- Privacy Policy
Home » Data Collection – Methods Types and Examples

Data Collection – Methods Types and Examples
Table of Contents

Data Collection
Definition:
Data collection is the process of gathering and collecting information from various sources to analyze and make informed decisions based on the data collected. This can involve various methods, such as surveys, interviews, experiments, and observation.
In order for data collection to be effective, it is important to have a clear understanding of what data is needed and what the purpose of the data collection is. This can involve identifying the population or sample being studied, determining the variables to be measured, and selecting appropriate methods for collecting and recording data.
Types of Data Collection
Types of Data Collection are as follows:
Primary Data Collection
Primary data collection is the process of gathering original and firsthand information directly from the source or target population. This type of data collection involves collecting data that has not been previously gathered, recorded, or published. Primary data can be collected through various methods such as surveys, interviews, observations, experiments, and focus groups. The data collected is usually specific to the research question or objective and can provide valuable insights that cannot be obtained from secondary data sources. Primary data collection is often used in market research, social research, and scientific research.
Secondary Data Collection
Secondary data collection is the process of gathering information from existing sources that have already been collected and analyzed by someone else, rather than conducting new research to collect primary data. Secondary data can be collected from various sources, such as published reports, books, journals, newspapers, websites, government publications, and other documents.
Qualitative Data Collection
Qualitative data collection is used to gather non-numerical data such as opinions, experiences, perceptions, and feelings, through techniques such as interviews, focus groups, observations, and document analysis. It seeks to understand the deeper meaning and context of a phenomenon or situation and is often used in social sciences, psychology, and humanities. Qualitative data collection methods allow for a more in-depth and holistic exploration of research questions and can provide rich and nuanced insights into human behavior and experiences.
Quantitative Data Collection
Quantitative data collection is a used to gather numerical data that can be analyzed using statistical methods. This data is typically collected through surveys, experiments, and other structured data collection methods. Quantitative data collection seeks to quantify and measure variables, such as behaviors, attitudes, and opinions, in a systematic and objective way. This data is often used to test hypotheses, identify patterns, and establish correlations between variables. Quantitative data collection methods allow for precise measurement and generalization of findings to a larger population. It is commonly used in fields such as economics, psychology, and natural sciences.
Data Collection Methods
Data Collection Methods are as follows:
Surveys involve asking questions to a sample of individuals or organizations to collect data. Surveys can be conducted in person, over the phone, or online.
Interviews involve a one-on-one conversation between the interviewer and the respondent. Interviews can be structured or unstructured and can be conducted in person or over the phone.
Focus Groups
Focus groups are group discussions that are moderated by a facilitator. Focus groups are used to collect qualitative data on a specific topic.
Observation
Observation involves watching and recording the behavior of people, objects, or events in their natural setting. Observation can be done overtly or covertly, depending on the research question.
Experiments
Experiments involve manipulating one or more variables and observing the effect on another variable. Experiments are commonly used in scientific research.
Case Studies
Case studies involve in-depth analysis of a single individual, organization, or event. Case studies are used to gain detailed information about a specific phenomenon.
Secondary Data Analysis
Secondary data analysis involves using existing data that was collected for another purpose. Secondary data can come from various sources, such as government agencies, academic institutions, or private companies.
How to Collect Data
The following are some steps to consider when collecting data:
- Define the objective : Before you start collecting data, you need to define the objective of the study. This will help you determine what data you need to collect and how to collect it.
- Identify the data sources : Identify the sources of data that will help you achieve your objective. These sources can be primary sources, such as surveys, interviews, and observations, or secondary sources, such as books, articles, and databases.
- Determine the data collection method : Once you have identified the data sources, you need to determine the data collection method. This could be through online surveys, phone interviews, or face-to-face meetings.
- Develop a data collection plan : Develop a plan that outlines the steps you will take to collect the data. This plan should include the timeline, the tools and equipment needed, and the personnel involved.
- Test the data collection process: Before you start collecting data, test the data collection process to ensure that it is effective and efficient.
- Collect the data: Collect the data according to the plan you developed in step 4. Make sure you record the data accurately and consistently.
- Analyze the data: Once you have collected the data, analyze it to draw conclusions and make recommendations.
- Report the findings: Report the findings of your data analysis to the relevant stakeholders. This could be in the form of a report, a presentation, or a publication.
- Monitor and evaluate the data collection process: After the data collection process is complete, monitor and evaluate the process to identify areas for improvement in future data collection efforts.
- Ensure data quality: Ensure that the collected data is of high quality and free from errors. This can be achieved by validating the data for accuracy, completeness, and consistency.
- Maintain data security: Ensure that the collected data is secure and protected from unauthorized access or disclosure. This can be achieved by implementing data security protocols and using secure storage and transmission methods.
- Follow ethical considerations: Follow ethical considerations when collecting data, such as obtaining informed consent from participants, protecting their privacy and confidentiality, and ensuring that the research does not cause harm to participants.
- Use appropriate data analysis methods : Use appropriate data analysis methods based on the type of data collected and the research objectives. This could include statistical analysis, qualitative analysis, or a combination of both.
- Record and store data properly: Record and store the collected data properly, in a structured and organized format. This will make it easier to retrieve and use the data in future research or analysis.
- Collaborate with other stakeholders : Collaborate with other stakeholders, such as colleagues, experts, or community members, to ensure that the data collected is relevant and useful for the intended purpose.
Applications of Data Collection
Data collection methods are widely used in different fields, including social sciences, healthcare, business, education, and more. Here are some examples of how data collection methods are used in different fields:
- Social sciences : Social scientists often use surveys, questionnaires, and interviews to collect data from individuals or groups. They may also use observation to collect data on social behaviors and interactions. This data is often used to study topics such as human behavior, attitudes, and beliefs.
- Healthcare : Data collection methods are used in healthcare to monitor patient health and track treatment outcomes. Electronic health records and medical charts are commonly used to collect data on patients’ medical history, diagnoses, and treatments. Researchers may also use clinical trials and surveys to collect data on the effectiveness of different treatments.
- Business : Businesses use data collection methods to gather information on consumer behavior, market trends, and competitor activity. They may collect data through customer surveys, sales reports, and market research studies. This data is used to inform business decisions, develop marketing strategies, and improve products and services.
- Education : In education, data collection methods are used to assess student performance and measure the effectiveness of teaching methods. Standardized tests, quizzes, and exams are commonly used to collect data on student learning outcomes. Teachers may also use classroom observation and student feedback to gather data on teaching effectiveness.
- Agriculture : Farmers use data collection methods to monitor crop growth and health. Sensors and remote sensing technology can be used to collect data on soil moisture, temperature, and nutrient levels. This data is used to optimize crop yields and minimize waste.
- Environmental sciences : Environmental scientists use data collection methods to monitor air and water quality, track climate patterns, and measure the impact of human activity on the environment. They may use sensors, satellite imagery, and laboratory analysis to collect data on environmental factors.
- Transportation : Transportation companies use data collection methods to track vehicle performance, optimize routes, and improve safety. GPS systems, on-board sensors, and other tracking technologies are used to collect data on vehicle speed, fuel consumption, and driver behavior.
Examples of Data Collection
Examples of Data Collection are as follows:
- Traffic Monitoring: Cities collect real-time data on traffic patterns and congestion through sensors on roads and cameras at intersections. This information can be used to optimize traffic flow and improve safety.
- Social Media Monitoring : Companies can collect real-time data on social media platforms such as Twitter and Facebook to monitor their brand reputation, track customer sentiment, and respond to customer inquiries and complaints in real-time.
- Weather Monitoring: Weather agencies collect real-time data on temperature, humidity, air pressure, and precipitation through weather stations and satellites. This information is used to provide accurate weather forecasts and warnings.
- Stock Market Monitoring : Financial institutions collect real-time data on stock prices, trading volumes, and other market indicators to make informed investment decisions and respond to market fluctuations in real-time.
- Health Monitoring : Medical devices such as wearable fitness trackers and smartwatches can collect real-time data on a person’s heart rate, blood pressure, and other vital signs. This information can be used to monitor health conditions and detect early warning signs of health issues.
Purpose of Data Collection
The purpose of data collection can vary depending on the context and goals of the study, but generally, it serves to:
- Provide information: Data collection provides information about a particular phenomenon or behavior that can be used to better understand it.
- Measure progress : Data collection can be used to measure the effectiveness of interventions or programs designed to address a particular issue or problem.
- Support decision-making : Data collection provides decision-makers with evidence-based information that can be used to inform policies, strategies, and actions.
- Identify trends : Data collection can help identify trends and patterns over time that may indicate changes in behaviors or outcomes.
- Monitor and evaluate : Data collection can be used to monitor and evaluate the implementation and impact of policies, programs, and initiatives.
When to use Data Collection
Data collection is used when there is a need to gather information or data on a specific topic or phenomenon. It is typically used in research, evaluation, and monitoring and is important for making informed decisions and improving outcomes.
Data collection is particularly useful in the following scenarios:
- Research : When conducting research, data collection is used to gather information on variables of interest to answer research questions and test hypotheses.
- Evaluation : Data collection is used in program evaluation to assess the effectiveness of programs or interventions, and to identify areas for improvement.
- Monitoring : Data collection is used in monitoring to track progress towards achieving goals or targets, and to identify any areas that require attention.
- Decision-making: Data collection is used to provide decision-makers with information that can be used to inform policies, strategies, and actions.
- Quality improvement : Data collection is used in quality improvement efforts to identify areas where improvements can be made and to measure progress towards achieving goals.
Characteristics of Data Collection
Data collection can be characterized by several important characteristics that help to ensure the quality and accuracy of the data gathered. These characteristics include:
- Validity : Validity refers to the accuracy and relevance of the data collected in relation to the research question or objective.
- Reliability : Reliability refers to the consistency and stability of the data collection process, ensuring that the results obtained are consistent over time and across different contexts.
- Objectivity : Objectivity refers to the impartiality of the data collection process, ensuring that the data collected is not influenced by the biases or personal opinions of the data collector.
- Precision : Precision refers to the degree of accuracy and detail in the data collected, ensuring that the data is specific and accurate enough to answer the research question or objective.
- Timeliness : Timeliness refers to the efficiency and speed with which the data is collected, ensuring that the data is collected in a timely manner to meet the needs of the research or evaluation.
- Ethical considerations : Ethical considerations refer to the ethical principles that must be followed when collecting data, such as ensuring confidentiality and obtaining informed consent from participants.
Advantages of Data Collection
There are several advantages of data collection that make it an important process in research, evaluation, and monitoring. These advantages include:
- Better decision-making : Data collection provides decision-makers with evidence-based information that can be used to inform policies, strategies, and actions, leading to better decision-making.
- Improved understanding: Data collection helps to improve our understanding of a particular phenomenon or behavior by providing empirical evidence that can be analyzed and interpreted.
- Evaluation of interventions: Data collection is essential in evaluating the effectiveness of interventions or programs designed to address a particular issue or problem.
- Identifying trends and patterns: Data collection can help identify trends and patterns over time that may indicate changes in behaviors or outcomes.
- Increased accountability: Data collection increases accountability by providing evidence that can be used to monitor and evaluate the implementation and impact of policies, programs, and initiatives.
- Validation of theories: Data collection can be used to test hypotheses and validate theories, leading to a better understanding of the phenomenon being studied.
- Improved quality: Data collection is used in quality improvement efforts to identify areas where improvements can be made and to measure progress towards achieving goals.
Limitations of Data Collection
While data collection has several advantages, it also has some limitations that must be considered. These limitations include:
- Bias : Data collection can be influenced by the biases and personal opinions of the data collector, which can lead to inaccurate or misleading results.
- Sampling bias : Data collection may not be representative of the entire population, resulting in sampling bias and inaccurate results.
- Cost : Data collection can be expensive and time-consuming, particularly for large-scale studies.
- Limited scope: Data collection is limited to the variables being measured, which may not capture the entire picture or context of the phenomenon being studied.
- Ethical considerations : Data collection must follow ethical principles to protect the rights and confidentiality of the participants, which can limit the type of data that can be collected.
- Data quality issues: Data collection may result in data quality issues such as missing or incomplete data, measurement errors, and inconsistencies.
- Limited generalizability : Data collection may not be generalizable to other contexts or populations, limiting the generalizability of the findings.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Delimitations in Research – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples

Institutional Review Board – Application Sample...

Evaluating Research – Process, Examples and...

Research Questions – Types, Examples and Writing...
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Collection: What It Is, Methods & Tools + Examples

Let’s face it, no one wants to make decisions based on guesswork or gut feelings. The most important objective of data collection is to ensure that the data gathered is reliable and packed to the brim with juicy insights that can be analyzed and turned into data-driven decisions. There’s nothing better than good statistical analysis .
LEARN ABOUT: Level of Analysis
Collecting high-quality data is essential for conducting market research, analyzing user behavior, or just trying to get a handle on business operations. With the right approach and a few handy tools, gathering reliable and informative data.
So, let’s get ready to collect some data because when it comes to data collection, it’s all about the details.
Content Index
What is Data Collection?
Data collection methods, data collection examples, reasons to conduct online research and data collection, conducting customer surveys for data collection to multiply sales, steps to effectively conduct an online survey for data collection, survey design for data collection.
Data collection is the procedure of collecting, measuring, and analyzing accurate insights for research using standard validated techniques.
Put simply, data collection is the process of gathering information for a specific purpose. It can be used to answer research questions, make informed business decisions, or improve products and services.
To collect data, we must first identify what information we need and how we will collect it. We can also evaluate a hypothesis based on collected data. In most cases, data collection is the primary and most important step for research. The approach to data collection is different for different fields of study, depending on the required information.
LEARN ABOUT: Action Research
There are many ways to collect information when doing research. The data collection methods that the researcher chooses will depend on the research question posed. Some data collection methods include surveys, interviews, tests, physiological evaluations, observations, reviews of existing records, and biological samples. Let’s explore them.
LEARN ABOUT: Best Data Collection Tools

Phone vs. Online vs. In-Person Interviews
Essentially there are four choices for data collection – in-person interviews, mail, phone, and online. There are pros and cons to each of these modes.
- Pros: In-depth and a high degree of confidence in the data
- Cons: Time-consuming, expensive, and can be dismissed as anecdotal
- Pros: Can reach anyone and everyone – no barrier
- Cons: Expensive, data collection errors, lag time
- Pros: High degree of confidence in the data collected, reach almost anyone
- Cons: Expensive, cannot self-administer, need to hire an agency
- Pros: Cheap, can self-administer, very low probability of data errors
- Cons: Not all your customers might have an email address/be on the internet, customers may be wary of divulging information online.
In-person interviews always are better, but the big drawback is the trap you might fall into if you don’t do them regularly. It is expensive to regularly conduct interviews and not conducting enough interviews might give you false positives. Validating your research is almost as important as designing and conducting it.
We’ve seen many instances where after the research is conducted – if the results do not match up with the “gut-feel” of upper management, it has been dismissed off as anecdotal and a “one-time” phenomenon. To avoid such traps, we strongly recommend that data-collection be done on an “ongoing and regular” basis.
LEARN ABOUT: Research Process Steps
This will help you compare and analyze the change in perceptions according to marketing for your products/services. The other issue here is sample size. To be confident with your research, you must interview enough people to weed out the fringe elements.
A couple of years ago there was a lot of discussion about online surveys and their statistical analysis plan . The fact that not every customer had internet connectivity was one of the main concerns.
LEARN ABOUT: Statistical Analysis Methods
Although some of the discussions are still valid, the reach of the internet as a means of communication has become vital in the majority of customer interactions. According to the US Census Bureau, the number of households with computers has doubled between 1997 and 2001.
Learn more: Quantitative Market Research
In 2001 nearly 50% of households had a computer. Nearly 55% of all households with an income of more than 35,000 have internet access, which jumps to 70% for households with an annual income of 50,000. This data is from the US Census Bureau for 2001.
There are primarily three modes of data collection that can be employed to gather feedback – Mail, Phone, and Online. The method actually used for data collection is really a cost-benefit analysis. There is no slam-dunk solution but you can use the table below to understand the risks and advantages associated with each of the mediums:
Keep in mind, the reach here is defined as “All U.S. Households.” In most cases, you need to look at how many of your customers are online and determine. If all your customers have email addresses, you have a 100% reach of your customers.
Another important thing to keep in mind is the ever-increasing dominance of cellular phones over landline phones. United States FCC rules prevent automated dialing and calling cellular phone numbers and there is a noticeable trend towards people having cellular phones as the only voice communication device.
This introduces the inability to reach cellular phone customers who are dropping home phone lines in favor of going entirely wireless. Even if automated dialing is not used, another FCC rule prohibits from phoning anyone who would have to pay for the call.
Learn more: Qualitative Market Research
Multi-Mode Surveys
Surveys, where the data is collected via different modes (online, paper, phone etc.), is also another way of going. It is fairly straightforward and easy to have an online survey and have data-entry operators to enter in data (from the phone as well as paper surveys) into the system. The same system can also be used to collect data directly from the respondents.
Learn more: Survey Research
Data collection is an important aspect of research. Let’s consider an example of a mobile manufacturer, company X, which is launching a new product variant. To conduct research about features, price range, target market, competitor analysis, etc. data has to be collected from appropriate sources.
The marketing team can conduct various data collection activities such as online surveys or focus groups .
The survey should have all the right questions about features and pricing, such as “What are the top 3 features expected from an upcoming product?” or “How much are your likely to spend on this product?” or “Which competitors provide similar products?” etc.
For conducting a focus group, the marketing team should decide the participants and the mediator. The topic of discussion and objective behind conducting a focus group should be clarified beforehand to conduct a conclusive discussion.
Data collection methods are chosen depending on the available resources. For example, conducting questionnaires and surveys would require the least resources, while focus groups require moderately high resources.
Feedback is a vital part of any organization’s growth. Whether you conduct regular focus groups to elicit information from key players or, your account manager calls up all your marquee accounts to find out how things are going – essentially they are all processes to find out from your customers’ eyes – How are we doing? What can we do better?
Online surveys are just another medium to collect feedback from your customers , employees and anyone your business interacts with. With the advent of Do-It-Yourself tools for online surveys, data collection on the internet has become really easy, cheap and effective.
Learn more: Online Research
It is a well-established marketing fact that acquiring a new customer is 10 times more difficult and expensive than retaining an existing one. This is one of the fundamental driving forces behind the extensive adoption and interest in CRM and related customer retention tactics.
In a research study conducted by Rice University Professor Dr. Paul Dholakia and Dr. Vicki Morwitz, published in Harvard Business Review, the experiment inferred that the simple fact of asking customers how an organization was performing by itself to deliver results proved to be an effective customer retention strategy.
In the research study, conducted over the course of a year, one set of customers were sent out a satisfaction and opinion survey and the other set was not surveyed. In the next one year, the group that took the survey saw twice the number of people continuing and renewing their loyalty towards the organization data .
Learn more: Research Design
The research study provided a couple of interesting reasons on the basis of consumer psychology, behind this phenomenon:
- Satisfaction surveys boost the customers’ desire to be coddled and induce positive feelings. This crops from a section of the human psychology that intends to “appreciate” a product or service they already like or prefer. The survey feedback collection method is solely a medium to convey this. The survey is a vehicle to “interact” with the company and reinforces the customer’s commitment to the company.
- Surveys may increase awareness of auxiliary products and services. Surveys can be considered modes of both inbound as well as outbound communication. Surveys are generally considered to be a data collection and analysis source. Most people are unaware of the fact that consumer surveys can also serve as a medium for distributing data. It is important to note a few caveats here.
- In most countries, including the US, “selling under the guise of research” is illegal. b. However, we all know that information is distributed while collecting information. c. Other disclaimers may be included in the survey to ensure users are aware of this fact. For example: “We will collect your opinion and inform you about products and services that have come online in the last year…”
- Induced Judgments: The entire procedure of asking people for their feedback can prompt them to build an opinion on something they otherwise would not have thought about. This is a very underlying yet powerful argument that can be compared to the “Product Placement” strategy currently used for marketing products in mass media like movies and television shows. One example is the extensive and exclusive use of the “mini-Cooper” in the blockbuster movie “Italian Job.” This strategy is questionable and should be used with great caution.
Surveys should be considered as a critical tool in the customer journey dialog. The best thing about surveys is its ability to carry “bi-directional” information. The research conducted by Paul Dholakia and Vicki Morwitz shows that surveys not only get you the information that is critical for your business, but also enhances and builds upon the established relationship you have with your customers.
Recent technological advances have made it incredibly easy to conduct real-time surveys and opinion polls . Online tools make it easy to frame questions and answers and create surveys on the Web. Distributing surveys via email, website links or even integration with online CRM tools like Salesforce.com have made online surveying a quick-win solution.
So, you’ve decided to conduct an online survey. There are a few questions in your mind that you would like answered, and you are looking for a fast and inexpensive way to find out more about your customers, clients, etc.
First and foremost thing you need to decide what the smart objectives of the study are. Ensure that you can phrase these objectives as questions or measurements. If you can’t, you are better off looking at other data sources like focus groups and other qualitative methods . The data collected via online surveys is dominantly quantitative in nature.
Review the basic objectives of the study. What are you trying to discover? What actions do you want to take as a result of the survey? – Answers to these questions help in validating collected data. Online surveys are just one way of collecting and quantifying data .
Learn more: Qualitative Data & Qualitative Data Collection Methods
- Visualize all of the relevant information items you would like to have. What will the output survey research report look like? What charts and graphs will be prepared? What information do you need to be assured that action is warranted?
- Assign ranks to each topic (1 and 2) according to their priority, including the most important topics first. Revisit these items again to ensure that the objectives, topics, and information you need are appropriate. Remember, you can’t solve the research problem if you ask the wrong questions.
- How easy or difficult is it for the respondent to provide information on each topic? If it is difficult, is there an alternative medium to gain insights by asking a different question? This is probably the most important step. Online surveys have to be Precise, Clear and Concise. Due to the nature of the internet and the fluctuations involved, if your questions are too difficult to understand, the survey dropout rate will be high.
- Create a sequence for the topics that are unbiased. Make sure that the questions asked first do not bias the results of the next questions. Sometimes providing too much information, or disclosing purpose of the study can create bias. Once you have a series of decided topics, you can have a basic structure of a survey. It is always advisable to add an “Introductory” paragraph before the survey to explain the project objective and what is expected of the respondent. It is also sensible to have a “Thank You” text as well as information about where to find the results of the survey when they are published.
- Page Breaks – The attention span of respondents can be very low when it comes to a long scrolling survey. Add page breaks as wherever possible. Having said that, a single question per page can also hamper response rates as it increases the time to complete the survey as well as increases the chances for dropouts.
- Branching – Create smart and effective surveys with the implementation of branching wherever required. Eliminate the use of text such as, “If you answered No to Q1 then Answer Q4” – this leads to annoyance amongst respondents which result in increase survey dropout rates. Design online surveys using the branching logic so that appropriate questions are automatically routed based on previous responses.
- Write the questions . Initially, write a significant number of survey questions out of which you can use the one which is best suited for the survey. Divide the survey into sections so that respondents do not get confused seeing a long list of questions.
- Sequence the questions so that they are unbiased.
- Repeat all of the steps above to find any major holes. Are the questions really answered? Have someone review it for you.
- Time the length of the survey. A survey should take less than five minutes. At three to four research questions per minute, you are limited to about 15 questions. One open end text question counts for three multiple choice questions. Most online software tools will record the time taken for the respondents to answer questions.
- Include a few open-ended survey questions that support your survey object. This will be a type of feedback survey.
- Send an email to the project survey to your test group and then email the feedback survey afterward.
- This way, you can have your test group provide their opinion about the functionality as well as usability of your project survey by using the feedback survey.
- Make changes to your questionnaire based on the received feedback.
- Send the survey out to all your respondents!
Online surveys have, over the course of time, evolved into an effective alternative to expensive mail or telephone surveys. However, you must be aware of a few conditions that need to be met for online surveys. If you are trying to survey a sample representing the target population, please remember that not everyone is online.
Moreover, not everyone is receptive to an online survey also. Generally, the demographic segmentation of younger individuals is inclined toward responding to an online survey.
Learn More: Examples of Qualitarive Data in Education
Good survey design is crucial for accurate data collection. From question-wording to response options, let’s explore how to create effective surveys that yield valuable insights with our tips to survey design.
- Writing Great Questions for data collection
Writing great questions can be considered an art. Art always requires a significant amount of hard work, practice, and help from others.
The questions in a survey need to be clear, concise, and unbiased. A poorly worded question or a question with leading language can result in inaccurate or irrelevant responses, ultimately impacting the data’s validity.
Moreover, the questions should be relevant and specific to the research objectives. Questions that are irrelevant or do not capture the necessary information can lead to incomplete or inconsistent responses too.
- Avoid loaded or leading words or questions
A small change in content can produce effective results. Words such as could , should and might are all used for almost the same purpose, but may produce a 20% difference in agreement to a question. For example, “The management could.. should.. might.. have shut the factory”.
Intense words such as – prohibit or action, representing control or action, produce similar results. For example, “Do you believe Donald Trump should prohibit insurance companies from raising rates?”.
Sometimes the content is just biased. For instance, “You wouldn’t want to go to Rudolpho’s Restaurant for the organization’s annual party, would you?”
- Misplaced questions
Questions should always reference the intended context, and questions placed out of order or without its requirement should be avoided. Generally, a funnel approach should be implemented – generic questions should be included in the initial section of the questionnaire as a warm-up and specific ones should follow. Toward the end, demographic or geographic questions should be included.
- Mutually non-overlapping response categories
Multiple-choice answers should be mutually unique to provide distinct choices. Overlapping answer options frustrate the respondent and make interpretation difficult at best. Also, the questions should always be precise.
For example: “Do you like water juice?”
This question is vague. In which terms is the liking for orange juice is to be rated? – Sweetness, texture, price, nutrition etc.
- Avoid the use of confusing/unfamiliar words
Asking about industry-related terms such as caloric content, bits, bytes, MBS , as well as other terms and acronyms can confuse respondents . Ensure that the audience understands your language level, terminology, and, above all, the question you ask.
- Non-directed questions give respondents excessive leeway
In survey design for data collection, non-directed questions can give respondents excessive leeway, which can lead to vague and unreliable data. These types of questions are also known as open-ended questions, and they do not provide any structure for the respondent to follow.
For instance, a non-directed question like “ What suggestions do you have for improving our shoes?” can elicit a wide range of answers, some of which may not be relevant to the research objectives. Some respondents may give short answers, while others may provide lengthy and detailed responses, making comparing and analyzing the data challenging.
To avoid these issues, it’s essential to ask direct questions that are specific and have a clear structure. Closed-ended questions, for example, offer structured response options and can be easier to analyze as they provide a quantitative measure of respondents’ opinions.
- Never force questions
There will always be certain questions that cross certain privacy rules. Since privacy is an important issue for most people, these questions should either be eliminated from the survey or not be kept as mandatory. Survey questions about income, family income, status, religious and political beliefs, etc., should always be avoided as they are considered to be intruding, and respondents can choose not to answer them.
- Unbalanced answer options in scales
Unbalanced answer options in scales such as Likert Scale and Semantic Scale may be appropriate for some situations and biased in others. When analyzing a pattern in eating habits, a study used a quantity scale that made obese people appear in the middle of the scale with the polar ends reflecting a state where people starve and an irrational amount to consume. There are cases where we usually do not expect poor service, such as hospitals.
- Questions that cover two points
In survey design for data collection, questions that cover two points can be problematic for several reasons. These types of questions are often called “double-barreled” questions and can cause confusion for respondents, leading to inaccurate or irrelevant data.
For instance, a question like “Do you like the food and the service at the restaurant?” covers two points, the food and the service, and it assumes that the respondent has the same opinion about both. If the respondent only liked the food, their opinion of the service could affect their answer.
It’s important to ask one question at a time to avoid confusion and ensure that the respondent’s answer is focused and accurate. This also applies to questions with multiple concepts or ideas. In these cases, it’s best to break down the question into multiple questions that address each concept or idea separately.
- Dichotomous questions
Dichotomous questions are used in case you want a distinct answer, such as: Yes/No or Male/Female . For example, the question “Do you think this candidate will win the election?” can be Yes or No.
- Avoid the use of long questions
The use of long questions will definitely increase the time taken for completion, which will generally lead to an increase in the survey dropout rate. Multiple-choice questions are the longest and most complex, and open-ended questions are the shortest and easiest to answer.
Data collection is an essential part of the research process, whether you’re conducting scientific experiments, market research, or surveys. The methods and tools used for data collection will vary depending on the research type, the sample size required, and the resources available.
Several data collection methods include surveys, observations, interviews, and focus groups. We learn each method has advantages and disadvantages, and choosing the one that best suits the research goals is important.
With the rise of technology, many tools are now available to facilitate data collection, including online survey software and data visualization tools. These tools can help researchers collect, store, and analyze data more efficiently, providing greater results and accuracy.
By understanding the various methods and tools available for data collection, we can develop a solid foundation for conducting research. With these research skills , we can make informed decisions, solve problems, and contribute to advancing our understanding of the world around us.
Analyze your survey data to gauge in-depth market drivers, including competitive intelligence, purchasing behavior, and price sensitivity, with QuestionPro.
You will obtain accurate insights with various techniques, including conjoint analysis, MaxDiff analysis, sentiment analysis, TURF analysis, heatmap analysis, etc. Export quality data to external in-depth analysis tools such as SPSS and R Software, and integrate your research with external business applications. Everything you need for your data collection. Start today for free!
LEARN MORE FREE TRIAL
MORE LIKE THIS
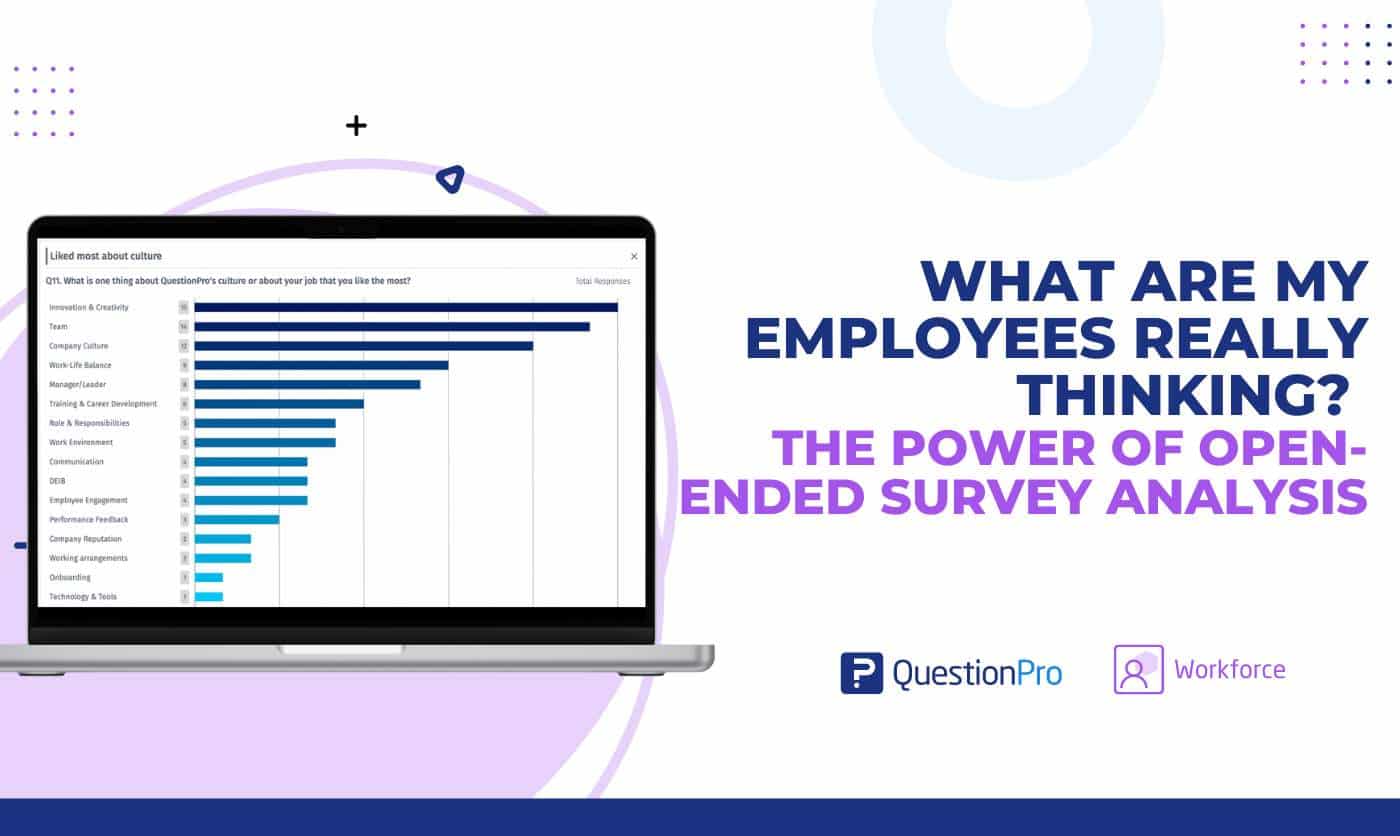
What Are My Employees Really Thinking? The Power of Open-ended Survey Analysis
May 24, 2024

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024

20 Best Customer Success Tools of 2024
May 20, 2024

AI-Based Services Buying Guide for Market Research (based on ESOMAR’s 20 Questions)
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
What is Data Collection? Methods, Types, Tools, Examples
Appinio Research · 09.11.2023 · 33min read

Are you ready to unlock the power of data? In today's data-driven world, understanding the art and science of data collection is the key to informed decision-making and achieving your objectives.
This guide will walk you through the intricate data collection process, from its fundamental principles to advanced strategies and ethical considerations. Whether you're a business professional, researcher, or simply curious about the world of data, this guide will equip you with the knowledge and tools needed to harness the potential of data collection effectively.
What is Data Collection?
Data collection is the systematic process of gathering and recording information or data from various sources for analysis, interpretation, and decision-making. It is a fundamental step in research, business operations, and virtually every field where information is used to understand, improve, or make informed choices.
Key Elements of Data Collection
- Sources: Data can be collected from a wide range of sources, including surveys , interviews, observations, sensors, databases, social media, and more.
- Methods: Various methods are employed to collect data, such as questionnaires, data entry, web scraping, and sensor networks. The choice of method depends on the type of data, research objectives, and available resources.
- Data Types: Data can be qualitative (descriptive) or quantitative (numerical), structured (organized into a predefined format) or unstructured (free-form text or media), and primary (collected directly) or secondary (obtained from existing sources).
- Data Collection Tools: Technology plays a significant role in modern data collection, with software applications, mobile apps, sensors, and data collection platforms facilitating efficient and accurate data capture.
- Ethical Considerations: Ethical guidelines, including informed consent and privacy protection, must be followed to ensure that data collection respects the rights and well-being of individuals.
- Data Quality: The accuracy, completeness, and reliability of collected data are critical to its usefulness. Data quality assurance measures are implemented to minimize errors and biases.
- Data Storage: Collected data needs to be securely stored and managed to prevent loss, unauthorized access, and breaches. Data storage solutions range from on-premises servers to cloud-based platforms.
Importance of Data Collection in Modern Businesses
Data collection is of paramount importance in modern businesses for several compelling reasons:
- Informed Decision-Making: Collected data serves as the foundation for informed decision-making at all levels of an organization. It provides valuable insights into customer behavior, market trends, operational efficiency, and more.
- Competitive Advantage: Businesses that effectively collect and analyze data gain a competitive edge. Data-driven insights help identify opportunities, optimize processes, and stay ahead of competitors .
- Customer Understanding: Data collection allows businesses to better understand their customers, their preferences, and their pain points. This insight is invaluable for tailoring products, services, and marketing strategies.
- Performance Measurement: Data collection enables organizations to assess the performance of various aspects of their operations, from marketing campaigns to production processes. This helps identify areas for improvement.
- Risk Management: Businesses can use data to identify potential risks and develop strategies to mitigate them. This includes financial risks, supply chain disruptions, and cybersecurity threats.
- Innovation: Data collection supports innovation by providing insights into emerging trends and customer demands. Businesses can use this information to develop new products or services.
- Resource Allocation: Data-driven decision-making helps allocate resources efficiently. For example, marketing budgets can be optimized based on the performance of different channels.
Goals and Objectives of Data Collection
The goals and objectives of data collection depend on the specific context and the needs of the organization or research project. However, there are some common overarching objectives:
- Information Gathering: The primary goal is to gather accurate, relevant, and reliable information that addresses specific questions or objectives.
- Analysis and Insight: Collected data is meant to be analyzed to uncover patterns, trends, relationships, and insights that can inform decision-making and strategy development.
- Measurement and Evaluation: Data collection allows for the measurement and evaluation of various factors, such as performance, customer satisfaction , or market potential.
- Problem Solving: Data collection can be directed toward solving specific problems or challenges faced by an organization, such as identifying the root causes of quality issues.
- Monitoring and Surveillance: In some cases, data collection serves as a continuous monitoring or surveillance function, allowing organizations to track ongoing processes or conditions.
- Benchmarking: Data collection can be used for benchmarking against industry standards or competitors, helping organizations assess their performance relative to others.
- Planning and Strategy: Data collected over time can support long-term planning and strategy development, ensuring that organizations adapt to changing circumstances.
In summary, data collection is a foundational activity with diverse applications across industries and sectors. Its objectives range from understanding customers and making informed decisions to improving processes, managing risks, and driving innovation. The quality and relevance of collected data are pivotal in achieving these goals.
How to Plan Your Data Collection Strategy?
Before kicking things off, we'll review the crucial steps of planning your data collection strategy. Your success in data collection largely depends on how well you define your objectives, select suitable sources, set clear goals, and choose appropriate collection methods.
Defining Your Research Questions
Defining your research questions is the foundation of any effective data collection effort. The more precise and relevant your questions, the more valuable the data you collect.
- Specificity is Key: Make sure your research questions are specific and focused. Instead of asking, "How can we improve customer satisfaction?" ask, "What specific aspects of our service do customers find most satisfying or dissatisfying?"
- Prioritize Questions: Determine the most critical questions that will have the most significant impact on your goals. Not all questions are equally important, so allocate your resources accordingly.
- Alignment with Objectives: Ensure that your research questions directly align with your overall objectives. If your goal is to increase sales, your research questions should be geared toward understanding customer buying behaviors and preferences.
Identifying Key Data Sources
Identifying the proper data sources is essential for gathering accurate and relevant information. Here are some examples of key data sources for different industries and purposes.
- Customer Data: This can include customer demographics, purchase history, website behavior, and feedback from customer service interactions.
- Market Research Reports: Utilize industry reports, competitor analyses, and market trend studies to gather external data and insights.
- Internal Records: Your organization's databases, financial records, and operational data can provide valuable insights into your business's performance.
- Social Media Platforms: Monitor social media channels to gather customer feedback, track brand mentions , and identify emerging trends in your industry.
- Web Analytics: Collect data on website traffic, user behavior, and conversion rates to optimize your online presence.
Setting Clear Data Collection Goals
Setting clear and measurable goals is essential to ensure your data collection efforts remain on track and deliver valuable results. Goals should be:
- Specific: Clearly define what you aim to achieve with your data collection. For instance, increasing website traffic by 20% in six months is a specific goal.
- Measurable: Establish criteria to measure your progress and success. Use metrics such as revenue growth, customer satisfaction scores, or conversion rates.
- Achievable: Set realistic goals that your team can realistically work towards. Overly ambitious goals can lead to frustration and burnout.
- Relevant : Ensure your goals align with your organization's broader objectives and strategic initiatives.
- Time-Bound: Set a timeframe within which you plan to achieve your goals. This adds a sense of urgency and helps you track progress effectively.
Choosing Data Collection Methods
Selecting the correct data collection methods is crucial for obtaining accurate and reliable data. Your choice should align with your research questions and goals. Here's a closer look at various data collection methods and their practical applications.
Types of Data Collection Methods
Now, let's explore different data collection methods in greater detail, including examples of when and how to use them effectively:
Surveys and Questionnaires
Surveys and questionnaires are versatile tools for gathering data from a large number of respondents. They are commonly used for:
- Customer Feedback: Collecting opinions and feedback on products, services, and overall satisfaction.
- Market Research: Assessing market preferences, identifying trends, and evaluating consumer behavior .
- Employee Surveys : Measuring employee engagement, job satisfaction, and feedback on workplace conditions.
Example: If you're running an e-commerce business and want to understand customer preferences, you can create an online survey asking customers about their favorite product categories, preferred payment methods, and shopping frequency.
To enhance your data collection endeavors, check out Appinio , a modern research platform that simplifies the process and maximizes the quality of insights. Appinio offers user-friendly survey and questionnaire tools that enable you to effortlessly design surveys tailored to your needs. It also provides seamless integration with interview and observation data, allowing you to consolidate your findings in one place.
Discover how Appinio can elevate your data collection efforts. Book a demo today to unlock a world of possibilities in gathering valuable insights!
Book a Demo
Interviews involve one-on-one or group conversations with participants to gather detailed insights. They are particularly useful for:
- Qualitative Research: Exploring complex topics, motivations, and personal experiences.
- In-Depth Analysis: Gaining a deep understanding of specific issues or situations.
- Expert Opinions: Interviewing industry experts or thought leaders to gather valuable insights.
Example: If you're a healthcare provider aiming to improve patient experiences, conducting interviews with patients can help you uncover specific pain points and suggestions for improvement.
Observations
Observations entail watching and recording behaviors or events in their natural context. This method is ideal for:
- Behavioral Studies: Analyzing how people interact with products or environments.
- Field Research : Collecting data in real-world settings, such as retail stores, public spaces, or classrooms.
- Ethnographic Research : Immersing yourself in a specific culture or community to understand their practices and customs.
Example: If you manage a retail store, observing customer traffic flow and purchasing behaviors can help optimize store layout and product placement.
Document Analysis
Document analysis involves reviewing and extracting information from written or digital documents. It is valuable for:
- Historical Research: Studying historical records, manuscripts, and archives.
- Content Analysis: Analyzing textual or visual content from websites, reports, or publications.
- Legal and Compliance: Reviewing contracts, policies, and legal documents for compliance purposes.
Example: If you're a content marketer, you can analyze competitor blog posts to identify common topics and keywords used in your industry.
Web Scraping
Web scraping is the automated process of extracting data from websites. It's suitable for:
- Competitor Analysis: Gathering data on competitor product prices, descriptions, and customer reviews.
- Market Research: Collecting data on product listings, reviews, and trends from e-commerce websites.
- News and Social Media Monitoring: Tracking news articles, social media posts, and comments related to your brand or industry.
Example: If you're in the travel industry, web scraping can help you collect pricing data for flights and accommodations from various travel booking websites to stay competitive.
Social Media Monitoring
Social media monitoring involves tracking and analyzing conversations and activities on social media platforms. It's valuable for:
- Brand Reputation Management: Monitoring brand mentions and sentiment to address customer concerns or capitalize on positive feedback.
- Competitor Analysis: Keeping tabs on competitors' social media strategies and customer engagement.
- Trend Identification: Identifying emerging trends and viral content within your industry.
Example: If you run a restaurant, social media monitoring can help you track customer reviews, comments, and hashtags related to your establishment, allowing you to respond promptly to customer feedback and trends.
By understanding the nuances and applications of these data collection methods, you can choose the most appropriate approach to gather valuable insights for your specific objectives. Remember that a well-thought-out data collection strategy is the cornerstone of informed decision-making and business success.
How to Design Your Data Collection Instruments?
Now that you've defined your research questions, identified data sources, set clear goals, and chosen appropriate data collection methods, it's time to design the instruments you'll use to collect data effectively.
Design Effective Survey Questions
Designing survey questions is a crucial step in gathering accurate and meaningful data. Here are some key considerations:
- Clarity: Ensure that your questions are clear and concise. Avoid jargon or ambiguous language that may confuse respondents.
- Relevance: Ask questions that directly relate to your research objectives. Avoid unnecessary or irrelevant questions that can lead to survey fatigue.
- Avoid Leading Questions: Formulate questions that do not guide respondents toward a particular answer. Maintain neutrality to get unbiased responses.
- Response Options: Provide appropriate response options, including multiple-choice, Likert scales , or open-ended formats, depending on the type of data you need.
- Pilot Testing: Before deploying your survey, conduct pilot tests with a small group to identify any issues with question wording or response options.
Craft Interview Questions for Insightful Conversations
Developing interview questions requires thoughtful consideration to elicit valuable insights from participants:
- Open-Ended Questions: Use open-ended questions to encourage participants to share their thoughts, experiences, and perspectives without being constrained by predefined answers.
- Probing Questions: Prepare follow-up questions to delve deeper into specific topics or clarify responses.
- Structured vs. Semi-Structured Interviews: Decide whether your interviews will follow a structured format with predefined questions or a semi-structured approach that allows flexibility.
- Avoid Biased Questions: Ensure your questions do not steer participants toward desired responses. Maintain objectivity throughout the interview.
Build an Observation Checklist for Data Collection
When conducting observations, having a well-structured checklist is essential:
- Clearly Defined Variables: Identify the specific variables or behaviors you are observing and ensure they are well-defined.
- Checklist Format: Create a checklist format that is easy to use and follow during observations. This may include checkboxes, scales, or space for notes.
- Training Observers: If you have a team of observers, provide thorough training to ensure consistency and accuracy in data collection.
- Pilot Observations: Before starting formal data collection, conduct pilot observations to refine your checklist and ensure it captures the necessary information.
Streamline Data Collection with Forms and Templates
Creating user-friendly data collection forms and templates helps streamline the process:
- Consistency: Ensure that all data collection forms follow a consistent format and structure, making it easier to compare and analyze data.
- Data Validation: Incorporate data validation checks to reduce errors during data entry. This can include dropdown menus, date pickers, or required fields.
- Digital vs. Paper Forms: Decide whether digital forms or traditional paper forms are more suitable for your data collection needs. Digital forms often offer real-time data validation and remote access.
- Accessibility: Make sure your forms and templates are accessible to all team members involved in data collection. Provide training if necessary.
The Data Collection Process
Now that your data collection instruments are ready, it's time to embark on the data collection process itself. This section covers the practical steps involved in collecting high-quality data.
1. Preparing for Data Collection
Adequate preparation is essential to ensure a smooth data collection process:
- Resource Allocation: Allocate the necessary resources, including personnel, technology, and materials, to support data collection activities.
- Training: Train data collection teams or individuals on the use of data collection instruments and adherence to protocols.
- Pilot Testing: Conduct pilot data collection runs to identify and resolve any issues or challenges that may arise.
- Ethical Considerations: Ensure that data collection adheres to ethical standards and legal requirements. Obtain necessary permissions or consent as applicable.
2. Conducting Data Collection
During data collection, it's crucial to maintain consistency and accuracy:
- Follow Protocols: Ensure that data collection teams adhere to established protocols and procedures to maintain data integrity.
- Supervision: Supervise data collection teams to address questions, provide guidance, and resolve any issues that may arise.
- Documentation: Maintain detailed records of the data collection process, including dates, locations, and any deviations from the plan.
- Data Security: Implement data security measures to protect collected information from unauthorized access or breaches.
3. Ensuring Data Quality and Reliability
After collecting data, it's essential to validate and ensure its quality:
- Data Cleaning: Review collected data for errors, inconsistencies, and missing values. Clean and preprocess the data to ensure accuracy.
- Quality Checks: Perform quality checks to identify outliers or anomalies that may require further investigation or correction.
- Data Validation: Cross-check data with source documents or original records to verify its accuracy and reliability.
- Data Auditing: Conduct periodic audits to assess the overall quality of the collected data and make necessary adjustments.
4. Managing Data Collection Teams
If you have multiple team members involved in data collection, effective management is crucial:
- Communication: Maintain open and transparent communication channels with team members to address questions, provide guidance, and ensure consistency.
- Performance Monitoring: Regularly monitor the performance of data collection teams, identifying areas for improvement or additional training.
- Problem Resolution: Be prepared to promptly address any challenges or issues that arise during data collection.
- Feedback Loop: Establish a feedback loop for data collection teams to share insights and best practices, promoting continuous improvement.
By following these steps and best practices in the data collection process, you can ensure that the data you collect is reliable, accurate, and aligned with your research objectives. This lays the foundation for meaningful analysis and informed decision-making.
How to Store and Manage Data?
It's time to explore the critical aspects of data storage and management, which are pivotal in ensuring the security, accessibility, and usability of your collected data.
Choosing Data Storage Solutions
Selecting the proper data storage solutions is a strategic decision that impacts data accessibility, scalability, and security. Consider the following factors:
- Cloud vs. On-Premises: Decide whether to store your data in the cloud or on-premises. Cloud solutions offer scalability, accessibility, and automatic backups, while on-premises solutions provide more control but require significant infrastructure investments.
- Data Types: Assess the types of data you're collecting, such as structured, semi-structured, or unstructured data. Choose storage solutions that accommodate your data formats efficiently.
- Scalability: Ensure that your chosen solution can scale as your data volume grows. This is crucial for preventing storage bottlenecks.
- Data Accessibility: Opt for storage solutions that provide easy and secure access to authorized users, whether they are on-site or remote.
- Data Recovery and Backup: Implement robust data backup and recovery mechanisms to safeguard against data loss due to hardware failures or disasters.
Data Security and Privacy
Data security and privacy are paramount, especially when handling sensitive or personal information.
- Encryption: Implement encryption for data at rest and in transit. Use encryption protocols like SSL/TLS for communication and robust encryption algorithms for storage.
- Access Control: Set up role-based access control (RBAC) to restrict access to data based on job roles and responsibilities. Limit access to only those who need it.
- Compliance: Ensure that your data storage and management practices comply with relevant data protection regulations, such as GDPR, HIPAA, or CCPA.
- Data Masking: Use data masking techniques to conceal sensitive information in non-production environments.
- Monitoring and Auditing: Continuously monitor access logs and perform regular audits to detect unauthorized activities and maintain compliance.
Data Organization and Cataloging
Organizing and cataloging your data is essential for efficient retrieval, analysis, and decision-making.
- Metadata Management: Maintain detailed metadata for each dataset, including data source, date of collection, data owner, and description. This makes it easier to locate and understand your data.
- Taxonomies and Categories: Develop taxonomies or data categorization schemes to classify data into logical groups, making it easier to find and manage.
- Data Versioning: Implement data versioning to track changes and updates over time. This ensures data lineage and transparency.
- Data Catalogs: Use data cataloging tools and platforms to create a searchable inventory of your data assets, facilitating discovery and reuse.
- Data Retention Policies: Establish clear data retention policies that specify how long data should be retained and when it should be securely deleted or archived.
How to Analyze and Interpret Data?
Once you've collected your data, let's take a look at the process of extracting valuable insights from your collected data through analysis and interpretation.
Data Cleaning and Preprocessing
Data cleaning and preprocessing are essential steps to ensure that your data is accurate and ready for analysis.
- Handling Missing Data: Develop strategies for dealing with missing data, such as imputation or removal, based on the nature of your data and research objectives.
- Outlier Detection: Identify and address outliers that can skew analysis results. Consider whether outliers should be corrected, removed, or retained based on their significance.
- Normalization and Scaling: Normalize or scale data to bring it within a common range, making it suitable for certain algorithms and models.
- Data Transformation: Apply data transformations, such as logarithmic scaling or categorical encoding, to prepare data for specific types of analysis.
- Data Imbalance: Address class imbalance issues in datasets, particularly machine learning applications, to avoid biased model training.
Exploratory Data Analysis (EDA)
EDA is the process of visually and statistically exploring your data to uncover patterns, trends, and potential insights.
- Descriptive Statistics: Calculate basic statistics like mean, median, and standard deviation to summarize data distributions.
- Data Visualization: Create visualizations such as histograms, scatter plots, and heatmaps to reveal relationships and patterns within the data.
- Correlation Analysis: Examine correlations between variables to understand how they influence each other.
- Hypothesis Testing: Conduct hypothesis tests to assess the significance of observed differences or relationships in your data.
Statistical Analysis Techniques
Choose appropriate statistical analysis techniques based on your research questions and data types.
- Descriptive Statistics: Use descriptive statistics to summarize and describe your data, providing an initial overview of key features.
- Inferential Statistics: Apply inferential statistics, including t-tests, ANOVA, or regression analysis, to test hypotheses and draw conclusions about population parameters.
- Non-parametric Tests: Employ non-parametric tests when assumptions of normality are not met or when dealing with ordinal or nominal data .
- Time Series Analysis: Analyze time-series data to uncover trends, seasonality, and temporal patterns.
Data Visualization
Data visualization is a powerful tool for conveying complex information in a digestible format.
- Charts and Graphs: Utilize various charts and graphs, such as bar charts, line charts, pie charts, and heatmaps, to represent data visually.
- Interactive Dashboards: Create interactive dashboards using tools like Tableau, Power BI, or custom web applications to allow stakeholders to explore data dynamically.
- Storytelling: Use data visualization to tell a compelling data-driven story, highlighting key findings and insights.
- Accessibility: Ensure that data visualizations are accessible to all audiences, including those with disabilities, by following accessibility guidelines.
Drawing Conclusions and Insights
Finally, drawing conclusions and insights from your data analysis is the ultimate goal.
- Contextual Interpretation: Interpret your findings in the context of your research objectives and the broader business or research landscape.
- Actionable Insights: Identify actionable insights that can inform decision-making, strategy development, or future research directions.
- Report Generation: Create comprehensive reports or presentations that communicate your findings clearly and concisely to stakeholders.
- Validation: Cross-check your conclusions with domain experts or subject matter specialists to ensure accuracy and relevance.
By following these steps in data analysis and interpretation, you can transform raw data into valuable insights that drive informed decisions, optimize processes, and create new opportunities for your organization.
How to Report and Present Data?
Now, let's explore the crucial steps of reporting and presenting data effectively, ensuring that your findings are communicated clearly and meaningfully to stakeholders.
1. Create Data Reports
Data reports are the culmination of your data analysis efforts, presenting your findings in a structured and comprehensible manner.
- Report Structure: Organize your report with a clear structure, including an introduction, methodology, results, discussion, and conclusions.
- Visualization Integration: Incorporate data visualizations, charts, and graphs to illustrate key points and trends.
- Clarity and Conciseness: Use clear and concise language, avoiding technical jargon, to make your report accessible to a diverse audience.
- Actionable Insights: Highlight actionable insights and recommendations that stakeholders can use to make informed decisions.
- Appendices: Include appendices with detailed methodology, data sources, and any additional information that supports your findings.
2. Leverage Data Visualization Tools
Data visualization tools can significantly enhance your ability to convey complex information effectively. Top data visualization tools include:
- Tableau: Tableau offers a wide range of visualization options and interactive dashboards, making it a popular choice for data professionals.
- Power BI: Microsoft's Power BI provides powerful data visualization and business intelligence capabilities, suitable for creating dynamic reports and dashboards.
- Python Libraries: Utilize Python libraries such as Matplotlib, Seaborn, and Plotly for custom data visualizations and analysis.
- Excel: Microsoft Excel remains a versatile tool for creating basic charts and graphs, particularly for smaller datasets.
- Custom Development: Consider custom development for specialized visualization needs or when existing tools don't meet your requirements.
3. Communicate Findings to Stakeholders
Effectively communicating your findings to stakeholders is essential for driving action and decision-making.
- Audience Understanding : Tailor your communication to the specific needs and background knowledge of your audience. Avoid technical jargon when speaking to non-technical stakeholders.
- Visual Storytelling: Craft a narrative that guides stakeholders through the data, highlighting key insights and their implications.
- Engagement: Use engaging and interactive presentations or reports to maintain the audience's interest and encourage participation.
- Question Handling: Be prepared to answer questions and provide clarifications during presentations or discussions. Anticipate potential concerns or objections.
- Feedback Loop: Encourage feedback and open dialogue with stakeholders to ensure your findings align with their objectives and expectations.
Data Collection Examples
To better understand the practical application of data collection in various domains, let's explore some real-world examples, including those in the business context. These examples illustrate how data collection can drive informed decision-making and lead to meaningful insights.
Business Customer Feedback Surveys
Scenario: A retail company wants to enhance its customer experience and improve product offerings. To achieve this, they initiate customer feedback surveys.
Data Collection Approach:
- Survey Creation: The company designs a survey with specific questions about customer preferences , shopping experiences , and product satisfaction.
- Distribution: Surveys are distributed through various channels, including email, in-store kiosks, and the company's website.
- Data Gathering: Responses from thousands of customers are collected and stored in a centralized database.
Data Analysis and Insights:
- Customer Sentiment Analysis : Using natural language processing (NLP) techniques, the company analyzes open-ended responses to gauge customer sentiment.
- Product Performance: Analyzing survey data, the company identifies which products receive the highest and lowest ratings, leading to decisions on which products to improve or discontinue.
- Store Layout Optimization: By examining feedback related to in-store experiences, the company can adjust store layouts and signage to enhance customer flow and convenience.
Healthcare Patient Record Digitization
Scenario: A healthcare facility aims to transition from paper-based patient records to digital records for improved efficiency and patient care.
- Scanning and Data Entry: Existing paper records are scanned, and data entry personnel convert them into digital format.
- Electronic Health Record (EHR) Implementation: The facility adopts an EHR system to store and manage patient data securely.
- Continuous Data Entry: As new patient information is collected, it is directly entered into the EHR system.
- Patient History Access: Physicians and nurses gain instant access to patient records, improving diagnostic accuracy and treatment.
- Data Analytics: Aggregated patient data can be analyzed to identify trends in diseases, treatment outcomes, and healthcare resource utilization.
- Resource Optimization: Analysis of patient data allows the facility to allocate resources more efficiently, such as staff scheduling based on patient admission patterns.
Social Media Engagement Monitoring
Scenario: A digital marketing agency manages social media campaigns for various clients and wants to track campaign performance and audience engagement.
- Social Media Monitoring Tools: The agency employs social media monitoring tools to collect data on post engagement, reach, likes, shares, and comments.
- Custom Tracking Links: Unique tracking links are created for each campaign to monitor traffic and conversions.
- Audience Demographics: Data on the demographics of engaged users is gathered from platform analytics.
- Campaign Effectiveness: The agency assesses which campaigns are most effective in terms of engagement and conversion rates.
- Audience Segmentation: Insights into audience demographics help tailor future campaigns to specific target demographics.
- Content Strategy: Analyzing which types of content (e.g., videos, infographics) generate the most engagement informs content strategy decisions.
These examples showcase how data collection serves as the foundation for informed decision-making and strategy development across diverse sectors. Whether improving customer experiences, enhancing healthcare services, or optimizing marketing efforts, data collection empowers organizations to harness valuable insights for growth and improvement.
Ethical Considerations in Data Collection
Ethical considerations are paramount in data collection to ensure privacy, fairness, and transparency. Addressing these issues is not only responsible but also crucial for building trust with stakeholders.
Informed Consent
Obtaining informed consent from participants is an ethical imperative. Transparency is critical, and participants should fully understand the purpose of data collection, how their data will be used, and any potential risks or benefits involved. Consent should be voluntary, and participants should have the option to withdraw their consent at any time without consequences.
Consent forms should be clear and comprehensible, avoiding overly complex language or legal jargon. Special care should be taken when collecting sensitive or personal data to ensure privacy rights are respected.
Privacy Protection
Protecting individuals' privacy is essential to maintain trust and comply with data protection regulations. Data anonymization or pseudonymization should be used to prevent the identification of individuals, especially when sharing or publishing data. Data encryption methods should be implemented to protect data both in transit and at rest, safeguarding it from unauthorized access.
Strict access controls should be in place to restrict data access to authorized personnel only, and clear data retention policies should be established and adhered to, preventing unnecessary data storage. Regular privacy audits should be conducted to identify and address potential vulnerabilities or compliance issues.
Bias and Fairness in Data Collection
Addressing bias and ensuring fairness in data collection is critical to avoid perpetuating inequalities. Data collection methods should be designed to minimize potential biases , such as selection bias or response bias. Efforts should be made to achieve diverse and representative samples , ensuring that data accurately reflects the population of interest. Fair treatment of all participants and data sources is essential, with discrimination based on characteristics such as race, gender, or socioeconomic status strictly avoided.
If algorithms are used in data collection or analysis, biases that may arise from automated processes should be assessed and mitigated. Ethical reviews or expert consultations may be considered when dealing with sensitive or potentially biased data. By adhering to ethical principles throughout the data collection process, individuals' rights are protected, and a foundation for responsible and trustworthy data-driven decision-making is established.
Data collection is the cornerstone of informed decision-making and insight generation in today's data-driven world. Whether you're a business seeking to understand your customers better, a researcher uncovering valuable trends, or anyone eager to harness the power of data, this guide has equipped you with the essential knowledge and tools. Remember, ethical considerations are paramount, and the quality of data matters.
Furthermore, as you embark on your data collection journey, always keep in mind the impact and potential of the information you gather. Each data point is a piece of the puzzle that can help you shape strategies, optimize operations, and make a positive difference. Data collection is not just a task; it's a powerful tool that empowers you to unlock opportunities, solve challenges, and stay ahead in a dynamic and ever-changing landscape. So, continue to explore, analyze, and draw valuable insights from your data, and let it be your compass on the path to success.
How to Collect Data in Minutes?
Imagine having the power to conduct your own market research in minutes, without the need for a PhD in research. Appinio is the real-time market research platform that empowers you to get instant consumer insights, fueling your data-driven decisions. We've transformed market research from boring and intimidating to exciting and intuitive.
Here's why Appinio is your go-to platform:
- Lightning-Fast Insights: From questions to insights in minutes. When you need answers, Appinio delivers swiftly.
- User-Friendly: Our platform is so intuitive that anyone can use it; no research degree required.
- Global Reach: Define your target group from over 1200 characteristics and survey them in 90+ countries.
- Guided Expertise: Our dedicated research consultants will support you every step of the way, ensuring your research journey is seamless and effective.
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

16.05.2024 | 30min read
Time Series Analysis: Definition, Types, Techniques, Examples

14.05.2024 | 31min read
Experimental Research: Definition, Types, Design, Examples

07.05.2024 | 29min read
Interval Scale: Definition, Characteristics, Examples

A Guide to Data Collection: Methods, Process, and Tools

Whether your field is development economics, international development, the nonprofit sector, or myriad other industries, effective data collection is essential. It informs decision-making and increases your organization’s impact. However, the process of data collection can be complex and challenging. If you’re in the beginning stages of creating a data collection process, this guide is for you. It outlines tested methods, efficient procedures, and effective tools to help you improve your data collection activities and outcomes. At SurveyCTO, we’ve used our years of experience and expertise to build a robust, secure, and scalable mobile data collection platform. It’s trusted by respected institutions like The World Bank, J-PAL, Oxfam, and the Gates Foundation, and it’s changed the way many organizations collect and use data. With this guide, we want to share what we know and help you get ready to take the first step in your data collection journey.
Main takeaways from this guide
- Before starting the data collection process, define your goals and identify data sources, which can be primary (first-hand research) or secondary (existing resources).
- Your data collection method should align with your goals, resources, and the nature of the data needed. Surveys, interviews, observations, focus groups, and forms are common data collection methods.
- Sampling involves selecting a representative group from a larger population. Choosing the right sampling method to gather representative and relevant data is crucial.
- Crafting effective data collection instruments like surveys and questionnaires is key. Instruments should undergo rigorous testing for reliability and accuracy.
- Data collection is an ongoing, iterative process that demands real-time monitoring and adjustments to ensure high-quality, reliable results.
- After data collection, data should be cleaned to eliminate errors and organized for efficient analysis. The data collection journey further extends into data analysis, where patterns and useful information that can inform decision-making are discovered.
- Common challenges in data collection include data quality and consistency issues, data security concerns, and limitations with offline surveys . Employing robust data validation processes, implementing strong security protocols, and using offline-enabled data collection tools can help overcome these challenges.
- Data collection, entry, and management tools and data analysis, visualization, reporting, and workflow tools can streamline the data collection process, improve data quality, and facilitate data analysis.
What is data collection?

The traditional definition of data collection might lead us to think of gathering information through surveys, observations, or interviews. However, the modern-age definition of data collection extends beyond conducting surveys and observations. It encompasses the systematic gathering and recording of any kind of information through digital or manual methods. Data collection can be as routine as a doctor logging a patient’s information into an electronic medical record system during each clinic visit, or as specific as keeping a record of mosquito nets delivered to a rural household.
Getting started with data collection

Before starting your data collection process, you must clearly understand what you aim to achieve and how you’ll get there. Below are some actionable steps to help you get started.
1. Define your goals
Defining your goals is a crucial first step. Engage relevant stakeholders and team members in an iterative and collaborative process to establish clear goals. It’s important that projects start with the identification of key questions and desired outcomes to ensure you focus your efforts on gathering the right information.
Start by understanding the purpose of your project– what problem are you trying to solve, or what change do you want to bring about? Think about your project’s potential outcomes and obstacles and try to anticipate what kind of data would be useful in these scenarios. Consider who will be using the data you collect and what data would be the most valuable to them. Think about the long-term effects of your project and how you will measure these over time. Lastly, leverage any historical data from previous projects to help you refine key questions that may have been overlooked previously.
Once questions and outcomes are established, your data collection goals may still vary based on the context of your work. To demonstrate, let’s use the example of an international organization working on a healthcare project in a remote area.
- If you’re a researcher , your goal will revolve around collecting primary data to answer specific questions. This could involve designing a survey or conducting interviews to collect first-hand data on patient improvement, disease or illness prevalence, and behavior changes (such as an increase in patients seeking healthcare).
- If you’re part of the monitoring and evaluation ( M&E) team , your goal will revolve around measuring the success of your healthcare project. This could involve collecting primary data through surveys or observations and developing a dashboard to display real-time metrics like the number of patients treated, percentage of reduction in incidences of disease,, and average patient wait times. Your focus would be using this data to implement any needed program changes and ensure your project meets its objectives.
- If you’re part of a field team , your goal will center around the efficient and accurate execution of project plans. You might be responsible for using data collection tools to capture pertinent information in different settings, such as in interviews takendirectly from the sample community or over the phone. The data you collect and manage will directly influence the operational efficiency of the project and assist in achieving the project’s overarching objectives.
2. Identify your data sources
The crucial next step in your research process is determining your data source. Essentially, there are two main data types to choose from: primary and secondary.
- Primary data is the information you collect directly from first-hand engagements. It’s gathered specifically for your research and tailored to your research question. Primary data collection methods can range from surveys and interviews to focus groups and observations. Because you design the data collection process, primary data can offer precise, context-specific information directly related to your research objectives. For example, suppose you are investigating the impact of a new education policy. In that case, primary data might be collected through surveys distributed to teachers or interviews with school administrators dealing directly with the policy’s implementation.
- Secondary data, on the other hand, is derived from resources that already exist. This can include information gathered for other research projects, administrative records, historical documents, statistical databases, and more. While not originally collected for your specific study, secondary data can offer valuable insights and background information that complement your primary data. For instance, continuing with the education policy example, secondary data might involve academic articles about similar policies, government reports on education or previous survey data about teachers’ opinions on educational reforms.
While both types of data have their strengths, this guide will predominantly focus on primary data and the methods to collect it. Primary data is often emphasized in research because it provides fresh, first-hand insights that directly address your research questions. Primary data also allows for more control over the data collection process, ensuring data is relevant, accurate, and up-to-date.
However, secondary data can offer critical context, allow for longitudinal analysis, save time and resources, and provide a comparative framework for interpreting your primary data. It can be a crucial backdrop against which your primary data can be understood and analyzed. While we focus on primary data collection methods in this guide, we encourage you not to overlook the value of incorporating secondary data into your research design where appropriate.
3. Choose your data collection method
When choosing your data collection method, there are many options at your disposal. Data collection is not limited to methods like surveys and interviews. In fact, many of the processes in our daily lives serve the goal of collecting data, from intake forms to automated endpoints, such as payment terminals and mass transit card readers. Let us dive into some common types of data collection methods:
Surveys and Questionnaires
Surveys and questionnaires are tools for gathering information about a group of individuals, typically by asking them predefined questions. They can be used to collect quantitative and qualitative data and be administered in various ways, including online, over the phone, in person (offline), or by mail.
- Advantages : They allow researchers to reach many participants quickly and cost-effectively, making them ideal for large-scale studies. The structured format of questions makes analysis easier.
- Disadvantages : They may not capture complex or nuanced information as participants are limited to predefined response choices. Also, there can be issues with response bias, where participants might provide socially desirable answers rather than honest ones.
Interviews involve a one-on-one conversation between the researcher and the participant. The interviewer asks open-ended questions to gain detailed information about the participant’s thoughts, feelings, experiences, and behaviors.
- Advantages : They allow for an in-depth understanding of the topic at hand. The researcher can adapt the questioning in real time based on the participant’s responses, allowing for more flexibility.
- Disadvantages : They can be time-consuming and resource-intensive, as they require trained interviewers and a significant amount of time for both conducting and analyzing responses. They may also introduce interviewer bias if not conducted carefully, due to how an interviewer presents questions and perceives the respondent, and how the respondent perceives the interviewer.
Observations
Observations involve directly observing and recording behavior or other phenomena as they occur in their natural settings.
- Advantages : Observations can provide valuable contextual information, as researchers can study behavior in the environment where it naturally occurs, reducing the risk of artificiality associated with laboratory settings or self-reported measures.
- Disadvantages : Observational studies may suffer from observer bias, where the observer’s expectations or biases could influence their interpretation of the data. Also, some behaviors might be altered if subjects are aware they are being observed.
Focus Groups
Focus groups are guided discussions among selected individuals to gain information about their views and experiences.
- Advantages : Focus groups allow for interaction among participants, which can generate a diverse range of opinions and ideas. They are good for exploring new topics where there is little pre-existing knowledge.
- Disadvantages : Dominant voices in the group can sway the discussion, potentially silencing less assertive participants. They also require skilled facilitators to moderate the discussion effectively.
Forms are standardized documents with blank fields for collecting data in a systematic manner. They are often used in fields like Customer Relationship Management (CRM) or Electronic Medical Records (EMR) data entry. Surveys may also be referred to as forms.
- Advantages : Forms are versatile, easy to use, and efficient for data collection. They can streamline workflows by standardizing the data entry process.
- Disadvantages : They may not provide in-depth insights as the responses are typically structured and limited. There is also potential for errors in data entry, especially when done manually.
Selecting the right data collection method should be an intentional process, taking into consideration the unique requirements of your project. The method selected should align with your goals, available resources, and the nature of the data you need to collect.
If you aim to collect quantitative data, surveys, questionnaires, and forms can be excellent tools, particularly for large-scale studies. These methods are suited to providing structured responses that can be analyzed statistically, delivering solid numerical data.
However, if you’re looking to uncover a deeper understanding of a subject, qualitative data might be more suitable. In such cases, interviews, observations, and focus groups can provide richer, more nuanced insights. These methods allow you to explore experiences, opinions, and behaviors deeply. Some surveys can also include open-ended questions that provide qualitative data.
The cost of data collection is also an important consideration. If you have budget constraints, in-depth, in-person conversations with every member of your target population may not be practical. In such cases, distributing questionnaires or forms can be a cost-saving approach.
Additional considerations include language barriers and connectivity issues. If your respondents speak different languages, consider translation services or multilingual data collection tools . If your target population resides in areas with limited connectivity and your method will be to collect data using mobile devices, ensure your tool provides offline data collection , which will allow you to carry out your data collection plan without internet connectivity.
4. Determine your sampling method
Now that you’ve established your data collection goals and how you’ll collect your data, the next step is deciding whom to collect your data from. Sampling involves carefully selecting a representative group from a larger population. Choosing the right sampling method is crucial for gathering representative and relevant data that aligns with your data collection goal.
Consider the following guidelines to choose the appropriate sampling method for your research goal and data collection method:
- Understand Your Target Population: Start by conducting thorough research of your target population. Understand who they are, their characteristics, and subgroups within the population.
- Anticipate and Minimize Biases: Anticipate and address potential biases within the target population to help minimize their impact on the data. For example, will your sampling method accurately reflect all ages, gender, cultures, etc., of your target population? Are there barriers to participation for any subgroups? Your sampling method should allow you to capture the most accurate representation of your target population.
- Maintain Cost-Effective Practices: Consider the cost implications of your chosen sampling methods. Some sampling methods will require more resources, time, and effort. Your chosen sampling method should balance the cost factors with the ability to collect your data effectively and accurately.
- Consider Your Project’s Objectives: Tailor the sampling method to meet your specific objectives and constraints, such as M&E teams requiring real-time impact data and researchers needing representative samples for statistical analysis.
By adhering to these guidelines, you can make informed choices when selecting a sampling method, maximizing the quality and relevance of your data collection efforts.
5. Identify and train collectors
Not every data collection use case requires data collectors, but training individuals responsible for data collection becomes crucial in scenarios involving field presence.
The SurveyCTO platform supports both self-response survey modes and surveys that require a human field worker to do in-person interviews. Whether you’re hiring and training data collectors, utilizing an existing team, or training existing field staff, we offer comprehensive guidance and the right tools to ensure effective data collection practices.
Here are some common training approaches for data collectors:
- In-Class Training: Comprehensive sessions covering protocols, survey instruments, and best practices empower data collectors with skills and knowledge.
- Tests and Assessments: Assessments evaluate collectors’ understanding and competence, highlighting areas where additional support is needed.
- Mock Interviews: Simulated interviews refine collectors’ techniques and communication skills.
- Pre-Recorded Training Sessions: Accessible reinforcement and self-paced learning to refresh and stay updated.
Training data collectors is vital for successful data collection techniques. Your training should focus on proper instrument usage and effective interaction with respondents, including communication skills, cultural literacy, and ethical considerations.
Remember, training is an ongoing process. Knowledge gaps and issues may arise in the field, necessitating further training.
Moving Ahead: Iterative Steps in Data Collection

Once you’ve established the preliminary elements of your data collection process, you’re ready to start your data collection journey. In this section, we’ll delve into the specifics of designing and testing your instruments, collecting data, and organizing data while embracing the iterative nature of the data collection process, which requires diligent monitoring and making adjustments when needed.
6. Design and test your instruments
Designing effective data collection instruments like surveys and questionnaires is key. It’s crucial to prioritize respondent consent and privacy to ensure the integrity of your research. Thoughtful design and careful testing of survey questions are essential for optimizing research insights. Other critical considerations are:
- Clear and Unbiased Question Wording: Craft unambiguous, neutral questions free from bias to gather accurate and meaningful data. For example, instead of asking, “Shouldn’t we invest more into renewable energy that will combat the effects of climate change?” ask your question in a neutral way that allows the respondent to voice their thoughts. For example: “What are your thoughts on investing more in renewable energy?”
- Logical Ordering and Appropriate Response Format: Arrange questions logically and choose response formats (such as multiple-choice, Likert scale, or open-ended) that suit the nature of the data you aim to collect.
- Coverage of Relevant Topics: Ensure that your instrument covers all topics pertinent to your data collection goals while respecting cultural and social sensitivities. Make sure your instrument avoids assumptions, stereotypes, and languages or topics that could be considered offensive or taboo in certain contexts. The goal is to avoid marginalizing or offending respondents based on their social or cultural background.
- Collect Only Necessary Data: Design survey instruments that focus solely on gathering the data required for your research objectives, avoiding unnecessary information.
- Language(s) of the Respondent Population: Tailor your instruments to accommodate the languages your target respondents speak, offering translated versions if needed. Similarly, take into account accessibility for respondents who can’t read by offering alternative formats like images in place of text.
- Desired Length of Time for Completion: Respect respondents’ time by designing instruments that can be completed within a reasonable timeframe, balancing thoroughness with engagement. Having a general timeframe for the amount of time needed to complete a response will also help you weed out bad responses. For example, a response that was rushed and completed outside of your response timeframe could indicate a response that needs to be excluded.
- Collecting and Documenting Respondents’ Consent and Privacy: Ensure a robust consent process, transparent data usage communication, and privacy protection throughout data collection.
Perform Cognitive Interviewing
Cognitive interviewing is a method used to refine survey instruments and improve the accuracy of survey responses by evaluating how respondents understand, process, and respond to the instrument’s questions. In practice, cognitive interviewing involves an interview with the respondent, asking them to verbalize their thoughts as they interact with the instrument. By actively probing and observing their responses, you can identify and address ambiguities, ensuring accurate data collection.
Thoughtful question wording, well-organized response options, and logical sequencing enhance comprehension, minimize biases, and ensure accurate data collection. Iterative testing and refinement based on respondent feedback improve the validity, reliability, and actionability of insights obtained.
Put Your Instrument to the Test
Through rigorous testing, you can uncover flaws, ensure reliability, maximize accuracy, and validate your instrument’s performance. This can be achieved by:
- Conducting pilot testing to enhance the reliability and effectiveness of data collection. Administer the instrument, identify difficulties, gather feedback, and assess performance in real-world conditions.
- Making revisions based on pilot testing to enhance clarity, accuracy, usability, and participant satisfaction. Refine questions, instructions, and format for effective data collection.
- Continuously iterating and refining your instrument based on feedback and real-world testing. This ensures reliable, accurate, and audience-aligned methods of data collection. Additionally, this ensures your instrument adapts to changes, incorporates insights, and maintains ongoing effectiveness.
7. Collect your data
Now that you have your well-designed survey, interview questions, observation plan, or form, it’s time to implement it and gather the needed data. Data collection is not a one-and-done deal; it’s an ongoing process that demands attention to detail. Imagine spending weeks collecting data, only to discover later that a significant portion is unusable due to incomplete responses, improper collection methods, or falsified responses. To avoid such setbacks, adopt an iterative approach.
Leverage data collection tools with real-time monitoring to proactively identify outliers and issues. Take immediate action by fine-tuning your instruments, optimizing the data collection process, addressing concerns like additional training, or reevaluating personnel responsible for inaccurate data (for example, a field worker who sits in a coffee shop entering fake responses rather than doing the work of knocking on doors).
SurveyCTO’s Data Explorer was specifically designed to fulfill this requirement, empowering you to monitor incoming data, gain valuable insights, and know where changes may be needed. Embracing this iterative approach ensures ongoing improvement in data collection, resulting in more reliable and precise results.
8. Clean and organize your data
After data collection, the next step is to clean and organize the data to ensure its integrity and usability.
- Data Cleaning: This stage involves sifting through your data to identify and rectify any errors, inconsistencies, or missing values. It’s essential to maintain the accuracy of your data and ensure that it’s reliable for further analysis. Data cleaning can uncover duplicates, outliers, and gaps that could skew your results if left unchecked. With real-time data monitoring , this continuous cleaning process keeps your data precise and current throughout the data collection period. Similarly, review and corrections workflows allow you to monitor the quality of your incoming data.
- Organizing Your Data: Post-cleaning, it’s time to organize your data for efficient analysis and interpretation. Labeling your data using appropriate codes or categorizations can simplify navigation and streamline the extraction of insights. When you use a survey or form, labeling your data is often not necessary because you can design the instrument to collect in the right categories or return the right codes. An organized dataset is easier to manage, analyze, and interpret, ensuring that your collection efforts are not wasted but lead to valuable, actionable insights.
Remember, each stage of the data collection process, from design to cleaning, is iterative and interconnected. By diligently cleaning and organizing your data, you are setting the stage for robust, meaningful analysis that can inform your data-driven decisions and actions.
What happens after data collection?

The data collection journey takes us next into data analysis, where you’ll uncover patterns, empowering informed decision-making for researchers, evaluation teams, and field personnel.
Process and Analyze Your Data
Explore data through statistical and qualitative techniques to discover patterns, correlations, and insights during this pivotal stage. It’s about extracting the essence of your data and translating numbers into knowledge. Whether applying descriptive statistics, conducting regression analysis, or using thematic coding for qualitative data, this process drives decision-making and charts the path toward actionable outcomes.
Interpret and Report Your Results
Interpreting and reporting your data brings meaning and context to the numbers. Translating raw data into digestible insights for informed decision-making and effective stakeholder communication is critical.
The approach to interpretation and reporting varies depending on the perspective and role:
- Researchers often lean heavily on statistical methods to identify trends, extract meaningful conclusions, and share their findings in academic circles, contributing to their knowledge pool.
- M&E teams typically produce comprehensive reports, shedding light on the effectiveness and impact of programs. These reports guide internal and sometimes external stakeholders, supporting informed decisions and driving program improvements.
Field teams provide a first-hand perspective. Since they are often the first to see the results of the practical implementation of data, field teams are instrumental in providing immediate feedback loops on project initiatives. Field teams do the work that provides context to help research and M&E teams understand external factors like the local environment, cultural nuances, and logistical challenges that impact data results.
Safely store and handle data
Throughout the data collection process, and after it has been collected, it is vital to follow best practices for storing and handling data to ensure the integrity of your research. While the specifics of how to best store and handle data will depend on your project, here are some important guidelines to keep in mind:
- Use cloud storage to hold your data if possible, since this is safer than storing data on hard drives and keeps it more accessible,
- Periodically back up and purge old data from your system, since it’s safer to not retain data longer than necessary,
- If you use mobile devices to collect and store data, use options for private, internal apps-specific storage if and when possible,
- Restrict access to stored data to only those who need to work with that data.
Further considerations for data safety are discussed below in the section on data security .
Remember to uphold ethical standards in interpreting and reporting your data, regardless of your role. Clear communication, respectful handling of sensitive information, and adhering to confidentiality and privacy rights are all essential to fostering trust, promoting transparency, and bolstering your work’s credibility.
Common Data Collection Challenges

Data collection is vital to data-driven initiatives, but it comes with challenges. Addressing common challenges such as poor data quality, privacy concerns, inadequate sample sizes, and bias is essential to ensure the collected data is reliable, trustworthy, and secure.
In this section, we’ll explore three major challenges: data quality and consistency issues, data security concerns, and limitations with offline data collection , along with strategies to overcome them.
Data Quality and Consistency
Data quality and consistency refer to data accuracy and reliability throughout the collection and analysis process.
Challenges such as incomplete or missing data, data entry errors, measurement errors, and data coding/categorization errors can impact the integrity and usefulness of the data.
To navigate these complexities and maintain high standards, consistency, and integrity in the dataset:
- Implement robust data validation processes,
- Ensure proper training for data entry personnel,
- Employ automated data validation techniques, and
- Conduct regular data quality audits.
Data security
Data security encompasses safeguarding data through ensuring data privacy and confidentiality, securing storage and backup, and controlling data sharing and access.
Challenges include the risk of potential breaches, unauthorized access, and the need to comply with data protection regulations.
To address these setbacks and maintain privacy, trust, and confidence during the data collection process:
- Use encryption and authentication methods,
- Implement robust security protocols,
- Update security measures regularly,
- Provide employee training on data security, and
- Adopt secure cloud storage solutions.
Offline Data Collection
Offline data collection refers to the process of gathering data using modes like mobile device-based computer-assisted personal interviewing (CAPI) when t here is an inconsistent or unreliable internet connection, and the data collection tool being used for CAPI has the functionality to work offline.
Challenges associated with offline data collection include synchronization issues, difficulty transferring data, and compatibility problems between devices, and data collection tools.
To overcome these challenges and enable efficient and reliable offline data collection processes, employ the following strategies:
- Leverage offline-enabled data collection apps or tools that enable you to survey respondents even when there’s no internet connection, and upload data to a central repository at a later time.
- Your data collection plan should include times for periodic data synchronization when connectivity is available,
- Use offline, device-based storage for seamless data transfer and compatibility, and
- Provide clear instructions to field personnel on handling offline data collection scenarios.
Utilizing Technology in Data Collection

Embracing technology throughout your data collection process can help you overcome many challenges described in the previous section. Data collection tools can streamline your data collection, improve the quality and security of your data, and facilitate the analysis of your data. Let’s look at two broad categories of tools that are essential for data collection:
Data Collection, Entry, & Management Tools
These tools help with data collection, input, and organization. They can range from digital survey platforms to comprehensive database systems, allowing you to gather, enter, and manage your data effectively. They can significantly simplify the data collection process, minimize human error, and offer practical ways to organize and manage large volumes of data. Some of these tools are:
- Microsoft Office
- Google Docs
- SurveyMonkey
- Google Forms
Data Analysis, Visualization, Reporting, & Workflow Tools
These tools assist in processing and interpreting the collected data. They provide a way to visualize data in a user-friendly format, making it easier to identify trends and patterns. These tools can also generate comprehensive reports to share your findings with stakeholders and help manage your workflow efficiently. By automating complex tasks, they can help ensure accuracy and save time. Tools for these purposes include:
- Google sheets
Data collection tools like SurveyCTO often have integrations to help users seamlessly transition from data collection to data analysis, visualization, reporting, and managing workflows.
Master Your Data Collection Process With SurveyCTO
As we bring this guide to a close, you now possess a wealth of knowledge to develop your data collection process. From understanding the significance of setting clear goals to the crucial process of selecting your data collection methods and addressing common challenges, you are equipped to handle the intricate details of this dynamic process.
Remember, you’re not venturing into this complex process alone. At SurveyCTO, we offer not just a tool but an entire support system committed to your success. Beyond troubleshooting support, our success team serves as research advisors and expert partners, ready to provide guidance at every stage of your data collection journey.
With SurveyCTO , you can design flexible surveys in Microsoft Excel or Google Sheets, collect data online and offline with above-industry-standard security, monitor your data in real time, and effortlessly export it for further analysis in any tool of your choice. You also get access to our Data Explorer, which allows you to visualize incoming data at both individual survey and aggregate levels instantly.
In the iterative data collection process, our users tell us that SurveyCTO stands out with its capacity to establish review and correction workflows. It enables you to monitor incoming data and configure automated quality checks to flag error-prone submissions.
Finally, data security is of paramount importance to us. We ensure best-in-class security measures like SOC 2 compliance, end-to-end encryption, single sign-on (SSO), GDPR-compliant setups, customizable user roles, and self-hosting options to keep your data safe.
As you embark on your data collection journey, you can count on SurveyCTO’s experience and expertise to be by your side every step of the way. Our team would be excited and honored to be a part of your research project, offering you the tools and processes to gain informative insights and make effective decisions. Partner with us today and revolutionize the way you collect data.
Better data, better decision making, better world.

INTEGRATIONS
- Research Data Lifecycle Guide
Data Collection
Data collection is the process of gathering and measuring information used for research. Collecting data is one of the most important steps in the research process, and is part of all disciplines including physical and social sciences, humanities, business, etc. Data comes in many forms with different ways to store and record data, either written in a lab notebook and or recorded digitally on a computer system.
While methods may differ across disciplines, good data management processes begin with accurately and clearly describing the information recorded, the process used to collect the data, practices that ensure the quality of the data, and sharing data to enable reproducibility. This section breaks down different topics that need to be addressed while collecting and managing data for research.
Learn more about what’s required for data collection as a researcher at Case Western Reserve University.
Ensuring Accurate and Appropriate Data Collection
Accurate data collection is vital to ensure the integrity of research . It is important when planning and executing a research project to consider methods collection and the storage of data to ensure that results can be used for publications and reporting. The consequences from improper data collection include:
- inability to answer research questions accurately
- inability to repeat and validate the study
- distorted findings resulting in wasted resources
- misleading other researchers to pursue fruitless avenues of investigation
- compromising decisions for public policy
- causing harm to human participants and animal subjects
While the degree of impact from inaccurate data may vary by discipline, there is a potential to cause disproportionate harm when data is misrepresented and misused. This includes fraud or scientific misconduct.
Any data collected in the course of your research should follow RDM best practices to ensure accurate and appropriate data collection. This includes as appropriate, developing data collection protocols and processes to ensure inconsistencies and other errors are caught and corrected in a timely manner.
Examples of Research Data
Research data is any information that has been collected, observed, generated or created in association with research processes and findings.
Much research data is digital in format, but research data can also be extended to include non-digital formats such as laboratory notebook, diaries, or written responses to surveys. Examples may include (but are not limited to):
- Excel spreadsheets that contains instrument data
- Documents (text, Word), containing study results
- Laboratory notebooks, field notebooks, diaries
- Questionnaires, transcripts, codebooks
- Audiotapes, videotapes
- Photographs, films
- Protein or genetic sequences
- Test responses
- Slides, artifacts, specimens, samples
- Collection of digital objects acquired and generated during the process of research
- Database contents (video, audio, text, images)
- Models, algorithms, scripts
- Contents of an application (input, output, logfiles for analysis software, simulation software, schemas)
- Source code used in application development
To ensure reproducibility of experiments and results, be sure to include and document information such as:
- Methodologies and workflows
- Standard operating procedures and protocols
Data Use Agreements
When working with data it is important to understand any restrictions that need to be addressed due to the sensitivity of the data. This includes how you download and share with other collaborators, and how it needs to be properly secured.
Datasets can include potentially sensitive data that needs to be protected, and not openly shared. In this case, the dataset cannot be shared and or downloaded without permission from CWRU Research Administration and may require an agreement between collaborators and their institutions. All parties will need to abide by the agreement terms including the destruction of data once the collaboration is complete.
Storage Options
UTech provides cloud and on-premise storage to support the university research mission. This includes Google Drive , Box , Microsoft 365 , and various on-premise solutions for high speed access and mass storage. A listing of supported options can be found on UTech’s website .
In addition to UTech-supported storage solutions, CWRU also maintains an institutional subscription to OSF (Open Science Framework) . OSF is a cloud-based data storage, sharing, and project collaboration platform that connects to many other cloud services like Drive, Box, and Github to amplify your research and data visibility and discoverability. OSF storage is functionally unlimited.
When selecting a storage platform it is important to understand how you plan to analyze and store your data. Cloud storage provides the ability to store and share data effortlessly and provides capabilities such as revisioning and other means to protect your data. On-premise storage is useful when you have large storage demands and require a high speed connection to instruments that generate data and systems that process data. Both types of storage have their advantages and disadvantages that you should consider when planning your research project.
Data Security
Data security is a set of processes and ongoing practices designed to protect information and the systems used to store and process data. This includes computer systems, files, databases, applications, user accounts, networks, and services on institutional premises, in the cloud, and remotely at the location of individual researchers.
Effective data security takes into account the confidentiality, integrity, and availability of the information and its use. This is especially important when data contains personally identifiable information, intellectual property, trade secrets, and or technical data supporting technology transfer agreements (before public disclosure decisions have been made).
Data Categorization
CWRU uses a 3-tier system to categorize research data based on information types and sensitivity . Determination is based upon risk to the University in the areas of confidentiality, integrity, and availability of data in support of the University's research mission. In this context, confidentiality measures to what extent information can be disclosed to others, integrity is the assurance that the information is trustworthy and accurate, and availability is a guarantee of reliable access to the information by authorized users.
Information (or data) owners are responsible for determining the impact levels of their information, i.e. what happens if the data is improperly accessed or lost accidentally, implementing the necessary security controls, and managing the risk of negative events including data loss and unauthorized access.
Loss, corruption, or inappropriate access to information can interfere with CWRU's mission, interrupt business and damage reputations or finances.
Securing Data
The classification of data requires certain safeguards or countermeasures, known as controls, to be applied to systems that store data. This can include restricting access to the data, detecting unauthorized access, preventative measures to avoid loss of data, encrypting the transfer and storage of data, keeping the system and data in a secure location, and receiving training on best practices for handling data. Controls are classified according to their characteristics, for example:
- Physical controls e.g. doors, locks, climate control, and fire extinguishers;
- Procedural or administrative controls e.g. policies, incident response processes, management oversight, security awareness and training;
- Technical or logical controls e.g. user authentication (login) and logical access controls, antivirus software, firewalls;
- Legal and regulatory or compliance controls e.g. privacy laws, policies and clauses.
Principal Investigator (PI) Responsibilities
The CWRU Faculty Handbook provides guidelines for PIs regarding the custody of research data. This includes, where applicable, appropriate measures to protect confidential information. It is everyone’s responsibility to ensure that our research data is kept securely and available for reproducibility and future research opportunities.
University Technology provides many services and resources related to data security including assistance with planning and securing data. This includes processing and storing restricted information used in research.
Data Collected as Part of Human Subject Research
To ensure the privacy and safety of the individual participating in a human subject research study, additional rules and processes are in place that describe how one can use and disclose data collected, The Office of Research Administration provides information relevant to conducting this type of research. This includes:
- Guidance on data use agreements and processes for agreements that involve human-related data or human-derived samples coming in or going out of CWRU.
- Compliance with human subject research rules and regulations.
According to 45 CFR 46 , a human subject is "a living individual about whom an investigator (whether professional or student) conducting research:
- Obtains information or biospecimens through intervention or interaction with the individual, and uses, studies, or analyzes the information or biospecimens; or
- Obtains, uses, studies, analyzes, or generates identifiable private information or identifiable biospecimens."
The CWRU Institutional Review Board reviews social science/behavioral studies, and low-risk biomedical research not conducted in a hospital setting for all faculty, staff, and students of the University. This includes data collected and used for human subjects research.
Research conducted in a hospital setting including University Hospitals requires IRB protocol approval.
Questions regarding the management of human subject research data should be addressed to the CWRU Institutional Review Board .
Getting Help With Data Collection
If you are looking for datasets and other resources for your research you can contact your subject area librarian for assistance.
- Kelvin Smith Library
If you need assistance with administrative items such as data use agreements or finding the appropriate storage solution please contact the following offices.
- Research Administration
- UTech Research Computing
- Information Security Office
Guidance and Resources
- Information Security Policy
- Research Data Protection
- CWRU Faculty Handbook
- CWRU IRB Guidance

Data Collection Methods
Data collection is a process of collecting information from all the relevant sources to find answers to the research problem, test the hypothesis (if you are following deductive approach ) and evaluate the outcomes. Data collection methods can be divided into two categories: secondary methods of data collection and primary methods of data collection.
Secondary Data Collection Methods
Secondary data is a type of data that has already been published in books, newspapers, magazines, journals, online portals etc. There is an abundance of data available in these sources about your research area in business studies, almost regardless of the nature of the research area. Therefore, application of appropriate set of criteria to select secondary data to be used in the study plays an important role in terms of increasing the levels of research validity and reliability.
These criteria include, but not limited to date of publication, credential of the author, reliability of the source, quality of discussions, depth of analyses, the extent of contribution of the text to the development of the research area etc. Secondary data collection is discussed in greater depth in Literature Review chapter.
Secondary data collection methods offer a range of advantages such as saving time, effort and expenses. However they have a major disadvantage. Specifically, secondary research does not make contribution to the expansion of the literature by producing fresh (new) data.
Primary Data Collection Methods
Primary data is the type of data that has not been around before. Primary data is unique findings of your research. Primary data collection and analysis typically requires more time and effort to conduct compared to the secondary data research. Primary data collection methods can be divided into two groups: quantitative and qualitative.
Quantitative data collection methods are based on mathematical calculations in various formats. Methods of quantitative data collection and analysis include questionnaires with closed-ended questions, methods of correlation and regression, mean, mode and median and others.
Quantitative methods are cheaper to apply and they can be applied within shorter duration of time compared to qualitative methods. Moreover, due to a high level of standardisation of quantitative methods, it is easy to make comparisons of findings.
Qualitative research methods , on the contrary, do not involve numbers or mathematical calculations. Qualitative research is closely associated with words, sounds, feeling, emotions, colours and other elements that are non-quantifiable.
Qualitative studies aim to ensure greater level of depth of understanding and qualitative data collection methods include interviews, questionnaires with open-ended questions, focus groups, observation, game or role-playing, case studies etc.
Your choice between quantitative or qualitative methods of data collection depends on the area of your research and the nature of research aims and objectives.
My e-book, The Ultimate Guide to Writing a Dissertation in Business Studies: a step by step assistance offers practical assistance to complete a dissertation with minimum or no stress. The e-book covers all stages of writing a dissertation starting from the selection to the research area to submitting the completed version of the work within the deadline.
John Dudovskiy

- Business Essentials
- Leadership & Management
- Credential of Leadership, Impact, and Management in Business (CLIMB)
- Entrepreneurship & Innovation
- Digital Transformation
- Finance & Accounting
- Business in Society
- For Organizations
- Support Portal
- Media Coverage
- Founding Donors
- Leadership Team

- Harvard Business School →
- HBS Online →
- Business Insights →
Business Insights
Harvard Business School Online's Business Insights Blog provides the career insights you need to achieve your goals and gain confidence in your business skills.
- Career Development
- Communication
- Decision-Making
- Earning Your MBA
- Negotiation
- News & Events
- Productivity
- Staff Spotlight
- Student Profiles
- Work-Life Balance
- AI Essentials for Business
- Alternative Investments
- Business Analytics
- Business Strategy
- Business and Climate Change
- Design Thinking and Innovation
- Digital Marketing Strategy
- Disruptive Strategy
- Economics for Managers
- Entrepreneurship Essentials
- Financial Accounting
- Global Business
- Launching Tech Ventures
- Leadership Principles
- Leadership, Ethics, and Corporate Accountability
- Leading Change and Organizational Renewal
- Leading with Finance
- Management Essentials
- Negotiation Mastery
- Organizational Leadership
- Power and Influence for Positive Impact
- Strategy Execution
- Sustainable Business Strategy
- Sustainable Investing
- Winning with Digital Platforms
7 Data Collection Methods in Business Analytics

- 02 Dec 2021
Data is being generated at an ever-increasing pace. According to Statista , the total volume of data was 64.2 zettabytes in 2020; it’s predicted to reach 181 zettabytes by 2025. This abundance of data can be overwhelming if you aren’t sure where to start.
So, how do you ensure the data you use is relevant and important to the business problems you aim to solve? After all, a data-driven decision is only as strong as the data it’s based on. One way is to collect data yourself.
Here’s a breakdown of data types, why data collection is important, what to know before you begin collecting, and seven data collection methods to leverage.
Access your free e-book today.
What Is Data Collection?
Data collection is the methodological process of gathering information about a specific subject. It’s crucial to ensure your data is complete during the collection phase and that it’s collected legally and ethically . If not, your analysis won’t be accurate and could have far-reaching consequences.
In general, there are three types of consumer data:
- First-party data , which is collected directly from users by your organization
- Second-party data , which is data shared by another organization about its customers (or its first-party data)
- Third-party data , which is data that’s been aggregated and rented or sold by organizations that don’t have a connection to your company or users
Although there are use cases for second- and third-party data, first-party data (data you’ve collected yourself) is more valuable because you receive information about how your audience behaves, thinks, and feels—all from a trusted source.
Data can be qualitative (meaning contextual in nature) or quantitative (meaning numeric in nature). Many data collection methods apply to either type, but some are better suited to one over the other.
In the data life cycle , data collection is the second step. After data is generated, it must be collected to be of use to your team. After that, it can be processed, stored, managed, analyzed, and visualized to aid in your organization’s decision-making.

Before collecting data, there are several factors you need to define:
- The question you aim to answer
- The data subject(s) you need to collect data from
- The collection timeframe
- The data collection method(s) best suited to your needs
The data collection method you select should be based on the question you want to answer, the type of data you need, your timeframe, and your company’s budget.
The Importance of Data Collection
Collecting data is an integral part of a business’s success; it can enable you to ensure the data’s accuracy, completeness, and relevance to your organization and the issue at hand. The information gathered allows organizations to analyze past strategies and stay informed on what needs to change.
The insights gleaned from data can make you hyperaware of your organization’s efforts and give you actionable steps to improve various strategies—from altering marketing strategies to assessing customer complaints.
Basing decisions on inaccurate data can have far-reaching negative consequences, so it’s important to be able to trust your own data collection procedures and abilities. By ensuring accurate data collection, business professionals can feel secure in their business decisions.
Explore the options in the next section to see which data collection method is the best fit for your company.
7 Data Collection Methods Used in Business Analytics
Surveys are physical or digital questionnaires that gather both qualitative and quantitative data from subjects. One situation in which you might conduct a survey is gathering attendee feedback after an event. This can provide a sense of what attendees enjoyed, what they wish was different, and areas in which you can improve or save money during your next event for a similar audience.
While physical copies of surveys can be sent out to participants, online surveys present the opportunity for distribution at scale. They can also be inexpensive; running a survey can cost nothing if you use a free tool. If you wish to target a specific group of people, partnering with a market research firm to get the survey in front of that demographic may be worth the money.
Something to watch out for when crafting and running surveys is the effect of bias, including:
- Collection bias : It can be easy to accidentally write survey questions with a biased lean. Watch out for this when creating questions to ensure your subjects answer honestly and aren’t swayed by your wording.
- Subject bias : Because your subjects know their responses will be read by you, their answers may be biased toward what seems socially acceptable. For this reason, consider pairing survey data with behavioral data from other collection methods to get the full picture.
Related: 3 Examples of Bad Survey Questions & How to Fix Them
2. Transactional Tracking
Each time your customers make a purchase, tracking that data can allow you to make decisions about targeted marketing efforts and understand your customer base better.
Often, e-commerce and point-of-sale platforms allow you to store data as soon as it’s generated, making this a seamless data collection method that can pay off in the form of customer insights.
3. Interviews and Focus Groups
Interviews and focus groups consist of talking to subjects face-to-face about a specific topic or issue. Interviews tend to be one-on-one, and focus groups are typically made up of several people. You can use both to gather qualitative and quantitative data.
Through interviews and focus groups, you can gather feedback from people in your target audience about new product features. Seeing them interact with your product in real-time and recording their reactions and responses to questions can provide valuable data about which product features to pursue.
As is the case with surveys, these collection methods allow you to ask subjects anything you want about their opinions, motivations, and feelings regarding your product or brand. It also introduces the potential for bias. Aim to craft questions that don’t lead them in one particular direction.
One downside of interviewing and conducting focus groups is they can be time-consuming and expensive. If you plan to conduct them yourself, it can be a lengthy process. To avoid this, you can hire a market research facilitator to organize and conduct interviews on your behalf.
4. Observation
Observing people interacting with your website or product can be useful for data collection because of the candor it offers. If your user experience is confusing or difficult, you can witness it in real-time.
Yet, setting up observation sessions can be difficult. You can use a third-party tool to record users’ journeys through your site or observe a user’s interaction with a beta version of your site or product.
While less accessible than other data collection methods, observations enable you to see firsthand how users interact with your product or site. You can leverage the qualitative and quantitative data gleaned from this to make improvements and double down on points of success.

5. Online Tracking
To gather behavioral data, you can implement pixels and cookies. These are both tools that track users’ online behavior across websites and provide insight into what content they’re interested in and typically engage with.
You can also track users’ behavior on your company’s website, including which parts are of the highest interest, whether users are confused when using it, and how long they spend on product pages. This can enable you to improve the website’s design and help users navigate to their destination.
Inserting a pixel is often free and relatively easy to set up. Implementing cookies may come with a fee but could be worth it for the quality of data you’ll receive. Once pixels and cookies are set, they gather data on their own and don’t need much maintenance, if any.
It’s important to note: Tracking online behavior can have legal and ethical privacy implications. Before tracking users’ online behavior, ensure you’re in compliance with local and industry data privacy standards .
Online forms are beneficial for gathering qualitative data about users, specifically demographic data or contact information. They’re relatively inexpensive and simple to set up, and you can use them to gate content or registrations, such as webinars and email newsletters.
You can then use this data to contact people who may be interested in your product, build out demographic profiles of existing customers, and in remarketing efforts, such as email workflows and content recommendations.
Related: What Is Marketing Analytics?
7. Social Media Monitoring
Monitoring your company’s social media channels for follower engagement is an accessible way to track data about your audience’s interests and motivations. Many social media platforms have analytics built in, but there are also third-party social platforms that give more detailed, organized insights pulled from multiple channels.
You can use data collected from social media to determine which issues are most important to your followers. For instance, you may notice that the number of engagements dramatically increases when your company posts about its sustainability efforts.

Building Your Data Capabilities
Understanding the variety of data collection methods available can help you decide which is best for your timeline, budget, and the question you’re aiming to answer. When stored together and combined, multiple data types collected through different methods can give an informed picture of your subjects and help you make better business decisions.
Do you want to become a data-driven professional? Explore our eight-week Business Analytics course and our three-course Credential of Readiness (CORe) program to deepen your analytical skills and apply them to real-world business problems. Not sure which course is right for you? Download our free flowchart .
This post was updated on October 17, 2022. It was originally published on December 2, 2021.

About the Author
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Data Collection Methods | Step-by-Step Guide & Examples
Data Collection Methods | Step-by-Step Guide & Examples
Published on 4 May 2022 by Pritha Bhandari .
Data collection is a systematic process of gathering observations or measurements. Whether you are performing research for business, governmental, or academic purposes, data collection allows you to gain first-hand knowledge and original insights into your research problem .
While methods and aims may differ between fields, the overall process of data collection remains largely the same. Before you begin collecting data, you need to consider:
- The aim of the research
- The type of data that you will collect
- The methods and procedures you will use to collect, store, and process the data
To collect high-quality data that is relevant to your purposes, follow these four steps.
Table of contents
Step 1: define the aim of your research, step 2: choose your data collection method, step 3: plan your data collection procedures, step 4: collect the data, frequently asked questions about data collection.
Before you start the process of data collection, you need to identify exactly what you want to achieve. You can start by writing a problem statement : what is the practical or scientific issue that you want to address, and why does it matter?
Next, formulate one or more research questions that precisely define what you want to find out. Depending on your research questions, you might need to collect quantitative or qualitative data :
- Quantitative data is expressed in numbers and graphs and is analysed through statistical methods .
- Qualitative data is expressed in words and analysed through interpretations and categorisations.
If your aim is to test a hypothesis , measure something precisely, or gain large-scale statistical insights, collect quantitative data. If your aim is to explore ideas, understand experiences, or gain detailed insights into a specific context, collect qualitative data.
If you have several aims, you can use a mixed methods approach that collects both types of data.
- Your first aim is to assess whether there are significant differences in perceptions of managers across different departments and office locations.
- Your second aim is to gather meaningful feedback from employees to explore new ideas for how managers can improve.
Prevent plagiarism, run a free check.
Based on the data you want to collect, decide which method is best suited for your research.
- Experimental research is primarily a quantitative method.
- Interviews , focus groups , and ethnographies are qualitative methods.
- Surveys , observations, archival research, and secondary data collection can be quantitative or qualitative methods.
Carefully consider what method you will use to gather data that helps you directly answer your research questions.
When you know which method(s) you are using, you need to plan exactly how you will implement them. What procedures will you follow to make accurate observations or measurements of the variables you are interested in?
For instance, if you’re conducting surveys or interviews, decide what form the questions will take; if you’re conducting an experiment, make decisions about your experimental design .
Operationalisation
Sometimes your variables can be measured directly: for example, you can collect data on the average age of employees simply by asking for dates of birth. However, often you’ll be interested in collecting data on more abstract concepts or variables that can’t be directly observed.
Operationalisation means turning abstract conceptual ideas into measurable observations. When planning how you will collect data, you need to translate the conceptual definition of what you want to study into the operational definition of what you will actually measure.
- You ask managers to rate their own leadership skills on 5-point scales assessing the ability to delegate, decisiveness, and dependability.
- You ask their direct employees to provide anonymous feedback on the managers regarding the same topics.
You may need to develop a sampling plan to obtain data systematically. This involves defining a population , the group you want to draw conclusions about, and a sample, the group you will actually collect data from.
Your sampling method will determine how you recruit participants or obtain measurements for your study. To decide on a sampling method you will need to consider factors like the required sample size, accessibility of the sample, and time frame of the data collection.
Standardising procedures
If multiple researchers are involved, write a detailed manual to standardise data collection procedures in your study.
This means laying out specific step-by-step instructions so that everyone in your research team collects data in a consistent way – for example, by conducting experiments under the same conditions and using objective criteria to record and categorise observations.
This helps ensure the reliability of your data, and you can also use it to replicate the study in the future.
Creating a data management plan
Before beginning data collection, you should also decide how you will organise and store your data.
- If you are collecting data from people, you will likely need to anonymise and safeguard the data to prevent leaks of sensitive information (e.g. names or identity numbers).
- If you are collecting data via interviews or pencil-and-paper formats, you will need to perform transcriptions or data entry in systematic ways to minimise distortion.
- You can prevent loss of data by having an organisation system that is routinely backed up.
Finally, you can implement your chosen methods to measure or observe the variables you are interested in.
The closed-ended questions ask participants to rate their manager’s leadership skills on scales from 1 to 5. The data produced is numerical and can be statistically analysed for averages and patterns.
To ensure that high-quality data is recorded in a systematic way, here are some best practices:
- Record all relevant information as and when you obtain data. For example, note down whether or how lab equipment is recalibrated during an experimental study.
- Double-check manual data entry for errors.
- If you collect quantitative data, you can assess the reliability and validity to get an indication of your data quality.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organisations.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g., understanding the needs of your consumers or user testing your website).
- You can control and standardise the process for high reliability and validity (e.g., choosing appropriate measurements and sampling methods ).
However, there are also some drawbacks: data collection can be time-consuming, labour-intensive, and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to test a hypothesis by systematically collecting and analysing data, while qualitative methods allow you to explore ideas and experiences in depth.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research , you also have to consider the internal and external validity of your experiment.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, May 04). Data Collection Methods | Step-by-Step Guide & Examples. Scribbr. Retrieved 26 May 2024, from https://www.scribbr.co.uk/research-methods/data-collection-guide/
Is this article helpful?

Pritha Bhandari
Other students also liked, qualitative vs quantitative research | examples & methods, triangulation in research | guide, types, examples, what is a conceptual framework | tips & examples.
Table of Contents
What is data collection, why do we need data collection, what are the different data collection methods, data collection tools, the importance of ensuring accurate and appropriate data collection, issues related to maintaining the integrity of data collection, what are common challenges in data collection, what are the key steps in the data collection process, data collection considerations and best practices, choose the right data science program, are you interested in a career in data science, what is data collection: methods, types, tools.

The process of gathering and analyzing accurate data from various sources to find answers to research problems, trends and probabilities, etc., to evaluate possible outcomes is Known as Data Collection. Knowledge is power, information is knowledge, and data is information in digitized form, at least as defined in IT. Hence, data is power. But before you can leverage that data into a successful strategy for your organization or business, you need to gather it. That’s your first step.
So, to help you get the process started, we shine a spotlight on data collection. What exactly is it? Believe it or not, it’s more than just doing a Google search! Furthermore, what are the different types of data collection? And what kinds of data collection tools and data collection techniques exist?
If you want to get up to speed about what is data collection process, you’ve come to the right place.
Transform raw data into captivating visuals with Simplilearn's hands-on Data Visualization Courses and captivate your audience. Also, master the art of data management with Simplilearn's comprehensive data management courses - unlock new career opportunities today!
Data collection is the process of collecting and evaluating information or data from multiple sources to find answers to research problems, answer questions, evaluate outcomes, and forecast trends and probabilities. It is an essential phase in all types of research, analysis, and decision-making, including that done in the social sciences, business, and healthcare.
Accurate data collection is necessary to make informed business decisions, ensure quality assurance, and keep research integrity.
During data collection, the researchers must identify the data types, the sources of data, and what methods are being used. We will soon see that there are many different data collection methods . There is heavy reliance on data collection in research, commercial, and government fields.
Before an analyst begins collecting data, they must answer three questions first:
- What’s the goal or purpose of this research?
- What kinds of data are they planning on gathering?
- What methods and procedures will be used to collect, store, and process the information?
Additionally, we can break up data into qualitative and quantitative types. Qualitative data covers descriptions such as color, size, quality, and appearance. Quantitative data, unsurprisingly, deals with numbers, such as statistics, poll numbers, percentages, etc.
Before a judge makes a ruling in a court case or a general creates a plan of attack, they must have as many relevant facts as possible. The best courses of action come from informed decisions, and information and data are synonymous.
The concept of data collection isn’t a new one, as we’ll see later, but the world has changed. There is far more data available today, and it exists in forms that were unheard of a century ago. The data collection process has had to change and grow with the times, keeping pace with technology.
Whether you’re in the world of academia, trying to conduct research, or part of the commercial sector, thinking of how to promote a new product, you need data collection to help you make better choices.
Now that you know what is data collection and why we need it, let's take a look at the different methods of data collection. While the phrase “data collection” may sound all high-tech and digital, it doesn’t necessarily entail things like computers, big data , and the internet. Data collection could mean a telephone survey, a mail-in comment card, or even some guy with a clipboard asking passersby some questions. But let’s see if we can sort the different data collection methods into a semblance of organized categories.
Primary and secondary methods of data collection are two approaches used to gather information for research or analysis purposes. Let's explore each data collection method in detail:
1. Primary Data Collection:
Primary data collection involves the collection of original data directly from the source or through direct interaction with the respondents. This method allows researchers to obtain firsthand information specifically tailored to their research objectives. There are various techniques for primary data collection, including:
a. Surveys and Questionnaires: Researchers design structured questionnaires or surveys to collect data from individuals or groups. These can be conducted through face-to-face interviews, telephone calls, mail, or online platforms.
b. Interviews: Interviews involve direct interaction between the researcher and the respondent. They can be conducted in person, over the phone, or through video conferencing. Interviews can be structured (with predefined questions), semi-structured (allowing flexibility), or unstructured (more conversational).
c. Observations: Researchers observe and record behaviors, actions, or events in their natural setting. This method is useful for gathering data on human behavior, interactions, or phenomena without direct intervention.
d. Experiments: Experimental studies involve the manipulation of variables to observe their impact on the outcome. Researchers control the conditions and collect data to draw conclusions about cause-and-effect relationships.
e. Focus Groups: Focus groups bring together a small group of individuals who discuss specific topics in a moderated setting. This method helps in understanding opinions, perceptions, and experiences shared by the participants.
2. Secondary Data Collection:
Secondary data collection involves using existing data collected by someone else for a purpose different from the original intent. Researchers analyze and interpret this data to extract relevant information. Secondary data can be obtained from various sources, including:
a. Published Sources: Researchers refer to books, academic journals, magazines, newspapers, government reports, and other published materials that contain relevant data.
b. Online Databases: Numerous online databases provide access to a wide range of secondary data, such as research articles, statistical information, economic data, and social surveys.
c. Government and Institutional Records: Government agencies, research institutions, and organizations often maintain databases or records that can be used for research purposes.
d. Publicly Available Data: Data shared by individuals, organizations, or communities on public platforms, websites, or social media can be accessed and utilized for research.
e. Past Research Studies: Previous research studies and their findings can serve as valuable secondary data sources. Researchers can review and analyze the data to gain insights or build upon existing knowledge.
Now that we’ve explained the various techniques, let’s narrow our focus even further by looking at some specific tools. For example, we mentioned interviews as a technique, but we can further break that down into different interview types (or “tools”).
Word Association
The researcher gives the respondent a set of words and asks them what comes to mind when they hear each word.
Sentence Completion
Researchers use sentence completion to understand what kind of ideas the respondent has. This tool involves giving an incomplete sentence and seeing how the interviewee finishes it.
Role-Playing
Respondents are presented with an imaginary situation and asked how they would act or react if it was real.
In-Person Surveys
The researcher asks questions in person.
Online/Web Surveys
These surveys are easy to accomplish, but some users may be unwilling to answer truthfully, if at all.
Mobile Surveys
These surveys take advantage of the increasing proliferation of mobile technology. Mobile collection surveys rely on mobile devices like tablets or smartphones to conduct surveys via SMS or mobile apps.
Phone Surveys
No researcher can call thousands of people at once, so they need a third party to handle the chore. However, many people have call screening and won’t answer.
Observation
Sometimes, the simplest method is the best. Researchers who make direct observations collect data quickly and easily, with little intrusion or third-party bias. Naturally, it’s only effective in small-scale situations.
Accurate data collecting is crucial to preserving the integrity of research, regardless of the subject of study or preferred method for defining data (quantitative, qualitative). Errors are less likely to occur when the right data gathering tools are used (whether they are brand-new ones, updated versions of them, or already available).
Among the effects of data collection done incorrectly, include the following -
- Erroneous conclusions that squander resources
- Decisions that compromise public policy
- Incapacity to correctly respond to research inquiries
- Bringing harm to participants who are humans or animals
- Deceiving other researchers into pursuing futile research avenues
- The study's inability to be replicated and validated
When these study findings are used to support recommendations for public policy, there is the potential to result in disproportionate harm, even if the degree of influence from flawed data collecting may vary by discipline and the type of investigation.
Let us now look at the various issues that we might face while maintaining the integrity of data collection.
In order to assist the errors detection process in the data gathering process, whether they were done purposefully (deliberate falsifications) or not, maintaining data integrity is the main justification (systematic or random errors).
Quality assurance and quality control are two strategies that help protect data integrity and guarantee the scientific validity of study results.
Each strategy is used at various stages of the research timeline:
- Quality control - tasks that are performed both after and during data collecting
- Quality assurance - events that happen before data gathering starts
Let us explore each of them in more detail now.
Quality Assurance
As data collecting comes before quality assurance, its primary goal is "prevention" (i.e., forestalling problems with data collection). The best way to protect the accuracy of data collection is through prevention. The uniformity of protocol created in the thorough and exhaustive procedures manual for data collecting serves as the best example of this proactive step.
The likelihood of failing to spot issues and mistakes early in the research attempt increases when guides are written poorly. There are several ways to show these shortcomings:
- Failure to determine the precise subjects and methods for retraining or training staff employees in data collecting
- List of goods to be collected, in part
- There isn't a system in place to track modifications to processes that may occur as the investigation continues.
- Instead of detailed, step-by-step instructions on how to deliver tests, there is a vague description of the data gathering tools that will be employed.
- Uncertainty regarding the date, procedure, and identity of the person or people in charge of examining the data
- Incomprehensible guidelines for using, adjusting, and calibrating the data collection equipment.
Now, let us look at how to ensure Quality Control.
Become a Data Scientist With Real-World Experience
Quality Control
Despite the fact that quality control actions (detection/monitoring and intervention) take place both after and during data collection, the specifics should be meticulously detailed in the procedures manual. Establishing monitoring systems requires a specific communication structure, which is a prerequisite. Following the discovery of data collection problems, there should be no ambiguity regarding the information flow between the primary investigators and staff personnel. A poorly designed communication system promotes slack oversight and reduces opportunities for error detection.
Direct staff observation conference calls, during site visits, or frequent or routine assessments of data reports to spot discrepancies, excessive numbers, or invalid codes can all be used as forms of detection or monitoring. Site visits might not be appropriate for all disciplines. Still, without routine auditing of records, whether qualitative or quantitative, it will be challenging for investigators to confirm that data gathering is taking place in accordance with the manual's defined methods. Additionally, quality control determines the appropriate solutions, or "actions," to fix flawed data gathering procedures and reduce recurrences.
Problems with data collection, for instance, that call for immediate action include:
- Fraud or misbehavior
- Systematic mistakes, procedure violations
- Individual data items with errors
- Issues with certain staff members or a site's performance
Researchers are trained to include one or more secondary measures that can be used to verify the quality of information being obtained from the human subject in the social and behavioral sciences where primary data collection entails using human subjects.
For instance, a researcher conducting a survey would be interested in learning more about the prevalence of risky behaviors among young adults as well as the social factors that influence these risky behaviors' propensity for and frequency. Let us now explore the common challenges with regard to data collection.
There are some prevalent challenges faced while collecting data, let us explore a few of them to understand them better and avoid them.
Data Quality Issues
The main threat to the broad and successful application of machine learning is poor data quality. Data quality must be your top priority if you want to make technologies like machine learning work for you. Let's talk about some of the most prevalent data quality problems in this blog article and how to fix them.
Inconsistent Data
When working with various data sources, it's conceivable that the same information will have discrepancies between sources. The differences could be in formats, units, or occasionally spellings. The introduction of inconsistent data might also occur during firm mergers or relocations. Inconsistencies in data have a tendency to accumulate and reduce the value of data if they are not continually resolved. Organizations that have heavily focused on data consistency do so because they only want reliable data to support their analytics.
Data Downtime
Data is the driving force behind the decisions and operations of data-driven businesses. However, there may be brief periods when their data is unreliable or not prepared. Customer complaints and subpar analytical outcomes are only two ways that this data unavailability can have a significant impact on businesses. A data engineer spends about 80% of their time updating, maintaining, and guaranteeing the integrity of the data pipeline. In order to ask the next business question, there is a high marginal cost due to the lengthy operational lead time from data capture to insight.
Schema modifications and migration problems are just two examples of the causes of data downtime. Data pipelines can be difficult due to their size and complexity. Data downtime must be continuously monitored, and it must be reduced through automation.
Ambiguous Data
Even with thorough oversight, some errors can still occur in massive databases or data lakes. For data streaming at a fast speed, the issue becomes more overwhelming. Spelling mistakes can go unnoticed, formatting difficulties can occur, and column heads might be deceptive. This unclear data might cause a number of problems for reporting and analytics.
Become a Data Science Expert & Get Your Dream Job
Duplicate Data
Streaming data, local databases, and cloud data lakes are just a few of the sources of data that modern enterprises must contend with. They might also have application and system silos. These sources are likely to duplicate and overlap each other quite a bit. For instance, duplicate contact information has a substantial impact on customer experience. If certain prospects are ignored while others are engaged repeatedly, marketing campaigns suffer. The likelihood of biased analytical outcomes increases when duplicate data are present. It can also result in ML models with biased training data.
Too Much Data
While we emphasize data-driven analytics and its advantages, a data quality problem with excessive data exists. There is a risk of getting lost in an abundance of data when searching for information pertinent to your analytical efforts. Data scientists, data analysts, and business users devote 80% of their work to finding and organizing the appropriate data. With an increase in data volume, other problems with data quality become more serious, particularly when dealing with streaming data and big files or databases.
Inaccurate Data
For highly regulated businesses like healthcare, data accuracy is crucial. Given the current experience, it is more important than ever to increase the data quality for COVID-19 and later pandemics. Inaccurate information does not provide you with a true picture of the situation and cannot be used to plan the best course of action. Personalized customer experiences and marketing strategies underperform if your customer data is inaccurate.
Data inaccuracies can be attributed to a number of things, including data degradation, human mistake, and data drift. Worldwide data decay occurs at a rate of about 3% per month, which is quite concerning. Data integrity can be compromised while being transferred between different systems, and data quality might deteriorate with time.
Hidden Data
The majority of businesses only utilize a portion of their data, with the remainder sometimes being lost in data silos or discarded in data graveyards. For instance, the customer service team might not receive client data from sales, missing an opportunity to build more precise and comprehensive customer profiles. Missing out on possibilities to develop novel products, enhance services, and streamline procedures is caused by hidden data.
Finding Relevant Data
Finding relevant data is not so easy. There are several factors that we need to consider while trying to find relevant data, which include -
- Relevant Domain
- Relevant demographics
- Relevant Time period and so many more factors that we need to consider while trying to find relevant data.
Data that is not relevant to our study in any of the factors render it obsolete and we cannot effectively proceed with its analysis. This could lead to incomplete research or analysis, re-collecting data again and again, or shutting down the study.
Deciding the Data to Collect
Determining what data to collect is one of the most important factors while collecting data and should be one of the first factors while collecting data. We must choose the subjects the data will cover, the sources we will be used to gather it, and the quantity of information we will require. Our responses to these queries will depend on our aims, or what we expect to achieve utilizing your data. As an illustration, we may choose to gather information on the categories of articles that website visitors between the ages of 20 and 50 most frequently access. We can also decide to compile data on the typical age of all the clients who made a purchase from your business over the previous month.
Not addressing this could lead to double work and collection of irrelevant data or ruining your study as a whole.
Dealing With Big Data
Big data refers to exceedingly massive data sets with more intricate and diversified structures. These traits typically result in increased challenges while storing, analyzing, and using additional methods of extracting results. Big data refers especially to data sets that are quite enormous or intricate that conventional data processing tools are insufficient. The overwhelming amount of data, both unstructured and structured, that a business faces on a daily basis.
The amount of data produced by healthcare applications, the internet, social networking sites social, sensor networks, and many other businesses are rapidly growing as a result of recent technological advancements. Big data refers to the vast volume of data created from numerous sources in a variety of formats at extremely fast rates. Dealing with this kind of data is one of the many challenges of Data Collection and is a crucial step toward collecting effective data.
Low Response and Other Research Issues
Poor design and low response rates were shown to be two issues with data collecting, particularly in health surveys that used questionnaires. This might lead to an insufficient or inadequate supply of data for the study. Creating an incentivized data collection program might be beneficial in this case to get more responses.
Now, let us look at the key steps in the data collection process.
In the Data Collection Process, there are 5 key steps. They are explained briefly below -
1. Decide What Data You Want to Gather
The first thing that we need to do is decide what information we want to gather. We must choose the subjects the data will cover, the sources we will use to gather it, and the quantity of information that we would require. For instance, we may choose to gather information on the categories of products that an average e-commerce website visitor between the ages of 30 and 45 most frequently searches for.
2. Establish a Deadline for Data Collection
The process of creating a strategy for data collection can now begin. We should set a deadline for our data collection at the outset of our planning phase. Some forms of data we might want to continuously collect. We might want to build up a technique for tracking transactional data and website visitor statistics over the long term, for instance. However, we will track the data throughout a certain time frame if we are tracking it for a particular campaign. In these situations, we will have a schedule for when we will begin and finish gathering data.
3. Select a Data Collection Approach
We will select the data collection technique that will serve as the foundation of our data gathering plan at this stage. We must take into account the type of information that we wish to gather, the time period during which we will receive it, and the other factors we decide on to choose the best gathering strategy.
4. Gather Information
Once our plan is complete, we can put our data collection plan into action and begin gathering data. In our DMP, we can store and arrange our data. We need to be careful to follow our plan and keep an eye on how it's doing. Especially if we are collecting data regularly, setting up a timetable for when we will be checking in on how our data gathering is going may be helpful. As circumstances alter and we learn new details, we might need to amend our plan.
5. Examine the Information and Apply Your Findings
It's time to examine our data and arrange our findings after we have gathered all of our information. The analysis stage is essential because it transforms unprocessed data into insightful knowledge that can be applied to better our marketing plans, goods, and business judgments. The analytics tools included in our DMP can be used to assist with this phase. We can put the discoveries to use to enhance our business once we have discovered the patterns and insights in our data.
Let us now look at some data collection considerations and best practices that one might follow.
We must carefully plan before spending time and money traveling to the field to gather data. While saving time and resources, effective data collection strategies can help us collect richer, more accurate, and richer data.
Below, we will be discussing some of the best practices that we can follow for the best results -
1. Take Into Account the Price of Each Extra Data Point
Once we have decided on the data we want to gather, we need to make sure to take the expense of doing so into account. Our surveyors and respondents will incur additional costs for each additional data point or survey question.
2. Plan How to Gather Each Data Piece
There is a dearth of freely accessible data. Sometimes the data is there, but we may not have access to it. For instance, unless we have a compelling cause, we cannot openly view another person's medical information. It could be challenging to measure several types of information.
Consider how time-consuming and difficult it will be to gather each piece of information while deciding what data to acquire.
3. Think About Your Choices for Data Collecting Using Mobile Devices
Mobile-based data collecting can be divided into three categories -
- IVRS (interactive voice response technology) - Will call the respondents and ask them questions that have already been recorded.
- SMS data collection - Will send a text message to the respondent, who can then respond to questions by text on their phone.
- Field surveyors - Can directly enter data into an interactive questionnaire while speaking to each respondent, thanks to smartphone apps.
We need to make sure to select the appropriate tool for our survey and responders because each one has its own disadvantages and advantages.
4. Carefully Consider the Data You Need to Gather
It's all too easy to get information about anything and everything, but it's crucial to only gather the information that we require.
It is helpful to consider these 3 questions:
- What details will be helpful?
- What details are available?
- What specific details do you require?
5. Remember to Consider Identifiers
Identifiers, or details describing the context and source of a survey response, are just as crucial as the information about the subject or program that we are actually researching.
In general, adding more identifiers will enable us to pinpoint our program's successes and failures with greater accuracy, but moderation is the key.
6. Data Collecting Through Mobile Devices is the Way to Go
Although collecting data on paper is still common, modern technology relies heavily on mobile devices. They enable us to gather many various types of data at relatively lower prices and are accurate as well as quick. There aren't many reasons not to pick mobile-based data collecting with the boom of low-cost Android devices that are available nowadays.
The Ultimate Ticket to Top Data Science Job Roles
1. What is data collection with example?
Data collection is the process of collecting and analyzing information on relevant variables in a predetermined, methodical way so that one can respond to specific research questions, test hypotheses, and assess results. Data collection can be either qualitative or quantitative. Example: A company collects customer feedback through online surveys and social media monitoring to improve their products and services.
2. What are the primary data collection methods?
As is well known, gathering primary data is costly and time intensive. The main techniques for gathering data are observation, interviews, questionnaires, schedules, and surveys.
3. What are data collection tools?
The term "data collecting tools" refers to the tools/devices used to gather data, such as a paper questionnaire or a system for computer-assisted interviews. Tools used to gather data include case studies, checklists, interviews, occasionally observation, surveys, and questionnaires.
4. What’s the difference between quantitative and qualitative methods?
While qualitative research focuses on words and meanings, quantitative research deals with figures and statistics. You can systematically measure variables and test hypotheses using quantitative methods. You can delve deeper into ideas and experiences using qualitative methodologies.
5. What are quantitative data collection methods?
While there are numerous other ways to get quantitative information, the methods indicated above—probability sampling, interviews, questionnaire observation, and document review—are the most typical and frequently employed, whether collecting information offline or online.
6. What is mixed methods research?
User research that includes both qualitative and quantitative techniques is known as mixed methods research. For deeper user insights, mixed methods research combines insightful user data with useful statistics.
7. What are the benefits of collecting data?
Collecting data offers several benefits, including:
- Knowledge and Insight
- Evidence-Based Decision Making
- Problem Identification and Solution
- Validation and Evaluation
- Identifying Trends and Predictions
- Support for Research and Development
- Policy Development
- Quality Improvement
- Personalization and Targeting
- Knowledge Sharing and Collaboration
8. What’s the difference between reliability and validity?
Reliability is about consistency and stability, while validity is about accuracy and appropriateness. Reliability focuses on the consistency of results, while validity focuses on whether the results are actually measuring what they are intended to measure. Both reliability and validity are crucial considerations in research to ensure the trustworthiness and meaningfulness of the collected data and measurements.
Are you thinking about pursuing a career in the field of data science? Simplilearn's Data Science courses are designed to provide you with the necessary skills and expertise to excel in this rapidly changing field. Here's a detailed comparison for your reference:
Program Name Data Scientist Master's Program Post Graduate Program In Data Science Post Graduate Program In Data Science Geo All Geos All Geos Not Applicable in US University Simplilearn Purdue Caltech Course Duration 11 Months 11 Months 11 Months Coding Experience Required Basic Basic No Skills You Will Learn 10+ skills including data structure, data manipulation, NumPy, Scikit-Learn, Tableau and more 8+ skills including Exploratory Data Analysis, Descriptive Statistics, Inferential Statistics, and more 8+ skills including Supervised & Unsupervised Learning Deep Learning Data Visualization, and more Additional Benefits Applied Learning via Capstone and 25+ Data Science Projects Purdue Alumni Association Membership Free IIMJobs Pro-Membership of 6 months Resume Building Assistance Upto 14 CEU Credits Caltech CTME Circle Membership Cost $$ $$$$ $$$$ Explore Program Explore Program Explore Program
We live in the Data Age, and if you want a career that fully takes advantage of this, you should consider a career in data science. Simplilearn offers a Caltech Post Graduate Program in Data Science that will train you in everything you need to know to secure the perfect position. This Data Science PG program is ideal for all working professionals, covering job-critical topics like R, Python programming , machine learning algorithms , NLP concepts , and data visualization with Tableau in great detail. This is all provided via our interactive learning model with live sessions by global practitioners, practical labs, and industry projects.
Data Science & Business Analytics Courses Duration and Fees
Data Science & Business Analytics programs typically range from a few weeks to several months, with fees varying based on program and institution.
Recommended Reads
Data Science Career Guide: A Comprehensive Playbook To Becoming A Data Scientist
Difference Between Collection and Collections in Java
An Ultimate One-Stop Solution Guide to Collections in C# Programming With Examples
Managing Data
Capped Collection in MongoDB
What Are Java Collections and How to Implement Them?
Get Affiliated Certifications with Live Class programs
Data scientist.
- Industry-recognized Data Scientist Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
Caltech Data Sciences-Bootcamp
- Exclusive visit to Caltech’s Robotics Lab
Caltech Post Graduate Program in Data Science
- Earn a program completion certificate from Caltech CTME
- Curriculum delivered in live online sessions by industry experts
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
- 7 Data Collection Methods & Tools For Research

- Data Collection
The underlying need for Data collection is to capture quality evidence that seeks to answer all the questions that have been posed. Through data collection businesses or management can deduce quality information that is a prerequisite for making informed decisions.
To improve the quality of information, it is expedient that data is collected so that you can draw inferences and make informed decisions on what is considered factual.
At the end of this article, you would understand why picking the best data collection method is necessary for achieving your set objective.
Sign up on Formplus Builder to create your preferred online surveys or questionnaire for data collection. You don’t need to be tech-savvy! Start creating quality questionnaires with Formplus.
What is Data Collection?
Data collection is a methodical process of gathering and analyzing specific information to proffer solutions to relevant questions and evaluate the results. It focuses on finding out all there is to a particular subject matter. Data is collected to be further subjected to hypothesis testing which seeks to explain a phenomenon.
Hypothesis testing eliminates assumptions while making a proposition from the basis of reason.

For collectors of data, there is a range of outcomes for which the data is collected. But the key purpose for which data is collected is to put a researcher in a vantage position to make predictions about future probabilities and trends.
The core forms in which data can be collected are primary and secondary data. While the former is collected by a researcher through first-hand sources, the latter is collected by an individual other than the user.
Types of Data Collection
Before broaching the subject of the various types of data collection. It is pertinent to note that data collection in itself falls under two broad categories; Primary data collection and secondary data collection.
Primary Data Collection
Primary data collection by definition is the gathering of raw data collected at the source. It is a process of collecting the original data collected by a researcher for a specific research purpose. It could be further analyzed into two segments; qualitative research and quantitative data collection methods.
- Qualitative Research Method
The qualitative research methods of data collection do not involve the collection of data that involves numbers or a need to be deduced through a mathematical calculation, rather it is based on the non-quantifiable elements like the feeling or emotion of the researcher. An example of such a method is an open-ended questionnaire.

- Quantitative Method
Quantitative methods are presented in numbers and require a mathematical calculation to deduce. An example would be the use of a questionnaire with close-ended questions to arrive at figures to be calculated Mathematically. Also, methods of correlation and regression, mean, mode and median.

Read Also: 15 Reasons to Choose Quantitative over Qualitative Research
Secondary Data Collection
Secondary data collection, on the other hand, is referred to as the gathering of second-hand data collected by an individual who is not the original user. It is the process of collecting data that is already existing, be it already published books, journals, and/or online portals. In terms of ease, it is much less expensive and easier to collect.
Your choice between Primary data collection and secondary data collection depends on the nature, scope, and area of your research as well as its aims and objectives.
Importance of Data Collection
There are a bunch of underlying reasons for collecting data, especially for a researcher. Walking you through them, here are a few reasons;
- Integrity of the Research
A key reason for collecting data, be it through quantitative or qualitative methods is to ensure that the integrity of the research question is indeed maintained.
- Reduce the likelihood of errors
The correct use of appropriate data collection of methods reduces the likelihood of errors consistent with the results.
- Decision Making
To minimize the risk of errors in decision-making, it is important that accurate data is collected so that the researcher doesn’t make uninformed decisions.
- Save Cost and Time
Data collection saves the researcher time and funds that would otherwise be misspent without a deeper understanding of the topic or subject matter.
- To support a need for a new idea, change, and/or innovation
To prove the need for a change in the norm or the introduction of new information that will be widely accepted, it is important to collect data as evidence to support these claims.
What is a Data Collection Tool?
Data collection tools refer to the devices/instruments used to collect data, such as a paper questionnaire or computer-assisted interviewing system. Case Studies, Checklists, Interviews, Observation sometimes, and Surveys or Questionnaires are all tools used to collect data.
It is important to decide on the tools for data collection because research is carried out in different ways and for different purposes. The objective behind data collection is to capture quality evidence that allows analysis to lead to the formulation of convincing and credible answers to the posed questions.
The objective behind data collection is to capture quality evidence that allows analysis to lead to the formulation of convincing and credible answers to the questions that have been posed – Click to Tweet
The Formplus online data collection tool is perfect for gathering primary data, i.e. raw data collected from the source. You can easily get data with at least three data collection methods with our online and offline data-gathering tool. I.e Online Questionnaires , Focus Groups, and Reporting.
In our previous articles, we’ve explained why quantitative research methods are more effective than qualitative methods . However, with the Formplus data collection tool, you can gather all types of primary data for academic, opinion or product research.
Top Data Collection Methods and Tools for Academic, Opinion, or Product Research
The following are the top 7 data collection methods for Academic, Opinion-based, or product research. Also discussed in detail are the nature, pros, and cons of each one. At the end of this segment, you will be best informed about which method best suits your research.
An interview is a face-to-face conversation between two individuals with the sole purpose of collecting relevant information to satisfy a research purpose. Interviews are of different types namely; Structured, Semi-structured , and unstructured with each having a slight variation from the other.
Use this interview consent form template to let an interviewee give you consent to use data gotten from your interviews for investigative research purposes.
- Structured Interviews – Simply put, it is a verbally administered questionnaire. In terms of depth, it is surface level and is usually completed within a short period. For speed and efficiency, it is highly recommendable, but it lacks depth.
- Semi-structured Interviews – In this method, there subsist several key questions which cover the scope of the areas to be explored. It allows a little more leeway for the researcher to explore the subject matter.
- Unstructured Interviews – It is an in-depth interview that allows the researcher to collect a wide range of information with a purpose. An advantage of this method is the freedom it gives a researcher to combine structure with flexibility even though it is more time-consuming.
- In-depth information
- Freedom of flexibility
- Accurate data.
- Time-consuming
- Expensive to collect.
What are The Best Data Collection Tools for Interviews?
For collecting data through interviews, here are a few tools you can use to easily collect data.
- Audio Recorder
An audio recorder is used for recording sound on disc, tape, or film. Audio information can meet the needs of a wide range of people, as well as provide alternatives to print data collection tools.
- Digital Camera
An advantage of a digital camera is that it can be used for transmitting those images to a monitor screen when the need arises.
A camcorder is used for collecting data through interviews. It provides a combination of both an audio recorder and a video camera. The data provided is qualitative in nature and allows the respondents to answer questions asked exhaustively. If you need to collect sensitive information during an interview, a camcorder might not work for you as you would need to maintain your subject’s privacy.
Want to conduct an interview for qualitative data research or a special report? Use this online interview consent form template to allow the interviewee to give their consent before you use the interview data for research or report. With premium features like e-signature, upload fields, form security, etc., Formplus Builder is the perfect tool to create your preferred online consent forms without coding experience.
- QUESTIONNAIRES
This is the process of collecting data through an instrument consisting of a series of questions and prompts to receive a response from the individuals it is administered to. Questionnaires are designed to collect data from a group.
For clarity, it is important to note that a questionnaire isn’t a survey, rather it forms a part of it. A survey is a process of data gathering involving a variety of data collection methods, including a questionnaire.
On a questionnaire, there are three kinds of questions used. They are; fixed-alternative, scale, and open-ended. With each of the questions tailored to the nature and scope of the research.
- Can be administered in large numbers and is cost-effective.
- It can be used to compare and contrast previous research to measure change.
- Easy to visualize and analyze.
- Questionnaires offer actionable data.
- Respondent identity is protected.
- Questionnaires can cover all areas of a topic.
- Relatively inexpensive.
- Answers may be dishonest or the respondents lose interest midway.
- Questionnaires can’t produce qualitative data.
- Questions might be left unanswered.
- Respondents may have a hidden agenda.
- Not all questions can be analyzed easily.
What are the Best Data Collection Tools for Questionnaires?
- Formplus Online Questionnaire
Formplus lets you create powerful forms to help you collect the information you need. Formplus helps you create the online forms that you like. The Formplus online questionnaire form template to get actionable trends and measurable responses. Conduct research, optimize knowledge of your brand or just get to know an audience with this form template. The form template is fast, free and fully customizable.
- Paper Questionnaire
A paper questionnaire is a data collection tool consisting of a series of questions and/or prompts for the purpose of gathering information from respondents. Mostly designed for statistical analysis of the responses, they can also be used as a form of data collection.
By definition, data reporting is the process of gathering and submitting data to be further subjected to analysis. The key aspect of data reporting is reporting accurate data because inaccurate data reporting leads to uninformed decision-making.
- Informed decision-making.
- Easily accessible.
- Self-reported answers may be exaggerated.
- The results may be affected by bias.
- Respondents may be too shy to give out all the details.
- Inaccurate reports will lead to uninformed decisions.
What are the Best Data Collection Tools for Reporting?
Reporting tools enable you to extract and present data in charts, tables, and other visualizations so users can find useful information. You could source data for reporting from Non-Governmental Organizations (NGO) reports, newspapers, website articles, and hospital records.
- NGO Reports
Contained in NGO report is an in-depth and comprehensive report on the activities carried out by the NGO, covering areas such as business and human rights. The information contained in these reports is research-specific and forms an acceptable academic base for collecting data. NGOs often focus on development projects which are organized to promote particular causes.
Newspaper data are relatively easy to collect and are sometimes the only continuously available source of event data. Even though there is a problem of bias in newspaper data, it is still a valid tool in collecting data for Reporting.
- Website Articles
Gathering and using data contained in website articles is also another tool for data collection. Collecting data from web articles is a quicker and less expensive data collection Two major disadvantages of using this data reporting method are biases inherent in the data collection process and possible security/confidentiality concerns.
- Hospital Care records
Health care involves a diverse set of public and private data collection systems, including health surveys, administrative enrollment and billing records, and medical records, used by various entities, including hospitals, CHCs, physicians, and health plans. The data provided is clear, unbiased and accurate, but must be obtained under legal means as medical data is kept with the strictest regulations.
- EXISTING DATA
This is the introduction of new investigative questions in addition to/other than the ones originally used when the data was initially gathered. It involves adding measurement to a study or research. An example would be sourcing data from an archive.
- Accuracy is very high.
- Easily accessible information.
- Problems with evaluation.
- Difficulty in understanding.
What are the Best Data Collection Tools for Existing Data?
The concept of Existing data means that data is collected from existing sources to investigate research questions other than those for which the data were originally gathered. Tools to collect existing data include:
- Research Journals – Unlike newspapers and magazines, research journals are intended for an academic or technical audience, not general readers. A journal is a scholarly publication containing articles written by researchers, professors, and other experts.
- Surveys – A survey is a data collection tool for gathering information from a sample population, with the intention of generalizing the results to a larger population. Surveys have a variety of purposes and can be carried out in many ways depending on the objectives to be achieved.
- OBSERVATION
This is a data collection method by which information on a phenomenon is gathered through observation. The nature of the observation could be accomplished either as a complete observer, an observer as a participant, a participant as an observer, or as a complete participant. This method is a key base for formulating a hypothesis.
- Easy to administer.
- There subsists a greater accuracy with results.
- It is a universally accepted practice.
- It diffuses the situation of the unwillingness of respondents to administer a report.
- It is appropriate for certain situations.
- Some phenomena aren’t open to observation.
- It cannot be relied upon.
- Bias may arise.
- It is expensive to administer.
- Its validity cannot be predicted accurately.
What are the Best Data Collection Tools for Observation?
Observation involves the active acquisition of information from a primary source. Observation can also involve the perception and recording of data via the use of scientific instruments. The best tools for Observation are:
- Checklists – state-specific criteria, that allow users to gather information and make judgments about what they should know in relation to the outcomes. They offer systematic ways of collecting data about specific behaviors, knowledge, and skills.
- Direct observation – This is an observational study method of collecting evaluative information. The evaluator watches the subject in his or her usual environment without altering that environment.
FOCUS GROUPS
The opposite of quantitative research which involves numerical-based data, this data collection method focuses more on qualitative research. It falls under the primary category of data based on the feelings and opinions of the respondents. This research involves asking open-ended questions to a group of individuals usually ranging from 6-10 people, to provide feedback.
- Information obtained is usually very detailed.
- Cost-effective when compared to one-on-one interviews.
- It reflects speed and efficiency in the supply of results.
- Lacking depth in covering the nitty-gritty of a subject matter.
- Bias might still be evident.
- Requires interviewer training
- The researcher has very little control over the outcome.
- A few vocal voices can drown out the rest.
- Difficulty in assembling an all-inclusive group.
What are the Best Data Collection Tools for Focus Groups?
A focus group is a data collection method that is tightly facilitated and structured around a set of questions. The purpose of the meeting is to extract from the participants’ detailed responses to these questions. The best tools for tackling Focus groups are:
- Two-Way – One group watches another group answer the questions posed by the moderator. After listening to what the other group has to offer, the group that listens is able to facilitate more discussion and could potentially draw different conclusions .
- Dueling-Moderator – There are two moderators who play the devil’s advocate. The main positive of the dueling-moderator focus group is to facilitate new ideas by introducing new ways of thinking and varying viewpoints.
- COMBINATION RESEARCH
This method of data collection encompasses the use of innovative methods to enhance participation in both individuals and groups. Also under the primary category, it is a combination of Interviews and Focus Groups while collecting qualitative data . This method is key when addressing sensitive subjects.
- Encourage participants to give responses.
- It stimulates a deeper connection between participants.
- The relative anonymity of respondents increases participation.
- It improves the richness of the data collected.
- It costs the most out of all the top 7.
- It’s the most time-consuming.
What are the Best Data Collection Tools for Combination Research?
The Combination Research method involves two or more data collection methods, for instance, interviews as well as questionnaires or a combination of semi-structured telephone interviews and focus groups. The best tools for combination research are:
- Online Survey – The two tools combined here are online interviews and the use of questionnaires. This is a questionnaire that the target audience can complete over the Internet. It is timely, effective, and efficient. Especially since the data to be collected is quantitative in nature.
- Dual-Moderator – The two tools combined here are focus groups and structured questionnaires. The structured questionnaires give a direction as to where the research is headed while two moderators take charge of the proceedings. Whilst one ensures the focus group session progresses smoothly, the other makes sure that the topics in question are all covered. Dual-moderator focus groups typically result in a more productive session and essentially lead to an optimum collection of data.
Why Formplus is the Best Data Collection Tool
- Vast Options for Form Customization
With Formplus, you can create your unique survey form. With options to change themes, font color, font, font type, layout, width, and more, you can create an attractive survey form. The builder also gives you as many features as possible to choose from and you do not need to be a graphic designer to create a form.
- Extensive Analytics
Form Analytics, a feature in formplus helps you view the number of respondents, unique visits, total visits, abandonment rate, and average time spent before submission. This tool eliminates the need for a manual calculation of the received data and/or responses as well as the conversion rate for your poll.
- Embed Survey Form on Your Website
Copy the link to your form and embed it as an iframe which will automatically load as your website loads, or as a popup that opens once the respondent clicks on the link. Embed the link on your Twitter page to give instant access to your followers.
.png?resize=845%2C418&ssl=1 "a research data collection")
- Geolocation Support
The geolocation feature on Formplus lets you ascertain where individual responses are coming. It utilises Google Maps to pinpoint the longitude and latitude of the respondent, to the nearest accuracy, along with the responses.
- Multi-Select feature
This feature helps to conserve horizontal space as it allows you to put multiple options in one field. This translates to including more information on the survey form.
Read Also: 10 Reasons to Use Formplus for Online Data Collection
How to Use Formplus to collect online data in 7 simple steps.
- Register or sign up on Formplus builder : Start creating your preferred questionnaire or survey by signing up with either your Google, Facebook, or Email account.

Formplus gives you a free plan with basic features you can use to collect online data. Pricing plans with vast features starts at $20 monthly, with reasonable discounts for Education and Non-Profit Organizations.
2. Input your survey title and use the form builder choice options to start creating your surveys.
Use the choice option fields like single select, multiple select, checkbox, radio, and image choices to create your preferred multi-choice surveys online.

3. Do you want customers to rate any of your products or services delivery?
Use the rating to allow survey respondents rate your products or services. This is an ideal quantitative research method of collecting data.

4. Beautify your online questionnaire with Formplus Customisation features.

- Change the theme color
- Add your brand’s logo and image to the forms
- Change the form width and layout
- Edit the submission button if you want
- Change text font color and sizes
- Do you have already made custom CSS to beautify your questionnaire? If yes, just copy and paste it to the CSS option.
5. Edit your survey questionnaire settings for your specific needs
Choose where you choose to store your files and responses. Select a submission deadline, choose a timezone, limit respondents’ responses, enable Captcha to prevent spam, and collect location data of customers.

Set an introductory message to respondents before they begin the survey, toggle the “start button” post final submission message or redirect respondents to another page when they submit their questionnaires.
Change the Email Notifications inventory and initiate an autoresponder message to all your survey questionnaire respondents. You can also transfer your forms to other users who can become form administrators.
6. Share links to your survey questionnaire page with customers.
There’s an option to copy and share the link as “Popup” or “Embed code” The data collection tool automatically creates a QR Code for Survey Questionnaire which you can download and share as appropriate.

Congratulations if you’ve made it to this stage. You can start sharing the link to your survey questionnaire with your customers.
7. View your Responses to the Survey Questionnaire
Toggle with the presentation of your summary from the options. Whether as a single, table or cards.

8. Allow Formplus Analytics to interpret your Survey Questionnaire Data

With online form builder analytics, a business can determine;
- The number of times the survey questionnaire was filled
- The number of customers reached
- Abandonment Rate: The rate at which customers exit the form without submitting it.
- Conversion Rate: The percentage of customers who completed the online form
- Average time spent per visit
- Location of customers/respondents.
- The type of device used by the customer to complete the survey questionnaire.
7 Tips to Create The Best Surveys For Data Collections
- Define the goal of your survey – Once the goal of your survey is outlined, it will aid in deciding which questions are the top priority. A clear attainable goal would, for example, mirror a clear reason as to why something is happening. e.g. “The goal of this survey is to understand why Employees are leaving an establishment.”
- Use close-ended clearly defined questions – Avoid open-ended questions and ensure you’re not suggesting your preferred answer to the respondent. If possible offer a range of answers with choice options and ratings.
- Survey outlook should be attractive and Inviting – An attractive-looking survey encourages a higher number of recipients to respond to the survey. Check out Formplus Builder for colorful options to integrate into your survey design. You could use images and videos to keep participants glued to their screens.
- Assure Respondents about the safety of their data – You want your respondents to be assured whilst disclosing details of their personal information to you. It’s your duty to inform the respondents that the data they provide is confidential and only collected for the purpose of research.
- Ensure your survey can be completed in record time – Ideally, in a typical survey, users should be able to respond in 100 seconds. It is pertinent to note that they, the respondents, are doing you a favor. Don’t stress them. Be brief and get straight to the point.
- Do a trial survey – Preview your survey before sending out your surveys to the intended respondents. Make a trial version which you’ll send to a few individuals. Based on their responses, you can draw inferences and decide whether or not your survey is ready for the big time.
- Attach a reward upon completion for users – Give your respondents something to look forward to at the end of the survey. Think of it as a penny for their troubles. It could well be the encouragement they need to not abandon the survey midway.
Try out Formplus today . You can start making your own surveys with the Formplus online survey builder. By applying these tips, you will definitely get the most out of your online surveys.
Top Survey Templates For Data Collection
- Customer Satisfaction Survey Template
On the template, you can collect data to measure customer satisfaction over key areas like the commodity purchase and the level of service they received. It also gives insight as to which products the customer enjoyed, how often they buy such a product, and whether or not the customer is likely to recommend the product to a friend or acquaintance.
- Demographic Survey Template
With this template, you would be able to measure, with accuracy, the ratio of male to female, age range, and the number of unemployed persons in a particular country as well as obtain their personal details such as names and addresses.
Respondents are also able to state their religious and political views about the country under review.
- Feedback Form Template
Contained in the template for the online feedback form is the details of a product and/or service used. Identifying this product or service and documenting how long the customer has used them.
The overall satisfaction is measured as well as the delivery of the services. The likelihood that the customer also recommends said product is also measured.
- Online Questionnaire Template
The online questionnaire template houses the respondent’s data as well as educational qualifications to collect information to be used for academic research.
Respondents can also provide their gender, race, and field of study as well as present living conditions as prerequisite data for the research study.
- Student Data Sheet Form Template
The template is a data sheet containing all the relevant information of a student. The student’s name, home address, guardian’s name, record of attendance as well as performance in school is well represented on this template. This is a perfect data collection method to deploy for a school or an education organization.
Also included is a record for interaction with others as well as a space for a short comment on the overall performance and attitude of the student.
- Interview Consent Form Template
This online interview consent form template allows the interviewee to sign off their consent to use the interview data for research or report to journalists. With premium features like short text fields, upload, e-signature, etc., Formplus Builder is the perfect tool to create your preferred online consent forms without coding experience.
What is the Best Data Collection Method for Qualitative Data?
Answer: Combination Research
The best data collection method for a researcher for gathering qualitative data which generally is data relying on the feelings, opinions, and beliefs of the respondents would be Combination Research.
The reason why combination research is the best fit is that it encompasses the attributes of Interviews and Focus Groups. It is also useful when gathering data that is sensitive in nature. It can be described as an all-purpose quantitative data collection method.
Above all, combination research improves the richness of data collected when compared with other data collection methods for qualitative data.

What is the Best Data Collection Method for Quantitative Research Data?
Ans: Questionnaire
The best data collection method a researcher can employ in gathering quantitative data which takes into consideration data that can be represented in numbers and figures that can be deduced mathematically is the Questionnaire.
These can be administered to a large number of respondents while saving costs. For quantitative data that may be bulky or voluminous in nature, the use of a Questionnaire makes such data easy to visualize and analyze.
Another key advantage of the Questionnaire is that it can be used to compare and contrast previous research work done to measure changes.
Technology-Enabled Data Collection Methods
There are so many diverse methods available now in the world because technology has revolutionized the way data is being collected. It has provided efficient and innovative methods that anyone, especially researchers and organizations. Below are some technology-enabled data collection methods:
- Online Surveys: Online surveys have gained popularity due to their ease of use and wide reach. You can distribute them through email, social media, or embed them on websites. Online surveys allow you to quickly complete data collection, automated data capture, and real-time analysis. Online surveys also offer features like skip logic, validation checks, and multimedia integration.
- Mobile Surveys: With the widespread use of smartphones, mobile surveys’ popularity is also on the rise. Mobile surveys leverage the capabilities of mobile devices, and this allows respondents to participate at their convenience. This includes multimedia elements, location-based information, and real-time feedback. Mobile surveys are the best for capturing in-the-moment experiences or opinions.
- Social Media Listening: Social media platforms are a good source of unstructured data that you can analyze to gain insights into customer sentiment and trends. Social media listening involves monitoring and analyzing social media conversations, mentions, and hashtags to understand public opinion, identify emerging topics, and assess brand reputation.
- Wearable Devices and Sensors: You can embed wearable devices, such as fitness trackers or smartwatches, and sensors in everyday objects to capture continuous data on various physiological and environmental variables. This data can provide you with insights into health behaviors, activity patterns, sleep quality, and environmental conditions, among others.
- Big Data Analytics: Big data analytics leverages large volumes of structured and unstructured data from various sources, such as transaction records, social media, and internet browsing. Advanced analytics techniques, like machine learning and natural language processing, can extract meaningful insights and patterns from this data, enabling organizations to make data-driven decisions.
Read Also: How Technology is Revolutionizing Data Collection
Faulty Data Collection Practices – Common Mistakes & Sources of Error
While technology-enabled data collection methods offer numerous advantages, there are some pitfalls and sources of error that you should be aware of. Here are some common mistakes and sources of error in data collection:
- Population Specification Error: Population specification error occurs when the target population is not clearly defined or misidentified. This error leads to a mismatch between the research objectives and the actual population being studied, resulting in biased or inaccurate findings.
- Sample Frame Error: Sample frame error occurs when the sampling frame, the list or source from which the sample is drawn, does not adequately represent the target population. This error can introduce selection bias and affect the generalizability of the findings.
- Selection Error: Selection error occurs when the process of selecting participants or units for the study introduces bias. It can happen due to nonrandom sampling methods, inadequate sampling techniques, or self-selection bias. Selection error compromises the representativeness of the sample and affects the validity of the results.
- Nonresponse Error: Nonresponse error occurs when selected participants choose not to participate or fail to respond to the data collection effort. Nonresponse bias can result in an unrepresentative sample if those who choose not to respond differ systematically from those who do respond. Efforts should be made to mitigate nonresponse and encourage participation to minimize this error.
- Measurement Error: Measurement error arises from inaccuracies or inconsistencies in the measurement process. It can happen due to poorly designed survey instruments, ambiguous questions, respondent bias, or errors in data entry or coding. Measurement errors can lead to distorted or unreliable data, affecting the validity and reliability of the findings.
In order to mitigate these errors and ensure high-quality data collection, you should carefully plan your data collection procedures, and validate measurement tools. You should also use appropriate sampling techniques, employ randomization where possible, and minimize nonresponse through effective communication and incentives. Ensure you conduct regular checks and implement validation processes, and data cleaning procedures to identify and rectify errors during data analysis.
Best Practices for Data Collection
- Clearly Define Objectives: Clearly define the research objectives and questions to guide the data collection process. This helps ensure that the collected data aligns with the research goals and provides relevant insights.
- Plan Ahead: Develop a detailed data collection plan that includes the timeline, resources needed, and specific procedures to follow. This helps maintain consistency and efficiency throughout the data collection process.
- Choose the Right Method: Select data collection methods that are appropriate for the research objectives and target population. Consider factors such as feasibility, cost-effectiveness, and the ability to capture the required data accurately.
- Pilot Test : Before full-scale data collection, conduct a pilot test to identify any issues with the data collection instruments or procedures. This allows for refinement and improvement before data collection with the actual sample.
- Train Data Collectors: If data collection involves human interaction, ensure that data collectors are properly trained on the data collection protocols, instruments, and ethical considerations. Consistent training helps minimize errors and maintain data quality.
- Maintain Consistency: Follow standardized procedures throughout the data collection process to ensure consistency across data collectors and time. This includes using consistent measurement scales, instructions, and data recording methods.
- Minimize Bias: Be aware of potential sources of bias in data collection and take steps to minimize their impact. Use randomization techniques, employ diverse data collectors, and implement strategies to mitigate response biases.
- Ensure Data Quality: Implement quality control measures to ensure the accuracy, completeness, and reliability of the collected data. Conduct regular checks for data entry errors, inconsistencies, and missing values.
- Maintain Data Confidentiality: Protect the privacy and confidentiality of participants’ data by implementing appropriate security measures. Ensure compliance with data protection regulations and obtain informed consent from participants.
- Document the Process: Keep detailed documentation of the data collection process, including any deviations from the original plan, challenges encountered, and decisions made. This documentation facilitates transparency, replicability, and future analysis.
FAQs about Data Collection
- What are secondary sources of data collection? Secondary sources of data collection are defined as the data that has been previously gathered and is available for your use as a researcher. These sources can include published research papers, government reports, statistical databases, and other existing datasets.
- What are the primary sources of data collection? Primary sources of data collection involve collecting data directly from the original source also known as the firsthand sources. You can do this through surveys, interviews, observations, experiments, or other direct interactions with individuals or subjects of study.
- How many types of data are there? There are two main types of data: qualitative and quantitative. Qualitative data is non-numeric and it includes information in the form of words, images, or descriptions. Quantitative data, on the other hand, is numeric and you can measure and analyze it statistically.
Sign up on Formplus Builder to create your preferred online surveys or questionnaire for data collection. You don’t need to be tech-savvy!
Connect to Formplus, Get Started Now - It's Free!
- academic research
- Data collection method
- data collection techniques
- data collection tool
- data collection tools
- field data collection
- online data collection tool
- product research
- qualitative research data
- quantitative research data
- scientific research
- busayo.longe
You may also like:
How Technology is Revolutionizing Data Collection
As global industrialization continues to transform, it is becoming evident that there is a ubiquity of large datasets driven by the need...
Data Collection Sheet: Types + [Template Examples]
Simple guide on data collection sheet. Types, tools, and template examples.
Data Collection Plan: Definition + Steps to Do It
Introduction A data collection plan is a way to get specific information on your audience. You can use it to better understand what they...
User Research: Definition, Methods, Tools and Guide
In this article, you’ll learn to provide value to your target market with user research. As a bonus, we’ve added user research tools and...
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 24 May 2024
Research collaboration data platform ensuring general data protection
- Monica Toma 1 na1 ,
- Caroline Bönisch 2 , 3 na1 ,
- Benjamin Löhnhardt 4 ,
- Michael Kelm 1 ,
- Hanibal Bohnenberger 6 ,
- Sven Winkelmann 1 , 5 ,
- Philipp Ströbel 6 &
- Tibor Kesztyüs 2
Scientific Reports volume 14 , Article number: 11887 ( 2024 ) Cite this article
Metrics details
- Medical research
- Translational research
Translational data is of paramount importance for medical research and clinical innovation. It has the potential to benefit individuals and organizations, however, the protection of personal data must be guaranteed. Collecting diverse omics data and electronic health records (EHR), re-using the minimized data, as well as providing a reliable data transfer between different institutions are mandatory steps for the development of the promising field of big data and artificial intelligence in medical research. This is made possible within the proposed data platform in this research project. The established data platform enables the collaboration between public and commercial organizations by data transfer from various clinical systems into a cloud for supporting multi-site research while ensuring compliant data governance.
Similar content being viewed by others

Reconciling the biomedical data commons and the GDPR: three lessons from the EUCAN ELSI collaboratory

Scalable Infrastructure Supporting Reproducible Nationwide Healthcare Data Analysis toward FAIR Stewardship

PlatformTM, a standards-based data custodianship platform for translational medicine research
Introduction.
Translational data is of paramount importance for medical research and clinical innovation. The combination of different omics data (e.g., genomics, radiomics, proteomics) and clinical health data with big data analytics and artificial intelligence (AI) has the potential to transform the healthcare to a proactive P4 medicine that is predictive, preventive, personalized, and participatory 1 . Based on this potential, medical research builds on data, which should be easily findable, accessible, interoperable, and re-usable (FAIR) for (secondary) use 2 . Unfortunately, clinical health data is usually stored in so called data or information silos. These silos are prone to restrict access and reuse of the data by holding disparate data sets 3 , 4 , 5 . However, to enable AI, an extraordinarily large amount of data is needed to train or model the neural network 6 . For this purpose, data must be collected and curated appropriately besides being stored (professionally) so that it is reliable for (further) exploitation 7 . In medical areas like pathology or radiology, where diagnostics rely on medical imaging managed by the Digital Imaging and Communications in Medicine (DICOM) standard, a large amount of data can be collected during examination and treatment, while machine learning is already well established 8 , 9 , 10 .
The Medical Informatics Initiative (MII) 11 , funded by the German Ministry of Education and Research (BMBF) is a joined collaboration project, connecting various German university hospitals, research institutions, and businesses while overcoming enclosed clinical health data silos and exchange medical information. To create interoperable research frameworks, different consortia have been formed, within the MII. Every consortium established a Medical Data Integration Center (MeDIC) at German university hospitals to bridge and merge data from different clinical source systems. This pooling of data is mostly done within a (research) data platform. A data platform is a set of technologies that enables the acquisition, storage, curation, and governance of data while ensuring security for its users and applications. With the integration of multi omics and electronic health records (EHR), important information can enrich the information in a health data platform 12 .
Additionally, most of the clinical health data within university hospitals contain personal data and are therefore subject to specific privacy protection laws and regulations. Within the European Union (EU) the data protection directive from 1995 was replaced by the General Data Protection Regulation (GDPR) ( https://gdpr.eu/tag/gdpr/ .) in 2016. The GDPR applies to organizations everywhere if they deal with data related to people in the EU. In contrast to the previous legislation, the country-specific protection laws were harmonized within the GDPR. The Regulation now contains detailed requirements for commercial and public organizations when collecting, storing, and managing personal data.
The GDPR sets the scene for a lawful, fair, and transparent usage of data in the Article 5, defining the principles related to processing of personal data. The data should only be collected for specified purposes (purpose limitation) and should be minimized accordingly (data minimization). The personal data should rely on accuracy, integrity, and confidentiality, while storage limitations should be carefully considered. The GDPR also specifies the principle of accountability, according to which the controller shall be responsible for processing of personal data in compliance with the principles of the GDPR and able to demonstrate this compliance as in the Article 5.2 of the GDPR. Especially when processing is based on the data subject’s consent, the controller should be able to demonstrate this consent as defined in the Article 7.1 of the GDPR. Furthermore, the purpose-based consent should be, not only informed and specific, but unambiguous as well, so that the data subject’s wishes are reflected in the processing of personal data.
Each of the principles under GDPR Article 5 apply to all data processing, including research purposes. Scientific research is seen, as an important area of public interest, hence derogations from the general rules are provided in Article 89 of the GDPR. Within a valid legal basis and subject to the principle of proportionality and appropriate safeguards, secondary use of research data is possible: “those measures may include pseudonymization provided that those purposes can be fulfilled in that manner. Where those purposes can be fulfilled by further processing which does not permit or no longer permits the identification of data subjects, those purposes shall be fulfilled in that manner” 13 . Nevertheless, secondary use of data in research projects remain a gray area in this field 14 , 15 , 16 . Especially if considering to use the data by third parties, like commercial partners.
According to GDPR, data minimization refers to the regulation of personal data being “adequate, relevant, and limited to what is necessary in relation to the purposes for which they are processed” 17 . This means, that data beyond this scope should not be included in the data collection and analysis process. Because of the data minimization requirements, it is essential for data platforms to retain the scope for every data set, making it possible to refer to the scope at every step of the data processing. Especially the area of data minimization is essential for the use of data platforms, because of the potential threat of violation of user’s privacy by combining data independently from a dedicated scope or use case 18 .
The challenge. Based on the aforementioned GDPR regulation requirements, that need to be taken into account, processing of data from the data platform for research purposes necessitates transferring data from clinical data storage into the cloud considering data privacy issues and legal constraints in a collaborative research environment. A crucial aspect of this work is providing a reliable data transfer between different institutions, while ensuring compliance with data privacy regulations, e.g., GDPR. Despite the data being minimized locally by the university medical site, the purpose limitation is ensured.
Literature review
To contextualize the work presented, the authors executed a comprehensive literature review. Literature databases, such as PubMed and Embase were searched for publications on the topic of the article with a restriction to English and German language in a period from January 2016 to January 2024. The search strategy was created by combining database specific index terms (e.g., Emtree - Embase Subject Headings) and free terms relevant to the aim of the study with Boolean operators as shown in Table 1 . In result, 103 hits from both databases PubMed and Embase could be obtained by the literature search. Proceeding from these hits, 67 matches were considered after the title and abstract screening. Continuing from this step, all full texts of these hits were retrieved and examined. After reviewing the full texts, further 18 results could be excluded. The remaining matches form the foundation of the work presented and are addressed inter alia in the Section Related Work.
Related work
The work in this research project is closely related to (research) data platform approaches which exchange data (on) through cloud services between different stakeholders including both commercial and public organizations.
Froehlicher et al. 19 proposes an encrypted, federated learning approach, to overcome the hurdle of processing privacy-protected data within a centralized storage. In differentiation, the rationale of this present article includes centralized data for research purposes, while considering GDPR compliant strategies to make data interoperable and accessible and neglecting technical workarounds to bypass the GDPR requirements.
A technical solution similar to the results presented in this article is shown by Bahmani et al. 20 . They present a platform for minimized data which is transferred from an app e.g., wearables to a cloud service. However, it must be noted that the approach of Bahmani et al. does not include a legal framework in relation to data privacy and the inclusion of a data contract.
The commentary of Brody et al. introduces a “cloud-based Analysis Commons” 21 , a framework that combines genotype and phenotype data from whole-genome sequencing, which are provided via multiple studies, by including data-sharing mechanism. Although this commentary provides a likely similar approach to bridge the gap between data collection within multiple studies and data transfer and interoperability to an analytical platform it does not touch on the implementation of the framework in compliance with data privacy principles as required by the GDPR. The exchange of data is secured via a “consortium agreement rather than through the typical series of bilateral agreements” 21 to share data across institutions.
The research data portal for health (“Forschungsdatenportal für Gesundheit”) developed within the MII 22 was made available in September 2022.The portal is currently running within a pilot phase and allows researchers to apply centrally for health data and biological samples for scientific studies.The data to be queried is based on a core data set 23 that was developed within the MII. The proposed approach in this manuscript allows both clinical researchers associated with university hospitals as well AI researchers associated with industrial partners to work together on the same dataset at the same time. Furthermore, the data available in the described research platform is already cleared by the ethic committee of the organization uploading the data, so that a new vote is not necessary in contrary to the approach taken by the MII. Furthermore, the exchange between the university hospital and the commercial partner is provided via a data contract with specific data governance measures including rights and permissions. This data contract is registered in the cloud prior to a data transfer.
Continuing from the MII, the Network of University Medicine (NUM), established in 2020, 24 , 25 contributes through its coordinated efforts and platforms to better prepare German health research and, consequently, the healthcare system as a whole for future pandemics and other crises. NUM, started as part of crisis management against COVID-19, coordinating clinical COVID-19 research across all university hospital sites, fostering collaboration among researchers for practical, patient-centric outcomes and better management of public health crises.The sub-project Radiological Cooperative Network (RACOON) is the first of its kind to bring together all university departments of a medical discipline and establish a nationwide platform for collaborative analysis of radiological image data 26 , 27 , 28 . This platform supports clinical and clinical-epidemiological studies as well as the training of AI models. The project utilizes technology allowing structured data capture from the outset, ensuring data quality, traceability, and long-term usability. The collected data provide valuable insights for epidemiological studies, situational assessments, and early warning mechanisms. Within RACOON the Joint Imaging Platform (JIP) established by the German Cancer Consortium (DKTK) incorporates federated data analysis technology, where the imaging data remain at the site, where it originated and the analysis algorithm are shared within the platform. JIP provides a unified infrastructure across radiology and nuclear medicine departments of 10 university hospitals in Germany. A core component is “SATORI”, a browser-based application for viewing, curating and processing medical data. SATORI supports images, videos and clinical data, with particular benefits for radiological image data. While this project is very promising and brings great potential, it is designed for radiological data and images, while the project adressed in this research manuscript is laying its focus on pathology data. Furthermore, the exchange with an industrial partner differs from the network partners listed for RACOON (university radiology centers and non-university research institutes).
Another additional infrastructure for the exchange of federated data is GAIA-X 29 . GAIA-X aims to exchange data in a trustworthy environment and give users control over their data. The GAIA-X infrastructure is based on a shared model with the components - data ecosystems and infrastructure ecosystems. Data is exchanged via a trust framework with a set of rules for participation in GAIA-X. This approach differs from the approach written in the manuscript in the form of the data contract between the partners involved and the pseudonymization of the data during exchange.
The results of the literature search led to the conclusion that there are few comparable approaches of research data platforms which exchange medical data via a cloud. However, no identical approaches could be identified. In particular, the exchange of data under consideration of a data contract in relation to a legal framework regarding GDPR could not be found amongst the research results.
Clinical infrastructure and data minimization
To ensure the exchange of medical data while considering GDPR regulations between a MeDIC - the network used in this research project, is divided using network segmentation to handle data with a higher protection class accordingly. The clinical systems (e.g., pathology systems) are located in the so-called patient network segment (PatLAN) of the research facility and is kept separated from the research network segment (WissLAN). In regards of keeping the data stored, to a minimum, a data minimization step is performed in the staging layer between the patient network segment and the research network segment. Only data items required for further processing are transferred between the two networks. In regards of collecting the data it could have been useful and advised to use the broad patient consent (as established within the MII) in such a research project. But at the start of research project presented in 2022, it had not been introduced at the UMG at that time. The underlying patient consent is recorded manually on paper, but was afterwards be entered digitally by a study nurse and passed through into the study data pool within the UMG-MeDIC. From there it is then provided to the industrial partner, as part of the data shared. It includes consent to data release and further processing within the study mentioned in Section “ Methods ”. After collecting the patient consents, personal data is replaced by a pseudonymization process. Here, an independent trusted third party (TTP) takes over the task of replacing the personally identifiable data (PII) with a pseudonym (unique generated key code). This pseudonymization can only be reversed by the TTP. This TTP is established at the MeDIC. Mapping tables of personal data and assigned pseudonyms are exclusively known to the TTP and the TTP can, if medically advised and if there is a corresponding consent for re-contact, carry out a de-pseudonymization. The staff of the TTP office is released from the authority of the MeDIC executive board regarding the pseudonymization of personal data. The TTP staff is the only party that could perform the process of de-pseudonymization based on a documented medical reason.
Cloud infrastructure
The described current status under Section “ Clinical infrastructure and data minimization ” with regard to the clinical infrastructure and the approach of making the data available for analysis via a cloud infrastructure made it necessary to deal with cloud services that enable sharing big data in medical research. Efficient data management is more important than ever, helping businesses and hospitals to gain analytical insights, as well as using machine learning in the medical field (e.g., to predict molecular alterations of tumors 30 ). The first generation of big data management mainly consisted of data warehouses which provided storage for structured data. Over time as more unstructured data emerges and is stored within clinical infrastructures, a second generation of big data management platforms called data lakes were developed. They incorporate low-cost (cloud) storages (e.g., Amazon Simple Storage Service, Microsoft Azure Storage, Hadoop Distributed File System) while holding generic raw data.

Three-layered cloud infrastructure with uniform data access. Figure based on 31 and 32 .
Although combining data from warehouses and data lakes is highly complex for data users, Zaharia et al. 32 propose an integrated architecture which combines a low-cost data lake (cf. Fig. 1 ) with direct file access and performance features of a data warehouse and database management system (DBMS) such as: atomicity, consistency, isolation, durability (ACID) transactions, data versioning, auditing, and indexing on the storage level. All these components can be combined with a three-layer clustering (cf. Fig. 1 ) which is usually used for data warehouses: staging area (or bronze layer) for incoming data, data warehouse (or silver layer) for curated data, and data access (or gold layer, or data mart) for end users or business applications 31 , 33 , 34 . The cloud infrastructure used, is structured accordingly, to enhance the benefits of this three-layer clustering.
Ethic review
Ethical approval for the study was obtained from the Ethics Review Committee of the University Medical Center Göttingen (Ref No. 24/4/20, dated 30.04.2020), and all developments and experiments were performed in accordance with relevant guidelines and regulations. Furthermore, informed consent was obtained from all subjects and/or their legal guardian(s).
Establishing a data transfer from clinical data storage of a MeDIC into a cloud requires connecting different source systems. A system overview of the approach is shown in Fig. 2 . Firstly, data retrieved from clinical systems (segment PatLAN as patient network segment, which is separated from the internet) is processed and saved in the MeDIC (segment MeDIC as part of the research network segment WissLAN). Secondly, the data is transferred from the MeDIC to the cloud with a software component (called edge-device) that ensures authentication and data encryption. The solution proposed in this research project is based on European Privacy Seal-certified cloud products ( https://euprivacyseal.com/de/eps-en-siemens-healthcare-teamplay/ [Online 2024/01/16].) to be privacy compliant with the GDPR. The approach was validated by the development, testing, and deployment of a novel AI tool to predict molecular alterations of tumors 30 based on the data transferred from one clinical institution.
Clinical infrastructure

System overview to transfer data from clinical systems to the cloud providing access for commercial partners.
The data transfer from the PatLAN segment to the MeDIC (and vice versa) is only possible under certain conditions. The University Medical Center Göttingen (UMG) established the MeDIC as a data platform to integrate the data from the clinical source systems in patient care (e.g., pathology). Subsequently the collected data is processed and made available in different formats to different infrastructures (e.g., cloud) depending on the use case.
As described in Fig. 2 the data in the source systems contain both personal data (IDAT) and the medical data (MDAT). The MeDIC receives the data from the clinical source systems in a particular network segment within PatLAN. In this step of the operation the data is handled by an ETL (extract, transform, load) process for data minimization and transformation 35 . This means that only the minimized data is stored in the MeDIC. This step replaces the personal data (IDAT) with a pseudonym (PSN) as a prerequisite for being able to process the data in the research network. Only by means of the trusted third party (as described in Section “ Clinical infrastructure and data minimization ”) the pseudonyms can be resolved back to an actual person. Additionally, this information is not transferred to the research network segment (WissLAN). In case of a consent withdrawal, the medical data involved will be deleted from all storage locations at the MeDIC and commercial partner. To ensure the revocation, an automatic process is initiated. The process performs the deletion of the data within the MeDIC and triggers a deletion process to the commercial partner by sending the pseudonyms (PSN) to be deleted.
Data contract
After the data is processed within the clinical infrastructure of the MeDIC, the data, received by the commercial partner will be stored after a so called “data contract”, which is designed as a questionnaire, that specifies data governance measures, including rights and permissions. For the provision of the data via the edge-device to the cloud infrastructure, the minimized data from the MeDIC will be used. It is submitted and registered on the cloud prior to the data transfer. The “data contract” includes a data protection impact assessment (DPIA) by design to assess the re-identification risks that may arise from the content and context of the data aggregation. A data owner affiliated with the commercial partner will be assigned to a specific data set. The data owner must therefore ensure that the data is processed in compliance with the purpose stipulated in the legal obligations.The data contract triggers the correct distribution and storage of data in the respective regional data center. Moreover, only designated parties can process the data to the extent which is necessary for the permitted purpose. Logs to all data activities are provided. The period of storage and usage is defined including the obligations to cite the origin of the data or to disclose the results generated by the data usage. Furthermore, it is ensured that when a request to delete a specific data set is received (e.g., withdrawal of consent) it is possible to track this data and remove it completely in a timely manner.
Cloud infrastructure supporting research
In addition to the mentioned data privacy issues (see Section “ Data contract ”) data transfer from university medical centers (hospital) networks into cloud environments (e.g., OneDrive, GoogleDrive, Dropbox,) is often restricted by security rules such as blocked ports or firewall settings. Facilitating the firewall configurations, an edge-device was established, tunneling messages and data from and to the cloud through one connection which is secured by encryption and certificates (SSL/TLS with RSA encryption using keys with at least4096 Bit). The edge-device is setup on a virtual machine within the MeDIC as part of the research network segment, while being configured, operated, and monitored from the cloud (see Fig. 3 ). This enables technical IT personal to establish data channels for medical end users without on-side involvement. Focusing on the user experience for medical users, a similar approach to Microsoft OneDrive was followed, by creating local folders for each upload and download channel, which are connected to a secured cloud storage container.

Screenshot of the cloud-based configuration for one edge-device.
For the cloud platform storage of the commercial partner, we use a similar approach to Zaharia et al. 32 by combining Microsoft Azure Data Lake with concepts from data warehouses and direct file access for cloud data analytic platform tools (e.g., cloud hosted Jupyter Notebooks ( https://jupyter.org/ [Online 2022/09/09]). While supporting ACID transactions (see Section “ Cloud infrastructure supporting research ”), data versioning, lineage, and metadata for each file, it also covers the requirements for handling personal data. Following the three-layer approach of data warehouses, files are uploaded to an ingestion zone which scans and associates them with a data contract before they are moved into a bronze data lake storage (layer 1: staging). From this layer the data is extracted, transformed/curated, and loaded/published by data engineers on a silver zone (layer 2). Due to the data contract reference saved in the meta data, the data privacy constraints are always known for each file regardless in which zone it is located. As big amounts of data are being processed, mounting data zones within data analytic platform tools avoids copying large files from one destination to another. Furthermore, cloud-hosted machine learning tools such as MLFlow ( https://mlflow.org/ [Online 2022/08/01].) were employed, with direct file access to enable the management of the complete machine learning lifecycle.
Technical evaluation
To show that the orchestration of the MeDIC’s clinical infrastructure together with the cloud infrastructure of the commercial partner is technically feasible, an evaluation of the approach was conducted.
Overall, data from 2000 cancer patients (treated between 2000 and 2020) were transferred from the UMG to two commercial partners. Differences were expected between small and therefore fast transferrable clinical files and large files, requiring longer transfer times. For many small files the number of parallel transfers are important, whereas large files benefit from few parallel data transfers with high bandwidth each. To evaluate both cases, we transferred whole pathology slide images and multi-omics data. The data transfer is based on Microsoft Azure platform and correspondent C# libraries - thus no problems in terms of scalability were encountered. Nevertheless, sometimes connection issues were observed and when comparing the MD5 hashes between source files and destination files large files were corrupted. The issue could be traced to regular Windows Updates, reboots of the virtual machine, and/or local IT scripts changing firewall settings. Future system designs will provide an automatic validation of source and destination file.
Within the project Cancer Scout, a research collaboration platform was used for an end-to-end machine learning lifecycle, working on a large dataset, which cannot be handled on standard local hardware. In the first step, data scientists curated raw data (bronze data lake zone) to a clean data set (silver zone) by eliminating duplicates and converting whole slide imaging (WSI) iSyntax format to Tagged Image File Format (TIFF) using cloud hosted Jupyter Notebooks. Furthermore, pathologists annotated the WSIs with cancer subtypes using the cloud-hosted EXACT tool 36 , working directly with data on the cloud data storage. The trained machine learning model for WSI classification is described in Teichmann et al. 30 . Currently, model serving is done with a cloud-based API, however, it needs to be integrated in a medical decision support tool.
GDPR has been introduced with the goal to protect personal data of Europeans when processed in all sectors of the economy. Notably, it fails to provide a clear instruction for processing personal data for secondary research purposes, like under which circumstances key-coded data could be considered anonymous 37 , 38 . Nevertheless, data collection and processing are of paramount importance for further innovation and development of the promising fields of big data and artificial intelligence in drug discovery, clinical trials, personalized medicine and medical research 39 . While secure data collection enables the collaboration between multiple public and commercial organizations to scientifically explore multi-omics data, it also facilitates medical research by using AI technologies to analyze and identify patterns in large and complex data sets faster and more precisely. From a technical point of view, the task of collecting and transferring medical data from hospitals to a collaborative cloud data platform, while ensuring privacy and security, is not trivial. To address this issue, a three layer-approach was validated, consisting of clinical data storages, a MeDIC, and a cloud platform. Firstly, the data from the clinical systems are minimized during the ETL process to the MeDIC. Secondly, each data is linked to a “data contract” when transferred from the MeDIC to the cloud, specifying data governance and defining the rights and permissions to use the data. Currently, only the trusted third party of the MeDIC can link PSN to IDAT, thus no data record linkage between different locations is possible. As linking different kinds of data from different institutions increases the risk to identify a patient (e.g., head CT, genome sequencing), this topic needs further research.
We successfully established a data platform which enables the collaboration between a public and commercial organization by enabling data transfer from various clinical systems via a MeDIC into a cloud for supporting multi-site research while ensuring compliant data governance. In a first step the approach was validated by the collaboration between one clinical institution and an industrial partner and is therefore specific to the UMG and MeDIC, as the TTP is located at the MeDIC. Based on a dataset containing 2085 diagnostic slides from 840 colon cancer patients a new AI algorithm for classification of WSI in digital pathology 30 was proposed. Considering the literature review this implementation is, to the authors knowledge, the first work that implements this concept. To contribute the results gained from this research project the following measures were taken into account to ensure that this research meets the requirements of the FAIR principles as well. The research was made findable (F) by submitting it to a respected journal, providing a DOI (F1, F3) and further described keywords (F2). The data is findable and can be requested from the authors (F4). The data of the submission can be retrieved by the given DOI (A1), the access protocol is open, free (A1.1) and the manuscript, ones published, is accessible from different online libraries (A2). A formal language for knowledge representation was used (I1) and improved the manuscript to include vocabulary that follow the FAIR principles (I2). Furthermore, the data was described with as much information and relevant attributes (R1).
Data availability
The data that support the findings of this study are available from the university medical center Göttingen, but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of University Medical Center Göttingen. Please contact the corresponding author CB for all data requests.
Hood, L. & Flores, M. A personal view on systems medicine and the emergence of proactive p4 medicine: Predictive, preventive, personalized and participatory. New Biotechnol. 29 (6), 613–24. https://doi.org/10.1016/j.nbt.2012.03.004 (2012).
Article CAS Google Scholar
Wilkinson, M. D. et al. The fair guiding principles for scientific data management and stewardship. Sci. Data https://doi.org/10.1038/sdata.2016.18 (2016).
Article PubMed PubMed Central Google Scholar
Patel, J. Bridging data silos usind big data integration. Int. J. Database Manag. Syst. https://doi.org/10.5121/ijdms.2019.11301 (2019).
Article Google Scholar
Cherico-Hsii, S. et al. Sharing overdose data across state agencies to inform public health strategies: A case study. Public Health Rep. 131 (2), 258–263. https://doi.org/10.1177/003335491613100209 (2016).
Rosenbaum, L. Bridging the data-sharing divide–seeing the devil in the details, not the other camp. N. Engl. J. Med. https://doi.org/10.1056/NEJMp1704482 (2017).
Article PubMed Google Scholar
Shafiee, M. J., Chung, A. G., Khalvati, F., Haider, M. A. & Wong, A. Discovery radiomics via evolutionary deep radiomic sequencer discovery for pathologically proven lung cancer detection. J. Med. Imaging 4 (4), 041305. https://doi.org/10.1117/1.JMI.4.4.041305 (2017).
DeVries, M. et al. Name it! store it! protect it!: A systems approach to managing data in research core facilities. J. Biomol. Tech. 28 (4), 137–141. https://doi.org/10.7171/jbt.17-2804-003 (2017).
Hosny, A., Parmar, C., Quackenbush, J., Schwartz, L. & Aerts, H. Artificial intelligence in radiology. Nat. Rev. Cancer 18 (18), 500–510. https://doi.org/10.1038/s41568-018-0016-5 (2018).
Article CAS PubMed PubMed Central Google Scholar
Cui, M. & Zhang, D. Artificial intelligence and computational pathology. Lab. Invest. 101 , 412–422. https://doi.org/10.2217/fon.15.295 (2016).
Mathur, P. & Burns, M. Artificial intelligence in critical care. Int. Anesthesiol. Clin. 57 (2), 89–102. https://doi.org/10.1097/AIA.0000000000000221 (2019).
Semler, S. C., Wissing, F. & Heyder, R. German medical informatics initiative. Methods Inf. Med. https://doi.org/10.3414/ME18-03-0003 (2018).
Casey, J., Schwartz, B., Stewart, W. & Adler, N. Using electronic health records for population health research: A review of methods and applications. Annu. Rev. Public Health 37 (1), 61–81. https://doi.org/10.1146/annurev-publhealth-032315-021353 (2016).
EuropeanDataProtectionSupervisor. A preliminary opinion on data protection and scientific research (2020). https://edps.europa.eu/sites/edp/files/publication/20-01-06_opinion_research_en.pdf,p.17 .
Soini, S. Using electronic health records for population health research: A review of methods and applications. Eur. J. Hum. Genet. https://doi.org/10.1038/s41431-020-0608-x (2020).
Chico, V. The impact of the general data protection regulation on health research. Br. Med. Bull. https://doi.org/10.1093/bmb/ldy038 (2018).
Rumbold, J. M. M. & Pierscionek, B. K. A critique of the regulation of data science in healthcare research in the European union. BMC Med. Ethics https://doi.org/10.1186/s12910-017-0184-y (2017).
EuropeanParliament. General data protection regulation (2016). https://eur-lex.europa.eu/eli/reg/2016/679/oj,p.35 .
Senarath, A. & Arachchilage, N. A. G. A data minimization model for embedding privacy into software systems. Comput. Secur. 87 , 61–81. https://doi.org/10.1016/j.cose.2019.101605 (2019).
Froelicher, D. et al. Truly privacy-preserving federated analytics for precision medicine with multiparty homomorphic encryption. Nat. Commun. 12 (1), 5910. https://doi.org/10.1038/s41467-021-25972-y (2021).
Article ADS CAS PubMed PubMed Central Google Scholar
Bahmani, A. et al. A scalable, secure, and interoperable platform for deep data-driven health management. Nat. Commun. 12 , 5757. https://doi.org/10.1038/s41467-021-26040-1 (2021).
Brody, J. A. et al. Analysis commons, a team approach to discovery in a big-data environment for genetic epidemiology. Nat. Commun. 49 , 1560–1563. https://doi.org/10.1038/ng.3968 (2017).
Prokosch, H.-U. et al. Towards a national portal for medical research data (fdpg): Vision, status, and lessons learned. Stud. Health Technol. Inform. 302 , 307–311. https://doi.org/10.3233/SHTI230124 (2023).
Medizininformatik-Initiative. Der kerndatensatz der medizininformatik-initiative, 3.0 (2021).
Schmidt, C. et al. Making covid-19 research data more accessible-building a nationwide information infrastructure. Bundesgesundheitsblatt Gesundheitsforschung Gesundheitsschutz https://doi.org/10.1007/s00103-021-03386-x (2021).
Heyder, R. et al. The german network of university medicine: Technical and organizational approaches for research data platforms. Bundesgesundheitsblatt Gesundheitsforschung Gesundheitsschutz https://doi.org/10.1007/s00103-022-03649-1 (2023).
Schmidt, M. et al. Codex meets racoon - a concept for collaborative documentation of clinical and radiological covid-19 data. Stud. Health Technol. Inform. https://doi.org/10.3233/SHTI220804 (2022).
RACOON, N. Radiologische forschung in der entwicklung. RoFo : Fortschritte auf dem Gebiete der Rontgenstrahlen und der Nuklearmedizin (2022). https://doi.org/10.1055/a-1888-9285 .
RACOON, N. Racoon: Das radiological cooperative network zur beantwortung der großen fragen in der radiologie. RoFo : Fortschritte auf dem Gebiete der Rontgenstrahlen und der Nuklearmedizin (2022). https://doi.org/10.1055/a-1544-2240 .
Pedreira, V., Barros, D. & Pinto, P. A review of attacks, vulnerabilities, and defenses in industry 4.0 with new challenges on data sovereignty ahead. Sensors 21 , 15. https://doi.org/10.3390/s21155189 (2021).
Teichmann, M., Aichert, A., Bohnenberger, H., Ströbel, P. & Heimann, T. Wang, L., Dou, Q., Fletcher, P. T., Speidel, S. & Li, S. End-to-end learning for image-based detection of molecular alterations in digital pathology. (eds Wang, L., Dou, Q., Fletcher, P. T., Speidel, S. & Li, S.) Medical Image Computing and Computer Assisted Intervention—MICCAI 2022 , (Springer Nature: Switzerland, 2022). 88–98
Inmon, W. H. Building the Data Warehouse (John Wiley & Sons, 2005).
Google Scholar
Zaharia, M., Ghodsi, A., Xin, R. & Armbrust, M. Lakehouse: A new generation of open platforms that unify data warehousing and advanced analytics. 11th Conference on Innovative Data Systems Research, CIDR 2021, Virtual Event, January 11-15, 2021, Online Proceedings (2021). http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf .
Kimball, R. & Ross, M. The Data Warehouse Toolkit (John Wiley & Sons, 2013).
Lee, D. & Heintz, B. Productionizing machine learning with delta lake. databricks Engineering Blog (2019). https://databricks.com/de/blog/2019/08/14/productionizing-machine-learning-with-delta-lake.html .
Parciak, M. et al. Fairness through automation: Development of an automated medical data integration infrastructure for fair health data in a maximum care university hospital. BMC Med. Inform. Decision Making https://doi.org/10.1186/s12911-023-02195-3 (2023).
Marzahl, C. et al. Exact: A collaboration toolset for algorithm-aided annotation of images with annotation version control. Sci. Rep. 11 (1), 4343. https://doi.org/10.1038/s41598-021-83827-4 (2021).
van Ooijen, I. & Vrabec, H. U. Does the gdpr enhance consumers’ control over personal data? an analysis from a behavioural perspective. J. Consum. Policy https://doi.org/10.1007/s10603-018-9399-7 (2019).
Zarsky, T. Z. Incompatible: The Gdpr in the Age of Big Data (Seton Hall Law Review, 2017).
Mallappallil, M., Sabu, J., Gruessner, A. & Salifu, M. A review of big data and medical research. SAGE Open Med. 8 , 2050312120934839. https://doi.org/10.1177/2050312120934839 (2020).
Download references
Acknowledgements
The research presented in this work was funded by the German federal ministry of education and research (BMBF) as part of the Cancer Scout project (13GW0451). We thank all members of the Cancer Scout consortium for their contributions.
Author information
These authors contributed equally: Monica Toma and Caroline Bönisch.
Authors and Affiliations
Siemens Healthineers AG, Erlangen, Germany
Monica Toma, Michael Kelm & Sven Winkelmann
Medical Data Integration Center, Department of Medical Informatics, University Medical Center Göttingen, Göttingen, Germany
Caroline Bönisch & Tibor Kesztyüs
Faculty of Electrical Engineering and Computer Science, University of Applied Sciences Stralsund, Stralsund, Germany
Caroline Bönisch
Department of Medical Informatics, University Medical Center Göttingen, Göttingen, Germany
Benjamin Löhnhardt
Nuremberg Institute of Technology, Nuremberg, Germany
Sven Winkelmann
Institute of Pathology, University Medical Center Göttingen, Göttingen, Germany
Hanibal Bohnenberger & Philipp Ströbel
You can also search for this author in PubMed Google Scholar
Contributions
T.K. and M.K. coordinated and supervised this research project. T. K., M.K., and P.S. contributed to the conceptualization of the research and were involved in the revision, editing, and final approval of the manuscript. All authors read and approved the final manuscript. C. B. wrote the introduction including the problem statement, the literature review and related work sections, and performed the literature review, as well as contributed to clinical infrastructure and data minimization. M.T. wrote the abstract, the section in the results concerned with the data contract, and the discussion; contributed to the introduction and technical evaluation; proofreading. B.L. wrote the section in the results concerned with the clinical infrastructure, and the sections in methods concerned with the clinical infrastructure and data minimization. S.W. wrote the section in the results concerned with the cloud infrastructure, the section in methods concerned with the cloud infrastructure, and the technical evaluation.
Corresponding authors
Correspondence to Monica Toma or Caroline Bönisch .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Toma, M., Bönisch, C., Löhnhardt, B. et al. Research collaboration data platform ensuring general data protection. Sci Rep 14 , 11887 (2024). https://doi.org/10.1038/s41598-024-61912-8
Download citation
Received : 10 October 2023
Accepted : 10 May 2024
Published : 24 May 2024
DOI : https://doi.org/10.1038/s41598-024-61912-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Translational Research newsletter — top stories in biotechnology, drug discovery and pharma.

More From Forbes
Enhancing environmental research: web scraping and sustainability.

- Share to Facebook
- Share to Twitter
- Share to Linkedin
Founder & CEO at Datamam .
Climate change, pollution, environmental degradation and resource depletion are just a few of the greatest challenges facing the world in the 21st century. Tackling these challenges means carrying out thorough research involving a huge pool of world data from sources such as satellite imagery, environmental monitoring stations and local field studies, providing an array of information on human interaction with nature.
But the real challenge comes in capturing massive amounts of real-time data so wise decisions can be made within the shortest time possible. To do this, we must better understand the role of modern data collection technologies in environmental research and how we can adapt our strategies to leverage these technologies more effectively.
Introduction To Environmental Research
Historical records show that concern for the environment goes back thousands of years. In fact, in 2700 BC, some of the first known laws were implemented to protect trees from continued deforestation in Ur, Mesopotamia. Centuries later, the establishment of Scotland's Coal Smoke Abatement Society in 1898 marked a significant community-driven response to environmental issues.
These movements have been fueled in the 21st century by advancements in technology—particularly in computing and data analysis—that have significantly impacted the research industry as a whole, beyond just the environmental sector. This then begs the question: With large-scale, global environmental data collection, how do we integrate and put such information to use to address environmental challenges?
Saw The Eclipse And Aurora Now Comes A Third Once In A Lifetime Event
Netflix’s new #1 movie is an overlooked, must-watch crime comedy thriller, reacher season 3 casts a villain that looks like he ate reacher, worldwide data collection for environmental insights.
Environmental monitoring is critical for evaluating vital factors such as air and water quality. Across the globe, various organizations and research groups deploy sophisticated data collection techniques to track environmental health.
For instance, the World Air Quality Index project collects data from over 12,000 stations in more than 1,000 cities worldwide. This project aggregates real-time data on air pollution levels, which is crucial for assessing health risks, informing the public and shaping policy decisions. Most of this data is publicly available, allowing analysts and researchers to utilize it for further studies and environmental assessments.
In the U.S., the National Weather Service gathers data from weather stations nationwide. This data, essential for generating accurate weather forecasts, plays a crucial role in emergency preparedness, particularly in areas susceptible to extreme weather events. This information is also generally accessible to the public, supporting a variety of applications from academic research to commercial use in weather-related industries.
Furthermore, conservation organizations like the World Wildlife Fund monitor deforestation, wildlife trafficking and illegal fishing activities. Public access to this data can vary, with some information available for open use to aid in raising awareness and promoting conservation efforts.
This transparency not only promotes accountability but also fosters a collaborative approach to tackling environmental challenges.
The Impact Of Web Scraping On Environmental Policy And Advocacy
In the context of environmental research and policymaking, the ability to access information without source limitations can be a significant advantage. Web scraping can be a useful tool in this scenario, enabling researchers, policymakers and advocates to gather and analyze data from virtually any online source, irrespective of geographical and linguistic boundaries. This capability is particularly helpful in environmental science, in which the global nature of challenges like climate change, pollution and biodiversity loss demands a comprehensive understanding that spans across nations.
Considerations When Using Web Scraping For Environmental Purposes
Ensure data integrity..
Credibility checking of sources is important to confirm the dependability of data collected using web scraping. If the data that web scraping provides is incorrect, it could lead to misguided decisions and policymaking; hence, data accuracy is the top-most priority. The data needs to be updated regularly to keep it relevant, and using as many sources as possible for cross-verification will add strength to your dataset.
Use data effectively.
Data can be used to track changes in the environment, monitor ecosystem health and inform policymakers. Actively participate in the collection and data analysis processes to ensure optimal environmental management.
Use high-level analytic tools.
Integrate advanced analytical tools and technologies to further enhance the value of the data collected through web scraping. Tools like AI and machine learning can help identify patterns and predictions that might not be evident through traditional analysis methods. Incorporating these technologies can provide deeper insights into environmental data, leading to more effective strategies and solutions.
Looking Ahead: The Evolving Role Of Data In Environmental Advocacy
Web scraping has emerged as one important tool in environmental research, offering a method to rapidly collect and analyze data from a multitude of sources. As technology advances, the capabilities of data collection technology will expand, offering even more sophisticated tools for data extraction and analysis. These advancements will not only enhance the accuracy and depth of environmental research but also open new avenues for public engagement and policy influence.
Forbes Technology Council is an invitation-only community for world-class CIOs, CTOs and technology executives. Do I qualify?

- Editorial Standards
- Reprints & Permissions
- Open access
- Published: 22 May 2024
Feasibility and acceptability of a cohort study baseline data collection of device-measured physical behaviors and cardiometabolic health in Saudi Arabia: expanding the Prospective Physical Activity, Sitting and Sleep consortium (ProPASS) in the Middle East
- Abdulrahman I. Alaqil ORCID: orcid.org/0000-0003-0458-2354 1 , 2 , 3 ,
- Borja del Pozo Cruz ORCID: orcid.org/0000-0002-9728-1317 2 , 4 , 5 ,
- Shaima A. Alothman ORCID: orcid.org/0000-0003-2739-0929 6 ,
- Matthew N. Ahmadi ORCID: orcid.org/0000-0002-3115-338X 7 , 8 ,
- Paolo Caserotti 2 ,
- Hazzaa M. Al-Hazzaa ORCID: orcid.org/0000-0002-3099-0389 6 , 9 ,
- Andreas Holtermann ORCID: orcid.org/0000-0003-4825-5697 3 ,
- Emmanuel Stamatakis 7 , 8 &
- Nidhi Gupta 3
BMC Public Health volume 24 , Article number: 1379 ( 2024 ) Cite this article
366 Accesses
5 Altmetric
Metrics details
Physical behaviors such physical activity, sedentary behavior, and sleep are associated with mortality, but there is a lack of epidemiological data and knowledge using device-measured physical behaviors.
To assess the feasibility of baseline data collection using the Prospective Physical Activity, Sitting, and Sleep consortium (ProPASS) protocols in the specific context of Saudi Arabia. ProPASS is a recently developed global platform for collaborative research that aims to harmonize retrospective and prospective data on device-measured behaviors and health. Using ProPASS methods for collecting data to perform such studies in Saudi Arabia will provide standardized data from underrepresented countries.
This study explored the feasibility of baseline data collection in Saudi Arabia between November and December 2022 with a target recruitment of 50 participants aged ≥ 30 years. Established ProPASS methods were used to measure anthropometrics, measure blood pressure, collect blood samples, carry out physical function test, and measure health status and context of physical behaviors using questionnaires. The ActivPal™ device was used to assess physical behaviors and the participants were asked to attend two sessions at (LHRC). The feasibility of the current study was assessed by evaluating recruitment capability, acceptability, suitability of study procedures, and resources and abilities to manage and implement the study. Exit interviews were conducted with all participants.
A total of 75 participants expressed an interest in the study, out of whom 54 initially agreed to participate. Ultimately, 48 participants were recruited in the study (recruitment rate: 64%). The study completion rate was 87.5% of the recruited participants; 95% participants were satisfied with their participation in the study and 90% reported no negative feelings related to participating in the study. One participant reported experiencing moderate skin irritation related to placement of the accelerometer. Additionally, 96% of participants expressed their willingness to participate in the study again.
Based on successful methodology, data collection results, and participants’ acceptability, the ProPASS protocols are feasible to administer in Saudi Arabia. These findings are promising for establishing a prospective cohort in Saudi Arabia.
Peer Review reports
Global data from 2023 indicate that an estimated 27.5% of adults do not meet physical activity guidelines and have poor physical behaviors (e.g., physical activity, sedentary behavior, and sleep) that are linked with an increased risk of morbidity and mortality [ 1 , 2 , 3 , 4 ]. Sufficient physical activity and sensible sedentary times are associated with better health outcomes (e.g., cardiovascular health, mental health, and physical function) [ 1 , 2 ]. Despite this fact, 50–90% of Saudi Arabian adults perform low or insufficient daily physical activity; about 50% spend at least five hours per day sitting [ 5 ]. Furthermore, around 33% of the population experiences sleep durations of less than 7 h per night [ 6 ]. These trends could be a reason why non-communicable diseases account for 73% of mortality and cardiovascular diseases account for 37% of all deaths among Saudi Arabian adults [ 7 ]. However, there have been few studies in Middle Eastern countries, and the evidence that links between physical behaviors and health outcomes is under-represented in Saudi Arabia [ 1 ].
Furthermore, within Saudi Arabia, the few studies exploring this connection often rely on self-reported physical behaviors that often do not provide the most accurate picture [ 5 , 8 , 9 , 10 , 11 ]. This lack of data necessitates studies that incorporate measurements from devices that directly track these behaviors among Saudi Arabian adults, which aligns with recent guidance from the World Health Organization (WHO) on the necessity of incorporating device-measured physical behaviors into future studies to explore their relationships with various health aspects [ 1 , 12 ]. By employing such a method, we can gain more precise insights into the dose-response relationships between different physical behaviors and various health outcomes among Saudi Arabian adults.
The Prospective Physical Activity, Sitting, and Sleep Consortium (ProPASS) is an initiative that aims to explore how thigh-based accelerometry measurement of physical behaviors influences a wide range of health outcomes. This initiative operates on a global scale and aims to harmonize data from both retrospective and future studies [ 13 ]. To fulfill the aim, ProPASS is developing methods for collecting prospective data and processing, harmonizing, and pooling data from previous and future studies [ 14 ]. To date, the methods of the ProPASS consortium have been used to harmonize data from large-scale epidemiological studies, such as the 1970 British Birth Cohort, the Australian Longitudinal Study on Women’s Health [ 15 ], and Norway’s Trøndelag Health Study (HUNT) [ 16 , 17 ]. As such, this study seeks to determine if the ProPASS methodologies will be effective in the context of data collection within Saudi Arabia. This will be beneficial because it will help to standardize the measurement of physical behaviors, enhance harmonization across studies, and create more a representative and valid understanding of the associations between physical behaviors and health globally, including under-represented countries such as Saudi Arabia.
This paper describes the feasibility of baseline ProPASS data collection in Saudi Arabia with prospectively harmonized data with the main resource. This feasibility study of baseline data collection will serve as a framework for a future cohort study that will investigate the associations between device-measured physical behavior (e.g., physical activity, sedentary behavior, and sleep) and cardiometabolic health in Saudi adults.
The study was approved by the Institutional Review Board at Princess Nourah Bint Abdul Rahman University, Riyadh, Saudi Arabia (IRB 22–0146), and was carried out in accordance with the principles of the Declaration of Helsinki.
Study design and procedures
Participants were informed about the study’s aims and asked to read and sign the consent form before any measurements were taken. After agreeing to participate, they were asked to attend two sessions at the Lifestyle and Health Research Center (LHRC) at the Health Sciences Research Center of Princess Nourah Bint Abdulrahman University. During the first visit, each participant’s anthropometric measurements (e.g., height, weight, waist circumference), blood pressure and heart rate, blood samples, and handgrip strength were measured. Next, the participants completed questionnaires on demographic information, dietary habits, self-rated health, self-reported smoking status, and the Global Physical Activity, Sedentary Behaviors, and Sleep behavior questionnaires. At the end of the first visit, the researcher attached the ActivPAL™ accelerometer device to their thigh which they were asked to wear for seven consecutive days. Participants were also provided with a diary to record their waking and sleeping hours [ 18 ]. On the 8th day of study, the participants were asked to attend the LHRC for session two where they returned the device and were interviewed (see Fig. 1 ).

Demonstration and summary of the study procedure
Participants and eligibility
The study aimed to recruit a total of 50 Saudi adults aged ≥ 30 years, which is generally considered a common sample size for feasibility studies [ 19 , 20 ]. The eligibility criteria were: (1) Saudi nationals (2), resident in Riyadh, and (3) aged ≥ 30 years old. The exclusion criteria were: (1) having a current medical condition that forces them to be chair-bound or bedridden for more than half of their waking hours (2), being allergic to plasters or adhesives (3), being allergic to low-density polyethylene (4), having a skin condition that would prevent them from wearing the monitor, and (5) those who may need to pass through a metal detector/security checkpoint during the duration of the study. The study’s aims, protocol, and procedures were clearly described to all participants before any measurements were taken.
Recruitment
Participant recruitment was carried out over the month of November 2022. Participants were recruited from different locations across Riyadh, Saudi Arabia, by using electronic flyers on social media (e.g., Twitter, WhatsApp) that provided information about the study and the researcher’s contact details. Prospective participants who were interested in joining the study were asked to provide their contact information via a link to Google Forms featured in the study description. The participants who initially expressed interest but later decided not to join were invited to share their reasons for non-participation through a physical or telephonic meeting.
Measurements based on ProPASS methodology
The current study employed the ProPASS method and protocol for new cohort studies that seek to join ProPASS prospectively [ 14 , 21 ]. All measurements were taken by researchers that were well-trained in the ProPASS protocol and methods. Blood pressure and hand grip strength measurements were taken three times, and the mean average was then calculated; all other measurements were taken only once.
Anthropometric measurements
Height (to the nearest 0.1 cm) and weight (to the nearest 0.1 kg) were measured with a stadiometer (SECA 284; Seca, Hamburg, Germany), and scale (SECA 284; Seca, Hamburg, Germany), respectively. Waist circumference (to the nearest 0.1 cm) was measured midway between the lower rib margin and the iliac crest at the end of a gentle expiration [ 22 ]. Body mass index (BMI) was calculated using the standard calculation (height in meters squared/body weight in kilograms).
Blood pressure and heart rate
Blood pressure was taken after resting for five minutes in a sitting position. Blood pressure was taken three times with one minute between measurements and the average reading was recorded [ 23 ]. Blood pressure and heart rate were measured using a Welch Allyn Connex 7300 Spot Vital Signs Monitor, which provides a high degree of accuracy [ 24 ]. Mean arterial pressure (MAP) was then calculated (MAP = 1/3 * SBP + 2/3 * DBP in mm Hg) using the average of both the SBP and DBP values [ 25 ].
Blood samples
Non-fasting finger-prick (capillary) blood samples (40 µL) were collected for analysis after warming the finger for five minutes. A drop of blood was taken directly from the heated finger to be analysed for blood glucose, triglycerides, total cholesterol, high-density lipoprotein cholesterol, and low-density lipoprotein cholesterol. A previously validated CardioChek PA analyser (CardioChek PA Blood Analyser, UK) was used to analyse the blood samples [ 26 , 27 ].
Medication use
Participants’ medication use was evaluated by the question: Do you currently use any prescription medicines ? If the answer was yes, the participants were asked which medications they use, such as medication for high blood pressure, high cholesterol, asthma, COPD, anxiety, depression, thyroid problems, allergies. They were also asked whether the medication was in the form of tablets, or nasal sprays, whether the medication was anti-inflammatory, chemotherapeutic, urological, birth control, or neurological, and the age at which the participants had begun using the medication.
Familial disease history
Familial disease history was assessed by the question: Do your parents, siblings or children have, or have they ever had, some of the following diseases before the age of 60 ? The responses included asthma, hay fever/nasal allergies, chronic bronchitis, emphysema or COPD, anxiety or depression, myocardial infarction (heart attack), diabetes, stroke or brain hemorrhage, and cancer. The responses were yes, no , and I don’t know .
Chronic health status
Participants’ chronic disease status and/or long-term health issues were assessed by the question: Have you had, or do you have any of the following diseases? The responses included angina, myocardial infarction (heart attack), heart failure, peripheral vascular disease, atrial fibrillation, stroke/brain hemorrhage, thrombosis, pulmonary embolism, asthma, COPD or emphysema, diabetes, hypothyroidism (low metabolism), hyperthyroidism (high metabolism), cancer, migraine, psoriasis, kidney disease, arthritis (rheumatoid arthritis), Bechterew’s disease, gout, mental health problems, osteoporosis, sleep apnea, arthrosis, nerve disease, hearing/ear disease, eye disease, and infection. Those who replied yes were asked a follow-up question: How old were you when you had it for the first time?
Mobility limitations
The questionnaire was based on three questions on performance-based measures of mobility, which had already been translated and culturally adapted into Arabic [ 28 ]. These three questions are valid and reliable tools to identify the early indications of disability and can be used as indicators to identify those at high risk of future disability [ 29 ]. Self-reported mobility was assessed via the following questions: (1) Do you have difficulty in walking 2.0 km? (2) Do you have difficulty in walking 0.5 km ? and (3) Do you have difficulty in walking up one flight of stairs? The five response options were: (1) able to manage without difficulty (2), able to manage with some difficulty (3), able to manage with a great deal of difficulty (4), able to manage only with the help of another person, and (5) unable to manage even with help.
Dietary habits
The dietary habits questionnaire was translated and culturally adapted into Arabic [ 28 ]. The questionnaire assessed the dietary habits of the participants was adapted from the Survey of Health, Aging, and Retirement in Europe (SHARE), which has been demonstrated to be a valid and reliable tool for assessing diet [ 30 ]. The questionnaire focused on the consumption of dairy products, legumes, eggs, meat, fruit and vegetables.
Self-rated health
A set of valid and reliable questions adapted from Idler et al.’s (1997) questionnaire was used to assess participants’ self-rated health by asking them to rate their health status using the following questions: (1) In general, would you say your health is…: Excellent; Very good; Good; Fair; Poor; (2) Compared to one year ago, how would you rate your health in general now?: Much better now than one year ago; Somewhat better now than one year ago; About the same; Somewhat worse now than one year ago; Much worse now than one year ago [ 31 , 32 ].
Smoking habits
Self-report questions on smoking behavior were adapted from the UK Biobank questionnaire and were used to assess participants’ present and past smoking habits including at what age they began smoking. the number of cigarettes smoked per day, the type of tobacco used, the duration of smoking, and, among former smokers, the age when smoking ceased [ 33 ].
Physical behaviours
Physical behaviors such as physical activity, sedentary behavior, and sleep were measured by using (1) self-reported and (2) device-based measures:
Self-report measures
Physical activity was measured on a self-report basis via the Global Physical Activity Questionnaire (GPAQ) which was translated into Arabic and previously validated [ 34 ]. In addition, the Sedentary Behavior Questionnaire (SBQ), which had already been translated into Arabic [ 28 ], was used to subjectively assess participants’ sedentary behavior time [ 35 ]. Lastly, the Pittsburgh Sleep Quality Index was used to assess sleep quality and sleep disturbances over a one-month period [ 36 ].
Device-based measures
Physical behaviors were measured by wearing a thigh-worn accelerometer device (an ActivPAL™ Micro4, PAL technologies, Glasgow, Scotland) that participants wore continuously for 24 h for seven full days [ 37 ]. The Activpal™ device was sealed with a nitrile sleeve and attached with a medical waterproof 3 M Tegaderm transparent dressing on the front of the right mid-thigh on the muscle belly by a well-trained member of researcher team. The ActivPAL™ monitor is a valid and reliable measure of time spent walking [ 38 ], sitting, and standing time in healthy adults [ 39 ]. In addition, the participants were asked to fill in a recording sheet that included a sleep diary (times that the participant went to and got out of bed), as well as, the dates and times when the accelerometer fell off or was removed.
Physical function
Physical function was objectively measured using a digital hand-grip strength dynamometer (Takei Hand Grip Dynamometer 5401-C, Japan) via three successive hand-grip assessments for each hand (left and right); the mean value for each hand was then recorded. The instrument can measure hand-grip values from 5 to 100 kg; the minimum unit of measurement is 0.1 kg. The tool is a good health outcomes predictor [ 40 , 41 ].
Data collection evaluation of feasibility
Overall, the study evaluated feasibility in two main stages where feedback from the first six participants was used to resolve any unforeseen issues in the protocol implementation on the remaining participants. Any changes to the procedure were documented.
The current study evaluated the feasibility of Saudi adults’ participation based on the following constructs: (1) recruitment capability (2), acceptability and suitability of study procedures, and (3) resources and ability to manage and implement the study. Table 1 outlines the feasibility constructs, measures, outcome definitions, and methods employed. In evaluating feasibility, the current study followed the recommendations for a feasibility study as reported by Orsmond and Cohn, 2015 [ 42 ].
Overall, the study collected data on the feasibility constructs via tracking the registration, equipment availability, and time spent on various tasks performed (for example training researchers, performing various tasks like attaching the sensor) and completion rate (such as tracking diary entries, questionnaire entries and number of days with accelerometer data), via personal contacts (for information on barriers and facilitators of participation), via processing sensor data, and via interviews after the measurement (for example obtaining information on potential issues during measurement and willingness to participate).
Participant interviews after measurement
After the completion of the study, face-to-face semi-structured interviews were conducted with all participants who had completed the 7-day study period. The aim of these interviews was to collect comprehensive feedback regarding participants’ experiences with the study protocol, with the goal of capturing additional insights that was not captured by other feasibility measures. Some examples of such measures were motivations for joining the study, their expectations prior to participation, and their levels of satisfaction with the study procedures. A detailed interview guide is described in Appendix A [ 28 , 43 , 44 ].
Statistical analysis
Descriptive analysis summarized participants’ demographics, anthropometric measurements, health status, clinical measurements, physical behaviors characteristics, and interview questions responses. The continuous variables were characterized using mean ± standard deviations (SD), while categorical variables were presented using frequencies accompanied by percentages (%). The recruitment rate was calculated by the number of participants who participated and signed the consent form / total number of participants who registered in the study (see Fig. 2 ). Additional analyses were performed to compare participants who reported burden with those who reported no burden of participation (see supplementary materials). T-tests and Chi-square tests were employed for this comparison. IBM’s Statistical Package for the Social Sciences (SPSS) (version 27 SPSS, Inc. Chicago, Illinois) was used to conduct the qualitative analysis. The raw data of ActivPAL were analyzed by using the ActiPASS software (ActiPASS © 2021 - Uppsala University, Sweden).

Recruitment and study participant’s diagram
A total of 75 participants initially volunteered to participate. Ten participants were excluded from the study as they did not meet the inclusion criteria ( n = 8) or could not be contacted ( n = 2). In addition, 11 participants withdrew their interest in participating for various reasons: (1) excessive distance between the location of the study (LRHC) and their residence ( n = 3) (2), hesitant about joining the study ( n = 1) (3), believed that the ActivPAL™ device would interfere with his/her health ( n = 1) (4), believed that the ActivPAL™ device would interfere with their regular exercise routine ( n = 2) (5), had family and work commitments ( n = 3), and (6) claimed that the timing was unsuitable ( n = 1). Out of a total of 54 participants who had agreed to participate in the study, 48 participants from Riyadh, Saudi Arabia, attended and completed the consent form. However, four of those participants provided incomplete data (i.e., they completed the questionnaires only and did not wear an ActivPAL™ device). Therefore, a total of 44 participants out of 75 potential participants (59%) successfully completed the study (wore an ActivPAL™ device and completed all questionnaires). See Fig. 2 for the study’s recruitment flow.
Participants
Of the 48 participants, nearly half were female (47.9%). On average, the participants were 37 ± 7.3 years old, had a BMI of 28.3 ± 5.6, and a waist circumference of 86.9 ± 16.4 cm. Most participants were married, had college degrees, were employed as office workers and professionals, had never smoked, and did not use any medication (see Table 2 ). A total of 87.5% of participants had a family history of disease; 85.4%, 95.8%, and 89.6%, reported having no difficulty walking 2 km, 500 m, and up one flight of stairs, respectively. Approximately 48% of participants rated their health as very good , while 39.6% reported their health as about the same compared to one year ago . In terms of dietary habits, nearly half the participants reported consuming dairy products every day, 25% consumed legumes and eggs 3 to 6 times a week, 56.3% consumed meat every day, and 45.8% consumed fruits and vegeTables 3, 4, 5 and 6 times a week.
Table 3 presents the primary variables of the study: including average systolic, diastolic, and mean arterial pressure values of 121.13 ± 11.81 mmHg, 79.26 ± 8.92 mmHg, and 93.15 ± 9.20 mmHg, respectively. The mean resting heart rate was 74.3 ± 12.66. Furthermore, the non-fasting blood profile of the sample was analyzed and showed the following values: total cholesterol: 177.89 ± 33.79 mg/dL; HDL-cholesterol: 50.96 ± 13.02 mg/dL; triglycerides: 123.94 ± 68.92 mg/dL; LDL-cholesterol: 103 ± 29.89 mg/dL; TC/HDL-cholesterol ratio: 3.71 ± 1.11; LDL/HDL-cholesterol ratio: 2.19 ± 0.81; non-HDL-cholesterol: 127.06 ± 33.51 mg/dL; non-fasting glucose: 102.98 ± 35.36 mg/dL. Table 3 provides an overview of the participants’ physical activity related behaviors.
Feasibility evaluation
The following results highlight the approaches taken by the current study to assess the feasibility of baseline data collection using ProPASS methodology specifically in the context of Saudi Arabia.
The evaluation of the feasibility of the study protocol was conducted in two stages, initially involving six participants, whose feedback was used to refine and improve the protocol implementation for the remaining participants. Of the six selected participants, three were female. In the pre-evaluation, only two minor issues were encountered; (1) accessing the lab outside of working hours (16:00–22:00) as most participants were unable to attend during the day (07:00–16:00) due to work commitments. This issue was resolved in all subsequent data collection points by receiving approval for extended lab hours; (2) obtaining the required number of ActivPAL™ devices from the technical coordinator due to miscommunication and high demand by other researchers. To prevent further issues, the author obtained 30 devices in advance for the feasibility evaluation.
Recruitment capability
The recruitment rate was used to measure the feasibility of recruitment methodology to collect baseline ProPASS data; the results showed that 64% ( n = 48) of participants signed the consent form and attended the LRHC lab (see Fig. 2 ). After screening the eligibility criteria, out of a total of 75 participants, 65 met the study criteria, and 11 were excluded from participating due to the reasons as detailed in Fig. 2 . As Fig. 2 illustrates, although 54 participants scheduled an appointment for the study, only 48 (64%) attended and signed the consent form. In the final stage of the recruitment process, around 59% ( n = 44) of participants completed all the required measurements for the study.
Acceptability and suitability of study procedures
The adherence rate (i.e., the extent to which participants adhered to the outlined procedures in terms of the number of days with valid accelerometry data) was 5.7 days. Furthermore, participants provided sleep diary entries for 85.4% of days. All questionnaires were completed with a 100% response rate.
To assess the study’s time demands on participants, the length of time participants needed to complete all measurements was mean time of 25 min (23 min to complete the questionnaires and two minutes to attach the sensor). Additionally, the completion rates for the registered participants who completed all the required measurements (i.e., accelerometer measurement, diary registration, and questionnaires) was 91.6%. (See Table 4 ).
Resources and ability
The final feasibility outcomes (i.e., having the required resources and ability to manage and implement the study) are presented in Table 5 . This objective was assessed based on four domains: skin irritation, equipment availability, training requirements, and accelerometer loss (see Table 5 ). The first domain revealed that three participants experienced skin irritation during the study; of these, two participants had mild symptoms, such as itchiness and discomfort that lasted for the first three days but did not lead to their withdrawal from the study. However, one participant reported moderate irritation resulting in red skin which required them to withdraw from the study. The second domain, equipment availability, indicated that all the necessary equipment was available 100% of the time. The third domain was training requirements, and the researchers required four hours of training on how to use it correctly. Finally, in the accelerometer loss domain, the study recorded four failed devices out of 30 that did not generate data for seven days.
Participant interview after measurement
After completing the study, all participants were interviewed around five primary themes: (1) motivation and expectations of participation (2), participant satisfaction (3), the burden of participation (4), willingness to participate again , and (5) perception of time usage (see Fig. 3 ).

Interview outcomes of participant’s experience with the study protocol
To determine the participants’ motivations for and expectations about joining the study, they were asked: What made you want to join this study? The results showed that 90% of participants were interested in learning about their physical behaviors and health status; 43% participated in supporting the researcher, and 14% reported that the final report attracted them to participate (see Fig. 3 a and the example of final report in supplementary material). Participant satisfaction was assessed via two questions: (1) What was your overall experience of participating in the study? and (2) Was it as you expected? The findings indicated that 62% of participants were satisfied that the study was as expected, 33% were more satisfied than expected, and 5% were unsatisfied and found the study below their expectations (see Fig. 3 b).
Regarding the overall burden of participation, 76% of participants reported that it was no burden , 5% reported that it was a burden , and 14% believed it was somewhat burdensome (see Fig. 3 c). Additionally, 79% of participants expressed their willingness to participate again in the future (see Fig. 3 d). Finally, regarding time usage, 67% of participants found it easy to complete the seven-day study without any concerns (see Fig. 3 h).
The feasibility of the baseline ProPASS data collection methodology was evaluated among Saudi adults who participated in this study. The findings revealed that the methodology was both feasible and acceptable, paving the way for large-scale prospective cohort research in Saudi Arabia. This research marks the first attempt to establish a prospective cohort study in Saudi Arabia using established ProPASS methods [ 13 , 15 ] and protocols. Conducting such a cohort study in Saudi Arabia is crucial due to the country’s high prevalence of non-communicable diseases that are mostly due to poor physical behaviors (e.g., lack of physical activity, sedentary behavior, and sleep) [ 7 ], due to recent enormous economic growth accompanied by technological transformations and urbanization [ 11 ].
The first aspect of feasibility evaluated of the baseline ProPASS data collection methodology was the capability to recruit participants. The findings indicated that the recruitment rate was 64% which is similar to prior studies [ 46 , 47 ]. One study indicated that a recruitment rate of at least between 20 and 40% is required to be deemed feasible [ 48 ]. Thus, the recruitment rate in the current study seems acceptable for creating a future cohort using ProPASS methods in Saudi Arabia. Additionally, in the current study, the refusal rate was only 15% which is significantly lower than in previous studies [ 45 , 49 ] where refusal rates ranged from 50 to 66%. One reason for the low refusal rate in the current study is that the recruitment was material specifically designed to motivate Saudi participants to join the study by indicating that the study would provide data and insight into their current state of health. For example, the results of the semi-structured interviews illustrated that 90% of participants joined the study because they wanted to know about their physical behaviors and health status (see Fig. 3 ). This result also indicates that our recruitment material might be suitable for ensuring high participation in the future cohort study.
The second aspect of feasibility for the baseline ProPASS data collection methodology that was evaluated in this study was the acceptability and suitability of the study procedures. Previous studies have shown that in order to obtain reliable estimates of adults’ habitual physical activity, it is necessary to record accelerometer data for 3–5 days [ 50 , 51 ] to gather valid data to perform analysis and provide information about the habitual physical behaviors. A recent study indicated that distributing accelerometers in person was associated with a high proposition of participants consenting to wear an accelerometer and meeting minimum wear criteria [ 21 ]. Our study was able to collect an average six days of valid data which was sufficient to obtain representative descriptions of the participants’ physical behaviors [ 52 ]. There were high general adherence rates for participant diary entries, questionnaires completion, and adherence to the study protocol, indicating that the ProPASS methods could be feasibly implemented with a larger study population. The study also assessed the time commitment necessary to complete the questionnaires and attach the ActivPAL™ devices to participants’ thighs. Completing the questionnaires took approximately 23 min (SD = 8). Prior studies have indicated that shorter questionnaires (e.g., 20 min) yield a higher response rate from participants, a finding that was consistent with our study [ 53 , 54 ]. Additionally, attaching the sensor to the participant’s thigh took about two minutes. These findings indicate that participation in this study was not burdensome, which was confirmed by the interviews that showed that 95% of participants felt that participating in the study (i.e., filling out all questionnaires and wearing the ActivPal™ device for 7 days) was not a burden. Overall, ProPASS methods appear to be less burdensome, well-suited, and readily accepted by participants.
The third aspect of feasibility for the baseline ProPASS data collection methodology was the availability of resources and the ability to manage and execute the study. As we aim to create a new cohort adhering to global (ProPASS) standards, protocol training was vital to obtain quality outcomes as per the ProPASS protocol. As a result, the protocol training took around four hours which was similar to a prior study [ 45 ]. In terms of the availability of resources, all essential equipment was always accessible. The study also considered skin irritation as an important factor. One study noted that 38% of participants stopped using ActivPal™ due to skin irritation from PALstickies or Tegaderm dressings [ 55 ]; another reported one discontinuation due to irritation associated with a Tegaderm dressing [ 56 ]. In the current study, there were three reported irritations, with two having mild initial discomfort that eventually subsided. One participant left the study due to moderate irritation. Nonetheless, it is important to note that the data collection occurred during colder winter periods (average 20 degrees Celsius). It is possible that instances of skin irritation could be more pronounced during Saudi Arabia’s hot summer season, characterized by temperatures of approximately 40 degrees Celsius. Future studies should investigate the feasibility of using devices and tape suitable for summer temperatures. In addition, the current study also had a low accelerometer failure rate: only four accelerometers failed to record, which is similar to previous studies [ 57 , 58 ]. All ActivPal™ devices were returned at the end of the study during visit two, ensuring that the ProPASS method is suitable to be used in future cohorts in Saudi Arabia.
Strengths and limitations of Study
This study represents the first of its kind to utilize device-based measures for assessing physical behaviors among adults in Saudi Arabia. The device-based measure has been shown to provide useful information about physical behaviors when compared to using self-report questionnaires [ 16 ]. Furthermore, it marks the initial examination of the ProPASS consortium method in the Middle East, particularly in Saudi Arabia. Nevertheless, the current study has certain limitations including recruiting among relatively young participants, presumably without any medical conditions and with postgraduate qualifications. This may limit the generalization of the findings to the entire population. The acceptability of the study in other age groups and among individuals with lower educational backgrounds is yet to be studied. In addition, the feasibility of the baseline ProPASS data collection methodology study was conducted during winter, which might have influenced the observed levels of physical behaviors in our sample. Similarly, the study was unable to evaluate the feasibility of utilizing 3 M Tegaderm dressings in hot summer months. Lastly, it’s important to note that our study employed a relatively small sample size; nonetheless, this size is considered acceptable for feasibility studies.
The baseline ProPASS data collection methodology and protocol for a future cohort study are both feasible and acceptable for implementation within the context of Saudi Arabia. This feasibility study represents the first step toward establishing a prospective ProPASS cohort study to examine the association between physical behaviors and cardiometabolic health among Saudi Arabian adults.
Availability of data and materials
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
Abbreviations
The Prospective Physical Activity, Sitting and Sleep consortium
Physical activity, sedentary behavior, and sleep
Bull FC, Al-Ansari SS, Biddle S, Borodulin K, Buman MP, Cardon G, et al. World health organization 2020 guidelines on physical activity and sedentary behaviour. Br J Sports Med. 2020;54(24):1451–62.
Article PubMed Google Scholar
Chrysant SG, Chrysant GS. Association of physical activity and trajectories of physical activity with cardiovascular disease. Expert Rev Cardiovasc Ther. 2023;0(0):1–10.
Google Scholar
Falck RS, Davis JC, Li L, Stamatakis E, Liu-Ambrose T. Preventing the ‘24-hour Babel’: the need for a consensus on a consistent terminology scheme for physical activity, sedentary behaviour and sleep. Br J Sports Med. 2022;56(7):367–8.
Guthold R, Stevens GA, Riley LM, Bull FC. Worldwide trends in insufficient physical activity from 2001 to 2016: a pooled analysis of 358 population-based surveys with 1·9 million participants. Lancet Global Health. 2018;6(10):e1077-1086.
Evenson KR, Alhusseini N, Moore CC, Hamza MM, Al-Qunaibet A, Rakic S, et al. Scoping review of Population-based physical activity and sedentary behavior in Saudi Arabia. J Phys Activity Health. 2023;20(6):471–86.
Article Google Scholar
Ahmed AE, Al-Jahdali F, AlALwan A, Abuabat F, Salih SB, Al-Harbi A, et al. Prevalence of sleep duration among Saudi adults. Saudi Med J. 2017;38(3):276–83.
Article PubMed PubMed Central Google Scholar
World Health Organization. Noncommunicable Diseases Progress Monitor 2022. 2022. Available from: https://www.who.int/publications-detail-redirect/9789240047761 . Cited 2023 Jun 22.
Besson H, Brage S, Jakes RW, Ekelund U, Wareham NJ. Estimating physical activity energy expenditure, sedentary time, and physical activity intensity by self-report in adults. Am J Clin Nutr. 2010;91(1):106–14.
Article CAS PubMed Google Scholar
Cerin E, Cain KL, Owen Oyeyemial, Conway N, Cochrane TL. Correlates of agreement between accelerometry and self-reported physical activity. Med Sci Sports Exerc. 2016;48(6):1075–84.
Klesges RC, Eck LH, Mellon MW, Fulliton W, Somes GW, Hanson CL. The accuracy of self-reports of physical activity. Med Sci Sports Exerc. 1990;22(5):690–7.
Al-Hazzaa HM. Physical inactivity in Saudi Arabia revisited: a systematic review of inactivity prevalence and perceived barriers to active living. Int J Health Sci (Qassim). 2018;12(6):50–64.
PubMed Google Scholar
DiPietro L, Al-Ansari SS, Biddle SJH, Borodulin K, Bull FC, Buman MP, et al. Advancing the global physical activity agenda: recommendations for future research by the 2020 WHO physical activity and sedentary behavior guidelines development group. Int J Behav Nutr Phys Act. 2020;17(1):143.
Stamatakis E, Koster A, Hamer M, Rangul V, Lee IM, Bauman AE, et al. Emerging collaborative research platforms for the next generation of physical activity, sleep and exercise medicine guidelines: the prospective physical activity, sitting, and Sleep consortium (ProPASS). Br J Sports Med. 2020;54(8):435–7.
The prospective physical activity, sitting and sleep consortium. Prospective Physical. 2022. ProPASS - prospective physical activity, sitting, and sleep consortium. Available from: https://www.propassconsortium.org . Cited 2022 May 20.
Wei L, Ahmadi MN, Chan HW, Chastin S, Hamer M, Mishra GD, et al. Association between device-measured stepping behaviors and cardiometabolic health markers in middle-aged women: the Australian longitudinal study on women’s Health. Scand J Med Sci Sports. 2023;33(8):1384–98.
Ahmadi MN, Blodgett JM, Atkin AJ, Chan HW, Pozo CB del, Suorsa K, et al. Device-measured physical activity type, posture, and cardiometabolic health markers: pooled dose-response associations from the ProPASS Consortium. medRxiv. 2023; 2023.07.31.23293468. Available from: https://www.medrxiv.org/content/10.1101/2023.07.31.23293468v1 . Cited 2023 Aug 28.
Blodgett JM, Ahmadi MN, Atkin AJ, Chastin S, Chan HW, Suorsa K, et al. Device measured sedentary behaviour, sleep, light and moderate-vigorous physical activity and cardio-metabolic health: A compositional individual participant data analysis in the ProPASS consortium. medRxiv. 2023:2023.08.01.23293499. Available from: https://www.medrxiv.org/content/10.1101/2023.08.01.23293499v1 . Cited 2023 Aug 28.
Inan-Eroglu E, Huang BH, Shepherd L, Pearson N, Koster A, Palm P, et al. Comparison of a thigh-worn accelerometer algorithm with diary estimates of time in bed and time asleep: the 1970 British cohort study. J Meas Phys Behav. 2021;4(1):60–7.
Lancaster GA, Dodd S, Williamson PR. Design and analysis of pilot studies: recommendations for good practice. J Eval Clin Pract. 2004;10(2):307–12.
Thabane L, Ma J, Chu R, Cheng J, Ismaila A, Rios LP, et al. A tutorial on pilot studies: the what, why and how. BMC Med Res Methodol. 2010;10(1):1.
Pulsford RM, Brocklebank L, Fenton SAM, Bakker E, Mielke GI, Tsai LT, et al. The impact of selected methodological factors on data collection outcomes in observational studies of device-measured physical behaviour in adults: a systematic review. Int J Behav Nutr Phys Act. 2023;20(1):26.
Ma WY, Yang CY, Shih SR, Hsieh HJ, Hung CS, Chiu FC, et al. Measurement of Waist circumference. Diabetes Care. 2013;36(6):1660–6.
Article CAS PubMed PubMed Central Google Scholar
Berenson GS, Srinivasan SR, Bao W, Newman WP, Tracy RE, Wattigney WA. Association between multiple cardiovascular risk factors and atherosclerosis in children and young adults. The Bogalusa heart study. N Engl J Med. 1998;338(23):1650–6.
Alpert BS, Quinn D, Kinsley M, Whitaker T, John TT. Accurate blood pressure during patient arm movement: the Welch allyn connex spot monitor’s SureBP algorithm. Blood Press Monit. 2019;24(1):42–4.
The Sixth Report of the Joint National Committee on Prevention. Detection, evaluation, and treatment of high blood pressure. Arch Intern Med. 1997;157(21):2413–46.
Panz VR, Raal FJ, Paiker J, Immelman R, Miles H. Performance of the CardioChek PA and Cholestech LDX point-of-care analysers compared to clinical diagnostic laboratory methods for the measurement of lipids. Cardiovasc J S Afr. 2005;16(2):112–7.
CAS PubMed Google Scholar
PTS Diagnostics. CardioChek PA Analyzer. PTS Diagnostics. 2022. Available from: https://ptsdiagnostics.com/cardiochek-pa-analyzer/ . Cited 2022 Feb 26.
Alaqil AI, Gupta N, Alothman SA, Al-Hazzaa HM, Stamatakis E, del Pozo Cruz B. Arabic translation and cultural adaptation of sedentary behavior, dietary habits, and preclinical mobility limitation questionnaires: a cognitive interview study. PLOS One. 2023;18(6):e0286375.
Mänty M, Heinonen A, Leinonen R, Törmäkangas T, Sakari-Rantala R, Hirvensalo M, et al. Construct and predictive validity of a self-reported measure of preclinical mobility limitation. Arch Phys Med Rehabil. 2007;88(9):1108–13.
Börsch-Supan A, Brandt M, Hunkler C, Kneip T, Korbmacher J, Malter F, et al. Data Resource Profile: the Survey of Health, Ageing and Retirement in Europe (SHARE). Int J Epidemiol. 2013;42(4):992–1001.
Idler EL, Benyamini Y. Self-rated health and mortality: a review of twenty-seven community studies. J Health Soc Behav. 1997;38(1):21–37.
Lundberg O, Manderbacka K. Assessing reliability of a measure of self-rated health. Scand J Soc Med. 1996;24(3):218–24.
Peters SAE, Huxley RR, Woodward M. Do smoking habits differ between women and men in contemporary western populations? Evidence from half a million people in the UK Biobank study. BMJ Open. 2014;4(12):e005663.
Doyle C, Khan A, Burton N. Reliability and validity of a self-administered arabic version of the global physical activity questionnaire (GPAQ-A). J Sports Med Phys Fit. 2019;59(7):1221–8.
Rosenberg DE, Norman GJ, Wagner N, Patrick K, Calfas KJ, Sallis JF. Reliability and validity of the sedentary behavior questionnaire (SBQ) for adults. J Phys Act Health. 2010;7(6):697–705.
Buysse DJ, Reynolds CF, Monk TH, Berman SR, Kupfer DJ. The Pittsburgh sleep quality index: a new instrument for psychiatric practice and research. Psychiatry Res. 1989;28(2):193–213.
Crowley P, Skotte J, Stamatakis E, Hamer M, Aadahl M, Stevens ML, et al. Comparison of physical behavior estimates from three different thigh-worn accelerometers brands: a proof-of-concept for the prospective physical activity, sitting, and Sleep consortium (ProPASS). Int J Behav Nutr Phys Act. 2019;16(1):65.
Ryan CG, Grant PM, Tigbe WW, Granat MH. The validity and reliability of a novel activity monitor as a measure of walking. Br J Sports Med. 2006;40(9):779–84.
Kozey-Keadle S, Libertine A, Lyden K, Staudenmayer J, Freedson PS. Validation of wearable monitors for assessing sedentary behavior. Med Sci Sports Exerc. 2011;43(8):1561–7.
Altankhuyag I, Byambaa A, Tuvshinjargal A, Bayarmunkh A, Jadamba T, Dagvajantsan B, et al. Association between hand-grip strength and risk of stroke among Mongolian adults: results from a population-based study. Neurosci Res Notes. 2021;4(3Suppl):8–16.
Bohannon RW. Hand-grip dynamometry predicts future outcomes in aging adults. J Geriatr Phys Ther. 2008;31(1):3–10.
Garcia L, Ferguson SE, Facio L, Schary D, Guenther CH. Assessment of well-being using fitbit technology in college students, faculty and staff completing breathing meditation during COVID-19: a pilot study. Mental Health Prev. 2023;30:200280.
Al-Hazzaa HM, Alothman SA, Albawardi NM, Alghannam AF, Almasud AA. An arabic sedentary behaviors questionnaire (ASBQ): development, content validation, and pre-testing findings. Behav Sci. 2022;12(6):183.
Orsmond GI, Cohn ES. The distinctive features of a feasibility study: objectives and guiding questions. OTJR. 2015;35(3):169–77. https://doi.org/10.1177/1539449215578649 . (Cited 2022 Aug 4).
Marmash D, Ha K, Sakaki JR, Hair R, Morales E, Duffy VB, et al. A feasibility and pilot study of a personalized nutrition intervention in mobile food pantry users in Northeastern connecticut. Nutrients. 2021;13(9):2939.
Ouchi K, Lee RS, Block SD, Aaronson EL, Hasdianda MA, Wang W, Rossmassler S, Palan Lopez R, Berry D, Sudore R, Schonberg MA, Tulsky JA. An emergency department nurse led intervention to facilitate serious illness conversations among seriously ill older adults: A feasibility study. Palliat Med. 2023;37(5):730–9. https://doi.org/10.1177/02692163221136641 .
Bajwah S, Ross JR, Wells AU, Mohammed K, Oyebode C, Birring SS, et al. Palliative care for patients with advanced fibrotic lung disease: a randomised controlled phase II and feasibility trial of a community case conference intervention. Thorax. 2015;70(9):830–9.
Mosadeghi S, Reid MW, Martinez B, Rosen BT, Spiegel BMR. Feasibility of an immersive virtual reality intervention for hospitalized patients: an observational cohort study. JMIR Mental Health. 2016;3(2):e5801.
Papatzikis E, Elhalik M, Inocencio SAM, Agapaki M, Selvan RN, Muhammed FS, et al. Key challenges and future directions when running auditory Brainstem Response (ABR) Research Protocols with newborns: a Music and Language EEG Feasibility Study. Brain Sci. 2021;11(12):1562.
Trost SG, Mciver KL, Pate RR. Conducting accelerometer-based activity assessments in field-based research. Med Sci Sports Exerc. 2005;37(11):S531-543.
Wagnild JM, Hinshaw K, Pollard TM. Associations of sedentary time and self-reported television time during pregnancy with incident gestational diabetes and plasma glucose levels in women at risk of gestational diabetes in the UK. BMC Public Health. 2019;19(1):575.
Ham SA, Ainsworth BE. Disparities in data on healthy people 2010 physical activity objectives collected by accelerometry and self-report. Am J Public Health. 2010;100(S1):S263-268.
Marcus B, Bosnjak M, Lindner S, Pilischenko S, Schütz A. Compensating for low topic interest and long surveys: a field experiment on nonresponse in web surveys. Social Sci Comput Rev. 2007;25(3):372–83.
Sharma H. How short or long should be a questionnaire for any research? Researchers dilemma in deciding the appropriate questionnaire length. Saudi J Anaesth. 2022;16(1):65–8.
De Decker E, De Craemer M, Santos-Lozano A, Van Cauwenberghe E, De Bourdeaudhuij I, Cardon G. Validity of the ActivPAL ™ and the ActiGraph monitors in preschoolers. Med Sci Sports Exerc. 2013;45(10):2002.
Aguilar-Farias N, Martino-Fuentealba P, Chandia-Poblete D. Cultural adaptation, translation and validation of the Spanish version of past-day adults’ sedentary time. BMC Public Health. 2021;21(1):182.
Reid RER, Carver TE, Andersen KM, Court O, Andersen RE. Physical activity and sedentary behavior in bariatric patients long-term post-surgery. Obes Surg. 2015;25(6):1073–7.
Reid RER, Carver TE, Reid TGR, Picard-Turcot MA, Andersen KM, Christou NV, et al. Effects of neighborhood walkability on physical activity and sedentary behavior long-term post-bariatric surgery. Obes Surg. 2017;27(6):1589–94.
Download references
Acknowledgements
The authors would like to express gratitude to all participants for their involvement in the study. Additionally, we extend our appreciation to the research assistants (Rasil Alhadi, Ragad Alasiri, and Khalid Aldosari) who assisted in the data collection. Finally, we would like to thank the LHRC, Princess Nourah Bint Abdulrahman University for providing their site for collecting the data.
This research was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Project No. GrantA353]. The funders had no role in study design, data collection and analysis, the decision to publish, or the preparation of the manuscript.
Author information
Authors and affiliations.
Department of Physical Education, College of Education, King Faisal University, Al-Ahsa, 31982, Saudi Arabia
Abdulrahman I. Alaqil
Center for Active and Healthy Ageing (CAHA), Department of Sports Science and Clinical Biomechanics, University of Southern Denmark, Odense, 5230, Denmark
Abdulrahman I. Alaqil, Borja del Pozo Cruz & Paolo Caserotti
Department of Musculoskeletal Disorders and Physical Workload, National Research Centre for the Working Environment, Lersø Parkalle 105, Copenhagen, 2100, Denmark
Abdulrahman I. Alaqil, Andreas Holtermann & Nidhi Gupta
Faculty of Education, Department of Physical Education, University of Cádiz, Cádiz, Spain
Borja del Pozo Cruz
Biomedical Research and Innovation Institute of Cádiz (INiBICA) Research Unit, University of Cádiz, Cadiz, Spain
Lifestyle and Health Research Center, Health Sciences Research Center, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
Shaima A. Alothman & Hazzaa M. Al-Hazzaa
Mackenzie Wearables Research Hub, Charles Perkins Centre, The University of Sydney, Camperdown, NSW, Australia
Matthew N. Ahmadi & Emmanuel Stamatakis
School of Health Sciences, Faculty of Medicine and Health, The University of Sydney, Camperdown, NSW, Australia
School of Sports Sciences, University of Jordan, Amman, Jordan
Hazzaa M. Al-Hazzaa
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization: AIA, NG, ES, and BdCMethodology: AIA, NG, ES, HMA, and BdCInvestigation: AIAData collection: AIAInterpretation of the findings: AIA, HMA, ES, NG, AH, PC, MNA, and BdCDrafting the paper: AIAReviewing and editing the draft: AIA, ES, HMA, BdC, SAA, PC, MNA, AH, and NGAll authors critically read, revised the draft for important intellectual content, approved the final version of the manuscript to be published, and agreed to be accountable for all aspects of the work.
Corresponding author
Correspondence to Abdulrahman I. Alaqil .
Ethics declarations
Ethics approval and consent to participate.
The Ethic approval was obtained from the Institutional Review Board at Princess Nourah Bint Abdul Rahman University, Riyadh, Saudi Arabia (IRB 22–0146). Written informed consent was obtained from participants. All methods were carried out in accordance with the Declaration of Helsinki.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., supplementary material 2., supplementary material 3., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Alaqil, A.I., del Pozo Cruz, B., Alothman, S.A. et al. Feasibility and acceptability of a cohort study baseline data collection of device-measured physical behaviors and cardiometabolic health in Saudi Arabia: expanding the Prospective Physical Activity, Sitting and Sleep consortium (ProPASS) in the Middle East. BMC Public Health 24 , 1379 (2024). https://doi.org/10.1186/s12889-024-18867-2
Download citation
Received : 12 September 2023
Accepted : 16 May 2024
Published : 22 May 2024
DOI : https://doi.org/10.1186/s12889-024-18867-2
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Feasibility
- Epidemiology
- Physical activity
- Physical behavior
- Sedentary behaviors
- Accelerometry
- Saudi adults
BMC Public Health
ISSN: 1471-2458
- General enquiries: [email protected]
Research Data Analyst - TP130050
Job description, #tp130050 research data analyst.
Position available through UCSD Temporary Employment Services (TES). Employment through TES is an excellent way to gain valuable UCSD experience and get your foot in the door for career positions. TES employment includes medical coverage, paid vacation & sick time, paid holidays, as well as training and development opportunities!
ASSIGNMENT DETAILS
UC San Diego is hiring a temporary Research Data Analyst to support the campus operations for the 2023 - 2024 School Year.
Duration: This role is anticipated to last 3 months (*may be extended)
Compensation: $29.60 - $34.00 / hour. Eligible for paid holidays and vacation/sick leave. Full-medical insurance also available.
Work Schedule: 8:00am - 4:30pm, Monday - Friday
Location: Remote
DESCRIPTION
This position handles data collection and monitoring, ensures quality assurance, handles data requests and documentation, and provides administrative support.
Assists the Data Manager with monitoring and maintaining data collection from multiple internal and external data sources. Communicates efficiently and identifies potential issues as they arise.
Conducts analysis of information as directed and performs ad hoc updates to the EVAL reporting database including exporting, analyzing, correcting, and importing new or existing data. May include outreach to UC San Diego students, faculty, or staff to corroborate or validate information.
Fields internal email or chat requests for data with collaborative customer service and team skills with a continuous improvement mindset in a professional setting.
Contributes to and takes initiative in maintaining a robust, redundant, inter-operable and transparent system of documentation in project intake meetings, administrative check-ins, and ongoing as needed.
Works collaboratively alongside the Data Manager and other Research Administration Staff in preparing for meetings, presentations, and supporting other teams as directed within the cancer center to meet multi-team project milestones.
QUALIFICATIONS
Working knowledge of a wide range of standard computer software, such as spreadsheets, email, file storage, remote meeting, project management, presentations, etc.
Ability to work independently and efficiently to collect, clean, transform, analyze, and prepare large sets of data (n>1000) within Microsoft Excel as directed.
Ability to balance recurring projects, long-term initiatives, and ad hoc or urgent requests while communicating quickly and efficiently as needs or questions arise.
Desire and ability to learn new systems and develop expertise in cancer research administration.
Ability to work efficiently with minimal supervision as part of a team to meet the collective mission of the Cancer Center to facilitate and foster a diverse community of innovation and excellence at UC San Diego.
SPECIAL CONDITIONS
Background check is required
This position has been identified as a Mandated Reporter pursuant to the California Child Abuse and Neglect Reporting Act (CANRA) and requires immediate reporting of physical abuse, sexual abuse, emotional abuse, or neglect of anyone under the age of 18. It is the responsibility of the Mandated Reporter to ensure that they obtain proper training in order to fulfill their reporting responsibilities as required by the California Child Abuse and Neglect Reporting Act and University policy, and to complete and submit the required reports to the UC San Diego Police Department without delay.
Pay Transparency Act
Annual Full Pay Range: $61,800 - $108,000 (will be prorated if the appointment percentage is less than 100%)
Hourly Equivalent: $29.60 - $51.72
Factors in determining the appropriate compensation for a role include experience, skills, knowledge, abilities, education, licensure and certifications, and other business and organizational needs. The Hiring Pay Scale referenced in the job posting is the budgeted salary or hourly range that the University reasonably expects to pay for this position. The Annual Full Pay Range may be broader than what the University anticipates to pay for this position, based on internal equity, budget, and collective bargaining agreements (when applicable).
If employed by the University of California, you will be required to comply with our Policy on Vaccination Programs, which may be amended or revised from time to time. Federal, state, or local public health directives may impose additional requirements.
To foster the best possible working and learning environment, UC San Diego strives to cultivate a rich and diverse environment, inclusive and supportive of all students, faculty, staff and visitors. For more information, please visit UC San Diego Principles of Community .
UC San Diego is an Equal Opportunity/Affirmative Action Employer. All qualified applicants will receive consideration for employment without regard to race, color, religion, sex, sexual orientation, gender identity, national origin, disability, age or protected veteran status.
For the University of California’s Affirmative Action Policy please visit: https://policy.ucop.edu/doc/4010393/PPSM-20 For the University of California’s Anti-Discrimination Policy, please visit: https://policy.ucop.edu/doc/1001004/Anti-Discrimination
UC San Diego is a smoke and tobacco free environment. Please visit smokefree.ucsd.edu for more information.
Application Instructions
Please click on the link below to apply for this position. A new window will open and direct you to apply at our corporate careers page. We look forward to hearing from you!
Share This Page
Posted : 5/22/2024
Job Reference # : TP130050
JOIN OUR TALENT COMMUNITY
Interested in working at UC San Diego and UC San Diego Health but can't find a position that's right for you? Submit your resume to our Talent Community to be considered for future opportunities that may align with your expertise. Please note, by joining our Talent Community, you are not applying for a position with UC San Diego Campus and Health. Rather, this is an additional way for our Talent Acquisition team to find candidates with specific credentials, if an opportunity arises. You are still encouraged to regularly check back on our career site or sign up for Job Alerts to apply for openings that are a match for your background.
- Career Sites by Recruiting.com

An official website of the United States government, Department of Justice.
Here's how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
Taking Action to Reduce Deaths in Custody
I have spent most of my 30-plus-year career focused on corrections and reentry reform, working to change the climate inside prisons and jails so that conditions are safer and healthier for people who are incarcerated and for the professionals who work in those facilities. And at the Office of Justice Programs (OJP), we continue to invest resources to make considerable progress on many fronts. Through grants, research, training and technical assistance:
- We are helping to transform corrections culture, supporting training, research, technical assistance and demonstration projects designed to make correctional facilities safer and more humane.
- We’re investing in research to better understand the factors that contribute to in-custody deaths and identify opportunities to intervene and prevent fatal encounters.
- We have taken steps toward reducing reliance on solitary confinement and protecting people in confinement facilities from sexual assault.
- We’ve expanded job and educational opportunities and opened avenues to treatment for individuals reentering their communities from incarceration.
- And de-escalation training is being adopted and deployed in both corrections and law enforcement settings to reduce the chances of harm during encounters with justice system professionals.
These actions are providing a greater measure of protection and a wider path to opportunity for people who come into contact with our criminal legal system. But admittedly, we have a long way to go when it comes to collecting data about and ultimately reducing the number of fatalities that occur when individuals are taken into custody by the police or incarcerated in correctional facilities.
Our work to implement the Death in Custody Reporting Act—specifically, to understand the nature and scope of the problem and identify strategies for reducing in-custody deaths—is central to achieving this critical goal. And while we have much more to do, we are making significant headway and we are deeply committed to finding ways to prevent and reduce deaths in custody.
Not every death in custody is preventable. But the power of the state confers upon it a responsibility to account for the lives lost while under its care and control in the clearest terms possible. The Death in Custody Reporting Act, signed into law in 2000 and reauthorized 14 years later as the Death in Custody Reporting Act of 2013 (DCRA), is intended to bring a measure of transparency to the circumstances surrounding in-custody deaths and, even more important, to help prevent and reduce future tragedies.
Collecting Complete and Accurate Data
The first step toward prevention is understanding the scope of the problem, and we are committed to collecting complete and accurate data. When DCRA first became law, the Bureau of Justice Statistics (BJS) served as the primary collector of information about deaths in custody, and its methods yielded a robust response from corrections institutions. Ninety-eight percent of jails and 100 percent of state prisons submitted data on in-custody deaths to BJS.
But DCRA of 2013 set in motion changes that, perhaps unintentionally, limited BJS’s role in the collection of federal DCRA data. The new legislation also required reporting from a single state-level agency instead of directly from local entities, another major shift. The Department of Justice proposed a technical legislative fix to explicitly enable BJS to resume its data collection activities for state and local agencies, but the legislative fix has not yet moved forward. The state and local data collection role is now in the hands of our Bureau of Justice Assistance (BJA), a grantmaking office of OJP.
BJA has since been working on many fronts to substantially and urgently improve data collection. But the challenge is significant: A report from the Government Accountability Office comparing publicly available information to the data reported to BJA in fiscal year 2021 found that more than 1,000 in-custody deaths were unaccounted for in the states’ submissions. Moreover, 70 percent of the submitted records were missing at least one required element (information about the deceased; date, time and location of the death; the agency involved; and circumstances surrounding the death).
This gap in data pains me: The gathering and reporting of this information are fundamental responsibilities owed to the public, and ones that OJP takes seriously. And yet with more than 18,000 distinct law enforcement agencies, more than 50 state- and territory-run prison systems and over 3,000 autonomous jails in the U.S., this is no simple task. BJA must encourage and assist these independently governed institutions to gather the relevant data and report it through a single point of contact within each state. Many states report major challenges to collecting and consolidating data from multiple sources and ensuring the completeness and accuracy of data prior to reporting to BJA. These issues are especially difficult to overcome without an appropriated funding source or in-state infrastructure.
Efforts to Improve Data Collection
We are redoubling our efforts to provide the tools we’ve got—technical assistance and support—to jurisdictions to improve the completeness and quality of reporting, from local agencies to the state, and from the state to the federal government.
For example, BJA has launched a DCRA Training and Technical Assistance Center , managed by the Justice Information Resource Network (JIRN), which provides onsite and virtual training and technical assistance to state administering agencies and other DCRA reporters. The Center produces materials that identify and describe additional data sources that may help agencies provide complete and accurate reporting.
The Center’s efforts build on momentum from a December 2022 meeting with 118 representatives of state, territory and D.C. governments and several non-profit and professional member organizations. The meeting tackled many of the challenges around DCRA implementation and highlighted promising strategies for reporting. BJA and JIRN have continued to provide trainings, webinars and one-on-one outreach to support progress on data collection and reporting.
BJA has also been using data from two open-source databases— Mapping Police Violence and The Washington Post’s Fatal Force —to identify otherwise unreported arrest-related deaths, and in the spring of 2023, BJA shared with states the data it gathered. Based on this information, state administering agencies have reported back over 200 new arrest-related deaths, a 47% increase in the number of reported deaths in this category. Twenty-five states back reported at least one new arrest-related death. BJA shared another round of data with states this spring, and while results are still being gathered, we expect a large increase in the number of reported deaths.
The goal here, of course, is to close the data gap and the open-source analysis is one additional tool. We are also working closely with the FBI’s National Use-of-Force Data Collection program to gain a better understanding of the scope of unreported arrest-related deaths.
BJA also developed DCRA Compliance Guidelines that lay out the steps states must take to meet DCRA reporting requirements. In addition to reporting complete and comprehensive quarterly data and evidence of quality improvements where gaps and challenges are identified, each state is obligated to submit a DCRA implementation plan for approval by BJA, describing the state’s data collection infrastructure, data collection methods and reporting methods. BJA and JIRN review these plans and use them to help target training and technical assistance resources to pressing challenges. State administering agencies are expected to submit either updated plans or implementation reports annually in subsequent fiscal years. Each state’s implementation plan is posted here .
We aim to give state and local organizations the tools, training and assistance needed to vastly improve reporting. Most states are working hard to do so and taking advantage of the new guidance and assistance. For others, we are taking corrective actions that may include withholding from states a percentage of funds under the Edward Byrne Memorial Justice Assistance Grant Program [i] , or they could be assessed up to a 10% penalty of their allocated amount (a provision known as “the DCRA penalty”). In 2024, BJA will conduct the first annual review of DCRA compliance for all states and make recommendations for corrective actions.
As noted earlier, BJS continues to collect, analyze and report information about deaths that occur in the custody of federal law enforcement agencies. In a recent report, Federal Deaths in Custody and During Arrest, 2021 , BJS achieved a 100% response rate from federal agencies. The report describes decedent, incident and facility characteristics of deaths in federal custody and during arrest by federal law enforcement agencies during fiscal year 2021. Nine agencies reported at least one arrest-related death, and six agencies reported at least one death in custody.
Through the National Institute of Justice (NIJ), we are supporting rigorous research to analyze data collected through DCRA and other sources to produce data-driven recommendations for reducing deaths in custody. NIJ released an initial report titled Literature Review and Data Analysis on Deaths in Custody in 2022. This study reviewed existing research and data focused on the prevalence, patterns and contexts of deaths in custody and explored factors associated with deaths in correctional institutions. To build on the first study, NIJ contracted with RTI International in late 2021 to conduct a broader three-year study involving a national-level review and analysis of policies, practices (including management practices) and available data addressing deaths in custody, along with in-depth case studies of multiple sites and agency types. This research is ongoing and scheduled for completion in late 2024.
Meanwhile, the President’s fiscal year 2025 budget proposes to strengthen states’ ability to carry out their DCRA responsibilities. The budget requests $5 million to support DCRA implementation which would provide states new funding to aid in collecting and reporting DCRA data, and for states to provide subawards to local entities to support their needs.
Preventing and reducing deaths in custody is both a legal responsibility and a solemn moral obligation that the Office of Justice Programs is working hard to fulfill. By collaborating with our state and local partners to accurately report deaths in custody and assess their efforts to protect those under their charge, we can help save lives and uphold the principles of fairness, equity and safety on which our system of justice is built.
[i] The JAG Program provides grants to states, which then award subgrants to local jurisdictions to support law enforcement and other public safety activities. Last year, BJA awarded more than $200 million in state JAG funding.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
IDEES energy system database gets updated to improve analyses of policy assessments
A new version of a JRC-developed database simplifies data collection and data integration into modelling tools, allowing for an in-depth analysis of climate, energy and transport policy.

To better understand the current state of the energy system and support decision-making for climate, energy and transport policy, researchers and policy analysts require a wide range of data.
For instance, they need to know how much energy different transport technologies consume in different Member States, and determine the potential for improvement in the future, based on the advancements made in these technologies over the past few decades.
Facilitating this data collection and offering a solid starting point for researchers and analysts, the JRC has published an updated version of its open-access Integrated Database of the European Energy System (JRC-IDEES) , which consolidates a wealth of information, providing a granular breakdown of energy consumption and emissions.
This comprehensive approach, which was also employed to support the European Commission's recommendations on climate action by 2040 , offers valuable insights into the dynamics shaping the European energy landscape, facilitating the assessment of past policies, technological advancements, structural shifts, and macroeconomic factors.
Harmonised approach
First released in 2018, JRC-IDEES harmonises existing statistics with extensive technical assumptions to describe the recent history of all key sectors of the energy system: industry, the building sector, transport, and power generation.
For each Member State, it breaks the energy use and emissions of each of these sectors down to the level of specific processes or technologies. This level of detail enables a granular analysis of recent changes in the energy system, for instance to assess past policies, technology dynamics, structural changes, and macro-economic factors.
Since its initial release, JRC-IDEES has played an important role in EU research and policy analysis, serving as the primary data source for the JRC's Policy Oriented Tool for Energy & Climate Change Impact Assessment ( POTEnCIA model ).
New features
The latest update expands the time coverage of the database from 2000 to 2021 and incorporates new statistical sources as well as feedback from the user community. One key improvement is making the dataset easier to use within automated data workflows, so that researchers can better integrate JRC-IDEES into their analyses.
The data is freely accessible under the Creative Commons BY 4.0 license, ensuring that it can be used by a wide range of stakeholders.
A technical report summarises the statistics and assumptions used to compile the database
Related links
Integrated Database of the European Energy System (JRC-IDEES) (dataset)
JRC-IDEES-2021: the Integrated Database of the European Energy System – Data update and technical documentation
- Climate neutrality
More news on a similar topic

- General publications
- 28 February 2024

- News announcement
- 14 February 2024

- 9 February 2024

Share this page

An official website of the United States government
Here’s how you know
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
Take action
- Report an antitrust violation
- File adjudicative documents
- Find banned debt collectors
- View competition guidance
- Competition Matters Blog
Slow the Roll-up: Help Shine a Light on Serial Acquisitions
View all Competition Matters Blog posts
We work to advance government policies that protect consumers and promote competition.
View Policy
Search or browse the Legal Library
Find legal resources and guidance to understand your business responsibilities and comply with the law.
Browse legal resources
- Find policy statements
- Submit a public comment

Vision and Priorities
Memo from Chair Lina M. Khan to commission staff and commissioners regarding the vision and priorities for the FTC.
Technology Blog
P = np not exactly, but here are some research questions from the office of technology..
View all Technology Blog posts
Advice and Guidance
Learn more about your rights as a consumer and how to spot and avoid scams. Find the resources you need to understand how consumer protection law impacts your business.
- Report fraud
- Report identity theft
- Register for Do Not Call
- Sign up for consumer alerts
Get Business Blog updates
- Get your free credit report
- Find refund cases
- Order bulk publications
- Consumer Advice
- Shopping and Donating
- Credit, Loans, and Debt
- Jobs and Making Money
- Unwanted Calls, Emails, and Texts
- Identity Theft and Online Security
- Business Guidance
- Advertising and Marketing
- Credit and Finance
- Privacy and Security
- By Industry
- For Small Businesses
- Browse Business Guidance Resources
- Business Blog
Servicemembers: Your tool for financial readiness
Visit militaryconsumer.gov
Get consumer protection basics, plain and simple
Visit consumer.gov
Learn how the FTC protects free enterprise and consumers
Visit Competition Counts
Looking for competition guidance?
- Competition Guidance
News and Events
Latest news, new ftc data shed light on companies most frequently impersonated by scammers.
View News and Events
Upcoming Event
Apoyando a las personas mayores en la lucha contra el fraude.
View more Events
Sign up for the latest news
Follow us on social media
--> --> --> --> -->

Playing it Safe: Explore the FTC's Top Video Game Cases
Learn about the FTC's notable video game cases and what our agency is doing to keep the public safe.
Latest Data Visualization

FTC Refunds to Consumers
Explore refund statistics including where refunds were sent and the dollar amounts refunded with this visualization.
About the FTC
Our mission is protecting the public from deceptive or unfair business practices and from unfair methods of competition through law enforcement, advocacy, research, and education.
Learn more about the FTC

Meet the Chair
Lina M. Khan was sworn in as Chair of the Federal Trade Commission on June 15, 2021.
Chair Lina M. Khan
Looking for legal documents or records? Search the Legal Library instead.
- Cases and Proceedings
- Premerger Notification Program
- Merger Review
- Anticompetitive Practices
- Competition and Consumer Protection Guidance Documents
- Warning Letters
- Consumer Sentinel Network
- Criminal Liaison Unit
- FTC Refund Programs
- Notices of Penalty Offenses
- Advocacy and Research
- Advisory Opinions
- Cooperation Agreements
- Federal Register Notices
- Public Comments
- Policy Statements
- International
- Office of Technology Blog
- Military Consumer
- Consumer.gov
- Bulk Publications
- Data and Visualizations
- Stay Connected
- Commissioners and Staff
- Bureaus and Offices
- Budget and Strategy
- Office of Inspector General
- Careers at the FTC
Cars & Consumer Data: On Unlawful Collection & Use
Some say the car a person drives can say a lot about them. As cars get “connected,” this turns out to be truer than many people might have realized. While connectivity can let drivers do things like play their favorite internet radio stations or unlock their car with an app, connected cars can also collect a lot of data about people. This data could be sensitive—such as biometric information or location—and its collection, use, and disclosure can threaten consumers’ privacy and financial welfare .
Connected cars have been on the FTC’s radar for years. The FTC highlighted concerns related to connected cars as part of an “Internet of Things” workshop held in 2013, followed by a 2015 report . In 2018, the FTC hosted a connected cars workshop highlighting issues ranging from unexpected secondary uses of data to security risks. The agency has also published guidance to consumers reminding them to wipe the data on their cars before selling them—much as anyone would when trying to resell a computer or smart phone.
Over the years, privacy advocates have raised concerns about the vast amount of data that could be collected from cars, such as biometric , telematic, geolocation, video, and other personal information. News reports have also suggested that data from connected cars could be used to stalk people or affect their insurance rates. Many have noted that when any company collects a large amount of sensitive data, it can pose national security issues if that data is shared with foreign actors.
Car manufacturers—and all businesses—should take note that the FTC will take action to protect consumers against the illegal collection, use, and disclosure of their personal data. Recent enforcement actions illustrate this point:
- Geolocation data is sensitive and subject to enhanced protections under the FTC Act . Cars are much like mobile phones when it comes to revealing consumers’ persistent, precise location. In a series of seminal cases in recent years, the Commission has established that the collection, use, and disclosure of location can be an unfair practice. In X-Mode , the FTC alleged that the data could be used to track people’s visits to sensitive locations like medical or reproductive health clinics, places of worship, or domestic abuse shelters. Similarly, in InMarket, the Commission alleged that the company’s internal use of sensitive data to group consumers into highly sensitive categories for advertising purposes was unlawful. The orders resolving these matters prohibit these companies from selling sensitive location information.
- Surreptitious disclosure of sensitive information can be an unfair practice. Companies that have legitimate access to consumers’ sensitive information must ensure that the data is used only for the reasons they collected that information. For example, the Commission recently alleged that BetterHelp , which offers online counseling services—including those marketed to specific groups like Christians, teens, and the LGBTQ+ community—revealed consumers’ email addresses and health questionnaire information to third parties for advertising purposes. Similarly, the Commission took action against mental telehealth provider Cerebral for, among other things, the company’s unfair privacy and security practices. The FTC obtained settlements requiring BetterHelp and Cerebral to pay millions of dollars so that affected consumers could receive partial refunds, and the Cerebral settlement bans the company from using or disclosing consumers’ personal information for advertising purposes.
- Using sensitive data for automated decisions can also be unlawful. Companies that feed consumer data into algorithms may be liable for harmful automated decisions. The FTC recently took action against Rite Aid, saying in a complaint that the company enrolled people into a facial recognition program that alerted employees when suspected matches entered their stores. The complaint includes allegations that Rite Aid failed to take reasonable steps to prevent low-quality images from being used with the program, increasing the likelihood of false-positive match alerts. In some cases, false alerts came with recommended actions, such as removing people from the store or calling the police, and employees followed through on those recommendations. As a result of the FTC’s action, Rite Aid agreed to a 5-year ban on the use of facial recognition technology.
These cases underscore the significant potential liability associated with the collection, use, and disclosure of sensitive data, such as biometrics and location data. As the FTC has stated , firms do not have the free license to monetize people’s information beyond purposes needed to provide their requested product or service, and firms shouldn’t let business model incentives outweigh the need for meaningful privacy safeguards.
The easiest way that companies can avoid harming consumers from the collection, use, and sharing of sensitive information is by simply not collecting it in the first place. When they are motivated to, all businesses—including auto manufacturers—are capable of building products with safeguards that protect consumers.
Thank you to staff from across the Office of Technology and the Division of Privacy and Identity Protection in the Bureau of Consumer Protection who collaborated on this post.
- Consumer Protection
- Consumer Privacy
- Data Security
- Office of Technology
More from the Technology Blog
Consumer facing applications: a quote book from the tech summit on ai, data and models: a quote book from the tech summit on ai, security principles: addressing vulnerabilities systematically.
IMAGES
VIDEO
COMMENTS
Data collection is a systematic process of gathering observations or measurements. Whether you are performing research for business, governmental or academic purposes, data collection allows you to gain first-hand knowledge and original insights into your research problem. While methods and aims may differ between fields, the overall process of ...
Data collection is the process of gathering and collecting information from various sources to analyze and make informed decisions based on the data collected. This can involve various methods, such as surveys, interviews, experiments, and observation. In order for data collection to be effective, it is important to have a clear understanding ...
Data collection methods are chosen depending on the available resources. For example, conducting questionnaires and surveys would require the least resources, while focus groups require moderately high resources. Reasons to Conduct Online Research and Data Collection . Feedback is a vital part of any organization's growth.
Our recommendations regarding data collection address (a) type of research design, (b) control variables, (c) sampling procedures, and (d) missing data management. Our recommendations regarding data preparation address (e) outlier management, (f) use of corrections for statistical and methodological artifacts, and (g) data transformations.
In this Rip Out we focus on data collection, but in qualitative research, the entire project must be considered. 1, 2 Careful design of the data collection phase requires the following: deciding who will do what, where, when, and how at the different stages of the research process; acknowledging the role of the researcher as an instrument of ...
Data collection is the systematic process of gathering and recording information or data from various sources for analysis, interpretation, and decision-making. It is a fundamental step in research, business operations, and virtually every field where information is used to understand, improve, or make informed choices.
While we focus on primary data collection methods in this guide, we encourage you not to overlook the value of incorporating secondary data into your research design where appropriate. 3. Choose your data collection method. When choosing your data collection method, there are many options at your disposal.
Data collection is the process of gathering and measuring information used for research. Collecting data is one of the most important steps in the research process, and is part of all disciplines including physical and social sciences, humanities, business, etc. Data comes in many forms with different ways to store and record data, either written in a lab notebook and or recorded digitally on ...
Data collection is a process of collecting information from all the relevant sources to find answers to the research problem, test the hypothesis (if you are following deductive approach) and evaluate the outcomes.Data collection methods can be divided into two categories: secondary methods of data collection and primary methods of data collection.
To analyze data collected in a statistically valid manner (e.g. from experiments, surveys, and observations). Meta-analysis. Quantitative. To statistically analyze the results of a large collection of studies. Can only be applied to studies that collected data in a statistically valid manner.
Data collection or data gathering is the process of gathering and measuring information on targeted variables in an established system, which then enables one to answer relevant questions and evaluate outcomes. Data collection is a research component in all study fields, including physical and social sciences, humanities, [2] and business.
One of the main stages in a research study is data collection that enables the researcher to find answers to research questions. Data collection is the process of collecting data aiming to gain ...
There are actually two kinds of mixing of the six major methods of data collection (Johnson & Turner, 2003). The first is intermethod mixing, which means two or more of the different methods of data collection are used in a research study. This is seen in the two examples in the previous paragraph.
Data Collection, Research Methodology, Data Collection Methods, Academic Research Paper, Data Collection Techniques. I. INTRODUCTION Different methods for gathering information regarding specific variables of the study aiming to employ them in the data analysis phase to achieve the results of the study, gain the answer of the research ...
Doing qualitative research is not easy and may require a complete rethink of how research is conducted, particularly for researchers who are more familiar with quantitative approaches. There are many ways of conducting qualitative research, and this paper has covered some of the practical issues regarding data collection, analysis, and management.
7 Data Collection Methods Used in Business Analytics. 1. Surveys. Surveys are physical or digital questionnaires that gather both qualitative and quantitative data from subjects. One situation in which you might conduct a survey is gathering attendee feedback after an event.
Step 2: Choose your data collection method. Based on the data you want to collect, decide which method is best suited for your research. Experimental research is primarily a quantitative method. Interviews, focus groups, and ethnographies are qualitative methods. Surveys, observations, archival research, and secondary data collection can be ...
Data collection is the process of collecting and evaluating information or data from multiple sources to find answers to research problems, answer questions, evaluate outcomes, and forecast trends and probabilities. It is an essential phase in all types of research, analysis, and decision-making, including that done in the social sciences ...
Primary Data Collection. Primary data collection by definition is the gathering of raw data collected at the source. It is a process of collecting the original data collected by a researcher for a specific research purpose. It could be further analyzed into two segments; qualitative research and quantitative data collection methods.
How to conduct qualitative research? Given that qualitative research is characterised by flexibility, openness and responsivity to context, the steps of data collection and analysis are not as separate and consecutive as they tend to be in quantitative research [13, 14].As Fossey puts it: "sampling, data collection, analysis and interpretation are related to each other in a cyclical ...
Qualitative research methods. Each of the research approaches involve using one or more data collection methods.These are some of the most common qualitative methods: Observations: recording what you have seen, heard, or encountered in detailed field notes. Interviews: personally asking people questions in one-on-one conversations. Focus groups: asking questions and generating discussion among ...
For students and novice researchers, the choice of qualitative approach and subsequent alignment among problems, research questions, data collection, and data analysis can be particularly tricky. Therefore, the purpose of this paper is to provide a concise explanation of four common qualitative approaches, case study, ethnography, narrative ...
Translational data is of paramount importance for medical research and clinical innovation. The combination of different omics data (e.g., genomics, radiomics, proteomics) and clinical health data ...
Web scraping can be a useful tool in this scenario, enabling researchers, policymakers and advocates to gather and analyze data from virtually any online source, irrespective of geographical and ...
Physical behaviors such physical activity, sedentary behavior, and sleep are associated with mortality, but there is a lack of epidemiological data and knowledge using device-measured physical behaviors. To assess the feasibility of baseline data collection using the Prospective Physical Activity, Sitting, and Sleep consortium (ProPASS) protocols in the specific context of Saudi Arabia.
UC San Diego is hiring a temporary Research Data Analyst to support the campus operations for the 2023 - 2024 School Year. Duration: This role is anticipated to last 3 months (*may be extended) Compensation: $29.60 - $34.00 / hour. Eligible for paid holidays and vacation/sick leave.
Efforts to Improve Data Collection. ... This study reviewed existing research and data focused on the prevalence, patterns and contexts of deaths in custody and explored factors associated with deaths in correctional institutions. To build on the first study, NIJ contracted with RTI International in late 2021 to conduct a broader three-year ...
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
Facilitating this data collection and offering a solid starting point for researchers and analysts, the JRC has published an updated version of its open-access Integrated Database of the European Energy System (JRC-IDEES), which consolidates a wealth of information, providing a granular breakdown of energy consumption and emissions.
This data could be sensitive—such as biometric information or location—and its collection, use, and disclosure can threaten consumers' privacy and financial welfare. Connected cars have been on the FTC's radar for years. The FTC highlighted concerns related to connected cars as part of an "Internet of Things" workshop held in 2013 ...