How to Convert Audio to Text with Timestamps

Transkriptor 2022-10-28

What is a Timestamp?
A timestamp is an indication of the date and time stamped on a file, log, or notification and records. Here are some examples of where and how to use audio-to-text timestamps .
Timestamps record time in relation to a specific starting point in time.
What are Timestamps for?
Timestamps keep track of online information or information on a computer. A timestamp indicates the date of creation, exchange, modification, and deletion of data.
Here are some examples of how to use timestamps:
- A timestamp in a computer file indicates a modification of the file.
- Photographs with digital cameras have timestamps that show the date and time of day of the picture.
- The date and time of the post are in social media posts.
- Timestamps are used in online chat and instant messages to record the date and time a message was sent, received, or viewed.
- Timestamps are used in blockchain blocks to ensure the validity of transactions, such as those involving cryptocurrencies.
- To ensure the integrity and quality of data, data management relies on timestamps.
- Timestamps are used in digital contracts and digital signatures to show when a document was signed.
- Audio-to-text timestamps are another popular using area.
Why are Timestamps Useful?
- They can be reference materials or bookmarks. Timestamps can easily be used as reference points or bookmarks for reviewing, double-checking, and more. You won’t have to go through hours of audio or video recordings if you use timestamps. You won’t have to go through your entire transcript.
- Timestamps can also track progress. You can track your progress as you collect data, analyze feedback, review interviews or discussions, and more by using timestamps.
- They provide emphasis . You can use timestamps to highlight a specific section of the recording. You can use it to draw the attention of your audience or colleagues to a specific line in the transcript or to emphasize a point in the discussion. Audio-to-text timestamps are another helpful example.

What are the Types of Speech to Text?
Below are the types of speech to text:
- Audio Typing: Apps can dictate long texts. They are capable of sending text messages, emails, and documents.
- Audio Commanding: Voice commands can initiate specific actions.
- Audio to text translation: Using Speech-to-Text technology, customers can communicate with users who speak different languages.
How to Convert Speech to Text Feature
Real conversations take place in real time, using accurate and easy-to-read language.
The speech to text feature allows users to read their conversations, identify the speakers, and communicate more efficiently than ever before, regardless of their hearing abilities.
Simply record the audio, and the software will convert it to text instantly. So that you can clearly see what other people are saying even if you can’t hear or understand them.
You can add timestamps by using various applications.
- Choose one of the apps or sites that you want to use speech to text feature
- On the home screen of the apps, click on the transcribe icon.
- Most of the apps will inform you that using the speech-to-text feature will allow sending the audio and transcription data to its servers. Click on ‘ OK ’ to proceed.
- Record the audio you’d like to transcribe, and the app will convert it to text.
- So that, even though you are not able to hear what the other people say clearly, you can see what they say clearly in a written form.
- As a result, you will save time and be more involved in communication.
Speech to Text
Transkriptor
Convert your audio and video files to text
Audio to Text
Video Transcription
Transcription Service
Privacy Policy
Terms of Service
Contact Information
© 2024 Transkriptor
Speech to Text Converter
Descript instantly turns speech into text in real time. Just start recording and watch our AI speech recognition transcribe your voice—with 95% accuracy—into text that’s ready to edit or export.

How to automatically convert speech to text with Descript
Create a project in Descript, select record, and choose your microphone input to start a recording session. Or upload a voice file to convert the audio to text.
As you speak into your mic, Descript’s speech-to-text software turns what you say into text in real time. Don’t worry about filler words or mistakes; Descript makes it easy to find and remove those from both the generated text and recorded audio.
Enter Correct mode (press the C key) to edit, apply formatting, highlight sections, and leave comments on your speech-to-text transcript. Filler words will be highlighted, which you can remove by right clicking to remove some or all instances. When ready, export your text as HTML, Markdown, Plain text, Word file, or Rich Text format.
Download the app for free
More articles and resources.

New: Free Overdub on all Descript accounts, with easier voice cloning

What is a video crossfade effect?

New one-click integrations with Riverside, SquadCast, Restream, Captivate
Other tools from descript, advertising video maker, facebook video maker, youtube video summarizer, rotate video, marketing video maker, promo video maker, collaborative video editing.
Speech to Text
- 3 Create a new project Drag your file into the box above, or click Select file and import it from your computer or wherever it lives.
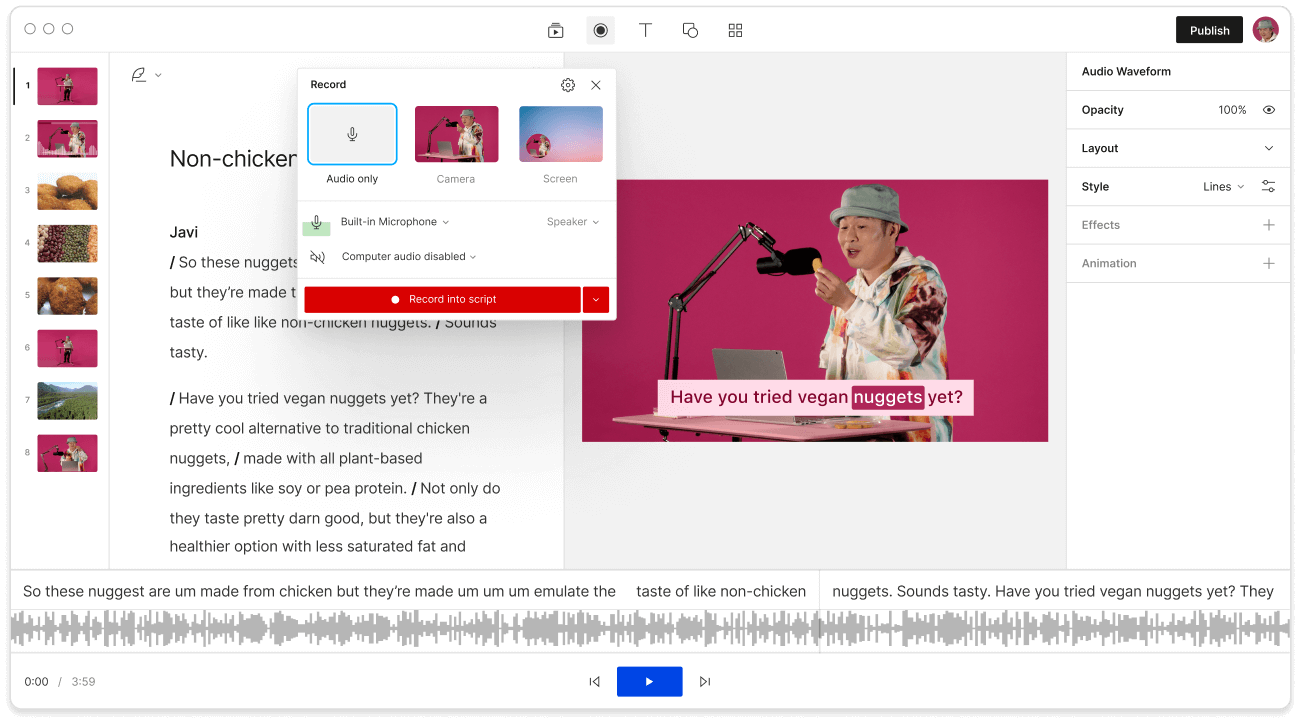
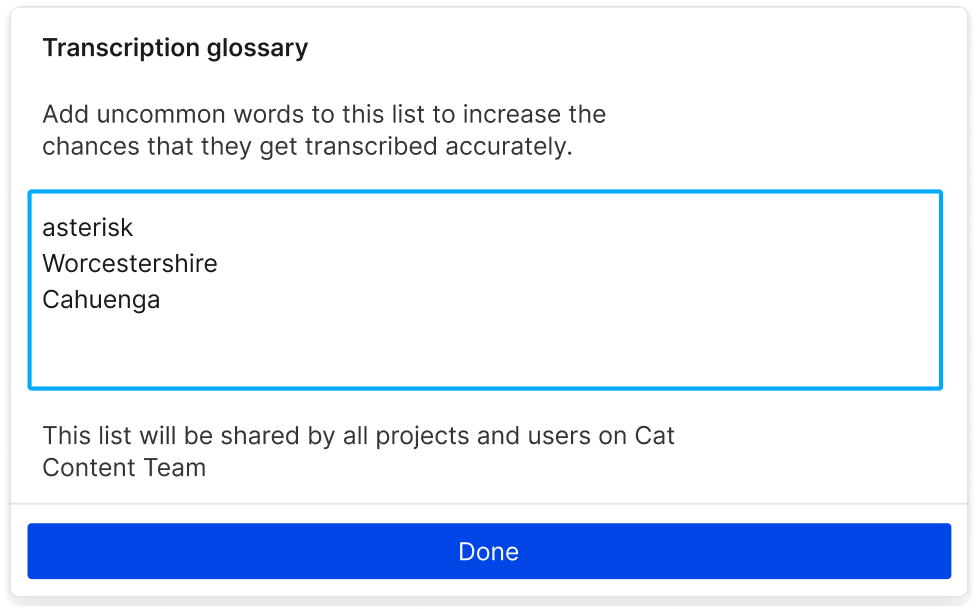
Expand Descript’s online voice recognition powers with an expandable transcription glossary to recognize hard-to-translate words like names and jargon.
Record yourself talking and turn it into text, audio, and video that’s ready to edit in Descript’s timeline. You can format, search, highlight, and other actions you’d perform in a Google Doc, while taking advantage of features like text-to-speec h, captions, and more.

Go from speech to text in over 22 different languages, plus English. Transcribe audio in French , Spanish , Italian, German and other languages from around the world. Finnish? Oh we’re just getting started.

Yes, basic real-time speech to text conversion is included for free with most modern devices (Android, Mac, etc.) Descript also offers a 95% accurate text-to-speech converter for up to 1 hour per month for free.
Speech-to-text conversion works by using AI and large quantities of diverse training data to recognize the acoustic qualities of specific words, despite the different speech patterns and accents people have, to generate it as text.
Yes! Descript‘s AI-powered Overdub feature lets you not only turn speech to text but also generate human-sounding speech from a script in your choice of AI stock voices.
Descript supports speech-to-text conversion in Catalan, Finnish, Lithuanian, Slovak, Croatian, French (FR), Malay, Slovenian, Czech, German, Norwegian, Spanish (US), Danish, Hungarian, Polish, Swedish, Dutch, Italian, Portuguese (BR), Turkish.
Descript’s included AI transcription offers up to 95% accurate speech to text generation. We also offer a white glove pay-per-word transcription service and 99% accuracy. Expanding your transcription glossary makes the automatic transcription more accurate over time.
Audio Course documentation
Transcribe a meeting
Audio course.
and get access to the augmented documentation experience
to get started
In this final section, we’ll use the Whisper model to generate a transcription for a conversation or meeting between two or more speakers. We’ll then pair it with a speaker diarization model to predict “who spoke when”. By matching the timestamps from the Whisper transcriptions with the timestamps from the speaker diarization model, we can predict an end-to-end meeting transcription with fully formatted start / end times for each speaker. This is a basic version of the meeting transcription services you might have seen online from the likes of Otter.ai and co:

Speaker Diarization
Speaker diarization (or diarisation) is the task of taking an unlabelled audio input and predicting “who spoke when”. In doing so, we can predict start / end timestamps for each speaker turn, corresponding to when each speaker starts speaking and when they finish.
🤗 Transformers currently does not have a model for speaker diarization included in the library, but there are checkpoints on the Hub that can be used with relative ease. In this example, we’ll use the pre-trained speaker diarization model from pyannote.audio . Let’s get started and pip install the package:
Great! The weights for this model are hosted on the Hugging Face Hub. To access them, we first have to agree to the speaker diarization model’s terms of use: pyannote/speaker-diarization . And subsequently the segmentation model’s terms of use: pyannote/segmentation .
Once complete, we can load the pre-trained speaker diarization pipeline locally on our device:
Let’s try it out on a sample audio file! For this, we’ll load a sample of the LibriSpeech ASR dataset that consists of two different speakers that have been concatenated together to give a single audio file:
We can listen to the audio to see what it sounds like:
Cool! We can clearly hear two different speakers, with a transition roughly 15s of the way through. Let’s pass this audio file to the diarization model to get the speaker start / end times. Note that pyannote.audio expects the audio input to be a PyTorch tensor of shape (channels, seq_len) , so we need to perform this conversion prior to running the model:
This looks pretty good! We can see that the first speaker is predicted as speaking up until the 14.5 second mark, and the second speaker from 15.4s onwards. Now we need to get our transcription!
Speech transcription
For the third time in this Unit, we’ll use the Whisper model for our speech transcription system. Specifically, we’ll load the Whisper Base checkpoint, since it’s small enough to give good inference speed with reasonable transcription accuracy. As before, feel free to use any speech recognition checkpoint on the Hub , including Wav2Vec2, MMS ASR or other Whisper checkpoints:
Let’s get the transcription for our sample audio, returning the segment level timestamps as well so that we know the start / end times for each segment. You’ll remember from Unit 5 that we need to pass the argument return_timestamps=True to activate the timestamp prediction task for Whisper:
Alright! We see that each segment of the transcript has a start and end time, with the speakers changing at the 15.48 second mark. We can now pair this transcription with the speaker timestamps that we got from our diarization model to get our final transcription.
To get the final transcription, we’ll align the timestamps from the diarization model with those from the Whisper model. The diarization model predicted the first speaker to end at 14.5 seconds, and the second speaker to start at 15.4s, whereas Whisper predicted segment boundaries at 13.88, 15.48 and 19.44 seconds respectively. Since the timestamps from Whisper don’t match perfectly with those from the diarization model, we need to find which of these boundaries are closest to 14.5 and 15.4 seconds, and segment the transcription by speakers accordingly. Specifically, we’ll find the closest alignment between diarization and transcription timestamps by minimising the absolute distance between both.
Luckily for us, we can use the 🤗 Speechbox package to perform this alignment. First, let’s pip install speechbox from main:
We can now instantiate our combined diarization plus transcription pipeline, by passing the diarization model and ASR model to the ASRDiarizationPipeline class:
pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")
Let’s pass the audio file to the composite pipeline and see what we get out:
Excellent! The first speaker is segmented as speaking from 0 to 15.48 seconds, and the second speaker from 15.48 to 21.28 seconds, with the corresponding transcriptions for each.
We can format the timestamps a little more nicely by defining two helper functions. The first converts a tuple of timestamps to a string, rounded to a set number of decimal places. The second combines the speaker id, timestamp and text information onto one line, and splits each speaker onto their own line for ease of reading:
Let’s re-run the pipeline, this time formatting the transcription according to the function we’ve just defined:
There we go! With that, we’ve both diarized and transcribe our input audio and returned speaker-segmented transcriptions. While the minimum distance algoirthm to align the diarized timestamps and transcribed timestamps is simple, it works well in practice. If you want to explore more advanced methods for combining the timestamps, the source code for the ASRDiarizationPipeline is a good place to start: speechbox/diarize.py
whisper-timestamped 1.15.4
pip install whisper-timestamped Copy PIP instructions
Released: Apr 22, 2024
Multi-lingual Automatic Speech Recognition (ASR) based on Whisper models, with accurate word timestamps, access to language detection confidence, several options for Voice Activity Detection (VAD), and more.
Verified details
Maintainers.

Unverified details
Project links, github statistics.
- Open issues:
View statistics for this project via Libraries.io , or by using our public dataset on Google BigQuery
License: GPLv3
Author: Jeronymous
Requires: Python >=3.7
Project description
Multi-lingual Automatic Speech Recognition (ASR) based on Whisper models, with accurate word timestamps, access to language detection confidence, several options for Voice Activity Detection (VAD), and more. See https://github.com/linto-ai/whisper-timestamped for more information.
Project details
Release history release notifications | rss feed.
Apr 22, 2024
Mar 14, 2024
Mar 11, 2024
Mar 3, 2024
Feb 25, 2024
Jan 15, 2024
Jan 8, 2024
Dec 22, 2023
Dec 8, 2023
Nov 21, 2023
Jul 1, 2023
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages .
Source Distribution
Uploaded Apr 22, 2024 Source
Built Distribution
Uploaded Apr 22, 2024 Python 3
Hashes for whisper_timestamped-1.15.4.tar.gz
Hashes for whisper_timestamped-1.15.4-py3-none-any.whl.
- português (Brasil)
Supported by

Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
How to get word time stamp events using Azure TTS
Azure TTS can return the audio time stamp and the words spoken from the SDK. With this feature, in Microsoft Edge, the word can be highlighted when it is reading out. It is a useful feature for immersive reading scenario like ebook reading.
Here is a sample. Look at SynthesisWordBoundaryEventAsync function in this sample file:
https://github.com/Azure-Samples/cognitive-services-speech-sdk/blob/1d1b13a7ab154cb884c9db1be3f22a0a8a876301/samples/csharp/sharedcontent/console/speech_synthesis_samples.cs
- Azure TTS: Empower every person and every organization on the planet to have a delightful digital voice!
- Azure Custom Voice: Build your one-of-a-kind Custom Voice and close to human Neural TTS in cloud and edge!
Azure Speech Document
Create Custom Neural Voice
Azure Speech Containers
Clone this wiki locally
We use cookies to enhance your experience.
Speech-to-Text
Experience industry-leading speech-to-text accuracy with Speech AI models on the cutting-edge of AI research, accessible through a simple API.
Call Transcript (04.02.2024)
Thank you for calling Acme Corporation, Sarah speaking. How may I assist you today? Hi Sarah, this is John. I’m having trouble with my Acme Widget. It seems to be malfunctioning. I’m sorry to hear that, John. Let’s get that sorted out for you. Could you please provide me with the serial number of your widget? Thank you, John. Now, could you describe the issue you’re experiencing with your widget? Well, it’s not turning on at all, even though I’ve replaced the batteries. Let’s try a few troubleshooting steps. Have you checked if the batteries are inserted correctly? Yes, I’ve double-checked that.
Universal-1
State-of-the-art multilingual speech-to-text model
Latency on 30 min audio file
Hours of multilingual training data
Industry’s lowest Word Error Rate (WER)
See how Universal-1 performs against other Automatic Speech Recognition providers.
See it in action
*Benchmark performed across 11 datasets, including 8 academic datasets & 3 internally curated datasets representing real world English audio.
Harness best-in-class accuracy and powerful Speech AI capabilities
Async speech-to-text.
The AssemblyAI API can transcribe pre-recorded audio and/or video files in seconds, with human-level accuracy. Highly scalable to tens of thousands of files in parallel.
See how in docs
Custom Vocabulary
Boost accuracy for vocabulary that is unique or custom to your specific use case or product.
Speaker Diarization
Detect the number of speakers in your audio file, with each word in the text associated with its speaker.
International Language Support
Gain support to transcribe over 99+ languages and counting, including Global English (English and all of its accents).
Auto Punctuation and Casing
Automatically add casing and punctuation of proper nouns to the transcription text.
Confidence Scores
Get a confidence score for each word in the transcript.
Word Timings
View word-by-word timestamps across the entire transcript text.
Filler Words
Optionally include disfluencies in the transcripts of your audio files.
Profanity Filtering
Detect and replace profanity in the transcription text with ease.
Automatic Language Detection
Automatically detect if the dominant language of the spoken audio is supported by our API and route it to the appropriate model for transcription.
Custom Spelling
Specify how you would like certain words to be spelled or formatted in the transcription text.
Continuously up-to-date and secure
Monthly updates and improvements.
View weekly product and accuracy improvements in our changelog.
View changelog
Enterprise-grade security
AssemblyAI is committed to the highest standards of security practices to keep your data and your customers' data safe.
Read more about our security
AssemblyAI's accuracy is better than any other tools in the market (and we have tried them all).
Vedant Maheshwari , Co-Founder and CEO
Explore more
Streaming speech-to-text.
Transcribe audio streams synchronously with high accuracy and low latency.
Speech Understanding
Extract maximum value from voice data with Audio Intelligence, and leverage Large Language Models with LeMUR.
Get started in seconds
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Speech-to-Text API, where can I found timestamps for DisplayText
We are building a UI where the timestamp and confidence for each word will be displayed alongside with the transcript. My only question is there any way we can find the timestamps for Normalized Text (after ITN, capitalization, punctuation detection etc..)?
For example,
the lexical text display: "nineteen eighty four" and we have the timestamps and confidences for each word, but we want to show on the UI is a single word "1984" and a single timestamp, perhaps the confidence in that case can just be the average.
Of course it isn't a big task to re-do the normalization ourself on those lexical words and try to match the timestamps with to the DisplayText. For that number example, we can show the timestamp of "nineteen" for "1984". But it would be nice if we can get that information from the API instead of spending time reverse-engineering the process which could be error-prone.
Hope that make sense and thanks for reading my question. Big thanks to you all.
Azure AI Speech An Azure service that integrates speech processing into apps and services. 1,426 questions Sign in to follow
Thanks for reaching out to us. Could you please try below? Let me know if you have more questions.
Please set:
in the speech config of azure sdk will allow you to get the transcripts along with the timestamps for each word.
This statement would allow you get the detailed json object from the azure sdk.
Below is a sample code. Make sure you replace the keys. Some error handling might be needed at places where speech to text could fail.
Thank you for your reply. Apologies for not clarifying which APIs I'm using. I'm using the Speech Services Batch Transcription API and example code found there:
https://github.com/Azure-Samples/cognitive-services-speech-sdk/tree/master/samples/batch/python
These are the parameters I set: I assume wordLevelTimestampsEnabled is the equivalent of speech_config.request_word_level_timestamps()
Are these the only parameters I can set for the API call?
I've tried your code, but unfortunately, I didn't find the information I need, i.e. word-level timestamp for DisplayText.
Thanks for the information. Yes, batch API is another scenario, I will look into this again.
Regards, Yutong
Did you have already a solution for this? Because I also want to have the time stamps for the Display text. We do get back the time stamps for the lexical field, but we want the timestamps for the Display text.
- Transcription
Timestamps are markers in the transcription to indicate when the adjacent text was spoken. For example:
Timestamps are in the format [HH:MM:SS] where HH, MM, and SS are hours, minutes, and seconds from the beginning of the audio or video file.
When Are Timestamps Helpful?
Timestamps are helpful when someone reading the transcript wants to listen to the audio that corresponds to a particular segment of the transcript. They are also useful when referring to a specific part of the transcript. For example: “At [00:21:30], the interviewer asks the driver if he had anything to drink that evening.” This allows the reader to quickly find the section of the transcript where that question was asked.
Timestamps are often ordered with transcripts of interviews, panel discussions, depositions, legal transcripts, and raw footage of documentaries or other video productions before editing. When used with video transcription, timestamps can help to synchronize the text with a specific scene within the video file. Editors find them useful when looking for a particular part of the video that needs to be edited. Market researchers find them useful when writing reports summarizing what they’ve learned from reading interview transcripts or panel discussions.
Timestamps vs. Captions for Videos
If you need transcript text to appear over the top of a video, then Speechpad’s Standard Captions or Premium Captions services might be more appropriate choices. When you order captions from Speechpad, you’ll not only receive a transcript, but also a caption file that can be utilized by most video players to display synchronized text on the video as it is playing. However, if you only need a transcript that can be read alongside a video, then timestamps would be the more economical choice.
Timestamp Options
Speechpad can provide timestamps at various frequencies or locations:
- Periodic timestamps
- Paragraph timestamps
- Sentence timestamps
- Speaker timestamps
Periodic Timestamps
Periodic timestamps appear at a consistent frequency, such as every 15 seconds, 30 seconds, 1 minute, or 2 minutes. They appear next to the word that is spoken exactly at that time. For example the following transcript has timestamps every 15 seconds:
Periodic timestamps are a popular choice for raw video footage and also cases where timestamps are not too frequent (e.g. every minute or two).
Paragraph Timestamps
Paragraph timestamps appear at the beginning or end of each paragraph. They are less frequent than other types of timestamps, but also less obtrusive, especially when placed at the end of paragraphs. Despite the lower frequency, they are still useful for helping readers locate the general location of the audio corresponding to a particular part of the transcript. Here is an example of paragraph timestamps:
Sentence Timestamps
As the name implies, sentence timestamps appear at the beginning of each sentence. Although they can be more distracting to the reader, they do provide a higher resolution for when exact locations of the audio need to be referenced. Here is an example of how sentence timestamps look in a finished transcript:
Speaker Timestamps
Speaker timestamps are placed whenever there is a change in speakers. They are more commonly used for depositions, interviews, panel discussions, and conversational material. They make it easy to reference and find specific questions or responses. Here is an example of speaker timestamps in a finished transcript:
Timestamps incur an additional charge of $0.25/audio minute. At this price we can provide Periodic Timestamps as frequent as every 15 seconds, Paragraph Timestamps, or Sentence Timestamps. We can generally provide Speaker Timestamps at this price as well, but if the conversation is dynamic, with lots of speaker changes, then we may need to charge more. If you need timestamps at a higher frequency than every 15 seconds, or you have other custom requirements, please contact us , and we’ll be happy to provide a quote for you.
How to Order Timestamps
To order timestamps, simply select the “Request Timestamps” link when placing your order. A dialog box will appear allowing you to select the type of timestamp and frequency. Periodic and Paragraph Timestamps are the only choices presented. If you need Sentence or Speaker Timestamps, please select “Paragraph” and then please use the “Add Transcriber Instructions” link to specify the exact type of timestamps you need.
Additional Questions?
If you still have special timestamping requirements, or additional questions we have not answered here, please contact us , and we’ll do our best to help.
Page contents

How to use autocaptions in Clipchamp
Note: The information in this article applies to both Clipchamp for personal accounts and Clipchamp for work . The captions feature slightly varies in design and tutorial.
Make your videos more accessible and easier to watch on mute by adding subtitles. Our intuitive captions feature automatically detects what’s said in a video or audio track, then generates real-time subtitles in just one click.
Find out how to add captions to your videos in the following sections:
How to use autocaptions
How to edit autocaptions
How to download the SRT file
How to hide autocaptions
How to turn off autocaptions.
Troubleshooting
Frequently asked questions
Autocaptions can be used for:
Generating a transcript located in the captions tab.
Indexing your video to easily go directly to a specific timestamp using the transcript.
Creating subtitles for a video automatically.
The feature is available in many languages that you can choose from, see the full list of languages here .
Note: When using the autocaptions feature, Clipchamp must use Azure Cognitive Services to process your video's audio to generate your captions.
Step 1. Import your video
To import your own videos, photos, and audio, click on the import media button in the your media tab on the toolbar to browse your computer files, or connect your OneDrive.

You can also record a video directly in the editor using our webcam recorder in the record & create tab on the toolbar. To learn how to do this, read: how to record a webcam video .
Next, drag and drop each video onto the timeline from the your media tab.

Step 2. Turn on autocaptions
Click on the captions tab on the property panel.

Next, click on the turn on autocaptions button.

A popup window will appear with caption recognition language options. Select the language that is used throughout your video. You can also check the box to filter out any profanity and offensive language.
Currently, we offer single languages per video. After you select a language, autocaptions will attempt to interpret all spoken audio as the same language.
Click on the transcribe media button to continue.

You will automatically return to the editor and see your subtitle text being generated in the captions tab on the property panel. The captions generation time will depend on your internet connection, speed, and the length of your video.

Once your captions have loaded, a transcript will appear in the transcript section of the captions tab on the property panel. Your captions will also appear on the video preview window.

To playback your autocaptions, click on the play button under the video preview.
Step 3. Save your video with captions
Before saving your video, make sure to preview by clicking on the play button. When you’re ready to save, click on the export button and select a video resolution. We recommend saving all videos in 1080p video resolution for the best quality. Paid subscribers can save in 4K video resolution.

How to edit autocaptions and customize appearance
Editing the transcript.
If a word is misspelled or incorrect in the transcript, click on the specific word on the transcript and rewrite the word(s). Only the owner of the video will have access to view and edit the video and transcript.

Editing the appearance of autocaptions
To edit the appearance of your subtitles, click on your captions on the video preview. This will open up different options on the property panel. Next, click on the text tab on the property panel. Here, you can edit the font, size, alignment, colors, and position.

How to download the SRT file from the autocaptions
SRT is a standard format for representing subtitles, also known as SubRip Subtitle file format. SRT files give you the option to add subtitles to a video after it’s produced.
You can download the SRT file for the captions in your Clipchamp project by clicking on the download captions button in the captions tab on the property panel.

You can hide captions on your video by clicking on the hide captions in video toggle. This will hide the captions from your video preview, but keep the transcript in the captions tab.

To turn off autocaptions, click on the captions tab then click turn off autocaptions button . The captions will be removed from your video, and will not export with captions.

To import your own videos, photos, and audio, click on the import media button in the your media tab on the toolbar to browse your computer files.

Step 2. Turn on captions
Click on the captions tab on the property panel, then click on the transcribe media button to turn on captions.

Once your captions have loaded, a transcript will appear in the transcript section of the captions tab on the property panel. Your captions will also appear on the video preview window.

If a word is misspelled or incorrect in the transcript, select the specific word on the transcript and rewrite the word(s). Only the owner of the video will have access to view and edit the video and transcript.
To edit the appearance of your subtitles, click on your captions on the video preview. This will open up different options on the property panel in the text tab . Here, you can edit the font, size, alignment, colors, and position.
Downloading the SRT file

Troubleshooting when captions aren't working
When you turn on the captioning feature and there is an error during the processing such as incorrect captions getting generated or no captions appearing even after some time, here are some suggestions you can try to resolve the issue:
Reload the browser tab Clipchamp is open in, or close and reopen the Clipchamp app in Windows, then try captioning again.
Remove your clip from the editing project, add it again and try captioning again.
Turn off auto-captioning, export the project, then import the resulting MP4 video in your project and try the captioning with the new clip version. The background for this suggestion is that if your original input video was of a different format such as WebM, converting it to MP4 can lead to the captioning feature recognizing its audio track correctly.
Try the captioning with a different source video to test if the issue lies with one particular input file.
Check if your computer's firewall (or your organization's firewall, if you're in a corporate network) or a browser extension you might have installed is blocking connections to the Azure speech to text service. Either whitelist the connection, disable the browser extension on Clipchamp, or connect to another Wifi network to test if autocaptioning starts working.
Who has access to the data? No one has access to the data. Microsoft Automatic Speech Recognition (ASR) involves no human intervention, meaning no one will have access to the audio at any time. [ Learn more ].
Does Clipchamp store any caption data? Yes. Caption data is stored with your Clipchamp video, which can only be accessed by yourself.
If I don't want Clipchamp to process this data to begin with, can I prevent it? Yes. If you don’t want Clipchamp to process any captions-related data, simply do not turn on the auto-captioning feature.
Important: Microsoft reserves the right to restrict transcription and translation services, with reasonable notice, in order to limit excessive use and/or fraud and to maintain service performance.

Need more help?
Want more options.
Explore subscription benefits, browse training courses, learn how to secure your device, and more.

Microsoft 365 subscription benefits

Microsoft 365 training

Microsoft security

Accessibility center
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.

Ask the Microsoft Community

Microsoft Tech Community

Windows Insiders
Microsoft 365 Insiders
Was this information helpful?
Thank you for your feedback.
Fact Check: Fake quote about benefits for London’s Muslims attributed to mayor
- Medium Text

Our Standards: The Thomson Reuters Trust Principles. New Tab , opens new tab

Fact Check Chevron

Fact Check: No evidence of pencil-related voter fraud in London election, officials say
Election officials are not aware of any credible evidence that votes in London’s mayoral election were cast fraudulently with pencils, based on statements made to Reuters, in contrast to claims made in a widely shared social media video.

IMAGES
VIDEO
COMMENTS
Speech-to-Text can include time offset (timestamp) values in the response text for your recognize request. Time offset values show the beginning and end of each spoken word that is recognized in the supplied audio. A time offset value represents the amount of time that has elapsed from the beginning of the audio, in increments of 100ms.
The Audio API provides two speech to text endpoints, transcriptions and translations, based on our state-of-the-art open source large-v2 ... the Whisper API will output a transcript of the provided audio in text. The timestamp_granularities[] parameter enables a more structured and timestamped json output format, with timestamps at the segment ...
This technique enhances the conversational flow and aids viewers in tracking the discussion more effectively. Our timestamping transcription service leverages advanced speech-to-text technology with timestamp functionality, ensuring the production of accurate, high-quality transcriptions consistently. Experience the efficiency of Wavel's ...
WhisperX: Automatic Speech Recognition with Word-level Timestamps (& Diarization) - m-bain/whisperX. ... For increased timestamp accuracy, at the cost of higher gpu mem, use bigger models (bigger alignment model not found to be that helpful, see paper) e.g. ... --condition_on_prev_text is set to False by default ...
Choose one of the apps or sites that you want to use speech to text feature. On the home screen of the apps, click on the transcribe icon. Most of the apps will inform you that using the speech-to-text feature will allow sending the audio and transcription data to its servers. Click on ' OK ' to proceed.
0. A new software (chrome web-app) named Speechlogger ( https://speechlogger.appspot.com) was made exactly for that purpose. It preserves timestamps, and lets you export to srt (captions) format. It is supposed to be the best technology out there as it utilizes Google's speech recognition engine.
Whisper is a set of multi-lingual, robust speech recognition models trained by OpenAI that achieve state-of-the-art results in many languages. Whisper models were trained to predict approximate timestamps on speech segments (most of the time with 1-second accuracy), but they cannot originally predict word timestamps.
Edit and export your text. Enter Correct mode (press the C key) to edit, apply formatting, highlight sections, and leave comments on your speech-to-text transcript. Filler words will be highlighted, which you can remove by right clicking to remove some or all instances. When ready, export your text as HTML, Markdown, Plain text, Word file, or ...
1. Speech recognition with timestamps. Image by Author. In this article, I will tell you how to implement offline speech recognition with timestamps using Python. Code in the examples below will allow you to recognize the audio file and get the confidence level, start and end time for each word, for more than 15 languages, offline and free.
Speech transcription. For the third time in this Unit, we'll use the Whisper model for our speech transcription system. ... The second combines the speaker id, timestamp and text information onto one line, and splits each speaker onto their own line for ease of reading: Copied. def tuple_to_string (start_end_tuple, ...
Speech-to-Text functionality has been gaining momentum recently as it offers a whole new user experience to users. It is being widely adopted by companies in the market especially in the customer services industry. ... Besides that, the display text after transcription is in dictation mode which differs from the text in word-level timestamp ...
In this quickstart, you run an application for speech to text transcription with real-time diarization. Diarization distinguishes between the different speakers who participate in the conversation. The Speech service provides information about which speaker was speaking a particular part of transcribed speech.
Demo iOS application to generate an accurately timestamped transcript given an audio file and its pre-supplied text. It leverages Google Cloud Platform's Speech-to-Text API for its time offsets feature (that is, returning the absolute timestamp of each word relative to the beginning of the audio). Any mistranscriptions from the service can then be corrected using the pre-supplied text and a ...
3. Setting. speech_config.request_word_level_timestamps() in the speech config of azure sdk will allow you to get the transcripts along with the timestamps for each word. speech_config.output_format = speechsdk.OutputFormat(1) This statement would allow you get the detailed json object from the azure sdk. Below is a sample code.
whisper-timestamped 1.15.4. Released: Apr 22, 2024. Multi-lingual Automatic Speech Recognition (ASR) based on Whisper models, with accurate word timestamps, access to language detection confidence, several options for Voice Activity Detection (VAD), and more.
How to get word time stamp events using Azure TTS. Azure TTS can return the audio time stamp and the words spoken from the SDK. With this feature, in Microsoft Edge, the word can be highlighted when it is reading out. It is a useful feature for immersive reading scenario like ebook reading. Here is a sample.
Your blood comes from dukes and great houses. Here, we're equal. What we do, we do for the benefit of all. Well, I'd very much like to be equal to you. Maybe I'll show you the way. Deal with this prophet. Send assassins. Theodorother, he's psychotic. I see possible futures all at once.
Please set: Copy. speech_config.request_word_level_timestamps() in the speech config of azure sdk will allow you to get the transcripts along with the timestamps for each word. Copy. speech_config.output_format = speechsdk.OutputFormat(1) This statement would allow you get the detailed json object from the azure sdk. Below is a sample code.
Periodic Timestamps. Periodic timestamps appear at a consistent frequency, such as every 15 seconds, 30 seconds, 1 minute, or 2 minutes. They appear next to the word that is spoken exactly at that time. For example the following transcript has timestamps every 15 seconds: [00:00:15] Interviewer: Hello bloggers.
How to use autocaptions. Step 1. Import your video. To import your own videos, photos, and audio, click on the import media button in the your media tab on the toolbar to browse your computer files, or connect your OneDrive. You can also record a video directly in the editor using our webcam recorder in the record & create tab on the toolbar.
i´ve worked with Google´s txt to speech API. When i would like to encode an wav audio file (extracted from an video), the timestamps for some words are not very precise. (the resolution according google is 0,1sec - but in my case, sometimes its more weak/delay).
9. Yes, it is very much possible. All you need to do is: In the config set enable_word_time_offsets=True. config = types.RecognitionConfig(. .... enable_word_time_offsets=True) Then, for each word in the alternative, you can print its start time and end time as in this code: for result in result.results:
Social media posts attribute a fabricated quote to London's mayor, Sadiq Khan, suggesting he pledged specific benefits for the city's Muslim population in an April 2024 speech about his ...