Speech to Text - Voice Typing & Transcription
Take notes with your voice for free, or automatically transcribe audio & video recordings. secure, accurate & blazing fast..
~ Proudly serving millions of users since 2015 ~
I need to >

Dictate Notes
Start taking notes, on our online voice-enabled notepad right away, for free.
Transcribe Recordings
Automatically transcribe (and optionally translate) audios & videos - upload files from your device or link to an online resource (Drive, YouTube, TikTok or other). Export to text, docx, video subtitles and more.
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export options, Speechnotes provides an efficient and user-friendly dictation and transcription experience. Proudly serving millions of users since 2015, Speechnotes is the go-to tool for anyone who needs fast, accurate & private transcription. Our Portfolio of Complementary Speech-To-Text Tools Includes:
Voice typing - Chrome extension
Dictate instead of typing on any form & text-box across the web. Including on Gmail, and more.
Transcription API & webhooks
Speechnotes' API enables you to send us files via standard POST requests, and get the transcription results sent directly to your server.
Zapier integration
Combine the power of automatic transcriptions with Zapier's automatic processes. Serverless & codeless automation! Connect with your CRM, phone calls, Docs, email & more.
Android Speechnotes app
Speechnotes' notepad for Android, for notes taking on your mobile, battle tested with more than 5Million downloads. Rated 4.3+ ⭐
iOS TextHear app
TextHear for iOS, works great on iPhones, iPads & Macs. Designed specifically to help people with hearing impairment participate in conversations. Please note, this is a sister app - so it has its own pricing plan.
Audio & video converting tools
Tools developed for fast - batch conversions of audio files from one type to another and extracting audio only from videos for minimizing uploads.
Our Sister Apps for Text-To-Speech & Live Captioning
Complementary to Speechnotes
Reads out loud texts, files & web pages
Reads out loud texts, PDFs, e-books & websites for free
Speechlogger
Live Captioning & Translation
Live captions & translations for online meetings, webinars, and conferences.
Need Human Transcription? We Can Offer a 10% Discount Coupon
We do not provide human transcription services ourselves, but, we partnered with a UK company that does. Learn more on human transcription and the 10% discount .
Dictation Notepad
Start taking notes with your voice for free
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing.
Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts. We strive to provide the best online dictation tool by engaging cutting-edge speech-recognition technology for the most accurate results technology can achieve today, together with incorporating built-in tools (automatic or manual) to increase users' efficiency, productivity and comfort. Works entirely online in your Chrome browser. No download, no install and even no registration needed, so you can start working right away.
Speechnotes is especially designed to provide you a distraction-free environment. Every note, starts with a new clear white paper, so to stimulate your mind with a clean fresh start. All other elements but the text itself are out of sight by fading out, so you can concentrate on the most important part - your own creativity. In addition to that, speaking instead of typing, enables you to think and speak it out fluently, uninterrupted, which again encourages creative, clear thinking. Fonts and colors all over the app were designed to be sharp and have excellent legibility characteristics.
Example use cases
- Voice typing
- Writing notes, thoughts
- Medical forms - dictate
- Transcribers (listen and dictate)
Transcription Service
Start transcribing
Fast turnaround - results within minutes. Includes timestamps, auto punctuation and subtitles at unbeatable price. Protects your privacy: no human in the loop, and (unlike many other vendors) we do NOT keep your audio. Pay per use, no recurring payments. Upload your files or transcribe directly from Google Drive, YouTube or any other online source. Simple. No download or install. Just send us the file and get the results in minutes.
- Transcribe interviews
- Captions for Youtubes & movies
- Auto-transcribe phone calls or voice messages
- Students - transcribe lectures
- Podcasters - enlarge your audience by turning your podcasts into textual content
- Text-index entire audio archives
Key Advantages
Speechnotes is powered by the leading most accurate speech recognition AI engines by Google & Microsoft. We always check - and make sure we still use the best. Accuracy in English is very good and can easily reach 95% accuracy for good quality dictation or recording.
Lightweight & fast
Both Speechnotes dictation & transcription are lightweight-online no install, work out of the box anywhere you are. Dictation works in real time. Transcription will get you results in a matter of minutes.
Super Private & Secure!
Super private - no human handles, sees or listens to your recordings! In addition, we take great measures to protect your privacy. For example, for transcribing your recordings - we pay Google's speech to text engines extra - just so they do not keep your audio for their own research purposes.
Health advantages
Typing may result in different types of Computer Related Repetitive Strain Injuries (RSI). Voice typing is one of the main recommended ways to minimize these risks, as it enables you to sit back comfortably, freeing your arms, hands, shoulders and back altogether.
Saves you time
Need to transcribe a recording? If it's an hour long, transcribing it yourself will take you about 6! hours of work. If you send it to a transcriber - you will get it back in days! Upload it to Speechnotes - it will take you less than a minute, and you will get the results in about 20 minutes to your email.
Saves you money
Speechnotes dictation notepad is completely free - with ads - or a small fee to get it ad-free. Speechnotes transcription is only $0.1/minute, which is X10 times cheaper than a human transcriber! We offer the best deal on the market - whether it's the free dictation notepad ot the pay-as-you-go transcription service.
Dictation - Free
- Online dictation notepad
- Voice typing Chrome extension
Dictation - Premium
- Premium online dictation notepad
- Premium voice typing Chrome extension
- Support from the development team
Transcription
$0.1 /minute.
- Pay as you go - no subscription
- Audio & video recordings
- Speaker diarization in English
- Generate captions .srt files
- REST API, webhooks & Zapier integration
Compare plans
Privacy policy.
We at Speechnotes, Speechlogger, TextHear, Speechkeys value your privacy, and that's why we do not store anything you say or type or in fact any other data about you - unless it is solely needed for the purpose of your operation. We don't share it with 3rd parties, other than Google / Microsoft for the speech-to-text engine.
Privacy - how are the recordings and results handled?
- transcription service.
Our transcription service is probably the most private and secure transcription service available.
- HIPAA compliant.
- No human in the loop. No passing your recording between PCs, emails, employees, etc.
- Secure encrypted communications (https) with and between our servers.
- Recordings are automatically deleted from our servers as soon as the transcription is done.
- Our contract with Google / Microsoft (our speech engines providers) prohibits them from keeping any audio or results.
- Transcription results are securely kept on our secure database. Only you have access to them - only if you sign in (or provide your secret credentials through the API)
- You may choose to delete the transcription results - once you do - no copy remains on our servers.
- Dictation notepad & extension
For dictation, the recording & recognition - is delegated to and done by the browser (Chrome / Edge) or operating system (Android). So, we never even have access to the recorded audio, and Edge's / Chrome's / Android's (depending the one you use) privacy policy apply here.
The results of the dictation are saved locally on your machine - via the browser's / app's local storage. It never gets to our servers. So, as long as your device is private - your notes are private.
Payments method privacy
The whole payments process is delegated to PayPal / Stripe / Google Pay / Play Store / App Store and secured by these providers. We never receive any of your credit card information.
More generic notes regarding our site, cookies, analytics, ads, etc.
- We may use Google Analytics on our site - which is a generic tool to track usage statistics.
- We use cookies - which means we save data on your browser to send to our servers when needed. This is used for instance to sign you in, and then keep you signed in.
- For the dictation tool - we use your browser's local storage to store your notes, so you can access them later.
- Non premium dictation tool serves ads by Google. Users may opt out of personalized advertising by visiting Ads Settings . Alternatively, users can opt out of a third-party vendor's use of cookies for personalized advertising by visiting https://youradchoices.com/
- In case you would like to upload files to Google Drive directly from Speechnotes - we'll ask for your permission to do so. We will use that permission for that purpose only - syncing your speech-notes to your Google Drive, per your request.
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Inference and training library for high-quality TTS models.
huggingface/parler-tts
Folders and files, repository files navigation.
Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker (gender, pitch, speaking style, etc). It is a reproduction of work from the paper Natural language guidance of high-fidelity text-to-speech with synthetic annotations by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively.
Contrarily to other TTS models, Parler-TTS is a fully open-source release. All of the datasets, pre-processing, training code and weights are released publicly under permissive license, enabling the community to build on our work and develop their own powerful TTS models.
This repository contains the inference and training code for Parler-TTS. It is designed to accompany the Data-Speech repository for dataset annotation.
We're proud to release Parler-TTS Mini v0.1 , our first 600M parameter model, trained on 10.5K hours of audio data. In the coming weeks, we'll be working on scaling up to 50k hours of data, in preparation for the v1 model.
📖 Quick Index
Installation.
- Model weights and datasets
Parler-TTS has light-weight dependencies and can be installed in one line:
You can directly try it out in an interactive demo here !
Using Parler-TTS is as simple as "bonjour". Simply use the following inference snippet.
The training folder contains all the information to train or fine-tune your own Parler-TTS model. It consists of:
- 1. An introduction to the Parler-TTS architecture
- 2. The first steps to get started
- 3. A training guide
TL;DR: After having followed the installation steps , you can reproduce the Parler-TTS Mini v0.1 training recipe with the following command line:
Acknowledgements
This library builds on top of a number of open-source giants, to whom we'd like to extend our warmest thanks for providing these tools!
Special thanks to:
- Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively, for publishing such a promising and clear research paper: Natural language guidance of high-fidelity text-to-speech with synthetic annotations .
- the many libraries used, namely 🤗 datasets , 🤗 accelerate , jiwer , wandb , and 🤗 transformers .
- Descript for the DAC codec model
- Hugging Face 🤗 for providing compute resources and time to explore!
If you found this repository useful, please consider citing this work and also the original Stability AI paper:
Contribution
Contributions are welcome, as the project offers many possibilities for improvement and exploration.
Namely, we're looking at ways to improve both quality and speed:
- Train on more data
- Add more features such as accents
- Add PEFT compatibility to do Lora fine-tuning.
- Add possibility to train without description column.
- Add notebook training.
- Explore multilingual training.
- Explore mono-speaker finetuning.
- Explore more architectures.
- Compilation and static cache
- Support to FA2 and SDPA
- Add more evaluation metrics
Contributors 2
- Python 99.9%
- Makefile 0.1%
Want to try a dynamic demo of ReadSpeaker’s AI voices for your application?
Get in touch with our sales team to request a full demo with your own content.
Explore ReadSpeaker's AI voices
See our Languages & Voices page for a complete list of available languages for each solution.
ReadSpeaker text-to-speech voices are humanlike, relatable voices. There are 110+ voices available in 35+ languages , with more on their way. Meet the ReadSpeaker TTS family of high-quality voice personas and put them to the test.
Industry-Leading TTS Voices
At ReadSpeaker, we have a passion for developing high-quality TTS voices. In fact, expert third party industry observers rate the US English ReadSpeaker TTS voice as being the most accurate on the market .
The enthusiastic feedback we receive from our customers confirms that we deliver the very best TTS solutions for successful online, offline, embedded, and server-based applications around the world.
Our commitment to providing outstanding TTS solutions is made possible by our uncompromising production process, designed to guarantee the quality levels that have earned ReadSpeaker TTS the trust of customers from across countries and markets.

How Our TTS Voices Are Made
To create our speech personas, we select and record professional voice talents.
Once a voice talent has been selected, she or he works with our voice development team for several days or weeks, depending on the type of voice, or the voice technology, we want to use.
A diverse script is used for the recordings, designed to contain all the sound patterns of the language in development. The team closely monitors the recording process to check for consistency in pronunciation, accentuation, and style.
Neural Voices
ReadSpeaker creates so-called neural voices, using techniques based on deep learning AI technology. This revolutionary method involves mapping linguistic properties to acoustic features using Deep Neural Networks (DNNs)
An iterative learning process minimises objectively measurable differences between the predicted acoustic features and the observed acoustic features in the training set.
One of the advantages of the new DNN TTS method is that the acoustic database can be much smaller than for a USS voice. Only a few hours of recorded speech are needed for a neural voice, compared to at least three times as many for a good quality USS voice.
Also, the resulting speech is generally smoother and even more human-like. This makes developing new, smart ReadSpeaker TTS voices with even more lifelike, expressive speech and customizable intonation faster than ever.
Custom voices
If your strategy is to offer an exclusive customer experience and you want to take your brand appeal to a new level, one of the most powerful ways to differentiate yourself is by using a custom voice to represent you.
A custom voice sets your brand apart and creates a powerful bond with your customers across your various communication touchpoints. If a preferred celebrity or other talent reflects your brand best and you want to be able to use their voice anytime you need it.
ReadSpeaker can create a custom TTS voice powered by our leading-edge speech engine, to give your brand instant recognition in the voice user interface.

- ReadSpeaker webReader
- ReadSpeaker docReader
- ReadSpeaker TextAid
- Assessments
- Text to Speech for K12
- Higher Education
- Corporate Learning
- Learning Management Systems
- Custom Text-To-Speech (TTS) Voices
- Voice Cloning Software
- Text-To-Speech (TTS) Voices
- ReadSpeaker speechMaker Desktop
- ReadSpeaker speechMaker
- ReadSpeaker speechCloud API
- ReadSpeaker speechEngine SAPI
- ReadSpeaker speechServer
- ReadSpeaker speechServer MRCP
- ReadSpeaker speechEngine SDK
- ReadSpeaker speechEngine SDK Embedded
- Accessibility
- Automotive Applications
- Conversational AI
- Entertainment
- Experiential Marketing
- Guidance & Navigation
- Smart Home Devices
- Transportation
- Virtual Assistant Persona
- Voice Commerce
- Customer Stories & e-Books
- About ReadSpeaker
- TTS Languages and Voices
- The Top 10 Benefits of Text to Speech for Businesses
- Learning Library
- e-Learning Voices: Text to Speech or Voice Actors?
- TTS Talks & Webinars
Make your products more engaging with our voice solutions.
- Solutions ReadSpeaker Online ReadSpeaker webReader ReadSpeaker docReader ReadSpeaker TextAid ReadSpeaker Learning Education Assessments Text to Speech for K12 Higher Education Corporate Learning Learning Management Systems ReadSpeaker Enterprise AI Voice Generator Custom Text-To-Speech (TTS) Voices Voice Cloning Software Text-To-Speech (TTS) Voices ReadSpeaker speechCloud API ReadSpeaker speechEngine SAPI ReadSpeaker speechServer ReadSpeaker speechServer MRCP ReadSpeaker speechEngine SDK ReadSpeaker speechEngine SDK Embedded
- Applications Accessibility Automotive Applications Conversational AI Education Entertainment Experiential Marketing Fintech Gaming Government Guidance & Navigation Healthcare Media Publishing Smart Home Devices Transportation Virtual Assistant Persona Voice Commerce
- Resources Resources TTS Languages and Voices Learning Library TTS Talks and Webinars About ReadSpeaker Careers Support Blog The Top 10 Benefits of Text to Speech for Businesses e-Learning Voices: Text to Speech or Voice Actors?
- Get started
Search on ReadSpeaker.com ...
All languages.
- Norsk Bokmål
- Latviešu valoda
Request a full dynamic demo to try our voices with your scripts!
Please provide a brief project overview for a customized dynamic demo setup.
Web Speech API Demonstration
Click on the microphone icon and begin speaking for as long as you like.
No speech was detected. You may need to adjust your microphone settings .
No microphone was found. Ensure that a microphone is installed and that microphone settings are configured correctly.
Click the "Allow" button above to enable your microphone.
Permission to use microphone was denied.
Permission to use microphone is blocked. To change, go to chrome://settings/contentExceptions#media-stream
Web Speech API is not supported by this browser. Upgrade to Chrome version 25 or later.
Press Control-C to copy text.
(Command-C on Mac.)
Text sent to default email application.
(See chrome://settings/handlers to change.)
- Alan (Australian)
- Allison (US)
- Ashley (US)
- Brenda (US)
- Bridget (UK)
- Catherine (UK)
- Daniel (UK)
- Elizabeth (UK)
- Fiona (Scottish)
- Grace (Australian)
- Karen (Australian)
- Lakshmi (Indian)
- Lee (Australian)
- Matilda (Australian)
- Moira (Irish)
- Oliver (UK)
- Olivia (UK)
- Prashant (Indian)
- Samantha (US)
- Sangeeta (Indian)
- Serena (UK)
- Steven (US)
- Tessa (South African)
- Veena (Indian)
Language ID:

Our Text-To-Speech

Our Characters

Search Acapela
Type & Talk demo
Try our online free demo. Test our voices with your own input and instantly listen the audio result of what you want to say. This is the magic of TTS (Text To Speech) with our real time solutions.
Try our demo
Talk to an expert.
Our offer is wide and covering very different markets. We built business models adapted to different type of applications. Our team will guide you to the solution best adapted to your project. Let’s talk!
The User of this demo undertakes to use the demo in accordance with customs and standard practices. the User shall ensure that the demo will not be used to create prompts which are unlawful, harmful, threatening, abusive, harassing, tortuous, defamatory, vulgar, obscene, libellous, invasive of another's privacy, hateful, or racially, ethnically or otherwise objectionable.
Check out our Legal information .
Check out Acapela’s voice portfolio
Over 30 languages and 200 voices are ready to speak. Meet Acapela’s voice family.
Acapela’s text to speech solutions convert normal language text into a spoken voice output. Originally created for the visually impaired, type and talk technologies have become very popular, for numerous uses or businesses. Give it a try: you’ll be impressed. Whether you are an individual or a professional, we have text to speech generators matching your needs .
Need more information about our solutions? Let’s talk 😊!
We are here to guide you towards the right solution for your voice enabled project.
Text-to-Speech Simulator
A simple web app demonstrating how text sounds in different TTS voices.
- Conversation

Your Recent Chatter Clear All

Vocalware's TTS supports SSML tags, which allow you to control the manner in which the text in your app is spoken. Below are a few examples.
Click on a tag below to insert an example in to the text box:
There are many more SSML tags. Listed here are only those tags which are supported by all of our voices. Additional tags may be supported by a subset of our voices, feel free to experiment.
How It Works
API Reference
Contact support
Privacy Policy
Terms of Use
© 2024 Oddcast, Inc.

Contact sales
Free AI Text to Speech Online

Click to generate speech in:
Intelligent ai speech synthesis, diverse and dynamic voices, emotional range..
Diverse emotional inflections tailored for every narrative need.
Multilingual Capability.
All our voices fluently span 29 languages, retaining unique characteristics across each.
Voice Variety.
Design with Voice Design, explore with Voice Library, or select top-tier voice actors for unmatched natural voice quality.

Text to Speech in 29 Languages
Precision voice tuning.
Choose between expressive variability or consistent stability to fit your content's tone.
Clarity + Similarity Enhancement
Optimize for clear, artifact-free voices or enhance for speaker resemblance.
Style Exaggeration
Accentuate voice styles or prioritize speed and stability.
Text to speech for teams of all sizes

The voices are really amazing and very natural sounding. Even the voices for other languages are impressive. This allows us to do things with our educational content that would not have been possible in the past.
It's amazing to see that text to speech became that good. Write your text, select a voice and receive stunning and near-perfect results! Regenerating results will also give you different results (depending on the settings). The service supports 30+ languages, including Dutch (which is very rare). ElevenLabs has proved that it isn't impossible to have near-perfect text-to-speech 'Dutch'...
We use the tool daily for our content creation. Cloning our voices was incredibly simple. It's an easy-to-navigate platform that delivers exceptionally high quality. Voice cloning is just a matter of uploading an audio file, and you're ready to use the voice. We also build apps where we utilize the API from ElevenLabs; the API is very simple for developers to use. So, if you need a...
As an author I have written numerous books but have been limited by my inability to write them in other languages period now that I have found 11 labs, it has allowed me to create my own voice so that when writing them in different languages it's not someone else's voice but my own. That's certainly lends a level of authenticity that no other narrator can provide me.
ElevenLabs came to my notice from some Youtube videos that complained how this app was used to clone the US presidents voice. Apparently the app did its job very well. And that is the best thing about ElevenLabs. It does its job well. Converting text to speech is done very accurately. If you choose one of the 100s of voices available in the app, the quality of the output is superior to all...
Absolutely loving ElevenLabs for their spot-on voice generations! 🎉 Their pronunciation of Bahasa Indonesia is just fantastic - so natural and precise. It's been a game-changer for making tech and communication feel more authentic and easy. Big thumbs up! 👍
I have found ElevenLabs extremely useful in helping me create an audio book utilizing a clone of my own voice. The clone was super easy to create using audio clips from a previous audio book I recorded. And, I feel as though my cloned voice is pretty similar to my own. Using ElevenLabs has been a lot easier than sitting in front of a boom mic for hours on end. Bravo for a great AI product!
The variety of voices and the realness that expresses everything that is asked of it
I like that ElevenLabs uses cutting-edge AI and deep learning to create incredibly natural-sounding speech synthesis and text-to-speech. The voices generated are lifelike and emotive.
A fast and easy-to-use text to speech API
We obsess over building the fastest and simplest text to speech API so you can focus on building incredible applications.

Ultra-low latency.
We deliver streamed audio in under a second.
Ease of use.
ElevenLabs brings the most compelling, rich and lifelike voices to developers in just a few lines of code.
Developer Community.
Get all the help you need through our expert community.
Global AI Speech Generator

Language selection
Accent selection, audio generation, wall of text to speech voices, how to use text to speech, choose your preferred voice, settings, and model..
For a pre-made voice, you can use our extensive library of voices. Or, you can clone, customize and fine-tune voices.

Enter the text you want to convert to speech.
Write naturally in any of our supported languages. Our AI will understand the language and context.

Generate spoken audio and instantly listen to the results.
Convert written text to high-quality files that can be downloaded in a variety of audio formats.

Perfect Your Sound
Punctuation.
The placement of commas, periods, and other punctuation significantly influences the delivery and pauses in the output.
Longer text provides added context, ensuring a smoother and more natural audio flow.
Speaker Profile
Match your content to the ideal speaker. Different profiles have distinct delivery styles, catering to various tones and emotions.
Voice Settings
Refine your output by adjusting voice settings. Find the perfect balance to enhance clarity and authenticity.
Text to Speech Use Cases
Our AI text to speech software is designed to be flexible and easy to use, with a variety of voice options to suit your needs.
Take content creation to the next level
Create immersive gaming experiences, publish your written works, build engaging ai chatbots.

Why ElevenLabs Text to Speech?
Efficient content production..
Transform long written content to audio, fast. Maximize reach without traditional recording constraints.
Advanced API.
Seamlessly integrate and experience dynamic TTS capabilities.
Contextual TTS.
Our AI reads between the lines, capturing the heart of the content.
Language Authenticity.
Experience genuine speech in 29 languages, from nuances to native idioms.
Comprehensive Support.
Never feel lost. Our dedicated support and rich resource library mean you're always equipped to make the most of our cutting-edge technology.
Ethical AI Principles.
We prioritize user privacy, data protection, and uphold the highest ethical standards in AI development and deployment.
Frequently asked questions
How does the elevenlabs ai text to speech differ from other tts technologies.
ElevenLabs TTS leverages advanced deep learning models which are regularly updated and refined, ensuring high-quality audio output, emotion mapping, and a vast range of vocal choices for your ideal custom voice.
Can I customize the voice settings to match specific content needs?
Absolutely. Users can adjust Stability, Clarity, and Enhancement settings, allowing for voice outputs that range from entertainingly expressive to professionally sincere. Our platform provides the flexibility to match your content's unique requirements.
What is AI text to speech used for?
Text to speech has a vast array of applications, some are well established but more are emerging all the time. TTS is ideal for creating explainer videos, converting books into audio and producing creative video content without hiring voice actors. Our speech technology is ideal for any situation where accessibility and engagement can be improved through communicated written content in a high-quality voice.
What does "text to speech with emotion" mean?
It means our artificial intelligence model understands the context and can deliver the natural sounding speech with appropriate emotional intonations – be it excitement, sorrow, or neutrality. It adds a layer of realism, making the speech output more relatable and engaging.
How many languages does ElevenLabs support?
ElevenLabs proudly supports text to speech synthesis in 29 languages, ensuring that your content can resonate with a global audience.
How varied are the voice options available on ElevenLabs?
We offer a diverse range of voice profiles, catering to different tones, accents, and emotions. Whether you're seeking a particular regional accent or a specific emotional delivery, ElevenLabs ensures you find the perfect match for your content.
How secure is my data with ElevenLabs?
User data privacy and security are our top priorities. All user data and text inputs are handled with the utmost care, ensuring they are not used beyond the specified service purpose.
Does ElevenLabs offer an API for developers?
Yes, we provide a robust API that allows developers to integrate our advanced text-to-speech capabilities into their own applications, platforms, or tools.
How can I turn text into mp3 speech?
ElevenLabs makes it easy to turn text into mp3. Simply enter your text, choose a voice, generate the audio, and download.
- Sign up for a Speechify demo
Schedule a demo
- Custom rates for work teams and classrooms of all sizes.
- Special pricing for schools and businesses in one easy-to-manage subscription.
- Premium features on every platform. Every user gets access on Chrome, iOS, + Android.
- 30+ high quality, natural-sounding reading voices and unlimited Premium words.
Please enter a valid business email. Commercial email domains like @gmail.com, @outlook.com, @yahoo.com, or others are not allowed.
By submitting this form, I acknowledge and accept the Speechify Privacy Policy
Trusted by teams at
Give your content a voice
Listen at any speed.
2.8x more visits
Our clients have seen an average increase of 2.8x more site visits per user after rollout.
Less cancellations
And average an 11% decrease in paid subscription cancellations in the first month alone.
Users love us

Kate Marfori
Product Manager at The Star Tribune
With Speechify’s API, we can offer our users a new and accessible way to consume our content. We’ve seen that readers who choose to listen to articles with Speechify are on average 20% more engaged than users who choose not to listen.

Inline player
Our player fits seamlessly into your site or publication’s existing design. Users can play or pause the document and see how long it will take to read at normal speed.
Active text highlighting
Speechify highlights the sentence and word as it reads to make it easy for users to follow along as they listen.

Floating widget
The floating widget follows users down the page as it reads. Users can play, pause, and change the reading voice or speed. All API integrations use our highest quality, natural-sounding Premium voices.

Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.

Text to speech
An AI Speech feature that converts text to lifelike speech.
Bring your apps to life with natural-sounding voices
Build apps and services that speak naturally. Differentiate your brand with a customized, realistic voice generator, and access voices with different speaking styles and emotional tones to fit your use case—from text readers and talkers to customer support chatbots.
Lifelike synthesized speech
Enable fluid, natural-sounding text to speech that matches the intonation and emotion of human voices.
Customizable text-talker voices
Create a unique AI voice generator that reflects your brand's identity.
Fine-grained text-to-talk audio controls
Tune voice output for your scenarios by easily adjusting rate, pitch, pronunciation, pauses, and more.
Flexible deployment
Run Text to Speech anywhere—in the cloud, on-premises, or at the edge in containers.
Tailor your speech output
Fine-tune synthesized speech audio to fit your scenario. Define lexicons and control speech parameters such as pronunciation, pitch, rate, pauses, and intonation with Speech Synthesis Markup Language (SSML) or with the audio content creation tool .
Deploy Text to Speech anywhere, from the cloud to the edge
Run Text to Speech wherever your data resides. Build lifelike speech synthesis into applications optimized for both robust cloud capabilities and edge locality using containers .
Build a custom voice for your brand
Differentiate your brand with a unique custom voice . Develop a highly realistic voice for more natural conversational interfaces using the Custom Neural Voice capability, starting with 30 minutes of audio.
Fuel App Innovation with Cloud AI Services
Learn five key ways your organization can get started with AI to realize value quickly.
Comprehensive privacy and security
Documentation.
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO.
View and delete your custom voice data and synthesized speech models at any time. Your data is encrypted while it’s in storage.
Your data remains yours. Your text data isn't stored during data processing or audio voice generation.
Backed by Azure infrastructure, AI Speech offers enterprise-grade security, availability, compliance, and manageability.
Comprehensive security and compliance, built in
Microsoft invests more than $1 billion annually on cybersecurity research and development.

We employ more than 3,500 security experts who are dedicated to data security and privacy.

Azure has more certifications than any other cloud provider. View the comprehensive list .

Flexible pricing gives you the power and control you need
Pay only for what you use, with no upfront costs. With Text to Speech, you pay as you go based on the number of characters you convert to audio.
Get started with an Azure free account

After your credit, move to pay as you go to keep building with the same free services. Pay only if you use more than your free monthly amounts.

Guidelines for building responsible synthetic voices

Learn about responsible deployment
Synthetic voices must be designed to earn the trust of others. Learn the principles of building synthesized voices that create confidence in your company and services.

Obtain consent from voice talent
Help voice talent understand how neural text-to-speech (TTS) works and get information on recommended use cases.

Be transparent
Transparency is foundational to responsible use of computer voice generators and synthetic voices. Help ensure that users understand when they’re hearing a synthetic voice and that voice talent is aware of how their voice will be used. Learn more with our disclosure design guidelines.
Documentation and resources
Get started.
Read the documentation
Take the Microsoft Learn course
Get started with a 30-day learning journey
Explore code samples
Check out the sample code
See customization resources
Customize your speech solution with Speech studio . No code required.
Start building with AI Services
- Store (Open a new window)
- Blog (Open a new window)

- Conversational AI
- Security AI
- Analytics AI
- Virtual assistant & chatbot
- Live Assist
- Messaging channels
- Proactive Engagement
- Voice-to-Digital
Conversational IVR
- Biometric authentication
- Intelligent fraud prevention
- Agent Coach
- Agent Wrap-up
- Nuance Insights
- Financial services
- Telecommunications
- Travel & hospitality
- Healthcare payors
- services"> Professional services
- Work with a partner
- Case studies
- Resource library
- What's next blog (Open a new window)
Text-to-Speech (TTS) Engine in 119 Voices
Create a human voice for your brand.
Nuance's Text-to-Speech (TTS) technology leverages neural network techniques to deliver a human‑like, engaging, and personalized user experience. Enhance any customer self‑service application with high‑quality audio tailored to your brand.
- Solutions & technologies
- Professional services
Try Nuance Text-to-Speech
Select a voice and enter text into the box below to hear how Vocalizer can be the voice of your brand.
Safari Users: If there is no audio playback, please enable Audio Autoplay in your browser preferences under the Websites tab and refresh the page.
Enterprise users
If you enjoyed the Nuance Text-to-Speech demo, then contact us to learn how Nuance Vocalizer can become the voice of your brand.
Individual users
If you enjoyed the Nuance Text-to-Speech demo, then check out our Dragon Speech Recognition Solutions and improve documentation productivity and get more done—simply by speaking.
Nuance Vocalizer delivers life‑like voices that are trained on your use cases and dialogues, and speak your language as fluently as a live agent. Vocalizer uses advanced text-to-speech technology based on recurrent neural networks, delivering a far more human‑sounding voice with key benefits including:
- A superior caller experience
- Reduced costs by automating more calls
- Flexibility and control to update your application
- Differentiate your brand with a custom voice experience
It couldn’t be easier
Nuance TTS establishes a unique voice for your brand and maintains consistent caller experience across your IVR and mobile channels. Designed to empower high‑quality self‑service applications, Nuance TTS creates natural sounding speech in 53 languages and 119 voice options. With Vocalizer, your brand can say whatever you want it to and whenever you need it to—without having to hire, brief or record voice talent. Nuance Text-to-Speech expertise has been perfected over 20 years. By pursuing more natural and expressive speech synthesis, we have developed technology that can pronounce challenging words better than most humans.
Benefit include:
- A wide portfolio of human-sounding voices
- Enhanced expressivity
- Expanded multilingual support
- AI-optimized text processing
- The ability to create unique custom voice personas
- Access to our voice, Zoe: a breakthrough in natural‑sounding automated voice
See how our technology stacks up
years of Nuance TTS expertise
languages available to support your global business efforts.
unique voices—17 of them multi‑lingual—to distinguish your brand
Nuance Text-to-Speech technology powers many of our solutions
Nuance TTS is the voice of conversational IVR, making interactions sound natural and helping you deliver an enhanced self‑service experience without sacrificing customer satisfaction. Click here to view our infographic – "Current State of the IVR" to learn how modernizing your IVR can improve the customer experience
Nuance Vocalizer
An advanced, flexible, enterprise-level Tex-to-Speech solution, Nuance Vocalizer delivers intelligent self-service for organizations of all sizes and complexities. Vocalizer enhances the contact center experience by enabling more human, personalized customer interactions. It also reduces costs by facilitating more automation of calls across web, mobile and IVR.
- Nuance Vocalizer 7 data sheet (pdf. Open a new window)
Vocalizer for embedded solutions
An embedded Text-to-Speech engine geared for automotive, mobile and other electronic applications. It provides more natural-sounding speech in a variety of applications and technologies.
Vocalizer Studio
A comprehensive, user-friendly suite of tools that allows users to prototype and optimize speech output applications by easily creating optimization data such as user text rules, user dictionaries and prompts.
- Nuance Vocalizer Studio brochure (pdf. Open a new window)
We've got an API for that
Quickly and easily bring the power of our Text‑to‑Speech services to your solutions. Discover how Conversational AI Services from Nuance give you more speed, choice and flexibility in how you deploy text‑to‑speech capabilities.
Our expertise, your success
Nuance professional services leverage 25 years of experience and thousands of successful deployments to offer thought leadership and commitment to your results. We use the latest tools and techniques to design, develop, deploy, and optimize your speech-enabled IVR applications.
Learn how natural, expressive Text-to-Speech, gives your brand back its voice.
- Search for: Toggle Search
The Building Blocks of AI: Decoding the Role and Significance of Foundation Models
Editor’s note: This post is part of the AI Decoded series , which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
Skyscrapers start with strong foundations. The same goes for apps powered by AI.
A foundation model is an AI neural network trained on immense amounts of raw data, generally with unsupervised learning .
It’s a type of artificial intelligence model trained to understand and generate human-like language. Imagine giving a computer a huge library of books to read and learn from, so it can understand the context and meaning behind words and sentences, just like a human does.
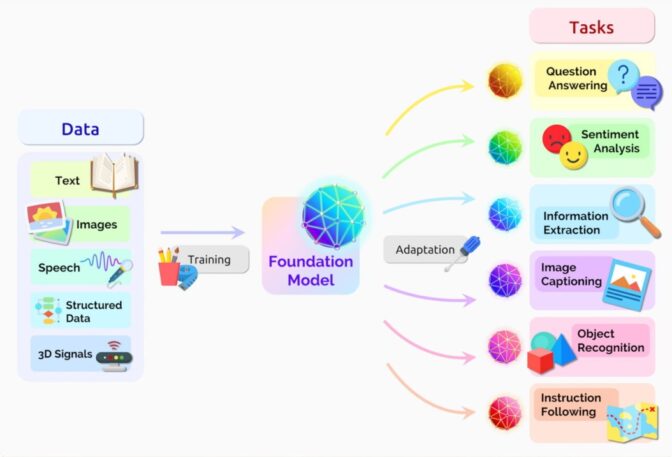
A foundation model’s deep knowledge base and ability to communicate in natural language make it useful for a broad range of applications, including text generation and summarization, copilot production and computer code analysis, image and video creation, and audio transcription and speech synthesis.
ChatGPT, one of the most notable generative AI applications, is a chatbot built with OpenAI’s GPT foundation model. Now in its fourth version, GPT-4 is a large multimodal model that can ingest text or images and generate text or image responses.
Online apps built on foundation models typically access the models from a data center. But many of these models, and the applications they power, can now run locally on PCs and workstations with NVIDIA GeForce and NVIDIA RTX GPUs.
Foundation Model Uses
Foundation models can perform a variety of functions, including:
- Language processing: understanding and generating text
- Code generation: analyzing and debugging computer code in many programming languages
- Visual processing: analyzing and generating images
- Speech: generating text to speech and transcribing speech to text
They can be used as is or with further refinement. Rather than training an entirely new AI model for each generative AI application — a costly and time-consuming endeavor — users commonly fine-tune foundation models for specialized use cases.
Pretrained foundation models are remarkably capable, thanks to prompts and data-retrieval techniques like retrieval-augmented generation , or RAG. Foundation models also excel at transfer learning , which means they can be trained to perform a second task related to their original purpose.
For example, a general-purpose large language model (LLM) designed to converse with humans can be further trained to act as a customer service chatbot capable of answering inquiries using a corporate knowledge base.
Enterprises across industries are fine-tuning foundation models to get the best performance from their AI applications.
Types of Foundation Models
More than 100 foundation models are in use — a number that continues to grow. LLMs and image generators are the two most popular types of foundation models. And many of them are free for anyone to try — on any hardware — in the NVIDIA API Catalog .
LLMs are models that understand natural language and can respond to queries. Google’s Gemma is one example; it excels at text comprehension, transformation and code generation. When asked about the astronomer Cornelius Gemma, it shared that his “contributions to celestial navigation and astronomy significantly impacted scientific progress.” It also provided information on his key achievements, legacy and other facts.
Extending the collaboration of the Gemma models , accelerated with the NVIDIA TensorRT-LLM on RTX GPUs, Google’s CodeGemma brings powerful yet lightweight coding capabilities to the community. CodeGemma models are available as 7B and 2B pretrained variants that specialize in code completion and code generation tasks.
MistralAI’s Mistral LLM can follow instructions, complete requests and generate creative text. In fact, it helped brainstorm the headline for this blog, including the requirement that it use a variation of the series’ name “AI Decoded,” and it assisted in writing the definition of a foundation model.
Meta’s Llama 2 is a cutting-edge LLM that generates text and code in response to prompts.
Mistral and Llama 2 are available in the NVIDIA ChatRTX tech demo, running on RTX PCs and workstations. ChatRTX lets users personalize these foundation models by connecting them to personal content — such as documents, doctors’ notes and other data — through RAG. It’s accelerated by TensorRT-LLM for quick, contextually relevant answers. And because it runs locally, results are fast and secure.
Image generators like StabilityAI’s Stable Diffusion XL and SDXL Turbo let users generate images and stunning, realistic visuals. StabilityAI’s video generator, Stable Video Diffusion , uses a generative diffusion model to synthesize video sequences with a single image as a conditioning frame.
Multimodal foundation models can simultaneously process more than one type of data — such as text and images — to generate more sophisticated outputs.
A multimodal model that works with both text and images could let users upload an image and ask questions about it. These types of models are quickly working their way into real-world applications like customer service, where they can serve as faster, more user-friendly versions of traditional manuals.
Kosmos 2 is Microsoft’s groundbreaking multimodal model designed to understand and reason about visual elements in images.
Think Globally, Run AI Models Locally
GeForce RTX and NVIDIA RTX GPUs can run foundation models locally.
The results are fast and secure. Rather than relying on cloud-based services, users can harness apps like ChatRTX to process sensitive data on their local PC without sharing the data with a third party or needing an internet connection.
Users can choose from a rapidly growing catalog of open foundation models to download and run on their own hardware. This lowers costs compared with using cloud-based apps and APIs, and it eliminates latency and network connectivity issues. Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter .
NVIDIA websites use cookies to deliver and improve the website experience. See our cookie policy for further details on how we use cookies and how to change your cookie settings.
Share on Mastodon
IMAGES
VIDEO
COMMENTS
Watson Speech to Text Demo - IBM is a live demonstration of how the IBM Watson Speech to Text service can transcribe audio to text in real time. You can try it yourself by uploading an audio file, using a microphone, or typing a text. You can also explore the features and capabilities of the service, such as customization, language support, and punctuation. Learn more about how Watson Speech ...
Make spoken audio actionable. Quickly and accurately transcribe audio to text in more than 100 languages and variants. Customize models to enhance accuracy for domain-specific terminology. Get more value from spoken audio by enabling search or analytics on transcribed text or facilitating action—all in your preferred programming language.
Explore, try out, and view sample code for some of common use cases using Azure Speech Services features like speech to text and text to speech. Captioning with speech to text Convert the audio content of TV broadcast, webcast, film, video, live event or other productions into text to make your content more accessible to your audience.
Use the sample text or enter your own text in English. Adjust speed. 0.2x 1.7x. Adjust pitch. 0%. Play voice. This system is for demonstration purposes only and is not intended to process Personal Data. No Personal Data is to be entered into this system as it may not have the necessary controls in place to meet the requirements of the General ...
ReadSpeaker is leading the way in text to speech. ReadSpeaker offers a range of powerful text-to-speech solutions for instantly deploying lifelike, tailored voice interaction in any environment. With more than 20 years' experience, ReadSpeaker is "Pioneering Voice Technology". 10000. customers worldwide. 115. market-leading own-brand ...
Cloud Computing Services | Google Cloud
Optimize audio files. Shows you how to perform a preflight check on audio files that you're preparing for use with Speech-to-Text. Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers ...
Text to Speech - Google Cloud
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export ...
It is a reproduction of work from the paper Natural language guidance of high-fidelity text-to-speech with synthetic annotations by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively. Contrarily to other TTS models, Parler-TTS is a fully open-source release. All of the datasets, pre-processing, training code and ...
Try our Text-to-Speech Demo. Select your options below to hear samples of ReadSpeaker's TTS voices. Kayla. English (US) Female. Hello, my name is Kayla, I'm one of the voices that you can use to speech enable your website. When I'm reading your text it sounds like this.
Web Speech API Demonstration Click on the microphone icon and begin speaking for as long as you like. . ... Press Control-C to copy text. (Command-C on Mac.) ...
Use our characters in your site or app.Try It for FREE. Try SitePal's talking avatars with our free Text to Speech online demo. Our virtual characters read text aloud naturally in over 25 languages. Use our text to speach (txt 2 speech) tool to test speech voices. No speaking software needed.
Over 30 languages and 200 voices are ready to speak. Meet Acapela's voice family. Acapela's text to speech solutions convert normal language text into a spoken voice output. Originally created for the visually impaired, type and talk technologies have become very popular, for numerous uses or businesses. Give it a try: you'll be impressed.
Text-to-Speech Simulator. A simple web app demonstrating how text sounds in different TTS voices.
Try Vocalware's demo to sample our text-to-speech voices and our Audio Effects. Select from over 20 languages and more than 100 voices! Loading... Vocalware lets developers speech-enable any online application by using our powerful online API. Sign up now for your 15 day Free Trial!
Text to speech (TTS) is a technology that converts text into spoken audio. It can read aloud PDFs, websites, and books using natural AI voices. Text-to-speech (TTS) technology can be helpful for anyone who needs to access written content in an auditory format, and it can provide a more inclusive and accessible way of communication for many ...
Write your text, select a voice and receive stunning and near-perfect results! Regenerating results will also give you different results (depending on the settings). The service supports 30+ languages, including Dutch (which is very rare). ElevenLabs has proved that it isn't impossible to have near-perfect text-to-speech 'Dutch'...
Schedule a demo. Custom rates for work teams and classrooms of all sizes. Special pricing for schools and businesses in one easy-to-manage subscription. Premium features on every platform. Every user gets access on Chrome, iOS, + Android. 30+ high quality, natural-sounding reading voices and unlimited Premium words.
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO. View and delete your custom voice data and synthesized speech models at any time. Your data is encrypted while it's in storage. Your data remains yours. Your text data isn't stored during data processing or audio voice generation.
Watson Text to Speech supports a wide variety of voices in all supported languages and dialects. Customize for your brand and use case Adapt and customize Watson Text to Speech voices for the vocabulary of your business and the tone of your brand.
Designed to empower high‑quality self‑service applications, Nuance TTS creates natural sounding speech in 53 languages and 119 voice options. With Vocalizer, your brand can say whatever you want it to and whenever you need it to—without having to hire, brief or record voice talent. Nuance Text-to-Speech expertise has been perfected over ...
Meta's Llama 2 is a cutting-edge LLM that generates text and code in response to prompts. Mistral and Llama 2 are available in the NVIDIA ChatRTX tech demo, running on RTX PCs and workstations. ChatRTX lets users personalize these foundation models by connecting them to personal content — such as documents, doctors' notes and other data ...
Low-income credit unions that want to apply for 2024 Community Development Revolving Loan Fund grants can get valuable information from a National Credit Union Administration webinar on May 2. Online registration for this webinar, "Applying for the CDRLF Grant," is now open. The webinar is scheduled to begin at 2 p.m. Eastern and is expected to run one hour.