We Review ‘Semantic Scholar’: An AI-Powered Literature Searching Tool
Semantic Scholar is a free literature search tool developed by the Allen Institute of AI (nicknamed AI2), a non-profit research institute. It has had a meteoric rise to prominence recently. Back in 2015, it could only be used to search through about 3 million computer science papers; not exactly useful to a wide range of scholars. But today, Semantic Scholar can search through over 180 million papers across all academic disciplines, and it’s starting to become a mainstream research tool.
The team behind Semantic Scholar claims to be all about smart information retrieval and reducing information overload. Their mission has been to make the (sometimes onerous) job of searching through research papers faster and easier. As if to prove their dedication to this mission, they preview their own research papers on their website not with abstracts, but with ‘TL;DR’ summaries*… and they’ve just started publishing auto-generated single-sentence TL;DR summaries for papers in their database too.
But can you really take a TL;DR approach to literature searching? After all, surely the whole point of a literature review is to help researchers develop a nuanced and rich understanding of the subject matter. I’ve had countless supervisors and professors over the years who have preached the merits of deep reading, and bemoaned the abbreviations and oversimplifications of internet-era research. TL;DR research? I can almost hear them crying . What is this, Buzzfeed?
Hypothetically offended past professors: hear me out. I’m quietly excited about this tool, and others like it . Let’s face it: the volume of available research has exploded in the age of the internet, and methods of literature searching have changed accordingly.

But despite these updates to our literature searching, the way we narrow down our reading list hasn’t really changed. Fifty years ago, you could assess a paper’s relevance by reading a 200-word abstract. And now… yeah, same thing. So we have exponentially more sources to wade through, and no obvious quicker way to identify what’s relevant to our research. That’s a problem.
Tools like Semantic Scholar don’t (and shouldn’t) replace deep reading. But they can (and do) limit the amount of time spent on fruitless searching.
Here’s how it works. Semantic Scholar looks and feels like a scholarly search engine – just type in your search query, and the results pop up. There are filters to enable you to limit your search to particular date ranges, publication types, and so on. At first glance it’s not dissimilar to, say, Google Scholar.
But the difference is that there’s artificial intelligence at play here.** Semantic Scholar uses natural language processing and machine learning models to power its search engine, giving you (in theory) more relevant search results.
I tested Semantic Scholar against Google Scholar by using the same search phrase in both – a phrase relevant to my literary PhD research, but which also applies in multiple other disciplines. Since Semantic Scholar has focused mainly on the sciences, I was skeptical that my search phrase would bring up anything at all. On the contrary: it brought up more results, and more relevant results, than Google Scholar.

Not only were my Semantic Scholar search results more relevant, the post-search tools are fabulous. This search phrase occurs across disciplines; but I was able to quickly filter down to the philosophy papers I was interested in. Plus, the option to filter for listings that include a PDF gave me a quick way to find full-text results.
But by far, my favourite feature of Semantic Scholar is how it connects papers together. When you click on a search result, you go to a page with different tabs. The ‘references’ tab lifts and digitises the bibliography of the paper; and the ‘citations’ tab lists other papers that have cited this one. In both cases, you can filter and sort the results to find what you need. Semantic Scholar also distinguishes between citations that are incidental, and those that are ‘highly influential.’ This makes it much easier to trace the relationships between sources and quickly see what you should read next.
So, should Semantic Scholar become part of your regular literature searching strategy? It only takes a minute to have a go – I say give it a shot, and see how it works for you.
*TL;DR is internet speak for ‘too long; didn’t read’ – often used to denote a quick summary of a long block of text.
**Those interested in the technology behind the AI might like to read AI2’s research website here , and staffer Sergey Feldman’s write-up of their development process here.


About Anaise Irvine
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 18 December 2023
Evidence for optimal semantic search throughout adulthood
- Jeffrey C. Zemla 1 ,
- Diane C. Gooding 2 , 3 , 4 &
- Joseph L. Austerweil 2
Scientific Reports volume 13 , Article number: 22528 ( 2023 ) Cite this article
752 Accesses
Metrics details
- Cognitive ageing
- Human behaviour
As people age, they learn and store new knowledge in their semantic memory. Despite learning a tremendous amount of information, people can still recall information relevant to the current situation with ease. To accomplish this, the mind must efficiently organize and search a vast store of information. It also must continue to retrieve information effectively despite changes in cognitive mechanisms due to healthy aging, including a general slowing in information processing and a decline in executive functioning. How effectively does the mind of an individual adjust its search to account for changes due to aging? We tested 746 people ages 25 through 69 on a semantic fluency task (free listing animals) and found that, on average, retrieval follows an optimal path through semantic memory. Participants tended to list a sequence of semantically related animals (e.g., lion, tiger, puma) before switching to a semantically unrelated animal (e.g., whale). We found that the timing of these transitions to semantically unrelated animals was remarkably consistent with an optimal strategy for maximizing the overall rate of retrieval (i.e., the number of animals listed per unit time). Age did not affect an individual’s deviation from the optimal strategy given their general performance, suggesting that people adapt and continue to search memory optimally throughout their lives. We argue that this result is more likely due to compensating for a general slowing than a decline in executive functioning.
Similar content being viewed by others

Microdosing with psilocybin mushrooms: a double-blind placebo-controlled study

Control of working memory by phase–amplitude coupling of human hippocampal neurons

Principal component analysis
Introduction.
Most organisms engage in costly search for food, nutrients, and other resources necessary to live. Organisms that search their environmental niche in an efficient manner have a competitive advantage over their peers in survival and reproduction. As a result of natural selection, many organisms exhibit behavior that is consistent with the goal of optimizing search: maximizing the rate at which resources are encountered 1 , 2 , 3 .
To search efficiently, organisms store knowledge of their environment and retrieve it to guide their search 4 . The human mind is faced with an analogous search problem: it stores a vast amount of semantic knowledge, and people must search through that knowledge efficiently to find contextually relevant information. Individuals who search their semantic memory efficiently are at an advantage compared to those who do not. While most people no longer need to forage for food in the wild, semantic search is still ubiquitous in everyday life. Across physical, visual, and mental search, researchers have found that the mind searches for information in a way that is close to optimally adapted to the environment 5 , 6 , 7 , 8 , 9 , 10 . For example, empirical learning and forgetting curves in memory 11 reflect the actual probabilities that we encounter information in the real world 12 . One limitation of these studies is that they focus on younger adults, and do not address how performance changes with age. Stored knowledge and retrieval mechanisms change across the lifespan 13 , but to date little research has explored whether the mind compensates for these changes to preserve optimal semantic search throughout adulthood.
In this paper we test whether semantic search is optimal (relative to an individual) in the semantic fluency task (listing as many animals as possible in a fixed time limit), and whether search remains optimal or becomes suboptimal with age. Prior research has found that in aggregate, people search memory optimally in this task, listing animals in a sequence that maximizes the total number of animals retrieved in the time period 7 . We expand on this by using a different analytic technique to obtain a participant-level measure of optimality, and assess whether adherence to optimal search changes across the lifespan. The experiment focuses on adults who are young or middle-aged (approximately 25-50 years old), with fewer participants above the age of 60. The results have implications for how executive functioning and processing speed declines that commonly accompany aging 14 , 15 may affect search performance.
Optimal search and the semantic fluency task
The computational problem of how to efficiently retrieve semantic information can be likened to foraging in a physical environment 16 . In physical environments resources are often distributed in clumpy patches rather than uniformly. Within a patch, a forager faces diminishing returns: the rate of retrieving resources declines over time until the patch has been exhausted. For example, berries are distributed on berry bushes (patches). The more berries one has found on a bush, the longer it will take to find the next berry on that same bush. As a result, it is not efficient to exhaust the resources within a patch entirely. Rather, it is better to leave the patch at some point in search of a new patch that is more plentiful. This also has a cost: searching for a new patch takes time and effort, and no resources are retrieved until a new patch is found. The structure of the environment invokes a classic exploration-exploitation dilemma: How long should a forager exploit the current patch, and when should they search for a new patch? Understanding the cognitive mechanisms that guide explore-exploit decisions has proven crucial to explaining behavior across a variety of psychological domains 17 , 18 .
In the case of physical search, the solution to this problem is to switch between exploring and exploiting resources in a way that maximizes the rate of encountering resources. If the rate of encountering resources within a patch and the time cost of exploring for a new patch are known, the optimal behavior is to leave a patch when the local rate of return within a patch drops below the average rate of return across all patches. This optimality result is called the marginal value theorem 1 and can be used to assess whether search is optimal. See Fig. 1 A.

( A ) Resources are encountered with diminishing returns within a patch. A forager who leaves the patch at T2 (optimal leave time) maximizes the average rate of return, whereas a forager who leaves earlier (T1) or later (T3) does not. The optimal solution is to leave a patch when the local rate of return drops below the average rate of return across all patches, i.e., when the rate of return line lies tangent to the curve. ( B ) Mental search through semantic memory resembles a forager searching over semantic patches. ( C ) Performance in the semantic fluency data can be measured by the response times that span semantic patches (switch times) and the time spent within patches (observed leave times).
Analogously, semantic search resembles foraging over semantically related patches of information. In the semantic fluency task, participants list items from a semantic category (typically animals or foods ). A robust finding is that people will list items in semantically related clusters (i.e., patches; 19 ). For example, one might list dog, fox, wolf in sequence (all canines) before switching to a different semantic cluster like whale, fish (all aquatic animals). See Fig. 1 B. In spatial foraging, search time increases with the physical distance that is traversed. In semantic search, inter-item response times are a useful proxy for semantic distance, as the time needed to mentally move from one concept to another is proportional to their semantic similarity 20 , 21 .
Previous work has found that response times in the semantic fluency task are qualitatively consistent with optimal search of semantic memory. Inter-item response times within a semantic cluster tend to be smaller than the mean response time, while response times that span cluster boundaries tend to be larger than the mean response time 6 , 7 , 22 . This pattern suggests that, at minimum, people do not search within a semantic patch for longer than is optimal. In the current study, we quantify adherence to optimal search using the marginal value theorem both at the group level and at the individual level to measure the degree to which people are optimal. Throughout the paper, we use the term “optimal” to refer to whether the timing of cluster switches adheres to the marginal value theorem, i.e., whether a participant switches clusters in a manner that maximizes the number of animals listed given the rate of retrieval within a semantic cluster and the average time needed to switch clusters. While there are other ways that optimality can be construed, our use is consistent with optimal foraging both in the ecology literature and in the semantic retrieval literature 1 , 3 , 6 , 7 .
A different approach to investigating mental search is to explore the many different cognitive strategies that can be used to retrieve concepts from semantic memory 13 , 23 , 24 . For example, one might visualize walking through a zoo, or list animals alphabetically. While this work is informative, it is orthogonal to whether people switch clusters optimally in the semantic fluency task. This is because the marginal value theorem is agnostic to the explicit cognitive strategy or retrieval algorithm: It provides a computational-level analysis of behavior, rather than an algorithmic one 25 .
Age-related decline and semantic retrieval
Many aspects of semantic memory and retrieval change with age. Adults continue to acquire new semantic information with age, evidenced by their larger vocabularies 26 , 27 , and the mental organization of that knowledge changes throughout life 28 , 29 , 30 , 31 . Changes in the quantity or structure of stored semantic knowledge may contribute to retrieval difficulties in older adults 32 . For example, older adults experience more retrieval failures than younger adults when asked to recall a word given its definition, and are slower to name the word on successful attempts 33 . Older adults also experience more tip-of-the-tongue states when recalling low-frequency words 34 , and list fewer exemplars from a semantic category under time constraints 19 . These findings show that aging is associated with declines in the ability to explicitly retrieve semantic information.
Why is semantic retrieval impaired with age? One proposal is that it is due to impaired executive functioning 15 , 35 , 36 . In the semantic fluency task, clustering and switching may reflect two distinct components of search 7 , 19 . Clustering is largely driven by automatic, associative processes, in which new responses are generated based on their semantic similarity to the previous response. Switching is associated with executive functioning processes, and allows individuals to guide search towards concepts that are semantically unrelated to the previous response. In support of this account, neuropsychological studies have found that individuals with frontal lobe lesions (associated with executive functioning deficits) switched clusters less often 37 . Additionally, the number of responses generated is correlated with measures of executive functioning like operation span 38 .
We discuss the executive functioning hypothesis in which declines in executive functioning selectively affect the timing of cluster switches, but do not impact the timing of within-cluster search 19 . Under this hypothesis, an individual might take longer to switch clusters but experience no change in the rate of listing items within a cluster. This can result in sub-optimal search when evaluated by the marginal value theorem, because a failure to disengage from a cluster results in spending too much time within a cluster. It is worth noting that some work has cast doubt on the selectivity of executive functioning in cluster switching 39 , 40 , 41 , 42 , 43 . For example, Mayr and Kliegl 42 compare performance on a standard fluency task to an alternating fluency task (listing items from two categories in an alternating fashion). An age by condition interaction (larger switch costs for older adults in the alternating condition) is expected if executive functioning is selective to switching. The authors find no evidence of this and conclude their results are “not consistent with the idea of a general, age-related switching deficit.” Our definition of the executive functioning hypothesis differs from this alternative theory in that our hypothesis assumes executive functioning demands are larger for switches than non-switches.
A second proposal is that semantic retrieval is impaired due to a general slowing of cognitive processing that accompanies age 14 , 44 , which is also supported by prior research. The number of responses generated in semantic fluency is correlated with processing speed (measured using a shared variance component derived from multiple tasks, including the digit symbol substitution task and trail making task) 45 , 46 . We explore the processing speed hypothesis that semantic retrieval slows by a fixed factor, but does not selectively affect within-cluster search or cluster switches. Under this hypothesis, declines in processing speed lead to a proportional increase in response times for all responses generated, regardless of whether they span a cluster boundary or not. This hypothesis predicts that adherence to optimal search should not vary with age, because the predictions of the marginal value theorem are scale invariant.
In this study, we test whether adherence to optimal semantic search in the fluency task varies with age using the marginal value theorem. If processing speed is the primary determinant of age-related semantic deficits, then the optimality of semantic search should not vary with age. However if executive functioning plays a special role in cluster switching, then people may become less optimal as they age.
Participants
We recruited 746 participants for our study using Amazon’s Mechanical Turk and e-mail lists distributed through community organizations. Prior to recruitment and data collection, this study was approved by the University of Wisconsin-Madison Institutional Review Board (protocol 2018-1223). All methods were performed in accordance with the relevant guidelines and regulations. Informed consent was obtained from all subjects.
Data from 527 participants were analyzed (see exclusion criteria below). These participants had a mean age of 38.1 years old (range 25–69, sd 9.5). Participants were not binned into age groups. We use the terms “younger” and “older” participants to refer to participant ages in this range relative to each other (i.e., a 50 year-old is an “older” participant in our sample despite not being “old” in the colloquial sense). 256 participants (48.6%) were female, 270 (51.2%) were male, and 1 participant was transgender. Most participants identified as either white (64%) and/or Black/African American (16%). 515 participants (97.7%) reported that English was their native language (monolingual or multilingual). See Table 1 for additional demographic information.
The participants took part in a large personality survey of attitudes and experiences, however this survey is not part of the present investigation and is not discussed further. Interspersed within this group of surveys were three trials of the semantic fluency task 47 . In each trial, participants were asked to “List as many animals as you can think of” in three minutes. Participants typed each response into a text field and pressed Enter after each response. After pressing Enter, the response faded from the screen (fading animation lasted 100ms). This procedure was designed to minimize the possibility of previously generated responses cueing subsequent responses. Participants were instructed to not list any animal more than once within a list but could repeat the same animal across lists. The median time to complete the entire study (including unrelated surveys) was 35.4 minutes. Mechanical Turk participants were compensated with a cash reward, while community participants received a Starbucks gift card of equal value.
A time limit of three minutes per fluency trial was used in order to ensure sufficient data was collected from each participant to estimate their retrieval curve. While one minute is perhaps the most common, there is no standard time limit for the task. Other research has employed time limits that vary from thirty seconds 48 to five minutes 24 . However, increasing the time limit provides diminishing returns (fewer animals listed per unit time), which makes collecting a large quantity of data per participant difficult. To compensate for this, we used three trials of the fluency task per participant 49 , 50 which allows us to collect more data than would be possible from a single, nine minute trial.
Data analysis
The data were pre-processed to ensure participants followed instructions. Fluency lists were removed from the dataset if: the participant did not hit Enter after each response (resulting in the absence of response times); the participant listed fewer than five animals (an arbitrarily low threshold to make sure participants attempted the task in earnest); or the participant listed three or more intrusions (non-animals) across all three lists. Participants who did not complete three valid lists (for the reasons above, or due to attrition) were removed from the dataset. After pre-processing, the dataset contained 1581 lists from 527 participants.
Each response in the dataset was assigned to one or more semantic categories using SNAFU, a software tool for automatically coding fluency data 51 . For example, the response dog is a member of both the Pets category and the Canine category. SNAFU assigns category labels using a pre-existing dictionary of animals and their categories. The dictionary we used is an amalgam of several animal taxonomies previously used in the animal fluency literature 7 , 19 , 51 and contains 30 categories of animals. While it is not an exhaustive taxonomy, Zemla et al. 51 found that it reliably agrees with fluency data that is manually coded for clusters. The dictionary we use is available in the Supplementary Materials. Each animal was assigned to at least one animal category. If a response did not share any category with the previous response, it was marked as a semantic cluster switch. Otherwise, the transition was marked as a continuation of the previous semantic cluster.
Optimal search was quantified using the marginal value theorem 1 , which stipulates that optimal search is achieved by leaving a cluster when the rate of return within a cluster drops below the average rate of return across all clusters. In the context of the semantic fluency task, an individual can maximize their rate of listing animals if they stop listing animals from a given cluster when the rate of listing animals in that cluster drops below the average rate of listing animals (across all clusters). Three key pieces of information are needed for this calculation: (1) the average between-cluster switch time, (2) the average empirical (observed) cluster leave time (i.e., the average time spent in a cluster), and (3) a retrieval curve, indicating the average number of animals listed at any point in time within a cluster.
The between-cluster switch time was measured as the inter-item response time between the last item of one cluster (e.g., giraffe ) and the first item of a new cluster (e.g., dog ). The empirical cluster leave time was measured as the time between the first item of a cluster (e.g., dog ) and the last item of that same cluster (e.g., wolf ). See Fig. 1 C. The optimal cluster leave time was found by calculating the rate of return at any time in a cluster (i.e., the average number of animals listed at time t since entering a cluster, divided by the sum of the switch time and t ), and choosing the time t that maximizes this rate of return.
In total, 27,736 clusters were identified in the dataset. The retrieval curve for a single cluster in the data can be depicted as a step function; an example is shown in Fig. 2 A. By averaging over the step functions of all clusters in the dataset, we can depict the average retrieval curve over the entire dataset (Fig. 2 B). Following the convention of Stephens and Krebs 3 , we plot the average switch time (5926ms) to the left of the graph origin and within-cluster time to the right of the graph origin.
The data were analyzed in multiple ways. First, the behavior of the sample was assessed to see whether people search optimally in aggregate. This was followed by an individual-level analysis that allows us to test whether search behavior changes with age. Finally, the group-level analysis was repeated for each fluency trial to examine whether adherence to optimal search changes with practice.
Participants listed a mean of 33.73 animals per list (range 5–90, sd 12.25). The mean number of animals generated per participant was not correlated with age ( \(R = -.01, p =.77\) ). Additionally, age was not correlated with average cluster size (number of animals in a cluster), average number of cluster switches, cluster switch rate (number of switches per item), or mean response time (all \(|R| < .04\) , all \(p > .46\) ). Here and in subsequent analyses, response times were not log-transformed. Statistical significance did not change when they were log-transformed, except where noted.
Participants spent an average of 6994ms listing items in a cluster before leaving. Given the average retrieval curve and average switch time, the rate of return is maximized with a cluster leave time of 6892ms (absolute deviance = 102ms). This result suggests that in the aggregate, people are remarkably close to optimal in their cluster switching behavior: When listing animals, people switch between clusters in such a way that maximizes the total number of animals generated.

( A ) A retrieval curve for a single cluster of one participant, starting from the last item of the previous cluster (giraffe) and continuing through the last item of the current cluster (wolf). ( B ) A retrieval curve constructed from averaging all 27,736 clusters in the data. After generating the first animal in a new cluster (at 0s), the rate at which participants list new animals starts to decline (solid black curve). The average rate of listing animals, from the last animal in the previous cluster (red dot) to the last animal of the current cluster (dotted vertical red line), is shown by the dashed diagonal line. This rate is maximized if participants leave the current cluster at 6892ms (dotted vertical green line), whereas participants leave a cluster on average at 6994ms (dotted vertical red line). Given the resolution of this figure, the optimal leave time and empirical leave time virtually overlap (absolute deviance = 102 ms).
We further assessed whether this result could have been due to chance alone by resampling the data to simulate new fluency datasets. To construct each simulated dataset, we permuted the response times in the dataset. This method of simulating datasets preserves the pattern of cluster switches across the data (i.e., the sequence of animals and cluster switches remained the same), but results in a new empirical and optimal cluster leave time for each simulated dataset. We repeated this procedure 1,000 times and measured the absolute deviance from optimal search for each simulated dataset. We calculated the distribution of deviances from optimal search across simulated datasets (mean absolute deviance = 1980ms, minimum absolute deviance = 829ms). This does not overlap with the empirical deviation from optimal search (102ms). As such, our result is highly unlikely to be observed by chance alone.
Individual behavior
Between-cluster switch times did not vary by age, \(p =.4\) (Fig. 3 ). However, the amount of time spent in a cluster before leaving increased with age, \(r(525) =.17\) , \(p = .0001\) (Fig. 4 A). Optimal cluster leave times increased with age as well, \(r(525) =.22\) , \(p <.0001\) (Fig. 4 B), and optimal leave times and empirical leave times were strongly correlated, \(r(525) =.53\) , \(p <.0001\) (Fig. 4 C). As a result of increases in both optimal and empirical leave times, adherence to optimal policy did not vary with age ( \(p =.5\) ; Fig. 4 D). A corresponding Bayes Factor of 0.128 indicates substantial evidence that age does not affect adherence to optimal policy. We use a Bayesian statistic here because one a priori hypothesis predicts that age has no effect on optimality. This finding is consistent with declines in processing speed, which predicts that adherence to optimality does not vary with age. It is more difficult to explain with the executive functioning hypothesis, which predicts that only switch times would vary with age and subsequently optimality would vary with age. This supports processing speed as the primary determinant of age-related changes in semantic fluency.
Older adults retrieved animals from memory at a slower rate, with a lower average rate of listing animals within clusters (i.e., a shallower slope of line tangent to the individual’s within-cluster retrieval curve) , \(r(525) = -.09\) , \(p =.035\) , reflecting, a shallower retrieval curve for older adults (Fig. 5 ). It may seem surprising that the rate of within-cluster search varies with age, while the total number of responses does not. However this demonstrates that the rate of within-cluster search is not the sole determinant of performance on the task. In addition, one’s ability to switch clusters at the optimal time given this change in retrieval rate is critical to performance. The change in the within-cluster retrieval rate with age is precisely why the marginal value theorem suggests that older adults should spend more time in a cluster (Fig. 4 B).

We found no difference in the between-cluster switch times with age. Each point denotes the average between-cluster switch time for a single participant.

As people age, they do ( A ) and should ( B ) search within a cluster for longer. Optimal cluster leave times correlated significantly with empirical cluster leave times ( C ). We found no difference with age in exhibiting optimal search ( D ).

The rate of listing animals within a cluster over time was steeper for younger adults (red line) compared to older adults (blue line). For visualization purposes, we operationalized older adults as the upper quartile of participant ages (44–69) relative to younger participants in the lower three quartile (25–43).
Each individual had a relatively small number of clusters in their data (mean = 52.6, range = 16–123 across all three lists). Deviance from optimal leave times were expected to be larger on average for individuals compared to the group-level analysis, due to the law of large numbers. Deviance from optimal leave time was negatively correlated with the number of clusters in an individual’s data. Additional resampling simulations revealed that deviance from optimal leave time approached zero as the number of clusters increased, but (as expected) not when the response times were permuted. As a result, examining individual behavior without correcting for the number of clusters in each participant’s data (such as Fig. 4 ) can be misleading. We performed additional simulations to correct for this.
To examine whether participants were more optimal than would be predicted by chance, we conducted a permutation analysis. Mirroring the group analysis, we constructed simulated fluency datasets for each participant by permuting the response times of that participant (1000 times for each participant). On average, participants were 1777ms from optimal, compared to 3209ms in the simulated data. 80% of participants had a deviance from optimal that was lower than the mean of their simulated dataset. This result is not expected by chance alone, \(p <.001\) by binomial test.
We also tested whether adherence to optimal search improved performance in the fluency task. For each participant, we calculated the total number of animals listed across the three trials of the task. Performance should improve with both a higher rate of listing animals within a cluster, and a lower deviance from optimal cluster leave times. Using multiple regression we found that both within-cluster rate of return, \(\beta = 926300\) , \(t(522) = 20.43\) , \(p <.001\) , and deviance from optimal cluster leave times, \(\beta = -.003\) , \(t(522) = -4.24\) , \(p <.001\) , were significant independent predictors of the total number of animals listed by each participant (multiple \(R^2 =.49\) ). We also tested a model that included an interaction term (within-cluster rate of return times deviance from optimal cluster leave time). While the interaction term was not significant ( \(p =.14\) ), we still observed a main effect for both factors (both \(p <.001\) ). When response times were log-transformed, we observed a significant interaction but not a main effect.
Trial-level analysis of behavior
One limitation of the above analysis is that the data are collapsed across all three semantic fluency trials. The repeated nature of the task leaves open the possibility that mental search operates differently across the three trials. On the second and third fluency trials, short-term episodic memory of animals retrieved in previous trials may affect how responses are generated, rather than being reflective solely of semantic retrieval. Here, we explore this possibility by analyzing the data from each of the three fluency trials separately.
In the first trial, where performance is driven solely by semantic retrieval, participants searched each cluster an average of 6663ms, whereas the rate of return is optimized switching at 6073ms. While search is still close to optimal (absolute deviance = 590ms), the deviance is not as small as when aggregating over all three trials. On the second trial, behavior was closer to optimal (empirical leave time = 7267ms; optimal leave time = 6892ms; absolute deviance = 375ms), and even more so on the third trial (empirical leave time = 7073ms; optimal leave time = 7008ms; absolute deviance = 65ms). See Fig. 6 .

Optimal leave times (green dotted lines) are shown relative to empirical leave times (red dotted lines) for each of the three fluency trials. Leave times are close to optimal for each trial, though the deviance from optimal is largest on the first trial and smallest on the last trial.
There are several possible explanations for this. One possibility is that short-term memory for animals generated on previous trials facilitate retrieval at an optimal rate. However, another interpretation is that participants become more familiar with the task with practice and adopt better meta-cognitive strategies for when to switch clusters. The data were also analyzed separately for each trial per participant. Many (but not all) of the results mirror those reported in the Individual Behavior section above, and additional information regarding these analyses can be found in the Supplementary Material.
The marginal value theorem 1 was originally proposed to evaluate whether animals search for food and other resources optimally, given the patchy structure of their environment. Here, we used the same theorem to evaluate whether people are optimal in semantic search. Using data from a semantic fluency task, we find strong evidence that semantic retrieval adheres to the marginal value theorem both in aggregate and at an individual level. Our work builds on previous research that has also found evidence of optimal foraging in the semantic fluency task 6 , 7 . It differs in that we employ a new methodological approach to analyzing fluency data that allows for an individual-level measure of optimality and, using this measure, we demonstrate that adherence to optimality does not vary with age. These results add to the growing body of literature that emphasizes the importance of applying computational tools from optimal foraging to improve our understanding how the mind works 17 , 52 .
Throughout adulthood, people acquire new knowledge and the structure of our semantic knowledge changes. Despite this, we find no evidence that people search less optimally as they age. Although the amount of time spent searching within a cluster increased with age, this is exactly what the marginal value theorem indicates people should do if the rate of retrieval within a cluster decreases. Accordingly, prolonged search within a cluster may represent a compensatory mechanism of the aging mind, as opposed to an age-related impairment in the ability to switch clusters.
We evaluated our results in the context of two theories of age related decline: the executive functioning hypothesis and the processing speed hypothesis. Our results are more consistent with the processing speed theory, though neither captures the behavior perfectly. Under this theory, semantic retrieval slows by a fixed factor which should not impact adherence to the marginal value theorem.
Though optimal search was preserved with age, we also found response time differences for only some components of the task, but not all: average response times and cluster switch times did not change with age, while within-cluster times slowed. This selectivity is inconsistent with the processing speed hypothesis, but not in a way that is compatible with the executive functioning theory, which predicts a selective deficit in switching (i.e., increased switch times) and a change in adherence to optimal search with age. Our results did not support either of these predictions, so we interpret our results as being less compatible with the executive functioning hypothesis. Other factors that change with age, such as memory search demands 32 likely play a role as well.
Limitations and future directions
Our work has several limitations. Foremost, we treat the between-cluster switch time and within-cluster rate of retrieval as fixed and well characterized by their averages. In reality, these quantities may change throughout the task: with each encountered cluster, there are fewer animal clusters known to the participant. This may cause between-cluster switch times to increase and within-cluster retrieval rates to decrease. Treating these quantities as dynamic may lead to a better characterization of retrieval behavior, but is more computationally complex. Still, our work provides a benchmark for evaluating more complex models of search, and provides insight into how the mind solves the explore-exploit dilemma central to mental search 17 under a narrower set of circumstances.
We discuss our results in the context of two hypotheses central to the aging literature, the executive functioning and processing speed hypotheses. However, we did not independently measure these constructs using secondary tasks, nor did we collect measures of vocabulary size that may influence retrieval during the semantic fluency task 38 . Related work has benefited from controlling for lexical or cognitive abilities 53 .
We have shown that people search optimally throughout most of adulthood, but our participant sample does not equally represent all age groups. Our sample skews younger and contains few participants over the age of sixty. Previous research has found that while there are changes in performance on the semantic fluency task throughout adulthood, the sharpest declines occur at later ages (e.g., 70+ years) 54 , 55 . This may help to explain why some of our results differ from the prior literature. For example, we do not find commonly reported age-related differences in the number of responses generated or average cluster size. However, declines in the 40-60 age range (which is more representative of the older adults in our sample) are less pronounced or sometimes not observed 53 , 56 , 57 . The demographic differences in samples have implications for theory as well. For example, Hills et al. 53 found that semantic retrieval is affected more by changes to executive functioning than processing speed, in contrast to our findings, but their sample had a median age of 68 and a maximum of 99 years old. We caution against generalizing our findings to others who are not representative of our sample demographics (e.g., those 70+ years old). Future work could fill this gap by assessing optimal foraging patterns in a wider age range and in a longitudinal rather than cross-sectional study.
In our data, we denote a cluster switch as any two adjacent responses that do not share a taxonomic category, also known as an associative cluster switch 58 or fluid cluster switch 51 . However, several methods for demarcating clusters have been used in the literature, including human annotation 59 , word-embedding approaches 7 , 60 , 61 , and a single-category cluster approach 19 . We have not verified whether our results hold using alternative methods.
It is important to note that we do not make claims about how people choose to search on an explicit or conscious level. For example, people may choose to list animals alphabetically, or by visualizing themselves walking around a zoo 24 , but our analyses are theoretically neutral regarding this. Rather, our use of the term “optimal” refers to the fact that the timing of cluster switches maximizes the total number of animal listed given the within-cluster retrieval rate, consistent with previous work in the optimal foraging literature, both in ecology and in semantic retrieval 1 , 3 , 6 , 7 . Future work could explore whether instructing participants to engage in a specific cognitive retrieval strategy 13 affects whether search is optimal.
Finally, we provide evidence for optimal retrieval only in animal naming. Animal naming is the most commonly used category for the semantic fluency task, and is used in both research and clinical settings 62 . However, many semantic categories have been explored in the literature (e.g. 48 ) and it is possible that our results do not extend to all semantic categories. Future work should explore whether these results extend to retrieval in other semantic categories (e.g., tools) and to other variants of the fluency task such as phonemic fluency (e.g., listing words that begin with a particular letter).
Conclusions
We provide an analogy between animal foraging and mental search, and borrow a mathematical framework from the former to evaluate the latter. In the animal foraging literature, the foraging environment is directly observable. In contrast, the semantic representation that we use for mental search is not observable. Though techniques have been developed to estimate semantic representations 49 , 63 , they still rely on making inferences from behavioral data. As a result, it is difficult to differentiate between competing accounts of how optimal search is implemented in the mind.
We provided a normative analysis of semantic retrieval at the level of an individual and demonstrated that the mind is nearly optimal given the goal of maximizing retrieval rate. How might the mind accomplish this? Broadly, there are two mechanisms that could produce this behavioral pattern: we call them the efficient retrieval hypothesis and the efficient representation hypothesis .
Under the efficient retrieval hypothesis, people engage in strategic search over a clustered semantic representation 7 , 61 , 64 . The decision to switch clusters is guided by a metacognitive process in which people keep track of how long it takes to mentally switch between semantic clusters and the rate of return within the current cluster. With this information, the mind could monitor the rate of retrieval within a cluster and “decide” to switch clusters when the local rate of return drops below the average rate of return across all clusters.
Alternatively, the efficient representation hypothesis suggests that the mind has developed an efficient way of organizing semantic knowledge. Under this hypothesis, an individual’s semantic representation adapts to exhibit optimal search behavior with a simple retrieval process, such as a random walk or Levy flight 6 , 65 , 66 , even though the same process does not necessarily produce optimal search behavior under other representations. Previous evidence has suggested that we may use preferential attachment to integrate newly learned concepts within our existing semantic knowledge 67 , which can result in highly efficient small-world-like semantic representations 68 . Under this account, people do not need to possess any metacognitive awareness of clusters or switching. Rather, these constructs may be epiphenomenal—observable in the data, but not resulting from any real psychological mechanism associated with “switching” as previously proposed 19 .
Prior work has found evidence that is consistent with each of these hypotheses. In support of the efficient retrieval hypothesis, there is ample evidence that executive functioning plays a role in semantic fluency and this is commonly (though not always) attributed to strategic search 19 . Recent work has found a unique neural signature associated with switching but not clustering 61 as well as ramping activity during within-cluster search that could encode rate of retrieval necessary to guide switching behavior. Computational models of the fluency task that assume a special role for cluster switching also provide a good fit to behavioral data 7 .
In support of the efficient representation hypothesis, there is growing evidence that one’s semantic representation changes with age 28 , 29 , 30 . For example, clusters within a semantic representation become more sparse 31 , which may explain why within-cluster search slowed with age for participants in the experiment. Other work has shown that semantic representations may become more modular with age 69 , 70 . If executive functioning plays a selective role in cluster switching 19 , 61 , one might expect age-related declines in executive functioning to disrupt efficient retrieval. The persistence of optimal foraging across the lifespan may be taken as evidence that representational changes counteract a decline in executive functioning. In other words, perhaps optimal foraging is preserved with age because of these structural changes, rather than in spite of them. Computational models of the semantic fluency task have also been proposed that do not assume a special role for cluster switching and predict optimal foraging behavior ( 6 ; though see 71 ).
Still, the two hypotheses are not mutually exclusive, as semantic representation and retrieval processes can interact in complex ways 72 , 73 . Isolating the contributions of representation and process in semantic search has proved difficult 74 , 75 , making it hard to provide strong support in favor of the efficient retrieval or efficient representation hypotheses. Future empirical contributions combined with advancements in cognitive modeling and neuroimaging may lead to predictions that disambiguate these theories.
Data availibility
Supplementary material including all data and code is available at https://osf.io/yc625/ .
Charnov, E. L. Optimal foraging: The marginal value theorem. Theor. Popul. Biol. 9 , 129–136 (1976).
Article PubMed CAS Google Scholar
Pyke, G. H. Optimal foraging theory: A critical review. Annu. Rev. Ecol. Syst. 15 (1), 523–575 (1984).
Article MathSciNet Google Scholar
Stephens, D. W. & Krebs, J. R. Foraging Theory Vol. 1 (Princeton University Press, 1986).
Google Scholar
Ranc, N., Moorcroft, P. R., Ossi, F. & Cagnacci, F. Experimental evidence of memory-based foraging decisions in a large wild mammal. Proc. Natl. Acad. Sci. 118 (15), e2014856118 (2021).
Article PubMed PubMed Central CAS Google Scholar
Ehinger, K. A. & Wolfe, J. M. When is it time to move to the next map? Optimal foraging in guided visual search. Atten. Percept. Psychophys. 78 (7), 2135–2151 (2016).
Article PubMed PubMed Central Google Scholar
Abbott, J., Austerweil, J. & Griffiths, T. Random walks on semantic networks can resemble optimal foraging. Psychol. Rev. 122 (3), 558–569 (2015).
Article PubMed Google Scholar
Hills, T. T., Jones, M. N. & Todd, P. M. Optimal foraging in semantic memory. Psychol. Rev. 119 (2), 431–440 (2012).
Pirolli, P. Information Foraging Theory: Adaptive Interaction with Information (Oxford University Press, 2007).
Book Google Scholar
Hutchinson, J. M. C., Wilke, A. & Todd, P. M. Patch leaving in humans: Can a generalist adapt its rules to dispersal of items across patches? Anim. Behav. 75 , 1331–1349 (2008).
Article Google Scholar
Hart, Y. et al. Creative foraging: An experimental paradigm for studying exploration and discovery. PloS One 12 (8), e0182133 (2017).
Ebbinghaus, H. Über das gedächtnis (Dunker, Lepzig, 1885).
Anderson, J. R. Is human cognition adaptive? Behav. Brain Sci. 14 (3), 471–485 (1991).
Wulff, D. U., Hills, T. T. & Hertwig, R. Memory is one representation not many: Evidence against wormholes in memory. (Retrieved from https://psyarxiv.com/b5ynj/ ), (2020).
Salthouse, T. A. The processing-speed theory of adult age differences in cognition. Psychol. Rev. 103 (3), 403–428 (1996).
Hasher, L. & Zacks, R. T. Working memory, comprehension, and aging: A review and a new view. Psychol. Learn. Motiv. 22 , 193–225 (1988).
Todd, P. M. & Hills, T. T. Foraging in mind. Curr. Dir. Psychol. Sci. 29 (3), 309–315 (2020).
Hills, T. T., Todd, P. M., Lazer, D., Redish, A. D. & Couzin, I. D. Exploration versus exploitation in space, mind, and society. Trends Cogn. Sci. 19 (1), 46–54 (2015).
Mehlhorn, K. et al. Unpacking the exploration-exploitation tradeoff: A synthesis of human and animal literatures. Decision 2 (3), 191–216 (2015).
Troyer, A. K., Moscovitch, M. & Winocur, G. Clustering and switching as two components of verbal fluency: Evidence from younger and older healthy adults. Neuropsychology 11 (1), 138–146 (1997).
Kenett, Y. N., Levi, E., Anaki, D. & Faust, M. The semantic distance task: Quantifying semantic distance with semantic network path length. J. Exp. Psychol. Learn. Mem. Cogn. 43 (9), 1470–1489 (2017).
Kumar, A. A., Balota, D. A. & Steyvers, M. Distant connectivity and multiple-step priming in large-scale semantic networks. J. Exp. Psychol. Learn. Mem. Cogn. 46 (12), 2261 (2020).
Montez, P., Thompson, G. & Kello, C. T. The role of semantic clustering in optimal memory foraging. Cogn. Sci. 39 (8), 1925–1939 (2015).
Unsworth, N. Examining the dynamics of strategic search from long-term memory. J. Mem. Lang. 93 , 135–153 (2017).
Unsworth, N., Brewer, G. A. & Spillers, G. J. Strategic search from long-term memory: An examination of semantic and autobiographical recall. Memory 22 (6), 687–699 (2014).
Marr, D. & Poggio, T. From understanding computation to understanding neural circuitry. AI Memo 357 , 1–22 (1976).
Brysbaert, M., Stevens, M., Mandera, P. & Keuleers, E. How many words do we know? Practical estimates of vocabulary size dependent on word definition, the degree of language input and the participant’s age. Front. Psychol. 7 , 1116 (2016).
Verhaeghen, P. Aging and vocabulary score: A meta-analysis. Psychol. Aging 18 (2), 332–339 (2003).
Wulff, D. U. et al. New perspectives on the aging lexicon. Trends Cogn. Sci. 23 (8), 686–698 (2019).
Wulff, D. U., Hills, T. T. & Mata, R. Structural differences in the semantic networks of younger and older adults. Sci. Rep. 12 (1), 21459 (2022).
Article PubMed PubMed Central ADS CAS Google Scholar
Amer, T., Wynn, J. S. & Hasher, L. Cluttered memory representations shape cognition in old age. Trends Cogn. Sci. 26 (3), 255–267 (2022).
Dubossarsky, H., De Deyne, S. & Hills, T. T. Quantifying the structure of free association networks across the life span. Dev. Psychol. 53 (8) (2017).
Ramscar, M., Hendrix, P., Shaoul, C., Milin, P. & Baayen, H. The myth of cognitive decline: Non-linear dynamics of lifelong learning. Top. Cogn. Sci. 6 (1), 5–42 (2014).
Bowles, N. L. & Poon, L. W. Aging and retrieval of words in semantic memory. J. Gerontol. 40 (1), 71–77 (1985).
Burke, D. M. & Shafto, M. A. Aging and language production. Curr. Dir. Psychol. Sci. 13 (1), 21–24 (2004).
Lustig, C., Hasher, L. & Zacks, R. T. Inhibitory deficit theory: Recent developments in a “new view’’. In Inhibition in Cognition (eds Gorfein, D. S. & MacLeod, C. M.) 145–162 (American Psychological Association, 2007).
Chapter Google Scholar
Phillips, L. H. & Henry, J. D. Adult aging and executive functioning. In Executive functions and the frontal lobes 91–114. (Psychology Press, 2010).
Troyer, A. K., Moscovitch, M., Winocur, G., Alexander, M. P. & Stuss, D. Clustering and switching on verbal fluency: The effects of focal frontal-and temporal-lobe lesions. Neuropsychologia 36 (6), 499–504 (1998).
Shao, Z., Janse, E., Visser, K. & Meyer, A. S. What do verbal fluency tasks measure? Predictors of verbal fluency performance in older adults. Front. Psychol. 5 , 1–10 (2014).
Amunts, J., Camilleri, J. A., Eickhoff, S. B., Heim, S. & Weis, S. Executive functions predict verbal fluency scores in healthy participants. Sci. Rep. 10 (1), 11141 (2020).
Ovando-Tellez, M. et al. An investigation of the cognitive and neural correlates of semantic memory search related to creative ability. Commun. Biol. 5 (1), 1–16 (2022).
Moscovitch, M. Cognitive resources and dual-task interference effects at retrieval in normal people: The role of the frontal lobes and medial temporal cortex. Neuropsychology 8 (4), 524–534 (1994).
Mayr, U. & Kliegl, R. Complex semantic processing in old age: Does it stay or does it go? Psychol. Aging 15 (1), 29–43 (2000).
Mayr, U. On the dissociation between clustering and switching in verbal fluency: Comment on Troyer, Moscovitch, Winocur, Alexander and Stuss. Neuropsychologia 40 (5), 562–566 (2002).
Verhaeghen, P. Aging and executive control: Reports of a demise greatly exaggerated. Curr. Dir. Psychol. Sci. 20 (3), 174–180 (2011).
Elgamal, S. A., Roy, E. A. & Sharratt, M. T. Age and verbal fluency: The mediating effect of speed of processing. Can. Geriatr. J CGJ 14 (3), 66–72 (2011).
McDowd, J. et al. Understanding verbal fluency in healthy aging, Alzheimer’s disease, and Parkinson’s disease. Neuropsychology 25 (2), 210–225 (2011).
Bousfield, W. A. & Sedgewick, C. H. W. An analysis of sequences of restricted associative responses. J. Gen. Psychol. 30 (2), 149–165 (1944).
Castro, N., Curley, T. & Hertzog, C. Category norms with a cross-sectional sample of adults in the United States: Consideration of cohort, age, and historical effects on semantic categories. Behav. Res. Methods 53 , 898–917 (2021).
Zemla, J. C. & Austerweil, J. L. Estimating semantic networks of groups and individuals from fluency data. Comput. Brain Behav. 1 (1), 36–58 (2018).
Zemla, J. C. & Austerweil, J. L. Modeling semantic fluency data as search on a semantic network. In Annual Conference of the Cognitive Science Society Vol. 2017, 3646–3651 (2017).
Zemla, J. C., Cao, K., Mueller, K. D. & Austerweil, J. L. SNAFU: The semantic network and fluency utility. Behav. Res. Methods 1–19 (2020).
Mobbs, D., Trimmer, P. C., Blumstein, D. T. & Dayan, P. Foraging for foundations in decision neuroscience: Insights from ethology. Nat. Rev. Neurosci. 19 (7), 419–427 (2018).
Hills, T. T., Mata, R., Wilke, A. & Samanez-Larkin, G. R. Mechanisms of age-related decline in memory search across the adult life span. Dev. Psychol. 49 (12), (2013).
Kavé, G. & Knafo-Noam, A. Lifespan development of phonemic and semantic fluency: Universal increase, differential decrease. J. Clin. Exp. Neuropsychol. 37 (7), 751–763 (2015).
Kavé, G., Knafo, A. & Gilboa, A. The rise and fall of word retrieval across the lifespan. Psychol. Aging 25 (3), 719–734 (2010).
Tombaugh, T. N., Kozak, J. & Rees, L. Normative data stratified by age and education for two measures of verbal fluency: FAS and animal naming. Arch. Clin. Neuropsychol. 14 (2), 167–177 (1999).
PubMed CAS Google Scholar
Brickman, A. M. et al. Category and letter verbal fluency across the adult lifespan: Relationship to EEG theta power. Arch. Clin. Neuropsychol. 20 (5), 561–573 (2005).
Hills, T. T., Todd, P. M. & Jones, M. N. Foraging in semantic fields: How we search through memory. Top. Cogn. Sci. 7 , 513–534 (2015).
Mueller, K. D. et al. Verbal fluency and early memory decline: Results from the Wisconsin Registry for Alzheimer’s Prevention. Arch. Clin. Neuropsychol. 30 (5), 448–457 (2015).
Kumar, A., Apsel, M., Zhang, L., Xing, N. & Jones, M. N. forager: A Python package and web interface for modeling mental search. (Retrieved from https://psyarxiv.com/3y9df/ ), (2023).
Lundin, N. B. et al. Neural evidence of switch processes during semantic and phonetic foraging in human memory. Proc. Natl. Acad. Sci. 120 (42), e2312462120 (2023).
Weintraub, S. et al. The Alzheimer’s disease centers’ uniform data set (UDS): The neuropsychological test battery. Alzheimer Dis. Assoc. Disord. 23 (2), 91–101 (2009).
Zemla, J. C. Knowledge representations derived from semantic fluency data. Front. Psychol. 13 (2022).
Zhang, Q. & Anderson, J. R. A rational account of human memory search. bioRxiv, 326397 (2018).
Viswanathan, G. M. et al. Optimizing the success of random searches. Nature 401 (6756), 911–914 (1999).
Article PubMed ADS CAS Google Scholar
Patten, K. J., Greer, K., Likens, A. D., Amazeen, E. L. & Amazeen, P. G. The trajectory of thought: Heavy-tailed distributions in memory foraging promote efficiency. Mem. Cogn. , 1–16 (2020).
Mak, M. H. & Twitchell, H. Evidence for preferential attachment: Words that are more well connected in semantic networks are better at acquiring new links in paired-associate learning. Psychon. Bull. Rev. 27 (5), 1059–1069 (2020).
Steyvers, M. & Tenenbaum, J. B. The large-scale structure of semantic networks: Statistical analyses and a model of semantic growth. Cogn. Sci. 29 (1), 41–78 (2005).
Cosgrove, A. L., Beaty, R. E., Diaz, M. T. & Kenett, Y. N. Age differences in semantic network structure: Acquiring knowledge shapes semantic memory. Psychol. Aging (2023).
Cosgrove, A. L., Kenett, Y. N., Beaty, R. E. & Diaz, M. T. Quantifying flexibility in thought: The resiliency of semantic networks differs across the lifespan. Cognition 211 , 104631 (2021).
Jones, M. N., Hills, T. T. & Todd, P. M. Hidden processes in structural representations: A reply to Abbott, Austerweil, and Griffiths (2015). Psychol. Rev. 122 (3), 570–574 (2015).
Marko, M. & Riečanskỳ, I. The structure of semantic representation shapes controlled semantic retrieval. Memory 29 (4), 538–546 (2021).
Michalko, D., Marko, M. & Riečanskỳ, I. Response modularity moderates how executive control aids fluent semantic memory retrieval. Memory , 1–8 (2023).
Castro, N. & Siew, C. S. Contributions of modern network science to the cognitive sciences: Revisiting research spirals of representation and process. Proc. R. Soc. A 476 (2238), 20190825 (2020).
Article MathSciNet PubMed PubMed Central ADS Google Scholar
Hills, T. T. & Kenett, Y. N. Is the mind a network? Maps, vehicles, and skyhooks in cognitive network science. Top. Cogn. Sci. 14 (1), 189–208 (2022).
Download references
Acknowledgements
The authors would like to thank the study participants, Blake Chambers and Maggie Parker for their assistance with data management and scoring, as well as Thomas Hills and two anonymous reviewers for their feedback on earlier versions of this manuscript.
J.Z. was supported in part by NLM T15LM007359. D.G. was supported by a Leon Epstein Faculty Research Fellowship.
Author information
Authors and affiliations.
Department of Psychology, Syracuse University, Syracuse, NY, USA
Jeffrey C. Zemla
Department of Psychology, College of Letters and Science, University of Wisconsin-Madison, Madison, WI, USA
Diane C. Gooding & Joseph L. Austerweil
Department of Psychiatry, SMPH, University of Wisconsin-Madison, Madison, WI, USA
Diane C. Gooding
Department of Medicine, Division of Gerontology and Geriatrics, SMPH, University of Wisconsin-Madison, Madison, WI, USA
You can also search for this author in PubMed Google Scholar
Contributions
The study hypotheses were conceived of by J.Z. and J.A. The analyses were conducted by J.Z. and the figures were prepared by J.Z. The manuscript was initially written by J.Z. and reviewed and edited by D.G. and J.A. Funding was provided by D.G. and J.A.
Corresponding author
Correspondence to Jeffrey C. Zemla .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Zemla, J.C., Gooding, D.C. & Austerweil, J.L. Evidence for optimal semantic search throughout adulthood. Sci Rep 13 , 22528 (2023). https://doi.org/10.1038/s41598-023-49858-9
Download citation
Received : 02 February 2023
Accepted : 12 December 2023
Published : 18 December 2023
DOI : https://doi.org/10.1038/s41598-023-49858-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Leveraging Semantic Search and LLMs for Domain-Adaptive Information Retrieval
- Conference paper
- First Online: 10 January 2024
- Cite this conference paper

- Falk Maoro ORCID: orcid.org/0009-0008-9041-3963 8 ,
- Benjamin Vehmeyer ORCID: orcid.org/0009-0009-7974-8479 8 &
- Michaela Geierhos ORCID: orcid.org/0000-0002-8180-5606 8
Part of the book series: Communications in Computer and Information Science ((CCIS,volume 1979))
Included in the following conference series:
- International Conference on Information and Software Technologies
249 Accesses
The rapid growth of digital information and the increasing complexity of user queries have made traditional search methods less effective in the context of business-related websites. This paper presents an innovative approach to improve the search experience across a variety of domains, particularly in the industrial sector, by integrating semantic search and conversational large language models such as GPT-3.5 into a domain-adaptive question-answering framework. Our proposed solution aims at complementing existing keyword-based approaches with the ability to capture entire questions or problems. By using all types of text, such as product manuals, documentation, advertisements, and other documents, all types of questions relevant to a website can be answered. These questions can be simple requests for product or domain knowledge, assistance in using a product, or more complex questions that may be relevant in determining the value of organizations as potential collaborators. We also introduce a mechanism for users to ask follow-up questions and to establish subject-specific communication with the search system. The results of our feasibility study show that the integration of semantic search and GPT-3.5 leads to significant improvements in the search experience, which could then translate into higher user satisfaction when querying the corporate portfolio. This research contributes to the ongoing development of advanced search technologies and has implications for a variety of industries seeking to unlock their hidden value.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Search Support Tools

NL-Graphs: A Hybrid Approach toward Interactively Querying Semantic Data

How Ontology Based Information Retrieval Systems May Benefit from Lexical Text Analysis
https://solr.apache.org , last accessed 2023-07-24.
https://openai.com/blog/new-and-improved-embedding-model , last accessed 2023-07-24.
https://streamlit.io , last accessed 2023-07-24.
https://haystack.deepset.ai , last accessed 2023-07-24.
https://platform.openai.com , last accessed 2023-07-24.
Almazrouei, E., et al.: Falcon-40B: an open large language model with state-of-the-art performance (2023)
Google Scholar
Bast, H., Buchhold, B., Haussmann, E.: Semantic search on text and knowledge bases. Found. Trends® Inf. Retrieval 10 (2–3), 119–271 (2016). https://doi.org/10.1561/1500000032
Article Google Scholar
Brown, T., et al.: Language models are few-shot learners. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901. Curran Associates, Inc. (2020). https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
Cer, D., et al.: Universal sentence encoder for English. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 169–174. Association for Computational Linguistics, Brussels (2018). https://doi.org/10.18653/v1/D18-2029 . https://aclanthology.org/D18-2029
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics, Minneapolis (2019). https://doi.org/10.18653/v1/N19-1423 . https://aclanthology.org/N19-1423
Hirschberg, J., Manning, C.D.: Advances in natural language processing. Science 349 (6245), 261–266 (2015). https://doi.org/10.1126/science.aaa8685
Article MathSciNet Google Scholar
Liu, Y., et al.: RoBERTa: a robustly optimized BERT pretraining approach. CoRR abs/1907.11692 (2019). http://arxiv.org/abs/1907.11692
Ouyang, L., et al.: Training language models to follow instructions with human feedback. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems, vol. 35, pp. 27730–27744. Curran Associates, Inc. (2022). https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I., et al.: Improving language understanding by generative pre-training. OpenAI Blog (2018)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al.: Language models are unsupervised multitask learners. OpenAI Blog 1 (8), 9 (2019)
Raffel, C., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21 (140), 1–67 (2020). http://jmlr.org/papers/v21/20-074.html
Reimers, N., Gurevych, I.: Sentence-BERT: sentence embeddings using Siamese BERT-networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3982–3992. Association for Computational Linguistics, Hong Kong (2019). https://doi.org/10.18653/v1/D19-1410 . https://aclanthology.org/D19-1410
Saini, B., Singh, V., Kumar, S.: Information retrieval models and searching methodologies: survey. Int. J. Adv. Found. Res. Sci. Eng. (IJAFRSE) 1 , 20 (2014)
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR abs/1910.01108 (2019). http://arxiv.org/abs/1910.01108
Team, M.N.: Introducing MPT-7B: a new standard for open-source, commercially usable LLMs (2023). www.mosaicml.com/blog/mpt-7b . Accessed 24 July 2023
Touvron, H., et al.: LLaMA: open and efficient foundation language models (2023)
Vaswani, A., et al.: Attention is all you need. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc. (2017). https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Yang, Z., Dai, Z., Yang, Y., Carbonell, J.G., Salakhutdinov, R., Le, Q.V.: XLNet: generalized autoregressive pretraining for language understanding. In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32: NeurIPS 2019, Vancouver, BC, Canada, pp. 5754–5764 (2019)
Zhang, S., et al.: OPT: open pre-trained transformer language models (2022)
Download references
Acknowledgments
This work was co-funded by the German Federal Ministry of Education and Research under grants 13N16242 and 01IO2208E.
Author information
Authors and affiliations.
University of the Bundeswehr Munich, Neubiberg, Germany
Falk Maoro, Benjamin Vehmeyer & Michaela Geierhos
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Falk Maoro .
Editor information
Editors and affiliations.
Kaunas University of Technology, Kaunas, Lithuania
Audrius Lopata
Daina Gudonienė
Rita Butkienė
Rights and permissions
Reprints and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper
Cite this paper.
Maoro, F., Vehmeyer, B., Geierhos, M. (2024). Leveraging Semantic Search and LLMs for Domain-Adaptive Information Retrieval. In: Lopata, A., Gudonienė, D., Butkienė, R. (eds) Information and Software Technologies. ICIST 2023. Communications in Computer and Information Science, vol 1979. Springer, Cham. https://doi.org/10.1007/978-3-031-48981-5_12
Download citation
DOI : https://doi.org/10.1007/978-3-031-48981-5_12
Published : 10 January 2024
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-48980-8
Online ISBN : 978-3-031-48981-5
eBook Packages : Computer Science Computer Science (R0)
Share this paper
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Literature Reviews
- Getting Started
- Choosing a Type of Review
- Developing a Research Question
- Searching the Literature
- Searching Tips
Literature Searching using Artificial Intelligence
- Research Rabbit
- Semantic Scholar
- ChatGPT [beta]
- Documenting your Search
- Using Citation Managers
- Concept Mapping
- Writing the Review
- Further Resources
Plug-ins for GenAI
Artificial Intelligence tools are fast-changing. Make sure to check each tool for features you are looking for.
Click the tool name below to jump directly there.

www.researchrabbit.ai
100s of millions of academic articles and covers more than 90%+ of materials that can be found in major databases used by academic institutions (such as Scopus, Web of Science, and others).
- See its FAQs page. Search algorithms were borrowed from NIH and Semantic Scholar.
The default “Untitled Collection” will collect your search histories, based on which Research Rabbit will send you recommendations for three types of related results: Similar Works / Earlier Works / Later Works, viewable in graph such as Network, Timeline, First Authors etc.
Zotero integration: importing and exporting between these two apps.
- Example - SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality [Login required] Try it to see its Similar Works, Earlier Works and Later Works or other documents.
- Export Results - Findings can be exported in BibTxt, RIS or CSV format.

MORE RESOURCES
Video Introduction to Research Rabbit

https://elicit.org
Elicit is a research assistant using language models like GPT-3 to automate parts of researchers’ workflows. Currently, the main workflow in Elicit is Literature Review. If you ask a question, Elicit will show relevant papers and summaries of key information about those papers in an easy-to-use table.
- Find answers from 175 million papers. FAQS
- Example - How do mental health interventions vary by age group? / Fish oil and depression Results: [Login required] (1) Summary of top 4 papers > Paper #1 - #4 with Title, abstract, citations, DOI, and pdf (2) Table view: Abstract / Interventions / Outcomes measured / Number of participants (3) Relevant studies and citations. (4) Click on Search for Paper Information to find - Metadata about Sources ( SJR etc.) >Population ( age etc.) >Intervention ( duration etc.) > Results ( outcome, limitations etc.) and > Methodology (detailed study design etc.) (5) Export as BIB or CSV
- How to Search Enter a research question or multiple keywords about a research question. Enter the title of a paper. The stared or selected studies will lead to Semantic Scholar 's site for detailed information for all citations.
- Export Results - Various ways to export results.
- How to Cite - Includes the elicit.org URL in the citation, for example: Ought; Elicit: The AI Research Assistant; https://elicit.org; accessed xxxx/xx/xx
www.semanticscholar.org
A free, AI-powered research tool for scientific literature.
- Over 200 millions of papers from all fields of science.
The 4000+ results can be sorted by Fields of Study, Date Range, Author, Journals & Conferences
Save the papers in your Library folder. The Research Feeds will recommend similar papers based on the items saved.
Example - SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality Total Citations: 22,438 [Note: these numbers were gathered when this guide was created] Highly Influential Citations 2,001 Background Citations 6,109 Methods Citations 3,273 Results Citations 385
Semantic Reader "Semantic Reader is an augmented reader with the potential to revolutionize scientific reading by making it more accessible and richly contextual" . It "uses artificial intelligence to understand a document’s structure and merge it with the Semantic Scholar’s academic corpus, providing detailed information in context via tooltips and other overlays ." <https://www.semanticscholar.org/product/semantic-reader>. Skim Papers Faster "Find key points of this paper using automatically highlighted overlays. Available in beta on limited papers for desktop devices only." <https://www.semanticscholar.org/product/semantic-reader>. Press on the pen icon to activate the highlights.
TLDRs (Too Long; Didn't Read) Try this example . Press the pen icon to reveal the highlighted key points . TLDRs "are super-short summaries of the main objective and results of a scientific paper generated using expert background knowledge and the latest GPT-3 style NLP techniques. This new feature is available in beta for nearly 60 million papers in computer science, biology, and medicine..." < https://www.semanticscholar.org/product/tldr>
- << Previous: Searching Tips
- Next: ChatGPT [beta] >>
- Last Updated: May 9, 2024 11:44 AM
- URL: https://guides.lib.umich.edu/litreview
- Research Guides
- University Libraries
AI-Based Literature Review Tools
- Dialogues: Insightful Facts
- How to Craft Prompts
- Plugins / Extensions for AI-powered Searches
- Cite ChatGPT in APA / MLA
- AI and Plagiarism
- ChatGPT & Higher Education
- Author Profile
Selected AI-Based Literature Review Tools
Updates: See news or release of AI (Beta) across various academic research databases including Web of Science , Scopus , Ebsco , ProQues t, OVID , Dimensions , JStor , Westlaw , and LexisNexis . ********* ********** ********** ********** **********
Disclaimer: TAMU libraries do not have subscription access to the AI-powered tools listed below the divider line. The guide serves solely as an informational resource. It is recommended that you assess these tools and their usage methodologies independently. ------------------------------------------------------------------------------------------------------------------------------------------------------------- SEMANTIC SCHOLAR
- SCIENTIFIC LITERATURE SEARCH ENGINE - finding semantically similar research papers.
- " A free, AI-powered research tool for scientific literature." <https://www.semanticscholar.org/>. But login is required in order to use all functions.
- Over 200 millions of papers from all fields of science, the data of which has also served as a wellspring for the development of other AI-driven tools.
The 4000+ results can be sorted by Fields of Study, Date Range, Author, Journals & Conferences
Save the papers in your Library folder. The Research Feeds will recommend similar papers based on the items saved.
Example - SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality Total Citations: 22,438 [Note: these numbers were gathered when this guide was created] Highly Influential Citations 2,001 Background Citations 6,109 Methods Citations 3,273 Results Citations 385

TLDRs (Too Long; Didn't Read) Try this example . Press the pen icon to reveal the highlighted key points . TLDRs "are super-short summaries of the main objective and results of a scientific paper generated using expert background knowledge and the latest GPT-3 style NLP techniques. This new feature is available in beta for nearly 60 million papers in computer science, biology, and medicine..." < https://www.semanticscholar.org/product/tldr>
- https://www.openread.academy/
- Institutionally accessed by Harvard, MIT, University of Oxford, Johns Hopkins, Standford, Beijing University. .
- AI-powered Academic Searching + Web Searching - Over 300 million papers and real-time web content.
- Every keyword search or AI quest will yield a synthesis report with citations. If you want to re-orient the search outcomes, just click on the Re-generate button and all citations will be refreshed accordingly. After that click on Follow-Up Questions to delve deeper into a particular area or subject.
- Use Paper Q&A to interact with a text directly, e.g. " What does this paper say about literature review ?"
- Click on the Translation to put a text or search results into another language.
- Upload a PDF document and let Paper Expresso to read it for you and parse the content into an academic report format for easy screening: Background and context> Research objectives and hypotheses> Methodology> Results and findings> Discussion and interpretation> Contributions to the field > Structure and flow> Achievements and significance> Limitations and future work>
- AI-POWERED RESEARCH ASSISTANT - finding papers, filtering study types, automating research flow, brainstorming, summarizing and more.
- " Elicit is a research assistant using language models like GPT-3 to automate parts of researchers’ workflows. Currently, the main workflow in Elicit is Literature Review. If you ask a question, Elicit will show relevant papers and summaries of key information about those papers in an easy-to-use table." <https://elicit.org/faq#what-is-elicit.>; Find answers from 175 million papers. FAQS
- Example - How do mental health interventions vary by age group? / Fish oil and depression Results: [Login required] (1) Summary of top 4 papers > Paper #1 - #4 with Title, abstract, citations, DOI, and pdf (2) Table view: Abstract / Interventions / Outcomes measured / Number of participants (3) Relevant studies and citations. (4) Click on Search for Paper Information to find - Metadata about Sources ( SJR etc.) >Population ( age etc.) >Intervention ( duration etc.) > Results ( outcome, limitations etc.) and > Methodology (detailed study design etc.) (5) Export as BIB or CSV
- How to Search / Extract Data / List of Concept Search -Enter a research question >Workflow: Searching > Summarizing 8 papers> A summary of 4 top papers > Final answers. Each result will show its citation counts, DOI, and a full-text link to Semantic Scholar website for more information such as background citations, methods citation, related papers and more. - List of Concepts search - e.g. adult learning motivation . The results will present a list the related concepts. - Extract data from a pdf file - Upload a paper and let Elicit extract data for you.
- Export Results - Various ways to export results.
- How to Cite - Includes the elicit.org URL in the citation, for example: Ought; Elicit: The AI Research Assistant; https://elicit.org; accessed xxxx/xx/xx
CONSENSUS.APP
ACADEMIC SEARCH ENGINE- using AI to find insights in research papers.
"We are a search engine that is designed to accept research questions, find relevant answers within research papers, and synthesize the results using the same language model technology." <https://consensus.app/home/blog/maximize-your-consensus-experience-with-these-best-practices/>
- Example - Does the death penalty reduce the crime? / Fish oil and depression / (1) Extracted & aggregated findings from relevant papers. (2) Results may include AIMS, DESIGN, PARTICIPANTS, FINDINGS or other methodological or report components. (3) Summaries and Full Text
- How to Search Direct questions - Does the death penalty reduce the crime? Relationship between two concepts - Fish oil and depression / Does X cause Y? Open-ended concepts - effects of immigration on local economics Tips and search examples from Consensus' Best Practice
- Synthesize (beta) / Consensus Meter When the AI recognizes certain types of research questions, this functionality may be activated. It will examine a selection of some studies and provide a summary along with a Consensus Meter illustrating their collective agreement. Try this search: Is white rice linked to diabetes? The Consensus Meter reveals the following outcomes after analyzing 10 papers: 70% indicate a positive association, 20% suggest a possible connection, and 10% indicate no link.
Prompt “ write me a paragraph about the impact of climate change on GDP with citations “
CITATIONS IN CONTEXT
Integrated with Research Solutions.
Over 1.2 billion Citation Statements and metadata from over 181 million papers suggested reference.
How does it work? - "scite uses access to full-text articles and its deep learning model to tell you, for a given publication: - how many times it was cited by others - how it was cited by others by displaying the text where the citation happened from each citing paper - whether each citation offers supporting or contrasting evidence of the cited claims in the publication of interest, or simply mention it." <https://help.scite.ai/en-us/article/what-is-scite-1widqmr/>
EXAMPLE of seeing all citations and citation statements in one place
More information: Scite: A smart citation index that displays the context of citations and classifies their intent using deep learning
- GPT3.5 by OpenAI. Knowledge cutoff date is September 2021.
- Input/ Output length - ChatGPT-3.5 allows a maximum token limit of 4096 tokens. According to ChatGPT " On average, a token in English is roughly equivalent to 4 bytes or characters. English words are typically around 5 characters long. This means that, very roughly, you could fit around 800 to 1000 English words within 4096 tokens."
- According to ChatGPT, the generated responses are non-deterministic by default. So if you run the searches again and get slightly or very different results, it's likely due to this factor.
- ChatGPT may find non-existent references.
- According to this study < https://arxiv.org/ftp/arxiv/papers/2304/2304.06794.pdf > "ChatGPT cites the most-cited articles and journals, relying solely on Google Scholar's citation counts" within the field of environmental science.
- Example - "INTERVIEW WITH CHATGPT" as a Research Method & Teaching Tool Some researchers began to use this approach to obtain their research data. Try this Google Scholar search link "interview with ChatGPT" or see two articles below: (1) Chatting about ChatGPT: how may AI and GPT impact academia and libraries? BD Lund, T Wang - Library Hi Tech News, 2023 (2) An interview with ChatGPT: discussing artificial intelligence in teaching, research, and practice , G Scaringi, M Loche - 2023
Increased risk of sudden infant death syndrome (SIDS) Increased risk of premature birth Increased risk of low birth weight Increased risk of respiratory problems in newborns Increased risk of respiratory problems in infants exposed to secondhand smoke Increased risk of developing asthma and other respiratory illnesses later in life for infants exposed to secondhand smoke [Note : ChatGPT may generate non-existent references or false knowledge. To find out why Large Language Models hallucinate, check out this Wiki article: Hallucination (artificial intelligence) and this blog post - A Gentle Introduction to Hallucinations in Large Language Models by Adrian Tam ]
Infant death Neonatal mortality (referring specifically to deaths within the first 28 days of life) Perinatal mortality (referring to deaths occurring during the period from 22 completed weeks of gestation to 7 completed days after birth) Early childhood mortality (referring to deaths occurring within the first five years of life) Child mortality (referring to deaths occurring before the age of 18) [Press the Regenerate button to get more.]
- Example - RELATED WORDS What are the related words of infant mortality? Neonatal mortality, Post-neonatal mortality, Stillbirths, Low birth weight, Malnutrition, Infectious diseases, Vaccination, Maternal health, Access to healthcare, Poverty, Social inequality, Sanitation, Hygiene, Water quality, Childbirth complications, Congenital abnormalities, Birth defects, Maternal age, Under-five mortality, Child mortality, Perinatal mortality, Preterm birth, Low birth weight, Sudden infant death syndrome (SIDS), Maternal mortality, Postnatal care, Malnutrition, Immunization, Access to healthcare, Clean water and sanitation, Congenital anomalies, Infant health disparities, Infant mortality rate (IMR), Infant survival.
(("Infant Death"[Mesh] OR "Sudden Infant Death Syndrome"[Mesh] OR "Infant Mortality"[Mesh] OR "Perinatal Mortality"[Mesh] OR "Neonatal Mortality"[Mesh] OR "Fetal Mortality"[Mesh] OR "Infant Death" OR "Sudden Infant Death Syndrome" OR "Infant Mortality" OR "Perinatal Mortality" OR "Neonatal Mortality" OR "Fetal Mortality") AND ("Risk Factors"[Mesh] OR "Etiology"[Mesh] OR "Prevention and Control"[Mesh] OR "Interventions"[Mesh] OR "Public Health"[Mesh] OR "Health Disparities"[Mesh] OR "Healthcare Disparities"[Mesh] OR "Poverty"[Mesh] OR "Malnutrition"[Mesh] OR "Infection"[Mesh] OR "Congenital Abnormalities"[Mesh] OR "Prematurity"[Mesh] OR "Low Birth Weight"[Mesh] OR "Maternal Education"[Mesh] OR "Maternal Health"[Mesh] OR "Risk Factors" OR "Etiology" OR "Prevention and Control" OR "Interventions" OR "Public Health" OR "Health Disparities" OR "Healthcare Disparities" OR "Poverty" OR "Malnutrition" OR "Infection" OR "Congenital Abnormalities" OR "Prematurity" OR "Low Birth Weight" OR "Maternal Education" OR "Maternal Health")) Comments and Suggestions: #1 -This search string may not work on all database platforms. For example, Medline (OVID) may not be able to run it, Medline & CINAHL (EBSCO) can run it without any problems while PubMed will run it but it will indicate which MeSH terms are not indexed. See PubMed's search History and Details under Advanced . #2 - This is just one possible combination. You may need to adjust it based on your task and the databases you are using . #3 - It might be easier if you break the task into 3 parts: ask for synonyms > ask for thesauri terms > and ask it to combine them.
Examples - DATABASE RECOMMENDATIONS Heath Science - Which databases to use to find articles on the EFFECTS OF MATERNAL SMOKING ON INFANT DEATH? PubMed: This is a database of biomedical literature from the National Library of Medicine. It includes articles from medical journals and other sources on a wide range of health-related topics. Embase: This is a database of biomedical literature that covers more international and pharmaceutical content than PubMed. It includes articles from medical journals and other sources on a wide range of health-related topics. Cochrane Library : This is a collection of databases that provides systematic reviews and meta-analyses of healthcare interventions, including interventions related to maternal smoking and infant death. Scopus: This is a multidisciplinary database that covers research from a wide range of fields, including health sciences. It includes articles from scientific journals, books, and conference proceedings. Web of Science: This is a database that covers research from a wide range of fields, including health sciences. It includes articles from scientific journals, books, and conference proceedings. CINAHL: This is a database of nursing and allied health literature, including articles on maternal smoking and infant death. [Note: The response above was copied and pasted directly from ChatGPT. No editing was added.] Education -- I am doing a meta-analysis on k-12 STEM education. What databases should I use? ERIC : This is a database of education research and information, including articles from journals, reports, and conference papers. It is a commonly used database for educational research. Education Source : This is a comprehensive database of education research and information, including articles from journals, books, and conference papers. Web of Science: This is a multidisciplinary database that covers research from a wide range of fields, including education. It includes articles from scientific journals, books, and conference proceedings. Scopus: This is another multidisciplinary database that covers research from a wide range of fields, including education. It includes articles from scientific journals, books, and conference proceedings. PsycINFO: This is a database of psychology research, including articles from journals, books, and dissertations. It can be useful for research on STEM education that includes psychological factors. Cochrane Library : This is a collection of databases that provides systematic reviews and meta-analyses of healthcare interventions including interventions related to education. [Author's note: You could also ask for the GREY LITERATURE sources related to the topic above,]
Example: ACT-AS-AN-EXPERT PROMPT Here's an alternative way to consolidate all the questions into a single consultation by using this popular Act-As-An-Expert prompt, aka, system message prompt: I am going to conduct a systematic review on games and mathematics related to K-12 education I want you to act as a systematic review expert . I will ask you some questions related to my research topic and you advise me on how to do it.
[You may ask one question at a time] My first question is "which databases should I use?" My second question is "what are the relevant subject terms, descriptors and key words?" My third question is "how to do data extraction?" ..... , .... Please note that the above prompts are merely for illustrative purposes. Actual questions may contain more specific instructions. As an example, for the first question, could you provide guidance on how to identify relevant publications? Specifically, can you provide a list of the primary databases and grey literature sources related to my topic?
Example - GREY LITERATURE Please show me all the resources that offer grey literature for conducting research in the field of education ERIC (Education Resources Information Center): https://eric.ed.gov/ OpenGrey: http://www.opengrey.eu/ British Education Index: https://www.ebscohost.com/academic/british-education-index WorldCat: https://www.worldcat.org/ ProQuest Dissertations & Theses Global: https://www.proquest.com/products-services/pqdtglobal.html EThOS (Electronic Theses Online Service): https://ethos.bl.uk/ Institutional Repositories of universities and academic institutions (search for specific institution repositories) American Educational Research Association (AERA): https://www.aera.net/ National Education Association (NEA): https://www.nea.org/ Association for Supervision and Curriculum Development (ASCD): http://www.ascd.org/ RAND Corporation: https://www.rand.org/ National Center for Education Research (NCER): https://ies.ed.gov/ncer/ National Center for Education Statistics (NCES): https://nces.ed.gov/ European Educational Research Association (EERA): https://www.eera-ecer.de/ UNESCO International Institute for Educational Planning (IIEP): http://www.iiep.unesco.org/ Organization for Economic Cooperation and Development (OECD): https://www.oecd.org/education/ Education Development Center (EDC): https://www.edc.org/ National Institute for Educational Policy Research (NIER) - Japan: https://www.nier.go.jp/ Australian Council for Educational Research (ACER): https://www.acer.org/ Canadian Education Association (CEA): https://www.cea-ace.ca/ My topic is about stem education. Which grey literature databases should I use? STEM Education Research Centre (SERC) Grey Literature Database National STEM Education Research Repository (NSERR) National Science Digital Library (NSDL) STEM Education Resource Center (SERC) GrayLit Network STEM Education Grey Literature Library
See other Comparison Examples under Bing AI.
Examples - ZERO SHOT, ONE SHOT & FEW SHOT PROMPTING for literature review See the examples on the left panel- How to Fine Tune Prompts
Bing Chat / Copilot
- Bing Chat has become Copilot.
- CONVERSATIONAL LLM 4.0 + SEARCH ENGINE. Connects to the Internet.
- Three conversation modes: More Creative, More Balanced or More Precise.
- Comparison - Prompt: My topic is about psychology. Which grey literature databases should I use? More Precise - PsycExtra, NIH Library and links to library guides, .gov and .org websites More Balanced - PsycExtra and three main research guides that mention psychology grey literature sources. More Creative- PsycExtra, LILACS, and Worldcat + definition of grey literature + suggestions on searching for professional association websites, newsletters, magazines, standards and guidelines, and other sources that may contain relevant information for your topic.
- Some examples below were tested in Bing Chat only.
- Example - factors of infant mortality Infant mortality is a term that refers to the death of infants before their first birthday. The leading causes of infant mortality include birth asphyxia, pneumonia, congenital malformations, term birth complications such as abnormal presentation of the fetus umbilical cord prolapse, or prolonged labor, neonatal infection, diarrhea, malaria, measles, and malnutrition1. Many situational factors lead to infant mortality such as the pregnant woman’s level of education, environmental conditions, political infrastructure, and level of medical support1. In the United States, a primary determinant of infant mortality risk is infant birth weight with lower birth weights increasing the risk of infant mortality. The determinants of low birth weight include socioeconomic, psychological, behavioral and environmental factors2.
- Example: PEER REVIEWED SOURCES I need to find some peer reviewed articles about infant mortality? The answer includes 5 articles. The first one is “Causes of death and infant mortality rates among full-term births in the United States between 2010 and 2012: An observational study” by Neha Bairoliya and Günther Fink1. A click on " Tell me more about the first article " leads to this summary: " The first article is titled “Causes of death and infant mortality rates among full-term births in the United States between 2010 and 2012: An observational study” and was published in PLOS Medicine on March 20, 2018. The authors are Neha Bairoliya and Günther Fink. The study used linked birth and death records for the period 2010–2012 to identify the state- and cause-specific burden of infant mortality among full-term infants (born at 37–42 weeks of gestation) in the United States. The researchers found that the full-term infant mortality rate (FTIMR) was 2.2 per 1,000 live births overall and ranged between 1.29 (Connecticut) and 3.77 (Mississippi) at the state level. Sudden unexpected death in infancy (SUDI) accounted for 43% of FTIM; congenital malformations and perinatal conditions accounted for 31% and 11.3% of FTIM, respectively. The largest mortality differentials between states with good and states with poor FTIMR were found for SUDI, with particularly large risk differentials for deaths due to sudden infant death syndrome (SIDS) and suffocation." More searches: Please find five empirical studies focusing on the factors influencing adult learners engaged in online education. Please locate five scholarly articles on stress management among college students site:pubmed.ncbi.nlm.nih.gov

The ERIC Thesaurus contains nearly 12,000 terms, including more than 4,500 descriptors and 7,000 synonyms1. You can use the term “Academic Achievement” or its synonyms such as “Educational Achievement”, “Student Achievement”, “Academic Performance”, “Academic Success”, “Learning Achievement” and more. [ Note : The follow-up responses include some additional sources. See two below: https://www.powerthesaurus.org/academic_achievement https://eric.ed.gov/?ti=Achievement+Gap including https://eric.ed.gov/?ti=Academic+Achievement |
My topic is about psychology. Which grey literature databases should I use?
ChatGPT PsycEXTRA : This database is produced by the American Psychological Association (APA) and includes grey literature such as conference papers, white papers, and government reports. OpenGrey : This database provides access to grey literature produced in Europe, including reports, theses, and conference papers Grey Literature Report : This database is produced by The New York Academy of Medicine and includes reports, conference papers, and other grey literature on health and biomedical topics, including psychology. ProQuest Dissertations and Theses Global : This database provides access to graduate-level research, including theses and dissertations related to psychology. Google Scholar: While not exclusively a grey literature database, Google Scholar can be a useful tool for finding conference papers and other grey literature related to psychology. National Technical Information Service (NTIS) : This database provides access to technical reports produced by U.S. government agencies, including those related to psychology. Bing AI - [asked in the Precise mode] For psychology, some recommended grey literature databases include PsycEXTRA and PsyArXiv . PsycEXTRA is a database of grey literature material relating to psychology, behavioral sciences and health. PsyArXiv is a psychology archive designed to facilitate rapid dissemination of psychological research. What other models have been developed based on SERVQUAL?
ChatGPT SERVPERF: This is a modified version of SERVQUAL that measures service performance instead of service quality. It was developed by Cronin and Taylor (1992) and is based on the same five dimensions as SERVQUAL. SERVPERF-GAP: This model, developed by Caruana and Ewing (2006), extends the SERVQUAL model to include three additional gaps that can occur when customers evaluate service quality. E-SERVQUAL: This model, developed by Parasuraman et al. (2005), adapts the SERVQUAL scale to measure the quality of online services. SERVCO: This is a modified version of SERVQUAL that includes a sixth dimension, "cost," in addition to the five original dimensions. It was developed by Sureshchandar et al. (2002) to address the importance of cost in service quality evaluation. SERVQ-HC: This is a modified version of SERVQUAL that is specifically designed for evaluating the quality of health care services. It was developed by Cronin et al. (2000) and includes 20 items across five dimensions. Bing AI The Nordic model of service quality2. The hierarchical model of service quality3. The American Customer Satisfaction Index (ACSI)4.
Bing AI Sidebar - CHAT, THINK, & WRITE
- Examples of Using AI sidebar to Recap Google Scholar findings
Chat - If you highlight a study in the search results of Google Scholar, you will be prompted with a question by AI sidebar asking if you want to send the selected text to it. If you choose to do so, you can then select either EXPLAIN or EXPAND to learn more about the chosen article. It's worth noting that EXPAND provides more detailed information. You can then click on any of the follow-up links to delve further into the selected article or topic. If the text of the chosen study is written in a foreign language, the AI sidebar can also provide an explanation of the text in English. Another option for extracting the key points from a selected article is to submit the URL of the PDF. Insights - Use the insights button to get more ideas about the topic. Compose - Tell the Edge sidebar your topic and let its Compose tool to generate a draft for you. Google Scholar Button- See also the Plugins and Extension page for how to perform a combined search using Google, Google Scholar, and ChatGPT .
Example: FINDING SIMILAR ARTICLES Find similar articles like this one - [then paste in the abstract ] Note - Use this prompt with Bing chat since real-time web info is required.
Examples: SUMMARIZE + REFERENCE Use a basic prompt like " Please summarize . ..." or add a REFERENCE TEXT that provides the necessary information about what you want it to focus or how the summary or resolution should look like. The reference could be a quote, an excerpt, a partial sentence, a conversation, an abstract, a code snippet and so on. Formula : Specify a role > assign a task > provide a reference text. Example#1 - Scholarly Journal Quote
STEP 1 Prompt: As a research assistant specializing in renewable energy, your task is to locate comparable research studies based on the provided abstract from an article: "This paper discusses the perspective of renewable energy (wind, solar, wave and biomass) in the making of strategies for a sustainable development. Such strategies typically involve three major technological changes: energy savings on the demand side, efficiency improvements in the energy production, and replacement of fossil fuels by various sources of renewable energy."
Bing Chat then found 3 documents: the ScienceDirect paper where the abstract came from and two other documents from un.org and frontiersin.org respectively.
STEP 2 Prompt: Please synthesize the findings of the three studies provided above.
Bing Chat: "Sure! Here is a synthesis of the findings from the three studies:
All three studies emphasize the importance of renewable energy in achieving sustainable development and mitigating climate change. They all discuss various strategies and actions that can be taken to increase the use of renewable energy sources and reduce reliance on fossil fuels.
Henrik Lund’s paper discusses the perspective of renewable energy (wind, solar, wave and biomass) in the making of strategies for a sustainable development. Such strategies typically involve three major technological changes: energy savings on the demand side, efficiency improvements in the energy production, and .....
The United Nations outlines five critical actions the world needs to prioritize now to transform our energy systems and speed up the shift to renewable energy: Make renewable energy technology a global public good, Improve global access to components and raw materials......
“Sustainable Energy Transition for Renewable and Low Carbon Grid” discusses that a sustainable global electricity transition will entail increased use of renewable energy sources particularly wind and solar, nuclear energy as a low carbon energy source, electrification of transport and.......
In summary , these studies suggest that transitioning to renewable energy sources is crucial for sustainable development and mitigating climate change. This can be achieved through various strategies such as increasing energy efficiency, improving access to renewable technology and materials, leveling the playing field for renewables, ending fossil fuel subsidies, and redirecting investments towards renewables." Example #2 Y ou are an expert researcher, given the following article, please discuss its key findings. Reference: How Large Language Models are Transforming Machine-Paraphrased Plagiarism at https://arxiv.org/abs/2210.03568 This is another way to put REFERENCE TEXT. As a side not, role specifying or the use of persona is important as it can impact the level of responses obtained. Just imagine if the designated role were " You are a high school student... ." Example #3 Please read this article and summarize it f or me - "Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision-Making" and then find 5 similar studies and please also summarize each for me.

CONNECTED PAPERS
- RELATED STUDIES
- Uses visual graphs or other ways to show relevant studies. The database is connected to the Semantic Scholar Paper Corpus which has compiled hundreds of millions of published papers across many science and social science fields.
- See more details about how it works .
- Example - SERVQUAL and then click on SELECT A PAPER TO BUILD THE GRAPH > The first paper was selected. Results: (1) Origin paper - SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality + Connected papers with links to Connected Papers / PDF / DOI or Publisher's site / Semantic Scholar / Google Scholar. (2) Graph showing the origin paper + connected papers with links to the major sources . See above. (3) Links to Prior Works and Derivative Works See the detailed citations by Semantic Scholar on the origin SERVQUAL paper on the top of this page within Semantic Scholars.
- How to Search Search by work title. Enter some keywords about a topic.
- Download / Save Download your saved Items in Bib format.
PAPER DIGEST
- SUMMARY & SYNTHESIS
- " Knowledge graph & natural language processing platform tailored for technology domain . <"https://www.paperdigest.org/> Areas covered: technology, biology/health, all sciences areas, business, humanities/ social sciences, patents and grants ...

- LITERATURE REVIEW - https://www.paperdigest.org/review/ Systematic Review - https://www.paperdigest.org/literature-review/
- SEARCH CONSOLE - https://www.paperdigest.org/search/ Conference Digest - NIPS conference papers ... Tech AI Tools: Literature Review | Literature Search | Question Answering | Text Summarization Expert AI Tools: Org AI | Expert search | Executive Search, Reviewer Search, Patent Lawyer Search...
Daily paper digest / Conference papers digest / Best paper digest / Topic tracking. In Account enter the subject areas interested. Daily Digest will upload studies based on your interests.
RESEARCH RABBIT
- CITATION-BASED MAPPING: SIMILAR / EARLY / LATER WORKS
- " 100s of millions of academic articles and covers more than 90%+ of materials that can be found in major databases used by academic institutions (such as Scopus, Web of Science, and others) ." See its FAQs page. Search algorithms were borrowed from NIH and Semantic Scholar.
The default “Untitled Collection” will collect your search histories, based on which Research Rabbit will send you recommendations for three types of related results: Similar Works / Earlier Works / Later Works, viewable in graph such as Network, Timeline, First Authors etc.
Zotero integration: importing and exporting between these two apps.
- Example - SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality [Login required] Try it to see its Similar Works, Earlier Works and Later Works or other documents.
- Export Results - Findings can be exported in BibTxt, RIS or CSV format.
CITING GENERATIVE AI
- How to cite ChatGPT [APA] - https://apastyle. apa.org/blog /how-to-cite-chatgpt
- How to Cite Generative AI [MLA] https://style. mla.org /citing-generative-ai/
- Citation Guide - Citing ChatGPT and Other Generative AI (University of Queensland, Australia)
- Next: Dialogues: Insightful Facts >>
- Last Updated: May 9, 2024 2:16 PM
- URL: https://tamu.libguides.com/c.php?g=1289555

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Int J Clin Pract
- v.2022; 2022
Semantic Web in Healthcare: A Systematic Literature Review of Application, Research Gap, and Future Research Avenues
A. k. m. bahalul haque.
1 Electrical and Computer Engineering, North South University, Dhaka 1229, Bangladesh
B. M. Arifuzzaman
Sayed abu noman siddik, tabassum sadia shahjahan, t. s. saleena.
2 PG & Research Department of Computer Science, Sullamussalam Science College Areekode, Malappuram, Kerala 673639, India
Morshed Alam
3 Institute of Education and Research, Jagannath University, Dhaka 1100, Bangladesh
Md. Rabiul Islam
4 Department of Pharmacy, University of Asia Pacific, 74/A Green Road, Farmgate, Dhaka 1205, Bangladesh
Foyez Ahmmed
5 Department of Statistics, Comilla University, Kotbari, Cumilla, Bangladesh
Md. Jamal Hossain
6 Department of Pharmacy, State University of Bangladesh, 77 Satmasjid Road, Dhanmondi, Dhaka 1205, Bangladesh
Associated Data
The data used to support the findings of this study are included within the article.
Today, healthcare has become one of the largest and most fast-paced industries due to the rapid development of digital healthcare technologies. The fundamental thing to enhance healthcare services is communicating and linking massive volumes of available healthcare data. However, the key challenge in reaching this ambitious goal is letting the information exchange across heterogeneous sources and methods as well as establishing efficient tools and techniques. Semantic Web (SW) technology can help to tackle these problems. They can enhance knowledge exchange, information management, data interoperability, and decision support in healthcare systems. They can also be utilized to create various e-healthcare systems that aid medical practitioners in making decisions and provide patients with crucial medical information and automated hospital services. This systematic literature review (SLR) on SW in healthcare systems aims to assess and critique previous findings while adhering to appropriate research procedures. We looked at 65 papers and came up with five themes: e-service, disease, information management, frontier technology, and regulatory conditions. In each thematic research area, we presented the contributions of previous literature. We emphasized the topic by responding to five specific research questions. We have finished the SLR study by identifying research gaps and establishing future research goals that will help to minimize the difficulty of adopting SW in healthcare systems and provide new approaches for SW-based medical systems' progress.
1. Introduction
The detection and remedy of illnesses through medical professionals are expressed as healthcare. The healthcare system consists of medical practitioners, researchers, and technologists that work together to provide affordable and quality healthcare services. They tend to generate considerable amounts of data from heterogeneous sources to enhance diagnostic accuracy, elevate quick treatment decisions, and pave the way for the effective distribution of information between medical practitioners and patients. However, it is necessary to organize those valuable data appropriately so that they can fetch those, while required.
One of the main challenges in utilizing medical healthcare data is extracting knowledge from heterogeneous data sources. The interoperability of well-being and clinical information poses tremendous obstacles due to data irregularity and inconsistency in structure and organization [ 1 , 2 ]. This is also because data are stored in various authoritative areas, making it challenging to retrieve knowledge and authorize a primary route along with information analysis. The information from a hospital can prove to be very useful in healthcare if these data are shared, analyzed, integrated, and managed regularly. Again, platforms that provide healthcare services also face dilemmas in automating time-efficient and low-cost web service arrangements [ 3 ]. This indicates that meaningful healthcare solutions must be proposed and implemented to provide extensive functionality based on electronic health record (EHR) workflows and data flow to enable scalable and interoperable systems [ 4 ], such as a blockchain-based smart e-health system that provides patients with an easy-to-access electronic health record system through a distributed ledger containing records of all occurrences [ 5 – 8 ]. A standard-based and scalable semantic interoperability framework is required to integrate patient care and clinical research domains [ 9 ]. The increasing number of knowledge grounds, heterogeneity of schema representation, and lack of conceptual description make the processing of these knowledge bases complicated. Non-experts find mixing knowledge with patient databases challenging to facilitate data sharing [ 10 ]. Similarly, ensuring the certainty of disease diagnosis also becomes a more significant challenge for health providers. Brashers et al. [ 11 ] in their work examined the significance of credible authority and the level of confidence HIV patients have in their medical professionals. Many participants agreed that doctors might not be fully informed of their ailment, but they emphasized the value of a strong patient-physician bond. With the help of big data management techniques, these challenges can be minimized. Likewise, Crowd HEALTH aims to establish a new paradigm of holistic health records (HHRs) that incorporate all factors defining health status by facilitating individual illness prevention and health promotion through the provision of collective knowledge and intelligence [ 11 – 13 ]. Another similar approach is adopted by the beHealthier platform which constructs health policies out of collective knowledge by using a newly proposed type of electronic health records (i.e., eXtended Health Records (XHRs)) and analysis of ingested healthcare data [ 14 ]. Making healthcare decisions during the diagnosis of a disease is a complex undertaking. Clinicians combine their subjectivity with experimental and research artifacts to make diagnostic decisions [ 9 ].
In recent years, Web 2.0 technologies have significantly changed the healthcare domain. However, in proportion to the growing trend of being able to access data from anywhere, which is primarily driven by the widespread use of smartphones, computers, and cloud applications, it is no longer sufficient. To address such challenges, Semantic Web Technologies have been adopted over time to facilitate efficient sharing of medical knowledge and establish a unified healthcare system. Tim Berners-Lee, also known as the father of the web, first introduced Semantic Web (SW) in 1989 [ 15 ]. The term “Semantic Web” refers to linked data formed by combining information with intelligent content. SW is an extension of the World Wide Web (WWW) and provides technologies for human agents and machines to understand web page contents, metadata, and other information objects. It also provides a framework for any kind of content, such as web pages, text documents, videos, speech files, and so on. The linked data comprise technologies such as Resource Description Framework (RDF), Web Ontology Language (OWL), SPARQL, and SKOS. It aims to create an intelligent, flexible, and personalized environment that influences various sectors and professions, including the healthcare system.
Data interoperability can only be improved when the semantics of the content are well defined across heterogeneous data sources. Ontology is one of the semantic tools, which is frequently used to support interoperability and communication between software, communities, and healthcare organizations [ 16 , 17 ]. It is also commonly used to personalize a patient's environment. Kumari et al. [ 18 ] and Haque et al. [ 19 ] proposed an Android-based personalized healthcare monitoring and appointment application that considers the health parameters such as body temperature, blood pressure, and so on to keep track of the patient's health and provide in-home medical services. Some existing ontologies of medicine are Gene, NCI, GALEN,LinkBase, and UMLS [ 20 ]. They have also been used in offering e-healthcare systems based on GPS tracking and user queries. Osama et al. proposed two ontologies for a medical differential diagnosis: disease symptom ontology (DSO) and patient ontology (PO) [ 21 ]. Sreekanth et al. used semantic interoperability to propose an application that brings together different actors in the health insurance sector [ 22 ]. Semantic Web not only enables information system interoperability but also addresses some of the most challenging issues with automated healthcare web service settings. SW combined with AI, IoT, and other technologies has produced a smart healthcare system that enables the standardization and depiction of medical data [ 1 , 23 , 24 ]. In terms of economic efficiency, the Semantic Web-Based Healthcare Framework (SWBHF) is said to benchmark the existing BioMedLib Search Engine [ 25 ]. SW also offered a new user-oriented dataset information resource (DIR) to boost dataset knowledge and health informatics [ 26 ]. This technology is also used in the rigorous registration process to discover, classify, and composite web services for the service owner [ 4 ]. To provide answers to medical questions, it has been integrated with NLP to create RDF datasets and attach them with source text [ 27 ]. Babylon Health, which enables doctors to prescribe medications to patients using mobile applications, has benefited from the spread of semantic technology. Archetypes, ontology, and datasets have been used in web-based methods for diagnosing colorectal cancer screening. Clinical information and knowledge about disease diagnosis are encoded for decision making with the use of ontological understanding and probabilistic reasoning. The integration of pharmaceutical and medical knowledge, as well as IoT-enabled smart cities, has made extensive use of SW technologies [ 8 ]. To put it briefly, this emerging technology has revolutionized the healthcare and medical system.
Despite its relevance, researchers who looked into the benefits of SW efforts showed substantial deficiencies in the wide range of semantic information in the medical and healthcare sectors. To the best of our knowledge, no previous systematic literature review (SLR) has been published on the Semantic Web and none of the research has previously classified the precise application area in which SW can be applied. Furthermore, there was an absence of research questions in the previous literature for analyzing and comparing similar works in order to understand their flaws, strengths, and problems.
In this study, we present a systematic review of the literature on Semantic Web in healthcare, with an emphasis on its application domain. It is absolutely essential to point the SW user community in the right direction for future research, to broaden knowledge on research topics, and to determine which domains of study are essential and must be performed. Thus, the current SLR can help researchers by addressing a number of factors that either limit or encourage medical and healthcare industries to employ Semantic Web technologies. Furthermore, the study also identifies various gaps in the existing literature and suggests future research directions to help resolve them. The research questions (RQs) that this systematic review will seek to answer are as follows. ( RQ1 ) What is the research profile of existing literature on the Semantic Web in the healthcare context? ( RQ2 ) What are the primary objectives of using the Semantic Web, and what are the major areas of medical and healthcare where Semantic Web technologies are adopted? ( RQ3 ) Which Semantic Web technologies are used in the literature, and what are the familiar technologies considered by each solution? ( RQ4 ) What are the evaluating procedures used to assess the efficiency of each solution? ( RQ5 ) What are the research gaps and limitations of the prior literature, and what future research avenues can be derived to advance Web 3.0 or Semantic Web technology in medical and healthcare?
This research contributes in a number of ways. This paper's main focus is centered on the collection of some statistical data and analysis results that are mostly focused on the adoption of SW technologies in the medical and healthcare fields. First, we gathered data from five publishers, including Scopus, IEEE Xplore Digital Library, ACM Digital Library, and Semantic Scholar, to thoroughly review, analyze, and synthesize past research findings. Furthermore, the current study does not focus on a specific theme, rather, it offers a broad overview of all possible research themes related to the use of SW in healthcare. Finally, this SLR identifies gaps in the existing literature and suggests a future research agenda. The primary contributions of our study are listed as follows:
- To find out the up-to-date research progress of SW technology in medical and healthcare.
- To open up new technical fields in healthcare where SW technologies can be used.
- To identify all the constraints in the healthcare industry during the adoption of SW technologies.
- To identify key future trends for semantics in the healthcare sector.
- To analyze and investigate alternative strategies for ensuring semantic interoperability in the healthcare contexts.
This review paper is organized as follows. Section 1 introduces Semantic Web technologies in healthcare followed by Section 2 which describes the methodology followed, the inclusion/exclusion criteria, and the data extracted and analyzed in this literature review paper. Section 3 elaborately discusses different thematic areas, and Section 4 presents the research gaps to address future research agendas. Section 5 presents a detailed discussion of the specified RQs. Lastly, Section 6 consists of the conclusion for this SLR.
2. Methodology
A systematic review is a research study that looks at many publications to answer a specific research topic. This study follows such a review to examine previous research studies that include identifying, analyzing, and interpreting all accessible information relevant to the recent progress of pertinent literature on Web 3.0 or Semantic Web in medical and healthcare or our phenomenon of interest. In the advancement of medical and healthcare analysis, numerous SLRs have been undertaken with inductive methodologies to identify major themes where Semantic Web technologies are being adopted [ 28 , 29 ]. In our study, we adopted the procedures outlined by Keele with a few important distinctions to assure the study's transferability, dependability, and transparency, emphasizing and documenting the selection method [ 30 ]. The guidelines outlined in that paper were derived from three existing approaches used by medical researchers, two books written by social science researchers, and a discussion with other academics interested in evidence-based practice [ 8 , 31 – 40 ]. The guidelines have been modified to include medical policies in order to address the unique challenges of software engineering research.
Our study sequentially conducted an SLR to accomplish the precise objectives. At first, we planned the necessary approach to identify the problems. Next, we collected related study materials and retrieved data from them. Finally, we documented the findings and carried out the research in the following steps (see Figure 1 ) maintaining its replicability as well as precision.
- Step 1 . Plan the review by finding appropriate research measures to detect corresponding documents.
- Step 2 . Collect analyses by outlining the inclusion and exclusion criteria to assess their applicability.
- Step 3 . Extract relevant data using numerous screening approaches to use accordingly.
- Step 4 . Document the research findings.

SLR methodology and protocols.
2.1. Planning the Review
The very first stage in conducting SLR is to identify the needs for a specific systematic review, outline the research questions, design a procedural review, and offer a study framework to assist the investigation in subsequent phases to identify the systematic review's significant objectives. This phase begins with the identification of needs for the proposed systematic review. Section 1 of this paper went into detail about why a systematic review of Semantic Web technologies in healthcare was deemed necessary. Following that, the definition of research questions, the selection of a synthesis method, initial keywords, and databases are given. To begin, we devised the RQs for this SLR in order to gain a comprehensive understanding of the semantic-based solutions in the field of healthcare. Defining research questions is an important part of conducting a systematic review because they guide the overall review methodology. Based on the objectives, we conducted a pilot study of a systematic review of fifteen sample studies, resulting in the broad application of the Semantic Web to a specific niche, refinement of research questions, and redefinition of the review research protocol. To find relevant scientific contributions for our RQs, we used Scopus, IEEE Xplore Digital Library, ACM Digital Library, and Semantic Scholar. Furthermore, we utilized the primary term “Web 3.0 or Semantic Web” to search the databases and then identified and refined the comprehensive keywords that would be used as search strings. We did not limit our search to a single period instead; we looked at all linked studies.
2.2. Collecting Analyses
A systematic review's unit of analysis is crucial since it broadens the scope of the overall approach. This study aims to better understand how Web 3.0 or Semantic Web technologies are employed in medical and healthcare settings, as well as to identify the extent to which they have been applied. We have selected academic research articles and journals as the unit of analysis for our SLR. We specified inclusion and exclusion criteria to narrow the investigation in the following study selection process, as shown in Table 1 . To gather our search phrases, we used a nine-step procedure as mentioned in [ 41 ]. The studies obtained from online repositories were compared with exclusion criteria to select peer-reviewed papers and eliminate any non-peer-reviewed studies. To perform this review, we employed decisive exclusion criteria to identify grey literature, which included white papers, theses, project reports, and working papers. To remove language barriers, we only selected papers written in English. We did not consider any review papers or project reports to maintain the quality. Older publications that have never been cited were excluded from the review to explore the potential value of Web 3.0 and SW technologies in medical and healthcare.
Criteria for inclusion and exclusion.
2.3. Extracting Relevant Data
Initially, we searched for papers in Google Scholar with “Web 3.0 in medical and healthcare” keywords. However, reviewing the title and abstract from the top 50 articles further improved the search keyword to develop a more appropriate search string. The top search string (“Semantic Web” OR “Web 3.0”) AND (“Healthcare” OR “medical”) was used in Scopus, IEEE Xplore Digital Library, ACM Digital Library, and Semantic Scholar to find related papers for our SLR on 22 January 2022. We found a total of 4137 papers, including 2237 from IEEE Xplore Digital Library, 1761 from Scopus, 103 from Semantic Scholar, and 36 from ACM Digital library. Primary review grasped articles up to 2001. So, all the identified publications were from 2001 to 2021. Four authors performed the screening method through different stages. After each step, a discussion session was held to finalize the step and move further.
At first, we checked for any duplicate articles from both indexing databases. We eliminated available duplicate articles by checking the Digital Object Identifier (DOI) and the research heading. After removing the duplicate articles, we were left with 1923 articles. After that, titles, keywords, and abstracts were read as part of the preliminary screening process. During the screening procedure, articles were divided into three categories: retain, exclude, and suspect. After removing articles unrelated to Web 3.0 or Semantic Web in medical and healthcare, only 1741 articles were retrained. Upon analyzing the contents of both suspect and retain studies using the inclusion and exclusion criteria listed in Table 1 , we were left with 343 publications. Following that, we read the full text of the articles that were picked, and we were left with 54 papers being considered for our conclusive stage. Finally, we applied the snowballing strategy, also known as the citation chaining technique [ 42 ]. Surprisingly, this step resulted in the addition of another ten studies (7 from backward citation and three from forwarding citation). The final review pool thus comprised 65 papers being considered for our conclusive stage ( Figure 2 depicts the study selection process in detail).

Study selection process.
2.4. Document Research Findings
The shortlisted research papers were profiled using descriptive statistics, which include publication year, methodology, and publication sources [ 23 , 43 , 44 ]. According to the chronology of the number of publications, the majority of the research articles were published in 2013. However, between 2018 and 2021, the number declined. Figure 3 depicts the yearly (between 2001 and 2022) distribution of published papers.
The majority of the studies presented a framework for developing a medical data information management system. Web 3.0 technologies appear to be in their early phases of adoption, with scholars only recently becoming interested in the topic. A few other papers discussed medical data interchange mechanisms, diseases, frontier technology such as AI and NLP, and regulatory conditions. Nearly half of the research ( n = 39) was published between 2001 and 2012, with the remaining studies ( n = 26) published after that (see Figure 3 ). The Semantic Web theory gained widespread interest after the architect of the World Wide Web, Tim Berners-Lee, James Hendler, and Ora Lassila popularized it in a Scientific American article in May 2001 [ 15 ]. This trend also gained momentum in recent years, with John Markoff coining the term Web 3.0 in 2006 and Gavin Wood, Ethereum's co-founder, coining the word later in 2014.

Number of articles published yearly.
Medical and healthcare writings have been published in several renowned conferences, journals, book series, and events. The 65 shortlisted papers are distributed throughout 27 conference proceedings, 21 journals, and 17 book series. The descriptive analysis depicts that 65 shortlisted analyses were authored by 25 publishers, accompanied by Springer ( n = 17), IEEE Xplore ( n = 15), IOS Press ( n = 6), ACM ( n = 5), and Elsevier ( n = 3). Only a few publishers published many studies. The reset included 15 publishers, each of whom only published one study. However, the majority of the papers were published in Lecture Notes in Computer Science (LNCS), CEUR Workshop Proceedings, and Studies in Health Technology and Informatics Series (see Figure 4 ). Furthermore, our SLR demonstrates the wide geographic span of existing research papers. The United States (11 articles), France (23 articles), India (9 articles), Canada (8 articles), Belgium (4 articles), and South Korea (4 articles) all had a significant number of studies. Figure 5 summarizes the past literature's geographical distribution.

Publication-source-wise distribution.

Country-wise article distribution.
According to the systematic literature review, the application of Semantic Web technologies in the field of healthcare is a prominent classical research theme, with many innovative and promising research topics. The number of Semantic Web publications and interest in healthcare has increased rapidly in recent years, and Semantic Web methods, tools, and languages are being used to solve the complex problems that today's healthcare industries face. Semantic Web technology allows comprehensive knowledge management and sharing, as well as semantic interoperability across application, enterprise, and community boundaries. This makes the Semantic Web a viable option for improving healthcare services by improving tasks such as standards and interoperable rich semantic metadata for complex systems, representing patient records, investigating the integration of Internet of Things and artificial computational methods in disease identification, and outlining SW-based security. While there are interesting possibilities for the application of Semantic Web technologies in the healthcare setting, some limitations may explain why those possibilities are less apparent. We believe one reason is a lack of support for developers and researchers. Semantic Web-based healthcare applications should be viewed as independent research prototypes that must be implemented in real-world scenarios rather than as a widget that is integrated with the Web 2.0-based solution. This study discusses the findings and future directions from two different perspectives. First, consider the potential applications of Semantic Web technologies in different healthcare scenarios and also look at the barriers to their practical application and how to overcome them (see Section 3 ). Last, the fourth (see Section 4 ) section discusses the scope of research in Semantic Web-enabled healthcare.
3. Analysis of the Selected Articles: Thematic Areas
This section focuses on three key steps: summarizing, comparing, and discussing the shortlisted papers to describe and categorize them into common themes. To systematically analyze all 65 studies, we adopted the technique used in recently published SLRs [ 23 , 43 ]. After identifying and selecting relevant papers that could answer our research questions, we used the content analysis technique to classify, code, and synthesize the findings of those studies. A three-step approach was proposed by Erika Hayes et al., which was used to interpret unambiguous and unbiased meaning from the content of text data [ 45 ]. The steps were as follows: (a) the authors assigned categories to each study and a coding scheme created directly and inductively from raw data using valid reasoning and interpretation; (b) the authors immersed themselves in the material and allowed themes to arise from the data to validate or extend categories and coding schemes using directed content analysis; (c) the authors used summative content analysis, which begins with manifesting content and then expands to identify hidden meanings and themes in the research areas.
This thematic analysis answers the second research question (RQ2), “What are the primary objectives of using the Semantic Web, and what are the major areas of medical and healthcare where Semantic Web technologies are adopted?”, and this analysis architecture highlights five broad medical and healthcare-related research themes based on their primary contribution (see Table 2 ), notably e-healthcare service, diseases, information management, frontier technology, and regulatory conditions.
Derived themes and their descriptions.
Two themes, namely, IoT and cloud computing, were nevertheless left out since they lack a wide description that would be useful in developing a meaningful theme. Some of the papers from which we defined these two thematic areas were included in the selected themes based on their similarity to the chosen thematic areas. Figure 6 illustrates this categorization, with different themes' description, which emerged from our review.

Thematic description of Semantic Web approaches in medical and healthcare.
3.1. E-Healthcare Service
The use of various technologies to provide healthcare support is known as e-service in healthcare or e-healthcare service. While staying at home, a person can obtain all the necessary medical information as well as a variety of healthcare services such as disease reasoning, medication, and recommendation through e-healthcare services. It is similar to a door-to-door service. The Semantic Web or Web 3.0 plays a critical role in this regard. The Semantic Web offers a variety of technologies, including semantic interoperability, semantic reasoning, and morphological variation that can be used to create a variety of frameworks that improve e-healthcare services.
SW makes the task of sharing medical information among healthcare experts more efficient and easier [ 2 , 46 – 48 ]. A dataset information resource for medical knowledge makes the work more trouble-free and faster. A healthcare dataset information resource has been created along with a question-answering module related to health information [ 26 ]. Combining different databases can be more effective as it expands the information range of knowledge. In this respect, Barisevičius et al. [ 49 ] designed a medical linked data graph that combines different medical databases and they also developed a chatbot using NLP-based knowledge extraction that provides healthcare services by supplying knowledge about various medical information. Besides information sharing and database combining, Semantic Web-based frameworks can provide virtual medical and hospital-based services. A system has been created that provides medical health planning according to patient's information [ 50 ]. Concerning this, it could be very helpful if there is a system that can match patient requirements with the services. Such a matchmaking system has been developed to match the web services with the patient's requirements for medical appointments [ 51 ]. To provide hospital-based services, a Semantic Web-based dynamic healthcare system was developed using ontologies [ 17 ]. Disease reasoning is a vital task for e-healthcare services. A number of frameworks were developed that are used for reasoning diseases [ 49 , 52 , 53 ]. In addition, some authors implemented systems that provide support for sequential decision making [ 54 – 57 ]. Moreover, Mohammed and Benlamri [ 21 ] designed a system that could help to prescribe differential diagnosis recommendations. Grouping similar diagnosis patients can be useful to enhance the medication process. In this regard, Fernández-Breis et al. [ 58 ] created a framework to group the patients by identifying patient cohorts. Moreover, Kiourtis et al. [ 59 ] proposed a new device-to-device (D2D) protocol for short-distance health data exchange between a healthcare professional and a citizen utilizing a sequence of Bluetooth communications. Supplying medical information to people is one of the main tasks of e-healthcare services [ 58 ]. Before proceeding with a medical diagnosis, we need to be sure about the correctness of the procedure. Andreasik et al. [ 60 ] developed a Semantic Web-based framework to determine the correctness of medical procedures. Various systems for medical education were developed using Semantic Web technologies such as a web service delivery system [ 4 ], a web service searching system [ 61 ], and an e-learning framework for the patients to learn about different medical information [ 62 , 63 ]. Some articles discussed the rule-based approaches for the advancement of medical applications [ 64 , 65 ]. Quality assurance of Semantic Web services is necessary, and so a framework was created using a Semantic Web-based replacement policy to assure the quality of a set of services and replace it with a newly defined subset of services when the existing one fails in execution [ 3 ]. A framework was designed for Semantic Web-based data representation [ 66 ]. Meilender et al. [ 67 ] described the migration of Web 2.0 data into Semantic Web data for the ease of further advancement in Web 3.0.
Researchers used different Semantic Web services to convert the relational database to create Resource Description Framework (RDF) and Web Ontology Language (OWL)-based ontologies. It is done by extracting the instances from the relational databases and representing them into RDF datasets [ 21 , 55 , 57 , 62 ]. In some prior literature, many RDF datasets were created using Apache JENA 4.0 [ 4 ], different versions of protégé were used to construct and represent various healthcare ontologies [ 2 , 17 ], Apache Jena framework was used for OWL reasoning on the RDF datasets [ 50 , 53 ], and the EYE engine was used for reasoning [ 54 ]. Besides, Kiourtis et al. [ 68 ] developed a technique for converting healthcare data into its equivalent HL7 FHIR structure, which principally corresponds to the most used data structures for describing healthcare information. Furthermore, a sublanguage of F-logic named Frame Logic for Semantic Web Services (FLOG4SWS) and web services along with some features of Flora-2 was used to represent the ontology [ 51 ]. The authors of some papers used RDF and OWL for data representation of different ontologies [ 50 , 52 , 54 , 66 ]. Mohammed and Benlamri [ 21 ] offered a number of Semantic Web strategies for ontology alignment, such as ontology matching and ontology linking, and some used ontology mapping for the ontology alignment [ 58 , 66 ]. By combining RDF and semantic mapping features, Perumal et al. [ 69 ] provided a translation mechanism for healthcare event data along with Semantic Web Services and decision making. In addition, a linked data graph (LDG) is utilized to combine numerous publicly available medical data sources using RDF converters [ 49 ]. The works in [ 52 , 54 ] used Notation3 for data mapping. SPARQL was used as the query language for the database [ 2 , 17 , 50 , 52 , 57 ]. Besides, the Jena API was also used as a query language [ 21 ]. The Semantic Web's rules and logic were expressed in terms of OWL concepts using the Semantic Web Rule Language (SWRL) [ 55 , 57 ]. TopBraid Composer is used as the Semantic Web modeling tool [ 60 ].
There was no proof that the system created using semantic networks was able to share knowledge among healthcare services [ 2 , 46 , 48 ]. Researchers did not mention how a system can be integrated with different types of datasets in the world [ 2 , 47 ]. In their paper, Ramasamy et al. [ 3 ] did not mention whether the system could replace all types of services or not. Shi et al. [ 26 ] did not discuss the success rate of the datasets in their dataset information resource and the accuracies of different systems created with these datasets. No proper evaluation techniques have been given for linked data graph [ 49 ], Semantic Web service delivery systems [ 4 , 50 ], and Semantic Web reasoning system [ 52 , 53 ] in their studies. There is no discussion of the reliability and validity of numerous decision making and recommendation systems [ 21 , 54 , 70 ]. Podgorelec and Gradišnik [ 64 ] did not provide information about the betterment of the combined Semantic Web technologies and rule-based systems against other alternatives. Most of the articles discussed or offered various techniques to build different healthcare services, but there are only a few articles that implemented the proposed systems and tested them in a real-life context.
3.2. Diseases
This thematic area aims to specifically identify and discuss the contributions of Semantic Web technologies to reach interoperability of information in the healthcare sector and aid in the initial detection and nursing of diseases, such as diabetes, chronic conditions, cardiovascular disease, dementia, and so on. SW provides a framework to integrate medical knowledge and data for effective diagnosis and clinical service. They help to select patients, recognize drug effects, and analyze results by using electronic health data from numerous sources. The queryMed packages were proposed for pharmaco-epidemiologists that link medical and pharmacological knowledge with electronic health records [ 10 ]. This application searches for people with critical limb ischemia (CLI) with at least one medication or none at all and gives them healthcare recommendations. SW also emphasizes the study of phenotypes and their influence on personal genomics. The Mayo Clinic's project, Linked Clinical Data (LCD), facilitates the use of SW and makes it easier to extract and express phenotypes from electronic medical records [ 71 ]. It also emphasizes the use of semantic reasoning for the identification of cardiovascular diseases. Besides this, it aims to improve healthcare service quality for people suffering from chronic conditions. Proper planning and management are required for the better treatment and management of chronic diseases. Thus, the Chronic Care Model (CCM) provides knowledge-based acquisition to patients [ 72 ].
Ontology-based applications such as the Concept Unique Identifier (CUI) from Unified Medical Language System, Drug Indication Database (DID), and Drug Interaction Knowledge Base (DIKB) are widely used in the medical domain to establish mappings between medical terms [ 10 ]. In the context of ontology, the ECOIN framework uses a single ontology, multiple view approach that exploits modifiers and conversion functions for context mediation between different data sources [ 73 ]. To support clinical knowledge sharing through interaction models, the OpenKnowledge project has been initiated from different data sources [ 9 ], and K-MORPH architecture has been proposed for a unified prostate cancer clinical pathway.
Along with information sharing, medical data management is critical in the diagnosis of disorders like dementia. To establish a better diagnosis method for dementia, a medical information management system (MIMS) was designed using SW technologies through the extraction of metadata from medical databases [ 74 , 75 ]. In order to further eliminate the e-health information and knowledge sharing crisis, Bai and Zhang [ 76 ] suggested Integrated Mobile Information System (IMIS) for healthcare. It provides a platform to connect diabetic patients with care providers to receive proper treatment and diagnosis facilities at home. The Diabetes Healthcare Knowledge Management project also aims to ease decision support and clinical data management in diabetes healthcare processes [ 72 ].
To construct decision models for the Diabetes Healthcare Knowledge Management framework, tools such as Semantic Web Rule Language (SWRL), OWL, and RDF were used. This ontology-based knowledge framework provides ontologies, patient registries, and an evidence-based healthcare resource repository for chronic care services [ 72 ]. Web Ontology Language (OWL), Resource Description Framework (RDF), and SPARQL were also commonly used for the creation of metadata in dementia diagnosis [ 77 ]. On the other hand, the Semantic Web-based retrieval system for the pathology project, known as “A Semantic Web for Pathology,” involves building and managing ontology for lungs which was made up of common semantic tools RDF and OWL which were used along with RDQL query language [ 20 ].
Even though effective frameworks were proposed to diagnose certain diseases, research gaps still exist that affect medical data management. For instance, the fuzzy technique-based service-oriented architecture has proved to be beneficial in terms of adjustability and reliability. But still, in the context of domain-specific ontologies, the applicability of this architecture is yet to be validated [ 78 ]. Effective distribution of knowledge into the existing healthcare system is a huge challenge in augmenting decision making and improving the care service quality. Therefore, future works are intended to focus on embedding knowledge and conducting user evaluations for better disease management.
3.3. Information Management
Managing patients' information and storing test results are significant tasks in the medical and healthcare industries. The application of the SW-based approach in this area can make an influential impact on this data organization. Such an approach to gather valuable and new medical information was primarily made by creating a network of computers [ 79 ]. Domain ontology was created according to the user's choice, suggesting medical terminologies to retrieve customized medical information [ 80 ]. RDF datasets can be used to find the trustworthiness of intensive care unit (ICU) medical data [ 70 ]. The SW has also been used to document healthcare video contents [ 81 ] and radiological images to provide appropriate information about those records [ 82 ].
However, moving from the conventional web-based information management to the Semantic Web had some reasons. As medical knowledge is essential to verify and share across hospitals and medical centers, introducing the Semantic Web approach helped to achieve a proper mapping system [ 83 ]. A medical discussion forum based on the SW helped to exchange valuable data among healthcare practitioners to map-related information in the dataset [ 84 ]. The use of the fuzzy cognitive system in the SW also helped to share and reuse knowledge from databases and simplify maintenance [ 85 ]. This methodology also helped to improve data integration, analysis, and sharing between clinical and information systems and researchers [ 86 ]. Moving towards this approach also aided the researchers in connecting different data storage domains and creating effective mapping graphs [ 87 ].
Though the approach of SW in healthcare has a broad area, most applications are pretty similar. The framework mainly proposed the use of RDF, SPARQL, and OWL [ 4 , 76 ]. Link relevance methods were used to produce semantically relevant results to extract pertinent information from domain knowledge [ 49 ]. Ontology-based logical framework procedures and SMS architecture helped to organize the heterogeneous domain network [ 88 , 89 ].
Evaluating the system's performance is necessary to get the actual results. A Health Level 7 (HL7) messaging mechanism has been developed for mapping the generated Web Service Modeling Ontology [ 90 ]. However, there were some issues regarding the heterogeneity problem. JavaSIG API was used to generate the HL7 message to resolve these issues [ 91 ]. Some of the evaluation tools are not advanced enough to handle vast amounts of data. PMCEPT physics algorithms were used to verify the algorithm [ 92 ]. Abidi and Hussain [ 9 ] created two levels to characterize different ontological models to establish morphing. BioMedLib Search Engine creation for economic efficiency helped to develop a Semantic Web framework for rural people [ 25 ]. The Metamorphosis installation wizard converted the text format UMLS into a MySQL database UMLS in order to access a SPARQL endpoint [ 93 ].
However, the frameworks proposed in different statements were not implemented precisely, which created a gap in each framework. Some frameworks are proposed to integrate with the blockchain for additional security and privacy [ 23 , 94 – 96 ]. AI and IoT integration can also enhance system maintenance [ 1 ]. Hussain et al. [ 97 ] suggested a framework named Electronic Health Record for Clinical Research (EHR4CR), but they did not get any actual results from this framework in the real world [ 97 ]. The proposed framework's implementation result will provide more development on this.
3.4. Frontier Technology
In this segment, we critically analyze works that are primarily keen on how cutting-edge technologies like AI and computer vision can be applied to the medical field with the continuous advancement of science and technology. Semantic Web-enabled intelligent systems leverage a knowledge base and a reasoning engine to solve problems, and they can help healthcare professionals with diagnosis and therapy. They can assist with medical training in a resource-constrained environment. To illustrate, Haque et al. [ 8 ], Chondrogiannis et al. [ 98 ], Haque and Bhushan [ 99 ], and Haque et al. [ 24 ] created a secure, fast, and decentralized application that uses blockchain technologies to allow users and health insurance organizations to reach an agreement during the implementation of the healthcare insurance policies in each contract. To preserve the formal expression of both insured users' data and contract terms, health standards and Semantic Web technologies were used. Accordingly, significant work has been proposed by Tamilarasi and Shanmugam [ 100 ] which explores the relationship between the Semantic Web, machine learning, deep learning, and computer vision in the context of medical informatics and introduces a few areas of applications of machine learning and deep learning algorithms. This study also presents a hypothesis on how image as ontology can be used in medical informatics and how ontology-based deep learning models can help in the advancement of computer vision.
The real-world healthcare datasets are prone to missing, inconsistent, and noisy data due to their heterogeneous nature. Machine learning and data mining algorithms would fail to identify patterns effectively in this noisy data, resulting in low accuracy. To get these high-quality data, data preprocessing is essential. Besides, RDF datasets representing healthcare knowledge graphs are very important in data mining and integrating IoT data with machine learning applications [ 8 , 101 ]. RDF datasets are made up of a distinguishable RDF graph and zero or more named graphs, which are pairings of an IRI or blank node with an RDF graph. While RDF graphs have formal model-theoretic semantics that indicate which world configurations make an RDF graph true, there are no formal semantics for RDF datasets. Unlike traditional tabular format datasets, RDF datasets require a declarative SPARQL query language to match graph patterns to RDF triples, which makes data preprocessing more crucial. In the context of data preprocessing, Monika and Raju [ 101 ] proposed a cluster-based missing value imputation (CMVI) preprocessing strategy for preparing raw data to enhance the imputed data quality of a diabetes ontology graph. The data quality evaluation metrics R2, D2, and root mean square error (RMSE) were used to assess simulated missing values.
Nowadays, question-answering (QA) systems (e.g., chatbots and forums) are becoming increasingly popular in providing digital healthcare. In order to retrieve the required information, such systems require in-depth analysis of both user queries and records. NLP is an underlying technology, which converts unstructured text into standardized data to increase the accuracy and reliability of electronic health records. A Semantic Web application has been deployed for question-answering using NLP where users can ask questions about health-related information [ 27 ]. In addition, this study introduces a novel query simplification methodology for question-answering systems, which overcomes issues or limitations in existing NLP methodologies (e.g., implicit information and need for reasoning).
The majority of contributions to this category have organized their work using semantic languages on a smaller scale. Besides, it is noteworthy that hardly any of the approaches, except [ 27 , 101 ], adopted a framework for developing their models. Asma Ben et al. used a benchmark (corpus for evidence-based medicine summarization) to evaluate the question-answering (QA) system and analyzed the obtained outcomes [ 27 ]. Some studies have not included a prior literature review for the discovery of available frontier services [ 100 ]. In addition, the study shows that with the soaring demand for better, speedier, more accurate, and personalized patient treatment, deep learning powered models in production are becoming increasingly prevalent. Often these models are not easily explainable and prone to biases. Explainable AI (XAI) has grown in popularity in healthcare due to its extraordinary success in explaining decision-making criteria to systems, reducing unintended outcomes and bias, and assisting in gaining patients' trust—even when making life-or-death decisions [ 102 ]. To the best of our knowledge, XIA has gleaned attention on ontology-based data management but received relatively little attention on collaborating Semantic Web technologies across healthcare, biomedical, clinical research, and genomic medicine. Similarly, within the IoT system spectrum, invocation of semantic knowledge and logic across various Medical Internet of Things (MIoT) applications, gathering vast amounts of data, monitoring vital body parameters, and gathering detailed information from sensors and other connected devices, as well as maintaining safety, data confidentiality, and service availability also received relatively little attention.
3.5. Regulatory Conditions
This segment concentrates on Semantic Web-based tools, technologies, and terminologies for documenting the semantics of medical and healthcare data and resources. As the healthcare industries generate a massive amount of heterogeneous data on a global scale, the use of a knowledge-based ontology on such data can reduce mortality rate and healthcare costs and also facilitate early detection of contagious diseases. Besides, the SW provides a single platform for sharing and reusing data across apps, companies, and communities. The biomedical community has specific requirements for the Semantic Web of the future. There are a variety of languages that can be used to formalize ontologies for medical healthcare, each with its expressiveness. A collaborative effort led by W3C, involving many research and industrial partners, set the requirements of medical ontologies. A real ontology of brain cortex anatomy has been used to assess the requirements stated by W3C in two available languages at that time, Protégé and DAML + OIL [ 103 ]. The development and comparative analysis contexts of brain cortex anatomy ontologies are partially addressed in this. In 2019, a survey-based study was conducted to determine faculty and researcher usage, impact, and satisfaction with Web 3.0 networking sites on medical academic performance [ 104 ]. This study explores the awareness and willingness to implement Web 3.0 technologies within healthcare at Rajiv Gandhi University of Health Sciences. The results of this study imply that Web 3.0 technologies have an impact on professor and researcher academic performance, with those who are tech-savvy being disproportionately found in high-income groups [ 104 ].
Documentation of semantic tools and data is required to resolve healthcare reimbursement challenges. Besides, regulations are also necessary to standardize semantic tools while ensuring that healthcare communities and systems adhere to general health policies. Unfortunately, we found only a few works focusing on this challenge based on SWT. Only the study conducted by Sugihartati [ 104 ] adopted a proper survey methodology. Therefore, future efforts should focus on regulating, documenting, and standardizing semantic tools, technologies, and health resources, as well as conducting user evaluations to understand and optimize functional efficiency and accelerate market access for medicines for general health.
Tables Tables3 3 3 – 5 provide a detailed analysis of the studied works for the derived five categories.
Summarization of the research contribution of the selected articles.
Summarization of the research gaps and future research avenues.
Future research avenues in the form of research questions.
4. Research Gaps
This systematic literature review presents a vast knowledge about the use of Web 3.0 or Semantic Web technology in different approaches to the medical and healthcare sector. By analyzing various kinds of literature, we recognized different research gaps to address future research avenues, which will enable scholars from different parts to examine the area and discover new developments. Table 4 summarizes the overall research gaps and Table 5 summarizes the future research avenues we encounter during the literature review.
4.1. Scope of E-Healthcare Service Research
Even though studies in the domain of e-healthcare services suggested and created numerous frameworks to provide vital support to the users, there are still research gaps among the methods. Several frameworks were proposed to facilitate data interoperability. However, based on what we know best, none of the proposed frameworks has been implemented in the actual world. Furthermore, there is no evidence of knowledge sharing among organizations using semantic network-based systems. Besides, just a handful of the research papers included assessment methodologies and a discussion of the findings. Furthermore, the frameworks that provide medical services such as disease reasoning, decision making, and drug recommendations lack reliability and validity. Most of the research articles suggested architectures but did not implement them, and their intended prototypes were never built.
4.2. Scope of Disease Research
Semantic Web technologies are being used in the healthcare sector to improve information interoperability and aid in identifying and treating diseases. Only a few studies among the 65 papers have examined the various frameworks for developing a fully functional system for either diabetic healthcare or disease collection of prebuilt queries. Earlier research also lacks mapping triplets of one illness RDF to other existing medical services, applications, and administrations. Researchers also lack the creation of intelligent user interfaces that grasp the semantics of clinical data. This paper shows that more study is required to efficiently use ontology in the healthcare sector to preserve data with proper evaluation criteria.
4.3. Scope of Information Management Research
Medical data are considered valuable information utilized to assist patients in receiving better care. It is challenging to implement Semantic Web technologies to store and search for data. Various studies attempt to adopt specific methods that may aid in the proper management of medical information; however, some gaps remain. There is no attempt to index high-quality videos and collect attributes for categorizing them. A validation gap exists due to the lack of suitable evaluation techniques. In most studies, RDF ontologies are used to collect information from websites and represent those data. However, no information is provided about how effective those models are in real-world applications.
4.4. Scope of Frontier Technology Research
Even though cutting-edge technology such as AI, ML, robotics, and the IoT has revolutionized the healthcare industry and helped improve everything from routine tasks to data management and pharmaceutical development, the industry is still evolving and looking for ways to improve. If we consider the aspect of research, the history of the Semantic Web and frontier technology is technically not new at all, yet the Semantic Web presents some limitations. Since the web began as a web of documents, converting each document into data is incredibly challenging. Various tools and approaches, such as natural language processing (NLP), may be used to do this task, but it would take a long time. However, only a small attempt has been made to integrate NLP and domain knowledge induction. Ontology and AI, and logic, have always been and will continue to be essential elements of AI development. Besides, connecting ontology to AI is frequently a problem in and of itself. Furthermore, because ontology trees often have a large number of nodes, real-time execution is problematic. Earlier studies have apparently failed to solve this problem. There have been significant attempts to incorporate the various aspects of IoT resources into ontology creation, such as connectivity, virtualization, mobility, energy, or life cycle [ 108 , 109 ]. The authors attempted to enhance the computerization of the health and medical industry by utilizing the Internet of Things (IoT) and Semantic Web technologies (SWTs), which are two key emerging technologies that play a significant role in overcoming the challenges of handling and presenting data searches in hospitals, clinics, and other medical establishments on a regular basis. Despite its significant efforts to collaborate different IoT spectrum and Semantic Web technologies, research gaps in medical data management persist. For instance, after its introduction, the Medical Internet of Things (MIoT) has taken an active role in improving the health, safety, and care of billions of people. Rather than going to the hospital for help and support, patients' health-related parameters can now be monitored remotely, constantly, consistently, and in real time and then processed and transferred to medical data enters via cloud storage. Because of cloud platforms' security risks, choosing one is a major technological challenge for the healthcare industry. Some of these cloud-based storage systems cannot adequately preserve patients' data and information regarding semantic data [ 6 , 8 ]. However, none of the research articles suggested any architectures, nor were any intended prototypes built to address these cloud security issues of MIoT in general.
4.5. Scope of Regulatory Condition Research
Regulations are paramount for the healthcare and medical industries to function properly. They support the global healthcare market, ensure the delivery of healthcare services, and safeguard patients,' doctors,' developers,' researchers,' and healthcare agents' rights and safety. The Semantic Web also has its detractors, like many other technologies, in terms of legislation and regulation. Historically, scaling medical knowledge graphs has always been a challenge. As a result of privacy and legal clarity, healthcare companies are not sufficiently incentivized to share their data as linked data. Only a few academic papers and documents disclose how these corporations use to automate the process. Furthermore, compared to other types of datasets, many linked datasets representing tools are of poor quality. As a result, applying them to real-world problems is highly challenging. Other alternatives, such as property graph databases like Neo4j and mixed models like OriendDB, have grown in popularity due to the RDF format's complexity. Healthcare application developers and designers prefer to use web APIs over SPARQL endpoint to send data in JSON format. This study illustrates that more research is needed to improve the semantic quality of available technologies (e.g., RDF, OWL, and SPARQL) to effectively use them in the healthcare industry to ease healthcare development.
5. Discussion
This section describes the findings from the selected studies based on answer to the research questions. Therefore, the readers will be able to map the research questions with the contribution of this systematic review.
5.1. (RQ1) What Is the Research Profile of Existing Literature on the Semantic Web in the Healthcare Context?
The research aims to determine the primary objectives of using the Semantic Web and the major medical and healthcare sectors where Semantic Web technologies are adopted. As the Semantic Web has shown incremental research trends in recent years, there is a need for a structured bibliometric study. This study collected data from the Scopus, IEEE Xplore Digital Library, ACM Digital Library, and Semantic Scholar databases, focusing on various aspects and seeing their affinity. We performed bibliometric analysis to look at essential details like preliminary information, country, author, and application area where these publications are being used for the Semantic Web in the context of healthcare. We conducted the bibliometric analysis using an open-source application called VOS viewer. The outcomes and specifics of the experiment are detailed in Section 2 .
As stated in the methodology section, our study consists of 65 documents. A number of prestigious conferences, publications, and events have published these healthcare-related articles. Out of these 65 shortlisted papers, 27 were presented in conferences, 21 in journals, and 17 from book chapters. Our study observes that the field of “Semantic Web in Healthcare” is not comparatively new. The first paper from the shortlisted documents on this topic was published in 2001. Since then, there has been minimal growth in this field, with 2007 appearing to be the start. Surprisingly, the maximum number of articles (8) published in this discipline was in 2013, but from 2013 to 2016, there was only a minor shift by researchers globally. It is most likely due to the introduction of Web 3.0 in 2014. It is yet to be found how Web 3.0 will effectively leverage the Semantic Web as a core component rather than seeing it as a competing technology in the medical healthcare field. The decrease in the number of articles shows how the interests of researchers switched from the Semantic Web to the emerging Web 3.0. However, the Semantic Web remains the top choice of medical practitioners as Web 3.0 evolves. Furthermore, the United States is the country with the most research papers, followed by France and India (see Figure 4 ). It implies that both developed and emerging countries use the Semantic Web in their healthcare industries. VOS viewer also discovered 35 works titled to be published in Computer Science, 16 in Engineering, 9 in Medicine, and 5 in Mathematics. We also used the VOS viewer software to visually represent the keyword co-occurrences from those shortlisted 65 publications. The total number of keywords was 774. The minimum number of times a keyword appears is set at 5. The terms that occurred more than five times in all texts are included in our representation. We found 76 keywords that meet our requirements. Figure 7 shows our findings in a co-occurrence graph containing the other essential phrases. As expected, Semantic Web and healthcare are the most occurring keywords, and both are mentioned 55 times. Following that, web services, decision support systems, interoperability, etc. are listed. These terms are used to categorize the Semantic Web's application areas in healthcare.

Co-occurrence network of the index's keywords.
Our analysis also reveals that most proposed frameworks for improving and expanding the healthcare system do so without the involvement of health professionals. Some of them discussed data interoperability, diseases, frontier technologies, and regulatory issues, while others emphasized the use of video as ontologies and video conferences in bridging communication gaps. The majority of the publications only propose frameworks with no implementation. Web services currently merely make services available, with no automatic mechanism to connect them in a meaningful way.
5.2. (RQ2) What Are the Primary Objectives of Using the Semantic Web, and What Are the Major Areas of Medical and Healthcare Where Semantic Web Technologies Are Adopted?
The adoption of the Semantic Web in healthcare strives to improve collaboration, research, development, and organizational innovation. The Semantic Web has two primary objectives: (1) facilitating semantic interoperability and (2) providing end-users with more intelligent support. Semantic interoperability, a key bottleneck in many healthcare applications, is one of today's major problems. Semantic Web technologies can help with data integration, knowledge administration, exchange of information, and semantic interoperability between healthcare information systems. It focuses on building a web of data and making it appropriate for machine processing with little to no human participation. So, healthcare computer programs can better assist in finding information, personalizing healthcare information, selecting information sources, collaborating within and across organizational boundaries, and so on by inferring the consequences of data on the Internet.
Based on our review of the findings, we found five application domains where the Semantic Web is being adopted in the healthcare context. This study will brief those domains from Sections 5.2.1 to 5.2.5 as well as justify them in relation to healthcare.
5.2.1. E-Healthcare Service
More than two-fifth of the total studies (65) considered in this study is about e-healthcare services (see Table 2 ). These studies focus on ways to use the Internet and related technologies to offer and promote health services and information, as well as diagnosis recommendation systems and online healthcare service automation.
In this study, researchers developed a web-based prototype that generates the required reports with a high degree of data integration and a rule-based production technique for establishing a link between prevalent diseases and the range of diseases in a specific gene [ 64 ].
Another group of e-healthcare service studies focused on how current electronic information and communication technology could help people's health and healthcare [ 46 , 49 , 50 , 61 – 64 , 97 ]. Most of the authors used a WSMO (Web Service Modeling Ontology) service delivery platform and an automatic alignment of user-defined EHR (electronic health record) workflows, where service owners can register a service, and the system will automate prefiltering, discovery, composition, ranking, and invocation of that service to provide healthcare.
The adoption of e-healthcare in developing countries has shown to be a feasible and effective option for improving healthcare. It allows easy access to health records and information and reduces paperwork, duplicate charges, and other healthcare costs. If the proper implementation of e-healthcare technologies is ensured, everyone will benefit.
5.2.2. Diseases
Out of 65 articles, there are only 8 articles regarding the adoption of the Semantic Web in the diseases sector (see Table 2 ). These articles present a discussion on the deployment of a disease-specific healthcare platform, disease information exchange system, knowledge base generation, and research portal for a specialized disease.
This study developed a web-based prototype for an Integrated Mobile Information System (IMIS) for diabetic patient care [ 20 ]. The authors used ontology mapping so that related organizations could access each other's information. They also embedded feedback and communication mechanisms within the system to include user feedback.
Another study developed queryMed packages for pharmaco-epidemiologists to access and link medical and pharmacological knowledge to electronic health records [ 10 ]. The authors distinguished all the medications endorsed for critical limb ischemia (CLI) and recognized one contraindicated solution for one patient.
Disease management/prediction systems are necessary for finding the hidden knowledge within a group of disease data and can be used to analyze and predict the future behavior of diseases. An all-in-one strategy rarely works in the healthcare industry. It is critical to develop a personalized and contextualized disease prediction system to enhance user experience.
5.2.3. Information Management
Almost two-fifths of the total studies considered in this study (65) are about information management (see Table 2 ). After e-healthcare service, this category has the most studies. These articles are particularly about healthcare management systems, medical information indexing, healthcare interoperability systems, decision making, coordination, control, analysis, and visualization of healthcare information.
This study presented a medical knowledge morphing system that focuses on ontology-based knowledge articulation and morphing of heterogeneous information using logic and ontology mediation [ 105 ]. The authors used high-level domain ontology to describe fundamental medical concepts and low-level artifact ontology to capture the content and structure.
In another study, an annotation image (AIM) ontology was developed to provide important semantic information within photographs, allowing radiological images to be mined for image patterns that predict the structures' biological features. The authors transformed XML data into OWL and DICOM-SR to control ontological terminology in order to create image annotation.
A well-designed healthcare information system is required for management, evaluation, observations, and overall quality assurance and improvement of key stakeholders of the health system. Even though a significant amount of work is done in this sector, it is far from sufficient. It is something on which we should focus.
5.2.4. Frontier Technology
We found only 3 publications on frontier technology (see Table 2 ). These articles describe healthcare application domains that use AI, machine learning, or computer vision to automate medical coding, generate medical informatics, and deal with intelligent IoT data and services.
The first review article is about a method for preprocessing raw cluster-based missing value imputation (CMVI), with the goal of improving the imputed data quality of a diabetes ontology graph [ 27 ]. Their findings show that preprocessed data have better imputation accuracy than raw, unprocessed data, as measured against coefficient of determination (R2), index of agreement (D2), and root mean square error (RMSE).
Another article talks about ideas on how image as ontology can be used in health informatics and how deep learning models built on ontologies can support computer vision [ 100 ].
Frontier technology such as AI, ML, and IoT offers many advantages over traditional analytics and clinical decision-making methodologies. At a granular level, those technologies provide
- Increased efficiency.
- Better treatment alternatives.
- Faster diagnosis.
- Faster drug discovery.
- Better disease outbreak prediction.
- Medical consultations with patients with little or no participation of healthcare providers.
There is a lack of research on the integration of frontier technologies with the Semantic Web. Researchers should focus their efforts on this area. Students must take the initiative to develop creative technological inventions.
5.2.5. Regulatory Conditions
There were only 3 publications that used Semantic Web technology to address regulatory conditions (see Table 2 ). These studies focus on the challenges and requirements of the Semantic Web and technologies that represent the Semantic Web, awareness, and policy and regulations.
An article describes how to design, operate, and extend a Semantic Web-based ontology for an information system of pathology [ 103 ]. The authors of this paper highlight what technologies, regulations, and best practices should be followed during the entire lung pathology knowledge base creation process.
Another study talks about the challenges of integrating healthcare web service composition with domain ontology to implement diverse business solutions to accomplish complex business logic [ 104 ].
Privacy and regulation are important in establishing a clear framework within which healthcare providers, patients, healthcare agents, and healthcare application developers can learn and maintain the skills needed to provide high-quality health services which are safe, productive, and patient-centered. From these regulatory condition-type articles, we can understand whether technology is easy to use, has challenges, and is emerging, secure, and valuable to the healthcare community. We need to do more work on this.
5.3. (RQ3) Which Semantic Web Technologies Are Used in the Literature, and What Are the Familiar Technologies Considered by Each Solution?
This section discusses the various Semantic Web technologies used in the literature, as well as the most common ones among them. There are numerous Semantic Web technologies available that make the applications more advanced. The healthcare industry makes extensive use of these Semantic Web technologies. As a result of these technologies, the healthcare industry is getting more advanced. The most prevalent Semantic Web technologies that are used in the healthcare sector are Resource Description Framework (RDF), Web Ontology Language (OWL), SPARQL Protocol and RDF Query Language (SPARQL), Semantic Web Rule Language (SWRL), Web Service Modeling Ontology (WSMO), Notation3 (N3), SPARQL Inferencing Notation (SPIN), Euler Yap Engine (EYE), Web Service Modeling Language (WSML), and RDF Data Query Language (RDQL).
Various Semantic Web technologies are used to accomplish various goals, such as converting relational databases to RDF/OWL-based databases, data linking, reasoning, data sharing, data representation, and so on. Ontologies are considered the basis of the Semantic Web. All of the data on the Semantic Web are based on ontologies. To take advantage of ontology-based data, it must first be transformed into RDF-based datasets. The RDF is an Internet standard model for data transfer that includes qualities that make data merging easier, as well as the ability to evolve schemas over time without having to update all of the data [ 52 ]. The majority of the researchers utilized RDF to represent the linked data and interchange data. In the Semantic Web, Notation3 is used as an alternative to RDF to construct notations. It was created to serialize RDF models and it supports RDF-based principles and constraints. Humans can understand Notation3-based notations more easily than RDF-based notations. In addition to RDF, OWL is employed in the research articles to express ontology-based data. The OWL is a semantic markup language for exchanging and distributing ontologies on the web [ 52 ]. Furthermore, there is a second version of OWL available which is known as OWL2. The improved descriptive ability for attributes, enhanced compatibility for object types, simplified metamodeling abilities, and enhanced annotation functionality are among the new features added in OWL2. Numerous OWL-based ontologies are available on the web. OWL-S is one of them which is a Semantic Web ontology [ 78 ]. The OWL is also used for semantic reasoning. Combining Description Logic with OWL (OWL-DL) takes the reasoning capability to another level. OWL-DL provides desired algorithmic features for reasoning engines and is meant to assist the current Description Logic industry area [ 82 ]. As an alternative to OWL, EYE is used which is an advanced chaining reasoner with Euler path detection [ 85 ]. It uses backward and forward reasoning to arrive at more accurate conclusions and results. To query the RDF and OWL-based datasets, the scholars made use of SPARQL. SPARQL is the sole query language that may be used to query RDF and OWL-based databases. However, RDQL was employed as a query language for RDF datasets in a study [ 20 ]. Only RDF datasets can be queried with it. In several papers, writing the semantic rules and constraints was necessary. So, they used SWRL which is a language for writing semantic rules based on OWL principles. Alongside SWRL, scholars used SPIN which is a rule language for the Semantic Web that is based on SPARQL [ 60 ]. In the Semantic Web, specifying web services for different purposes is essential. In this regard, some research papers discussed leveraging the WSMO which is a Semantic Web framework for characterizing and specifying web services in a semantic way. A linguistic framework called WSML is used to express the Semantic Web services specified in WSMO. The WSML is a syntactic and semantic language framework for describing the elements in WSMO [ 48 ]. Tables Tables4 4 4 – 8 summarize the Semantic Web technologies employed in different thematic research areas. Section 3 has detailed information regarding the discussion.
Summary of Semantic Web technologies used in e-healthcare services.
Summary of Semantic Web technologies used in diseases.
Summary of Semantic Web technologies used in information management.
Table 6 summarizes Semantic Web technologies used in e-healthcare services. In this field of theme research, RDF, OWL, and SPARQL are the most commonly utilized technologies. Researchers employed RDF and OWL to construct RDF-based datasets, represent RDF datasets, and develop links between data. As an alternative to RDF, an article used Notation3 to construct RDF notations which are easier to read than RDF-based notations. In a paper, the scholars used OWL2, the second version of OWL, to utilize the latest features offered by the technology. For all of the articles, SPARQL is the only query language utilized to query the datasets. To construct rules and limits for the systems, most of the articles used SWRL. In addition to SWRL, an article used the SPIN to generate semantic rules and constraints. Furthermore, SPIN has not been used in any other research area. Besides, two articles used WSMO for the identification of Semantic Web services required for the systems. On the other hand, three articles in this theme did not use any Semantic Web technology.
Table 7 summarizes Semantic Web technologies used in diseases. Similar to the preceding thematic research area, RDF, OWL, and SPARQL are the most frequently used technologies. Also, the motivations for using these technologies are identical. However, an article utilized RDQL as an alternative to SPARQL to conduct queries on RDF datasets. SWRL was used to construct rules and limitations, just as it had been previously. It is also worth noting that a study built a model using the OWL-S, an OWL-based semantic ontology. Then, there is a study in this field that did not utilize any Semantic Web technology at all.
Table 8 summarizes Semantic Web technologies used in information management. Nine distinct Semantic Web technologies are used in this thematic research area. RDF, OWL, and SPARQL, like the previous topic groups, are the most extensively used technologies. It is worth repeating that the technologies' goals are the same as they were previously. In addition, the usage of Notation3 for more accessible RDF notations, OWL2 to take advantage of new capabilities, OWL-S semantic ontology as the data source, and WSMO to identify Semantic Web services are also mentioned in this thematic area. In this field of research, there are two new technologies that are not present in prior fields. OWL-DL, which combines OWL with Description Logic for information reasoning, is one of the new technologies. The other one is EYE reasoner, which is also a reasoning engine. On the contrary, a significant proportion of articles, six to be exact, did not employ any Semantic Web technologies.
Table 7 summarizes Semantic Web technologies used in frontier technology. In this thematic study field, there are just three articles, and two of them did not employ any kind of Semantic Web technology. The other paper includes RDF and SPARQL, which were very commonly used in the prior thematic research fields.
Table 8 summarizes Semantic Web technologies used in regulatory conditions. Only one of the two articles in this research area includes Semantic Web technology. Also, the sole semantic technology used in the article is RDF for the purpose of semantic data representation.
There are different applications of Semantic Web technologies in the articles, but most of the technologies are common in several articles. The most commonly used Semantic Web technologies are the SPARQL query language, RDF, OWL, and SWRL. Almost 80 percent of the analyzed papers used different functionalities of RDF. Furthermore, OWL and SPARQL technologies were used in nearly three-quarters of the articles. Besides, SWRL technology was applied in one-third of the analyzed studies. It is now obvious that these technologies have the potential to improve the healthcare industry.
5.4. (RQ4) What Are the Evaluating Procedures Used to Assess the Efficiency of Each Solution?
The suggested technologies and procedures for evaluating these works are included in this category. In truth, assessing the designed healthcare system's quality, performance, and utility is a crucial responsibility. Because the healthcare industry is highly sensitive, suitable evaluation standards are necessary. Due to technological limitations, however, the evaluation system is not well organized or maintained. Because the notion of Semantic Web technology is new in the medical field, overall development and evaluation are inadequate.
In the e-healthcare service-based theme (see Table 6 ), the authors in [ 51 ] established a set of setups to test the matcher's efficiency for scalability in terms of the number of Semantic Web services for medical appointments and their complexity. They consider the logical complexity of Flora-2 expressions used in pre and post-conditions, which can handle various web service and goal descriptions, including ontology consistency check. Some other evaluation methods like OSHCO validation for automatic decision support in medical services were also introduced by the authors in [ 57 ]. An experiment was established to assess the system utilizing two metrics via WS datasets, the execution time measurement and the correctness measurement, for graph-based Semantic Web services for healthcare data integration [ 62 ] and histopathology for evaluating the performance of semantic mappings [ 58 ].
However, only two publications presented evaluation procedures from the vast portion of information management system-related work (see Table 7 ). Tonguo et al. [ 25 ] used BioMedLib to evaluate a system that takes a user's search query and pulls articles from millions of national biomedical article databases. Another one used evaluation criteria like D2RQ for default semantic mapping generation [ 83 ].
In terms of frontier technology (see Table 9 ), the cluster-based missing value imputation algorithm (CMVI) was used to extract knowledge in the Semantic Web's healthcare domain [ 101 ]. The imputation accuracy was measured using a couple of well-known performance metrics, namely, coefficient of determination (R2) and index of agreement (DK), along with the root mean square error (RMSE) test. In addition, various open-domain question-answer evaluation campaigns such as TREC21, CLEF22, NTCIR23, and Quaero24 have been launched to evaluate a Semantic Web and NLP-based medical questionnaire system [ 27 ].
Summary of Semantic Web technologies used in frontier technology.
None of the writers provide any evaluation methodologies connected to diseases and regulatory conditions (see Tables Tables9 9 and and10). 10 ). To assess the consequences of Semantic Web discussions on specific diseases, well-designed evaluation criteria are required. As studies focus on the obstacles and problems of the Semantic Web in healthcare services, the necessity of evaluation is also missing in regulatory conditions.
Summary of Semantic Web technologies used in regulatory conditions.
5.5. (RQ5) What Are the Research Gaps and Limitations of the Prior Literature, and What Future Research Avenues Can Be Derived to Advance Web 3.0 or Semantic Web Technology in Medical and Healthcare?
The healthcare industry is on the verge of a real Internet revolution. It intends to bring in a new era of web interaction through the adoption of the Semantic Web, with significant changes in how developers and content creators use it. This web will make healthcare web services, applications, and healthcare agents more intelligent and even provide care with human-like intelligence by utilizing an AI system. Despite the tremendous amount of innovation, it may bring its adoption in healthcare considerable challenges.
The problem with the “Semantic Web” is that it requires a certain level of implementation commitment from web developers and content creators that will not be forthcoming. First, a large portion of existing healthcare web content does not use semantic markup and will never do so due to a lack of resources to rewrite the HTML code. Second, there is no guarantee that new healthcare content will utilize semantic markup because it would need additional effort. However, it is essential to guide the Semantic Web developer community in the right direction so that they can help contribute to future medical healthcare development. The following are the primary obstacles the Semantic Web faces in general: (i) content availability, (ii) expanding ontologies, (iii) scalability, (iv) multilingualism, (v) visualization to decrease information overload, and (vi) Semantic Web language stability.
Furthermore, based on our thorough examination of the 65 publications, the following are some of the most technologically severe obstacles that the Semantic Web in general faces in the healthcare context and must overcome; future research may be able to alleviate a few of these challenges:
- Integrated Data Issue . The vulnerability of interconnected data is one of the most significant challenges with Semantic Web adoption. All of a patient's health records and personal information are stored and interlinked to an endpoint, and a malicious party may gain control of one's life if the record is compromised.
- Vastness . The current Internet contains a vast amount of healthcare records not yet semantically indexed; any reasoning system that wants to analyze all of these data and figure out how it functions will have to handle massive amounts of data.
- Vagueness . As Semantic Web is not yet mature enough, applications cannot handle non-specific user queries adequately.
- Accessibility . Semantic Web may not work on older or low-end devices; only highly configured devices will be able to manage web content.
- Usability . It will be difficult for beginners to comprehend because the SPARQL queries are often used in websites and services.
- Deceit . What if the information provided by the source is false and deceptive? Management and regulation have become crucial.
The study also identifies future research opportunities and gives research recommendations to the developer and researcher communities for each of the identified theme areas where the Semantic Web is being used in medical and healthcare (see Section 4 ). Tables Tables4 4 and and5 5 summarize the research gap and probable future research direction.
6. Conclusion
The purpose of this SLR is to discover the most recent advances in SW technology in the medical and healthcare fields. We used well-established research techniques to find relevant studies in prestigious databases such as Scopus, IEEE Xplore Digital Library, ACM Digital Library, and Semantic Scholar. Consequently, we were able to answer five significant RQs. We answered RQ1 by giving a bibliometric analysis-based research profile of the existing literature. The study profile includes information on annual trends, publishing sources, methodological approaches, geographic coverage, and theories applied (see Sections 2.4 and 5.1 ). We performed content analysis to determine the answers to RQ2 , RQ3 , and RQ4 ; we also identified research themes, with a focus on technical challenges in healthcare where SW technologies can be used (see Sections 3 and 5.2 – 5.4 ). Finally, the synthesis of prior literature helped us to identify research gaps in the existing literature and suggest areas for future research in RQ5 (see Section 5.5 and Tables Tables4 4 and and5). 5 ). The findings of this study have important implications for healthcare practitioners and scholars who are interested in the Semantic Web and how it might be used in medical and healthcare contexts.
The global digital healthcare market is growing to meet the health needs of society, individuals, and the environment. As a result, a substantial study is required to assist governments and organizations in overcoming technological challenges. We successfully reviewed 65 academic papers comprising journal articles, conference papers, and book chapters from prestigious databases. We have identified five thematic areas based on our research questions to discuss the objectives, solutions, and prior work of Semantic Web technology in the healthcare field. Among these, we observed that e-healthcare services and medical information management are the most discussed topics [ 105 , 107 ]. According to our findings, with the emergence of Semantic Web technology, integration, discovery, and exploration of medical data from disparate sources have become more accessible. Accordingly, medical applications are incorporating semantic technology to establish a unified healthcare system to facilitate the retrieval of information and link data from multiple sources. Most of the studies that we examined discussed the importance of knowledge sharing among clinicians and patients to develop an effective medical service. The frameworks described depended on the proper data distribution from various sources supported by specific technology interventions [ 24 ]. To answer patient queries, SW-based systems such as appointment matchmaking, quality assurance, and NLP-based chatbots have been proposed to improve healthcare services [ 24 , 111 , 112 ]. In short, the Semantic Web has huge potential and is widely regarded as the web's future, Web 3.0, which will present a new challenge and opportunity in combining healthcare big data with the web to make it more intelligent [ 6 , 113 ].
The analysis of the proposed solutions discussed in the papers helped us to identify the main challenges in healthcare systems. Besides that, this study also identifies future challenges and research opportunities for future medical researchers. We observed that most of the proposed solutions are yet to be implemented and many problems are only rudimentarily tackled so far. In conclusion, by exchanging knowledge among physicians, researchers, and healthcare professionals, the SW encourages improvement from the “syntactic” to “semantic” and finally to the “pragmatic” level of services, applications, and people. From the overall observation of the findings of this SLR, a future strategy will be to adopt some of the suggested solutions to overcome the shortcomings and open a new door for the medical industry. In the future, we will try to implement such solutions and eliminate the problems.
Data Availability
Conflicts of interest.
The authors declare that they have no conflicts of interest.
Analyze research papers at superhuman speed
Search for research papers, get one sentence abstract summaries, select relevant papers and search for more like them, extract details from papers into an organized table.
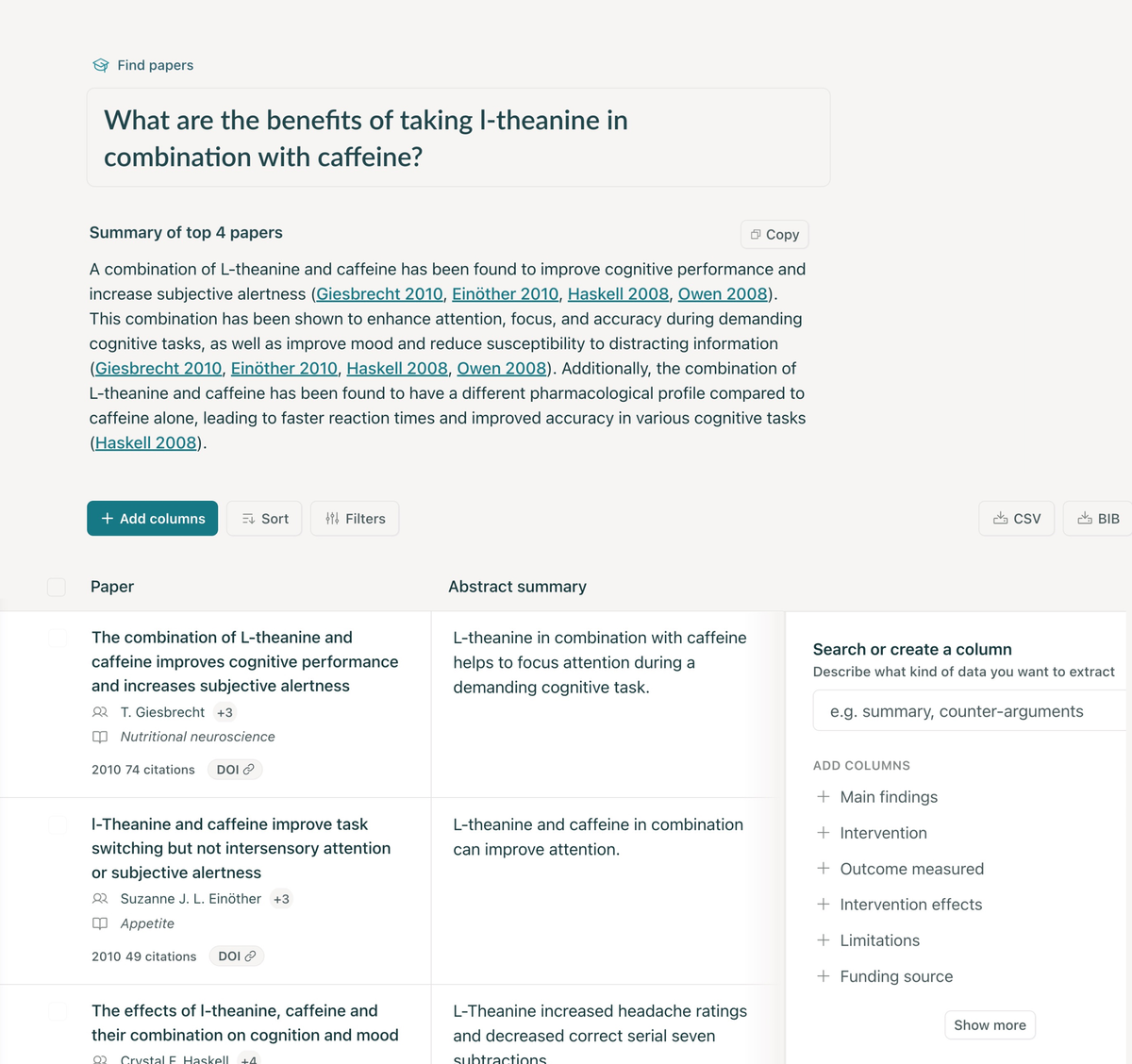
Find themes and concepts across many papers
Don't just take our word for it.
.webp)
Tons of features to speed up your research
Upload your own pdfs, orient with a quick summary, view sources for every answer, ask questions to papers, research for the machine intelligence age, pick a plan that's right for you, get in touch, enterprise and institutions, custom pricing, common questions. great answers., how do researchers use elicit.
Over 2 million researchers have used Elicit. Researchers commonly use Elicit to:
- Speed up literature review
- Find papers they couldn’t find elsewhere
- Automate systematic reviews and meta-analyses
- Learn about a new domain
Elicit tends to work best for empirical domains that involve experiments and concrete results. This type of research is common in biomedicine and machine learning.
What is Elicit not a good fit for?
Elicit does not currently answer questions or surface information that is not written about in an academic paper. It tends to work less well for identifying facts (e.g. “How many cars were sold in Malaysia last year?”) and theoretical or non-empirical domains.
What types of data can Elicit search over?
Elicit searches across 125 million academic papers from the Semantic Scholar corpus, which covers all academic disciplines. When you extract data from papers in Elicit, Elicit will use the full text if available or the abstract if not.
How accurate are the answers in Elicit?
A good rule of thumb is to assume that around 90% of the information you see in Elicit is accurate. While we do our best to increase accuracy without skyrocketing costs, it’s very important for you to check the work in Elicit closely. We try to make this easier for you by identifying all of the sources for information generated with language models.
What is Elicit Plus?
Elicit Plus is Elicit's subscription offering, which comes with a set of features, as well as monthly credits. On Elicit Plus, you may use up to 12,000 credits a month. Unused monthly credits do not carry forward into the next month. Plus subscriptions auto-renew every month.
What are credits?
Elicit uses a credit system to pay for the costs of running our app. When you run workflows and add columns to tables it will cost you credits. When you sign up you get 5,000 credits to use. Once those run out, you'll need to subscribe to Elicit Plus to get more. Credits are non-transferable.
How can you get in contact with the team?
Please email us at [email protected] or post in our Slack community if you have feedback or general comments! We log and incorporate all user comments. If you have a problem, please email [email protected] and we will try to help you as soon as possible.
What happens to papers uploaded to Elicit?
When you upload papers to analyze in Elicit, those papers will remain private to you and will not be shared with anyone else.
How accurate is Elicit?
Training our models on specific tasks, searching over academic papers, making it easy to double-check answers, save time, think more. try elicit for free..
Something went wrong when searching for seed articles. Please try again soon.
No articles were found for that search term.
Author, year The title of the article goes here
LITERATURE REVIEW SOFTWARE FOR BETTER RESEARCH
“Litmaps is a game changer for finding novel literature... it has been invaluable for my productivity.... I also got my PhD student to use it and they also found it invaluable, finding several gaps they missed”
Varun Venkatesh
Austin Health, Australia

As a full-time researcher, Litmaps has become an indispensable tool in my arsenal. The Seed Maps and Discover features of Litmaps have transformed my literature review process, streamlining the identification of key citations while revealing previously overlooked relevant literature, ensuring no crucial connection goes unnoticed. A true game-changer indeed!
Ritwik Pandey
Doctoral Research Scholar – Sri Sathya Sai Institute of Higher Learning

Using Litmaps for my research papers has significantly improved my workflow. Typically, I start with a single paper related to my topic. Whenever I find an interesting work, I add it to my search. From there, I can quickly cover my entire Related Work section.
David Fischer
Research Associate – University of Applied Sciences Kempten
“It's nice to get a quick overview of related literature. Really easy to use, and it helps getting on top of the often complicated structures of referencing”
Christoph Ludwig
Technische Universität Dresden, Germany
“This has helped me so much in researching the literature. Currently, I am beginning to investigate new fields and this has helped me hugely”
Aran Warren
Canterbury University, NZ
“I can’t live without you anymore! I also recommend you to my students.”
Professor at The Chinese University of Hong Kong
“Seeing my literature list as a network enhances my thinking process!”
Katholieke Universiteit Leuven, Belgium
“Incredibly useful tool to get to know more literature, and to gain insight in existing research”
KU Leuven, Belgium
“As a student just venturing into the world of lit reviews, this is a tool that is outstanding and helping me find deeper results for my work.”
Franklin Jeffers
South Oregon University, USA
“Any researcher could use it! The paper recommendations are great for anyone and everyone”
Swansea University, Wales
“This tool really helped me to create good bibtex references for my research papers”
Ali Mohammed-Djafari
Director of Research at LSS-CNRS, France
“Litmaps is extremely helpful with my research. It helps me organize each one of my projects and see how they relate to each other, as well as to keep up to date on publications done in my field”
Daniel Fuller
Clarkson University, USA
As a person who is an early researcher and identifies as dyslexic, I can say that having research articles laid out in the date vs cite graph format is much more approachable than looking at a standard database interface. I feel that the maps Litmaps offers lower the barrier of entry for researchers by giving them the connections between articles spaced out visually. This helps me orientate where a paper is in the history of a field. Thus, new researchers can look at one of Litmap's "seed maps" and have the same information as hours of digging through a database.
Baylor Fain
Postdoctoral Associate – University of Florida
Our Course: Learn and Teach with Litmaps
Neural decoding of semantic concepts: a systematic literature review
Affiliation.
- 1 Brain-Computer Interfacing and Neural Engineering Laboratory, School of Computer Science and Electronic Engineering, University of Essex, Colchester, United Kingdom.
- PMID: 35344941
- DOI: 10.1088/1741-2552/ac619a
Objective. Semantic concepts are coherent entities within our minds. They underpin our thought processes and are a part of the basis for our understanding of the world. Modern neuroscience research is increasingly exploring how individual semantic concepts are encoded within our brains and a number of studies are beginning to reveal key patterns of neural activity that underpin specific concepts. Building upon this basic understanding of the process of semantic neural encoding, neural engineers are beginning to explore tools and methods for semantic decoding: identifying which semantic concepts an individual is focused on at a given moment in time from recordings of their neural activity. In this paper we review the current literature on semantic neural decoding. Approach. We conducted this review according to the Preferred Reporting Items for Systematic reviews and Meta-Analysis (PRISMA) guidelines. Specifically, we assess the eligibility of published peer-reviewed reports via a search of PubMed and Google Scholar. We identify a total of 74 studies in which semantic neural decoding is used to attempt to identify individual semantic concepts from neural activity. Main results. Our review reveals how modern neuroscientific tools have been developed to allow decoding of individual concepts from a range of neuroimaging modalities. We discuss specific neuroimaging methods, experimental designs, and machine learning pipelines that are employed to aid the decoding of semantic concepts. We quantify the efficacy of semantic decoders by measuring information transfer rates. We also discuss current challenges presented by this research area and present some possible solutions. Finally, we discuss some possible emerging and speculative future directions for this research area. Significance. Semantic decoding is a rapidly growing area of research. However, despite its increasingly widespread popularity and use in neuroscientific research this is the first literature review focusing on this topic across neuroimaging modalities and with a focus on quantifying the efficacy of semantic decoders.
Keywords: conceptual decoding; electroencephalography (EEG); functional magnetic resonance imaging (fMRI); functional near infrared spectroscopy (fNIRS); intracranial electrodes; literature review; semantic decoding.
© 2022 IOP Publishing Ltd.
Publication types
- Systematic Review
- Brain* / diagnostic imaging
- Machine Learning
- Magnetic Resonance Imaging
- Neuroimaging
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

CHAPTER II REVIEW OF RELATED LITERATURE 2.1 Theory of Semantics

Related Papers
Anisoara Adriana
English Linguistics: Essentials
Bernd Kortmann
Rajendran S
The aim of the subject of study is to give a brief introduction to semantics and pragmatics. Semantics is the study of meaning. More precisely it is the study of the relation between linguistic expressions and their meanings. Pragmatics is the study of context. More precisely it is the study of the way context can influence our understanding of linguistic utterances. The term semantics simply means the study of meanings. The study explores how meaning in language is produced or created. Semantics not only concentrates on how words express meaning but also on how words, phrases and sentences come together to make meaning in language. To start with, you will be motivated to focus on the nature and scope of semantics. Hence, here in this unit, you will be introduced to the concept and definition semantics, brief history of semantics, semantics and other disciplines, major concern of semantics, and the different approaches to the study of semantics. The symbols employed in language must be patterned in a systematic way. You have been already informed that language is organized at four principal levels – sounds (i.e. Phonetics/phonology), words (i.e. Morphology), sentences (i.e. syntax) and meaning (i.e. semantics). Phonology and syntax are concerned with the expressive power of language while semantics studies the meaning of what has been expressed. Knowledge of grammar is an aspect of the innate cognitive ability of human beings. The power of interpretation complements that innate ability. Interpretation is an aspect of semantics. Therefore, language acquisition or learning includes not only the knowledge of the organization of sounds and structures, but also how to associate meaning to the structures. Semantics can, therefore, be characterized as the scientific study of meaning in language. Semantics has been the subject of discourse for many years for philosophers and other scholars but later was introduced formally in literature in the late 1800’s. Hence, we have philosophical semantics and linguistic semantics among other varieties of semantics. Earlier scholars in philosophical semantics were interested in pointing out the relationship between linguistic expressions and identified phenomena in the external world. In the contemporary world, especially in the United States philosophical semantics has led to the development of semiotics. In some other parts of the world, and especially, France, the term semiology has been favoured. The reliance on logical calculations in issues of meaning has led to the development of logical semantics. However, for your purpose in this course, emphasis is on linguistic semantics, with our interest on the properties of natural languages. You shall see how this study relates to other disciplines. We shall also examine the real issues in linguistic semantics. Semantics has been identified as a component of linguistics. In its widest sense, linguistics is the scientific study of language. As a field of study, semantics is related to other disciplines. In semantics, we study the meaning of words and also how the meanings of words in a sentence are put together to form sentential meaning. Linguistic semantics studies meaning in a systematic and objective way. Since meaning as a concept is not static, a great deal of the idea of meaning still depends on the context and participants in the act of communication (discourse). There is a strong connection between meaning and pragmatics. The exchange or relay of information, message, attitude, feelings or values from one person to another contributes to the interpretation of meaning. This is done mainly by the use of language. It is often expressed that language is a system which uses a set of symbols agreed upon by a group to communicate their ideas or message or information. These symbols can be spoken or written, expressed as gestures or drawings. Depending upon the focus of study, semantics can be compartmentalized as lexical semantics, grammatical semantics, logical semantics and semantics in relation to pragmatics.
Global Journal of Research in Education & Literature
GJR Publication
The literature of pragmatics, discourse analysis and semantics reveals that several studies attempt the explanation of “meaning” within and beyond the physical properties of language. If there is any reason why language is worthy of such scholarly attention, it is because it is very meaningful to its users; language is systematic, broad and analytic. The works of early language phylosophers and grammarians are the bedrocks of the study of “meaning”. As a means of human communication, language is meaning-laden. Theoretical perspectives in semantics, are instrumental in the systematic and expository presentation of the features and properties of “meaning”, and the literature of semantics corroborates this claim. Semantics is a meaning-elucidating field of language study. Language use is not arbitrary; writers and speakers deploy their knowledge of semantic universals to engage in effective communication. This paper examines issues in semantics with a view to providing rich insights on the nature of “meaning” in language. The paper concludes that “meaning” is contextual, sentence-tructure-driven, literal, non-literal, reference-making, truth-conditional, speaker-based and language-specific.
Journal Language and Linguistics
Yuchau Hsiao
GIS Business
Nargiza Masharipova
This article highlights briefly the issues related to the notions like meaning and semantics and at the same time looks through the branches of semantics providing linguistic scholars views in this field
Rajendran Sankaravelayuthan
Technoarete Transactions on Language and Linguistics
Jerson Catoto
This overall report is revolving around developing an idea about semantics and psycholinguistics. Semantics and psycholinguistics are closely related that explain the way word can be interpreted by different individuals. Secondary data collection method has been chosen as the appropriate data collection method which will be sourced form already published articles and journals. Thematic analysis has been chosen for this study that has helped to duly meet the objectives and reach conclusion about particular topic. Keyword : Language processing, Psycholinguistic, Semantics
Fartas Mohamad
This booklet provides an introduction to the field of semantics and aims to give university students a brief summary of the main concepts and theories. Semantics is the study of meaning in language and encompasses a wide range of topics, from word meanings and sentence structures to the interpretation of texts and discourse. The purpose of this book is to help students understand the fundamental ideas of semantics and prepare them for exams and other assessments. The book is structured in a way that allows students to work through the material systematically. The booklet starts with an overview of semantics followed by an important theory in semantics namely compositionality theory , it covers also some related topics of the field including types of meaning, figures of speech and finally lexical relations. While this book is not meant to be a comprehensive guide to semantics, it is designed to give students a solid foundation in the subject and help them develop critical thinking skills. Whether you are new to the field or looking to refresh your knowledge, this book is a valuable resource for anyone studying semantics. However, it is primarily made for students of Ibn Zoh university ,AitMelloul , who could not attend to the sessions of the module, hoping this booklet would put them in the picture and making things clear for them.
RELATED PAPERS
Rafael Galeas
hendra Mulya
Putuberbagi
Putuberbagi Blog
MedienPädagogik
Martin Ebner
Wschód Europy. Studia humanistyczno-społeczne
Oleksandr Kashynskyi
Charmaine Borg
Colette Kirwan
Biology and Fertility of Soils
Dawit Solomon
Yashvant Singh
Forensic Science International: Reports
Evelyne Soriano
Nuwan Chathuranga
Revista Brasileira de Ensino de Ciência e Tecnologia
gustavo gutierrez
Eating Behaviors
Sofia Fernandez
Revista telemática de filosofía del derecho ( RTFD )
Francisco Bariffi
Ciencia y Salud
Journal of Power Sources
Abant İzzet Baysal Üniversitesi Eğitim Fakültesi Dergisi
Cemil Öztürk
Sandro Dettori
Proceedings of the 11th Biannual Conference on Italian SIGCHI Chapter
Patrizia Marti
Indian Journal of Community Medicine
Neera Marathe
Salud mental
Elsa Tirado-Durán
F1000Research
Matilde Colella
Palgrave studies in cross-disciplinary business research, in association with EuroMed Academy of Business
Alkis Thrassou
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: mambaout: do we really need mamba for vision.
Abstract: Mamba, an architecture with RNN-like token mixer of state space model (SSM), was recently introduced to address the quadratic complexity of the attention mechanism and subsequently applied to vision tasks. Nevertheless, the performance of Mamba for vision is often underwhelming when compared with convolutional and attention-based models. In this paper, we delve into the essence of Mamba, and conceptually conclude that Mamba is ideally suited for tasks with long-sequence and autoregressive characteristics. For vision tasks, as image classification does not align with either characteristic, we hypothesize that Mamba is not necessary for this task; Detection and segmentation tasks are also not autoregressive, yet they adhere to the long-sequence characteristic, so we believe it is still worthwhile to explore Mamba's potential for these tasks. To empirically verify our hypotheses, we construct a series of models named MambaOut through stacking Mamba blocks while removing their core token mixer, SSM. Experimental results strongly support our hypotheses. Specifically, our MambaOut model surpasses all visual Mamba models on ImageNet image classification, indicating that Mamba is indeed unnecessary for this task. As for detection and segmentation, MambaOut cannot match the performance of state-of-the-art visual Mamba models, demonstrating the potential of Mamba for long-sequence visual tasks. The code is available at this https URL
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
IMAGES
VIDEO
COMMENTS
Effective sharing requires findability, and for this we must understand research efforts on search mechanisms. To this purpose, this paper presented a systematic literature review on semantic search issues - analyzing and synthesizing 297 papers as a result of processing the entire contents of IEEE Xplore and Scopus.
Semantic Reader is an augmented reader with the potential to revolutionize scientific reading by making it more accessible and richly contextual. Try it for select papers. Semantic Scholar uses groundbreaking AI and engineering to understand the semantics of scientific literature to help Scholars discover relevant research.
This literature review gives an overview of current approaches to perform domain adaptation in a low-resource and approaches to perform multilingual semantic search in a low-resource setting. We developed a new typology to cluster domain adaptation approaches based on the part of dense textual information retrieval systems, which they adapt ...
LitLLM is an interactive tool to help scientists write the literature review or related work section of a scientific paper starting from a user-provided abstract (see Figure 1). The specific objectives of this work are to create a system to help users navigate through research papers and write a literature review for a given paper or project.
Background. Systematic literature searching is recognised as a critical component of the systematic review process. It involves a systematic search for studies and aims for a transparent report of study identification, leaving readers clear about what was done to identify studies, and how the findings of the review are situated in the relevant evidence.
8 OUTLOOK AND CONCLUSION. This literature review explored how to perform domain adapta-tion for multilingual semantic search. We introduced a systematic clustering of domain adaptation methods in a low resource setup, based on parts of the tIR system they alter, summarised in Ta-ble 1.
Semantic Scholar is a free literature search tool developed by the Allen Institute of AI (nicknamed AI2), a non-profit research institute. It has had a meteoric rise to prominence recently. Back in 2015, it could only be used to search through about 3 million computer science papers; not exactly useful to a wide range of scholars. But today, Semantic Scholar
In semantic search, ... with optimal foraging both in the ecology literature and in the semantic retrieval literature ... by the University of Wisconsin-Madison Institutional Review Board ...
Motivation As the number of public data resources continues to proliferate, identifying relevant datasets across heterogenous repositories is becoming critical to answering scientific questions. To help researchers navigate this data landscape, we developed Dug: a semantic search tool for biomedical datasets that utilizes evidence-based relationships from curated knowledge graphs to find ...
In this section, we review the existing literature and related work in Natural Language Processing (NLP), specifically discussing the state of the art in LLMs (c.f. Sect. 2.1) and semantic search (c.f. Sect. 2.2). 2.1 Large Language Models. The emergence of LLMs, particularly those based on transformer architectures [] such as BERT [], GPT [], and their successors, has revolutionized the field ...
Search algorithms were borrowed from NIH and Semantic Scholar. ... language models like GPT-3 to automate parts of researchers' workflows. Currently, the main workflow in Elicit is Literature Review. If you ask a question, Elicit will show relevant papers and summaries of key information about those papers in an easy-to-use table ...
Examples: Literature Review Matrix Find five articles on a given topic first, and then use a prompt like this one: Generate a 3-column table: 1st column list paper title, 2nd column list their research methods and 3rd column list their major findings. You can also leverage ChatGPT 3.5 to convert your search results into a review matrix. Begin ...
A systematic review is a type of literature review that collects and critically analyzes multiple research studies or papers. A review of existing studies is often quicker and cheaper than embarking on a new study. Researchers use methods that are selected before one or more research questions are formulated, and then they aim to find and analyze studies that relate to and answer those questions.
2. Methodology. A systematic review is a research study that looks at many publications to answer a specific research topic. This study follows such a review to examine previous research studies that include identifying, analyzing, and interpreting all accessible information relevant to the recent progress of pertinent literature on Web 3.0 or Semantic Web in medical and healthcare or our ...
Use AI to search, summarize, extract data from, and chat with over 125 million papers. ... Speed up literature review; Find papers they couldn't find elsewhere; ... Elicit searches across 125 million academic papers from the Semantic Scholar corpus, which covers all academic disciplines. When you extract data from papers in Elicit, Elicit ...
Our Mastering Literature Review with Litmaps course allows instructors to seamlessly bring Litmaps into the classroom to teach fundamental literature review and research concepts. Learn More. Join the 250,000+ researchers, students, and professionals using Litmaps to accelerate their literature review. Find the right papers faster.
In this paper we review the current literature on semantic neural decoding. Approach. We conducted this review according to the Preferred Reporting Items for Systematic reviews and Meta-Analysis (PRISMA) guidelines. Specifically, we assess the eligibility of published peer-reviewed reports via a search of PubMed and Google Scholar.
The way scholarly knowledge and in particular literature reviews are communicated today rather resembles static, unstructured, pseudo-digitized articles, which are hardly processable by machines and AI. This demo showcases a novel way to create and publish scholarly literature reviews, also called semantic reviews.
In this paper we review the current literature on semantic neural decoding. Approach. We conducted this review according to the Preferred Reporting Items for Systematic reviews and Meta-Analysis (PRISMA) guidelines. Specifically, we assess the eligibility of published peer-reviewed reports via a search of PubMed and Google Scholar.
Initial evidence is introduced on the utility of Research Screener, a semi-automated machine learning tool to facilitate abstract screening and suggests that analysts who scan 50% of the total pool of articles identified via a systematic search are highly likely to have identified 100% of eligible papers. Expand. 65. PDF.
Drawing upon a series of semi-structured interviews with Greek SEO experts and a systematic review of the notion of semantic search, and the corresponding semantic SEO technologies, the objective of this work is to present an analysis of how Semantic SEO affects news media and journalism content. ... Literature Review Semantic SEO. Search ...
Research directions for semantic web enabled software testing are presented in Section 12.3. 12.1. Potential value of semantic web technologies to software testing. From the point of view of test management, it is crucial to be able to store, retrieve, and analyze different kinds of data related to the test process.
Language use is not arbitrary; writers and speakers deploy their knowledge of semantic universals to engage in effective communication. This paper examines issues in semantics with a view to providing rich insights on the nature of "meaning" in language. ... CHAPTER II REVIEW OF RELATED LITERATURE 2.1 Theory of Semantics Semantics is a ...
DOI: 10.20961/shes.v5i2.58350 Corpus ID: 249210435; Literature Review: Mathematical Literacy using PMRI in Elementary School @article{Yuliana2022LiteratureRM, title={Literature Review: Mathematical Literacy using PMRI in Elementary School}, author={Yuliana Yuliana and Fembriani Fembriani}, journal={Social, Humanities, and Educational Studies (SHEs): Conference Series}, year={2022}, url={https ...
Semantic Scholar extracted view of "Tumor-induced osteomalacia: A systematic literature review" by Noelia Álvarez Rivas et al. ... Search 218,463,651 papers from all fields of science. Search. Sign In Create Free Account. DOI: 10.1016/j.bonr.2024.101772; Corpus ID: 269674609;
Mamba, an architecture with RNN-like token mixer of state space model (SSM), was recently introduced to address the quadratic complexity of the attention mechanism and subsequently applied to vision tasks. Nevertheless, the performance of Mamba for vision is often underwhelming when compared with convolutional and attention-based models. In this paper, we delve into the essence of Mamba, and ...
A systematic review on various recent contributions in the domain of recommender systems, focusing on diverse applications like books, movies, products, etc, provides a much-needed overview of the current state of research in this field.
The present literature study delves into the development of language teaching methodologies, with particular emphasis on three well-known techniques: Grammar Translation, Direct Method, and Audiolingual Method. The background underscores how pedagogical ideas have changed throughout time and stresses the historical context of language learning. The evaluation analyzes important academic ...
The characteristics that facilitate the adoption of Accounting Information Systems in Small and Medium Enterprises (SMEs) and their influence on corporate performance are investigated to ensure the long-term viability of SMEs in the face of business challenges and advancements. The viability of Small and Medium Enterprises is heavily reliant on effectively managed firm finance management ...