in-communities-across-america/ .
[15] . Robin Gaster, “The Hydrogen Hubs Conundrum: How to Fund an Ecosystem,” ITIF, September 12, 2022, https://itif.org/publications/2022/09/12/hydrogen-hubs-conundrum-how-to-fund-an-ecosystem/; Robin Gaster, “Why DOE Should Prioritize Transformational Investments in Industrial Technology,” December 19, 2022, https://itif.org/publications/2022/12/19/why-doe-should-prioritize-transformational-investments-in-industrial-technology/; Energy Futures Initiative Foundation, “Transforming the Energy Innovation Enterprise,” November 8, 2023, https://efifoundation.org/foundation-reports/transforming-the-energy-innovation-enterprise/ ; Noah Kaufman, “The US Needs a Playbook for Place-Based Investments in Fossil Fuel Communities,” Columbia University Center for Global Energy Policy, August 3, 2023, https://www.energypolicy.columbia.edu/the-us-needs-a-playbook-for-place-based-investments-in-fossil-fuel-communities/ .
[16] . Cooke, op. cit. ; Jennifer S. Vey et al., “Assessing Your Innovation District: A How-To Guide,” Brookings Institution, February 21, 2018, https://www.brookings.edu/articles/assessing-your-innovation-district-a-how-to-guide/; Lachlan Carey and Aaron Brickman, “Accelerating Clean Regional Economies: A Great Lakes Investment Strategy,” RMI, September 26, 2023, https://rmi.org/accelerating-clean-regional-economies-a-great-lakes-investment-strategy/ .
[17] . Robert D. Atkinson, Mark Muro, and Jacob Whiton, “The Case for Growth Centers: How to Spread Tech Innovation Across America,” ITIF, December 9, 2019, https://itif.org/publications/2019/12/09/case-growth-centers-how-spread-tech-innovation-across-america/ ; Economic Development Administration, “Tech Hubs Aim to Make United States a Global Leader in Technologies of the Future,” October 20, 2023, https://www.eda.gov/news/blog/2023/10/20/tech-hubs-aim-make-united-states-global-leader-technologies-future ; Economic Development Administration, “Notice of Funding Opportunity,” October 2023, https://www.eda.gov/sites/default/files/2023-10/Tech_Hubs_NOFO_2_FINAL.pdf ? 5.
[18] . EDA, “Notice of Funding Opportunity,” https://www.eda.gov/sites/default/files/2023-10/Tech_Hubs_NOFO_2_FINAL.pdf .
[19] . White House, “31 Regional Tech Hubs;” EDA, “Biden-Harris Administration Designates 31 Tech Hubs Across America,” October 23, 2023, https://www.eda.gov/news/press-release/2023/10/23/biden-harris-administration-designates-31-tech-hubs-across-america ; Economic Development Administration, “Tech Hubs: Benefits of Designation,” October 2023, https://www.eda.gov/sites/default/files/2023-10/EDA_TECH_HUBS_Designation_Benefits.pdf .
[20] . EDA, “Benefits of Designation.”
[21] . EDA, “Notice of Funding Opportunity,” 33–37.
[22] . M.P. Hekkert et al., “Functions of Innovation Systems: A New Approach for Analyzing Technological Change,” Technological Forecasting and Social Change 74:413–432 (2007); Anna Bergek et al., “Analyzing the Functional Dynamics of Technological Innovation Systems: A Scheme of Analysis,” Research Policy 34:407–429 (2008).
[23] . Office of the State Comptroller, “The Changing Manufacturing Sector in Upstate New York,” June 2010, https://www.osc.ny.gov/files/local-government/publications/pdf/manufacturingreport.pdf ; Susanne Craig, “New York’s Southern Tier: Once a Home for Big Business, Is Struggling, September 30, 2015, https://www.nytimes.com/2015/09/30/nyregion/new-yorks-southern-tier-once-a-home-for-big-business-is-struggling.html .
[24] . “New Energy New York Coalition Members” accessed April 5, 2024, https://newenergynewyork.com/#coalition ; American Jobs Project, “The New York Jobs Project,” December 2018, http://americanjobsproject.us/wp/wp-content/uploads/2018/12/The-New-York-Jobs-Project.pdf .
[25] . Per Stromberg, interview, March 5, 2024; BingUNews, “This Is a Big Deal,” February 24, 2022, https://www.binghamton.edu/news/story/3495/this-is-a-big-deal-new-energy-new-york-stakeholders-meet-to-discuss-lithium-ion-battery-manufacturing-proposal ; Spectrum News, “Endicott Prepares for Resurgence,” September 26, 2022, https://spectrumlocalnews.com/nys/binghamton/news/2022/09/25/endicott-prepares-for-resurgence--here-s-how-they-got-here .
[26] . “New Energy New York: Overarching Narrative,” https://www.eda.gov/sites/default/files/2022-09/New_Energy_New_York.pdf ; New Energy New York, “Battery Tech Hub,” https://www.eda.gov/sites/default/files/2023-11/New_Energy_New_York_Battery_Tech_Hub.pdf ; New Energy New York, “NSF Engines: Upstate New York Energy Storage Engine,” https://newenergynewyork.com/nsf-engine-upstate-ny-energy-storage-engine/ .
[27] . Krys Merryman, “BMW’s $26B Impact on South Carolina Economy Still Growing,” SC Biz News, March 22, 2023 https://scbiznews.com/bmws-26b-impact-on-south-carolina-economy-still-growing/ ; Business Facilities, “Boeing To Consolidate 787 Production in South Carolina in 2021, October 6, 2021, https://businessfacilities.com/boeing-to-consolidate-787-production-in-south-carolina-in-2021 ; South Carolina Manufacturers Alliance, “The Impact of Manufacturing in South Carolina,” April 2021, https://scfuturemakers.com/wp-content/uploads/2021/04/SCManufacturingEconomicImpact.pdf .
[28] . Harry Lightsey, interview, February 20, 2024.
[29] . SC Nexus for Advanced Resilient Energy, “Tech Hub Designation Application,” https://www.eda.gov/sites/default/files/2023-11/SC_Nexus_for_Advanced_Resilient_Energy.pdf .
[30] . Ibid.
[31] . “SC Nexus Webinar,” January 3, 2024, https://www.sccommerce.com/sites/default/files/2024-01/20240103_SC%20NEXUS_Webinar_vS_0.pdf ; Lightsey interview.
[32] . Congressional Research Service, “Regional Innovation: Federal Programs and Issues for Consideration,” April 3, 2023, https://crsreports.congress.gov/product/pdf/R/R47495 .
[33] . EDA, “Notice of Funding Opportunity,”
[34] . RMI, “Accelerating Clean Regional Economies: A Great Lakes Investment Strategy,” September 2023, https://rmi.org/accelerating-clean-regional-economies-a-great-lakes-investment-strategy/ .
[35] . NSF, “Regional Innovation Engines Broad Agency Announcement,” May 3, 2022, https://new.nsf.gov/funding/initiatives/regional-innovation-engines/updates/funding-opportunity-nsf-regional-innovation .
[36] . Scott Andes and Alex Jones, interview, February 14, 2024; Joda Thognopnua, interview, February 22, 2024.
Editors’ Recommendations
May 28, 2024
US State and Regional Energy Innovation Index: State Dataviz
Us state and regional energy innovation index: regional dataviz, us state and regional energy innovation index: metropolitan statistical area dataviz, us state and regional energy innovation index: combined statistical area dataviz, us state and regional energy innovation index: metropolitan division dataviz.
- Search Menu
- Sign in through your institution
- Advance Access
- Collections
- Author Guidelines
- Submission Site
- Open Access Policy
- Self-Archiving Policy
- Why Submit?
- About Horticulture Research
- About Nanjing Agricultural University
- Editorial Board
- Advertising & Corporate Services
- Journals on Oxford Academic
- Books on Oxford Academic

Article Contents
Introduction, materials and methods, acknowledgements, author contributions, conflict of interest statement, data availability, supplementary data.
- < Previous
The high-quality genome of Grona styracifolia uncovers the genomic mechanism of high levels of schaftoside, a promising drug candidate for treatment of COVID-19
These authors contributed equally.
- Article contents
- Figures & tables
- Supplementary Data
Shaohua Zeng, Zhiqiang Wang, Dingding Shi, Fangqin Yu, Ting Liu, Ting Peng, Guiqi Bi, Jianbin Yan, Ying Wang, The high-quality genome of Grona styracifolia uncovers the genomic mechanism of high levels of schaftoside, a promising drug candidate for treatment of COVID-19, Horticulture Research , Volume 11, Issue 5, May 2024, uhae089, https://doi.org/10.1093/hr/uhae089
- Permissions Icon Permissions
Recent study has evidenced that traditional Chinese medicinal (TCM) plant-derived schaftoside shows promise as a potential drug candidate for COVID-19 treatment. However, the biosynthetic pathway of schaftoside in TCM plants remains unknown. In this study, the genome of the TCM herb Grona styracifolia (Osbeck) H.Ohashi & K.Ohashi (GSO), which is rich in schaftoside, was sequenced, and a high-quality assembly of GSO genome was obtained. Our findings revealed that GSO did not undergo recent whole genome duplication (WGD) but shared an ancestral papilionoid polyploidy event, leading to the gene expansion of chalcone synthase ( CHS ) and isoflavone 2′-hydroxylase ( HIDH ). Furthermore, GSO-specific tandem gene duplication resulted in the gene expansion of C-glucosyltransferase ( CGT ). Integrative analysis of the metabolome and transcriptome identified 13 CGTs and eight HIDHs involved in the biosynthetic pathway of schaftoside. Functional studies indicated that CGTs and HIDHs identified here are bona fide responsible for the biosynthesis of schaftoside in GSO, as confirmed through hairy root transgenic system and in vitro enzyme activity assay. Taken together, the ancestral papilionoid polyploidy event expanding CHSs and HIDHs , along with the GSO-specific tandem duplication of CGT, contributes, partially if not completely, to the robust biosynthesis of schaftoside in GSO. These findings provide insights into the genomic mechanisms underlying the abundant biosynthesis of schaftoside in GSO, highlighting the potential of GSO as a source of bioactive compounds for pharmaceutical development.
Recently, it has been reported that traditional Chinese medicine has demonstrated efficacy in treating coronavirus disease 2019 (COVID-19) caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [ 1 ]. Recent study has also evidenced that schaftoside inhibits the 3CL pro and PL pro of SARS-CoV-2 virus, while also enhancing the immune response of host cells treated by COVID-19. This dual mechanism positions schaftoside as a promising candidate for the treatment of COVID-19 [ 2 ]. In 2022, the total flavonoids capsule derived from Herba Desmodii styracifolii , an innovative traditional Chinese medicine, received approval from the National Medical Products Administration of China (Z20220003). According to the Chinese pharmacopoeia, schaftoside is the characteristic compound of Herba Desmodii styracifolii , which is obtained from the dried aerial parts of the Desmodium styracifolium Merr. plant. This herb is known for its significant therapeutic effects on the conditions such as urination disturbance, urolithiasis, edema, and jaundice [ 3 ]. Recently, D. styracifolium was taxonomically renamed as Grona styracifolia (Osbeck) H.Ohashi & K.Ohashi, hereafter referred to as GSO ( Fig. 1A ) [ 4 ]. GSO contains abundant terpenoids and flavonoids, which are primarily responsible for its pharmacological properties. The key flavonoids present in GSO are schaftoside (Apigenin-6C-Glucoside-8C-Arabinoside) and isoschaftoside (Apigenin-6C-Arabinoside-8C-Glucoside), which exhibit diverse biological activities, including anti-respiratory syncytial virus, antidiabetic properties, antihypertensive effects, hepatoprotective benefits, and anti-inflammatory actions [ 5 ]. Furthermore, schaftoside has been shown to have positive effects in various conditions, such as treating pentylenetetrazol-induced seizures [ 6 ], exerting anti-melanogenic activity [ 7 ], alleviating nonalcoholic fatty liver disease induced by a high-fat diet [ 8 ], and restoring renal function [ 9 ].

The GSO plants and its genome landscape. A the phenotype of GSO. B intensity heat map of Hi-C chromosome interaction for GSO; The high probabilities of contact is denoted by red yellow pixels. Most interactions were observed within the chromosomes. C the genome landscape of GSO. a, pseudochromosomes number and length (on a Mb scale); b–d, the gene expression level at 10ML/10MS/10MR, separately; e, distribution of Gypsy-type transposons (sliding window size 100 Kb); f, distribution of Copia-type transposons (sliding window size 100 Kb); g, the density of genes; h, the distribution of GC content (sliding window size 100 Kb); i, genome synteny.
Although the biosynthesis of aglycone apigenin has been extensively studied, little is known about the modification/decoration of apigenin derivatives such as schaftoside, which was recently predicted in the related plant Desmodium spp. [ 10 ]. Furthermore, the C-glycosyltransferase enzymes responsible for biosynthesizing C-glycosylated flavonoids have been characterized [ 5 ]. However, the exact biosynthetic pathway of schaftoside in GSO remains unknown. Additionally, the genomic mechanisms underlying the robust biosynthesis of schaftoside in GSO are not well understood. Recently, whole-genome sequencing technology has been successfully employed to study the specialized metabolites in medicinal plants such as Astragalus sinicus [ 11 ], Cercis chinensis [ 12 ], and Morinda officinalis [ 13 ]. Genomic information serves as a foundation for identifying functional genes, facilitating the molecular breeding, and improving the quality of medicinal materials [ 14 ]. However, the genome sequence of GSO has been not yet reported to date, which severely restricts the functional genomics and molecular breeding in GSO.
In this study, the genome of GSO was sequenced and de novo assembled through a combination of advanced technologies to elucidate its genomic characteristics, including PacBio sequencing, Illumina sequencing, and Hi-C technology. Comparative Genomics with other sequenced legume species, along with integrative analysis of transcriptome and metabolome data, were performed to obtain fundamental insights into the genetic mechanisms underlying flavonoids biosynthesis, particularly schaftoside production. Our findings reveal that GSO did not undergo recent whole genome duplication (WGD) but experienced an ancestral papilionoid polyploidy event, leading to the gene expansion of chalcone synthase ( CHS ) and isoflavone 2′-hydroxylase ( HIDH ). GSO-specific tandem gene duplication resulted in the gene expansion of C-glucosyltransferase ( CGT ), which resulting in the robust biosynthesis of schaftoside in GSO. The reference genome of GSO obtained here will serve as a valuable resource for elucidating the biosynthesis of bioactive ingredients and facilitating the genetic improvement of G. styracifolia .
Genome sequencing and annotation
In this study, the GSO genome was sequenced and de novo assembled using a combination of technologies to elucidate its genomic characteristics, including PacBio CLR sequencing, Illumina sequencing, and Hi-C sequencing ( Table S1 , see online supplementary material). Genome survey indicates that the estimated genome size of GSO is 638.82 Mb, with a heterozygosity rate of 0.152% and a transposable elements (TEs) ratio of 72.13% ( Fig. S1 , see online supplementary material). Flow cytometry estimated the genome size to be 581.2 Mb ( Table S2 , Fig. S2 , see online supplementary material). The resulting GSO assembly consisted of 11 chromosomes with a genome size of 641.82 Mb and an N50 contig/scaffold of 14.28/57.49 Mb ( Fig. 1B and C; Table S3, see online supplementary material). It seems that the genome size of GSO is slightly larger than its derivatives common bean ( Phaseolus vulgaris L., 587 Mb) [ 50 ] and mung bean ( Vigna radiate , 579 Mb) [ 51 ], which might be attributed to the higher ratio of TEs in GSO genome when compared to P. vulgaris (45.4%) and V. radiate (50.1%). Based on the combined data from ab initio , homology-based analyses, and RNA sequencing-assisted annotation, the GSO genome contains 35 865 protein-coding genes ( Table S4 and Fig. S3 , see online supplementary material), which is significantly higher than P. vulgaris (27197) and V. radiate (22427) [ 50 , 51 ].

Phylogenetic and evolutionary analysis of GSO. A Divergence time estimation and gene family expansion/contraction analyses. The numbers on the nodes represent the divergence time of the species (million years ago, Mya), with confidence range in brackets. The gain (expansion) and loss (contraction) number of gene families were indicated by green and grey pies, respectively. The red star indicates the whole genome duplication event shared by the legume species. The orange circle indicates the tandem duplication in GSO. B Distributions of synonymous substitutions per site ( Ks ) of syntenic blocks of GSO paralogs and orthologs with other eudicots. C Four-fold synonymous (degenerative) third-codon transversion (4Dtv) of one-to-one orthologs identified between GSO, Glycine max , Lupinus albus , Lotus japonicus , Medicago truncatula , and Phaseolus vulgaris . D Venn analysis of common and species-specific gene families in GSO genome.
The quality of the assembled genomes was assessed through various analyses. Firstly, the high LTR assembly index (LAI) score of 19.0 indicated that the continuity of the GSO genome approached to reference quality ( Fig. S4 , see online supplementary material). Secondly, 93.5% to 97.8% of the Illumina reads successfully mapped to the genome assembly, supporting a high level of genome coverage ( Table S5 , see online supplementary material). Thirdly, a total of 98.6% (1365) of core genes was identified in the GSO genome using the Core Eukaryotic Genes Mapping Approach (CEGMA) analysis ( Table S6 , see online supplementary material). Furthermore, the Benchmarking Universal Single-Copy Orthologs (BUSCO) assessment indicated that 98.2% and 94.8% of BUSCO gene models for genome assembly and predicted coding genes were respectively identified, suggesting the near completeness of genome assembly and annotation ( Table S7 , see online supplementary material). These findings demonstrate the high quality of the GSO genome assembly and annotation.
Genome duplication and evolution analysis
To investigate the evolution of GSO in the legume family, Arabidopsis, rice, and five sequenced legume species, including Glycine max , Medicago truncatula , Lupinus albus , Lotus japonicus , and P. vulgaris were compared, which resulted in the identification of 28 193 gene families and 658 single-copy genes ( Fig. 2A ; Figs S5 and S6 , see online supplementary material). Maximum-likelihood phylogenetic analysis using the single-copy genes revealed that GSO is closely related to G. max and P. vulgaris . MCMCTree analysis showed that P. vulgaris and G. max diverged at 24.59 m illion y ears a go (MYA), which is similar to the previous estimation [ 50 ], and that the palaeopolyploidy event shared by all bean-like (papilionoid) legume species occurred at ~65 MYA, which is consistent to previous studies [ 52 ]. According to the MCMCTree analysis, GSO and G. max diverged at approximately 29.67 MYA ( Fig. 2A ).
Whole genome duplication (WGD) is an important evolutionary force contributing to the diversity of specialized metabolites in plants [ 53 ]. In addition, WGD is a ubiquitous feature and an evolutionary driver of genetic innovations in flowering plants [ 54 , 55 ]. Synonymous substitutions per site ( Ks ) and 4-fold synonymous third-codon transversion (4DTv) rates of the duplicated gene pairs were investigated to assess the occurrence of WGD events in GSO. The genome synteny and Ks values of paralogs and orthologs among GSO, G. max , M. truncatula , and Vitis vinifera genomes were investigated.
The intra-genomic collinearity showed that the GSO experienced only one WGD event (Papilionoideae-common WGD) after the core-eudicot whole-genome triplication (WGT, or γ event) ( Fig. S7 , see online supplementary material). In contrast, the G. max underwent two rounds of polyploidization (Gm-beta and Gm-alpha genome duplications) ( Fig. S7, see online supplementary material ) [ 56 , 57 ]. The median Ks value of paralog gene pairs on synteny blocks from the GSO genome was about 0.75, while the Gm-beta and Gm-alpha corresponded to the median Ks values of ~0.1 and ~ 0.75, indicating they may share a WGD events ( Figs S7 and S8, see online supplementary material ). Subsequently, the well-characterized grape ( V. vinifera ) genome, which is a relatively stable genome and is likely not affected by any polyploidization event after the γ event [ 58 ], was used as a reference for inter-genomic dotplot comparison with GSO and G. max . If there had been an extra diploidization event in GSO, assuming no DNA loss, we would expect a grape gene (or chromosomal region) to have four best-matched or orthologous GSO genes (chromosomal regions). However, the ratios of the best-matched orthologous regions between two species (GSO and G. max ) and V. vinifera were 2:1 and 4:1, respectively ( Figs S9 – S11, see online supplementary material ). Moreover, G. max and M. truncatula compared with GSO show a 2:1 and 1:1 result, respectively ( Figs S12 and S13 , see online supplementary material). In summary, our findings suggest that GSO did not experience a recent WGD but instead shared a papilionoideae WGD event described in a previous study [ 59 ] ( Fig. 2C and D ).
Gene family analysis
Positive selection is a critical driving force for gene neofunctionalization in species [ 60 , 61 ]. To evaluate the positive selection in GSO, the Ka/Ks ratio of the single-copy genes was calculated. A total of 82 genes undergo positive selection ( P < 0.05) and are over-represented in gene ontology (GO) terms related to ‘meiotic chromosome segregation’, ‘DNA topoisomerase’, ‘DNA repair’, and ‘homologous recombination’ ( Fig. S14 and Tables S8 – S10, see online supplementary material ). OrthoMCL analysis indicated that a total of 32 633 (91.0%) genes were categorized into 17 607 gene families, with 930 of them being specific to GSO ( Fig. 2B ; Table S11 , see online supplementary material). As shown in Fig. S15 and Tables S12 and S13 (see online supplementary material), the KEGG pathway related to the indeterminate nodule organogenesis, including ‘cell cycle’, ‘DNA replication’, ‘Plant-pathogen interaction’, and ‘NOD-like receptor signaling pathway’ are over-represented, which agree with previous study [ 11 ]. Notably, ‘Flavonoid biosynthesis’ and ‘flavone and flavonol biosynthesis’ are also enriched. These results suggest that the evolutionarily generated species-specific gene families contribute to active nodule organogenesis and flavonoid production in GSO.
The CAFE analysis revealed that GSO has expanded 233 gene families and contracted 86 gene families ( Fig. 2A ). KEGG enrichment analysis of the expanded genes showed an overrepresentation of pathways such as ‘DNA replication’, ‘nucleotide excision repair’, ‘homologous recombination’, ‘mismatch repair’, ‘plant-pathogen interaction’, ‘phenylpropanoid biosynthesis’, ‘anthocyanin biosynthesis’, and ‘isoflavonoid biosynthesis’ ( Fig. S16 and Table S14, see online supplementary material ). These results suggest a significant expansion of genes related to secondary metabolic pathways, particularly nodule organogenesis-related flavonoid genes. GO enrichment analysis of the expanded genes indicated involvement in processes such as ‘flavonoid metabolic process (18 genes)’, ‘UDP-glycosyltransferase activity (UGT, 34 genes)’, O-methyltransferase activity (31 genes), and ‘monooxygenase activity (83 genes)’ ( Fig. S16 and Table S15 , see online supplementary material). Notably, among the expanded UGTs, a cluster of 13 UGTs belonging to the UGT708 clade encoding C-glucosyltransferase (CGT) was found on chromosome 7 (Chr7) ( Fig. S17 , see online supplementary material). Previous studies documented that CGT is involved in C-glycosylation of flavonoids [ 62 , 63 ]. These findings suggest that the expanded CGTs in GSO may contribute to the high levels and diversity of flavonoid C-glucosides. Among the expanded O-methyltransferase genes, 10 genes encode isoflavone-7-O-methyltransferase (IF7OMT) clustered on Chr4. Similarly, 21 out of 83 expanded monooxygenase genes encode isoflavone 2′-hydroxylase (I2’H). Additionally, 10 copies of 2-hydroxyisoflavanone dehydratase (HIDH) were also expanded ( Fig. 3 ). The GSO assembly contains 17 chalcone synthase (CHS) gene members, confirming the expansion of the CHS gene family in legume species [ 11 ]. These findings support the hypothesis that an ancestral polyploidy event led to the expansion of flavonoid biosynthetic genes, including CHS , HIDH , I2’H , and IF70MT , in the papilionoideae [ 59 ]. This conclusion is further supported by the gene number, phylogenetic tree, and collinear analysis in legume species ( Figs S18 – S24, see online supplementary material ). As mentioned above, the GSO genome did not undergo a recent WGD event. Taken together, our findings suggest that the papilionoideae WGD event, leading to the expansion of CHS and HIDH genes, and the GSO-specific CGT tandem duplication contribute to the robust biosynthesis of flavonoids in GSO, especially for schaftoside.

The biosynthesis of schaftoside in GSO. A the biosynthetic pathway of schaftoside. B The collinear relationship of CGT in GSO, Glycine max , Medicago truncatula , Lupinus albus , Lotus japonicus , and Phaseolus vulgaris . The orange box indicated GsCGTs in GSO. The forward and reverse directions of genes on chromosomes are labeled with green and blue box, respectively. The syntenic blocks are connected by light-green lines. C The number of CHS (chalcone synthase), CGT (C-glycosyltransferase), and HIDH (2-hydroxyisoflavanone dehydratase) in GSO and other seven species. D The expression profile of schaftoside and its predicted biosynthetic genes in roots, stems, and leaves. E The co-expression network of schaftoside and biosynthetic genes. The shape size is proportional to the number of nodes linked, and the line thickness is proportional to the size of the correlation.
Uncovering the schaftoside biosynthetic pathway in GSO
To dissect the schaftoside biosynthesis in GSO, a potential pathway for schaftoside is proposed based on previous studies [ 5 , 10 ], which include 17 CHSs , five CHIs , six F2Hs , 13 CGTs , and 10 HIDHs structural genes in GSO assembly ( Fig. 3A ). To further elucidate the genomic mechanism behind the abundant biosynthesis of schaftoside in GSO, the synteny analysis was performed. As shown in Fig. 3B and Figs S22 and S25 (see online supplementary material), CGT , CHS , and HIDH undergo tandem gene duplication events in GSO, resulting in a higher number of CGTs in GSO compared to other legume species ( Fig. 3C ). The diverse expression profile of CHS , CGT , and HIDH members suggest the neo/subfunctionalizational role of these duplicated genes in the biosynthesis of schaftoside ( Fig. 3D ). The metabolome and transcriptome of eight-month-old roots stems, and leaves are integrated to identify candidate CGT and HIDH genes responsible for schaftoside biosynthesis. A total of 10 251 DEGs and seven metabolites involved in the biosynthetic pathway of (iso)schaftoside were selected for WGNCA analysis. As shown in Fig. S26 (see online supplementary material), the MEblue and MEturquoise modules were found to be significantly associated with (iso)schaftoside biosynthesis compared to other modules. WGCNA analysis indicated that 13 CGTs and eight HIDHs , located within the MEblue or MEturquoise modules, are involved in the biosynthetic network of schaftoside ( Fig. 3E ; Fig. S25, see online supplementary material ).
To validate the function of candidate genes and understand the biosynthetic pathway of schaftoside in GSO, CGTa (Gs07G20770), CGTb (Gs07G20750), and HIDH (Gs10G00790) were selected for metabolic engineering in Escherichia coli for functional characterization according to the WGCNA results. As shown in Fig. 4A and B , overexpression of CGTa (Gs07G20770), or CGTa (Gs07G20770) coupled with CGTb (Gs07G20750), produces C-glucosyl-2-hydroxynaringenin and C-glucosyl-C-arabinosyl-2-hydroxynaringenin, respectively, when 2-hydroxynaringenin is used as substrate. Additionally, coexpression of CGTa (Gs07G20770), CGTb (Gs07G20750), and HIDH (Gs10G00790) in E. coli successfully produces (iso)schaftoside ( Fig. 4B and C ). Furthermore, overexpression of CGTa (Gs07G20770) or CGTb (Gs07G20750) in GSO hairy roots also enhances the content of (iso)schaftoside ( Fig. 4E and H ). These results confirm that the CGTs and HIDHs identified in this study are bona fide involved in the biosynthesis of schaftoside in G. styracifolia .
![Functional characterization of GsCGTa, GsCGTb, and GsHIDH involved in biosynthesis of schaftoside (4) and isoschaftoside (4′). A The corresponding biosynthetic pathway for the stepwise formation of (4) and (4′). CHS, chalcone synthase; CHI, chalcone isomerase; CGT, C-glycosyltransferase; F2H, favanone 2-hydroxylase; HIDH, 2-hydroxyisoflavanone dehydratase. B The in vitro enzymes activity assay of GsCGTa, GsCGTb, and GsHIDH. Recombinant GsCGTa, GsCGTb, and GsHIDH enzyme produced in Escherichia coli cells with 2-hydroxynaringenin (1) as substrate leads to stepwise transformation into (4) and (4′). C (−)-ESI-MS and MS [2] spectra of (4) and (4′). D The relative intensity of the verified pathway intermediates/products observed upon the addition of GsCGTa, GsCGTb, and GsHIDH enzymes, as measured by HPLC analysis. E Positive hairy roots transgened by empty vector (EV) and GsCGT construct with GFP marker were detected under bright field and fluorescence. F Transcript levels of GsCGTs in EV and in overexpression (OE) lines were detected using qPCR. G Relative protein abundance of GsCGTs in EV and OE lines. H Relative content of schaftoside and isoschaftoside in EV and OE lines. Data are presented as mean values ± SD (n = 5 independent biological replicates). Significant differences (P-values <0.05) between the groups were showed with Student’s t-test in F or variance (ANOVA) combined with Duncan’s multiple range test.](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/hr/11/5/10.1093_hr_uhae089/2/m_uhae089f4.jpeg?Expires=1719970197&Signature=sMDRBRDx6wsjs3RU3rmVSGhl9VmZFLDgmEdISOxPj6wUcc9QMOrUkmnYkNZWyABmjhyLe7NEJiDEwqAaqzhFIDnr9NYiSL~dznRK0rRaAMpH~DlGcQJw6D7uOBfCIaTBswR-KyXtdUGv5FodQG1Yvj2Ajh3v32lC4IC~TT0XPXBZ9NmrEK5UVC2~U2L88iIyZlmesHRn9PGWdVB2dseRkp3L~a3v5munwWE4YJ8OYAD~FnX0Q71iN0~Sgv7H4gDW8br11f43ep8i4WQlg~YLyVFWTZul82lZWSBJwQqkY8tcGPHfFRtaEYfkWQUj4R0AdRBaIz0rFQHegGDEoIKWGA__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "introduction of research")
Functional characterization of GsCGTa, GsCGTb, and GsHIDH involved in biosynthesis of schaftoside (4) and isoschaftoside (4′). A The corresponding biosynthetic pathway for the stepwise formation of (4) and (4′). CHS, chalcone synthase; CHI, chalcone isomerase; CGT, C-glycosyltransferase; F2H, favanone 2-hydroxylase; HIDH, 2-hydroxyisoflavanone dehydratase. B The in vitro enzymes activity assay of GsCGTa, GsCGTb, and GsHIDH. Recombinant GsCGTa, GsCGTb, and GsHIDH enzyme produced in Escherichia coli cells with 2-hydroxynaringenin (1) as substrate leads to stepwise transformation into (4) and (4′). C (−)-ESI-MS and MS [ 2 ] spectra of (4) and (4′). D The relative intensity of the verified pathway intermediates/products observed upon the addition of GsCGTa, GsCGTb, and GsHIDH enzymes, as measured by HPLC analysis. E Positive hairy roots transgened by empty vector (EV) and GsCGT construct with GFP marker were detected under bright field and fluorescence. F Transcript levels of GsCGTs in EV and in overexpression (OE) lines were detected using qPCR. G Relative protein abundance of GsCGTs in EV and OE lines. H Relative content of schaftoside and isoschaftoside in EV and OE lines. Data are presented as mean values ± SD ( n = 5 independent biological replicates). Significant differences ( P -values <0.05) between the groups were showed with Student’s t -test in F or variance (ANOVA) combined with Duncan’s multiple range test.
G. styracifolia is a renowned traditional medicinal plant recognized for its high content of schaftoside, which is the characteristic bioactive component recorded in Chinese pharmacopoeia for its therapeutic effects such as urination disturbances, urolithiasis, and jaundice. Recently, schaftoside has also been discovered to possess potential in the treatment of COVID-19 [ 2 ]. Although G. styracifolia biosynthesizes and accumulates a large amount of schaftoside, the underlying genomic mechanism responsible for its biosynthesis remains elusive. The advent of third-generation high-throughput sequencing has greatly enhanced the ability to obtain high-quality genomes, as demonstrated in species like A. sinicus [ 11 ], C. chinensis [ 12 ], and Magnolia biondii [ 13 ], enabling a deeper understanding of the biosynthesis and regulation of specialized metabolites in these plants. In this study, a comprehensive approach was employed to sequence the genome of G. styracifolia , resulting in a near-complete genome assembly with 19.0 LAI, 98.6% CEGMA, and 98.2% BUSCO completeness.
The genomic analysis of GSO revealed an expansion of 233 gene families and a contraction of 86 gene families ( Fig. 2A ). Particularly, there was enrichment observed in flavonoid-related biosynthetic pathways, potentially contributing to the high levels of flavonoids such as schaftoside. Moreover, 34 UDP-glycosyltransferase genes were found to be overrepresented, with 13 of them encoding UGT708 subclade CGTs arranged in tandem on Chr7. Interestingly, WGD analysis indicated that the GSO assembly did not undergo a recent genome duplication event. This suggests that the gene cluster containing the 13 UGT708 genes likely arose from a tandem duplication event rather than a WGD event. Additionally, the common papilionoideae genome duplication event was found to have contributed to the expansion of CHS and HIDH genes in the GSO assembly, consistent with a previous study [ 59 ]. Furthermore, functional characterization studies confirmed the involvement of CGTa (Gs07G20770), CGTb (Gs07G20750), and HIDH (Gs10G00790) in the biosynthesis of schaftoside in G. styracifolia . As a result, the biosynthetic pathway of schaftoside in G. styracifolia has been completely elucidated in this study.
In conclusion, a high-quality GSO assembly was obtained, which did not undergo a recent genome duplication event but shared an ancestral papilionoid polyploidy event, leading to the expansion of CHS and HIDH . Additionally, a GSO-specific tandem gene duplication event resulted in the CGT expansion in the GSO genome. Taken together, the ancestral papilionoid polyploidy event expanding CHSs and HIDHs , along with the GSO-specific tandem duplication of CGT , contributes, at least partially, to the robust biosynthesis of schaftoside in GSO.
Plant materials and genome-survey analysis
Young leaves were harvested from seedlings of G. styracifolia grown at the South China Botanical Garden, Chinese Academy of Sciences, for the purpose of isolating genomic DNA. The isolated DNA was subsequently utilized for Illumina, PacBio, and Hi-C sequencing. A total of 93.33 gigabase (Gb) of clean paired-end reads were obtained through sequencing on the Illumina HiSeq 6000 platform (Illumina, San Diego, CA, USA). These reads were then subjected to filtering using SOAPnuke software v2.0.2 [ 15 ]. Genome survey analysis was conducted by examining K - mer distribution ( K = 17) with Jellyfish (v2.3.0) [ 16 ] and GenomeScope [ 17 ] software to predict genome size, heterozygosity, and repeat-sequence characteristics.
Genome sequencing, assembly, and quality assessment
The subreads obtained through PacBio sequencing were assembled into contigs using NextDenovo (v2.5.2) ( https://github.com/Nextomics/NextPolish ). The resulting consensus genome was refined by aligning it to the PacBio subreads using minimap2 (v2.24) [ 18 ] and undergoing three rounds of corrections with Racon (v1.4.21) [ 19 ]. Subsequently, the 10X Genomics data was mapped to the assembled genome using BWA-MEM (v0.7.17) [ 20 ] with default parameters. FragScaff ( https://github.com/adeylab/fragScaff ) was employed for scaffolding. In addition, Illumina reads were utilized to improve the GSO assembly using Pilon (v1.23) [ 21 ]. Chromosome-level assembly was facilitated using Hi-C technology through Juicer (v2.041) [ 22 ] and 3D-DNA (v180922) [ 23 ]. The final assembly was assessed using BUSCO v5.1.2 [ 24 ] (fabales_odb10), CEGMA [ 25 ] and LAI (LTR Assembly Index) [ 26 ]. The multi-omics data has been deposited in National Genomics Database Center (NGDC, https://ngdc.cncb.ac.cn/?lang=zh ) under the accession number PRJCA016945.
Genome annotation
The repeat sequence structures within the GSO genome were identified and masked using RepeatModeler ( http://www.repeatmasker.org/RepeatModeler.html ) and RepeatMasker ( http://www.repeatmasker.org , v3.3.0), respectively. A comprehensive approach was then employed for gene structure annotation, integrating homology-based, de novo gene prediction, and transcriptome-based prediction methods. Initially, homologous proteins from Arabidopsis thaliana , Oryza sativa , Glycine max , and Phaseolus vulgaris were aligned to the masked GSO genome using TblastN [ 27 ] with an E-value threshold of 1e-5. Subsequently, the BLAST hits were merged using Solar [ 28 ]. GeneWise ( https://www.ebi.ac.uk/Tools/psa/genewise ) was utilized for precise gene structure prediction. Next, GeneMark-ET and AUGUSTUS, integrated within the BRAKER2 framework [ 29 ], were employed for ab initio gene prediction. RNA-seq reads aligned to the masked genome by HISAT2 [ 30 ] were assembled to predict transcripts using Stringtie [ 31 ]. The results from the aforementioned methods were integrated using EVidenceModeler (EVM) ( http://evidencemodeler.sourceforge.net/ ) to generate a non-redundant set of gene structures [ 32 ], which were further refined and updated by PASA. For gene annotation, the resulting genes sets were compared against several databases, including SwissProt, NR, InterPro ( http://www.ebi.ac.uk/interpro/ , V32.0), Pfam ( http://pfam.xfam.org/ , V27.0), InterProScan (V4.8), HMMER ( http://www.hmmer.org/ , V3.1), GO ( http://www.geneontology.org/page/go-database ), and KEGG ( http://www.kegg.jp/kegg/kegg1.html , release 53) databases based on sequence similarity and domain conservation.
Comparative genomics analyses
In order to investigate the evolutionary relationship of the GSO genome among legume species, protein sequences from five leguminous species, namely G. max , L. albus , L. japonicus , M. truncatula , and P. vulgaris were selected for analysis. In addition, two model plants, A. thaliana and O. sativa , were included as outgroup species. The protein families were classified using OrthoFinder v2.5.1 [ 33 ] through a blast analysis with default parameters in diamond. Subsequently, the gene families were annotated using the Pfam 33.1 database. Single-copy gene families were aligned and identified using MAFFT v7.205 [ 34 ] and Gblocks v0.91b [ 35 ]. The well-aligned gene family sequences for each species were concatenated end-to-end to create supergenes, and the alignments of each gene family were combined into a super-alignment matrix. A maximum likelihood (ML) phylogenetic tree was constructed using RAxML ( http://sco.h-its.org/exelixis/web/software/raxml/index.html ) with the optimal model determined by ModelFinder [ 36 ] implemented in IQ-TREE [ 37 ]. The MCMCTree program ( http://abacus.gene.ucl.ac.uk/software/paml.html ), part of the Phylogenetic Analysis by Maximum Likelihood (PAML) [ 38 ], was employed to infer divergence times based on the phylogenetic tree, with calibration points selected from the TimeTree database ( http://timetree.org ) for A. thaliana and O. sativa . The CAFE 4.2 (Computational Analysis of gene Family Evolution) program [ 39 ] was utilized to evaluate the expansion and contraction of gene families relative to their ancestors. Additionally, the CodeML program in PAML was applied to identify genes under positive selection. Finally, GO and KEGG enrichment analysis were conducted using ClusterProfiler v4.0 [ 40 ] for the expanded, contracted, and positively selected genes, respectively.
Genome synteny and whole-genome duplication (WGD) analysis
To identify syntenic blocks across different species, the protein sequences of G. max , L. albus , L. japonicus , M. truncatula , P. vulgaris , A. thaliana , and O. sativa were subjected to self and cross-species searches using DIAMOND v0.9.29.130 [ 41 ]. Syntenic block regions containing a minimum of five gene pairs were defined using MCScanX [ 42 ]. The Ks (synonymous mutation rate) and 4DTv (fourfold synonymous third-codon transversion rate) methods were employed to detect whole-genome duplication events (WGDs). JCVI v0.9.13 was utilized for visualizing synteny blocks between chromosomes. Additionally, wgdi [ 43 ] was used to validate the occurrence of WGD events in the GSO species.
Transcriptome and metabolism analysis
Total RNA was extracted from various tissues of GSO, including the root, stem, leaf, and flower, to construct transcriptome sequencing libraries. The alignment of reads filtered by fastp v0.23.2 [ 44 ] to the GSO genome was performed using HISAT2 [ 30 ]. Subsequently, SAMtools [ 45 ] was employed to convert the alignment results to bam format, and featureCounts [ 46 ] was used to generate the reads count matrix. Differential expression analysis was carried out using DESeq2 [ 47 ], with the criteria of P- adj < 0.05 and |Log2FC| > = 1 for identifying differentially expressed genes (DEGs). Metabolome analysis was conducted on the root, stem, and leaf tissues using LC–MS/MS method as described in a previous study [ 48 ]. Differential accumulation of metabolites (DAMs) was identified using the OPLS-DA method, with the criteria of VIP > = 1 and |Log2FC| > = 1. The weighted gene co-expression network analysis (WGCNA) strategy employed in this study followed a previous study [ 49 ]. In brief, after filtering out genes with low expression (average FPKM <1), DEGs with a coefficient of variation (CV) > 0.5 were selected for co-expression network module generation using the WGCNA package in R. The co-expression modules were constructed using the blockwiseModules function with default parameters, a soft-threshold power of 2, TOMtype set to signed, mergeCutHeight of 0.25, and minModuleSize of 30. Seven metabolites involved in the (iso)schaftoside biosynthetic pathway were selected for WGCNA analysis in this study.
Expression and purification of GsCGTs and GsHIDH in E. coli
Total RNA was extracted from the stem, root, and leaf tissues of GSO using the HiPure Total RNA Plus Mini Kit (Magen, China). The extracted RNA was then utilized to synthesize first-strand cDNA with the PrimeScript™ II 1st Strand cDNA Synthesis Kit (Takara, Japan). The genes GsCGTs or GsHIDH were integrated into the Nde I/Hind III cloning sites of the pCold II vector (Takara, Japan) via homologous recombination using the Fast DNA Assembly Mix kit (#E0201L) from Shanghai Moqian Biosciences Co., Ltd, China. The constructed vectors were validated through sequencing by Beijing Tsingke Biotech Co., Ltd, China. Subsequently, the resulting vectors were introduced into E. coli BL21(DE3) strain for heterologous expression.
Single colonies were cultured in 100 mL LB medium supplemented with ampicillin (100 mg/L) and grown at 37°C until reaching an optical density of approximately 0.6 at 600 nm. Following pre-cooling for 20 minutes, the 6 × His-tagged fusion protein were induced with 0.1 mM IPTG at 15°C for 20 h. The recombinant proteins were purified using Ni-NTA agarose (Qiagen, Germany), and the target protein was eluted with elution buffer (50 mM NaH 2 PO 4 pH 8.0, 300 mM NaCl, 250 mM imidazole). The eluate was concentrated using Amicon Ultra-15, PLTK Ultracel-PL 10 kDa (Merck Millipore, Germany). Finally, the purified protein was desalted with storage buffer (50 mM NaH 2 PO 4 pH 8.0, 20% glycerol) and stored at −80°C. A 10 μL aliquot of the supernatant was taken for SDS-PAGE analysis.
Enzyme activity assay
The enzymatic activity was conducted according to previously established methods with slight modifications [ 5 ]. The biochemical characteristics of GsCGTa, GsCGTb, and GsHIDH were investigated using continuous catalysis in a 50 mM Na 2 HPO 4 -NaH 2 PO 4 buffer (pH 8.0). GsCGTa initiated the catalytic reaction with UDP-Glc (0.5 mM) as the sugar donor and 2-hydroxynaringenin (0.2 mM) as the receptor at 35°C for 5 min. Subsequently, GsCGTb catalyzed the reaction with UDP-Ara as the sugar donor for 1 h. Following this, an equal volume of GsHIDH was added to the samples and incubated at 35°C for 2 h. The reactions were quenched with an equal volume of methanol and subjected to separation by high-performance liquid chromatography (HPLC). The mobile phase consisted of water containing 0.1% formic acid (v/v, A) and methanol (B) and a gradient elution program was employed as follows: 0–3 min, 27% B; 19 min, 27–65% B; 20 min, 65–60% B; 25 min, 60% B; 29 min, 67% B; 30 min, 95% B. The liquid chromatography column used was InertSustain C18 (4.6 × 150 mm, 5 μm) with a flow rate of 1 mL/min. Detection was performed at wavelengths of 335 nm and 290 nm, with the column temperature maintained at 40°C. Mass spectrometer (MS) analysis was carried out using the Thermo Scientific TSQ Endura LC-ESI-MS system with a UPLC Hypersil Gold column (100 |$\times$| 2.1 mm 1.9 μm, Thermo Scientific) at 40°C and a flow rate 0.2 mL/min. The injection volume for analysis was 1 μL. The MS operating parameters were set as follows: ion source temperature 250°C, sheath gas 35 arb, aux gas 10 arb, ion transfer tube temperature 275°C, ion spray voltage 2.5 KV for negative mode, and a mass scan range (m/z) of 200–1000.
Hairy roots transformation in GSO
To investigate the catalytic activity of GsCGTa and GsCGTb in vivo , the full-length cDNAs were cloned into the psuper1300-GFP vector to generate over-expression constructs. These constructs were then individually introduced into Agrobacterium rhizogenes K599 strain to induce hairy roots from the hypocotyl of 7-day-old GSO seedlings. Subsequently, the explants were cultured on 1/2 MS solid medium supplemented with 200 mg/L cefotaxime for 2 weeks until hairy roots appeared at the wounded sites. The positive transgenic hairy roots expressing green fluorescent protein (GFP) were identified using fluorescence microscopy and confirmed by both RT-qPCR as well as Western blot analysis. The positive hairy roots were then cultured independently on 1/2 MS solid medium with 200 mg/L cefotaxime for an additional two weeks before being transferred to liquid 1/2 MS medium containing 50 mg/L cefotaxime and incubated at 60 rpm. After 30 days, the hairy roots were harvested, extracted twice with methanol using a sonicator for 20 minutes each, and subjected to HPLC analysis as described in the enzyme activity assay section.
This work was supported partially by grants from Key Area R&D Project of Guangdong Province (2020B020221001), Key Technologies R&D Program of Guangdong Province (2022B1111230001), Guangdong Provincial Key Laboratory of Applied Botany (AB2018017), Youth Innovation Promotion Association CAS (2015286), and Guangdong Provincial Special Fund for Modern Agriculture Industry Technology Innovation Teams, China (2024KJ148).
S.Z. and Y.W. conceived and supervised the project. S.Z., Z.W., D.S., and G.B. analysed the data. Z.W., D.S., F.Y., and T.L. performed the experiments. T.P., J.Y., and S.Z. discussed and revised the manuscript. S.Z. and Z.W. drafted the manuscript. All the authors reviewed the final manuscript.
The authors declare that they have no conflict of interest.
The genome raw sequencing (including PacBio, 10X-Genomics, Hi-C, Illumina) are accessible in the Genome Sequence Archive (GSA) database ( https://ngdc.cncb.ac.cn/gsa/ ) with the accession number CRA013313. Moreover, the assembled genome was deposited in the Figshare ( https://figshare.com/ ).
Supplementary data is available at Horticulture Research online.
Li L , Wu Y , Wang J . et al. Potential treatment of COVID-19 with traditional Chinese medicine: what herbs can help win the battle with SARS-CoV-2? Engineering . 2022 ; 19 : 139 – 52
Google Scholar
Yi Y , Zhang M , Xue H . et al. Schaftoside inhibits 3CL pro and PL pro of SARS-CoV-2 virus and regulates immune response and inflammation of host cells for the treatment of COVID-19 . Acta Pharm Sin B . 2022 ; 12 : 4154 – 64
Committee CP . Pharmacopoeia of the People’s Republic of China . Beijing : Peoples Medicinal Publishing House ; 2020 :
Google Preview
Ohashi H , Ohashi K . Grona, a genus separated from Desmodium ( Leguminosae tribe Desmodieae ) . J Jpn Bot (Article) . 2018 ; 93 : 104 – 20
Wang ZL , Gao HM , Wang S . et al. Dissection of the general two-step di-C-glycosylation pathway for the biosynthesis of (iso)schaftosides in higher plants . Proc Natl Acad Sci USA . 2020 ; 117 : 30816 – 23
Dang J , Paudel YN , Yang X . et al. Schaftoside suppresses pentylenetetrazol-induced seizures in zebrafish via suppressing apoptosis, modulating inflammation, and oxidative stress . ACS Chem Neurosci . 2021 ; 12 : 2542 – 52
Kim PS , Shin JH , Jo DS . et al. Anti-melanogenic activity of schaftoside in Rhizoma Arisaematis by increasing autophagy in B16F1 cells . Biochem Biophys Res Commun . 2018 ; 503 : 309 – 15
Liu M , Zhang G , Wu S . et al. Schaftoside alleviates HFD-induced hepatic lipid accumulation in mice via upregulating farnesoid X receptor . J Ethnopharmacol . 2020 ; 255 :112776
Amorim JM , Ribeiro de Souza LC , Lemos de Souza RA . et al. Costus spiralis extract restores kidney function in cisplatin-induced nephrotoxicity model: Ethnopharmacological use, chemical and toxicological investigation . J Ethnopharmacol . 2022 ; 299 :115510
Hamilton ML , Kuate SP , Brazier-Hicks M . et al. Elucidation of the biosynthesis of the di-C-glycosylflavone isoschaftoside, an allelopathic component from Desmodium spp. that inhibits Striga spp. development . Phytochemistry . 2012 ; 84 : 169 – 76
Chang D , Gao S , Zhou G . et al. The chromosome-level genome assembly of Astragalus sinicus and comparative genomic analyses provide new resources and insights for understanding legume-rhizobial interactions . Plant Commun . 2022 ; 3 :100263
Li J , Shen J , Wang R . et al. The nearly complete assembly of the Cercis chinensis genome and Fabaceae phylogenomic studies provide insights into new gene evolution . Plant Commun . 2023 ; 4 : 100422
Dong S , Liu M , Liu Y . et al. The genome of Magnolia biondii Pamp. provides insights into the evolution of Magnoliales and biosynthesis of terpenoids . Hortic Res . 2021 ; 8 : 38
Yang J , Jia M , Guo J . In: Huang L-Q , ed. Functional genome of medicinal plants. In Molecular Pharmacognosy . Singapore: Springer , 2019 , 191 – 234
Chen Y , Chen Y , Shi C . et al. SOAPnuke: a MapReduce acceleration-supported software for integrated quality control and preprocessing of high-throughput sequencing data . GigaScience . 2018 ; 7 : 1 – 6
Marçais G , Kingsford C . A fast, lock-free approach for efficient parallel counting of occurrences of k-mers . Bioinformatics . 2011 ; 27 : 764 – 70
Vurture GW , Sedlazeck FJ , Nattestad M . et al. GenomeScope: fast reference-free genome profiling from short reads . Bioinformatics . 2017 ; 33 : 2202 – 4
Li H , Birol I . Minimap2: pairwise alignment for nucleotide sequences . Bioinformatics . 2018 ; 34 : 3094 – 100
Vaser R , Sović I , Nagarajan N . et al. Fast and accurate de novo genome assembly from long uncorrected reads . Genome Res . 2017 ; 27 : 737 – 46
Li H , Durbin R . Fast and accurate short read alignment with Burrows–Wheeler transform . Bioinformatics . 2009 ; 25 : 1754 – 60
Shen X , Zeng S , Wu M . et al. Characterization of proanthocyaninrelated leucoanthocyanidin reductase and anthocyanidin reductase genes in Lycium ruthenicum Murr . J Chin Pharm Sci . 2014 ; 23 : 369 – 77
Durand NC , Shamim MS , Machol I . et al. Juicer provides a one-click system for analyzing loop-resolution hi-C experiments . Cell Systems . 2016 ; 3 : 95 – 8
Dudchenko O , Batra SS , Omer AD . et al. De novo assembly of the Aedes aegypti genome using hi-C yields chromosome-length scaffolds . Science . 2017 ; 356 : 92 – 5
Simão FA , Waterhouse RM , Ioannidis P . et al. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs . Bioinformatics . 2015 ; 31 : 3210 – 2
Parra G , Bradnam K , Korf I . CEGMA: a pipeline to accurately annotate core genes in eukaryotic genomes . Bioinformatics . 2007 ; 23 : 1061 – 7
Ou S , Chen J , Jiang N . Assessing genome assembly quality using the LTR Assembly Index (LAI) . Nucleic Acids Res . 2018 ; 46 : e126
Camacho C , Coulouris G , Avagyan V . et al. BLAST+: architecture and applications . BMC Bioinformatics . 2009 ; 10 :421
Yu XJ , Zheng HK , Wang J . et al. Detecting lineage-specific adaptive evolution of brain-expressed genes in human using rhesus macaque as outgroup . Genomics . 2006 ; 88 : 745 – 51
Hoff KJ , Lange S , Lomsadze A . et al. BRAKER1: unsupervised RNA-Seq-based genome annotation with GeneMark-ET and AUGUSTUS . Bioinformatics . 2016 ; 32 : 767 – 9
Kim D , Langmead B , Salzberg SL . HISAT: a fast spliced aligner with low memory requirements . Nat Methods . 2015 ; 12 : 357 – 60
Pertea M , Kim D , Pertea G . et al. Transcript-level expression analysis of RNA-seq experiments with HISAT, StringTie and Ballgown . Nat Protoc . 2016 ; 11 : 1650 – 67
Haas BJ , Salzberg SL , Zhu W . et al. Automated eukaryotic gene structure annotation using EVidenceModeler and the program to assemble spliced alignments . Genome Biol . 2008 ; 9 : R7
Emms DM , Kelly S . OrthoFinder: phylogenetic orthology inference for comparative genomics . Genome Biol . 2019 ; 20 : 238
Katoh K , Standley DM . MAFFT multiple sequence alignment software version 7: improvements in performance and usability . Mol Biol Evol . 2013 ; 30 : 772 – 80
Talavera G , Castresana J , Kjer K . et al. Improvement of phylogenies after removing divergent and ambiguously aligned blocks from protein sequence alignments . Syst Biol . 2007 ; 56 : 564 – 77
Kalyaanamoorthy S , Minh BQ , Wong TKF . et al. ModelFinder: fast model selection for accurate phylogenetic estimates . Nat Methods . 2017 ; 14 : 587 – 9
Nguyen L-T , Schmidt HA , von Haeseler A . et al. IQ-TREE: a fast and effective stochastic algorithm for estimating maximum-likelihood phylogenies . Mol Biol Evol . 2015 ; 32 : 268 – 74
Yang Z , Yang ZH . PAML 4: phylogenetic analysis by maximum likelihood . Mol Biol Evol . 2007 ; 24 : 1586 – 91
Midega CAO , Pittchar J , Salifu D . et al. Effects of mulching, N-fertilization and intercropping with Desmodium uncinatum on Striga hermonthica infestation in maize . Crop Prot . 2013 ; 44 : 44 – 9
Wu T , Hu E , Xu S . et al. clusterProfiler 4.0: a universal enrichment tool for interpreting omics data . The Innovation . 2021 ; 2 : 100141
Buchfink B , Xie C , Huson DH . Fast and sensitive protein alignment using DIAMOND . Nat Methods . 2015 ; 12 : 59 – 60
Tang H , Bowers JE , Wang X . et al. Synteny and collinearity in plant genomes . Science . 2008 ; 320 : 486 – 8
Sun P , Jiao B , Yang Y . et al. WGDI: a user-friendly toolkit for evolutionary analyses of whole-genome duplications and ancestral karyotypes . Mol Plant . 2022 ; 15 : 1841 – 51
Chen S , Zhou Y , Chen Y . et al. Fastp: an ultra-fast all-in-one FASTQ preprocessor . Bioinformatics . 2018 ; 34 : i884 – 90
Danecek P , Bonfield JK , Liddle J . et al. Twelve years of SAMtools and BCFtools . GigaScience . 2021 ; 10 : 1 – 4
Liao Y , Smyth GK , Shi W . featureCounts: an efficient general purpose program for assigning sequence reads to genomic features . Bioinformatics . 2014 ; 30 : 923 – 30
Love MI , Huber W , Anders S . Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2 . Genome Biol . 2014 ; 15 : 550
Song L , Huang Y , Zuo H . et al. Chromosome-level assembly of triploid genome of Sichuan pepper ( Zanthoxylum armatum ) . Hortic Plant J . 2024 ; 10 : 437 – 49
Wang R , Shu P , Zhang C . et al. Integrative analyses of metabolome and genome-wide transcriptome reveal the regulatory network governing flavor formation in kiwifruit ( Actinidia chinensis ) . New Phytol . 2022 ; 233 : 373 – 89
Schmutz J , McClean PE , Mamidi S . et al. A reference genome for common bean and genome-wide analysis of dual domestications . Nature Genet . 2014 ; 46 : 707 – 13
Kang YJ , Kim SK , Kim MY . et al. Genome sequence of mungbean and insights into evolution within Vigna species . Nat Commun . 2014 ; 5 : 5443
Koenen EJM , Ojeda DI , Steeves R . et al. Large-scale genomic sequence data resolve the deepest divergences in the legume phylogeny and support a near-simultaneous evolutionary origin of all six subfamilies . New Phytol . 2020 ; 225 : 1355 – 69
Jiao Y , Wickett NJ , Ayyampalayam S . et al. Ancestral polyploidy in seed plants and angiosperms . Nature . 2011 ; 473 : 97 – 100
Soltis PS , Soltis DE . Ancient WGD events as drivers of key innovations in angiosperms . Curr Opin Plant Biol . 2016 ; 30 : 159 – 65
Soltis PS , Marchant DB , Van de Peer Y . et al. Polyploidy and genome evolution in plants . Curr Opin Genet Dev . 2015 ; 35 : 119 – 25
Doyle JJ , Egan AN . Dating the origins of polyploidy events . New Phytol . 2010 ; 186 : 73 – 85
Egan AN , Doyle J . A comparison of global, gene-specific, and relaxed clock methods in a comparative genomics framework: dating the polyploid history of soybean ( Glycine max ) . Syst Biol . 2010 ; 59 : 534 – 47
Wang Y , Zhang H , Ri HC . et al. Deletion and tandem duplications of biosynthetic genes drive the diversity of triterpenoids in Aralia elata . Nat Commun . 2022 ; 13 : 2224
Li Q , Zhang L , Li C . et al. Comparative genomics suggests that an ancestral polyploidy event leads to enhanced root nodule symbiosis in the Papilionoideae . Mol Biol Evol . 2013 ; 30 : 2602 – 11
Matsuno M . et al. Evolution of a novel phenolic pathway for pollen development . Science . 2009 ; 325 : 1688 – 92
Wang J , Chu S , Zhu Y . et al. Positive selection drives neofunctionalization of the UbiA prenyltransferase gene family . Plant Mol Biol . 2015 ; 87 : 383 – 94
Liu M , Wang D , Li Y . et al. Crystal structures of the C-glycosyltransferase UGT708C1 from buckwheat provide insights into the mechanism of C-glycosylation . Plant Cell . 2020 ; 32 : 2917 – 31
Zhang Y , Zhang M , Wang Z . et al. Advances in plant-derived C-glycosides: Phytochemistry, bioactivities, and biotechnological production . Biotechnol Adv . 2022 ; 60 :108030
Author notes
Email alerts, citing articles via.
- International Horticulture Research Conference
- Advertising & Corporate Services
Affiliations
- Online ISSN 2052-7276
- Print ISSN 2662-6810
- Copyright © 2024 Nanjing Agricultural University
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 27 May 2024
Research on domain ontology construction based on the content features of online rumors
- Jianbo Zhao 1 ,
- Huailiang Liu 1 ,
- Weili Zhang 1 ,
- Tong Sun 1 ,
- Qiuyi Chen 1 ,
- Yuehai Wang 2 ,
- Jiale Cheng 2 ,
- Yan Zhuang 1 ,
- Xiaojin Zhang 1 ,
- Shanzhuang Zhang 1 ,
- Bowei Li 3 &
- Ruiyu Ding 2
Scientific Reports volume 14 , Article number: 12134 ( 2024 ) Cite this article
1 Altmetric
Metrics details
- Computational neuroscience
- Computer science
- Data acquisition
- Data integration
- Data mining
- Data processing
- Human behaviour
- Information technology
- Literature mining
- Machine learning
- Scientific data
Online rumors are widespread and difficult to identify, which bring serious harm to society and individuals. To effectively detect and govern online rumors, it is necessary to conduct in-depth semantic analysis and understand the content features of rumors. This paper proposes a TFI domain ontology construction method, which aims to achieve semantic parsing and reasoning of the rumor text content. This paper starts from the term layer, the frame layer, and the instance layer, and based on the reuse of the top-level ontology, the extraction of core literature content features, and the discovery of new concepts in the real corpus, obtains the core classes (five parent classes and 88 subclasses) of the rumor domain ontology and defines their concept hierarchy. Object properties and data properties are designed to describe relationships between entities or their features, and the instance layer is created according to the real rumor datasets. OWL language is used to encode the ontology, Protégé is used to visualize it, and SWRL rules and pellet reasoner are used to mine and verify implicit knowledge of the ontology, and judge the category of rumor text. This paper constructs a rumor domain ontology with high consistency and reliability.
Similar content being viewed by others

From rumor to genetic mutation detection with explanations: a GAN approach

Improving long COVID-related text classification: a novel end-to-end domain-adaptive paraphrasing framework

How do we study misogyny in the digital age? A systematic literature review using a computational linguistic approach
Introduction.
Online rumors are false information spread through online media, which have the characteristics of wide content 1 , hard to identify 2 , 3 . Online rumors can mislead the public, disrupt social order, damage personal and collective reputations, and pose a great challenge to the governance of internet information content. Therefore, in order to effectively detect and govern online rumors, it is necessary to conduct an in-depth semantic analysis and understanding of the rumor text content features.
The research on the content features of online rumors focuses on the lexical, syntactic and semantic features of the rumor text, including lexical, syntactic and semantic features 4 , syntactic structure and functional features 5 , source features 5 , 6 , rhetorical methods 7 , narrative structure 6 , 7 , 8 , language style 6 , 9 , 10 , corroborative means 10 , 11 and emotional features 10 , 12 , 13 , 14 , 15 , 16 , 17 , 18 . Most of the existing researches on rumor content features are feature mining under a single domain topic type, and lack of mining the influence relationship between multiple features. Therefore, this paper proposes to build an online rumor domain ontology to realize fine-grained hierarchical modeling of the relationship between rumor content features and credible verification of its effectiveness. Domain ontology is a systematic description of the objective existence in a specific discipline 19 . The construction methods mainly include TOVE method 20 , skeleton method 21 , IDEF-5 method 22 , 23 , methontology method 24 , 25 and seven-step method 26 , 27 , among which seven-step method is the most mature and widely used method at present 28 , which has strong systematicness and applicability 29 , but it does not provide quantitative indicators and methods about the quality and effect of ontology. The construction technology can be divided into the construction technology based on thesaurus conversion, the construction technology based on existing ontology reuse and the semi-automatic and automatic construction technology based on ontology engineering method 30 . The construction technology based on thesaurus conversion and the construction technology based on existing ontology reuse can save construction time and cost, and improve ontology reusability and interoperability, but there are often differences in structure, semantics and scene. Semi-automatic and automatic construction technology based on ontology engineering method The application of artificial intelligence technology can automatically extract ontology elements and structures from data sources with high efficiency and low cost, but the quality and accuracy are difficult to guarantee. Traditional domain ontology construction methods lack effective quality evaluation support, and construction technology lacks effective integration application. Therefore, this paper proposes an improved TFI network rumor domain ontology construction method based on the seven-step method. Starting from the terminology layer, the framework layer and the instance layer, it integrates the top-level ontology and core document content feature reuse technology, the bottom-up semi-automatic construction technology based on N-gram new word discovery algorithm and RoBERTa-Kmeans clustering algorithm, defines the fine-grained features of network rumor content and carries out hierarchical modeling. Using SWRL rules and pellet inference machine, the tacit knowledge of ontology is mined, and the quality of ontology validity and consistency is evaluated and verified.
The structure of this paper is as follows: Sect “ Related work ” introduces the characteristics of rumor content and the related work of domain ontology construction.; Sect “ Research method ” constructs the term layer, the frame layer and the instance layer of the domain ontology; Sect “ Domain ontology construction ” mines and verifies the implicit knowledge of the ontology based on SWRL rules and Pellet reasoner; Sect “ Ontology reasoning and validation ” points out the research limitations and future research directions; Sect “ Discussion ” summarizes the research content and contribution; Sect “ Conclusion ” summarizes the research content and contribution of this paper.
Related Work
Content features of online rumors.
The content features of online rumors refer to the adaptive description of vocabulary, syntax and semantics in rumor texts. Fu et al. 5 have made a linguistic analysis of COVID-19’s online rumors from the perspectives of pragmatics, discourse analysis and syntax, and concluded that the source of information, the specific place and time of the event, the length of the title and statement, and the emotions aroused are the important characteristics to judge the authenticity of the rumors; Zhang et al. 6 summarized the narrative theme, narrative characteristics, topic characteristics, language style and source characteristics of new media rumors; Li et al. 7 found that rumors have authoritative blessing and fear appeal in headline rhetoric, and they use news and digital headlines extensively, and the topic construction mostly uses programmed fixed structure; Yu et al. 8 analyzed and summarized the content distribution, narrative structure, topic scene construction and title characteristics of rumors in detail; Mourao et al. 9 found that the language style of rumors is significantly different from that of real texts, and rumors tend to use simpler, more emotional and more radical discourse strategies; Zhou et al. 10 analyzed the rumor text based on six analysis categories, such as content type, focus object and corroboration means, and found that the epidemic rumors were mostly “infectious” topics, with narrative expression being the most common, strong fear, and preference for exaggerated and polarized discourse style. Huang et al. 11 conducted an empirical study based on WeChat rumors, and found that the “confirmation” means of rumors include data corroboration and specific information, hot events and authoritative release; Butt et al. 12 analyzed the psycholinguistic features of rumors, and extracted four features from the rumor data set: LIWC, readability, senticnet and emotions. Zhou et al. 13 analyzed the semantic features of fake news content in theme and emotion, and found that the distribution of fake news and real news is different in theme features, and the overall mood, negative mood and anger of fake news are higher; Tan et al. 14 divided the content characteristics of rumors into content characteristics with certain emotional tendency and social characteristics that affect credibility; Damstra et al. 15 identified the elements as a consistent indicator of intentionally deceptive news content, including negative emotions causing anger or fear, lengthy sensational headlines, using informal language or swearing, etc. Lai et al. 16 put forward that emotional rumors can make the rumor audience have similar positive and negative emotions through emotional contagion; Yuan et al. 17 found that multimedia evidence form and topic shaping are important means to create rumors, which mostly convey negative emotions of fear and anger, and the provision of information sources is related to the popularity and duration of rumors; Ruan et al. 18 analyzed the content types, emotional types and discourse focus of Weibo’s rumor samples, and found that the proportion of social life rumors was the highest, and the emotional types were mainly hostile and fearful, with the focus on the general public and the personnel of the party, government and military institutions.
The forms and contents of online rumors tend to be diversified and complicated. The existing research on the content features of rumors is mostly aimed at the mining of content characteristics under specific topics, which cannot cover various types of rumor topics, and lacks fine-grained hierarchical modeling of the relationship between features and credible verification of their effectiveness.
Domain ontology construction
Domain ontology is a unified definition, standardized organization and visual representation of the concepts of knowledge in a specific domain 31 , 32 , and it is an important source of information for knowledge-based systems 19 , 33 . Theoretical methods include TOVE method 20 , skeleton method 21 , IDEF-5 method 22 , 23 , methontology method 24 , 25 and seven-step method 26 , 27 . TOVE method transforms informal description into formal ontology, which is suitable for fields that need accurate knowledge, but it is complex and time-consuming, requires high-level domain knowledge and is not easy to expand and maintain. Skeleton method forms an ontology skeleton by defining the concepts and relationships of goals, activities, resources, organizations and environment, which can be adjusted according to needs and is suitable for fields that need multi-perspective and multi-level knowledge, but it lacks formal semantics and reasoning ability. Based on this method, Ran et al. 34 constructed the ontology of idioms and allusions. IDEF5 method uses chart language and detailed description language to construct ontology, formalizes and visualizes objective knowledge, and is suitable for fields that need multi-source data and multi-participation, but it lacks a unified ontology representation language. Based on this method, Li et al. 35 constructed the business process activity ontology of military equipment maintenance support, and Song et al. 36 established the air defense and anti-missile operation process ontology. Methontology is a method close to software engineering. It systematically develops ontologies through the processes of specification, knowledge acquisition, conceptualization, integration, implementation, evaluation and document arrangement, which is suitable for fields that need multi-technology and multi-ontology integration, but it is too complicated and tedious, and requires a lot of resources and time 37 . Based on this method, Yang et al. 38 completed the ontology of emergency plan, Duan et al. 39 established the ontology of high-resolution images of rural residents, and Chen et al. 40 constructed the corpus ontology of Jiangui. Seven-step method is the most mature and widely used method at present 28 . It is systematic and applicable to construct ontology by determining its purpose, scope, terms, structure, attributes, limitations and examples 29 , but it does not provide quantitative indicators and methods about the quality and effect of ontology. Based on this method, Zhu et al. 41 constructed the disease ontology of asthma, Li et al. 42 constructed the ontology of military events, the ontology of weapons and equipment and the ontology model of battlefield environment, and Zhang et al. 43 constructed the ontology of stroke nursing field, and verified the construction results by expert consultation.
Domain ontology construction technology includes thesaurus conversion, existing ontology reuse and semi-automatic and automatic construction technology based on ontology engineering method 30 . The construction technology based on thesaurus transformation takes the existing thesaurus as the knowledge source, and transforms the concepts, terms and relationships in the thesaurus into the entities and relationships of domain ontology through certain rules and methods, which saves the time and cost of ontology construction and improves the quality and reusability of ontology. However, it is necessary to solve the structural and semantic differences between thesaurus and ontology and adjust and optimize them according to the characteristics of different fields and application scenarios. Wu et al. 44 constructed the ontology of the natural gas market according to the thesaurus of the natural gas market and the mapping of subject words to ontology, and Li et al. 45 constructed the ontology of the medical field according to the Chinese medical thesaurus. The construction technology based on existing ontology reuse uses existing ontologies or knowledge resources to generate new domain ontologies through modification, expansion, merger and mapping, which saves time and cost and improves the consistency and interoperability of ontologies, but it also needs to solve semantic differences and conflicts between ontologies. Chen et al. 46 reuse the top-level framework of scientific evidence source information ontology (SEPIO) and traditional Chinese medicine language system (TCMLS) to construct the ontology of clinical trials of traditional Chinese medicine, and Xiao et al. 47 construct the domain ontology of COVID-19 by extracting the existing ontology and the knowledge related to COVID-19 in the diagnosis and treatment guide. Semi-automatic and automatic construction technology based on ontology engineering method semi-automatically or automatically extracts the elements and structures of ontology from data sources by using natural language processing, machine learning and other technologies to realize large-scale, fast and low-cost domain ontology construction 48 , but there are technical difficulties, the quality and accuracy of knowledge extraction can not be well guaranteed, and the quality and consistency of different knowledge sources need to be considered. Suet al. 48 used regular templates and clustering algorithm to construct the ontology of port machinery, Zheng et al. 49 realized the automatic construction of mobile phone ontology through LDA and other models, Dong et al. 50 realized the automatic construction of ontology for human–machine ternary data fusion in manufacturing field, Linli et al. 51 proposed an ontology learning algorithm based on hypergraph, and Zhai et al. 52 learned from it through part-of-speech tagging, dependency syntax analysis and pattern matching.
At present, domain ontology construction methods are not easy to expand, lack of effective quality evaluation support, lack of effective integration and application of construction technology, construction divorced from reality can not guide subsequent practice, subjective ontology verification and so on. Aiming at the problems existing in the research of content characteristics and domain ontology construction of online rumors, this paper proposes an improved TFI network rumor domain ontology construction method based on seven-step method, which combines top-down existing ontology reuse technology with bottom-up semi-automatic construction technology, and establishes rumor domain ontology based on top-level ontology reuse, core document content feature extraction and new concept discovery in the real corpus from the terminology layer, framework layer and instance layer. Using Protégé as a visualization tool, the implicit knowledge mining of ontology is carried out by constructing SWRL rules to verify the semantic parsing ability and consistency of domain ontology.
Research method
This paper proposes a TFI online rumor domain ontology construction method based on the improvement of the seven-step method, which includes the term layer, the frame layer and the instance layer construction.
Term layer construction
Determine the domain and scope: the purpose of constructing the rumor domain ontology is to support the credible detection and governance of online rumors, and the domain and scope of the ontology are determined by answering questions.
Three-dimensional term set construction: investigate the top-level ontology and related core literature, complete the mapping of reusable top-level ontology and rumor content feature concept extraction semi-automatically from top to bottom; establish authoritative real rumor datasets, and complete the domain new concept discovery automatically from bottom to top; based on this, determine the term set of the domain ontology.
Frame layer construction
Define core classes and hierarchical relationships: combine the concepts of the three-dimensional rumor term set, based on the data distribution of the rumor dataset, define the parent class, summarize the subclasses, design hierarchical relationships and explain the content of each class.
Define core properties and facets of properties: in order to achieve deep semantic parsing of rumor text contents, define object properties, data properties and property facets for each category in the ontology.
Instance layer construction
Create instances: analyze the real rumor dataset, extract instance data, and add them to the corresponding concepts in the ontology.
Encode and visualize ontology: use OWL language to encode ontology, and use Protégé to visualize ontology, so that ontology can be understood and operated by computer.
Ontology verification: use SWRL rules and pellet reasoner to mine implicit knowledge of ontology, and verify its semantic parsing ability and consistency.
Ethical statements
This article does not contain any studies with human participants performed by any of the authors.
Determine the professional domain and scope of the ontology description
This paper determines the domain and scope of the online rumor domain ontology by answering the following four questions:
(1) What is the domain covered by the ontology?
The “Rumor Domain Ontology” constructed in this paper only considers content features, not user features and propagation features; the data covers six rumor types of politics and military, disease prevention and treatment, social life, science and technology, nutrition and health, and others involved in China’s mainstream internet rumor-refuting websites.
(2) What is the purpose of the ontology?
To perform fine-grained hierarchical modeling of the relationships among the features of multi-domain online rumor contents, realize semantic parsing and credibility reasoning verification of rumor texts, and guide fine-grained rumor detection and governance. It can also be used as a guiding framework and constraint condition for online rumor knowledge graph construction.
(3) What kind of questions should the information in the ontology provide answers for?
To provide answers for questions such as the fine-grained rumor types of rumor instances, the valid features of rumor types, etc.
(4) Who will use the ontology in the future?
Users of online rumor detection and governance, users of online rumor knowledge graphs construction.
Three-dimensional term set construction
Domain concepts reused by top-level ontology.
As a mature and authoritative common ontology, top-level ontology can be shared and reused in a large range, providing reference and support for the construction of domain ontology. The domain ontology of online rumors established in this paper focuses on the content characteristics, mainly including the content theme, events and emotions of rumor texts. By reusing the terminology concepts in the existing top-level ontology, the terminology in the terminology set can be unified and standardized. At the same time, the top-level concept and its subclass structure can guide the framework construction of domain ontology and reduce the difficulty and cost of ontology construction. Reusable top-level ontologies include: SUMO, senticnet and ERE after screening.
SUMO ontology: a public upper-level knowledge ontology containing some general concepts and relations for describing knowledge in different domains. The partial reusable SUMO top-level concepts and subclasses selected in this paper are shown in Table 1 , which provides support for the sub-concept design of text topics in rumor domain ontology.
Senticnet: a knowledge base for concept-based sentiment analysis, which contains semantic, emotional, and polarity information related to natural language concepts. The partial reusable SenticNet top-level concepts and subclasses selected in this paper are shown in Table 2 , which provides support for the sub-concept design of text topics in rumor domain ontology.
Entities, relations, and events (ERE): a knowledge base of events and entity relations. The partial reusable ERE top-level concepts and subclasses selected in this paper are shown in Table 3 , which provides support for the sub-concept design of text elements in the rumor domain ontology.
Extracting domain concepts based on core literature content features
Domain core literature is an important source for extracting feature concepts. This paper uses ‘rumor detection’ as the search term to retrieve 274 WOS papers and 257 CNKI papers from the WOS and CNKI core literature databases. The content features of rumor texts involved in the literature samples are extracted, the repetition content features are eliminated, the core content features are screened, and the canonical naming of synonymous concepts from different literatures yields the domain concepts as shown in Table 4 . Among them, text theme, text element, text style, text feature and text rhetoric are classified as text features; emotional category, emotional appeal and rumor motive are classified as emotional characteristics; source credibility, evidence credibility and testimony method are classified as information credibility characteristics; social context is implicit.
Extracting domain concepts based on new concept discovery
This paper builds a general rumor dataset based on China’s mainstream rumor-refuting websites as data sources, and proposes a domain new concept discovery algorithm to discover domain new words in the dataset, add them to the word segmentation dictionary to improve the accuracy of word segmentation, and cluster them according to rumor type, resulting in a concept subclass dictionary based on the real rumor dataset, which provided realistic basis and data support for the conceptual design of each subclass in domain ontology.
Building a general rumor dataset
The rumor dataset constructed in this paper contains 12,472 texts, with 6236 rumors and 6236 non-rumors; the data sources are China’s mainstream internet rumor-refuting websites: 1032 from the internet rumor exposure platform of China internet joint rumor-refuting platform, 270 from today’s rumor-refuting of China internet joint rumor-refuting platform, 1852 from Tencent news Jiaozhen platform, 1744 from Baidu rumor-refuting platform, 7036 from science rumor-refuting platform, and 538 from Weibo community management center. This paper invited eight researchers to annotate the labels (rumor, non-rumor), categories (politics and military, disease prevention and treatment, social life, science and technology, nutrition and health, others) of the rumor dataset. Because data annotation is artificial and subjective, in order to ensure the effectiveness and consistency of annotation, before inviting researchers to annotate, this paper formulates annotation standards, including the screening method, trigger words and sentence break identification of rumor information and corresponding rumor information, and clearly explains and exemplifies the screening method and trigger words of rumor categories, so as to reduce the understanding differences among researchers; in view of this standard, researchers are trained in labeling to familiarize them with labeling specifications, so as to improve their labeling ability and efficiency. The method of multi-person cross-labeling is adopted when labeling, and each piece of data is independently labeled by at least two researchers. In case of conflicting labeling results, the labeling results are jointly decided by the data annotators to increase the reliability and accuracy of labeling. After labeling, multi-person cross-validation method is used to evaluate the labeling results. Each piece of data is independently verified by at least two researchers who did not participate in labeling, and conflicting labeling results are jointly decided by at least five researchers to ensure the consistency of evaluation results. Examples of the results are shown in Table 5 .
N-gram word granularity rumor text new word discovery algorithm
Existing neologism discovery algorithms are mostly based on the granularity of Chinese characters, and the time complexity of long word discovery is high and the accuracy rate is low. The algorithm’s usefulness is low, and the newly discovered words are mostly already found in general domain dictionaries. To solve these problems, this paper proposes an online rumor new word discovery algorithm based on N-gram word granularity, as shown in Fig. 1 .

Flowchart of domain new word discovery algorithm.
First, obtain the corpus to be processed \({\varvec{c}}=\{{{\varvec{s}}}_{1},{{\varvec{s}}}_{2},...,{{\varvec{s}}}_{{{\varvec{n}}}_{{\varvec{c}}}}\}\) , and perform the first preprocessing on the corpus to be processed, which includes: sentence segmentation, Chinese word segmentation and punctuation removal for the corpus to be processed. Obtain the first corpus \({{\varvec{c}}}^{{\varvec{p}}}=\{{{\varvec{s}}}_{1}^{{\varvec{p}}},{{\varvec{s}}}_{2}^{{\varvec{p}}},...,{{\varvec{s}}}_{{{\varvec{n}}}_{{\varvec{c}}}}^{{\varvec{p}}}\}\) ; where \({s}_{i}\) represents the \(i\) -th sentence in the corpus to be processed, \({n}_{c}\) represents the number of sentences in the corpus to be processed, and \({s}_{i}^{p}\) is the i-th sentence in the first corpus; perform N-gram operation on each sentence in the first corpus separately, and obtain multiple candidate words \(n=2\sim 5\) ; count the word frequency of each candidate word in the first corpus, and remove the candidate words with word frequency less than the first threshold, and obtain the first class of candidate word set;calculate the cohesion of each candidate word in the first class of candidate word set according to the following formula:
In the formula, \(P(\cdot )\) represents word frequency.Then filter according to the second threshold corresponding to N-gram operation, and obtain the second class of candidate word set; after loading the new words in the second class of candidate word set into LTP dictionary, perform the second preprocessing on the corpus to be processed \({\varvec{c}}=\{{{\varvec{s}}}_{1},{{\varvec{s}}}_{2},...,{{\varvec{s}}}_{{{\varvec{n}}}_{{\varvec{c}}}}\}\) ; and obtain the second corpus \({{\varvec{c}}}^{{\varvec{p}}\boldsymbol{^{\prime}}}=\{{{\varvec{s}}}_{1}^{{\varvec{p}}\boldsymbol{^{\prime}}},{{\varvec{s}}}_{2}^{{\varvec{p}}\boldsymbol{^{\prime}}},...,{{\varvec{s}}}_{{{\varvec{n}}}_{{\varvec{c}}}}^{{\varvec{p}}\boldsymbol{^{\prime}}}\}\) ; where the second preprocessing includes: sentence segmentation, Chinese word segmentation and stop word removal for the corpus to be processed; after obtaining the vector representation of each word in the second corpus, determine the vector representation of each new word in the second class of candidate word set; according to the vector representation of each new word, use K-means algorithm for clustering; according to the clustering results and preset classification rules, classify each new word to the corresponding domain. The examples of new words discovered are shown in Table 6 :
RoBERTa-Kmeans rumor text concepts extraction algorithm
After adding the new words obtained by the new word discovery to the LTP dictionary, the accuracy of LTP word segmentation is improved. The five types of rumor texts established in this paper are segmented by using the new LTP dictionary, and the word vectors are obtained by inputting them into the RoBERTa word embedding layer after removing the stop words. The word vectors are clustered by k-means according to rumor type to obtain the concept subclass dictionary. The main process is as follows:
(1) Word embedding layer
The RoBERTa model uses Transformer-Encode for computation, and each module contains multi-head attention mechanism, residual connection and layer normalization, feed-forward neural network. The word vectors are obtained by representing the rumor texts after accurate word segmentation through one-hot encoding, and the position encoding represents the relative or absolute position of the word in the sequence. The word embedding vectors generated by superimposing the two are used as input X. The multi-head attention mechanism uses multiple independent Attention modules to perform parallel operations on the input information, as shown in formula ( 2 ):
where \(\left\{{\varvec{Q}},{\varvec{K}},{\varvec{V}}\right\}\) is the input matrix, \({{\varvec{d}}}_{{\varvec{k}}}\) is the dimension of the input matrix. After calculation, the hidden vectors obtained after computation are residual concatenated with layer normalization, and then calculated by two fully connected layers of feed-forward neural network for input, as shown in formula ( 3 ):
where \(\left\{{{\varvec{W}}}_{{\varvec{e}}},{{\varvec{W}}}_{0}\boldsymbol{^{\prime}}\right\}\) are the weight matrices of two connected layers, \(\left\{{{\varvec{b}}}_{{\varvec{e}}},{{\varvec{b}}}_{0}\boldsymbol{^{\prime}}\right\}\) are the bias terms of two connected layers.
After calculation, a bidirectional association between word embedding vectors is established, which enables the model to learn the semantic features contained in each word embedding vector in different contexts. Through fine-tuning, the learned knowledge is transferred to the downstream clustering task.
(2) K-means clustering
Randomly select k initial points to obtain k classes, and iterate until the loss function of the clustering result is minimized. The loss function can be defined as the sum of squared errors of each sample point from its cluster center point, as shown in formula ( 4 ).
where \({x}_{i}\) represents the \(i\) sample, \({a}_{i}\) is the cluster that \({x}_{i}\) belongs to, \({u}_{{a}_{i}}\) represents the corresponding center point, \(N\) is the total number of samples.
After RoBERTa-kmeans calculation, the concept subclasses obtained are manually screened, merged repetition items, deleted invalid items, and finally obtained 79 rumor concept subclasses, including 14 politics and military subclasses, 23 disease prevention and treatment subclasses, 15 social life subclasses, 13 science and technology subclasses, and 14 nutrition and health subclasses. Some statistics are shown in Table 7 .
Each concept subclass is obtained by clustering several topic words. For example, the topic words that constitute the subclasses of body part, epidemic prevention and control, chemical drugs, etc. under the disease prevention and treatment topic are shown in Table 8 .
(3) Determining the terminology set
This paper constructs a three-dimensional rumor domain ontology terminology set based on the above three methods, and unifies the naming of the terms. Some of the terms are shown in Table 9 .
Framework layer construction
Define core classes and hierarchy, define parent classes.
This paper aims at fine-grained hierarchical modeling of the relationship between the content characteristics of multi-domain network rumors. Therefore, the top-level parent class needs to include the rumor category and the main content characteristics of a sub-category rumor design. The main content characteristics are the clustering results of domain concepts extracted based on the content characteristics of core documents, that is, rumor text feature, rumor emotional characteristic, rumor credibility and social context. The specific contents of the five top parent classes are as follows:
Rumor type: the specific classification of rumors under different subject categories; Rumor text feature, the common features of rumor texts in terms of theme, style, rhetoric, etc. Rumor emotional characteristic: the emotional elements of rumor texts, the Rumor motive of the publisher, and the emotional changes they hope to trigger in the receiver. Rumor credibility: the authority of the information source, the credibility of the evidence material provided by the publisher, and the effectiveness of the testimony method. Social context: the relevant issues and events in the society when the rumor is published.
Induce subclasses and design hierarchical relationships
In this paper, under the top-level parent class, according to the top-level concepts of top-level ontologies such as SUMO, senticnet and ERE and their subclass structures, and the rumor text features of each category extracted from the real rumor text dataset, we summarize its 88 subclasses and design the hierarchical relationships, as shown in Fig. 2 , which include:
(1) Rumor text feature

Diagram of the core classes and hierarchy of the rumor domain ontology.
① Text theme 6 , 8 , 13 , 18 , 53 : the theme or topic that the rumor text content involves. Based on the self-built rumor dataset, it is divided into politics and military 54 , involving information such as political figures, political policies, political relations, political activities, military actions, military events, strategic objectives, politics and military reviews, etc.; nutrition and health 55 , involving information such as the relationship between human health and nutrition, the nutritional components and value of food, the plan and advice for healthy eating, health problems and habits, etc.; disease prevention and treatment 10 , involving information such as the definition of disease, vaccine, treatment, prevention, data, etc.; social life 56 , involving information such as social issues, social environment, social values, cultural activities, social media, education system, etc.; science and technology 57 , involving information such as scientific research, scientific discovery, technological innovation, technological application, technological enterprise, etc.; other categories.
② Text element 15 : the structured information of the rumor text contents. It is divided into character, political character, public character, etc.; geographical position, city, region, area, etc.; event, historical event, current event, crisis event, policy event, etc.; action, protection, prevention and control, exercise, fighting, crime, eating, breeding, health preservation, rest, exercise, education, sports, social, cultural, ideological, business, economic, transportation, etc.; material, food, products (food, medicine, health products, cosmetics, etc.) and the materials they contain and their relationship with human health. effect, nutrition, health, harm, natural disaster, man-made disaster, guarantee, prevention, treatment, etc.; institution, government, enterprise, school, hospital, army, police, social group, etc.; nature, weather, astronomy, environment, agriculture, disease, etc.
③ Text style 7 , 10 : the discourse style of the rumor text contents, preferring exaggerated and emotional expression. It is divided into gossip style, creating conflict or entertainment effect; curious style, satisfying people’s curiosity and stimulation; critical style, using receivers’ stereotypes or preconceptions; lyrical style, creating resonance and influencing emotion; didactic style influencing receivers’ thought and behavior from an authoritative perspective; plain style concise objective arousing resonance etc.
④ Text feature 7 , 58 : special language means in the rumor text contents that can increase the transmission and influence of the rumor. It is divided into extensive punctuation reminding or attracting receivers’ attention; many mood words enhancing emotional color and persuasiveness; many emoji conveying attitude; induce forwarding using @ symbol etc. to induce receivers to forward etc.
⑤ Text rhetoric 15 : common rhetorical devices in rumor contents. It is divided into metaphor hyperbole repetition personification etc.
(2) Rumor emotional characteristic
① Emotion category 17 , 59 , 60 : the emotional tendency and intensity expressed in the rumor texts. It is divided into positive emotion happy praise etc.; negative emotion fear 10 anger sadness anxiety 61 dissatisfaction depression etc.; neutral emotion no preference plain objective etc.
② Emotional appeal 16 , 62 , 63 : the online rumor disseminator hopes that the rumor they disseminate can trigger some emotional changes in the receiver. It is divided into “joy” happy pleasant satisfied emotions that prompt receivers to spread or believe some rumors that are conducive to social harmony; “love” love appreciation admiration emotions that prompt receivers to spread or believe some rumors that are conducive to some people or group interests; “anger” angry annoyed dissatisfied emotions that prompt receivers to spread or believe some rumors that are anti-social or intensify conflicts; “fear” fearful afraid nervous emotions that prompt receivers to spread or believe some rumors that have bad effects deliberately exaggerated; “repugnance” disgusted nauseous emotions that prompt receivers to spread or believe some rumors that are detrimental to social harmony; “surprise” surprised shocked amazed emotions that prompt receivers to spread or believe some rumors that deliberately attract traffic exaggerated fabricated etc.
③ Rumor motive 17 , 64 , 65 , 66 : the purpose and need of the rumor publisher to publish rumors and the receiver to forward rumors. Such as profit-driven seeking fame and fortune deceiving receivers; emotional catharsis relieving dissatisfaction emotions by venting; creating panic creating social unrest and riots disrupting social order; entertainment fooling receivers seeking stimulation; information verification digging out the truth of events etc.
(3) Rumor credibility
① source credibility 7 , 17 : the degree of trustworthiness that the information source has. Such as official institutions and authoritative experts and scholars in the field with high credibility; well-known encyclopedias and large-scale civil organizations with medium credibility; small-scale civil organizations and personal hearsay personal experience with low credibility etc.
② evidence credibility 61 : the credibility of the information proof material provided by the publisher. Data support such as scientific basis based on scientific theory or method; related feature with definite research or investigation result in data support; temporal background with clear time place character event and other elements which related to the information content; the common sense of life in line with the facts and scientific common sense that are widely recognized.
③ testimony method 10 , 11 , 17 : the method to support or refute a certain point of view. Such as multimedia material expressing or fabricating content details through pictures videos audio; authority endorsement policy documents research papers etc. of authorized institutions or persons; social identity identity of social relation groups.
(4) Social context
① social issue 67 : some bad phenomena or difficulties in society such as poverty pollution corruption crime government credibility decline 68 etc.
② public attention 63 : events or topics that arouse widespread attention or discussion in the society such as sports events technological innovation food safety religious beliefs Myanmar fraud nuclear wastewater discharge etc.
③ emergency(public sentiment) 69 : some major or urgent events that suddenly occur in society such as earthquake flood public safety malignant infectious disease outbreaks etc.
(5) Rumor type
① Political and military rumor:
Political image rumor: rumors related to images closely connected to politics and military, such as countries, political figures, institutions, symbols, etc. These include positive political image smear rumor, negative political image whitewash rumor, political image fabrication and distortion rumor, etc.
Political event rumor: rumors about military and political events, such as international relations, security cooperation, military strategy, judicial trial, etc. These include positive political event smear rumor, negative political event whitewash rumor, political event fabrication and distortion rumor, etc.
② Nutrition and health rumor:
Food product rumor: rumors related to food, products (food, medicine, health products, cosmetics, etc.), the materials they contain and their association with human health. These include positive effect of food product rumor, negative effect of food product rumor, food product knowledge rumor, etc.
Living habit rumor: rumors related to habitual actions in life and their association with human health. These include positive effect of living habit rumor, negative effect of living habit rumor, living habit knowledge rumor, etc.
③ Disease prevention and treatment rumor:
Disease management rumor: rumors related to disease management and control methods that maintain and promote individual and group health. These include positive prevention and treatment rumor, negative aggravating disease rumor, disease management knowledge rumor, etc.
Disease confirmed transmission rumor: rumors about the confirmation, transmission, and immunity of epidemic diseases at the social level in terms of causes, processes, results, etc. These include local confirmed cases rumor, celebrity confirmed cases rumor, transmission mechanism rumor, etc.
Disease notification and advice rumor: rumors that fabricate or distort the statements of authorized institutions or experts in the field, and provide false policies or suggestions related to diseases. These include institutional notification rumor, expert advice rumor, etc.
④ Social life rumor:
Public figure public opinion rumor: rumors related to public figures’ opinions, actions, private lives, etc. These include positive public figure smear rumor, negative public figure whitewash rumor, public figure life exposure rumor, etc.
Social life event rumor: rumors related to events, actions, and impacts on people's social life. These include positive event sharing rumor, negative event exposure rumor, neutral event knowledge rumor, etc.
Disaster occurrence rumor: rumors related to natural disasters or man-made disasters and their subsequent developments. These include natural disaster occurrence rumor, man-made disaster occurrence rumor, etc.
⑤ Science and technology rumor:
Scientific knowledge rumor: rumors related to natural science or social science theories and knowledge. These include scientific theory rumor, scientific concept rumor, etc.
Science and technology application rumor: rumors related to the research and development and practical application of science and technology and related products. These include scientific and technological product rumor, scientific and technological information rumor, etc.
⑥ Other rumor: rumors that do not contain elements from the above categories.
Definition of core properties and facets of properties
Properties in the ontology are used to describe the relationships between entities or the characteristics of entities. Object properties are relationships that connect two entities, describing the interactions between entities; data properties represent the characteristics of entities, usually in the form of some data type. Based on the self-built rumor dataset, this paper designs object properties, data properties and facets of properties for the parent classes and subclasses of the rumor domain ontology.
Object properties
A partial set of object properties is shown in Table 10 .
Data attributes
The partial data attribute set is shown in Table 11 .
Creating instances
Based on the defined core classes and properties, this paper creates instances according to the real rumor dataset. An example is shown in Table 12 .
This paper selects the online rumor that “Lin Chi-ling was abused by her husband Kuroki Meisa, the tears of betrayal, the shadow of gambling, all shrouded her head. Even if she tried to divorce, she could not get a solution…..” as an example, and draws a structure diagram of the rumor domain ontology instance, as shown in Fig. 3 . This instance shows the seven major text features of the rumor text: text theme, text element, text style, emotion category, emotional appeal, rumor motivation, and rumor credibility, as well as the related subclass instances, laying a foundation for building a multi-source rumor domain knowledge graph.

Schematic example of the rumor domain ontology.
Encoding ontology and visualization
Encoding ontology.
This paper uses OWL language to encode the rumor domain ontology, to accurately describe the entities, concepts and their relationships, and to facilitate knowledge reasoning and semantic understanding. Classes in the rumor domain ontology are represented by the class “Class” in OWL and the hierarchical relationship is represented by subclassof. For example, in the creation of the rumor emotional characteristic class and its subclasses, the OWL code is shown in Fig. 4 :

Partial OWL codes of the rumor domain ontology.
The ontology is formalized and stored as a code file using the above OWL language, providing support for reasoning.
Ontology visualization
This paper uses protégé5.5 to visualize the rumor domain ontology, showing the hierarchical structure and relationship of the ontology parent class and its subclasses. Due to space limitations, this paper only shows the ontology parent class “RumorEmotionalFeatures” and its subclasses, as shown in Fig. 5 .

Ontology parent class “RumorEmotionalFeatures” and its subclasses.
Ontology reasoning and validation
Swrl reasoning rule construction.
SWRL reasoning rule is an ontology-based rule language that can be used to define Horn-like rules to enhance the reasoning and expressive ability of the ontology. This paper uses SWRL reasoning rules to deal with the conflict relationships between classes and between classes and instances in the rumor domain ontology, and uses pellet reasoner to deeply mine the implicit semantic relationships between classes and instances, to verify the semantic parsing ability and consistency of the rumor domain ontology.
This paper summarizes the object property features of various types of online rumors based on the self-built rumor dataset, maps the real rumor texts with the rumor domain ontology, constructs typical SWRL reasoning rules for judging 32 typical rumor types, as shown in Table 13 , and imports them into the protégé rule library, as shown in Fig. 6 . In which x, n, e, z, i, t, v, l, etc. are instances of rumor types, text theme, emotion category, effect, institution, event, action, geographical position, etc. in the ontology. HasTheme, HasEmotion, HasElement, HasSource, HasMood and HasSupport are object property relationships. Polarity value is a data property relationship.

Partial SWRL rules for the rumor domain ontology.
Implicit knowledge mining and verification based on pellet reasoner
This paper extracts corresponding instances from the rumor dataset, imports the rumor domain ontology and SWRL rule description into the pellet reasoner in the protégé software, performs implicit knowledge mining of the rumor domain ontology, judges the rumor type of the instance, and verifies the semantic parsing ability and consistency of the ontology.
Positive prevention and treatment of disease rumors are mainly based on the theme of disease prevention and treatment, usually containing products to be sold (including drugs, vaccines, equipment, etc.) and effect of disease names, claiming to have positive effects (such as prevention, cure, relief, etc.) on certain diseases or symptoms, causing positive emotions such as surprise and happiness among patients and their families, thereby achieving the purpose of selling products. The text features and emotional features of this kind of rumors are relatively clear, so this paper takes the rumor text “Hong Kong MDX Medical Group released the ‘DCV Cancer Vaccine’, which can prevent more than 12 kinds of cancers, including prostate cancer, breast cancer and lung cancer.” as an example to verify the semantic parsing ability of the rumor domain ontology. The analysis result of this instance is shown in Fig. 7 . The text theme is cancer prevention in disease prevention and treatment, the text style is plain narrative style, and the text element includes product-DCV cancer vaccine, positive effect-prevention, disease name-prostate cancer, disease name-breast cancer, disease name-lung cancer; the emotion category of this instance is a positive emotion, emotional appeal is joy, love, surprise; The motive for releasing rumors is profit-driven in selling products, the information source is Hong Kong MDX medical group, and pictures and celebrity endorsements are used as testimony method. This paper uses a pellet reasoner to reason on the parsed instance based on SWRL rules, and mines out the specific rumor type of this instance as positive prevention and treatment of disease rumor. This paper also conducted similar instance analysis and reasoning verification for other types of rumor texts, and the results show that the ontology has high consistency and reliability.

Implicit relationship between rumor instance parsing results and pellet reasoner mining.
Comparison and evaluation of ontology performance
In this paper, the constructed ontology is compared with the representative rumor index system in the field. By inviting four experts to make a comprehensive evaluation based on the self-built index system 70 , 71 , 72 , their performance in the indicators of reliability, coverage and operability is evaluated. According to the ranking order given by experts, they are given 1–4 points, and the first place in each indicator item gets four points. The average value given by three experts is taken as the single indicator score of each subject, and the total score of each indicator item is taken as the final score of the subject.
As can be seen from Table 14 , the rumor domain ontology constructed in this paper constructs a term set through three ways: reusing the existing ontology, extracting the content features of core documents and discovering new concepts based on real rumor data sets, and the ontology structure has been verified by SWRL rule reasoning of pellet inference machine, which has high reliability; ontology covers six kinds of Chinese online rumors, including the grammatical, semantic, pragmatic and social characteristics of rumor text characteristics, emotional characteristics, rumor credibility and social background, which has a high coverage; ontology is coded by OWL language specification and displayed visually on protege, which is convenient for further expansion and reuse of scholars and has high operability.
The construction method of TFI domain ontology proposed in this paper includes terminology layer, framework layer and instance layer. Compared with the traditional methods, this paper adopts three-dimensional data set construction method in terminology layer construction, investigates top-level ontology and related core documents, and completes the mapping of reusable top-level ontology from top to bottom and the concept extraction of rumor content features in existing literature research. Based on the mainstream internet rumor websites in China, the authoritative real rumor data set is established, and the new word discovery algorithm of N-gram combined with RoBERTa-Kmeans clustering algorithm is used to automatically discover new concepts in the field from bottom to top; determine the terminology set of domain ontology more comprehensively and efficiently. This paper extracts the clustering results of domain concepts based on the content characteristics of core documents in the selection of parent rumors content characteristics in the framework layer construction, that is, rumors text characteristics, rumors emotional characteristics, rumors credibility characteristics and social background characteristics; based on the emotional characteristics and the entity categories of real rumor data sets, the characteristics of rumor categories are defined. Sub-category rumor content features combine the concept of three-dimensional rumor term set and the concept distribution based on real rumor data set, define the sub-category concept and hierarchical relationship close to the real needs, and realize the fine-grained hierarchical modeling of the relationship between multi-domain network rumor content features. In this paper, OWL language is used to encode the rumor domain ontology in the instance layer construction, and SWRL rule language and Pellet inference machine are used to deal with the conflict and mine tacit knowledge, judge the fine-grained categories of rumor texts, and realize the effective quality evaluation of rumor ontology. This makes the rumor domain ontology constructed in this paper have high consistency and reliability, and can effectively analyze and reason different types of rumor texts, which enriches the knowledge system in this field and provides a solid foundation for subsequent credible rumor detection and governance.
However, the study of the text has the following limitations and deficiencies:
(1) The rumor domain ontology constructed in this paper only considers the content characteristics, but does not consider the user characteristics and communication characteristics. User characteristics and communication characteristics are important factors affecting the emergence and spread of online rumors, and the motivation and influence of rumors can be analyzed. In this paper, these factors are not included in the rumor feature system, which may limit the expressive ability and reasoning ability of the rumor ontology and fail to fully reflect the complexity and multidimensional nature of online rumors.
(2) In this paper, the mainstream Internet rumor-dispelling websites in China are taken as the data source of ontology instantiation. The data covers five rumor categories: political and military, disease prevention, social life, science and technology, and nutrition and health, and the data range is limited. And these data sources are mainly official or authoritative rumor websites, and their data volume and update frequency may not be enough to reflect the diversity and variability of online rumors, and can not fully guarantee the timeliness and comprehensiveness of rumor data.
(3) The SWRL reasoning rules used in this paper are based on manual writing, which may not cover all reasoning scenarios, and the degree of automation needs to be improved. The pellet inference engine used in this paper is an ontology inference engine based on OWL-DL, which may have some computational complexity problems and lack of advanced reasoning ability.
The following aspects can be considered for optimization and improvement in the future:
(1) This paper will introduce user characteristics into the rumor ontology, and analyze the factors that cause and accept rumors, such as social attributes, psychological state, knowledge level, beliefs and attitudes, behavioral intentions and so on. This paper will introduce the characteristics of communication, and analyze the propagation dynamic factors of various types of rumors, such as propagation path, propagation speed, propagation range, propagation period, propagation effect, etc. This paper hopes to introduce these factors into the rumor feature system, increase the breadth and depth of the rumor domain ontology, and provide more credible clues and basis for the detection, intervention and prevention of rumors.
(2) This paper will expand the data sources, collect the original rumor data directly from social media, news media, authoritative rumor dispelling institutions and other channels, and build a rumor data set with comprehensive types, diverse expressions and rich characteristics; regularly grab the latest rumor data from these data sources and update and improve the rumor data set in time; strengthen the expressive ability of rumor ontology instance layer, and provide full data support and verification for the effective application of ontology.
(3) The text will introduce GPT, LLaMA, ChantGLM and other language models, and explore the automatic generation algorithm and technology of ontology inference rules based on rumor ontology and dynamic Prompt, so as to realize more effective and intelligent rumor ontology evaluation and complex reasoning.
This paper proposed a method of constructing TFI network rumor domain ontology. Based on the concept distribution of three-dimensional term set and real rumor data set, the main features of network rumors are defined, including text features, emotional features, credibility features, social background features and category features, and the relationships among these multi-domain features are modeled in a fine-grained hierarchy, including five parent classes and 88 subcategories. At the instance level, 32 types of typical rumor category judgment and reasoning rules are constructed, and the ontology is processed by using SWRL rule language and pellet inference machine for conflict processing and tacit knowledge mining, so that the semantic analysis and reasoning of rumor text content are realized, which proves its effectiveness in dealing with complex, fuzzy and uncertain information in online rumors and provides a new perspective and tool for the interpretable analysis and processing of online rumors.
Data availability
The datasets generated during the current study are available from the corresponding author upon reasonable request.
Jiang, S. The production scene and content characteristics of scientific rumors. Youth J. https://doi.org/10.15997/j.cnki.qnjz.2020.33.011 (2020).
Article Google Scholar
Jin, X. & Zhao, Y. Analysis of internet rumors from the perspective of co-governance—Practice of rumor governance on wechat platform. News and Writing. 6 , 41–44 (2017).
Bai, S. Research on the causes and countermeasures of internet rumors. Press https://doi.org/10.15897/j.cnki.cn51-1046/g2.2010.04.035 (2010).
Garg, S. & Sharma, D. K. Linguistic features based framework for automatic fake news detection. Comput. Ind. Eng. 172 , 108432 (2022).
Zhao, J., Fu, C. & Kang, X. Content characteristics predict the putative authenticity of COVID-19 rumors. Front. Public Health 10 , 920103 (2022).
Article PubMed PubMed Central Google Scholar
Zhang, Z., Shu, K. & He, L. The theme and characteristics of wechat rumors. News and Writing. 1 , 60–64 (2016).
Li, B. & Yu, G. Research on the discourse space and communication field of internet rumors in the post-truth era—Based on the analysis of 4160 rumors in wechat circle of friends. Journalism Research. 2 , 103–112 (2018).
Yu, G. Text structure and expression characteristics of internet rumors—Analysis of 6000+ rumors based on tencent big data screening and identification. News and Writing. 2 , 53–59 (2018).
Mourão, R. R. & Robertson, C. T. Fake news as discursive integration: An analysis of sites that publish false, misleading, hyperpartisan and sensational information. J. Stud. 20 , 2077–2095 (2019).
Google Scholar
Zhou, G. Analysis on the content characteristics and strategies of epidemic rumors—Based on Sina’s “novel coronavirus epidemic rumors list”. Sci. Popul. https://doi.org/10.19293/j.cnki.1673-8357.2021.05.002 (2021).
Huang, Y. An analysis of the internal logic and methods of rumor “confirmation”—An empirical study based on 60 rumors spread on wechat. J. Party Sch. Tianjin Munic. Comm. CPC 20 , 7 (2018).
Butt, S. et al . What goes on inside rumour and non-rumour tweets and their reactions: A psycholinguistic analyses. Comput. Hum. Behav. 135 , 107345 (2022).
Zhou, L., Tao, J. & Zhang, D. Does fake news in different languages tell the same story? An analysis of multi-level thematic and emotional characteristics of news about COVID-19. Inf. Syst. Front. 25 , 493–512. https://doi.org/10.1007/s10796-022-10329-7 (2023).
Article PubMed Google Scholar
Tan, L. et al . Research status of deep learning methods for rumor detection. Multimed. Tools Appl. 82 , 2941–2982 (2023).
Damstra, A. et al. What does fake look like? A review of the literature on intentional deception in the news and on social media. J. Stud. 22 , 1947–1963. https://doi.org/10.1080/1461670X.2021.1979423 (2021).
Lai, S. & Tang, X. Research on the influence of information emotionality on the spread of online rumors. J. Inf. 35 , 116–121 (2016).
ADS Google Scholar
Yuan, H. & Xie, Y. Research on the rumor maker of internet rumors about public events—Based on the content analysis of 118 influential Internet rumors about public events. Journalist https://doi.org/10.16057/j.cnki.31-1171/g2.2015.05.008 (2015).
Ruan, Z. & Yin, L. Types and discourse focus of weibo rumors—Based on the content analysis of 307 weibo rumors. Contemporary Communication. 4 , 77–78+84 (2014).
Zhang, W. & Zhu, Q. Research on the Construction Method of Domain Ontology. Books and Information. 5 , 16–19+40 (2011).
Tham, K.D., Fox, M.S. & Gruninger, M. A cost ontology for enterprise modelling. In Proceedings of 3rd IEEE Workshop on Enabling Technologies: Infrastructure for Collaborative Enterprises. IEEE , 197–210. https://doi.org/10.1109/ENABL.1994.330502 (1994).
Uschold, M. & Gruninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 11 , 93–136 (1996).
Menzel, C. P., Mayer, R. J. & Painter, M. K. IDEF5 ontology description capture method: Concepts and formal foundations (Armstrong Laboratory, Air Force Materiel Command, Wright-Patterson Air Force, 1992).
Book Google Scholar
Song, Z., Zhu, F. & ZHANG, D. Research on air and missile defense domain ontology development based on IDEF5 and OWL. Journal of Projectiles, Rockets, Missiles and Guidance. 30 , 176–178 (2010).
Fernández-López, M., Gómez-Pérez, A. & Juristo, N. Methontology: From ontological art towards ontological engineering. AAAI-97 Spring Symposium Series . https://oa.upm.es/5484/ (1997).
Sawsaa, A. & Lu, J. Building information science ontology (OIS) with methontology and protégé. J. Internet Technol. Secur. Trans. 1 , 100–109 (2012).
Yue, L. & Liu, W. Comparative study on the construction methods of domain ontology at home and abroad. Inf. Stud. Theory Appl. 39 , 119–125. https://doi.org/10.16353/j.cnki.1000-7490.2016.08.024 (2016).
Noy, N.F. & McGuinness, D.L. Ontology development 101: A guide to creating your first ontology. Stanford knowledge systems laboratory technical report. KSL-01–05 (2001).
Luo, Y. et al . vim: Research on OWL-based vocabulary ontology construction method for units of measurement. Electronics 12 , 3783 (2023).
Al-Aswadi, F. N., Chan, H. Y. & Gan, K. H. Automatic ontology construction from text: A review from shallow to deep learning trend. Artif. Intell. Rev. 53 , 3901–3928 (2020).
Chen, X. & Mao, T. Ontology construction of documentary heritage—Taking China archives documentary heritage list as an example. Libr. Trib. 43 , 120–131 (2023).
CAS Google Scholar
Zhao, X. & Li, T. Research on the ontology construction of archives oriented to digital humanism—Taking Wanli tea ceremony archives as an example. Inf. Stud. Theory Appl. 45 , 154–161. https://doi.org/10.16353/j.cnki.1000-7490.2022.08.021 (2022).
Huang, X. et al . Construction of special knowledge base of government website pages based on domain ontology—Taking “COVID-19 vaccine science popularization” as an example. Libr. Inf. Serv. 66 , 35–46. https://doi.org/10.13266/j.issn.0252-3116.2022.17.004 (2022).
Jindal, R., Seeja, K. & Jain, S. Construction of domain ontology utilizing formal concept analysis and social media analytics. Int. J. Cogn. Comput. Eng. 1 , 62–69 (2020).
Ran, J. et al . Research on ontology construction of idioms and allusions based on OWL. Comput. Technol. Dev. 20 , 63–66 (2010).
Li, L. et al . Research on business process modeling of army equipment maintenance support based on IDEF5. Technol. Innov. Appl. 11 , 80–82 (2021).
Song, Z. et al . Ontology modeling of air defense and anti-missile operation process based on IDEF5/OWL. J. Missiles Guid. 30 , 176–178 (2010).
Li, A., Xu, Y. & Chi, Y. Summary of ontology construction and application. Inf. Stud. Theory Appl 46 , 189–195. https://doi.org/10.16353/j.cnki.1000-7490.2023.11.024 (2023).
Yang, J., Song, C. & Jin, L. Ontology construction of emergency plan based on methontology method. J. Saf. Environ. 18 , 1427–1431. https://doi.org/10.13637/j.issn.1009-6094.2018.04.033 (2018).
Duan, L. & Li, H. Ontology modeling method of high-resolution image rural residential area supported by OIA technology. Modern Agricultural Science and Technology. 2 , 338–340 (2016).
Chen, Y. & Jiang, H. Construction of fire inspection knowledge map based on GIS geospatial relationship. J. Subtrop. Resour. Environ. 18 , 109–118. https://doi.org/10.19687/j.cnki.1673-7105.2023.03.014 (2023).
Zhu, L. et al. Construction of TCM asthma domain ontology. Chin. J. Exp. Tradit. Med. Formulae 23 , 222–226. https://doi.org/10.13422/j.cnki.syfjx.2017150222 (2017).
Li, H. et al . Domain ontology construction and relational reasoning. J. Inf. Eng. Univ. 24 , 321–327 (2023).
Zhang, Y. et al. Construction of ontology of stroke nursing field based on corpus. Chin. Nurs. Res. 36 , 4186–4190 (2022).
Wu, M. et al. Ontology construction of natural gas market knowledge map. Pet. New Energy 34 , 71–76 (2022).
Li, X. et al . Research on ontology construction based on thesaurus and its semantic relationship. Inf. Sci. 36 , 83–87 (2018).
Article ADS CAS Google Scholar
Chen, Q. et al . Construction of knowledge ontology of clinical trial literature of traditional Chinese medicine. Chin. J. Exp. Tradit. Med. Formulae 29 , 190–197. https://doi.org/10.13422/j.cnki.syfjx.20231115 (2023).
Xiao, Y. et al. Construction and application of novel coronavirus domain ontology. Mil. Med. 46 , 263–268 (2022).
Su, N. et al . Automatic construction method of domain-limited ontology. Lifting the Transport Machinery. 8 , 49–57 (2023).
Zheng, S. et al . Ontology construction method for user-generated content. Inf. Sci. 37 , 43–47. https://doi.org/10.13833/j.issn.1007-7634.2019.11.007 (2019).
Dong, J., Wang, J. & Wang, Z. Ontology automatic construction method for human-machine-object ternary data fusion in manufacturing field. Control Decis. 37 , 1251–1257. https://doi.org/10.13195/j.kzyjc.2020.1298 (2022).
Zhu, L., Hua, G. & Gao, W. Mapping ontology vertices to a line using hypergraph framework. Int. J. Cogn. Comput. Eng. 1 , 1–8 (2020).
Zhai, Y. & Wang, F. Research on the construction method of Chinese domain ontology based on text mining. Inf. Sci. 33 , 3–10. https://doi.org/10.13833/j.cnki.is.2015.06.001 (2015).
Duan, Z. Generation mechanism of internet rumors and countermeasures. Guizhou Soc. Sci. https://doi.org/10.13713/j.cnki.cssci.2016.04.014 (2016).
Du, Z. & Zhi, S. The harm and governance of network political rumors. Academic Journal of Zhongzhou. 4 , 161–165 (2019).
Song, X. et al . Research on influencing factors of health rumor sharing willingness based on MOA theory. J. China Soc. Sci. Tech. Inf. 39 , 511–520 (2020).
Jiang, S. Research on the characteristics, causes and countermeasures of social rumors dissemination in china in recent years. Red Flag Manuscript . 16 , 4 (2011).
Huang, J., Wang, G. & Zhong, S. Research on the propagation law and function mode of sci-tech rumors. Journal of Information. 34 , 156–160 (2015).
Liu, Y. et al . A survey of rumor recognition in social media. Chin. J. Comput. 41 , 1536–1558 (2018).
Wei, D. et al. Public emotions and rumors spread during the covid-19 epidemic in China: Web-based correlation study. J. Med. Internet Res. 22 , e21933 (2020).
Runxi, Z. & Di, Z. A model and simulation of the emotional contagion of netizens in the process of rumor refutation. Sci. Rep. https://doi.org/10.1038/s41598-019-50770-4 (2019).
Tang, X. & Lai, S. Research on the forwarding of network health rumors in public health security incidents—Interaction between perceived risk and information credibility. J. Inf. 40 , 101–107 (2021).
Nicolas, P., Dominik, B. & Stefan, F. Emotions in online rumor diffusion. EPJ Data Sci. https://doi.org/10.1140/epjds/s13688-021-00307-5 (2021).
Deng, G. & Tang, G. Research on the spread of network rumors and its social impact. Seeker https://doi.org/10.16059/j.cnki.cn43-1008/c.2005.10.031 (2005).
Ji, Y. Research on the communication motivation of wechat rumors. Youth J. https://doi.org/10.15997/j.cnki.qnjz.2019.17.006 (2019).
Yuan, G. Analysis on the causes and motives of internet rumors in emergencies—Taking social media as an example. Media. 21 , 80–83 (2016).
Zhao, N., Li, Y. & Zhang, J. A review of the research on influencing factors and motivation mechanism of rumor spread. J. Psychol. Sci. 36 , 965–970. https://doi.org/10.16719/j.cnki.1671-6981.2013.04.015 (2013).
Article CAS Google Scholar
Hu, H. On the formation mechanism of social rumors from the perspective of “rumors and salt storm”. J. Henan Univ. 52 , 63–68 (2012).
Yue, Y. et al. Trust in government buffers the negative effect of rumor exposure on people’s emotions. Curr. Psychol. 42 , 23917–23930 (2023).
Wang, C. & Hou, X. Analysis of rumor discourse in major emergencies. J. Commun. 19 , 34–38 (2012).
Xu, L. Research progress of ontology evaluation. J. China Soc. Scie. Tech. Inf. 35 , 772–784 (2016).
Lantow, B. & Sandkuhl, K. An analysis of applicability using quality metrics for ontologies on ontology design patterns. Intell. Syst. Acc. Financ. Manag. 22 , 81–99 (2015).
Pak, J. & Zhou, L. A framework for ontology evaluationIn. Exploring the Grand Challenges for Next Generation E-Business: 8th Workshop on E-Business, WEB 2009, Phoenix, AZ, USA, December 15, 2009, Revised Selected Papers 8. , 10–18. https://doi.org/10.1007/978-3-642-17449-0_2 (Springer Berlin Heidelberg, 2011).
Download references
Acknowledgements
This study was financially supported by Xi'an Major Scientific and Technological Achievements Transformation and Industrialization Project (20KYPT0003-10).
This work was supported by Xi’an Municipal Bureau of Science and Technology, 20KYPT0003-10.
Author information
Authors and affiliations.
School of Economics and Management, Xidian University, 266 Xifeng Road, Xi’an, 710071, China
Jianbo Zhao, Huailiang Liu, Weili Zhang, Tong Sun, Qiuyi Chen, Yan Zhuang, Xiaojin Zhang & Shanzhuang Zhang
School of Artificial Intelligence, Xidian University, 266 Xifeng Road, Xi’an, 710071, China
Yuehai Wang, Jiale Cheng & Ruiyu Ding
School of Telecommunications Engineering, Xidian University, 266 Xifeng Road, Xi’an, 710071, China
You can also search for this author in PubMed Google Scholar
Contributions
H.L. formulated the overall research strategy and guided the work. J.Z kept the original data on which the paper was based and verified whether the charts and conclusions accurately reflected the collected data. J.Z. W.Z. and T.S. wrote the main manuscript text. W.Z. Y.W. and Q.C. finished collecting and sorting out the data. J.C. Y.Z. and X.Z. prepared Figs. 1 – 7 , S.Z. B.L. and R.D. prepared Tables 1 – 14 . All authors reviewed the manuscript.
Corresponding author
Correspondence to Jianbo Zhao .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Zhao, J., Liu, H., Zhang, W. et al. Research on domain ontology construction based on the content features of online rumors. Sci Rep 14 , 12134 (2024). https://doi.org/10.1038/s41598-024-62459-4
Download citation
Received : 07 December 2023
Accepted : 16 May 2024
Published : 27 May 2024
DOI : https://doi.org/10.1038/s41598-024-62459-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Rumor content features
- Domain ontology
- Top-level ontology reuse
- New concept discovery
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

Pritzker Legal Research Center
Nulr heritage months, recent publications.
- Black History Month - February
- Women's History Month - March
- Arab American History Month - April
- Asian Pacific Islander Desi American Heritage Month - May
- Jewish Heritage Month - May
- LGBTQ+ Pride Month - June
- Disability Pride Month - July
- Hispanic/Latinx Heritage Month - Sept. 15 - Oct. 15
- Native American History Month - November
- Racial Justice
Want to talk with a reference librarian? Send us a chat.
This guide highlights NULR publications and abstracts relevant to heritage months. Although intersectionality teaches us that many of these articles can fit into more than one category, articles are only linked to once within the guide.
Many of these articles have been published within the past ten years. Older articles can be found on HeinOnline: click here for articles on racial justice , and here for articles about gender .
Last updated: 5/17/2024
Scott Shimizu, Toward Accessing HIV-Preventative Medication in Prisons , 118 Nw. U. L. Rev. 1735 (2024).
The Eighth Amendment is meant to protect incarcerated individuals against harm from the state, including state inaction in the face of a known risk of harm. While the Eighth Amendment’s protection prohibits certain prison disciplinary measures and conditions of confinement, the constitutional ambit should arguably encompass protection from the serious risk of harm of sexual assault, as well as a corollary to sexual violence: the likelihood of contracting a deadly sexually transmitted infection like HIV. Yet Eighth Amendment scholars frequently question the degree to which the constitutional provision actually protects incarcerated individuals.
Atinuke O. Adediran, Racial Targets , 118 Nw. U. L. Rev. 1455 (2024).
It is common scholarly and popular wisdom that racial quotas are illegal. However, the reality is that since 2020’s racial reckoning, many of the largest companies have been touting specific, albeit voluntary, goals to hire or promote people of color, which this Article refers to as “racial targets.” The Article addresses this phenomenon and shows that companies can defend racial targets as distinct from racial quotas, which involve a rigid number or proportion of opportunities reserved exclusively for minority groups. The political implications of the legal defensibility of racial targets are significant in this moment in American history, where race relations have become polarized and the conservative, pro-business U.S. Supreme Court may weigh in on the legality of voluntary goals set by some of the largest companies in the country. Large companies have historically been granted discretion to choose their strategies for paving the way toward equal employment opportunity for people of color. The Article grapples with whether this corporate-discretion ideal would inform the legal posture of racial targets.
Joyce A. Hughes, Dear Sisters, Dear Daughters , 118 Nw. U. L. Rev. 575 (2023).
Professor Joyce A. Hughes was honored in August, 2021, with the ABA's Margaret Brent Women Lawyers of Achievement Award. This award recognizes outstanding women lawyers who have paved the way to success for other women in the legal profession.
As part of receiving this award, Professor Hughes wrote the following essay. The Northwestern University Law Review is honored to reprint this essay here. For more information about Professor Hughes, click here . For more about Professor Hughes receiving the Margaret Brent award, please click here .
Cary Martin Shelby, Racism as a Threat to Financial Stability , 118 Nw. U. L. Rev. 757 (2023).
This Article draws from several theoretical frameworks such as critical race theory, law and economics, and rule of law conceptions to argue that the Financial Stability Oversight Council (FSOC) should formally recognize racism as a threat to financial stability due to its interconnectedness with recent and projected systemic disruptions. This Article begins by first introducing a novel model created by the author through which to dissect this claim. This “Systemic Disruption Model” provides a theoretical depiction of how racism drives every phase along the life-cycle continuum of a systemic disruption.
Norrinda Brown, Black Liberty in Emergency , 118 Nw. U. L. Rev. 691 (2023).
COVID-19 pandemic orders were weaponized by state and local governments in Black neighborhoods, often through violent acts of the police. This revealed an intersection of three centuries-old patterns— criminalizing Black movement, quarantining racial minorities in public health crises, and segregation. The geographic borders of the most restrictive pandemic order enforcement were nearly identical to the borders of highly segregated, historically Black neighborhoods.
Lynnise Phillips Pantin, Financial Inclusion, Cryptocurrency, and Afrofuturism , 118 Nw. U. L. Rev. 621 (2023).
As a community, Black people consistently face barriers to full participation in traditional financial markets. The decentralized nature of the cryptocurrency market is attractive to a community that has been historically and systematically excluded from the traditional financial markets by both private and public actors. As new entrants to any type of financial market, Black people have increasingly embraced blockchain technology and cryptocurrency as a path towards the wealth-building opportunities and financial freedom they have been denied in traditional markets. This Article analyzes whether the technology’s decentralized system will lead to financial inclusion or increased financial exclusion. Without reconciling the racially discriminatory history or effects of the current central financial system, the innovative decentralized appeal to Black people will do little to overcome economic inequity. It may be possible that some cryptocurrencies can be tools for financial inclusion by improving economic outcomes and building wealth outside of traditional financial institutions, but without an intervention, a decentralized system will not necessarily lead to decentralized wealth.
Daiquiri J. Steele, Enforcing Equity , 118 Nw. U. L. Rev. 577 (2023).
Federal administrative agencies that enforce workplace laws have dual responsibilities: (1) to prevent or remedy noncompliance with the underlying workplace law and (2) to prevent or remedy noncompliance with the law’s antiretaliation provisions. Disparities based on race, sex, and their intersection exist with respect to both of these types of employer noncompliance, as female workers and workers of color experience more violations of the substantive provisions and the retaliation provisions of these laws. While effective enforcement is vital to preserving workplace regulation as a whole, there is also an equity component to enforcement. Because workplace law violations disproportionately harm women and people of color, ineffective enforcement by administrative agencies disproportionately harms these groups.
Gregory Klass and Tess Wilkinson-Ryan, Gender and Deception: Moral Perceptions and Legal Responses , 118 Nw. U. L. Rev. 193 (2023).
Decades of social science research has shown that the identity of the parties in a legal action can affect case outcomes. Parties’ race, gender, class, and age all affect decisions of prosecutors, judges, juries, and other actors in a criminal prosecution or civil litigation. Less studied has been how identity might affect other forms of legal regulation. This Essay begins to explore perceptions of deceptive behavior—i.e., how wrongful it is, and the extent to which it should be regulated or punished—and the relationship of those perceptions to the gender of the actors. We hypothesize that ordinary people tend to perceive deception of women as more wrongful than deception of men, and that such perceptions can affect both case outcomes and decisions to regulate.
- Next: Black History Month - February >>
- Last Updated: May 28, 2024 9:09 AM
- URL: https://library.law.northwestern.edu/NURLheritage

Demi Moore's Confusing Introduction of Cher at the 2024 amfAR Gala Cannes Has Fans Raising Eyebrows
On May 23, actors, singers, models and much more joined at the annual star-studded amfAR Gala at the 2024 Cannes Film Festival . And while the Gala's biggest goal is to raise funds for groundbreaking AIDS research, having Demi Moore as host and Cher perform might've definitely made some attendees RSVP "yes" right away.
But as a new video from Variety co-editor-in-chief Ramin Setoodeh shows (see it HERE! ), Moore's hosting abilities weren't as much crowd-pleaser as we expected. In the clip, the Oscar winner can be seen presenting Cher before she takes the stage.
"I'm gonna see if this is the moment we've all been waiting for," Moore said in a gorgeous silver shimmering dress. "I'm just making sure that you're really, really with me."
And while her words indicate that she wanted the crowd to get hyped and make some noise, her delivery was quite the opposite. In fact, Moore said everything slowly, and quietly, almost like she wanted the whole room to quiet down instead.
"Because this incredible woman that I'm about to introduce she's a Grammy winner, an Oscar winner, an Emmy winner," Moore continued.
Then, someone in the crowd shouts something and Moore pauses her sentence, per Page Six . "Are you an Emmy winner over there in the back of the room?" Moore told the heckler. "I f- don't think so." Moore certainly wasn't playing around…
After addressing the heckler, Moore continued her introduction.
"She's a style icon and my personal hair inspiration," Moore said, swaying her long black hair. "And she was honored by amfAR for their award of inspiration in 2015."
"The bottom line is she is just one of the most talented, successful, and best-loved performers of all time, so please," she said, taking another long pause. "Please give a warm welcome to the incredible, one and only, Cher."
In the comments of Setoodeh's video, fans are already raising eyebrows and questioning her energy. After all, why does she feel so calm and quiet when she's supposed to hype everyone as the host?
"Why did she keep pausing like that? What a weird way to introduce Cher?" wrote one X user. "Demi Moore making it about her," another wrote. "Just make the introduction minus your arrogance."
Looks like Moore won't be adding "host" to resume anytime soon.
Before you go, click here to see all the celebrities at the 2024 Cannes Film Festival.
More from SheKnows
- Kelly Rowland's Explanation of the Cannes Red Carpet Scuffle Tells Us Everything We Needed to Know

IMAGES
VIDEO
COMMENTS
Learn how to introduce your topic, provide background, establish your research problem, and specify your objective in a research paper introduction. Follow the step-by-step guide with examples and tips for argumentative and empirical papers.
Define your specific research problem and problem statement. Highlight the novelty and contributions of the study. Give an overview of the paper's structure. The research paper introduction can vary in size and structure depending on whether your paper presents the results of original empirical research or is a review paper.
Learn how to write an effective introduction for a research paper, including the structure, purpose, and examples. An introduction should provide an overview of the topic, the research problem, the objectives, and the significance of the study.
The introduction leads the reader from a general subject area to a particular topic of inquiry. It establishes the scope, context, and significance of the research being conducted by summarizing current understanding and background information about the topic, stating the purpose of the work in the form of the research problem supported by a hypothesis or a set of questions, explaining briefly ...
Emphasizing the importance of the proposed research and how the gaps will be addressed. Stating the research problem/ questions. Stating the hypotheses briefly. Figure 17.1 depicts how the introduction needs to be written. A scientific paper should have an introduction in the form of an inverted pyramid.
Download Article. 1. Announce your research topic. You can start your introduction with a few sentences which announce the topic of your paper and give an indication of the kind of research questions you will be asking. This is a good way to introduce your readers to your topic and pique their interest.
Learn the purpose, structure, and strategies of writing an introduction for a research paper. Find tips, examples, and phrases to grab your readers' attention and preview your thesis statement.
Learn the key elements and steps to write an effective introduction for your research paper. Find out how to hook the reader, present your topic, thesis statement, and context, and revise your introduction.
In general, your introductions should contain the following elements: When you're writing an essay, it's helpful to think about what your reader needs to know in order to follow your argument. Your introduction should include enough information so that readers can understand the context for your thesis. For example, if you are analyzing ...
Provide your readers with a road map to help them understand what you will address throughout the research. Be succinct - it is advised that your opening introduction consists of around 8-9 percent of the overall amount of words in your article (for example, 160 words for a 2000 words essay). Make a strong and unambiguous thesis statement.
The key thing is. to guide the reader into your topic and situate your ideas. Step 2: Describe the background. This part of the introduction differs depending on what approach your paper is ...
Learn the purpose, structure and tips for creating a good introduction for your research paper. Find out what to include, such as overview, prior research, rationale, methodology, thesis and outline.
An introduction is a paragraph that provides information about your entire paper and aims to attract and inform the reader. Before writing an introduction or even starting your paper, you need to research academic sources. The first one or two sentences of an introduction paragraph should be a hook to attract the reader's attention.
Introductions for class essays. Introductions for class essays are simpler than research articles introductions. Most of the time they include the following elements: (1) a general problem that needs a solution; (2) a brief review of solutions that didn't work out; (3) a research question; (4) a hypothesis that answers the research question.
The introduction serves the purpose of leading the reader from a general subject area to a particular field of research. It establishes the context of the research being conducted by summarizing current understanding and background information about the topic, stating the purpose of the work in the form of the hypothesis, question, or research problem, briefly explaining your rationale ...
Step 1: Hook your reader. Step 2: Give background information. Step 3: Present your thesis statement. Step 4: Map your essay's structure. Step 5: Check and revise. More examples of essay introductions. Other interesting articles. Frequently asked questions about the essay introduction.
Hannah, a writer and editor since 2017, specializes in clear and concise academic and business writing. She has mentored countless scholars and companies in writing authoritative and engaging content. A great research paper introduction starts with a catchy hook and ends with a road map for the research. At every step, QuillBot can help.
Accepted February 25, 2023. This paper provides an in-depth introduction to r esearch methods. and discusses numerous aspects r elated to the r esearch process. It. begins with an overview of ...
Learn how research is defined, why it is important, and how it uses the scientific method to discover new knowledge. Find out what is a hypothesis, a protocol, and a principal investigator, and how they guide the research process.
Introduction To Environmental Research. Historical records show that concern for the environment goes back thousands of years. In fact, in 2700 BC, ...
Introduction. The United States, along with the rest of the world, has embarked on a transition to clean energy. ... Federal agencies should support data collection and related research that enable state and regional economic development strategists to make better-informed decisions about the growth potential and resource and asset requirements ...
Introduction. Recently, it has been reported that traditional Chinese medicine has demonstrated efficacy in treating coronavirus disease 2019 (COVID-19) caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [].Recent study has also evidenced that schaftoside inhibits the 3CL pro and PL pro of SARS-CoV-2 virus, while also enhancing the immune response of host cells treated by ...
A research proposal describes what you will investigate, why it's important, and how you will conduct your research. The format of a research proposal varies between fields, but most proposals will contain at least these elements: Title page; Introduction; Literature review; Research design; Reference list
Li, B. & Yu, G. Research on the discourse space and communication field of internet rumors in the post-truth era—Based on the analysis of 4160 rumors in wechat circle of friends. Journalism ...
Decades of social science research has shown that the identity of the parties in a legal action can affect case outcomes. Parties' race, gender, class, and age all affect decisions of prosecutors, judges, juries, and other actors in a criminal prosecution or civil litigation.
SheKnows. Demi Moore's Confusing Introduction of Cher at the 2024 amfAR Gala Cannes Has Fans Raising Eyebrows. Story by Giovana Gelhoren. • 47m. On May 23, actors, singers, models and much more ...
An Introduction to REDCap . REDCap (Research Electronic Data Capture) is a secure web application for building and managing online surveys and databases. It is free to use for all UB researchers, staff, and students. This UB CTSI Educational Modules video: Discusses the origins of REDCap;
Authors: Prints & Photographs Division staff ; Editors: Leigh Gleason, Head, Reference Section, Prints & Photographs Division Note: This guide was adapted from the "First Ladies of the United States: Selected Images From the Collections of the Library of Congress" web guide created by Prints & Photographs staff, previously available on the Prints & Photographs Reading Room web site.