19+ Experimental Design Examples (Methods + Types)
Ever wondered how scientists discover new medicines, psychologists learn about behavior, or even how marketers figure out what kind of ads you like? Well, they all have something in common: they use a special plan or recipe called an "experimental design."
Imagine you're baking cookies. You can't just throw random amounts of flour, sugar, and chocolate chips into a bowl and hope for the best. You follow a recipe, right? Scientists and researchers do something similar. They follow a "recipe" called an experimental design to make sure their experiments are set up in a way that the answers they find are meaningful and reliable.
Experimental design is the roadmap researchers use to answer questions. It's a set of rules and steps that researchers follow to collect information, or "data," in a way that is fair, accurate, and makes sense.

Long ago, people didn't have detailed game plans for experiments. They often just tried things out and saw what happened. But over time, people got smarter about this. They started creating structured plans—what we now call experimental designs—to get clearer, more trustworthy answers to their questions.
In this article, we'll take you on a journey through the world of experimental designs. We'll talk about the different types, or "flavors," of experimental designs, where they're used, and even give you a peek into how they came to be.

What Is Experimental Design?
Alright, before we dive into the different types of experimental designs, let's get crystal clear on what experimental design actually is.
Imagine you're a detective trying to solve a mystery. You need clues, right? Well, in the world of research, experimental design is like the roadmap that helps you find those clues. It's like the game plan in sports or the blueprint when you're building a house. Just like you wouldn't start building without a good blueprint, researchers won't start their studies without a strong experimental design.
So, why do we need experimental design? Think about baking a cake. If you toss ingredients into a bowl without measuring, you'll end up with a mess instead of a tasty dessert.
Similarly, in research, if you don't have a solid plan, you might get confusing or incorrect results. A good experimental design helps you ask the right questions ( think critically ), decide what to measure ( come up with an idea ), and figure out how to measure it (test it). It also helps you consider things that might mess up your results, like outside influences you hadn't thought of.
For example, let's say you want to find out if listening to music helps people focus better. Your experimental design would help you decide things like: Who are you going to test? What kind of music will you use? How will you measure focus? And, importantly, how will you make sure that it's really the music affecting focus and not something else, like the time of day or whether someone had a good breakfast?
In short, experimental design is the master plan that guides researchers through the process of collecting data, so they can answer questions in the most reliable way possible. It's like the GPS for the journey of discovery!
History of Experimental Design
Around 350 BCE, people like Aristotle were trying to figure out how the world works, but they mostly just thought really hard about things. They didn't test their ideas much. So while they were super smart, their methods weren't always the best for finding out the truth.
Fast forward to the Renaissance (14th to 17th centuries), a time of big changes and lots of curiosity. People like Galileo started to experiment by actually doing tests, like rolling balls down inclined planes to study motion. Galileo's work was cool because he combined thinking with doing. He'd have an idea, test it, look at the results, and then think some more. This approach was a lot more reliable than just sitting around and thinking.
Now, let's zoom ahead to the 18th and 19th centuries. This is when people like Francis Galton, an English polymath, started to get really systematic about experimentation. Galton was obsessed with measuring things. Seriously, he even tried to measure how good-looking people were ! His work helped create the foundations for a more organized approach to experiments.
Next stop: the early 20th century. Enter Ronald A. Fisher , a brilliant British statistician. Fisher was a game-changer. He came up with ideas that are like the bread and butter of modern experimental design.
Fisher invented the concept of the " control group "—that's a group of people or things that don't get the treatment you're testing, so you can compare them to those who do. He also stressed the importance of " randomization ," which means assigning people or things to different groups by chance, like drawing names out of a hat. This makes sure the experiment is fair and the results are trustworthy.
Around the same time, American psychologists like John B. Watson and B.F. Skinner were developing " behaviorism ." They focused on studying things that they could directly observe and measure, like actions and reactions.
Skinner even built boxes—called Skinner Boxes —to test how animals like pigeons and rats learn. Their work helped shape how psychologists design experiments today. Watson performed a very controversial experiment called The Little Albert experiment that helped describe behaviour through conditioning—in other words, how people learn to behave the way they do.
In the later part of the 20th century and into our time, computers have totally shaken things up. Researchers now use super powerful software to help design their experiments and crunch the numbers.
With computers, they can simulate complex experiments before they even start, which helps them predict what might happen. This is especially helpful in fields like medicine, where getting things right can be a matter of life and death.
Also, did you know that experimental designs aren't just for scientists in labs? They're used by people in all sorts of jobs, like marketing, education, and even video game design! Yes, someone probably ran an experiment to figure out what makes a game super fun to play.
So there you have it—a quick tour through the history of experimental design, from Aristotle's deep thoughts to Fisher's groundbreaking ideas, and all the way to today's computer-powered research. These designs are the recipes that help people from all walks of life find answers to their big questions.
Key Terms in Experimental Design
Before we dig into the different types of experimental designs, let's get comfy with some key terms. Understanding these terms will make it easier for us to explore the various types of experimental designs that researchers use to answer their big questions.
Independent Variable : This is what you change or control in your experiment to see what effect it has. Think of it as the "cause" in a cause-and-effect relationship. For example, if you're studying whether different types of music help people focus, the kind of music is the independent variable.
Dependent Variable : This is what you're measuring to see the effect of your independent variable. In our music and focus experiment, how well people focus is the dependent variable—it's what "depends" on the kind of music played.
Control Group : This is a group of people who don't get the special treatment or change you're testing. They help you see what happens when the independent variable is not applied. If you're testing whether a new medicine works, the control group would take a fake pill, called a placebo , instead of the real medicine.
Experimental Group : This is the group that gets the special treatment or change you're interested in. Going back to our medicine example, this group would get the actual medicine to see if it has any effect.
Randomization : This is like shaking things up in a fair way. You randomly put people into the control or experimental group so that each group is a good mix of different kinds of people. This helps make the results more reliable.
Sample : This is the group of people you're studying. They're a "sample" of a larger group that you're interested in. For instance, if you want to know how teenagers feel about a new video game, you might study a sample of 100 teenagers.
Bias : This is anything that might tilt your experiment one way or another without you realizing it. Like if you're testing a new kind of dog food and you only test it on poodles, that could create a bias because maybe poodles just really like that food and other breeds don't.
Data : This is the information you collect during the experiment. It's like the treasure you find on your journey of discovery!
Replication : This means doing the experiment more than once to make sure your findings hold up. It's like double-checking your answers on a test.
Hypothesis : This is your educated guess about what will happen in the experiment. It's like predicting the end of a movie based on the first half.
Steps of Experimental Design
Alright, let's say you're all fired up and ready to run your own experiment. Cool! But where do you start? Well, designing an experiment is a bit like planning a road trip. There are some key steps you've got to take to make sure you reach your destination. Let's break it down:
- Ask a Question : Before you hit the road, you've got to know where you're going. Same with experiments. You start with a question you want to answer, like "Does eating breakfast really make you do better in school?"
- Do Some Homework : Before you pack your bags, you look up the best places to visit, right? In science, this means reading up on what other people have already discovered about your topic.
- Form a Hypothesis : This is your educated guess about what you think will happen. It's like saying, "I bet this route will get us there faster."
- Plan the Details : Now you decide what kind of car you're driving (your experimental design), who's coming with you (your sample), and what snacks to bring (your variables).
- Randomization : Remember, this is like shuffling a deck of cards. You want to mix up who goes into your control and experimental groups to make sure it's a fair test.
- Run the Experiment : Finally, the rubber hits the road! You carry out your plan, making sure to collect your data carefully.
- Analyze the Data : Once the trip's over, you look at your photos and decide which ones are keepers. In science, this means looking at your data to see what it tells you.
- Draw Conclusions : Based on your data, did you find an answer to your question? This is like saying, "Yep, that route was faster," or "Nope, we hit a ton of traffic."
- Share Your Findings : After a great trip, you want to tell everyone about it, right? Scientists do the same by publishing their results so others can learn from them.
- Do It Again? : Sometimes one road trip just isn't enough. In the same way, scientists often repeat their experiments to make sure their findings are solid.
So there you have it! Those are the basic steps you need to follow when you're designing an experiment. Each step helps make sure that you're setting up a fair and reliable way to find answers to your big questions.
Let's get into examples of experimental designs.
1) True Experimental Design

In the world of experiments, the True Experimental Design is like the superstar quarterback everyone talks about. Born out of the early 20th-century work of statisticians like Ronald A. Fisher, this design is all about control, precision, and reliability.
Researchers carefully pick an independent variable to manipulate (remember, that's the thing they're changing on purpose) and measure the dependent variable (the effect they're studying). Then comes the magic trick—randomization. By randomly putting participants into either the control or experimental group, scientists make sure their experiment is as fair as possible.
No sneaky biases here!
True Experimental Design Pros
The pros of True Experimental Design are like the perks of a VIP ticket at a concert: you get the best and most trustworthy results. Because everything is controlled and randomized, you can feel pretty confident that the results aren't just a fluke.
True Experimental Design Cons
However, there's a catch. Sometimes, it's really tough to set up these experiments in a real-world situation. Imagine trying to control every single detail of your day, from the food you eat to the air you breathe. Not so easy, right?
True Experimental Design Uses
The fields that get the most out of True Experimental Designs are those that need super reliable results, like medical research.
When scientists were developing COVID-19 vaccines, they used this design to run clinical trials. They had control groups that received a placebo (a harmless substance with no effect) and experimental groups that got the actual vaccine. Then they measured how many people in each group got sick. By comparing the two, they could say, "Yep, this vaccine works!"
So next time you read about a groundbreaking discovery in medicine or technology, chances are a True Experimental Design was the VIP behind the scenes, making sure everything was on point. It's been the go-to for rigorous scientific inquiry for nearly a century, and it's not stepping off the stage anytime soon.
2) Quasi-Experimental Design
So, let's talk about the Quasi-Experimental Design. Think of this one as the cool cousin of True Experimental Design. It wants to be just like its famous relative, but it's a bit more laid-back and flexible. You'll find quasi-experimental designs when it's tricky to set up a full-blown True Experimental Design with all the bells and whistles.
Quasi-experiments still play with an independent variable, just like their stricter cousins. The big difference? They don't use randomization. It's like wanting to divide a bag of jelly beans equally between your friends, but you can't quite do it perfectly.
In real life, it's often not possible or ethical to randomly assign people to different groups, especially when dealing with sensitive topics like education or social issues. And that's where quasi-experiments come in.
Quasi-Experimental Design Pros
Even though they lack full randomization, quasi-experimental designs are like the Swiss Army knives of research: versatile and practical. They're especially popular in fields like education, sociology, and public policy.
For instance, when researchers wanted to figure out if the Head Start program , aimed at giving young kids a "head start" in school, was effective, they used a quasi-experimental design. They couldn't randomly assign kids to go or not go to preschool, but they could compare kids who did with kids who didn't.
Quasi-Experimental Design Cons
Of course, quasi-experiments come with their own bag of pros and cons. On the plus side, they're easier to set up and often cheaper than true experiments. But the flip side is that they're not as rock-solid in their conclusions. Because the groups aren't randomly assigned, there's always that little voice saying, "Hey, are we missing something here?"
Quasi-Experimental Design Uses
Quasi-Experimental Design gained traction in the mid-20th century. Researchers were grappling with real-world problems that didn't fit neatly into a laboratory setting. Plus, as society became more aware of ethical considerations, the need for flexible designs increased. So, the quasi-experimental approach was like a breath of fresh air for scientists wanting to study complex issues without a laundry list of restrictions.
In short, if True Experimental Design is the superstar quarterback, Quasi-Experimental Design is the versatile player who can adapt and still make significant contributions to the game.
3) Pre-Experimental Design
Now, let's talk about the Pre-Experimental Design. Imagine it as the beginner's skateboard you get before you try out for all the cool tricks. It has wheels, it rolls, but it's not built for the professional skatepark.
Similarly, pre-experimental designs give researchers a starting point. They let you dip your toes in the water of scientific research without diving in head-first.
So, what's the deal with pre-experimental designs?
Pre-Experimental Designs are the basic, no-frills versions of experiments. Researchers still mess around with an independent variable and measure a dependent variable, but they skip over the whole randomization thing and often don't even have a control group.
It's like baking a cake but forgetting the frosting and sprinkles; you'll get some results, but they might not be as complete or reliable as you'd like.
Pre-Experimental Design Pros
Why use such a simple setup? Because sometimes, you just need to get the ball rolling. Pre-experimental designs are great for quick-and-dirty research when you're short on time or resources. They give you a rough idea of what's happening, which you can use to plan more detailed studies later.
A good example of this is early studies on the effects of screen time on kids. Researchers couldn't control every aspect of a child's life, but they could easily ask parents to track how much time their kids spent in front of screens and then look for trends in behavior or school performance.
Pre-Experimental Design Cons
But here's the catch: pre-experimental designs are like that first draft of an essay. It helps you get your ideas down, but you wouldn't want to turn it in for a grade. Because these designs lack the rigorous structure of true or quasi-experimental setups, they can't give you rock-solid conclusions. They're more like clues or signposts pointing you in a certain direction.
Pre-Experimental Design Uses
This type of design became popular in the early stages of various scientific fields. Researchers used them to scratch the surface of a topic, generate some initial data, and then decide if it's worth exploring further. In other words, pre-experimental designs were the stepping stones that led to more complex, thorough investigations.
So, while Pre-Experimental Design may not be the star player on the team, it's like the practice squad that helps everyone get better. It's the starting point that can lead to bigger and better things.
4) Factorial Design
Now, buckle up, because we're moving into the world of Factorial Design, the multi-tasker of the experimental universe.
Imagine juggling not just one, but multiple balls in the air—that's what researchers do in a factorial design.
In Factorial Design, researchers are not satisfied with just studying one independent variable. Nope, they want to study two or more at the same time to see how they interact.
It's like cooking with several spices to see how they blend together to create unique flavors.
Factorial Design became the talk of the town with the rise of computers. Why? Because this design produces a lot of data, and computers are the number crunchers that help make sense of it all. So, thanks to our silicon friends, researchers can study complicated questions like, "How do diet AND exercise together affect weight loss?" instead of looking at just one of those factors.
Factorial Design Pros
This design's main selling point is its ability to explore interactions between variables. For instance, maybe a new study drug works really well for young people but not so great for older adults. A factorial design could reveal that age is a crucial factor, something you might miss if you only studied the drug's effectiveness in general. It's like being a detective who looks for clues not just in one room but throughout the entire house.
Factorial Design Cons
However, factorial designs have their own bag of challenges. First off, they can be pretty complicated to set up and run. Imagine coordinating a four-way intersection with lots of cars coming from all directions—you've got to make sure everything runs smoothly, or you'll end up with a traffic jam. Similarly, researchers need to carefully plan how they'll measure and analyze all the different variables.
Factorial Design Uses
Factorial designs are widely used in psychology to untangle the web of factors that influence human behavior. They're also popular in fields like marketing, where companies want to understand how different aspects like price, packaging, and advertising influence a product's success.
And speaking of success, the factorial design has been a hit since statisticians like Ronald A. Fisher (yep, him again!) expanded on it in the early-to-mid 20th century. It offered a more nuanced way of understanding the world, proving that sometimes, to get the full picture, you've got to juggle more than one ball at a time.
So, if True Experimental Design is the quarterback and Quasi-Experimental Design is the versatile player, Factorial Design is the strategist who sees the entire game board and makes moves accordingly.
5) Longitudinal Design

Alright, let's take a step into the world of Longitudinal Design. Picture it as the grand storyteller, the kind who doesn't just tell you about a single event but spins an epic tale that stretches over years or even decades. This design isn't about quick snapshots; it's about capturing the whole movie of someone's life or a long-running process.
You know how you might take a photo every year on your birthday to see how you've changed? Longitudinal Design is kind of like that, but for scientific research.
With Longitudinal Design, instead of measuring something just once, researchers come back again and again, sometimes over many years, to see how things are going. This helps them understand not just what's happening, but why it's happening and how it changes over time.
This design really started to shine in the latter half of the 20th century, when researchers began to realize that some questions can't be answered in a hurry. Think about studies that look at how kids grow up, or research on how a certain medicine affects you over a long period. These aren't things you can rush.
The famous Framingham Heart Study , started in 1948, is a prime example. It's been studying heart health in a small town in Massachusetts for decades, and the findings have shaped what we know about heart disease.
Longitudinal Design Pros
So, what's to love about Longitudinal Design? First off, it's the go-to for studying change over time, whether that's how people age or how a forest recovers from a fire.
Longitudinal Design Cons
But it's not all sunshine and rainbows. Longitudinal studies take a lot of patience and resources. Plus, keeping track of participants over many years can be like herding cats—difficult and full of surprises.
Longitudinal Design Uses
Despite these challenges, longitudinal studies have been key in fields like psychology, sociology, and medicine. They provide the kind of deep, long-term insights that other designs just can't match.
So, if the True Experimental Design is the superstar quarterback, and the Quasi-Experimental Design is the flexible athlete, then the Factorial Design is the strategist, and the Longitudinal Design is the wise elder who has seen it all and has stories to tell.
6) Cross-Sectional Design
Now, let's flip the script and talk about Cross-Sectional Design, the polar opposite of the Longitudinal Design. If Longitudinal is the grand storyteller, think of Cross-Sectional as the snapshot photographer. It captures a single moment in time, like a selfie that you take to remember a fun day. Researchers using this design collect all their data at one point, providing a kind of "snapshot" of whatever they're studying.
In a Cross-Sectional Design, researchers look at multiple groups all at the same time to see how they're different or similar.
This design rose to popularity in the mid-20th century, mainly because it's so quick and efficient. Imagine wanting to know how people of different ages feel about a new video game. Instead of waiting for years to see how opinions change, you could just ask people of all ages what they think right now. That's Cross-Sectional Design for you—fast and straightforward.
You'll find this type of research everywhere from marketing studies to healthcare. For instance, you might have heard about surveys asking people what they think about a new product or political issue. Those are usually cross-sectional studies, aimed at getting a quick read on public opinion.
Cross-Sectional Design Pros
So, what's the big deal with Cross-Sectional Design? Well, it's the go-to when you need answers fast and don't have the time or resources for a more complicated setup.
Cross-Sectional Design Cons
Remember, speed comes with trade-offs. While you get your results quickly, those results are stuck in time. They can't tell you how things change or why they're changing, just what's happening right now.
Cross-Sectional Design Uses
Also, because they're so quick and simple, cross-sectional studies often serve as the first step in research. They give scientists an idea of what's going on so they can decide if it's worth digging deeper. In that way, they're a bit like a movie trailer, giving you a taste of the action to see if you're interested in seeing the whole film.
So, in our lineup of experimental designs, if True Experimental Design is the superstar quarterback and Longitudinal Design is the wise elder, then Cross-Sectional Design is like the speedy running back—fast, agile, but not designed for long, drawn-out plays.
7) Correlational Design
Next on our roster is the Correlational Design, the keen observer of the experimental world. Imagine this design as the person at a party who loves people-watching. They don't interfere or get involved; they just observe and take mental notes about what's going on.
In a correlational study, researchers don't change or control anything; they simply observe and measure how two variables relate to each other.
The correlational design has roots in the early days of psychology and sociology. Pioneers like Sir Francis Galton used it to study how qualities like intelligence or height could be related within families.
This design is all about asking, "Hey, when this thing happens, does that other thing usually happen too?" For example, researchers might study whether students who have more study time get better grades or whether people who exercise more have lower stress levels.
One of the most famous correlational studies you might have heard of is the link between smoking and lung cancer. Back in the mid-20th century, researchers started noticing that people who smoked a lot also seemed to get lung cancer more often. They couldn't say smoking caused cancer—that would require a true experiment—but the strong correlation was a red flag that led to more research and eventually, health warnings.
Correlational Design Pros
This design is great at proving that two (or more) things can be related. Correlational designs can help prove that more detailed research is needed on a topic. They can help us see patterns or possible causes for things that we otherwise might not have realized.
Correlational Design Cons
But here's where you need to be careful: correlational designs can be tricky. Just because two things are related doesn't mean one causes the other. That's like saying, "Every time I wear my lucky socks, my team wins." Well, it's a fun thought, but those socks aren't really controlling the game.
Correlational Design Uses
Despite this limitation, correlational designs are popular in psychology, economics, and epidemiology, to name a few fields. They're often the first step in exploring a possible relationship between variables. Once a strong correlation is found, researchers may decide to conduct more rigorous experimental studies to examine cause and effect.
So, if the True Experimental Design is the superstar quarterback and the Longitudinal Design is the wise elder, the Factorial Design is the strategist, and the Cross-Sectional Design is the speedster, then the Correlational Design is the clever scout, identifying interesting patterns but leaving the heavy lifting of proving cause and effect to the other types of designs.
8) Meta-Analysis
Last but not least, let's talk about Meta-Analysis, the librarian of experimental designs.
If other designs are all about creating new research, Meta-Analysis is about gathering up everyone else's research, sorting it, and figuring out what it all means when you put it together.
Imagine a jigsaw puzzle where each piece is a different study. Meta-Analysis is the process of fitting all those pieces together to see the big picture.
The concept of Meta-Analysis started to take shape in the late 20th century, when computers became powerful enough to handle massive amounts of data. It was like someone handed researchers a super-powered magnifying glass, letting them examine multiple studies at the same time to find common trends or results.
You might have heard of the Cochrane Reviews in healthcare . These are big collections of meta-analyses that help doctors and policymakers figure out what treatments work best based on all the research that's been done.
For example, if ten different studies show that a certain medicine helps lower blood pressure, a meta-analysis would pull all that information together to give a more accurate answer.
Meta-Analysis Pros
The beauty of Meta-Analysis is that it can provide really strong evidence. Instead of relying on one study, you're looking at the whole landscape of research on a topic.
Meta-Analysis Cons
However, it does have some downsides. For one, Meta-Analysis is only as good as the studies it includes. If those studies are flawed, the meta-analysis will be too. It's like baking a cake: if you use bad ingredients, it doesn't matter how good your recipe is—the cake won't turn out well.
Meta-Analysis Uses
Despite these challenges, meta-analyses are highly respected and widely used in many fields like medicine, psychology, and education. They help us make sense of a world that's bursting with information by showing us the big picture drawn from many smaller snapshots.
So, in our all-star lineup, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, the Factorial Design is the strategist, the Cross-Sectional Design is the speedster, and the Correlational Design is the scout, then the Meta-Analysis is like the coach, using insights from everyone else's plays to come up with the best game plan.
9) Non-Experimental Design
Now, let's talk about a player who's a bit of an outsider on this team of experimental designs—the Non-Experimental Design. Think of this design as the commentator or the journalist who covers the game but doesn't actually play.
In a Non-Experimental Design, researchers are like reporters gathering facts, but they don't interfere or change anything. They're simply there to describe and analyze.
Non-Experimental Design Pros
So, what's the deal with Non-Experimental Design? Its strength is in description and exploration. It's really good for studying things as they are in the real world, without changing any conditions.
Non-Experimental Design Cons
Because a non-experimental design doesn't manipulate variables, it can't prove cause and effect. It's like a weather reporter: they can tell you it's raining, but they can't tell you why it's raining.
The downside? Since researchers aren't controlling variables, it's hard to rule out other explanations for what they observe. It's like hearing one side of a story—you get an idea of what happened, but it might not be the complete picture.
Non-Experimental Design Uses
Non-Experimental Design has always been a part of research, especially in fields like anthropology, sociology, and some areas of psychology.
For instance, if you've ever heard of studies that describe how people behave in different cultures or what teens like to do in their free time, that's often Non-Experimental Design at work. These studies aim to capture the essence of a situation, like painting a portrait instead of taking a snapshot.
One well-known example you might have heard about is the Kinsey Reports from the 1940s and 1950s, which described sexual behavior in men and women. Researchers interviewed thousands of people but didn't manipulate any variables like you would in a true experiment. They simply collected data to create a comprehensive picture of the subject matter.
So, in our metaphorical team of research designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, and Meta-Analysis is the coach, then Non-Experimental Design is the sports journalist—always present, capturing the game, but not part of the action itself.
10) Repeated Measures Design

Time to meet the Repeated Measures Design, the time traveler of our research team. If this design were a player in a sports game, it would be the one who keeps revisiting past plays to figure out how to improve the next one.
Repeated Measures Design is all about studying the same people or subjects multiple times to see how they change or react under different conditions.
The idea behind Repeated Measures Design isn't new; it's been around since the early days of psychology and medicine. You could say it's a cousin to the Longitudinal Design, but instead of looking at how things naturally change over time, it focuses on how the same group reacts to different things.
Imagine a study looking at how a new energy drink affects people's running speed. Instead of comparing one group that drank the energy drink to another group that didn't, a Repeated Measures Design would have the same group of people run multiple times—once with the energy drink, and once without. This way, you're really zeroing in on the effect of that energy drink, making the results more reliable.
Repeated Measures Design Pros
The strong point of Repeated Measures Design is that it's super focused. Because it uses the same subjects, you don't have to worry about differences between groups messing up your results.
Repeated Measures Design Cons
But the downside? Well, people can get tired or bored if they're tested too many times, which might affect how they respond.
Repeated Measures Design Uses
A famous example of this design is the "Little Albert" experiment, conducted by John B. Watson and Rosalie Rayner in 1920. In this study, a young boy was exposed to a white rat and other stimuli several times to see how his emotional responses changed. Though the ethical standards of this experiment are often criticized today, it was groundbreaking in understanding conditioned emotional responses.
In our metaphorical lineup of research designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, and Non-Experimental Design is the journalist, then Repeated Measures Design is the time traveler—always looping back to fine-tune the game plan.
11) Crossover Design
Next up is Crossover Design, the switch-hitter of the research world. If you're familiar with baseball, you'll know a switch-hitter is someone who can bat both right-handed and left-handed.
In a similar way, Crossover Design allows subjects to experience multiple conditions, flipping them around so that everyone gets a turn in each role.
This design is like the utility player on our team—versatile, flexible, and really good at adapting.
The Crossover Design has its roots in medical research and has been popular since the mid-20th century. It's often used in clinical trials to test the effectiveness of different treatments.
Crossover Design Pros
The neat thing about this design is that it allows each participant to serve as their own control group. Imagine you're testing two new kinds of headache medicine. Instead of giving one type to one group and another type to a different group, you'd give both kinds to the same people but at different times.
Crossover Design Cons
What's the big deal with Crossover Design? Its major strength is in reducing the "noise" that comes from individual differences. Since each person experiences all conditions, it's easier to see real effects. However, there's a catch. This design assumes that there's no lasting effect from the first condition when you switch to the second one. That might not always be true. If the first treatment has a long-lasting effect, it could mess up the results when you switch to the second treatment.
Crossover Design Uses
A well-known example of Crossover Design is in studies that look at the effects of different types of diets—like low-carb vs. low-fat diets. Researchers might have participants follow a low-carb diet for a few weeks, then switch them to a low-fat diet. By doing this, they can more accurately measure how each diet affects the same group of people.
In our team of experimental designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, and Repeated Measures Design is the time traveler, then Crossover Design is the versatile utility player—always ready to adapt and play multiple roles to get the most accurate results.
12) Cluster Randomized Design
Meet the Cluster Randomized Design, the team captain of group-focused research. In our imaginary lineup of experimental designs, if other designs focus on individual players, then Cluster Randomized Design is looking at how the entire team functions.
This approach is especially common in educational and community-based research, and it's been gaining traction since the late 20th century.
Here's how Cluster Randomized Design works: Instead of assigning individual people to different conditions, researchers assign entire groups, or "clusters." These could be schools, neighborhoods, or even entire towns. This helps you see how the new method works in a real-world setting.
Imagine you want to see if a new anti-bullying program really works. Instead of selecting individual students, you'd introduce the program to a whole school or maybe even several schools, and then compare the results to schools without the program.
Cluster Randomized Design Pros
Why use Cluster Randomized Design? Well, sometimes it's just not practical to assign conditions at the individual level. For example, you can't really have half a school following a new reading program while the other half sticks with the old one; that would be way too confusing! Cluster Randomization helps get around this problem by treating each "cluster" as its own mini-experiment.
Cluster Randomized Design Cons
There's a downside, too. Because entire groups are assigned to each condition, there's a risk that the groups might be different in some important way that the researchers didn't account for. That's like having one sports team that's full of veterans playing against a team of rookies; the match wouldn't be fair.
Cluster Randomized Design Uses
A famous example is the research conducted to test the effectiveness of different public health interventions, like vaccination programs. Researchers might roll out a vaccination program in one community but not in another, then compare the rates of disease in both.
In our metaphorical research team, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, and Crossover Design is the utility player, then Cluster Randomized Design is the team captain—always looking out for the group as a whole.
13) Mixed-Methods Design
Say hello to Mixed-Methods Design, the all-rounder or the "Renaissance player" of our research team.
Mixed-Methods Design uses a blend of both qualitative and quantitative methods to get a more complete picture, just like a Renaissance person who's good at lots of different things. It's like being good at both offense and defense in a sport; you've got all your bases covered!
Mixed-Methods Design is a fairly new kid on the block, becoming more popular in the late 20th and early 21st centuries as researchers began to see the value in using multiple approaches to tackle complex questions. It's the Swiss Army knife in our research toolkit, combining the best parts of other designs to be more versatile.
Here's how it could work: Imagine you're studying the effects of a new educational app on students' math skills. You might use quantitative methods like tests and grades to measure how much the students improve—that's the 'numbers part.'
But you also want to know how the students feel about math now, or why they think they got better or worse. For that, you could conduct interviews or have students fill out journals—that's the 'story part.'
Mixed-Methods Design Pros
So, what's the scoop on Mixed-Methods Design? The strength is its versatility and depth; you're not just getting numbers or stories, you're getting both, which gives a fuller picture.
Mixed-Methods Design Cons
But, it's also more challenging. Imagine trying to play two sports at the same time! You have to be skilled in different research methods and know how to combine them effectively.
Mixed-Methods Design Uses
A high-profile example of Mixed-Methods Design is research on climate change. Scientists use numbers and data to show temperature changes (quantitative), but they also interview people to understand how these changes are affecting communities (qualitative).
In our team of experimental designs, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, Crossover Design is the utility player, and Cluster Randomized Design is the team captain, then Mixed-Methods Design is the Renaissance player—skilled in multiple areas and able to bring them all together for a winning strategy.
14) Multivariate Design
Now, let's turn our attention to Multivariate Design, the multitasker of the research world.
If our lineup of research designs were like players on a basketball court, Multivariate Design would be the player dribbling, passing, and shooting all at once. This design doesn't just look at one or two things; it looks at several variables simultaneously to see how they interact and affect each other.
Multivariate Design is like baking a cake with many ingredients. Instead of just looking at how flour affects the cake, you also consider sugar, eggs, and milk all at once. This way, you understand how everything works together to make the cake taste good or bad.
Multivariate Design has been a go-to method in psychology, economics, and social sciences since the latter half of the 20th century. With the advent of computers and advanced statistical software, analyzing multiple variables at once became a lot easier, and Multivariate Design soared in popularity.
Multivariate Design Pros
So, what's the benefit of using Multivariate Design? Its power lies in its complexity. By studying multiple variables at the same time, you can get a really rich, detailed understanding of what's going on.
Multivariate Design Cons
But that complexity can also be a drawback. With so many variables, it can be tough to tell which ones are really making a difference and which ones are just along for the ride.
Multivariate Design Uses
Imagine you're a coach trying to figure out the best strategy to win games. You wouldn't just look at how many points your star player scores; you'd also consider assists, rebounds, turnovers, and maybe even how loud the crowd is. A Multivariate Design would help you understand how all these factors work together to determine whether you win or lose.
A well-known example of Multivariate Design is in market research. Companies often use this approach to figure out how different factors—like price, packaging, and advertising—affect sales. By studying multiple variables at once, they can find the best combination to boost profits.
In our metaphorical research team, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, Crossover Design is the utility player, Cluster Randomized Design is the team captain, and Mixed-Methods Design is the Renaissance player, then Multivariate Design is the multitasker—juggling many variables at once to get a fuller picture of what's happening.
15) Pretest-Posttest Design
Let's introduce Pretest-Posttest Design, the "Before and After" superstar of our research team. You've probably seen those before-and-after pictures in ads for weight loss programs or home renovations, right?
Well, this design is like that, but for science! Pretest-Posttest Design checks out what things are like before the experiment starts and then compares that to what things are like after the experiment ends.
This design is one of the classics, a staple in research for decades across various fields like psychology, education, and healthcare. It's so simple and straightforward that it has stayed popular for a long time.
In Pretest-Posttest Design, you measure your subject's behavior or condition before you introduce any changes—that's your "before" or "pretest." Then you do your experiment, and after it's done, you measure the same thing again—that's your "after" or "posttest."
Pretest-Posttest Design Pros
What makes Pretest-Posttest Design special? It's pretty easy to understand and doesn't require fancy statistics.
Pretest-Posttest Design Cons
But there are some pitfalls. For example, what if the kids in our math example get better at multiplication just because they're older or because they've taken the test before? That would make it hard to tell if the program is really effective or not.
Pretest-Posttest Design Uses
Let's say you're a teacher and you want to know if a new math program helps kids get better at multiplication. First, you'd give all the kids a multiplication test—that's your pretest. Then you'd teach them using the new math program. At the end, you'd give them the same test again—that's your posttest. If the kids do better on the second test, you might conclude that the program works.
One famous use of Pretest-Posttest Design is in evaluating the effectiveness of driver's education courses. Researchers will measure people's driving skills before and after the course to see if they've improved.
16) Solomon Four-Group Design
Next up is the Solomon Four-Group Design, the "chess master" of our research team. This design is all about strategy and careful planning. Named after Richard L. Solomon who introduced it in the 1940s, this method tries to correct some of the weaknesses in simpler designs, like the Pretest-Posttest Design.
Here's how it rolls: The Solomon Four-Group Design uses four different groups to test a hypothesis. Two groups get a pretest, then one of them receives the treatment or intervention, and both get a posttest. The other two groups skip the pretest, and only one of them receives the treatment before they both get a posttest.
Sound complicated? It's like playing 4D chess; you're thinking several moves ahead!
Solomon Four-Group Design Pros
What's the pro and con of the Solomon Four-Group Design? On the plus side, it provides really robust results because it accounts for so many variables.
Solomon Four-Group Design Cons
The downside? It's a lot of work and requires a lot of participants, making it more time-consuming and costly.
Solomon Four-Group Design Uses
Let's say you want to figure out if a new way of teaching history helps students remember facts better. Two classes take a history quiz (pretest), then one class uses the new teaching method while the other sticks with the old way. Both classes take another quiz afterward (posttest).
Meanwhile, two more classes skip the initial quiz, and then one uses the new method before both take the final quiz. Comparing all four groups will give you a much clearer picture of whether the new teaching method works and whether the pretest itself affects the outcome.
The Solomon Four-Group Design is less commonly used than simpler designs but is highly respected for its ability to control for more variables. It's a favorite in educational and psychological research where you really want to dig deep and figure out what's actually causing changes.
17) Adaptive Designs
Now, let's talk about Adaptive Designs, the chameleons of the experimental world.
Imagine you're a detective, and halfway through solving a case, you find a clue that changes everything. You wouldn't just stick to your old plan; you'd adapt and change your approach, right? That's exactly what Adaptive Designs allow researchers to do.
In an Adaptive Design, researchers can make changes to the study as it's happening, based on early results. In a traditional study, once you set your plan, you stick to it from start to finish.
Adaptive Design Pros
This method is particularly useful in fast-paced or high-stakes situations, like developing a new vaccine in the middle of a pandemic. The ability to adapt can save both time and resources, and more importantly, it can save lives by getting effective treatments out faster.
Adaptive Design Cons
But Adaptive Designs aren't without their drawbacks. They can be very complex to plan and carry out, and there's always a risk that the changes made during the study could introduce bias or errors.
Adaptive Design Uses
Adaptive Designs are most often seen in clinical trials, particularly in the medical and pharmaceutical fields.
For instance, if a new drug is showing really promising results, the study might be adjusted to give more participants the new treatment instead of a placebo. Or if one dose level is showing bad side effects, it might be dropped from the study.
The best part is, these changes are pre-planned. Researchers lay out in advance what changes might be made and under what conditions, which helps keep everything scientific and above board.
In terms of applications, besides their heavy usage in medical and pharmaceutical research, Adaptive Designs are also becoming increasingly popular in software testing and market research. In these fields, being able to quickly adjust to early results can give companies a significant advantage.
Adaptive Designs are like the agile startups of the research world—quick to pivot, keen to learn from ongoing results, and focused on rapid, efficient progress. However, they require a great deal of expertise and careful planning to ensure that the adaptability doesn't compromise the integrity of the research.
18) Bayesian Designs
Next, let's dive into Bayesian Designs, the data detectives of the research universe. Named after Thomas Bayes, an 18th-century statistician and minister, this design doesn't just look at what's happening now; it also takes into account what's happened before.
Imagine if you were a detective who not only looked at the evidence in front of you but also used your past cases to make better guesses about your current one. That's the essence of Bayesian Designs.
Bayesian Designs are like detective work in science. As you gather more clues (or data), you update your best guess on what's really happening. This way, your experiment gets smarter as it goes along.
In the world of research, Bayesian Designs are most notably used in areas where you have some prior knowledge that can inform your current study. For example, if earlier research shows that a certain type of medicine usually works well for a specific illness, a Bayesian Design would include that information when studying a new group of patients with the same illness.
Bayesian Design Pros
One of the major advantages of Bayesian Designs is their efficiency. Because they use existing data to inform the current experiment, often fewer resources are needed to reach a reliable conclusion.
Bayesian Design Cons
However, they can be quite complicated to set up and require a deep understanding of both statistics and the subject matter at hand.
Bayesian Design Uses
Bayesian Designs are highly valued in medical research, finance, environmental science, and even in Internet search algorithms. Their ability to continually update and refine hypotheses based on new evidence makes them particularly useful in fields where data is constantly evolving and where quick, informed decisions are crucial.
Here's a real-world example: In the development of personalized medicine, where treatments are tailored to individual patients, Bayesian Designs are invaluable. If a treatment has been effective for patients with similar genetics or symptoms in the past, a Bayesian approach can use that data to predict how well it might work for a new patient.
This type of design is also increasingly popular in machine learning and artificial intelligence. In these fields, Bayesian Designs help algorithms "learn" from past data to make better predictions or decisions in new situations. It's like teaching a computer to be a detective that gets better and better at solving puzzles the more puzzles it sees.
19) Covariate Adaptive Randomization

Now let's turn our attention to Covariate Adaptive Randomization, which you can think of as the "matchmaker" of experimental designs.
Picture a soccer coach trying to create the most balanced teams for a friendly match. They wouldn't just randomly assign players; they'd take into account each player's skills, experience, and other traits.
Covariate Adaptive Randomization is all about creating the most evenly matched groups possible for an experiment.
In traditional randomization, participants are allocated to different groups purely by chance. This is a pretty fair way to do things, but it can sometimes lead to unbalanced groups.
Imagine if all the professional-level players ended up on one soccer team and all the beginners on another; that wouldn't be a very informative match! Covariate Adaptive Randomization fixes this by using important traits or characteristics (called "covariates") to guide the randomization process.
Covariate Adaptive Randomization Pros
The benefits of this design are pretty clear: it aims for balance and fairness, making the final results more trustworthy.
Covariate Adaptive Randomization Cons
But it's not perfect. It can be complex to implement and requires a deep understanding of which characteristics are most important to balance.
Covariate Adaptive Randomization Uses
This design is particularly useful in medical trials. Let's say researchers are testing a new medication for high blood pressure. Participants might have different ages, weights, or pre-existing conditions that could affect the results.
Covariate Adaptive Randomization would make sure that each treatment group has a similar mix of these characteristics, making the results more reliable and easier to interpret.
In practical terms, this design is often seen in clinical trials for new drugs or therapies, but its principles are also applicable in fields like psychology, education, and social sciences.
For instance, in educational research, it might be used to ensure that classrooms being compared have similar distributions of students in terms of academic ability, socioeconomic status, and other factors.
Covariate Adaptive Randomization is like the wise elder of the group, ensuring that everyone has an equal opportunity to show their true capabilities, thereby making the collective results as reliable as possible.
20) Stepped Wedge Design
Let's now focus on the Stepped Wedge Design, a thoughtful and cautious member of the experimental design family.
Imagine you're trying out a new gardening technique, but you're not sure how well it will work. You decide to apply it to one section of your garden first, watch how it performs, and then gradually extend the technique to other sections. This way, you get to see its effects over time and across different conditions. That's basically how Stepped Wedge Design works.
In a Stepped Wedge Design, all participants or clusters start off in the control group, and then, at different times, they 'step' over to the intervention or treatment group. This creates a wedge-like pattern over time where more and more participants receive the treatment as the study progresses. It's like rolling out a new policy in phases, monitoring its impact at each stage before extending it to more people.
Stepped Wedge Design Pros
The Stepped Wedge Design offers several advantages. Firstly, it allows for the study of interventions that are expected to do more good than harm, which makes it ethically appealing.
Secondly, it's useful when resources are limited and it's not feasible to roll out a new treatment to everyone at once. Lastly, because everyone eventually receives the treatment, it can be easier to get buy-in from participants or organizations involved in the study.
Stepped Wedge Design Cons
However, this design can be complex to analyze because it has to account for both the time factor and the changing conditions in each 'step' of the wedge. And like any study where participants know they're receiving an intervention, there's the potential for the results to be influenced by the placebo effect or other biases.
Stepped Wedge Design Uses
This design is particularly useful in health and social care research. For instance, if a hospital wants to implement a new hygiene protocol, it might start in one department, assess its impact, and then roll it out to other departments over time. This allows the hospital to adjust and refine the new protocol based on real-world data before it's fully implemented.
In terms of applications, Stepped Wedge Designs are commonly used in public health initiatives, organizational changes in healthcare settings, and social policy trials. They are particularly useful in situations where an intervention is being rolled out gradually and it's important to understand its impacts at each stage.
21) Sequential Design
Next up is Sequential Design, the dynamic and flexible member of our experimental design family.
Imagine you're playing a video game where you can choose different paths. If you take one path and find a treasure chest, you might decide to continue in that direction. If you hit a dead end, you might backtrack and try a different route. Sequential Design operates in a similar fashion, allowing researchers to make decisions at different stages based on what they've learned so far.
In a Sequential Design, the experiment is broken down into smaller parts, or "sequences." After each sequence, researchers pause to look at the data they've collected. Based on those findings, they then decide whether to stop the experiment because they've got enough information, or to continue and perhaps even modify the next sequence.
Sequential Design Pros
This allows for a more efficient use of resources, as you're only continuing with the experiment if the data suggests it's worth doing so.
One of the great things about Sequential Design is its efficiency. Because you're making data-driven decisions along the way, you can often reach conclusions more quickly and with fewer resources.
Sequential Design Cons
However, it requires careful planning and expertise to ensure that these "stop or go" decisions are made correctly and without bias.
Sequential Design Uses
In terms of its applications, besides healthcare and medicine, Sequential Design is also popular in quality control in manufacturing, environmental monitoring, and financial modeling. In these areas, being able to make quick decisions based on incoming data can be a big advantage.
This design is often used in clinical trials involving new medications or treatments. For example, if early results show that a new drug has significant side effects, the trial can be stopped before more people are exposed to it.
On the flip side, if the drug is showing promising results, the trial might be expanded to include more participants or to extend the testing period.
Think of Sequential Design as the nimble athlete of experimental designs, capable of quick pivots and adjustments to reach the finish line in the most effective way possible. But just like an athlete needs a good coach, this design requires expert oversight to make sure it stays on the right track.
22) Field Experiments
Last but certainly not least, let's explore Field Experiments—the adventurers of the experimental design world.
Picture a scientist leaving the controlled environment of a lab to test a theory in the real world, like a biologist studying animals in their natural habitat or a social scientist observing people in a real community. These are Field Experiments, and they're all about getting out there and gathering data in real-world settings.
Field Experiments embrace the messiness of the real world, unlike laboratory experiments, where everything is controlled down to the smallest detail. This makes them both exciting and challenging.
Field Experiment Pros
On one hand, the results often give us a better understanding of how things work outside the lab.
While Field Experiments offer real-world relevance, they come with challenges like controlling for outside factors and the ethical considerations of intervening in people's lives without their knowledge.
Field Experiment Cons
On the other hand, the lack of control can make it harder to tell exactly what's causing what. Yet, despite these challenges, they remain a valuable tool for researchers who want to understand how theories play out in the real world.
Field Experiment Uses
Let's say a school wants to improve student performance. In a Field Experiment, they might change the school's daily schedule for one semester and keep track of how students perform compared to another school where the schedule remained the same.
Because the study is happening in a real school with real students, the results could be very useful for understanding how the change might work in other schools. But since it's the real world, lots of other factors—like changes in teachers or even the weather—could affect the results.
Field Experiments are widely used in economics, psychology, education, and public policy. For example, you might have heard of the famous "Broken Windows" experiment in the 1980s that looked at how small signs of disorder, like broken windows or graffiti, could encourage more serious crime in neighborhoods. This experiment had a big impact on how cities think about crime prevention.
From the foundational concepts of control groups and independent variables to the sophisticated layouts like Covariate Adaptive Randomization and Sequential Design, it's clear that the realm of experimental design is as varied as it is fascinating.
We've seen that each design has its own special talents, ideal for specific situations. Some designs, like the Classic Controlled Experiment, are like reliable old friends you can always count on.
Others, like Sequential Design, are flexible and adaptable, making quick changes based on what they learn. And let's not forget the adventurous Field Experiments, which take us out of the lab and into the real world to discover things we might not see otherwise.
Choosing the right experimental design is like picking the right tool for the job. The method you choose can make a big difference in how reliable your results are and how much people will trust what you've discovered. And as we've learned, there's a design to suit just about every question, every problem, and every curiosity.
So the next time you read about a new discovery in medicine, psychology, or any other field, you'll have a better understanding of the thought and planning that went into figuring things out. Experimental design is more than just a set of rules; it's a structured way to explore the unknown and answer questions that can change the world.
Related posts:
- Experimental Psychologist Career (Salary + Duties + Interviews)
- 40+ Famous Psychologists (Images + Biographies)
- 11+ Psychology Experiment Ideas (Goals + Methods)
- The Little Albert Experiment
- 41+ White Collar Job Examples (Salary + Path)
Reference this article:
About The Author
Free Personality Test

Free Memory Test

Free IQ Test

PracticalPie.com is a participant in the Amazon Associates Program. As an Amazon Associate we earn from qualifying purchases.
Follow Us On:
Youtube Facebook Instagram X/Twitter
Psychology Resources
Developmental
Personality
Relationships
Psychologists
Serial Killers
Psychology Tests
Personality Quiz
Memory Test
Depression test
Type A/B Personality Test
© PracticalPsychology. All rights reserved
Privacy Policy | Terms of Use

Experimental Research Design — 6 mistakes you should never make!
Since school days’ students perform scientific experiments that provide results that define and prove the laws and theorems in science. These experiments are laid on a strong foundation of experimental research designs.
An experimental research design helps researchers execute their research objectives with more clarity and transparency.
In this article, we will not only discuss the key aspects of experimental research designs but also the issues to avoid and problems to resolve while designing your research study.
Table of Contents
What Is Experimental Research Design?
Experimental research design is a framework of protocols and procedures created to conduct experimental research with a scientific approach using two sets of variables. Herein, the first set of variables acts as a constant, used to measure the differences of the second set. The best example of experimental research methods is quantitative research .
Experimental research helps a researcher gather the necessary data for making better research decisions and determining the facts of a research study.
When Can a Researcher Conduct Experimental Research?
A researcher can conduct experimental research in the following situations —
- When time is an important factor in establishing a relationship between the cause and effect.
- When there is an invariable or never-changing behavior between the cause and effect.
- Finally, when the researcher wishes to understand the importance of the cause and effect.
Importance of Experimental Research Design
To publish significant results, choosing a quality research design forms the foundation to build the research study. Moreover, effective research design helps establish quality decision-making procedures, structures the research to lead to easier data analysis, and addresses the main research question. Therefore, it is essential to cater undivided attention and time to create an experimental research design before beginning the practical experiment.
By creating a research design, a researcher is also giving oneself time to organize the research, set up relevant boundaries for the study, and increase the reliability of the results. Through all these efforts, one could also avoid inconclusive results. If any part of the research design is flawed, it will reflect on the quality of the results derived.
Types of Experimental Research Designs
Based on the methods used to collect data in experimental studies, the experimental research designs are of three primary types:
1. Pre-experimental Research Design
A research study could conduct pre-experimental research design when a group or many groups are under observation after implementing factors of cause and effect of the research. The pre-experimental design will help researchers understand whether further investigation is necessary for the groups under observation.
Pre-experimental research is of three types —
- One-shot Case Study Research Design
- One-group Pretest-posttest Research Design
- Static-group Comparison
2. True Experimental Research Design
A true experimental research design relies on statistical analysis to prove or disprove a researcher’s hypothesis. It is one of the most accurate forms of research because it provides specific scientific evidence. Furthermore, out of all the types of experimental designs, only a true experimental design can establish a cause-effect relationship within a group. However, in a true experiment, a researcher must satisfy these three factors —
- There is a control group that is not subjected to changes and an experimental group that will experience the changed variables
- A variable that can be manipulated by the researcher
- Random distribution of the variables
This type of experimental research is commonly observed in the physical sciences.
3. Quasi-experimental Research Design
The word “Quasi” means similarity. A quasi-experimental design is similar to a true experimental design. However, the difference between the two is the assignment of the control group. In this research design, an independent variable is manipulated, but the participants of a group are not randomly assigned. This type of research design is used in field settings where random assignment is either irrelevant or not required.
The classification of the research subjects, conditions, or groups determines the type of research design to be used.

Advantages of Experimental Research
Experimental research allows you to test your idea in a controlled environment before taking the research to clinical trials. Moreover, it provides the best method to test your theory because of the following advantages:
- Researchers have firm control over variables to obtain results.
- The subject does not impact the effectiveness of experimental research. Anyone can implement it for research purposes.
- The results are specific.
- Post results analysis, research findings from the same dataset can be repurposed for similar research ideas.
- Researchers can identify the cause and effect of the hypothesis and further analyze this relationship to determine in-depth ideas.
- Experimental research makes an ideal starting point. The collected data could be used as a foundation to build new research ideas for further studies.
6 Mistakes to Avoid While Designing Your Research
There is no order to this list, and any one of these issues can seriously compromise the quality of your research. You could refer to the list as a checklist of what to avoid while designing your research.
1. Invalid Theoretical Framework
Usually, researchers miss out on checking if their hypothesis is logical to be tested. If your research design does not have basic assumptions or postulates, then it is fundamentally flawed and you need to rework on your research framework.
2. Inadequate Literature Study
Without a comprehensive research literature review , it is difficult to identify and fill the knowledge and information gaps. Furthermore, you need to clearly state how your research will contribute to the research field, either by adding value to the pertinent literature or challenging previous findings and assumptions.
3. Insufficient or Incorrect Statistical Analysis
Statistical results are one of the most trusted scientific evidence. The ultimate goal of a research experiment is to gain valid and sustainable evidence. Therefore, incorrect statistical analysis could affect the quality of any quantitative research.
4. Undefined Research Problem
This is one of the most basic aspects of research design. The research problem statement must be clear and to do that, you must set the framework for the development of research questions that address the core problems.
5. Research Limitations
Every study has some type of limitations . You should anticipate and incorporate those limitations into your conclusion, as well as the basic research design. Include a statement in your manuscript about any perceived limitations, and how you considered them while designing your experiment and drawing the conclusion.
6. Ethical Implications
The most important yet less talked about topic is the ethical issue. Your research design must include ways to minimize any risk for your participants and also address the research problem or question at hand. If you cannot manage the ethical norms along with your research study, your research objectives and validity could be questioned.
Experimental Research Design Example
In an experimental design, a researcher gathers plant samples and then randomly assigns half the samples to photosynthesize in sunlight and the other half to be kept in a dark box without sunlight, while controlling all the other variables (nutrients, water, soil, etc.)
By comparing their outcomes in biochemical tests, the researcher can confirm that the changes in the plants were due to the sunlight and not the other variables.
Experimental research is often the final form of a study conducted in the research process which is considered to provide conclusive and specific results. But it is not meant for every research. It involves a lot of resources, time, and money and is not easy to conduct, unless a foundation of research is built. Yet it is widely used in research institutes and commercial industries, for its most conclusive results in the scientific approach.
Have you worked on research designs? How was your experience creating an experimental design? What difficulties did you face? Do write to us or comment below and share your insights on experimental research designs!
Frequently Asked Questions
Randomization is important in an experimental research because it ensures unbiased results of the experiment. It also measures the cause-effect relationship on a particular group of interest.
Experimental research design lay the foundation of a research and structures the research to establish quality decision making process.
There are 3 types of experimental research designs. These are pre-experimental research design, true experimental research design, and quasi experimental research design.
The difference between an experimental and a quasi-experimental design are: 1. The assignment of the control group in quasi experimental research is non-random, unlike true experimental design, which is randomly assigned. 2. Experimental research group always has a control group; on the other hand, it may not be always present in quasi experimental research.
Experimental research establishes a cause-effect relationship by testing a theory or hypothesis using experimental groups or control variables. In contrast, descriptive research describes a study or a topic by defining the variables under it and answering the questions related to the same.

good and valuable
Very very good
Good presentation.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles
![What is Academic Integrity and How to Uphold it [FREE CHECKLIST]](https://www.enago.com/academy/wp-content/uploads/2024/05/FeatureImages-59-210x136.png "experimental research design sample study")
Ensuring Academic Integrity and Transparency in Academic Research: A comprehensive checklist for researchers
Academic integrity is the foundation upon which the credibility and value of scientific findings are…

- Publishing Research
- Reporting Research
How to Optimize Your Research Process: A step-by-step guide
For researchers across disciplines, the path to uncovering novel findings and insights is often filled…

- Industry News
- Trending Now
Breaking Barriers: Sony and Nature unveil “Women in Technology Award”
Sony Group Corporation and the prestigious scientific journal Nature have collaborated to launch the inaugural…

Achieving Research Excellence: Checklist for good research practices
Academia is built on the foundation of trustworthy and high-quality research, supported by the pillars…

- Promoting Research
Plain Language Summary — Communicating your research to bridge the academic-lay gap
Science can be complex, but does that mean it should not be accessible to the…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right…
Research Recommendations – Guiding policy-makers for evidence-based decision making

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

As a researcher, what do you consider most when choosing an image manipulation detector?
- Experimental Research Designs: Types, Examples & Methods

Experimental research is the most familiar type of research design for individuals in the physical sciences and a host of other fields. This is mainly because experimental research is a classical scientific experiment, similar to those performed in high school science classes.
Imagine taking 2 samples of the same plant and exposing one of them to sunlight, while the other is kept away from sunlight. Let the plant exposed to sunlight be called sample A, while the latter is called sample B.
If after the duration of the research, we find out that sample A grows and sample B dies, even though they are both regularly wetted and given the same treatment. Therefore, we can conclude that sunlight will aid growth in all similar plants.
What is Experimental Research?
Experimental research is a scientific approach to research, where one or more independent variables are manipulated and applied to one or more dependent variables to measure their effect on the latter. The effect of the independent variables on the dependent variables is usually observed and recorded over some time, to aid researchers in drawing a reasonable conclusion regarding the relationship between these 2 variable types.
The experimental research method is widely used in physical and social sciences, psychology, and education. It is based on the comparison between two or more groups with a straightforward logic, which may, however, be difficult to execute.
Mostly related to a laboratory test procedure, experimental research designs involve collecting quantitative data and performing statistical analysis on them during research. Therefore, making it an example of quantitative research method .
What are The Types of Experimental Research Design?
The types of experimental research design are determined by the way the researcher assigns subjects to different conditions and groups. They are of 3 types, namely; pre-experimental, quasi-experimental, and true experimental research.
Pre-experimental Research Design
In pre-experimental research design, either a group or various dependent groups are observed for the effect of the application of an independent variable which is presumed to cause change. It is the simplest form of experimental research design and is treated with no control group.
Although very practical, experimental research is lacking in several areas of the true-experimental criteria. The pre-experimental research design is further divided into three types
- One-shot Case Study Research Design
In this type of experimental study, only one dependent group or variable is considered. The study is carried out after some treatment which was presumed to cause change, making it a posttest study.
- One-group Pretest-posttest Research Design:
This research design combines both posttest and pretest study by carrying out a test on a single group before the treatment is administered and after the treatment is administered. With the former being administered at the beginning of treatment and later at the end.
- Static-group Comparison:
In a static-group comparison study, 2 or more groups are placed under observation, where only one of the groups is subjected to some treatment while the other groups are held static. All the groups are post-tested, and the observed differences between the groups are assumed to be a result of the treatment.
Quasi-experimental Research Design
The word “quasi” means partial, half, or pseudo. Therefore, the quasi-experimental research bearing a resemblance to the true experimental research, but not the same. In quasi-experiments, the participants are not randomly assigned, and as such, they are used in settings where randomization is difficult or impossible.
This is very common in educational research, where administrators are unwilling to allow the random selection of students for experimental samples.
Some examples of quasi-experimental research design include; the time series, no equivalent control group design, and the counterbalanced design.
True Experimental Research Design
The true experimental research design relies on statistical analysis to approve or disprove a hypothesis. It is the most accurate type of experimental design and may be carried out with or without a pretest on at least 2 randomly assigned dependent subjects.
The true experimental research design must contain a control group, a variable that can be manipulated by the researcher, and the distribution must be random. The classification of true experimental design include:
- The posttest-only Control Group Design: In this design, subjects are randomly selected and assigned to the 2 groups (control and experimental), and only the experimental group is treated. After close observation, both groups are post-tested, and a conclusion is drawn from the difference between these groups.
- The pretest-posttest Control Group Design: For this control group design, subjects are randomly assigned to the 2 groups, both are presented, but only the experimental group is treated. After close observation, both groups are post-tested to measure the degree of change in each group.
- Solomon four-group Design: This is the combination of the pretest-only and the pretest-posttest control groups. In this case, the randomly selected subjects are placed into 4 groups.
The first two of these groups are tested using the posttest-only method, while the other two are tested using the pretest-posttest method.
Examples of Experimental Research
Experimental research examples are different, depending on the type of experimental research design that is being considered. The most basic example of experimental research is laboratory experiments, which may differ in nature depending on the subject of research.
Administering Exams After The End of Semester
During the semester, students in a class are lectured on particular courses and an exam is administered at the end of the semester. In this case, the students are the subjects or dependent variables while the lectures are the independent variables treated on the subjects.
Only one group of carefully selected subjects are considered in this research, making it a pre-experimental research design example. We will also notice that tests are only carried out at the end of the semester, and not at the beginning.
Further making it easy for us to conclude that it is a one-shot case study research.
Employee Skill Evaluation
Before employing a job seeker, organizations conduct tests that are used to screen out less qualified candidates from the pool of qualified applicants. This way, organizations can determine an employee’s skill set at the point of employment.
In the course of employment, organizations also carry out employee training to improve employee productivity and generally grow the organization. Further evaluation is carried out at the end of each training to test the impact of the training on employee skills, and test for improvement.
Here, the subject is the employee, while the treatment is the training conducted. This is a pretest-posttest control group experimental research example.
Evaluation of Teaching Method
Let us consider an academic institution that wants to evaluate the teaching method of 2 teachers to determine which is best. Imagine a case whereby the students assigned to each teacher is carefully selected probably due to personal request by parents or due to stubbornness and smartness.
This is a no equivalent group design example because the samples are not equal. By evaluating the effectiveness of each teacher’s teaching method this way, we may conclude after a post-test has been carried out.
However, this may be influenced by factors like the natural sweetness of a student. For example, a very smart student will grab more easily than his or her peers irrespective of the method of teaching.
What are the Characteristics of Experimental Research?
Experimental research contains dependent, independent and extraneous variables. The dependent variables are the variables being treated or manipulated and are sometimes called the subject of the research.
The independent variables are the experimental treatment being exerted on the dependent variables. Extraneous variables, on the other hand, are other factors affecting the experiment that may also contribute to the change.
The setting is where the experiment is carried out. Many experiments are carried out in the laboratory, where control can be exerted on the extraneous variables, thereby eliminating them.
Other experiments are carried out in a less controllable setting. The choice of setting used in research depends on the nature of the experiment being carried out.
- Multivariable
Experimental research may include multiple independent variables, e.g. time, skills, test scores, etc.
Why Use Experimental Research Design?
Experimental research design can be majorly used in physical sciences, social sciences, education, and psychology. It is used to make predictions and draw conclusions on a subject matter.
Some uses of experimental research design are highlighted below.
- Medicine: Experimental research is used to provide the proper treatment for diseases. In most cases, rather than directly using patients as the research subject, researchers take a sample of the bacteria from the patient’s body and are treated with the developed antibacterial
The changes observed during this period are recorded and evaluated to determine its effectiveness. This process can be carried out using different experimental research methods.
- Education: Asides from science subjects like Chemistry and Physics which involves teaching students how to perform experimental research, it can also be used in improving the standard of an academic institution. This includes testing students’ knowledge on different topics, coming up with better teaching methods, and the implementation of other programs that will aid student learning.
- Human Behavior: Social scientists are the ones who mostly use experimental research to test human behaviour. For example, consider 2 people randomly chosen to be the subject of the social interaction research where one person is placed in a room without human interaction for 1 year.
The other person is placed in a room with a few other people, enjoying human interaction. There will be a difference in their behaviour at the end of the experiment.
- UI/UX: During the product development phase, one of the major aims of the product team is to create a great user experience with the product. Therefore, before launching the final product design, potential are brought in to interact with the product.
For example, when finding it difficult to choose how to position a button or feature on the app interface, a random sample of product testers are allowed to test the 2 samples and how the button positioning influences the user interaction is recorded.
What are the Disadvantages of Experimental Research?
- It is highly prone to human error due to its dependency on variable control which may not be properly implemented. These errors could eliminate the validity of the experiment and the research being conducted.
- Exerting control of extraneous variables may create unrealistic situations. Eliminating real-life variables will result in inaccurate conclusions. This may also result in researchers controlling the variables to suit his or her personal preferences.
- It is a time-consuming process. So much time is spent on testing dependent variables and waiting for the effect of the manipulation of dependent variables to manifest.
- It is expensive.
- It is very risky and may have ethical complications that cannot be ignored. This is common in medical research, where failed trials may lead to a patient’s death or a deteriorating health condition.
- Experimental research results are not descriptive.
- Response bias can also be supplied by the subject of the conversation.
- Human responses in experimental research can be difficult to measure.
What are the Data Collection Methods in Experimental Research?
Data collection methods in experimental research are the different ways in which data can be collected for experimental research. They are used in different cases, depending on the type of research being carried out.
1. Observational Study
This type of study is carried out over a long period. It measures and observes the variables of interest without changing existing conditions.
When researching the effect of social interaction on human behavior, the subjects who are placed in 2 different environments are observed throughout the research. No matter the kind of absurd behavior that is exhibited by the subject during this period, its condition will not be changed.
This may be a very risky thing to do in medical cases because it may lead to death or worse medical conditions.
2. Simulations
This procedure uses mathematical, physical, or computer models to replicate a real-life process or situation. It is frequently used when the actual situation is too expensive, dangerous, or impractical to replicate in real life.
This method is commonly used in engineering and operational research for learning purposes and sometimes as a tool to estimate possible outcomes of real research. Some common situation software are Simulink, MATLAB, and Simul8.
Not all kinds of experimental research can be carried out using simulation as a data collection tool . It is very impractical for a lot of laboratory-based research that involves chemical processes.
A survey is a tool used to gather relevant data about the characteristics of a population and is one of the most common data collection tools. A survey consists of a group of questions prepared by the researcher, to be answered by the research subject.
Surveys can be shared with the respondents both physically and electronically. When collecting data through surveys, the kind of data collected depends on the respondent, and researchers have limited control over it.
Formplus is the best tool for collecting experimental data using survey s. It has relevant features that will aid the data collection process and can also be used in other aspects of experimental research.
Differences between Experimental and Non-Experimental Research
1. In experimental research, the researcher can control and manipulate the environment of the research, including the predictor variable which can be changed. On the other hand, non-experimental research cannot be controlled or manipulated by the researcher at will.
This is because it takes place in a real-life setting, where extraneous variables cannot be eliminated. Therefore, it is more difficult to conclude non-experimental studies, even though they are much more flexible and allow for a greater range of study fields.
2. The relationship between cause and effect cannot be established in non-experimental research, while it can be established in experimental research. This may be because many extraneous variables also influence the changes in the research subject, making it difficult to point at a particular variable as the cause of a particular change
3. Independent variables are not introduced, withdrawn, or manipulated in non-experimental designs, but the same may not be said about experimental research.
Conclusion
Experimental research designs are often considered to be the standard in research designs. This is partly due to the common misconception that research is equivalent to scientific experiments—a component of experimental research design.
In this research design, one or more subjects or dependent variables are randomly assigned to different treatments (i.e. independent variables manipulated by the researcher) and the results are observed to conclude. One of the uniqueness of experimental research is in its ability to control the effect of extraneous variables.
Experimental research is suitable for research whose goal is to examine cause-effect relationships, e.g. explanatory research. It can be conducted in the laboratory or field settings, depending on the aim of the research that is being carried out.
Connect to Formplus, Get Started Now - It's Free!
- examples of experimental research
- experimental research methods
- types of experimental research
- busayo.longe
You may also like:
Experimental Vs Non-Experimental Research: 15 Key Differences
Differences between experimental and non experimental research on definitions, types, examples, data collection tools, uses, advantages etc.
Response vs Explanatory Variables: Definition & Examples
In this article, we’ll be comparing the two types of variables, what they both mean and see some of their real-life applications in research
Simpson’s Paradox & How to Avoid it in Experimental Research
In this article, we are going to look at Simpson’s Paradox from its historical point and later, we’ll consider its effect in...
What is Experimenter Bias? Definition, Types & Mitigation
In this article, we will look into the concept of experimental bias and how it can be identified in your research
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
Experimental Design: Types, Examples & Methods
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs.
Probably the most common way to design an experiment in psychology is to divide the participants into two groups, the experimental group and the control group, and then introduce a change to the experimental group, not the control group.
The researcher must decide how he/she will allocate their sample to the different experimental groups. For example, if there are 10 participants, will all 10 participants participate in both groups (e.g., repeated measures), or will the participants be split in half and take part in only one group each?
Three types of experimental designs are commonly used:
1. Independent Measures
Independent measures design, also known as between-groups , is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group.
Independent measures involve using two separate groups of participants, one in each condition. For example:

- Con : More people are needed than with the repeated measures design (i.e., more time-consuming).
- Pro : Avoids order effects (such as practice or fatigue) as people participate in one condition only. If a person is involved in several conditions, they may become bored, tired, and fed up by the time they come to the second condition or become wise to the requirements of the experiment!
- Con : Differences between participants in the groups may affect results, for example, variations in age, gender, or social background. These differences are known as participant variables (i.e., a type of extraneous variable ).
- Control : After the participants have been recruited, they should be randomly assigned to their groups. This should ensure the groups are similar, on average (reducing participant variables).
2. Repeated Measures Design
Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants.
Repeated Measures design is also known as within-groups or within-subjects design .
- Pro : As the same participants are used in each condition, participant variables (i.e., individual differences) are reduced.
- Con : There may be order effects. Order effects refer to the order of the conditions affecting the participants’ behavior. Performance in the second condition may be better because the participants know what to do (i.e., practice effect). Or their performance might be worse in the second condition because they are tired (i.e., fatigue effect). This limitation can be controlled using counterbalancing.
- Pro : Fewer people are needed as they participate in all conditions (i.e., saves time).
- Control : To combat order effects, the researcher counter-balances the order of the conditions for the participants. Alternating the order in which participants perform in different conditions of an experiment.
Counterbalancing
Suppose we used a repeated measures design in which all of the participants first learned words in “loud noise” and then learned them in “no noise.”
We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
The sample would be split into two groups: experimental (A) and control (B). For example, group 1 does ‘A’ then ‘B,’ and group 2 does ‘B’ then ‘A.’ This is to eliminate order effects.
Although order effects occur for each participant, they balance each other out in the results because they occur equally in both groups.

3. Matched Pairs Design
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group .
One member of each matched pair must be randomly assigned to the experimental group and the other to the control group.

- Con : If one participant drops out, you lose 2 PPs’ data.
- Pro : Reduces participant variables because the researcher has tried to pair up the participants so that each condition has people with similar abilities and characteristics.
- Con : Very time-consuming trying to find closely matched pairs.
- Pro : It avoids order effects, so counterbalancing is not necessary.
- Con : Impossible to match people exactly unless they are identical twins!
- Control : Members of each pair should be randomly assigned to conditions. However, this does not solve all these problems.
Experimental design refers to how participants are allocated to an experiment’s different conditions (or IV levels). There are three types:
1. Independent measures / between-groups : Different participants are used in each condition of the independent variable.
2. Repeated measures /within groups : The same participants take part in each condition of the independent variable.
3. Matched pairs : Each condition uses different participants, but they are matched in terms of important characteristics, e.g., gender, age, intelligence, etc.
Learning Check
Read about each of the experiments below. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design.
1 . To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period.
The researchers attempted to ensure that the patients in the two groups had similar severity of depressed symptoms by administering a standardized test of depression to each participant, then pairing them according to the severity of their symptoms.
2 . To assess the difference in reading comprehension between 7 and 9-year-olds, a researcher recruited each group from a local primary school. They were given the same passage of text to read and then asked a series of questions to assess their understanding.
3 . To assess the effectiveness of two different ways of teaching reading, a group of 5-year-olds was recruited from a primary school. Their level of reading ability was assessed, and then they were taught using scheme one for 20 weeks.
At the end of this period, their reading was reassessed, and a reading improvement score was calculated. They were then taught using scheme two for a further 20 weeks, and another reading improvement score for this period was calculated. The reading improvement scores for each child were then compared.
4 . To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page.
Experiment Terminology
Ecological validity.
The degree to which an investigation represents real-life experiences.
Experimenter effects
These are the ways that the experimenter can accidentally influence the participant through their appearance or behavior.
Demand characteristics
The clues in an experiment lead the participants to think they know what the researcher is looking for (e.g., the experimenter’s body language).
Independent variable (IV)
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable.
Dependent variable (DV)
Variable the experimenter measures. This is the outcome (i.e., the result) of a study.
Extraneous variables (EV)
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible.
Confounding variables
Variable(s) that have affected the results (DV), apart from the IV. A confounding variable could be an extraneous variable that has not been controlled.
Random Allocation
Randomly allocating participants to independent variable conditions means that all participants should have an equal chance of taking part in each condition.
The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effects
Changes in participants’ performance due to their repeating the same or similar test more than once. Examples of order effects include:
(i) practice effect: an improvement in performance on a task due to repetition, for example, because of familiarity with the task;
(ii) fatigue effect: a decrease in performance of a task due to repetition, for example, because of boredom or tiredness.
Related Articles

Research Methodology
Qualitative Data Coding

What Is a Focus Group?

Cross-Cultural Research Methodology In Psychology

What Is Internal Validity In Research?

Research Methodology , Statistics
What Is Face Validity In Research? Importance & How To Measure

Criterion Validity: Definition & Examples
Experimental design: Guide, steps, examples
Last updated
27 April 2023
Reviewed by
Miroslav Damyanov
Experimental research design is a scientific framework that allows you to manipulate one or more variables while controlling the test environment.
When testing a theory or new product, it can be helpful to have a certain level of control and manipulate variables to discover different outcomes. You can use these experiments to determine cause and effect or study variable associations.
This guide explores the types of experimental design, the steps in designing an experiment, and the advantages and limitations of experimental design.
Make research less tedious
Dovetail streamlines research to help you uncover and share actionable insights
- What is experimental research design?
You can determine the relationship between each of the variables by:
Manipulating one or more independent variables (i.e., stimuli or treatments)
Applying the changes to one or more dependent variables (i.e., test groups or outcomes)
With the ability to analyze the relationship between variables and using measurable data, you can increase the accuracy of the result.
What is a good experimental design?
A good experimental design requires:
Significant planning to ensure control over the testing environment
Sound experimental treatments
Properly assigning subjects to treatment groups
Without proper planning, unexpected external variables can alter an experiment's outcome.
To meet your research goals, your experimental design should include these characteristics:
Provide unbiased estimates of inputs and associated uncertainties
Enable the researcher to detect differences caused by independent variables
Include a plan for analysis and reporting of the results
Provide easily interpretable results with specific conclusions
What's the difference between experimental and quasi-experimental design?
The major difference between experimental and quasi-experimental design is the random assignment of subjects to groups.
A true experiment relies on certain controls. Typically, the researcher designs the treatment and randomly assigns subjects to control and treatment groups.
However, these conditions are unethical or impossible to achieve in some situations.
When it's unethical or impractical to assign participants randomly, that’s when a quasi-experimental design comes in.
This design allows researchers to conduct a similar experiment by assigning subjects to groups based on non-random criteria.
Another type of quasi-experimental design might occur when the researcher doesn't have control over the treatment but studies pre-existing groups after they receive different treatments.
When can a researcher conduct experimental research?
Various settings and professions can use experimental research to gather information and observe behavior in controlled settings.
Basically, a researcher can conduct experimental research any time they want to test a theory with variable and dependent controls.
Experimental research is an option when the project includes an independent variable and a desire to understand the relationship between cause and effect.
- The importance of experimental research design
Experimental research enables researchers to conduct studies that provide specific, definitive answers to questions and hypotheses.
Researchers can test Independent variables in controlled settings to:
Test the effectiveness of a new medication
Design better products for consumers
Answer questions about human health and behavior
Developing a quality research plan means a researcher can accurately answer vital research questions with minimal error. As a result, definitive conclusions can influence the future of the independent variable.
Types of experimental research designs
There are three main types of experimental research design. The research type you use will depend on the criteria of your experiment, your research budget, and environmental limitations.
Pre-experimental research design
A pre-experimental research study is a basic observational study that monitors independent variables’ effects.
During research, you observe one or more groups after applying a treatment to test whether the treatment causes any change.
The three subtypes of pre-experimental research design are:
One-shot case study research design
This research method introduces a single test group to a single stimulus to study the results at the end of the application.
After researchers presume the stimulus or treatment has caused changes, they gather results to determine how it affects the test subjects.
One-group pretest-posttest design
This method uses a single test group but includes a pretest study as a benchmark. The researcher applies a test before and after the group’s exposure to a specific stimulus.
Static group comparison design
This method includes two or more groups, enabling the researcher to use one group as a control. They apply a stimulus to one group and leave the other group static.
A posttest study compares the results among groups.
True experimental research design
A true experiment is the most common research method. It involves statistical analysis to prove or disprove a specific hypothesis .
Under completely experimental conditions, researchers expose participants in two or more randomized groups to different stimuli.
Random selection removes any potential for bias, providing more reliable results.
These are the three main sub-groups of true experimental research design:
Posttest-only control group design
This structure requires the researcher to divide participants into two random groups. One group receives no stimuli and acts as a control while the other group experiences stimuli.
Researchers perform a test at the end of the experiment to observe the stimuli exposure results.
Pretest-posttest control group design
This test also requires two groups. It includes a pretest as a benchmark before introducing the stimulus.
The pretest introduces multiple ways to test subjects. For instance, if the control group also experiences a change, it reveals that taking the test twice changes the results.
Solomon four-group design
This structure divides subjects into two groups, with two as control groups. Researchers assign the first control group a posttest only and the second control group a pretest and a posttest.
The two variable groups mirror the control groups, but researchers expose them to stimuli. The ability to differentiate between groups in multiple ways provides researchers with more testing approaches for data-based conclusions.
Quasi-experimental research design
Although closely related to a true experiment, quasi-experimental research design differs in approach and scope.
Quasi-experimental research design doesn’t have randomly selected participants. Researchers typically divide the groups in this research by pre-existing differences.
Quasi-experimental research is more common in educational studies, nursing, or other research projects where it's not ethical or practical to use randomized subject groups.
- 5 steps for designing an experiment
Experimental research requires a clearly defined plan to outline the research parameters and expected goals.
Here are five key steps in designing a successful experiment:
Step 1: Define variables and their relationship
Your experiment should begin with a question: What are you hoping to learn through your experiment?
The relationship between variables in your study will determine your answer.
Define the independent variable (the intended stimuli) and the dependent variable (the expected effect of the stimuli). After identifying these groups, consider how you might control them in your experiment.
Could natural variations affect your research? If so, your experiment should include a pretest and posttest.
Step 2: Develop a specific, testable hypothesis
With a firm understanding of the system you intend to study, you can write a specific, testable hypothesis.
What is the expected outcome of your study?
Develop a prediction about how the independent variable will affect the dependent variable.
How will the stimuli in your experiment affect your test subjects?
Your hypothesis should provide a prediction of the answer to your research question .
Step 3: Design experimental treatments to manipulate your independent variable
Depending on your experiment, your variable may be a fixed stimulus (like a medical treatment) or a variable stimulus (like a period during which an activity occurs).
Determine which type of stimulus meets your experiment’s needs and how widely or finely to vary your stimuli.
Step 4: Assign subjects to groups
When you have a clear idea of how to carry out your experiment, you can determine how to assemble test groups for an accurate study.
When choosing your study groups, consider:
The size of your experiment
Whether you can select groups randomly
Your target audience for the outcome of the study
You should be able to create groups with an equal number of subjects and include subjects that match your target audience. Remember, you should assign one group as a control and use one or more groups to study the effects of variables.
Step 5: Plan how to measure your dependent variable
This step determines how you'll collect data to determine the study's outcome. You should seek reliable and valid measurements that minimize research bias or error.
You can measure some data with scientific tools, while you’ll need to operationalize other forms to turn them into measurable observations.
- Advantages of experimental research
Experimental research is an integral part of our world. It allows researchers to conduct experiments that answer specific questions.
While researchers use many methods to conduct different experiments, experimental research offers these distinct benefits:
Researchers can determine cause and effect by manipulating variables.
It gives researchers a high level of control.
Researchers can test multiple variables within a single experiment.
All industries and fields of knowledge can use it.
Researchers can duplicate results to promote the validity of the study .
Replicating natural settings rapidly means immediate research.
Researchers can combine it with other research methods.
It provides specific conclusions about the validity of a product, theory, or idea.
- Disadvantages (or limitations) of experimental research
Unfortunately, no research type yields ideal conditions or perfect results.
While experimental research might be the right choice for some studies, certain conditions could render experiments useless or even dangerous.
Before conducting experimental research, consider these disadvantages and limitations:
Required professional qualification
Only competent professionals with an academic degree and specific training are qualified to conduct rigorous experimental research. This ensures results are unbiased and valid.
Limited scope
Experimental research may not capture the complexity of some phenomena, such as social interactions or cultural norms. These are difficult to control in a laboratory setting.
Resource-intensive
Experimental research can be expensive, time-consuming, and require significant resources, such as specialized equipment or trained personnel.
Limited generalizability
The controlled nature means the research findings may not fully apply to real-world situations or people outside the experimental setting.
Practical or ethical concerns
Some experiments may involve manipulating variables that could harm participants or violate ethical guidelines .
Researchers must ensure their experiments do not cause harm or discomfort to participants.
Sometimes, recruiting a sample of people to randomly assign may be difficult.
- Experimental research design example
Experiments across all industries and research realms provide scientists, developers, and other researchers with definitive answers. These experiments can solve problems, create inventions, and heal illnesses.
Product design testing is an excellent example of experimental research.
A company in the product development phase creates multiple prototypes for testing. With a randomized selection, researchers introduce each test group to a different prototype.
When groups experience different product designs , the company can assess which option most appeals to potential customers.
Experimental research design provides researchers with a controlled environment to conduct experiments that evaluate cause and effect.
Using the five steps to develop a research plan ensures you anticipate and eliminate external variables while answering life’s crucial questions.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 11 January 2024
Last updated: 15 January 2024
Last updated: 17 January 2024
Last updated: 25 November 2023
Last updated: 12 May 2023
Last updated: 30 April 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next.

Users report unexpectedly high data usage, especially during streaming sessions.

Users find it hard to navigate from the home page to relevant playlists in the app.

It would be great to have a sleep timer feature, especially for bedtime listening.

I need better filters to find the songs or artists I’m looking for.
- Types of experimental
Log in or sign up
Get started for free
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- A Quick Guide to Experimental Design | 5 Steps & Examples
A Quick Guide to Experimental Design | 5 Steps & Examples
Published on 11 April 2022 by Rebecca Bevans . Revised on 5 December 2022.
Experiments are used to study causal relationships . You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design means creating a set of procedures to systematically test a hypothesis . A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If if random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead.
Table of contents
Step 1: define your variables, step 2: write your hypothesis, step 3: design your experimental treatments, step 4: assign your subjects to treatment groups, step 5: measure your dependent variable, frequently asked questions about experimental design.
You should begin with a specific research question . We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables .
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.

Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Prevent plagiarism, run a free check.
Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
The next steps will describe how to design a controlled experiment . In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalised and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable : either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size : how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power , which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups . Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group , which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomised design vs a randomised block design .
- A between-subjects design vs a within-subjects design .
Randomisation
An experiment can be completely randomised or randomised within blocks (aka strata):
- In a completely randomised design , every subject is assigned to a treatment group at random.
- In a randomised block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
Sometimes randomisation isn’t practical or ethical , so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design .
Between-subjects vs within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomising or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimise bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalised to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
Experimental designs are a set of procedures that you plan in order to examine the relationship between variables that interest you.
To design a successful experiment, first identify:
- A testable hypothesis
- One or more independent variables that you will manipulate
- One or more dependent variables that you will measure
When designing the experiment, first decide:
- How your variable(s) will be manipulated
- How you will control for any potential confounding or lurking variables
- How many subjects you will include
- How you will assign treatments to your subjects
The key difference between observational studies and experiments is that, done correctly, an observational study will never influence the responses or behaviours of participants. Experimental designs will have a treatment condition applied to at least a portion of participants.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word ‘between’ means that you’re comparing different conditions between groups, while the word ‘within’ means you’re comparing different conditions within the same group.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bevans, R. (2022, December 05). A Quick Guide to Experimental Design | 5 Steps & Examples. Scribbr. Retrieved 20 May 2024, from https://www.scribbr.co.uk/research-methods/guide-to-experimental-design/
Is this article helpful?

Rebecca Bevans
Chapter 10 Experimental Research
Experimental research, often considered to be the “gold standard” in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research (rather than for descriptive or exploratory research), where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalizability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments , conducted in field settings such as in a real organization, and high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic Concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favorably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receives a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the “cause” in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and assures that each unit in the population has a positive chance of being selected into the sample. Random assignment is however a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group, prior to treatment administration. Random selection is related to sampling, and is therefore, more closely related to the external validity (generalizability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
- History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
- Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
- Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam. Not conducting a pretest can help avoid this threat.
- Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
- Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
- Regression threat , also called a regression to the mean, refers to the statistical tendency of a group’s overall performance on a measure during a posttest to regress toward the mean of that measure rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest was possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-Group Experimental Designs
The simplest true experimental designs are two group designs involving one treatment group and one control group, and are ideally suited for testing the effects of a single independent variable that can be manipulated as a treatment. The two basic two-group designs are the pretest-posttest control group design and the posttest-only control group design, while variations may include covariance designs. These designs are often depicted using a standardized design notation, where R represents random assignment of subjects to groups, X represents the treatment administered to the treatment group, and O represents pretest or posttest observations of the dependent variable (with different subscripts to distinguish between pretest and posttest observations of treatment and control groups).
Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Figure 10.1. Pretest-posttest control group design
The effect E of the experimental treatment in the pretest posttest design is measured as the difference in the posttest and pretest scores between the treatment and control groups:
E = (O 2 – O 1 ) – (O 4 – O 3 )
Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement (especially if the pretest introduces unusual topics or content).
Posttest-only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

Figure 10.2. Posttest only control group design.
The treatment effect is measured simply as the difference in the posttest scores between the two groups:
E = (O 1 – O 2 )
The appropriate statistical analysis of this design is also a two- group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.
Covariance designs . Sometimes, measures of dependent variables may be influenced by extraneous variables called covariates . Covariates are those variables that are not of central interest to an experimental study, but should nevertheless be controlled in an experimental design in order to eliminate their potential effect on the dependent variable and therefore allow for a more accurate detection of the effects of the independent variables of interest. The experimental designs discussed earlier did not control for such covariates. A covariance design (also called a concomitant variable design) is a special type of pretest posttest control group design where the pretest measure is essentially a measurement of the covariates of interest rather than that of the dependent variables. The design notation is shown in Figure 10.3, where C represents the covariates:

Figure 10.3. Covariance design
Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:

Factorial Designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each sub-division of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).
The most basic factorial design is a 2 x 2 factorial design, which consists of two treatments, each with two levels (such as high/low or present/absent). For instance, let’s say that you want to compare the learning outcomes of two different types of instructional techniques (in-class and online instruction), and you also want to examine whether these effects vary with the time of instruction (1.5 or 3 hours per week). In this case, you have two factors: instructional type and instructional time; each with two levels (in-class and online for instructional type, and 1.5 and 3 hours/week for instructional time), as shown in Figure 8.1. If you wish to add a third level of instructional time (say 6 hours/week), then the second factor will consist of three levels and you will have a 2 x 3 factorial design. On the other hand, if you wish to add a third factor such as group work (present versus absent), you will have a 2 x 2 x 2 factorial design. In this notation, each number represents a factor, and the value of each factor represents the number of levels in that factor.

Figure 10.4. 2 x 2 factorial design
Factorial designs can also be depicted using a design notation, such as that shown on the right panel of Figure 10.4. R represents random assignment of subjects to treatment groups, X represents the treatment groups themselves (the subscripts of X represents the level of each factor), and O represent observations of the dependent variable. Notice that the 2 x 2 factorial design will have four treatment groups, corresponding to the four combinations of the two levels of each factor. Correspondingly, the 2 x 3 design will have six treatment groups, and the 2 x 2 x 2 design will have eight treatment groups. As a rule of thumb, each cell in a factorial design should have a minimum sample size of 20 (this estimate is derived from Cohen’s power calculations based on medium effect sizes). So a 2 x 2 x 2 factorial design requires a minimum total sample size of 160 subjects, with at least 20 subjects in each cell. As you can see, the cost of data collection can increase substantially with more levels or factors in your factorial design. Sometimes, due to resource constraints, some cells in such factorial designs may not receive any treatment at all, which are called incomplete factorial designs . Such incomplete designs hurt our ability to draw inferences about the incomplete factors.
In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for 3 hours/week of instructional time than for 1.5 hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid Experimental Designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomized bocks design, Solomon four-group design, and switched replications design.
Randomized block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full -time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between treatment group (receiving the same treatment) or control group (see Figure 10.5). The purpose of this design is to reduce the “noise” or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.
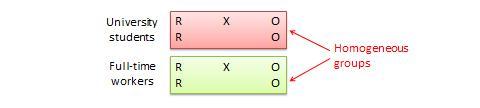
Figure 10.5. Randomized blocks design.
Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs but not in posttest only designs. The design notation is shown in Figure 10.6.

Figure 10.6. Solomon four-group design
Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organizational contexts where organizational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.
Figure 10.7. Switched replication design.
Quasi-Experimental Designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organization is used as the treatment group, while another section of the same class or a different organization in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of a certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impact by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.
Many true experimental designs can be converted to quasi-experimental designs by omitting random assignment. For instance, the quasi-equivalent version of pretest-posttest control group design is called nonequivalent groups design (NEGD), as shown in Figure 10.8, with random assignment R replaced by non-equivalent (non-random) assignment N . Likewise, the quasi -experimental version of switched replication design is called non-equivalent switched replication design (see Figure 10.9).

Figure 10.8. NEGD design.
Figure 10.9. Non-equivalent switched replication design.
In addition, there are quite a few unique non -equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression-discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to treatment or control group based on a cutoff score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardized test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program. The design notation can be represented as follows, where C represents the cutoff score:
Figure 10.10. RD design.
Because of the use of a cutoff score, it is possible that the observed results may be a function of the cutoff score rather than the treatment, which introduces a new threat to internal validity. However, using the cutoff score also ensures that limited or costly resources are distributed to people who need them the most rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design does not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.
Figure 10.11. Proxy pretest design.
Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data are not available from the same subjects.

Figure 10.12. Separate pretest-posttest samples design.
Nonequivalent dependent variable (NEDV) design . This is a single-group pre-post quasi-experimental design with two outcome measures, where one measure is theoretically expected to be influenced by the treatment and the other measure is not. For instance, if you are designing a new calculus curriculum for high school students, this curriculum is likely to influence students’ posttest calculus scores but not algebra scores. However, the posttest algebra scores may still vary due to extraneous factors such as history or maturation. Hence, the pre-post algebra scores can be used as a control measure, while that of pre-post calculus can be treated as the treatment measure. The design notation, shown in Figure 10.13, indicates the single group by a single N , followed by pretest O 1 and posttest O 2 for calculus and algebra for the same group of students. This design is weak in internal validity, but its advantage lies in not having to use a separate control group.
An interesting variation of the NEDV design is a pattern matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique, based on the degree of correspondence between theoretical and observed patterns is a powerful way of alleviating internal validity concerns in the original NEDV design.
Figure 10.13. NEDV design.
Perils of Experimental Research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, many experimental research use inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artifact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if doubt, using tasks that are simpler and familiar for the respondent sample than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Experimental Research: What it is + Types of designs

Any research conducted under scientifically acceptable conditions uses experimental methods. The success of experimental studies hinges on researchers confirming the change of a variable is based solely on the manipulation of the constant variable. The research should establish a notable cause and effect.
What is Experimental Research?
Experimental research is a study conducted with a scientific approach using two sets of variables. The first set acts as a constant, which you use to measure the differences of the second set. Quantitative research methods , for example, are experimental.
If you don’t have enough data to support your decisions, you must first determine the facts. This research gathers the data necessary to help you make better decisions.
You can conduct experimental research in the following situations:
- Time is a vital factor in establishing a relationship between cause and effect.
- Invariable behavior between cause and effect.
- You wish to understand the importance of cause and effect.
Experimental Research Design Types
The classic experimental design definition is: “The methods used to collect data in experimental studies.”
There are three primary types of experimental design:
- Pre-experimental research design
- True experimental research design
- Quasi-experimental research design
The way you classify research subjects based on conditions or groups determines the type of research design you should use.
0 1. Pre-Experimental Design
A group, or various groups, are kept under observation after implementing cause and effect factors. You’ll conduct this research to understand whether further investigation is necessary for these particular groups.
You can break down pre-experimental research further into three types:
- One-shot Case Study Research Design
- One-group Pretest-posttest Research Design
- Static-group Comparison
0 2. True Experimental Design
It relies on statistical analysis to prove or disprove a hypothesis, making it the most accurate form of research. Of the types of experimental design, only true design can establish a cause-effect relationship within a group. In a true experiment, three factors need to be satisfied:
- There is a Control Group, which won’t be subject to changes, and an Experimental Group, which will experience the changed variables.
- A variable that can be manipulated by the researcher
- Random distribution
This experimental research method commonly occurs in the physical sciences.
0 3. Quasi-Experimental Design
The word “Quasi” indicates similarity. A quasi-experimental design is similar to an experimental one, but it is not the same. The difference between the two is the assignment of a control group. In this research, an independent variable is manipulated, but the participants of a group are not randomly assigned. Quasi-research is used in field settings where random assignment is either irrelevant or not required.
Importance of Experimental Design
Experimental research is a powerful tool for understanding cause-and-effect relationships. It allows us to manipulate variables and observe the effects, which is crucial for understanding how different factors influence the outcome of a study.
But the importance of experimental research goes beyond that. It’s a critical method for many scientific and academic studies. It allows us to test theories, develop new products, and make groundbreaking discoveries.
For example, this research is essential for developing new drugs and medical treatments. Researchers can understand how a new drug works by manipulating dosage and administration variables and identifying potential side effects.
Similarly, experimental research is used in the field of psychology to test theories and understand human behavior. By manipulating variables such as stimuli, researchers can gain insights into how the brain works and identify new treatment options for mental health disorders.
It is also widely used in the field of education. It allows educators to test new teaching methods and identify what works best. By manipulating variables such as class size, teaching style, and curriculum, researchers can understand how students learn and identify new ways to improve educational outcomes.
In addition, experimental research is a powerful tool for businesses and organizations. By manipulating variables such as marketing strategies, product design, and customer service, companies can understand what works best and identify new opportunities for growth.
Advantages of Experimental Research
When talking about this research, we can think of human life. Babies do their own rudimentary experiments (such as putting objects in their mouths) to learn about the world around them, while older children and teens do experiments at school to learn more about science.
Ancient scientists used this research to prove that their hypotheses were correct. For example, Galileo Galilei and Antoine Lavoisier conducted various experiments to discover key concepts in physics and chemistry. The same is true of modern experts, who use this scientific method to see if new drugs are effective, discover treatments for diseases, and create new electronic devices (among others).
It’s vital to test new ideas or theories. Why put time, effort, and funding into something that may not work?
This research allows you to test your idea in a controlled environment before marketing. It also provides the best method to test your theory thanks to the following advantages:

- Researchers have a stronger hold over variables to obtain desired results.
- The subject or industry does not impact the effectiveness of experimental research. Any industry can implement it for research purposes.
- The results are specific.
- After analyzing the results, you can apply your findings to similar ideas or situations.
- You can identify the cause and effect of a hypothesis. Researchers can further analyze this relationship to determine more in-depth ideas.
- Experimental research makes an ideal starting point. The data you collect is a foundation for building more ideas and conducting more action research .
Whether you want to know how the public will react to a new product or if a certain food increases the chance of disease, experimental research is the best place to start. Begin your research by finding subjects using QuestionPro Audience and other tools today.
LEARN MORE FREE TRIAL
MORE LIKE THIS

AI-Based Services Buying Guide for Market Research (based on ESOMAR’s 20 Questions)
May 20, 2024

Data Information vs Insight: Essential differences
May 14, 2024

Pricing Analytics Software: Optimize Your Pricing Strategy
May 13, 2024

Relationship Marketing: What It Is, Examples & Top 7 Benefits
May 8, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Athl Train
- v.45(1); Jan-Feb 2010
Study/Experimental/Research Design: Much More Than Statistics
Kenneth l. knight.
Brigham Young University, Provo, UT
The purpose of study, experimental, or research design in scientific manuscripts has changed significantly over the years. It has evolved from an explanation of the design of the experiment (ie, data gathering or acquisition) to an explanation of the statistical analysis. This practice makes “Methods” sections hard to read and understand.
To clarify the difference between study design and statistical analysis, to show the advantages of a properly written study design on article comprehension, and to encourage authors to correctly describe study designs.
Description:
The role of study design is explored from the introduction of the concept by Fisher through modern-day scientists and the AMA Manual of Style . At one time, when experiments were simpler, the study design and statistical design were identical or very similar. With the complex research that is common today, which often includes manipulating variables to create new variables and the multiple (and different) analyses of a single data set, data collection is very different than statistical design. Thus, both a study design and a statistical design are necessary.
Advantages:
Scientific manuscripts will be much easier to read and comprehend. A proper experimental design serves as a road map to the study methods, helping readers to understand more clearly how the data were obtained and, therefore, assisting them in properly analyzing the results.
Study, experimental, or research design is the backbone of good research. It directs the experiment by orchestrating data collection, defines the statistical analysis of the resultant data, and guides the interpretation of the results. When properly described in the written report of the experiment, it serves as a road map to readers, 1 helping them negotiate the “Methods” section, and, thus, it improves the clarity of communication between authors and readers.
A growing trend is to equate study design with only the statistical analysis of the data. The design statement typically is placed at the end of the “Methods” section as a subsection called “Experimental Design” or as part of a subsection called “Data Analysis.” This placement, however, equates experimental design and statistical analysis, minimizing the effect of experimental design on the planning and reporting of an experiment. This linkage is inappropriate, because some of the elements of the study design that should be described at the beginning of the “Methods” section are instead placed in the “Statistical Analysis” section or, worse, are absent from the manuscript entirely.
Have you ever interrupted your reading of the “Methods” to sketch out the variables in the margins of the paper as you attempt to understand how they all fit together? Or have you jumped back and forth from the early paragraphs of the “Methods” section to the “Statistics” section to try to understand which variables were collected and when? These efforts would be unnecessary if a road map at the beginning of the “Methods” section outlined how the independent variables were related, which dependent variables were measured, and when they were measured. When they were measured is especially important if the variables used in the statistical analysis were a subset of the measured variables or were computed from measured variables (such as change scores).
The purpose of this Communications article is to clarify the purpose and placement of study design elements in an experimental manuscript. Adopting these ideas may improve your science and surely will enhance the communication of that science. These ideas will make experimental manuscripts easier to read and understand and, therefore, will allow them to become part of readers' clinical decision making.
WHAT IS A STUDY (OR EXPERIMENTAL OR RESEARCH) DESIGN?
The terms study design, experimental design, and research design are often thought to be synonymous and are sometimes used interchangeably in a single paper. Avoid doing so. Use the term that is preferred by the style manual of the journal for which you are writing. Study design is the preferred term in the AMA Manual of Style , 2 so I will use it here.
A study design is the architecture of an experimental study 3 and a description of how the study was conducted, 4 including all elements of how the data were obtained. 5 The study design should be the first subsection of the “Methods” section in an experimental manuscript (see the Table ). “Statistical Design” or, preferably, “Statistical Analysis” or “Data Analysis” should be the last subsection of the “Methods” section.
Table. Elements of a “Methods” Section

The “Study Design” subsection describes how the variables and participants interacted. It begins with a general statement of how the study was conducted (eg, crossover trials, parallel, or observational study). 2 The second element, which usually begins with the second sentence, details the number of independent variables or factors, the levels of each variable, and their names. A shorthand way of doing so is with a statement such as “A 2 × 4 × 8 factorial guided data collection.” This tells us that there were 3 independent variables (factors), with 2 levels of the first factor, 4 levels of the second factor, and 8 levels of the third factor. Following is a sentence that names the levels of each factor: for example, “The independent variables were sex (male or female), training program (eg, walking, running, weight lifting, or plyometrics), and time (2, 4, 6, 8, 10, 15, 20, or 30 weeks).” Such an approach clearly outlines for readers how the various procedures fit into the overall structure and, therefore, enhances their understanding of how the data were collected. Thus, the design statement is a road map of the methods.
The dependent (or measurement or outcome) variables are then named. Details of how they were measured are not given at this point in the manuscript but are explained later in the “Instruments” and “Procedures” subsections.
Next is a paragraph detailing who the participants were and how they were selected, placed into groups, and assigned to a particular treatment order, if the experiment was a repeated-measures design. And although not a part of the design per se, a statement about obtaining written informed consent from participants and institutional review board approval is usually included in this subsection.
The nuts and bolts of the “Methods” section follow, including such things as equipment, materials, protocols, etc. These are beyond the scope of this commentary, however, and so will not be discussed.
The last part of the “Methods” section and last part of the “Study Design” section is the “Data Analysis” subsection. It begins with an explanation of any data manipulation, such as how data were combined or how new variables (eg, ratios or differences between collected variables) were calculated. Next, readers are told of the statistical measures used to analyze the data, such as a mixed 2 × 4 × 8 analysis of variance (ANOVA) with 2 between-groups factors (sex and training program) and 1 within-groups factor (time of measurement). Researchers should state and reference the statistical package and procedure(s) within the package used to compute the statistics. (Various statistical packages perform analyses slightly differently, so it is important to know the package and specific procedure used.) This detail allows readers to judge the appropriateness of the statistical measures and the conclusions drawn from the data.
STATISTICAL DESIGN VERSUS STATISTICAL ANALYSIS
Avoid using the term statistical design . Statistical methods are only part of the overall design. The term gives too much emphasis to the statistics, which are important, but only one of many tools used in interpreting data and only part of the study design:
The most important issues in biostatistics are not expressed with statistical procedures. The issues are inherently scientific, rather than purely statistical, and relate to the architectural design of the research, not the numbers with which the data are cited and interpreted. 6
Stated another way, “The justification for the analysis lies not in the data collected but in the manner in which the data were collected.” 3 “Without the solid foundation of a good design, the edifice of statistical analysis is unsafe.” 7 (pp4–5)
The intertwining of study design and statistical analysis may have been caused (unintentionally) by R.A. Fisher, “… a genius who almost single-handedly created the foundations for modern statistical science.” 8 Most research did not involve statistics until Fisher invented the concepts and procedures of ANOVA (in 1921) 9 , 10 and experimental design (in 1935). 11 His books became standard references for scientists in many disciplines. As a result, many ANOVA books were titled Experimental Design (see, for example, Edwards 12 ), and ANOVA courses taught in psychology and education departments included the words experimental design in their course titles.
Before the widespread use of computers to analyze data, designs were much simpler, and often there was little difference between study design and statistical analysis. So combining the 2 elements did not cause serious problems. This is no longer true, however, for 3 reasons: (1) Research studies are becoming more complex, with multiple independent and dependent variables. The procedures sections of these complex studies can be difficult to understand if your only reference point is the statistical analysis and design. (2) Dependent variables are frequently measured at different times. (3) How the data were collected is often not directly correlated with the statistical design.
For example, assume the goal is to determine the strength gain in novice and experienced athletes as a result of 3 strength training programs. Rate of change in strength is not a measurable variable; rather, it is calculated from strength measurements taken at various time intervals during the training. So the study design would be a 2 × 2 × 3 factorial with independent variables of time (pretest or posttest), experience (novice or advanced), and training (isokinetic, isotonic, or isometric) and a dependent variable of strength. The statistical design , however, would be a 2 × 3 factorial with independent variables of experience (novice or advanced) and training (isokinetic, isotonic, or isometric) and a dependent variable of strength gain. Note that data were collected according to a 3-factor design but were analyzed according to a 2-factor design and that the dependent variables were different. So a single design statement, usually a statistical design statement, would not communicate which data were collected or how. Readers would be left to figure out on their own how the data were collected.
MULTIVARIATE RESEARCH AND THE NEED FOR STUDY DESIGNS
With the advent of electronic data gathering and computerized data handling and analysis, research projects have increased in complexity. Many projects involve multiple dependent variables measured at different times, and, therefore, multiple design statements may be needed for both data collection and statistical analysis. Consider, for example, a study of the effects of heat and cold on neural inhibition. The variables of H max and M max are measured 3 times each: before, immediately after, and 30 minutes after a 20-minute treatment with heat or cold. Muscle temperature might be measured each minute before, during, and after the treatment. Although the minute-by-minute data are important for graphing temperature fluctuations during the procedure, only 3 temperatures (time 0, time 20, and time 50) are used for statistical analysis. A single dependent variable H max :M max ratio is computed to illustrate neural inhibition. Again, a single statistical design statement would tell little about how the data were obtained. And in this example, separate design statements would be needed for temperature measurement and H max :M max measurements.
As stated earlier, drawing conclusions from the data depends more on how the data were measured than on how they were analyzed. 3 , 6 , 7 , 13 So a single study design statement (or multiple such statements) at the beginning of the “Methods” section acts as a road map to the study and, thus, increases scientists' and readers' comprehension of how the experiment was conducted (ie, how the data were collected). Appropriate study design statements also increase the accuracy of conclusions drawn from the study.
CONCLUSIONS
The goal of scientific writing, or any writing, for that matter, is to communicate information. Including 2 design statements or subsections in scientific papers—one to explain how the data were collected and another to explain how they were statistically analyzed—will improve the clarity of communication and bring praise from readers. To summarize:
- Purge from your thoughts and vocabulary the idea that experimental design and statistical design are synonymous.
- Study or experimental design plays a much broader role than simply defining and directing the statistical analysis of an experiment.
- A properly written study design serves as a road map to the “Methods” section of an experiment and, therefore, improves communication with the reader.
- Study design should include a description of the type of design used, each factor (and each level) involved in the experiment, and the time at which each measurement was made.
- Clarify when the variables involved in data collection and data analysis are different, such as when data analysis involves only a subset of a collected variable or a resultant variable from the mathematical manipulation of 2 or more collected variables.
Acknowledgments
Thanks to Thomas A. Cappaert, PhD, ATC, CSCS, CSE, for suggesting the link between R.A. Fisher and the melding of the concepts of research design and statistics.
- En español – ExME
- Em português – EME
An introduction to different types of study design
Posted on 6th April 2021 by Hadi Abbas

Study designs are the set of methods and procedures used to collect and analyze data in a study.
Broadly speaking, there are 2 types of study designs: descriptive studies and analytical studies.
Descriptive studies
- Describes specific characteristics in a population of interest
- The most common forms are case reports and case series
- In a case report, we discuss our experience with the patient’s symptoms, signs, diagnosis, and treatment
- In a case series, several patients with similar experiences are grouped.
Analytical Studies
Analytical studies are of 2 types: observational and experimental.
Observational studies are studies that we conduct without any intervention or experiment. In those studies, we purely observe the outcomes. On the other hand, in experimental studies, we conduct experiments and interventions.
Observational studies
Observational studies include many subtypes. Below, I will discuss the most common designs.
Cross-sectional study:
- This design is transverse where we take a specific sample at a specific time without any follow-up
- It allows us to calculate the frequency of disease ( p revalence ) or the frequency of a risk factor
- This design is easy to conduct
- For example – if we want to know the prevalence of migraine in a population, we can conduct a cross-sectional study whereby we take a sample from the population and calculate the number of patients with migraine headaches.
Cohort study:
- We conduct this study by comparing two samples from the population: one sample with a risk factor while the other lacks this risk factor
- It shows us the risk of developing the disease in individuals with the risk factor compared to those without the risk factor ( RR = relative risk )
- Prospective : we follow the individuals in the future to know who will develop the disease
- Retrospective : we look to the past to know who developed the disease (e.g. using medical records)
- This design is the strongest among the observational studies
- For example – to find out the relative risk of developing chronic obstructive pulmonary disease (COPD) among smokers, we take a sample including smokers and non-smokers. Then, we calculate the number of individuals with COPD among both.
Case-Control Study:
- We conduct this study by comparing 2 groups: one group with the disease (cases) and another group without the disease (controls)
- This design is always retrospective
- We aim to find out the odds of having a risk factor or an exposure if an individual has a specific disease (Odds ratio)
- Relatively easy to conduct
- For example – we want to study the odds of being a smoker among hypertensive patients compared to normotensive ones. To do so, we choose a group of patients diagnosed with hypertension and another group that serves as the control (normal blood pressure). Then we study their smoking history to find out if there is a correlation.
Experimental Studies
- Also known as interventional studies
- Can involve animals and humans
- Pre-clinical trials involve animals
- Clinical trials are experimental studies involving humans
- In clinical trials, we study the effect of an intervention compared to another intervention or placebo. As an example, I have listed the four phases of a drug trial:
I: We aim to assess the safety of the drug ( is it safe ? )
II: We aim to assess the efficacy of the drug ( does it work ? )
III: We want to know if this drug is better than the old treatment ( is it better ? )
IV: We follow-up to detect long-term side effects ( can it stay in the market ? )
- In randomized controlled trials, one group of participants receives the control, while the other receives the tested drug/intervention. Those studies are the best way to evaluate the efficacy of a treatment.
Finally, the figure below will help you with your understanding of different types of study designs.

References (pdf)
You may also be interested in the following blogs for further reading:
An introduction to randomized controlled trials
Case-control and cohort studies: a brief overview
Cohort studies: prospective and retrospective designs
Prevalence vs Incidence: what is the difference?

Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on An introduction to different types of study design

you are amazing one!! if I get you I’m working with you! I’m student from Ethiopian higher education. health sciences student

Very informative and easy understandable

You are my kind of doctor. Do not lose sight of your objective.

Wow very erll explained and easy to understand

I’m Khamisu Habibu community health officer student from Abubakar Tafawa Balewa university teaching hospital Bauchi, Nigeria, I really appreciate your write up and you have make it clear for the learner. thank you

well understood,thank you so much

Well understood…thanks

Simply explained. Thank You.

Thanks a lot for this nice informative article which help me to understand different study designs that I felt difficult before

That’s lovely to hear, Mona, thank you for letting the author know how useful this was. If there are any other particular topics you think would be useful to you, and are not already on the website, please do let us know.

it is very informative and useful.
thank you statistician
Fabulous to hear, thank you John.

Thanks for this information
Thanks so much for this information….I have clearly known the types of study design Thanks
That’s so good to hear, Mirembe, thank you for letting the author know.

Very helpful article!! U have simplified everything for easy understanding

I’m a health science major currently taking statistics for health care workers…this is a challenging class…thanks for the simified feedback.
That’s good to hear this has helped you. Hopefully you will find some of the other blogs useful too. If you see any topics that are missing from the website, please do let us know!

Hello. I liked your presentation, the fact that you ranked them clearly is very helpful to understand for people like me who is a novelist researcher. However, I was expecting to read much more about the Experimental studies. So please direct me if you already have or will one day. Thank you
Dear Ay. My sincere apologies for not responding to your comment sooner. You may find it useful to filter the blogs by the topic of ‘Study design and research methods’ – here is a link to that filter: https://s4be.cochrane.org/blog/topic/study-design/ This will cover more detail about experimental studies. Or have a look on our library page for further resources there – you’ll find that on the ‘Resources’ drop down from the home page.
However, if there are specific things you feel you would like to learn about experimental studies, that are missing from the website, it would be great if you could let me know too. Thank you, and best of luck. Emma

Great job Mr Hadi. I advise you to prepare and study for the Australian Medical Board Exams as soon as you finish your undergrad study in Lebanon. Good luck and hope we can meet sometime in the future. Regards ;)

You have give a good explaination of what am looking for. However, references am not sure of where to get them from.
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Expertise-based Randomized Controlled Trials
This blog summarizes the concepts of Expertise-based randomized controlled trials with a focus on the advantages and challenges associated with this type of study.

A well-designed cohort study can provide powerful results. This blog introduces prospective and retrospective cohort studies, discussing the advantages, disadvantages and use of these type of study designs.
- Privacy Policy
Home » Experimental Design – Types, Methods, Guide
Experimental Design – Types, Methods, Guide
Table of Contents

Experimental Design
Experimental design is a process of planning and conducting scientific experiments to investigate a hypothesis or research question. It involves carefully designing an experiment that can test the hypothesis, and controlling for other variables that may influence the results.
Experimental design typically includes identifying the variables that will be manipulated or measured, defining the sample or population to be studied, selecting an appropriate method of sampling, choosing a method for data collection and analysis, and determining the appropriate statistical tests to use.
Types of Experimental Design
Here are the different types of experimental design:
Completely Randomized Design
In this design, participants are randomly assigned to one of two or more groups, and each group is exposed to a different treatment or condition.
Randomized Block Design
This design involves dividing participants into blocks based on a specific characteristic, such as age or gender, and then randomly assigning participants within each block to one of two or more treatment groups.
Factorial Design
In a factorial design, participants are randomly assigned to one of several groups, each of which receives a different combination of two or more independent variables.
Repeated Measures Design
In this design, each participant is exposed to all of the different treatments or conditions, either in a random order or in a predetermined order.
Crossover Design
This design involves randomly assigning participants to one of two or more treatment groups, with each group receiving one treatment during the first phase of the study and then switching to a different treatment during the second phase.
Split-plot Design
In this design, the researcher manipulates one or more variables at different levels and uses a randomized block design to control for other variables.
Nested Design
This design involves grouping participants within larger units, such as schools or households, and then randomly assigning these units to different treatment groups.
Laboratory Experiment
Laboratory experiments are conducted under controlled conditions, which allows for greater precision and accuracy. However, because laboratory conditions are not always representative of real-world conditions, the results of these experiments may not be generalizable to the population at large.
Field Experiment
Field experiments are conducted in naturalistic settings and allow for more realistic observations. However, because field experiments are not as controlled as laboratory experiments, they may be subject to more sources of error.
Experimental Design Methods
Experimental design methods refer to the techniques and procedures used to design and conduct experiments in scientific research. Here are some common experimental design methods:
Randomization
This involves randomly assigning participants to different groups or treatments to ensure that any observed differences between groups are due to the treatment and not to other factors.
Control Group
The use of a control group is an important experimental design method that involves having a group of participants that do not receive the treatment or intervention being studied. The control group is used as a baseline to compare the effects of the treatment group.
Blinding involves keeping participants, researchers, or both unaware of which treatment group participants are in, in order to reduce the risk of bias in the results.
Counterbalancing
This involves systematically varying the order in which participants receive treatments or interventions in order to control for order effects.
Replication
Replication involves conducting the same experiment with different samples or under different conditions to increase the reliability and validity of the results.
This experimental design method involves manipulating multiple independent variables simultaneously to investigate their combined effects on the dependent variable.
This involves dividing participants into subgroups or blocks based on specific characteristics, such as age or gender, in order to reduce the risk of confounding variables.
Data Collection Method
Experimental design data collection methods are techniques and procedures used to collect data in experimental research. Here are some common experimental design data collection methods:
Direct Observation
This method involves observing and recording the behavior or phenomenon of interest in real time. It may involve the use of structured or unstructured observation, and may be conducted in a laboratory or naturalistic setting.
Self-report Measures
Self-report measures involve asking participants to report their thoughts, feelings, or behaviors using questionnaires, surveys, or interviews. These measures may be administered in person or online.
Behavioral Measures
Behavioral measures involve measuring participants’ behavior directly, such as through reaction time tasks or performance tests. These measures may be administered using specialized equipment or software.
Physiological Measures
Physiological measures involve measuring participants’ physiological responses, such as heart rate, blood pressure, or brain activity, using specialized equipment. These measures may be invasive or non-invasive, and may be administered in a laboratory or clinical setting.
Archival Data
Archival data involves using existing records or data, such as medical records, administrative records, or historical documents, as a source of information. These data may be collected from public or private sources.
Computerized Measures
Computerized measures involve using software or computer programs to collect data on participants’ behavior or responses. These measures may include reaction time tasks, cognitive tests, or other types of computer-based assessments.
Video Recording
Video recording involves recording participants’ behavior or interactions using cameras or other recording equipment. This method can be used to capture detailed information about participants’ behavior or to analyze social interactions.
Data Analysis Method
Experimental design data analysis methods refer to the statistical techniques and procedures used to analyze data collected in experimental research. Here are some common experimental design data analysis methods:
Descriptive Statistics
Descriptive statistics are used to summarize and describe the data collected in the study. This includes measures such as mean, median, mode, range, and standard deviation.
Inferential Statistics
Inferential statistics are used to make inferences or generalizations about a larger population based on the data collected in the study. This includes hypothesis testing and estimation.
Analysis of Variance (ANOVA)
ANOVA is a statistical technique used to compare means across two or more groups in order to determine whether there are significant differences between the groups. There are several types of ANOVA, including one-way ANOVA, two-way ANOVA, and repeated measures ANOVA.
Regression Analysis
Regression analysis is used to model the relationship between two or more variables in order to determine the strength and direction of the relationship. There are several types of regression analysis, including linear regression, logistic regression, and multiple regression.
Factor Analysis
Factor analysis is used to identify underlying factors or dimensions in a set of variables. This can be used to reduce the complexity of the data and identify patterns in the data.
Structural Equation Modeling (SEM)
SEM is a statistical technique used to model complex relationships between variables. It can be used to test complex theories and models of causality.
Cluster Analysis
Cluster analysis is used to group similar cases or observations together based on similarities or differences in their characteristics.
Time Series Analysis
Time series analysis is used to analyze data collected over time in order to identify trends, patterns, or changes in the data.
Multilevel Modeling
Multilevel modeling is used to analyze data that is nested within multiple levels, such as students nested within schools or employees nested within companies.
Applications of Experimental Design
Experimental design is a versatile research methodology that can be applied in many fields. Here are some applications of experimental design:
- Medical Research: Experimental design is commonly used to test new treatments or medications for various medical conditions. This includes clinical trials to evaluate the safety and effectiveness of new drugs or medical devices.
- Agriculture : Experimental design is used to test new crop varieties, fertilizers, and other agricultural practices. This includes randomized field trials to evaluate the effects of different treatments on crop yield, quality, and pest resistance.
- Environmental science: Experimental design is used to study the effects of environmental factors, such as pollution or climate change, on ecosystems and wildlife. This includes controlled experiments to study the effects of pollutants on plant growth or animal behavior.
- Psychology : Experimental design is used to study human behavior and cognitive processes. This includes experiments to test the effects of different interventions, such as therapy or medication, on mental health outcomes.
- Engineering : Experimental design is used to test new materials, designs, and manufacturing processes in engineering applications. This includes laboratory experiments to test the strength and durability of new materials, or field experiments to test the performance of new technologies.
- Education : Experimental design is used to evaluate the effectiveness of teaching methods, educational interventions, and programs. This includes randomized controlled trials to compare different teaching methods or evaluate the impact of educational programs on student outcomes.
- Marketing : Experimental design is used to test the effectiveness of marketing campaigns, pricing strategies, and product designs. This includes experiments to test the impact of different marketing messages or pricing schemes on consumer behavior.
Examples of Experimental Design
Here are some examples of experimental design in different fields:
- Example in Medical research : A study that investigates the effectiveness of a new drug treatment for a particular condition. Patients are randomly assigned to either a treatment group or a control group, with the treatment group receiving the new drug and the control group receiving a placebo. The outcomes, such as improvement in symptoms or side effects, are measured and compared between the two groups.
- Example in Education research: A study that examines the impact of a new teaching method on student learning outcomes. Students are randomly assigned to either a group that receives the new teaching method or a group that receives the traditional teaching method. Student achievement is measured before and after the intervention, and the results are compared between the two groups.
- Example in Environmental science: A study that tests the effectiveness of a new method for reducing pollution in a river. Two sections of the river are selected, with one section treated with the new method and the other section left untreated. The water quality is measured before and after the intervention, and the results are compared between the two sections.
- Example in Marketing research: A study that investigates the impact of a new advertising campaign on consumer behavior. Participants are randomly assigned to either a group that is exposed to the new campaign or a group that is not. Their behavior, such as purchasing or product awareness, is measured and compared between the two groups.
- Example in Social psychology: A study that examines the effect of a new social intervention on reducing prejudice towards a marginalized group. Participants are randomly assigned to either a group that receives the intervention or a control group that does not. Their attitudes and behavior towards the marginalized group are measured before and after the intervention, and the results are compared between the two groups.
When to use Experimental Research Design
Experimental research design should be used when a researcher wants to establish a cause-and-effect relationship between variables. It is particularly useful when studying the impact of an intervention or treatment on a particular outcome.
Here are some situations where experimental research design may be appropriate:
- When studying the effects of a new drug or medical treatment: Experimental research design is commonly used in medical research to test the effectiveness and safety of new drugs or medical treatments. By randomly assigning patients to treatment and control groups, researchers can determine whether the treatment is effective in improving health outcomes.
- When evaluating the effectiveness of an educational intervention: An experimental research design can be used to evaluate the impact of a new teaching method or educational program on student learning outcomes. By randomly assigning students to treatment and control groups, researchers can determine whether the intervention is effective in improving academic performance.
- When testing the effectiveness of a marketing campaign: An experimental research design can be used to test the effectiveness of different marketing messages or strategies. By randomly assigning participants to treatment and control groups, researchers can determine whether the marketing campaign is effective in changing consumer behavior.
- When studying the effects of an environmental intervention: Experimental research design can be used to study the impact of environmental interventions, such as pollution reduction programs or conservation efforts. By randomly assigning locations or areas to treatment and control groups, researchers can determine whether the intervention is effective in improving environmental outcomes.
- When testing the effects of a new technology: An experimental research design can be used to test the effectiveness and safety of new technologies or engineering designs. By randomly assigning participants or locations to treatment and control groups, researchers can determine whether the new technology is effective in achieving its intended purpose.
How to Conduct Experimental Research
Here are the steps to conduct Experimental Research:
- Identify a Research Question : Start by identifying a research question that you want to answer through the experiment. The question should be clear, specific, and testable.
- Develop a Hypothesis: Based on your research question, develop a hypothesis that predicts the relationship between the independent and dependent variables. The hypothesis should be clear and testable.
- Design the Experiment : Determine the type of experimental design you will use, such as a between-subjects design or a within-subjects design. Also, decide on the experimental conditions, such as the number of independent variables, the levels of the independent variable, and the dependent variable to be measured.
- Select Participants: Select the participants who will take part in the experiment. They should be representative of the population you are interested in studying.
- Randomly Assign Participants to Groups: If you are using a between-subjects design, randomly assign participants to groups to control for individual differences.
- Conduct the Experiment : Conduct the experiment by manipulating the independent variable(s) and measuring the dependent variable(s) across the different conditions.
- Analyze the Data: Analyze the data using appropriate statistical methods to determine if there is a significant effect of the independent variable(s) on the dependent variable(s).
- Draw Conclusions: Based on the data analysis, draw conclusions about the relationship between the independent and dependent variables. If the results support the hypothesis, then it is accepted. If the results do not support the hypothesis, then it is rejected.
- Communicate the Results: Finally, communicate the results of the experiment through a research report or presentation. Include the purpose of the study, the methods used, the results obtained, and the conclusions drawn.
Purpose of Experimental Design
The purpose of experimental design is to control and manipulate one or more independent variables to determine their effect on a dependent variable. Experimental design allows researchers to systematically investigate causal relationships between variables, and to establish cause-and-effect relationships between the independent and dependent variables. Through experimental design, researchers can test hypotheses and make inferences about the population from which the sample was drawn.
Experimental design provides a structured approach to designing and conducting experiments, ensuring that the results are reliable and valid. By carefully controlling for extraneous variables that may affect the outcome of the study, experimental design allows researchers to isolate the effect of the independent variable(s) on the dependent variable(s), and to minimize the influence of other factors that may confound the results.
Experimental design also allows researchers to generalize their findings to the larger population from which the sample was drawn. By randomly selecting participants and using statistical techniques to analyze the data, researchers can make inferences about the larger population with a high degree of confidence.
Overall, the purpose of experimental design is to provide a rigorous, systematic, and scientific method for testing hypotheses and establishing cause-and-effect relationships between variables. Experimental design is a powerful tool for advancing scientific knowledge and informing evidence-based practice in various fields, including psychology, biology, medicine, engineering, and social sciences.
Advantages of Experimental Design
Experimental design offers several advantages in research. Here are some of the main advantages:
- Control over extraneous variables: Experimental design allows researchers to control for extraneous variables that may affect the outcome of the study. By manipulating the independent variable and holding all other variables constant, researchers can isolate the effect of the independent variable on the dependent variable.
- Establishing causality: Experimental design allows researchers to establish causality by manipulating the independent variable and observing its effect on the dependent variable. This allows researchers to determine whether changes in the independent variable cause changes in the dependent variable.
- Replication : Experimental design allows researchers to replicate their experiments to ensure that the findings are consistent and reliable. Replication is important for establishing the validity and generalizability of the findings.
- Random assignment: Experimental design often involves randomly assigning participants to conditions. This helps to ensure that individual differences between participants are evenly distributed across conditions, which increases the internal validity of the study.
- Precision : Experimental design allows researchers to measure variables with precision, which can increase the accuracy and reliability of the data.
- Generalizability : If the study is well-designed, experimental design can increase the generalizability of the findings. By controlling for extraneous variables and using random assignment, researchers can increase the likelihood that the findings will apply to other populations and contexts.
Limitations of Experimental Design
Experimental design has some limitations that researchers should be aware of. Here are some of the main limitations:
- Artificiality : Experimental design often involves creating artificial situations that may not reflect real-world situations. This can limit the external validity of the findings, or the extent to which the findings can be generalized to real-world settings.
- Ethical concerns: Some experimental designs may raise ethical concerns, particularly if they involve manipulating variables that could cause harm to participants or if they involve deception.
- Participant bias : Participants in experimental studies may modify their behavior in response to the experiment, which can lead to participant bias.
- Limited generalizability: The conditions of the experiment may not reflect the complexities of real-world situations. As a result, the findings may not be applicable to all populations and contexts.
- Cost and time : Experimental design can be expensive and time-consuming, particularly if the experiment requires specialized equipment or if the sample size is large.
- Researcher bias : Researchers may unintentionally bias the results of the experiment if they have expectations or preferences for certain outcomes.
- Lack of feasibility : Experimental design may not be feasible in some cases, particularly if the research question involves variables that cannot be manipulated or controlled.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Quantitative Research – Methods, Types and...

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide
15 Experimental Design Examples

Experimental design involves testing an independent variable against a dependent variable. It is a central feature of the scientific method .
A simple example of an experimental design is a clinical trial, where research participants are placed into control and treatment groups in order to determine the degree to which an intervention in the treatment group is effective.
There are three categories of experimental design . They are:
- Pre-Experimental Design: Testing the effects of the independent variable on a single participant or a small group of participants (e.g. a case study).
- Quasi-Experimental Design: Testing the effects of the independent variable on a group of participants who aren’t randomly assigned to treatment and control groups (e.g. purposive sampling).
- True Experimental Design: Testing the effects of the independent variable on a group of participants who are randomly assigned to treatment and control groups in order to infer causality (e.g. clinical trials).
A good research student can look at a design’s methodology and correctly categorize it. Below are some typical examples of experimental designs, with their type indicated.
Experimental Design Examples
The following are examples of experimental design (with their type indicated).
1. Action Research in the Classroom
Type: Pre-Experimental Design
A teacher wants to know if a small group activity will help students learn how to conduct a survey. So, they test the activity out on a few of their classes and make careful observations regarding the outcome.
The teacher might observe that the students respond well to the activity and seem to be learning the material quickly.
However, because there was no comparison group of students that learned how to do a survey with a different methodology, the teacher cannot be certain that the activity is actually the best method for teaching that subject.
2. Study on the Impact of an Advertisement
An advertising firm has assigned two of their best staff to develop a quirky ad about eating a brand’s new breakfast product.
The team puts together an unusual skit that involves characters enjoying the breakfast while engaged in silly gestures and zany background music. The ad agency doesn’t want to spend a great deal of money on the ad just yet, so the commercial is shot with a low budget. The firm then shows the ad to a small group of people just to see their reactions.
Afterwards they determine that the ad had a strong impact on viewers so they move forward with a much larger budget.
3. Case Study
A medical doctor has a hunch that an old treatment regimen might be effective in treating a rare illness.
The treatment has never been used in this manner before. So, the doctor applies the treatment to two of their patients with the illness. After several weeks, the results seem to indicate that the treatment is not causing any change in the illness. The doctor concludes that there is no need to continue the treatment or conduct a larger study with a control condition.
4. Fertilizer and Plant Growth Study
An agricultural farmer is exploring different combinations of nutrients on plant growth, so she does a small experiment.
Instead of spending a lot of time and money applying the different mixes to acres of land and waiting several months to see the results, she decides to apply the fertilizer to some small plants in the lab.
After several weeks, it appears that the plants are responding well. They are growing rapidly and producing dense branching. She shows the plants to her colleagues and they all agree that further testing is needed under better controlled conditions .
5. Mood States Study
A team of psychologists is interested in studying how mood affects altruistic behavior. They are undecided however, on how to put the research participants in a bad mood, so they try a few pilot studies out.
They try one suggestion and make a 3-minute video that shows sad scenes from famous heart-wrenching movies.
They then recruit a few people to watch the clips and measure their mood states afterwards.
The results indicate that people were put in a negative mood, but since there was no control group, the researchers cannot be 100% confident in the clip’s effectiveness.
6. Math Games and Learning Study
Type: Quasi-Experimental Design
Two teachers have developed a set of math games that they think will make learning math more enjoyable for their students. They decide to test out the games on their classes.
So, for two weeks, one teacher has all of her students play the math games. The other teacher uses the standard teaching techniques. At the end of the two weeks, all students take the same math test. The results indicate that students that played the math games did better on the test.
Although the teachers would like to say the games were the cause of the improved performance, they cannot be 100% sure because the study lacked random assignment . There are many other differences between the groups that played the games and those that did not.
Learn More: Random Assignment Examples
7. Economic Impact of Policy
An economic policy institute has decided to test the effectiveness of a new policy on the development of small business. The institute identifies two cities in a third-world country for testing.
The two cities are similar in terms of size, economic output, and other characteristics. The city in which the new policy was implemented showed a much higher growth of small businesses than the other city.
Although the two cities were similar in many ways, the researchers must be cautious in their conclusions. There may exist other differences between the two cities that effected small business growth other than the policy.
8. Parenting Styles and Academic Performance
Psychologists want to understand how parenting style affects children’s academic performance.
So, they identify a large group of parents that have one of four parenting styles: authoritarian, authoritative, permissive, or neglectful. The researchers then compare the grades of each group and discover that children raised with the authoritative parenting style had better grades than the other three groups. Although these results may seem convincing, it turns out that parents that use the authoritative parenting style also have higher SES class and can afford to provide their children with more intellectually enriching activities like summer STEAM camps.
9. Movies and Donations Study
Will the type of movie a person watches affect the likelihood that they donate to a charitable cause? To answer this question, a researcher decides to solicit donations at the exit point of a large theatre.
He chooses to study two types of movies: action-hero and murder mystery. After collecting donations for one month, he tallies the results. Patrons that watched the action-hero movie donated more than those that watched the murder mystery. Can you think of why these results could be due to something other than the movie?
10. Gender and Mindfulness Apps Study
Researchers decide to conduct a study on whether men or women benefit from mindfulness the most. So, they recruit office workers in large corporations at all levels of management.
Then, they divide the research sample up into males and females and ask the participants to use a mindfulness app once each day for at least 15 minutes.
At the end of three weeks, the researchers give all the participants a questionnaire that measures stress and also take swabs from their saliva to measure stress hormones.
The results indicate the women responded much better to the apps than males and showed lower stress levels on both measures.
Unfortunately, it is difficult to conclude that women respond to apps better than men because the researchers could not randomly assign participants to gender. This means that there may be extraneous variables that are causing the results.
11. Eyewitness Testimony Study
Type: True Experimental Design
To study the how leading questions on the memories of eyewitnesses leads to retroactive inference , Loftus and Palmer (1974) conducted a simple experiment consistent with true experimental design.
Research participants all watched the same short video of two cars having an accident. Each were randomly assigned to be asked either one of two versions of a question regarding the accident.
Half of the participants were asked the question “How fast were the two cars going when they smashed into each other?” and the other half were asked “How fast were the two cars going when they contacted each other?”
Participants’ estimates were affected by the wording of the question. Participants that responded to the question with the word “smashed” gave much higher estimates than participants that responded to the word “contacted.”
12. Sports Nutrition Bars Study
A company wants to test the effects of their sports nutrition bars. So, they recruited students on a college campus to participate in their study. The students were randomly assigned to either the treatment condition or control condition.
Participants in the treatment condition ate two nutrition bars. Participants in the control condition ate two similar looking bars that tasted nearly identical, but offered no nutritional value.
One hour after consuming the bars, participants ran on a treadmill at a moderate pace for 15 minutes. The researchers recorded their speed, breathing rates, and level of exhaustion.
The results indicated that participants that ate the nutrition bars ran faster, breathed more easily, and reported feeling less exhausted than participants that ate the non-nutritious bar.
13. Clinical Trials
Medical researchers often use true experiments to assess the effectiveness of various treatment regimens. For a simplified example: people from the population are randomly selected to participate in a study on the effects of a medication on heart disease.
Participants are randomly assigned to either receive the medication or nothing at all. Three months later, all participants are contacted and they are given a full battery of heart disease tests.
The results indicate that participants that received the medication had significantly lower levels of heart disease than participants that received no medication.
14. Leadership Training Study
A large corporation wants to improve the leadership skills of its mid-level managers. The HR department has developed two programs, one online and the other in-person in small classes.
HR randomly selects 120 employees to participate and then randomly assigned them to one of three conditions: one-third are assigned to the online program, one-third to the in-class version, and one-third are put on a waiting list.
The training lasts for 6 weeks and 4 months later, supervisors of the participants are asked to rate their staff in terms of leadership potential. The supervisors were not informed about which of their staff participated in the program.
The results indicated that the in-person participants received the highest ratings from their supervisors. The online class participants came in second, followed by those on the waiting list.
15. Reading Comprehension and Lighting Study
Different wavelengths of light may affect cognitive processing. To put this hypothesis to the test, a researcher randomly assigned students on a college campus to read a history chapter in one of three lighting conditions: natural sunlight, artificial yellow light, and standard fluorescent light.
At the end of the chapter all students took the same exam. The researcher then compared the scores on the exam for students in each condition. The results revealed that natural sunlight produced the best test scores, followed by yellow light and fluorescent light.
Therefore, the researcher concludes that natural sunlight improves reading comprehension.
See Also: Experimental Study vs Observational Study
Experimental design is a central feature of scientific research. When done using true experimental design, causality can be infered, which allows researchers to provide proof that an independent variable affects a dependent variable. This is necessary in just about every field of research, and especially in medical sciences.

Chris Drew (PhD)
Dr. Chris Drew is the founder of the Helpful Professor. He holds a PhD in education and has published over 20 articles in scholarly journals. He is the former editor of the Journal of Learning Development in Higher Education. [Image Descriptor: Photo of Chris]
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd/ 15 Animism Examples
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd/ 10 Magical Thinking Examples
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd/ Social-Emotional Learning (Definition, Examples, Pros & Cons)
- Chris Drew (PhD) https://helpfulprofessor.com/author/chris-drew-phd/ What is Educational Psychology?
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *
Experimental Research: Definition, Types, Design, Examples
Appinio Research · 14.05.2024 · 31min read

Experimental research is a cornerstone of scientific inquiry, providing a systematic approach to understanding cause-and-effect relationships and advancing knowledge in various fields. At its core, experimental research involves manipulating variables, observing outcomes, and drawing conclusions based on empirical evidence. By controlling factors that could influence the outcome, researchers can isolate the effects of specific variables and make reliable inferences about their impact. This guide offers a step-by-step exploration of experimental research, covering key elements such as research design, data collection, analysis, and ethical considerations. Whether you're a novice researcher seeking to understand the basics or an experienced scientist looking to refine your experimental techniques, this guide will equip you with the knowledge and tools needed to conduct rigorous and insightful research.
What is Experimental Research?
Experimental research is a systematic approach to scientific inquiry that aims to investigate cause-and-effect relationships by manipulating independent variables and observing their effects on dependent variables. Experimental research primarily aims to test hypotheses, make predictions, and draw conclusions based on empirical evidence.
By controlling extraneous variables and randomizing participant assignment, researchers can isolate the effects of specific variables and establish causal relationships. Experimental research is characterized by its rigorous methodology, emphasis on objectivity, and reliance on empirical data to support conclusions.
Importance of Experimental Research
- Establishing Cause-and-Effect Relationships : Experimental research allows researchers to establish causal relationships between variables by systematically manipulating independent variables and observing their effects on dependent variables. This provides valuable insights into the underlying mechanisms driving phenomena and informs theory development.
- Testing Hypotheses and Making Predictions : Experimental research provides a structured framework for testing hypotheses and predicting the relationship between variables . By systematically manipulating variables and controlling for confounding factors, researchers can empirically test the validity of their hypotheses and refine theoretical models.
- Informing Evidence-Based Practice : Experimental research generates empirical evidence that informs evidence-based practice in various fields, including healthcare, education, and business. Experimental research contributes to improving outcomes and informing decision-making in real-world settings by identifying effective interventions, treatments, and strategies.
- Driving Innovation and Advancement : Experimental research drives innovation and advancement by uncovering new insights, challenging existing assumptions, and pushing the boundaries of knowledge. Through rigorous experimentation and empirical validation, researchers can develop novel solutions to complex problems and contribute to the advancement of science and technology.
- Enhancing Research Rigor and Validity : Experimental research upholds high research rigor and validity standards by employing systematic methods, controlling for confounding variables, and ensuring replicability of findings. By adhering to rigorous methodology and ethical principles, experimental research produces reliable and credible evidence that withstands scrutiny and contributes to the cumulative body of knowledge.
Experimental research plays a pivotal role in advancing scientific understanding, informing evidence-based practice, and driving innovation across various disciplines. By systematically testing hypotheses, establishing causal relationships, and generating empirical evidence, experimental research contributes to the collective pursuit of knowledge and the improvement of society.
Understanding Experimental Design
Experimental design serves as the blueprint for your study, outlining how you'll manipulate variables and control factors to draw valid conclusions.
Experimental Design Components
Experimental design comprises several essential elements:
- Independent Variable (IV) : This is the variable manipulated by the researcher. It's what you change to observe its effect on the dependent variable. For example, in a study testing the impact of different study techniques on exam scores, the independent variable might be the study method (e.g., flashcards, reading, or practice quizzes).
- Dependent Variable (DV) : The dependent variable is what you measure to assess the effect of the independent variable. It's the outcome variable affected by the manipulation of the independent variable. In our study example, the dependent variable would be the exam scores.
- Control Variables : These factors could influence the outcome but are kept constant or controlled to isolate the effect of the independent variable. Controlling variables helps ensure that any observed changes in the dependent variable can be attributed to manipulating the independent variable rather than other factors.
- Experimental Group : This group receives the treatment or intervention being tested. It's exposed to the manipulated independent variable. In contrast, the control group does not receive the treatment and serves as a baseline for comparison.
Types of Experimental Designs
Experimental designs can vary based on the research question, the nature of the variables, and the desired level of control. Here are some common types:
- Between-Subjects Design : In this design, different groups of participants are exposed to varying levels of the independent variable. Each group represents a different experimental condition, and participants are only exposed to one condition. For instance, in a study comparing the effectiveness of two teaching methods, one group of students would use Method A, while another would use Method B.
- Within-Subjects Design : Also known as repeated measures design , this approach involves exposing the same group of participants to all levels of the independent variable. Participants serve as their own controls, and the order of conditions is typically counterbalanced to control for order effects. For example, participants might be tested on their reaction times under different lighting conditions, with the order of conditions randomized to eliminate any research bias .
- Mixed Designs : Mixed designs combine elements of both between-subjects and within-subjects designs. This allows researchers to examine both between-group differences and within-group changes over time. Mixed designs help study complex phenomena that involve multiple variables and temporal dynamics.
Factors Influencing Experimental Design Choices
Several factors influence the selection of an appropriate experimental design:
- Research Question : The nature of your research question will guide your choice of experimental design. Some questions may be better suited to between-subjects designs, while others may require a within-subjects approach.
- Variables : Consider the number and type of variables involved in your study. A factorial design might be appropriate if you're interested in exploring multiple factors simultaneously. Conversely, if you're focused on investigating the effects of a single variable, a simpler design may suffice.
- Practical Considerations : Practical constraints such as time, resources, and access to participants can impact your choice of experimental design. Depending on your study's specific requirements, some designs may be more feasible or cost-effective than others .
- Ethical Considerations : Ethical concerns, such as the potential risks to participants or the need to minimize harm, should also inform your experimental design choices. Ensure that your design adheres to ethical guidelines and safeguards the rights and well-being of participants.
By carefully considering these factors and selecting an appropriate experimental design, you can ensure that your study is well-designed and capable of yielding meaningful insights.
Experimental Research Elements
When conducting experimental research, understanding the key elements is crucial for designing and executing a robust study. Let's explore each of these elements in detail to ensure your experiment is well-planned and executed effectively.
Independent and Dependent Variables
In experimental research, the independent variable (IV) is the factor that the researcher manipulates or controls, while the dependent variable (DV) is the measured outcome or response. The independent variable is what you change in the experiment to observe its effect on the dependent variable.
For example, in a study investigating the effect of different fertilizers on plant growth, the type of fertilizer used would be the independent variable, while the plant growth (height, number of leaves, etc.) would be the dependent variable.
Control Groups and Experimental Groups
Control groups and experimental groups are essential components of experimental design. The control group serves as a baseline for comparison and does not receive the treatment or intervention being studied. Its purpose is to provide a reference point to assess the effects of the independent variable.
In contrast, the experimental group receives the treatment or intervention and is used to measure the impact of the independent variable. For example, in a drug trial, the control group would receive a placebo, while the experimental group would receive the actual medication.
Randomization and Random Sampling
Randomization is the process of randomly assigning participants to different experimental conditions to minimize biases and ensure that each participant has an equal chance of being assigned to any condition. Randomization helps control for extraneous variables and increases the study's internal validity .
Random sampling, on the other hand, involves selecting a representative sample from the population of interest to generalize the findings to the broader population. Random sampling ensures that each member of the population has an equal chance of being included in the sample, reducing the risk of sampling bias .
Replication and Reliability
Replication involves repeating the experiment to confirm the results and assess the reliability of the findings . It is essential for ensuring the validity of scientific findings and building confidence in the robustness of the results. A study that can be replicated consistently across different settings and by various researchers is considered more reliable. Researchers should strive to design experiments that are easily replicable and transparently report their methods to facilitate replication by others.
Validity: Internal, External, Construct, and Statistical Conclusion Validity
Validity refers to the degree to which an experiment measures what it intends to measure and the extent to which the results can be generalized to other populations or contexts. There are several types of validity that researchers should consider:
- Internal Validity : Internal validity refers to the extent to which the study accurately assesses the causal relationship between variables. Internal validity is threatened by factors such as confounding variables, selection bias, and experimenter effects. Researchers can enhance internal validity through careful experimental design and control procedures.
- External Validity : External validity refers to the extent to which the study's findings can be generalized to other populations or settings. External validity is influenced by factors such as the representativeness of the sample and the ecological validity of the experimental conditions. Researchers should consider the relevance and applicability of their findings to real-world situations.
- Construct Validity : Construct validity refers to the degree to which the study accurately measures the theoretical constructs of interest. Construct validity is concerned with whether the operational definitions of the variables align with the underlying theoretical concepts. Researchers can establish construct validity through careful measurement selection and validation procedures.
- Statistical Conclusion Validity : Statistical conclusion validity refers to the accuracy of the statistical analyses and conclusions drawn from the data. It ensures that the statistical tests used are appropriate for the data and that the conclusions drawn are warranted. Researchers should use robust statistical methods and report effect sizes and confidence intervals to enhance statistical conclusion validity.
By addressing these elements of experimental research and ensuring the validity and reliability of your study, you can conduct research that contributes meaningfully to the advancement of knowledge in your field.
How to Conduct Experimental Research?
Embarking on an experimental research journey involves a series of well-defined phases, each crucial for the success of your study. Let's explore the pre-experimental, experimental, and post-experimental phases to ensure you're equipped to conduct rigorous and insightful research.
Pre-Experimental Phase
The pre-experimental phase lays the foundation for your study, setting the stage for what's to come. Here's what you need to do:
- Formulating Research Questions and Hypotheses : Start by clearly defining your research questions and formulating testable hypotheses. Your research questions should be specific, relevant, and aligned with your research objectives. Hypotheses provide a framework for testing the relationships between variables and making predictions about the outcomes of your study.
- Reviewing Literature and Establishing Theoretical Framework : Dive into existing literature relevant to your research topic and establish a solid theoretical framework. Literature review helps you understand the current state of knowledge, identify research gaps, and build upon existing theories. A well-defined theoretical framework provides a conceptual basis for your study and guides your research design and analysis.
Experimental Phase
The experimental phase is where the magic happens – it's time to put your hypotheses to the test and gather data. Here's what you need to consider:
- Participant Recruitment and Sampling Techniques : Carefully recruit participants for your study using appropriate sampling techniques . The sample should be representative of the population you're studying to ensure the generalizability of your findings. Consider factors such as sample size , demographics , and inclusion criteria when recruiting participants.
- Implementing Experimental Procedures : Once you've recruited participants, it's time to implement your experimental procedures. Clearly outline the experimental protocol, including instructions for participants, procedures for administering treatments or interventions, and measures for controlling extraneous variables. Standardize your procedures to ensure consistency across participants and minimize sources of bias.
- Data Collection and Measurement : Collect data using reliable and valid measurement instruments. Depending on your research questions and variables of interest, data collection methods may include surveys , observations, physiological measurements, or experimental tasks. Ensure that your data collection procedures are ethical, respectful of participants' rights, and designed to minimize errors and biases.
Post-Experimental Phase
In the post-experimental phase, you make sense of your data, draw conclusions, and communicate your findings to the world . Here's what you need to do:
- Data Analysis Techniques : Analyze your data using appropriate statistical techniques . Choose methods that are aligned with your research design and hypotheses. Standard statistical analyses include descriptive statistics, inferential statistics (e.g., t-tests, ANOVA), regression analysis , and correlation analysis. Interpret your findings in the context of your research questions and theoretical framework.
- Interpreting Results and Drawing Conclusions : Once you've analyzed your data, interpret the results and draw conclusions. Discuss the implications of your findings, including any theoretical, practical, or real-world implications. Consider alternative explanations and limitations of your study and propose avenues for future research. Be transparent about the strengths and weaknesses of your study to enhance the credibility of your conclusions.
- Reporting Findings : Finally, communicate your findings through research reports, academic papers, or presentations. Follow standard formatting guidelines and adhere to ethical standards for research reporting. Clearly articulate your research objectives, methods, results, and conclusions. Consider your target audience and choose appropriate channels for disseminating your findings to maximize impact and reach.
By meticulously planning and executing each experimental research phase, you can generate valuable insights, advance knowledge in your field, and contribute to scientific progress.
A s you navigate the intricate phases of experimental research, leveraging Appinio can streamline your journey toward actionable insights. With our intuitive platform, you can swiftly gather real-time consumer data, empowering you to make informed decisions with confidence. Say goodbye to the complexities of traditional market research and hello to a seamless, efficient process that puts you in the driver's seat of your research endeavors.
Ready to revolutionize your approach to data-driven decision-making? Book a demo today and discover the power of Appinio in transforming your research experience!
Book a Demo
Experimental Research Examples
Understanding how experimental research is applied in various contexts can provide valuable insights into its practical significance and effectiveness. Here are some examples illustrating the application of experimental research in different domains:
Market Research
Experimental studies are crucial in market research in testing hypotheses, evaluating marketing strategies, and understanding consumer behavior . For example, a company may conduct an experiment to determine the most effective advertising message for a new product. Participants could be exposed to different versions of an advertisement, each emphasizing different product features or appeals.
By measuring variables such as brand recall, purchase intent, and brand perception, researchers can assess the impact of each advertising message and identify the most persuasive approach.
Software as a Service (SaaS)
In the SaaS industry, experimental research is often used to optimize user interfaces, features, and pricing models to enhance user experience and drive engagement. For instance, a SaaS company may conduct A/B tests to compare two versions of its software interface, each with a different layout or navigation structure.
Researchers can identify design elements that lead to higher user satisfaction and retention by tracking user interactions, conversion rates, and customer feedback . Experimental research also enables SaaS companies to test new product features or pricing strategies before full-scale implementation, minimizing risks and maximizing return on investment.
Business Management
Experimental research is increasingly utilized in business management to inform decision-making, improve organizational processes, and drive innovation. For example, a business may conduct an experiment to evaluate the effectiveness of a new training program on employee productivity. Participants could be randomly assigned to either receive the training or serve as a control group.
By measuring performance metrics such as sales revenue, customer satisfaction, and employee turnover, researchers can assess the training program's impact and determine its return on investment. Experimental research in business management provides empirical evidence to support strategic initiatives and optimize resource allocation.
In healthcare , experimental research is instrumental in testing new treatments, interventions, and healthcare delivery models to improve patient outcomes and quality of care. For instance, a clinical trial may be conducted to evaluate the efficacy of a new drug in treating a specific medical condition. Participants are randomly assigned to either receive the experimental drug or a placebo, and their health outcomes are monitored over time.
By comparing the effectiveness of the treatment and placebo groups, researchers can determine the drug's efficacy, safety profile, and potential side effects. Experimental research in healthcare informs evidence-based practice and drives advancements in medical science and patient care.
These examples illustrate the versatility and applicability of experimental research across diverse domains, demonstrating its value in generating actionable insights, informing decision-making, and driving innovation. Whether in market research or healthcare, experimental research provides a rigorous and systematic approach to testing hypotheses, evaluating interventions, and advancing knowledge.
Experimental Research Challenges
Even with careful planning and execution, experimental research can present various challenges. Understanding these challenges and implementing effective solutions is crucial for ensuring the validity and reliability of your study. Here are some common challenges and strategies for addressing them.
Sample Size and Statistical Power
Challenge : Inadequate sample size can limit your study's generalizability and statistical power, making it difficult to detect meaningful effects. Small sample sizes increase the risk of Type II errors (false negatives) and reduce the reliability of your findings.
Solution : Increase your sample size to improve statistical power and enhance the robustness of your results. Conduct a power analysis before starting your study to determine the minimum sample size required to detect the effects of interest with sufficient power. Consider factors such as effect size, alpha level, and desired power when calculating sample size requirements. Additionally, consider using techniques such as bootstrapping or resampling to augment small sample sizes and improve the stability of your estimates.
To enhance the reliability of your experimental research findings, you can leverage our Sample Size Calculator . By determining the optimal sample size based on your desired margin of error, confidence level, and standard deviation, you can ensure the representativeness of your survey results. Don't let inadequate sample sizes hinder the validity of your study and unlock the power of precise research planning!
Confounding Variables and Bias
Challenge : Confounding variables are extraneous factors that co-vary with the independent variable and can distort the relationship between the independent and dependent variables. Confounding variables threaten the internal validity of your study and can lead to erroneous conclusions.
Solution : Implement control measures to minimize the influence of confounding variables on your results. Random assignment of participants to experimental conditions helps distribute confounding variables evenly across groups, reducing their impact on the dependent variable. Additionally, consider using matching or blocking techniques to ensure that groups are comparable on relevant variables. Conduct sensitivity analyses to assess the robustness of your findings to potential confounders and explore alternative explanations for your results.
Researcher Effects and Experimenter Bias
Challenge : Researcher effects and experimenter bias occur when the experimenter's expectations or actions inadvertently influence the study's outcomes. This bias can manifest through subtle cues, unintentional behaviors, or unconscious biases , leading to invalid conclusions.
Solution : Implement double-blind procedures whenever possible to mitigate researcher effects and experimenter bias. Double-blind designs conceal information about the experimental conditions from both the participants and the experimenters, minimizing the potential for bias. Standardize experimental procedures and instructions to ensure consistency across conditions and minimize experimenter variability. Additionally, consider using objective outcome measures or automated data collection procedures to reduce the influence of experimenter bias on subjective assessments.
External Validity and Generalizability
Challenge : External validity refers to the extent to which your study's findings can be generalized to other populations, settings, or conditions. Limited external validity restricts the applicability of your results and may hinder their relevance to real-world contexts.
Solution : Enhance external validity by designing studies closely resembling real-world conditions and populations of interest. Consider using diverse samples that represent the target population's demographic, cultural, and ecological variability. Conduct replication studies in different contexts or with different populations to assess the robustness and generalizability of your findings. Additionally, consider conducting meta-analyses or systematic reviews to synthesize evidence from multiple studies and enhance the external validity of your conclusions.
By proactively addressing these challenges and implementing effective solutions, you can strengthen the validity, reliability, and impact of your experimental research. Remember to remain vigilant for potential pitfalls throughout the research process and adapt your strategies as needed to ensure the integrity of your findings.
Advanced Topics in Experimental Research
As you delve deeper into experimental research, you'll encounter advanced topics and methodologies that offer greater complexity and nuance.
Quasi-Experimental Designs
Quasi-experimental designs resemble true experiments but lack random assignment to experimental conditions. They are often used when random assignment is impractical, unethical, or impossible. Quasi-experimental designs allow researchers to investigate cause-and-effect relationships in real-world settings where strict experimental control is challenging. Common examples include:
- Non-Equivalent Groups Design : This design compares two or more groups that were not created through random assignment. While similar to between-subjects designs, non-equivalent group designs lack the random assignment of participants, increasing the risk of confounding variables.
- Interrupted Time Series Design : In this design, multiple measurements are taken over time before and after an intervention is introduced. Changes in the dependent variable are assessed over time, allowing researchers to infer the impact of the intervention.
- Regression Discontinuity Design : This design involves assigning participants to different groups based on a cutoff score on a continuous variable. Participants just above and below the cutoff are treated as if they were randomly assigned to different conditions, allowing researchers to estimate causal effects.
Quasi-experimental designs offer valuable insights into real-world phenomena but require careful consideration of potential confounding variables and limitations inherent to non-random assignment.
Factorial Designs
Factorial designs involve manipulating two or more independent variables simultaneously to examine their main effects and interactions. By systematically varying multiple factors, factorial designs allow researchers to explore complex relationships between variables and identify how they interact to influence outcomes. Common types of factorial designs include:
- 2x2 Factorial Design : This design manipulates two independent variables, each with two levels. It allows researchers to examine the main effects of each variable as well as any interaction between them.
- Mixed Factorial Design : In this design, one independent variable is manipulated between subjects, while another is manipulated within subjects. Mixed factorial designs enable researchers to investigate both between-subjects and within-subjects effects simultaneously.
Factorial designs provide a comprehensive understanding of how multiple factors contribute to outcomes and offer greater statistical efficiency compared to studying variables in isolation.
Longitudinal and Cross-Sectional Studies
Longitudinal studies involve collecting data from the same participants over an extended period, allowing researchers to observe changes and trajectories over time. Cross-sectional studies , on the other hand, involve collecting data from different participants at a single point in time, providing a snapshot of the population at that moment. Both longitudinal and cross-sectional studies offer unique advantages and challenges:
- Longitudinal Studies : Longitudinal designs allow researchers to examine developmental processes, track changes over time, and identify causal relationships. However, longitudinal studies require long-term commitment, are susceptible to attrition and dropout, and may be subject to practice effects and cohort effects.
- Cross-Sectional Studies : Cross-sectional designs are relatively quick and cost-effective, provide a snapshot of population characteristics, and allow for comparisons across different groups. However, cross-sectional studies cannot assess changes over time or establish causal relationships between variables.
Researchers should carefully consider the research question, objectives, and constraints when choosing between longitudinal and cross-sectional designs.
Meta-Analysis and Systematic Reviews
Meta-analysis and systematic reviews are quantitative methods used to synthesize findings from multiple studies and draw robust conclusions. These methods offer several advantages:
- Meta-Analysis : Meta-analysis combines the results of multiple studies using statistical techniques to estimate overall effect sizes and assess the consistency of findings across studies. Meta-analysis increases statistical power, enhances generalizability, and provides more precise estimates of effect sizes.
- Systematic Reviews : Systematic reviews involve systematically searching, appraising, and synthesizing existing literature on a specific topic. Systematic reviews provide a comprehensive summary of the evidence, identify gaps and inconsistencies in the literature, and inform future research directions.
Meta-analysis and systematic reviews are valuable tools for evidence-based practice, guiding policy decisions, and advancing scientific knowledge by aggregating and synthesizing empirical evidence from diverse sources.
By exploring these advanced topics in experimental research, you can expand your methodological toolkit, tackle more complex research questions, and contribute to deeper insights and understanding in your field.
Experimental Research Ethical Considerations
When conducting experimental research, it's imperative to uphold ethical standards and prioritize the well-being and rights of participants. Here are some key ethical considerations to keep in mind throughout the research process:
- Informed Consent : Obtain informed consent from participants before they participate in your study. Ensure that participants understand the purpose of the study, the procedures involved, any potential risks or benefits, and their right to withdraw from the study at any time without penalty.
- Protection of Participants' Rights : Respect participants' autonomy, privacy, and confidentiality throughout the research process. Safeguard sensitive information and ensure that participants' identities are protected. Be transparent about how their data will be used and stored.
- Minimizing Harm and Risks : Take steps to mitigate any potential physical or psychological harm to participants. Conduct a risk assessment before starting your study and implement appropriate measures to reduce risks. Provide support services and resources for participants who may experience distress or adverse effects as a result of their participation.
- Confidentiality and Data Security : Protect participants' privacy and ensure the security of their data. Use encryption and secure storage methods to prevent unauthorized access to sensitive information. Anonymize data whenever possible to minimize the risk of data breaches or privacy violations.
- Avoiding Deception : Minimize the use of deception in your research and ensure that any deception is justified by the scientific objectives of the study. If deception is necessary, debrief participants fully at the end of the study and provide them with an opportunity to withdraw their data if they wish.
- Respecting Diversity and Cultural Sensitivity : Be mindful of participants' diverse backgrounds, cultural norms, and values. Avoid imposing your own cultural biases on participants and ensure that your research is conducted in a culturally sensitive manner. Seek input from diverse stakeholders to ensure your research is inclusive and respectful.
- Compliance with Ethical Guidelines : Familiarize yourself with relevant ethical guidelines and regulations governing research with human participants, such as those outlined by institutional review boards (IRBs) or ethics committees. Ensure that your research adheres to these guidelines and that any potential ethical concerns are addressed appropriately.
- Transparency and Openness : Be transparent about your research methods, procedures, and findings. Clearly communicate the purpose of your study, any potential risks or limitations, and how participants' data will be used. Share your research findings openly and responsibly, contributing to the collective body of knowledge in your field.
By prioritizing ethical considerations in your experimental research, you demonstrate integrity, respect, and responsibility as a researcher, fostering trust and credibility in the scientific community.
Conclusion for Experimental Research
Experimental research is a powerful tool for uncovering causal relationships and expanding our understanding of the world around us. By carefully designing experiments, collecting data, and analyzing results, researchers can make meaningful contributions to their fields and address pressing questions. However, conducting experimental research comes with responsibilities. Ethical considerations are paramount to ensure the well-being and rights of participants, as well as the integrity of the research process. Researchers can build trust and credibility in their work by upholding ethical standards and prioritizing participant safety and autonomy. Furthermore, as you continue to explore and innovate in experimental research, you must remain open to new ideas and methodologies. Embracing diversity in perspectives and approaches fosters creativity and innovation, leading to breakthrough discoveries and scientific advancements. By promoting collaboration and sharing findings openly, we can collectively push the boundaries of knowledge and tackle some of society's most pressing challenges.
How to Conduct Research in Minutes?
Discover the power of Appinio , the real-time market research platform revolutionizing experimental research. With Appinio, you can access real-time consumer insights to make better data-driven decisions in minutes. Join the thousands of companies worldwide who trust Appinio to deliver fast, reliable consumer insights.
Here's why you should consider using Appinio for your research needs:
- From questions to insights in minutes: With Appinio, you can conduct your own market research and get actionable insights in record time, allowing you to make fast, informed decisions for your business.
- Intuitive platform for anyone: You don't need a PhD in research to use Appinio. Our platform is designed to be user-friendly and intuitive so that anyone can easily create and launch surveys.
- Extensive reach and targeting options: Define your target audience from over 1200 characteristics and survey them in over 90 countries. Our platform ensures you reach the right people for your research needs, no matter where they are.

Get free access to the platform!
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

16.05.2024 | 30min read
Time Series Analysis: Definition, Types, Techniques, Examples
14.05.2024 | 31min read

07.05.2024 | 29min read
Interval Scale: Definition, Characteristics, Examples
- - Google Chrome
Intended for healthcare professionals
- Access provided by Google Indexer
- My email alerts
- BMA member login
- Username * Password * Forgot your log in details? Need to activate BMA Member Log In Log in via OpenAthens Log in via your institution
Search form
- Advanced search
- Search responses
- Search blogs
- Clinical and...
Clinical and healthcare use outcomes after cessation of long term opioid treatment due to prescriber workforce exit: quasi-experimental difference-in-differences study
- Related content
- Peer review
- Adrienne H Sabety , assistant professor 1 ,
- Hannah T Neprash , assistant professor 2 ,
- Marema Gaye , doctoral student 3 ,
- Michael L Barnett , associate professor 4
- 1 Department of Health Policy, Stanford University School of Medicine, Stanford, CA, USA
- 2 Division of Health Policy and Management, School of Public Health, University of Minnesota, Minneapolis, MN, USA
- 3 Interfaculty Initiative in Health Policy, Harvard University, Cambridge, MA, USA
- 4 Department of Health Policy and Management, Harvard T H Chan School of Public Health and Division of General Internal Medicine and Primary Care, Department of Medicine, Brigham and Women’s Hospital
- Correspondence to: M L Barnett mbarnett{at}hsph.harvard.edu ( @ml_barnett on X)
- Accepted 13 March 2024
Objective To examine the association between prescriber workforce exit, long term opioid treatment discontinuation, and clinical outcomes.
Design Quasi-experimental difference-in-differences study
Setting 20% sample of US Medicare beneficiaries, 2011-18.
Participants People receiving long term opioid treatment whose prescriber stopped providing office based patient care or exited the workforce, as in the case of retirement or death (n=48 079), and people whose prescriber did not exit the workforce (n=48 079).
Main outcomes Discontinuation from long term opioid treatment, drug overdose, mental health crises, admissions to hospital or emergency department visits, and death. Long term opioid treatment was defined as at least 60 days of opioids per quarter for four consecutive quarters, attributed to the plurality opioid prescriber. A difference-in-differences analysis was used to compare individuals who received long term opioid treatment and who had a prescriber leave the workforce to propensity-matched patients on long term opioid treatment who did not lose a prescriber, before and after prescriber exit.
Results Discontinuation of long term opioid treatment increased from 132 to 229 per 10 000 patients who had prescriber exit from the quarter before to the quarter after exit, compared with 97 to 100 for patients who had a continuation of prescriber (adjusted difference 1.22 percentage points, 95% confidence interval 1.02 to 1.42). In the first quarter after provider exit, when discontinuation rates were highest, a transient but significant elevation was noted between the two groups of patients in suicide attempts (adjusted difference 0.05 percentage points (95% confidence interval 0.01 to 0.09)), opioid or alcohol withdrawal (0.14 (0.01 to 0.27)), and admissions to hospital or emergency department visits (0.04 visits (0.01 to 0.06)). These differences receded after one to two quarters. No significant change in rates of overdose was noted. Across all four quarters after prescriber exit, an increase was reported in the rate of mental health crises (0.39 percentage points (95% confidence interval 0.08 to 0.69)) and opioid or alcohol withdrawal (0.31 (0.014 to 0.58)), but no change was seen for drug overdose (−0.12 (−0.41 to 0.18)).
Conclusions The loss of a prescriber was associated with increased occurrences of discontinuation of long term opioid treatment and transient increases in adverse outcomes, such as suicide attempts, but not other outcomes, such as overdoses. Long term opioid treatment discontinuation may be associated with a temporary period of adverse health impacts after accounting for unobserved confounding.
Introduction
Chronic pain affects more than one in four American adults over 65 years old and is commonly managed using long term opioid treatment (LTOT). 1 2 3 However, the general shift away from prescribing opioids has meant that millions of patients in chronic pain are also being removed from LTOT, often at faster taper speeds than recommended by guidelines. 4 5 6 3 7 8 9 Many have raised concerns that poor adherence to guideline-suggested tapering may lead to undertreated pain, mental health crises, and suicide. 10 11
Work examining the association between tapering or discontinuation of LTOT and health outcomes has important limitations. Systematic reviews on the reduction or discontinuation of LTOT find little high quality evidence, although studies generally indicate improvement in pain and quality of life after discontinuation or tapering. 12 13 By contrast, large scale observational studies find both increased and decreased risk for death or addiction related adverse events. 7 14 15 16 17 18 19 20 21 These studies typically use statistical techniques adjusting for observable, but not unobservable, differences between users of LTOT who taper or discontinue versus those who do not, populations whose clinical profiles can diverge around the time of LTOT changes. 3 22 23 For instance, a patient may be discontinued because prescribers suspect that patients are bordering on behavioral, substance use, or mental health disorders, whereas patients continued on LTOT are maintaining baseline. Without robust evidence that accounts for selection and confounding, clinical knowledge on the association between LTOT discontinuation and patient outcomes is incomplete, impeding both therapeutic management of LTOT and the development of opioid policy.
In this study, we investigated the evidence gap by leveraging prescriber exit from the workforce, a common event, 24 25 26 as an external shock to prescribing patterns. Previous work found that primary care physician exit was associated with substantial shifts in patient prescribing patterns. 27 28 We hypothesized that prescriber market exit would lead to an increase in discontinuation of LTOT unrelated to observed or unobserved patient clinical factors. Patients receiving LTOT who discontinued or tapered from opioids are likely different from those who have not tapered, therefore, we addressed selection bias and confounding by defining the exposure as prescriber workforce exit, an event plausibly not driven by clinical events leading to LTOT discontinuation. 18 This method of experimentation enabled testing for the independent effect of discontinuation of LTOT on patient outcomes.
Data source and study population
The cohort study used a 20% random sample of Medicare fee-for-service and Medicare Advantage beneficiaries from 1 January 2011 to 31 December 2018. Medicare is a public insurance program that enrolls 65 million Americans who are age 65 years or older, receiving social security disability income, or diagnosed with amyotrophic lateral sclerosis or end stage renal disease. Our primary study cohort captured all clinical and healthcare use outcomes for fee-for-service beneficiaries enrolled in fee-for service Medicare parts A, B, and D. For outcomes related to prescriptions, we also included Medicare Advantage beneficiaries with Medicare part D prescription claims. We excluded data with missing racial status accounting for less than 1% of the sample. Additionally, we excluded patients diagnosed with cancer at any point over the sample period because the role of LTOT may differ between cancer and non-cancer indications (see appendix figure 1 for cohort flow diagrams).
Identification of prescribers who exited Medicare
The main study exposure occurred when a prescriber stopped providing office based patient care or exited, as in the case of retirement or death. Patients attributed to such an exiting prescriber were considered exposed to this discontinuation. A prescriber’s exit date was defined as the last date the prescriber billed Medicare for an office based service with no subsequent services observed, as defined in prior research. 29 30 Prescribers were considered exiting if they had at least one office visit 6-12 months before their last observed office visit and had a last office visit between 1 January 2012 and 31 December 2017. These restrictions allowed us to observe patients prescribed an opioid at least four quarters before and after prescriber workforce exit ( fig 1 ). Patients attributed to prescribers with an exit date were considered exposed while those without prescriber exit were considered unexposed.

Matching algorithm. The dashed line indicates the period between the patients’ long term opioid treatment (LTOT) episode and quarter (Q) −5 relative to prescriber exit. The first quarter before exit was excluded when capturing eligible LTOT episodes to avoid bias from anticipation of prescriber exit that could affect patterns of LTOT and subsequent outcomes. Prescriber exit is denoted as quarter 0, with minus numbers indicating quarters before prescriber exit. Patients were matched on calendar year the initial LTOT episode began (2011, 2012, 2013, 2014, 2015, or 2016/2017), patient age, gender (female v male), race (white v not white), state of residence, whether the patient resided in a rural area, Medicare eligible due to disability, Medicare eligible due to end stage renal disease, dual eligibility for Medicare and Medicaid, Medicare Advantage enrollment, diagnosis of chronic non-cancer pain, total number of chronic conditions, average daily morphine milligram equivalents in initial LTOT episode. Information on dual eligibility, Medicare Advantage enrollment, diagnosis of chronic non-cancer pain, and average daily morphine milligram equivalents for the entire duration of the initial LTOT episode were also collected. All other covariate information was obtained from the calendar year in which the initial LTOT episode began
- Download figure
- Open in new tab
- Download powerpoint
Study sample and LTOT definition
The study sample included Medicare beneficiaries receiving LTOT who were exposed and unexposed to prescriber exit. To be included, the beneficiary had to be at least 18 years old and continuously enrolled in Medicare. LTOT was defined as receipt of at least 60 days’ supply of opioids at a dosage of 25 daily morphine milligram equivalents or more on average per quarter for at least four consecutive quarters. The first four or more quarter period meeting this definition was the initial LTOT episode for patients.
Patients in the exposed group were limited to those with an LTOT episode beginning at least five quarters before prescriber exit (meaning the first quarter before exit was excluded when capturing eligible LTOT episodes) to avoid bias from anticipation of prescriber exit that could affect patterns of LTOT and subsequent outcomes ( fig 1 ). 3 Unexposed patients were comprised of those meeting the definition for having an LTOT episode. Patients were attributed to the prescriber providing the plurality of opioid prescriptions over the initial four quarter LTOT episode.
Matching and exit date assignment
To control for observed patient differences, we used propensity score matching to match patients of exiting prescribers (exposed patients) to patients who did not lose their prescriber (unexposed patients). The propensity score, which estimates the likelihood that a given patient would be in the exposed group, was estimated using patient covariates measured the first year they began LTOT. We only matched patients who were unexposed and exposed with an initial LTOT episode in the same calendar year to account for nationwide changes in opioid prescribing over time (appendix methods 1). 31
After propensity score matching, we assigned the patient who was unexposed to the same prescriber exit date of the matched patient who was exposed. For example, consider patient A who was exposed to LTOT in January 2011, subsequently losing their prescriber in August 2013. The closest propensity score match is patient B who was not exposed and began LTOT in January 2011 but did not lose their prescriber. We therefore assigned the exit date of August 2013 from exposed patient A’s prescriber to be the synthetic exit date for unexposed patient B. This assignment of exit dates to unexposed patients enabled us to model changes in exposed patients’ outcomes in response to the loss of a prescriber compared with observably similar unexposed patients before and after prescriber exit in a difference-in-differences design ( fig 1 ).
Defining opioid discontinuation
Discontinuation from opioid treatment occurred when a patient had no resumption of opioid treatment at the end of the prescription’s days supplied for at least one year after discontinuation (see appendix figure 2 for the allocation of prescriptions, as well as by provider type). Discontinuation was defined as equal to one in the quarter of discontinuation and zero in the quarters before and after the discontinuation event.
Outcome measures
Our main outcomes were adverse clinical events that could plausibly be a clinical outcome in response to discontinuation of LTOT: all drug overdoses, mental health crises, opioid or alcohol withdrawal, gastrointestinal bleeding or kidney failure due to substitution to non-steroidal anti-inflammatory drugs, or all cause mortality. We measured all cause hospital use as admission to hospital or emergency department visits identified by claims in the inpatient file or outpatient claims. We categorized emergency department visits for pain by using claims with a primary diagnosis of pain (appendix table 1). Mental health crises included hospital visits with a primary diagnosis of depression, anxiety, or a suicide attempt (appendix table 1). We captured mortality using the Medicare beneficiary summary file. We also quantified beneficiaries’ annual rate of office visits to any type of provider, including specialist and primary care providers. Medicare spending included all charges listed on beneficiaries’ claims for the study period. For prescription outcomes, we used prescription data from Medicare part D (which also captures patients using Medicare Advantage) to estimate all filled prescription quarterly as well as mutually exclusive groups of opioid, buprenorphine, naloxone, and non-opioid prescription drugs.
We collected information on patients’ age, gender, race or ethnicity, state of residence, dual eligibility for Medicaid and Medicare coverage, Medicare Advantage enrollment, disability as the original reason for Medicare enrollment, diagnosis of chronic non-cancer pain (appendix table 1), and morphine milligram equivalent daily dose in the period before prescriber exit, so none of the covariates was causally influenced by future exposure or outcomes. 32 We quantified patients’ opioid total morphine milligram equivalent, average daily dose, and the total number of days supplied during the first four consecutive quarters a patient met the definition of LTOT. We calculated the total morphine milligram equivalent and days supplied from prescriptions’ generic ingredients for opioid compounds. 33 We calculated the average daily dose of opioids as the total morphine milligram equivalent of opioids supplied divided by the total number of days supplied during the initial LTOT episode.
We classified whether the patient’s county of residence was rural or urban, 34 and included 27 chronic conditions classified following prior work: acquired hyperthyroidism, acute myocardial infarction, Alzheimer’s disease, Alzheimer’s disease and related senile dementia disorders, anemia, asthma, atrial fibrillation, benign prostatic hyperplasia, cataract, chronic kidney disease, chronic obstructive pulmonary disease, diabetes, depression, heart failure, glaucoma, hip or pelvic fracture, hyperlipidemia, hypertension, ischemic heart disease, osteoporosis, rheumatoid arthritis or osteoarthritis, stroke or transient ischemic attack, breast cancer, colorectal cancer, prostate cancer, lung cancer, endometrial cancer. 3
Statistical analysis
We compared outcomes for matched exposed and unexposed patients receiving LTOT before and after prescriber exit in a difference-in-differences framework. The framework allowed us to estimate the average treatment effect of physician exit on exposed patients. The difference-in-differences design required two key assumptions in our context. We first assumed that outcomes would trend similarly for unexposed and exposed patients in the absence of treatment. We visually tested this assumption in figure 1 and figure 2 by observing whether outcomes for exposed and unexposed patients moved in parallel before treatment (visual inspection of pre-trends is another advantage of propensity score matching exposed and unexposed groups).We then assumed the exit of a patient’s assigned prescriber was independent of baseline patient outcomes. Table 1 shows that matching unexposed and exposed patients through a propensity score match effectively limited baseline differences between exposed and unexposed patients, supporting this assumption.

Unadjusted change in quarterly rates of long term opioid treatment (LTOT) discontinuation, clinical, and healthcare use outcomes for patients receiving LTOT who had a prescriber exit versus those who did not have a prescriber exit. Prescriber exit is denoted as quarter 0, with minus numbers indicating quarters before prescriber exit. The vertical dashed line delineates the periods before exit (left) and after exit (right). Appendix Table 4 shows adjusted quarterly point estimates. Appendix Figure 1a and 1b diagrams the sample construction. ED=emergency department
Patient characteristics for matched patients whose prescriber exited the workforce versus those whose prescriber remained the same
- View inline
We used linear regression at the level of quarter per patient to estimate a set of interaction terms between indicators for being an exposed patient and indicators for eight quarters relative to prescriber exit (four before exit and four after exit; details in appendix methods 3). The interaction terms describe the mean differential change in the outcome between unexposed and exposed patients by quarter relative to prescriber exit, using quarter −5 as the baseline period. All regression models also included patient and prescriber fixed effects (except for the outcome of mortality, which only contained prescriber fixed effects; appendix methods 3) 29 35 and clustered standard errors at the matched level of the prescriber pair. 30 The use of fixed effects controlled for time invariant differences among patients and prescribers, such as baseline age, race, sex, living in a rural area, reason and type of Medicare enrollment, and baseline chronic conditions.
In a separate set of models, we used the same regression approach, but estimated the differential change between unexposed and exposed patients by year relative to prescriber exit (one year before exit, one year after exit). All regression analyses at the year level defined the period before prescribe exit as quarters −5 to −2 before a prescriber’s exit, excluding quarter −1 to account for potential anticipation (appendix methods 2)
We assessed the robustness of findings with several alternative specifications, including examining patients qualifying for Medicare because of social security disability income as a separate subgroup; repeating adjusted analyses over the entire sample but excluding Medicare Advantage patients; and including patient with cancer. We also examined changes in outcomes attributable to prescriber exit among patients not receiving LTOT with the same prescribers as patients who were receiving LTOT to determine the effect of the exit alone. 30 Additionally, we compared treatment effects by whether the patient lost a primary care physician or specialist. We tested the sensitivity of results by adjusting for multiple comparisons and compared treated patients who discontinued to treated patients who did not discontinue to quantify how the provider’s exit alone affected estimates. The 95% confidence intervals (CI) reflected 0.025 in each tail or P≤0.05. Analyses were performed in Stata, version 16 (StataCorp LLC).
Patient and public involvement
No patients were involved in setting the research question or the outcome measures, nor were they involved in developing plans to design or implement the study. No patients advised the interpretation or writing up of results. We used previously collected, de-identified data purchased from the Centers for Medicare and Medicaid Services that is restricted use. The institutional review board at the Harvard TH Chan School of Public Health approved the study, waived informed consent, and did not require us to involve patients and the public in the research process.
Study sample
Before matching, the full study sample consisted of 80 158 exposed and 322 970 unexposed patients who received LTOT. Propensity score matching led to the exclusion of 32 079 exposed patients and 274 891 unexposed patients, leaving 48 079 patients assigned to 15 713 exiting prescribers (exposed) and 48 079 patients assigned to 28 150 stable prescribers (unexposed (appendix figure 1)). Propensity score matching improved balance on observable characteristics (appendix figures 3 and 4). After matching, patients in both exposed and not exposed groups had similar demographic and clinical characteristics, with almost all standardized mean differences of 0.05 or less ( table 1 ). Comparisons of exiting versus stable prescribers and patients receiving versus not receiving LTOT are in appendix tables 2 and 3.
LTOT discontinuation and prescription outcomes
In the first quarter after prescriber exit, the opioid discontinuation rate for exposed patients receiving LTOT increased from 132 to 229 per 10 000 patients per quarter, compared with 97 to 100 per 10 000 unexposed patients ( fig 2 ; adjusted difference of 1.22 percentage points ((95% CI 1.02 to 1.42), 160% increase from a baseline of 0.77%, appendix table 4). The adjusted yearly rate of discontinuation differentially increased 2.08 percentage points (1.66 to 2.50), or a 56% increase from the baseline 3.70% rate of discontinuation, for exposed patients relative to unexposed patients ( table 2 ). In the overall post-exit period, the yearly number of opioid prescriptions declined by 1.01 prescriptions ((95% CI −1.11 to −0.91) or −6% off the baseline mean of 15.71 prescriptions), total days’ supply of opioids declined by 29 days ((95% CI −31 to −26), or −7% off the baseline mean of 414 days’ supply), and total morphine milligram equivalent of opioids declined by 5311 morphine milligram equivalent ((95% CI −5759 to −4864), or −15% off baseline mean of 35 336 morphine milligram equivalent). Further, non-opioid prescriptions declined by 0.66 ((95% CI −1.03 to −0.3) or −1% off baseline mean of 59.68 prescriptions), and buprenorphine prescriptions increased by 0.03 ((0.01 to 0.05), or 25% off baseline mean of 0.12 prescriptions). Naloxone prescriptions increased by 0.0025 ((0.0002 to 0.0047), or 40% off baseline mean of 0.0047 prescriptions).
Adjusted differential change in annual rates of LTOT discontinuation, clinical, and healthcare use outcomes for LTOT patients receiving LTOT who were exposed versus not exposed to prescriber exit
Clinical and healthcare use outcomes
From quarter −5 to −1 before provider exit, unadjusted trends in outcomes were similar between exposed and unexposed patients receiving LTOT, supporting the parallel trends assumption needed for the differences-in-difference research design ( fig 3 ). Some outcomes showed potential anticipation of an upcoming prescriber exit, most notably mortality, which motivated our exclusion of quarter −1 from year-level regressions.

Adjusted differential change in quarterly rates of long term opioid treatment (LTOT) discontinuation, clinical, and healthcare use outcomes for patients receiving LTOT who had a prescriber exit versus those who did not have a prescriber exit. Prescriber exit is denoted as quarter 0, with minus numbers indicating quarters before prescriber exit. The vertical dashed line delineates the periods before exit (left) and after exit (right). Absolute risk difference estimates are from the matched difference-in-differences model described in the methods, with an indicator for outcomes for each quarter relative to exit. All cause mortality is modeled similarly but without patient fixed effects. Point estimates are relative to quarter −5 (ie, five quarters before prescriber exit). Regressions patient and prescriber fixed effects, and cluster at the prescriber level. Outer lines show the boundaries of the 95% confidence interval for each quarterly estimate. Appendix Figure 1a and 1b diagrams the sample construction. ED=emergency department
In the first quarter after prescriber exit (denoted quarter 0), when discontinuation rates were highest, a significant increase was noted in the rate of suicide attempts (0.05 absolute percentage points (95% CI 0.01 to 0.09); 122% increase off baseline 0.04% suicide attempt), opioid or alcohol withdrawals (0.14 absolute percentage points (0.004 to 0.28); 50% increase off baseline 0.28% withdrawal rate), and emergency department visits or admissions to hospital (0.04 visits (0.01 to 0.06); 9% increase off baseline 0.45 visits), including emergency department visits with a pain diagnosis (0.011 visits (0.002 to 0.02); 10% increase off baseline 0.11 visits with a pain diagnosis), compared with patients who had a prescriber that exited the workforce and those who had a continuous prescriber ( fig 3 and appendix table 4). Mortality declined by −0.15 percentage points ((95% CI −0.29 to −0.02); 52% decline off base of 0.5%). Significant differences receded by quarter two except for emergency department visits and admissions to hospital, which were 0.02 visits ((0.001 to 0.04); increase of 4.4% from baseline mean) higher among patients with a provider exit but then receded by quarter three. No significant change in the rate of overdose was noted across all quarters of the study period.
In adjusted analyses averaging across the whole post prescriber exit period, a significant increase was noted in opioid or alcohol withdrawal (0.31 percentage points (95% CI 0.041 to 0.58), or 31% increase from baseline mean of 0.99%) and mental health crises (0.39 (0.08 to 0.69), or a 24% increase from a 1.6% baseline mean) comparing patients who had prescriber workforce exit versus those who did not. Additionally, a significant decrease in mortality was recorded (−0.50 (−0.77 to −0.23), or −23% from baseline mean of 2.18%) ( table 2 ). No significant difference in percentage points was noted between patients who were exposed and unexposed in annual rates of drug overdose (−0.12 (−0.41 to 0.18), or 9% decrease from 1.37% baseline rate), suicide attempt (0.02 (−0.07 to 0.11), or 13% from 0.15% increase from baseline rate), gastrointestinal bleeding (0.33 (−0.07 to 0.73), or 11% increase from 2.87% baseline rate), or kidney failure (0.16 (−0.40 to 0.71), or 2% increase from 7.61% baseline rate).
To quantify the effect of only losing a prescriber on results, we examined changes in outcomes associated with prescriber exit among all patients who were not receiving LTOT but lost the same prescriber (appendix table 3, appendix table 5). The unadjusted differences reflect differences in the main results in table 2 that may be attributable to prescriber exit instead of to LTOT discontinuation. After the loss of a prescriber, increases among patients not receiving LTOT were noted for overdose (0.12 percentage points, or a 27% increase from baseline mean of 0.45%), anxiety (0.10, or a 59% increase from baseline mean of 0.17%), opioid or alcohol withdrawal (0.21, or a 47% increase from baseline mean of 0.45%), and mortality (0.90, or 16% increase from baseline rate of 5.68%). Additionally, differences in mental health crises (0.08, or 15% increase from the baseline mean of 0.55%) were small among patients not receiving LTOT when compared with estimates among patients receiving LTOT ( table 2 ).
Additional analyses
In sensitivity analyses, we focused on: beneficiaries qualifying for social security disability income (people with disabilities); excluding patients in Medicare Advantage; including patients with cancer; and separately, patients above or below median morphine milligram equivalent (median 54.36 average daily), which were all similar to the main analysis (appendix tables 6 and 7). Appendix table 8 replicates the main results focusing on patients who were alive after a prescriber’s exit. Appendix table 9 compares treatment effects modeled in table 2 by whether the patient’s main prescriber was a primary care physician or specialist, showing that effects are similar across the two groups. Appendix table 10 indicates that effects maintain significance when adjusting for multiple comparisons. Appendix table 11 compares exposed LTOT patients who did versus did not discontinue LTOT in response to prescriber exit, showing standardized mean differences of 0.12 or less.
Principal findings
The loss of a prescriber was associated with increased discontinuation of LTOT and transient, but significant, increases in adverse outcomes among patients, including suicide attempts, withdrawal, and admissions to hospital or emergency department visits. Rates of adverse outcomes among patients reverted to baseline rates within four to seven months after prescriber exit. However, a significant increase in mental health crises and opioid or alcohol withdrawal was noted on average across the full four quarters after the exit period. Despite these outcomes, drug overdose rates did not change. Our findings suggest that discontinuation of LTOT may be associated with a temporary period of negative health effects, not including overdose or mortality, after accounting for unobserved confounding.
While a small proportion of patients discontinued LTOT in both groups, a substantial increase in discontinuation was reported in the quarter after prescriber exit. As seen in figure 2 , the increase in the first quarter after a prescriber’s exit was not associated with any visible or regression estimated change in overdose rates, despite large increases that might be expected based on standard observational models. 7 15 21 The difference in results is likely because discontinuation is a clinical event associated with other health changes, and patients with discontinuation differ from others, preventing the estimation of a causal effect. 3 22 23 The small or null results over the post prescriber exit period for outcomes such as overdose suggest that despite potential harm, discontinuation of LTOT may have counteracting benefits, such as reduced overdose risk, for some patients. The overall reduction in mortality among patients receiving LTOT who had a prescriber exit supports the potential longer term benefit of shorter duration and lower dosage to LTOT, although we interpret our mortality results with caution given pre-exit period trends that diverged prior to prescriber exit ( fig 2 ).
The harm we do observe associated with discontinuation of LTOT could be related to low quality management of transitioning patients across prescribers. Most discontinuations have excessively rapid tapers, 3 and patients receiving LTOT are a population at high risk with many comorbidities who must frequently navigate substantial stigma in the health care system. 36 For instance, discontinuation may accompany distressing clinician abandonment of patients with LTOT and cause opioid withdrawal, emotional harm, and undertreated pain, events that were unobservable in claims data unless they result in diagnoses that we captured.
One question is whether the observed associations were attributable to prescriber exit rather than the accompanying rise in overdose. To address this, we focused on patients receiving LTOT and those who were not on this treatment but who lost the same prescriber. If the prescriber exit explains the effects, patients not receiving LTOT should be impacted similarly to those who were receiving LTOT after prescriber exit. Instead, analyses show that clinical outcomes for patients not on LTOT were either null or opposite to those observed for patients receiving LTOT after the loss of a prescriber. Therefore, the loss of the physician is unlikely to explain the observed results among patients on LTOT and, if anything, may lead to an underestimation of the effects of discontinuation.
Comparison with other studies
One clear conclusion is that the observed clinical effect of LTOT discontinuation is highly dependent on the methods used. Prior research on tapering or discontinuation of LTOT finds a doubling in the rate of overdose and mental health crises comparing populations with discontinuation directly to those without. 7 15 16 17 19 By contrast, the absence of change in overdose rates in our analysis is closer to other observational studies using techniques to control for unobserved confounding, which have found opioid discontinuation to have a small or null impact on rates of addiction related adverse events. 14 18 22 This discrepancy suggests that overdose risk is more likely to be misestimated in conventional approaches.
Policy implications
While the choice of methods is a technical issue, it has great relevance to patients and policymakers struggling with the clinical and public health challenges of LTOT. Some mechanisms are plausible by which LTOT discontinuation could lead to either benefit, harm, or a mixture of both. Both observational research 37 and randomized trials 38 describe that LTOT, especially at a high dose, is associated with a multitude of adverse outcomes. On the one hand, discontinuing LTOT without replacing the clinical role of LTOT could lead to untreated pain, withdrawal, or worsening of mental health issues as described previously. On the other hand, discontinuing LTOT could mitigate these risks and promote patient safety in some circumstances. The clinical and scientific uncertainty around this question suggests clinical equipoise to justify ongoing 39 40 41 and future randomized interventions that promote patient centered, clinically appropriate LTOT discontinuation or tapering to investigate how tapering LTOT can be done safely and respectfully while prioritizing quality of life.
Limitations
This study has several limitations. Firstly, the findings may not generalize to the entire Medicare population or to populations outside of Medicare beneficiaries. 32 Our sample was a younger, Medicare qualifying population: the average patient in our sample was 58.0 years old, and only 33% of the population was over age 65 years ( table 1 ). Additionally, the study may not generalize to discontinuations outside of those caused by losing a prescriber. Secondly, we cannot observe the reason for a prescriber’s exit, which may be associated with patient outcomes in certain circumstances. We attempt to circumvent this issue by controlling for prescriber specific factors by comparing patients receiving LTOT with patients not receiving LTOT with the same assigned, exiting prescriber, showing that effects are directionally opposed between the two groups. Thirdly, our findings may not apply to patients on LTOT not meeting the threshold of the restrictive definition used in this study, such as those receiving lower doses of opioids or those on LTOT for less than a year. Fourthly, our statistical power, as assessed by the size of confidence intervals in the adjusted results, does not enable us to rule out a low magnitude of harm in response to discontinuation. However, across multiple outcomes, point estimates were consistently close to zero, and they did not change in any consistent pattern with the timing of a large change in discontinuation associated with prescriber exit. Fifthly, we chose what we believe to be the best strategy to handle confounding, but other strategies might be equally valid.
An additional limitation is that, while our analysis overcomes the confounding in prior work, our statistical strategy leverages a specific group of patients: those who have their opioid prescriptions discontinued in response to the loss of a prescriber. For instance, the increase in buprenorphine and naloxone prescriptions may suggest that patients receive replacement prescribers who initiated treatment of opioid use disorder in response to the loss of their prescriber. Also, not all patients had their opioid prescriptions discontinued after losing their main prescriber, suggesting that our results do not generalize to all patients who are discontinued or tapered from opioids. Since we followed up patient outcomes for only four quarters, our study does not consider the effects on patients losing a prescriber beyond four quarters after prescriber exit. We also do not observe prescriptions not billed to Medicare. Finally, our definition of LTOT discontinuation follows prior work to support comparability across studies. However, our results might not generalize to all alternative definitions of LTOT and discontinuation.
This study finds a complex association between the discontinuation of LTOT coinciding with prescriber exit and subsequent health effects. The cessation of LTOT was linked to a short term increase in negative health events, such as suicide attempts and admissions to hospital, indicating a potential need for heightened mental health support during the transition. Despite this, we found no effect of discontinuation on overdose rates or mortality. These findings differ from prior evidence that did not control unobserved confounding, implying that the observed consequences of LTOT discontinuation may vary considerably depending on the methods used. This variation underscores the importance of randomized interventions to better understand how LTOT discontinuation can be managed safely and effectively.
What is known on the topic
Much research shows that discontinued versus continued long term opioid treatment (LTOT) is associated with an increased rate of overdoses and mental health crises
Uncertainty remains because studies used observational models comparing individuals that discontinue LTOT to those that do not, populations whose clinical profiles diverge around the time of LTOT changes
What this study adds
Unobserved confounding was accounted for by leveraging prescriber workforce exit as an external shock increasing LTOT discontinuation and quantify outcomes in a difference-in-differences analysis
Prescriber workforce exit significantly changed opioid prescriptions and short term increases in adverse events of opioid or alcohol withdrawal, suicide attempts, and admission to hospital, but overdose rates changed little
LTOT discontinuation may be associated with a temporary period of adverse health impacts after accounting for unobserved confounding
Ethics statements
Ethical approval.
The study was approved by the institutional review board at the Harvard TH Chan School of Public Heath.
Data availability statement
No additional data available.
Contributors: All authors contributed to the design and conduct of the study; management, analysis, and interpretation of the data; and preparation, review, or approval of the manuscript. MLB supervised the study and is the guarantor. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted.
Funding: Supported by grants from the Retirement Research Foundation for Aging and the National Institute on Aging (K23 AG058806, MLB). The National Institute of Aging had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication. The funders had no role in considering the study design or in the collection, analysis, interpretation of data, writing of the report, or decision to submit the article for publication.
Competing interests: All authors have completed the ICMJE uniform disclosure form at www.icmje.org/disclosure-of-interest and declare: funding from Supported by grants from the Retirement Research Foundation for Aging and the National Institute on Aging; no support from any organization for the submitted work; no financial relationships with any organizations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
Transparency: MLB affirms that the manuscript is an honest, accurate, and transparent account of the study being reported; that no important aspects of the study have been omitted; and that any discrepancies have been disclosed.
Dissemination to participants and related patient and public communities: Results will be shared through the dissemination teams at Harvard University, University of Minnesota, and Stanford University. Typical mediums include press releases, social media posts (Twitter, Instagram, Facebook, and LinkedIn), and emails sent directly to journalists representing outlets such as the New York Times, San Francisco Chronicle, CNN, Bloomberg, and Becker’s Hospital Review, which condense the study into its main findings.
Provenance and peer review: Not commissioned; externally peer reviewed.
This is an Open Access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/ .
- Dahlhamer J ,
- Neprash HT ,
- Jeffery MM ,
- Hooten WM ,
- Tancredi DJ ,
- Fenton JJ ,
- Agnoli AL ,
- Haegerich TM ,
- O’Donnell J ,
- Alltucker K
- ↵ Human Rights Watch. Fears of prescribing hurt chronic pain patients. https://www.hrw.org/news/2018/12/18/us-fears-prescribing-hurt-chronic-pain-patients . Published 18 Dec 2018. Accessed 14 Jan 2022.
- Lovejoy TI ,
- Becker WC ,
- ↵ Mackey K, Anderson J, Bourne D, Chen E, Peterson K. Evidence brief: benefits and harms of long-term opioid dose reduction or discontinuation in patients with chronic pain. Department of Veterans Affairs (US); 2019. Accessed 5 May 2022. https://www.ncbi.nlm.nih.gov/books/NBK549202/
- Manhapra A ,
- Gordon KS ,
- Crystal S ,
- Hallvik SE ,
- El Ibrahimi S ,
- Johnston K ,
- DiPrete BL ,
- Ranapurwala SI ,
- Maierhofer CN ,
- Larochelle MR ,
- Clothier BA ,
- Goldsmith ES ,
- Bohnert ASB
- Tseregounis IE ,
- Tancredi DJ
- Husain JM ,
- LaRochelle M ,
- Keosaian J ,
- Lasser KE ,
- Liebschutz JM
- Morasco BJ ,
- Demidenko MI ,
- Meath THA ,
- Sinsky CA ,
- Shanafelt TD ,
- Dyrbye LN ,
- Sabety AH ,
- Carlasare LE ,
- McWilliams JM ,
- Hatfield LA
- ↵ Leuven E, Sianesi B. PSMATCH2: Stata module to perform full Mahalanobis and propensity score matching, common support graphing, and covariate imbalance testing. Published online 1 Feb 2018. Accessed 1 Dec 2023. https://ideas.repec.org//c/boc/bocode/s432001.html
- ↵ Chronic Conditions Data Warehouse. Center for Medicare and Medicaid Services; 2014. Accessed 25 Mar 2015. Number https://www.ccwdata.org/
- ↵ Center for Medicare and Medicaid Services. Opioid oral morphine milligram equivalent conversion factors. Accessed 13 Aug 2018. https://www.cms.gov/Medicare/Prescription-Drug-Coverage/PrescriptionDrugCovContra/Downloads/Opioid-Morphine-EQ-Conversion-Factors-April-2017.pdf
- ↵ Centers for disease control. NCHS Urban-Rural Classification Scheme for Counties. National Center for Health Statistics; 2019. Accessed 12 Jun 2019. https://www.cdc.gov/nchs/data_access/urban_rural.htm
- Angrist J ,
- Barnett ML ,
- Gravely A ,
- ↵ Gilman J. Evaluation of medical cannabis and prescription opioid taper support for reduction of pain and opioid dose in patients with chronic non-cancer pain. clinicaltrials.gov; 2022. Accessed 1 May 2022. https://clinicaltrials.gov/ct2/show/NCT04827992
- ↵ Lund University Hospital. Tapering of prescribed opioids in patients with long-term non-malignant pain - efficacy and effects on pain, pain cognitions, and quality of life (TOPIO): a study protocol for a randomized controlled clinical trial with a 12 month follow-up. clinicaltrials.gov; 2022. Accessed 1 May 2022. https://clinicaltrials.gov/ct2/show/NCT03485430
- ↵ Turcotte DD. Evaluation of a patient-centred, multidisciplinary opioid tapering program for individuals with chronic non-cancer pain on long term opioid therapy. clinicaltrials.gov; 2021. Accessed 1 May 2022. https://clinicaltrials.gov/ct2/show/NCT04902547
- Open access
- Published: 08 May 2024
Does health voucher intervention increase antenatal consultations and skilled birth attendances in Cameroon? Results from an interrupted time series analysis
- Isidore Sieleunou ORCID: orcid.org/0000-0001-7264-4540 1 , 2 &
- Roland Pascal Enok Bonong ORCID: orcid.org/0000-0002-9552-5365 2
BMC Health Services Research volume 24 , Article number: 602 ( 2024 ) Cite this article
341 Accesses
Metrics details
Limited access to health services during the antenatal period and during childbirth, due to financial barriers, is an obstacle to reducing maternal and child mortality. To improve the use of health services in the three regions of Cameroon, which have the worst reproductive, maternal, neonatal, child and adolescent health indicators, a health voucher project aiming to reduce financial barriers has been progressively implemented since 2015 in these three regions. Our research aimed to assess the impact of the voucher scheme on first antenatal consultation (ANC) and skilled birth attendance (SBA).
Routine aggregated data by month over the period January 2013 to May 2018 for each of the 33 and 37 health facilities included in the study sample were used to measure the effect of the voucher project on the first ANC and SBA, respectively. We estimated changes attributable to the intervention in terms of the levels of outcome indicators immediately after the start of the project and over time using an interrupted time series regression. A meta-analysis was used to obtain the overall estimates.
Overall, the voucher project contributed to an immediate and statistically significant increase, one month after the start of the project, in the monthly number of ANCs (by 26%) and the monthly number of SBAs (by 57%). Compared to the period before the start of the project, a statistically significant monthly increase was observed during the project implementation for SBAs but not for the first ANCs. The results at the level of health facilities (HFs) were mixed. Some HFs experienced an improvement, while others were faced with the status quo or a decrease.
Conclusions
Unlike SBAs, the voucher project in Cameroon had mixed results in improving first ANCs. These limited effects were likely the consequence of poor design and implementation challenges.
Peer Review reports
Reducing maternal, newborn, and child mortality is one of the world's top public health priorities. The third of the seventeen Sustainable Development Goals (SDGs) reflects the international commitment to improving maternal and child health. By 2030, the goals include reducing the global maternal mortality ratio to less than 70 per 100,000 live births, neonatal mortality to 12 per 1,000 live births at most, and under-five mortality to less than 25 per 1,000 live births [ 1 ].
However, despite considerable improvements in recent decades, maternal mortality has remained a major public health concern globally, with more than 295,000 maternal deaths in 2017 and sub-Saharan Africa (SSA) alone accounting for approximately 66% of this global picture [ 2 ]. On the other hand, despite dramatic reductions in child mortality over the last 30 years, the global burden of child deaths has remained immense, with a total of 5.2 million under-five deaths in 2019, representing an average of 14,000 deaths every day [ 3 ].
While from 2000 to 2017, the global maternal mortality ratio (MMR) decreased by 38% [ 2 ], Cameroon's MMR skyrocketed from 511 in 1998 to 782 in 2011 before declining to 467 in 2018 [ 4 ].
A priority toward ending preventable maternal and child deaths is to improve access to and use of quality health services and qualified nurses at birth [ 5 , 6 ]. One of the basic elements is the presence of pregnant women at antenatal consultations. Previous studies have shown that performing prenatal consultations reduces the risk of neonatal mortality [ 7 , 8 ].
However, women in developing countries encounter significant barriers to accessing conventional health services, including poor education, physical and financial barriers, and limited voice and decision-making power [ 9 , 10 ]. The poor quality of available health services offers a further disincentive [ 6 ]. This translates to only half of parturient women receiving skilled assistance at delivery and many fewer receiving postpartum cares [ 6 ].
In Cameroon, the country’s comparatively slow reduction in maternal and child mortalities is likely due to insufficient coverage of reproductive, maternal, neonatal, child and adolescent health (RMNCAH) services; for instance, in 2018, an estimated 65% of women in Cameroon attended at least four antenatal consultations (ANC) visits, 69% gave birth with the assistance of qualified personnel, and 59% received postnatal care (PNC) [ 11 ]. In addition, these general estimates hide enormous disparities. Overall, 65% of the pregnant women who attended the four ANCs included more than 79% of those in urban areas but only 52% of those in rural areas. Moreover, while this rate was 91% in the richest quintile, only one-third (37%) of the poorest pregnant women attended the four ANCs [ 11 ].
The complexity of barriers to accessing care in developing countries indicates that any solution to improving maternal health service utilization must be comprehensive and address both supply- and demand-side health system constraints. This is particularly important in a context such as Cameroon where household out-of-pocket (OOP) spending was the single largest source of financing for the health sector, at 71 percent of total health spending in 2017, well above the WHO benchmark of 15-20 percent, and exceeding the average for SSA (33 percent) and countries of similar income such as Kenya (24 percent) and Ghana (40 percent) [ 12 ].
As ability to pay remains an important determinant of women’s access to healthcare, many countries have sought to improve coverage of maternal services by reducing financial barriers to seeking services [ 13 , 14 ]. Strategies implemented at the country level include national health insurance and user fee removals/exemptions, and at the subnational level, community-based health insurance, health vouchers and conditional cash transfers [ 15 ].
Given that limited access to emergency obstetric and neonatal care (EmONC) is a major contributor to high maternal mortality [ 16 ], increasing pregnant women's use of health facilities for assisted delivery could help reduce maternal and new born morbidity and mortality, as previous studies have indicated [ 17 , 18 ].
In recent years, there has been growing interest in the use of vouchers and other innovative financing mechanisms to increase access to EmONCs for low-income women [ 19 , 20 , 21 , 22 , 23 , 24 , 25 ]. By providing a financial or in-kind reward conditioned on the achievement of agreed-upon performance goals, vouchers are described as a promising holistic approach to foster the use of cost-effective services by the poor and other disadvantaged populations [ 22 ].
Vouchers can act on the demand side, the supply side, or both sides. Demand-side incentives encourage service use not only by reducing the financial burden but also by offering women a choice of providers and informing them of the benefits of using maternal health services. Supply-side incentives aim to improve the quality and responsiveness of service delivery.
To date, findings from the few assessments of reproductive health voucher programs suggest that, if implemented well, they have the potential to improve both assisted and facility-based deliveries [ 19 , 20 , 22 , 24 , 26 ]. Yet, there is a paucity of evidence based on rigorous evaluation studies, making it challenging to draw consistent conclusions about the impact of voucher initiatives and to make subsequent policy recommendations.
The current study evaluated a pilot voucher program in Cameroon, a country where approximately 39% of all deliveries took place at home at the time of the program’s inception [ 27 ]. The research aimed to assess the impact of the voucher scheme on first antenatal consultation and skilled birth attendance (SBA). In the following, we present a brief description of the Cameroon voucher program. We then present our data and methods, followed by the results. We end with a discussion of the study’s results, as well as the implications of these findings.
Voucher program in Cameroon
Results from the 2014 Multiple Indicator Cluster Survey (MICS) indicate an enormous disparity in health outcomes among Cameroon's ten regions, with the three northern regions (Adamawa, North, Far North) bearing the brunt of the disease burden [ 27 ]. For example, while the Far North and North regions represented 27.5% of the total population of children under five years in 2014, both regions accounted for 63% of the total excess mortality during the same period [ 27 ]. In addition, while 65% of women nationwide gave birth with the help of qualified personnel, only 29%, 36% and 53% in the Far North, North and Adamawa regions, respectively, gave birth in the same conditions. Moreover, these three regions featuring the lowest frequencies of ANCs and assisted deliveries, were home to more than 60% of the country’s poorest population [ 28 ].
Initiated in 2015, the voucher programme is a government programme, supported with funding from German and French partners, that aims to reduce financial barriers to maternal and neonatal care in the three northern regions of Cameroon.
Under the project, (poor) women can purchase subsidized vouchers for 6000 FCFA (≈$11), a co-payment of 10% of the actual cost of the service package estimated at 60,000 FCFA (approximately USD109), that covered the cost of a benefit package including services for pregnant women and their new-borns up to 42 days after delivery. In addition, beneficiaries are provided with transportation from their house to the nearest health facility and transportation from health centers to referral hospitals. Health facilities offering services for the voucher scheme are compensated for extra costs incurred. All pregnant women living within the 3 northern regions of Cameroon were eligible for the programme. To be included in the programme, health facilities are required to meet minimum quality standards based on national guidelines for the provision of maternal care. Women can redeem vouchers at any participating facility, and the contracted facilities submit claims to be reimbursed at standard rates for each service provided.
At its inception, the programme implementation was outsourced to the ‘Centre International de Développement et de Recherche’ (CIDR), an international organization. Since November 2018, the management of the scheme has been transferred to a national entity: the Regional Funds for Health Promotion (RFHP). A transfer protocol signed between the ministry of public health (MPH) and CIDR made provisions for the training of the RFHP personnel to take over the implementation.
Study design, data source and study sample
To achieve the study objectives, we used a quasi-experimental study design. Specifically, for each health facility (HF) that was enrolled in the health voucher project, the potential effect of the project was measured using an analysis of interrupted time series [ 29 , 30 , 31 , 32 ]. This method compares changes in the indicators of interest before and after the start of the intervention. It is based on the fundamental assumption that, in the absence of intervention, the trend of the interest indicator remains unchanged over time [ 31 ]. It is desirable to have at least 12 observation points for the indicator or variable of interest before and after the start of the intervention, respectively [ 29 ].
We used secondary data from the monitoring and evaluation system database populated by the three regional implementing agencies of the health voucher project, let by the CIDR-CARE prior to the transfer of the project to the RFHP that began in 2018. These databases were updated quarterly by trained research assistants after monthly data collection from the registries of all health facilities enrolled in the project. Data quality control was carried out jointly by the team from the MPH in charge of monitoring project implementation and by the project team. The data used in this study are monthly aggregates of the variables of interest over the period from January 2013 to May 2018 (i.e., 65 months of observation).
The database contains information on 42 health facilities (HFs) enrolled in the health voucher project, spread across three regions: 12 HFs in the Adamawa region, 15 in the North region and 14 in the Far North region. These HFs were sequentially enrolled in the health voucher project and not at the same time. In the Adamawa region, activities started in 9 HFs in May 2015 and in 3 HFs in March 2016. In the North region, the implementation of activities started in May 2015 in one HF, in June 2015 in 5 HFs and in July 2016 in 9 HFs. For the Far North region, the intervention started in 4 HFs in June 2015, in 3 HFs in March 2016 and in 7 HFs in July 2016. For the analysis of each outcome, HFs included in the sample were those with at least 90% data completeness over the selected period. Thus, the sample sizes for analysis of the outcomes associated with the first antenatal consultation and assisted deliveries were 33 and 37, respectively.
Study variables
Two dependent variables were considered for this evaluation: (i) the monthly number of first ANC visits in each HF and (ii) the monthly number of SBA in each HF.
Covariables
X it : a time-dependent dichotomous variable that takes the value 0 for the months before the start of the health voucher project in HF i and 1 after the start of the project.
T t : time variable measured in months, with values ranging from 0 (January 2013) to 64 (May 2018).
X it *(T t -θ i ): interaction variable between the variables X it and T t centered on the value corresponding to the month of project start in HF i (θ i ).
Statistical analysis
Descriptive analysis.
To explore the outcomes, we used descriptive statistics (mean, median, standard deviation, interquartile range, absolute frequency, relative frequency) and trend curves.
Statistical modeling
For each HF and for each outcome, the estimation of the effects of the health voucher project was carried out using a negative binomial regression.
Since both outcomes are count variables, the choice of negative binomial regression instead of Poisson regression, which is the classic model for this type of variable, was considered to overcome the violation of the fundamental assumption underlying Poisson regression, which states that the mean is equal to the variance. Let Y it be the value of the considered outcome observed in HF i at time t. Y it follows a Poisson distribution with parameter μ it (Y it ~Poisson (μ it )). The general equation of the model used is shown below:
The other parameters of the model are described below.
β 0 = intercept (value of the dependent variable at month 1 of follow-up);
β 1 = slope of the outcome trajectory before the start of the health voucher project;
β 2 = change in the level of outcome at the end of the first month of implementation of the health voucher project;
β 3 = difference between the slope of the outcome trajectory after and before the start of the health voucher project;
variable γ it is the term that differentiates Poisson regression from negative binomial regression. In other words, e γit follows a gamma distribution with mean 1 and variance α (e γit ~ gamma (1/α, α)), with α being the overdispersion parameter.
The coefficient β 2 assesses the immediate effect of the project and β 3 assesses the effect of the project over time.
The graphs used to explore the evolution of outcomes over time highlighted the presence of seasonality. Thus, 11 dichotomous variables were considered in the different models. Equation ( 1 ) becomes log (μ it ) = β 0 + β 1 T t + β 2 X it + β 3 X it *(T t -θ i ) + ɸ 1 February + ɸ 2 March + ɸ 3 April + ɸ 4 May + ɸ 5 June + ɸ 6 July + ɸ 7 August + ɸ 8 September + ɸ 9 October + ɸ 10 November + ɸ 11 December + γ it .
The variables February, March … December take the value 1 if the observation relates to this month and 0 otherwise. The month of January was considered a reference.
Because the project did not start at the same time in all HFs, to obtain estimates representing the overall situation, a meta-analysis was used [ 33 ]. Thus, the pooled estimates and their confidence intervals were obtained by combining the regression coefficients of each HF using the inverse variance method. Random effects models were used to consider the strong heterogeneity highlighted by the statistics I 2 =100*(Q-df)/Q (with Q the statistics of Cochran's Q-test of heterogeneity and df the number of degrees of freedom corresponding here to the number of HFs minus one). The values 0%, 25%, 50% and 75% of the I 2 statistics represent the following levels of heterogeneity: absent, weak, moderate, and strong, respectively [ 33 , 34 ]. The incidence-rate ratio (IRR) for each HF per month as well as the aggregate estimates were graphically represented using a "forest plot". The analysis was stratified by region.
The statistical significance threshold used for interpreting the results was 5%. All the statistical analyses were performed with Stata/SE software version 14.2.
Descriptive statistics
The results in Table 1 show that the overall level of data completeness is 98.9% for the monthly number of first ANC visits and 99.3% for the monthly number of SBAs. In all regions, better data completeness was observed in the post-start period of the intervention. For the descriptive statistics of the two variables of interest, overall, the average (respectively the median) of the monthly number of first ANC visits was 58.6 (respectively 50.0). For the monthly number of SBAs, the mean and median were 52.3 and 31.0, respectively. The observed differences between the means and medians illustrate the asymmetry of the distributions of these variables. We also found that the means and medians of these two variables appeared to be greater during the implementation period of the project than during the period prior to the intervention.
Furthermore, Fig. 1 shows that there was an increasing trend over time for the monthly average of the first ANC and the monthly average of the SBA. It also emerged that the positive slope was more abrupt for SBA.

Evolution of the monthly averages of the number of first ANC visits and SBAs in the selected Health facilities between January 2013 and May 2018
Effects of the health voucher project
First antenatal consultation (anc).
Table 2 and Figure S 3 displays contrasting results. Overall, at the end of the first month of implementation of the project, controlling for other variables, a statistically significant increase of nearly 26% in the monthly number of first ANCs was observed in the 33 HFs considered in the study sample (IRR = 1.258 [95% CI: 1.075, 1.472]). A similar increase was recorded in the North region but was not statistically significant (IRR = 1.246 [95% CI: 0.976, 1.591]). In the Adamawa region, the increase was nearly 73% (IRR = 1.726 [95% CI: 1.117, 2.668]). Conversely, in the Far North region, a nonsignificant reduction of 0.2% was noted (IRR = 0.998 [95% CI: 0.882, 1.129]). These overall results hid disparities across facilities. In the Adamawa region, out of 10 HFs, there was a statistically significant increase in the monthly number of first ANCs at the end of the first month of project implementation in five HFs and a statistically significant decrease in one HF. In the Far North region, of the 10 HFs, a statistically significant increase was recorded in two HFs, and a statistically significant reduction was recorded in one HF. In the North region, of the 13 HFs, six exhibited a statistically significant increase in the aforementioned indicator and one exhibited a statistically significant decrease.
Moreover, regarding the difference between the slope of the trajectory of the first ANC after and before the start of the project, Table 2 and Figure S 4 does not show statistically significant results, either overall or by region. However, in one HF in the Adamawa region, a statistically significant increase in the slope of the trajectory of the first ANC was observed during the project implementation period compared to the situation prior to the intervention. Conversely, a statistically significant decrease was recorded in one HF. In the Far North region, no HF exhibited a statistically significant increase, but a statistically significant decrease was observed in two HFs. In the North region, two HFs exhibited a statistically significant increase, and five HFs exhibited a statistically significant decrease.
Skilled birth attendance (SBA)
Table 2 and Figure S 7 shows that by the end of the first month of implementation of the project, a statistically significant increase of nearly 57% in the monthly number of SBAs was recorded in the 37 HFs selected in the study sample, controlling for other variables (IRR = 1.566 [95% CI: 1.358, 1.806]).
A statistically significant increase in this indicator was also observed in each of the three regions. However, there were disparities between HFs. In the Adamawa region, out of 13 health facilities, there was a statistically significant increase in the monthly number of assisted deliveries at the end of the first month of project implementation in nine HFs and a statistically significant decrease in one HF. In the Far North region, of the 11 HFs, a statistically significant increase was recorded in eight HFs and a statistically significant decrease was recorded in two HFs. In the North region, of the 13 HFs, seven recorded a statistically significant increase and one a statistically significant decrease in the indicator of interest.
In addition, Table 2 and Figure S 8 indicates that, overall, the intervention had a positive effect on SBAs (IRR = 1.009 [95% CI: 1.002, 1.016]). A similar finding is observed in the three regions, with the Far North region being the only region that was statistically significant. When considering the analysis of HFs, the results are mixed. In the Adamawa region, a positive and statistically significant result was recorded for four HFs while a negative and statistically significant result was observed for three HFs. In the Far North region, statistically significant results were recorded for five HFs and all these results were positive. In the North region, two HFs recorded a positive result and three recorded a negative result.
The high values of the I 2 statistics reveal that a very large proportion of the total observed variance is due to a real difference in effect measures between HFs (Figure S 1 to S 8 ).
Our study explored the effect of the Health voucher Project on the use of health services. Overall, a statistically significant increase was observed in the number of first ANCs at the end of the first month of project implementation (success). However, this improvement was not sustained over time, with less than 10% of all HFs (3/33) experiencing an increase in ANCs.
For the SBAs, there was a statistically significant increase at the end of the first month of project implementation, with a sustained pattern over time. When looking at the individual HFs, 2/3 (65%) recorded success at the end of the first month of implementation, while 30% experienced overall improvement during the project implementation compared to the period before the start of the project.
These findings suggest that between the pre-intervention/roll-out and full implementation phases, the Cameroon voucher programme modestly increased the use of facility for ANC and SBA, consistent with previously reported results from evaluations of maternal health voucher programmes from other LMICs [ 21 , 35 , 36 , 37 , 38 ].
Our results therefore indicate that in a country such as Cameroon, where progress toward universal health coverage is still to be achieved [ 39 ], reducing financial risk by providing subsidies to offset the costs of receiving RMNCAH services may be a good cost-effective intervention to improve service utilization.
Pregnant women were more likely to use the voucher system for SBAs than for the first ANC visits. One explanation could be the late attendance of pregnant women at health facilities, as more than 70% of pregnant women in these three regions are reported to have their first contact with a health facility after the first trimester of pregnancy [ 27 ], or the late acquisition of vouchers. In-depth discussions with health care providers and direct beneficiaries are needed to better understand the realities underlying these trends.
The decrease in first ANC and SBA over time in some HFs could be explained by the increasing expansion of service coverage, with the opening of new health facilities that were not yet included in the project and that were used by some pregnant women. On the other hand, the context of growing insecurity linked to Boko Haram and other rebel groups in neighboring countries could also constitute a barrier to the use of health facilities in these regions.
It is also important to note that the voucher program is conceptually designed to target the poorest populations. In Cameroon, however, the project covers all women of reproductive age in the intervention areas, regardless of socioeconomic status. We suspect that the contribution of the 6,000 FCFA ($11 US) remains a major barrier to the use of health services for the poorest women, especially since the project covers mostly urban areas, raising the question of program equity as reported elsewhere [ 13 , 14 , 16 ]. This challenge was also highlighted in an unpublished qualitative study.
Focusing on strategies that prioritize the poorest women and strengthen community engagement can ensure equity and achieve sustainable results over time. For example, in Bangladesh and Cambodia, the voucher programme focused on those most in need and reimbursed care givers in facilities to motivate them [ 40 , 41 ]. Moreover, both countries have successfully partnered with recipient communities to improve the targeting of the poor [ 40 , 41 , 42 ].
In addition to stimulating demand, voucher schemes are often proposed as a way to improve the quality of care, as is the case in Cameroon, where health facility accreditation mechanisms are used, alongside the performance-based financing scheme implemented nationwide. However, experiences show that providers may find reimbursement rates to be unattractive and engage in practices such as providing inconsistent quality of care or ‘skimming’ programme users who require minimal intervention. Moreover, as reported in other voucher programs, the most significant problem faced by the voucher scheme in Cameroon was the delay in paying for health facilities, which led to staff demotivation and mistrust between the managers of the scheme and the beneficiaries [ 41 ] and suggested a need for greater attention to issues related to implementation in such a program [ 26 ].
This study helps to extend the body of knowledge generated by previous research on health voucher programmes in LMICs. However, in interpreting our findings, the strengths and limitations of the study design should be considered.
First, most studies on voucher programmes to date have examined the immediate or shorter-term impact of the intervention on service utilization [ 21 ]. Our study examined the immediate to longer-term effects of the intervention and used a quasi-experimental design, known as a reliable approach, to provide robust estimates of the effect of an intervention when a randomized controlled trial cannot be conducted or when a control group is lacking [ 29 , 31 ]. Unlike in cross-sectional observational studies, interrupted time series analysis allows us to estimate the dynamics of change driven by the intervention, controlling for secular changes that might have occurred in the absence of the intervention [ 29 , 43 ]. This approach thus makes it possible to observe whether the intervention has an immediate or delayed, sudden or gradual effect and whether this effect persists or is temporary. Furthermore, there is no real consensus on the number of observation points needed to use the interrupted time series method. However, the statistical power increases with the number of time points [ 30 ]. Some authors recommend 12 observation points before and after the start of the intervention [ 29 ]. In our study, only one HF had 10 observation points before the start of the project, and the others had observation points ranging from 14 and 42. During the project implementation period, the number of observations varied between 23 and 37.
At the time of the study, 81 facilities had already enrolled in the voucher project. We limited ourselves to 33 HFs for the first ANC and to 37 HFs for the SBA analysis because the data prior to the project were either unavailable or insufficient. Therefore, the results presented in this study may be a fragmented view of the project’s effect. In addition, analysis that could provide insight into the RMNCAH continuum of care was not possible due to the limited quality of data (high frequency of missing data) for some key indicators, such as the fourth ANC and postnatal consultation, as reported with other voucher programs [ 22 , 44 , 45 , 46 ].
In identifying the impact of an intervention, it is important that there are no exogenous factors influencing the results. During the implementation of the voucher program in Cameroon, there were no closures of health facilities that could have an impact on the two selected indicators. Population growth naturally leads to an increase in the number of pregnant women in absolute terms, and consequently to an increase in the number of SBAs. Because demographic data were only available for each health district and not for each health facility, estimates of expected populations or pregnant women were not included into the various negative binomial regression models as a control variable. As a result, the estimates obtained may be biased.
It is also important to point out that due to its fragility, the northern part of the country is a convergence zone of several programs and projects, including those of health. Therefore, other interventions may have also contributed to the achievement of these outcome levels. One of the most important programmes is the National Multi-sector Program to Combat Maternal, Newborn and Child Mortality, which was created in 2013.
Finally, we would like to underline that the fidelity of the program's implementation was hampered by deviations, leading for instance to extending the intervention to all women of childbearing age. At present, the program is more akin to an obstetric risk insurance system, as described for example in Mauritania [ 47 ].
This study provided important insight into the Cameroon voucher scheme. The intervention had a significant early effect on the first ANC and SBA but failed to effectively sustain these results over time for the first indicator. These mixed effects were likely the consequence of poor design and implementation challenges, including the fact that the programme did not include specific equity measures to facilitate uptake by the poorest people. This suggests that for a complex intervention such as a voucher, it is critical to properly implement practice strategies that can sustain the long-term impact of the programme.
Availability of data and materials
The data that support the findings of this study are available from the Ministry of Public Health (MPH) of Cameroon, but restrictions apply due to the terms of our contract with the MPH, and so, data are not publicly available. The corresponding author should be contacted for the process to request data access.
Abbreviations
- Antenatal consultation
Centre International de Développement et de Recherche
Emergency obstetric and neonatal care
Communauté financière africaine
Health facility
Low- and middle-income country
Maternal mortality ratio
Multiple Indicator Cluster Survey
Ministry of public health
Out-of-pocket
Post-natal care
Regional Funds for Health Promotion
Reproductive, maternal, neonatal, child and adolescent health
- Skilled birth attendance
Sustainable Development Goals
Sub Saharan Africa
United States dollar
World health organization
Nations Unies. Développement durable. 2021. Objectif de Développement Durable - Santé et Bien-Être pour tous. 2021. Available at: https://www.un.org/sustainabledevelopment/fr/health/ . Accessed 3 June 2023.
WHO, UNICEF, UNFPA, World Bank Group, United Nations Population Division. Trends in maternal mortality: 2000 to 2017. Geneva, Switzerland: World Health Organization; 2019. p. 119. Available at: http://www.who.int/reproductivehealth/publications/maternal-mortality-2000-2017/en/ . Accessed 10 May 2023.
UN Inter-agency Group for Child Mortality Estimation. Levels & Trends in Child Mortality. New York, NY 10017 États-Unis: United Nations Children’s Fund; 2020 p. 56. Available at: https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/unpd_2020_levels-and-trends-in-child-mortality-igme-.pdf . Accessed 2 Jul 2023.
Institut National de la Statistique (INS). Enquête Démographique et de Santé et à Indicateurs Multiples EDS-MICS 2011. 2011. Available at: https://dhsprogram.com/pubs/pdf/fr260/fr260.pdf . Accessed 2 Feb 2023.
Donnay F. Maternal survival in developing countries: what has been done, what can be achieved in the next decade. Int J Gynecol Obstet. 2000;70(1):89–97. https://doi.org/10.1016/S0020-7292(00)00236-8 .
Article CAS Google Scholar
Singh S, Darroch JE, Ashford LS, Vlassoff M. Adding It Up: The costs and Benefits of Investing in family Planning and maternal and new born health. GUTTMACHER INSTITUTE; 2009. Available at: https://www.guttmacher.org/sites/default/files/pdfs/pubs/AddingItUp2009.pdf . Accessed 20 April 2023.
Tekelab T, Chojenta C, Smith R, Loxton D. The impact of antenatal care on neonatal mortality in sub-Saharan Africa: a systematic review and meta-analysis. PLOS One. 2019;14(9):e0222566. https://doi.org/10.1371/journal.pone.0222566 .
Article CAS PubMed PubMed Central Google Scholar
Wondemagegn AT, Alebel A, Tesema C, Abie W. The effect of antenatal care follow-up on neonatal health outcomes: a systematic review and meta-analysis. Public Health Rev. 2018;39(1):33. https://doi.org/10.1186/s40985-018-0110-y .
Article PubMed PubMed Central Google Scholar
Matsuoka S, Aiga H, Rasmey LC, Rathavy T, Okitsu A. Perceived barriers to utilization of maternal health services in rural Cambodia. Health Policy. 2010;95(2):255–63. https://doi.org/10.1016/j.healthpol.2009.12.011 .
Article PubMed Google Scholar
Sharma S, Smith S, Sonneveldt E, Pine M, Dayaratna V, Sanders R. Formal and Informal Fees for Maternal Health Care Services in Five Countries. USAID; 2005. Available at: http://www.policyproject.com/pubs/workingpapers/WPS16.pdf . Accessed 30 Jan 2023.
Institut National de la Statistique (INS) and IFC. Enquête Démographique et de Santé EDS 2018. INS et IFC 2020. Available at: https://dhsprogram.com/what-we-do/survey/survey-display-511.cfm . Accessed 4 Jan 2023.
WHO. World Health Organization. 2020. Global Health Expenditure Database. Available at: https://apps.who.int/nha/database/Home/Index/en . Accessed 13 Feb 2023.
Gabrysch S, Campbell OM. Still too far to walk: Literature review of the determinants of delivery service use. BMC Pregnancy Childbirth. 2009;11(9):34. https://doi.org/10.1186/1471-2393-9-34 .
Article Google Scholar
Dzakpasu S, Powell-Jackson T, Campbell OMR. Impact of user fees on maternal health service utilization and related health outcomes: a systematic review. Health Policy Plan. 2014;29(2):137–50. https://doi.org/10.1093/heapol/czs142 .
Ensor T, Ronoh J. Effective financing of maternal health services: a review of the literature. Health Policy. 2005;75(1):49–58. https://doi.org/10.1016/j.healthpol.2005.02.002 .
Richard F, Witter S, de Brouwere V. Innovative approaches to reducing financial barriers to obstetric care in low-income countries. Am J Public Health. 2010;100(10):1845–52. https://doi.org/10.2105/AJPH.2009.179689 .
World Health Organization. Making pregnancy safer: the critical role of the skilled attendant: a joint statement by WHO, ICM and FIGO. Geneva: WHO; 2004. 24 p. Available at: https://apps.who.int/iris/bitstream/handle/10665/42955/9241591692.pdf?sequence=1&isAllowed=y . Accessed 15 April 2023.
Baral YR, Lyons K, Skinner J, van Teijlingen ER. Determinants of skilled birth attendants for delivery in Nepal. Kathmandu Univ Med J. 2010;8(3):325–32. https://doi.org/10.3126/kumj.v8i3.6223 .
Bellows NM, Bellows BW, Warren C. Systematic review: the use of vouchers for reproductive health services in developing countries: systematic review. Trop Med Int Health TM IH. 2011;16(1):84–96. https://doi.org/10.1111/j.1365-3156.2010.02667.x .
Brody CM, Bellows N, Campbell M, Potts M. The impact of vouchers on the use and quality of health care in developing countries: a systematic review. Glob Public Health. 2013;8(4):363–88. https://doi.org/10.1080/17441692.2012.759254 .
Hunter BM, Harrison S, Portela A, Bick D. The effects of cash transfers and vouchers on the use and quality of maternity care services: a systematic review. PLOS One. 2017;12(3):e0173068. https://doi.org/10.1371/journal.pone.0173068 .
Nguyen HTH, Hatt L, Islam M, Sloan NL, Chowdhury J, Schmidt JO, et al. Encouraging maternal health service utilization: an evaluation of the Bangladesh voucher program. Soc Sci Med. 2012;74(7):989–96. https://doi.org/10.1016/j.socscimed.2011.11.030 .
Azmat SK, Ali M, Rahman MdM. Assessing the sustainability of two independent voucher-based family planning programs in Pakistan: a 24-months post-intervention evaluation. Contracept Reprod Med. 2023;8(1):43. https://doi.org/10.1186/s40834-023-00244-w .
Nandi A, Charters TJ, Quamruzzaman A, Strumpf EC, Kaufman JS, Heymann J, et al. Health care services use, stillbirth, and neonatal and infant survival following implementation of the Maternal Health Voucher Scheme in Bangladesh: A difference-in-differences analysis of Bangladesh Demographic and Health Survey data, 2000 to 2016. PLOS Med. 2022;19(8):e1004022. https://doi.org/10.1371/journal.pmed.1004022 .
Sultana N, Hossain A, Das H, Pallikadavath S, Koeryaman M, Rahman M, et al. Is the maternal health voucher scheme associated with increasing routine immunization coverage? Experience from Bangladesh. Front Public Health. 2023;2(11):963162. https://doi.org/10.3389/fpubh.2023.963162 .
Hunter BM, Murray SF. Demand-side financing for maternal and newborn health: what do we know about factors that affect implementation of cash transfers and voucher programmes? BMC Pregnancy Childbirth. 2017;17(1):262. https://doi.org/10.1186/s12884-017-1445-y .
Institut National de la Statistique. Cameroon - Enquête par Grappes à Indicateurs Multiples 2014. Yaoundé, Cameroun: Institut National de la Statistique; 2015; p. 504. Available at: https://mics-surveys-prod.s3.amazonaws.com/MICS5/West%20and%20Central%20Africa/Cameroon/2014/Final/Cameroon%202014%20MICS_French.pdf . Accessed 22 Jan 2023
Institut National de la Statistique. Annuaire statistique 2017. 2018. Available at: http://www.statistics-cameroon.org/news.php?id=513 . Accessed May 10, 2023.
Wagner AK, Soumerai SB, Zhang F, Ross-Degnan D. Segmented regression analysis of interrupted time series studies in medication use research. J Clin Pharm Ther. 2002;27(4):299–309. https://doi.org/10.1046/j.1365-2710.2002.00430.x .
Article CAS PubMed Google Scholar
Bernal JL, Cummins S, Gasparrini A. Interrupted time series regression for the evaluation of public health interventions: a tutorial. Int J Epidemiol. 2017;46(1):348–55. https://doi.org/10.1093/ije/dyw098 .
Linden A. ITSA: Stata module to perform interrupted time series analysis for single and multiple groups. Statistical Software Components. Boston College Department of Economics; 2021. Available at: https://ideas.repec.org/c/boc/bocode/s457793.html . Accessed 21Oct 2023.
Ramsay CR, Matowe L, Grilli R, Grimshaw JM, Thomas RE. Interrupted time series designs in health technology assessment: Lessons from two systematic reviews of behavior change strategies. Int J Technol Assess Health Care. 2003;19(4):613–23. https://doi.org/10.1017/S0266462303000576 .
Gebski V, Ellingson K, Edwards J, Jernigan J, Kleinbaum D. Modelling interrupted time series to evaluate prevention and control of infection in healthcare. Epidemiol Infect. 2012;140(12):2131–41. https://doi.org/10.1017/S0950268812000179 .
Borenstein M, Hedges LV, Higgins J, Rothstein HR. Introduction to Meta-Analysis. 2nd ed. Hoboken: Wiley; 2021. p. 500.
Book Google Scholar
Obare F., Warren C., Abuya T., Askew I., Bellows B. Assessing the population-level impact of vouchers on access to health facility delivery for women in Kenya. Soc Sci Med. 2014;183–9. https://doi.org/10.1016/j.socscimed.2013.12.007 .
Obare F, Warren C, Kanya L, Abuya T, Bellows B. Community-level effect of the reproductive health vouchers program on out-of-pocket spending on family planning and safe motherhood services in Kenya. BMC Health Serv Res. 2015;15(1):343. https://doi.org/10.1186/s12913-015-1000-3 .
Bellows B, Kyobutungi C, Mutua MK, Warren C, Ezeh A. Increase in facility-based deliveries associated with a maternal health voucher programme in informal settlements in Nairobi Kenya. Health Policy Plan. 2013;28(2):134–42. https://doi.org/10.1093/heapol/czs030 .
Amendah DD, Mutua MK, Kyobutungi C, Buliva E, Bellows B. Reproductive health voucher program and facility based delivery in informal settlements in nairobi: a longitudinal analysis. PLOS One. 2013;8(11):e80582. https://doi.org/10.1371/journal.pone.0080582 .
Sieleunou I, Tamga DM, Maabo Tankwa J, Aseh Munteh P, Longang Tchatchouang EV. Strategic health purchasing progress mapping in cameroon: a scoping review. Health Syst Reform. 2021;10(7):1. https://doi.org/10.1080/23288604.2021.1909311 .
Ir P, Horemans D, Souk N, Van Damme W. Using targeted vouchers and health equity funds to improve access to skilled birth attendants for poor women: a case study in three rural health districts in Cambodia. BMC Pregnancy Childbirth. 2010;10(1):1. https://doi.org/10.1186/1471-2393-10-1 .
Ahmed S, Khan MM. A maternal health voucher scheme: what have we learned from the demand-side financing scheme in Bangladesh? Health Policy Plan. 2011;26(1):25–32. https://doi.org/10.1093/heapol/czq015 .
Ridde V, Yaogo M, Kafando Y, Sanfo O, Coulibaly N, Nitiema PA, et al. A community-based targeting approach to exempt the worst-off from user fees in Burkina Faso. J Epidemiol Community Health. 2010;64(01):10–5. https://doi.org/10.1136/jech.2008.086793 .
Eccles M, Grimshaw J, Campbell M, Ramsay C. Research designs for studies evaluating the effectiveness of change and improvement strategies. BMJ Qual Saf. 2003;12(1):47–52. https://doi.org/10.1136/qhc.12.1.47 .
Ahmed S, Khan MM. Is demand-side financing equity enhancing? Lessons from a maternal health voucher scheme in Bangladesh. Soc Sci Med. 2011;72(10):1704–10. https://doi.org/10.1016/j.socscimed.2011.03.031 .
Agha S. Impact of a maternal health voucher scheme on institutional delivery among low income women in Pakistan. Reprod Health. 2011;8(1):10. https://doi.org/10.1186/1742-4755-8-10 .
Van de Poel E, Flores G, Ir P, O’Donnell O, Van Doorslaer E. Can vouchers deliver? An evaluation of subsidies for maternal health care in Cambodia. Bull World Health Organ. 2014;92(5):331–9. https://doi.org/10.2471/BLT.13.129122 .
Philibert A, Ravit M, Ridde V, Dossa I, Bonnet E, Bedecarrats F, Dumont A. Maternal and neonatal health impact of obstetrical risk insurance scheme in Mauritania: a quasi experimental before-and-after study. Health Policy Plan. 2017;32(3):405–17. https://doi.org/10.1093/heapol/czw142 .
Download references
Acknowledgements
We would like to thank Dr Bassirou Bouba and Dr Okala from the voucher project, Dr Yumo Habakkuk and Bashirou Ndindumouh from Research for Development International, Dr Denise Tamga from the Worlb Bank Office, and Dr Aubin Baleba from UNFPA. We are much indebted to the SPARC team for continuously reviewed our work and provided valuable comments. Finally, the authors would also like to acknowledge the work of the anonymous reviewers who provided us with extremely helpful comments and feedback.
This work was supported by the Bill & Melinda Gates Foundation [Grant number: OPP1179622].
Author information
Authors and affiliations.
The Global Financing Facility (GFF), Dakar, Senegal
Isidore Sieleunou
Research for Development International, 30883, Yaoundé, Cameroon
Isidore Sieleunou & Roland Pascal Enok Bonong
You can also search for this author in PubMed Google Scholar
Contributions
IS and RPEB conceived and designed the study. RPEB managed the data, including quality control, provided statistical advice on study design and analyzed the data. IS drafted the manuscript, and all authors contributed substantially to its revision. All authors agreed to the final approval of the version to be published. All authors agreed to be accountable for all aspects of the work.
Corresponding author
Correspondence to Isidore Sieleunou .
Ethics declarations
Ethics approval and consent to participate.
Ethical approval for the study was obtained from the Cameroon National Ethics Committee for Human Health Research (CNECHHR) (N0 2020/07/1274/CE/CNERSH/SP). Administrative authorization was granted by the Cameroonian Ministry of Health (D30-607/N/MINSANTE/SG/DROS/CRSPE/BBM, N0 631-32-20). All methods were performed in accordance with the relevant guidelines and regulations. The CNECHHR waived the need for participants’ informed consent in this retrospective study because the data used were fully anonymised and aggregated.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Sieleunou, I., Enok Bonong, R.P. Does health voucher intervention increase antenatal consultations and skilled birth attendances in Cameroon? Results from an interrupted time series analysis. BMC Health Serv Res 24 , 602 (2024). https://doi.org/10.1186/s12913-024-10962-9
Download citation
Received : 27 December 2023
Accepted : 08 April 2024
Published : 08 May 2024
DOI : https://doi.org/10.1186/s12913-024-10962-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Results-based financing
- Health financing
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
10 Experimental research
Experimental research—often considered to be the ‘gold standard’ in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research—rather than for descriptive or exploratory research—where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalisability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments are conducted in field settings such as in a real organisation, and are high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favourably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receiving a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the ‘cause’ in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and ensures that each unit in the population has a positive chance of being selected into the sample. Random assignment, however, is a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group prior to treatment administration. Random selection is related to sampling, and is therefore more closely related to the external validity (generalisability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam.
Not conducting a pretest can help avoid this threat.
Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
Regression threat —also called a regression to the mean—refers to the statistical tendency of a group’s overall performance to regress toward the mean during a posttest rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest were possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-group experimental designs

Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest-posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement—especially if the pretest introduces unusual topics or content.
Posttest -only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

The treatment effect is measured simply as the difference in the posttest scores between the two groups:
![\[E = (O_{1} - O_{2})\,.\]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f2ce47275e7b35def5c5b52b7d7d45_l3.png "Rendered by QuickLaTeX.com")
The appropriate statistical analysis of this design is also a two-group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.

Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:
Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of posttest-only design, but with internal validity due to the controlling of covariates. Covariance designs can also be extended to pretest-posttest control group design.
Factorial designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each subdivision of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).

In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for three hours/week of instructional time than for one and a half hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid experimental designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomised bocks design, Solomon four-group design, and switched replications design.
Randomised block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full-time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between the treatment group (receiving the same treatment) and the control group (see Figure 10.5). The purpose of this design is to reduce the ‘noise’ or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.

Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs, but not in posttest-only designs. The design notation is shown in Figure 10.6.

Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organisational contexts where organisational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.

Quasi-experimental designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organisation is used as the treatment group, while another section of the same class or a different organisation in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impacted by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.

In addition, there are quite a few unique non-equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to the treatment or control group based on a cut-off score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardised test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program.

Because of the use of a cut-off score, it is possible that the observed results may be a function of the cut-off score rather than the treatment, which introduces a new threat to internal validity. However, using the cut-off score also ensures that limited or costly resources are distributed to people who need them the most, rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design do not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.

Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, say you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data is not available from the same subjects.

An interesting variation of the NEDV design is a pattern-matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique—based on the degree of correspondence between theoretical and observed patterns—is a powerful way of alleviating internal validity concerns in the original NEDV design.

Perils of experimental research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, often experimental research uses inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies, and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artefact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if in doubt, use tasks that are simple and familiar for the respondent sample rather than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
IMAGES
VIDEO
COMMENTS
Step 1: Define your variables. You should begin with a specific research question. We will work with two research question examples, one from health sciences and one from ecology: Example question 1: Phone use and sleep. You want to know how phone use before bedtime affects sleep patterns.
Randomization: This is like shaking things up in a fair way. You randomly put people into the control or experimental group so that each group is a good mix of different kinds of people. This helps make the results more reliable. Sample: This is the group of people you're studying.
Pre-experimental research is of three types —. One-shot Case Study Research Design. One-group Pretest-posttest Research Design. Static-group Comparison. 2. True Experimental Research Design. A true experimental research design relies on statistical analysis to prove or disprove a researcher's hypothesis.
The pre-experimental research design is further divided into three types. One-shot Case Study Research Design. In this type of experimental study, only one dependent group or variable is considered. The study is carried out after some treatment which was presumed to cause change, making it a posttest study.
Experimental research serves as a fundamental scientific method aimed at unraveling. cause-and-effect relationships between variables across various disciplines. This. paper delineates the key ...
Three types of experimental designs are commonly used: 1. Independent Measures. Independent measures design, also known as between-groups, is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
Pre-experimental research design. A pre-experimental research study is a basic observational study that monitors independent variables' effects. During research, you observe one or more groups after applying a treatment to test whether the treatment causes any change. The three subtypes of pre-experimental research design are: One-shot case ...
Step 1: Consider your aims and approach. Step 2: Choose a type of research design. Step 3: Identify your population and sampling method. Step 4: Choose your data collection methods. Step 5: Plan your data collection procedures. Step 6: Decide on your data analysis strategies. Frequently asked questions.
Step 1: Define your variables. You should begin with a specific research question. We will work with two research question examples, one from health sciences and one from ecology: Example question 1: Phone use and sleep. You want to know how phone use before bedtime affects sleep patterns.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
An experiment is a data collection procedure that occurs in controlled conditions to identify and understand causal relationships between variables. Researchers can use many potential designs. The ultimate choice depends on their research question, resources, goals, and constraints. In some fields of study, researchers refer to experimental ...
Experimental research design is centrally concerned with constructing research that is high in causal (internal) validity. Randomized experimental designs provide the highest levels of causal validity. Quasi-experimental designs have a number of potential threats to their causal validity. Yet, new quasi-experimental designs adopted from fields ...
Research study design is a framework, or the set of methods and procedures used to collect and analyze data on variables specified in a particular research problem. Research study designs are of many types, each with its advantages and limitations. The type of study design used to answer a particular research question is determined by the ...
An experimental research design is typically focused on the relationship between two variables: the independent variable and the dependent variable. The researcher uses random sampling and random ...
Chapter 10 Experimental Research. Experimental research, often considered to be the "gold standard" in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels ...
Introduction. In clinical research, our aim is to design a study, which would be able to derive a valid and meaningful scientific conclusion using appropriate statistical methods that can be translated to the "real world" setting. 1 Before choosing a study design, one must establish aims and objectives of the study, and choose an appropriate target population that is most representative of ...
The classic experimental design definition is: "The methods used to collect data in experimental studies.". There are three primary types of experimental design: The way you classify research subjects based on conditions or groups determines the type of research design you should use. 01. Pre-Experimental Design.
Study, experimental, or research design is the backbone of good research. It directs the experiment by orchestrating data collection, defines the statistical analysis of the resultant data, and guides the interpretation of the results. When properly described in the written report of the experiment, it serves as a road map to readers, 1 helping ...
On the other hand, in experimental studies, we conduct experiments and interventions. Observational studies. Observational studies include many subtypes. Below, I will discuss the most common designs. Cross-sectional study: This design is transverse where we take a specific sample at a specific time without any follow-up
Examples of Experimental Design . Here are some examples of experimental design in different fields: Example in Medical research: A study that investigates the effectiveness of a new drug treatment for a particular condition. Patients are randomly assigned to either a treatment group or a control group, with the treatment group receiving the ...
15 Experimental Design Examples. By Chris Drew (PhD) / October 9, 2023. Experimental design involves testing an independent variable against a dependent variable. It is a central feature of the scientific method. A simple example of an experimental design is a clinical trial, where research participants are placed into control and treatment ...
Content. Experimental research is a cornerstone of scientific inquiry, providing a systematic approach to understanding cause-and-effect relationships and advancing knowledge in various fields. At its core, experimental research involves manipulating variables, observing outcomes, and drawing conclusions based on empirical evidence.
PurposeThis study examined the early efficacy of a new theory-driven principle of grammar intervention, graduated input type variation (GITV).MethodThree Cantonese-speaking children, aged between 4;01 and 5;10, with oral language difficulties participated in this single baseline within-participant single case experimental study. The children received a total of 300 teaching episodes of the ...
The principles that a researcher planning an animal study should follow within the scope of the research (animal ethics, 3R, and other R rules, determination of sample size, randomization, and blinding) are briefly mentioned. Research using animals contributes significantly to many research and development studies, especially in the biomedical field. Within the scope of the study, conducting ...
Alzheimer's disease (AD), the most common form of dementia, remains challenging to understand and treat despite decades of research and clinical investigation. This might be partly due to a lack of widely available and cost-effective modalities for diagnosis and prognosis. Recently, the blood-based AD biomarker field has seen significant progress driven by technological advances, mainly ...
Objective To examine the association between prescriber workforce exit, long term opioid treatment discontinuation, and clinical outcomes. Design Quasi-experimental difference-in-differences study Setting 20% sample of US Medicare beneficiaries, 2011-18. Participants People receiving long term opioid treatment whose prescriber stopped providing office based patient care or exited the workforce ...
Study design, data source and study sample. To achieve the study objectives, we used a quasi-experimental study design. Specifically, for each health facility (HF) that was enrolled in the health voucher project, the potential effect of the project was measured using an analysis of interrupted time series [29,30,31,32].This method compares changes in the indicators of interest before and after ...
Establishing reliable and effective prediction models is a major research priority for air quality parameter monitoring and prediction and is utilized extensively in numerous fields. The sample dataset of air quality metrics often established has missing data and outliers because of certain uncontrollable causes. A broad learning system based on a semi-supervised mechanism is built to address ...
10 Experimental research. 10. Experimental research. Experimental research—often considered to be the 'gold standard' in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different ...
The trial, which started in 2019, enrolled 12 adults, ages 17 to 63, and two children, ages 9 and 14, with inherited retinal degeneration caused by mutations in the CEP290 gene. That gene provides ...