- Reviews / Why join our community?
- For companies
- Frequently asked questions

Visual Representation
What is visual representation.
Visual Representation refers to the principles by which markings on a surface are made and interpreted. Designers use representations like typography and illustrations to communicate information, emotions and concepts. Color, imagery, typography and layout are crucial in this communication.
Alan Blackwell, cognition scientist and professor, gives a brief introduction to visual representation:
- Transcript loading…
We can see visual representation throughout human history, from cave drawings to data visualization :
Art uses visual representation to express emotions and abstract ideas.
Financial forecasting graphs condense data and research into a more straightforward format.
Icons on user interfaces (UI) represent different actions users can take.
The color of a notification indicates its nature and meaning.

Van Gogh's "The Starry Night" uses visuals to evoke deep emotions, representing an abstract, dreamy night sky. It exemplifies how art can communicate complex feelings and ideas.
© Public domain
Importance of Visual Representation in Design
Designers use visual representation for internal and external use throughout the design process . For example:
Storyboards are illustrations that outline users’ actions and where they perform them.
Sitemaps are diagrams that show the hierarchy and navigation structure of a website.
Wireframes are sketches that bring together elements of a user interface's structure.
Usability reports use graphs and charts to communicate data gathered from usability testing.
User interfaces visually represent information contained in applications and computerized devices.

This usability report is straightforward to understand. Yet, the data behind the visualizations could come from thousands of answered surveys.
© Interaction Design Foundation, CC BY-SA 4.0
Visual representation simplifies complex ideas and data and makes them easy to understand. Without these visual aids, designers would struggle to communicate their ideas, findings and products . For example, it would be easier to create a mockup of an e-commerce website interface than to describe it with words.

Visual representation simplifies the communication of designs. Without mockups, it would be difficult for developers to reproduce designs using words alone.
Types of Visual Representation
Below are some of the most common forms of visual representation designers use.
Text and Typography
Text represents language and ideas through written characters and symbols. Readers visually perceive and interpret these characters. Typography turns text into a visual form, influencing its perception and interpretation.
We have developed the conventions of typography over centuries , for example, in documents, newspapers and magazines. These conventions include:
Text arranged on a grid brings clarity and structure. Gridded text makes complex information easier to navigate and understand. Tables, columns and other formats help organize content logically and enhance readability.
Contrasting text sizes create a visual hierarchy and draw attention to critical areas. For example, headings use larger text while body copy uses smaller text. This contrast helps readers distinguish between primary and secondary information.
Adequate spacing and paragraphing improve the readability and appearance of the text. These conventions prevent the content from appearing cluttered. Spacing and paragraphing make it easier for the eye to follow and for the brain to process the information.
Balanced image-to-text ratios create engaging layouts. Images break the monotony of text, provide visual relief and illustrate or emphasize points made in the text. A well-planned ratio ensures neither text nor images overwhelm each other. Effective ratios make designs more effective and appealing.
Designers use these conventions because people are familiar with them and better understand text presented in this manner.

This table of funerals from the plague in London in 1665 uses typographic conventions still used today. For example, the author arranged the information in a table and used contrasting text styling to highlight information in the header.
Illustrations and Drawings
Designers use illustrations and drawings independently or alongside text. An example of illustration used to communicate information is the assembly instructions created by furniture retailer IKEA. If IKEA used text instead of illustrations in their instructions, people would find it harder to assemble the furniture.

IKEA assembly instructions use illustrations to inform customers how to build their furniture. The only text used is numeric to denote step and part numbers. IKEA communicates this information visually to: 1. Enable simple communication, 2. Ensure their instructions are easy to follow, regardless of the customer’s language.
© IKEA, Fair use
Illustrations and drawings can often convey the core message of a visual representation more effectively than a photograph. They focus on the core message , while a photograph might distract a viewer with additional details (such as who this person is, where they are from, etc.)
For example, in IKEA’s case, photographing a person building a piece of furniture might be complicated. Further, photographs may not be easy to understand in a black-and-white print, leading to higher printing costs. To be useful, the pictures would also need to be larger and would occupy more space on a printed manual, further adding to the costs.
But imagine a girl winking—this is something we can easily photograph.
Ivan Sutherland, creator of the first graphical user interface, used his computer program Sketchpad to draw a winking girl. While not realistic, Sutherland's representation effectively portrays a winking girl. The drawing's abstract, generic elements contrast with the distinct winking eye. The graphical conventions of lines and shapes represent the eyes and mouth. The simplicity of the drawing does not draw attention away from the winking.

A photo might distract from the focused message compared to Sutherland's representation. In the photo, the other aspects of the image (i.e., the particular person) distract the viewer from this message.
© Ivan Sutherland, CC BY-SA 3.0 and Amina Filkins, Pexels License
Information and Data Visualization
Designers and other stakeholders use data and information visualization across many industries.
Data visualization uses charts and graphs to show raw data in a graphic form. Information visualization goes further, including more context and complex data sets. Information visualization often uses interactive elements to share a deeper understanding.
For example, most computerized devices have a battery level indicator. This is a type of data visualization. IV takes this further by allowing you to click on the battery indicator for further insights. These insights may include the apps that use the most battery and the last time you charged your device.

macOS displays a battery icon in the menu bar that visualizes your device’s battery level. This is an example of data visualization. Meanwhile, macOS’s settings tell you battery level over time, screen-on-usage and when you last charged your device. These insights are actionable; users may notice their battery drains at a specific time. This is an example of information visualization.
© Low Battery by Jemis Mali, CC BY-NC-ND 4.0, and Apple, Fair use
Information visualization is not exclusive to numeric data. It encompasses representations like diagrams and maps. For example, Google Maps collates various types of data and information into one interface:
Data Representation: Google Maps transforms complex geographical data into an easily understandable and navigable visual map.
Interactivity: Users can interactively customize views that show traffic, satellite imagery and more in real-time.
Layered Information: Google Maps layers multiple data types (e.g., traffic, weather) over geographical maps for comprehensive visualization.
User-Centered Design : The interface is intuitive and user-friendly, with symbols and colors for straightforward data interpretation.

The volume of data contained in one screenshot of Google Maps is massive. However, this information is presented clearly to the user. Google Maps highlights different terrains with colors and local places and businesses with icons and colors. The panel on the left lists the selected location’s profile, which includes an image, rating and contact information.
© Google, Fair use
Symbolic Correspondence
Symbolic correspondence uses universally recognized symbols and signs to convey specific meanings . This method employs widely recognized visual cues for immediate understanding. Symbolic correspondence removes the need for textual explanation.
For instance, a magnifying glass icon in UI design signifies the search function. Similarly, in environmental design, symbols for restrooms, parking and amenities guide visitors effectively.

The Interaction Design Foundation (IxDF) website uses the universal magnifying glass symbol to signify the search function. Similarly, the play icon draws attention to a link to watch a video.
How Designers Create Visual Representations
Visual language.
Designers use elements like color , shape and texture to create a communicative visual experience. Designers use these 8 principles:
Size – Larger elements tend to capture users' attention readily.
Color – Users are typically drawn to bright colors over muted shades.
Contrast – Colors with stark contrasts catch the eye more effectively.
Alignment – Unaligned elements are more noticeable than those aligned ones.
Repetition – Similar styles repeated imply a relationship in content.
Proximity – Elements placed near each other appear to be connected.
Whitespace – Elements surrounded by ample space attract the eye.
Texture and Style – Users often notice richer textures before flat designs.
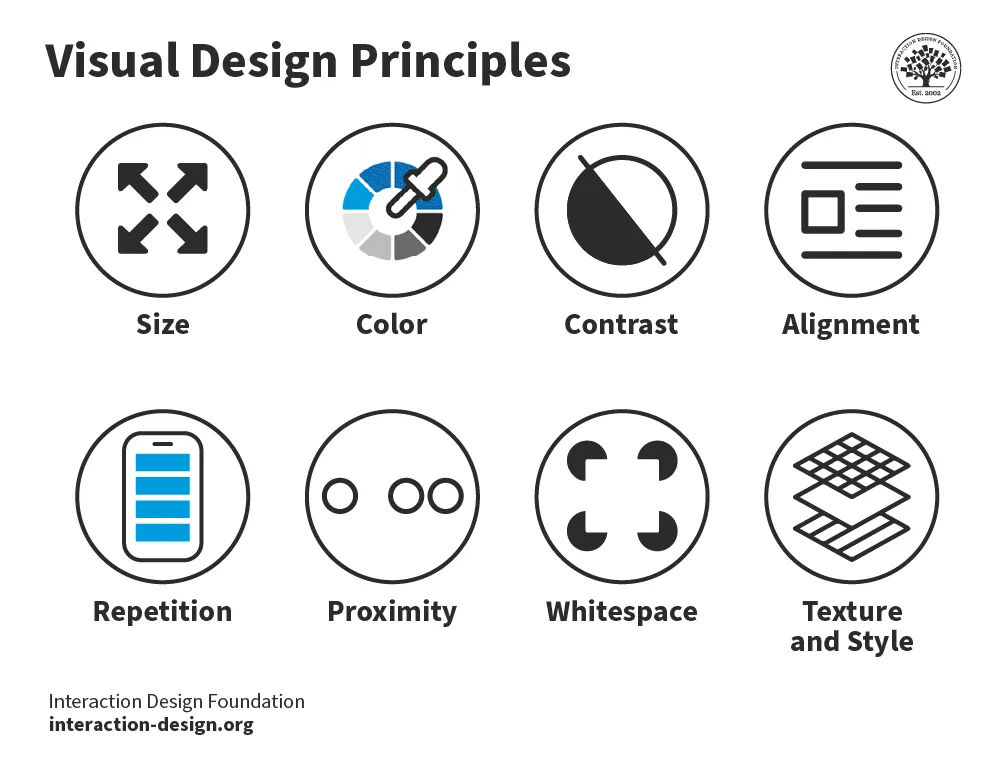
The 8 visual design principles.
In web design , visual hierarchy uses color and repetition to direct the user's attention. Color choice is crucial as it creates contrast between different elements. Repetition helps to organize the design—it uses recurring elements to establish consistency and familiarity.
In this video, Alan Dix, Professor and Expert in Human-Computer Interaction, explains how visual alignment affects how we read and absorb information:
Correspondence Techniques
Designers use correspondence techniques to align visual elements with their conceptual meanings. These techniques include color coding, spatial arrangement and specific imagery. In information visualization, different colors can represent various data sets. This correspondence aids users in quickly identifying trends and relationships .

Color coding enables the stakeholder to see the relationship and trend between the two pie charts easily.
In user interface design, correspondence techniques link elements with meaning. An example is color-coding notifications to state their nature. For instance, red for warnings and green for confirmation. These techniques are informative and intuitive and enhance the user experience.

The IxDF website uses blue for call-to-actions (CTAs) and red for warnings. These colors inform the user of the nature of the action of buttons and other interactive elements.
Perception and Interpretation
If visual language is how designers create representations, then visual perception and interpretation are how users receive those representations. Consider a painting—the viewer’s eyes take in colors, shapes and lines, and the brain perceives these visual elements as a painting.
In this video, Alan Dix explains how the interplay of sensation, perception and culture is crucial to understanding visual experiences in design:
Copyright holder: Michael Murphy _ Appearance time: 07:19 - 07:37 _ Link: https://www.youtube.com/watch?v=C67JuZnBBDc
Visual perception principles are essential for creating compelling, engaging visual representations. For example, Gestalt principles explain how we perceive visual information. These rules describe how we group similar items, spot patterns and simplify complex images. Designers apply Gestalt principles to arrange content on websites and other interfaces. This application creates visually appealing and easily understood designs.
In this video, design expert and teacher Mia Cinelli discusses the significance of Gestalt principles in visual design . She introduces fundamental principles, like figure/ground relationships, similarity and proximity.
Interpretation
Everyone's experiences, culture and physical abilities dictate how they interpret visual representations. For this reason, designers carefully consider how users interpret their visual representations. They employ user research and testing to ensure their designs are attractive and functional.

Leonardo da Vinci's "Mona Lisa", is one of the most famous paintings in the world. The piece is renowned for its subject's enigmatic expression. Some interpret her smile as content and serene, while others see it as sad or mischievous. Not everyone interprets this visual representation in the same way.
Color is an excellent example of how one person, compared to another, may interpret a visual element. Take the color red:
In Chinese culture, red symbolizes luck, while in some parts of Africa, it can mean death or illness.
A personal experience may mean a user has a negative or positive connotation with red.
People with protanopia and deuteranopia color blindness cannot distinguish between red and green.
In this video, Joann and Arielle Eckstut, leading color consultants and authors, explain how many factors influence how we perceive and interpret color:
Learn More about Visual Representation
Read Alan Blackwell’s chapter on visual representation from The Encyclopedia of Human-Computer Interaction.
Learn about the F-Shaped Pattern For Reading Web Content from Jakob Nielsen.
Read Smashing Magazine’s article, Visual Design Language: The Building Blocks Of Design .
Take the IxDF’s course, Perception and Memory in HCI and UX .
Questions related to Visual Representation
Some highly cited research on visual representation and related topics includes:
Roland, P. E., & Gulyás, B. (1994). Visual imagery and visual representation. Trends in Neurosciences, 17(7), 281-287. Roland and Gulyás' study explores how the brain creates visual imagination. They look at whether imagining things like objects and scenes uses the same parts of the brain as seeing them does. Their research shows the brain uses certain areas specifically for imagination. These areas are different from the areas used for seeing. This research is essential for understanding how our brain works with vision.
Lurie, N. H., & Mason, C. H. (2007). Visual Representation: Implications for Decision Making. Journal of Marketing, 71(1), 160-177.
This article looks at how visualization tools help in understanding complicated marketing data. It discusses how these tools affect decision-making in marketing. The article gives a detailed method to assess the impact of visuals on the study and combination of vast quantities of marketing data. It explores the benefits and possible biases visuals can bring to marketing choices. These factors make the article an essential resource for researchers and marketing experts. The article suggests using visual tools and detailed analysis together for the best results.
Lohse, G. L., Biolsi, K., Walker, N., & Rueter, H. H. (1994, December). A classification of visual representations. Communications of the ACM, 37(12), 36+.
This publication looks at how visuals help communicate and make information easier to understand. It divides these visuals into six types: graphs, tables, maps, diagrams, networks and icons. The article also looks at different ways these visuals share information effectively.
If you’d like to cite content from the IxDF website , click the ‘cite this article’ button near the top of your screen.
Some recommended books on visual representation and related topics include:
Chaplin, E. (1994). Sociology and Visual Representation (1st ed.) . Routledge.
Chaplin's book describes how visual art analysis has changed from ancient times to today. It shows how photography, post-modernism and feminism have changed how we see art. The book combines words and images in its analysis and looks into real-life social sciences studies.
Mitchell, W. J. T. (1994). Picture Theory. The University of Chicago Press.
Mitchell's book explores the important role and meaning of pictures in the late twentieth century. It discusses the change from focusing on language to focusing on images in cultural studies. The book deeply examines the interaction between images and text in different cultural forms like literature, art and media. This detailed study of how we see and read visual representations has become an essential reference for scholars and professionals.
Koffka, K. (1935). Principles of Gestalt Psychology. Harcourt, Brace & World.
"Principles of Gestalt Psychology" by Koffka, released in 1935, is a critical book in its field. It's known as a foundational work in Gestalt psychology, laying out the basic ideas of the theory and how they apply to how we see and think. Koffka's thorough study of Gestalt psychology's principles has profoundly influenced how we understand human perception. This book has been a significant reference in later research and writings.
A visual representation, like an infographic or chart, uses visual elements to show information or data. These types of visuals make complicated information easier to understand and more user-friendly.
Designers harness visual representations in design and communication. Infographics and charts, for instance, distill data for easier audience comprehension and retention.
For an introduction to designing basic information visualizations, take our course, Information Visualization .
Text is a crucial design and communication element, transforming language visually. Designers use font style, size, color and layout to convey emotions and messages effectively.
Designers utilize text for both literal communication and aesthetic enhancement. Their typography choices significantly impact design aesthetics, user experience and readability.
Designers should always consider text's visual impact in their designs. This consideration includes font choice, placement, color and interaction with other design elements.
In this video, design expert and teacher Mia Cinelli teaches how Gestalt principles apply to typography:
Designers use visual elements in projects to convey information, ideas, and messages. Designers use images, colors, shapes and typography for impactful designs.
In UI/UX design, visual representation is vital. Icons, buttons and colors provide contrast for intuitive, user-friendly website and app interfaces.
Graphic design leverages visual representation to create attention-grabbing marketing materials. Careful color, imagery and layout choices create an emotional connection.
Product design relies on visual representation for prototyping and idea presentation. Designers and stakeholders use visual representations to envision functional, aesthetically pleasing products.
Our brains process visuals 60,000 times faster than text. This fact highlights the crucial role of visual representation in design.
Our course, Visual Design: The Ultimate Guide , teaches you how to use visual design elements and principles in your work effectively.
Visual representation, crucial in UX, facilitates interaction, comprehension and emotion. It combines elements like images and typography for better interfaces.
Effective visuals guide users, highlight features and improve navigation. Icons and color schemes communicate functions and set interaction tones.
UX design research shows visual elements significantly impact emotions. 90% of brain-transmitted information is visual.
To create functional, accessible visuals, designers use color contrast and consistent iconography. These elements improve readability and inclusivity.
An excellent example of visual representation in UX is Apple's iOS interface. iOS combines a clean, minimalist design with intuitive navigation. As a result, the operating system is both visually appealing and user-friendly.
Michal Malewicz, Creative Director and CEO at Hype4, explains why visual skills are important in design:
Learn more about UI design from Michal in our Master Class, Beyond Interfaces: The UI Design Skills You Need to Know .
The fundamental principles of effective visual representation are:
Clarity : Designers convey messages clearly, avoiding clutter.
Simplicity : Embrace simple designs for ease and recall.
Emphasis : Designers highlight key elements distinctively.
Balance : Balance ensures design stability and structure.
Alignment : Designers enhance coherence through alignment.
Contrast : Use contrast for dynamic, distinct designs.
Repetition : Repeating elements unify and guide designs.
Designers practice these principles in their projects. They also analyze successful designs and seek feedback to improve their skills.
Read our topic description of Gestalt principles to learn more about creating effective visual designs. The Gestalt principles explain how humans group elements, recognize patterns and simplify object perception.
Color theory is vital in design, helping designers craft visually appealing and compelling works. Designers understand color interactions, psychological impacts and symbolism. These elements help designers enhance communication and guide attention.
Designers use complementary , analogous and triadic colors for contrast, harmony and balance. Understanding color temperature also plays a crucial role in design perception.
Color symbolism is crucial, as different colors can represent specific emotions and messages. For instance, blue can symbolize trust and calmness, while red can indicate energy and urgency.
Cultural variations significantly influence color perception and symbolism. Designers consider these differences to ensure their designs resonate with diverse audiences.
For actionable insights, designers should:
Experiment with color schemes for effective messaging.
Assess colors' psychological impact on the audience.
Use color contrast to highlight critical elements.
Ensure color choices are accessible to all.
In this video, Joann and Arielle Eckstut, leading color consultants and authors, give their six tips for choosing color:
Learn more about color from Joann and Arielle in our Master Class, How To Use Color Theory To Enhance Your Designs .
Typography and font choice are crucial in design, impacting readability and mood. Designers utilize them for effective communication and expression.
Designers' perception of information varies with font type. Serif fonts can imply formality, while sans-serifs can give a more modern look.
Typography choices by designers influence readability and user experience. Well-spaced, distinct fonts enhance readability, whereas decorative fonts may hinder it.
Designers use typography to evoke emotions and set a design's tone. Choices in font size, style and color affect the emotional impact and message clarity.
Designers use typography to direct attention, create hierarchy and establish rhythm. These benefits help with brand recognition and consistency across mediums.
Read our article to learn how web fonts are critical to the online user experience .
Designers create a balance between simplicity and complexity in their work. They focus on the main messages and highlight important parts. Designers use the principles of visual hierarchy, like size, color and spacing. They also use empty space to make their designs clear and understandable.
The Gestalt law of Prägnanz suggests people naturally simplify complex images. This principle aids in making even intricate information accessible and engaging.
Through iteration and feedback, designers refine visuals. They remove extraneous elements and highlight vital information. Testing with the target audience ensures the design resonates and is comprehensible.
Michal Malewicz explains how to master hierarchy in UI design using the Gestalt rule of proximity:
Answer a Short Quiz to Earn a Gift
Why do designers use visual representation?
- To guarantee only a specific audience can understand the information
- To replace the need for any form of written communication
- To simplify complex information and make it understandable
Which type of visual representation helps to compare data?
- Article images
- Line charts
- Text paragraphs
What is the main purpose of visual hierarchy in design?
- To decorate the design with more colors
- To guide the viewer’s attention to the most important elements first
- To provide complex text for high-level readers
How does color impact visual representation?
- It has no impact on the design at all.
- It helps to distinguish different elements and set the mood.
- It makes the design less engaging for a serious mood.
Why is consistency important in visual representation?
- It limits creativity, but allows variation in design.
- It makes sure the visual elements are cohesive and easy to understand.
- It makes the design unpredictable yet interesting.
Better luck next time!
Do you want to improve your UX / UI Design skills? Join us now
Congratulations! You did amazing
You earned your gift with a perfect score! Let us send it to you.
Check Your Inbox
We’ve emailed your gift to [email protected] .
Literature on Visual Representation
Here’s the entire UX literature on Visual Representation by the Interaction Design Foundation, collated in one place:
Learn more about Visual Representation
Take a deep dive into Visual Representation with our course Perception and Memory in HCI and UX .
How does all of this fit with interaction design and user experience? The simple answer is that most of our understanding of human experience comes from our own experiences and just being ourselves. That might extend to people like us, but it gives us no real grasp of the whole range of human experience and abilities. By considering more closely how humans perceive and interact with our world, we can gain real insights into what designs will work for a broader audience: those younger or older than us, more or less capable, more or less skilled and so on.
“You can design for all the people some of the time, and some of the people all the time, but you cannot design for all the people all the time.“ – William Hudson (with apologies to Abraham Lincoln)
While “design for all of the people all of the time” is an impossible goal, understanding how the human machine operates is essential to getting ever closer. And of course, building solutions for people with a wide range of abilities, including those with accessibility issues, involves knowing how and why some human faculties fail. As our course tutor, Professor Alan Dix, points out, this is not only a moral duty but, in most countries, also a legal obligation.
Portfolio Project
In the “ Build Your Portfolio: Perception and Memory Project ”, you’ll find a series of practical exercises that will give you first-hand experience in applying what we’ll cover. If you want to complete these optional exercises, you’ll create a series of case studies for your portfolio which you can show your future employer or freelance customers.
This in-depth, video-based course is created with the amazing Alan Dix , the co-author of the internationally best-selling textbook Human-Computer Interaction and a superstar in the field of Human-Computer Interaction . Alan is currently a professor and Director of the Computational Foundry at Swansea University.
Gain an Industry-Recognized UX Course Certificate
Use your industry-recognized Course Certificate on your resume , CV , LinkedIn profile or your website.
All open-source articles on Visual Representation
Data visualization for human perception.

The Key Elements & Principles of Visual Design

- 1.1k shares
Guidelines for Good Visual Information Representations

- 4 years ago
Philosophy of Interaction
Information visualization – an introduction to multivariate analysis.

- 8 years ago
Aesthetic Computing
How to represent linear data visually for information visualization.

- 5 years ago
Open Access—Link to us!
We believe in Open Access and the democratization of knowledge . Unfortunately, world-class educational materials such as this page are normally hidden behind paywalls or in expensive textbooks.
If you want this to change , cite this page , link to us, or join us to help us democratize design knowledge !
Privacy Settings
Our digital services use necessary tracking technologies, including third-party cookies, for security, functionality, and to uphold user rights. Optional cookies offer enhanced features, and analytics.
Experience the full potential of our site that remembers your preferences and supports secure sign-in.
Governs the storage of data necessary for maintaining website security, user authentication, and fraud prevention mechanisms.
Enhanced Functionality
Saves your settings and preferences, like your location, for a more personalized experience.
Referral Program
We use cookies to enable our referral program, giving you and your friends discounts.
Error Reporting
We share user ID with Bugsnag and NewRelic to help us track errors and fix issues.
Optimize your experience by allowing us to monitor site usage. You’ll enjoy a smoother, more personalized journey without compromising your privacy.
Analytics Storage
Collects anonymous data on how you navigate and interact, helping us make informed improvements.
Differentiates real visitors from automated bots, ensuring accurate usage data and improving your website experience.
Lets us tailor your digital ads to match your interests, making them more relevant and useful to you.
Advertising Storage
Stores information for better-targeted advertising, enhancing your online ad experience.
Personalization Storage
Permits storing data to personalize content and ads across Google services based on user behavior, enhancing overall user experience.
Advertising Personalization
Allows for content and ad personalization across Google services based on user behavior. This consent enhances user experiences.
Enables personalizing ads based on user data and interactions, allowing for more relevant advertising experiences across Google services.
Receive more relevant advertisements by sharing your interests and behavior with our trusted advertising partners.
Enables better ad targeting and measurement on Meta platforms, making ads you see more relevant.
Allows for improved ad effectiveness and measurement through Meta’s Conversions API, ensuring privacy-compliant data sharing.
LinkedIn Insights
Tracks conversions, retargeting, and web analytics for LinkedIn ad campaigns, enhancing ad relevance and performance.
LinkedIn CAPI
Enhances LinkedIn advertising through server-side event tracking, offering more accurate measurement and personalization.
Google Ads Tag
Tracks ad performance and user engagement, helping deliver ads that are most useful to you.
Share Knowledge, Get Respect!
or copy link
Cite according to academic standards
Simply copy and paste the text below into your bibliographic reference list, onto your blog, or anywhere else. You can also just hyperlink to this page.
New to UX Design? We’re Giving You a Free ebook!

Download our free ebook The Basics of User Experience Design to learn about core concepts of UX design.
In 9 chapters, we’ll cover: conducting user interviews, design thinking, interaction design, mobile UX design, usability, UX research, and many more!
What is visual representation?
In the vast landscape of communication, where words alone may fall short, visual representation emerges as a powerful ally. In a world inundated with information, the ability to convey complex ideas, emotions, and data through visual means is becoming increasingly crucial. But what exactly is visual representation, and why does it hold such sway in our understanding?
Defining Visual Representation:
Visual representation is the act of conveying information, ideas, or concepts through visual elements such as images, charts, graphs, maps, and other graphical forms. It’s a means of translating the abstract into the tangible, providing a visual language that transcends the limitations of words alone.
The Power of Images:
The adage “a picture is worth a thousand words” encapsulates the essence of visual representation. Images have an unparalleled ability to evoke emotions, tell stories, and communicate complex ideas in an instant. Whether it’s a photograph capturing a poignant moment or an infographic distilling intricate data, images possess a unique capacity to resonate with and engage the viewer on a visceral level.
Facilitating Understanding:
One of the primary functions of visual representation is to enhance understanding. Humans are inherently visual creatures, and we often process and retain visual information more effectively than text. Complex concepts that might be challenging to grasp through written explanations can be simplified and clarified through visual aids. This is particularly valuable in fields such as science, where intricate processes and structures can be elucidated through diagrams and illustrations.
Visual representation also plays a crucial role in education. In classrooms around the world, teachers leverage visual aids to facilitate learning, making lessons more engaging and accessible. From simple charts that break down historical timelines to interactive simulations that bring scientific principles to life, visual representation is a cornerstone of effective pedagogy.
Data Visualization:
In an era dominated by big data, the importance of data visualization cannot be overstated. Raw numbers and statistics can be overwhelming and abstract, but when presented visually, they transform into meaningful insights. Graphs, charts, and maps are powerful tools for conveying trends, patterns, and correlations, enabling decision-makers to glean actionable intelligence from vast datasets.
Consider the impact of a well-crafted infographic that distills complex research findings into a visually digestible format. Data visualization not only simplifies information but also allows for more informed decision-making in fields ranging from business and healthcare to social sciences and environmental studies.
Cultural and Artistic Expression:
Visual representation extends beyond the realm of information and education; it is also a potent form of cultural and artistic expression. Paintings, sculptures, photographs, and other visual arts serve as mediums through which individuals can convey their emotions, perspectives, and cultural narratives. Artistic visual representation has the power to transcend language barriers, fostering a shared human experience that resonates universally.
Conclusion:
In a world inundated with information, visual representation stands as a beacon of clarity and understanding. Whether it’s simplifying complex concepts, conveying data-driven insights, or expressing the depth of human emotion, visual elements enrich our communication in ways that words alone cannot. As we navigate an increasingly visual society, recognizing and harnessing the power of visual representation is not just a skill but a necessity for effective communication and comprehension. So, let us embrace the visual language that surrounds us, unlocking a deeper, more nuanced understanding of the world.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 7: Visual Language
Learning Objectives
- Describe the nature of different writing systems
- Differentiate the rules that govern grapheme-to-phoneme conversion
- Describe the standard reading model as a basis for further exploration
In this chapter we will explore the basics of the written word. Writing involves the representation of language with written symbols. A system of writing is not in itself a language. It is a way to render language in a manner that is retrievable across space and time. Writing is not a natural part of language and most languages have not had a writing system for most of their history. We will not explore the history of writing in much detail. We will however look at some prominent writing systems that will give you some idea about how it may have developed in human societies. Look through the sentences below and think of how they differ from one another. Each of them represents a different writing paradigm which we will be exploring.

Media Attributions
- Figure 7.1 The Universal Declaration of Human Rights in Different Scripts by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence .
Psychology of Language Copyright © 2021 by Dinesh Ramoo is licensed under a Creative Commons Attribution 4.0 International License , except where otherwise noted.
Share This Book
- Write for US
Visual Language: Communicating Ideas Through Artistic Expression

Enter the bright world of the arts, where pictures and colors speak more than words ever could. This article examines the value of visual language and how artists convey concepts, feelings, and stories via it. Discover the common language that cuts across cultural barriers and speaks to the human soul as we go through the many artistic expressions .
The Essence of Visual Language
Learn the fundamentals of visual language and how it may communicate in ways that spoken or written language cannot. Investigate the ways in which artists use line, form, color, texture, and composition to communicate message and arouse feelings. Discover how visual clues like contrast, symbolism, and light and shadow add to the complexity and depth of creative expression.
Cultural Context and Symbolism
Examine the symbolism and cultural background that are included into the works of art. Consider how other cultures convey their distinct viewpoints and beliefs through symbols, themes, and visual metaphors . Learn how artists make works that resonate with certain audiences by drawing on cultural allusions, historical occurrences, and personal experiences, bridging the gap between individual expression and group comprehension.
Abstract and Non-Representational Art
Investigate the world of abstract and non-representational art, where the use of visual language becomes more individualized and flexible. Explore the universe of abstract motions, forms, and textures to encourage viewers to interact viscerally with the works of art and give them their own unique interpretations. Viewers are encouraged to explore their own visual and emotional responses as abstract art disrupts conventional conceptions of representation.
Narrative and Storytelling
Narrative creation and storytelling are frequently carried out through artistic expression. Learn how visual clues, composition, and sequential imagery are used by artists to tell engaging stories in their works. Witness the power of visual storytelling in captivating the imagination and delivering complex storylines, from prehistoric cave paintings and illuminated manuscripts to modern graphic novels and conceptual art.
Social Commentary and Political Expression

Politics and social commentary have long been expressed via art. Learn how artists have questioned authority, challenged established standards, and brought attention to current concerns throughout history. Investigate the visual language used in protest art, political cartoons, and socially involved works that reflects the artist’s function as a change-agent and a voice for the oppressed.
Embracing the Multilingual Nature of Art
Celebrate the multilingual nature of art, which combines a variety of artistic styles and materials to provide a complex tapestry of expression. Watch how artists experiment with new forms of communication and combine painting, sculpture, photography, digital art, performance, and installation. Accept the multiplicity and interdependence of creative languages, realizing that each one broadens the dialogue and our comprehension of the human experience.
Visual language transcends words, engaging our imagination and speaking directly to the human soul. We learn a global language that transcends cultural boundaries as we get immersed in the realm of artistic expression, engaging spectators in a discourse that goes beyond spoken language. Through their artistic expressions, artists remind us of the limitless possibilities of human imagination and the transformative potential of art. Let us embrace the power of visual language and appreciate the myriad ways in which artists communicate ideas, evoke emotions, and shape our understanding of the world.
Photo Attribution:
1 st and featured image by https://unsplash.com/photos/EP6_VZhzXM8
2 nd image by https://unsplash.com/photos/JaNvmkxVY74
About the author

Visual Grammar: How To Communicate Without Words
I often use the phrase “visual design” when describing what we do as web designers. Recently I came across what I think is better phrase, “communication design.” When we design and build websites our goal is usually to communicate something to an audience.
Communication requires language. That language can be aural as in the spoken word, it can be gestural as in sign language, or it can be visual as in design. The more you understand any language the better you can communicate using that language. The visual language of design is no exception. Design elements are like letters and words. When we add design principles and apply them to our elements, our words, we form a visual grammar . As we learn to use both we enable ourselves to communicate visually .
Defining Visual Grammar
Most of the information in this post is coming from Christian Leborg’s book Visual Grammar shown above. From the preface of the book:
The reason for writing a grammar of visual language is the same as for any language: to define its basic elements, describe its patterns and processes, and to understand the relationship between the individual elements in the system. Visual language has no formal syntax or semantics, but the visual objects themselves can be classified.
The last point in the quote above is important. It would be great if we could place a circle on the page, a rectangle to the right of it, and a curved line to the right of the rectangle and have it mean the same thing to all people. It won’t. That makes it harder to think and communicate visually , though also much more interesting. It’s one reason a single design problem can have so many different design solutions.
However, we can classify much of this visual grammar. I’m going to deviate just a bit from the way Christian organizes his book and organize visual grammar as:
- Objects – The basic elements we have to work with. Can be abstract or concrete.
- Structures – The patterns formed from our basic elements. Can be abstract or concrete.
- Activities – The processes we can represent with our basic elements and patterns.
- Relations – The relationships between objects, patterns, and processes. They’re the way everything in your design relates to each other and the viewer.
Objects and structures will both further be subdivided into abstract and concrete sections. In the book the main sections are Abstract and Concrete, with objects and structures being the subsections, but I think it makes more sense to organize them as I have here.
As you read through the rest of this post you’ll see many connections to design principles that myself and others have written about. In many ways this post and Leborg’s book are a way to organize all those principles and ideas to see how they fit an overall visual grammar
Objects are the basic elements at our disposal. They’re akin to letters and words. We use objects to express different ideas and concepts. A circle is an object as is a line as is a single character of type. A single point is an object as is an image of a person holding your product. Objects are the most basic elements we can add to any design.
Objects can be abstract or concrete.
Abstract Objects
Abstract objects are idealized shapes that can’t physically be created. For example take a point. A point by definition has no area. It only has a position. Any point we try to draw will have some kind of area if we are to see it and once it does, it ceases to become a point. It can only exist as an abstract concept and not as a physical thing.
Abstract objects include:
- Points – A position on a coordinate system without area. Points have no dimensions
- Lines – A series of points adjacent to each other. Points have one dimensions
- Surfaces – A series of lines that are adjacent to each other and perpendicular to their direction. Surfaces have two dimensions.
- Volumes – An empty space defined by surfaces, lines, and points. Volumes have three dimensions.
Theoretically objects can have an infinite amount of dimensions. Of course we can only perceive three of them, width, height, and depth so our abstract objects end with volumes. Beyond volumes we can only imagine more abstract objects and we can only represent these additional abstract objects using points, lines, surfaces, and volumes.
Everything we see is perceived in relation to some kind of external limit. This external limit is the format. For example this post is seen in relation to the format of your browser window. The format of a book or magazine is the page.
Concrete Objects
Concrete objects are perceived within defined limits called contours. Inside and including the contour itself is our object, our shape , our form, and outside the contour is everything else. Forms or shapes can be geometric, organic, or random (sometimes called abstract). A circle is an example of a concrete object. It’s contour being the curved line that encloses it.
Concrete objects have:
- Form – defined by a contour of surfaces and lines . A form is how a thing looks.
- Size – Forms can be large or small. They are perceived relative to the person viewing, other forms in the compositon, and the format of the design.
- Color – we perceive different wavelengths of light as color . A form can be any color , though we are limited to seeing only those colors in the visual spectrum
Any element we place on the page is a concrete object. Remember abstract objects can not physically be created. Abstract objects exist to talk about objects in general in order to better describe them.
Whenever we place two or more objects in relation to one another we form a structure. We describe these structures by the patterns they form. We must be able to recognize the presence of a pattern in order to describe the structure.
Structures have structure lines connecting objects. These lines are the axis along which the objects are arranged. Structure lines may be visible or invisible and they may be active or inactive.
As with objects, structures can be abstract or concrete.
Abstract Structures
When the structure lines of a structure are invisible and inactive the structure is considered to be abstract. Consider the image below. The circles are clearly arranged in a pattern. There is a structure present, but the lines defining that structure are invisible.
Even when the structure lines are invisible we can often see them in our minds. Through the gestalt principle closure we fill in what’s missing to complete the picture. Again consider the image above. While no lines are visibly connecting the circles, it’s easy to imagine straight lines from the center of one circle to the next. Structure lines are not limited to running through the center of objects though.
In the image above the structure lines are not only invisible, but inactive as well. That is they don’t influence the form of the structure in any way even while they are defining the position of the structure.
The circles above are an example of a formal structure. The objects are evenly distributed. They’re symmetrical and arranged on a grid. The structure lines are either horizontal or perpendicular.
Formal structures are not the only type of abstract structures we can encounter or use. Structures can be categorized as:
- Formal – even distribution of elements and spacing (structure units) between them
- Informal – lacking regularity in the arrangement of objects. Even if a pattern is observed the structure is informal if the objects do not follow straight structural lines
- Gradation – structure units change in form or size, but at an even rate
- Radiation – structure units radiate from a common center
- Spiral – uneven distribution from a common center
When the structure organizing the objects can be judged by the eye alone we say the structure has visual distribution. Each form is allowed to occupy a similar amount of space as the others in the structure.
All compositions or objects are bound within certain limits of the surface on which they exist. These limiting forces follow certain axis or paths which are considered the structural skeleton of the composition or object.
Concrete Structures
Concrete structures have either visible or active structure lines. Where abstract structures indirectly show the structure, concrete structures directly show the structure. Concrete structures can be visible compositions on their own such as the patterns that form into textures.
Visible structures do not have to include objects. As long as the structure lines are visible, the structure itself is visible. Visible structures can include the objects being organized, but they don’t have to. Both of the structures in the image below are visible structures despite the absence of any objects in the second one.
Active structures are those where the structure lines influence the form of the objects within the structure. In an active structure the objects need to be present, but the structure lines can be absent as long as their influence is seen. In the image below both structures are active despite the absence of any visible structure lines in the second one.
Structures that can be seen and/or felt are textures. Textures can be formed from either objects or structure lines or both. Textures can be ornamental, random, or mechanical and we can classify them in the same way we classify abstract structures. They can be formal, informal, gradations, radiations, or spirals.
The elements we design, the objects we place on the page don’t move. Ignore for a moment the idea that as the browser gets resized elements can move or we can use javascript to move elements around the page or use css and javascript to respond to different mouse and keyboard inputs. For the sake of this discussion our elements don’t move and our compositions are static representations.
To convey the idea that some activity is taking place on the page we generally need to create some kind of sequence of objects or create the illusion of the activity through some static representation of it.
If you can understand how to show activities through sequence and the illusion of activity you can better understand how to make use of css, javascript, and browser resizing to express activity as well.
Instead of trying to give you a couple paragraphs on each kind of activity, I’ll summarize them in the table below. Notice how many of these activities are the design principles you’ve seen myself and others write about. In the future I’ll also look to covering some of the activities below in greater detail.
I’m sure many of the above terms needed no definition and you were likely familiar with all or many of them. We’re building a vocabulary in order to be able to communicate better about design and also through design. Again notice how several of the above find their way into the principles of design.
Objects placed in a composition relate to each other, they relate to the overall design, the format and, they relate to the viewer. Through relations with each other, elements can attract or repel, they can imply movement and flow . Through relation to the overall design, elements convey a concept and theme . Through relation with the viewer elements communicate different messages.
As with activities there are a number of relations defined by Leborg and again notice how many of them are design principles that I and others have given a more detailed treatment. Since many of these relations are deserving of their own post, I’ll again present a table summarizing each here and look to writing more detailed posts about those I haven’t covered in the past.
As with the table of activities above, I’m sure many of these relation terms were familiar to you and needed little or no definition. As with the activities we’re building a vocabulary to talk about design and to use design to talk to others. Many of the terms in both tables above are deserving of their own posts, some of which I’ve already written about and others I’ll write about in the future.
As communication designers it’s our job to communicate. Communications requires language and for designers that language is visual (PDF) . How can we communicate if we don’t understand the language to at least some degree?
In life we can communicate through the spoken word or through gestures. In design we’re bound by a visual language . Even the words on the page are made up of characters of type which are abstract shapes. Written language itself is a visual representation of spoken language.
This post has been an introduction to the grammar of the visual language we use in each of our designs. The more we understand that grammar, the better we can speak the language, and the more effectively we can communicate with our audience.
This visual language, this visual grammar , is the context within which we study design principles. When we learn to use girds or better understand typography or color we are doing so in order to communicate more effectively with our audience. The principles are the trees. Visual grammar is the forest.
« Prev Post Next Post »
If you liked this post, consider buying my book Design Fundamentals
Download a free sample from my book, Design Fundamentals.
Thanks for reading. Please share this post.

15 comments
Thank you for the lesson. Also, thank you for using proper grammar. This was a refreshing, and informative “read.”
Thanks Rain. I hope my grammar was ok. I’m always finding mistakes in everything I publish when I read again later. I do try, though.
Totally agree… I did a full University Degree in Visual Communication! Brilliant!
Thanks Carol. No degree in this stuff for me, but I’ve been putting a lot of time into teaching everything to myself. I really enjoy learning in general and about design in particular.
Thank you for writing this. It is very interesting. I’m currently doing jewelry design project about MAXIMIZATION. and your table of activities inspired me a lot.
Glad I could help, though the credit really goes to Christian Leborg. All the ideas here are from his book Visual Grammar. Definitely worth reading.
Thank you this really helped. I have an assignment in class that has to do with non verbal communication and this helped a lot. I appreciate you posting this for the world to see .
Thanks K.K. I’m glad I could help. I hope the assignment went well.
Thanks, this really helped. I also have an assignment on visual grammar this term, so this helped a lot 🙂 Thanks again!
I am a high school English teacher who is teaching a graphic novel. I found your site while looking for a vocabulary that could help my students talk about how the words and the figures interplay to create meaning. What I’m trying to understand is how when you say “Remember abstract objects can not physically be created,” then how would you explain abstract art? (I’m sure I’m taking your definition too literally but I would love a little elaboration.)
Abstract art is still a physical thing. It’s a real painting or sculpture. It might be trying to communicate something abstract, but the art itself is physical and real. A painting uses real paint on a real canvas, etc.
You can’t draw a point, because a point by definition has no physical dimensions. Anything you draw to represent a point can’t be a true point, because for us to see it, it needs to have dimensions.
A point is an abstract object because we can understand what it is intellectually, but we can’t actually create one. What we create has dimensions and so can’t be a point.
Does that make sense.
had difficulties using the write words in the right context and using them in a way where i can express myself properly so thanks, i can express my self through visual language no probs. this helped alot xx
Thanks Patrice. Glad I could help.
I’m taking 2D Design and I found this fascinating and helpful.
I’m doing an assignment requiring abstract visuals for a list of words. The visuals have to convey the words without representational symbols.
Thanks Brooke. How did your assignment turn out?
Hi there, very nice article! You will might find interesting to read the phd thesis “The Language of Graphics” by Yuri Engelhardt ( https://dare.uva.nl/search?arno.record.id=105970 ) I was introduced to this work about 15 years ago and I loved it. It changed my way of thinking in design.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *

- Contributors
- Links
- Translations
- What is Gendered Innovations ?
Sex & Gender Analysis
- Research Priorities
- Rethinking Concepts
- Research Questions
- Analyzing Sex
- Analyzing Gender
- Sex and Gender Interact
- Intersectional Approaches
- Engineering Innovation
- Participatory Research
- Reference Models
- Language & Visualizations
- Tissues & Cells
- Lab Animal Research
- Sex in Biomedicine
- Gender in Health & Biomedicine
- Evolutionary Biology
- Machine Learning
- Social Robotics
- Hermaphroditic Species
- Impact Assessment
- Norm-Critical Innovation
- Intersectionality
- Race and Ethnicity
- Age and Sex in Drug Development
- Engineering
- Health & Medicine
- SABV in Biomedicine
- Tissues & Cells
- Urban Planning & Design
Case Studies
- Animal Research
- Animal Research 2
- Computer Science Curriculum
- Genetics of Sex Determination
- Chronic Pain
- Colorectal Cancer
- De-Gendering the Knee
- Dietary Assessment Method
- Heart Disease in Diverse Populations
- Medical Technology
- Nanomedicine
- Nanotechnology-Based Screening for HPV
- Nutrigenomics
- Osteoporosis Research in Men
- Prescription Drugs
- Systems Biology
- Assistive Technologies for the Elderly
- Domestic Robots
- Extended Virtual Reality
- Facial Recognition
- Gendering Social Robots
- Haptic Technology
- HIV Microbicides
- Inclusive Crash Test Dummies
- Human Thorax Model
- Machine Translation
- Making Machines Talk
- Video Games
- Virtual Assistants and Chatbots
- Agriculture
- Climate Change
- Environmental Chemicals
- Housing and Neighborhood Design
- Marine Science
- Menstrual Cups
- Population and Climate Change
- Quality Urban Spaces
- Smart Energy Solutions
- Smart Mobility
- Sustainable Fashion
- Waste Management
- Water Infrastructure
- Intersectional Design
- Major Granting Agencies
- Peer-Reviewed Journals
- Universities
Rethinking Language and Visual Representations
Language and visual representations are central to all knowledge-based activities, including those in science, health & medicine, and engineering. Word choice, charts, graphs, images, and icons have the power to shape scientific practice, questions asked, results obtained, and interpretations made. “Sharing a language means sharing a conceptual universe” within which assumptions, judgments, and interpretations of data can be said to “make sense” (Keller, 1992). Rethinking language also involves Rethinking Concepts and Theories.
Rethinking language and visual representations can:
- 1. Remove assumptions that may limit or restrict innovation and knowledge in unconscious ways.
- 2. Remove assumptions that unconsciously reinforce gender inequalities.
Consider the following examples:
- ● Unintended hypothesis-creating metaphors. Analogies and metaphors function to construct as well as describe. They have both a hypothesis-creating and proof-making function. By analyzing language—by “waking up” metaphors—we can critically judge how the imagery may be lending structure to our research (Martin, 1992; Martin, 1991). For example, zoologists often refer to herds of animals (horses, antelope, elephant seals, etc.) as “harems.” The word “harem” embeds assumptions about social organization, in this case polygyny. In this example, researchers failed to “see” what lies outside the logic of the metaphor. Recent DNA studies of mustangs show, however, that a given stallion typically sires less than a third of the foals in a band. Researchers who questioned the notion of a “harem” found that female mustangs range from band to band, often mating with a stallion of their choice (Brown, 1995). Other scholars have shown how the metaphor of the “cell as a factory” works to naturalize patriarchal norms in which the male “head” (coded as the nucleus) controls the domestic labor of women (Navare, 2023).
- ♦ In English, new words have been devised and usage altered to be more inclusive. For example, “fireman” has been replaced with “fire fighter,” “infantrymen” are now “soldiers,” and “animal husbandry” can be replaced with the more neutral “animal breeding and care.” Some old terms such as “aviatrix” and “lady doctor” have completely disappeared.
- ♦ In English, “they” should be used rather than the generic “he” when referring to a researcher, subject, or student whose gender is unknown. Many dictionaries now accept “they” as a singular, gender-neutral pronoun, or the sentence can be recast in the plural to avoid specific referents.
Visual Representations
Visual representations in science, medicine and engineering may contain gender-inflected messages in 1) the content of a field or discipline, or 2) the practitioners of a field or discipline. Consider the following:
- ● Visual Display of Data
- Visual displays of data may embed gender assumptions. As discussed in the case study on Public Transportation, the charts below represent trips made in Madrid in 2014. The first chart (left below) graphs transportation data as traditionally collected and reported. It privileges paid employment by presenting it as a single, large category. Caring work (shown in red) is divided into numerous small categories and hidden under other headings, such as escorting, shopping and leisure. The second chart (right) reconceptualizes public transportation trips by collecting care trips under one category. Visualizing care trips in one dedicated category emphasizes the importance of caring work and allows transportation engineers to design systems that work well for all segments of the population, improve urban efficiency, and guard against global warming (Sánchez de Madariaga, 2013, 2019).

- ● How might metaphors be gendered and create unintended hypotheses?
- ● Do gendered metaphors reinforce stereotypes?
- ● Are word choices or naming practices gendered?
- ● Do naming practices or pronoun choices exclude gender-diverse individuals?
- ● How does nomenclature influence who becomes a scientist or engineer?
- ● Are the language and images being used gender inclusive?
- ● Are graphs, charts, or images used to visualize abstract concepts gendered in unintended ways?
- ● Does a particular field of science or engineering promote a self-image that carries messages about the “gender appropriateness” of participation by women, men, and gender-diverse people?
- ● Are problem sets or training exercises chosen to illustrate basic scientific principles gendered in unintended ways?
Related Case Studies
Works cited.
Brown, N. (1995). The Wild Mares of Assateague. Research at Pennsylvania State University, 16, 15-19.
Christidou, V., & Kouvatas, A. (2011). Visual Self-Images of Scientists and Science in Greece. Public Understanding of Science, (Online in Advance of Print).
Keller, E. (1992). Secrets of Life, Secrets of Death: Essays on Language, Gender and Science . New York: Routledge. The European Journal of Women's Studies, 2 (3) , 379-394.
Lie, M. (1998). Computer Dialogues: Technology, Gender, and Change . Trondheim: Senter for kvinneforskning, Norges Teknisk-naturvitenskapelige Universitet.
Martin, E. (1992). The Woman in the Body: A Cultural Analysis of Reproduction . Boston: Beacon.
Martin, E. (1991). The egg and the sperm: How science has constructed a romance based on stereotypical male-female roles. Signs: Journal of Women in Culture and Society, 16 (3), 485-501.
Ministerio de Fomento. (2007). Encuesta de Movilidad de las Personas Residentes en España (Movilia 2006/2007) . Madrid: Ministerio de Fomento.
Navare, C. (2023). Instructions, commands, and coercive control: A critical discourse analysis of the textbook representation of the living cell. Cultural Studies of Science Education.
Sánchez de Madariaga, I. (2013). The Mobility of Care: A New Concept in Urban Transportation. In Sánchez de Madariaga, I., & Roberts, M. (Eds.) Fair Share Cities. The Impact of Gender Planning in Europe. London: Ashgate.
Sánchez de Madariaga, I. (2009). Vivienda, Movilidad, y Urbanismo para la Igualdad en la Diversidad: Ciudades, Género, y Dependencia. Ciudad y Territorio Estudios Territoriales, XLI (161-162), 581-598.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 28 October 2021
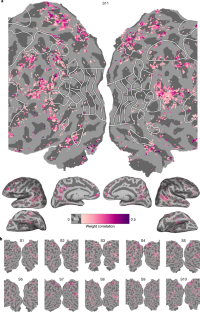
Visual and linguistic semantic representations are aligned at the border of human visual cortex
- Sara F. Popham 1 ,
- Alexander G. Huth 1 nAff3 ,
- Natalia Y. Bilenko 1 ,
- Fatma Deniz 1 nAff4 ,
- James S. Gao 1 ,
- Anwar O. Nunez-Elizalde 1 &
- Jack L. Gallant ORCID: orcid.org/0000-0001-7273-1054 1 , 2
Nature Neuroscience volume 24 , pages 1628–1636 ( 2021 ) Cite this article
14k Accesses
41 Citations
184 Altmetric
Metrics details
- Neural encoding
- Visual system
Semantic information in the human brain is organized into multiple networks, but the fine-grain relationships between them are poorly understood. In this study, we compared semantic maps obtained from two functional magnetic resonance imaging experiments in the same participants: one that used silent movies as stimuli and another that used narrative stories. Movies evoked activity from a network of modality-specific, semantically selective areas in visual cortex. Stories evoked activity from another network of semantically selective areas immediately anterior to visual cortex. Remarkably, the pattern of semantic selectivity in these two distinct networks corresponded along the boundary of visual cortex: for visual categories represented posterior to the boundary, the same categories were represented linguistically on the anterior side. These results suggest that these two networks are smoothly joined to form one contiguous map.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
195,33 € per year
only 16,28 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Similar content being viewed by others

Temporal multiplexing of perception and memory codes in IT cortex

Neuronal activation sequences in lateral prefrontal cortex encode visuospatial working memory during virtual navigation

Hippocampal sharp-wave ripples correlate with periods of naturally occurring self-generated thoughts in humans
Data availability.
Data are available on Box ( https://berkeley.box.com/s/l95gie5xtv56zocsgugmb7fs12nujpog ) and at https://gallantlab.org/ . All data other than anatomical brain images (as there is concern that anatomical images could violate participant privacy) have been shared. However, we have provided matrices that map from volumetric data to cortical flat maps for visualization purposes.
Code availability
Custom code used for cortical surface-based analyses is available at https://github.com/gallantlab/vl_interface .
Barsalou, L. W. Perceptual symbol systems. Behav. Brain Sci. 22 , 577–609 (1999).
Article CAS Google Scholar
Damasio, A. R. The brain binds entities and events by multiregional activation from convergence zones. Neural Comput. 1 , 123–132 (1989).
Article Google Scholar
Ralph, M. A. L., Jefferies, E., Patterson, K. & Rogers, T. T. The neural and computational bases of semantic cognition. Nat. Rev. Neurosci. 18 , 42–55 (2017).
Snowden, J. S., Goulding, P. J. & Neary, D. Semantic dementia: a form of circumscribed cerebral atrophy. Behav. Neurol . 2 , 167–182 (1989).
Warrington, E. K. The selective impairment of semantic memory. Q. J. Exp. Psychol. 27 , 635–657 (1975).
Wilkins, A. & Moscovitch, M. Selective impairment of semantic memory after temporal lobectomy. Neuropsychologia 16 , 73–79 (1978).
Jefferies, E., Patterson, K., Jones, R. W., Bateman, D. & Lambon Ralph, M. A. A category-specific advantage for numbers in verbal short-term memory: evidence from semantic dementia. Neuropsychologia 42 , 639–660 (2004).
Kramer, J. H. et al. Distinctive neuropsychological patterns in frontotemporal dementia, semantic dementia, and Alzheimer disease. Cogn. Behav. Neurol. 16 , 211–218 (2003).
Hodges, J. R., Patterson, K., Oxbury, S. & Funnell, E. Semantic dementia. Progressive fluent aphasia with temporal lobe atrophy. Brain 115 , 1783–1806 (1992).
Hodges, J. R. et al. The differentiation of semantic dementia and frontal lobe dementia (temporal and frontal variants of frontotemporal dementia) from early Alzheimer’s disease: a comparative neuropsychological study. Neuropsychology 13 , 31–40 (1999).
Damasio, H., Grabowski, T. J., Tranel, D., Hichwa, R. D. & Damasio, A. R. A neural basis for lexical retrieval. Nature 380 , 499–505 (1996).
Damasio, H., Tranel, D., Grabowski, T., Adolphs, R. & Damasio, A. Neural systems behind word and concept retrieval. Cognition 92 , 179–229 (2004).
Devereux, B. J., Clarke, A., Marouchos, A. & Tyler, L. K. Representational similarity analysis reveals commonalities and differences in the semantic processing of words and objects. J. Neurosci. 33 , 18906–18916 (2013).
Fairhall, S. L. & Caramazza, A. Brain regions that represent amodal conceptual knowledge. J. Neurosci. 33 , 10552–10558 (2013).
Kanwisher, N., McDermott, J. & Chun, M. M. The fusiform face area: a module in human extrastriate cortex specialized for face perception. J. Neurosci. 17 , 4302–4311 (1997).
Epstein, R. & Kanwisher, N. A cortical representation of the local visual environment. Nature 392 , 598–601 (1998).
Downing, P. E., Jiang, Y., Shuman, M. & Kanwisher, N. A cortical area selective for visual processing of the human body. Science 293 , 2470–2473 (2001).
Huth, A. G., Nishimoto, S., Vu, A. T. & Gallant, J. L. A continuous semantic space describes the representation of thousands of object and action categories across the human brain. Neuron 76 , 1210–1224 (2012).
Huth, A. G., de Heer, W. A., Griffiths, T. L., Theunissen, F. E. & Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 532 , 453–458 (2016).
Deniz, F., Nunez-Elizalde, A. O., Huth, A. G. & Gallant, J. L. The representation of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality. J. Neurosci. 39 , 7722–7736 (2019).
Kay, K. N., Naselaris, T., Prenger, R. J. & Gallant, J. L. Identifying natural images from human brain activity. Nature 452 , 352–355 (2008).
Mitchell, T. M. et al. Predicting human brain activity associated with the meanings of nouns. Science 320 , 1191–1195 (2008).
Naselaris, T., Kay, K. N., Nishimoto, S. & Gallant, J. L. Encoding and decoding in fMRI. Neuroimage 56 , 400–410 (2011).
Nishimoto, S. et al. Reconstructing visual experiences from brain activity evoked by natural movies. Curr. Biol. 21 , 1641–1646 (2011).
Miller, G. A. WordNet: a lexical database for English. Commun. ACM 38 , 39–41 (1995).
Nakamura, K. et al. Functional delineation of the human occipito-temporal areas related to face and scene processing. A PET study. Brain 123 , 1903–1912 (2000).
Hasson, U., Harel, M., Levy, I. & Malach, R. Large-scale mirror-symmetry organization of human occipito-temporal object areas. Neuron 37 , 1027–1041 (2003).
Dilks, D. D., Julian, J. B., Paunov, A. M. & Kanwisher, N. The occipital place area is causally and selectively involved in scene perception. J. Neurosci. 33 , 1331–6a (2013).
Aguirre, G. K., Zarahn, E. & D’Esposito, M. An area within human ventral cortex sensitive to ‘building’ stimuli: evidence and implications. Neuron 21 , 373–383 (1998).
Ono, M., Kubik, S. & Abernathy, C. D. Atlas of the Cerebral Sulci (Thieme Medical Publishers, 1990).
Friedman, L. & Glover, G. H., Fbirn Consortium. Reducing interscanner variability of activation in a multicenter fMRI study: controlling for signal-to-fluctuation-noise-ratio (SFNR) differences. Neuroimage 33 , 471–481 (2006).
Ojemann, J. G. et al. Anatomic localization and quantitative analysis of gradient refocused echo-planar fMRI susceptibility artifacts. Neuroimage 6 , 156–167 (1997).
Van Essen, D. C., Anderson, C. H. & Felleman, D. J. Information processing in the primate visual system: an integrated systems perspective. Science 255 , 419–423 (1992).
Modha, D. S. & Singh, R. Network architecture of the long-distance pathways in the macaque brain. Proc. Natl Acad. Sci. USA 107 , 13485–13490 (2010).
Ercsey-Ravasz, M. et al. A predictive network model of cerebral cortical connectivity based on a distance rule. Neuron 80 , 184–197 (2013).
Visser, M., Jefferies, E. & Lambon Ralph, M. A. Semantic processing in the anterior temporal lobes: a meta-analysis of the functional neuroimaging literature. J. Cogn. Neurosci. 22 , 1083–1094 (2009).
Lewis, J. W., Talkington, W. J., Puce, A., Engel, L. R. & Frum, C. Cortical networks representing object categories and high-level attributes of familiar real-world action sounds. J. Cogn. Neurosci. 23 , 2079–2101 (2011).
Norman-Haignere, S., Kanwisher, N. G. & McDermott, J. H. Distinct cortical pathways for music and speech revealed by hypothesis-free voxel decomposition. Neuron 88 , 1281–1296 (2015).
Levy, I., Hasson, U., Avidan, G., Hendler, T. & Malach, R. Center–periphery organization of human object areas. Nat. Neurosci. 4 , 533 (2001).
Nunez-Elizalde, A. O., Huth, A. G. & Gallant, J. L. Voxelwise encoding models with non-spherical multivariate normal priors. Neuroimage 197 , 482–492 (2019).
Gao, J. S., Huth, A. G., Lescroart, M. D. & Gallant, J. L. Pycortex: an interactive surface visualizer for fMRI. Front. Neuroinform. 9 , 23 (2015).
Download references
Acknowledgements
We thank J. Nguyen for assistance transcribing and aligning story stimuli and B. Griffin and M.-L. Kieseler for segmenting and flattening cortical surfaces. Funding: This work was supported by grants from the National Science Foundation (NSF) (IIS1208203), the National Eye Institute (EY019684 and EY022454) and the Center for Science of Information, an NSF Science and Technology Center, under grant agreement CCF-0939370. S.F.P. was also supported by the William Orr Dingwall Neurolinguistics Fellowship. A.G.H. was also supported by the William Orr Dingwall Neurolinguistics Fellowship and the Burroughs-Wellcome Fund Career Award at the Scientific Interface.
Author information
Alexander G. Huth
Present address: Departments of Neuroscience & Computer Science, The University of Texas at Austin, Austin TX, USA
Fatma Deniz
Present address: Department of Software Engineering and Theoretical Computer Science, Technische Universität Berlin, Berlin, Germany
Authors and Affiliations
Helen Wills Neuroscience Institute, University of California, Berkeley, Berkeley, CA, USA
Sara F. Popham, Alexander G. Huth, Natalia Y. Bilenko, Fatma Deniz, James S. Gao, Anwar O. Nunez-Elizalde & Jack L. Gallant
Department of Psychology, University of California, Berkeley, Berkeley, CA, USA
Jack L. Gallant
You can also search for this author in PubMed Google Scholar
Contributions
S.F.P., A.G.H. and J.L.G. conceptualized the experiment. A.G.H., N.Y.B. and F.D. collected the data. S.F.P., A.G.H., N.Y.B., J.S.G. and A.O.N.-E. contributed to analysis. S.F.P., A.G.H. and J.L.G. wrote the paper.
Corresponding author
Correspondence to Jack L. Gallant .
Ethics declarations
Competing interests.
The authors declare no competing financial interests.
Additional information
Peer review information Nature Neuroscience thanks Christopher Baldassano and Johan Carlin for their contribution to the peer review of this work.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended data fig. 1 evaluation of the visual and linguistic semantic models..
Model weights are estimated on the training dataset, then are used to predict brain activity to a held-out dataset. Prediction performance is the correlation of actual and predicted brain activity for each voxel. These performance values are presented simultaneously using a 2-dimensional colormap on the flattened cortex around the occipital pole for each subject. Red voxels are locations where the visual semantic model is performing well, blue voxels are where the linguistic semantic model is performing well, and white voxels are where both models are performing equally well. These maps show where the visual and linguistic networks of the brain abut each other.
Extended Data Fig. 2 Visual and linguistic representations of place concepts.
Identical analysis to Fig. 2a , but for the other 10 subjects. The color of each voxel indicates the representation of place-related information according to the legend at the right. The model weights for vision and language are shown in red and blue, respectively. White borders indicate ROIs found in separate localizer experiments. Three relevant place ROIs are labeled: PPA, OPA, and RSC. Centered on each ROI there is a modality shift gradient that runs from visual semantic categories (red) posterior to linguistic semantic categories (blue) anterior.
Extended Data Fig. 3 Visual and linguistic representations of body part concepts.
Identical analysis to Fig. 2b , but for the other 10 subjects. The color of each voxel indicates the representation of body-related information according to the legend at the right. The model weights for vision and language are shown in red and blue, respectively. White borders indicate ROIs found in separate localizer experiments. The relevant body ROI is labeled: EBA. Centered on each ROI there is a modality shift gradient that runs from visual semantic categories (red) posterior to linguistic semantic categories (blue) anterior.
Extended Data Fig. 4 Visual and linguistic representations of face concepts.
Identical analysis to Fig. 2c , but for the other 10 subjects. The color of each voxel indicates the representation of face-related information according to the legend at the right. The model weights for vision and language are shown in red and blue, respectively. White borders indicate ROIs found in separate localizer experiments. The relevant face ROI is labeled: FFA. Centered on each ROI there is a modality shift gradient that runs from visual semantic categories (red) posterior to linguistic semantic categories (blue) anterior.
Extended Data Fig. 5 Analysis region around the boundary of the occipital lobe.
The thin yellow line indicates the estimated border of the occipital lobe of the brain in each individual subject. This was manually drawn to follow the parieto-occipital sulcus and connect to the preoccipital notch on both ends. The area of the brain which was analyzed in this study was limited to vertices within 50 mm of this border, which is shown in black on each individual’s brain.
Extended Data Fig. 6 Locations of category-specific modality shifts across cortex for alternate parameter set 1.
Identical analysis to Fig. 4 , but with an ROI size of 10x25mm. Shown here is the flattened cortex around the occipital pole for one typical subject, along with inflated hemispheres. The modality shift metric calculated at each location near the boundary of the occipital lobe is plotted as an arrow. The arrow color represents the magnitude of the shift. The arrow is directed to show the shift from vision to language. Only locations where the modality shift is statistically significant are shown. Areas of fMRI signal dropout are indicated with hash marks. There are strong modality shifts in a clear ring around visual cortex in the same locations seen in Fig. 4 .
Extended Data Fig. 7 Locations of category-specific modality shifts across cortex for alternate parameter set 2.
Identical analysis to Fig. 4 , but with an ROI size of 10x10mm. Shown here is the flattened cortex around the occipital pole for one typical subject, along with inflated hemispheres. The modality shift metric calculated at each location near the boundary of the occipital lobe is plotted as an arrow. The arrow color represents the magnitude of the shift. The arrow is directed to show the shift from vision to language. Only locations where the modality shift is statistically significant are shown. Areas of fMRI signal dropout are indicated with hash marks. There are strong modality shifts in a ring around visual cortex in the same locations seen in Fig. 4 , though the pattern is more noisy due to the shortened analysis windows.
Supplementary information
Supplementary information.
Supplementary Table 1
Reporting Summary
Rights and permissions.
Reprints and permissions
About this article
Cite this article.
Popham, S.F., Huth, A.G., Bilenko, N.Y. et al. Visual and linguistic semantic representations are aligned at the border of human visual cortex. Nat Neurosci 24 , 1628–1636 (2021). https://doi.org/10.1038/s41593-021-00921-6
Download citation
Received : 28 June 2019
Accepted : 11 August 2021
Published : 28 October 2021
Issue Date : November 2021
DOI : https://doi.org/10.1038/s41593-021-00921-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Revealing the mechanisms of semantic satiation with deep learning models.
- Xinyu Zhang
- Jian K. Liu
Communications Biology (2024)
The neural and cognitive basis of expository text comprehension
- Timothy A. Keller
- Robert A. Mason
- Marcel Adam Just
npj Science of Learning (2024)
A retinotopic code structures the interaction between perception and memory systems
- Edward H. Silson
- Caroline E. Robertson
Nature Neuroscience (2024)
Network neurosurgery
- Jizong Zhao
Chinese Neurosurgical Journal (2023)
Immediate neural impact and incomplete compensation after semantic hub disconnection
- Zsuzsanna Kocsis
- Rick L. Jenison
- Christopher I. Petkov
Nature Communications (2023)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Microsoft Research Blog
Vinvl: advancing the state of the art for vision-language models.
Published January 14, 2021
By Pengchuan Zhang , Senior Researcher Lei Zhang , Principal Research Manager Jianfeng Gao , Distinguished Scientist & Vice President
Share this page
- Share on Facebook
- Share on Twitter
- Share on LinkedIn
- Share on Reddit
- Subscribe to our RSS feed
Humans understand the world by perceiving and fusing information from multiple channels, such as images viewed by the eyes, voices heard by the ears, and other forms of sensory input. One of the core aspirations in AI is to develop algorithms that endow computers with a similar ability: to effectively learn from multimodal data like vision-language to make sense of the world around us. For example, vision-language (VL) systems allow searching the relevant images for a text query (or vice versa) and describing the content of an image using natural language.
As illustrated in Figure 1, a typical VL system uses a modular architecture with two modules to achieve VL understanding:
- An image encoding module, also known as a visual feature extractor, is implemented using convolutional neural network (CNN) models to generate feature maps of input image. The CNN-based object detection model trained on the Visual Genome (VG) dataset is the most popular choice before our work.
- A vision-language fusion module maps the encoded image and text into vectors in the same semantic space so that their semantic similarity can be computed using cosine distance of their vectors. The module is typically implemented using a Transformer-based model, such as OSCAR .
Recently, vision-language pretraining (VLP) has made great progress in improving the vision-language fusion module by pretraining it on a large-scale paired image-text corpus. The most representative approach is to train large Transformer-based models on massive image-text pair data in a self-supervised manner, for example, predicting the masked elements based on their context. The pretrained vision-language fusion model can be fine-tuned to adapt to various downstream vision-language tasks. However, existing VLP methods treat the image encoding module as a black box and leave the visual feature improvement untouched since the development of the classical bottom-up region features in 2017, despite that there has been much research progress on improving image encoding and object detection.
Here, we introduce recent Microsoft work on improving the image encoding module. Researchers from Microsoft have developed a new object-attribute detection model for image encoding, dubbed VinVL ( V isual features in V ision- L anguage), and performed a comprehensive empirical study to show that visual features matter significantly in VL models. Combining VinVL with state-of-the-art VL fusion modules such as OSCAR (opens in new tab) and VIVO (opens in new tab) , the Microsoft VL system sets new state of the art on all seven major VL benchmarks, achieving top position in the most competitive VL leaderboards, including Visual Question Answering (VQA) (opens in new tab) , Microsoft COCO Image Captioning (opens in new tab) , and Novel Object Captioning (nocaps) (opens in new tab) . Most notably, the Microsoft VL system significantly surpasses human performance on the nocaps leaderboard in terms of CIDEr (92.5 vs. 85.3).
- Publication VinVL: Making Visual Representations Matter in Vision-Language Models
Microsoft will release the VinVL model and the source code to the public. Please refer to the research paper and GitHub repository . In addition, VinVL is being integrated into the Azure Cognitive Services, powering a wide range of multimodal scenarios (such as Seeing AI, Image Captioning in Office and LinkedIn, and others) to benefit millions of users through the Microsoft AI at Scale initiative.

VinVL: A generic object-attribute detection model
As opposed to classical computer vision tasks such as object detection, VL tasks require understanding more diverse visual concepts and aligning them with corresponding concepts in the text modality. On one hand, most popular object detection benchmarks (such as COCO, Open Images, Objects365) contain annotations for up to 600 object classes, mainly focusing on objects with a well-defined shape (such as car, person) but missing visual objects occupying amorphous regions (such as grass, sky), which are typically useful for describing an image. The limited and biased object classes make these object detection datasets insufficient for training very useful VL understanding models for real-world applications. On the other hand, although the VG dataset has annotations for more diverse and unbiased object and attribute classes, it contains only 110,000 images and is statistically too small to learn a reliable image encoding model.
To train our object-attribute detection model for VL tasks, we constructed a large object detection dataset containing 2.49M images for 1,848 object classes and 524 attribute classes, by merging four public object detection datasets, that is, COCO, Open Images, Objects365 and VG. As most datasets do not have attribute annotations, we adopted a pretraining and fine-tuning strategy to build our object-attribute detection model. We first pretrained an object detection model on the merged dataset, and then fine-tuned the model with an additional attribute branch on VG, making it capable of detecting both objects and attributes. The resultant object-attribute detection model is a Faster-RCNN model with 152 convolutional layers and 133M parameters, which is the largest image encoding model for VL tasks reported.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
Our object-attribute detection model can detect 1,594 object classes and 524 visual attributes. As a result, the model can detect and encode nearly all the semantically meaningful regions in an input image, according to our experiments. As illustrated in Figure 2, compared with detections of a classical object detection model (left), our model (right) can detect more visual objects and attributes in an image and encode them with richer visual features, which are crucial for a wide range of VL tasks.

State-of-the-art performance on vision-language tasks
Since the image encoding module is fundamental to VL systems, as illustrated in Figure 1, our new image encoding can be used together with many existing VL fusion modules to improve the performance of VL tasks. For example, as reported in Table 1, by simply replacing visual features produced by the popular bottom-up model with the ones produced by our model, but keeping the VL fusion module (for example, OSCAR and VIVO ) intact1, we observe significant improvement on all seven established VL tasks, often outperforming previous SoTA models by a significantly large margin.
[1] Note that we still perform training for the VL fusion module, but use the same model architecture, training data, and training recipe.

To account for parameter efficiency, we compare models of different sizes in Table 2. Our base model outperforms previous large models on most tasks, indicating that with better image encoding the VL fusion module can be much more parameter efficient.

Our new VL models, which consist of the new object-attribute detection model as its image encoding module and OSCAR as its VL fusion module, sit comfortably atop several AI benchmarks as of December 31, 2020, including Visual Question Answering (VQA) (opens in new tab) , Microsoft COCO Image Captioning (opens in new tab) , and Novel Object Captioning (nocaps) (opens in new tab) . Most notably, our VL model performance on nocaps substantially surpasses human performance in terms of CIDEr (92.5 vs. 85.3). On the GQA benchmark (opens in new tab) , our model is also the first VL model that outperforms NSM, which contains some sophisticated reasoning components deliberately designed for that specific task.

Looking forward
VinVL has demonstrated great potential in improving image encoding for VL understanding. Our newly developed image encoding model can benefit a wide range of VL tasks, as illustrated by examples in this paper . Despite the promising results we obtained, such as surpassing human performance on image captioning benchmarks, our model is by no means reaching the human-level intelligence of VL understanding. Interesting directions of future works include: (1) further scale up the object-attribute detection pretraining by leveraging massive image classification/tagging data, and (2) extend the methods of cross-modal VL representation learning to building perception-grounded language models that can ground visual concepts in natural language and vice versa like humans do.
Acknowledgments: This research was conducted by Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Additional thanks go to the Microsoft Research Service Engineering Group for providing computer resources for large-scale modeling. The baseline models used in our experiments are based on the open-source code released in the GitHub repository; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.
Related publications
Oscar: object-semantics aligned pre-training for vision-language tasks, vivo: surpassing human performance in novel object captioning with visual vocabulary pre-training, vinvl: revisiting visual representations in vision-language models, meet the authors.
Pengchuan Zhang
Senior Researcher

Principal Research Manager

Jianfeng Gao
Distinguished Scientist & Vice President
Continue reading

Structured knowledge from LLMs improves prompt learning for visual language models

Microsoft at VL/HCC 2023: Focus on co-audit tools for spreadsheets
REACT — A synergistic cloud-edge fusion architecture

Advancing human-centered AI: Updates on responsible AI research
Research areas.
Research Groups
- Deep Learning Group
- Azure Computer Vision Research
Related tools
Related projects.
- Project Florence (AI)
- AI at Scale
Related labs
- Microsoft Research Lab - Redmond
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
Share this page:
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Research areas.
Machine Perception
Natural Language Processing
Meet the teams driving innovation
Our teams advance the state of the art through research, systems engineering, and collaboration across Google.

Subscribe to the PwC Newsletter
Join the community, edit social preview.

Add a new code entry for this paper
Remove a code repository from this paper.

Mark the official implementation from paper authors
Add a new evaluation result row.
- CONTRASTIVE LEARNING
- REPRESENTATION LEARNING
Remove a task

Add a method
Remove a method.
- CONTRASTIVE LEARNING -
Edit Datasets
Learning visual representations via language-guided sampling.
CVPR 2023 · Mohamed El Banani , Karan Desai , Justin Johnson · Edit social preview
Although an object may appear in numerous contexts, we often describe it in a limited number of ways. Language allows us to abstract away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual representation learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach diverges from image-based contrastive learning by sampling view pairs using language similarity instead of hand-crafted augmentations or learned clusters. Our approach also differs from image-text contrastive learning by relying on pre-trained language models to guide the learning rather than directly minimizing a cross-modal loss. Through a series of experiments, we show that language-guided learning yields better features than image-based and image-text representation learning approaches.
Code Edit Add Remove Mark official
Tasks edit add remove, datasets edit.

Results from the Paper Edit
Methods edit add remove.
Visual Representations Of Language
- Tyler Bryden
- September 27, 2021

This is is part of my live-learning series! I will be updating this post as I continue through my journey. I apologize for any grammatical errors or incoherent thoughts. This is a practice to help me share things that are valuable without falling apart from the pressure of perfection.
Above, you can see a visual representation of Donald Trump’s Georgia Rally speech on September 25th.
I used our system at Speak Ai to automatically find the entities within the speech and organize them by what was mentioned most.
I then sourced images for those entities. The ones that are mentioned most are the largest and in the middle. The entities that appear less are smaller and positioned towards the outside of the image.
I don’t know, but I am obsessed with visual representations of language. We learn through visuals. We comprehend information so quickly through images, animations and videos. Maybe this image above isn’t data-driven from a bar chart graph display, but it certainly does something to represent the speech that was.
Other Attempts
I’ve done this a few times before. One of them was a get-together a group of friends had online where we recorded and transcribed the video and then ran it through Speak. I pulled out the images and put them into a square image like this. I got such good feedback, I actually generated an animated version of the conversation. You can see the video of that here:
Some people who had been following what we had been doing at Speak Ai told me this was some of the most interesting output they had seen from us. If we can take raw audio files, text, and transcripts and translate them into visual representations automatically, that is a lot of power.
You can transcend languages. You can help people gather a high-level understanding very quickly. You can create something engaging that people will look at, examine, and spend time on. In an internet age where time is a measure of engagement, that is incredibly valuable.
Entities Displayed
If you’re wondering about the image above, the entities displayed are:
- Russia (18)
- Democrats (12)
- America (8)
- Georgia (7)
- Brian Kemp (4)
- Hillary Clinton (4)
- Adam Schiff (2)
- Taliban (2)
- Republicans (2)
- Mitch McConnell (1)
- The Oval Office (1)
- Nancy Pelosi (1)
- Stacey Abrams (1)
Manual Process
It’s not perfect. I did this manually. It takes too much time. I’d say 45 minutes. Some entities you can’t find images for. Others you aren’t sure are good enough references or well-known enough to introduce as an image.
This introduces my own bias into the visual representation.
It’s also not mathematically done. Ideally, you can use the number of mentions to generate properly rendered images at the proper size and in the right location.
Aesthetically Pleasing
It’s also not pretty. That’s one thing I find very challenging. I am not a designer by nature. This image-populated version of a word cloud is fascinating but not necessarily beautiful to look at. How can you use frameworks to populate these image-word clouds automatically in a way that is visually appealing?
Another way to come at this would be to display a bar chart with small icon images on top or as part of the label to add a bit more visual representation. This may not be the best practice for data visualization but sharing online it has a significant impact.
Recently, I’ve been thinking a lot about Canva . They are one of the most valuable private companies in the world. They are being used every day with a passionate customer base. They recently raised $200 million at a $40 billion valuation. Software is eating the world.
What they have done is made it easy for anyone to generate beautiful graphics. Repeatedly. On all platforms. For visual representations of language to be successful, it needs to use the Canva-model to quickly and automatically generate graphics that you want to share!
Along with that comes the need for clean data. It is hard to analyze and visualize information properly when the data is not clean. This is pretty easy for text information, but once you get into speech and transcripts, the level of difficulty turns up significantly.
If you work with automated transcriptions, you know what I mean. Even professional human transcribers struggle with accuracy. Data cleaning is an important part of the process I’ve spent a long time on. In the end, all we want is good data that can help us create compelling analyses and hopefully, visuals.
All In Stats
I really love the way All In Stats is presenting their visuals:

The data visualizations Kay Singh and Keerat Singh still have a humble following but their process and outputs can be scaled and create value for a lot of speeches, media and bodies of text. Thank you for your contribution to this work!
Drake’s Certified Lover Boy Album Analysis
I’ve had other ways of trying to tackle this myself. I recently did an analysis of Drake’s Certified Lover Boy album . Here’s an image of the locations that were mentioned most across the album:

Timeline Representation
Another way I approached this in simple MVP form was a timeline. This adds the time series representation to the graphic which especially in a speech, is an important part of the information.
Here is an example of that from an Office Hours we did as a team at Speak Ai:

This is also not perfect. Timestamps would be helpful to know when an entity or topic emerges. You also can’t really capture how many times that entity was mentioned you can only understand when it first emerged. Otherwise, this would get very cluttered.
Interactive Web Display
I believe there is another opportunity to take any conversation we want and turn it into interactive web pages populated into a visual display and/or timeline. If you click on one of the images, it will jump you to that moment in the speech.
It may seem silly and unnecessary but I believe it will be interesting and there are people who would enjoy those experiences a lot.
Innovating Together
Again, I don’t know why I am so obsessed with this. I just am. Language and communication is beautiful, complex, and the reason we are here today. I think trying to push the envelope on how we capture, analyze, and display language information is a worthwhile endeavour. If you’re reading this, I hope you think so too.
If you have any ideas on generating visual representations of language, please feel encouraged to reach out. I’ve been surprised at how infantile this space is. Generally, we only present word clouds, bar graphs, quotes, and clips to represent language and generate compelling insights. I believe there is a lot more possible. Let’s figure out what that may look like together!
Thanks so much for checking this out. I’ll be back to improve this content for you.
Connect with me on LinkedIn
Follow me on Twitter
Follow me on Instagram
Subscribe on YouTube
Email me at [email protected]
Give me a text or call at (647) 372-1565
Easily book a meeting with Calendly
Listen to my podcast:
Google Podcast
Apple Podcast
Support my work
Learn more about me
Shop on my site
Learn more about Sessions
Learn more about Speak Ai
Support my music
Join the Forest City Psychedelic Community
Sign up on Speakai.co
Share This Post
Join my personal newsletter ❤, get insights and resources into awareness, well-being, productivity, technology, psychedelics and more., more to explore.

Google Launches AI Overviews
Interested in Google Launches AI Overviews? Check out the latest video and resources from Tyler Bryden on Google Launches AI Overviews!
London, Ontario Safe Injection Sites & Decriminalization Woes
Interested in London, Ontario Safe Injection Sites & Decriminalization Woes? Check out the latest video and resources from Tyler Bryden on London, Ontario Safe Injection Sites & Decriminalization Woes!

Don't want to chat but want to keep updated?
I'd love if you subscribed today. I promise I will only send you great, valuable content that has transformed me and helped others flourish.
You have Successfully Subscribed!
Pin it on pinterest.
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
[CVPR 2024 Highlight🔥] Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
PKU-YuanGroup/Chat-UniVi
Folders and files, repository files navigation.

Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
If you like our project, please give us a star ⭐ on github for the latest update..
- [2024/04/05] We've revised the temporal evaluation performance of video understanding, resulting in an actual model performance of 47.9 instead of the previously stated 57.8. We sincerely apologize for any inconvenience our oversight may have caused you.
- [2024/04/05] Chat-UniVi has been selected as a Highlight paper at CVPR 2024! (Top 3% of 11532 submissions).
- [2024/02/27] Our Chat-UniVi has been accepted by CVPR 2024!
- [2024/01/05] We enhance the video loading code by introducing support for variable-length videos . This improvement involves eliminating the previous zero-filling operation on the video. We find that this updated video loading method significantly boosts performance ( Results ).
- [2023/12/05] The visualization script is available at VISUALIZATION.md .
- [2023/11/22] ⚡ The online demo is available at Hugging Face Demo . Welcome to try!
- [2023/11/22] The processed data is available at DATA.md .
- [2023/11/21] 💡 We release Chat-UniVi-13B . Our proposed unified visual representation framework greatly reduces the number of visual tokens, so you can train 13B unified image and video understanding models in full parameters directly on 8 A100 GPUs within 3 days . Chat-UniVi-13B has better performance ( Results ). The training code for Chat-UniVi-13B has been updated ( TRAIN_AND_VALIDATE.md ).
- [2023/11/21] We provide inference code for video understanding and image understanding .
- [2023/11/21] We enhance the video loading code by introducing support for variable-length videos . This improvement involves eliminating the previous zero-filling operation on the video. We find that this updated video loading method significantly boosts performance.
- [2023/11/15] Code are available now! Welcome to watch 👀 this repository for the latest updates.
😮 Highlights
💡 unified visual representation for image and video.
We employ a set of dynamic visual tokens to uniformly represent images and videos. This representation framework empowers the model to efficiently utilize a limited number of visual tokens to simultaneously capture the spatial details necessary for images and the comprehensive temporal relationship required for videos .

🔥 Joint training strategy, making LLMs understand both image and video
Chat-UniVi is trained on a mixed dataset containing both images and videos, allowing direct application to tasks involving both mediums without requiring any modifications.

🤗 High performance, complementary learning with image and video
Extensive experimental results demonstrate that Chat-UniVi, as a unified model, consistently outperforms even existing methods exclusively designed for either images or videos.

Please change the model path on line 15 of the main_demo.py first. Then run the demo:
A conversation with both image and video
A conversation includes multiple videos, a conversation includes multiple images, a conversation includes the video, a conversation in chinese.
With translation API, our model can also support Chinese conversations. We will add code to support Chinese conversations in future updates.
🚀 Main Results
Image understanding.
Following LLaVA, we report the relative scores to GPT-4 for instruction-following questions.
Video understanding
Following Video-ChatGPT, we report the relative scores between the output of the model and the ground truth, with the assistance of GPT. It is worth noting that the results reported in Video-ChatGPT span a range from 0 to 5. To standardize the metrics, we normalize all scores to a scale of 0 to 100.
We report both zero-shot and fine-tuning results on the ScienceQA test set.
We follow the evaluation protocol in Video-ChatGPT, i.e., employing GPT-assisted evaluation to assess the capabilities of models.
Hallucination Evaluation (POPE)
Our model also achieves impressive results in the object hallucination benchmark.
😍 Visualization
Visualization for the image inputs.

Visualization for the video inputs

🛠️ Requirements and Installation
Attention! If you are using a Windows system, please make sure to comment out deepspeed in pyproject.toml (#Line 20), as installing deepspeed may result in errors on Windows (see Link ). Keep in mind that deepspeed is intended for training models only. If you are solely engaged in inference and not training models, it is recommended to comment it out.
- Python >= 3.10
- Install required packages:
We open source all modalities preprocessing code. If you want to load the model from the model hub on Hugging Face or on local, you can use the following code snippets.
Inference for Video Understanding
Inference for image understanding, 🗝️ training & validating.
- The data instruction is in DATA.md .
- The training instruction is in TRAIN_AND_VALIDATE.md .
👍 Acknowledgement
- LLaVA The codebase we built upon and it is an efficient large language and vision assistant.
- Video-ChatGPT Great job contributing the evaluation code and dataset.
🤝 Related Projects
- Video-LLaVA This framework exhibits remarkable interactive capabilities between images and videos.
- The majority of this project is released under the Apache 2.0 license as found in the LICENSE file.
- The service is a research preview intended for non-commercial use only, subject to the model License of LLaMA, Terms of Use of the data generated by OpenAI, and Privacy Practices of ShareGPT. Please contact us if you find any potential violations.
✏️ Citation
If you find this paper useful, please consider staring 🌟 this repo and citing 📑 our paper:
✨ Contributors
Contributors 2
- Python 100.0%

How the Brain Processes Different Components of Language
Moving beyond neural localization of language..
Posted May 28, 2024 | Reviewed by Devon Frye
In a new article appearing in the Journal of Cognitive Neuroscience , researchers at the Massachusetts Institute of Technology, led by Cory Shain and Hope Kean, explore how the human brain shows signatures for linguistic composition . This refers to the ability we have to put together individual units of meaning into larger units, typically hierarchically organized.
The research is an excellent example of innovative neuroscience methods being paired with thoughtful and critical linguistic hypotheses to deliver novel insights on the question: “Which parts of the brain care about different core components of language?”
Shain and colleagues discovered an intricate profile of distributed sensitivity to both syntax and semantics throughout a broad frontotemporal network. This spanned from the posterior and middle lateral temporal cortex to the inferior frontal cortex.
The main take-home message here is that language network regions do not display binary sensitivity to either words, grammar, or larger meanings built from multiple words; rather, they vary in their sensitivity to at least two of these features.
They make the important conclusion that the “internal specialization” for language “is primarily a matter of degree rather than kind.” In addition, they practice something that should be standard across the field: they provide a Table with full definitions of working concepts and a Figure plotting a full schema of possible neural response profiles based on various hypothetical effects.
The authors show that major language network nodes display different levels of sensitivity to syntax, "combinatorial semantics" (referring to the types of complex meanings we can only derive from multi-word phrases, as opposed to individual words), and lexicality (referring to our ability to judge whether a string of letter forms a real word or not), rather than one fixed region being selective for a specific component.
Cortical Mosaics for Linguistic Structure
The authors found that posterior temporal and inferior frontal language sites showed a length effect in so-called "Jabberwocky" sentences (i.e., sentences in which all the "content words," like nouns, verbs, adjectives, and adverbs, have been replaced with fake words) for linguistic structural context, and all language areas showed at least some effect of lexicality (i.e., a difference for real words vs. fake words).
This is in line with recent ideas about a "cortical mosaic" architecture for linguistic structure within overlapping portions of posterior temporal and inferior frontal cortices for processing demands that bias syntactic and semantic computations, whereby, for example, effects of composition can be found within a narrow strip of tissue within the broader lexicality-sensitive cortical sites (a spatial mosaic), or where different demands of sentence-level inferential semantics can be detected over closely overlapping temporal windows within a small area of cortex (a spatiotemporal mosaic).
Shain and colleagues also found that the posterior temporal cortex uniquely exhibits equal sensitivity to syntactic structure and combinatorial semantics, with or without lexical content. This potentially points to this region as a site heavily involved in linguistic structure-building.
This provides strong evidence that the brain’s language hubs are not monolithic in their interest in specific components of linguistic structure—meaning it's not syntax over here and semantics over there, as has been claimed by some of the field’s most influential researchers such as Friederici, Duffau, and Hagoort. Instead, it points to a kind of mosaic-like architecture whereby syntax and semantics are closely intermingled, but different regions exhibit various biases for processing loads and strategies.
Someone Must Extinguish Thy Flame: Finding Signatures of Syntax
There is a qualification to be made about the hypothesis presented by many authors before Shain and colleagues, and replicated in their study, that “syntactic hubs” would be unveiled via “identical responses” for real sentences and Jabberwocky sentences. Lexico-semantic modulations inevitably tax syntactic processes , given the centrality of lexical syntax in driving and initiating phrase structure formation and, subsequently, long-distance dependency formation.
As such, there are some core syntactic processes certainly captured in both real sentences and Jabberwocky sentences, such as hierarchical depth. But even here, as Shain and colleagues mention, there are certain properties of lexical meaning that can be inferred by specific properties of pseudowords, and every phrase structure is built out of properties such as lexical selection criteria (pseudowords do not select for anything).

Even if a brain region did in fact execute the same level of local neuronal cortical processing for real sentences and Jabberwocky sentences with respect to building inferences of recursive hierarchical structure, the lexico-semantic differences would naturally interfere here, given the close regulation of semantics by syntax.
In other words, why would we expect to find a “pure” syntactic response profile when syntax is itself anything but pure? It is in the game of regulating semantic structure via a complex interface of 'morphophonological' transformations .
In addition, while one of the advantages of fMRI is its spatial resolution, the authors keep to large macroanatomical areas (i.e. the entire anterior temporal surface, the entire posterior temporal surface, etc.), which may be neurobiologically implausible in terms of making spatiotemporal claims of cortical computation and the possibility of distinct response profiles that might, nevertheless, bias much more heavily towards combinatorial semantic and/or syntactic information.
The authors also cite Fedorenko’s intracranial study (using electrodes recorded directly from the surface of the brain in epilepsy patients), and Nelson and colleague’s intracranial study, using this to motivate their analysis of nodal structure-building. They do not cite more recent intracranial work failing to replicate much of Nelson and colleagues’ major effects of structure (including discussion of why this might be the case).
The authors’ finding that “no language region appears to be a hub for abstract (i.e., content-independent) combinatorics” speaks to the idea of unbounded hierarchical structure-generation being uniquely tied to its elements of selection, as per many models of minimalist syntax, as opposed to models that claim, for instance, that the human brain has a domain-general structure-building capacity that applies over distinct representational domains (e.g., language, mathematics, music, etc).
Overall, it may not be the case, as some have claimed (e.g., Dehaene, Fitch, Bornkessel-Schlesewsky) that there are dedicated neural circuits for abstract combinatorics. Instead, human language might be built off a constellation of domain-general neural codes but with unique integration of these codes alongside domain-specific stored representations (as proposed in the recent ROSE model for the brain’s neurocomputational architecture for language, in which lexical units are intrinsically maintained in their base code throughout higher-order syntactic operations), partly accounting for the kind of “difference of degree but not kind” perspective unveiled by Shain and colleagues. Still, there may be types of neural signatures that fall outside of the poor temporal resolution afforded by fMRI that can detect more rapid shifts between distinct levels of linguistic structure.

Elliot Murphy, Ph.D. , is the author of The Oscillatory Nature of Language.
- Find a Therapist
- Find a Treatment Center
- Find a Psychiatrist
- Find a Support Group
- Find Online Therapy
- United States
- Brooklyn, NY
- Chicago, IL
- Houston, TX
- Los Angeles, CA
- New York, NY
- Portland, OR
- San Diego, CA
- San Francisco, CA
- Seattle, WA
- Washington, DC
- Asperger's
- Bipolar Disorder
- Chronic Pain
- Eating Disorders
- Passive Aggression
- Personality
- Goal Setting
- Positive Psychology
- Stopping Smoking
- Low Sexual Desire
- Relationships
- Child Development
- Self Tests NEW
- Therapy Center
- Diagnosis Dictionary
- Types of Therapy

At any moment, someone’s aggravating behavior or our own bad luck can set us off on an emotional spiral that threatens to derail our entire day. Here’s how we can face our triggers with less reactivity so that we can get on with our lives.
- Emotional Intelligence
- Gaslighting
- Affective Forecasting
- Neuroscience
- Skip to content
The Cornell Lab of Ornithology builds the eBird global platform for communities and partners around the world to advance data-driven science, education, and conservation.
Macaulay Library Unveils New Look for Spectrograms
Image: Black-Throated Blue Warbler © Ryan Justice, Macaulay Library / Recording: Black-Throated Blue Warbler © Bob McGuire, Macaulay Library
The Macaulay Library hosts the world’s largest archive of digital audio of birds with nearly 2.4 million sound recordings. To easily identify and navigate the multitude of recordings in the archive, we use spectrograms , visual representations of the intensity of sound frequencies across time. Spectrograms allow us to compare recordings by sight, which can be more efficient and precise than by sound alone. Spectrograms are used by bioacoustics scientists who want to analyze sounds, by Merlin Sound ID to offer identification suggestions, and by anyone wanting to learn more about sounds. After more than a decade of using the same spectrograms, the Macaulay Library team is excited to share an update to our spectrograms designed to enhance both their visual appeal and functionality!
Media Search and individual media pages are now using the new spectrograms, and other views, such as checklists and trip reports, will start using them in the coming weeks. We improved our spectrograms in the following ways:
Longer recording support . Macaulay Library spectrograms no longer have a length cutoff, allowing us to display very long recordings. As passive acoustic monitoring becomes more and more common, these long recordings are important for our research and conservation goals and improving sound ID.
Long recordings like this 13 minute Carolina Wren song sequence are now easier to explore.
Better resolution. We’ve adjusted the spectrogram settings to allow better visualization of quieter background sounds, as well as sharper-looking focal sounds and a much more detailed “timeline” preview below the main spectrogram.
Better visibility. Changes have been made to the default zoom on the spectrograms. Previews in Media Search now show 10 seconds so you can get a better idea of what’s in a recording at a glance, and once you play the audio, more of the recording is visible at once. But now that the spectrograms are higher resolution, you can also zoom in to see more detail—or zoom out to get a birds-eye view.
Higher frequencies . We’re now showing frequencies up to 12kHz. While most bird sounds occur below the previous limit of 10kHz, many sounds go above that point and are useful to see. Expanding up to 12kHz will allow more of the bird’s sound to be visible.
The high-pitched song of a Costa’s Hummingbird looks much more complete with the new settings.
Data efficiency . Spectrograms are now composed of multiple smaller images, so loading the recording to listen to it should be more efficient than before.
Accessibility . Lots of behind-the-scenes settings have been adjusted to make sure the maximum number of users are able to see and listen to the amazing sounds of birds and other animals.
Spectrograms are a vital tool for anyone interested in the study of bird vocalizations. We invite you to explore the updated spectrograms in the Macaulay Library . Whether you’re a seasoned ornithologist or a curious birder, these new features are designed to make your exploration of bird sounds more informative and enjoyable.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: enhancing vision-language model with unmasked token alignment.
Abstract: Contrastive pre-training on image-text pairs, exemplified by CLIP, becomes a standard technique for learning multi-modal visual-language representations. Although CLIP has demonstrated remarkable performance, training it from scratch on noisy web-scale datasets is computationally demanding. On the other hand, mask-then-predict pre-training approaches, like Masked Image Modeling (MIM), offer efficient self-supervised learning for single-modal representations. This paper introduces Unmasked Token Alignment (UTA), a method that leverages existing CLIP models to further enhance its vision-language representations. UTA trains a Vision Transformer (ViT) by aligning unmasked visual tokens to the corresponding image tokens from a frozen CLIP vision encoder, which automatically aligns the ViT model with the CLIP text encoder. The pre-trained ViT can be directly applied for zero-shot evaluation even without training on image-text pairs. Compared to MIM approaches, UTA does not suffer from training-finetuning inconsistency and is much more training-efficient by avoiding using the extra [MASK] tokens. Extensive experimental results demonstrate that UTA can enhance CLIP models and outperform existing MIM methods on various uni- and multi-modal benchmarks. Code and models are available at this https URL .
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
IMAGES
VIDEO
COMMENTS
Visual Representation refers to the principles by which markings on a surface are made and interpreted. Designers use representations like typography and illustrations to communicate information, emotions and concepts. Color, imagery, typography and layout are crucial in this communication. Alan Blackwell, cognition scientist and professor ...
Visual language is a system that communicates through visual elements. It helps users perceive and understand visible signs. A painting is an example of visual communication because your eyes perceive its signs (like shapes and colors) and your brain interprets them. That way, to understand what is visual language, let's take a look into ...
A visual language is a system of communication using visual elements. ... proportion and colour convey meaning directly without the use of words or pictorial representation. Wassily Kandinsky showed how drawn lines and marks can be expressive without any association with a representational image. From the most ancient cultures and throughout ...
Defining Visual Representation: Visual representation is the act of conveying information, ideas, or concepts through visual elements such as images, charts, graphs, maps, and other graphical forms. It's a means of translating the abstract into the tangible, providing a visual language that transcends the limitations of words alone.
Chapter 7: Visual Language. Learning Objectives. Describe the nature of different writing systems. Differentiate the rules that govern grapheme-to-phoneme conversion. Describe the standard reading model as a basis for further exploration. In this chapter we will explore the basics of the written word. Writing involves the representation of ...
Visual language transcends words, engaging our imagination and speaking directly to the human soul. We learn a global language that transcends cultural boundaries as we get immersed in the realm of artistic expression, engaging spectators in a discourse that goes beyond spoken language. Through their artistic expressions, artists remind us of ...
Written language itself is a visual representation of spoken language. This post has been an introduction to the grammar of the visual language we use in each of our designs. The more we understand that grammar, the better we can speak the language, and the more effectively we can communicate with our audience. ...
Language and visual representations are central to all knowledge-based activities, including those in science, health & medicine, and engineering. Word choice, charts, graphs, images, and icons have the power to shape scientific practice, questions asked, results obtained, and interpretations made. ...
A similar examination of semantic selectivity for body parts and faces suggests that these modality shifts from visual to linguistic semantic representations also appear along other portions of ...
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding. For the purpose of building larger and more powerful models easily, we employ a simple dual-encoder architecture that learns to align visual and language representations of the image and text pairs. Image and text encoders are learned via a contrastive loss (formulated as normalized softmax ...
Although an object may appear in numerous contexts, we often describe it in a limited number of ways. Language allows us to abstract away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual representation learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our ...
3.3. Language-Guided Visual Learning. Our approach is applicable to several representation learning methods as it only changes the training view pairs. We focus on contrastive learning since its fairly minimal setting allows us to analyze the impact of language guidance with minimal confounding factors.
Interesting directions of future works include: (1) further scale up the object-attribute detection pretraining by leveraging massive image classification/tagging data, and (2) extend the methods of cross-modal VL representation learning to building perception-grounded language models that can ground visual concepts in natural language and vice ...
Vision language pre-training (VLP) has proved effective for a wide range of vision-language (VL) tasks [25, 35, 4, 33, 19, 18, 44, 20]. VLP typically consists of two stages: (1) an object detection model is pre-trained to encode an image and the visual objects in the image to feature vectors, and. (2) a cross-modal fusion model is pre-trained ...
ABSTRACT. While the language portrait (LP) is a visual research method that can make visible speakers' multilingualism, this article considers how and why speakers may use the LP to make elements of their linguistic repertoire invisible.Analysing the portraits created by three primary school students in Luxembourg, I explore why these young people omitted different linguistic resources in ...
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge.
Language allows us to abstract away visual variation to represent and communicate concepts. Building on this intuition, we propose an alternative approach to visual representation learning: using language similarity to sample semantically similar image pairs for contrastive learning. Our approach diverges from image-based contrastive learning ...
This makes language-sampled images an excellent source for visual representation learning as they implicitly capture human-like visual invariances. 3.2. Sampling Image Pairs using Language. Given a captioned image dataset, we want to sample im-age pairs that have very similar captions.
generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a prelim-inary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM ...
If you have any ideas on generating visual representations of language, please feel encouraged to reach out. I've been surprised at how infantile this space is. Generally, we only present word clouds, bar graphs, quotes, and clips to represent language and generate compelling insights. I believe there is a lot more possible.
@article{jin2023chatunivi, title={Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding}, author={Peng Jin and Ryuichi Takanobu and Caiwan Zhang and Xiaochun Cao and Li Yuan}, journal={arXiv preprint arXiv:2311.08046}, year={2023} } Contributors ...
The Complete HSC English Visual Techniques Cheat Sheet. 3 min remaining. Remembering every visual technique your teacher has ever raved about can be a tough one - there just seem to be so many! Luckily for you we've compiled this awesome English visual techniques cheatsheet, listing all the biggest and best visual techniques to namedrop in ...
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \\emph{bottom-up and top-down} model \\cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger ...
Instead, human language might be built off a constellation of domain-general neural codes but with unique integration of these codes alongside domain-specific stored representations (as proposed ...
Refining Skewed Perceptions in Vision-Language Models through Visual Representations. Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the ...
The Macaulay Library hosts the world's largest archive of digital audio of birds with nearly 2.4 million sound recordings. To easily identify and navigate the multitude of recordings in the archive, we use spectrograms, visual representations of the intensity of sound frequencies across time. Spectrograms allow us to compare recordings by sight, which can be more efficient and precise than ...
Contrastive pre-training on image-text pairs, exemplified by CLIP, becomes a standard technique for learning multi-modal visual-language representations. Although CLIP has demonstrated remarkable performance, training it from scratch on noisy web-scale datasets is computationally demanding. On the other hand, mask-then-predict pre-training approaches, like Masked Image Modeling (MIM), offer ...